| \n", " | wals code | \n", "language | \n", "genus | \n", "family | \n", "area | \n", "coordinates | \n", "_1A | \n", "_2A | \n", "
|---|---|---|---|---|---|---|---|---|
| 0 | \n", "kiw | \n", "Kiwai (Southern) | \n", "Kiwaian | \n", "Kiwaian | \n", "Phonology | \n", "(-8.0, 143.5) | \n", "Small | \n", "Average (5-6) | \n", "
| 1 | \n", "xoo | \n", "!Xóõ | \n", "Tu | \n", "Tu | \n", "Phonology | \n", "(-24.0, 21.5) | \n", "Large | \n", "Average (5-6) | \n", "
| 2 | \n", "ani | \n", "//Ani | \n", "Khoe-Kwadi | \n", "Khoe-Kwadi | \n", "Phonology | \n", "(-18.9166666667, 21.9166666667) | \n", "Large | \n", "Average (5-6) | \n", "
| 3 | \n", "abi | \n", "Abipón | \n", "South Guaicuruan | \n", "Guaicuruan | \n", "Phonology | \n", "(-29.0, -61.0) | \n", "Moderately small | \n", "Average (5-6) | \n", "
| 4 | \n", "abk | \n", "Abkhaz | \n", "Northwest Caucasian | \n", "Northwest Caucasian | \n", "Phonology | \n", "(43.0833333333, 41.0) | \n", "Large | \n", "Small (2-4) | \n", "
| \n", " | Language | \n", "LID | \n", "Gender.n | \n", "Gender.binned4 | \n", "Gender.Presence | \n", "
|---|---|---|---|---|---|
| 0 | \n", "Godoberi | \n", "1531 | \n", "3 | \n", "3 genders | \n", "True | \n", "
| 1 | \n", "Bininj Kun-Wok | \n", "655 | \n", "4 | \n", "4 genders | \n", "True | \n", "
| 2 | \n", "Luvale | \n", "553 | \n", "10 | \n", "more than 4 genders | \n", "True | \n", "
| 3 | \n", "Chamalal | \n", "1149 | \n", "5 | \n", "more than 4 genders | \n", "True | \n", "
| 4 | \n", "North-Central Dargwa | \n", "2949 | \n", "3 | \n", "3 genders | \n", "True | \n", "
Database APIs ¶
APIs for different linguistic databases can be accessed with lingtypology.db_apis.
import lingtypology.db_apis
1. General ¶
Lingtypology attempts to provide unified API for given language databases. Therefore, classes in this module share some common attributes and methods. In this paragraph I will describe them and provide examples for Autotyp, Wals and Phoible.
from lingtypology.db_apis import Autotyp, Wals, Phoible
1.1. features_list ¶
You can get the list of available features from the database using this attribute.
Autotyp().features_list[:10] #It's cutoff in order not to take took much space
Note: Phoible has no features_list attribute because there are no features. However, it has subsets_list that shows list of available subsets of Phoible data.
Phoible().subsets_list
1.2. get_df and get_json ¶
These two methods access the database and return data as pandas.Series or dict. Example of usage:
Autotyp('Agreement', 'Clusivity').get_df().head()
Note: for Phoible and Autotyp you can use strip_na parameter (list, default: []) to strip rows in which there is empty cell in the given columns. Compare the following.
No strip_na (empty cells are replaced with '~N/A~'):
Phoible().get_df().head()
tones column given to strip_na:
Phoible().get_df(strip_na=['tones']).head()
Note: By default when you call get_df or get_json it prints the citation. If you want to disable it, you shoud set the show_citation to False.
p = Phoible()
p.show_citation = False
p.get_df(strip_na=['tones']).head()
1.3. citation ¶
You can get the citation for each database using citation attribute.
E.g.:
from lingtypology.db_apis import Autotyp
print(Autotyp().citation)
Note: if you use Wals, citation will be shown for every feature. If you want general citation for the whole Wals, use general_citation.
w = Wals('1a', '2a')
print(w.citation)
print(w.general_citation)
2. Wals ¶
It is possible to access Wals data (online) using lingtypology.db_apis.Wals
from lingtypology.db_apis import Wals
wals_page = Wals('1a', '2a').get_df()
wals_page.head()
Map example for feature 1A:
m = lingtypology.LingMap(wals_page.language)
m.add_custom_coordinates(wals_page.coordinates)
m.add_features(wals_page._1A)
m.legend_title = 'Consonant Inventory'
m.create_map()
2. Autotyp ¶
It is possible to access Autotyp data (online) using lingtypology.db_apis.
Unlike in Wals, each new tablename passed into Autotyp gives several additional columns:
Autotyp_table = Autotyp('Gender', 'Agreement').get_df(strip_na=['Gender.binned4'])
Autotyp_table.head()
Now we can draw a map out of gender data from multiple languages.
m = lingtypology.LingMap(Autotyp_table.language)
m.add_features(Autotyp_table['Gender.binned4'])
m.colors = lingtypology.gradient(4, color1='yellow', color2='red')
m.legend_title = 'Genders'
m.create_map()
3. AfBo ¶
from lingtypology.db_apis import AfBo
adj = AfBo('adjectivizer').get_df()
adj.head()
m = lingtypology.LingMap(adj.language_recipient)
m.add_features(adj['adjectivizer'], numeric=True)
m.legend_title = 'Adj'
m.create_map()
4. SAILS ¶
from lingtypology.db_apis import Sails
To get a pandas.DataFrame of features and descriptions:
Sails().features_descriptions.head()
Get description for particular features:
Sails().feature_descriptions('ICU10', 'ICU11')
To get the SAILS data as dict, you can use get_json method. To get data as pandas.DataFrame you can run:
sails = Sails('ICU10', 'ICU11')
df = sails.get_df()
df.head()
Map example:
m = lingtypology.LingMap(df.language)
m.add_features(df.ICU10_desc)
m.legend_title = sails.feature_descriptions('ICU10').Description.at[0]
m.start_location = (9, -79)
m.start_zoom = 5
m.create_map()
5. Phoible ¶
from lingtypology.db_apis import Phoible
Unlike in other databases you do not pass features into Phoible. You should pass the subset. Take a look:
p = Phoible()
p.get_df().head()
There are several entries for different languages: it happens because Phoible data consists of several different subsets. You can get the list of available subsets:
p.subsets_list
... and pass them into the class:
p = Phoible(subset='SPA')
df = p.get_df(strip_na=['tones'])
df.head()
You can also get non-aggregated data by setting aggregated to False while initializing the class.
Phoible(aggregated=False).get_df().head()
Map example:
m = lingtypology.LingMap(df.language)
m.colormap_colors = ('white', 'red')
m.add_features(df.tones, numeric=True)
m.start_zoom = 1
m.legend_title = 'Tones'
m.create_map()
Another example (slow due to large amount of data):
df = Phoible(subset='UPSID', aggregated=False).get_df()
#Get all languages with ejectives
df = df[df.raisedLarynxEjective == '+']
#Remove duplicates
df = df.drop_duplicates(subset='Glottocode')
df.head()
#A warning appears randomly. No idea why.
m = lingtypology.LingMap(df.Glottocode, glottocode=True)
m.title = 'Languages with Ejectives'
m.create_map()
| \n", " | language | \n", "LID | \n", "VPolyagreement.Presence.v2 | \n", "VPolyagreement.Presence.v1 | \n", "InclExclAsPerson.Presence | \n", "InclExclAny.Presence | \n", "InclExclType | \n", "InclExclAsMinAug.Presence | \n", "
|---|---|---|---|---|---|---|---|---|
| 0 | \n", "Ambulas | \n", "6 | \n", "False | \n", "False | \n", "False | \n", "False | \n", "no i/e | \n", "False | \n", "
| 1 | \n", "Abkhazian | \n", "7 | \n", "True | \n", "True | \n", "False | \n", "False | \n", "no i/e | \n", "False | \n", "
| 2 | \n", "Achinese | \n", "9 | \n", "True | \n", "False | \n", "False | \n", "True | \n", "plain i/e type | \n", "False | \n", "
| 3 | \n", "Western Keres | \n", "10 | \n", "True | \n", "True | \n", "False | \n", "False | \n", "no i/e | \n", "False | \n", "
| 4 | \n", "Hokkaido Ainu | \n", "12 | \n", "True | \n", "True | \n", "False | \n", "True | \n", "plain i/e type | \n", "False | \n", "
| \n", " | contribution_name | \n", "language | \n", "coordinates | \n", "glottocode | \n", "macroarea | \n", "phonemes | \n", "consonants | \n", "vowels | \n", "tones | \n", "source | \n", "inventory_page | \n", "
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", "Korean (SPA 1) | \n", "Korean | \n", "(37.5, 128.0) | \n", "kore1280 | \n", "Eurasia | \n", "40 | \n", "22 | \n", "18 | \n", "0 | \n", "https://archive.org/details/kor_SPA1979_phon | \n", "https://phoible.org/languages/kore1280 | \n", "
| 1 | \n", "KOREAN (UPSID 423) | \n", "Korean | \n", "(37.5, 128.0) | \n", "kore1280 | \n", "Eurasia | \n", "32 | \n", "21 | \n", "11 | \n", "~N/A~ | \n", "http://web.phonetik.uni-frankfurt.de/L/L2170.html | \n", "https://phoible.org/languages/kore1280 | \n", "
| 2 | \n", "Ket (SPA 2) | \n", "Ket | \n", "(63.7551, 87.5466) | \n", "kett1243 | \n", "Eurasia | \n", "32 | \n", "18 | \n", "14 | \n", "0 | \n", "https://archive.org/details/ket_SPA1979_phon | \n", "https://phoible.org/languages/kett1243 | \n", "
| 3 | \n", "KET (UPSID 399) | \n", "Ket | \n", "(63.7551, 87.5466) | \n", "kett1243 | \n", "Eurasia | \n", "25 | \n", "18 | \n", "7 | \n", "~N/A~ | \n", "http://web.phonetik.uni-frankfurt.de/L/L2706.html | \n", "https://phoible.org/languages/kett1243 | \n", "
| 4 | \n", "Lak (SPA 3) | \n", "Lak | \n", "(42.1328, 47.0809) | \n", "lakk1252 | \n", "Eurasia | \n", "69 | \n", "60 | \n", "9 | \n", "0 | \n", "https://archive.org/details/lbe_SPA1979_phon | \n", "https://phoible.org/languages/lakk1252 | \n", "
| \n", " | contribution_name | \n", "language | \n", "coordinates | \n", "glottocode | \n", "macroarea | \n", "phonemes | \n", "consonants | \n", "vowels | \n", "tones | \n", "source | \n", "inventory_page | \n", "
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", "Korean (SPA 1) | \n", "Korean | \n", "(37.5, 128.0) | \n", "kore1280 | \n", "Eurasia | \n", "40 | \n", "22 | \n", "18 | \n", "0 | \n", "https://archive.org/details/kor_SPA1979_phon | \n", "https://phoible.org/languages/kore1280 | \n", "
| 2 | \n", "Ket (SPA 2) | \n", "Ket | \n", "(63.7551, 87.5466) | \n", "kett1243 | \n", "Eurasia | \n", "32 | \n", "18 | \n", "14 | \n", "0 | \n", "https://archive.org/details/ket_SPA1979_phon | \n", "https://phoible.org/languages/kett1243 | \n", "
| 4 | \n", "Lak (SPA 3) | \n", "Lak | \n", "(42.1328, 47.0809) | \n", "lakk1252 | \n", "Eurasia | \n", "69 | \n", "60 | \n", "9 | \n", "0 | \n", "https://archive.org/details/lbe_SPA1979_phon | \n", "https://phoible.org/languages/lakk1252 | \n", "
| 6 | \n", "Kabardian (SPA 4) | \n", "Kabardian | \n", "(43.5082, 43.3918) | \n", "kaba1278 | \n", "Eurasia | \n", "56 | \n", "49 | \n", "7 | \n", "0 | \n", "https://archive.org/details/kbd_SPA1979_phon | \n", "https://phoible.org/languages/kaba1278 | \n", "
| 8 | \n", "Georgian (SPA 5) | \n", "Georgian | \n", "(41.850396999999994, 43.78613) | \n", "nucl1302 | \n", "Eurasia | \n", "35 | \n", "29 | \n", "6 | \n", "0 | \n", "https://archive.org/details/kat_SPA1979_phon | \n", "https://phoible.org/languages/nucl1302 | \n", "
| \n", " | contribution_name | \n", "language | \n", "coordinates | \n", "glottocode | \n", "macroarea | \n", "phonemes | \n", "consonants | \n", "vowels | \n", "tones | \n", "source | \n", "inventory_page | \n", "
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", "Korean (SPA 1) | \n", "Korean | \n", "(37.5, 128.0) | \n", "kore1280 | \n", "Eurasia | \n", "40 | \n", "22 | \n", "18 | \n", "0 | \n", "https://archive.org/details/kor_SPA1979_phon | \n", "https://phoible.org/languages/kore1280 | \n", "
| 2 | \n", "Ket (SPA 2) | \n", "Ket | \n", "(63.7551, 87.5466) | \n", "kett1243 | \n", "Eurasia | \n", "32 | \n", "18 | \n", "14 | \n", "0 | \n", "https://archive.org/details/ket_SPA1979_phon | \n", "https://phoible.org/languages/kett1243 | \n", "
| 4 | \n", "Lak (SPA 3) | \n", "Lak | \n", "(42.1328, 47.0809) | \n", "lakk1252 | \n", "Eurasia | \n", "69 | \n", "60 | \n", "9 | \n", "0 | \n", "https://archive.org/details/lbe_SPA1979_phon | \n", "https://phoible.org/languages/lakk1252 | \n", "
| 6 | \n", "Kabardian (SPA 4) | \n", "Kabardian | \n", "(43.5082, 43.3918) | \n", "kaba1278 | \n", "Eurasia | \n", "56 | \n", "49 | \n", "7 | \n", "0 | \n", "https://archive.org/details/kbd_SPA1979_phon | \n", "https://phoible.org/languages/kaba1278 | \n", "
| 8 | \n", "Georgian (SPA 5) | \n", "Georgian | \n", "(41.850396999999994, 43.78613) | \n", "nucl1302 | \n", "Eurasia | \n", "35 | \n", "29 | \n", "6 | \n", "0 | \n", "https://archive.org/details/kat_SPA1979_phon | \n", "https://phoible.org/languages/nucl1302 | \n", "
| \n", " | wals code | \n", "language | \n", "genus | \n", "family | \n", "area | \n", "coordinates | \n", "_1A | \n", "_2A | \n", "
|---|---|---|---|---|---|---|---|---|
| 0 | \n", "kiw | \n", "Kiwai (Southern) | \n", "Kiwaian | \n", "Kiwaian | \n", "Phonology | \n", "(-8.0, 143.5) | \n", "Small | \n", "Average (5-6) | \n", "
| 1 | \n", "xoo | \n", "!Xóõ | \n", "Tu | \n", "Tu | \n", "Phonology | \n", "(-24.0, 21.5) | \n", "Large | \n", "Average (5-6) | \n", "
| 2 | \n", "ani | \n", "//Ani | \n", "Khoe-Kwadi | \n", "Khoe-Kwadi | \n", "Phonology | \n", "(-18.9166666667, 21.9166666667) | \n", "Large | \n", "Average (5-6) | \n", "
| 3 | \n", "abi | \n", "Abipón | \n", "South Guaicuruan | \n", "Guaicuruan | \n", "Phonology | \n", "(-29.0, -61.0) | \n", "Moderately small | \n", "Average (5-6) | \n", "
| 4 | \n", "abk | \n", "Abkhaz | \n", "Northwest Caucasian | \n", "Northwest Caucasian | \n", "Phonology | \n", "(43.0833333333, 41.0) | \n", "Large | \n", "Small (2-4) | \n", "
| \n", " | language | \n", "LID | \n", "Gender.n | \n", "Gender.binned4 | \n", "Gender.Presence | \n", "VPolyagreement.Presence.v2 | \n", "VPolyagreement.Presence.v1 | \n", "
|---|---|---|---|---|---|---|---|
| 0 | \n", "Godoberi | \n", "1531 | \n", "3 | \n", "3 genders | \n", "True | \n", "False | \n", "False | \n", "
| 1 | \n", "Bininj Kun-Wok | \n", "655 | \n", "4 | \n", "4 genders | \n", "True | \n", "True | \n", "True | \n", "
| 2 | \n", "Luvale | \n", "553 | \n", "10 | \n", "more than 4 genders | \n", "True | \n", "True | \n", "False | \n", "
| 3 | \n", "North-Central Dargwa | \n", "2949 | \n", "3 | \n", "3 genders | \n", "True | \n", "True | \n", "True | \n", "
| 4 | \n", "Gaagudju | \n", "82 | \n", "4 | \n", "4 genders | \n", "True | \n", "True | \n", "True | \n", "
| \n", " | language_recipient | \n", "language_donor | \n", "reliability | \n", "adjectivizer | \n", "
|---|---|---|---|---|
| 0 | \n", "Resígaro | \n", "Bora | \n", "high | \n", "0 | \n", "
| 1 | \n", "Gurindji Kriol | \n", "Gurindji | \n", "high | \n", "0 | \n", "
| 2 | \n", "Copper Island Aleut | \n", "Russian | \n", "high | \n", "0 | \n", "
| 3 | \n", "Sakha | \n", "Mongolian | \n", "high | \n", "4 | \n", "
| 4 | \n", "Kalderash Romani | \n", "Romanian | \n", "high | \n", "1 | \n", "
| \n", " | Feature | \n", "Description | \n", "
|---|---|---|
| 0 | \n", "ICU17 | \n", "Is plurality in independent pronouns expressed... | \n", "
| 1 | \n", "ICU16 | \n", "Is plurality in independent pronouns expressed... | \n", "
| 2 | \n", "ICU15 | \n", "Is plurality in independent pronouns expressed... | \n", "
| 3 | \n", "ICU14 | \n", "Is an associative or collective plural disting... | \n", "
| 4 | \n", "ICU13 | \n", "Are nouns denoting inanimates marked for plural? | \n", "
| \n", " | Feature | \n", "Description | \n", "
|---|---|---|
| 0 | \n", "ICU10 | \n", "Is nominal plural marking obligatory? | \n", "
| 1 | \n", "ICU11 | \n", "Are nouns denoting humans marked for plural? | \n", "
| \n", " | language | \n", "coordinates | \n", "ICU10 | \n", "ICU10_desc | \n", "ICU11 | \n", "ICU11_desc | \n", "
|---|---|---|---|---|---|---|
| 0 | \n", "Tol | \n", "(14.66859, -87.03719) | \n", "0 | \n", "No | \n", "1 | \n", "Yes | \n", "
| 1 | \n", "San Blas Kuna | \n", "(9.15686, -78.3075) | \n", "0 | \n", "No | \n", "1 | \n", "Yes | \n", "
| 2 | \n", "Wayuu | \n", "(10.22515, -71.81012) | \n", "0 | \n", "No | \n", "1 | \n", "Yes | \n", "
| 3 | \n", "Northern Emberá | \n", "(7.127610000000001, -77.57396) | \n", "0 | \n", "No | \n", "1 | \n", "Yes | \n", "
| 4 | \n", "Páez | \n", "(2.61516, -76.31254) | \n", "0 | \n", "No | \n", "1 | \n", "Yes | \n", "
| \n", " | contribution_name | \n", "language | \n", "coordinates | \n", "glottocode | \n", "macroarea | \n", "phonemes | \n", "consonants | \n", "vowels | \n", "tones | \n", "source | \n", "inventory_page | \n", "
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", "Korean (SPA 1) | \n", "Korean | \n", "(37.5, 128.0) | \n", "kore1280 | \n", "Eurasia | \n", "40 | \n", "22 | \n", "18 | \n", "0 | \n", "https://archive.org/details/kor_SPA1979_phon | \n", "https://phoible.org/languages/kore1280 | \n", "
| 1 | \n", "KOREAN (UPSID 423) | \n", "Korean | \n", "(37.5, 128.0) | \n", "kore1280 | \n", "Eurasia | \n", "32 | \n", "21 | \n", "11 | \n", "~N/A~ | \n", "http://web.phonetik.uni-frankfurt.de/L/L2170.html | \n", "https://phoible.org/languages/kore1280 | \n", "
| 2 | \n", "Ket (SPA 2) | \n", "Ket | \n", "(63.7551, 87.5466) | \n", "kett1243 | \n", "Eurasia | \n", "32 | \n", "18 | \n", "14 | \n", "0 | \n", "https://archive.org/details/ket_SPA1979_phon | \n", "https://phoible.org/languages/kett1243 | \n", "
| 3 | \n", "KET (UPSID 399) | \n", "Ket | \n", "(63.7551, 87.5466) | \n", "kett1243 | \n", "Eurasia | \n", "25 | \n", "18 | \n", "7 | \n", "~N/A~ | \n", "http://web.phonetik.uni-frankfurt.de/L/L2706.html | \n", "https://phoible.org/languages/kett1243 | \n", "
| 4 | \n", "Lak (SPA 3) | \n", "Lak | \n", "(42.1328, 47.0809) | \n", "lakk1252 | \n", "Eurasia | \n", "69 | \n", "60 | \n", "9 | \n", "0 | \n", "https://archive.org/details/lbe_SPA1979_phon | \n", "https://phoible.org/languages/lakk1252 | \n", "
| \n", " | contribution_name | \n", "language | \n", "coordinates | \n", "glottocode | \n", "macroarea | \n", "phonemes | \n", "consonants | \n", "vowels | \n", "tones | \n", "source | \n", "inventory_page | \n", "
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", "Korean (SPA 1) | \n", "Korean | \n", "(37.5, 128.0) | \n", "kore1280 | \n", "Eurasia | \n", "40 | \n", "22 | \n", "18 | \n", "0 | \n", "https://archive.org/details/kor_SPA1979_phon | \n", "https://phoible.org/languages/kore1280 | \n", "
| 1 | \n", "Ket (SPA 2) | \n", "Ket | \n", "(63.7551, 87.5466) | \n", "kett1243 | \n", "Eurasia | \n", "32 | \n", "18 | \n", "14 | \n", "0 | \n", "https://archive.org/details/ket_SPA1979_phon | \n", "https://phoible.org/languages/kett1243 | \n", "
| 2 | \n", "Lak (SPA 3) | \n", "Lak | \n", "(42.1328, 47.0809) | \n", "lakk1252 | \n", "Eurasia | \n", "69 | \n", "60 | \n", "9 | \n", "0 | \n", "https://archive.org/details/lbe_SPA1979_phon | \n", "https://phoible.org/languages/lakk1252 | \n", "
| 3 | \n", "Kabardian (SPA 4) | \n", "Kabardian | \n", "(43.5082, 43.3918) | \n", "kaba1278 | \n", "Eurasia | \n", "56 | \n", "49 | \n", "7 | \n", "0 | \n", "https://archive.org/details/kbd_SPA1979_phon | \n", "https://phoible.org/languages/kaba1278 | \n", "
| 4 | \n", "Georgian (SPA 5) | \n", "Georgian | \n", "(41.850396999999994, 43.78613) | \n", "nucl1302 | \n", "Eurasia | \n", "35 | \n", "29 | \n", "6 | \n", "0 | \n", "https://archive.org/details/kat_SPA1979_phon | \n", "https://phoible.org/languages/nucl1302 | \n", "
| \n", " | InventoryID | \n", "Glottocode | \n", "ISO6393 | \n", "LanguageName | \n", "SpecificDialect | \n", "GlyphID | \n", "Phoneme | \n", "Allophones | \n", "Marginal | \n", "SegmentClass | \n", "... | \n", "retractedTongueRoot | \n", "advancedTongueRoot | \n", "periodicGlottalSource | \n", "epilaryngealSource | \n", "spreadGlottis | \n", "constrictedGlottis | \n", "fortis | \n", "raisedLarynxEjective | \n", "loweredLarynxImplosive | \n", "click | \n", "
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", "1 | \n", "kore1280 | \n", "kor | \n", "Korean | \n", "~N/A~ | \n", "0061 | \n", "a | \n", "a | \n", "~N/A~ | \n", "vowel | \n", "... | \n", "- | \n", "- | \n", "+ | \n", "- | \n", "- | \n", "- | \n", "0 | \n", "- | \n", "- | \n", "0 | \n", "
| 1 | \n", "1 | \n", "kore1280 | \n", "kor | \n", "Korean | \n", "~N/A~ | \n", "0061+02D0 | \n", "aː | \n", "aː | \n", "~N/A~ | \n", "vowel | \n", "... | \n", "- | \n", "- | \n", "+ | \n", "- | \n", "- | \n", "- | \n", "0 | \n", "- | \n", "- | \n", "0 | \n", "
| 2 | \n", "1 | \n", "kore1280 | \n", "kor | \n", "Korean | \n", "~N/A~ | \n", "00E6 | \n", "æ | \n", "ɛ æ | \n", "~N/A~ | \n", "vowel | \n", "... | \n", "- | \n", "- | \n", "+ | \n", "- | \n", "- | \n", "- | \n", "0 | \n", "- | \n", "- | \n", "0 | \n", "
| 3 | \n", "1 | \n", "kore1280 | \n", "kor | \n", "Korean | \n", "~N/A~ | \n", "00E6+02D0 | \n", "æː | \n", "æː | \n", "~N/A~ | \n", "vowel | \n", "... | \n", "- | \n", "- | \n", "+ | \n", "- | \n", "- | \n", "- | \n", "0 | \n", "- | \n", "- | \n", "0 | \n", "
| 4 | \n", "1 | \n", "kore1280 | \n", "kor | \n", "Korean | \n", "~N/A~ | \n", "0065 | \n", "e | \n", "e | \n", "~N/A~ | \n", "vowel | \n", "... | \n", "- | \n", "- | \n", "+ | \n", "- | \n", "- | \n", "- | \n", "0 | \n", "- | \n", "- | \n", "0 | \n", "
5 rows × 48 columns
\n", "| \n", " | InventoryID | \n", "Glottocode | \n", "ISO6393 | \n", "LanguageName | \n", "SpecificDialect | \n", "GlyphID | \n", "Phoneme | \n", "Allophones | \n", "Marginal | \n", "SegmentClass | \n", "... | \n", "retractedTongueRoot | \n", "advancedTongueRoot | \n", "periodicGlottalSource | \n", "epilaryngealSource | \n", "spreadGlottis | \n", "constrictedGlottis | \n", "fortis | \n", "raisedLarynxEjective | \n", "loweredLarynxImplosive | \n", "click | \n", "
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7570 | \n", "198 | \n", "afad1236 | \n", "aal | \n", "KOTOKO | \n", "~N/A~ | \n", "0063+02BC | \n", "cʼ | \n", "~N/A~ | \n", "False | \n", "consonant | \n", "... | \n", "0 | \n", "0 | \n", "- | \n", "- | \n", "- | \n", "+ | \n", "- | \n", "+ | \n", "- | \n", "- | \n", "
| 7802 | \n", "206 | \n", "ahte1237 | \n", "aht | \n", "AHTNA | \n", "~N/A~ | \n", "006B+02BC | \n", "kʼ | \n", "~N/A~ | \n", "False | \n", "consonant | \n", "... | \n", "0 | \n", "0 | \n", "- | \n", "- | \n", "- | \n", "+ | \n", "- | \n", "+ | \n", "- | \n", "- | \n", "
| 7920 | \n", "211 | \n", "qawa1238 | \n", "alc | \n", "QAWASQAR | \n", "~N/A~ | \n", "006B+02BC | \n", "kʼ | \n", "~N/A~ | \n", "False | \n", "consonant | \n", "... | \n", "0 | \n", "0 | \n", "- | \n", "- | \n", "- | \n", "+ | \n", "- | \n", "+ | \n", "- | \n", "- | \n", "
| 8131 | \n", "218 | \n", "hame1242 | \n", "amf | \n", "HAMER | \n", "~N/A~ | \n", "0071+02BC | \n", "qʼ | \n", "~N/A~ | \n", "False | \n", "consonant | \n", "... | \n", "0 | \n", "0 | \n", "- | \n", "- | \n", "- | \n", "+ | \n", "- | \n", "+ | \n", "- | \n", "- | \n", "
| 8157 | \n", "219 | \n", "amha1245 | \n", "amh | \n", "AMHARIC | \n", "~N/A~ | \n", "006B+02B7+02BC | \n", "kʷʼ | \n", "~N/A~ | \n", "False | \n", "consonant | \n", "... | \n", "0 | \n", "0 | \n", "- | \n", "- | \n", "- | \n", "+ | \n", "- | \n", "+ | \n", "- | \n", "- | \n", "
5 rows × 48 columns
\n", "Glottolog¶
You can access Glottolog data using lingtypology.glottolog
from lingtypology import glottolog
0. Table of Contents¶
1. Glottolog Usage¶
2. Glottolog Version¶
1. Usage ¶
You can use a number of functions to work with Glottolog data.
Get genealogy information:
glottolog.get_affiliations(('Russian', 'English'))
Get coordinates of a language:
glottolog.get_coordinates('Russian')
Get the Glottolog ID (aka Glottocode):
glottolog.get_glot_id('Russian')
Get coordinates by Glottocode:
glottolog.get_coordinates_by_glot_id('russ1263')
Get the macroarea:
glottolog.get_macro_area('Russian')
Get the ISO code:
glottolog.get_iso('Russian')
Get language by ISO code:
glottolog.get_by_iso('rus')
Get language by Glottocode:
glottolog.get_by_glot_id('russ1263')
Get Glottocode by ISO:
glottolog.get_glot_id_by_iso('rus')
Get ISO by Glottocode:
glottolog.get_iso_by_glot_id('russ1263')
2. Versions ¶
Each new release of lingtypology is shipped with the latest version of the Glottolog data. The information about the version of Glottolog can be retrieved using:
from lingtypology import glottolog
#Yet, I cannot guarantee that this tutorial is updated with each release.
#If you want to get your version, run this code on your machine.
glottolog.version
Nevertheless, if you want to get the newest release and do not wish to wait for the next version of lingtypology, you can download the version you wish locally by following these steps:
1) Download glottolog from here.
2) If you downloaded it as an archive, unpack it.
3) In your home directory make a folder and call it .lingtypology_data (with . in the beginning).
4) Move glottolog into .lingtypology_data.
5) Run the following command:
glottolog --repos=glottolog languoids
6) It will generate two small files (csv and json). Now you can delete everything except for these files from the directory.
Lingtypology¶
Lingtypology is a package that tries to bring functionality of the R
package
of the same name.
By now lingtypology is able to create interactive linguistic maps and has API for several linguistic databases.
There is a tutorial that allows to start using lingtypology:
Credits ¶
This Python package is inspired by the R package made by agricolamz.
Also this module uses JavaScript library Leaflet and its Python-wrapper Folium and Branca.
Also, special thanks to Xrotwang for helping me with the package.
Citation ¶
It will be most appreciated if you cite lingtypology. To find out the recommended way to do so, consult the readme.
License ¶
Copyright (C) 2018-2019 Michael Voronov
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
| lingtypology | index /home/misha/Проекты/lingtypology/lingtypology/lingtypology/lingtypology.py |
This module draws a map
| Modules | ||||||
| ||||||
| Classes | ||||||||||||||||||
|
| ||||||||||||||||||
Maps ¶
It is possible to draw interactive linguistic maps using lingtypology
import lingtypology
0. Table of Contents¶
1. Maps¶
1.1. Simplest example¶
1.2. Save, Render or Save as an image¶
1.3. Features¶
1.4. Map Customization¶
1.5. Popups¶
1.6. Accessing Glottolog¶
1.7. Customizing Features and Controls¶
1.8. Stroke Features¶
1.9. Heatmaps¶
1.10. Lines¶
1.11. Customizing markers¶
1.12. Start Location/Zoom shortcuts¶
1.13. Color Gradients¶
1.14. Minicharts¶
1.15. Overlapping Features¶
1.16. Using Existing folium.Map¶
1.17. Tiles¶
2. Real examples¶
2.1. Circassian Example¶
2.2. Another way¶
2.3. Consonants Example¶
1. Maps ¶
In this paragraph I will consider some basic features that you can use.
1.1. Simplest example ¶
The simplest script that draws a map with Romanian and Ukrainian languages will be:
m = lingtypology.LingMap(('Romanian', 'Afrikaans', 'Tlingit', 'Japanese'))
m.create_map()
If you have Glottocodes rather then language names, you can pass them as well (you need to set glottocode to True).
m = lingtypology.LingMap(('russ1263', 'afri1274', 'tlin1245', 'nucl1643'), glottocode=True)
m.create_map()
1.2. Save, Render or Save as Image ¶
Be advised that create_map() returns a Folium map. In this notebook it is used because the map may
be displayed this way.
To save your map as html run: m.save('map.html')
To get html as str run: m.render()
To get a png image run m.save_static(fname=fname) (if no arguments are given it will be returned as bytes).
Note: save_static is an experimental method.
m.save_static(fname='map.png')
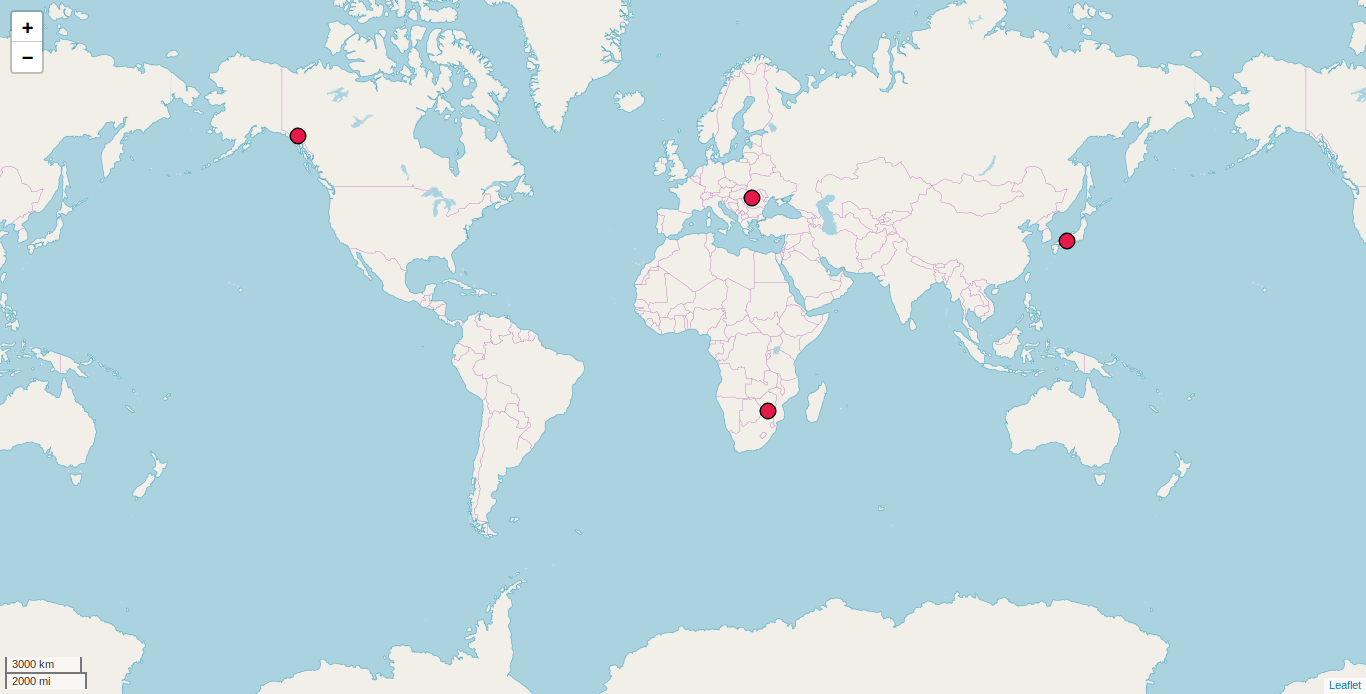
1.3. Features ¶
Simply drawing languages on a map is not very interesting. Let's say that we want to mark some morphological features as different colors.
languages = ["Adyghe", "Kabardian", "Polish", "Russian", "Bulgarian"]
features = ["Agglutinative", "Agglutinative", "Inflected", "Inflected", "Analythic"]
m = lingtypology.LingMap(languages)
m.add_features(features)
m.create_map()
1.4. Customizing the map ¶
As you can see, the map is not centered properly. It can be fixed with passing coordinates to the start_location attribute. You can change start zoom as well start_zoom.
Also, you can change colors using the colors attribute.
m.start_location = (40, 40)
m.start_zoom = 3
m.colors = ("#00FFFF", "#FF00FF", "#FFFF00")
m.create_map()
1.5. Popups ¶
You can add popups using add_popups method.
You can disable links to Glottolog by setting languages_in_popups attribute to False.
Basically, you can set any html-code in the popups.
contents = ('Caucasus', 'Caucasus', 'Europe', 'Europe', 'Europe')
html = '''
<a href="https://en.wikipedia.org/wiki/{data}" target="_blank">
{data}
</a>
'''
m.add_popups([html.format(data=popup) for popup in contents])
m.languages_in_popups = False
m.create_map()
affs = lingtypology.glottolog.get_affiliations(languages)
m.add_popups(affs)
m.create_map()
1.7. Customizing features and controls ¶
You can pass additional parameters to the add_features method.
If for some reason you do not wish to use colors, you could use shapes.
If you want to add controls, you can do it as well.
m.add_features(features, use_shapes=True, control=True)
m.create_map()
1.8. Stroke features ¶
It is possible to add another set of features to strokes of markers.
stroke_features = ['Ergative', 'Ergative', 'Accusative', 'Accusative', 'Accusative']
m = lingtypology.LingMap(languages)
m.add_features(features)
m.add_stroke_features(stroke_features)
m.create_map()
from lingtypology.db_apis import Wals
wals_page = Wals('1a').get_df()
#First initialize LingMap without languages
m = lingtypology.LingMap()
#Add heatmap from the Wals data
m.add_heatmap(wals_page[wals_page._1A == 'Large'].coordinates)
#Let's also add a title to the map
m.title = 'Large Consonant Inventories'
m.create_map()
1.10. Lines ¶
Let's say we have this list of languages:
balkan = ['Modern Greek', 'Romanian', 'Bulgarian', 'Macedonian', 'Gheg Albanian']
other = ['Ukrainian', 'Turkish', 'Italian']
languages_all = balkan + other
We want the ones from Balkan sprachbund connected with lines with a popup that says 'Balkan'.
#Let's get the coordinates that we need to draw a line
coordinates = map(lingtypology.glottolog.get_coordinates, balkan)
m = lingtypology.LingMap(languages_all)
m.add_line(coordinates, popup='Balkan')
m.start_location = (43, 27)
m.start_zoom = 5
m.create_map()
1.11. Customizing markers ¶
It is possible to set opacity and width of markers.
m = lingtypology.LingMap(languages)
m.add_features(features, radius=7, opacity=0.9)
m.add_stroke_features(stroke_features, opacity=0.7)
m.create_map()
1.12. Start Location/Zoom shortcuts ¶
There are some shortcuts that can allow not to choose start_location and start_zoom manually.
m = lingtypology.LingMap([
'Irish', 'Estonian', 'Norwegian', 'Romanian', 'Polish',
'Italian', 'Turkish', 'French', 'English', 'Spanish'
])
m.start_location = 'Central Europe'
m.create_map()
Full list of shortcuts:
m.start_location_mapping
1.13. Color gradients ¶
There are two ways to use color gradients. Let's say we have features called "Millions of native speakers".
native_speakers = [0, 1, 5, 24, 44, 62, 78, 78, 378, 442]
m.legend_title = 'Native speakers (mln)'
m.legend_position = 'topright'
The first way is simply pass the features as numeric:
m.add_features(native_speakers, numeric=True)
m.colormap_colors = ('white', 'red')
m.create_map()
Or you can simply set attribute color to a gradient using gradient function.
m.add_features(native_speakers)
m.colors = lingtypology.gradient(10, color2='red')
m.create_map()
1.14. Minicharts ¶
You can add minicharts to the map using add_minicharts method. Just pass all the data.
Note, that if you are passing data as anything except for pandas.Series you should specify names
parameter (e.g. names=('consonants', 'vowels')).
import pandas
data = pandas.read_csv(
'https://raw.githubusercontent.com/ropensci/lingtypology/master/database_creation/ejective_and_n_consonants.csv',
delimiter=',',
header=0,
)
m = lingtypology.LingMap(data.language)
m.add_minicharts(data.consonants, data.vowels)
m.create_map()
It is possible to customize them using these parameters:
colors
Colors for your features. If not given, default colors (LingMap().colors) will be used.size
Size of the chart. Please, bear in mind that they should be small. Default:0.6.startangle
Start angle. Default90. Pie-chart only.labels
Show values inside the chart. Pie-chart only.textprops
Set text properties (matplotlibformat). Default:None. E.g.:textprops={'color': 'red'}.
m = lingtypology.LingMap(data.language)
m.add_minicharts(
data.consonants, data.vowels,
colors = ('#0020c2', '#c22000'),
size = 0.8,
startangle = 45,
labels = True,
textprops = {'color': 'white'}
)
m.create_map()
You can also use bar charts.
m = lingtypology.LingMap(data.language)
m.add_minicharts(
data.consonants, data.vowels,
typ = 'bar',
colors = ('blue', 'red'),
size = 0.4
)
m.create_map()
1.15. Overlapping Features ¶
Let's say we want to see info about whether language:
- is ergative;
- has cases;
- is slavic.
It is possible with add_overlapping_features method. It allows to draw several markers of different radius and color for each given language.
languages = ('Tsakhur', 'Russian', 'Bulgarian')
m = lingtypology.LingMap(languages)
m.add_overlapping_features([
['ergative', 'has cases'],
['has cases', 'slavic'],
['slavic']
])
m.create_map()
You can use these parameters:
radiusDefault radius. Default: 7.radius_incrementRadius increment. By how much the size of the marker increases with each additional feature. Default: 4.mappingIf you want to use custom colors, use this parameter. If it is not given, the default color will be used.
m.add_overlapping_features(
[
['ergative', 'has cases'],
['has cases', 'slavic'],
['slavic']
],
radius = 10,
radius_increment = 5,
mapping = {
'ergative': '#e6194b',
'has cases': '#4be619',
'slavic': '#194be6'
}
)
m.create_map()
1.16. Using Existing Folium Map ¶
If you already have a folium.Map that you want to edit using lingtypology, you can pass it as base_map attribute.
import folium
folium_map = folium.Map((0, 0), zoom_start=2)
marker = folium.Marker((0, 0))
icon = folium.DivIcon(
html='<img src="https://raw.githubusercontent.com/OneAdder' + \
'/lingtypology/master/data_processing/waifu6060.jpg"></img>'
)
marker.add_child(icon)
folium_map.add_child(marker)
m = lingtypology.LingMap(('Russian', 'Afrikaans'))
m.base_map = folium_map
m.create_map()
m = lingtypology.LingMap([
'Irish', 'Estonian', 'Norwegian', 'Romanian', 'Polish',
'Italian', 'Turkish', 'French', 'English', 'Spanish'
])
m.add_features(native_speakers, numeric=True)
m.colormap_colors = ('white', 'red')
m.legend_title = 'Native Speakers'
m.legend_position = 'topright'
m1 = m.create_map()
m2 = lingtypology.LingMap(data.language)
m2.base_map = m1
m2.legend_title = 'Consonants/Vowels'
m2.add_minicharts(data.consonants, data.vowels)
m2.create_map()
1.17. Using Different Tiles ¶
You can change tiles using tiles attribute. Let's use Stamen Terrain.
m2 = lingtypology.LingMap(data.language)
m2.tiles = 'Stamen Terrain'
m2.legend_title = 'Consonants/Vowels'
m2.add_minicharts(data.consonants, data.vowels, colors=('black', 'white'))
m2.create_map()
import pandas
circassian = pandas.read_csv(
'https://raw.githubusercontent.com/ropensci/lingtypology/master/database_creation/circassian.csv',
delimiter=',',
header=0,
)
circassian.head()
coordinates = zip(list(circassian.latitude), list(circassian.longitude))
dialects = circassian.dialect
languages = circassian.language
popups = circassian.village
#Creating LingMap object
m = lingtypology.LingMap(languages)
#Setting up start location
m.start_location = (44.21, 42.32)
#Setting up start zoom
m.start_zoom = 7
#Inner features < dialect
m.add_features(dialects, opacity=0.7)
#Outer features < language
m.add_stroke_features(languages, opacity=0.8)
#Popups < village
m.add_popups(popups)
#Tooltips < language
m.add_tooltips(languages)
#Custom coordinates (override the ones from Glottolog)
m.add_custom_coordinates(coordinates)
#Inner legend title and position
m.legend_title = 'Dialects'
m.legend_position = 'bottomright'
#Outer legend title and position
m.stroke_legend_title = 'Languages'
m.stroke_legend_position = 'topright'
m.create_map()
2.2. Another way ¶
If you are used to the R package, you may find this way to program the second example more appealing.
However, it is not recommended because most of customization is impossible.
coordinates = zip(list(circassian.latitude), list(circassian.longitude))
dialects = circassian.dialect
languages = circassian.language
popups = circassian.village
lingtypology.map_feature(
languages,
custom_coordinates = coordinates,
features = dialects,
stroke_features = languages,
popups = popups,
tooltips = languages,
legend_title = 'Dialects',
legend_position = 'bottomright',
stroke_legend_title = 'Languages',
stroke_legend_position = 'topright',
start_zoom = 7,
start_location = (44.21, 42.32),
save_html = 'circassian.html',
)
data = pandas.read_csv(
'https://raw.githubusercontent.com/ropensci/lingtypology/master/database_creation/ejective_and_n_consonants.csv',
delimiter=',',
header=0,
)
m = lingtypology.LingMap(data.language)
m.legend_title = 'Amount of consonants'
m.add_tooltips(data.consonants)
#If numeric is True, it will look like this
m.add_features(data.consonants, numeric=True)
m.create_map()
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.3. Features \n",
"Simply drawing languages on a map is not very interesting. Let's say that we want to mark some morphological features as different colors."
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"| \n", " | latitude | \n", "longitude | \n", "village | \n", "district | \n", "dialect | \n", "language | \n", "
|---|---|---|---|---|---|---|
| 0 | \n", "45.183330 | \n", "39.666670 | \n", "Khatukay | \n", "ra | \n", "Temirgoy | \n", "Adyghe | \n", "
| 1 | \n", "43.092518 | \n", "43.522085 | \n", "Psygansu | \n", "kbr | \n", "Baksan | \n", "Kabardian | \n", "
| 2 | \n", "43.217748 | \n", "43.738020 | \n", "Verkhny Lesken | \n", "kbr | \n", "Baksan | \n", "Kabardian | \n", "
| 3 | \n", "43.260246 | \n", "43.653788 | \n", "Zhemtala | \n", "kbr | \n", "Baksan | \n", "Kabardian | \n", "
| 4 | \n", "43.317842 | \n", "43.876519 | \n", "Erokko | \n", "kbr | \n", "Baksan | \n", "Kabardian | \n", "
- Abadzex
- Baksan
- Besleney
- Bzhedukh
- Kuban
- Malkin
- Shapsug
- Temirgoy
- Terek
- Xakuch
- Adyghe
- Kabardian
- ◧Abadzex
- ◼Baksan
- ▣Besleney
- ◐Bzhedukh
- △Kuban
- ◯Malkin
- ◉Shapsug
- ⬤Temirgoy
- ▲Terek
- ◻Xakuch
- 8
- 47
- 11
- 161
- ⬤Agglutinative
- ▲Analythic
- ◼Inflected
- no
- yes
- Average
- Large
- Moderately large
- Moderately small
- Small
-
{{data}}
''' if self.languages_in_popups: if self.popups: if parse_html: raise LingMapError(''' It is impossible to add both language links and large HTML strings. You can either not use html_popups option or set ling_map_object.languages_in_popups = False. ''') popup = folium.Popup(popup_href.format(lingtypology.glottolog.get_glot_id(language), language) + self.popups[i]) else: popup = folium.Popup(popup_href.format(lingtypology.glottolog.get_glot_id(language), language)) popup.add_to(marker) else: if self.popups: if parse_html: iframe = folium.IFrame(html=self.popups[i]) popup = folium.Popup(iframe) else: popup = folium.Popup(self.popups[i]) popup.add_to(marker) def _create_legend(self, m, legend_data, title='Legend', position='bottomright'): """Creates legend and adds it to the map m: folium.Map The map. legend_data: str Html string with the contents for the legend. title: str, default 'Legend' Legend title. position: str, default 'bottomright' Legend position. """ module_directory = os.path.dirname(os.path.realpath(__file__)) with open(os.path.join(module_directory, 'legend.html'), 'r', encoding='utf-8') as f: template = f.read() template = jinja2.Template(template) template = template.render(data=legend_data, position=position, title=title, use_shapes=self.use_shapes, legend_id=self._legend_id) template = '{% macro html(this, kwargs) %}' + template + '{% endmacro %}' macro = branca.element.MacroElement() macro._template = branca.element.Template(template) m.get_root().add_child(macro) self._legend_id += 1 def _create_heatmap(self, m, heatmap): """Creates heatmap and adds it to the map m: folium.Map The map. heatmap: list List of coordinates. """ folium.plugins.HeatMap(heatmap).add_to(m) def _create_title(self, m, title): """Creates title and adds it to the map m: folium.Map The map. title: str Title. """ template = '''
' for name, value in zip(names, minichart): popup += '{}: {}
'.format(name, str(value)) self.popups.append(popup) plt.clf() plt.close() def add_overlapping_features(self, marker_groups, radius=7, radius_increment=4, mapping=None): """Add overlapping features For example, if you want to draw on map whether language 'is ergative', 'is slavic', 'is spoken in Russia'. It will draw several markers of different size for each location. """ self.marker_groups = marker_groups self.radius = radius self.radius_increment = radius_increment self.custom_mapping = mapping def _sanity_check(self, features, feature_name='corresponding lists'): """Checks if length of features, popups and tooltips is equal to the length of languages features: list feature_name: str, default 'corresponding list' feature_name is what will appear in the exception. """ if len(self.languages) != len(features): raise LingMapError("Length of languages and {} does not match".format(feature_name)) def create_map(self): """Draw the map Gets all necessary attributes and draws everything on the map. How it works: * Set up start location and zoom if start_location is passed as shortcut. * Create folium.Map object using [self.start_location, zoom_start=self.start_zoom, control_scale=self.control_scale, prefer_canvas=self.prefer_canvas] * Create default_group (folium.FeatureGroup) * Declare lists: markers, strokes, s_markers, s_strokes * Check whether minimap, rectangles, lines and title are here and draw them. * If the user sets self.heatmap_only to True, draw it and return the map. {{ first ending }} * If user passes minicharts: * Walk in self.languages: * Apply custom coordinates or the ones from Glottolog. * Set folium.Marker with plot SVG as folium.DivIcon * Create popups with links to Glottolog (if necessary) and data from plots. * Draw the logend using names from plots and colors. * Return the map. {{ second ending }} * If user passes overlapping_features (LingMap().marker_groups): * If color_mapping is not given, make it. * Walk in languages: * Get coordinates if not given. * Set markers, popups and tooltips. * Create legend. {{ third ending }} * If features are given, prepare them (_prepare_features). This includes: * Creating folium.FeatureGroup. * Creating data for legend. * Storing info on features as list of tuples (len = 2) * The first element: color (HEX) of shape (Unicode) * The second element: folium.FeatureGroup * If stroke features are given, prepare them as well. * Walk in languages: * Apply custom coordinates or the ones from Glottolog. * Create unified marker using: coordinates, color/shape for features and color for stroke features. Unified marker is a dict that consists of information necessary to draw 1-4 markers (more look in docstring for _create_unified_marker. * Create popup for the marker (_create_popups method). * Create tooltips. * Append the unified_marker to the the folium.FeatureGroup. * If features are numeric: * Add them to the default FeatureGroup. * Draw the legend (_create_legend). * If not: * Add them to proper FeatureGroups. * If LayerControl if asked for, draw it. * Draw the legend (_create_legend). * If heatmap is asked for, draw it (_create_heatmap). * Return the map. {{true ending}} Returns ---------- m: folium.Map """ if isinstance(self.start_location, str): if not self.start_location in self.start_location_mapping: raise LingMapError('No such start location shortcut. Try passing coordinates.') mapped_location_and_zoom = self.start_location_mapping[self.start_location] self.start_location = mapped_location_and_zoom['start_location'] self.start_zoom = mapped_location_and_zoom['start_zoom'] if self.base_map: m = self.base_map else: m = folium.Map(location=self.start_location, zoom_start=self.start_zoom, control_scale=self.control_scale, prefer_canvas=self.prefer_canvas, tiles=self.tiles) default_group = folium.FeatureGroup() markers = [] strokes = [] s_markers = [] s_strokes = [] if self.minimap: minimap = folium.plugins.MiniMap(**self.minimap) m.add_child(minimap) if self.rectangles: for rectangle in self.rectangles: folium.Rectangle(**rectangle).add_to(m) if self.lines: for line in self.lines: folium.PolyLine(**line).add_to(m) if self.title: self._create_title(m, self.title) if self.heatmap_only: if self.heatmap: self._create_heatmap(m, self.heatmap) #If we don't draw markers, we're done here return m if self.minicharts: #we'll draw minicharts separately for i, language in enumerate(self.languages): coordinates = self._get_coordinates(language, i) if not coordinates: continue marker = folium.Marker(coordinates, self.minicharts[i]) if self.languages_in_popups or self.minichart_names: popup_contents = '' if self.languages_in_popups: popup_href = '''{}''' popup_contents += popup_href.format(lingtypology.glottolog.get_glot_id(language), language) if self.popups: marker.add_child(folium.Popup(popup_contents + self.popups[i])) else: marker.add_child(folium.Popup(popup_contents)) if self.tooltips: tooltip = folium.Tooltip(self.tooltips[i]) tooltip.add_to(marker) m.add_child(marker) if self.minichart_names: legend_data = '' for i, name in enumerate(self.minichart_names): legend_data += '