Coverage report: 50%
Files Functions Classes
coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
{{ oauth_error }}
{% endblock %} ``` 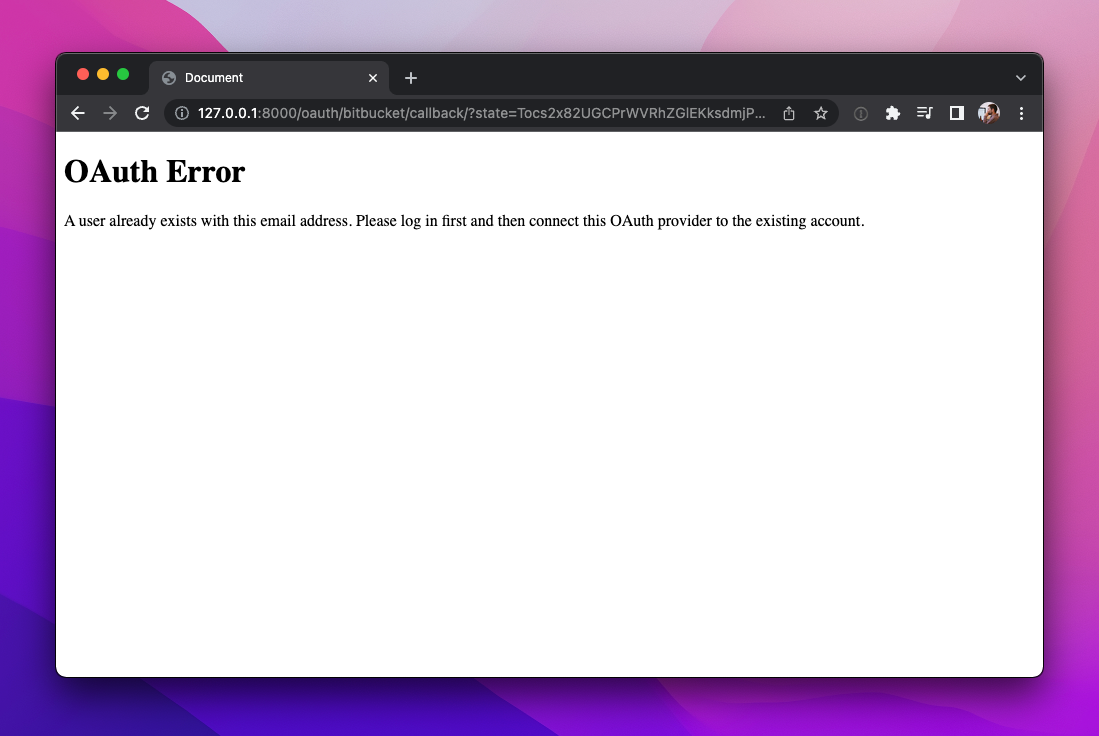 ### Connecting and disconnecting OAuth accounts To connect and disconnect OAuth accounts, you can add a series of forms to a user/profile settings page. Here's an very basic example: ```html {% extends "base.html" %} {% block content %} Hello {{ request.user }}!{{ oauth_error }}
{% endblock %} ��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������plain_oauth-0.9.0/provider_examples/__init__.py�����������������������������������������������������0000644�0000000�0000000�00000000000�13615410400�016572� 0����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������plain_oauth-0.9.0/provider_examples/bitbucket.py����������������������������������������������������0000644�0000000�0000000�00000004424�13615410400�017025� 0����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import datetime import requests from plain.oauth.providers import OAuthProvider, OAuthToken, OAuthUser from plain.utils import timezone class BitbucketOAuthProvider(OAuthProvider): authorization_url = "https://bitbucket.org/site/oauth2/authorize" def _get_token(self, request_data): response = requests.post( "https://bitbucket.org/site/oauth2/access_token", auth=(self.get_client_id(), self.get_client_secret()), headers={ "Accept": "application/json", }, data=request_data, ) response.raise_for_status() data = response.json() return OAuthToken( access_token=data["access_token"], refresh_token=data["refresh_token"], access_token_expires_at=timezone.now() + datetime.timedelta(seconds=data["expires_in"]), ) def get_oauth_token(self, *, code, request): return self._get_token( { "grant_type": "authorization_code", "code": code, "redirect_uri": self.get_callback_url(request=request), } ) def refresh_oauth_token(self, *, oauth_token): return self._get_token( { "grant_type": "refresh_token", "refresh_token": oauth_token.refresh_token, } ) def get_oauth_user(self, *, oauth_token): response = requests.get( "https://api.bitbucket.org/2.0/user", headers={ "Authorization": f"Bearer {oauth_token.access_token}", }, ) response.raise_for_status() user_id = response.json()["uuid"] username = response.json()["username"] response = requests.get( "https://api.bitbucket.org/2.0/user/emails", headers={ "Authorization": f"Bearer {oauth_token.access_token}", }, ) response.raise_for_status() confirmed_primary_email = [ x["email"] for x in response.json()["values"] if x["is_primary"] and x["is_confirmed"] ][0] return OAuthUser( id=user_id, email=confirmed_primary_email, username=username, ) ��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������plain_oauth-0.9.0/provider_examples/github.py�������������������������������������������������������0000644�0000000�0000000�00000006264�13615410400�016337� 0����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import datetime import requests from plain.oauth.exceptions import OAuthError from plain.oauth.providers import OAuthProvider, OAuthToken, OAuthUser from plain.utils import timezone class GitHubOAuthProvider(OAuthProvider): authorization_url = "https://github.com/login/oauth/authorize" github_token_url = "https://github.com/login/oauth/access_token" github_user_url = "https://api.github.com/user" github_emails_url = "https://api.github.com/user/emails" def _get_token(self, request_data): response = requests.post( self.github_token_url, headers={ "Accept": "application/json", }, data=request_data, ) response.raise_for_status() data = response.json() oauth_token = OAuthToken( access_token=data["access_token"], ) # Expiration and refresh tokens are optional in GitHub depending on the app if "expires_in" in data: oauth_token.access_token_expires_at = timezone.now() + datetime.timedelta( seconds=data["expires_in"] ) if "refresh_token" in data: oauth_token.refresh_token = data["refresh_token"] if "refresh_token_expires_in" in data: oauth_token.refresh_token_expires_at = timezone.now() + datetime.timedelta( seconds=data["refresh_token_expires_in"] ) return oauth_token def get_oauth_token(self, *, code, request): return self._get_token( { "client_id": self.get_client_id(), "client_secret": self.get_client_secret(), "code": code, } ) def refresh_oauth_token(self, *, oauth_token): return self._get_token( { "client_id": self.get_client_id(), "client_secret": self.get_client_secret(), "refresh_token": oauth_token.refresh_token, "grant_type": "refresh_token", } ) def get_oauth_user(self, *, oauth_token): response = requests.get( self.github_user_url, headers={ "Accept": "application/json", "Authorization": f"token {oauth_token.access_token}", }, ) response.raise_for_status() data = response.json() user_id = data["id"] username = data["login"] # Use the verified, primary email address (not the public profile email, which is optional anyway) response = requests.get( self.github_emails_url, headers={ "Accept": "application/json", "Authorization": f"token {oauth_token.access_token}", }, ) response.raise_for_status() try: verified_primary_email = [ x["email"] for x in response.json() if x["primary"] and x["verified"] ][0] except IndexError: raise OAuthError("A verified primary email address is required on GitHub") return OAuthUser( id=user_id, email=verified_primary_email, username=username, ) ��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������plain_oauth-0.9.0/provider_examples/gitlab.py�������������������������������������������������������0000644�0000000�0000000�00000003336�13615410400�016314� 0����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import requests from plain.oauth.providers import OAuthProvider, OAuthToken, OAuthUser class GitLabOAuthProvider(OAuthProvider): authorization_url = "https://gitlab.com/oauth/authorize" def _get_token(self, request_data): request_data["client_id"] = self.get_client_id() request_data["client_secret"] = self.get_client_secret() response = requests.post( "https://gitlab.com/oauth/token", headers={ "Accept": "application/json", }, data=request_data, ) response.raise_for_status() data = response.json() return OAuthToken( access_token=data["access_token"], refresh_token=data["refresh_token"], # expires_in is missing in response? ) def get_oauth_token(self, *, code, request): return self._get_token( { "grant_type": "authorization_code", "code": code, "redirect_uri": self.get_callback_url(request=request), } ) def refresh_oauth_token(self, *, oauth_token): return self._get_token( { "grant_type": "refresh_token", "refresh_token": oauth_token.refresh_token, } ) def get_oauth_user(self, *, oauth_token): response = requests.get( "https://gitlab.com/api/v4/user", headers={ "Authorization": f"Bearer {oauth_token.access_token}", }, ) response.raise_for_status() data = response.json() return OAuthUser( id=data["id"], email=data["email"], username=data["username"], ) ��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������plain_oauth-0.9.0/tests/test_backends.py������������������������������������������������������������0000644�0000000�0000000�00000003260�13615410400�015271� 0����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������from plain.oauth.providers import OAuthProvider, OAuthToken, OAuthUser class DummyProvider(OAuthProvider): def get_oauth_token(self, *, code, request): return OAuthToken( access_token="dummy_token", ) def get_oauth_user(self, *, oauth_token): return OAuthUser( id="dummy_user_id", username="dummy_username", email="dummy@example.com", ) def check_request_state(self, *, request): """Don't check the state""" return def test_single_backend(db, client, settings): settings.OAUTH_LOGIN_PROVIDERS = { "dummy": { "class": "test_backends.DummyProvider", "kwargs": { "client_id": "dummy_client_id", "client_secret": "dummy_client_secret", "scope": "dummy_scope", }, } } response = client.get("/oauth/dummy/callback/?code=test_code&state=dummy_state") assert response.status_code == 302 assert response.url == "/" # Now logged in response = client.get("/") assert response.user def test_multiple_backends(db, client, settings): settings.OAUTH_LOGIN_PROVIDERS = { "dummy": { "class": "test_backends.DummyProvider", "kwargs": { "client_id": "dummy_client_id", "client_secret": "dummy_client_secret", "scope": "dummy_scope", }, } } response = client.get("/oauth/dummy/callback/?code=test_code&state=dummy_state") assert response.status_code == 302 assert response.url == "/" # Now logged in response = client.get("/") assert response.user ������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������plain_oauth-0.9.0/tests/test_checks.py��������������������������������������������������������������0000644�0000000�0000000�00000003426�13615410400�014763� 0����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������from plain.auth import get_user_model from plain.oauth.models import OAuthConnection def test_oauth_provider_keys_check_pass(db, settings): settings.OAUTH_LOGIN_PROVIDERS = { "google": { "client_id": "test_client_id", "client_secret": "test_client_secret", }, "foo": { "client_id": "test_client_id", "client_secret": "test_client_secret", }, } user = get_user_model().objects.create( username="test_user", email="test@example.com" ) OAuthConnection.objects.create( user=user, provider_key="google", provider_user_id="test_provider_user_id", access_token="test", ) errors = OAuthConnection.check(databases=["default"]) assert len(errors) == 0 def test_oauth_provider_keys_check_fail(db, settings): settings.OAUTH_LOGIN_PROVIDERS = { "google": { "client_id": "test_client_id", "client_secret": "test_client_secret", }, "foo": { "client_id": "test_client_id", "client_secret": "test_client_secret", }, } user = get_user_model().objects.create( username="test_user", email="test@example.com" ) OAuthConnection.objects.create( user=user, provider_key="google", provider_user_id="test_provider_user_id", access_token="test", ) OAuthConnection.objects.create( user=user, provider_key="bar", provider_user_id="test_provider_user_id", access_token="test", ) errors = OAuthConnection.check(databases=["default"]) assert len(errors) == 1 assert ( errors[0].msg == "The following OAuth providers are in the database but not in the settings: bar" ) ������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������plain_oauth-0.9.0/tests/test_providers.py�����������������������������������������������������������0000644�0000000�0000000�00000040735�13615410400�015544� 0����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import datetime from plain.auth import get_user_model from plain.oauth.models import OAuthConnection from plain.oauth.providers import OAuthProvider, OAuthToken, OAuthUser class DummyProvider(OAuthProvider): authorization_url = "https://example.com/oauth/authorize" def generate_state(self) -> str: return "dummy_state" def refresh_oauth_token(self, *, oauth_token: OAuthToken) -> OAuthToken: return OAuthToken( access_token="refreshed_dummy_access_token", refresh_token="refreshed_dummy_refresh_token", access_token_expires_at=datetime.datetime( 2029, 1, 1, 0, 0, tzinfo=datetime.UTC ), refresh_token_expires_at=datetime.datetime( 2029, 1, 2, 0, 0, tzinfo=datetime.UTC ), ) def get_oauth_token(self, *, code, request) -> OAuthToken: return OAuthToken( access_token="dummy_access_token", refresh_token="dummy_refresh_token", access_token_expires_at=datetime.datetime( 2020, 1, 1, 0, 0, tzinfo=datetime.UTC ), refresh_token_expires_at=datetime.datetime( 2020, 1, 2, 0, 0, tzinfo=datetime.UTC ), ) def get_oauth_user(self, *, oauth_token: OAuthToken) -> OAuthUser: return OAuthUser( id="dummy_id", email="dummy@example.com", username="dummy_username", ) def test_dummy_signup(db, client, settings): settings.OAUTH_LOGIN_PROVIDERS = { "dummy": { "class": "test_providers.DummyProvider", "kwargs": { "client_id": "dummy_client_id", "client_secret": "dummy_client_secret", "scope": "dummy_scope", }, } } assert get_user_model().objects.count() == 0 assert OAuthConnection.objects.count() == 0 # Login required for this view response = client.get("/") assert response.status_code == 302 assert response.url == "/login/?next=/" # User clicks the login link (form submit) response = client.post("/oauth/dummy/login/") assert response.status_code == 302 assert ( response.url == "https://example.com/oauth/authorize?client_id=dummy_client_id&redirect_uri=https%3A%2F%2Ftestserver%2Foauth%2Fdummy%2Fcallback%2F&response_type=code&scope=dummy_scope&state=dummy_state" ) # Provider redirects to the callback url response = client.get("/oauth/dummy/callback/?code=test_code&state=dummy_state") assert response.status_code == 302 assert response.url == "/" # Now logged in response = client.get("/") assert response.status_code == 200 assert b"Hello dummy_username!\n" in response.content # Check the user and connection that was created user = response.user assert user.username == "dummy_username" assert user.email == "dummy@example.com" connections = user.oauth_connections.all() assert len(connections) == 1 assert connections[0].provider_key == "dummy" assert connections[0].provider_user_id == "dummy_id" assert connections[0].access_token == "dummy_access_token" assert connections[0].refresh_token == "dummy_refresh_token" assert connections[0].access_token_expires_at == datetime.datetime( 2020, 1, 1, 0, 0, tzinfo=datetime.UTC ) assert connections[0].refresh_token_expires_at == datetime.datetime( 2020, 1, 2, 0, 0, tzinfo=datetime.UTC ) assert get_user_model().objects.count() == 1 assert OAuthConnection.objects.count() == 1 def test_dummy_login_connection(db, client, settings): settings.OAUTH_LOGIN_PROVIDERS = { "dummy": { "class": "test_providers.DummyProvider", "kwargs": { "client_id": "dummy_client_id", "client_secret": "dummy_client_secret", "scope": "dummy_scope", }, } } assert get_user_model().objects.count() == 0 assert OAuthConnection.objects.count() == 0 # Create a user user = get_user_model().objects.create( username="dummy_username", email="dummy@example.com" ) OAuthConnection.objects.create( user=user, provider_key="dummy", provider_user_id="dummy_id", access_token="dummy_access_token", refresh_token="dummy_refresh_token", access_token_expires_at=datetime.datetime( 2020, 1, 1, 0, 0, tzinfo=datetime.UTC ), refresh_token_expires_at=datetime.datetime( 2020, 1, 2, 0, 0, tzinfo=datetime.UTC ), ) assert get_user_model().objects.count() == 1 assert OAuthConnection.objects.count() == 1 # Login required for this view response = client.get("/") assert response.status_code == 302 assert response.url == "/login/?next=/" # User clicks the login link (form submit) response = client.post("/oauth/dummy/login/") assert response.status_code == 302 assert ( response.url == "https://example.com/oauth/authorize?client_id=dummy_client_id&redirect_uri=https%3A%2F%2Ftestserver%2Foauth%2Fdummy%2Fcallback%2F&response_type=code&scope=dummy_scope&state=dummy_state" ) # Provider redirects to the callback url response = client.get("/oauth/dummy/callback/?code=test_code&state=dummy_state") assert response.status_code == 302 assert response.url == "/" # Now logged in response = client.get("/") assert response.status_code == 200 assert b"Hello dummy_username!\n" in response.content # Check the user and connection that was created user = response.user assert user.username == "dummy_username" assert user.email == "dummy@example.com" connections = user.oauth_connections.all() assert len(connections) == 1 assert connections[0].provider_key == "dummy" assert connections[0].provider_user_id == "dummy_id" assert connections[0].access_token == "dummy_access_token" assert connections[0].refresh_token == "dummy_refresh_token" assert connections[0].access_token_expires_at == datetime.datetime( 2020, 1, 1, 0, 0, tzinfo=datetime.UTC ) assert connections[0].refresh_token_expires_at == datetime.datetime( 2020, 1, 2, 0, 0, tzinfo=datetime.UTC ) assert get_user_model().objects.count() == 1 assert OAuthConnection.objects.count() == 1 def test_dummy_login_without_connection(db, client, settings): settings.OAUTH_LOGIN_PROVIDERS = { "dummy": { "class": "test_providers.DummyProvider", "kwargs": { "client_id": "dummy_client_id", "client_secret": "dummy_client_secret", "scope": "dummy_scope", }, } } assert get_user_model().objects.count() == 0 assert OAuthConnection.objects.count() == 0 # Create a user get_user_model().objects.create( username="dummy_username", email="dummy@example.com" ) assert get_user_model().objects.count() == 1 assert OAuthConnection.objects.count() == 0 # Login required for this view response = client.get("/") assert response.status_code == 302 assert response.url == "/login/?next=/" # User clicks the login link (form submit) response = client.post("/oauth/dummy/login/") assert response.status_code == 302 assert ( response.url == "https://example.com/oauth/authorize?client_id=dummy_client_id&redirect_uri=https%3A%2F%2Ftestserver%2Foauth%2Fdummy%2Fcallback%2F&response_type=code&scope=dummy_scope&state=dummy_state" ) # Provider redirects to the callback url response = client.get("/oauth/dummy/callback/?code=test_code&state=dummy_state") assert response.status_code == 400 assert b"OAuth Error" in response.content def test_dummy_connect(db, client, settings): settings.OAUTH_LOGIN_PROVIDERS = { "dummy": { "class": "test_providers.DummyProvider", "kwargs": { "client_id": "dummy_client_id", "client_secret": "dummy_client_secret", "scope": "dummy_scope", }, } } assert get_user_model().objects.count() == 0 assert OAuthConnection.objects.count() == 0 # Create a user user = get_user_model().objects.create( username="dummy_username", email="dummy@example.com" ) assert get_user_model().objects.count() == 1 assert OAuthConnection.objects.count() == 0 client.force_login(user) response = client.post("/oauth/dummy/connect/") assert response.status_code == 302 assert ( response.url == "https://example.com/oauth/authorize?client_id=dummy_client_id&redirect_uri=https%3A%2F%2Ftestserver%2Foauth%2Fdummy%2Fcallback%2F&response_type=code&scope=dummy_scope&state=dummy_state" ) # Provider redirects to the callback url response = client.get("/oauth/dummy/callback/?code=test_code&state=dummy_state") assert response.status_code == 302 assert response.url == "/" # Now logged in response = client.get("/") # Check the user and connection that was created user = response.user connections = user.oauth_connections.all() assert len(connections) == 1 assert connections[0].provider_key == "dummy" assert connections[0].provider_user_id == "dummy_id" assert connections[0].access_token == "dummy_access_token" assert connections[0].refresh_token == "dummy_refresh_token" assert connections[0].access_token_expires_at == datetime.datetime( 2020, 1, 1, 0, 0, tzinfo=datetime.UTC ) assert connections[0].refresh_token_expires_at == datetime.datetime( 2020, 1, 2, 0, 0, tzinfo=datetime.UTC ) assert get_user_model().objects.count() == 1 assert OAuthConnection.objects.count() == 1 # def test_dummy_disconnect_to_password(db, client, settings): # settings.OAUTH_LOGIN_PROVIDERS = { # "dummy": { # "class": "test_providers.DummyProvider", # "kwargs": { # "client_id": "dummy_client_id", # "client_secret": "dummy_client_secret", # "scope": "dummy_scope", # }, # } # } # assert get_user_model().objects.count() == 0 # assert OAuthConnection.objects.count() == 0 # # Create a user # user = get_user_model().objects.create( # username="dummy_username", email="dummy@example.com", password="dummy_password" # ) # OAuthConnection.objects.create( # user=user, # provider_key="dummy", # provider_user_id="dummy_id", # access_token="dummy_access_token", # refresh_token="dummy_refresh_token", # access_token_expires_at=datetime.datetime( # 2020, 1, 1, 0, 0, tzinfo=datetime.timezone.utc # ), # refresh_token_expires_at=datetime.datetime( # 2020, 1, 2, 0, 0, tzinfo=datetime.timezone.utc # ), # ) # assert get_user_model().objects.count() == 1 # assert OAuthConnection.objects.count() == 1 # client.force_login(user) # # Raises a BadRequest error - can't disconnect the last connection without a password # response = client.post( # "/oauth/dummy/disconnect/", data={"provider_user_id": "dummy_id"} # ) # assert response.status_code == 302 # assert response.url == "/" # assert get_user_model().objects.count() == 1 # assert OAuthConnection.objects.count() == 0 # def test_dummy_disconnect_to_connection(db, client, settings): # settings.OAUTH_LOGIN_PROVIDERS = { # "dummy": { # "class": "test_providers.DummyProvider", # "kwargs": { # "client_id": "dummy_client_id", # "client_secret": "dummy_client_secret", # "scope": "dummy_scope", # }, # } # } # assert get_user_model().objects.count() == 0 # assert OAuthConnection.objects.count() == 0 # # Create a user # user = get_user_model().objects.create( # username="dummy_username", email="dummy@example.com" # ) # OAuthConnection.objects.create( # user=user, # provider_key="dummy", # provider_user_id="dummy_id", # access_token="dummy_access_token", # refresh_token="dummy_refresh_token", # access_token_expires_at=datetime.datetime( # 2020, 1, 1, 0, 0, tzinfo=datetime.timezone.utc # ), # refresh_token_expires_at=datetime.datetime( # 2020, 1, 2, 0, 0, tzinfo=datetime.timezone.utc # ), # ) # OAuthConnection.objects.create( # user=user, # provider_key="dummy", # provider_user_id="dummy_id2", # access_token="dummy_access_token", # refresh_token="dummy_refresh_token", # access_token_expires_at=datetime.datetime( # 2020, 1, 1, 0, 0, tzinfo=datetime.timezone.utc # ), # refresh_token_expires_at=datetime.datetime( # 2020, 1, 2, 0, 0, tzinfo=datetime.timezone.utc # ), # ) # assert get_user_model().objects.count() == 1 # assert OAuthConnection.objects.count() == 2 # client.force_login(user) # # Raises a BadRequest error - can't disconnect the last connection without a password # response = client.post( # "/oauth/dummy/disconnect/", data={"provider_user_id": "dummy_id"} # ) # assert response.status_code == 302 # assert response.url == "/" # assert get_user_model().objects.count() == 1 # assert OAuthConnection.objects.count() == 1 # def test_dummy_disconnect_last(db, client, settings): # settings.OAUTH_LOGIN_PROVIDERS = { # "dummy": { # "class": "test_providers.DummyProvider", # "kwargs": { # "client_id": "dummy_client_id", # "client_secret": "dummy_client_secret", # "scope": "dummy_scope", # }, # } # } # assert get_user_model().objects.count() == 0 # assert OAuthConnection.objects.count() == 0 # # Create a user # user = get_user_model().objects.create( # username="dummy_username", email="dummy@example.com" # ) # OAuthConnection.objects.create( # user=user, # provider_key="dummy", # provider_user_id="dummy_id", # access_token="dummy_access_token", # refresh_token="dummy_refresh_token", # access_token_expires_at=datetime.datetime( # 2020, 1, 1, 0, 0, tzinfo=datetime.timezone.utc # ), # refresh_token_expires_at=datetime.datetime( # 2020, 1, 2, 0, 0, tzinfo=datetime.timezone.utc # ), # ) # assert get_user_model().objects.count() == 1 # assert OAuthConnection.objects.count() == 1 # client.force_login(user) # # Raises a BadRequest error - can't disconnect the last connection without a password # response = client.post( # "/oauth/dummy/disconnect/", data={"provider_user_id": "dummy_id"} # ) # assert response.status_code == 400 # assert response.templates[0].name == "oauth/error.html" # assert get_user_model().objects.count() == 1 # assert OAuthConnection.objects.count() == 1 def test_dummy_refresh(db, settings, monkeypatch): settings.OAUTH_LOGIN_PROVIDERS = { "dummy": { "class": "test_providers.DummyProvider", "kwargs": { "client_id": "dummy_client_id", "client_secret": "dummy_client_secret", "scope": "dummy_scope", }, } } user = get_user_model().objects.create( username="dummy_username", email="dummy@example.com" ) connection = OAuthConnection.objects.create( user=user, provider_key="dummy", provider_user_id="dummy_id", access_token="dummy_access_token", refresh_token="dummy_refresh_token", access_token_expires_at=datetime.datetime( 2020, 1, 1, 0, 0, tzinfo=datetime.UTC ), refresh_token_expires_at=datetime.datetime( 2020, 1, 2, 0, 0, tzinfo=datetime.UTC ), ) connection.refresh_access_token() assert connection.provider_key == "dummy" assert connection.provider_user_id == "dummy_id" assert connection.access_token == "refreshed_dummy_access_token" assert connection.refresh_token == "refreshed_dummy_refresh_token" assert connection.access_token_expires_at == datetime.datetime( 2029, 1, 1, 0, 0, tzinfo=datetime.UTC ) assert connection.refresh_token_expires_at == datetime.datetime( 2029, 1, 2, 0, 0, tzinfo=datetime.UTC ) �����������������������������������plain_oauth-0.9.0/tests/app/settings.py�������������������������������������������������������������0000644�0000000�0000000�00000002564�13615410400�015106� 0����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������from os import environ SECRET_KEY = "test" INSTALLED_PACKAGES = [ "plain.auth", "plain.sessions", "plain.models", "plain.oauth", "app.users", ] DATABASES = { "default": { "ENGINE": "plain.models.backends.sqlite3", "NAME": ":memory:", } } MIDDLEWARE = [ "plain.sessions.middleware.SessionMiddleware", "plain.auth.middleware.AuthenticationMiddleware", ] AUTH_LOGIN_URL = "login" AUTH_USER_MODEL = "users.User" # OAuth providers to use for a real, interactive test # (in a real config you'd probably do environ["key"] to raise a KeyError if an env var is forgotten) OAUTH_LOGIN_PROVIDERS = { "github": { "class": "providers.github.GitHubOAuthProvider", "kwargs": { "client_id": environ.get("GITHUB_CLIENT_ID"), "client_secret": environ.get("GITHUB_CLIENT_SECRET"), }, }, "bitbucket": { "class": "providers.bitbucket.BitbucketOAuthProvider", "kwargs": { "client_id": environ.get("BITBUCKET_KEY"), "client_secret": environ.get("BITBUCKET_SECRET"), }, }, "gitlab": { "class": "providers.gitlab.GitLabOAuthProvider", "kwargs": { "client_id": environ.get("GITLAB_APPLICATION_ID"), "client_secret": environ.get("GITLAB_APPLICATION_SECRET"), "scope": "read_user", }, }, } ��������������������������������������������������������������������������������������������������������������������������������������������plain_oauth-0.9.0/tests/app/urls.py�����������������������������������������������������������������0000644�0000000�0000000�00000001434�13615410400�014226� 0����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import plain.oauth.urls from plain.auth.views import AuthViewMixin, LogoutView from plain.oauth.providers import get_provider_keys from plain.urls import RouterBase, include, path, register_router from plain.views import TemplateView class LoggedInView(AuthViewMixin, TemplateView): template_name = "index.html" def get_template_context(self): context = super().get_template_context() context["oauth_provider_keys"] = get_provider_keys() return context class LoginView(TemplateView): template_name = "login.html" @register_router class Router(RouterBase): urls = [ include("oauth/", plain.oauth.urls), path("login/", LoginView, name="login"), path("logout/", LogoutView, name="logout"), path("", LoggedInView), ] ������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������plain_oauth-0.9.0/tests/app/templates/base.html�����������������������������������������������������0000644�0000000�0000000�00000000456�13615410400�016470� 0����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������No items found using the specified filter.
219 empty classes skipped.
No items found using the specified filter.
1 empty function skipped.
No items found using the specified filter.
14 empty files skipped.
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.oauth.providers import OAuthProvider, OAuthToken, OAuthUser
4class DummyProvider(OAuthProvider):
5 def get_oauth_token(self, *, code, request):
6 return OAuthToken(
7 access_token="dummy_token",
8 )
10 def get_oauth_user(self, *, oauth_token):
11 return OAuthUser(
12 id="dummy_user_id",
13 username="dummy_username",
14 email="dummy@example.com",
15 )
17 def check_request_state(self, *, request):
18 """Don't check the state"""
19 return
22def test_single_backend(db, client, settings):
23 settings.OAUTH_LOGIN_PROVIDERS = {
24 "dummy": {
25 "class": "test_backends.DummyProvider",
26 "kwargs": {
27 "client_id": "dummy_client_id",
28 "client_secret": "dummy_client_secret",
29 "scope": "dummy_scope",
30 },
31 }
32 }
34 response = client.get("/oauth/dummy/callback/?code=test_code&state=dummy_state")
35 assert response.status_code == 302
36 assert response.url == "/"
38 # Now logged in
39 response = client.get("/")
40 assert response.user
43def test_multiple_backends(db, client, settings):
44 settings.OAUTH_LOGIN_PROVIDERS = {
45 "dummy": {
46 "class": "test_backends.DummyProvider",
47 "kwargs": {
48 "client_id": "dummy_client_id",
49 "client_secret": "dummy_client_secret",
50 "scope": "dummy_scope",
51 },
52 }
53 }
55 response = client.get("/oauth/dummy/callback/?code=test_code&state=dummy_state")
56 assert response.status_code == 302
57 assert response.url == "/"
59 # Now logged in
60 response = client.get("/")
61 assert response.user
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.auth import get_user_model
2from plain.oauth.models import OAuthConnection
5def test_oauth_provider_keys_check_pass(db, settings):
6 settings.OAUTH_LOGIN_PROVIDERS = {
7 "google": {
8 "client_id": "test_client_id",
9 "client_secret": "test_client_secret",
10 },
11 "foo": {
12 "client_id": "test_client_id",
13 "client_secret": "test_client_secret",
14 },
15 }
17 user = get_user_model().objects.create(
18 username="test_user", email="test@example.com"
19 )
21 OAuthConnection.objects.create(
22 user=user,
23 provider_key="google",
24 provider_user_id="test_provider_user_id",
25 access_token="test",
26 )
28 errors = OAuthConnection.check(databases=["default"])
29 assert len(errors) == 0
32def test_oauth_provider_keys_check_fail(db, settings):
33 settings.OAUTH_LOGIN_PROVIDERS = {
34 "google": {
35 "client_id": "test_client_id",
36 "client_secret": "test_client_secret",
37 },
38 "foo": {
39 "client_id": "test_client_id",
40 "client_secret": "test_client_secret",
41 },
42 }
44 user = get_user_model().objects.create(
45 username="test_user", email="test@example.com"
46 )
48 OAuthConnection.objects.create(
49 user=user,
50 provider_key="google",
51 provider_user_id="test_provider_user_id",
52 access_token="test",
53 )
54 OAuthConnection.objects.create(
55 user=user,
56 provider_key="bar",
57 provider_user_id="test_provider_user_id",
58 access_token="test",
59 )
61 errors = OAuthConnection.check(databases=["default"])
62 assert len(errors) == 1
63 assert (
64 errors[0].msg
65 == "The following OAuth providers are in the database but not in the settings: bar"
66 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
3from plain.auth import get_user_model
4from plain.oauth.models import OAuthConnection
5from plain.oauth.providers import OAuthProvider, OAuthToken, OAuthUser
8class DummyProvider(OAuthProvider):
9 authorization_url = "https://example.com/oauth/authorize"
11 def generate_state(self) -> str:
12 return "dummy_state"
14 def refresh_oauth_token(self, *, oauth_token: OAuthToken) -> OAuthToken:
15 return OAuthToken(
16 access_token="refreshed_dummy_access_token",
17 refresh_token="refreshed_dummy_refresh_token",
18 access_token_expires_at=datetime.datetime(
19 2029, 1, 1, 0, 0, tzinfo=datetime.UTC
20 ),
21 refresh_token_expires_at=datetime.datetime(
22 2029, 1, 2, 0, 0, tzinfo=datetime.UTC
23 ),
24 )
26 def get_oauth_token(self, *, code, request) -> OAuthToken:
27 return OAuthToken(
28 access_token="dummy_access_token",
29 refresh_token="dummy_refresh_token",
30 access_token_expires_at=datetime.datetime(
31 2020, 1, 1, 0, 0, tzinfo=datetime.UTC
32 ),
33 refresh_token_expires_at=datetime.datetime(
34 2020, 1, 2, 0, 0, tzinfo=datetime.UTC
35 ),
36 )
38 def get_oauth_user(self, *, oauth_token: OAuthToken) -> OAuthUser:
39 return OAuthUser(
40 id="dummy_id",
41 email="dummy@example.com",
42 username="dummy_username",
43 )
46def test_dummy_signup(db, client, settings):
47 settings.OAUTH_LOGIN_PROVIDERS = {
48 "dummy": {
49 "class": "test_providers.DummyProvider",
50 "kwargs": {
51 "client_id": "dummy_client_id",
52 "client_secret": "dummy_client_secret",
53 "scope": "dummy_scope",
54 },
55 }
56 }
58 assert get_user_model().objects.count() == 0
59 assert OAuthConnection.objects.count() == 0
61 # Login required for this view
62 response = client.get("/")
63 assert response.status_code == 302
64 assert response.url == "/login/?next=/"
66 # User clicks the login link (form submit)
67 response = client.post("/oauth/dummy/login/")
68 assert response.status_code == 302
69 assert (
70 response.url
71 == "https://example.com/oauth/authorize?client_id=dummy_client_id&redirect_uri=https%3A%2F%2Ftestserver%2Foauth%2Fdummy%2Fcallback%2F&response_type=code&scope=dummy_scope&state=dummy_state"
72 )
74 # Provider redirects to the callback url
75 response = client.get("/oauth/dummy/callback/?code=test_code&state=dummy_state")
76 assert response.status_code == 302
77 assert response.url == "/"
79 # Now logged in
80 response = client.get("/")
81 assert response.status_code == 200
82 assert b"Hello dummy_username!\n" in response.content
84 # Check the user and connection that was created
85 user = response.user
86 assert user.username == "dummy_username"
87 assert user.email == "dummy@example.com"
88 connections = user.oauth_connections.all()
89 assert len(connections) == 1
90 assert connections[0].provider_key == "dummy"
91 assert connections[0].provider_user_id == "dummy_id"
92 assert connections[0].access_token == "dummy_access_token"
93 assert connections[0].refresh_token == "dummy_refresh_token"
94 assert connections[0].access_token_expires_at == datetime.datetime(
95 2020, 1, 1, 0, 0, tzinfo=datetime.UTC
96 )
97 assert connections[0].refresh_token_expires_at == datetime.datetime(
98 2020, 1, 2, 0, 0, tzinfo=datetime.UTC
99 )
101 assert get_user_model().objects.count() == 1
102 assert OAuthConnection.objects.count() == 1
105def test_dummy_login_connection(db, client, settings):
106 settings.OAUTH_LOGIN_PROVIDERS = {
107 "dummy": {
108 "class": "test_providers.DummyProvider",
109 "kwargs": {
110 "client_id": "dummy_client_id",
111 "client_secret": "dummy_client_secret",
112 "scope": "dummy_scope",
113 },
114 }
115 }
117 assert get_user_model().objects.count() == 0
118 assert OAuthConnection.objects.count() == 0
120 # Create a user
121 user = get_user_model().objects.create(
122 username="dummy_username", email="dummy@example.com"
123 )
124 OAuthConnection.objects.create(
125 user=user,
126 provider_key="dummy",
127 provider_user_id="dummy_id",
128 access_token="dummy_access_token",
129 refresh_token="dummy_refresh_token",
130 access_token_expires_at=datetime.datetime(
131 2020, 1, 1, 0, 0, tzinfo=datetime.UTC
132 ),
133 refresh_token_expires_at=datetime.datetime(
134 2020, 1, 2, 0, 0, tzinfo=datetime.UTC
135 ),
136 )
138 assert get_user_model().objects.count() == 1
139 assert OAuthConnection.objects.count() == 1
141 # Login required for this view
142 response = client.get("/")
143 assert response.status_code == 302
144 assert response.url == "/login/?next=/"
146 # User clicks the login link (form submit)
147 response = client.post("/oauth/dummy/login/")
148 assert response.status_code == 302
149 assert (
150 response.url
151 == "https://example.com/oauth/authorize?client_id=dummy_client_id&redirect_uri=https%3A%2F%2Ftestserver%2Foauth%2Fdummy%2Fcallback%2F&response_type=code&scope=dummy_scope&state=dummy_state"
152 )
154 # Provider redirects to the callback url
155 response = client.get("/oauth/dummy/callback/?code=test_code&state=dummy_state")
156 assert response.status_code == 302
157 assert response.url == "/"
159 # Now logged in
160 response = client.get("/")
161 assert response.status_code == 200
162 assert b"Hello dummy_username!\n" in response.content
164 # Check the user and connection that was created
165 user = response.user
166 assert user.username == "dummy_username"
167 assert user.email == "dummy@example.com"
168 connections = user.oauth_connections.all()
169 assert len(connections) == 1
170 assert connections[0].provider_key == "dummy"
171 assert connections[0].provider_user_id == "dummy_id"
172 assert connections[0].access_token == "dummy_access_token"
173 assert connections[0].refresh_token == "dummy_refresh_token"
174 assert connections[0].access_token_expires_at == datetime.datetime(
175 2020, 1, 1, 0, 0, tzinfo=datetime.UTC
176 )
177 assert connections[0].refresh_token_expires_at == datetime.datetime(
178 2020, 1, 2, 0, 0, tzinfo=datetime.UTC
179 )
181 assert get_user_model().objects.count() == 1
182 assert OAuthConnection.objects.count() == 1
185def test_dummy_login_without_connection(db, client, settings):
186 settings.OAUTH_LOGIN_PROVIDERS = {
187 "dummy": {
188 "class": "test_providers.DummyProvider",
189 "kwargs": {
190 "client_id": "dummy_client_id",
191 "client_secret": "dummy_client_secret",
192 "scope": "dummy_scope",
193 },
194 }
195 }
197 assert get_user_model().objects.count() == 0
198 assert OAuthConnection.objects.count() == 0
200 # Create a user
201 get_user_model().objects.create(
202 username="dummy_username", email="dummy@example.com"
203 )
205 assert get_user_model().objects.count() == 1
206 assert OAuthConnection.objects.count() == 0
208 # Login required for this view
209 response = client.get("/")
210 assert response.status_code == 302
211 assert response.url == "/login/?next=/"
213 # User clicks the login link (form submit)
214 response = client.post("/oauth/dummy/login/")
215 assert response.status_code == 302
216 assert (
217 response.url
218 == "https://example.com/oauth/authorize?client_id=dummy_client_id&redirect_uri=https%3A%2F%2Ftestserver%2Foauth%2Fdummy%2Fcallback%2F&response_type=code&scope=dummy_scope&state=dummy_state"
219 )
221 # Provider redirects to the callback url
222 response = client.get("/oauth/dummy/callback/?code=test_code&state=dummy_state")
223 assert response.status_code == 400
224 assert b"OAuth Error" in response.content
227def test_dummy_connect(db, client, settings):
228 settings.OAUTH_LOGIN_PROVIDERS = {
229 "dummy": {
230 "class": "test_providers.DummyProvider",
231 "kwargs": {
232 "client_id": "dummy_client_id",
233 "client_secret": "dummy_client_secret",
234 "scope": "dummy_scope",
235 },
236 }
237 }
239 assert get_user_model().objects.count() == 0
240 assert OAuthConnection.objects.count() == 0
242 # Create a user
243 user = get_user_model().objects.create(
244 username="dummy_username", email="dummy@example.com"
245 )
247 assert get_user_model().objects.count() == 1
248 assert OAuthConnection.objects.count() == 0
250 client.force_login(user)
252 response = client.post("/oauth/dummy/connect/")
253 assert response.status_code == 302
254 assert (
255 response.url
256 == "https://example.com/oauth/authorize?client_id=dummy_client_id&redirect_uri=https%3A%2F%2Ftestserver%2Foauth%2Fdummy%2Fcallback%2F&response_type=code&scope=dummy_scope&state=dummy_state"
257 )
259 # Provider redirects to the callback url
260 response = client.get("/oauth/dummy/callback/?code=test_code&state=dummy_state")
261 assert response.status_code == 302
262 assert response.url == "/"
264 # Now logged in
265 response = client.get("/")
267 # Check the user and connection that was created
268 user = response.user
269 connections = user.oauth_connections.all()
270 assert len(connections) == 1
271 assert connections[0].provider_key == "dummy"
272 assert connections[0].provider_user_id == "dummy_id"
273 assert connections[0].access_token == "dummy_access_token"
274 assert connections[0].refresh_token == "dummy_refresh_token"
275 assert connections[0].access_token_expires_at == datetime.datetime(
276 2020, 1, 1, 0, 0, tzinfo=datetime.UTC
277 )
278 assert connections[0].refresh_token_expires_at == datetime.datetime(
279 2020, 1, 2, 0, 0, tzinfo=datetime.UTC
280 )
282 assert get_user_model().objects.count() == 1
283 assert OAuthConnection.objects.count() == 1
286# def test_dummy_disconnect_to_password(db, client, settings):
287# settings.OAUTH_LOGIN_PROVIDERS = {
288# "dummy": {
289# "class": "test_providers.DummyProvider",
290# "kwargs": {
291# "client_id": "dummy_client_id",
292# "client_secret": "dummy_client_secret",
293# "scope": "dummy_scope",
294# },
295# }
296# }
298# assert get_user_model().objects.count() == 0
299# assert OAuthConnection.objects.count() == 0
301# # Create a user
302# user = get_user_model().objects.create(
303# username="dummy_username", email="dummy@example.com", password="dummy_password"
304# )
305# OAuthConnection.objects.create(
306# user=user,
307# provider_key="dummy",
308# provider_user_id="dummy_id",
309# access_token="dummy_access_token",
310# refresh_token="dummy_refresh_token",
311# access_token_expires_at=datetime.datetime(
312# 2020, 1, 1, 0, 0, tzinfo=datetime.timezone.utc
313# ),
314# refresh_token_expires_at=datetime.datetime(
315# 2020, 1, 2, 0, 0, tzinfo=datetime.timezone.utc
316# ),
317# )
319# assert get_user_model().objects.count() == 1
320# assert OAuthConnection.objects.count() == 1
322# client.force_login(user)
324# # Raises a BadRequest error - can't disconnect the last connection without a password
325# response = client.post(
326# "/oauth/dummy/disconnect/", data={"provider_user_id": "dummy_id"}
327# )
328# assert response.status_code == 302
329# assert response.url == "/"
331# assert get_user_model().objects.count() == 1
332# assert OAuthConnection.objects.count() == 0
335# def test_dummy_disconnect_to_connection(db, client, settings):
336# settings.OAUTH_LOGIN_PROVIDERS = {
337# "dummy": {
338# "class": "test_providers.DummyProvider",
339# "kwargs": {
340# "client_id": "dummy_client_id",
341# "client_secret": "dummy_client_secret",
342# "scope": "dummy_scope",
343# },
344# }
345# }
347# assert get_user_model().objects.count() == 0
348# assert OAuthConnection.objects.count() == 0
350# # Create a user
351# user = get_user_model().objects.create(
352# username="dummy_username", email="dummy@example.com"
353# )
354# OAuthConnection.objects.create(
355# user=user,
356# provider_key="dummy",
357# provider_user_id="dummy_id",
358# access_token="dummy_access_token",
359# refresh_token="dummy_refresh_token",
360# access_token_expires_at=datetime.datetime(
361# 2020, 1, 1, 0, 0, tzinfo=datetime.timezone.utc
362# ),
363# refresh_token_expires_at=datetime.datetime(
364# 2020, 1, 2, 0, 0, tzinfo=datetime.timezone.utc
365# ),
366# )
367# OAuthConnection.objects.create(
368# user=user,
369# provider_key="dummy",
370# provider_user_id="dummy_id2",
371# access_token="dummy_access_token",
372# refresh_token="dummy_refresh_token",
373# access_token_expires_at=datetime.datetime(
374# 2020, 1, 1, 0, 0, tzinfo=datetime.timezone.utc
375# ),
376# refresh_token_expires_at=datetime.datetime(
377# 2020, 1, 2, 0, 0, tzinfo=datetime.timezone.utc
378# ),
379# )
381# assert get_user_model().objects.count() == 1
382# assert OAuthConnection.objects.count() == 2
384# client.force_login(user)
386# # Raises a BadRequest error - can't disconnect the last connection without a password
387# response = client.post(
388# "/oauth/dummy/disconnect/", data={"provider_user_id": "dummy_id"}
389# )
390# assert response.status_code == 302
391# assert response.url == "/"
393# assert get_user_model().objects.count() == 1
394# assert OAuthConnection.objects.count() == 1
397# def test_dummy_disconnect_last(db, client, settings):
398# settings.OAUTH_LOGIN_PROVIDERS = {
399# "dummy": {
400# "class": "test_providers.DummyProvider",
401# "kwargs": {
402# "client_id": "dummy_client_id",
403# "client_secret": "dummy_client_secret",
404# "scope": "dummy_scope",
405# },
406# }
407# }
409# assert get_user_model().objects.count() == 0
410# assert OAuthConnection.objects.count() == 0
412# # Create a user
413# user = get_user_model().objects.create(
414# username="dummy_username", email="dummy@example.com"
415# )
416# OAuthConnection.objects.create(
417# user=user,
418# provider_key="dummy",
419# provider_user_id="dummy_id",
420# access_token="dummy_access_token",
421# refresh_token="dummy_refresh_token",
422# access_token_expires_at=datetime.datetime(
423# 2020, 1, 1, 0, 0, tzinfo=datetime.timezone.utc
424# ),
425# refresh_token_expires_at=datetime.datetime(
426# 2020, 1, 2, 0, 0, tzinfo=datetime.timezone.utc
427# ),
428# )
430# assert get_user_model().objects.count() == 1
431# assert OAuthConnection.objects.count() == 1
433# client.force_login(user)
435# # Raises a BadRequest error - can't disconnect the last connection without a password
436# response = client.post(
437# "/oauth/dummy/disconnect/", data={"provider_user_id": "dummy_id"}
438# )
439# assert response.status_code == 400
440# assert response.templates[0].name == "oauth/error.html"
442# assert get_user_model().objects.count() == 1
443# assert OAuthConnection.objects.count() == 1
446def test_dummy_refresh(db, settings, monkeypatch):
447 settings.OAUTH_LOGIN_PROVIDERS = {
448 "dummy": {
449 "class": "test_providers.DummyProvider",
450 "kwargs": {
451 "client_id": "dummy_client_id",
452 "client_secret": "dummy_client_secret",
453 "scope": "dummy_scope",
454 },
455 }
456 }
458 user = get_user_model().objects.create(
459 username="dummy_username", email="dummy@example.com"
460 )
461 connection = OAuthConnection.objects.create(
462 user=user,
463 provider_key="dummy",
464 provider_user_id="dummy_id",
465 access_token="dummy_access_token",
466 refresh_token="dummy_refresh_token",
467 access_token_expires_at=datetime.datetime(
468 2020, 1, 1, 0, 0, tzinfo=datetime.UTC
469 ),
470 refresh_token_expires_at=datetime.datetime(
471 2020, 1, 2, 0, 0, tzinfo=datetime.UTC
472 ),
473 )
475 connection.refresh_access_token()
476 assert connection.provider_key == "dummy"
477 assert connection.provider_user_id == "dummy_id"
478 assert connection.access_token == "refreshed_dummy_access_token"
479 assert connection.refresh_token == "refreshed_dummy_refresh_token"
480 assert connection.access_token_expires_at == datetime.datetime(
481 2029, 1, 1, 0, 0, tzinfo=datetime.UTC
482 )
483 assert connection.refresh_token_expires_at == datetime.datetime(
484 2029, 1, 2, 0, 0, tzinfo=datetime.UTC
485 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.models.sql.query import * # NOQA
2from plain.models.sql.query import Query
3from plain.models.sql.subqueries import * # NOQA
4from plain.models.sql.where import AND, OR, XOR
6__all__ = ["Query", "AND", "OR", "XOR"]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import collections
2import json
3import re
4from functools import partial
5from itertools import chain
7from plain.exceptions import EmptyResultSet, FieldError, FullResultSet
8from plain.models.constants import LOOKUP_SEP
9from plain.models.db import DatabaseError, NotSupportedError
10from plain.models.expressions import F, OrderBy, RawSQL, Ref, Value
11from plain.models.functions import Cast, Random
12from plain.models.lookups import Lookup
13from plain.models.query_utils import select_related_descend
14from plain.models.sql.constants import (
15 CURSOR,
16 GET_ITERATOR_CHUNK_SIZE,
17 MULTI,
18 NO_RESULTS,
19 ORDER_DIR,
20 SINGLE,
21)
22from plain.models.sql.query import Query, get_order_dir
23from plain.models.sql.where import AND
24from plain.models.transaction import TransactionManagementError
25from plain.utils.functional import cached_property
26from plain.utils.hashable import make_hashable
27from plain.utils.regex_helper import _lazy_re_compile
30class PositionRef(Ref):
31 def __init__(self, ordinal, refs, source):
32 self.ordinal = ordinal
33 super().__init__(refs, source)
35 def as_sql(self, compiler, connection):
36 return str(self.ordinal), ()
39class SQLCompiler:
40 # Multiline ordering SQL clause may appear from RawSQL.
41 ordering_parts = _lazy_re_compile(
42 r"^(.*)\s(?:ASC|DESC).*",
43 re.MULTILINE | re.DOTALL,
44 )
46 def __init__(self, query, connection, using, elide_empty=True):
47 self.query = query
48 self.connection = connection
49 self.using = using
50 # Some queries, e.g. coalesced aggregation, need to be executed even if
51 # they would return an empty result set.
52 self.elide_empty = elide_empty
53 self.quote_cache = {"*": "*"}
54 # The select, klass_info, and annotations are needed by QuerySet.iterator()
55 # these are set as a side-effect of executing the query. Note that we calculate
56 # separately a list of extra select columns needed for grammatical correctness
57 # of the query, but these columns are not included in self.select.
58 self.select = None
59 self.annotation_col_map = None
60 self.klass_info = None
61 self._meta_ordering = None
63 def __repr__(self):
64 return (
65 f"<{self.__class__.__qualname__} "
66 f"model={self.query.model.__qualname__} "
67 f"connection={self.connection!r} using={self.using!r}>"
68 )
70 def setup_query(self, with_col_aliases=False):
71 if all(self.query.alias_refcount[a] == 0 for a in self.query.alias_map):
72 self.query.get_initial_alias()
73 self.select, self.klass_info, self.annotation_col_map = self.get_select(
74 with_col_aliases=with_col_aliases,
75 )
76 self.col_count = len(self.select)
78 def pre_sql_setup(self, with_col_aliases=False):
79 """
80 Do any necessary class setup immediately prior to producing SQL. This
81 is for things that can't necessarily be done in __init__ because we
82 might not have all the pieces in place at that time.
83 """
84 self.setup_query(with_col_aliases=with_col_aliases)
85 order_by = self.get_order_by()
86 self.where, self.having, self.qualify = self.query.where.split_having_qualify(
87 must_group_by=self.query.group_by is not None
88 )
89 extra_select = self.get_extra_select(order_by, self.select)
90 self.has_extra_select = bool(extra_select)
91 group_by = self.get_group_by(self.select + extra_select, order_by)
92 return extra_select, order_by, group_by
94 def get_group_by(self, select, order_by):
95 """
96 Return a list of 2-tuples of form (sql, params).
98 The logic of what exactly the GROUP BY clause contains is hard
99 to describe in other words than "if it passes the test suite,
100 then it is correct".
101 """
102 # Some examples:
103 # SomeModel.objects.annotate(Count('somecol'))
104 # GROUP BY: all fields of the model
105 #
106 # SomeModel.objects.values('name').annotate(Count('somecol'))
107 # GROUP BY: name
108 #
109 # SomeModel.objects.annotate(Count('somecol')).values('name')
110 # GROUP BY: all cols of the model
111 #
112 # SomeModel.objects.values('name', 'pk')
113 # .annotate(Count('somecol')).values('pk')
114 # GROUP BY: name, pk
115 #
116 # SomeModel.objects.values('name').annotate(Count('somecol')).values('pk')
117 # GROUP BY: name, pk
118 #
119 # In fact, the self.query.group_by is the minimal set to GROUP BY. It
120 # can't be ever restricted to a smaller set, but additional columns in
121 # HAVING, ORDER BY, and SELECT clauses are added to it. Unfortunately
122 # the end result is that it is impossible to force the query to have
123 # a chosen GROUP BY clause - you can almost do this by using the form:
124 # .values(*wanted_cols).annotate(AnAggregate())
125 # but any later annotations, extra selects, values calls that
126 # refer some column outside of the wanted_cols, order_by, or even
127 # filter calls can alter the GROUP BY clause.
129 # The query.group_by is either None (no GROUP BY at all), True
130 # (group by select fields), or a list of expressions to be added
131 # to the group by.
132 if self.query.group_by is None:
133 return []
134 expressions = []
135 group_by_refs = set()
136 if self.query.group_by is not True:
137 # If the group by is set to a list (by .values() call most likely),
138 # then we need to add everything in it to the GROUP BY clause.
139 # Backwards compatibility hack for setting query.group_by. Remove
140 # when we have public API way of forcing the GROUP BY clause.
141 # Converts string references to expressions.
142 for expr in self.query.group_by:
143 if not hasattr(expr, "as_sql"):
144 expr = self.query.resolve_ref(expr)
145 if isinstance(expr, Ref):
146 if expr.refs not in group_by_refs:
147 group_by_refs.add(expr.refs)
148 expressions.append(expr.source)
149 else:
150 expressions.append(expr)
151 # Note that even if the group_by is set, it is only the minimal
152 # set to group by. So, we need to add cols in select, order_by, and
153 # having into the select in any case.
154 selected_expr_positions = {}
155 for ordinal, (expr, _, alias) in enumerate(select, start=1):
156 if alias:
157 selected_expr_positions[expr] = ordinal
158 # Skip members of the select clause that are already explicitly
159 # grouped against.
160 if alias in group_by_refs:
161 continue
162 expressions.extend(expr.get_group_by_cols())
163 if not self._meta_ordering:
164 for expr, (sql, params, is_ref) in order_by:
165 # Skip references to the SELECT clause, as all expressions in
166 # the SELECT clause are already part of the GROUP BY.
167 if not is_ref:
168 expressions.extend(expr.get_group_by_cols())
169 having_group_by = self.having.get_group_by_cols() if self.having else ()
170 for expr in having_group_by:
171 expressions.append(expr)
172 result = []
173 seen = set()
174 expressions = self.collapse_group_by(expressions, having_group_by)
176 allows_group_by_select_index = (
177 self.connection.features.allows_group_by_select_index
178 )
179 for expr in expressions:
180 try:
181 sql, params = self.compile(expr)
182 except (EmptyResultSet, FullResultSet):
183 continue
184 if (
185 allows_group_by_select_index
186 and (position := selected_expr_positions.get(expr)) is not None
187 ):
188 sql, params = str(position), ()
189 else:
190 sql, params = expr.select_format(self, sql, params)
191 params_hash = make_hashable(params)
192 if (sql, params_hash) not in seen:
193 result.append((sql, params))
194 seen.add((sql, params_hash))
195 return result
197 def collapse_group_by(self, expressions, having):
198 # If the database supports group by functional dependence reduction,
199 # then the expressions can be reduced to the set of selected table
200 # primary keys as all other columns are functionally dependent on them.
201 if self.connection.features.allows_group_by_selected_pks:
202 # Filter out all expressions associated with a table's primary key
203 # present in the grouped columns. This is done by identifying all
204 # tables that have their primary key included in the grouped
205 # columns and removing non-primary key columns referring to them.
206 # Unmanaged models are excluded because they could be representing
207 # database views on which the optimization might not be allowed.
208 pks = {
209 expr
210 for expr in expressions
211 if (
212 hasattr(expr, "target")
213 and expr.target.primary_key
214 and self.connection.features.allows_group_by_selected_pks_on_model(
215 expr.target.model
216 )
217 )
218 }
219 aliases = {expr.alias for expr in pks}
220 expressions = [
221 expr
222 for expr in expressions
223 if expr in pks
224 or expr in having
225 or getattr(expr, "alias", None) not in aliases
226 ]
227 return expressions
229 def get_select(self, with_col_aliases=False):
230 """
231 Return three values:
232 - a list of 3-tuples of (expression, (sql, params), alias)
233 - a klass_info structure,
234 - a dictionary of annotations
236 The (sql, params) is what the expression will produce, and alias is the
237 "AS alias" for the column (possibly None).
239 The klass_info structure contains the following information:
240 - The base model of the query.
241 - Which columns for that model are present in the query (by
242 position of the select clause).
243 - related_klass_infos: [f, klass_info] to descent into
245 The annotations is a dictionary of {'attname': column position} values.
246 """
247 select = []
248 klass_info = None
249 annotations = {}
250 select_idx = 0
251 for alias, (sql, params) in self.query.extra_select.items():
252 annotations[alias] = select_idx
253 select.append((RawSQL(sql, params), alias))
254 select_idx += 1
255 assert not (self.query.select and self.query.default_cols)
256 select_mask = self.query.get_select_mask()
257 if self.query.default_cols:
258 cols = self.get_default_columns(select_mask)
259 else:
260 # self.query.select is a special case. These columns never go to
261 # any model.
262 cols = self.query.select
263 if cols:
264 select_list = []
265 for col in cols:
266 select_list.append(select_idx)
267 select.append((col, None))
268 select_idx += 1
269 klass_info = {
270 "model": self.query.model,
271 "select_fields": select_list,
272 }
273 for alias, annotation in self.query.annotation_select.items():
274 annotations[alias] = select_idx
275 select.append((annotation, alias))
276 select_idx += 1
278 if self.query.select_related:
279 related_klass_infos = self.get_related_selections(select, select_mask)
280 klass_info["related_klass_infos"] = related_klass_infos
282 def get_select_from_parent(klass_info):
283 for ki in klass_info["related_klass_infos"]:
284 if ki["from_parent"]:
285 ki["select_fields"] = (
286 klass_info["select_fields"] + ki["select_fields"]
287 )
288 get_select_from_parent(ki)
290 get_select_from_parent(klass_info)
292 ret = []
293 col_idx = 1
294 for col, alias in select:
295 try:
296 sql, params = self.compile(col)
297 except EmptyResultSet:
298 empty_result_set_value = getattr(
299 col, "empty_result_set_value", NotImplemented
300 )
301 if empty_result_set_value is NotImplemented:
302 # Select a predicate that's always False.
303 sql, params = "0", ()
304 else:
305 sql, params = self.compile(Value(empty_result_set_value))
306 except FullResultSet:
307 sql, params = self.compile(Value(True))
308 else:
309 sql, params = col.select_format(self, sql, params)
310 if alias is None and with_col_aliases:
311 alias = f"col{col_idx}"
312 col_idx += 1
313 ret.append((col, (sql, params), alias))
314 return ret, klass_info, annotations
316 def _order_by_pairs(self):
317 if self.query.extra_order_by:
318 ordering = self.query.extra_order_by
319 elif not self.query.default_ordering:
320 ordering = self.query.order_by
321 elif self.query.order_by:
322 ordering = self.query.order_by
323 elif (meta := self.query.get_meta()) and meta.ordering:
324 ordering = meta.ordering
325 self._meta_ordering = ordering
326 else:
327 ordering = []
328 if self.query.standard_ordering:
329 default_order, _ = ORDER_DIR["ASC"]
330 else:
331 default_order, _ = ORDER_DIR["DESC"]
333 selected_exprs = {}
334 if select := self.select:
335 for ordinal, (expr, _, alias) in enumerate(select, start=1):
336 pos_expr = PositionRef(ordinal, alias, expr)
337 if alias:
338 selected_exprs[alias] = pos_expr
339 selected_exprs[expr] = pos_expr
341 for field in ordering:
342 if hasattr(field, "resolve_expression"):
343 if isinstance(field, Value):
344 # output_field must be resolved for constants.
345 field = Cast(field, field.output_field)
346 if not isinstance(field, OrderBy):
347 field = field.asc()
348 if not self.query.standard_ordering:
349 field = field.copy()
350 field.reverse_ordering()
351 select_ref = selected_exprs.get(field.expression)
352 if select_ref or (
353 isinstance(field.expression, F)
354 and (select_ref := selected_exprs.get(field.expression.name))
355 ):
356 # Emulation of NULLS (FIRST|LAST) cannot be combined with
357 # the usage of ordering by position.
358 if (
359 field.nulls_first is None and field.nulls_last is None
360 ) or self.connection.features.supports_order_by_nulls_modifier:
361 field = field.copy()
362 field.expression = select_ref
363 # Alias collisions are not possible when dealing with
364 # combined queries so fallback to it if emulation of NULLS
365 # handling is required.
366 elif self.query.combinator:
367 field = field.copy()
368 field.expression = Ref(select_ref.refs, select_ref.source)
369 yield field, select_ref is not None
370 continue
371 if field == "?": # random
372 yield OrderBy(Random()), False
373 continue
375 col, order = get_order_dir(field, default_order)
376 descending = order == "DESC"
378 if select_ref := selected_exprs.get(col):
379 # Reference to expression in SELECT clause
380 yield (
381 OrderBy(
382 select_ref,
383 descending=descending,
384 ),
385 True,
386 )
387 continue
388 if col in self.query.annotations:
389 # References to an expression which is masked out of the SELECT
390 # clause.
391 if self.query.combinator and self.select:
392 # Don't use the resolved annotation because other
393 # combinated queries might define it differently.
394 expr = F(col)
395 else:
396 expr = self.query.annotations[col]
397 if isinstance(expr, Value):
398 # output_field must be resolved for constants.
399 expr = Cast(expr, expr.output_field)
400 yield OrderBy(expr, descending=descending), False
401 continue
403 if "." in field:
404 # This came in through an extra(order_by=...) addition. Pass it
405 # on verbatim.
406 table, col = col.split(".", 1)
407 yield (
408 OrderBy(
409 RawSQL(f"{self.quote_name_unless_alias(table)}.{col}", []),
410 descending=descending,
411 ),
412 False,
413 )
414 continue
416 if self.query.extra and col in self.query.extra:
417 if col in self.query.extra_select:
418 yield (
419 OrderBy(
420 Ref(col, RawSQL(*self.query.extra[col])),
421 descending=descending,
422 ),
423 True,
424 )
425 else:
426 yield (
427 OrderBy(RawSQL(*self.query.extra[col]), descending=descending),
428 False,
429 )
430 else:
431 if self.query.combinator and self.select:
432 # Don't use the first model's field because other
433 # combinated queries might define it differently.
434 yield OrderBy(F(col), descending=descending), False
435 else:
436 # 'col' is of the form 'field' or 'field1__field2' or
437 # '-field1__field2__field', etc.
438 yield from self.find_ordering_name(
439 field,
440 self.query.get_meta(),
441 default_order=default_order,
442 )
444 def get_order_by(self):
445 """
446 Return a list of 2-tuples of the form (expr, (sql, params, is_ref)) for
447 the ORDER BY clause.
449 The order_by clause can alter the select clause (for example it can add
450 aliases to clauses that do not yet have one, or it can add totally new
451 select clauses).
452 """
453 result = []
454 seen = set()
455 for expr, is_ref in self._order_by_pairs():
456 resolved = expr.resolve_expression(self.query, allow_joins=True, reuse=None)
457 if not is_ref and self.query.combinator and self.select:
458 src = resolved.expression
459 expr_src = expr.expression
460 for sel_expr, _, col_alias in self.select:
461 if src == sel_expr:
462 # When values() is used the exact alias must be used to
463 # reference annotations.
464 if (
465 self.query.has_select_fields
466 and col_alias in self.query.annotation_select
467 and not (
468 isinstance(expr_src, F) and col_alias == expr_src.name
469 )
470 ):
471 continue
472 resolved.set_source_expressions(
473 [Ref(col_alias if col_alias else src.target.column, src)]
474 )
475 break
476 else:
477 # Add column used in ORDER BY clause to the selected
478 # columns and to each combined query.
479 order_by_idx = len(self.query.select) + 1
480 col_alias = f"__orderbycol{order_by_idx}"
481 for q in self.query.combined_queries:
482 # If fields were explicitly selected through values()
483 # combined queries cannot be augmented.
484 if q.has_select_fields:
485 raise DatabaseError(
486 "ORDER BY term does not match any column in "
487 "the result set."
488 )
489 q.add_annotation(expr_src, col_alias)
490 self.query.add_select_col(resolved, col_alias)
491 resolved.set_source_expressions([Ref(col_alias, src)])
492 sql, params = self.compile(resolved)
493 # Don't add the same column twice, but the order direction is
494 # not taken into account so we strip it. When this entire method
495 # is refactored into expressions, then we can check each part as we
496 # generate it.
497 without_ordering = self.ordering_parts.search(sql)[1]
498 params_hash = make_hashable(params)
499 if (without_ordering, params_hash) in seen:
500 continue
501 seen.add((without_ordering, params_hash))
502 result.append((resolved, (sql, params, is_ref)))
503 return result
505 def get_extra_select(self, order_by, select):
506 extra_select = []
507 if self.query.distinct and not self.query.distinct_fields:
508 select_sql = [t[1] for t in select]
509 for expr, (sql, params, is_ref) in order_by:
510 without_ordering = self.ordering_parts.search(sql)[1]
511 if not is_ref and (without_ordering, params) not in select_sql:
512 extra_select.append((expr, (without_ordering, params), None))
513 return extra_select
515 def quote_name_unless_alias(self, name):
516 """
517 A wrapper around connection.ops.quote_name that doesn't quote aliases
518 for table names. This avoids problems with some SQL dialects that treat
519 quoted strings specially (e.g. PostgreSQL).
520 """
521 if name in self.quote_cache:
522 return self.quote_cache[name]
523 if (
524 (name in self.query.alias_map and name not in self.query.table_map)
525 or name in self.query.extra_select
526 or (
527 self.query.external_aliases.get(name)
528 and name not in self.query.table_map
529 )
530 ):
531 self.quote_cache[name] = name
532 return name
533 r = self.connection.ops.quote_name(name)
534 self.quote_cache[name] = r
535 return r
537 def compile(self, node):
538 vendor_impl = getattr(node, "as_" + self.connection.vendor, None)
539 if vendor_impl:
540 sql, params = vendor_impl(self, self.connection)
541 else:
542 sql, params = node.as_sql(self, self.connection)
543 return sql, params
545 def get_combinator_sql(self, combinator, all):
546 features = self.connection.features
547 compilers = [
548 query.get_compiler(self.using, self.connection, self.elide_empty)
549 for query in self.query.combined_queries
550 ]
551 if not features.supports_slicing_ordering_in_compound:
552 for compiler in compilers:
553 if compiler.query.is_sliced:
554 raise DatabaseError(
555 "LIMIT/OFFSET not allowed in subqueries of compound statements."
556 )
557 if compiler.get_order_by():
558 raise DatabaseError(
559 "ORDER BY not allowed in subqueries of compound statements."
560 )
561 elif self.query.is_sliced and combinator == "union":
562 for compiler in compilers:
563 # A sliced union cannot have its parts elided as some of them
564 # might be sliced as well and in the event where only a single
565 # part produces a non-empty resultset it might be impossible to
566 # generate valid SQL.
567 compiler.elide_empty = False
568 parts = ()
569 for compiler in compilers:
570 try:
571 # If the columns list is limited, then all combined queries
572 # must have the same columns list. Set the selects defined on
573 # the query on all combined queries, if not already set.
574 if not compiler.query.values_select and self.query.values_select:
575 compiler.query = compiler.query.clone()
576 compiler.query.set_values(
577 (
578 *self.query.extra_select,
579 *self.query.values_select,
580 *self.query.annotation_select,
581 )
582 )
583 part_sql, part_args = compiler.as_sql(with_col_aliases=True)
584 if compiler.query.combinator:
585 # Wrap in a subquery if wrapping in parentheses isn't
586 # supported.
587 if not features.supports_parentheses_in_compound:
588 part_sql = f"SELECT * FROM ({part_sql})"
589 # Add parentheses when combining with compound query if not
590 # already added for all compound queries.
591 elif (
592 self.query.subquery
593 or not features.supports_slicing_ordering_in_compound
594 ):
595 part_sql = f"({part_sql})"
596 elif (
597 self.query.subquery
598 and features.supports_slicing_ordering_in_compound
599 ):
600 part_sql = f"({part_sql})"
601 parts += ((part_sql, part_args),)
602 except EmptyResultSet:
603 # Omit the empty queryset with UNION and with DIFFERENCE if the
604 # first queryset is nonempty.
605 if combinator == "union" or (combinator == "difference" and parts):
606 continue
607 raise
608 if not parts:
609 raise EmptyResultSet
610 combinator_sql = self.connection.ops.set_operators[combinator]
611 if all and combinator == "union":
612 combinator_sql += " ALL"
613 braces = "{}"
614 if not self.query.subquery and features.supports_slicing_ordering_in_compound:
615 braces = "({})"
616 sql_parts, args_parts = zip(
617 *((braces.format(sql), args) for sql, args in parts)
618 )
619 result = [f" {combinator_sql} ".join(sql_parts)]
620 params = []
621 for part in args_parts:
622 params.extend(part)
623 return result, params
625 def get_qualify_sql(self):
626 where_parts = []
627 if self.where:
628 where_parts.append(self.where)
629 if self.having:
630 where_parts.append(self.having)
631 inner_query = self.query.clone()
632 inner_query.subquery = True
633 inner_query.where = inner_query.where.__class__(where_parts)
634 # Augment the inner query with any window function references that
635 # might have been masked via values() and alias(). If any masked
636 # aliases are added they'll be masked again to avoid fetching
637 # the data in the `if qual_aliases` branch below.
638 select = {
639 expr: alias for expr, _, alias in self.get_select(with_col_aliases=True)[0]
640 }
641 select_aliases = set(select.values())
642 qual_aliases = set()
643 replacements = {}
645 def collect_replacements(expressions):
646 while expressions:
647 expr = expressions.pop()
648 if expr in replacements:
649 continue
650 elif select_alias := select.get(expr):
651 replacements[expr] = select_alias
652 elif isinstance(expr, Lookup):
653 expressions.extend(expr.get_source_expressions())
654 elif isinstance(expr, Ref):
655 if expr.refs not in select_aliases:
656 expressions.extend(expr.get_source_expressions())
657 else:
658 num_qual_alias = len(qual_aliases)
659 select_alias = f"qual{num_qual_alias}"
660 qual_aliases.add(select_alias)
661 inner_query.add_annotation(expr, select_alias)
662 replacements[expr] = select_alias
664 collect_replacements(list(self.qualify.leaves()))
665 self.qualify = self.qualify.replace_expressions(
666 {expr: Ref(alias, expr) for expr, alias in replacements.items()}
667 )
668 order_by = []
669 for order_by_expr, *_ in self.get_order_by():
670 collect_replacements(order_by_expr.get_source_expressions())
671 order_by.append(
672 order_by_expr.replace_expressions(
673 {expr: Ref(alias, expr) for expr, alias in replacements.items()}
674 )
675 )
676 inner_query_compiler = inner_query.get_compiler(
677 self.using, connection=self.connection, elide_empty=self.elide_empty
678 )
679 inner_sql, inner_params = inner_query_compiler.as_sql(
680 # The limits must be applied to the outer query to avoid pruning
681 # results too eagerly.
682 with_limits=False,
683 # Force unique aliasing of selected columns to avoid collisions
684 # and make rhs predicates referencing easier.
685 with_col_aliases=True,
686 )
687 qualify_sql, qualify_params = self.compile(self.qualify)
688 result = [
689 "SELECT * FROM (",
690 inner_sql,
691 ")",
692 self.connection.ops.quote_name("qualify"),
693 "WHERE",
694 qualify_sql,
695 ]
696 if qual_aliases:
697 # If some select aliases were unmasked for filtering purposes they
698 # must be masked back.
699 cols = [self.connection.ops.quote_name(alias) for alias in select.values()]
700 result = [
701 "SELECT",
702 ", ".join(cols),
703 "FROM (",
704 *result,
705 ")",
706 self.connection.ops.quote_name("qualify_mask"),
707 ]
708 params = list(inner_params) + qualify_params
709 # As the SQL spec is unclear on whether or not derived tables
710 # ordering must propagate it has to be explicitly repeated on the
711 # outer-most query to ensure it's preserved.
712 if order_by:
713 ordering_sqls = []
714 for ordering in order_by:
715 ordering_sql, ordering_params = self.compile(ordering)
716 ordering_sqls.append(ordering_sql)
717 params.extend(ordering_params)
718 result.extend(["ORDER BY", ", ".join(ordering_sqls)])
719 return result, params
721 def as_sql(self, with_limits=True, with_col_aliases=False):
722 """
723 Create the SQL for this query. Return the SQL string and list of
724 parameters.
726 If 'with_limits' is False, any limit/offset information is not included
727 in the query.
728 """
729 refcounts_before = self.query.alias_refcount.copy()
730 try:
731 combinator = self.query.combinator
732 extra_select, order_by, group_by = self.pre_sql_setup(
733 with_col_aliases=with_col_aliases or bool(combinator),
734 )
735 for_update_part = None
736 # Is a LIMIT/OFFSET clause needed?
737 with_limit_offset = with_limits and self.query.is_sliced
738 combinator = self.query.combinator
739 features = self.connection.features
740 if combinator:
741 if not getattr(features, f"supports_select_{combinator}"):
742 raise NotSupportedError(
743 f"{combinator} is not supported on this database backend."
744 )
745 result, params = self.get_combinator_sql(
746 combinator, self.query.combinator_all
747 )
748 elif self.qualify:
749 result, params = self.get_qualify_sql()
750 order_by = None
751 else:
752 distinct_fields, distinct_params = self.get_distinct()
753 # This must come after 'select', 'ordering', and 'distinct'
754 # (see docstring of get_from_clause() for details).
755 from_, f_params = self.get_from_clause()
756 try:
757 where, w_params = (
758 self.compile(self.where) if self.where is not None else ("", [])
759 )
760 except EmptyResultSet:
761 if self.elide_empty:
762 raise
763 # Use a predicate that's always False.
764 where, w_params = "0 = 1", []
765 except FullResultSet:
766 where, w_params = "", []
767 try:
768 having, h_params = (
769 self.compile(self.having)
770 if self.having is not None
771 else ("", [])
772 )
773 except FullResultSet:
774 having, h_params = "", []
775 result = ["SELECT"]
776 params = []
778 if self.query.distinct:
779 distinct_result, distinct_params = self.connection.ops.distinct_sql(
780 distinct_fields,
781 distinct_params,
782 )
783 result += distinct_result
784 params += distinct_params
786 out_cols = []
787 for _, (s_sql, s_params), alias in self.select + extra_select:
788 if alias:
789 s_sql = f"{s_sql} AS {self.connection.ops.quote_name(alias)}"
790 params.extend(s_params)
791 out_cols.append(s_sql)
793 result += [", ".join(out_cols)]
794 if from_:
795 result += ["FROM", *from_]
796 elif self.connection.features.bare_select_suffix:
797 result += [self.connection.features.bare_select_suffix]
798 params.extend(f_params)
800 if self.query.select_for_update and features.has_select_for_update:
801 if (
802 self.connection.get_autocommit()
803 # Don't raise an exception when database doesn't
804 # support transactions, as it's a noop.
805 and features.supports_transactions
806 ):
807 raise TransactionManagementError(
808 "select_for_update cannot be used outside of a transaction."
809 )
811 if (
812 with_limit_offset
813 and not features.supports_select_for_update_with_limit
814 ):
815 raise NotSupportedError(
816 "LIMIT/OFFSET is not supported with "
817 "select_for_update on this database backend."
818 )
819 nowait = self.query.select_for_update_nowait
820 skip_locked = self.query.select_for_update_skip_locked
821 of = self.query.select_for_update_of
822 no_key = self.query.select_for_no_key_update
823 # If it's a NOWAIT/SKIP LOCKED/OF/NO KEY query but the
824 # backend doesn't support it, raise NotSupportedError to
825 # prevent a possible deadlock.
826 if nowait and not features.has_select_for_update_nowait:
827 raise NotSupportedError(
828 "NOWAIT is not supported on this database backend."
829 )
830 elif skip_locked and not features.has_select_for_update_skip_locked:
831 raise NotSupportedError(
832 "SKIP LOCKED is not supported on this database backend."
833 )
834 elif of and not features.has_select_for_update_of:
835 raise NotSupportedError(
836 "FOR UPDATE OF is not supported on this database backend."
837 )
838 elif no_key and not features.has_select_for_no_key_update:
839 raise NotSupportedError(
840 "FOR NO KEY UPDATE is not supported on this "
841 "database backend."
842 )
843 for_update_part = self.connection.ops.for_update_sql(
844 nowait=nowait,
845 skip_locked=skip_locked,
846 of=self.get_select_for_update_of_arguments(),
847 no_key=no_key,
848 )
850 if for_update_part and features.for_update_after_from:
851 result.append(for_update_part)
853 if where:
854 result.append("WHERE %s" % where)
855 params.extend(w_params)
857 grouping = []
858 for g_sql, g_params in group_by:
859 grouping.append(g_sql)
860 params.extend(g_params)
861 if grouping:
862 if distinct_fields:
863 raise NotImplementedError(
864 "annotate() + distinct(fields) is not implemented."
865 )
866 order_by = order_by or self.connection.ops.force_no_ordering()
867 result.append("GROUP BY %s" % ", ".join(grouping))
868 if self._meta_ordering:
869 order_by = None
870 if having:
871 result.append("HAVING %s" % having)
872 params.extend(h_params)
874 if self.query.explain_info:
875 result.insert(
876 0,
877 self.connection.ops.explain_query_prefix(
878 self.query.explain_info.format,
879 **self.query.explain_info.options,
880 ),
881 )
883 if order_by:
884 ordering = []
885 for _, (o_sql, o_params, _) in order_by:
886 ordering.append(o_sql)
887 params.extend(o_params)
888 order_by_sql = "ORDER BY %s" % ", ".join(ordering)
889 if combinator and features.requires_compound_order_by_subquery:
890 result = ["SELECT * FROM (", *result, ")", order_by_sql]
891 else:
892 result.append(order_by_sql)
894 if with_limit_offset:
895 result.append(
896 self.connection.ops.limit_offset_sql(
897 self.query.low_mark, self.query.high_mark
898 )
899 )
901 if for_update_part and not features.for_update_after_from:
902 result.append(for_update_part)
904 if self.query.subquery and extra_select:
905 # If the query is used as a subquery, the extra selects would
906 # result in more columns than the left-hand side expression is
907 # expecting. This can happen when a subquery uses a combination
908 # of order_by() and distinct(), forcing the ordering expressions
909 # to be selected as well. Wrap the query in another subquery
910 # to exclude extraneous selects.
911 sub_selects = []
912 sub_params = []
913 for index, (select, _, alias) in enumerate(self.select, start=1):
914 if alias:
915 sub_selects.append(
916 "{}.{}".format(
917 self.connection.ops.quote_name("subquery"),
918 self.connection.ops.quote_name(alias),
919 )
920 )
921 else:
922 select_clone = select.relabeled_clone(
923 {select.alias: "subquery"}
924 )
925 subselect, subparams = select_clone.as_sql(
926 self, self.connection
927 )
928 sub_selects.append(subselect)
929 sub_params.extend(subparams)
930 return "SELECT {} FROM ({}) subquery".format(
931 ", ".join(sub_selects),
932 " ".join(result),
933 ), tuple(sub_params + params)
935 return " ".join(result), tuple(params)
936 finally:
937 # Finally do cleanup - get rid of the joins we created above.
938 self.query.reset_refcounts(refcounts_before)
940 def get_default_columns(
941 self, select_mask, start_alias=None, opts=None, from_parent=None
942 ):
943 """
944 Compute the default columns for selecting every field in the base
945 model. Will sometimes be called to pull in related models (e.g. via
946 select_related), in which case "opts" and "start_alias" will be given
947 to provide a starting point for the traversal.
949 Return a list of strings, quoted appropriately for use in SQL
950 directly, as well as a set of aliases used in the select statement (if
951 'as_pairs' is True, return a list of (alias, col_name) pairs instead
952 of strings as the first component and None as the second component).
953 """
954 result = []
955 if opts is None:
956 if (opts := self.query.get_meta()) is None:
957 return result
958 start_alias = start_alias or self.query.get_initial_alias()
959 # The 'seen_models' is used to optimize checking the needed parent
960 # alias for a given field. This also includes None -> start_alias to
961 # be used by local fields.
962 seen_models = {None: start_alias}
964 for field in opts.concrete_fields:
965 model = field.model._meta.concrete_model
966 # A proxy model will have a different model and concrete_model. We
967 # will assign None if the field belongs to this model.
968 if model == opts.model:
969 model = None
970 if (
971 from_parent
972 and model is not None
973 and issubclass(
974 from_parent._meta.concrete_model, model._meta.concrete_model
975 )
976 ):
977 # Avoid loading data for already loaded parents.
978 # We end up here in the case select_related() resolution
979 # proceeds from parent model to child model. In that case the
980 # parent model data is already present in the SELECT clause,
981 # and we want to avoid reloading the same data again.
982 continue
983 if select_mask and field not in select_mask:
984 continue
985 alias = self.query.join_parent_model(opts, model, start_alias, seen_models)
986 column = field.get_col(alias)
987 result.append(column)
988 return result
990 def get_distinct(self):
991 """
992 Return a quoted list of fields to use in DISTINCT ON part of the query.
994 This method can alter the tables in the query, and thus it must be
995 called before get_from_clause().
996 """
997 result = []
998 params = []
999 opts = self.query.get_meta()
1001 for name in self.query.distinct_fields:
1002 parts = name.split(LOOKUP_SEP)
1003 _, targets, alias, joins, path, _, transform_function = self._setup_joins(
1004 parts, opts, None
1005 )
1006 targets, alias, _ = self.query.trim_joins(targets, joins, path)
1007 for target in targets:
1008 if name in self.query.annotation_select:
1009 result.append(self.connection.ops.quote_name(name))
1010 else:
1011 r, p = self.compile(transform_function(target, alias))
1012 result.append(r)
1013 params.append(p)
1014 return result, params
1016 def find_ordering_name(
1017 self, name, opts, alias=None, default_order="ASC", already_seen=None
1018 ):
1019 """
1020 Return the table alias (the name might be ambiguous, the alias will
1021 not be) and column name for ordering by the given 'name' parameter.
1022 The 'name' is of the form 'field1__field2__...__fieldN'.
1023 """
1024 name, order = get_order_dir(name, default_order)
1025 descending = order == "DESC"
1026 pieces = name.split(LOOKUP_SEP)
1027 (
1028 field,
1029 targets,
1030 alias,
1031 joins,
1032 path,
1033 opts,
1034 transform_function,
1035 ) = self._setup_joins(pieces, opts, alias)
1037 # If we get to this point and the field is a relation to another model,
1038 # append the default ordering for that model unless it is the pk
1039 # shortcut or the attribute name of the field that is specified or
1040 # there are transforms to process.
1041 if (
1042 field.is_relation
1043 and opts.ordering
1044 and getattr(field, "attname", None) != pieces[-1]
1045 and name != "pk"
1046 and not getattr(transform_function, "has_transforms", False)
1047 ):
1048 # Firstly, avoid infinite loops.
1049 already_seen = already_seen or set()
1050 join_tuple = tuple(
1051 getattr(self.query.alias_map[j], "join_cols", None) for j in joins
1052 )
1053 if join_tuple in already_seen:
1054 raise FieldError("Infinite loop caused by ordering.")
1055 already_seen.add(join_tuple)
1057 results = []
1058 for item in opts.ordering:
1059 if hasattr(item, "resolve_expression") and not isinstance(
1060 item, OrderBy
1061 ):
1062 item = item.desc() if descending else item.asc()
1063 if isinstance(item, OrderBy):
1064 results.append(
1065 (item.prefix_references(f"{name}{LOOKUP_SEP}"), False)
1066 )
1067 continue
1068 results.extend(
1069 (expr.prefix_references(f"{name}{LOOKUP_SEP}"), is_ref)
1070 for expr, is_ref in self.find_ordering_name(
1071 item, opts, alias, order, already_seen
1072 )
1073 )
1074 return results
1075 targets, alias, _ = self.query.trim_joins(targets, joins, path)
1076 return [
1077 (OrderBy(transform_function(t, alias), descending=descending), False)
1078 for t in targets
1079 ]
1081 def _setup_joins(self, pieces, opts, alias):
1082 """
1083 Helper method for get_order_by() and get_distinct().
1085 get_ordering() and get_distinct() must produce same target columns on
1086 same input, as the prefixes of get_ordering() and get_distinct() must
1087 match. Executing SQL where this is not true is an error.
1088 """
1089 alias = alias or self.query.get_initial_alias()
1090 field, targets, opts, joins, path, transform_function = self.query.setup_joins(
1091 pieces, opts, alias
1092 )
1093 alias = joins[-1]
1094 return field, targets, alias, joins, path, opts, transform_function
1096 def get_from_clause(self):
1097 """
1098 Return a list of strings that are joined together to go after the
1099 "FROM" part of the query, as well as a list any extra parameters that
1100 need to be included. Subclasses, can override this to create a
1101 from-clause via a "select".
1103 This should only be called after any SQL construction methods that
1104 might change the tables that are needed. This means the select columns,
1105 ordering, and distinct must be done first.
1106 """
1107 result = []
1108 params = []
1109 for alias in tuple(self.query.alias_map):
1110 if not self.query.alias_refcount[alias]:
1111 continue
1112 try:
1113 from_clause = self.query.alias_map[alias]
1114 except KeyError:
1115 # Extra tables can end up in self.tables, but not in the
1116 # alias_map if they aren't in a join. That's OK. We skip them.
1117 continue
1118 clause_sql, clause_params = self.compile(from_clause)
1119 result.append(clause_sql)
1120 params.extend(clause_params)
1121 for t in self.query.extra_tables:
1122 alias, _ = self.query.table_alias(t)
1123 # Only add the alias if it's not already present (the table_alias()
1124 # call increments the refcount, so an alias refcount of one means
1125 # this is the only reference).
1126 if (
1127 alias not in self.query.alias_map
1128 or self.query.alias_refcount[alias] == 1
1129 ):
1130 result.append(", %s" % self.quote_name_unless_alias(alias))
1131 return result, params
1133 def get_related_selections(
1134 self,
1135 select,
1136 select_mask,
1137 opts=None,
1138 root_alias=None,
1139 cur_depth=1,
1140 requested=None,
1141 restricted=None,
1142 ):
1143 """
1144 Fill in the information needed for a select_related query. The current
1145 depth is measured as the number of connections away from the root model
1146 (for example, cur_depth=1 means we are looking at models with direct
1147 connections to the root model).
1148 """
1150 def _get_field_choices():
1151 direct_choices = (f.name for f in opts.fields if f.is_relation)
1152 reverse_choices = (
1153 f.field.related_query_name()
1154 for f in opts.related_objects
1155 if f.field.unique
1156 )
1157 return chain(
1158 direct_choices, reverse_choices, self.query._filtered_relations
1159 )
1161 related_klass_infos = []
1162 if not restricted and cur_depth > self.query.max_depth:
1163 # We've recursed far enough; bail out.
1164 return related_klass_infos
1166 if not opts:
1167 opts = self.query.get_meta()
1168 root_alias = self.query.get_initial_alias()
1170 # Setup for the case when only particular related fields should be
1171 # included in the related selection.
1172 fields_found = set()
1173 if requested is None:
1174 restricted = isinstance(self.query.select_related, dict)
1175 if restricted:
1176 requested = self.query.select_related
1178 def get_related_klass_infos(klass_info, related_klass_infos):
1179 klass_info["related_klass_infos"] = related_klass_infos
1181 for f in opts.fields:
1182 fields_found.add(f.name)
1184 if restricted:
1185 next = requested.get(f.name, {})
1186 if not f.is_relation:
1187 # If a non-related field is used like a relation,
1188 # or if a single non-relational field is given.
1189 if next or f.name in requested:
1190 raise FieldError(
1191 "Non-relational field given in select_related: '{}'. "
1192 "Choices are: {}".format(
1193 f.name,
1194 ", ".join(_get_field_choices()) or "(none)",
1195 )
1196 )
1197 else:
1198 next = False
1200 if not select_related_descend(f, restricted, requested, select_mask):
1201 continue
1202 related_select_mask = select_mask.get(f) or {}
1203 klass_info = {
1204 "model": f.remote_field.model,
1205 "field": f,
1206 "reverse": False,
1207 "local_setter": f.set_cached_value,
1208 "remote_setter": f.remote_field.set_cached_value
1209 if f.unique
1210 else lambda x, y: None,
1211 "from_parent": False,
1212 }
1213 related_klass_infos.append(klass_info)
1214 select_fields = []
1215 _, _, _, joins, _, _ = self.query.setup_joins([f.name], opts, root_alias)
1216 alias = joins[-1]
1217 columns = self.get_default_columns(
1218 related_select_mask, start_alias=alias, opts=f.remote_field.model._meta
1219 )
1220 for col in columns:
1221 select_fields.append(len(select))
1222 select.append((col, None))
1223 klass_info["select_fields"] = select_fields
1224 next_klass_infos = self.get_related_selections(
1225 select,
1226 related_select_mask,
1227 f.remote_field.model._meta,
1228 alias,
1229 cur_depth + 1,
1230 next,
1231 restricted,
1232 )
1233 get_related_klass_infos(klass_info, next_klass_infos)
1235 if restricted:
1236 related_fields = [
1237 (o.field, o.related_model)
1238 for o in opts.related_objects
1239 if o.field.unique and not o.many_to_many
1240 ]
1241 for related_field, model in related_fields:
1242 related_select_mask = select_mask.get(related_field) or {}
1243 if not select_related_descend(
1244 related_field,
1245 restricted,
1246 requested,
1247 related_select_mask,
1248 reverse=True,
1249 ):
1250 continue
1252 related_field_name = related_field.related_query_name()
1253 fields_found.add(related_field_name)
1255 join_info = self.query.setup_joins(
1256 [related_field_name], opts, root_alias
1257 )
1258 alias = join_info.joins[-1]
1259 from_parent = issubclass(model, opts.model) and model is not opts.model
1260 klass_info = {
1261 "model": model,
1262 "field": related_field,
1263 "reverse": True,
1264 "local_setter": related_field.remote_field.set_cached_value,
1265 "remote_setter": related_field.set_cached_value,
1266 "from_parent": from_parent,
1267 }
1268 related_klass_infos.append(klass_info)
1269 select_fields = []
1270 columns = self.get_default_columns(
1271 related_select_mask,
1272 start_alias=alias,
1273 opts=model._meta,
1274 from_parent=opts.model,
1275 )
1276 for col in columns:
1277 select_fields.append(len(select))
1278 select.append((col, None))
1279 klass_info["select_fields"] = select_fields
1280 next = requested.get(related_field.related_query_name(), {})
1281 next_klass_infos = self.get_related_selections(
1282 select,
1283 related_select_mask,
1284 model._meta,
1285 alias,
1286 cur_depth + 1,
1287 next,
1288 restricted,
1289 )
1290 get_related_klass_infos(klass_info, next_klass_infos)
1292 def local_setter(final_field, obj, from_obj):
1293 # Set a reverse fk object when relation is non-empty.
1294 if from_obj:
1295 final_field.remote_field.set_cached_value(from_obj, obj)
1297 def local_setter_noop(obj, from_obj):
1298 pass
1300 def remote_setter(name, obj, from_obj):
1301 setattr(from_obj, name, obj)
1303 for name in list(requested):
1304 # Filtered relations work only on the topmost level.
1305 if cur_depth > 1:
1306 break
1307 if name in self.query._filtered_relations:
1308 fields_found.add(name)
1309 final_field, _, join_opts, joins, _, _ = self.query.setup_joins(
1310 [name], opts, root_alias
1311 )
1312 model = join_opts.model
1313 alias = joins[-1]
1314 from_parent = (
1315 issubclass(model, opts.model) and model is not opts.model
1316 )
1317 klass_info = {
1318 "model": model,
1319 "field": final_field,
1320 "reverse": True,
1321 "local_setter": (
1322 partial(local_setter, final_field)
1323 if len(joins) <= 2
1324 else local_setter_noop
1325 ),
1326 "remote_setter": partial(remote_setter, name),
1327 "from_parent": from_parent,
1328 }
1329 related_klass_infos.append(klass_info)
1330 select_fields = []
1331 field_select_mask = select_mask.get((name, final_field)) or {}
1332 columns = self.get_default_columns(
1333 field_select_mask,
1334 start_alias=alias,
1335 opts=model._meta,
1336 from_parent=opts.model,
1337 )
1338 for col in columns:
1339 select_fields.append(len(select))
1340 select.append((col, None))
1341 klass_info["select_fields"] = select_fields
1342 next_requested = requested.get(name, {})
1343 next_klass_infos = self.get_related_selections(
1344 select,
1345 field_select_mask,
1346 opts=model._meta,
1347 root_alias=alias,
1348 cur_depth=cur_depth + 1,
1349 requested=next_requested,
1350 restricted=restricted,
1351 )
1352 get_related_klass_infos(klass_info, next_klass_infos)
1353 fields_not_found = set(requested).difference(fields_found)
1354 if fields_not_found:
1355 invalid_fields = ("'%s'" % s for s in fields_not_found)
1356 raise FieldError(
1357 "Invalid field name(s) given in select_related: {}. "
1358 "Choices are: {}".format(
1359 ", ".join(invalid_fields),
1360 ", ".join(_get_field_choices()) or "(none)",
1361 )
1362 )
1363 return related_klass_infos
1365 def get_select_for_update_of_arguments(self):
1366 """
1367 Return a quoted list of arguments for the SELECT FOR UPDATE OF part of
1368 the query.
1369 """
1371 def _get_parent_klass_info(klass_info):
1372 concrete_model = klass_info["model"]._meta.concrete_model
1373 for parent_model, parent_link in concrete_model._meta.parents.items():
1374 parent_list = parent_model._meta.get_parent_list()
1375 yield {
1376 "model": parent_model,
1377 "field": parent_link,
1378 "reverse": False,
1379 "select_fields": [
1380 select_index
1381 for select_index in klass_info["select_fields"]
1382 # Selected columns from a model or its parents.
1383 if (
1384 self.select[select_index][0].target.model == parent_model
1385 or self.select[select_index][0].target.model in parent_list
1386 )
1387 ],
1388 }
1390 def _get_first_selected_col_from_model(klass_info):
1391 """
1392 Find the first selected column from a model. If it doesn't exist,
1393 don't lock a model.
1395 select_fields is filled recursively, so it also contains fields
1396 from the parent models.
1397 """
1398 concrete_model = klass_info["model"]._meta.concrete_model
1399 for select_index in klass_info["select_fields"]:
1400 if self.select[select_index][0].target.model == concrete_model:
1401 return self.select[select_index][0]
1403 def _get_field_choices():
1404 """Yield all allowed field paths in breadth-first search order."""
1405 queue = collections.deque([(None, self.klass_info)])
1406 while queue:
1407 parent_path, klass_info = queue.popleft()
1408 if parent_path is None:
1409 path = []
1410 yield "self"
1411 else:
1412 field = klass_info["field"]
1413 if klass_info["reverse"]:
1414 field = field.remote_field
1415 path = parent_path + [field.name]
1416 yield LOOKUP_SEP.join(path)
1417 queue.extend(
1418 (path, klass_info)
1419 for klass_info in _get_parent_klass_info(klass_info)
1420 )
1421 queue.extend(
1422 (path, klass_info)
1423 for klass_info in klass_info.get("related_klass_infos", [])
1424 )
1426 if not self.klass_info:
1427 return []
1428 result = []
1429 invalid_names = []
1430 for name in self.query.select_for_update_of:
1431 klass_info = self.klass_info
1432 if name == "self":
1433 col = _get_first_selected_col_from_model(klass_info)
1434 else:
1435 for part in name.split(LOOKUP_SEP):
1436 klass_infos = (
1437 *klass_info.get("related_klass_infos", []),
1438 *_get_parent_klass_info(klass_info),
1439 )
1440 for related_klass_info in klass_infos:
1441 field = related_klass_info["field"]
1442 if related_klass_info["reverse"]:
1443 field = field.remote_field
1444 if field.name == part:
1445 klass_info = related_klass_info
1446 break
1447 else:
1448 klass_info = None
1449 break
1450 if klass_info is None:
1451 invalid_names.append(name)
1452 continue
1453 col = _get_first_selected_col_from_model(klass_info)
1454 if col is not None:
1455 if self.connection.features.select_for_update_of_column:
1456 result.append(self.compile(col)[0])
1457 else:
1458 result.append(self.quote_name_unless_alias(col.alias))
1459 if invalid_names:
1460 raise FieldError(
1461 "Invalid field name(s) given in select_for_update(of=(...)): {}. "
1462 "Only relational fields followed in the query are allowed. "
1463 "Choices are: {}.".format(
1464 ", ".join(invalid_names),
1465 ", ".join(_get_field_choices()),
1466 )
1467 )
1468 return result
1470 def get_converters(self, expressions):
1471 converters = {}
1472 for i, expression in enumerate(expressions):
1473 if expression:
1474 backend_converters = self.connection.ops.get_db_converters(expression)
1475 field_converters = expression.get_db_converters(self.connection)
1476 if backend_converters or field_converters:
1477 converters[i] = (backend_converters + field_converters, expression)
1478 return converters
1480 def apply_converters(self, rows, converters):
1481 connection = self.connection
1482 converters = list(converters.items())
1483 for row in map(list, rows):
1484 for pos, (convs, expression) in converters:
1485 value = row[pos]
1486 for converter in convs:
1487 value = converter(value, expression, connection)
1488 row[pos] = value
1489 yield row
1491 def results_iter(
1492 self,
1493 results=None,
1494 tuple_expected=False,
1495 chunked_fetch=False,
1496 chunk_size=GET_ITERATOR_CHUNK_SIZE,
1497 ):
1498 """Return an iterator over the results from executing this query."""
1499 if results is None:
1500 results = self.execute_sql(
1501 MULTI, chunked_fetch=chunked_fetch, chunk_size=chunk_size
1502 )
1503 fields = [s[0] for s in self.select[0 : self.col_count]]
1504 converters = self.get_converters(fields)
1505 rows = chain.from_iterable(results)
1506 if converters:
1507 rows = self.apply_converters(rows, converters)
1508 if tuple_expected:
1509 rows = map(tuple, rows)
1510 return rows
1512 def has_results(self):
1513 """
1514 Backends (e.g. NoSQL) can override this in order to use optimized
1515 versions of "query has any results."
1516 """
1517 return bool(self.execute_sql(SINGLE))
1519 def execute_sql(
1520 self, result_type=MULTI, chunked_fetch=False, chunk_size=GET_ITERATOR_CHUNK_SIZE
1521 ):
1522 """
1523 Run the query against the database and return the result(s). The
1524 return value is a single data item if result_type is SINGLE, or an
1525 iterator over the results if the result_type is MULTI.
1527 result_type is either MULTI (use fetchmany() to retrieve all rows),
1528 SINGLE (only retrieve a single row), or None. In this last case, the
1529 cursor is returned if any query is executed, since it's used by
1530 subclasses such as InsertQuery). It's possible, however, that no query
1531 is needed, as the filters describe an empty set. In that case, None is
1532 returned, to avoid any unnecessary database interaction.
1533 """
1534 result_type = result_type or NO_RESULTS
1535 try:
1536 sql, params = self.as_sql()
1537 if not sql:
1538 raise EmptyResultSet
1539 except EmptyResultSet:
1540 if result_type == MULTI:
1541 return iter([])
1542 else:
1543 return
1544 if chunked_fetch:
1545 cursor = self.connection.chunked_cursor()
1546 else:
1547 cursor = self.connection.cursor()
1548 try:
1549 cursor.execute(sql, params)
1550 except Exception:
1551 # Might fail for server-side cursors (e.g. connection closed)
1552 cursor.close()
1553 raise
1555 if result_type == CURSOR:
1556 # Give the caller the cursor to process and close.
1557 return cursor
1558 if result_type == SINGLE:
1559 try:
1560 val = cursor.fetchone()
1561 if val:
1562 return val[0 : self.col_count]
1563 return val
1564 finally:
1565 # done with the cursor
1566 cursor.close()
1567 if result_type == NO_RESULTS:
1568 cursor.close()
1569 return
1571 result = cursor_iter(
1572 cursor,
1573 self.connection.features.empty_fetchmany_value,
1574 self.col_count if self.has_extra_select else None,
1575 chunk_size,
1576 )
1577 if not chunked_fetch or not self.connection.features.can_use_chunked_reads:
1578 # If we are using non-chunked reads, we return the same data
1579 # structure as normally, but ensure it is all read into memory
1580 # before going any further. Use chunked_fetch if requested,
1581 # unless the database doesn't support it.
1582 return list(result)
1583 return result
1585 def as_subquery_condition(self, alias, columns, compiler):
1586 qn = compiler.quote_name_unless_alias
1587 qn2 = self.connection.ops.quote_name
1589 for index, select_col in enumerate(self.query.select):
1590 lhs_sql, lhs_params = self.compile(select_col)
1591 rhs = f"{qn(alias)}.{qn2(columns[index])}"
1592 self.query.where.add(RawSQL(f"{lhs_sql} = {rhs}", lhs_params), AND)
1594 sql, params = self.as_sql()
1595 return "EXISTS (%s)" % sql, params
1597 def explain_query(self):
1598 result = list(self.execute_sql())
1599 # Some backends return 1 item tuples with strings, and others return
1600 # tuples with integers and strings. Flatten them out into strings.
1601 format_ = self.query.explain_info.format
1602 output_formatter = json.dumps if format_ and format_.lower() == "json" else str
1603 for row in result[0]:
1604 if not isinstance(row, str):
1605 yield " ".join(output_formatter(c) for c in row)
1606 else:
1607 yield row
1610class SQLInsertCompiler(SQLCompiler):
1611 returning_fields = None
1612 returning_params = ()
1614 def field_as_sql(self, field, val):
1615 """
1616 Take a field and a value intended to be saved on that field, and
1617 return placeholder SQL and accompanying params. Check for raw values,
1618 expressions, and fields with get_placeholder() defined in that order.
1620 When field is None, consider the value raw and use it as the
1621 placeholder, with no corresponding parameters returned.
1622 """
1623 if field is None:
1624 # A field value of None means the value is raw.
1625 sql, params = val, []
1626 elif hasattr(val, "as_sql"):
1627 # This is an expression, let's compile it.
1628 sql, params = self.compile(val)
1629 elif hasattr(field, "get_placeholder"):
1630 # Some fields (e.g. geo fields) need special munging before
1631 # they can be inserted.
1632 sql, params = field.get_placeholder(val, self, self.connection), [val]
1633 else:
1634 # Return the common case for the placeholder
1635 sql, params = "%s", [val]
1637 # The following hook is only used by Oracle Spatial, which sometimes
1638 # needs to yield 'NULL' and [] as its placeholder and params instead
1639 # of '%s' and [None]. The 'NULL' placeholder is produced earlier by
1640 # OracleOperations.get_geom_placeholder(). The following line removes
1641 # the corresponding None parameter. See ticket #10888.
1642 params = self.connection.ops.modify_insert_params(sql, params)
1644 return sql, params
1646 def prepare_value(self, field, value):
1647 """
1648 Prepare a value to be used in a query by resolving it if it is an
1649 expression and otherwise calling the field's get_db_prep_save().
1650 """
1651 if hasattr(value, "resolve_expression"):
1652 value = value.resolve_expression(
1653 self.query, allow_joins=False, for_save=True
1654 )
1655 # Don't allow values containing Col expressions. They refer to
1656 # existing columns on a row, but in the case of insert the row
1657 # doesn't exist yet.
1658 if value.contains_column_references:
1659 raise ValueError(
1660 'Failed to insert expression "{}" on {}. F() expressions '
1661 "can only be used to update, not to insert.".format(value, field)
1662 )
1663 if value.contains_aggregate:
1664 raise FieldError(
1665 "Aggregate functions are not allowed in this query "
1666 f"({field.name}={value!r})."
1667 )
1668 if value.contains_over_clause:
1669 raise FieldError(
1670 "Window expressions are not allowed in this query ({}={!r}).".format(
1671 field.name, value
1672 )
1673 )
1674 return field.get_db_prep_save(value, connection=self.connection)
1676 def pre_save_val(self, field, obj):
1677 """
1678 Get the given field's value off the given obj. pre_save() is used for
1679 things like auto_now on DateTimeField. Skip it if this is a raw query.
1680 """
1681 if self.query.raw:
1682 return getattr(obj, field.attname)
1683 return field.pre_save(obj, add=True)
1685 def assemble_as_sql(self, fields, value_rows):
1686 """
1687 Take a sequence of N fields and a sequence of M rows of values, and
1688 generate placeholder SQL and parameters for each field and value.
1689 Return a pair containing:
1690 * a sequence of M rows of N SQL placeholder strings, and
1691 * a sequence of M rows of corresponding parameter values.
1693 Each placeholder string may contain any number of '%s' interpolation
1694 strings, and each parameter row will contain exactly as many params
1695 as the total number of '%s's in the corresponding placeholder row.
1696 """
1697 if not value_rows:
1698 return [], []
1700 # list of (sql, [params]) tuples for each object to be saved
1701 # Shape: [n_objs][n_fields][2]
1702 rows_of_fields_as_sql = (
1703 (self.field_as_sql(field, v) for field, v in zip(fields, row))
1704 for row in value_rows
1705 )
1707 # tuple like ([sqls], [[params]s]) for each object to be saved
1708 # Shape: [n_objs][2][n_fields]
1709 sql_and_param_pair_rows = (zip(*row) for row in rows_of_fields_as_sql)
1711 # Extract separate lists for placeholders and params.
1712 # Each of these has shape [n_objs][n_fields]
1713 placeholder_rows, param_rows = zip(*sql_and_param_pair_rows)
1715 # Params for each field are still lists, and need to be flattened.
1716 param_rows = [[p for ps in row for p in ps] for row in param_rows]
1718 return placeholder_rows, param_rows
1720 def as_sql(self):
1721 # We don't need quote_name_unless_alias() here, since these are all
1722 # going to be column names (so we can avoid the extra overhead).
1723 qn = self.connection.ops.quote_name
1724 opts = self.query.get_meta()
1725 insert_statement = self.connection.ops.insert_statement(
1726 on_conflict=self.query.on_conflict,
1727 )
1728 result = [f"{insert_statement} {qn(opts.db_table)}"]
1729 fields = self.query.fields or [opts.pk]
1730 result.append("(%s)" % ", ".join(qn(f.column) for f in fields))
1732 if self.query.fields:
1733 value_rows = [
1734 [
1735 self.prepare_value(field, self.pre_save_val(field, obj))
1736 for field in fields
1737 ]
1738 for obj in self.query.objs
1739 ]
1740 else:
1741 # An empty object.
1742 value_rows = [
1743 [self.connection.ops.pk_default_value()] for _ in self.query.objs
1744 ]
1745 fields = [None]
1747 # Currently the backends just accept values when generating bulk
1748 # queries and generate their own placeholders. Doing that isn't
1749 # necessary and it should be possible to use placeholders and
1750 # expressions in bulk inserts too.
1751 can_bulk = (
1752 not self.returning_fields and self.connection.features.has_bulk_insert
1753 )
1755 placeholder_rows, param_rows = self.assemble_as_sql(fields, value_rows)
1757 on_conflict_suffix_sql = self.connection.ops.on_conflict_suffix_sql(
1758 fields,
1759 self.query.on_conflict,
1760 (f.column for f in self.query.update_fields),
1761 (f.column for f in self.query.unique_fields),
1762 )
1763 if (
1764 self.returning_fields
1765 and self.connection.features.can_return_columns_from_insert
1766 ):
1767 if self.connection.features.can_return_rows_from_bulk_insert:
1768 result.append(
1769 self.connection.ops.bulk_insert_sql(fields, placeholder_rows)
1770 )
1771 params = param_rows
1772 else:
1773 result.append("VALUES (%s)" % ", ".join(placeholder_rows[0]))
1774 params = [param_rows[0]]
1775 if on_conflict_suffix_sql:
1776 result.append(on_conflict_suffix_sql)
1777 # Skip empty r_sql to allow subclasses to customize behavior for
1778 # 3rd party backends. Refs #19096.
1779 r_sql, self.returning_params = self.connection.ops.return_insert_columns(
1780 self.returning_fields
1781 )
1782 if r_sql:
1783 result.append(r_sql)
1784 params += [self.returning_params]
1785 return [(" ".join(result), tuple(chain.from_iterable(params)))]
1787 if can_bulk:
1788 result.append(self.connection.ops.bulk_insert_sql(fields, placeholder_rows))
1789 if on_conflict_suffix_sql:
1790 result.append(on_conflict_suffix_sql)
1791 return [(" ".join(result), tuple(p for ps in param_rows for p in ps))]
1792 else:
1793 if on_conflict_suffix_sql:
1794 result.append(on_conflict_suffix_sql)
1795 return [
1796 (" ".join(result + ["VALUES (%s)" % ", ".join(p)]), vals)
1797 for p, vals in zip(placeholder_rows, param_rows)
1798 ]
1800 def execute_sql(self, returning_fields=None):
1801 assert not (
1802 returning_fields
1803 and len(self.query.objs) != 1
1804 and not self.connection.features.can_return_rows_from_bulk_insert
1805 )
1806 opts = self.query.get_meta()
1807 self.returning_fields = returning_fields
1808 with self.connection.cursor() as cursor:
1809 for sql, params in self.as_sql():
1810 cursor.execute(sql, params)
1811 if not self.returning_fields:
1812 return []
1813 if (
1814 self.connection.features.can_return_rows_from_bulk_insert
1815 and len(self.query.objs) > 1
1816 ):
1817 rows = self.connection.ops.fetch_returned_insert_rows(cursor)
1818 elif self.connection.features.can_return_columns_from_insert:
1819 assert len(self.query.objs) == 1
1820 rows = [
1821 self.connection.ops.fetch_returned_insert_columns(
1822 cursor,
1823 self.returning_params,
1824 )
1825 ]
1826 else:
1827 rows = [
1828 (
1829 self.connection.ops.last_insert_id(
1830 cursor,
1831 opts.db_table,
1832 opts.pk.column,
1833 ),
1834 )
1835 ]
1836 cols = [field.get_col(opts.db_table) for field in self.returning_fields]
1837 converters = self.get_converters(cols)
1838 if converters:
1839 rows = list(self.apply_converters(rows, converters))
1840 return rows
1843class SQLDeleteCompiler(SQLCompiler):
1844 @cached_property
1845 def single_alias(self):
1846 # Ensure base table is in aliases.
1847 self.query.get_initial_alias()
1848 return sum(self.query.alias_refcount[t] > 0 for t in self.query.alias_map) == 1
1850 @classmethod
1851 def _expr_refs_base_model(cls, expr, base_model):
1852 if isinstance(expr, Query):
1853 return expr.model == base_model
1854 if not hasattr(expr, "get_source_expressions"):
1855 return False
1856 return any(
1857 cls._expr_refs_base_model(source_expr, base_model)
1858 for source_expr in expr.get_source_expressions()
1859 )
1861 @cached_property
1862 def contains_self_reference_subquery(self):
1863 return any(
1864 self._expr_refs_base_model(expr, self.query.model)
1865 for expr in chain(
1866 self.query.annotations.values(), self.query.where.children
1867 )
1868 )
1870 def _as_sql(self, query):
1871 delete = "DELETE FROM %s" % self.quote_name_unless_alias(query.base_table)
1872 try:
1873 where, params = self.compile(query.where)
1874 except FullResultSet:
1875 return delete, ()
1876 return f"{delete} WHERE {where}", tuple(params)
1878 def as_sql(self):
1879 """
1880 Create the SQL for this query. Return the SQL string and list of
1881 parameters.
1882 """
1883 if self.single_alias and not self.contains_self_reference_subquery:
1884 return self._as_sql(self.query)
1885 innerq = self.query.clone()
1886 innerq.__class__ = Query
1887 innerq.clear_select_clause()
1888 pk = self.query.model._meta.pk
1889 innerq.select = [pk.get_col(self.query.get_initial_alias())]
1890 outerq = Query(self.query.model)
1891 if not self.connection.features.update_can_self_select:
1892 # Force the materialization of the inner query to allow reference
1893 # to the target table on MySQL.
1894 sql, params = innerq.get_compiler(connection=self.connection).as_sql()
1895 innerq = RawSQL("SELECT * FROM (%s) subquery" % sql, params)
1896 outerq.add_filter("pk__in", innerq)
1897 return self._as_sql(outerq)
1900class SQLUpdateCompiler(SQLCompiler):
1901 def as_sql(self):
1902 """
1903 Create the SQL for this query. Return the SQL string and list of
1904 parameters.
1905 """
1906 self.pre_sql_setup()
1907 if not self.query.values:
1908 return "", ()
1909 qn = self.quote_name_unless_alias
1910 values, update_params = [], []
1911 for field, model, val in self.query.values:
1912 if hasattr(val, "resolve_expression"):
1913 val = val.resolve_expression(
1914 self.query, allow_joins=False, for_save=True
1915 )
1916 if val.contains_aggregate:
1917 raise FieldError(
1918 "Aggregate functions are not allowed in this query "
1919 f"({field.name}={val!r})."
1920 )
1921 if val.contains_over_clause:
1922 raise FieldError(
1923 "Window expressions are not allowed in this query "
1924 f"({field.name}={val!r})."
1925 )
1926 elif hasattr(val, "prepare_database_save"):
1927 if field.remote_field:
1928 val = val.prepare_database_save(field)
1929 else:
1930 raise TypeError(
1931 "Tried to update field {} with a model instance, {!r}. "
1932 "Use a value compatible with {}.".format(
1933 field, val, field.__class__.__name__
1934 )
1935 )
1936 val = field.get_db_prep_save(val, connection=self.connection)
1938 # Getting the placeholder for the field.
1939 if hasattr(field, "get_placeholder"):
1940 placeholder = field.get_placeholder(val, self, self.connection)
1941 else:
1942 placeholder = "%s"
1943 name = field.column
1944 if hasattr(val, "as_sql"):
1945 sql, params = self.compile(val)
1946 values.append(f"{qn(name)} = {placeholder % sql}")
1947 update_params.extend(params)
1948 elif val is not None:
1949 values.append(f"{qn(name)} = {placeholder}")
1950 update_params.append(val)
1951 else:
1952 values.append("%s = NULL" % qn(name))
1953 table = self.query.base_table
1954 result = [
1955 "UPDATE %s SET" % qn(table),
1956 ", ".join(values),
1957 ]
1958 try:
1959 where, params = self.compile(self.query.where)
1960 except FullResultSet:
1961 params = []
1962 else:
1963 result.append("WHERE %s" % where)
1964 return " ".join(result), tuple(update_params + params)
1966 def execute_sql(self, result_type):
1967 """
1968 Execute the specified update. Return the number of rows affected by
1969 the primary update query. The "primary update query" is the first
1970 non-empty query that is executed. Row counts for any subsequent,
1971 related queries are not available.
1972 """
1973 cursor = super().execute_sql(result_type)
1974 try:
1975 rows = cursor.rowcount if cursor else 0
1976 is_empty = cursor is None
1977 finally:
1978 if cursor:
1979 cursor.close()
1980 for query in self.query.get_related_updates():
1981 aux_rows = query.get_compiler(self.using).execute_sql(result_type)
1982 if is_empty and aux_rows:
1983 rows = aux_rows
1984 is_empty = False
1985 return rows
1987 def pre_sql_setup(self):
1988 """
1989 If the update depends on results from other tables, munge the "where"
1990 conditions to match the format required for (portable) SQL updates.
1992 If multiple updates are required, pull out the id values to update at
1993 this point so that they don't change as a result of the progressive
1994 updates.
1995 """
1996 refcounts_before = self.query.alias_refcount.copy()
1997 # Ensure base table is in the query
1998 self.query.get_initial_alias()
1999 count = self.query.count_active_tables()
2000 if not self.query.related_updates and count == 1:
2001 return
2002 query = self.query.chain(klass=Query)
2003 query.select_related = False
2004 query.clear_ordering(force=True)
2005 query.extra = {}
2006 query.select = []
2007 meta = query.get_meta()
2008 fields = [meta.pk.name]
2009 related_ids_index = []
2010 for related in self.query.related_updates:
2011 if all(
2012 path.join_field.primary_key for path in meta.get_path_to_parent(related)
2013 ):
2014 # If a primary key chain exists to the targeted related update,
2015 # then the meta.pk value can be used for it.
2016 related_ids_index.append((related, 0))
2017 else:
2018 # This branch will only be reached when updating a field of an
2019 # ancestor that is not part of the primary key chain of a MTI
2020 # tree.
2021 related_ids_index.append((related, len(fields)))
2022 fields.append(related._meta.pk.name)
2023 query.add_fields(fields)
2024 super().pre_sql_setup()
2026 must_pre_select = (
2027 count > 1 and not self.connection.features.update_can_self_select
2028 )
2030 # Now we adjust the current query: reset the where clause and get rid
2031 # of all the tables we don't need (since they're in the sub-select).
2032 self.query.clear_where()
2033 if self.query.related_updates or must_pre_select:
2034 # Either we're using the idents in multiple update queries (so
2035 # don't want them to change), or the db backend doesn't support
2036 # selecting from the updating table (e.g. MySQL).
2037 idents = []
2038 related_ids = collections.defaultdict(list)
2039 for rows in query.get_compiler(self.using).execute_sql(MULTI):
2040 idents.extend(r[0] for r in rows)
2041 for parent, index in related_ids_index:
2042 related_ids[parent].extend(r[index] for r in rows)
2043 self.query.add_filter("pk__in", idents)
2044 self.query.related_ids = related_ids
2045 else:
2046 # The fast path. Filters and updates in one query.
2047 self.query.add_filter("pk__in", query)
2048 self.query.reset_refcounts(refcounts_before)
2051class SQLAggregateCompiler(SQLCompiler):
2052 def as_sql(self):
2053 """
2054 Create the SQL for this query. Return the SQL string and list of
2055 parameters.
2056 """
2057 sql, params = [], []
2058 for annotation in self.query.annotation_select.values():
2059 ann_sql, ann_params = self.compile(annotation)
2060 ann_sql, ann_params = annotation.select_format(self, ann_sql, ann_params)
2061 sql.append(ann_sql)
2062 params.extend(ann_params)
2063 self.col_count = len(self.query.annotation_select)
2064 sql = ", ".join(sql)
2065 params = tuple(params)
2067 inner_query_sql, inner_query_params = self.query.inner_query.get_compiler(
2068 self.using,
2069 elide_empty=self.elide_empty,
2070 ).as_sql(with_col_aliases=True)
2071 sql = f"SELECT {sql} FROM ({inner_query_sql}) subquery"
2072 params += inner_query_params
2073 return sql, params
2076def cursor_iter(cursor, sentinel, col_count, itersize):
2077 """
2078 Yield blocks of rows from a cursor and ensure the cursor is closed when
2079 done.
2080 """
2081 try:
2082 for rows in iter((lambda: cursor.fetchmany(itersize)), sentinel):
2083 yield rows if col_count is None else [r[:col_count] for r in rows]
2084 finally:
2085 cursor.close()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Constants specific to the SQL storage portion of the ORM.
3"""
5# Size of each "chunk" for get_iterator calls.
6# Larger values are slightly faster at the expense of more storage space.
7GET_ITERATOR_CHUNK_SIZE = 100
9# Namedtuples for sql.* internal use.
11# How many results to expect from a cursor.execute call
12MULTI = "multi"
13SINGLE = "single"
14CURSOR = "cursor"
15NO_RESULTS = "no results"
17ORDER_DIR = {
18 "ASC": ("ASC", "DESC"),
19 "DESC": ("DESC", "ASC"),
20}
22# SQL join types.
23INNER = "INNER JOIN"
24LOUTER = "LEFT OUTER JOIN"
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Useful auxiliary data structures for query construction. Not useful outside
3the SQL domain.
4"""
5from plain.exceptions import FullResultSet
6from plain.models.sql.constants import INNER, LOUTER
9class MultiJoin(Exception):
10 """
11 Used by join construction code to indicate the point at which a
12 multi-valued join was attempted (if the caller wants to treat that
13 exceptionally).
14 """
16 def __init__(self, names_pos, path_with_names):
17 self.level = names_pos
18 # The path travelled, this includes the path to the multijoin.
19 self.names_with_path = path_with_names
22class Empty:
23 pass
26class Join:
27 """
28 Used by sql.Query and sql.SQLCompiler to generate JOIN clauses into the
29 FROM entry. For example, the SQL generated could be
30 LEFT OUTER JOIN "sometable" T1
31 ON ("othertable"."sometable_id" = "sometable"."id")
33 This class is primarily used in Query.alias_map. All entries in alias_map
34 must be Join compatible by providing the following attributes and methods:
35 - table_name (string)
36 - table_alias (possible alias for the table, can be None)
37 - join_type (can be None for those entries that aren't joined from
38 anything)
39 - parent_alias (which table is this join's parent, can be None similarly
40 to join_type)
41 - as_sql()
42 - relabeled_clone()
43 """
45 def __init__(
46 self,
47 table_name,
48 parent_alias,
49 table_alias,
50 join_type,
51 join_field,
52 nullable,
53 filtered_relation=None,
54 ):
55 # Join table
56 self.table_name = table_name
57 self.parent_alias = parent_alias
58 # Note: table_alias is not necessarily known at instantiation time.
59 self.table_alias = table_alias
60 # LOUTER or INNER
61 self.join_type = join_type
62 # A list of 2-tuples to use in the ON clause of the JOIN.
63 # Each 2-tuple will create one join condition in the ON clause.
64 self.join_cols = join_field.get_joining_columns()
65 # Along which field (or ForeignObjectRel in the reverse join case)
66 self.join_field = join_field
67 # Is this join nullabled?
68 self.nullable = nullable
69 self.filtered_relation = filtered_relation
71 def as_sql(self, compiler, connection):
72 """
73 Generate the full
74 LEFT OUTER JOIN sometable ON sometable.somecol = othertable.othercol, params
75 clause for this join.
76 """
77 join_conditions = []
78 params = []
79 qn = compiler.quote_name_unless_alias
80 qn2 = connection.ops.quote_name
82 # Add a join condition for each pair of joining columns.
83 for lhs_col, rhs_col in self.join_cols:
84 join_conditions.append(
85 "{}.{} = {}.{}".format(
86 qn(self.parent_alias),
87 qn2(lhs_col),
88 qn(self.table_alias),
89 qn2(rhs_col),
90 )
91 )
93 # Add a single condition inside parentheses for whatever
94 # get_extra_restriction() returns.
95 extra_cond = self.join_field.get_extra_restriction(
96 self.table_alias, self.parent_alias
97 )
98 if extra_cond:
99 extra_sql, extra_params = compiler.compile(extra_cond)
100 join_conditions.append("(%s)" % extra_sql)
101 params.extend(extra_params)
102 if self.filtered_relation:
103 try:
104 extra_sql, extra_params = compiler.compile(self.filtered_relation)
105 except FullResultSet:
106 pass
107 else:
108 join_conditions.append("(%s)" % extra_sql)
109 params.extend(extra_params)
110 if not join_conditions:
111 # This might be a rel on the other end of an actual declared field.
112 declared_field = getattr(self.join_field, "field", self.join_field)
113 raise ValueError(
114 "Join generated an empty ON clause. %s did not yield either "
115 "joining columns or extra restrictions." % declared_field.__class__
116 )
117 on_clause_sql = " AND ".join(join_conditions)
118 alias_str = (
119 "" if self.table_alias == self.table_name else (" %s" % self.table_alias)
120 )
121 sql = f"{self.join_type} {qn(self.table_name)}{alias_str} ON ({on_clause_sql})"
122 return sql, params
124 def relabeled_clone(self, change_map):
125 new_parent_alias = change_map.get(self.parent_alias, self.parent_alias)
126 new_table_alias = change_map.get(self.table_alias, self.table_alias)
127 if self.filtered_relation is not None:
128 filtered_relation = self.filtered_relation.clone()
129 filtered_relation.path = [
130 change_map.get(p, p) for p in self.filtered_relation.path
131 ]
132 else:
133 filtered_relation = None
134 return self.__class__(
135 self.table_name,
136 new_parent_alias,
137 new_table_alias,
138 self.join_type,
139 self.join_field,
140 self.nullable,
141 filtered_relation=filtered_relation,
142 )
144 @property
145 def identity(self):
146 return (
147 self.__class__,
148 self.table_name,
149 self.parent_alias,
150 self.join_field,
151 self.filtered_relation,
152 )
154 def __eq__(self, other):
155 if not isinstance(other, Join):
156 return NotImplemented
157 return self.identity == other.identity
159 def __hash__(self):
160 return hash(self.identity)
162 def equals(self, other):
163 # Ignore filtered_relation in equality check.
164 return self.identity[:-1] == other.identity[:-1]
166 def demote(self):
167 new = self.relabeled_clone({})
168 new.join_type = INNER
169 return new
171 def promote(self):
172 new = self.relabeled_clone({})
173 new.join_type = LOUTER
174 return new
177class BaseTable:
178 """
179 The BaseTable class is used for base table references in FROM clause. For
180 example, the SQL "foo" in
181 SELECT * FROM "foo" WHERE somecond
182 could be generated by this class.
183 """
185 join_type = None
186 parent_alias = None
187 filtered_relation = None
189 def __init__(self, table_name, alias):
190 self.table_name = table_name
191 self.table_alias = alias
193 def as_sql(self, compiler, connection):
194 alias_str = (
195 "" if self.table_alias == self.table_name else (" %s" % self.table_alias)
196 )
197 base_sql = compiler.quote_name_unless_alias(self.table_name)
198 return base_sql + alias_str, []
200 def relabeled_clone(self, change_map):
201 return self.__class__(
202 self.table_name, change_map.get(self.table_alias, self.table_alias)
203 )
205 @property
206 def identity(self):
207 return self.__class__, self.table_name, self.table_alias
209 def __eq__(self, other):
210 if not isinstance(other, BaseTable):
211 return NotImplemented
212 return self.identity == other.identity
214 def __hash__(self):
215 return hash(self.identity)
217 def equals(self, other):
218 return self.identity == other.identity
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Create SQL statements for QuerySets.
4The code in here encapsulates all of the SQL construction so that QuerySets
5themselves do not have to (and could be backed by things other than SQL
6databases). The abstraction barrier only works one way: this module has to know
7all about the internals of models in order to get the information it needs.
8"""
9import copy
10import difflib
11import functools
12import sys
13from collections import Counter, namedtuple
14from collections.abc import Iterator, Mapping
15from itertools import chain, count, product
16from string import ascii_uppercase
18from plain.exceptions import FieldDoesNotExist, FieldError
19from plain.models.aggregates import Count
20from plain.models.constants import LOOKUP_SEP
21from plain.models.db import DEFAULT_DB_ALIAS, NotSupportedError, connections
22from plain.models.expressions import (
23 BaseExpression,
24 Col,
25 Exists,
26 F,
27 OuterRef,
28 Ref,
29 ResolvedOuterRef,
30 Value,
31)
32from plain.models.fields import Field
33from plain.models.fields.related_lookups import MultiColSource
34from plain.models.lookups import Lookup
35from plain.models.query_utils import (
36 Q,
37 check_rel_lookup_compatibility,
38 refs_expression,
39)
40from plain.models.sql.constants import INNER, LOUTER, ORDER_DIR, SINGLE
41from plain.models.sql.datastructures import BaseTable, Empty, Join, MultiJoin
42from plain.models.sql.where import AND, OR, ExtraWhere, NothingNode, WhereNode
43from plain.utils.functional import cached_property
44from plain.utils.regex_helper import _lazy_re_compile
45from plain.utils.tree import Node
47__all__ = ["Query", "RawQuery"]
49# Quotation marks ('"`[]), whitespace characters, semicolons, or inline
50# SQL comments are forbidden in column aliases.
51FORBIDDEN_ALIAS_PATTERN = _lazy_re_compile(r"['`\"\]\[;\s]|--|/\*|\*/")
53# Inspired from
54# https://www.postgresql.org/docs/current/sql-syntax-lexical.html#SQL-SYNTAX-IDENTIFIERS
55EXPLAIN_OPTIONS_PATTERN = _lazy_re_compile(r"[\w\-]+")
58def get_field_names_from_opts(opts):
59 if opts is None:
60 return set()
61 return set(
62 chain.from_iterable(
63 (f.name, f.attname) if f.concrete else (f.name,) for f in opts.get_fields()
64 )
65 )
68def get_children_from_q(q):
69 for child in q.children:
70 if isinstance(child, Node):
71 yield from get_children_from_q(child)
72 else:
73 yield child
76JoinInfo = namedtuple(
77 "JoinInfo",
78 ("final_field", "targets", "opts", "joins", "path", "transform_function"),
79)
82class RawQuery:
83 """A single raw SQL query."""
85 def __init__(self, sql, using, params=()):
86 self.params = params
87 self.sql = sql
88 self.using = using
89 self.cursor = None
91 # Mirror some properties of a normal query so that
92 # the compiler can be used to process results.
93 self.low_mark, self.high_mark = 0, None # Used for offset/limit
94 self.extra_select = {}
95 self.annotation_select = {}
97 def chain(self, using):
98 return self.clone(using)
100 def clone(self, using):
101 return RawQuery(self.sql, using, params=self.params)
103 def get_columns(self):
104 if self.cursor is None:
105 self._execute_query()
106 converter = connections[self.using].introspection.identifier_converter
107 return [converter(column_meta[0]) for column_meta in self.cursor.description]
109 def __iter__(self):
110 # Always execute a new query for a new iterator.
111 # This could be optimized with a cache at the expense of RAM.
112 self._execute_query()
113 if not connections[self.using].features.can_use_chunked_reads:
114 # If the database can't use chunked reads we need to make sure we
115 # evaluate the entire query up front.
116 result = list(self.cursor)
117 else:
118 result = self.cursor
119 return iter(result)
121 def __repr__(self):
122 return f"<{self.__class__.__name__}: {self}>"
124 @property
125 def params_type(self):
126 if self.params is None:
127 return None
128 return dict if isinstance(self.params, Mapping) else tuple
130 def __str__(self):
131 if self.params_type is None:
132 return self.sql
133 return self.sql % self.params_type(self.params)
135 def _execute_query(self):
136 connection = connections[self.using]
138 # Adapt parameters to the database, as much as possible considering
139 # that the target type isn't known. See #17755.
140 params_type = self.params_type
141 adapter = connection.ops.adapt_unknown_value
142 if params_type is tuple:
143 params = tuple(adapter(val) for val in self.params)
144 elif params_type is dict:
145 params = {key: adapter(val) for key, val in self.params.items()}
146 elif params_type is None:
147 params = None
148 else:
149 raise RuntimeError("Unexpected params type: %s" % params_type)
151 self.cursor = connection.cursor()
152 self.cursor.execute(self.sql, params)
155ExplainInfo = namedtuple("ExplainInfo", ("format", "options"))
158class Query(BaseExpression):
159 """A single SQL query."""
161 alias_prefix = "T"
162 empty_result_set_value = None
163 subq_aliases = frozenset([alias_prefix])
165 compiler = "SQLCompiler"
167 base_table_class = BaseTable
168 join_class = Join
170 default_cols = True
171 default_ordering = True
172 standard_ordering = True
174 filter_is_sticky = False
175 subquery = False
177 # SQL-related attributes.
178 # Select and related select clauses are expressions to use in the SELECT
179 # clause of the query. The select is used for cases where we want to set up
180 # the select clause to contain other than default fields (values(),
181 # subqueries...). Note that annotations go to annotations dictionary.
182 select = ()
183 # The group_by attribute can have one of the following forms:
184 # - None: no group by at all in the query
185 # - A tuple of expressions: group by (at least) those expressions.
186 # String refs are also allowed for now.
187 # - True: group by all select fields of the model
188 # See compiler.get_group_by() for details.
189 group_by = None
190 order_by = ()
191 low_mark = 0 # Used for offset/limit.
192 high_mark = None # Used for offset/limit.
193 distinct = False
194 distinct_fields = ()
195 select_for_update = False
196 select_for_update_nowait = False
197 select_for_update_skip_locked = False
198 select_for_update_of = ()
199 select_for_no_key_update = False
200 select_related = False
201 has_select_fields = False
202 # Arbitrary limit for select_related to prevents infinite recursion.
203 max_depth = 5
204 # Holds the selects defined by a call to values() or values_list()
205 # excluding annotation_select and extra_select.
206 values_select = ()
208 # SQL annotation-related attributes.
209 annotation_select_mask = None
210 _annotation_select_cache = None
212 # Set combination attributes.
213 combinator = None
214 combinator_all = False
215 combined_queries = ()
217 # These are for extensions. The contents are more or less appended verbatim
218 # to the appropriate clause.
219 extra_select_mask = None
220 _extra_select_cache = None
222 extra_tables = ()
223 extra_order_by = ()
225 # A tuple that is a set of model field names and either True, if these are
226 # the fields to defer, or False if these are the only fields to load.
227 deferred_loading = (frozenset(), True)
229 explain_info = None
231 def __init__(self, model, alias_cols=True):
232 self.model = model
233 self.alias_refcount = {}
234 # alias_map is the most important data structure regarding joins.
235 # It's used for recording which joins exist in the query and what
236 # types they are. The key is the alias of the joined table (possibly
237 # the table name) and the value is a Join-like object (see
238 # sql.datastructures.Join for more information).
239 self.alias_map = {}
240 # Whether to provide alias to columns during reference resolving.
241 self.alias_cols = alias_cols
242 # Sometimes the query contains references to aliases in outer queries (as
243 # a result of split_exclude). Correct alias quoting needs to know these
244 # aliases too.
245 # Map external tables to whether they are aliased.
246 self.external_aliases = {}
247 self.table_map = {} # Maps table names to list of aliases.
248 self.used_aliases = set()
250 self.where = WhereNode()
251 # Maps alias -> Annotation Expression.
252 self.annotations = {}
253 # These are for extensions. The contents are more or less appended
254 # verbatim to the appropriate clause.
255 self.extra = {} # Maps col_alias -> (col_sql, params).
257 self._filtered_relations = {}
259 @property
260 def output_field(self):
261 if len(self.select) == 1:
262 select = self.select[0]
263 return getattr(select, "target", None) or select.field
264 elif len(self.annotation_select) == 1:
265 return next(iter(self.annotation_select.values())).output_field
267 @cached_property
268 def base_table(self):
269 for alias in self.alias_map:
270 return alias
272 def __str__(self):
273 """
274 Return the query as a string of SQL with the parameter values
275 substituted in (use sql_with_params() to see the unsubstituted string).
277 Parameter values won't necessarily be quoted correctly, since that is
278 done by the database interface at execution time.
279 """
280 sql, params = self.sql_with_params()
281 return sql % params
283 def sql_with_params(self):
284 """
285 Return the query as an SQL string and the parameters that will be
286 substituted into the query.
287 """
288 return self.get_compiler(DEFAULT_DB_ALIAS).as_sql()
290 def __deepcopy__(self, memo):
291 """Limit the amount of work when a Query is deepcopied."""
292 result = self.clone()
293 memo[id(self)] = result
294 return result
296 def get_compiler(self, using=None, connection=None, elide_empty=True):
297 if using is None and connection is None:
298 raise ValueError("Need either using or connection")
299 if using:
300 connection = connections[using]
301 return connection.ops.compiler(self.compiler)(
302 self, connection, using, elide_empty
303 )
305 def get_meta(self):
306 """
307 Return the Options instance (the model._meta) from which to start
308 processing. Normally, this is self.model._meta, but it can be changed
309 by subclasses.
310 """
311 if self.model:
312 return self.model._meta
314 def clone(self):
315 """
316 Return a copy of the current Query. A lightweight alternative to
317 deepcopy().
318 """
319 obj = Empty()
320 obj.__class__ = self.__class__
321 # Copy references to everything.
322 obj.__dict__ = self.__dict__.copy()
323 # Clone attributes that can't use shallow copy.
324 obj.alias_refcount = self.alias_refcount.copy()
325 obj.alias_map = self.alias_map.copy()
326 obj.external_aliases = self.external_aliases.copy()
327 obj.table_map = self.table_map.copy()
328 obj.where = self.where.clone()
329 obj.annotations = self.annotations.copy()
330 if self.annotation_select_mask is not None:
331 obj.annotation_select_mask = self.annotation_select_mask.copy()
332 if self.combined_queries:
333 obj.combined_queries = tuple(
334 [query.clone() for query in self.combined_queries]
335 )
336 # _annotation_select_cache cannot be copied, as doing so breaks the
337 # (necessary) state in which both annotations and
338 # _annotation_select_cache point to the same underlying objects.
339 # It will get re-populated in the cloned queryset the next time it's
340 # used.
341 obj._annotation_select_cache = None
342 obj.extra = self.extra.copy()
343 if self.extra_select_mask is not None:
344 obj.extra_select_mask = self.extra_select_mask.copy()
345 if self._extra_select_cache is not None:
346 obj._extra_select_cache = self._extra_select_cache.copy()
347 if self.select_related is not False:
348 # Use deepcopy because select_related stores fields in nested
349 # dicts.
350 obj.select_related = copy.deepcopy(obj.select_related)
351 if "subq_aliases" in self.__dict__:
352 obj.subq_aliases = self.subq_aliases.copy()
353 obj.used_aliases = self.used_aliases.copy()
354 obj._filtered_relations = self._filtered_relations.copy()
355 # Clear the cached_property, if it exists.
356 obj.__dict__.pop("base_table", None)
357 return obj
359 def chain(self, klass=None):
360 """
361 Return a copy of the current Query that's ready for another operation.
362 The klass argument changes the type of the Query, e.g. UpdateQuery.
363 """
364 obj = self.clone()
365 if klass and obj.__class__ != klass:
366 obj.__class__ = klass
367 if not obj.filter_is_sticky:
368 obj.used_aliases = set()
369 obj.filter_is_sticky = False
370 if hasattr(obj, "_setup_query"):
371 obj._setup_query()
372 return obj
374 def relabeled_clone(self, change_map):
375 clone = self.clone()
376 clone.change_aliases(change_map)
377 return clone
379 def _get_col(self, target, field, alias):
380 if not self.alias_cols:
381 alias = None
382 return target.get_col(alias, field)
384 def get_aggregation(self, using, aggregate_exprs):
385 """
386 Return the dictionary with the values of the existing aggregations.
387 """
388 if not aggregate_exprs:
389 return {}
390 aggregates = {}
391 for alias, aggregate_expr in aggregate_exprs.items():
392 self.check_alias(alias)
393 aggregate = aggregate_expr.resolve_expression(
394 self, allow_joins=True, reuse=None, summarize=True
395 )
396 if not aggregate.contains_aggregate:
397 raise TypeError("%s is not an aggregate expression" % alias)
398 aggregates[alias] = aggregate
399 # Existing usage of aggregation can be determined by the presence of
400 # selected aggregates but also by filters against aliased aggregates.
401 _, having, qualify = self.where.split_having_qualify()
402 has_existing_aggregation = (
403 any(
404 getattr(annotation, "contains_aggregate", True)
405 for annotation in self.annotations.values()
406 )
407 or having
408 )
409 # Decide if we need to use a subquery.
410 #
411 # Existing aggregations would cause incorrect results as
412 # get_aggregation() must produce just one result and thus must not use
413 # GROUP BY.
414 #
415 # If the query has limit or distinct, or uses set operations, then
416 # those operations must be done in a subquery so that the query
417 # aggregates on the limit and/or distinct results instead of applying
418 # the distinct and limit after the aggregation.
419 if (
420 isinstance(self.group_by, tuple)
421 or self.is_sliced
422 or has_existing_aggregation
423 or qualify
424 or self.distinct
425 or self.combinator
426 ):
427 from plain.models.sql.subqueries import AggregateQuery
429 inner_query = self.clone()
430 inner_query.subquery = True
431 outer_query = AggregateQuery(self.model, inner_query)
432 inner_query.select_for_update = False
433 inner_query.select_related = False
434 inner_query.set_annotation_mask(self.annotation_select)
435 # Queries with distinct_fields need ordering and when a limit is
436 # applied we must take the slice from the ordered query. Otherwise
437 # no need for ordering.
438 inner_query.clear_ordering(force=False)
439 if not inner_query.distinct:
440 # If the inner query uses default select and it has some
441 # aggregate annotations, then we must make sure the inner
442 # query is grouped by the main model's primary key. However,
443 # clearing the select clause can alter results if distinct is
444 # used.
445 if inner_query.default_cols and has_existing_aggregation:
446 inner_query.group_by = (
447 self.model._meta.pk.get_col(inner_query.get_initial_alias()),
448 )
449 inner_query.default_cols = False
450 if not qualify:
451 # Mask existing annotations that are not referenced by
452 # aggregates to be pushed to the outer query unless
453 # filtering against window functions is involved as it
454 # requires complex realising.
455 annotation_mask = set()
456 for aggregate in aggregates.values():
457 annotation_mask |= aggregate.get_refs()
458 inner_query.set_annotation_mask(annotation_mask)
460 # Add aggregates to the outer AggregateQuery. This requires making
461 # sure all columns referenced by the aggregates are selected in the
462 # inner query. It is achieved by retrieving all column references
463 # by the aggregates, explicitly selecting them in the inner query,
464 # and making sure the aggregates are repointed to them.
465 col_refs = {}
466 for alias, aggregate in aggregates.items():
467 replacements = {}
468 for col in self._gen_cols([aggregate], resolve_refs=False):
469 if not (col_ref := col_refs.get(col)):
470 index = len(col_refs) + 1
471 col_alias = f"__col{index}"
472 col_ref = Ref(col_alias, col)
473 col_refs[col] = col_ref
474 inner_query.annotations[col_alias] = col
475 inner_query.append_annotation_mask([col_alias])
476 replacements[col] = col_ref
477 outer_query.annotations[alias] = aggregate.replace_expressions(
478 replacements
479 )
480 if (
481 inner_query.select == ()
482 and not inner_query.default_cols
483 and not inner_query.annotation_select_mask
484 ):
485 # In case of Model.objects[0:3].count(), there would be no
486 # field selected in the inner query, yet we must use a subquery.
487 # So, make sure at least one field is selected.
488 inner_query.select = (
489 self.model._meta.pk.get_col(inner_query.get_initial_alias()),
490 )
491 else:
492 outer_query = self
493 self.select = ()
494 self.default_cols = False
495 self.extra = {}
496 if self.annotations:
497 # Inline reference to existing annotations and mask them as
498 # they are unnecessary given only the summarized aggregations
499 # are requested.
500 replacements = {
501 Ref(alias, annotation): annotation
502 for alias, annotation in self.annotations.items()
503 }
504 self.annotations = {
505 alias: aggregate.replace_expressions(replacements)
506 for alias, aggregate in aggregates.items()
507 }
508 else:
509 self.annotations = aggregates
510 self.set_annotation_mask(aggregates)
512 empty_set_result = [
513 expression.empty_result_set_value
514 for expression in outer_query.annotation_select.values()
515 ]
516 elide_empty = not any(result is NotImplemented for result in empty_set_result)
517 outer_query.clear_ordering(force=True)
518 outer_query.clear_limits()
519 outer_query.select_for_update = False
520 outer_query.select_related = False
521 compiler = outer_query.get_compiler(using, elide_empty=elide_empty)
522 result = compiler.execute_sql(SINGLE)
523 if result is None:
524 result = empty_set_result
525 else:
526 converters = compiler.get_converters(outer_query.annotation_select.values())
527 result = next(compiler.apply_converters((result,), converters))
529 return dict(zip(outer_query.annotation_select, result))
531 def get_count(self, using):
532 """
533 Perform a COUNT() query using the current filter constraints.
534 """
535 obj = self.clone()
536 return obj.get_aggregation(using, {"__count": Count("*")})["__count"]
538 def has_filters(self):
539 return self.where
541 def exists(self, limit=True):
542 q = self.clone()
543 if not (q.distinct and q.is_sliced):
544 if q.group_by is True:
545 q.add_fields(
546 (f.attname for f in self.model._meta.concrete_fields), False
547 )
548 # Disable GROUP BY aliases to avoid orphaning references to the
549 # SELECT clause which is about to be cleared.
550 q.set_group_by(allow_aliases=False)
551 q.clear_select_clause()
552 if q.combined_queries and q.combinator == "union":
553 q.combined_queries = tuple(
554 combined_query.exists(limit=False)
555 for combined_query in q.combined_queries
556 )
557 q.clear_ordering(force=True)
558 if limit:
559 q.set_limits(high=1)
560 q.add_annotation(Value(1), "a")
561 return q
563 def has_results(self, using):
564 q = self.exists(using)
565 compiler = q.get_compiler(using=using)
566 return compiler.has_results()
568 def explain(self, using, format=None, **options):
569 q = self.clone()
570 for option_name in options:
571 if (
572 not EXPLAIN_OPTIONS_PATTERN.fullmatch(option_name)
573 or "--" in option_name
574 ):
575 raise ValueError(f"Invalid option name: {option_name!r}.")
576 q.explain_info = ExplainInfo(format, options)
577 compiler = q.get_compiler(using=using)
578 return "\n".join(compiler.explain_query())
580 def combine(self, rhs, connector):
581 """
582 Merge the 'rhs' query into the current one (with any 'rhs' effects
583 being applied *after* (that is, "to the right of") anything in the
584 current query. 'rhs' is not modified during a call to this function.
586 The 'connector' parameter describes how to connect filters from the
587 'rhs' query.
588 """
589 if self.model != rhs.model:
590 raise TypeError("Cannot combine queries on two different base models.")
591 if self.is_sliced:
592 raise TypeError("Cannot combine queries once a slice has been taken.")
593 if self.distinct != rhs.distinct:
594 raise TypeError("Cannot combine a unique query with a non-unique query.")
595 if self.distinct_fields != rhs.distinct_fields:
596 raise TypeError("Cannot combine queries with different distinct fields.")
598 # If lhs and rhs shares the same alias prefix, it is possible to have
599 # conflicting alias changes like T4 -> T5, T5 -> T6, which might end up
600 # as T4 -> T6 while combining two querysets. To prevent this, change an
601 # alias prefix of the rhs and update current aliases accordingly,
602 # except if the alias is the base table since it must be present in the
603 # query on both sides.
604 initial_alias = self.get_initial_alias()
605 rhs.bump_prefix(self, exclude={initial_alias})
607 # Work out how to relabel the rhs aliases, if necessary.
608 change_map = {}
609 conjunction = connector == AND
611 # Determine which existing joins can be reused. When combining the
612 # query with AND we must recreate all joins for m2m filters. When
613 # combining with OR we can reuse joins. The reason is that in AND
614 # case a single row can't fulfill a condition like:
615 # revrel__col=1 & revrel__col=2
616 # But, there might be two different related rows matching this
617 # condition. In OR case a single True is enough, so single row is
618 # enough, too.
619 #
620 # Note that we will be creating duplicate joins for non-m2m joins in
621 # the AND case. The results will be correct but this creates too many
622 # joins. This is something that could be fixed later on.
623 reuse = set() if conjunction else set(self.alias_map)
624 joinpromoter = JoinPromoter(connector, 2, False)
625 joinpromoter.add_votes(
626 j for j in self.alias_map if self.alias_map[j].join_type == INNER
627 )
628 rhs_votes = set()
629 # Now, add the joins from rhs query into the new query (skipping base
630 # table).
631 rhs_tables = list(rhs.alias_map)[1:]
632 for alias in rhs_tables:
633 join = rhs.alias_map[alias]
634 # If the left side of the join was already relabeled, use the
635 # updated alias.
636 join = join.relabeled_clone(change_map)
637 new_alias = self.join(join, reuse=reuse)
638 if join.join_type == INNER:
639 rhs_votes.add(new_alias)
640 # We can't reuse the same join again in the query. If we have two
641 # distinct joins for the same connection in rhs query, then the
642 # combined query must have two joins, too.
643 reuse.discard(new_alias)
644 if alias != new_alias:
645 change_map[alias] = new_alias
646 if not rhs.alias_refcount[alias]:
647 # The alias was unused in the rhs query. Unref it so that it
648 # will be unused in the new query, too. We have to add and
649 # unref the alias so that join promotion has information of
650 # the join type for the unused alias.
651 self.unref_alias(new_alias)
652 joinpromoter.add_votes(rhs_votes)
653 joinpromoter.update_join_types(self)
655 # Combine subqueries aliases to ensure aliases relabelling properly
656 # handle subqueries when combining where and select clauses.
657 self.subq_aliases |= rhs.subq_aliases
659 # Now relabel a copy of the rhs where-clause and add it to the current
660 # one.
661 w = rhs.where.clone()
662 w.relabel_aliases(change_map)
663 self.where.add(w, connector)
665 # Selection columns and extra extensions are those provided by 'rhs'.
666 if rhs.select:
667 self.set_select([col.relabeled_clone(change_map) for col in rhs.select])
668 else:
669 self.select = ()
671 if connector == OR:
672 # It would be nice to be able to handle this, but the queries don't
673 # really make sense (or return consistent value sets). Not worth
674 # the extra complexity when you can write a real query instead.
675 if self.extra and rhs.extra:
676 raise ValueError(
677 "When merging querysets using 'or', you cannot have "
678 "extra(select=...) on both sides."
679 )
680 self.extra.update(rhs.extra)
681 extra_select_mask = set()
682 if self.extra_select_mask is not None:
683 extra_select_mask.update(self.extra_select_mask)
684 if rhs.extra_select_mask is not None:
685 extra_select_mask.update(rhs.extra_select_mask)
686 if extra_select_mask:
687 self.set_extra_mask(extra_select_mask)
688 self.extra_tables += rhs.extra_tables
690 # Ordering uses the 'rhs' ordering, unless it has none, in which case
691 # the current ordering is used.
692 self.order_by = rhs.order_by or self.order_by
693 self.extra_order_by = rhs.extra_order_by or self.extra_order_by
695 def _get_defer_select_mask(self, opts, mask, select_mask=None):
696 if select_mask is None:
697 select_mask = {}
698 select_mask[opts.pk] = {}
699 # All concrete fields that are not part of the defer mask must be
700 # loaded. If a relational field is encountered it gets added to the
701 # mask for it be considered if `select_related` and the cycle continues
702 # by recursively calling this function.
703 for field in opts.concrete_fields:
704 field_mask = mask.pop(field.name, None)
705 if field_mask is None:
706 select_mask.setdefault(field, {})
707 elif field_mask:
708 if not field.is_relation:
709 raise FieldError(next(iter(field_mask)))
710 field_select_mask = select_mask.setdefault(field, {})
711 related_model = field.remote_field.model._meta.concrete_model
712 self._get_defer_select_mask(
713 related_model._meta, field_mask, field_select_mask
714 )
715 # Remaining defer entries must be references to reverse relationships.
716 # The following code is expected to raise FieldError if it encounters
717 # a malformed defer entry.
718 for field_name, field_mask in mask.items():
719 if filtered_relation := self._filtered_relations.get(field_name):
720 relation = opts.get_field(filtered_relation.relation_name)
721 field_select_mask = select_mask.setdefault((field_name, relation), {})
722 field = relation.field
723 else:
724 field = opts.get_field(field_name).field
725 field_select_mask = select_mask.setdefault(field, {})
726 related_model = field.model._meta.concrete_model
727 self._get_defer_select_mask(
728 related_model._meta, field_mask, field_select_mask
729 )
730 return select_mask
732 def _get_only_select_mask(self, opts, mask, select_mask=None):
733 if select_mask is None:
734 select_mask = {}
735 select_mask[opts.pk] = {}
736 # Only include fields mentioned in the mask.
737 for field_name, field_mask in mask.items():
738 field = opts.get_field(field_name)
739 field_select_mask = select_mask.setdefault(field, {})
740 if field_mask:
741 if not field.is_relation:
742 raise FieldError(next(iter(field_mask)))
743 related_model = field.remote_field.model._meta.concrete_model
744 self._get_only_select_mask(
745 related_model._meta, field_mask, field_select_mask
746 )
747 return select_mask
749 def get_select_mask(self):
750 """
751 Convert the self.deferred_loading data structure to an alternate data
752 structure, describing the field that *will* be loaded. This is used to
753 compute the columns to select from the database and also by the
754 QuerySet class to work out which fields are being initialized on each
755 model. Models that have all their fields included aren't mentioned in
756 the result, only those that have field restrictions in place.
757 """
758 field_names, defer = self.deferred_loading
759 if not field_names:
760 return {}
761 mask = {}
762 for field_name in field_names:
763 part_mask = mask
764 for part in field_name.split(LOOKUP_SEP):
765 part_mask = part_mask.setdefault(part, {})
766 opts = self.get_meta()
767 if defer:
768 return self._get_defer_select_mask(opts, mask)
769 return self._get_only_select_mask(opts, mask)
771 def table_alias(self, table_name, create=False, filtered_relation=None):
772 """
773 Return a table alias for the given table_name and whether this is a
774 new alias or not.
776 If 'create' is true, a new alias is always created. Otherwise, the
777 most recently created alias for the table (if one exists) is reused.
778 """
779 alias_list = self.table_map.get(table_name)
780 if not create and alias_list:
781 alias = alias_list[0]
782 self.alias_refcount[alias] += 1
783 return alias, False
785 # Create a new alias for this table.
786 if alias_list:
787 alias = "%s%d" % (self.alias_prefix, len(self.alias_map) + 1)
788 alias_list.append(alias)
789 else:
790 # The first occurrence of a table uses the table name directly.
791 alias = (
792 filtered_relation.alias if filtered_relation is not None else table_name
793 )
794 self.table_map[table_name] = [alias]
795 self.alias_refcount[alias] = 1
796 return alias, True
798 def ref_alias(self, alias):
799 """Increases the reference count for this alias."""
800 self.alias_refcount[alias] += 1
802 def unref_alias(self, alias, amount=1):
803 """Decreases the reference count for this alias."""
804 self.alias_refcount[alias] -= amount
806 def promote_joins(self, aliases):
807 """
808 Promote recursively the join type of given aliases and its children to
809 an outer join. If 'unconditional' is False, only promote the join if
810 it is nullable or the parent join is an outer join.
812 The children promotion is done to avoid join chains that contain a LOUTER
813 b INNER c. So, if we have currently a INNER b INNER c and a->b is promoted,
814 then we must also promote b->c automatically, or otherwise the promotion
815 of a->b doesn't actually change anything in the query results.
816 """
817 aliases = list(aliases)
818 while aliases:
819 alias = aliases.pop(0)
820 if self.alias_map[alias].join_type is None:
821 # This is the base table (first FROM entry) - this table
822 # isn't really joined at all in the query, so we should not
823 # alter its join type.
824 continue
825 # Only the first alias (skipped above) should have None join_type
826 assert self.alias_map[alias].join_type is not None
827 parent_alias = self.alias_map[alias].parent_alias
828 parent_louter = (
829 parent_alias and self.alias_map[parent_alias].join_type == LOUTER
830 )
831 already_louter = self.alias_map[alias].join_type == LOUTER
832 if (self.alias_map[alias].nullable or parent_louter) and not already_louter:
833 self.alias_map[alias] = self.alias_map[alias].promote()
834 # Join type of 'alias' changed, so re-examine all aliases that
835 # refer to this one.
836 aliases.extend(
837 join
838 for join in self.alias_map
839 if self.alias_map[join].parent_alias == alias
840 and join not in aliases
841 )
843 def demote_joins(self, aliases):
844 """
845 Change join type from LOUTER to INNER for all joins in aliases.
847 Similarly to promote_joins(), this method must ensure no join chains
848 containing first an outer, then an inner join are generated. If we
849 are demoting b->c join in chain a LOUTER b LOUTER c then we must
850 demote a->b automatically, or otherwise the demotion of b->c doesn't
851 actually change anything in the query results. .
852 """
853 aliases = list(aliases)
854 while aliases:
855 alias = aliases.pop(0)
856 if self.alias_map[alias].join_type == LOUTER:
857 self.alias_map[alias] = self.alias_map[alias].demote()
858 parent_alias = self.alias_map[alias].parent_alias
859 if self.alias_map[parent_alias].join_type == INNER:
860 aliases.append(parent_alias)
862 def reset_refcounts(self, to_counts):
863 """
864 Reset reference counts for aliases so that they match the value passed
865 in `to_counts`.
866 """
867 for alias, cur_refcount in self.alias_refcount.copy().items():
868 unref_amount = cur_refcount - to_counts.get(alias, 0)
869 self.unref_alias(alias, unref_amount)
871 def change_aliases(self, change_map):
872 """
873 Change the aliases in change_map (which maps old-alias -> new-alias),
874 relabelling any references to them in select columns and the where
875 clause.
876 """
877 # If keys and values of change_map were to intersect, an alias might be
878 # updated twice (e.g. T4 -> T5, T5 -> T6, so also T4 -> T6) depending
879 # on their order in change_map.
880 assert set(change_map).isdisjoint(change_map.values())
882 # 1. Update references in "select" (normal columns plus aliases),
883 # "group by" and "where".
884 self.where.relabel_aliases(change_map)
885 if isinstance(self.group_by, tuple):
886 self.group_by = tuple(
887 [col.relabeled_clone(change_map) for col in self.group_by]
888 )
889 self.select = tuple([col.relabeled_clone(change_map) for col in self.select])
890 self.annotations = self.annotations and {
891 key: col.relabeled_clone(change_map)
892 for key, col in self.annotations.items()
893 }
895 # 2. Rename the alias in the internal table/alias datastructures.
896 for old_alias, new_alias in change_map.items():
897 if old_alias not in self.alias_map:
898 continue
899 alias_data = self.alias_map[old_alias].relabeled_clone(change_map)
900 self.alias_map[new_alias] = alias_data
901 self.alias_refcount[new_alias] = self.alias_refcount[old_alias]
902 del self.alias_refcount[old_alias]
903 del self.alias_map[old_alias]
905 table_aliases = self.table_map[alias_data.table_name]
906 for pos, alias in enumerate(table_aliases):
907 if alias == old_alias:
908 table_aliases[pos] = new_alias
909 break
910 self.external_aliases = {
911 # Table is aliased or it's being changed and thus is aliased.
912 change_map.get(alias, alias): (aliased or alias in change_map)
913 for alias, aliased in self.external_aliases.items()
914 }
916 def bump_prefix(self, other_query, exclude=None):
917 """
918 Change the alias prefix to the next letter in the alphabet in a way
919 that the other query's aliases and this query's aliases will not
920 conflict. Even tables that previously had no alias will get an alias
921 after this call. To prevent changing aliases use the exclude parameter.
922 """
924 def prefix_gen():
925 """
926 Generate a sequence of characters in alphabetical order:
927 -> 'A', 'B', 'C', ...
929 When the alphabet is finished, the sequence will continue with the
930 Cartesian product:
931 -> 'AA', 'AB', 'AC', ...
932 """
933 alphabet = ascii_uppercase
934 prefix = chr(ord(self.alias_prefix) + 1)
935 yield prefix
936 for n in count(1):
937 seq = alphabet[alphabet.index(prefix) :] if prefix else alphabet
938 for s in product(seq, repeat=n):
939 yield "".join(s)
940 prefix = None
942 if self.alias_prefix != other_query.alias_prefix:
943 # No clashes between self and outer query should be possible.
944 return
946 # Explicitly avoid infinite loop. The constant divider is based on how
947 # much depth recursive subquery references add to the stack. This value
948 # might need to be adjusted when adding or removing function calls from
949 # the code path in charge of performing these operations.
950 local_recursion_limit = sys.getrecursionlimit() // 16
951 for pos, prefix in enumerate(prefix_gen()):
952 if prefix not in self.subq_aliases:
953 self.alias_prefix = prefix
954 break
955 if pos > local_recursion_limit:
956 raise RecursionError(
957 "Maximum recursion depth exceeded: too many subqueries."
958 )
959 self.subq_aliases = self.subq_aliases.union([self.alias_prefix])
960 other_query.subq_aliases = other_query.subq_aliases.union(self.subq_aliases)
961 if exclude is None:
962 exclude = {}
963 self.change_aliases(
964 {
965 alias: "%s%d" % (self.alias_prefix, pos)
966 for pos, alias in enumerate(self.alias_map)
967 if alias not in exclude
968 }
969 )
971 def get_initial_alias(self):
972 """
973 Return the first alias for this query, after increasing its reference
974 count.
975 """
976 if self.alias_map:
977 alias = self.base_table
978 self.ref_alias(alias)
979 elif self.model:
980 alias = self.join(self.base_table_class(self.get_meta().db_table, None))
981 else:
982 alias = None
983 return alias
985 def count_active_tables(self):
986 """
987 Return the number of tables in this query with a non-zero reference
988 count. After execution, the reference counts are zeroed, so tables
989 added in compiler will not be seen by this method.
990 """
991 return len([1 for count in self.alias_refcount.values() if count])
993 def join(self, join, reuse=None, reuse_with_filtered_relation=False):
994 """
995 Return an alias for the 'join', either reusing an existing alias for
996 that join or creating a new one. 'join' is either a base_table_class or
997 join_class.
999 The 'reuse' parameter can be either None which means all joins are
1000 reusable, or it can be a set containing the aliases that can be reused.
1002 The 'reuse_with_filtered_relation' parameter is used when computing
1003 FilteredRelation instances.
1005 A join is always created as LOUTER if the lhs alias is LOUTER to make
1006 sure chains like t1 LOUTER t2 INNER t3 aren't generated. All new
1007 joins are created as LOUTER if the join is nullable.
1008 """
1009 if reuse_with_filtered_relation and reuse:
1010 reuse_aliases = [
1011 a for a, j in self.alias_map.items() if a in reuse and j.equals(join)
1012 ]
1013 else:
1014 reuse_aliases = [
1015 a
1016 for a, j in self.alias_map.items()
1017 if (reuse is None or a in reuse) and j == join
1018 ]
1019 if reuse_aliases:
1020 if join.table_alias in reuse_aliases:
1021 reuse_alias = join.table_alias
1022 else:
1023 # Reuse the most recent alias of the joined table
1024 # (a many-to-many relation may be joined multiple times).
1025 reuse_alias = reuse_aliases[-1]
1026 self.ref_alias(reuse_alias)
1027 return reuse_alias
1029 # No reuse is possible, so we need a new alias.
1030 alias, _ = self.table_alias(
1031 join.table_name, create=True, filtered_relation=join.filtered_relation
1032 )
1033 if join.join_type:
1034 if self.alias_map[join.parent_alias].join_type == LOUTER or join.nullable:
1035 join_type = LOUTER
1036 else:
1037 join_type = INNER
1038 join.join_type = join_type
1039 join.table_alias = alias
1040 self.alias_map[alias] = join
1041 return alias
1043 def join_parent_model(self, opts, model, alias, seen):
1044 """
1045 Make sure the given 'model' is joined in the query. If 'model' isn't
1046 a parent of 'opts' or if it is None this method is a no-op.
1048 The 'alias' is the root alias for starting the join, 'seen' is a dict
1049 of model -> alias of existing joins. It must also contain a mapping
1050 of None -> some alias. This will be returned in the no-op case.
1051 """
1052 if model in seen:
1053 return seen[model]
1054 chain = opts.get_base_chain(model)
1055 if not chain:
1056 return alias
1057 curr_opts = opts
1058 for int_model in chain:
1059 if int_model in seen:
1060 curr_opts = int_model._meta
1061 alias = seen[int_model]
1062 continue
1063 # Proxy model have elements in base chain
1064 # with no parents, assign the new options
1065 # object and skip to the next base in that
1066 # case
1067 if not curr_opts.parents[int_model]:
1068 curr_opts = int_model._meta
1069 continue
1070 link_field = curr_opts.get_ancestor_link(int_model)
1071 join_info = self.setup_joins([link_field.name], curr_opts, alias)
1072 curr_opts = int_model._meta
1073 alias = seen[int_model] = join_info.joins[-1]
1074 return alias or seen[None]
1076 def check_alias(self, alias):
1077 if FORBIDDEN_ALIAS_PATTERN.search(alias):
1078 raise ValueError(
1079 "Column aliases cannot contain whitespace characters, quotation marks, "
1080 "semicolons, or SQL comments."
1081 )
1083 def add_annotation(self, annotation, alias, select=True):
1084 """Add a single annotation expression to the Query."""
1085 self.check_alias(alias)
1086 annotation = annotation.resolve_expression(self, allow_joins=True, reuse=None)
1087 if select:
1088 self.append_annotation_mask([alias])
1089 else:
1090 self.set_annotation_mask(set(self.annotation_select).difference({alias}))
1091 self.annotations[alias] = annotation
1093 def resolve_expression(self, query, *args, **kwargs):
1094 clone = self.clone()
1095 # Subqueries need to use a different set of aliases than the outer query.
1096 clone.bump_prefix(query)
1097 clone.subquery = True
1098 clone.where.resolve_expression(query, *args, **kwargs)
1099 # Resolve combined queries.
1100 if clone.combinator:
1101 clone.combined_queries = tuple(
1102 [
1103 combined_query.resolve_expression(query, *args, **kwargs)
1104 for combined_query in clone.combined_queries
1105 ]
1106 )
1107 for key, value in clone.annotations.items():
1108 resolved = value.resolve_expression(query, *args, **kwargs)
1109 if hasattr(resolved, "external_aliases"):
1110 resolved.external_aliases.update(clone.external_aliases)
1111 clone.annotations[key] = resolved
1112 # Outer query's aliases are considered external.
1113 for alias, table in query.alias_map.items():
1114 clone.external_aliases[alias] = (
1115 isinstance(table, Join)
1116 and table.join_field.related_model._meta.db_table != alias
1117 ) or (
1118 isinstance(table, BaseTable) and table.table_name != table.table_alias
1119 )
1120 return clone
1122 def get_external_cols(self):
1123 exprs = chain(self.annotations.values(), self.where.children)
1124 return [
1125 col
1126 for col in self._gen_cols(exprs, include_external=True)
1127 if col.alias in self.external_aliases
1128 ]
1130 def get_group_by_cols(self, wrapper=None):
1131 # If wrapper is referenced by an alias for an explicit GROUP BY through
1132 # values() a reference to this expression and not the self must be
1133 # returned to ensure external column references are not grouped against
1134 # as well.
1135 external_cols = self.get_external_cols()
1136 if any(col.possibly_multivalued for col in external_cols):
1137 return [wrapper or self]
1138 return external_cols
1140 def as_sql(self, compiler, connection):
1141 # Some backends (e.g. Oracle) raise an error when a subquery contains
1142 # unnecessary ORDER BY clause.
1143 if (
1144 self.subquery
1145 and not connection.features.ignores_unnecessary_order_by_in_subqueries
1146 ):
1147 self.clear_ordering(force=False)
1148 for query in self.combined_queries:
1149 query.clear_ordering(force=False)
1150 sql, params = self.get_compiler(connection=connection).as_sql()
1151 if self.subquery:
1152 sql = "(%s)" % sql
1153 return sql, params
1155 def resolve_lookup_value(self, value, can_reuse, allow_joins):
1156 if hasattr(value, "resolve_expression"):
1157 value = value.resolve_expression(
1158 self,
1159 reuse=can_reuse,
1160 allow_joins=allow_joins,
1161 )
1162 elif isinstance(value, list | tuple):
1163 # The items of the iterable may be expressions and therefore need
1164 # to be resolved independently.
1165 values = (
1166 self.resolve_lookup_value(sub_value, can_reuse, allow_joins)
1167 for sub_value in value
1168 )
1169 type_ = type(value)
1170 if hasattr(type_, "_make"): # namedtuple
1171 return type_(*values)
1172 return type_(values)
1173 return value
1175 def solve_lookup_type(self, lookup, summarize=False):
1176 """
1177 Solve the lookup type from the lookup (e.g.: 'foobar__id__icontains').
1178 """
1179 lookup_splitted = lookup.split(LOOKUP_SEP)
1180 if self.annotations:
1181 annotation, expression_lookups = refs_expression(
1182 lookup_splitted, self.annotations
1183 )
1184 if annotation:
1185 expression = self.annotations[annotation]
1186 if summarize:
1187 expression = Ref(annotation, expression)
1188 return expression_lookups, (), expression
1189 _, field, _, lookup_parts = self.names_to_path(lookup_splitted, self.get_meta())
1190 field_parts = lookup_splitted[0 : len(lookup_splitted) - len(lookup_parts)]
1191 if len(lookup_parts) > 1 and not field_parts:
1192 raise FieldError(
1193 'Invalid lookup "{}" for model {}".'.format(
1194 lookup, self.get_meta().model.__name__
1195 )
1196 )
1197 return lookup_parts, field_parts, False
1199 def check_query_object_type(self, value, opts, field):
1200 """
1201 Check whether the object passed while querying is of the correct type.
1202 If not, raise a ValueError specifying the wrong object.
1203 """
1204 if hasattr(value, "_meta"):
1205 if not check_rel_lookup_compatibility(value._meta.model, opts, field):
1206 raise ValueError(
1207 f'Cannot query "{value}": Must be "{opts.object_name}" instance.'
1208 )
1210 def check_related_objects(self, field, value, opts):
1211 """Check the type of object passed to query relations."""
1212 if field.is_relation:
1213 # Check that the field and the queryset use the same model in a
1214 # query like .filter(author=Author.objects.all()). For example, the
1215 # opts would be Author's (from the author field) and value.model
1216 # would be Author.objects.all() queryset's .model (Author also).
1217 # The field is the related field on the lhs side.
1218 if (
1219 isinstance(value, Query)
1220 and not value.has_select_fields
1221 and not check_rel_lookup_compatibility(value.model, opts, field)
1222 ):
1223 raise ValueError(
1224 'Cannot use QuerySet for "{}": Use a QuerySet for "{}".'.format(
1225 value.model._meta.object_name, opts.object_name
1226 )
1227 )
1228 elif hasattr(value, "_meta"):
1229 self.check_query_object_type(value, opts, field)
1230 elif hasattr(value, "__iter__"):
1231 for v in value:
1232 self.check_query_object_type(v, opts, field)
1234 def check_filterable(self, expression):
1235 """Raise an error if expression cannot be used in a WHERE clause."""
1236 if hasattr(expression, "resolve_expression") and not getattr(
1237 expression, "filterable", True
1238 ):
1239 raise NotSupportedError(
1240 expression.__class__.__name__ + " is disallowed in the filter "
1241 "clause."
1242 )
1243 if hasattr(expression, "get_source_expressions"):
1244 for expr in expression.get_source_expressions():
1245 self.check_filterable(expr)
1247 def build_lookup(self, lookups, lhs, rhs):
1248 """
1249 Try to extract transforms and lookup from given lhs.
1251 The lhs value is something that works like SQLExpression.
1252 The rhs value is what the lookup is going to compare against.
1253 The lookups is a list of names to extract using get_lookup()
1254 and get_transform().
1255 """
1256 # __exact is the default lookup if one isn't given.
1257 *transforms, lookup_name = lookups or ["exact"]
1258 for name in transforms:
1259 lhs = self.try_transform(lhs, name)
1260 # First try get_lookup() so that the lookup takes precedence if the lhs
1261 # supports both transform and lookup for the name.
1262 lookup_class = lhs.get_lookup(lookup_name)
1263 if not lookup_class:
1264 # A lookup wasn't found. Try to interpret the name as a transform
1265 # and do an Exact lookup against it.
1266 lhs = self.try_transform(lhs, lookup_name)
1267 lookup_name = "exact"
1268 lookup_class = lhs.get_lookup(lookup_name)
1269 if not lookup_class:
1270 return
1272 lookup = lookup_class(lhs, rhs)
1273 # Interpret '__exact=None' as the sql 'is NULL'; otherwise, reject all
1274 # uses of None as a query value unless the lookup supports it.
1275 if lookup.rhs is None and not lookup.can_use_none_as_rhs:
1276 if lookup_name not in ("exact", "iexact"):
1277 raise ValueError("Cannot use None as a query value")
1278 return lhs.get_lookup("isnull")(lhs, True)
1280 # For Oracle '' is equivalent to null. The check must be done at this
1281 # stage because join promotion can't be done in the compiler. Using
1282 # DEFAULT_DB_ALIAS isn't nice but it's the best that can be done here.
1283 # A similar thing is done in is_nullable(), too.
1284 if (
1285 lookup_name == "exact"
1286 and lookup.rhs == ""
1287 and connections[DEFAULT_DB_ALIAS].features.interprets_empty_strings_as_nulls
1288 ):
1289 return lhs.get_lookup("isnull")(lhs, True)
1291 return lookup
1293 def try_transform(self, lhs, name):
1294 """
1295 Helper method for build_lookup(). Try to fetch and initialize
1296 a transform for name parameter from lhs.
1297 """
1298 transform_class = lhs.get_transform(name)
1299 if transform_class:
1300 return transform_class(lhs)
1301 else:
1302 output_field = lhs.output_field.__class__
1303 suggested_lookups = difflib.get_close_matches(
1304 name, output_field.get_lookups()
1305 )
1306 if suggested_lookups:
1307 suggestion = ", perhaps you meant %s?" % " or ".join(suggested_lookups)
1308 else:
1309 suggestion = "."
1310 raise FieldError(
1311 "Unsupported lookup '{}' for {} or join on the field not "
1312 "permitted{}".format(name, output_field.__name__, suggestion)
1313 )
1315 def build_filter(
1316 self,
1317 filter_expr,
1318 branch_negated=False,
1319 current_negated=False,
1320 can_reuse=None,
1321 allow_joins=True,
1322 split_subq=True,
1323 reuse_with_filtered_relation=False,
1324 check_filterable=True,
1325 summarize=False,
1326 ):
1327 """
1328 Build a WhereNode for a single filter clause but don't add it
1329 to this Query. Query.add_q() will then add this filter to the where
1330 Node.
1332 The 'branch_negated' tells us if the current branch contains any
1333 negations. This will be used to determine if subqueries are needed.
1335 The 'current_negated' is used to determine if the current filter is
1336 negated or not and this will be used to determine if IS NULL filtering
1337 is needed.
1339 The difference between current_negated and branch_negated is that
1340 branch_negated is set on first negation, but current_negated is
1341 flipped for each negation.
1343 Note that add_filter will not do any negating itself, that is done
1344 upper in the code by add_q().
1346 The 'can_reuse' is a set of reusable joins for multijoins.
1348 If 'reuse_with_filtered_relation' is True, then only joins in can_reuse
1349 will be reused.
1351 The method will create a filter clause that can be added to the current
1352 query. However, if the filter isn't added to the query then the caller
1353 is responsible for unreffing the joins used.
1354 """
1355 if isinstance(filter_expr, dict):
1356 raise FieldError("Cannot parse keyword query as dict")
1357 if isinstance(filter_expr, Q):
1358 return self._add_q(
1359 filter_expr,
1360 branch_negated=branch_negated,
1361 current_negated=current_negated,
1362 used_aliases=can_reuse,
1363 allow_joins=allow_joins,
1364 split_subq=split_subq,
1365 check_filterable=check_filterable,
1366 summarize=summarize,
1367 )
1368 if hasattr(filter_expr, "resolve_expression"):
1369 if not getattr(filter_expr, "conditional", False):
1370 raise TypeError("Cannot filter against a non-conditional expression.")
1371 condition = filter_expr.resolve_expression(
1372 self, allow_joins=allow_joins, summarize=summarize
1373 )
1374 if not isinstance(condition, Lookup):
1375 condition = self.build_lookup(["exact"], condition, True)
1376 return WhereNode([condition], connector=AND), []
1377 arg, value = filter_expr
1378 if not arg:
1379 raise FieldError("Cannot parse keyword query %r" % arg)
1380 lookups, parts, reffed_expression = self.solve_lookup_type(arg, summarize)
1382 if check_filterable:
1383 self.check_filterable(reffed_expression)
1385 if not allow_joins and len(parts) > 1:
1386 raise FieldError("Joined field references are not permitted in this query")
1388 pre_joins = self.alias_refcount.copy()
1389 value = self.resolve_lookup_value(value, can_reuse, allow_joins)
1390 used_joins = {
1391 k for k, v in self.alias_refcount.items() if v > pre_joins.get(k, 0)
1392 }
1394 if check_filterable:
1395 self.check_filterable(value)
1397 if reffed_expression:
1398 condition = self.build_lookup(lookups, reffed_expression, value)
1399 return WhereNode([condition], connector=AND), []
1401 opts = self.get_meta()
1402 alias = self.get_initial_alias()
1403 allow_many = not branch_negated or not split_subq
1405 try:
1406 join_info = self.setup_joins(
1407 parts,
1408 opts,
1409 alias,
1410 can_reuse=can_reuse,
1411 allow_many=allow_many,
1412 reuse_with_filtered_relation=reuse_with_filtered_relation,
1413 )
1415 # Prevent iterator from being consumed by check_related_objects()
1416 if isinstance(value, Iterator):
1417 value = list(value)
1418 self.check_related_objects(join_info.final_field, value, join_info.opts)
1420 # split_exclude() needs to know which joins were generated for the
1421 # lookup parts
1422 self._lookup_joins = join_info.joins
1423 except MultiJoin as e:
1424 return self.split_exclude(filter_expr, can_reuse, e.names_with_path)
1426 # Update used_joins before trimming since they are reused to determine
1427 # which joins could be later promoted to INNER.
1428 used_joins.update(join_info.joins)
1429 targets, alias, join_list = self.trim_joins(
1430 join_info.targets, join_info.joins, join_info.path
1431 )
1432 if can_reuse is not None:
1433 can_reuse.update(join_list)
1435 if join_info.final_field.is_relation:
1436 if len(targets) == 1:
1437 col = self._get_col(targets[0], join_info.final_field, alias)
1438 else:
1439 col = MultiColSource(
1440 alias, targets, join_info.targets, join_info.final_field
1441 )
1442 else:
1443 col = self._get_col(targets[0], join_info.final_field, alias)
1445 condition = self.build_lookup(lookups, col, value)
1446 lookup_type = condition.lookup_name
1447 clause = WhereNode([condition], connector=AND)
1449 require_outer = (
1450 lookup_type == "isnull" and condition.rhs is True and not current_negated
1451 )
1452 if (
1453 current_negated
1454 and (lookup_type != "isnull" or condition.rhs is False)
1455 and condition.rhs is not None
1456 ):
1457 require_outer = True
1458 if lookup_type != "isnull":
1459 # The condition added here will be SQL like this:
1460 # NOT (col IS NOT NULL), where the first NOT is added in
1461 # upper layers of code. The reason for addition is that if col
1462 # is null, then col != someval will result in SQL "unknown"
1463 # which isn't the same as in Python. The Python None handling
1464 # is wanted, and it can be gotten by
1465 # (col IS NULL OR col != someval)
1466 # <=>
1467 # NOT (col IS NOT NULL AND col = someval).
1468 if (
1469 self.is_nullable(targets[0])
1470 or self.alias_map[join_list[-1]].join_type == LOUTER
1471 ):
1472 lookup_class = targets[0].get_lookup("isnull")
1473 col = self._get_col(targets[0], join_info.targets[0], alias)
1474 clause.add(lookup_class(col, False), AND)
1475 # If someval is a nullable column, someval IS NOT NULL is
1476 # added.
1477 if isinstance(value, Col) and self.is_nullable(value.target):
1478 lookup_class = value.target.get_lookup("isnull")
1479 clause.add(lookup_class(value, False), AND)
1480 return clause, used_joins if not require_outer else ()
1482 def add_filter(self, filter_lhs, filter_rhs):
1483 self.add_q(Q((filter_lhs, filter_rhs)))
1485 def add_q(self, q_object):
1486 """
1487 A preprocessor for the internal _add_q(). Responsible for doing final
1488 join promotion.
1489 """
1490 # For join promotion this case is doing an AND for the added q_object
1491 # and existing conditions. So, any existing inner join forces the join
1492 # type to remain inner. Existing outer joins can however be demoted.
1493 # (Consider case where rel_a is LOUTER and rel_a__col=1 is added - if
1494 # rel_a doesn't produce any rows, then the whole condition must fail.
1495 # So, demotion is OK.
1496 existing_inner = {
1497 a for a in self.alias_map if self.alias_map[a].join_type == INNER
1498 }
1499 clause, _ = self._add_q(q_object, self.used_aliases)
1500 if clause:
1501 self.where.add(clause, AND)
1502 self.demote_joins(existing_inner)
1504 def build_where(self, filter_expr):
1505 return self.build_filter(filter_expr, allow_joins=False)[0]
1507 def clear_where(self):
1508 self.where = WhereNode()
1510 def _add_q(
1511 self,
1512 q_object,
1513 used_aliases,
1514 branch_negated=False,
1515 current_negated=False,
1516 allow_joins=True,
1517 split_subq=True,
1518 check_filterable=True,
1519 summarize=False,
1520 ):
1521 """Add a Q-object to the current filter."""
1522 connector = q_object.connector
1523 current_negated ^= q_object.negated
1524 branch_negated = branch_negated or q_object.negated
1525 target_clause = WhereNode(connector=connector, negated=q_object.negated)
1526 joinpromoter = JoinPromoter(
1527 q_object.connector, len(q_object.children), current_negated
1528 )
1529 for child in q_object.children:
1530 child_clause, needed_inner = self.build_filter(
1531 child,
1532 can_reuse=used_aliases,
1533 branch_negated=branch_negated,
1534 current_negated=current_negated,
1535 allow_joins=allow_joins,
1536 split_subq=split_subq,
1537 check_filterable=check_filterable,
1538 summarize=summarize,
1539 )
1540 joinpromoter.add_votes(needed_inner)
1541 if child_clause:
1542 target_clause.add(child_clause, connector)
1543 needed_inner = joinpromoter.update_join_types(self)
1544 return target_clause, needed_inner
1546 def build_filtered_relation_q(
1547 self, q_object, reuse, branch_negated=False, current_negated=False
1548 ):
1549 """Add a FilteredRelation object to the current filter."""
1550 connector = q_object.connector
1551 current_negated ^= q_object.negated
1552 branch_negated = branch_negated or q_object.negated
1553 target_clause = WhereNode(connector=connector, negated=q_object.negated)
1554 for child in q_object.children:
1555 if isinstance(child, Node):
1556 child_clause = self.build_filtered_relation_q(
1557 child,
1558 reuse=reuse,
1559 branch_negated=branch_negated,
1560 current_negated=current_negated,
1561 )
1562 else:
1563 child_clause, _ = self.build_filter(
1564 child,
1565 can_reuse=reuse,
1566 branch_negated=branch_negated,
1567 current_negated=current_negated,
1568 allow_joins=True,
1569 split_subq=False,
1570 reuse_with_filtered_relation=True,
1571 )
1572 target_clause.add(child_clause, connector)
1573 return target_clause
1575 def add_filtered_relation(self, filtered_relation, alias):
1576 filtered_relation.alias = alias
1577 lookups = dict(get_children_from_q(filtered_relation.condition))
1578 relation_lookup_parts, relation_field_parts, _ = self.solve_lookup_type(
1579 filtered_relation.relation_name
1580 )
1581 if relation_lookup_parts:
1582 raise ValueError(
1583 "FilteredRelation's relation_name cannot contain lookups "
1584 "(got %r)." % filtered_relation.relation_name
1585 )
1586 for lookup in chain(lookups):
1587 lookup_parts, lookup_field_parts, _ = self.solve_lookup_type(lookup)
1588 shift = 2 if not lookup_parts else 1
1589 lookup_field_path = lookup_field_parts[:-shift]
1590 for idx, lookup_field_part in enumerate(lookup_field_path):
1591 if len(relation_field_parts) > idx:
1592 if relation_field_parts[idx] != lookup_field_part:
1593 raise ValueError(
1594 "FilteredRelation's condition doesn't support "
1595 "relations outside the {!r} (got {!r}).".format(
1596 filtered_relation.relation_name, lookup
1597 )
1598 )
1599 else:
1600 raise ValueError(
1601 "FilteredRelation's condition doesn't support nested "
1602 f"relations deeper than the relation_name (got {lookup!r} for "
1603 f"{filtered_relation.relation_name!r})."
1604 )
1605 self._filtered_relations[filtered_relation.alias] = filtered_relation
1607 def names_to_path(self, names, opts, allow_many=True, fail_on_missing=False):
1608 """
1609 Walk the list of names and turns them into PathInfo tuples. A single
1610 name in 'names' can generate multiple PathInfos (m2m, for example).
1612 'names' is the path of names to travel, 'opts' is the model Options we
1613 start the name resolving from, 'allow_many' is as for setup_joins().
1614 If fail_on_missing is set to True, then a name that can't be resolved
1615 will generate a FieldError.
1617 Return a list of PathInfo tuples. In addition return the final field
1618 (the last used join field) and target (which is a field guaranteed to
1619 contain the same value as the final field). Finally, return those names
1620 that weren't found (which are likely transforms and the final lookup).
1621 """
1622 path, names_with_path = [], []
1623 for pos, name in enumerate(names):
1624 cur_names_with_path = (name, [])
1625 if name == "pk":
1626 name = opts.pk.name
1628 field = None
1629 filtered_relation = None
1630 try:
1631 if opts is None:
1632 raise FieldDoesNotExist
1633 field = opts.get_field(name)
1634 except FieldDoesNotExist:
1635 if name in self.annotation_select:
1636 field = self.annotation_select[name].output_field
1637 elif name in self._filtered_relations and pos == 0:
1638 filtered_relation = self._filtered_relations[name]
1639 if LOOKUP_SEP in filtered_relation.relation_name:
1640 parts = filtered_relation.relation_name.split(LOOKUP_SEP)
1641 filtered_relation_path, field, _, _ = self.names_to_path(
1642 parts,
1643 opts,
1644 allow_many,
1645 fail_on_missing,
1646 )
1647 path.extend(filtered_relation_path[:-1])
1648 else:
1649 field = opts.get_field(filtered_relation.relation_name)
1650 if field is not None:
1651 # Fields that contain one-to-many relations with a generic
1652 # model (like a GenericForeignKey) cannot generate reverse
1653 # relations and therefore cannot be used for reverse querying.
1654 if field.is_relation and not field.related_model:
1655 raise FieldError(
1656 "Field %r does not generate an automatic reverse "
1657 "relation and therefore cannot be used for reverse "
1658 "querying. If it is a GenericForeignKey, consider "
1659 "adding a GenericRelation." % name
1660 )
1661 try:
1662 model = field.model._meta.concrete_model
1663 except AttributeError:
1664 # QuerySet.annotate() may introduce fields that aren't
1665 # attached to a model.
1666 model = None
1667 else:
1668 # We didn't find the current field, so move position back
1669 # one step.
1670 pos -= 1
1671 if pos == -1 or fail_on_missing:
1672 available = sorted(
1673 [
1674 *get_field_names_from_opts(opts),
1675 *self.annotation_select,
1676 *self._filtered_relations,
1677 ]
1678 )
1679 raise FieldError(
1680 "Cannot resolve keyword '{}' into field. "
1681 "Choices are: {}".format(name, ", ".join(available))
1682 )
1683 break
1684 # Check if we need any joins for concrete inheritance cases (the
1685 # field lives in parent, but we are currently in one of its
1686 # children)
1687 if opts is not None and model is not opts.model:
1688 path_to_parent = opts.get_path_to_parent(model)
1689 if path_to_parent:
1690 path.extend(path_to_parent)
1691 cur_names_with_path[1].extend(path_to_parent)
1692 opts = path_to_parent[-1].to_opts
1693 if hasattr(field, "path_infos"):
1694 if filtered_relation:
1695 pathinfos = field.get_path_info(filtered_relation)
1696 else:
1697 pathinfos = field.path_infos
1698 if not allow_many:
1699 for inner_pos, p in enumerate(pathinfos):
1700 if p.m2m:
1701 cur_names_with_path[1].extend(pathinfos[0 : inner_pos + 1])
1702 names_with_path.append(cur_names_with_path)
1703 raise MultiJoin(pos + 1, names_with_path)
1704 last = pathinfos[-1]
1705 path.extend(pathinfos)
1706 final_field = last.join_field
1707 opts = last.to_opts
1708 targets = last.target_fields
1709 cur_names_with_path[1].extend(pathinfos)
1710 names_with_path.append(cur_names_with_path)
1711 else:
1712 # Local non-relational field.
1713 final_field = field
1714 targets = (field,)
1715 if fail_on_missing and pos + 1 != len(names):
1716 raise FieldError(
1717 "Cannot resolve keyword {!r} into field. Join on '{}'"
1718 " not permitted.".format(names[pos + 1], name)
1719 )
1720 break
1721 return path, final_field, targets, names[pos + 1 :]
1723 def setup_joins(
1724 self,
1725 names,
1726 opts,
1727 alias,
1728 can_reuse=None,
1729 allow_many=True,
1730 reuse_with_filtered_relation=False,
1731 ):
1732 """
1733 Compute the necessary table joins for the passage through the fields
1734 given in 'names'. 'opts' is the Options class for the current model
1735 (which gives the table we are starting from), 'alias' is the alias for
1736 the table to start the joining from.
1738 The 'can_reuse' defines the reverse foreign key joins we can reuse. It
1739 can be None in which case all joins are reusable or a set of aliases
1740 that can be reused. Note that non-reverse foreign keys are always
1741 reusable when using setup_joins().
1743 The 'reuse_with_filtered_relation' can be used to force 'can_reuse'
1744 parameter and force the relation on the given connections.
1746 If 'allow_many' is False, then any reverse foreign key seen will
1747 generate a MultiJoin exception.
1749 Return the final field involved in the joins, the target field (used
1750 for any 'where' constraint), the final 'opts' value, the joins, the
1751 field path traveled to generate the joins, and a transform function
1752 that takes a field and alias and is equivalent to `field.get_col(alias)`
1753 in the simple case but wraps field transforms if they were included in
1754 names.
1756 The target field is the field containing the concrete value. Final
1757 field can be something different, for example foreign key pointing to
1758 that value. Final field is needed for example in some value
1759 conversions (convert 'obj' in fk__id=obj to pk val using the foreign
1760 key field for example).
1761 """
1762 joins = [alias]
1763 # The transform can't be applied yet, as joins must be trimmed later.
1764 # To avoid making every caller of this method look up transforms
1765 # directly, compute transforms here and create a partial that converts
1766 # fields to the appropriate wrapped version.
1768 def final_transformer(field, alias):
1769 if not self.alias_cols:
1770 alias = None
1771 return field.get_col(alias)
1773 # Try resolving all the names as fields first. If there's an error,
1774 # treat trailing names as lookups until a field can be resolved.
1775 last_field_exception = None
1776 for pivot in range(len(names), 0, -1):
1777 try:
1778 path, final_field, targets, rest = self.names_to_path(
1779 names[:pivot],
1780 opts,
1781 allow_many,
1782 fail_on_missing=True,
1783 )
1784 except FieldError as exc:
1785 if pivot == 1:
1786 # The first item cannot be a lookup, so it's safe
1787 # to raise the field error here.
1788 raise
1789 else:
1790 last_field_exception = exc
1791 else:
1792 # The transforms are the remaining items that couldn't be
1793 # resolved into fields.
1794 transforms = names[pivot:]
1795 break
1796 for name in transforms:
1798 def transform(field, alias, *, name, previous):
1799 try:
1800 wrapped = previous(field, alias)
1801 return self.try_transform(wrapped, name)
1802 except FieldError:
1803 # FieldError is raised if the transform doesn't exist.
1804 if isinstance(final_field, Field) and last_field_exception:
1805 raise last_field_exception
1806 else:
1807 raise
1809 final_transformer = functools.partial(
1810 transform, name=name, previous=final_transformer
1811 )
1812 final_transformer.has_transforms = True
1813 # Then, add the path to the query's joins. Note that we can't trim
1814 # joins at this stage - we will need the information about join type
1815 # of the trimmed joins.
1816 for join in path:
1817 if join.filtered_relation:
1818 filtered_relation = join.filtered_relation.clone()
1819 table_alias = filtered_relation.alias
1820 else:
1821 filtered_relation = None
1822 table_alias = None
1823 opts = join.to_opts
1824 if join.direct:
1825 nullable = self.is_nullable(join.join_field)
1826 else:
1827 nullable = True
1828 connection = self.join_class(
1829 opts.db_table,
1830 alias,
1831 table_alias,
1832 INNER,
1833 join.join_field,
1834 nullable,
1835 filtered_relation=filtered_relation,
1836 )
1837 reuse = can_reuse if join.m2m or reuse_with_filtered_relation else None
1838 alias = self.join(
1839 connection,
1840 reuse=reuse,
1841 reuse_with_filtered_relation=reuse_with_filtered_relation,
1842 )
1843 joins.append(alias)
1844 if filtered_relation:
1845 filtered_relation.path = joins[:]
1846 return JoinInfo(final_field, targets, opts, joins, path, final_transformer)
1848 def trim_joins(self, targets, joins, path):
1849 """
1850 The 'target' parameter is the final field being joined to, 'joins'
1851 is the full list of join aliases. The 'path' contain the PathInfos
1852 used to create the joins.
1854 Return the final target field and table alias and the new active
1855 joins.
1857 Always trim any direct join if the target column is already in the
1858 previous table. Can't trim reverse joins as it's unknown if there's
1859 anything on the other side of the join.
1860 """
1861 joins = joins[:]
1862 for pos, info in enumerate(reversed(path)):
1863 if len(joins) == 1 or not info.direct:
1864 break
1865 if info.filtered_relation:
1866 break
1867 join_targets = {t.column for t in info.join_field.foreign_related_fields}
1868 cur_targets = {t.column for t in targets}
1869 if not cur_targets.issubset(join_targets):
1870 break
1871 targets_dict = {
1872 r[1].column: r[0]
1873 for r in info.join_field.related_fields
1874 if r[1].column in cur_targets
1875 }
1876 targets = tuple(targets_dict[t.column] for t in targets)
1877 self.unref_alias(joins.pop())
1878 return targets, joins[-1], joins
1880 @classmethod
1881 def _gen_cols(cls, exprs, include_external=False, resolve_refs=True):
1882 for expr in exprs:
1883 if isinstance(expr, Col):
1884 yield expr
1885 elif include_external and callable(
1886 getattr(expr, "get_external_cols", None)
1887 ):
1888 yield from expr.get_external_cols()
1889 elif hasattr(expr, "get_source_expressions"):
1890 if not resolve_refs and isinstance(expr, Ref):
1891 continue
1892 yield from cls._gen_cols(
1893 expr.get_source_expressions(),
1894 include_external=include_external,
1895 resolve_refs=resolve_refs,
1896 )
1898 @classmethod
1899 def _gen_col_aliases(cls, exprs):
1900 yield from (expr.alias for expr in cls._gen_cols(exprs))
1902 def resolve_ref(self, name, allow_joins=True, reuse=None, summarize=False):
1903 annotation = self.annotations.get(name)
1904 if annotation is not None:
1905 if not allow_joins:
1906 for alias in self._gen_col_aliases([annotation]):
1907 if isinstance(self.alias_map[alias], Join):
1908 raise FieldError(
1909 "Joined field references are not permitted in this query"
1910 )
1911 if summarize:
1912 # Summarize currently means we are doing an aggregate() query
1913 # which is executed as a wrapped subquery if any of the
1914 # aggregate() elements reference an existing annotation. In
1915 # that case we need to return a Ref to the subquery's annotation.
1916 if name not in self.annotation_select:
1917 raise FieldError(
1918 "Cannot aggregate over the '%s' alias. Use annotate() "
1919 "to promote it." % name
1920 )
1921 return Ref(name, self.annotation_select[name])
1922 else:
1923 return annotation
1924 else:
1925 field_list = name.split(LOOKUP_SEP)
1926 annotation = self.annotations.get(field_list[0])
1927 if annotation is not None:
1928 for transform in field_list[1:]:
1929 annotation = self.try_transform(annotation, transform)
1930 return annotation
1931 join_info = self.setup_joins(
1932 field_list, self.get_meta(), self.get_initial_alias(), can_reuse=reuse
1933 )
1934 targets, final_alias, join_list = self.trim_joins(
1935 join_info.targets, join_info.joins, join_info.path
1936 )
1937 if not allow_joins and len(join_list) > 1:
1938 raise FieldError(
1939 "Joined field references are not permitted in this query"
1940 )
1941 if len(targets) > 1:
1942 raise FieldError(
1943 "Referencing multicolumn fields with F() objects isn't supported"
1944 )
1945 # Verify that the last lookup in name is a field or a transform:
1946 # transform_function() raises FieldError if not.
1947 transform = join_info.transform_function(targets[0], final_alias)
1948 if reuse is not None:
1949 reuse.update(join_list)
1950 return transform
1952 def split_exclude(self, filter_expr, can_reuse, names_with_path):
1953 """
1954 When doing an exclude against any kind of N-to-many relation, we need
1955 to use a subquery. This method constructs the nested query, given the
1956 original exclude filter (filter_expr) and the portion up to the first
1957 N-to-many relation field.
1959 For example, if the origin filter is ~Q(child__name='foo'), filter_expr
1960 is ('child__name', 'foo') and can_reuse is a set of joins usable for
1961 filters in the original query.
1963 We will turn this into equivalent of:
1964 WHERE NOT EXISTS(
1965 SELECT 1
1966 FROM child
1967 WHERE name = 'foo' AND child.parent_id = parent.id
1968 LIMIT 1
1969 )
1970 """
1971 # Generate the inner query.
1972 query = self.__class__(self.model)
1973 query._filtered_relations = self._filtered_relations
1974 filter_lhs, filter_rhs = filter_expr
1975 if isinstance(filter_rhs, OuterRef):
1976 filter_rhs = OuterRef(filter_rhs)
1977 elif isinstance(filter_rhs, F):
1978 filter_rhs = OuterRef(filter_rhs.name)
1979 query.add_filter(filter_lhs, filter_rhs)
1980 query.clear_ordering(force=True)
1981 # Try to have as simple as possible subquery -> trim leading joins from
1982 # the subquery.
1983 trimmed_prefix, contains_louter = query.trim_start(names_with_path)
1985 col = query.select[0]
1986 select_field = col.target
1987 alias = col.alias
1988 if alias in can_reuse:
1989 pk = select_field.model._meta.pk
1990 # Need to add a restriction so that outer query's filters are in effect for
1991 # the subquery, too.
1992 query.bump_prefix(self)
1993 lookup_class = select_field.get_lookup("exact")
1994 # Note that the query.select[0].alias is different from alias
1995 # due to bump_prefix above.
1996 lookup = lookup_class(pk.get_col(query.select[0].alias), pk.get_col(alias))
1997 query.where.add(lookup, AND)
1998 query.external_aliases[alias] = True
2000 lookup_class = select_field.get_lookup("exact")
2001 lookup = lookup_class(col, ResolvedOuterRef(trimmed_prefix))
2002 query.where.add(lookup, AND)
2003 condition, needed_inner = self.build_filter(Exists(query))
2005 if contains_louter:
2006 or_null_condition, _ = self.build_filter(
2007 ("%s__isnull" % trimmed_prefix, True),
2008 current_negated=True,
2009 branch_negated=True,
2010 can_reuse=can_reuse,
2011 )
2012 condition.add(or_null_condition, OR)
2013 # Note that the end result will be:
2014 # (outercol NOT IN innerq AND outercol IS NOT NULL) OR outercol IS NULL.
2015 # This might look crazy but due to how IN works, this seems to be
2016 # correct. If the IS NOT NULL check is removed then outercol NOT
2017 # IN will return UNKNOWN. If the IS NULL check is removed, then if
2018 # outercol IS NULL we will not match the row.
2019 return condition, needed_inner
2021 def set_empty(self):
2022 self.where.add(NothingNode(), AND)
2023 for query in self.combined_queries:
2024 query.set_empty()
2026 def is_empty(self):
2027 return any(isinstance(c, NothingNode) for c in self.where.children)
2029 def set_limits(self, low=None, high=None):
2030 """
2031 Adjust the limits on the rows retrieved. Use low/high to set these,
2032 as it makes it more Pythonic to read and write. When the SQL query is
2033 created, convert them to the appropriate offset and limit values.
2035 Apply any limits passed in here to the existing constraints. Add low
2036 to the current low value and clamp both to any existing high value.
2037 """
2038 if high is not None:
2039 if self.high_mark is not None:
2040 self.high_mark = min(self.high_mark, self.low_mark + high)
2041 else:
2042 self.high_mark = self.low_mark + high
2043 if low is not None:
2044 if self.high_mark is not None:
2045 self.low_mark = min(self.high_mark, self.low_mark + low)
2046 else:
2047 self.low_mark = self.low_mark + low
2049 if self.low_mark == self.high_mark:
2050 self.set_empty()
2052 def clear_limits(self):
2053 """Clear any existing limits."""
2054 self.low_mark, self.high_mark = 0, None
2056 @property
2057 def is_sliced(self):
2058 return self.low_mark != 0 or self.high_mark is not None
2060 def has_limit_one(self):
2061 return self.high_mark is not None and (self.high_mark - self.low_mark) == 1
2063 def can_filter(self):
2064 """
2065 Return True if adding filters to this instance is still possible.
2067 Typically, this means no limits or offsets have been put on the results.
2068 """
2069 return not self.is_sliced
2071 def clear_select_clause(self):
2072 """Remove all fields from SELECT clause."""
2073 self.select = ()
2074 self.default_cols = False
2075 self.select_related = False
2076 self.set_extra_mask(())
2077 self.set_annotation_mask(())
2079 def clear_select_fields(self):
2080 """
2081 Clear the list of fields to select (but not extra_select columns).
2082 Some queryset types completely replace any existing list of select
2083 columns.
2084 """
2085 self.select = ()
2086 self.values_select = ()
2088 def add_select_col(self, col, name):
2089 self.select += (col,)
2090 self.values_select += (name,)
2092 def set_select(self, cols):
2093 self.default_cols = False
2094 self.select = tuple(cols)
2096 def add_distinct_fields(self, *field_names):
2097 """
2098 Add and resolve the given fields to the query's "distinct on" clause.
2099 """
2100 self.distinct_fields = field_names
2101 self.distinct = True
2103 def add_fields(self, field_names, allow_m2m=True):
2104 """
2105 Add the given (model) fields to the select set. Add the field names in
2106 the order specified.
2107 """
2108 alias = self.get_initial_alias()
2109 opts = self.get_meta()
2111 try:
2112 cols = []
2113 for name in field_names:
2114 # Join promotion note - we must not remove any rows here, so
2115 # if there is no existing joins, use outer join.
2116 join_info = self.setup_joins(
2117 name.split(LOOKUP_SEP), opts, alias, allow_many=allow_m2m
2118 )
2119 targets, final_alias, joins = self.trim_joins(
2120 join_info.targets,
2121 join_info.joins,
2122 join_info.path,
2123 )
2124 for target in targets:
2125 cols.append(join_info.transform_function(target, final_alias))
2126 if cols:
2127 self.set_select(cols)
2128 except MultiJoin:
2129 raise FieldError("Invalid field name: '%s'" % name)
2130 except FieldError:
2131 if LOOKUP_SEP in name:
2132 # For lookups spanning over relationships, show the error
2133 # from the model on which the lookup failed.
2134 raise
2135 elif name in self.annotations:
2136 raise FieldError(
2137 "Cannot select the '%s' alias. Use annotate() to promote "
2138 "it." % name
2139 )
2140 else:
2141 names = sorted(
2142 [
2143 *get_field_names_from_opts(opts),
2144 *self.extra,
2145 *self.annotation_select,
2146 *self._filtered_relations,
2147 ]
2148 )
2149 raise FieldError(
2150 "Cannot resolve keyword {!r} into field. Choices are: {}".format(
2151 name, ", ".join(names)
2152 )
2153 )
2155 def add_ordering(self, *ordering):
2156 """
2157 Add items from the 'ordering' sequence to the query's "order by"
2158 clause. These items are either field names (not column names) --
2159 possibly with a direction prefix ('-' or '?') -- or OrderBy
2160 expressions.
2162 If 'ordering' is empty, clear all ordering from the query.
2163 """
2164 errors = []
2165 for item in ordering:
2166 if isinstance(item, str):
2167 if item == "?":
2168 continue
2169 item = item.removeprefix("-")
2170 if item in self.annotations:
2171 continue
2172 if self.extra and item in self.extra:
2173 continue
2174 # names_to_path() validates the lookup. A descriptive
2175 # FieldError will be raise if it's not.
2176 self.names_to_path(item.split(LOOKUP_SEP), self.model._meta)
2177 elif not hasattr(item, "resolve_expression"):
2178 errors.append(item)
2179 if getattr(item, "contains_aggregate", False):
2180 raise FieldError(
2181 "Using an aggregate in order_by() without also including "
2182 "it in annotate() is not allowed: %s" % item
2183 )
2184 if errors:
2185 raise FieldError("Invalid order_by arguments: %s" % errors)
2186 if ordering:
2187 self.order_by += ordering
2188 else:
2189 self.default_ordering = False
2191 def clear_ordering(self, force=False, clear_default=True):
2192 """
2193 Remove any ordering settings if the current query allows it without
2194 side effects, set 'force' to True to clear the ordering regardless.
2195 If 'clear_default' is True, there will be no ordering in the resulting
2196 query (not even the model's default).
2197 """
2198 if not force and (
2199 self.is_sliced or self.distinct_fields or self.select_for_update
2200 ):
2201 return
2202 self.order_by = ()
2203 self.extra_order_by = ()
2204 if clear_default:
2205 self.default_ordering = False
2207 def set_group_by(self, allow_aliases=True):
2208 """
2209 Expand the GROUP BY clause required by the query.
2211 This will usually be the set of all non-aggregate fields in the
2212 return data. If the database backend supports grouping by the
2213 primary key, and the query would be equivalent, the optimization
2214 will be made automatically.
2215 """
2216 if allow_aliases and self.values_select:
2217 # If grouping by aliases is allowed assign selected value aliases
2218 # by moving them to annotations.
2219 group_by_annotations = {}
2220 values_select = {}
2221 for alias, expr in zip(self.values_select, self.select):
2222 if isinstance(expr, Col):
2223 values_select[alias] = expr
2224 else:
2225 group_by_annotations[alias] = expr
2226 self.annotations = {**group_by_annotations, **self.annotations}
2227 self.append_annotation_mask(group_by_annotations)
2228 self.select = tuple(values_select.values())
2229 self.values_select = tuple(values_select)
2230 group_by = list(self.select)
2231 for alias, annotation in self.annotation_select.items():
2232 if not (group_by_cols := annotation.get_group_by_cols()):
2233 continue
2234 if allow_aliases and not annotation.contains_aggregate:
2235 group_by.append(Ref(alias, annotation))
2236 else:
2237 group_by.extend(group_by_cols)
2238 self.group_by = tuple(group_by)
2240 def add_select_related(self, fields):
2241 """
2242 Set up the select_related data structure so that we only select
2243 certain related models (as opposed to all models, when
2244 self.select_related=True).
2245 """
2246 if isinstance(self.select_related, bool):
2247 field_dict = {}
2248 else:
2249 field_dict = self.select_related
2250 for field in fields:
2251 d = field_dict
2252 for part in field.split(LOOKUP_SEP):
2253 d = d.setdefault(part, {})
2254 self.select_related = field_dict
2256 def add_extra(self, select, select_params, where, params, tables, order_by):
2257 """
2258 Add data to the various extra_* attributes for user-created additions
2259 to the query.
2260 """
2261 if select:
2262 # We need to pair any placeholder markers in the 'select'
2263 # dictionary with their parameters in 'select_params' so that
2264 # subsequent updates to the select dictionary also adjust the
2265 # parameters appropriately.
2266 select_pairs = {}
2267 if select_params:
2268 param_iter = iter(select_params)
2269 else:
2270 param_iter = iter([])
2271 for name, entry in select.items():
2272 self.check_alias(name)
2273 entry = str(entry)
2274 entry_params = []
2275 pos = entry.find("%s")
2276 while pos != -1:
2277 if pos == 0 or entry[pos - 1] != "%":
2278 entry_params.append(next(param_iter))
2279 pos = entry.find("%s", pos + 2)
2280 select_pairs[name] = (entry, entry_params)
2281 self.extra.update(select_pairs)
2282 if where or params:
2283 self.where.add(ExtraWhere(where, params), AND)
2284 if tables:
2285 self.extra_tables += tuple(tables)
2286 if order_by:
2287 self.extra_order_by = order_by
2289 def clear_deferred_loading(self):
2290 """Remove any fields from the deferred loading set."""
2291 self.deferred_loading = (frozenset(), True)
2293 def add_deferred_loading(self, field_names):
2294 """
2295 Add the given list of model field names to the set of fields to
2296 exclude from loading from the database when automatic column selection
2297 is done. Add the new field names to any existing field names that
2298 are deferred (or removed from any existing field names that are marked
2299 as the only ones for immediate loading).
2300 """
2301 # Fields on related models are stored in the literal double-underscore
2302 # format, so that we can use a set datastructure. We do the foo__bar
2303 # splitting and handling when computing the SQL column names (as part of
2304 # get_columns()).
2305 existing, defer = self.deferred_loading
2306 if defer:
2307 # Add to existing deferred names.
2308 self.deferred_loading = existing.union(field_names), True
2309 else:
2310 # Remove names from the set of any existing "immediate load" names.
2311 if new_existing := existing.difference(field_names):
2312 self.deferred_loading = new_existing, False
2313 else:
2314 self.clear_deferred_loading()
2315 if new_only := set(field_names).difference(existing):
2316 self.deferred_loading = new_only, True
2318 def add_immediate_loading(self, field_names):
2319 """
2320 Add the given list of model field names to the set of fields to
2321 retrieve when the SQL is executed ("immediate loading" fields). The
2322 field names replace any existing immediate loading field names. If
2323 there are field names already specified for deferred loading, remove
2324 those names from the new field_names before storing the new names
2325 for immediate loading. (That is, immediate loading overrides any
2326 existing immediate values, but respects existing deferrals.)
2327 """
2328 existing, defer = self.deferred_loading
2329 field_names = set(field_names)
2330 if "pk" in field_names:
2331 field_names.remove("pk")
2332 field_names.add(self.get_meta().pk.name)
2334 if defer:
2335 # Remove any existing deferred names from the current set before
2336 # setting the new names.
2337 self.deferred_loading = field_names.difference(existing), False
2338 else:
2339 # Replace any existing "immediate load" field names.
2340 self.deferred_loading = frozenset(field_names), False
2342 def set_annotation_mask(self, names):
2343 """Set the mask of annotations that will be returned by the SELECT."""
2344 if names is None:
2345 self.annotation_select_mask = None
2346 else:
2347 self.annotation_select_mask = set(names)
2348 self._annotation_select_cache = None
2350 def append_annotation_mask(self, names):
2351 if self.annotation_select_mask is not None:
2352 self.set_annotation_mask(self.annotation_select_mask.union(names))
2354 def set_extra_mask(self, names):
2355 """
2356 Set the mask of extra select items that will be returned by SELECT.
2357 Don't remove them from the Query since they might be used later.
2358 """
2359 if names is None:
2360 self.extra_select_mask = None
2361 else:
2362 self.extra_select_mask = set(names)
2363 self._extra_select_cache = None
2365 def set_values(self, fields):
2366 self.select_related = False
2367 self.clear_deferred_loading()
2368 self.clear_select_fields()
2369 self.has_select_fields = True
2371 if fields:
2372 field_names = []
2373 extra_names = []
2374 annotation_names = []
2375 if not self.extra and not self.annotations:
2376 # Shortcut - if there are no extra or annotations, then
2377 # the values() clause must be just field names.
2378 field_names = list(fields)
2379 else:
2380 self.default_cols = False
2381 for f in fields:
2382 if f in self.extra_select:
2383 extra_names.append(f)
2384 elif f in self.annotation_select:
2385 annotation_names.append(f)
2386 else:
2387 field_names.append(f)
2388 self.set_extra_mask(extra_names)
2389 self.set_annotation_mask(annotation_names)
2390 selected = frozenset(field_names + extra_names + annotation_names)
2391 else:
2392 field_names = [f.attname for f in self.model._meta.concrete_fields]
2393 selected = frozenset(field_names)
2394 # Selected annotations must be known before setting the GROUP BY
2395 # clause.
2396 if self.group_by is True:
2397 self.add_fields(
2398 (f.attname for f in self.model._meta.concrete_fields), False
2399 )
2400 # Disable GROUP BY aliases to avoid orphaning references to the
2401 # SELECT clause which is about to be cleared.
2402 self.set_group_by(allow_aliases=False)
2403 self.clear_select_fields()
2404 elif self.group_by:
2405 # Resolve GROUP BY annotation references if they are not part of
2406 # the selected fields anymore.
2407 group_by = []
2408 for expr in self.group_by:
2409 if isinstance(expr, Ref) and expr.refs not in selected:
2410 expr = self.annotations[expr.refs]
2411 group_by.append(expr)
2412 self.group_by = tuple(group_by)
2414 self.values_select = tuple(field_names)
2415 self.add_fields(field_names, True)
2417 @property
2418 def annotation_select(self):
2419 """
2420 Return the dictionary of aggregate columns that are not masked and
2421 should be used in the SELECT clause. Cache this result for performance.
2422 """
2423 if self._annotation_select_cache is not None:
2424 return self._annotation_select_cache
2425 elif not self.annotations:
2426 return {}
2427 elif self.annotation_select_mask is not None:
2428 self._annotation_select_cache = {
2429 k: v
2430 for k, v in self.annotations.items()
2431 if k in self.annotation_select_mask
2432 }
2433 return self._annotation_select_cache
2434 else:
2435 return self.annotations
2437 @property
2438 def extra_select(self):
2439 if self._extra_select_cache is not None:
2440 return self._extra_select_cache
2441 if not self.extra:
2442 return {}
2443 elif self.extra_select_mask is not None:
2444 self._extra_select_cache = {
2445 k: v for k, v in self.extra.items() if k in self.extra_select_mask
2446 }
2447 return self._extra_select_cache
2448 else:
2449 return self.extra
2451 def trim_start(self, names_with_path):
2452 """
2453 Trim joins from the start of the join path. The candidates for trim
2454 are the PathInfos in names_with_path structure that are m2m joins.
2456 Also set the select column so the start matches the join.
2458 This method is meant to be used for generating the subquery joins &
2459 cols in split_exclude().
2461 Return a lookup usable for doing outerq.filter(lookup=self) and a
2462 boolean indicating if the joins in the prefix contain a LEFT OUTER join.
2463 _"""
2464 all_paths = []
2465 for _, paths in names_with_path:
2466 all_paths.extend(paths)
2467 contains_louter = False
2468 # Trim and operate only on tables that were generated for
2469 # the lookup part of the query. That is, avoid trimming
2470 # joins generated for F() expressions.
2471 lookup_tables = [
2472 t for t in self.alias_map if t in self._lookup_joins or t == self.base_table
2473 ]
2474 for trimmed_paths, path in enumerate(all_paths):
2475 if path.m2m:
2476 break
2477 if self.alias_map[lookup_tables[trimmed_paths + 1]].join_type == LOUTER:
2478 contains_louter = True
2479 alias = lookup_tables[trimmed_paths]
2480 self.unref_alias(alias)
2481 # The path.join_field is a Rel, lets get the other side's field
2482 join_field = path.join_field.field
2483 # Build the filter prefix.
2484 paths_in_prefix = trimmed_paths
2485 trimmed_prefix = []
2486 for name, path in names_with_path:
2487 if paths_in_prefix - len(path) < 0:
2488 break
2489 trimmed_prefix.append(name)
2490 paths_in_prefix -= len(path)
2491 trimmed_prefix.append(join_field.foreign_related_fields[0].name)
2492 trimmed_prefix = LOOKUP_SEP.join(trimmed_prefix)
2493 # Lets still see if we can trim the first join from the inner query
2494 # (that is, self). We can't do this for:
2495 # - LEFT JOINs because we would miss those rows that have nothing on
2496 # the outer side,
2497 # - INNER JOINs from filtered relations because we would miss their
2498 # filters.
2499 first_join = self.alias_map[lookup_tables[trimmed_paths + 1]]
2500 if first_join.join_type != LOUTER and not first_join.filtered_relation:
2501 select_fields = [r[0] for r in join_field.related_fields]
2502 select_alias = lookup_tables[trimmed_paths + 1]
2503 self.unref_alias(lookup_tables[trimmed_paths])
2504 extra_restriction = join_field.get_extra_restriction(
2505 None, lookup_tables[trimmed_paths + 1]
2506 )
2507 if extra_restriction:
2508 self.where.add(extra_restriction, AND)
2509 else:
2510 # TODO: It might be possible to trim more joins from the start of the
2511 # inner query if it happens to have a longer join chain containing the
2512 # values in select_fields. Lets punt this one for now.
2513 select_fields = [r[1] for r in join_field.related_fields]
2514 select_alias = lookup_tables[trimmed_paths]
2515 # The found starting point is likely a join_class instead of a
2516 # base_table_class reference. But the first entry in the query's FROM
2517 # clause must not be a JOIN.
2518 for table in self.alias_map:
2519 if self.alias_refcount[table] > 0:
2520 self.alias_map[table] = self.base_table_class(
2521 self.alias_map[table].table_name,
2522 table,
2523 )
2524 break
2525 self.set_select([f.get_col(select_alias) for f in select_fields])
2526 return trimmed_prefix, contains_louter
2528 def is_nullable(self, field):
2529 """
2530 Check if the given field should be treated as nullable.
2532 Some backends treat '' as null and Plain treats such fields as
2533 nullable for those backends. In such situations field.null can be
2534 False even if we should treat the field as nullable.
2535 """
2536 # We need to use DEFAULT_DB_ALIAS here, as QuerySet does not have
2537 # (nor should it have) knowledge of which connection is going to be
2538 # used. The proper fix would be to defer all decisions where
2539 # is_nullable() is needed to the compiler stage, but that is not easy
2540 # to do currently.
2541 return field.null or (
2542 field.empty_strings_allowed
2543 and connections[DEFAULT_DB_ALIAS].features.interprets_empty_strings_as_nulls
2544 )
2547def get_order_dir(field, default="ASC"):
2548 """
2549 Return the field name and direction for an order specification. For
2550 example, '-foo' is returned as ('foo', 'DESC').
2552 The 'default' param is used to indicate which way no prefix (or a '+'
2553 prefix) should sort. The '-' prefix always sorts the opposite way.
2554 """
2555 dirn = ORDER_DIR[default]
2556 if field[0] == "-":
2557 return field[1:], dirn[1]
2558 return field, dirn[0]
2561class JoinPromoter:
2562 """
2563 A class to abstract away join promotion problems for complex filter
2564 conditions.
2565 """
2567 def __init__(self, connector, num_children, negated):
2568 self.connector = connector
2569 self.negated = negated
2570 if self.negated:
2571 if connector == AND:
2572 self.effective_connector = OR
2573 else:
2574 self.effective_connector = AND
2575 else:
2576 self.effective_connector = self.connector
2577 self.num_children = num_children
2578 # Maps of table alias to how many times it is seen as required for
2579 # inner and/or outer joins.
2580 self.votes = Counter()
2582 def __repr__(self):
2583 return (
2584 f"{self.__class__.__qualname__}(connector={self.connector!r}, "
2585 f"num_children={self.num_children!r}, negated={self.negated!r})"
2586 )
2588 def add_votes(self, votes):
2589 """
2590 Add single vote per item to self.votes. Parameter can be any
2591 iterable.
2592 """
2593 self.votes.update(votes)
2595 def update_join_types(self, query):
2596 """
2597 Change join types so that the generated query is as efficient as
2598 possible, but still correct. So, change as many joins as possible
2599 to INNER, but don't make OUTER joins INNER if that could remove
2600 results from the query.
2601 """
2602 to_promote = set()
2603 to_demote = set()
2604 # The effective_connector is used so that NOT (a AND b) is treated
2605 # similarly to (a OR b) for join promotion.
2606 for table, votes in self.votes.items():
2607 # We must use outer joins in OR case when the join isn't contained
2608 # in all of the joins. Otherwise the INNER JOIN itself could remove
2609 # valid results. Consider the case where a model with rel_a and
2610 # rel_b relations is queried with rel_a__col=1 | rel_b__col=2. Now,
2611 # if rel_a join doesn't produce any results is null (for example
2612 # reverse foreign key or null value in direct foreign key), and
2613 # there is a matching row in rel_b with col=2, then an INNER join
2614 # to rel_a would remove a valid match from the query. So, we need
2615 # to promote any existing INNER to LOUTER (it is possible this
2616 # promotion in turn will be demoted later on).
2617 if self.effective_connector == OR and votes < self.num_children:
2618 to_promote.add(table)
2619 # If connector is AND and there is a filter that can match only
2620 # when there is a joinable row, then use INNER. For example, in
2621 # rel_a__col=1 & rel_b__col=2, if either of the rels produce NULL
2622 # as join output, then the col=1 or col=2 can't match (as
2623 # NULL=anything is always false).
2624 # For the OR case, if all children voted for a join to be inner,
2625 # then we can use INNER for the join. For example:
2626 # (rel_a__col__icontains=Alex | rel_a__col__icontains=Russell)
2627 # then if rel_a doesn't produce any rows, the whole condition
2628 # can't match. Hence we can safely use INNER join.
2629 if self.effective_connector == AND or (
2630 self.effective_connector == OR and votes == self.num_children
2631 ):
2632 to_demote.add(table)
2633 # Finally, what happens in cases where we have:
2634 # (rel_a__col=1|rel_b__col=2) & rel_a__col__gte=0
2635 # Now, we first generate the OR clause, and promote joins for it
2636 # in the first if branch above. Both rel_a and rel_b are promoted
2637 # to LOUTER joins. After that we do the AND case. The OR case
2638 # voted no inner joins but the rel_a__col__gte=0 votes inner join
2639 # for rel_a. We demote it back to INNER join (in AND case a single
2640 # vote is enough). The demotion is OK, if rel_a doesn't produce
2641 # rows, then the rel_a__col__gte=0 clause can't be true, and thus
2642 # the whole clause must be false. So, it is safe to use INNER
2643 # join.
2644 # Note that in this example we could just as well have the __gte
2645 # clause and the OR clause swapped. Or we could replace the __gte
2646 # clause with an OR clause containing rel_a__col=1|rel_a__col=2,
2647 # and again we could safely demote to INNER.
2648 query.promote_joins(to_promote)
2649 query.demote_joins(to_demote)
2650 return to_demote
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Query subclasses which provide extra functionality beyond simple data retrieval.
3"""
5from plain.exceptions import FieldError
6from plain.models.sql.constants import CURSOR, GET_ITERATOR_CHUNK_SIZE, NO_RESULTS
7from plain.models.sql.query import Query
9__all__ = ["DeleteQuery", "UpdateQuery", "InsertQuery", "AggregateQuery"]
12class DeleteQuery(Query):
13 """A DELETE SQL query."""
15 compiler = "SQLDeleteCompiler"
17 def do_query(self, table, where, using):
18 self.alias_map = {table: self.alias_map[table]}
19 self.where = where
20 cursor = self.get_compiler(using).execute_sql(CURSOR)
21 if cursor:
22 with cursor:
23 return cursor.rowcount
24 return 0
26 def delete_batch(self, pk_list, using):
27 """
28 Set up and execute delete queries for all the objects in pk_list.
30 More than one physical query may be executed if there are a
31 lot of values in pk_list.
32 """
33 # number of objects deleted
34 num_deleted = 0
35 field = self.get_meta().pk
36 for offset in range(0, len(pk_list), GET_ITERATOR_CHUNK_SIZE):
37 self.clear_where()
38 self.add_filter(
39 f"{field.attname}__in",
40 pk_list[offset : offset + GET_ITERATOR_CHUNK_SIZE],
41 )
42 num_deleted += self.do_query(
43 self.get_meta().db_table, self.where, using=using
44 )
45 return num_deleted
48class UpdateQuery(Query):
49 """An UPDATE SQL query."""
51 compiler = "SQLUpdateCompiler"
53 def __init__(self, *args, **kwargs):
54 super().__init__(*args, **kwargs)
55 self._setup_query()
57 def _setup_query(self):
58 """
59 Run on initialization and at the end of chaining. Any attributes that
60 would normally be set in __init__() should go here instead.
61 """
62 self.values = []
63 self.related_ids = None
64 self.related_updates = {}
66 def clone(self):
67 obj = super().clone()
68 obj.related_updates = self.related_updates.copy()
69 return obj
71 def update_batch(self, pk_list, values, using):
72 self.add_update_values(values)
73 for offset in range(0, len(pk_list), GET_ITERATOR_CHUNK_SIZE):
74 self.clear_where()
75 self.add_filter(
76 "pk__in", pk_list[offset : offset + GET_ITERATOR_CHUNK_SIZE]
77 )
78 self.get_compiler(using).execute_sql(NO_RESULTS)
80 def add_update_values(self, values):
81 """
82 Convert a dictionary of field name to value mappings into an update
83 query. This is the entry point for the public update() method on
84 querysets.
85 """
86 values_seq = []
87 for name, val in values.items():
88 field = self.get_meta().get_field(name)
89 direct = (
90 not (field.auto_created and not field.concrete) or not field.concrete
91 )
92 model = field.model._meta.concrete_model
93 if not direct or (field.is_relation and field.many_to_many):
94 raise FieldError(
95 "Cannot update model field %r (only non-relations and "
96 "foreign keys permitted)." % field
97 )
98 if model is not self.get_meta().concrete_model:
99 self.add_related_update(model, field, val)
100 continue
101 values_seq.append((field, model, val))
102 return self.add_update_fields(values_seq)
104 def add_update_fields(self, values_seq):
105 """
106 Append a sequence of (field, model, value) triples to the internal list
107 that will be used to generate the UPDATE query. Might be more usefully
108 called add_update_targets() to hint at the extra information here.
109 """
110 for field, model, val in values_seq:
111 if hasattr(val, "resolve_expression"):
112 # Resolve expressions here so that annotations are no longer needed
113 val = val.resolve_expression(self, allow_joins=False, for_save=True)
114 self.values.append((field, model, val))
116 def add_related_update(self, model, field, value):
117 """
118 Add (name, value) to an update query for an ancestor model.
120 Update are coalesced so that only one update query per ancestor is run.
121 """
122 self.related_updates.setdefault(model, []).append((field, None, value))
124 def get_related_updates(self):
125 """
126 Return a list of query objects: one for each update required to an
127 ancestor model. Each query will have the same filtering conditions as
128 the current query but will only update a single table.
129 """
130 if not self.related_updates:
131 return []
132 result = []
133 for model, values in self.related_updates.items():
134 query = UpdateQuery(model)
135 query.values = values
136 if self.related_ids is not None:
137 query.add_filter("pk__in", self.related_ids[model])
138 result.append(query)
139 return result
142class InsertQuery(Query):
143 compiler = "SQLInsertCompiler"
145 def __init__(
146 self, *args, on_conflict=None, update_fields=None, unique_fields=None, **kwargs
147 ):
148 super().__init__(*args, **kwargs)
149 self.fields = []
150 self.objs = []
151 self.on_conflict = on_conflict
152 self.update_fields = update_fields or []
153 self.unique_fields = unique_fields or []
155 def insert_values(self, fields, objs, raw=False):
156 self.fields = fields
157 self.objs = objs
158 self.raw = raw
161class AggregateQuery(Query):
162 """
163 Take another query as a parameter to the FROM clause and only select the
164 elements in the provided list.
165 """
167 compiler = "SQLAggregateCompiler"
169 def __init__(self, model, inner_query):
170 self.inner_query = inner_query
171 super().__init__(model)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Code to manage the creation and SQL rendering of 'where' constraints.
3"""
4import operator
5from functools import reduce
7from plain.exceptions import EmptyResultSet, FullResultSet
8from plain.models.expressions import Case, When
9from plain.models.lookups import Exact
10from plain.utils import tree
11from plain.utils.functional import cached_property
13# Connection types
14AND = "AND"
15OR = "OR"
16XOR = "XOR"
19class WhereNode(tree.Node):
20 """
21 An SQL WHERE clause.
23 The class is tied to the Query class that created it (in order to create
24 the correct SQL).
26 A child is usually an expression producing boolean values. Most likely the
27 expression is a Lookup instance.
29 However, a child could also be any class with as_sql() and either
30 relabeled_clone() method or relabel_aliases() and clone() methods and
31 contains_aggregate attribute.
32 """
34 default = AND
35 resolved = False
36 conditional = True
38 def split_having_qualify(self, negated=False, must_group_by=False):
39 """
40 Return three possibly None nodes: one for those parts of self that
41 should be included in the WHERE clause, one for those parts of self
42 that must be included in the HAVING clause, and one for those parts
43 that refer to window functions.
44 """
45 if not self.contains_aggregate and not self.contains_over_clause:
46 return self, None, None
47 in_negated = negated ^ self.negated
48 # Whether or not children must be connected in the same filtering
49 # clause (WHERE > HAVING > QUALIFY) to maintain logical semantic.
50 must_remain_connected = (
51 (in_negated and self.connector == AND)
52 or (not in_negated and self.connector == OR)
53 or self.connector == XOR
54 )
55 if (
56 must_remain_connected
57 and self.contains_aggregate
58 and not self.contains_over_clause
59 ):
60 # It's must cheaper to short-circuit and stash everything in the
61 # HAVING clause than split children if possible.
62 return None, self, None
63 where_parts = []
64 having_parts = []
65 qualify_parts = []
66 for c in self.children:
67 if hasattr(c, "split_having_qualify"):
68 where_part, having_part, qualify_part = c.split_having_qualify(
69 in_negated, must_group_by
70 )
71 if where_part is not None:
72 where_parts.append(where_part)
73 if having_part is not None:
74 having_parts.append(having_part)
75 if qualify_part is not None:
76 qualify_parts.append(qualify_part)
77 elif c.contains_over_clause:
78 qualify_parts.append(c)
79 elif c.contains_aggregate:
80 having_parts.append(c)
81 else:
82 where_parts.append(c)
83 if must_remain_connected and qualify_parts:
84 # Disjunctive heterogeneous predicates can be pushed down to
85 # qualify as long as no conditional aggregation is involved.
86 if not where_parts or (where_parts and not must_group_by):
87 return None, None, self
88 elif where_parts:
89 # In theory this should only be enforced when dealing with
90 # where_parts containing predicates against multi-valued
91 # relationships that could affect aggregation results but this
92 # is complex to infer properly.
93 raise NotImplementedError(
94 "Heterogeneous disjunctive predicates against window functions are "
95 "not implemented when performing conditional aggregation."
96 )
97 where_node = (
98 self.create(where_parts, self.connector, self.negated)
99 if where_parts
100 else None
101 )
102 having_node = (
103 self.create(having_parts, self.connector, self.negated)
104 if having_parts
105 else None
106 )
107 qualify_node = (
108 self.create(qualify_parts, self.connector, self.negated)
109 if qualify_parts
110 else None
111 )
112 return where_node, having_node, qualify_node
114 def as_sql(self, compiler, connection):
115 """
116 Return the SQL version of the where clause and the value to be
117 substituted in. Return '', [] if this node matches everything,
118 None, [] if this node is empty, and raise EmptyResultSet if this
119 node can't match anything.
120 """
121 result = []
122 result_params = []
123 if self.connector == AND:
124 full_needed, empty_needed = len(self.children), 1
125 else:
126 full_needed, empty_needed = 1, len(self.children)
128 if self.connector == XOR and not connection.features.supports_logical_xor:
129 # Convert if the database doesn't support XOR:
130 # a XOR b XOR c XOR ...
131 # to:
132 # (a OR b OR c OR ...) AND (a + b + c + ...) == 1
133 lhs = self.__class__(self.children, OR)
134 rhs_sum = reduce(
135 operator.add,
136 (Case(When(c, then=1), default=0) for c in self.children),
137 )
138 rhs = Exact(1, rhs_sum)
139 return self.__class__([lhs, rhs], AND, self.negated).as_sql(
140 compiler, connection
141 )
143 for child in self.children:
144 try:
145 sql, params = compiler.compile(child)
146 except EmptyResultSet:
147 empty_needed -= 1
148 except FullResultSet:
149 full_needed -= 1
150 else:
151 if sql:
152 result.append(sql)
153 result_params.extend(params)
154 else:
155 full_needed -= 1
156 # Check if this node matches nothing or everything.
157 # First check the amount of full nodes and empty nodes
158 # to make this node empty/full.
159 # Now, check if this node is full/empty using the
160 # counts.
161 if empty_needed == 0:
162 if self.negated:
163 raise FullResultSet
164 else:
165 raise EmptyResultSet
166 if full_needed == 0:
167 if self.negated:
168 raise EmptyResultSet
169 else:
170 raise FullResultSet
171 conn = " %s " % self.connector
172 sql_string = conn.join(result)
173 if not sql_string:
174 raise FullResultSet
175 if self.negated:
176 # Some backends (Oracle at least) need parentheses around the inner
177 # SQL in the negated case, even if the inner SQL contains just a
178 # single expression.
179 sql_string = "NOT (%s)" % sql_string
180 elif len(result) > 1 or self.resolved:
181 sql_string = "(%s)" % sql_string
182 return sql_string, result_params
184 def get_group_by_cols(self):
185 cols = []
186 for child in self.children:
187 cols.extend(child.get_group_by_cols())
188 return cols
190 def get_source_expressions(self):
191 return self.children[:]
193 def set_source_expressions(self, children):
194 assert len(children) == len(self.children)
195 self.children = children
197 def relabel_aliases(self, change_map):
198 """
199 Relabel the alias values of any children. 'change_map' is a dictionary
200 mapping old (current) alias values to the new values.
201 """
202 for pos, child in enumerate(self.children):
203 if hasattr(child, "relabel_aliases"):
204 # For example another WhereNode
205 child.relabel_aliases(change_map)
206 elif hasattr(child, "relabeled_clone"):
207 self.children[pos] = child.relabeled_clone(change_map)
209 def clone(self):
210 clone = self.create(connector=self.connector, negated=self.negated)
211 for child in self.children:
212 if hasattr(child, "clone"):
213 child = child.clone()
214 clone.children.append(child)
215 return clone
217 def relabeled_clone(self, change_map):
218 clone = self.clone()
219 clone.relabel_aliases(change_map)
220 return clone
222 def replace_expressions(self, replacements):
223 if replacement := replacements.get(self):
224 return replacement
225 clone = self.create(connector=self.connector, negated=self.negated)
226 for child in self.children:
227 clone.children.append(child.replace_expressions(replacements))
228 return clone
230 def get_refs(self):
231 refs = set()
232 for child in self.children:
233 refs |= child.get_refs()
234 return refs
236 @classmethod
237 def _contains_aggregate(cls, obj):
238 if isinstance(obj, tree.Node):
239 return any(cls._contains_aggregate(c) for c in obj.children)
240 return obj.contains_aggregate
242 @cached_property
243 def contains_aggregate(self):
244 return self._contains_aggregate(self)
246 @classmethod
247 def _contains_over_clause(cls, obj):
248 if isinstance(obj, tree.Node):
249 return any(cls._contains_over_clause(c) for c in obj.children)
250 return obj.contains_over_clause
252 @cached_property
253 def contains_over_clause(self):
254 return self._contains_over_clause(self)
256 @property
257 def is_summary(self):
258 return any(child.is_summary for child in self.children)
260 @staticmethod
261 def _resolve_leaf(expr, query, *args, **kwargs):
262 if hasattr(expr, "resolve_expression"):
263 expr = expr.resolve_expression(query, *args, **kwargs)
264 return expr
266 @classmethod
267 def _resolve_node(cls, node, query, *args, **kwargs):
268 if hasattr(node, "children"):
269 for child in node.children:
270 cls._resolve_node(child, query, *args, **kwargs)
271 if hasattr(node, "lhs"):
272 node.lhs = cls._resolve_leaf(node.lhs, query, *args, **kwargs)
273 if hasattr(node, "rhs"):
274 node.rhs = cls._resolve_leaf(node.rhs, query, *args, **kwargs)
276 def resolve_expression(self, *args, **kwargs):
277 clone = self.clone()
278 clone._resolve_node(clone, *args, **kwargs)
279 clone.resolved = True
280 return clone
282 @cached_property
283 def output_field(self):
284 from plain.models.fields import BooleanField
286 return BooleanField()
288 @property
289 def _output_field_or_none(self):
290 return self.output_field
292 def select_format(self, compiler, sql, params):
293 # Wrap filters with a CASE WHEN expression if a database backend
294 # (e.g. Oracle) doesn't support boolean expression in SELECT or GROUP
295 # BY list.
296 if not compiler.connection.features.supports_boolean_expr_in_select_clause:
297 sql = f"CASE WHEN {sql} THEN 1 ELSE 0 END"
298 return sql, params
300 def get_db_converters(self, connection):
301 return self.output_field.get_db_converters(connection)
303 def get_lookup(self, lookup):
304 return self.output_field.get_lookup(lookup)
306 def leaves(self):
307 for child in self.children:
308 if isinstance(child, WhereNode):
309 yield from child.leaves()
310 else:
311 yield child
314class NothingNode:
315 """A node that matches nothing."""
317 contains_aggregate = False
318 contains_over_clause = False
320 def as_sql(self, compiler=None, connection=None):
321 raise EmptyResultSet
324class ExtraWhere:
325 # The contents are a black box - assume no aggregates or windows are used.
326 contains_aggregate = False
327 contains_over_clause = False
329 def __init__(self, sqls, params):
330 self.sqls = sqls
331 self.params = params
333 def as_sql(self, compiler=None, connection=None):
334 sqls = ["(%s)" % sql for sql in self.sqls]
335 return " AND ".join(sqls), list(self.params or ())
338class SubqueryConstraint:
339 # Even if aggregates or windows would be used in a subquery,
340 # the outer query isn't interested about those.
341 contains_aggregate = False
342 contains_over_clause = False
344 def __init__(self, alias, columns, targets, query_object):
345 self.alias = alias
346 self.columns = columns
347 self.targets = targets
348 query_object.clear_ordering(clear_default=True)
349 self.query_object = query_object
351 def as_sql(self, compiler, connection):
352 query = self.query_object
353 query.set_values(self.targets)
354 query_compiler = query.get_compiler(connection=connection)
355 return query_compiler.as_subquery_condition(self.alias, self.columns, compiler)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Implementations of SQL functions for SQLite.
3"""
5import functools
6import random
7import statistics
8import zoneinfo
9from datetime import timedelta
10from hashlib import md5, sha1, sha224, sha256, sha384, sha512
11from math import (
12 acos,
13 asin,
14 atan,
15 atan2,
16 ceil,
17 cos,
18 degrees,
19 exp,
20 floor,
21 fmod,
22 log,
23 pi,
24 radians,
25 sin,
26 sqrt,
27 tan,
28)
29from re import search as re_search
31from plain.models.backends.utils import (
32 split_tzname_delta,
33 typecast_time,
34 typecast_timestamp,
35)
36from plain.utils import timezone
37from plain.utils.duration import duration_microseconds
40def register(connection):
41 create_deterministic_function = functools.partial(
42 connection.create_function,
43 deterministic=True,
44 )
45 create_deterministic_function("plain_date_extract", 2, _sqlite_datetime_extract)
46 create_deterministic_function("plain_date_trunc", 4, _sqlite_date_trunc)
47 create_deterministic_function(
48 "plain_datetime_cast_date", 3, _sqlite_datetime_cast_date
49 )
50 create_deterministic_function(
51 "plain_datetime_cast_time", 3, _sqlite_datetime_cast_time
52 )
53 create_deterministic_function("plain_datetime_extract", 4, _sqlite_datetime_extract)
54 create_deterministic_function("plain_datetime_trunc", 4, _sqlite_datetime_trunc)
55 create_deterministic_function("plain_time_extract", 2, _sqlite_time_extract)
56 create_deterministic_function("plain_time_trunc", 4, _sqlite_time_trunc)
57 create_deterministic_function("plain_time_diff", 2, _sqlite_time_diff)
58 create_deterministic_function("plain_timestamp_diff", 2, _sqlite_timestamp_diff)
59 create_deterministic_function("plain_format_dtdelta", 3, _sqlite_format_dtdelta)
60 create_deterministic_function("regexp", 2, _sqlite_regexp)
61 create_deterministic_function("BITXOR", 2, _sqlite_bitxor)
62 create_deterministic_function("COT", 1, _sqlite_cot)
63 create_deterministic_function("LPAD", 3, _sqlite_lpad)
64 create_deterministic_function("MD5", 1, _sqlite_md5)
65 create_deterministic_function("REPEAT", 2, _sqlite_repeat)
66 create_deterministic_function("REVERSE", 1, _sqlite_reverse)
67 create_deterministic_function("RPAD", 3, _sqlite_rpad)
68 create_deterministic_function("SHA1", 1, _sqlite_sha1)
69 create_deterministic_function("SHA224", 1, _sqlite_sha224)
70 create_deterministic_function("SHA256", 1, _sqlite_sha256)
71 create_deterministic_function("SHA384", 1, _sqlite_sha384)
72 create_deterministic_function("SHA512", 1, _sqlite_sha512)
73 create_deterministic_function("SIGN", 1, _sqlite_sign)
74 # Don't use the built-in RANDOM() function because it returns a value
75 # in the range [-1 * 2^63, 2^63 - 1] instead of [0, 1).
76 connection.create_function("RAND", 0, random.random)
77 connection.create_aggregate("STDDEV_POP", 1, StdDevPop)
78 connection.create_aggregate("STDDEV_SAMP", 1, StdDevSamp)
79 connection.create_aggregate("VAR_POP", 1, VarPop)
80 connection.create_aggregate("VAR_SAMP", 1, VarSamp)
81 # Some math functions are enabled by default in SQLite 3.35+.
82 sql = "select sqlite_compileoption_used('ENABLE_MATH_FUNCTIONS')"
83 if not connection.execute(sql).fetchone()[0]:
84 create_deterministic_function("ACOS", 1, _sqlite_acos)
85 create_deterministic_function("ASIN", 1, _sqlite_asin)
86 create_deterministic_function("ATAN", 1, _sqlite_atan)
87 create_deterministic_function("ATAN2", 2, _sqlite_atan2)
88 create_deterministic_function("CEILING", 1, _sqlite_ceiling)
89 create_deterministic_function("COS", 1, _sqlite_cos)
90 create_deterministic_function("DEGREES", 1, _sqlite_degrees)
91 create_deterministic_function("EXP", 1, _sqlite_exp)
92 create_deterministic_function("FLOOR", 1, _sqlite_floor)
93 create_deterministic_function("LN", 1, _sqlite_ln)
94 create_deterministic_function("LOG", 2, _sqlite_log)
95 create_deterministic_function("MOD", 2, _sqlite_mod)
96 create_deterministic_function("PI", 0, _sqlite_pi)
97 create_deterministic_function("POWER", 2, _sqlite_power)
98 create_deterministic_function("RADIANS", 1, _sqlite_radians)
99 create_deterministic_function("SIN", 1, _sqlite_sin)
100 create_deterministic_function("SQRT", 1, _sqlite_sqrt)
101 create_deterministic_function("TAN", 1, _sqlite_tan)
104def _sqlite_datetime_parse(dt, tzname=None, conn_tzname=None):
105 if dt is None:
106 return None
107 try:
108 dt = typecast_timestamp(dt)
109 except (TypeError, ValueError):
110 return None
111 if conn_tzname:
112 dt = dt.replace(tzinfo=zoneinfo.ZoneInfo(conn_tzname))
113 if tzname is not None and tzname != conn_tzname:
114 tzname, sign, offset = split_tzname_delta(tzname)
115 if offset:
116 hours, minutes = offset.split(":")
117 offset_delta = timedelta(hours=int(hours), minutes=int(minutes))
118 dt += offset_delta if sign == "+" else -offset_delta
119 dt = timezone.localtime(dt, zoneinfo.ZoneInfo(tzname))
120 return dt
123def _sqlite_date_trunc(lookup_type, dt, tzname, conn_tzname):
124 dt = _sqlite_datetime_parse(dt, tzname, conn_tzname)
125 if dt is None:
126 return None
127 if lookup_type == "year":
128 return f"{dt.year:04d}-01-01"
129 elif lookup_type == "quarter":
130 month_in_quarter = dt.month - (dt.month - 1) % 3
131 return f"{dt.year:04d}-{month_in_quarter:02d}-01"
132 elif lookup_type == "month":
133 return f"{dt.year:04d}-{dt.month:02d}-01"
134 elif lookup_type == "week":
135 dt -= timedelta(days=dt.weekday())
136 return f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d}"
137 elif lookup_type == "day":
138 return f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d}"
139 raise ValueError(f"Unsupported lookup type: {lookup_type!r}")
142def _sqlite_time_trunc(lookup_type, dt, tzname, conn_tzname):
143 if dt is None:
144 return None
145 dt_parsed = _sqlite_datetime_parse(dt, tzname, conn_tzname)
146 if dt_parsed is None:
147 try:
148 dt = typecast_time(dt)
149 except (ValueError, TypeError):
150 return None
151 else:
152 dt = dt_parsed
153 if lookup_type == "hour":
154 return f"{dt.hour:02d}:00:00"
155 elif lookup_type == "minute":
156 return f"{dt.hour:02d}:{dt.minute:02d}:00"
157 elif lookup_type == "second":
158 return f"{dt.hour:02d}:{dt.minute:02d}:{dt.second:02d}"
159 raise ValueError(f"Unsupported lookup type: {lookup_type!r}")
162def _sqlite_datetime_cast_date(dt, tzname, conn_tzname):
163 dt = _sqlite_datetime_parse(dt, tzname, conn_tzname)
164 if dt is None:
165 return None
166 return dt.date().isoformat()
169def _sqlite_datetime_cast_time(dt, tzname, conn_tzname):
170 dt = _sqlite_datetime_parse(dt, tzname, conn_tzname)
171 if dt is None:
172 return None
173 return dt.time().isoformat()
176def _sqlite_datetime_extract(lookup_type, dt, tzname=None, conn_tzname=None):
177 dt = _sqlite_datetime_parse(dt, tzname, conn_tzname)
178 if dt is None:
179 return None
180 if lookup_type == "week_day":
181 return (dt.isoweekday() % 7) + 1
182 elif lookup_type == "iso_week_day":
183 return dt.isoweekday()
184 elif lookup_type == "week":
185 return dt.isocalendar().week
186 elif lookup_type == "quarter":
187 return ceil(dt.month / 3)
188 elif lookup_type == "iso_year":
189 return dt.isocalendar().year
190 else:
191 return getattr(dt, lookup_type)
194def _sqlite_datetime_trunc(lookup_type, dt, tzname, conn_tzname):
195 dt = _sqlite_datetime_parse(dt, tzname, conn_tzname)
196 if dt is None:
197 return None
198 if lookup_type == "year":
199 return f"{dt.year:04d}-01-01 00:00:00"
200 elif lookup_type == "quarter":
201 month_in_quarter = dt.month - (dt.month - 1) % 3
202 return f"{dt.year:04d}-{month_in_quarter:02d}-01 00:00:00"
203 elif lookup_type == "month":
204 return f"{dt.year:04d}-{dt.month:02d}-01 00:00:00"
205 elif lookup_type == "week":
206 dt -= timedelta(days=dt.weekday())
207 return f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d} 00:00:00"
208 elif lookup_type == "day":
209 return f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d} 00:00:00"
210 elif lookup_type == "hour":
211 return f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d} {dt.hour:02d}:00:00"
212 elif lookup_type == "minute":
213 return (
214 f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d} "
215 f"{dt.hour:02d}:{dt.minute:02d}:00"
216 )
217 elif lookup_type == "second":
218 return (
219 f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d} "
220 f"{dt.hour:02d}:{dt.minute:02d}:{dt.second:02d}"
221 )
222 raise ValueError(f"Unsupported lookup type: {lookup_type!r}")
225def _sqlite_time_extract(lookup_type, dt):
226 if dt is None:
227 return None
228 try:
229 dt = typecast_time(dt)
230 except (ValueError, TypeError):
231 return None
232 return getattr(dt, lookup_type)
235def _sqlite_prepare_dtdelta_param(conn, param):
236 if conn in ["+", "-"]:
237 if isinstance(param, int):
238 return timedelta(0, 0, param)
239 else:
240 return typecast_timestamp(param)
241 return param
244def _sqlite_format_dtdelta(connector, lhs, rhs):
245 """
246 LHS and RHS can be either:
247 - An integer number of microseconds
248 - A string representing a datetime
249 - A scalar value, e.g. float
250 """
251 if connector is None or lhs is None or rhs is None:
252 return None
253 connector = connector.strip()
254 try:
255 real_lhs = _sqlite_prepare_dtdelta_param(connector, lhs)
256 real_rhs = _sqlite_prepare_dtdelta_param(connector, rhs)
257 except (ValueError, TypeError):
258 return None
259 if connector == "+":
260 # typecast_timestamp() returns a date or a datetime without timezone.
261 # It will be formatted as "%Y-%m-%d" or "%Y-%m-%d %H:%M:%S[.%f]"
262 out = str(real_lhs + real_rhs)
263 elif connector == "-":
264 out = str(real_lhs - real_rhs)
265 elif connector == "*":
266 out = real_lhs * real_rhs
267 else:
268 out = real_lhs / real_rhs
269 return out
272def _sqlite_time_diff(lhs, rhs):
273 if lhs is None or rhs is None:
274 return None
275 left = typecast_time(lhs)
276 right = typecast_time(rhs)
277 return (
278 (left.hour * 60 * 60 * 1000000)
279 + (left.minute * 60 * 1000000)
280 + (left.second * 1000000)
281 + (left.microsecond)
282 - (right.hour * 60 * 60 * 1000000)
283 - (right.minute * 60 * 1000000)
284 - (right.second * 1000000)
285 - (right.microsecond)
286 )
289def _sqlite_timestamp_diff(lhs, rhs):
290 if lhs is None or rhs is None:
291 return None
292 left = typecast_timestamp(lhs)
293 right = typecast_timestamp(rhs)
294 return duration_microseconds(left - right)
297def _sqlite_regexp(pattern, string):
298 if pattern is None or string is None:
299 return None
300 if not isinstance(string, str):
301 string = str(string)
302 return bool(re_search(pattern, string))
305def _sqlite_acos(x):
306 if x is None:
307 return None
308 return acos(x)
311def _sqlite_asin(x):
312 if x is None:
313 return None
314 return asin(x)
317def _sqlite_atan(x):
318 if x is None:
319 return None
320 return atan(x)
323def _sqlite_atan2(y, x):
324 if y is None or x is None:
325 return None
326 return atan2(y, x)
329def _sqlite_bitxor(x, y):
330 if x is None or y is None:
331 return None
332 return x ^ y
335def _sqlite_ceiling(x):
336 if x is None:
337 return None
338 return ceil(x)
341def _sqlite_cos(x):
342 if x is None:
343 return None
344 return cos(x)
347def _sqlite_cot(x):
348 if x is None:
349 return None
350 return 1 / tan(x)
353def _sqlite_degrees(x):
354 if x is None:
355 return None
356 return degrees(x)
359def _sqlite_exp(x):
360 if x is None:
361 return None
362 return exp(x)
365def _sqlite_floor(x):
366 if x is None:
367 return None
368 return floor(x)
371def _sqlite_ln(x):
372 if x is None:
373 return None
374 return log(x)
377def _sqlite_log(base, x):
378 if base is None or x is None:
379 return None
380 # Arguments reversed to match SQL standard.
381 return log(x, base)
384def _sqlite_lpad(text, length, fill_text):
385 if text is None or length is None or fill_text is None:
386 return None
387 delta = length - len(text)
388 if delta <= 0:
389 return text[:length]
390 return (fill_text * length)[:delta] + text
393def _sqlite_md5(text):
394 if text is None:
395 return None
396 return md5(text.encode()).hexdigest()
399def _sqlite_mod(x, y):
400 if x is None or y is None:
401 return None
402 return fmod(x, y)
405def _sqlite_pi():
406 return pi
409def _sqlite_power(x, y):
410 if x is None or y is None:
411 return None
412 return x**y
415def _sqlite_radians(x):
416 if x is None:
417 return None
418 return radians(x)
421def _sqlite_repeat(text, count):
422 if text is None or count is None:
423 return None
424 return text * count
427def _sqlite_reverse(text):
428 if text is None:
429 return None
430 return text[::-1]
433def _sqlite_rpad(text, length, fill_text):
434 if text is None or length is None or fill_text is None:
435 return None
436 return (text + fill_text * length)[:length]
439def _sqlite_sha1(text):
440 if text is None:
441 return None
442 return sha1(text.encode()).hexdigest()
445def _sqlite_sha224(text):
446 if text is None:
447 return None
448 return sha224(text.encode()).hexdigest()
451def _sqlite_sha256(text):
452 if text is None:
453 return None
454 return sha256(text.encode()).hexdigest()
457def _sqlite_sha384(text):
458 if text is None:
459 return None
460 return sha384(text.encode()).hexdigest()
463def _sqlite_sha512(text):
464 if text is None:
465 return None
466 return sha512(text.encode()).hexdigest()
469def _sqlite_sign(x):
470 if x is None:
471 return None
472 return (x > 0) - (x < 0)
475def _sqlite_sin(x):
476 if x is None:
477 return None
478 return sin(x)
481def _sqlite_sqrt(x):
482 if x is None:
483 return None
484 return sqrt(x)
487def _sqlite_tan(x):
488 if x is None:
489 return None
490 return tan(x)
493class ListAggregate(list):
494 step = list.append
497class StdDevPop(ListAggregate):
498 finalize = statistics.pstdev
501class StdDevSamp(ListAggregate):
502 finalize = statistics.stdev
505class VarPop(ListAggregate):
506 finalize = statistics.pvariance
509class VarSamp(ListAggregate):
510 finalize = statistics.variance
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2SQLite backend for the sqlite3 module in the standard library.
3"""
5import datetime
6import decimal
7import warnings
8from collections.abc import Mapping
9from itertools import chain, tee
10from sqlite3 import dbapi2 as Database
12from plain.exceptions import ImproperlyConfigured
13from plain.models.backends.base.base import BaseDatabaseWrapper
14from plain.models.db import IntegrityError
15from plain.utils.dateparse import parse_date, parse_datetime, parse_time
16from plain.utils.regex_helper import _lazy_re_compile
18from ._functions import register as register_functions
19from .client import DatabaseClient
20from .creation import DatabaseCreation
21from .features import DatabaseFeatures
22from .introspection import DatabaseIntrospection
23from .operations import DatabaseOperations
24from .schema import DatabaseSchemaEditor
27def decoder(conv_func):
28 """
29 Convert bytestrings from Python's sqlite3 interface to a regular string.
30 """
31 return lambda s: conv_func(s.decode())
34def adapt_date(val):
35 return val.isoformat()
38def adapt_datetime(val):
39 return val.isoformat(" ")
42Database.register_converter("bool", b"1".__eq__)
43Database.register_converter("date", decoder(parse_date))
44Database.register_converter("time", decoder(parse_time))
45Database.register_converter("datetime", decoder(parse_datetime))
46Database.register_converter("timestamp", decoder(parse_datetime))
48Database.register_adapter(decimal.Decimal, str)
49Database.register_adapter(datetime.date, adapt_date)
50Database.register_adapter(datetime.datetime, adapt_datetime)
53class DatabaseWrapper(BaseDatabaseWrapper):
54 vendor = "sqlite"
55 display_name = "SQLite"
56 # SQLite doesn't actually support most of these types, but it "does the right
57 # thing" given more verbose field definitions, so leave them as is so that
58 # schema inspection is more useful.
59 data_types = {
60 "AutoField": "integer",
61 "BigAutoField": "integer",
62 "BinaryField": "BLOB",
63 "BooleanField": "bool",
64 "CharField": "varchar(%(max_length)s)",
65 "DateField": "date",
66 "DateTimeField": "datetime",
67 "DecimalField": "decimal",
68 "DurationField": "bigint",
69 "FloatField": "real",
70 "IntegerField": "integer",
71 "BigIntegerField": "bigint",
72 "IPAddressField": "char(15)",
73 "GenericIPAddressField": "char(39)",
74 "JSONField": "text",
75 "OneToOneField": "integer",
76 "PositiveBigIntegerField": "bigint unsigned",
77 "PositiveIntegerField": "integer unsigned",
78 "PositiveSmallIntegerField": "smallint unsigned",
79 "SlugField": "varchar(%(max_length)s)",
80 "SmallAutoField": "integer",
81 "SmallIntegerField": "smallint",
82 "TextField": "text",
83 "TimeField": "time",
84 "UUIDField": "char(32)",
85 }
86 data_type_check_constraints = {
87 "PositiveBigIntegerField": '"%(column)s" >= 0',
88 "JSONField": '(JSON_VALID("%(column)s") OR "%(column)s" IS NULL)',
89 "PositiveIntegerField": '"%(column)s" >= 0',
90 "PositiveSmallIntegerField": '"%(column)s" >= 0',
91 }
92 data_types_suffix = {
93 "AutoField": "AUTOINCREMENT",
94 "BigAutoField": "AUTOINCREMENT",
95 "SmallAutoField": "AUTOINCREMENT",
96 }
97 # SQLite requires LIKE statements to include an ESCAPE clause if the value
98 # being escaped has a percent or underscore in it.
99 # See https://www.sqlite.org/lang_expr.html for an explanation.
100 operators = {
101 "exact": "= %s",
102 "iexact": "LIKE %s ESCAPE '\\'",
103 "contains": "LIKE %s ESCAPE '\\'",
104 "icontains": "LIKE %s ESCAPE '\\'",
105 "regex": "REGEXP %s",
106 "iregex": "REGEXP '(?i)' || %s",
107 "gt": "> %s",
108 "gte": ">= %s",
109 "lt": "< %s",
110 "lte": "<= %s",
111 "startswith": "LIKE %s ESCAPE '\\'",
112 "endswith": "LIKE %s ESCAPE '\\'",
113 "istartswith": "LIKE %s ESCAPE '\\'",
114 "iendswith": "LIKE %s ESCAPE '\\'",
115 }
117 # The patterns below are used to generate SQL pattern lookup clauses when
118 # the right-hand side of the lookup isn't a raw string (it might be an expression
119 # or the result of a bilateral transformation).
120 # In those cases, special characters for LIKE operators (e.g. \, *, _) should be
121 # escaped on database side.
122 #
123 # Note: we use str.format() here for readability as '%' is used as a wildcard for
124 # the LIKE operator.
125 pattern_esc = r"REPLACE(REPLACE(REPLACE({}, '\', '\\'), '%%', '\%%'), '_', '\_')"
126 pattern_ops = {
127 "contains": r"LIKE '%%' || {} || '%%' ESCAPE '\'",
128 "icontains": r"LIKE '%%' || UPPER({}) || '%%' ESCAPE '\'",
129 "startswith": r"LIKE {} || '%%' ESCAPE '\'",
130 "istartswith": r"LIKE UPPER({}) || '%%' ESCAPE '\'",
131 "endswith": r"LIKE '%%' || {} ESCAPE '\'",
132 "iendswith": r"LIKE '%%' || UPPER({}) ESCAPE '\'",
133 }
135 Database = Database
136 SchemaEditorClass = DatabaseSchemaEditor
137 # Classes instantiated in __init__().
138 client_class = DatabaseClient
139 creation_class = DatabaseCreation
140 features_class = DatabaseFeatures
141 introspection_class = DatabaseIntrospection
142 ops_class = DatabaseOperations
144 def get_connection_params(self):
145 settings_dict = self.settings_dict
146 if not settings_dict["NAME"]:
147 raise ImproperlyConfigured(
148 "settings.DATABASES is improperly configured. "
149 "Please supply the NAME value."
150 )
151 kwargs = {
152 "database": settings_dict["NAME"],
153 "detect_types": Database.PARSE_DECLTYPES | Database.PARSE_COLNAMES,
154 **settings_dict["OPTIONS"],
155 }
156 # Always allow the underlying SQLite connection to be shareable
157 # between multiple threads. The safe-guarding will be handled at a
158 # higher level by the `BaseDatabaseWrapper.allow_thread_sharing`
159 # property. This is necessary as the shareability is disabled by
160 # default in sqlite3 and it cannot be changed once a connection is
161 # opened.
162 if "check_same_thread" in kwargs and kwargs["check_same_thread"]:
163 warnings.warn(
164 "The `check_same_thread` option was provided and set to "
165 "True. It will be overridden with False. Use the "
166 "`DatabaseWrapper.allow_thread_sharing` property instead "
167 "for controlling thread shareability.",
168 RuntimeWarning,
169 )
170 kwargs.update({"check_same_thread": False, "uri": True})
171 return kwargs
173 def get_database_version(self):
174 return self.Database.sqlite_version_info
176 def get_new_connection(self, conn_params):
177 conn = Database.connect(**conn_params)
178 register_functions(conn)
180 conn.execute("PRAGMA foreign_keys = ON")
181 # The macOS bundled SQLite defaults legacy_alter_table ON, which
182 # prevents atomic table renames (feature supports_atomic_references_rename)
183 conn.execute("PRAGMA legacy_alter_table = OFF")
184 return conn
186 def create_cursor(self, name=None):
187 return self.connection.cursor(factory=SQLiteCursorWrapper)
189 def close(self):
190 self.validate_thread_sharing()
191 # If database is in memory, closing the connection destroys the
192 # database. To prevent accidental data loss, ignore close requests on
193 # an in-memory db.
194 if not self.is_in_memory_db():
195 BaseDatabaseWrapper.close(self)
197 def _savepoint_allowed(self):
198 # When 'isolation_level' is not None, sqlite3 commits before each
199 # savepoint; it's a bug. When it is None, savepoints don't make sense
200 # because autocommit is enabled. The only exception is inside 'atomic'
201 # blocks. To work around that bug, on SQLite, 'atomic' starts a
202 # transaction explicitly rather than simply disable autocommit.
203 return self.in_atomic_block
205 def _set_autocommit(self, autocommit):
206 if autocommit:
207 level = None
208 else:
209 # sqlite3's internal default is ''. It's different from None.
210 # See Modules/_sqlite/connection.c.
211 level = ""
212 # 'isolation_level' is a misleading API.
213 # SQLite always runs at the SERIALIZABLE isolation level.
214 with self.wrap_database_errors:
215 self.connection.isolation_level = level
217 def disable_constraint_checking(self):
218 with self.cursor() as cursor:
219 cursor.execute("PRAGMA foreign_keys = OFF")
220 # Foreign key constraints cannot be turned off while in a multi-
221 # statement transaction. Fetch the current state of the pragma
222 # to determine if constraints are effectively disabled.
223 enabled = cursor.execute("PRAGMA foreign_keys").fetchone()[0]
224 return not bool(enabled)
226 def enable_constraint_checking(self):
227 with self.cursor() as cursor:
228 cursor.execute("PRAGMA foreign_keys = ON")
230 def check_constraints(self, table_names=None):
231 """
232 Check each table name in `table_names` for rows with invalid foreign
233 key references. This method is intended to be used in conjunction with
234 `disable_constraint_checking()` and `enable_constraint_checking()`, to
235 determine if rows with invalid references were entered while constraint
236 checks were off.
237 """
238 with self.cursor() as cursor:
239 if table_names is None:
240 violations = cursor.execute("PRAGMA foreign_key_check").fetchall()
241 else:
242 violations = chain.from_iterable(
243 cursor.execute(
244 f"PRAGMA foreign_key_check({self.ops.quote_name(table_name)})"
245 ).fetchall()
246 for table_name in table_names
247 )
248 # See https://www.sqlite.org/pragma.html#pragma_foreign_key_check
249 for (
250 table_name,
251 rowid,
252 referenced_table_name,
253 foreign_key_index,
254 ) in violations:
255 foreign_key = cursor.execute(
256 f"PRAGMA foreign_key_list({self.ops.quote_name(table_name)})"
257 ).fetchall()[foreign_key_index]
258 column_name, referenced_column_name = foreign_key[3:5]
259 primary_key_column_name = self.introspection.get_primary_key_column(
260 cursor, table_name
261 )
262 primary_key_value, bad_value = cursor.execute(
263 f"SELECT {self.ops.quote_name(primary_key_column_name)}, {self.ops.quote_name(column_name)} FROM {self.ops.quote_name(table_name)} WHERE rowid = %s",
264 (rowid,),
265 ).fetchone()
266 raise IntegrityError(
267 f"The row in table '{table_name}' with primary key '{primary_key_value}' has an "
268 f"invalid foreign key: {table_name}.{column_name} contains a value '{bad_value}' that "
269 f"does not have a corresponding value in {referenced_table_name}.{referenced_column_name}."
270 )
272 def is_usable(self):
273 return True
275 def _start_transaction_under_autocommit(self):
276 """
277 Start a transaction explicitly in autocommit mode.
279 Staying in autocommit mode works around a bug of sqlite3 that breaks
280 savepoints when autocommit is disabled.
281 """
282 self.cursor().execute("BEGIN")
284 def is_in_memory_db(self):
285 return self.creation.is_in_memory_db(self.settings_dict["NAME"])
288FORMAT_QMARK_REGEX = _lazy_re_compile(r"(?<!%)%s")
291class SQLiteCursorWrapper(Database.Cursor):
292 """
293 Plain uses the "format" and "pyformat" styles, but Python's sqlite3 module
294 supports neither of these styles.
296 This wrapper performs the following conversions:
298 - "format" style to "qmark" style
299 - "pyformat" style to "named" style
301 In both cases, if you want to use a literal "%s", you'll need to use "%%s".
302 """
304 def execute(self, query, params=None):
305 if params is None:
306 return super().execute(query)
307 # Extract names if params is a mapping, i.e. "pyformat" style is used.
308 param_names = list(params) if isinstance(params, Mapping) else None
309 query = self.convert_query(query, param_names=param_names)
310 return super().execute(query, params)
312 def executemany(self, query, param_list):
313 # Extract names if params is a mapping, i.e. "pyformat" style is used.
314 # Peek carefully as a generator can be passed instead of a list/tuple.
315 peekable, param_list = tee(iter(param_list))
316 if (params := next(peekable, None)) and isinstance(params, Mapping):
317 param_names = list(params)
318 else:
319 param_names = None
320 query = self.convert_query(query, param_names=param_names)
321 return super().executemany(query, param_list)
323 def convert_query(self, query, *, param_names=None):
324 if param_names is None:
325 # Convert from "format" style to "qmark" style.
326 return FORMAT_QMARK_REGEX.sub("?", query).replace("%%", "%")
327 else:
328 # Convert from "pyformat" style to "named" style.
329 return query % {name: f":{name}" for name in param_names}
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.models.backends.base.client import BaseDatabaseClient
4class DatabaseClient(BaseDatabaseClient):
5 executable_name = "sqlite3"
7 @classmethod
8 def settings_to_cmd_args_env(cls, settings_dict, parameters):
9 args = [cls.executable_name, settings_dict["NAME"], *parameters]
10 return args, None
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import multiprocessing
2import os
3import shutil
4import sqlite3
5import sys
6from pathlib import Path
8from plain.models.backends.base.creation import BaseDatabaseCreation
9from plain.models.db import NotSupportedError
12class DatabaseCreation(BaseDatabaseCreation):
13 @staticmethod
14 def is_in_memory_db(database_name):
15 return not isinstance(database_name, Path) and (
16 database_name == ":memory:" or "mode=memory" in database_name
17 )
19 def _get_test_db_name(self):
20 test_database_name = self.connection.settings_dict["TEST"]["NAME"] or ":memory:"
21 if test_database_name == ":memory:":
22 return f"file:memorydb_{self.connection.alias}?mode=memory&cache=shared"
23 return test_database_name
25 def _create_test_db(self, verbosity, autoclobber, keepdb=False):
26 test_database_name = self._get_test_db_name()
28 if keepdb:
29 return test_database_name
30 if not self.is_in_memory_db(test_database_name):
31 # Erase the old test database
32 if verbosity >= 1:
33 self.log(
34 f"Destroying old test database for alias {self._get_database_display_str(verbosity, test_database_name)}..."
35 )
36 if os.access(test_database_name, os.F_OK):
37 if not autoclobber:
38 confirm = input(
39 "Type 'yes' if you would like to try deleting the test "
40 f"database '{test_database_name}', or 'no' to cancel: "
41 )
42 if autoclobber or confirm == "yes":
43 try:
44 os.remove(test_database_name)
45 except Exception as e:
46 self.log(f"Got an error deleting the old test database: {e}")
47 sys.exit(2)
48 else:
49 self.log("Tests cancelled.")
50 sys.exit(1)
51 return test_database_name
53 def get_test_db_clone_settings(self, suffix):
54 orig_settings_dict = self.connection.settings_dict
55 source_database_name = orig_settings_dict["NAME"]
57 if not self.is_in_memory_db(source_database_name):
58 root, ext = os.path.splitext(source_database_name)
59 return {**orig_settings_dict, "NAME": f"{root}_{suffix}{ext}"}
61 start_method = multiprocessing.get_start_method()
62 if start_method == "fork":
63 return orig_settings_dict
64 if start_method == "spawn":
65 return {
66 **orig_settings_dict,
67 "NAME": f"{self.connection.alias}_{suffix}.sqlite3",
68 }
69 raise NotSupportedError(
70 f"Cloning with start method {start_method!r} is not supported."
71 )
73 def _clone_test_db(self, suffix, verbosity, keepdb=False):
74 source_database_name = self.connection.settings_dict["NAME"]
75 target_database_name = self.get_test_db_clone_settings(suffix)["NAME"]
76 if not self.is_in_memory_db(source_database_name):
77 # Erase the old test database
78 if os.access(target_database_name, os.F_OK):
79 if keepdb:
80 return
81 if verbosity >= 1:
82 self.log(
83 "Destroying old test database for alias {}...".format(
84 self._get_database_display_str(
85 verbosity, target_database_name
86 ),
87 )
88 )
89 try:
90 os.remove(target_database_name)
91 except Exception as e:
92 self.log(f"Got an error deleting the old test database: {e}")
93 sys.exit(2)
94 try:
95 shutil.copy(source_database_name, target_database_name)
96 except Exception as e:
97 self.log(f"Got an error cloning the test database: {e}")
98 sys.exit(2)
99 # Forking automatically makes a copy of an in-memory database.
100 # Spawn requires migrating to disk which will be re-opened in
101 # setup_worker_connection.
102 elif multiprocessing.get_start_method() == "spawn":
103 ondisk_db = sqlite3.connect(target_database_name, uri=True)
104 self.connection.connection.backup(ondisk_db)
105 ondisk_db.close()
107 def _destroy_test_db(self, test_database_name, verbosity):
108 if test_database_name and not self.is_in_memory_db(test_database_name):
109 # Remove the SQLite database file
110 os.remove(test_database_name)
112 def test_db_signature(self):
113 """
114 Return a tuple that uniquely identifies a test database.
116 This takes into account the special cases of ":memory:" and "" for
117 SQLite since the databases will be distinct despite having the same
118 TEST NAME. See https://www.sqlite.org/inmemorydb.html
119 """
120 test_database_name = self._get_test_db_name()
121 sig = [self.connection.settings_dict["NAME"]]
122 if self.is_in_memory_db(test_database_name):
123 sig.append(self.connection.alias)
124 else:
125 sig.append(test_database_name)
126 return tuple(sig)
128 def setup_worker_connection(self, _worker_id):
129 settings_dict = self.get_test_db_clone_settings(_worker_id)
130 # connection.settings_dict must be updated in place for changes to be
131 # reflected in plain.models.connections. Otherwise new threads would
132 # connect to the default database instead of the appropriate clone.
133 start_method = multiprocessing.get_start_method()
134 if start_method == "fork":
135 # Update settings_dict in place.
136 self.connection.settings_dict.update(settings_dict)
137 self.connection.close()
138 elif start_method == "spawn":
139 alias = self.connection.alias
140 connection_str = (
141 f"file:memorydb_{alias}_{_worker_id}?mode=memory&cache=shared"
142 )
143 source_db = self.connection.Database.connect(
144 f"file:{alias}_{_worker_id}.sqlite3", uri=True
145 )
146 target_db = sqlite3.connect(connection_str, uri=True)
147 source_db.backup(target_db)
148 source_db.close()
149 # Update settings_dict in place.
150 self.connection.settings_dict.update(settings_dict)
151 self.connection.settings_dict["NAME"] = connection_str
152 # Re-open connection to in-memory database before closing copy
153 # connection.
154 self.connection.connect()
155 target_db.close()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import operator
3from plain.models import transaction
4from plain.models.backends.base.features import BaseDatabaseFeatures
5from plain.models.db import OperationalError
6from plain.utils.functional import cached_property
8from .base import Database
11class DatabaseFeatures(BaseDatabaseFeatures):
12 minimum_database_version = (3, 21)
13 test_db_allows_multiple_connections = False
14 supports_unspecified_pk = True
15 supports_timezones = False
16 max_query_params = 999
17 supports_transactions = True
18 atomic_transactions = False
19 can_rollback_ddl = True
20 can_create_inline_fk = False
21 requires_literal_defaults = True
22 can_clone_databases = True
23 supports_temporal_subtraction = True
24 ignores_table_name_case = True
25 supports_cast_with_precision = False
26 time_cast_precision = 3
27 can_release_savepoints = True
28 has_case_insensitive_like = True
29 # Is "ALTER TABLE ... RENAME COLUMN" supported?
30 can_alter_table_rename_column = Database.sqlite_version_info >= (3, 25, 0)
31 # Is "ALTER TABLE ... DROP COLUMN" supported?
32 can_alter_table_drop_column = Database.sqlite_version_info >= (3, 35, 5)
33 supports_parentheses_in_compound = False
34 can_defer_constraint_checks = True
35 supports_over_clause = Database.sqlite_version_info >= (3, 25, 0)
36 supports_frame_range_fixed_distance = Database.sqlite_version_info >= (3, 28, 0)
37 supports_aggregate_filter_clause = Database.sqlite_version_info >= (3, 30, 1)
38 supports_order_by_nulls_modifier = Database.sqlite_version_info >= (3, 30, 0)
39 # NULLS LAST/FIRST emulation on < 3.30 requires subquery wrapping.
40 requires_compound_order_by_subquery = Database.sqlite_version_info < (3, 30)
41 order_by_nulls_first = True
42 supports_json_field_contains = False
43 supports_update_conflicts = Database.sqlite_version_info >= (3, 24, 0)
44 supports_update_conflicts_with_target = supports_update_conflicts
45 test_collations = {
46 "ci": "nocase",
47 "cs": "binary",
48 "non_default": "nocase",
49 }
50 create_test_table_with_composite_primary_key = """
51 CREATE TABLE test_table_composite_pk (
52 column_1 INTEGER NOT NULL,
53 column_2 INTEGER NOT NULL,
54 PRIMARY KEY(column_1, column_2)
55 )
56 """
58 @cached_property
59 def supports_atomic_references_rename(self):
60 return Database.sqlite_version_info >= (3, 26, 0)
62 @cached_property
63 def introspected_field_types(self):
64 return {
65 **super().introspected_field_types,
66 "BigAutoField": "AutoField",
67 "DurationField": "BigIntegerField",
68 "GenericIPAddressField": "CharField",
69 "SmallAutoField": "AutoField",
70 }
72 @cached_property
73 def supports_json_field(self):
74 with self.connection.cursor() as cursor:
75 try:
76 with transaction.atomic(self.connection.alias):
77 cursor.execute('SELECT JSON(\'{"a": "b"}\')')
78 except OperationalError:
79 return False
80 return True
82 can_introspect_json_field = property(operator.attrgetter("supports_json_field"))
83 has_json_object_function = property(operator.attrgetter("supports_json_field"))
85 @cached_property
86 def can_return_columns_from_insert(self):
87 return Database.sqlite_version_info >= (3, 35)
89 can_return_rows_from_bulk_insert = property(
90 operator.attrgetter("can_return_columns_from_insert")
91 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from collections import namedtuple
3import sqlparse
5from plain.models import Index
6from plain.models.backends.base.introspection import (
7 BaseDatabaseIntrospection,
8 TableInfo,
9)
10from plain.models.backends.base.introspection import FieldInfo as BaseFieldInfo
11from plain.models.db import DatabaseError
12from plain.utils.regex_helper import _lazy_re_compile
14FieldInfo = namedtuple(
15 "FieldInfo", BaseFieldInfo._fields + ("pk", "has_json_constraint")
16)
18field_size_re = _lazy_re_compile(r"^\s*(?:var)?char\s*\(\s*(\d+)\s*\)\s*$")
21def get_field_size(name):
22 """Extract the size number from a "varchar(11)" type name"""
23 m = field_size_re.search(name)
24 return int(m[1]) if m else None
27# This light wrapper "fakes" a dictionary interface, because some SQLite data
28# types include variables in them -- e.g. "varchar(30)" -- and can't be matched
29# as a simple dictionary lookup.
30class FlexibleFieldLookupDict:
31 # Maps SQL types to Plain Field types. Some of the SQL types have multiple
32 # entries here because SQLite allows for anything and doesn't normalize the
33 # field type; it uses whatever was given.
34 base_data_types_reverse = {
35 "bool": "BooleanField",
36 "boolean": "BooleanField",
37 "smallint": "SmallIntegerField",
38 "smallint unsigned": "PositiveSmallIntegerField",
39 "smallinteger": "SmallIntegerField",
40 "int": "IntegerField",
41 "integer": "IntegerField",
42 "bigint": "BigIntegerField",
43 "integer unsigned": "PositiveIntegerField",
44 "bigint unsigned": "PositiveBigIntegerField",
45 "decimal": "DecimalField",
46 "real": "FloatField",
47 "text": "TextField",
48 "char": "CharField",
49 "varchar": "CharField",
50 "blob": "BinaryField",
51 "date": "DateField",
52 "datetime": "DateTimeField",
53 "time": "TimeField",
54 }
56 def __getitem__(self, key):
57 key = key.lower().split("(", 1)[0].strip()
58 return self.base_data_types_reverse[key]
61class DatabaseIntrospection(BaseDatabaseIntrospection):
62 data_types_reverse = FlexibleFieldLookupDict()
64 def get_field_type(self, data_type, description):
65 field_type = super().get_field_type(data_type, description)
66 if description.pk and field_type in {
67 "BigIntegerField",
68 "IntegerField",
69 "SmallIntegerField",
70 }:
71 # No support for BigAutoField or SmallAutoField as SQLite treats
72 # all integer primary keys as signed 64-bit integers.
73 return "AutoField"
74 if description.has_json_constraint:
75 return "JSONField"
76 return field_type
78 def get_table_list(self, cursor):
79 """Return a list of table and view names in the current database."""
80 # Skip the sqlite_sequence system table used for autoincrement key
81 # generation.
82 cursor.execute(
83 """
84 SELECT name, type FROM sqlite_master
85 WHERE type in ('table', 'view') AND NOT name='sqlite_sequence'
86 ORDER BY name"""
87 )
88 return [TableInfo(row[0], row[1][0]) for row in cursor.fetchall()]
90 def get_table_description(self, cursor, table_name):
91 """
92 Return a description of the table with the DB-API cursor.description
93 interface.
94 """
95 cursor.execute(
96 f"PRAGMA table_info({self.connection.ops.quote_name(table_name)})"
97 )
98 table_info = cursor.fetchall()
99 if not table_info:
100 raise DatabaseError(f"Table {table_name} does not exist (empty pragma).")
101 collations = self._get_column_collations(cursor, table_name)
102 json_columns = set()
103 if self.connection.features.can_introspect_json_field:
104 for line in table_info:
105 column = line[1]
106 json_constraint_sql = f'%json_valid("{column}")%'
107 has_json_constraint = cursor.execute(
108 """
109 SELECT sql
110 FROM sqlite_master
111 WHERE
112 type = 'table' AND
113 name = %s AND
114 sql LIKE %s
115 """,
116 [table_name, json_constraint_sql],
117 ).fetchone()
118 if has_json_constraint:
119 json_columns.add(column)
120 return [
121 FieldInfo(
122 name,
123 data_type,
124 get_field_size(data_type),
125 None,
126 None,
127 None,
128 not notnull,
129 default,
130 collations.get(name),
131 pk == 1,
132 name in json_columns,
133 )
134 for cid, name, data_type, notnull, default, pk in table_info
135 ]
137 def get_sequences(self, cursor, table_name, table_fields=()):
138 pk_col = self.get_primary_key_column(cursor, table_name)
139 return [{"table": table_name, "column": pk_col}]
141 def get_relations(self, cursor, table_name):
142 """
143 Return a dictionary of {column_name: (ref_column_name, ref_table_name)}
144 representing all foreign keys in the given table.
145 """
146 cursor.execute(
147 f"PRAGMA foreign_key_list({self.connection.ops.quote_name(table_name)})"
148 )
149 return {
150 column_name: (ref_column_name, ref_table_name)
151 for (
152 _,
153 _,
154 ref_table_name,
155 column_name,
156 ref_column_name,
157 *_,
158 ) in cursor.fetchall()
159 }
161 def get_primary_key_columns(self, cursor, table_name):
162 cursor.execute(
163 f"PRAGMA table_info({self.connection.ops.quote_name(table_name)})"
164 )
165 return [name for _, name, *_, pk in cursor.fetchall() if pk]
167 def _parse_column_or_constraint_definition(self, tokens, columns):
168 token = None
169 is_constraint_definition = None
170 field_name = None
171 constraint_name = None
172 unique = False
173 unique_columns = []
174 check = False
175 check_columns = []
176 braces_deep = 0
177 for token in tokens:
178 if token.match(sqlparse.tokens.Punctuation, "("):
179 braces_deep += 1
180 elif token.match(sqlparse.tokens.Punctuation, ")"):
181 braces_deep -= 1
182 if braces_deep < 0:
183 # End of columns and constraints for table definition.
184 break
185 elif braces_deep == 0 and token.match(sqlparse.tokens.Punctuation, ","):
186 # End of current column or constraint definition.
187 break
188 # Detect column or constraint definition by first token.
189 if is_constraint_definition is None:
190 is_constraint_definition = token.match(
191 sqlparse.tokens.Keyword, "CONSTRAINT"
192 )
193 if is_constraint_definition:
194 continue
195 if is_constraint_definition:
196 # Detect constraint name by second token.
197 if constraint_name is None:
198 if token.ttype in (sqlparse.tokens.Name, sqlparse.tokens.Keyword):
199 constraint_name = token.value
200 elif token.ttype == sqlparse.tokens.Literal.String.Symbol:
201 constraint_name = token.value[1:-1]
202 # Start constraint columns parsing after UNIQUE keyword.
203 if token.match(sqlparse.tokens.Keyword, "UNIQUE"):
204 unique = True
205 unique_braces_deep = braces_deep
206 elif unique:
207 if unique_braces_deep == braces_deep:
208 if unique_columns:
209 # Stop constraint parsing.
210 unique = False
211 continue
212 if token.ttype in (sqlparse.tokens.Name, sqlparse.tokens.Keyword):
213 unique_columns.append(token.value)
214 elif token.ttype == sqlparse.tokens.Literal.String.Symbol:
215 unique_columns.append(token.value[1:-1])
216 else:
217 # Detect field name by first token.
218 if field_name is None:
219 if token.ttype in (sqlparse.tokens.Name, sqlparse.tokens.Keyword):
220 field_name = token.value
221 elif token.ttype == sqlparse.tokens.Literal.String.Symbol:
222 field_name = token.value[1:-1]
223 if token.match(sqlparse.tokens.Keyword, "UNIQUE"):
224 unique_columns = [field_name]
225 # Start constraint columns parsing after CHECK keyword.
226 if token.match(sqlparse.tokens.Keyword, "CHECK"):
227 check = True
228 check_braces_deep = braces_deep
229 elif check:
230 if check_braces_deep == braces_deep:
231 if check_columns:
232 # Stop constraint parsing.
233 check = False
234 continue
235 if token.ttype in (sqlparse.tokens.Name, sqlparse.tokens.Keyword):
236 if token.value in columns:
237 check_columns.append(token.value)
238 elif token.ttype == sqlparse.tokens.Literal.String.Symbol:
239 if token.value[1:-1] in columns:
240 check_columns.append(token.value[1:-1])
241 unique_constraint = (
242 {
243 "unique": True,
244 "columns": unique_columns,
245 "primary_key": False,
246 "foreign_key": None,
247 "check": False,
248 "index": False,
249 }
250 if unique_columns
251 else None
252 )
253 check_constraint = (
254 {
255 "check": True,
256 "columns": check_columns,
257 "primary_key": False,
258 "unique": False,
259 "foreign_key": None,
260 "index": False,
261 }
262 if check_columns
263 else None
264 )
265 return constraint_name, unique_constraint, check_constraint, token
267 def _parse_table_constraints(self, sql, columns):
268 # Check constraint parsing is based of SQLite syntax diagram.
269 # https://www.sqlite.org/syntaxdiagrams.html#table-constraint
270 statement = sqlparse.parse(sql)[0]
271 constraints = {}
272 unnamed_constrains_index = 0
273 tokens = (token for token in statement.flatten() if not token.is_whitespace)
274 # Go to columns and constraint definition
275 for token in tokens:
276 if token.match(sqlparse.tokens.Punctuation, "("):
277 break
278 # Parse columns and constraint definition
279 while True:
280 (
281 constraint_name,
282 unique,
283 check,
284 end_token,
285 ) = self._parse_column_or_constraint_definition(tokens, columns)
286 if unique:
287 if constraint_name:
288 constraints[constraint_name] = unique
289 else:
290 unnamed_constrains_index += 1
291 constraints[
292 f"__unnamed_constraint_{unnamed_constrains_index}__"
293 ] = unique
294 if check:
295 if constraint_name:
296 constraints[constraint_name] = check
297 else:
298 unnamed_constrains_index += 1
299 constraints[
300 f"__unnamed_constraint_{unnamed_constrains_index}__"
301 ] = check
302 if end_token.match(sqlparse.tokens.Punctuation, ")"):
303 break
304 return constraints
306 def get_constraints(self, cursor, table_name):
307 """
308 Retrieve any constraints or keys (unique, pk, fk, check, index) across
309 one or more columns.
310 """
311 constraints = {}
312 # Find inline check constraints.
313 try:
314 table_schema = cursor.execute(
315 f"SELECT sql FROM sqlite_master WHERE type='table' and name={self.connection.ops.quote_name(table_name)}"
316 ).fetchone()[0]
317 except TypeError:
318 # table_name is a view.
319 pass
320 else:
321 columns = {
322 info.name for info in self.get_table_description(cursor, table_name)
323 }
324 constraints.update(self._parse_table_constraints(table_schema, columns))
326 # Get the index info
327 cursor.execute(
328 f"PRAGMA index_list({self.connection.ops.quote_name(table_name)})"
329 )
330 for row in cursor.fetchall():
331 # SQLite 3.8.9+ has 5 columns, however older versions only give 3
332 # columns. Discard last 2 columns if there.
333 number, index, unique = row[:3]
334 cursor.execute(
335 "SELECT sql FROM sqlite_master "
336 f"WHERE type='index' AND name={self.connection.ops.quote_name(index)}"
337 )
338 # There's at most one row.
339 (sql,) = cursor.fetchone() or (None,)
340 # Inline constraints are already detected in
341 # _parse_table_constraints(). The reasons to avoid fetching inline
342 # constraints from `PRAGMA index_list` are:
343 # - Inline constraints can have a different name and information
344 # than what `PRAGMA index_list` gives.
345 # - Not all inline constraints may appear in `PRAGMA index_list`.
346 if not sql:
347 # An inline constraint
348 continue
349 # Get the index info for that index
350 cursor.execute(
351 f"PRAGMA index_info({self.connection.ops.quote_name(index)})"
352 )
353 for index_rank, column_rank, column in cursor.fetchall():
354 if index not in constraints:
355 constraints[index] = {
356 "columns": [],
357 "primary_key": False,
358 "unique": bool(unique),
359 "foreign_key": None,
360 "check": False,
361 "index": True,
362 }
363 constraints[index]["columns"].append(column)
364 # Add type and column orders for indexes
365 if constraints[index]["index"]:
366 # SQLite doesn't support any index type other than b-tree
367 constraints[index]["type"] = Index.suffix
368 orders = self._get_index_columns_orders(sql)
369 if orders is not None:
370 constraints[index]["orders"] = orders
371 # Get the PK
372 pk_columns = self.get_primary_key_columns(cursor, table_name)
373 if pk_columns:
374 # SQLite doesn't actually give a name to the PK constraint,
375 # so we invent one. This is fine, as the SQLite backend never
376 # deletes PK constraints by name, as you can't delete constraints
377 # in SQLite; we remake the table with a new PK instead.
378 constraints["__primary__"] = {
379 "columns": pk_columns,
380 "primary_key": True,
381 "unique": False, # It's not actually a unique constraint.
382 "foreign_key": None,
383 "check": False,
384 "index": False,
385 }
386 relations = enumerate(self.get_relations(cursor, table_name).items())
387 constraints.update(
388 {
389 f"fk_{index}": {
390 "columns": [column_name],
391 "primary_key": False,
392 "unique": False,
393 "foreign_key": (ref_table_name, ref_column_name),
394 "check": False,
395 "index": False,
396 }
397 for index, (column_name, (ref_column_name, ref_table_name)) in relations
398 }
399 )
400 return constraints
402 def _get_index_columns_orders(self, sql):
403 tokens = sqlparse.parse(sql)[0]
404 for token in tokens:
405 if isinstance(token, sqlparse.sql.Parenthesis):
406 columns = str(token).strip("()").split(", ")
407 return ["DESC" if info.endswith("DESC") else "ASC" for info in columns]
408 return None
410 def _get_column_collations(self, cursor, table_name):
411 row = cursor.execute(
412 """
413 SELECT sql
414 FROM sqlite_master
415 WHERE type = 'table' AND name = %s
416 """,
417 [table_name],
418 ).fetchone()
419 if not row:
420 return {}
422 sql = row[0]
423 columns = str(sqlparse.parse(sql)[0][-1]).strip("()").split(", ")
424 collations = {}
425 for column in columns:
426 tokens = column[1:].split()
427 column_name = tokens[0].strip('"')
428 for index, token in enumerate(tokens):
429 if token == "COLLATE":
430 collation = tokens[index + 1]
431 break
432 else:
433 collation = None
434 collations[column_name] = collation
435 return collations
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
2import decimal
3import uuid
4from functools import lru_cache
6from plain import models
7from plain.exceptions import FieldError
8from plain.models.backends.base.operations import BaseDatabaseOperations
9from plain.models.constants import OnConflict
10from plain.models.db import DatabaseError, NotSupportedError
11from plain.models.expressions import Col
12from plain.utils import timezone
13from plain.utils.dateparse import parse_date, parse_datetime, parse_time
14from plain.utils.functional import cached_property
17class DatabaseOperations(BaseDatabaseOperations):
18 cast_char_field_without_max_length = "text"
19 cast_data_types = {
20 "DateField": "TEXT",
21 "DateTimeField": "TEXT",
22 }
23 explain_prefix = "EXPLAIN QUERY PLAN"
24 # List of datatypes to that cannot be extracted with JSON_EXTRACT() on
25 # SQLite. Use JSON_TYPE() instead.
26 jsonfield_datatype_values = frozenset(["null", "false", "true"])
28 def bulk_batch_size(self, fields, objs):
29 """
30 SQLite has a compile-time default (SQLITE_LIMIT_VARIABLE_NUMBER) of
31 999 variables per query.
33 If there's only a single field to insert, the limit is 500
34 (SQLITE_MAX_COMPOUND_SELECT).
35 """
36 if len(fields) == 1:
37 return 500
38 elif len(fields) > 1:
39 return self.connection.features.max_query_params // len(fields)
40 else:
41 return len(objs)
43 def check_expression_support(self, expression):
44 bad_fields = (models.DateField, models.DateTimeField, models.TimeField)
45 bad_aggregates = (models.Sum, models.Avg, models.Variance, models.StdDev)
46 if isinstance(expression, bad_aggregates):
47 for expr in expression.get_source_expressions():
48 try:
49 output_field = expr.output_field
50 except (AttributeError, FieldError):
51 # Not every subexpression has an output_field which is fine
52 # to ignore.
53 pass
54 else:
55 if isinstance(output_field, bad_fields):
56 raise NotSupportedError(
57 "You cannot use Sum, Avg, StdDev, and Variance "
58 "aggregations on date/time fields in sqlite3 "
59 "since date/time is saved as text."
60 )
61 if (
62 isinstance(expression, models.Aggregate)
63 and expression.distinct
64 and len(expression.source_expressions) > 1
65 ):
66 raise NotSupportedError(
67 "SQLite doesn't support DISTINCT on aggregate functions "
68 "accepting multiple arguments."
69 )
71 def date_extract_sql(self, lookup_type, sql, params):
72 """
73 Support EXTRACT with a user-defined function plain_date_extract()
74 that's registered in connect(). Use single quotes because this is a
75 string and could otherwise cause a collision with a field name.
76 """
77 return f"plain_date_extract(%s, {sql})", (lookup_type.lower(), *params)
79 def fetch_returned_insert_rows(self, cursor):
80 """
81 Given a cursor object that has just performed an INSERT...RETURNING
82 statement into a table, return the list of returned data.
83 """
84 return cursor.fetchall()
86 def format_for_duration_arithmetic(self, sql):
87 """Do nothing since formatting is handled in the custom function."""
88 return sql
90 def date_trunc_sql(self, lookup_type, sql, params, tzname=None):
91 return f"plain_date_trunc(%s, {sql}, %s, %s)", (
92 lookup_type.lower(),
93 *params,
94 *self._convert_tznames_to_sql(tzname),
95 )
97 def time_trunc_sql(self, lookup_type, sql, params, tzname=None):
98 return f"plain_time_trunc(%s, {sql}, %s, %s)", (
99 lookup_type.lower(),
100 *params,
101 *self._convert_tznames_to_sql(tzname),
102 )
104 def _convert_tznames_to_sql(self, tzname):
105 if tzname:
106 return tzname, self.connection.timezone_name
107 return None, None
109 def datetime_cast_date_sql(self, sql, params, tzname):
110 return f"plain_datetime_cast_date({sql}, %s, %s)", (
111 *params,
112 *self._convert_tznames_to_sql(tzname),
113 )
115 def datetime_cast_time_sql(self, sql, params, tzname):
116 return f"plain_datetime_cast_time({sql}, %s, %s)", (
117 *params,
118 *self._convert_tznames_to_sql(tzname),
119 )
121 def datetime_extract_sql(self, lookup_type, sql, params, tzname):
122 return f"plain_datetime_extract(%s, {sql}, %s, %s)", (
123 lookup_type.lower(),
124 *params,
125 *self._convert_tznames_to_sql(tzname),
126 )
128 def datetime_trunc_sql(self, lookup_type, sql, params, tzname):
129 return f"plain_datetime_trunc(%s, {sql}, %s, %s)", (
130 lookup_type.lower(),
131 *params,
132 *self._convert_tznames_to_sql(tzname),
133 )
135 def time_extract_sql(self, lookup_type, sql, params):
136 return f"plain_time_extract(%s, {sql})", (lookup_type.lower(), *params)
138 def pk_default_value(self):
139 return "NULL"
141 def _quote_params_for_last_executed_query(self, params):
142 """
143 Only for last_executed_query! Don't use this to execute SQL queries!
144 """
145 # This function is limited both by SQLITE_LIMIT_VARIABLE_NUMBER (the
146 # number of parameters, default = 999) and SQLITE_MAX_COLUMN (the
147 # number of return values, default = 2000). Since Python's sqlite3
148 # module doesn't expose the get_limit() C API, assume the default
149 # limits are in effect and split the work in batches if needed.
150 BATCH_SIZE = 999
151 if len(params) > BATCH_SIZE:
152 results = ()
153 for index in range(0, len(params), BATCH_SIZE):
154 chunk = params[index : index + BATCH_SIZE]
155 results += self._quote_params_for_last_executed_query(chunk)
156 return results
158 sql = "SELECT " + ", ".join(["QUOTE(?)"] * len(params))
159 # Bypass Plain's wrappers and use the underlying sqlite3 connection
160 # to avoid logging this query - it would trigger infinite recursion.
161 cursor = self.connection.connection.cursor()
162 # Native sqlite3 cursors cannot be used as context managers.
163 try:
164 return cursor.execute(sql, params).fetchone()
165 finally:
166 cursor.close()
168 def last_executed_query(self, cursor, sql, params):
169 # Python substitutes parameters in Modules/_sqlite/cursor.c with:
170 # bind_parameters(state, self->statement, parameters);
171 # Unfortunately there is no way to reach self->statement from Python,
172 # so we quote and substitute parameters manually.
173 if params:
174 if isinstance(params, list | tuple):
175 params = self._quote_params_for_last_executed_query(params)
176 else:
177 values = tuple(params.values())
178 values = self._quote_params_for_last_executed_query(values)
179 params = dict(zip(params, values))
180 return sql % params
181 # For consistency with SQLiteCursorWrapper.execute(), just return sql
182 # when there are no parameters. See #13648 and #17158.
183 else:
184 return sql
186 def quote_name(self, name):
187 if name.startswith('"') and name.endswith('"'):
188 return name # Quoting once is enough.
189 return f'"{name}"'
191 def no_limit_value(self):
192 return -1
194 def __references_graph(self, table_name):
195 query = """
196 WITH tables AS (
197 SELECT %s name
198 UNION
199 SELECT sqlite_master.name
200 FROM sqlite_master
201 JOIN tables ON (sql REGEXP %s || tables.name || %s)
202 ) SELECT name FROM tables;
203 """
204 params = (
205 table_name,
206 r'(?i)\s+references\s+("|\')?',
207 r'("|\')?\s*\(',
208 )
209 with self.connection.cursor() as cursor:
210 results = cursor.execute(query, params)
211 return [row[0] for row in results.fetchall()]
213 @cached_property
214 def _references_graph(self):
215 # 512 is large enough to fit the ~330 tables (as of this writing) in
216 # Plain's test suite.
217 return lru_cache(maxsize=512)(self.__references_graph)
219 def sequence_reset_by_name_sql(self, style, sequences):
220 if not sequences:
221 return []
222 return [
223 "{} {} {} {} = 0 {} {} {} ({});".format(
224 style.SQL_KEYWORD("UPDATE"),
225 style.SQL_TABLE(self.quote_name("sqlite_sequence")),
226 style.SQL_KEYWORD("SET"),
227 style.SQL_FIELD(self.quote_name("seq")),
228 style.SQL_KEYWORD("WHERE"),
229 style.SQL_FIELD(self.quote_name("name")),
230 style.SQL_KEYWORD("IN"),
231 ", ".join(
232 [
233 "'{}'".format(sequence_info["table"])
234 for sequence_info in sequences
235 ]
236 ),
237 ),
238 ]
240 def adapt_datetimefield_value(self, value):
241 if value is None:
242 return None
244 # Expression values are adapted by the database.
245 if hasattr(value, "resolve_expression"):
246 return value
248 # SQLite doesn't support tz-aware datetimes
249 if timezone.is_aware(value):
250 value = timezone.make_naive(value, self.connection.timezone)
252 return str(value)
254 def adapt_timefield_value(self, value):
255 if value is None:
256 return None
258 # Expression values are adapted by the database.
259 if hasattr(value, "resolve_expression"):
260 return value
262 # SQLite doesn't support tz-aware datetimes
263 if timezone.is_aware(value):
264 raise ValueError("SQLite backend does not support timezone-aware times.")
266 return str(value)
268 def get_db_converters(self, expression):
269 converters = super().get_db_converters(expression)
270 internal_type = expression.output_field.get_internal_type()
271 if internal_type == "DateTimeField":
272 converters.append(self.convert_datetimefield_value)
273 elif internal_type == "DateField":
274 converters.append(self.convert_datefield_value)
275 elif internal_type == "TimeField":
276 converters.append(self.convert_timefield_value)
277 elif internal_type == "DecimalField":
278 converters.append(self.get_decimalfield_converter(expression))
279 elif internal_type == "UUIDField":
280 converters.append(self.convert_uuidfield_value)
281 elif internal_type == "BooleanField":
282 converters.append(self.convert_booleanfield_value)
283 return converters
285 def convert_datetimefield_value(self, value, expression, connection):
286 if value is not None:
287 if not isinstance(value, datetime.datetime):
288 value = parse_datetime(value)
289 if not timezone.is_aware(value):
290 value = timezone.make_aware(value, self.connection.timezone)
291 return value
293 def convert_datefield_value(self, value, expression, connection):
294 if value is not None:
295 if not isinstance(value, datetime.date):
296 value = parse_date(value)
297 return value
299 def convert_timefield_value(self, value, expression, connection):
300 if value is not None:
301 if not isinstance(value, datetime.time):
302 value = parse_time(value)
303 return value
305 def get_decimalfield_converter(self, expression):
306 # SQLite stores only 15 significant digits. Digits coming from
307 # float inaccuracy must be removed.
308 create_decimal = decimal.Context(prec=15).create_decimal_from_float
309 if isinstance(expression, Col):
310 quantize_value = decimal.Decimal(1).scaleb(
311 -expression.output_field.decimal_places
312 )
314 def converter(value, expression, connection):
315 if value is not None:
316 return create_decimal(value).quantize(
317 quantize_value, context=expression.output_field.context
318 )
320 else:
322 def converter(value, expression, connection):
323 if value is not None:
324 return create_decimal(value)
326 return converter
328 def convert_uuidfield_value(self, value, expression, connection):
329 if value is not None:
330 value = uuid.UUID(value)
331 return value
333 def convert_booleanfield_value(self, value, expression, connection):
334 return bool(value) if value in (1, 0) else value
336 def bulk_insert_sql(self, fields, placeholder_rows):
337 placeholder_rows_sql = (", ".join(row) for row in placeholder_rows)
338 values_sql = ", ".join(f"({sql})" for sql in placeholder_rows_sql)
339 return f"VALUES {values_sql}"
341 def combine_expression(self, connector, sub_expressions):
342 # SQLite doesn't have a ^ operator, so use the user-defined POWER
343 # function that's registered in connect().
344 if connector == "^":
345 return "POWER({})".format(",".join(sub_expressions))
346 elif connector == "#":
347 return "BITXOR({})".format(",".join(sub_expressions))
348 return super().combine_expression(connector, sub_expressions)
350 def combine_duration_expression(self, connector, sub_expressions):
351 if connector not in ["+", "-", "*", "/"]:
352 raise DatabaseError(f"Invalid connector for timedelta: {connector}.")
353 fn_params = [f"'{connector}'"] + sub_expressions
354 if len(fn_params) > 3:
355 raise ValueError("Too many params for timedelta operations.")
356 return "plain_format_dtdelta({})".format(", ".join(fn_params))
358 def integer_field_range(self, internal_type):
359 # SQLite doesn't enforce any integer constraints, but sqlite3 supports
360 # integers up to 64 bits.
361 if internal_type in [
362 "PositiveBigIntegerField",
363 "PositiveIntegerField",
364 "PositiveSmallIntegerField",
365 ]:
366 return (0, 9223372036854775807)
367 return (-9223372036854775808, 9223372036854775807)
369 def subtract_temporals(self, internal_type, lhs, rhs):
370 lhs_sql, lhs_params = lhs
371 rhs_sql, rhs_params = rhs
372 params = (*lhs_params, *rhs_params)
373 if internal_type == "TimeField":
374 return f"plain_time_diff({lhs_sql}, {rhs_sql})", params
375 return f"plain_timestamp_diff({lhs_sql}, {rhs_sql})", params
377 def insert_statement(self, on_conflict=None):
378 if on_conflict == OnConflict.IGNORE:
379 return "INSERT OR IGNORE INTO"
380 return super().insert_statement(on_conflict=on_conflict)
382 def return_insert_columns(self, fields):
383 # SQLite < 3.35 doesn't support an INSERT...RETURNING statement.
384 if not fields:
385 return "", ()
386 columns = [
387 f"{self.quote_name(field.model._meta.db_table)}.{self.quote_name(field.column)}"
388 for field in fields
389 ]
390 return "RETURNING {}".format(", ".join(columns)), ()
392 def on_conflict_suffix_sql(self, fields, on_conflict, update_fields, unique_fields):
393 if (
394 on_conflict == OnConflict.UPDATE
395 and self.connection.features.supports_update_conflicts_with_target
396 ):
397 return "ON CONFLICT({}) DO UPDATE SET {}".format(
398 ", ".join(map(self.quote_name, unique_fields)),
399 ", ".join(
400 [
401 f"{field} = EXCLUDED.{field}"
402 for field in map(self.quote_name, update_fields)
403 ]
404 ),
405 )
406 return super().on_conflict_suffix_sql(
407 fields,
408 on_conflict,
409 update_fields,
410 unique_fields,
411 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import copy
2from decimal import Decimal
4from plain.models.backends.base.schema import BaseDatabaseSchemaEditor
5from plain.models.backends.ddl_references import Statement
6from plain.models.backends.utils import strip_quotes
7from plain.models.constraints import UniqueConstraint
8from plain.models.db import NotSupportedError
9from plain.models.transaction import atomic
10from plain.packages.registry import Packages
13class DatabaseSchemaEditor(BaseDatabaseSchemaEditor):
14 sql_delete_table = "DROP TABLE %(table)s"
15 sql_create_fk = None
16 sql_create_inline_fk = (
17 "REFERENCES %(to_table)s (%(to_column)s) DEFERRABLE INITIALLY DEFERRED"
18 )
19 sql_create_column_inline_fk = sql_create_inline_fk
20 sql_delete_column = "ALTER TABLE %(table)s DROP COLUMN %(column)s"
21 sql_create_unique = "CREATE UNIQUE INDEX %(name)s ON %(table)s (%(columns)s)"
22 sql_delete_unique = "DROP INDEX %(name)s"
24 def __enter__(self):
25 # Some SQLite schema alterations need foreign key constraints to be
26 # disabled. Enforce it here for the duration of the schema edition.
27 if not self.connection.disable_constraint_checking():
28 raise NotSupportedError(
29 "SQLite schema editor cannot be used while foreign key "
30 "constraint checks are enabled. Make sure to disable them "
31 "before entering a transaction.atomic() context because "
32 "SQLite does not support disabling them in the middle of "
33 "a multi-statement transaction."
34 )
35 return super().__enter__()
37 def __exit__(self, exc_type, exc_value, traceback):
38 self.connection.check_constraints()
39 super().__exit__(exc_type, exc_value, traceback)
40 self.connection.enable_constraint_checking()
42 def quote_value(self, value):
43 # The backend "mostly works" without this function and there are use
44 # cases for compiling Python without the sqlite3 libraries (e.g.
45 # security hardening).
46 try:
47 import sqlite3
49 value = sqlite3.adapt(value)
50 except ImportError:
51 pass
52 except sqlite3.ProgrammingError:
53 pass
54 # Manual emulation of SQLite parameter quoting
55 if isinstance(value, bool):
56 return str(int(value))
57 elif isinstance(value, Decimal | float | int):
58 return str(value)
59 elif isinstance(value, str):
60 return "'{}'".format(value.replace("'", "''"))
61 elif value is None:
62 return "NULL"
63 elif isinstance(value, bytes | bytearray | memoryview):
64 # Bytes are only allowed for BLOB fields, encoded as string
65 # literals containing hexadecimal data and preceded by a single "X"
66 # character.
67 return f"X'{value.hex()}'"
68 else:
69 raise ValueError(
70 f"Cannot quote parameter value {value!r} of type {type(value)}"
71 )
73 def prepare_default(self, value):
74 return self.quote_value(value)
76 def _is_referenced_by_fk_constraint(
77 self, table_name, column_name=None, ignore_self=False
78 ):
79 """
80 Return whether or not the provided table name is referenced by another
81 one. If `column_name` is specified, only references pointing to that
82 column are considered. If `ignore_self` is True, self-referential
83 constraints are ignored.
84 """
85 with self.connection.cursor() as cursor:
86 for other_table in self.connection.introspection.get_table_list(cursor):
87 if ignore_self and other_table.name == table_name:
88 continue
89 relations = self.connection.introspection.get_relations(
90 cursor, other_table.name
91 )
92 for constraint_column, constraint_table in relations.values():
93 if constraint_table == table_name and (
94 column_name is None or constraint_column == column_name
95 ):
96 return True
97 return False
99 def alter_db_table(
100 self, model, old_db_table, new_db_table, disable_constraints=True
101 ):
102 if (
103 not self.connection.features.supports_atomic_references_rename
104 and disable_constraints
105 and self._is_referenced_by_fk_constraint(old_db_table)
106 ):
107 if self.connection.in_atomic_block:
108 raise NotSupportedError(
109 f"Renaming the {old_db_table!r} table while in a transaction is not "
110 "supported on SQLite < 3.26 because it would break referential "
111 "integrity. Try adding `atomic = False` to the Migration class."
112 )
113 self.connection.enable_constraint_checking()
114 super().alter_db_table(model, old_db_table, new_db_table)
115 self.connection.disable_constraint_checking()
116 else:
117 super().alter_db_table(model, old_db_table, new_db_table)
119 def alter_field(self, model, old_field, new_field, strict=False):
120 if not self._field_should_be_altered(old_field, new_field):
121 return
122 old_field_name = old_field.name
123 table_name = model._meta.db_table
124 _, old_column_name = old_field.get_attname_column()
125 if (
126 new_field.name != old_field_name
127 and not self.connection.features.supports_atomic_references_rename
128 and self._is_referenced_by_fk_constraint(
129 table_name, old_column_name, ignore_self=True
130 )
131 ):
132 if self.connection.in_atomic_block:
133 raise NotSupportedError(
134 f"Renaming the {model._meta.db_table!r}.{old_field_name!r} column while in a transaction is not "
135 "supported on SQLite < 3.26 because it would break referential "
136 "integrity. Try adding `atomic = False` to the Migration class."
137 )
138 with atomic(self.connection.alias):
139 super().alter_field(model, old_field, new_field, strict=strict)
140 # Follow SQLite's documented procedure for performing changes
141 # that don't affect the on-disk content.
142 # https://sqlite.org/lang_altertable.html#otheralter
143 with self.connection.cursor() as cursor:
144 schema_version = cursor.execute("PRAGMA schema_version").fetchone()[
145 0
146 ]
147 cursor.execute("PRAGMA writable_schema = 1")
148 references_template = f' REFERENCES "{table_name}" ("%s") '
149 new_column_name = new_field.get_attname_column()[1]
150 search = references_template % old_column_name
151 replacement = references_template % new_column_name
152 cursor.execute(
153 "UPDATE sqlite_master SET sql = replace(sql, %s, %s)",
154 (search, replacement),
155 )
156 cursor.execute("PRAGMA schema_version = %d" % (schema_version + 1))
157 cursor.execute("PRAGMA writable_schema = 0")
158 # The integrity check will raise an exception and rollback
159 # the transaction if the sqlite_master updates corrupt the
160 # database.
161 cursor.execute("PRAGMA integrity_check")
162 # Perform a VACUUM to refresh the database representation from
163 # the sqlite_master table.
164 with self.connection.cursor() as cursor:
165 cursor.execute("VACUUM")
166 else:
167 super().alter_field(model, old_field, new_field, strict=strict)
169 def _remake_table(
170 self, model, create_field=None, delete_field=None, alter_fields=None
171 ):
172 """
173 Shortcut to transform a model from old_model into new_model
175 This follows the correct procedure to perform non-rename or column
176 addition operations based on SQLite's documentation
178 https://www.sqlite.org/lang_altertable.html#caution
180 The essential steps are:
181 1. Create a table with the updated definition called "new__app_model"
182 2. Copy the data from the existing "app_model" table to the new table
183 3. Drop the "app_model" table
184 4. Rename the "new__app_model" table to "app_model"
185 5. Restore any index of the previous "app_model" table.
186 """
188 # Self-referential fields must be recreated rather than copied from
189 # the old model to ensure their remote_field.field_name doesn't refer
190 # to an altered field.
191 def is_self_referential(f):
192 return f.is_relation and f.remote_field.model is model
194 # Work out the new fields dict / mapping
195 body = {
196 f.name: f.clone() if is_self_referential(f) else f
197 for f in model._meta.local_concrete_fields
198 }
199 # Since mapping might mix column names and default values,
200 # its values must be already quoted.
201 mapping = {
202 f.column: self.quote_name(f.column)
203 for f in model._meta.local_concrete_fields
204 }
205 # If any of the new or altered fields is introducing a new PK,
206 # remove the old one
207 restore_pk_field = None
208 alter_fields = alter_fields or []
209 if getattr(create_field, "primary_key", False) or any(
210 getattr(new_field, "primary_key", False) for _, new_field in alter_fields
211 ):
212 for name, field in list(body.items()):
213 if field.primary_key and not any(
214 # Do not remove the old primary key when an altered field
215 # that introduces a primary key is the same field.
216 name == new_field.name
217 for _, new_field in alter_fields
218 ):
219 field.primary_key = False
220 restore_pk_field = field
221 if field.auto_created:
222 del body[name]
223 del mapping[field.column]
224 # Add in any created fields
225 if create_field:
226 body[create_field.name] = create_field
227 # Choose a default and insert it into the copy map
228 if not create_field.many_to_many and create_field.concrete:
229 mapping[create_field.column] = self.prepare_default(
230 self.effective_default(create_field),
231 )
232 # Add in any altered fields
233 for alter_field in alter_fields:
234 old_field, new_field = alter_field
235 body.pop(old_field.name, None)
236 mapping.pop(old_field.column, None)
237 body[new_field.name] = new_field
238 if old_field.null and not new_field.null:
239 case_sql = f"coalesce({self.quote_name(old_field.column)}, {self.prepare_default(self.effective_default(new_field))})"
240 mapping[new_field.column] = case_sql
241 else:
242 mapping[new_field.column] = self.quote_name(old_field.column)
243 # Remove any deleted fields
244 if delete_field:
245 del body[delete_field.name]
246 del mapping[delete_field.column]
247 # Remove any implicit M2M tables
248 if (
249 delete_field.many_to_many
250 and delete_field.remote_field.through._meta.auto_created
251 ):
252 return self.delete_model(delete_field.remote_field.through)
253 # Work inside a new app registry
254 packages = Packages()
256 indexes = model._meta.indexes
257 if delete_field:
258 indexes = [
259 index for index in indexes if delete_field.name not in index.fields
260 ]
262 constraints = list(model._meta.constraints)
264 # Provide isolated instances of the fields to the new model body so
265 # that the existing model's internals aren't interfered with when
266 # the dummy model is constructed.
267 body_copy = copy.deepcopy(body)
269 # Construct a new model with the new fields to allow self referential
270 # primary key to resolve to. This model won't ever be materialized as a
271 # table and solely exists for foreign key reference resolution purposes.
272 # This wouldn't be required if the schema editor was operating on model
273 # states instead of rendered models.
274 meta_contents = {
275 "package_label": model._meta.package_label,
276 "db_table": model._meta.db_table,
277 "indexes": indexes,
278 "constraints": constraints,
279 "packages": packages,
280 }
281 meta = type("Meta", (), meta_contents)
282 body_copy["Meta"] = meta
283 body_copy["__module__"] = model.__module__
284 type(model._meta.object_name, model.__bases__, body_copy)
286 # Construct a model with a renamed table name.
287 body_copy = copy.deepcopy(body)
288 meta_contents = {
289 "package_label": model._meta.package_label,
290 "db_table": f"new__{strip_quotes(model._meta.db_table)}",
291 "indexes": indexes,
292 "constraints": constraints,
293 "packages": packages,
294 }
295 meta = type("Meta", (), meta_contents)
296 body_copy["Meta"] = meta
297 body_copy["__module__"] = model.__module__
298 new_model = type(f"New{model._meta.object_name}", model.__bases__, body_copy)
300 # Create a new table with the updated schema.
301 self.create_model(new_model)
303 # Copy data from the old table into the new table
304 self.execute(
305 "INSERT INTO {} ({}) SELECT {} FROM {}".format(
306 self.quote_name(new_model._meta.db_table),
307 ", ".join(self.quote_name(x) for x in mapping),
308 ", ".join(mapping.values()),
309 self.quote_name(model._meta.db_table),
310 )
311 )
313 # Delete the old table to make way for the new
314 self.delete_model(model, handle_autom2m=False)
316 # Rename the new table to take way for the old
317 self.alter_db_table(
318 new_model,
319 new_model._meta.db_table,
320 model._meta.db_table,
321 disable_constraints=False,
322 )
324 # Run deferred SQL on correct table
325 for sql in self.deferred_sql:
326 self.execute(sql)
327 self.deferred_sql = []
328 # Fix any PK-removed field
329 if restore_pk_field:
330 restore_pk_field.primary_key = True
332 def delete_model(self, model, handle_autom2m=True):
333 if handle_autom2m:
334 super().delete_model(model)
335 else:
336 # Delete the table (and only that)
337 self.execute(
338 self.sql_delete_table
339 % {
340 "table": self.quote_name(model._meta.db_table),
341 }
342 )
343 # Remove all deferred statements referencing the deleted table.
344 for sql in list(self.deferred_sql):
345 if isinstance(sql, Statement) and sql.references_table(
346 model._meta.db_table
347 ):
348 self.deferred_sql.remove(sql)
350 def add_field(self, model, field):
351 """Create a field on a model."""
352 # Special-case implicit M2M tables.
353 if field.many_to_many and field.remote_field.through._meta.auto_created:
354 self.create_model(field.remote_field.through)
355 elif (
356 # Primary keys and unique fields are not supported in ALTER TABLE
357 # ADD COLUMN.
358 field.primary_key
359 or field.unique
360 or
361 # Fields with default values cannot by handled by ALTER TABLE ADD
362 # COLUMN statement because DROP DEFAULT is not supported in
363 # ALTER TABLE.
364 not field.null
365 or self.effective_default(field) is not None
366 ):
367 self._remake_table(model, create_field=field)
368 else:
369 super().add_field(model, field)
371 def remove_field(self, model, field):
372 """
373 Remove a field from a model. Usually involves deleting a column,
374 but for M2Ms may involve deleting a table.
375 """
376 # M2M fields are a special case
377 if field.many_to_many:
378 # For implicit M2M tables, delete the auto-created table
379 if field.remote_field.through._meta.auto_created:
380 self.delete_model(field.remote_field.through)
381 # For explicit "through" M2M fields, do nothing
382 elif (
383 self.connection.features.can_alter_table_drop_column
384 # Primary keys, unique fields, indexed fields, and foreign keys are
385 # not supported in ALTER TABLE DROP COLUMN.
386 and not field.primary_key
387 and not field.unique
388 and not field.db_index
389 and not (field.remote_field and field.db_constraint)
390 ):
391 super().remove_field(model, field)
392 # For everything else, remake.
393 else:
394 # It might not actually have a column behind it
395 if field.db_parameters(connection=self.connection)["type"] is None:
396 return
397 self._remake_table(model, delete_field=field)
399 def _alter_field(
400 self,
401 model,
402 old_field,
403 new_field,
404 old_type,
405 new_type,
406 old_db_params,
407 new_db_params,
408 strict=False,
409 ):
410 """Perform a "physical" (non-ManyToMany) field update."""
411 # Use "ALTER TABLE ... RENAME COLUMN" if only the column name
412 # changed and there aren't any constraints.
413 if (
414 self.connection.features.can_alter_table_rename_column
415 and old_field.column != new_field.column
416 and self.column_sql(model, old_field) == self.column_sql(model, new_field)
417 and not (
418 old_field.remote_field
419 and old_field.db_constraint
420 or new_field.remote_field
421 and new_field.db_constraint
422 )
423 ):
424 return self.execute(
425 self._rename_field_sql(
426 model._meta.db_table, old_field, new_field, new_type
427 )
428 )
429 # Alter by remaking table
430 self._remake_table(model, alter_fields=[(old_field, new_field)])
431 # Rebuild tables with FKs pointing to this field.
432 old_collation = old_db_params.get("collation")
433 new_collation = new_db_params.get("collation")
434 if new_field.unique and (
435 old_type != new_type or old_collation != new_collation
436 ):
437 related_models = set()
438 opts = new_field.model._meta
439 for remote_field in opts.related_objects:
440 # Ignore self-relationship since the table was already rebuilt.
441 if remote_field.related_model == model:
442 continue
443 if not remote_field.many_to_many:
444 if remote_field.field_name == new_field.name:
445 related_models.add(remote_field.related_model)
446 elif new_field.primary_key and remote_field.through._meta.auto_created:
447 related_models.add(remote_field.through)
448 if new_field.primary_key:
449 for many_to_many in opts.many_to_many:
450 # Ignore self-relationship since the table was already rebuilt.
451 if many_to_many.related_model == model:
452 continue
453 if many_to_many.remote_field.through._meta.auto_created:
454 related_models.add(many_to_many.remote_field.through)
455 for related_model in related_models:
456 self._remake_table(related_model)
458 def _alter_many_to_many(self, model, old_field, new_field, strict):
459 """Alter M2Ms to repoint their to= endpoints."""
460 if (
461 old_field.remote_field.through._meta.db_table
462 == new_field.remote_field.through._meta.db_table
463 ):
464 # The field name didn't change, but some options did, so we have to
465 # propagate this altering.
466 self._remake_table(
467 old_field.remote_field.through,
468 alter_fields=[
469 (
470 # The field that points to the target model is needed,
471 # so that table can be remade with the new m2m field -
472 # this is m2m_reverse_field_name().
473 old_field.remote_field.through._meta.get_field(
474 old_field.m2m_reverse_field_name()
475 ),
476 new_field.remote_field.through._meta.get_field(
477 new_field.m2m_reverse_field_name()
478 ),
479 ),
480 (
481 # The field that points to the model itself is needed,
482 # so that table can be remade with the new self field -
483 # this is m2m_field_name().
484 old_field.remote_field.through._meta.get_field(
485 old_field.m2m_field_name()
486 ),
487 new_field.remote_field.through._meta.get_field(
488 new_field.m2m_field_name()
489 ),
490 ),
491 ],
492 )
493 return
495 # Make a new through table
496 self.create_model(new_field.remote_field.through)
497 # Copy the data across
498 self.execute(
499 "INSERT INTO {} ({}) SELECT {} FROM {}".format(
500 self.quote_name(new_field.remote_field.through._meta.db_table),
501 ", ".join(
502 [
503 "id",
504 new_field.m2m_column_name(),
505 new_field.m2m_reverse_name(),
506 ]
507 ),
508 ", ".join(
509 [
510 "id",
511 old_field.m2m_column_name(),
512 old_field.m2m_reverse_name(),
513 ]
514 ),
515 self.quote_name(old_field.remote_field.through._meta.db_table),
516 )
517 )
518 # Delete the old through table
519 self.delete_model(old_field.remote_field.through)
521 def add_constraint(self, model, constraint):
522 if isinstance(constraint, UniqueConstraint) and (
523 constraint.condition
524 or constraint.contains_expressions
525 or constraint.include
526 or constraint.deferrable
527 ):
528 super().add_constraint(model, constraint)
529 else:
530 self._remake_table(model)
532 def remove_constraint(self, model, constraint):
533 if isinstance(constraint, UniqueConstraint) and (
534 constraint.condition
535 or constraint.contains_expressions
536 or constraint.include
537 or constraint.deferrable
538 ):
539 super().remove_constraint(model, constraint)
540 else:
541 self._remake_table(model)
543 def _collate_sql(self, collation):
544 return "COLLATE " + collation
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.packages import PackageConfig
4class PlainOAuthConfig(PackageConfig):
5 name = "plain.oauth"
6 label = "plainoauth" # Primarily for migrations
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1OAUTH_LOGIN_PROVIDERS: dict
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1class OAuthError(Exception):
2 """Base class for OAuth errors"""
4 pass
7class OAuthStateMismatchError(OAuthError):
8 pass
11class OAuthUserAlreadyExistsError(OAuthError):
12 pass
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from typing import TYPE_CHECKING
3from plain import models
4from plain.auth import get_user_model
5from plain.exceptions import ValidationError
6from plain.models import transaction
7from plain.models.db import IntegrityError, OperationalError, ProgrammingError
8from plain.preflight import Error
9from plain.runtime import settings
10from plain.utils import timezone
12from .exceptions import OAuthUserAlreadyExistsError
14if TYPE_CHECKING:
15 from .providers import OAuthToken, OAuthUser
18# TODO preflight check for deploy that ensures all provider keys in db are also in settings?
21class OAuthConnection(models.Model):
22 created_at = models.DateTimeField(auto_now_add=True)
23 updated_at = models.DateTimeField(auto_now=True)
25 user = models.ForeignKey(
26 settings.AUTH_USER_MODEL,
27 on_delete=models.CASCADE,
28 related_name="oauth_connections",
29 )
31 # The key used to refer to this provider type (in settings)
32 provider_key = models.CharField(max_length=100, db_index=True)
34 # The unique ID of the user on the provider's system
35 provider_user_id = models.CharField(max_length=100, db_index=True)
37 # Token data
38 access_token = models.CharField(max_length=2000)
39 refresh_token = models.CharField(max_length=2000, blank=True)
40 access_token_expires_at = models.DateTimeField(blank=True, null=True)
41 refresh_token_expires_at = models.DateTimeField(blank=True, null=True)
43 class Meta:
44 constraints = [
45 models.UniqueConstraint(
46 fields=["provider_key", "provider_user_id"],
47 name="unique_oauth_provider_user_id",
48 )
49 ]
50 ordering = ("provider_key",)
52 def __str__(self):
53 return f"{self.provider_key}[{self.user}:{self.provider_user_id}]"
55 def refresh_access_token(self) -> None:
56 from .providers import OAuthToken, get_oauth_provider_instance
58 provider_instance = get_oauth_provider_instance(provider_key=self.provider_key)
59 oauth_token = OAuthToken(
60 access_token=self.access_token,
61 refresh_token=self.refresh_token,
62 access_token_expires_at=self.access_token_expires_at,
63 refresh_token_expires_at=self.refresh_token_expires_at,
64 )
65 refreshed_oauth_token = provider_instance.refresh_oauth_token(
66 oauth_token=oauth_token
67 )
68 self.set_token_fields(refreshed_oauth_token)
69 self.save()
71 def set_token_fields(self, oauth_token: "OAuthToken"):
72 self.access_token = oauth_token.access_token
73 self.refresh_token = oauth_token.refresh_token
74 self.access_token_expires_at = oauth_token.access_token_expires_at
75 self.refresh_token_expires_at = oauth_token.refresh_token_expires_at
77 def set_user_fields(self, oauth_user: "OAuthUser"):
78 self.provider_user_id = oauth_user.id
80 def access_token_expired(self) -> bool:
81 return (
82 self.access_token_expires_at is not None
83 and self.access_token_expires_at < timezone.now()
84 )
86 def refresh_token_expired(self) -> bool:
87 return (
88 self.refresh_token_expires_at is not None
89 and self.refresh_token_expires_at < timezone.now()
90 )
92 @classmethod
93 def get_or_create_user(
94 cls, *, provider_key: str, oauth_token: "OAuthToken", oauth_user: "OAuthUser"
95 ) -> "OAuthConnection":
96 try:
97 connection = cls.objects.get(
98 provider_key=provider_key,
99 provider_user_id=oauth_user.id,
100 )
101 connection.set_token_fields(oauth_token)
102 connection.save()
103 return connection
104 except cls.DoesNotExist:
105 with transaction.atomic():
106 # If email needs to be unique, then we expect
107 # that to be taken care of on the user model itself
108 try:
109 user = get_user_model()(
110 **oauth_user.user_model_fields,
111 )
112 user.save()
113 except (IntegrityError, ValidationError):
114 raise OAuthUserAlreadyExistsError()
116 return cls.connect(
117 user=user,
118 provider_key=provider_key,
119 oauth_token=oauth_token,
120 oauth_user=oauth_user,
121 )
123 @classmethod
124 def connect(
125 cls,
126 *,
127 user: settings.AUTH_USER_MODEL,
128 provider_key: str,
129 oauth_token: "OAuthToken",
130 oauth_user: "OAuthUser",
131 ) -> "OAuthConnection":
132 """
133 Connect will either create a new connection or update an existing connection
134 """
135 try:
136 connection = cls.objects.get(
137 user=user,
138 provider_key=provider_key,
139 provider_user_id=oauth_user.id,
140 )
141 except cls.DoesNotExist:
142 # Create our own instance (not using get_or_create)
143 # so that any created signals contain the token fields too
144 connection = cls(
145 user=user,
146 provider_key=provider_key,
147 provider_user_id=oauth_user.id,
148 )
150 connection.set_user_fields(oauth_user)
151 connection.set_token_fields(oauth_token)
152 connection.save()
154 return connection
156 @classmethod
157 def check(cls, **kwargs):
158 """
159 A system check for ensuring that provider_keys in the database are also present in settings.
161 Note that the --database flag is required for this to work:
162 python manage.py check --database default
163 """
164 errors = super().check(**kwargs)
166 databases = kwargs.get("databases", None)
167 if not databases:
168 return errors
170 from .providers import get_provider_keys
172 for database in databases:
173 try:
174 keys_in_db = set(
175 cls.objects.using(database)
176 .values_list("provider_key", flat=True)
177 .distinct()
178 )
179 except (OperationalError, ProgrammingError):
180 # Check runs on manage.py migrate, and the table may not exist yet
181 # or it may not be installed on the particular database intentionally
182 continue
184 keys_in_settings = set(get_provider_keys())
186 if keys_in_db - keys_in_settings:
187 errors.append(
188 Error(
189 "The following OAuth providers are in the database but not in the settings: {}".format(
190 ", ".join(keys_in_db - keys_in_settings)
191 ),
192 id="plain.oauth.E001",
193 )
194 )
196 return errors
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
2import secrets
3from typing import Any
4from urllib.parse import urlencode
6from plain.auth import login as auth_login
7from plain.http import HttpRequest, Response, ResponseRedirect
8from plain.runtime import settings
9from plain.urls import reverse
10from plain.utils.crypto import get_random_string
11from plain.utils.module_loading import import_string
13from .exceptions import OAuthError, OAuthStateMismatchError
14from .models import OAuthConnection
16SESSION_STATE_KEY = "plainoauth_state"
17SESSION_NEXT_KEY = "plainoauth_next"
20class OAuthToken:
21 def __init__(
22 self,
23 *,
24 access_token: str,
25 refresh_token: str = "",
26 access_token_expires_at: datetime.datetime = None,
27 refresh_token_expires_at: datetime.datetime = None,
28 ):
29 self.access_token = access_token
30 self.refresh_token = refresh_token
31 self.access_token_expires_at = access_token_expires_at
32 self.refresh_token_expires_at = refresh_token_expires_at
35class OAuthUser:
36 def __init__(self, *, id: str, **user_model_fields: dict):
37 self.id = id # ID on the provider's system
38 self.user_model_fields = user_model_fields
40 def __str__(self):
41 if "email" in self.user_model_fields:
42 return self.user_model_fields["email"]
43 if "username" in self.user_model_fields:
44 return self.user_model_fields["username"]
45 return str(self.id)
48class OAuthProvider:
49 authorization_url = ""
51 def __init__(
52 self,
53 *,
54 # Provided automatically
55 provider_key: str,
56 # Required as kwargs in OAUTH_LOGIN_PROVIDERS setting
57 client_id: str,
58 client_secret: str,
59 # Not necessarily required, but commonly used
60 scope: str = "",
61 ):
62 self.provider_key = provider_key
63 self.client_id = client_id
64 self.client_secret = client_secret
65 self.scope = scope
67 def get_authorization_url_params(self, *, request: HttpRequest) -> dict:
68 return {
69 "redirect_uri": self.get_callback_url(request=request),
70 "client_id": self.get_client_id(),
71 "scope": self.get_scope(),
72 "state": self.generate_state(),
73 "response_type": "code",
74 }
76 def refresh_oauth_token(self, *, oauth_token: OAuthToken) -> OAuthToken:
77 raise NotImplementedError()
79 def get_oauth_token(self, *, code: str, request: HttpRequest) -> OAuthToken:
80 raise NotImplementedError()
82 def get_oauth_user(self, *, oauth_token: OAuthToken) -> OAuthUser:
83 raise NotImplementedError()
85 def get_authorization_url(self, *, request: HttpRequest) -> str:
86 return self.authorization_url
88 def get_client_id(self) -> str:
89 return self.client_id
91 def get_client_secret(self) -> str:
92 return self.client_secret
94 def get_scope(self) -> str:
95 return self.scope
97 def get_callback_url(self, *, request: HttpRequest) -> str:
98 url = reverse("oauth:callback", kwargs={"provider": self.provider_key})
99 return request.build_absolute_uri(url)
101 def generate_state(self) -> str:
102 return get_random_string(length=32)
104 def check_request_state(self, *, request: HttpRequest) -> None:
105 if error := request.GET.get("error"):
106 raise OAuthError(error)
108 state = request.GET["state"]
109 expected_state = request.session.pop(SESSION_STATE_KEY)
110 request.session.save() # Make sure the pop is saved (won't save on an exception)
111 if not secrets.compare_digest(state, expected_state):
112 raise OAuthStateMismatchError()
114 def handle_login_request(
115 self, *, request: HttpRequest, redirect_to: str = ""
116 ) -> Response:
117 authorization_url = self.get_authorization_url(request=request)
118 authorization_params = self.get_authorization_url_params(request=request)
120 if "state" in authorization_params:
121 # Store the state in the session so we can check on callback
122 request.session[SESSION_STATE_KEY] = authorization_params["state"]
124 # Store next url in session so we can get it on the callback request
125 if redirect_to:
126 request.session[SESSION_NEXT_KEY] = redirect_to
127 elif "next" in request.POST:
128 request.session[SESSION_NEXT_KEY] = request.POST["next"]
130 # Sort authorization params for consistency
131 sorted_authorization_params = sorted(authorization_params.items())
132 redirect_url = authorization_url + "?" + urlencode(sorted_authorization_params)
133 return ResponseRedirect(redirect_url)
135 def handle_connect_request(
136 self, *, request: HttpRequest, redirect_to: str = ""
137 ) -> Response:
138 return self.handle_login_request(request=request, redirect_to=redirect_to)
140 def handle_disconnect_request(self, *, request: HttpRequest) -> Response:
141 provider_user_id = request.POST["provider_user_id"]
142 connection = OAuthConnection.objects.get(
143 provider_key=self.provider_key, provider_user_id=provider_user_id
144 )
145 connection.delete()
146 redirect_url = self.get_disconnect_redirect_url(request=request)
147 return ResponseRedirect(redirect_url)
149 def handle_callback_request(self, *, request: HttpRequest) -> Response:
150 self.check_request_state(request=request)
152 oauth_token = self.get_oauth_token(code=request.GET["code"], request=request)
153 oauth_user = self.get_oauth_user(oauth_token=oauth_token)
155 if request.user:
156 connection = OAuthConnection.connect(
157 user=request.user,
158 provider_key=self.provider_key,
159 oauth_token=oauth_token,
160 oauth_user=oauth_user,
161 )
162 user = connection.user
163 else:
164 connection = OAuthConnection.get_or_create_user(
165 provider_key=self.provider_key,
166 oauth_token=oauth_token,
167 oauth_user=oauth_user,
168 )
170 user = connection.user
172 self.login(request=request, user=user)
174 redirect_url = self.get_login_redirect_url(request=request)
175 return ResponseRedirect(redirect_url)
177 def login(self, *, request: HttpRequest, user: Any) -> Response:
178 auth_login(request=request, user=user)
180 def get_login_redirect_url(self, *, request: HttpRequest) -> str:
181 return request.session.pop(SESSION_NEXT_KEY, "/")
183 def get_disconnect_redirect_url(self, *, request: HttpRequest) -> str:
184 return request.POST.get("next", "/")
187def get_oauth_provider_instance(*, provider_key: str) -> OAuthProvider:
188 OAUTH_LOGIN_PROVIDERS = getattr(settings, "OAUTH_LOGIN_PROVIDERS", {})
189 provider_class_path = OAUTH_LOGIN_PROVIDERS[provider_key]["class"]
190 provider_class = import_string(provider_class_path)
191 provider_kwargs = OAUTH_LOGIN_PROVIDERS[provider_key].get("kwargs", {})
192 return provider_class(provider_key=provider_key, **provider_kwargs)
195def get_provider_keys() -> list[str]:
196 return list(getattr(settings, "OAUTH_LOGIN_PROVIDERS", {}).keys())
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.urls import include, path
3from . import views
5default_namespace = "oauth"
7urlpatterns = [
8 path(
9 "<str:provider>/",
10 include(
11 [
12 # Login and Signup are both handled here, because the intent is the same
13 path("login/", views.OAuthLoginView, name="login"),
14 path("connect/", views.OAuthConnectView, name="connect"),
15 path(
16 "disconnect/",
17 views.OAuthDisconnectView,
18 name="disconnect",
19 ),
20 path("callback/", views.OAuthCallbackView, name="callback"),
21 ]
22 ),
23 ),
24]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import logging
3from plain.auth.views import AuthViewMixin
4from plain.http import ResponseBadRequest, ResponseRedirect
5from plain.templates import Template
6from plain.views import View
8from .exceptions import (
9 OAuthError,
10 OAuthStateMismatchError,
11 OAuthUserAlreadyExistsError,
12)
13from .providers import get_oauth_provider_instance
15logger = logging.getLogger(__name__)
18class OAuthLoginView(View):
19 def post(self):
20 request = self.request
21 provider = self.url_kwargs["provider"]
22 if request.user:
23 return ResponseRedirect("/")
25 provider_instance = get_oauth_provider_instance(provider_key=provider)
26 return provider_instance.handle_login_request(request=request)
29class OAuthCallbackView(View):
30 """
31 The callback view is used for signup, login, and connect.
32 """
34 def get(self):
35 request = self.request
36 provider = self.url_kwargs["provider"]
37 provider_instance = get_oauth_provider_instance(provider_key=provider)
38 try:
39 return provider_instance.handle_callback_request(request=request)
40 except OAuthUserAlreadyExistsError:
41 template = Template("oauth/error.html")
42 return ResponseBadRequest(
43 template.render(
44 {
45 "oauth_error": "A user already exists with this email address. Please log in first and then connect this OAuth provider to the existing account."
46 }
47 )
48 )
49 except OAuthStateMismatchError:
50 template = Template("oauth/error.html")
51 return ResponseBadRequest(
52 template.render(
53 {
54 "oauth_error": "The state parameter did not match. Please try again."
55 }
56 )
57 )
58 except OAuthError as e:
59 logger.exception("OAuth error")
60 template = Template("oauth/error.html")
61 return ResponseBadRequest(template.render({"oauth_error": str(e)}))
64class OAuthConnectView(AuthViewMixin, View):
65 def post(self):
66 request = self.request
67 provider = self.url_kwargs["provider"]
68 provider_instance = get_oauth_provider_instance(provider_key=provider)
69 return provider_instance.handle_connect_request(request=request)
72class OAuthDisconnectView(AuthViewMixin, View):
73 def post(self):
74 request = self.request
75 provider = self.url_kwargs["provider"]
76 provider_instance = get_oauth_provider_instance(provider_key=provider)
77 # try:
78 return provider_instance.handle_disconnect_request(request=request)
79 # except OAuthCannotDisconnectError:
80 # return render(
81 # request,
82 # "oauth/error.html",
83 # {
84 # "oauth_error": "This connection can't be removed. You must have a usable password or at least one active connection."
85 # },
86 # status=400,
87 # )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""Multi-consumer multi-producer dispatching mechanism
3Originally based on pydispatch (BSD) https://pypi.org/project/PyDispatcher/2.0.1/
4See license.txt for original license.
6Heavily modified for Plain's purposes.
7"""
9from plain.signals.dispatch.dispatcher import Signal, receiver # NOQA
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:05 -0500
1import logging
2import threading
3import weakref
5from plain.utils.inspect import func_accepts_kwargs
7logger = logging.getLogger("plain.signals.dispatch")
10def _make_id(target):
11 if hasattr(target, "__func__"):
12 return (id(target.__self__), id(target.__func__))
13 return id(target)
16NONE_ID = _make_id(None)
18# A marker for caching
19NO_RECEIVERS = object()
22class Signal:
23 """
24 Base class for all signals
26 Internal attributes:
28 receivers
29 { receiverkey (id) : weakref(receiver) }
30 """
32 def __init__(self, use_caching=False):
33 """
34 Create a new signal.
35 """
36 self.receivers = []
37 self.lock = threading.Lock()
38 self.use_caching = use_caching
39 # For convenience we create empty caches even if they are not used.
40 # A note about caching: if use_caching is defined, then for each
41 # distinct sender we cache the receivers that sender has in
42 # 'sender_receivers_cache'. The cache is cleaned when .connect() or
43 # .disconnect() is called and populated on send().
44 self.sender_receivers_cache = weakref.WeakKeyDictionary() if use_caching else {}
45 self._dead_receivers = False
47 def connect(self, receiver, sender=None, weak=True, dispatch_uid=None):
48 """
49 Connect receiver to sender for signal.
51 Arguments:
53 receiver
54 A function or an instance method which is to receive signals.
55 Receivers must be hashable objects. Receivers can be
56 asynchronous.
58 If weak is True, then receiver must be weak referenceable.
60 Receivers must be able to accept keyword arguments.
62 If a receiver is connected with a dispatch_uid argument, it
63 will not be added if another receiver was already connected
64 with that dispatch_uid.
66 sender
67 The sender to which the receiver should respond. Must either be
68 a Python object, or None to receive events from any sender.
70 weak
71 Whether to use weak references to the receiver. By default, the
72 module will attempt to use weak references to the receiver
73 objects. If this parameter is false, then strong references will
74 be used.
76 dispatch_uid
77 An identifier used to uniquely identify a particular instance of
78 a receiver. This will usually be a string, though it may be
79 anything hashable.
80 """
81 from plain.runtime import settings
83 # If DEBUG is on, check that we got a good receiver
84 if settings.configured and settings.DEBUG:
85 if not callable(receiver):
86 raise TypeError("Signal receivers must be callable.")
87 # Check for **kwargs
88 if not func_accepts_kwargs(receiver):
89 raise ValueError(
90 "Signal receivers must accept keyword arguments (**kwargs)."
91 )
93 if dispatch_uid:
94 lookup_key = (dispatch_uid, _make_id(sender))
95 else:
96 lookup_key = (_make_id(receiver), _make_id(sender))
98 if weak:
99 ref = weakref.ref
100 receiver_object = receiver
101 # Check for bound methods
102 if hasattr(receiver, "__self__") and hasattr(receiver, "__func__"):
103 ref = weakref.WeakMethod
104 receiver_object = receiver.__self__
105 receiver = ref(receiver)
106 weakref.finalize(receiver_object, self._remove_receiver)
108 with self.lock:
109 self._clear_dead_receivers()
110 if not any(r_key == lookup_key for r_key, _ in self.receivers):
111 self.receivers.append((lookup_key, receiver))
112 self.sender_receivers_cache.clear()
114 def disconnect(self, receiver=None, sender=None, dispatch_uid=None):
115 """
116 Disconnect receiver from sender for signal.
118 If weak references are used, disconnect need not be called. The receiver
119 will be removed from dispatch automatically.
121 Arguments:
123 receiver
124 The registered receiver to disconnect. May be none if
125 dispatch_uid is specified.
127 sender
128 The registered sender to disconnect
130 dispatch_uid
131 the unique identifier of the receiver to disconnect
132 """
133 if dispatch_uid:
134 lookup_key = (dispatch_uid, _make_id(sender))
135 else:
136 lookup_key = (_make_id(receiver), _make_id(sender))
138 disconnected = False
139 with self.lock:
140 self._clear_dead_receivers()
141 for index in range(len(self.receivers)):
142 r_key, *_ = self.receivers[index]
143 if r_key == lookup_key:
144 disconnected = True
145 del self.receivers[index]
146 break
147 self.sender_receivers_cache.clear()
148 return disconnected
150 def has_listeners(self, sender=None):
151 sync_receivers = self._live_receivers(sender)
152 return bool(sync_receivers)
154 def send(self, sender, **named):
155 """
156 Send signal from sender to all connected receivers.
158 If any receiver raises an error, the error propagates back through send,
159 terminating the dispatch loop. So it's possible that all receivers
160 won't be called if an error is raised.
162 If any receivers are asynchronous, they are called after all the
163 synchronous receivers via a single call to async_to_sync(). They are
164 also executed concurrently with asyncio.gather().
166 Arguments:
168 sender
169 The sender of the signal. Either a specific object or None.
171 named
172 Named arguments which will be passed to receivers.
174 Return a list of tuple pairs [(receiver, response), ... ].
175 """
176 if (
177 not self.receivers
178 or self.sender_receivers_cache.get(sender) is NO_RECEIVERS
179 ):
180 return []
181 responses = []
182 sync_receivers = self._live_receivers(sender)
183 for receiver in sync_receivers:
184 response = receiver(signal=self, sender=sender, **named)
185 responses.append((receiver, response))
186 return responses
188 def _log_robust_failure(self, receiver, err):
189 logger.error(
190 "Error calling %s in Signal.send_robust() (%s)",
191 receiver.__qualname__,
192 err,
193 exc_info=err,
194 )
196 def send_robust(self, sender, **named):
197 """
198 Send signal from sender to all connected receivers catching errors.
200 If any receivers are asynchronous, they are called after all the
201 synchronous receivers via a single call to async_to_sync(). They are
202 also executed concurrently with asyncio.gather().
204 Arguments:
206 sender
207 The sender of the signal. Can be any Python object (normally one
208 registered with a connect if you actually want something to
209 occur).
211 named
212 Named arguments which will be passed to receivers.
214 Return a list of tuple pairs [(receiver, response), ... ].
216 If any receiver raises an error (specifically any subclass of
217 Exception), return the error instance as the result for that receiver.
218 """
219 if (
220 not self.receivers
221 or self.sender_receivers_cache.get(sender) is NO_RECEIVERS
222 ):
223 return []
225 # Call each receiver with whatever arguments it can accept.
226 # Return a list of tuple pairs [(receiver, response), ... ].
227 responses = []
228 sync_receivers = self._live_receivers(sender)
229 for receiver in sync_receivers:
230 try:
231 response = receiver(signal=self, sender=sender, **named)
232 except Exception as err:
233 self._log_robust_failure(receiver, err)
234 responses.append((receiver, err))
235 else:
236 responses.append((receiver, response))
237 return responses
239 def _clear_dead_receivers(self):
240 # Note: caller is assumed to hold self.lock.
241 if self._dead_receivers:
242 self._dead_receivers = False
243 self.receivers = [
244 r
245 for r in self.receivers
246 if not (isinstance(r[1], weakref.ReferenceType) and r[1]() is None)
247 ]
249 def _live_receivers(self, sender):
250 """
251 Filter sequence of receivers to get resolved, live receivers.
253 This checks for weak references and resolves them, then returning only
254 live receivers.
255 """
256 receivers = None
257 if self.use_caching and not self._dead_receivers:
258 receivers = self.sender_receivers_cache.get(sender)
259 # We could end up here with NO_RECEIVERS even if we do check this case in
260 # .send() prior to calling _live_receivers() due to concurrent .send() call.
261 if receivers is NO_RECEIVERS:
262 return []
263 if receivers is None:
264 with self.lock:
265 self._clear_dead_receivers()
266 senderkey = _make_id(sender)
267 receivers = []
268 for (_receiverkey, r_senderkey), receiver in self.receivers:
269 if r_senderkey == NONE_ID or r_senderkey == senderkey:
270 receivers.append(receiver)
271 if self.use_caching:
272 if not receivers:
273 self.sender_receivers_cache[sender] = NO_RECEIVERS
274 else:
275 # Note, we must cache the weakref versions.
276 self.sender_receivers_cache[sender] = receivers
277 non_weak_sync_receivers = []
278 for receiver in receivers:
279 if isinstance(receiver, weakref.ReferenceType):
280 # Dereference the weak reference.
281 receiver = receiver()
282 if receiver is not None:
283 non_weak_sync_receivers.append(receiver)
284 else:
285 non_weak_sync_receivers.append(receiver)
286 return non_weak_sync_receivers
288 def _remove_receiver(self, receiver=None):
289 # Mark that the self.receivers list has dead weakrefs. If so, we will
290 # clean those up in connect, disconnect and _live_receivers while
291 # holding self.lock. Note that doing the cleanup here isn't a good
292 # idea, _remove_receiver() will be called as side effect of garbage
293 # collection, and so the call can happen while we are already holding
294 # self.lock.
295 self._dead_receivers = True
298def receiver(signal, **kwargs):
299 """
300 A decorator for connecting receivers to signals. Used by passing in the
301 signal (or list of signals) and keyword arguments to connect::
303 @receiver(post_save, sender=MyModel)
304 def signal_receiver(sender, **kwargs):
305 ...
307 @receiver([post_save, post_delete], sender=MyModel)
308 def signals_receiver(sender, **kwargs):
309 ...
310 """
312 def _decorator(func):
313 if isinstance(signal, list | tuple):
314 for s in signal:
315 s.connect(func, **kwargs)
316 else:
317 signal.connect(func, **kwargs)
318 return func
320 return _decorator
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from .base import (
2 clear_url_caches,
3 get_urlconf,
4 is_valid_path,
5 resolve,
6 reverse,
7 reverse_lazy,
8 set_urlconf,
9)
10from .conf import include, path, re_path
11from .converters import register_converter
12from .exceptions import NoReverseMatch, Resolver404
13from .resolvers import (
14 ResolverMatch,
15 URLPattern,
16 URLResolver,
17 get_ns_resolver,
18 get_resolver,
19)
21__all__ = [
22 "NoReverseMatch",
23 "URLPattern",
24 "URLResolver",
25 "Resolver404",
26 "ResolverMatch",
27 "clear_url_caches",
28 "get_ns_resolver",
29 "get_resolver",
30 "get_urlconf",
31 "include",
32 "is_valid_path",
33 "path",
34 "re_path",
35 "register_converter",
36 "resolve",
37 "reverse",
38 "reverse_lazy",
39 "set_urlconf",
40]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from threading import local
3from plain.utils.functional import lazy
5from .exceptions import NoReverseMatch, Resolver404
6from .resolvers import _get_cached_resolver, get_ns_resolver, get_resolver
8# Overridden URLconfs for each thread are stored here.
9_urlconfs = local()
12def resolve(path, urlconf=None):
13 if urlconf is None:
14 urlconf = get_urlconf()
15 return get_resolver(urlconf).resolve(path)
18def reverse(viewname, urlconf=None, args=None, kwargs=None, using_namespace=None):
19 if urlconf is None:
20 urlconf = get_urlconf()
21 resolver = get_resolver(urlconf)
22 args = args or []
23 kwargs = kwargs or {}
25 if not isinstance(viewname, str):
26 view = viewname
27 else:
28 *path, view = viewname.split(":")
30 if using_namespace:
31 current_path = using_namespace.split(":")
32 current_path.reverse()
33 else:
34 current_path = None
36 resolved_path = []
37 ns_pattern = ""
38 ns_converters = {}
39 for ns in path:
40 current_ns = current_path.pop() if current_path else None
41 # Lookup the name to see if it could be an app identifier.
42 try:
43 app_list = resolver.app_dict[ns]
44 # Yes! Path part matches an app in the current Resolver.
45 if current_ns and current_ns in app_list:
46 # If we are reversing for a particular app, use that
47 # namespace.
48 ns = current_ns
49 elif ns not in app_list:
50 # The name isn't shared by one of the instances (i.e.,
51 # the default) so pick the first instance as the default.
52 ns = app_list[0]
53 except KeyError:
54 pass
56 if ns != current_ns:
57 current_path = None
59 try:
60 extra, resolver = resolver.namespace_dict[ns]
61 resolved_path.append(ns)
62 ns_pattern += extra
63 ns_converters.update(resolver.pattern.converters)
64 except KeyError as key:
65 if resolved_path:
66 raise NoReverseMatch(
67 "{} is not a registered namespace inside '{}'".format(
68 key, ":".join(resolved_path)
69 )
70 )
71 else:
72 raise NoReverseMatch(f"{key} is not a registered namespace")
73 if ns_pattern:
74 resolver = get_ns_resolver(
75 ns_pattern, resolver, tuple(ns_converters.items())
76 )
78 return resolver.reverse(view, *args, **kwargs)
81reverse_lazy = lazy(reverse, str)
84def clear_url_caches():
85 _get_cached_resolver.cache_clear()
86 get_ns_resolver.cache_clear()
89def set_urlconf(urlconf_name):
90 """
91 Set the URLconf for the current thread (overriding the default one in
92 settings). If urlconf_name is None, revert back to the default.
93 """
94 if urlconf_name:
95 _urlconfs.value = urlconf_name
96 else:
97 if hasattr(_urlconfs, "value"):
98 del _urlconfs.value
101def get_urlconf(default=None):
102 """
103 Return the root URLconf to use for the current thread if it has been
104 changed from the default one.
105 """
106 return getattr(_urlconfs, "value", default)
109def is_valid_path(path, urlconf=None):
110 """
111 Return the ResolverMatch if the given path resolves against the default URL
112 resolver, False otherwise. This is a convenience method to make working
113 with "is this a match?" cases easier, avoiding try...except blocks.
114 """
115 try:
116 return resolve(path, urlconf)
117 except Resolver404:
118 return False
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""Functions for use in URLsconfs."""
3from functools import partial
5from plain.exceptions import ImproperlyConfigured
7from .resolvers import (
8 RegexPattern,
9 RoutePattern,
10 URLPattern,
11 URLResolver,
12)
15def include(arg, namespace=None):
16 default_namespace = None
17 if isinstance(arg, tuple):
18 # Callable returning a namespace hint.
19 try:
20 urlconf_module, default_namespace = arg
21 except ValueError:
22 if namespace:
23 raise ImproperlyConfigured(
24 "Cannot override the namespace for a dynamic module that "
25 "provides a namespace."
26 )
27 raise ImproperlyConfigured(
28 "Passing a %d-tuple to include() is not supported. Pass a "
29 "2-tuple containing the list of patterns and default_namespace, and "
30 "provide the namespace argument to include() instead." % len(arg)
31 )
32 else:
33 # No namespace hint - use manually provided namespace.
34 urlconf_module = arg
36 patterns = getattr(urlconf_module, "urlpatterns", urlconf_module)
37 default_namespace = getattr(urlconf_module, "default_namespace", default_namespace)
38 if namespace and not default_namespace:
39 raise ImproperlyConfigured(
40 "Specifying a namespace in include() without providing an default_namespace "
41 "is not supported. Set the default_namespace attribute in the included "
42 "module, or pass a 2-tuple containing the list of patterns and "
43 "default_namespace instead.",
44 )
45 namespace = namespace or default_namespace
46 # Make sure the patterns can be iterated through (without this, some
47 # testcases will break).
48 if isinstance(patterns, list | tuple):
49 for url_pattern in patterns:
50 getattr(url_pattern, "pattern", None)
51 return (urlconf_module, default_namespace, namespace)
54def _path(route, view, kwargs=None, name=None, Pattern=None):
55 from plain.views import View
57 if kwargs is not None and not isinstance(kwargs, dict):
58 raise TypeError(
59 f"kwargs argument must be a dict, but got {kwargs.__class__.__name__}."
60 )
62 if isinstance(view, list | tuple):
63 # For include(...) processing.
64 pattern = Pattern(route, is_endpoint=False)
65 urlconf_module, default_namespace, namespace = view
66 return URLResolver(
67 pattern,
68 urlconf_module,
69 kwargs,
70 default_namespace=default_namespace,
71 namespace=namespace,
72 )
74 if isinstance(view, View):
75 view_cls_name = view.__class__.__name__
76 raise TypeError(
77 f"view must be a callable, pass {view_cls_name} or {view_cls_name}.as_view(*args, **kwargs), not "
78 f"{view_cls_name}()."
79 )
81 # Automatically call view.as_view() for class-based views
82 if as_view := getattr(view, "as_view", None):
83 pattern = Pattern(route, name=name, is_endpoint=True)
84 return URLPattern(pattern, as_view(), kwargs, name)
86 # Function-based views or view_class.as_view() usage
87 if callable(view):
88 pattern = Pattern(route, name=name, is_endpoint=True)
89 return URLPattern(pattern, view, kwargs, name)
91 raise TypeError("view must be a callable or a list/tuple in the case of include().")
94path = partial(_path, Pattern=RoutePattern)
95re_path = partial(_path, Pattern=RegexPattern)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import functools
2import uuid
5class IntConverter:
6 regex = "[0-9]+"
8 def to_python(self, value):
9 return int(value)
11 def to_url(self, value):
12 return str(value)
15class StringConverter:
16 regex = "[^/]+"
18 def to_python(self, value):
19 return value
21 def to_url(self, value):
22 return value
25class UUIDConverter:
26 regex = "[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}"
28 def to_python(self, value):
29 return uuid.UUID(value)
31 def to_url(self, value):
32 return str(value)
35class SlugConverter(StringConverter):
36 regex = "[-a-zA-Z0-9_]+"
39class PathConverter(StringConverter):
40 regex = ".+"
43DEFAULT_CONVERTERS = {
44 "int": IntConverter(),
45 "path": PathConverter(),
46 "slug": SlugConverter(),
47 "str": StringConverter(),
48 "uuid": UUIDConverter(),
49}
52REGISTERED_CONVERTERS = {}
55def register_converter(converter, type_name):
56 REGISTERED_CONVERTERS[type_name] = converter()
57 get_converters.cache_clear()
60@functools.cache
61def get_converters():
62 return {**DEFAULT_CONVERTERS, **REGISTERED_CONVERTERS}
65def get_converter(raw_converter):
66 return get_converters()[raw_converter]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.http import Http404
4class Resolver404(Http404):
5 pass
8class NoReverseMatch(Exception):
9 pass
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2This module converts requested URLs to callback view functions.
4URLResolver is the main class here. Its resolve() method takes a URL (as
5a string) and returns a ResolverMatch object which provides access to all
6attributes of the resolved URL match.
7"""
9import functools
10import inspect
11import re
12import string
13from importlib import import_module
14from pickle import PicklingError
15from threading import local
16from urllib.parse import quote
18from plain.exceptions import ImproperlyConfigured
19from plain.preflight import Error, Warning
20from plain.preflight.urls import check_resolver
21from plain.runtime import settings
22from plain.utils.datastructures import MultiValueDict
23from plain.utils.functional import cached_property
24from plain.utils.http import RFC3986_SUBDELIMS, escape_leading_slashes
25from plain.utils.regex_helper import _lazy_re_compile, normalize
27from .converters import get_converter
28from .exceptions import NoReverseMatch, Resolver404
31class ResolverMatch:
32 def __init__(
33 self,
34 func,
35 args,
36 kwargs,
37 url_name=None,
38 default_namespaces=None,
39 namespaces=None,
40 route=None,
41 tried=None,
42 captured_kwargs=None,
43 extra_kwargs=None,
44 ):
45 self.func = func
46 self.args = args
47 self.kwargs = kwargs
48 self.url_name = url_name
49 self.route = route
50 self.tried = tried
51 self.captured_kwargs = captured_kwargs
52 self.extra_kwargs = extra_kwargs
54 # If a URLRegexResolver doesn't have a namespace or default_namespace, it passes
55 # in an empty value.
56 self.default_namespaces = (
57 [x for x in default_namespaces if x] if default_namespaces else []
58 )
59 self.default_namespace = ":".join(self.default_namespaces)
60 self.namespaces = [x for x in namespaces if x] if namespaces else []
61 self.namespace = ":".join(self.namespaces)
63 if hasattr(func, "view_class"):
64 func = func.view_class
65 if not hasattr(func, "__name__"):
66 # A class-based view
67 self._func_path = func.__class__.__module__ + "." + func.__class__.__name__
68 else:
69 # A function-based view
70 self._func_path = func.__module__ + "." + func.__name__
72 view_path = url_name or self._func_path
73 self.view_name = ":".join(self.namespaces + [view_path])
75 def __getitem__(self, index):
76 return (self.func, self.args, self.kwargs)[index]
78 def __repr__(self):
79 if isinstance(self.func, functools.partial):
80 func = repr(self.func)
81 else:
82 func = self._func_path
83 return (
84 "ResolverMatch(func={}, args={!r}, kwargs={!r}, url_name={!r}, "
85 "default_namespaces={!r}, namespaces={!r}, route={!r}{}{})".format(
86 func,
87 self.args,
88 self.kwargs,
89 self.url_name,
90 self.default_namespaces,
91 self.namespaces,
92 self.route,
93 f", captured_kwargs={self.captured_kwargs!r}"
94 if self.captured_kwargs
95 else "",
96 f", extra_kwargs={self.extra_kwargs!r}" if self.extra_kwargs else "",
97 )
98 )
100 def __reduce_ex__(self, protocol):
101 raise PicklingError(f"Cannot pickle {self.__class__.__qualname__}.")
104def get_resolver(urlconf=None):
105 if urlconf is None:
106 urlconf = settings.ROOT_URLCONF
107 return _get_cached_resolver(urlconf)
110@functools.cache
111def _get_cached_resolver(urlconf=None):
112 return URLResolver(RegexPattern(r"^/"), urlconf)
115@functools.cache
116def get_ns_resolver(ns_pattern, resolver, converters):
117 # Build a namespaced resolver for the given parent URLconf pattern.
118 # This makes it possible to have captured parameters in the parent
119 # URLconf pattern.
120 pattern = RegexPattern(ns_pattern)
121 pattern.converters = dict(converters)
122 ns_resolver = URLResolver(pattern, resolver.url_patterns)
123 return URLResolver(RegexPattern(r"^/"), [ns_resolver])
126class CheckURLMixin:
127 def describe(self):
128 """
129 Format the URL pattern for display in warning messages.
130 """
131 description = f"'{self}'"
132 if self.name:
133 description += f" [name='{self.name}']"
134 return description
136 def _check_pattern_startswith_slash(self):
137 """
138 Check that the pattern does not begin with a forward slash.
139 """
140 regex_pattern = self.regex.pattern
141 if not settings.APPEND_SLASH:
142 # Skip check as it can be useful to start a URL pattern with a slash
143 # when APPEND_SLASH=False.
144 return []
145 if regex_pattern.startswith(("/", "^/", "^\\/")) and not regex_pattern.endswith(
146 "/"
147 ):
148 warning = Warning(
149 f"Your URL pattern {self.describe()} has a route beginning with a '/'. Remove this "
150 "slash as it is unnecessary. If this pattern is targeted in an "
151 "include(), ensure the include() pattern has a trailing '/'.",
152 id="urls.W002",
153 )
154 return [warning]
155 else:
156 return []
159class RegexPattern(CheckURLMixin):
160 def __init__(self, regex, name=None, is_endpoint=False):
161 self._regex = regex
162 self._regex_dict = {}
163 self._is_endpoint = is_endpoint
164 self.name = name
165 self.converters = {}
166 self.regex = self._compile(str(regex))
168 def match(self, path):
169 match = (
170 self.regex.fullmatch(path)
171 if self._is_endpoint and self.regex.pattern.endswith("$")
172 else self.regex.search(path)
173 )
174 if match:
175 # If there are any named groups, use those as kwargs, ignoring
176 # non-named groups. Otherwise, pass all non-named arguments as
177 # positional arguments.
178 kwargs = match.groupdict()
179 args = () if kwargs else match.groups()
180 kwargs = {k: v for k, v in kwargs.items() if v is not None}
181 return path[match.end() :], args, kwargs
182 return None
184 def check(self):
185 warnings = []
186 warnings.extend(self._check_pattern_startswith_slash())
187 if not self._is_endpoint:
188 warnings.extend(self._check_include_trailing_dollar())
189 return warnings
191 def _check_include_trailing_dollar(self):
192 regex_pattern = self.regex.pattern
193 if regex_pattern.endswith("$") and not regex_pattern.endswith(r"\$"):
194 return [
195 Warning(
196 f"Your URL pattern {self.describe()} uses include with a route ending with a '$'. "
197 "Remove the dollar from the route to avoid problems including "
198 "URLs.",
199 id="urls.W001",
200 )
201 ]
202 else:
203 return []
205 def _compile(self, regex):
206 """Compile and return the given regular expression."""
207 try:
208 return re.compile(regex)
209 except re.error as e:
210 raise ImproperlyConfigured(
211 f'"{regex}" is not a valid regular expression: {e}'
212 ) from e
214 def __str__(self):
215 return str(self._regex)
218_PATH_PARAMETER_COMPONENT_RE = _lazy_re_compile(
219 r"<(?:(?P<converter>[^>:]+):)?(?P<parameter>[^>]+)>"
220)
223def _route_to_regex(route, is_endpoint=False):
224 """
225 Convert a path pattern into a regular expression. Return the regular
226 expression and a dictionary mapping the capture names to the converters.
227 For example, 'foo/<int:pk>' returns '^foo\\/(?P<pk>[0-9]+)'
228 and {'pk': <plain.urls.converters.IntConverter>}.
229 """
230 original_route = route
231 parts = ["^"]
232 converters = {}
233 while True:
234 match = _PATH_PARAMETER_COMPONENT_RE.search(route)
235 if not match:
236 parts.append(re.escape(route))
237 break
238 elif not set(match.group()).isdisjoint(string.whitespace):
239 raise ImproperlyConfigured(
240 f"URL route '{original_route}' cannot contain whitespace in angle brackets "
241 "<…>."
242 )
243 parts.append(re.escape(route[: match.start()]))
244 route = route[match.end() :]
245 parameter = match["parameter"]
246 if not parameter.isidentifier():
247 raise ImproperlyConfigured(
248 f"URL route '{original_route}' uses parameter name {parameter!r} which isn't a valid "
249 "Python identifier."
250 )
251 raw_converter = match["converter"]
252 if raw_converter is None:
253 # If a converter isn't specified, the default is `str`.
254 raw_converter = "str"
255 try:
256 converter = get_converter(raw_converter)
257 except KeyError as e:
258 raise ImproperlyConfigured(
259 f"URL route {original_route!r} uses invalid converter {raw_converter!r}."
260 ) from e
261 converters[parameter] = converter
262 parts.append("(?P<" + parameter + ">" + converter.regex + ")")
263 if is_endpoint:
264 parts.append(r"\Z")
265 return "".join(parts), converters
268class RoutePattern(CheckURLMixin):
269 def __init__(self, route, name=None, is_endpoint=False):
270 self._route = route
271 self._regex_dict = {}
272 self._is_endpoint = is_endpoint
273 self.name = name
274 self.converters = _route_to_regex(str(route), is_endpoint)[1]
275 self.regex = self._compile(str(route))
277 def match(self, path):
278 match = self.regex.search(path)
279 if match:
280 # RoutePattern doesn't allow non-named groups so args are ignored.
281 kwargs = match.groupdict()
282 for key, value in kwargs.items():
283 converter = self.converters[key]
284 try:
285 kwargs[key] = converter.to_python(value)
286 except ValueError:
287 return None
288 return path[match.end() :], (), kwargs
289 return None
291 def check(self):
292 warnings = self._check_pattern_startswith_slash()
293 route = self._route
294 if "(?P<" in route or route.startswith("^") or route.endswith("$"):
295 warnings.append(
296 Warning(
297 f"Your URL pattern {self.describe()} has a route that contains '(?P<', begins "
298 "with a '^', or ends with a '$'. This was likely an oversight "
299 "when migrating to plain.urls.path().",
300 id="2_0.W001",
301 )
302 )
303 return warnings
305 def _compile(self, route):
306 return re.compile(_route_to_regex(route, self._is_endpoint)[0])
308 def __str__(self):
309 return str(self._route)
312class URLPattern:
313 def __init__(self, pattern, callback, default_args=None, name=None):
314 self.pattern = pattern
315 self.callback = callback # the view
316 self.default_args = default_args or {}
317 self.name = name
319 def __repr__(self):
320 return f"<{self.__class__.__name__} {self.pattern.describe()}>"
322 def check(self):
323 warnings = self._check_pattern_name()
324 warnings.extend(self.pattern.check())
325 warnings.extend(self._check_callback())
326 return warnings
328 def _check_pattern_name(self):
329 """
330 Check that the pattern name does not contain a colon.
331 """
332 if self.pattern.name is not None and ":" in self.pattern.name:
333 warning = Warning(
334 f"Your URL pattern {self.pattern.describe()} has a name including a ':'. Remove the colon, to "
335 "avoid ambiguous namespace references.",
336 id="urls.W003",
337 )
338 return [warning]
339 else:
340 return []
342 def _check_callback(self):
343 from plain.views import View
345 view = self.callback
346 if inspect.isclass(view) and issubclass(view, View):
347 return [
348 Error(
349 f"Your URL pattern {self.pattern.describe()} has an invalid view, pass {view.__name__}.as_view() "
350 f"instead of {view.__name__}.",
351 id="urls.E009",
352 )
353 ]
354 return []
356 def resolve(self, path):
357 match = self.pattern.match(path)
358 if match:
359 new_path, args, captured_kwargs = match
360 # Pass any default args as **kwargs.
361 kwargs = {**captured_kwargs, **self.default_args}
362 return ResolverMatch(
363 self.callback,
364 args,
365 kwargs,
366 self.pattern.name,
367 route=str(self.pattern),
368 captured_kwargs=captured_kwargs,
369 extra_kwargs=self.default_args,
370 )
372 @cached_property
373 def lookup_str(self):
374 """
375 A string that identifies the view (e.g. 'path.to.view_function' or
376 'path.to.ClassBasedView').
377 """
378 callback = self.callback
379 if isinstance(callback, functools.partial):
380 callback = callback.func
381 if hasattr(callback, "view_class"):
382 callback = callback.view_class
383 elif not hasattr(callback, "__name__"):
384 return callback.__module__ + "." + callback.__class__.__name__
385 return callback.__module__ + "." + callback.__qualname__
388class URLResolver:
389 def __init__(
390 self,
391 pattern,
392 urlconf_name,
393 default_kwargs=None,
394 default_namespace=None,
395 namespace=None,
396 ):
397 self.pattern = pattern
398 # urlconf_name is the dotted Python path to the module defining
399 # urlpatterns. It may also be an object with an urlpatterns attribute
400 # or urlpatterns itself.
401 self.urlconf_name = urlconf_name
402 self.callback = None
403 self.default_kwargs = default_kwargs or {}
404 self.namespace = namespace
405 self.default_namespace = default_namespace
406 self._reverse_dict = {}
407 self._namespace_dict = {}
408 self._app_dict = {}
409 # set of dotted paths to all functions and classes that are used in
410 # urlpatterns
411 self._callback_strs = set()
412 self._populated = False
413 self._local = local()
415 def __repr__(self):
416 if isinstance(self.urlconf_name, list) and self.urlconf_name:
417 # Don't bother to output the whole list, it can be huge
418 urlconf_repr = f"<{self.urlconf_name[0].__class__.__name__} list>"
419 else:
420 urlconf_repr = repr(self.urlconf_name)
421 return f"<{self.__class__.__name__} {urlconf_repr} ({self.default_namespace}:{self.namespace}) {self.pattern.describe()}>"
423 def check(self):
424 messages = []
425 for pattern in self.url_patterns:
426 messages.extend(check_resolver(pattern))
427 return messages or self.pattern.check()
429 def _populate(self):
430 # Short-circuit if called recursively in this thread to prevent
431 # infinite recursion. Concurrent threads may call this at the same
432 # time and will need to continue, so set 'populating' on a
433 # thread-local variable.
434 if getattr(self._local, "populating", False):
435 return
436 try:
437 self._local.populating = True
438 lookups = MultiValueDict()
439 namespaces = {}
440 packages = {}
441 for url_pattern in reversed(self.url_patterns):
442 p_pattern = url_pattern.pattern.regex.pattern
443 p_pattern = p_pattern.removeprefix("^")
444 if isinstance(url_pattern, URLPattern):
445 self._callback_strs.add(url_pattern.lookup_str)
446 bits = normalize(url_pattern.pattern.regex.pattern)
447 lookups.appendlist(
448 url_pattern.callback,
449 (
450 bits,
451 p_pattern,
452 url_pattern.default_args,
453 url_pattern.pattern.converters,
454 ),
455 )
456 if url_pattern.name is not None:
457 lookups.appendlist(
458 url_pattern.name,
459 (
460 bits,
461 p_pattern,
462 url_pattern.default_args,
463 url_pattern.pattern.converters,
464 ),
465 )
466 else: # url_pattern is a URLResolver.
467 url_pattern._populate()
468 if url_pattern.default_namespace:
469 packages.setdefault(url_pattern.default_namespace, []).append(
470 url_pattern.namespace
471 )
472 namespaces[url_pattern.namespace] = (p_pattern, url_pattern)
473 else:
474 for name in url_pattern.reverse_dict:
475 for (
476 matches,
477 pat,
478 defaults,
479 converters,
480 ) in url_pattern.reverse_dict.getlist(name):
481 new_matches = normalize(p_pattern + pat)
482 lookups.appendlist(
483 name,
484 (
485 new_matches,
486 p_pattern + pat,
487 {**defaults, **url_pattern.default_kwargs},
488 {
489 **self.pattern.converters,
490 **url_pattern.pattern.converters,
491 **converters,
492 },
493 ),
494 )
495 for namespace, (
496 prefix,
497 sub_pattern,
498 ) in url_pattern.namespace_dict.items():
499 current_converters = url_pattern.pattern.converters
500 sub_pattern.pattern.converters.update(current_converters)
501 namespaces[namespace] = (p_pattern + prefix, sub_pattern)
502 for (
503 default_namespace,
504 namespace_list,
505 ) in url_pattern.app_dict.items():
506 packages.setdefault(default_namespace, []).extend(
507 namespace_list
508 )
509 self._callback_strs.update(url_pattern._callback_strs)
510 self._namespace_dict = namespaces
511 self._app_dict = packages
512 self._reverse_dict = lookups
513 self._populated = True
514 finally:
515 self._local.populating = False
517 @property
518 def reverse_dict(self):
519 if not self._reverse_dict:
520 self._populate()
521 return self._reverse_dict
523 @property
524 def namespace_dict(self):
525 if not self._namespace_dict:
526 self._populate()
527 return self._namespace_dict
529 @property
530 def app_dict(self):
531 if not self._app_dict:
532 self._populate()
533 return self._app_dict
535 @staticmethod
536 def _extend_tried(tried, pattern, sub_tried=None):
537 if sub_tried is None:
538 tried.append([pattern])
539 else:
540 tried.extend([pattern, *t] for t in sub_tried)
542 @staticmethod
543 def _join_route(route1, route2):
544 """Join two routes, without the starting ^ in the second route."""
545 if not route1:
546 return route2
547 route2 = route2.removeprefix("^")
548 return route1 + route2
550 def _is_callback(self, name):
551 if not self._populated:
552 self._populate()
553 return name in self._callback_strs
555 def resolve(self, path):
556 path = str(path) # path may be a reverse_lazy object
557 tried = []
558 match = self.pattern.match(path)
559 if match:
560 new_path, args, kwargs = match
561 for pattern in self.url_patterns:
562 try:
563 sub_match = pattern.resolve(new_path)
564 except Resolver404 as e:
565 self._extend_tried(tried, pattern, e.args[0].get("tried"))
566 else:
567 if sub_match:
568 # Merge captured arguments in match with submatch
569 sub_match_dict = {**kwargs, **self.default_kwargs}
570 # Update the sub_match_dict with the kwargs from the sub_match.
571 sub_match_dict.update(sub_match.kwargs)
572 # If there are *any* named groups, ignore all non-named groups.
573 # Otherwise, pass all non-named arguments as positional
574 # arguments.
575 sub_match_args = sub_match.args
576 if not sub_match_dict:
577 sub_match_args = args + sub_match.args
578 current_route = (
579 ""
580 if isinstance(pattern, URLPattern)
581 else str(pattern.pattern)
582 )
583 self._extend_tried(tried, pattern, sub_match.tried)
584 return ResolverMatch(
585 sub_match.func,
586 sub_match_args,
587 sub_match_dict,
588 sub_match.url_name,
589 [self.default_namespace] + sub_match.default_namespaces,
590 [self.namespace] + sub_match.namespaces,
591 self._join_route(current_route, sub_match.route),
592 tried,
593 captured_kwargs=sub_match.captured_kwargs,
594 extra_kwargs={
595 **self.default_kwargs,
596 **sub_match.extra_kwargs,
597 },
598 )
599 tried.append([pattern])
600 raise Resolver404({"tried": tried, "path": new_path})
601 raise Resolver404({"path": path})
603 @cached_property
604 def urlconf_module(self):
605 if isinstance(self.urlconf_name, str):
606 return import_module(self.urlconf_name)
607 else:
608 return self.urlconf_name
610 @cached_property
611 def url_patterns(self):
612 # urlconf_module might be a valid set of patterns, so we default to it
613 patterns = getattr(self.urlconf_module, "urlpatterns", self.urlconf_module)
614 try:
615 iter(patterns)
616 except TypeError as e:
617 msg = (
618 "The included URLconf '{name}' does not appear to have "
619 "any patterns in it. If you see the 'urlpatterns' variable "
620 "with valid patterns in the file then the issue is probably "
621 "caused by a circular import."
622 )
623 raise ImproperlyConfigured(msg.format(name=self.urlconf_name)) from e
624 return patterns
626 def reverse(self, lookup_view, *args, **kwargs):
627 if args and kwargs:
628 raise ValueError("Don't mix *args and **kwargs in call to reverse()!")
630 if not self._populated:
631 self._populate()
633 possibilities = self.reverse_dict.getlist(lookup_view)
635 for possibility, pattern, defaults, converters in possibilities:
636 for result, params in possibility:
637 if args:
638 if len(args) != len(params):
639 continue
640 candidate_subs = dict(zip(params, args))
641 else:
642 if set(kwargs).symmetric_difference(params).difference(defaults):
643 continue
644 matches = True
645 for k, v in defaults.items():
646 if k in params:
647 continue
648 if kwargs.get(k, v) != v:
649 matches = False
650 break
651 if not matches:
652 continue
653 candidate_subs = kwargs
654 # Convert the candidate subs to text using Converter.to_url().
655 text_candidate_subs = {}
656 match = True
657 for k, v in candidate_subs.items():
658 if k in converters:
659 try:
660 text_candidate_subs[k] = converters[k].to_url(v)
661 except ValueError:
662 match = False
663 break
664 else:
665 text_candidate_subs[k] = str(v)
666 if not match:
667 continue
668 # WSGI provides decoded URLs, without %xx escapes, and the URL
669 # resolver operates on such URLs. First substitute arguments
670 # without quoting to build a decoded URL and look for a match.
671 # Then, if we have a match, redo the substitution with quoted
672 # arguments in order to return a properly encoded URL.
674 # There was a lot of script_prefix handling code before,
675 # so this is a crutch to leave the below as-is for now.
676 _prefix = "/"
678 candidate_pat = _prefix.replace("%", "%%") + result
679 if re.search(
680 f"^{re.escape(_prefix)}{pattern}",
681 candidate_pat % text_candidate_subs,
682 ):
683 # safe characters from `pchar` definition of RFC 3986
684 url = quote(
685 candidate_pat % text_candidate_subs,
686 safe=RFC3986_SUBDELIMS + "/~:@",
687 )
688 # Don't allow construction of scheme relative urls.
689 return escape_leading_slashes(url)
690 # lookup_view can be URL name or callable, but callables are not
691 # friendly in error messages.
692 m = getattr(lookup_view, "__module__", None)
693 n = getattr(lookup_view, "__name__", None)
694 if m is not None and n is not None:
695 lookup_view_s = f"{m}.{n}"
696 else:
697 lookup_view_s = lookup_view
699 patterns = [pattern for (_, pattern, _, _) in possibilities]
700 if patterns:
701 if args:
702 arg_msg = f"arguments '{args}'"
703 elif kwargs:
704 arg_msg = f"keyword arguments '{kwargs}'"
705 else:
706 arg_msg = "no arguments"
707 msg = "Reverse for '%s' with %s not found. %d pattern(s) tried: %s" % (
708 lookup_view_s,
709 arg_msg,
710 len(patterns),
711 patterns,
712 )
713 else:
714 msg = (
715 f"Reverse for '{lookup_view_s}' not found. '{lookup_view_s}' is not "
716 "a valid view function or pattern name."
717 )
718 raise NoReverseMatch(msg)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Implementations of SQL functions for SQLite.
3"""
4import functools
5import random
6import statistics
7import zoneinfo
8from datetime import timedelta
9from hashlib import md5, sha1, sha224, sha256, sha384, sha512
10from math import (
11 acos,
12 asin,
13 atan,
14 atan2,
15 ceil,
16 cos,
17 degrees,
18 exp,
19 floor,
20 fmod,
21 log,
22 pi,
23 radians,
24 sin,
25 sqrt,
26 tan,
27)
28from re import search as re_search
30from plain.models.backends.utils import (
31 split_tzname_delta,
32 typecast_time,
33 typecast_timestamp,
34)
35from plain.utils import timezone
36from plain.utils.duration import duration_microseconds
39def register(connection):
40 create_deterministic_function = functools.partial(
41 connection.create_function,
42 deterministic=True,
43 )
44 create_deterministic_function("plain_date_extract", 2, _sqlite_datetime_extract)
45 create_deterministic_function("plain_date_trunc", 4, _sqlite_date_trunc)
46 create_deterministic_function(
47 "plain_datetime_cast_date", 3, _sqlite_datetime_cast_date
48 )
49 create_deterministic_function(
50 "plain_datetime_cast_time", 3, _sqlite_datetime_cast_time
51 )
52 create_deterministic_function("plain_datetime_extract", 4, _sqlite_datetime_extract)
53 create_deterministic_function("plain_datetime_trunc", 4, _sqlite_datetime_trunc)
54 create_deterministic_function("plain_time_extract", 2, _sqlite_time_extract)
55 create_deterministic_function("plain_time_trunc", 4, _sqlite_time_trunc)
56 create_deterministic_function("plain_time_diff", 2, _sqlite_time_diff)
57 create_deterministic_function("plain_timestamp_diff", 2, _sqlite_timestamp_diff)
58 create_deterministic_function("plain_format_dtdelta", 3, _sqlite_format_dtdelta)
59 create_deterministic_function("regexp", 2, _sqlite_regexp)
60 create_deterministic_function("BITXOR", 2, _sqlite_bitxor)
61 create_deterministic_function("COT", 1, _sqlite_cot)
62 create_deterministic_function("LPAD", 3, _sqlite_lpad)
63 create_deterministic_function("MD5", 1, _sqlite_md5)
64 create_deterministic_function("REPEAT", 2, _sqlite_repeat)
65 create_deterministic_function("REVERSE", 1, _sqlite_reverse)
66 create_deterministic_function("RPAD", 3, _sqlite_rpad)
67 create_deterministic_function("SHA1", 1, _sqlite_sha1)
68 create_deterministic_function("SHA224", 1, _sqlite_sha224)
69 create_deterministic_function("SHA256", 1, _sqlite_sha256)
70 create_deterministic_function("SHA384", 1, _sqlite_sha384)
71 create_deterministic_function("SHA512", 1, _sqlite_sha512)
72 create_deterministic_function("SIGN", 1, _sqlite_sign)
73 # Don't use the built-in RANDOM() function because it returns a value
74 # in the range [-1 * 2^63, 2^63 - 1] instead of [0, 1).
75 connection.create_function("RAND", 0, random.random)
76 connection.create_aggregate("STDDEV_POP", 1, StdDevPop)
77 connection.create_aggregate("STDDEV_SAMP", 1, StdDevSamp)
78 connection.create_aggregate("VAR_POP", 1, VarPop)
79 connection.create_aggregate("VAR_SAMP", 1, VarSamp)
80 # Some math functions are enabled by default in SQLite 3.35+.
81 sql = "select sqlite_compileoption_used('ENABLE_MATH_FUNCTIONS')"
82 if not connection.execute(sql).fetchone()[0]:
83 create_deterministic_function("ACOS", 1, _sqlite_acos)
84 create_deterministic_function("ASIN", 1, _sqlite_asin)
85 create_deterministic_function("ATAN", 1, _sqlite_atan)
86 create_deterministic_function("ATAN2", 2, _sqlite_atan2)
87 create_deterministic_function("CEILING", 1, _sqlite_ceiling)
88 create_deterministic_function("COS", 1, _sqlite_cos)
89 create_deterministic_function("DEGREES", 1, _sqlite_degrees)
90 create_deterministic_function("EXP", 1, _sqlite_exp)
91 create_deterministic_function("FLOOR", 1, _sqlite_floor)
92 create_deterministic_function("LN", 1, _sqlite_ln)
93 create_deterministic_function("LOG", 2, _sqlite_log)
94 create_deterministic_function("MOD", 2, _sqlite_mod)
95 create_deterministic_function("PI", 0, _sqlite_pi)
96 create_deterministic_function("POWER", 2, _sqlite_power)
97 create_deterministic_function("RADIANS", 1, _sqlite_radians)
98 create_deterministic_function("SIN", 1, _sqlite_sin)
99 create_deterministic_function("SQRT", 1, _sqlite_sqrt)
100 create_deterministic_function("TAN", 1, _sqlite_tan)
103def _sqlite_datetime_parse(dt, tzname=None, conn_tzname=None):
104 if dt is None:
105 return None
106 try:
107 dt = typecast_timestamp(dt)
108 except (TypeError, ValueError):
109 return None
110 if conn_tzname:
111 dt = dt.replace(tzinfo=zoneinfo.ZoneInfo(conn_tzname))
112 if tzname is not None and tzname != conn_tzname:
113 tzname, sign, offset = split_tzname_delta(tzname)
114 if offset:
115 hours, minutes = offset.split(":")
116 offset_delta = timedelta(hours=int(hours), minutes=int(minutes))
117 dt += offset_delta if sign == "+" else -offset_delta
118 dt = timezone.localtime(dt, zoneinfo.ZoneInfo(tzname))
119 return dt
122def _sqlite_date_trunc(lookup_type, dt, tzname, conn_tzname):
123 dt = _sqlite_datetime_parse(dt, tzname, conn_tzname)
124 if dt is None:
125 return None
126 if lookup_type == "year":
127 return f"{dt.year:04d}-01-01"
128 elif lookup_type == "quarter":
129 month_in_quarter = dt.month - (dt.month - 1) % 3
130 return f"{dt.year:04d}-{month_in_quarter:02d}-01"
131 elif lookup_type == "month":
132 return f"{dt.year:04d}-{dt.month:02d}-01"
133 elif lookup_type == "week":
134 dt -= timedelta(days=dt.weekday())
135 return f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d}"
136 elif lookup_type == "day":
137 return f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d}"
138 raise ValueError(f"Unsupported lookup type: {lookup_type!r}")
141def _sqlite_time_trunc(lookup_type, dt, tzname, conn_tzname):
142 if dt is None:
143 return None
144 dt_parsed = _sqlite_datetime_parse(dt, tzname, conn_tzname)
145 if dt_parsed is None:
146 try:
147 dt = typecast_time(dt)
148 except (ValueError, TypeError):
149 return None
150 else:
151 dt = dt_parsed
152 if lookup_type == "hour":
153 return f"{dt.hour:02d}:00:00"
154 elif lookup_type == "minute":
155 return f"{dt.hour:02d}:{dt.minute:02d}:00"
156 elif lookup_type == "second":
157 return f"{dt.hour:02d}:{dt.minute:02d}:{dt.second:02d}"
158 raise ValueError(f"Unsupported lookup type: {lookup_type!r}")
161def _sqlite_datetime_cast_date(dt, tzname, conn_tzname):
162 dt = _sqlite_datetime_parse(dt, tzname, conn_tzname)
163 if dt is None:
164 return None
165 return dt.date().isoformat()
168def _sqlite_datetime_cast_time(dt, tzname, conn_tzname):
169 dt = _sqlite_datetime_parse(dt, tzname, conn_tzname)
170 if dt is None:
171 return None
172 return dt.time().isoformat()
175def _sqlite_datetime_extract(lookup_type, dt, tzname=None, conn_tzname=None):
176 dt = _sqlite_datetime_parse(dt, tzname, conn_tzname)
177 if dt is None:
178 return None
179 if lookup_type == "week_day":
180 return (dt.isoweekday() % 7) + 1
181 elif lookup_type == "iso_week_day":
182 return dt.isoweekday()
183 elif lookup_type == "week":
184 return dt.isocalendar().week
185 elif lookup_type == "quarter":
186 return ceil(dt.month / 3)
187 elif lookup_type == "iso_year":
188 return dt.isocalendar().year
189 else:
190 return getattr(dt, lookup_type)
193def _sqlite_datetime_trunc(lookup_type, dt, tzname, conn_tzname):
194 dt = _sqlite_datetime_parse(dt, tzname, conn_tzname)
195 if dt is None:
196 return None
197 if lookup_type == "year":
198 return f"{dt.year:04d}-01-01 00:00:00"
199 elif lookup_type == "quarter":
200 month_in_quarter = dt.month - (dt.month - 1) % 3
201 return f"{dt.year:04d}-{month_in_quarter:02d}-01 00:00:00"
202 elif lookup_type == "month":
203 return f"{dt.year:04d}-{dt.month:02d}-01 00:00:00"
204 elif lookup_type == "week":
205 dt -= timedelta(days=dt.weekday())
206 return f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d} 00:00:00"
207 elif lookup_type == "day":
208 return f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d} 00:00:00"
209 elif lookup_type == "hour":
210 return f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d} {dt.hour:02d}:00:00"
211 elif lookup_type == "minute":
212 return (
213 f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d} "
214 f"{dt.hour:02d}:{dt.minute:02d}:00"
215 )
216 elif lookup_type == "second":
217 return (
218 f"{dt.year:04d}-{dt.month:02d}-{dt.day:02d} "
219 f"{dt.hour:02d}:{dt.minute:02d}:{dt.second:02d}"
220 )
221 raise ValueError(f"Unsupported lookup type: {lookup_type!r}")
224def _sqlite_time_extract(lookup_type, dt):
225 if dt is None:
226 return None
227 try:
228 dt = typecast_time(dt)
229 except (ValueError, TypeError):
230 return None
231 return getattr(dt, lookup_type)
234def _sqlite_prepare_dtdelta_param(conn, param):
235 if conn in ["+", "-"]:
236 if isinstance(param, int):
237 return timedelta(0, 0, param)
238 else:
239 return typecast_timestamp(param)
240 return param
243def _sqlite_format_dtdelta(connector, lhs, rhs):
244 """
245 LHS and RHS can be either:
246 - An integer number of microseconds
247 - A string representing a datetime
248 - A scalar value, e.g. float
249 """
250 if connector is None or lhs is None or rhs is None:
251 return None
252 connector = connector.strip()
253 try:
254 real_lhs = _sqlite_prepare_dtdelta_param(connector, lhs)
255 real_rhs = _sqlite_prepare_dtdelta_param(connector, rhs)
256 except (ValueError, TypeError):
257 return None
258 if connector == "+":
259 # typecast_timestamp() returns a date or a datetime without timezone.
260 # It will be formatted as "%Y-%m-%d" or "%Y-%m-%d %H:%M:%S[.%f]"
261 out = str(real_lhs + real_rhs)
262 elif connector == "-":
263 out = str(real_lhs - real_rhs)
264 elif connector == "*":
265 out = real_lhs * real_rhs
266 else:
267 out = real_lhs / real_rhs
268 return out
271def _sqlite_time_diff(lhs, rhs):
272 if lhs is None or rhs is None:
273 return None
274 left = typecast_time(lhs)
275 right = typecast_time(rhs)
276 return (
277 (left.hour * 60 * 60 * 1000000)
278 + (left.minute * 60 * 1000000)
279 + (left.second * 1000000)
280 + (left.microsecond)
281 - (right.hour * 60 * 60 * 1000000)
282 - (right.minute * 60 * 1000000)
283 - (right.second * 1000000)
284 - (right.microsecond)
285 )
288def _sqlite_timestamp_diff(lhs, rhs):
289 if lhs is None or rhs is None:
290 return None
291 left = typecast_timestamp(lhs)
292 right = typecast_timestamp(rhs)
293 return duration_microseconds(left - right)
296def _sqlite_regexp(pattern, string):
297 if pattern is None or string is None:
298 return None
299 if not isinstance(string, str):
300 string = str(string)
301 return bool(re_search(pattern, string))
304def _sqlite_acos(x):
305 if x is None:
306 return None
307 return acos(x)
310def _sqlite_asin(x):
311 if x is None:
312 return None
313 return asin(x)
316def _sqlite_atan(x):
317 if x is None:
318 return None
319 return atan(x)
322def _sqlite_atan2(y, x):
323 if y is None or x is None:
324 return None
325 return atan2(y, x)
328def _sqlite_bitxor(x, y):
329 if x is None or y is None:
330 return None
331 return x ^ y
334def _sqlite_ceiling(x):
335 if x is None:
336 return None
337 return ceil(x)
340def _sqlite_cos(x):
341 if x is None:
342 return None
343 return cos(x)
346def _sqlite_cot(x):
347 if x is None:
348 return None
349 return 1 / tan(x)
352def _sqlite_degrees(x):
353 if x is None:
354 return None
355 return degrees(x)
358def _sqlite_exp(x):
359 if x is None:
360 return None
361 return exp(x)
364def _sqlite_floor(x):
365 if x is None:
366 return None
367 return floor(x)
370def _sqlite_ln(x):
371 if x is None:
372 return None
373 return log(x)
376def _sqlite_log(base, x):
377 if base is None or x is None:
378 return None
379 # Arguments reversed to match SQL standard.
380 return log(x, base)
383def _sqlite_lpad(text, length, fill_text):
384 if text is None or length is None or fill_text is None:
385 return None
386 delta = length - len(text)
387 if delta <= 0:
388 return text[:length]
389 return (fill_text * length)[:delta] + text
392def _sqlite_md5(text):
393 if text is None:
394 return None
395 return md5(text.encode()).hexdigest()
398def _sqlite_mod(x, y):
399 if x is None or y is None:
400 return None
401 return fmod(x, y)
404def _sqlite_pi():
405 return pi
408def _sqlite_power(x, y):
409 if x is None or y is None:
410 return None
411 return x**y
414def _sqlite_radians(x):
415 if x is None:
416 return None
417 return radians(x)
420def _sqlite_repeat(text, count):
421 if text is None or count is None:
422 return None
423 return text * count
426def _sqlite_reverse(text):
427 if text is None:
428 return None
429 return text[::-1]
432def _sqlite_rpad(text, length, fill_text):
433 if text is None or length is None or fill_text is None:
434 return None
435 return (text + fill_text * length)[:length]
438def _sqlite_sha1(text):
439 if text is None:
440 return None
441 return sha1(text.encode()).hexdigest()
444def _sqlite_sha224(text):
445 if text is None:
446 return None
447 return sha224(text.encode()).hexdigest()
450def _sqlite_sha256(text):
451 if text is None:
452 return None
453 return sha256(text.encode()).hexdigest()
456def _sqlite_sha384(text):
457 if text is None:
458 return None
459 return sha384(text.encode()).hexdigest()
462def _sqlite_sha512(text):
463 if text is None:
464 return None
465 return sha512(text.encode()).hexdigest()
468def _sqlite_sign(x):
469 if x is None:
470 return None
471 return (x > 0) - (x < 0)
474def _sqlite_sin(x):
475 if x is None:
476 return None
477 return sin(x)
480def _sqlite_sqrt(x):
481 if x is None:
482 return None
483 return sqrt(x)
486def _sqlite_tan(x):
487 if x is None:
488 return None
489 return tan(x)
492class ListAggregate(list):
493 step = list.append
496class StdDevPop(ListAggregate):
497 finalize = statistics.pstdev
500class StdDevSamp(ListAggregate):
501 finalize = statistics.stdev
504class VarPop(ListAggregate):
505 finalize = statistics.pvariance
508class VarSamp(ListAggregate):
509 finalize = statistics.variance
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2SQLite backend for the sqlite3 module in the standard library.
3"""
4import datetime
5import decimal
6import warnings
7from collections.abc import Mapping
8from itertools import chain, tee
9from sqlite3 import dbapi2 as Database
11from plain.exceptions import ImproperlyConfigured
12from plain.models.backends.base.base import BaseDatabaseWrapper
13from plain.models.db import IntegrityError
14from plain.utils.dateparse import parse_date, parse_datetime, parse_time
15from plain.utils.regex_helper import _lazy_re_compile
17from ._functions import register as register_functions
18from .client import DatabaseClient
19from .creation import DatabaseCreation
20from .features import DatabaseFeatures
21from .introspection import DatabaseIntrospection
22from .operations import DatabaseOperations
23from .schema import DatabaseSchemaEditor
26def decoder(conv_func):
27 """
28 Convert bytestrings from Python's sqlite3 interface to a regular string.
29 """
30 return lambda s: conv_func(s.decode())
33def adapt_date(val):
34 return val.isoformat()
37def adapt_datetime(val):
38 return val.isoformat(" ")
41Database.register_converter("bool", b"1".__eq__)
42Database.register_converter("date", decoder(parse_date))
43Database.register_converter("time", decoder(parse_time))
44Database.register_converter("datetime", decoder(parse_datetime))
45Database.register_converter("timestamp", decoder(parse_datetime))
47Database.register_adapter(decimal.Decimal, str)
48Database.register_adapter(datetime.date, adapt_date)
49Database.register_adapter(datetime.datetime, adapt_datetime)
52class DatabaseWrapper(BaseDatabaseWrapper):
53 vendor = "sqlite"
54 display_name = "SQLite"
55 # SQLite doesn't actually support most of these types, but it "does the right
56 # thing" given more verbose field definitions, so leave them as is so that
57 # schema inspection is more useful.
58 data_types = {
59 "AutoField": "integer",
60 "BigAutoField": "integer",
61 "BinaryField": "BLOB",
62 "BooleanField": "bool",
63 "CharField": "varchar(%(max_length)s)",
64 "DateField": "date",
65 "DateTimeField": "datetime",
66 "DecimalField": "decimal",
67 "DurationField": "bigint",
68 "FloatField": "real",
69 "IntegerField": "integer",
70 "BigIntegerField": "bigint",
71 "IPAddressField": "char(15)",
72 "GenericIPAddressField": "char(39)",
73 "JSONField": "text",
74 "OneToOneField": "integer",
75 "PositiveBigIntegerField": "bigint unsigned",
76 "PositiveIntegerField": "integer unsigned",
77 "PositiveSmallIntegerField": "smallint unsigned",
78 "SlugField": "varchar(%(max_length)s)",
79 "SmallAutoField": "integer",
80 "SmallIntegerField": "smallint",
81 "TextField": "text",
82 "TimeField": "time",
83 "UUIDField": "char(32)",
84 }
85 data_type_check_constraints = {
86 "PositiveBigIntegerField": '"%(column)s" >= 0',
87 "JSONField": '(JSON_VALID("%(column)s") OR "%(column)s" IS NULL)',
88 "PositiveIntegerField": '"%(column)s" >= 0',
89 "PositiveSmallIntegerField": '"%(column)s" >= 0',
90 }
91 data_types_suffix = {
92 "AutoField": "AUTOINCREMENT",
93 "BigAutoField": "AUTOINCREMENT",
94 "SmallAutoField": "AUTOINCREMENT",
95 }
96 # SQLite requires LIKE statements to include an ESCAPE clause if the value
97 # being escaped has a percent or underscore in it.
98 # See https://www.sqlite.org/lang_expr.html for an explanation.
99 operators = {
100 "exact": "= %s",
101 "iexact": "LIKE %s ESCAPE '\\'",
102 "contains": "LIKE %s ESCAPE '\\'",
103 "icontains": "LIKE %s ESCAPE '\\'",
104 "regex": "REGEXP %s",
105 "iregex": "REGEXP '(?i)' || %s",
106 "gt": "> %s",
107 "gte": ">= %s",
108 "lt": "< %s",
109 "lte": "<= %s",
110 "startswith": "LIKE %s ESCAPE '\\'",
111 "endswith": "LIKE %s ESCAPE '\\'",
112 "istartswith": "LIKE %s ESCAPE '\\'",
113 "iendswith": "LIKE %s ESCAPE '\\'",
114 }
116 # The patterns below are used to generate SQL pattern lookup clauses when
117 # the right-hand side of the lookup isn't a raw string (it might be an expression
118 # or the result of a bilateral transformation).
119 # In those cases, special characters for LIKE operators (e.g. \, *, _) should be
120 # escaped on database side.
121 #
122 # Note: we use str.format() here for readability as '%' is used as a wildcard for
123 # the LIKE operator.
124 pattern_esc = r"REPLACE(REPLACE(REPLACE({}, '\', '\\'), '%%', '\%%'), '_', '\_')"
125 pattern_ops = {
126 "contains": r"LIKE '%%' || {} || '%%' ESCAPE '\'",
127 "icontains": r"LIKE '%%' || UPPER({}) || '%%' ESCAPE '\'",
128 "startswith": r"LIKE {} || '%%' ESCAPE '\'",
129 "istartswith": r"LIKE UPPER({}) || '%%' ESCAPE '\'",
130 "endswith": r"LIKE '%%' || {} ESCAPE '\'",
131 "iendswith": r"LIKE '%%' || UPPER({}) ESCAPE '\'",
132 }
134 Database = Database
135 SchemaEditorClass = DatabaseSchemaEditor
136 # Classes instantiated in __init__().
137 client_class = DatabaseClient
138 creation_class = DatabaseCreation
139 features_class = DatabaseFeatures
140 introspection_class = DatabaseIntrospection
141 ops_class = DatabaseOperations
143 def get_connection_params(self):
144 settings_dict = self.settings_dict
145 if not settings_dict["NAME"]:
146 raise ImproperlyConfigured(
147 "settings.DATABASES is improperly configured. "
148 "Please supply the NAME value."
149 )
150 kwargs = {
151 "database": settings_dict["NAME"],
152 "detect_types": Database.PARSE_DECLTYPES | Database.PARSE_COLNAMES,
153 **settings_dict["OPTIONS"],
154 }
155 # Always allow the underlying SQLite connection to be shareable
156 # between multiple threads. The safe-guarding will be handled at a
157 # higher level by the `BaseDatabaseWrapper.allow_thread_sharing`
158 # property. This is necessary as the shareability is disabled by
159 # default in sqlite3 and it cannot be changed once a connection is
160 # opened.
161 if "check_same_thread" in kwargs and kwargs["check_same_thread"]:
162 warnings.warn(
163 "The `check_same_thread` option was provided and set to "
164 "True. It will be overridden with False. Use the "
165 "`DatabaseWrapper.allow_thread_sharing` property instead "
166 "for controlling thread shareability.",
167 RuntimeWarning,
168 )
169 kwargs.update({"check_same_thread": False, "uri": True})
170 return kwargs
172 def get_database_version(self):
173 return self.Database.sqlite_version_info
175 def get_new_connection(self, conn_params):
176 conn = Database.connect(**conn_params)
177 register_functions(conn)
179 conn.execute("PRAGMA foreign_keys = ON")
180 # The macOS bundled SQLite defaults legacy_alter_table ON, which
181 # prevents atomic table renames (feature supports_atomic_references_rename)
182 conn.execute("PRAGMA legacy_alter_table = OFF")
183 return conn
185 def create_cursor(self, name=None):
186 return self.connection.cursor(factory=SQLiteCursorWrapper)
188 def close(self):
189 self.validate_thread_sharing()
190 # If database is in memory, closing the connection destroys the
191 # database. To prevent accidental data loss, ignore close requests on
192 # an in-memory db.
193 if not self.is_in_memory_db():
194 BaseDatabaseWrapper.close(self)
196 def _savepoint_allowed(self):
197 # When 'isolation_level' is not None, sqlite3 commits before each
198 # savepoint; it's a bug. When it is None, savepoints don't make sense
199 # because autocommit is enabled. The only exception is inside 'atomic'
200 # blocks. To work around that bug, on SQLite, 'atomic' starts a
201 # transaction explicitly rather than simply disable autocommit.
202 return self.in_atomic_block
204 def _set_autocommit(self, autocommit):
205 if autocommit:
206 level = None
207 else:
208 # sqlite3's internal default is ''. It's different from None.
209 # See Modules/_sqlite/connection.c.
210 level = ""
211 # 'isolation_level' is a misleading API.
212 # SQLite always runs at the SERIALIZABLE isolation level.
213 with self.wrap_database_errors:
214 self.connection.isolation_level = level
216 def disable_constraint_checking(self):
217 with self.cursor() as cursor:
218 cursor.execute("PRAGMA foreign_keys = OFF")
219 # Foreign key constraints cannot be turned off while in a multi-
220 # statement transaction. Fetch the current state of the pragma
221 # to determine if constraints are effectively disabled.
222 enabled = cursor.execute("PRAGMA foreign_keys").fetchone()[0]
223 return not bool(enabled)
225 def enable_constraint_checking(self):
226 with self.cursor() as cursor:
227 cursor.execute("PRAGMA foreign_keys = ON")
229 def check_constraints(self, table_names=None):
230 """
231 Check each table name in `table_names` for rows with invalid foreign
232 key references. This method is intended to be used in conjunction with
233 `disable_constraint_checking()` and `enable_constraint_checking()`, to
234 determine if rows with invalid references were entered while constraint
235 checks were off.
236 """
237 with self.cursor() as cursor:
238 if table_names is None:
239 violations = cursor.execute("PRAGMA foreign_key_check").fetchall()
240 else:
241 violations = chain.from_iterable(
242 cursor.execute(
243 "PRAGMA foreign_key_check(%s)" % self.ops.quote_name(table_name)
244 ).fetchall()
245 for table_name in table_names
246 )
247 # See https://www.sqlite.org/pragma.html#pragma_foreign_key_check
248 for (
249 table_name,
250 rowid,
251 referenced_table_name,
252 foreign_key_index,
253 ) in violations:
254 foreign_key = cursor.execute(
255 "PRAGMA foreign_key_list(%s)" % self.ops.quote_name(table_name)
256 ).fetchall()[foreign_key_index]
257 column_name, referenced_column_name = foreign_key[3:5]
258 primary_key_column_name = self.introspection.get_primary_key_column(
259 cursor, table_name
260 )
261 primary_key_value, bad_value = cursor.execute(
262 "SELECT {}, {} FROM {} WHERE rowid = %s".format(
263 self.ops.quote_name(primary_key_column_name),
264 self.ops.quote_name(column_name),
265 self.ops.quote_name(table_name),
266 ),
267 (rowid,),
268 ).fetchone()
269 raise IntegrityError(
270 "The row in table '{}' with primary key '{}' has an "
271 "invalid foreign key: {}.{} contains a value '{}' that "
272 "does not have a corresponding value in {}.{}.".format(
273 table_name,
274 primary_key_value,
275 table_name,
276 column_name,
277 bad_value,
278 referenced_table_name,
279 referenced_column_name,
280 )
281 )
283 def is_usable(self):
284 return True
286 def _start_transaction_under_autocommit(self):
287 """
288 Start a transaction explicitly in autocommit mode.
290 Staying in autocommit mode works around a bug of sqlite3 that breaks
291 savepoints when autocommit is disabled.
292 """
293 self.cursor().execute("BEGIN")
295 def is_in_memory_db(self):
296 return self.creation.is_in_memory_db(self.settings_dict["NAME"])
299FORMAT_QMARK_REGEX = _lazy_re_compile(r"(?<!%)%s")
302class SQLiteCursorWrapper(Database.Cursor):
303 """
304 Plain uses the "format" and "pyformat" styles, but Python's sqlite3 module
305 supports neither of these styles.
307 This wrapper performs the following conversions:
309 - "format" style to "qmark" style
310 - "pyformat" style to "named" style
312 In both cases, if you want to use a literal "%s", you'll need to use "%%s".
313 """
315 def execute(self, query, params=None):
316 if params is None:
317 return super().execute(query)
318 # Extract names if params is a mapping, i.e. "pyformat" style is used.
319 param_names = list(params) if isinstance(params, Mapping) else None
320 query = self.convert_query(query, param_names=param_names)
321 return super().execute(query, params)
323 def executemany(self, query, param_list):
324 # Extract names if params is a mapping, i.e. "pyformat" style is used.
325 # Peek carefully as a generator can be passed instead of a list/tuple.
326 peekable, param_list = tee(iter(param_list))
327 if (params := next(peekable, None)) and isinstance(params, Mapping):
328 param_names = list(params)
329 else:
330 param_names = None
331 query = self.convert_query(query, param_names=param_names)
332 return super().executemany(query, param_list)
334 def convert_query(self, query, *, param_names=None):
335 if param_names is None:
336 # Convert from "format" style to "qmark" style.
337 return FORMAT_QMARK_REGEX.sub("?", query).replace("%%", "%")
338 else:
339 # Convert from "pyformat" style to "named" style.
340 return query % {name: f":{name}" for name in param_names}
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.models.backends.base.client import BaseDatabaseClient
4class DatabaseClient(BaseDatabaseClient):
5 executable_name = "sqlite3"
7 @classmethod
8 def settings_to_cmd_args_env(cls, settings_dict, parameters):
9 args = [cls.executable_name, settings_dict["NAME"], *parameters]
10 return args, None
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import multiprocessing
2import os
3import shutil
4import sqlite3
5import sys
6from pathlib import Path
8from plain.models.backends.base.creation import BaseDatabaseCreation
9from plain.models.db import NotSupportedError
12class DatabaseCreation(BaseDatabaseCreation):
13 @staticmethod
14 def is_in_memory_db(database_name):
15 return not isinstance(database_name, Path) and (
16 database_name == ":memory:" or "mode=memory" in database_name
17 )
19 def _get_test_db_name(self):
20 test_database_name = self.connection.settings_dict["TEST"]["NAME"] or ":memory:"
21 if test_database_name == ":memory:":
22 return "file:memorydb_%s?mode=memory&cache=shared" % self.connection.alias
23 return test_database_name
25 def _create_test_db(self, verbosity, autoclobber, keepdb=False):
26 test_database_name = self._get_test_db_name()
28 if keepdb:
29 return test_database_name
30 if not self.is_in_memory_db(test_database_name):
31 # Erase the old test database
32 if verbosity >= 1:
33 self.log(
34 "Destroying old test database for alias {}...".format(
35 self._get_database_display_str(verbosity, test_database_name)
36 )
37 )
38 if os.access(test_database_name, os.F_OK):
39 if not autoclobber:
40 confirm = input(
41 "Type 'yes' if you would like to try deleting the test "
42 "database '%s', or 'no' to cancel: " % test_database_name
43 )
44 if autoclobber or confirm == "yes":
45 try:
46 os.remove(test_database_name)
47 except Exception as e:
48 self.log("Got an error deleting the old test database: %s" % e)
49 sys.exit(2)
50 else:
51 self.log("Tests cancelled.")
52 sys.exit(1)
53 return test_database_name
55 def get_test_db_clone_settings(self, suffix):
56 orig_settings_dict = self.connection.settings_dict
57 source_database_name = orig_settings_dict["NAME"]
59 if not self.is_in_memory_db(source_database_name):
60 root, ext = os.path.splitext(source_database_name)
61 return {**orig_settings_dict, "NAME": f"{root}_{suffix}{ext}"}
63 start_method = multiprocessing.get_start_method()
64 if start_method == "fork":
65 return orig_settings_dict
66 if start_method == "spawn":
67 return {
68 **orig_settings_dict,
69 "NAME": f"{self.connection.alias}_{suffix}.sqlite3",
70 }
71 raise NotSupportedError(
72 f"Cloning with start method {start_method!r} is not supported."
73 )
75 def _clone_test_db(self, suffix, verbosity, keepdb=False):
76 source_database_name = self.connection.settings_dict["NAME"]
77 target_database_name = self.get_test_db_clone_settings(suffix)["NAME"]
78 if not self.is_in_memory_db(source_database_name):
79 # Erase the old test database
80 if os.access(target_database_name, os.F_OK):
81 if keepdb:
82 return
83 if verbosity >= 1:
84 self.log(
85 "Destroying old test database for alias {}...".format(
86 self._get_database_display_str(
87 verbosity, target_database_name
88 ),
89 )
90 )
91 try:
92 os.remove(target_database_name)
93 except Exception as e:
94 self.log("Got an error deleting the old test database: %s" % e)
95 sys.exit(2)
96 try:
97 shutil.copy(source_database_name, target_database_name)
98 except Exception as e:
99 self.log("Got an error cloning the test database: %s" % e)
100 sys.exit(2)
101 # Forking automatically makes a copy of an in-memory database.
102 # Spawn requires migrating to disk which will be re-opened in
103 # setup_worker_connection.
104 elif multiprocessing.get_start_method() == "spawn":
105 ondisk_db = sqlite3.connect(target_database_name, uri=True)
106 self.connection.connection.backup(ondisk_db)
107 ondisk_db.close()
109 def _destroy_test_db(self, test_database_name, verbosity):
110 if test_database_name and not self.is_in_memory_db(test_database_name):
111 # Remove the SQLite database file
112 os.remove(test_database_name)
114 def test_db_signature(self):
115 """
116 Return a tuple that uniquely identifies a test database.
118 This takes into account the special cases of ":memory:" and "" for
119 SQLite since the databases will be distinct despite having the same
120 TEST NAME. See https://www.sqlite.org/inmemorydb.html
121 """
122 test_database_name = self._get_test_db_name()
123 sig = [self.connection.settings_dict["NAME"]]
124 if self.is_in_memory_db(test_database_name):
125 sig.append(self.connection.alias)
126 else:
127 sig.append(test_database_name)
128 return tuple(sig)
130 def setup_worker_connection(self, _worker_id):
131 settings_dict = self.get_test_db_clone_settings(_worker_id)
132 # connection.settings_dict must be updated in place for changes to be
133 # reflected in plain.models.connections. Otherwise new threads would
134 # connect to the default database instead of the appropriate clone.
135 start_method = multiprocessing.get_start_method()
136 if start_method == "fork":
137 # Update settings_dict in place.
138 self.connection.settings_dict.update(settings_dict)
139 self.connection.close()
140 elif start_method == "spawn":
141 alias = self.connection.alias
142 connection_str = (
143 f"file:memorydb_{alias}_{_worker_id}?mode=memory&cache=shared"
144 )
145 source_db = self.connection.Database.connect(
146 f"file:{alias}_{_worker_id}.sqlite3", uri=True
147 )
148 target_db = sqlite3.connect(connection_str, uri=True)
149 source_db.backup(target_db)
150 source_db.close()
151 # Update settings_dict in place.
152 self.connection.settings_dict.update(settings_dict)
153 self.connection.settings_dict["NAME"] = connection_str
154 # Re-open connection to in-memory database before closing copy
155 # connection.
156 self.connection.connect()
157 target_db.close()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import operator
3from plain.models import transaction
4from plain.models.backends.base.features import BaseDatabaseFeatures
5from plain.models.db import OperationalError
6from plain.utils.functional import cached_property
8from .base import Database
11class DatabaseFeatures(BaseDatabaseFeatures):
12 minimum_database_version = (3, 21)
13 test_db_allows_multiple_connections = False
14 supports_unspecified_pk = True
15 supports_timezones = False
16 max_query_params = 999
17 supports_transactions = True
18 atomic_transactions = False
19 can_rollback_ddl = True
20 can_create_inline_fk = False
21 requires_literal_defaults = True
22 can_clone_databases = True
23 supports_temporal_subtraction = True
24 ignores_table_name_case = True
25 supports_cast_with_precision = False
26 time_cast_precision = 3
27 can_release_savepoints = True
28 has_case_insensitive_like = True
29 # Is "ALTER TABLE ... RENAME COLUMN" supported?
30 can_alter_table_rename_column = Database.sqlite_version_info >= (3, 25, 0)
31 # Is "ALTER TABLE ... DROP COLUMN" supported?
32 can_alter_table_drop_column = Database.sqlite_version_info >= (3, 35, 5)
33 supports_parentheses_in_compound = False
34 can_defer_constraint_checks = True
35 supports_over_clause = Database.sqlite_version_info >= (3, 25, 0)
36 supports_frame_range_fixed_distance = Database.sqlite_version_info >= (3, 28, 0)
37 supports_aggregate_filter_clause = Database.sqlite_version_info >= (3, 30, 1)
38 supports_order_by_nulls_modifier = Database.sqlite_version_info >= (3, 30, 0)
39 # NULLS LAST/FIRST emulation on < 3.30 requires subquery wrapping.
40 requires_compound_order_by_subquery = Database.sqlite_version_info < (3, 30)
41 order_by_nulls_first = True
42 supports_json_field_contains = False
43 supports_update_conflicts = Database.sqlite_version_info >= (3, 24, 0)
44 supports_update_conflicts_with_target = supports_update_conflicts
45 test_collations = {
46 "ci": "nocase",
47 "cs": "binary",
48 "non_default": "nocase",
49 }
50 create_test_table_with_composite_primary_key = """
51 CREATE TABLE test_table_composite_pk (
52 column_1 INTEGER NOT NULL,
53 column_2 INTEGER NOT NULL,
54 PRIMARY KEY(column_1, column_2)
55 )
56 """
58 @cached_property
59 def supports_atomic_references_rename(self):
60 return Database.sqlite_version_info >= (3, 26, 0)
62 @cached_property
63 def introspected_field_types(self):
64 return {
65 **super().introspected_field_types,
66 "BigAutoField": "AutoField",
67 "DurationField": "BigIntegerField",
68 "GenericIPAddressField": "CharField",
69 "SmallAutoField": "AutoField",
70 }
72 @cached_property
73 def supports_json_field(self):
74 with self.connection.cursor() as cursor:
75 try:
76 with transaction.atomic(self.connection.alias):
77 cursor.execute('SELECT JSON(\'{"a": "b"}\')')
78 except OperationalError:
79 return False
80 return True
82 can_introspect_json_field = property(operator.attrgetter("supports_json_field"))
83 has_json_object_function = property(operator.attrgetter("supports_json_field"))
85 @cached_property
86 def can_return_columns_from_insert(self):
87 return Database.sqlite_version_info >= (3, 35)
89 can_return_rows_from_bulk_insert = property(
90 operator.attrgetter("can_return_columns_from_insert")
91 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from collections import namedtuple
3import sqlparse
5from plain.models import Index
6from plain.models.backends.base.introspection import (
7 BaseDatabaseIntrospection,
8 TableInfo,
9)
10from plain.models.backends.base.introspection import FieldInfo as BaseFieldInfo
11from plain.models.db import DatabaseError
12from plain.utils.regex_helper import _lazy_re_compile
14FieldInfo = namedtuple(
15 "FieldInfo", BaseFieldInfo._fields + ("pk", "has_json_constraint")
16)
18field_size_re = _lazy_re_compile(r"^\s*(?:var)?char\s*\(\s*(\d+)\s*\)\s*$")
21def get_field_size(name):
22 """Extract the size number from a "varchar(11)" type name"""
23 m = field_size_re.search(name)
24 return int(m[1]) if m else None
27# This light wrapper "fakes" a dictionary interface, because some SQLite data
28# types include variables in them -- e.g. "varchar(30)" -- and can't be matched
29# as a simple dictionary lookup.
30class FlexibleFieldLookupDict:
31 # Maps SQL types to Plain Field types. Some of the SQL types have multiple
32 # entries here because SQLite allows for anything and doesn't normalize the
33 # field type; it uses whatever was given.
34 base_data_types_reverse = {
35 "bool": "BooleanField",
36 "boolean": "BooleanField",
37 "smallint": "SmallIntegerField",
38 "smallint unsigned": "PositiveSmallIntegerField",
39 "smallinteger": "SmallIntegerField",
40 "int": "IntegerField",
41 "integer": "IntegerField",
42 "bigint": "BigIntegerField",
43 "integer unsigned": "PositiveIntegerField",
44 "bigint unsigned": "PositiveBigIntegerField",
45 "decimal": "DecimalField",
46 "real": "FloatField",
47 "text": "TextField",
48 "char": "CharField",
49 "varchar": "CharField",
50 "blob": "BinaryField",
51 "date": "DateField",
52 "datetime": "DateTimeField",
53 "time": "TimeField",
54 }
56 def __getitem__(self, key):
57 key = key.lower().split("(", 1)[0].strip()
58 return self.base_data_types_reverse[key]
61class DatabaseIntrospection(BaseDatabaseIntrospection):
62 data_types_reverse = FlexibleFieldLookupDict()
64 def get_field_type(self, data_type, description):
65 field_type = super().get_field_type(data_type, description)
66 if description.pk and field_type in {
67 "BigIntegerField",
68 "IntegerField",
69 "SmallIntegerField",
70 }:
71 # No support for BigAutoField or SmallAutoField as SQLite treats
72 # all integer primary keys as signed 64-bit integers.
73 return "AutoField"
74 if description.has_json_constraint:
75 return "JSONField"
76 return field_type
78 def get_table_list(self, cursor):
79 """Return a list of table and view names in the current database."""
80 # Skip the sqlite_sequence system table used for autoincrement key
81 # generation.
82 cursor.execute(
83 """
84 SELECT name, type FROM sqlite_master
85 WHERE type in ('table', 'view') AND NOT name='sqlite_sequence'
86 ORDER BY name"""
87 )
88 return [TableInfo(row[0], row[1][0]) for row in cursor.fetchall()]
90 def get_table_description(self, cursor, table_name):
91 """
92 Return a description of the table with the DB-API cursor.description
93 interface.
94 """
95 cursor.execute(
96 "PRAGMA table_info(%s)" % self.connection.ops.quote_name(table_name)
97 )
98 table_info = cursor.fetchall()
99 if not table_info:
100 raise DatabaseError(f"Table {table_name} does not exist (empty pragma).")
101 collations = self._get_column_collations(cursor, table_name)
102 json_columns = set()
103 if self.connection.features.can_introspect_json_field:
104 for line in table_info:
105 column = line[1]
106 json_constraint_sql = '%%json_valid("%s")%%' % column
107 has_json_constraint = cursor.execute(
108 """
109 SELECT sql
110 FROM sqlite_master
111 WHERE
112 type = 'table' AND
113 name = %s AND
114 sql LIKE %s
115 """,
116 [table_name, json_constraint_sql],
117 ).fetchone()
118 if has_json_constraint:
119 json_columns.add(column)
120 return [
121 FieldInfo(
122 name,
123 data_type,
124 get_field_size(data_type),
125 None,
126 None,
127 None,
128 not notnull,
129 default,
130 collations.get(name),
131 pk == 1,
132 name in json_columns,
133 )
134 for cid, name, data_type, notnull, default, pk in table_info
135 ]
137 def get_sequences(self, cursor, table_name, table_fields=()):
138 pk_col = self.get_primary_key_column(cursor, table_name)
139 return [{"table": table_name, "column": pk_col}]
141 def get_relations(self, cursor, table_name):
142 """
143 Return a dictionary of {column_name: (ref_column_name, ref_table_name)}
144 representing all foreign keys in the given table.
145 """
146 cursor.execute(
147 "PRAGMA foreign_key_list(%s)" % self.connection.ops.quote_name(table_name)
148 )
149 return {
150 column_name: (ref_column_name, ref_table_name)
151 for (
152 _,
153 _,
154 ref_table_name,
155 column_name,
156 ref_column_name,
157 *_,
158 ) in cursor.fetchall()
159 }
161 def get_primary_key_columns(self, cursor, table_name):
162 cursor.execute(
163 "PRAGMA table_info(%s)" % self.connection.ops.quote_name(table_name)
164 )
165 return [name for _, name, *_, pk in cursor.fetchall() if pk]
167 def _parse_column_or_constraint_definition(self, tokens, columns):
168 token = None
169 is_constraint_definition = None
170 field_name = None
171 constraint_name = None
172 unique = False
173 unique_columns = []
174 check = False
175 check_columns = []
176 braces_deep = 0
177 for token in tokens:
178 if token.match(sqlparse.tokens.Punctuation, "("):
179 braces_deep += 1
180 elif token.match(sqlparse.tokens.Punctuation, ")"):
181 braces_deep -= 1
182 if braces_deep < 0:
183 # End of columns and constraints for table definition.
184 break
185 elif braces_deep == 0 and token.match(sqlparse.tokens.Punctuation, ","):
186 # End of current column or constraint definition.
187 break
188 # Detect column or constraint definition by first token.
189 if is_constraint_definition is None:
190 is_constraint_definition = token.match(
191 sqlparse.tokens.Keyword, "CONSTRAINT"
192 )
193 if is_constraint_definition:
194 continue
195 if is_constraint_definition:
196 # Detect constraint name by second token.
197 if constraint_name is None:
198 if token.ttype in (sqlparse.tokens.Name, sqlparse.tokens.Keyword):
199 constraint_name = token.value
200 elif token.ttype == sqlparse.tokens.Literal.String.Symbol:
201 constraint_name = token.value[1:-1]
202 # Start constraint columns parsing after UNIQUE keyword.
203 if token.match(sqlparse.tokens.Keyword, "UNIQUE"):
204 unique = True
205 unique_braces_deep = braces_deep
206 elif unique:
207 if unique_braces_deep == braces_deep:
208 if unique_columns:
209 # Stop constraint parsing.
210 unique = False
211 continue
212 if token.ttype in (sqlparse.tokens.Name, sqlparse.tokens.Keyword):
213 unique_columns.append(token.value)
214 elif token.ttype == sqlparse.tokens.Literal.String.Symbol:
215 unique_columns.append(token.value[1:-1])
216 else:
217 # Detect field name by first token.
218 if field_name is None:
219 if token.ttype in (sqlparse.tokens.Name, sqlparse.tokens.Keyword):
220 field_name = token.value
221 elif token.ttype == sqlparse.tokens.Literal.String.Symbol:
222 field_name = token.value[1:-1]
223 if token.match(sqlparse.tokens.Keyword, "UNIQUE"):
224 unique_columns = [field_name]
225 # Start constraint columns parsing after CHECK keyword.
226 if token.match(sqlparse.tokens.Keyword, "CHECK"):
227 check = True
228 check_braces_deep = braces_deep
229 elif check:
230 if check_braces_deep == braces_deep:
231 if check_columns:
232 # Stop constraint parsing.
233 check = False
234 continue
235 if token.ttype in (sqlparse.tokens.Name, sqlparse.tokens.Keyword):
236 if token.value in columns:
237 check_columns.append(token.value)
238 elif token.ttype == sqlparse.tokens.Literal.String.Symbol:
239 if token.value[1:-1] in columns:
240 check_columns.append(token.value[1:-1])
241 unique_constraint = (
242 {
243 "unique": True,
244 "columns": unique_columns,
245 "primary_key": False,
246 "foreign_key": None,
247 "check": False,
248 "index": False,
249 }
250 if unique_columns
251 else None
252 )
253 check_constraint = (
254 {
255 "check": True,
256 "columns": check_columns,
257 "primary_key": False,
258 "unique": False,
259 "foreign_key": None,
260 "index": False,
261 }
262 if check_columns
263 else None
264 )
265 return constraint_name, unique_constraint, check_constraint, token
267 def _parse_table_constraints(self, sql, columns):
268 # Check constraint parsing is based of SQLite syntax diagram.
269 # https://www.sqlite.org/syntaxdiagrams.html#table-constraint
270 statement = sqlparse.parse(sql)[0]
271 constraints = {}
272 unnamed_constrains_index = 0
273 tokens = (token for token in statement.flatten() if not token.is_whitespace)
274 # Go to columns and constraint definition
275 for token in tokens:
276 if token.match(sqlparse.tokens.Punctuation, "("):
277 break
278 # Parse columns and constraint definition
279 while True:
280 (
281 constraint_name,
282 unique,
283 check,
284 end_token,
285 ) = self._parse_column_or_constraint_definition(tokens, columns)
286 if unique:
287 if constraint_name:
288 constraints[constraint_name] = unique
289 else:
290 unnamed_constrains_index += 1
291 constraints[
292 "__unnamed_constraint_%s__" % unnamed_constrains_index
293 ] = unique
294 if check:
295 if constraint_name:
296 constraints[constraint_name] = check
297 else:
298 unnamed_constrains_index += 1
299 constraints[
300 "__unnamed_constraint_%s__" % unnamed_constrains_index
301 ] = check
302 if end_token.match(sqlparse.tokens.Punctuation, ")"):
303 break
304 return constraints
306 def get_constraints(self, cursor, table_name):
307 """
308 Retrieve any constraints or keys (unique, pk, fk, check, index) across
309 one or more columns.
310 """
311 constraints = {}
312 # Find inline check constraints.
313 try:
314 table_schema = cursor.execute(
315 "SELECT sql FROM sqlite_master WHERE type='table' and name={}".format(
316 self.connection.ops.quote_name(table_name)
317 )
318 ).fetchone()[0]
319 except TypeError:
320 # table_name is a view.
321 pass
322 else:
323 columns = {
324 info.name for info in self.get_table_description(cursor, table_name)
325 }
326 constraints.update(self._parse_table_constraints(table_schema, columns))
328 # Get the index info
329 cursor.execute(
330 "PRAGMA index_list(%s)" % self.connection.ops.quote_name(table_name)
331 )
332 for row in cursor.fetchall():
333 # SQLite 3.8.9+ has 5 columns, however older versions only give 3
334 # columns. Discard last 2 columns if there.
335 number, index, unique = row[:3]
336 cursor.execute(
337 "SELECT sql FROM sqlite_master "
338 "WHERE type='index' AND name=%s" % self.connection.ops.quote_name(index)
339 )
340 # There's at most one row.
341 (sql,) = cursor.fetchone() or (None,)
342 # Inline constraints are already detected in
343 # _parse_table_constraints(). The reasons to avoid fetching inline
344 # constraints from `PRAGMA index_list` are:
345 # - Inline constraints can have a different name and information
346 # than what `PRAGMA index_list` gives.
347 # - Not all inline constraints may appear in `PRAGMA index_list`.
348 if not sql:
349 # An inline constraint
350 continue
351 # Get the index info for that index
352 cursor.execute(
353 "PRAGMA index_info(%s)" % self.connection.ops.quote_name(index)
354 )
355 for index_rank, column_rank, column in cursor.fetchall():
356 if index not in constraints:
357 constraints[index] = {
358 "columns": [],
359 "primary_key": False,
360 "unique": bool(unique),
361 "foreign_key": None,
362 "check": False,
363 "index": True,
364 }
365 constraints[index]["columns"].append(column)
366 # Add type and column orders for indexes
367 if constraints[index]["index"]:
368 # SQLite doesn't support any index type other than b-tree
369 constraints[index]["type"] = Index.suffix
370 orders = self._get_index_columns_orders(sql)
371 if orders is not None:
372 constraints[index]["orders"] = orders
373 # Get the PK
374 pk_columns = self.get_primary_key_columns(cursor, table_name)
375 if pk_columns:
376 # SQLite doesn't actually give a name to the PK constraint,
377 # so we invent one. This is fine, as the SQLite backend never
378 # deletes PK constraints by name, as you can't delete constraints
379 # in SQLite; we remake the table with a new PK instead.
380 constraints["__primary__"] = {
381 "columns": pk_columns,
382 "primary_key": True,
383 "unique": False, # It's not actually a unique constraint.
384 "foreign_key": None,
385 "check": False,
386 "index": False,
387 }
388 relations = enumerate(self.get_relations(cursor, table_name).items())
389 constraints.update(
390 {
391 f"fk_{index}": {
392 "columns": [column_name],
393 "primary_key": False,
394 "unique": False,
395 "foreign_key": (ref_table_name, ref_column_name),
396 "check": False,
397 "index": False,
398 }
399 for index, (column_name, (ref_column_name, ref_table_name)) in relations
400 }
401 )
402 return constraints
404 def _get_index_columns_orders(self, sql):
405 tokens = sqlparse.parse(sql)[0]
406 for token in tokens:
407 if isinstance(token, sqlparse.sql.Parenthesis):
408 columns = str(token).strip("()").split(", ")
409 return ["DESC" if info.endswith("DESC") else "ASC" for info in columns]
410 return None
412 def _get_column_collations(self, cursor, table_name):
413 row = cursor.execute(
414 """
415 SELECT sql
416 FROM sqlite_master
417 WHERE type = 'table' AND name = %s
418 """,
419 [table_name],
420 ).fetchone()
421 if not row:
422 return {}
424 sql = row[0]
425 columns = str(sqlparse.parse(sql)[0][-1]).strip("()").split(", ")
426 collations = {}
427 for column in columns:
428 tokens = column[1:].split()
429 column_name = tokens[0].strip('"')
430 for index, token in enumerate(tokens):
431 if token == "COLLATE":
432 collation = tokens[index + 1]
433 break
434 else:
435 collation = None
436 collations[column_name] = collation
437 return collations
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import datetime
2import decimal
3import uuid
4from functools import lru_cache
6from plain import models
7from plain.exceptions import FieldError
8from plain.models.backends.base.operations import BaseDatabaseOperations
9from plain.models.constants import OnConflict
10from plain.models.db import DatabaseError, NotSupportedError
11from plain.models.expressions import Col
12from plain.utils import timezone
13from plain.utils.dateparse import parse_date, parse_datetime, parse_time
14from plain.utils.functional import cached_property
17class DatabaseOperations(BaseDatabaseOperations):
18 cast_char_field_without_max_length = "text"
19 cast_data_types = {
20 "DateField": "TEXT",
21 "DateTimeField": "TEXT",
22 }
23 explain_prefix = "EXPLAIN QUERY PLAN"
24 # List of datatypes to that cannot be extracted with JSON_EXTRACT() on
25 # SQLite. Use JSON_TYPE() instead.
26 jsonfield_datatype_values = frozenset(["null", "false", "true"])
28 def bulk_batch_size(self, fields, objs):
29 """
30 SQLite has a compile-time default (SQLITE_LIMIT_VARIABLE_NUMBER) of
31 999 variables per query.
33 If there's only a single field to insert, the limit is 500
34 (SQLITE_MAX_COMPOUND_SELECT).
35 """
36 if len(fields) == 1:
37 return 500
38 elif len(fields) > 1:
39 return self.connection.features.max_query_params // len(fields)
40 else:
41 return len(objs)
43 def check_expression_support(self, expression):
44 bad_fields = (models.DateField, models.DateTimeField, models.TimeField)
45 bad_aggregates = (models.Sum, models.Avg, models.Variance, models.StdDev)
46 if isinstance(expression, bad_aggregates):
47 for expr in expression.get_source_expressions():
48 try:
49 output_field = expr.output_field
50 except (AttributeError, FieldError):
51 # Not every subexpression has an output_field which is fine
52 # to ignore.
53 pass
54 else:
55 if isinstance(output_field, bad_fields):
56 raise NotSupportedError(
57 "You cannot use Sum, Avg, StdDev, and Variance "
58 "aggregations on date/time fields in sqlite3 "
59 "since date/time is saved as text."
60 )
61 if (
62 isinstance(expression, models.Aggregate)
63 and expression.distinct
64 and len(expression.source_expressions) > 1
65 ):
66 raise NotSupportedError(
67 "SQLite doesn't support DISTINCT on aggregate functions "
68 "accepting multiple arguments."
69 )
71 def date_extract_sql(self, lookup_type, sql, params):
72 """
73 Support EXTRACT with a user-defined function plain_date_extract()
74 that's registered in connect(). Use single quotes because this is a
75 string and could otherwise cause a collision with a field name.
76 """
77 return f"plain_date_extract(%s, {sql})", (lookup_type.lower(), *params)
79 def fetch_returned_insert_rows(self, cursor):
80 """
81 Given a cursor object that has just performed an INSERT...RETURNING
82 statement into a table, return the list of returned data.
83 """
84 return cursor.fetchall()
86 def format_for_duration_arithmetic(self, sql):
87 """Do nothing since formatting is handled in the custom function."""
88 return sql
90 def date_trunc_sql(self, lookup_type, sql, params, tzname=None):
91 return f"plain_date_trunc(%s, {sql}, %s, %s)", (
92 lookup_type.lower(),
93 *params,
94 *self._convert_tznames_to_sql(tzname),
95 )
97 def time_trunc_sql(self, lookup_type, sql, params, tzname=None):
98 return f"plain_time_trunc(%s, {sql}, %s, %s)", (
99 lookup_type.lower(),
100 *params,
101 *self._convert_tznames_to_sql(tzname),
102 )
104 def _convert_tznames_to_sql(self, tzname):
105 if tzname:
106 return tzname, self.connection.timezone_name
107 return None, None
109 def datetime_cast_date_sql(self, sql, params, tzname):
110 return f"plain_datetime_cast_date({sql}, %s, %s)", (
111 *params,
112 *self._convert_tznames_to_sql(tzname),
113 )
115 def datetime_cast_time_sql(self, sql, params, tzname):
116 return f"plain_datetime_cast_time({sql}, %s, %s)", (
117 *params,
118 *self._convert_tznames_to_sql(tzname),
119 )
121 def datetime_extract_sql(self, lookup_type, sql, params, tzname):
122 return f"plain_datetime_extract(%s, {sql}, %s, %s)", (
123 lookup_type.lower(),
124 *params,
125 *self._convert_tznames_to_sql(tzname),
126 )
128 def datetime_trunc_sql(self, lookup_type, sql, params, tzname):
129 return f"plain_datetime_trunc(%s, {sql}, %s, %s)", (
130 lookup_type.lower(),
131 *params,
132 *self._convert_tznames_to_sql(tzname),
133 )
135 def time_extract_sql(self, lookup_type, sql, params):
136 return f"plain_time_extract(%s, {sql})", (lookup_type.lower(), *params)
138 def pk_default_value(self):
139 return "NULL"
141 def _quote_params_for_last_executed_query(self, params):
142 """
143 Only for last_executed_query! Don't use this to execute SQL queries!
144 """
145 # This function is limited both by SQLITE_LIMIT_VARIABLE_NUMBER (the
146 # number of parameters, default = 999) and SQLITE_MAX_COLUMN (the
147 # number of return values, default = 2000). Since Python's sqlite3
148 # module doesn't expose the get_limit() C API, assume the default
149 # limits are in effect and split the work in batches if needed.
150 BATCH_SIZE = 999
151 if len(params) > BATCH_SIZE:
152 results = ()
153 for index in range(0, len(params), BATCH_SIZE):
154 chunk = params[index : index + BATCH_SIZE]
155 results += self._quote_params_for_last_executed_query(chunk)
156 return results
158 sql = "SELECT " + ", ".join(["QUOTE(?)"] * len(params))
159 # Bypass Plain's wrappers and use the underlying sqlite3 connection
160 # to avoid logging this query - it would trigger infinite recursion.
161 cursor = self.connection.connection.cursor()
162 # Native sqlite3 cursors cannot be used as context managers.
163 try:
164 return cursor.execute(sql, params).fetchone()
165 finally:
166 cursor.close()
168 def last_executed_query(self, cursor, sql, params):
169 # Python substitutes parameters in Modules/_sqlite/cursor.c with:
170 # bind_parameters(state, self->statement, parameters);
171 # Unfortunately there is no way to reach self->statement from Python,
172 # so we quote and substitute parameters manually.
173 if params:
174 if isinstance(params, list | tuple):
175 params = self._quote_params_for_last_executed_query(params)
176 else:
177 values = tuple(params.values())
178 values = self._quote_params_for_last_executed_query(values)
179 params = dict(zip(params, values))
180 return sql % params
181 # For consistency with SQLiteCursorWrapper.execute(), just return sql
182 # when there are no parameters. See #13648 and #17158.
183 else:
184 return sql
186 def quote_name(self, name):
187 if name.startswith('"') and name.endswith('"'):
188 return name # Quoting once is enough.
189 return '"%s"' % name
191 def no_limit_value(self):
192 return -1
194 def __references_graph(self, table_name):
195 query = """
196 WITH tables AS (
197 SELECT %s name
198 UNION
199 SELECT sqlite_master.name
200 FROM sqlite_master
201 JOIN tables ON (sql REGEXP %s || tables.name || %s)
202 ) SELECT name FROM tables;
203 """
204 params = (
205 table_name,
206 r'(?i)\s+references\s+("|\')?',
207 r'("|\')?\s*\(',
208 )
209 with self.connection.cursor() as cursor:
210 results = cursor.execute(query, params)
211 return [row[0] for row in results.fetchall()]
213 @cached_property
214 def _references_graph(self):
215 # 512 is large enough to fit the ~330 tables (as of this writing) in
216 # Plain's test suite.
217 return lru_cache(maxsize=512)(self.__references_graph)
219 def sequence_reset_by_name_sql(self, style, sequences):
220 if not sequences:
221 return []
222 return [
223 "{} {} {} {} = 0 {} {} {} ({});".format(
224 style.SQL_KEYWORD("UPDATE"),
225 style.SQL_TABLE(self.quote_name("sqlite_sequence")),
226 style.SQL_KEYWORD("SET"),
227 style.SQL_FIELD(self.quote_name("seq")),
228 style.SQL_KEYWORD("WHERE"),
229 style.SQL_FIELD(self.quote_name("name")),
230 style.SQL_KEYWORD("IN"),
231 ", ".join(
232 ["'%s'" % sequence_info["table"] for sequence_info in sequences]
233 ),
234 ),
235 ]
237 def adapt_datetimefield_value(self, value):
238 if value is None:
239 return None
241 # Expression values are adapted by the database.
242 if hasattr(value, "resolve_expression"):
243 return value
245 # SQLite doesn't support tz-aware datetimes
246 if timezone.is_aware(value):
247 value = timezone.make_naive(value, self.connection.timezone)
249 return str(value)
251 def adapt_timefield_value(self, value):
252 if value is None:
253 return None
255 # Expression values are adapted by the database.
256 if hasattr(value, "resolve_expression"):
257 return value
259 # SQLite doesn't support tz-aware datetimes
260 if timezone.is_aware(value):
261 raise ValueError("SQLite backend does not support timezone-aware times.")
263 return str(value)
265 def get_db_converters(self, expression):
266 converters = super().get_db_converters(expression)
267 internal_type = expression.output_field.get_internal_type()
268 if internal_type == "DateTimeField":
269 converters.append(self.convert_datetimefield_value)
270 elif internal_type == "DateField":
271 converters.append(self.convert_datefield_value)
272 elif internal_type == "TimeField":
273 converters.append(self.convert_timefield_value)
274 elif internal_type == "DecimalField":
275 converters.append(self.get_decimalfield_converter(expression))
276 elif internal_type == "UUIDField":
277 converters.append(self.convert_uuidfield_value)
278 elif internal_type == "BooleanField":
279 converters.append(self.convert_booleanfield_value)
280 return converters
282 def convert_datetimefield_value(self, value, expression, connection):
283 if value is not None:
284 if not isinstance(value, datetime.datetime):
285 value = parse_datetime(value)
286 if not timezone.is_aware(value):
287 value = timezone.make_aware(value, self.connection.timezone)
288 return value
290 def convert_datefield_value(self, value, expression, connection):
291 if value is not None:
292 if not isinstance(value, datetime.date):
293 value = parse_date(value)
294 return value
296 def convert_timefield_value(self, value, expression, connection):
297 if value is not None:
298 if not isinstance(value, datetime.time):
299 value = parse_time(value)
300 return value
302 def get_decimalfield_converter(self, expression):
303 # SQLite stores only 15 significant digits. Digits coming from
304 # float inaccuracy must be removed.
305 create_decimal = decimal.Context(prec=15).create_decimal_from_float
306 if isinstance(expression, Col):
307 quantize_value = decimal.Decimal(1).scaleb(
308 -expression.output_field.decimal_places
309 )
311 def converter(value, expression, connection):
312 if value is not None:
313 return create_decimal(value).quantize(
314 quantize_value, context=expression.output_field.context
315 )
317 else:
319 def converter(value, expression, connection):
320 if value is not None:
321 return create_decimal(value)
323 return converter
325 def convert_uuidfield_value(self, value, expression, connection):
326 if value is not None:
327 value = uuid.UUID(value)
328 return value
330 def convert_booleanfield_value(self, value, expression, connection):
331 return bool(value) if value in (1, 0) else value
333 def bulk_insert_sql(self, fields, placeholder_rows):
334 placeholder_rows_sql = (", ".join(row) for row in placeholder_rows)
335 values_sql = ", ".join(f"({sql})" for sql in placeholder_rows_sql)
336 return f"VALUES {values_sql}"
338 def combine_expression(self, connector, sub_expressions):
339 # SQLite doesn't have a ^ operator, so use the user-defined POWER
340 # function that's registered in connect().
341 if connector == "^":
342 return "POWER(%s)" % ",".join(sub_expressions)
343 elif connector == "#":
344 return "BITXOR(%s)" % ",".join(sub_expressions)
345 return super().combine_expression(connector, sub_expressions)
347 def combine_duration_expression(self, connector, sub_expressions):
348 if connector not in ["+", "-", "*", "/"]:
349 raise DatabaseError("Invalid connector for timedelta: %s." % connector)
350 fn_params = ["'%s'" % connector] + sub_expressions
351 if len(fn_params) > 3:
352 raise ValueError("Too many params for timedelta operations.")
353 return "plain_format_dtdelta(%s)" % ", ".join(fn_params)
355 def integer_field_range(self, internal_type):
356 # SQLite doesn't enforce any integer constraints, but sqlite3 supports
357 # integers up to 64 bits.
358 if internal_type in [
359 "PositiveBigIntegerField",
360 "PositiveIntegerField",
361 "PositiveSmallIntegerField",
362 ]:
363 return (0, 9223372036854775807)
364 return (-9223372036854775808, 9223372036854775807)
366 def subtract_temporals(self, internal_type, lhs, rhs):
367 lhs_sql, lhs_params = lhs
368 rhs_sql, rhs_params = rhs
369 params = (*lhs_params, *rhs_params)
370 if internal_type == "TimeField":
371 return f"plain_time_diff({lhs_sql}, {rhs_sql})", params
372 return f"plain_timestamp_diff({lhs_sql}, {rhs_sql})", params
374 def insert_statement(self, on_conflict=None):
375 if on_conflict == OnConflict.IGNORE:
376 return "INSERT OR IGNORE INTO"
377 return super().insert_statement(on_conflict=on_conflict)
379 def return_insert_columns(self, fields):
380 # SQLite < 3.35 doesn't support an INSERT...RETURNING statement.
381 if not fields:
382 return "", ()
383 columns = [
384 "{}.{}".format(
385 self.quote_name(field.model._meta.db_table),
386 self.quote_name(field.column),
387 )
388 for field in fields
389 ]
390 return "RETURNING %s" % ", ".join(columns), ()
392 def on_conflict_suffix_sql(self, fields, on_conflict, update_fields, unique_fields):
393 if (
394 on_conflict == OnConflict.UPDATE
395 and self.connection.features.supports_update_conflicts_with_target
396 ):
397 return "ON CONFLICT({}) DO UPDATE SET {}".format(
398 ", ".join(map(self.quote_name, unique_fields)),
399 ", ".join(
400 [
401 f"{field} = EXCLUDED.{field}"
402 for field in map(self.quote_name, update_fields)
403 ]
404 ),
405 )
406 return super().on_conflict_suffix_sql(
407 fields,
408 on_conflict,
409 update_fields,
410 unique_fields,
411 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import copy
2from decimal import Decimal
4from plain.models.backends.base.schema import BaseDatabaseSchemaEditor
5from plain.models.backends.ddl_references import Statement
6from plain.models.backends.utils import strip_quotes
7from plain.models.constraints import UniqueConstraint
8from plain.models.db import NotSupportedError
9from plain.models.transaction import atomic
10from plain.packages.registry import Packages
13class DatabaseSchemaEditor(BaseDatabaseSchemaEditor):
14 sql_delete_table = "DROP TABLE %(table)s"
15 sql_create_fk = None
16 sql_create_inline_fk = (
17 "REFERENCES %(to_table)s (%(to_column)s) DEFERRABLE INITIALLY DEFERRED"
18 )
19 sql_create_column_inline_fk = sql_create_inline_fk
20 sql_delete_column = "ALTER TABLE %(table)s DROP COLUMN %(column)s"
21 sql_create_unique = "CREATE UNIQUE INDEX %(name)s ON %(table)s (%(columns)s)"
22 sql_delete_unique = "DROP INDEX %(name)s"
24 def __enter__(self):
25 # Some SQLite schema alterations need foreign key constraints to be
26 # disabled. Enforce it here for the duration of the schema edition.
27 if not self.connection.disable_constraint_checking():
28 raise NotSupportedError(
29 "SQLite schema editor cannot be used while foreign key "
30 "constraint checks are enabled. Make sure to disable them "
31 "before entering a transaction.atomic() context because "
32 "SQLite does not support disabling them in the middle of "
33 "a multi-statement transaction."
34 )
35 return super().__enter__()
37 def __exit__(self, exc_type, exc_value, traceback):
38 self.connection.check_constraints()
39 super().__exit__(exc_type, exc_value, traceback)
40 self.connection.enable_constraint_checking()
42 def quote_value(self, value):
43 # The backend "mostly works" without this function and there are use
44 # cases for compiling Python without the sqlite3 libraries (e.g.
45 # security hardening).
46 try:
47 import sqlite3
49 value = sqlite3.adapt(value)
50 except ImportError:
51 pass
52 except sqlite3.ProgrammingError:
53 pass
54 # Manual emulation of SQLite parameter quoting
55 if isinstance(value, bool):
56 return str(int(value))
57 elif isinstance(value, Decimal | float | int):
58 return str(value)
59 elif isinstance(value, str):
60 return "'%s'" % value.replace("'", "''")
61 elif value is None:
62 return "NULL"
63 elif isinstance(value, bytes | bytearray | memoryview):
64 # Bytes are only allowed for BLOB fields, encoded as string
65 # literals containing hexadecimal data and preceded by a single "X"
66 # character.
67 return "X'%s'" % value.hex()
68 else:
69 raise ValueError(
70 f"Cannot quote parameter value {value!r} of type {type(value)}"
71 )
73 def prepare_default(self, value):
74 return self.quote_value(value)
76 def _is_referenced_by_fk_constraint(
77 self, table_name, column_name=None, ignore_self=False
78 ):
79 """
80 Return whether or not the provided table name is referenced by another
81 one. If `column_name` is specified, only references pointing to that
82 column are considered. If `ignore_self` is True, self-referential
83 constraints are ignored.
84 """
85 with self.connection.cursor() as cursor:
86 for other_table in self.connection.introspection.get_table_list(cursor):
87 if ignore_self and other_table.name == table_name:
88 continue
89 relations = self.connection.introspection.get_relations(
90 cursor, other_table.name
91 )
92 for constraint_column, constraint_table in relations.values():
93 if constraint_table == table_name and (
94 column_name is None or constraint_column == column_name
95 ):
96 return True
97 return False
99 def alter_db_table(
100 self, model, old_db_table, new_db_table, disable_constraints=True
101 ):
102 if (
103 not self.connection.features.supports_atomic_references_rename
104 and disable_constraints
105 and self._is_referenced_by_fk_constraint(old_db_table)
106 ):
107 if self.connection.in_atomic_block:
108 raise NotSupportedError(
109 (
110 "Renaming the %r table while in a transaction is not "
111 "supported on SQLite < 3.26 because it would break referential "
112 "integrity. Try adding `atomic = False` to the Migration class."
113 )
114 % old_db_table
115 )
116 self.connection.enable_constraint_checking()
117 super().alter_db_table(model, old_db_table, new_db_table)
118 self.connection.disable_constraint_checking()
119 else:
120 super().alter_db_table(model, old_db_table, new_db_table)
122 def alter_field(self, model, old_field, new_field, strict=False):
123 if not self._field_should_be_altered(old_field, new_field):
124 return
125 old_field_name = old_field.name
126 table_name = model._meta.db_table
127 _, old_column_name = old_field.get_attname_column()
128 if (
129 new_field.name != old_field_name
130 and not self.connection.features.supports_atomic_references_rename
131 and self._is_referenced_by_fk_constraint(
132 table_name, old_column_name, ignore_self=True
133 )
134 ):
135 if self.connection.in_atomic_block:
136 raise NotSupportedError(
137 (
138 "Renaming the {!r}.{!r} column while in a transaction is not "
139 "supported on SQLite < 3.26 because it would break referential "
140 "integrity. Try adding `atomic = False` to the Migration class."
141 ).format(model._meta.db_table, old_field_name)
142 )
143 with atomic(self.connection.alias):
144 super().alter_field(model, old_field, new_field, strict=strict)
145 # Follow SQLite's documented procedure for performing changes
146 # that don't affect the on-disk content.
147 # https://sqlite.org/lang_altertable.html#otheralter
148 with self.connection.cursor() as cursor:
149 schema_version = cursor.execute("PRAGMA schema_version").fetchone()[
150 0
151 ]
152 cursor.execute("PRAGMA writable_schema = 1")
153 references_template = ' REFERENCES "%s" ("%%s") ' % table_name
154 new_column_name = new_field.get_attname_column()[1]
155 search = references_template % old_column_name
156 replacement = references_template % new_column_name
157 cursor.execute(
158 "UPDATE sqlite_master SET sql = replace(sql, %s, %s)",
159 (search, replacement),
160 )
161 cursor.execute("PRAGMA schema_version = %d" % (schema_version + 1))
162 cursor.execute("PRAGMA writable_schema = 0")
163 # The integrity check will raise an exception and rollback
164 # the transaction if the sqlite_master updates corrupt the
165 # database.
166 cursor.execute("PRAGMA integrity_check")
167 # Perform a VACUUM to refresh the database representation from
168 # the sqlite_master table.
169 with self.connection.cursor() as cursor:
170 cursor.execute("VACUUM")
171 else:
172 super().alter_field(model, old_field, new_field, strict=strict)
174 def _remake_table(
175 self, model, create_field=None, delete_field=None, alter_fields=None
176 ):
177 """
178 Shortcut to transform a model from old_model into new_model
180 This follows the correct procedure to perform non-rename or column
181 addition operations based on SQLite's documentation
183 https://www.sqlite.org/lang_altertable.html#caution
185 The essential steps are:
186 1. Create a table with the updated definition called "new__app_model"
187 2. Copy the data from the existing "app_model" table to the new table
188 3. Drop the "app_model" table
189 4. Rename the "new__app_model" table to "app_model"
190 5. Restore any index of the previous "app_model" table.
191 """
193 # Self-referential fields must be recreated rather than copied from
194 # the old model to ensure their remote_field.field_name doesn't refer
195 # to an altered field.
196 def is_self_referential(f):
197 return f.is_relation and f.remote_field.model is model
199 # Work out the new fields dict / mapping
200 body = {
201 f.name: f.clone() if is_self_referential(f) else f
202 for f in model._meta.local_concrete_fields
203 }
204 # Since mapping might mix column names and default values,
205 # its values must be already quoted.
206 mapping = {
207 f.column: self.quote_name(f.column)
208 for f in model._meta.local_concrete_fields
209 }
210 # If any of the new or altered fields is introducing a new PK,
211 # remove the old one
212 restore_pk_field = None
213 alter_fields = alter_fields or []
214 if getattr(create_field, "primary_key", False) or any(
215 getattr(new_field, "primary_key", False) for _, new_field in alter_fields
216 ):
217 for name, field in list(body.items()):
218 if field.primary_key and not any(
219 # Do not remove the old primary key when an altered field
220 # that introduces a primary key is the same field.
221 name == new_field.name
222 for _, new_field in alter_fields
223 ):
224 field.primary_key = False
225 restore_pk_field = field
226 if field.auto_created:
227 del body[name]
228 del mapping[field.column]
229 # Add in any created fields
230 if create_field:
231 body[create_field.name] = create_field
232 # Choose a default and insert it into the copy map
233 if not create_field.many_to_many and create_field.concrete:
234 mapping[create_field.column] = self.prepare_default(
235 self.effective_default(create_field),
236 )
237 # Add in any altered fields
238 for alter_field in alter_fields:
239 old_field, new_field = alter_field
240 body.pop(old_field.name, None)
241 mapping.pop(old_field.column, None)
242 body[new_field.name] = new_field
243 if old_field.null and not new_field.null:
244 case_sql = "coalesce({col}, {default})".format(
245 col=self.quote_name(old_field.column),
246 default=self.prepare_default(self.effective_default(new_field)),
247 )
248 mapping[new_field.column] = case_sql
249 else:
250 mapping[new_field.column] = self.quote_name(old_field.column)
251 # Remove any deleted fields
252 if delete_field:
253 del body[delete_field.name]
254 del mapping[delete_field.column]
255 # Remove any implicit M2M tables
256 if (
257 delete_field.many_to_many
258 and delete_field.remote_field.through._meta.auto_created
259 ):
260 return self.delete_model(delete_field.remote_field.through)
261 # Work inside a new app registry
262 packages = Packages()
264 indexes = model._meta.indexes
265 if delete_field:
266 indexes = [
267 index for index in indexes if delete_field.name not in index.fields
268 ]
270 constraints = list(model._meta.constraints)
272 # Provide isolated instances of the fields to the new model body so
273 # that the existing model's internals aren't interfered with when
274 # the dummy model is constructed.
275 body_copy = copy.deepcopy(body)
277 # Construct a new model with the new fields to allow self referential
278 # primary key to resolve to. This model won't ever be materialized as a
279 # table and solely exists for foreign key reference resolution purposes.
280 # This wouldn't be required if the schema editor was operating on model
281 # states instead of rendered models.
282 meta_contents = {
283 "package_label": model._meta.package_label,
284 "db_table": model._meta.db_table,
285 "indexes": indexes,
286 "constraints": constraints,
287 "packages": packages,
288 }
289 meta = type("Meta", (), meta_contents)
290 body_copy["Meta"] = meta
291 body_copy["__module__"] = model.__module__
292 type(model._meta.object_name, model.__bases__, body_copy)
294 # Construct a model with a renamed table name.
295 body_copy = copy.deepcopy(body)
296 meta_contents = {
297 "package_label": model._meta.package_label,
298 "db_table": "new__%s" % strip_quotes(model._meta.db_table),
299 "indexes": indexes,
300 "constraints": constraints,
301 "packages": packages,
302 }
303 meta = type("Meta", (), meta_contents)
304 body_copy["Meta"] = meta
305 body_copy["__module__"] = model.__module__
306 new_model = type("New%s" % model._meta.object_name, model.__bases__, body_copy)
308 # Create a new table with the updated schema.
309 self.create_model(new_model)
311 # Copy data from the old table into the new table
312 self.execute(
313 "INSERT INTO {} ({}) SELECT {} FROM {}".format(
314 self.quote_name(new_model._meta.db_table),
315 ", ".join(self.quote_name(x) for x in mapping),
316 ", ".join(mapping.values()),
317 self.quote_name(model._meta.db_table),
318 )
319 )
321 # Delete the old table to make way for the new
322 self.delete_model(model, handle_autom2m=False)
324 # Rename the new table to take way for the old
325 self.alter_db_table(
326 new_model,
327 new_model._meta.db_table,
328 model._meta.db_table,
329 disable_constraints=False,
330 )
332 # Run deferred SQL on correct table
333 for sql in self.deferred_sql:
334 self.execute(sql)
335 self.deferred_sql = []
336 # Fix any PK-removed field
337 if restore_pk_field:
338 restore_pk_field.primary_key = True
340 def delete_model(self, model, handle_autom2m=True):
341 if handle_autom2m:
342 super().delete_model(model)
343 else:
344 # Delete the table (and only that)
345 self.execute(
346 self.sql_delete_table
347 % {
348 "table": self.quote_name(model._meta.db_table),
349 }
350 )
351 # Remove all deferred statements referencing the deleted table.
352 for sql in list(self.deferred_sql):
353 if isinstance(sql, Statement) and sql.references_table(
354 model._meta.db_table
355 ):
356 self.deferred_sql.remove(sql)
358 def add_field(self, model, field):
359 """Create a field on a model."""
360 # Special-case implicit M2M tables.
361 if field.many_to_many and field.remote_field.through._meta.auto_created:
362 self.create_model(field.remote_field.through)
363 elif (
364 # Primary keys and unique fields are not supported in ALTER TABLE
365 # ADD COLUMN.
366 field.primary_key
367 or field.unique
368 or
369 # Fields with default values cannot by handled by ALTER TABLE ADD
370 # COLUMN statement because DROP DEFAULT is not supported in
371 # ALTER TABLE.
372 not field.null
373 or self.effective_default(field) is not None
374 ):
375 self._remake_table(model, create_field=field)
376 else:
377 super().add_field(model, field)
379 def remove_field(self, model, field):
380 """
381 Remove a field from a model. Usually involves deleting a column,
382 but for M2Ms may involve deleting a table.
383 """
384 # M2M fields are a special case
385 if field.many_to_many:
386 # For implicit M2M tables, delete the auto-created table
387 if field.remote_field.through._meta.auto_created:
388 self.delete_model(field.remote_field.through)
389 # For explicit "through" M2M fields, do nothing
390 elif (
391 self.connection.features.can_alter_table_drop_column
392 # Primary keys, unique fields, indexed fields, and foreign keys are
393 # not supported in ALTER TABLE DROP COLUMN.
394 and not field.primary_key
395 and not field.unique
396 and not field.db_index
397 and not (field.remote_field and field.db_constraint)
398 ):
399 super().remove_field(model, field)
400 # For everything else, remake.
401 else:
402 # It might not actually have a column behind it
403 if field.db_parameters(connection=self.connection)["type"] is None:
404 return
405 self._remake_table(model, delete_field=field)
407 def _alter_field(
408 self,
409 model,
410 old_field,
411 new_field,
412 old_type,
413 new_type,
414 old_db_params,
415 new_db_params,
416 strict=False,
417 ):
418 """Perform a "physical" (non-ManyToMany) field update."""
419 # Use "ALTER TABLE ... RENAME COLUMN" if only the column name
420 # changed and there aren't any constraints.
421 if (
422 self.connection.features.can_alter_table_rename_column
423 and old_field.column != new_field.column
424 and self.column_sql(model, old_field) == self.column_sql(model, new_field)
425 and not (
426 old_field.remote_field
427 and old_field.db_constraint
428 or new_field.remote_field
429 and new_field.db_constraint
430 )
431 ):
432 return self.execute(
433 self._rename_field_sql(
434 model._meta.db_table, old_field, new_field, new_type
435 )
436 )
437 # Alter by remaking table
438 self._remake_table(model, alter_fields=[(old_field, new_field)])
439 # Rebuild tables with FKs pointing to this field.
440 old_collation = old_db_params.get("collation")
441 new_collation = new_db_params.get("collation")
442 if new_field.unique and (
443 old_type != new_type or old_collation != new_collation
444 ):
445 related_models = set()
446 opts = new_field.model._meta
447 for remote_field in opts.related_objects:
448 # Ignore self-relationship since the table was already rebuilt.
449 if remote_field.related_model == model:
450 continue
451 if not remote_field.many_to_many:
452 if remote_field.field_name == new_field.name:
453 related_models.add(remote_field.related_model)
454 elif new_field.primary_key and remote_field.through._meta.auto_created:
455 related_models.add(remote_field.through)
456 if new_field.primary_key:
457 for many_to_many in opts.many_to_many:
458 # Ignore self-relationship since the table was already rebuilt.
459 if many_to_many.related_model == model:
460 continue
461 if many_to_many.remote_field.through._meta.auto_created:
462 related_models.add(many_to_many.remote_field.through)
463 for related_model in related_models:
464 self._remake_table(related_model)
466 def _alter_many_to_many(self, model, old_field, new_field, strict):
467 """Alter M2Ms to repoint their to= endpoints."""
468 if (
469 old_field.remote_field.through._meta.db_table
470 == new_field.remote_field.through._meta.db_table
471 ):
472 # The field name didn't change, but some options did, so we have to
473 # propagate this altering.
474 self._remake_table(
475 old_field.remote_field.through,
476 alter_fields=[
477 (
478 # The field that points to the target model is needed,
479 # so that table can be remade with the new m2m field -
480 # this is m2m_reverse_field_name().
481 old_field.remote_field.through._meta.get_field(
482 old_field.m2m_reverse_field_name()
483 ),
484 new_field.remote_field.through._meta.get_field(
485 new_field.m2m_reverse_field_name()
486 ),
487 ),
488 (
489 # The field that points to the model itself is needed,
490 # so that table can be remade with the new self field -
491 # this is m2m_field_name().
492 old_field.remote_field.through._meta.get_field(
493 old_field.m2m_field_name()
494 ),
495 new_field.remote_field.through._meta.get_field(
496 new_field.m2m_field_name()
497 ),
498 ),
499 ],
500 )
501 return
503 # Make a new through table
504 self.create_model(new_field.remote_field.through)
505 # Copy the data across
506 self.execute(
507 "INSERT INTO {} ({}) SELECT {} FROM {}".format(
508 self.quote_name(new_field.remote_field.through._meta.db_table),
509 ", ".join(
510 [
511 "id",
512 new_field.m2m_column_name(),
513 new_field.m2m_reverse_name(),
514 ]
515 ),
516 ", ".join(
517 [
518 "id",
519 old_field.m2m_column_name(),
520 old_field.m2m_reverse_name(),
521 ]
522 ),
523 self.quote_name(old_field.remote_field.through._meta.db_table),
524 )
525 )
526 # Delete the old through table
527 self.delete_model(old_field.remote_field.through)
529 def add_constraint(self, model, constraint):
530 if isinstance(constraint, UniqueConstraint) and (
531 constraint.condition
532 or constraint.contains_expressions
533 or constraint.include
534 or constraint.deferrable
535 ):
536 super().add_constraint(model, constraint)
537 else:
538 self._remake_table(model)
540 def remove_constraint(self, model, constraint):
541 if isinstance(constraint, UniqueConstraint) and (
542 constraint.condition
543 or constraint.contains_expressions
544 or constraint.include
545 or constraint.deferrable
546 ):
547 super().remove_constraint(model, constraint)
548 else:
549 self._remake_table(model)
551 def _collate_sql(self, collation):
552 return "COLLATE " + collation
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:27 -0500
1from plain.runtime import settings
4class DefaultHeadersMiddleware:
5 def __init__(self, get_response):
6 self.get_response = get_response
8 def __call__(self, request):
9 response = self.get_response(request)
11 for header, value in settings.DEFAULT_RESPONSE_HEADERS.items():
12 response.headers.setdefault(header, value)
14 # Add the Content-Length header to non-streaming responses if not
15 # already set.
16 if not response.streaming and not response.has_header("Content-Length"):
17 response.headers["Content-Length"] = str(len(response.content))
19 return response
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:27 -0500
1import re
3from plain.http import ResponsePermanentRedirect
4from plain.runtime import settings
7class HttpsRedirectMiddleware:
8 def __init__(self, get_response):
9 self.get_response = get_response
11 # Settings for https (compile regexes once)
12 self.https_redirect_enabled = settings.HTTPS_REDIRECT_ENABLED
13 self.https_redirect_host = settings.HTTPS_REDIRECT_HOST
14 self.https_redirect_exempt = [
15 re.compile(r) for r in settings.HTTPS_REDIRECT_EXEMPT
16 ]
18 def __call__(self, request):
19 """
20 Rewrite the URL based on settings.APPEND_SLASH
21 """
23 if redirect_response := self.maybe_https_redirect(request):
24 return redirect_response
26 return self.get_response(request)
28 def maybe_https_redirect(self, request):
29 path = request.path.lstrip("/")
30 if (
31 self.https_redirect_enabled
32 and not request.is_https()
33 and not any(pattern.search(path) for pattern in self.https_redirect_exempt)
34 ):
35 host = self.https_redirect_host or request.get_host()
36 return ResponsePermanentRedirect(f"https://{host}{request.get_full_path()}")
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:27 -0500
1from plain.http import ResponsePermanentRedirect
2from plain.runtime import settings
3from plain.urls import is_valid_path
4from plain.utils.http import escape_leading_slashes
7class RedirectSlashMiddleware:
8 def __init__(self, get_response):
9 self.get_response = get_response
11 def __call__(self, request):
12 """
13 Rewrite the URL based on settings.APPEND_SLASH
14 """
16 response = self.get_response(request)
18 """
19 When the status code of the response is 404, it may redirect to a path
20 with an appended slash if should_redirect_with_slash() returns True.
21 """
22 # If the given URL is "Not Found", then check if we should redirect to
23 # a path with a slash appended.
24 if response.status_code == 404 and self.should_redirect_with_slash(request):
25 return ResponsePermanentRedirect(self.get_full_path_with_slash(request))
27 return response
29 def should_redirect_with_slash(self, request):
30 """
31 Return True if settings.APPEND_SLASH is True and appending a slash to
32 the request path turns an invalid path into a valid one.
33 """
34 if settings.APPEND_SLASH and not request.path_info.endswith("/"):
35 urlconf = getattr(request, "urlconf", None)
36 if not is_valid_path(request.path_info, urlconf):
37 match = is_valid_path("%s/" % request.path_info, urlconf)
38 if match:
39 view = match.func
40 return getattr(view, "should_append_slash", True)
41 return False
43 def get_full_path_with_slash(self, request):
44 """
45 Return the full path of the request with a trailing slash appended.
47 Raise a RuntimeError if settings.DEBUG is True and request.method is
48 POST, PUT, or PATCH.
49 """
50 new_path = request.get_full_path(force_append_slash=True)
51 # Prevent construction of scheme relative urls.
52 new_path = escape_leading_slashes(new_path)
53 if settings.DEBUG and request.method in ("POST", "PUT", "PATCH"):
54 raise RuntimeError(
55 "You called this URL via {method}, but the URL doesn't end "
56 "in a slash and you have APPEND_SLASH set. Plain can't "
57 "redirect to the slash URL while maintaining {method} data. "
58 "Change your form to point to {url} (note the trailing "
59 "slash), or set APPEND_SLASH=False in your Plain settings.".format(
60 method=request.method,
61 url=request.get_host() + new_path,
62 )
63 )
64 return new_path
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import _thread
2import copy
3import datetime
4import logging
5import threading
6import time
7import warnings
8import zoneinfo
9from collections import deque
10from contextlib import contextmanager
12from plain.models.backends import utils
13from plain.models.backends.base.validation import BaseDatabaseValidation
14from plain.models.backends.signals import connection_created
15from plain.models.backends.utils import debug_transaction
16from plain.models.db import (
17 DEFAULT_DB_ALIAS,
18 DatabaseError,
19 DatabaseErrorWrapper,
20 NotSupportedError,
21)
22from plain.models.transaction import TransactionManagementError
23from plain.runtime import settings
24from plain.utils.functional import cached_property
26NO_DB_ALIAS = "__no_db__"
27RAN_DB_VERSION_CHECK = set()
29logger = logging.getLogger("plain.models.backends.base")
32class BaseDatabaseWrapper:
33 """Represent a database connection."""
35 # Mapping of Field objects to their column types.
36 data_types = {}
37 # Mapping of Field objects to their SQL suffix such as AUTOINCREMENT.
38 data_types_suffix = {}
39 # Mapping of Field objects to their SQL for CHECK constraints.
40 data_type_check_constraints = {}
41 ops = None
42 vendor = "unknown"
43 display_name = "unknown"
44 SchemaEditorClass = None
45 # Classes instantiated in __init__().
46 client_class = None
47 creation_class = None
48 features_class = None
49 introspection_class = None
50 ops_class = None
51 validation_class = BaseDatabaseValidation
53 queries_limit = 9000
55 def __init__(self, settings_dict, alias=DEFAULT_DB_ALIAS):
56 # Connection related attributes.
57 # The underlying database connection.
58 self.connection = None
59 # `settings_dict` should be a dictionary containing keys such as
60 # NAME, USER, etc. It's called `settings_dict` instead of `settings`
61 # to disambiguate it from Plain settings modules.
62 self.settings_dict = settings_dict
63 self.alias = alias
64 # Query logging in debug mode or when explicitly enabled.
65 self.queries_log = deque(maxlen=self.queries_limit)
66 self.force_debug_cursor = False
68 # Transaction related attributes.
69 # Tracks if the connection is in autocommit mode. Per PEP 249, by
70 # default, it isn't.
71 self.autocommit = False
72 # Tracks if the connection is in a transaction managed by 'atomic'.
73 self.in_atomic_block = False
74 # Increment to generate unique savepoint ids.
75 self.savepoint_state = 0
76 # List of savepoints created by 'atomic'.
77 self.savepoint_ids = []
78 # Stack of active 'atomic' blocks.
79 self.atomic_blocks = []
80 # Tracks if the outermost 'atomic' block should commit on exit,
81 # ie. if autocommit was active on entry.
82 self.commit_on_exit = True
83 # Tracks if the transaction should be rolled back to the next
84 # available savepoint because of an exception in an inner block.
85 self.needs_rollback = False
86 self.rollback_exc = None
88 # Connection termination related attributes.
89 self.close_at = None
90 self.closed_in_transaction = False
91 self.errors_occurred = False
92 self.health_check_enabled = False
93 self.health_check_done = False
95 # Thread-safety related attributes.
96 self._thread_sharing_lock = threading.Lock()
97 self._thread_sharing_count = 0
98 self._thread_ident = _thread.get_ident()
100 # A list of no-argument functions to run when the transaction commits.
101 # Each entry is an (sids, func, robust) tuple, where sids is a set of
102 # the active savepoint IDs when this function was registered and robust
103 # specifies whether it's allowed for the function to fail.
104 self.run_on_commit = []
106 # Should we run the on-commit hooks the next time set_autocommit(True)
107 # is called?
108 self.run_commit_hooks_on_set_autocommit_on = False
110 # A stack of wrappers to be invoked around execute()/executemany()
111 # calls. Each entry is a function taking five arguments: execute, sql,
112 # params, many, and context. It's the function's responsibility to
113 # call execute(sql, params, many, context).
114 self.execute_wrappers = []
116 self.client = self.client_class(self)
117 self.creation = self.creation_class(self)
118 self.features = self.features_class(self)
119 self.introspection = self.introspection_class(self)
120 self.ops = self.ops_class(self)
121 self.validation = self.validation_class(self)
123 def __repr__(self):
124 return (
125 f"<{self.__class__.__qualname__} "
126 f"vendor={self.vendor!r} alias={self.alias!r}>"
127 )
129 def ensure_timezone(self):
130 """
131 Ensure the connection's timezone is set to `self.timezone_name` and
132 return whether it changed or not.
133 """
134 return False
136 @cached_property
137 def timezone(self):
138 """
139 Return a tzinfo of the database connection time zone.
141 This is only used when time zone support is enabled. When a datetime is
142 read from the database, it is always returned in this time zone.
144 When the database backend supports time zones, it doesn't matter which
145 time zone Plain uses, as long as aware datetimes are used everywhere.
146 Other users connecting to the database can choose their own time zone.
148 When the database backend doesn't support time zones, the time zone
149 Plain uses may be constrained by the requirements of other users of
150 the database.
151 """
152 if self.settings_dict["TIME_ZONE"] is None:
153 return datetime.UTC
154 else:
155 return zoneinfo.ZoneInfo(self.settings_dict["TIME_ZONE"])
157 @cached_property
158 def timezone_name(self):
159 """
160 Name of the time zone of the database connection.
161 """
162 if self.settings_dict["TIME_ZONE"] is None:
163 return "UTC"
164 else:
165 return self.settings_dict["TIME_ZONE"]
167 @property
168 def queries_logged(self):
169 return self.force_debug_cursor or settings.DEBUG
171 @property
172 def queries(self):
173 if len(self.queries_log) == self.queries_log.maxlen:
174 warnings.warn(
175 f"Limit for query logging exceeded, only the last {self.queries_log.maxlen} queries "
176 "will be returned."
177 )
178 return list(self.queries_log)
180 def get_database_version(self):
181 """Return a tuple of the database's version."""
182 raise NotImplementedError(
183 "subclasses of BaseDatabaseWrapper may require a get_database_version() "
184 "method."
185 )
187 def check_database_version_supported(self):
188 """
189 Raise an error if the database version isn't supported by this
190 version of Plain.
191 """
192 if (
193 self.features.minimum_database_version is not None
194 and self.get_database_version() < self.features.minimum_database_version
195 ):
196 db_version = ".".join(map(str, self.get_database_version()))
197 min_db_version = ".".join(map(str, self.features.minimum_database_version))
198 raise NotSupportedError(
199 f"{self.display_name} {min_db_version} or later is required "
200 f"(found {db_version})."
201 )
203 # ##### Backend-specific methods for creating connections and cursors #####
205 def get_connection_params(self):
206 """Return a dict of parameters suitable for get_new_connection."""
207 raise NotImplementedError(
208 "subclasses of BaseDatabaseWrapper may require a get_connection_params() "
209 "method"
210 )
212 def get_new_connection(self, conn_params):
213 """Open a connection to the database."""
214 raise NotImplementedError(
215 "subclasses of BaseDatabaseWrapper may require a get_new_connection() "
216 "method"
217 )
219 def init_connection_state(self):
220 """Initialize the database connection settings."""
221 global RAN_DB_VERSION_CHECK
222 if self.alias not in RAN_DB_VERSION_CHECK:
223 self.check_database_version_supported()
224 RAN_DB_VERSION_CHECK.add(self.alias)
226 def create_cursor(self, name=None):
227 """Create a cursor. Assume that a connection is established."""
228 raise NotImplementedError(
229 "subclasses of BaseDatabaseWrapper may require a create_cursor() method"
230 )
232 # ##### Backend-specific methods for creating connections #####
234 def connect(self):
235 """Connect to the database. Assume that the connection is closed."""
236 # In case the previous connection was closed while in an atomic block
237 self.in_atomic_block = False
238 self.savepoint_ids = []
239 self.atomic_blocks = []
240 self.needs_rollback = False
241 # Reset parameters defining when to close/health-check the connection.
242 self.health_check_enabled = self.settings_dict["CONN_HEALTH_CHECKS"]
243 max_age = self.settings_dict["CONN_MAX_AGE"]
244 self.close_at = None if max_age is None else time.monotonic() + max_age
245 self.closed_in_transaction = False
246 self.errors_occurred = False
247 # New connections are healthy.
248 self.health_check_done = True
249 # Establish the connection
250 conn_params = self.get_connection_params()
251 self.connection = self.get_new_connection(conn_params)
252 self.set_autocommit(self.settings_dict["AUTOCOMMIT"])
253 self.init_connection_state()
254 connection_created.send(sender=self.__class__, connection=self)
256 self.run_on_commit = []
258 def ensure_connection(self):
259 """Guarantee that a connection to the database is established."""
260 if self.connection is None:
261 with self.wrap_database_errors:
262 self.connect()
264 # ##### Backend-specific wrappers for PEP-249 connection methods #####
266 def _prepare_cursor(self, cursor):
267 """
268 Validate the connection is usable and perform database cursor wrapping.
269 """
270 self.validate_thread_sharing()
271 if self.queries_logged:
272 wrapped_cursor = self.make_debug_cursor(cursor)
273 else:
274 wrapped_cursor = self.make_cursor(cursor)
275 return wrapped_cursor
277 def _cursor(self, name=None):
278 self.close_if_health_check_failed()
279 self.ensure_connection()
280 with self.wrap_database_errors:
281 return self._prepare_cursor(self.create_cursor(name))
283 def _commit(self):
284 if self.connection is not None:
285 with debug_transaction(self, "COMMIT"), self.wrap_database_errors:
286 return self.connection.commit()
288 def _rollback(self):
289 if self.connection is not None:
290 with debug_transaction(self, "ROLLBACK"), self.wrap_database_errors:
291 return self.connection.rollback()
293 def _close(self):
294 if self.connection is not None:
295 with self.wrap_database_errors:
296 return self.connection.close()
298 # ##### Generic wrappers for PEP-249 connection methods #####
300 def cursor(self):
301 """Create a cursor, opening a connection if necessary."""
302 return self._cursor()
304 def commit(self):
305 """Commit a transaction and reset the dirty flag."""
306 self.validate_thread_sharing()
307 self.validate_no_atomic_block()
308 self._commit()
309 # A successful commit means that the database connection works.
310 self.errors_occurred = False
311 self.run_commit_hooks_on_set_autocommit_on = True
313 def rollback(self):
314 """Roll back a transaction and reset the dirty flag."""
315 self.validate_thread_sharing()
316 self.validate_no_atomic_block()
317 self._rollback()
318 # A successful rollback means that the database connection works.
319 self.errors_occurred = False
320 self.needs_rollback = False
321 self.run_on_commit = []
323 def close(self):
324 """Close the connection to the database."""
325 self.validate_thread_sharing()
326 self.run_on_commit = []
328 # Don't call validate_no_atomic_block() to avoid making it difficult
329 # to get rid of a connection in an invalid state. The next connect()
330 # will reset the transaction state anyway.
331 if self.closed_in_transaction or self.connection is None:
332 return
333 try:
334 self._close()
335 finally:
336 if self.in_atomic_block:
337 self.closed_in_transaction = True
338 self.needs_rollback = True
339 else:
340 self.connection = None
342 # ##### Backend-specific savepoint management methods #####
344 def _savepoint(self, sid):
345 with self.cursor() as cursor:
346 cursor.execute(self.ops.savepoint_create_sql(sid))
348 def _savepoint_rollback(self, sid):
349 with self.cursor() as cursor:
350 cursor.execute(self.ops.savepoint_rollback_sql(sid))
352 def _savepoint_commit(self, sid):
353 with self.cursor() as cursor:
354 cursor.execute(self.ops.savepoint_commit_sql(sid))
356 def _savepoint_allowed(self):
357 # Savepoints cannot be created outside a transaction
358 return self.features.uses_savepoints and not self.get_autocommit()
360 # ##### Generic savepoint management methods #####
362 def savepoint(self):
363 """
364 Create a savepoint inside the current transaction. Return an
365 identifier for the savepoint that will be used for the subsequent
366 rollback or commit. Do nothing if savepoints are not supported.
367 """
368 if not self._savepoint_allowed():
369 return
371 thread_ident = _thread.get_ident()
372 tid = str(thread_ident).replace("-", "")
374 self.savepoint_state += 1
375 sid = "s%s_x%d" % (tid, self.savepoint_state)
377 self.validate_thread_sharing()
378 self._savepoint(sid)
380 return sid
382 def savepoint_rollback(self, sid):
383 """
384 Roll back to a savepoint. Do nothing if savepoints are not supported.
385 """
386 if not self._savepoint_allowed():
387 return
389 self.validate_thread_sharing()
390 self._savepoint_rollback(sid)
392 # Remove any callbacks registered while this savepoint was active.
393 self.run_on_commit = [
394 (sids, func, robust)
395 for (sids, func, robust) in self.run_on_commit
396 if sid not in sids
397 ]
399 def savepoint_commit(self, sid):
400 """
401 Release a savepoint. Do nothing if savepoints are not supported.
402 """
403 if not self._savepoint_allowed():
404 return
406 self.validate_thread_sharing()
407 self._savepoint_commit(sid)
409 def clean_savepoints(self):
410 """
411 Reset the counter used to generate unique savepoint ids in this thread.
412 """
413 self.savepoint_state = 0
415 # ##### Backend-specific transaction management methods #####
417 def _set_autocommit(self, autocommit):
418 """
419 Backend-specific implementation to enable or disable autocommit.
420 """
421 raise NotImplementedError(
422 "subclasses of BaseDatabaseWrapper may require a _set_autocommit() method"
423 )
425 # ##### Generic transaction management methods #####
427 def get_autocommit(self):
428 """Get the autocommit state."""
429 self.ensure_connection()
430 return self.autocommit
432 def set_autocommit(
433 self, autocommit, force_begin_transaction_with_broken_autocommit=False
434 ):
435 """
436 Enable or disable autocommit.
438 The usual way to start a transaction is to turn autocommit off.
439 SQLite does not properly start a transaction when disabling
440 autocommit. To avoid this buggy behavior and to actually enter a new
441 transaction, an explicit BEGIN is required. Using
442 force_begin_transaction_with_broken_autocommit=True will issue an
443 explicit BEGIN with SQLite. This option will be ignored for other
444 backends.
445 """
446 self.validate_no_atomic_block()
447 self.close_if_health_check_failed()
448 self.ensure_connection()
450 start_transaction_under_autocommit = (
451 force_begin_transaction_with_broken_autocommit
452 and not autocommit
453 and hasattr(self, "_start_transaction_under_autocommit")
454 )
456 if start_transaction_under_autocommit:
457 self._start_transaction_under_autocommit()
458 elif autocommit:
459 self._set_autocommit(autocommit)
460 else:
461 with debug_transaction(self, "BEGIN"):
462 self._set_autocommit(autocommit)
463 self.autocommit = autocommit
465 if autocommit and self.run_commit_hooks_on_set_autocommit_on:
466 self.run_and_clear_commit_hooks()
467 self.run_commit_hooks_on_set_autocommit_on = False
469 def get_rollback(self):
470 """Get the "needs rollback" flag -- for *advanced use* only."""
471 if not self.in_atomic_block:
472 raise TransactionManagementError(
473 "The rollback flag doesn't work outside of an 'atomic' block."
474 )
475 return self.needs_rollback
477 def set_rollback(self, rollback):
478 """
479 Set or unset the "needs rollback" flag -- for *advanced use* only.
480 """
481 if not self.in_atomic_block:
482 raise TransactionManagementError(
483 "The rollback flag doesn't work outside of an 'atomic' block."
484 )
485 self.needs_rollback = rollback
487 def validate_no_atomic_block(self):
488 """Raise an error if an atomic block is active."""
489 if self.in_atomic_block:
490 raise TransactionManagementError(
491 "This is forbidden when an 'atomic' block is active."
492 )
494 def validate_no_broken_transaction(self):
495 if self.needs_rollback:
496 raise TransactionManagementError(
497 "An error occurred in the current transaction. You can't "
498 "execute queries until the end of the 'atomic' block."
499 ) from self.rollback_exc
501 # ##### Foreign key constraints checks handling #####
503 @contextmanager
504 def constraint_checks_disabled(self):
505 """
506 Disable foreign key constraint checking.
507 """
508 disabled = self.disable_constraint_checking()
509 try:
510 yield
511 finally:
512 if disabled:
513 self.enable_constraint_checking()
515 def disable_constraint_checking(self):
516 """
517 Backends can implement as needed to temporarily disable foreign key
518 constraint checking. Should return True if the constraints were
519 disabled and will need to be reenabled.
520 """
521 return False
523 def enable_constraint_checking(self):
524 """
525 Backends can implement as needed to re-enable foreign key constraint
526 checking.
527 """
528 pass
530 def check_constraints(self, table_names=None):
531 """
532 Backends can override this method if they can apply constraint
533 checking (e.g. via "SET CONSTRAINTS ALL IMMEDIATE"). Should raise an
534 IntegrityError if any invalid foreign key references are encountered.
535 """
536 pass
538 # ##### Connection termination handling #####
540 def is_usable(self):
541 """
542 Test if the database connection is usable.
544 This method may assume that self.connection is not None.
546 Actual implementations should take care not to raise exceptions
547 as that may prevent Plain from recycling unusable connections.
548 """
549 raise NotImplementedError(
550 "subclasses of BaseDatabaseWrapper may require an is_usable() method"
551 )
553 def close_if_health_check_failed(self):
554 """Close existing connection if it fails a health check."""
555 if (
556 self.connection is None
557 or not self.health_check_enabled
558 or self.health_check_done
559 ):
560 return
562 if not self.is_usable():
563 self.close()
564 self.health_check_done = True
566 def close_if_unusable_or_obsolete(self):
567 """
568 Close the current connection if unrecoverable errors have occurred
569 or if it outlived its maximum age.
570 """
571 if self.connection is not None:
572 self.health_check_done = False
573 # If the application didn't restore the original autocommit setting,
574 # don't take chances, drop the connection.
575 if self.get_autocommit() != self.settings_dict["AUTOCOMMIT"]:
576 self.close()
577 return
579 # If an exception other than DataError or IntegrityError occurred
580 # since the last commit / rollback, check if the connection works.
581 if self.errors_occurred:
582 if self.is_usable():
583 self.errors_occurred = False
584 self.health_check_done = True
585 else:
586 self.close()
587 return
589 if self.close_at is not None and time.monotonic() >= self.close_at:
590 self.close()
591 return
593 # ##### Thread safety handling #####
595 @property
596 def allow_thread_sharing(self):
597 with self._thread_sharing_lock:
598 return self._thread_sharing_count > 0
600 def inc_thread_sharing(self):
601 with self._thread_sharing_lock:
602 self._thread_sharing_count += 1
604 def dec_thread_sharing(self):
605 with self._thread_sharing_lock:
606 if self._thread_sharing_count <= 0:
607 raise RuntimeError(
608 "Cannot decrement the thread sharing count below zero."
609 )
610 self._thread_sharing_count -= 1
612 def validate_thread_sharing(self):
613 """
614 Validate that the connection isn't accessed by another thread than the
615 one which originally created it, unless the connection was explicitly
616 authorized to be shared between threads (via the `inc_thread_sharing()`
617 method). Raise an exception if the validation fails.
618 """
619 if not (self.allow_thread_sharing or self._thread_ident == _thread.get_ident()):
620 raise DatabaseError(
621 "DatabaseWrapper objects created in a "
622 "thread can only be used in that same thread. The object "
623 f"with alias '{self.alias}' was created in thread id {self._thread_ident} and this is "
624 f"thread id {_thread.get_ident()}."
625 )
627 # ##### Miscellaneous #####
629 def prepare_database(self):
630 """
631 Hook to do any database check or preparation, generally called before
632 migrating a project or an app.
633 """
634 pass
636 @cached_property
637 def wrap_database_errors(self):
638 """
639 Context manager and decorator that re-throws backend-specific database
640 exceptions using Plain's common wrappers.
641 """
642 return DatabaseErrorWrapper(self)
644 def chunked_cursor(self):
645 """
646 Return a cursor that tries to avoid caching in the database (if
647 supported by the database), otherwise return a regular cursor.
648 """
649 return self.cursor()
651 def make_debug_cursor(self, cursor):
652 """Create a cursor that logs all queries in self.queries_log."""
653 return utils.CursorDebugWrapper(cursor, self)
655 def make_cursor(self, cursor):
656 """Create a cursor without debug logging."""
657 return utils.CursorWrapper(cursor, self)
659 @contextmanager
660 def temporary_connection(self):
661 """
662 Context manager that ensures that a connection is established, and
663 if it opened one, closes it to avoid leaving a dangling connection.
664 This is useful for operations outside of the request-response cycle.
666 Provide a cursor: with self.temporary_connection() as cursor: ...
667 """
668 must_close = self.connection is None
669 try:
670 with self.cursor() as cursor:
671 yield cursor
672 finally:
673 if must_close:
674 self.close()
676 @contextmanager
677 def _nodb_cursor(self):
678 """
679 Return a cursor from an alternative connection to be used when there is
680 no need to access the main database, specifically for test db
681 creation/deletion. This also prevents the production database from
682 being exposed to potential child threads while (or after) the test
683 database is destroyed. Refs #10868, #17786, #16969.
684 """
685 conn = self.__class__({**self.settings_dict, "NAME": None}, alias=NO_DB_ALIAS)
686 try:
687 with conn.cursor() as cursor:
688 yield cursor
689 finally:
690 conn.close()
692 def schema_editor(self, *args, **kwargs):
693 """
694 Return a new instance of this backend's SchemaEditor.
695 """
696 if self.SchemaEditorClass is None:
697 raise NotImplementedError(
698 "The SchemaEditorClass attribute of this database wrapper is still None"
699 )
700 return self.SchemaEditorClass(self, *args, **kwargs)
702 def on_commit(self, func, robust=False):
703 if not callable(func):
704 raise TypeError("on_commit()'s callback must be a callable.")
705 if self.in_atomic_block:
706 # Transaction in progress; save for execution on commit.
707 self.run_on_commit.append((set(self.savepoint_ids), func, robust))
708 elif not self.get_autocommit():
709 raise TransactionManagementError(
710 "on_commit() cannot be used in manual transaction management"
711 )
712 else:
713 # No transaction in progress and in autocommit mode; execute
714 # immediately.
715 if robust:
716 try:
717 func()
718 except Exception as e:
719 logger.error(
720 f"Error calling {func.__qualname__} in on_commit() (%s).",
721 e,
722 exc_info=True,
723 )
724 else:
725 func()
727 def run_and_clear_commit_hooks(self):
728 self.validate_no_atomic_block()
729 current_run_on_commit = self.run_on_commit
730 self.run_on_commit = []
731 while current_run_on_commit:
732 _, func, robust = current_run_on_commit.pop(0)
733 if robust:
734 try:
735 func()
736 except Exception as e:
737 logger.error(
738 f"Error calling {func.__qualname__} in on_commit() during "
739 f"transaction (%s).",
740 e,
741 exc_info=True,
742 )
743 else:
744 func()
746 @contextmanager
747 def execute_wrapper(self, wrapper):
748 """
749 Return a context manager under which the wrapper is applied to suitable
750 database query executions.
751 """
752 self.execute_wrappers.append(wrapper)
753 try:
754 yield
755 finally:
756 self.execute_wrappers.pop()
758 def copy(self, alias=None):
759 """
760 Return a copy of this connection.
762 For tests that require two connections to the same database.
763 """
764 settings_dict = copy.deepcopy(self.settings_dict)
765 if alias is None:
766 alias = self.alias
767 return type(self)(settings_dict, alias)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import os
2import subprocess
5class BaseDatabaseClient:
6 """Encapsulate backend-specific methods for opening a client shell."""
8 # This should be a string representing the name of the executable
9 # (e.g., "psql"). Subclasses must override this.
10 executable_name = None
12 def __init__(self, connection):
13 # connection is an instance of BaseDatabaseWrapper.
14 self.connection = connection
16 @classmethod
17 def settings_to_cmd_args_env(cls, settings_dict, parameters):
18 raise NotImplementedError(
19 "subclasses of BaseDatabaseClient must provide a "
20 "settings_to_cmd_args_env() method or override a runshell()."
21 )
23 def runshell(self, parameters):
24 args, env = self.settings_to_cmd_args_env(
25 self.connection.settings_dict, parameters
26 )
27 env = {**os.environ, **env} if env else None
28 subprocess.run(args, env=env, check=True)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import os
2import sys
4from plain.packages import packages
5from plain.runtime import settings
7# The prefix to put on the default database name when creating
8# the test database.
9TEST_DATABASE_PREFIX = "test_"
12class BaseDatabaseCreation:
13 """
14 Encapsulate backend-specific differences pertaining to creation and
15 destruction of the test database.
16 """
18 def __init__(self, connection):
19 self.connection = connection
21 def _nodb_cursor(self):
22 return self.connection._nodb_cursor()
24 def log(self, msg):
25 sys.stderr.write(msg + os.linesep)
27 def create_test_db(
28 self, verbosity=1, autoclobber=False, serialize=True, keepdb=False
29 ):
30 """
31 Create a test database, prompting the user for confirmation if the
32 database already exists. Return the name of the test database created.
33 """
34 from plain.models.cli import migrate
36 test_database_name = self._get_test_db_name()
38 if verbosity >= 1:
39 action = "Creating"
40 if keepdb:
41 action = "Using existing"
43 self.log(
44 f"{action} test database for alias {self._get_database_display_str(verbosity, test_database_name)}..."
45 )
47 # We could skip this call if keepdb is True, but we instead
48 # give it the keepdb param. This is to handle the case
49 # where the test DB doesn't exist, in which case we need to
50 # create it, then just not destroy it. If we instead skip
51 # this, we will get an exception.
52 self._create_test_db(verbosity, autoclobber, keepdb)
54 self.connection.close()
55 settings.DATABASES[self.connection.alias]["NAME"] = test_database_name
56 self.connection.settings_dict["NAME"] = test_database_name
58 try:
59 if self.connection.settings_dict["TEST"]["MIGRATE"] is False:
60 # Disable migrations for all packages.
61 for app in packages.get_package_configs():
62 app._old_migrations_module = app.migrations_module
63 app.migrations_module = None
64 # We report migrate messages at one level lower than that
65 # requested. This ensures we don't get flooded with messages during
66 # testing (unless you really ask to be flooded).
67 migrate.callback(
68 package_label=None,
69 migration_name=None,
70 no_input=True,
71 database=self.connection.alias,
72 fake=False,
73 fake_initial=False,
74 plan=False,
75 check_unapplied=False,
76 run_syncdb=True,
77 prune=False,
78 verbosity=max(verbosity - 1, 0),
79 )
80 finally:
81 if self.connection.settings_dict["TEST"]["MIGRATE"] is False:
82 for app in packages.get_package_configs():
83 app.migrations_module = app._old_migrations_module
84 del app._old_migrations_module
86 # We then serialize the current state of the database into a string
87 # and store it on the connection. This slightly horrific process is so people
88 # who are testing on databases without transactions or who are using
89 # a TransactionTestCase still get a clean database on every test run.
90 # if serialize:
91 # self.connection._test_serialized_contents = self.serialize_db_to_string()
93 # Ensure a connection for the side effect of initializing the test database.
94 self.connection.ensure_connection()
96 return test_database_name
98 def set_as_test_mirror(self, primary_settings_dict):
99 """
100 Set this database up to be used in testing as a mirror of a primary
101 database whose settings are given.
102 """
103 self.connection.settings_dict["NAME"] = primary_settings_dict["NAME"]
105 # def serialize_db_to_string(self):
106 # """
107 # Serialize all data in the database into a JSON string.
108 # Designed only for test runner usage; will not handle large
109 # amounts of data.
110 # """
112 # # Iteratively return every object for all models to serialize.
113 # def get_objects():
114 # from plain.models.migrations.loader import MigrationLoader
116 # loader = MigrationLoader(self.connection)
117 # for package_config in packages.get_package_configs():
118 # if (
119 # package_config.models_module is not None
120 # and package_config.label in loader.migrated_packages
121 # ):
122 # for model in package_config.get_models():
123 # if model._meta.can_migrate(
124 # self.connection
125 # ) and router.allow_migrate_model(self.connection.alias, model):
126 # queryset = model._base_manager.using(
127 # self.connection.alias,
128 # ).order_by(model._meta.pk.name)
129 # yield from queryset.iterator()
131 # # Serialize to a string
132 # out = StringIO()
133 # serializers.serialize("json", get_objects(), indent=None, stream=out)
134 # return out.getvalue()
136 # def deserialize_db_from_string(self, data):
137 # """
138 # Reload the database with data from a string generated by
139 # the serialize_db_to_string() method.
140 # """
141 # data = StringIO(data)
142 # table_names = set()
143 # # Load data in a transaction to handle forward references and cycles.
144 # with atomic(using=self.connection.alias):
145 # # Disable constraint checks, because some databases (MySQL) doesn't
146 # # support deferred checks.
147 # with self.connection.constraint_checks_disabled():
148 # for obj in serializers.deserialize(
149 # "json", data, using=self.connection.alias
150 # ):
151 # obj.save()
152 # table_names.add(obj.object.__class__._meta.db_table)
153 # # Manually check for any invalid keys that might have been added,
154 # # because constraint checks were disabled.
155 # self.connection.check_constraints(table_names=table_names)
157 def _get_database_display_str(self, verbosity, database_name):
158 """
159 Return display string for a database for use in various actions.
160 """
161 return "'{}'{}".format(
162 self.connection.alias,
163 (f" ('{database_name}')") if verbosity >= 2 else "",
164 )
166 def _get_test_db_name(self):
167 """
168 Internal implementation - return the name of the test DB that will be
169 created. Only useful when called from create_test_db() and
170 _create_test_db() and when no external munging is done with the 'NAME'
171 settings.
172 """
173 if self.connection.settings_dict["TEST"]["NAME"]:
174 return self.connection.settings_dict["TEST"]["NAME"]
175 return TEST_DATABASE_PREFIX + self.connection.settings_dict["NAME"]
177 def _execute_create_test_db(self, cursor, parameters, keepdb=False):
178 cursor.execute("CREATE DATABASE {dbname} {suffix}".format(**parameters))
180 def _create_test_db(self, verbosity, autoclobber, keepdb=False):
181 """
182 Internal implementation - create the test db tables.
183 """
184 test_database_name = self._get_test_db_name()
185 test_db_params = {
186 "dbname": self.connection.ops.quote_name(test_database_name),
187 "suffix": self.sql_table_creation_suffix(),
188 }
189 # Create the test database and connect to it.
190 with self._nodb_cursor() as cursor:
191 try:
192 self._execute_create_test_db(cursor, test_db_params, keepdb)
193 except Exception as e:
194 # if we want to keep the db, then no need to do any of the below,
195 # just return and skip it all.
196 if keepdb:
197 return test_database_name
199 self.log(f"Got an error creating the test database: {e}")
200 if not autoclobber:
201 confirm = input(
202 "Type 'yes' if you would like to try deleting the test "
203 f"database '{test_database_name}', or 'no' to cancel: "
204 )
205 if autoclobber or confirm == "yes":
206 try:
207 if verbosity >= 1:
208 self.log(
209 "Destroying old test database for alias {}...".format(
210 self._get_database_display_str(
211 verbosity, test_database_name
212 ),
213 )
214 )
215 cursor.execute(
216 "DROP DATABASE {dbname}".format(**test_db_params)
217 )
218 self._execute_create_test_db(cursor, test_db_params, keepdb)
219 except Exception as e:
220 self.log(f"Got an error recreating the test database: {e}")
221 sys.exit(2)
222 else:
223 self.log("Tests cancelled.")
224 sys.exit(1)
226 return test_database_name
228 def clone_test_db(self, suffix, verbosity=1, autoclobber=False, keepdb=False):
229 """
230 Clone a test database.
231 """
232 source_database_name = self.connection.settings_dict["NAME"]
234 if verbosity >= 1:
235 action = "Cloning test database"
236 if keepdb:
237 action = "Using existing clone"
238 self.log(
239 f"{action} for alias {self._get_database_display_str(verbosity, source_database_name)}..."
240 )
242 # We could skip this call if keepdb is True, but we instead
243 # give it the keepdb param. See create_test_db for details.
244 self._clone_test_db(suffix, verbosity, keepdb)
246 def get_test_db_clone_settings(self, suffix):
247 """
248 Return a modified connection settings dict for the n-th clone of a DB.
249 """
250 # When this function is called, the test database has been created
251 # already and its name has been copied to settings_dict['NAME'] so
252 # we don't need to call _get_test_db_name.
253 orig_settings_dict = self.connection.settings_dict
254 return {
255 **orig_settings_dict,
256 "NAME": "{}_{}".format(orig_settings_dict["NAME"], suffix),
257 }
259 def _clone_test_db(self, suffix, verbosity, keepdb=False):
260 """
261 Internal implementation - duplicate the test db tables.
262 """
263 raise NotImplementedError(
264 "The database backend doesn't support cloning databases. "
265 "Disable the option to run tests in parallel processes."
266 )
268 def destroy_test_db(
269 self, old_database_name=None, verbosity=1, keepdb=False, suffix=None
270 ):
271 """
272 Destroy a test database, prompting the user for confirmation if the
273 database already exists.
274 """
275 self.connection.close()
276 if suffix is None:
277 test_database_name = self.connection.settings_dict["NAME"]
278 else:
279 test_database_name = self.get_test_db_clone_settings(suffix)["NAME"]
281 if verbosity >= 1:
282 action = "Destroying"
283 if keepdb:
284 action = "Preserving"
285 self.log(
286 f"{action} test database for alias {self._get_database_display_str(verbosity, test_database_name)}..."
287 )
289 # if we want to preserve the database
290 # skip the actual destroying piece.
291 if not keepdb:
292 self._destroy_test_db(test_database_name, verbosity)
294 # Restore the original database name
295 if old_database_name is not None:
296 settings.DATABASES[self.connection.alias]["NAME"] = old_database_name
297 self.connection.settings_dict["NAME"] = old_database_name
299 def _destroy_test_db(self, test_database_name, verbosity):
300 """
301 Internal implementation - remove the test db tables.
302 """
303 # Remove the test database to clean up after
304 # ourselves. Connect to the previous database (not the test database)
305 # to do so, because it's not allowed to delete a database while being
306 # connected to it.
307 with self._nodb_cursor() as cursor:
308 cursor.execute(
309 f"DROP DATABASE {self.connection.ops.quote_name(test_database_name)}"
310 )
312 def sql_table_creation_suffix(self):
313 """
314 SQL to append to the end of the test table creation statements.
315 """
316 return ""
318 def test_db_signature(self):
319 """
320 Return a tuple with elements of self.connection.settings_dict (a
321 DATABASES setting value) that uniquely identify a database
322 accordingly to the RDBMS particularities.
323 """
324 settings_dict = self.connection.settings_dict
325 return (
326 settings_dict["HOST"],
327 settings_dict["PORT"],
328 settings_dict["ENGINE"],
329 self._get_test_db_name(),
330 )
332 def setup_worker_connection(self, _worker_id):
333 settings_dict = self.get_test_db_clone_settings(str(_worker_id))
334 # connection.settings_dict must be updated in place for changes to be
335 # reflected in plain.models.connections. If the following line assigned
336 # connection.settings_dict = settings_dict, new threads would connect
337 # to the default database instead of the appropriate clone.
338 self.connection.settings_dict.update(settings_dict)
339 self.connection.close()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.models.db import ProgrammingError
2from plain.utils.functional import cached_property
5class BaseDatabaseFeatures:
6 # An optional tuple indicating the minimum supported database version.
7 minimum_database_version = None
8 gis_enabled = False
9 # Oracle can't group by LOB (large object) data types.
10 allows_group_by_lob = True
11 allows_group_by_selected_pks = False
12 allows_group_by_select_index = True
13 empty_fetchmany_value = []
14 update_can_self_select = True
16 # Does the backend distinguish between '' and None?
17 interprets_empty_strings_as_nulls = False
19 # Does the backend allow inserting duplicate NULL rows in a nullable
20 # unique field? All core backends implement this correctly, but other
21 # databases such as SQL Server do not.
22 supports_nullable_unique_constraints = True
24 # Does the backend support initially deferrable unique constraints?
25 supports_deferrable_unique_constraints = False
27 can_use_chunked_reads = True
28 can_return_columns_from_insert = False
29 can_return_rows_from_bulk_insert = False
30 has_bulk_insert = True
31 uses_savepoints = True
32 can_release_savepoints = False
34 # If True, don't use integer foreign keys referring to, e.g., positive
35 # integer primary keys.
36 related_fields_match_type = False
37 allow_sliced_subqueries_with_in = True
38 has_select_for_update = False
39 has_select_for_update_nowait = False
40 has_select_for_update_skip_locked = False
41 has_select_for_update_of = False
42 has_select_for_no_key_update = False
43 # Does the database's SELECT FOR UPDATE OF syntax require a column rather
44 # than a table?
45 select_for_update_of_column = False
47 # Does the default test database allow multiple connections?
48 # Usually an indication that the test database is in-memory
49 test_db_allows_multiple_connections = True
51 # Can an object be saved without an explicit primary key?
52 supports_unspecified_pk = False
54 # Can a fixture contain forward references? i.e., are
55 # FK constraints checked at the end of transaction, or
56 # at the end of each save operation?
57 supports_forward_references = True
59 # Does the backend truncate names properly when they are too long?
60 truncates_names = False
62 # Is there a REAL datatype in addition to floats/doubles?
63 has_real_datatype = False
64 supports_subqueries_in_group_by = True
66 # Does the backend ignore unnecessary ORDER BY clauses in subqueries?
67 ignores_unnecessary_order_by_in_subqueries = True
69 # Is there a true datatype for uuid?
70 has_native_uuid_field = False
72 # Is there a true datatype for timedeltas?
73 has_native_duration_field = False
75 # Does the database driver supports same type temporal data subtraction
76 # by returning the type used to store duration field?
77 supports_temporal_subtraction = False
79 # Does the __regex lookup support backreferencing and grouping?
80 supports_regex_backreferencing = True
82 # Can date/datetime lookups be performed using a string?
83 supports_date_lookup_using_string = True
85 # Can datetimes with timezones be used?
86 supports_timezones = True
88 # Does the database have a copy of the zoneinfo database?
89 has_zoneinfo_database = True
91 # When performing a GROUP BY, is an ORDER BY NULL required
92 # to remove any ordering?
93 requires_explicit_null_ordering_when_grouping = False
95 # Does the backend order NULL values as largest or smallest?
96 nulls_order_largest = False
98 # Does the backend support NULLS FIRST and NULLS LAST in ORDER BY?
99 supports_order_by_nulls_modifier = True
101 # Does the backend orders NULLS FIRST by default?
102 order_by_nulls_first = False
104 # The database's limit on the number of query parameters.
105 max_query_params = None
107 # Can an object have an autoincrement primary key of 0?
108 allows_auto_pk_0 = True
110 # Do we need to NULL a ForeignKey out, or can the constraint check be
111 # deferred
112 can_defer_constraint_checks = False
114 # Does the backend support tablespaces? Default to False because it isn't
115 # in the SQL standard.
116 supports_tablespaces = False
118 # Does the backend reset sequences between tests?
119 supports_sequence_reset = True
121 # Can the backend introspect the default value of a column?
122 can_introspect_default = True
124 # Confirm support for introspected foreign keys
125 # Every database can do this reliably, except MySQL,
126 # which can't do it for MyISAM tables
127 can_introspect_foreign_keys = True
129 # Map fields which some backends may not be able to differentiate to the
130 # field it's introspected as.
131 introspected_field_types = {
132 "AutoField": "AutoField",
133 "BigAutoField": "BigAutoField",
134 "BigIntegerField": "BigIntegerField",
135 "BinaryField": "BinaryField",
136 "BooleanField": "BooleanField",
137 "CharField": "CharField",
138 "DurationField": "DurationField",
139 "GenericIPAddressField": "GenericIPAddressField",
140 "IntegerField": "IntegerField",
141 "PositiveBigIntegerField": "PositiveBigIntegerField",
142 "PositiveIntegerField": "PositiveIntegerField",
143 "PositiveSmallIntegerField": "PositiveSmallIntegerField",
144 "SmallAutoField": "SmallAutoField",
145 "SmallIntegerField": "SmallIntegerField",
146 "TimeField": "TimeField",
147 }
149 # Can the backend introspect the column order (ASC/DESC) for indexes?
150 supports_index_column_ordering = True
152 # Does the backend support introspection of materialized views?
153 can_introspect_materialized_views = False
155 # Support for the DISTINCT ON clause
156 can_distinct_on_fields = False
158 # Does the backend prevent running SQL queries in broken transactions?
159 atomic_transactions = True
161 # Can we roll back DDL in a transaction?
162 can_rollback_ddl = False
164 schema_editor_uses_clientside_param_binding = False
166 # Does it support operations requiring references rename in a transaction?
167 supports_atomic_references_rename = True
169 # Can we issue more than one ALTER COLUMN clause in an ALTER TABLE?
170 supports_combined_alters = False
172 # Does it support foreign keys?
173 supports_foreign_keys = True
175 # Can it create foreign key constraints inline when adding columns?
176 can_create_inline_fk = True
178 # Can an index be renamed?
179 can_rename_index = False
181 # Does it automatically index foreign keys?
182 indexes_foreign_keys = True
184 # Does it support CHECK constraints?
185 supports_column_check_constraints = True
186 supports_table_check_constraints = True
187 # Does the backend support introspection of CHECK constraints?
188 can_introspect_check_constraints = True
190 # Does the backend support 'pyformat' style ("... %(name)s ...", {'name': value})
191 # parameter passing? Note this can be provided by the backend even if not
192 # supported by the Python driver
193 supports_paramstyle_pyformat = True
195 # Does the backend require literal defaults, rather than parameterized ones?
196 requires_literal_defaults = False
198 # Does the backend require a connection reset after each material schema change?
199 connection_persists_old_columns = False
201 # What kind of error does the backend throw when accessing closed cursor?
202 closed_cursor_error_class = ProgrammingError
204 # Does 'a' LIKE 'A' match?
205 has_case_insensitive_like = False
207 # Suffix for backends that don't support "SELECT xxx;" queries.
208 bare_select_suffix = ""
210 # If NULL is implied on columns without needing to be explicitly specified
211 implied_column_null = False
213 # Does the backend support "select for update" queries with limit (and offset)?
214 supports_select_for_update_with_limit = True
216 # Does the backend ignore null expressions in GREATEST and LEAST queries unless
217 # every expression is null?
218 greatest_least_ignores_nulls = False
220 # Can the backend clone databases for parallel test execution?
221 # Defaults to False to allow third-party backends to opt-in.
222 can_clone_databases = False
224 # Does the backend consider table names with different casing to
225 # be equal?
226 ignores_table_name_case = False
228 # Place FOR UPDATE right after FROM clause. Used on MSSQL.
229 for_update_after_from = False
231 # Combinatorial flags
232 supports_select_union = True
233 supports_select_intersection = True
234 supports_select_difference = True
235 supports_slicing_ordering_in_compound = False
236 supports_parentheses_in_compound = True
237 requires_compound_order_by_subquery = False
239 # Does the database support SQL 2003 FILTER (WHERE ...) in aggregate
240 # expressions?
241 supports_aggregate_filter_clause = False
243 # Does the backend support indexing a TextField?
244 supports_index_on_text_field = True
246 # Does the backend support window expressions (expression OVER (...))?
247 supports_over_clause = False
248 supports_frame_range_fixed_distance = False
249 only_supports_unbounded_with_preceding_and_following = False
251 # Does the backend support CAST with precision?
252 supports_cast_with_precision = True
254 # How many second decimals does the database return when casting a value to
255 # a type with time?
256 time_cast_precision = 6
258 # SQL to create a procedure for use by the Plain test suite. The
259 # functionality of the procedure isn't important.
260 create_test_procedure_without_params_sql = None
261 create_test_procedure_with_int_param_sql = None
263 # SQL to create a table with a composite primary key for use by the Plain
264 # test suite.
265 create_test_table_with_composite_primary_key = None
267 # Does the backend support keyword parameters for cursor.callproc()?
268 supports_callproc_kwargs = False
270 # What formats does the backend EXPLAIN syntax support?
271 supported_explain_formats = set()
273 # Does the backend support the default parameter in lead() and lag()?
274 supports_default_in_lead_lag = True
276 # Does the backend support ignoring constraint or uniqueness errors during
277 # INSERT?
278 supports_ignore_conflicts = True
279 # Does the backend support updating rows on constraint or uniqueness errors
280 # during INSERT?
281 supports_update_conflicts = False
282 supports_update_conflicts_with_target = False
284 # Does this backend require casting the results of CASE expressions used
285 # in UPDATE statements to ensure the expression has the correct type?
286 requires_casted_case_in_updates = False
288 # Does the backend support partial indexes (CREATE INDEX ... WHERE ...)?
289 supports_partial_indexes = True
290 supports_functions_in_partial_indexes = True
291 # Does the backend support covering indexes (CREATE INDEX ... INCLUDE ...)?
292 supports_covering_indexes = False
293 # Does the backend support indexes on expressions?
294 supports_expression_indexes = True
295 # Does the backend treat COLLATE as an indexed expression?
296 collate_as_index_expression = False
298 # Does the backend support boolean expressions in SELECT and GROUP BY
299 # clauses?
300 supports_boolean_expr_in_select_clause = True
301 # Does the backend support comparing boolean expressions in WHERE clauses?
302 # Eg: WHERE (price > 0) IS NOT NULL
303 supports_comparing_boolean_expr = True
305 # Does the backend support JSONField?
306 supports_json_field = True
307 # Can the backend introspect a JSONField?
308 can_introspect_json_field = True
309 # Does the backend support primitives in JSONField?
310 supports_primitives_in_json_field = True
311 # Is there a true datatype for JSON?
312 has_native_json_field = False
313 # Does the backend use PostgreSQL-style JSON operators like '->'?
314 has_json_operators = False
315 # Does the backend support __contains and __contained_by lookups for
316 # a JSONField?
317 supports_json_field_contains = True
318 # Does value__d__contains={'f': 'g'} (without a list around the dict) match
319 # {'d': [{'f': 'g'}]}?
320 json_key_contains_list_matching_requires_list = False
321 # Does the backend support JSONObject() database function?
322 has_json_object_function = True
324 # Does the backend support column collations?
325 supports_collation_on_charfield = True
326 supports_collation_on_textfield = True
327 # Does the backend support non-deterministic collations?
328 supports_non_deterministic_collations = True
330 # Does the backend support column and table comments?
331 supports_comments = False
332 # Does the backend support column comments in ADD COLUMN statements?
333 supports_comments_inline = False
335 # Does the backend support the logical XOR operator?
336 supports_logical_xor = False
338 # Set to (exception, message) if null characters in text are disallowed.
339 prohibits_null_characters_in_text_exception = None
341 # Does the backend support unlimited character columns?
342 supports_unlimited_charfield = False
344 # Collation names for use by the Plain test suite.
345 test_collations = {
346 "ci": None, # Case-insensitive.
347 "cs": None, # Case-sensitive.
348 "non_default": None, # Non-default.
349 "swedish_ci": None, # Swedish case-insensitive.
350 }
351 # SQL template override for tests.aggregation.tests.NowUTC
352 test_now_utc_template = None
354 def __init__(self, connection):
355 self.connection = connection
357 @cached_property
358 def supports_explaining_query_execution(self):
359 """Does this backend support explaining query execution?"""
360 return self.connection.ops.explain_prefix is not None
362 @cached_property
363 def supports_transactions(self):
364 """Confirm support for transactions."""
365 with self.connection.cursor() as cursor:
366 cursor.execute("CREATE TABLE ROLLBACK_TEST (X INT)")
367 self.connection.set_autocommit(False)
368 cursor.execute("INSERT INTO ROLLBACK_TEST (X) VALUES (8)")
369 self.connection.rollback()
370 self.connection.set_autocommit(True)
371 cursor.execute("SELECT COUNT(X) FROM ROLLBACK_TEST")
372 (count,) = cursor.fetchone()
373 cursor.execute("DROP TABLE ROLLBACK_TEST")
374 return count == 0
376 def allows_group_by_selected_pks_on_model(self, model):
377 if not self.allows_group_by_selected_pks:
378 return False
379 return model._meta.managed
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from collections import namedtuple
3# Structure returned by DatabaseIntrospection.get_table_list()
4TableInfo = namedtuple("TableInfo", ["name", "type"])
6# Structure returned by the DB-API cursor.description interface (PEP 249)
7FieldInfo = namedtuple(
8 "FieldInfo",
9 "name type_code display_size internal_size precision scale null_ok "
10 "default collation",
11)
14class BaseDatabaseIntrospection:
15 """Encapsulate backend-specific introspection utilities."""
17 data_types_reverse = {}
19 def __init__(self, connection):
20 self.connection = connection
22 def get_field_type(self, data_type, description):
23 """
24 Hook for a database backend to use the cursor description to
25 match a Plain field type to a database column.
27 For Oracle, the column data_type on its own is insufficient to
28 distinguish between a FloatField and IntegerField, for example.
29 """
30 return self.data_types_reverse[data_type]
32 def identifier_converter(self, name):
33 """
34 Apply a conversion to the identifier for the purposes of comparison.
36 The default identifier converter is for case sensitive comparison.
37 """
38 return name
40 def table_names(self, cursor=None, include_views=False):
41 """
42 Return a list of names of all tables that exist in the database.
43 Sort the returned table list by Python's default sorting. Do NOT use
44 the database's ORDER BY here to avoid subtle differences in sorting
45 order between databases.
46 """
48 def get_names(cursor):
49 return sorted(
50 ti.name
51 for ti in self.get_table_list(cursor)
52 if include_views or ti.type == "t"
53 )
55 if cursor is None:
56 with self.connection.cursor() as cursor:
57 return get_names(cursor)
58 return get_names(cursor)
60 def get_table_list(self, cursor):
61 """
62 Return an unsorted list of TableInfo named tuples of all tables and
63 views that exist in the database.
64 """
65 raise NotImplementedError(
66 "subclasses of BaseDatabaseIntrospection may require a get_table_list() "
67 "method"
68 )
70 def get_table_description(self, cursor, table_name):
71 """
72 Return a description of the table with the DB-API cursor.description
73 interface.
74 """
75 raise NotImplementedError(
76 "subclasses of BaseDatabaseIntrospection may require a "
77 "get_table_description() method."
78 )
80 def get_migratable_models(self):
81 from plain.models.db import router
82 from plain.packages import packages
84 return (
85 model
86 for package_config in packages.get_package_configs()
87 for model in router.get_migratable_models(
88 package_config, self.connection.alias
89 )
90 if model._meta.can_migrate(self.connection)
91 )
93 def plain_table_names(self, only_existing=False, include_views=True):
94 """
95 Return a list of all table names that have associated Plain models and
96 are in INSTALLED_PACKAGES.
98 If only_existing is True, include only the tables in the database.
99 """
100 tables = set()
101 for model in self.get_migratable_models():
102 if not model._meta.managed:
103 continue
104 tables.add(model._meta.db_table)
105 tables.update(
106 f.m2m_db_table()
107 for f in model._meta.local_many_to_many
108 if f.remote_field.through._meta.managed
109 )
110 tables = list(tables)
111 if only_existing:
112 existing_tables = set(self.table_names(include_views=include_views))
113 tables = [
114 t for t in tables if self.identifier_converter(t) in existing_tables
115 ]
116 return tables
118 def installed_models(self, tables):
119 """
120 Return a set of all models represented by the provided list of table
121 names.
122 """
123 tables = set(map(self.identifier_converter, tables))
124 return {
125 m
126 for m in self.get_migratable_models()
127 if self.identifier_converter(m._meta.db_table) in tables
128 }
130 def sequence_list(self):
131 """
132 Return a list of information about all DB sequences for all models in
133 all packages.
134 """
135 sequence_list = []
136 with self.connection.cursor() as cursor:
137 for model in self.get_migratable_models():
138 if not model._meta.managed:
139 continue
140 if model._meta.swapped:
141 continue
142 sequence_list.extend(
143 self.get_sequences(
144 cursor, model._meta.db_table, model._meta.local_fields
145 )
146 )
147 for f in model._meta.local_many_to_many:
148 # If this is an m2m using an intermediate table,
149 # we don't need to reset the sequence.
150 if f.remote_field.through._meta.auto_created:
151 sequence = self.get_sequences(cursor, f.m2m_db_table())
152 sequence_list.extend(
153 sequence or [{"table": f.m2m_db_table(), "column": None}]
154 )
155 return sequence_list
157 def get_sequences(self, cursor, table_name, table_fields=()):
158 """
159 Return a list of introspected sequences for table_name. Each sequence
160 is a dict: {'table': <table_name>, 'column': <column_name>}. An optional
161 'name' key can be added if the backend supports named sequences.
162 """
163 raise NotImplementedError(
164 "subclasses of BaseDatabaseIntrospection may require a get_sequences() "
165 "method"
166 )
168 def get_relations(self, cursor, table_name):
169 """
170 Return a dictionary of {field_name: (field_name_other_table, other_table)}
171 representing all foreign keys in the given table.
172 """
173 raise NotImplementedError(
174 "subclasses of BaseDatabaseIntrospection may require a "
175 "get_relations() method."
176 )
178 def get_primary_key_column(self, cursor, table_name):
179 """
180 Return the name of the primary key column for the given table.
181 """
182 columns = self.get_primary_key_columns(cursor, table_name)
183 return columns[0] if columns else None
185 def get_primary_key_columns(self, cursor, table_name):
186 """Return a list of primary key columns for the given table."""
187 for constraint in self.get_constraints(cursor, table_name).values():
188 if constraint["primary_key"]:
189 return constraint["columns"]
190 return None
192 def get_constraints(self, cursor, table_name):
193 """
194 Retrieve any constraints or keys (unique, pk, fk, check, index)
195 across one or more columns.
197 Return a dict mapping constraint names to their attributes,
198 where attributes is a dict with keys:
199 * columns: List of columns this covers
200 * primary_key: True if primary key, False otherwise
201 * unique: True if this is a unique constraint, False otherwise
202 * foreign_key: (table, column) of target, or None
203 * check: True if check constraint, False otherwise
204 * index: True if index, False otherwise.
205 * orders: The order (ASC/DESC) defined for the columns of indexes
206 * type: The type of the index (btree, hash, etc.)
208 Some backends may return special constraint names that don't exist
209 if they don't name constraints of a certain type (e.g. SQLite)
210 """
211 raise NotImplementedError(
212 "subclasses of BaseDatabaseIntrospection may require a get_constraints() "
213 "method"
214 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
2import decimal
3import json
4from importlib import import_module
6import sqlparse
8from plain.models.backends import utils
9from plain.models.db import NotSupportedError
10from plain.utils import timezone
11from plain.utils.encoding import force_str
14class BaseDatabaseOperations:
15 """
16 Encapsulate backend-specific differences, such as the way a backend
17 performs ordering or calculates the ID of a recently-inserted row.
18 """
20 compiler_module = "plain.models.sql.compiler"
22 # Integer field safe ranges by `internal_type` as documented
23 # in docs/ref/models/fields.txt.
24 integer_field_ranges = {
25 "SmallIntegerField": (-32768, 32767),
26 "IntegerField": (-2147483648, 2147483647),
27 "BigIntegerField": (-9223372036854775808, 9223372036854775807),
28 "PositiveBigIntegerField": (0, 9223372036854775807),
29 "PositiveSmallIntegerField": (0, 32767),
30 "PositiveIntegerField": (0, 2147483647),
31 "SmallAutoField": (-32768, 32767),
32 "AutoField": (-2147483648, 2147483647),
33 "BigAutoField": (-9223372036854775808, 9223372036854775807),
34 }
35 set_operators = {
36 "union": "UNION",
37 "intersection": "INTERSECT",
38 "difference": "EXCEPT",
39 }
40 # Mapping of Field.get_internal_type() (typically the model field's class
41 # name) to the data type to use for the Cast() function, if different from
42 # DatabaseWrapper.data_types.
43 cast_data_types = {}
44 # CharField data type if the max_length argument isn't provided.
45 cast_char_field_without_max_length = None
47 # Start and end points for window expressions.
48 PRECEDING = "PRECEDING"
49 FOLLOWING = "FOLLOWING"
50 UNBOUNDED_PRECEDING = "UNBOUNDED " + PRECEDING
51 UNBOUNDED_FOLLOWING = "UNBOUNDED " + FOLLOWING
52 CURRENT_ROW = "CURRENT ROW"
54 # Prefix for EXPLAIN queries, or None EXPLAIN isn't supported.
55 explain_prefix = None
57 def __init__(self, connection):
58 self.connection = connection
59 self._cache = None
61 def autoinc_sql(self, table, column):
62 """
63 Return any SQL needed to support auto-incrementing primary keys, or
64 None if no SQL is necessary.
66 This SQL is executed when a table is created.
67 """
68 return None
70 def bulk_batch_size(self, fields, objs):
71 """
72 Return the maximum allowed batch size for the backend. The fields
73 are the fields going to be inserted in the batch, the objs contains
74 all the objects to be inserted.
75 """
76 return len(objs)
78 def format_for_duration_arithmetic(self, sql):
79 raise NotImplementedError(
80 "subclasses of BaseDatabaseOperations may require a "
81 "format_for_duration_arithmetic() method."
82 )
84 def cache_key_culling_sql(self):
85 """
86 Return an SQL query that retrieves the first cache key greater than the
87 n smallest.
89 This is used by the 'db' cache backend to determine where to start
90 culling.
91 """
92 cache_key = self.quote_name("cache_key")
93 return f"SELECT {cache_key} FROM %s ORDER BY {cache_key} LIMIT 1 OFFSET %%s"
95 def unification_cast_sql(self, output_field):
96 """
97 Given a field instance, return the SQL that casts the result of a union
98 to that type. The resulting string should contain a '%s' placeholder
99 for the expression being cast.
100 """
101 return "%s"
103 def date_extract_sql(self, lookup_type, sql, params):
104 """
105 Given a lookup_type of 'year', 'month', or 'day', return the SQL that
106 extracts a value from the given date field field_name.
107 """
108 raise NotImplementedError(
109 "subclasses of BaseDatabaseOperations may require a date_extract_sql() "
110 "method"
111 )
113 def date_trunc_sql(self, lookup_type, sql, params, tzname=None):
114 """
115 Given a lookup_type of 'year', 'month', or 'day', return the SQL that
116 truncates the given date or datetime field field_name to a date object
117 with only the given specificity.
119 If `tzname` is provided, the given value is truncated in a specific
120 timezone.
121 """
122 raise NotImplementedError(
123 "subclasses of BaseDatabaseOperations may require a date_trunc_sql() "
124 "method."
125 )
127 def datetime_cast_date_sql(self, sql, params, tzname):
128 """
129 Return the SQL to cast a datetime value to date value.
130 """
131 raise NotImplementedError(
132 "subclasses of BaseDatabaseOperations may require a "
133 "datetime_cast_date_sql() method."
134 )
136 def datetime_cast_time_sql(self, sql, params, tzname):
137 """
138 Return the SQL to cast a datetime value to time value.
139 """
140 raise NotImplementedError(
141 "subclasses of BaseDatabaseOperations may require a "
142 "datetime_cast_time_sql() method"
143 )
145 def datetime_extract_sql(self, lookup_type, sql, params, tzname):
146 """
147 Given a lookup_type of 'year', 'month', 'day', 'hour', 'minute', or
148 'second', return the SQL that extracts a value from the given
149 datetime field field_name.
150 """
151 raise NotImplementedError(
152 "subclasses of BaseDatabaseOperations may require a datetime_extract_sql() "
153 "method"
154 )
156 def datetime_trunc_sql(self, lookup_type, sql, params, tzname):
157 """
158 Given a lookup_type of 'year', 'month', 'day', 'hour', 'minute', or
159 'second', return the SQL that truncates the given datetime field
160 field_name to a datetime object with only the given specificity.
161 """
162 raise NotImplementedError(
163 "subclasses of BaseDatabaseOperations may require a datetime_trunc_sql() "
164 "method"
165 )
167 def time_trunc_sql(self, lookup_type, sql, params, tzname=None):
168 """
169 Given a lookup_type of 'hour', 'minute' or 'second', return the SQL
170 that truncates the given time or datetime field field_name to a time
171 object with only the given specificity.
173 If `tzname` is provided, the given value is truncated in a specific
174 timezone.
175 """
176 raise NotImplementedError(
177 "subclasses of BaseDatabaseOperations may require a time_trunc_sql() method"
178 )
180 def time_extract_sql(self, lookup_type, sql, params):
181 """
182 Given a lookup_type of 'hour', 'minute', or 'second', return the SQL
183 that extracts a value from the given time field field_name.
184 """
185 return self.date_extract_sql(lookup_type, sql, params)
187 def deferrable_sql(self):
188 """
189 Return the SQL to make a constraint "initially deferred" during a
190 CREATE TABLE statement.
191 """
192 return ""
194 def distinct_sql(self, fields, params):
195 """
196 Return an SQL DISTINCT clause which removes duplicate rows from the
197 result set. If any fields are given, only check the given fields for
198 duplicates.
199 """
200 if fields:
201 raise NotSupportedError(
202 "DISTINCT ON fields is not supported by this database backend"
203 )
204 else:
205 return ["DISTINCT"], []
207 def fetch_returned_insert_columns(self, cursor, returning_params):
208 """
209 Given a cursor object that has just performed an INSERT...RETURNING
210 statement into a table, return the newly created data.
211 """
212 return cursor.fetchone()
214 def field_cast_sql(self, db_type, internal_type):
215 """
216 Given a column type (e.g. 'BLOB', 'VARCHAR') and an internal type
217 (e.g. 'GenericIPAddressField'), return the SQL to cast it before using
218 it in a WHERE statement. The resulting string should contain a '%s'
219 placeholder for the column being searched against.
220 """
221 return "%s"
223 def force_no_ordering(self):
224 """
225 Return a list used in the "ORDER BY" clause to force no ordering at
226 all. Return an empty list to include nothing in the ordering.
227 """
228 return []
230 def for_update_sql(self, nowait=False, skip_locked=False, of=(), no_key=False):
231 """
232 Return the FOR UPDATE SQL clause to lock rows for an update operation.
233 """
234 return "FOR{} UPDATE{}{}{}".format(
235 " NO KEY" if no_key else "",
236 " OF {}".format(", ".join(of)) if of else "",
237 " NOWAIT" if nowait else "",
238 " SKIP LOCKED" if skip_locked else "",
239 )
241 def _get_limit_offset_params(self, low_mark, high_mark):
242 offset = low_mark or 0
243 if high_mark is not None:
244 return (high_mark - offset), offset
245 elif offset:
246 return self.connection.ops.no_limit_value(), offset
247 return None, offset
249 def limit_offset_sql(self, low_mark, high_mark):
250 """Return LIMIT/OFFSET SQL clause."""
251 limit, offset = self._get_limit_offset_params(low_mark, high_mark)
252 return " ".join(
253 sql
254 for sql in (
255 ("LIMIT %d" % limit) if limit else None,
256 ("OFFSET %d" % offset) if offset else None,
257 )
258 if sql
259 )
261 def last_executed_query(self, cursor, sql, params):
262 """
263 Return a string of the query last executed by the given cursor, with
264 placeholders replaced with actual values.
266 `sql` is the raw query containing placeholders and `params` is the
267 sequence of parameters. These are used by default, but this method
268 exists for database backends to provide a better implementation
269 according to their own quoting schemes.
270 """
272 # Convert params to contain string values.
273 def to_string(s):
274 return force_str(s, strings_only=True, errors="replace")
276 if isinstance(params, list | tuple):
277 u_params = tuple(to_string(val) for val in params)
278 elif params is None:
279 u_params = ()
280 else:
281 u_params = {to_string(k): to_string(v) for k, v in params.items()}
283 return f"QUERY = {sql!r} - PARAMS = {u_params!r}"
285 def last_insert_id(self, cursor, table_name, pk_name):
286 """
287 Given a cursor object that has just performed an INSERT statement into
288 a table that has an auto-incrementing ID, return the newly created ID.
290 `pk_name` is the name of the primary-key column.
291 """
292 return cursor.lastrowid
294 def lookup_cast(self, lookup_type, internal_type=None):
295 """
296 Return the string to use in a query when performing lookups
297 ("contains", "like", etc.). It should contain a '%s' placeholder for
298 the column being searched against.
299 """
300 return "%s"
302 def max_in_list_size(self):
303 """
304 Return the maximum number of items that can be passed in a single 'IN'
305 list condition, or None if the backend does not impose a limit.
306 """
307 return None
309 def max_name_length(self):
310 """
311 Return the maximum length of table and column names, or None if there
312 is no limit.
313 """
314 return None
316 def no_limit_value(self):
317 """
318 Return the value to use for the LIMIT when we are wanting "LIMIT
319 infinity". Return None if the limit clause can be omitted in this case.
320 """
321 raise NotImplementedError(
322 "subclasses of BaseDatabaseOperations may require a no_limit_value() method"
323 )
325 def pk_default_value(self):
326 """
327 Return the value to use during an INSERT statement to specify that
328 the field should use its default value.
329 """
330 return "DEFAULT"
332 def prepare_sql_script(self, sql):
333 """
334 Take an SQL script that may contain multiple lines and return a list
335 of statements to feed to successive cursor.execute() calls.
337 Since few databases are able to process raw SQL scripts in a single
338 cursor.execute() call and PEP 249 doesn't talk about this use case,
339 the default implementation is conservative.
340 """
341 return [
342 sqlparse.format(statement, strip_comments=True)
343 for statement in sqlparse.split(sql)
344 if statement
345 ]
347 def process_clob(self, value):
348 """
349 Return the value of a CLOB column, for backends that return a locator
350 object that requires additional processing.
351 """
352 return value
354 def return_insert_columns(self, fields):
355 """
356 For backends that support returning columns as part of an insert query,
357 return the SQL and params to append to the INSERT query. The returned
358 fragment should contain a format string to hold the appropriate column.
359 """
360 pass
362 def compiler(self, compiler_name):
363 """
364 Return the SQLCompiler class corresponding to the given name,
365 in the namespace corresponding to the `compiler_module` attribute
366 on this backend.
367 """
368 if self._cache is None:
369 self._cache = import_module(self.compiler_module)
370 return getattr(self._cache, compiler_name)
372 def quote_name(self, name):
373 """
374 Return a quoted version of the given table, index, or column name. Do
375 not quote the given name if it's already been quoted.
376 """
377 raise NotImplementedError(
378 "subclasses of BaseDatabaseOperations may require a quote_name() method"
379 )
381 def regex_lookup(self, lookup_type):
382 """
383 Return the string to use in a query when performing regular expression
384 lookups (using "regex" or "iregex"). It should contain a '%s'
385 placeholder for the column being searched against.
387 If the feature is not supported (or part of it is not supported), raise
388 NotImplementedError.
389 """
390 raise NotImplementedError(
391 "subclasses of BaseDatabaseOperations may require a regex_lookup() method"
392 )
394 def savepoint_create_sql(self, sid):
395 """
396 Return the SQL for starting a new savepoint. Only required if the
397 "uses_savepoints" feature is True. The "sid" parameter is a string
398 for the savepoint id.
399 """
400 return f"SAVEPOINT {self.quote_name(sid)}"
402 def savepoint_commit_sql(self, sid):
403 """
404 Return the SQL for committing the given savepoint.
405 """
406 return f"RELEASE SAVEPOINT {self.quote_name(sid)}"
408 def savepoint_rollback_sql(self, sid):
409 """
410 Return the SQL for rolling back the given savepoint.
411 """
412 return f"ROLLBACK TO SAVEPOINT {self.quote_name(sid)}"
414 def set_time_zone_sql(self):
415 """
416 Return the SQL that will set the connection's time zone.
418 Return '' if the backend doesn't support time zones.
419 """
420 return ""
422 def sequence_reset_by_name_sql(self, style, sequences):
423 """
424 Return a list of the SQL statements required to reset sequences
425 passed in `sequences`.
427 The `style` argument is a Style object as returned by either
428 color_style() or no_style() in plain.internal.legacy.management.color.
429 """
430 return []
432 def sequence_reset_sql(self, style, model_list):
433 """
434 Return a list of the SQL statements required to reset sequences for
435 the given models.
437 The `style` argument is a Style object as returned by either
438 color_style() or no_style() in plain.internal.legacy.management.color.
439 """
440 return [] # No sequence reset required by default.
442 def start_transaction_sql(self):
443 """Return the SQL statement required to start a transaction."""
444 return "BEGIN;"
446 def end_transaction_sql(self, success=True):
447 """Return the SQL statement required to end a transaction."""
448 if not success:
449 return "ROLLBACK;"
450 return "COMMIT;"
452 def tablespace_sql(self, tablespace, inline=False):
453 """
454 Return the SQL that will be used in a query to define the tablespace.
456 Return '' if the backend doesn't support tablespaces.
458 If `inline` is True, append the SQL to a row; otherwise append it to
459 the entire CREATE TABLE or CREATE INDEX statement.
460 """
461 return ""
463 def prep_for_like_query(self, x):
464 """Prepare a value for use in a LIKE query."""
465 return str(x).replace("\\", "\\\\").replace("%", r"\%").replace("_", r"\_")
467 # Same as prep_for_like_query(), but called for "iexact" matches, which
468 # need not necessarily be implemented using "LIKE" in the backend.
469 prep_for_iexact_query = prep_for_like_query
471 def validate_autopk_value(self, value):
472 """
473 Certain backends do not accept some values for "serial" fields
474 (for example zero in MySQL). Raise a ValueError if the value is
475 invalid, otherwise return the validated value.
476 """
477 return value
479 def adapt_unknown_value(self, value):
480 """
481 Transform a value to something compatible with the backend driver.
483 This method only depends on the type of the value. It's designed for
484 cases where the target type isn't known, such as .raw() SQL queries.
485 As a consequence it may not work perfectly in all circumstances.
486 """
487 if isinstance(value, datetime.datetime): # must be before date
488 return self.adapt_datetimefield_value(value)
489 elif isinstance(value, datetime.date):
490 return self.adapt_datefield_value(value)
491 elif isinstance(value, datetime.time):
492 return self.adapt_timefield_value(value)
493 elif isinstance(value, decimal.Decimal):
494 return self.adapt_decimalfield_value(value)
495 else:
496 return value
498 def adapt_integerfield_value(self, value, internal_type):
499 return value
501 def adapt_datefield_value(self, value):
502 """
503 Transform a date value to an object compatible with what is expected
504 by the backend driver for date columns.
505 """
506 if value is None:
507 return None
508 return str(value)
510 def adapt_datetimefield_value(self, value):
511 """
512 Transform a datetime value to an object compatible with what is expected
513 by the backend driver for datetime columns.
514 """
515 if value is None:
516 return None
517 # Expression values are adapted by the database.
518 if hasattr(value, "resolve_expression"):
519 return value
521 return str(value)
523 def adapt_timefield_value(self, value):
524 """
525 Transform a time value to an object compatible with what is expected
526 by the backend driver for time columns.
527 """
528 if value is None:
529 return None
530 # Expression values are adapted by the database.
531 if hasattr(value, "resolve_expression"):
532 return value
534 if timezone.is_aware(value):
535 raise ValueError("Plain does not support timezone-aware times.")
536 return str(value)
538 def adapt_decimalfield_value(self, value, max_digits=None, decimal_places=None):
539 """
540 Transform a decimal.Decimal value to an object compatible with what is
541 expected by the backend driver for decimal (numeric) columns.
542 """
543 return utils.format_number(value, max_digits, decimal_places)
545 def adapt_ipaddressfield_value(self, value):
546 """
547 Transform a string representation of an IP address into the expected
548 type for the backend driver.
549 """
550 return value or None
552 def adapt_json_value(self, value, encoder):
553 return json.dumps(value, cls=encoder)
555 def year_lookup_bounds_for_date_field(self, value, iso_year=False):
556 """
557 Return a two-elements list with the lower and upper bound to be used
558 with a BETWEEN operator to query a DateField value using a year
559 lookup.
561 `value` is an int, containing the looked-up year.
562 If `iso_year` is True, return bounds for ISO-8601 week-numbering years.
563 """
564 if iso_year:
565 first = datetime.date.fromisocalendar(value, 1, 1)
566 second = datetime.date.fromisocalendar(
567 value + 1, 1, 1
568 ) - datetime.timedelta(days=1)
569 else:
570 first = datetime.date(value, 1, 1)
571 second = datetime.date(value, 12, 31)
572 first = self.adapt_datefield_value(first)
573 second = self.adapt_datefield_value(second)
574 return [first, second]
576 def year_lookup_bounds_for_datetime_field(self, value, iso_year=False):
577 """
578 Return a two-elements list with the lower and upper bound to be used
579 with a BETWEEN operator to query a DateTimeField value using a year
580 lookup.
582 `value` is an int, containing the looked-up year.
583 If `iso_year` is True, return bounds for ISO-8601 week-numbering years.
584 """
585 if iso_year:
586 first = datetime.datetime.fromisocalendar(value, 1, 1)
587 second = datetime.datetime.fromisocalendar(
588 value + 1, 1, 1
589 ) - datetime.timedelta(microseconds=1)
590 else:
591 first = datetime.datetime(value, 1, 1)
592 second = datetime.datetime(value, 12, 31, 23, 59, 59, 999999)
594 # Make sure that datetimes are aware in the current timezone
595 tz = timezone.get_current_timezone()
596 first = timezone.make_aware(first, tz)
597 second = timezone.make_aware(second, tz)
599 first = self.adapt_datetimefield_value(first)
600 second = self.adapt_datetimefield_value(second)
601 return [first, second]
603 def get_db_converters(self, expression):
604 """
605 Return a list of functions needed to convert field data.
607 Some field types on some backends do not provide data in the correct
608 format, this is the hook for converter functions.
609 """
610 return []
612 def convert_durationfield_value(self, value, expression, connection):
613 if value is not None:
614 return datetime.timedelta(0, 0, value)
616 def check_expression_support(self, expression):
617 """
618 Check that the backend supports the provided expression.
620 This is used on specific backends to rule out known expressions
621 that have problematic or nonexistent implementations. If the
622 expression has a known problem, the backend should raise
623 NotSupportedError.
624 """
625 pass
627 def conditional_expression_supported_in_where_clause(self, expression):
628 """
629 Return True, if the conditional expression is supported in the WHERE
630 clause.
631 """
632 return True
634 def combine_expression(self, connector, sub_expressions):
635 """
636 Combine a list of subexpressions into a single expression, using
637 the provided connecting operator. This is required because operators
638 can vary between backends (e.g., Oracle with %% and &) and between
639 subexpression types (e.g., date expressions).
640 """
641 conn = f" {connector} "
642 return conn.join(sub_expressions)
644 def combine_duration_expression(self, connector, sub_expressions):
645 return self.combine_expression(connector, sub_expressions)
647 def binary_placeholder_sql(self, value):
648 """
649 Some backends require special syntax to insert binary content (MySQL
650 for example uses '_binary %s').
651 """
652 return "%s"
654 def modify_insert_params(self, placeholder, params):
655 """
656 Allow modification of insert parameters. Needed for Oracle Spatial
657 backend due to #10888.
658 """
659 return params
661 def integer_field_range(self, internal_type):
662 """
663 Given an integer field internal type (e.g. 'PositiveIntegerField'),
664 return a tuple of the (min_value, max_value) form representing the
665 range of the column type bound to the field.
666 """
667 return self.integer_field_ranges[internal_type]
669 def subtract_temporals(self, internal_type, lhs, rhs):
670 if self.connection.features.supports_temporal_subtraction:
671 lhs_sql, lhs_params = lhs
672 rhs_sql, rhs_params = rhs
673 return f"({lhs_sql} - {rhs_sql})", (*lhs_params, *rhs_params)
674 raise NotSupportedError(
675 f"This backend does not support {internal_type} subtraction."
676 )
678 def window_frame_start(self, start):
679 if isinstance(start, int):
680 if start < 0:
681 return "%d %s" % (abs(start), self.PRECEDING)
682 elif start == 0:
683 return self.CURRENT_ROW
684 elif start is None:
685 return self.UNBOUNDED_PRECEDING
686 raise ValueError(
687 f"start argument must be a negative integer, zero, or None, but got '{start}'."
688 )
690 def window_frame_end(self, end):
691 if isinstance(end, int):
692 if end == 0:
693 return self.CURRENT_ROW
694 elif end > 0:
695 return "%d %s" % (end, self.FOLLOWING)
696 elif end is None:
697 return self.UNBOUNDED_FOLLOWING
698 raise ValueError(
699 f"end argument must be a positive integer, zero, or None, but got '{end}'."
700 )
702 def window_frame_rows_start_end(self, start=None, end=None):
703 """
704 Return SQL for start and end points in an OVER clause window frame.
705 """
706 if not self.connection.features.supports_over_clause:
707 raise NotSupportedError("This backend does not support window expressions.")
708 return self.window_frame_start(start), self.window_frame_end(end)
710 def window_frame_range_start_end(self, start=None, end=None):
711 start_, end_ = self.window_frame_rows_start_end(start, end)
712 features = self.connection.features
713 if features.only_supports_unbounded_with_preceding_and_following and (
714 (start and start < 0) or (end and end > 0)
715 ):
716 raise NotSupportedError(
717 f"{self.connection.display_name} only supports UNBOUNDED together with PRECEDING and "
718 "FOLLOWING."
719 )
720 return start_, end_
722 def explain_query_prefix(self, format=None, **options):
723 if not self.connection.features.supports_explaining_query_execution:
724 raise NotSupportedError(
725 "This backend does not support explaining query execution."
726 )
727 if format:
728 supported_formats = self.connection.features.supported_explain_formats
729 normalized_format = format.upper()
730 if normalized_format not in supported_formats:
731 msg = f"{normalized_format} is not a recognized format."
732 if supported_formats:
733 msg += " Allowed formats: {}".format(
734 ", ".join(sorted(supported_formats))
735 )
736 else:
737 msg += (
738 f" {self.connection.display_name} does not support any formats."
739 )
740 raise ValueError(msg)
741 if options:
742 raise ValueError(
743 "Unknown options: {}".format(", ".join(sorted(options.keys())))
744 )
745 return self.explain_prefix
747 def insert_statement(self, on_conflict=None):
748 return "INSERT INTO"
750 def on_conflict_suffix_sql(self, fields, on_conflict, update_fields, unique_fields):
751 return ""
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import logging
2import operator
3from datetime import datetime
5from plain.models.backends.ddl_references import (
6 Columns,
7 Expressions,
8 ForeignKeyName,
9 IndexName,
10 Statement,
11 Table,
12)
13from plain.models.backends.utils import names_digest, split_identifier, truncate_name
14from plain.models.constraints import Deferrable
15from plain.models.indexes import Index
16from plain.models.sql import Query
17from plain.models.transaction import TransactionManagementError, atomic
18from plain.runtime import settings
19from plain.utils import timezone
21logger = logging.getLogger("plain.models.backends.schema")
24def _is_relevant_relation(relation, altered_field):
25 """
26 When altering the given field, must constraints on its model from the given
27 relation be temporarily dropped?
28 """
29 field = relation.field
30 if field.many_to_many:
31 # M2M reverse field
32 return False
33 if altered_field.primary_key and field.to_fields == [None]:
34 # Foreign key constraint on the primary key, which is being altered.
35 return True
36 # Is the constraint targeting the field being altered?
37 return altered_field.name in field.to_fields
40def _all_related_fields(model):
41 # Related fields must be returned in a deterministic order.
42 return sorted(
43 model._meta._get_fields(
44 forward=False,
45 reverse=True,
46 include_hidden=True,
47 include_parents=False,
48 ),
49 key=operator.attrgetter("name"),
50 )
53def _related_non_m2m_objects(old_field, new_field):
54 # Filter out m2m objects from reverse relations.
55 # Return (old_relation, new_relation) tuples.
56 related_fields = zip(
57 (
58 obj
59 for obj in _all_related_fields(old_field.model)
60 if _is_relevant_relation(obj, old_field)
61 ),
62 (
63 obj
64 for obj in _all_related_fields(new_field.model)
65 if _is_relevant_relation(obj, new_field)
66 ),
67 )
68 for old_rel, new_rel in related_fields:
69 yield old_rel, new_rel
70 yield from _related_non_m2m_objects(
71 old_rel.remote_field,
72 new_rel.remote_field,
73 )
76class BaseDatabaseSchemaEditor:
77 """
78 This class and its subclasses are responsible for emitting schema-changing
79 statements to the databases - model creation/removal/alteration, field
80 renaming, index fiddling, and so on.
81 """
83 # Overrideable SQL templates
84 sql_create_table = "CREATE TABLE %(table)s (%(definition)s)"
85 sql_rename_table = "ALTER TABLE %(old_table)s RENAME TO %(new_table)s"
86 sql_retablespace_table = "ALTER TABLE %(table)s SET TABLESPACE %(new_tablespace)s"
87 sql_delete_table = "DROP TABLE %(table)s CASCADE"
89 sql_create_column = "ALTER TABLE %(table)s ADD COLUMN %(column)s %(definition)s"
90 sql_alter_column = "ALTER TABLE %(table)s %(changes)s"
91 sql_alter_column_type = "ALTER COLUMN %(column)s TYPE %(type)s%(collation)s"
92 sql_alter_column_null = "ALTER COLUMN %(column)s DROP NOT NULL"
93 sql_alter_column_not_null = "ALTER COLUMN %(column)s SET NOT NULL"
94 sql_alter_column_default = "ALTER COLUMN %(column)s SET DEFAULT %(default)s"
95 sql_alter_column_no_default = "ALTER COLUMN %(column)s DROP DEFAULT"
96 sql_alter_column_no_default_null = sql_alter_column_no_default
97 sql_delete_column = "ALTER TABLE %(table)s DROP COLUMN %(column)s CASCADE"
98 sql_rename_column = (
99 "ALTER TABLE %(table)s RENAME COLUMN %(old_column)s TO %(new_column)s"
100 )
101 sql_update_with_default = (
102 "UPDATE %(table)s SET %(column)s = %(default)s WHERE %(column)s IS NULL"
103 )
105 sql_unique_constraint = "UNIQUE (%(columns)s)%(deferrable)s"
106 sql_check_constraint = "CHECK (%(check)s)"
107 sql_delete_constraint = "ALTER TABLE %(table)s DROP CONSTRAINT %(name)s"
108 sql_constraint = "CONSTRAINT %(name)s %(constraint)s"
110 sql_create_check = "ALTER TABLE %(table)s ADD CONSTRAINT %(name)s CHECK (%(check)s)"
111 sql_delete_check = sql_delete_constraint
113 sql_create_unique = (
114 "ALTER TABLE %(table)s ADD CONSTRAINT %(name)s "
115 "UNIQUE (%(columns)s)%(deferrable)s"
116 )
117 sql_delete_unique = sql_delete_constraint
119 sql_create_fk = (
120 "ALTER TABLE %(table)s ADD CONSTRAINT %(name)s FOREIGN KEY (%(column)s) "
121 "REFERENCES %(to_table)s (%(to_column)s)%(deferrable)s"
122 )
123 sql_create_inline_fk = None
124 sql_create_column_inline_fk = None
125 sql_delete_fk = sql_delete_constraint
127 sql_create_index = (
128 "CREATE INDEX %(name)s ON %(table)s "
129 "(%(columns)s)%(include)s%(extra)s%(condition)s"
130 )
131 sql_create_unique_index = (
132 "CREATE UNIQUE INDEX %(name)s ON %(table)s "
133 "(%(columns)s)%(include)s%(condition)s"
134 )
135 sql_rename_index = "ALTER INDEX %(old_name)s RENAME TO %(new_name)s"
136 sql_delete_index = "DROP INDEX %(name)s"
138 sql_create_pk = (
139 "ALTER TABLE %(table)s ADD CONSTRAINT %(name)s PRIMARY KEY (%(columns)s)"
140 )
141 sql_delete_pk = sql_delete_constraint
143 sql_delete_procedure = "DROP PROCEDURE %(procedure)s"
145 sql_alter_table_comment = "COMMENT ON TABLE %(table)s IS %(comment)s"
146 sql_alter_column_comment = "COMMENT ON COLUMN %(table)s.%(column)s IS %(comment)s"
148 def __init__(self, connection, collect_sql=False, atomic=True):
149 self.connection = connection
150 self.collect_sql = collect_sql
151 if self.collect_sql:
152 self.collected_sql = []
153 self.atomic_migration = self.connection.features.can_rollback_ddl and atomic
155 # State-managing methods
157 def __enter__(self):
158 self.deferred_sql = []
159 if self.atomic_migration:
160 self.atomic = atomic(self.connection.alias)
161 self.atomic.__enter__()
162 return self
164 def __exit__(self, exc_type, exc_value, traceback):
165 if exc_type is None:
166 for sql in self.deferred_sql:
167 self.execute(sql)
168 if self.atomic_migration:
169 self.atomic.__exit__(exc_type, exc_value, traceback)
171 # Core utility functions
173 def execute(self, sql, params=()):
174 """Execute the given SQL statement, with optional parameters."""
175 # Don't perform the transactional DDL check if SQL is being collected
176 # as it's not going to be executed anyway.
177 if (
178 not self.collect_sql
179 and self.connection.in_atomic_block
180 and not self.connection.features.can_rollback_ddl
181 ):
182 raise TransactionManagementError(
183 "Executing DDL statements while in a transaction on databases "
184 "that can't perform a rollback is prohibited."
185 )
186 # Account for non-string statement objects.
187 sql = str(sql)
188 # Log the command we're running, then run it
189 logger.debug(
190 "%s; (params %r)", sql, params, extra={"params": params, "sql": sql}
191 )
192 if self.collect_sql:
193 ending = "" if sql.rstrip().endswith(";") else ";"
194 if params is not None:
195 self.collected_sql.append(
196 (sql % tuple(map(self.quote_value, params))) + ending
197 )
198 else:
199 self.collected_sql.append(sql + ending)
200 else:
201 with self.connection.cursor() as cursor:
202 cursor.execute(sql, params)
204 def quote_name(self, name):
205 return self.connection.ops.quote_name(name)
207 def table_sql(self, model):
208 """Take a model and return its table definition."""
209 # Create column SQL, add FK deferreds if needed.
210 column_sqls = []
211 params = []
212 for field in model._meta.local_fields:
213 # SQL.
214 definition, extra_params = self.column_sql(model, field)
215 if definition is None:
216 continue
217 # Check constraints can go on the column SQL here.
218 db_params = field.db_parameters(connection=self.connection)
219 if db_params["check"]:
220 definition += " " + self.sql_check_constraint % db_params
221 # Autoincrement SQL (for backends with inline variant).
222 col_type_suffix = field.db_type_suffix(connection=self.connection)
223 if col_type_suffix:
224 definition += f" {col_type_suffix}"
225 params.extend(extra_params)
226 # FK.
227 if field.remote_field and field.db_constraint:
228 to_table = field.remote_field.model._meta.db_table
229 to_column = field.remote_field.model._meta.get_field(
230 field.remote_field.field_name
231 ).column
232 if self.sql_create_inline_fk:
233 definition += " " + self.sql_create_inline_fk % {
234 "to_table": self.quote_name(to_table),
235 "to_column": self.quote_name(to_column),
236 }
237 elif self.connection.features.supports_foreign_keys:
238 self.deferred_sql.append(
239 self._create_fk_sql(
240 model, field, "_fk_%(to_table)s_%(to_column)s"
241 )
242 )
243 # Add the SQL to our big list.
244 column_sqls.append(f"{self.quote_name(field.column)} {definition}")
245 # Autoincrement SQL (for backends with post table definition
246 # variant).
247 if field.get_internal_type() in (
248 "AutoField",
249 "BigAutoField",
250 "SmallAutoField",
251 ):
252 autoinc_sql = self.connection.ops.autoinc_sql(
253 model._meta.db_table, field.column
254 )
255 if autoinc_sql:
256 self.deferred_sql.extend(autoinc_sql)
257 constraints = [
258 constraint.constraint_sql(model, self)
259 for constraint in model._meta.constraints
260 ]
261 sql = self.sql_create_table % {
262 "table": self.quote_name(model._meta.db_table),
263 "definition": ", ".join(
264 str(constraint)
265 for constraint in (*column_sqls, *constraints)
266 if constraint
267 ),
268 }
269 if model._meta.db_tablespace:
270 tablespace_sql = self.connection.ops.tablespace_sql(
271 model._meta.db_tablespace
272 )
273 if tablespace_sql:
274 sql += " " + tablespace_sql
275 return sql, params
277 # Field <-> database mapping functions
279 def _iter_column_sql(
280 self, column_db_type, params, model, field, field_db_params, include_default
281 ):
282 yield column_db_type
283 if collation := field_db_params.get("collation"):
284 yield self._collate_sql(collation)
285 if self.connection.features.supports_comments_inline and field.db_comment:
286 yield self._comment_sql(field.db_comment)
287 # Work out nullability.
288 null = field.null
289 # Include a default value, if requested.
290 include_default = (
291 include_default
292 and not self.skip_default(field)
293 and
294 # Don't include a default value if it's a nullable field and the
295 # default cannot be dropped in the ALTER COLUMN statement (e.g.
296 # MySQL longtext and longblob).
297 not (null and self.skip_default_on_alter(field))
298 )
299 if include_default:
300 default_value = self.effective_default(field)
301 if default_value is not None:
302 column_default = "DEFAULT " + self._column_default_sql(field)
303 if self.connection.features.requires_literal_defaults:
304 # Some databases can't take defaults as a parameter (Oracle).
305 # If this is the case, the individual schema backend should
306 # implement prepare_default().
307 yield column_default % self.prepare_default(default_value)
308 else:
309 yield column_default
310 params.append(default_value)
311 # Oracle treats the empty string ('') as null, so coerce the null
312 # option whenever '' is a possible value.
313 if (
314 field.empty_strings_allowed
315 and not field.primary_key
316 and self.connection.features.interprets_empty_strings_as_nulls
317 ):
318 null = True
319 if not null:
320 yield "NOT NULL"
321 elif not self.connection.features.implied_column_null:
322 yield "NULL"
323 if field.primary_key:
324 yield "PRIMARY KEY"
325 elif field.unique:
326 yield "UNIQUE"
327 # Optionally add the tablespace if it's an implicitly indexed column.
328 tablespace = field.db_tablespace or model._meta.db_tablespace
329 if (
330 tablespace
331 and self.connection.features.supports_tablespaces
332 and field.unique
333 ):
334 yield self.connection.ops.tablespace_sql(tablespace, inline=True)
336 def column_sql(self, model, field, include_default=False):
337 """
338 Return the column definition for a field. The field must already have
339 had set_attributes_from_name() called.
340 """
341 # Get the column's type and use that as the basis of the SQL.
342 field_db_params = field.db_parameters(connection=self.connection)
343 column_db_type = field_db_params["type"]
344 # Check for fields that aren't actually columns (e.g. M2M).
345 if column_db_type is None:
346 return None, None
347 params = []
348 return (
349 " ".join(
350 # This appends to the params being returned.
351 self._iter_column_sql(
352 column_db_type,
353 params,
354 model,
355 field,
356 field_db_params,
357 include_default,
358 )
359 ),
360 params,
361 )
363 def skip_default(self, field):
364 """
365 Some backends don't accept default values for certain columns types
366 (i.e. MySQL longtext and longblob).
367 """
368 return False
370 def skip_default_on_alter(self, field):
371 """
372 Some backends don't accept default values for certain columns types
373 (i.e. MySQL longtext and longblob) in the ALTER COLUMN statement.
374 """
375 return False
377 def prepare_default(self, value):
378 """
379 Only used for backends which have requires_literal_defaults feature
380 """
381 raise NotImplementedError(
382 "subclasses of BaseDatabaseSchemaEditor for backends which have "
383 "requires_literal_defaults must provide a prepare_default() method"
384 )
386 def _column_default_sql(self, field):
387 """
388 Return the SQL to use in a DEFAULT clause. The resulting string should
389 contain a '%s' placeholder for a default value.
390 """
391 return "%s"
393 @staticmethod
394 def _effective_default(field):
395 # This method allows testing its logic without a connection.
396 if field.has_default():
397 default = field.get_default()
398 elif not field.null and field.blank and field.empty_strings_allowed:
399 if field.get_internal_type() == "BinaryField":
400 default = b""
401 else:
402 default = ""
403 elif getattr(field, "auto_now", False) or getattr(field, "auto_now_add", False):
404 internal_type = field.get_internal_type()
405 if internal_type == "DateTimeField":
406 default = timezone.now()
407 else:
408 default = datetime.now()
409 if internal_type == "DateField":
410 default = default.date()
411 elif internal_type == "TimeField":
412 default = default.time()
413 else:
414 default = None
415 return default
417 def effective_default(self, field):
418 """Return a field's effective database default value."""
419 return field.get_db_prep_save(self._effective_default(field), self.connection)
421 def quote_value(self, value):
422 """
423 Return a quoted version of the value so it's safe to use in an SQL
424 string. This is not safe against injection from user code; it is
425 intended only for use in making SQL scripts or preparing default values
426 for particularly tricky backends (defaults are not user-defined, though,
427 so this is safe).
428 """
429 raise NotImplementedError()
431 # Actions
433 def create_model(self, model):
434 """
435 Create a table and any accompanying indexes or unique constraints for
436 the given `model`.
437 """
438 sql, params = self.table_sql(model)
439 # Prevent using [] as params, in the case a literal '%' is used in the
440 # definition.
441 self.execute(sql, params or None)
443 if self.connection.features.supports_comments:
444 # Add table comment.
445 if model._meta.db_table_comment:
446 self.alter_db_table_comment(model, None, model._meta.db_table_comment)
447 # Add column comments.
448 if not self.connection.features.supports_comments_inline:
449 for field in model._meta.local_fields:
450 if field.db_comment:
451 field_db_params = field.db_parameters(
452 connection=self.connection
453 )
454 field_type = field_db_params["type"]
455 self.execute(
456 *self._alter_column_comment_sql(
457 model, field, field_type, field.db_comment
458 )
459 )
460 # Add any field index (deferred as SQLite _remake_table needs it).
461 self.deferred_sql.extend(self._model_indexes_sql(model))
463 # Make M2M tables
464 for field in model._meta.local_many_to_many:
465 if field.remote_field.through._meta.auto_created:
466 self.create_model(field.remote_field.through)
468 def delete_model(self, model):
469 """Delete a model from the database."""
470 # Handle auto-created intermediary models
471 for field in model._meta.local_many_to_many:
472 if field.remote_field.through._meta.auto_created:
473 self.delete_model(field.remote_field.through)
475 # Delete the table
476 self.execute(
477 self.sql_delete_table
478 % {
479 "table": self.quote_name(model._meta.db_table),
480 }
481 )
482 # Remove all deferred statements referencing the deleted table.
483 for sql in list(self.deferred_sql):
484 if isinstance(sql, Statement) and sql.references_table(
485 model._meta.db_table
486 ):
487 self.deferred_sql.remove(sql)
489 def add_index(self, model, index):
490 """Add an index on a model."""
491 if (
492 index.contains_expressions
493 and not self.connection.features.supports_expression_indexes
494 ):
495 return None
496 # Index.create_sql returns interpolated SQL which makes params=None a
497 # necessity to avoid escaping attempts on execution.
498 self.execute(index.create_sql(model, self), params=None)
500 def remove_index(self, model, index):
501 """Remove an index from a model."""
502 if (
503 index.contains_expressions
504 and not self.connection.features.supports_expression_indexes
505 ):
506 return None
507 self.execute(index.remove_sql(model, self))
509 def rename_index(self, model, old_index, new_index):
510 if self.connection.features.can_rename_index:
511 self.execute(
512 self._rename_index_sql(model, old_index.name, new_index.name),
513 params=None,
514 )
515 else:
516 self.remove_index(model, old_index)
517 self.add_index(model, new_index)
519 def add_constraint(self, model, constraint):
520 """Add a constraint to a model."""
521 sql = constraint.create_sql(model, self)
522 if sql:
523 # Constraint.create_sql returns interpolated SQL which makes
524 # params=None a necessity to avoid escaping attempts on execution.
525 self.execute(sql, params=None)
527 def remove_constraint(self, model, constraint):
528 """Remove a constraint from a model."""
529 sql = constraint.remove_sql(model, self)
530 if sql:
531 self.execute(sql)
533 def alter_db_table(self, model, old_db_table, new_db_table):
534 """Rename the table a model points to."""
535 if old_db_table == new_db_table or (
536 self.connection.features.ignores_table_name_case
537 and old_db_table.lower() == new_db_table.lower()
538 ):
539 return
540 self.execute(
541 self.sql_rename_table
542 % {
543 "old_table": self.quote_name(old_db_table),
544 "new_table": self.quote_name(new_db_table),
545 }
546 )
547 # Rename all references to the old table name.
548 for sql in self.deferred_sql:
549 if isinstance(sql, Statement):
550 sql.rename_table_references(old_db_table, new_db_table)
552 def alter_db_table_comment(self, model, old_db_table_comment, new_db_table_comment):
553 self.execute(
554 self.sql_alter_table_comment
555 % {
556 "table": self.quote_name(model._meta.db_table),
557 "comment": self.quote_value(new_db_table_comment or ""),
558 }
559 )
561 def alter_db_tablespace(self, model, old_db_tablespace, new_db_tablespace):
562 """Move a model's table between tablespaces."""
563 self.execute(
564 self.sql_retablespace_table
565 % {
566 "table": self.quote_name(model._meta.db_table),
567 "old_tablespace": self.quote_name(old_db_tablespace),
568 "new_tablespace": self.quote_name(new_db_tablespace),
569 }
570 )
572 def add_field(self, model, field):
573 """
574 Create a field on a model. Usually involves adding a column, but may
575 involve adding a table instead (for M2M fields).
576 """
577 # Special-case implicit M2M tables
578 if field.many_to_many and field.remote_field.through._meta.auto_created:
579 return self.create_model(field.remote_field.through)
580 # Get the column's definition
581 definition, params = self.column_sql(model, field, include_default=True)
582 # It might not actually have a column behind it
583 if definition is None:
584 return
585 if col_type_suffix := field.db_type_suffix(connection=self.connection):
586 definition += f" {col_type_suffix}"
587 # Check constraints can go on the column SQL here
588 db_params = field.db_parameters(connection=self.connection)
589 if db_params["check"]:
590 definition += " " + self.sql_check_constraint % db_params
591 if (
592 field.remote_field
593 and self.connection.features.supports_foreign_keys
594 and field.db_constraint
595 ):
596 constraint_suffix = "_fk_%(to_table)s_%(to_column)s"
597 # Add FK constraint inline, if supported.
598 if self.sql_create_column_inline_fk:
599 to_table = field.remote_field.model._meta.db_table
600 to_column = field.remote_field.model._meta.get_field(
601 field.remote_field.field_name
602 ).column
603 namespace, _ = split_identifier(model._meta.db_table)
604 definition += " " + self.sql_create_column_inline_fk % {
605 "name": self._fk_constraint_name(model, field, constraint_suffix),
606 "namespace": f"{self.quote_name(namespace)}." if namespace else "",
607 "column": self.quote_name(field.column),
608 "to_table": self.quote_name(to_table),
609 "to_column": self.quote_name(to_column),
610 "deferrable": self.connection.ops.deferrable_sql(),
611 }
612 # Otherwise, add FK constraints later.
613 else:
614 self.deferred_sql.append(
615 self._create_fk_sql(model, field, constraint_suffix)
616 )
617 # Build the SQL and run it
618 sql = self.sql_create_column % {
619 "table": self.quote_name(model._meta.db_table),
620 "column": self.quote_name(field.column),
621 "definition": definition,
622 }
623 self.execute(sql, params)
624 # Drop the default if we need to
625 # (Plain usually does not use in-database defaults)
626 if (
627 not self.skip_default_on_alter(field)
628 and self.effective_default(field) is not None
629 ):
630 changes_sql, params = self._alter_column_default_sql(
631 model, None, field, drop=True
632 )
633 sql = self.sql_alter_column % {
634 "table": self.quote_name(model._meta.db_table),
635 "changes": changes_sql,
636 }
637 self.execute(sql, params)
638 # Add field comment, if required.
639 if (
640 field.db_comment
641 and self.connection.features.supports_comments
642 and not self.connection.features.supports_comments_inline
643 ):
644 field_type = db_params["type"]
645 self.execute(
646 *self._alter_column_comment_sql(
647 model, field, field_type, field.db_comment
648 )
649 )
650 # Add an index, if required
651 self.deferred_sql.extend(self._field_indexes_sql(model, field))
652 # Reset connection if required
653 if self.connection.features.connection_persists_old_columns:
654 self.connection.close()
656 def remove_field(self, model, field):
657 """
658 Remove a field from a model. Usually involves deleting a column,
659 but for M2Ms may involve deleting a table.
660 """
661 # Special-case implicit M2M tables
662 if field.many_to_many and field.remote_field.through._meta.auto_created:
663 return self.delete_model(field.remote_field.through)
664 # It might not actually have a column behind it
665 if field.db_parameters(connection=self.connection)["type"] is None:
666 return
667 # Drop any FK constraints, MySQL requires explicit deletion
668 if field.remote_field:
669 fk_names = self._constraint_names(model, [field.column], foreign_key=True)
670 for fk_name in fk_names:
671 self.execute(self._delete_fk_sql(model, fk_name))
672 # Delete the column
673 sql = self.sql_delete_column % {
674 "table": self.quote_name(model._meta.db_table),
675 "column": self.quote_name(field.column),
676 }
677 self.execute(sql)
678 # Reset connection if required
679 if self.connection.features.connection_persists_old_columns:
680 self.connection.close()
681 # Remove all deferred statements referencing the deleted column.
682 for sql in list(self.deferred_sql):
683 if isinstance(sql, Statement) and sql.references_column(
684 model._meta.db_table, field.column
685 ):
686 self.deferred_sql.remove(sql)
688 def alter_field(self, model, old_field, new_field, strict=False):
689 """
690 Allow a field's type, uniqueness, nullability, default, column,
691 constraints, etc. to be modified.
692 `old_field` is required to compute the necessary changes.
693 If `strict` is True, raise errors if the old column does not match
694 `old_field` precisely.
695 """
696 if not self._field_should_be_altered(old_field, new_field):
697 return
698 # Ensure this field is even column-based
699 old_db_params = old_field.db_parameters(connection=self.connection)
700 old_type = old_db_params["type"]
701 new_db_params = new_field.db_parameters(connection=self.connection)
702 new_type = new_db_params["type"]
703 if (old_type is None and old_field.remote_field is None) or (
704 new_type is None and new_field.remote_field is None
705 ):
706 raise ValueError(
707 f"Cannot alter field {old_field} into {new_field} - they do not properly define "
708 "db_type (are you using a badly-written custom field?)",
709 )
710 elif (
711 old_type is None
712 and new_type is None
713 and (
714 old_field.remote_field.through
715 and new_field.remote_field.through
716 and old_field.remote_field.through._meta.auto_created
717 and new_field.remote_field.through._meta.auto_created
718 )
719 ):
720 return self._alter_many_to_many(model, old_field, new_field, strict)
721 elif (
722 old_type is None
723 and new_type is None
724 and (
725 old_field.remote_field.through
726 and new_field.remote_field.through
727 and not old_field.remote_field.through._meta.auto_created
728 and not new_field.remote_field.through._meta.auto_created
729 )
730 ):
731 # Both sides have through models; this is a no-op.
732 return
733 elif old_type is None or new_type is None:
734 raise ValueError(
735 f"Cannot alter field {old_field} into {new_field} - they are not compatible types "
736 "(you cannot alter to or from M2M fields, or add or remove "
737 "through= on M2M fields)"
738 )
740 self._alter_field(
741 model,
742 old_field,
743 new_field,
744 old_type,
745 new_type,
746 old_db_params,
747 new_db_params,
748 strict,
749 )
751 def _field_db_check(self, field, field_db_params):
752 # Always check constraints with the same mocked column name to avoid
753 # recreating constrains when the column is renamed.
754 check_constraints = self.connection.data_type_check_constraints
755 data = field.db_type_parameters(self.connection)
756 data["column"] = "__column_name__"
757 try:
758 return check_constraints[field.get_internal_type()] % data
759 except KeyError:
760 return None
762 def _alter_field(
763 self,
764 model,
765 old_field,
766 new_field,
767 old_type,
768 new_type,
769 old_db_params,
770 new_db_params,
771 strict=False,
772 ):
773 """Perform a "physical" (non-ManyToMany) field update."""
774 # Drop any FK constraints, we'll remake them later
775 fks_dropped = set()
776 if (
777 self.connection.features.supports_foreign_keys
778 and old_field.remote_field
779 and old_field.db_constraint
780 and self._field_should_be_altered(
781 old_field,
782 new_field,
783 ignore={"db_comment"},
784 )
785 ):
786 fk_names = self._constraint_names(
787 model, [old_field.column], foreign_key=True
788 )
789 if strict and len(fk_names) != 1:
790 raise ValueError(
791 f"Found wrong number ({len(fk_names)}) of foreign key constraints for {model._meta.db_table}.{old_field.column}"
792 )
793 for fk_name in fk_names:
794 fks_dropped.add((old_field.column,))
795 self.execute(self._delete_fk_sql(model, fk_name))
796 # Has unique been removed?
797 if old_field.unique and (
798 not new_field.unique or self._field_became_primary_key(old_field, new_field)
799 ):
800 # Find the unique constraint for this field
801 meta_constraint_names = {
802 constraint.name for constraint in model._meta.constraints
803 }
804 constraint_names = self._constraint_names(
805 model,
806 [old_field.column],
807 unique=True,
808 primary_key=False,
809 exclude=meta_constraint_names,
810 )
811 if strict and len(constraint_names) != 1:
812 raise ValueError(
813 f"Found wrong number ({len(constraint_names)}) of unique constraints for {model._meta.db_table}.{old_field.column}"
814 )
815 for constraint_name in constraint_names:
816 self.execute(self._delete_unique_sql(model, constraint_name))
817 # Drop incoming FK constraints if the field is a primary key or unique,
818 # which might be a to_field target, and things are going to change.
819 old_collation = old_db_params.get("collation")
820 new_collation = new_db_params.get("collation")
821 drop_foreign_keys = (
822 self.connection.features.supports_foreign_keys
823 and (
824 (old_field.primary_key and new_field.primary_key)
825 or (old_field.unique and new_field.unique)
826 )
827 and ((old_type != new_type) or (old_collation != new_collation))
828 )
829 if drop_foreign_keys:
830 # '_meta.related_field' also contains M2M reverse fields, these
831 # will be filtered out
832 for _old_rel, new_rel in _related_non_m2m_objects(old_field, new_field):
833 rel_fk_names = self._constraint_names(
834 new_rel.related_model, [new_rel.field.column], foreign_key=True
835 )
836 for fk_name in rel_fk_names:
837 self.execute(self._delete_fk_sql(new_rel.related_model, fk_name))
838 # Removed an index? (no strict check, as multiple indexes are possible)
839 # Remove indexes if db_index switched to False or a unique constraint
840 # will now be used in lieu of an index. The following lines from the
841 # truth table show all True cases; the rest are False:
842 #
843 # old_field.db_index | old_field.unique | new_field.db_index | new_field.unique
844 # ------------------------------------------------------------------------------
845 # True | False | False | False
846 # True | False | False | True
847 # True | False | True | True
848 if (
849 old_field.db_index
850 and not old_field.unique
851 and (not new_field.db_index or new_field.unique)
852 ):
853 # Find the index for this field
854 meta_index_names = {index.name for index in model._meta.indexes}
855 # Retrieve only BTREE indexes since this is what's created with
856 # db_index=True.
857 index_names = self._constraint_names(
858 model,
859 [old_field.column],
860 index=True,
861 type_=Index.suffix,
862 exclude=meta_index_names,
863 )
864 for index_name in index_names:
865 # The only way to check if an index was created with
866 # db_index=True or with Index(['field'], name='foo')
867 # is to look at its name (refs #28053).
868 self.execute(self._delete_index_sql(model, index_name))
869 # Change check constraints?
870 old_db_check = self._field_db_check(old_field, old_db_params)
871 new_db_check = self._field_db_check(new_field, new_db_params)
872 if old_db_check != new_db_check and old_db_check:
873 meta_constraint_names = {
874 constraint.name for constraint in model._meta.constraints
875 }
876 constraint_names = self._constraint_names(
877 model,
878 [old_field.column],
879 check=True,
880 exclude=meta_constraint_names,
881 )
882 if strict and len(constraint_names) != 1:
883 raise ValueError(
884 f"Found wrong number ({len(constraint_names)}) of check constraints for {model._meta.db_table}.{old_field.column}"
885 )
886 for constraint_name in constraint_names:
887 self.execute(self._delete_check_sql(model, constraint_name))
888 # Have they renamed the column?
889 if old_field.column != new_field.column:
890 self.execute(
891 self._rename_field_sql(
892 model._meta.db_table, old_field, new_field, new_type
893 )
894 )
895 # Rename all references to the renamed column.
896 for sql in self.deferred_sql:
897 if isinstance(sql, Statement):
898 sql.rename_column_references(
899 model._meta.db_table, old_field.column, new_field.column
900 )
901 # Next, start accumulating actions to do
902 actions = []
903 null_actions = []
904 post_actions = []
905 # Type suffix change? (e.g. auto increment).
906 old_type_suffix = old_field.db_type_suffix(connection=self.connection)
907 new_type_suffix = new_field.db_type_suffix(connection=self.connection)
908 # Type, collation, or comment change?
909 if (
910 old_type != new_type
911 or old_type_suffix != new_type_suffix
912 or old_collation != new_collation
913 or (
914 self.connection.features.supports_comments
915 and old_field.db_comment != new_field.db_comment
916 )
917 ):
918 fragment, other_actions = self._alter_column_type_sql(
919 model, old_field, new_field, new_type, old_collation, new_collation
920 )
921 actions.append(fragment)
922 post_actions.extend(other_actions)
923 # When changing a column NULL constraint to NOT NULL with a given
924 # default value, we need to perform 4 steps:
925 # 1. Add a default for new incoming writes
926 # 2. Update existing NULL rows with new default
927 # 3. Replace NULL constraint with NOT NULL
928 # 4. Drop the default again.
929 # Default change?
930 needs_database_default = False
931 if old_field.null and not new_field.null:
932 old_default = self.effective_default(old_field)
933 new_default = self.effective_default(new_field)
934 if (
935 not self.skip_default_on_alter(new_field)
936 and old_default != new_default
937 and new_default is not None
938 ):
939 needs_database_default = True
940 actions.append(
941 self._alter_column_default_sql(model, old_field, new_field)
942 )
943 # Nullability change?
944 if old_field.null != new_field.null:
945 fragment = self._alter_column_null_sql(model, old_field, new_field)
946 if fragment:
947 null_actions.append(fragment)
948 # Only if we have a default and there is a change from NULL to NOT NULL
949 four_way_default_alteration = new_field.has_default() and (
950 old_field.null and not new_field.null
951 )
952 if actions or null_actions:
953 if not four_way_default_alteration:
954 # If we don't have to do a 4-way default alteration we can
955 # directly run a (NOT) NULL alteration
956 actions += null_actions
957 # Combine actions together if we can (e.g. postgres)
958 if self.connection.features.supports_combined_alters and actions:
959 sql, params = tuple(zip(*actions))
960 actions = [(", ".join(sql), sum(params, []))]
961 # Apply those actions
962 for sql, params in actions:
963 self.execute(
964 self.sql_alter_column
965 % {
966 "table": self.quote_name(model._meta.db_table),
967 "changes": sql,
968 },
969 params,
970 )
971 if four_way_default_alteration:
972 # Update existing rows with default value
973 self.execute(
974 self.sql_update_with_default
975 % {
976 "table": self.quote_name(model._meta.db_table),
977 "column": self.quote_name(new_field.column),
978 "default": "%s",
979 },
980 [new_default],
981 )
982 # Since we didn't run a NOT NULL change before we need to do it
983 # now
984 for sql, params in null_actions:
985 self.execute(
986 self.sql_alter_column
987 % {
988 "table": self.quote_name(model._meta.db_table),
989 "changes": sql,
990 },
991 params,
992 )
993 if post_actions:
994 for sql, params in post_actions:
995 self.execute(sql, params)
996 # If primary_key changed to False, delete the primary key constraint.
997 if old_field.primary_key and not new_field.primary_key:
998 self._delete_primary_key(model, strict)
999 # Added a unique?
1000 if self._unique_should_be_added(old_field, new_field):
1001 self.execute(self._create_unique_sql(model, [new_field]))
1002 # Added an index? Add an index if db_index switched to True or a unique
1003 # constraint will no longer be used in lieu of an index. The following
1004 # lines from the truth table show all True cases; the rest are False:
1005 #
1006 # old_field.db_index | old_field.unique | new_field.db_index | new_field.unique
1007 # ------------------------------------------------------------------------------
1008 # False | False | True | False
1009 # False | True | True | False
1010 # True | True | True | False
1011 if (
1012 (not old_field.db_index or old_field.unique)
1013 and new_field.db_index
1014 and not new_field.unique
1015 ):
1016 self.execute(self._create_index_sql(model, fields=[new_field]))
1017 # Type alteration on primary key? Then we need to alter the column
1018 # referring to us.
1019 rels_to_update = []
1020 if drop_foreign_keys:
1021 rels_to_update.extend(_related_non_m2m_objects(old_field, new_field))
1022 # Changed to become primary key?
1023 if self._field_became_primary_key(old_field, new_field):
1024 # Make the new one
1025 self.execute(self._create_primary_key_sql(model, new_field))
1026 # Update all referencing columns
1027 rels_to_update.extend(_related_non_m2m_objects(old_field, new_field))
1028 # Handle our type alters on the other end of rels from the PK stuff above
1029 for old_rel, new_rel in rels_to_update:
1030 rel_db_params = new_rel.field.db_parameters(connection=self.connection)
1031 rel_type = rel_db_params["type"]
1032 rel_collation = rel_db_params.get("collation")
1033 old_rel_db_params = old_rel.field.db_parameters(connection=self.connection)
1034 old_rel_collation = old_rel_db_params.get("collation")
1035 fragment, other_actions = self._alter_column_type_sql(
1036 new_rel.related_model,
1037 old_rel.field,
1038 new_rel.field,
1039 rel_type,
1040 old_rel_collation,
1041 rel_collation,
1042 )
1043 self.execute(
1044 self.sql_alter_column
1045 % {
1046 "table": self.quote_name(new_rel.related_model._meta.db_table),
1047 "changes": fragment[0],
1048 },
1049 fragment[1],
1050 )
1051 for sql, params in other_actions:
1052 self.execute(sql, params)
1053 # Does it have a foreign key?
1054 if (
1055 self.connection.features.supports_foreign_keys
1056 and new_field.remote_field
1057 and (
1058 fks_dropped or not old_field.remote_field or not old_field.db_constraint
1059 )
1060 and new_field.db_constraint
1061 ):
1062 self.execute(
1063 self._create_fk_sql(model, new_field, "_fk_%(to_table)s_%(to_column)s")
1064 )
1065 # Rebuild FKs that pointed to us if we previously had to drop them
1066 if drop_foreign_keys:
1067 for _, rel in rels_to_update:
1068 if rel.field.db_constraint:
1069 self.execute(
1070 self._create_fk_sql(rel.related_model, rel.field, "_fk")
1071 )
1072 # Does it have check constraints we need to add?
1073 if old_db_check != new_db_check and new_db_check:
1074 constraint_name = self._create_index_name(
1075 model._meta.db_table, [new_field.column], suffix="_check"
1076 )
1077 self.execute(
1078 self._create_check_sql(model, constraint_name, new_db_params["check"])
1079 )
1080 # Drop the default if we need to
1081 # (Plain usually does not use in-database defaults)
1082 if needs_database_default:
1083 changes_sql, params = self._alter_column_default_sql(
1084 model, old_field, new_field, drop=True
1085 )
1086 sql = self.sql_alter_column % {
1087 "table": self.quote_name(model._meta.db_table),
1088 "changes": changes_sql,
1089 }
1090 self.execute(sql, params)
1091 # Reset connection if required
1092 if self.connection.features.connection_persists_old_columns:
1093 self.connection.close()
1095 def _alter_column_null_sql(self, model, old_field, new_field):
1096 """
1097 Hook to specialize column null alteration.
1099 Return a (sql, params) fragment to set a column to null or non-null
1100 as required by new_field, or None if no changes are required.
1101 """
1102 if (
1103 self.connection.features.interprets_empty_strings_as_nulls
1104 and new_field.empty_strings_allowed
1105 ):
1106 # The field is nullable in the database anyway, leave it alone.
1107 return
1108 else:
1109 new_db_params = new_field.db_parameters(connection=self.connection)
1110 sql = (
1111 self.sql_alter_column_null
1112 if new_field.null
1113 else self.sql_alter_column_not_null
1114 )
1115 return (
1116 sql
1117 % {
1118 "column": self.quote_name(new_field.column),
1119 "type": new_db_params["type"],
1120 },
1121 [],
1122 )
1124 def _alter_column_default_sql(self, model, old_field, new_field, drop=False):
1125 """
1126 Hook to specialize column default alteration.
1128 Return a (sql, params) fragment to add or drop (depending on the drop
1129 argument) a default to new_field's column.
1130 """
1131 new_default = self.effective_default(new_field)
1132 default = self._column_default_sql(new_field)
1133 params = [new_default]
1135 if drop:
1136 params = []
1137 elif self.connection.features.requires_literal_defaults:
1138 # Some databases (Oracle) can't take defaults as a parameter
1139 # If this is the case, the SchemaEditor for that database should
1140 # implement prepare_default().
1141 default = self.prepare_default(new_default)
1142 params = []
1144 new_db_params = new_field.db_parameters(connection=self.connection)
1145 if drop:
1146 if new_field.null:
1147 sql = self.sql_alter_column_no_default_null
1148 else:
1149 sql = self.sql_alter_column_no_default
1150 else:
1151 sql = self.sql_alter_column_default
1152 return (
1153 sql
1154 % {
1155 "column": self.quote_name(new_field.column),
1156 "type": new_db_params["type"],
1157 "default": default,
1158 },
1159 params,
1160 )
1162 def _alter_column_type_sql(
1163 self, model, old_field, new_field, new_type, old_collation, new_collation
1164 ):
1165 """
1166 Hook to specialize column type alteration for different backends,
1167 for cases when a creation type is different to an alteration type
1168 (e.g. SERIAL in PostgreSQL, PostGIS fields).
1170 Return a two-tuple of: an SQL fragment of (sql, params) to insert into
1171 an ALTER TABLE statement and a list of extra (sql, params) tuples to
1172 run once the field is altered.
1173 """
1174 other_actions = []
1175 if collate_sql := self._collate_sql(
1176 new_collation, old_collation, model._meta.db_table
1177 ):
1178 collate_sql = f" {collate_sql}"
1179 else:
1180 collate_sql = ""
1181 # Comment change?
1182 comment_sql = ""
1183 if self.connection.features.supports_comments and not new_field.many_to_many:
1184 if old_field.db_comment != new_field.db_comment:
1185 # PostgreSQL and Oracle can't execute 'ALTER COLUMN ...' and
1186 # 'COMMENT ON ...' at the same time.
1187 sql, params = self._alter_column_comment_sql(
1188 model, new_field, new_type, new_field.db_comment
1189 )
1190 if sql:
1191 other_actions.append((sql, params))
1192 if new_field.db_comment:
1193 comment_sql = self._comment_sql(new_field.db_comment)
1194 return (
1195 (
1196 self.sql_alter_column_type
1197 % {
1198 "column": self.quote_name(new_field.column),
1199 "type": new_type,
1200 "collation": collate_sql,
1201 "comment": comment_sql,
1202 },
1203 [],
1204 ),
1205 other_actions,
1206 )
1208 def _alter_column_comment_sql(self, model, new_field, new_type, new_db_comment):
1209 return (
1210 self.sql_alter_column_comment
1211 % {
1212 "table": self.quote_name(model._meta.db_table),
1213 "column": self.quote_name(new_field.column),
1214 "comment": self._comment_sql(new_db_comment),
1215 },
1216 [],
1217 )
1219 def _comment_sql(self, comment):
1220 return self.quote_value(comment or "")
1222 def _alter_many_to_many(self, model, old_field, new_field, strict):
1223 """Alter M2Ms to repoint their to= endpoints."""
1224 # Rename the through table
1225 if (
1226 old_field.remote_field.through._meta.db_table
1227 != new_field.remote_field.through._meta.db_table
1228 ):
1229 self.alter_db_table(
1230 old_field.remote_field.through,
1231 old_field.remote_field.through._meta.db_table,
1232 new_field.remote_field.through._meta.db_table,
1233 )
1234 # Repoint the FK to the other side
1235 self.alter_field(
1236 new_field.remote_field.through,
1237 # The field that points to the target model is needed, so we can
1238 # tell alter_field to change it - this is m2m_reverse_field_name()
1239 # (as opposed to m2m_field_name(), which points to our model).
1240 old_field.remote_field.through._meta.get_field(
1241 old_field.m2m_reverse_field_name()
1242 ),
1243 new_field.remote_field.through._meta.get_field(
1244 new_field.m2m_reverse_field_name()
1245 ),
1246 )
1247 self.alter_field(
1248 new_field.remote_field.through,
1249 # for self-referential models we need to alter field from the other end too
1250 old_field.remote_field.through._meta.get_field(old_field.m2m_field_name()),
1251 new_field.remote_field.through._meta.get_field(new_field.m2m_field_name()),
1252 )
1254 def _create_index_name(self, table_name, column_names, suffix=""):
1255 """
1256 Generate a unique name for an index/unique constraint.
1258 The name is divided into 3 parts: the table name, the column names,
1259 and a unique digest and suffix.
1260 """
1261 _, table_name = split_identifier(table_name)
1262 hash_suffix_part = (
1263 f"{names_digest(table_name, *column_names, length=8)}{suffix}"
1264 )
1265 max_length = self.connection.ops.max_name_length() or 200
1266 # If everything fits into max_length, use that name.
1267 index_name = "{}_{}_{}".format(
1268 table_name, "_".join(column_names), hash_suffix_part
1269 )
1270 if len(index_name) <= max_length:
1271 return index_name
1272 # Shorten a long suffix.
1273 if len(hash_suffix_part) > max_length / 3:
1274 hash_suffix_part = hash_suffix_part[: max_length // 3]
1275 other_length = (max_length - len(hash_suffix_part)) // 2 - 1
1276 index_name = "{}_{}_{}".format(
1277 table_name[:other_length],
1278 "_".join(column_names)[:other_length],
1279 hash_suffix_part,
1280 )
1281 # Prepend D if needed to prevent the name from starting with an
1282 # underscore or a number (not permitted on Oracle).
1283 if index_name[0] == "_" or index_name[0].isdigit():
1284 index_name = f"D{index_name[:-1]}"
1285 return index_name
1287 def _get_index_tablespace_sql(self, model, fields, db_tablespace=None):
1288 if db_tablespace is None:
1289 if len(fields) == 1 and fields[0].db_tablespace:
1290 db_tablespace = fields[0].db_tablespace
1291 elif settings.DEFAULT_INDEX_TABLESPACE:
1292 db_tablespace = settings.DEFAULT_INDEX_TABLESPACE
1293 elif model._meta.db_tablespace:
1294 db_tablespace = model._meta.db_tablespace
1295 if db_tablespace is not None:
1296 return " " + self.connection.ops.tablespace_sql(db_tablespace)
1297 return ""
1299 def _index_condition_sql(self, condition):
1300 if condition:
1301 return " WHERE " + condition
1302 return ""
1304 def _index_include_sql(self, model, columns):
1305 if not columns or not self.connection.features.supports_covering_indexes:
1306 return ""
1307 return Statement(
1308 " INCLUDE (%(columns)s)",
1309 columns=Columns(model._meta.db_table, columns, self.quote_name),
1310 )
1312 def _create_index_sql(
1313 self,
1314 model,
1315 *,
1316 fields=None,
1317 name=None,
1318 suffix="",
1319 using="",
1320 db_tablespace=None,
1321 col_suffixes=(),
1322 sql=None,
1323 opclasses=(),
1324 condition=None,
1325 include=None,
1326 expressions=None,
1327 ):
1328 """
1329 Return the SQL statement to create the index for one or several fields
1330 or expressions. `sql` can be specified if the syntax differs from the
1331 standard (GIS indexes, ...).
1332 """
1333 fields = fields or []
1334 expressions = expressions or []
1335 compiler = Query(model, alias_cols=False).get_compiler(
1336 connection=self.connection,
1337 )
1338 tablespace_sql = self._get_index_tablespace_sql(
1339 model, fields, db_tablespace=db_tablespace
1340 )
1341 columns = [field.column for field in fields]
1342 sql_create_index = sql or self.sql_create_index
1343 table = model._meta.db_table
1345 def create_index_name(*args, **kwargs):
1346 nonlocal name
1347 if name is None:
1348 name = self._create_index_name(*args, **kwargs)
1349 return self.quote_name(name)
1351 return Statement(
1352 sql_create_index,
1353 table=Table(table, self.quote_name),
1354 name=IndexName(table, columns, suffix, create_index_name),
1355 using=using,
1356 columns=(
1357 self._index_columns(table, columns, col_suffixes, opclasses)
1358 if columns
1359 else Expressions(table, expressions, compiler, self.quote_value)
1360 ),
1361 extra=tablespace_sql,
1362 condition=self._index_condition_sql(condition),
1363 include=self._index_include_sql(model, include),
1364 )
1366 def _delete_index_sql(self, model, name, sql=None):
1367 return Statement(
1368 sql or self.sql_delete_index,
1369 table=Table(model._meta.db_table, self.quote_name),
1370 name=self.quote_name(name),
1371 )
1373 def _rename_index_sql(self, model, old_name, new_name):
1374 return Statement(
1375 self.sql_rename_index,
1376 table=Table(model._meta.db_table, self.quote_name),
1377 old_name=self.quote_name(old_name),
1378 new_name=self.quote_name(new_name),
1379 )
1381 def _index_columns(self, table, columns, col_suffixes, opclasses):
1382 return Columns(table, columns, self.quote_name, col_suffixes=col_suffixes)
1384 def _model_indexes_sql(self, model):
1385 """
1386 Return a list of all index SQL statements (field indexes, Meta.indexes) for the specified model.
1387 """
1388 if not model._meta.managed or model._meta.swapped:
1389 return []
1390 output = []
1391 for field in model._meta.local_fields:
1392 output.extend(self._field_indexes_sql(model, field))
1394 for index in model._meta.indexes:
1395 if (
1396 not index.contains_expressions
1397 or self.connection.features.supports_expression_indexes
1398 ):
1399 output.append(index.create_sql(model, self))
1400 return output
1402 def _field_indexes_sql(self, model, field):
1403 """
1404 Return a list of all index SQL statements for the specified field.
1405 """
1406 output = []
1407 if self._field_should_be_indexed(model, field):
1408 output.append(self._create_index_sql(model, fields=[field]))
1409 return output
1411 def _field_should_be_altered(self, old_field, new_field, ignore=None):
1412 ignore = ignore or set()
1413 _, old_path, old_args, old_kwargs = old_field.deconstruct()
1414 _, new_path, new_args, new_kwargs = new_field.deconstruct()
1415 # Don't alter when:
1416 # - changing only a field name
1417 # - changing an attribute that doesn't affect the schema
1418 # - changing an attribute in the provided set of ignored attributes
1419 # - adding only a db_column and the column name is not changed
1420 for attr in ignore.union(old_field.non_db_attrs):
1421 old_kwargs.pop(attr, None)
1422 for attr in ignore.union(new_field.non_db_attrs):
1423 new_kwargs.pop(attr, None)
1424 return self.quote_name(old_field.column) != self.quote_name(
1425 new_field.column
1426 ) or (old_path, old_args, old_kwargs) != (new_path, new_args, new_kwargs)
1428 def _field_should_be_indexed(self, model, field):
1429 return field.db_index and not field.unique
1431 def _field_became_primary_key(self, old_field, new_field):
1432 return not old_field.primary_key and new_field.primary_key
1434 def _unique_should_be_added(self, old_field, new_field):
1435 return (
1436 not new_field.primary_key
1437 and new_field.unique
1438 and (not old_field.unique or old_field.primary_key)
1439 )
1441 def _rename_field_sql(self, table, old_field, new_field, new_type):
1442 return self.sql_rename_column % {
1443 "table": self.quote_name(table),
1444 "old_column": self.quote_name(old_field.column),
1445 "new_column": self.quote_name(new_field.column),
1446 "type": new_type,
1447 }
1449 def _create_fk_sql(self, model, field, suffix):
1450 table = Table(model._meta.db_table, self.quote_name)
1451 name = self._fk_constraint_name(model, field, suffix)
1452 column = Columns(model._meta.db_table, [field.column], self.quote_name)
1453 to_table = Table(field.target_field.model._meta.db_table, self.quote_name)
1454 to_column = Columns(
1455 field.target_field.model._meta.db_table,
1456 [field.target_field.column],
1457 self.quote_name,
1458 )
1459 deferrable = self.connection.ops.deferrable_sql()
1460 return Statement(
1461 self.sql_create_fk,
1462 table=table,
1463 name=name,
1464 column=column,
1465 to_table=to_table,
1466 to_column=to_column,
1467 deferrable=deferrable,
1468 )
1470 def _fk_constraint_name(self, model, field, suffix):
1471 def create_fk_name(*args, **kwargs):
1472 return self.quote_name(self._create_index_name(*args, **kwargs))
1474 return ForeignKeyName(
1475 model._meta.db_table,
1476 [field.column],
1477 split_identifier(field.target_field.model._meta.db_table)[1],
1478 [field.target_field.column],
1479 suffix,
1480 create_fk_name,
1481 )
1483 def _delete_fk_sql(self, model, name):
1484 return self._delete_constraint_sql(self.sql_delete_fk, model, name)
1486 def _deferrable_constraint_sql(self, deferrable):
1487 if deferrable is None:
1488 return ""
1489 if deferrable == Deferrable.DEFERRED:
1490 return " DEFERRABLE INITIALLY DEFERRED"
1491 if deferrable == Deferrable.IMMEDIATE:
1492 return " DEFERRABLE INITIALLY IMMEDIATE"
1494 def _unique_sql(
1495 self,
1496 model,
1497 fields,
1498 name,
1499 condition=None,
1500 deferrable=None,
1501 include=None,
1502 opclasses=None,
1503 expressions=None,
1504 ):
1505 if (
1506 deferrable
1507 and not self.connection.features.supports_deferrable_unique_constraints
1508 ):
1509 return None
1510 if condition or include or opclasses or expressions:
1511 # Databases support conditional, covering, and functional unique
1512 # constraints via a unique index.
1513 sql = self._create_unique_sql(
1514 model,
1515 fields,
1516 name=name,
1517 condition=condition,
1518 include=include,
1519 opclasses=opclasses,
1520 expressions=expressions,
1521 )
1522 if sql:
1523 self.deferred_sql.append(sql)
1524 return None
1525 constraint = self.sql_unique_constraint % {
1526 "columns": ", ".join([self.quote_name(field.column) for field in fields]),
1527 "deferrable": self._deferrable_constraint_sql(deferrable),
1528 }
1529 return self.sql_constraint % {
1530 "name": self.quote_name(name),
1531 "constraint": constraint,
1532 }
1534 def _create_unique_sql(
1535 self,
1536 model,
1537 fields,
1538 name=None,
1539 condition=None,
1540 deferrable=None,
1541 include=None,
1542 opclasses=None,
1543 expressions=None,
1544 ):
1545 if (
1546 (
1547 deferrable
1548 and not self.connection.features.supports_deferrable_unique_constraints
1549 )
1550 or (condition and not self.connection.features.supports_partial_indexes)
1551 or (include and not self.connection.features.supports_covering_indexes)
1552 or (
1553 expressions and not self.connection.features.supports_expression_indexes
1554 )
1555 ):
1556 return None
1558 compiler = Query(model, alias_cols=False).get_compiler(
1559 connection=self.connection
1560 )
1561 table = model._meta.db_table
1562 columns = [field.column for field in fields]
1563 if name is None:
1564 name = self._unique_constraint_name(table, columns, quote=True)
1565 else:
1566 name = self.quote_name(name)
1567 if condition or include or opclasses or expressions:
1568 sql = self.sql_create_unique_index
1569 else:
1570 sql = self.sql_create_unique
1571 if columns:
1572 columns = self._index_columns(
1573 table, columns, col_suffixes=(), opclasses=opclasses
1574 )
1575 else:
1576 columns = Expressions(table, expressions, compiler, self.quote_value)
1577 return Statement(
1578 sql,
1579 table=Table(table, self.quote_name),
1580 name=name,
1581 columns=columns,
1582 condition=self._index_condition_sql(condition),
1583 deferrable=self._deferrable_constraint_sql(deferrable),
1584 include=self._index_include_sql(model, include),
1585 )
1587 def _unique_constraint_name(self, table, columns, quote=True):
1588 if quote:
1590 def create_unique_name(*args, **kwargs):
1591 return self.quote_name(self._create_index_name(*args, **kwargs))
1593 else:
1594 create_unique_name = self._create_index_name
1596 return IndexName(table, columns, "_uniq", create_unique_name)
1598 def _delete_unique_sql(
1599 self,
1600 model,
1601 name,
1602 condition=None,
1603 deferrable=None,
1604 include=None,
1605 opclasses=None,
1606 expressions=None,
1607 ):
1608 if (
1609 (
1610 deferrable
1611 and not self.connection.features.supports_deferrable_unique_constraints
1612 )
1613 or (condition and not self.connection.features.supports_partial_indexes)
1614 or (include and not self.connection.features.supports_covering_indexes)
1615 or (
1616 expressions and not self.connection.features.supports_expression_indexes
1617 )
1618 ):
1619 return None
1620 if condition or include or opclasses or expressions:
1621 sql = self.sql_delete_index
1622 else:
1623 sql = self.sql_delete_unique
1624 return self._delete_constraint_sql(sql, model, name)
1626 def _check_sql(self, name, check):
1627 return self.sql_constraint % {
1628 "name": self.quote_name(name),
1629 "constraint": self.sql_check_constraint % {"check": check},
1630 }
1632 def _create_check_sql(self, model, name, check):
1633 if not self.connection.features.supports_table_check_constraints:
1634 return None
1635 return Statement(
1636 self.sql_create_check,
1637 table=Table(model._meta.db_table, self.quote_name),
1638 name=self.quote_name(name),
1639 check=check,
1640 )
1642 def _delete_check_sql(self, model, name):
1643 if not self.connection.features.supports_table_check_constraints:
1644 return None
1645 return self._delete_constraint_sql(self.sql_delete_check, model, name)
1647 def _delete_constraint_sql(self, template, model, name):
1648 return Statement(
1649 template,
1650 table=Table(model._meta.db_table, self.quote_name),
1651 name=self.quote_name(name),
1652 )
1654 def _constraint_names(
1655 self,
1656 model,
1657 column_names=None,
1658 unique=None,
1659 primary_key=None,
1660 index=None,
1661 foreign_key=None,
1662 check=None,
1663 type_=None,
1664 exclude=None,
1665 ):
1666 """Return all constraint names matching the columns and conditions."""
1667 if column_names is not None:
1668 column_names = [
1669 self.connection.introspection.identifier_converter(
1670 truncate_name(name, self.connection.ops.max_name_length())
1671 )
1672 if self.connection.features.truncates_names
1673 else self.connection.introspection.identifier_converter(name)
1674 for name in column_names
1675 ]
1676 with self.connection.cursor() as cursor:
1677 constraints = self.connection.introspection.get_constraints(
1678 cursor, model._meta.db_table
1679 )
1680 result = []
1681 for name, infodict in constraints.items():
1682 if column_names is None or column_names == infodict["columns"]:
1683 if unique is not None and infodict["unique"] != unique:
1684 continue
1685 if primary_key is not None and infodict["primary_key"] != primary_key:
1686 continue
1687 if index is not None and infodict["index"] != index:
1688 continue
1689 if check is not None and infodict["check"] != check:
1690 continue
1691 if foreign_key is not None and not infodict["foreign_key"]:
1692 continue
1693 if type_ is not None and infodict["type"] != type_:
1694 continue
1695 if not exclude or name not in exclude:
1696 result.append(name)
1697 return result
1699 def _delete_primary_key(self, model, strict=False):
1700 constraint_names = self._constraint_names(model, primary_key=True)
1701 if strict and len(constraint_names) != 1:
1702 raise ValueError(
1703 f"Found wrong number ({len(constraint_names)}) of PK constraints for {model._meta.db_table}"
1704 )
1705 for constraint_name in constraint_names:
1706 self.execute(self._delete_primary_key_sql(model, constraint_name))
1708 def _create_primary_key_sql(self, model, field):
1709 return Statement(
1710 self.sql_create_pk,
1711 table=Table(model._meta.db_table, self.quote_name),
1712 name=self.quote_name(
1713 self._create_index_name(
1714 model._meta.db_table, [field.column], suffix="_pk"
1715 )
1716 ),
1717 columns=Columns(model._meta.db_table, [field.column], self.quote_name),
1718 )
1720 def _delete_primary_key_sql(self, model, name):
1721 return self._delete_constraint_sql(self.sql_delete_pk, model, name)
1723 def _collate_sql(self, collation, old_collation=None, table_name=None):
1724 return "COLLATE " + self.quote_name(collation) if collation else ""
1726 def remove_procedure(self, procedure_name, param_types=()):
1727 sql = self.sql_delete_procedure % {
1728 "procedure": self.quote_name(procedure_name),
1729 "param_types": ",".join(param_types),
1730 }
1731 self.execute(sql)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1class BaseDatabaseValidation:
2 """Encapsulate backend-specific validation."""
4 def __init__(self, connection):
5 self.connection = connection
7 def check(self, **kwargs):
8 return []
10 def check_field(self, field, **kwargs):
11 errors = []
12 # Backends may implement a check_field_type() method.
13 if (
14 hasattr(self, "check_field_type")
15 and
16 # Ignore any related fields.
17 not getattr(field, "remote_field", None)
18 ):
19 # Ignore fields with unsupported features.
20 db_supports_all_required_features = all(
21 getattr(self.connection.features, feature, False)
22 for feature in field.model._meta.required_db_features
23 )
24 if db_supports_all_required_features:
25 field_type = field.db_type(self.connection)
26 # Ignore non-concrete fields.
27 if field_type is not None:
28 errors.extend(self.check_field_type(field, field_type))
29 return errors
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""Plain Unit Test framework."""
3from plain.test.client import Client, RequestFactory
5__all__ = [
6 "Client",
7 "RequestFactory",
8]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import json
2import mimetypes
3import os
4import sys
5from functools import partial
6from http import HTTPStatus
7from http.cookies import SimpleCookie
8from importlib import import_module
9from io import BytesIO, IOBase
10from itertools import chain
11from urllib.parse import unquote_to_bytes, urljoin, urlparse, urlsplit
13from plain.http import HttpHeaders, HttpRequest, QueryDict
14from plain.internal.handlers.base import BaseHandler
15from plain.internal.handlers.wsgi import WSGIRequest
16from plain.json import PlainJSONEncoder
17from plain.runtime import settings
18from plain.signals import got_request_exception, request_started
19from plain.urls import resolve
20from plain.utils.encoding import force_bytes
21from plain.utils.functional import SimpleLazyObject
22from plain.utils.http import urlencode
23from plain.utils.itercompat import is_iterable
24from plain.utils.regex_helper import _lazy_re_compile
26__all__ = (
27 "Client",
28 "RedirectCycleError",
29 "RequestFactory",
30 "encode_file",
31 "encode_multipart",
32)
35BOUNDARY = "BoUnDaRyStRiNg"
36MULTIPART_CONTENT = f"multipart/form-data; boundary={BOUNDARY}"
37CONTENT_TYPE_RE = _lazy_re_compile(r".*; charset=([\w-]+);?")
38# Structured suffix spec: https://tools.ietf.org/html/rfc6838#section-4.2.8
39JSON_CONTENT_TYPE_RE = _lazy_re_compile(r"^application\/(.+\+)?json")
42class ContextList(list):
43 """
44 A wrapper that provides direct key access to context items contained
45 in a list of context objects.
46 """
48 def __getitem__(self, key):
49 if isinstance(key, str):
50 for subcontext in self:
51 if key in subcontext:
52 return subcontext[key]
53 raise KeyError(key)
54 else:
55 return super().__getitem__(key)
57 def get(self, key, default=None):
58 try:
59 return self.__getitem__(key)
60 except KeyError:
61 return default
63 def __contains__(self, key):
64 try:
65 self[key]
66 except KeyError:
67 return False
68 return True
70 def keys(self):
71 """
72 Flattened keys of subcontexts.
73 """
74 return set(chain.from_iterable(d for subcontext in self for d in subcontext))
77class RedirectCycleError(Exception):
78 """The test client has been asked to follow a redirect loop."""
80 def __init__(self, message, last_response):
81 super().__init__(message)
82 self.last_response = last_response
83 self.redirect_chain = last_response.redirect_chain
86class FakePayload(IOBase):
87 """
88 A wrapper around BytesIO that restricts what can be read since data from
89 the network can't be sought and cannot be read outside of its content
90 length. This makes sure that views can't do anything under the test client
91 that wouldn't work in real life.
92 """
94 def __init__(self, initial_bytes=None):
95 self.__content = BytesIO()
96 self.__len = 0
97 self.read_started = False
98 if initial_bytes is not None:
99 self.write(initial_bytes)
101 def __len__(self):
102 return self.__len
104 def read(self, size=-1, /):
105 if not self.read_started:
106 self.__content.seek(0)
107 self.read_started = True
108 if size == -1 or size is None:
109 size = self.__len
110 assert (
111 self.__len >= size
112 ), "Cannot read more than the available bytes from the HTTP incoming data."
113 content = self.__content.read(size)
114 self.__len -= len(content)
115 return content
117 def readline(self, size=-1, /):
118 if not self.read_started:
119 self.__content.seek(0)
120 self.read_started = True
121 if size == -1 or size is None:
122 size = self.__len
123 assert (
124 self.__len >= size
125 ), "Cannot read more than the available bytes from the HTTP incoming data."
126 content = self.__content.readline(size)
127 self.__len -= len(content)
128 return content
130 def write(self, b, /):
131 if self.read_started:
132 raise ValueError("Unable to write a payload after it's been read")
133 content = force_bytes(b)
134 self.__content.write(content)
135 self.__len += len(content)
138def conditional_content_removal(request, response):
139 """
140 Simulate the behavior of most web servers by removing the content of
141 responses for HEAD requests, 1xx, 204, and 304 responses. Ensure
142 compliance with RFC 9112 Section 6.3.
143 """
144 if 100 <= response.status_code < 200 or response.status_code in (204, 304):
145 if response.streaming:
146 response.streaming_content = []
147 else:
148 response.content = b""
149 if request.method == "HEAD":
150 if response.streaming:
151 response.streaming_content = []
152 else:
153 response.content = b""
154 return response
157class ClientHandler(BaseHandler):
158 """
159 An HTTP Handler that can be used for testing purposes. Use the WSGI
160 interface to compose requests, but return the raw Response object with
161 the originating WSGIRequest attached to its ``wsgi_request`` attribute.
162 """
164 def __init__(self, enforce_csrf_checks=True, *args, **kwargs):
165 self.enforce_csrf_checks = enforce_csrf_checks
166 super().__init__(*args, **kwargs)
168 def __call__(self, environ):
169 # Set up middleware if needed. We couldn't do this earlier, because
170 # settings weren't available.
171 if self._middleware_chain is None:
172 self.load_middleware()
174 request_started.send(sender=self.__class__, environ=environ)
175 request = WSGIRequest(environ)
176 # sneaky little hack so that we can easily get round
177 # CsrfViewMiddleware. This makes life easier, and is probably
178 # required for backwards compatibility with external tests against
179 # admin views.
180 request._dont_enforce_csrf_checks = not self.enforce_csrf_checks
182 # Request goes through middleware.
183 response = self.get_response(request)
185 # Simulate behaviors of most web servers.
186 conditional_content_removal(request, response)
188 # Attach the originating request to the response so that it could be
189 # later retrieved.
190 response.wsgi_request = request
192 # Emulate a WSGI server by calling the close method on completion.
193 response.close()
195 return response
198def encode_multipart(boundary, data):
199 """
200 Encode multipart POST data from a dictionary of form values.
202 The key will be used as the form data name; the value will be transmitted
203 as content. If the value is a file, the contents of the file will be sent
204 as an application/octet-stream; otherwise, str(value) will be sent.
205 """
206 lines = []
208 def to_bytes(s):
209 return force_bytes(s, settings.DEFAULT_CHARSET)
211 # Not by any means perfect, but good enough for our purposes.
212 def is_file(thing):
213 return hasattr(thing, "read") and callable(thing.read)
215 # Each bit of the multipart form data could be either a form value or a
216 # file, or a *list* of form values and/or files. Remember that HTTP field
217 # names can be duplicated!
218 for key, value in data.items():
219 if value is None:
220 raise TypeError(
221 f"Cannot encode None for key '{key}' as POST data. Did you mean "
222 "to pass an empty string or omit the value?"
223 )
224 elif is_file(value):
225 lines.extend(encode_file(boundary, key, value))
226 elif not isinstance(value, str) and is_iterable(value):
227 for item in value:
228 if is_file(item):
229 lines.extend(encode_file(boundary, key, item))
230 else:
231 lines.extend(
232 to_bytes(val)
233 for val in [
234 f"--{boundary}",
235 f'Content-Disposition: form-data; name="{key}"',
236 "",
237 item,
238 ]
239 )
240 else:
241 lines.extend(
242 to_bytes(val)
243 for val in [
244 f"--{boundary}",
245 f'Content-Disposition: form-data; name="{key}"',
246 "",
247 value,
248 ]
249 )
251 lines.extend(
252 [
253 to_bytes(f"--{boundary}--"),
254 b"",
255 ]
256 )
257 return b"\r\n".join(lines)
260def encode_file(boundary, key, file):
261 def to_bytes(s):
262 return force_bytes(s, settings.DEFAULT_CHARSET)
264 # file.name might not be a string. For example, it's an int for
265 # tempfile.TemporaryFile().
266 file_has_string_name = hasattr(file, "name") and isinstance(file.name, str)
267 filename = os.path.basename(file.name) if file_has_string_name else ""
269 if hasattr(file, "content_type"):
270 content_type = file.content_type
271 elif filename:
272 content_type = mimetypes.guess_type(filename)[0]
273 else:
274 content_type = None
276 if content_type is None:
277 content_type = "application/octet-stream"
278 filename = filename or key
279 return [
280 to_bytes(f"--{boundary}"),
281 to_bytes(
282 f'Content-Disposition: form-data; name="{key}"; filename="{filename}"'
283 ),
284 to_bytes(f"Content-Type: {content_type}"),
285 b"",
286 to_bytes(file.read()),
287 ]
290class RequestFactory:
291 """
292 Class that lets you create mock Request objects for use in testing.
294 Usage:
296 rf = RequestFactory()
297 get_request = rf.get('/hello/')
298 post_request = rf.post('/submit/', {'foo': 'bar'})
300 Once you have a request object you can pass it to any view function,
301 just as if that view had been hooked up using a URLconf.
302 """
304 def __init__(self, *, json_encoder=PlainJSONEncoder, headers=None, **defaults):
305 self.json_encoder = json_encoder
306 self.defaults = defaults
307 self.cookies = SimpleCookie()
308 self.errors = BytesIO()
309 if headers:
310 self.defaults.update(HttpHeaders.to_wsgi_names(headers))
312 def _base_environ(self, **request):
313 """
314 The base environment for a request.
315 """
316 # This is a minimal valid WSGI environ dictionary, plus:
317 # - HTTP_COOKIE: for cookie support,
318 # - REMOTE_ADDR: often useful, see #8551.
319 # See https://www.python.org/dev/peps/pep-3333/#environ-variables
320 return {
321 "HTTP_COOKIE": "; ".join(
322 sorted(
323 f"{morsel.key}={morsel.coded_value}"
324 for morsel in self.cookies.values()
325 )
326 ),
327 "PATH_INFO": "/",
328 "REMOTE_ADDR": "127.0.0.1",
329 "REQUEST_METHOD": "GET",
330 "SCRIPT_NAME": "",
331 "SERVER_NAME": "testserver",
332 "SERVER_PORT": "80",
333 "SERVER_PROTOCOL": "HTTP/1.1",
334 "wsgi.version": (1, 0),
335 "wsgi.url_scheme": "http",
336 "wsgi.input": FakePayload(b""),
337 "wsgi.errors": self.errors,
338 "wsgi.multiprocess": True,
339 "wsgi.multithread": False,
340 "wsgi.run_once": False,
341 **self.defaults,
342 **request,
343 }
345 def request(self, **request):
346 "Construct a generic request object."
347 return WSGIRequest(self._base_environ(**request))
349 def _encode_data(self, data, content_type):
350 if content_type is MULTIPART_CONTENT:
351 return encode_multipart(BOUNDARY, data)
352 else:
353 # Encode the content so that the byte representation is correct.
354 match = CONTENT_TYPE_RE.match(content_type)
355 if match:
356 charset = match[1]
357 else:
358 charset = settings.DEFAULT_CHARSET
359 return force_bytes(data, encoding=charset)
361 def _encode_json(self, data, content_type):
362 """
363 Return encoded JSON if data is a dict, list, or tuple and content_type
364 is application/json.
365 """
366 should_encode = JSON_CONTENT_TYPE_RE.match(content_type) and isinstance(
367 data, dict | list | tuple
368 )
369 return json.dumps(data, cls=self.json_encoder) if should_encode else data
371 def _get_path(self, parsed):
372 path = parsed.path
373 # If there are parameters, add them
374 if parsed.params:
375 path += ";" + parsed.params
376 path = unquote_to_bytes(path)
377 # Replace the behavior where non-ASCII values in the WSGI environ are
378 # arbitrarily decoded with ISO-8859-1.
379 # Refs comment in `get_bytes_from_wsgi()`.
380 return path.decode("iso-8859-1")
382 def get(self, path, data=None, secure=True, *, headers=None, **extra):
383 """Construct a GET request."""
384 data = {} if data is None else data
385 return self.generic(
386 "GET",
387 path,
388 secure=secure,
389 headers=headers,
390 **{
391 "QUERY_STRING": urlencode(data, doseq=True),
392 **extra,
393 },
394 )
396 def post(
397 self,
398 path,
399 data=None,
400 content_type=MULTIPART_CONTENT,
401 secure=True,
402 *,
403 headers=None,
404 **extra,
405 ):
406 """Construct a POST request."""
407 data = self._encode_json({} if data is None else data, content_type)
408 post_data = self._encode_data(data, content_type)
410 return self.generic(
411 "POST",
412 path,
413 post_data,
414 content_type,
415 secure=secure,
416 headers=headers,
417 **extra,
418 )
420 def head(self, path, data=None, secure=True, *, headers=None, **extra):
421 """Construct a HEAD request."""
422 data = {} if data is None else data
423 return self.generic(
424 "HEAD",
425 path,
426 secure=secure,
427 headers=headers,
428 **{
429 "QUERY_STRING": urlencode(data, doseq=True),
430 **extra,
431 },
432 )
434 def trace(self, path, secure=True, *, headers=None, **extra):
435 """Construct a TRACE request."""
436 return self.generic("TRACE", path, secure=secure, headers=headers, **extra)
438 def options(
439 self,
440 path,
441 data="",
442 content_type="application/octet-stream",
443 secure=True,
444 *,
445 headers=None,
446 **extra,
447 ):
448 "Construct an OPTIONS request."
449 return self.generic(
450 "OPTIONS", path, data, content_type, secure=secure, headers=headers, **extra
451 )
453 def put(
454 self,
455 path,
456 data="",
457 content_type="application/octet-stream",
458 secure=True,
459 *,
460 headers=None,
461 **extra,
462 ):
463 """Construct a PUT request."""
464 data = self._encode_json(data, content_type)
465 return self.generic(
466 "PUT", path, data, content_type, secure=secure, headers=headers, **extra
467 )
469 def patch(
470 self,
471 path,
472 data="",
473 content_type="application/octet-stream",
474 secure=True,
475 *,
476 headers=None,
477 **extra,
478 ):
479 """Construct a PATCH request."""
480 data = self._encode_json(data, content_type)
481 return self.generic(
482 "PATCH", path, data, content_type, secure=secure, headers=headers, **extra
483 )
485 def delete(
486 self,
487 path,
488 data="",
489 content_type="application/octet-stream",
490 secure=True,
491 *,
492 headers=None,
493 **extra,
494 ):
495 """Construct a DELETE request."""
496 data = self._encode_json(data, content_type)
497 return self.generic(
498 "DELETE", path, data, content_type, secure=secure, headers=headers, **extra
499 )
501 def generic(
502 self,
503 method,
504 path,
505 data="",
506 content_type="application/octet-stream",
507 secure=True,
508 *,
509 headers=None,
510 **extra,
511 ):
512 """Construct an arbitrary HTTP request."""
513 parsed = urlparse(str(path)) # path can be lazy
514 data = force_bytes(data, settings.DEFAULT_CHARSET)
515 r = {
516 "PATH_INFO": self._get_path(parsed),
517 "REQUEST_METHOD": method,
518 "SERVER_PORT": "443" if secure else "80",
519 "wsgi.url_scheme": "https" if secure else "http",
520 }
521 if data:
522 r.update(
523 {
524 "CONTENT_LENGTH": str(len(data)),
525 "CONTENT_TYPE": content_type,
526 "wsgi.input": FakePayload(data),
527 }
528 )
529 if headers:
530 extra.update(HttpHeaders.to_wsgi_names(headers))
531 r.update(extra)
532 # If QUERY_STRING is absent or empty, we want to extract it from the URL.
533 if not r.get("QUERY_STRING"):
534 # WSGI requires latin-1 encoded strings. See get_path_info().
535 query_string = parsed[4].encode().decode("iso-8859-1")
536 r["QUERY_STRING"] = query_string
537 return self.request(**r)
540class ClientMixin:
541 """
542 Mixin with common methods between Client and AsyncClient.
543 """
545 def store_exc_info(self, **kwargs):
546 """Store exceptions when they are generated by a view."""
547 self.exc_info = sys.exc_info()
549 def check_exception(self, response):
550 """
551 Look for a signaled exception, clear the current context exception
552 data, re-raise the signaled exception, and clear the signaled exception
553 from the local cache.
554 """
555 response.exc_info = self.exc_info
556 if self.exc_info:
557 _, exc_value, _ = self.exc_info
558 self.exc_info = None
559 if self.raise_request_exception:
560 raise exc_value
562 @property
563 def session(self):
564 """Return the current session variables."""
565 engine = import_module(settings.SESSION_ENGINE)
566 cookie = self.cookies.get(settings.SESSION_COOKIE_NAME)
567 if cookie:
568 return engine.SessionStore(cookie.value)
569 session = engine.SessionStore()
570 session.save()
571 self.cookies[settings.SESSION_COOKIE_NAME] = session.session_key
572 return session
574 def force_login(self, user):
575 self._login(user)
577 def _login(self, user):
578 from plain.auth import login
580 # Create a fake request to store login details.
581 request = HttpRequest()
582 if self.session:
583 request.session = self.session
584 else:
585 engine = import_module(settings.SESSION_ENGINE)
586 request.session = engine.SessionStore()
587 login(request, user)
588 # Save the session values.
589 request.session.save()
590 # Set the cookie to represent the session.
591 session_cookie = settings.SESSION_COOKIE_NAME
592 self.cookies[session_cookie] = request.session.session_key
593 cookie_data = {
594 "max-age": None,
595 "path": "/",
596 "domain": settings.SESSION_COOKIE_DOMAIN,
597 "secure": settings.SESSION_COOKIE_SECURE or None,
598 "expires": None,
599 }
600 self.cookies[session_cookie].update(cookie_data)
602 def logout(self):
603 """Log out the user by removing the cookies and session object."""
604 from plain.auth import get_user, logout
606 request = HttpRequest()
607 if self.session:
608 request.session = self.session
609 request.user = get_user(request)
610 else:
611 engine = import_module(settings.SESSION_ENGINE)
612 request.session = engine.SessionStore()
613 logout(request)
614 self.cookies = SimpleCookie()
616 def _parse_json(self, response, **extra):
617 if not hasattr(response, "_json"):
618 if not JSON_CONTENT_TYPE_RE.match(response.get("Content-Type")):
619 raise ValueError(
620 'Content-Type header is "{}", not "application/json"'.format(
621 response.get("Content-Type")
622 )
623 )
624 response._json = json.loads(
625 response.content.decode(response.charset), **extra
626 )
627 return response._json
630class Client(ClientMixin, RequestFactory):
631 """
632 A class that can act as a client for testing purposes.
634 It allows the user to compose GET and POST requests, and
635 obtain the response that the server gave to those requests.
636 The server Response objects are annotated with the details
637 of the contexts and templates that were rendered during the
638 process of serving the request.
640 Client objects are stateful - they will retain cookie (and
641 thus session) details for the lifetime of the Client instance.
643 This is not intended as a replacement for Twill/Selenium or
644 the like - it is here to allow testing against the
645 contexts and templates produced by a view, rather than the
646 HTML rendered to the end-user.
647 """
649 def __init__(
650 self,
651 enforce_csrf_checks=False,
652 raise_request_exception=True,
653 *,
654 headers=None,
655 **defaults,
656 ):
657 super().__init__(headers=headers, **defaults)
658 self.handler = ClientHandler(enforce_csrf_checks)
659 self.raise_request_exception = raise_request_exception
660 self.exc_info = None
661 self.extra = None
662 self.headers = None
664 def request(self, **request):
665 """
666 Make a generic request. Compose the environment dictionary and pass
667 to the handler, return the result of the handler. Assume defaults for
668 the query environment, which can be overridden using the arguments to
669 the request.
670 """
671 environ = self._base_environ(**request)
673 # Capture exceptions created by the handler.
674 exception_uid = f"request-exception-{id(request)}"
675 got_request_exception.connect(self.store_exc_info, dispatch_uid=exception_uid)
676 try:
677 response = self.handler(environ)
678 finally:
679 # signals.template_rendered.disconnect(dispatch_uid=signal_uid)
680 got_request_exception.disconnect(dispatch_uid=exception_uid)
681 # Check for signaled exceptions.
682 self.check_exception(response)
683 # Save the client and request that stimulated the response.
684 response.client = self
685 response.request = request
686 response.json = partial(self._parse_json, response)
688 # If the request had a user attached, make it available on the response.
689 if hasattr(response.wsgi_request, "user"):
690 response.user = response.wsgi_request.user
692 # Attach the ResolverMatch instance to the response.
693 urlconf = getattr(response.wsgi_request, "urlconf", None)
694 response.resolver_match = SimpleLazyObject(
695 lambda: resolve(request["PATH_INFO"], urlconf=urlconf),
696 )
698 # Update persistent cookie data.
699 if response.cookies:
700 self.cookies.update(response.cookies)
701 return response
703 def get(
704 self,
705 path,
706 data=None,
707 follow=False,
708 secure=True,
709 *,
710 headers=None,
711 **extra,
712 ):
713 """Request a response from the server using GET."""
714 self.extra = extra
715 self.headers = headers
716 response = super().get(path, data=data, secure=secure, headers=headers, **extra)
717 if follow:
718 response = self._handle_redirects(
719 response, data=data, headers=headers, **extra
720 )
721 return response
723 def post(
724 self,
725 path,
726 data=None,
727 content_type=MULTIPART_CONTENT,
728 follow=False,
729 secure=True,
730 *,
731 headers=None,
732 **extra,
733 ):
734 """Request a response from the server using POST."""
735 self.extra = extra
736 self.headers = headers
737 response = super().post(
738 path,
739 data=data,
740 content_type=content_type,
741 secure=secure,
742 headers=headers,
743 **extra,
744 )
745 if follow:
746 response = self._handle_redirects(
747 response, data=data, content_type=content_type, headers=headers, **extra
748 )
749 return response
751 def head(
752 self,
753 path,
754 data=None,
755 follow=False,
756 secure=True,
757 *,
758 headers=None,
759 **extra,
760 ):
761 """Request a response from the server using HEAD."""
762 self.extra = extra
763 self.headers = headers
764 response = super().head(
765 path, data=data, secure=secure, headers=headers, **extra
766 )
767 if follow:
768 response = self._handle_redirects(
769 response, data=data, headers=headers, **extra
770 )
771 return response
773 def options(
774 self,
775 path,
776 data="",
777 content_type="application/octet-stream",
778 follow=False,
779 secure=True,
780 *,
781 headers=None,
782 **extra,
783 ):
784 """Request a response from the server using OPTIONS."""
785 self.extra = extra
786 self.headers = headers
787 response = super().options(
788 path,
789 data=data,
790 content_type=content_type,
791 secure=secure,
792 headers=headers,
793 **extra,
794 )
795 if follow:
796 response = self._handle_redirects(
797 response, data=data, content_type=content_type, headers=headers, **extra
798 )
799 return response
801 def put(
802 self,
803 path,
804 data="",
805 content_type="application/octet-stream",
806 follow=False,
807 secure=True,
808 *,
809 headers=None,
810 **extra,
811 ):
812 """Send a resource to the server using PUT."""
813 self.extra = extra
814 self.headers = headers
815 response = super().put(
816 path,
817 data=data,
818 content_type=content_type,
819 secure=secure,
820 headers=headers,
821 **extra,
822 )
823 if follow:
824 response = self._handle_redirects(
825 response, data=data, content_type=content_type, headers=headers, **extra
826 )
827 return response
829 def patch(
830 self,
831 path,
832 data="",
833 content_type="application/octet-stream",
834 follow=False,
835 secure=True,
836 *,
837 headers=None,
838 **extra,
839 ):
840 """Send a resource to the server using PATCH."""
841 self.extra = extra
842 self.headers = headers
843 response = super().patch(
844 path,
845 data=data,
846 content_type=content_type,
847 secure=secure,
848 headers=headers,
849 **extra,
850 )
851 if follow:
852 response = self._handle_redirects(
853 response, data=data, content_type=content_type, headers=headers, **extra
854 )
855 return response
857 def delete(
858 self,
859 path,
860 data="",
861 content_type="application/octet-stream",
862 follow=False,
863 secure=True,
864 *,
865 headers=None,
866 **extra,
867 ):
868 """Send a DELETE request to the server."""
869 self.extra = extra
870 self.headers = headers
871 response = super().delete(
872 path,
873 data=data,
874 content_type=content_type,
875 secure=secure,
876 headers=headers,
877 **extra,
878 )
879 if follow:
880 response = self._handle_redirects(
881 response, data=data, content_type=content_type, headers=headers, **extra
882 )
883 return response
885 def trace(
886 self,
887 path,
888 data="",
889 follow=False,
890 secure=True,
891 *,
892 headers=None,
893 **extra,
894 ):
895 """Send a TRACE request to the server."""
896 self.extra = extra
897 self.headers = headers
898 response = super().trace(
899 path, data=data, secure=secure, headers=headers, **extra
900 )
901 if follow:
902 response = self._handle_redirects(
903 response, data=data, headers=headers, **extra
904 )
905 return response
907 def _handle_redirects(
908 self,
909 response,
910 data="",
911 content_type="",
912 headers=None,
913 **extra,
914 ):
915 """
916 Follow any redirects by requesting responses from the server using GET.
917 """
918 response.redirect_chain = []
919 redirect_status_codes = (
920 HTTPStatus.MOVED_PERMANENTLY,
921 HTTPStatus.FOUND,
922 HTTPStatus.SEE_OTHER,
923 HTTPStatus.TEMPORARY_REDIRECT,
924 HTTPStatus.PERMANENT_REDIRECT,
925 )
926 while response.status_code in redirect_status_codes:
927 response_url = response.url
928 redirect_chain = response.redirect_chain
929 redirect_chain.append((response_url, response.status_code))
931 url = urlsplit(response_url)
932 if url.scheme:
933 extra["wsgi.url_scheme"] = url.scheme
934 if url.hostname:
935 extra["SERVER_NAME"] = url.hostname
936 if url.port:
937 extra["SERVER_PORT"] = str(url.port)
939 path = url.path
940 # RFC 3986 Section 6.2.3: Empty path should be normalized to "/".
941 if not path and url.netloc:
942 path = "/"
943 # Prepend the request path to handle relative path redirects
944 if not path.startswith("/"):
945 path = urljoin(response.request["PATH_INFO"], path)
947 if response.status_code in (
948 HTTPStatus.TEMPORARY_REDIRECT,
949 HTTPStatus.PERMANENT_REDIRECT,
950 ):
951 # Preserve request method and query string (if needed)
952 # post-redirect for 307/308 responses.
953 request_method = response.request["REQUEST_METHOD"].lower()
954 if request_method not in ("get", "head"):
955 extra["QUERY_STRING"] = url.query
956 request_method = getattr(self, request_method)
957 else:
958 request_method = self.get
959 data = QueryDict(url.query)
960 content_type = None
962 response = request_method(
963 path,
964 data=data,
965 content_type=content_type,
966 follow=False,
967 headers=headers,
968 **extra,
969 )
970 response.redirect_chain = redirect_chain
972 if redirect_chain[-1] in redirect_chain[:-1]:
973 # Check that we're not redirecting to somewhere we've already
974 # been to, to prevent loops.
975 raise RedirectCycleError(
976 "Redirect loop detected.", last_response=response
977 )
978 if len(redirect_chain) > 20:
979 # Such a lengthy chain likely also means a loop, but one with
980 # a growing path, changing view, or changing query argument;
981 # 20 is the value of "network.http.redirection-limit" from Firefox.
982 raise RedirectCycleError("Too many redirects.", last_response=response)
984 return response
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.http.cookie import parse_cookie
2from plain.http.request import (
3 HttpHeaders,
4 HttpRequest,
5 QueryDict,
6 RawPostDataException,
7 UnreadablePostError,
8)
9from plain.http.response import (
10 BadHeaderError,
11 FileResponse,
12 Http404,
13 JsonResponse,
14 Response,
15 ResponseBadRequest,
16 ResponseBase,
17 ResponseForbidden,
18 ResponseGone,
19 ResponseNotAllowed,
20 ResponseNotFound,
21 ResponseNotModified,
22 ResponsePermanentRedirect,
23 ResponseRedirect,
24 ResponseServerError,
25 StreamingResponse,
26)
28__all__ = [
29 "parse_cookie",
30 "HttpHeaders",
31 "HttpRequest",
32 "QueryDict",
33 "RawPostDataException",
34 "UnreadablePostError",
35 "Response",
36 "ResponseBase",
37 "StreamingResponse",
38 "ResponseRedirect",
39 "ResponsePermanentRedirect",
40 "ResponseNotModified",
41 "ResponseBadRequest",
42 "ResponseForbidden",
43 "ResponseNotFound",
44 "ResponseNotAllowed",
45 "ResponseGone",
46 "ResponseServerError",
47 "Http404",
48 "BadHeaderError",
49 "JsonResponse",
50 "FileResponse",
51]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from http import cookies
4def parse_cookie(cookie):
5 """
6 Return a dictionary parsed from a `Cookie:` header string.
7 """
8 cookiedict = {}
9 for chunk in cookie.split(";"):
10 if "=" in chunk:
11 key, val = chunk.split("=", 1)
12 else:
13 # Assume an empty name per
14 # https://bugzilla.mozilla.org/show_bug.cgi?id=169091
15 key, val = "", chunk
16 key, val = key.strip(), val.strip()
17 if key or val:
18 # unquote using Python's algorithm.
19 cookiedict[key] = cookies._unquote(val)
20 return cookiedict
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Multi-part parsing for file uploads.
4Exposes one class, ``MultiPartParser``, which feeds chunks of uploaded data to
5file upload handlers for processing.
6"""
8import base64
9import binascii
10import collections
11import html
13from plain.exceptions import (
14 RequestDataTooBig,
15 SuspiciousMultipartForm,
16 TooManyFieldsSent,
17 TooManyFilesSent,
18)
19from plain.internal.files.uploadhandler import SkipFile, StopFutureHandlers, StopUpload
20from plain.runtime import settings
21from plain.utils.datastructures import MultiValueDict
22from plain.utils.encoding import force_str
23from plain.utils.http import parse_header_parameters
24from plain.utils.regex_helper import _lazy_re_compile
26__all__ = ("MultiPartParser", "MultiPartParserError", "InputStreamExhausted")
29class MultiPartParserError(Exception):
30 pass
33class InputStreamExhausted(Exception):
34 """
35 No more reads are allowed from this device.
36 """
38 pass
41RAW = "raw"
42FILE = "file"
43FIELD = "field"
44FIELD_TYPES = frozenset([FIELD, RAW])
47class MultiPartParser:
48 """
49 An RFC 7578 multipart/form-data parser.
51 ``MultiValueDict.parse()`` reads the input stream in ``chunk_size`` chunks
52 and returns a tuple of ``(MultiValueDict(POST), MultiValueDict(FILES))``.
53 """
55 boundary_re = _lazy_re_compile(r"[ -~]{0,200}[!-~]")
57 def __init__(self, META, input_data, upload_handlers, encoding=None):
58 """
59 Initialize the MultiPartParser object.
61 :META:
62 The standard ``META`` dictionary in Plain request objects.
63 :input_data:
64 The raw post data, as a file-like object.
65 :upload_handlers:
66 A list of UploadHandler instances that perform operations on the
67 uploaded data.
68 :encoding:
69 The encoding with which to treat the incoming data.
70 """
71 # Content-Type should contain multipart and the boundary information.
72 content_type = META.get("CONTENT_TYPE", "")
73 if not content_type.startswith("multipart/"):
74 raise MultiPartParserError(f"Invalid Content-Type: {content_type}")
76 try:
77 content_type.encode("ascii")
78 except UnicodeEncodeError:
79 raise MultiPartParserError(
80 f"Invalid non-ASCII Content-Type in multipart: {force_str(content_type)}"
81 )
83 # Parse the header to get the boundary to split the parts.
84 _, opts = parse_header_parameters(content_type)
85 boundary = opts.get("boundary")
86 if not boundary or not self.boundary_re.fullmatch(boundary):
87 raise MultiPartParserError(
88 f"Invalid boundary in multipart: {force_str(boundary)}"
89 )
91 # Content-Length should contain the length of the body we are about
92 # to receive.
93 try:
94 content_length = int(META.get("CONTENT_LENGTH", 0))
95 except (ValueError, TypeError):
96 content_length = 0
98 if content_length < 0:
99 # This means we shouldn't continue...raise an error.
100 raise MultiPartParserError(f"Invalid content length: {content_length!r}")
102 self._boundary = boundary.encode("ascii")
103 self._input_data = input_data
105 # For compatibility with low-level network APIs (with 32-bit integers),
106 # the chunk size should be < 2^31, but still divisible by 4.
107 possible_sizes = [x.chunk_size for x in upload_handlers if x.chunk_size]
108 self._chunk_size = min([2**31 - 4] + possible_sizes)
110 self._meta = META
111 self._encoding = encoding or settings.DEFAULT_CHARSET
112 self._content_length = content_length
113 self._upload_handlers = upload_handlers
115 def parse(self):
116 # Call the actual parse routine and close all open files in case of
117 # errors. This is needed because if exceptions are thrown the
118 # MultiPartParser will not be garbage collected immediately and
119 # resources would be kept alive. This is only needed for errors because
120 # the Request object closes all uploaded files at the end of the
121 # request.
122 try:
123 return self._parse()
124 except Exception:
125 if hasattr(self, "_files"):
126 for _, files in self._files.lists():
127 for fileobj in files:
128 fileobj.close()
129 raise
131 def _parse(self):
132 """
133 Parse the POST data and break it into a FILES MultiValueDict and a POST
134 MultiValueDict.
136 Return a tuple containing the POST and FILES dictionary, respectively.
137 """
138 from plain.http import QueryDict
140 encoding = self._encoding
141 handlers = self._upload_handlers
143 # HTTP spec says that Content-Length >= 0 is valid
144 # handling content-length == 0 before continuing
145 if self._content_length == 0:
146 return QueryDict(encoding=self._encoding), MultiValueDict()
148 # See if any of the handlers take care of the parsing.
149 # This allows overriding everything if need be.
150 for handler in handlers:
151 result = handler.handle_raw_input(
152 self._input_data,
153 self._meta,
154 self._content_length,
155 self._boundary,
156 encoding,
157 )
158 # Check to see if it was handled
159 if result is not None:
160 return result[0], result[1]
162 # Create the data structures to be used later.
163 self._post = QueryDict(mutable=True)
164 self._files = MultiValueDict()
166 # Instantiate the parser and stream:
167 stream = LazyStream(ChunkIter(self._input_data, self._chunk_size))
169 # Whether or not to signal a file-completion at the beginning of the loop.
170 old_field_name = None
171 counters = [0] * len(handlers)
173 # Number of bytes that have been read.
174 num_bytes_read = 0
175 # To count the number of keys in the request.
176 num_post_keys = 0
177 # To count the number of files in the request.
178 num_files = 0
179 # To limit the amount of data read from the request.
180 read_size = None
181 # Whether a file upload is finished.
182 uploaded_file = True
184 try:
185 for item_type, meta_data, field_stream in Parser(stream, self._boundary):
186 if old_field_name:
187 # We run this at the beginning of the next loop
188 # since we cannot be sure a file is complete until
189 # we hit the next boundary/part of the multipart content.
190 self.handle_file_complete(old_field_name, counters)
191 old_field_name = None
192 uploaded_file = True
194 if (
195 item_type in FIELD_TYPES
196 and settings.DATA_UPLOAD_MAX_NUMBER_FIELDS is not None
197 ):
198 # Avoid storing more than DATA_UPLOAD_MAX_NUMBER_FIELDS.
199 num_post_keys += 1
200 # 2 accounts for empty raw fields before and after the
201 # last boundary.
202 if settings.DATA_UPLOAD_MAX_NUMBER_FIELDS + 2 < num_post_keys:
203 raise TooManyFieldsSent(
204 "The number of GET/POST parameters exceeded "
205 "settings.DATA_UPLOAD_MAX_NUMBER_FIELDS."
206 )
208 try:
209 disposition = meta_data["content-disposition"][1]
210 field_name = disposition["name"].strip()
211 except (KeyError, IndexError, AttributeError):
212 continue
214 transfer_encoding = meta_data.get("content-transfer-encoding")
215 if transfer_encoding is not None:
216 transfer_encoding = transfer_encoding[0].strip()
217 field_name = force_str(field_name, encoding, errors="replace")
219 if item_type == FIELD:
220 # Avoid reading more than DATA_UPLOAD_MAX_MEMORY_SIZE.
221 if settings.DATA_UPLOAD_MAX_MEMORY_SIZE is not None:
222 read_size = (
223 settings.DATA_UPLOAD_MAX_MEMORY_SIZE - num_bytes_read
224 )
226 # This is a post field, we can just set it in the post
227 if transfer_encoding == "base64":
228 raw_data = field_stream.read(size=read_size)
229 num_bytes_read += len(raw_data)
230 try:
231 data = base64.b64decode(raw_data)
232 except binascii.Error:
233 data = raw_data
234 else:
235 data = field_stream.read(size=read_size)
236 num_bytes_read += len(data)
238 # Add two here to make the check consistent with the
239 # x-www-form-urlencoded check that includes '&='.
240 num_bytes_read += len(field_name) + 2
241 if (
242 settings.DATA_UPLOAD_MAX_MEMORY_SIZE is not None
243 and num_bytes_read > settings.DATA_UPLOAD_MAX_MEMORY_SIZE
244 ):
245 raise RequestDataTooBig(
246 "Request body exceeded "
247 "settings.DATA_UPLOAD_MAX_MEMORY_SIZE."
248 )
250 self._post.appendlist(
251 field_name, force_str(data, encoding, errors="replace")
252 )
253 elif item_type == FILE:
254 # Avoid storing more than DATA_UPLOAD_MAX_NUMBER_FILES.
255 num_files += 1
256 if (
257 settings.DATA_UPLOAD_MAX_NUMBER_FILES is not None
258 and num_files > settings.DATA_UPLOAD_MAX_NUMBER_FILES
259 ):
260 raise TooManyFilesSent(
261 "The number of files exceeded "
262 "settings.DATA_UPLOAD_MAX_NUMBER_FILES."
263 )
264 # This is a file, use the handler...
265 file_name = disposition.get("filename")
266 if file_name:
267 file_name = force_str(file_name, encoding, errors="replace")
268 file_name = self.sanitize_file_name(file_name)
269 if not file_name:
270 continue
272 content_type, content_type_extra = meta_data.get(
273 "content-type", ("", {})
274 )
275 content_type = content_type.strip()
276 charset = content_type_extra.get("charset")
278 try:
279 content_length = int(meta_data.get("content-length")[0])
280 except (IndexError, TypeError, ValueError):
281 content_length = None
283 counters = [0] * len(handlers)
284 uploaded_file = False
285 try:
286 for handler in handlers:
287 try:
288 handler.new_file(
289 field_name,
290 file_name,
291 content_type,
292 content_length,
293 charset,
294 content_type_extra,
295 )
296 except StopFutureHandlers:
297 break
299 for chunk in field_stream:
300 if transfer_encoding == "base64":
301 # We only special-case base64 transfer encoding
302 # We should always decode base64 chunks by
303 # multiple of 4, ignoring whitespace.
305 stripped_chunk = b"".join(chunk.split())
307 remaining = len(stripped_chunk) % 4
308 while remaining != 0:
309 over_chunk = field_stream.read(4 - remaining)
310 if not over_chunk:
311 break
312 stripped_chunk += b"".join(over_chunk.split())
313 remaining = len(stripped_chunk) % 4
315 try:
316 chunk = base64.b64decode(stripped_chunk)
317 except Exception as exc:
318 # Since this is only a chunk, any error is
319 # an unfixable error.
320 raise MultiPartParserError(
321 "Could not decode base64 data."
322 ) from exc
324 for i, handler in enumerate(handlers):
325 chunk_length = len(chunk)
326 chunk = handler.receive_data_chunk(chunk, counters[i])
327 counters[i] += chunk_length
328 if chunk is None:
329 # Don't continue if the chunk received by
330 # the handler is None.
331 break
333 except SkipFile:
334 self._close_files()
335 # Just use up the rest of this file...
336 exhaust(field_stream)
337 else:
338 # Handle file upload completions on next iteration.
339 old_field_name = field_name
340 else:
341 # If this is neither a FIELD nor a FILE, exhaust the field
342 # stream. Note: There could be an error here at some point,
343 # but there will be at least two RAW types (before and
344 # after the other boundaries). This branch is usually not
345 # reached at all, because a missing content-disposition
346 # header will skip the whole boundary.
347 exhaust(field_stream)
348 except StopUpload as e:
349 self._close_files()
350 if not e.connection_reset:
351 exhaust(self._input_data)
352 else:
353 if not uploaded_file:
354 for handler in handlers:
355 handler.upload_interrupted()
356 # Make sure that the request data is all fed
357 exhaust(self._input_data)
359 # Signal that the upload has completed.
360 # any() shortcircuits if a handler's upload_complete() returns a value.
361 any(handler.upload_complete() for handler in handlers)
362 self._post._mutable = False
363 return self._post, self._files
365 def handle_file_complete(self, old_field_name, counters):
366 """
367 Handle all the signaling that takes place when a file is complete.
368 """
369 for i, handler in enumerate(self._upload_handlers):
370 file_obj = handler.file_complete(counters[i])
371 if file_obj:
372 # If it returns a file object, then set the files dict.
373 self._files.appendlist(
374 force_str(old_field_name, self._encoding, errors="replace"),
375 file_obj,
376 )
377 break
379 def sanitize_file_name(self, file_name):
380 """
381 Sanitize the filename of an upload.
383 Remove all possible path separators, even though that might remove more
384 than actually required by the target system. Filenames that could
385 potentially cause problems (current/parent dir) are also discarded.
387 It should be noted that this function could still return a "filepath"
388 like "C:some_file.txt" which is handled later on by the storage layer.
389 So while this function does sanitize filenames to some extent, the
390 resulting filename should still be considered as untrusted user input.
391 """
392 file_name = html.unescape(file_name)
393 file_name = file_name.rsplit("/")[-1]
394 file_name = file_name.rsplit("\\")[-1]
395 # Remove non-printable characters.
396 file_name = "".join([char for char in file_name if char.isprintable()])
398 if file_name in {"", ".", ".."}:
399 return None
400 return file_name
402 IE_sanitize = sanitize_file_name
404 def _close_files(self):
405 # Free up all file handles.
406 # FIXME: this currently assumes that upload handlers store the file as 'file'
407 # We should document that...
408 # (Maybe add handler.free_file to complement new_file)
409 for handler in self._upload_handlers:
410 if hasattr(handler, "file"):
411 handler.file.close()
414class LazyStream:
415 """
416 The LazyStream wrapper allows one to get and "unget" bytes from a stream.
418 Given a producer object (an iterator that yields bytestrings), the
419 LazyStream object will support iteration, reading, and keeping a "look-back"
420 variable in case you need to "unget" some bytes.
421 """
423 def __init__(self, producer, length=None):
424 """
425 Every LazyStream must have a producer when instantiated.
427 A producer is an iterable that returns a string each time it
428 is called.
429 """
430 self._producer = producer
431 self._empty = False
432 self._leftover = b""
433 self.length = length
434 self.position = 0
435 self._remaining = length
436 self._unget_history = []
438 def tell(self):
439 return self.position
441 def read(self, size=None):
442 def parts():
443 remaining = self._remaining if size is None else size
444 # do the whole thing in one shot if no limit was provided.
445 if remaining is None:
446 yield b"".join(self)
447 return
449 # otherwise do some bookkeeping to return exactly enough
450 # of the stream and stashing any extra content we get from
451 # the producer
452 while remaining != 0:
453 assert remaining > 0, "remaining bytes to read should never go negative"
455 try:
456 chunk = next(self)
457 except StopIteration:
458 return
459 else:
460 emitting = chunk[:remaining]
461 self.unget(chunk[remaining:])
462 remaining -= len(emitting)
463 yield emitting
465 return b"".join(parts())
467 def __next__(self):
468 """
469 Used when the exact number of bytes to read is unimportant.
471 Return whatever chunk is conveniently returned from the iterator.
472 Useful to avoid unnecessary bookkeeping if performance is an issue.
473 """
474 if self._leftover:
475 output = self._leftover
476 self._leftover = b""
477 else:
478 output = next(self._producer)
479 self._unget_history = []
480 self.position += len(output)
481 return output
483 def close(self):
484 """
485 Used to invalidate/disable this lazy stream.
487 Replace the producer with an empty list. Any leftover bytes that have
488 already been read will still be reported upon read() and/or next().
489 """
490 self._producer = []
492 def __iter__(self):
493 return self
495 def unget(self, bytes):
496 """
497 Place bytes back onto the front of the lazy stream.
499 Future calls to read() will return those bytes first. The
500 stream position and thus tell() will be rewound.
501 """
502 if not bytes:
503 return
504 self._update_unget_history(len(bytes))
505 self.position -= len(bytes)
506 self._leftover = bytes + self._leftover
508 def _update_unget_history(self, num_bytes):
509 """
510 Update the unget history as a sanity check to see if we've pushed
511 back the same number of bytes in one chunk. If we keep ungetting the
512 same number of bytes many times (here, 50), we're mostly likely in an
513 infinite loop of some sort. This is usually caused by a
514 maliciously-malformed MIME request.
515 """
516 self._unget_history = [num_bytes] + self._unget_history[:49]
517 number_equal = len(
518 [
519 current_number
520 for current_number in self._unget_history
521 if current_number == num_bytes
522 ]
523 )
525 if number_equal > 40:
526 raise SuspiciousMultipartForm(
527 "The multipart parser got stuck, which shouldn't happen with"
528 " normal uploaded files. Check for malicious upload activity;"
529 " if there is none, report this to the Plain developers."
530 )
533class ChunkIter:
534 """
535 An iterable that will yield chunks of data. Given a file-like object as the
536 constructor, yield chunks of read operations from that object.
537 """
539 def __init__(self, flo, chunk_size=64 * 1024):
540 self.flo = flo
541 self.chunk_size = chunk_size
543 def __next__(self):
544 try:
545 data = self.flo.read(self.chunk_size)
546 except InputStreamExhausted:
547 raise StopIteration()
548 if data:
549 return data
550 else:
551 raise StopIteration()
553 def __iter__(self):
554 return self
557class InterBoundaryIter:
558 """
559 A Producer that will iterate over boundaries.
560 """
562 def __init__(self, stream, boundary):
563 self._stream = stream
564 self._boundary = boundary
566 def __iter__(self):
567 return self
569 def __next__(self):
570 try:
571 return LazyStream(BoundaryIter(self._stream, self._boundary))
572 except InputStreamExhausted:
573 raise StopIteration()
576class BoundaryIter:
577 """
578 A Producer that is sensitive to boundaries.
580 Will happily yield bytes until a boundary is found. Will yield the bytes
581 before the boundary, throw away the boundary bytes themselves, and push the
582 post-boundary bytes back on the stream.
584 The future calls to next() after locating the boundary will raise a
585 StopIteration exception.
586 """
588 def __init__(self, stream, boundary):
589 self._stream = stream
590 self._boundary = boundary
591 self._done = False
592 # rollback an additional six bytes because the format is like
593 # this: CRLF<boundary>[--CRLF]
594 self._rollback = len(boundary) + 6
596 # Try to use mx fast string search if available. Otherwise
597 # use Python find. Wrap the latter for consistency.
598 unused_char = self._stream.read(1)
599 if not unused_char:
600 raise InputStreamExhausted()
601 self._stream.unget(unused_char)
603 def __iter__(self):
604 return self
606 def __next__(self):
607 if self._done:
608 raise StopIteration()
610 stream = self._stream
611 rollback = self._rollback
613 bytes_read = 0
614 chunks = []
615 for bytes in stream:
616 bytes_read += len(bytes)
617 chunks.append(bytes)
618 if bytes_read > rollback:
619 break
620 if not bytes:
621 break
622 else:
623 self._done = True
625 if not chunks:
626 raise StopIteration()
628 chunk = b"".join(chunks)
629 boundary = self._find_boundary(chunk)
631 if boundary:
632 end, next = boundary
633 stream.unget(chunk[next:])
634 self._done = True
635 return chunk[:end]
636 else:
637 # make sure we don't treat a partial boundary (and
638 # its separators) as data
639 if not chunk[:-rollback]: # and len(chunk) >= (len(self._boundary) + 6):
640 # There's nothing left, we should just return and mark as done.
641 self._done = True
642 return chunk
643 else:
644 stream.unget(chunk[-rollback:])
645 return chunk[:-rollback]
647 def _find_boundary(self, data):
648 """
649 Find a multipart boundary in data.
651 Should no boundary exist in the data, return None. Otherwise, return
652 a tuple containing the indices of the following:
653 * the end of current encapsulation
654 * the start of the next encapsulation
655 """
656 index = data.find(self._boundary)
657 if index < 0:
658 return None
659 else:
660 end = index
661 next = index + len(self._boundary)
662 # backup over CRLF
663 last = max(0, end - 1)
664 if data[last : last + 1] == b"\n":
665 end -= 1
666 last = max(0, end - 1)
667 if data[last : last + 1] == b"\r":
668 end -= 1
669 return end, next
672def exhaust(stream_or_iterable):
673 """Exhaust an iterator or stream."""
674 try:
675 iterator = iter(stream_or_iterable)
676 except TypeError:
677 iterator = ChunkIter(stream_or_iterable, 16384)
678 collections.deque(iterator, maxlen=0) # consume iterator quickly.
681def parse_boundary_stream(stream, max_header_size):
682 """
683 Parse one and exactly one stream that encapsulates a boundary.
684 """
685 # Stream at beginning of header, look for end of header
686 # and parse it if found. The header must fit within one
687 # chunk.
688 chunk = stream.read(max_header_size)
690 # 'find' returns the top of these four bytes, so we'll
691 # need to munch them later to prevent them from polluting
692 # the payload.
693 header_end = chunk.find(b"\r\n\r\n")
695 if header_end == -1:
696 # we find no header, so we just mark this fact and pass on
697 # the stream verbatim
698 stream.unget(chunk)
699 return (RAW, {}, stream)
701 header = chunk[:header_end]
703 # here we place any excess chunk back onto the stream, as
704 # well as throwing away the CRLFCRLF bytes from above.
705 stream.unget(chunk[header_end + 4 :])
707 TYPE = RAW
708 outdict = {}
710 # Eliminate blank lines
711 for line in header.split(b"\r\n"):
712 # This terminology ("main value" and "dictionary of
713 # parameters") is from the Python docs.
714 try:
715 main_value_pair, params = parse_header_parameters(line.decode())
716 name, value = main_value_pair.split(":", 1)
717 params = {k: v.encode() for k, v in params.items()}
718 except ValueError: # Invalid header.
719 continue
721 if name == "content-disposition":
722 TYPE = FIELD
723 if params.get("filename"):
724 TYPE = FILE
726 outdict[name] = value, params
728 if TYPE == RAW:
729 stream.unget(chunk)
731 return (TYPE, outdict, stream)
734class Parser:
735 def __init__(self, stream, boundary):
736 self._stream = stream
737 self._separator = b"--" + boundary
739 def __iter__(self):
740 boundarystream = InterBoundaryIter(self._stream, self._separator)
741 for sub_stream in boundarystream:
742 # Iterate over each part
743 yield parse_boundary_stream(sub_stream, 1024)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import codecs
2import copy
3import uuid
4from io import BytesIO
5from itertools import chain
6from urllib.parse import parse_qsl, quote, urlencode, urljoin, urlsplit
8from plain import signing
9from plain.exceptions import (
10 DisallowedHost,
11 ImproperlyConfigured,
12 RequestDataTooBig,
13 TooManyFieldsSent,
14)
15from plain.http.multipartparser import (
16 MultiPartParser,
17 MultiPartParserError,
18 TooManyFilesSent,
19)
20from plain.internal.files import uploadhandler
21from plain.runtime import settings
22from plain.utils.datastructures import (
23 CaseInsensitiveMapping,
24 ImmutableList,
25 MultiValueDict,
26)
27from plain.utils.encoding import escape_uri_path, iri_to_uri
28from plain.utils.functional import cached_property
29from plain.utils.http import is_same_domain, parse_header_parameters
30from plain.utils.regex_helper import _lazy_re_compile
32RAISE_ERROR = object()
33host_validation_re = _lazy_re_compile(
34 r"^([a-z0-9.-]+|\[[a-f0-9]*:[a-f0-9\.:]+\])(:[0-9]+)?$"
35)
38class UnreadablePostError(OSError):
39 pass
42class RawPostDataException(Exception):
43 """
44 You cannot access raw_post_data from a request that has
45 multipart/* POST data if it has been accessed via POST,
46 FILES, etc..
47 """
49 pass
52class HttpRequest:
53 """A basic HTTP request."""
55 # The encoding used in GET/POST dicts. None means use default setting.
56 _encoding = None
57 _upload_handlers = []
59 non_picklable_attrs = frozenset(["resolver_match", "_stream"])
61 def __init__(self):
62 # WARNING: The `WSGIRequest` subclass doesn't call `super`.
63 # Any variable assignment made here should also happen in
64 # `WSGIRequest.__init__()`.
66 # A unique ID we can use to trace this request
67 self.unique_id = str(uuid.uuid4())
69 self.GET = QueryDict(mutable=True)
70 self.POST = QueryDict(mutable=True)
71 self.COOKIES = {}
72 self.META = {}
73 self.FILES = MultiValueDict()
75 self.path = ""
76 self.path_info = ""
77 self.method = None
78 self.resolver_match = None
79 self.content_type = None
80 self.content_params = None
82 def __repr__(self):
83 if self.method is None or not self.get_full_path():
84 return f"<{self.__class__.__name__}>"
85 return f"<{self.__class__.__name__}: {self.method} {self.get_full_path()!r}>"
87 def __getstate__(self):
88 obj_dict = self.__dict__.copy()
89 for attr in self.non_picklable_attrs:
90 if attr in obj_dict:
91 del obj_dict[attr]
92 return obj_dict
94 def __deepcopy__(self, memo):
95 obj = copy.copy(self)
96 for attr in self.non_picklable_attrs:
97 if hasattr(self, attr):
98 setattr(obj, attr, copy.deepcopy(getattr(self, attr), memo))
99 memo[id(self)] = obj
100 return obj
102 @cached_property
103 def headers(self):
104 return HttpHeaders(self.META)
106 @cached_property
107 def accepted_types(self):
108 """Return a list of MediaType instances."""
109 return parse_accept_header(self.headers.get("Accept", "*/*"))
111 def accepts(self, media_type):
112 return any(
113 accepted_type.match(media_type) for accepted_type in self.accepted_types
114 )
116 def _set_content_type_params(self, meta):
117 """Set content_type, content_params, and encoding."""
118 self.content_type, self.content_params = parse_header_parameters(
119 meta.get("CONTENT_TYPE", "")
120 )
121 if "charset" in self.content_params:
122 try:
123 codecs.lookup(self.content_params["charset"])
124 except LookupError:
125 pass
126 else:
127 self.encoding = self.content_params["charset"]
129 def _get_raw_host(self):
130 """
131 Return the HTTP host using the environment or request headers. Skip
132 allowed hosts protection, so may return an insecure host.
133 """
134 # We try three options, in order of decreasing preference.
135 if settings.USE_X_FORWARDED_HOST and ("HTTP_X_FORWARDED_HOST" in self.META):
136 host = self.META["HTTP_X_FORWARDED_HOST"]
137 elif "HTTP_HOST" in self.META:
138 host = self.META["HTTP_HOST"]
139 else:
140 # Reconstruct the host using the algorithm from PEP 333.
141 host = self.META["SERVER_NAME"]
142 server_port = self.get_port()
143 if server_port != ("443" if self.is_https() else "80"):
144 host = f"{host}:{server_port}"
145 return host
147 def get_host(self):
148 """Return the HTTP host using the environment or request headers."""
149 host = self._get_raw_host()
151 # Allow variants of localhost if ALLOWED_HOSTS is empty and DEBUG=True.
152 allowed_hosts = settings.ALLOWED_HOSTS
153 if settings.DEBUG and not allowed_hosts:
154 allowed_hosts = [".localhost", "127.0.0.1", "[::1]"]
156 domain, port = split_domain_port(host)
157 if domain and validate_host(domain, allowed_hosts):
158 return host
159 else:
160 msg = f"Invalid HTTP_HOST header: {host!r}."
161 if domain:
162 msg += f" You may need to add {domain!r} to ALLOWED_HOSTS."
163 else:
164 msg += (
165 " The domain name provided is not valid according to RFC 1034/1035."
166 )
167 raise DisallowedHost(msg)
169 def get_port(self):
170 """Return the port number for the request as a string."""
171 if settings.USE_X_FORWARDED_PORT and "HTTP_X_FORWARDED_PORT" in self.META:
172 port = self.META["HTTP_X_FORWARDED_PORT"]
173 else:
174 port = self.META["SERVER_PORT"]
175 return str(port)
177 def get_full_path(self, force_append_slash=False):
178 return self._get_full_path(self.path, force_append_slash)
180 def get_full_path_info(self, force_append_slash=False):
181 return self._get_full_path(self.path_info, force_append_slash)
183 def _get_full_path(self, path, force_append_slash):
184 # RFC 3986 requires query string arguments to be in the ASCII range.
185 # Rather than crash if this doesn't happen, we encode defensively.
186 return "{}{}{}".format(
187 escape_uri_path(path),
188 "/" if force_append_slash and not path.endswith("/") else "",
189 ("?" + iri_to_uri(self.META.get("QUERY_STRING", "")))
190 if self.META.get("QUERY_STRING", "")
191 else "",
192 )
194 def get_signed_cookie(self, key, default=RAISE_ERROR, salt="", max_age=None):
195 """
196 Attempt to return a signed cookie. If the signature fails or the
197 cookie has expired, raise an exception, unless the `default` argument
198 is provided, in which case return that value.
199 """
200 try:
201 cookie_value = self.COOKIES[key]
202 except KeyError:
203 if default is not RAISE_ERROR:
204 return default
205 else:
206 raise
207 try:
208 value = signing.get_cookie_signer(salt=key + salt).unsign(
209 cookie_value, max_age=max_age
210 )
211 except signing.BadSignature:
212 if default is not RAISE_ERROR:
213 return default
214 else:
215 raise
216 return value
218 def build_absolute_uri(self, location=None):
219 """
220 Build an absolute URI from the location and the variables available in
221 this request. If no ``location`` is specified, build the absolute URI
222 using request.get_full_path(). If the location is absolute, convert it
223 to an RFC 3987 compliant URI and return it. If location is relative or
224 is scheme-relative (i.e., ``//example.com/``), urljoin() it to a base
225 URL constructed from the request variables.
226 """
227 if location is None:
228 # Make it an absolute url (but schemeless and domainless) for the
229 # edge case that the path starts with '//'.
230 location = f"//{self.get_full_path()}"
231 else:
232 # Coerce lazy locations.
233 location = str(location)
234 bits = urlsplit(location)
235 if not (bits.scheme and bits.netloc):
236 # Handle the simple, most common case. If the location is absolute
237 # and a scheme or host (netloc) isn't provided, skip an expensive
238 # urljoin() as long as no path segments are '.' or '..'.
239 if (
240 bits.path.startswith("/")
241 and not bits.scheme
242 and not bits.netloc
243 and "/./" not in bits.path
244 and "/../" not in bits.path
245 ):
246 # If location starts with '//' but has no netloc, reuse the
247 # schema and netloc from the current request. Strip the double
248 # slashes and continue as if it wasn't specified.
249 location = self._current_scheme_host + location.removeprefix("//")
250 else:
251 # Join the constructed URL with the provided location, which
252 # allows the provided location to apply query strings to the
253 # base path.
254 location = urljoin(self._current_scheme_host + self.path, location)
255 return iri_to_uri(location)
257 @cached_property
258 def _current_scheme_host(self):
259 return f"{self.scheme}://{self.get_host()}"
261 def _get_scheme(self):
262 """
263 Hook for subclasses like WSGIRequest to implement. Return 'http' by
264 default.
265 """
266 return "http"
268 @property
269 def scheme(self):
270 if settings.HTTPS_PROXY_HEADER:
271 try:
272 header, secure_value = settings.HTTPS_PROXY_HEADER
273 except ValueError:
274 raise ImproperlyConfigured(
275 "The HTTPS_PROXY_HEADER setting must be a tuple containing "
276 "two values."
277 )
278 header_value = self.META.get(header)
279 if header_value is not None:
280 header_value, *_ = header_value.split(",", 1)
281 return "https" if header_value.strip() == secure_value else "http"
282 return self._get_scheme()
284 def is_https(self):
285 return self.scheme == "https"
287 @property
288 def encoding(self):
289 return self._encoding
291 @encoding.setter
292 def encoding(self, val):
293 """
294 Set the encoding used for GET/POST accesses. If the GET or POST
295 dictionary has already been created, remove and recreate it on the
296 next access (so that it is decoded correctly).
297 """
298 self._encoding = val
299 if hasattr(self, "GET"):
300 del self.GET
301 if hasattr(self, "_post"):
302 del self._post
304 def _initialize_handlers(self):
305 self._upload_handlers = [
306 uploadhandler.load_handler(handler, self)
307 for handler in settings.FILE_UPLOAD_HANDLERS
308 ]
310 @property
311 def upload_handlers(self):
312 if not self._upload_handlers:
313 # If there are no upload handlers defined, initialize them from settings.
314 self._initialize_handlers()
315 return self._upload_handlers
317 @upload_handlers.setter
318 def upload_handlers(self, upload_handlers):
319 if hasattr(self, "_files"):
320 raise AttributeError(
321 "You cannot set the upload handlers after the upload has been "
322 "processed."
323 )
324 self._upload_handlers = upload_handlers
326 def parse_file_upload(self, META, post_data):
327 """Return a tuple of (POST QueryDict, FILES MultiValueDict)."""
328 self.upload_handlers = ImmutableList(
329 self.upload_handlers,
330 warning=(
331 "You cannot alter upload handlers after the upload has been "
332 "processed."
333 ),
334 )
335 parser = MultiPartParser(META, post_data, self.upload_handlers, self.encoding)
336 return parser.parse()
338 @property
339 def body(self):
340 if not hasattr(self, "_body"):
341 if self._read_started:
342 raise RawPostDataException(
343 "You cannot access body after reading from request's data stream"
344 )
346 # Limit the maximum request data size that will be handled in-memory.
347 if (
348 settings.DATA_UPLOAD_MAX_MEMORY_SIZE is not None
349 and int(self.META.get("CONTENT_LENGTH") or 0)
350 > settings.DATA_UPLOAD_MAX_MEMORY_SIZE
351 ):
352 raise RequestDataTooBig(
353 "Request body exceeded settings.DATA_UPLOAD_MAX_MEMORY_SIZE."
354 )
356 try:
357 self._body = self.read()
358 except OSError as e:
359 raise UnreadablePostError(*e.args) from e
360 finally:
361 self._stream.close()
362 self._stream = BytesIO(self._body)
363 return self._body
365 def _mark_post_parse_error(self):
366 self._post = QueryDict()
367 self._files = MultiValueDict()
369 def _load_post_and_files(self):
370 """Populate self._post and self._files if the content-type is a form type"""
371 if self.method != "POST":
372 self._post, self._files = (
373 QueryDict(encoding=self._encoding),
374 MultiValueDict(),
375 )
376 return
377 if self._read_started and not hasattr(self, "_body"):
378 self._mark_post_parse_error()
379 return
381 if self.content_type == "multipart/form-data":
382 if hasattr(self, "_body"):
383 # Use already read data
384 data = BytesIO(self._body)
385 else:
386 data = self
387 try:
388 self._post, self._files = self.parse_file_upload(self.META, data)
389 except (MultiPartParserError, TooManyFilesSent):
390 # An error occurred while parsing POST data. Since when
391 # formatting the error the request handler might access
392 # self.POST, set self._post and self._file to prevent
393 # attempts to parse POST data again.
394 self._mark_post_parse_error()
395 raise
396 elif self.content_type == "application/x-www-form-urlencoded":
397 self._post, self._files = (
398 QueryDict(self.body, encoding=self._encoding),
399 MultiValueDict(),
400 )
401 else:
402 self._post, self._files = (
403 QueryDict(encoding=self._encoding),
404 MultiValueDict(),
405 )
407 def close(self):
408 if hasattr(self, "_files"):
409 for f in chain.from_iterable(list_[1] for list_ in self._files.lists()):
410 f.close()
412 # File-like and iterator interface.
413 #
414 # Expects self._stream to be set to an appropriate source of bytes by
415 # a corresponding request subclass (e.g. WSGIRequest).
416 # Also when request data has already been read by request.POST or
417 # request.body, self._stream points to a BytesIO instance
418 # containing that data.
420 def read(self, *args, **kwargs):
421 self._read_started = True
422 try:
423 return self._stream.read(*args, **kwargs)
424 except OSError as e:
425 raise UnreadablePostError(*e.args) from e
427 def readline(self, *args, **kwargs):
428 self._read_started = True
429 try:
430 return self._stream.readline(*args, **kwargs)
431 except OSError as e:
432 raise UnreadablePostError(*e.args) from e
434 def __iter__(self):
435 return iter(self.readline, b"")
437 def readlines(self):
438 return list(self)
441class HttpHeaders(CaseInsensitiveMapping):
442 HTTP_PREFIX = "HTTP_"
443 # PEP 333 gives two headers which aren't prepended with HTTP_.
444 UNPREFIXED_HEADERS = {"CONTENT_TYPE", "CONTENT_LENGTH"}
446 def __init__(self, environ):
447 headers = {}
448 for header, value in environ.items():
449 name = self.parse_header_name(header)
450 if name:
451 headers[name] = value
452 super().__init__(headers)
454 def __getitem__(self, key):
455 """Allow header lookup using underscores in place of hyphens."""
456 return super().__getitem__(key.replace("_", "-"))
458 @classmethod
459 def parse_header_name(cls, header):
460 if header.startswith(cls.HTTP_PREFIX):
461 header = header.removeprefix(cls.HTTP_PREFIX)
462 elif header not in cls.UNPREFIXED_HEADERS:
463 return None
464 return header.replace("_", "-").title()
466 @classmethod
467 def to_wsgi_name(cls, header):
468 header = header.replace("-", "_").upper()
469 if header in cls.UNPREFIXED_HEADERS:
470 return header
471 return f"{cls.HTTP_PREFIX}{header}"
473 @classmethod
474 def to_asgi_name(cls, header):
475 return header.replace("-", "_").upper()
477 @classmethod
478 def to_wsgi_names(cls, headers):
479 return {
480 cls.to_wsgi_name(header_name): value
481 for header_name, value in headers.items()
482 }
484 @classmethod
485 def to_asgi_names(cls, headers):
486 return {
487 cls.to_asgi_name(header_name): value
488 for header_name, value in headers.items()
489 }
492class QueryDict(MultiValueDict):
493 """
494 A specialized MultiValueDict which represents a query string.
496 A QueryDict can be used to represent GET or POST data. It subclasses
497 MultiValueDict since keys in such data can be repeated, for instance
498 in the data from a form with a <select multiple> field.
500 By default QueryDicts are immutable, though the copy() method
501 will always return a mutable copy.
503 Both keys and values set on this class are converted from the given encoding
504 (DEFAULT_CHARSET by default) to str.
505 """
507 # These are both reset in __init__, but is specified here at the class
508 # level so that unpickling will have valid values
509 _mutable = True
510 _encoding = None
512 def __init__(self, query_string=None, mutable=False, encoding=None):
513 super().__init__()
514 self.encoding = encoding or settings.DEFAULT_CHARSET
515 query_string = query_string or ""
516 parse_qsl_kwargs = {
517 "keep_blank_values": True,
518 "encoding": self.encoding,
519 "max_num_fields": settings.DATA_UPLOAD_MAX_NUMBER_FIELDS,
520 }
521 if isinstance(query_string, bytes):
522 # query_string normally contains URL-encoded data, a subset of ASCII.
523 try:
524 query_string = query_string.decode(self.encoding)
525 except UnicodeDecodeError:
526 # ... but some user agents are misbehaving :-(
527 query_string = query_string.decode("iso-8859-1")
528 try:
529 for key, value in parse_qsl(query_string, **parse_qsl_kwargs):
530 self.appendlist(key, value)
531 except ValueError as e:
532 # ValueError can also be raised if the strict_parsing argument to
533 # parse_qsl() is True. As that is not used by Plain, assume that
534 # the exception was raised by exceeding the value of max_num_fields
535 # instead of fragile checks of exception message strings.
536 raise TooManyFieldsSent(
537 "The number of GET/POST parameters exceeded "
538 "settings.DATA_UPLOAD_MAX_NUMBER_FIELDS."
539 ) from e
540 self._mutable = mutable
542 @classmethod
543 def fromkeys(cls, iterable, value="", mutable=False, encoding=None):
544 """
545 Return a new QueryDict with keys (may be repeated) from an iterable and
546 values from value.
547 """
548 q = cls("", mutable=True, encoding=encoding)
549 for key in iterable:
550 q.appendlist(key, value)
551 if not mutable:
552 q._mutable = False
553 return q
555 @property
556 def encoding(self):
557 if self._encoding is None:
558 self._encoding = settings.DEFAULT_CHARSET
559 return self._encoding
561 @encoding.setter
562 def encoding(self, value):
563 self._encoding = value
565 def _assert_mutable(self):
566 if not self._mutable:
567 raise AttributeError("This QueryDict instance is immutable")
569 def __setitem__(self, key, value):
570 self._assert_mutable()
571 key = bytes_to_text(key, self.encoding)
572 value = bytes_to_text(value, self.encoding)
573 super().__setitem__(key, value)
575 def __delitem__(self, key):
576 self._assert_mutable()
577 super().__delitem__(key)
579 def __copy__(self):
580 result = self.__class__("", mutable=True, encoding=self.encoding)
581 for key, value in self.lists():
582 result.setlist(key, value)
583 return result
585 def __deepcopy__(self, memo):
586 result = self.__class__("", mutable=True, encoding=self.encoding)
587 memo[id(self)] = result
588 for key, value in self.lists():
589 result.setlist(copy.deepcopy(key, memo), copy.deepcopy(value, memo))
590 return result
592 def setlist(self, key, list_):
593 self._assert_mutable()
594 key = bytes_to_text(key, self.encoding)
595 list_ = [bytes_to_text(elt, self.encoding) for elt in list_]
596 super().setlist(key, list_)
598 def setlistdefault(self, key, default_list=None):
599 self._assert_mutable()
600 return super().setlistdefault(key, default_list)
602 def appendlist(self, key, value):
603 self._assert_mutable()
604 key = bytes_to_text(key, self.encoding)
605 value = bytes_to_text(value, self.encoding)
606 super().appendlist(key, value)
608 def pop(self, key, *args):
609 self._assert_mutable()
610 return super().pop(key, *args)
612 def popitem(self):
613 self._assert_mutable()
614 return super().popitem()
616 def clear(self):
617 self._assert_mutable()
618 super().clear()
620 def setdefault(self, key, default=None):
621 self._assert_mutable()
622 key = bytes_to_text(key, self.encoding)
623 default = bytes_to_text(default, self.encoding)
624 return super().setdefault(key, default)
626 def copy(self):
627 """Return a mutable copy of this object."""
628 return self.__deepcopy__({})
630 def urlencode(self, safe=None):
631 """
632 Return an encoded string of all query string arguments.
634 `safe` specifies characters which don't require quoting, for example::
636 >>> q = QueryDict(mutable=True)
637 >>> q['next'] = '/a&b/'
638 >>> q.urlencode()
639 'next=%2Fa%26b%2F'
640 >>> q.urlencode(safe='/')
641 'next=/a%26b/'
642 """
643 output = []
644 if safe:
645 safe = safe.encode(self.encoding)
647 def encode(k, v):
648 return f"{quote(k, safe)}={quote(v, safe)}"
650 else:
652 def encode(k, v):
653 return urlencode({k: v})
655 for k, list_ in self.lists():
656 output.extend(
657 encode(k.encode(self.encoding), str(v).encode(self.encoding))
658 for v in list_
659 )
660 return "&".join(output)
663class MediaType:
664 def __init__(self, media_type_raw_line):
665 full_type, self.params = parse_header_parameters(
666 media_type_raw_line if media_type_raw_line else ""
667 )
668 self.main_type, _, self.sub_type = full_type.partition("/")
670 def __str__(self):
671 params_str = "".join(f"; {k}={v}" for k, v in self.params.items())
672 return "{}{}{}".format(
673 self.main_type,
674 (f"/{self.sub_type}") if self.sub_type else "",
675 params_str,
676 )
678 def __repr__(self):
679 return f"<{self.__class__.__qualname__}: {self}>"
681 @property
682 def is_all_types(self):
683 return self.main_type == "*" and self.sub_type == "*"
685 def match(self, other):
686 if self.is_all_types:
687 return True
688 other = MediaType(other)
689 if self.main_type == other.main_type and self.sub_type in {"*", other.sub_type}:
690 return True
691 return False
694# It's neither necessary nor appropriate to use
695# plain.utils.encoding.force_str() for parsing URLs and form inputs. Thus,
696# this slightly more restricted function, used by QueryDict.
697def bytes_to_text(s, encoding):
698 """
699 Convert bytes objects to strings, using the given encoding. Illegally
700 encoded input characters are replaced with Unicode "unknown" codepoint
701 (\ufffd).
703 Return any non-bytes objects without change.
704 """
705 if isinstance(s, bytes):
706 return str(s, encoding, "replace")
707 else:
708 return s
711def split_domain_port(host):
712 """
713 Return a (domain, port) tuple from a given host.
715 Returned domain is lowercased. If the host is invalid, the domain will be
716 empty.
717 """
718 host = host.lower()
720 if not host_validation_re.match(host):
721 return "", ""
723 if host[-1] == "]":
724 # It's an IPv6 address without a port.
725 return host, ""
726 bits = host.rsplit(":", 1)
727 domain, port = bits if len(bits) == 2 else (bits[0], "")
728 # Remove a trailing dot (if present) from the domain.
729 domain = domain.removesuffix(".")
730 return domain, port
733def validate_host(host, allowed_hosts):
734 """
735 Validate the given host for this site.
737 Check that the host looks valid and matches a host or host pattern in the
738 given list of ``allowed_hosts``. Any pattern beginning with a period
739 matches a domain and all its subdomains (e.g. ``.example.com`` matches
740 ``example.com`` and any subdomain), ``*`` matches anything, and anything
741 else must match exactly.
743 Note: This function assumes that the given host is lowercased and has
744 already had the port, if any, stripped off.
746 Return ``True`` for a valid host, ``False`` otherwise.
747 """
748 return any(
749 pattern == "*" or is_same_domain(host, pattern) for pattern in allowed_hosts
750 )
753def parse_accept_header(header):
754 return [MediaType(token) for token in header.split(",") if token.strip()]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
2import io
3import json
4import mimetypes
5import os
6import re
7import sys
8import time
9from email.header import Header
10from http.client import responses
11from http.cookies import SimpleCookie
12from urllib.parse import urlparse
14from plain import signals, signing
15from plain.exceptions import DisallowedRedirect
16from plain.json import PlainJSONEncoder
17from plain.runtime import settings
18from plain.utils import timezone
19from plain.utils.datastructures import CaseInsensitiveMapping
20from plain.utils.encoding import iri_to_uri
21from plain.utils.http import content_disposition_header, http_date
22from plain.utils.regex_helper import _lazy_re_compile
24_charset_from_content_type_re = _lazy_re_compile(
25 r";\s*charset=(?P<charset>[^\s;]+)", re.I
26)
29class ResponseHeaders(CaseInsensitiveMapping):
30 def __init__(self, data):
31 """
32 Populate the initial data using __setitem__ to ensure values are
33 correctly encoded.
34 """
35 self._store = {}
36 if data:
37 for header, value in self._unpack_items(data):
38 self[header] = value
40 def _convert_to_charset(self, value, charset, mime_encode=False):
41 """
42 Convert headers key/value to ascii/latin-1 native strings.
43 `charset` must be 'ascii' or 'latin-1'. If `mime_encode` is True and
44 `value` can't be represented in the given charset, apply MIME-encoding.
45 """
46 try:
47 if isinstance(value, str):
48 # Ensure string is valid in given charset
49 value.encode(charset)
50 elif isinstance(value, bytes):
51 # Convert bytestring using given charset
52 value = value.decode(charset)
53 else:
54 value = str(value)
55 # Ensure string is valid in given charset.
56 value.encode(charset)
57 if "\n" in value or "\r" in value:
58 raise BadHeaderError(
59 f"Header values can't contain newlines (got {value!r})"
60 )
61 except UnicodeError as e:
62 # Encoding to a string of the specified charset failed, but we
63 # don't know what type that value was, or if it contains newlines,
64 # which we may need to check for before sending it to be
65 # encoded for multiple character sets.
66 if (isinstance(value, bytes) and (b"\n" in value or b"\r" in value)) or (
67 isinstance(value, str) and ("\n" in value or "\r" in value)
68 ):
69 raise BadHeaderError(
70 f"Header values can't contain newlines (got {value!r})"
71 ) from e
72 if mime_encode:
73 value = Header(value, "utf-8", maxlinelen=sys.maxsize).encode()
74 else:
75 e.reason += f", HTTP response headers must be in {charset} format"
76 raise
77 return value
79 def __delitem__(self, key):
80 self.pop(key)
82 def __setitem__(self, key, value):
83 key = self._convert_to_charset(key, "ascii")
84 value = self._convert_to_charset(value, "latin-1", mime_encode=True)
85 self._store[key.lower()] = (key, value)
87 def pop(self, key, default=None):
88 return self._store.pop(key.lower(), default)
90 def setdefault(self, key, value):
91 if key not in self:
92 self[key] = value
95class BadHeaderError(ValueError):
96 pass
99class ResponseBase:
100 """
101 An HTTP response base class with dictionary-accessed headers.
103 This class doesn't handle content. It should not be used directly.
104 Use the Response and StreamingResponse subclasses instead.
105 """
107 status_code = 200
109 def __init__(
110 self, content_type=None, status=None, reason=None, charset=None, headers=None
111 ):
112 self.headers = ResponseHeaders(headers)
113 self._charset = charset
114 if "Content-Type" not in self.headers:
115 if content_type is None:
116 content_type = f"text/html; charset={self.charset}"
117 self.headers["Content-Type"] = content_type
118 elif content_type:
119 raise ValueError(
120 "'headers' must not contain 'Content-Type' when the "
121 "'content_type' parameter is provided."
122 )
123 self._resource_closers = []
124 # This parameter is set by the handler. It's necessary to preserve the
125 # historical behavior of request_finished.
126 self._handler_class = None
127 self.cookies = SimpleCookie()
128 self.closed = False
129 if status is not None:
130 try:
131 self.status_code = int(status)
132 except (ValueError, TypeError):
133 raise TypeError("HTTP status code must be an integer.")
135 if not 100 <= self.status_code <= 599:
136 raise ValueError("HTTP status code must be an integer from 100 to 599.")
137 self._reason_phrase = reason
139 @property
140 def reason_phrase(self):
141 if self._reason_phrase is not None:
142 return self._reason_phrase
143 # Leave self._reason_phrase unset in order to use the default
144 # reason phrase for status code.
145 return responses.get(self.status_code, "Unknown Status Code")
147 @reason_phrase.setter
148 def reason_phrase(self, value):
149 self._reason_phrase = value
151 @property
152 def charset(self):
153 if self._charset is not None:
154 return self._charset
155 # The Content-Type header may not yet be set, because the charset is
156 # being inserted *into* it.
157 if content_type := self.headers.get("Content-Type"):
158 if matched := _charset_from_content_type_re.search(content_type):
159 # Extract the charset and strip its double quotes.
160 # Note that having parsed it from the Content-Type, we don't
161 # store it back into the _charset for later intentionally, to
162 # allow for the Content-Type to be switched again later.
163 return matched["charset"].replace('"', "")
164 return settings.DEFAULT_CHARSET
166 @charset.setter
167 def charset(self, value):
168 self._charset = value
170 def serialize_headers(self):
171 """HTTP headers as a bytestring."""
172 return b"\r\n".join(
173 [
174 key.encode("ascii") + b": " + value.encode("latin-1")
175 for key, value in self.headers.items()
176 ]
177 )
179 __bytes__ = serialize_headers
181 @property
182 def _content_type_for_repr(self):
183 return (
184 ', "{}"'.format(self.headers["Content-Type"])
185 if "Content-Type" in self.headers
186 else ""
187 )
189 def __setitem__(self, header, value):
190 self.headers[header] = value
192 def __delitem__(self, header):
193 del self.headers[header]
195 def __getitem__(self, header):
196 return self.headers[header]
198 def has_header(self, header):
199 """Case-insensitive check for a header."""
200 return header in self.headers
202 __contains__ = has_header
204 def items(self):
205 return self.headers.items()
207 def get(self, header, alternate=None):
208 return self.headers.get(header, alternate)
210 def set_cookie(
211 self,
212 key,
213 value="",
214 max_age=None,
215 expires=None,
216 path="/",
217 domain=None,
218 secure=False,
219 httponly=False,
220 samesite=None,
221 ):
222 """
223 Set a cookie.
225 ``expires`` can be:
226 - a string in the correct format,
227 - a naive ``datetime.datetime`` object in UTC,
228 - an aware ``datetime.datetime`` object in any time zone.
229 If it is a ``datetime.datetime`` object then calculate ``max_age``.
231 ``max_age`` can be:
232 - int/float specifying seconds,
233 - ``datetime.timedelta`` object.
234 """
235 self.cookies[key] = value
236 if expires is not None:
237 if isinstance(expires, datetime.datetime):
238 if timezone.is_naive(expires):
239 expires = timezone.make_aware(expires, datetime.UTC)
240 delta = expires - datetime.datetime.now(tz=datetime.UTC)
241 # Add one second so the date matches exactly (a fraction of
242 # time gets lost between converting to a timedelta and
243 # then the date string).
244 delta += datetime.timedelta(seconds=1)
245 # Just set max_age - the max_age logic will set expires.
246 expires = None
247 if max_age is not None:
248 raise ValueError("'expires' and 'max_age' can't be used together.")
249 max_age = max(0, delta.days * 86400 + delta.seconds)
250 else:
251 self.cookies[key]["expires"] = expires
252 else:
253 self.cookies[key]["expires"] = ""
254 if max_age is not None:
255 if isinstance(max_age, datetime.timedelta):
256 max_age = max_age.total_seconds()
257 self.cookies[key]["max-age"] = int(max_age)
258 # IE requires expires, so set it if hasn't been already.
259 if not expires:
260 self.cookies[key]["expires"] = http_date(time.time() + max_age)
261 if path is not None:
262 self.cookies[key]["path"] = path
263 if domain is not None:
264 self.cookies[key]["domain"] = domain
265 if secure:
266 self.cookies[key]["secure"] = True
267 if httponly:
268 self.cookies[key]["httponly"] = True
269 if samesite:
270 if samesite.lower() not in ("lax", "none", "strict"):
271 raise ValueError('samesite must be "lax", "none", or "strict".')
272 self.cookies[key]["samesite"] = samesite
274 def setdefault(self, key, value):
275 """Set a header unless it has already been set."""
276 self.headers.setdefault(key, value)
278 def set_signed_cookie(self, key, value, salt="", **kwargs):
279 value = signing.get_cookie_signer(salt=key + salt).sign(value)
280 return self.set_cookie(key, value, **kwargs)
282 def delete_cookie(self, key, path="/", domain=None, samesite=None):
283 # Browsers can ignore the Set-Cookie header if the cookie doesn't use
284 # the secure flag and:
285 # - the cookie name starts with "__Host-" or "__Secure-", or
286 # - the samesite is "none".
287 secure = key.startswith(("__Secure-", "__Host-")) or (
288 samesite and samesite.lower() == "none"
289 )
290 self.set_cookie(
291 key,
292 max_age=0,
293 path=path,
294 domain=domain,
295 secure=secure,
296 expires="Thu, 01 Jan 1970 00:00:00 GMT",
297 samesite=samesite,
298 )
300 # Common methods used by subclasses
302 def make_bytes(self, value):
303 """Turn a value into a bytestring encoded in the output charset."""
304 # Per PEP 3333, this response body must be bytes. To avoid returning
305 # an instance of a subclass, this function returns `bytes(value)`.
306 # This doesn't make a copy when `value` already contains bytes.
308 # Handle string types -- we can't rely on force_bytes here because:
309 # - Python attempts str conversion first
310 # - when self._charset != 'utf-8' it re-encodes the content
311 if isinstance(value, bytes | memoryview):
312 return bytes(value)
313 if isinstance(value, str):
314 return bytes(value.encode(self.charset))
315 # Handle non-string types.
316 return str(value).encode(self.charset)
318 # These methods partially implement the file-like object interface.
319 # See https://docs.python.org/library/io.html#io.IOBase
321 # The WSGI server must call this method upon completion of the request.
322 # See http://blog.dscpl.com.au/2012/10/obligations-for-calling-close-on.html
323 def close(self):
324 for closer in self._resource_closers:
325 try:
326 closer()
327 except Exception:
328 pass
329 # Free resources that were still referenced.
330 self._resource_closers.clear()
331 self.closed = True
332 signals.request_finished.send(sender=self._handler_class)
334 def write(self, content):
335 raise OSError(f"This {self.__class__.__name__} instance is not writable")
337 def flush(self):
338 pass
340 def tell(self):
341 raise OSError(
342 f"This {self.__class__.__name__} instance cannot tell its position"
343 )
345 # These methods partially implement a stream-like object interface.
346 # See https://docs.python.org/library/io.html#io.IOBase
348 def readable(self):
349 return False
351 def seekable(self):
352 return False
354 def writable(self):
355 return False
357 def writelines(self, lines):
358 raise OSError(f"This {self.__class__.__name__} instance is not writable")
361class Response(ResponseBase):
362 """
363 An HTTP response class with a string as content.
365 This content can be read, appended to, or replaced.
366 """
368 streaming = False
369 non_picklable_attrs = frozenset(
370 [
371 "resolver_match",
372 # Non-picklable attributes added by test clients.
373 "client",
374 "context",
375 "json",
376 "templates",
377 ]
378 )
380 def __init__(self, content=b"", *args, **kwargs):
381 super().__init__(*args, **kwargs)
382 # Content is a bytestring. See the `content` property methods.
383 self.content = content
385 def __getstate__(self):
386 obj_dict = self.__dict__.copy()
387 for attr in self.non_picklable_attrs:
388 if attr in obj_dict:
389 del obj_dict[attr]
390 return obj_dict
392 def __repr__(self):
393 return "<%(cls)s status_code=%(status_code)d%(content_type)s>" % {
394 "cls": self.__class__.__name__,
395 "status_code": self.status_code,
396 "content_type": self._content_type_for_repr,
397 }
399 def serialize(self):
400 """Full HTTP message, including headers, as a bytestring."""
401 return self.serialize_headers() + b"\r\n\r\n" + self.content
403 __bytes__ = serialize
405 @property
406 def content(self):
407 return b"".join(self._container)
409 @content.setter
410 def content(self, value):
411 # Consume iterators upon assignment to allow repeated iteration.
412 if hasattr(value, "__iter__") and not isinstance(
413 value, bytes | memoryview | str
414 ):
415 content = b"".join(self.make_bytes(chunk) for chunk in value)
416 if hasattr(value, "close"):
417 try:
418 value.close()
419 except Exception:
420 pass
421 else:
422 content = self.make_bytes(value)
423 # Create a list of properly encoded bytestrings to support write().
424 self._container = [content]
426 def __iter__(self):
427 return iter(self._container)
429 def write(self, content):
430 self._container.append(self.make_bytes(content))
432 def tell(self):
433 return len(self.content)
435 def getvalue(self):
436 return self.content
438 def writable(self):
439 return True
441 def writelines(self, lines):
442 for line in lines:
443 self.write(line)
446class StreamingResponse(ResponseBase):
447 """
448 A streaming HTTP response class with an iterator as content.
450 This should only be iterated once, when the response is streamed to the
451 client. However, it can be appended to or replaced with a new iterator
452 that wraps the original content (or yields entirely new content).
453 """
455 streaming = True
457 def __init__(self, streaming_content=(), *args, **kwargs):
458 super().__init__(*args, **kwargs)
459 # `streaming_content` should be an iterable of bytestrings.
460 # See the `streaming_content` property methods.
461 self.streaming_content = streaming_content
463 def __repr__(self):
464 return "<%(cls)s status_code=%(status_code)d%(content_type)s>" % {
465 "cls": self.__class__.__qualname__,
466 "status_code": self.status_code,
467 "content_type": self._content_type_for_repr,
468 }
470 @property
471 def content(self):
472 raise AttributeError(
473 f"This {self.__class__.__name__} instance has no `content` attribute. Use "
474 "`streaming_content` instead."
475 )
477 @property
478 def streaming_content(self):
479 return map(self.make_bytes, self._iterator)
481 @streaming_content.setter
482 def streaming_content(self, value):
483 self._set_streaming_content(value)
485 def _set_streaming_content(self, value):
486 # Ensure we can never iterate on "value" more than once.
487 self._iterator = iter(value)
488 if hasattr(value, "close"):
489 self._resource_closers.append(value.close)
491 def __iter__(self):
492 return iter(self.streaming_content)
494 def getvalue(self):
495 return b"".join(self.streaming_content)
498class FileResponse(StreamingResponse):
499 """
500 A streaming HTTP response class optimized for files.
501 """
503 block_size = 4096
505 def __init__(self, *args, as_attachment=False, filename="", **kwargs):
506 self.as_attachment = as_attachment
507 self.filename = filename
508 self._no_explicit_content_type = (
509 "content_type" not in kwargs or kwargs["content_type"] is None
510 )
511 super().__init__(*args, **kwargs)
513 def _set_streaming_content(self, value):
514 if not hasattr(value, "read"):
515 self.file_to_stream = None
516 return super()._set_streaming_content(value)
518 self.file_to_stream = filelike = value
519 if hasattr(filelike, "close"):
520 self._resource_closers.append(filelike.close)
521 value = iter(lambda: filelike.read(self.block_size), b"")
522 self.set_headers(filelike)
523 super()._set_streaming_content(value)
525 def set_headers(self, filelike):
526 """
527 Set some common response headers (Content-Length, Content-Type, and
528 Content-Disposition) based on the `filelike` response content.
529 """
530 filename = getattr(filelike, "name", "")
531 filename = filename if isinstance(filename, str) else ""
532 seekable = hasattr(filelike, "seek") and (
533 not hasattr(filelike, "seekable") or filelike.seekable()
534 )
535 if hasattr(filelike, "tell"):
536 if seekable:
537 initial_position = filelike.tell()
538 filelike.seek(0, io.SEEK_END)
539 self.headers["Content-Length"] = filelike.tell() - initial_position
540 filelike.seek(initial_position)
541 elif hasattr(filelike, "getbuffer"):
542 self.headers["Content-Length"] = (
543 filelike.getbuffer().nbytes - filelike.tell()
544 )
545 elif os.path.exists(filename):
546 self.headers["Content-Length"] = (
547 os.path.getsize(filename) - filelike.tell()
548 )
549 elif seekable:
550 self.headers["Content-Length"] = sum(
551 iter(lambda: len(filelike.read(self.block_size)), 0)
552 )
553 filelike.seek(-int(self.headers["Content-Length"]), io.SEEK_END)
555 filename = os.path.basename(self.filename or filename)
556 if self._no_explicit_content_type:
557 if filename:
558 content_type, encoding = mimetypes.guess_type(filename)
559 # Encoding isn't set to prevent browsers from automatically
560 # uncompressing files.
561 content_type = {
562 "br": "application/x-brotli",
563 "bzip2": "application/x-bzip",
564 "compress": "application/x-compress",
565 "gzip": "application/gzip",
566 "xz": "application/x-xz",
567 }.get(encoding, content_type)
568 self.headers["Content-Type"] = (
569 content_type or "application/octet-stream"
570 )
571 else:
572 self.headers["Content-Type"] = "application/octet-stream"
574 if content_disposition := content_disposition_header(
575 self.as_attachment, filename
576 ):
577 self.headers["Content-Disposition"] = content_disposition
580class ResponseRedirectBase(Response):
581 allowed_schemes = ["http", "https", "ftp"]
583 def __init__(self, redirect_to, *args, **kwargs):
584 super().__init__(*args, **kwargs)
585 self["Location"] = iri_to_uri(redirect_to)
586 parsed = urlparse(str(redirect_to))
587 if parsed.scheme and parsed.scheme not in self.allowed_schemes:
588 raise DisallowedRedirect(
589 f"Unsafe redirect to URL with protocol '{parsed.scheme}'"
590 )
592 url = property(lambda self: self["Location"])
594 def __repr__(self):
595 return (
596 '<%(cls)s status_code=%(status_code)d%(content_type)s, url="%(url)s">'
597 % {
598 "cls": self.__class__.__name__,
599 "status_code": self.status_code,
600 "content_type": self._content_type_for_repr,
601 "url": self.url,
602 }
603 )
606class ResponseRedirect(ResponseRedirectBase):
607 """HTTP 302 response"""
609 status_code = 302
612class ResponsePermanentRedirect(ResponseRedirectBase):
613 """HTTP 301 response"""
615 status_code = 301
618class ResponseNotModified(Response):
619 """HTTP 304 response"""
621 status_code = 304
623 def __init__(self, *args, **kwargs):
624 super().__init__(*args, **kwargs)
625 del self["content-type"]
627 @Response.content.setter
628 def content(self, value):
629 if value:
630 raise AttributeError(
631 "You cannot set content to a 304 (Not Modified) response"
632 )
633 self._container = []
636class ResponseBadRequest(Response):
637 """HTTP 400 response"""
639 status_code = 400
642class ResponseNotFound(Response):
643 """HTTP 404 response"""
645 status_code = 404
648class ResponseForbidden(Response):
649 """HTTP 403 response"""
651 status_code = 403
654class ResponseNotAllowed(Response):
655 """HTTP 405 response"""
657 status_code = 405
659 def __init__(self, permitted_methods, *args, **kwargs):
660 super().__init__(*args, **kwargs)
661 self["Allow"] = ", ".join(permitted_methods)
663 def __repr__(self):
664 return "<%(cls)s [%(methods)s] status_code=%(status_code)d%(content_type)s>" % {
665 "cls": self.__class__.__name__,
666 "status_code": self.status_code,
667 "content_type": self._content_type_for_repr,
668 "methods": self["Allow"],
669 }
672class ResponseGone(Response):
673 """HTTP 410 response"""
675 status_code = 410
678class ResponseServerError(Response):
679 """HTTP 500 response"""
681 status_code = 500
684class Http404(Exception):
685 pass
688class JsonResponse(Response):
689 """
690 An HTTP response class that consumes data to be serialized to JSON.
692 :param data: Data to be dumped into json. By default only ``dict`` objects
693 are allowed to be passed due to a security flaw before ECMAScript 5. See
694 the ``safe`` parameter for more information.
695 :param encoder: Should be a json encoder class. Defaults to
696 ``plain.json.PlainJSONEncoder``.
697 :param safe: Controls if only ``dict`` objects may be serialized. Defaults
698 to ``True``.
699 :param json_dumps_params: A dictionary of kwargs passed to json.dumps().
700 """
702 def __init__(
703 self,
704 data,
705 encoder=PlainJSONEncoder,
706 safe=True,
707 json_dumps_params=None,
708 **kwargs,
709 ):
710 if safe and not isinstance(data, dict):
711 raise TypeError(
712 "In order to allow non-dict objects to be serialized set the "
713 "safe parameter to False."
714 )
715 if json_dumps_params is None:
716 json_dumps_params = {}
717 kwargs.setdefault("content_type", "application/json")
718 data = json.dumps(data, cls=encoder, **json_dumps_params)
719 super().__init__(content=data, **kwargs)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import collections.abc
2import copy
3import datetime
4import decimal
5import operator
6import uuid
7import warnings
8from base64 import b64decode, b64encode
9from functools import partialmethod, total_ordering
11from plain import exceptions, preflight, validators
12from plain.models.constants import LOOKUP_SEP
13from plain.models.db import connection, connections, router
14from plain.models.enums import ChoicesMeta
15from plain.models.query_utils import DeferredAttribute, RegisterLookupMixin
16from plain.packages import packages
17from plain.runtime import settings
18from plain.utils import timezone
19from plain.utils.datastructures import DictWrapper
20from plain.utils.dateparse import (
21 parse_date,
22 parse_datetime,
23 parse_duration,
24 parse_time,
25)
26from plain.utils.duration import duration_microseconds, duration_string
27from plain.utils.functional import Promise, cached_property
28from plain.utils.ipv6 import clean_ipv6_address
29from plain.utils.itercompat import is_iterable
31__all__ = [
32 "AutoField",
33 "BLANK_CHOICE_DASH",
34 "BigAutoField",
35 "BigIntegerField",
36 "BinaryField",
37 "BooleanField",
38 "CharField",
39 "CommaSeparatedIntegerField",
40 "DateField",
41 "DateTimeField",
42 "DecimalField",
43 "DurationField",
44 "EmailField",
45 "Empty",
46 "Field",
47 "FloatField",
48 "GenericIPAddressField",
49 "IPAddressField",
50 "IntegerField",
51 "NOT_PROVIDED",
52 "NullBooleanField",
53 "PositiveBigIntegerField",
54 "PositiveIntegerField",
55 "PositiveSmallIntegerField",
56 "SlugField",
57 "SmallAutoField",
58 "SmallIntegerField",
59 "TextField",
60 "TimeField",
61 "URLField",
62 "UUIDField",
63]
66class Empty:
67 pass
70class NOT_PROVIDED:
71 pass
74# The values to use for "blank" in SelectFields. Will be appended to the start
75# of most "choices" lists.
76BLANK_CHOICE_DASH = [("", "---------")]
79def _load_field(package_label, model_name, field_name):
80 return packages.get_model(package_label, model_name)._meta.get_field(field_name)
83# A guide to Field parameters:
84#
85# * name: The name of the field specified in the model.
86# * attname: The attribute to use on the model object. This is the same as
87# "name", except in the case of ForeignKeys, where "_id" is
88# appended.
89# * db_column: The db_column specified in the model (or None).
90# * column: The database column for this field. This is the same as
91# "attname", except if db_column is specified.
92#
93# Code that introspects values, or does other dynamic things, should use
94# attname. For example, this gets the primary key value of object "obj":
95#
96# getattr(obj, opts.pk.attname)
99def _empty(of_cls):
100 new = Empty()
101 new.__class__ = of_cls
102 return new
105def return_None():
106 return None
109@total_ordering
110class Field(RegisterLookupMixin):
111 """Base class for all field types"""
113 # Designates whether empty strings fundamentally are allowed at the
114 # database level.
115 empty_strings_allowed = True
116 empty_values = list(validators.EMPTY_VALUES)
118 # These track each time a Field instance is created. Used to retain order.
119 # The auto_creation_counter is used for fields that Plain implicitly
120 # creates, creation_counter is used for all user-specified fields.
121 creation_counter = 0
122 auto_creation_counter = -1
123 default_validators = [] # Default set of validators
124 default_error_messages = {
125 "invalid_choice": "Value %(value)r is not a valid choice.",
126 "null": "This field cannot be null.",
127 "blank": "This field cannot be blank.",
128 "unique": "A %(model_name)s with this %(field_label)s already exists.",
129 }
130 system_check_deprecated_details = None
131 system_check_removed_details = None
133 # Attributes that don't affect a column definition.
134 # These attributes are ignored when altering the field.
135 non_db_attrs = (
136 "blank",
137 "choices",
138 "db_column",
139 "editable",
140 "error_messages",
141 "limit_choices_to",
142 # Database-level options are not supported, see #21961.
143 "on_delete",
144 "related_name",
145 "related_query_name",
146 "validators",
147 )
149 # Field flags
150 hidden = False
152 many_to_many = None
153 many_to_one = None
154 one_to_many = None
155 one_to_one = None
156 related_model = None
158 descriptor_class = DeferredAttribute
160 # Generic field type description, usually overridden by subclasses
161 def _description(self):
162 return f"Field of type: {self.__class__.__name__}"
164 description = property(_description)
166 def __init__(
167 self,
168 name=None,
169 primary_key=False,
170 max_length=None,
171 unique=False,
172 blank=False,
173 null=False,
174 db_index=False,
175 rel=None,
176 default=NOT_PROVIDED,
177 editable=True,
178 choices=None,
179 db_column=None,
180 db_tablespace=None,
181 auto_created=False,
182 validators=(),
183 error_messages=None,
184 db_comment=None,
185 ):
186 self.name = name
187 self.primary_key = primary_key
188 self.max_length, self._unique = max_length, unique
189 self.blank, self.null = blank, null
190 self.remote_field = rel
191 self.is_relation = self.remote_field is not None
192 self.default = default
193 self.editable = editable
194 if isinstance(choices, ChoicesMeta):
195 choices = choices.choices
196 if isinstance(choices, collections.abc.Iterator):
197 choices = list(choices)
198 self.choices = choices
199 self.db_index = db_index
200 self.db_column = db_column
201 self.db_comment = db_comment
202 self._db_tablespace = db_tablespace
203 self.auto_created = auto_created
205 # Adjust the appropriate creation counter, and save our local copy.
206 if auto_created:
207 self.creation_counter = Field.auto_creation_counter
208 Field.auto_creation_counter -= 1
209 else:
210 self.creation_counter = Field.creation_counter
211 Field.creation_counter += 1
213 self._validators = list(validators) # Store for deconstruction later
215 self._error_messages = error_messages # Store for deconstruction later
217 def __str__(self):
218 """
219 Return "package_label.model_label.field_name" for fields attached to
220 models.
221 """
222 if not hasattr(self, "model"):
223 return super().__str__()
224 model = self.model
225 return f"{model._meta.label}.{self.name}"
227 def __repr__(self):
228 """Display the module, class, and name of the field."""
229 path = f"{self.__class__.__module__}.{self.__class__.__qualname__}"
230 name = getattr(self, "name", None)
231 if name is not None:
232 return f"<{path}: {name}>"
233 return f"<{path}>"
235 def check(self, **kwargs):
236 return [
237 *self._check_field_name(),
238 *self._check_choices(),
239 *self._check_db_index(),
240 *self._check_db_comment(**kwargs),
241 *self._check_null_allowed_for_primary_keys(),
242 *self._check_backend_specific_checks(**kwargs),
243 *self._check_validators(),
244 *self._check_deprecation_details(),
245 ]
247 def _check_field_name(self):
248 """
249 Check if field name is valid, i.e. 1) does not end with an
250 underscore, 2) does not contain "__" and 3) is not "pk".
251 """
252 if self.name.endswith("_"):
253 return [
254 preflight.Error(
255 "Field names must not end with an underscore.",
256 obj=self,
257 id="fields.E001",
258 )
259 ]
260 elif LOOKUP_SEP in self.name:
261 return [
262 preflight.Error(
263 f'Field names must not contain "{LOOKUP_SEP}".',
264 obj=self,
265 id="fields.E002",
266 )
267 ]
268 elif self.name == "pk":
269 return [
270 preflight.Error(
271 "'pk' is a reserved word that cannot be used as a field name.",
272 obj=self,
273 id="fields.E003",
274 )
275 ]
276 else:
277 return []
279 @classmethod
280 def _choices_is_value(cls, value):
281 return isinstance(value, str | Promise) or not is_iterable(value)
283 def _check_choices(self):
284 if not self.choices:
285 return []
287 if not is_iterable(self.choices) or isinstance(self.choices, str):
288 return [
289 preflight.Error(
290 "'choices' must be an iterable (e.g., a list or tuple).",
291 obj=self,
292 id="fields.E004",
293 )
294 ]
296 choice_max_length = 0
297 # Expect [group_name, [value, display]]
298 for choices_group in self.choices:
299 try:
300 group_name, group_choices = choices_group
301 except (TypeError, ValueError):
302 # Containing non-pairs
303 break
304 try:
305 if not all(
306 self._choices_is_value(value) and self._choices_is_value(human_name)
307 for value, human_name in group_choices
308 ):
309 break
310 if self.max_length is not None and group_choices:
311 choice_max_length = max(
312 [
313 choice_max_length,
314 *(
315 len(value)
316 for value, _ in group_choices
317 if isinstance(value, str)
318 ),
319 ]
320 )
321 except (TypeError, ValueError):
322 # No groups, choices in the form [value, display]
323 value, human_name = group_name, group_choices
324 if not self._choices_is_value(value) or not self._choices_is_value(
325 human_name
326 ):
327 break
328 if self.max_length is not None and isinstance(value, str):
329 choice_max_length = max(choice_max_length, len(value))
331 # Special case: choices=['ab']
332 if isinstance(choices_group, str):
333 break
334 else:
335 if self.max_length is not None and choice_max_length > self.max_length:
336 return [
337 preflight.Error(
338 "'max_length' is too small to fit the longest value "
339 "in 'choices' (%d characters)." % choice_max_length,
340 obj=self,
341 id="fields.E009",
342 ),
343 ]
344 return []
346 return [
347 preflight.Error(
348 "'choices' must be an iterable containing "
349 "(actual value, human readable name) tuples.",
350 obj=self,
351 id="fields.E005",
352 )
353 ]
355 def _check_db_index(self):
356 if self.db_index not in (None, True, False):
357 return [
358 preflight.Error(
359 "'db_index' must be None, True or False.",
360 obj=self,
361 id="fields.E006",
362 )
363 ]
364 else:
365 return []
367 def _check_db_comment(self, databases=None, **kwargs):
368 if not self.db_comment or not databases:
369 return []
370 errors = []
371 for db in databases:
372 if not router.allow_migrate_model(db, self.model):
373 continue
374 connection = connections[db]
375 if not (
376 connection.features.supports_comments
377 or "supports_comments" in self.model._meta.required_db_features
378 ):
379 errors.append(
380 preflight.Warning(
381 f"{connection.display_name} does not support comments on "
382 f"columns (db_comment).",
383 obj=self,
384 id="fields.W163",
385 )
386 )
387 return errors
389 def _check_null_allowed_for_primary_keys(self):
390 if (
391 self.primary_key
392 and self.null
393 and not connection.features.interprets_empty_strings_as_nulls
394 ):
395 # We cannot reliably check this for backends like Oracle which
396 # consider NULL and '' to be equal (and thus set up
397 # character-based fields a little differently).
398 return [
399 preflight.Error(
400 "Primary keys must not have null=True.",
401 hint=(
402 "Set null=False on the field, or "
403 "remove primary_key=True argument."
404 ),
405 obj=self,
406 id="fields.E007",
407 )
408 ]
409 else:
410 return []
412 def _check_backend_specific_checks(self, databases=None, **kwargs):
413 if databases is None:
414 return []
415 errors = []
416 for alias in databases:
417 if router.allow_migrate_model(alias, self.model):
418 errors.extend(connections[alias].validation.check_field(self, **kwargs))
419 return errors
421 def _check_validators(self):
422 errors = []
423 for i, validator in enumerate(self.validators):
424 if not callable(validator):
425 errors.append(
426 preflight.Error(
427 "All 'validators' must be callable.",
428 hint=(
429 f"validators[{i}] ({repr(validator)}) isn't a function or "
430 "instance of a validator class."
431 ),
432 obj=self,
433 id="fields.E008",
434 )
435 )
436 return errors
438 def _check_deprecation_details(self):
439 if self.system_check_removed_details is not None:
440 return [
441 preflight.Error(
442 self.system_check_removed_details.get(
443 "msg",
444 f"{self.__class__.__name__} has been removed except for support in historical "
445 "migrations.",
446 ),
447 hint=self.system_check_removed_details.get("hint"),
448 obj=self,
449 id=self.system_check_removed_details.get("id", "fields.EXXX"),
450 )
451 ]
452 elif self.system_check_deprecated_details is not None:
453 return [
454 preflight.Warning(
455 self.system_check_deprecated_details.get(
456 "msg", f"{self.__class__.__name__} has been deprecated."
457 ),
458 hint=self.system_check_deprecated_details.get("hint"),
459 obj=self,
460 id=self.system_check_deprecated_details.get("id", "fields.WXXX"),
461 )
462 ]
463 return []
465 def get_col(self, alias, output_field=None):
466 if alias == self.model._meta.db_table and (
467 output_field is None or output_field == self
468 ):
469 return self.cached_col
470 from plain.models.expressions import Col
472 return Col(alias, self, output_field)
474 @cached_property
475 def cached_col(self):
476 from plain.models.expressions import Col
478 return Col(self.model._meta.db_table, self)
480 def select_format(self, compiler, sql, params):
481 """
482 Custom format for select clauses. For example, GIS columns need to be
483 selected as AsText(table.col) on MySQL as the table.col data can't be
484 used by Plain.
485 """
486 return sql, params
488 def deconstruct(self):
489 """
490 Return enough information to recreate the field as a 4-tuple:
492 * The name of the field on the model, if contribute_to_class() has
493 been run.
494 * The import path of the field, including the class, e.g.
495 plain.models.IntegerField. This should be the most portable
496 version, so less specific may be better.
497 * A list of positional arguments.
498 * A dict of keyword arguments.
500 Note that the positional or keyword arguments must contain values of
501 the following types (including inner values of collection types):
503 * None, bool, str, int, float, complex, set, frozenset, list, tuple,
504 dict
505 * UUID
506 * datetime.datetime (naive), datetime.date
507 * top-level classes, top-level functions - will be referenced by their
508 full import path
509 * Storage instances - these have their own deconstruct() method
511 This is because the values here must be serialized into a text format
512 (possibly new Python code, possibly JSON) and these are the only types
513 with encoding handlers defined.
515 There's no need to return the exact way the field was instantiated this
516 time, just ensure that the resulting field is the same - prefer keyword
517 arguments over positional ones, and omit parameters with their default
518 values.
519 """
520 # Short-form way of fetching all the default parameters
521 keywords = {}
522 possibles = {
523 "primary_key": False,
524 "max_length": None,
525 "unique": False,
526 "blank": False,
527 "null": False,
528 "db_index": False,
529 "default": NOT_PROVIDED,
530 "editable": True,
531 "choices": None,
532 "db_column": None,
533 "db_comment": None,
534 "db_tablespace": None,
535 "auto_created": False,
536 "validators": [],
537 "error_messages": None,
538 }
539 attr_overrides = {
540 "unique": "_unique",
541 "error_messages": "_error_messages",
542 "validators": "_validators",
543 "db_tablespace": "_db_tablespace",
544 }
545 equals_comparison = {"choices", "validators"}
546 for name, default in possibles.items():
547 value = getattr(self, attr_overrides.get(name, name))
548 # Unroll anything iterable for choices into a concrete list
549 if name == "choices" and isinstance(value, collections.abc.Iterable):
550 value = list(value)
551 # Do correct kind of comparison
552 if name in equals_comparison:
553 if value != default:
554 keywords[name] = value
555 else:
556 if value is not default:
557 keywords[name] = value
558 # Work out path - we shorten it for known Plain core fields
559 path = f"{self.__class__.__module__}.{self.__class__.__qualname__}"
560 if path.startswith("plain.models.fields.related"):
561 path = path.replace("plain.models.fields.related", "plain.models")
562 elif path.startswith("plain.models.fields.json"):
563 path = path.replace("plain.models.fields.json", "plain.models")
564 elif path.startswith("plain.models.fields.proxy"):
565 path = path.replace("plain.models.fields.proxy", "plain.models")
566 elif path.startswith("plain.models.fields"):
567 path = path.replace("plain.models.fields", "plain.models")
568 # Return basic info - other fields should override this.
569 return (self.name, path, [], keywords)
571 def clone(self):
572 """
573 Uses deconstruct() to clone a new copy of this Field.
574 Will not preserve any class attachments/attribute names.
575 """
576 name, path, args, kwargs = self.deconstruct()
577 return self.__class__(*args, **kwargs)
579 def __eq__(self, other):
580 # Needed for @total_ordering
581 if isinstance(other, Field):
582 return self.creation_counter == other.creation_counter and getattr(
583 self, "model", None
584 ) == getattr(other, "model", None)
585 return NotImplemented
587 def __lt__(self, other):
588 # This is needed because bisect does not take a comparison function.
589 # Order by creation_counter first for backward compatibility.
590 if isinstance(other, Field):
591 if (
592 self.creation_counter != other.creation_counter
593 or not hasattr(self, "model")
594 and not hasattr(other, "model")
595 ):
596 return self.creation_counter < other.creation_counter
597 elif hasattr(self, "model") != hasattr(other, "model"):
598 return not hasattr(self, "model") # Order no-model fields first
599 else:
600 # creation_counter's are equal, compare only models.
601 return (self.model._meta.package_label, self.model._meta.model_name) < (
602 other.model._meta.package_label,
603 other.model._meta.model_name,
604 )
605 return NotImplemented
607 def __hash__(self):
608 return hash(self.creation_counter)
610 def __deepcopy__(self, memodict):
611 # We don't have to deepcopy very much here, since most things are not
612 # intended to be altered after initial creation.
613 obj = copy.copy(self)
614 if self.remote_field:
615 obj.remote_field = copy.copy(self.remote_field)
616 if hasattr(self.remote_field, "field") and self.remote_field.field is self:
617 obj.remote_field.field = obj
618 memodict[id(self)] = obj
619 return obj
621 def __copy__(self):
622 # We need to avoid hitting __reduce__, so define this
623 # slightly weird copy construct.
624 obj = Empty()
625 obj.__class__ = self.__class__
626 obj.__dict__ = self.__dict__.copy()
627 return obj
629 def __reduce__(self):
630 """
631 Pickling should return the model._meta.fields instance of the field,
632 not a new copy of that field. So, use the app registry to load the
633 model and then the field back.
634 """
635 if not hasattr(self, "model"):
636 # Fields are sometimes used without attaching them to models (for
637 # example in aggregation). In this case give back a plain field
638 # instance. The code below will create a new empty instance of
639 # class self.__class__, then update its dict with self.__dict__
640 # values - so, this is very close to normal pickle.
641 state = self.__dict__.copy()
642 # The _get_default cached_property can't be pickled due to lambda
643 # usage.
644 state.pop("_get_default", None)
645 return _empty, (self.__class__,), state
646 return _load_field, (
647 self.model._meta.package_label,
648 self.model._meta.object_name,
649 self.name,
650 )
652 def get_pk_value_on_save(self, instance):
653 """
654 Hook to generate new PK values on save. This method is called when
655 saving instances with no primary key value set. If this method returns
656 something else than None, then the returned value is used when saving
657 the new instance.
658 """
659 if self.default:
660 return self.get_default()
661 return None
663 def to_python(self, value):
664 """
665 Convert the input value into the expected Python data type, raising
666 plain.exceptions.ValidationError if the data can't be converted.
667 Return the converted value. Subclasses should override this.
668 """
669 return value
671 @cached_property
672 def error_messages(self):
673 messages = {}
674 for c in reversed(self.__class__.__mro__):
675 messages.update(getattr(c, "default_error_messages", {}))
676 messages.update(self._error_messages or {})
677 return messages
679 @cached_property
680 def validators(self):
681 """
682 Some validators can't be created at field initialization time.
683 This method provides a way to delay their creation until required.
684 """
685 return [*self.default_validators, *self._validators]
687 def run_validators(self, value):
688 if value in self.empty_values:
689 return
691 errors = []
692 for v in self.validators:
693 try:
694 v(value)
695 except exceptions.ValidationError as e:
696 if hasattr(e, "code") and e.code in self.error_messages:
697 e.message = self.error_messages[e.code]
698 errors.extend(e.error_list)
700 if errors:
701 raise exceptions.ValidationError(errors)
703 def validate(self, value, model_instance):
704 """
705 Validate value and raise ValidationError if necessary. Subclasses
706 should override this to provide validation logic.
707 """
708 if not self.editable:
709 # Skip validation for non-editable fields.
710 return
712 if self.choices is not None and value not in self.empty_values:
713 for option_key, option_value in self.choices:
714 if isinstance(option_value, list | tuple):
715 # This is an optgroup, so look inside the group for
716 # options.
717 for optgroup_key, optgroup_value in option_value:
718 if value == optgroup_key:
719 return
720 elif value == option_key:
721 return
722 raise exceptions.ValidationError(
723 self.error_messages["invalid_choice"],
724 code="invalid_choice",
725 params={"value": value},
726 )
728 if value is None and not self.null:
729 raise exceptions.ValidationError(self.error_messages["null"], code="null")
731 if not self.blank and value in self.empty_values:
732 raise exceptions.ValidationError(self.error_messages["blank"], code="blank")
734 def clean(self, value, model_instance):
735 """
736 Convert the value's type and run validation. Validation errors
737 from to_python() and validate() are propagated. Return the correct
738 value if no error is raised.
739 """
740 value = self.to_python(value)
741 self.validate(value, model_instance)
742 self.run_validators(value)
743 return value
745 def db_type_parameters(self, connection):
746 return DictWrapper(self.__dict__, connection.ops.quote_name, "qn_")
748 def db_check(self, connection):
749 """
750 Return the database column check constraint for this field, for the
751 provided connection. Works the same way as db_type() for the case that
752 get_internal_type() does not map to a preexisting model field.
753 """
754 data = self.db_type_parameters(connection)
755 try:
756 return (
757 connection.data_type_check_constraints[self.get_internal_type()] % data
758 )
759 except KeyError:
760 return None
762 def db_type(self, connection):
763 """
764 Return the database column data type for this field, for the provided
765 connection.
766 """
767 # The default implementation of this method looks at the
768 # backend-specific data_types dictionary, looking up the field by its
769 # "internal type".
770 #
771 # A Field class can implement the get_internal_type() method to specify
772 # which *preexisting* Plain Field class it's most similar to -- i.e.,
773 # a custom field might be represented by a TEXT column type, which is
774 # the same as the TextField Plain field type, which means the custom
775 # field's get_internal_type() returns 'TextField'.
776 #
777 # But the limitation of the get_internal_type() / data_types approach
778 # is that it cannot handle database column types that aren't already
779 # mapped to one of the built-in Plain field types. In this case, you
780 # can implement db_type() instead of get_internal_type() to specify
781 # exactly which wacky database column type you want to use.
782 data = self.db_type_parameters(connection)
783 try:
784 column_type = connection.data_types[self.get_internal_type()]
785 except KeyError:
786 return None
787 else:
788 # column_type is either a single-parameter function or a string.
789 if callable(column_type):
790 return column_type(data)
791 return column_type % data
793 def rel_db_type(self, connection):
794 """
795 Return the data type that a related field pointing to this field should
796 use. For example, this method is called by ForeignKey and OneToOneField
797 to determine its data type.
798 """
799 return self.db_type(connection)
801 def cast_db_type(self, connection):
802 """Return the data type to use in the Cast() function."""
803 db_type = connection.ops.cast_data_types.get(self.get_internal_type())
804 if db_type:
805 return db_type % self.db_type_parameters(connection)
806 return self.db_type(connection)
808 def db_parameters(self, connection):
809 """
810 Extension of db_type(), providing a range of different return values
811 (type, checks). This will look at db_type(), allowing custom model
812 fields to override it.
813 """
814 type_string = self.db_type(connection)
815 check_string = self.db_check(connection)
816 return {
817 "type": type_string,
818 "check": check_string,
819 }
821 def db_type_suffix(self, connection):
822 return connection.data_types_suffix.get(self.get_internal_type())
824 def get_db_converters(self, connection):
825 if hasattr(self, "from_db_value"):
826 return [self.from_db_value]
827 return []
829 @property
830 def unique(self):
831 return self._unique or self.primary_key
833 @property
834 def db_tablespace(self):
835 return self._db_tablespace or settings.DEFAULT_INDEX_TABLESPACE
837 @property
838 def db_returning(self):
839 """
840 Private API intended only to be used by Plain itself. Currently only
841 the PostgreSQL backend supports returning multiple fields on a model.
842 """
843 return False
845 def set_attributes_from_name(self, name):
846 self.name = self.name or name
847 self.attname, self.column = self.get_attname_column()
848 self.concrete = self.column is not None
850 def contribute_to_class(self, cls, name, private_only=False):
851 """
852 Register the field with the model class it belongs to.
854 If private_only is True, create a separate instance of this field
855 for every subclass of cls, even if cls is not an abstract model.
856 """
857 self.set_attributes_from_name(name)
858 self.model = cls
859 cls._meta.add_field(self, private=private_only)
860 if self.column:
861 setattr(cls, self.attname, self.descriptor_class(self))
862 if self.choices is not None:
863 # Don't override a get_FOO_display() method defined explicitly on
864 # this class, but don't check methods derived from inheritance, to
865 # allow overriding inherited choices. For more complex inheritance
866 # structures users should override contribute_to_class().
867 if f"get_{self.name}_display" not in cls.__dict__:
868 setattr(
869 cls,
870 f"get_{self.name}_display",
871 partialmethod(cls._get_FIELD_display, field=self),
872 )
874 def get_filter_kwargs_for_object(self, obj):
875 """
876 Return a dict that when passed as kwargs to self.model.filter(), would
877 yield all instances having the same value for this field as obj has.
878 """
879 return {self.name: getattr(obj, self.attname)}
881 def get_attname(self):
882 return self.name
884 def get_attname_column(self):
885 attname = self.get_attname()
886 column = self.db_column or attname
887 return attname, column
889 def get_internal_type(self):
890 return self.__class__.__name__
892 def pre_save(self, model_instance, add):
893 """Return field's value just before saving."""
894 return getattr(model_instance, self.attname)
896 def get_prep_value(self, value):
897 """Perform preliminary non-db specific value checks and conversions."""
898 if isinstance(value, Promise):
899 value = value._proxy____cast()
900 return value
902 def get_db_prep_value(self, value, connection, prepared=False):
903 """
904 Return field's value prepared for interacting with the database backend.
906 Used by the default implementations of get_db_prep_save().
907 """
908 if not prepared:
909 value = self.get_prep_value(value)
910 return value
912 def get_db_prep_save(self, value, connection):
913 """Return field's value prepared for saving into a database."""
914 if hasattr(value, "as_sql"):
915 return value
916 return self.get_db_prep_value(value, connection=connection, prepared=False)
918 def has_default(self):
919 """Return a boolean of whether this field has a default value."""
920 return self.default is not NOT_PROVIDED
922 def get_default(self):
923 """Return the default value for this field."""
924 return self._get_default()
926 @cached_property
927 def _get_default(self):
928 if self.has_default():
929 if callable(self.default):
930 return self.default
931 return lambda: self.default
933 if (
934 not self.empty_strings_allowed
935 or self.null
936 and not connection.features.interprets_empty_strings_as_nulls
937 ):
938 return return_None
939 return str # return empty string
941 def get_choices(
942 self,
943 include_blank=True,
944 blank_choice=BLANK_CHOICE_DASH,
945 limit_choices_to=None,
946 ordering=(),
947 ):
948 """
949 Return choices with a default blank choices included, for use
950 as <select> choices for this field.
951 """
952 if self.choices is not None:
953 choices = list(self.choices)
954 if include_blank:
955 blank_defined = any(
956 choice in ("", None) for choice, _ in self.flatchoices
957 )
958 if not blank_defined:
959 choices = blank_choice + choices
960 return choices
961 rel_model = self.remote_field.model
962 limit_choices_to = limit_choices_to or self.get_limit_choices_to()
963 choice_func = operator.attrgetter(
964 self.remote_field.get_related_field().attname
965 if hasattr(self.remote_field, "get_related_field")
966 else "pk"
967 )
968 qs = rel_model._default_manager.complex_filter(limit_choices_to)
969 if ordering:
970 qs = qs.order_by(*ordering)
971 return (blank_choice if include_blank else []) + [
972 (choice_func(x), str(x)) for x in qs
973 ]
975 def value_to_string(self, obj):
976 """
977 Return a string value of this field from the passed obj.
978 This is used by the serialization framework.
979 """
980 return str(self.value_from_object(obj))
982 def _get_flatchoices(self):
983 """Flattened version of choices tuple."""
984 if self.choices is None:
985 return []
986 flat = []
987 for choice, value in self.choices:
988 if isinstance(value, list | tuple):
989 flat.extend(value)
990 else:
991 flat.append((choice, value))
992 return flat
994 flatchoices = property(_get_flatchoices)
996 def save_form_data(self, instance, data):
997 setattr(instance, self.name, data)
999 def value_from_object(self, obj):
1000 """Return the value of this field in the given model instance."""
1001 return getattr(obj, self.attname)
1004class BooleanField(Field):
1005 empty_strings_allowed = False
1006 default_error_messages = {
1007 "invalid": "“%(value)s” value must be either True or False.",
1008 "invalid_nullable": "“%(value)s” value must be either True, False, or None.",
1009 }
1010 description = "Boolean (Either True or False)"
1012 def get_internal_type(self):
1013 return "BooleanField"
1015 def to_python(self, value):
1016 if self.null and value in self.empty_values:
1017 return None
1018 if value in (True, False):
1019 # 1/0 are equal to True/False. bool() converts former to latter.
1020 return bool(value)
1021 if value in ("t", "True", "1"):
1022 return True
1023 if value in ("f", "False", "0"):
1024 return False
1025 raise exceptions.ValidationError(
1026 self.error_messages["invalid_nullable" if self.null else "invalid"],
1027 code="invalid",
1028 params={"value": value},
1029 )
1031 def get_prep_value(self, value):
1032 value = super().get_prep_value(value)
1033 if value is None:
1034 return None
1035 return self.to_python(value)
1038class CharField(Field):
1039 def __init__(self, *args, db_collation=None, **kwargs):
1040 super().__init__(*args, **kwargs)
1041 self.db_collation = db_collation
1042 if self.max_length is not None:
1043 self.validators.append(validators.MaxLengthValidator(self.max_length))
1045 @property
1046 def description(self):
1047 if self.max_length is not None:
1048 return "String (up to %(max_length)s)"
1049 else:
1050 return "String (unlimited)"
1052 def check(self, **kwargs):
1053 databases = kwargs.get("databases") or []
1054 return [
1055 *super().check(**kwargs),
1056 *self._check_db_collation(databases),
1057 *self._check_max_length_attribute(**kwargs),
1058 ]
1060 def _check_max_length_attribute(self, **kwargs):
1061 if self.max_length is None:
1062 if (
1063 connection.features.supports_unlimited_charfield
1064 or "supports_unlimited_charfield"
1065 in self.model._meta.required_db_features
1066 ):
1067 return []
1068 return [
1069 preflight.Error(
1070 "CharFields must define a 'max_length' attribute.",
1071 obj=self,
1072 id="fields.E120",
1073 )
1074 ]
1075 elif (
1076 not isinstance(self.max_length, int)
1077 or isinstance(self.max_length, bool)
1078 or self.max_length <= 0
1079 ):
1080 return [
1081 preflight.Error(
1082 "'max_length' must be a positive integer.",
1083 obj=self,
1084 id="fields.E121",
1085 )
1086 ]
1087 else:
1088 return []
1090 def _check_db_collation(self, databases):
1091 errors = []
1092 for db in databases:
1093 if not router.allow_migrate_model(db, self.model):
1094 continue
1095 connection = connections[db]
1096 if not (
1097 self.db_collation is None
1098 or "supports_collation_on_charfield"
1099 in self.model._meta.required_db_features
1100 or connection.features.supports_collation_on_charfield
1101 ):
1102 errors.append(
1103 preflight.Error(
1104 f"{connection.display_name} does not support a database collation on "
1105 "CharFields.",
1106 obj=self,
1107 id="fields.E190",
1108 ),
1109 )
1110 return errors
1112 def cast_db_type(self, connection):
1113 if self.max_length is None:
1114 return connection.ops.cast_char_field_without_max_length
1115 return super().cast_db_type(connection)
1117 def db_parameters(self, connection):
1118 db_params = super().db_parameters(connection)
1119 db_params["collation"] = self.db_collation
1120 return db_params
1122 def get_internal_type(self):
1123 return "CharField"
1125 def to_python(self, value):
1126 if isinstance(value, str) or value is None:
1127 return value
1128 return str(value)
1130 def get_prep_value(self, value):
1131 value = super().get_prep_value(value)
1132 return self.to_python(value)
1134 def deconstruct(self):
1135 name, path, args, kwargs = super().deconstruct()
1136 if self.db_collation:
1137 kwargs["db_collation"] = self.db_collation
1138 return name, path, args, kwargs
1141class CommaSeparatedIntegerField(CharField):
1142 default_validators = [validators.validate_comma_separated_integer_list]
1143 description = "Comma-separated integers"
1144 system_check_removed_details = {
1145 "msg": (
1146 "CommaSeparatedIntegerField is removed except for support in "
1147 "historical migrations."
1148 ),
1149 "hint": (
1150 "Use CharField(validators=[validate_comma_separated_integer_list]) "
1151 "instead."
1152 ),
1153 "id": "fields.E901",
1154 }
1157def _to_naive(value):
1158 if timezone.is_aware(value):
1159 value = timezone.make_naive(value, datetime.UTC)
1160 return value
1163def _get_naive_now():
1164 return _to_naive(timezone.now())
1167class DateTimeCheckMixin:
1168 def check(self, **kwargs):
1169 return [
1170 *super().check(**kwargs),
1171 *self._check_mutually_exclusive_options(),
1172 *self._check_fix_default_value(),
1173 ]
1175 def _check_mutually_exclusive_options(self):
1176 # auto_now, auto_now_add, and default are mutually exclusive
1177 # options. The use of more than one of these options together
1178 # will trigger an Error
1179 mutually_exclusive_options = [
1180 self.auto_now_add,
1181 self.auto_now,
1182 self.has_default(),
1183 ]
1184 enabled_options = [
1185 option not in (None, False) for option in mutually_exclusive_options
1186 ].count(True)
1187 if enabled_options > 1:
1188 return [
1189 preflight.Error(
1190 "The options auto_now, auto_now_add, and default "
1191 "are mutually exclusive. Only one of these options "
1192 "may be present.",
1193 obj=self,
1194 id="fields.E160",
1195 )
1196 ]
1197 else:
1198 return []
1200 def _check_fix_default_value(self):
1201 return []
1203 # Concrete subclasses use this in their implementations of
1204 # _check_fix_default_value().
1205 def _check_if_value_fixed(self, value, now=None):
1206 """
1207 Check if the given value appears to have been provided as a "fixed"
1208 time value, and include a warning in the returned list if it does. The
1209 value argument must be a date object or aware/naive datetime object. If
1210 now is provided, it must be a naive datetime object.
1211 """
1212 if now is None:
1213 now = _get_naive_now()
1214 offset = datetime.timedelta(seconds=10)
1215 lower = now - offset
1216 upper = now + offset
1217 if isinstance(value, datetime.datetime):
1218 value = _to_naive(value)
1219 else:
1220 assert isinstance(value, datetime.date)
1221 lower = lower.date()
1222 upper = upper.date()
1223 if lower <= value <= upper:
1224 return [
1225 preflight.Warning(
1226 "Fixed default value provided.",
1227 hint=(
1228 "It seems you set a fixed date / time / datetime "
1229 "value as default for this field. This may not be "
1230 "what you want. If you want to have the current date "
1231 "as default, use `plain.utils.timezone.now`"
1232 ),
1233 obj=self,
1234 id="fields.W161",
1235 )
1236 ]
1237 return []
1240class DateField(DateTimeCheckMixin, Field):
1241 empty_strings_allowed = False
1242 default_error_messages = {
1243 "invalid": "“%(value)s” value has an invalid date format. It must be in YYYY-MM-DD format.",
1244 "invalid_date": "“%(value)s” value has the correct format (YYYY-MM-DD) but it is an invalid date.",
1245 }
1246 description = "Date (without time)"
1248 def __init__(self, name=None, auto_now=False, auto_now_add=False, **kwargs):
1249 self.auto_now, self.auto_now_add = auto_now, auto_now_add
1250 if auto_now or auto_now_add:
1251 kwargs["editable"] = False
1252 kwargs["blank"] = True
1253 super().__init__(name, **kwargs)
1255 def _check_fix_default_value(self):
1256 """
1257 Warn that using an actual date or datetime value is probably wrong;
1258 it's only evaluated on server startup.
1259 """
1260 if not self.has_default():
1261 return []
1263 value = self.default
1264 if isinstance(value, datetime.datetime):
1265 value = _to_naive(value).date()
1266 elif isinstance(value, datetime.date):
1267 pass
1268 else:
1269 # No explicit date / datetime value -- no checks necessary
1270 return []
1271 # At this point, value is a date object.
1272 return self._check_if_value_fixed(value)
1274 def deconstruct(self):
1275 name, path, args, kwargs = super().deconstruct()
1276 if self.auto_now:
1277 kwargs["auto_now"] = True
1278 if self.auto_now_add:
1279 kwargs["auto_now_add"] = True
1280 if self.auto_now or self.auto_now_add:
1281 del kwargs["editable"]
1282 del kwargs["blank"]
1283 return name, path, args, kwargs
1285 def get_internal_type(self):
1286 return "DateField"
1288 def to_python(self, value):
1289 if value is None:
1290 return value
1291 if isinstance(value, datetime.datetime):
1292 if timezone.is_aware(value):
1293 # Convert aware datetimes to the default time zone
1294 # before casting them to dates (#17742).
1295 default_timezone = timezone.get_default_timezone()
1296 value = timezone.make_naive(value, default_timezone)
1297 return value.date()
1298 if isinstance(value, datetime.date):
1299 return value
1301 try:
1302 parsed = parse_date(value)
1303 if parsed is not None:
1304 return parsed
1305 except ValueError:
1306 raise exceptions.ValidationError(
1307 self.error_messages["invalid_date"],
1308 code="invalid_date",
1309 params={"value": value},
1310 )
1312 raise exceptions.ValidationError(
1313 self.error_messages["invalid"],
1314 code="invalid",
1315 params={"value": value},
1316 )
1318 def pre_save(self, model_instance, add):
1319 if self.auto_now or (self.auto_now_add and add):
1320 value = datetime.date.today()
1321 setattr(model_instance, self.attname, value)
1322 return value
1323 else:
1324 return super().pre_save(model_instance, add)
1326 def contribute_to_class(self, cls, name, **kwargs):
1327 super().contribute_to_class(cls, name, **kwargs)
1328 if not self.null:
1329 setattr(
1330 cls,
1331 f"get_next_by_{self.name}",
1332 partialmethod(
1333 cls._get_next_or_previous_by_FIELD, field=self, is_next=True
1334 ),
1335 )
1336 setattr(
1337 cls,
1338 f"get_previous_by_{self.name}",
1339 partialmethod(
1340 cls._get_next_or_previous_by_FIELD, field=self, is_next=False
1341 ),
1342 )
1344 def get_prep_value(self, value):
1345 value = super().get_prep_value(value)
1346 return self.to_python(value)
1348 def get_db_prep_value(self, value, connection, prepared=False):
1349 # Casts dates into the format expected by the backend
1350 if not prepared:
1351 value = self.get_prep_value(value)
1352 return connection.ops.adapt_datefield_value(value)
1354 def value_to_string(self, obj):
1355 val = self.value_from_object(obj)
1356 return "" if val is None else val.isoformat()
1359class DateTimeField(DateField):
1360 empty_strings_allowed = False
1361 default_error_messages = {
1362 "invalid": "“%(value)s” value has an invalid format. It must be in YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ] format.",
1363 "invalid_date": "“%(value)s” value has the correct format (YYYY-MM-DD) but it is an invalid date.",
1364 "invalid_datetime": "“%(value)s” value has the correct format (YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ]) but it is an invalid date/time.",
1365 }
1366 description = "Date (with time)"
1368 # __init__ is inherited from DateField
1370 def _check_fix_default_value(self):
1371 """
1372 Warn that using an actual date or datetime value is probably wrong;
1373 it's only evaluated on server startup.
1374 """
1375 if not self.has_default():
1376 return []
1378 value = self.default
1379 if isinstance(value, datetime.datetime | datetime.date):
1380 return self._check_if_value_fixed(value)
1381 # No explicit date / datetime value -- no checks necessary.
1382 return []
1384 def get_internal_type(self):
1385 return "DateTimeField"
1387 def to_python(self, value):
1388 if value is None:
1389 return value
1390 if isinstance(value, datetime.datetime):
1391 return value
1392 if isinstance(value, datetime.date):
1393 value = datetime.datetime(value.year, value.month, value.day)
1395 # For backwards compatibility, interpret naive datetimes in
1396 # local time. This won't work during DST change, but we can't
1397 # do much about it, so we let the exceptions percolate up the
1398 # call stack.
1399 warnings.warn(
1400 f"DateTimeField {self.model.__name__}.{self.name} received a naive datetime "
1401 f"({value}) while time zone support is active.",
1402 RuntimeWarning,
1403 )
1404 default_timezone = timezone.get_default_timezone()
1405 value = timezone.make_aware(value, default_timezone)
1407 return value
1409 try:
1410 parsed = parse_datetime(value)
1411 if parsed is not None:
1412 return parsed
1413 except ValueError:
1414 raise exceptions.ValidationError(
1415 self.error_messages["invalid_datetime"],
1416 code="invalid_datetime",
1417 params={"value": value},
1418 )
1420 try:
1421 parsed = parse_date(value)
1422 if parsed is not None:
1423 return datetime.datetime(parsed.year, parsed.month, parsed.day)
1424 except ValueError:
1425 raise exceptions.ValidationError(
1426 self.error_messages["invalid_date"],
1427 code="invalid_date",
1428 params={"value": value},
1429 )
1431 raise exceptions.ValidationError(
1432 self.error_messages["invalid"],
1433 code="invalid",
1434 params={"value": value},
1435 )
1437 def pre_save(self, model_instance, add):
1438 if self.auto_now or (self.auto_now_add and add):
1439 value = timezone.now()
1440 setattr(model_instance, self.attname, value)
1441 return value
1442 else:
1443 return super().pre_save(model_instance, add)
1445 # contribute_to_class is inherited from DateField, it registers
1446 # get_next_by_FOO and get_prev_by_FOO
1448 def get_prep_value(self, value):
1449 value = super().get_prep_value(value)
1450 value = self.to_python(value)
1451 if value is not None and timezone.is_naive(value):
1452 # For backwards compatibility, interpret naive datetimes in local
1453 # time. This won't work during DST change, but we can't do much
1454 # about it, so we let the exceptions percolate up the call stack.
1455 try:
1456 name = f"{self.model.__name__}.{self.name}"
1457 except AttributeError:
1458 name = "(unbound)"
1459 warnings.warn(
1460 f"DateTimeField {name} received a naive datetime ({value})"
1461 " while time zone support is active.",
1462 RuntimeWarning,
1463 )
1464 default_timezone = timezone.get_default_timezone()
1465 value = timezone.make_aware(value, default_timezone)
1466 return value
1468 def get_db_prep_value(self, value, connection, prepared=False):
1469 # Casts datetimes into the format expected by the backend
1470 if not prepared:
1471 value = self.get_prep_value(value)
1472 return connection.ops.adapt_datetimefield_value(value)
1474 def value_to_string(self, obj):
1475 val = self.value_from_object(obj)
1476 return "" if val is None else val.isoformat()
1479class DecimalField(Field):
1480 empty_strings_allowed = False
1481 default_error_messages = {
1482 "invalid": "“%(value)s” value must be a decimal number.",
1483 }
1484 description = "Decimal number"
1486 def __init__(
1487 self,
1488 name=None,
1489 max_digits=None,
1490 decimal_places=None,
1491 **kwargs,
1492 ):
1493 self.max_digits, self.decimal_places = max_digits, decimal_places
1494 super().__init__(name, **kwargs)
1496 def check(self, **kwargs):
1497 errors = super().check(**kwargs)
1499 digits_errors = [
1500 *self._check_decimal_places(),
1501 *self._check_max_digits(),
1502 ]
1503 if not digits_errors:
1504 errors.extend(self._check_decimal_places_and_max_digits(**kwargs))
1505 else:
1506 errors.extend(digits_errors)
1507 return errors
1509 def _check_decimal_places(self):
1510 try:
1511 decimal_places = int(self.decimal_places)
1512 if decimal_places < 0:
1513 raise ValueError()
1514 except TypeError:
1515 return [
1516 preflight.Error(
1517 "DecimalFields must define a 'decimal_places' attribute.",
1518 obj=self,
1519 id="fields.E130",
1520 )
1521 ]
1522 except ValueError:
1523 return [
1524 preflight.Error(
1525 "'decimal_places' must be a non-negative integer.",
1526 obj=self,
1527 id="fields.E131",
1528 )
1529 ]
1530 else:
1531 return []
1533 def _check_max_digits(self):
1534 try:
1535 max_digits = int(self.max_digits)
1536 if max_digits <= 0:
1537 raise ValueError()
1538 except TypeError:
1539 return [
1540 preflight.Error(
1541 "DecimalFields must define a 'max_digits' attribute.",
1542 obj=self,
1543 id="fields.E132",
1544 )
1545 ]
1546 except ValueError:
1547 return [
1548 preflight.Error(
1549 "'max_digits' must be a positive integer.",
1550 obj=self,
1551 id="fields.E133",
1552 )
1553 ]
1554 else:
1555 return []
1557 def _check_decimal_places_and_max_digits(self, **kwargs):
1558 if int(self.decimal_places) > int(self.max_digits):
1559 return [
1560 preflight.Error(
1561 "'max_digits' must be greater or equal to 'decimal_places'.",
1562 obj=self,
1563 id="fields.E134",
1564 )
1565 ]
1566 return []
1568 @cached_property
1569 def validators(self):
1570 return super().validators + [
1571 validators.DecimalValidator(self.max_digits, self.decimal_places)
1572 ]
1574 @cached_property
1575 def context(self):
1576 return decimal.Context(prec=self.max_digits)
1578 def deconstruct(self):
1579 name, path, args, kwargs = super().deconstruct()
1580 if self.max_digits is not None:
1581 kwargs["max_digits"] = self.max_digits
1582 if self.decimal_places is not None:
1583 kwargs["decimal_places"] = self.decimal_places
1584 return name, path, args, kwargs
1586 def get_internal_type(self):
1587 return "DecimalField"
1589 def to_python(self, value):
1590 if value is None:
1591 return value
1592 try:
1593 if isinstance(value, float):
1594 decimal_value = self.context.create_decimal_from_float(value)
1595 else:
1596 decimal_value = decimal.Decimal(value)
1597 except (decimal.InvalidOperation, TypeError, ValueError):
1598 raise exceptions.ValidationError(
1599 self.error_messages["invalid"],
1600 code="invalid",
1601 params={"value": value},
1602 )
1603 if not decimal_value.is_finite():
1604 raise exceptions.ValidationError(
1605 self.error_messages["invalid"],
1606 code="invalid",
1607 params={"value": value},
1608 )
1609 return decimal_value
1611 def get_db_prep_value(self, value, connection, prepared=False):
1612 if not prepared:
1613 value = self.get_prep_value(value)
1614 if hasattr(value, "as_sql"):
1615 return value
1616 return connection.ops.adapt_decimalfield_value(
1617 value, self.max_digits, self.decimal_places
1618 )
1620 def get_prep_value(self, value):
1621 value = super().get_prep_value(value)
1622 return self.to_python(value)
1625class DurationField(Field):
1626 """
1627 Store timedelta objects.
1629 Use interval on PostgreSQL, INTERVAL DAY TO SECOND on Oracle, and bigint
1630 of microseconds on other databases.
1631 """
1633 empty_strings_allowed = False
1634 default_error_messages = {
1635 "invalid": "“%(value)s” value has an invalid format. It must be in [DD] [[HH:]MM:]ss[.uuuuuu] format.",
1636 }
1637 description = "Duration"
1639 def get_internal_type(self):
1640 return "DurationField"
1642 def to_python(self, value):
1643 if value is None:
1644 return value
1645 if isinstance(value, datetime.timedelta):
1646 return value
1647 try:
1648 parsed = parse_duration(value)
1649 except ValueError:
1650 pass
1651 else:
1652 if parsed is not None:
1653 return parsed
1655 raise exceptions.ValidationError(
1656 self.error_messages["invalid"],
1657 code="invalid",
1658 params={"value": value},
1659 )
1661 def get_db_prep_value(self, value, connection, prepared=False):
1662 if connection.features.has_native_duration_field:
1663 return value
1664 if value is None:
1665 return None
1666 return duration_microseconds(value)
1668 def get_db_converters(self, connection):
1669 converters = []
1670 if not connection.features.has_native_duration_field:
1671 converters.append(connection.ops.convert_durationfield_value)
1672 return converters + super().get_db_converters(connection)
1674 def value_to_string(self, obj):
1675 val = self.value_from_object(obj)
1676 return "" if val is None else duration_string(val)
1679class EmailField(CharField):
1680 default_validators = [validators.validate_email]
1681 description = "Email address"
1683 def __init__(self, *args, **kwargs):
1684 # max_length=254 to be compliant with RFCs 3696 and 5321
1685 kwargs.setdefault("max_length", 254)
1686 super().__init__(*args, **kwargs)
1688 def deconstruct(self):
1689 name, path, args, kwargs = super().deconstruct()
1690 # We do not exclude max_length if it matches default as we want to change
1691 # the default in future.
1692 return name, path, args, kwargs
1695class FloatField(Field):
1696 empty_strings_allowed = False
1697 default_error_messages = {
1698 "invalid": "“%(value)s” value must be a float.",
1699 }
1700 description = "Floating point number"
1702 def get_prep_value(self, value):
1703 value = super().get_prep_value(value)
1704 if value is None:
1705 return None
1706 try:
1707 return float(value)
1708 except (TypeError, ValueError) as e:
1709 raise e.__class__(
1710 f"Field '{self.name}' expected a number but got {value!r}.",
1711 ) from e
1713 def get_internal_type(self):
1714 return "FloatField"
1716 def to_python(self, value):
1717 if value is None:
1718 return value
1719 try:
1720 return float(value)
1721 except (TypeError, ValueError):
1722 raise exceptions.ValidationError(
1723 self.error_messages["invalid"],
1724 code="invalid",
1725 params={"value": value},
1726 )
1729class IntegerField(Field):
1730 empty_strings_allowed = False
1731 default_error_messages = {
1732 "invalid": "“%(value)s” value must be an integer.",
1733 }
1734 description = "Integer"
1736 def check(self, **kwargs):
1737 return [
1738 *super().check(**kwargs),
1739 *self._check_max_length_warning(),
1740 ]
1742 def _check_max_length_warning(self):
1743 if self.max_length is not None:
1744 return [
1745 preflight.Warning(
1746 f"'max_length' is ignored when used with {self.__class__.__name__}.",
1747 hint="Remove 'max_length' from field",
1748 obj=self,
1749 id="fields.W122",
1750 )
1751 ]
1752 return []
1754 @cached_property
1755 def validators(self):
1756 # These validators can't be added at field initialization time since
1757 # they're based on values retrieved from `connection`.
1758 validators_ = super().validators
1759 internal_type = self.get_internal_type()
1760 min_value, max_value = connection.ops.integer_field_range(internal_type)
1761 if min_value is not None and not any(
1762 (
1763 isinstance(validator, validators.MinValueValidator)
1764 and (
1765 validator.limit_value()
1766 if callable(validator.limit_value)
1767 else validator.limit_value
1768 )
1769 >= min_value
1770 )
1771 for validator in validators_
1772 ):
1773 validators_.append(validators.MinValueValidator(min_value))
1774 if max_value is not None and not any(
1775 (
1776 isinstance(validator, validators.MaxValueValidator)
1777 and (
1778 validator.limit_value()
1779 if callable(validator.limit_value)
1780 else validator.limit_value
1781 )
1782 <= max_value
1783 )
1784 for validator in validators_
1785 ):
1786 validators_.append(validators.MaxValueValidator(max_value))
1787 return validators_
1789 def get_prep_value(self, value):
1790 value = super().get_prep_value(value)
1791 if value is None:
1792 return None
1793 try:
1794 return int(value)
1795 except (TypeError, ValueError) as e:
1796 raise e.__class__(
1797 f"Field '{self.name}' expected a number but got {value!r}.",
1798 ) from e
1800 def get_db_prep_value(self, value, connection, prepared=False):
1801 value = super().get_db_prep_value(value, connection, prepared)
1802 return connection.ops.adapt_integerfield_value(value, self.get_internal_type())
1804 def get_internal_type(self):
1805 return "IntegerField"
1807 def to_python(self, value):
1808 if value is None:
1809 return value
1810 try:
1811 return int(value)
1812 except (TypeError, ValueError):
1813 raise exceptions.ValidationError(
1814 self.error_messages["invalid"],
1815 code="invalid",
1816 params={"value": value},
1817 )
1820class BigIntegerField(IntegerField):
1821 description = "Big (8 byte) integer"
1822 MAX_BIGINT = 9223372036854775807
1824 def get_internal_type(self):
1825 return "BigIntegerField"
1828class SmallIntegerField(IntegerField):
1829 description = "Small integer"
1831 def get_internal_type(self):
1832 return "SmallIntegerField"
1835class IPAddressField(Field):
1836 empty_strings_allowed = False
1837 description = "IPv4 address"
1838 system_check_removed_details = {
1839 "msg": (
1840 "IPAddressField has been removed except for support in "
1841 "historical migrations."
1842 ),
1843 "hint": "Use GenericIPAddressField instead.",
1844 "id": "fields.E900",
1845 }
1847 def __init__(self, *args, **kwargs):
1848 kwargs["max_length"] = 15
1849 super().__init__(*args, **kwargs)
1851 def deconstruct(self):
1852 name, path, args, kwargs = super().deconstruct()
1853 del kwargs["max_length"]
1854 return name, path, args, kwargs
1856 def get_prep_value(self, value):
1857 value = super().get_prep_value(value)
1858 if value is None:
1859 return None
1860 return str(value)
1862 def get_internal_type(self):
1863 return "IPAddressField"
1866class GenericIPAddressField(Field):
1867 empty_strings_allowed = False
1868 description = "IP address"
1869 default_error_messages = {}
1871 def __init__(
1872 self,
1873 name=None,
1874 protocol="both",
1875 unpack_ipv4=False,
1876 *args,
1877 **kwargs,
1878 ):
1879 self.unpack_ipv4 = unpack_ipv4
1880 self.protocol = protocol
1881 (
1882 self.default_validators,
1883 invalid_error_message,
1884 ) = validators.ip_address_validators(protocol, unpack_ipv4)
1885 self.default_error_messages["invalid"] = invalid_error_message
1886 kwargs["max_length"] = 39
1887 super().__init__(name, *args, **kwargs)
1889 def check(self, **kwargs):
1890 return [
1891 *super().check(**kwargs),
1892 *self._check_blank_and_null_values(**kwargs),
1893 ]
1895 def _check_blank_and_null_values(self, **kwargs):
1896 if not getattr(self, "null", False) and getattr(self, "blank", False):
1897 return [
1898 preflight.Error(
1899 "GenericIPAddressFields cannot have blank=True if null=False, "
1900 "as blank values are stored as nulls.",
1901 obj=self,
1902 id="fields.E150",
1903 )
1904 ]
1905 return []
1907 def deconstruct(self):
1908 name, path, args, kwargs = super().deconstruct()
1909 if self.unpack_ipv4 is not False:
1910 kwargs["unpack_ipv4"] = self.unpack_ipv4
1911 if self.protocol != "both":
1912 kwargs["protocol"] = self.protocol
1913 if kwargs.get("max_length") == 39:
1914 del kwargs["max_length"]
1915 return name, path, args, kwargs
1917 def get_internal_type(self):
1918 return "GenericIPAddressField"
1920 def to_python(self, value):
1921 if value is None:
1922 return None
1923 if not isinstance(value, str):
1924 value = str(value)
1925 value = value.strip()
1926 if ":" in value:
1927 return clean_ipv6_address(
1928 value, self.unpack_ipv4, self.error_messages["invalid"]
1929 )
1930 return value
1932 def get_db_prep_value(self, value, connection, prepared=False):
1933 if not prepared:
1934 value = self.get_prep_value(value)
1935 return connection.ops.adapt_ipaddressfield_value(value)
1937 def get_prep_value(self, value):
1938 value = super().get_prep_value(value)
1939 if value is None:
1940 return None
1941 if value and ":" in value:
1942 try:
1943 return clean_ipv6_address(value, self.unpack_ipv4)
1944 except exceptions.ValidationError:
1945 pass
1946 return str(value)
1949class NullBooleanField(BooleanField):
1950 default_error_messages = {
1951 "invalid": "“%(value)s” value must be either None, True or False.",
1952 "invalid_nullable": "“%(value)s” value must be either None, True or False.",
1953 }
1954 description = "Boolean (Either True, False or None)"
1955 system_check_removed_details = {
1956 "msg": (
1957 "NullBooleanField is removed except for support in historical "
1958 "migrations."
1959 ),
1960 "hint": "Use BooleanField(null=True) instead.",
1961 "id": "fields.E903",
1962 }
1964 def __init__(self, *args, **kwargs):
1965 kwargs["null"] = True
1966 kwargs["blank"] = True
1967 super().__init__(*args, **kwargs)
1969 def deconstruct(self):
1970 name, path, args, kwargs = super().deconstruct()
1971 del kwargs["null"]
1972 del kwargs["blank"]
1973 return name, path, args, kwargs
1976class PositiveIntegerRelDbTypeMixin:
1977 def __init_subclass__(cls, **kwargs):
1978 super().__init_subclass__(**kwargs)
1979 if not hasattr(cls, "integer_field_class"):
1980 cls.integer_field_class = next(
1981 (
1982 parent
1983 for parent in cls.__mro__[1:]
1984 if issubclass(parent, IntegerField)
1985 ),
1986 None,
1987 )
1989 def rel_db_type(self, connection):
1990 """
1991 Return the data type that a related field pointing to this field should
1992 use. In most cases, a foreign key pointing to a positive integer
1993 primary key will have an integer column data type but some databases
1994 (e.g. MySQL) have an unsigned integer type. In that case
1995 (related_fields_match_type=True), the primary key should return its
1996 db_type.
1997 """
1998 if connection.features.related_fields_match_type:
1999 return self.db_type(connection)
2000 else:
2001 return self.integer_field_class().db_type(connection=connection)
2004class PositiveBigIntegerField(PositiveIntegerRelDbTypeMixin, BigIntegerField):
2005 description = "Positive big integer"
2007 def get_internal_type(self):
2008 return "PositiveBigIntegerField"
2011class PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField):
2012 description = "Positive integer"
2014 def get_internal_type(self):
2015 return "PositiveIntegerField"
2018class PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, SmallIntegerField):
2019 description = "Positive small integer"
2021 def get_internal_type(self):
2022 return "PositiveSmallIntegerField"
2025class SlugField(CharField):
2026 default_validators = [validators.validate_slug]
2027 description = "Slug (up to %(max_length)s)"
2029 def __init__(
2030 self, *args, max_length=50, db_index=True, allow_unicode=False, **kwargs
2031 ):
2032 self.allow_unicode = allow_unicode
2033 if self.allow_unicode:
2034 self.default_validators = [validators.validate_unicode_slug]
2035 super().__init__(*args, max_length=max_length, db_index=db_index, **kwargs)
2037 def deconstruct(self):
2038 name, path, args, kwargs = super().deconstruct()
2039 if kwargs.get("max_length") == 50:
2040 del kwargs["max_length"]
2041 if self.db_index is False:
2042 kwargs["db_index"] = False
2043 else:
2044 del kwargs["db_index"]
2045 if self.allow_unicode is not False:
2046 kwargs["allow_unicode"] = self.allow_unicode
2047 return name, path, args, kwargs
2049 def get_internal_type(self):
2050 return "SlugField"
2053class TextField(Field):
2054 description = "Text"
2056 def __init__(self, *args, db_collation=None, **kwargs):
2057 super().__init__(*args, **kwargs)
2058 self.db_collation = db_collation
2060 def check(self, **kwargs):
2061 databases = kwargs.get("databases") or []
2062 return [
2063 *super().check(**kwargs),
2064 *self._check_db_collation(databases),
2065 ]
2067 def _check_db_collation(self, databases):
2068 errors = []
2069 for db in databases:
2070 if not router.allow_migrate_model(db, self.model):
2071 continue
2072 connection = connections[db]
2073 if not (
2074 self.db_collation is None
2075 or "supports_collation_on_textfield"
2076 in self.model._meta.required_db_features
2077 or connection.features.supports_collation_on_textfield
2078 ):
2079 errors.append(
2080 preflight.Error(
2081 f"{connection.display_name} does not support a database collation on "
2082 "TextFields.",
2083 obj=self,
2084 id="fields.E190",
2085 ),
2086 )
2087 return errors
2089 def db_parameters(self, connection):
2090 db_params = super().db_parameters(connection)
2091 db_params["collation"] = self.db_collation
2092 return db_params
2094 def get_internal_type(self):
2095 return "TextField"
2097 def to_python(self, value):
2098 if isinstance(value, str) or value is None:
2099 return value
2100 return str(value)
2102 def get_prep_value(self, value):
2103 value = super().get_prep_value(value)
2104 return self.to_python(value)
2106 def deconstruct(self):
2107 name, path, args, kwargs = super().deconstruct()
2108 if self.db_collation:
2109 kwargs["db_collation"] = self.db_collation
2110 return name, path, args, kwargs
2113class TimeField(DateTimeCheckMixin, Field):
2114 empty_strings_allowed = False
2115 default_error_messages = {
2116 "invalid": "“%(value)s” value has an invalid format. It must be in HH:MM[:ss[.uuuuuu]] format.",
2117 "invalid_time": "“%(value)s” value has the correct format (HH:MM[:ss[.uuuuuu]]) but it is an invalid time.",
2118 }
2119 description = "Time"
2121 def __init__(self, name=None, auto_now=False, auto_now_add=False, **kwargs):
2122 self.auto_now, self.auto_now_add = auto_now, auto_now_add
2123 if auto_now or auto_now_add:
2124 kwargs["editable"] = False
2125 kwargs["blank"] = True
2126 super().__init__(name, **kwargs)
2128 def _check_fix_default_value(self):
2129 """
2130 Warn that using an actual date or datetime value is probably wrong;
2131 it's only evaluated on server startup.
2132 """
2133 if not self.has_default():
2134 return []
2136 value = self.default
2137 if isinstance(value, datetime.datetime):
2138 now = None
2139 elif isinstance(value, datetime.time):
2140 now = _get_naive_now()
2141 # This will not use the right date in the race condition where now
2142 # is just before the date change and value is just past 0:00.
2143 value = datetime.datetime.combine(now.date(), value)
2144 else:
2145 # No explicit time / datetime value -- no checks necessary
2146 return []
2147 # At this point, value is a datetime object.
2148 return self._check_if_value_fixed(value, now=now)
2150 def deconstruct(self):
2151 name, path, args, kwargs = super().deconstruct()
2152 if self.auto_now is not False:
2153 kwargs["auto_now"] = self.auto_now
2154 if self.auto_now_add is not False:
2155 kwargs["auto_now_add"] = self.auto_now_add
2156 if self.auto_now or self.auto_now_add:
2157 del kwargs["blank"]
2158 del kwargs["editable"]
2159 return name, path, args, kwargs
2161 def get_internal_type(self):
2162 return "TimeField"
2164 def to_python(self, value):
2165 if value is None:
2166 return None
2167 if isinstance(value, datetime.time):
2168 return value
2169 if isinstance(value, datetime.datetime):
2170 # Not usually a good idea to pass in a datetime here (it loses
2171 # information), but this can be a side-effect of interacting with a
2172 # database backend (e.g. Oracle), so we'll be accommodating.
2173 return value.time()
2175 try:
2176 parsed = parse_time(value)
2177 if parsed is not None:
2178 return parsed
2179 except ValueError:
2180 raise exceptions.ValidationError(
2181 self.error_messages["invalid_time"],
2182 code="invalid_time",
2183 params={"value": value},
2184 )
2186 raise exceptions.ValidationError(
2187 self.error_messages["invalid"],
2188 code="invalid",
2189 params={"value": value},
2190 )
2192 def pre_save(self, model_instance, add):
2193 if self.auto_now or (self.auto_now_add and add):
2194 value = datetime.datetime.now().time()
2195 setattr(model_instance, self.attname, value)
2196 return value
2197 else:
2198 return super().pre_save(model_instance, add)
2200 def get_prep_value(self, value):
2201 value = super().get_prep_value(value)
2202 return self.to_python(value)
2204 def get_db_prep_value(self, value, connection, prepared=False):
2205 # Casts times into the format expected by the backend
2206 if not prepared:
2207 value = self.get_prep_value(value)
2208 return connection.ops.adapt_timefield_value(value)
2210 def value_to_string(self, obj):
2211 val = self.value_from_object(obj)
2212 return "" if val is None else val.isoformat()
2215class URLField(CharField):
2216 default_validators = [validators.URLValidator()]
2217 description = "URL"
2219 def __init__(self, name=None, **kwargs):
2220 kwargs.setdefault("max_length", 200)
2221 super().__init__(name, **kwargs)
2223 def deconstruct(self):
2224 name, path, args, kwargs = super().deconstruct()
2225 if kwargs.get("max_length") == 200:
2226 del kwargs["max_length"]
2227 return name, path, args, kwargs
2230class BinaryField(Field):
2231 description = "Raw binary data"
2232 empty_values = [None, b""]
2234 def __init__(self, *args, **kwargs):
2235 kwargs.setdefault("editable", False)
2236 super().__init__(*args, **kwargs)
2237 if self.max_length is not None:
2238 self.validators.append(validators.MaxLengthValidator(self.max_length))
2240 def check(self, **kwargs):
2241 return [*super().check(**kwargs), *self._check_str_default_value()]
2243 def _check_str_default_value(self):
2244 if self.has_default() and isinstance(self.default, str):
2245 return [
2246 preflight.Error(
2247 "BinaryField's default cannot be a string. Use bytes "
2248 "content instead.",
2249 obj=self,
2250 id="fields.E170",
2251 )
2252 ]
2253 return []
2255 def deconstruct(self):
2256 name, path, args, kwargs = super().deconstruct()
2257 if self.editable:
2258 kwargs["editable"] = True
2259 else:
2260 del kwargs["editable"]
2261 return name, path, args, kwargs
2263 def get_internal_type(self):
2264 return "BinaryField"
2266 def get_placeholder(self, value, compiler, connection):
2267 return connection.ops.binary_placeholder_sql(value)
2269 def get_default(self):
2270 if self.has_default() and not callable(self.default):
2271 return self.default
2272 default = super().get_default()
2273 if default == "":
2274 return b""
2275 return default
2277 def get_db_prep_value(self, value, connection, prepared=False):
2278 value = super().get_db_prep_value(value, connection, prepared)
2279 if value is not None:
2280 return connection.Database.Binary(value)
2281 return value
2283 def value_to_string(self, obj):
2284 """Binary data is serialized as base64"""
2285 return b64encode(self.value_from_object(obj)).decode("ascii")
2287 def to_python(self, value):
2288 # If it's a string, it should be base64-encoded data
2289 if isinstance(value, str):
2290 return memoryview(b64decode(value.encode("ascii")))
2291 return value
2294class UUIDField(Field):
2295 default_error_messages = {
2296 "invalid": "“%(value)s” is not a valid UUID.",
2297 }
2298 description = "Universally unique identifier"
2299 empty_strings_allowed = False
2301 def __init__(self, **kwargs):
2302 kwargs["max_length"] = 32
2303 super().__init__(**kwargs)
2305 def deconstruct(self):
2306 name, path, args, kwargs = super().deconstruct()
2307 del kwargs["max_length"]
2308 return name, path, args, kwargs
2310 def get_internal_type(self):
2311 return "UUIDField"
2313 def get_prep_value(self, value):
2314 value = super().get_prep_value(value)
2315 return self.to_python(value)
2317 def get_db_prep_value(self, value, connection, prepared=False):
2318 if value is None:
2319 return None
2320 if not isinstance(value, uuid.UUID):
2321 value = self.to_python(value)
2323 if connection.features.has_native_uuid_field:
2324 return value
2325 return value.hex
2327 def to_python(self, value):
2328 if value is not None and not isinstance(value, uuid.UUID):
2329 input_form = "int" if isinstance(value, int) else "hex"
2330 try:
2331 return uuid.UUID(**{input_form: value})
2332 except (AttributeError, ValueError):
2333 raise exceptions.ValidationError(
2334 self.error_messages["invalid"],
2335 code="invalid",
2336 params={"value": value},
2337 )
2338 return value
2341class AutoFieldMixin:
2342 db_returning = True
2344 def __init__(self, *args, **kwargs):
2345 kwargs["blank"] = True
2346 super().__init__(*args, **kwargs)
2348 def check(self, **kwargs):
2349 return [
2350 *super().check(**kwargs),
2351 *self._check_primary_key(),
2352 ]
2354 def _check_primary_key(self):
2355 if not self.primary_key:
2356 return [
2357 preflight.Error(
2358 "AutoFields must set primary_key=True.",
2359 obj=self,
2360 id="fields.E100",
2361 ),
2362 ]
2363 else:
2364 return []
2366 def deconstruct(self):
2367 name, path, args, kwargs = super().deconstruct()
2368 del kwargs["blank"]
2369 kwargs["primary_key"] = True
2370 return name, path, args, kwargs
2372 def validate(self, value, model_instance):
2373 pass
2375 def get_db_prep_value(self, value, connection, prepared=False):
2376 if not prepared:
2377 value = self.get_prep_value(value)
2378 value = connection.ops.validate_autopk_value(value)
2379 return value
2381 def contribute_to_class(self, cls, name, **kwargs):
2382 if cls._meta.auto_field:
2383 raise ValueError(
2384 f"Model {cls._meta.label} can't have more than one auto-generated field."
2385 )
2386 super().contribute_to_class(cls, name, **kwargs)
2387 cls._meta.auto_field = self
2390class AutoFieldMeta(type):
2391 """
2392 Metaclass to maintain backward inheritance compatibility for AutoField.
2394 It is intended that AutoFieldMixin become public API when it is possible to
2395 create a non-integer automatically-generated field using column defaults
2396 stored in the database.
2398 In many areas Plain also relies on using isinstance() to check for an
2399 automatically-generated field as a subclass of AutoField. A new flag needs
2400 to be implemented on Field to be used instead.
2402 When these issues have been addressed, this metaclass could be used to
2403 deprecate inheritance from AutoField and use of isinstance() with AutoField
2404 for detecting automatically-generated fields.
2405 """
2407 @property
2408 def _subclasses(self):
2409 return (BigAutoField, SmallAutoField)
2411 def __instancecheck__(self, instance):
2412 return isinstance(instance, self._subclasses) or super().__instancecheck__(
2413 instance
2414 )
2416 def __subclasscheck__(self, subclass):
2417 return issubclass(subclass, self._subclasses) or super().__subclasscheck__(
2418 subclass
2419 )
2422class AutoField(AutoFieldMixin, IntegerField, metaclass=AutoFieldMeta):
2423 def get_internal_type(self):
2424 return "AutoField"
2426 def rel_db_type(self, connection):
2427 return IntegerField().db_type(connection=connection)
2430class BigAutoField(AutoFieldMixin, BigIntegerField):
2431 def get_internal_type(self):
2432 return "BigAutoField"
2434 def rel_db_type(self, connection):
2435 return BigIntegerField().db_type(connection=connection)
2438class SmallAutoField(AutoFieldMixin, SmallIntegerField):
2439 def get_internal_type(self):
2440 return "SmallAutoField"
2442 def rel_db_type(self, connection):
2443 return SmallIntegerField().db_type(connection=connection)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import json
2import warnings
4from plain import exceptions, preflight
5from plain.models import expressions, lookups
6from plain.models.constants import LOOKUP_SEP
7from plain.models.db import NotSupportedError, connections, router
8from plain.models.fields import TextField
9from plain.models.lookups import (
10 FieldGetDbPrepValueMixin,
11 PostgresOperatorLookup,
12 Transform,
13)
14from plain.utils.deprecation import RemovedInDjango51Warning
16from . import Field
17from .mixins import CheckFieldDefaultMixin
19__all__ = ["JSONField"]
22class JSONField(CheckFieldDefaultMixin, Field):
23 empty_strings_allowed = False
24 description = "A JSON object"
25 default_error_messages = {
26 "invalid": "Value must be valid JSON.",
27 }
28 _default_hint = ("dict", "{}")
30 def __init__(
31 self,
32 name=None,
33 encoder=None,
34 decoder=None,
35 **kwargs,
36 ):
37 if encoder and not callable(encoder):
38 raise ValueError("The encoder parameter must be a callable object.")
39 if decoder and not callable(decoder):
40 raise ValueError("The decoder parameter must be a callable object.")
41 self.encoder = encoder
42 self.decoder = decoder
43 super().__init__(name, **kwargs)
45 def check(self, **kwargs):
46 errors = super().check(**kwargs)
47 databases = kwargs.get("databases") or []
48 errors.extend(self._check_supported(databases))
49 return errors
51 def _check_supported(self, databases):
52 errors = []
53 for db in databases:
54 if not router.allow_migrate_model(db, self.model):
55 continue
56 connection = connections[db]
57 if (
58 self.model._meta.required_db_vendor
59 and self.model._meta.required_db_vendor != connection.vendor
60 ):
61 continue
62 if not (
63 "supports_json_field" in self.model._meta.required_db_features
64 or connection.features.supports_json_field
65 ):
66 errors.append(
67 preflight.Error(
68 f"{connection.display_name} does not support JSONFields.",
69 obj=self.model,
70 id="fields.E180",
71 )
72 )
73 return errors
75 def deconstruct(self):
76 name, path, args, kwargs = super().deconstruct()
77 if self.encoder is not None:
78 kwargs["encoder"] = self.encoder
79 if self.decoder is not None:
80 kwargs["decoder"] = self.decoder
81 return name, path, args, kwargs
83 def from_db_value(self, value, expression, connection):
84 if value is None:
85 return value
86 # Some backends (SQLite at least) extract non-string values in their
87 # SQL datatypes.
88 if isinstance(expression, KeyTransform) and not isinstance(value, str):
89 return value
90 try:
91 return json.loads(value, cls=self.decoder)
92 except json.JSONDecodeError:
93 return value
95 def get_internal_type(self):
96 return "JSONField"
98 def get_db_prep_value(self, value, connection, prepared=False):
99 # RemovedInDjango51Warning: When the deprecation ends, replace with:
100 # if (
101 # isinstance(value, expressions.Value)
102 # and isinstance(value.output_field, JSONField)
103 # ):
104 # value = value.value
105 # elif hasattr(value, "as_sql"): ...
106 if isinstance(value, expressions.Value):
107 if isinstance(value.value, str) and not isinstance(
108 value.output_field, JSONField
109 ):
110 try:
111 value = json.loads(value.value, cls=self.decoder)
112 except json.JSONDecodeError:
113 value = value.value
114 else:
115 warnings.warn(
116 "Providing an encoded JSON string via Value() is deprecated. "
117 f"Use Value({value!r}, output_field=JSONField()) instead.",
118 category=RemovedInDjango51Warning,
119 )
120 elif isinstance(value.output_field, JSONField):
121 value = value.value
122 else:
123 return value
124 elif hasattr(value, "as_sql"):
125 return value
126 return connection.ops.adapt_json_value(value, self.encoder)
128 def get_db_prep_save(self, value, connection):
129 if value is None:
130 return value
131 return self.get_db_prep_value(value, connection)
133 def get_transform(self, name):
134 transform = super().get_transform(name)
135 if transform:
136 return transform
137 return KeyTransformFactory(name)
139 def validate(self, value, model_instance):
140 super().validate(value, model_instance)
141 try:
142 json.dumps(value, cls=self.encoder)
143 except TypeError:
144 raise exceptions.ValidationError(
145 self.error_messages["invalid"],
146 code="invalid",
147 params={"value": value},
148 )
150 def value_to_string(self, obj):
151 return self.value_from_object(obj)
154def compile_json_path(key_transforms, include_root=True):
155 path = ["$"] if include_root else []
156 for key_transform in key_transforms:
157 try:
158 num = int(key_transform)
159 except ValueError: # non-integer
160 path.append(".")
161 path.append(json.dumps(key_transform))
162 else:
163 path.append(f"[{num}]")
164 return "".join(path)
167class DataContains(FieldGetDbPrepValueMixin, PostgresOperatorLookup):
168 lookup_name = "contains"
169 postgres_operator = "@>"
171 def as_sql(self, compiler, connection):
172 if not connection.features.supports_json_field_contains:
173 raise NotSupportedError(
174 "contains lookup is not supported on this database backend."
175 )
176 lhs, lhs_params = self.process_lhs(compiler, connection)
177 rhs, rhs_params = self.process_rhs(compiler, connection)
178 params = tuple(lhs_params) + tuple(rhs_params)
179 return f"JSON_CONTAINS({lhs}, {rhs})", params
182class ContainedBy(FieldGetDbPrepValueMixin, PostgresOperatorLookup):
183 lookup_name = "contained_by"
184 postgres_operator = "<@"
186 def as_sql(self, compiler, connection):
187 if not connection.features.supports_json_field_contains:
188 raise NotSupportedError(
189 "contained_by lookup is not supported on this database backend."
190 )
191 lhs, lhs_params = self.process_lhs(compiler, connection)
192 rhs, rhs_params = self.process_rhs(compiler, connection)
193 params = tuple(rhs_params) + tuple(lhs_params)
194 return f"JSON_CONTAINS({rhs}, {lhs})", params
197class HasKeyLookup(PostgresOperatorLookup):
198 logical_operator = None
200 def compile_json_path_final_key(self, key_transform):
201 # Compile the final key without interpreting ints as array elements.
202 return f".{json.dumps(key_transform)}"
204 def as_sql(self, compiler, connection, template=None):
205 # Process JSON path from the left-hand side.
206 if isinstance(self.lhs, KeyTransform):
207 lhs, lhs_params, lhs_key_transforms = self.lhs.preprocess_lhs(
208 compiler, connection
209 )
210 lhs_json_path = compile_json_path(lhs_key_transforms)
211 else:
212 lhs, lhs_params = self.process_lhs(compiler, connection)
213 lhs_json_path = "$"
214 sql = template % lhs
215 # Process JSON path from the right-hand side.
216 rhs = self.rhs
217 rhs_params = []
218 if not isinstance(rhs, list | tuple):
219 rhs = [rhs]
220 for key in rhs:
221 if isinstance(key, KeyTransform):
222 *_, rhs_key_transforms = key.preprocess_lhs(compiler, connection)
223 else:
224 rhs_key_transforms = [key]
225 *rhs_key_transforms, final_key = rhs_key_transforms
226 rhs_json_path = compile_json_path(rhs_key_transforms, include_root=False)
227 rhs_json_path += self.compile_json_path_final_key(final_key)
228 rhs_params.append(lhs_json_path + rhs_json_path)
229 # Add condition for each key.
230 if self.logical_operator:
231 sql = f"({self.logical_operator.join([sql] * len(rhs_params))})"
232 return sql, tuple(lhs_params) + tuple(rhs_params)
234 def as_mysql(self, compiler, connection):
235 return self.as_sql(
236 compiler, connection, template="JSON_CONTAINS_PATH(%s, 'one', %%s)"
237 )
239 def as_postgresql(self, compiler, connection):
240 if isinstance(self.rhs, KeyTransform):
241 *_, rhs_key_transforms = self.rhs.preprocess_lhs(compiler, connection)
242 for key in rhs_key_transforms[:-1]:
243 self.lhs = KeyTransform(key, self.lhs)
244 self.rhs = rhs_key_transforms[-1]
245 return super().as_postgresql(compiler, connection)
247 def as_sqlite(self, compiler, connection):
248 return self.as_sql(
249 compiler, connection, template="JSON_TYPE(%s, %%s) IS NOT NULL"
250 )
253class HasKey(HasKeyLookup):
254 lookup_name = "has_key"
255 postgres_operator = "?"
256 prepare_rhs = False
259class HasKeys(HasKeyLookup):
260 lookup_name = "has_keys"
261 postgres_operator = "?&"
262 logical_operator = " AND "
264 def get_prep_lookup(self):
265 return [str(item) for item in self.rhs]
268class HasAnyKeys(HasKeys):
269 lookup_name = "has_any_keys"
270 postgres_operator = "?|"
271 logical_operator = " OR "
274class HasKeyOrArrayIndex(HasKey):
275 def compile_json_path_final_key(self, key_transform):
276 return compile_json_path([key_transform], include_root=False)
279class CaseInsensitiveMixin:
280 """
281 Mixin to allow case-insensitive comparison of JSON values on MySQL.
282 MySQL handles strings used in JSON context using the utf8mb4_bin collation.
283 Because utf8mb4_bin is a binary collation, comparison of JSON values is
284 case-sensitive.
285 """
287 def process_lhs(self, compiler, connection):
288 lhs, lhs_params = super().process_lhs(compiler, connection)
289 if connection.vendor == "mysql":
290 return f"LOWER({lhs})", lhs_params
291 return lhs, lhs_params
293 def process_rhs(self, compiler, connection):
294 rhs, rhs_params = super().process_rhs(compiler, connection)
295 if connection.vendor == "mysql":
296 return f"LOWER({rhs})", rhs_params
297 return rhs, rhs_params
300class JSONExact(lookups.Exact):
301 can_use_none_as_rhs = True
303 def process_rhs(self, compiler, connection):
304 rhs, rhs_params = super().process_rhs(compiler, connection)
305 # Treat None lookup values as null.
306 if rhs == "%s" and rhs_params == [None]:
307 rhs_params = ["null"]
308 if connection.vendor == "mysql":
309 func = ["JSON_EXTRACT(%s, '$')"] * len(rhs_params)
310 rhs %= tuple(func)
311 return rhs, rhs_params
314class JSONIContains(CaseInsensitiveMixin, lookups.IContains):
315 pass
318JSONField.register_lookup(DataContains)
319JSONField.register_lookup(ContainedBy)
320JSONField.register_lookup(HasKey)
321JSONField.register_lookup(HasKeys)
322JSONField.register_lookup(HasAnyKeys)
323JSONField.register_lookup(JSONExact)
324JSONField.register_lookup(JSONIContains)
327class KeyTransform(Transform):
328 postgres_operator = "->"
329 postgres_nested_operator = "#>"
331 def __init__(self, key_name, *args, **kwargs):
332 super().__init__(*args, **kwargs)
333 self.key_name = str(key_name)
335 def preprocess_lhs(self, compiler, connection):
336 key_transforms = [self.key_name]
337 previous = self.lhs
338 while isinstance(previous, KeyTransform):
339 key_transforms.insert(0, previous.key_name)
340 previous = previous.lhs
341 lhs, params = compiler.compile(previous)
342 return lhs, params, key_transforms
344 def as_mysql(self, compiler, connection):
345 lhs, params, key_transforms = self.preprocess_lhs(compiler, connection)
346 json_path = compile_json_path(key_transforms)
347 return f"JSON_EXTRACT({lhs}, %s)", tuple(params) + (json_path,)
349 def as_postgresql(self, compiler, connection):
350 lhs, params, key_transforms = self.preprocess_lhs(compiler, connection)
351 if len(key_transforms) > 1:
352 sql = f"({lhs} {self.postgres_nested_operator} %s)"
353 return sql, tuple(params) + (key_transforms,)
354 try:
355 lookup = int(self.key_name)
356 except ValueError:
357 lookup = self.key_name
358 return f"({lhs} {self.postgres_operator} %s)", tuple(params) + (lookup,)
360 def as_sqlite(self, compiler, connection):
361 lhs, params, key_transforms = self.preprocess_lhs(compiler, connection)
362 json_path = compile_json_path(key_transforms)
363 datatype_values = ",".join(
364 [repr(datatype) for datatype in connection.ops.jsonfield_datatype_values]
365 )
366 return (
367 f"(CASE WHEN JSON_TYPE({lhs}, %s) IN ({datatype_values}) "
368 f"THEN JSON_TYPE({lhs}, %s) ELSE JSON_EXTRACT({lhs}, %s) END)"
369 ), (tuple(params) + (json_path,)) * 3
372class KeyTextTransform(KeyTransform):
373 postgres_operator = "->>"
374 postgres_nested_operator = "#>>"
375 output_field = TextField()
377 def as_mysql(self, compiler, connection):
378 if connection.mysql_is_mariadb:
379 # MariaDB doesn't support -> and ->> operators (see MDEV-13594).
380 sql, params = super().as_mysql(compiler, connection)
381 return f"JSON_UNQUOTE({sql})", params
382 else:
383 lhs, params, key_transforms = self.preprocess_lhs(compiler, connection)
384 json_path = compile_json_path(key_transforms)
385 return f"({lhs} ->> %s)", tuple(params) + (json_path,)
387 @classmethod
388 def from_lookup(cls, lookup):
389 transform, *keys = lookup.split(LOOKUP_SEP)
390 if not keys:
391 raise ValueError("Lookup must contain key or index transforms.")
392 for key in keys:
393 transform = cls(key, transform)
394 return transform
397KT = KeyTextTransform.from_lookup
400class KeyTransformTextLookupMixin:
401 """
402 Mixin for combining with a lookup expecting a text lhs from a JSONField
403 key lookup. On PostgreSQL, make use of the ->> operator instead of casting
404 key values to text and performing the lookup on the resulting
405 representation.
406 """
408 def __init__(self, key_transform, *args, **kwargs):
409 if not isinstance(key_transform, KeyTransform):
410 raise TypeError(
411 "Transform should be an instance of KeyTransform in order to "
412 "use this lookup."
413 )
414 key_text_transform = KeyTextTransform(
415 key_transform.key_name,
416 *key_transform.source_expressions,
417 **key_transform.extra,
418 )
419 super().__init__(key_text_transform, *args, **kwargs)
422class KeyTransformIsNull(lookups.IsNull):
423 # key__isnull=False is the same as has_key='key'
424 def as_sqlite(self, compiler, connection):
425 template = "JSON_TYPE(%s, %%s) IS NULL"
426 if not self.rhs:
427 template = "JSON_TYPE(%s, %%s) IS NOT NULL"
428 return HasKeyOrArrayIndex(self.lhs.lhs, self.lhs.key_name).as_sql(
429 compiler,
430 connection,
431 template=template,
432 )
435class KeyTransformIn(lookups.In):
436 def resolve_expression_parameter(self, compiler, connection, sql, param):
437 sql, params = super().resolve_expression_parameter(
438 compiler,
439 connection,
440 sql,
441 param,
442 )
443 if (
444 not hasattr(param, "as_sql")
445 and not connection.features.has_native_json_field
446 ):
447 if connection.vendor == "mysql" or (
448 connection.vendor == "sqlite"
449 and params[0] not in connection.ops.jsonfield_datatype_values
450 ):
451 sql = "JSON_EXTRACT(%s, '$')"
452 if connection.vendor == "mysql" and connection.mysql_is_mariadb:
453 sql = f"JSON_UNQUOTE({sql})"
454 return sql, params
457class KeyTransformExact(JSONExact):
458 def process_rhs(self, compiler, connection):
459 if isinstance(self.rhs, KeyTransform):
460 return super(lookups.Exact, self).process_rhs(compiler, connection)
461 rhs, rhs_params = super().process_rhs(compiler, connection)
462 if connection.vendor == "sqlite":
463 func = []
464 for value in rhs_params:
465 if value in connection.ops.jsonfield_datatype_values:
466 func.append("%s")
467 else:
468 func.append("JSON_EXTRACT(%s, '$')")
469 rhs %= tuple(func)
470 return rhs, rhs_params
473class KeyTransformIExact(
474 CaseInsensitiveMixin, KeyTransformTextLookupMixin, lookups.IExact
475):
476 pass
479class KeyTransformIContains(
480 CaseInsensitiveMixin, KeyTransformTextLookupMixin, lookups.IContains
481):
482 pass
485class KeyTransformStartsWith(KeyTransformTextLookupMixin, lookups.StartsWith):
486 pass
489class KeyTransformIStartsWith(
490 CaseInsensitiveMixin, KeyTransformTextLookupMixin, lookups.IStartsWith
491):
492 pass
495class KeyTransformEndsWith(KeyTransformTextLookupMixin, lookups.EndsWith):
496 pass
499class KeyTransformIEndsWith(
500 CaseInsensitiveMixin, KeyTransformTextLookupMixin, lookups.IEndsWith
501):
502 pass
505class KeyTransformRegex(KeyTransformTextLookupMixin, lookups.Regex):
506 pass
509class KeyTransformIRegex(
510 CaseInsensitiveMixin, KeyTransformTextLookupMixin, lookups.IRegex
511):
512 pass
515class KeyTransformNumericLookupMixin:
516 def process_rhs(self, compiler, connection):
517 rhs, rhs_params = super().process_rhs(compiler, connection)
518 if not connection.features.has_native_json_field:
519 rhs_params = [json.loads(value) for value in rhs_params]
520 return rhs, rhs_params
523class KeyTransformLt(KeyTransformNumericLookupMixin, lookups.LessThan):
524 pass
527class KeyTransformLte(KeyTransformNumericLookupMixin, lookups.LessThanOrEqual):
528 pass
531class KeyTransformGt(KeyTransformNumericLookupMixin, lookups.GreaterThan):
532 pass
535class KeyTransformGte(KeyTransformNumericLookupMixin, lookups.GreaterThanOrEqual):
536 pass
539KeyTransform.register_lookup(KeyTransformIn)
540KeyTransform.register_lookup(KeyTransformExact)
541KeyTransform.register_lookup(KeyTransformIExact)
542KeyTransform.register_lookup(KeyTransformIsNull)
543KeyTransform.register_lookup(KeyTransformIContains)
544KeyTransform.register_lookup(KeyTransformStartsWith)
545KeyTransform.register_lookup(KeyTransformIStartsWith)
546KeyTransform.register_lookup(KeyTransformEndsWith)
547KeyTransform.register_lookup(KeyTransformIEndsWith)
548KeyTransform.register_lookup(KeyTransformRegex)
549KeyTransform.register_lookup(KeyTransformIRegex)
551KeyTransform.register_lookup(KeyTransformLt)
552KeyTransform.register_lookup(KeyTransformLte)
553KeyTransform.register_lookup(KeyTransformGt)
554KeyTransform.register_lookup(KeyTransformGte)
557class KeyTransformFactory:
558 def __init__(self, key_name):
559 self.key_name = key_name
561 def __call__(self, *args, **kwargs):
562 return KeyTransform(self.key_name, *args, **kwargs)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain import preflight
3NOT_PROVIDED = object()
6class FieldCacheMixin:
7 """Provide an API for working with the model's fields value cache."""
9 def get_cache_name(self):
10 raise NotImplementedError
12 def get_cached_value(self, instance, default=NOT_PROVIDED):
13 cache_name = self.get_cache_name()
14 try:
15 return instance._state.fields_cache[cache_name]
16 except KeyError:
17 if default is NOT_PROVIDED:
18 raise
19 return default
21 def is_cached(self, instance):
22 return self.get_cache_name() in instance._state.fields_cache
24 def set_cached_value(self, instance, value):
25 instance._state.fields_cache[self.get_cache_name()] = value
27 def delete_cached_value(self, instance):
28 del instance._state.fields_cache[self.get_cache_name()]
31class CheckFieldDefaultMixin:
32 _default_hint = ("<valid default>", "<invalid default>")
34 def _check_default(self):
35 if (
36 self.has_default()
37 and self.default is not None
38 and not callable(self.default)
39 ):
40 return [
41 preflight.Warning(
42 f"{self.__class__.__name__} default should be a callable instead of an instance "
43 "so that it's not shared between all field instances.",
44 hint=(
45 "Use a callable instead, e.g., use `{}` instead of "
46 "`{}`.".format(*self._default_hint)
47 ),
48 obj=self,
49 id="fields.E010",
50 )
51 ]
52 else:
53 return []
55 def check(self, **kwargs):
56 errors = super().check(**kwargs)
57 errors.extend(self._check_default())
58 return errors
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Field-like classes that aren't really fields. It's easier to use objects that
3have the same attributes as fields sometimes (avoids a lot of special casing).
4"""
6from plain.models import fields
9class OrderWrt(fields.IntegerField):
10 """
11 A proxy for the _order database field that is used when
12 Meta.order_with_respect_to is specified.
13 """
15 def __init__(self, *args, **kwargs):
16 kwargs["name"] = "_order"
17 kwargs["editable"] = False
18 super().__init__(*args, **kwargs)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Accessors for related objects.
4When a field defines a relation between two models, each model class provides
5an attribute to access related instances of the other model class (unless the
6reverse accessor has been disabled with related_name='+').
8Accessors are implemented as descriptors in order to customize access and
9assignment. This module defines the descriptor classes.
11Forward accessors follow foreign keys. Reverse accessors trace them back. For
12example, with the following models::
14 class Parent(Model):
15 pass
17 class Child(Model):
18 parent = ForeignKey(Parent, related_name='children')
20 ``child.parent`` is a forward many-to-one relation. ``parent.children`` is a
21reverse many-to-one relation.
23There are three types of relations (many-to-one, one-to-one, and many-to-many)
24and two directions (forward and reverse) for a total of six combinations.
261. Related instance on the forward side of a many-to-one relation:
27 ``ForwardManyToOneDescriptor``.
29 Uniqueness of foreign key values is irrelevant to accessing the related
30 instance, making the many-to-one and one-to-one cases identical as far as
31 the descriptor is concerned. The constraint is checked upstream (unicity
32 validation in forms) or downstream (unique indexes in the database).
342. Related instance on the forward side of a one-to-one
35 relation: ``ForwardOneToOneDescriptor``.
37 It avoids querying the database when accessing the parent link field in
38 a multi-table inheritance scenario.
403. Related instance on the reverse side of a one-to-one relation:
41 ``ReverseOneToOneDescriptor``.
43 One-to-one relations are asymmetrical, despite the apparent symmetry of the
44 name, because they're implemented in the database with a foreign key from
45 one table to another. As a consequence ``ReverseOneToOneDescriptor`` is
46 slightly different from ``ForwardManyToOneDescriptor``.
484. Related objects manager for related instances on the reverse side of a
49 many-to-one relation: ``ReverseManyToOneDescriptor``.
51 Unlike the previous two classes, this one provides access to a collection
52 of objects. It returns a manager rather than an instance.
545. Related objects manager for related instances on the forward or reverse
55 sides of a many-to-many relation: ``ManyToManyDescriptor``.
57 Many-to-many relations are symmetrical. The syntax of Plain models
58 requires declaring them on one side but that's an implementation detail.
59 They could be declared on the other side without any change in behavior.
60 Therefore the forward and reverse descriptors can be the same.
62 If you're looking for ``ForwardManyToManyDescriptor`` or
63 ``ReverseManyToManyDescriptor``, use ``ManyToManyDescriptor`` instead.
64"""
66from plain.exceptions import FieldError
67from plain.models import signals, transaction
68from plain.models.db import (
69 DEFAULT_DB_ALIAS,
70 NotSupportedError,
71 connections,
72 router,
73)
74from plain.models.expressions import Window
75from plain.models.functions import RowNumber
76from plain.models.lookups import GreaterThan, LessThanOrEqual
77from plain.models.query import QuerySet
78from plain.models.query_utils import DeferredAttribute, Q
79from plain.models.utils import AltersData, resolve_callables
80from plain.utils.functional import cached_property
83class ForeignKeyDeferredAttribute(DeferredAttribute):
84 def __set__(self, instance, value):
85 if instance.__dict__.get(self.field.attname) != value and self.field.is_cached(
86 instance
87 ):
88 self.field.delete_cached_value(instance)
89 instance.__dict__[self.field.attname] = value
92def _filter_prefetch_queryset(queryset, field_name, instances):
93 predicate = Q(**{f"{field_name}__in": instances})
94 db = queryset._db or DEFAULT_DB_ALIAS
95 if queryset.query.is_sliced:
96 if not connections[db].features.supports_over_clause:
97 raise NotSupportedError(
98 "Prefetching from a limited queryset is only supported on backends "
99 "that support window functions."
100 )
101 low_mark, high_mark = queryset.query.low_mark, queryset.query.high_mark
102 order_by = [
103 expr for expr, _ in queryset.query.get_compiler(using=db).get_order_by()
104 ]
105 window = Window(RowNumber(), partition_by=field_name, order_by=order_by)
106 predicate &= GreaterThan(window, low_mark)
107 if high_mark is not None:
108 predicate &= LessThanOrEqual(window, high_mark)
109 queryset.query.clear_limits()
110 return queryset.filter(predicate)
113class ForwardManyToOneDescriptor:
114 """
115 Accessor to the related object on the forward side of a many-to-one or
116 one-to-one (via ForwardOneToOneDescriptor subclass) relation.
118 In the example::
120 class Child(Model):
121 parent = ForeignKey(Parent, related_name='children')
123 ``Child.parent`` is a ``ForwardManyToOneDescriptor`` instance.
124 """
126 def __init__(self, field_with_rel):
127 self.field = field_with_rel
129 @cached_property
130 def RelatedObjectDoesNotExist(self):
131 # The exception can't be created at initialization time since the
132 # related model might not be resolved yet; `self.field.model` might
133 # still be a string model reference.
134 return type(
135 "RelatedObjectDoesNotExist",
136 (self.field.remote_field.model.DoesNotExist, AttributeError),
137 {
138 "__module__": self.field.model.__module__,
139 "__qualname__": f"{self.field.model.__qualname__}.{self.field.name}.RelatedObjectDoesNotExist",
140 },
141 )
143 def is_cached(self, instance):
144 return self.field.is_cached(instance)
146 def get_queryset(self, **hints):
147 return self.field.remote_field.model._base_manager.db_manager(hints=hints).all()
149 def get_prefetch_queryset(self, instances, queryset=None):
150 if queryset is None:
151 queryset = self.get_queryset()
152 queryset._add_hints(instance=instances[0])
154 rel_obj_attr = self.field.get_foreign_related_value
155 instance_attr = self.field.get_local_related_value
156 instances_dict = {instance_attr(inst): inst for inst in instances}
157 related_field = self.field.foreign_related_fields[0]
158 remote_field = self.field.remote_field
160 # FIXME: This will need to be revisited when we introduce support for
161 # composite fields. In the meantime we take this practical approach to
162 # solve a regression on 1.6 when the reverse manager in hidden
163 # (related_name ends with a '+'). Refs #21410.
164 # The check for len(...) == 1 is a special case that allows the query
165 # to be join-less and smaller. Refs #21760.
166 if remote_field.is_hidden() or len(self.field.foreign_related_fields) == 1:
167 query = {
168 f"{related_field.name}__in": {
169 instance_attr(inst)[0] for inst in instances
170 }
171 }
172 else:
173 query = {f"{self.field.related_query_name()}__in": instances}
174 queryset = queryset.filter(**query)
176 # Since we're going to assign directly in the cache,
177 # we must manage the reverse relation cache manually.
178 if not remote_field.multiple:
179 for rel_obj in queryset:
180 instance = instances_dict[rel_obj_attr(rel_obj)]
181 remote_field.set_cached_value(rel_obj, instance)
182 return (
183 queryset,
184 rel_obj_attr,
185 instance_attr,
186 True,
187 self.field.get_cache_name(),
188 False,
189 )
191 def get_object(self, instance):
192 qs = self.get_queryset(instance=instance)
193 # Assuming the database enforces foreign keys, this won't fail.
194 return qs.get(self.field.get_reverse_related_filter(instance))
196 def __get__(self, instance, cls=None):
197 """
198 Get the related instance through the forward relation.
200 With the example above, when getting ``child.parent``:
202 - ``self`` is the descriptor managing the ``parent`` attribute
203 - ``instance`` is the ``child`` instance
204 - ``cls`` is the ``Child`` class (we don't need it)
205 """
206 if instance is None:
207 return self
209 # The related instance is loaded from the database and then cached
210 # by the field on the model instance state. It can also be pre-cached
211 # by the reverse accessor (ReverseOneToOneDescriptor).
212 try:
213 rel_obj = self.field.get_cached_value(instance)
214 except KeyError:
215 has_value = None not in self.field.get_local_related_value(instance)
216 ancestor_link = (
217 instance._meta.get_ancestor_link(self.field.model)
218 if has_value
219 else None
220 )
221 if ancestor_link and ancestor_link.is_cached(instance):
222 # An ancestor link will exist if this field is defined on a
223 # multi-table inheritance parent of the instance's class.
224 ancestor = ancestor_link.get_cached_value(instance)
225 # The value might be cached on an ancestor if the instance
226 # originated from walking down the inheritance chain.
227 rel_obj = self.field.get_cached_value(ancestor, default=None)
228 else:
229 rel_obj = None
230 if rel_obj is None and has_value:
231 rel_obj = self.get_object(instance)
232 remote_field = self.field.remote_field
233 # If this is a one-to-one relation, set the reverse accessor
234 # cache on the related object to the current instance to avoid
235 # an extra SQL query if it's accessed later on.
236 if not remote_field.multiple:
237 remote_field.set_cached_value(rel_obj, instance)
238 self.field.set_cached_value(instance, rel_obj)
240 if rel_obj is None and not self.field.null:
241 raise self.RelatedObjectDoesNotExist(
242 f"{self.field.model.__name__} has no {self.field.name}."
243 )
244 else:
245 return rel_obj
247 def __set__(self, instance, value):
248 """
249 Set the related instance through the forward relation.
251 With the example above, when setting ``child.parent = parent``:
253 - ``self`` is the descriptor managing the ``parent`` attribute
254 - ``instance`` is the ``child`` instance
255 - ``value`` is the ``parent`` instance on the right of the equal sign
256 """
257 # An object must be an instance of the related class.
258 if value is not None and not isinstance(
259 value, self.field.remote_field.model._meta.concrete_model
260 ):
261 raise ValueError(
262 f'Cannot assign "{value!r}": "{instance._meta.object_name}.{self.field.name}" must be a "{self.field.remote_field.model._meta.object_name}" instance.'
263 )
264 elif value is not None:
265 if instance._state.db is None:
266 instance._state.db = router.db_for_write(
267 instance.__class__, instance=value
268 )
269 if value._state.db is None:
270 value._state.db = router.db_for_write(
271 value.__class__, instance=instance
272 )
273 if not router.allow_relation(value, instance):
274 raise ValueError(
275 f'Cannot assign "{value!r}": the current database router prevents this '
276 "relation."
277 )
279 remote_field = self.field.remote_field
280 # If we're setting the value of a OneToOneField to None, we need to clear
281 # out the cache on any old related object. Otherwise, deleting the
282 # previously-related object will also cause this object to be deleted,
283 # which is wrong.
284 if value is None:
285 # Look up the previously-related object, which may still be available
286 # since we've not yet cleared out the related field.
287 # Use the cache directly, instead of the accessor; if we haven't
288 # populated the cache, then we don't care - we're only accessing
289 # the object to invalidate the accessor cache, so there's no
290 # need to populate the cache just to expire it again.
291 related = self.field.get_cached_value(instance, default=None)
293 # If we've got an old related object, we need to clear out its
294 # cache. This cache also might not exist if the related object
295 # hasn't been accessed yet.
296 if related is not None:
297 remote_field.set_cached_value(related, None)
299 for lh_field, rh_field in self.field.related_fields:
300 setattr(instance, lh_field.attname, None)
302 # Set the values of the related field.
303 else:
304 for lh_field, rh_field in self.field.related_fields:
305 setattr(instance, lh_field.attname, getattr(value, rh_field.attname))
307 # Set the related instance cache used by __get__ to avoid an SQL query
308 # when accessing the attribute we just set.
309 self.field.set_cached_value(instance, value)
311 # If this is a one-to-one relation, set the reverse accessor cache on
312 # the related object to the current instance to avoid an extra SQL
313 # query if it's accessed later on.
314 if value is not None and not remote_field.multiple:
315 remote_field.set_cached_value(value, instance)
317 def __reduce__(self):
318 """
319 Pickling should return the instance attached by self.field on the
320 model, not a new copy of that descriptor. Use getattr() to retrieve
321 the instance directly from the model.
322 """
323 return getattr, (self.field.model, self.field.name)
326class ForwardOneToOneDescriptor(ForwardManyToOneDescriptor):
327 """
328 Accessor to the related object on the forward side of a one-to-one relation.
330 In the example::
332 class Restaurant(Model):
333 place = OneToOneField(Place, related_name='restaurant')
335 ``Restaurant.place`` is a ``ForwardOneToOneDescriptor`` instance.
336 """
338 def get_object(self, instance):
339 if self.field.remote_field.parent_link:
340 deferred = instance.get_deferred_fields()
341 # Because it's a parent link, all the data is available in the
342 # instance, so populate the parent model with this data.
343 rel_model = self.field.remote_field.model
344 fields = [field.attname for field in rel_model._meta.concrete_fields]
346 # If any of the related model's fields are deferred, fallback to
347 # fetching all fields from the related model. This avoids a query
348 # on the related model for every deferred field.
349 if not any(field in fields for field in deferred):
350 kwargs = {field: getattr(instance, field) for field in fields}
351 obj = rel_model(**kwargs)
352 obj._state.adding = instance._state.adding
353 obj._state.db = instance._state.db
354 return obj
355 return super().get_object(instance)
357 def __set__(self, instance, value):
358 super().__set__(instance, value)
359 # If the primary key is a link to a parent model and a parent instance
360 # is being set, update the value of the inherited pk(s).
361 if self.field.primary_key and self.field.remote_field.parent_link:
362 opts = instance._meta
363 # Inherited primary key fields from this object's base classes.
364 inherited_pk_fields = [
365 field
366 for field in opts.concrete_fields
367 if field.primary_key and field.remote_field
368 ]
369 for field in inherited_pk_fields:
370 rel_model_pk_name = field.remote_field.model._meta.pk.attname
371 raw_value = (
372 getattr(value, rel_model_pk_name) if value is not None else None
373 )
374 setattr(instance, rel_model_pk_name, raw_value)
377class ReverseOneToOneDescriptor:
378 """
379 Accessor to the related object on the reverse side of a one-to-one
380 relation.
382 In the example::
384 class Restaurant(Model):
385 place = OneToOneField(Place, related_name='restaurant')
387 ``Place.restaurant`` is a ``ReverseOneToOneDescriptor`` instance.
388 """
390 def __init__(self, related):
391 # Following the example above, `related` is an instance of OneToOneRel
392 # which represents the reverse restaurant field (place.restaurant).
393 self.related = related
395 @cached_property
396 def RelatedObjectDoesNotExist(self):
397 # The exception isn't created at initialization time for the sake of
398 # consistency with `ForwardManyToOneDescriptor`.
399 return type(
400 "RelatedObjectDoesNotExist",
401 (self.related.related_model.DoesNotExist, AttributeError),
402 {
403 "__module__": self.related.model.__module__,
404 "__qualname__": f"{self.related.model.__qualname__}.{self.related.name}.RelatedObjectDoesNotExist",
405 },
406 )
408 def is_cached(self, instance):
409 return self.related.is_cached(instance)
411 def get_queryset(self, **hints):
412 return self.related.related_model._base_manager.db_manager(hints=hints).all()
414 def get_prefetch_queryset(self, instances, queryset=None):
415 if queryset is None:
416 queryset = self.get_queryset()
417 queryset._add_hints(instance=instances[0])
419 rel_obj_attr = self.related.field.get_local_related_value
420 instance_attr = self.related.field.get_foreign_related_value
421 instances_dict = {instance_attr(inst): inst for inst in instances}
422 query = {f"{self.related.field.name}__in": instances}
423 queryset = queryset.filter(**query)
425 # Since we're going to assign directly in the cache,
426 # we must manage the reverse relation cache manually.
427 for rel_obj in queryset:
428 instance = instances_dict[rel_obj_attr(rel_obj)]
429 self.related.field.set_cached_value(rel_obj, instance)
430 return (
431 queryset,
432 rel_obj_attr,
433 instance_attr,
434 True,
435 self.related.get_cache_name(),
436 False,
437 )
439 def __get__(self, instance, cls=None):
440 """
441 Get the related instance through the reverse relation.
443 With the example above, when getting ``place.restaurant``:
445 - ``self`` is the descriptor managing the ``restaurant`` attribute
446 - ``instance`` is the ``place`` instance
447 - ``cls`` is the ``Place`` class (unused)
449 Keep in mind that ``Restaurant`` holds the foreign key to ``Place``.
450 """
451 if instance is None:
452 return self
454 # The related instance is loaded from the database and then cached
455 # by the field on the model instance state. It can also be pre-cached
456 # by the forward accessor (ForwardManyToOneDescriptor).
457 try:
458 rel_obj = self.related.get_cached_value(instance)
459 except KeyError:
460 related_pk = instance.pk
461 if related_pk is None:
462 rel_obj = None
463 else:
464 filter_args = self.related.field.get_forward_related_filter(instance)
465 try:
466 rel_obj = self.get_queryset(instance=instance).get(**filter_args)
467 except self.related.related_model.DoesNotExist:
468 rel_obj = None
469 else:
470 # Set the forward accessor cache on the related object to
471 # the current instance to avoid an extra SQL query if it's
472 # accessed later on.
473 self.related.field.set_cached_value(rel_obj, instance)
474 self.related.set_cached_value(instance, rel_obj)
476 if rel_obj is None:
477 raise self.RelatedObjectDoesNotExist(
478 f"{instance.__class__.__name__} has no {self.related.get_accessor_name()}."
479 )
480 else:
481 return rel_obj
483 def __set__(self, instance, value):
484 """
485 Set the related instance through the reverse relation.
487 With the example above, when setting ``place.restaurant = restaurant``:
489 - ``self`` is the descriptor managing the ``restaurant`` attribute
490 - ``instance`` is the ``place`` instance
491 - ``value`` is the ``restaurant`` instance on the right of the equal sign
493 Keep in mind that ``Restaurant`` holds the foreign key to ``Place``.
494 """
495 # The similarity of the code below to the code in
496 # ForwardManyToOneDescriptor is annoying, but there's a bunch
497 # of small differences that would make a common base class convoluted.
499 if value is None:
500 # Update the cached related instance (if any) & clear the cache.
501 # Following the example above, this would be the cached
502 # ``restaurant`` instance (if any).
503 rel_obj = self.related.get_cached_value(instance, default=None)
504 if rel_obj is not None:
505 # Remove the ``restaurant`` instance from the ``place``
506 # instance cache.
507 self.related.delete_cached_value(instance)
508 # Set the ``place`` field on the ``restaurant``
509 # instance to None.
510 setattr(rel_obj, self.related.field.name, None)
511 elif not isinstance(value, self.related.related_model):
512 # An object must be an instance of the related class.
513 raise ValueError(
514 f'Cannot assign "{value!r}": "{instance._meta.object_name}.{self.related.get_accessor_name()}" must be a "{self.related.related_model._meta.object_name}" instance.'
515 )
516 else:
517 if instance._state.db is None:
518 instance._state.db = router.db_for_write(
519 instance.__class__, instance=value
520 )
521 if value._state.db is None:
522 value._state.db = router.db_for_write(
523 value.__class__, instance=instance
524 )
525 if not router.allow_relation(value, instance):
526 raise ValueError(
527 f'Cannot assign "{value!r}": the current database router prevents this '
528 "relation."
529 )
531 related_pk = tuple(
532 getattr(instance, field.attname)
533 for field in self.related.field.foreign_related_fields
534 )
535 # Set the value of the related field to the value of the related
536 # object's related field.
537 for index, field in enumerate(self.related.field.local_related_fields):
538 setattr(value, field.attname, related_pk[index])
540 # Set the related instance cache used by __get__ to avoid an SQL query
541 # when accessing the attribute we just set.
542 self.related.set_cached_value(instance, value)
544 # Set the forward accessor cache on the related object to the current
545 # instance to avoid an extra SQL query if it's accessed later on.
546 self.related.field.set_cached_value(value, instance)
548 def __reduce__(self):
549 # Same purpose as ForwardManyToOneDescriptor.__reduce__().
550 return getattr, (self.related.model, self.related.name)
553class ReverseManyToOneDescriptor:
554 """
555 Accessor to the related objects manager on the reverse side of a
556 many-to-one relation.
558 In the example::
560 class Child(Model):
561 parent = ForeignKey(Parent, related_name='children')
563 ``Parent.children`` is a ``ReverseManyToOneDescriptor`` instance.
565 Most of the implementation is delegated to a dynamically defined manager
566 class built by ``create_forward_many_to_many_manager()`` defined below.
567 """
569 def __init__(self, rel):
570 self.rel = rel
571 self.field = rel.field
573 @cached_property
574 def related_manager_cls(self):
575 related_model = self.rel.related_model
577 return create_reverse_many_to_one_manager(
578 related_model._default_manager.__class__,
579 self.rel,
580 )
582 def __get__(self, instance, cls=None):
583 """
584 Get the related objects through the reverse relation.
586 With the example above, when getting ``parent.children``:
588 - ``self`` is the descriptor managing the ``children`` attribute
589 - ``instance`` is the ``parent`` instance
590 - ``cls`` is the ``Parent`` class (unused)
591 """
592 if instance is None:
593 return self
595 return self.related_manager_cls(instance)
597 def _get_set_deprecation_msg_params(self):
598 return (
599 "reverse side of a related set",
600 self.rel.get_accessor_name(),
601 )
603 def __set__(self, instance, value):
604 raise TypeError(
605 "Direct assignment to the {} is prohibited. Use {}.set() instead.".format(
606 *self._get_set_deprecation_msg_params()
607 ),
608 )
611def create_reverse_many_to_one_manager(superclass, rel):
612 """
613 Create a manager for the reverse side of a many-to-one relation.
615 This manager subclasses another manager, generally the default manager of
616 the related model, and adds behaviors specific to many-to-one relations.
617 """
619 class RelatedManager(superclass, AltersData):
620 def __init__(self, instance):
621 super().__init__()
623 self.instance = instance
624 self.model = rel.related_model
625 self.field = rel.field
627 self.core_filters = {self.field.name: instance}
629 def __call__(self, *, manager):
630 manager = getattr(self.model, manager)
631 manager_class = create_reverse_many_to_one_manager(manager.__class__, rel)
632 return manager_class(self.instance)
634 do_not_call_in_templates = True
636 def _check_fk_val(self):
637 for field in self.field.foreign_related_fields:
638 if getattr(self.instance, field.attname) is None:
639 raise ValueError(
640 f'"{self.instance!r}" needs to have a value for field '
641 f'"{field.attname}" before this relationship can be used.'
642 )
644 def _apply_rel_filters(self, queryset):
645 """
646 Filter the queryset for the instance this manager is bound to.
647 """
648 db = self._db or router.db_for_read(self.model, instance=self.instance)
649 empty_strings_as_null = connections[
650 db
651 ].features.interprets_empty_strings_as_nulls
652 queryset._add_hints(instance=self.instance)
653 if self._db:
654 queryset = queryset.using(self._db)
655 queryset._defer_next_filter = True
656 queryset = queryset.filter(**self.core_filters)
657 for field in self.field.foreign_related_fields:
658 val = getattr(self.instance, field.attname)
659 if val is None or (val == "" and empty_strings_as_null):
660 return queryset.none()
661 if self.field.many_to_one:
662 # Guard against field-like objects such as GenericRelation
663 # that abuse create_reverse_many_to_one_manager() with reverse
664 # one-to-many relationships instead and break known related
665 # objects assignment.
666 try:
667 target_field = self.field.target_field
668 except FieldError:
669 # The relationship has multiple target fields. Use a tuple
670 # for related object id.
671 rel_obj_id = tuple(
672 [
673 getattr(self.instance, target_field.attname)
674 for target_field in self.field.path_infos[-1].target_fields
675 ]
676 )
677 else:
678 rel_obj_id = getattr(self.instance, target_field.attname)
679 queryset._known_related_objects = {
680 self.field: {rel_obj_id: self.instance}
681 }
682 return queryset
684 def _remove_prefetched_objects(self):
685 try:
686 self.instance._prefetched_objects_cache.pop(
687 self.field.remote_field.get_cache_name()
688 )
689 except (AttributeError, KeyError):
690 pass # nothing to clear from cache
692 def get_queryset(self):
693 # Even if this relation is not to pk, we require still pk value.
694 # The wish is that the instance has been already saved to DB,
695 # although having a pk value isn't a guarantee of that.
696 if self.instance.pk is None:
697 raise ValueError(
698 f"{self.instance.__class__.__name__!r} instance needs to have a "
699 f"primary key value before this relationship can be used."
700 )
701 try:
702 return self.instance._prefetched_objects_cache[
703 self.field.remote_field.get_cache_name()
704 ]
705 except (AttributeError, KeyError):
706 queryset = super().get_queryset()
707 return self._apply_rel_filters(queryset)
709 def get_prefetch_queryset(self, instances, queryset=None):
710 if queryset is None:
711 queryset = super().get_queryset()
713 queryset._add_hints(instance=instances[0])
714 queryset = queryset.using(queryset._db or self._db)
716 rel_obj_attr = self.field.get_local_related_value
717 instance_attr = self.field.get_foreign_related_value
718 instances_dict = {instance_attr(inst): inst for inst in instances}
719 queryset = _filter_prefetch_queryset(queryset, self.field.name, instances)
721 # Since we just bypassed this class' get_queryset(), we must manage
722 # the reverse relation manually.
723 for rel_obj in queryset:
724 if not self.field.is_cached(rel_obj):
725 instance = instances_dict[rel_obj_attr(rel_obj)]
726 setattr(rel_obj, self.field.name, instance)
727 cache_name = self.field.remote_field.get_cache_name()
728 return queryset, rel_obj_attr, instance_attr, False, cache_name, False
730 def add(self, *objs, bulk=True):
731 self._check_fk_val()
732 self._remove_prefetched_objects()
733 db = router.db_for_write(self.model, instance=self.instance)
735 def check_and_update_obj(obj):
736 if not isinstance(obj, self.model):
737 raise TypeError(
738 f"'{self.model._meta.object_name}' instance expected, got {obj!r}"
739 )
740 setattr(obj, self.field.name, self.instance)
742 if bulk:
743 pks = []
744 for obj in objs:
745 check_and_update_obj(obj)
746 if obj._state.adding or obj._state.db != db:
747 raise ValueError(
748 f"{obj!r} instance isn't saved. Use bulk=False or save "
749 "the object first."
750 )
751 pks.append(obj.pk)
752 self.model._base_manager.using(db).filter(pk__in=pks).update(
753 **{
754 self.field.name: self.instance,
755 }
756 )
757 else:
758 with transaction.atomic(using=db, savepoint=False):
759 for obj in objs:
760 check_and_update_obj(obj)
761 obj.save()
763 add.alters_data = True
765 def create(self, **kwargs):
766 self._check_fk_val()
767 kwargs[self.field.name] = self.instance
768 db = router.db_for_write(self.model, instance=self.instance)
769 return super(RelatedManager, self.db_manager(db)).create(**kwargs)
771 create.alters_data = True
773 def get_or_create(self, **kwargs):
774 self._check_fk_val()
775 kwargs[self.field.name] = self.instance
776 db = router.db_for_write(self.model, instance=self.instance)
777 return super(RelatedManager, self.db_manager(db)).get_or_create(**kwargs)
779 get_or_create.alters_data = True
781 def update_or_create(self, **kwargs):
782 self._check_fk_val()
783 kwargs[self.field.name] = self.instance
784 db = router.db_for_write(self.model, instance=self.instance)
785 return super(RelatedManager, self.db_manager(db)).update_or_create(**kwargs)
787 update_or_create.alters_data = True
789 # remove() and clear() are only provided if the ForeignKey can have a
790 # value of null.
791 if rel.field.null:
793 def remove(self, *objs, bulk=True):
794 if not objs:
795 return
796 self._check_fk_val()
797 val = self.field.get_foreign_related_value(self.instance)
798 old_ids = set()
799 for obj in objs:
800 if not isinstance(obj, self.model):
801 raise TypeError(
802 f"'{self.model._meta.object_name}' instance expected, got {obj!r}"
803 )
804 # Is obj actually part of this descriptor set?
805 if self.field.get_local_related_value(obj) == val:
806 old_ids.add(obj.pk)
807 else:
808 raise self.field.remote_field.model.DoesNotExist(
809 f"{obj!r} is not related to {self.instance!r}."
810 )
811 self._clear(self.filter(pk__in=old_ids), bulk)
813 remove.alters_data = True
815 def clear(self, *, bulk=True):
816 self._check_fk_val()
817 self._clear(self, bulk)
819 clear.alters_data = True
821 def _clear(self, queryset, bulk):
822 self._remove_prefetched_objects()
823 db = router.db_for_write(self.model, instance=self.instance)
824 queryset = queryset.using(db)
825 if bulk:
826 # `QuerySet.update()` is intrinsically atomic.
827 queryset.update(**{self.field.name: None})
828 else:
829 with transaction.atomic(using=db, savepoint=False):
830 for obj in queryset:
831 setattr(obj, self.field.name, None)
832 obj.save(update_fields=[self.field.name])
834 _clear.alters_data = True
836 def set(self, objs, *, bulk=True, clear=False):
837 self._check_fk_val()
838 # Force evaluation of `objs` in case it's a queryset whose value
839 # could be affected by `manager.clear()`. Refs #19816.
840 objs = tuple(objs)
842 if self.field.null:
843 db = router.db_for_write(self.model, instance=self.instance)
844 with transaction.atomic(using=db, savepoint=False):
845 if clear:
846 self.clear(bulk=bulk)
847 self.add(*objs, bulk=bulk)
848 else:
849 old_objs = set(self.using(db).all())
850 new_objs = []
851 for obj in objs:
852 if obj in old_objs:
853 old_objs.remove(obj)
854 else:
855 new_objs.append(obj)
857 self.remove(*old_objs, bulk=bulk)
858 self.add(*new_objs, bulk=bulk)
859 else:
860 self.add(*objs, bulk=bulk)
862 set.alters_data = True
864 return RelatedManager
867class ManyToManyDescriptor(ReverseManyToOneDescriptor):
868 """
869 Accessor to the related objects manager on the forward and reverse sides of
870 a many-to-many relation.
872 In the example::
874 class Pizza(Model):
875 toppings = ManyToManyField(Topping, related_name='pizzas')
877 ``Pizza.toppings`` and ``Topping.pizzas`` are ``ManyToManyDescriptor``
878 instances.
880 Most of the implementation is delegated to a dynamically defined manager
881 class built by ``create_forward_many_to_many_manager()`` defined below.
882 """
884 def __init__(self, rel, reverse=False):
885 super().__init__(rel)
887 self.reverse = reverse
889 @property
890 def through(self):
891 # through is provided so that you have easy access to the through
892 # model (Book.authors.through) for inlines, etc. This is done as
893 # a property to ensure that the fully resolved value is returned.
894 return self.rel.through
896 @cached_property
897 def related_manager_cls(self):
898 related_model = self.rel.related_model if self.reverse else self.rel.model
900 return create_forward_many_to_many_manager(
901 related_model._default_manager.__class__,
902 self.rel,
903 reverse=self.reverse,
904 )
906 def _get_set_deprecation_msg_params(self):
907 return (
908 "%s side of a many-to-many set"
909 % ("reverse" if self.reverse else "forward"),
910 self.rel.get_accessor_name() if self.reverse else self.field.name,
911 )
914def create_forward_many_to_many_manager(superclass, rel, reverse):
915 """
916 Create a manager for the either side of a many-to-many relation.
918 This manager subclasses another manager, generally the default manager of
919 the related model, and adds behaviors specific to many-to-many relations.
920 """
922 class ManyRelatedManager(superclass, AltersData):
923 def __init__(self, instance=None):
924 super().__init__()
926 self.instance = instance
928 if not reverse:
929 self.model = rel.model
930 self.query_field_name = rel.field.related_query_name()
931 self.prefetch_cache_name = rel.field.name
932 self.source_field_name = rel.field.m2m_field_name()
933 self.target_field_name = rel.field.m2m_reverse_field_name()
934 self.symmetrical = rel.symmetrical
935 else:
936 self.model = rel.related_model
937 self.query_field_name = rel.field.name
938 self.prefetch_cache_name = rel.field.related_query_name()
939 self.source_field_name = rel.field.m2m_reverse_field_name()
940 self.target_field_name = rel.field.m2m_field_name()
941 self.symmetrical = False
943 self.through = rel.through
944 self.reverse = reverse
946 self.source_field = self.through._meta.get_field(self.source_field_name)
947 self.target_field = self.through._meta.get_field(self.target_field_name)
949 self.core_filters = {}
950 self.pk_field_names = {}
951 for lh_field, rh_field in self.source_field.related_fields:
952 core_filter_key = f"{self.query_field_name}__{rh_field.name}"
953 self.core_filters[core_filter_key] = getattr(instance, rh_field.attname)
954 self.pk_field_names[lh_field.name] = rh_field.name
956 self.related_val = self.source_field.get_foreign_related_value(instance)
957 if None in self.related_val:
958 raise ValueError(
959 f'"{instance!r}" needs to have a value for field "{self.pk_field_names[self.source_field_name]}" before '
960 "this many-to-many relationship can be used."
961 )
962 # Even if this relation is not to pk, we require still pk value.
963 # The wish is that the instance has been already saved to DB,
964 # although having a pk value isn't a guarantee of that.
965 if instance.pk is None:
966 raise ValueError(
967 f"{instance.__class__.__name__!r} instance needs to have a primary key value before "
968 "a many-to-many relationship can be used."
969 )
971 def __call__(self, *, manager):
972 manager = getattr(self.model, manager)
973 manager_class = create_forward_many_to_many_manager(
974 manager.__class__, rel, reverse
975 )
976 return manager_class(instance=self.instance)
978 do_not_call_in_templates = True
980 def _build_remove_filters(self, removed_vals):
981 filters = Q.create([(self.source_field_name, self.related_val)])
982 # No need to add a subquery condition if removed_vals is a QuerySet without
983 # filters.
984 removed_vals_filters = (
985 not isinstance(removed_vals, QuerySet) or removed_vals._has_filters()
986 )
987 if removed_vals_filters:
988 filters &= Q.create([(f"{self.target_field_name}__in", removed_vals)])
989 if self.symmetrical:
990 symmetrical_filters = Q.create(
991 [(self.target_field_name, self.related_val)]
992 )
993 if removed_vals_filters:
994 symmetrical_filters &= Q.create(
995 [(f"{self.source_field_name}__in", removed_vals)]
996 )
997 filters |= symmetrical_filters
998 return filters
1000 def _apply_rel_filters(self, queryset):
1001 """
1002 Filter the queryset for the instance this manager is bound to.
1003 """
1004 queryset._add_hints(instance=self.instance)
1005 if self._db:
1006 queryset = queryset.using(self._db)
1007 queryset._defer_next_filter = True
1008 return queryset._next_is_sticky().filter(**self.core_filters)
1010 def _remove_prefetched_objects(self):
1011 try:
1012 self.instance._prefetched_objects_cache.pop(self.prefetch_cache_name)
1013 except (AttributeError, KeyError):
1014 pass # nothing to clear from cache
1016 def get_queryset(self):
1017 try:
1018 return self.instance._prefetched_objects_cache[self.prefetch_cache_name]
1019 except (AttributeError, KeyError):
1020 queryset = super().get_queryset()
1021 return self._apply_rel_filters(queryset)
1023 def get_prefetch_queryset(self, instances, queryset=None):
1024 if queryset is None:
1025 queryset = super().get_queryset()
1027 queryset._add_hints(instance=instances[0])
1028 queryset = queryset.using(queryset._db or self._db)
1029 queryset = _filter_prefetch_queryset(
1030 queryset._next_is_sticky(), self.query_field_name, instances
1031 )
1033 # M2M: need to annotate the query in order to get the primary model
1034 # that the secondary model was actually related to. We know that
1035 # there will already be a join on the join table, so we can just add
1036 # the select.
1038 # For non-autocreated 'through' models, can't assume we are
1039 # dealing with PK values.
1040 fk = self.through._meta.get_field(self.source_field_name)
1041 join_table = fk.model._meta.db_table
1042 connection = connections[queryset.db]
1043 qn = connection.ops.quote_name
1044 queryset = queryset.extra(
1045 select={
1046 f"_prefetch_related_val_{f.attname}": f"{qn(join_table)}.{qn(f.column)}"
1047 for f in fk.local_related_fields
1048 }
1049 )
1050 return (
1051 queryset,
1052 lambda result: tuple(
1053 getattr(result, f"_prefetch_related_val_{f.attname}")
1054 for f in fk.local_related_fields
1055 ),
1056 lambda inst: tuple(
1057 f.get_db_prep_value(getattr(inst, f.attname), connection)
1058 for f in fk.foreign_related_fields
1059 ),
1060 False,
1061 self.prefetch_cache_name,
1062 False,
1063 )
1065 def add(self, *objs, through_defaults=None):
1066 self._remove_prefetched_objects()
1067 db = router.db_for_write(self.through, instance=self.instance)
1068 with transaction.atomic(using=db, savepoint=False):
1069 self._add_items(
1070 self.source_field_name,
1071 self.target_field_name,
1072 *objs,
1073 through_defaults=through_defaults,
1074 )
1075 # If this is a symmetrical m2m relation to self, add the mirror
1076 # entry in the m2m table.
1077 if self.symmetrical:
1078 self._add_items(
1079 self.target_field_name,
1080 self.source_field_name,
1081 *objs,
1082 through_defaults=through_defaults,
1083 )
1085 add.alters_data = True
1087 def remove(self, *objs):
1088 self._remove_prefetched_objects()
1089 self._remove_items(self.source_field_name, self.target_field_name, *objs)
1091 remove.alters_data = True
1093 def clear(self):
1094 db = router.db_for_write(self.through, instance=self.instance)
1095 with transaction.atomic(using=db, savepoint=False):
1096 signals.m2m_changed.send(
1097 sender=self.through,
1098 action="pre_clear",
1099 instance=self.instance,
1100 reverse=self.reverse,
1101 model=self.model,
1102 pk_set=None,
1103 using=db,
1104 )
1105 self._remove_prefetched_objects()
1106 filters = self._build_remove_filters(super().get_queryset().using(db))
1107 self.through._default_manager.using(db).filter(filters).delete()
1109 signals.m2m_changed.send(
1110 sender=self.through,
1111 action="post_clear",
1112 instance=self.instance,
1113 reverse=self.reverse,
1114 model=self.model,
1115 pk_set=None,
1116 using=db,
1117 )
1119 clear.alters_data = True
1121 def set(self, objs, *, clear=False, through_defaults=None):
1122 # Force evaluation of `objs` in case it's a queryset whose value
1123 # could be affected by `manager.clear()`. Refs #19816.
1124 objs = tuple(objs)
1126 db = router.db_for_write(self.through, instance=self.instance)
1127 with transaction.atomic(using=db, savepoint=False):
1128 if clear:
1129 self.clear()
1130 self.add(*objs, through_defaults=through_defaults)
1131 else:
1132 old_ids = set(
1133 self.using(db).values_list(
1134 self.target_field.target_field.attname, flat=True
1135 )
1136 )
1138 new_objs = []
1139 for obj in objs:
1140 fk_val = (
1141 self.target_field.get_foreign_related_value(obj)[0]
1142 if isinstance(obj, self.model)
1143 else self.target_field.get_prep_value(obj)
1144 )
1145 if fk_val in old_ids:
1146 old_ids.remove(fk_val)
1147 else:
1148 new_objs.append(obj)
1150 self.remove(*old_ids)
1151 self.add(*new_objs, through_defaults=through_defaults)
1153 set.alters_data = True
1155 def create(self, *, through_defaults=None, **kwargs):
1156 db = router.db_for_write(self.instance.__class__, instance=self.instance)
1157 new_obj = super(ManyRelatedManager, self.db_manager(db)).create(**kwargs)
1158 self.add(new_obj, through_defaults=through_defaults)
1159 return new_obj
1161 create.alters_data = True
1163 def get_or_create(self, *, through_defaults=None, **kwargs):
1164 db = router.db_for_write(self.instance.__class__, instance=self.instance)
1165 obj, created = super(ManyRelatedManager, self.db_manager(db)).get_or_create(
1166 **kwargs
1167 )
1168 # We only need to add() if created because if we got an object back
1169 # from get() then the relationship already exists.
1170 if created:
1171 self.add(obj, through_defaults=through_defaults)
1172 return obj, created
1174 get_or_create.alters_data = True
1176 def update_or_create(self, *, through_defaults=None, **kwargs):
1177 db = router.db_for_write(self.instance.__class__, instance=self.instance)
1178 obj, created = super(
1179 ManyRelatedManager, self.db_manager(db)
1180 ).update_or_create(**kwargs)
1181 # We only need to add() if created because if we got an object back
1182 # from get() then the relationship already exists.
1183 if created:
1184 self.add(obj, through_defaults=through_defaults)
1185 return obj, created
1187 update_or_create.alters_data = True
1189 def _get_target_ids(self, target_field_name, objs):
1190 """
1191 Return the set of ids of `objs` that the target field references.
1192 """
1193 from plain.models import Model
1195 target_ids = set()
1196 target_field = self.through._meta.get_field(target_field_name)
1197 for obj in objs:
1198 if isinstance(obj, self.model):
1199 if not router.allow_relation(obj, self.instance):
1200 raise ValueError(
1201 f'Cannot add "{obj!r}": instance is on database "{self.instance._state.db}", '
1202 f'value is on database "{obj._state.db}"'
1203 )
1204 target_id = target_field.get_foreign_related_value(obj)[0]
1205 if target_id is None:
1206 raise ValueError(
1207 f'Cannot add "{obj!r}": the value for field "{target_field_name}" is None'
1208 )
1209 target_ids.add(target_id)
1210 elif isinstance(obj, Model):
1211 raise TypeError(
1212 f"'{self.model._meta.object_name}' instance expected, got {obj!r}"
1213 )
1214 else:
1215 target_ids.add(target_field.get_prep_value(obj))
1216 return target_ids
1218 def _get_missing_target_ids(
1219 self, source_field_name, target_field_name, db, target_ids
1220 ):
1221 """
1222 Return the subset of ids of `objs` that aren't already assigned to
1223 this relationship.
1224 """
1225 vals = (
1226 self.through._default_manager.using(db)
1227 .values_list(target_field_name, flat=True)
1228 .filter(
1229 **{
1230 source_field_name: self.related_val[0],
1231 f"{target_field_name}__in": target_ids,
1232 }
1233 )
1234 )
1235 return target_ids.difference(vals)
1237 def _get_add_plan(self, db, source_field_name):
1238 """
1239 Return a boolean triple of the way the add should be performed.
1241 The first element is whether or not bulk_create(ignore_conflicts)
1242 can be used, the second whether or not signals must be sent, and
1243 the third element is whether or not the immediate bulk insertion
1244 with conflicts ignored can be performed.
1245 """
1246 # Conflicts can be ignored when the intermediary model is
1247 # auto-created as the only possible collision is on the
1248 # (source_id, target_id) tuple. The same assertion doesn't hold for
1249 # user-defined intermediary models as they could have other fields
1250 # causing conflicts which must be surfaced.
1251 can_ignore_conflicts = (
1252 self.through._meta.auto_created is not False
1253 and connections[db].features.supports_ignore_conflicts
1254 )
1255 # Don't send the signal when inserting duplicate data row
1256 # for symmetrical reverse entries.
1257 must_send_signals = (
1258 self.reverse or source_field_name == self.source_field_name
1259 ) and (signals.m2m_changed.has_listeners(self.through))
1260 # Fast addition through bulk insertion can only be performed
1261 # if no m2m_changed listeners are connected for self.through
1262 # as they require the added set of ids to be provided via
1263 # pk_set.
1264 return (
1265 can_ignore_conflicts,
1266 must_send_signals,
1267 (can_ignore_conflicts and not must_send_signals),
1268 )
1270 def _add_items(
1271 self, source_field_name, target_field_name, *objs, through_defaults=None
1272 ):
1273 # source_field_name: the PK fieldname in join table for the source object
1274 # target_field_name: the PK fieldname in join table for the target object
1275 # *objs - objects to add. Either object instances, or primary keys
1276 # of object instances.
1277 if not objs:
1278 return
1280 through_defaults = dict(resolve_callables(through_defaults or {}))
1281 target_ids = self._get_target_ids(target_field_name, objs)
1282 db = router.db_for_write(self.through, instance=self.instance)
1283 can_ignore_conflicts, must_send_signals, can_fast_add = self._get_add_plan(
1284 db, source_field_name
1285 )
1286 if can_fast_add:
1287 self.through._default_manager.using(db).bulk_create(
1288 [
1289 self.through(
1290 **{
1291 f"{source_field_name}_id": self.related_val[0],
1292 f"{target_field_name}_id": target_id,
1293 }
1294 )
1295 for target_id in target_ids
1296 ],
1297 ignore_conflicts=True,
1298 )
1299 return
1301 missing_target_ids = self._get_missing_target_ids(
1302 source_field_name, target_field_name, db, target_ids
1303 )
1304 with transaction.atomic(using=db, savepoint=False):
1305 if must_send_signals:
1306 signals.m2m_changed.send(
1307 sender=self.through,
1308 action="pre_add",
1309 instance=self.instance,
1310 reverse=self.reverse,
1311 model=self.model,
1312 pk_set=missing_target_ids,
1313 using=db,
1314 )
1315 # Add the ones that aren't there already.
1316 self.through._default_manager.using(db).bulk_create(
1317 [
1318 self.through(
1319 **through_defaults,
1320 **{
1321 f"{source_field_name}_id": self.related_val[0],
1322 f"{target_field_name}_id": target_id,
1323 },
1324 )
1325 for target_id in missing_target_ids
1326 ],
1327 ignore_conflicts=can_ignore_conflicts,
1328 )
1330 if must_send_signals:
1331 signals.m2m_changed.send(
1332 sender=self.through,
1333 action="post_add",
1334 instance=self.instance,
1335 reverse=self.reverse,
1336 model=self.model,
1337 pk_set=missing_target_ids,
1338 using=db,
1339 )
1341 def _remove_items(self, source_field_name, target_field_name, *objs):
1342 # source_field_name: the PK colname in join table for the source object
1343 # target_field_name: the PK colname in join table for the target object
1344 # *objs - objects to remove. Either object instances, or primary
1345 # keys of object instances.
1346 if not objs:
1347 return
1349 # Check that all the objects are of the right type
1350 old_ids = set()
1351 for obj in objs:
1352 if isinstance(obj, self.model):
1353 fk_val = self.target_field.get_foreign_related_value(obj)[0]
1354 old_ids.add(fk_val)
1355 else:
1356 old_ids.add(obj)
1358 db = router.db_for_write(self.through, instance=self.instance)
1359 with transaction.atomic(using=db, savepoint=False):
1360 # Send a signal to the other end if need be.
1361 signals.m2m_changed.send(
1362 sender=self.through,
1363 action="pre_remove",
1364 instance=self.instance,
1365 reverse=self.reverse,
1366 model=self.model,
1367 pk_set=old_ids,
1368 using=db,
1369 )
1370 target_model_qs = super().get_queryset()
1371 if target_model_qs._has_filters():
1372 old_vals = target_model_qs.using(db).filter(
1373 **{f"{self.target_field.target_field.attname}__in": old_ids}
1374 )
1375 else:
1376 old_vals = old_ids
1377 filters = self._build_remove_filters(old_vals)
1378 self.through._default_manager.using(db).filter(filters).delete()
1380 signals.m2m_changed.send(
1381 sender=self.through,
1382 action="post_remove",
1383 instance=self.instance,
1384 reverse=self.reverse,
1385 model=self.model,
1386 pk_set=old_ids,
1387 using=db,
1388 )
1390 return ManyRelatedManager
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.models.lookups import (
2 Exact,
3 GreaterThan,
4 GreaterThanOrEqual,
5 In,
6 IsNull,
7 LessThan,
8 LessThanOrEqual,
9)
12class MultiColSource:
13 contains_aggregate = False
14 contains_over_clause = False
16 def __init__(self, alias, targets, sources, field):
17 self.targets, self.sources, self.field, self.alias = (
18 targets,
19 sources,
20 field,
21 alias,
22 )
23 self.output_field = self.field
25 def __repr__(self):
26 return f"{self.__class__.__name__}({self.alias}, {self.field})"
28 def relabeled_clone(self, relabels):
29 return self.__class__(
30 relabels.get(self.alias, self.alias), self.targets, self.sources, self.field
31 )
33 def get_lookup(self, lookup):
34 return self.output_field.get_lookup(lookup)
36 def resolve_expression(self, *args, **kwargs):
37 return self
40def get_normalized_value(value, lhs):
41 from plain.models import Model
43 if isinstance(value, Model):
44 if value.pk is None:
45 raise ValueError("Model instances passed to related filters must be saved.")
46 value_list = []
47 sources = lhs.output_field.path_infos[-1].target_fields
48 for source in sources:
49 while not isinstance(value, source.model) and source.remote_field:
50 source = source.remote_field.model._meta.get_field(
51 source.remote_field.field_name
52 )
53 try:
54 value_list.append(getattr(value, source.attname))
55 except AttributeError:
56 # A case like Restaurant.objects.filter(place=restaurant_instance),
57 # where place is a OneToOneField and the primary key of Restaurant.
58 return (value.pk,)
59 return tuple(value_list)
60 if not isinstance(value, tuple):
61 return (value,)
62 return value
65class RelatedIn(In):
66 def get_prep_lookup(self):
67 if not isinstance(self.lhs, MultiColSource):
68 if self.rhs_is_direct_value():
69 # If we get here, we are dealing with single-column relations.
70 self.rhs = [get_normalized_value(val, self.lhs)[0] for val in self.rhs]
71 # We need to run the related field's get_prep_value(). Consider
72 # case ForeignKey to IntegerField given value 'abc'. The
73 # ForeignKey itself doesn't have validation for non-integers,
74 # so we must run validation using the target field.
75 if hasattr(self.lhs.output_field, "path_infos"):
76 # Run the target field's get_prep_value. We can safely
77 # assume there is only one as we don't get to the direct
78 # value branch otherwise.
79 target_field = self.lhs.output_field.path_infos[-1].target_fields[
80 -1
81 ]
82 self.rhs = [target_field.get_prep_value(v) for v in self.rhs]
83 elif not getattr(self.rhs, "has_select_fields", True) and not getattr(
84 self.lhs.field.target_field, "primary_key", False
85 ):
86 if (
87 getattr(self.lhs.output_field, "primary_key", False)
88 and self.lhs.output_field.model == self.rhs.model
89 ):
90 # A case like
91 # Restaurant.objects.filter(place__in=restaurant_qs), where
92 # place is a OneToOneField and the primary key of
93 # Restaurant.
94 target_field = self.lhs.field.name
95 else:
96 target_field = self.lhs.field.target_field.name
97 self.rhs.set_values([target_field])
98 return super().get_prep_lookup()
100 def as_sql(self, compiler, connection):
101 if isinstance(self.lhs, MultiColSource):
102 # For multicolumn lookups we need to build a multicolumn where clause.
103 # This clause is either a SubqueryConstraint (for values that need
104 # to be compiled to SQL) or an OR-combined list of
105 # (col1 = val1 AND col2 = val2 AND ...) clauses.
106 from plain.models.sql.where import (
107 AND,
108 OR,
109 SubqueryConstraint,
110 WhereNode,
111 )
113 root_constraint = WhereNode(connector=OR)
114 if self.rhs_is_direct_value():
115 values = [get_normalized_value(value, self.lhs) for value in self.rhs]
116 for value in values:
117 value_constraint = WhereNode()
118 for source, target, val in zip(
119 self.lhs.sources, self.lhs.targets, value
120 ):
121 lookup_class = target.get_lookup("exact")
122 lookup = lookup_class(
123 target.get_col(self.lhs.alias, source), val
124 )
125 value_constraint.add(lookup, AND)
126 root_constraint.add(value_constraint, OR)
127 else:
128 root_constraint.add(
129 SubqueryConstraint(
130 self.lhs.alias,
131 [target.column for target in self.lhs.targets],
132 [source.name for source in self.lhs.sources],
133 self.rhs,
134 ),
135 AND,
136 )
137 return root_constraint.as_sql(compiler, connection)
138 return super().as_sql(compiler, connection)
141class RelatedLookupMixin:
142 def get_prep_lookup(self):
143 if not isinstance(self.lhs, MultiColSource) and not hasattr(
144 self.rhs, "resolve_expression"
145 ):
146 # If we get here, we are dealing with single-column relations.
147 self.rhs = get_normalized_value(self.rhs, self.lhs)[0]
148 # We need to run the related field's get_prep_value(). Consider case
149 # ForeignKey to IntegerField given value 'abc'. The ForeignKey itself
150 # doesn't have validation for non-integers, so we must run validation
151 # using the target field.
152 if self.prepare_rhs and hasattr(self.lhs.output_field, "path_infos"):
153 # Get the target field. We can safely assume there is only one
154 # as we don't get to the direct value branch otherwise.
155 target_field = self.lhs.output_field.path_infos[-1].target_fields[-1]
156 self.rhs = target_field.get_prep_value(self.rhs)
158 return super().get_prep_lookup()
160 def as_sql(self, compiler, connection):
161 if isinstance(self.lhs, MultiColSource):
162 assert self.rhs_is_direct_value()
163 self.rhs = get_normalized_value(self.rhs, self.lhs)
164 from plain.models.sql.where import AND, WhereNode
166 root_constraint = WhereNode()
167 for target, source, val in zip(
168 self.lhs.targets, self.lhs.sources, self.rhs
169 ):
170 lookup_class = target.get_lookup(self.lookup_name)
171 root_constraint.add(
172 lookup_class(target.get_col(self.lhs.alias, source), val), AND
173 )
174 return root_constraint.as_sql(compiler, connection)
175 return super().as_sql(compiler, connection)
178class RelatedExact(RelatedLookupMixin, Exact):
179 pass
182class RelatedLessThan(RelatedLookupMixin, LessThan):
183 pass
186class RelatedGreaterThan(RelatedLookupMixin, GreaterThan):
187 pass
190class RelatedGreaterThanOrEqual(RelatedLookupMixin, GreaterThanOrEqual):
191 pass
194class RelatedLessThanOrEqual(RelatedLookupMixin, LessThanOrEqual):
195 pass
198class RelatedIsNull(RelatedLookupMixin, IsNull):
199 pass
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import functools
2import inspect
3from functools import partial
5from plain import exceptions, preflight
6from plain.models.backends import utils
7from plain.models.constants import LOOKUP_SEP
8from plain.models.db import connection, router
9from plain.models.deletion import CASCADE, SET_DEFAULT, SET_NULL
10from plain.models.query_utils import PathInfo, Q
11from plain.models.utils import make_model_tuple
12from plain.packages import packages
13from plain.runtime import settings
14from plain.runtime.user_settings import SettingsReference
15from plain.utils.functional import cached_property
17from . import Field
18from .mixins import FieldCacheMixin
19from .related_descriptors import (
20 ForeignKeyDeferredAttribute,
21 ForwardManyToOneDescriptor,
22 ForwardOneToOneDescriptor,
23 ManyToManyDescriptor,
24 ReverseManyToOneDescriptor,
25 ReverseOneToOneDescriptor,
26)
27from .related_lookups import (
28 RelatedExact,
29 RelatedGreaterThan,
30 RelatedGreaterThanOrEqual,
31 RelatedIn,
32 RelatedIsNull,
33 RelatedLessThan,
34 RelatedLessThanOrEqual,
35)
36from .reverse_related import ForeignObjectRel, ManyToManyRel, ManyToOneRel, OneToOneRel
38RECURSIVE_RELATIONSHIP_CONSTANT = "self"
41def resolve_relation(scope_model, relation):
42 """
43 Transform relation into a model or fully-qualified model string of the form
44 "package_label.ModelName", relative to scope_model.
46 The relation argument can be:
47 * RECURSIVE_RELATIONSHIP_CONSTANT, i.e. the string "self", in which case
48 the model argument will be returned.
49 * A bare model name without an package_label, in which case scope_model's
50 package_label will be prepended.
51 * An "package_label.ModelName" string.
52 * A model class, which will be returned unchanged.
53 """
54 # Check for recursive relations
55 if relation == RECURSIVE_RELATIONSHIP_CONSTANT:
56 relation = scope_model
58 # Look for an "app.Model" relation
59 if isinstance(relation, str):
60 if "." not in relation:
61 relation = f"{scope_model._meta.package_label}.{relation}"
63 return relation
66def lazy_related_operation(function, model, *related_models, **kwargs):
67 """
68 Schedule `function` to be called once `model` and all `related_models`
69 have been imported and registered with the app registry. `function` will
70 be called with the newly-loaded model classes as its positional arguments,
71 plus any optional keyword arguments.
73 The `model` argument must be a model class. Each subsequent positional
74 argument is another model, or a reference to another model - see
75 `resolve_relation()` for the various forms these may take. Any relative
76 references will be resolved relative to `model`.
78 This is a convenience wrapper for `Packages.lazy_model_operation` - the app
79 registry model used is the one found in `model._meta.packages`.
80 """
81 models = [model] + [resolve_relation(model, rel) for rel in related_models]
82 model_keys = (make_model_tuple(m) for m in models)
83 packages = model._meta.packages
84 return packages.lazy_model_operation(partial(function, **kwargs), *model_keys)
87class RelatedField(FieldCacheMixin, Field):
88 """Base class that all relational fields inherit from."""
90 # Field flags
91 one_to_many = False
92 one_to_one = False
93 many_to_many = False
94 many_to_one = False
96 def __init__(
97 self,
98 related_name=None,
99 related_query_name=None,
100 limit_choices_to=None,
101 **kwargs,
102 ):
103 self._related_name = related_name
104 self._related_query_name = related_query_name
105 self._limit_choices_to = limit_choices_to
106 super().__init__(**kwargs)
108 @cached_property
109 def related_model(self):
110 # Can't cache this property until all the models are loaded.
111 packages.check_models_ready()
112 return self.remote_field.model
114 def check(self, **kwargs):
115 return [
116 *super().check(**kwargs),
117 *self._check_related_name_is_valid(),
118 *self._check_related_query_name_is_valid(),
119 *self._check_relation_model_exists(),
120 *self._check_referencing_to_swapped_model(),
121 *self._check_clashes(),
122 ]
124 def _check_related_name_is_valid(self):
125 import keyword
127 related_name = self.remote_field.related_name
128 if related_name is None:
129 return []
130 is_valid_id = (
131 not keyword.iskeyword(related_name) and related_name.isidentifier()
132 )
133 if not (is_valid_id or related_name.endswith("+")):
134 return [
135 preflight.Error(
136 f"The name '{self.remote_field.related_name}' is invalid related_name for field {self.model._meta.object_name}.{self.name}",
137 hint=(
138 "Related name must be a valid Python identifier or end with a "
139 "'+'"
140 ),
141 obj=self,
142 id="fields.E306",
143 )
144 ]
145 return []
147 def _check_related_query_name_is_valid(self):
148 if self.remote_field.is_hidden():
149 return []
150 rel_query_name = self.related_query_name()
151 errors = []
152 if rel_query_name.endswith("_"):
153 errors.append(
154 preflight.Error(
155 f"Reverse query name '{rel_query_name}' must not end with an underscore.",
156 hint=(
157 "Add or change a related_name or related_query_name "
158 "argument for this field."
159 ),
160 obj=self,
161 id="fields.E308",
162 )
163 )
164 if LOOKUP_SEP in rel_query_name:
165 errors.append(
166 preflight.Error(
167 f"Reverse query name '{rel_query_name}' must not contain '{LOOKUP_SEP}'.",
168 hint=(
169 "Add or change a related_name or related_query_name "
170 "argument for this field."
171 ),
172 obj=self,
173 id="fields.E309",
174 )
175 )
176 return errors
178 def _check_relation_model_exists(self):
179 rel_is_missing = self.remote_field.model not in self.opts.packages.get_models()
180 rel_is_string = isinstance(self.remote_field.model, str)
181 model_name = (
182 self.remote_field.model
183 if rel_is_string
184 else self.remote_field.model._meta.object_name
185 )
186 if rel_is_missing and (
187 rel_is_string or not self.remote_field.model._meta.swapped
188 ):
189 return [
190 preflight.Error(
191 f"Field defines a relation with model '{model_name}', which is either "
192 "not installed, or is abstract.",
193 obj=self,
194 id="fields.E300",
195 )
196 ]
197 return []
199 def _check_referencing_to_swapped_model(self):
200 if (
201 self.remote_field.model not in self.opts.packages.get_models()
202 and not isinstance(self.remote_field.model, str)
203 and self.remote_field.model._meta.swapped
204 ):
205 return [
206 preflight.Error(
207 f"Field defines a relation with the model '{self.remote_field.model._meta.label}', which has "
208 "been swapped out.",
209 hint=f"Update the relation to point at 'settings.{self.remote_field.model._meta.swappable}'.",
210 obj=self,
211 id="fields.E301",
212 )
213 ]
214 return []
216 def _check_clashes(self):
217 """Check accessor and reverse query name clashes."""
218 from plain.models.base import ModelBase
220 errors = []
221 opts = self.model._meta
223 # f.remote_field.model may be a string instead of a model. Skip if
224 # model name is not resolved.
225 if not isinstance(self.remote_field.model, ModelBase):
226 return []
228 # Consider that we are checking field `Model.foreign` and the models
229 # are:
230 #
231 # class Target(models.Model):
232 # model = models.IntegerField()
233 # model_set = models.IntegerField()
234 #
235 # class Model(models.Model):
236 # foreign = models.ForeignKey(Target)
237 # m2m = models.ManyToManyField(Target)
239 # rel_opts.object_name == "Target"
240 rel_opts = self.remote_field.model._meta
241 # If the field doesn't install a backward relation on the target model
242 # (so `is_hidden` returns True), then there are no clashes to check
243 # and we can skip these fields.
244 rel_is_hidden = self.remote_field.is_hidden()
245 rel_name = self.remote_field.get_accessor_name() # i. e. "model_set"
246 rel_query_name = self.related_query_name() # i. e. "model"
247 # i.e. "package_label.Model.field".
248 field_name = f"{opts.label}.{self.name}"
250 # Check clashes between accessor or reverse query name of `field`
251 # and any other field name -- i.e. accessor for Model.foreign is
252 # model_set and it clashes with Target.model_set.
253 potential_clashes = rel_opts.fields + rel_opts.many_to_many
254 for clash_field in potential_clashes:
255 # i.e. "package_label.Target.model_set".
256 clash_name = f"{rel_opts.label}.{clash_field.name}"
257 if not rel_is_hidden and clash_field.name == rel_name:
258 errors.append(
259 preflight.Error(
260 f"Reverse accessor '{rel_opts.object_name}.{rel_name}' "
261 f"for '{field_name}' clashes with field name "
262 f"'{clash_name}'.",
263 hint=(
264 f"Rename field '{clash_name}', or add/change a related_name "
265 f"argument to the definition for field '{field_name}'."
266 ),
267 obj=self,
268 id="fields.E302",
269 )
270 )
272 if clash_field.name == rel_query_name:
273 errors.append(
274 preflight.Error(
275 f"Reverse query name for '{field_name}' clashes with field name '{clash_name}'.",
276 hint=(
277 f"Rename field '{clash_name}', or add/change a related_name "
278 f"argument to the definition for field '{field_name}'."
279 ),
280 obj=self,
281 id="fields.E303",
282 )
283 )
285 # Check clashes between accessors/reverse query names of `field` and
286 # any other field accessor -- i. e. Model.foreign accessor clashes with
287 # Model.m2m accessor.
288 potential_clashes = (r for r in rel_opts.related_objects if r.field is not self)
289 for clash_field in potential_clashes:
290 # i.e. "package_label.Model.m2m".
291 clash_name = (
292 f"{clash_field.related_model._meta.label}.{clash_field.field.name}"
293 )
294 if not rel_is_hidden and clash_field.get_accessor_name() == rel_name:
295 errors.append(
296 preflight.Error(
297 f"Reverse accessor '{rel_opts.object_name}.{rel_name}' "
298 f"for '{field_name}' clashes with reverse accessor for "
299 f"'{clash_name}'.",
300 hint=(
301 "Add or change a related_name argument "
302 f"to the definition for '{field_name}' or '{clash_name}'."
303 ),
304 obj=self,
305 id="fields.E304",
306 )
307 )
309 if clash_field.get_accessor_name() == rel_query_name:
310 errors.append(
311 preflight.Error(
312 f"Reverse query name for '{field_name}' clashes with reverse query name "
313 f"for '{clash_name}'.",
314 hint=(
315 "Add or change a related_name argument "
316 f"to the definition for '{field_name}' or '{clash_name}'."
317 ),
318 obj=self,
319 id="fields.E305",
320 )
321 )
323 return errors
325 def db_type(self, connection):
326 # By default related field will not have a column as it relates to
327 # columns from another table.
328 return None
330 def contribute_to_class(self, cls, name, private_only=False, **kwargs):
331 super().contribute_to_class(cls, name, private_only=private_only, **kwargs)
333 self.opts = cls._meta
335 if not cls._meta.abstract:
336 if self.remote_field.related_name:
337 related_name = self.remote_field.related_name
338 else:
339 related_name = self.opts.default_related_name
340 if related_name:
341 related_name %= {
342 "class": cls.__name__.lower(),
343 "model_name": cls._meta.model_name.lower(),
344 "package_label": cls._meta.package_label.lower(),
345 }
346 self.remote_field.related_name = related_name
348 if self.remote_field.related_query_name:
349 related_query_name = self.remote_field.related_query_name % {
350 "class": cls.__name__.lower(),
351 "package_label": cls._meta.package_label.lower(),
352 }
353 self.remote_field.related_query_name = related_query_name
355 def resolve_related_class(model, related, field):
356 field.remote_field.model = related
357 field.do_related_class(related, model)
359 lazy_related_operation(
360 resolve_related_class, cls, self.remote_field.model, field=self
361 )
363 def deconstruct(self):
364 name, path, args, kwargs = super().deconstruct()
365 if self._limit_choices_to:
366 kwargs["limit_choices_to"] = self._limit_choices_to
367 if self._related_name is not None:
368 kwargs["related_name"] = self._related_name
369 if self._related_query_name is not None:
370 kwargs["related_query_name"] = self._related_query_name
371 return name, path, args, kwargs
373 def get_forward_related_filter(self, obj):
374 """
375 Return the keyword arguments that when supplied to
376 self.model.object.filter(), would select all instances related through
377 this field to the remote obj. This is used to build the querysets
378 returned by related descriptors. obj is an instance of
379 self.related_field.model.
380 """
381 return {
382 f"{self.name}__{rh_field.name}": getattr(obj, rh_field.attname)
383 for _, rh_field in self.related_fields
384 }
386 def get_reverse_related_filter(self, obj):
387 """
388 Complement to get_forward_related_filter(). Return the keyword
389 arguments that when passed to self.related_field.model.object.filter()
390 select all instances of self.related_field.model related through
391 this field to obj. obj is an instance of self.model.
392 """
393 base_q = Q.create(
394 [
395 (rh_field.attname, getattr(obj, lh_field.attname))
396 for lh_field, rh_field in self.related_fields
397 ]
398 )
399 descriptor_filter = self.get_extra_descriptor_filter(obj)
400 if isinstance(descriptor_filter, dict):
401 return base_q & Q(**descriptor_filter)
402 elif descriptor_filter:
403 return base_q & descriptor_filter
404 return base_q
406 @property
407 def swappable_setting(self):
408 """
409 Get the setting that this is powered from for swapping, or None
410 if it's not swapped in / marked with swappable=False.
411 """
412 if self.swappable:
413 # Work out string form of "to"
414 if isinstance(self.remote_field.model, str):
415 to_string = self.remote_field.model
416 else:
417 to_string = self.remote_field.model._meta.label
418 return packages.get_swappable_settings_name(to_string)
419 return None
421 def set_attributes_from_rel(self):
422 self.name = self.name or (
423 self.remote_field.model._meta.model_name
424 + "_"
425 + self.remote_field.model._meta.pk.name
426 )
427 self.remote_field.set_field_name()
429 def do_related_class(self, other, cls):
430 self.set_attributes_from_rel()
431 self.contribute_to_related_class(other, self.remote_field)
433 def get_limit_choices_to(self):
434 """
435 Return ``limit_choices_to`` for this model field.
437 If it is a callable, it will be invoked and the result will be
438 returned.
439 """
440 if callable(self.remote_field.limit_choices_to):
441 return self.remote_field.limit_choices_to()
442 return self.remote_field.limit_choices_to
444 def related_query_name(self):
445 """
446 Define the name that can be used to identify this related object in a
447 table-spanning query.
448 """
449 return (
450 self.remote_field.related_query_name
451 or self.remote_field.related_name
452 or self.opts.model_name
453 )
455 @property
456 def target_field(self):
457 """
458 When filtering against this relation, return the field on the remote
459 model against which the filtering should happen.
460 """
461 target_fields = self.path_infos[-1].target_fields
462 if len(target_fields) > 1:
463 raise exceptions.FieldError(
464 "The relation has multiple target fields, but only single target field "
465 "was asked for"
466 )
467 return target_fields[0]
469 def get_cache_name(self):
470 return self.name
473class ForeignObject(RelatedField):
474 """
475 Abstraction of the ForeignKey relation to support multi-column relations.
476 """
478 # Field flags
479 many_to_many = False
480 many_to_one = True
481 one_to_many = False
482 one_to_one = False
484 requires_unique_target = True
485 related_accessor_class = ReverseManyToOneDescriptor
486 forward_related_accessor_class = ForwardManyToOneDescriptor
487 rel_class = ForeignObjectRel
489 def __init__(
490 self,
491 to,
492 on_delete,
493 from_fields,
494 to_fields,
495 rel=None,
496 related_name=None,
497 related_query_name=None,
498 limit_choices_to=None,
499 parent_link=False,
500 swappable=True,
501 **kwargs,
502 ):
503 if rel is None:
504 rel = self.rel_class(
505 self,
506 to,
507 related_name=related_name,
508 related_query_name=related_query_name,
509 limit_choices_to=limit_choices_to,
510 parent_link=parent_link,
511 on_delete=on_delete,
512 )
514 super().__init__(
515 rel=rel,
516 related_name=related_name,
517 related_query_name=related_query_name,
518 limit_choices_to=limit_choices_to,
519 **kwargs,
520 )
522 self.from_fields = from_fields
523 self.to_fields = to_fields
524 self.swappable = swappable
526 def __copy__(self):
527 obj = super().__copy__()
528 # Remove any cached PathInfo values.
529 obj.__dict__.pop("path_infos", None)
530 obj.__dict__.pop("reverse_path_infos", None)
531 return obj
533 def check(self, **kwargs):
534 return [
535 *super().check(**kwargs),
536 *self._check_to_fields_exist(),
537 *self._check_unique_target(),
538 ]
540 def _check_to_fields_exist(self):
541 # Skip nonexistent models.
542 if isinstance(self.remote_field.model, str):
543 return []
545 errors = []
546 for to_field in self.to_fields:
547 if to_field:
548 try:
549 self.remote_field.model._meta.get_field(to_field)
550 except exceptions.FieldDoesNotExist:
551 errors.append(
552 preflight.Error(
553 f"The to_field '{to_field}' doesn't exist on the related "
554 f"model '{self.remote_field.model._meta.label}'.",
555 obj=self,
556 id="fields.E312",
557 )
558 )
559 return errors
561 def _check_unique_target(self):
562 rel_is_string = isinstance(self.remote_field.model, str)
563 if rel_is_string or not self.requires_unique_target:
564 return []
566 try:
567 self.foreign_related_fields
568 except exceptions.FieldDoesNotExist:
569 return []
571 if not self.foreign_related_fields:
572 return []
574 unique_foreign_fields = {
575 frozenset([f.name])
576 for f in self.remote_field.model._meta.get_fields()
577 if getattr(f, "unique", False)
578 }
579 unique_foreign_fields.update(
580 {
581 frozenset(uc.fields)
582 for uc in self.remote_field.model._meta.total_unique_constraints
583 }
584 )
585 foreign_fields = {f.name for f in self.foreign_related_fields}
586 has_unique_constraint = any(u <= foreign_fields for u in unique_foreign_fields)
588 if not has_unique_constraint and len(self.foreign_related_fields) > 1:
589 field_combination = ", ".join(
590 f"'{rel_field.name}'" for rel_field in self.foreign_related_fields
591 )
592 model_name = self.remote_field.model.__name__
593 return [
594 preflight.Error(
595 f"No subset of the fields {field_combination} on model '{model_name}' is unique.",
596 hint=(
597 "Mark a single field as unique=True or add a set of "
598 "fields to a unique constraint (via "
599 "a UniqueConstraint (without condition) in the "
600 "model Meta.constraints)."
601 ),
602 obj=self,
603 id="fields.E310",
604 )
605 ]
606 elif not has_unique_constraint:
607 field_name = self.foreign_related_fields[0].name
608 model_name = self.remote_field.model.__name__
609 return [
610 preflight.Error(
611 f"'{model_name}.{field_name}' must be unique because it is referenced by "
612 "a foreign key.",
613 hint=(
614 "Add unique=True to this field or add a "
615 "UniqueConstraint (without condition) in the model "
616 "Meta.constraints."
617 ),
618 obj=self,
619 id="fields.E311",
620 )
621 ]
622 else:
623 return []
625 def deconstruct(self):
626 name, path, args, kwargs = super().deconstruct()
627 kwargs["on_delete"] = self.remote_field.on_delete
628 kwargs["from_fields"] = self.from_fields
629 kwargs["to_fields"] = self.to_fields
631 if self.remote_field.parent_link:
632 kwargs["parent_link"] = self.remote_field.parent_link
633 if isinstance(self.remote_field.model, str):
634 if "." in self.remote_field.model:
635 package_label, model_name = self.remote_field.model.split(".")
636 kwargs["to"] = f"{package_label}.{model_name.lower()}"
637 else:
638 kwargs["to"] = self.remote_field.model.lower()
639 else:
640 kwargs["to"] = self.remote_field.model._meta.label_lower
641 # If swappable is True, then see if we're actually pointing to the target
642 # of a swap.
643 swappable_setting = self.swappable_setting
644 if swappable_setting is not None:
645 # If it's already a settings reference, error
646 if hasattr(kwargs["to"], "setting_name"):
647 if kwargs["to"].setting_name != swappable_setting:
648 raise ValueError(
649 "Cannot deconstruct a ForeignKey pointing to a model "
650 "that is swapped in place of more than one model ({} and {})".format(
651 kwargs["to"].setting_name, swappable_setting
652 )
653 )
654 # Set it
655 kwargs["to"] = SettingsReference(
656 kwargs["to"],
657 swappable_setting,
658 )
659 return name, path, args, kwargs
661 def resolve_related_fields(self):
662 if not self.from_fields or len(self.from_fields) != len(self.to_fields):
663 raise ValueError(
664 "Foreign Object from and to fields must be the same non-zero length"
665 )
666 if isinstance(self.remote_field.model, str):
667 raise ValueError(
668 f"Related model {self.remote_field.model!r} cannot be resolved"
669 )
670 related_fields = []
671 for index in range(len(self.from_fields)):
672 from_field_name = self.from_fields[index]
673 to_field_name = self.to_fields[index]
674 from_field = (
675 self
676 if from_field_name == RECURSIVE_RELATIONSHIP_CONSTANT
677 else self.opts.get_field(from_field_name)
678 )
679 to_field = (
680 self.remote_field.model._meta.pk
681 if to_field_name is None
682 else self.remote_field.model._meta.get_field(to_field_name)
683 )
684 related_fields.append((from_field, to_field))
685 return related_fields
687 @cached_property
688 def related_fields(self):
689 return self.resolve_related_fields()
691 @cached_property
692 def reverse_related_fields(self):
693 return [(rhs_field, lhs_field) for lhs_field, rhs_field in self.related_fields]
695 @cached_property
696 def local_related_fields(self):
697 return tuple(lhs_field for lhs_field, rhs_field in self.related_fields)
699 @cached_property
700 def foreign_related_fields(self):
701 return tuple(
702 rhs_field for lhs_field, rhs_field in self.related_fields if rhs_field
703 )
705 def get_local_related_value(self, instance):
706 return self.get_instance_value_for_fields(instance, self.local_related_fields)
708 def get_foreign_related_value(self, instance):
709 return self.get_instance_value_for_fields(instance, self.foreign_related_fields)
711 @staticmethod
712 def get_instance_value_for_fields(instance, fields):
713 ret = []
714 opts = instance._meta
715 for field in fields:
716 # Gotcha: in some cases (like fixture loading) a model can have
717 # different values in parent_ptr_id and parent's id. So, use
718 # instance.pk (that is, parent_ptr_id) when asked for instance.id.
719 if field.primary_key:
720 possible_parent_link = opts.get_ancestor_link(field.model)
721 if (
722 not possible_parent_link
723 or possible_parent_link.primary_key
724 or possible_parent_link.model._meta.abstract
725 ):
726 ret.append(instance.pk)
727 continue
728 ret.append(getattr(instance, field.attname))
729 return tuple(ret)
731 def get_attname_column(self):
732 attname, column = super().get_attname_column()
733 return attname, None
735 def get_joining_columns(self, reverse_join=False):
736 source = self.reverse_related_fields if reverse_join else self.related_fields
737 return tuple(
738 (lhs_field.column, rhs_field.column) for lhs_field, rhs_field in source
739 )
741 def get_reverse_joining_columns(self):
742 return self.get_joining_columns(reverse_join=True)
744 def get_extra_descriptor_filter(self, instance):
745 """
746 Return an extra filter condition for related object fetching when
747 user does 'instance.fieldname', that is the extra filter is used in
748 the descriptor of the field.
750 The filter should be either a dict usable in .filter(**kwargs) call or
751 a Q-object. The condition will be ANDed together with the relation's
752 joining columns.
754 A parallel method is get_extra_restriction() which is used in
755 JOIN and subquery conditions.
756 """
757 return {}
759 def get_extra_restriction(self, alias, related_alias):
760 """
761 Return a pair condition used for joining and subquery pushdown. The
762 condition is something that responds to as_sql(compiler, connection)
763 method.
765 Note that currently referring both the 'alias' and 'related_alias'
766 will not work in some conditions, like subquery pushdown.
768 A parallel method is get_extra_descriptor_filter() which is used in
769 instance.fieldname related object fetching.
770 """
771 return None
773 def get_path_info(self, filtered_relation=None):
774 """Get path from this field to the related model."""
775 opts = self.remote_field.model._meta
776 from_opts = self.model._meta
777 return [
778 PathInfo(
779 from_opts=from_opts,
780 to_opts=opts,
781 target_fields=self.foreign_related_fields,
782 join_field=self,
783 m2m=False,
784 direct=True,
785 filtered_relation=filtered_relation,
786 )
787 ]
789 @cached_property
790 def path_infos(self):
791 return self.get_path_info()
793 def get_reverse_path_info(self, filtered_relation=None):
794 """Get path from the related model to this field's model."""
795 opts = self.model._meta
796 from_opts = self.remote_field.model._meta
797 return [
798 PathInfo(
799 from_opts=from_opts,
800 to_opts=opts,
801 target_fields=(opts.pk,),
802 join_field=self.remote_field,
803 m2m=not self.unique,
804 direct=False,
805 filtered_relation=filtered_relation,
806 )
807 ]
809 @cached_property
810 def reverse_path_infos(self):
811 return self.get_reverse_path_info()
813 @classmethod
814 @functools.cache
815 def get_class_lookups(cls):
816 bases = inspect.getmro(cls)
817 bases = bases[: bases.index(ForeignObject) + 1]
818 class_lookups = [parent.__dict__.get("class_lookups", {}) for parent in bases]
819 return cls.merge_dicts(class_lookups)
821 def contribute_to_class(self, cls, name, private_only=False, **kwargs):
822 super().contribute_to_class(cls, name, private_only=private_only, **kwargs)
823 setattr(cls, self.name, self.forward_related_accessor_class(self))
825 def contribute_to_related_class(self, cls, related):
826 # Internal FK's - i.e., those with a related name ending with '+' -
827 # and swapped models don't get a related descriptor.
828 if (
829 not self.remote_field.is_hidden()
830 and not related.related_model._meta.swapped
831 ):
832 setattr(
833 cls._meta.concrete_model,
834 related.get_accessor_name(),
835 self.related_accessor_class(related),
836 )
837 # While 'limit_choices_to' might be a callable, simply pass
838 # it along for later - this is too early because it's still
839 # model load time.
840 if self.remote_field.limit_choices_to:
841 cls._meta.related_fkey_lookups.append(
842 self.remote_field.limit_choices_to
843 )
846ForeignObject.register_lookup(RelatedIn)
847ForeignObject.register_lookup(RelatedExact)
848ForeignObject.register_lookup(RelatedLessThan)
849ForeignObject.register_lookup(RelatedGreaterThan)
850ForeignObject.register_lookup(RelatedGreaterThanOrEqual)
851ForeignObject.register_lookup(RelatedLessThanOrEqual)
852ForeignObject.register_lookup(RelatedIsNull)
855class ForeignKey(ForeignObject):
856 """
857 Provide a many-to-one relation by adding a column to the local model
858 to hold the remote value.
860 By default ForeignKey will target the pk of the remote model but this
861 behavior can be changed by using the ``to_field`` argument.
862 """
864 descriptor_class = ForeignKeyDeferredAttribute
865 # Field flags
866 many_to_many = False
867 many_to_one = True
868 one_to_many = False
869 one_to_one = False
871 rel_class = ManyToOneRel
873 empty_strings_allowed = False
874 default_error_messages = {
875 "invalid": "%(model)s instance with %(field)s %(value)r does not exist."
876 }
877 description = "Foreign Key (type determined by related field)"
879 def __init__(
880 self,
881 to,
882 on_delete,
883 related_name=None,
884 related_query_name=None,
885 limit_choices_to=None,
886 parent_link=False,
887 to_field=None,
888 db_constraint=True,
889 **kwargs,
890 ):
891 try:
892 to._meta.model_name
893 except AttributeError:
894 if not isinstance(to, str):
895 raise TypeError(
896 f"{self.__class__.__name__}({to!r}) is invalid. First parameter to ForeignKey must be "
897 f"either a model, a model name, or the string {RECURSIVE_RELATIONSHIP_CONSTANT!r}"
898 )
899 else:
900 # For backwards compatibility purposes, we need to *try* and set
901 # the to_field during FK construction. It won't be guaranteed to
902 # be correct until contribute_to_class is called. Refs #12190.
903 to_field = to_field or (to._meta.pk and to._meta.pk.name)
904 if not callable(on_delete):
905 raise TypeError("on_delete must be callable.")
907 kwargs["rel"] = self.rel_class(
908 self,
909 to,
910 to_field,
911 related_name=related_name,
912 related_query_name=related_query_name,
913 limit_choices_to=limit_choices_to,
914 parent_link=parent_link,
915 on_delete=on_delete,
916 )
917 kwargs.setdefault("db_index", True)
919 super().__init__(
920 to,
921 on_delete,
922 related_name=related_name,
923 related_query_name=related_query_name,
924 limit_choices_to=limit_choices_to,
925 from_fields=[RECURSIVE_RELATIONSHIP_CONSTANT],
926 to_fields=[to_field],
927 **kwargs,
928 )
929 self.db_constraint = db_constraint
931 def __class_getitem__(cls, *args, **kwargs):
932 return cls
934 def check(self, **kwargs):
935 return [
936 *super().check(**kwargs),
937 *self._check_on_delete(),
938 *self._check_unique(),
939 ]
941 def _check_on_delete(self):
942 on_delete = getattr(self.remote_field, "on_delete", None)
943 if on_delete == SET_NULL and not self.null:
944 return [
945 preflight.Error(
946 "Field specifies on_delete=SET_NULL, but cannot be null.",
947 hint=(
948 "Set null=True argument on the field, or change the on_delete "
949 "rule."
950 ),
951 obj=self,
952 id="fields.E320",
953 )
954 ]
955 elif on_delete == SET_DEFAULT and not self.has_default():
956 return [
957 preflight.Error(
958 "Field specifies on_delete=SET_DEFAULT, but has no default value.",
959 hint="Set a default value, or change the on_delete rule.",
960 obj=self,
961 id="fields.E321",
962 )
963 ]
964 else:
965 return []
967 def _check_unique(self, **kwargs):
968 return (
969 [
970 preflight.Warning(
971 "Setting unique=True on a ForeignKey has the same effect as using "
972 "a OneToOneField.",
973 hint=(
974 "ForeignKey(unique=True) is usually better served by a "
975 "OneToOneField."
976 ),
977 obj=self,
978 id="fields.W342",
979 )
980 ]
981 if self.unique
982 else []
983 )
985 def deconstruct(self):
986 name, path, args, kwargs = super().deconstruct()
987 del kwargs["to_fields"]
988 del kwargs["from_fields"]
989 # Handle the simpler arguments
990 if self.db_index:
991 del kwargs["db_index"]
992 else:
993 kwargs["db_index"] = False
994 if self.db_constraint is not True:
995 kwargs["db_constraint"] = self.db_constraint
996 # Rel needs more work.
997 to_meta = getattr(self.remote_field.model, "_meta", None)
998 if self.remote_field.field_name and (
999 not to_meta
1000 or (to_meta.pk and self.remote_field.field_name != to_meta.pk.name)
1001 ):
1002 kwargs["to_field"] = self.remote_field.field_name
1003 return name, path, args, kwargs
1005 def to_python(self, value):
1006 return self.target_field.to_python(value)
1008 @property
1009 def target_field(self):
1010 return self.foreign_related_fields[0]
1012 def validate(self, value, model_instance):
1013 if self.remote_field.parent_link:
1014 return
1015 super().validate(value, model_instance)
1016 if value is None:
1017 return
1019 using = router.db_for_read(self.remote_field.model, instance=model_instance)
1020 qs = self.remote_field.model._base_manager.using(using).filter(
1021 **{self.remote_field.field_name: value}
1022 )
1023 qs = qs.complex_filter(self.get_limit_choices_to())
1024 if not qs.exists():
1025 raise exceptions.ValidationError(
1026 self.error_messages["invalid"],
1027 code="invalid",
1028 params={
1029 "model": self.remote_field.model._meta.model_name,
1030 "pk": value,
1031 "field": self.remote_field.field_name,
1032 "value": value,
1033 }, # 'pk' is included for backwards compatibility
1034 )
1036 def resolve_related_fields(self):
1037 related_fields = super().resolve_related_fields()
1038 for from_field, to_field in related_fields:
1039 if (
1040 to_field
1041 and to_field.model != self.remote_field.model._meta.concrete_model
1042 ):
1043 raise exceptions.FieldError(
1044 f"'{self.model._meta.label}.{self.name}' refers to field '{to_field.name}' which is not local to model "
1045 f"'{self.remote_field.model._meta.concrete_model._meta.label}'."
1046 )
1047 return related_fields
1049 def get_attname(self):
1050 return f"{self.name}_id"
1052 def get_attname_column(self):
1053 attname = self.get_attname()
1054 column = self.db_column or attname
1055 return attname, column
1057 def get_default(self):
1058 """Return the to_field if the default value is an object."""
1059 field_default = super().get_default()
1060 if isinstance(field_default, self.remote_field.model):
1061 return getattr(field_default, self.target_field.attname)
1062 return field_default
1064 def get_db_prep_save(self, value, connection):
1065 if value is None or (
1066 value == ""
1067 and (
1068 not self.target_field.empty_strings_allowed
1069 or connection.features.interprets_empty_strings_as_nulls
1070 )
1071 ):
1072 return None
1073 else:
1074 return self.target_field.get_db_prep_save(value, connection=connection)
1076 def get_db_prep_value(self, value, connection, prepared=False):
1077 return self.target_field.get_db_prep_value(value, connection, prepared)
1079 def get_prep_value(self, value):
1080 return self.target_field.get_prep_value(value)
1082 def contribute_to_related_class(self, cls, related):
1083 super().contribute_to_related_class(cls, related)
1084 if self.remote_field.field_name is None:
1085 self.remote_field.field_name = cls._meta.pk.name
1087 def db_check(self, connection):
1088 return None
1090 def db_type(self, connection):
1091 return self.target_field.rel_db_type(connection=connection)
1093 def cast_db_type(self, connection):
1094 return self.target_field.cast_db_type(connection=connection)
1096 def db_parameters(self, connection):
1097 target_db_parameters = self.target_field.db_parameters(connection)
1098 return {
1099 "type": self.db_type(connection),
1100 "check": self.db_check(connection),
1101 "collation": target_db_parameters.get("collation"),
1102 }
1104 def convert_empty_strings(self, value, expression, connection):
1105 if (not value) and isinstance(value, str):
1106 return None
1107 return value
1109 def get_db_converters(self, connection):
1110 converters = super().get_db_converters(connection)
1111 if connection.features.interprets_empty_strings_as_nulls:
1112 converters += [self.convert_empty_strings]
1113 return converters
1115 def get_col(self, alias, output_field=None):
1116 if output_field is None:
1117 output_field = self.target_field
1118 while isinstance(output_field, ForeignKey):
1119 output_field = output_field.target_field
1120 if output_field is self:
1121 raise ValueError("Cannot resolve output_field.")
1122 return super().get_col(alias, output_field)
1125class OneToOneField(ForeignKey):
1126 """
1127 A OneToOneField is essentially the same as a ForeignKey, with the exception
1128 that it always carries a "unique" constraint with it and the reverse
1129 relation always returns the object pointed to (since there will only ever
1130 be one), rather than returning a list.
1131 """
1133 # Field flags
1134 many_to_many = False
1135 many_to_one = False
1136 one_to_many = False
1137 one_to_one = True
1139 related_accessor_class = ReverseOneToOneDescriptor
1140 forward_related_accessor_class = ForwardOneToOneDescriptor
1141 rel_class = OneToOneRel
1143 description = "One-to-one relationship"
1145 def __init__(self, to, on_delete, to_field=None, **kwargs):
1146 kwargs["unique"] = True
1147 super().__init__(to, on_delete, to_field=to_field, **kwargs)
1149 def deconstruct(self):
1150 name, path, args, kwargs = super().deconstruct()
1151 if "unique" in kwargs:
1152 del kwargs["unique"]
1153 return name, path, args, kwargs
1155 def save_form_data(self, instance, data):
1156 if isinstance(data, self.remote_field.model):
1157 setattr(instance, self.name, data)
1158 else:
1159 setattr(instance, self.attname, data)
1160 # Remote field object must be cleared otherwise Model.save()
1161 # will reassign attname using the related object pk.
1162 if data is None:
1163 setattr(instance, self.name, data)
1165 def _check_unique(self, **kwargs):
1166 # Override ForeignKey since check isn't applicable here.
1167 return []
1170def create_many_to_many_intermediary_model(field, klass):
1171 from plain import models
1173 def set_managed(model, related, through):
1174 through._meta.managed = model._meta.managed or related._meta.managed
1176 to_model = resolve_relation(klass, field.remote_field.model)
1177 name = f"{klass._meta.object_name}_{field.name}"
1178 lazy_related_operation(set_managed, klass, to_model, name)
1180 to = make_model_tuple(to_model)[1]
1181 from_ = klass._meta.model_name
1182 if to == from_:
1183 to = f"to_{to}"
1184 from_ = f"from_{from_}"
1186 meta = type(
1187 "Meta",
1188 (),
1189 {
1190 "db_table": field._get_m2m_db_table(klass._meta),
1191 "auto_created": klass,
1192 "package_label": klass._meta.package_label,
1193 "db_tablespace": klass._meta.db_tablespace,
1194 "constraints": [
1195 models.UniqueConstraint(
1196 fields=[from_, to],
1197 name=f"{klass._meta.package_label}_{name.lower()}_unique",
1198 )
1199 ],
1200 "packages": field.model._meta.packages,
1201 },
1202 )
1203 # Construct and return the new class.
1204 return type(
1205 name,
1206 (models.Model,),
1207 {
1208 "Meta": meta,
1209 "__module__": klass.__module__,
1210 from_: models.ForeignKey(
1211 klass,
1212 related_name=f"{name}+",
1213 db_tablespace=field.db_tablespace,
1214 db_constraint=field.remote_field.db_constraint,
1215 on_delete=CASCADE,
1216 ),
1217 to: models.ForeignKey(
1218 to_model,
1219 related_name=f"{name}+",
1220 db_tablespace=field.db_tablespace,
1221 db_constraint=field.remote_field.db_constraint,
1222 on_delete=CASCADE,
1223 ),
1224 },
1225 )
1228class ManyToManyField(RelatedField):
1229 """
1230 Provide a many-to-many relation by using an intermediary model that
1231 holds two ForeignKey fields pointed at the two sides of the relation.
1233 Unless a ``through`` model was provided, ManyToManyField will use the
1234 create_many_to_many_intermediary_model factory to automatically generate
1235 the intermediary model.
1236 """
1238 # Field flags
1239 many_to_many = True
1240 many_to_one = False
1241 one_to_many = False
1242 one_to_one = False
1244 rel_class = ManyToManyRel
1246 description = "Many-to-many relationship"
1248 def __init__(
1249 self,
1250 to,
1251 related_name=None,
1252 related_query_name=None,
1253 limit_choices_to=None,
1254 symmetrical=None,
1255 through=None,
1256 through_fields=None,
1257 db_constraint=True,
1258 db_table=None,
1259 swappable=True,
1260 **kwargs,
1261 ):
1262 try:
1263 to._meta
1264 except AttributeError:
1265 if not isinstance(to, str):
1266 raise TypeError(
1267 f"{self.__class__.__name__}({to!r}) is invalid. First parameter to ManyToManyField "
1268 f"must be either a model, a model name, or the string {RECURSIVE_RELATIONSHIP_CONSTANT!r}"
1269 )
1271 if symmetrical is None:
1272 symmetrical = to == RECURSIVE_RELATIONSHIP_CONSTANT
1274 if through is not None and db_table is not None:
1275 raise ValueError(
1276 "Cannot specify a db_table if an intermediary model is used."
1277 )
1279 kwargs["rel"] = self.rel_class(
1280 self,
1281 to,
1282 related_name=related_name,
1283 related_query_name=related_query_name,
1284 limit_choices_to=limit_choices_to,
1285 symmetrical=symmetrical,
1286 through=through,
1287 through_fields=through_fields,
1288 db_constraint=db_constraint,
1289 )
1290 self.has_null_arg = "null" in kwargs
1292 super().__init__(
1293 related_name=related_name,
1294 related_query_name=related_query_name,
1295 limit_choices_to=limit_choices_to,
1296 **kwargs,
1297 )
1299 self.db_table = db_table
1300 self.swappable = swappable
1302 def check(self, **kwargs):
1303 return [
1304 *super().check(**kwargs),
1305 *self._check_unique(**kwargs),
1306 *self._check_relationship_model(**kwargs),
1307 *self._check_ignored_options(**kwargs),
1308 *self._check_table_uniqueness(**kwargs),
1309 ]
1311 def _check_unique(self, **kwargs):
1312 if self.unique:
1313 return [
1314 preflight.Error(
1315 "ManyToManyFields cannot be unique.",
1316 obj=self,
1317 id="fields.E330",
1318 )
1319 ]
1320 return []
1322 def _check_ignored_options(self, **kwargs):
1323 warnings = []
1325 if self.has_null_arg:
1326 warnings.append(
1327 preflight.Warning(
1328 "null has no effect on ManyToManyField.",
1329 obj=self,
1330 id="fields.W340",
1331 )
1332 )
1334 if self._validators:
1335 warnings.append(
1336 preflight.Warning(
1337 "ManyToManyField does not support validators.",
1338 obj=self,
1339 id="fields.W341",
1340 )
1341 )
1342 if self.remote_field.symmetrical and self._related_name:
1343 warnings.append(
1344 preflight.Warning(
1345 "related_name has no effect on ManyToManyField "
1346 'with a symmetrical relationship, e.g. to "self".',
1347 obj=self,
1348 id="fields.W345",
1349 )
1350 )
1351 if self.db_comment:
1352 warnings.append(
1353 preflight.Warning(
1354 "db_comment has no effect on ManyToManyField.",
1355 obj=self,
1356 id="fields.W346",
1357 )
1358 )
1360 return warnings
1362 def _check_relationship_model(self, from_model=None, **kwargs):
1363 if hasattr(self.remote_field.through, "_meta"):
1364 qualified_model_name = f"{self.remote_field.through._meta.package_label}.{self.remote_field.through.__name__}"
1365 else:
1366 qualified_model_name = self.remote_field.through
1368 errors = []
1370 if self.remote_field.through not in self.opts.packages.get_models(
1371 include_auto_created=True
1372 ):
1373 # The relationship model is not installed.
1374 errors.append(
1375 preflight.Error(
1376 "Field specifies a many-to-many relation through model "
1377 f"'{qualified_model_name}', which has not been installed.",
1378 obj=self,
1379 id="fields.E331",
1380 )
1381 )
1383 else:
1384 assert from_model is not None, (
1385 "ManyToManyField with intermediate "
1386 "tables cannot be checked if you don't pass the model "
1387 "where the field is attached to."
1388 )
1389 # Set some useful local variables
1390 to_model = resolve_relation(from_model, self.remote_field.model)
1391 from_model_name = from_model._meta.object_name
1392 if isinstance(to_model, str):
1393 to_model_name = to_model
1394 else:
1395 to_model_name = to_model._meta.object_name
1396 relationship_model_name = self.remote_field.through._meta.object_name
1397 self_referential = from_model == to_model
1398 # Count foreign keys in intermediate model
1399 if self_referential:
1400 seen_self = sum(
1401 from_model == getattr(field.remote_field, "model", None)
1402 for field in self.remote_field.through._meta.fields
1403 )
1405 if seen_self > 2 and not self.remote_field.through_fields:
1406 errors.append(
1407 preflight.Error(
1408 "The model is used as an intermediate model by "
1409 f"'{self}', but it has more than two foreign keys "
1410 f"to '{from_model_name}', which is ambiguous. You must specify "
1411 "which two foreign keys Plain should use via the "
1412 "through_fields keyword argument.",
1413 hint=(
1414 "Use through_fields to specify which two foreign keys "
1415 "Plain should use."
1416 ),
1417 obj=self.remote_field.through,
1418 id="fields.E333",
1419 )
1420 )
1422 else:
1423 # Count foreign keys in relationship model
1424 seen_from = sum(
1425 from_model == getattr(field.remote_field, "model", None)
1426 for field in self.remote_field.through._meta.fields
1427 )
1428 seen_to = sum(
1429 to_model == getattr(field.remote_field, "model", None)
1430 for field in self.remote_field.through._meta.fields
1431 )
1433 if seen_from > 1 and not self.remote_field.through_fields:
1434 errors.append(
1435 preflight.Error(
1436 (
1437 "The model is used as an intermediate model by "
1438 f"'{self}', but it has more than one foreign key "
1439 f"from '{from_model_name}', which is ambiguous. You must specify "
1440 "which foreign key Plain should use via the "
1441 "through_fields keyword argument."
1442 ),
1443 hint=(
1444 "If you want to create a recursive relationship, "
1445 f'use ManyToManyField("{RECURSIVE_RELATIONSHIP_CONSTANT}", through="{relationship_model_name}").'
1446 ),
1447 obj=self,
1448 id="fields.E334",
1449 )
1450 )
1452 if seen_to > 1 and not self.remote_field.through_fields:
1453 errors.append(
1454 preflight.Error(
1455 "The model is used as an intermediate model by "
1456 f"'{self}', but it has more than one foreign key "
1457 f"to '{to_model_name}', which is ambiguous. You must specify "
1458 "which foreign key Plain should use via the "
1459 "through_fields keyword argument.",
1460 hint=(
1461 "If you want to create a recursive relationship, "
1462 f'use ManyToManyField("{RECURSIVE_RELATIONSHIP_CONSTANT}", through="{relationship_model_name}").'
1463 ),
1464 obj=self,
1465 id="fields.E335",
1466 )
1467 )
1469 if seen_from == 0 or seen_to == 0:
1470 errors.append(
1471 preflight.Error(
1472 "The model is used as an intermediate model by "
1473 f"'{self}', but it does not have a foreign key to '{from_model_name}' or '{to_model_name}'.",
1474 obj=self.remote_field.through,
1475 id="fields.E336",
1476 )
1477 )
1479 # Validate `through_fields`.
1480 if self.remote_field.through_fields is not None:
1481 # Validate that we're given an iterable of at least two items
1482 # and that none of them is "falsy".
1483 if not (
1484 len(self.remote_field.through_fields) >= 2
1485 and self.remote_field.through_fields[0]
1486 and self.remote_field.through_fields[1]
1487 ):
1488 errors.append(
1489 preflight.Error(
1490 "Field specifies 'through_fields' but does not provide "
1491 "the names of the two link fields that should be used "
1492 f"for the relation through model '{qualified_model_name}'.",
1493 hint=(
1494 "Make sure you specify 'through_fields' as "
1495 "through_fields=('field1', 'field2')"
1496 ),
1497 obj=self,
1498 id="fields.E337",
1499 )
1500 )
1502 # Validate the given through fields -- they should be actual
1503 # fields on the through model, and also be foreign keys to the
1504 # expected models.
1505 else:
1506 assert from_model is not None, (
1507 "ManyToManyField with intermediate "
1508 "tables cannot be checked if you don't pass the model "
1509 "where the field is attached to."
1510 )
1512 source, through, target = (
1513 from_model,
1514 self.remote_field.through,
1515 self.remote_field.model,
1516 )
1517 source_field_name, target_field_name = self.remote_field.through_fields[
1518 :2
1519 ]
1521 for field_name, related_model in (
1522 (source_field_name, source),
1523 (target_field_name, target),
1524 ):
1525 possible_field_names = []
1526 for f in through._meta.fields:
1527 if (
1528 hasattr(f, "remote_field")
1529 and getattr(f.remote_field, "model", None) == related_model
1530 ):
1531 possible_field_names.append(f.name)
1532 if possible_field_names:
1533 hint = (
1534 "Did you mean one of the following foreign keys to '{}': "
1535 "{}?".format(
1536 related_model._meta.object_name,
1537 ", ".join(possible_field_names),
1538 )
1539 )
1540 else:
1541 hint = None
1543 try:
1544 field = through._meta.get_field(field_name)
1545 except exceptions.FieldDoesNotExist:
1546 errors.append(
1547 preflight.Error(
1548 f"The intermediary model '{qualified_model_name}' has no field '{field_name}'.",
1549 hint=hint,
1550 obj=self,
1551 id="fields.E338",
1552 )
1553 )
1554 else:
1555 if not (
1556 hasattr(field, "remote_field")
1557 and getattr(field.remote_field, "model", None)
1558 == related_model
1559 ):
1560 errors.append(
1561 preflight.Error(
1562 f"'{through._meta.object_name}.{field_name}' is not a foreign key to '{related_model._meta.object_name}'.",
1563 hint=hint,
1564 obj=self,
1565 id="fields.E339",
1566 )
1567 )
1569 return errors
1571 def _check_table_uniqueness(self, **kwargs):
1572 if (
1573 isinstance(self.remote_field.through, str)
1574 or not self.remote_field.through._meta.managed
1575 ):
1576 return []
1577 registered_tables = {
1578 model._meta.db_table: model
1579 for model in self.opts.packages.get_models(include_auto_created=True)
1580 if model != self.remote_field.through and model._meta.managed
1581 }
1582 m2m_db_table = self.m2m_db_table()
1583 model = registered_tables.get(m2m_db_table)
1584 # The second condition allows multiple m2m relations on a model if
1585 # some point to a through model that proxies another through model.
1586 if (
1587 model
1588 and model._meta.concrete_model
1589 != self.remote_field.through._meta.concrete_model
1590 ):
1591 if model._meta.auto_created:
1593 def _get_field_name(model):
1594 for field in model._meta.auto_created._meta.many_to_many:
1595 if field.remote_field.through is model:
1596 return field.name
1598 opts = model._meta.auto_created._meta
1599 clashing_obj = f"{opts.label}.{_get_field_name(model)}"
1600 else:
1601 clashing_obj = model._meta.label
1602 if settings.DATABASE_ROUTERS:
1603 error_class, error_id = preflight.Warning, "fields.W344"
1604 error_hint = (
1605 "You have configured settings.DATABASE_ROUTERS. Verify "
1606 f"that the table of {clashing_obj!r} is correctly routed to a separate "
1607 "database."
1608 )
1609 else:
1610 error_class, error_id = preflight.Error, "fields.E340"
1611 error_hint = None
1612 return [
1613 error_class(
1614 f"The field's intermediary table '{m2m_db_table}' clashes with the "
1615 f"table name of '{clashing_obj}'.",
1616 obj=self,
1617 hint=error_hint,
1618 id=error_id,
1619 )
1620 ]
1621 return []
1623 def deconstruct(self):
1624 name, path, args, kwargs = super().deconstruct()
1625 # Handle the simpler arguments.
1626 if self.db_table is not None:
1627 kwargs["db_table"] = self.db_table
1628 if self.remote_field.db_constraint is not True:
1629 kwargs["db_constraint"] = self.remote_field.db_constraint
1630 # Lowercase model names as they should be treated as case-insensitive.
1631 if isinstance(self.remote_field.model, str):
1632 if "." in self.remote_field.model:
1633 package_label, model_name = self.remote_field.model.split(".")
1634 kwargs["to"] = f"{package_label}.{model_name.lower()}"
1635 else:
1636 kwargs["to"] = self.remote_field.model.lower()
1637 else:
1638 kwargs["to"] = self.remote_field.model._meta.label_lower
1639 if getattr(self.remote_field, "through", None) is not None:
1640 if isinstance(self.remote_field.through, str):
1641 kwargs["through"] = self.remote_field.through
1642 elif not self.remote_field.through._meta.auto_created:
1643 kwargs["through"] = self.remote_field.through._meta.label
1644 # If swappable is True, then see if we're actually pointing to the target
1645 # of a swap.
1646 swappable_setting = self.swappable_setting
1647 if swappable_setting is not None:
1648 # If it's already a settings reference, error.
1649 if hasattr(kwargs["to"], "setting_name"):
1650 if kwargs["to"].setting_name != swappable_setting:
1651 raise ValueError(
1652 "Cannot deconstruct a ManyToManyField pointing to a "
1653 "model that is swapped in place of more than one model "
1654 "({} and {})".format(
1655 kwargs["to"].setting_name, swappable_setting
1656 )
1657 )
1659 kwargs["to"] = SettingsReference(
1660 kwargs["to"],
1661 swappable_setting,
1662 )
1663 return name, path, args, kwargs
1665 def _get_path_info(self, direct=False, filtered_relation=None):
1666 """Called by both direct and indirect m2m traversal."""
1667 int_model = self.remote_field.through
1668 linkfield1 = int_model._meta.get_field(self.m2m_field_name())
1669 linkfield2 = int_model._meta.get_field(self.m2m_reverse_field_name())
1670 if direct:
1671 join1infos = linkfield1.reverse_path_infos
1672 if filtered_relation:
1673 join2infos = linkfield2.get_path_info(filtered_relation)
1674 else:
1675 join2infos = linkfield2.path_infos
1676 else:
1677 join1infos = linkfield2.reverse_path_infos
1678 if filtered_relation:
1679 join2infos = linkfield1.get_path_info(filtered_relation)
1680 else:
1681 join2infos = linkfield1.path_infos
1682 # Get join infos between the last model of join 1 and the first model
1683 # of join 2. Assume the only reason these may differ is due to model
1684 # inheritance.
1685 join1_final = join1infos[-1].to_opts
1686 join2_initial = join2infos[0].from_opts
1687 if join1_final is join2_initial:
1688 intermediate_infos = []
1689 elif issubclass(join1_final.model, join2_initial.model):
1690 intermediate_infos = join1_final.get_path_to_parent(join2_initial.model)
1691 else:
1692 intermediate_infos = join2_initial.get_path_from_parent(join1_final.model)
1694 return [*join1infos, *intermediate_infos, *join2infos]
1696 def get_path_info(self, filtered_relation=None):
1697 return self._get_path_info(direct=True, filtered_relation=filtered_relation)
1699 @cached_property
1700 def path_infos(self):
1701 return self.get_path_info()
1703 def get_reverse_path_info(self, filtered_relation=None):
1704 return self._get_path_info(direct=False, filtered_relation=filtered_relation)
1706 @cached_property
1707 def reverse_path_infos(self):
1708 return self.get_reverse_path_info()
1710 def _get_m2m_db_table(self, opts):
1711 """
1712 Function that can be curried to provide the m2m table name for this
1713 relation.
1714 """
1715 if self.remote_field.through is not None:
1716 return self.remote_field.through._meta.db_table
1717 elif self.db_table:
1718 return self.db_table
1719 else:
1720 m2m_table_name = f"{utils.strip_quotes(opts.db_table)}_{self.name}"
1721 return utils.truncate_name(m2m_table_name, connection.ops.max_name_length())
1723 def _get_m2m_attr(self, related, attr):
1724 """
1725 Function that can be curried to provide the source accessor or DB
1726 column name for the m2m table.
1727 """
1728 cache_attr = f"_m2m_{attr}_cache"
1729 if hasattr(self, cache_attr):
1730 return getattr(self, cache_attr)
1731 if self.remote_field.through_fields is not None:
1732 link_field_name = self.remote_field.through_fields[0]
1733 else:
1734 link_field_name = None
1735 for f in self.remote_field.through._meta.fields:
1736 if (
1737 f.is_relation
1738 and f.remote_field.model == related.related_model
1739 and (link_field_name is None or link_field_name == f.name)
1740 ):
1741 setattr(self, cache_attr, getattr(f, attr))
1742 return getattr(self, cache_attr)
1744 def _get_m2m_reverse_attr(self, related, attr):
1745 """
1746 Function that can be curried to provide the related accessor or DB
1747 column name for the m2m table.
1748 """
1749 cache_attr = f"_m2m_reverse_{attr}_cache"
1750 if hasattr(self, cache_attr):
1751 return getattr(self, cache_attr)
1752 found = False
1753 if self.remote_field.through_fields is not None:
1754 link_field_name = self.remote_field.through_fields[1]
1755 else:
1756 link_field_name = None
1757 for f in self.remote_field.through._meta.fields:
1758 if f.is_relation and f.remote_field.model == related.model:
1759 if link_field_name is None and related.related_model == related.model:
1760 # If this is an m2m-intermediate to self,
1761 # the first foreign key you find will be
1762 # the source column. Keep searching for
1763 # the second foreign key.
1764 if found:
1765 setattr(self, cache_attr, getattr(f, attr))
1766 break
1767 else:
1768 found = True
1769 elif link_field_name is None or link_field_name == f.name:
1770 setattr(self, cache_attr, getattr(f, attr))
1771 break
1772 return getattr(self, cache_attr)
1774 def contribute_to_class(self, cls, name, **kwargs):
1775 # To support multiple relations to self, it's useful to have a non-None
1776 # related name on symmetrical relations for internal reasons. The
1777 # concept doesn't make a lot of sense externally ("you want me to
1778 # specify *what* on my non-reversible relation?!"), so we set it up
1779 # automatically. The funky name reduces the chance of an accidental
1780 # clash.
1781 if self.remote_field.symmetrical and (
1782 self.remote_field.model == RECURSIVE_RELATIONSHIP_CONSTANT
1783 or self.remote_field.model == cls._meta.object_name
1784 ):
1785 self.remote_field.related_name = f"{name}_rel_+"
1786 elif self.remote_field.is_hidden():
1787 # If the backwards relation is disabled, replace the original
1788 # related_name with one generated from the m2m field name. Django
1789 # still uses backwards relations internally and we need to avoid
1790 # clashes between multiple m2m fields with related_name == '+'.
1791 self.remote_field.related_name = (
1792 f"_{cls._meta.package_label}_{cls.__name__.lower()}_{name}_+"
1793 )
1795 super().contribute_to_class(cls, name, **kwargs)
1797 # The intermediate m2m model is not auto created if:
1798 # 1) There is a manually specified intermediate, or
1799 # 2) The class owning the m2m field is abstract.
1800 # 3) The class owning the m2m field has been swapped out.
1801 if not cls._meta.abstract:
1802 if self.remote_field.through:
1804 def resolve_through_model(_, model, field):
1805 field.remote_field.through = model
1807 lazy_related_operation(
1808 resolve_through_model, cls, self.remote_field.through, field=self
1809 )
1810 elif not cls._meta.swapped:
1811 self.remote_field.through = create_many_to_many_intermediary_model(
1812 self, cls
1813 )
1815 # Add the descriptor for the m2m relation.
1816 setattr(cls, self.name, ManyToManyDescriptor(self.remote_field, reverse=False))
1818 # Set up the accessor for the m2m table name for the relation.
1819 self.m2m_db_table = partial(self._get_m2m_db_table, cls._meta)
1821 def contribute_to_related_class(self, cls, related):
1822 # Internal M2Ms (i.e., those with a related name ending with '+')
1823 # and swapped models don't get a related descriptor.
1824 if (
1825 not self.remote_field.is_hidden()
1826 and not related.related_model._meta.swapped
1827 ):
1828 setattr(
1829 cls,
1830 related.get_accessor_name(),
1831 ManyToManyDescriptor(self.remote_field, reverse=True),
1832 )
1834 # Set up the accessors for the column names on the m2m table.
1835 self.m2m_column_name = partial(self._get_m2m_attr, related, "column")
1836 self.m2m_reverse_name = partial(self._get_m2m_reverse_attr, related, "column")
1838 self.m2m_field_name = partial(self._get_m2m_attr, related, "name")
1839 self.m2m_reverse_field_name = partial(
1840 self._get_m2m_reverse_attr, related, "name"
1841 )
1843 get_m2m_rel = partial(self._get_m2m_attr, related, "remote_field")
1844 self.m2m_target_field_name = lambda: get_m2m_rel().field_name
1845 get_m2m_reverse_rel = partial(
1846 self._get_m2m_reverse_attr, related, "remote_field"
1847 )
1848 self.m2m_reverse_target_field_name = lambda: get_m2m_reverse_rel().field_name
1850 def set_attributes_from_rel(self):
1851 pass
1853 def value_from_object(self, obj):
1854 return [] if obj.pk is None else list(getattr(obj, self.attname).all())
1856 def save_form_data(self, instance, data):
1857 getattr(instance, self.attname).set(data)
1859 def db_check(self, connection):
1860 return None
1862 def db_type(self, connection):
1863 # A ManyToManyField is not represented by a single column,
1864 # so return None.
1865 return None
1867 def db_parameters(self, connection):
1868 return {"type": None, "check": None}
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2"Rel objects" for related fields.
4"Rel objects" (for lack of a better name) carry information about the relation
5modeled by a related field and provide some utility functions. They're stored
6in the ``remote_field`` attribute of the field.
8They also act as reverse fields for the purposes of the Meta API because
9they're the closest concept currently available.
10"""
12from plain import exceptions
13from plain.utils.functional import cached_property
14from plain.utils.hashable import make_hashable
16from . import BLANK_CHOICE_DASH
17from .mixins import FieldCacheMixin
20class ForeignObjectRel(FieldCacheMixin):
21 """
22 Used by ForeignObject to store information about the relation.
24 ``_meta.get_fields()`` returns this class to provide access to the field
25 flags for the reverse relation.
26 """
28 # Field flags
29 auto_created = True
30 concrete = False
31 editable = False
32 is_relation = True
34 # Reverse relations are always nullable (Plain can't enforce that a
35 # foreign key on the related model points to this model).
36 null = True
37 empty_strings_allowed = False
39 def __init__(
40 self,
41 field,
42 to,
43 related_name=None,
44 related_query_name=None,
45 limit_choices_to=None,
46 parent_link=False,
47 on_delete=None,
48 ):
49 self.field = field
50 self.model = to
51 self.related_name = related_name
52 self.related_query_name = related_query_name
53 self.limit_choices_to = {} if limit_choices_to is None else limit_choices_to
54 self.parent_link = parent_link
55 self.on_delete = on_delete
57 self.symmetrical = False
58 self.multiple = True
60 # Some of the following cached_properties can't be initialized in
61 # __init__ as the field doesn't have its model yet. Calling these methods
62 # before field.contribute_to_class() has been called will result in
63 # AttributeError
64 @cached_property
65 def hidden(self):
66 return self.is_hidden()
68 @cached_property
69 def name(self):
70 return self.field.related_query_name()
72 @property
73 def remote_field(self):
74 return self.field
76 @property
77 def target_field(self):
78 """
79 When filtering against this relation, return the field on the remote
80 model against which the filtering should happen.
81 """
82 target_fields = self.path_infos[-1].target_fields
83 if len(target_fields) > 1:
84 raise exceptions.FieldError(
85 "Can't use target_field for multicolumn relations."
86 )
87 return target_fields[0]
89 @cached_property
90 def related_model(self):
91 if not self.field.model:
92 raise AttributeError(
93 "This property can't be accessed before self.field.contribute_to_class "
94 "has been called."
95 )
96 return self.field.model
98 @cached_property
99 def many_to_many(self):
100 return self.field.many_to_many
102 @cached_property
103 def many_to_one(self):
104 return self.field.one_to_many
106 @cached_property
107 def one_to_many(self):
108 return self.field.many_to_one
110 @cached_property
111 def one_to_one(self):
112 return self.field.one_to_one
114 def get_lookup(self, lookup_name):
115 return self.field.get_lookup(lookup_name)
117 def get_internal_type(self):
118 return self.field.get_internal_type()
120 @property
121 def db_type(self):
122 return self.field.db_type
124 def __repr__(self):
125 return f"<{type(self).__name__}: {self.related_model._meta.package_label}.{self.related_model._meta.model_name}>"
127 @property
128 def identity(self):
129 return (
130 self.field,
131 self.model,
132 self.related_name,
133 self.related_query_name,
134 make_hashable(self.limit_choices_to),
135 self.parent_link,
136 self.on_delete,
137 self.symmetrical,
138 self.multiple,
139 )
141 def __eq__(self, other):
142 if not isinstance(other, self.__class__):
143 return NotImplemented
144 return self.identity == other.identity
146 def __hash__(self):
147 return hash(self.identity)
149 def __getstate__(self):
150 state = self.__dict__.copy()
151 # Delete the path_infos cached property because it can be recalculated
152 # at first invocation after deserialization. The attribute must be
153 # removed because subclasses like ManyToOneRel may have a PathInfo
154 # which contains an intermediate M2M table that's been dynamically
155 # created and doesn't exist in the .models module.
156 # This is a reverse relation, so there is no reverse_path_infos to
157 # delete.
158 state.pop("path_infos", None)
159 return state
161 def get_choices(
162 self,
163 include_blank=True,
164 blank_choice=BLANK_CHOICE_DASH,
165 limit_choices_to=None,
166 ordering=(),
167 ):
168 """
169 Return choices with a default blank choices included, for use
170 as <select> choices for this field.
172 Analog of plain.models.fields.Field.get_choices(), provided
173 initially for utilization by RelatedFieldListFilter.
174 """
175 limit_choices_to = limit_choices_to or self.limit_choices_to
176 qs = self.related_model._default_manager.complex_filter(limit_choices_to)
177 if ordering:
178 qs = qs.order_by(*ordering)
179 return (blank_choice if include_blank else []) + [(x.pk, str(x)) for x in qs]
181 def is_hidden(self):
182 """Should the related object be hidden?"""
183 return bool(self.related_name) and self.related_name[-1] == "+"
185 def get_joining_columns(self):
186 return self.field.get_reverse_joining_columns()
188 def get_extra_restriction(self, alias, related_alias):
189 return self.field.get_extra_restriction(related_alias, alias)
191 def set_field_name(self):
192 """
193 Set the related field's name, this is not available until later stages
194 of app loading, so set_field_name is called from
195 set_attributes_from_rel()
196 """
197 # By default foreign object doesn't relate to any remote field (for
198 # example custom multicolumn joins currently have no remote field).
199 self.field_name = None
201 def get_accessor_name(self, model=None):
202 # This method encapsulates the logic that decides what name to give an
203 # accessor descriptor that retrieves related many-to-one or
204 # many-to-many objects. It uses the lowercased object_name + "_set",
205 # but this can be overridden with the "related_name" option. Due to
206 # backwards compatibility ModelForms need to be able to provide an
207 # alternate model. See BaseInlineFormSet.get_default_prefix().
208 opts = model._meta if model else self.related_model._meta
209 model = model or self.related_model
210 if self.multiple:
211 # If this is a symmetrical m2m relation on self, there is no
212 # reverse accessor.
213 if self.symmetrical and model == self.model:
214 return None
215 if self.related_name:
216 return self.related_name
217 return opts.model_name + ("_set" if self.multiple else "")
219 def get_path_info(self, filtered_relation=None):
220 if filtered_relation:
221 return self.field.get_reverse_path_info(filtered_relation)
222 else:
223 return self.field.reverse_path_infos
225 @cached_property
226 def path_infos(self):
227 return self.get_path_info()
229 def get_cache_name(self):
230 """
231 Return the name of the cache key to use for storing an instance of the
232 forward model on the reverse model.
233 """
234 return self.get_accessor_name()
237class ManyToOneRel(ForeignObjectRel):
238 """
239 Used by the ForeignKey field to store information about the relation.
241 ``_meta.get_fields()`` returns this class to provide access to the field
242 flags for the reverse relation.
244 Note: Because we somewhat abuse the Rel objects by using them as reverse
245 fields we get the funny situation where
246 ``ManyToOneRel.many_to_one == False`` and
247 ``ManyToOneRel.one_to_many == True``. This is unfortunate but the actual
248 ManyToOneRel class is a private API and there is work underway to turn
249 reverse relations into actual fields.
250 """
252 def __init__(
253 self,
254 field,
255 to,
256 field_name,
257 related_name=None,
258 related_query_name=None,
259 limit_choices_to=None,
260 parent_link=False,
261 on_delete=None,
262 ):
263 super().__init__(
264 field,
265 to,
266 related_name=related_name,
267 related_query_name=related_query_name,
268 limit_choices_to=limit_choices_to,
269 parent_link=parent_link,
270 on_delete=on_delete,
271 )
273 self.field_name = field_name
275 def __getstate__(self):
276 state = super().__getstate__()
277 state.pop("related_model", None)
278 return state
280 @property
281 def identity(self):
282 return super().identity + (self.field_name,)
284 def get_related_field(self):
285 """
286 Return the Field in the 'to' object to which this relationship is tied.
287 """
288 field = self.model._meta.get_field(self.field_name)
289 if not field.concrete:
290 raise exceptions.FieldDoesNotExist(
291 f"No related field named '{self.field_name}'"
292 )
293 return field
295 def set_field_name(self):
296 self.field_name = self.field_name or self.model._meta.pk.name
299class OneToOneRel(ManyToOneRel):
300 """
301 Used by OneToOneField to store information about the relation.
303 ``_meta.get_fields()`` returns this class to provide access to the field
304 flags for the reverse relation.
305 """
307 def __init__(
308 self,
309 field,
310 to,
311 field_name,
312 related_name=None,
313 related_query_name=None,
314 limit_choices_to=None,
315 parent_link=False,
316 on_delete=None,
317 ):
318 super().__init__(
319 field,
320 to,
321 field_name,
322 related_name=related_name,
323 related_query_name=related_query_name,
324 limit_choices_to=limit_choices_to,
325 parent_link=parent_link,
326 on_delete=on_delete,
327 )
329 self.multiple = False
332class ManyToManyRel(ForeignObjectRel):
333 """
334 Used by ManyToManyField to store information about the relation.
336 ``_meta.get_fields()`` returns this class to provide access to the field
337 flags for the reverse relation.
338 """
340 def __init__(
341 self,
342 field,
343 to,
344 related_name=None,
345 related_query_name=None,
346 limit_choices_to=None,
347 symmetrical=True,
348 through=None,
349 through_fields=None,
350 db_constraint=True,
351 ):
352 super().__init__(
353 field,
354 to,
355 related_name=related_name,
356 related_query_name=related_query_name,
357 limit_choices_to=limit_choices_to,
358 )
360 if through and not db_constraint:
361 raise ValueError("Can't supply a through model and db_constraint=False")
362 self.through = through
364 if through_fields and not through:
365 raise ValueError("Cannot specify through_fields without a through model")
366 self.through_fields = through_fields
368 self.symmetrical = symmetrical
369 self.db_constraint = db_constraint
371 @property
372 def identity(self):
373 return super().identity + (
374 self.through,
375 make_hashable(self.through_fields),
376 self.db_constraint,
377 )
379 def get_related_field(self):
380 """
381 Return the field in the 'to' object to which this relationship is tied.
382 Provided for symmetry with ManyToOneRel.
383 """
384 opts = self.through._meta
385 if self.through_fields:
386 field = opts.get_field(self.through_fields[0])
387 else:
388 for field in opts.fields:
389 rel = getattr(field, "remote_field", None)
390 if rel and rel.model == self.model:
391 break
392 return field.foreign_related_fields[0]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import collections.abc
2import copy
3import datetime
4import decimal
5import operator
6import uuid
7import warnings
8from base64 import b64decode, b64encode
9from functools import partialmethod, total_ordering
11from plain import exceptions, preflight, validators
12from plain.models.constants import LOOKUP_SEP
13from plain.models.db import connection, connections, router
14from plain.models.enums import ChoicesMeta
15from plain.models.query_utils import DeferredAttribute, RegisterLookupMixin
16from plain.packages import packages
17from plain.runtime import settings
18from plain.utils import timezone
19from plain.utils.datastructures import DictWrapper
20from plain.utils.dateparse import (
21 parse_date,
22 parse_datetime,
23 parse_duration,
24 parse_time,
25)
26from plain.utils.duration import duration_microseconds, duration_string
27from plain.utils.functional import Promise, cached_property
28from plain.utils.ipv6 import clean_ipv6_address
29from plain.utils.itercompat import is_iterable
31__all__ = [
32 "AutoField",
33 "BLANK_CHOICE_DASH",
34 "BigAutoField",
35 "BigIntegerField",
36 "BinaryField",
37 "BooleanField",
38 "CharField",
39 "CommaSeparatedIntegerField",
40 "DateField",
41 "DateTimeField",
42 "DecimalField",
43 "DurationField",
44 "EmailField",
45 "Empty",
46 "Field",
47 "FloatField",
48 "GenericIPAddressField",
49 "IPAddressField",
50 "IntegerField",
51 "NOT_PROVIDED",
52 "NullBooleanField",
53 "PositiveBigIntegerField",
54 "PositiveIntegerField",
55 "PositiveSmallIntegerField",
56 "SlugField",
57 "SmallAutoField",
58 "SmallIntegerField",
59 "TextField",
60 "TimeField",
61 "URLField",
62 "UUIDField",
63]
66class Empty:
67 pass
70class NOT_PROVIDED:
71 pass
74# The values to use for "blank" in SelectFields. Will be appended to the start
75# of most "choices" lists.
76BLANK_CHOICE_DASH = [("", "---------")]
79def _load_field(package_label, model_name, field_name):
80 return packages.get_model(package_label, model_name)._meta.get_field(field_name)
83# A guide to Field parameters:
84#
85# * name: The name of the field specified in the model.
86# * attname: The attribute to use on the model object. This is the same as
87# "name", except in the case of ForeignKeys, where "_id" is
88# appended.
89# * db_column: The db_column specified in the model (or None).
90# * column: The database column for this field. This is the same as
91# "attname", except if db_column is specified.
92#
93# Code that introspects values, or does other dynamic things, should use
94# attname. For example, this gets the primary key value of object "obj":
95#
96# getattr(obj, opts.pk.attname)
99def _empty(of_cls):
100 new = Empty()
101 new.__class__ = of_cls
102 return new
105def return_None():
106 return None
109@total_ordering
110class Field(RegisterLookupMixin):
111 """Base class for all field types"""
113 # Designates whether empty strings fundamentally are allowed at the
114 # database level.
115 empty_strings_allowed = True
116 empty_values = list(validators.EMPTY_VALUES)
118 # These track each time a Field instance is created. Used to retain order.
119 # The auto_creation_counter is used for fields that Plain implicitly
120 # creates, creation_counter is used for all user-specified fields.
121 creation_counter = 0
122 auto_creation_counter = -1
123 default_validators = [] # Default set of validators
124 default_error_messages = {
125 "invalid_choice": "Value %(value)r is not a valid choice.",
126 "null": "This field cannot be null.",
127 "blank": "This field cannot be blank.",
128 "unique": "A %(model_name)s with this %(field_label)s already exists.",
129 }
130 system_check_deprecated_details = None
131 system_check_removed_details = None
133 # Attributes that don't affect a column definition.
134 # These attributes are ignored when altering the field.
135 non_db_attrs = (
136 "blank",
137 "choices",
138 "db_column",
139 "editable",
140 "error_messages",
141 "limit_choices_to",
142 # Database-level options are not supported, see #21961.
143 "on_delete",
144 "related_name",
145 "related_query_name",
146 "validators",
147 )
149 # Field flags
150 hidden = False
152 many_to_many = None
153 many_to_one = None
154 one_to_many = None
155 one_to_one = None
156 related_model = None
158 descriptor_class = DeferredAttribute
160 # Generic field type description, usually overridden by subclasses
161 def _description(self):
162 return f"Field of type: {self.__class__.__name__}"
164 description = property(_description)
166 def __init__(
167 self,
168 name=None,
169 primary_key=False,
170 max_length=None,
171 unique=False,
172 blank=False,
173 null=False,
174 db_index=False,
175 rel=None,
176 default=NOT_PROVIDED,
177 editable=True,
178 choices=None,
179 db_column=None,
180 db_tablespace=None,
181 auto_created=False,
182 validators=(),
183 error_messages=None,
184 db_comment=None,
185 ):
186 self.name = name
187 self.primary_key = primary_key
188 self.max_length, self._unique = max_length, unique
189 self.blank, self.null = blank, null
190 self.remote_field = rel
191 self.is_relation = self.remote_field is not None
192 self.default = default
193 self.editable = editable
194 if isinstance(choices, ChoicesMeta):
195 choices = choices.choices
196 if isinstance(choices, collections.abc.Iterator):
197 choices = list(choices)
198 self.choices = choices
199 self.db_index = db_index
200 self.db_column = db_column
201 self.db_comment = db_comment
202 self._db_tablespace = db_tablespace
203 self.auto_created = auto_created
205 # Adjust the appropriate creation counter, and save our local copy.
206 if auto_created:
207 self.creation_counter = Field.auto_creation_counter
208 Field.auto_creation_counter -= 1
209 else:
210 self.creation_counter = Field.creation_counter
211 Field.creation_counter += 1
213 self._validators = list(validators) # Store for deconstruction later
215 self._error_messages = error_messages # Store for deconstruction later
217 def __str__(self):
218 """
219 Return "package_label.model_label.field_name" for fields attached to
220 models.
221 """
222 if not hasattr(self, "model"):
223 return super().__str__()
224 model = self.model
225 return f"{model._meta.label}.{self.name}"
227 def __repr__(self):
228 """Display the module, class, and name of the field."""
229 path = f"{self.__class__.__module__}.{self.__class__.__qualname__}"
230 name = getattr(self, "name", None)
231 if name is not None:
232 return f"<{path}: {name}>"
233 return "<%s>" % path
235 def check(self, **kwargs):
236 return [
237 *self._check_field_name(),
238 *self._check_choices(),
239 *self._check_db_index(),
240 *self._check_db_comment(**kwargs),
241 *self._check_null_allowed_for_primary_keys(),
242 *self._check_backend_specific_checks(**kwargs),
243 *self._check_validators(),
244 *self._check_deprecation_details(),
245 ]
247 def _check_field_name(self):
248 """
249 Check if field name is valid, i.e. 1) does not end with an
250 underscore, 2) does not contain "__" and 3) is not "pk".
251 """
252 if self.name.endswith("_"):
253 return [
254 preflight.Error(
255 "Field names must not end with an underscore.",
256 obj=self,
257 id="fields.E001",
258 )
259 ]
260 elif LOOKUP_SEP in self.name:
261 return [
262 preflight.Error(
263 'Field names must not contain "%s".' % LOOKUP_SEP,
264 obj=self,
265 id="fields.E002",
266 )
267 ]
268 elif self.name == "pk":
269 return [
270 preflight.Error(
271 "'pk' is a reserved word that cannot be used as a field name.",
272 obj=self,
273 id="fields.E003",
274 )
275 ]
276 else:
277 return []
279 @classmethod
280 def _choices_is_value(cls, value):
281 return isinstance(value, str | Promise) or not is_iterable(value)
283 def _check_choices(self):
284 if not self.choices:
285 return []
287 if not is_iterable(self.choices) or isinstance(self.choices, str):
288 return [
289 preflight.Error(
290 "'choices' must be an iterable (e.g., a list or tuple).",
291 obj=self,
292 id="fields.E004",
293 )
294 ]
296 choice_max_length = 0
297 # Expect [group_name, [value, display]]
298 for choices_group in self.choices:
299 try:
300 group_name, group_choices = choices_group
301 except (TypeError, ValueError):
302 # Containing non-pairs
303 break
304 try:
305 if not all(
306 self._choices_is_value(value) and self._choices_is_value(human_name)
307 for value, human_name in group_choices
308 ):
309 break
310 if self.max_length is not None and group_choices:
311 choice_max_length = max(
312 [
313 choice_max_length,
314 *(
315 len(value)
316 for value, _ in group_choices
317 if isinstance(value, str)
318 ),
319 ]
320 )
321 except (TypeError, ValueError):
322 # No groups, choices in the form [value, display]
323 value, human_name = group_name, group_choices
324 if not self._choices_is_value(value) or not self._choices_is_value(
325 human_name
326 ):
327 break
328 if self.max_length is not None and isinstance(value, str):
329 choice_max_length = max(choice_max_length, len(value))
331 # Special case: choices=['ab']
332 if isinstance(choices_group, str):
333 break
334 else:
335 if self.max_length is not None and choice_max_length > self.max_length:
336 return [
337 preflight.Error(
338 "'max_length' is too small to fit the longest value "
339 "in 'choices' (%d characters)." % choice_max_length,
340 obj=self,
341 id="fields.E009",
342 ),
343 ]
344 return []
346 return [
347 preflight.Error(
348 "'choices' must be an iterable containing "
349 "(actual value, human readable name) tuples.",
350 obj=self,
351 id="fields.E005",
352 )
353 ]
355 def _check_db_index(self):
356 if self.db_index not in (None, True, False):
357 return [
358 preflight.Error(
359 "'db_index' must be None, True or False.",
360 obj=self,
361 id="fields.E006",
362 )
363 ]
364 else:
365 return []
367 def _check_db_comment(self, databases=None, **kwargs):
368 if not self.db_comment or not databases:
369 return []
370 errors = []
371 for db in databases:
372 if not router.allow_migrate_model(db, self.model):
373 continue
374 connection = connections[db]
375 if not (
376 connection.features.supports_comments
377 or "supports_comments" in self.model._meta.required_db_features
378 ):
379 errors.append(
380 preflight.Warning(
381 f"{connection.display_name} does not support comments on "
382 f"columns (db_comment).",
383 obj=self,
384 id="fields.W163",
385 )
386 )
387 return errors
389 def _check_null_allowed_for_primary_keys(self):
390 if (
391 self.primary_key
392 and self.null
393 and not connection.features.interprets_empty_strings_as_nulls
394 ):
395 # We cannot reliably check this for backends like Oracle which
396 # consider NULL and '' to be equal (and thus set up
397 # character-based fields a little differently).
398 return [
399 preflight.Error(
400 "Primary keys must not have null=True.",
401 hint=(
402 "Set null=False on the field, or "
403 "remove primary_key=True argument."
404 ),
405 obj=self,
406 id="fields.E007",
407 )
408 ]
409 else:
410 return []
412 def _check_backend_specific_checks(self, databases=None, **kwargs):
413 if databases is None:
414 return []
415 errors = []
416 for alias in databases:
417 if router.allow_migrate_model(alias, self.model):
418 errors.extend(connections[alias].validation.check_field(self, **kwargs))
419 return errors
421 def _check_validators(self):
422 errors = []
423 for i, validator in enumerate(self.validators):
424 if not callable(validator):
425 errors.append(
426 preflight.Error(
427 "All 'validators' must be callable.",
428 hint=(
429 f"validators[{i}] ({repr(validator)}) isn't a function or "
430 "instance of a validator class."
431 ),
432 obj=self,
433 id="fields.E008",
434 )
435 )
436 return errors
438 def _check_deprecation_details(self):
439 if self.system_check_removed_details is not None:
440 return [
441 preflight.Error(
442 self.system_check_removed_details.get(
443 "msg",
444 "%s has been removed except for support in historical "
445 "migrations." % self.__class__.__name__,
446 ),
447 hint=self.system_check_removed_details.get("hint"),
448 obj=self,
449 id=self.system_check_removed_details.get("id", "fields.EXXX"),
450 )
451 ]
452 elif self.system_check_deprecated_details is not None:
453 return [
454 preflight.Warning(
455 self.system_check_deprecated_details.get(
456 "msg", "%s has been deprecated." % self.__class__.__name__
457 ),
458 hint=self.system_check_deprecated_details.get("hint"),
459 obj=self,
460 id=self.system_check_deprecated_details.get("id", "fields.WXXX"),
461 )
462 ]
463 return []
465 def get_col(self, alias, output_field=None):
466 if alias == self.model._meta.db_table and (
467 output_field is None or output_field == self
468 ):
469 return self.cached_col
470 from plain.models.expressions import Col
472 return Col(alias, self, output_field)
474 @cached_property
475 def cached_col(self):
476 from plain.models.expressions import Col
478 return Col(self.model._meta.db_table, self)
480 def select_format(self, compiler, sql, params):
481 """
482 Custom format for select clauses. For example, GIS columns need to be
483 selected as AsText(table.col) on MySQL as the table.col data can't be
484 used by Plain.
485 """
486 return sql, params
488 def deconstruct(self):
489 """
490 Return enough information to recreate the field as a 4-tuple:
492 * The name of the field on the model, if contribute_to_class() has
493 been run.
494 * The import path of the field, including the class, e.g.
495 plain.models.IntegerField. This should be the most portable
496 version, so less specific may be better.
497 * A list of positional arguments.
498 * A dict of keyword arguments.
500 Note that the positional or keyword arguments must contain values of
501 the following types (including inner values of collection types):
503 * None, bool, str, int, float, complex, set, frozenset, list, tuple,
504 dict
505 * UUID
506 * datetime.datetime (naive), datetime.date
507 * top-level classes, top-level functions - will be referenced by their
508 full import path
509 * Storage instances - these have their own deconstruct() method
511 This is because the values here must be serialized into a text format
512 (possibly new Python code, possibly JSON) and these are the only types
513 with encoding handlers defined.
515 There's no need to return the exact way the field was instantiated this
516 time, just ensure that the resulting field is the same - prefer keyword
517 arguments over positional ones, and omit parameters with their default
518 values.
519 """
520 # Short-form way of fetching all the default parameters
521 keywords = {}
522 possibles = {
523 "primary_key": False,
524 "max_length": None,
525 "unique": False,
526 "blank": False,
527 "null": False,
528 "db_index": False,
529 "default": NOT_PROVIDED,
530 "editable": True,
531 "choices": None,
532 "db_column": None,
533 "db_comment": None,
534 "db_tablespace": None,
535 "auto_created": False,
536 "validators": [],
537 "error_messages": None,
538 }
539 attr_overrides = {
540 "unique": "_unique",
541 "error_messages": "_error_messages",
542 "validators": "_validators",
543 "db_tablespace": "_db_tablespace",
544 }
545 equals_comparison = {"choices", "validators"}
546 for name, default in possibles.items():
547 value = getattr(self, attr_overrides.get(name, name))
548 # Unroll anything iterable for choices into a concrete list
549 if name == "choices" and isinstance(value, collections.abc.Iterable):
550 value = list(value)
551 # Do correct kind of comparison
552 if name in equals_comparison:
553 if value != default:
554 keywords[name] = value
555 else:
556 if value is not default:
557 keywords[name] = value
558 # Work out path - we shorten it for known Plain core fields
559 path = f"{self.__class__.__module__}.{self.__class__.__qualname__}"
560 if path.startswith("plain.models.fields.related"):
561 path = path.replace("plain.models.fields.related", "plain.models")
562 elif path.startswith("plain.models.fields.json"):
563 path = path.replace("plain.models.fields.json", "plain.models")
564 elif path.startswith("plain.models.fields.proxy"):
565 path = path.replace("plain.models.fields.proxy", "plain.models")
566 elif path.startswith("plain.models.fields"):
567 path = path.replace("plain.models.fields", "plain.models")
568 # Return basic info - other fields should override this.
569 return (self.name, path, [], keywords)
571 def clone(self):
572 """
573 Uses deconstruct() to clone a new copy of this Field.
574 Will not preserve any class attachments/attribute names.
575 """
576 name, path, args, kwargs = self.deconstruct()
577 return self.__class__(*args, **kwargs)
579 def __eq__(self, other):
580 # Needed for @total_ordering
581 if isinstance(other, Field):
582 return self.creation_counter == other.creation_counter and getattr(
583 self, "model", None
584 ) == getattr(other, "model", None)
585 return NotImplemented
587 def __lt__(self, other):
588 # This is needed because bisect does not take a comparison function.
589 # Order by creation_counter first for backward compatibility.
590 if isinstance(other, Field):
591 if (
592 self.creation_counter != other.creation_counter
593 or not hasattr(self, "model")
594 and not hasattr(other, "model")
595 ):
596 return self.creation_counter < other.creation_counter
597 elif hasattr(self, "model") != hasattr(other, "model"):
598 return not hasattr(self, "model") # Order no-model fields first
599 else:
600 # creation_counter's are equal, compare only models.
601 return (self.model._meta.package_label, self.model._meta.model_name) < (
602 other.model._meta.package_label,
603 other.model._meta.model_name,
604 )
605 return NotImplemented
607 def __hash__(self):
608 return hash(self.creation_counter)
610 def __deepcopy__(self, memodict):
611 # We don't have to deepcopy very much here, since most things are not
612 # intended to be altered after initial creation.
613 obj = copy.copy(self)
614 if self.remote_field:
615 obj.remote_field = copy.copy(self.remote_field)
616 if hasattr(self.remote_field, "field") and self.remote_field.field is self:
617 obj.remote_field.field = obj
618 memodict[id(self)] = obj
619 return obj
621 def __copy__(self):
622 # We need to avoid hitting __reduce__, so define this
623 # slightly weird copy construct.
624 obj = Empty()
625 obj.__class__ = self.__class__
626 obj.__dict__ = self.__dict__.copy()
627 return obj
629 def __reduce__(self):
630 """
631 Pickling should return the model._meta.fields instance of the field,
632 not a new copy of that field. So, use the app registry to load the
633 model and then the field back.
634 """
635 if not hasattr(self, "model"):
636 # Fields are sometimes used without attaching them to models (for
637 # example in aggregation). In this case give back a plain field
638 # instance. The code below will create a new empty instance of
639 # class self.__class__, then update its dict with self.__dict__
640 # values - so, this is very close to normal pickle.
641 state = self.__dict__.copy()
642 # The _get_default cached_property can't be pickled due to lambda
643 # usage.
644 state.pop("_get_default", None)
645 return _empty, (self.__class__,), state
646 return _load_field, (
647 self.model._meta.package_label,
648 self.model._meta.object_name,
649 self.name,
650 )
652 def get_pk_value_on_save(self, instance):
653 """
654 Hook to generate new PK values on save. This method is called when
655 saving instances with no primary key value set. If this method returns
656 something else than None, then the returned value is used when saving
657 the new instance.
658 """
659 if self.default:
660 return self.get_default()
661 return None
663 def to_python(self, value):
664 """
665 Convert the input value into the expected Python data type, raising
666 plain.exceptions.ValidationError if the data can't be converted.
667 Return the converted value. Subclasses should override this.
668 """
669 return value
671 @cached_property
672 def error_messages(self):
673 messages = {}
674 for c in reversed(self.__class__.__mro__):
675 messages.update(getattr(c, "default_error_messages", {}))
676 messages.update(self._error_messages or {})
677 return messages
679 @cached_property
680 def validators(self):
681 """
682 Some validators can't be created at field initialization time.
683 This method provides a way to delay their creation until required.
684 """
685 return [*self.default_validators, *self._validators]
687 def run_validators(self, value):
688 if value in self.empty_values:
689 return
691 errors = []
692 for v in self.validators:
693 try:
694 v(value)
695 except exceptions.ValidationError as e:
696 if hasattr(e, "code") and e.code in self.error_messages:
697 e.message = self.error_messages[e.code]
698 errors.extend(e.error_list)
700 if errors:
701 raise exceptions.ValidationError(errors)
703 def validate(self, value, model_instance):
704 """
705 Validate value and raise ValidationError if necessary. Subclasses
706 should override this to provide validation logic.
707 """
708 if not self.editable:
709 # Skip validation for non-editable fields.
710 return
712 if self.choices is not None and value not in self.empty_values:
713 for option_key, option_value in self.choices:
714 if isinstance(option_value, list | tuple):
715 # This is an optgroup, so look inside the group for
716 # options.
717 for optgroup_key, optgroup_value in option_value:
718 if value == optgroup_key:
719 return
720 elif value == option_key:
721 return
722 raise exceptions.ValidationError(
723 self.error_messages["invalid_choice"],
724 code="invalid_choice",
725 params={"value": value},
726 )
728 if value is None and not self.null:
729 raise exceptions.ValidationError(self.error_messages["null"], code="null")
731 if not self.blank and value in self.empty_values:
732 raise exceptions.ValidationError(self.error_messages["blank"], code="blank")
734 def clean(self, value, model_instance):
735 """
736 Convert the value's type and run validation. Validation errors
737 from to_python() and validate() are propagated. Return the correct
738 value if no error is raised.
739 """
740 value = self.to_python(value)
741 self.validate(value, model_instance)
742 self.run_validators(value)
743 return value
745 def db_type_parameters(self, connection):
746 return DictWrapper(self.__dict__, connection.ops.quote_name, "qn_")
748 def db_check(self, connection):
749 """
750 Return the database column check constraint for this field, for the
751 provided connection. Works the same way as db_type() for the case that
752 get_internal_type() does not map to a preexisting model field.
753 """
754 data = self.db_type_parameters(connection)
755 try:
756 return (
757 connection.data_type_check_constraints[self.get_internal_type()] % data
758 )
759 except KeyError:
760 return None
762 def db_type(self, connection):
763 """
764 Return the database column data type for this field, for the provided
765 connection.
766 """
767 # The default implementation of this method looks at the
768 # backend-specific data_types dictionary, looking up the field by its
769 # "internal type".
770 #
771 # A Field class can implement the get_internal_type() method to specify
772 # which *preexisting* Plain Field class it's most similar to -- i.e.,
773 # a custom field might be represented by a TEXT column type, which is
774 # the same as the TextField Plain field type, which means the custom
775 # field's get_internal_type() returns 'TextField'.
776 #
777 # But the limitation of the get_internal_type() / data_types approach
778 # is that it cannot handle database column types that aren't already
779 # mapped to one of the built-in Plain field types. In this case, you
780 # can implement db_type() instead of get_internal_type() to specify
781 # exactly which wacky database column type you want to use.
782 data = self.db_type_parameters(connection)
783 try:
784 column_type = connection.data_types[self.get_internal_type()]
785 except KeyError:
786 return None
787 else:
788 # column_type is either a single-parameter function or a string.
789 if callable(column_type):
790 return column_type(data)
791 return column_type % data
793 def rel_db_type(self, connection):
794 """
795 Return the data type that a related field pointing to this field should
796 use. For example, this method is called by ForeignKey and OneToOneField
797 to determine its data type.
798 """
799 return self.db_type(connection)
801 def cast_db_type(self, connection):
802 """Return the data type to use in the Cast() function."""
803 db_type = connection.ops.cast_data_types.get(self.get_internal_type())
804 if db_type:
805 return db_type % self.db_type_parameters(connection)
806 return self.db_type(connection)
808 def db_parameters(self, connection):
809 """
810 Extension of db_type(), providing a range of different return values
811 (type, checks). This will look at db_type(), allowing custom model
812 fields to override it.
813 """
814 type_string = self.db_type(connection)
815 check_string = self.db_check(connection)
816 return {
817 "type": type_string,
818 "check": check_string,
819 }
821 def db_type_suffix(self, connection):
822 return connection.data_types_suffix.get(self.get_internal_type())
824 def get_db_converters(self, connection):
825 if hasattr(self, "from_db_value"):
826 return [self.from_db_value]
827 return []
829 @property
830 def unique(self):
831 return self._unique or self.primary_key
833 @property
834 def db_tablespace(self):
835 return self._db_tablespace or settings.DEFAULT_INDEX_TABLESPACE
837 @property
838 def db_returning(self):
839 """
840 Private API intended only to be used by Plain itself. Currently only
841 the PostgreSQL backend supports returning multiple fields on a model.
842 """
843 return False
845 def set_attributes_from_name(self, name):
846 self.name = self.name or name
847 self.attname, self.column = self.get_attname_column()
848 self.concrete = self.column is not None
850 def contribute_to_class(self, cls, name, private_only=False):
851 """
852 Register the field with the model class it belongs to.
854 If private_only is True, create a separate instance of this field
855 for every subclass of cls, even if cls is not an abstract model.
856 """
857 self.set_attributes_from_name(name)
858 self.model = cls
859 cls._meta.add_field(self, private=private_only)
860 if self.column:
861 setattr(cls, self.attname, self.descriptor_class(self))
862 if self.choices is not None:
863 # Don't override a get_FOO_display() method defined explicitly on
864 # this class, but don't check methods derived from inheritance, to
865 # allow overriding inherited choices. For more complex inheritance
866 # structures users should override contribute_to_class().
867 if "get_%s_display" % self.name not in cls.__dict__:
868 setattr(
869 cls,
870 "get_%s_display" % self.name,
871 partialmethod(cls._get_FIELD_display, field=self),
872 )
874 def get_filter_kwargs_for_object(self, obj):
875 """
876 Return a dict that when passed as kwargs to self.model.filter(), would
877 yield all instances having the same value for this field as obj has.
878 """
879 return {self.name: getattr(obj, self.attname)}
881 def get_attname(self):
882 return self.name
884 def get_attname_column(self):
885 attname = self.get_attname()
886 column = self.db_column or attname
887 return attname, column
889 def get_internal_type(self):
890 return self.__class__.__name__
892 def pre_save(self, model_instance, add):
893 """Return field's value just before saving."""
894 return getattr(model_instance, self.attname)
896 def get_prep_value(self, value):
897 """Perform preliminary non-db specific value checks and conversions."""
898 if isinstance(value, Promise):
899 value = value._proxy____cast()
900 return value
902 def get_db_prep_value(self, value, connection, prepared=False):
903 """
904 Return field's value prepared for interacting with the database backend.
906 Used by the default implementations of get_db_prep_save().
907 """
908 if not prepared:
909 value = self.get_prep_value(value)
910 return value
912 def get_db_prep_save(self, value, connection):
913 """Return field's value prepared for saving into a database."""
914 if hasattr(value, "as_sql"):
915 return value
916 return self.get_db_prep_value(value, connection=connection, prepared=False)
918 def has_default(self):
919 """Return a boolean of whether this field has a default value."""
920 return self.default is not NOT_PROVIDED
922 def get_default(self):
923 """Return the default value for this field."""
924 return self._get_default()
926 @cached_property
927 def _get_default(self):
928 if self.has_default():
929 if callable(self.default):
930 return self.default
931 return lambda: self.default
933 if (
934 not self.empty_strings_allowed
935 or self.null
936 and not connection.features.interprets_empty_strings_as_nulls
937 ):
938 return return_None
939 return str # return empty string
941 def get_choices(
942 self,
943 include_blank=True,
944 blank_choice=BLANK_CHOICE_DASH,
945 limit_choices_to=None,
946 ordering=(),
947 ):
948 """
949 Return choices with a default blank choices included, for use
950 as <select> choices for this field.
951 """
952 if self.choices is not None:
953 choices = list(self.choices)
954 if include_blank:
955 blank_defined = any(
956 choice in ("", None) for choice, _ in self.flatchoices
957 )
958 if not blank_defined:
959 choices = blank_choice + choices
960 return choices
961 rel_model = self.remote_field.model
962 limit_choices_to = limit_choices_to or self.get_limit_choices_to()
963 choice_func = operator.attrgetter(
964 self.remote_field.get_related_field().attname
965 if hasattr(self.remote_field, "get_related_field")
966 else "pk"
967 )
968 qs = rel_model._default_manager.complex_filter(limit_choices_to)
969 if ordering:
970 qs = qs.order_by(*ordering)
971 return (blank_choice if include_blank else []) + [
972 (choice_func(x), str(x)) for x in qs
973 ]
975 def value_to_string(self, obj):
976 """
977 Return a string value of this field from the passed obj.
978 This is used by the serialization framework.
979 """
980 return str(self.value_from_object(obj))
982 def _get_flatchoices(self):
983 """Flattened version of choices tuple."""
984 if self.choices is None:
985 return []
986 flat = []
987 for choice, value in self.choices:
988 if isinstance(value, list | tuple):
989 flat.extend(value)
990 else:
991 flat.append((choice, value))
992 return flat
994 flatchoices = property(_get_flatchoices)
996 def save_form_data(self, instance, data):
997 setattr(instance, self.name, data)
999 def value_from_object(self, obj):
1000 """Return the value of this field in the given model instance."""
1001 return getattr(obj, self.attname)
1004class BooleanField(Field):
1005 empty_strings_allowed = False
1006 default_error_messages = {
1007 "invalid": "“%(value)s” value must be either True or False.",
1008 "invalid_nullable": "“%(value)s” value must be either True, False, or None.",
1009 }
1010 description = "Boolean (Either True or False)"
1012 def get_internal_type(self):
1013 return "BooleanField"
1015 def to_python(self, value):
1016 if self.null and value in self.empty_values:
1017 return None
1018 if value in (True, False):
1019 # 1/0 are equal to True/False. bool() converts former to latter.
1020 return bool(value)
1021 if value in ("t", "True", "1"):
1022 return True
1023 if value in ("f", "False", "0"):
1024 return False
1025 raise exceptions.ValidationError(
1026 self.error_messages["invalid_nullable" if self.null else "invalid"],
1027 code="invalid",
1028 params={"value": value},
1029 )
1031 def get_prep_value(self, value):
1032 value = super().get_prep_value(value)
1033 if value is None:
1034 return None
1035 return self.to_python(value)
1038class CharField(Field):
1039 def __init__(self, *args, db_collation=None, **kwargs):
1040 super().__init__(*args, **kwargs)
1041 self.db_collation = db_collation
1042 if self.max_length is not None:
1043 self.validators.append(validators.MaxLengthValidator(self.max_length))
1045 @property
1046 def description(self):
1047 if self.max_length is not None:
1048 return "String (up to %(max_length)s)"
1049 else:
1050 return "String (unlimited)"
1052 def check(self, **kwargs):
1053 databases = kwargs.get("databases") or []
1054 return [
1055 *super().check(**kwargs),
1056 *self._check_db_collation(databases),
1057 *self._check_max_length_attribute(**kwargs),
1058 ]
1060 def _check_max_length_attribute(self, **kwargs):
1061 if self.max_length is None:
1062 if (
1063 connection.features.supports_unlimited_charfield
1064 or "supports_unlimited_charfield"
1065 in self.model._meta.required_db_features
1066 ):
1067 return []
1068 return [
1069 preflight.Error(
1070 "CharFields must define a 'max_length' attribute.",
1071 obj=self,
1072 id="fields.E120",
1073 )
1074 ]
1075 elif (
1076 not isinstance(self.max_length, int)
1077 or isinstance(self.max_length, bool)
1078 or self.max_length <= 0
1079 ):
1080 return [
1081 preflight.Error(
1082 "'max_length' must be a positive integer.",
1083 obj=self,
1084 id="fields.E121",
1085 )
1086 ]
1087 else:
1088 return []
1090 def _check_db_collation(self, databases):
1091 errors = []
1092 for db in databases:
1093 if not router.allow_migrate_model(db, self.model):
1094 continue
1095 connection = connections[db]
1096 if not (
1097 self.db_collation is None
1098 or "supports_collation_on_charfield"
1099 in self.model._meta.required_db_features
1100 or connection.features.supports_collation_on_charfield
1101 ):
1102 errors.append(
1103 preflight.Error(
1104 "%s does not support a database collation on "
1105 "CharFields." % connection.display_name,
1106 obj=self,
1107 id="fields.E190",
1108 ),
1109 )
1110 return errors
1112 def cast_db_type(self, connection):
1113 if self.max_length is None:
1114 return connection.ops.cast_char_field_without_max_length
1115 return super().cast_db_type(connection)
1117 def db_parameters(self, connection):
1118 db_params = super().db_parameters(connection)
1119 db_params["collation"] = self.db_collation
1120 return db_params
1122 def get_internal_type(self):
1123 return "CharField"
1125 def to_python(self, value):
1126 if isinstance(value, str) or value is None:
1127 return value
1128 return str(value)
1130 def get_prep_value(self, value):
1131 value = super().get_prep_value(value)
1132 return self.to_python(value)
1134 def deconstruct(self):
1135 name, path, args, kwargs = super().deconstruct()
1136 if self.db_collation:
1137 kwargs["db_collation"] = self.db_collation
1138 return name, path, args, kwargs
1141class CommaSeparatedIntegerField(CharField):
1142 default_validators = [validators.validate_comma_separated_integer_list]
1143 description = "Comma-separated integers"
1144 system_check_removed_details = {
1145 "msg": (
1146 "CommaSeparatedIntegerField is removed except for support in "
1147 "historical migrations."
1148 ),
1149 "hint": (
1150 "Use CharField(validators=[validate_comma_separated_integer_list]) "
1151 "instead."
1152 ),
1153 "id": "fields.E901",
1154 }
1157def _to_naive(value):
1158 if timezone.is_aware(value):
1159 value = timezone.make_naive(value, datetime.timezone.utc)
1160 return value
1163def _get_naive_now():
1164 return _to_naive(timezone.now())
1167class DateTimeCheckMixin:
1168 def check(self, **kwargs):
1169 return [
1170 *super().check(**kwargs),
1171 *self._check_mutually_exclusive_options(),
1172 *self._check_fix_default_value(),
1173 ]
1175 def _check_mutually_exclusive_options(self):
1176 # auto_now, auto_now_add, and default are mutually exclusive
1177 # options. The use of more than one of these options together
1178 # will trigger an Error
1179 mutually_exclusive_options = [
1180 self.auto_now_add,
1181 self.auto_now,
1182 self.has_default(),
1183 ]
1184 enabled_options = [
1185 option not in (None, False) for option in mutually_exclusive_options
1186 ].count(True)
1187 if enabled_options > 1:
1188 return [
1189 preflight.Error(
1190 "The options auto_now, auto_now_add, and default "
1191 "are mutually exclusive. Only one of these options "
1192 "may be present.",
1193 obj=self,
1194 id="fields.E160",
1195 )
1196 ]
1197 else:
1198 return []
1200 def _check_fix_default_value(self):
1201 return []
1203 # Concrete subclasses use this in their implementations of
1204 # _check_fix_default_value().
1205 def _check_if_value_fixed(self, value, now=None):
1206 """
1207 Check if the given value appears to have been provided as a "fixed"
1208 time value, and include a warning in the returned list if it does. The
1209 value argument must be a date object or aware/naive datetime object. If
1210 now is provided, it must be a naive datetime object.
1211 """
1212 if now is None:
1213 now = _get_naive_now()
1214 offset = datetime.timedelta(seconds=10)
1215 lower = now - offset
1216 upper = now + offset
1217 if isinstance(value, datetime.datetime):
1218 value = _to_naive(value)
1219 else:
1220 assert isinstance(value, datetime.date)
1221 lower = lower.date()
1222 upper = upper.date()
1223 if lower <= value <= upper:
1224 return [
1225 preflight.Warning(
1226 "Fixed default value provided.",
1227 hint=(
1228 "It seems you set a fixed date / time / datetime "
1229 "value as default for this field. This may not be "
1230 "what you want. If you want to have the current date "
1231 "as default, use `plain.utils.timezone.now`"
1232 ),
1233 obj=self,
1234 id="fields.W161",
1235 )
1236 ]
1237 return []
1240class DateField(DateTimeCheckMixin, Field):
1241 empty_strings_allowed = False
1242 default_error_messages = {
1243 "invalid": "“%(value)s” value has an invalid date format. It must be in YYYY-MM-DD format.",
1244 "invalid_date": "“%(value)s” value has the correct format (YYYY-MM-DD) but it is an invalid date.",
1245 }
1246 description = "Date (without time)"
1248 def __init__(self, name=None, auto_now=False, auto_now_add=False, **kwargs):
1249 self.auto_now, self.auto_now_add = auto_now, auto_now_add
1250 if auto_now or auto_now_add:
1251 kwargs["editable"] = False
1252 kwargs["blank"] = True
1253 super().__init__(name, **kwargs)
1255 def _check_fix_default_value(self):
1256 """
1257 Warn that using an actual date or datetime value is probably wrong;
1258 it's only evaluated on server startup.
1259 """
1260 if not self.has_default():
1261 return []
1263 value = self.default
1264 if isinstance(value, datetime.datetime):
1265 value = _to_naive(value).date()
1266 elif isinstance(value, datetime.date):
1267 pass
1268 else:
1269 # No explicit date / datetime value -- no checks necessary
1270 return []
1271 # At this point, value is a date object.
1272 return self._check_if_value_fixed(value)
1274 def deconstruct(self):
1275 name, path, args, kwargs = super().deconstruct()
1276 if self.auto_now:
1277 kwargs["auto_now"] = True
1278 if self.auto_now_add:
1279 kwargs["auto_now_add"] = True
1280 if self.auto_now or self.auto_now_add:
1281 del kwargs["editable"]
1282 del kwargs["blank"]
1283 return name, path, args, kwargs
1285 def get_internal_type(self):
1286 return "DateField"
1288 def to_python(self, value):
1289 if value is None:
1290 return value
1291 if isinstance(value, datetime.datetime):
1292 if timezone.is_aware(value):
1293 # Convert aware datetimes to the default time zone
1294 # before casting them to dates (#17742).
1295 default_timezone = timezone.get_default_timezone()
1296 value = timezone.make_naive(value, default_timezone)
1297 return value.date()
1298 if isinstance(value, datetime.date):
1299 return value
1301 try:
1302 parsed = parse_date(value)
1303 if parsed is not None:
1304 return parsed
1305 except ValueError:
1306 raise exceptions.ValidationError(
1307 self.error_messages["invalid_date"],
1308 code="invalid_date",
1309 params={"value": value},
1310 )
1312 raise exceptions.ValidationError(
1313 self.error_messages["invalid"],
1314 code="invalid",
1315 params={"value": value},
1316 )
1318 def pre_save(self, model_instance, add):
1319 if self.auto_now or (self.auto_now_add and add):
1320 value = datetime.date.today()
1321 setattr(model_instance, self.attname, value)
1322 return value
1323 else:
1324 return super().pre_save(model_instance, add)
1326 def contribute_to_class(self, cls, name, **kwargs):
1327 super().contribute_to_class(cls, name, **kwargs)
1328 if not self.null:
1329 setattr(
1330 cls,
1331 "get_next_by_%s" % self.name,
1332 partialmethod(
1333 cls._get_next_or_previous_by_FIELD, field=self, is_next=True
1334 ),
1335 )
1336 setattr(
1337 cls,
1338 "get_previous_by_%s" % self.name,
1339 partialmethod(
1340 cls._get_next_or_previous_by_FIELD, field=self, is_next=False
1341 ),
1342 )
1344 def get_prep_value(self, value):
1345 value = super().get_prep_value(value)
1346 return self.to_python(value)
1348 def get_db_prep_value(self, value, connection, prepared=False):
1349 # Casts dates into the format expected by the backend
1350 if not prepared:
1351 value = self.get_prep_value(value)
1352 return connection.ops.adapt_datefield_value(value)
1354 def value_to_string(self, obj):
1355 val = self.value_from_object(obj)
1356 return "" if val is None else val.isoformat()
1359class DateTimeField(DateField):
1360 empty_strings_allowed = False
1361 default_error_messages = {
1362 "invalid": "“%(value)s” value has an invalid format. It must be in YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ] format.",
1363 "invalid_date": "“%(value)s” value has the correct format (YYYY-MM-DD) but it is an invalid date.",
1364 "invalid_datetime": "“%(value)s” value has the correct format (YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ]) but it is an invalid date/time.",
1365 }
1366 description = "Date (with time)"
1368 # __init__ is inherited from DateField
1370 def _check_fix_default_value(self):
1371 """
1372 Warn that using an actual date or datetime value is probably wrong;
1373 it's only evaluated on server startup.
1374 """
1375 if not self.has_default():
1376 return []
1378 value = self.default
1379 if isinstance(value, datetime.datetime | datetime.date):
1380 return self._check_if_value_fixed(value)
1381 # No explicit date / datetime value -- no checks necessary.
1382 return []
1384 def get_internal_type(self):
1385 return "DateTimeField"
1387 def to_python(self, value):
1388 if value is None:
1389 return value
1390 if isinstance(value, datetime.datetime):
1391 return value
1392 if isinstance(value, datetime.date):
1393 value = datetime.datetime(value.year, value.month, value.day)
1395 # For backwards compatibility, interpret naive datetimes in
1396 # local time. This won't work during DST change, but we can't
1397 # do much about it, so we let the exceptions percolate up the
1398 # call stack.
1399 warnings.warn(
1400 "DateTimeField {}.{} received a naive datetime "
1401 "({}) while time zone support is active.".format(
1402 self.model.__name__, self.name, value
1403 ),
1404 RuntimeWarning,
1405 )
1406 default_timezone = timezone.get_default_timezone()
1407 value = timezone.make_aware(value, default_timezone)
1409 return value
1411 try:
1412 parsed = parse_datetime(value)
1413 if parsed is not None:
1414 return parsed
1415 except ValueError:
1416 raise exceptions.ValidationError(
1417 self.error_messages["invalid_datetime"],
1418 code="invalid_datetime",
1419 params={"value": value},
1420 )
1422 try:
1423 parsed = parse_date(value)
1424 if parsed is not None:
1425 return datetime.datetime(parsed.year, parsed.month, parsed.day)
1426 except ValueError:
1427 raise exceptions.ValidationError(
1428 self.error_messages["invalid_date"],
1429 code="invalid_date",
1430 params={"value": value},
1431 )
1433 raise exceptions.ValidationError(
1434 self.error_messages["invalid"],
1435 code="invalid",
1436 params={"value": value},
1437 )
1439 def pre_save(self, model_instance, add):
1440 if self.auto_now or (self.auto_now_add and add):
1441 value = timezone.now()
1442 setattr(model_instance, self.attname, value)
1443 return value
1444 else:
1445 return super().pre_save(model_instance, add)
1447 # contribute_to_class is inherited from DateField, it registers
1448 # get_next_by_FOO and get_prev_by_FOO
1450 def get_prep_value(self, value):
1451 value = super().get_prep_value(value)
1452 value = self.to_python(value)
1453 if value is not None and timezone.is_naive(value):
1454 # For backwards compatibility, interpret naive datetimes in local
1455 # time. This won't work during DST change, but we can't do much
1456 # about it, so we let the exceptions percolate up the call stack.
1457 try:
1458 name = f"{self.model.__name__}.{self.name}"
1459 except AttributeError:
1460 name = "(unbound)"
1461 warnings.warn(
1462 f"DateTimeField {name} received a naive datetime ({value})"
1463 " while time zone support is active.",
1464 RuntimeWarning,
1465 )
1466 default_timezone = timezone.get_default_timezone()
1467 value = timezone.make_aware(value, default_timezone)
1468 return value
1470 def get_db_prep_value(self, value, connection, prepared=False):
1471 # Casts datetimes into the format expected by the backend
1472 if not prepared:
1473 value = self.get_prep_value(value)
1474 return connection.ops.adapt_datetimefield_value(value)
1476 def value_to_string(self, obj):
1477 val = self.value_from_object(obj)
1478 return "" if val is None else val.isoformat()
1481class DecimalField(Field):
1482 empty_strings_allowed = False
1483 default_error_messages = {
1484 "invalid": "“%(value)s” value must be a decimal number.",
1485 }
1486 description = "Decimal number"
1488 def __init__(
1489 self,
1490 name=None,
1491 max_digits=None,
1492 decimal_places=None,
1493 **kwargs,
1494 ):
1495 self.max_digits, self.decimal_places = max_digits, decimal_places
1496 super().__init__(name, **kwargs)
1498 def check(self, **kwargs):
1499 errors = super().check(**kwargs)
1501 digits_errors = [
1502 *self._check_decimal_places(),
1503 *self._check_max_digits(),
1504 ]
1505 if not digits_errors:
1506 errors.extend(self._check_decimal_places_and_max_digits(**kwargs))
1507 else:
1508 errors.extend(digits_errors)
1509 return errors
1511 def _check_decimal_places(self):
1512 try:
1513 decimal_places = int(self.decimal_places)
1514 if decimal_places < 0:
1515 raise ValueError()
1516 except TypeError:
1517 return [
1518 preflight.Error(
1519 "DecimalFields must define a 'decimal_places' attribute.",
1520 obj=self,
1521 id="fields.E130",
1522 )
1523 ]
1524 except ValueError:
1525 return [
1526 preflight.Error(
1527 "'decimal_places' must be a non-negative integer.",
1528 obj=self,
1529 id="fields.E131",
1530 )
1531 ]
1532 else:
1533 return []
1535 def _check_max_digits(self):
1536 try:
1537 max_digits = int(self.max_digits)
1538 if max_digits <= 0:
1539 raise ValueError()
1540 except TypeError:
1541 return [
1542 preflight.Error(
1543 "DecimalFields must define a 'max_digits' attribute.",
1544 obj=self,
1545 id="fields.E132",
1546 )
1547 ]
1548 except ValueError:
1549 return [
1550 preflight.Error(
1551 "'max_digits' must be a positive integer.",
1552 obj=self,
1553 id="fields.E133",
1554 )
1555 ]
1556 else:
1557 return []
1559 def _check_decimal_places_and_max_digits(self, **kwargs):
1560 if int(self.decimal_places) > int(self.max_digits):
1561 return [
1562 preflight.Error(
1563 "'max_digits' must be greater or equal to 'decimal_places'.",
1564 obj=self,
1565 id="fields.E134",
1566 )
1567 ]
1568 return []
1570 @cached_property
1571 def validators(self):
1572 return super().validators + [
1573 validators.DecimalValidator(self.max_digits, self.decimal_places)
1574 ]
1576 @cached_property
1577 def context(self):
1578 return decimal.Context(prec=self.max_digits)
1580 def deconstruct(self):
1581 name, path, args, kwargs = super().deconstruct()
1582 if self.max_digits is not None:
1583 kwargs["max_digits"] = self.max_digits
1584 if self.decimal_places is not None:
1585 kwargs["decimal_places"] = self.decimal_places
1586 return name, path, args, kwargs
1588 def get_internal_type(self):
1589 return "DecimalField"
1591 def to_python(self, value):
1592 if value is None:
1593 return value
1594 try:
1595 if isinstance(value, float):
1596 decimal_value = self.context.create_decimal_from_float(value)
1597 else:
1598 decimal_value = decimal.Decimal(value)
1599 except (decimal.InvalidOperation, TypeError, ValueError):
1600 raise exceptions.ValidationError(
1601 self.error_messages["invalid"],
1602 code="invalid",
1603 params={"value": value},
1604 )
1605 if not decimal_value.is_finite():
1606 raise exceptions.ValidationError(
1607 self.error_messages["invalid"],
1608 code="invalid",
1609 params={"value": value},
1610 )
1611 return decimal_value
1613 def get_db_prep_value(self, value, connection, prepared=False):
1614 if not prepared:
1615 value = self.get_prep_value(value)
1616 if hasattr(value, "as_sql"):
1617 return value
1618 return connection.ops.adapt_decimalfield_value(
1619 value, self.max_digits, self.decimal_places
1620 )
1622 def get_prep_value(self, value):
1623 value = super().get_prep_value(value)
1624 return self.to_python(value)
1627class DurationField(Field):
1628 """
1629 Store timedelta objects.
1631 Use interval on PostgreSQL, INTERVAL DAY TO SECOND on Oracle, and bigint
1632 of microseconds on other databases.
1633 """
1635 empty_strings_allowed = False
1636 default_error_messages = {
1637 "invalid": "“%(value)s” value has an invalid format. It must be in [DD] [[HH:]MM:]ss[.uuuuuu] format.",
1638 }
1639 description = "Duration"
1641 def get_internal_type(self):
1642 return "DurationField"
1644 def to_python(self, value):
1645 if value is None:
1646 return value
1647 if isinstance(value, datetime.timedelta):
1648 return value
1649 try:
1650 parsed = parse_duration(value)
1651 except ValueError:
1652 pass
1653 else:
1654 if parsed is not None:
1655 return parsed
1657 raise exceptions.ValidationError(
1658 self.error_messages["invalid"],
1659 code="invalid",
1660 params={"value": value},
1661 )
1663 def get_db_prep_value(self, value, connection, prepared=False):
1664 if connection.features.has_native_duration_field:
1665 return value
1666 if value is None:
1667 return None
1668 return duration_microseconds(value)
1670 def get_db_converters(self, connection):
1671 converters = []
1672 if not connection.features.has_native_duration_field:
1673 converters.append(connection.ops.convert_durationfield_value)
1674 return converters + super().get_db_converters(connection)
1676 def value_to_string(self, obj):
1677 val = self.value_from_object(obj)
1678 return "" if val is None else duration_string(val)
1681class EmailField(CharField):
1682 default_validators = [validators.validate_email]
1683 description = "Email address"
1685 def __init__(self, *args, **kwargs):
1686 # max_length=254 to be compliant with RFCs 3696 and 5321
1687 kwargs.setdefault("max_length", 254)
1688 super().__init__(*args, **kwargs)
1690 def deconstruct(self):
1691 name, path, args, kwargs = super().deconstruct()
1692 # We do not exclude max_length if it matches default as we want to change
1693 # the default in future.
1694 return name, path, args, kwargs
1697class FloatField(Field):
1698 empty_strings_allowed = False
1699 default_error_messages = {
1700 "invalid": "“%(value)s” value must be a float.",
1701 }
1702 description = "Floating point number"
1704 def get_prep_value(self, value):
1705 value = super().get_prep_value(value)
1706 if value is None:
1707 return None
1708 try:
1709 return float(value)
1710 except (TypeError, ValueError) as e:
1711 raise e.__class__(
1712 f"Field '{self.name}' expected a number but got {value!r}.",
1713 ) from e
1715 def get_internal_type(self):
1716 return "FloatField"
1718 def to_python(self, value):
1719 if value is None:
1720 return value
1721 try:
1722 return float(value)
1723 except (TypeError, ValueError):
1724 raise exceptions.ValidationError(
1725 self.error_messages["invalid"],
1726 code="invalid",
1727 params={"value": value},
1728 )
1731class IntegerField(Field):
1732 empty_strings_allowed = False
1733 default_error_messages = {
1734 "invalid": "“%(value)s” value must be an integer.",
1735 }
1736 description = "Integer"
1738 def check(self, **kwargs):
1739 return [
1740 *super().check(**kwargs),
1741 *self._check_max_length_warning(),
1742 ]
1744 def _check_max_length_warning(self):
1745 if self.max_length is not None:
1746 return [
1747 preflight.Warning(
1748 "'max_length' is ignored when used with %s."
1749 % self.__class__.__name__,
1750 hint="Remove 'max_length' from field",
1751 obj=self,
1752 id="fields.W122",
1753 )
1754 ]
1755 return []
1757 @cached_property
1758 def validators(self):
1759 # These validators can't be added at field initialization time since
1760 # they're based on values retrieved from `connection`.
1761 validators_ = super().validators
1762 internal_type = self.get_internal_type()
1763 min_value, max_value = connection.ops.integer_field_range(internal_type)
1764 if min_value is not None and not any(
1765 (
1766 isinstance(validator, validators.MinValueValidator)
1767 and (
1768 validator.limit_value()
1769 if callable(validator.limit_value)
1770 else validator.limit_value
1771 )
1772 >= min_value
1773 )
1774 for validator in validators_
1775 ):
1776 validators_.append(validators.MinValueValidator(min_value))
1777 if max_value is not None and not any(
1778 (
1779 isinstance(validator, validators.MaxValueValidator)
1780 and (
1781 validator.limit_value()
1782 if callable(validator.limit_value)
1783 else validator.limit_value
1784 )
1785 <= max_value
1786 )
1787 for validator in validators_
1788 ):
1789 validators_.append(validators.MaxValueValidator(max_value))
1790 return validators_
1792 def get_prep_value(self, value):
1793 value = super().get_prep_value(value)
1794 if value is None:
1795 return None
1796 try:
1797 return int(value)
1798 except (TypeError, ValueError) as e:
1799 raise e.__class__(
1800 f"Field '{self.name}' expected a number but got {value!r}.",
1801 ) from e
1803 def get_db_prep_value(self, value, connection, prepared=False):
1804 value = super().get_db_prep_value(value, connection, prepared)
1805 return connection.ops.adapt_integerfield_value(value, self.get_internal_type())
1807 def get_internal_type(self):
1808 return "IntegerField"
1810 def to_python(self, value):
1811 if value is None:
1812 return value
1813 try:
1814 return int(value)
1815 except (TypeError, ValueError):
1816 raise exceptions.ValidationError(
1817 self.error_messages["invalid"],
1818 code="invalid",
1819 params={"value": value},
1820 )
1823class BigIntegerField(IntegerField):
1824 description = "Big (8 byte) integer"
1825 MAX_BIGINT = 9223372036854775807
1827 def get_internal_type(self):
1828 return "BigIntegerField"
1831class SmallIntegerField(IntegerField):
1832 description = "Small integer"
1834 def get_internal_type(self):
1835 return "SmallIntegerField"
1838class IPAddressField(Field):
1839 empty_strings_allowed = False
1840 description = "IPv4 address"
1841 system_check_removed_details = {
1842 "msg": (
1843 "IPAddressField has been removed except for support in "
1844 "historical migrations."
1845 ),
1846 "hint": "Use GenericIPAddressField instead.",
1847 "id": "fields.E900",
1848 }
1850 def __init__(self, *args, **kwargs):
1851 kwargs["max_length"] = 15
1852 super().__init__(*args, **kwargs)
1854 def deconstruct(self):
1855 name, path, args, kwargs = super().deconstruct()
1856 del kwargs["max_length"]
1857 return name, path, args, kwargs
1859 def get_prep_value(self, value):
1860 value = super().get_prep_value(value)
1861 if value is None:
1862 return None
1863 return str(value)
1865 def get_internal_type(self):
1866 return "IPAddressField"
1869class GenericIPAddressField(Field):
1870 empty_strings_allowed = False
1871 description = "IP address"
1872 default_error_messages = {}
1874 def __init__(
1875 self,
1876 name=None,
1877 protocol="both",
1878 unpack_ipv4=False,
1879 *args,
1880 **kwargs,
1881 ):
1882 self.unpack_ipv4 = unpack_ipv4
1883 self.protocol = protocol
1884 (
1885 self.default_validators,
1886 invalid_error_message,
1887 ) = validators.ip_address_validators(protocol, unpack_ipv4)
1888 self.default_error_messages["invalid"] = invalid_error_message
1889 kwargs["max_length"] = 39
1890 super().__init__(name, *args, **kwargs)
1892 def check(self, **kwargs):
1893 return [
1894 *super().check(**kwargs),
1895 *self._check_blank_and_null_values(**kwargs),
1896 ]
1898 def _check_blank_and_null_values(self, **kwargs):
1899 if not getattr(self, "null", False) and getattr(self, "blank", False):
1900 return [
1901 preflight.Error(
1902 "GenericIPAddressFields cannot have blank=True if null=False, "
1903 "as blank values are stored as nulls.",
1904 obj=self,
1905 id="fields.E150",
1906 )
1907 ]
1908 return []
1910 def deconstruct(self):
1911 name, path, args, kwargs = super().deconstruct()
1912 if self.unpack_ipv4 is not False:
1913 kwargs["unpack_ipv4"] = self.unpack_ipv4
1914 if self.protocol != "both":
1915 kwargs["protocol"] = self.protocol
1916 if kwargs.get("max_length") == 39:
1917 del kwargs["max_length"]
1918 return name, path, args, kwargs
1920 def get_internal_type(self):
1921 return "GenericIPAddressField"
1923 def to_python(self, value):
1924 if value is None:
1925 return None
1926 if not isinstance(value, str):
1927 value = str(value)
1928 value = value.strip()
1929 if ":" in value:
1930 return clean_ipv6_address(
1931 value, self.unpack_ipv4, self.error_messages["invalid"]
1932 )
1933 return value
1935 def get_db_prep_value(self, value, connection, prepared=False):
1936 if not prepared:
1937 value = self.get_prep_value(value)
1938 return connection.ops.adapt_ipaddressfield_value(value)
1940 def get_prep_value(self, value):
1941 value = super().get_prep_value(value)
1942 if value is None:
1943 return None
1944 if value and ":" in value:
1945 try:
1946 return clean_ipv6_address(value, self.unpack_ipv4)
1947 except exceptions.ValidationError:
1948 pass
1949 return str(value)
1952class NullBooleanField(BooleanField):
1953 default_error_messages = {
1954 "invalid": "“%(value)s” value must be either None, True or False.",
1955 "invalid_nullable": "“%(value)s” value must be either None, True or False.",
1956 }
1957 description = "Boolean (Either True, False or None)"
1958 system_check_removed_details = {
1959 "msg": (
1960 "NullBooleanField is removed except for support in historical "
1961 "migrations."
1962 ),
1963 "hint": "Use BooleanField(null=True) instead.",
1964 "id": "fields.E903",
1965 }
1967 def __init__(self, *args, **kwargs):
1968 kwargs["null"] = True
1969 kwargs["blank"] = True
1970 super().__init__(*args, **kwargs)
1972 def deconstruct(self):
1973 name, path, args, kwargs = super().deconstruct()
1974 del kwargs["null"]
1975 del kwargs["blank"]
1976 return name, path, args, kwargs
1979class PositiveIntegerRelDbTypeMixin:
1980 def __init_subclass__(cls, **kwargs):
1981 super().__init_subclass__(**kwargs)
1982 if not hasattr(cls, "integer_field_class"):
1983 cls.integer_field_class = next(
1984 (
1985 parent
1986 for parent in cls.__mro__[1:]
1987 if issubclass(parent, IntegerField)
1988 ),
1989 None,
1990 )
1992 def rel_db_type(self, connection):
1993 """
1994 Return the data type that a related field pointing to this field should
1995 use. In most cases, a foreign key pointing to a positive integer
1996 primary key will have an integer column data type but some databases
1997 (e.g. MySQL) have an unsigned integer type. In that case
1998 (related_fields_match_type=True), the primary key should return its
1999 db_type.
2000 """
2001 if connection.features.related_fields_match_type:
2002 return self.db_type(connection)
2003 else:
2004 return self.integer_field_class().db_type(connection=connection)
2007class PositiveBigIntegerField(PositiveIntegerRelDbTypeMixin, BigIntegerField):
2008 description = "Positive big integer"
2010 def get_internal_type(self):
2011 return "PositiveBigIntegerField"
2014class PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField):
2015 description = "Positive integer"
2017 def get_internal_type(self):
2018 return "PositiveIntegerField"
2021class PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, SmallIntegerField):
2022 description = "Positive small integer"
2024 def get_internal_type(self):
2025 return "PositiveSmallIntegerField"
2028class SlugField(CharField):
2029 default_validators = [validators.validate_slug]
2030 description = "Slug (up to %(max_length)s)"
2032 def __init__(
2033 self, *args, max_length=50, db_index=True, allow_unicode=False, **kwargs
2034 ):
2035 self.allow_unicode = allow_unicode
2036 if self.allow_unicode:
2037 self.default_validators = [validators.validate_unicode_slug]
2038 super().__init__(*args, max_length=max_length, db_index=db_index, **kwargs)
2040 def deconstruct(self):
2041 name, path, args, kwargs = super().deconstruct()
2042 if kwargs.get("max_length") == 50:
2043 del kwargs["max_length"]
2044 if self.db_index is False:
2045 kwargs["db_index"] = False
2046 else:
2047 del kwargs["db_index"]
2048 if self.allow_unicode is not False:
2049 kwargs["allow_unicode"] = self.allow_unicode
2050 return name, path, args, kwargs
2052 def get_internal_type(self):
2053 return "SlugField"
2056class TextField(Field):
2057 description = "Text"
2059 def __init__(self, *args, db_collation=None, **kwargs):
2060 super().__init__(*args, **kwargs)
2061 self.db_collation = db_collation
2063 def check(self, **kwargs):
2064 databases = kwargs.get("databases") or []
2065 return [
2066 *super().check(**kwargs),
2067 *self._check_db_collation(databases),
2068 ]
2070 def _check_db_collation(self, databases):
2071 errors = []
2072 for db in databases:
2073 if not router.allow_migrate_model(db, self.model):
2074 continue
2075 connection = connections[db]
2076 if not (
2077 self.db_collation is None
2078 or "supports_collation_on_textfield"
2079 in self.model._meta.required_db_features
2080 or connection.features.supports_collation_on_textfield
2081 ):
2082 errors.append(
2083 preflight.Error(
2084 "%s does not support a database collation on "
2085 "TextFields." % connection.display_name,
2086 obj=self,
2087 id="fields.E190",
2088 ),
2089 )
2090 return errors
2092 def db_parameters(self, connection):
2093 db_params = super().db_parameters(connection)
2094 db_params["collation"] = self.db_collation
2095 return db_params
2097 def get_internal_type(self):
2098 return "TextField"
2100 def to_python(self, value):
2101 if isinstance(value, str) or value is None:
2102 return value
2103 return str(value)
2105 def get_prep_value(self, value):
2106 value = super().get_prep_value(value)
2107 return self.to_python(value)
2109 def deconstruct(self):
2110 name, path, args, kwargs = super().deconstruct()
2111 if self.db_collation:
2112 kwargs["db_collation"] = self.db_collation
2113 return name, path, args, kwargs
2116class TimeField(DateTimeCheckMixin, Field):
2117 empty_strings_allowed = False
2118 default_error_messages = {
2119 "invalid": "“%(value)s” value has an invalid format. It must be in HH:MM[:ss[.uuuuuu]] format.",
2120 "invalid_time": "“%(value)s” value has the correct format (HH:MM[:ss[.uuuuuu]]) but it is an invalid time.",
2121 }
2122 description = "Time"
2124 def __init__(self, name=None, auto_now=False, auto_now_add=False, **kwargs):
2125 self.auto_now, self.auto_now_add = auto_now, auto_now_add
2126 if auto_now or auto_now_add:
2127 kwargs["editable"] = False
2128 kwargs["blank"] = True
2129 super().__init__(name, **kwargs)
2131 def _check_fix_default_value(self):
2132 """
2133 Warn that using an actual date or datetime value is probably wrong;
2134 it's only evaluated on server startup.
2135 """
2136 if not self.has_default():
2137 return []
2139 value = self.default
2140 if isinstance(value, datetime.datetime):
2141 now = None
2142 elif isinstance(value, datetime.time):
2143 now = _get_naive_now()
2144 # This will not use the right date in the race condition where now
2145 # is just before the date change and value is just past 0:00.
2146 value = datetime.datetime.combine(now.date(), value)
2147 else:
2148 # No explicit time / datetime value -- no checks necessary
2149 return []
2150 # At this point, value is a datetime object.
2151 return self._check_if_value_fixed(value, now=now)
2153 def deconstruct(self):
2154 name, path, args, kwargs = super().deconstruct()
2155 if self.auto_now is not False:
2156 kwargs["auto_now"] = self.auto_now
2157 if self.auto_now_add is not False:
2158 kwargs["auto_now_add"] = self.auto_now_add
2159 if self.auto_now or self.auto_now_add:
2160 del kwargs["blank"]
2161 del kwargs["editable"]
2162 return name, path, args, kwargs
2164 def get_internal_type(self):
2165 return "TimeField"
2167 def to_python(self, value):
2168 if value is None:
2169 return None
2170 if isinstance(value, datetime.time):
2171 return value
2172 if isinstance(value, datetime.datetime):
2173 # Not usually a good idea to pass in a datetime here (it loses
2174 # information), but this can be a side-effect of interacting with a
2175 # database backend (e.g. Oracle), so we'll be accommodating.
2176 return value.time()
2178 try:
2179 parsed = parse_time(value)
2180 if parsed is not None:
2181 return parsed
2182 except ValueError:
2183 raise exceptions.ValidationError(
2184 self.error_messages["invalid_time"],
2185 code="invalid_time",
2186 params={"value": value},
2187 )
2189 raise exceptions.ValidationError(
2190 self.error_messages["invalid"],
2191 code="invalid",
2192 params={"value": value},
2193 )
2195 def pre_save(self, model_instance, add):
2196 if self.auto_now or (self.auto_now_add and add):
2197 value = datetime.datetime.now().time()
2198 setattr(model_instance, self.attname, value)
2199 return value
2200 else:
2201 return super().pre_save(model_instance, add)
2203 def get_prep_value(self, value):
2204 value = super().get_prep_value(value)
2205 return self.to_python(value)
2207 def get_db_prep_value(self, value, connection, prepared=False):
2208 # Casts times into the format expected by the backend
2209 if not prepared:
2210 value = self.get_prep_value(value)
2211 return connection.ops.adapt_timefield_value(value)
2213 def value_to_string(self, obj):
2214 val = self.value_from_object(obj)
2215 return "" if val is None else val.isoformat()
2218class URLField(CharField):
2219 default_validators = [validators.URLValidator()]
2220 description = "URL"
2222 def __init__(self, name=None, **kwargs):
2223 kwargs.setdefault("max_length", 200)
2224 super().__init__(name, **kwargs)
2226 def deconstruct(self):
2227 name, path, args, kwargs = super().deconstruct()
2228 if kwargs.get("max_length") == 200:
2229 del kwargs["max_length"]
2230 return name, path, args, kwargs
2233class BinaryField(Field):
2234 description = "Raw binary data"
2235 empty_values = [None, b""]
2237 def __init__(self, *args, **kwargs):
2238 kwargs.setdefault("editable", False)
2239 super().__init__(*args, **kwargs)
2240 if self.max_length is not None:
2241 self.validators.append(validators.MaxLengthValidator(self.max_length))
2243 def check(self, **kwargs):
2244 return [*super().check(**kwargs), *self._check_str_default_value()]
2246 def _check_str_default_value(self):
2247 if self.has_default() and isinstance(self.default, str):
2248 return [
2249 preflight.Error(
2250 "BinaryField's default cannot be a string. Use bytes "
2251 "content instead.",
2252 obj=self,
2253 id="fields.E170",
2254 )
2255 ]
2256 return []
2258 def deconstruct(self):
2259 name, path, args, kwargs = super().deconstruct()
2260 if self.editable:
2261 kwargs["editable"] = True
2262 else:
2263 del kwargs["editable"]
2264 return name, path, args, kwargs
2266 def get_internal_type(self):
2267 return "BinaryField"
2269 def get_placeholder(self, value, compiler, connection):
2270 return connection.ops.binary_placeholder_sql(value)
2272 def get_default(self):
2273 if self.has_default() and not callable(self.default):
2274 return self.default
2275 default = super().get_default()
2276 if default == "":
2277 return b""
2278 return default
2280 def get_db_prep_value(self, value, connection, prepared=False):
2281 value = super().get_db_prep_value(value, connection, prepared)
2282 if value is not None:
2283 return connection.Database.Binary(value)
2284 return value
2286 def value_to_string(self, obj):
2287 """Binary data is serialized as base64"""
2288 return b64encode(self.value_from_object(obj)).decode("ascii")
2290 def to_python(self, value):
2291 # If it's a string, it should be base64-encoded data
2292 if isinstance(value, str):
2293 return memoryview(b64decode(value.encode("ascii")))
2294 return value
2297class UUIDField(Field):
2298 default_error_messages = {
2299 "invalid": "“%(value)s” is not a valid UUID.",
2300 }
2301 description = "Universally unique identifier"
2302 empty_strings_allowed = False
2304 def __init__(self, **kwargs):
2305 kwargs["max_length"] = 32
2306 super().__init__(**kwargs)
2308 def deconstruct(self):
2309 name, path, args, kwargs = super().deconstruct()
2310 del kwargs["max_length"]
2311 return name, path, args, kwargs
2313 def get_internal_type(self):
2314 return "UUIDField"
2316 def get_prep_value(self, value):
2317 value = super().get_prep_value(value)
2318 return self.to_python(value)
2320 def get_db_prep_value(self, value, connection, prepared=False):
2321 if value is None:
2322 return None
2323 if not isinstance(value, uuid.UUID):
2324 value = self.to_python(value)
2326 if connection.features.has_native_uuid_field:
2327 return value
2328 return value.hex
2330 def to_python(self, value):
2331 if value is not None and not isinstance(value, uuid.UUID):
2332 input_form = "int" if isinstance(value, int) else "hex"
2333 try:
2334 return uuid.UUID(**{input_form: value})
2335 except (AttributeError, ValueError):
2336 raise exceptions.ValidationError(
2337 self.error_messages["invalid"],
2338 code="invalid",
2339 params={"value": value},
2340 )
2341 return value
2344class AutoFieldMixin:
2345 db_returning = True
2347 def __init__(self, *args, **kwargs):
2348 kwargs["blank"] = True
2349 super().__init__(*args, **kwargs)
2351 def check(self, **kwargs):
2352 return [
2353 *super().check(**kwargs),
2354 *self._check_primary_key(),
2355 ]
2357 def _check_primary_key(self):
2358 if not self.primary_key:
2359 return [
2360 preflight.Error(
2361 "AutoFields must set primary_key=True.",
2362 obj=self,
2363 id="fields.E100",
2364 ),
2365 ]
2366 else:
2367 return []
2369 def deconstruct(self):
2370 name, path, args, kwargs = super().deconstruct()
2371 del kwargs["blank"]
2372 kwargs["primary_key"] = True
2373 return name, path, args, kwargs
2375 def validate(self, value, model_instance):
2376 pass
2378 def get_db_prep_value(self, value, connection, prepared=False):
2379 if not prepared:
2380 value = self.get_prep_value(value)
2381 value = connection.ops.validate_autopk_value(value)
2382 return value
2384 def contribute_to_class(self, cls, name, **kwargs):
2385 if cls._meta.auto_field:
2386 raise ValueError(
2387 "Model %s can't have more than one auto-generated field."
2388 % cls._meta.label
2389 )
2390 super().contribute_to_class(cls, name, **kwargs)
2391 cls._meta.auto_field = self
2394class AutoFieldMeta(type):
2395 """
2396 Metaclass to maintain backward inheritance compatibility for AutoField.
2398 It is intended that AutoFieldMixin become public API when it is possible to
2399 create a non-integer automatically-generated field using column defaults
2400 stored in the database.
2402 In many areas Plain also relies on using isinstance() to check for an
2403 automatically-generated field as a subclass of AutoField. A new flag needs
2404 to be implemented on Field to be used instead.
2406 When these issues have been addressed, this metaclass could be used to
2407 deprecate inheritance from AutoField and use of isinstance() with AutoField
2408 for detecting automatically-generated fields.
2409 """
2411 @property
2412 def _subclasses(self):
2413 return (BigAutoField, SmallAutoField)
2415 def __instancecheck__(self, instance):
2416 return isinstance(instance, self._subclasses) or super().__instancecheck__(
2417 instance
2418 )
2420 def __subclasscheck__(self, subclass):
2421 return issubclass(subclass, self._subclasses) or super().__subclasscheck__(
2422 subclass
2423 )
2426class AutoField(AutoFieldMixin, IntegerField, metaclass=AutoFieldMeta):
2427 def get_internal_type(self):
2428 return "AutoField"
2430 def rel_db_type(self, connection):
2431 return IntegerField().db_type(connection=connection)
2434class BigAutoField(AutoFieldMixin, BigIntegerField):
2435 def get_internal_type(self):
2436 return "BigAutoField"
2438 def rel_db_type(self, connection):
2439 return BigIntegerField().db_type(connection=connection)
2442class SmallAutoField(AutoFieldMixin, SmallIntegerField):
2443 def get_internal_type(self):
2444 return "SmallAutoField"
2446 def rel_db_type(self, connection):
2447 return SmallIntegerField().db_type(connection=connection)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import json
2import warnings
4from plain import exceptions, preflight
5from plain.models import expressions, lookups
6from plain.models.constants import LOOKUP_SEP
7from plain.models.db import NotSupportedError, connections, router
8from plain.models.fields import TextField
9from plain.models.lookups import (
10 FieldGetDbPrepValueMixin,
11 PostgresOperatorLookup,
12 Transform,
13)
14from plain.utils.deprecation import RemovedInDjango51Warning
16from . import Field
17from .mixins import CheckFieldDefaultMixin
19__all__ = ["JSONField"]
22class JSONField(CheckFieldDefaultMixin, Field):
23 empty_strings_allowed = False
24 description = "A JSON object"
25 default_error_messages = {
26 "invalid": "Value must be valid JSON.",
27 }
28 _default_hint = ("dict", "{}")
30 def __init__(
31 self,
32 name=None,
33 encoder=None,
34 decoder=None,
35 **kwargs,
36 ):
37 if encoder and not callable(encoder):
38 raise ValueError("The encoder parameter must be a callable object.")
39 if decoder and not callable(decoder):
40 raise ValueError("The decoder parameter must be a callable object.")
41 self.encoder = encoder
42 self.decoder = decoder
43 super().__init__(name, **kwargs)
45 def check(self, **kwargs):
46 errors = super().check(**kwargs)
47 databases = kwargs.get("databases") or []
48 errors.extend(self._check_supported(databases))
49 return errors
51 def _check_supported(self, databases):
52 errors = []
53 for db in databases:
54 if not router.allow_migrate_model(db, self.model):
55 continue
56 connection = connections[db]
57 if (
58 self.model._meta.required_db_vendor
59 and self.model._meta.required_db_vendor != connection.vendor
60 ):
61 continue
62 if not (
63 "supports_json_field" in self.model._meta.required_db_features
64 or connection.features.supports_json_field
65 ):
66 errors.append(
67 preflight.Error(
68 "%s does not support JSONFields." % connection.display_name,
69 obj=self.model,
70 id="fields.E180",
71 )
72 )
73 return errors
75 def deconstruct(self):
76 name, path, args, kwargs = super().deconstruct()
77 if self.encoder is not None:
78 kwargs["encoder"] = self.encoder
79 if self.decoder is not None:
80 kwargs["decoder"] = self.decoder
81 return name, path, args, kwargs
83 def from_db_value(self, value, expression, connection):
84 if value is None:
85 return value
86 # Some backends (SQLite at least) extract non-string values in their
87 # SQL datatypes.
88 if isinstance(expression, KeyTransform) and not isinstance(value, str):
89 return value
90 try:
91 return json.loads(value, cls=self.decoder)
92 except json.JSONDecodeError:
93 return value
95 def get_internal_type(self):
96 return "JSONField"
98 def get_db_prep_value(self, value, connection, prepared=False):
99 # RemovedInDjango51Warning: When the deprecation ends, replace with:
100 # if (
101 # isinstance(value, expressions.Value)
102 # and isinstance(value.output_field, JSONField)
103 # ):
104 # value = value.value
105 # elif hasattr(value, "as_sql"): ...
106 if isinstance(value, expressions.Value):
107 if isinstance(value.value, str) and not isinstance(
108 value.output_field, JSONField
109 ):
110 try:
111 value = json.loads(value.value, cls=self.decoder)
112 except json.JSONDecodeError:
113 value = value.value
114 else:
115 warnings.warn(
116 "Providing an encoded JSON string via Value() is deprecated. "
117 f"Use Value({value!r}, output_field=JSONField()) instead.",
118 category=RemovedInDjango51Warning,
119 )
120 elif isinstance(value.output_field, JSONField):
121 value = value.value
122 else:
123 return value
124 elif hasattr(value, "as_sql"):
125 return value
126 return connection.ops.adapt_json_value(value, self.encoder)
128 def get_db_prep_save(self, value, connection):
129 if value is None:
130 return value
131 return self.get_db_prep_value(value, connection)
133 def get_transform(self, name):
134 transform = super().get_transform(name)
135 if transform:
136 return transform
137 return KeyTransformFactory(name)
139 def validate(self, value, model_instance):
140 super().validate(value, model_instance)
141 try:
142 json.dumps(value, cls=self.encoder)
143 except TypeError:
144 raise exceptions.ValidationError(
145 self.error_messages["invalid"],
146 code="invalid",
147 params={"value": value},
148 )
150 def value_to_string(self, obj):
151 return self.value_from_object(obj)
154def compile_json_path(key_transforms, include_root=True):
155 path = ["$"] if include_root else []
156 for key_transform in key_transforms:
157 try:
158 num = int(key_transform)
159 except ValueError: # non-integer
160 path.append(".")
161 path.append(json.dumps(key_transform))
162 else:
163 path.append("[%s]" % num)
164 return "".join(path)
167class DataContains(FieldGetDbPrepValueMixin, PostgresOperatorLookup):
168 lookup_name = "contains"
169 postgres_operator = "@>"
171 def as_sql(self, compiler, connection):
172 if not connection.features.supports_json_field_contains:
173 raise NotSupportedError(
174 "contains lookup is not supported on this database backend."
175 )
176 lhs, lhs_params = self.process_lhs(compiler, connection)
177 rhs, rhs_params = self.process_rhs(compiler, connection)
178 params = tuple(lhs_params) + tuple(rhs_params)
179 return f"JSON_CONTAINS({lhs}, {rhs})", params
182class ContainedBy(FieldGetDbPrepValueMixin, PostgresOperatorLookup):
183 lookup_name = "contained_by"
184 postgres_operator = "<@"
186 def as_sql(self, compiler, connection):
187 if not connection.features.supports_json_field_contains:
188 raise NotSupportedError(
189 "contained_by lookup is not supported on this database backend."
190 )
191 lhs, lhs_params = self.process_lhs(compiler, connection)
192 rhs, rhs_params = self.process_rhs(compiler, connection)
193 params = tuple(rhs_params) + tuple(lhs_params)
194 return f"JSON_CONTAINS({rhs}, {lhs})", params
197class HasKeyLookup(PostgresOperatorLookup):
198 logical_operator = None
200 def compile_json_path_final_key(self, key_transform):
201 # Compile the final key without interpreting ints as array elements.
202 return ".%s" % json.dumps(key_transform)
204 def as_sql(self, compiler, connection, template=None):
205 # Process JSON path from the left-hand side.
206 if isinstance(self.lhs, KeyTransform):
207 lhs, lhs_params, lhs_key_transforms = self.lhs.preprocess_lhs(
208 compiler, connection
209 )
210 lhs_json_path = compile_json_path(lhs_key_transforms)
211 else:
212 lhs, lhs_params = self.process_lhs(compiler, connection)
213 lhs_json_path = "$"
214 sql = template % lhs
215 # Process JSON path from the right-hand side.
216 rhs = self.rhs
217 rhs_params = []
218 if not isinstance(rhs, list | tuple):
219 rhs = [rhs]
220 for key in rhs:
221 if isinstance(key, KeyTransform):
222 *_, rhs_key_transforms = key.preprocess_lhs(compiler, connection)
223 else:
224 rhs_key_transforms = [key]
225 *rhs_key_transforms, final_key = rhs_key_transforms
226 rhs_json_path = compile_json_path(rhs_key_transforms, include_root=False)
227 rhs_json_path += self.compile_json_path_final_key(final_key)
228 rhs_params.append(lhs_json_path + rhs_json_path)
229 # Add condition for each key.
230 if self.logical_operator:
231 sql = "(%s)" % self.logical_operator.join([sql] * len(rhs_params))
232 return sql, tuple(lhs_params) + tuple(rhs_params)
234 def as_mysql(self, compiler, connection):
235 return self.as_sql(
236 compiler, connection, template="JSON_CONTAINS_PATH(%s, 'one', %%s)"
237 )
239 def as_postgresql(self, compiler, connection):
240 if isinstance(self.rhs, KeyTransform):
241 *_, rhs_key_transforms = self.rhs.preprocess_lhs(compiler, connection)
242 for key in rhs_key_transforms[:-1]:
243 self.lhs = KeyTransform(key, self.lhs)
244 self.rhs = rhs_key_transforms[-1]
245 return super().as_postgresql(compiler, connection)
247 def as_sqlite(self, compiler, connection):
248 return self.as_sql(
249 compiler, connection, template="JSON_TYPE(%s, %%s) IS NOT NULL"
250 )
253class HasKey(HasKeyLookup):
254 lookup_name = "has_key"
255 postgres_operator = "?"
256 prepare_rhs = False
259class HasKeys(HasKeyLookup):
260 lookup_name = "has_keys"
261 postgres_operator = "?&"
262 logical_operator = " AND "
264 def get_prep_lookup(self):
265 return [str(item) for item in self.rhs]
268class HasAnyKeys(HasKeys):
269 lookup_name = "has_any_keys"
270 postgres_operator = "?|"
271 logical_operator = " OR "
274class HasKeyOrArrayIndex(HasKey):
275 def compile_json_path_final_key(self, key_transform):
276 return compile_json_path([key_transform], include_root=False)
279class CaseInsensitiveMixin:
280 """
281 Mixin to allow case-insensitive comparison of JSON values on MySQL.
282 MySQL handles strings used in JSON context using the utf8mb4_bin collation.
283 Because utf8mb4_bin is a binary collation, comparison of JSON values is
284 case-sensitive.
285 """
287 def process_lhs(self, compiler, connection):
288 lhs, lhs_params = super().process_lhs(compiler, connection)
289 if connection.vendor == "mysql":
290 return "LOWER(%s)" % lhs, lhs_params
291 return lhs, lhs_params
293 def process_rhs(self, compiler, connection):
294 rhs, rhs_params = super().process_rhs(compiler, connection)
295 if connection.vendor == "mysql":
296 return "LOWER(%s)" % rhs, rhs_params
297 return rhs, rhs_params
300class JSONExact(lookups.Exact):
301 can_use_none_as_rhs = True
303 def process_rhs(self, compiler, connection):
304 rhs, rhs_params = super().process_rhs(compiler, connection)
305 # Treat None lookup values as null.
306 if rhs == "%s" and rhs_params == [None]:
307 rhs_params = ["null"]
308 if connection.vendor == "mysql":
309 func = ["JSON_EXTRACT(%s, '$')"] * len(rhs_params)
310 rhs %= tuple(func)
311 return rhs, rhs_params
314class JSONIContains(CaseInsensitiveMixin, lookups.IContains):
315 pass
318JSONField.register_lookup(DataContains)
319JSONField.register_lookup(ContainedBy)
320JSONField.register_lookup(HasKey)
321JSONField.register_lookup(HasKeys)
322JSONField.register_lookup(HasAnyKeys)
323JSONField.register_lookup(JSONExact)
324JSONField.register_lookup(JSONIContains)
327class KeyTransform(Transform):
328 postgres_operator = "->"
329 postgres_nested_operator = "#>"
331 def __init__(self, key_name, *args, **kwargs):
332 super().__init__(*args, **kwargs)
333 self.key_name = str(key_name)
335 def preprocess_lhs(self, compiler, connection):
336 key_transforms = [self.key_name]
337 previous = self.lhs
338 while isinstance(previous, KeyTransform):
339 key_transforms.insert(0, previous.key_name)
340 previous = previous.lhs
341 lhs, params = compiler.compile(previous)
342 return lhs, params, key_transforms
344 def as_mysql(self, compiler, connection):
345 lhs, params, key_transforms = self.preprocess_lhs(compiler, connection)
346 json_path = compile_json_path(key_transforms)
347 return "JSON_EXTRACT(%s, %%s)" % lhs, tuple(params) + (json_path,)
349 def as_postgresql(self, compiler, connection):
350 lhs, params, key_transforms = self.preprocess_lhs(compiler, connection)
351 if len(key_transforms) > 1:
352 sql = f"({lhs} {self.postgres_nested_operator} %s)"
353 return sql, tuple(params) + (key_transforms,)
354 try:
355 lookup = int(self.key_name)
356 except ValueError:
357 lookup = self.key_name
358 return f"({lhs} {self.postgres_operator} %s)", tuple(params) + (lookup,)
360 def as_sqlite(self, compiler, connection):
361 lhs, params, key_transforms = self.preprocess_lhs(compiler, connection)
362 json_path = compile_json_path(key_transforms)
363 datatype_values = ",".join(
364 [repr(datatype) for datatype in connection.ops.jsonfield_datatype_values]
365 )
366 return (
367 f"(CASE WHEN JSON_TYPE({lhs}, %s) IN ({datatype_values}) "
368 f"THEN JSON_TYPE({lhs}, %s) ELSE JSON_EXTRACT({lhs}, %s) END)"
369 ), (tuple(params) + (json_path,)) * 3
372class KeyTextTransform(KeyTransform):
373 postgres_operator = "->>"
374 postgres_nested_operator = "#>>"
375 output_field = TextField()
377 def as_mysql(self, compiler, connection):
378 if connection.mysql_is_mariadb:
379 # MariaDB doesn't support -> and ->> operators (see MDEV-13594).
380 sql, params = super().as_mysql(compiler, connection)
381 return "JSON_UNQUOTE(%s)" % sql, params
382 else:
383 lhs, params, key_transforms = self.preprocess_lhs(compiler, connection)
384 json_path = compile_json_path(key_transforms)
385 return "(%s ->> %%s)" % lhs, tuple(params) + (json_path,)
387 @classmethod
388 def from_lookup(cls, lookup):
389 transform, *keys = lookup.split(LOOKUP_SEP)
390 if not keys:
391 raise ValueError("Lookup must contain key or index transforms.")
392 for key in keys:
393 transform = cls(key, transform)
394 return transform
397KT = KeyTextTransform.from_lookup
400class KeyTransformTextLookupMixin:
401 """
402 Mixin for combining with a lookup expecting a text lhs from a JSONField
403 key lookup. On PostgreSQL, make use of the ->> operator instead of casting
404 key values to text and performing the lookup on the resulting
405 representation.
406 """
408 def __init__(self, key_transform, *args, **kwargs):
409 if not isinstance(key_transform, KeyTransform):
410 raise TypeError(
411 "Transform should be an instance of KeyTransform in order to "
412 "use this lookup."
413 )
414 key_text_transform = KeyTextTransform(
415 key_transform.key_name,
416 *key_transform.source_expressions,
417 **key_transform.extra,
418 )
419 super().__init__(key_text_transform, *args, **kwargs)
422class KeyTransformIsNull(lookups.IsNull):
423 # key__isnull=False is the same as has_key='key'
424 def as_sqlite(self, compiler, connection):
425 template = "JSON_TYPE(%s, %%s) IS NULL"
426 if not self.rhs:
427 template = "JSON_TYPE(%s, %%s) IS NOT NULL"
428 return HasKeyOrArrayIndex(self.lhs.lhs, self.lhs.key_name).as_sql(
429 compiler,
430 connection,
431 template=template,
432 )
435class KeyTransformIn(lookups.In):
436 def resolve_expression_parameter(self, compiler, connection, sql, param):
437 sql, params = super().resolve_expression_parameter(
438 compiler,
439 connection,
440 sql,
441 param,
442 )
443 if (
444 not hasattr(param, "as_sql")
445 and not connection.features.has_native_json_field
446 ):
447 if connection.vendor == "mysql" or (
448 connection.vendor == "sqlite"
449 and params[0] not in connection.ops.jsonfield_datatype_values
450 ):
451 sql = "JSON_EXTRACT(%s, '$')"
452 if connection.vendor == "mysql" and connection.mysql_is_mariadb:
453 sql = "JSON_UNQUOTE(%s)" % sql
454 return sql, params
457class KeyTransformExact(JSONExact):
458 def process_rhs(self, compiler, connection):
459 if isinstance(self.rhs, KeyTransform):
460 return super(lookups.Exact, self).process_rhs(compiler, connection)
461 rhs, rhs_params = super().process_rhs(compiler, connection)
462 if connection.vendor == "sqlite":
463 func = []
464 for value in rhs_params:
465 if value in connection.ops.jsonfield_datatype_values:
466 func.append("%s")
467 else:
468 func.append("JSON_EXTRACT(%s, '$')")
469 rhs %= tuple(func)
470 return rhs, rhs_params
473class KeyTransformIExact(
474 CaseInsensitiveMixin, KeyTransformTextLookupMixin, lookups.IExact
475):
476 pass
479class KeyTransformIContains(
480 CaseInsensitiveMixin, KeyTransformTextLookupMixin, lookups.IContains
481):
482 pass
485class KeyTransformStartsWith(KeyTransformTextLookupMixin, lookups.StartsWith):
486 pass
489class KeyTransformIStartsWith(
490 CaseInsensitiveMixin, KeyTransformTextLookupMixin, lookups.IStartsWith
491):
492 pass
495class KeyTransformEndsWith(KeyTransformTextLookupMixin, lookups.EndsWith):
496 pass
499class KeyTransformIEndsWith(
500 CaseInsensitiveMixin, KeyTransformTextLookupMixin, lookups.IEndsWith
501):
502 pass
505class KeyTransformRegex(KeyTransformTextLookupMixin, lookups.Regex):
506 pass
509class KeyTransformIRegex(
510 CaseInsensitiveMixin, KeyTransformTextLookupMixin, lookups.IRegex
511):
512 pass
515class KeyTransformNumericLookupMixin:
516 def process_rhs(self, compiler, connection):
517 rhs, rhs_params = super().process_rhs(compiler, connection)
518 if not connection.features.has_native_json_field:
519 rhs_params = [json.loads(value) for value in rhs_params]
520 return rhs, rhs_params
523class KeyTransformLt(KeyTransformNumericLookupMixin, lookups.LessThan):
524 pass
527class KeyTransformLte(KeyTransformNumericLookupMixin, lookups.LessThanOrEqual):
528 pass
531class KeyTransformGt(KeyTransformNumericLookupMixin, lookups.GreaterThan):
532 pass
535class KeyTransformGte(KeyTransformNumericLookupMixin, lookups.GreaterThanOrEqual):
536 pass
539KeyTransform.register_lookup(KeyTransformIn)
540KeyTransform.register_lookup(KeyTransformExact)
541KeyTransform.register_lookup(KeyTransformIExact)
542KeyTransform.register_lookup(KeyTransformIsNull)
543KeyTransform.register_lookup(KeyTransformIContains)
544KeyTransform.register_lookup(KeyTransformStartsWith)
545KeyTransform.register_lookup(KeyTransformIStartsWith)
546KeyTransform.register_lookup(KeyTransformEndsWith)
547KeyTransform.register_lookup(KeyTransformIEndsWith)
548KeyTransform.register_lookup(KeyTransformRegex)
549KeyTransform.register_lookup(KeyTransformIRegex)
551KeyTransform.register_lookup(KeyTransformLt)
552KeyTransform.register_lookup(KeyTransformLte)
553KeyTransform.register_lookup(KeyTransformGt)
554KeyTransform.register_lookup(KeyTransformGte)
557class KeyTransformFactory:
558 def __init__(self, key_name):
559 self.key_name = key_name
561 def __call__(self, *args, **kwargs):
562 return KeyTransform(self.key_name, *args, **kwargs)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain import preflight
3NOT_PROVIDED = object()
6class FieldCacheMixin:
7 """Provide an API for working with the model's fields value cache."""
9 def get_cache_name(self):
10 raise NotImplementedError
12 def get_cached_value(self, instance, default=NOT_PROVIDED):
13 cache_name = self.get_cache_name()
14 try:
15 return instance._state.fields_cache[cache_name]
16 except KeyError:
17 if default is NOT_PROVIDED:
18 raise
19 return default
21 def is_cached(self, instance):
22 return self.get_cache_name() in instance._state.fields_cache
24 def set_cached_value(self, instance, value):
25 instance._state.fields_cache[self.get_cache_name()] = value
27 def delete_cached_value(self, instance):
28 del instance._state.fields_cache[self.get_cache_name()]
31class CheckFieldDefaultMixin:
32 _default_hint = ("<valid default>", "<invalid default>")
34 def _check_default(self):
35 if (
36 self.has_default()
37 and self.default is not None
38 and not callable(self.default)
39 ):
40 return [
41 preflight.Warning(
42 "{} default should be a callable instead of an instance "
43 "so that it's not shared between all field instances.".format(
44 self.__class__.__name__
45 ),
46 hint=(
47 "Use a callable instead, e.g., use `{}` instead of "
48 "`{}`.".format(*self._default_hint)
49 ),
50 obj=self,
51 id="fields.E010",
52 )
53 ]
54 else:
55 return []
57 def check(self, **kwargs):
58 errors = super().check(**kwargs)
59 errors.extend(self._check_default())
60 return errors
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Field-like classes that aren't really fields. It's easier to use objects that
3have the same attributes as fields sometimes (avoids a lot of special casing).
4"""
6from plain.models import fields
9class OrderWrt(fields.IntegerField):
10 """
11 A proxy for the _order database field that is used when
12 Meta.order_with_respect_to is specified.
13 """
15 def __init__(self, *args, **kwargs):
16 kwargs["name"] = "_order"
17 kwargs["editable"] = False
18 super().__init__(*args, **kwargs)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Accessors for related objects.
4When a field defines a relation between two models, each model class provides
5an attribute to access related instances of the other model class (unless the
6reverse accessor has been disabled with related_name='+').
8Accessors are implemented as descriptors in order to customize access and
9assignment. This module defines the descriptor classes.
11Forward accessors follow foreign keys. Reverse accessors trace them back. For
12example, with the following models::
14 class Parent(Model):
15 pass
17 class Child(Model):
18 parent = ForeignKey(Parent, related_name='children')
20 ``child.parent`` is a forward many-to-one relation. ``parent.children`` is a
21reverse many-to-one relation.
23There are three types of relations (many-to-one, one-to-one, and many-to-many)
24and two directions (forward and reverse) for a total of six combinations.
261. Related instance on the forward side of a many-to-one relation:
27 ``ForwardManyToOneDescriptor``.
29 Uniqueness of foreign key values is irrelevant to accessing the related
30 instance, making the many-to-one and one-to-one cases identical as far as
31 the descriptor is concerned. The constraint is checked upstream (unicity
32 validation in forms) or downstream (unique indexes in the database).
342. Related instance on the forward side of a one-to-one
35 relation: ``ForwardOneToOneDescriptor``.
37 It avoids querying the database when accessing the parent link field in
38 a multi-table inheritance scenario.
403. Related instance on the reverse side of a one-to-one relation:
41 ``ReverseOneToOneDescriptor``.
43 One-to-one relations are asymmetrical, despite the apparent symmetry of the
44 name, because they're implemented in the database with a foreign key from
45 one table to another. As a consequence ``ReverseOneToOneDescriptor`` is
46 slightly different from ``ForwardManyToOneDescriptor``.
484. Related objects manager for related instances on the reverse side of a
49 many-to-one relation: ``ReverseManyToOneDescriptor``.
51 Unlike the previous two classes, this one provides access to a collection
52 of objects. It returns a manager rather than an instance.
545. Related objects manager for related instances on the forward or reverse
55 sides of a many-to-many relation: ``ManyToManyDescriptor``.
57 Many-to-many relations are symmetrical. The syntax of Plain models
58 requires declaring them on one side but that's an implementation detail.
59 They could be declared on the other side without any change in behavior.
60 Therefore the forward and reverse descriptors can be the same.
62 If you're looking for ``ForwardManyToManyDescriptor`` or
63 ``ReverseManyToManyDescriptor``, use ``ManyToManyDescriptor`` instead.
64"""
66from plain.exceptions import FieldError
67from plain.models import signals, transaction
68from plain.models.db import (
69 DEFAULT_DB_ALIAS,
70 NotSupportedError,
71 connections,
72 router,
73)
74from plain.models.expressions import Window
75from plain.models.functions import RowNumber
76from plain.models.lookups import GreaterThan, LessThanOrEqual
77from plain.models.query import QuerySet
78from plain.models.query_utils import DeferredAttribute, Q
79from plain.models.utils import AltersData, resolve_callables
80from plain.utils.functional import cached_property
83class ForeignKeyDeferredAttribute(DeferredAttribute):
84 def __set__(self, instance, value):
85 if instance.__dict__.get(self.field.attname) != value and self.field.is_cached(
86 instance
87 ):
88 self.field.delete_cached_value(instance)
89 instance.__dict__[self.field.attname] = value
92def _filter_prefetch_queryset(queryset, field_name, instances):
93 predicate = Q(**{f"{field_name}__in": instances})
94 db = queryset._db or DEFAULT_DB_ALIAS
95 if queryset.query.is_sliced:
96 if not connections[db].features.supports_over_clause:
97 raise NotSupportedError(
98 "Prefetching from a limited queryset is only supported on backends "
99 "that support window functions."
100 )
101 low_mark, high_mark = queryset.query.low_mark, queryset.query.high_mark
102 order_by = [
103 expr for expr, _ in queryset.query.get_compiler(using=db).get_order_by()
104 ]
105 window = Window(RowNumber(), partition_by=field_name, order_by=order_by)
106 predicate &= GreaterThan(window, low_mark)
107 if high_mark is not None:
108 predicate &= LessThanOrEqual(window, high_mark)
109 queryset.query.clear_limits()
110 return queryset.filter(predicate)
113class ForwardManyToOneDescriptor:
114 """
115 Accessor to the related object on the forward side of a many-to-one or
116 one-to-one (via ForwardOneToOneDescriptor subclass) relation.
118 In the example::
120 class Child(Model):
121 parent = ForeignKey(Parent, related_name='children')
123 ``Child.parent`` is a ``ForwardManyToOneDescriptor`` instance.
124 """
126 def __init__(self, field_with_rel):
127 self.field = field_with_rel
129 @cached_property
130 def RelatedObjectDoesNotExist(self):
131 # The exception can't be created at initialization time since the
132 # related model might not be resolved yet; `self.field.model` might
133 # still be a string model reference.
134 return type(
135 "RelatedObjectDoesNotExist",
136 (self.field.remote_field.model.DoesNotExist, AttributeError),
137 {
138 "__module__": self.field.model.__module__,
139 "__qualname__": "{}.{}.RelatedObjectDoesNotExist".format(
140 self.field.model.__qualname__,
141 self.field.name,
142 ),
143 },
144 )
146 def is_cached(self, instance):
147 return self.field.is_cached(instance)
149 def get_queryset(self, **hints):
150 return self.field.remote_field.model._base_manager.db_manager(hints=hints).all()
152 def get_prefetch_queryset(self, instances, queryset=None):
153 if queryset is None:
154 queryset = self.get_queryset()
155 queryset._add_hints(instance=instances[0])
157 rel_obj_attr = self.field.get_foreign_related_value
158 instance_attr = self.field.get_local_related_value
159 instances_dict = {instance_attr(inst): inst for inst in instances}
160 related_field = self.field.foreign_related_fields[0]
161 remote_field = self.field.remote_field
163 # FIXME: This will need to be revisited when we introduce support for
164 # composite fields. In the meantime we take this practical approach to
165 # solve a regression on 1.6 when the reverse manager in hidden
166 # (related_name ends with a '+'). Refs #21410.
167 # The check for len(...) == 1 is a special case that allows the query
168 # to be join-less and smaller. Refs #21760.
169 if remote_field.is_hidden() or len(self.field.foreign_related_fields) == 1:
170 query = {
171 "%s__in" % related_field.name: {
172 instance_attr(inst)[0] for inst in instances
173 }
174 }
175 else:
176 query = {"%s__in" % self.field.related_query_name(): instances}
177 queryset = queryset.filter(**query)
179 # Since we're going to assign directly in the cache,
180 # we must manage the reverse relation cache manually.
181 if not remote_field.multiple:
182 for rel_obj in queryset:
183 instance = instances_dict[rel_obj_attr(rel_obj)]
184 remote_field.set_cached_value(rel_obj, instance)
185 return (
186 queryset,
187 rel_obj_attr,
188 instance_attr,
189 True,
190 self.field.get_cache_name(),
191 False,
192 )
194 def get_object(self, instance):
195 qs = self.get_queryset(instance=instance)
196 # Assuming the database enforces foreign keys, this won't fail.
197 return qs.get(self.field.get_reverse_related_filter(instance))
199 def __get__(self, instance, cls=None):
200 """
201 Get the related instance through the forward relation.
203 With the example above, when getting ``child.parent``:
205 - ``self`` is the descriptor managing the ``parent`` attribute
206 - ``instance`` is the ``child`` instance
207 - ``cls`` is the ``Child`` class (we don't need it)
208 """
209 if instance is None:
210 return self
212 # The related instance is loaded from the database and then cached
213 # by the field on the model instance state. It can also be pre-cached
214 # by the reverse accessor (ReverseOneToOneDescriptor).
215 try:
216 rel_obj = self.field.get_cached_value(instance)
217 except KeyError:
218 has_value = None not in self.field.get_local_related_value(instance)
219 ancestor_link = (
220 instance._meta.get_ancestor_link(self.field.model)
221 if has_value
222 else None
223 )
224 if ancestor_link and ancestor_link.is_cached(instance):
225 # An ancestor link will exist if this field is defined on a
226 # multi-table inheritance parent of the instance's class.
227 ancestor = ancestor_link.get_cached_value(instance)
228 # The value might be cached on an ancestor if the instance
229 # originated from walking down the inheritance chain.
230 rel_obj = self.field.get_cached_value(ancestor, default=None)
231 else:
232 rel_obj = None
233 if rel_obj is None and has_value:
234 rel_obj = self.get_object(instance)
235 remote_field = self.field.remote_field
236 # If this is a one-to-one relation, set the reverse accessor
237 # cache on the related object to the current instance to avoid
238 # an extra SQL query if it's accessed later on.
239 if not remote_field.multiple:
240 remote_field.set_cached_value(rel_obj, instance)
241 self.field.set_cached_value(instance, rel_obj)
243 if rel_obj is None and not self.field.null:
244 raise self.RelatedObjectDoesNotExist(
245 f"{self.field.model.__name__} has no {self.field.name}."
246 )
247 else:
248 return rel_obj
250 def __set__(self, instance, value):
251 """
252 Set the related instance through the forward relation.
254 With the example above, when setting ``child.parent = parent``:
256 - ``self`` is the descriptor managing the ``parent`` attribute
257 - ``instance`` is the ``child`` instance
258 - ``value`` is the ``parent`` instance on the right of the equal sign
259 """
260 # An object must be an instance of the related class.
261 if value is not None and not isinstance(
262 value, self.field.remote_field.model._meta.concrete_model
263 ):
264 raise ValueError(
265 'Cannot assign "{!r}": "{}.{}" must be a "{}" instance.'.format(
266 value,
267 instance._meta.object_name,
268 self.field.name,
269 self.field.remote_field.model._meta.object_name,
270 )
271 )
272 elif value is not None:
273 if instance._state.db is None:
274 instance._state.db = router.db_for_write(
275 instance.__class__, instance=value
276 )
277 if value._state.db is None:
278 value._state.db = router.db_for_write(
279 value.__class__, instance=instance
280 )
281 if not router.allow_relation(value, instance):
282 raise ValueError(
283 'Cannot assign "%r": the current database router prevents this '
284 "relation." % value
285 )
287 remote_field = self.field.remote_field
288 # If we're setting the value of a OneToOneField to None, we need to clear
289 # out the cache on any old related object. Otherwise, deleting the
290 # previously-related object will also cause this object to be deleted,
291 # which is wrong.
292 if value is None:
293 # Look up the previously-related object, which may still be available
294 # since we've not yet cleared out the related field.
295 # Use the cache directly, instead of the accessor; if we haven't
296 # populated the cache, then we don't care - we're only accessing
297 # the object to invalidate the accessor cache, so there's no
298 # need to populate the cache just to expire it again.
299 related = self.field.get_cached_value(instance, default=None)
301 # If we've got an old related object, we need to clear out its
302 # cache. This cache also might not exist if the related object
303 # hasn't been accessed yet.
304 if related is not None:
305 remote_field.set_cached_value(related, None)
307 for lh_field, rh_field in self.field.related_fields:
308 setattr(instance, lh_field.attname, None)
310 # Set the values of the related field.
311 else:
312 for lh_field, rh_field in self.field.related_fields:
313 setattr(instance, lh_field.attname, getattr(value, rh_field.attname))
315 # Set the related instance cache used by __get__ to avoid an SQL query
316 # when accessing the attribute we just set.
317 self.field.set_cached_value(instance, value)
319 # If this is a one-to-one relation, set the reverse accessor cache on
320 # the related object to the current instance to avoid an extra SQL
321 # query if it's accessed later on.
322 if value is not None and not remote_field.multiple:
323 remote_field.set_cached_value(value, instance)
325 def __reduce__(self):
326 """
327 Pickling should return the instance attached by self.field on the
328 model, not a new copy of that descriptor. Use getattr() to retrieve
329 the instance directly from the model.
330 """
331 return getattr, (self.field.model, self.field.name)
334class ForwardOneToOneDescriptor(ForwardManyToOneDescriptor):
335 """
336 Accessor to the related object on the forward side of a one-to-one relation.
338 In the example::
340 class Restaurant(Model):
341 place = OneToOneField(Place, related_name='restaurant')
343 ``Restaurant.place`` is a ``ForwardOneToOneDescriptor`` instance.
344 """
346 def get_object(self, instance):
347 if self.field.remote_field.parent_link:
348 deferred = instance.get_deferred_fields()
349 # Because it's a parent link, all the data is available in the
350 # instance, so populate the parent model with this data.
351 rel_model = self.field.remote_field.model
352 fields = [field.attname for field in rel_model._meta.concrete_fields]
354 # If any of the related model's fields are deferred, fallback to
355 # fetching all fields from the related model. This avoids a query
356 # on the related model for every deferred field.
357 if not any(field in fields for field in deferred):
358 kwargs = {field: getattr(instance, field) for field in fields}
359 obj = rel_model(**kwargs)
360 obj._state.adding = instance._state.adding
361 obj._state.db = instance._state.db
362 return obj
363 return super().get_object(instance)
365 def __set__(self, instance, value):
366 super().__set__(instance, value)
367 # If the primary key is a link to a parent model and a parent instance
368 # is being set, update the value of the inherited pk(s).
369 if self.field.primary_key and self.field.remote_field.parent_link:
370 opts = instance._meta
371 # Inherited primary key fields from this object's base classes.
372 inherited_pk_fields = [
373 field
374 for field in opts.concrete_fields
375 if field.primary_key and field.remote_field
376 ]
377 for field in inherited_pk_fields:
378 rel_model_pk_name = field.remote_field.model._meta.pk.attname
379 raw_value = (
380 getattr(value, rel_model_pk_name) if value is not None else None
381 )
382 setattr(instance, rel_model_pk_name, raw_value)
385class ReverseOneToOneDescriptor:
386 """
387 Accessor to the related object on the reverse side of a one-to-one
388 relation.
390 In the example::
392 class Restaurant(Model):
393 place = OneToOneField(Place, related_name='restaurant')
395 ``Place.restaurant`` is a ``ReverseOneToOneDescriptor`` instance.
396 """
398 def __init__(self, related):
399 # Following the example above, `related` is an instance of OneToOneRel
400 # which represents the reverse restaurant field (place.restaurant).
401 self.related = related
403 @cached_property
404 def RelatedObjectDoesNotExist(self):
405 # The exception isn't created at initialization time for the sake of
406 # consistency with `ForwardManyToOneDescriptor`.
407 return type(
408 "RelatedObjectDoesNotExist",
409 (self.related.related_model.DoesNotExist, AttributeError),
410 {
411 "__module__": self.related.model.__module__,
412 "__qualname__": "{}.{}.RelatedObjectDoesNotExist".format(
413 self.related.model.__qualname__,
414 self.related.name,
415 ),
416 },
417 )
419 def is_cached(self, instance):
420 return self.related.is_cached(instance)
422 def get_queryset(self, **hints):
423 return self.related.related_model._base_manager.db_manager(hints=hints).all()
425 def get_prefetch_queryset(self, instances, queryset=None):
426 if queryset is None:
427 queryset = self.get_queryset()
428 queryset._add_hints(instance=instances[0])
430 rel_obj_attr = self.related.field.get_local_related_value
431 instance_attr = self.related.field.get_foreign_related_value
432 instances_dict = {instance_attr(inst): inst for inst in instances}
433 query = {"%s__in" % self.related.field.name: instances}
434 queryset = queryset.filter(**query)
436 # Since we're going to assign directly in the cache,
437 # we must manage the reverse relation cache manually.
438 for rel_obj in queryset:
439 instance = instances_dict[rel_obj_attr(rel_obj)]
440 self.related.field.set_cached_value(rel_obj, instance)
441 return (
442 queryset,
443 rel_obj_attr,
444 instance_attr,
445 True,
446 self.related.get_cache_name(),
447 False,
448 )
450 def __get__(self, instance, cls=None):
451 """
452 Get the related instance through the reverse relation.
454 With the example above, when getting ``place.restaurant``:
456 - ``self`` is the descriptor managing the ``restaurant`` attribute
457 - ``instance`` is the ``place`` instance
458 - ``cls`` is the ``Place`` class (unused)
460 Keep in mind that ``Restaurant`` holds the foreign key to ``Place``.
461 """
462 if instance is None:
463 return self
465 # The related instance is loaded from the database and then cached
466 # by the field on the model instance state. It can also be pre-cached
467 # by the forward accessor (ForwardManyToOneDescriptor).
468 try:
469 rel_obj = self.related.get_cached_value(instance)
470 except KeyError:
471 related_pk = instance.pk
472 if related_pk is None:
473 rel_obj = None
474 else:
475 filter_args = self.related.field.get_forward_related_filter(instance)
476 try:
477 rel_obj = self.get_queryset(instance=instance).get(**filter_args)
478 except self.related.related_model.DoesNotExist:
479 rel_obj = None
480 else:
481 # Set the forward accessor cache on the related object to
482 # the current instance to avoid an extra SQL query if it's
483 # accessed later on.
484 self.related.field.set_cached_value(rel_obj, instance)
485 self.related.set_cached_value(instance, rel_obj)
487 if rel_obj is None:
488 raise self.RelatedObjectDoesNotExist(
489 "{} has no {}.".format(
490 instance.__class__.__name__, self.related.get_accessor_name()
491 )
492 )
493 else:
494 return rel_obj
496 def __set__(self, instance, value):
497 """
498 Set the related instance through the reverse relation.
500 With the example above, when setting ``place.restaurant = restaurant``:
502 - ``self`` is the descriptor managing the ``restaurant`` attribute
503 - ``instance`` is the ``place`` instance
504 - ``value`` is the ``restaurant`` instance on the right of the equal sign
506 Keep in mind that ``Restaurant`` holds the foreign key to ``Place``.
507 """
508 # The similarity of the code below to the code in
509 # ForwardManyToOneDescriptor is annoying, but there's a bunch
510 # of small differences that would make a common base class convoluted.
512 if value is None:
513 # Update the cached related instance (if any) & clear the cache.
514 # Following the example above, this would be the cached
515 # ``restaurant`` instance (if any).
516 rel_obj = self.related.get_cached_value(instance, default=None)
517 if rel_obj is not None:
518 # Remove the ``restaurant`` instance from the ``place``
519 # instance cache.
520 self.related.delete_cached_value(instance)
521 # Set the ``place`` field on the ``restaurant``
522 # instance to None.
523 setattr(rel_obj, self.related.field.name, None)
524 elif not isinstance(value, self.related.related_model):
525 # An object must be an instance of the related class.
526 raise ValueError(
527 'Cannot assign "{!r}": "{}.{}" must be a "{}" instance.'.format(
528 value,
529 instance._meta.object_name,
530 self.related.get_accessor_name(),
531 self.related.related_model._meta.object_name,
532 )
533 )
534 else:
535 if instance._state.db is None:
536 instance._state.db = router.db_for_write(
537 instance.__class__, instance=value
538 )
539 if value._state.db is None:
540 value._state.db = router.db_for_write(
541 value.__class__, instance=instance
542 )
543 if not router.allow_relation(value, instance):
544 raise ValueError(
545 'Cannot assign "%r": the current database router prevents this '
546 "relation." % value
547 )
549 related_pk = tuple(
550 getattr(instance, field.attname)
551 for field in self.related.field.foreign_related_fields
552 )
553 # Set the value of the related field to the value of the related
554 # object's related field.
555 for index, field in enumerate(self.related.field.local_related_fields):
556 setattr(value, field.attname, related_pk[index])
558 # Set the related instance cache used by __get__ to avoid an SQL query
559 # when accessing the attribute we just set.
560 self.related.set_cached_value(instance, value)
562 # Set the forward accessor cache on the related object to the current
563 # instance to avoid an extra SQL query if it's accessed later on.
564 self.related.field.set_cached_value(value, instance)
566 def __reduce__(self):
567 # Same purpose as ForwardManyToOneDescriptor.__reduce__().
568 return getattr, (self.related.model, self.related.name)
571class ReverseManyToOneDescriptor:
572 """
573 Accessor to the related objects manager on the reverse side of a
574 many-to-one relation.
576 In the example::
578 class Child(Model):
579 parent = ForeignKey(Parent, related_name='children')
581 ``Parent.children`` is a ``ReverseManyToOneDescriptor`` instance.
583 Most of the implementation is delegated to a dynamically defined manager
584 class built by ``create_forward_many_to_many_manager()`` defined below.
585 """
587 def __init__(self, rel):
588 self.rel = rel
589 self.field = rel.field
591 @cached_property
592 def related_manager_cls(self):
593 related_model = self.rel.related_model
595 return create_reverse_many_to_one_manager(
596 related_model._default_manager.__class__,
597 self.rel,
598 )
600 def __get__(self, instance, cls=None):
601 """
602 Get the related objects through the reverse relation.
604 With the example above, when getting ``parent.children``:
606 - ``self`` is the descriptor managing the ``children`` attribute
607 - ``instance`` is the ``parent`` instance
608 - ``cls`` is the ``Parent`` class (unused)
609 """
610 if instance is None:
611 return self
613 return self.related_manager_cls(instance)
615 def _get_set_deprecation_msg_params(self):
616 return (
617 "reverse side of a related set",
618 self.rel.get_accessor_name(),
619 )
621 def __set__(self, instance, value):
622 raise TypeError(
623 "Direct assignment to the {} is prohibited. Use {}.set() instead.".format(
624 *self._get_set_deprecation_msg_params()
625 ),
626 )
629def create_reverse_many_to_one_manager(superclass, rel):
630 """
631 Create a manager for the reverse side of a many-to-one relation.
633 This manager subclasses another manager, generally the default manager of
634 the related model, and adds behaviors specific to many-to-one relations.
635 """
637 class RelatedManager(superclass, AltersData):
638 def __init__(self, instance):
639 super().__init__()
641 self.instance = instance
642 self.model = rel.related_model
643 self.field = rel.field
645 self.core_filters = {self.field.name: instance}
647 def __call__(self, *, manager):
648 manager = getattr(self.model, manager)
649 manager_class = create_reverse_many_to_one_manager(manager.__class__, rel)
650 return manager_class(self.instance)
652 do_not_call_in_templates = True
654 def _check_fk_val(self):
655 for field in self.field.foreign_related_fields:
656 if getattr(self.instance, field.attname) is None:
657 raise ValueError(
658 f'"{self.instance!r}" needs to have a value for field '
659 f'"{field.attname}" before this relationship can be used.'
660 )
662 def _apply_rel_filters(self, queryset):
663 """
664 Filter the queryset for the instance this manager is bound to.
665 """
666 db = self._db or router.db_for_read(self.model, instance=self.instance)
667 empty_strings_as_null = connections[
668 db
669 ].features.interprets_empty_strings_as_nulls
670 queryset._add_hints(instance=self.instance)
671 if self._db:
672 queryset = queryset.using(self._db)
673 queryset._defer_next_filter = True
674 queryset = queryset.filter(**self.core_filters)
675 for field in self.field.foreign_related_fields:
676 val = getattr(self.instance, field.attname)
677 if val is None or (val == "" and empty_strings_as_null):
678 return queryset.none()
679 if self.field.many_to_one:
680 # Guard against field-like objects such as GenericRelation
681 # that abuse create_reverse_many_to_one_manager() with reverse
682 # one-to-many relationships instead and break known related
683 # objects assignment.
684 try:
685 target_field = self.field.target_field
686 except FieldError:
687 # The relationship has multiple target fields. Use a tuple
688 # for related object id.
689 rel_obj_id = tuple(
690 [
691 getattr(self.instance, target_field.attname)
692 for target_field in self.field.path_infos[-1].target_fields
693 ]
694 )
695 else:
696 rel_obj_id = getattr(self.instance, target_field.attname)
697 queryset._known_related_objects = {
698 self.field: {rel_obj_id: self.instance}
699 }
700 return queryset
702 def _remove_prefetched_objects(self):
703 try:
704 self.instance._prefetched_objects_cache.pop(
705 self.field.remote_field.get_cache_name()
706 )
707 except (AttributeError, KeyError):
708 pass # nothing to clear from cache
710 def get_queryset(self):
711 # Even if this relation is not to pk, we require still pk value.
712 # The wish is that the instance has been already saved to DB,
713 # although having a pk value isn't a guarantee of that.
714 if self.instance.pk is None:
715 raise ValueError(
716 f"{self.instance.__class__.__name__!r} instance needs to have a "
717 f"primary key value before this relationship can be used."
718 )
719 try:
720 return self.instance._prefetched_objects_cache[
721 self.field.remote_field.get_cache_name()
722 ]
723 except (AttributeError, KeyError):
724 queryset = super().get_queryset()
725 return self._apply_rel_filters(queryset)
727 def get_prefetch_queryset(self, instances, queryset=None):
728 if queryset is None:
729 queryset = super().get_queryset()
731 queryset._add_hints(instance=instances[0])
732 queryset = queryset.using(queryset._db or self._db)
734 rel_obj_attr = self.field.get_local_related_value
735 instance_attr = self.field.get_foreign_related_value
736 instances_dict = {instance_attr(inst): inst for inst in instances}
737 queryset = _filter_prefetch_queryset(queryset, self.field.name, instances)
739 # Since we just bypassed this class' get_queryset(), we must manage
740 # the reverse relation manually.
741 for rel_obj in queryset:
742 if not self.field.is_cached(rel_obj):
743 instance = instances_dict[rel_obj_attr(rel_obj)]
744 setattr(rel_obj, self.field.name, instance)
745 cache_name = self.field.remote_field.get_cache_name()
746 return queryset, rel_obj_attr, instance_attr, False, cache_name, False
748 def add(self, *objs, bulk=True):
749 self._check_fk_val()
750 self._remove_prefetched_objects()
751 db = router.db_for_write(self.model, instance=self.instance)
753 def check_and_update_obj(obj):
754 if not isinstance(obj, self.model):
755 raise TypeError(
756 "'{}' instance expected, got {!r}".format(
757 self.model._meta.object_name,
758 obj,
759 )
760 )
761 setattr(obj, self.field.name, self.instance)
763 if bulk:
764 pks = []
765 for obj in objs:
766 check_and_update_obj(obj)
767 if obj._state.adding or obj._state.db != db:
768 raise ValueError(
769 "%r instance isn't saved. Use bulk=False or save "
770 "the object first." % obj
771 )
772 pks.append(obj.pk)
773 self.model._base_manager.using(db).filter(pk__in=pks).update(
774 **{
775 self.field.name: self.instance,
776 }
777 )
778 else:
779 with transaction.atomic(using=db, savepoint=False):
780 for obj in objs:
781 check_and_update_obj(obj)
782 obj.save()
784 add.alters_data = True
786 def create(self, **kwargs):
787 self._check_fk_val()
788 kwargs[self.field.name] = self.instance
789 db = router.db_for_write(self.model, instance=self.instance)
790 return super(RelatedManager, self.db_manager(db)).create(**kwargs)
792 create.alters_data = True
794 def get_or_create(self, **kwargs):
795 self._check_fk_val()
796 kwargs[self.field.name] = self.instance
797 db = router.db_for_write(self.model, instance=self.instance)
798 return super(RelatedManager, self.db_manager(db)).get_or_create(**kwargs)
800 get_or_create.alters_data = True
802 def update_or_create(self, **kwargs):
803 self._check_fk_val()
804 kwargs[self.field.name] = self.instance
805 db = router.db_for_write(self.model, instance=self.instance)
806 return super(RelatedManager, self.db_manager(db)).update_or_create(**kwargs)
808 update_or_create.alters_data = True
810 # remove() and clear() are only provided if the ForeignKey can have a
811 # value of null.
812 if rel.field.null:
814 def remove(self, *objs, bulk=True):
815 if not objs:
816 return
817 self._check_fk_val()
818 val = self.field.get_foreign_related_value(self.instance)
819 old_ids = set()
820 for obj in objs:
821 if not isinstance(obj, self.model):
822 raise TypeError(
823 "'{}' instance expected, got {!r}".format(
824 self.model._meta.object_name,
825 obj,
826 )
827 )
828 # Is obj actually part of this descriptor set?
829 if self.field.get_local_related_value(obj) == val:
830 old_ids.add(obj.pk)
831 else:
832 raise self.field.remote_field.model.DoesNotExist(
833 f"{obj!r} is not related to {self.instance!r}."
834 )
835 self._clear(self.filter(pk__in=old_ids), bulk)
837 remove.alters_data = True
839 def clear(self, *, bulk=True):
840 self._check_fk_val()
841 self._clear(self, bulk)
843 clear.alters_data = True
845 def _clear(self, queryset, bulk):
846 self._remove_prefetched_objects()
847 db = router.db_for_write(self.model, instance=self.instance)
848 queryset = queryset.using(db)
849 if bulk:
850 # `QuerySet.update()` is intrinsically atomic.
851 queryset.update(**{self.field.name: None})
852 else:
853 with transaction.atomic(using=db, savepoint=False):
854 for obj in queryset:
855 setattr(obj, self.field.name, None)
856 obj.save(update_fields=[self.field.name])
858 _clear.alters_data = True
860 def set(self, objs, *, bulk=True, clear=False):
861 self._check_fk_val()
862 # Force evaluation of `objs` in case it's a queryset whose value
863 # could be affected by `manager.clear()`. Refs #19816.
864 objs = tuple(objs)
866 if self.field.null:
867 db = router.db_for_write(self.model, instance=self.instance)
868 with transaction.atomic(using=db, savepoint=False):
869 if clear:
870 self.clear(bulk=bulk)
871 self.add(*objs, bulk=bulk)
872 else:
873 old_objs = set(self.using(db).all())
874 new_objs = []
875 for obj in objs:
876 if obj in old_objs:
877 old_objs.remove(obj)
878 else:
879 new_objs.append(obj)
881 self.remove(*old_objs, bulk=bulk)
882 self.add(*new_objs, bulk=bulk)
883 else:
884 self.add(*objs, bulk=bulk)
886 set.alters_data = True
888 return RelatedManager
891class ManyToManyDescriptor(ReverseManyToOneDescriptor):
892 """
893 Accessor to the related objects manager on the forward and reverse sides of
894 a many-to-many relation.
896 In the example::
898 class Pizza(Model):
899 toppings = ManyToManyField(Topping, related_name='pizzas')
901 ``Pizza.toppings`` and ``Topping.pizzas`` are ``ManyToManyDescriptor``
902 instances.
904 Most of the implementation is delegated to a dynamically defined manager
905 class built by ``create_forward_many_to_many_manager()`` defined below.
906 """
908 def __init__(self, rel, reverse=False):
909 super().__init__(rel)
911 self.reverse = reverse
913 @property
914 def through(self):
915 # through is provided so that you have easy access to the through
916 # model (Book.authors.through) for inlines, etc. This is done as
917 # a property to ensure that the fully resolved value is returned.
918 return self.rel.through
920 @cached_property
921 def related_manager_cls(self):
922 related_model = self.rel.related_model if self.reverse else self.rel.model
924 return create_forward_many_to_many_manager(
925 related_model._default_manager.__class__,
926 self.rel,
927 reverse=self.reverse,
928 )
930 def _get_set_deprecation_msg_params(self):
931 return (
932 "%s side of a many-to-many set"
933 % ("reverse" if self.reverse else "forward"),
934 self.rel.get_accessor_name() if self.reverse else self.field.name,
935 )
938def create_forward_many_to_many_manager(superclass, rel, reverse):
939 """
940 Create a manager for the either side of a many-to-many relation.
942 This manager subclasses another manager, generally the default manager of
943 the related model, and adds behaviors specific to many-to-many relations.
944 """
946 class ManyRelatedManager(superclass, AltersData):
947 def __init__(self, instance=None):
948 super().__init__()
950 self.instance = instance
952 if not reverse:
953 self.model = rel.model
954 self.query_field_name = rel.field.related_query_name()
955 self.prefetch_cache_name = rel.field.name
956 self.source_field_name = rel.field.m2m_field_name()
957 self.target_field_name = rel.field.m2m_reverse_field_name()
958 self.symmetrical = rel.symmetrical
959 else:
960 self.model = rel.related_model
961 self.query_field_name = rel.field.name
962 self.prefetch_cache_name = rel.field.related_query_name()
963 self.source_field_name = rel.field.m2m_reverse_field_name()
964 self.target_field_name = rel.field.m2m_field_name()
965 self.symmetrical = False
967 self.through = rel.through
968 self.reverse = reverse
970 self.source_field = self.through._meta.get_field(self.source_field_name)
971 self.target_field = self.through._meta.get_field(self.target_field_name)
973 self.core_filters = {}
974 self.pk_field_names = {}
975 for lh_field, rh_field in self.source_field.related_fields:
976 core_filter_key = f"{self.query_field_name}__{rh_field.name}"
977 self.core_filters[core_filter_key] = getattr(instance, rh_field.attname)
978 self.pk_field_names[lh_field.name] = rh_field.name
980 self.related_val = self.source_field.get_foreign_related_value(instance)
981 if None in self.related_val:
982 raise ValueError(
983 '"{!r}" needs to have a value for field "{}" before '
984 "this many-to-many relationship can be used.".format(
985 instance, self.pk_field_names[self.source_field_name]
986 )
987 )
988 # Even if this relation is not to pk, we require still pk value.
989 # The wish is that the instance has been already saved to DB,
990 # although having a pk value isn't a guarantee of that.
991 if instance.pk is None:
992 raise ValueError(
993 "%r instance needs to have a primary key value before "
994 "a many-to-many relationship can be used."
995 % instance.__class__.__name__
996 )
998 def __call__(self, *, manager):
999 manager = getattr(self.model, manager)
1000 manager_class = create_forward_many_to_many_manager(
1001 manager.__class__, rel, reverse
1002 )
1003 return manager_class(instance=self.instance)
1005 do_not_call_in_templates = True
1007 def _build_remove_filters(self, removed_vals):
1008 filters = Q.create([(self.source_field_name, self.related_val)])
1009 # No need to add a subquery condition if removed_vals is a QuerySet without
1010 # filters.
1011 removed_vals_filters = (
1012 not isinstance(removed_vals, QuerySet) or removed_vals._has_filters()
1013 )
1014 if removed_vals_filters:
1015 filters &= Q.create([(f"{self.target_field_name}__in", removed_vals)])
1016 if self.symmetrical:
1017 symmetrical_filters = Q.create(
1018 [(self.target_field_name, self.related_val)]
1019 )
1020 if removed_vals_filters:
1021 symmetrical_filters &= Q.create(
1022 [(f"{self.source_field_name}__in", removed_vals)]
1023 )
1024 filters |= symmetrical_filters
1025 return filters
1027 def _apply_rel_filters(self, queryset):
1028 """
1029 Filter the queryset for the instance this manager is bound to.
1030 """
1031 queryset._add_hints(instance=self.instance)
1032 if self._db:
1033 queryset = queryset.using(self._db)
1034 queryset._defer_next_filter = True
1035 return queryset._next_is_sticky().filter(**self.core_filters)
1037 def _remove_prefetched_objects(self):
1038 try:
1039 self.instance._prefetched_objects_cache.pop(self.prefetch_cache_name)
1040 except (AttributeError, KeyError):
1041 pass # nothing to clear from cache
1043 def get_queryset(self):
1044 try:
1045 return self.instance._prefetched_objects_cache[self.prefetch_cache_name]
1046 except (AttributeError, KeyError):
1047 queryset = super().get_queryset()
1048 return self._apply_rel_filters(queryset)
1050 def get_prefetch_queryset(self, instances, queryset=None):
1051 if queryset is None:
1052 queryset = super().get_queryset()
1054 queryset._add_hints(instance=instances[0])
1055 queryset = queryset.using(queryset._db or self._db)
1056 queryset = _filter_prefetch_queryset(
1057 queryset._next_is_sticky(), self.query_field_name, instances
1058 )
1060 # M2M: need to annotate the query in order to get the primary model
1061 # that the secondary model was actually related to. We know that
1062 # there will already be a join on the join table, so we can just add
1063 # the select.
1065 # For non-autocreated 'through' models, can't assume we are
1066 # dealing with PK values.
1067 fk = self.through._meta.get_field(self.source_field_name)
1068 join_table = fk.model._meta.db_table
1069 connection = connections[queryset.db]
1070 qn = connection.ops.quote_name
1071 queryset = queryset.extra(
1072 select={
1073 "_prefetch_related_val_%s"
1074 % f.attname: f"{qn(join_table)}.{qn(f.column)}"
1075 for f in fk.local_related_fields
1076 }
1077 )
1078 return (
1079 queryset,
1080 lambda result: tuple(
1081 getattr(result, "_prefetch_related_val_%s" % f.attname)
1082 for f in fk.local_related_fields
1083 ),
1084 lambda inst: tuple(
1085 f.get_db_prep_value(getattr(inst, f.attname), connection)
1086 for f in fk.foreign_related_fields
1087 ),
1088 False,
1089 self.prefetch_cache_name,
1090 False,
1091 )
1093 def add(self, *objs, through_defaults=None):
1094 self._remove_prefetched_objects()
1095 db = router.db_for_write(self.through, instance=self.instance)
1096 with transaction.atomic(using=db, savepoint=False):
1097 self._add_items(
1098 self.source_field_name,
1099 self.target_field_name,
1100 *objs,
1101 through_defaults=through_defaults,
1102 )
1103 # If this is a symmetrical m2m relation to self, add the mirror
1104 # entry in the m2m table.
1105 if self.symmetrical:
1106 self._add_items(
1107 self.target_field_name,
1108 self.source_field_name,
1109 *objs,
1110 through_defaults=through_defaults,
1111 )
1113 add.alters_data = True
1115 def remove(self, *objs):
1116 self._remove_prefetched_objects()
1117 self._remove_items(self.source_field_name, self.target_field_name, *objs)
1119 remove.alters_data = True
1121 def clear(self):
1122 db = router.db_for_write(self.through, instance=self.instance)
1123 with transaction.atomic(using=db, savepoint=False):
1124 signals.m2m_changed.send(
1125 sender=self.through,
1126 action="pre_clear",
1127 instance=self.instance,
1128 reverse=self.reverse,
1129 model=self.model,
1130 pk_set=None,
1131 using=db,
1132 )
1133 self._remove_prefetched_objects()
1134 filters = self._build_remove_filters(super().get_queryset().using(db))
1135 self.through._default_manager.using(db).filter(filters).delete()
1137 signals.m2m_changed.send(
1138 sender=self.through,
1139 action="post_clear",
1140 instance=self.instance,
1141 reverse=self.reverse,
1142 model=self.model,
1143 pk_set=None,
1144 using=db,
1145 )
1147 clear.alters_data = True
1149 def set(self, objs, *, clear=False, through_defaults=None):
1150 # Force evaluation of `objs` in case it's a queryset whose value
1151 # could be affected by `manager.clear()`. Refs #19816.
1152 objs = tuple(objs)
1154 db = router.db_for_write(self.through, instance=self.instance)
1155 with transaction.atomic(using=db, savepoint=False):
1156 if clear:
1157 self.clear()
1158 self.add(*objs, through_defaults=through_defaults)
1159 else:
1160 old_ids = set(
1161 self.using(db).values_list(
1162 self.target_field.target_field.attname, flat=True
1163 )
1164 )
1166 new_objs = []
1167 for obj in objs:
1168 fk_val = (
1169 self.target_field.get_foreign_related_value(obj)[0]
1170 if isinstance(obj, self.model)
1171 else self.target_field.get_prep_value(obj)
1172 )
1173 if fk_val in old_ids:
1174 old_ids.remove(fk_val)
1175 else:
1176 new_objs.append(obj)
1178 self.remove(*old_ids)
1179 self.add(*new_objs, through_defaults=through_defaults)
1181 set.alters_data = True
1183 def create(self, *, through_defaults=None, **kwargs):
1184 db = router.db_for_write(self.instance.__class__, instance=self.instance)
1185 new_obj = super(ManyRelatedManager, self.db_manager(db)).create(**kwargs)
1186 self.add(new_obj, through_defaults=through_defaults)
1187 return new_obj
1189 create.alters_data = True
1191 def get_or_create(self, *, through_defaults=None, **kwargs):
1192 db = router.db_for_write(self.instance.__class__, instance=self.instance)
1193 obj, created = super(ManyRelatedManager, self.db_manager(db)).get_or_create(
1194 **kwargs
1195 )
1196 # We only need to add() if created because if we got an object back
1197 # from get() then the relationship already exists.
1198 if created:
1199 self.add(obj, through_defaults=through_defaults)
1200 return obj, created
1202 get_or_create.alters_data = True
1204 def update_or_create(self, *, through_defaults=None, **kwargs):
1205 db = router.db_for_write(self.instance.__class__, instance=self.instance)
1206 obj, created = super(
1207 ManyRelatedManager, self.db_manager(db)
1208 ).update_or_create(**kwargs)
1209 # We only need to add() if created because if we got an object back
1210 # from get() then the relationship already exists.
1211 if created:
1212 self.add(obj, through_defaults=through_defaults)
1213 return obj, created
1215 update_or_create.alters_data = True
1217 def _get_target_ids(self, target_field_name, objs):
1218 """
1219 Return the set of ids of `objs` that the target field references.
1220 """
1221 from plain.models import Model
1223 target_ids = set()
1224 target_field = self.through._meta.get_field(target_field_name)
1225 for obj in objs:
1226 if isinstance(obj, self.model):
1227 if not router.allow_relation(obj, self.instance):
1228 raise ValueError(
1229 'Cannot add "{!r}": instance is on database "{}", '
1230 'value is on database "{}"'.format(
1231 obj, self.instance._state.db, obj._state.db
1232 )
1233 )
1234 target_id = target_field.get_foreign_related_value(obj)[0]
1235 if target_id is None:
1236 raise ValueError(
1237 'Cannot add "{!r}": the value for field "{}" is None'.format(
1238 obj, target_field_name
1239 )
1240 )
1241 target_ids.add(target_id)
1242 elif isinstance(obj, Model):
1243 raise TypeError(
1244 "'{}' instance expected, got {!r}".format(
1245 self.model._meta.object_name, obj
1246 )
1247 )
1248 else:
1249 target_ids.add(target_field.get_prep_value(obj))
1250 return target_ids
1252 def _get_missing_target_ids(
1253 self, source_field_name, target_field_name, db, target_ids
1254 ):
1255 """
1256 Return the subset of ids of `objs` that aren't already assigned to
1257 this relationship.
1258 """
1259 vals = (
1260 self.through._default_manager.using(db)
1261 .values_list(target_field_name, flat=True)
1262 .filter(
1263 **{
1264 source_field_name: self.related_val[0],
1265 "%s__in" % target_field_name: target_ids,
1266 }
1267 )
1268 )
1269 return target_ids.difference(vals)
1271 def _get_add_plan(self, db, source_field_name):
1272 """
1273 Return a boolean triple of the way the add should be performed.
1275 The first element is whether or not bulk_create(ignore_conflicts)
1276 can be used, the second whether or not signals must be sent, and
1277 the third element is whether or not the immediate bulk insertion
1278 with conflicts ignored can be performed.
1279 """
1280 # Conflicts can be ignored when the intermediary model is
1281 # auto-created as the only possible collision is on the
1282 # (source_id, target_id) tuple. The same assertion doesn't hold for
1283 # user-defined intermediary models as they could have other fields
1284 # causing conflicts which must be surfaced.
1285 can_ignore_conflicts = (
1286 self.through._meta.auto_created is not False
1287 and connections[db].features.supports_ignore_conflicts
1288 )
1289 # Don't send the signal when inserting duplicate data row
1290 # for symmetrical reverse entries.
1291 must_send_signals = (
1292 self.reverse or source_field_name == self.source_field_name
1293 ) and (signals.m2m_changed.has_listeners(self.through))
1294 # Fast addition through bulk insertion can only be performed
1295 # if no m2m_changed listeners are connected for self.through
1296 # as they require the added set of ids to be provided via
1297 # pk_set.
1298 return (
1299 can_ignore_conflicts,
1300 must_send_signals,
1301 (can_ignore_conflicts and not must_send_signals),
1302 )
1304 def _add_items(
1305 self, source_field_name, target_field_name, *objs, through_defaults=None
1306 ):
1307 # source_field_name: the PK fieldname in join table for the source object
1308 # target_field_name: the PK fieldname in join table for the target object
1309 # *objs - objects to add. Either object instances, or primary keys
1310 # of object instances.
1311 if not objs:
1312 return
1314 through_defaults = dict(resolve_callables(through_defaults or {}))
1315 target_ids = self._get_target_ids(target_field_name, objs)
1316 db = router.db_for_write(self.through, instance=self.instance)
1317 can_ignore_conflicts, must_send_signals, can_fast_add = self._get_add_plan(
1318 db, source_field_name
1319 )
1320 if can_fast_add:
1321 self.through._default_manager.using(db).bulk_create(
1322 [
1323 self.through(
1324 **{
1325 "%s_id" % source_field_name: self.related_val[0],
1326 "%s_id" % target_field_name: target_id,
1327 }
1328 )
1329 for target_id in target_ids
1330 ],
1331 ignore_conflicts=True,
1332 )
1333 return
1335 missing_target_ids = self._get_missing_target_ids(
1336 source_field_name, target_field_name, db, target_ids
1337 )
1338 with transaction.atomic(using=db, savepoint=False):
1339 if must_send_signals:
1340 signals.m2m_changed.send(
1341 sender=self.through,
1342 action="pre_add",
1343 instance=self.instance,
1344 reverse=self.reverse,
1345 model=self.model,
1346 pk_set=missing_target_ids,
1347 using=db,
1348 )
1349 # Add the ones that aren't there already.
1350 self.through._default_manager.using(db).bulk_create(
1351 [
1352 self.through(
1353 **through_defaults,
1354 **{
1355 "%s_id" % source_field_name: self.related_val[0],
1356 "%s_id" % target_field_name: target_id,
1357 },
1358 )
1359 for target_id in missing_target_ids
1360 ],
1361 ignore_conflicts=can_ignore_conflicts,
1362 )
1364 if must_send_signals:
1365 signals.m2m_changed.send(
1366 sender=self.through,
1367 action="post_add",
1368 instance=self.instance,
1369 reverse=self.reverse,
1370 model=self.model,
1371 pk_set=missing_target_ids,
1372 using=db,
1373 )
1375 def _remove_items(self, source_field_name, target_field_name, *objs):
1376 # source_field_name: the PK colname in join table for the source object
1377 # target_field_name: the PK colname in join table for the target object
1378 # *objs - objects to remove. Either object instances, or primary
1379 # keys of object instances.
1380 if not objs:
1381 return
1383 # Check that all the objects are of the right type
1384 old_ids = set()
1385 for obj in objs:
1386 if isinstance(obj, self.model):
1387 fk_val = self.target_field.get_foreign_related_value(obj)[0]
1388 old_ids.add(fk_val)
1389 else:
1390 old_ids.add(obj)
1392 db = router.db_for_write(self.through, instance=self.instance)
1393 with transaction.atomic(using=db, savepoint=False):
1394 # Send a signal to the other end if need be.
1395 signals.m2m_changed.send(
1396 sender=self.through,
1397 action="pre_remove",
1398 instance=self.instance,
1399 reverse=self.reverse,
1400 model=self.model,
1401 pk_set=old_ids,
1402 using=db,
1403 )
1404 target_model_qs = super().get_queryset()
1405 if target_model_qs._has_filters():
1406 old_vals = target_model_qs.using(db).filter(
1407 **{"%s__in" % self.target_field.target_field.attname: old_ids}
1408 )
1409 else:
1410 old_vals = old_ids
1411 filters = self._build_remove_filters(old_vals)
1412 self.through._default_manager.using(db).filter(filters).delete()
1414 signals.m2m_changed.send(
1415 sender=self.through,
1416 action="post_remove",
1417 instance=self.instance,
1418 reverse=self.reverse,
1419 model=self.model,
1420 pk_set=old_ids,
1421 using=db,
1422 )
1424 return ManyRelatedManager
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.models.lookups import (
2 Exact,
3 GreaterThan,
4 GreaterThanOrEqual,
5 In,
6 IsNull,
7 LessThan,
8 LessThanOrEqual,
9)
12class MultiColSource:
13 contains_aggregate = False
14 contains_over_clause = False
16 def __init__(self, alias, targets, sources, field):
17 self.targets, self.sources, self.field, self.alias = (
18 targets,
19 sources,
20 field,
21 alias,
22 )
23 self.output_field = self.field
25 def __repr__(self):
26 return f"{self.__class__.__name__}({self.alias}, {self.field})"
28 def relabeled_clone(self, relabels):
29 return self.__class__(
30 relabels.get(self.alias, self.alias), self.targets, self.sources, self.field
31 )
33 def get_lookup(self, lookup):
34 return self.output_field.get_lookup(lookup)
36 def resolve_expression(self, *args, **kwargs):
37 return self
40def get_normalized_value(value, lhs):
41 from plain.models import Model
43 if isinstance(value, Model):
44 if value.pk is None:
45 raise ValueError("Model instances passed to related filters must be saved.")
46 value_list = []
47 sources = lhs.output_field.path_infos[-1].target_fields
48 for source in sources:
49 while not isinstance(value, source.model) and source.remote_field:
50 source = source.remote_field.model._meta.get_field(
51 source.remote_field.field_name
52 )
53 try:
54 value_list.append(getattr(value, source.attname))
55 except AttributeError:
56 # A case like Restaurant.objects.filter(place=restaurant_instance),
57 # where place is a OneToOneField and the primary key of Restaurant.
58 return (value.pk,)
59 return tuple(value_list)
60 if not isinstance(value, tuple):
61 return (value,)
62 return value
65class RelatedIn(In):
66 def get_prep_lookup(self):
67 if not isinstance(self.lhs, MultiColSource):
68 if self.rhs_is_direct_value():
69 # If we get here, we are dealing with single-column relations.
70 self.rhs = [get_normalized_value(val, self.lhs)[0] for val in self.rhs]
71 # We need to run the related field's get_prep_value(). Consider
72 # case ForeignKey to IntegerField given value 'abc'. The
73 # ForeignKey itself doesn't have validation for non-integers,
74 # so we must run validation using the target field.
75 if hasattr(self.lhs.output_field, "path_infos"):
76 # Run the target field's get_prep_value. We can safely
77 # assume there is only one as we don't get to the direct
78 # value branch otherwise.
79 target_field = self.lhs.output_field.path_infos[-1].target_fields[
80 -1
81 ]
82 self.rhs = [target_field.get_prep_value(v) for v in self.rhs]
83 elif not getattr(self.rhs, "has_select_fields", True) and not getattr(
84 self.lhs.field.target_field, "primary_key", False
85 ):
86 if (
87 getattr(self.lhs.output_field, "primary_key", False)
88 and self.lhs.output_field.model == self.rhs.model
89 ):
90 # A case like
91 # Restaurant.objects.filter(place__in=restaurant_qs), where
92 # place is a OneToOneField and the primary key of
93 # Restaurant.
94 target_field = self.lhs.field.name
95 else:
96 target_field = self.lhs.field.target_field.name
97 self.rhs.set_values([target_field])
98 return super().get_prep_lookup()
100 def as_sql(self, compiler, connection):
101 if isinstance(self.lhs, MultiColSource):
102 # For multicolumn lookups we need to build a multicolumn where clause.
103 # This clause is either a SubqueryConstraint (for values that need
104 # to be compiled to SQL) or an OR-combined list of
105 # (col1 = val1 AND col2 = val2 AND ...) clauses.
106 from plain.models.sql.where import (
107 AND,
108 OR,
109 SubqueryConstraint,
110 WhereNode,
111 )
113 root_constraint = WhereNode(connector=OR)
114 if self.rhs_is_direct_value():
115 values = [get_normalized_value(value, self.lhs) for value in self.rhs]
116 for value in values:
117 value_constraint = WhereNode()
118 for source, target, val in zip(
119 self.lhs.sources, self.lhs.targets, value
120 ):
121 lookup_class = target.get_lookup("exact")
122 lookup = lookup_class(
123 target.get_col(self.lhs.alias, source), val
124 )
125 value_constraint.add(lookup, AND)
126 root_constraint.add(value_constraint, OR)
127 else:
128 root_constraint.add(
129 SubqueryConstraint(
130 self.lhs.alias,
131 [target.column for target in self.lhs.targets],
132 [source.name for source in self.lhs.sources],
133 self.rhs,
134 ),
135 AND,
136 )
137 return root_constraint.as_sql(compiler, connection)
138 return super().as_sql(compiler, connection)
141class RelatedLookupMixin:
142 def get_prep_lookup(self):
143 if not isinstance(self.lhs, MultiColSource) and not hasattr(
144 self.rhs, "resolve_expression"
145 ):
146 # If we get here, we are dealing with single-column relations.
147 self.rhs = get_normalized_value(self.rhs, self.lhs)[0]
148 # We need to run the related field's get_prep_value(). Consider case
149 # ForeignKey to IntegerField given value 'abc'. The ForeignKey itself
150 # doesn't have validation for non-integers, so we must run validation
151 # using the target field.
152 if self.prepare_rhs and hasattr(self.lhs.output_field, "path_infos"):
153 # Get the target field. We can safely assume there is only one
154 # as we don't get to the direct value branch otherwise.
155 target_field = self.lhs.output_field.path_infos[-1].target_fields[-1]
156 self.rhs = target_field.get_prep_value(self.rhs)
158 return super().get_prep_lookup()
160 def as_sql(self, compiler, connection):
161 if isinstance(self.lhs, MultiColSource):
162 assert self.rhs_is_direct_value()
163 self.rhs = get_normalized_value(self.rhs, self.lhs)
164 from plain.models.sql.where import AND, WhereNode
166 root_constraint = WhereNode()
167 for target, source, val in zip(
168 self.lhs.targets, self.lhs.sources, self.rhs
169 ):
170 lookup_class = target.get_lookup(self.lookup_name)
171 root_constraint.add(
172 lookup_class(target.get_col(self.lhs.alias, source), val), AND
173 )
174 return root_constraint.as_sql(compiler, connection)
175 return super().as_sql(compiler, connection)
178class RelatedExact(RelatedLookupMixin, Exact):
179 pass
182class RelatedLessThan(RelatedLookupMixin, LessThan):
183 pass
186class RelatedGreaterThan(RelatedLookupMixin, GreaterThan):
187 pass
190class RelatedGreaterThanOrEqual(RelatedLookupMixin, GreaterThanOrEqual):
191 pass
194class RelatedLessThanOrEqual(RelatedLookupMixin, LessThanOrEqual):
195 pass
198class RelatedIsNull(RelatedLookupMixin, IsNull):
199 pass
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import functools
2import inspect
3from functools import partial
5from plain import exceptions, preflight
6from plain.models.backends import utils
7from plain.models.constants import LOOKUP_SEP
8from plain.models.db import connection, router
9from plain.models.deletion import CASCADE, SET_DEFAULT, SET_NULL
10from plain.models.query_utils import PathInfo, Q
11from plain.models.utils import make_model_tuple
12from plain.packages import packages
13from plain.runtime import settings
14from plain.runtime.user_settings import SettingsReference
15from plain.utils.functional import cached_property
17from . import Field
18from .mixins import FieldCacheMixin
19from .related_descriptors import (
20 ForeignKeyDeferredAttribute,
21 ForwardManyToOneDescriptor,
22 ForwardOneToOneDescriptor,
23 ManyToManyDescriptor,
24 ReverseManyToOneDescriptor,
25 ReverseOneToOneDescriptor,
26)
27from .related_lookups import (
28 RelatedExact,
29 RelatedGreaterThan,
30 RelatedGreaterThanOrEqual,
31 RelatedIn,
32 RelatedIsNull,
33 RelatedLessThan,
34 RelatedLessThanOrEqual,
35)
36from .reverse_related import ForeignObjectRel, ManyToManyRel, ManyToOneRel, OneToOneRel
38RECURSIVE_RELATIONSHIP_CONSTANT = "self"
41def resolve_relation(scope_model, relation):
42 """
43 Transform relation into a model or fully-qualified model string of the form
44 "package_label.ModelName", relative to scope_model.
46 The relation argument can be:
47 * RECURSIVE_RELATIONSHIP_CONSTANT, i.e. the string "self", in which case
48 the model argument will be returned.
49 * A bare model name without an package_label, in which case scope_model's
50 package_label will be prepended.
51 * An "package_label.ModelName" string.
52 * A model class, which will be returned unchanged.
53 """
54 # Check for recursive relations
55 if relation == RECURSIVE_RELATIONSHIP_CONSTANT:
56 relation = scope_model
58 # Look for an "app.Model" relation
59 if isinstance(relation, str):
60 if "." not in relation:
61 relation = f"{scope_model._meta.package_label}.{relation}"
63 return relation
66def lazy_related_operation(function, model, *related_models, **kwargs):
67 """
68 Schedule `function` to be called once `model` and all `related_models`
69 have been imported and registered with the app registry. `function` will
70 be called with the newly-loaded model classes as its positional arguments,
71 plus any optional keyword arguments.
73 The `model` argument must be a model class. Each subsequent positional
74 argument is another model, or a reference to another model - see
75 `resolve_relation()` for the various forms these may take. Any relative
76 references will be resolved relative to `model`.
78 This is a convenience wrapper for `Packages.lazy_model_operation` - the app
79 registry model used is the one found in `model._meta.packages`.
80 """
81 models = [model] + [resolve_relation(model, rel) for rel in related_models]
82 model_keys = (make_model_tuple(m) for m in models)
83 packages = model._meta.packages
84 return packages.lazy_model_operation(partial(function, **kwargs), *model_keys)
87class RelatedField(FieldCacheMixin, Field):
88 """Base class that all relational fields inherit from."""
90 # Field flags
91 one_to_many = False
92 one_to_one = False
93 many_to_many = False
94 many_to_one = False
96 def __init__(
97 self,
98 related_name=None,
99 related_query_name=None,
100 limit_choices_to=None,
101 **kwargs,
102 ):
103 self._related_name = related_name
104 self._related_query_name = related_query_name
105 self._limit_choices_to = limit_choices_to
106 super().__init__(**kwargs)
108 @cached_property
109 def related_model(self):
110 # Can't cache this property until all the models are loaded.
111 packages.check_models_ready()
112 return self.remote_field.model
114 def check(self, **kwargs):
115 return [
116 *super().check(**kwargs),
117 *self._check_related_name_is_valid(),
118 *self._check_related_query_name_is_valid(),
119 *self._check_relation_model_exists(),
120 *self._check_referencing_to_swapped_model(),
121 *self._check_clashes(),
122 ]
124 def _check_related_name_is_valid(self):
125 import keyword
127 related_name = self.remote_field.related_name
128 if related_name is None:
129 return []
130 is_valid_id = (
131 not keyword.iskeyword(related_name) and related_name.isidentifier()
132 )
133 if not (is_valid_id or related_name.endswith("+")):
134 return [
135 preflight.Error(
136 "The name '{}' is invalid related_name for field {}.{}".format(
137 self.remote_field.related_name,
138 self.model._meta.object_name,
139 self.name,
140 ),
141 hint=(
142 "Related name must be a valid Python identifier or end with a "
143 "'+'"
144 ),
145 obj=self,
146 id="fields.E306",
147 )
148 ]
149 return []
151 def _check_related_query_name_is_valid(self):
152 if self.remote_field.is_hidden():
153 return []
154 rel_query_name = self.related_query_name()
155 errors = []
156 if rel_query_name.endswith("_"):
157 errors.append(
158 preflight.Error(
159 "Reverse query name '%s' must not end with an underscore."
160 % rel_query_name,
161 hint=(
162 "Add or change a related_name or related_query_name "
163 "argument for this field."
164 ),
165 obj=self,
166 id="fields.E308",
167 )
168 )
169 if LOOKUP_SEP in rel_query_name:
170 errors.append(
171 preflight.Error(
172 "Reverse query name '{}' must not contain '{}'.".format(
173 rel_query_name, LOOKUP_SEP
174 ),
175 hint=(
176 "Add or change a related_name or related_query_name "
177 "argument for this field."
178 ),
179 obj=self,
180 id="fields.E309",
181 )
182 )
183 return errors
185 def _check_relation_model_exists(self):
186 rel_is_missing = self.remote_field.model not in self.opts.packages.get_models()
187 rel_is_string = isinstance(self.remote_field.model, str)
188 model_name = (
189 self.remote_field.model
190 if rel_is_string
191 else self.remote_field.model._meta.object_name
192 )
193 if rel_is_missing and (
194 rel_is_string or not self.remote_field.model._meta.swapped
195 ):
196 return [
197 preflight.Error(
198 "Field defines a relation with model '%s', which is either "
199 "not installed, or is abstract." % model_name,
200 obj=self,
201 id="fields.E300",
202 )
203 ]
204 return []
206 def _check_referencing_to_swapped_model(self):
207 if (
208 self.remote_field.model not in self.opts.packages.get_models()
209 and not isinstance(self.remote_field.model, str)
210 and self.remote_field.model._meta.swapped
211 ):
212 return [
213 preflight.Error(
214 "Field defines a relation with the model '%s', which has "
215 "been swapped out." % self.remote_field.model._meta.label,
216 hint="Update the relation to point at 'settings.%s'."
217 % self.remote_field.model._meta.swappable,
218 obj=self,
219 id="fields.E301",
220 )
221 ]
222 return []
224 def _check_clashes(self):
225 """Check accessor and reverse query name clashes."""
226 from plain.models.base import ModelBase
228 errors = []
229 opts = self.model._meta
231 # f.remote_field.model may be a string instead of a model. Skip if
232 # model name is not resolved.
233 if not isinstance(self.remote_field.model, ModelBase):
234 return []
236 # Consider that we are checking field `Model.foreign` and the models
237 # are:
238 #
239 # class Target(models.Model):
240 # model = models.IntegerField()
241 # model_set = models.IntegerField()
242 #
243 # class Model(models.Model):
244 # foreign = models.ForeignKey(Target)
245 # m2m = models.ManyToManyField(Target)
247 # rel_opts.object_name == "Target"
248 rel_opts = self.remote_field.model._meta
249 # If the field doesn't install a backward relation on the target model
250 # (so `is_hidden` returns True), then there are no clashes to check
251 # and we can skip these fields.
252 rel_is_hidden = self.remote_field.is_hidden()
253 rel_name = self.remote_field.get_accessor_name() # i. e. "model_set"
254 rel_query_name = self.related_query_name() # i. e. "model"
255 # i.e. "package_label.Model.field".
256 field_name = f"{opts.label}.{self.name}"
258 # Check clashes between accessor or reverse query name of `field`
259 # and any other field name -- i.e. accessor for Model.foreign is
260 # model_set and it clashes with Target.model_set.
261 potential_clashes = rel_opts.fields + rel_opts.many_to_many
262 for clash_field in potential_clashes:
263 # i.e. "package_label.Target.model_set".
264 clash_name = f"{rel_opts.label}.{clash_field.name}"
265 if not rel_is_hidden and clash_field.name == rel_name:
266 errors.append(
267 preflight.Error(
268 f"Reverse accessor '{rel_opts.object_name}.{rel_name}' "
269 f"for '{field_name}' clashes with field name "
270 f"'{clash_name}'.",
271 hint=(
272 "Rename field '{}', or add/change a related_name "
273 "argument to the definition for field '{}'."
274 ).format(clash_name, field_name),
275 obj=self,
276 id="fields.E302",
277 )
278 )
280 if clash_field.name == rel_query_name:
281 errors.append(
282 preflight.Error(
283 "Reverse query name for '{}' clashes with field name '{}'.".format(
284 field_name, clash_name
285 ),
286 hint=(
287 "Rename field '{}', or add/change a related_name "
288 "argument to the definition for field '{}'."
289 ).format(clash_name, field_name),
290 obj=self,
291 id="fields.E303",
292 )
293 )
295 # Check clashes between accessors/reverse query names of `field` and
296 # any other field accessor -- i. e. Model.foreign accessor clashes with
297 # Model.m2m accessor.
298 potential_clashes = (r for r in rel_opts.related_objects if r.field is not self)
299 for clash_field in potential_clashes:
300 # i.e. "package_label.Model.m2m".
301 clash_name = "{}.{}".format(
302 clash_field.related_model._meta.label,
303 clash_field.field.name,
304 )
305 if not rel_is_hidden and clash_field.get_accessor_name() == rel_name:
306 errors.append(
307 preflight.Error(
308 f"Reverse accessor '{rel_opts.object_name}.{rel_name}' "
309 f"for '{field_name}' clashes with reverse accessor for "
310 f"'{clash_name}'.",
311 hint=(
312 "Add or change a related_name argument "
313 f"to the definition for '{field_name}' or '{clash_name}'."
314 ),
315 obj=self,
316 id="fields.E304",
317 )
318 )
320 if clash_field.get_accessor_name() == rel_query_name:
321 errors.append(
322 preflight.Error(
323 "Reverse query name for '{}' clashes with reverse query name "
324 "for '{}'.".format(field_name, clash_name),
325 hint=(
326 "Add or change a related_name argument "
327 f"to the definition for '{field_name}' or '{clash_name}'."
328 ),
329 obj=self,
330 id="fields.E305",
331 )
332 )
334 return errors
336 def db_type(self, connection):
337 # By default related field will not have a column as it relates to
338 # columns from another table.
339 return None
341 def contribute_to_class(self, cls, name, private_only=False, **kwargs):
342 super().contribute_to_class(cls, name, private_only=private_only, **kwargs)
344 self.opts = cls._meta
346 if not cls._meta.abstract:
347 if self.remote_field.related_name:
348 related_name = self.remote_field.related_name
349 else:
350 related_name = self.opts.default_related_name
351 if related_name:
352 related_name %= {
353 "class": cls.__name__.lower(),
354 "model_name": cls._meta.model_name.lower(),
355 "package_label": cls._meta.package_label.lower(),
356 }
357 self.remote_field.related_name = related_name
359 if self.remote_field.related_query_name:
360 related_query_name = self.remote_field.related_query_name % {
361 "class": cls.__name__.lower(),
362 "package_label": cls._meta.package_label.lower(),
363 }
364 self.remote_field.related_query_name = related_query_name
366 def resolve_related_class(model, related, field):
367 field.remote_field.model = related
368 field.do_related_class(related, model)
370 lazy_related_operation(
371 resolve_related_class, cls, self.remote_field.model, field=self
372 )
374 def deconstruct(self):
375 name, path, args, kwargs = super().deconstruct()
376 if self._limit_choices_to:
377 kwargs["limit_choices_to"] = self._limit_choices_to
378 if self._related_name is not None:
379 kwargs["related_name"] = self._related_name
380 if self._related_query_name is not None:
381 kwargs["related_query_name"] = self._related_query_name
382 return name, path, args, kwargs
384 def get_forward_related_filter(self, obj):
385 """
386 Return the keyword arguments that when supplied to
387 self.model.object.filter(), would select all instances related through
388 this field to the remote obj. This is used to build the querysets
389 returned by related descriptors. obj is an instance of
390 self.related_field.model.
391 """
392 return {
393 f"{self.name}__{rh_field.name}": getattr(obj, rh_field.attname)
394 for _, rh_field in self.related_fields
395 }
397 def get_reverse_related_filter(self, obj):
398 """
399 Complement to get_forward_related_filter(). Return the keyword
400 arguments that when passed to self.related_field.model.object.filter()
401 select all instances of self.related_field.model related through
402 this field to obj. obj is an instance of self.model.
403 """
404 base_q = Q.create(
405 [
406 (rh_field.attname, getattr(obj, lh_field.attname))
407 for lh_field, rh_field in self.related_fields
408 ]
409 )
410 descriptor_filter = self.get_extra_descriptor_filter(obj)
411 if isinstance(descriptor_filter, dict):
412 return base_q & Q(**descriptor_filter)
413 elif descriptor_filter:
414 return base_q & descriptor_filter
415 return base_q
417 @property
418 def swappable_setting(self):
419 """
420 Get the setting that this is powered from for swapping, or None
421 if it's not swapped in / marked with swappable=False.
422 """
423 if self.swappable:
424 # Work out string form of "to"
425 if isinstance(self.remote_field.model, str):
426 to_string = self.remote_field.model
427 else:
428 to_string = self.remote_field.model._meta.label
429 return packages.get_swappable_settings_name(to_string)
430 return None
432 def set_attributes_from_rel(self):
433 self.name = self.name or (
434 self.remote_field.model._meta.model_name
435 + "_"
436 + self.remote_field.model._meta.pk.name
437 )
438 self.remote_field.set_field_name()
440 def do_related_class(self, other, cls):
441 self.set_attributes_from_rel()
442 self.contribute_to_related_class(other, self.remote_field)
444 def get_limit_choices_to(self):
445 """
446 Return ``limit_choices_to`` for this model field.
448 If it is a callable, it will be invoked and the result will be
449 returned.
450 """
451 if callable(self.remote_field.limit_choices_to):
452 return self.remote_field.limit_choices_to()
453 return self.remote_field.limit_choices_to
455 def related_query_name(self):
456 """
457 Define the name that can be used to identify this related object in a
458 table-spanning query.
459 """
460 return (
461 self.remote_field.related_query_name
462 or self.remote_field.related_name
463 or self.opts.model_name
464 )
466 @property
467 def target_field(self):
468 """
469 When filtering against this relation, return the field on the remote
470 model against which the filtering should happen.
471 """
472 target_fields = self.path_infos[-1].target_fields
473 if len(target_fields) > 1:
474 raise exceptions.FieldError(
475 "The relation has multiple target fields, but only single target field "
476 "was asked for"
477 )
478 return target_fields[0]
480 def get_cache_name(self):
481 return self.name
484class ForeignObject(RelatedField):
485 """
486 Abstraction of the ForeignKey relation to support multi-column relations.
487 """
489 # Field flags
490 many_to_many = False
491 many_to_one = True
492 one_to_many = False
493 one_to_one = False
495 requires_unique_target = True
496 related_accessor_class = ReverseManyToOneDescriptor
497 forward_related_accessor_class = ForwardManyToOneDescriptor
498 rel_class = ForeignObjectRel
500 def __init__(
501 self,
502 to,
503 on_delete,
504 from_fields,
505 to_fields,
506 rel=None,
507 related_name=None,
508 related_query_name=None,
509 limit_choices_to=None,
510 parent_link=False,
511 swappable=True,
512 **kwargs,
513 ):
514 if rel is None:
515 rel = self.rel_class(
516 self,
517 to,
518 related_name=related_name,
519 related_query_name=related_query_name,
520 limit_choices_to=limit_choices_to,
521 parent_link=parent_link,
522 on_delete=on_delete,
523 )
525 super().__init__(
526 rel=rel,
527 related_name=related_name,
528 related_query_name=related_query_name,
529 limit_choices_to=limit_choices_to,
530 **kwargs,
531 )
533 self.from_fields = from_fields
534 self.to_fields = to_fields
535 self.swappable = swappable
537 def __copy__(self):
538 obj = super().__copy__()
539 # Remove any cached PathInfo values.
540 obj.__dict__.pop("path_infos", None)
541 obj.__dict__.pop("reverse_path_infos", None)
542 return obj
544 def check(self, **kwargs):
545 return [
546 *super().check(**kwargs),
547 *self._check_to_fields_exist(),
548 *self._check_unique_target(),
549 ]
551 def _check_to_fields_exist(self):
552 # Skip nonexistent models.
553 if isinstance(self.remote_field.model, str):
554 return []
556 errors = []
557 for to_field in self.to_fields:
558 if to_field:
559 try:
560 self.remote_field.model._meta.get_field(to_field)
561 except exceptions.FieldDoesNotExist:
562 errors.append(
563 preflight.Error(
564 f"The to_field '{to_field}' doesn't exist on the related "
565 f"model '{self.remote_field.model._meta.label}'.",
566 obj=self,
567 id="fields.E312",
568 )
569 )
570 return errors
572 def _check_unique_target(self):
573 rel_is_string = isinstance(self.remote_field.model, str)
574 if rel_is_string or not self.requires_unique_target:
575 return []
577 try:
578 self.foreign_related_fields
579 except exceptions.FieldDoesNotExist:
580 return []
582 if not self.foreign_related_fields:
583 return []
585 unique_foreign_fields = {
586 frozenset([f.name])
587 for f in self.remote_field.model._meta.get_fields()
588 if getattr(f, "unique", False)
589 }
590 unique_foreign_fields.update(
591 {
592 frozenset(uc.fields)
593 for uc in self.remote_field.model._meta.total_unique_constraints
594 }
595 )
596 foreign_fields = {f.name for f in self.foreign_related_fields}
597 has_unique_constraint = any(u <= foreign_fields for u in unique_foreign_fields)
599 if not has_unique_constraint and len(self.foreign_related_fields) > 1:
600 field_combination = ", ".join(
601 "'%s'" % rel_field.name for rel_field in self.foreign_related_fields
602 )
603 model_name = self.remote_field.model.__name__
604 return [
605 preflight.Error(
606 "No subset of the fields {} on model '{}' is unique.".format(
607 field_combination, model_name
608 ),
609 hint=(
610 "Mark a single field as unique=True or add a set of "
611 "fields to a unique constraint (via "
612 "a UniqueConstraint (without condition) in the "
613 "model Meta.constraints)."
614 ),
615 obj=self,
616 id="fields.E310",
617 )
618 ]
619 elif not has_unique_constraint:
620 field_name = self.foreign_related_fields[0].name
621 model_name = self.remote_field.model.__name__
622 return [
623 preflight.Error(
624 "'{}.{}' must be unique because it is referenced by "
625 "a foreign key.".format(model_name, field_name),
626 hint=(
627 "Add unique=True to this field or add a "
628 "UniqueConstraint (without condition) in the model "
629 "Meta.constraints."
630 ),
631 obj=self,
632 id="fields.E311",
633 )
634 ]
635 else:
636 return []
638 def deconstruct(self):
639 name, path, args, kwargs = super().deconstruct()
640 kwargs["on_delete"] = self.remote_field.on_delete
641 kwargs["from_fields"] = self.from_fields
642 kwargs["to_fields"] = self.to_fields
644 if self.remote_field.parent_link:
645 kwargs["parent_link"] = self.remote_field.parent_link
646 if isinstance(self.remote_field.model, str):
647 if "." in self.remote_field.model:
648 package_label, model_name = self.remote_field.model.split(".")
649 kwargs["to"] = f"{package_label}.{model_name.lower()}"
650 else:
651 kwargs["to"] = self.remote_field.model.lower()
652 else:
653 kwargs["to"] = self.remote_field.model._meta.label_lower
654 # If swappable is True, then see if we're actually pointing to the target
655 # of a swap.
656 swappable_setting = self.swappable_setting
657 if swappable_setting is not None:
658 # If it's already a settings reference, error
659 if hasattr(kwargs["to"], "setting_name"):
660 if kwargs["to"].setting_name != swappable_setting:
661 raise ValueError(
662 "Cannot deconstruct a ForeignKey pointing to a model "
663 "that is swapped in place of more than one model ({} and {})".format(
664 kwargs["to"].setting_name, swappable_setting
665 )
666 )
667 # Set it
668 kwargs["to"] = SettingsReference(
669 kwargs["to"],
670 swappable_setting,
671 )
672 return name, path, args, kwargs
674 def resolve_related_fields(self):
675 if not self.from_fields or len(self.from_fields) != len(self.to_fields):
676 raise ValueError(
677 "Foreign Object from and to fields must be the same non-zero length"
678 )
679 if isinstance(self.remote_field.model, str):
680 raise ValueError(
681 "Related model %r cannot be resolved" % self.remote_field.model
682 )
683 related_fields = []
684 for index in range(len(self.from_fields)):
685 from_field_name = self.from_fields[index]
686 to_field_name = self.to_fields[index]
687 from_field = (
688 self
689 if from_field_name == RECURSIVE_RELATIONSHIP_CONSTANT
690 else self.opts.get_field(from_field_name)
691 )
692 to_field = (
693 self.remote_field.model._meta.pk
694 if to_field_name is None
695 else self.remote_field.model._meta.get_field(to_field_name)
696 )
697 related_fields.append((from_field, to_field))
698 return related_fields
700 @cached_property
701 def related_fields(self):
702 return self.resolve_related_fields()
704 @cached_property
705 def reverse_related_fields(self):
706 return [(rhs_field, lhs_field) for lhs_field, rhs_field in self.related_fields]
708 @cached_property
709 def local_related_fields(self):
710 return tuple(lhs_field for lhs_field, rhs_field in self.related_fields)
712 @cached_property
713 def foreign_related_fields(self):
714 return tuple(
715 rhs_field for lhs_field, rhs_field in self.related_fields if rhs_field
716 )
718 def get_local_related_value(self, instance):
719 return self.get_instance_value_for_fields(instance, self.local_related_fields)
721 def get_foreign_related_value(self, instance):
722 return self.get_instance_value_for_fields(instance, self.foreign_related_fields)
724 @staticmethod
725 def get_instance_value_for_fields(instance, fields):
726 ret = []
727 opts = instance._meta
728 for field in fields:
729 # Gotcha: in some cases (like fixture loading) a model can have
730 # different values in parent_ptr_id and parent's id. So, use
731 # instance.pk (that is, parent_ptr_id) when asked for instance.id.
732 if field.primary_key:
733 possible_parent_link = opts.get_ancestor_link(field.model)
734 if (
735 not possible_parent_link
736 or possible_parent_link.primary_key
737 or possible_parent_link.model._meta.abstract
738 ):
739 ret.append(instance.pk)
740 continue
741 ret.append(getattr(instance, field.attname))
742 return tuple(ret)
744 def get_attname_column(self):
745 attname, column = super().get_attname_column()
746 return attname, None
748 def get_joining_columns(self, reverse_join=False):
749 source = self.reverse_related_fields if reverse_join else self.related_fields
750 return tuple(
751 (lhs_field.column, rhs_field.column) for lhs_field, rhs_field in source
752 )
754 def get_reverse_joining_columns(self):
755 return self.get_joining_columns(reverse_join=True)
757 def get_extra_descriptor_filter(self, instance):
758 """
759 Return an extra filter condition for related object fetching when
760 user does 'instance.fieldname', that is the extra filter is used in
761 the descriptor of the field.
763 The filter should be either a dict usable in .filter(**kwargs) call or
764 a Q-object. The condition will be ANDed together with the relation's
765 joining columns.
767 A parallel method is get_extra_restriction() which is used in
768 JOIN and subquery conditions.
769 """
770 return {}
772 def get_extra_restriction(self, alias, related_alias):
773 """
774 Return a pair condition used for joining and subquery pushdown. The
775 condition is something that responds to as_sql(compiler, connection)
776 method.
778 Note that currently referring both the 'alias' and 'related_alias'
779 will not work in some conditions, like subquery pushdown.
781 A parallel method is get_extra_descriptor_filter() which is used in
782 instance.fieldname related object fetching.
783 """
784 return None
786 def get_path_info(self, filtered_relation=None):
787 """Get path from this field to the related model."""
788 opts = self.remote_field.model._meta
789 from_opts = self.model._meta
790 return [
791 PathInfo(
792 from_opts=from_opts,
793 to_opts=opts,
794 target_fields=self.foreign_related_fields,
795 join_field=self,
796 m2m=False,
797 direct=True,
798 filtered_relation=filtered_relation,
799 )
800 ]
802 @cached_property
803 def path_infos(self):
804 return self.get_path_info()
806 def get_reverse_path_info(self, filtered_relation=None):
807 """Get path from the related model to this field's model."""
808 opts = self.model._meta
809 from_opts = self.remote_field.model._meta
810 return [
811 PathInfo(
812 from_opts=from_opts,
813 to_opts=opts,
814 target_fields=(opts.pk,),
815 join_field=self.remote_field,
816 m2m=not self.unique,
817 direct=False,
818 filtered_relation=filtered_relation,
819 )
820 ]
822 @cached_property
823 def reverse_path_infos(self):
824 return self.get_reverse_path_info()
826 @classmethod
827 @functools.cache
828 def get_class_lookups(cls):
829 bases = inspect.getmro(cls)
830 bases = bases[: bases.index(ForeignObject) + 1]
831 class_lookups = [parent.__dict__.get("class_lookups", {}) for parent in bases]
832 return cls.merge_dicts(class_lookups)
834 def contribute_to_class(self, cls, name, private_only=False, **kwargs):
835 super().contribute_to_class(cls, name, private_only=private_only, **kwargs)
836 setattr(cls, self.name, self.forward_related_accessor_class(self))
838 def contribute_to_related_class(self, cls, related):
839 # Internal FK's - i.e., those with a related name ending with '+' -
840 # and swapped models don't get a related descriptor.
841 if (
842 not self.remote_field.is_hidden()
843 and not related.related_model._meta.swapped
844 ):
845 setattr(
846 cls._meta.concrete_model,
847 related.get_accessor_name(),
848 self.related_accessor_class(related),
849 )
850 # While 'limit_choices_to' might be a callable, simply pass
851 # it along for later - this is too early because it's still
852 # model load time.
853 if self.remote_field.limit_choices_to:
854 cls._meta.related_fkey_lookups.append(
855 self.remote_field.limit_choices_to
856 )
859ForeignObject.register_lookup(RelatedIn)
860ForeignObject.register_lookup(RelatedExact)
861ForeignObject.register_lookup(RelatedLessThan)
862ForeignObject.register_lookup(RelatedGreaterThan)
863ForeignObject.register_lookup(RelatedGreaterThanOrEqual)
864ForeignObject.register_lookup(RelatedLessThanOrEqual)
865ForeignObject.register_lookup(RelatedIsNull)
868class ForeignKey(ForeignObject):
869 """
870 Provide a many-to-one relation by adding a column to the local model
871 to hold the remote value.
873 By default ForeignKey will target the pk of the remote model but this
874 behavior can be changed by using the ``to_field`` argument.
875 """
877 descriptor_class = ForeignKeyDeferredAttribute
878 # Field flags
879 many_to_many = False
880 many_to_one = True
881 one_to_many = False
882 one_to_one = False
884 rel_class = ManyToOneRel
886 empty_strings_allowed = False
887 default_error_messages = {
888 "invalid": "%(model)s instance with %(field)s %(value)r does not exist."
889 }
890 description = "Foreign Key (type determined by related field)"
892 def __init__(
893 self,
894 to,
895 on_delete,
896 related_name=None,
897 related_query_name=None,
898 limit_choices_to=None,
899 parent_link=False,
900 to_field=None,
901 db_constraint=True,
902 **kwargs,
903 ):
904 try:
905 to._meta.model_name
906 except AttributeError:
907 if not isinstance(to, str):
908 raise TypeError(
909 "{}({!r}) is invalid. First parameter to ForeignKey must be "
910 "either a model, a model name, or the string {!r}".format(
911 self.__class__.__name__,
912 to,
913 RECURSIVE_RELATIONSHIP_CONSTANT,
914 )
915 )
916 else:
917 # For backwards compatibility purposes, we need to *try* and set
918 # the to_field during FK construction. It won't be guaranteed to
919 # be correct until contribute_to_class is called. Refs #12190.
920 to_field = to_field or (to._meta.pk and to._meta.pk.name)
921 if not callable(on_delete):
922 raise TypeError("on_delete must be callable.")
924 kwargs["rel"] = self.rel_class(
925 self,
926 to,
927 to_field,
928 related_name=related_name,
929 related_query_name=related_query_name,
930 limit_choices_to=limit_choices_to,
931 parent_link=parent_link,
932 on_delete=on_delete,
933 )
934 kwargs.setdefault("db_index", True)
936 super().__init__(
937 to,
938 on_delete,
939 related_name=related_name,
940 related_query_name=related_query_name,
941 limit_choices_to=limit_choices_to,
942 from_fields=[RECURSIVE_RELATIONSHIP_CONSTANT],
943 to_fields=[to_field],
944 **kwargs,
945 )
946 self.db_constraint = db_constraint
948 def __class_getitem__(cls, *args, **kwargs):
949 return cls
951 def check(self, **kwargs):
952 return [
953 *super().check(**kwargs),
954 *self._check_on_delete(),
955 *self._check_unique(),
956 ]
958 def _check_on_delete(self):
959 on_delete = getattr(self.remote_field, "on_delete", None)
960 if on_delete == SET_NULL and not self.null:
961 return [
962 preflight.Error(
963 "Field specifies on_delete=SET_NULL, but cannot be null.",
964 hint=(
965 "Set null=True argument on the field, or change the on_delete "
966 "rule."
967 ),
968 obj=self,
969 id="fields.E320",
970 )
971 ]
972 elif on_delete == SET_DEFAULT and not self.has_default():
973 return [
974 preflight.Error(
975 "Field specifies on_delete=SET_DEFAULT, but has no default value.",
976 hint="Set a default value, or change the on_delete rule.",
977 obj=self,
978 id="fields.E321",
979 )
980 ]
981 else:
982 return []
984 def _check_unique(self, **kwargs):
985 return (
986 [
987 preflight.Warning(
988 "Setting unique=True on a ForeignKey has the same effect as using "
989 "a OneToOneField.",
990 hint=(
991 "ForeignKey(unique=True) is usually better served by a "
992 "OneToOneField."
993 ),
994 obj=self,
995 id="fields.W342",
996 )
997 ]
998 if self.unique
999 else []
1000 )
1002 def deconstruct(self):
1003 name, path, args, kwargs = super().deconstruct()
1004 del kwargs["to_fields"]
1005 del kwargs["from_fields"]
1006 # Handle the simpler arguments
1007 if self.db_index:
1008 del kwargs["db_index"]
1009 else:
1010 kwargs["db_index"] = False
1011 if self.db_constraint is not True:
1012 kwargs["db_constraint"] = self.db_constraint
1013 # Rel needs more work.
1014 to_meta = getattr(self.remote_field.model, "_meta", None)
1015 if self.remote_field.field_name and (
1016 not to_meta
1017 or (to_meta.pk and self.remote_field.field_name != to_meta.pk.name)
1018 ):
1019 kwargs["to_field"] = self.remote_field.field_name
1020 return name, path, args, kwargs
1022 def to_python(self, value):
1023 return self.target_field.to_python(value)
1025 @property
1026 def target_field(self):
1027 return self.foreign_related_fields[0]
1029 def validate(self, value, model_instance):
1030 if self.remote_field.parent_link:
1031 return
1032 super().validate(value, model_instance)
1033 if value is None:
1034 return
1036 using = router.db_for_read(self.remote_field.model, instance=model_instance)
1037 qs = self.remote_field.model._base_manager.using(using).filter(
1038 **{self.remote_field.field_name: value}
1039 )
1040 qs = qs.complex_filter(self.get_limit_choices_to())
1041 if not qs.exists():
1042 raise exceptions.ValidationError(
1043 self.error_messages["invalid"],
1044 code="invalid",
1045 params={
1046 "model": self.remote_field.model._meta.model_name,
1047 "pk": value,
1048 "field": self.remote_field.field_name,
1049 "value": value,
1050 }, # 'pk' is included for backwards compatibility
1051 )
1053 def resolve_related_fields(self):
1054 related_fields = super().resolve_related_fields()
1055 for from_field, to_field in related_fields:
1056 if (
1057 to_field
1058 and to_field.model != self.remote_field.model._meta.concrete_model
1059 ):
1060 raise exceptions.FieldError(
1061 "'{}.{}' refers to field '{}' which is not local to model "
1062 "'{}'.".format(
1063 self.model._meta.label,
1064 self.name,
1065 to_field.name,
1066 self.remote_field.model._meta.concrete_model._meta.label,
1067 )
1068 )
1069 return related_fields
1071 def get_attname(self):
1072 return "%s_id" % self.name
1074 def get_attname_column(self):
1075 attname = self.get_attname()
1076 column = self.db_column or attname
1077 return attname, column
1079 def get_default(self):
1080 """Return the to_field if the default value is an object."""
1081 field_default = super().get_default()
1082 if isinstance(field_default, self.remote_field.model):
1083 return getattr(field_default, self.target_field.attname)
1084 return field_default
1086 def get_db_prep_save(self, value, connection):
1087 if value is None or (
1088 value == ""
1089 and (
1090 not self.target_field.empty_strings_allowed
1091 or connection.features.interprets_empty_strings_as_nulls
1092 )
1093 ):
1094 return None
1095 else:
1096 return self.target_field.get_db_prep_save(value, connection=connection)
1098 def get_db_prep_value(self, value, connection, prepared=False):
1099 return self.target_field.get_db_prep_value(value, connection, prepared)
1101 def get_prep_value(self, value):
1102 return self.target_field.get_prep_value(value)
1104 def contribute_to_related_class(self, cls, related):
1105 super().contribute_to_related_class(cls, related)
1106 if self.remote_field.field_name is None:
1107 self.remote_field.field_name = cls._meta.pk.name
1109 def db_check(self, connection):
1110 return None
1112 def db_type(self, connection):
1113 return self.target_field.rel_db_type(connection=connection)
1115 def cast_db_type(self, connection):
1116 return self.target_field.cast_db_type(connection=connection)
1118 def db_parameters(self, connection):
1119 target_db_parameters = self.target_field.db_parameters(connection)
1120 return {
1121 "type": self.db_type(connection),
1122 "check": self.db_check(connection),
1123 "collation": target_db_parameters.get("collation"),
1124 }
1126 def convert_empty_strings(self, value, expression, connection):
1127 if (not value) and isinstance(value, str):
1128 return None
1129 return value
1131 def get_db_converters(self, connection):
1132 converters = super().get_db_converters(connection)
1133 if connection.features.interprets_empty_strings_as_nulls:
1134 converters += [self.convert_empty_strings]
1135 return converters
1137 def get_col(self, alias, output_field=None):
1138 if output_field is None:
1139 output_field = self.target_field
1140 while isinstance(output_field, ForeignKey):
1141 output_field = output_field.target_field
1142 if output_field is self:
1143 raise ValueError("Cannot resolve output_field.")
1144 return super().get_col(alias, output_field)
1147class OneToOneField(ForeignKey):
1148 """
1149 A OneToOneField is essentially the same as a ForeignKey, with the exception
1150 that it always carries a "unique" constraint with it and the reverse
1151 relation always returns the object pointed to (since there will only ever
1152 be one), rather than returning a list.
1153 """
1155 # Field flags
1156 many_to_many = False
1157 many_to_one = False
1158 one_to_many = False
1159 one_to_one = True
1161 related_accessor_class = ReverseOneToOneDescriptor
1162 forward_related_accessor_class = ForwardOneToOneDescriptor
1163 rel_class = OneToOneRel
1165 description = "One-to-one relationship"
1167 def __init__(self, to, on_delete, to_field=None, **kwargs):
1168 kwargs["unique"] = True
1169 super().__init__(to, on_delete, to_field=to_field, **kwargs)
1171 def deconstruct(self):
1172 name, path, args, kwargs = super().deconstruct()
1173 if "unique" in kwargs:
1174 del kwargs["unique"]
1175 return name, path, args, kwargs
1177 def save_form_data(self, instance, data):
1178 if isinstance(data, self.remote_field.model):
1179 setattr(instance, self.name, data)
1180 else:
1181 setattr(instance, self.attname, data)
1182 # Remote field object must be cleared otherwise Model.save()
1183 # will reassign attname using the related object pk.
1184 if data is None:
1185 setattr(instance, self.name, data)
1187 def _check_unique(self, **kwargs):
1188 # Override ForeignKey since check isn't applicable here.
1189 return []
1192def create_many_to_many_intermediary_model(field, klass):
1193 from plain import models
1195 def set_managed(model, related, through):
1196 through._meta.managed = model._meta.managed or related._meta.managed
1198 to_model = resolve_relation(klass, field.remote_field.model)
1199 name = f"{klass._meta.object_name}_{field.name}"
1200 lazy_related_operation(set_managed, klass, to_model, name)
1202 to = make_model_tuple(to_model)[1]
1203 from_ = klass._meta.model_name
1204 if to == from_:
1205 to = "to_%s" % to
1206 from_ = "from_%s" % from_
1208 meta = type(
1209 "Meta",
1210 (),
1211 {
1212 "db_table": field._get_m2m_db_table(klass._meta),
1213 "auto_created": klass,
1214 "package_label": klass._meta.package_label,
1215 "db_tablespace": klass._meta.db_tablespace,
1216 "constraints": [
1217 models.UniqueConstraint(
1218 fields=[from_, to],
1219 name=f"{klass._meta.package_label}_{name.lower()}_unique",
1220 )
1221 ],
1222 "packages": field.model._meta.packages,
1223 },
1224 )
1225 # Construct and return the new class.
1226 return type(
1227 name,
1228 (models.Model,),
1229 {
1230 "Meta": meta,
1231 "__module__": klass.__module__,
1232 from_: models.ForeignKey(
1233 klass,
1234 related_name="%s+" % name,
1235 db_tablespace=field.db_tablespace,
1236 db_constraint=field.remote_field.db_constraint,
1237 on_delete=CASCADE,
1238 ),
1239 to: models.ForeignKey(
1240 to_model,
1241 related_name="%s+" % name,
1242 db_tablespace=field.db_tablespace,
1243 db_constraint=field.remote_field.db_constraint,
1244 on_delete=CASCADE,
1245 ),
1246 },
1247 )
1250class ManyToManyField(RelatedField):
1251 """
1252 Provide a many-to-many relation by using an intermediary model that
1253 holds two ForeignKey fields pointed at the two sides of the relation.
1255 Unless a ``through`` model was provided, ManyToManyField will use the
1256 create_many_to_many_intermediary_model factory to automatically generate
1257 the intermediary model.
1258 """
1260 # Field flags
1261 many_to_many = True
1262 many_to_one = False
1263 one_to_many = False
1264 one_to_one = False
1266 rel_class = ManyToManyRel
1268 description = "Many-to-many relationship"
1270 def __init__(
1271 self,
1272 to,
1273 related_name=None,
1274 related_query_name=None,
1275 limit_choices_to=None,
1276 symmetrical=None,
1277 through=None,
1278 through_fields=None,
1279 db_constraint=True,
1280 db_table=None,
1281 swappable=True,
1282 **kwargs,
1283 ):
1284 try:
1285 to._meta
1286 except AttributeError:
1287 if not isinstance(to, str):
1288 raise TypeError(
1289 "{}({!r}) is invalid. First parameter to ManyToManyField "
1290 "must be either a model, a model name, or the string {!r}".format(
1291 self.__class__.__name__,
1292 to,
1293 RECURSIVE_RELATIONSHIP_CONSTANT,
1294 )
1295 )
1297 if symmetrical is None:
1298 symmetrical = to == RECURSIVE_RELATIONSHIP_CONSTANT
1300 if through is not None and db_table is not None:
1301 raise ValueError(
1302 "Cannot specify a db_table if an intermediary model is used."
1303 )
1305 kwargs["rel"] = self.rel_class(
1306 self,
1307 to,
1308 related_name=related_name,
1309 related_query_name=related_query_name,
1310 limit_choices_to=limit_choices_to,
1311 symmetrical=symmetrical,
1312 through=through,
1313 through_fields=through_fields,
1314 db_constraint=db_constraint,
1315 )
1316 self.has_null_arg = "null" in kwargs
1318 super().__init__(
1319 related_name=related_name,
1320 related_query_name=related_query_name,
1321 limit_choices_to=limit_choices_to,
1322 **kwargs,
1323 )
1325 self.db_table = db_table
1326 self.swappable = swappable
1328 def check(self, **kwargs):
1329 return [
1330 *super().check(**kwargs),
1331 *self._check_unique(**kwargs),
1332 *self._check_relationship_model(**kwargs),
1333 *self._check_ignored_options(**kwargs),
1334 *self._check_table_uniqueness(**kwargs),
1335 ]
1337 def _check_unique(self, **kwargs):
1338 if self.unique:
1339 return [
1340 preflight.Error(
1341 "ManyToManyFields cannot be unique.",
1342 obj=self,
1343 id="fields.E330",
1344 )
1345 ]
1346 return []
1348 def _check_ignored_options(self, **kwargs):
1349 warnings = []
1351 if self.has_null_arg:
1352 warnings.append(
1353 preflight.Warning(
1354 "null has no effect on ManyToManyField.",
1355 obj=self,
1356 id="fields.W340",
1357 )
1358 )
1360 if self._validators:
1361 warnings.append(
1362 preflight.Warning(
1363 "ManyToManyField does not support validators.",
1364 obj=self,
1365 id="fields.W341",
1366 )
1367 )
1368 if self.remote_field.symmetrical and self._related_name:
1369 warnings.append(
1370 preflight.Warning(
1371 "related_name has no effect on ManyToManyField "
1372 'with a symmetrical relationship, e.g. to "self".',
1373 obj=self,
1374 id="fields.W345",
1375 )
1376 )
1377 if self.db_comment:
1378 warnings.append(
1379 preflight.Warning(
1380 "db_comment has no effect on ManyToManyField.",
1381 obj=self,
1382 id="fields.W346",
1383 )
1384 )
1386 return warnings
1388 def _check_relationship_model(self, from_model=None, **kwargs):
1389 if hasattr(self.remote_field.through, "_meta"):
1390 qualified_model_name = "{}.{}".format(
1391 self.remote_field.through._meta.package_label,
1392 self.remote_field.through.__name__,
1393 )
1394 else:
1395 qualified_model_name = self.remote_field.through
1397 errors = []
1399 if self.remote_field.through not in self.opts.packages.get_models(
1400 include_auto_created=True
1401 ):
1402 # The relationship model is not installed.
1403 errors.append(
1404 preflight.Error(
1405 "Field specifies a many-to-many relation through model "
1406 "'%s', which has not been installed." % qualified_model_name,
1407 obj=self,
1408 id="fields.E331",
1409 )
1410 )
1412 else:
1413 assert from_model is not None, (
1414 "ManyToManyField with intermediate "
1415 "tables cannot be checked if you don't pass the model "
1416 "where the field is attached to."
1417 )
1418 # Set some useful local variables
1419 to_model = resolve_relation(from_model, self.remote_field.model)
1420 from_model_name = from_model._meta.object_name
1421 if isinstance(to_model, str):
1422 to_model_name = to_model
1423 else:
1424 to_model_name = to_model._meta.object_name
1425 relationship_model_name = self.remote_field.through._meta.object_name
1426 self_referential = from_model == to_model
1427 # Count foreign keys in intermediate model
1428 if self_referential:
1429 seen_self = sum(
1430 from_model == getattr(field.remote_field, "model", None)
1431 for field in self.remote_field.through._meta.fields
1432 )
1434 if seen_self > 2 and not self.remote_field.through_fields:
1435 errors.append(
1436 preflight.Error(
1437 "The model is used as an intermediate model by "
1438 "'{}', but it has more than two foreign keys "
1439 "to '{}', which is ambiguous. You must specify "
1440 "which two foreign keys Plain should use via the "
1441 "through_fields keyword argument.".format(
1442 self, from_model_name
1443 ),
1444 hint=(
1445 "Use through_fields to specify which two foreign keys "
1446 "Plain should use."
1447 ),
1448 obj=self.remote_field.through,
1449 id="fields.E333",
1450 )
1451 )
1453 else:
1454 # Count foreign keys in relationship model
1455 seen_from = sum(
1456 from_model == getattr(field.remote_field, "model", None)
1457 for field in self.remote_field.through._meta.fields
1458 )
1459 seen_to = sum(
1460 to_model == getattr(field.remote_field, "model", None)
1461 for field in self.remote_field.through._meta.fields
1462 )
1464 if seen_from > 1 and not self.remote_field.through_fields:
1465 errors.append(
1466 preflight.Error(
1467 (
1468 "The model is used as an intermediate model by "
1469 "'{}', but it has more than one foreign key "
1470 "from '{}', which is ambiguous. You must specify "
1471 "which foreign key Plain should use via the "
1472 "through_fields keyword argument."
1473 ).format(self, from_model_name),
1474 hint=(
1475 "If you want to create a recursive relationship, "
1476 'use ManyToManyField("{}", through="{}").'
1477 ).format(
1478 RECURSIVE_RELATIONSHIP_CONSTANT,
1479 relationship_model_name,
1480 ),
1481 obj=self,
1482 id="fields.E334",
1483 )
1484 )
1486 if seen_to > 1 and not self.remote_field.through_fields:
1487 errors.append(
1488 preflight.Error(
1489 "The model is used as an intermediate model by "
1490 "'{}', but it has more than one foreign key "
1491 "to '{}', which is ambiguous. You must specify "
1492 "which foreign key Plain should use via the "
1493 "through_fields keyword argument.".format(
1494 self, to_model_name
1495 ),
1496 hint=(
1497 "If you want to create a recursive relationship, "
1498 'use ManyToManyField("{}", through="{}").'
1499 ).format(
1500 RECURSIVE_RELATIONSHIP_CONSTANT,
1501 relationship_model_name,
1502 ),
1503 obj=self,
1504 id="fields.E335",
1505 )
1506 )
1508 if seen_from == 0 or seen_to == 0:
1509 errors.append(
1510 preflight.Error(
1511 "The model is used as an intermediate model by "
1512 "'{}', but it does not have a foreign key to '{}' or '{}'.".format(
1513 self, from_model_name, to_model_name
1514 ),
1515 obj=self.remote_field.through,
1516 id="fields.E336",
1517 )
1518 )
1520 # Validate `through_fields`.
1521 if self.remote_field.through_fields is not None:
1522 # Validate that we're given an iterable of at least two items
1523 # and that none of them is "falsy".
1524 if not (
1525 len(self.remote_field.through_fields) >= 2
1526 and self.remote_field.through_fields[0]
1527 and self.remote_field.through_fields[1]
1528 ):
1529 errors.append(
1530 preflight.Error(
1531 "Field specifies 'through_fields' but does not provide "
1532 "the names of the two link fields that should be used "
1533 "for the relation through model '%s'." % qualified_model_name,
1534 hint=(
1535 "Make sure you specify 'through_fields' as "
1536 "through_fields=('field1', 'field2')"
1537 ),
1538 obj=self,
1539 id="fields.E337",
1540 )
1541 )
1543 # Validate the given through fields -- they should be actual
1544 # fields on the through model, and also be foreign keys to the
1545 # expected models.
1546 else:
1547 assert from_model is not None, (
1548 "ManyToManyField with intermediate "
1549 "tables cannot be checked if you don't pass the model "
1550 "where the field is attached to."
1551 )
1553 source, through, target = (
1554 from_model,
1555 self.remote_field.through,
1556 self.remote_field.model,
1557 )
1558 source_field_name, target_field_name = self.remote_field.through_fields[
1559 :2
1560 ]
1562 for field_name, related_model in (
1563 (source_field_name, source),
1564 (target_field_name, target),
1565 ):
1566 possible_field_names = []
1567 for f in through._meta.fields:
1568 if (
1569 hasattr(f, "remote_field")
1570 and getattr(f.remote_field, "model", None) == related_model
1571 ):
1572 possible_field_names.append(f.name)
1573 if possible_field_names:
1574 hint = (
1575 "Did you mean one of the following foreign keys to '{}': "
1576 "{}?".format(
1577 related_model._meta.object_name,
1578 ", ".join(possible_field_names),
1579 )
1580 )
1581 else:
1582 hint = None
1584 try:
1585 field = through._meta.get_field(field_name)
1586 except exceptions.FieldDoesNotExist:
1587 errors.append(
1588 preflight.Error(
1589 "The intermediary model '{}' has no field '{}'.".format(
1590 qualified_model_name, field_name
1591 ),
1592 hint=hint,
1593 obj=self,
1594 id="fields.E338",
1595 )
1596 )
1597 else:
1598 if not (
1599 hasattr(field, "remote_field")
1600 and getattr(field.remote_field, "model", None)
1601 == related_model
1602 ):
1603 errors.append(
1604 preflight.Error(
1605 "'{}.{}' is not a foreign key to '{}'.".format(
1606 through._meta.object_name,
1607 field_name,
1608 related_model._meta.object_name,
1609 ),
1610 hint=hint,
1611 obj=self,
1612 id="fields.E339",
1613 )
1614 )
1616 return errors
1618 def _check_table_uniqueness(self, **kwargs):
1619 if (
1620 isinstance(self.remote_field.through, str)
1621 or not self.remote_field.through._meta.managed
1622 ):
1623 return []
1624 registered_tables = {
1625 model._meta.db_table: model
1626 for model in self.opts.packages.get_models(include_auto_created=True)
1627 if model != self.remote_field.through and model._meta.managed
1628 }
1629 m2m_db_table = self.m2m_db_table()
1630 model = registered_tables.get(m2m_db_table)
1631 # The second condition allows multiple m2m relations on a model if
1632 # some point to a through model that proxies another through model.
1633 if (
1634 model
1635 and model._meta.concrete_model
1636 != self.remote_field.through._meta.concrete_model
1637 ):
1638 if model._meta.auto_created:
1640 def _get_field_name(model):
1641 for field in model._meta.auto_created._meta.many_to_many:
1642 if field.remote_field.through is model:
1643 return field.name
1645 opts = model._meta.auto_created._meta
1646 clashing_obj = f"{opts.label}.{_get_field_name(model)}"
1647 else:
1648 clashing_obj = model._meta.label
1649 if settings.DATABASE_ROUTERS:
1650 error_class, error_id = preflight.Warning, "fields.W344"
1651 error_hint = (
1652 "You have configured settings.DATABASE_ROUTERS. Verify "
1653 "that the table of %r is correctly routed to a separate "
1654 "database." % clashing_obj
1655 )
1656 else:
1657 error_class, error_id = preflight.Error, "fields.E340"
1658 error_hint = None
1659 return [
1660 error_class(
1661 f"The field's intermediary table '{m2m_db_table}' clashes with the "
1662 f"table name of '{clashing_obj}'.",
1663 obj=self,
1664 hint=error_hint,
1665 id=error_id,
1666 )
1667 ]
1668 return []
1670 def deconstruct(self):
1671 name, path, args, kwargs = super().deconstruct()
1672 # Handle the simpler arguments.
1673 if self.db_table is not None:
1674 kwargs["db_table"] = self.db_table
1675 if self.remote_field.db_constraint is not True:
1676 kwargs["db_constraint"] = self.remote_field.db_constraint
1677 # Lowercase model names as they should be treated as case-insensitive.
1678 if isinstance(self.remote_field.model, str):
1679 if "." in self.remote_field.model:
1680 package_label, model_name = self.remote_field.model.split(".")
1681 kwargs["to"] = f"{package_label}.{model_name.lower()}"
1682 else:
1683 kwargs["to"] = self.remote_field.model.lower()
1684 else:
1685 kwargs["to"] = self.remote_field.model._meta.label_lower
1686 if getattr(self.remote_field, "through", None) is not None:
1687 if isinstance(self.remote_field.through, str):
1688 kwargs["through"] = self.remote_field.through
1689 elif not self.remote_field.through._meta.auto_created:
1690 kwargs["through"] = self.remote_field.through._meta.label
1691 # If swappable is True, then see if we're actually pointing to the target
1692 # of a swap.
1693 swappable_setting = self.swappable_setting
1694 if swappable_setting is not None:
1695 # If it's already a settings reference, error.
1696 if hasattr(kwargs["to"], "setting_name"):
1697 if kwargs["to"].setting_name != swappable_setting:
1698 raise ValueError(
1699 "Cannot deconstruct a ManyToManyField pointing to a "
1700 "model that is swapped in place of more than one model "
1701 "({} and {})".format(
1702 kwargs["to"].setting_name, swappable_setting
1703 )
1704 )
1706 kwargs["to"] = SettingsReference(
1707 kwargs["to"],
1708 swappable_setting,
1709 )
1710 return name, path, args, kwargs
1712 def _get_path_info(self, direct=False, filtered_relation=None):
1713 """Called by both direct and indirect m2m traversal."""
1714 int_model = self.remote_field.through
1715 linkfield1 = int_model._meta.get_field(self.m2m_field_name())
1716 linkfield2 = int_model._meta.get_field(self.m2m_reverse_field_name())
1717 if direct:
1718 join1infos = linkfield1.reverse_path_infos
1719 if filtered_relation:
1720 join2infos = linkfield2.get_path_info(filtered_relation)
1721 else:
1722 join2infos = linkfield2.path_infos
1723 else:
1724 join1infos = linkfield2.reverse_path_infos
1725 if filtered_relation:
1726 join2infos = linkfield1.get_path_info(filtered_relation)
1727 else:
1728 join2infos = linkfield1.path_infos
1729 # Get join infos between the last model of join 1 and the first model
1730 # of join 2. Assume the only reason these may differ is due to model
1731 # inheritance.
1732 join1_final = join1infos[-1].to_opts
1733 join2_initial = join2infos[0].from_opts
1734 if join1_final is join2_initial:
1735 intermediate_infos = []
1736 elif issubclass(join1_final.model, join2_initial.model):
1737 intermediate_infos = join1_final.get_path_to_parent(join2_initial.model)
1738 else:
1739 intermediate_infos = join2_initial.get_path_from_parent(join1_final.model)
1741 return [*join1infos, *intermediate_infos, *join2infos]
1743 def get_path_info(self, filtered_relation=None):
1744 return self._get_path_info(direct=True, filtered_relation=filtered_relation)
1746 @cached_property
1747 def path_infos(self):
1748 return self.get_path_info()
1750 def get_reverse_path_info(self, filtered_relation=None):
1751 return self._get_path_info(direct=False, filtered_relation=filtered_relation)
1753 @cached_property
1754 def reverse_path_infos(self):
1755 return self.get_reverse_path_info()
1757 def _get_m2m_db_table(self, opts):
1758 """
1759 Function that can be curried to provide the m2m table name for this
1760 relation.
1761 """
1762 if self.remote_field.through is not None:
1763 return self.remote_field.through._meta.db_table
1764 elif self.db_table:
1765 return self.db_table
1766 else:
1767 m2m_table_name = f"{utils.strip_quotes(opts.db_table)}_{self.name}"
1768 return utils.truncate_name(m2m_table_name, connection.ops.max_name_length())
1770 def _get_m2m_attr(self, related, attr):
1771 """
1772 Function that can be curried to provide the source accessor or DB
1773 column name for the m2m table.
1774 """
1775 cache_attr = "_m2m_%s_cache" % attr
1776 if hasattr(self, cache_attr):
1777 return getattr(self, cache_attr)
1778 if self.remote_field.through_fields is not None:
1779 link_field_name = self.remote_field.through_fields[0]
1780 else:
1781 link_field_name = None
1782 for f in self.remote_field.through._meta.fields:
1783 if (
1784 f.is_relation
1785 and f.remote_field.model == related.related_model
1786 and (link_field_name is None or link_field_name == f.name)
1787 ):
1788 setattr(self, cache_attr, getattr(f, attr))
1789 return getattr(self, cache_attr)
1791 def _get_m2m_reverse_attr(self, related, attr):
1792 """
1793 Function that can be curried to provide the related accessor or DB
1794 column name for the m2m table.
1795 """
1796 cache_attr = "_m2m_reverse_%s_cache" % attr
1797 if hasattr(self, cache_attr):
1798 return getattr(self, cache_attr)
1799 found = False
1800 if self.remote_field.through_fields is not None:
1801 link_field_name = self.remote_field.through_fields[1]
1802 else:
1803 link_field_name = None
1804 for f in self.remote_field.through._meta.fields:
1805 if f.is_relation and f.remote_field.model == related.model:
1806 if link_field_name is None and related.related_model == related.model:
1807 # If this is an m2m-intermediate to self,
1808 # the first foreign key you find will be
1809 # the source column. Keep searching for
1810 # the second foreign key.
1811 if found:
1812 setattr(self, cache_attr, getattr(f, attr))
1813 break
1814 else:
1815 found = True
1816 elif link_field_name is None or link_field_name == f.name:
1817 setattr(self, cache_attr, getattr(f, attr))
1818 break
1819 return getattr(self, cache_attr)
1821 def contribute_to_class(self, cls, name, **kwargs):
1822 # To support multiple relations to self, it's useful to have a non-None
1823 # related name on symmetrical relations for internal reasons. The
1824 # concept doesn't make a lot of sense externally ("you want me to
1825 # specify *what* on my non-reversible relation?!"), so we set it up
1826 # automatically. The funky name reduces the chance of an accidental
1827 # clash.
1828 if self.remote_field.symmetrical and (
1829 self.remote_field.model == RECURSIVE_RELATIONSHIP_CONSTANT
1830 or self.remote_field.model == cls._meta.object_name
1831 ):
1832 self.remote_field.related_name = "%s_rel_+" % name
1833 elif self.remote_field.is_hidden():
1834 # If the backwards relation is disabled, replace the original
1835 # related_name with one generated from the m2m field name. Django
1836 # still uses backwards relations internally and we need to avoid
1837 # clashes between multiple m2m fields with related_name == '+'.
1838 self.remote_field.related_name = "_{}_{}_{}_+".format(
1839 cls._meta.package_label,
1840 cls.__name__.lower(),
1841 name,
1842 )
1844 super().contribute_to_class(cls, name, **kwargs)
1846 # The intermediate m2m model is not auto created if:
1847 # 1) There is a manually specified intermediate, or
1848 # 2) The class owning the m2m field is abstract.
1849 # 3) The class owning the m2m field has been swapped out.
1850 if not cls._meta.abstract:
1851 if self.remote_field.through:
1853 def resolve_through_model(_, model, field):
1854 field.remote_field.through = model
1856 lazy_related_operation(
1857 resolve_through_model, cls, self.remote_field.through, field=self
1858 )
1859 elif not cls._meta.swapped:
1860 self.remote_field.through = create_many_to_many_intermediary_model(
1861 self, cls
1862 )
1864 # Add the descriptor for the m2m relation.
1865 setattr(cls, self.name, ManyToManyDescriptor(self.remote_field, reverse=False))
1867 # Set up the accessor for the m2m table name for the relation.
1868 self.m2m_db_table = partial(self._get_m2m_db_table, cls._meta)
1870 def contribute_to_related_class(self, cls, related):
1871 # Internal M2Ms (i.e., those with a related name ending with '+')
1872 # and swapped models don't get a related descriptor.
1873 if (
1874 not self.remote_field.is_hidden()
1875 and not related.related_model._meta.swapped
1876 ):
1877 setattr(
1878 cls,
1879 related.get_accessor_name(),
1880 ManyToManyDescriptor(self.remote_field, reverse=True),
1881 )
1883 # Set up the accessors for the column names on the m2m table.
1884 self.m2m_column_name = partial(self._get_m2m_attr, related, "column")
1885 self.m2m_reverse_name = partial(self._get_m2m_reverse_attr, related, "column")
1887 self.m2m_field_name = partial(self._get_m2m_attr, related, "name")
1888 self.m2m_reverse_field_name = partial(
1889 self._get_m2m_reverse_attr, related, "name"
1890 )
1892 get_m2m_rel = partial(self._get_m2m_attr, related, "remote_field")
1893 self.m2m_target_field_name = lambda: get_m2m_rel().field_name
1894 get_m2m_reverse_rel = partial(
1895 self._get_m2m_reverse_attr, related, "remote_field"
1896 )
1897 self.m2m_reverse_target_field_name = lambda: get_m2m_reverse_rel().field_name
1899 def set_attributes_from_rel(self):
1900 pass
1902 def value_from_object(self, obj):
1903 return [] if obj.pk is None else list(getattr(obj, self.attname).all())
1905 def save_form_data(self, instance, data):
1906 getattr(instance, self.attname).set(data)
1908 def db_check(self, connection):
1909 return None
1911 def db_type(self, connection):
1912 # A ManyToManyField is not represented by a single column,
1913 # so return None.
1914 return None
1916 def db_parameters(self, connection):
1917 return {"type": None, "check": None}
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2"Rel objects" for related fields.
4"Rel objects" (for lack of a better name) carry information about the relation
5modeled by a related field and provide some utility functions. They're stored
6in the ``remote_field`` attribute of the field.
8They also act as reverse fields for the purposes of the Meta API because
9they're the closest concept currently available.
10"""
12from plain import exceptions
13from plain.utils.functional import cached_property
14from plain.utils.hashable import make_hashable
16from . import BLANK_CHOICE_DASH
17from .mixins import FieldCacheMixin
20class ForeignObjectRel(FieldCacheMixin):
21 """
22 Used by ForeignObject to store information about the relation.
24 ``_meta.get_fields()`` returns this class to provide access to the field
25 flags for the reverse relation.
26 """
28 # Field flags
29 auto_created = True
30 concrete = False
31 editable = False
32 is_relation = True
34 # Reverse relations are always nullable (Plain can't enforce that a
35 # foreign key on the related model points to this model).
36 null = True
37 empty_strings_allowed = False
39 def __init__(
40 self,
41 field,
42 to,
43 related_name=None,
44 related_query_name=None,
45 limit_choices_to=None,
46 parent_link=False,
47 on_delete=None,
48 ):
49 self.field = field
50 self.model = to
51 self.related_name = related_name
52 self.related_query_name = related_query_name
53 self.limit_choices_to = {} if limit_choices_to is None else limit_choices_to
54 self.parent_link = parent_link
55 self.on_delete = on_delete
57 self.symmetrical = False
58 self.multiple = True
60 # Some of the following cached_properties can't be initialized in
61 # __init__ as the field doesn't have its model yet. Calling these methods
62 # before field.contribute_to_class() has been called will result in
63 # AttributeError
64 @cached_property
65 def hidden(self):
66 return self.is_hidden()
68 @cached_property
69 def name(self):
70 return self.field.related_query_name()
72 @property
73 def remote_field(self):
74 return self.field
76 @property
77 def target_field(self):
78 """
79 When filtering against this relation, return the field on the remote
80 model against which the filtering should happen.
81 """
82 target_fields = self.path_infos[-1].target_fields
83 if len(target_fields) > 1:
84 raise exceptions.FieldError(
85 "Can't use target_field for multicolumn relations."
86 )
87 return target_fields[0]
89 @cached_property
90 def related_model(self):
91 if not self.field.model:
92 raise AttributeError(
93 "This property can't be accessed before self.field.contribute_to_class "
94 "has been called."
95 )
96 return self.field.model
98 @cached_property
99 def many_to_many(self):
100 return self.field.many_to_many
102 @cached_property
103 def many_to_one(self):
104 return self.field.one_to_many
106 @cached_property
107 def one_to_many(self):
108 return self.field.many_to_one
110 @cached_property
111 def one_to_one(self):
112 return self.field.one_to_one
114 def get_lookup(self, lookup_name):
115 return self.field.get_lookup(lookup_name)
117 def get_internal_type(self):
118 return self.field.get_internal_type()
120 @property
121 def db_type(self):
122 return self.field.db_type
124 def __repr__(self):
125 return "<{}: {}.{}>".format(
126 type(self).__name__,
127 self.related_model._meta.package_label,
128 self.related_model._meta.model_name,
129 )
131 @property
132 def identity(self):
133 return (
134 self.field,
135 self.model,
136 self.related_name,
137 self.related_query_name,
138 make_hashable(self.limit_choices_to),
139 self.parent_link,
140 self.on_delete,
141 self.symmetrical,
142 self.multiple,
143 )
145 def __eq__(self, other):
146 if not isinstance(other, self.__class__):
147 return NotImplemented
148 return self.identity == other.identity
150 def __hash__(self):
151 return hash(self.identity)
153 def __getstate__(self):
154 state = self.__dict__.copy()
155 # Delete the path_infos cached property because it can be recalculated
156 # at first invocation after deserialization. The attribute must be
157 # removed because subclasses like ManyToOneRel may have a PathInfo
158 # which contains an intermediate M2M table that's been dynamically
159 # created and doesn't exist in the .models module.
160 # This is a reverse relation, so there is no reverse_path_infos to
161 # delete.
162 state.pop("path_infos", None)
163 return state
165 def get_choices(
166 self,
167 include_blank=True,
168 blank_choice=BLANK_CHOICE_DASH,
169 limit_choices_to=None,
170 ordering=(),
171 ):
172 """
173 Return choices with a default blank choices included, for use
174 as <select> choices for this field.
176 Analog of plain.models.fields.Field.get_choices(), provided
177 initially for utilization by RelatedFieldListFilter.
178 """
179 limit_choices_to = limit_choices_to or self.limit_choices_to
180 qs = self.related_model._default_manager.complex_filter(limit_choices_to)
181 if ordering:
182 qs = qs.order_by(*ordering)
183 return (blank_choice if include_blank else []) + [(x.pk, str(x)) for x in qs]
185 def is_hidden(self):
186 """Should the related object be hidden?"""
187 return bool(self.related_name) and self.related_name[-1] == "+"
189 def get_joining_columns(self):
190 return self.field.get_reverse_joining_columns()
192 def get_extra_restriction(self, alias, related_alias):
193 return self.field.get_extra_restriction(related_alias, alias)
195 def set_field_name(self):
196 """
197 Set the related field's name, this is not available until later stages
198 of app loading, so set_field_name is called from
199 set_attributes_from_rel()
200 """
201 # By default foreign object doesn't relate to any remote field (for
202 # example custom multicolumn joins currently have no remote field).
203 self.field_name = None
205 def get_accessor_name(self, model=None):
206 # This method encapsulates the logic that decides what name to give an
207 # accessor descriptor that retrieves related many-to-one or
208 # many-to-many objects. It uses the lowercased object_name + "_set",
209 # but this can be overridden with the "related_name" option. Due to
210 # backwards compatibility ModelForms need to be able to provide an
211 # alternate model. See BaseInlineFormSet.get_default_prefix().
212 opts = model._meta if model else self.related_model._meta
213 model = model or self.related_model
214 if self.multiple:
215 # If this is a symmetrical m2m relation on self, there is no
216 # reverse accessor.
217 if self.symmetrical and model == self.model:
218 return None
219 if self.related_name:
220 return self.related_name
221 return opts.model_name + ("_set" if self.multiple else "")
223 def get_path_info(self, filtered_relation=None):
224 if filtered_relation:
225 return self.field.get_reverse_path_info(filtered_relation)
226 else:
227 return self.field.reverse_path_infos
229 @cached_property
230 def path_infos(self):
231 return self.get_path_info()
233 def get_cache_name(self):
234 """
235 Return the name of the cache key to use for storing an instance of the
236 forward model on the reverse model.
237 """
238 return self.get_accessor_name()
241class ManyToOneRel(ForeignObjectRel):
242 """
243 Used by the ForeignKey field to store information about the relation.
245 ``_meta.get_fields()`` returns this class to provide access to the field
246 flags for the reverse relation.
248 Note: Because we somewhat abuse the Rel objects by using them as reverse
249 fields we get the funny situation where
250 ``ManyToOneRel.many_to_one == False`` and
251 ``ManyToOneRel.one_to_many == True``. This is unfortunate but the actual
252 ManyToOneRel class is a private API and there is work underway to turn
253 reverse relations into actual fields.
254 """
256 def __init__(
257 self,
258 field,
259 to,
260 field_name,
261 related_name=None,
262 related_query_name=None,
263 limit_choices_to=None,
264 parent_link=False,
265 on_delete=None,
266 ):
267 super().__init__(
268 field,
269 to,
270 related_name=related_name,
271 related_query_name=related_query_name,
272 limit_choices_to=limit_choices_to,
273 parent_link=parent_link,
274 on_delete=on_delete,
275 )
277 self.field_name = field_name
279 def __getstate__(self):
280 state = super().__getstate__()
281 state.pop("related_model", None)
282 return state
284 @property
285 def identity(self):
286 return super().identity + (self.field_name,)
288 def get_related_field(self):
289 """
290 Return the Field in the 'to' object to which this relationship is tied.
291 """
292 field = self.model._meta.get_field(self.field_name)
293 if not field.concrete:
294 raise exceptions.FieldDoesNotExist(
295 "No related field named '%s'" % self.field_name
296 )
297 return field
299 def set_field_name(self):
300 self.field_name = self.field_name or self.model._meta.pk.name
303class OneToOneRel(ManyToOneRel):
304 """
305 Used by OneToOneField to store information about the relation.
307 ``_meta.get_fields()`` returns this class to provide access to the field
308 flags for the reverse relation.
309 """
311 def __init__(
312 self,
313 field,
314 to,
315 field_name,
316 related_name=None,
317 related_query_name=None,
318 limit_choices_to=None,
319 parent_link=False,
320 on_delete=None,
321 ):
322 super().__init__(
323 field,
324 to,
325 field_name,
326 related_name=related_name,
327 related_query_name=related_query_name,
328 limit_choices_to=limit_choices_to,
329 parent_link=parent_link,
330 on_delete=on_delete,
331 )
333 self.multiple = False
336class ManyToManyRel(ForeignObjectRel):
337 """
338 Used by ManyToManyField to store information about the relation.
340 ``_meta.get_fields()`` returns this class to provide access to the field
341 flags for the reverse relation.
342 """
344 def __init__(
345 self,
346 field,
347 to,
348 related_name=None,
349 related_query_name=None,
350 limit_choices_to=None,
351 symmetrical=True,
352 through=None,
353 through_fields=None,
354 db_constraint=True,
355 ):
356 super().__init__(
357 field,
358 to,
359 related_name=related_name,
360 related_query_name=related_query_name,
361 limit_choices_to=limit_choices_to,
362 )
364 if through and not db_constraint:
365 raise ValueError("Can't supply a through model and db_constraint=False")
366 self.through = through
368 if through_fields and not through:
369 raise ValueError("Cannot specify through_fields without a through model")
370 self.through_fields = through_fields
372 self.symmetrical = symmetrical
373 self.db_constraint = db_constraint
375 @property
376 def identity(self):
377 return super().identity + (
378 self.through,
379 make_hashable(self.through_fields),
380 self.db_constraint,
381 )
383 def get_related_field(self):
384 """
385 Return the field in the 'to' object to which this relationship is tied.
386 Provided for symmetry with ManyToOneRel.
387 """
388 opts = self.through._meta
389 if self.through_fields:
390 field = opts.get_field(self.through_fields[0])
391 else:
392 for field in opts.fields:
393 rel = getattr(field, "remote_field", None)
394 if rel and rel.model == self.model:
395 break
396 return field.foreign_related_fields[0]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.exceptions import ImproperlyConfigured
2from plain.runtime import settings
4from .. import Warning, register
6SECRET_KEY_INSECURE_PREFIX = "plain-insecure-"
7SECRET_KEY_MIN_LENGTH = 50
8SECRET_KEY_MIN_UNIQUE_CHARACTERS = 5
10SECRET_KEY_WARNING_MSG = (
11 f"Your %s has less than {SECRET_KEY_MIN_LENGTH} characters, less than "
12 f"{SECRET_KEY_MIN_UNIQUE_CHARACTERS} unique characters, or it's prefixed "
13 f"with '{SECRET_KEY_INSECURE_PREFIX}' indicating that it was generated "
14 f"automatically by Plain. Please generate a long and random value, "
15 f"otherwise many of Plain's security-critical features will be "
16 f"vulnerable to attack."
17)
19# TODO
20W001 = Warning(
21 "You do not have 'plain.middleware.https.HttpsRedirectMiddleware' "
22 "in your MIDDLEWARE so the SECURE_HSTS_SECONDS, "
23 "SECURE_CONTENT_TYPE_NOSNIFF, SECURE_REFERRER_POLICY, "
24 "SECURE_CROSS_ORIGIN_OPENER_POLICY, and HTTPS_REDIRECT_ENABLED settings will "
25 "have no effect.",
26 id="security.W001",
27)
29W008 = Warning(
30 "Your HTTPS_REDIRECT_ENABLED setting is not set to True. "
31 "Unless your site should be available over both SSL and non-SSL "
32 "connections, you may want to either set this setting True "
33 "or configure a load balancer or reverse-proxy server "
34 "to redirect all connections to HTTPS.",
35 id="security.W008",
36)
38W009 = Warning(
39 SECRET_KEY_WARNING_MSG % "SECRET_KEY",
40 id="security.W009",
41)
43W018 = Warning(
44 "You should not have DEBUG set to True in deployment.",
45 id="security.W018",
46)
48W020 = Warning(
49 "ALLOWED_HOSTS must not be empty in deployment.",
50 id="security.W020",
51)
53W025 = Warning(SECRET_KEY_WARNING_MSG, id="security.W025")
56def _check_secret_key(secret_key):
57 return (
58 len(set(secret_key)) >= SECRET_KEY_MIN_UNIQUE_CHARACTERS
59 and len(secret_key) >= SECRET_KEY_MIN_LENGTH
60 and not secret_key.startswith(SECRET_KEY_INSECURE_PREFIX)
61 )
64@register(deploy=True)
65def check_secret_key(package_configs, **kwargs):
66 try:
67 secret_key = settings.SECRET_KEY
68 except (ImproperlyConfigured, AttributeError):
69 passed_check = False
70 else:
71 passed_check = _check_secret_key(secret_key)
72 return [] if passed_check else [W009]
75@register(deploy=True)
76def check_secret_key_fallbacks(package_configs, **kwargs):
77 warnings = []
78 try:
79 fallbacks = settings.SECRET_KEY_FALLBACKS
80 except (ImproperlyConfigured, AttributeError):
81 warnings.append(Warning(W025.msg % "SECRET_KEY_FALLBACKS", id=W025.id))
82 else:
83 for index, key in enumerate(fallbacks):
84 if not _check_secret_key(key):
85 warnings.append(
86 Warning(W025.msg % f"SECRET_KEY_FALLBACKS[{index}]", id=W025.id)
87 )
88 return warnings
91@register(deploy=True)
92def check_debug(package_configs, **kwargs):
93 passed_check = not settings.DEBUG
94 return [] if passed_check else [W018]
97@register(deploy=True)
98def check_allowed_hosts(package_configs, **kwargs):
99 return [] if settings.ALLOWED_HOSTS else [W020]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:27 -0500
1from plain.runtime import settings
3from .. import Warning, register
5W003 = Warning(
6 "You don't appear to be using Plain's built-in "
7 "cross-site request forgery protection via the middleware "
8 "('plain.csrf.middleware.CsrfViewMiddleware' is not in your "
9 "MIDDLEWARE). Enabling the middleware is the safest approach "
10 "to ensure you don't leave any holes.",
11 id="security.W003",
12)
14W016 = Warning(
15 "You have 'plain.csrf.middleware.CsrfViewMiddleware' in your "
16 "MIDDLEWARE, but you have not set CSRF_COOKIE_SECURE to True. "
17 "Using a secure-only CSRF cookie makes it more difficult for network "
18 "traffic sniffers to steal the CSRF token.",
19 id="security.W016",
20)
23def _csrf_middleware():
24 return "plain.csrf.middleware.CsrfViewMiddleware" in settings.MIDDLEWARE
27@register(deploy=True)
28def check_csrf_middleware(package_configs, **kwargs):
29 passed_check = _csrf_middleware()
30 return [] if passed_check else [W003]
33@register(deploy=True)
34def check_csrf_cookie_secure(package_configs, **kwargs):
35 passed_check = not _csrf_middleware() or settings.CSRF_COOKIE_SECURE is True
36 return [] if passed_check else [W016]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from .messages import (
2 CRITICAL,
3 DEBUG,
4 ERROR,
5 INFO,
6 WARNING,
7 CheckMessage,
8 Critical,
9 Debug,
10 Error,
11 Info,
12 Warning,
13)
14from .registry import register, run_checks
16# Import these to force registration of checks
17import plain.preflight.files # NOQA isort:skip
18import plain.preflight.security # NOQA isort:skip
19import plain.preflight.urls # NOQA isort:skip
22__all__ = [
23 "CheckMessage",
24 "Debug",
25 "Info",
26 "Warning",
27 "Error",
28 "Critical",
29 "DEBUG",
30 "INFO",
31 "WARNING",
32 "ERROR",
33 "CRITICAL",
34 "register",
35 "run_checks",
36]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from pathlib import Path
3from plain.runtime import settings
5from . import Error, register
8@register
9def check_setting_file_upload_temp_dir(package_configs, **kwargs):
10 setting = getattr(settings, "FILE_UPLOAD_TEMP_DIR", None)
11 if setting and not Path(setting).is_dir():
12 return [
13 Error(
14 f"The FILE_UPLOAD_TEMP_DIR setting refers to the nonexistent "
15 f"directory '{setting}'.",
16 id="files.E001",
17 ),
18 ]
19 return []
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1# Levels
2DEBUG = 10
3INFO = 20
4WARNING = 30
5ERROR = 40
6CRITICAL = 50
9class CheckMessage:
10 def __init__(self, level, msg, hint=None, obj=None, id=None):
11 if not isinstance(level, int):
12 raise TypeError("The first argument should be level.")
13 self.level = level
14 self.msg = msg
15 self.hint = hint
16 self.obj = obj
17 self.id = id
19 def __eq__(self, other):
20 return isinstance(other, self.__class__) and all(
21 getattr(self, attr) == getattr(other, attr)
22 for attr in ["level", "msg", "hint", "obj", "id"]
23 )
25 def __str__(self):
26 try:
27 from plain import models
29 ModelBase = models.base.ModelBase
30 using_db = True
31 except ImportError:
32 using_db = False
33 ModelBase = object
35 if self.obj is None:
36 obj = "?"
37 elif using_db and isinstance(self.obj, ModelBase):
38 # We need to hardcode ModelBase and Field cases because its __str__
39 # method doesn't return "applabel.modellabel" and cannot be changed.
40 obj = self.obj._meta.label
41 else:
42 obj = str(self.obj)
43 id = f"({self.id}) " if self.id else ""
44 hint = f"\n\tHINT: {self.hint}" if self.hint else ""
45 return f"{obj}: {id}{self.msg}{hint}"
47 def __repr__(self):
48 return f"<{self.__class__.__name__}: level={self.level!r}, msg={self.msg!r}, hint={self.hint!r}, obj={self.obj!r}, id={self.id!r}>"
50 def is_serious(self, level=ERROR):
51 return self.level >= level
53 def is_silenced(self):
54 from plain.runtime import settings
56 return self.id in settings.SILENCED_PREFLIGHT_CHECKS
59class Debug(CheckMessage):
60 def __init__(self, *args, **kwargs):
61 super().__init__(DEBUG, *args, **kwargs)
64class Info(CheckMessage):
65 def __init__(self, *args, **kwargs):
66 super().__init__(INFO, *args, **kwargs)
69class Warning(CheckMessage):
70 def __init__(self, *args, **kwargs):
71 super().__init__(WARNING, *args, **kwargs)
74class Error(CheckMessage):
75 def __init__(self, *args, **kwargs):
76 super().__init__(ERROR, *args, **kwargs)
79class Critical(CheckMessage):
80 def __init__(self, *args, **kwargs):
81 super().__init__(CRITICAL, *args, **kwargs)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.utils.inspect import func_accepts_kwargs
2from plain.utils.itercompat import is_iterable
5class CheckRegistry:
6 def __init__(self):
7 self.registered_checks = set()
8 self.deployment_checks = set()
10 def register(self, check=None, deploy=False):
11 """
12 Can be used as a function or a decorator. Register given function
13 `f`. The function should receive **kwargs
14 and return list of Errors and Warnings.
16 Example::
18 registry = CheckRegistry()
19 @registry.register('mytag', 'anothertag')
20 def my_check(package_configs, **kwargs):
21 # ... perform checks and collect `errors` ...
22 return errors
23 # or
24 registry.register(my_check, 'mytag', 'anothertag')
25 """
27 def inner(check):
28 if not func_accepts_kwargs(check):
29 raise TypeError(
30 "Check functions must accept keyword arguments (**kwargs)."
31 )
32 checks = self.deployment_checks if deploy else self.registered_checks
33 checks.add(check)
34 return check
36 if callable(check):
37 return inner(check)
38 else:
39 return inner
41 def run_checks(
42 self,
43 package_configs=None,
44 include_deployment_checks=False,
45 databases=None,
46 ):
47 """
48 Run all registered checks and return list of Errors and Warnings.
49 """
50 errors = []
51 checks = self.get_checks(include_deployment_checks)
53 for check in checks:
54 new_errors = check(package_configs=package_configs, databases=databases)
55 if not is_iterable(new_errors):
56 raise TypeError(
57 f"The function {check!r} did not return a list. All functions "
58 "registered with the checks registry must return a list.",
59 )
60 errors.extend(new_errors)
61 return errors
63 def get_checks(self, include_deployment_checks=False):
64 checks = list(self.registered_checks)
65 if include_deployment_checks:
66 checks.extend(self.deployment_checks)
67 return checks
70registry = CheckRegistry()
71register = registry.register
72run_checks = registry.run_checks
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.exceptions import ImproperlyConfigured
2from plain.runtime import settings
4from .messages import Warning
5from .registry import register
7SECRET_KEY_INSECURE_PREFIX = "plain-insecure-"
8SECRET_KEY_MIN_LENGTH = 50
9SECRET_KEY_MIN_UNIQUE_CHARACTERS = 5
11SECRET_KEY_WARNING_MSG = (
12 f"Your %s has less than {SECRET_KEY_MIN_LENGTH} characters, less than "
13 f"{SECRET_KEY_MIN_UNIQUE_CHARACTERS} unique characters, or it's prefixed "
14 f"with '{SECRET_KEY_INSECURE_PREFIX}' indicating that it was generated "
15 f"automatically by Plain. Please generate a long and random value, "
16 f"otherwise many of Plain's security-critical features will be "
17 f"vulnerable to attack."
18)
20W025 = Warning(SECRET_KEY_WARNING_MSG, id="security.W025")
23def _check_secret_key(secret_key):
24 return (
25 len(set(secret_key)) >= SECRET_KEY_MIN_UNIQUE_CHARACTERS
26 and len(secret_key) >= SECRET_KEY_MIN_LENGTH
27 and not secret_key.startswith(SECRET_KEY_INSECURE_PREFIX)
28 )
31@register(deploy=True)
32def check_secret_key(package_configs, **kwargs):
33 try:
34 secret_key = settings.SECRET_KEY
35 except (ImproperlyConfigured, AttributeError):
36 passed_check = False
37 else:
38 passed_check = _check_secret_key(secret_key)
39 return (
40 []
41 if passed_check
42 else [
43 Warning(
44 SECRET_KEY_WARNING_MSG % "SECRET_KEY",
45 id="security.W009",
46 )
47 ]
48 )
51@register(deploy=True)
52def check_secret_key_fallbacks(package_configs, **kwargs):
53 warnings = []
54 try:
55 fallbacks = settings.SECRET_KEY_FALLBACKS
56 except (ImproperlyConfigured, AttributeError):
57 warnings.append(Warning(W025.msg % "SECRET_KEY_FALLBACKS", id=W025.id))
58 else:
59 for index, key in enumerate(fallbacks):
60 if not _check_secret_key(key):
61 warnings.append(
62 Warning(W025.msg % f"SECRET_KEY_FALLBACKS[{index}]", id=W025.id)
63 )
64 return warnings
67@register(deploy=True)
68def check_debug(package_configs, **kwargs):
69 passed_check = not settings.DEBUG
70 return (
71 []
72 if passed_check
73 else [
74 Warning(
75 "You should not have DEBUG set to True in deployment.",
76 id="security.W018",
77 )
78 ]
79 )
82@register(deploy=True)
83def check_allowed_hosts(package_configs, **kwargs):
84 return (
85 []
86 if settings.ALLOWED_HOSTS
87 else [
88 Warning(
89 "ALLOWED_HOSTS must not be empty in deployment.",
90 id="security.W020",
91 )
92 ]
93 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from collections import Counter
3from plain.runtime import settings
5from . import Error, Warning, register
8@register
9def check_url_config(package_configs, **kwargs):
10 if getattr(settings, "ROOT_URLCONF", None):
11 from plain.urls import get_resolver
13 resolver = get_resolver()
14 return check_resolver(resolver)
15 return []
18def check_resolver(resolver):
19 """
20 Recursively check the resolver.
21 """
22 check_method = getattr(resolver, "check", None)
23 if check_method is not None:
24 return check_method()
25 elif not hasattr(resolver, "resolve"):
26 return get_warning_for_invalid_pattern(resolver)
27 else:
28 return []
31@register
32def check_url_namespaces_unique(package_configs, **kwargs):
33 """
34 Warn if URL namespaces used in applications aren't unique.
35 """
36 if not getattr(settings, "ROOT_URLCONF", None):
37 return []
39 from plain.urls import get_resolver
41 resolver = get_resolver()
42 all_namespaces = _load_all_namespaces(resolver)
43 counter = Counter(all_namespaces)
44 non_unique_namespaces = [n for n, count in counter.items() if count > 1]
45 errors = []
46 for namespace in non_unique_namespaces:
47 errors.append(
48 Warning(
49 f"URL namespace '{namespace}' isn't unique. You may not be able to reverse "
50 "all URLs in this namespace",
51 id="urls.W005",
52 )
53 )
54 return errors
57def _load_all_namespaces(resolver, parents=()):
58 """
59 Recursively load all namespaces from URL patterns.
60 """
61 url_patterns = getattr(resolver, "url_patterns", [])
62 namespaces = [
63 ":".join(parents + (url.namespace,))
64 for url in url_patterns
65 if getattr(url, "namespace", None) is not None
66 ]
67 for pattern in url_patterns:
68 namespace = getattr(pattern, "namespace", None)
69 current = parents
70 if namespace is not None:
71 current += (namespace,)
72 namespaces.extend(_load_all_namespaces(pattern, current))
73 return namespaces
76def get_warning_for_invalid_pattern(pattern):
77 """
78 Return a list containing a warning that the pattern is invalid.
80 describe_pattern() cannot be used here, because we cannot rely on the
81 urlpattern having regex or name attributes.
82 """
83 if isinstance(pattern, str):
84 hint = (
85 f"Try removing the string '{pattern}'. The list of urlpatterns should not "
86 "have a prefix string as the first element."
87 )
88 elif isinstance(pattern, tuple):
89 hint = "Try using path() instead of a tuple."
90 else:
91 hint = None
93 return [
94 Error(
95 f"Your URL pattern {pattern!r} is invalid. Ensure that urlpatterns is a list "
96 "of path() and/or re_path() instances.",
97 hint=hint,
98 id="urls.E004",
99 )
100 ]
103def E006(name):
104 return Error(
105 f"The {name} setting must end with a slash.",
106 id="urls.E006",
107 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from .cli import cli
3__all__ = ["cli"]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-17 21:27 -0500
1import os
2import sys
4import click
5from dotenv import load_dotenv
7import pytest
10@click.command(
11 context_settings={
12 "ignore_unknown_options": True,
13 }
14)
15@click.argument("pytest_args", nargs=-1, type=click.UNPROCESSED)
16def cli(pytest_args):
17 """Run tests with pytest"""
19 if os.path.exists(".env.test"):
20 click.secho("Loading environment variables from .env.test", fg="yellow")
21 load_dotenv(".env.test")
23 returncode = pytest.main(list(pytest_args))
24 if returncode:
25 sys.exit(returncode)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import pytest
2from plain.runtime import settings as plain_settings
3from plain.runtime import setup
4from plain.test.client import Client, RequestFactory
7def pytest_configure(config):
8 # Run Plain setup before anything else
9 setup()
12@pytest.fixture(autouse=True, scope="session")
13def _allowed_hosts_testserver():
14 # Add testserver to ALLOWED_HOSTS so the test client can make requests
15 plain_settings.ALLOWED_HOSTS = [*plain_settings.ALLOWED_HOSTS, "testserver"]
18@pytest.fixture()
19def client() -> Client:
20 """A Plain test client instance."""
21 return Client()
24@pytest.fixture()
25def request_factory() -> RequestFactory:
26 """A Plain RequestFactory instance."""
27 return RequestFactory()
30@pytest.fixture()
31def settings():
32 class SettingsProxy:
33 def __init__(self):
34 self._original = {}
36 def __getattr__(self, name):
37 return getattr(plain_settings, name)
39 def __setattr__(self, name, value):
40 if name.startswith("_"):
41 super().__setattr__(name, value)
42 else:
43 if name not in self._original:
44 self._original[name] = getattr(plain_settings, name, None)
45 setattr(plain_settings, name, value)
47 def _restore(self):
48 for key, value in self._original.items():
49 setattr(plain_settings, key, value)
51 proxy = SettingsProxy()
52 yield proxy
53 proxy._restore()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from .sessions import get_user, get_user_model, login, logout
3__all__ = ["login", "logout", "get_user_model", "get_user"]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.packages import PackageConfig
4class AuthConfig(PackageConfig):
5 name = "plain.auth"
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from importlib.util import find_spec
3AUTH_USER_MODEL: str
4AUTH_LOGIN_URL: str
6if find_spec("plain.passwords"):
7 # Automatically invalidate sessions on password field change,
8 # if the plain-passwords is installed. You can change this value
9 # if your password field is named differently, or you want
10 # to use a different field to invalidate sessions.
11 AUTH_USER_SESSION_HASH_FIELD: str = "password"
12else:
13 AUTH_USER_SESSION_HASH_FIELD: str = ""
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain import auth
2from plain.exceptions import ImproperlyConfigured
3from plain.utils.functional import SimpleLazyObject
6def get_user(request):
7 if not hasattr(request, "_cached_user"):
8 request._cached_user = auth.get_user(request)
9 return request._cached_user
12class AuthenticationMiddleware:
13 def __init__(self, get_response):
14 self.get_response = get_response
16 def __call__(self, request):
17 if not hasattr(request, "session"):
18 raise ImproperlyConfigured(
19 "The Plain authentication middleware requires session "
20 "middleware to be installed. Edit your MIDDLEWARE setting to "
21 "insert "
22 "'plain.sessions.middleware.SessionMiddleware' before "
23 "'plain.auth.middleware.AuthenticationMiddleware'."
24 )
25 request.user = SimpleLazyObject(lambda: get_user(request))
26 response = self.get_response(request)
27 return response
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.csrf.middleware import rotate_token
2from plain.exceptions import ImproperlyConfigured
3from plain.packages import packages as plain_packages
4from plain.runtime import settings
5from plain.utils.crypto import constant_time_compare, salted_hmac
7from .signals import user_logged_in, user_logged_out
9USER_ID_SESSION_KEY = "_auth_user_id"
10USER_HASH_SESSION_KEY = "_auth_user_hash"
13def _get_user_id_from_session(request):
14 # This value in the session is always serialized to a string, so we need
15 # to convert it back to Python whenever we access it.
16 return get_user_model()._meta.pk.to_python(request.session[USER_ID_SESSION_KEY])
19def get_session_auth_hash(user):
20 """
21 Return an HMAC of the password field.
22 """
23 return _get_session_auth_hash(user)
26def get_session_auth_fallback_hash(user):
27 for fallback_secret in settings.SECRET_KEY_FALLBACKS:
28 yield _get_session_auth_hash(user, secret=fallback_secret)
31def _get_session_auth_hash(user, secret=None):
32 key_salt = "plain.auth.get_session_auth_hash"
33 return salted_hmac(
34 key_salt,
35 getattr(user, settings.AUTH_USER_SESSION_HASH_FIELD),
36 secret=secret,
37 algorithm="sha256",
38 ).hexdigest()
41def login(request, user):
42 """
43 Persist a user id and a backend in the request. This way a user doesn't
44 have to reauthenticate on every request. Note that data set during
45 the anonymous session is retained when the user logs in.
46 """
47 if settings.AUTH_USER_SESSION_HASH_FIELD:
48 session_auth_hash = get_session_auth_hash(user)
49 else:
50 session_auth_hash = ""
52 if USER_ID_SESSION_KEY in request.session:
53 if _get_user_id_from_session(request) != user.pk:
54 # To avoid reusing another user's session, create a new, empty
55 # session if the existing session corresponds to a different
56 # authenticated user.
57 request.session.flush()
58 elif session_auth_hash and not constant_time_compare(
59 request.session.get(USER_HASH_SESSION_KEY, ""), session_auth_hash
60 ):
61 # If the session hash does not match the current hash, reset the
62 # session. Most likely this means the password was changed.
63 request.session.flush()
64 else:
65 request.session.cycle_key()
67 request.session[USER_ID_SESSION_KEY] = user._meta.pk.value_to_string(user)
68 request.session[USER_HASH_SESSION_KEY] = session_auth_hash
69 if hasattr(request, "user"):
70 request.user = user
71 rotate_token(request)
72 user_logged_in.send(sender=user.__class__, request=request, user=user)
75def logout(request):
76 """
77 Remove the authenticated user's ID from the request and flush their session
78 data.
79 """
80 # Dispatch the signal before the user is logged out so the receivers have a
81 # chance to find out *who* logged out.
82 user = getattr(request, "user", None)
83 user_logged_out.send(sender=user.__class__, request=request, user=user)
84 request.session.flush()
85 if hasattr(request, "user"):
86 request.user = None
89def get_user_model():
90 """
91 Return the User model that is active in this project.
92 """
93 try:
94 return plain_packages.get_model(settings.AUTH_USER_MODEL, require_ready=False)
95 except ValueError:
96 raise ImproperlyConfigured(
97 "AUTH_USER_MODEL must be of the form 'package_label.model_name'"
98 )
99 except LookupError:
100 raise ImproperlyConfigured(
101 "AUTH_USER_MODEL refers to model '%s' that has not been installed"
102 % settings.AUTH_USER_MODEL
103 )
106def get_user(request):
107 """
108 Return the user model instance associated with the given request session.
109 If no user is retrieved, return None.
110 """
111 if USER_ID_SESSION_KEY not in request.session:
112 return None
114 user_id = _get_user_id_from_session(request)
116 UserModel = get_user_model()
117 try:
118 user = UserModel._default_manager.get(pk=user_id)
119 except UserModel.DoesNotExist:
120 return None
122 # If the user models defines a specific field to also hash and compare
123 # (like password), then we verify that the hash of that field is still
124 # the same as when the session was created.
125 #
126 # If it has changed (i.e. password changed), then the session
127 # is no longer valid and cleared out.
128 if settings.AUTH_USER_SESSION_HASH_FIELD:
129 session_hash = request.session.get(USER_HASH_SESSION_KEY)
130 if not session_hash:
131 session_hash_verified = False
132 else:
133 session_auth_hash = get_session_auth_hash(user)
134 session_hash_verified = constant_time_compare(
135 session_hash, session_auth_hash
136 )
137 if not session_hash_verified:
138 # If the current secret does not verify the session, try
139 # with the fallback secrets and stop when a matching one is
140 # found.
141 if session_hash and any(
142 constant_time_compare(session_hash, fallback_auth_hash)
143 for fallback_auth_hash in get_session_auth_fallback_hash(user)
144 ):
145 request.session.cycle_key()
146 request.session[USER_HASH_SESSION_KEY] = session_auth_hash
147 else:
148 request.session.flush()
149 user = None
151 return user
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.signals.dispatch import Signal
3user_logged_in = Signal()
4user_login_failed = Signal()
5user_logged_out = Signal()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.urls import NoReverseMatch, reverse
2from plain.utils.functional import Promise
5def resolve_url(to, *args, **kwargs):
6 """
7 Return a URL appropriate for the arguments passed.
9 The arguments could be:
11 * A model: the model's `get_absolute_url()` function will be called.
13 * A view name, possibly with arguments: `urls.reverse()` will be used
14 to reverse-resolve the name.
16 * A URL, which will be returned as-is.
17 """
18 # If it's a model, use get_absolute_url()
19 if hasattr(to, "get_absolute_url"):
20 return to.get_absolute_url()
22 if isinstance(to, Promise):
23 # Expand the lazy instance, as it can cause issues when it is passed
24 # further to some Python functions like urlparse.
25 to = str(to)
27 # Handle relative URLs
28 if isinstance(to, str) and to.startswith(("./", "../")):
29 return to
31 # Next try a reverse URL resolution.
32 try:
33 return reverse(to, args=args, kwargs=kwargs)
34 except NoReverseMatch:
35 # If this is a callable, re-raise.
36 if callable(to):
37 raise
38 # If this doesn't "feel" like a URL, re-raise.
39 if "/" not in to and "." not in to:
40 raise
42 # Finally, fall back and assume it's a URL
43 return to
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from urllib.parse import urlparse, urlunparse
3from plain.exceptions import PermissionDenied
4from plain.http import (
5 Http404,
6 QueryDict,
7 Response,
8 ResponseRedirect,
9)
10from plain.runtime import settings
11from plain.urls import reverse
12from plain.views import View
14from .sessions import logout
15from .utils import resolve_url
18class LoginRequired(Exception):
19 def __init__(self, login_url=None, redirect_field_name="next"):
20 self.login_url = login_url or settings.AUTH_LOGIN_URL
21 self.redirect_field_name = redirect_field_name
24class AuthViewMixin:
25 login_required = True
26 staff_required = False
27 login_url = None
29 def check_auth(self) -> None:
30 """
31 Raises either LoginRequired or PermissionDenied.
32 - LoginRequired can specify a login_url and redirect_field_name
33 - PermissionDenied can specify a message
34 """
36 if not hasattr(self, "request"):
37 raise AttributeError(
38 "AuthViewMixin requires the request attribute to be set."
39 )
41 if self.login_required and not self.request.user:
42 raise LoginRequired(login_url=self.login_url)
44 if impersonator := getattr(self.request, "impersonator", None):
45 # Impersonators should be able to view staff pages while impersonating.
46 # There's probably never a case where an impersonator isn't staff, but it can be configured.
47 if self.staff_required and not impersonator.is_staff:
48 raise PermissionDenied(
49 "You do not have permission to access this page."
50 )
51 elif self.staff_required and not self.request.user.is_staff:
52 # Show a 404 so we don't expose staff urls to non-staff users
53 raise Http404()
55 def get_response(self) -> Response:
56 if not hasattr(self, "request"):
57 raise AttributeError(
58 "AuthViewMixin requires the request attribute to be set."
59 )
61 try:
62 self.check_auth()
63 except LoginRequired as e:
64 # Ideally this could be handled elsewhere... like PermissionDenied
65 # also seems like this code is used multiple places anyway...
66 # could be easier to get redirect query param
67 path = self.request.build_absolute_uri()
68 resolved_login_url = reverse(e.login_url)
69 # If the login url is the same scheme and net location then use the
70 # path as the "next" url.
71 login_scheme, login_netloc = urlparse(resolved_login_url)[:2]
72 current_scheme, current_netloc = urlparse(path)[:2]
73 if (not login_scheme or login_scheme == current_scheme) and (
74 not login_netloc or login_netloc == current_netloc
75 ):
76 path = self.request.get_full_path()
77 return redirect_to_login(
78 path,
79 resolved_login_url,
80 e.redirect_field_name,
81 )
83 return super().get_response() # type: ignore
86class LogoutView(View):
87 def post(self):
88 logout(self.request)
89 return ResponseRedirect("/")
92def redirect_to_login(next, login_url=None, redirect_field_name="next"):
93 """
94 Redirect the user to the login page, passing the given 'next' page.
95 """
96 resolved_url = resolve_url(login_url or settings.AUTH_LOGIN_URL)
98 login_url_parts = list(urlparse(resolved_url))
99 if redirect_field_name:
100 querystring = QueryDict(login_url_parts[4], mutable=True)
101 querystring[redirect_field_name] = next
102 login_url_parts[4] = querystring.urlencode(safe="/")
104 return ResponseRedirect(urlunparse(login_url_parts))
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.exceptions import ObjectDoesNotExist
3from . import (
4 preflight, # noqa
5)
6from .aggregates import * # NOQA
7from .aggregates import __all__ as aggregates_all
8from .constraints import * # NOQA
9from .constraints import __all__ as constraints_all
10from .db import (
11 DEFAULT_DB_ALIAS,
12 PLAIN_VERSION_PICKLE_KEY,
13 DatabaseError,
14 DataError,
15 Error,
16 IntegrityError,
17 InterfaceError,
18 InternalError,
19 NotSupportedError,
20 OperationalError,
21 ProgrammingError,
22 close_old_connections,
23 connection,
24 connections,
25 reset_queries,
26 router,
27)
28from .deletion import (
29 CASCADE,
30 DO_NOTHING,
31 PROTECT,
32 RESTRICT,
33 SET,
34 SET_DEFAULT,
35 SET_NULL,
36 ProtectedError,
37 RestrictedError,
38)
39from .enums import * # NOQA
40from .enums import __all__ as enums_all
41from .expressions import (
42 Case,
43 Exists,
44 Expression,
45 ExpressionList,
46 ExpressionWrapper,
47 F,
48 Func,
49 OrderBy,
50 OuterRef,
51 RowRange,
52 Subquery,
53 Value,
54 ValueRange,
55 When,
56 Window,
57 WindowFrame,
58)
59from .fields import * # NOQA
60from .fields import __all__ as fields_all
61from .fields.json import JSONField
62from .fields.proxy import OrderWrt
63from .indexes import * # NOQA
64from .indexes import __all__ as indexes_all
65from .lookups import Lookup, Transform
66from .manager import Manager
67from .query import Prefetch, QuerySet, prefetch_related_objects
68from .query_utils import FilteredRelation, Q
70# Imports that would create circular imports if sorted
71from .base import DEFERRED, Model # isort:skip
72from .fields.related import ( # isort:skip
73 ForeignKey,
74 ForeignObject,
75 OneToOneField,
76 ManyToManyField,
77 ForeignObjectRel,
78 ManyToOneRel,
79 ManyToManyRel,
80 OneToOneRel,
81)
84__all__ = aggregates_all + constraints_all + enums_all + fields_all + indexes_all
85__all__ += [
86 "ObjectDoesNotExist",
87 "CASCADE",
88 "DO_NOTHING",
89 "PROTECT",
90 "RESTRICT",
91 "SET",
92 "SET_DEFAULT",
93 "SET_NULL",
94 "ProtectedError",
95 "RestrictedError",
96 "Case",
97 "Exists",
98 "Expression",
99 "ExpressionList",
100 "ExpressionWrapper",
101 "F",
102 "Func",
103 "OrderBy",
104 "OuterRef",
105 "RowRange",
106 "Subquery",
107 "Value",
108 "ValueRange",
109 "When",
110 "Window",
111 "WindowFrame",
112 "JSONField",
113 "OrderWrt",
114 "Lookup",
115 "Transform",
116 "Manager",
117 "Prefetch",
118 "Q",
119 "QuerySet",
120 "prefetch_related_objects",
121 "DEFERRED",
122 "Model",
123 "FilteredRelation",
124 "ForeignKey",
125 "ForeignObject",
126 "OneToOneField",
127 "ManyToManyField",
128 "ForeignObjectRel",
129 "ManyToOneRel",
130 "ManyToManyRel",
131 "OneToOneRel",
132]
134# DB-related exports
135__all__ += [
136 "connection",
137 "connections",
138 "router",
139 "reset_queries",
140 "close_old_connections",
141 "DatabaseError",
142 "IntegrityError",
143 "InternalError",
144 "ProgrammingError",
145 "DataError",
146 "NotSupportedError",
147 "Error",
148 "InterfaceError",
149 "OperationalError",
150 "DEFAULT_DB_ALIAS",
151 "PLAIN_VERSION_PICKLE_KEY",
152]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Classes to represent the definitions of aggregate functions.
3"""
4from plain.exceptions import FieldError, FullResultSet
5from plain.models.expressions import Case, Func, Star, Value, When
6from plain.models.fields import IntegerField
7from plain.models.functions.comparison import Coalesce
8from plain.models.functions.mixins import (
9 FixDurationInputMixin,
10 NumericOutputFieldMixin,
11)
13__all__ = [
14 "Aggregate",
15 "Avg",
16 "Count",
17 "Max",
18 "Min",
19 "StdDev",
20 "Sum",
21 "Variance",
22]
25class Aggregate(Func):
26 template = "%(function)s(%(distinct)s%(expressions)s)"
27 contains_aggregate = True
28 name = None
29 filter_template = "%s FILTER (WHERE %%(filter)s)"
30 window_compatible = True
31 allow_distinct = False
32 empty_result_set_value = None
34 def __init__(
35 self, *expressions, distinct=False, filter=None, default=None, **extra
36 ):
37 if distinct and not self.allow_distinct:
38 raise TypeError("%s does not allow distinct." % self.__class__.__name__)
39 if default is not None and self.empty_result_set_value is not None:
40 raise TypeError(f"{self.__class__.__name__} does not allow default.")
41 self.distinct = distinct
42 self.filter = filter
43 self.default = default
44 super().__init__(*expressions, **extra)
46 def get_source_fields(self):
47 # Don't return the filter expression since it's not a source field.
48 return [e._output_field_or_none for e in super().get_source_expressions()]
50 def get_source_expressions(self):
51 source_expressions = super().get_source_expressions()
52 if self.filter:
53 return source_expressions + [self.filter]
54 return source_expressions
56 def set_source_expressions(self, exprs):
57 self.filter = self.filter and exprs.pop()
58 return super().set_source_expressions(exprs)
60 def resolve_expression(
61 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
62 ):
63 # Aggregates are not allowed in UPDATE queries, so ignore for_save
64 c = super().resolve_expression(query, allow_joins, reuse, summarize)
65 c.filter = c.filter and c.filter.resolve_expression(
66 query, allow_joins, reuse, summarize
67 )
68 if not summarize:
69 # Call Aggregate.get_source_expressions() to avoid
70 # returning self.filter and including that in this loop.
71 expressions = super(Aggregate, c).get_source_expressions()
72 for index, expr in enumerate(expressions):
73 if expr.contains_aggregate:
74 before_resolved = self.get_source_expressions()[index]
75 name = (
76 before_resolved.name
77 if hasattr(before_resolved, "name")
78 else repr(before_resolved)
79 )
80 raise FieldError(
81 f"Cannot compute {c.name}('{name}'): '{name}' is an aggregate"
82 )
83 if (default := c.default) is None:
84 return c
85 if hasattr(default, "resolve_expression"):
86 default = default.resolve_expression(query, allow_joins, reuse, summarize)
87 if default._output_field_or_none is None:
88 default.output_field = c._output_field_or_none
89 else:
90 default = Value(default, c._output_field_or_none)
91 c.default = None # Reset the default argument before wrapping.
92 coalesce = Coalesce(c, default, output_field=c._output_field_or_none)
93 coalesce.is_summary = c.is_summary
94 return coalesce
96 @property
97 def default_alias(self):
98 expressions = self.get_source_expressions()
99 if len(expressions) == 1 and hasattr(expressions[0], "name"):
100 return f"{expressions[0].name}__{self.name.lower()}"
101 raise TypeError("Complex expressions require an alias")
103 def get_group_by_cols(self):
104 return []
106 def as_sql(self, compiler, connection, **extra_context):
107 extra_context["distinct"] = "DISTINCT " if self.distinct else ""
108 if self.filter:
109 if connection.features.supports_aggregate_filter_clause:
110 try:
111 filter_sql, filter_params = self.filter.as_sql(compiler, connection)
112 except FullResultSet:
113 pass
114 else:
115 template = self.filter_template % extra_context.get(
116 "template", self.template
117 )
118 sql, params = super().as_sql(
119 compiler,
120 connection,
121 template=template,
122 filter=filter_sql,
123 **extra_context,
124 )
125 return sql, (*params, *filter_params)
126 else:
127 copy = self.copy()
128 copy.filter = None
129 source_expressions = copy.get_source_expressions()
130 condition = When(self.filter, then=source_expressions[0])
131 copy.set_source_expressions([Case(condition)] + source_expressions[1:])
132 return super(Aggregate, copy).as_sql(
133 compiler, connection, **extra_context
134 )
135 return super().as_sql(compiler, connection, **extra_context)
137 def _get_repr_options(self):
138 options = super()._get_repr_options()
139 if self.distinct:
140 options["distinct"] = self.distinct
141 if self.filter:
142 options["filter"] = self.filter
143 return options
146class Avg(FixDurationInputMixin, NumericOutputFieldMixin, Aggregate):
147 function = "AVG"
148 name = "Avg"
149 allow_distinct = True
152class Count(Aggregate):
153 function = "COUNT"
154 name = "Count"
155 output_field = IntegerField()
156 allow_distinct = True
157 empty_result_set_value = 0
159 def __init__(self, expression, filter=None, **extra):
160 if expression == "*":
161 expression = Star()
162 if isinstance(expression, Star) and filter is not None:
163 raise ValueError("Star cannot be used with filter. Please specify a field.")
164 super().__init__(expression, filter=filter, **extra)
167class Max(Aggregate):
168 function = "MAX"
169 name = "Max"
172class Min(Aggregate):
173 function = "MIN"
174 name = "Min"
177class StdDev(NumericOutputFieldMixin, Aggregate):
178 name = "StdDev"
180 def __init__(self, expression, sample=False, **extra):
181 self.function = "STDDEV_SAMP" if sample else "STDDEV_POP"
182 super().__init__(expression, **extra)
184 def _get_repr_options(self):
185 return {**super()._get_repr_options(), "sample": self.function == "STDDEV_SAMP"}
188class Sum(FixDurationInputMixin, Aggregate):
189 function = "SUM"
190 name = "Sum"
191 allow_distinct = True
194class Variance(NumericOutputFieldMixin, Aggregate):
195 name = "Variance"
197 def __init__(self, expression, sample=False, **extra):
198 self.function = "VAR_SAMP" if sample else "VAR_POP"
199 super().__init__(expression, **extra)
201 def _get_repr_options(self):
202 return {**super()._get_repr_options(), "sample": self.function == "VAR_SAMP"}
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import copy
2import inspect
3import warnings
4from functools import partialmethod
5from itertools import chain
7import plain.runtime
8from plain import preflight
9from plain.exceptions import (
10 NON_FIELD_ERRORS,
11 FieldDoesNotExist,
12 FieldError,
13 MultipleObjectsReturned,
14 ObjectDoesNotExist,
15 ValidationError,
16)
17from plain.models import transaction
18from plain.models.aggregates import Max
19from plain.models.constants import LOOKUP_SEP
20from plain.models.constraints import CheckConstraint, UniqueConstraint
21from plain.models.db import (
22 PLAIN_VERSION_PICKLE_KEY,
23 DatabaseError,
24 connection,
25 connections,
26 router,
27)
28from plain.models.deletion import CASCADE, Collector
29from plain.models.expressions import ExpressionWrapper, RawSQL, Value
30from plain.models.fields import NOT_PROVIDED, IntegerField
31from plain.models.fields.related import (
32 ForeignObjectRel,
33 OneToOneField,
34 lazy_related_operation,
35 resolve_relation,
36)
37from plain.models.functions import Coalesce
38from plain.models.manager import Manager
39from plain.models.options import Options
40from plain.models.query import F, Q
41from plain.models.signals import (
42 class_prepared,
43 post_init,
44 post_save,
45 pre_init,
46 pre_save,
47)
48from plain.models.utils import AltersData, make_model_tuple
49from plain.packages import packages
50from plain.utils.encoding import force_str
51from plain.utils.hashable import make_hashable
54class Deferred:
55 def __repr__(self):
56 return "<Deferred field>"
58 def __str__(self):
59 return "<Deferred field>"
62DEFERRED = Deferred()
65def subclass_exception(name, bases, module, attached_to):
66 """
67 Create exception subclass. Used by ModelBase below.
69 The exception is created in a way that allows it to be pickled, assuming
70 that the returned exception class will be added as an attribute to the
71 'attached_to' class.
72 """
73 return type(
74 name,
75 bases,
76 {
77 "__module__": module,
78 "__qualname__": f"{attached_to.__qualname__}.{name}",
79 },
80 )
83def _has_contribute_to_class(value):
84 # Only call contribute_to_class() if it's bound.
85 return not inspect.isclass(value) and hasattr(value, "contribute_to_class")
88class ModelBase(type):
89 """Metaclass for all models."""
91 def __new__(cls, name, bases, attrs, **kwargs):
92 super_new = super().__new__
94 # Also ensure initialization is only performed for subclasses of Model
95 # (excluding Model class itself).
96 parents = [b for b in bases if isinstance(b, ModelBase)]
97 if not parents:
98 return super_new(cls, name, bases, attrs)
100 # Create the class.
101 module = attrs.pop("__module__")
102 new_attrs = {"__module__": module}
103 classcell = attrs.pop("__classcell__", None)
104 if classcell is not None:
105 new_attrs["__classcell__"] = classcell
106 attr_meta = attrs.pop("Meta", None)
107 # Pass all attrs without a (Plain-specific) contribute_to_class()
108 # method to type.__new__() so that they're properly initialized
109 # (i.e. __set_name__()).
110 contributable_attrs = {}
111 for obj_name, obj in attrs.items():
112 if _has_contribute_to_class(obj):
113 contributable_attrs[obj_name] = obj
114 else:
115 new_attrs[obj_name] = obj
116 new_class = super_new(cls, name, bases, new_attrs, **kwargs)
118 abstract = getattr(attr_meta, "abstract", False)
119 meta = attr_meta or getattr(new_class, "Meta", None)
120 base_meta = getattr(new_class, "_meta", None)
122 package_label = None
124 # Look for an application configuration to attach the model to.
125 package_config = packages.get_containing_package_config(module)
127 if getattr(meta, "package_label", None) is None:
128 if package_config is None:
129 if not abstract:
130 raise RuntimeError(
131 f"Model class {module}.{name} doesn't declare an explicit "
132 "package_label and isn't in an application in "
133 "INSTALLED_PACKAGES."
134 )
136 else:
137 package_label = package_config.label
139 new_class.add_to_class("_meta", Options(meta, package_label))
140 if not abstract:
141 new_class.add_to_class(
142 "DoesNotExist",
143 subclass_exception(
144 "DoesNotExist",
145 tuple(
146 x.DoesNotExist
147 for x in parents
148 if hasattr(x, "_meta") and not x._meta.abstract
149 )
150 or (ObjectDoesNotExist,),
151 module,
152 attached_to=new_class,
153 ),
154 )
155 new_class.add_to_class(
156 "MultipleObjectsReturned",
157 subclass_exception(
158 "MultipleObjectsReturned",
159 tuple(
160 x.MultipleObjectsReturned
161 for x in parents
162 if hasattr(x, "_meta") and not x._meta.abstract
163 )
164 or (MultipleObjectsReturned,),
165 module,
166 attached_to=new_class,
167 ),
168 )
169 if base_meta and not base_meta.abstract:
170 # Non-abstract child classes inherit some attributes from their
171 # non-abstract parent (unless an ABC comes before it in the
172 # method resolution order).
173 if not hasattr(meta, "ordering"):
174 new_class._meta.ordering = base_meta.ordering
175 if not hasattr(meta, "get_latest_by"):
176 new_class._meta.get_latest_by = base_meta.get_latest_by
178 # Add remaining attributes (those with a contribute_to_class() method)
179 # to the class.
180 for obj_name, obj in contributable_attrs.items():
181 new_class.add_to_class(obj_name, obj)
183 # All the fields of any type declared on this model
184 new_fields = chain(
185 new_class._meta.local_fields,
186 new_class._meta.local_many_to_many,
187 new_class._meta.private_fields,
188 )
189 field_names = {f.name for f in new_fields}
191 new_class._meta.concrete_model = new_class
193 # Collect the parent links for multi-table inheritance.
194 parent_links = {}
195 for base in reversed([new_class] + parents):
196 # Conceptually equivalent to `if base is Model`.
197 if not hasattr(base, "_meta"):
198 continue
199 # Skip concrete parent classes.
200 if base != new_class and not base._meta.abstract:
201 continue
202 # Locate OneToOneField instances.
203 for field in base._meta.local_fields:
204 if isinstance(field, OneToOneField) and field.remote_field.parent_link:
205 related = resolve_relation(new_class, field.remote_field.model)
206 parent_links[make_model_tuple(related)] = field
208 # Track fields inherited from base models.
209 inherited_attributes = set()
210 # Do the appropriate setup for any model parents.
211 for base in new_class.mro():
212 if base not in parents or not hasattr(base, "_meta"):
213 # Things without _meta aren't functional models, so they're
214 # uninteresting parents.
215 inherited_attributes.update(base.__dict__)
216 continue
218 parent_fields = base._meta.local_fields + base._meta.local_many_to_many
219 if not base._meta.abstract:
220 # Check for clashes between locally declared fields and those
221 # on the base classes.
222 for field in parent_fields:
223 if field.name in field_names:
224 raise FieldError(
225 "Local field {!r} in class {!r} clashes with field of "
226 "the same name from base class {!r}.".format(
227 field.name,
228 name,
229 base.__name__,
230 )
231 )
232 else:
233 inherited_attributes.add(field.name)
235 # Concrete classes...
236 base = base._meta.concrete_model
237 base_key = make_model_tuple(base)
238 if base_key in parent_links:
239 field = parent_links[base_key]
240 else:
241 attr_name = "%s_ptr" % base._meta.model_name
242 field = OneToOneField(
243 base,
244 on_delete=CASCADE,
245 name=attr_name,
246 auto_created=True,
247 parent_link=True,
248 )
250 if attr_name in field_names:
251 raise FieldError(
252 f"Auto-generated field '{attr_name}' in class {name!r} for "
253 f"parent_link to base class {base.__name__!r} clashes with "
254 "declared field of the same name."
255 )
257 # Only add the ptr field if it's not already present;
258 # e.g. migrations will already have it specified
259 if not hasattr(new_class, attr_name):
260 new_class.add_to_class(attr_name, field)
261 new_class._meta.parents[base] = field
262 else:
263 base_parents = base._meta.parents.copy()
265 # Add fields from abstract base class if it wasn't overridden.
266 for field in parent_fields:
267 if (
268 field.name not in field_names
269 and field.name not in new_class.__dict__
270 and field.name not in inherited_attributes
271 ):
272 new_field = copy.deepcopy(field)
273 new_class.add_to_class(field.name, new_field)
274 # Replace parent links defined on this base by the new
275 # field. It will be appropriately resolved if required.
276 if field.one_to_one:
277 for parent, parent_link in base_parents.items():
278 if field == parent_link:
279 base_parents[parent] = new_field
281 # Pass any non-abstract parent classes onto child.
282 new_class._meta.parents.update(base_parents)
284 # Inherit private fields (like GenericForeignKey) from the parent
285 # class
286 for field in base._meta.private_fields:
287 if field.name in field_names:
288 if not base._meta.abstract:
289 raise FieldError(
290 "Local field {!r} in class {!r} clashes with field of "
291 "the same name from base class {!r}.".format(
292 field.name,
293 name,
294 base.__name__,
295 )
296 )
297 else:
298 field = copy.deepcopy(field)
299 if not base._meta.abstract:
300 field.mti_inherited = True
301 new_class.add_to_class(field.name, field)
303 # Copy indexes so that index names are unique when models extend an
304 # abstract model.
305 new_class._meta.indexes = [
306 copy.deepcopy(idx) for idx in new_class._meta.indexes
307 ]
309 if abstract:
310 # Abstract base models can't be instantiated and don't appear in
311 # the list of models for an app. We do the final setup for them a
312 # little differently from normal models.
313 attr_meta.abstract = False
314 new_class.Meta = attr_meta
315 return new_class
317 new_class._prepare()
318 new_class._meta.packages.register_model(
319 new_class._meta.package_label, new_class
320 )
321 return new_class
323 def add_to_class(cls, name, value):
324 if _has_contribute_to_class(value):
325 value.contribute_to_class(cls, name)
326 else:
327 setattr(cls, name, value)
329 def _prepare(cls):
330 """Create some methods once self._meta has been populated."""
331 opts = cls._meta
332 opts._prepare(cls)
334 if opts.order_with_respect_to:
335 cls.get_next_in_order = partialmethod(
336 cls._get_next_or_previous_in_order, is_next=True
337 )
338 cls.get_previous_in_order = partialmethod(
339 cls._get_next_or_previous_in_order, is_next=False
340 )
342 # Defer creating accessors on the foreign class until it has been
343 # created and registered. If remote_field is None, we're ordering
344 # with respect to a GenericForeignKey and don't know what the
345 # foreign class is - we'll add those accessors later in
346 # contribute_to_class().
347 if opts.order_with_respect_to.remote_field:
348 wrt = opts.order_with_respect_to
349 remote = wrt.remote_field.model
350 lazy_related_operation(make_foreign_order_accessors, cls, remote)
352 # Give the class a docstring -- its definition.
353 if cls.__doc__ is None:
354 cls.__doc__ = "{}({})".format(
355 cls.__name__,
356 ", ".join(f.name for f in opts.fields),
357 )
359 if not opts.managers:
360 if any(f.name == "objects" for f in opts.fields):
361 raise ValueError(
362 "Model %s must specify a custom Manager, because it has a "
363 "field named 'objects'." % cls.__name__
364 )
365 manager = Manager()
366 manager.auto_created = True
367 cls.add_to_class("objects", manager)
369 # Set the name of _meta.indexes. This can't be done in
370 # Options.contribute_to_class() because fields haven't been added to
371 # the model at that point.
372 for index in cls._meta.indexes:
373 if not index.name:
374 index.set_name_with_model(cls)
376 class_prepared.send(sender=cls)
378 @property
379 def _base_manager(cls):
380 return cls._meta.base_manager
382 @property
383 def _default_manager(cls):
384 return cls._meta.default_manager
387class ModelStateFieldsCacheDescriptor:
388 def __get__(self, instance, cls=None):
389 if instance is None:
390 return self
391 res = instance.fields_cache = {}
392 return res
395class ModelState:
396 """Store model instance state."""
398 db = None
399 # If true, uniqueness validation checks will consider this a new, unsaved
400 # object. Necessary for correct validation of new instances of objects with
401 # explicit (non-auto) PKs. This impacts validation only; it has no effect
402 # on the actual save.
403 adding = True
404 fields_cache = ModelStateFieldsCacheDescriptor()
407class Model(AltersData, metaclass=ModelBase):
408 def __init__(self, *args, **kwargs):
409 # Alias some things as locals to avoid repeat global lookups
410 cls = self.__class__
411 opts = self._meta
412 _setattr = setattr
413 _DEFERRED = DEFERRED
414 if opts.abstract:
415 raise TypeError("Abstract models cannot be instantiated.")
417 pre_init.send(sender=cls, args=args, kwargs=kwargs)
419 # Set up the storage for instance state
420 self._state = ModelState()
422 # There is a rather weird disparity here; if kwargs, it's set, then args
423 # overrides it. It should be one or the other; don't duplicate the work
424 # The reason for the kwargs check is that standard iterator passes in by
425 # args, and instantiation for iteration is 33% faster.
426 if len(args) > len(opts.concrete_fields):
427 # Daft, but matches old exception sans the err msg.
428 raise IndexError("Number of args exceeds number of fields")
430 if not kwargs:
431 fields_iter = iter(opts.concrete_fields)
432 # The ordering of the zip calls matter - zip throws StopIteration
433 # when an iter throws it. So if the first iter throws it, the second
434 # is *not* consumed. We rely on this, so don't change the order
435 # without changing the logic.
436 for val, field in zip(args, fields_iter):
437 if val is _DEFERRED:
438 continue
439 _setattr(self, field.attname, val)
440 else:
441 # Slower, kwargs-ready version.
442 fields_iter = iter(opts.fields)
443 for val, field in zip(args, fields_iter):
444 if val is _DEFERRED:
445 continue
446 _setattr(self, field.attname, val)
447 if kwargs.pop(field.name, NOT_PROVIDED) is not NOT_PROVIDED:
448 raise TypeError(
449 f"{cls.__qualname__}() got both positional and "
450 f"keyword arguments for field '{field.name}'."
451 )
453 # Now we're left with the unprocessed fields that *must* come from
454 # keywords, or default.
456 for field in fields_iter:
457 is_related_object = False
458 # Virtual field
459 if field.attname not in kwargs and field.column is None:
460 continue
461 if kwargs:
462 if isinstance(field.remote_field, ForeignObjectRel):
463 try:
464 # Assume object instance was passed in.
465 rel_obj = kwargs.pop(field.name)
466 is_related_object = True
467 except KeyError:
468 try:
469 # Object instance wasn't passed in -- must be an ID.
470 val = kwargs.pop(field.attname)
471 except KeyError:
472 val = field.get_default()
473 else:
474 try:
475 val = kwargs.pop(field.attname)
476 except KeyError:
477 # This is done with an exception rather than the
478 # default argument on pop because we don't want
479 # get_default() to be evaluated, and then not used.
480 # Refs #12057.
481 val = field.get_default()
482 else:
483 val = field.get_default()
485 if is_related_object:
486 # If we are passed a related instance, set it using the
487 # field.name instead of field.attname (e.g. "user" instead of
488 # "user_id") so that the object gets properly cached (and type
489 # checked) by the RelatedObjectDescriptor.
490 if rel_obj is not _DEFERRED:
491 _setattr(self, field.name, rel_obj)
492 else:
493 if val is not _DEFERRED:
494 _setattr(self, field.attname, val)
496 if kwargs:
497 property_names = opts._property_names
498 unexpected = ()
499 for prop, value in kwargs.items():
500 # Any remaining kwargs must correspond to properties or virtual
501 # fields.
502 if prop in property_names:
503 if value is not _DEFERRED:
504 _setattr(self, prop, value)
505 else:
506 try:
507 opts.get_field(prop)
508 except FieldDoesNotExist:
509 unexpected += (prop,)
510 else:
511 if value is not _DEFERRED:
512 _setattr(self, prop, value)
513 if unexpected:
514 unexpected_names = ", ".join(repr(n) for n in unexpected)
515 raise TypeError(
516 f"{cls.__name__}() got unexpected keyword arguments: "
517 f"{unexpected_names}"
518 )
519 super().__init__()
520 post_init.send(sender=cls, instance=self)
522 @classmethod
523 def from_db(cls, db, field_names, values):
524 if len(values) != len(cls._meta.concrete_fields):
525 values_iter = iter(values)
526 values = [
527 next(values_iter) if f.attname in field_names else DEFERRED
528 for f in cls._meta.concrete_fields
529 ]
530 new = cls(*values)
531 new._state.adding = False
532 new._state.db = db
533 return new
535 def __repr__(self):
536 return f"<{self.__class__.__name__}: {self}>"
538 def __str__(self):
539 return f"{self.__class__.__name__} object ({self.pk})"
541 def __eq__(self, other):
542 if not isinstance(other, Model):
543 return NotImplemented
544 if self._meta.concrete_model != other._meta.concrete_model:
545 return False
546 my_pk = self.pk
547 if my_pk is None:
548 return self is other
549 return my_pk == other.pk
551 def __hash__(self):
552 if self.pk is None:
553 raise TypeError("Model instances without primary key value are unhashable")
554 return hash(self.pk)
556 def __reduce__(self):
557 data = self.__getstate__()
558 data[PLAIN_VERSION_PICKLE_KEY] = plain.runtime.__version__
559 class_id = self._meta.package_label, self._meta.object_name
560 return model_unpickle, (class_id,), data
562 def __getstate__(self):
563 """Hook to allow choosing the attributes to pickle."""
564 state = self.__dict__.copy()
565 state["_state"] = copy.copy(state["_state"])
566 state["_state"].fields_cache = state["_state"].fields_cache.copy()
567 # memoryview cannot be pickled, so cast it to bytes and store
568 # separately.
569 _memoryview_attrs = []
570 for attr, value in state.items():
571 if isinstance(value, memoryview):
572 _memoryview_attrs.append((attr, bytes(value)))
573 if _memoryview_attrs:
574 state["_memoryview_attrs"] = _memoryview_attrs
575 for attr, value in _memoryview_attrs:
576 state.pop(attr)
577 return state
579 def __setstate__(self, state):
580 pickled_version = state.get(PLAIN_VERSION_PICKLE_KEY)
581 if pickled_version:
582 if pickled_version != plain.runtime.__version__:
583 warnings.warn(
584 f"Pickled model instance's Plain version {pickled_version} does not "
585 f"match the current version {plain.runtime.__version__}.",
586 RuntimeWarning,
587 stacklevel=2,
588 )
589 else:
590 warnings.warn(
591 "Pickled model instance's Plain version is not specified.",
592 RuntimeWarning,
593 stacklevel=2,
594 )
595 if "_memoryview_attrs" in state:
596 for attr, value in state.pop("_memoryview_attrs"):
597 state[attr] = memoryview(value)
598 self.__dict__.update(state)
600 def _get_pk_val(self, meta=None):
601 meta = meta or self._meta
602 return getattr(self, meta.pk.attname)
604 def _set_pk_val(self, value):
605 for parent_link in self._meta.parents.values():
606 if parent_link and parent_link != self._meta.pk:
607 setattr(self, parent_link.target_field.attname, value)
608 return setattr(self, self._meta.pk.attname, value)
610 pk = property(_get_pk_val, _set_pk_val)
612 def get_deferred_fields(self):
613 """
614 Return a set containing names of deferred fields for this instance.
615 """
616 return {
617 f.attname
618 for f in self._meta.concrete_fields
619 if f.attname not in self.__dict__
620 }
622 def refresh_from_db(self, using=None, fields=None):
623 """
624 Reload field values from the database.
626 By default, the reloading happens from the database this instance was
627 loaded from, or by the read router if this instance wasn't loaded from
628 any database. The using parameter will override the default.
630 Fields can be used to specify which fields to reload. The fields
631 should be an iterable of field attnames. If fields is None, then
632 all non-deferred fields are reloaded.
634 When accessing deferred fields of an instance, the deferred loading
635 of the field will call this method.
636 """
637 if fields is None:
638 self._prefetched_objects_cache = {}
639 else:
640 prefetched_objects_cache = getattr(self, "_prefetched_objects_cache", ())
641 for field in fields:
642 if field in prefetched_objects_cache:
643 del prefetched_objects_cache[field]
644 fields.remove(field)
645 if not fields:
646 return
647 if any(LOOKUP_SEP in f for f in fields):
648 raise ValueError(
649 'Found "%s" in fields argument. Relations and transforms '
650 "are not allowed in fields." % LOOKUP_SEP
651 )
653 hints = {"instance": self}
654 db_instance_qs = self.__class__._base_manager.db_manager(
655 using, hints=hints
656 ).filter(pk=self.pk)
658 # Use provided fields, if not set then reload all non-deferred fields.
659 deferred_fields = self.get_deferred_fields()
660 if fields is not None:
661 fields = list(fields)
662 db_instance_qs = db_instance_qs.only(*fields)
663 elif deferred_fields:
664 fields = [
665 f.attname
666 for f in self._meta.concrete_fields
667 if f.attname not in deferred_fields
668 ]
669 db_instance_qs = db_instance_qs.only(*fields)
671 db_instance = db_instance_qs.get()
672 non_loaded_fields = db_instance.get_deferred_fields()
673 for field in self._meta.concrete_fields:
674 if field.attname in non_loaded_fields:
675 # This field wasn't refreshed - skip ahead.
676 continue
677 setattr(self, field.attname, getattr(db_instance, field.attname))
678 # Clear cached foreign keys.
679 if field.is_relation and field.is_cached(self):
680 field.delete_cached_value(self)
682 # Clear cached relations.
683 for field in self._meta.related_objects:
684 if field.is_cached(self):
685 field.delete_cached_value(self)
687 # Clear cached private relations.
688 for field in self._meta.private_fields:
689 if field.is_relation and field.is_cached(self):
690 field.delete_cached_value(self)
692 self._state.db = db_instance._state.db
694 def serializable_value(self, field_name):
695 """
696 Return the value of the field name for this instance. If the field is
697 a foreign key, return the id value instead of the object. If there's
698 no Field object with this name on the model, return the model
699 attribute's value.
701 Used to serialize a field's value (in the serializer, or form output,
702 for example). Normally, you would just access the attribute directly
703 and not use this method.
704 """
705 try:
706 field = self._meta.get_field(field_name)
707 except FieldDoesNotExist:
708 return getattr(self, field_name)
709 return getattr(self, field.attname)
711 def save(
712 self,
713 *,
714 clean_and_validate=True,
715 force_insert=False,
716 force_update=False,
717 using=None,
718 update_fields=None,
719 ):
720 """
721 Save the current instance. Override this in a subclass if you want to
722 control the saving process.
724 The 'force_insert' and 'force_update' parameters can be used to insist
725 that the "save" must be an SQL insert or update (or equivalent for
726 non-SQL backends), respectively. Normally, they should not be set.
727 """
728 self._prepare_related_fields_for_save(operation_name="save")
730 using = using or router.db_for_write(self.__class__, instance=self)
731 if force_insert and (force_update or update_fields):
732 raise ValueError("Cannot force both insert and updating in model saving.")
734 deferred_fields = self.get_deferred_fields()
735 if update_fields is not None:
736 # If update_fields is empty, skip the save. We do also check for
737 # no-op saves later on for inheritance cases. This bailout is
738 # still needed for skipping signal sending.
739 if not update_fields:
740 return
742 update_fields = frozenset(update_fields)
743 field_names = self._meta._non_pk_concrete_field_names
744 non_model_fields = update_fields.difference(field_names)
746 if non_model_fields:
747 raise ValueError(
748 "The following fields do not exist in this model, are m2m "
749 "fields, or are non-concrete fields: %s"
750 % ", ".join(non_model_fields)
751 )
753 # If saving to the same database, and this model is deferred, then
754 # automatically do an "update_fields" save on the loaded fields.
755 elif not force_insert and deferred_fields and using == self._state.db:
756 field_names = set()
757 for field in self._meta.concrete_fields:
758 if not field.primary_key and not hasattr(field, "through"):
759 field_names.add(field.attname)
760 loaded_fields = field_names.difference(deferred_fields)
761 if loaded_fields:
762 update_fields = frozenset(loaded_fields)
764 if clean_and_validate:
765 self.full_clean(exclude=deferred_fields)
767 self.save_base(
768 using=using,
769 force_insert=force_insert,
770 force_update=force_update,
771 update_fields=update_fields,
772 )
774 save.alters_data = True
776 def save_base(
777 self,
778 *,
779 raw=False,
780 force_insert=False,
781 force_update=False,
782 using=None,
783 update_fields=None,
784 ):
785 """
786 Handle the parts of saving which should be done only once per save,
787 yet need to be done in raw saves, too. This includes some sanity
788 checks and signal sending.
790 The 'raw' argument is telling save_base not to save any parent
791 models and not to do any changes to the values before save. This
792 is used by fixture loading.
793 """
794 using = using or router.db_for_write(self.__class__, instance=self)
795 assert not (force_insert and (force_update or update_fields))
796 assert update_fields is None or update_fields
797 cls = origin = self.__class__
798 meta = cls._meta
799 if not meta.auto_created:
800 pre_save.send(
801 sender=origin,
802 instance=self,
803 raw=raw,
804 using=using,
805 update_fields=update_fields,
806 )
807 # A transaction isn't needed if one query is issued.
808 if meta.parents:
809 context_manager = transaction.atomic(using=using, savepoint=False)
810 else:
811 context_manager = transaction.mark_for_rollback_on_error(using=using)
812 with context_manager:
813 parent_inserted = False
814 if not raw:
815 parent_inserted = self._save_parents(cls, using, update_fields)
816 updated = self._save_table(
817 raw,
818 cls,
819 force_insert or parent_inserted,
820 force_update,
821 using,
822 update_fields,
823 )
824 # Store the database on which the object was saved
825 self._state.db = using
826 # Once saved, this is no longer a to-be-added instance.
827 self._state.adding = False
829 # Signal that the save is complete
830 if not meta.auto_created:
831 post_save.send(
832 sender=origin,
833 instance=self,
834 created=(not updated),
835 update_fields=update_fields,
836 raw=raw,
837 using=using,
838 )
840 save_base.alters_data = True
842 def _save_parents(self, cls, using, update_fields):
843 """Save all the parents of cls using values from self."""
844 meta = cls._meta
845 inserted = False
846 for parent, field in meta.parents.items():
847 # Make sure the link fields are synced between parent and self.
848 if (
849 field
850 and getattr(self, parent._meta.pk.attname) is None
851 and getattr(self, field.attname) is not None
852 ):
853 setattr(self, parent._meta.pk.attname, getattr(self, field.attname))
854 parent_inserted = self._save_parents(
855 cls=parent, using=using, update_fields=update_fields
856 )
857 updated = self._save_table(
858 cls=parent,
859 using=using,
860 update_fields=update_fields,
861 force_insert=parent_inserted,
862 )
863 if not updated:
864 inserted = True
865 # Set the parent's PK value to self.
866 if field:
867 setattr(self, field.attname, self._get_pk_val(parent._meta))
868 # Since we didn't have an instance of the parent handy set
869 # attname directly, bypassing the descriptor. Invalidate
870 # the related object cache, in case it's been accidentally
871 # populated. A fresh instance will be re-built from the
872 # database if necessary.
873 if field.is_cached(self):
874 field.delete_cached_value(self)
875 return inserted
877 def _save_table(
878 self,
879 raw=False,
880 cls=None,
881 force_insert=False,
882 force_update=False,
883 using=None,
884 update_fields=None,
885 ):
886 """
887 Do the heavy-lifting involved in saving. Update or insert the data
888 for a single table.
889 """
890 meta = cls._meta
891 non_pks = [f for f in meta.local_concrete_fields if not f.primary_key]
893 if update_fields:
894 non_pks = [
895 f
896 for f in non_pks
897 if f.name in update_fields or f.attname in update_fields
898 ]
900 pk_val = self._get_pk_val(meta)
901 if pk_val is None:
902 pk_val = meta.pk.get_pk_value_on_save(self)
903 setattr(self, meta.pk.attname, pk_val)
904 pk_set = pk_val is not None
905 if not pk_set and (force_update or update_fields):
906 raise ValueError("Cannot force an update in save() with no primary key.")
907 updated = False
908 # Skip an UPDATE when adding an instance and primary key has a default.
909 if (
910 not raw
911 and not force_insert
912 and self._state.adding
913 and meta.pk.default
914 and meta.pk.default is not NOT_PROVIDED
915 ):
916 force_insert = True
917 # If possible, try an UPDATE. If that doesn't update anything, do an INSERT.
918 if pk_set and not force_insert:
919 base_qs = cls._base_manager.using(using)
920 values = [
921 (
922 f,
923 None,
924 (getattr(self, f.attname) if raw else f.pre_save(self, False)),
925 )
926 for f in non_pks
927 ]
928 forced_update = update_fields or force_update
929 updated = self._do_update(
930 base_qs, using, pk_val, values, update_fields, forced_update
931 )
932 if force_update and not updated:
933 raise DatabaseError("Forced update did not affect any rows.")
934 if update_fields and not updated:
935 raise DatabaseError("Save with update_fields did not affect any rows.")
936 if not updated:
937 if meta.order_with_respect_to:
938 # If this is a model with an order_with_respect_to
939 # autopopulate the _order field
940 field = meta.order_with_respect_to
941 filter_args = field.get_filter_kwargs_for_object(self)
942 self._order = (
943 cls._base_manager.using(using)
944 .filter(**filter_args)
945 .aggregate(
946 _order__max=Coalesce(
947 ExpressionWrapper(
948 Max("_order") + Value(1), output_field=IntegerField()
949 ),
950 Value(0),
951 ),
952 )["_order__max"]
953 )
954 fields = meta.local_concrete_fields
955 if not pk_set:
956 fields = [f for f in fields if f is not meta.auto_field]
958 returning_fields = meta.db_returning_fields
959 results = self._do_insert(
960 cls._base_manager, using, fields, returning_fields, raw
961 )
962 if results:
963 for value, field in zip(results[0], returning_fields):
964 setattr(self, field.attname, value)
965 return updated
967 def _do_update(self, base_qs, using, pk_val, values, update_fields, forced_update):
968 """
969 Try to update the model. Return True if the model was updated (if an
970 update query was done and a matching row was found in the DB).
971 """
972 filtered = base_qs.filter(pk=pk_val)
973 if not values:
974 # We can end up here when saving a model in inheritance chain where
975 # update_fields doesn't target any field in current model. In that
976 # case we just say the update succeeded. Another case ending up here
977 # is a model with just PK - in that case check that the PK still
978 # exists.
979 return update_fields is not None or filtered.exists()
980 if self._meta.select_on_save and not forced_update:
981 return (
982 filtered.exists()
983 and
984 # It may happen that the object is deleted from the DB right after
985 # this check, causing the subsequent UPDATE to return zero matching
986 # rows. The same result can occur in some rare cases when the
987 # database returns zero despite the UPDATE being executed
988 # successfully (a row is matched and updated). In order to
989 # distinguish these two cases, the object's existence in the
990 # database is again checked for if the UPDATE query returns 0.
991 (filtered._update(values) > 0 or filtered.exists())
992 )
993 return filtered._update(values) > 0
995 def _do_insert(self, manager, using, fields, returning_fields, raw):
996 """
997 Do an INSERT. If returning_fields is defined then this method should
998 return the newly created data for the model.
999 """
1000 return manager._insert(
1001 [self],
1002 fields=fields,
1003 returning_fields=returning_fields,
1004 using=using,
1005 raw=raw,
1006 )
1008 def _prepare_related_fields_for_save(self, operation_name, fields=None):
1009 # Ensure that a model instance without a PK hasn't been assigned to
1010 # a ForeignKey, GenericForeignKey or OneToOneField on this model. If
1011 # the field is nullable, allowing the save would result in silent data
1012 # loss.
1013 for field in self._meta.concrete_fields:
1014 if fields and field not in fields:
1015 continue
1016 # If the related field isn't cached, then an instance hasn't been
1017 # assigned and there's no need to worry about this check.
1018 if field.is_relation and field.is_cached(self):
1019 obj = getattr(self, field.name, None)
1020 if not obj:
1021 continue
1022 # A pk may have been assigned manually to a model instance not
1023 # saved to the database (or auto-generated in a case like
1024 # UUIDField), but we allow the save to proceed and rely on the
1025 # database to raise an IntegrityError if applicable. If
1026 # constraints aren't supported by the database, there's the
1027 # unavoidable risk of data corruption.
1028 if obj.pk is None:
1029 # Remove the object from a related instance cache.
1030 if not field.remote_field.multiple:
1031 field.remote_field.delete_cached_value(obj)
1032 raise ValueError(
1033 "{}() prohibited to prevent data loss due to unsaved "
1034 "related object '{}'.".format(operation_name, field.name)
1035 )
1036 elif getattr(self, field.attname) in field.empty_values:
1037 # Set related object if it has been saved after an
1038 # assignment.
1039 setattr(self, field.name, obj)
1040 # If the relationship's pk/to_field was changed, clear the
1041 # cached relationship.
1042 if getattr(obj, field.target_field.attname) != getattr(
1043 self, field.attname
1044 ):
1045 field.delete_cached_value(self)
1046 # GenericForeignKeys are private.
1047 for field in self._meta.private_fields:
1048 if fields and field not in fields:
1049 continue
1050 if (
1051 field.is_relation
1052 and field.is_cached(self)
1053 and hasattr(field, "fk_field")
1054 ):
1055 obj = field.get_cached_value(self, default=None)
1056 if obj and obj.pk is None:
1057 raise ValueError(
1058 f"{operation_name}() prohibited to prevent data loss due to "
1059 f"unsaved related object '{field.name}'."
1060 )
1062 def delete(self, using=None, keep_parents=False):
1063 if self.pk is None:
1064 raise ValueError(
1065 "{} object can't be deleted because its {} attribute is set "
1066 "to None.".format(self._meta.object_name, self._meta.pk.attname)
1067 )
1068 using = using or router.db_for_write(self.__class__, instance=self)
1069 collector = Collector(using=using, origin=self)
1070 collector.collect([self], keep_parents=keep_parents)
1071 return collector.delete()
1073 delete.alters_data = True
1075 def _get_FIELD_display(self, field):
1076 value = getattr(self, field.attname)
1077 choices_dict = dict(make_hashable(field.flatchoices))
1078 # force_str() to coerce lazy strings.
1079 return force_str(
1080 choices_dict.get(make_hashable(value), value), strings_only=True
1081 )
1083 def _get_next_or_previous_by_FIELD(self, field, is_next, **kwargs):
1084 if not self.pk:
1085 raise ValueError("get_next/get_previous cannot be used on unsaved objects.")
1086 op = "gt" if is_next else "lt"
1087 order = "" if is_next else "-"
1088 param = getattr(self, field.attname)
1089 q = Q.create([(field.name, param), (f"pk__{op}", self.pk)], connector=Q.AND)
1090 q = Q.create([q, (f"{field.name}__{op}", param)], connector=Q.OR)
1091 qs = (
1092 self.__class__._default_manager.using(self._state.db)
1093 .filter(**kwargs)
1094 .filter(q)
1095 .order_by(f"{order}{field.name}", "%spk" % order)
1096 )
1097 try:
1098 return qs[0]
1099 except IndexError:
1100 raise self.DoesNotExist(
1101 "%s matching query does not exist." % self.__class__._meta.object_name
1102 )
1104 def _get_next_or_previous_in_order(self, is_next):
1105 cachename = "__%s_order_cache" % is_next
1106 if not hasattr(self, cachename):
1107 op = "gt" if is_next else "lt"
1108 order = "_order" if is_next else "-_order"
1109 order_field = self._meta.order_with_respect_to
1110 filter_args = order_field.get_filter_kwargs_for_object(self)
1111 obj = (
1112 self.__class__._default_manager.filter(**filter_args)
1113 .filter(
1114 **{
1115 "_order__%s" % op: self.__class__._default_manager.values(
1116 "_order"
1117 ).filter(**{self._meta.pk.name: self.pk})
1118 }
1119 )
1120 .order_by(order)[:1]
1121 .get()
1122 )
1123 setattr(self, cachename, obj)
1124 return getattr(self, cachename)
1126 def _get_field_value_map(self, meta, exclude=None):
1127 if exclude is None:
1128 exclude = set()
1129 meta = meta or self._meta
1130 return {
1131 field.name: Value(getattr(self, field.attname), field)
1132 for field in meta.local_concrete_fields
1133 if field.name not in exclude
1134 }
1136 def prepare_database_save(self, field):
1137 if self.pk is None:
1138 raise ValueError(
1139 "Unsaved model instance %r cannot be used in an ORM query." % self
1140 )
1141 return getattr(self, field.remote_field.get_related_field().attname)
1143 def clean(self):
1144 """
1145 Hook for doing any extra model-wide validation after clean() has been
1146 called on every field by self.clean_fields. Any ValidationError raised
1147 by this method will not be associated with a particular field; it will
1148 have a special-case association with the field defined by NON_FIELD_ERRORS.
1149 """
1150 pass
1152 def validate_unique(self, exclude=None):
1153 """
1154 Check unique constraints on the model and raise ValidationError if any
1155 failed.
1156 """
1157 unique_checks = self._get_unique_checks(exclude=exclude)
1159 if errors := self._perform_unique_checks(unique_checks):
1160 raise ValidationError(errors)
1162 def _get_unique_checks(self, exclude=None):
1163 """
1164 Return a list of checks to perform. Since validate_unique() could be
1165 called from a ModelForm, some fields may have been excluded; we can't
1166 perform a unique check on a model that is missing fields involved
1167 in that check. Fields that did not validate should also be excluded,
1168 but they need to be passed in via the exclude argument.
1169 """
1170 if exclude is None:
1171 exclude = set()
1172 unique_checks = []
1174 # Gather a list of checks for fields declared as unique and add them to
1175 # the list of checks.
1177 fields_with_class = [(self.__class__, self._meta.local_fields)]
1178 for parent_class in self._meta.get_parent_list():
1179 fields_with_class.append((parent_class, parent_class._meta.local_fields))
1181 for model_class, fields in fields_with_class:
1182 for f in fields:
1183 name = f.name
1184 if name in exclude:
1185 continue
1186 if f.unique:
1187 unique_checks.append((model_class, (name,)))
1189 return unique_checks
1191 def _perform_unique_checks(self, unique_checks):
1192 errors = {}
1194 for model_class, unique_check in unique_checks:
1195 # Try to look up an existing object with the same values as this
1196 # object's values for all the unique field.
1198 lookup_kwargs = {}
1199 for field_name in unique_check:
1200 f = self._meta.get_field(field_name)
1201 lookup_value = getattr(self, f.attname)
1202 # TODO: Handle multiple backends with different feature flags.
1203 if lookup_value is None or (
1204 lookup_value == ""
1205 and connection.features.interprets_empty_strings_as_nulls
1206 ):
1207 # no value, skip the lookup
1208 continue
1209 if f.primary_key and not self._state.adding:
1210 # no need to check for unique primary key when editing
1211 continue
1212 lookup_kwargs[str(field_name)] = lookup_value
1214 # some fields were skipped, no reason to do the check
1215 if len(unique_check) != len(lookup_kwargs):
1216 continue
1218 qs = model_class._default_manager.filter(**lookup_kwargs)
1220 # Exclude the current object from the query if we are editing an
1221 # instance (as opposed to creating a new one)
1222 # Note that we need to use the pk as defined by model_class, not
1223 # self.pk. These can be different fields because model inheritance
1224 # allows single model to have effectively multiple primary keys.
1225 # Refs #17615.
1226 model_class_pk = self._get_pk_val(model_class._meta)
1227 if not self._state.adding and model_class_pk is not None:
1228 qs = qs.exclude(pk=model_class_pk)
1229 if qs.exists():
1230 if len(unique_check) == 1:
1231 key = unique_check[0]
1232 else:
1233 key = NON_FIELD_ERRORS
1234 errors.setdefault(key, []).append(
1235 self.unique_error_message(model_class, unique_check)
1236 )
1238 return errors
1240 def unique_error_message(self, model_class, unique_check):
1241 opts = model_class._meta
1243 params = {
1244 "model": self,
1245 "model_class": model_class,
1246 "model_name": opts.model_name,
1247 "unique_check": unique_check,
1248 }
1250 if len(unique_check) == 1:
1251 field = opts.get_field(unique_check[0])
1252 params["field_label"] = field.name
1253 return ValidationError(
1254 message=field.error_messages["unique"],
1255 code="unique",
1256 params=params,
1257 )
1258 else:
1259 field_names = [opts.get_field(f).name for f in unique_check]
1261 # Put an "and" before the last one
1262 field_names[-1] = f"and {field_names[-1]}"
1264 if len(field_names) > 2:
1265 # Comma join if more than 2
1266 params["field_label"] = ", ".join(field_names)
1267 else:
1268 # Just a space if there are only 2
1269 params["field_label"] = " ".join(field_names)
1271 # Use the first field as the message format...
1272 message = opts.get_field(unique_check[0]).error_messages["unique"]
1274 return ValidationError(
1275 message=message,
1276 code="unique",
1277 params=params,
1278 )
1280 def get_constraints(self):
1281 constraints = [(self.__class__, self._meta.constraints)]
1282 for parent_class in self._meta.get_parent_list():
1283 if parent_class._meta.constraints:
1284 constraints.append((parent_class, parent_class._meta.constraints))
1285 return constraints
1287 def validate_constraints(self, exclude=None):
1288 constraints = self.get_constraints()
1289 using = router.db_for_write(self.__class__, instance=self)
1291 errors = {}
1292 for model_class, model_constraints in constraints:
1293 for constraint in model_constraints:
1294 try:
1295 constraint.validate(model_class, self, exclude=exclude, using=using)
1296 except ValidationError as e:
1297 if (
1298 getattr(e, "code", None) == "unique"
1299 and len(constraint.fields) == 1
1300 ):
1301 errors.setdefault(constraint.fields[0], []).append(e)
1302 else:
1303 errors = e.update_error_dict(errors)
1304 if errors:
1305 raise ValidationError(errors)
1307 def full_clean(
1308 self, *, exclude=None, validate_unique=True, validate_constraints=True
1309 ):
1310 """
1311 Call clean_fields(), clean(), validate_unique(), and
1312 validate_constraints() on the model. Raise a ValidationError for any
1313 errors that occur.
1314 """
1315 errors = {}
1316 if exclude is None:
1317 exclude = set()
1318 else:
1319 exclude = set(exclude)
1321 try:
1322 self.clean_fields(exclude=exclude)
1323 except ValidationError as e:
1324 errors = e.update_error_dict(errors)
1326 # Form.clean() is run even if other validation fails, so do the
1327 # same with Model.clean() for consistency.
1328 try:
1329 self.clean()
1330 except ValidationError as e:
1331 errors = e.update_error_dict(errors)
1333 # Run unique checks, but only for fields that passed validation.
1334 if validate_unique:
1335 for name in errors:
1336 if name != NON_FIELD_ERRORS and name not in exclude:
1337 exclude.add(name)
1338 try:
1339 self.validate_unique(exclude=exclude)
1340 except ValidationError as e:
1341 errors = e.update_error_dict(errors)
1343 # Run constraints checks, but only for fields that passed validation.
1344 if validate_constraints:
1345 for name in errors:
1346 if name != NON_FIELD_ERRORS and name not in exclude:
1347 exclude.add(name)
1348 try:
1349 self.validate_constraints(exclude=exclude)
1350 except ValidationError as e:
1351 errors = e.update_error_dict(errors)
1353 if errors:
1354 raise ValidationError(errors)
1356 def clean_fields(self, exclude=None):
1357 """
1358 Clean all fields and raise a ValidationError containing a dict
1359 of all validation errors if any occur.
1360 """
1361 if exclude is None:
1362 exclude = set()
1364 errors = {}
1365 for f in self._meta.fields:
1366 if f.name in exclude:
1367 continue
1368 # Skip validation for empty fields with blank=True. The developer
1369 # is responsible for making sure they have a valid value.
1370 raw_value = getattr(self, f.attname)
1371 if f.blank and raw_value in f.empty_values:
1372 continue
1373 try:
1374 setattr(self, f.attname, f.clean(raw_value, self))
1375 except ValidationError as e:
1376 errors[f.name] = e.error_list
1378 if errors:
1379 raise ValidationError(errors)
1381 @classmethod
1382 def check(cls, **kwargs):
1383 errors = [
1384 *cls._check_swappable(),
1385 *cls._check_managers(**kwargs),
1386 ]
1387 if not cls._meta.swapped:
1388 databases = kwargs.get("databases") or []
1389 errors += [
1390 *cls._check_fields(**kwargs),
1391 *cls._check_m2m_through_same_relationship(),
1392 *cls._check_long_column_names(databases),
1393 ]
1394 clash_errors = (
1395 *cls._check_id_field(),
1396 *cls._check_field_name_clashes(),
1397 *cls._check_model_name_db_lookup_clashes(),
1398 *cls._check_property_name_related_field_accessor_clashes(),
1399 *cls._check_single_primary_key(),
1400 )
1401 errors.extend(clash_errors)
1402 # If there are field name clashes, hide consequent column name
1403 # clashes.
1404 if not clash_errors:
1405 errors.extend(cls._check_column_name_clashes())
1406 errors += [
1407 *cls._check_indexes(databases),
1408 *cls._check_ordering(),
1409 *cls._check_constraints(databases),
1410 *cls._check_db_table_comment(databases),
1411 ]
1413 return errors
1415 @classmethod
1416 def _check_db_table_comment(cls, databases):
1417 if not cls._meta.db_table_comment:
1418 return []
1419 errors = []
1420 for db in databases:
1421 if not router.allow_migrate_model(db, cls):
1422 continue
1423 connection = connections[db]
1424 if not (
1425 connection.features.supports_comments
1426 or "supports_comments" in cls._meta.required_db_features
1427 ):
1428 errors.append(
1429 preflight.Warning(
1430 f"{connection.display_name} does not support comments on "
1431 f"tables (db_table_comment).",
1432 obj=cls,
1433 id="models.W046",
1434 )
1435 )
1436 return errors
1438 @classmethod
1439 def _check_swappable(cls):
1440 """Check if the swapped model exists."""
1441 errors = []
1442 if cls._meta.swapped:
1443 try:
1444 packages.get_model(cls._meta.swapped)
1445 except ValueError:
1446 errors.append(
1447 preflight.Error(
1448 "'%s' is not of the form 'package_label.package_name'."
1449 % cls._meta.swappable,
1450 id="models.E001",
1451 )
1452 )
1453 except LookupError:
1454 package_label, model_name = cls._meta.swapped.split(".")
1455 errors.append(
1456 preflight.Error(
1457 "'{}' references '{}.{}', which has not been "
1458 "installed, or is abstract.".format(
1459 cls._meta.swappable, package_label, model_name
1460 ),
1461 id="models.E002",
1462 )
1463 )
1464 return errors
1466 @classmethod
1467 def _check_managers(cls, **kwargs):
1468 """Perform all manager checks."""
1469 errors = []
1470 for manager in cls._meta.managers:
1471 errors.extend(manager.check(**kwargs))
1472 return errors
1474 @classmethod
1475 def _check_fields(cls, **kwargs):
1476 """Perform all field checks."""
1477 errors = []
1478 for field in cls._meta.local_fields:
1479 errors.extend(field.check(**kwargs))
1480 for field in cls._meta.local_many_to_many:
1481 errors.extend(field.check(from_model=cls, **kwargs))
1482 return errors
1484 @classmethod
1485 def _check_m2m_through_same_relationship(cls):
1486 """Check if no relationship model is used by more than one m2m field."""
1488 errors = []
1489 seen_intermediary_signatures = []
1491 fields = cls._meta.local_many_to_many
1493 # Skip when the target model wasn't found.
1494 fields = (f for f in fields if isinstance(f.remote_field.model, ModelBase))
1496 # Skip when the relationship model wasn't found.
1497 fields = (f for f in fields if isinstance(f.remote_field.through, ModelBase))
1499 for f in fields:
1500 signature = (
1501 f.remote_field.model,
1502 cls,
1503 f.remote_field.through,
1504 f.remote_field.through_fields,
1505 )
1506 if signature in seen_intermediary_signatures:
1507 errors.append(
1508 preflight.Error(
1509 "The model has two identical many-to-many relations "
1510 "through the intermediate model '%s'."
1511 % f.remote_field.through._meta.label,
1512 obj=cls,
1513 id="models.E003",
1514 )
1515 )
1516 else:
1517 seen_intermediary_signatures.append(signature)
1518 return errors
1520 @classmethod
1521 def _check_id_field(cls):
1522 """Check if `id` field is a primary key."""
1523 fields = [
1524 f for f in cls._meta.local_fields if f.name == "id" and f != cls._meta.pk
1525 ]
1526 # fields is empty or consists of the invalid "id" field
1527 if fields and not fields[0].primary_key and cls._meta.pk.name == "id":
1528 return [
1529 preflight.Error(
1530 "'id' can only be used as a field name if the field also "
1531 "sets 'primary_key=True'.",
1532 obj=cls,
1533 id="models.E004",
1534 )
1535 ]
1536 else:
1537 return []
1539 @classmethod
1540 def _check_field_name_clashes(cls):
1541 """Forbid field shadowing in multi-table inheritance."""
1542 errors = []
1543 used_fields = {} # name or attname -> field
1545 # Check that multi-inheritance doesn't cause field name shadowing.
1546 for parent in cls._meta.get_parent_list():
1547 for f in parent._meta.local_fields:
1548 clash = used_fields.get(f.name) or used_fields.get(f.attname) or None
1549 if clash:
1550 errors.append(
1551 preflight.Error(
1552 f"The field '{clash.name}' from parent model "
1553 f"'{clash.model._meta}' clashes with the field '{f.name}' "
1554 f"from parent model '{f.model._meta}'.",
1555 obj=cls,
1556 id="models.E005",
1557 )
1558 )
1559 used_fields[f.name] = f
1560 used_fields[f.attname] = f
1562 # Check that fields defined in the model don't clash with fields from
1563 # parents, including auto-generated fields like multi-table inheritance
1564 # child accessors.
1565 for parent in cls._meta.get_parent_list():
1566 for f in parent._meta.get_fields():
1567 if f not in used_fields:
1568 used_fields[f.name] = f
1570 for f in cls._meta.local_fields:
1571 clash = used_fields.get(f.name) or used_fields.get(f.attname) or None
1572 # Note that we may detect clash between user-defined non-unique
1573 # field "id" and automatically added unique field "id", both
1574 # defined at the same model. This special case is considered in
1575 # _check_id_field and here we ignore it.
1576 id_conflict = (
1577 f.name == "id" and clash and clash.name == "id" and clash.model == cls
1578 )
1579 if clash and not id_conflict:
1580 errors.append(
1581 preflight.Error(
1582 f"The field '{f.name}' clashes with the field '{clash.name}' "
1583 f"from model '{clash.model._meta}'.",
1584 obj=f,
1585 id="models.E006",
1586 )
1587 )
1588 used_fields[f.name] = f
1589 used_fields[f.attname] = f
1591 return errors
1593 @classmethod
1594 def _check_column_name_clashes(cls):
1595 # Store a list of column names which have already been used by other fields.
1596 used_column_names = []
1597 errors = []
1599 for f in cls._meta.local_fields:
1600 _, column_name = f.get_attname_column()
1602 # Ensure the column name is not already in use.
1603 if column_name and column_name in used_column_names:
1604 errors.append(
1605 preflight.Error(
1606 "Field '{}' has column name '{}' that is used by "
1607 "another field.".format(f.name, column_name),
1608 hint="Specify a 'db_column' for the field.",
1609 obj=cls,
1610 id="models.E007",
1611 )
1612 )
1613 else:
1614 used_column_names.append(column_name)
1616 return errors
1618 @classmethod
1619 def _check_model_name_db_lookup_clashes(cls):
1620 errors = []
1621 model_name = cls.__name__
1622 if model_name.startswith("_") or model_name.endswith("_"):
1623 errors.append(
1624 preflight.Error(
1625 "The model name '%s' cannot start or end with an underscore "
1626 "as it collides with the query lookup syntax." % model_name,
1627 obj=cls,
1628 id="models.E023",
1629 )
1630 )
1631 elif LOOKUP_SEP in model_name:
1632 errors.append(
1633 preflight.Error(
1634 "The model name '%s' cannot contain double underscores as "
1635 "it collides with the query lookup syntax." % model_name,
1636 obj=cls,
1637 id="models.E024",
1638 )
1639 )
1640 return errors
1642 @classmethod
1643 def _check_property_name_related_field_accessor_clashes(cls):
1644 errors = []
1645 property_names = cls._meta._property_names
1646 related_field_accessors = (
1647 f.get_attname()
1648 for f in cls._meta._get_fields(reverse=False)
1649 if f.is_relation and f.related_model is not None
1650 )
1651 for accessor in related_field_accessors:
1652 if accessor in property_names:
1653 errors.append(
1654 preflight.Error(
1655 "The property '%s' clashes with a related field "
1656 "accessor." % accessor,
1657 obj=cls,
1658 id="models.E025",
1659 )
1660 )
1661 return errors
1663 @classmethod
1664 def _check_single_primary_key(cls):
1665 errors = []
1666 if sum(1 for f in cls._meta.local_fields if f.primary_key) > 1:
1667 errors.append(
1668 preflight.Error(
1669 "The model cannot have more than one field with "
1670 "'primary_key=True'.",
1671 obj=cls,
1672 id="models.E026",
1673 )
1674 )
1675 return errors
1677 @classmethod
1678 def _check_indexes(cls, databases):
1679 """Check fields, names, and conditions of indexes."""
1680 errors = []
1681 references = set()
1682 for index in cls._meta.indexes:
1683 # Index name can't start with an underscore or a number, restricted
1684 # for cross-database compatibility with Oracle.
1685 if index.name[0] == "_" or index.name[0].isdigit():
1686 errors.append(
1687 preflight.Error(
1688 "The index name '%s' cannot start with an underscore "
1689 "or a number." % index.name,
1690 obj=cls,
1691 id="models.E033",
1692 ),
1693 )
1694 if len(index.name) > index.max_name_length:
1695 errors.append(
1696 preflight.Error(
1697 "The index name '%s' cannot be longer than %d "
1698 "characters." % (index.name, index.max_name_length),
1699 obj=cls,
1700 id="models.E034",
1701 ),
1702 )
1703 if index.contains_expressions:
1704 for expression in index.expressions:
1705 references.update(
1706 ref[0] for ref in cls._get_expr_references(expression)
1707 )
1708 for db in databases:
1709 if not router.allow_migrate_model(db, cls):
1710 continue
1711 connection = connections[db]
1712 if not (
1713 connection.features.supports_partial_indexes
1714 or "supports_partial_indexes" in cls._meta.required_db_features
1715 ) and any(index.condition is not None for index in cls._meta.indexes):
1716 errors.append(
1717 preflight.Warning(
1718 "%s does not support indexes with conditions."
1719 % connection.display_name,
1720 hint=(
1721 "Conditions will be ignored. Silence this warning "
1722 "if you don't care about it."
1723 ),
1724 obj=cls,
1725 id="models.W037",
1726 )
1727 )
1728 if not (
1729 connection.features.supports_covering_indexes
1730 or "supports_covering_indexes" in cls._meta.required_db_features
1731 ) and any(index.include for index in cls._meta.indexes):
1732 errors.append(
1733 preflight.Warning(
1734 "%s does not support indexes with non-key columns."
1735 % connection.display_name,
1736 hint=(
1737 "Non-key columns will be ignored. Silence this "
1738 "warning if you don't care about it."
1739 ),
1740 obj=cls,
1741 id="models.W040",
1742 )
1743 )
1744 if not (
1745 connection.features.supports_expression_indexes
1746 or "supports_expression_indexes" in cls._meta.required_db_features
1747 ) and any(index.contains_expressions for index in cls._meta.indexes):
1748 errors.append(
1749 preflight.Warning(
1750 "%s does not support indexes on expressions."
1751 % connection.display_name,
1752 hint=(
1753 "An index won't be created. Silence this warning "
1754 "if you don't care about it."
1755 ),
1756 obj=cls,
1757 id="models.W043",
1758 )
1759 )
1760 fields = [
1761 field for index in cls._meta.indexes for field, _ in index.fields_orders
1762 ]
1763 fields += [include for index in cls._meta.indexes for include in index.include]
1764 fields += references
1765 errors.extend(cls._check_local_fields(fields, "indexes"))
1766 return errors
1768 @classmethod
1769 def _check_local_fields(cls, fields, option):
1770 from plain import models
1772 # In order to avoid hitting the relation tree prematurely, we use our
1773 # own fields_map instead of using get_field()
1774 forward_fields_map = {}
1775 for field in cls._meta._get_fields(reverse=False):
1776 forward_fields_map[field.name] = field
1777 if hasattr(field, "attname"):
1778 forward_fields_map[field.attname] = field
1780 errors = []
1781 for field_name in fields:
1782 try:
1783 field = forward_fields_map[field_name]
1784 except KeyError:
1785 errors.append(
1786 preflight.Error(
1787 f"'{option}' refers to the nonexistent field '{field_name}'.",
1788 obj=cls,
1789 id="models.E012",
1790 )
1791 )
1792 else:
1793 if isinstance(field.remote_field, models.ManyToManyRel):
1794 errors.append(
1795 preflight.Error(
1796 "'{}' refers to a ManyToManyField '{}', but "
1797 "ManyToManyFields are not permitted in '{}'.".format(
1798 option,
1799 field_name,
1800 option,
1801 ),
1802 obj=cls,
1803 id="models.E013",
1804 )
1805 )
1806 elif field not in cls._meta.local_fields:
1807 errors.append(
1808 preflight.Error(
1809 "'{}' refers to field '{}' which is not local to model "
1810 "'{}'.".format(option, field_name, cls._meta.object_name),
1811 hint="This issue may be caused by multi-table inheritance.",
1812 obj=cls,
1813 id="models.E016",
1814 )
1815 )
1816 return errors
1818 @classmethod
1819 def _check_ordering(cls):
1820 """
1821 Check "ordering" option -- is it a list of strings and do all fields
1822 exist?
1823 """
1824 if cls._meta._ordering_clash:
1825 return [
1826 preflight.Error(
1827 "'ordering' and 'order_with_respect_to' cannot be used together.",
1828 obj=cls,
1829 id="models.E021",
1830 ),
1831 ]
1833 if cls._meta.order_with_respect_to or not cls._meta.ordering:
1834 return []
1836 if not isinstance(cls._meta.ordering, list | tuple):
1837 return [
1838 preflight.Error(
1839 "'ordering' must be a tuple or list (even if you want to order by "
1840 "only one field).",
1841 obj=cls,
1842 id="models.E014",
1843 )
1844 ]
1846 errors = []
1847 fields = cls._meta.ordering
1849 # Skip expressions and '?' fields.
1850 fields = (f for f in fields if isinstance(f, str) and f != "?")
1852 # Convert "-field" to "field".
1853 fields = (f.removeprefix("-") for f in fields)
1855 # Separate related fields and non-related fields.
1856 _fields = []
1857 related_fields = []
1858 for f in fields:
1859 if LOOKUP_SEP in f:
1860 related_fields.append(f)
1861 else:
1862 _fields.append(f)
1863 fields = _fields
1865 # Check related fields.
1866 for field in related_fields:
1867 _cls = cls
1868 fld = None
1869 for part in field.split(LOOKUP_SEP):
1870 try:
1871 # pk is an alias that won't be found by opts.get_field.
1872 if part == "pk":
1873 fld = _cls._meta.pk
1874 else:
1875 fld = _cls._meta.get_field(part)
1876 if fld.is_relation:
1877 _cls = fld.path_infos[-1].to_opts.model
1878 else:
1879 _cls = None
1880 except (FieldDoesNotExist, AttributeError):
1881 if fld is None or (
1882 fld.get_transform(part) is None and fld.get_lookup(part) is None
1883 ):
1884 errors.append(
1885 preflight.Error(
1886 "'ordering' refers to the nonexistent field, "
1887 "related field, or lookup '%s'." % field,
1888 obj=cls,
1889 id="models.E015",
1890 )
1891 )
1893 # Skip ordering on pk. This is always a valid order_by field
1894 # but is an alias and therefore won't be found by opts.get_field.
1895 fields = {f for f in fields if f != "pk"}
1897 # Check for invalid or nonexistent fields in ordering.
1898 invalid_fields = []
1900 # Any field name that is not present in field_names does not exist.
1901 # Also, ordering by m2m fields is not allowed.
1902 opts = cls._meta
1903 valid_fields = set(
1904 chain.from_iterable(
1905 (f.name, f.attname)
1906 if not (f.auto_created and not f.concrete)
1907 else (f.field.related_query_name(),)
1908 for f in chain(opts.fields, opts.related_objects)
1909 )
1910 )
1912 invalid_fields.extend(fields - valid_fields)
1914 for invalid_field in invalid_fields:
1915 errors.append(
1916 preflight.Error(
1917 "'ordering' refers to the nonexistent field, related "
1918 "field, or lookup '%s'." % invalid_field,
1919 obj=cls,
1920 id="models.E015",
1921 )
1922 )
1923 return errors
1925 @classmethod
1926 def _check_long_column_names(cls, databases):
1927 """
1928 Check that any auto-generated column names are shorter than the limits
1929 for each database in which the model will be created.
1930 """
1931 if not databases:
1932 return []
1933 errors = []
1934 allowed_len = None
1935 db_alias = None
1937 # Find the minimum max allowed length among all specified db_aliases.
1938 for db in databases:
1939 # skip databases where the model won't be created
1940 if not router.allow_migrate_model(db, cls):
1941 continue
1942 connection = connections[db]
1943 max_name_length = connection.ops.max_name_length()
1944 if max_name_length is None or connection.features.truncates_names:
1945 continue
1946 else:
1947 if allowed_len is None:
1948 allowed_len = max_name_length
1949 db_alias = db
1950 elif max_name_length < allowed_len:
1951 allowed_len = max_name_length
1952 db_alias = db
1954 if allowed_len is None:
1955 return errors
1957 for f in cls._meta.local_fields:
1958 _, column_name = f.get_attname_column()
1960 # Check if auto-generated name for the field is too long
1961 # for the database.
1962 if (
1963 f.db_column is None
1964 and column_name is not None
1965 and len(column_name) > allowed_len
1966 ):
1967 errors.append(
1968 preflight.Error(
1969 'Autogenerated column name too long for field "{}". '
1970 'Maximum length is "{}" for database "{}".'.format(
1971 column_name, allowed_len, db_alias
1972 ),
1973 hint="Set the column name manually using 'db_column'.",
1974 obj=cls,
1975 id="models.E018",
1976 )
1977 )
1979 for f in cls._meta.local_many_to_many:
1980 # Skip nonexistent models.
1981 if isinstance(f.remote_field.through, str):
1982 continue
1984 # Check if auto-generated name for the M2M field is too long
1985 # for the database.
1986 for m2m in f.remote_field.through._meta.local_fields:
1987 _, rel_name = m2m.get_attname_column()
1988 if (
1989 m2m.db_column is None
1990 and rel_name is not None
1991 and len(rel_name) > allowed_len
1992 ):
1993 errors.append(
1994 preflight.Error(
1995 "Autogenerated column name too long for M2M field "
1996 '"{}". Maximum length is "{}" for database "{}".'.format(
1997 rel_name, allowed_len, db_alias
1998 ),
1999 hint=(
2000 "Use 'through' to create a separate model for "
2001 "M2M and then set column_name using 'db_column'."
2002 ),
2003 obj=cls,
2004 id="models.E019",
2005 )
2006 )
2008 return errors
2010 @classmethod
2011 def _get_expr_references(cls, expr):
2012 if isinstance(expr, Q):
2013 for child in expr.children:
2014 if isinstance(child, tuple):
2015 lookup, value = child
2016 yield tuple(lookup.split(LOOKUP_SEP))
2017 yield from cls._get_expr_references(value)
2018 else:
2019 yield from cls._get_expr_references(child)
2020 elif isinstance(expr, F):
2021 yield tuple(expr.name.split(LOOKUP_SEP))
2022 elif hasattr(expr, "get_source_expressions"):
2023 for src_expr in expr.get_source_expressions():
2024 yield from cls._get_expr_references(src_expr)
2026 @classmethod
2027 def _check_constraints(cls, databases):
2028 errors = []
2029 for db in databases:
2030 if not router.allow_migrate_model(db, cls):
2031 continue
2032 connection = connections[db]
2033 if not (
2034 connection.features.supports_table_check_constraints
2035 or "supports_table_check_constraints" in cls._meta.required_db_features
2036 ) and any(
2037 isinstance(constraint, CheckConstraint)
2038 for constraint in cls._meta.constraints
2039 ):
2040 errors.append(
2041 preflight.Warning(
2042 "%s does not support check constraints."
2043 % connection.display_name,
2044 hint=(
2045 "A constraint won't be created. Silence this "
2046 "warning if you don't care about it."
2047 ),
2048 obj=cls,
2049 id="models.W027",
2050 )
2051 )
2052 if not (
2053 connection.features.supports_partial_indexes
2054 or "supports_partial_indexes" in cls._meta.required_db_features
2055 ) and any(
2056 isinstance(constraint, UniqueConstraint)
2057 and constraint.condition is not None
2058 for constraint in cls._meta.constraints
2059 ):
2060 errors.append(
2061 preflight.Warning(
2062 "%s does not support unique constraints with "
2063 "conditions." % connection.display_name,
2064 hint=(
2065 "A constraint won't be created. Silence this "
2066 "warning if you don't care about it."
2067 ),
2068 obj=cls,
2069 id="models.W036",
2070 )
2071 )
2072 if not (
2073 connection.features.supports_deferrable_unique_constraints
2074 or "supports_deferrable_unique_constraints"
2075 in cls._meta.required_db_features
2076 ) and any(
2077 isinstance(constraint, UniqueConstraint)
2078 and constraint.deferrable is not None
2079 for constraint in cls._meta.constraints
2080 ):
2081 errors.append(
2082 preflight.Warning(
2083 "%s does not support deferrable unique constraints."
2084 % connection.display_name,
2085 hint=(
2086 "A constraint won't be created. Silence this "
2087 "warning if you don't care about it."
2088 ),
2089 obj=cls,
2090 id="models.W038",
2091 )
2092 )
2093 if not (
2094 connection.features.supports_covering_indexes
2095 or "supports_covering_indexes" in cls._meta.required_db_features
2096 ) and any(
2097 isinstance(constraint, UniqueConstraint) and constraint.include
2098 for constraint in cls._meta.constraints
2099 ):
2100 errors.append(
2101 preflight.Warning(
2102 "%s does not support unique constraints with non-key "
2103 "columns." % connection.display_name,
2104 hint=(
2105 "A constraint won't be created. Silence this "
2106 "warning if you don't care about it."
2107 ),
2108 obj=cls,
2109 id="models.W039",
2110 )
2111 )
2112 if not (
2113 connection.features.supports_expression_indexes
2114 or "supports_expression_indexes" in cls._meta.required_db_features
2115 ) and any(
2116 isinstance(constraint, UniqueConstraint)
2117 and constraint.contains_expressions
2118 for constraint in cls._meta.constraints
2119 ):
2120 errors.append(
2121 preflight.Warning(
2122 "%s does not support unique constraints on "
2123 "expressions." % connection.display_name,
2124 hint=(
2125 "A constraint won't be created. Silence this "
2126 "warning if you don't care about it."
2127 ),
2128 obj=cls,
2129 id="models.W044",
2130 )
2131 )
2132 fields = set(
2133 chain.from_iterable(
2134 (*constraint.fields, *constraint.include)
2135 for constraint in cls._meta.constraints
2136 if isinstance(constraint, UniqueConstraint)
2137 )
2138 )
2139 references = set()
2140 for constraint in cls._meta.constraints:
2141 if isinstance(constraint, UniqueConstraint):
2142 if (
2143 connection.features.supports_partial_indexes
2144 or "supports_partial_indexes"
2145 not in cls._meta.required_db_features
2146 ) and isinstance(constraint.condition, Q):
2147 references.update(
2148 cls._get_expr_references(constraint.condition)
2149 )
2150 if (
2151 connection.features.supports_expression_indexes
2152 or "supports_expression_indexes"
2153 not in cls._meta.required_db_features
2154 ) and constraint.contains_expressions:
2155 for expression in constraint.expressions:
2156 references.update(cls._get_expr_references(expression))
2157 elif isinstance(constraint, CheckConstraint):
2158 if (
2159 connection.features.supports_table_check_constraints
2160 or "supports_table_check_constraints"
2161 not in cls._meta.required_db_features
2162 ):
2163 if isinstance(constraint.check, Q):
2164 references.update(
2165 cls._get_expr_references(constraint.check)
2166 )
2167 if any(
2168 isinstance(expr, RawSQL)
2169 for expr in constraint.check.flatten()
2170 ):
2171 errors.append(
2172 preflight.Warning(
2173 f"Check constraint {constraint.name!r} contains "
2174 f"RawSQL() expression and won't be validated "
2175 f"during the model full_clean().",
2176 hint=(
2177 "Silence this warning if you don't care about "
2178 "it."
2179 ),
2180 obj=cls,
2181 id="models.W045",
2182 ),
2183 )
2184 for field_name, *lookups in references:
2185 # pk is an alias that won't be found by opts.get_field.
2186 if field_name != "pk":
2187 fields.add(field_name)
2188 if not lookups:
2189 # If it has no lookups it cannot result in a JOIN.
2190 continue
2191 try:
2192 if field_name == "pk":
2193 field = cls._meta.pk
2194 else:
2195 field = cls._meta.get_field(field_name)
2196 if not field.is_relation or field.many_to_many or field.one_to_many:
2197 continue
2198 except FieldDoesNotExist:
2199 continue
2200 # JOIN must happen at the first lookup.
2201 first_lookup = lookups[0]
2202 if (
2203 hasattr(field, "get_transform")
2204 and hasattr(field, "get_lookup")
2205 and field.get_transform(first_lookup) is None
2206 and field.get_lookup(first_lookup) is None
2207 ):
2208 errors.append(
2209 preflight.Error(
2210 "'constraints' refers to the joined field '%s'."
2211 % LOOKUP_SEP.join([field_name] + lookups),
2212 obj=cls,
2213 id="models.E041",
2214 )
2215 )
2216 errors.extend(cls._check_local_fields(fields, "constraints"))
2217 return errors
2220############################################
2221# HELPER FUNCTIONS (CURRIED MODEL METHODS) #
2222############################################
2224# ORDERING METHODS #########################
2227def method_set_order(self, ordered_obj, id_list, using=None):
2228 order_wrt = ordered_obj._meta.order_with_respect_to
2229 filter_args = order_wrt.get_forward_related_filter(self)
2230 ordered_obj.objects.db_manager(using).filter(**filter_args).bulk_update(
2231 [ordered_obj(pk=pk, _order=order) for order, pk in enumerate(id_list)],
2232 ["_order"],
2233 )
2236def method_get_order(self, ordered_obj):
2237 order_wrt = ordered_obj._meta.order_with_respect_to
2238 filter_args = order_wrt.get_forward_related_filter(self)
2239 pk_name = ordered_obj._meta.pk.name
2240 return ordered_obj.objects.filter(**filter_args).values_list(pk_name, flat=True)
2243def make_foreign_order_accessors(model, related_model):
2244 setattr(
2245 related_model,
2246 "get_%s_order" % model.__name__.lower(),
2247 partialmethod(method_get_order, model),
2248 )
2249 setattr(
2250 related_model,
2251 "set_%s_order" % model.__name__.lower(),
2252 partialmethod(method_set_order, model),
2253 )
2256########
2257# MISC #
2258########
2261def model_unpickle(model_id):
2262 """Used to unpickle Model subclasses with deferred fields."""
2263 if isinstance(model_id, tuple):
2264 model = packages.get_model(*model_id)
2265 else:
2266 # Backwards compat - the model was cached directly in earlier versions.
2267 model = model_id
2268 return model.__new__(model)
2271model_unpickle.__safe_for_unpickle__ = True
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import os
2import subprocess
3import sys
4import time
5from importlib import import_module
6from itertools import takewhile
8import click
10from plain.models import migrations
11from plain.models.db import DEFAULT_DB_ALIAS, OperationalError, connections, router
12from plain.models.migrations.autodetector import MigrationAutodetector
13from plain.models.migrations.executor import MigrationExecutor
14from plain.models.migrations.loader import AmbiguityError, MigrationLoader
15from plain.models.migrations.migration import Migration, SwappableTuple
16from plain.models.migrations.optimizer import MigrationOptimizer
17from plain.models.migrations.questioner import (
18 InteractiveMigrationQuestioner,
19 MigrationQuestioner,
20 NonInteractiveMigrationQuestioner,
21)
22from plain.models.migrations.recorder import MigrationRecorder
23from plain.models.migrations.state import ModelState, ProjectState
24from plain.models.migrations.utils import get_migration_name_timestamp
25from plain.models.migrations.writer import MigrationWriter
26from plain.packages import packages
27from plain.runtime import settings
28from plain.utils.module_loading import module_has_submodule
29from plain.utils.text import Truncator
32@click.group()
33def cli():
34 pass
37@cli.command()
38@click.option(
39 "--database",
40 default=DEFAULT_DB_ALIAS,
41 help=(
42 "Nominates a database onto which to open a shell. Defaults to the "
43 '"default" database.'
44 ),
45)
46@click.argument("parameters", nargs=-1)
47def db_shell(database, parameters):
48 """Runs the command-line client for specified database, or the default database if none is provided."""
49 connection = connections[database]
50 try:
51 connection.client.runshell(parameters)
52 except FileNotFoundError:
53 # Note that we're assuming the FileNotFoundError relates to the
54 # command missing. It could be raised for some other reason, in
55 # which case this error message would be inaccurate. Still, this
56 # message catches the common case.
57 click.secho(
58 "You appear not to have the %r program installed or on your path."
59 % connection.client.executable_name,
60 fg="red",
61 err=True,
62 )
63 sys.exit(1)
64 except subprocess.CalledProcessError as e:
65 click.secho(
66 '"{}" returned non-zero exit status {}.'.format(
67 " ".join(e.cmd),
68 e.returncode,
69 ),
70 fg="red",
71 err=True,
72 )
73 sys.exit(e.returncode)
76@cli.command()
77def db_wait():
78 """Wait for the database to be ready"""
79 attempts = 0
80 while True:
81 attempts += 1
82 waiting_for = []
84 for conn in connections.all():
85 try:
86 conn.ensure_connection()
87 except OperationalError:
88 waiting_for.append(conn.alias)
90 if waiting_for:
91 click.secho(
92 f"Waiting for database (attempt {attempts}): {', '.join(waiting_for)}",
93 fg="yellow",
94 )
95 time.sleep(1.5)
96 else:
97 click.secho(f"Database ready: {', '.join(connections)}", fg="green")
98 break
101@cli.command()
102@click.argument("package_labels", nargs=-1)
103@click.option(
104 "--dry-run",
105 is_flag=True,
106 help="Just show what migrations would be made; don't actually write them.",
107)
108@click.option("--merge", is_flag=True, help="Enable fixing of migration conflicts.")
109@click.option("--empty", is_flag=True, help="Create an empty migration.")
110@click.option(
111 "--noinput",
112 "--no-input",
113 "no_input",
114 is_flag=True,
115 help="Tells Plain to NOT prompt the user for input of any kind.",
116)
117@click.option("-n", "--name", help="Use this name for migration file(s).")
118@click.option(
119 "--check",
120 is_flag=True,
121 help="Exit with a non-zero status if model changes are missing migrations and don't actually write them.",
122)
123@click.option(
124 "--update",
125 is_flag=True,
126 help="Merge model changes into the latest migration and optimize the resulting operations.",
127)
128@click.option(
129 "-v",
130 "--verbosity",
131 type=int,
132 default=1,
133 help="Verbosity level; 0=minimal output, 1=normal output, 2=verbose output, 3=very verbose output",
134)
135def makemigrations(
136 package_labels, dry_run, merge, empty, no_input, name, check, update, verbosity
137):
138 """Creates new migration(s) for packages."""
140 written_files = []
141 interactive = not no_input
142 migration_name = name
143 check_changes = check
145 def log(msg, level=1):
146 if verbosity >= level:
147 click.echo(msg)
149 def write_migration_files(changes, update_previous_migration_paths=None):
150 """Take a changes dict and write them out as migration files."""
151 directory_created = {}
152 for package_label, package_migrations in changes.items():
153 log(
154 click.style(f"Migrations for '{package_label}':", fg="cyan", bold=True),
155 level=1,
156 )
157 for migration in package_migrations:
158 writer = MigrationWriter(migration)
159 migration_string = os.path.relpath(writer.path)
160 log(f" {click.style(migration_string, fg='yellow')}\n", level=1)
161 for operation in migration.operations:
162 log(f" - {operation.describe()}", level=1)
164 if not dry_run:
165 migrations_directory = os.path.dirname(writer.path)
166 if not directory_created.get(package_label):
167 os.makedirs(migrations_directory, exist_ok=True)
168 init_path = os.path.join(migrations_directory, "__init__.py")
169 if not os.path.isfile(init_path):
170 open(init_path, "w").close()
171 directory_created[package_label] = True
173 migration_string = writer.as_string()
174 with open(writer.path, "w", encoding="utf-8") as fh:
175 fh.write(migration_string)
176 written_files.append(writer.path)
178 if update_previous_migration_paths:
179 prev_path = update_previous_migration_paths[package_label]
180 if writer.needs_manual_porting:
181 log(
182 click.style(
183 f"Updated migration {migration_string} requires manual porting.\n"
184 f"Previous migration {os.path.relpath(prev_path)} was kept and "
185 f"must be deleted after porting functions manually.",
186 fg="yellow",
187 ),
188 level=1,
189 )
190 else:
191 os.remove(prev_path)
192 log(f"Deleted {os.path.relpath(prev_path)}", level=1)
193 elif verbosity >= 3:
194 log(
195 click.style(
196 f"Full migrations file '{writer.filename}':",
197 fg="cyan",
198 bold=True,
199 ),
200 level=3,
201 )
202 log(writer.as_string(), level=3)
204 def write_to_last_migration_files(changes):
205 """Write changes to the last migration file for each package."""
206 loader = MigrationLoader(connections[DEFAULT_DB_ALIAS])
207 new_changes = {}
208 update_previous_migration_paths = {}
209 for package_label, package_migrations in changes.items():
210 leaf_migration_nodes = loader.graph.leaf_nodes(app=package_label)
211 if len(leaf_migration_nodes) == 0:
212 raise click.ClickException(
213 f"Package {package_label} has no migration, cannot update last migration."
214 )
215 leaf_migration_node = leaf_migration_nodes[0]
216 leaf_migration = loader.graph.nodes[leaf_migration_node]
218 if leaf_migration.replaces:
219 raise click.ClickException(
220 f"Cannot update squash migration '{leaf_migration}'."
221 )
222 if leaf_migration_node in loader.applied_migrations:
223 raise click.ClickException(
224 f"Cannot update applied migration '{leaf_migration}'."
225 )
227 depending_migrations = [
228 migration
229 for migration in loader.disk_migrations.values()
230 if leaf_migration_node in migration.dependencies
231 ]
232 if depending_migrations:
233 formatted_migrations = ", ".join(
234 [f"'{migration}'" for migration in depending_migrations]
235 )
236 raise click.ClickException(
237 f"Cannot update migration '{leaf_migration}' that migrations "
238 f"{formatted_migrations} depend on."
239 )
241 for migration in package_migrations:
242 leaf_migration.operations.extend(migration.operations)
243 for dependency in migration.dependencies:
244 if isinstance(dependency, SwappableTuple):
245 if settings.AUTH_USER_MODEL == dependency.setting:
246 leaf_migration.dependencies.append(
247 ("__setting__", "AUTH_USER_MODEL")
248 )
249 else:
250 leaf_migration.dependencies.append(dependency)
251 elif dependency[0] != migration.package_label:
252 leaf_migration.dependencies.append(dependency)
254 optimizer = MigrationOptimizer()
255 leaf_migration.operations = optimizer.optimize(
256 leaf_migration.operations, package_label
257 )
259 previous_migration_path = MigrationWriter(leaf_migration).path
260 suggested_name = (
261 leaf_migration.name[:4] + "_" + leaf_migration.suggest_name()
262 )
263 new_name = (
264 suggested_name
265 if leaf_migration.name != suggested_name
266 else leaf_migration.name + "_updated"
267 )
268 leaf_migration.name = new_name
270 new_changes[package_label] = [leaf_migration]
271 update_previous_migration_paths[package_label] = previous_migration_path
273 write_migration_files(new_changes, update_previous_migration_paths)
275 def handle_merge(loader, conflicts):
276 """Handle merging conflicting migrations."""
277 if interactive:
278 questioner = InteractiveMigrationQuestioner()
279 else:
280 questioner = MigrationQuestioner(defaults={"ask_merge": True})
282 for package_label, migration_names in conflicts.items():
283 log(click.style(f"Merging {package_label}", fg="cyan", bold=True), level=1)
285 merge_migrations = []
286 for migration_name in migration_names:
287 migration = loader.get_migration(package_label, migration_name)
288 migration.ancestry = [
289 mig
290 for mig in loader.graph.forwards_plan(
291 (package_label, migration_name)
292 )
293 if mig[0] == migration.package_label
294 ]
295 merge_migrations.append(migration)
297 def all_items_equal(seq):
298 return all(item == seq[0] for item in seq[1:])
300 merge_migrations_generations = zip(*(m.ancestry for m in merge_migrations))
301 common_ancestor_count = sum(
302 1 for _ in takewhile(all_items_equal, merge_migrations_generations)
303 )
304 if not common_ancestor_count:
305 raise ValueError(f"Could not find common ancestor of {migration_names}")
307 for migration in merge_migrations:
308 migration.branch = migration.ancestry[common_ancestor_count:]
309 migrations_ops = (
310 loader.get_migration(node_package, node_name).operations
311 for node_package, node_name in migration.branch
312 )
313 migration.merged_operations = sum(migrations_ops, [])
315 for migration in merge_migrations:
316 log(click.style(f" Branch {migration.name}", fg="yellow"), level=1)
317 for operation in migration.merged_operations:
318 log(f" - {operation.describe()}", level=1)
320 if questioner.ask_merge(package_label):
321 numbers = [
322 MigrationAutodetector.parse_number(migration.name)
323 for migration in merge_migrations
324 ]
325 biggest_number = (
326 max(x for x in numbers if x is not None) if numbers else 0
327 )
329 subclass = type(
330 "Migration",
331 (Migration,),
332 {
333 "dependencies": [
334 (package_label, migration.name)
335 for migration in merge_migrations
336 ],
337 },
338 )
340 parts = [f"{biggest_number + 1:04d}"]
341 if migration_name:
342 parts.append(migration_name)
343 else:
344 parts.append("merge")
345 leaf_names = "_".join(
346 sorted(migration.name for migration in merge_migrations)
347 )
348 if len(leaf_names) > 47:
349 parts.append(get_migration_name_timestamp())
350 else:
351 parts.append(leaf_names)
353 new_migration_name = "_".join(parts)
354 new_migration = subclass(new_migration_name, package_label)
355 writer = MigrationWriter(new_migration)
357 if not dry_run:
358 with open(writer.path, "w", encoding="utf-8") as fh:
359 fh.write(writer.as_string())
360 log(f"\nCreated new merge migration {writer.path}", level=1)
361 elif verbosity == 3:
362 log(
363 click.style(
364 f"Full merge migrations file '{writer.filename}':",
365 fg="cyan",
366 bold=True,
367 ),
368 level=3,
369 )
370 log(writer.as_string(), level=3)
372 # Validate package labels
373 package_labels = set(package_labels)
374 has_bad_labels = False
375 for package_label in package_labels:
376 try:
377 packages.get_package_config(package_label)
378 except LookupError as err:
379 click.echo(str(err), err=True)
380 has_bad_labels = True
381 if has_bad_labels:
382 sys.exit(2)
384 # Load the current graph state
385 loader = MigrationLoader(None, ignore_no_migrations=True)
387 # Raise an error if any migrations are applied before their dependencies.
388 consistency_check_labels = {
389 config.label for config in packages.get_package_configs()
390 }
391 # Non-default databases are only checked if database routers used.
392 aliases_to_check = connections if settings.DATABASE_ROUTERS else [DEFAULT_DB_ALIAS]
393 for alias in sorted(aliases_to_check):
394 connection = connections[alias]
395 if connection.settings_dict["ENGINE"] != "plain.models.backends.dummy" and any(
396 router.allow_migrate(
397 connection.alias, package_label, model_name=model._meta.object_name
398 )
399 for package_label in consistency_check_labels
400 for model in packages.get_package_config(package_label).get_models()
401 ):
402 loader.check_consistent_history(connection)
404 # Check for conflicts
405 conflicts = loader.detect_conflicts()
406 if package_labels:
407 conflicts = {
408 package_label: conflict
409 for package_label, conflict in conflicts.items()
410 if package_label in package_labels
411 }
413 if conflicts and not merge:
414 name_str = "; ".join(
415 "{} in {}".format(", ".join(names), package)
416 for package, names in conflicts.items()
417 )
418 raise click.ClickException(
419 f"Conflicting migrations detected; multiple leaf nodes in the "
420 f"migration graph: ({name_str}).\nTo fix them run "
421 f"'python manage.py makemigrations --merge'"
422 )
424 # Handle merge if requested
425 if merge and conflicts:
426 return handle_merge(loader, conflicts)
428 # Set up questioner
429 if interactive:
430 questioner = InteractiveMigrationQuestioner(
431 specified_packages=package_labels,
432 dry_run=dry_run,
433 )
434 else:
435 questioner = NonInteractiveMigrationQuestioner(
436 specified_packages=package_labels,
437 dry_run=dry_run,
438 verbosity=verbosity,
439 )
441 # Set up autodetector
442 autodetector = MigrationAutodetector(
443 loader.project_state(),
444 ProjectState.from_packages(packages),
445 questioner,
446 )
448 # Handle empty migrations if requested
449 if empty:
450 if not package_labels:
451 raise click.ClickException(
452 "You must supply at least one package label when using --empty."
453 )
454 changes = {
455 package: [Migration("custom", package)] for package in package_labels
456 }
457 changes = autodetector.arrange_for_graph(
458 changes=changes,
459 graph=loader.graph,
460 migration_name=migration_name,
461 )
462 write_migration_files(changes)
463 return
465 # Detect changes
466 changes = autodetector.changes(
467 graph=loader.graph,
468 trim_to_packages=package_labels or None,
469 convert_packages=package_labels or None,
470 migration_name=migration_name,
471 )
473 if not changes:
474 log(
475 "No changes detected"
476 if not package_labels
477 else f"No changes detected in {'package' if len(package_labels) == 1 else 'packages'} "
478 f"'{', '.join(package_labels)}'",
479 level=1,
480 )
481 else:
482 if check_changes:
483 sys.exit(1)
484 if update:
485 write_to_last_migration_files(changes)
486 else:
487 write_migration_files(changes)
490@cli.command()
491@click.argument("package_label", required=False)
492@click.argument("migration_name", required=False)
493@click.option(
494 "--noinput",
495 "--no-input",
496 "no_input",
497 is_flag=True,
498 help="Tells Plain to NOT prompt the user for input of any kind.",
499)
500@click.option(
501 "--database",
502 default=DEFAULT_DB_ALIAS,
503 help="Nominates a database to synchronize. Defaults to the 'default' database.",
504)
505@click.option(
506 "--fake", is_flag=True, help="Mark migrations as run without actually running them."
507)
508@click.option(
509 "--fake-initial",
510 is_flag=True,
511 help="Detect if tables already exist and fake-apply initial migrations if so. Make sure that the current database schema matches your initial migration before using this flag. Plain will only check for an existing table name.",
512)
513@click.option(
514 "--plan",
515 is_flag=True,
516 help="Shows a list of the migration actions that will be performed.",
517)
518@click.option(
519 "--check",
520 "check_unapplied",
521 is_flag=True,
522 help="Exits with a non-zero status if unapplied migrations exist and does not actually apply migrations.",
523)
524@click.option(
525 "--run-syncdb", is_flag=True, help="Creates tables for packages without migrations."
526)
527@click.option(
528 "--prune",
529 is_flag=True,
530 help="Delete nonexistent migrations from the plainmigrations table.",
531)
532@click.option(
533 "-v",
534 "--verbosity",
535 type=int,
536 default=1,
537 help="Verbosity level; 0=minimal output, 1=normal output, 2=verbose output, 3=very verbose output",
538)
539def migrate(
540 package_label,
541 migration_name,
542 no_input,
543 database,
544 fake,
545 fake_initial,
546 plan,
547 check_unapplied,
548 run_syncdb,
549 prune,
550 verbosity,
551):
552 """Updates database schema. Manages both packages with migrations and those without."""
554 def migration_progress_callback(action, migration=None, fake=False):
555 if verbosity >= 1:
556 compute_time = verbosity > 1
557 if action == "apply_start":
558 if compute_time:
559 start = time.monotonic()
560 click.echo(f" Applying {migration}...", nl=False)
561 elif action == "apply_success":
562 elapsed = f" ({time.monotonic() - start:.3f}s)" if compute_time else ""
563 if fake:
564 click.echo(click.style(f" FAKED{elapsed}", fg="green"))
565 else:
566 click.echo(click.style(f" OK{elapsed}", fg="green"))
567 elif action == "unapply_start":
568 if compute_time:
569 start = time.monotonic()
570 click.echo(f" Unapplying {migration}...", nl=False)
571 elif action == "unapply_success":
572 elapsed = f" ({time.monotonic() - start:.3f}s)" if compute_time else ""
573 if fake:
574 click.echo(click.style(f" FAKED{elapsed}", fg="green"))
575 else:
576 click.echo(click.style(f" OK{elapsed}", fg="green"))
577 elif action == "render_start":
578 if compute_time:
579 start = time.monotonic()
580 click.echo(" Rendering model states...", nl=False)
581 elif action == "render_success":
582 elapsed = f" ({time.monotonic() - start:.3f}s)" if compute_time else ""
583 click.echo(click.style(f" DONE{elapsed}", fg="green"))
585 def sync_packages(connection, package_labels):
586 """Run the old syncdb-style operation on a list of package_labels."""
587 with connection.cursor() as cursor:
588 tables = connection.introspection.table_names(cursor)
590 # Build the manifest of packages and models that are to be synchronized.
591 all_models = [
592 (
593 package_config.label,
594 router.get_migratable_models(
595 package_config, connection.alias, include_auto_created=False
596 ),
597 )
598 for package_config in packages.get_package_configs()
599 if package_config.models_module is not None
600 and package_config.label in package_labels
601 ]
603 def model_installed(model):
604 opts = model._meta
605 converter = connection.introspection.identifier_converter
606 return not (
607 (converter(opts.db_table) in tables)
608 or (
609 opts.auto_created
610 and converter(opts.auto_created._meta.db_table) in tables
611 )
612 )
614 manifest = {
615 package_name: list(filter(model_installed, model_list))
616 for package_name, model_list in all_models
617 }
619 # Create the tables for each model
620 if verbosity >= 1:
621 click.echo(" Creating tables...", color="cyan")
622 with connection.schema_editor() as editor:
623 for package_name, model_list in manifest.items():
624 for model in model_list:
625 # Never install unmanaged models, etc.
626 if not model._meta.can_migrate(connection):
627 continue
628 if verbosity >= 3:
629 click.echo(
630 f" Processing {package_name}.{model._meta.object_name} model"
631 )
632 if verbosity >= 1:
633 click.echo(f" Creating table {model._meta.db_table}")
634 editor.create_model(model)
636 # Deferred SQL is executed when exiting the editor's context.
637 if verbosity >= 1:
638 click.echo(" Running deferred SQL...", color="cyan")
640 def describe_operation(operation, backwards):
641 """Return a string that describes a migration operation for --plan."""
642 prefix = ""
643 is_error = False
644 if hasattr(operation, "code"):
645 code = operation.reverse_code if backwards else operation.code
646 action = (code.__doc__ or "") if code else None
647 elif hasattr(operation, "sql"):
648 action = operation.reverse_sql if backwards else operation.sql
649 else:
650 action = ""
651 if backwards:
652 prefix = "Undo "
653 if action is not None:
654 action = str(action).replace("\n", "")
655 elif backwards:
656 action = "IRREVERSIBLE"
657 is_error = True
658 if action:
659 action = " -> " + action
660 truncated = Truncator(action)
661 return prefix + operation.describe() + truncated.chars(40), is_error
663 # Import the 'management' module within each installed package, to register
664 # dispatcher events.
665 for package_config in packages.get_package_configs():
666 if module_has_submodule(package_config.module, "management"):
667 import_module(".management", package_config.name)
669 # Get the database we're operating from
670 connection = connections[database]
672 # Hook for backends needing any database preparation
673 connection.prepare_database()
675 # Work out which packages have migrations and which do not
676 executor = MigrationExecutor(connection, migration_progress_callback)
678 # Raise an error if any migrations are applied before their dependencies.
679 executor.loader.check_consistent_history(connection)
681 # Before anything else, see if there's conflicting packages and drop out
682 # hard if there are any
683 conflicts = executor.loader.detect_conflicts()
684 if conflicts:
685 name_str = "; ".join(
686 "{} in {}".format(", ".join(names), package)
687 for package, names in conflicts.items()
688 )
689 raise click.ClickException(
690 "Conflicting migrations detected; multiple leaf nodes in the "
691 "migration graph: (%s).\nTo fix them run "
692 "'python manage.py makemigrations --merge'" % name_str
693 )
695 # If they supplied command line arguments, work out what they mean.
696 target_package_labels_only = True
697 if package_label:
698 try:
699 packages.get_package_config(package_label)
700 except LookupError as err:
701 raise click.ClickException(str(err))
702 if run_syncdb:
703 if package_label in executor.loader.migrated_packages:
704 raise click.ClickException(
705 f"Can't use run_syncdb with package '{package_label}' as it has migrations."
706 )
707 elif package_label not in executor.loader.migrated_packages:
708 raise click.ClickException(
709 f"Package '{package_label}' does not have migrations."
710 )
712 if package_label and migration_name:
713 if migration_name == "zero":
714 targets = [(package_label, None)]
715 else:
716 try:
717 migration = executor.loader.get_migration_by_prefix(
718 package_label, migration_name
719 )
720 except AmbiguityError:
721 raise click.ClickException(
722 f"More than one migration matches '{migration_name}' in package '{package_label}'. "
723 "Please be more specific."
724 )
725 except KeyError:
726 raise click.ClickException(
727 f"Cannot find a migration matching '{migration_name}' from package '{package_label}'."
728 )
729 target = (package_label, migration.name)
730 if (
731 target not in executor.loader.graph.nodes
732 and target in executor.loader.replacements
733 ):
734 incomplete_migration = executor.loader.replacements[target]
735 target = incomplete_migration.replaces[-1]
736 targets = [target]
737 target_package_labels_only = False
738 elif package_label:
739 targets = [
740 key for key in executor.loader.graph.leaf_nodes() if key[0] == package_label
741 ]
742 else:
743 targets = executor.loader.graph.leaf_nodes()
745 if prune:
746 if not package_label:
747 raise click.ClickException(
748 "Migrations can be pruned only when a package is specified."
749 )
750 if verbosity > 0:
751 click.echo("Pruning migrations:", color="cyan")
752 to_prune = set(executor.loader.applied_migrations) - set(
753 executor.loader.disk_migrations
754 )
755 squashed_migrations_with_deleted_replaced_migrations = [
756 migration_key
757 for migration_key, migration_obj in executor.loader.replacements.items()
758 if any(replaced in to_prune for replaced in migration_obj.replaces)
759 ]
760 if squashed_migrations_with_deleted_replaced_migrations:
761 click.echo(
762 click.style(
763 " Cannot use --prune because the following squashed "
764 "migrations have their 'replaces' attributes and may not "
765 "be recorded as applied:",
766 fg="yellow",
767 )
768 )
769 for migration in squashed_migrations_with_deleted_replaced_migrations:
770 package, name = migration
771 click.echo(f" {package}.{name}")
772 click.echo(
773 click.style(
774 " Re-run 'manage.py migrate' if they are not marked as "
775 "applied, and remove 'replaces' attributes in their "
776 "Migration classes.",
777 fg="yellow",
778 )
779 )
780 else:
781 to_prune = sorted(
782 migration for migration in to_prune if migration[0] == package_label
783 )
784 if to_prune:
785 for migration in to_prune:
786 package, name = migration
787 if verbosity > 0:
788 click.echo(
789 click.style(f" Pruning {package}.{name}", fg="yellow"),
790 nl=False,
791 )
792 executor.recorder.record_unapplied(package, name)
793 if verbosity > 0:
794 click.echo(click.style(" OK", fg="green"))
795 elif verbosity > 0:
796 click.echo(" No migrations to prune.")
798 migration_plan = executor.migration_plan(targets)
800 if plan:
801 click.echo("Planned operations:", color="cyan")
802 if not migration_plan:
803 click.echo(" No planned migration operations.")
804 else:
805 for migration, backwards in migration_plan:
806 click.echo(str(migration), color="cyan")
807 for operation in migration.operations:
808 message, is_error = describe_operation(operation, backwards)
809 if is_error:
810 click.echo(" " + message, fg="yellow")
811 else:
812 click.echo(" " + message)
813 if check_unapplied:
814 sys.exit(1)
815 return
817 if check_unapplied:
818 if migration_plan:
819 sys.exit(1)
820 return
822 if prune:
823 return
825 # At this point, ignore run_syncdb if there aren't any packages to sync.
826 run_syncdb = run_syncdb and executor.loader.unmigrated_packages
827 # Print some useful info
828 if verbosity >= 1:
829 click.echo("Operations to perform:", color="cyan")
830 if run_syncdb:
831 if package_label:
832 click.echo(
833 f" Synchronize unmigrated package: {package_label}", color="yellow"
834 )
835 else:
836 click.echo(
837 " Synchronize unmigrated packages: "
838 + (", ".join(sorted(executor.loader.unmigrated_packages))),
839 color="yellow",
840 )
841 if target_package_labels_only:
842 click.echo(
843 " Apply all migrations: "
844 + (", ".join(sorted({a for a, n in targets})) or "(none)"),
845 color="yellow",
846 )
847 else:
848 if targets[0][1] is None:
849 click.echo(f" Unapply all migrations: {targets[0][0]}", color="yellow")
850 else:
851 click.echo(
852 f" Target specific migration: {targets[0][1]}, from {targets[0][0]}",
853 color="yellow",
854 )
856 pre_migrate_state = executor._create_project_state(with_applied_migrations=True)
858 # Run the syncdb phase.
859 if run_syncdb:
860 if verbosity >= 1:
861 click.echo("Synchronizing packages without migrations:", color="cyan")
862 if package_label:
863 sync_packages(connection, [package_label])
864 else:
865 sync_packages(connection, executor.loader.unmigrated_packages)
867 # Migrate!
868 if verbosity >= 1:
869 click.echo("Running migrations:", color="cyan")
870 if not migration_plan:
871 if verbosity >= 1:
872 click.echo(" No migrations to apply.")
873 # If there's changes that aren't in migrations yet, tell them
874 # how to fix it.
875 autodetector = MigrationAutodetector(
876 executor.loader.project_state(),
877 ProjectState.from_packages(packages),
878 )
879 changes = autodetector.changes(graph=executor.loader.graph)
880 if changes:
881 click.echo(
882 click.style(
883 f" Your models in package(s): {', '.join(repr(package) for package in sorted(changes))} "
884 "have changes that are not yet reflected in a migration, and so won't be applied.",
885 fg="yellow",
886 )
887 )
888 click.echo(
889 click.style(
890 " Run 'manage.py makemigrations' to make new "
891 "migrations, and then re-run 'manage.py migrate' to "
892 "apply them.",
893 fg="yellow",
894 )
895 )
896 else:
897 post_migrate_state = executor.migrate(
898 targets,
899 plan=migration_plan,
900 state=pre_migrate_state.clone(),
901 fake=fake,
902 fake_initial=fake_initial,
903 )
904 # post_migrate signals have access to all models. Ensure that all models
905 # are reloaded in case any are delayed.
906 post_migrate_state.clear_delayed_packages_cache()
907 post_migrate_packages = post_migrate_state.packages
909 # Re-render models of real packages to include relationships now that
910 # we've got a final state. This wouldn't be necessary if real packages
911 # models were rendered with relationships in the first place.
912 with post_migrate_packages.bulk_update():
913 model_keys = []
914 for model_state in post_migrate_packages.real_models:
915 model_key = model_state.package_label, model_state.name_lower
916 model_keys.append(model_key)
917 post_migrate_packages.unregister_model(*model_key)
918 post_migrate_packages.render_multiple(
919 [ModelState.from_model(packages.get_model(*model)) for model in model_keys]
920 )
923@cli.command()
924@click.argument("package_label")
925@click.argument("migration_name")
926@click.option(
927 "--check",
928 is_flag=True,
929 help="Exit with a non-zero status if the migration can be optimized.",
930)
931@click.option(
932 "-v",
933 "--verbosity",
934 type=int,
935 default=1,
936 help="Verbosity level; 0=minimal output, 1=normal output, 2=verbose output, 3=very verbose output",
937)
938def optimize_migration(package_label, migration_name, check, verbosity):
939 """Optimizes the operations for the named migration."""
940 try:
941 packages.get_package_config(package_label)
942 except LookupError as err:
943 raise click.ClickException(str(err))
945 # Load the current graph state.
946 loader = MigrationLoader(None)
947 if package_label not in loader.migrated_packages:
948 raise click.ClickException(
949 f"Package '{package_label}' does not have migrations."
950 )
952 # Find a migration.
953 try:
954 migration = loader.get_migration_by_prefix(package_label, migration_name)
955 except AmbiguityError:
956 raise click.ClickException(
957 f"More than one migration matches '{migration_name}' in package "
958 f"'{package_label}'. Please be more specific."
959 )
960 except KeyError:
961 raise click.ClickException(
962 f"Cannot find a migration matching '{migration_name}' from package "
963 f"'{package_label}'."
964 )
966 # Optimize the migration.
967 optimizer = MigrationOptimizer()
968 new_operations = optimizer.optimize(migration.operations, migration.package_label)
969 if len(migration.operations) == len(new_operations):
970 if verbosity > 0:
971 click.echo("No optimizations possible.")
972 return
973 else:
974 if verbosity > 0:
975 click.echo(
976 f"Optimizing from {len(migration.operations)} operations to {len(new_operations)} operations."
977 )
978 if check:
979 sys.exit(1)
981 # Set the new migration optimizations.
982 migration.operations = new_operations
984 # Write out the optimized migration file.
985 writer = MigrationWriter(migration)
986 migration_file_string = writer.as_string()
987 if writer.needs_manual_porting:
988 if migration.replaces:
989 raise click.ClickException(
990 "Migration will require manual porting but is already a squashed "
991 "migration.\nTransition to a normal migration first."
992 )
993 # Make a new migration with those operations.
994 subclass = type(
995 "Migration",
996 (migrations.Migration,),
997 {
998 "dependencies": migration.dependencies,
999 "operations": new_operations,
1000 "replaces": [(migration.package_label, migration.name)],
1001 },
1002 )
1003 optimized_migration_name = f"{migration.name}_optimized"
1004 optimized_migration = subclass(optimized_migration_name, package_label)
1005 writer = MigrationWriter(optimized_migration)
1006 migration_file_string = writer.as_string()
1007 if verbosity > 0:
1008 click.echo(click.style("Manual porting required", fg="yellow", bold=True))
1009 click.echo(
1010 " Your migrations contained functions that must be manually "
1011 "copied over,\n"
1012 " as we could not safely copy their implementation.\n"
1013 " See the comment at the top of the optimized migration for "
1014 "details."
1015 )
1017 with open(writer.path, "w", encoding="utf-8") as fh:
1018 fh.write(migration_file_string)
1020 if verbosity > 0:
1021 click.echo(
1022 click.style(f"Optimized migration {writer.path}", fg="green", bold=True)
1023 )
1026@cli.command()
1027@click.argument("package_labels", nargs=-1)
1028@click.option(
1029 "--database",
1030 default=DEFAULT_DB_ALIAS,
1031 help="Nominates a database to show migrations for. Defaults to the 'default' database.",
1032)
1033@click.option(
1034 "--format",
1035 type=click.Choice(["list", "plan"]),
1036 default="list",
1037 help="Output format.",
1038)
1039@click.option(
1040 "-v",
1041 "--verbosity",
1042 type=int,
1043 default=1,
1044 help="Verbosity level; 0=minimal output, 1=normal output, 2=verbose output, 3=very verbose output",
1045)
1046def show_migrations(package_labels, database, format, verbosity):
1047 """Shows all available migrations for the current project"""
1049 def _validate_package_names(package_names):
1050 has_bad_names = False
1051 for package_name in package_names:
1052 try:
1053 packages.get_package_config(package_name)
1054 except LookupError as err:
1055 click.echo(str(err), err=True)
1056 has_bad_names = True
1057 if has_bad_names:
1058 sys.exit(2)
1060 def show_list(connection, package_names):
1061 """
1062 Show a list of all migrations on the system, or only those of
1063 some named packages.
1064 """
1065 # Load migrations from disk/DB
1066 loader = MigrationLoader(connection, ignore_no_migrations=True)
1067 recorder = MigrationRecorder(connection)
1068 recorded_migrations = recorder.applied_migrations()
1069 graph = loader.graph
1070 # If we were passed a list of packages, validate it
1071 if package_names:
1072 _validate_package_names(package_names)
1073 # Otherwise, show all packages in alphabetic order
1074 else:
1075 package_names = sorted(loader.migrated_packages)
1076 # For each app, print its migrations in order from oldest (roots) to
1077 # newest (leaves).
1078 for package_name in package_names:
1079 click.secho(package_name, fg="cyan", bold=True)
1080 shown = set()
1081 for node in graph.leaf_nodes(package_name):
1082 for plan_node in graph.forwards_plan(node):
1083 if plan_node not in shown and plan_node[0] == package_name:
1084 # Give it a nice title if it's a squashed one
1085 title = plan_node[1]
1086 if graph.nodes[plan_node].replaces:
1087 title += f" ({len(graph.nodes[plan_node].replaces)} squashed migrations)"
1088 applied_migration = loader.applied_migrations.get(plan_node)
1089 # Mark it as applied/unapplied
1090 if applied_migration:
1091 if plan_node in recorded_migrations:
1092 output = f" [X] {title}"
1093 else:
1094 title += " Run 'manage.py migrate' to finish recording."
1095 output = f" [-] {title}"
1096 if verbosity >= 2 and hasattr(applied_migration, "applied"):
1097 output += f" (applied at {applied_migration.applied.strftime('%Y-%m-%d %H:%M:%S')})"
1098 click.echo(output)
1099 else:
1100 click.echo(f" [ ] {title}")
1101 shown.add(plan_node)
1102 # If we didn't print anything, then a small message
1103 if not shown:
1104 click.secho(" (no migrations)", fg="red")
1106 def show_plan(connection, package_names):
1107 """
1108 Show all known migrations (or only those of the specified package_names)
1109 in the order they will be applied.
1110 """
1111 # Load migrations from disk/DB
1112 loader = MigrationLoader(connection)
1113 graph = loader.graph
1114 if package_names:
1115 _validate_package_names(package_names)
1116 targets = [key for key in graph.leaf_nodes() if key[0] in package_names]
1117 else:
1118 targets = graph.leaf_nodes()
1119 plan = []
1120 seen = set()
1122 # Generate the plan
1123 for target in targets:
1124 for migration in graph.forwards_plan(target):
1125 if migration not in seen:
1126 node = graph.node_map[migration]
1127 plan.append(node)
1128 seen.add(migration)
1130 # Output
1131 def print_deps(node):
1132 out = []
1133 for parent in sorted(node.parents):
1134 out.append(f"{parent.key[0]}.{parent.key[1]}")
1135 if out:
1136 return f" ... ({', '.join(out)})"
1137 return ""
1139 for node in plan:
1140 deps = ""
1141 if verbosity >= 2:
1142 deps = print_deps(node)
1143 if node.key in loader.applied_migrations:
1144 click.echo(f"[X] {node.key[0]}.{node.key[1]}{deps}")
1145 else:
1146 click.echo(f"[ ] {node.key[0]}.{node.key[1]}{deps}")
1147 if not plan:
1148 click.secho("(no migrations)", fg="red")
1150 # Get the database we're operating from
1151 connection = connections[database]
1153 if format == "plan":
1154 show_plan(connection, package_labels)
1155 else:
1156 show_list(connection, package_labels)
1159@cli.command()
1160@click.argument("package_label")
1161@click.argument("start_migration_name", required=False)
1162@click.argument("migration_name")
1163@click.option(
1164 "--no-optimize",
1165 is_flag=True,
1166 help="Do not try to optimize the squashed operations.",
1167)
1168@click.option(
1169 "--noinput",
1170 "--no-input",
1171 "no_input",
1172 is_flag=True,
1173 help="Tells Plain to NOT prompt the user for input of any kind.",
1174)
1175@click.option("--squashed-name", help="Sets the name of the new squashed migration.")
1176@click.option(
1177 "-v",
1178 "--verbosity",
1179 type=int,
1180 default=1,
1181 help="Verbosity level; 0=minimal output, 1=normal output, 2=verbose output, 3=very verbose output",
1182)
1183def squash_migrations(
1184 package_label,
1185 start_migration_name,
1186 migration_name,
1187 no_optimize,
1188 no_input,
1189 squashed_name,
1190 verbosity,
1191):
1192 """
1193 Squashes an existing set of migrations (from first until specified) into a single new one.
1194 """
1195 interactive = not no_input
1197 def find_migration(loader, package_label, name):
1198 try:
1199 return loader.get_migration_by_prefix(package_label, name)
1200 except AmbiguityError:
1201 raise click.ClickException(
1202 f"More than one migration matches '{name}' in package '{package_label}'. Please be more specific."
1203 )
1204 except KeyError:
1205 raise click.ClickException(
1206 f"Cannot find a migration matching '{name}' from package '{package_label}'."
1207 )
1209 # Validate package_label
1210 try:
1211 packages.get_package_config(package_label)
1212 except LookupError as err:
1213 raise click.ClickException(str(err))
1215 # Load the current graph state, check the app and migration they asked for exists
1216 loader = MigrationLoader(connections[DEFAULT_DB_ALIAS])
1217 if package_label not in loader.migrated_packages:
1218 raise click.ClickException(
1219 f"Package '{package_label}' does not have migrations (so squashmigrations on it makes no sense)"
1220 )
1222 migration = find_migration(loader, package_label, migration_name)
1224 # Work out the list of predecessor migrations
1225 migrations_to_squash = [
1226 loader.get_migration(al, mn)
1227 for al, mn in loader.graph.forwards_plan(
1228 (migration.package_label, migration.name)
1229 )
1230 if al == migration.package_label
1231 ]
1233 if start_migration_name:
1234 start_migration = find_migration(loader, package_label, start_migration_name)
1235 start = loader.get_migration(
1236 start_migration.package_label, start_migration.name
1237 )
1238 try:
1239 start_index = migrations_to_squash.index(start)
1240 migrations_to_squash = migrations_to_squash[start_index:]
1241 except ValueError:
1242 raise click.ClickException(
1243 f"The migration '{start_migration}' cannot be found. Maybe it comes after "
1244 f"the migration '{migration}'?\n"
1245 f"Have a look at:\n"
1246 f" python manage.py showmigrations {package_label}\n"
1247 f"to debug this issue."
1248 )
1250 # Tell them what we're doing and optionally ask if we should proceed
1251 if verbosity > 0 or interactive:
1252 click.secho("Will squash the following migrations:", fg="cyan", bold=True)
1253 for migration in migrations_to_squash:
1254 click.echo(f" - {migration.name}")
1256 if interactive:
1257 if not click.confirm("Do you wish to proceed?"):
1258 return
1260 # Load the operations from all those migrations and concat together,
1261 # along with collecting external dependencies and detecting double-squashing
1262 operations = []
1263 dependencies = set()
1264 # We need to take all dependencies from the first migration in the list
1265 # as it may be 0002 depending on 0001
1266 first_migration = True
1267 for smigration in migrations_to_squash:
1268 if smigration.replaces:
1269 raise click.ClickException(
1270 "You cannot squash squashed migrations! Please transition it to a "
1271 "normal migration first"
1272 )
1273 operations.extend(smigration.operations)
1274 for dependency in smigration.dependencies:
1275 if isinstance(dependency, SwappableTuple):
1276 if settings.AUTH_USER_MODEL == dependency.setting:
1277 dependencies.add(("__setting__", "AUTH_USER_MODEL"))
1278 else:
1279 dependencies.add(dependency)
1280 elif dependency[0] != smigration.package_label or first_migration:
1281 dependencies.add(dependency)
1282 first_migration = False
1284 if no_optimize:
1285 if verbosity > 0:
1286 click.secho("(Skipping optimization.)", fg="yellow")
1287 new_operations = operations
1288 else:
1289 if verbosity > 0:
1290 click.secho("Optimizing...", fg="cyan")
1292 optimizer = MigrationOptimizer()
1293 new_operations = optimizer.optimize(operations, migration.package_label)
1295 if verbosity > 0:
1296 if len(new_operations) == len(operations):
1297 click.echo(" No optimizations possible.")
1298 else:
1299 click.echo(
1300 f" Optimized from {len(operations)} operations to {len(new_operations)} operations."
1301 )
1303 # Work out the value of replaces (any squashed ones we're re-squashing)
1304 # need to feed their replaces into ours
1305 replaces = []
1306 for migration in migrations_to_squash:
1307 if migration.replaces:
1308 replaces.extend(migration.replaces)
1309 else:
1310 replaces.append((migration.package_label, migration.name))
1312 # Make a new migration with those operations
1313 subclass = type(
1314 "Migration",
1315 (migrations.Migration,),
1316 {
1317 "dependencies": dependencies,
1318 "operations": new_operations,
1319 "replaces": replaces,
1320 },
1321 )
1322 if start_migration_name:
1323 if squashed_name:
1324 # Use the name from --squashed-name
1325 prefix, _ = start_migration.name.split("_", 1)
1326 name = f"{prefix}_{squashed_name}"
1327 else:
1328 # Generate a name
1329 name = f"{start_migration.name}_squashed_{migration.name}"
1330 new_migration = subclass(name, package_label)
1331 else:
1332 name = f"0001_{'squashed_' + migration.name if not squashed_name else squashed_name}"
1333 new_migration = subclass(name, package_label)
1334 new_migration.initial = True
1336 # Write out the new migration file
1337 writer = MigrationWriter(new_migration)
1338 if os.path.exists(writer.path):
1339 raise click.ClickException(
1340 f"Migration {new_migration.name} already exists. Use a different name."
1341 )
1342 with open(writer.path, "w", encoding="utf-8") as fh:
1343 fh.write(writer.as_string())
1345 if verbosity > 0:
1346 click.secho(
1347 f"Created new squashed migration {writer.path}", fg="green", bold=True
1348 )
1349 click.echo(
1350 " You should commit this migration but leave the old ones in place;\n"
1351 " the new migration will be used for new installs. Once you are sure\n"
1352 " all instances of the codebase have applied the migrations you squashed,\n"
1353 " you can delete them."
1354 )
1355 if writer.needs_manual_porting:
1356 click.secho("Manual porting required", fg="yellow", bold=True)
1357 click.echo(
1358 " Your migrations contained functions that must be manually copied over,\n"
1359 " as we could not safely copy their implementation.\n"
1360 " See the comment at the top of the squashed migration for details."
1361 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.packages import PackageConfig
4class PlainDBConfig(PackageConfig):
5 name = "plain.models"
6 # We wan to use the "migrations" module
7 # in this package but not for the standard purpose
8 migrations_module = None
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Constants used across the ORM in general.
3"""
4from enum import Enum
6# Separator used to split filter strings apart.
7LOOKUP_SEP = "__"
10class OnConflict(Enum):
11 IGNORE = "ignore"
12 UPDATE = "update"
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import warnings
2from enum import Enum
3from types import NoneType
5from plain.exceptions import FieldError, ValidationError
6from plain.models.db import DEFAULT_DB_ALIAS, connections
7from plain.models.expressions import Exists, ExpressionList, F, OrderBy
8from plain.models.indexes import IndexExpression
9from plain.models.lookups import Exact
10from plain.models.query_utils import Q
11from plain.models.sql.query import Query
12from plain.utils.deprecation import RemovedInDjango60Warning
14__all__ = ["BaseConstraint", "CheckConstraint", "Deferrable", "UniqueConstraint"]
17class BaseConstraint:
18 default_violation_error_message = "Constraint “%(name)s” is violated."
19 violation_error_code = None
20 violation_error_message = None
22 # RemovedInDjango60Warning: When the deprecation ends, replace with:
23 # def __init__(
24 # self, *, name, violation_error_code=None, violation_error_message=None
25 # ):
26 def __init__(
27 self, *args, name=None, violation_error_code=None, violation_error_message=None
28 ):
29 # RemovedInDjango60Warning.
30 if name is None and not args:
31 raise TypeError(
32 f"{self.__class__.__name__}.__init__() missing 1 required keyword-only "
33 f"argument: 'name'"
34 )
35 self.name = name
36 if violation_error_code is not None:
37 self.violation_error_code = violation_error_code
38 if violation_error_message is not None:
39 self.violation_error_message = violation_error_message
40 else:
41 self.violation_error_message = self.default_violation_error_message
42 # RemovedInDjango60Warning.
43 if args:
44 warnings.warn(
45 f"Passing positional arguments to {self.__class__.__name__} is "
46 f"deprecated.",
47 RemovedInDjango60Warning,
48 stacklevel=2,
49 )
50 for arg, attr in zip(args, ["name", "violation_error_message"]):
51 if arg:
52 setattr(self, attr, arg)
54 @property
55 def contains_expressions(self):
56 return False
58 def constraint_sql(self, model, schema_editor):
59 raise NotImplementedError("This method must be implemented by a subclass.")
61 def create_sql(self, model, schema_editor):
62 raise NotImplementedError("This method must be implemented by a subclass.")
64 def remove_sql(self, model, schema_editor):
65 raise NotImplementedError("This method must be implemented by a subclass.")
67 def validate(self, model, instance, exclude=None, using=DEFAULT_DB_ALIAS):
68 raise NotImplementedError("This method must be implemented by a subclass.")
70 def get_violation_error_message(self):
71 return self.violation_error_message % {"name": self.name}
73 def deconstruct(self):
74 path = f"{self.__class__.__module__}.{self.__class__.__name__}"
75 path = path.replace("plain.models.constraints", "plain.models")
76 kwargs = {"name": self.name}
77 if (
78 self.violation_error_message is not None
79 and self.violation_error_message != self.default_violation_error_message
80 ):
81 kwargs["violation_error_message"] = self.violation_error_message
82 if self.violation_error_code is not None:
83 kwargs["violation_error_code"] = self.violation_error_code
84 return (path, (), kwargs)
86 def clone(self):
87 _, args, kwargs = self.deconstruct()
88 return self.__class__(*args, **kwargs)
91class CheckConstraint(BaseConstraint):
92 def __init__(
93 self, *, check, name, violation_error_code=None, violation_error_message=None
94 ):
95 self.check = check
96 if not getattr(check, "conditional", False):
97 raise TypeError(
98 "CheckConstraint.check must be a Q instance or boolean expression."
99 )
100 super().__init__(
101 name=name,
102 violation_error_code=violation_error_code,
103 violation_error_message=violation_error_message,
104 )
106 def _get_check_sql(self, model, schema_editor):
107 query = Query(model=model, alias_cols=False)
108 where = query.build_where(self.check)
109 compiler = query.get_compiler(connection=schema_editor.connection)
110 sql, params = where.as_sql(compiler, schema_editor.connection)
111 return sql % tuple(schema_editor.quote_value(p) for p in params)
113 def constraint_sql(self, model, schema_editor):
114 check = self._get_check_sql(model, schema_editor)
115 return schema_editor._check_sql(self.name, check)
117 def create_sql(self, model, schema_editor):
118 check = self._get_check_sql(model, schema_editor)
119 return schema_editor._create_check_sql(model, self.name, check)
121 def remove_sql(self, model, schema_editor):
122 return schema_editor._delete_check_sql(model, self.name)
124 def validate(self, model, instance, exclude=None, using=DEFAULT_DB_ALIAS):
125 against = instance._get_field_value_map(meta=model._meta, exclude=exclude)
126 try:
127 if not Q(self.check).check(against, using=using):
128 raise ValidationError(
129 self.get_violation_error_message(), code=self.violation_error_code
130 )
131 except FieldError:
132 pass
134 def __repr__(self):
135 return "<{}: check={} name={}{}{}>".format(
136 self.__class__.__qualname__,
137 self.check,
138 repr(self.name),
139 (
140 ""
141 if self.violation_error_code is None
142 else " violation_error_code=%r" % self.violation_error_code
143 ),
144 (
145 ""
146 if self.violation_error_message is None
147 or self.violation_error_message == self.default_violation_error_message
148 else " violation_error_message=%r" % self.violation_error_message
149 ),
150 )
152 def __eq__(self, other):
153 if isinstance(other, CheckConstraint):
154 return (
155 self.name == other.name
156 and self.check == other.check
157 and self.violation_error_code == other.violation_error_code
158 and self.violation_error_message == other.violation_error_message
159 )
160 return super().__eq__(other)
162 def deconstruct(self):
163 path, args, kwargs = super().deconstruct()
164 kwargs["check"] = self.check
165 return path, args, kwargs
168class Deferrable(Enum):
169 DEFERRED = "deferred"
170 IMMEDIATE = "immediate"
172 # A similar format was proposed for Python 3.10.
173 def __repr__(self):
174 return f"{self.__class__.__qualname__}.{self._name_}"
177class UniqueConstraint(BaseConstraint):
178 def __init__(
179 self,
180 *expressions,
181 fields=(),
182 name=None,
183 condition=None,
184 deferrable=None,
185 include=None,
186 opclasses=(),
187 violation_error_code=None,
188 violation_error_message=None,
189 ):
190 if not name:
191 raise ValueError("A unique constraint must be named.")
192 if not expressions and not fields:
193 raise ValueError(
194 "At least one field or expression is required to define a "
195 "unique constraint."
196 )
197 if expressions and fields:
198 raise ValueError(
199 "UniqueConstraint.fields and expressions are mutually exclusive."
200 )
201 if not isinstance(condition, NoneType | Q):
202 raise ValueError("UniqueConstraint.condition must be a Q instance.")
203 if condition and deferrable:
204 raise ValueError("UniqueConstraint with conditions cannot be deferred.")
205 if include and deferrable:
206 raise ValueError("UniqueConstraint with include fields cannot be deferred.")
207 if opclasses and deferrable:
208 raise ValueError("UniqueConstraint with opclasses cannot be deferred.")
209 if expressions and deferrable:
210 raise ValueError("UniqueConstraint with expressions cannot be deferred.")
211 if expressions and opclasses:
212 raise ValueError(
213 "UniqueConstraint.opclasses cannot be used with expressions. "
214 "Use a custom OpClass() instead."
215 )
216 if not isinstance(deferrable, NoneType | Deferrable):
217 raise ValueError(
218 "UniqueConstraint.deferrable must be a Deferrable instance."
219 )
220 if not isinstance(include, NoneType | list | tuple):
221 raise ValueError("UniqueConstraint.include must be a list or tuple.")
222 if not isinstance(opclasses, list | tuple):
223 raise ValueError("UniqueConstraint.opclasses must be a list or tuple.")
224 if opclasses and len(fields) != len(opclasses):
225 raise ValueError(
226 "UniqueConstraint.fields and UniqueConstraint.opclasses must "
227 "have the same number of elements."
228 )
229 self.fields = tuple(fields)
230 self.condition = condition
231 self.deferrable = deferrable
232 self.include = tuple(include) if include else ()
233 self.opclasses = opclasses
234 self.expressions = tuple(
235 F(expression) if isinstance(expression, str) else expression
236 for expression in expressions
237 )
238 super().__init__(
239 name=name,
240 violation_error_code=violation_error_code,
241 violation_error_message=violation_error_message,
242 )
244 @property
245 def contains_expressions(self):
246 return bool(self.expressions)
248 def _get_condition_sql(self, model, schema_editor):
249 if self.condition is None:
250 return None
251 query = Query(model=model, alias_cols=False)
252 where = query.build_where(self.condition)
253 compiler = query.get_compiler(connection=schema_editor.connection)
254 sql, params = where.as_sql(compiler, schema_editor.connection)
255 return sql % tuple(schema_editor.quote_value(p) for p in params)
257 def _get_index_expressions(self, model, schema_editor):
258 if not self.expressions:
259 return None
260 index_expressions = []
261 for expression in self.expressions:
262 index_expression = IndexExpression(expression)
263 index_expression.set_wrapper_classes(schema_editor.connection)
264 index_expressions.append(index_expression)
265 return ExpressionList(*index_expressions).resolve_expression(
266 Query(model, alias_cols=False),
267 )
269 def constraint_sql(self, model, schema_editor):
270 fields = [model._meta.get_field(field_name) for field_name in self.fields]
271 include = [
272 model._meta.get_field(field_name).column for field_name in self.include
273 ]
274 condition = self._get_condition_sql(model, schema_editor)
275 expressions = self._get_index_expressions(model, schema_editor)
276 return schema_editor._unique_sql(
277 model,
278 fields,
279 self.name,
280 condition=condition,
281 deferrable=self.deferrable,
282 include=include,
283 opclasses=self.opclasses,
284 expressions=expressions,
285 )
287 def create_sql(self, model, schema_editor):
288 fields = [model._meta.get_field(field_name) for field_name in self.fields]
289 include = [
290 model._meta.get_field(field_name).column for field_name in self.include
291 ]
292 condition = self._get_condition_sql(model, schema_editor)
293 expressions = self._get_index_expressions(model, schema_editor)
294 return schema_editor._create_unique_sql(
295 model,
296 fields,
297 self.name,
298 condition=condition,
299 deferrable=self.deferrable,
300 include=include,
301 opclasses=self.opclasses,
302 expressions=expressions,
303 )
305 def remove_sql(self, model, schema_editor):
306 condition = self._get_condition_sql(model, schema_editor)
307 include = [
308 model._meta.get_field(field_name).column for field_name in self.include
309 ]
310 expressions = self._get_index_expressions(model, schema_editor)
311 return schema_editor._delete_unique_sql(
312 model,
313 self.name,
314 condition=condition,
315 deferrable=self.deferrable,
316 include=include,
317 opclasses=self.opclasses,
318 expressions=expressions,
319 )
321 def __repr__(self):
322 return "<{}:{}{}{}{}{}{}{}{}{}>".format(
323 self.__class__.__qualname__,
324 "" if not self.fields else " fields=%s" % repr(self.fields),
325 "" if not self.expressions else " expressions=%s" % repr(self.expressions),
326 " name=%s" % repr(self.name),
327 "" if self.condition is None else " condition=%s" % self.condition,
328 "" if self.deferrable is None else " deferrable=%r" % self.deferrable,
329 "" if not self.include else " include=%s" % repr(self.include),
330 "" if not self.opclasses else " opclasses=%s" % repr(self.opclasses),
331 (
332 ""
333 if self.violation_error_code is None
334 else " violation_error_code=%r" % self.violation_error_code
335 ),
336 (
337 ""
338 if self.violation_error_message is None
339 or self.violation_error_message == self.default_violation_error_message
340 else " violation_error_message=%r" % self.violation_error_message
341 ),
342 )
344 def __eq__(self, other):
345 if isinstance(other, UniqueConstraint):
346 return (
347 self.name == other.name
348 and self.fields == other.fields
349 and self.condition == other.condition
350 and self.deferrable == other.deferrable
351 and self.include == other.include
352 and self.opclasses == other.opclasses
353 and self.expressions == other.expressions
354 and self.violation_error_code == other.violation_error_code
355 and self.violation_error_message == other.violation_error_message
356 )
357 return super().__eq__(other)
359 def deconstruct(self):
360 path, args, kwargs = super().deconstruct()
361 if self.fields:
362 kwargs["fields"] = self.fields
363 if self.condition:
364 kwargs["condition"] = self.condition
365 if self.deferrable:
366 kwargs["deferrable"] = self.deferrable
367 if self.include:
368 kwargs["include"] = self.include
369 if self.opclasses:
370 kwargs["opclasses"] = self.opclasses
371 return path, self.expressions, kwargs
373 def validate(self, model, instance, exclude=None, using=DEFAULT_DB_ALIAS):
374 queryset = model._default_manager.using(using)
375 if self.fields:
376 lookup_kwargs = {}
377 for field_name in self.fields:
378 if exclude and field_name in exclude:
379 return
380 field = model._meta.get_field(field_name)
381 lookup_value = getattr(instance, field.attname)
382 if lookup_value is None or (
383 lookup_value == ""
384 and connections[using].features.interprets_empty_strings_as_nulls
385 ):
386 # A composite constraint containing NULL value cannot cause
387 # a violation since NULL != NULL in SQL.
388 return
389 lookup_kwargs[field.name] = lookup_value
390 queryset = queryset.filter(**lookup_kwargs)
391 else:
392 # Ignore constraints with excluded fields.
393 if exclude:
394 for expression in self.expressions:
395 if hasattr(expression, "flatten"):
396 for expr in expression.flatten():
397 if isinstance(expr, F) and expr.name in exclude:
398 return
399 elif isinstance(expression, F) and expression.name in exclude:
400 return
401 replacements = {
402 F(field): value
403 for field, value in instance._get_field_value_map(
404 meta=model._meta, exclude=exclude
405 ).items()
406 }
407 expressions = []
408 for expr in self.expressions:
409 # Ignore ordering.
410 if isinstance(expr, OrderBy):
411 expr = expr.expression
412 expressions.append(Exact(expr, expr.replace_expressions(replacements)))
413 queryset = queryset.filter(*expressions)
414 model_class_pk = instance._get_pk_val(model._meta)
415 if not instance._state.adding and model_class_pk is not None:
416 queryset = queryset.exclude(pk=model_class_pk)
417 if not self.condition:
418 if queryset.exists():
419 if self.expressions:
420 raise ValidationError(
421 self.get_violation_error_message(),
422 code=self.violation_error_code,
423 )
424 # When fields are defined, use the unique_error_message() for
425 # backward compatibility.
426 for model, constraints in instance.get_constraints():
427 for constraint in constraints:
428 if constraint is self:
429 raise ValidationError(
430 instance.unique_error_message(model, self.fields),
431 )
432 else:
433 against = instance._get_field_value_map(meta=model._meta, exclude=exclude)
434 try:
435 if (self.condition & Exists(queryset.filter(self.condition))).check(
436 against, using=using
437 ):
438 raise ValidationError(
439 self.get_violation_error_message(),
440 code=self.violation_error_code,
441 )
442 except FieldError:
443 pass
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1# Copyright (c) Kenneth Reitz & individual contributors
2# All rights reserved.
4# Redistribution and use in source and binary forms, with or without modification,
5# are permitted provided that the following conditions are met:
7# 1. Redistributions of source code must retain the above copyright notice,
8# this list of conditions and the following disclaimer.
10# 2. Redistributions in binary form must reproduce the above copyright
11# notice, this list of conditions and the following disclaimer in the
12# documentation and/or other materials provided with the distribution.
14# 3. Neither the name of Plain nor the names of its contributors may be used
15# to endorse or promote products derived from this software without
16# specific prior written permission.
18# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
19# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
20# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
21# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR
22# ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
23# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
24# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
25# ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
26# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
27# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
28import logging
29import os
30import urllib.parse as urlparse
31from typing import Any, TypedDict
33DEFAULT_ENV = "DATABASE_URL"
35SCHEMES = {
36 "postgres": "plain.models.backends.postgresql",
37 "postgresql": "plain.models.backends.postgresql",
38 "pgsql": "plain.models.backends.postgresql",
39 "mysql": "plain.models.backends.mysql",
40 "mysql2": "plain.models.backends.mysql",
41 "sqlite": "plain.models.backends.sqlite3",
42}
44# Register database schemes in URLs.
45for key in SCHEMES.keys():
46 urlparse.uses_netloc.append(key)
49class DBConfig(TypedDict, total=False):
50 AUTOCOMMIT: bool
51 CONN_MAX_AGE: int | None
52 CONN_HEALTH_CHECKS: bool
53 DISABLE_SERVER_SIDE_CURSORS: bool
54 ENGINE: str
55 HOST: str
56 NAME: str
57 OPTIONS: dict[str, Any] | None
58 PASSWORD: str
59 PORT: str | int
60 TEST: dict[str, Any]
61 TIME_ZONE: str
62 USER: str
65def config(
66 env: str = DEFAULT_ENV,
67 default: str | None = None,
68 engine: str | None = None,
69 conn_max_age: int | None = 0,
70 conn_health_checks: bool = False,
71 ssl_require: bool = False,
72 test_options: dict | None = None,
73) -> DBConfig:
74 """Returns configured DATABASE dictionary from DATABASE_URL."""
75 s = os.environ.get(env, default)
77 if s is None:
78 logging.warning(
79 "No %s environment variable set, and so no databases setup" % env
80 )
82 if s:
83 return parse(
84 s, engine, conn_max_age, conn_health_checks, ssl_require, test_options
85 )
87 return {}
90def parse(
91 url: str,
92 engine: str | None = None,
93 conn_max_age: int | None = 0,
94 conn_health_checks: bool = False,
95 ssl_require: bool = False,
96 test_options: dict | None = None,
97) -> DBConfig:
98 """Parses a database URL."""
99 if url == "sqlite://:memory:":
100 # this is a special case, because if we pass this URL into
101 # urlparse, urlparse will choke trying to interpret "memory"
102 # as a port number
103 return {"ENGINE": SCHEMES["sqlite"], "NAME": ":memory:"}
104 # note: no other settings are required for sqlite
106 # otherwise parse the url as normal
107 parsed_config: DBConfig = {}
109 if test_options is None:
110 test_options = {}
112 spliturl = urlparse.urlsplit(url)
114 # Split query strings from path.
115 path = spliturl.path[1:]
116 query = urlparse.parse_qs(spliturl.query)
118 # If we are using sqlite and we have no path, then assume we
119 # want an in-memory database (this is the behaviour of sqlalchemy)
120 if spliturl.scheme == "sqlite" and path == "":
121 path = ":memory:"
123 # Handle postgres percent-encoded paths.
124 hostname = spliturl.hostname or ""
125 if "%" in hostname:
126 # Switch to url.netloc to avoid lower cased paths
127 hostname = spliturl.netloc
128 if "@" in hostname:
129 hostname = hostname.rsplit("@", 1)[1]
130 # Use URL Parse library to decode % encodes
131 hostname = urlparse.unquote(hostname)
133 # Lookup specified engine.
134 if engine is None:
135 engine = SCHEMES.get(spliturl.scheme)
136 if engine is None:
137 raise ValueError(
138 "No support for '{}'. We support: {}".format(
139 spliturl.scheme, ", ".join(sorted(SCHEMES.keys()))
140 )
141 )
143 port = spliturl.port
145 # Update with environment configuration.
146 parsed_config.update(
147 {
148 "NAME": urlparse.unquote(path or ""),
149 "USER": urlparse.unquote(spliturl.username or ""),
150 "PASSWORD": urlparse.unquote(spliturl.password or ""),
151 "HOST": hostname,
152 "PORT": port or "",
153 "CONN_MAX_AGE": conn_max_age,
154 "CONN_HEALTH_CHECKS": conn_health_checks,
155 "ENGINE": engine,
156 }
157 )
158 if test_options:
159 parsed_config.update(
160 {
161 "TEST": test_options,
162 }
163 )
165 # Pass the query string into OPTIONS.
166 options: dict[str, Any] = {}
167 for key, values in query.items():
168 if spliturl.scheme == "mysql" and key == "ssl-ca":
169 options["ssl"] = {"ca": values[-1]}
170 continue
172 options[key] = values[-1]
174 if ssl_require:
175 options["sslmode"] = "require"
177 # Support for Postgres Schema URLs
178 if "currentSchema" in options and engine in (
179 "plain.models.backends.postgresql_psycopg2",
180 "plain.models.backends.postgresql",
181 ):
182 options["options"] = "-c search_path={}".format(options.pop("currentSchema"))
184 if options:
185 parsed_config["OPTIONS"] = options
187 return parsed_config
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import pkgutil
2from importlib import import_module
4from plain import signals
5from plain.exceptions import ImproperlyConfigured
6from plain.runtime import settings
7from plain.utils.connection import BaseConnectionHandler, ConnectionProxy
8from plain.utils.functional import cached_property
9from plain.utils.module_loading import import_string
11DEFAULT_DB_ALIAS = "default"
12PLAIN_VERSION_PICKLE_KEY = "_plain_version"
15class Error(Exception):
16 pass
19class InterfaceError(Error):
20 pass
23class DatabaseError(Error):
24 pass
27class DataError(DatabaseError):
28 pass
31class OperationalError(DatabaseError):
32 pass
35class IntegrityError(DatabaseError):
36 pass
39class InternalError(DatabaseError):
40 pass
43class ProgrammingError(DatabaseError):
44 pass
47class NotSupportedError(DatabaseError):
48 pass
51class DatabaseErrorWrapper:
52 """
53 Context manager and decorator that reraises backend-specific database
54 exceptions using Plain's common wrappers.
55 """
57 def __init__(self, wrapper):
58 """
59 wrapper is a database wrapper.
61 It must have a Database attribute defining PEP-249 exceptions.
62 """
63 self.wrapper = wrapper
65 def __enter__(self):
66 pass
68 def __exit__(self, exc_type, exc_value, traceback):
69 if exc_type is None:
70 return
71 for plain_exc_type in (
72 DataError,
73 OperationalError,
74 IntegrityError,
75 InternalError,
76 ProgrammingError,
77 NotSupportedError,
78 DatabaseError,
79 InterfaceError,
80 Error,
81 ):
82 db_exc_type = getattr(self.wrapper.Database, plain_exc_type.__name__)
83 if issubclass(exc_type, db_exc_type):
84 plain_exc_value = plain_exc_type(*exc_value.args)
85 # Only set the 'errors_occurred' flag for errors that may make
86 # the connection unusable.
87 if plain_exc_type not in (DataError, IntegrityError):
88 self.wrapper.errors_occurred = True
89 raise plain_exc_value.with_traceback(traceback) from exc_value
91 def __call__(self, func):
92 # Note that we are intentionally not using @wraps here for performance
93 # reasons. Refs #21109.
94 def inner(*args, **kwargs):
95 with self:
96 return func(*args, **kwargs)
98 return inner
101def load_backend(backend_name):
102 """
103 Return a database backend's "base" module given a fully qualified database
104 backend name, or raise an error if it doesn't exist.
105 """
106 try:
107 return import_module("%s.base" % backend_name)
108 except ImportError as e_user:
109 # The database backend wasn't found. Display a helpful error message
110 # listing all built-in database backends.
111 import plain.models.backends
113 builtin_backends = [
114 name
115 for _, name, ispkg in pkgutil.iter_modules(plain.models.backends.__path__)
116 if ispkg and name not in {"base", "dummy"}
117 ]
118 if backend_name not in [
119 "plain.models.backends.%s" % b for b in builtin_backends
120 ]:
121 backend_reprs = map(repr, sorted(builtin_backends))
122 raise ImproperlyConfigured(
123 "{!r} isn't an available database backend or couldn't be "
124 "imported. Check the above exception. To use one of the "
125 "built-in backends, use 'plain.models.backends.XXX', where XXX "
126 "is one of:\n"
127 " {}".format(backend_name, ", ".join(backend_reprs))
128 ) from e_user
129 else:
130 # If there's some other error, this must be an error in Plain
131 raise
134class ConnectionHandler(BaseConnectionHandler):
135 settings_name = "DATABASES"
137 def configure_settings(self, databases):
138 databases = super().configure_settings(databases)
139 if databases == {}:
140 databases[DEFAULT_DB_ALIAS] = {"ENGINE": "plain.models.backends.dummy"}
141 elif DEFAULT_DB_ALIAS not in databases:
142 raise ImproperlyConfigured(
143 f"You must define a '{DEFAULT_DB_ALIAS}' database."
144 )
145 elif databases[DEFAULT_DB_ALIAS] == {}:
146 databases[DEFAULT_DB_ALIAS]["ENGINE"] = "plain.models.backends.dummy"
148 # Configure default settings.
149 for conn in databases.values():
150 conn.setdefault("AUTOCOMMIT", True)
151 conn.setdefault("ENGINE", "plain.models.backends.dummy")
152 if conn["ENGINE"] == "plain.models.backends." or not conn["ENGINE"]:
153 conn["ENGINE"] = "plain.models.backends.dummy"
154 conn.setdefault("CONN_MAX_AGE", 0)
155 conn.setdefault("CONN_HEALTH_CHECKS", False)
156 conn.setdefault("OPTIONS", {})
157 conn.setdefault("TIME_ZONE", None)
158 for setting in ["NAME", "USER", "PASSWORD", "HOST", "PORT"]:
159 conn.setdefault(setting, "")
161 test_settings = conn.setdefault("TEST", {})
162 default_test_settings = [
163 ("CHARSET", None),
164 ("COLLATION", None),
165 ("MIGRATE", True),
166 ("MIRROR", None),
167 ("NAME", None),
168 ]
169 for key, value in default_test_settings:
170 test_settings.setdefault(key, value)
171 return databases
173 @property
174 def databases(self):
175 # Maintained for backward compatibility as some 3rd party packages have
176 # made use of this private API in the past. It is no longer used within
177 # Plain itself.
178 return self.settings
180 def create_connection(self, alias):
181 db = self.settings[alias]
182 backend = load_backend(db["ENGINE"])
183 return backend.DatabaseWrapper(db, alias)
186class ConnectionRouter:
187 def __init__(self, routers=None):
188 """
189 If routers is not specified, default to settings.DATABASE_ROUTERS.
190 """
191 self._routers = routers
193 @cached_property
194 def routers(self):
195 if self._routers is None:
196 self._routers = settings.DATABASE_ROUTERS
197 routers = []
198 for r in self._routers:
199 if isinstance(r, str):
200 router = import_string(r)()
201 else:
202 router = r
203 routers.append(router)
204 return routers
206 def _router_func(action):
207 def _route_db(self, model, **hints):
208 chosen_db = None
209 for router in self.routers:
210 try:
211 method = getattr(router, action)
212 except AttributeError:
213 # If the router doesn't have a method, skip to the next one.
214 pass
215 else:
216 chosen_db = method(model, **hints)
217 if chosen_db:
218 return chosen_db
219 instance = hints.get("instance")
220 if instance is not None and instance._state.db:
221 return instance._state.db
222 return DEFAULT_DB_ALIAS
224 return _route_db
226 db_for_read = _router_func("db_for_read")
227 db_for_write = _router_func("db_for_write")
229 def allow_relation(self, obj1, obj2, **hints):
230 for router in self.routers:
231 try:
232 method = router.allow_relation
233 except AttributeError:
234 # If the router doesn't have a method, skip to the next one.
235 pass
236 else:
237 allow = method(obj1, obj2, **hints)
238 if allow is not None:
239 return allow
240 return obj1._state.db == obj2._state.db
242 def allow_migrate(self, db, package_label, **hints):
243 for router in self.routers:
244 try:
245 method = router.allow_migrate
246 except AttributeError:
247 # If the router doesn't have a method, skip to the next one.
248 continue
250 allow = method(db, package_label, **hints)
252 if allow is not None:
253 return allow
254 return True
256 def allow_migrate_model(self, db, model):
257 return self.allow_migrate(
258 db,
259 model._meta.package_label,
260 model_name=model._meta.model_name,
261 model=model,
262 )
264 def get_migratable_models(self, package_config, db, include_auto_created=False):
265 """Return app models allowed to be migrated on provided db."""
266 models = package_config.get_models(include_auto_created=include_auto_created)
267 return [model for model in models if self.allow_migrate_model(db, model)]
270connections = ConnectionHandler()
272router = ConnectionRouter()
274# For backwards compatibility. Prefer connections['default'] instead.
275connection = ConnectionProxy(connections, DEFAULT_DB_ALIAS)
278# Register an event to reset saved queries when a Plain request is started.
279def reset_queries(**kwargs):
280 for conn in connections.all(initialized_only=True):
281 conn.queries_log.clear()
284signals.request_started.connect(reset_queries)
287# Register an event to reset transaction state and close connections past
288# their lifetime.
289def close_old_connections(**kwargs):
290 for conn in connections.all(initialized_only=True):
291 conn.close_if_unusable_or_obsolete()
294signals.request_started.connect(close_old_connections)
295signals.request_finished.connect(close_old_connections)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from os import environ
3from . import database_url
5# Make DATABASES a required setting
6DATABASES: dict
8# Automatically configure DATABASES if a DATABASE_URL was given in the environment
9if "DATABASE_URL" in environ:
10 DATABASES = {
11 "default": database_url.parse(
12 environ["DATABASE_URL"],
13 # Enable persistent connections by default
14 conn_max_age=int(environ.get("DATABASE_CONN_MAX_AGE", 600)),
15 conn_health_checks=environ.get(
16 "DATABASE_CONN_HEALTH_CHECKS", "true"
17 ).lower()
18 in [
19 "true",
20 "1",
21 ],
22 )
23 }
25# Classes used to implement DB routing behavior.
26DATABASE_ROUTERS = []
28# The tablespaces to use for each model when not specified otherwise.
29DEFAULT_TABLESPACE = ""
30DEFAULT_INDEX_TABLESPACE = ""
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from collections import Counter, defaultdict
2from functools import partial, reduce
3from itertools import chain
4from operator import attrgetter, or_
6from plain.models import (
7 query_utils,
8 signals,
9 sql,
10 transaction,
11)
12from plain.models.db import IntegrityError, connections
13from plain.models.query import QuerySet
16class ProtectedError(IntegrityError):
17 def __init__(self, msg, protected_objects):
18 self.protected_objects = protected_objects
19 super().__init__(msg, protected_objects)
22class RestrictedError(IntegrityError):
23 def __init__(self, msg, restricted_objects):
24 self.restricted_objects = restricted_objects
25 super().__init__(msg, restricted_objects)
28def CASCADE(collector, field, sub_objs, using):
29 collector.collect(
30 sub_objs,
31 source=field.remote_field.model,
32 source_attr=field.name,
33 nullable=field.null,
34 fail_on_restricted=False,
35 )
36 if field.null and not connections[using].features.can_defer_constraint_checks:
37 collector.add_field_update(field, None, sub_objs)
40def PROTECT(collector, field, sub_objs, using):
41 raise ProtectedError(
42 "Cannot delete some instances of model '{}' because they are "
43 "referenced through a protected foreign key: '{}.{}'".format(
44 field.remote_field.model.__name__,
45 sub_objs[0].__class__.__name__,
46 field.name,
47 ),
48 sub_objs,
49 )
52def RESTRICT(collector, field, sub_objs, using):
53 collector.add_restricted_objects(field, sub_objs)
54 collector.add_dependency(field.remote_field.model, field.model)
57def SET(value):
58 if callable(value):
60 def set_on_delete(collector, field, sub_objs, using):
61 collector.add_field_update(field, value(), sub_objs)
63 else:
65 def set_on_delete(collector, field, sub_objs, using):
66 collector.add_field_update(field, value, sub_objs)
68 set_on_delete.deconstruct = lambda: ("plain.models.SET", (value,), {})
69 set_on_delete.lazy_sub_objs = True
70 return set_on_delete
73def SET_NULL(collector, field, sub_objs, using):
74 collector.add_field_update(field, None, sub_objs)
77SET_NULL.lazy_sub_objs = True
80def SET_DEFAULT(collector, field, sub_objs, using):
81 collector.add_field_update(field, field.get_default(), sub_objs)
84SET_DEFAULT.lazy_sub_objs = True
87def DO_NOTHING(collector, field, sub_objs, using):
88 pass
91def get_candidate_relations_to_delete(opts):
92 # The candidate relations are the ones that come from N-1 and 1-1 relations.
93 # N-N (i.e., many-to-many) relations aren't candidates for deletion.
94 return (
95 f
96 for f in opts.get_fields(include_hidden=True)
97 if f.auto_created and not f.concrete and (f.one_to_one or f.one_to_many)
98 )
101class Collector:
102 def __init__(self, using, origin=None):
103 self.using = using
104 # A Model or QuerySet object.
105 self.origin = origin
106 # Initially, {model: {instances}}, later values become lists.
107 self.data = defaultdict(set)
108 # {(field, value): [instances, …]}
109 self.field_updates = defaultdict(list)
110 # {model: {field: {instances}}}
111 self.restricted_objects = defaultdict(partial(defaultdict, set))
112 # fast_deletes is a list of queryset-likes that can be deleted without
113 # fetching the objects into memory.
114 self.fast_deletes = []
116 # Tracks deletion-order dependency for databases without transactions
117 # or ability to defer constraint checks. Only concrete model classes
118 # should be included, as the dependencies exist only between actual
119 # database tables.
120 self.dependencies = defaultdict(set) # {model: {models}}
122 def add(self, objs, source=None, nullable=False, reverse_dependency=False):
123 """
124 Add 'objs' to the collection of objects to be deleted. If the call is
125 the result of a cascade, 'source' should be the model that caused it,
126 and 'nullable' should be set to True if the relation can be null.
128 Return a list of all objects that were not already collected.
129 """
130 if not objs:
131 return []
132 new_objs = []
133 model = objs[0].__class__
134 instances = self.data[model]
135 for obj in objs:
136 if obj not in instances:
137 new_objs.append(obj)
138 instances.update(new_objs)
139 # Nullable relationships can be ignored -- they are nulled out before
140 # deleting, and therefore do not affect the order in which objects have
141 # to be deleted.
142 if source is not None and not nullable:
143 self.add_dependency(source, model, reverse_dependency=reverse_dependency)
144 return new_objs
146 def add_dependency(self, model, dependency, reverse_dependency=False):
147 if reverse_dependency:
148 model, dependency = dependency, model
149 self.dependencies[model._meta.concrete_model].add(
150 dependency._meta.concrete_model
151 )
152 self.data.setdefault(dependency, self.data.default_factory())
154 def add_field_update(self, field, value, objs):
155 """
156 Schedule a field update. 'objs' must be a homogeneous iterable
157 collection of model instances (e.g. a QuerySet).
158 """
159 self.field_updates[field, value].append(objs)
161 def add_restricted_objects(self, field, objs):
162 if objs:
163 model = objs[0].__class__
164 self.restricted_objects[model][field].update(objs)
166 def clear_restricted_objects_from_set(self, model, objs):
167 if model in self.restricted_objects:
168 self.restricted_objects[model] = {
169 field: items - objs
170 for field, items in self.restricted_objects[model].items()
171 }
173 def clear_restricted_objects_from_queryset(self, model, qs):
174 if model in self.restricted_objects:
175 objs = set(
176 qs.filter(
177 pk__in=[
178 obj.pk
179 for objs in self.restricted_objects[model].values()
180 for obj in objs
181 ]
182 )
183 )
184 self.clear_restricted_objects_from_set(model, objs)
186 def _has_signal_listeners(self, model):
187 return signals.pre_delete.has_listeners(
188 model
189 ) or signals.post_delete.has_listeners(model)
191 def can_fast_delete(self, objs, from_field=None):
192 """
193 Determine if the objects in the given queryset-like or single object
194 can be fast-deleted. This can be done if there are no cascades, no
195 parents and no signal listeners for the object class.
197 The 'from_field' tells where we are coming from - we need this to
198 determine if the objects are in fact to be deleted. Allow also
199 skipping parent -> child -> parent chain preventing fast delete of
200 the child.
201 """
202 if from_field and from_field.remote_field.on_delete is not CASCADE:
203 return False
204 if hasattr(objs, "_meta"):
205 model = objs._meta.model
206 elif hasattr(objs, "model") and hasattr(objs, "_raw_delete"):
207 model = objs.model
208 else:
209 return False
210 if self._has_signal_listeners(model):
211 return False
212 # The use of from_field comes from the need to avoid cascade back to
213 # parent when parent delete is cascading to child.
214 opts = model._meta
215 return (
216 all(
217 link == from_field
218 for link in opts.concrete_model._meta.parents.values()
219 )
220 and
221 # Foreign keys pointing to this model.
222 all(
223 related.field.remote_field.on_delete is DO_NOTHING
224 for related in get_candidate_relations_to_delete(opts)
225 )
226 and (
227 # Something like generic foreign key.
228 not any(
229 hasattr(field, "bulk_related_objects")
230 for field in opts.private_fields
231 )
232 )
233 )
235 def get_del_batches(self, objs, fields):
236 """
237 Return the objs in suitably sized batches for the used connection.
238 """
239 field_names = [field.name for field in fields]
240 conn_batch_size = max(
241 connections[self.using].ops.bulk_batch_size(field_names, objs), 1
242 )
243 if len(objs) > conn_batch_size:
244 return [
245 objs[i : i + conn_batch_size]
246 for i in range(0, len(objs), conn_batch_size)
247 ]
248 else:
249 return [objs]
251 def collect(
252 self,
253 objs,
254 source=None,
255 nullable=False,
256 collect_related=True,
257 source_attr=None,
258 reverse_dependency=False,
259 keep_parents=False,
260 fail_on_restricted=True,
261 ):
262 """
263 Add 'objs' to the collection of objects to be deleted as well as all
264 parent instances. 'objs' must be a homogeneous iterable collection of
265 model instances (e.g. a QuerySet). If 'collect_related' is True,
266 related objects will be handled by their respective on_delete handler.
268 If the call is the result of a cascade, 'source' should be the model
269 that caused it and 'nullable' should be set to True, if the relation
270 can be null.
272 If 'reverse_dependency' is True, 'source' will be deleted before the
273 current model, rather than after. (Needed for cascading to parent
274 models, the one case in which the cascade follows the forwards
275 direction of an FK rather than the reverse direction.)
277 If 'keep_parents' is True, data of parent model's will be not deleted.
279 If 'fail_on_restricted' is False, error won't be raised even if it's
280 prohibited to delete such objects due to RESTRICT, that defers
281 restricted object checking in recursive calls where the top-level call
282 may need to collect more objects to determine whether restricted ones
283 can be deleted.
284 """
285 if self.can_fast_delete(objs):
286 self.fast_deletes.append(objs)
287 return
288 new_objs = self.add(
289 objs, source, nullable, reverse_dependency=reverse_dependency
290 )
291 if not new_objs:
292 return
294 model = new_objs[0].__class__
296 if not keep_parents:
297 # Recursively collect concrete model's parent models, but not their
298 # related objects. These will be found by meta.get_fields()
299 concrete_model = model._meta.concrete_model
300 for ptr in concrete_model._meta.parents.values():
301 if ptr:
302 parent_objs = [getattr(obj, ptr.name) for obj in new_objs]
303 self.collect(
304 parent_objs,
305 source=model,
306 source_attr=ptr.remote_field.related_name,
307 collect_related=False,
308 reverse_dependency=True,
309 fail_on_restricted=False,
310 )
311 if not collect_related:
312 return
314 if keep_parents:
315 parents = set(model._meta.get_parent_list())
316 model_fast_deletes = defaultdict(list)
317 protected_objects = defaultdict(list)
318 for related in get_candidate_relations_to_delete(model._meta):
319 # Preserve parent reverse relationships if keep_parents=True.
320 if keep_parents and related.model in parents:
321 continue
322 field = related.field
323 on_delete = field.remote_field.on_delete
324 if on_delete == DO_NOTHING:
325 continue
326 related_model = related.related_model
327 if self.can_fast_delete(related_model, from_field=field):
328 model_fast_deletes[related_model].append(field)
329 continue
330 batches = self.get_del_batches(new_objs, [field])
331 for batch in batches:
332 sub_objs = self.related_objects(related_model, [field], batch)
333 # Non-referenced fields can be deferred if no signal receivers
334 # are connected for the related model as they'll never be
335 # exposed to the user. Skip field deferring when some
336 # relationships are select_related as interactions between both
337 # features are hard to get right. This should only happen in
338 # the rare cases where .related_objects is overridden anyway.
339 if not (
340 sub_objs.query.select_related
341 or self._has_signal_listeners(related_model)
342 ):
343 referenced_fields = set(
344 chain.from_iterable(
345 (rf.attname for rf in rel.field.foreign_related_fields)
346 for rel in get_candidate_relations_to_delete(
347 related_model._meta
348 )
349 )
350 )
351 sub_objs = sub_objs.only(*tuple(referenced_fields))
352 if getattr(on_delete, "lazy_sub_objs", False) or sub_objs:
353 try:
354 on_delete(self, field, sub_objs, self.using)
355 except ProtectedError as error:
356 key = f"'{field.model.__name__}.{field.name}'"
357 protected_objects[key] += error.protected_objects
358 if protected_objects:
359 raise ProtectedError(
360 "Cannot delete some instances of model {!r} because they are "
361 "referenced through protected foreign keys: {}.".format(
362 model.__name__,
363 ", ".join(protected_objects),
364 ),
365 set(chain.from_iterable(protected_objects.values())),
366 )
367 for related_model, related_fields in model_fast_deletes.items():
368 batches = self.get_del_batches(new_objs, related_fields)
369 for batch in batches:
370 sub_objs = self.related_objects(related_model, related_fields, batch)
371 self.fast_deletes.append(sub_objs)
372 for field in model._meta.private_fields:
373 if hasattr(field, "bulk_related_objects"):
374 # It's something like generic foreign key.
375 sub_objs = field.bulk_related_objects(new_objs, self.using)
376 self.collect(
377 sub_objs, source=model, nullable=True, fail_on_restricted=False
378 )
380 if fail_on_restricted:
381 # Raise an error if collected restricted objects (RESTRICT) aren't
382 # candidates for deletion also collected via CASCADE.
383 for related_model, instances in self.data.items():
384 self.clear_restricted_objects_from_set(related_model, instances)
385 for qs in self.fast_deletes:
386 self.clear_restricted_objects_from_queryset(qs.model, qs)
387 if self.restricted_objects.values():
388 restricted_objects = defaultdict(list)
389 for related_model, fields in self.restricted_objects.items():
390 for field, objs in fields.items():
391 if objs:
392 key = f"'{related_model.__name__}.{field.name}'"
393 restricted_objects[key] += objs
394 if restricted_objects:
395 raise RestrictedError(
396 "Cannot delete some instances of model {!r} because "
397 "they are referenced through restricted foreign keys: "
398 "{}.".format(
399 model.__name__,
400 ", ".join(restricted_objects),
401 ),
402 set(chain.from_iterable(restricted_objects.values())),
403 )
405 def related_objects(self, related_model, related_fields, objs):
406 """
407 Get a QuerySet of the related model to objs via related fields.
408 """
409 predicate = query_utils.Q.create(
410 [(f"{related_field.name}__in", objs) for related_field in related_fields],
411 connector=query_utils.Q.OR,
412 )
413 return related_model._base_manager.using(self.using).filter(predicate)
415 def instances_with_model(self):
416 for model, instances in self.data.items():
417 for obj in instances:
418 yield model, obj
420 def sort(self):
421 sorted_models = []
422 concrete_models = set()
423 models = list(self.data)
424 while len(sorted_models) < len(models):
425 found = False
426 for model in models:
427 if model in sorted_models:
428 continue
429 dependencies = self.dependencies.get(model._meta.concrete_model)
430 if not (dependencies and dependencies.difference(concrete_models)):
431 sorted_models.append(model)
432 concrete_models.add(model._meta.concrete_model)
433 found = True
434 if not found:
435 return
436 self.data = {model: self.data[model] for model in sorted_models}
438 def delete(self):
439 # sort instance collections
440 for model, instances in self.data.items():
441 self.data[model] = sorted(instances, key=attrgetter("pk"))
443 # if possible, bring the models in an order suitable for databases that
444 # don't support transactions or cannot defer constraint checks until the
445 # end of a transaction.
446 self.sort()
447 # number of objects deleted for each model label
448 deleted_counter = Counter()
450 # Optimize for the case with a single obj and no dependencies
451 if len(self.data) == 1 and len(instances) == 1:
452 instance = list(instances)[0]
453 if self.can_fast_delete(instance):
454 with transaction.mark_for_rollback_on_error(self.using):
455 count = sql.DeleteQuery(model).delete_batch(
456 [instance.pk], self.using
457 )
458 setattr(instance, model._meta.pk.attname, None)
459 return count, {model._meta.label: count}
461 with transaction.atomic(using=self.using, savepoint=False):
462 # send pre_delete signals
463 for model, obj in self.instances_with_model():
464 if not model._meta.auto_created:
465 signals.pre_delete.send(
466 sender=model,
467 instance=obj,
468 using=self.using,
469 origin=self.origin,
470 )
472 # fast deletes
473 for qs in self.fast_deletes:
474 count = qs._raw_delete(using=self.using)
475 if count:
476 deleted_counter[qs.model._meta.label] += count
478 # update fields
479 for (field, value), instances_list in self.field_updates.items():
480 updates = []
481 objs = []
482 for instances in instances_list:
483 if (
484 isinstance(instances, QuerySet)
485 and instances._result_cache is None
486 ):
487 updates.append(instances)
488 else:
489 objs.extend(instances)
490 if updates:
491 combined_updates = reduce(or_, updates)
492 combined_updates.update(**{field.name: value})
493 if objs:
494 model = objs[0].__class__
495 query = sql.UpdateQuery(model)
496 query.update_batch(
497 list({obj.pk for obj in objs}), {field.name: value}, self.using
498 )
500 # reverse instance collections
501 for instances in self.data.values():
502 instances.reverse()
504 # delete instances
505 for model, instances in self.data.items():
506 query = sql.DeleteQuery(model)
507 pk_list = [obj.pk for obj in instances]
508 count = query.delete_batch(pk_list, self.using)
509 if count:
510 deleted_counter[model._meta.label] += count
512 if not model._meta.auto_created:
513 for obj in instances:
514 signals.post_delete.send(
515 sender=model,
516 instance=obj,
517 using=self.using,
518 origin=self.origin,
519 )
521 for model, instances in self.data.items():
522 for instance in instances:
523 setattr(instance, model._meta.pk.attname, None)
524 return sum(deleted_counter.values()), dict(deleted_counter)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import enum
2from types import DynamicClassAttribute
4from plain.utils.functional import Promise
6__all__ = ["Choices", "IntegerChoices", "TextChoices"]
9class ChoicesMeta(enum.EnumMeta):
10 """A metaclass for creating a enum choices."""
12 def __new__(metacls, classname, bases, classdict, **kwds):
13 labels = []
14 for key in classdict._member_names:
15 value = classdict[key]
16 if (
17 isinstance(value, list | tuple)
18 and len(value) > 1
19 and isinstance(value[-1], Promise | str)
20 ):
21 *value, label = value
22 value = tuple(value)
23 else:
24 label = key.replace("_", " ").title()
25 labels.append(label)
26 # Use dict.__setitem__() to suppress defenses against double
27 # assignment in enum's classdict.
28 dict.__setitem__(classdict, key, value)
29 cls = super().__new__(metacls, classname, bases, classdict, **kwds)
30 for member, label in zip(cls.__members__.values(), labels):
31 member._label_ = label
32 return enum.unique(cls)
34 def __contains__(cls, member):
35 if not isinstance(member, enum.Enum):
36 # Allow non-enums to match against member values.
37 return any(x.value == member for x in cls)
38 return super().__contains__(member)
40 @property
41 def names(cls):
42 empty = ["__empty__"] if hasattr(cls, "__empty__") else []
43 return empty + [member.name for member in cls]
45 @property
46 def choices(cls):
47 empty = [(None, cls.__empty__)] if hasattr(cls, "__empty__") else []
48 return empty + [(member.value, member.label) for member in cls]
50 @property
51 def labels(cls):
52 return [label for _, label in cls.choices]
54 @property
55 def values(cls):
56 return [value for value, _ in cls.choices]
59class Choices(enum.Enum, metaclass=ChoicesMeta):
60 """Class for creating enumerated choices."""
62 @DynamicClassAttribute
63 def label(self):
64 return self._label_
66 @property
67 def do_not_call_in_templates(self):
68 return True
70 def __str__(self):
71 """
72 Use value when cast to str, so that Choices set as model instance
73 attributes are rendered as expected in templates and similar contexts.
74 """
75 return str(self.value)
77 # A similar format was proposed for Python 3.10.
78 def __repr__(self):
79 return f"{self.__class__.__qualname__}.{self._name_}"
82class IntegerChoices(int, Choices):
83 """Class for creating enumerated integer choices."""
85 pass
88class TextChoices(str, Choices):
89 """Class for creating enumerated string choices."""
91 def _generate_next_value_(name, start, count, last_values):
92 return name
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import copy
2import datetime
3import functools
4import inspect
5from collections import defaultdict
6from decimal import Decimal
7from types import NoneType
8from uuid import UUID
10from plain.exceptions import EmptyResultSet, FieldError, FullResultSet
11from plain.models import fields
12from plain.models.constants import LOOKUP_SEP
13from plain.models.db import DatabaseError, NotSupportedError, connection
14from plain.models.query_utils import Q
15from plain.utils.deconstruct import deconstructible
16from plain.utils.functional import cached_property
17from plain.utils.hashable import make_hashable
20class SQLiteNumericMixin:
21 """
22 Some expressions with output_field=DecimalField() must be cast to
23 numeric to be properly filtered.
24 """
26 def as_sqlite(self, compiler, connection, **extra_context):
27 sql, params = self.as_sql(compiler, connection, **extra_context)
28 try:
29 if self.output_field.get_internal_type() == "DecimalField":
30 sql = "CAST(%s AS NUMERIC)" % sql
31 except FieldError:
32 pass
33 return sql, params
36class Combinable:
37 """
38 Provide the ability to combine one or two objects with
39 some connector. For example F('foo') + F('bar').
40 """
42 # Arithmetic connectors
43 ADD = "+"
44 SUB = "-"
45 MUL = "*"
46 DIV = "/"
47 POW = "^"
48 # The following is a quoted % operator - it is quoted because it can be
49 # used in strings that also have parameter substitution.
50 MOD = "%%"
52 # Bitwise operators - note that these are generated by .bitand()
53 # and .bitor(), the '&' and '|' are reserved for boolean operator
54 # usage.
55 BITAND = "&"
56 BITOR = "|"
57 BITLEFTSHIFT = "<<"
58 BITRIGHTSHIFT = ">>"
59 BITXOR = "#"
61 def _combine(self, other, connector, reversed):
62 if not hasattr(other, "resolve_expression"):
63 # everything must be resolvable to an expression
64 other = Value(other)
66 if reversed:
67 return CombinedExpression(other, connector, self)
68 return CombinedExpression(self, connector, other)
70 #############
71 # OPERATORS #
72 #############
74 def __neg__(self):
75 return self._combine(-1, self.MUL, False)
77 def __add__(self, other):
78 return self._combine(other, self.ADD, False)
80 def __sub__(self, other):
81 return self._combine(other, self.SUB, False)
83 def __mul__(self, other):
84 return self._combine(other, self.MUL, False)
86 def __truediv__(self, other):
87 return self._combine(other, self.DIV, False)
89 def __mod__(self, other):
90 return self._combine(other, self.MOD, False)
92 def __pow__(self, other):
93 return self._combine(other, self.POW, False)
95 def __and__(self, other):
96 if getattr(self, "conditional", False) and getattr(other, "conditional", False):
97 return Q(self) & Q(other)
98 raise NotImplementedError(
99 "Use .bitand(), .bitor(), and .bitxor() for bitwise logical operations."
100 )
102 def bitand(self, other):
103 return self._combine(other, self.BITAND, False)
105 def bitleftshift(self, other):
106 return self._combine(other, self.BITLEFTSHIFT, False)
108 def bitrightshift(self, other):
109 return self._combine(other, self.BITRIGHTSHIFT, False)
111 def __xor__(self, other):
112 if getattr(self, "conditional", False) and getattr(other, "conditional", False):
113 return Q(self) ^ Q(other)
114 raise NotImplementedError(
115 "Use .bitand(), .bitor(), and .bitxor() for bitwise logical operations."
116 )
118 def bitxor(self, other):
119 return self._combine(other, self.BITXOR, False)
121 def __or__(self, other):
122 if getattr(self, "conditional", False) and getattr(other, "conditional", False):
123 return Q(self) | Q(other)
124 raise NotImplementedError(
125 "Use .bitand(), .bitor(), and .bitxor() for bitwise logical operations."
126 )
128 def bitor(self, other):
129 return self._combine(other, self.BITOR, False)
131 def __radd__(self, other):
132 return self._combine(other, self.ADD, True)
134 def __rsub__(self, other):
135 return self._combine(other, self.SUB, True)
137 def __rmul__(self, other):
138 return self._combine(other, self.MUL, True)
140 def __rtruediv__(self, other):
141 return self._combine(other, self.DIV, True)
143 def __rmod__(self, other):
144 return self._combine(other, self.MOD, True)
146 def __rpow__(self, other):
147 return self._combine(other, self.POW, True)
149 def __rand__(self, other):
150 raise NotImplementedError(
151 "Use .bitand(), .bitor(), and .bitxor() for bitwise logical operations."
152 )
154 def __ror__(self, other):
155 raise NotImplementedError(
156 "Use .bitand(), .bitor(), and .bitxor() for bitwise logical operations."
157 )
159 def __rxor__(self, other):
160 raise NotImplementedError(
161 "Use .bitand(), .bitor(), and .bitxor() for bitwise logical operations."
162 )
164 def __invert__(self):
165 return NegatedExpression(self)
168class BaseExpression:
169 """Base class for all query expressions."""
171 empty_result_set_value = NotImplemented
172 # aggregate specific fields
173 is_summary = False
174 _output_field_resolved_to_none = False
175 # Can the expression be used in a WHERE clause?
176 filterable = True
177 # Can the expression can be used as a source expression in Window?
178 window_compatible = False
180 def __init__(self, output_field=None):
181 if output_field is not None:
182 self.output_field = output_field
184 def __getstate__(self):
185 state = self.__dict__.copy()
186 state.pop("convert_value", None)
187 return state
189 def get_db_converters(self, connection):
190 return (
191 []
192 if self.convert_value is self._convert_value_noop
193 else [self.convert_value]
194 ) + self.output_field.get_db_converters(connection)
196 def get_source_expressions(self):
197 return []
199 def set_source_expressions(self, exprs):
200 assert not exprs
202 def _parse_expressions(self, *expressions):
203 return [
204 arg
205 if hasattr(arg, "resolve_expression")
206 else (F(arg) if isinstance(arg, str) else Value(arg))
207 for arg in expressions
208 ]
210 def as_sql(self, compiler, connection):
211 """
212 Responsible for returning a (sql, [params]) tuple to be included
213 in the current query.
215 Different backends can provide their own implementation, by
216 providing an `as_{vendor}` method and patching the Expression:
218 ```
219 def override_as_sql(self, compiler, connection):
220 # custom logic
221 return super().as_sql(compiler, connection)
222 setattr(Expression, 'as_' + connection.vendor, override_as_sql)
223 ```
225 Arguments:
226 * compiler: the query compiler responsible for generating the query.
227 Must have a compile method, returning a (sql, [params]) tuple.
228 Calling compiler(value) will return a quoted `value`.
230 * connection: the database connection used for the current query.
232 Return: (sql, params)
233 Where `sql` is a string containing ordered sql parameters to be
234 replaced with the elements of the list `params`.
235 """
236 raise NotImplementedError("Subclasses must implement as_sql()")
238 @cached_property
239 def contains_aggregate(self):
240 return any(
241 expr and expr.contains_aggregate for expr in self.get_source_expressions()
242 )
244 @cached_property
245 def contains_over_clause(self):
246 return any(
247 expr and expr.contains_over_clause for expr in self.get_source_expressions()
248 )
250 @cached_property
251 def contains_column_references(self):
252 return any(
253 expr and expr.contains_column_references
254 for expr in self.get_source_expressions()
255 )
257 def resolve_expression(
258 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
259 ):
260 """
261 Provide the chance to do any preprocessing or validation before being
262 added to the query.
264 Arguments:
265 * query: the backend query implementation
266 * allow_joins: boolean allowing or denying use of joins
267 in this query
268 * reuse: a set of reusable joins for multijoins
269 * summarize: a terminal aggregate clause
270 * for_save: whether this expression about to be used in a save or update
272 Return: an Expression to be added to the query.
273 """
274 c = self.copy()
275 c.is_summary = summarize
276 c.set_source_expressions(
277 [
278 expr.resolve_expression(query, allow_joins, reuse, summarize)
279 if expr
280 else None
281 for expr in c.get_source_expressions()
282 ]
283 )
284 return c
286 @property
287 def conditional(self):
288 return isinstance(self.output_field, fields.BooleanField)
290 @property
291 def field(self):
292 return self.output_field
294 @cached_property
295 def output_field(self):
296 """Return the output type of this expressions."""
297 output_field = self._resolve_output_field()
298 if output_field is None:
299 self._output_field_resolved_to_none = True
300 raise FieldError("Cannot resolve expression type, unknown output_field")
301 return output_field
303 @cached_property
304 def _output_field_or_none(self):
305 """
306 Return the output field of this expression, or None if
307 _resolve_output_field() didn't return an output type.
308 """
309 try:
310 return self.output_field
311 except FieldError:
312 if not self._output_field_resolved_to_none:
313 raise
315 def _resolve_output_field(self):
316 """
317 Attempt to infer the output type of the expression.
319 As a guess, if the output fields of all source fields match then simply
320 infer the same type here.
322 If a source's output field resolves to None, exclude it from this check.
323 If all sources are None, then an error is raised higher up the stack in
324 the output_field property.
325 """
326 # This guess is mostly a bad idea, but there is quite a lot of code
327 # (especially 3rd party Func subclasses) that depend on it, we'd need a
328 # deprecation path to fix it.
329 sources_iter = (
330 source for source in self.get_source_fields() if source is not None
331 )
332 for output_field in sources_iter:
333 for source in sources_iter:
334 if not isinstance(output_field, source.__class__):
335 raise FieldError(
336 "Expression contains mixed types: {}, {}. You must "
337 "set output_field.".format(
338 output_field.__class__.__name__,
339 source.__class__.__name__,
340 )
341 )
342 return output_field
344 @staticmethod
345 def _convert_value_noop(value, expression, connection):
346 return value
348 @cached_property
349 def convert_value(self):
350 """
351 Expressions provide their own converters because users have the option
352 of manually specifying the output_field which may be a different type
353 from the one the database returns.
354 """
355 field = self.output_field
356 internal_type = field.get_internal_type()
357 if internal_type == "FloatField":
358 return (
359 lambda value, expression, connection: None
360 if value is None
361 else float(value)
362 )
363 elif internal_type.endswith("IntegerField"):
364 return (
365 lambda value, expression, connection: None
366 if value is None
367 else int(value)
368 )
369 elif internal_type == "DecimalField":
370 return (
371 lambda value, expression, connection: None
372 if value is None
373 else Decimal(value)
374 )
375 return self._convert_value_noop
377 def get_lookup(self, lookup):
378 return self.output_field.get_lookup(lookup)
380 def get_transform(self, name):
381 return self.output_field.get_transform(name)
383 def relabeled_clone(self, change_map):
384 clone = self.copy()
385 clone.set_source_expressions(
386 [
387 e.relabeled_clone(change_map) if e is not None else None
388 for e in self.get_source_expressions()
389 ]
390 )
391 return clone
393 def replace_expressions(self, replacements):
394 if replacement := replacements.get(self):
395 return replacement
396 clone = self.copy()
397 source_expressions = clone.get_source_expressions()
398 clone.set_source_expressions(
399 [
400 expr.replace_expressions(replacements) if expr else None
401 for expr in source_expressions
402 ]
403 )
404 return clone
406 def get_refs(self):
407 refs = set()
408 for expr in self.get_source_expressions():
409 refs |= expr.get_refs()
410 return refs
412 def copy(self):
413 return copy.copy(self)
415 def prefix_references(self, prefix):
416 clone = self.copy()
417 clone.set_source_expressions(
418 [
419 F(f"{prefix}{expr.name}")
420 if isinstance(expr, F)
421 else expr.prefix_references(prefix)
422 for expr in self.get_source_expressions()
423 ]
424 )
425 return clone
427 def get_group_by_cols(self):
428 if not self.contains_aggregate:
429 return [self]
430 cols = []
431 for source in self.get_source_expressions():
432 cols.extend(source.get_group_by_cols())
433 return cols
435 def get_source_fields(self):
436 """Return the underlying field types used by this aggregate."""
437 return [e._output_field_or_none for e in self.get_source_expressions()]
439 def asc(self, **kwargs):
440 return OrderBy(self, **kwargs)
442 def desc(self, **kwargs):
443 return OrderBy(self, descending=True, **kwargs)
445 def reverse_ordering(self):
446 return self
448 def flatten(self):
449 """
450 Recursively yield this expression and all subexpressions, in
451 depth-first order.
452 """
453 yield self
454 for expr in self.get_source_expressions():
455 if expr:
456 if hasattr(expr, "flatten"):
457 yield from expr.flatten()
458 else:
459 yield expr
461 def select_format(self, compiler, sql, params):
462 """
463 Custom format for select clauses. For example, EXISTS expressions need
464 to be wrapped in CASE WHEN on Oracle.
465 """
466 if hasattr(self.output_field, "select_format"):
467 return self.output_field.select_format(compiler, sql, params)
468 return sql, params
471@deconstructible
472class Expression(BaseExpression, Combinable):
473 """An expression that can be combined with other expressions."""
475 @cached_property
476 def identity(self):
477 constructor_signature = inspect.signature(self.__init__)
478 args, kwargs = self._constructor_args
479 signature = constructor_signature.bind_partial(*args, **kwargs)
480 signature.apply_defaults()
481 arguments = signature.arguments.items()
482 identity = [self.__class__]
483 for arg, value in arguments:
484 if isinstance(value, fields.Field):
485 if value.name and value.model:
486 value = (value.model._meta.label, value.name)
487 else:
488 value = type(value)
489 else:
490 value = make_hashable(value)
491 identity.append((arg, value))
492 return tuple(identity)
494 def __eq__(self, other):
495 if not isinstance(other, Expression):
496 return NotImplemented
497 return other.identity == self.identity
499 def __hash__(self):
500 return hash(self.identity)
503# Type inference for CombinedExpression.output_field.
504# Missing items will result in FieldError, by design.
505#
506# The current approach for NULL is based on lowest common denominator behavior
507# i.e. if one of the supported databases is raising an error (rather than
508# return NULL) for `val <op> NULL`, then Plain raises FieldError.
510_connector_combinations = [
511 # Numeric operations - operands of same type.
512 {
513 connector: [
514 (fields.IntegerField, fields.IntegerField, fields.IntegerField),
515 (fields.FloatField, fields.FloatField, fields.FloatField),
516 (fields.DecimalField, fields.DecimalField, fields.DecimalField),
517 ]
518 for connector in (
519 Combinable.ADD,
520 Combinable.SUB,
521 Combinable.MUL,
522 # Behavior for DIV with integer arguments follows Postgres/SQLite,
523 # not MySQL/Oracle.
524 Combinable.DIV,
525 Combinable.MOD,
526 Combinable.POW,
527 )
528 },
529 # Numeric operations - operands of different type.
530 {
531 connector: [
532 (fields.IntegerField, fields.DecimalField, fields.DecimalField),
533 (fields.DecimalField, fields.IntegerField, fields.DecimalField),
534 (fields.IntegerField, fields.FloatField, fields.FloatField),
535 (fields.FloatField, fields.IntegerField, fields.FloatField),
536 ]
537 for connector in (
538 Combinable.ADD,
539 Combinable.SUB,
540 Combinable.MUL,
541 Combinable.DIV,
542 Combinable.MOD,
543 )
544 },
545 # Bitwise operators.
546 {
547 connector: [
548 (fields.IntegerField, fields.IntegerField, fields.IntegerField),
549 ]
550 for connector in (
551 Combinable.BITAND,
552 Combinable.BITOR,
553 Combinable.BITLEFTSHIFT,
554 Combinable.BITRIGHTSHIFT,
555 Combinable.BITXOR,
556 )
557 },
558 # Numeric with NULL.
559 {
560 connector: [
561 (field_type, NoneType, field_type),
562 (NoneType, field_type, field_type),
563 ]
564 for connector in (
565 Combinable.ADD,
566 Combinable.SUB,
567 Combinable.MUL,
568 Combinable.DIV,
569 Combinable.MOD,
570 Combinable.POW,
571 )
572 for field_type in (fields.IntegerField, fields.DecimalField, fields.FloatField)
573 },
574 # Date/DateTimeField/DurationField/TimeField.
575 {
576 Combinable.ADD: [
577 # Date/DateTimeField.
578 (fields.DateField, fields.DurationField, fields.DateTimeField),
579 (fields.DateTimeField, fields.DurationField, fields.DateTimeField),
580 (fields.DurationField, fields.DateField, fields.DateTimeField),
581 (fields.DurationField, fields.DateTimeField, fields.DateTimeField),
582 # DurationField.
583 (fields.DurationField, fields.DurationField, fields.DurationField),
584 # TimeField.
585 (fields.TimeField, fields.DurationField, fields.TimeField),
586 (fields.DurationField, fields.TimeField, fields.TimeField),
587 ],
588 },
589 {
590 Combinable.SUB: [
591 # Date/DateTimeField.
592 (fields.DateField, fields.DurationField, fields.DateTimeField),
593 (fields.DateTimeField, fields.DurationField, fields.DateTimeField),
594 (fields.DateField, fields.DateField, fields.DurationField),
595 (fields.DateField, fields.DateTimeField, fields.DurationField),
596 (fields.DateTimeField, fields.DateField, fields.DurationField),
597 (fields.DateTimeField, fields.DateTimeField, fields.DurationField),
598 # DurationField.
599 (fields.DurationField, fields.DurationField, fields.DurationField),
600 # TimeField.
601 (fields.TimeField, fields.DurationField, fields.TimeField),
602 (fields.TimeField, fields.TimeField, fields.DurationField),
603 ],
604 },
605]
607_connector_combinators = defaultdict(list)
610def register_combinable_fields(lhs, connector, rhs, result):
611 """
612 Register combinable types:
613 lhs <connector> rhs -> result
614 e.g.
615 register_combinable_fields(
616 IntegerField, Combinable.ADD, FloatField, FloatField
617 )
618 """
619 _connector_combinators[connector].append((lhs, rhs, result))
622for d in _connector_combinations:
623 for connector, field_types in d.items():
624 for lhs, rhs, result in field_types:
625 register_combinable_fields(lhs, connector, rhs, result)
628@functools.lru_cache(maxsize=128)
629def _resolve_combined_type(connector, lhs_type, rhs_type):
630 combinators = _connector_combinators.get(connector, ())
631 for combinator_lhs_type, combinator_rhs_type, combined_type in combinators:
632 if issubclass(lhs_type, combinator_lhs_type) and issubclass(
633 rhs_type, combinator_rhs_type
634 ):
635 return combined_type
638class CombinedExpression(SQLiteNumericMixin, Expression):
639 def __init__(self, lhs, connector, rhs, output_field=None):
640 super().__init__(output_field=output_field)
641 self.connector = connector
642 self.lhs = lhs
643 self.rhs = rhs
645 def __repr__(self):
646 return f"<{self.__class__.__name__}: {self}>"
648 def __str__(self):
649 return f"{self.lhs} {self.connector} {self.rhs}"
651 def get_source_expressions(self):
652 return [self.lhs, self.rhs]
654 def set_source_expressions(self, exprs):
655 self.lhs, self.rhs = exprs
657 def _resolve_output_field(self):
658 # We avoid using super() here for reasons given in
659 # Expression._resolve_output_field()
660 combined_type = _resolve_combined_type(
661 self.connector,
662 type(self.lhs._output_field_or_none),
663 type(self.rhs._output_field_or_none),
664 )
665 if combined_type is None:
666 raise FieldError(
667 f"Cannot infer type of {self.connector!r} expression involving these "
668 f"types: {self.lhs.output_field.__class__.__name__}, "
669 f"{self.rhs.output_field.__class__.__name__}. You must set "
670 f"output_field."
671 )
672 return combined_type()
674 def as_sql(self, compiler, connection):
675 expressions = []
676 expression_params = []
677 sql, params = compiler.compile(self.lhs)
678 expressions.append(sql)
679 expression_params.extend(params)
680 sql, params = compiler.compile(self.rhs)
681 expressions.append(sql)
682 expression_params.extend(params)
683 # order of precedence
684 expression_wrapper = "(%s)"
685 sql = connection.ops.combine_expression(self.connector, expressions)
686 return expression_wrapper % sql, expression_params
688 def resolve_expression(
689 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
690 ):
691 lhs = self.lhs.resolve_expression(
692 query, allow_joins, reuse, summarize, for_save
693 )
694 rhs = self.rhs.resolve_expression(
695 query, allow_joins, reuse, summarize, for_save
696 )
697 if not isinstance(self, DurationExpression | TemporalSubtraction):
698 try:
699 lhs_type = lhs.output_field.get_internal_type()
700 except (AttributeError, FieldError):
701 lhs_type = None
702 try:
703 rhs_type = rhs.output_field.get_internal_type()
704 except (AttributeError, FieldError):
705 rhs_type = None
706 if "DurationField" in {lhs_type, rhs_type} and lhs_type != rhs_type:
707 return DurationExpression(
708 self.lhs, self.connector, self.rhs
709 ).resolve_expression(
710 query,
711 allow_joins,
712 reuse,
713 summarize,
714 for_save,
715 )
716 datetime_fields = {"DateField", "DateTimeField", "TimeField"}
717 if (
718 self.connector == self.SUB
719 and lhs_type in datetime_fields
720 and lhs_type == rhs_type
721 ):
722 return TemporalSubtraction(self.lhs, self.rhs).resolve_expression(
723 query,
724 allow_joins,
725 reuse,
726 summarize,
727 for_save,
728 )
729 c = self.copy()
730 c.is_summary = summarize
731 c.lhs = lhs
732 c.rhs = rhs
733 return c
736class DurationExpression(CombinedExpression):
737 def compile(self, side, compiler, connection):
738 try:
739 output = side.output_field
740 except FieldError:
741 pass
742 else:
743 if output.get_internal_type() == "DurationField":
744 sql, params = compiler.compile(side)
745 return connection.ops.format_for_duration_arithmetic(sql), params
746 return compiler.compile(side)
748 def as_sql(self, compiler, connection):
749 if connection.features.has_native_duration_field:
750 return super().as_sql(compiler, connection)
751 connection.ops.check_expression_support(self)
752 expressions = []
753 expression_params = []
754 sql, params = self.compile(self.lhs, compiler, connection)
755 expressions.append(sql)
756 expression_params.extend(params)
757 sql, params = self.compile(self.rhs, compiler, connection)
758 expressions.append(sql)
759 expression_params.extend(params)
760 # order of precedence
761 expression_wrapper = "(%s)"
762 sql = connection.ops.combine_duration_expression(self.connector, expressions)
763 return expression_wrapper % sql, expression_params
765 def as_sqlite(self, compiler, connection, **extra_context):
766 sql, params = self.as_sql(compiler, connection, **extra_context)
767 if self.connector in {Combinable.MUL, Combinable.DIV}:
768 try:
769 lhs_type = self.lhs.output_field.get_internal_type()
770 rhs_type = self.rhs.output_field.get_internal_type()
771 except (AttributeError, FieldError):
772 pass
773 else:
774 allowed_fields = {
775 "DecimalField",
776 "DurationField",
777 "FloatField",
778 "IntegerField",
779 }
780 if lhs_type not in allowed_fields or rhs_type not in allowed_fields:
781 raise DatabaseError(
782 f"Invalid arguments for operator {self.connector}."
783 )
784 return sql, params
787class TemporalSubtraction(CombinedExpression):
788 output_field = fields.DurationField()
790 def __init__(self, lhs, rhs):
791 super().__init__(lhs, self.SUB, rhs)
793 def as_sql(self, compiler, connection):
794 connection.ops.check_expression_support(self)
795 lhs = compiler.compile(self.lhs)
796 rhs = compiler.compile(self.rhs)
797 return connection.ops.subtract_temporals(
798 self.lhs.output_field.get_internal_type(), lhs, rhs
799 )
802@deconstructible(path="plain.models.F")
803class F(Combinable):
804 """An object capable of resolving references to existing query objects."""
806 def __init__(self, name):
807 """
808 Arguments:
809 * name: the name of the field this expression references
810 """
811 self.name = name
813 def __repr__(self):
814 return f"{self.__class__.__name__}({self.name})"
816 def resolve_expression(
817 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
818 ):
819 return query.resolve_ref(self.name, allow_joins, reuse, summarize)
821 def replace_expressions(self, replacements):
822 return replacements.get(self, self)
824 def asc(self, **kwargs):
825 return OrderBy(self, **kwargs)
827 def desc(self, **kwargs):
828 return OrderBy(self, descending=True, **kwargs)
830 def __eq__(self, other):
831 return self.__class__ == other.__class__ and self.name == other.name
833 def __hash__(self):
834 return hash(self.name)
836 def copy(self):
837 return copy.copy(self)
840class ResolvedOuterRef(F):
841 """
842 An object that contains a reference to an outer query.
844 In this case, the reference to the outer query has been resolved because
845 the inner query has been used as a subquery.
846 """
848 contains_aggregate = False
849 contains_over_clause = False
851 def as_sql(self, *args, **kwargs):
852 raise ValueError(
853 "This queryset contains a reference to an outer query and may "
854 "only be used in a subquery."
855 )
857 def resolve_expression(self, *args, **kwargs):
858 col = super().resolve_expression(*args, **kwargs)
859 if col.contains_over_clause:
860 raise NotSupportedError(
861 f"Referencing outer query window expression is not supported: "
862 f"{self.name}."
863 )
864 # FIXME: Rename possibly_multivalued to multivalued and fix detection
865 # for non-multivalued JOINs (e.g. foreign key fields). This should take
866 # into account only many-to-many and one-to-many relationships.
867 col.possibly_multivalued = LOOKUP_SEP in self.name
868 return col
870 def relabeled_clone(self, relabels):
871 return self
873 def get_group_by_cols(self):
874 return []
877class OuterRef(F):
878 contains_aggregate = False
880 def resolve_expression(self, *args, **kwargs):
881 if isinstance(self.name, self.__class__):
882 return self.name
883 return ResolvedOuterRef(self.name)
885 def relabeled_clone(self, relabels):
886 return self
889@deconstructible(path="plain.models.Func")
890class Func(SQLiteNumericMixin, Expression):
891 """An SQL function call."""
893 function = None
894 template = "%(function)s(%(expressions)s)"
895 arg_joiner = ", "
896 arity = None # The number of arguments the function accepts.
898 def __init__(self, *expressions, output_field=None, **extra):
899 if self.arity is not None and len(expressions) != self.arity:
900 raise TypeError(
901 "'{}' takes exactly {} {} ({} given)".format(
902 self.__class__.__name__,
903 self.arity,
904 "argument" if self.arity == 1 else "arguments",
905 len(expressions),
906 )
907 )
908 super().__init__(output_field=output_field)
909 self.source_expressions = self._parse_expressions(*expressions)
910 self.extra = extra
912 def __repr__(self):
913 args = self.arg_joiner.join(str(arg) for arg in self.source_expressions)
914 extra = {**self.extra, **self._get_repr_options()}
915 if extra:
916 extra = ", ".join(
917 str(key) + "=" + str(val) for key, val in sorted(extra.items())
918 )
919 return f"{self.__class__.__name__}({args}, {extra})"
920 return f"{self.__class__.__name__}({args})"
922 def _get_repr_options(self):
923 """Return a dict of extra __init__() options to include in the repr."""
924 return {}
926 def get_source_expressions(self):
927 return self.source_expressions
929 def set_source_expressions(self, exprs):
930 self.source_expressions = exprs
932 def resolve_expression(
933 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
934 ):
935 c = self.copy()
936 c.is_summary = summarize
937 for pos, arg in enumerate(c.source_expressions):
938 c.source_expressions[pos] = arg.resolve_expression(
939 query, allow_joins, reuse, summarize, for_save
940 )
941 return c
943 def as_sql(
944 self,
945 compiler,
946 connection,
947 function=None,
948 template=None,
949 arg_joiner=None,
950 **extra_context,
951 ):
952 connection.ops.check_expression_support(self)
953 sql_parts = []
954 params = []
955 for arg in self.source_expressions:
956 try:
957 arg_sql, arg_params = compiler.compile(arg)
958 except EmptyResultSet:
959 empty_result_set_value = getattr(
960 arg, "empty_result_set_value", NotImplemented
961 )
962 if empty_result_set_value is NotImplemented:
963 raise
964 arg_sql, arg_params = compiler.compile(Value(empty_result_set_value))
965 except FullResultSet:
966 arg_sql, arg_params = compiler.compile(Value(True))
967 sql_parts.append(arg_sql)
968 params.extend(arg_params)
969 data = {**self.extra, **extra_context}
970 # Use the first supplied value in this order: the parameter to this
971 # method, a value supplied in __init__()'s **extra (the value in
972 # `data`), or the value defined on the class.
973 if function is not None:
974 data["function"] = function
975 else:
976 data.setdefault("function", self.function)
977 template = template or data.get("template", self.template)
978 arg_joiner = arg_joiner or data.get("arg_joiner", self.arg_joiner)
979 data["expressions"] = data["field"] = arg_joiner.join(sql_parts)
980 return template % data, params
982 def copy(self):
983 copy = super().copy()
984 copy.source_expressions = self.source_expressions[:]
985 copy.extra = self.extra.copy()
986 return copy
989@deconstructible(path="plain.models.Value")
990class Value(SQLiteNumericMixin, Expression):
991 """Represent a wrapped value as a node within an expression."""
993 # Provide a default value for `for_save` in order to allow unresolved
994 # instances to be compiled until a decision is taken in #25425.
995 for_save = False
997 def __init__(self, value, output_field=None):
998 """
999 Arguments:
1000 * value: the value this expression represents. The value will be
1001 added into the sql parameter list and properly quoted.
1003 * output_field: an instance of the model field type that this
1004 expression will return, such as IntegerField() or CharField().
1005 """
1006 super().__init__(output_field=output_field)
1007 self.value = value
1009 def __repr__(self):
1010 return f"{self.__class__.__name__}({self.value!r})"
1012 def as_sql(self, compiler, connection):
1013 connection.ops.check_expression_support(self)
1014 val = self.value
1015 output_field = self._output_field_or_none
1016 if output_field is not None:
1017 if self.for_save:
1018 val = output_field.get_db_prep_save(val, connection=connection)
1019 else:
1020 val = output_field.get_db_prep_value(val, connection=connection)
1021 if hasattr(output_field, "get_placeholder"):
1022 return output_field.get_placeholder(val, compiler, connection), [val]
1023 if val is None:
1024 # cx_Oracle does not always convert None to the appropriate
1025 # NULL type (like in case expressions using numbers), so we
1026 # use a literal SQL NULL
1027 return "NULL", []
1028 return "%s", [val]
1030 def resolve_expression(
1031 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
1032 ):
1033 c = super().resolve_expression(query, allow_joins, reuse, summarize, for_save)
1034 c.for_save = for_save
1035 return c
1037 def get_group_by_cols(self):
1038 return []
1040 def _resolve_output_field(self):
1041 if isinstance(self.value, str):
1042 return fields.CharField()
1043 if isinstance(self.value, bool):
1044 return fields.BooleanField()
1045 if isinstance(self.value, int):
1046 return fields.IntegerField()
1047 if isinstance(self.value, float):
1048 return fields.FloatField()
1049 if isinstance(self.value, datetime.datetime):
1050 return fields.DateTimeField()
1051 if isinstance(self.value, datetime.date):
1052 return fields.DateField()
1053 if isinstance(self.value, datetime.time):
1054 return fields.TimeField()
1055 if isinstance(self.value, datetime.timedelta):
1056 return fields.DurationField()
1057 if isinstance(self.value, Decimal):
1058 return fields.DecimalField()
1059 if isinstance(self.value, bytes):
1060 return fields.BinaryField()
1061 if isinstance(self.value, UUID):
1062 return fields.UUIDField()
1064 @property
1065 def empty_result_set_value(self):
1066 return self.value
1069class RawSQL(Expression):
1070 def __init__(self, sql, params, output_field=None):
1071 if output_field is None:
1072 output_field = fields.Field()
1073 self.sql, self.params = sql, params
1074 super().__init__(output_field=output_field)
1076 def __repr__(self):
1077 return f"{self.__class__.__name__}({self.sql}, {self.params})"
1079 def as_sql(self, compiler, connection):
1080 return "(%s)" % self.sql, self.params
1082 def get_group_by_cols(self):
1083 return [self]
1085 def resolve_expression(
1086 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
1087 ):
1088 # Resolve parents fields used in raw SQL.
1089 if query.model:
1090 for parent in query.model._meta.get_parent_list():
1091 for parent_field in parent._meta.local_fields:
1092 _, column_name = parent_field.get_attname_column()
1093 if column_name.lower() in self.sql.lower():
1094 query.resolve_ref(
1095 parent_field.name, allow_joins, reuse, summarize
1096 )
1097 break
1098 return super().resolve_expression(
1099 query, allow_joins, reuse, summarize, for_save
1100 )
1103class Star(Expression):
1104 def __repr__(self):
1105 return "'*'"
1107 def as_sql(self, compiler, connection):
1108 return "*", []
1111class Col(Expression):
1112 contains_column_references = True
1113 possibly_multivalued = False
1115 def __init__(self, alias, target, output_field=None):
1116 if output_field is None:
1117 output_field = target
1118 super().__init__(output_field=output_field)
1119 self.alias, self.target = alias, target
1121 def __repr__(self):
1122 alias, target = self.alias, self.target
1123 identifiers = (alias, str(target)) if alias else (str(target),)
1124 return "{}({})".format(self.__class__.__name__, ", ".join(identifiers))
1126 def as_sql(self, compiler, connection):
1127 alias, column = self.alias, self.target.column
1128 identifiers = (alias, column) if alias else (column,)
1129 sql = ".".join(map(compiler.quote_name_unless_alias, identifiers))
1130 return sql, []
1132 def relabeled_clone(self, relabels):
1133 if self.alias is None:
1134 return self
1135 return self.__class__(
1136 relabels.get(self.alias, self.alias), self.target, self.output_field
1137 )
1139 def get_group_by_cols(self):
1140 return [self]
1142 def get_db_converters(self, connection):
1143 if self.target == self.output_field:
1144 return self.output_field.get_db_converters(connection)
1145 return self.output_field.get_db_converters(
1146 connection
1147 ) + self.target.get_db_converters(connection)
1150class Ref(Expression):
1151 """
1152 Reference to column alias of the query. For example, Ref('sum_cost') in
1153 qs.annotate(sum_cost=Sum('cost')) query.
1154 """
1156 def __init__(self, refs, source):
1157 super().__init__()
1158 self.refs, self.source = refs, source
1160 def __repr__(self):
1161 return f"{self.__class__.__name__}({self.refs}, {self.source})"
1163 def get_source_expressions(self):
1164 return [self.source]
1166 def set_source_expressions(self, exprs):
1167 (self.source,) = exprs
1169 def resolve_expression(
1170 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
1171 ):
1172 # The sub-expression `source` has already been resolved, as this is
1173 # just a reference to the name of `source`.
1174 return self
1176 def get_refs(self):
1177 return {self.refs}
1179 def relabeled_clone(self, relabels):
1180 return self
1182 def as_sql(self, compiler, connection):
1183 return connection.ops.quote_name(self.refs), []
1185 def get_group_by_cols(self):
1186 return [self]
1189class ExpressionList(Func):
1190 """
1191 An expression containing multiple expressions. Can be used to provide a
1192 list of expressions as an argument to another expression, like a partition
1193 clause.
1194 """
1196 template = "%(expressions)s"
1198 def __init__(self, *expressions, **extra):
1199 if not expressions:
1200 raise ValueError(
1201 "%s requires at least one expression." % self.__class__.__name__
1202 )
1203 super().__init__(*expressions, **extra)
1205 def __str__(self):
1206 return self.arg_joiner.join(str(arg) for arg in self.source_expressions)
1208 def as_sqlite(self, compiler, connection, **extra_context):
1209 # Casting to numeric is unnecessary.
1210 return self.as_sql(compiler, connection, **extra_context)
1213class OrderByList(Func):
1214 template = "ORDER BY %(expressions)s"
1216 def __init__(self, *expressions, **extra):
1217 expressions = (
1218 (
1219 OrderBy(F(expr[1:]), descending=True)
1220 if isinstance(expr, str) and expr[0] == "-"
1221 else expr
1222 )
1223 for expr in expressions
1224 )
1225 super().__init__(*expressions, **extra)
1227 def as_sql(self, *args, **kwargs):
1228 if not self.source_expressions:
1229 return "", ()
1230 return super().as_sql(*args, **kwargs)
1232 def get_group_by_cols(self):
1233 group_by_cols = []
1234 for order_by in self.get_source_expressions():
1235 group_by_cols.extend(order_by.get_group_by_cols())
1236 return group_by_cols
1239@deconstructible(path="plain.models.ExpressionWrapper")
1240class ExpressionWrapper(SQLiteNumericMixin, Expression):
1241 """
1242 An expression that can wrap another expression so that it can provide
1243 extra context to the inner expression, such as the output_field.
1244 """
1246 def __init__(self, expression, output_field):
1247 super().__init__(output_field=output_field)
1248 self.expression = expression
1250 def set_source_expressions(self, exprs):
1251 self.expression = exprs[0]
1253 def get_source_expressions(self):
1254 return [self.expression]
1256 def get_group_by_cols(self):
1257 if isinstance(self.expression, Expression):
1258 expression = self.expression.copy()
1259 expression.output_field = self.output_field
1260 return expression.get_group_by_cols()
1261 # For non-expressions e.g. an SQL WHERE clause, the entire
1262 # `expression` must be included in the GROUP BY clause.
1263 return super().get_group_by_cols()
1265 def as_sql(self, compiler, connection):
1266 return compiler.compile(self.expression)
1268 def __repr__(self):
1269 return f"{self.__class__.__name__}({self.expression})"
1272class NegatedExpression(ExpressionWrapper):
1273 """The logical negation of a conditional expression."""
1275 def __init__(self, expression):
1276 super().__init__(expression, output_field=fields.BooleanField())
1278 def __invert__(self):
1279 return self.expression.copy()
1281 def as_sql(self, compiler, connection):
1282 try:
1283 sql, params = super().as_sql(compiler, connection)
1284 except EmptyResultSet:
1285 features = compiler.connection.features
1286 if not features.supports_boolean_expr_in_select_clause:
1287 return "1=1", ()
1288 return compiler.compile(Value(True))
1289 ops = compiler.connection.ops
1290 # Some database backends (e.g. Oracle) don't allow EXISTS() and filters
1291 # to be compared to another expression unless they're wrapped in a CASE
1292 # WHEN.
1293 if not ops.conditional_expression_supported_in_where_clause(self.expression):
1294 return f"CASE WHEN {sql} = 0 THEN 1 ELSE 0 END", params
1295 return f"NOT {sql}", params
1297 def resolve_expression(
1298 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
1299 ):
1300 resolved = super().resolve_expression(
1301 query, allow_joins, reuse, summarize, for_save
1302 )
1303 if not getattr(resolved.expression, "conditional", False):
1304 raise TypeError("Cannot negate non-conditional expressions.")
1305 return resolved
1307 def select_format(self, compiler, sql, params):
1308 # Wrap boolean expressions with a CASE WHEN expression if a database
1309 # backend (e.g. Oracle) doesn't support boolean expression in SELECT or
1310 # GROUP BY list.
1311 expression_supported_in_where_clause = (
1312 compiler.connection.ops.conditional_expression_supported_in_where_clause
1313 )
1314 if (
1315 not compiler.connection.features.supports_boolean_expr_in_select_clause
1316 # Avoid double wrapping.
1317 and expression_supported_in_where_clause(self.expression)
1318 ):
1319 sql = f"CASE WHEN {sql} THEN 1 ELSE 0 END"
1320 return sql, params
1323@deconstructible(path="plain.models.When")
1324class When(Expression):
1325 template = "WHEN %(condition)s THEN %(result)s"
1326 # This isn't a complete conditional expression, must be used in Case().
1327 conditional = False
1329 def __init__(self, condition=None, then=None, **lookups):
1330 if lookups:
1331 if condition is None:
1332 condition, lookups = Q(**lookups), None
1333 elif getattr(condition, "conditional", False):
1334 condition, lookups = Q(condition, **lookups), None
1335 if condition is None or not getattr(condition, "conditional", False) or lookups:
1336 raise TypeError(
1337 "When() supports a Q object, a boolean expression, or lookups "
1338 "as a condition."
1339 )
1340 if isinstance(condition, Q) and not condition:
1341 raise ValueError("An empty Q() can't be used as a When() condition.")
1342 super().__init__(output_field=None)
1343 self.condition = condition
1344 self.result = self._parse_expressions(then)[0]
1346 def __str__(self):
1347 return f"WHEN {self.condition!r} THEN {self.result!r}"
1349 def __repr__(self):
1350 return f"<{self.__class__.__name__}: {self}>"
1352 def get_source_expressions(self):
1353 return [self.condition, self.result]
1355 def set_source_expressions(self, exprs):
1356 self.condition, self.result = exprs
1358 def get_source_fields(self):
1359 # We're only interested in the fields of the result expressions.
1360 return [self.result._output_field_or_none]
1362 def resolve_expression(
1363 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
1364 ):
1365 c = self.copy()
1366 c.is_summary = summarize
1367 if hasattr(c.condition, "resolve_expression"):
1368 c.condition = c.condition.resolve_expression(
1369 query, allow_joins, reuse, summarize, False
1370 )
1371 c.result = c.result.resolve_expression(
1372 query, allow_joins, reuse, summarize, for_save
1373 )
1374 return c
1376 def as_sql(self, compiler, connection, template=None, **extra_context):
1377 connection.ops.check_expression_support(self)
1378 template_params = extra_context
1379 sql_params = []
1380 condition_sql, condition_params = compiler.compile(self.condition)
1381 template_params["condition"] = condition_sql
1382 result_sql, result_params = compiler.compile(self.result)
1383 template_params["result"] = result_sql
1384 template = template or self.template
1385 return template % template_params, (
1386 *sql_params,
1387 *condition_params,
1388 *result_params,
1389 )
1391 def get_group_by_cols(self):
1392 # This is not a complete expression and cannot be used in GROUP BY.
1393 cols = []
1394 for source in self.get_source_expressions():
1395 cols.extend(source.get_group_by_cols())
1396 return cols
1399@deconstructible(path="plain.models.Case")
1400class Case(SQLiteNumericMixin, Expression):
1401 """
1402 An SQL searched CASE expression:
1404 CASE
1405 WHEN n > 0
1406 THEN 'positive'
1407 WHEN n < 0
1408 THEN 'negative'
1409 ELSE 'zero'
1410 END
1411 """
1413 template = "CASE %(cases)s ELSE %(default)s END"
1414 case_joiner = " "
1416 def __init__(self, *cases, default=None, output_field=None, **extra):
1417 if not all(isinstance(case, When) for case in cases):
1418 raise TypeError("Positional arguments must all be When objects.")
1419 super().__init__(output_field)
1420 self.cases = list(cases)
1421 self.default = self._parse_expressions(default)[0]
1422 self.extra = extra
1424 def __str__(self):
1425 return "CASE {}, ELSE {!r}".format(
1426 ", ".join(str(c) for c in self.cases),
1427 self.default,
1428 )
1430 def __repr__(self):
1431 return f"<{self.__class__.__name__}: {self}>"
1433 def get_source_expressions(self):
1434 return self.cases + [self.default]
1436 def set_source_expressions(self, exprs):
1437 *self.cases, self.default = exprs
1439 def resolve_expression(
1440 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
1441 ):
1442 c = self.copy()
1443 c.is_summary = summarize
1444 for pos, case in enumerate(c.cases):
1445 c.cases[pos] = case.resolve_expression(
1446 query, allow_joins, reuse, summarize, for_save
1447 )
1448 c.default = c.default.resolve_expression(
1449 query, allow_joins, reuse, summarize, for_save
1450 )
1451 return c
1453 def copy(self):
1454 c = super().copy()
1455 c.cases = c.cases[:]
1456 return c
1458 def as_sql(
1459 self, compiler, connection, template=None, case_joiner=None, **extra_context
1460 ):
1461 connection.ops.check_expression_support(self)
1462 if not self.cases:
1463 return compiler.compile(self.default)
1464 template_params = {**self.extra, **extra_context}
1465 case_parts = []
1466 sql_params = []
1467 default_sql, default_params = compiler.compile(self.default)
1468 for case in self.cases:
1469 try:
1470 case_sql, case_params = compiler.compile(case)
1471 except EmptyResultSet:
1472 continue
1473 except FullResultSet:
1474 default_sql, default_params = compiler.compile(case.result)
1475 break
1476 case_parts.append(case_sql)
1477 sql_params.extend(case_params)
1478 if not case_parts:
1479 return default_sql, default_params
1480 case_joiner = case_joiner or self.case_joiner
1481 template_params["cases"] = case_joiner.join(case_parts)
1482 template_params["default"] = default_sql
1483 sql_params.extend(default_params)
1484 template = template or template_params.get("template", self.template)
1485 sql = template % template_params
1486 if self._output_field_or_none is not None:
1487 sql = connection.ops.unification_cast_sql(self.output_field) % sql
1488 return sql, sql_params
1490 def get_group_by_cols(self):
1491 if not self.cases:
1492 return self.default.get_group_by_cols()
1493 return super().get_group_by_cols()
1496class Subquery(BaseExpression, Combinable):
1497 """
1498 An explicit subquery. It may contain OuterRef() references to the outer
1499 query which will be resolved when it is applied to that query.
1500 """
1502 template = "(%(subquery)s)"
1503 contains_aggregate = False
1504 empty_result_set_value = None
1506 def __init__(self, queryset, output_field=None, **extra):
1507 # Allow the usage of both QuerySet and sql.Query objects.
1508 self.query = getattr(queryset, "query", queryset).clone()
1509 self.query.subquery = True
1510 self.extra = extra
1511 super().__init__(output_field)
1513 def get_source_expressions(self):
1514 return [self.query]
1516 def set_source_expressions(self, exprs):
1517 self.query = exprs[0]
1519 def _resolve_output_field(self):
1520 return self.query.output_field
1522 def copy(self):
1523 clone = super().copy()
1524 clone.query = clone.query.clone()
1525 return clone
1527 @property
1528 def external_aliases(self):
1529 return self.query.external_aliases
1531 def get_external_cols(self):
1532 return self.query.get_external_cols()
1534 def as_sql(self, compiler, connection, template=None, **extra_context):
1535 connection.ops.check_expression_support(self)
1536 template_params = {**self.extra, **extra_context}
1537 subquery_sql, sql_params = self.query.as_sql(compiler, connection)
1538 template_params["subquery"] = subquery_sql[1:-1]
1540 template = template or template_params.get("template", self.template)
1541 sql = template % template_params
1542 return sql, sql_params
1544 def get_group_by_cols(self):
1545 return self.query.get_group_by_cols(wrapper=self)
1548class Exists(Subquery):
1549 template = "EXISTS(%(subquery)s)"
1550 output_field = fields.BooleanField()
1551 empty_result_set_value = False
1553 def __init__(self, queryset, **kwargs):
1554 super().__init__(queryset, **kwargs)
1555 self.query = self.query.exists()
1557 def select_format(self, compiler, sql, params):
1558 # Wrap EXISTS() with a CASE WHEN expression if a database backend
1559 # (e.g. Oracle) doesn't support boolean expression in SELECT or GROUP
1560 # BY list.
1561 if not compiler.connection.features.supports_boolean_expr_in_select_clause:
1562 sql = f"CASE WHEN {sql} THEN 1 ELSE 0 END"
1563 return sql, params
1566@deconstructible(path="plain.models.OrderBy")
1567class OrderBy(Expression):
1568 template = "%(expression)s %(ordering)s"
1569 conditional = False
1571 def __init__(self, expression, descending=False, nulls_first=None, nulls_last=None):
1572 if nulls_first and nulls_last:
1573 raise ValueError("nulls_first and nulls_last are mutually exclusive")
1574 if nulls_first is False or nulls_last is False:
1575 raise ValueError("nulls_first and nulls_last values must be True or None.")
1576 self.nulls_first = nulls_first
1577 self.nulls_last = nulls_last
1578 self.descending = descending
1579 if not hasattr(expression, "resolve_expression"):
1580 raise ValueError("expression must be an expression type")
1581 self.expression = expression
1583 def __repr__(self):
1584 return "{}({}, descending={})".format(
1585 self.__class__.__name__, self.expression, self.descending
1586 )
1588 def set_source_expressions(self, exprs):
1589 self.expression = exprs[0]
1591 def get_source_expressions(self):
1592 return [self.expression]
1594 def as_sql(self, compiler, connection, template=None, **extra_context):
1595 template = template or self.template
1596 if connection.features.supports_order_by_nulls_modifier:
1597 if self.nulls_last:
1598 template = "%s NULLS LAST" % template
1599 elif self.nulls_first:
1600 template = "%s NULLS FIRST" % template
1601 else:
1602 if self.nulls_last and not (
1603 self.descending and connection.features.order_by_nulls_first
1604 ):
1605 template = "%%(expression)s IS NULL, %s" % template
1606 elif self.nulls_first and not (
1607 not self.descending and connection.features.order_by_nulls_first
1608 ):
1609 template = "%%(expression)s IS NOT NULL, %s" % template
1610 connection.ops.check_expression_support(self)
1611 expression_sql, params = compiler.compile(self.expression)
1612 placeholders = {
1613 "expression": expression_sql,
1614 "ordering": "DESC" if self.descending else "ASC",
1615 **extra_context,
1616 }
1617 params *= template.count("%(expression)s")
1618 return (template % placeholders).rstrip(), params
1620 def get_group_by_cols(self):
1621 cols = []
1622 for source in self.get_source_expressions():
1623 cols.extend(source.get_group_by_cols())
1624 return cols
1626 def reverse_ordering(self):
1627 self.descending = not self.descending
1628 if self.nulls_first:
1629 self.nulls_last = True
1630 self.nulls_first = None
1631 elif self.nulls_last:
1632 self.nulls_first = True
1633 self.nulls_last = None
1634 return self
1636 def asc(self):
1637 self.descending = False
1639 def desc(self):
1640 self.descending = True
1643class Window(SQLiteNumericMixin, Expression):
1644 template = "%(expression)s OVER (%(window)s)"
1645 # Although the main expression may either be an aggregate or an
1646 # expression with an aggregate function, the GROUP BY that will
1647 # be introduced in the query as a result is not desired.
1648 contains_aggregate = False
1649 contains_over_clause = True
1651 def __init__(
1652 self,
1653 expression,
1654 partition_by=None,
1655 order_by=None,
1656 frame=None,
1657 output_field=None,
1658 ):
1659 self.partition_by = partition_by
1660 self.order_by = order_by
1661 self.frame = frame
1663 if not getattr(expression, "window_compatible", False):
1664 raise ValueError(
1665 "Expression '%s' isn't compatible with OVER clauses."
1666 % expression.__class__.__name__
1667 )
1669 if self.partition_by is not None:
1670 if not isinstance(self.partition_by, tuple | list):
1671 self.partition_by = (self.partition_by,)
1672 self.partition_by = ExpressionList(*self.partition_by)
1674 if self.order_by is not None:
1675 if isinstance(self.order_by, list | tuple):
1676 self.order_by = OrderByList(*self.order_by)
1677 elif isinstance(self.order_by, BaseExpression | str):
1678 self.order_by = OrderByList(self.order_by)
1679 else:
1680 raise ValueError(
1681 "Window.order_by must be either a string reference to a "
1682 "field, an expression, or a list or tuple of them."
1683 )
1684 super().__init__(output_field=output_field)
1685 self.source_expression = self._parse_expressions(expression)[0]
1687 def _resolve_output_field(self):
1688 return self.source_expression.output_field
1690 def get_source_expressions(self):
1691 return [self.source_expression, self.partition_by, self.order_by, self.frame]
1693 def set_source_expressions(self, exprs):
1694 self.source_expression, self.partition_by, self.order_by, self.frame = exprs
1696 def as_sql(self, compiler, connection, template=None):
1697 connection.ops.check_expression_support(self)
1698 if not connection.features.supports_over_clause:
1699 raise NotSupportedError("This backend does not support window expressions.")
1700 expr_sql, params = compiler.compile(self.source_expression)
1701 window_sql, window_params = [], ()
1703 if self.partition_by is not None:
1704 sql_expr, sql_params = self.partition_by.as_sql(
1705 compiler=compiler,
1706 connection=connection,
1707 template="PARTITION BY %(expressions)s",
1708 )
1709 window_sql.append(sql_expr)
1710 window_params += tuple(sql_params)
1712 if self.order_by is not None:
1713 order_sql, order_params = compiler.compile(self.order_by)
1714 window_sql.append(order_sql)
1715 window_params += tuple(order_params)
1717 if self.frame:
1718 frame_sql, frame_params = compiler.compile(self.frame)
1719 window_sql.append(frame_sql)
1720 window_params += tuple(frame_params)
1722 template = template or self.template
1724 return (
1725 template % {"expression": expr_sql, "window": " ".join(window_sql).strip()},
1726 (*params, *window_params),
1727 )
1729 def as_sqlite(self, compiler, connection):
1730 if isinstance(self.output_field, fields.DecimalField):
1731 # Casting to numeric must be outside of the window expression.
1732 copy = self.copy()
1733 source_expressions = copy.get_source_expressions()
1734 source_expressions[0].output_field = fields.FloatField()
1735 copy.set_source_expressions(source_expressions)
1736 return super(Window, copy).as_sqlite(compiler, connection)
1737 return self.as_sql(compiler, connection)
1739 def __str__(self):
1740 return "{} OVER ({}{}{})".format(
1741 str(self.source_expression),
1742 "PARTITION BY " + str(self.partition_by) if self.partition_by else "",
1743 str(self.order_by or ""),
1744 str(self.frame or ""),
1745 )
1747 def __repr__(self):
1748 return f"<{self.__class__.__name__}: {self}>"
1750 def get_group_by_cols(self):
1751 group_by_cols = []
1752 if self.partition_by:
1753 group_by_cols.extend(self.partition_by.get_group_by_cols())
1754 if self.order_by is not None:
1755 group_by_cols.extend(self.order_by.get_group_by_cols())
1756 return group_by_cols
1759class WindowFrame(Expression):
1760 """
1761 Model the frame clause in window expressions. There are two types of frame
1762 clauses which are subclasses, however, all processing and validation (by no
1763 means intended to be complete) is done here. Thus, providing an end for a
1764 frame is optional (the default is UNBOUNDED FOLLOWING, which is the last
1765 row in the frame).
1766 """
1768 template = "%(frame_type)s BETWEEN %(start)s AND %(end)s"
1770 def __init__(self, start=None, end=None):
1771 self.start = Value(start)
1772 self.end = Value(end)
1774 def set_source_expressions(self, exprs):
1775 self.start, self.end = exprs
1777 def get_source_expressions(self):
1778 return [self.start, self.end]
1780 def as_sql(self, compiler, connection):
1781 connection.ops.check_expression_support(self)
1782 start, end = self.window_frame_start_end(
1783 connection, self.start.value, self.end.value
1784 )
1785 return (
1786 self.template
1787 % {
1788 "frame_type": self.frame_type,
1789 "start": start,
1790 "end": end,
1791 },
1792 [],
1793 )
1795 def __repr__(self):
1796 return f"<{self.__class__.__name__}: {self}>"
1798 def get_group_by_cols(self):
1799 return []
1801 def __str__(self):
1802 if self.start.value is not None and self.start.value < 0:
1803 start = "%d %s" % (abs(self.start.value), connection.ops.PRECEDING)
1804 elif self.start.value is not None and self.start.value == 0:
1805 start = connection.ops.CURRENT_ROW
1806 else:
1807 start = connection.ops.UNBOUNDED_PRECEDING
1809 if self.end.value is not None and self.end.value > 0:
1810 end = "%d %s" % (self.end.value, connection.ops.FOLLOWING)
1811 elif self.end.value is not None and self.end.value == 0:
1812 end = connection.ops.CURRENT_ROW
1813 else:
1814 end = connection.ops.UNBOUNDED_FOLLOWING
1815 return self.template % {
1816 "frame_type": self.frame_type,
1817 "start": start,
1818 "end": end,
1819 }
1821 def window_frame_start_end(self, connection, start, end):
1822 raise NotImplementedError("Subclasses must implement window_frame_start_end().")
1825class RowRange(WindowFrame):
1826 frame_type = "ROWS"
1828 def window_frame_start_end(self, connection, start, end):
1829 return connection.ops.window_frame_rows_start_end(start, end)
1832class ValueRange(WindowFrame):
1833 frame_type = "RANGE"
1835 def window_frame_start_end(self, connection, start, end):
1836 return connection.ops.window_frame_range_start_end(start, end)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from types import NoneType
3from plain.models.backends.utils import names_digest, split_identifier
4from plain.models.expressions import Col, ExpressionList, F, Func, OrderBy
5from plain.models.functions import Collate
6from plain.models.query_utils import Q
7from plain.models.sql import Query
8from plain.utils.functional import partition
10__all__ = ["Index"]
13class Index:
14 suffix = "idx"
15 # The max length of the name of the index (restricted to 30 for
16 # cross-database compatibility with Oracle)
17 max_name_length = 30
19 def __init__(
20 self,
21 *expressions,
22 fields=(),
23 name=None,
24 db_tablespace=None,
25 opclasses=(),
26 condition=None,
27 include=None,
28 ):
29 if opclasses and not name:
30 raise ValueError("An index must be named to use opclasses.")
31 if not isinstance(condition, NoneType | Q):
32 raise ValueError("Index.condition must be a Q instance.")
33 if condition and not name:
34 raise ValueError("An index must be named to use condition.")
35 if not isinstance(fields, list | tuple):
36 raise ValueError("Index.fields must be a list or tuple.")
37 if not isinstance(opclasses, list | tuple):
38 raise ValueError("Index.opclasses must be a list or tuple.")
39 if not expressions and not fields:
40 raise ValueError(
41 "At least one field or expression is required to define an index."
42 )
43 if expressions and fields:
44 raise ValueError(
45 "Index.fields and expressions are mutually exclusive.",
46 )
47 if expressions and not name:
48 raise ValueError("An index must be named to use expressions.")
49 if expressions and opclasses:
50 raise ValueError(
51 "Index.opclasses cannot be used with expressions. Use "
52 "a custom OpClass() instead."
53 )
54 if opclasses and len(fields) != len(opclasses):
55 raise ValueError(
56 "Index.fields and Index.opclasses must have the same number of "
57 "elements."
58 )
59 if fields and not all(isinstance(field, str) for field in fields):
60 raise ValueError("Index.fields must contain only strings with field names.")
61 if include and not name:
62 raise ValueError("A covering index must be named.")
63 if not isinstance(include, NoneType | list | tuple):
64 raise ValueError("Index.include must be a list or tuple.")
65 self.fields = list(fields)
66 # A list of 2-tuple with the field name and ordering ('' or 'DESC').
67 self.fields_orders = [
68 (field_name.removeprefix("-"), "DESC" if field_name.startswith("-") else "")
69 for field_name in self.fields
70 ]
71 self.name = name or ""
72 self.db_tablespace = db_tablespace
73 self.opclasses = opclasses
74 self.condition = condition
75 self.include = tuple(include) if include else ()
76 self.expressions = tuple(
77 F(expression) if isinstance(expression, str) else expression
78 for expression in expressions
79 )
81 @property
82 def contains_expressions(self):
83 return bool(self.expressions)
85 def _get_condition_sql(self, model, schema_editor):
86 if self.condition is None:
87 return None
88 query = Query(model=model, alias_cols=False)
89 where = query.build_where(self.condition)
90 compiler = query.get_compiler(connection=schema_editor.connection)
91 sql, params = where.as_sql(compiler, schema_editor.connection)
92 return sql % tuple(schema_editor.quote_value(p) for p in params)
94 def create_sql(self, model, schema_editor, using="", **kwargs):
95 include = [
96 model._meta.get_field(field_name).column for field_name in self.include
97 ]
98 condition = self._get_condition_sql(model, schema_editor)
99 if self.expressions:
100 index_expressions = []
101 for expression in self.expressions:
102 index_expression = IndexExpression(expression)
103 index_expression.set_wrapper_classes(schema_editor.connection)
104 index_expressions.append(index_expression)
105 expressions = ExpressionList(*index_expressions).resolve_expression(
106 Query(model, alias_cols=False),
107 )
108 fields = None
109 col_suffixes = None
110 else:
111 fields = [
112 model._meta.get_field(field_name)
113 for field_name, _ in self.fields_orders
114 ]
115 if schema_editor.connection.features.supports_index_column_ordering:
116 col_suffixes = [order[1] for order in self.fields_orders]
117 else:
118 col_suffixes = [""] * len(self.fields_orders)
119 expressions = None
120 return schema_editor._create_index_sql(
121 model,
122 fields=fields,
123 name=self.name,
124 using=using,
125 db_tablespace=self.db_tablespace,
126 col_suffixes=col_suffixes,
127 opclasses=self.opclasses,
128 condition=condition,
129 include=include,
130 expressions=expressions,
131 **kwargs,
132 )
134 def remove_sql(self, model, schema_editor, **kwargs):
135 return schema_editor._delete_index_sql(model, self.name, **kwargs)
137 def deconstruct(self):
138 path = f"{self.__class__.__module__}.{self.__class__.__name__}"
139 path = path.replace("plain.models.indexes", "plain.models")
140 kwargs = {"name": self.name}
141 if self.fields:
142 kwargs["fields"] = self.fields
143 if self.db_tablespace is not None:
144 kwargs["db_tablespace"] = self.db_tablespace
145 if self.opclasses:
146 kwargs["opclasses"] = self.opclasses
147 if self.condition:
148 kwargs["condition"] = self.condition
149 if self.include:
150 kwargs["include"] = self.include
151 return (path, self.expressions, kwargs)
153 def clone(self):
154 """Create a copy of this Index."""
155 _, args, kwargs = self.deconstruct()
156 return self.__class__(*args, **kwargs)
158 def set_name_with_model(self, model):
159 """
160 Generate a unique name for the index.
162 The name is divided into 3 parts - table name (12 chars), field name
163 (8 chars) and unique hash + suffix (10 chars). Each part is made to
164 fit its size by truncating the excess length.
165 """
166 _, table_name = split_identifier(model._meta.db_table)
167 column_names = [
168 model._meta.get_field(field_name).column
169 for field_name, order in self.fields_orders
170 ]
171 column_names_with_order = [
172 (("-%s" if order else "%s") % column_name)
173 for column_name, (field_name, order) in zip(
174 column_names, self.fields_orders
175 )
176 ]
177 # The length of the parts of the name is based on the default max
178 # length of 30 characters.
179 hash_data = [table_name] + column_names_with_order + [self.suffix]
180 self.name = "{}_{}_{}".format(
181 table_name[:11],
182 column_names[0][:7],
183 f"{names_digest(*hash_data, length=6)}_{self.suffix}",
184 )
185 if len(self.name) > self.max_name_length:
186 raise ValueError(
187 "Index too long for multiple database support. Is self.suffix "
188 "longer than 3 characters?"
189 )
190 if self.name[0] == "_" or self.name[0].isdigit():
191 self.name = "D%s" % self.name[1:]
193 def __repr__(self):
194 return "<{}:{}{}{}{}{}{}{}>".format(
195 self.__class__.__qualname__,
196 "" if not self.fields else " fields=%s" % repr(self.fields),
197 "" if not self.expressions else " expressions=%s" % repr(self.expressions),
198 "" if not self.name else " name=%s" % repr(self.name),
199 ""
200 if self.db_tablespace is None
201 else " db_tablespace=%s" % repr(self.db_tablespace),
202 "" if self.condition is None else " condition=%s" % self.condition,
203 "" if not self.include else " include=%s" % repr(self.include),
204 "" if not self.opclasses else " opclasses=%s" % repr(self.opclasses),
205 )
207 def __eq__(self, other):
208 if self.__class__ == other.__class__:
209 return self.deconstruct() == other.deconstruct()
210 return NotImplemented
213class IndexExpression(Func):
214 """Order and wrap expressions for CREATE INDEX statements."""
216 template = "%(expressions)s"
217 wrapper_classes = (OrderBy, Collate)
219 def set_wrapper_classes(self, connection=None):
220 # Some databases (e.g. MySQL) treats COLLATE as an indexed expression.
221 if connection and connection.features.collate_as_index_expression:
222 self.wrapper_classes = tuple(
223 [
224 wrapper_cls
225 for wrapper_cls in self.wrapper_classes
226 if wrapper_cls is not Collate
227 ]
228 )
230 @classmethod
231 def register_wrappers(cls, *wrapper_classes):
232 cls.wrapper_classes = wrapper_classes
234 def resolve_expression(
235 self,
236 query=None,
237 allow_joins=True,
238 reuse=None,
239 summarize=False,
240 for_save=False,
241 ):
242 expressions = list(self.flatten())
243 # Split expressions and wrappers.
244 index_expressions, wrappers = partition(
245 lambda e: isinstance(e, self.wrapper_classes),
246 expressions,
247 )
248 wrapper_types = [type(wrapper) for wrapper in wrappers]
249 if len(wrapper_types) != len(set(wrapper_types)):
250 raise ValueError(
251 "Multiple references to %s can't be used in an indexed "
252 "expression."
253 % ", ".join(
254 [wrapper_cls.__qualname__ for wrapper_cls in self.wrapper_classes]
255 )
256 )
257 if expressions[1 : len(wrappers) + 1] != wrappers:
258 raise ValueError(
259 "%s must be topmost expressions in an indexed expression."
260 % ", ".join(
261 [wrapper_cls.__qualname__ for wrapper_cls in self.wrapper_classes]
262 )
263 )
264 # Wrap expressions in parentheses if they are not column references.
265 root_expression = index_expressions[1]
266 resolve_root_expression = root_expression.resolve_expression(
267 query,
268 allow_joins,
269 reuse,
270 summarize,
271 for_save,
272 )
273 if not isinstance(resolve_root_expression, Col):
274 root_expression = Func(root_expression, template="(%(expressions)s)")
276 if wrappers:
277 # Order wrappers and set their expressions.
278 wrappers = sorted(
279 wrappers,
280 key=lambda w: self.wrapper_classes.index(type(w)),
281 )
282 wrappers = [wrapper.copy() for wrapper in wrappers]
283 for i, wrapper in enumerate(wrappers[:-1]):
284 wrapper.set_source_expressions([wrappers[i + 1]])
285 # Set the root expression on the deepest wrapper.
286 wrappers[-1].set_source_expressions([root_expression])
287 self.set_source_expressions([wrappers[0]])
288 else:
289 # Use the root expression, if there are no wrappers.
290 self.set_source_expressions([root_expression])
291 return super().resolve_expression(
292 query, allow_joins, reuse, summarize, for_save
293 )
295 def as_sqlite(self, compiler, connection, **extra_context):
296 # Casting to numeric is unnecessary.
297 return self.as_sql(compiler, connection, **extra_context)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import itertools
2import math
4from plain.exceptions import EmptyResultSet, FullResultSet
5from plain.models.expressions import Expression, Func, Value
6from plain.models.fields import (
7 BooleanField,
8 CharField,
9 DateTimeField,
10 Field,
11 IntegerField,
12 UUIDField,
13)
14from plain.models.query_utils import RegisterLookupMixin
15from plain.utils.datastructures import OrderedSet
16from plain.utils.functional import cached_property
17from plain.utils.hashable import make_hashable
20class Lookup(Expression):
21 lookup_name = None
22 prepare_rhs = True
23 can_use_none_as_rhs = False
25 def __init__(self, lhs, rhs):
26 self.lhs, self.rhs = lhs, rhs
27 self.rhs = self.get_prep_lookup()
28 self.lhs = self.get_prep_lhs()
29 if hasattr(self.lhs, "get_bilateral_transforms"):
30 bilateral_transforms = self.lhs.get_bilateral_transforms()
31 else:
32 bilateral_transforms = []
33 if bilateral_transforms:
34 # Warn the user as soon as possible if they are trying to apply
35 # a bilateral transformation on a nested QuerySet: that won't work.
36 from plain.models.sql.query import Query # avoid circular import
38 if isinstance(rhs, Query):
39 raise NotImplementedError(
40 "Bilateral transformations on nested querysets are not implemented."
41 )
42 self.bilateral_transforms = bilateral_transforms
44 def apply_bilateral_transforms(self, value):
45 for transform in self.bilateral_transforms:
46 value = transform(value)
47 return value
49 def __repr__(self):
50 return f"{self.__class__.__name__}({self.lhs!r}, {self.rhs!r})"
52 def batch_process_rhs(self, compiler, connection, rhs=None):
53 if rhs is None:
54 rhs = self.rhs
55 if self.bilateral_transforms:
56 sqls, sqls_params = [], []
57 for p in rhs:
58 value = Value(p, output_field=self.lhs.output_field)
59 value = self.apply_bilateral_transforms(value)
60 value = value.resolve_expression(compiler.query)
61 sql, sql_params = compiler.compile(value)
62 sqls.append(sql)
63 sqls_params.extend(sql_params)
64 else:
65 _, params = self.get_db_prep_lookup(rhs, connection)
66 sqls, sqls_params = ["%s"] * len(params), params
67 return sqls, sqls_params
69 def get_source_expressions(self):
70 if self.rhs_is_direct_value():
71 return [self.lhs]
72 return [self.lhs, self.rhs]
74 def set_source_expressions(self, new_exprs):
75 if len(new_exprs) == 1:
76 self.lhs = new_exprs[0]
77 else:
78 self.lhs, self.rhs = new_exprs
80 def get_prep_lookup(self):
81 if not self.prepare_rhs or hasattr(self.rhs, "resolve_expression"):
82 return self.rhs
83 if hasattr(self.lhs, "output_field"):
84 if hasattr(self.lhs.output_field, "get_prep_value"):
85 return self.lhs.output_field.get_prep_value(self.rhs)
86 elif self.rhs_is_direct_value():
87 return Value(self.rhs)
88 return self.rhs
90 def get_prep_lhs(self):
91 if hasattr(self.lhs, "resolve_expression"):
92 return self.lhs
93 return Value(self.lhs)
95 def get_db_prep_lookup(self, value, connection):
96 return ("%s", [value])
98 def process_lhs(self, compiler, connection, lhs=None):
99 lhs = lhs or self.lhs
100 if hasattr(lhs, "resolve_expression"):
101 lhs = lhs.resolve_expression(compiler.query)
102 sql, params = compiler.compile(lhs)
103 if isinstance(lhs, Lookup):
104 # Wrapped in parentheses to respect operator precedence.
105 sql = f"({sql})"
106 return sql, params
108 def process_rhs(self, compiler, connection):
109 value = self.rhs
110 if self.bilateral_transforms:
111 if self.rhs_is_direct_value():
112 # Do not call get_db_prep_lookup here as the value will be
113 # transformed before being used for lookup
114 value = Value(value, output_field=self.lhs.output_field)
115 value = self.apply_bilateral_transforms(value)
116 value = value.resolve_expression(compiler.query)
117 if hasattr(value, "as_sql"):
118 sql, params = compiler.compile(value)
119 # Ensure expression is wrapped in parentheses to respect operator
120 # precedence but avoid double wrapping as it can be misinterpreted
121 # on some backends (e.g. subqueries on SQLite).
122 if sql and sql[0] != "(":
123 sql = "(%s)" % sql
124 return sql, params
125 else:
126 return self.get_db_prep_lookup(value, connection)
128 def rhs_is_direct_value(self):
129 return not hasattr(self.rhs, "as_sql")
131 def get_group_by_cols(self):
132 cols = []
133 for source in self.get_source_expressions():
134 cols.extend(source.get_group_by_cols())
135 return cols
137 @cached_property
138 def output_field(self):
139 return BooleanField()
141 @property
142 def identity(self):
143 return self.__class__, self.lhs, self.rhs
145 def __eq__(self, other):
146 if not isinstance(other, Lookup):
147 return NotImplemented
148 return self.identity == other.identity
150 def __hash__(self):
151 return hash(make_hashable(self.identity))
153 def resolve_expression(
154 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
155 ):
156 c = self.copy()
157 c.is_summary = summarize
158 c.lhs = self.lhs.resolve_expression(
159 query, allow_joins, reuse, summarize, for_save
160 )
161 if hasattr(self.rhs, "resolve_expression"):
162 c.rhs = self.rhs.resolve_expression(
163 query, allow_joins, reuse, summarize, for_save
164 )
165 return c
167 def select_format(self, compiler, sql, params):
168 # Wrap filters with a CASE WHEN expression if a database backend
169 # (e.g. Oracle) doesn't support boolean expression in SELECT or GROUP
170 # BY list.
171 if not compiler.connection.features.supports_boolean_expr_in_select_clause:
172 sql = f"CASE WHEN {sql} THEN 1 ELSE 0 END"
173 return sql, params
176class Transform(RegisterLookupMixin, Func):
177 """
178 RegisterLookupMixin() is first so that get_lookup() and get_transform()
179 first examine self and then check output_field.
180 """
182 bilateral = False
183 arity = 1
185 @property
186 def lhs(self):
187 return self.get_source_expressions()[0]
189 def get_bilateral_transforms(self):
190 if hasattr(self.lhs, "get_bilateral_transforms"):
191 bilateral_transforms = self.lhs.get_bilateral_transforms()
192 else:
193 bilateral_transforms = []
194 if self.bilateral:
195 bilateral_transforms.append(self.__class__)
196 return bilateral_transforms
199class BuiltinLookup(Lookup):
200 def process_lhs(self, compiler, connection, lhs=None):
201 lhs_sql, params = super().process_lhs(compiler, connection, lhs)
202 field_internal_type = self.lhs.output_field.get_internal_type()
203 db_type = self.lhs.output_field.db_type(connection=connection)
204 lhs_sql = connection.ops.field_cast_sql(db_type, field_internal_type) % lhs_sql
205 lhs_sql = (
206 connection.ops.lookup_cast(self.lookup_name, field_internal_type) % lhs_sql
207 )
208 return lhs_sql, list(params)
210 def as_sql(self, compiler, connection):
211 lhs_sql, params = self.process_lhs(compiler, connection)
212 rhs_sql, rhs_params = self.process_rhs(compiler, connection)
213 params.extend(rhs_params)
214 rhs_sql = self.get_rhs_op(connection, rhs_sql)
215 return f"{lhs_sql} {rhs_sql}", params
217 def get_rhs_op(self, connection, rhs):
218 return connection.operators[self.lookup_name] % rhs
221class FieldGetDbPrepValueMixin:
222 """
223 Some lookups require Field.get_db_prep_value() to be called on their
224 inputs.
225 """
227 get_db_prep_lookup_value_is_iterable = False
229 def get_db_prep_lookup(self, value, connection):
230 # For relational fields, use the 'target_field' attribute of the
231 # output_field.
232 field = getattr(self.lhs.output_field, "target_field", None)
233 get_db_prep_value = (
234 getattr(field, "get_db_prep_value", None)
235 or self.lhs.output_field.get_db_prep_value
236 )
237 return (
238 "%s",
239 [get_db_prep_value(v, connection, prepared=True) for v in value]
240 if self.get_db_prep_lookup_value_is_iterable
241 else [get_db_prep_value(value, connection, prepared=True)],
242 )
245class FieldGetDbPrepValueIterableMixin(FieldGetDbPrepValueMixin):
246 """
247 Some lookups require Field.get_db_prep_value() to be called on each value
248 in an iterable.
249 """
251 get_db_prep_lookup_value_is_iterable = True
253 def get_prep_lookup(self):
254 if hasattr(self.rhs, "resolve_expression"):
255 return self.rhs
256 prepared_values = []
257 for rhs_value in self.rhs:
258 if hasattr(rhs_value, "resolve_expression"):
259 # An expression will be handled by the database but can coexist
260 # alongside real values.
261 pass
262 elif self.prepare_rhs and hasattr(self.lhs.output_field, "get_prep_value"):
263 rhs_value = self.lhs.output_field.get_prep_value(rhs_value)
264 prepared_values.append(rhs_value)
265 return prepared_values
267 def process_rhs(self, compiler, connection):
268 if self.rhs_is_direct_value():
269 # rhs should be an iterable of values. Use batch_process_rhs()
270 # to prepare/transform those values.
271 return self.batch_process_rhs(compiler, connection)
272 else:
273 return super().process_rhs(compiler, connection)
275 def resolve_expression_parameter(self, compiler, connection, sql, param):
276 params = [param]
277 if hasattr(param, "resolve_expression"):
278 param = param.resolve_expression(compiler.query)
279 if hasattr(param, "as_sql"):
280 sql, params = compiler.compile(param)
281 return sql, params
283 def batch_process_rhs(self, compiler, connection, rhs=None):
284 pre_processed = super().batch_process_rhs(compiler, connection, rhs)
285 # The params list may contain expressions which compile to a
286 # sql/param pair. Zip them to get sql and param pairs that refer to the
287 # same argument and attempt to replace them with the result of
288 # compiling the param step.
289 sql, params = zip(
290 *(
291 self.resolve_expression_parameter(compiler, connection, sql, param)
292 for sql, param in zip(*pre_processed)
293 )
294 )
295 params = itertools.chain.from_iterable(params)
296 return sql, tuple(params)
299class PostgresOperatorLookup(Lookup):
300 """Lookup defined by operators on PostgreSQL."""
302 postgres_operator = None
304 def as_postgresql(self, compiler, connection):
305 lhs, lhs_params = self.process_lhs(compiler, connection)
306 rhs, rhs_params = self.process_rhs(compiler, connection)
307 params = tuple(lhs_params) + tuple(rhs_params)
308 return f"{lhs} {self.postgres_operator} {rhs}", params
311@Field.register_lookup
312class Exact(FieldGetDbPrepValueMixin, BuiltinLookup):
313 lookup_name = "exact"
315 def get_prep_lookup(self):
316 from plain.models.sql.query import Query # avoid circular import
318 if isinstance(self.rhs, Query):
319 if self.rhs.has_limit_one():
320 if not self.rhs.has_select_fields:
321 self.rhs.clear_select_clause()
322 self.rhs.add_fields(["pk"])
323 else:
324 raise ValueError(
325 "The QuerySet value for an exact lookup must be limited to "
326 "one result using slicing."
327 )
328 return super().get_prep_lookup()
330 def as_sql(self, compiler, connection):
331 # Avoid comparison against direct rhs if lhs is a boolean value. That
332 # turns "boolfield__exact=True" into "WHERE boolean_field" instead of
333 # "WHERE boolean_field = True" when allowed.
334 if (
335 isinstance(self.rhs, bool)
336 and getattr(self.lhs, "conditional", False)
337 and connection.ops.conditional_expression_supported_in_where_clause(
338 self.lhs
339 )
340 ):
341 lhs_sql, params = self.process_lhs(compiler, connection)
342 template = "%s" if self.rhs else "NOT %s"
343 return template % lhs_sql, params
344 return super().as_sql(compiler, connection)
347@Field.register_lookup
348class IExact(BuiltinLookup):
349 lookup_name = "iexact"
350 prepare_rhs = False
352 def process_rhs(self, qn, connection):
353 rhs, params = super().process_rhs(qn, connection)
354 if params:
355 params[0] = connection.ops.prep_for_iexact_query(params[0])
356 return rhs, params
359@Field.register_lookup
360class GreaterThan(FieldGetDbPrepValueMixin, BuiltinLookup):
361 lookup_name = "gt"
364@Field.register_lookup
365class GreaterThanOrEqual(FieldGetDbPrepValueMixin, BuiltinLookup):
366 lookup_name = "gte"
369@Field.register_lookup
370class LessThan(FieldGetDbPrepValueMixin, BuiltinLookup):
371 lookup_name = "lt"
374@Field.register_lookup
375class LessThanOrEqual(FieldGetDbPrepValueMixin, BuiltinLookup):
376 lookup_name = "lte"
379class IntegerFieldOverflow:
380 underflow_exception = EmptyResultSet
381 overflow_exception = EmptyResultSet
383 def process_rhs(self, compiler, connection):
384 rhs = self.rhs
385 if isinstance(rhs, int):
386 field_internal_type = self.lhs.output_field.get_internal_type()
387 min_value, max_value = connection.ops.integer_field_range(
388 field_internal_type
389 )
390 if min_value is not None and rhs < min_value:
391 raise self.underflow_exception
392 if max_value is not None and rhs > max_value:
393 raise self.overflow_exception
394 return super().process_rhs(compiler, connection)
397class IntegerFieldFloatRounding:
398 """
399 Allow floats to work as query values for IntegerField. Without this, the
400 decimal portion of the float would always be discarded.
401 """
403 def get_prep_lookup(self):
404 if isinstance(self.rhs, float):
405 self.rhs = math.ceil(self.rhs)
406 return super().get_prep_lookup()
409@IntegerField.register_lookup
410class IntegerFieldExact(IntegerFieldOverflow, Exact):
411 pass
414@IntegerField.register_lookup
415class IntegerGreaterThan(IntegerFieldOverflow, GreaterThan):
416 underflow_exception = FullResultSet
419@IntegerField.register_lookup
420class IntegerGreaterThanOrEqual(
421 IntegerFieldOverflow, IntegerFieldFloatRounding, GreaterThanOrEqual
422):
423 underflow_exception = FullResultSet
426@IntegerField.register_lookup
427class IntegerLessThan(IntegerFieldOverflow, IntegerFieldFloatRounding, LessThan):
428 overflow_exception = FullResultSet
431@IntegerField.register_lookup
432class IntegerLessThanOrEqual(IntegerFieldOverflow, LessThanOrEqual):
433 overflow_exception = FullResultSet
436@Field.register_lookup
437class In(FieldGetDbPrepValueIterableMixin, BuiltinLookup):
438 lookup_name = "in"
440 def get_prep_lookup(self):
441 from plain.models.sql.query import Query # avoid circular import
443 if isinstance(self.rhs, Query):
444 self.rhs.clear_ordering(clear_default=True)
445 if not self.rhs.has_select_fields:
446 self.rhs.clear_select_clause()
447 self.rhs.add_fields(["pk"])
448 return super().get_prep_lookup()
450 def process_rhs(self, compiler, connection):
451 db_rhs = getattr(self.rhs, "_db", None)
452 if db_rhs is not None and db_rhs != connection.alias:
453 raise ValueError(
454 "Subqueries aren't allowed across different databases. Force "
455 "the inner query to be evaluated using `list(inner_query)`."
456 )
458 if self.rhs_is_direct_value():
459 # Remove None from the list as NULL is never equal to anything.
460 try:
461 rhs = OrderedSet(self.rhs)
462 rhs.discard(None)
463 except TypeError: # Unhashable items in self.rhs
464 rhs = [r for r in self.rhs if r is not None]
466 if not rhs:
467 raise EmptyResultSet
469 # rhs should be an iterable; use batch_process_rhs() to
470 # prepare/transform those values.
471 sqls, sqls_params = self.batch_process_rhs(compiler, connection, rhs)
472 placeholder = "(" + ", ".join(sqls) + ")"
473 return (placeholder, sqls_params)
474 return super().process_rhs(compiler, connection)
476 def get_rhs_op(self, connection, rhs):
477 return "IN %s" % rhs
479 def as_sql(self, compiler, connection):
480 max_in_list_size = connection.ops.max_in_list_size()
481 if (
482 self.rhs_is_direct_value()
483 and max_in_list_size
484 and len(self.rhs) > max_in_list_size
485 ):
486 return self.split_parameter_list_as_sql(compiler, connection)
487 return super().as_sql(compiler, connection)
489 def split_parameter_list_as_sql(self, compiler, connection):
490 # This is a special case for databases which limit the number of
491 # elements which can appear in an 'IN' clause.
492 max_in_list_size = connection.ops.max_in_list_size()
493 lhs, lhs_params = self.process_lhs(compiler, connection)
494 rhs, rhs_params = self.batch_process_rhs(compiler, connection)
495 in_clause_elements = ["("]
496 params = []
497 for offset in range(0, len(rhs_params), max_in_list_size):
498 if offset > 0:
499 in_clause_elements.append(" OR ")
500 in_clause_elements.append("%s IN (" % lhs)
501 params.extend(lhs_params)
502 sqls = rhs[offset : offset + max_in_list_size]
503 sqls_params = rhs_params[offset : offset + max_in_list_size]
504 param_group = ", ".join(sqls)
505 in_clause_elements.append(param_group)
506 in_clause_elements.append(")")
507 params.extend(sqls_params)
508 in_clause_elements.append(")")
509 return "".join(in_clause_elements), params
512class PatternLookup(BuiltinLookup):
513 param_pattern = "%%%s%%"
514 prepare_rhs = False
516 def get_rhs_op(self, connection, rhs):
517 # Assume we are in startswith. We need to produce SQL like:
518 # col LIKE %s, ['thevalue%']
519 # For python values we can (and should) do that directly in Python,
520 # but if the value is for example reference to other column, then
521 # we need to add the % pattern match to the lookup by something like
522 # col LIKE othercol || '%%'
523 # So, for Python values we don't need any special pattern, but for
524 # SQL reference values or SQL transformations we need the correct
525 # pattern added.
526 if hasattr(self.rhs, "as_sql") or self.bilateral_transforms:
527 pattern = connection.pattern_ops[self.lookup_name].format(
528 connection.pattern_esc
529 )
530 return pattern.format(rhs)
531 else:
532 return super().get_rhs_op(connection, rhs)
534 def process_rhs(self, qn, connection):
535 rhs, params = super().process_rhs(qn, connection)
536 if self.rhs_is_direct_value() and params and not self.bilateral_transforms:
537 params[0] = self.param_pattern % connection.ops.prep_for_like_query(
538 params[0]
539 )
540 return rhs, params
543@Field.register_lookup
544class Contains(PatternLookup):
545 lookup_name = "contains"
548@Field.register_lookup
549class IContains(Contains):
550 lookup_name = "icontains"
553@Field.register_lookup
554class StartsWith(PatternLookup):
555 lookup_name = "startswith"
556 param_pattern = "%s%%"
559@Field.register_lookup
560class IStartsWith(StartsWith):
561 lookup_name = "istartswith"
564@Field.register_lookup
565class EndsWith(PatternLookup):
566 lookup_name = "endswith"
567 param_pattern = "%%%s"
570@Field.register_lookup
571class IEndsWith(EndsWith):
572 lookup_name = "iendswith"
575@Field.register_lookup
576class Range(FieldGetDbPrepValueIterableMixin, BuiltinLookup):
577 lookup_name = "range"
579 def get_rhs_op(self, connection, rhs):
580 return f"BETWEEN {rhs[0]} AND {rhs[1]}"
583@Field.register_lookup
584class IsNull(BuiltinLookup):
585 lookup_name = "isnull"
586 prepare_rhs = False
588 def as_sql(self, compiler, connection):
589 if not isinstance(self.rhs, bool):
590 raise ValueError(
591 "The QuerySet value for an isnull lookup must be True or False."
592 )
593 sql, params = self.process_lhs(compiler, connection)
594 if self.rhs:
595 return "%s IS NULL" % sql, params
596 else:
597 return "%s IS NOT NULL" % sql, params
600@Field.register_lookup
601class Regex(BuiltinLookup):
602 lookup_name = "regex"
603 prepare_rhs = False
605 def as_sql(self, compiler, connection):
606 if self.lookup_name in connection.operators:
607 return super().as_sql(compiler, connection)
608 else:
609 lhs, lhs_params = self.process_lhs(compiler, connection)
610 rhs, rhs_params = self.process_rhs(compiler, connection)
611 sql_template = connection.ops.regex_lookup(self.lookup_name)
612 return sql_template % (lhs, rhs), lhs_params + rhs_params
615@Field.register_lookup
616class IRegex(Regex):
617 lookup_name = "iregex"
620class YearLookup(Lookup):
621 def year_lookup_bounds(self, connection, year):
622 from plain.models.functions import ExtractIsoYear
624 iso_year = isinstance(self.lhs, ExtractIsoYear)
625 output_field = self.lhs.lhs.output_field
626 if isinstance(output_field, DateTimeField):
627 bounds = connection.ops.year_lookup_bounds_for_datetime_field(
628 year,
629 iso_year=iso_year,
630 )
631 else:
632 bounds = connection.ops.year_lookup_bounds_for_date_field(
633 year,
634 iso_year=iso_year,
635 )
636 return bounds
638 def as_sql(self, compiler, connection):
639 # Avoid the extract operation if the rhs is a direct value to allow
640 # indexes to be used.
641 if self.rhs_is_direct_value():
642 # Skip the extract part by directly using the originating field,
643 # that is self.lhs.lhs.
644 lhs_sql, params = self.process_lhs(compiler, connection, self.lhs.lhs)
645 rhs_sql, _ = self.process_rhs(compiler, connection)
646 rhs_sql = self.get_direct_rhs_sql(connection, rhs_sql)
647 start, finish = self.year_lookup_bounds(connection, self.rhs)
648 params.extend(self.get_bound_params(start, finish))
649 return f"{lhs_sql} {rhs_sql}", params
650 return super().as_sql(compiler, connection)
652 def get_direct_rhs_sql(self, connection, rhs):
653 return connection.operators[self.lookup_name] % rhs
655 def get_bound_params(self, start, finish):
656 raise NotImplementedError(
657 "subclasses of YearLookup must provide a get_bound_params() method"
658 )
661class YearExact(YearLookup, Exact):
662 def get_direct_rhs_sql(self, connection, rhs):
663 return "BETWEEN %s AND %s"
665 def get_bound_params(self, start, finish):
666 return (start, finish)
669class YearGt(YearLookup, GreaterThan):
670 def get_bound_params(self, start, finish):
671 return (finish,)
674class YearGte(YearLookup, GreaterThanOrEqual):
675 def get_bound_params(self, start, finish):
676 return (start,)
679class YearLt(YearLookup, LessThan):
680 def get_bound_params(self, start, finish):
681 return (start,)
684class YearLte(YearLookup, LessThanOrEqual):
685 def get_bound_params(self, start, finish):
686 return (finish,)
689class UUIDTextMixin:
690 """
691 Strip hyphens from a value when filtering a UUIDField on backends without
692 a native datatype for UUID.
693 """
695 def process_rhs(self, qn, connection):
696 if not connection.features.has_native_uuid_field:
697 from plain.models.functions import Replace
699 if self.rhs_is_direct_value():
700 self.rhs = Value(self.rhs)
701 self.rhs = Replace(
702 self.rhs, Value("-"), Value(""), output_field=CharField()
703 )
704 rhs, params = super().process_rhs(qn, connection)
705 return rhs, params
708@UUIDField.register_lookup
709class UUIDIExact(UUIDTextMixin, IExact):
710 pass
713@UUIDField.register_lookup
714class UUIDContains(UUIDTextMixin, Contains):
715 pass
718@UUIDField.register_lookup
719class UUIDIContains(UUIDTextMixin, IContains):
720 pass
723@UUIDField.register_lookup
724class UUIDStartsWith(UUIDTextMixin, StartsWith):
725 pass
728@UUIDField.register_lookup
729class UUIDIStartsWith(UUIDTextMixin, IStartsWith):
730 pass
733@UUIDField.register_lookup
734class UUIDEndsWith(UUIDTextMixin, EndsWith):
735 pass
738@UUIDField.register_lookup
739class UUIDIEndsWith(UUIDTextMixin, IEndsWith):
740 pass
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import copy
2import inspect
3from functools import wraps
4from importlib import import_module
6from plain.models.db import router
7from plain.models.query import QuerySet
10class BaseManager:
11 # To retain order, track each time a Manager instance is created.
12 creation_counter = 0
14 # Set to True for the 'objects' managers that are automatically created.
15 auto_created = False
17 #: If set to True the manager will be serialized into migrations and will
18 #: thus be available in e.g. RunPython operations.
19 use_in_migrations = False
21 def __new__(cls, *args, **kwargs):
22 # Capture the arguments to make returning them trivial.
23 obj = super().__new__(cls)
24 obj._constructor_args = (args, kwargs)
25 return obj
27 def __init__(self):
28 super().__init__()
29 self._set_creation_counter()
30 self.model = None
31 self.name = None
32 self._db = None
33 self._hints = {}
35 def __str__(self):
36 """Return "package_label.model_label.manager_name"."""
37 return f"{self.model._meta.label}.{self.name}"
39 def __class_getitem__(cls, *args, **kwargs):
40 return cls
42 def deconstruct(self):
43 """
44 Return a 5-tuple of the form (as_manager (True), manager_class,
45 queryset_class, args, kwargs).
47 Raise a ValueError if the manager is dynamically generated.
48 """
49 qs_class = self._queryset_class
50 if getattr(self, "_built_with_as_manager", False):
51 # using MyQuerySet.as_manager()
52 return (
53 True, # as_manager
54 None, # manager_class
55 f"{qs_class.__module__}.{qs_class.__name__}", # qs_class
56 None, # args
57 None, # kwargs
58 )
59 else:
60 module_name = self.__module__
61 name = self.__class__.__name__
62 # Make sure it's actually there and not an inner class
63 module = import_module(module_name)
64 if not hasattr(module, name):
65 raise ValueError(
66 f"Could not find manager {name} in {module_name}.\n"
67 "Please note that you need to inherit from managers you "
68 "dynamically generated with 'from_queryset()'."
69 )
70 return (
71 False, # as_manager
72 f"{module_name}.{name}", # manager_class
73 None, # qs_class
74 self._constructor_args[0], # args
75 self._constructor_args[1], # kwargs
76 )
78 def check(self, **kwargs):
79 return []
81 @classmethod
82 def _get_queryset_methods(cls, queryset_class):
83 def create_method(name, method):
84 @wraps(method)
85 def manager_method(self, *args, **kwargs):
86 return getattr(self.get_queryset(), name)(*args, **kwargs)
88 return manager_method
90 new_methods = {}
91 for name, method in inspect.getmembers(
92 queryset_class, predicate=inspect.isfunction
93 ):
94 # Only copy missing methods.
95 if hasattr(cls, name):
96 continue
97 # Only copy public methods or methods with the attribute
98 # queryset_only=False.
99 queryset_only = getattr(method, "queryset_only", None)
100 if queryset_only or (queryset_only is None and name.startswith("_")):
101 continue
102 # Copy the method onto the manager.
103 new_methods[name] = create_method(name, method)
104 return new_methods
106 @classmethod
107 def from_queryset(cls, queryset_class, class_name=None):
108 if class_name is None:
109 class_name = f"{cls.__name__}From{queryset_class.__name__}"
110 return type(
111 class_name,
112 (cls,),
113 {
114 "_queryset_class": queryset_class,
115 **cls._get_queryset_methods(queryset_class),
116 },
117 )
119 def contribute_to_class(self, cls, name):
120 self.name = self.name or name
121 self.model = cls
123 setattr(cls, name, ManagerDescriptor(self))
125 cls._meta.add_manager(self)
127 def _set_creation_counter(self):
128 """
129 Set the creation counter value for this instance and increment the
130 class-level copy.
131 """
132 self.creation_counter = BaseManager.creation_counter
133 BaseManager.creation_counter += 1
135 def db_manager(self, using=None, hints=None):
136 obj = copy.copy(self)
137 obj._db = using or self._db
138 obj._hints = hints or self._hints
139 return obj
141 @property
142 def db(self):
143 return self._db or router.db_for_read(self.model, **self._hints)
145 #######################
146 # PROXIES TO QUERYSET #
147 #######################
149 def get_queryset(self):
150 """
151 Return a new QuerySet object. Subclasses can override this method to
152 customize the behavior of the Manager.
153 """
154 return self._queryset_class(model=self.model, using=self._db, hints=self._hints)
156 def all(self):
157 # We can't proxy this method through the `QuerySet` like we do for the
158 # rest of the `QuerySet` methods. This is because `QuerySet.all()`
159 # works by creating a "copy" of the current queryset and in making said
160 # copy, all the cached `prefetch_related` lookups are lost. See the
161 # implementation of `RelatedManager.get_queryset()` for a better
162 # understanding of how this comes into play.
163 return self.get_queryset()
165 def __eq__(self, other):
166 return (
167 isinstance(other, self.__class__)
168 and self._constructor_args == other._constructor_args
169 )
171 def __hash__(self):
172 return id(self)
175class Manager(BaseManager.from_queryset(QuerySet)):
176 pass
179class ManagerDescriptor:
180 def __init__(self, manager):
181 self.manager = manager
183 def __get__(self, instance, cls=None):
184 if instance is not None:
185 raise AttributeError(
186 "Manager isn't accessible via %s instances" % cls.__name__
187 )
189 if cls._meta.abstract:
190 raise AttributeError(
191 f"Manager isn't available; {cls._meta.object_name} is abstract"
192 )
194 if cls._meta.swapped:
195 raise AttributeError(
196 "Manager isn't available; '{}' has been swapped for '{}'".format(
197 cls._meta.label,
198 cls._meta.swapped,
199 )
200 )
202 return cls._meta.managers_map[self.manager.name]
205class EmptyManager(Manager):
206 def __init__(self, model):
207 super().__init__()
208 self.model = model
210 def get_queryset(self):
211 return super().get_queryset().none()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import bisect
2import copy
3import inspect
4from collections import defaultdict
6from plain.exceptions import FieldDoesNotExist
7from plain.models.constraints import UniqueConstraint
8from plain.models.db import connections
9from plain.models.fields import BigAutoField
10from plain.models.fields.proxy import OrderWrt
11from plain.models.manager import Manager
12from plain.models.query_utils import PathInfo
13from plain.packages import packages
14from plain.runtime import settings
15from plain.utils.datastructures import ImmutableList, OrderedSet
16from plain.utils.functional import cached_property
18PROXY_PARENTS = object()
20EMPTY_RELATION_TREE = ()
22IMMUTABLE_WARNING = (
23 "The return type of '%s' should never be mutated. If you want to manipulate this "
24 "list for your own use, make a copy first."
25)
27DEFAULT_NAMES = (
28 "db_table",
29 "db_table_comment",
30 "ordering",
31 "get_latest_by",
32 "order_with_respect_to",
33 "package_label",
34 "db_tablespace",
35 "abstract",
36 "managed",
37 "swappable",
38 "auto_created",
39 "packages",
40 "select_on_save",
41 "default_related_name",
42 "required_db_features",
43 "required_db_vendor",
44 "base_manager_name",
45 "default_manager_name",
46 "indexes",
47 "constraints",
48)
51def make_immutable_fields_list(name, data):
52 return ImmutableList(data, warning=IMMUTABLE_WARNING % name)
55class Options:
56 FORWARD_PROPERTIES = {
57 "fields",
58 "many_to_many",
59 "concrete_fields",
60 "local_concrete_fields",
61 "_non_pk_concrete_field_names",
62 "_forward_fields_map",
63 "managers",
64 "managers_map",
65 "base_manager",
66 "default_manager",
67 }
68 REVERSE_PROPERTIES = {"related_objects", "fields_map", "_relation_tree"}
70 default_packages = packages
72 def __init__(self, meta, package_label=None):
73 self._get_fields_cache = {}
74 self.local_fields = []
75 self.local_many_to_many = []
76 self.private_fields = []
77 self.local_managers = []
78 self.base_manager_name = None
79 self.default_manager_name = None
80 self.model_name = None
81 self.db_table = ""
82 self.db_table_comment = ""
83 self.ordering = []
84 self._ordering_clash = False
85 self.indexes = []
86 self.constraints = []
87 self.select_on_save = False
88 self.object_name = None
89 self.package_label = package_label
90 self.get_latest_by = None
91 self.order_with_respect_to = None
92 self.db_tablespace = settings.DEFAULT_TABLESPACE
93 self.required_db_features = []
94 self.required_db_vendor = None
95 self.meta = meta
96 self.pk = None
97 self.auto_field = None
98 self.abstract = False
99 self.managed = True
100 # For any non-abstract class, the concrete class is the model
101 # in the end of the proxy_for_model chain. In particular, for
102 # concrete models, the concrete_model is always the class itself.
103 self.concrete_model = None
104 self.swappable = None
105 self.parents = {}
106 self.auto_created = False
108 # List of all lookups defined in ForeignKey 'limit_choices_to' options
109 # from *other* models. Needed for some admin checks. Internal use only.
110 self.related_fkey_lookups = []
112 # A custom app registry to use, if you're making a separate model set.
113 self.packages = self.default_packages
115 self.default_related_name = None
117 @property
118 def label(self):
119 return f"{self.package_label}.{self.object_name}"
121 @property
122 def label_lower(self):
123 return f"{self.package_label}.{self.model_name}"
125 @property
126 def package_config(self):
127 # Don't go through get_package_config to avoid triggering imports.
128 return self.packages.package_configs.get(self.package_label)
130 def contribute_to_class(self, cls, name):
131 from plain.models.backends.utils import truncate_name
132 from plain.models.db import connection
134 cls._meta = self
135 self.model = cls
136 # First, construct the default values for these options.
137 self.object_name = cls.__name__
138 self.model_name = self.object_name.lower()
140 # Store the original user-defined values for each option,
141 # for use when serializing the model definition
142 self.original_attrs = {}
144 # Next, apply any overridden values from 'class Meta'.
145 if self.meta:
146 meta_attrs = self.meta.__dict__.copy()
147 for name in self.meta.__dict__:
148 # Ignore any private attributes that Plain doesn't care about.
149 # NOTE: We can't modify a dictionary's contents while looping
150 # over it, so we loop over the *original* dictionary instead.
151 if name.startswith("_"):
152 del meta_attrs[name]
153 for attr_name in DEFAULT_NAMES:
154 if attr_name in meta_attrs:
155 setattr(self, attr_name, meta_attrs.pop(attr_name))
156 self.original_attrs[attr_name] = getattr(self, attr_name)
157 elif hasattr(self.meta, attr_name):
158 setattr(self, attr_name, getattr(self.meta, attr_name))
159 self.original_attrs[attr_name] = getattr(self, attr_name)
161 # Package label/class name interpolation for names of constraints and
162 # indexes.
163 if not getattr(cls._meta, "abstract", False):
164 for attr_name in {"constraints", "indexes"}:
165 objs = getattr(self, attr_name, [])
166 setattr(self, attr_name, self._format_names_with_class(cls, objs))
168 # order_with_respect_and ordering are mutually exclusive.
169 self._ordering_clash = bool(self.ordering and self.order_with_respect_to)
171 # Any leftover attributes must be invalid.
172 if meta_attrs != {}:
173 raise TypeError(
174 "'class Meta' got invalid attribute(s): %s" % ",".join(meta_attrs)
175 )
177 del self.meta
179 # If the db_table wasn't provided, use the package_label + model_name.
180 if not self.db_table:
181 self.db_table = f"{self.package_label}_{self.model_name}"
182 self.db_table = truncate_name(
183 self.db_table, connection.ops.max_name_length()
184 )
186 def _format_names_with_class(self, cls, objs):
187 """Package label/class name interpolation for object names."""
188 new_objs = []
189 for obj in objs:
190 obj = obj.clone()
191 obj.name = obj.name % {
192 "package_label": cls._meta.package_label.lower(),
193 "class": cls.__name__.lower(),
194 }
195 new_objs.append(obj)
196 return new_objs
198 def _prepare(self, model):
199 if self.order_with_respect_to:
200 # The app registry will not be ready at this point, so we cannot
201 # use get_field().
202 query = self.order_with_respect_to
203 try:
204 self.order_with_respect_to = next(
205 f
206 for f in self._get_fields(reverse=False)
207 if f.name == query or f.attname == query
208 )
209 except StopIteration:
210 raise FieldDoesNotExist(
211 f"{self.object_name} has no field named '{query}'"
212 )
214 self.ordering = ("_order",)
215 if not any(
216 isinstance(field, OrderWrt) for field in model._meta.local_fields
217 ):
218 model.add_to_class("_order", OrderWrt())
219 else:
220 self.order_with_respect_to = None
222 if self.pk is None:
223 if self.parents:
224 # Promote the first parent link in lieu of adding yet another
225 # field.
226 field = next(iter(self.parents.values()))
227 # Look for a local field with the same name as the
228 # first parent link. If a local field has already been
229 # created, use it instead of promoting the parent
230 already_created = [
231 fld for fld in self.local_fields if fld.name == field.name
232 ]
233 if already_created:
234 field = already_created[0]
235 field.primary_key = True
236 self.setup_pk(field)
237 else:
238 auto = BigAutoField(primary_key=True, auto_created=True)
239 model.add_to_class("id", auto)
241 def add_manager(self, manager):
242 self.local_managers.append(manager)
243 self._expire_cache()
245 def add_field(self, field, private=False):
246 # Insert the given field in the order in which it was created, using
247 # the "creation_counter" attribute of the field.
248 # Move many-to-many related fields from self.fields into
249 # self.many_to_many.
250 if private:
251 self.private_fields.append(field)
252 elif field.is_relation and field.many_to_many:
253 bisect.insort(self.local_many_to_many, field)
254 else:
255 bisect.insort(self.local_fields, field)
256 self.setup_pk(field)
258 # If the field being added is a relation to another known field,
259 # expire the cache on this field and the forward cache on the field
260 # being referenced, because there will be new relationships in the
261 # cache. Otherwise, expire the cache of references *to* this field.
262 # The mechanism for getting at the related model is slightly odd -
263 # ideally, we'd just ask for field.related_model. However, related_model
264 # is a cached property, and all the models haven't been loaded yet, so
265 # we need to make sure we don't cache a string reference.
266 if (
267 field.is_relation
268 and hasattr(field.remote_field, "model")
269 and field.remote_field.model
270 ):
271 try:
272 field.remote_field.model._meta._expire_cache(forward=False)
273 except AttributeError:
274 pass
275 self._expire_cache()
276 else:
277 self._expire_cache(reverse=False)
279 def setup_pk(self, field):
280 if not self.pk and field.primary_key:
281 self.pk = field
283 def __repr__(self):
284 return "<Options for %s>" % self.object_name
286 def __str__(self):
287 return self.label_lower
289 def can_migrate(self, connection):
290 """
291 Return True if the model can/should be migrated on the `connection`.
292 `connection` can be either a real connection or a connection alias.
293 """
294 if self.swapped or not self.managed:
295 return False
296 if isinstance(connection, str):
297 connection = connections[connection]
298 if self.required_db_vendor:
299 return self.required_db_vendor == connection.vendor
300 if self.required_db_features:
301 return all(
302 getattr(connection.features, feat, False)
303 for feat in self.required_db_features
304 )
305 return True
307 @property
308 def swapped(self):
309 """
310 Has this model been swapped out for another? If so, return the model
311 name of the replacement; otherwise, return None.
313 For historical reasons, model name lookups using get_model() are
314 case insensitive, so we make sure we are case insensitive here.
315 """
316 if self.swappable:
317 swapped_for = getattr(settings, self.swappable, None)
318 if swapped_for:
319 try:
320 swapped_label, swapped_object = swapped_for.split(".")
321 except ValueError:
322 # setting not in the format package_label.model_name
323 # raising ImproperlyConfigured here causes problems with
324 # test cleanup code - instead it is raised in get_user_model
325 # or as part of validation.
326 return swapped_for
328 if f"{swapped_label}.{swapped_object.lower()}" != self.label_lower:
329 return swapped_for
330 return None
332 @cached_property
333 def managers(self):
334 managers = []
335 seen_managers = set()
336 bases = (b for b in self.model.mro() if hasattr(b, "_meta"))
337 for depth, base in enumerate(bases):
338 for manager in base._meta.local_managers:
339 if manager.name in seen_managers:
340 continue
342 manager = copy.copy(manager)
343 manager.model = self.model
344 seen_managers.add(manager.name)
345 managers.append((depth, manager.creation_counter, manager))
347 return make_immutable_fields_list(
348 "managers",
349 (m[2] for m in sorted(managers)),
350 )
352 @cached_property
353 def managers_map(self):
354 return {manager.name: manager for manager in self.managers}
356 @cached_property
357 def base_manager(self):
358 base_manager_name = self.base_manager_name
359 if not base_manager_name:
360 # Get the first parent's base_manager_name if there's one.
361 for parent in self.model.mro()[1:]:
362 if hasattr(parent, "_meta"):
363 if parent._base_manager.name != "_base_manager":
364 base_manager_name = parent._base_manager.name
365 break
367 if base_manager_name:
368 try:
369 return self.managers_map[base_manager_name]
370 except KeyError:
371 raise ValueError(
372 f"{self.object_name} has no manager named {base_manager_name!r}"
373 )
375 manager = Manager()
376 manager.name = "_base_manager"
377 manager.model = self.model
378 manager.auto_created = True
379 return manager
381 @cached_property
382 def default_manager(self):
383 default_manager_name = self.default_manager_name
384 if not default_manager_name and not self.local_managers:
385 # Get the first parent's default_manager_name if there's one.
386 for parent in self.model.mro()[1:]:
387 if hasattr(parent, "_meta"):
388 default_manager_name = parent._meta.default_manager_name
389 break
391 if default_manager_name:
392 try:
393 return self.managers_map[default_manager_name]
394 except KeyError:
395 raise ValueError(
396 f"{self.object_name} has no manager named {default_manager_name!r}"
397 )
399 if self.managers:
400 return self.managers[0]
402 @cached_property
403 def fields(self):
404 """
405 Return a list of all forward fields on the model and its parents,
406 excluding ManyToManyFields.
408 Private API intended only to be used by Plain itself; get_fields()
409 combined with filtering of field properties is the public API for
410 obtaining this field list.
411 """
413 # For legacy reasons, the fields property should only contain forward
414 # fields that are not private or with a m2m cardinality. Therefore we
415 # pass these three filters as filters to the generator.
416 # The third lambda is a longwinded way of checking f.related_model - we don't
417 # use that property directly because related_model is a cached property,
418 # and all the models may not have been loaded yet; we don't want to cache
419 # the string reference to the related_model.
420 def is_not_an_m2m_field(f):
421 return not (f.is_relation and f.many_to_many)
423 def is_not_a_generic_relation(f):
424 return not (f.is_relation and f.one_to_many)
426 def is_not_a_generic_foreign_key(f):
427 return not (
428 f.is_relation
429 and f.many_to_one
430 and not (hasattr(f.remote_field, "model") and f.remote_field.model)
431 )
433 return make_immutable_fields_list(
434 "fields",
435 (
436 f
437 for f in self._get_fields(reverse=False)
438 if is_not_an_m2m_field(f)
439 and is_not_a_generic_relation(f)
440 and is_not_a_generic_foreign_key(f)
441 ),
442 )
444 @cached_property
445 def concrete_fields(self):
446 """
447 Return a list of all concrete fields on the model and its parents.
449 Private API intended only to be used by Plain itself; get_fields()
450 combined with filtering of field properties is the public API for
451 obtaining this field list.
452 """
453 return make_immutable_fields_list(
454 "concrete_fields", (f for f in self.fields if f.concrete)
455 )
457 @cached_property
458 def local_concrete_fields(self):
459 """
460 Return a list of all concrete fields on the model.
462 Private API intended only to be used by Plain itself; get_fields()
463 combined with filtering of field properties is the public API for
464 obtaining this field list.
465 """
466 return make_immutable_fields_list(
467 "local_concrete_fields", (f for f in self.local_fields if f.concrete)
468 )
470 @cached_property
471 def many_to_many(self):
472 """
473 Return a list of all many to many fields on the model and its parents.
475 Private API intended only to be used by Plain itself; get_fields()
476 combined with filtering of field properties is the public API for
477 obtaining this list.
478 """
479 return make_immutable_fields_list(
480 "many_to_many",
481 (
482 f
483 for f in self._get_fields(reverse=False)
484 if f.is_relation and f.many_to_many
485 ),
486 )
488 @cached_property
489 def related_objects(self):
490 """
491 Return all related objects pointing to the current model. The related
492 objects can come from a one-to-one, one-to-many, or many-to-many field
493 relation type.
495 Private API intended only to be used by Plain itself; get_fields()
496 combined with filtering of field properties is the public API for
497 obtaining this field list.
498 """
499 all_related_fields = self._get_fields(
500 forward=False, reverse=True, include_hidden=True
501 )
502 return make_immutable_fields_list(
503 "related_objects",
504 (
505 obj
506 for obj in all_related_fields
507 if not obj.hidden or obj.field.many_to_many
508 ),
509 )
511 @cached_property
512 def _forward_fields_map(self):
513 res = {}
514 fields = self._get_fields(reverse=False)
515 for field in fields:
516 res[field.name] = field
517 # Due to the way Plain's internals work, get_field() should also
518 # be able to fetch a field by attname. In the case of a concrete
519 # field with relation, includes the *_id name too
520 try:
521 res[field.attname] = field
522 except AttributeError:
523 pass
524 return res
526 @cached_property
527 def fields_map(self):
528 res = {}
529 fields = self._get_fields(forward=False, include_hidden=True)
530 for field in fields:
531 res[field.name] = field
532 # Due to the way Plain's internals work, get_field() should also
533 # be able to fetch a field by attname. In the case of a concrete
534 # field with relation, includes the *_id name too
535 try:
536 res[field.attname] = field
537 except AttributeError:
538 pass
539 return res
541 def get_field(self, field_name):
542 """
543 Return a field instance given the name of a forward or reverse field.
544 """
545 try:
546 # In order to avoid premature loading of the relation tree
547 # (expensive) we prefer checking if the field is a forward field.
548 return self._forward_fields_map[field_name]
549 except KeyError:
550 # If the app registry is not ready, reverse fields are
551 # unavailable, therefore we throw a FieldDoesNotExist exception.
552 if not self.packages.models_ready:
553 raise FieldDoesNotExist(
554 "{} has no field named '{}'. The app cache isn't ready yet, "
555 "so if this is an auto-created related field, it won't "
556 "be available yet.".format(self.object_name, field_name)
557 )
559 try:
560 # Retrieve field instance by name from cached or just-computed
561 # field map.
562 return self.fields_map[field_name]
563 except KeyError:
564 raise FieldDoesNotExist(
565 f"{self.object_name} has no field named '{field_name}'"
566 )
568 def get_base_chain(self, model):
569 """
570 Return a list of parent classes leading to `model` (ordered from
571 closest to most distant ancestor). This has to handle the case where
572 `model` is a grandparent or even more distant relation.
573 """
574 if not self.parents:
575 return []
576 if model in self.parents:
577 return [model]
578 for parent in self.parents:
579 res = parent._meta.get_base_chain(model)
580 if res:
581 res.insert(0, parent)
582 return res
583 return []
585 def get_parent_list(self):
586 """
587 Return all the ancestors of this model as a list ordered by MRO.
588 Useful for determining if something is an ancestor, regardless of lineage.
589 """
590 result = OrderedSet(self.parents)
591 for parent in self.parents:
592 for ancestor in parent._meta.get_parent_list():
593 result.add(ancestor)
594 return list(result)
596 def get_ancestor_link(self, ancestor):
597 """
598 Return the field on the current model which points to the given
599 "ancestor". This is possible an indirect link (a pointer to a parent
600 model, which points, eventually, to the ancestor). Used when
601 constructing table joins for model inheritance.
603 Return None if the model isn't an ancestor of this one.
604 """
605 if ancestor in self.parents:
606 return self.parents[ancestor]
607 for parent in self.parents:
608 # Tries to get a link field from the immediate parent
609 parent_link = parent._meta.get_ancestor_link(ancestor)
610 if parent_link:
611 # In case of a proxied model, the first link
612 # of the chain to the ancestor is that parent
613 # links
614 return self.parents[parent] or parent_link
616 def get_path_to_parent(self, parent):
617 """
618 Return a list of PathInfos containing the path from the current
619 model to the parent model, or an empty list if parent is not a
620 parent of the current model.
621 """
622 if self.model is parent:
623 return []
624 # Skip the chain of proxy to the concrete proxied model.
625 proxied_model = self.concrete_model
626 path = []
627 opts = self
628 for int_model in self.get_base_chain(parent):
629 if int_model is proxied_model:
630 opts = int_model._meta
631 else:
632 final_field = opts.parents[int_model]
633 targets = (final_field.remote_field.get_related_field(),)
634 opts = int_model._meta
635 path.append(
636 PathInfo(
637 from_opts=final_field.model._meta,
638 to_opts=opts,
639 target_fields=targets,
640 join_field=final_field,
641 m2m=False,
642 direct=True,
643 filtered_relation=None,
644 )
645 )
646 return path
648 def get_path_from_parent(self, parent):
649 """
650 Return a list of PathInfos containing the path from the parent
651 model to the current model, or an empty list if parent is not a
652 parent of the current model.
653 """
654 if self.model is parent:
655 return []
656 model = self.concrete_model
657 # Get a reversed base chain including both the current and parent
658 # models.
659 chain = model._meta.get_base_chain(parent)
660 chain.reverse()
661 chain.append(model)
662 # Construct a list of the PathInfos between models in chain.
663 path = []
664 for i, ancestor in enumerate(chain[:-1]):
665 child = chain[i + 1]
666 link = child._meta.get_ancestor_link(ancestor)
667 path.extend(link.reverse_path_infos)
668 return path
670 def _populate_directed_relation_graph(self):
671 """
672 This method is used by each model to find its reverse objects. As this
673 method is very expensive and is accessed frequently (it looks up every
674 field in a model, in every app), it is computed on first access and then
675 is set as a property on every model.
676 """
677 related_objects_graph = defaultdict(list)
679 all_models = self.packages.get_models(include_auto_created=True)
680 for model in all_models:
681 opts = model._meta
682 # Abstract model's fields are copied to child models, hence we will
683 # see the fields from the child models.
684 if opts.abstract:
685 continue
686 fields_with_relations = (
687 f
688 for f in opts._get_fields(reverse=False, include_parents=False)
689 if f.is_relation and f.related_model is not None
690 )
691 for f in fields_with_relations:
692 if not isinstance(f.remote_field.model, str):
693 remote_label = f.remote_field.model._meta.concrete_model._meta.label
694 related_objects_graph[remote_label].append(f)
696 for model in all_models:
697 # Set the relation_tree using the internal __dict__. In this way
698 # we avoid calling the cached property. In attribute lookup,
699 # __dict__ takes precedence over a data descriptor (such as
700 # @cached_property). This means that the _meta._relation_tree is
701 # only called if related_objects is not in __dict__.
702 related_objects = related_objects_graph[
703 model._meta.concrete_model._meta.label
704 ]
705 model._meta.__dict__["_relation_tree"] = related_objects
706 # It seems it is possible that self is not in all_models, so guard
707 # against that with default for get().
708 return self.__dict__.get("_relation_tree", EMPTY_RELATION_TREE)
710 @cached_property
711 def _relation_tree(self):
712 return self._populate_directed_relation_graph()
714 def _expire_cache(self, forward=True, reverse=True):
715 # This method is usually called by packages.cache_clear(), when the
716 # registry is finalized, or when a new field is added.
717 if forward:
718 for cache_key in self.FORWARD_PROPERTIES:
719 if cache_key in self.__dict__:
720 delattr(self, cache_key)
721 if reverse and not self.abstract:
722 for cache_key in self.REVERSE_PROPERTIES:
723 if cache_key in self.__dict__:
724 delattr(self, cache_key)
725 self._get_fields_cache = {}
727 def get_fields(self, include_parents=True, include_hidden=False):
728 """
729 Return a list of fields associated to the model. By default, include
730 forward and reverse fields, fields derived from inheritance, but not
731 hidden fields. The returned fields can be changed using the parameters:
733 - include_parents: include fields derived from inheritance
734 - include_hidden: include fields that have a related_name that
735 starts with a "+"
736 """
737 if include_parents is False:
738 include_parents = PROXY_PARENTS
739 return self._get_fields(
740 include_parents=include_parents, include_hidden=include_hidden
741 )
743 def _get_fields(
744 self,
745 forward=True,
746 reverse=True,
747 include_parents=True,
748 include_hidden=False,
749 seen_models=None,
750 ):
751 """
752 Internal helper function to return fields of the model.
753 * If forward=True, then fields defined on this model are returned.
754 * If reverse=True, then relations pointing to this model are returned.
755 * If include_hidden=True, then fields with is_hidden=True are returned.
756 * The include_parents argument toggles if fields from parent models
757 should be included. It has three values: True, False, and
758 PROXY_PARENTS. When set to PROXY_PARENTS, the call will return all
759 fields defined for the current model or any of its parents in the
760 parent chain to the model's concrete model.
761 """
762 if include_parents not in (True, False, PROXY_PARENTS):
763 raise TypeError(f"Invalid argument for include_parents: {include_parents}")
764 # This helper function is used to allow recursion in ``get_fields()``
765 # implementation and to provide a fast way for Plain's internals to
766 # access specific subsets of fields.
768 # We must keep track of which models we have already seen. Otherwise we
769 # could include the same field multiple times from different models.
770 topmost_call = seen_models is None
771 if topmost_call:
772 seen_models = set()
773 seen_models.add(self.model)
775 # Creates a cache key composed of all arguments
776 cache_key = (forward, reverse, include_parents, include_hidden, topmost_call)
778 try:
779 # In order to avoid list manipulation. Always return a shallow copy
780 # of the results.
781 return self._get_fields_cache[cache_key]
782 except KeyError:
783 pass
785 fields = []
786 # Recursively call _get_fields() on each parent, with the same
787 # options provided in this call.
788 if include_parents is not False:
789 for parent in self.parents:
790 # In diamond inheritance it is possible that we see the same
791 # model from two different routes. In that case, avoid adding
792 # fields from the same parent again.
793 if parent in seen_models:
794 continue
795 if (
796 parent._meta.concrete_model != self.concrete_model
797 and include_parents == PROXY_PARENTS
798 ):
799 continue
800 for obj in parent._meta._get_fields(
801 forward=forward,
802 reverse=reverse,
803 include_parents=include_parents,
804 include_hidden=include_hidden,
805 seen_models=seen_models,
806 ):
807 if (
808 not getattr(obj, "parent_link", False)
809 or obj.model == self.concrete_model
810 ):
811 fields.append(obj)
812 if reverse:
813 # Tree is computed once and cached until the app cache is expired.
814 # It is composed of a list of fields pointing to the current model
815 # from other models.
816 all_fields = self._relation_tree
817 for field in all_fields:
818 # If hidden fields should be included or the relation is not
819 # intentionally hidden, add to the fields dict.
820 if include_hidden or not field.remote_field.hidden:
821 fields.append(field.remote_field)
823 if forward:
824 fields += self.local_fields
825 fields += self.local_many_to_many
826 # Private fields are recopied to each child model, and they get a
827 # different model as field.model in each child. Hence we have to
828 # add the private fields separately from the topmost call. If we
829 # did this recursively similar to local_fields, we would get field
830 # instances with field.model != self.model.
831 if topmost_call:
832 fields += self.private_fields
834 # In order to avoid list manipulation. Always
835 # return a shallow copy of the results
836 fields = make_immutable_fields_list("get_fields()", fields)
838 # Store result into cache for later access
839 self._get_fields_cache[cache_key] = fields
840 return fields
842 @cached_property
843 def total_unique_constraints(self):
844 """
845 Return a list of total unique constraints. Useful for determining set
846 of fields guaranteed to be unique for all rows.
847 """
848 return [
849 constraint
850 for constraint in self.constraints
851 if (
852 isinstance(constraint, UniqueConstraint)
853 and constraint.condition is None
854 and not constraint.contains_expressions
855 )
856 ]
858 @cached_property
859 def _property_names(self):
860 """Return a set of the names of the properties defined on the model."""
861 names = []
862 for name in dir(self.model):
863 attr = inspect.getattr_static(self.model, name)
864 if isinstance(attr, property):
865 names.append(name)
866 return frozenset(names)
868 @cached_property
869 def _non_pk_concrete_field_names(self):
870 """
871 Return a set of the non-pk concrete field names defined on the model.
872 """
873 names = []
874 for field in self.concrete_fields:
875 if not field.primary_key:
876 names.append(field.name)
877 if field.name != field.attname:
878 names.append(field.attname)
879 return frozenset(names)
881 @cached_property
882 def db_returning_fields(self):
883 """
884 Private API intended only to be used by Plain itself.
885 Fields to be returned after a database insert.
886 """
887 return [
888 field
889 for field in self._get_fields(
890 forward=True, reverse=False, include_parents=PROXY_PARENTS
891 )
892 if getattr(field, "db_returning", False)
893 ]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import inspect
2import types
3from collections import defaultdict
4from itertools import chain
6from plain.packages import packages
7from plain.preflight import Error, Warning, register
8from plain.runtime import settings
11@register
12def check_database_backends(databases=None, **kwargs):
13 if databases is None:
14 return []
16 from plain.models.db import connections
18 issues = []
19 for alias in databases:
20 conn = connections[alias]
21 issues.extend(conn.validation.check(**kwargs))
22 return issues
25@register
26def check_all_models(package_configs=None, **kwargs):
27 db_table_models = defaultdict(list)
28 indexes = defaultdict(list)
29 constraints = defaultdict(list)
30 errors = []
31 if package_configs is None:
32 models = packages.get_models()
33 else:
34 models = chain.from_iterable(
35 package_config.get_models() for package_config in package_configs
36 )
37 for model in models:
38 if model._meta.managed:
39 db_table_models[model._meta.db_table].append(model._meta.label)
40 if not inspect.ismethod(model.check):
41 errors.append(
42 Error(
43 "The '{}.check()' class method is currently overridden by {!r}.".format(
44 model.__name__, model.check
45 ),
46 obj=model,
47 id="models.E020",
48 )
49 )
50 else:
51 errors.extend(model.check(**kwargs))
52 for model_index in model._meta.indexes:
53 indexes[model_index.name].append(model._meta.label)
54 for model_constraint in model._meta.constraints:
55 constraints[model_constraint.name].append(model._meta.label)
56 if settings.DATABASE_ROUTERS:
57 error_class, error_id = Warning, "models.W035"
58 error_hint = (
59 "You have configured settings.DATABASE_ROUTERS. Verify that %s "
60 "are correctly routed to separate databases."
61 )
62 else:
63 error_class, error_id = Error, "models.E028"
64 error_hint = None
65 for db_table, model_labels in db_table_models.items():
66 if len(model_labels) != 1:
67 model_labels_str = ", ".join(model_labels)
68 errors.append(
69 error_class(
70 "db_table '{}' is used by multiple models: {}.".format(
71 db_table, model_labels_str
72 ),
73 obj=db_table,
74 hint=(error_hint % model_labels_str) if error_hint else None,
75 id=error_id,
76 )
77 )
78 for index_name, model_labels in indexes.items():
79 if len(model_labels) > 1:
80 model_labels = set(model_labels)
81 errors.append(
82 Error(
83 "index name '{}' is not unique {} {}.".format(
84 index_name,
85 "for model" if len(model_labels) == 1 else "among models:",
86 ", ".join(sorted(model_labels)),
87 ),
88 id="models.E029" if len(model_labels) == 1 else "models.E030",
89 ),
90 )
91 for constraint_name, model_labels in constraints.items():
92 if len(model_labels) > 1:
93 model_labels = set(model_labels)
94 errors.append(
95 Error(
96 "constraint name '{}' is not unique {} {}.".format(
97 constraint_name,
98 "for model" if len(model_labels) == 1 else "among models:",
99 ", ".join(sorted(model_labels)),
100 ),
101 id="models.E031" if len(model_labels) == 1 else "models.E032",
102 ),
103 )
104 return errors
107def _check_lazy_references(packages, ignore=None):
108 """
109 Ensure all lazy (i.e. string) model references have been resolved.
111 Lazy references are used in various places throughout Plain, primarily in
112 related fields and model signals. Identify those common cases and provide
113 more helpful error messages for them.
115 The ignore parameter is used by StatePackages to exclude swappable models from
116 this check.
117 """
118 pending_models = set(packages._pending_operations) - (ignore or set())
120 # Short circuit if there aren't any errors.
121 if not pending_models:
122 return []
124 from plain.models import signals
126 model_signals = {
127 signal: name
128 for name, signal in vars(signals).items()
129 if isinstance(signal, signals.ModelSignal)
130 }
132 def extract_operation(obj):
133 """
134 Take a callable found in Packages._pending_operations and identify the
135 original callable passed to Packages.lazy_model_operation(). If that
136 callable was a partial, return the inner, non-partial function and
137 any arguments and keyword arguments that were supplied with it.
139 obj is a callback defined locally in Packages.lazy_model_operation() and
140 annotated there with a `func` attribute so as to imitate a partial.
141 """
142 operation, args, keywords = obj, [], {}
143 while hasattr(operation, "func"):
144 args.extend(getattr(operation, "args", []))
145 keywords.update(getattr(operation, "keywords", {}))
146 operation = operation.func
147 return operation, args, keywords
149 def app_model_error(model_key):
150 try:
151 packages.get_package_config(model_key[0])
152 model_error = "app '{}' doesn't provide model '{}'".format(*model_key)
153 except LookupError:
154 model_error = "app '%s' isn't installed" % model_key[0]
155 return model_error
157 # Here are several functions which return CheckMessage instances for the
158 # most common usages of lazy operations throughout Plain. These functions
159 # take the model that was being waited on as an (package_label, modelname)
160 # pair, the original lazy function, and its positional and keyword args as
161 # determined by extract_operation().
163 def field_error(model_key, func, args, keywords):
164 error_msg = (
165 "The field %(field)s was declared with a lazy reference "
166 "to '%(model)s', but %(model_error)s."
167 )
168 params = {
169 "model": ".".join(model_key),
170 "field": keywords["field"],
171 "model_error": app_model_error(model_key),
172 }
173 return Error(error_msg % params, obj=keywords["field"], id="fields.E307")
175 def signal_connect_error(model_key, func, args, keywords):
176 error_msg = (
177 "%(receiver)s was connected to the '%(signal)s' signal with a "
178 "lazy reference to the sender '%(model)s', but %(model_error)s."
179 )
180 receiver = args[0]
181 # The receiver is either a function or an instance of class
182 # defining a `__call__` method.
183 if isinstance(receiver, types.FunctionType):
184 description = "The function '%s'" % receiver.__name__
185 elif isinstance(receiver, types.MethodType):
186 description = "Bound method '{}.{}'".format(
187 receiver.__self__.__class__.__name__,
188 receiver.__name__,
189 )
190 else:
191 description = "An instance of class '%s'" % receiver.__class__.__name__
192 signal_name = model_signals.get(func.__self__, "unknown")
193 params = {
194 "model": ".".join(model_key),
195 "receiver": description,
196 "signal": signal_name,
197 "model_error": app_model_error(model_key),
198 }
199 return Error(error_msg % params, obj=receiver.__module__, id="signals.E001")
201 def default_error(model_key, func, args, keywords):
202 error_msg = (
203 "%(op)s contains a lazy reference to %(model)s, but %(model_error)s."
204 )
205 params = {
206 "op": func,
207 "model": ".".join(model_key),
208 "model_error": app_model_error(model_key),
209 }
210 return Error(error_msg % params, obj=func, id="models.E022")
212 # Maps common uses of lazy operations to corresponding error functions
213 # defined above. If a key maps to None, no error will be produced.
214 # default_error() will be used for usages that don't appear in this dict.
215 known_lazy = {
216 ("plain.models.fields.related", "resolve_related_class"): field_error,
217 ("plain.models.fields.related", "set_managed"): None,
218 ("plain.signals.dispatch.dispatcher", "connect"): signal_connect_error,
219 }
221 def build_error(model_key, func, args, keywords):
222 key = (func.__module__, func.__name__)
223 error_fn = known_lazy.get(key, default_error)
224 return error_fn(model_key, func, args, keywords) if error_fn else None
226 return sorted(
227 filter(
228 None,
229 (
230 build_error(model_key, *extract_operation(func))
231 for model_key in pending_models
232 for func in packages._pending_operations[model_key]
233 ),
234 ),
235 key=lambda error: error.msg,
236 )
239@register
240def check_lazy_references(package_configs=None, **kwargs):
241 return _check_lazy_references(packages)
244@register
245def check_database_tables(package_configs, **kwargs):
246 from plain.models.db import connection
248 databases = kwargs.get("databases", None)
249 if not databases:
250 return []
252 errors = []
254 for database in databases:
255 db_tables = connection.introspection.table_names()
256 model_tables = connection.introspection.plain_table_names()
258 unknown_tables = set(db_tables) - set(model_tables)
259 unknown_tables.discard("plainmigrations") # Know this could be there
260 if unknown_tables:
261 table_names = ", ".join(unknown_tables)
262 specific_hint = f'echo "DROP TABLE IF EXISTS {unknown_tables.pop()}" | plain models db-shell'
263 errors.append(
264 Warning(
265 f"Unknown tables in {database} database: {table_names}",
266 hint=(
267 "Tables may be from packages/models that have been uninstalled. "
268 "Make sure you have a backup and delete the tables manually "
269 f"(ex. `{specific_hint}`)."
270 ),
271 id="plain.models.W001",
272 )
273 )
275 return errors
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2The main QuerySet implementation. This provides the public API for the ORM.
3"""
5import copy
6import operator
7import warnings
8from itertools import chain, islice
10import plain.runtime
11from plain import exceptions
12from plain.exceptions import ValidationError
13from plain.models import (
14 sql,
15 transaction,
16)
17from plain.models.constants import LOOKUP_SEP, OnConflict
18from plain.models.db import (
19 PLAIN_VERSION_PICKLE_KEY,
20 IntegrityError,
21 NotSupportedError,
22 connections,
23 router,
24)
25from plain.models.expressions import Case, F, Value, When
26from plain.models.fields import (
27 AutoField,
28 DateField,
29 DateTimeField,
30 Field,
31)
32from plain.models.functions import Cast, Trunc
33from plain.models.query_utils import FilteredRelation, Q
34from plain.models.sql.constants import CURSOR, GET_ITERATOR_CHUNK_SIZE
35from plain.models.utils import (
36 AltersData,
37 create_namedtuple_class,
38 resolve_callables,
39)
40from plain.utils import timezone
41from plain.utils.functional import cached_property, partition
43# The maximum number of results to fetch in a get() query.
44MAX_GET_RESULTS = 21
46# The maximum number of items to display in a QuerySet.__repr__
47REPR_OUTPUT_SIZE = 20
50class BaseIterable:
51 def __init__(
52 self, queryset, chunked_fetch=False, chunk_size=GET_ITERATOR_CHUNK_SIZE
53 ):
54 self.queryset = queryset
55 self.chunked_fetch = chunked_fetch
56 self.chunk_size = chunk_size
59class ModelIterable(BaseIterable):
60 """Iterable that yields a model instance for each row."""
62 def __iter__(self):
63 queryset = self.queryset
64 db = queryset.db
65 compiler = queryset.query.get_compiler(using=db)
66 # Execute the query. This will also fill compiler.select, klass_info,
67 # and annotations.
68 results = compiler.execute_sql(
69 chunked_fetch=self.chunked_fetch, chunk_size=self.chunk_size
70 )
71 select, klass_info, annotation_col_map = (
72 compiler.select,
73 compiler.klass_info,
74 compiler.annotation_col_map,
75 )
76 model_cls = klass_info["model"]
77 select_fields = klass_info["select_fields"]
78 model_fields_start, model_fields_end = select_fields[0], select_fields[-1] + 1
79 init_list = [
80 f[0].target.attname for f in select[model_fields_start:model_fields_end]
81 ]
82 related_populators = get_related_populators(klass_info, select, db)
83 known_related_objects = [
84 (
85 field,
86 related_objs,
87 operator.attrgetter(
88 *[
89 field.attname
90 if from_field == "self"
91 else queryset.model._meta.get_field(from_field).attname
92 for from_field in field.from_fields
93 ]
94 ),
95 )
96 for field, related_objs in queryset._known_related_objects.items()
97 ]
98 for row in compiler.results_iter(results):
99 obj = model_cls.from_db(
100 db, init_list, row[model_fields_start:model_fields_end]
101 )
102 for rel_populator in related_populators:
103 rel_populator.populate(row, obj)
104 if annotation_col_map:
105 for attr_name, col_pos in annotation_col_map.items():
106 setattr(obj, attr_name, row[col_pos])
108 # Add the known related objects to the model.
109 for field, rel_objs, rel_getter in known_related_objects:
110 # Avoid overwriting objects loaded by, e.g., select_related().
111 if field.is_cached(obj):
112 continue
113 rel_obj_id = rel_getter(obj)
114 try:
115 rel_obj = rel_objs[rel_obj_id]
116 except KeyError:
117 pass # May happen in qs1 | qs2 scenarios.
118 else:
119 setattr(obj, field.name, rel_obj)
121 yield obj
124class RawModelIterable(BaseIterable):
125 """
126 Iterable that yields a model instance for each row from a raw queryset.
127 """
129 def __iter__(self):
130 # Cache some things for performance reasons outside the loop.
131 db = self.queryset.db
132 query = self.queryset.query
133 connection = connections[db]
134 compiler = connection.ops.compiler("SQLCompiler")(query, connection, db)
135 query_iterator = iter(query)
137 try:
138 (
139 model_init_names,
140 model_init_pos,
141 annotation_fields,
142 ) = self.queryset.resolve_model_init_order()
143 model_cls = self.queryset.model
144 if model_cls._meta.pk.attname not in model_init_names:
145 raise exceptions.FieldDoesNotExist(
146 "Raw query must include the primary key"
147 )
148 fields = [self.queryset.model_fields.get(c) for c in self.queryset.columns]
149 converters = compiler.get_converters(
150 [f.get_col(f.model._meta.db_table) if f else None for f in fields]
151 )
152 if converters:
153 query_iterator = compiler.apply_converters(query_iterator, converters)
154 for values in query_iterator:
155 # Associate fields to values
156 model_init_values = [values[pos] for pos in model_init_pos]
157 instance = model_cls.from_db(db, model_init_names, model_init_values)
158 if annotation_fields:
159 for column, pos in annotation_fields:
160 setattr(instance, column, values[pos])
161 yield instance
162 finally:
163 # Done iterating the Query. If it has its own cursor, close it.
164 if hasattr(query, "cursor") and query.cursor:
165 query.cursor.close()
168class ValuesIterable(BaseIterable):
169 """
170 Iterable returned by QuerySet.values() that yields a dict for each row.
171 """
173 def __iter__(self):
174 queryset = self.queryset
175 query = queryset.query
176 compiler = query.get_compiler(queryset.db)
178 # extra(select=...) cols are always at the start of the row.
179 names = [
180 *query.extra_select,
181 *query.values_select,
182 *query.annotation_select,
183 ]
184 indexes = range(len(names))
185 for row in compiler.results_iter(
186 chunked_fetch=self.chunked_fetch, chunk_size=self.chunk_size
187 ):
188 yield {names[i]: row[i] for i in indexes}
191class ValuesListIterable(BaseIterable):
192 """
193 Iterable returned by QuerySet.values_list(flat=False) that yields a tuple
194 for each row.
195 """
197 def __iter__(self):
198 queryset = self.queryset
199 query = queryset.query
200 compiler = query.get_compiler(queryset.db)
202 if queryset._fields:
203 # extra(select=...) cols are always at the start of the row.
204 names = [
205 *query.extra_select,
206 *query.values_select,
207 *query.annotation_select,
208 ]
209 fields = [
210 *queryset._fields,
211 *(f for f in query.annotation_select if f not in queryset._fields),
212 ]
213 if fields != names:
214 # Reorder according to fields.
215 index_map = {name: idx for idx, name in enumerate(names)}
216 rowfactory = operator.itemgetter(*[index_map[f] for f in fields])
217 return map(
218 rowfactory,
219 compiler.results_iter(
220 chunked_fetch=self.chunked_fetch, chunk_size=self.chunk_size
221 ),
222 )
223 return compiler.results_iter(
224 tuple_expected=True,
225 chunked_fetch=self.chunked_fetch,
226 chunk_size=self.chunk_size,
227 )
230class NamedValuesListIterable(ValuesListIterable):
231 """
232 Iterable returned by QuerySet.values_list(named=True) that yields a
233 namedtuple for each row.
234 """
236 def __iter__(self):
237 queryset = self.queryset
238 if queryset._fields:
239 names = queryset._fields
240 else:
241 query = queryset.query
242 names = [
243 *query.extra_select,
244 *query.values_select,
245 *query.annotation_select,
246 ]
247 tuple_class = create_namedtuple_class(*names)
248 new = tuple.__new__
249 for row in super().__iter__():
250 yield new(tuple_class, row)
253class FlatValuesListIterable(BaseIterable):
254 """
255 Iterable returned by QuerySet.values_list(flat=True) that yields single
256 values.
257 """
259 def __iter__(self):
260 queryset = self.queryset
261 compiler = queryset.query.get_compiler(queryset.db)
262 for row in compiler.results_iter(
263 chunked_fetch=self.chunked_fetch, chunk_size=self.chunk_size
264 ):
265 yield row[0]
268class QuerySet(AltersData):
269 """Represent a lazy database lookup for a set of objects."""
271 def __init__(self, model=None, query=None, using=None, hints=None):
272 self.model = model
273 self._db = using
274 self._hints = hints or {}
275 self._query = query or sql.Query(self.model)
276 self._result_cache = None
277 self._sticky_filter = False
278 self._for_write = False
279 self._prefetch_related_lookups = ()
280 self._prefetch_done = False
281 self._known_related_objects = {} # {rel_field: {pk: rel_obj}}
282 self._iterable_class = ModelIterable
283 self._fields = None
284 self._defer_next_filter = False
285 self._deferred_filter = None
287 @property
288 def query(self):
289 if self._deferred_filter:
290 negate, args, kwargs = self._deferred_filter
291 self._filter_or_exclude_inplace(negate, args, kwargs)
292 self._deferred_filter = None
293 return self._query
295 @query.setter
296 def query(self, value):
297 if value.values_select:
298 self._iterable_class = ValuesIterable
299 self._query = value
301 def as_manager(cls):
302 # Address the circular dependency between `Queryset` and `Manager`.
303 from plain.models.manager import Manager
305 manager = Manager.from_queryset(cls)()
306 manager._built_with_as_manager = True
307 return manager
309 as_manager.queryset_only = True
310 as_manager = classmethod(as_manager)
312 ########################
313 # PYTHON MAGIC METHODS #
314 ########################
316 def __deepcopy__(self, memo):
317 """Don't populate the QuerySet's cache."""
318 obj = self.__class__()
319 for k, v in self.__dict__.items():
320 if k == "_result_cache":
321 obj.__dict__[k] = None
322 else:
323 obj.__dict__[k] = copy.deepcopy(v, memo)
324 return obj
326 def __getstate__(self):
327 # Force the cache to be fully populated.
328 self._fetch_all()
329 return {**self.__dict__, PLAIN_VERSION_PICKLE_KEY: plain.runtime.__version__}
331 def __setstate__(self, state):
332 pickled_version = state.get(PLAIN_VERSION_PICKLE_KEY)
333 if pickled_version:
334 if pickled_version != plain.runtime.__version__:
335 warnings.warn(
336 "Pickled queryset instance's Plain version {} does not "
337 "match the current version {}.".format(
338 pickled_version, plain.runtime.__version__
339 ),
340 RuntimeWarning,
341 stacklevel=2,
342 )
343 else:
344 warnings.warn(
345 "Pickled queryset instance's Plain version is not specified.",
346 RuntimeWarning,
347 stacklevel=2,
348 )
349 self.__dict__.update(state)
351 def __repr__(self):
352 data = list(self[: REPR_OUTPUT_SIZE + 1])
353 if len(data) > REPR_OUTPUT_SIZE:
354 data[-1] = "...(remaining elements truncated)..."
355 return f"<{self.__class__.__name__} {data!r}>"
357 def __len__(self):
358 self._fetch_all()
359 return len(self._result_cache)
361 def __iter__(self):
362 """
363 The queryset iterator protocol uses three nested iterators in the
364 default case:
365 1. sql.compiler.execute_sql()
366 - Returns 100 rows at time (constants.GET_ITERATOR_CHUNK_SIZE)
367 using cursor.fetchmany(). This part is responsible for
368 doing some column masking, and returning the rows in chunks.
369 2. sql.compiler.results_iter()
370 - Returns one row at time. At this point the rows are still just
371 tuples. In some cases the return values are converted to
372 Python values at this location.
373 3. self.iterator()
374 - Responsible for turning the rows into model objects.
375 """
376 self._fetch_all()
377 return iter(self._result_cache)
379 def __bool__(self):
380 self._fetch_all()
381 return bool(self._result_cache)
383 def __getitem__(self, k):
384 """Retrieve an item or slice from the set of results."""
385 if not isinstance(k, int | slice):
386 raise TypeError(
387 "QuerySet indices must be integers or slices, not %s."
388 % type(k).__name__
389 )
390 if (isinstance(k, int) and k < 0) or (
391 isinstance(k, slice)
392 and (
393 (k.start is not None and k.start < 0)
394 or (k.stop is not None and k.stop < 0)
395 )
396 ):
397 raise ValueError("Negative indexing is not supported.")
399 if self._result_cache is not None:
400 return self._result_cache[k]
402 if isinstance(k, slice):
403 qs = self._chain()
404 if k.start is not None:
405 start = int(k.start)
406 else:
407 start = None
408 if k.stop is not None:
409 stop = int(k.stop)
410 else:
411 stop = None
412 qs.query.set_limits(start, stop)
413 return list(qs)[:: k.step] if k.step else qs
415 qs = self._chain()
416 qs.query.set_limits(k, k + 1)
417 qs._fetch_all()
418 return qs._result_cache[0]
420 def __class_getitem__(cls, *args, **kwargs):
421 return cls
423 def __and__(self, other):
424 self._check_operator_queryset(other, "&")
425 self._merge_sanity_check(other)
426 if isinstance(other, EmptyQuerySet):
427 return other
428 if isinstance(self, EmptyQuerySet):
429 return self
430 combined = self._chain()
431 combined._merge_known_related_objects(other)
432 combined.query.combine(other.query, sql.AND)
433 return combined
435 def __or__(self, other):
436 self._check_operator_queryset(other, "|")
437 self._merge_sanity_check(other)
438 if isinstance(self, EmptyQuerySet):
439 return other
440 if isinstance(other, EmptyQuerySet):
441 return self
442 query = (
443 self
444 if self.query.can_filter()
445 else self.model._base_manager.filter(pk__in=self.values("pk"))
446 )
447 combined = query._chain()
448 combined._merge_known_related_objects(other)
449 if not other.query.can_filter():
450 other = other.model._base_manager.filter(pk__in=other.values("pk"))
451 combined.query.combine(other.query, sql.OR)
452 return combined
454 def __xor__(self, other):
455 self._check_operator_queryset(other, "^")
456 self._merge_sanity_check(other)
457 if isinstance(self, EmptyQuerySet):
458 return other
459 if isinstance(other, EmptyQuerySet):
460 return self
461 query = (
462 self
463 if self.query.can_filter()
464 else self.model._base_manager.filter(pk__in=self.values("pk"))
465 )
466 combined = query._chain()
467 combined._merge_known_related_objects(other)
468 if not other.query.can_filter():
469 other = other.model._base_manager.filter(pk__in=other.values("pk"))
470 combined.query.combine(other.query, sql.XOR)
471 return combined
473 ####################################
474 # METHODS THAT DO DATABASE QUERIES #
475 ####################################
477 def _iterator(self, use_chunked_fetch, chunk_size):
478 iterable = self._iterable_class(
479 self,
480 chunked_fetch=use_chunked_fetch,
481 chunk_size=chunk_size or 2000,
482 )
483 if not self._prefetch_related_lookups or chunk_size is None:
484 yield from iterable
485 return
487 iterator = iter(iterable)
488 while results := list(islice(iterator, chunk_size)):
489 prefetch_related_objects(results, *self._prefetch_related_lookups)
490 yield from results
492 def iterator(self, chunk_size=None):
493 """
494 An iterator over the results from applying this QuerySet to the
495 database. chunk_size must be provided for QuerySets that prefetch
496 related objects. Otherwise, a default chunk_size of 2000 is supplied.
497 """
498 if chunk_size is None:
499 if self._prefetch_related_lookups:
500 raise ValueError(
501 "chunk_size must be provided when using QuerySet.iterator() after "
502 "prefetch_related()."
503 )
504 elif chunk_size <= 0:
505 raise ValueError("Chunk size must be strictly positive.")
506 use_chunked_fetch = not connections[self.db].settings_dict.get(
507 "DISABLE_SERVER_SIDE_CURSORS"
508 )
509 return self._iterator(use_chunked_fetch, chunk_size)
511 def aggregate(self, *args, **kwargs):
512 """
513 Return a dictionary containing the calculations (aggregation)
514 over the current queryset.
516 If args is present the expression is passed as a kwarg using
517 the Aggregate object's default alias.
518 """
519 if self.query.distinct_fields:
520 raise NotImplementedError("aggregate() + distinct(fields) not implemented.")
521 self._validate_values_are_expressions(
522 (*args, *kwargs.values()), method_name="aggregate"
523 )
524 for arg in args:
525 # The default_alias property raises TypeError if default_alias
526 # can't be set automatically or AttributeError if it isn't an
527 # attribute.
528 try:
529 arg.default_alias
530 except (AttributeError, TypeError):
531 raise TypeError("Complex aggregates require an alias")
532 kwargs[arg.default_alias] = arg
534 return self.query.chain().get_aggregation(self.db, kwargs)
536 def count(self):
537 """
538 Perform a SELECT COUNT() and return the number of records as an
539 integer.
541 If the QuerySet is already fully cached, return the length of the
542 cached results set to avoid multiple SELECT COUNT(*) calls.
543 """
544 if self._result_cache is not None:
545 return len(self._result_cache)
547 return self.query.get_count(using=self.db)
549 def get(self, *args, **kwargs):
550 """
551 Perform the query and return a single object matching the given
552 keyword arguments.
553 """
554 if self.query.combinator and (args or kwargs):
555 raise NotSupportedError(
556 "Calling QuerySet.get(...) with filters after %s() is not "
557 "supported." % self.query.combinator
558 )
559 clone = self._chain() if self.query.combinator else self.filter(*args, **kwargs)
560 if self.query.can_filter() and not self.query.distinct_fields:
561 clone = clone.order_by()
562 limit = None
563 if (
564 not clone.query.select_for_update
565 or connections[clone.db].features.supports_select_for_update_with_limit
566 ):
567 limit = MAX_GET_RESULTS
568 clone.query.set_limits(high=limit)
569 num = len(clone)
570 if num == 1:
571 return clone._result_cache[0]
572 if not num:
573 raise self.model.DoesNotExist(
574 "%s matching query does not exist." % self.model._meta.object_name
575 )
576 raise self.model.MultipleObjectsReturned(
577 "get() returned more than one {} -- it returned {}!".format(
578 self.model._meta.object_name,
579 num if not limit or num < limit else "more than %s" % (limit - 1),
580 )
581 )
583 def create(self, **kwargs):
584 """
585 Create a new object with the given kwargs, saving it to the database
586 and returning the created object.
587 """
588 obj = self.model(**kwargs)
589 self._for_write = True
590 obj.save(force_insert=True, using=self.db)
591 return obj
593 def _prepare_for_bulk_create(self, objs):
594 for obj in objs:
595 if obj.pk is None:
596 # Populate new PK values.
597 obj.pk = obj._meta.pk.get_pk_value_on_save(obj)
598 obj._prepare_related_fields_for_save(operation_name="bulk_create")
600 def _check_bulk_create_options(
601 self, ignore_conflicts, update_conflicts, update_fields, unique_fields
602 ):
603 if ignore_conflicts and update_conflicts:
604 raise ValueError(
605 "ignore_conflicts and update_conflicts are mutually exclusive."
606 )
607 db_features = connections[self.db].features
608 if ignore_conflicts:
609 if not db_features.supports_ignore_conflicts:
610 raise NotSupportedError(
611 "This database backend does not support ignoring conflicts."
612 )
613 return OnConflict.IGNORE
614 elif update_conflicts:
615 if not db_features.supports_update_conflicts:
616 raise NotSupportedError(
617 "This database backend does not support updating conflicts."
618 )
619 if not update_fields:
620 raise ValueError(
621 "Fields that will be updated when a row insertion fails "
622 "on conflicts must be provided."
623 )
624 if unique_fields and not db_features.supports_update_conflicts_with_target:
625 raise NotSupportedError(
626 "This database backend does not support updating "
627 "conflicts with specifying unique fields that can trigger "
628 "the upsert."
629 )
630 if not unique_fields and db_features.supports_update_conflicts_with_target:
631 raise ValueError(
632 "Unique fields that can trigger the upsert must be provided."
633 )
634 # Updating primary keys and non-concrete fields is forbidden.
635 if any(not f.concrete or f.many_to_many for f in update_fields):
636 raise ValueError(
637 "bulk_create() can only be used with concrete fields in "
638 "update_fields."
639 )
640 if any(f.primary_key for f in update_fields):
641 raise ValueError(
642 "bulk_create() cannot be used with primary keys in "
643 "update_fields."
644 )
645 if unique_fields:
646 if any(not f.concrete or f.many_to_many for f in unique_fields):
647 raise ValueError(
648 "bulk_create() can only be used with concrete fields "
649 "in unique_fields."
650 )
651 return OnConflict.UPDATE
652 return None
654 def bulk_create(
655 self,
656 objs,
657 batch_size=None,
658 ignore_conflicts=False,
659 update_conflicts=False,
660 update_fields=None,
661 unique_fields=None,
662 ):
663 """
664 Insert each of the instances into the database. Do *not* call
665 save() on each of the instances, do not send any pre/post_save
666 signals, and do not set the primary key attribute if it is an
667 autoincrement field (except if features.can_return_rows_from_bulk_insert=True).
668 Multi-table models are not supported.
669 """
670 # When you bulk insert you don't get the primary keys back (if it's an
671 # autoincrement, except if can_return_rows_from_bulk_insert=True), so
672 # you can't insert into the child tables which references this. There
673 # are two workarounds:
674 # 1) This could be implemented if you didn't have an autoincrement pk
675 # 2) You could do it by doing O(n) normal inserts into the parent
676 # tables to get the primary keys back and then doing a single bulk
677 # insert into the childmost table.
678 # We currently set the primary keys on the objects when using
679 # PostgreSQL via the RETURNING ID clause. It should be possible for
680 # Oracle as well, but the semantics for extracting the primary keys is
681 # trickier so it's not done yet.
682 if batch_size is not None and batch_size <= 0:
683 raise ValueError("Batch size must be a positive integer.")
684 # Check that the parents share the same concrete model with the our
685 # model to detect the inheritance pattern ConcreteGrandParent ->
686 # MultiTableParent -> ProxyChild. Simply checking self.model._meta.proxy
687 # would not identify that case as involving multiple tables.
688 for parent in self.model._meta.get_parent_list():
689 if parent._meta.concrete_model is not self.model._meta.concrete_model:
690 raise ValueError("Can't bulk create a multi-table inherited model")
691 if not objs:
692 return objs
693 opts = self.model._meta
694 if unique_fields:
695 # Primary key is allowed in unique_fields.
696 unique_fields = [
697 self.model._meta.get_field(opts.pk.name if name == "pk" else name)
698 for name in unique_fields
699 ]
700 if update_fields:
701 update_fields = [self.model._meta.get_field(name) for name in update_fields]
702 on_conflict = self._check_bulk_create_options(
703 ignore_conflicts,
704 update_conflicts,
705 update_fields,
706 unique_fields,
707 )
708 self._for_write = True
709 fields = opts.concrete_fields
710 objs = list(objs)
711 self._prepare_for_bulk_create(objs)
712 with transaction.atomic(using=self.db, savepoint=False):
713 objs_with_pk, objs_without_pk = partition(lambda o: o.pk is None, objs)
714 if objs_with_pk:
715 returned_columns = self._batched_insert(
716 objs_with_pk,
717 fields,
718 batch_size,
719 on_conflict=on_conflict,
720 update_fields=update_fields,
721 unique_fields=unique_fields,
722 )
723 for obj_with_pk, results in zip(objs_with_pk, returned_columns):
724 for result, field in zip(results, opts.db_returning_fields):
725 if field != opts.pk:
726 setattr(obj_with_pk, field.attname, result)
727 for obj_with_pk in objs_with_pk:
728 obj_with_pk._state.adding = False
729 obj_with_pk._state.db = self.db
730 if objs_without_pk:
731 fields = [f for f in fields if not isinstance(f, AutoField)]
732 returned_columns = self._batched_insert(
733 objs_without_pk,
734 fields,
735 batch_size,
736 on_conflict=on_conflict,
737 update_fields=update_fields,
738 unique_fields=unique_fields,
739 )
740 connection = connections[self.db]
741 if (
742 connection.features.can_return_rows_from_bulk_insert
743 and on_conflict is None
744 ):
745 assert len(returned_columns) == len(objs_without_pk)
746 for obj_without_pk, results in zip(objs_without_pk, returned_columns):
747 for result, field in zip(results, opts.db_returning_fields):
748 setattr(obj_without_pk, field.attname, result)
749 obj_without_pk._state.adding = False
750 obj_without_pk._state.db = self.db
752 return objs
754 def bulk_update(self, objs, fields, batch_size=None):
755 """
756 Update the given fields in each of the given objects in the database.
757 """
758 if batch_size is not None and batch_size <= 0:
759 raise ValueError("Batch size must be a positive integer.")
760 if not fields:
761 raise ValueError("Field names must be given to bulk_update().")
762 objs = tuple(objs)
763 if any(obj.pk is None for obj in objs):
764 raise ValueError("All bulk_update() objects must have a primary key set.")
765 fields = [self.model._meta.get_field(name) for name in fields]
766 if any(not f.concrete or f.many_to_many for f in fields):
767 raise ValueError("bulk_update() can only be used with concrete fields.")
768 if any(f.primary_key for f in fields):
769 raise ValueError("bulk_update() cannot be used with primary key fields.")
770 if not objs:
771 return 0
772 for obj in objs:
773 obj._prepare_related_fields_for_save(
774 operation_name="bulk_update", fields=fields
775 )
776 # PK is used twice in the resulting update query, once in the filter
777 # and once in the WHEN. Each field will also have one CAST.
778 self._for_write = True
779 connection = connections[self.db]
780 max_batch_size = connection.ops.bulk_batch_size(["pk", "pk"] + fields, objs)
781 batch_size = min(batch_size, max_batch_size) if batch_size else max_batch_size
782 requires_casting = connection.features.requires_casted_case_in_updates
783 batches = (objs[i : i + batch_size] for i in range(0, len(objs), batch_size))
784 updates = []
785 for batch_objs in batches:
786 update_kwargs = {}
787 for field in fields:
788 when_statements = []
789 for obj in batch_objs:
790 attr = getattr(obj, field.attname)
791 if not hasattr(attr, "resolve_expression"):
792 attr = Value(attr, output_field=field)
793 when_statements.append(When(pk=obj.pk, then=attr))
794 case_statement = Case(*when_statements, output_field=field)
795 if requires_casting:
796 case_statement = Cast(case_statement, output_field=field)
797 update_kwargs[field.attname] = case_statement
798 updates.append(([obj.pk for obj in batch_objs], update_kwargs))
799 rows_updated = 0
800 queryset = self.using(self.db)
801 with transaction.atomic(using=self.db, savepoint=False):
802 for pks, update_kwargs in updates:
803 rows_updated += queryset.filter(pk__in=pks).update(**update_kwargs)
804 return rows_updated
806 bulk_update.alters_data = True
808 def get_or_create(self, defaults=None, **kwargs):
809 """
810 Look up an object with the given kwargs, creating one if necessary.
811 Return a tuple of (object, created), where created is a boolean
812 specifying whether an object was created.
813 """
814 # The get() needs to be targeted at the write database in order
815 # to avoid potential transaction consistency problems.
816 self._for_write = True
817 try:
818 return self.get(**kwargs), False
819 except self.model.DoesNotExist:
820 params = self._extract_model_params(defaults, **kwargs)
821 # Try to create an object using passed params.
822 try:
823 with transaction.atomic(using=self.db):
824 params = dict(resolve_callables(params))
825 return self.create(**params), True
826 except (IntegrityError, ValidationError):
827 # Since create() also validates by default,
828 # we can get any kind of ValidationError here,
829 # or it can flow through and get an IntegrityError from the database.
830 # The main thing we're concerned about is uniqueness failures,
831 # but ValidationError could include other things too.
832 # In all cases though it should be fine to try the get() again
833 # and return an existing object.
834 try:
835 return self.get(**kwargs), False
836 except self.model.DoesNotExist:
837 pass
838 raise
840 def update_or_create(self, defaults=None, create_defaults=None, **kwargs):
841 """
842 Look up an object with the given kwargs, updating one with defaults
843 if it exists, otherwise create a new one. Optionally, an object can
844 be created with different values than defaults by using
845 create_defaults.
846 Return a tuple (object, created), where created is a boolean
847 specifying whether an object was created.
848 """
849 if create_defaults is None:
850 update_defaults = create_defaults = defaults or {}
851 else:
852 update_defaults = defaults or {}
853 self._for_write = True
854 with transaction.atomic(using=self.db):
855 # Lock the row so that a concurrent update is blocked until
856 # update_or_create() has performed its save.
857 obj, created = self.select_for_update().get_or_create(
858 create_defaults, **kwargs
859 )
860 if created:
861 return obj, created
862 for k, v in resolve_callables(update_defaults):
863 setattr(obj, k, v)
865 update_fields = set(update_defaults)
866 concrete_field_names = self.model._meta._non_pk_concrete_field_names
867 # update_fields does not support non-concrete fields.
868 if concrete_field_names.issuperset(update_fields):
869 # Add fields which are set on pre_save(), e.g. auto_now fields.
870 # This is to maintain backward compatibility as these fields
871 # are not updated unless explicitly specified in the
872 # update_fields list.
873 for field in self.model._meta.local_concrete_fields:
874 if not (
875 field.primary_key or field.__class__.pre_save is Field.pre_save
876 ):
877 update_fields.add(field.name)
878 if field.name != field.attname:
879 update_fields.add(field.attname)
880 obj.save(using=self.db, update_fields=update_fields)
881 else:
882 obj.save(using=self.db)
883 return obj, False
885 def _extract_model_params(self, defaults, **kwargs):
886 """
887 Prepare `params` for creating a model instance based on the given
888 kwargs; for use by get_or_create().
889 """
890 defaults = defaults or {}
891 params = {k: v for k, v in kwargs.items() if LOOKUP_SEP not in k}
892 params.update(defaults)
893 property_names = self.model._meta._property_names
894 invalid_params = []
895 for param in params:
896 try:
897 self.model._meta.get_field(param)
898 except exceptions.FieldDoesNotExist:
899 # It's okay to use a model's property if it has a setter.
900 if not (param in property_names and getattr(self.model, param).fset):
901 invalid_params.append(param)
902 if invalid_params:
903 raise exceptions.FieldError(
904 "Invalid field name(s) for model {}: '{}'.".format(
905 self.model._meta.object_name,
906 "', '".join(sorted(invalid_params)),
907 )
908 )
909 return params
911 def _earliest(self, *fields):
912 """
913 Return the earliest object according to fields (if given) or by the
914 model's Meta.get_latest_by.
915 """
916 if fields:
917 order_by = fields
918 else:
919 order_by = getattr(self.model._meta, "get_latest_by")
920 if order_by and not isinstance(order_by, tuple | list):
921 order_by = (order_by,)
922 if order_by is None:
923 raise ValueError(
924 "earliest() and latest() require either fields as positional "
925 "arguments or 'get_latest_by' in the model's Meta."
926 )
927 obj = self._chain()
928 obj.query.set_limits(high=1)
929 obj.query.clear_ordering(force=True)
930 obj.query.add_ordering(*order_by)
931 return obj.get()
933 def earliest(self, *fields):
934 if self.query.is_sliced:
935 raise TypeError("Cannot change a query once a slice has been taken.")
936 return self._earliest(*fields)
938 def latest(self, *fields):
939 """
940 Return the latest object according to fields (if given) or by the
941 model's Meta.get_latest_by.
942 """
943 if self.query.is_sliced:
944 raise TypeError("Cannot change a query once a slice has been taken.")
945 return self.reverse()._earliest(*fields)
947 def first(self):
948 """Return the first object of a query or None if no match is found."""
949 if self.ordered:
950 queryset = self
951 else:
952 self._check_ordering_first_last_queryset_aggregation(method="first")
953 queryset = self.order_by("pk")
954 for obj in queryset[:1]:
955 return obj
957 def last(self):
958 """Return the last object of a query or None if no match is found."""
959 if self.ordered:
960 queryset = self.reverse()
961 else:
962 self._check_ordering_first_last_queryset_aggregation(method="last")
963 queryset = self.order_by("-pk")
964 for obj in queryset[:1]:
965 return obj
967 def in_bulk(self, id_list=None, *, field_name="pk"):
968 """
969 Return a dictionary mapping each of the given IDs to the object with
970 that ID. If `id_list` isn't provided, evaluate the entire QuerySet.
971 """
972 if self.query.is_sliced:
973 raise TypeError("Cannot use 'limit' or 'offset' with in_bulk().")
974 opts = self.model._meta
975 unique_fields = [
976 constraint.fields[0]
977 for constraint in opts.total_unique_constraints
978 if len(constraint.fields) == 1
979 ]
980 if (
981 field_name != "pk"
982 and not opts.get_field(field_name).unique
983 and field_name not in unique_fields
984 and self.query.distinct_fields != (field_name,)
985 ):
986 raise ValueError(
987 "in_bulk()'s field_name must be a unique field but %r isn't."
988 % field_name
989 )
990 if id_list is not None:
991 if not id_list:
992 return {}
993 filter_key = f"{field_name}__in"
994 batch_size = connections[self.db].features.max_query_params
995 id_list = tuple(id_list)
996 # If the database has a limit on the number of query parameters
997 # (e.g. SQLite), retrieve objects in batches if necessary.
998 if batch_size and batch_size < len(id_list):
999 qs = ()
1000 for offset in range(0, len(id_list), batch_size):
1001 batch = id_list[offset : offset + batch_size]
1002 qs += tuple(self.filter(**{filter_key: batch}))
1003 else:
1004 qs = self.filter(**{filter_key: id_list})
1005 else:
1006 qs = self._chain()
1007 return {getattr(obj, field_name): obj for obj in qs}
1009 def delete(self):
1010 """Delete the records in the current QuerySet."""
1011 self._not_support_combined_queries("delete")
1012 if self.query.is_sliced:
1013 raise TypeError("Cannot use 'limit' or 'offset' with delete().")
1014 if self.query.distinct or self.query.distinct_fields:
1015 raise TypeError("Cannot call delete() after .distinct().")
1016 if self._fields is not None:
1017 raise TypeError("Cannot call delete() after .values() or .values_list()")
1019 del_query = self._chain()
1021 # The delete is actually 2 queries - one to find related objects,
1022 # and one to delete. Make sure that the discovery of related
1023 # objects is performed on the same database as the deletion.
1024 del_query._for_write = True
1026 # Disable non-supported fields.
1027 del_query.query.select_for_update = False
1028 del_query.query.select_related = False
1029 del_query.query.clear_ordering(force=True)
1031 from plain.models.deletion import Collector
1033 collector = Collector(using=del_query.db, origin=self)
1034 collector.collect(del_query)
1035 deleted, _rows_count = collector.delete()
1037 # Clear the result cache, in case this QuerySet gets reused.
1038 self._result_cache = None
1039 return deleted, _rows_count
1041 delete.alters_data = True
1042 delete.queryset_only = True
1044 def _raw_delete(self, using):
1045 """
1046 Delete objects found from the given queryset in single direct SQL
1047 query. No signals are sent and there is no protection for cascades.
1048 """
1049 query = self.query.clone()
1050 query.__class__ = sql.DeleteQuery
1051 cursor = query.get_compiler(using).execute_sql(CURSOR)
1052 if cursor:
1053 with cursor:
1054 return cursor.rowcount
1055 return 0
1057 _raw_delete.alters_data = True
1059 def update(self, **kwargs):
1060 """
1061 Update all elements in the current QuerySet, setting all the given
1062 fields to the appropriate values.
1063 """
1064 self._not_support_combined_queries("update")
1065 if self.query.is_sliced:
1066 raise TypeError("Cannot update a query once a slice has been taken.")
1067 self._for_write = True
1068 query = self.query.chain(sql.UpdateQuery)
1069 query.add_update_values(kwargs)
1071 # Inline annotations in order_by(), if possible.
1072 new_order_by = []
1073 for col in query.order_by:
1074 alias = col
1075 descending = False
1076 if isinstance(alias, str) and alias.startswith("-"):
1077 alias = alias.removeprefix("-")
1078 descending = True
1079 if annotation := query.annotations.get(alias):
1080 if getattr(annotation, "contains_aggregate", False):
1081 raise exceptions.FieldError(
1082 f"Cannot update when ordering by an aggregate: {annotation}"
1083 )
1084 if descending:
1085 annotation = annotation.desc()
1086 new_order_by.append(annotation)
1087 else:
1088 new_order_by.append(col)
1089 query.order_by = tuple(new_order_by)
1091 # Clear any annotations so that they won't be present in subqueries.
1092 query.annotations = {}
1093 with transaction.mark_for_rollback_on_error(using=self.db):
1094 rows = query.get_compiler(self.db).execute_sql(CURSOR)
1095 self._result_cache = None
1096 return rows
1098 update.alters_data = True
1100 def _update(self, values):
1101 """
1102 A version of update() that accepts field objects instead of field names.
1103 Used primarily for model saving and not intended for use by general
1104 code (it requires too much poking around at model internals to be
1105 useful at that level).
1106 """
1107 if self.query.is_sliced:
1108 raise TypeError("Cannot update a query once a slice has been taken.")
1109 query = self.query.chain(sql.UpdateQuery)
1110 query.add_update_fields(values)
1111 # Clear any annotations so that they won't be present in subqueries.
1112 query.annotations = {}
1113 self._result_cache = None
1114 return query.get_compiler(self.db).execute_sql(CURSOR)
1116 _update.alters_data = True
1117 _update.queryset_only = False
1119 def exists(self):
1120 """
1121 Return True if the QuerySet would have any results, False otherwise.
1122 """
1123 if self._result_cache is None:
1124 return self.query.has_results(using=self.db)
1125 return bool(self._result_cache)
1127 def contains(self, obj):
1128 """
1129 Return True if the QuerySet contains the provided obj,
1130 False otherwise.
1131 """
1132 self._not_support_combined_queries("contains")
1133 if self._fields is not None:
1134 raise TypeError(
1135 "Cannot call QuerySet.contains() after .values() or .values_list()."
1136 )
1137 try:
1138 if obj._meta.concrete_model != self.model._meta.concrete_model:
1139 return False
1140 except AttributeError:
1141 raise TypeError("'obj' must be a model instance.")
1142 if obj.pk is None:
1143 raise ValueError("QuerySet.contains() cannot be used on unsaved objects.")
1144 if self._result_cache is not None:
1145 return obj in self._result_cache
1146 return self.filter(pk=obj.pk).exists()
1148 def _prefetch_related_objects(self):
1149 # This method can only be called once the result cache has been filled.
1150 prefetch_related_objects(self._result_cache, *self._prefetch_related_lookups)
1151 self._prefetch_done = True
1153 def explain(self, *, format=None, **options):
1154 """
1155 Runs an EXPLAIN on the SQL query this QuerySet would perform, and
1156 returns the results.
1157 """
1158 return self.query.explain(using=self.db, format=format, **options)
1160 ##################################################
1161 # PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS #
1162 ##################################################
1164 def raw(self, raw_query, params=(), translations=None, using=None):
1165 if using is None:
1166 using = self.db
1167 qs = RawQuerySet(
1168 raw_query,
1169 model=self.model,
1170 params=params,
1171 translations=translations,
1172 using=using,
1173 )
1174 qs._prefetch_related_lookups = self._prefetch_related_lookups[:]
1175 return qs
1177 def _values(self, *fields, **expressions):
1178 clone = self._chain()
1179 if expressions:
1180 clone = clone.annotate(**expressions)
1181 clone._fields = fields
1182 clone.query.set_values(fields)
1183 return clone
1185 def values(self, *fields, **expressions):
1186 fields += tuple(expressions)
1187 clone = self._values(*fields, **expressions)
1188 clone._iterable_class = ValuesIterable
1189 return clone
1191 def values_list(self, *fields, flat=False, named=False):
1192 if flat and named:
1193 raise TypeError("'flat' and 'named' can't be used together.")
1194 if flat and len(fields) > 1:
1195 raise TypeError(
1196 "'flat' is not valid when values_list is called with more than one "
1197 "field."
1198 )
1200 field_names = {f for f in fields if not hasattr(f, "resolve_expression")}
1201 _fields = []
1202 expressions = {}
1203 counter = 1
1204 for field in fields:
1205 if hasattr(field, "resolve_expression"):
1206 field_id_prefix = getattr(
1207 field, "default_alias", field.__class__.__name__.lower()
1208 )
1209 while True:
1210 field_id = field_id_prefix + str(counter)
1211 counter += 1
1212 if field_id not in field_names:
1213 break
1214 expressions[field_id] = field
1215 _fields.append(field_id)
1216 else:
1217 _fields.append(field)
1219 clone = self._values(*_fields, **expressions)
1220 clone._iterable_class = (
1221 NamedValuesListIterable
1222 if named
1223 else FlatValuesListIterable
1224 if flat
1225 else ValuesListIterable
1226 )
1227 return clone
1229 def dates(self, field_name, kind, order="ASC"):
1230 """
1231 Return a list of date objects representing all available dates for
1232 the given field_name, scoped to 'kind'.
1233 """
1234 if kind not in ("year", "month", "week", "day"):
1235 raise ValueError("'kind' must be one of 'year', 'month', 'week', or 'day'.")
1236 if order not in ("ASC", "DESC"):
1237 raise ValueError("'order' must be either 'ASC' or 'DESC'.")
1238 return (
1239 self.annotate(
1240 datefield=Trunc(field_name, kind, output_field=DateField()),
1241 plain_field=F(field_name),
1242 )
1243 .values_list("datefield", flat=True)
1244 .distinct()
1245 .filter(plain_field__isnull=False)
1246 .order_by(("-" if order == "DESC" else "") + "datefield")
1247 )
1249 def datetimes(self, field_name, kind, order="ASC", tzinfo=None):
1250 """
1251 Return a list of datetime objects representing all available
1252 datetimes for the given field_name, scoped to 'kind'.
1253 """
1254 if kind not in ("year", "month", "week", "day", "hour", "minute", "second"):
1255 raise ValueError(
1256 "'kind' must be one of 'year', 'month', 'week', 'day', "
1257 "'hour', 'minute', or 'second'."
1258 )
1259 if order not in ("ASC", "DESC"):
1260 raise ValueError("'order' must be either 'ASC' or 'DESC'.")
1262 if tzinfo is None:
1263 tzinfo = timezone.get_current_timezone()
1265 return (
1266 self.annotate(
1267 datetimefield=Trunc(
1268 field_name,
1269 kind,
1270 output_field=DateTimeField(),
1271 tzinfo=tzinfo,
1272 ),
1273 plain_field=F(field_name),
1274 )
1275 .values_list("datetimefield", flat=True)
1276 .distinct()
1277 .filter(plain_field__isnull=False)
1278 .order_by(("-" if order == "DESC" else "") + "datetimefield")
1279 )
1281 def none(self):
1282 """Return an empty QuerySet."""
1283 clone = self._chain()
1284 clone.query.set_empty()
1285 return clone
1287 ##################################################################
1288 # PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET #
1289 ##################################################################
1291 def all(self):
1292 """
1293 Return a new QuerySet that is a copy of the current one. This allows a
1294 QuerySet to proxy for a model manager in some cases.
1295 """
1296 return self._chain()
1298 def filter(self, *args, **kwargs):
1299 """
1300 Return a new QuerySet instance with the args ANDed to the existing
1301 set.
1302 """
1303 self._not_support_combined_queries("filter")
1304 return self._filter_or_exclude(False, args, kwargs)
1306 def exclude(self, *args, **kwargs):
1307 """
1308 Return a new QuerySet instance with NOT (args) ANDed to the existing
1309 set.
1310 """
1311 self._not_support_combined_queries("exclude")
1312 return self._filter_or_exclude(True, args, kwargs)
1314 def _filter_or_exclude(self, negate, args, kwargs):
1315 if (args or kwargs) and self.query.is_sliced:
1316 raise TypeError("Cannot filter a query once a slice has been taken.")
1317 clone = self._chain()
1318 if self._defer_next_filter:
1319 self._defer_next_filter = False
1320 clone._deferred_filter = negate, args, kwargs
1321 else:
1322 clone._filter_or_exclude_inplace(negate, args, kwargs)
1323 return clone
1325 def _filter_or_exclude_inplace(self, negate, args, kwargs):
1326 if negate:
1327 self._query.add_q(~Q(*args, **kwargs))
1328 else:
1329 self._query.add_q(Q(*args, **kwargs))
1331 def complex_filter(self, filter_obj):
1332 """
1333 Return a new QuerySet instance with filter_obj added to the filters.
1335 filter_obj can be a Q object or a dictionary of keyword lookup
1336 arguments.
1338 This exists to support framework features such as 'limit_choices_to',
1339 and usually it will be more natural to use other methods.
1340 """
1341 if isinstance(filter_obj, Q):
1342 clone = self._chain()
1343 clone.query.add_q(filter_obj)
1344 return clone
1345 else:
1346 return self._filter_or_exclude(False, args=(), kwargs=filter_obj)
1348 def _combinator_query(self, combinator, *other_qs, all=False):
1349 # Clone the query to inherit the select list and everything
1350 clone = self._chain()
1351 # Clear limits and ordering so they can be reapplied
1352 clone.query.clear_ordering(force=True)
1353 clone.query.clear_limits()
1354 clone.query.combined_queries = (self.query,) + tuple(
1355 qs.query for qs in other_qs
1356 )
1357 clone.query.combinator = combinator
1358 clone.query.combinator_all = all
1359 return clone
1361 def union(self, *other_qs, all=False):
1362 # If the query is an EmptyQuerySet, combine all nonempty querysets.
1363 if isinstance(self, EmptyQuerySet):
1364 qs = [q for q in other_qs if not isinstance(q, EmptyQuerySet)]
1365 if not qs:
1366 return self
1367 if len(qs) == 1:
1368 return qs[0]
1369 return qs[0]._combinator_query("union", *qs[1:], all=all)
1370 return self._combinator_query("union", *other_qs, all=all)
1372 def intersection(self, *other_qs):
1373 # If any query is an EmptyQuerySet, return it.
1374 if isinstance(self, EmptyQuerySet):
1375 return self
1376 for other in other_qs:
1377 if isinstance(other, EmptyQuerySet):
1378 return other
1379 return self._combinator_query("intersection", *other_qs)
1381 def difference(self, *other_qs):
1382 # If the query is an EmptyQuerySet, return it.
1383 if isinstance(self, EmptyQuerySet):
1384 return self
1385 return self._combinator_query("difference", *other_qs)
1387 def select_for_update(self, nowait=False, skip_locked=False, of=(), no_key=False):
1388 """
1389 Return a new QuerySet instance that will select objects with a
1390 FOR UPDATE lock.
1391 """
1392 if nowait and skip_locked:
1393 raise ValueError("The nowait option cannot be used with skip_locked.")
1394 obj = self._chain()
1395 obj._for_write = True
1396 obj.query.select_for_update = True
1397 obj.query.select_for_update_nowait = nowait
1398 obj.query.select_for_update_skip_locked = skip_locked
1399 obj.query.select_for_update_of = of
1400 obj.query.select_for_no_key_update = no_key
1401 return obj
1403 def select_related(self, *fields):
1404 """
1405 Return a new QuerySet instance that will select related objects.
1407 If fields are specified, they must be ForeignKey fields and only those
1408 related objects are included in the selection.
1410 If select_related(None) is called, clear the list.
1411 """
1412 self._not_support_combined_queries("select_related")
1413 if self._fields is not None:
1414 raise TypeError(
1415 "Cannot call select_related() after .values() or .values_list()"
1416 )
1418 obj = self._chain()
1419 if fields == (None,):
1420 obj.query.select_related = False
1421 elif fields:
1422 obj.query.add_select_related(fields)
1423 else:
1424 obj.query.select_related = True
1425 return obj
1427 def prefetch_related(self, *lookups):
1428 """
1429 Return a new QuerySet instance that will prefetch the specified
1430 Many-To-One and Many-To-Many related objects when the QuerySet is
1431 evaluated.
1433 When prefetch_related() is called more than once, append to the list of
1434 prefetch lookups. If prefetch_related(None) is called, clear the list.
1435 """
1436 self._not_support_combined_queries("prefetch_related")
1437 clone = self._chain()
1438 if lookups == (None,):
1439 clone._prefetch_related_lookups = ()
1440 else:
1441 for lookup in lookups:
1442 if isinstance(lookup, Prefetch):
1443 lookup = lookup.prefetch_to
1444 lookup = lookup.split(LOOKUP_SEP, 1)[0]
1445 if lookup in self.query._filtered_relations:
1446 raise ValueError(
1447 "prefetch_related() is not supported with FilteredRelation."
1448 )
1449 clone._prefetch_related_lookups = clone._prefetch_related_lookups + lookups
1450 return clone
1452 def annotate(self, *args, **kwargs):
1453 """
1454 Return a query set in which the returned objects have been annotated
1455 with extra data or aggregations.
1456 """
1457 self._not_support_combined_queries("annotate")
1458 return self._annotate(args, kwargs, select=True)
1460 def alias(self, *args, **kwargs):
1461 """
1462 Return a query set with added aliases for extra data or aggregations.
1463 """
1464 self._not_support_combined_queries("alias")
1465 return self._annotate(args, kwargs, select=False)
1467 def _annotate(self, args, kwargs, select=True):
1468 self._validate_values_are_expressions(
1469 args + tuple(kwargs.values()), method_name="annotate"
1470 )
1471 annotations = {}
1472 for arg in args:
1473 # The default_alias property may raise a TypeError.
1474 try:
1475 if arg.default_alias in kwargs:
1476 raise ValueError(
1477 "The named annotation '%s' conflicts with the "
1478 "default name for another annotation." % arg.default_alias
1479 )
1480 except TypeError:
1481 raise TypeError("Complex annotations require an alias")
1482 annotations[arg.default_alias] = arg
1483 annotations.update(kwargs)
1485 clone = self._chain()
1486 names = self._fields
1487 if names is None:
1488 names = set(
1489 chain.from_iterable(
1490 (field.name, field.attname)
1491 if hasattr(field, "attname")
1492 else (field.name,)
1493 for field in self.model._meta.get_fields()
1494 )
1495 )
1497 for alias, annotation in annotations.items():
1498 if alias in names:
1499 raise ValueError(
1500 "The annotation '%s' conflicts with a field on "
1501 "the model." % alias
1502 )
1503 if isinstance(annotation, FilteredRelation):
1504 clone.query.add_filtered_relation(annotation, alias)
1505 else:
1506 clone.query.add_annotation(
1507 annotation,
1508 alias,
1509 select=select,
1510 )
1511 for alias, annotation in clone.query.annotations.items():
1512 if alias in annotations and annotation.contains_aggregate:
1513 if clone._fields is None:
1514 clone.query.group_by = True
1515 else:
1516 clone.query.set_group_by()
1517 break
1519 return clone
1521 def order_by(self, *field_names):
1522 """Return a new QuerySet instance with the ordering changed."""
1523 if self.query.is_sliced:
1524 raise TypeError("Cannot reorder a query once a slice has been taken.")
1525 obj = self._chain()
1526 obj.query.clear_ordering(force=True, clear_default=False)
1527 obj.query.add_ordering(*field_names)
1528 return obj
1530 def distinct(self, *field_names):
1531 """
1532 Return a new QuerySet instance that will select only distinct results.
1533 """
1534 self._not_support_combined_queries("distinct")
1535 if self.query.is_sliced:
1536 raise TypeError(
1537 "Cannot create distinct fields once a slice has been taken."
1538 )
1539 obj = self._chain()
1540 obj.query.add_distinct_fields(*field_names)
1541 return obj
1543 def extra(
1544 self,
1545 select=None,
1546 where=None,
1547 params=None,
1548 tables=None,
1549 order_by=None,
1550 select_params=None,
1551 ):
1552 """Add extra SQL fragments to the query."""
1553 self._not_support_combined_queries("extra")
1554 if self.query.is_sliced:
1555 raise TypeError("Cannot change a query once a slice has been taken.")
1556 clone = self._chain()
1557 clone.query.add_extra(select, select_params, where, params, tables, order_by)
1558 return clone
1560 def reverse(self):
1561 """Reverse the ordering of the QuerySet."""
1562 if self.query.is_sliced:
1563 raise TypeError("Cannot reverse a query once a slice has been taken.")
1564 clone = self._chain()
1565 clone.query.standard_ordering = not clone.query.standard_ordering
1566 return clone
1568 def defer(self, *fields):
1569 """
1570 Defer the loading of data for certain fields until they are accessed.
1571 Add the set of deferred fields to any existing set of deferred fields.
1572 The only exception to this is if None is passed in as the only
1573 parameter, in which case removal all deferrals.
1574 """
1575 self._not_support_combined_queries("defer")
1576 if self._fields is not None:
1577 raise TypeError("Cannot call defer() after .values() or .values_list()")
1578 clone = self._chain()
1579 if fields == (None,):
1580 clone.query.clear_deferred_loading()
1581 else:
1582 clone.query.add_deferred_loading(fields)
1583 return clone
1585 def only(self, *fields):
1586 """
1587 Essentially, the opposite of defer(). Only the fields passed into this
1588 method and that are not already specified as deferred are loaded
1589 immediately when the queryset is evaluated.
1590 """
1591 self._not_support_combined_queries("only")
1592 if self._fields is not None:
1593 raise TypeError("Cannot call only() after .values() or .values_list()")
1594 if fields == (None,):
1595 # Can only pass None to defer(), not only(), as the rest option.
1596 # That won't stop people trying to do this, so let's be explicit.
1597 raise TypeError("Cannot pass None as an argument to only().")
1598 for field in fields:
1599 field = field.split(LOOKUP_SEP, 1)[0]
1600 if field in self.query._filtered_relations:
1601 raise ValueError("only() is not supported with FilteredRelation.")
1602 clone = self._chain()
1603 clone.query.add_immediate_loading(fields)
1604 return clone
1606 def using(self, alias):
1607 """Select which database this QuerySet should execute against."""
1608 clone = self._chain()
1609 clone._db = alias
1610 return clone
1612 ###################################
1613 # PUBLIC INTROSPECTION ATTRIBUTES #
1614 ###################################
1616 @property
1617 def ordered(self):
1618 """
1619 Return True if the QuerySet is ordered -- i.e. has an order_by()
1620 clause or a default ordering on the model (or is empty).
1621 """
1622 if isinstance(self, EmptyQuerySet):
1623 return True
1624 if self.query.extra_order_by or self.query.order_by:
1625 return True
1626 elif (
1627 self.query.default_ordering
1628 and self.query.get_meta().ordering
1629 and
1630 # A default ordering doesn't affect GROUP BY queries.
1631 not self.query.group_by
1632 ):
1633 return True
1634 else:
1635 return False
1637 @property
1638 def db(self):
1639 """Return the database used if this query is executed now."""
1640 if self._for_write:
1641 return self._db or router.db_for_write(self.model, **self._hints)
1642 return self._db or router.db_for_read(self.model, **self._hints)
1644 ###################
1645 # PRIVATE METHODS #
1646 ###################
1648 def _insert(
1649 self,
1650 objs,
1651 fields,
1652 returning_fields=None,
1653 raw=False,
1654 using=None,
1655 on_conflict=None,
1656 update_fields=None,
1657 unique_fields=None,
1658 ):
1659 """
1660 Insert a new record for the given model. This provides an interface to
1661 the InsertQuery class and is how Model.save() is implemented.
1662 """
1663 self._for_write = True
1664 if using is None:
1665 using = self.db
1666 query = sql.InsertQuery(
1667 self.model,
1668 on_conflict=on_conflict,
1669 update_fields=update_fields,
1670 unique_fields=unique_fields,
1671 )
1672 query.insert_values(fields, objs, raw=raw)
1673 return query.get_compiler(using=using).execute_sql(returning_fields)
1675 _insert.alters_data = True
1676 _insert.queryset_only = False
1678 def _batched_insert(
1679 self,
1680 objs,
1681 fields,
1682 batch_size,
1683 on_conflict=None,
1684 update_fields=None,
1685 unique_fields=None,
1686 ):
1687 """
1688 Helper method for bulk_create() to insert objs one batch at a time.
1689 """
1690 connection = connections[self.db]
1691 ops = connection.ops
1692 max_batch_size = max(ops.bulk_batch_size(fields, objs), 1)
1693 batch_size = min(batch_size, max_batch_size) if batch_size else max_batch_size
1694 inserted_rows = []
1695 bulk_return = connection.features.can_return_rows_from_bulk_insert
1696 for item in [objs[i : i + batch_size] for i in range(0, len(objs), batch_size)]:
1697 if bulk_return and on_conflict is None:
1698 inserted_rows.extend(
1699 self._insert(
1700 item,
1701 fields=fields,
1702 using=self.db,
1703 returning_fields=self.model._meta.db_returning_fields,
1704 )
1705 )
1706 else:
1707 self._insert(
1708 item,
1709 fields=fields,
1710 using=self.db,
1711 on_conflict=on_conflict,
1712 update_fields=update_fields,
1713 unique_fields=unique_fields,
1714 )
1715 return inserted_rows
1717 def _chain(self):
1718 """
1719 Return a copy of the current QuerySet that's ready for another
1720 operation.
1721 """
1722 obj = self._clone()
1723 if obj._sticky_filter:
1724 obj.query.filter_is_sticky = True
1725 obj._sticky_filter = False
1726 return obj
1728 def _clone(self):
1729 """
1730 Return a copy of the current QuerySet. A lightweight alternative
1731 to deepcopy().
1732 """
1733 c = self.__class__(
1734 model=self.model,
1735 query=self.query.chain(),
1736 using=self._db,
1737 hints=self._hints,
1738 )
1739 c._sticky_filter = self._sticky_filter
1740 c._for_write = self._for_write
1741 c._prefetch_related_lookups = self._prefetch_related_lookups[:]
1742 c._known_related_objects = self._known_related_objects
1743 c._iterable_class = self._iterable_class
1744 c._fields = self._fields
1745 return c
1747 def _fetch_all(self):
1748 if self._result_cache is None:
1749 self._result_cache = list(self._iterable_class(self))
1750 if self._prefetch_related_lookups and not self._prefetch_done:
1751 self._prefetch_related_objects()
1753 def _next_is_sticky(self):
1754 """
1755 Indicate that the next filter call and the one following that should
1756 be treated as a single filter. This is only important when it comes to
1757 determining when to reuse tables for many-to-many filters. Required so
1758 that we can filter naturally on the results of related managers.
1760 This doesn't return a clone of the current QuerySet (it returns
1761 "self"). The method is only used internally and should be immediately
1762 followed by a filter() that does create a clone.
1763 """
1764 self._sticky_filter = True
1765 return self
1767 def _merge_sanity_check(self, other):
1768 """Check that two QuerySet classes may be merged."""
1769 if self._fields is not None and (
1770 set(self.query.values_select) != set(other.query.values_select)
1771 or set(self.query.extra_select) != set(other.query.extra_select)
1772 or set(self.query.annotation_select) != set(other.query.annotation_select)
1773 ):
1774 raise TypeError(
1775 "Merging '%s' classes must involve the same values in each case."
1776 % self.__class__.__name__
1777 )
1779 def _merge_known_related_objects(self, other):
1780 """
1781 Keep track of all known related objects from either QuerySet instance.
1782 """
1783 for field, objects in other._known_related_objects.items():
1784 self._known_related_objects.setdefault(field, {}).update(objects)
1786 def resolve_expression(self, *args, **kwargs):
1787 if self._fields and len(self._fields) > 1:
1788 # values() queryset can only be used as nested queries
1789 # if they are set up to select only a single field.
1790 raise TypeError("Cannot use multi-field values as a filter value.")
1791 query = self.query.resolve_expression(*args, **kwargs)
1792 query._db = self._db
1793 return query
1795 resolve_expression.queryset_only = True
1797 def _add_hints(self, **hints):
1798 """
1799 Update hinting information for use by routers. Add new key/values or
1800 overwrite existing key/values.
1801 """
1802 self._hints.update(hints)
1804 def _has_filters(self):
1805 """
1806 Check if this QuerySet has any filtering going on. This isn't
1807 equivalent with checking if all objects are present in results, for
1808 example, qs[1:]._has_filters() -> False.
1809 """
1810 return self.query.has_filters()
1812 @staticmethod
1813 def _validate_values_are_expressions(values, method_name):
1814 invalid_args = sorted(
1815 str(arg) for arg in values if not hasattr(arg, "resolve_expression")
1816 )
1817 if invalid_args:
1818 raise TypeError(
1819 "QuerySet.{}() received non-expression(s): {}.".format(
1820 method_name,
1821 ", ".join(invalid_args),
1822 )
1823 )
1825 def _not_support_combined_queries(self, operation_name):
1826 if self.query.combinator:
1827 raise NotSupportedError(
1828 "Calling QuerySet.{}() after {}() is not supported.".format(
1829 operation_name, self.query.combinator
1830 )
1831 )
1833 def _check_operator_queryset(self, other, operator_):
1834 if self.query.combinator or other.query.combinator:
1835 raise TypeError(f"Cannot use {operator_} operator with combined queryset.")
1837 def _check_ordering_first_last_queryset_aggregation(self, method):
1838 if isinstance(self.query.group_by, tuple) and not any(
1839 col.output_field is self.model._meta.pk for col in self.query.group_by
1840 ):
1841 raise TypeError(
1842 f"Cannot use QuerySet.{method}() on an unordered queryset performing "
1843 f"aggregation. Add an ordering with order_by()."
1844 )
1847class InstanceCheckMeta(type):
1848 def __instancecheck__(self, instance):
1849 return isinstance(instance, QuerySet) and instance.query.is_empty()
1852class EmptyQuerySet(metaclass=InstanceCheckMeta):
1853 """
1854 Marker class to checking if a queryset is empty by .none():
1855 isinstance(qs.none(), EmptyQuerySet) -> True
1856 """
1858 def __init__(self, *args, **kwargs):
1859 raise TypeError("EmptyQuerySet can't be instantiated")
1862class RawQuerySet:
1863 """
1864 Provide an iterator which converts the results of raw SQL queries into
1865 annotated model instances.
1866 """
1868 def __init__(
1869 self,
1870 raw_query,
1871 model=None,
1872 query=None,
1873 params=(),
1874 translations=None,
1875 using=None,
1876 hints=None,
1877 ):
1878 self.raw_query = raw_query
1879 self.model = model
1880 self._db = using
1881 self._hints = hints or {}
1882 self.query = query or sql.RawQuery(sql=raw_query, using=self.db, params=params)
1883 self.params = params
1884 self.translations = translations or {}
1885 self._result_cache = None
1886 self._prefetch_related_lookups = ()
1887 self._prefetch_done = False
1889 def resolve_model_init_order(self):
1890 """Resolve the init field names and value positions."""
1891 converter = connections[self.db].introspection.identifier_converter
1892 model_init_fields = [
1893 f for f in self.model._meta.fields if converter(f.column) in self.columns
1894 ]
1895 annotation_fields = [
1896 (column, pos)
1897 for pos, column in enumerate(self.columns)
1898 if column not in self.model_fields
1899 ]
1900 model_init_order = [
1901 self.columns.index(converter(f.column)) for f in model_init_fields
1902 ]
1903 model_init_names = [f.attname for f in model_init_fields]
1904 return model_init_names, model_init_order, annotation_fields
1906 def prefetch_related(self, *lookups):
1907 """Same as QuerySet.prefetch_related()"""
1908 clone = self._clone()
1909 if lookups == (None,):
1910 clone._prefetch_related_lookups = ()
1911 else:
1912 clone._prefetch_related_lookups = clone._prefetch_related_lookups + lookups
1913 return clone
1915 def _prefetch_related_objects(self):
1916 prefetch_related_objects(self._result_cache, *self._prefetch_related_lookups)
1917 self._prefetch_done = True
1919 def _clone(self):
1920 """Same as QuerySet._clone()"""
1921 c = self.__class__(
1922 self.raw_query,
1923 model=self.model,
1924 query=self.query,
1925 params=self.params,
1926 translations=self.translations,
1927 using=self._db,
1928 hints=self._hints,
1929 )
1930 c._prefetch_related_lookups = self._prefetch_related_lookups[:]
1931 return c
1933 def _fetch_all(self):
1934 if self._result_cache is None:
1935 self._result_cache = list(self.iterator())
1936 if self._prefetch_related_lookups and not self._prefetch_done:
1937 self._prefetch_related_objects()
1939 def __len__(self):
1940 self._fetch_all()
1941 return len(self._result_cache)
1943 def __bool__(self):
1944 self._fetch_all()
1945 return bool(self._result_cache)
1947 def __iter__(self):
1948 self._fetch_all()
1949 return iter(self._result_cache)
1951 def iterator(self):
1952 yield from RawModelIterable(self)
1954 def __repr__(self):
1955 return f"<{self.__class__.__name__}: {self.query}>"
1957 def __getitem__(self, k):
1958 return list(self)[k]
1960 @property
1961 def db(self):
1962 """Return the database used if this query is executed now."""
1963 return self._db or router.db_for_read(self.model, **self._hints)
1965 def using(self, alias):
1966 """Select the database this RawQuerySet should execute against."""
1967 return RawQuerySet(
1968 self.raw_query,
1969 model=self.model,
1970 query=self.query.chain(using=alias),
1971 params=self.params,
1972 translations=self.translations,
1973 using=alias,
1974 )
1976 @cached_property
1977 def columns(self):
1978 """
1979 A list of model field names in the order they'll appear in the
1980 query results.
1981 """
1982 columns = self.query.get_columns()
1983 # Adjust any column names which don't match field names
1984 for query_name, model_name in self.translations.items():
1985 # Ignore translations for nonexistent column names
1986 try:
1987 index = columns.index(query_name)
1988 except ValueError:
1989 pass
1990 else:
1991 columns[index] = model_name
1992 return columns
1994 @cached_property
1995 def model_fields(self):
1996 """A dict mapping column names to model field names."""
1997 converter = connections[self.db].introspection.identifier_converter
1998 model_fields = {}
1999 for field in self.model._meta.fields:
2000 name, column = field.get_attname_column()
2001 model_fields[converter(column)] = field
2002 return model_fields
2005class Prefetch:
2006 def __init__(self, lookup, queryset=None, to_attr=None):
2007 # `prefetch_through` is the path we traverse to perform the prefetch.
2008 self.prefetch_through = lookup
2009 # `prefetch_to` is the path to the attribute that stores the result.
2010 self.prefetch_to = lookup
2011 if queryset is not None and (
2012 isinstance(queryset, RawQuerySet)
2013 or (
2014 hasattr(queryset, "_iterable_class")
2015 and not issubclass(queryset._iterable_class, ModelIterable)
2016 )
2017 ):
2018 raise ValueError(
2019 "Prefetch querysets cannot use raw(), values(), and values_list()."
2020 )
2021 if to_attr:
2022 self.prefetch_to = LOOKUP_SEP.join(
2023 lookup.split(LOOKUP_SEP)[:-1] + [to_attr]
2024 )
2026 self.queryset = queryset
2027 self.to_attr = to_attr
2029 def __getstate__(self):
2030 obj_dict = self.__dict__.copy()
2031 if self.queryset is not None:
2032 queryset = self.queryset._chain()
2033 # Prevent the QuerySet from being evaluated
2034 queryset._result_cache = []
2035 queryset._prefetch_done = True
2036 obj_dict["queryset"] = queryset
2037 return obj_dict
2039 def add_prefix(self, prefix):
2040 self.prefetch_through = prefix + LOOKUP_SEP + self.prefetch_through
2041 self.prefetch_to = prefix + LOOKUP_SEP + self.prefetch_to
2043 def get_current_prefetch_to(self, level):
2044 return LOOKUP_SEP.join(self.prefetch_to.split(LOOKUP_SEP)[: level + 1])
2046 def get_current_to_attr(self, level):
2047 parts = self.prefetch_to.split(LOOKUP_SEP)
2048 to_attr = parts[level]
2049 as_attr = self.to_attr and level == len(parts) - 1
2050 return to_attr, as_attr
2052 def get_current_queryset(self, level):
2053 if self.get_current_prefetch_to(level) == self.prefetch_to:
2054 return self.queryset
2055 return None
2057 def __eq__(self, other):
2058 if not isinstance(other, Prefetch):
2059 return NotImplemented
2060 return self.prefetch_to == other.prefetch_to
2062 def __hash__(self):
2063 return hash((self.__class__, self.prefetch_to))
2066def normalize_prefetch_lookups(lookups, prefix=None):
2067 """Normalize lookups into Prefetch objects."""
2068 ret = []
2069 for lookup in lookups:
2070 if not isinstance(lookup, Prefetch):
2071 lookup = Prefetch(lookup)
2072 if prefix:
2073 lookup.add_prefix(prefix)
2074 ret.append(lookup)
2075 return ret
2078def prefetch_related_objects(model_instances, *related_lookups):
2079 """
2080 Populate prefetched object caches for a list of model instances based on
2081 the lookups/Prefetch instances given.
2082 """
2083 if not model_instances:
2084 return # nothing to do
2086 # We need to be able to dynamically add to the list of prefetch_related
2087 # lookups that we look up (see below). So we need some book keeping to
2088 # ensure we don't do duplicate work.
2089 done_queries = {} # dictionary of things like 'foo__bar': [results]
2091 auto_lookups = set() # we add to this as we go through.
2092 followed_descriptors = set() # recursion protection
2094 all_lookups = normalize_prefetch_lookups(reversed(related_lookups))
2095 while all_lookups:
2096 lookup = all_lookups.pop()
2097 if lookup.prefetch_to in done_queries:
2098 if lookup.queryset is not None:
2099 raise ValueError(
2100 "'%s' lookup was already seen with a different queryset. "
2101 "You may need to adjust the ordering of your lookups."
2102 % lookup.prefetch_to
2103 )
2105 continue
2107 # Top level, the list of objects to decorate is the result cache
2108 # from the primary QuerySet. It won't be for deeper levels.
2109 obj_list = model_instances
2111 through_attrs = lookup.prefetch_through.split(LOOKUP_SEP)
2112 for level, through_attr in enumerate(through_attrs):
2113 # Prepare main instances
2114 if not obj_list:
2115 break
2117 prefetch_to = lookup.get_current_prefetch_to(level)
2118 if prefetch_to in done_queries:
2119 # Skip any prefetching, and any object preparation
2120 obj_list = done_queries[prefetch_to]
2121 continue
2123 # Prepare objects:
2124 good_objects = True
2125 for obj in obj_list:
2126 # Since prefetching can re-use instances, it is possible to have
2127 # the same instance multiple times in obj_list, so obj might
2128 # already be prepared.
2129 if not hasattr(obj, "_prefetched_objects_cache"):
2130 try:
2131 obj._prefetched_objects_cache = {}
2132 except (AttributeError, TypeError):
2133 # Must be an immutable object from
2134 # values_list(flat=True), for example (TypeError) or
2135 # a QuerySet subclass that isn't returning Model
2136 # instances (AttributeError), either in Plain or a 3rd
2137 # party. prefetch_related() doesn't make sense, so quit.
2138 good_objects = False
2139 break
2140 if not good_objects:
2141 break
2143 # Descend down tree
2145 # We assume that objects retrieved are homogeneous (which is the premise
2146 # of prefetch_related), so what applies to first object applies to all.
2147 first_obj = obj_list[0]
2148 to_attr = lookup.get_current_to_attr(level)[0]
2149 prefetcher, descriptor, attr_found, is_fetched = get_prefetcher(
2150 first_obj, through_attr, to_attr
2151 )
2153 if not attr_found:
2154 raise AttributeError(
2155 "Cannot find '{}' on {} object, '{}' is an invalid "
2156 "parameter to prefetch_related()".format(
2157 through_attr,
2158 first_obj.__class__.__name__,
2159 lookup.prefetch_through,
2160 )
2161 )
2163 if level == len(through_attrs) - 1 and prefetcher is None:
2164 # Last one, this *must* resolve to something that supports
2165 # prefetching, otherwise there is no point adding it and the
2166 # developer asking for it has made a mistake.
2167 raise ValueError(
2168 "'%s' does not resolve to an item that supports "
2169 "prefetching - this is an invalid parameter to "
2170 "prefetch_related()." % lookup.prefetch_through
2171 )
2173 obj_to_fetch = None
2174 if prefetcher is not None:
2175 obj_to_fetch = [obj for obj in obj_list if not is_fetched(obj)]
2177 if obj_to_fetch:
2178 obj_list, additional_lookups = prefetch_one_level(
2179 obj_to_fetch,
2180 prefetcher,
2181 lookup,
2182 level,
2183 )
2184 # We need to ensure we don't keep adding lookups from the
2185 # same relationships to stop infinite recursion. So, if we
2186 # are already on an automatically added lookup, don't add
2187 # the new lookups from relationships we've seen already.
2188 if not (
2189 prefetch_to in done_queries
2190 and lookup in auto_lookups
2191 and descriptor in followed_descriptors
2192 ):
2193 done_queries[prefetch_to] = obj_list
2194 new_lookups = normalize_prefetch_lookups(
2195 reversed(additional_lookups), prefetch_to
2196 )
2197 auto_lookups.update(new_lookups)
2198 all_lookups.extend(new_lookups)
2199 followed_descriptors.add(descriptor)
2200 else:
2201 # Either a singly related object that has already been fetched
2202 # (e.g. via select_related), or hopefully some other property
2203 # that doesn't support prefetching but needs to be traversed.
2205 # We replace the current list of parent objects with the list
2206 # of related objects, filtering out empty or missing values so
2207 # that we can continue with nullable or reverse relations.
2208 new_obj_list = []
2209 for obj in obj_list:
2210 if through_attr in getattr(obj, "_prefetched_objects_cache", ()):
2211 # If related objects have been prefetched, use the
2212 # cache rather than the object's through_attr.
2213 new_obj = list(obj._prefetched_objects_cache.get(through_attr))
2214 else:
2215 try:
2216 new_obj = getattr(obj, through_attr)
2217 except exceptions.ObjectDoesNotExist:
2218 continue
2219 if new_obj is None:
2220 continue
2221 # We special-case `list` rather than something more generic
2222 # like `Iterable` because we don't want to accidentally match
2223 # user models that define __iter__.
2224 if isinstance(new_obj, list):
2225 new_obj_list.extend(new_obj)
2226 else:
2227 new_obj_list.append(new_obj)
2228 obj_list = new_obj_list
2231def get_prefetcher(instance, through_attr, to_attr):
2232 """
2233 For the attribute 'through_attr' on the given instance, find
2234 an object that has a get_prefetch_queryset().
2235 Return a 4 tuple containing:
2236 (the object with get_prefetch_queryset (or None),
2237 the descriptor object representing this relationship (or None),
2238 a boolean that is False if the attribute was not found at all,
2239 a function that takes an instance and returns a boolean that is True if
2240 the attribute has already been fetched for that instance)
2241 """
2243 def has_to_attr_attribute(instance):
2244 return hasattr(instance, to_attr)
2246 prefetcher = None
2247 is_fetched = has_to_attr_attribute
2249 # For singly related objects, we have to avoid getting the attribute
2250 # from the object, as this will trigger the query. So we first try
2251 # on the class, in order to get the descriptor object.
2252 rel_obj_descriptor = getattr(instance.__class__, through_attr, None)
2253 if rel_obj_descriptor is None:
2254 attr_found = hasattr(instance, through_attr)
2255 else:
2256 attr_found = True
2257 if rel_obj_descriptor:
2258 # singly related object, descriptor object has the
2259 # get_prefetch_queryset() method.
2260 if hasattr(rel_obj_descriptor, "get_prefetch_queryset"):
2261 prefetcher = rel_obj_descriptor
2262 is_fetched = rel_obj_descriptor.is_cached
2263 else:
2264 # descriptor doesn't support prefetching, so we go ahead and get
2265 # the attribute on the instance rather than the class to
2266 # support many related managers
2267 rel_obj = getattr(instance, through_attr)
2268 if hasattr(rel_obj, "get_prefetch_queryset"):
2269 prefetcher = rel_obj
2270 if through_attr != to_attr:
2271 # Special case cached_property instances because hasattr
2272 # triggers attribute computation and assignment.
2273 if isinstance(
2274 getattr(instance.__class__, to_attr, None), cached_property
2275 ):
2277 def has_cached_property(instance):
2278 return to_attr in instance.__dict__
2280 is_fetched = has_cached_property
2281 else:
2283 def in_prefetched_cache(instance):
2284 return through_attr in instance._prefetched_objects_cache
2286 is_fetched = in_prefetched_cache
2287 return prefetcher, rel_obj_descriptor, attr_found, is_fetched
2290def prefetch_one_level(instances, prefetcher, lookup, level):
2291 """
2292 Helper function for prefetch_related_objects().
2294 Run prefetches on all instances using the prefetcher object,
2295 assigning results to relevant caches in instance.
2297 Return the prefetched objects along with any additional prefetches that
2298 must be done due to prefetch_related lookups found from default managers.
2299 """
2300 # prefetcher must have a method get_prefetch_queryset() which takes a list
2301 # of instances, and returns a tuple:
2303 # (queryset of instances of self.model that are related to passed in instances,
2304 # callable that gets value to be matched for returned instances,
2305 # callable that gets value to be matched for passed in instances,
2306 # boolean that is True for singly related objects,
2307 # cache or field name to assign to,
2308 # boolean that is True when the previous argument is a cache name vs a field name).
2310 # The 'values to be matched' must be hashable as they will be used
2311 # in a dictionary.
2313 (
2314 rel_qs,
2315 rel_obj_attr,
2316 instance_attr,
2317 single,
2318 cache_name,
2319 is_descriptor,
2320 ) = prefetcher.get_prefetch_queryset(instances, lookup.get_current_queryset(level))
2321 # We have to handle the possibility that the QuerySet we just got back
2322 # contains some prefetch_related lookups. We don't want to trigger the
2323 # prefetch_related functionality by evaluating the query. Rather, we need
2324 # to merge in the prefetch_related lookups.
2325 # Copy the lookups in case it is a Prefetch object which could be reused
2326 # later (happens in nested prefetch_related).
2327 additional_lookups = [
2328 copy.copy(additional_lookup)
2329 for additional_lookup in getattr(rel_qs, "_prefetch_related_lookups", ())
2330 ]
2331 if additional_lookups:
2332 # Don't need to clone because the manager should have given us a fresh
2333 # instance, so we access an internal instead of using public interface
2334 # for performance reasons.
2335 rel_qs._prefetch_related_lookups = ()
2337 all_related_objects = list(rel_qs)
2339 rel_obj_cache = {}
2340 for rel_obj in all_related_objects:
2341 rel_attr_val = rel_obj_attr(rel_obj)
2342 rel_obj_cache.setdefault(rel_attr_val, []).append(rel_obj)
2344 to_attr, as_attr = lookup.get_current_to_attr(level)
2345 # Make sure `to_attr` does not conflict with a field.
2346 if as_attr and instances:
2347 # We assume that objects retrieved are homogeneous (which is the premise
2348 # of prefetch_related), so what applies to first object applies to all.
2349 model = instances[0].__class__
2350 try:
2351 model._meta.get_field(to_attr)
2352 except exceptions.FieldDoesNotExist:
2353 pass
2354 else:
2355 msg = "to_attr={} conflicts with a field on the {} model."
2356 raise ValueError(msg.format(to_attr, model.__name__))
2358 # Whether or not we're prefetching the last part of the lookup.
2359 leaf = len(lookup.prefetch_through.split(LOOKUP_SEP)) - 1 == level
2361 for obj in instances:
2362 instance_attr_val = instance_attr(obj)
2363 vals = rel_obj_cache.get(instance_attr_val, [])
2365 if single:
2366 val = vals[0] if vals else None
2367 if as_attr:
2368 # A to_attr has been given for the prefetch.
2369 setattr(obj, to_attr, val)
2370 elif is_descriptor:
2371 # cache_name points to a field name in obj.
2372 # This field is a descriptor for a related object.
2373 setattr(obj, cache_name, val)
2374 else:
2375 # No to_attr has been given for this prefetch operation and the
2376 # cache_name does not point to a descriptor. Store the value of
2377 # the field in the object's field cache.
2378 obj._state.fields_cache[cache_name] = val
2379 else:
2380 if as_attr:
2381 setattr(obj, to_attr, vals)
2382 else:
2383 manager = getattr(obj, to_attr)
2384 if leaf and lookup.queryset is not None:
2385 qs = manager._apply_rel_filters(lookup.queryset)
2386 else:
2387 qs = manager.get_queryset()
2388 qs._result_cache = vals
2389 # We don't want the individual qs doing prefetch_related now,
2390 # since we have merged this into the current work.
2391 qs._prefetch_done = True
2392 obj._prefetched_objects_cache[cache_name] = qs
2393 return all_related_objects, additional_lookups
2396class RelatedPopulator:
2397 """
2398 RelatedPopulator is used for select_related() object instantiation.
2400 The idea is that each select_related() model will be populated by a
2401 different RelatedPopulator instance. The RelatedPopulator instances get
2402 klass_info and select (computed in SQLCompiler) plus the used db as
2403 input for initialization. That data is used to compute which columns
2404 to use, how to instantiate the model, and how to populate the links
2405 between the objects.
2407 The actual creation of the objects is done in populate() method. This
2408 method gets row and from_obj as input and populates the select_related()
2409 model instance.
2410 """
2412 def __init__(self, klass_info, select, db):
2413 self.db = db
2414 # Pre-compute needed attributes. The attributes are:
2415 # - model_cls: the possibly deferred model class to instantiate
2416 # - either:
2417 # - cols_start, cols_end: usually the columns in the row are
2418 # in the same order model_cls.__init__ expects them, so we
2419 # can instantiate by model_cls(*row[cols_start:cols_end])
2420 # - reorder_for_init: When select_related descends to a child
2421 # class, then we want to reuse the already selected parent
2422 # data. However, in this case the parent data isn't necessarily
2423 # in the same order that Model.__init__ expects it to be, so
2424 # we have to reorder the parent data. The reorder_for_init
2425 # attribute contains a function used to reorder the field data
2426 # in the order __init__ expects it.
2427 # - pk_idx: the index of the primary key field in the reordered
2428 # model data. Used to check if a related object exists at all.
2429 # - init_list: the field attnames fetched from the database. For
2430 # deferred models this isn't the same as all attnames of the
2431 # model's fields.
2432 # - related_populators: a list of RelatedPopulator instances if
2433 # select_related() descends to related models from this model.
2434 # - local_setter, remote_setter: Methods to set cached values on
2435 # the object being populated and on the remote object. Usually
2436 # these are Field.set_cached_value() methods.
2437 select_fields = klass_info["select_fields"]
2438 from_parent = klass_info["from_parent"]
2439 if not from_parent:
2440 self.cols_start = select_fields[0]
2441 self.cols_end = select_fields[-1] + 1
2442 self.init_list = [
2443 f[0].target.attname for f in select[self.cols_start : self.cols_end]
2444 ]
2445 self.reorder_for_init = None
2446 else:
2447 attname_indexes = {
2448 select[idx][0].target.attname: idx for idx in select_fields
2449 }
2450 model_init_attnames = (
2451 f.attname for f in klass_info["model"]._meta.concrete_fields
2452 )
2453 self.init_list = [
2454 attname for attname in model_init_attnames if attname in attname_indexes
2455 ]
2456 self.reorder_for_init = operator.itemgetter(
2457 *[attname_indexes[attname] for attname in self.init_list]
2458 )
2460 self.model_cls = klass_info["model"]
2461 self.pk_idx = self.init_list.index(self.model_cls._meta.pk.attname)
2462 self.related_populators = get_related_populators(klass_info, select, self.db)
2463 self.local_setter = klass_info["local_setter"]
2464 self.remote_setter = klass_info["remote_setter"]
2466 def populate(self, row, from_obj):
2467 if self.reorder_for_init:
2468 obj_data = self.reorder_for_init(row)
2469 else:
2470 obj_data = row[self.cols_start : self.cols_end]
2471 if obj_data[self.pk_idx] is None:
2472 obj = None
2473 else:
2474 obj = self.model_cls.from_db(self.db, self.init_list, obj_data)
2475 for rel_iter in self.related_populators:
2476 rel_iter.populate(row, obj)
2477 self.local_setter(from_obj, obj)
2478 if obj is not None:
2479 self.remote_setter(obj, from_obj)
2482def get_related_populators(klass_info, select, db):
2483 iterators = []
2484 related_klass_infos = klass_info.get("related_klass_infos", [])
2485 for rel_klass_info in related_klass_infos:
2486 rel_cls = RelatedPopulator(rel_klass_info, select, db)
2487 iterators.append(rel_cls)
2488 return iterators
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Various data structures used in query construction.
4Factored out from plain.models.query to avoid making the main module very
5large and/or so that they can be used by other modules without getting into
6circular import difficulties.
7"""
8import functools
9import inspect
10import logging
11from collections import namedtuple
13from plain.exceptions import FieldError
14from plain.models.constants import LOOKUP_SEP
15from plain.models.db import DEFAULT_DB_ALIAS, DatabaseError, connections
16from plain.utils import tree
18logger = logging.getLogger("plain.models")
20# PathInfo is used when converting lookups (fk__somecol). The contents
21# describe the relation in Model terms (model Options and Fields for both
22# sides of the relation. The join_field is the field backing the relation.
23PathInfo = namedtuple(
24 "PathInfo",
25 "from_opts to_opts target_fields join_field m2m direct filtered_relation",
26)
29def subclasses(cls):
30 yield cls
31 for subclass in cls.__subclasses__():
32 yield from subclasses(subclass)
35class Q(tree.Node):
36 """
37 Encapsulate filters as objects that can then be combined logically (using
38 `&` and `|`).
39 """
41 # Connection types
42 AND = "AND"
43 OR = "OR"
44 XOR = "XOR"
45 default = AND
46 conditional = True
48 def __init__(self, *args, _connector=None, _negated=False, **kwargs):
49 super().__init__(
50 children=[*args, *sorted(kwargs.items())],
51 connector=_connector,
52 negated=_negated,
53 )
55 def _combine(self, other, conn):
56 if getattr(other, "conditional", False) is False:
57 raise TypeError(other)
58 if not self:
59 return other.copy()
60 if not other and isinstance(other, Q):
61 return self.copy()
63 obj = self.create(connector=conn)
64 obj.add(self, conn)
65 obj.add(other, conn)
66 return obj
68 def __or__(self, other):
69 return self._combine(other, self.OR)
71 def __and__(self, other):
72 return self._combine(other, self.AND)
74 def __xor__(self, other):
75 return self._combine(other, self.XOR)
77 def __invert__(self):
78 obj = self.copy()
79 obj.negate()
80 return obj
82 def resolve_expression(
83 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
84 ):
85 # We must promote any new joins to left outer joins so that when Q is
86 # used as an expression, rows aren't filtered due to joins.
87 clause, joins = query._add_q(
88 self,
89 reuse,
90 allow_joins=allow_joins,
91 split_subq=False,
92 check_filterable=False,
93 summarize=summarize,
94 )
95 query.promote_joins(joins)
96 return clause
98 def flatten(self):
99 """
100 Recursively yield this Q object and all subexpressions, in depth-first
101 order.
102 """
103 yield self
104 for child in self.children:
105 if isinstance(child, tuple):
106 # Use the lookup.
107 child = child[1]
108 if hasattr(child, "flatten"):
109 yield from child.flatten()
110 else:
111 yield child
113 def check(self, against, using=DEFAULT_DB_ALIAS):
114 """
115 Do a database query to check if the expressions of the Q instance
116 matches against the expressions.
117 """
118 # Avoid circular imports.
119 from plain.models.expressions import Value
120 from plain.models.fields import BooleanField
121 from plain.models.functions import Coalesce
122 from plain.models.sql import Query
123 from plain.models.sql.constants import SINGLE
125 query = Query(None)
126 for name, value in against.items():
127 if not hasattr(value, "resolve_expression"):
128 value = Value(value)
129 query.add_annotation(value, name, select=False)
130 query.add_annotation(Value(1), "_check")
131 # This will raise a FieldError if a field is missing in "against".
132 if connections[using].features.supports_comparing_boolean_expr:
133 query.add_q(Q(Coalesce(self, True, output_field=BooleanField())))
134 else:
135 query.add_q(self)
136 compiler = query.get_compiler(using=using)
137 try:
138 return compiler.execute_sql(SINGLE) is not None
139 except DatabaseError as e:
140 logger.warning("Got a database error calling check() on %r: %s", self, e)
141 return True
143 def deconstruct(self):
144 path = f"{self.__class__.__module__}.{self.__class__.__name__}"
145 if path.startswith("plain.models.query_utils"):
146 path = path.replace("plain.models.query_utils", "plain.models")
147 args = tuple(self.children)
148 kwargs = {}
149 if self.connector != self.default:
150 kwargs["_connector"] = self.connector
151 if self.negated:
152 kwargs["_negated"] = True
153 return path, args, kwargs
156class DeferredAttribute:
157 """
158 A wrapper for a deferred-loading field. When the value is read from this
159 object the first time, the query is executed.
160 """
162 def __init__(self, field):
163 self.field = field
165 def __get__(self, instance, cls=None):
166 """
167 Retrieve and caches the value from the datastore on the first lookup.
168 Return the cached value.
169 """
170 if instance is None:
171 return self
172 data = instance.__dict__
173 field_name = self.field.attname
174 if field_name not in data:
175 # Let's see if the field is part of the parent chain. If so we
176 # might be able to reuse the already loaded value. Refs #18343.
177 val = self._check_parent_chain(instance)
178 if val is None:
179 instance.refresh_from_db(fields=[field_name])
180 else:
181 data[field_name] = val
182 return data[field_name]
184 def _check_parent_chain(self, instance):
185 """
186 Check if the field value can be fetched from a parent field already
187 loaded in the instance. This can be done if the to-be fetched
188 field is a primary key field.
189 """
190 opts = instance._meta
191 link_field = opts.get_ancestor_link(self.field.model)
192 if self.field.primary_key and self.field != link_field:
193 return getattr(instance, link_field.attname)
194 return None
197class class_or_instance_method:
198 """
199 Hook used in RegisterLookupMixin to return partial functions depending on
200 the caller type (instance or class of models.Field).
201 """
203 def __init__(self, class_method, instance_method):
204 self.class_method = class_method
205 self.instance_method = instance_method
207 def __get__(self, instance, owner):
208 if instance is None:
209 return functools.partial(self.class_method, owner)
210 return functools.partial(self.instance_method, instance)
213class RegisterLookupMixin:
214 def _get_lookup(self, lookup_name):
215 return self.get_lookups().get(lookup_name, None)
217 @functools.cache
218 def get_class_lookups(cls):
219 class_lookups = [
220 parent.__dict__.get("class_lookups", {}) for parent in inspect.getmro(cls)
221 ]
222 return cls.merge_dicts(class_lookups)
224 def get_instance_lookups(self):
225 class_lookups = self.get_class_lookups()
226 if instance_lookups := getattr(self, "instance_lookups", None):
227 return {**class_lookups, **instance_lookups}
228 return class_lookups
230 get_lookups = class_or_instance_method(get_class_lookups, get_instance_lookups)
231 get_class_lookups = classmethod(get_class_lookups)
233 def get_lookup(self, lookup_name):
234 from plain.models.lookups import Lookup
236 found = self._get_lookup(lookup_name)
237 if found is None and hasattr(self, "output_field"):
238 return self.output_field.get_lookup(lookup_name)
239 if found is not None and not issubclass(found, Lookup):
240 return None
241 return found
243 def get_transform(self, lookup_name):
244 from plain.models.lookups import Transform
246 found = self._get_lookup(lookup_name)
247 if found is None and hasattr(self, "output_field"):
248 return self.output_field.get_transform(lookup_name)
249 if found is not None and not issubclass(found, Transform):
250 return None
251 return found
253 @staticmethod
254 def merge_dicts(dicts):
255 """
256 Merge dicts in reverse to preference the order of the original list. e.g.,
257 merge_dicts([a, b]) will preference the keys in 'a' over those in 'b'.
258 """
259 merged = {}
260 for d in reversed(dicts):
261 merged.update(d)
262 return merged
264 @classmethod
265 def _clear_cached_class_lookups(cls):
266 for subclass in subclasses(cls):
267 subclass.get_class_lookups.cache_clear()
269 def register_class_lookup(cls, lookup, lookup_name=None):
270 if lookup_name is None:
271 lookup_name = lookup.lookup_name
272 if "class_lookups" not in cls.__dict__:
273 cls.class_lookups = {}
274 cls.class_lookups[lookup_name] = lookup
275 cls._clear_cached_class_lookups()
276 return lookup
278 def register_instance_lookup(self, lookup, lookup_name=None):
279 if lookup_name is None:
280 lookup_name = lookup.lookup_name
281 if "instance_lookups" not in self.__dict__:
282 self.instance_lookups = {}
283 self.instance_lookups[lookup_name] = lookup
284 return lookup
286 register_lookup = class_or_instance_method(
287 register_class_lookup, register_instance_lookup
288 )
289 register_class_lookup = classmethod(register_class_lookup)
291 def _unregister_class_lookup(cls, lookup, lookup_name=None):
292 """
293 Remove given lookup from cls lookups. For use in tests only as it's
294 not thread-safe.
295 """
296 if lookup_name is None:
297 lookup_name = lookup.lookup_name
298 del cls.class_lookups[lookup_name]
299 cls._clear_cached_class_lookups()
301 def _unregister_instance_lookup(self, lookup, lookup_name=None):
302 """
303 Remove given lookup from instance lookups. For use in tests only as
304 it's not thread-safe.
305 """
306 if lookup_name is None:
307 lookup_name = lookup.lookup_name
308 del self.instance_lookups[lookup_name]
310 _unregister_lookup = class_or_instance_method(
311 _unregister_class_lookup, _unregister_instance_lookup
312 )
313 _unregister_class_lookup = classmethod(_unregister_class_lookup)
316def select_related_descend(field, restricted, requested, select_mask, reverse=False):
317 """
318 Return True if this field should be used to descend deeper for
319 select_related() purposes. Used by both the query construction code
320 (compiler.get_related_selections()) and the model instance creation code
321 (compiler.klass_info).
323 Arguments:
324 * field - the field to be checked
325 * restricted - a boolean field, indicating if the field list has been
326 manually restricted using a requested clause)
327 * requested - The select_related() dictionary.
328 * select_mask - the dictionary of selected fields.
329 * reverse - boolean, True if we are checking a reverse select related
330 """
331 if not field.remote_field:
332 return False
333 if field.remote_field.parent_link and not reverse:
334 return False
335 if restricted:
336 if reverse and field.related_query_name() not in requested:
337 return False
338 if not reverse and field.name not in requested:
339 return False
340 if not restricted and field.null:
341 return False
342 if (
343 restricted
344 and select_mask
345 and field.name in requested
346 and field not in select_mask
347 ):
348 raise FieldError(
349 f"Field {field.model._meta.object_name}.{field.name} cannot be both "
350 "deferred and traversed using select_related at the same time."
351 )
352 return True
355def refs_expression(lookup_parts, annotations):
356 """
357 Check if the lookup_parts contains references to the given annotations set.
358 Because the LOOKUP_SEP is contained in the default annotation names, check
359 each prefix of the lookup_parts for a match.
360 """
361 for n in range(1, len(lookup_parts) + 1):
362 level_n_lookup = LOOKUP_SEP.join(lookup_parts[0:n])
363 if annotations.get(level_n_lookup):
364 return level_n_lookup, lookup_parts[n:]
365 return None, ()
368def check_rel_lookup_compatibility(model, target_opts, field):
369 """
370 Check that self.model is compatible with target_opts. Compatibility
371 is OK if:
372 1) model and opts match (where proxy inheritance is removed)
373 2) model is parent of opts' model or the other way around
374 """
376 def check(opts):
377 return (
378 model._meta.concrete_model == opts.concrete_model
379 or opts.concrete_model in model._meta.get_parent_list()
380 or model in opts.get_parent_list()
381 )
383 # If the field is a primary key, then doing a query against the field's
384 # model is ok, too. Consider the case:
385 # class Restaurant(models.Model):
386 # place = OneToOneField(Place, primary_key=True):
387 # Restaurant.objects.filter(pk__in=Restaurant.objects.all()).
388 # If we didn't have the primary key check, then pk__in (== place__in) would
389 # give Place's opts as the target opts, but Restaurant isn't compatible
390 # with that. This logic applies only to primary keys, as when doing __in=qs,
391 # we are going to turn this into __in=qs.values('pk') later on.
392 return check(target_opts) or (
393 getattr(field, "primary_key", False) and check(field.model._meta)
394 )
397class FilteredRelation:
398 """Specify custom filtering in the ON clause of SQL joins."""
400 def __init__(self, relation_name, *, condition=Q()):
401 if not relation_name:
402 raise ValueError("relation_name cannot be empty.")
403 self.relation_name = relation_name
404 self.alias = None
405 if not isinstance(condition, Q):
406 raise ValueError("condition argument must be a Q() instance.")
407 self.condition = condition
408 self.path = []
410 def __eq__(self, other):
411 if not isinstance(other, self.__class__):
412 return NotImplemented
413 return (
414 self.relation_name == other.relation_name
415 and self.alias == other.alias
416 and self.condition == other.condition
417 )
419 def clone(self):
420 clone = FilteredRelation(self.relation_name, condition=self.condition)
421 clone.alias = self.alias
422 clone.path = self.path[:]
423 return clone
425 def resolve_expression(self, *args, **kwargs):
426 """
427 QuerySet.annotate() only accepts expression-like arguments
428 (with a resolve_expression() method).
429 """
430 raise NotImplementedError("FilteredRelation.resolve_expression() is unused.")
432 def as_sql(self, compiler, connection):
433 # Resolve the condition in Join.filtered_relation.
434 query = compiler.query
435 where = query.build_filtered_relation_q(self.condition, reuse=set(self.path))
436 return compiler.compile(where)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from functools import partial
3from plain.models.utils import make_model_tuple
4from plain.signals.dispatch import Signal
6class_prepared = Signal()
9class ModelSignal(Signal):
10 """
11 Signal subclass that allows the sender to be lazily specified as a string
12 of the `package_label.ModelName` form.
13 """
15 def _lazy_method(self, method, packages, receiver, sender, **kwargs):
16 from plain.models.options import Options
18 # This partial takes a single optional argument named "sender".
19 partial_method = partial(method, receiver, **kwargs)
20 if isinstance(sender, str):
21 packages = packages or Options.default_packages
22 packages.lazy_model_operation(partial_method, make_model_tuple(sender))
23 else:
24 return partial_method(sender)
26 def connect(
27 self, receiver, sender=None, weak=True, dispatch_uid=None, packages=None
28 ):
29 self._lazy_method(
30 super().connect,
31 packages,
32 receiver,
33 sender,
34 weak=weak,
35 dispatch_uid=dispatch_uid,
36 )
38 def disconnect(self, receiver=None, sender=None, dispatch_uid=None, packages=None):
39 return self._lazy_method(
40 super().disconnect, packages, receiver, sender, dispatch_uid=dispatch_uid
41 )
44pre_init = ModelSignal(use_caching=True)
45post_init = ModelSignal(use_caching=True)
47pre_save = ModelSignal(use_caching=True)
48post_save = ModelSignal(use_caching=True)
50pre_delete = ModelSignal(use_caching=True)
51post_delete = ModelSignal(use_caching=True)
53m2m_changed = ModelSignal(use_caching=True)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from contextlib import ContextDecorator, contextmanager
3from plain.models.db import (
4 DEFAULT_DB_ALIAS,
5 DatabaseError,
6 Error,
7 ProgrammingError,
8 connections,
9)
12class TransactionManagementError(ProgrammingError):
13 """Transaction management is used improperly."""
15 pass
18def get_connection(using=None):
19 """
20 Get a database connection by name, or the default database connection
21 if no name is provided. This is a private API.
22 """
23 if using is None:
24 using = DEFAULT_DB_ALIAS
25 return connections[using]
28def get_autocommit(using=None):
29 """Get the autocommit status of the connection."""
30 return get_connection(using).get_autocommit()
33def set_autocommit(autocommit, using=None):
34 """Set the autocommit status of the connection."""
35 return get_connection(using).set_autocommit(autocommit)
38def commit(using=None):
39 """Commit a transaction."""
40 get_connection(using).commit()
43def rollback(using=None):
44 """Roll back a transaction."""
45 get_connection(using).rollback()
48def savepoint(using=None):
49 """
50 Create a savepoint (if supported and required by the backend) inside the
51 current transaction. Return an identifier for the savepoint that will be
52 used for the subsequent rollback or commit.
53 """
54 return get_connection(using).savepoint()
57def savepoint_rollback(sid, using=None):
58 """
59 Roll back the most recent savepoint (if one exists). Do nothing if
60 savepoints are not supported.
61 """
62 get_connection(using).savepoint_rollback(sid)
65def savepoint_commit(sid, using=None):
66 """
67 Commit the most recent savepoint (if one exists). Do nothing if
68 savepoints are not supported.
69 """
70 get_connection(using).savepoint_commit(sid)
73def clean_savepoints(using=None):
74 """
75 Reset the counter used to generate unique savepoint ids in this thread.
76 """
77 get_connection(using).clean_savepoints()
80def get_rollback(using=None):
81 """Get the "needs rollback" flag -- for *advanced use* only."""
82 return get_connection(using).get_rollback()
85def set_rollback(rollback, using=None):
86 """
87 Set or unset the "needs rollback" flag -- for *advanced use* only.
89 When `rollback` is `True`, trigger a rollback when exiting the innermost
90 enclosing atomic block that has `savepoint=True` (that's the default). Use
91 this to force a rollback without raising an exception.
93 When `rollback` is `False`, prevent such a rollback. Use this only after
94 rolling back to a known-good state! Otherwise, you break the atomic block
95 and data corruption may occur.
96 """
97 return get_connection(using).set_rollback(rollback)
100@contextmanager
101def mark_for_rollback_on_error(using=None):
102 """
103 Internal low-level utility to mark a transaction as "needs rollback" when
104 an exception is raised while not enforcing the enclosed block to be in a
105 transaction. This is needed by Model.save() and friends to avoid starting a
106 transaction when in autocommit mode and a single query is executed.
108 It's equivalent to:
110 connection = get_connection(using)
111 if connection.get_autocommit():
112 yield
113 else:
114 with transaction.atomic(using=using, savepoint=False):
115 yield
117 but it uses low-level utilities to avoid performance overhead.
118 """
119 try:
120 yield
121 except Exception as exc:
122 connection = get_connection(using)
123 if connection.in_atomic_block:
124 connection.needs_rollback = True
125 connection.rollback_exc = exc
126 raise
129def on_commit(func, using=None, robust=False):
130 """
131 Register `func` to be called when the current transaction is committed.
132 If the current transaction is rolled back, `func` will not be called.
133 """
134 get_connection(using).on_commit(func, robust)
137#################################
138# Decorators / context managers #
139#################################
142class Atomic(ContextDecorator):
143 """
144 Guarantee the atomic execution of a given block.
146 An instance can be used either as a decorator or as a context manager.
148 When it's used as a decorator, __call__ wraps the execution of the
149 decorated function in the instance itself, used as a context manager.
151 When it's used as a context manager, __enter__ creates a transaction or a
152 savepoint, depending on whether a transaction is already in progress, and
153 __exit__ commits the transaction or releases the savepoint on normal exit,
154 and rolls back the transaction or to the savepoint on exceptions.
156 It's possible to disable the creation of savepoints if the goal is to
157 ensure that some code runs within a transaction without creating overhead.
159 A stack of savepoints identifiers is maintained as an attribute of the
160 connection. None denotes the absence of a savepoint.
162 This allows reentrancy even if the same AtomicWrapper is reused. For
163 example, it's possible to define `oa = atomic('other')` and use `@oa` or
164 `with oa:` multiple times.
166 Since database connections are thread-local, this is thread-safe.
168 An atomic block can be tagged as durable. In this case, raise a
169 RuntimeError if it's nested within another atomic block. This guarantees
170 that database changes in a durable block are committed to the database when
171 the block exists without error.
173 This is a private API.
174 """
176 def __init__(self, using, savepoint, durable):
177 self.using = using
178 self.savepoint = savepoint
179 self.durable = durable
180 self._from_testcase = False
182 def __enter__(self):
183 connection = get_connection(self.using)
185 if (
186 self.durable
187 and connection.atomic_blocks
188 and not connection.atomic_blocks[-1]._from_testcase
189 ):
190 raise RuntimeError(
191 "A durable atomic block cannot be nested within another "
192 "atomic block."
193 )
194 if not connection.in_atomic_block:
195 # Reset state when entering an outermost atomic block.
196 connection.commit_on_exit = True
197 connection.needs_rollback = False
198 if not connection.get_autocommit():
199 # Pretend we're already in an atomic block to bypass the code
200 # that disables autocommit to enter a transaction, and make a
201 # note to deal with this case in __exit__.
202 connection.in_atomic_block = True
203 connection.commit_on_exit = False
205 if connection.in_atomic_block:
206 # We're already in a transaction; create a savepoint, unless we
207 # were told not to or we're already waiting for a rollback. The
208 # second condition avoids creating useless savepoints and prevents
209 # overwriting needs_rollback until the rollback is performed.
210 if self.savepoint and not connection.needs_rollback:
211 sid = connection.savepoint()
212 connection.savepoint_ids.append(sid)
213 else:
214 connection.savepoint_ids.append(None)
215 else:
216 connection.set_autocommit(
217 False, force_begin_transaction_with_broken_autocommit=True
218 )
219 connection.in_atomic_block = True
221 if connection.in_atomic_block:
222 connection.atomic_blocks.append(self)
224 def __exit__(self, exc_type, exc_value, traceback):
225 connection = get_connection(self.using)
227 if connection.in_atomic_block:
228 connection.atomic_blocks.pop()
230 if connection.savepoint_ids:
231 sid = connection.savepoint_ids.pop()
232 else:
233 # Prematurely unset this flag to allow using commit or rollback.
234 connection.in_atomic_block = False
236 try:
237 if connection.closed_in_transaction:
238 # The database will perform a rollback by itself.
239 # Wait until we exit the outermost block.
240 pass
242 elif exc_type is None and not connection.needs_rollback:
243 if connection.in_atomic_block:
244 # Release savepoint if there is one
245 if sid is not None:
246 try:
247 connection.savepoint_commit(sid)
248 except DatabaseError:
249 try:
250 connection.savepoint_rollback(sid)
251 # The savepoint won't be reused. Release it to
252 # minimize overhead for the database server.
253 connection.savepoint_commit(sid)
254 except Error:
255 # If rolling back to a savepoint fails, mark for
256 # rollback at a higher level and avoid shadowing
257 # the original exception.
258 connection.needs_rollback = True
259 raise
260 else:
261 # Commit transaction
262 try:
263 connection.commit()
264 except DatabaseError:
265 try:
266 connection.rollback()
267 except Error:
268 # An error during rollback means that something
269 # went wrong with the connection. Drop it.
270 connection.close()
271 raise
272 else:
273 # This flag will be set to True again if there isn't a savepoint
274 # allowing to perform the rollback at this level.
275 connection.needs_rollback = False
276 if connection.in_atomic_block:
277 # Roll back to savepoint if there is one, mark for rollback
278 # otherwise.
279 if sid is None:
280 connection.needs_rollback = True
281 else:
282 try:
283 connection.savepoint_rollback(sid)
284 # The savepoint won't be reused. Release it to
285 # minimize overhead for the database server.
286 connection.savepoint_commit(sid)
287 except Error:
288 # If rolling back to a savepoint fails, mark for
289 # rollback at a higher level and avoid shadowing
290 # the original exception.
291 connection.needs_rollback = True
292 else:
293 # Roll back transaction
294 try:
295 connection.rollback()
296 except Error:
297 # An error during rollback means that something
298 # went wrong with the connection. Drop it.
299 connection.close()
301 finally:
302 # Outermost block exit when autocommit was enabled.
303 if not connection.in_atomic_block:
304 if connection.closed_in_transaction:
305 connection.connection = None
306 else:
307 connection.set_autocommit(True)
308 # Outermost block exit when autocommit was disabled.
309 elif not connection.savepoint_ids and not connection.commit_on_exit:
310 if connection.closed_in_transaction:
311 connection.connection = None
312 else:
313 connection.in_atomic_block = False
316def atomic(using=None, savepoint=True, durable=False):
317 # Bare decorator: @atomic -- although the first argument is called
318 # `using`, it's actually the function being decorated.
319 if callable(using):
320 return Atomic(DEFAULT_DB_ALIAS, savepoint, durable)(using)
321 # Decorator: @atomic(...) or context manager: with atomic(...): ...
322 else:
323 return Atomic(using, savepoint, durable)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import functools
2from collections import namedtuple
5def make_model_tuple(model):
6 """
7 Take a model or a string of the form "package_label.ModelName" and return a
8 corresponding ("package_label", "modelname") tuple. If a tuple is passed in,
9 assume it's a valid model tuple already and return it unchanged.
10 """
11 try:
12 if isinstance(model, tuple):
13 model_tuple = model
14 elif isinstance(model, str):
15 package_label, model_name = model.split(".")
16 model_tuple = package_label, model_name.lower()
17 else:
18 model_tuple = model._meta.package_label, model._meta.model_name
19 assert len(model_tuple) == 2
20 return model_tuple
21 except (ValueError, AssertionError):
22 raise ValueError(
23 "Invalid model reference '%s'. String model references "
24 "must be of the form 'package_label.ModelName'." % model
25 )
28def resolve_callables(mapping):
29 """
30 Generate key/value pairs for the given mapping where the values are
31 evaluated if they're callable.
32 """
33 for k, v in mapping.items():
34 yield k, v() if callable(v) else v
37def unpickle_named_row(names, values):
38 return create_namedtuple_class(*names)(*values)
41@functools.lru_cache
42def create_namedtuple_class(*names):
43 # Cache type() with @lru_cache since it's too slow to be called for every
44 # QuerySet evaluation.
45 def __reduce__(self):
46 return unpickle_named_row, (names, tuple(self))
48 return type(
49 "Row",
50 (namedtuple("Row", names),),
51 {"__reduce__": __reduce__, "__slots__": ()},
52 )
55class AltersData:
56 """
57 Make subclasses preserve the alters_data attribute on overridden methods.
58 """
60 def __init_subclass__(cls, **kwargs):
61 for fn_name, fn in vars(cls).items():
62 if callable(fn) and not hasattr(fn, "alters_data"):
63 for base in cls.__bases__:
64 if base_fn := getattr(base, fn_name, None):
65 if hasattr(base_fn, "alters_data"):
66 fn.alters_data = base_fn.alters_data
67 break
69 super().__init_subclass__(**kwargs)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain import models
4class User(models.Model):
5 email = models.EmailField(unique=True)
6 username = models.CharField(max_length=100, unique=True)
8 def __str__(self):
9 return self.username
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from .base import View
2from .forms import FormView
3from .objects import CreateView, DeleteView, DetailView, ListView, UpdateView
4from .redirect import RedirectView
5from .templates import TemplateView
7__all__ = [
8 "View",
9 "TemplateView",
10 "RedirectView",
11 "FormView",
12 "DetailView",
13 "CreateView",
14 "UpdateView",
15 "DeleteView",
16 "ListView",
17 "AuthViewMixin",
18]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import logging
3from plain.http import (
4 HttpRequest,
5 JsonResponse,
6 Response,
7 ResponseBase,
8 ResponseNotAllowed,
9)
10from plain.utils.decorators import classonlymethod
12from .exceptions import ResponseException
14logger = logging.getLogger("plain.request")
17class View:
18 request: HttpRequest
19 url_args: tuple
20 url_kwargs: dict
22 def __init__(self, *args, **kwargs) -> None:
23 # Views can customize their init, which receives
24 # the args and kwargs from as_view()
25 pass
27 def setup(self, request: HttpRequest, *args, **kwargs) -> None:
28 if hasattr(self, "get") and not hasattr(self, "head"):
29 self.head = self.get
31 self.request = request
32 self.url_args = args
33 self.url_kwargs = kwargs
35 @classonlymethod
36 def as_view(cls, *init_args, **init_kwargs):
37 def view(request, *args, **kwargs):
38 v = cls(*init_args, **init_kwargs)
39 v.setup(request, *args, **kwargs)
40 try:
41 return v.get_response()
42 except ResponseException as e:
43 return e.response
45 # Copy possible attributes set by decorators, e.g. @csrf_exempt, from
46 # the dispatch method.
47 view.__dict__.update(cls.get_response.__dict__)
48 view.view_class = cls
50 return view
52 def get_request_handler(self) -> callable:
53 """Return the handler for the current request method."""
55 if not self.request.method:
56 raise AttributeError("HTTP method is not set")
58 handler = getattr(self, self.request.method.lower(), None)
60 if not handler:
61 logger.warning(
62 "Method Not Allowed (%s): %s",
63 self.request.method,
64 self.request.path,
65 extra={"status_code": 405, "request": self.request},
66 )
67 raise ResponseException(ResponseNotAllowed(self._allowed_methods()))
69 return handler
71 def get_response(self) -> ResponseBase:
72 handler = self.get_request_handler()
74 result = handler()
76 if isinstance(result, ResponseBase):
77 return result
79 if isinstance(result, str):
80 return Response(result)
82 if isinstance(result, list):
83 return JsonResponse(result, safe=False)
85 if isinstance(result, dict):
86 return JsonResponse(result)
88 if isinstance(result, int):
89 return Response(status=result)
91 # Allow tuple for (status_code, content)?
93 raise ValueError(f"Unexpected view return type: {type(result)}")
95 def options(self) -> Response:
96 """Handle responding to requests for the OPTIONS HTTP verb."""
97 response = Response()
98 response.headers["Allow"] = ", ".join(self._allowed_methods())
99 response.headers["Content-Length"] = "0"
100 return response
102 def _allowed_methods(self) -> list[str]:
103 known_http_method_names = [
104 "get",
105 "post",
106 "put",
107 "patch",
108 "delete",
109 "head",
110 "options",
111 "trace",
112 ]
113 return [m.upper() for m in known_http_method_names if hasattr(self, m)]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.http import ResponseBase
2from plain.templates import TemplateFileMissing
4from .templates import TemplateView
7class ErrorView(TemplateView):
8 status_code: int
10 def __init__(self, status_code=None) -> None:
11 # Allow creating an ErrorView with a status code
12 # e.g. ErrorView.as_view(status_code=404)
13 if status_code is not None:
14 self.status_code = status_code
16 def get_template_names(self) -> list[str]:
17 return [f"{self.status_code}.html", "error.html"]
19 def get_request_handler(self):
20 return self.get # All methods (post, patch, etc.) will use the get()
22 def get_response(self) -> ResponseBase:
23 response = super().get_response()
24 # Set the status code we want
25 response.status_code = self.status_code
26 return response
28 def get(self):
29 try:
30 return super().get()
31 except TemplateFileMissing:
32 return self.status_code
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1class ResponseException(Exception):
2 def __init__(self, response):
3 self.response = response
4 super().__init__(response)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from collections.abc import Callable
2from typing import TYPE_CHECKING
4from plain.exceptions import ImproperlyConfigured
5from plain.http import Response, ResponseRedirect
7from .templates import TemplateView
9if TYPE_CHECKING:
10 from plain.forms import BaseForm
13class FormView(TemplateView):
14 """A view for displaying a form and rendering a template response."""
16 form_class: type["BaseForm"] | None = None
17 success_url: Callable | str | None = None
19 def get_form(self) -> "BaseForm":
20 """Return an instance of the form to be used in this view."""
21 if not self.form_class:
22 raise ImproperlyConfigured(
23 f"No form class provided. Define {self.__class__.__name__}.form_class or override "
24 f"{self.__class__.__name__}.get_form()."
25 )
26 return self.form_class(**self.get_form_kwargs())
28 def get_form_kwargs(self) -> dict:
29 """Return the keyword arguments for instantiating the form."""
30 kwargs: dict = {
31 "initial": {}, # Make it easier to set keys in subclasses
32 }
34 if hasattr(self, "request") and self.request.method in ("POST", "PUT"):
35 kwargs.update(
36 {
37 "data": self.request.POST,
38 "files": self.request.FILES,
39 }
40 )
41 return kwargs
43 def get_success_url(self) -> str:
44 """Return the URL to redirect to after processing a valid form."""
45 if not self.success_url:
46 raise ImproperlyConfigured("No URL to redirect to. Provide a success_url.")
47 return str(self.success_url) # success_url may be lazy
49 def form_valid(self, form: "BaseForm") -> Response:
50 """If the form is valid, redirect to the supplied URL."""
51 return ResponseRedirect(self.get_success_url())
53 def form_invalid(self, form: "BaseForm") -> Response:
54 """If the form is invalid, render the invalid form."""
55 context = {
56 **self.get_template_context(),
57 "form": form,
58 }
59 return self.get_template().render(context)
61 def get_template_context(self) -> dict:
62 """Insert the form into the context dict."""
63 context = super().get_template_context()
64 context["form"] = self.get_form()
65 return context
67 def post(self) -> Response:
68 """
69 Handle POST requests: instantiate a form instance with the passed
70 POST variables and then check if it's valid.
71 """
72 form = self.get_form()
73 if form.is_valid():
74 return self.form_valid(form)
75 else:
76 return self.form_invalid(form)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.exceptions import ImproperlyConfigured, ObjectDoesNotExist
2from plain.http import Http404, Response, ResponseRedirect
4from .forms import FormView
5from .templates import TemplateView
8class ObjectTemplateViewMixin:
9 context_object_name = ""
11 def get(self) -> Response:
12 self.load_object()
13 return self.render_template()
15 def load_object(self) -> None:
16 try:
17 self.object = self.get_object()
18 except ObjectDoesNotExist:
19 raise Http404
21 if not self.object:
22 # Also raise 404 if the object is None
23 raise Http404
25 def get_object(self): # Intentionally untyped... subclasses must override this.
26 raise NotImplementedError(
27 f"get_object() is not implemented on {self.__class__.__name__}"
28 )
30 def get_template_context(self) -> dict:
31 """Insert the single object into the context dict."""
32 context = super().get_template_context() # type: ignore
33 context["object"] = self.object
34 if self.context_object_name:
35 context[self.context_object_name] = self.object
36 elif hasattr(self.object, "_meta"):
37 context[self.object._meta.model_name] = self.object
38 return context
40 def get_template_names(self) -> list[str]:
41 """
42 Return a list of template names to be used for the request. May not be
43 called if render_to_response() is overridden. Return the following list:
45 * the value of ``template_name`` on the view (if provided)
46 object instance that the view is operating upon (if available)
47 * ``<package_label>/<model_name><template_name_suffix>.html``
48 """
49 if self.template_name: # type: ignore
50 return [self.template_name] # type: ignore
52 # If template_name isn't specified, it's not a problem --
53 # we just start with an empty list.
54 names = []
56 # The least-specific option is the default <app>/<model>_detail.html;
57 # only use this if the object in question is a model.
58 if hasattr(self.object, "_meta"):
59 object_meta = self.object._meta
60 names.append(
61 f"{object_meta.package_label}/{object_meta.model_name}{self.template_name_suffix}.html"
62 )
64 return names
67class DetailView(ObjectTemplateViewMixin, TemplateView):
68 """
69 Render a "detail" view of an object.
71 By default this is a model instance looked up from `self.queryset`, but the
72 view will support display of *any* object by overriding `self.get_object()`.
73 """
75 template_name_suffix = "_detail"
78class CreateView(ObjectTemplateViewMixin, FormView):
79 """
80 View for creating a new object, with a response rendered by a template.
81 """
83 def post(self) -> Response:
84 """
85 Handle POST requests: instantiate a form instance with the passed
86 POST variables and then check if it's valid.
87 """
88 # Context expects self.object to exist
89 self.load_object()
90 return super().post()
92 def load_object(self) -> None:
93 self.object = None
95 # TODO? would rather you have to specify this...
96 def get_success_url(self):
97 """Return the URL to redirect to after processing a valid form."""
98 if self.success_url:
99 url = self.success_url.format(**self.object.__dict__)
100 else:
101 try:
102 url = self.object.get_absolute_url()
103 except AttributeError:
104 raise ImproperlyConfigured(
105 "No URL to redirect to. Either provide a url or define"
106 " a get_absolute_url method on the Model."
107 )
108 return url
110 def form_valid(self, form):
111 """If the form is valid, save the associated model."""
112 self.object = form.save()
113 return super().form_valid(form)
116class UpdateView(ObjectTemplateViewMixin, FormView):
117 """View for updating an object, with a response rendered by a template."""
119 template_name_suffix = "_form"
121 def post(self) -> Response:
122 """
123 Handle POST requests: instantiate a form instance with the passed
124 POST variables and then check if it's valid.
125 """
126 self.load_object()
127 return super().post()
129 def get_success_url(self):
130 """Return the URL to redirect to after processing a valid form."""
131 if self.success_url:
132 url = self.success_url.format(**self.object.__dict__)
133 else:
134 try:
135 url = self.object.get_absolute_url()
136 except AttributeError:
137 raise ImproperlyConfigured(
138 "No URL to redirect to. Either provide a url or define"
139 " a get_absolute_url method on the Model."
140 )
141 return url
143 def form_valid(self, form):
144 """If the form is valid, save the associated model."""
145 self.object = form.save()
146 return super().form_valid(form)
148 def get_form_kwargs(self):
149 """Return the keyword arguments for instantiating the form."""
150 kwargs = super().get_form_kwargs()
151 kwargs.update({"instance": self.object})
152 return kwargs
155class DeleteView(ObjectTemplateViewMixin, TemplateView):
156 """
157 View for deleting an object retrieved with self.get_object(), with a
158 response rendered by a template.
159 """
161 template_name_suffix = "_confirm_delete"
163 def get_form_kwargs(self):
164 """Return the keyword arguments for instantiating the form."""
165 kwargs = super().get_form_kwargs()
166 kwargs.update({"instance": self.object})
167 return kwargs
169 def get_success_url(self):
170 if self.success_url:
171 return self.success_url.format(**self.object.__dict__)
172 else:
173 raise ImproperlyConfigured("No URL to redirect to. Provide a success_url.")
175 def post(self):
176 self.load_object()
177 self.object.delete()
178 return ResponseRedirect(self.get_success_url())
181class ListView(TemplateView):
182 """
183 Render some list of objects, set by `self.get_queryset()`, with a response
184 rendered by a template.
185 """
187 template_name_suffix = "_list"
188 context_object_name = "objects"
190 def get(self) -> Response:
191 self.objects = self.get_objects()
192 return super().get()
194 def get_objects(self):
195 raise NotImplementedError(
196 f"get_objects() is not implemented on {self.__class__.__name__}"
197 )
199 def get_template_context(self) -> dict:
200 """Insert the single object into the context dict."""
201 context = super().get_template_context() # type: ignore
202 context[self.context_object_name] = self.objects
203 return context
205 def get_template_names(self) -> list[str]:
206 """
207 Return a list of template names to be used for the request. May not be
208 called if render_to_response() is overridden. Return the following list:
210 * the value of ``template_name`` on the view (if provided)
211 object instance that the view is operating upon (if available)
212 * ``<package_label>/<model_name><template_name_suffix>.html``
213 """
214 if self.template_name: # type: ignore
215 return [self.template_name] # type: ignore
217 # If template_name isn't specified, it's not a problem --
218 # we just start with an empty list.
219 names = []
221 # The least-specific option is the default <app>/<model>_detail.html;
222 # only use this if the object in question is a model.
223 if hasattr(self.objects, "model") and hasattr(self.objects.model, "_meta"):
224 object_meta = self.objects.model._meta
225 names.append(
226 f"{object_meta.package_label}/{object_meta.model_name}{self.template_name_suffix}.html"
227 )
229 return names
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import logging
3from plain.http import (
4 ResponseGone,
5 ResponsePermanentRedirect,
6 ResponseRedirect,
7)
8from plain.urls import reverse
10from .base import View
12logger = logging.getLogger("plain.request")
15class RedirectView(View):
16 """Provide a redirect on any GET request."""
18 permanent = False
19 url: str | None = None
20 pattern_name: str | None = None
21 query_string = False
23 def get_redirect_url(self):
24 """
25 Return the URL redirect to. Keyword arguments from the URL pattern
26 match generating the redirect request are provided as kwargs to this
27 method.
28 """
29 if self.url:
30 url = self.url % self.url_kwargs
31 elif self.pattern_name:
32 url = reverse(self.pattern_name, args=self.url_args, kwargs=self.url_kwargs)
33 else:
34 return None
36 args = self.request.META.get("QUERY_STRING", "")
37 if args and self.query_string:
38 url = f"{url}?{args}"
39 return url
41 def get(self):
42 url = self.get_redirect_url()
43 if url:
44 if self.permanent:
45 return ResponsePermanentRedirect(url)
46 else:
47 return ResponseRedirect(url)
48 else:
49 logger.warning(
50 "Gone: %s",
51 self.request.path,
52 extra={"status_code": 410, "request": self.request},
53 )
54 return ResponseGone()
56 def head(self):
57 return self.get()
59 def post(self):
60 return self.get()
62 def options(self):
63 return self.get()
65 def delete(self):
66 return self.get()
68 def put(self):
69 return self.get()
71 def patch(self):
72 return self.get()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.csrf.middleware import get_token
2from plain.exceptions import ImproperlyConfigured
3from plain.runtime import settings
4from plain.templates import Template, TemplateFileMissing
5from plain.utils.functional import lazy
6from plain.utils.html import format_html
7from plain.utils.safestring import SafeString
9from .base import View
12def csrf_input(request):
13 return format_html(
14 '<input type="hidden" name="csrfmiddlewaretoken" value="{}">',
15 get_token(request),
16 )
19csrf_input_lazy = lazy(csrf_input, SafeString, str)
20csrf_token_lazy = lazy(get_token, str)
23class TemplateView(View):
24 """
25 Render a template. Pass keyword arguments from the URLconf to the context.
26 """
28 template_name: str | None = None
30 def get_template_context(self) -> dict:
31 return {
32 "request": self.request,
33 "csrf_input": csrf_input_lazy(self.request),
34 "csrf_token": csrf_token_lazy(self.request),
35 "DEBUG": settings.DEBUG,
36 }
38 def get_template_names(self) -> list[str]:
39 """
40 Return a list of template names to be used for the request. Must return
41 a list. May not be called if render_to_response() is overridden.
42 """
43 if self.template_name is None:
44 raise ImproperlyConfigured(
45 "TemplateView requires either a definition of "
46 "'template_name' or an implementation of 'get_template_names()'"
47 )
48 else:
49 return [self.template_name]
51 def get_template(self) -> Template:
52 template_names = self.get_template_names()
54 for template_name in template_names:
55 try:
56 return Template(template_name)
57 except TemplateFileMissing:
58 pass
60 raise TemplateFileMissing(template_names)
62 def render_template(self) -> str:
63 return self.get_template().render(self.get_template_context())
65 def get(self):
66 return self.render_template()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import plain.sessions.models
2from plain import models
3from plain.models import migrations
6class Migration(migrations.Migration):
7 dependencies = []
9 operations = [
10 migrations.CreateModel(
11 name="Session",
12 fields=[
13 (
14 "session_key",
15 models.CharField(
16 max_length=40,
17 primary_key=True,
18 ),
19 ),
20 ("session_data", models.TextField()),
21 (
22 "expire_date",
23 models.DateTimeField(db_index=True),
24 ),
25 ],
26 options={
27 "abstract": False,
28 },
29 managers=[
30 ("objects", plain.sessions.models.SessionManager()),
31 ],
32 ),
33 ]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1# Generated by Plain 5.0.dev20230814020017 on 2023-08-14 02:09
3from plain import models
4from plain.models import migrations
7class Migration(migrations.Migration):
8 dependencies = [
9 ("plainsessions", "0001_initial"),
10 ]
12 operations = [
13 migrations.AlterModelOptions(
14 name="session",
15 options={},
16 ),
17 migrations.AlterField(
18 model_name="session",
19 name="expire_date",
20 field=models.DateTimeField(db_index=True),
21 ),
22 migrations.AlterField(
23 model_name="session",
24 name="session_data",
25 field=models.TextField(),
26 ),
27 migrations.AlterField(
28 model_name="session",
29 name="session_key",
30 field=models.CharField(max_length=40, primary_key=True),
31 ),
32 ]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from .comparison import Cast, Coalesce, Collate, Greatest, JSONObject, Least, NullIf
2from .datetime import (
3 Extract,
4 ExtractDay,
5 ExtractHour,
6 ExtractIsoWeekDay,
7 ExtractIsoYear,
8 ExtractMinute,
9 ExtractMonth,
10 ExtractQuarter,
11 ExtractSecond,
12 ExtractWeek,
13 ExtractWeekDay,
14 ExtractYear,
15 Now,
16 Trunc,
17 TruncDate,
18 TruncDay,
19 TruncHour,
20 TruncMinute,
21 TruncMonth,
22 TruncQuarter,
23 TruncSecond,
24 TruncTime,
25 TruncWeek,
26 TruncYear,
27)
28from .math import (
29 Abs,
30 ACos,
31 ASin,
32 ATan,
33 ATan2,
34 Ceil,
35 Cos,
36 Cot,
37 Degrees,
38 Exp,
39 Floor,
40 Ln,
41 Log,
42 Mod,
43 Pi,
44 Power,
45 Radians,
46 Random,
47 Round,
48 Sign,
49 Sin,
50 Sqrt,
51 Tan,
52)
53from .text import (
54 MD5,
55 SHA1,
56 SHA224,
57 SHA256,
58 SHA384,
59 SHA512,
60 Chr,
61 Concat,
62 ConcatPair,
63 Left,
64 Length,
65 Lower,
66 LPad,
67 LTrim,
68 Ord,
69 Repeat,
70 Replace,
71 Reverse,
72 Right,
73 RPad,
74 RTrim,
75 StrIndex,
76 Substr,
77 Trim,
78 Upper,
79)
80from .window import (
81 CumeDist,
82 DenseRank,
83 FirstValue,
84 Lag,
85 LastValue,
86 Lead,
87 NthValue,
88 Ntile,
89 PercentRank,
90 Rank,
91 RowNumber,
92)
94__all__ = [
95 # comparison and conversion
96 "Cast",
97 "Coalesce",
98 "Collate",
99 "Greatest",
100 "JSONObject",
101 "Least",
102 "NullIf",
103 # datetime
104 "Extract",
105 "ExtractDay",
106 "ExtractHour",
107 "ExtractMinute",
108 "ExtractMonth",
109 "ExtractQuarter",
110 "ExtractSecond",
111 "ExtractWeek",
112 "ExtractIsoWeekDay",
113 "ExtractWeekDay",
114 "ExtractIsoYear",
115 "ExtractYear",
116 "Now",
117 "Trunc",
118 "TruncDate",
119 "TruncDay",
120 "TruncHour",
121 "TruncMinute",
122 "TruncMonth",
123 "TruncQuarter",
124 "TruncSecond",
125 "TruncTime",
126 "TruncWeek",
127 "TruncYear",
128 # math
129 "Abs",
130 "ACos",
131 "ASin",
132 "ATan",
133 "ATan2",
134 "Ceil",
135 "Cos",
136 "Cot",
137 "Degrees",
138 "Exp",
139 "Floor",
140 "Ln",
141 "Log",
142 "Mod",
143 "Pi",
144 "Power",
145 "Radians",
146 "Random",
147 "Round",
148 "Sign",
149 "Sin",
150 "Sqrt",
151 "Tan",
152 # text
153 "MD5",
154 "SHA1",
155 "SHA224",
156 "SHA256",
157 "SHA384",
158 "SHA512",
159 "Chr",
160 "Concat",
161 "ConcatPair",
162 "Left",
163 "Length",
164 "Lower",
165 "LPad",
166 "LTrim",
167 "Ord",
168 "Repeat",
169 "Replace",
170 "Reverse",
171 "Right",
172 "RPad",
173 "RTrim",
174 "StrIndex",
175 "Substr",
176 "Trim",
177 "Upper",
178 # window
179 "CumeDist",
180 "DenseRank",
181 "FirstValue",
182 "Lag",
183 "LastValue",
184 "Lead",
185 "NthValue",
186 "Ntile",
187 "PercentRank",
188 "Rank",
189 "RowNumber",
190]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""Database functions that do comparisons or type conversions."""
2from plain.models.db import NotSupportedError
3from plain.models.expressions import Func, Value
4from plain.models.fields import TextField
5from plain.models.fields.json import JSONField
6from plain.utils.regex_helper import _lazy_re_compile
9class Cast(Func):
10 """Coerce an expression to a new field type."""
12 function = "CAST"
13 template = "%(function)s(%(expressions)s AS %(db_type)s)"
15 def __init__(self, expression, output_field):
16 super().__init__(expression, output_field=output_field)
18 def as_sql(self, compiler, connection, **extra_context):
19 extra_context["db_type"] = self.output_field.cast_db_type(connection)
20 return super().as_sql(compiler, connection, **extra_context)
22 def as_sqlite(self, compiler, connection, **extra_context):
23 db_type = self.output_field.db_type(connection)
24 if db_type in {"datetime", "time"}:
25 # Use strftime as datetime/time don't keep fractional seconds.
26 template = "strftime(%%s, %(expressions)s)"
27 sql, params = super().as_sql(
28 compiler, connection, template=template, **extra_context
29 )
30 format_string = "%H:%M:%f" if db_type == "time" else "%Y-%m-%d %H:%M:%f"
31 params.insert(0, format_string)
32 return sql, params
33 elif db_type == "date":
34 template = "date(%(expressions)s)"
35 return super().as_sql(
36 compiler, connection, template=template, **extra_context
37 )
38 return self.as_sql(compiler, connection, **extra_context)
40 def as_mysql(self, compiler, connection, **extra_context):
41 template = None
42 output_type = self.output_field.get_internal_type()
43 # MySQL doesn't support explicit cast to float.
44 if output_type == "FloatField":
45 template = "(%(expressions)s + 0.0)"
46 # MariaDB doesn't support explicit cast to JSON.
47 elif output_type == "JSONField" and connection.mysql_is_mariadb:
48 template = "JSON_EXTRACT(%(expressions)s, '$')"
49 return self.as_sql(compiler, connection, template=template, **extra_context)
51 def as_postgresql(self, compiler, connection, **extra_context):
52 # CAST would be valid too, but the :: shortcut syntax is more readable.
53 # 'expressions' is wrapped in parentheses in case it's a complex
54 # expression.
55 return self.as_sql(
56 compiler,
57 connection,
58 template="(%(expressions)s)::%(db_type)s",
59 **extra_context,
60 )
63class Coalesce(Func):
64 """Return, from left to right, the first non-null expression."""
66 function = "COALESCE"
68 def __init__(self, *expressions, **extra):
69 if len(expressions) < 2:
70 raise ValueError("Coalesce must take at least two expressions")
71 super().__init__(*expressions, **extra)
73 @property
74 def empty_result_set_value(self):
75 for expression in self.get_source_expressions():
76 result = expression.empty_result_set_value
77 if result is NotImplemented or result is not None:
78 return result
79 return None
82class Collate(Func):
83 function = "COLLATE"
84 template = "%(expressions)s %(function)s %(collation)s"
85 # Inspired from
86 # https://www.postgresql.org/docs/current/sql-syntax-lexical.html#SQL-SYNTAX-IDENTIFIERS
87 collation_re = _lazy_re_compile(r"^[\w\-]+$")
89 def __init__(self, expression, collation):
90 if not (collation and self.collation_re.match(collation)):
91 raise ValueError("Invalid collation name: %r." % collation)
92 self.collation = collation
93 super().__init__(expression)
95 def as_sql(self, compiler, connection, **extra_context):
96 extra_context.setdefault("collation", connection.ops.quote_name(self.collation))
97 return super().as_sql(compiler, connection, **extra_context)
100class Greatest(Func):
101 """
102 Return the maximum expression.
104 If any expression is null the return value is database-specific:
105 On PostgreSQL, the maximum not-null expression is returned.
106 On MySQL, Oracle, and SQLite, if any expression is null, null is returned.
107 """
109 function = "GREATEST"
111 def __init__(self, *expressions, **extra):
112 if len(expressions) < 2:
113 raise ValueError("Greatest must take at least two expressions")
114 super().__init__(*expressions, **extra)
116 def as_sqlite(self, compiler, connection, **extra_context):
117 """Use the MAX function on SQLite."""
118 return super().as_sqlite(compiler, connection, function="MAX", **extra_context)
121class JSONObject(Func):
122 function = "JSON_OBJECT"
123 output_field = JSONField()
125 def __init__(self, **fields):
126 expressions = []
127 for key, value in fields.items():
128 expressions.extend((Value(key), value))
129 super().__init__(*expressions)
131 def as_sql(self, compiler, connection, **extra_context):
132 if not connection.features.has_json_object_function:
133 raise NotSupportedError(
134 "JSONObject() is not supported on this database backend."
135 )
136 return super().as_sql(compiler, connection, **extra_context)
138 def as_postgresql(self, compiler, connection, **extra_context):
139 copy = self.copy()
140 copy.set_source_expressions(
141 [
142 Cast(expression, TextField()) if index % 2 == 0 else expression
143 for index, expression in enumerate(copy.get_source_expressions())
144 ]
145 )
146 return super(JSONObject, copy).as_sql(
147 compiler,
148 connection,
149 function="JSONB_BUILD_OBJECT",
150 **extra_context,
151 )
154class Least(Func):
155 """
156 Return the minimum expression.
158 If any expression is null the return value is database-specific:
159 On PostgreSQL, return the minimum not-null expression.
160 On MySQL, Oracle, and SQLite, if any expression is null, return null.
161 """
163 function = "LEAST"
165 def __init__(self, *expressions, **extra):
166 if len(expressions) < 2:
167 raise ValueError("Least must take at least two expressions")
168 super().__init__(*expressions, **extra)
170 def as_sqlite(self, compiler, connection, **extra_context):
171 """Use the MIN function on SQLite."""
172 return super().as_sqlite(compiler, connection, function="MIN", **extra_context)
175class NullIf(Func):
176 function = "NULLIF"
177 arity = 2
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from datetime import datetime
3from plain.models.expressions import Func
4from plain.models.fields import (
5 DateField,
6 DateTimeField,
7 DurationField,
8 Field,
9 IntegerField,
10 TimeField,
11)
12from plain.models.lookups import (
13 Transform,
14 YearExact,
15 YearGt,
16 YearGte,
17 YearLt,
18 YearLte,
19)
20from plain.utils import timezone
23class TimezoneMixin:
24 tzinfo = None
26 def get_tzname(self):
27 # Timezone conversions must happen to the input datetime *before*
28 # applying a function. 2015-12-31 23:00:00 -02:00 is stored in the
29 # database as 2016-01-01 01:00:00 +00:00. Any results should be
30 # based on the input datetime not the stored datetime.
31 if self.tzinfo is None:
32 return timezone.get_current_timezone_name()
33 else:
34 return timezone._get_timezone_name(self.tzinfo)
37class Extract(TimezoneMixin, Transform):
38 lookup_name = None
39 output_field = IntegerField()
41 def __init__(self, expression, lookup_name=None, tzinfo=None, **extra):
42 if self.lookup_name is None:
43 self.lookup_name = lookup_name
44 if self.lookup_name is None:
45 raise ValueError("lookup_name must be provided")
46 self.tzinfo = tzinfo
47 super().__init__(expression, **extra)
49 def as_sql(self, compiler, connection):
50 sql, params = compiler.compile(self.lhs)
51 lhs_output_field = self.lhs.output_field
52 if isinstance(lhs_output_field, DateTimeField):
53 tzname = self.get_tzname()
54 sql, params = connection.ops.datetime_extract_sql(
55 self.lookup_name, sql, tuple(params), tzname
56 )
57 elif self.tzinfo is not None:
58 raise ValueError("tzinfo can only be used with DateTimeField.")
59 elif isinstance(lhs_output_field, DateField):
60 sql, params = connection.ops.date_extract_sql(
61 self.lookup_name, sql, tuple(params)
62 )
63 elif isinstance(lhs_output_field, TimeField):
64 sql, params = connection.ops.time_extract_sql(
65 self.lookup_name, sql, tuple(params)
66 )
67 elif isinstance(lhs_output_field, DurationField):
68 if not connection.features.has_native_duration_field:
69 raise ValueError(
70 "Extract requires native DurationField database support."
71 )
72 sql, params = connection.ops.time_extract_sql(
73 self.lookup_name, sql, tuple(params)
74 )
75 else:
76 # resolve_expression has already validated the output_field so this
77 # assert should never be hit.
78 raise ValueError("Tried to Extract from an invalid type.")
79 return sql, params
81 def resolve_expression(
82 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
83 ):
84 copy = super().resolve_expression(
85 query, allow_joins, reuse, summarize, for_save
86 )
87 field = getattr(copy.lhs, "output_field", None)
88 if field is None:
89 return copy
90 if not isinstance(field, DateField | DateTimeField | TimeField | DurationField):
91 raise ValueError(
92 "Extract input expression must be DateField, DateTimeField, "
93 "TimeField, or DurationField."
94 )
95 # Passing dates to functions expecting datetimes is most likely a mistake.
96 if type(field) == DateField and copy.lookup_name in (
97 "hour",
98 "minute",
99 "second",
100 ):
101 raise ValueError(
102 "Cannot extract time component '{}' from DateField '{}'.".format(
103 copy.lookup_name, field.name
104 )
105 )
106 if isinstance(field, DurationField) and copy.lookup_name in (
107 "year",
108 "iso_year",
109 "month",
110 "week",
111 "week_day",
112 "iso_week_day",
113 "quarter",
114 ):
115 raise ValueError(
116 "Cannot extract component '{}' from DurationField '{}'.".format(
117 copy.lookup_name, field.name
118 )
119 )
120 return copy
123class ExtractYear(Extract):
124 lookup_name = "year"
127class ExtractIsoYear(Extract):
128 """Return the ISO-8601 week-numbering year."""
130 lookup_name = "iso_year"
133class ExtractMonth(Extract):
134 lookup_name = "month"
137class ExtractDay(Extract):
138 lookup_name = "day"
141class ExtractWeek(Extract):
142 """
143 Return 1-52 or 53, based on ISO-8601, i.e., Monday is the first of the
144 week.
145 """
147 lookup_name = "week"
150class ExtractWeekDay(Extract):
151 """
152 Return Sunday=1 through Saturday=7.
154 To replicate this in Python: (mydatetime.isoweekday() % 7) + 1
155 """
157 lookup_name = "week_day"
160class ExtractIsoWeekDay(Extract):
161 """Return Monday=1 through Sunday=7, based on ISO-8601."""
163 lookup_name = "iso_week_day"
166class ExtractQuarter(Extract):
167 lookup_name = "quarter"
170class ExtractHour(Extract):
171 lookup_name = "hour"
174class ExtractMinute(Extract):
175 lookup_name = "minute"
178class ExtractSecond(Extract):
179 lookup_name = "second"
182DateField.register_lookup(ExtractYear)
183DateField.register_lookup(ExtractMonth)
184DateField.register_lookup(ExtractDay)
185DateField.register_lookup(ExtractWeekDay)
186DateField.register_lookup(ExtractIsoWeekDay)
187DateField.register_lookup(ExtractWeek)
188DateField.register_lookup(ExtractIsoYear)
189DateField.register_lookup(ExtractQuarter)
191TimeField.register_lookup(ExtractHour)
192TimeField.register_lookup(ExtractMinute)
193TimeField.register_lookup(ExtractSecond)
195DateTimeField.register_lookup(ExtractHour)
196DateTimeField.register_lookup(ExtractMinute)
197DateTimeField.register_lookup(ExtractSecond)
199ExtractYear.register_lookup(YearExact)
200ExtractYear.register_lookup(YearGt)
201ExtractYear.register_lookup(YearGte)
202ExtractYear.register_lookup(YearLt)
203ExtractYear.register_lookup(YearLte)
205ExtractIsoYear.register_lookup(YearExact)
206ExtractIsoYear.register_lookup(YearGt)
207ExtractIsoYear.register_lookup(YearGte)
208ExtractIsoYear.register_lookup(YearLt)
209ExtractIsoYear.register_lookup(YearLte)
212class Now(Func):
213 template = "CURRENT_TIMESTAMP"
214 output_field = DateTimeField()
216 def as_postgresql(self, compiler, connection, **extra_context):
217 # PostgreSQL's CURRENT_TIMESTAMP means "the time at the start of the
218 # transaction". Use STATEMENT_TIMESTAMP to be cross-compatible with
219 # other databases.
220 return self.as_sql(
221 compiler, connection, template="STATEMENT_TIMESTAMP()", **extra_context
222 )
224 def as_mysql(self, compiler, connection, **extra_context):
225 return self.as_sql(
226 compiler, connection, template="CURRENT_TIMESTAMP(6)", **extra_context
227 )
229 def as_sqlite(self, compiler, connection, **extra_context):
230 return self.as_sql(
231 compiler,
232 connection,
233 template="STRFTIME('%%%%Y-%%%%m-%%%%d %%%%H:%%%%M:%%%%f', 'NOW')",
234 **extra_context,
235 )
238class TruncBase(TimezoneMixin, Transform):
239 kind = None
240 tzinfo = None
242 def __init__(
243 self,
244 expression,
245 output_field=None,
246 tzinfo=None,
247 **extra,
248 ):
249 self.tzinfo = tzinfo
250 super().__init__(expression, output_field=output_field, **extra)
252 def as_sql(self, compiler, connection):
253 sql, params = compiler.compile(self.lhs)
254 tzname = None
255 if isinstance(self.lhs.output_field, DateTimeField):
256 tzname = self.get_tzname()
257 elif self.tzinfo is not None:
258 raise ValueError("tzinfo can only be used with DateTimeField.")
259 if isinstance(self.output_field, DateTimeField):
260 sql, params = connection.ops.datetime_trunc_sql(
261 self.kind, sql, tuple(params), tzname
262 )
263 elif isinstance(self.output_field, DateField):
264 sql, params = connection.ops.date_trunc_sql(
265 self.kind, sql, tuple(params), tzname
266 )
267 elif isinstance(self.output_field, TimeField):
268 sql, params = connection.ops.time_trunc_sql(
269 self.kind, sql, tuple(params), tzname
270 )
271 else:
272 raise ValueError(
273 "Trunc only valid on DateField, TimeField, or DateTimeField."
274 )
275 return sql, params
277 def resolve_expression(
278 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
279 ):
280 copy = super().resolve_expression(
281 query, allow_joins, reuse, summarize, for_save
282 )
283 field = copy.lhs.output_field
284 # DateTimeField is a subclass of DateField so this works for both.
285 if not isinstance(field, DateField | TimeField):
286 raise TypeError(
287 "%r isn't a DateField, TimeField, or DateTimeField." % field.name
288 )
289 # If self.output_field was None, then accessing the field will trigger
290 # the resolver to assign it to self.lhs.output_field.
291 if not isinstance(copy.output_field, DateField | DateTimeField | TimeField):
292 raise ValueError(
293 "output_field must be either DateField, TimeField, or DateTimeField"
294 )
295 # Passing dates or times to functions expecting datetimes is most
296 # likely a mistake.
297 class_output_field = (
298 self.__class__.output_field
299 if isinstance(self.__class__.output_field, Field)
300 else None
301 )
302 output_field = class_output_field or copy.output_field
303 has_explicit_output_field = (
304 class_output_field or field.__class__ is not copy.output_field.__class__
305 )
306 if type(field) == DateField and (
307 isinstance(output_field, DateTimeField)
308 or copy.kind in ("hour", "minute", "second", "time")
309 ):
310 raise ValueError(
311 "Cannot truncate DateField '{}' to {}.".format(
312 field.name,
313 output_field.__class__.__name__
314 if has_explicit_output_field
315 else "DateTimeField",
316 )
317 )
318 elif isinstance(field, TimeField) and (
319 isinstance(output_field, DateTimeField)
320 or copy.kind in ("year", "quarter", "month", "week", "day", "date")
321 ):
322 raise ValueError(
323 "Cannot truncate TimeField '{}' to {}.".format(
324 field.name,
325 output_field.__class__.__name__
326 if has_explicit_output_field
327 else "DateTimeField",
328 )
329 )
330 return copy
332 def convert_value(self, value, expression, connection):
333 if isinstance(self.output_field, DateTimeField):
334 if value is not None:
335 value = value.replace(tzinfo=None)
336 value = timezone.make_aware(value, self.tzinfo)
337 elif not connection.features.has_zoneinfo_database:
338 raise ValueError(
339 "Database returned an invalid datetime value. Are time "
340 "zone definitions for your database installed?"
341 )
342 elif isinstance(value, datetime):
343 if value is None:
344 pass
345 elif isinstance(self.output_field, DateField):
346 value = value.date()
347 elif isinstance(self.output_field, TimeField):
348 value = value.time()
349 return value
352class Trunc(TruncBase):
353 def __init__(
354 self,
355 expression,
356 kind,
357 output_field=None,
358 tzinfo=None,
359 **extra,
360 ):
361 self.kind = kind
362 super().__init__(expression, output_field=output_field, tzinfo=tzinfo, **extra)
365class TruncYear(TruncBase):
366 kind = "year"
369class TruncQuarter(TruncBase):
370 kind = "quarter"
373class TruncMonth(TruncBase):
374 kind = "month"
377class TruncWeek(TruncBase):
378 """Truncate to midnight on the Monday of the week."""
380 kind = "week"
383class TruncDay(TruncBase):
384 kind = "day"
387class TruncDate(TruncBase):
388 kind = "date"
389 lookup_name = "date"
390 output_field = DateField()
392 def as_sql(self, compiler, connection):
393 # Cast to date rather than truncate to date.
394 sql, params = compiler.compile(self.lhs)
395 tzname = self.get_tzname()
396 return connection.ops.datetime_cast_date_sql(sql, tuple(params), tzname)
399class TruncTime(TruncBase):
400 kind = "time"
401 lookup_name = "time"
402 output_field = TimeField()
404 def as_sql(self, compiler, connection):
405 # Cast to time rather than truncate to time.
406 sql, params = compiler.compile(self.lhs)
407 tzname = self.get_tzname()
408 return connection.ops.datetime_cast_time_sql(sql, tuple(params), tzname)
411class TruncHour(TruncBase):
412 kind = "hour"
415class TruncMinute(TruncBase):
416 kind = "minute"
419class TruncSecond(TruncBase):
420 kind = "second"
423DateTimeField.register_lookup(TruncDate)
424DateTimeField.register_lookup(TruncTime)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.models.expressions import Func, Value
2from plain.models.fields import FloatField, IntegerField
3from plain.models.functions import Cast
4from plain.models.functions.mixins import (
5 FixDecimalInputMixin,
6 NumericOutputFieldMixin,
7)
8from plain.models.lookups import Transform
11class Abs(Transform):
12 function = "ABS"
13 lookup_name = "abs"
16class ACos(NumericOutputFieldMixin, Transform):
17 function = "ACOS"
18 lookup_name = "acos"
21class ASin(NumericOutputFieldMixin, Transform):
22 function = "ASIN"
23 lookup_name = "asin"
26class ATan(NumericOutputFieldMixin, Transform):
27 function = "ATAN"
28 lookup_name = "atan"
31class ATan2(NumericOutputFieldMixin, Func):
32 function = "ATAN2"
33 arity = 2
35 def as_sqlite(self, compiler, connection, **extra_context):
36 if not getattr(
37 connection.ops, "spatialite", False
38 ) or connection.ops.spatial_version >= (5, 0, 0):
39 return self.as_sql(compiler, connection)
40 # This function is usually ATan2(y, x), returning the inverse tangent
41 # of y / x, but it's ATan2(x, y) on SpatiaLite < 5.0.0.
42 # Cast integers to float to avoid inconsistent/buggy behavior if the
43 # arguments are mixed between integer and float or decimal.
44 # https://www.gaia-gis.it/fossil/libspatialite/tktview?name=0f72cca3a2
45 clone = self.copy()
46 clone.set_source_expressions(
47 [
48 Cast(expression, FloatField())
49 if isinstance(expression.output_field, IntegerField)
50 else expression
51 for expression in self.get_source_expressions()[::-1]
52 ]
53 )
54 return clone.as_sql(compiler, connection, **extra_context)
57class Ceil(Transform):
58 function = "CEILING"
59 lookup_name = "ceil"
62class Cos(NumericOutputFieldMixin, Transform):
63 function = "COS"
64 lookup_name = "cos"
67class Cot(NumericOutputFieldMixin, Transform):
68 function = "COT"
69 lookup_name = "cot"
72class Degrees(NumericOutputFieldMixin, Transform):
73 function = "DEGREES"
74 lookup_name = "degrees"
77class Exp(NumericOutputFieldMixin, Transform):
78 function = "EXP"
79 lookup_name = "exp"
82class Floor(Transform):
83 function = "FLOOR"
84 lookup_name = "floor"
87class Ln(NumericOutputFieldMixin, Transform):
88 function = "LN"
89 lookup_name = "ln"
92class Log(FixDecimalInputMixin, NumericOutputFieldMixin, Func):
93 function = "LOG"
94 arity = 2
96 def as_sqlite(self, compiler, connection, **extra_context):
97 if not getattr(connection.ops, "spatialite", False):
98 return self.as_sql(compiler, connection)
99 # This function is usually Log(b, x) returning the logarithm of x to
100 # the base b, but on SpatiaLite it's Log(x, b).
101 clone = self.copy()
102 clone.set_source_expressions(self.get_source_expressions()[::-1])
103 return clone.as_sql(compiler, connection, **extra_context)
106class Mod(FixDecimalInputMixin, NumericOutputFieldMixin, Func):
107 function = "MOD"
108 arity = 2
111class Pi(NumericOutputFieldMixin, Func):
112 function = "PI"
113 arity = 0
116class Power(NumericOutputFieldMixin, Func):
117 function = "POWER"
118 arity = 2
121class Radians(NumericOutputFieldMixin, Transform):
122 function = "RADIANS"
123 lookup_name = "radians"
126class Random(NumericOutputFieldMixin, Func):
127 function = "RANDOM"
128 arity = 0
130 def as_mysql(self, compiler, connection, **extra_context):
131 return super().as_sql(compiler, connection, function="RAND", **extra_context)
133 def as_sqlite(self, compiler, connection, **extra_context):
134 return super().as_sql(compiler, connection, function="RAND", **extra_context)
136 def get_group_by_cols(self):
137 return []
140class Round(FixDecimalInputMixin, Transform):
141 function = "ROUND"
142 lookup_name = "round"
143 arity = None # Override Transform's arity=1 to enable passing precision.
145 def __init__(self, expression, precision=0, **extra):
146 super().__init__(expression, precision, **extra)
148 def as_sqlite(self, compiler, connection, **extra_context):
149 precision = self.get_source_expressions()[1]
150 if isinstance(precision, Value) and precision.value < 0:
151 raise ValueError("SQLite does not support negative precision.")
152 return super().as_sqlite(compiler, connection, **extra_context)
154 def _resolve_output_field(self):
155 source = self.get_source_expressions()[0]
156 return source.output_field
159class Sign(Transform):
160 function = "SIGN"
161 lookup_name = "sign"
164class Sin(NumericOutputFieldMixin, Transform):
165 function = "SIN"
166 lookup_name = "sin"
169class Sqrt(NumericOutputFieldMixin, Transform):
170 function = "SQRT"
171 lookup_name = "sqrt"
174class Tan(NumericOutputFieldMixin, Transform):
175 function = "TAN"
176 lookup_name = "tan"
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import sys
3from plain.models.fields import DecimalField, FloatField, IntegerField
4from plain.models.functions import Cast
7class FixDecimalInputMixin:
8 def as_postgresql(self, compiler, connection, **extra_context):
9 # Cast FloatField to DecimalField as PostgreSQL doesn't support the
10 # following function signatures:
11 # - LOG(double, double)
12 # - MOD(double, double)
13 output_field = DecimalField(decimal_places=sys.float_info.dig, max_digits=1000)
14 clone = self.copy()
15 clone.set_source_expressions(
16 [
17 Cast(expression, output_field)
18 if isinstance(expression.output_field, FloatField)
19 else expression
20 for expression in self.get_source_expressions()
21 ]
22 )
23 return clone.as_sql(compiler, connection, **extra_context)
26class FixDurationInputMixin:
27 def as_mysql(self, compiler, connection, **extra_context):
28 sql, params = super().as_sql(compiler, connection, **extra_context)
29 if self.output_field.get_internal_type() == "DurationField":
30 sql = "CAST(%s AS SIGNED)" % sql
31 return sql, params
34class NumericOutputFieldMixin:
35 def _resolve_output_field(self):
36 source_fields = self.get_source_fields()
37 if any(isinstance(s, DecimalField) for s in source_fields):
38 return DecimalField()
39 if any(isinstance(s, IntegerField) for s in source_fields):
40 return FloatField()
41 return super()._resolve_output_field() if source_fields else FloatField()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.models.expressions import Func, Value
2from plain.models.fields import CharField, IntegerField, TextField
3from plain.models.functions import Cast, Coalesce
4from plain.models.lookups import Transform
7class MySQLSHA2Mixin:
8 def as_mysql(self, compiler, connection, **extra_context):
9 return super().as_sql(
10 compiler,
11 connection,
12 template="SHA2(%%(expressions)s, %s)" % self.function[3:],
13 **extra_context,
14 )
17class PostgreSQLSHAMixin:
18 def as_postgresql(self, compiler, connection, **extra_context):
19 return super().as_sql(
20 compiler,
21 connection,
22 template="ENCODE(DIGEST(%(expressions)s, '%(function)s'), 'hex')",
23 function=self.function.lower(),
24 **extra_context,
25 )
28class Chr(Transform):
29 function = "CHR"
30 lookup_name = "chr"
32 def as_mysql(self, compiler, connection, **extra_context):
33 return super().as_sql(
34 compiler,
35 connection,
36 function="CHAR",
37 template="%(function)s(%(expressions)s USING utf16)",
38 **extra_context,
39 )
41 def as_sqlite(self, compiler, connection, **extra_context):
42 return super().as_sql(compiler, connection, function="CHAR", **extra_context)
45class ConcatPair(Func):
46 """
47 Concatenate two arguments together. This is used by `Concat` because not
48 all backend databases support more than two arguments.
49 """
51 function = "CONCAT"
53 def as_sqlite(self, compiler, connection, **extra_context):
54 coalesced = self.coalesce()
55 return super(ConcatPair, coalesced).as_sql(
56 compiler,
57 connection,
58 template="%(expressions)s",
59 arg_joiner=" || ",
60 **extra_context,
61 )
63 def as_postgresql(self, compiler, connection, **extra_context):
64 copy = self.copy()
65 copy.set_source_expressions(
66 [
67 Cast(expression, TextField())
68 for expression in copy.get_source_expressions()
69 ]
70 )
71 return super(ConcatPair, copy).as_sql(
72 compiler,
73 connection,
74 **extra_context,
75 )
77 def as_mysql(self, compiler, connection, **extra_context):
78 # Use CONCAT_WS with an empty separator so that NULLs are ignored.
79 return super().as_sql(
80 compiler,
81 connection,
82 function="CONCAT_WS",
83 template="%(function)s('', %(expressions)s)",
84 **extra_context,
85 )
87 def coalesce(self):
88 # null on either side results in null for expression, wrap with coalesce
89 c = self.copy()
90 c.set_source_expressions(
91 [
92 Coalesce(expression, Value(""))
93 for expression in c.get_source_expressions()
94 ]
95 )
96 return c
99class Concat(Func):
100 """
101 Concatenate text fields together. Backends that result in an entire
102 null expression when any arguments are null will wrap each argument in
103 coalesce functions to ensure a non-null result.
104 """
106 function = None
107 template = "%(expressions)s"
109 def __init__(self, *expressions, **extra):
110 if len(expressions) < 2:
111 raise ValueError("Concat must take at least two expressions")
112 paired = self._paired(expressions)
113 super().__init__(paired, **extra)
115 def _paired(self, expressions):
116 # wrap pairs of expressions in successive concat functions
117 # exp = [a, b, c, d]
118 # -> ConcatPair(a, ConcatPair(b, ConcatPair(c, d))))
119 if len(expressions) == 2:
120 return ConcatPair(*expressions)
121 return ConcatPair(expressions[0], self._paired(expressions[1:]))
124class Left(Func):
125 function = "LEFT"
126 arity = 2
127 output_field = CharField()
129 def __init__(self, expression, length, **extra):
130 """
131 expression: the name of a field, or an expression returning a string
132 length: the number of characters to return from the start of the string
133 """
134 if not hasattr(length, "resolve_expression"):
135 if length < 1:
136 raise ValueError("'length' must be greater than 0.")
137 super().__init__(expression, length, **extra)
139 def get_substr(self):
140 return Substr(self.source_expressions[0], Value(1), self.source_expressions[1])
142 def as_sqlite(self, compiler, connection, **extra_context):
143 return self.get_substr().as_sqlite(compiler, connection, **extra_context)
146class Length(Transform):
147 """Return the number of characters in the expression."""
149 function = "LENGTH"
150 lookup_name = "length"
151 output_field = IntegerField()
153 def as_mysql(self, compiler, connection, **extra_context):
154 return super().as_sql(
155 compiler, connection, function="CHAR_LENGTH", **extra_context
156 )
159class Lower(Transform):
160 function = "LOWER"
161 lookup_name = "lower"
164class LPad(Func):
165 function = "LPAD"
166 output_field = CharField()
168 def __init__(self, expression, length, fill_text=Value(" "), **extra):
169 if (
170 not hasattr(length, "resolve_expression")
171 and length is not None
172 and length < 0
173 ):
174 raise ValueError("'length' must be greater or equal to 0.")
175 super().__init__(expression, length, fill_text, **extra)
178class LTrim(Transform):
179 function = "LTRIM"
180 lookup_name = "ltrim"
183class MD5(Transform):
184 function = "MD5"
185 lookup_name = "md5"
188class Ord(Transform):
189 function = "ASCII"
190 lookup_name = "ord"
191 output_field = IntegerField()
193 def as_mysql(self, compiler, connection, **extra_context):
194 return super().as_sql(compiler, connection, function="ORD", **extra_context)
196 def as_sqlite(self, compiler, connection, **extra_context):
197 return super().as_sql(compiler, connection, function="UNICODE", **extra_context)
200class Repeat(Func):
201 function = "REPEAT"
202 output_field = CharField()
204 def __init__(self, expression, number, **extra):
205 if (
206 not hasattr(number, "resolve_expression")
207 and number is not None
208 and number < 0
209 ):
210 raise ValueError("'number' must be greater or equal to 0.")
211 super().__init__(expression, number, **extra)
214class Replace(Func):
215 function = "REPLACE"
217 def __init__(self, expression, text, replacement=Value(""), **extra):
218 super().__init__(expression, text, replacement, **extra)
221class Reverse(Transform):
222 function = "REVERSE"
223 lookup_name = "reverse"
226class Right(Left):
227 function = "RIGHT"
229 def get_substr(self):
230 return Substr(
231 self.source_expressions[0], self.source_expressions[1] * Value(-1)
232 )
235class RPad(LPad):
236 function = "RPAD"
239class RTrim(Transform):
240 function = "RTRIM"
241 lookup_name = "rtrim"
244class SHA1(PostgreSQLSHAMixin, Transform):
245 function = "SHA1"
246 lookup_name = "sha1"
249class SHA224(MySQLSHA2Mixin, PostgreSQLSHAMixin, Transform):
250 function = "SHA224"
251 lookup_name = "sha224"
254class SHA256(MySQLSHA2Mixin, PostgreSQLSHAMixin, Transform):
255 function = "SHA256"
256 lookup_name = "sha256"
259class SHA384(MySQLSHA2Mixin, PostgreSQLSHAMixin, Transform):
260 function = "SHA384"
261 lookup_name = "sha384"
264class SHA512(MySQLSHA2Mixin, PostgreSQLSHAMixin, Transform):
265 function = "SHA512"
266 lookup_name = "sha512"
269class StrIndex(Func):
270 """
271 Return a positive integer corresponding to the 1-indexed position of the
272 first occurrence of a substring inside another string, or 0 if the
273 substring is not found.
274 """
276 function = "INSTR"
277 arity = 2
278 output_field = IntegerField()
280 def as_postgresql(self, compiler, connection, **extra_context):
281 return super().as_sql(compiler, connection, function="STRPOS", **extra_context)
284class Substr(Func):
285 function = "SUBSTRING"
286 output_field = CharField()
288 def __init__(self, expression, pos, length=None, **extra):
289 """
290 expression: the name of a field, or an expression returning a string
291 pos: an integer > 0, or an expression returning an integer
292 length: an optional number of characters to return
293 """
294 if not hasattr(pos, "resolve_expression"):
295 if pos < 1:
296 raise ValueError("'pos' must be greater than 0")
297 expressions = [expression, pos]
298 if length is not None:
299 expressions.append(length)
300 super().__init__(*expressions, **extra)
302 def as_sqlite(self, compiler, connection, **extra_context):
303 return super().as_sql(compiler, connection, function="SUBSTR", **extra_context)
306class Trim(Transform):
307 function = "TRIM"
308 lookup_name = "trim"
311class Upper(Transform):
312 function = "UPPER"
313 lookup_name = "upper"
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.models.expressions import Func
2from plain.models.fields import FloatField, IntegerField
4__all__ = [
5 "CumeDist",
6 "DenseRank",
7 "FirstValue",
8 "Lag",
9 "LastValue",
10 "Lead",
11 "NthValue",
12 "Ntile",
13 "PercentRank",
14 "Rank",
15 "RowNumber",
16]
19class CumeDist(Func):
20 function = "CUME_DIST"
21 output_field = FloatField()
22 window_compatible = True
25class DenseRank(Func):
26 function = "DENSE_RANK"
27 output_field = IntegerField()
28 window_compatible = True
31class FirstValue(Func):
32 arity = 1
33 function = "FIRST_VALUE"
34 window_compatible = True
37class LagLeadFunction(Func):
38 window_compatible = True
40 def __init__(self, expression, offset=1, default=None, **extra):
41 if expression is None:
42 raise ValueError(
43 "%s requires a non-null source expression." % self.__class__.__name__
44 )
45 if offset is None or offset <= 0:
46 raise ValueError(
47 "%s requires a positive integer for the offset."
48 % self.__class__.__name__
49 )
50 args = (expression, offset)
51 if default is not None:
52 args += (default,)
53 super().__init__(*args, **extra)
55 def _resolve_output_field(self):
56 sources = self.get_source_expressions()
57 return sources[0].output_field
60class Lag(LagLeadFunction):
61 function = "LAG"
64class LastValue(Func):
65 arity = 1
66 function = "LAST_VALUE"
67 window_compatible = True
70class Lead(LagLeadFunction):
71 function = "LEAD"
74class NthValue(Func):
75 function = "NTH_VALUE"
76 window_compatible = True
78 def __init__(self, expression, nth=1, **extra):
79 if expression is None:
80 raise ValueError(
81 "%s requires a non-null source expression." % self.__class__.__name__
82 )
83 if nth is None or nth <= 0:
84 raise ValueError(
85 "%s requires a positive integer as for nth." % self.__class__.__name__
86 )
87 super().__init__(expression, nth, **extra)
89 def _resolve_output_field(self):
90 sources = self.get_source_expressions()
91 return sources[0].output_field
94class Ntile(Func):
95 function = "NTILE"
96 output_field = IntegerField()
97 window_compatible = True
99 def __init__(self, num_buckets=1, **extra):
100 if num_buckets <= 0:
101 raise ValueError("num_buckets must be greater than 0.")
102 super().__init__(num_buckets, **extra)
105class PercentRank(Func):
106 function = "PERCENT_RANK"
107 output_field = FloatField()
108 window_compatible = True
111class Rank(Func):
112 function = "RANK"
113 output_field = IntegerField()
114 window_compatible = True
117class RowNumber(Func):
118 function = "ROW_NUMBER"
119 output_field = IntegerField()
120 window_compatible = True
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from .fields import AddField, AlterField, RemoveField, RenameField
2from .models import (
3 AddConstraint,
4 AddIndex,
5 AlterModelManagers,
6 AlterModelOptions,
7 AlterModelTable,
8 AlterModelTableComment,
9 AlterOrderWithRespectTo,
10 CreateModel,
11 DeleteModel,
12 RemoveConstraint,
13 RemoveIndex,
14 RenameIndex,
15 RenameModel,
16)
17from .special import RunPython, RunSQL, SeparateDatabaseAndState
19__all__ = [
20 "CreateModel",
21 "DeleteModel",
22 "AlterModelTable",
23 "AlterModelTableComment",
24 "RenameModel",
25 "AlterModelOptions",
26 "AddIndex",
27 "RemoveIndex",
28 "RenameIndex",
29 "AddField",
30 "RemoveField",
31 "AlterField",
32 "RenameField",
33 "AddConstraint",
34 "RemoveConstraint",
35 "SeparateDatabaseAndState",
36 "RunSQL",
37 "RunPython",
38 "AlterOrderWithRespectTo",
39 "AlterModelManagers",
40]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.models.db import router
4class Operation:
5 """
6 Base class for migration operations.
8 It's responsible for both mutating the in-memory model state
9 (see db/migrations/state.py) to represent what it performs, as well
10 as actually performing it against a live database.
12 Note that some operations won't modify memory state at all (e.g. data
13 copying operations), and some will need their modifications to be
14 optionally specified by the user (e.g. custom Python code snippets)
16 Due to the way this class deals with deconstruction, it should be
17 considered immutable.
18 """
20 # If this migration can be run in reverse.
21 # Some operations are impossible to reverse, like deleting data.
22 reversible = True
24 # Can this migration be represented as SQL? (things like RunPython cannot)
25 reduces_to_sql = True
27 # Should this operation be forced as atomic even on backends with no
28 # DDL transaction support (i.e., does it have no DDL, like RunPython)
29 atomic = False
31 # Should this operation be considered safe to elide and optimize across?
32 elidable = False
34 serialization_expand_args = []
36 def __new__(cls, *args, **kwargs):
37 # We capture the arguments to make returning them trivial
38 self = object.__new__(cls)
39 self._constructor_args = (args, kwargs)
40 return self
42 def deconstruct(self):
43 """
44 Return a 3-tuple of class import path (or just name if it lives
45 under plain.models.migrations), positional arguments, and keyword
46 arguments.
47 """
48 return (
49 self.__class__.__name__,
50 self._constructor_args[0],
51 self._constructor_args[1],
52 )
54 def state_forwards(self, package_label, state):
55 """
56 Take the state from the previous migration, and mutate it
57 so that it matches what this migration would perform.
58 """
59 raise NotImplementedError(
60 "subclasses of Operation must provide a state_forwards() method"
61 )
63 def database_forwards(self, package_label, schema_editor, from_state, to_state):
64 """
65 Perform the mutation on the database schema in the normal
66 (forwards) direction.
67 """
68 raise NotImplementedError(
69 "subclasses of Operation must provide a database_forwards() method"
70 )
72 def database_backwards(self, package_label, schema_editor, from_state, to_state):
73 """
74 Perform the mutation on the database schema in the reverse
75 direction - e.g. if this were CreateModel, it would in fact
76 drop the model's table.
77 """
78 raise NotImplementedError(
79 "subclasses of Operation must provide a database_backwards() method"
80 )
82 def describe(self):
83 """
84 Output a brief summary of what the action does.
85 """
86 return f"{self.__class__.__name__}: {self._constructor_args}"
88 @property
89 def migration_name_fragment(self):
90 """
91 A filename part suitable for automatically naming a migration
92 containing this operation, or None if not applicable.
93 """
94 return None
96 def references_model(self, name, package_label):
97 """
98 Return True if there is a chance this operation references the given
99 model name (as a string), with an app label for accuracy.
101 Used for optimization. If in doubt, return True;
102 returning a false positive will merely make the optimizer a little
103 less efficient, while returning a false negative may result in an
104 unusable optimized migration.
105 """
106 return True
108 def references_field(self, model_name, name, package_label):
109 """
110 Return True if there is a chance this operation references the given
111 field name, with an app label for accuracy.
113 Used for optimization. If in doubt, return True.
114 """
115 return self.references_model(model_name, package_label)
117 def allow_migrate_model(self, connection_alias, model):
118 """
119 Return whether or not a model may be migrated.
121 This is a thin wrapper around router.allow_migrate_model() that
122 preemptively rejects any swapped out or unmanaged model.
123 """
124 if not model._meta.can_migrate(connection_alias):
125 return False
127 return router.allow_migrate_model(connection_alias, model)
129 def reduce(self, operation, package_label):
130 """
131 Return either a list of operations the actual operation should be
132 replaced with or a boolean that indicates whether or not the specified
133 operation can be optimized across.
134 """
135 if self.elidable:
136 return [operation]
137 elif operation.elidable:
138 return [self]
139 return False
141 def __repr__(self):
142 return "<{} {}{}>".format(
143 self.__class__.__name__,
144 ", ".join(map(repr, self._constructor_args[0])),
145 ",".join(" {}={!r}".format(*x) for x in self._constructor_args[1].items()),
146 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.models.fields import NOT_PROVIDED
2from plain.models.migrations.utils import field_references
3from plain.utils.functional import cached_property
5from .base import Operation
8class FieldOperation(Operation):
9 def __init__(self, model_name, name, field=None):
10 self.model_name = model_name
11 self.name = name
12 self.field = field
14 @cached_property
15 def model_name_lower(self):
16 return self.model_name.lower()
18 @cached_property
19 def name_lower(self):
20 return self.name.lower()
22 def is_same_model_operation(self, operation):
23 return self.model_name_lower == operation.model_name_lower
25 def is_same_field_operation(self, operation):
26 return (
27 self.is_same_model_operation(operation)
28 and self.name_lower == operation.name_lower
29 )
31 def references_model(self, name, package_label):
32 name_lower = name.lower()
33 if name_lower == self.model_name_lower:
34 return True
35 if self.field:
36 return bool(
37 field_references(
38 (package_label, self.model_name_lower),
39 self.field,
40 (package_label, name_lower),
41 )
42 )
43 return False
45 def references_field(self, model_name, name, package_label):
46 model_name_lower = model_name.lower()
47 # Check if this operation locally references the field.
48 if model_name_lower == self.model_name_lower:
49 if name == self.name:
50 return True
51 elif (
52 self.field
53 and hasattr(self.field, "from_fields")
54 and name in self.field.from_fields
55 ):
56 return True
57 # Check if this operation remotely references the field.
58 if self.field is None:
59 return False
60 return bool(
61 field_references(
62 (package_label, self.model_name_lower),
63 self.field,
64 (package_label, model_name_lower),
65 name,
66 )
67 )
69 def reduce(self, operation, package_label):
70 return super().reduce(
71 operation, package_label
72 ) or not operation.references_field(self.model_name, self.name, package_label)
75class AddField(FieldOperation):
76 """Add a field to a model."""
78 def __init__(self, model_name, name, field, preserve_default=True):
79 self.preserve_default = preserve_default
80 super().__init__(model_name, name, field)
82 def deconstruct(self):
83 kwargs = {
84 "model_name": self.model_name,
85 "name": self.name,
86 "field": self.field,
87 }
88 if self.preserve_default is not True:
89 kwargs["preserve_default"] = self.preserve_default
90 return (self.__class__.__name__, [], kwargs)
92 def state_forwards(self, package_label, state):
93 state.add_field(
94 package_label,
95 self.model_name_lower,
96 self.name,
97 self.field,
98 self.preserve_default,
99 )
101 def database_forwards(self, package_label, schema_editor, from_state, to_state):
102 to_model = to_state.packages.get_model(package_label, self.model_name)
103 if self.allow_migrate_model(schema_editor.connection.alias, to_model):
104 from_model = from_state.packages.get_model(package_label, self.model_name)
105 field = to_model._meta.get_field(self.name)
106 if not self.preserve_default:
107 field.default = self.field.default
108 schema_editor.add_field(
109 from_model,
110 field,
111 )
112 if not self.preserve_default:
113 field.default = NOT_PROVIDED
115 def database_backwards(self, package_label, schema_editor, from_state, to_state):
116 from_model = from_state.packages.get_model(package_label, self.model_name)
117 if self.allow_migrate_model(schema_editor.connection.alias, from_model):
118 schema_editor.remove_field(
119 from_model, from_model._meta.get_field(self.name)
120 )
122 def describe(self):
123 return f"Add field {self.name} to {self.model_name}"
125 @property
126 def migration_name_fragment(self):
127 return f"{self.model_name_lower}_{self.name_lower}"
129 def reduce(self, operation, package_label):
130 if isinstance(operation, FieldOperation) and self.is_same_field_operation(
131 operation
132 ):
133 if isinstance(operation, AlterField):
134 return [
135 AddField(
136 model_name=self.model_name,
137 name=operation.name,
138 field=operation.field,
139 ),
140 ]
141 elif isinstance(operation, RemoveField):
142 return []
143 elif isinstance(operation, RenameField):
144 return [
145 AddField(
146 model_name=self.model_name,
147 name=operation.new_name,
148 field=self.field,
149 ),
150 ]
151 return super().reduce(operation, package_label)
154class RemoveField(FieldOperation):
155 """Remove a field from a model."""
157 def deconstruct(self):
158 kwargs = {
159 "model_name": self.model_name,
160 "name": self.name,
161 }
162 return (self.__class__.__name__, [], kwargs)
164 def state_forwards(self, package_label, state):
165 state.remove_field(package_label, self.model_name_lower, self.name)
167 def database_forwards(self, package_label, schema_editor, from_state, to_state):
168 from_model = from_state.packages.get_model(package_label, self.model_name)
169 if self.allow_migrate_model(schema_editor.connection.alias, from_model):
170 schema_editor.remove_field(
171 from_model, from_model._meta.get_field(self.name)
172 )
174 def database_backwards(self, package_label, schema_editor, from_state, to_state):
175 to_model = to_state.packages.get_model(package_label, self.model_name)
176 if self.allow_migrate_model(schema_editor.connection.alias, to_model):
177 from_model = from_state.packages.get_model(package_label, self.model_name)
178 schema_editor.add_field(from_model, to_model._meta.get_field(self.name))
180 def describe(self):
181 return f"Remove field {self.name} from {self.model_name}"
183 @property
184 def migration_name_fragment(self):
185 return f"remove_{self.model_name_lower}_{self.name_lower}"
187 def reduce(self, operation, package_label):
188 from .models import DeleteModel
190 if (
191 isinstance(operation, DeleteModel)
192 and operation.name_lower == self.model_name_lower
193 ):
194 return [operation]
195 return super().reduce(operation, package_label)
198class AlterField(FieldOperation):
199 """
200 Alter a field's database column (e.g. null, max_length) to the provided
201 new field.
202 """
204 def __init__(self, model_name, name, field, preserve_default=True):
205 self.preserve_default = preserve_default
206 super().__init__(model_name, name, field)
208 def deconstruct(self):
209 kwargs = {
210 "model_name": self.model_name,
211 "name": self.name,
212 "field": self.field,
213 }
214 if self.preserve_default is not True:
215 kwargs["preserve_default"] = self.preserve_default
216 return (self.__class__.__name__, [], kwargs)
218 def state_forwards(self, package_label, state):
219 state.alter_field(
220 package_label,
221 self.model_name_lower,
222 self.name,
223 self.field,
224 self.preserve_default,
225 )
227 def database_forwards(self, package_label, schema_editor, from_state, to_state):
228 to_model = to_state.packages.get_model(package_label, self.model_name)
229 if self.allow_migrate_model(schema_editor.connection.alias, to_model):
230 from_model = from_state.packages.get_model(package_label, self.model_name)
231 from_field = from_model._meta.get_field(self.name)
232 to_field = to_model._meta.get_field(self.name)
233 if not self.preserve_default:
234 to_field.default = self.field.default
235 schema_editor.alter_field(from_model, from_field, to_field)
236 if not self.preserve_default:
237 to_field.default = NOT_PROVIDED
239 def database_backwards(self, package_label, schema_editor, from_state, to_state):
240 self.database_forwards(package_label, schema_editor, from_state, to_state)
242 def describe(self):
243 return f"Alter field {self.name} on {self.model_name}"
245 @property
246 def migration_name_fragment(self):
247 return f"alter_{self.model_name_lower}_{self.name_lower}"
249 def reduce(self, operation, package_label):
250 if isinstance(
251 operation, AlterField | RemoveField
252 ) and self.is_same_field_operation(operation):
253 return [operation]
254 elif (
255 isinstance(operation, RenameField)
256 and self.is_same_field_operation(operation)
257 and self.field.db_column is None
258 ):
259 return [
260 operation,
261 AlterField(
262 model_name=self.model_name,
263 name=operation.new_name,
264 field=self.field,
265 ),
266 ]
267 return super().reduce(operation, package_label)
270class RenameField(FieldOperation):
271 """Rename a field on the model. Might affect db_column too."""
273 def __init__(self, model_name, old_name, new_name):
274 self.old_name = old_name
275 self.new_name = new_name
276 super().__init__(model_name, old_name)
278 @cached_property
279 def old_name_lower(self):
280 return self.old_name.lower()
282 @cached_property
283 def new_name_lower(self):
284 return self.new_name.lower()
286 def deconstruct(self):
287 kwargs = {
288 "model_name": self.model_name,
289 "old_name": self.old_name,
290 "new_name": self.new_name,
291 }
292 return (self.__class__.__name__, [], kwargs)
294 def state_forwards(self, package_label, state):
295 state.rename_field(
296 package_label, self.model_name_lower, self.old_name, self.new_name
297 )
299 def database_forwards(self, package_label, schema_editor, from_state, to_state):
300 to_model = to_state.packages.get_model(package_label, self.model_name)
301 if self.allow_migrate_model(schema_editor.connection.alias, to_model):
302 from_model = from_state.packages.get_model(package_label, self.model_name)
303 schema_editor.alter_field(
304 from_model,
305 from_model._meta.get_field(self.old_name),
306 to_model._meta.get_field(self.new_name),
307 )
309 def database_backwards(self, package_label, schema_editor, from_state, to_state):
310 to_model = to_state.packages.get_model(package_label, self.model_name)
311 if self.allow_migrate_model(schema_editor.connection.alias, to_model):
312 from_model = from_state.packages.get_model(package_label, self.model_name)
313 schema_editor.alter_field(
314 from_model,
315 from_model._meta.get_field(self.new_name),
316 to_model._meta.get_field(self.old_name),
317 )
319 def describe(self):
320 return f"Rename field {self.old_name} on {self.model_name} to {self.new_name}"
322 @property
323 def migration_name_fragment(self):
324 return "rename_{}_{}_{}".format(
325 self.old_name_lower,
326 self.model_name_lower,
327 self.new_name_lower,
328 )
330 def references_field(self, model_name, name, package_label):
331 return self.references_model(model_name, package_label) and (
332 name.lower() == self.old_name_lower or name.lower() == self.new_name_lower
333 )
335 def reduce(self, operation, package_label):
336 if (
337 isinstance(operation, RenameField)
338 and self.is_same_model_operation(operation)
339 and self.new_name_lower == operation.old_name_lower
340 ):
341 return [
342 RenameField(
343 self.model_name,
344 self.old_name,
345 operation.new_name,
346 ),
347 ]
348 # Skip `FieldOperation.reduce` as we want to run `references_field`
349 # against self.old_name and self.new_name.
350 return super(FieldOperation, self).reduce(operation, package_label) or not (
351 operation.references_field(self.model_name, self.old_name, package_label)
352 or operation.references_field(self.model_name, self.new_name, package_label)
353 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain import models
2from plain.models.migrations.operations.base import Operation
3from plain.models.migrations.state import ModelState
4from plain.models.migrations.utils import field_references, resolve_relation
5from plain.utils.functional import cached_property
7from .fields import AddField, AlterField, FieldOperation, RemoveField, RenameField
10def _check_for_duplicates(arg_name, objs):
11 used_vals = set()
12 for val in objs:
13 if val in used_vals:
14 raise ValueError(
15 f"Found duplicate value {val} in CreateModel {arg_name} argument."
16 )
17 used_vals.add(val)
20class ModelOperation(Operation):
21 def __init__(self, name):
22 self.name = name
24 @cached_property
25 def name_lower(self):
26 return self.name.lower()
28 def references_model(self, name, package_label):
29 return name.lower() == self.name_lower
31 def reduce(self, operation, package_label):
32 return super().reduce(operation, package_label) or self.can_reduce_through(
33 operation, package_label
34 )
36 def can_reduce_through(self, operation, package_label):
37 return not operation.references_model(self.name, package_label)
40class CreateModel(ModelOperation):
41 """Create a model's table."""
43 serialization_expand_args = ["fields", "options", "managers"]
45 def __init__(self, name, fields, options=None, bases=None, managers=None):
46 self.fields = fields
47 self.options = options or {}
48 self.bases = bases or (models.Model,)
49 self.managers = managers or []
50 super().__init__(name)
51 # Sanity-check that there are no duplicated field names, bases, or
52 # manager names
53 _check_for_duplicates("fields", (name for name, _ in self.fields))
54 _check_for_duplicates(
55 "bases",
56 (
57 base._meta.label_lower
58 if hasattr(base, "_meta")
59 else base.lower()
60 if isinstance(base, str)
61 else base
62 for base in self.bases
63 ),
64 )
65 _check_for_duplicates("managers", (name for name, _ in self.managers))
67 def deconstruct(self):
68 kwargs = {
69 "name": self.name,
70 "fields": self.fields,
71 }
72 if self.options:
73 kwargs["options"] = self.options
74 if self.bases and self.bases != (models.Model,):
75 kwargs["bases"] = self.bases
76 if self.managers and self.managers != [("objects", models.Manager())]:
77 kwargs["managers"] = self.managers
78 return (self.__class__.__qualname__, [], kwargs)
80 def state_forwards(self, package_label, state):
81 state.add_model(
82 ModelState(
83 package_label,
84 self.name,
85 list(self.fields),
86 dict(self.options),
87 tuple(self.bases),
88 list(self.managers),
89 )
90 )
92 def database_forwards(self, package_label, schema_editor, from_state, to_state):
93 model = to_state.packages.get_model(package_label, self.name)
94 if self.allow_migrate_model(schema_editor.connection.alias, model):
95 schema_editor.create_model(model)
97 def database_backwards(self, package_label, schema_editor, from_state, to_state):
98 model = from_state.packages.get_model(package_label, self.name)
99 if self.allow_migrate_model(schema_editor.connection.alias, model):
100 schema_editor.delete_model(model)
102 def describe(self):
103 return f"Create model {self.name}"
105 @property
106 def migration_name_fragment(self):
107 return self.name_lower
109 def references_model(self, name, package_label):
110 name_lower = name.lower()
111 if name_lower == self.name_lower:
112 return True
114 # Check we didn't inherit from the model
115 reference_model_tuple = (package_label, name_lower)
116 for base in self.bases:
117 if (
118 base is not models.Model
119 and isinstance(base, models.base.ModelBase | str)
120 and resolve_relation(base, package_label) == reference_model_tuple
121 ):
122 return True
124 # Check we have no FKs/M2Ms with it
125 for _name, field in self.fields:
126 if field_references(
127 (package_label, self.name_lower), field, reference_model_tuple
128 ):
129 return True
130 return False
132 def reduce(self, operation, package_label):
133 if (
134 isinstance(operation, DeleteModel)
135 and self.name_lower == operation.name_lower
136 ):
137 return []
138 elif (
139 isinstance(operation, RenameModel)
140 and self.name_lower == operation.old_name_lower
141 ):
142 return [
143 CreateModel(
144 operation.new_name,
145 fields=self.fields,
146 options=self.options,
147 bases=self.bases,
148 managers=self.managers,
149 ),
150 ]
151 elif (
152 isinstance(operation, AlterModelOptions)
153 and self.name_lower == operation.name_lower
154 ):
155 options = {**self.options, **operation.options}
156 for key in operation.ALTER_OPTION_KEYS:
157 if key not in operation.options:
158 options.pop(key, None)
159 return [
160 CreateModel(
161 self.name,
162 fields=self.fields,
163 options=options,
164 bases=self.bases,
165 managers=self.managers,
166 ),
167 ]
168 elif (
169 isinstance(operation, AlterModelManagers)
170 and self.name_lower == operation.name_lower
171 ):
172 return [
173 CreateModel(
174 self.name,
175 fields=self.fields,
176 options=self.options,
177 bases=self.bases,
178 managers=operation.managers,
179 ),
180 ]
181 elif (
182 isinstance(operation, AlterOrderWithRespectTo)
183 and self.name_lower == operation.name_lower
184 ):
185 return [
186 CreateModel(
187 self.name,
188 fields=self.fields,
189 options={
190 **self.options,
191 "order_with_respect_to": operation.order_with_respect_to,
192 },
193 bases=self.bases,
194 managers=self.managers,
195 ),
196 ]
197 elif (
198 isinstance(operation, FieldOperation)
199 and self.name_lower == operation.model_name_lower
200 ):
201 if isinstance(operation, AddField):
202 return [
203 CreateModel(
204 self.name,
205 fields=self.fields + [(operation.name, operation.field)],
206 options=self.options,
207 bases=self.bases,
208 managers=self.managers,
209 ),
210 ]
211 elif isinstance(operation, AlterField):
212 return [
213 CreateModel(
214 self.name,
215 fields=[
216 (n, operation.field if n == operation.name else v)
217 for n, v in self.fields
218 ],
219 options=self.options,
220 bases=self.bases,
221 managers=self.managers,
222 ),
223 ]
224 elif isinstance(operation, RemoveField):
225 options = self.options.copy()
227 order_with_respect_to = options.get("order_with_respect_to")
228 if order_with_respect_to == operation.name_lower:
229 del options["order_with_respect_to"]
230 return [
231 CreateModel(
232 self.name,
233 fields=[
234 (n, v)
235 for n, v in self.fields
236 if n.lower() != operation.name_lower
237 ],
238 options=options,
239 bases=self.bases,
240 managers=self.managers,
241 ),
242 ]
243 elif isinstance(operation, RenameField):
244 options = self.options.copy()
246 order_with_respect_to = options.get("order_with_respect_to")
247 if order_with_respect_to == operation.old_name:
248 options["order_with_respect_to"] = operation.new_name
249 return [
250 CreateModel(
251 self.name,
252 fields=[
253 (operation.new_name if n == operation.old_name else n, v)
254 for n, v in self.fields
255 ],
256 options=options,
257 bases=self.bases,
258 managers=self.managers,
259 ),
260 ]
261 return super().reduce(operation, package_label)
264class DeleteModel(ModelOperation):
265 """Drop a model's table."""
267 def deconstruct(self):
268 kwargs = {
269 "name": self.name,
270 }
271 return (self.__class__.__qualname__, [], kwargs)
273 def state_forwards(self, package_label, state):
274 state.remove_model(package_label, self.name_lower)
276 def database_forwards(self, package_label, schema_editor, from_state, to_state):
277 model = from_state.packages.get_model(package_label, self.name)
278 if self.allow_migrate_model(schema_editor.connection.alias, model):
279 schema_editor.delete_model(model)
281 def database_backwards(self, package_label, schema_editor, from_state, to_state):
282 model = to_state.packages.get_model(package_label, self.name)
283 if self.allow_migrate_model(schema_editor.connection.alias, model):
284 schema_editor.create_model(model)
286 def references_model(self, name, package_label):
287 # The deleted model could be referencing the specified model through
288 # related fields.
289 return True
291 def describe(self):
292 return "Delete model %s" % self.name
294 @property
295 def migration_name_fragment(self):
296 return "delete_%s" % self.name_lower
299class RenameModel(ModelOperation):
300 """Rename a model."""
302 def __init__(self, old_name, new_name):
303 self.old_name = old_name
304 self.new_name = new_name
305 super().__init__(old_name)
307 @cached_property
308 def old_name_lower(self):
309 return self.old_name.lower()
311 @cached_property
312 def new_name_lower(self):
313 return self.new_name.lower()
315 def deconstruct(self):
316 kwargs = {
317 "old_name": self.old_name,
318 "new_name": self.new_name,
319 }
320 return (self.__class__.__qualname__, [], kwargs)
322 def state_forwards(self, package_label, state):
323 state.rename_model(package_label, self.old_name, self.new_name)
325 def database_forwards(self, package_label, schema_editor, from_state, to_state):
326 new_model = to_state.packages.get_model(package_label, self.new_name)
327 if self.allow_migrate_model(schema_editor.connection.alias, new_model):
328 old_model = from_state.packages.get_model(package_label, self.old_name)
329 # Move the main table
330 schema_editor.alter_db_table(
331 new_model,
332 old_model._meta.db_table,
333 new_model._meta.db_table,
334 )
335 # Alter the fields pointing to us
336 for related_object in old_model._meta.related_objects:
337 if related_object.related_model == old_model:
338 model = new_model
339 related_key = (package_label, self.new_name_lower)
340 else:
341 model = related_object.related_model
342 related_key = (
343 related_object.related_model._meta.package_label,
344 related_object.related_model._meta.model_name,
345 )
346 to_field = to_state.packages.get_model(*related_key)._meta.get_field(
347 related_object.field.name
348 )
349 schema_editor.alter_field(
350 model,
351 related_object.field,
352 to_field,
353 )
354 # Rename M2M fields whose name is based on this model's name.
355 fields = zip(
356 old_model._meta.local_many_to_many, new_model._meta.local_many_to_many
357 )
358 for old_field, new_field in fields:
359 # Skip self-referential fields as these are renamed above.
360 if (
361 new_field.model == new_field.related_model
362 or not new_field.remote_field.through._meta.auto_created
363 ):
364 continue
365 # Rename columns and the M2M table.
366 schema_editor._alter_many_to_many(
367 new_model,
368 old_field,
369 new_field,
370 strict=False,
371 )
373 def database_backwards(self, package_label, schema_editor, from_state, to_state):
374 self.new_name_lower, self.old_name_lower = (
375 self.old_name_lower,
376 self.new_name_lower,
377 )
378 self.new_name, self.old_name = self.old_name, self.new_name
380 self.database_forwards(package_label, schema_editor, from_state, to_state)
382 self.new_name_lower, self.old_name_lower = (
383 self.old_name_lower,
384 self.new_name_lower,
385 )
386 self.new_name, self.old_name = self.old_name, self.new_name
388 def references_model(self, name, package_label):
389 return (
390 name.lower() == self.old_name_lower or name.lower() == self.new_name_lower
391 )
393 def describe(self):
394 return f"Rename model {self.old_name} to {self.new_name}"
396 @property
397 def migration_name_fragment(self):
398 return f"rename_{self.old_name_lower}_{self.new_name_lower}"
400 def reduce(self, operation, package_label):
401 if (
402 isinstance(operation, RenameModel)
403 and self.new_name_lower == operation.old_name_lower
404 ):
405 return [
406 RenameModel(
407 self.old_name,
408 operation.new_name,
409 ),
410 ]
411 # Skip `ModelOperation.reduce` as we want to run `references_model`
412 # against self.new_name.
413 return super(ModelOperation, self).reduce(
414 operation, package_label
415 ) or not operation.references_model(self.new_name, package_label)
418class ModelOptionOperation(ModelOperation):
419 def reduce(self, operation, package_label):
420 if (
421 isinstance(operation, self.__class__ | DeleteModel)
422 and self.name_lower == operation.name_lower
423 ):
424 return [operation]
425 return super().reduce(operation, package_label)
428class AlterModelTable(ModelOptionOperation):
429 """Rename a model's table."""
431 def __init__(self, name, table):
432 self.table = table
433 super().__init__(name)
435 def deconstruct(self):
436 kwargs = {
437 "name": self.name,
438 "table": self.table,
439 }
440 return (self.__class__.__qualname__, [], kwargs)
442 def state_forwards(self, package_label, state):
443 state.alter_model_options(
444 package_label, self.name_lower, {"db_table": self.table}
445 )
447 def database_forwards(self, package_label, schema_editor, from_state, to_state):
448 new_model = to_state.packages.get_model(package_label, self.name)
449 if self.allow_migrate_model(schema_editor.connection.alias, new_model):
450 old_model = from_state.packages.get_model(package_label, self.name)
451 schema_editor.alter_db_table(
452 new_model,
453 old_model._meta.db_table,
454 new_model._meta.db_table,
455 )
456 # Rename M2M fields whose name is based on this model's db_table
457 for old_field, new_field in zip(
458 old_model._meta.local_many_to_many, new_model._meta.local_many_to_many
459 ):
460 if new_field.remote_field.through._meta.auto_created:
461 schema_editor.alter_db_table(
462 new_field.remote_field.through,
463 old_field.remote_field.through._meta.db_table,
464 new_field.remote_field.through._meta.db_table,
465 )
467 def database_backwards(self, package_label, schema_editor, from_state, to_state):
468 return self.database_forwards(
469 package_label, schema_editor, from_state, to_state
470 )
472 def describe(self):
473 return "Rename table for {} to {}".format(
474 self.name,
475 self.table if self.table is not None else "(default)",
476 )
478 @property
479 def migration_name_fragment(self):
480 return "alter_%s_table" % self.name_lower
483class AlterModelTableComment(ModelOptionOperation):
484 def __init__(self, name, table_comment):
485 self.table_comment = table_comment
486 super().__init__(name)
488 def deconstruct(self):
489 kwargs = {
490 "name": self.name,
491 "table_comment": self.table_comment,
492 }
493 return (self.__class__.__qualname__, [], kwargs)
495 def state_forwards(self, package_label, state):
496 state.alter_model_options(
497 package_label, self.name_lower, {"db_table_comment": self.table_comment}
498 )
500 def database_forwards(self, package_label, schema_editor, from_state, to_state):
501 new_model = to_state.packages.get_model(package_label, self.name)
502 if self.allow_migrate_model(schema_editor.connection.alias, new_model):
503 old_model = from_state.packages.get_model(package_label, self.name)
504 schema_editor.alter_db_table_comment(
505 new_model,
506 old_model._meta.db_table_comment,
507 new_model._meta.db_table_comment,
508 )
510 def database_backwards(self, package_label, schema_editor, from_state, to_state):
511 return self.database_forwards(
512 package_label, schema_editor, from_state, to_state
513 )
515 def describe(self):
516 return f"Alter {self.name} table comment"
518 @property
519 def migration_name_fragment(self):
520 return f"alter_{self.name_lower}_table_comment"
523class AlterOrderWithRespectTo(ModelOptionOperation):
524 """Represent a change with the order_with_respect_to option."""
526 option_name = "order_with_respect_to"
528 def __init__(self, name, order_with_respect_to):
529 self.order_with_respect_to = order_with_respect_to
530 super().__init__(name)
532 def deconstruct(self):
533 kwargs = {
534 "name": self.name,
535 "order_with_respect_to": self.order_with_respect_to,
536 }
537 return (self.__class__.__qualname__, [], kwargs)
539 def state_forwards(self, package_label, state):
540 state.alter_model_options(
541 package_label,
542 self.name_lower,
543 {self.option_name: self.order_with_respect_to},
544 )
546 def database_forwards(self, package_label, schema_editor, from_state, to_state):
547 to_model = to_state.packages.get_model(package_label, self.name)
548 if self.allow_migrate_model(schema_editor.connection.alias, to_model):
549 from_model = from_state.packages.get_model(package_label, self.name)
550 # Remove a field if we need to
551 if (
552 from_model._meta.order_with_respect_to
553 and not to_model._meta.order_with_respect_to
554 ):
555 schema_editor.remove_field(
556 from_model, from_model._meta.get_field("_order")
557 )
558 # Add a field if we need to (altering the column is untouched as
559 # it's likely a rename)
560 elif (
561 to_model._meta.order_with_respect_to
562 and not from_model._meta.order_with_respect_to
563 ):
564 field = to_model._meta.get_field("_order")
565 if not field.has_default():
566 field.default = 0
567 schema_editor.add_field(
568 from_model,
569 field,
570 )
572 def database_backwards(self, package_label, schema_editor, from_state, to_state):
573 self.database_forwards(package_label, schema_editor, from_state, to_state)
575 def references_field(self, model_name, name, package_label):
576 return self.references_model(model_name, package_label) and (
577 self.order_with_respect_to is None or name == self.order_with_respect_to
578 )
580 def describe(self):
581 return "Set order_with_respect_to on {} to {}".format(
582 self.name,
583 self.order_with_respect_to,
584 )
586 @property
587 def migration_name_fragment(self):
588 return "alter_%s_order_with_respect_to" % self.name_lower
591class AlterModelOptions(ModelOptionOperation):
592 """
593 Set new model options that don't directly affect the database schema
594 (like ordering). Python code in migrations
595 may still need them.
596 """
598 # Model options we want to compare and preserve in an AlterModelOptions op
599 ALTER_OPTION_KEYS = [
600 "base_manager_name",
601 "default_manager_name",
602 "default_related_name",
603 "get_latest_by",
604 "managed",
605 "ordering",
606 "select_on_save",
607 ]
609 def __init__(self, name, options):
610 self.options = options
611 super().__init__(name)
613 def deconstruct(self):
614 kwargs = {
615 "name": self.name,
616 "options": self.options,
617 }
618 return (self.__class__.__qualname__, [], kwargs)
620 def state_forwards(self, package_label, state):
621 state.alter_model_options(
622 package_label,
623 self.name_lower,
624 self.options,
625 self.ALTER_OPTION_KEYS,
626 )
628 def database_forwards(self, package_label, schema_editor, from_state, to_state):
629 pass
631 def database_backwards(self, package_label, schema_editor, from_state, to_state):
632 pass
634 def describe(self):
635 return "Change Meta options on %s" % self.name
637 @property
638 def migration_name_fragment(self):
639 return "alter_%s_options" % self.name_lower
642class AlterModelManagers(ModelOptionOperation):
643 """Alter the model's managers."""
645 serialization_expand_args = ["managers"]
647 def __init__(self, name, managers):
648 self.managers = managers
649 super().__init__(name)
651 def deconstruct(self):
652 return (self.__class__.__qualname__, [self.name, self.managers], {})
654 def state_forwards(self, package_label, state):
655 state.alter_model_managers(package_label, self.name_lower, self.managers)
657 def database_forwards(self, package_label, schema_editor, from_state, to_state):
658 pass
660 def database_backwards(self, package_label, schema_editor, from_state, to_state):
661 pass
663 def describe(self):
664 return "Change managers on %s" % self.name
666 @property
667 def migration_name_fragment(self):
668 return "alter_%s_managers" % self.name_lower
671class IndexOperation(Operation):
672 option_name = "indexes"
674 @cached_property
675 def model_name_lower(self):
676 return self.model_name.lower()
679class AddIndex(IndexOperation):
680 """Add an index on a model."""
682 def __init__(self, model_name, index):
683 self.model_name = model_name
684 if not index.name:
685 raise ValueError(
686 "Indexes passed to AddIndex operations require a name "
687 "argument. %r doesn't have one." % index
688 )
689 self.index = index
691 def state_forwards(self, package_label, state):
692 state.add_index(package_label, self.model_name_lower, self.index)
694 def database_forwards(self, package_label, schema_editor, from_state, to_state):
695 model = to_state.packages.get_model(package_label, self.model_name)
696 if self.allow_migrate_model(schema_editor.connection.alias, model):
697 schema_editor.add_index(model, self.index)
699 def database_backwards(self, package_label, schema_editor, from_state, to_state):
700 model = from_state.packages.get_model(package_label, self.model_name)
701 if self.allow_migrate_model(schema_editor.connection.alias, model):
702 schema_editor.remove_index(model, self.index)
704 def deconstruct(self):
705 kwargs = {
706 "model_name": self.model_name,
707 "index": self.index,
708 }
709 return (
710 self.__class__.__qualname__,
711 [],
712 kwargs,
713 )
715 def describe(self):
716 if self.index.expressions:
717 return "Create index {} on {} on model {}".format(
718 self.index.name,
719 ", ".join([str(expression) for expression in self.index.expressions]),
720 self.model_name,
721 )
722 return "Create index {} on field(s) {} of model {}".format(
723 self.index.name,
724 ", ".join(self.index.fields),
725 self.model_name,
726 )
728 @property
729 def migration_name_fragment(self):
730 return f"{self.model_name_lower}_{self.index.name.lower()}"
733class RemoveIndex(IndexOperation):
734 """Remove an index from a model."""
736 def __init__(self, model_name, name):
737 self.model_name = model_name
738 self.name = name
740 def state_forwards(self, package_label, state):
741 state.remove_index(package_label, self.model_name_lower, self.name)
743 def database_forwards(self, package_label, schema_editor, from_state, to_state):
744 model = from_state.packages.get_model(package_label, self.model_name)
745 if self.allow_migrate_model(schema_editor.connection.alias, model):
746 from_model_state = from_state.models[package_label, self.model_name_lower]
747 index = from_model_state.get_index_by_name(self.name)
748 schema_editor.remove_index(model, index)
750 def database_backwards(self, package_label, schema_editor, from_state, to_state):
751 model = to_state.packages.get_model(package_label, self.model_name)
752 if self.allow_migrate_model(schema_editor.connection.alias, model):
753 to_model_state = to_state.models[package_label, self.model_name_lower]
754 index = to_model_state.get_index_by_name(self.name)
755 schema_editor.add_index(model, index)
757 def deconstruct(self):
758 kwargs = {
759 "model_name": self.model_name,
760 "name": self.name,
761 }
762 return (
763 self.__class__.__qualname__,
764 [],
765 kwargs,
766 )
768 def describe(self):
769 return f"Remove index {self.name} from {self.model_name}"
771 @property
772 def migration_name_fragment(self):
773 return f"remove_{self.model_name_lower}_{self.name.lower()}"
776class RenameIndex(IndexOperation):
777 """Rename an index."""
779 def __init__(self, model_name, new_name, old_name=None, old_fields=None):
780 if not old_name and not old_fields:
781 raise ValueError(
782 "RenameIndex requires one of old_name and old_fields arguments to be "
783 "set."
784 )
785 if old_name and old_fields:
786 raise ValueError(
787 "RenameIndex.old_name and old_fields are mutually exclusive."
788 )
789 self.model_name = model_name
790 self.new_name = new_name
791 self.old_name = old_name
792 self.old_fields = old_fields
794 @cached_property
795 def old_name_lower(self):
796 return self.old_name.lower()
798 @cached_property
799 def new_name_lower(self):
800 return self.new_name.lower()
802 def deconstruct(self):
803 kwargs = {
804 "model_name": self.model_name,
805 "new_name": self.new_name,
806 }
807 if self.old_name:
808 kwargs["old_name"] = self.old_name
809 if self.old_fields:
810 kwargs["old_fields"] = self.old_fields
811 return (self.__class__.__qualname__, [], kwargs)
813 def state_forwards(self, package_label, state):
814 if self.old_fields:
815 state.add_index(
816 package_label,
817 self.model_name_lower,
818 models.Index(fields=self.old_fields, name=self.new_name),
819 )
820 else:
821 state.rename_index(
822 package_label, self.model_name_lower, self.old_name, self.new_name
823 )
825 def database_forwards(self, package_label, schema_editor, from_state, to_state):
826 model = to_state.packages.get_model(package_label, self.model_name)
827 if not self.allow_migrate_model(schema_editor.connection.alias, model):
828 return
830 if self.old_fields:
831 from_model = from_state.packages.get_model(package_label, self.model_name)
832 columns = [
833 from_model._meta.get_field(field).column for field in self.old_fields
834 ]
835 matching_index_name = schema_editor._constraint_names(
836 from_model, column_names=columns, index=True
837 )
838 if len(matching_index_name) != 1:
839 raise ValueError(
840 "Found wrong number ({}) of indexes for {}({}).".format(
841 len(matching_index_name),
842 from_model._meta.db_table,
843 ", ".join(columns),
844 )
845 )
846 old_index = models.Index(
847 fields=self.old_fields,
848 name=matching_index_name[0],
849 )
850 else:
851 from_model_state = from_state.models[package_label, self.model_name_lower]
852 old_index = from_model_state.get_index_by_name(self.old_name)
853 # Don't alter when the index name is not changed.
854 if old_index.name == self.new_name:
855 return
857 to_model_state = to_state.models[package_label, self.model_name_lower]
858 new_index = to_model_state.get_index_by_name(self.new_name)
859 schema_editor.rename_index(model, old_index, new_index)
861 def database_backwards(self, package_label, schema_editor, from_state, to_state):
862 if self.old_fields:
863 # Backward operation with unnamed index is a no-op.
864 return
866 self.new_name_lower, self.old_name_lower = (
867 self.old_name_lower,
868 self.new_name_lower,
869 )
870 self.new_name, self.old_name = self.old_name, self.new_name
872 self.database_forwards(package_label, schema_editor, from_state, to_state)
874 self.new_name_lower, self.old_name_lower = (
875 self.old_name_lower,
876 self.new_name_lower,
877 )
878 self.new_name, self.old_name = self.old_name, self.new_name
880 def describe(self):
881 if self.old_name:
882 return (
883 f"Rename index {self.old_name} on {self.model_name} to {self.new_name}"
884 )
885 return (
886 f"Rename unnamed index for {self.old_fields} on {self.model_name} to "
887 f"{self.new_name}"
888 )
890 @property
891 def migration_name_fragment(self):
892 if self.old_name:
893 return f"rename_{self.old_name_lower}_{self.new_name_lower}"
894 return "rename_{}_{}_{}".format(
895 self.model_name_lower,
896 "_".join(self.old_fields),
897 self.new_name_lower,
898 )
900 def reduce(self, operation, package_label):
901 if (
902 isinstance(operation, RenameIndex)
903 and self.model_name_lower == operation.model_name_lower
904 and operation.old_name
905 and self.new_name_lower == operation.old_name_lower
906 ):
907 return [
908 RenameIndex(
909 self.model_name,
910 new_name=operation.new_name,
911 old_name=self.old_name,
912 old_fields=self.old_fields,
913 )
914 ]
915 return super().reduce(operation, package_label)
918class AddConstraint(IndexOperation):
919 option_name = "constraints"
921 def __init__(self, model_name, constraint):
922 self.model_name = model_name
923 self.constraint = constraint
925 def state_forwards(self, package_label, state):
926 state.add_constraint(package_label, self.model_name_lower, self.constraint)
928 def database_forwards(self, package_label, schema_editor, from_state, to_state):
929 model = to_state.packages.get_model(package_label, self.model_name)
930 if self.allow_migrate_model(schema_editor.connection.alias, model):
931 schema_editor.add_constraint(model, self.constraint)
933 def database_backwards(self, package_label, schema_editor, from_state, to_state):
934 model = to_state.packages.get_model(package_label, self.model_name)
935 if self.allow_migrate_model(schema_editor.connection.alias, model):
936 schema_editor.remove_constraint(model, self.constraint)
938 def deconstruct(self):
939 return (
940 self.__class__.__name__,
941 [],
942 {
943 "model_name": self.model_name,
944 "constraint": self.constraint,
945 },
946 )
948 def describe(self):
949 return f"Create constraint {self.constraint.name} on model {self.model_name}"
951 @property
952 def migration_name_fragment(self):
953 return f"{self.model_name_lower}_{self.constraint.name.lower()}"
956class RemoveConstraint(IndexOperation):
957 option_name = "constraints"
959 def __init__(self, model_name, name):
960 self.model_name = model_name
961 self.name = name
963 def state_forwards(self, package_label, state):
964 state.remove_constraint(package_label, self.model_name_lower, self.name)
966 def database_forwards(self, package_label, schema_editor, from_state, to_state):
967 model = to_state.packages.get_model(package_label, self.model_name)
968 if self.allow_migrate_model(schema_editor.connection.alias, model):
969 from_model_state = from_state.models[package_label, self.model_name_lower]
970 constraint = from_model_state.get_constraint_by_name(self.name)
971 schema_editor.remove_constraint(model, constraint)
973 def database_backwards(self, package_label, schema_editor, from_state, to_state):
974 model = to_state.packages.get_model(package_label, self.model_name)
975 if self.allow_migrate_model(schema_editor.connection.alias, model):
976 to_model_state = to_state.models[package_label, self.model_name_lower]
977 constraint = to_model_state.get_constraint_by_name(self.name)
978 schema_editor.add_constraint(model, constraint)
980 def deconstruct(self):
981 return (
982 self.__class__.__name__,
983 [],
984 {
985 "model_name": self.model_name,
986 "name": self.name,
987 },
988 )
990 def describe(self):
991 return f"Remove constraint {self.name} from model {self.model_name}"
993 @property
994 def migration_name_fragment(self):
995 return f"remove_{self.model_name_lower}_{self.name.lower()}"
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.models.db import router
3from .base import Operation
6class SeparateDatabaseAndState(Operation):
7 """
8 Take two lists of operations - ones that will be used for the database,
9 and ones that will be used for the state change. This allows operations
10 that don't support state change to have it applied, or have operations
11 that affect the state or not the database, or so on.
12 """
14 serialization_expand_args = ["database_operations", "state_operations"]
16 def __init__(self, database_operations=None, state_operations=None):
17 self.database_operations = database_operations or []
18 self.state_operations = state_operations or []
20 def deconstruct(self):
21 kwargs = {}
22 if self.database_operations:
23 kwargs["database_operations"] = self.database_operations
24 if self.state_operations:
25 kwargs["state_operations"] = self.state_operations
26 return (self.__class__.__qualname__, [], kwargs)
28 def state_forwards(self, package_label, state):
29 for state_operation in self.state_operations:
30 state_operation.state_forwards(package_label, state)
32 def database_forwards(self, package_label, schema_editor, from_state, to_state):
33 # We calculate state separately in here since our state functions aren't useful
34 for database_operation in self.database_operations:
35 to_state = from_state.clone()
36 database_operation.state_forwards(package_label, to_state)
37 database_operation.database_forwards(
38 package_label, schema_editor, from_state, to_state
39 )
40 from_state = to_state
42 def database_backwards(self, package_label, schema_editor, from_state, to_state):
43 # We calculate state separately in here since our state functions aren't useful
44 to_states = {}
45 for dbop in self.database_operations:
46 to_states[dbop] = to_state
47 to_state = to_state.clone()
48 dbop.state_forwards(package_label, to_state)
49 # to_state now has the states of all the database_operations applied
50 # which is the from_state for the backwards migration of the last
51 # operation.
52 for database_operation in reversed(self.database_operations):
53 from_state = to_state
54 to_state = to_states[database_operation]
55 database_operation.database_backwards(
56 package_label, schema_editor, from_state, to_state
57 )
59 def describe(self):
60 return "Custom state/database change combination"
63class RunSQL(Operation):
64 """
65 Run some raw SQL. A reverse SQL statement may be provided.
67 Also accept a list of operations that represent the state change effected
68 by this SQL change, in case it's custom column/table creation/deletion.
69 """
71 noop = ""
73 def __init__(
74 self, sql, reverse_sql=None, state_operations=None, hints=None, elidable=False
75 ):
76 self.sql = sql
77 self.reverse_sql = reverse_sql
78 self.state_operations = state_operations or []
79 self.hints = hints or {}
80 self.elidable = elidable
82 def deconstruct(self):
83 kwargs = {
84 "sql": self.sql,
85 }
86 if self.reverse_sql is not None:
87 kwargs["reverse_sql"] = self.reverse_sql
88 if self.state_operations:
89 kwargs["state_operations"] = self.state_operations
90 if self.hints:
91 kwargs["hints"] = self.hints
92 return (self.__class__.__qualname__, [], kwargs)
94 @property
95 def reversible(self):
96 return self.reverse_sql is not None
98 def state_forwards(self, package_label, state):
99 for state_operation in self.state_operations:
100 state_operation.state_forwards(package_label, state)
102 def database_forwards(self, package_label, schema_editor, from_state, to_state):
103 if router.allow_migrate(
104 schema_editor.connection.alias, package_label, **self.hints
105 ):
106 self._run_sql(schema_editor, self.sql)
108 def database_backwards(self, package_label, schema_editor, from_state, to_state):
109 if self.reverse_sql is None:
110 raise NotImplementedError("You cannot reverse this operation")
111 if router.allow_migrate(
112 schema_editor.connection.alias, package_label, **self.hints
113 ):
114 self._run_sql(schema_editor, self.reverse_sql)
116 def describe(self):
117 return "Raw SQL operation"
119 def _run_sql(self, schema_editor, sqls):
120 if isinstance(sqls, list | tuple):
121 for sql in sqls:
122 params = None
123 if isinstance(sql, list | tuple):
124 elements = len(sql)
125 if elements == 2:
126 sql, params = sql
127 else:
128 raise ValueError("Expected a 2-tuple but got %d" % elements)
129 schema_editor.execute(sql, params=params)
130 elif sqls != RunSQL.noop:
131 statements = schema_editor.connection.ops.prepare_sql_script(sqls)
132 for statement in statements:
133 schema_editor.execute(statement, params=None)
136class RunPython(Operation):
137 """
138 Run Python code in a context suitable for doing versioned ORM operations.
139 """
141 reduces_to_sql = False
143 def __init__(
144 self, code, reverse_code=None, atomic=None, hints=None, elidable=False
145 ):
146 self.atomic = atomic
147 # Forwards code
148 if not callable(code):
149 raise ValueError("RunPython must be supplied with a callable")
150 self.code = code
151 # Reverse code
152 if reverse_code is None:
153 self.reverse_code = None
154 else:
155 if not callable(reverse_code):
156 raise ValueError("RunPython must be supplied with callable arguments")
157 self.reverse_code = reverse_code
158 self.hints = hints or {}
159 self.elidable = elidable
161 def deconstruct(self):
162 kwargs = {
163 "code": self.code,
164 }
165 if self.reverse_code is not None:
166 kwargs["reverse_code"] = self.reverse_code
167 if self.atomic is not None:
168 kwargs["atomic"] = self.atomic
169 if self.hints:
170 kwargs["hints"] = self.hints
171 return (self.__class__.__qualname__, [], kwargs)
173 @property
174 def reversible(self):
175 return self.reverse_code is not None
177 def state_forwards(self, package_label, state):
178 # RunPython objects have no state effect. To add some, combine this
179 # with SeparateDatabaseAndState.
180 pass
182 def database_forwards(self, package_label, schema_editor, from_state, to_state):
183 # RunPython has access to all models. Ensure that all models are
184 # reloaded in case any are delayed.
185 from_state.clear_delayed_packages_cache()
186 if router.allow_migrate(
187 schema_editor.connection.alias, package_label, **self.hints
188 ):
189 # We now execute the Python code in a context that contains a 'models'
190 # object, representing the versioned models as an app registry.
191 # We could try to override the global cache, but then people will still
192 # use direct imports, so we go with a documentation approach instead.
193 self.code(from_state.packages, schema_editor)
195 def database_backwards(self, package_label, schema_editor, from_state, to_state):
196 if self.reverse_code is None:
197 raise NotImplementedError("You cannot reverse this operation")
198 if router.allow_migrate(
199 schema_editor.connection.alias, package_label, **self.hints
200 ):
201 self.reverse_code(from_state.packages, schema_editor)
203 def describe(self):
204 return "Raw Python operation"
206 @staticmethod
207 def noop(packages, schema_editor):
208 return None
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from .core import Template, TemplateFileMissing
3__all__ = [
4 "Template",
5 "TemplateFileMissing",
6]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import jinja2
3from .jinja import environment
6class TemplateFileMissing(Exception):
7 def __str__(self) -> str:
8 if self.args:
9 return f"Template file {self.args[0]} not found"
10 else:
11 return "Template file not found"
14class Template:
15 def __init__(self, filename: str) -> None:
16 self.filename = filename
18 try:
19 self._jinja_template = environment.get_template(filename)
20 except jinja2.TemplateNotFound:
21 raise TemplateFileMissing(filename)
23 def render(self, context: dict) -> str:
24 return self._jinja_template.render(context)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from importlib import import_module
3from plain.packages import packages
4from plain.runtime import settings
5from plain.utils.functional import LazyObject
6from plain.utils.module_loading import import_string, module_has_submodule
8from .environments import DefaultEnvironment, get_template_dirs
11class JinjaEnvironment(LazyObject):
12 def __init__(self, *args, **kwargs):
13 self.__dict__["_imported_modules"] = set()
14 super().__init__(*args, **kwargs)
16 def _setup(self):
17 environment_setting = settings.TEMPLATES_JINJA_ENVIRONMENT
19 if isinstance(environment_setting, str):
20 env = import_string(environment_setting)()
21 else:
22 env = environment_setting()
24 # We have to set _wrapped before we trigger the autoloading of "register" commands
25 self._wrapped = env
27 def _maybe_import_module(name):
28 if name not in self._imported_modules:
29 import_module(name)
30 self._imported_modules.add(name)
32 for package_config in packages.get_package_configs():
33 if module_has_submodule(package_config.module, "templates"):
34 # Allow this to fail in case there are import errors inside of their file
35 _maybe_import_module(f"{package_config.name}.templates")
37 app = import_module("app")
38 if module_has_submodule(app, "templates"):
39 # Allow this to fail in case there are import errors inside of their file
40 _maybe_import_module("app.templates")
43environment = JinjaEnvironment()
46def register_template_extension(extension_class):
47 environment.add_extension(extension_class)
48 return extension_class
51def register_template_global(value, name=None):
52 """
53 Adds a global to the Jinja environment.
55 Can be used as a decorator on a function:
57 @register_template_global
58 def my_global():
59 return "Hello, world!"
61 Or as a function:
63 register_template_global("Hello, world!", name="my_global")
64 """
65 if callable(value):
66 environment.globals[name or value.__name__] = value
67 elif name:
68 environment.globals[name] = value
69 else:
70 raise ValueError("name must be provided if value is not callable")
72 return value
75def register_template_filter(func, name=None):
76 """Adds a filter to the Jinja environment."""
77 environment.filters[name or func.__name__] = func
78 return func
81__all__ = [
82 "environment",
83 "DefaultEnvironment",
84 "get_template_dirs",
85 "register_template_extension",
86 "register_template_filter",
87 "register_template_global",
88]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import functools
2from pathlib import Path
4from jinja2 import Environment, StrictUndefined
5from jinja2.loaders import FileSystemLoader
7from plain.packages import packages
8from plain.runtime import settings
10from .filters import default_filters
11from .globals import default_globals
14def finalize_callable_error(obj):
15 """Prevent direct rendering of a callable (likely just forgotten ()) by raising a TypeError"""
16 if callable(obj):
17 raise TypeError(f"{obj} is callable, did you forget parentheses?")
19 # TODO find a way to prevent <object representation> from being rendered
20 # if obj.__class__.__str__ is object.__str__:
21 # raise TypeError(f"{obj} does not have a __str__ method")
23 return obj
26def get_template_dirs():
27 jinja_templates = Path(__file__).parent / "templates"
28 app_templates = settings.path.parent / "templates"
29 return (jinja_templates, app_templates) + _get_app_template_dirs()
32@functools.lru_cache
33def _get_app_template_dirs():
34 """
35 Return an iterable of paths of directories to load app templates from.
37 dirname is the name of the subdirectory containing templates inside
38 installed applications.
39 """
40 dirname = "templates"
41 template_dirs = [
42 Path(package_config.path) / dirname
43 for package_config in packages.get_package_configs()
44 if package_config.path and (Path(package_config.path) / dirname).is_dir()
45 ]
46 # Immutable return value because it will be cached and shared by callers.
47 return tuple(template_dirs)
50class DefaultEnvironment(Environment):
51 def __init__(self):
52 super().__init__(
53 loader=FileSystemLoader(get_template_dirs()),
54 autoescape=True,
55 auto_reload=settings.DEBUG,
56 undefined=StrictUndefined,
57 finalize=finalize_callable_error,
58 extensions=["jinja2.ext.loopcontrols", "jinja2.ext.debug"],
59 )
61 # Load the top-level defaults
62 self.globals.update(default_globals)
63 self.filters.update(default_filters)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
2from itertools import islice
4from plain.utils.html import json_script
5from plain.utils.timesince import timesince, timeuntil
6from plain.utils.timezone import localtime
9def localtime_filter(value, timezone=None):
10 """Converts a datetime to local time in a template."""
11 if not value:
12 # Without this, we get the current localtime
13 # which doesn't make sense as a filter
14 raise ValueError("localtime filter requires a datetime")
15 return localtime(value, timezone)
18default_filters = {
19 # The standard Python ones
20 "strftime": datetime.datetime.strftime,
21 "strptime": datetime.datetime.strptime,
22 # To convert to user time zone
23 "localtime": localtime_filter,
24 "timeuntil": timeuntil,
25 "timesince": timesince,
26 "json_script": json_script,
27 "islice": islice, # slice for dict.items()
28}
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.paginator import Paginator
2from plain.utils import timezone
5def url(viewname, *args, **kwargs):
6 # A modified reverse that lets you pass args directly, excluding urlconf
7 from plain.urls import reverse
9 return reverse(viewname, args=args, kwargs=kwargs)
12def asset(url_path):
13 # An explicit callable we can control, but also delay the import of asset.urls->views->templates
14 # for circular import reasons
15 from plain.assets.urls import get_asset_url
17 return get_asset_url(url_path)
20default_globals = {
21 "asset": asset,
22 "url": url,
23 "Paginator": Paginator,
24 "now": timezone.now,
25 "localtime": timezone.localtime,
26}
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from .messages import (
2 CRITICAL,
3 DEBUG,
4 ERROR,
5 INFO,
6 WARNING,
7 CheckMessage,
8 Critical,
9 Debug,
10 Error,
11 Info,
12 Warning,
13)
14from .registry import register, run_checks
16# Import these to force registration of checks
17import plain.preflight.files # NOQA isort:skip
18import plain.preflight.security.base # NOQA isort:skip
19import plain.preflight.security.csrf # NOQA isort:skip
20import plain.preflight.urls # NOQA isort:skip
23__all__ = [
24 "CheckMessage",
25 "Debug",
26 "Info",
27 "Warning",
28 "Error",
29 "Critical",
30 "DEBUG",
31 "INFO",
32 "WARNING",
33 "ERROR",
34 "CRITICAL",
35 "register",
36 "run_checks",
37]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from pathlib import Path
3from plain.runtime import settings
5from . import Error, register
8@register
9def check_setting_file_upload_temp_dir(package_configs, **kwargs):
10 setting = getattr(settings, "FILE_UPLOAD_TEMP_DIR", None)
11 if setting and not Path(setting).is_dir():
12 return [
13 Error(
14 f"The FILE_UPLOAD_TEMP_DIR setting refers to the nonexistent "
15 f"directory '{setting}'.",
16 id="files.E001",
17 ),
18 ]
19 return []
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1# Levels
2DEBUG = 10
3INFO = 20
4WARNING = 30
5ERROR = 40
6CRITICAL = 50
9class CheckMessage:
10 def __init__(self, level, msg, hint=None, obj=None, id=None):
11 if not isinstance(level, int):
12 raise TypeError("The first argument should be level.")
13 self.level = level
14 self.msg = msg
15 self.hint = hint
16 self.obj = obj
17 self.id = id
19 def __eq__(self, other):
20 return isinstance(other, self.__class__) and all(
21 getattr(self, attr) == getattr(other, attr)
22 for attr in ["level", "msg", "hint", "obj", "id"]
23 )
25 def __str__(self):
26 try:
27 from plain import models
29 ModelBase = models.base.ModelBase
30 using_db = True
31 except ImportError:
32 using_db = False
33 ModelBase = object
35 if self.obj is None:
36 obj = "?"
37 elif using_db and isinstance(self.obj, ModelBase):
38 # We need to hardcode ModelBase and Field cases because its __str__
39 # method doesn't return "applabel.modellabel" and cannot be changed.
40 obj = self.obj._meta.label
41 else:
42 obj = str(self.obj)
43 id = "(%s) " % self.id if self.id else ""
44 hint = "\n\tHINT: %s" % self.hint if self.hint else ""
45 return f"{obj}: {id}{self.msg}{hint}"
47 def __repr__(self):
48 return "<{}: level={!r}, msg={!r}, hint={!r}, obj={!r}, id={!r}>".format(
49 self.__class__.__name__,
50 self.level,
51 self.msg,
52 self.hint,
53 self.obj,
54 self.id,
55 )
57 def is_serious(self, level=ERROR):
58 return self.level >= level
60 def is_silenced(self):
61 from plain.runtime import settings
63 return self.id in settings.SILENCED_PREFLIGHT_CHECKS
66class Debug(CheckMessage):
67 def __init__(self, *args, **kwargs):
68 super().__init__(DEBUG, *args, **kwargs)
71class Info(CheckMessage):
72 def __init__(self, *args, **kwargs):
73 super().__init__(INFO, *args, **kwargs)
76class Warning(CheckMessage):
77 def __init__(self, *args, **kwargs):
78 super().__init__(WARNING, *args, **kwargs)
81class Error(CheckMessage):
82 def __init__(self, *args, **kwargs):
83 super().__init__(ERROR, *args, **kwargs)
86class Critical(CheckMessage):
87 def __init__(self, *args, **kwargs):
88 super().__init__(CRITICAL, *args, **kwargs)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.utils.inspect import func_accepts_kwargs
2from plain.utils.itercompat import is_iterable
5class CheckRegistry:
6 def __init__(self):
7 self.registered_checks = set()
8 self.deployment_checks = set()
10 def register(self, check=None, deploy=False):
11 """
12 Can be used as a function or a decorator. Register given function
13 `f`. The function should receive **kwargs
14 and return list of Errors and Warnings.
16 Example::
18 registry = CheckRegistry()
19 @registry.register('mytag', 'anothertag')
20 def my_check(package_configs, **kwargs):
21 # ... perform checks and collect `errors` ...
22 return errors
23 # or
24 registry.register(my_check, 'mytag', 'anothertag')
25 """
27 def inner(check):
28 if not func_accepts_kwargs(check):
29 raise TypeError(
30 "Check functions must accept keyword arguments (**kwargs)."
31 )
32 checks = self.deployment_checks if deploy else self.registered_checks
33 checks.add(check)
34 return check
36 if callable(check):
37 return inner(check)
38 else:
39 return inner
41 def run_checks(
42 self,
43 package_configs=None,
44 include_deployment_checks=False,
45 databases=None,
46 ):
47 """
48 Run all registered checks and return list of Errors and Warnings.
49 """
50 errors = []
51 checks = self.get_checks(include_deployment_checks)
53 for check in checks:
54 new_errors = check(package_configs=package_configs, databases=databases)
55 if not is_iterable(new_errors):
56 raise TypeError(
57 "The function %r did not return a list. All functions "
58 "registered with the checks registry must return a list." % check,
59 )
60 errors.extend(new_errors)
61 return errors
63 def get_checks(self, include_deployment_checks=False):
64 checks = list(self.registered_checks)
65 if include_deployment_checks:
66 checks.extend(self.deployment_checks)
67 return checks
70registry = CheckRegistry()
71register = registry.register
72run_checks = registry.run_checks
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from collections import Counter
3from plain.runtime import settings
5from . import Error, Warning, register
8@register
9def check_url_config(package_configs, **kwargs):
10 if getattr(settings, "ROOT_URLCONF", None):
11 from plain.urls import get_resolver
13 resolver = get_resolver()
14 return check_resolver(resolver)
15 return []
18def check_resolver(resolver):
19 """
20 Recursively check the resolver.
21 """
22 check_method = getattr(resolver, "check", None)
23 if check_method is not None:
24 return check_method()
25 elif not hasattr(resolver, "resolve"):
26 return get_warning_for_invalid_pattern(resolver)
27 else:
28 return []
31@register
32def check_url_namespaces_unique(package_configs, **kwargs):
33 """
34 Warn if URL namespaces used in applications aren't unique.
35 """
36 if not getattr(settings, "ROOT_URLCONF", None):
37 return []
39 from plain.urls import get_resolver
41 resolver = get_resolver()
42 all_namespaces = _load_all_namespaces(resolver)
43 counter = Counter(all_namespaces)
44 non_unique_namespaces = [n for n, count in counter.items() if count > 1]
45 errors = []
46 for namespace in non_unique_namespaces:
47 errors.append(
48 Warning(
49 "URL namespace '{}' isn't unique. You may not be able to reverse "
50 "all URLs in this namespace".format(namespace),
51 id="urls.W005",
52 )
53 )
54 return errors
57def _load_all_namespaces(resolver, parents=()):
58 """
59 Recursively load all namespaces from URL patterns.
60 """
61 url_patterns = getattr(resolver, "url_patterns", [])
62 namespaces = [
63 ":".join(parents + (url.namespace,))
64 for url in url_patterns
65 if getattr(url, "namespace", None) is not None
66 ]
67 for pattern in url_patterns:
68 namespace = getattr(pattern, "namespace", None)
69 current = parents
70 if namespace is not None:
71 current += (namespace,)
72 namespaces.extend(_load_all_namespaces(pattern, current))
73 return namespaces
76def get_warning_for_invalid_pattern(pattern):
77 """
78 Return a list containing a warning that the pattern is invalid.
80 describe_pattern() cannot be used here, because we cannot rely on the
81 urlpattern having regex or name attributes.
82 """
83 if isinstance(pattern, str):
84 hint = (
85 f"Try removing the string '{pattern}'. The list of urlpatterns should not "
86 "have a prefix string as the first element."
87 )
88 elif isinstance(pattern, tuple):
89 hint = "Try using path() instead of a tuple."
90 else:
91 hint = None
93 return [
94 Error(
95 "Your URL pattern {!r} is invalid. Ensure that urlpatterns is a list "
96 "of path() and/or re_path() instances.".format(pattern),
97 hint=hint,
98 id="urls.E004",
99 )
100 ]
103def E006(name):
104 return Error(
105 f"The {name} setting must end with a slash.",
106 id="urls.E006",
107 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from .comparison import Cast, Coalesce, Collate, Greatest, JSONObject, Least, NullIf
2from .datetime import (
3 Extract,
4 ExtractDay,
5 ExtractHour,
6 ExtractIsoWeekDay,
7 ExtractIsoYear,
8 ExtractMinute,
9 ExtractMonth,
10 ExtractQuarter,
11 ExtractSecond,
12 ExtractWeek,
13 ExtractWeekDay,
14 ExtractYear,
15 Now,
16 Trunc,
17 TruncDate,
18 TruncDay,
19 TruncHour,
20 TruncMinute,
21 TruncMonth,
22 TruncQuarter,
23 TruncSecond,
24 TruncTime,
25 TruncWeek,
26 TruncYear,
27)
28from .math import (
29 Abs,
30 ACos,
31 ASin,
32 ATan,
33 ATan2,
34 Ceil,
35 Cos,
36 Cot,
37 Degrees,
38 Exp,
39 Floor,
40 Ln,
41 Log,
42 Mod,
43 Pi,
44 Power,
45 Radians,
46 Random,
47 Round,
48 Sign,
49 Sin,
50 Sqrt,
51 Tan,
52)
53from .text import (
54 MD5,
55 SHA1,
56 SHA224,
57 SHA256,
58 SHA384,
59 SHA512,
60 Chr,
61 Concat,
62 ConcatPair,
63 Left,
64 Length,
65 Lower,
66 LPad,
67 LTrim,
68 Ord,
69 Repeat,
70 Replace,
71 Reverse,
72 Right,
73 RPad,
74 RTrim,
75 StrIndex,
76 Substr,
77 Trim,
78 Upper,
79)
80from .window import (
81 CumeDist,
82 DenseRank,
83 FirstValue,
84 Lag,
85 LastValue,
86 Lead,
87 NthValue,
88 Ntile,
89 PercentRank,
90 Rank,
91 RowNumber,
92)
94__all__ = [
95 # comparison and conversion
96 "Cast",
97 "Coalesce",
98 "Collate",
99 "Greatest",
100 "JSONObject",
101 "Least",
102 "NullIf",
103 # datetime
104 "Extract",
105 "ExtractDay",
106 "ExtractHour",
107 "ExtractMinute",
108 "ExtractMonth",
109 "ExtractQuarter",
110 "ExtractSecond",
111 "ExtractWeek",
112 "ExtractIsoWeekDay",
113 "ExtractWeekDay",
114 "ExtractIsoYear",
115 "ExtractYear",
116 "Now",
117 "Trunc",
118 "TruncDate",
119 "TruncDay",
120 "TruncHour",
121 "TruncMinute",
122 "TruncMonth",
123 "TruncQuarter",
124 "TruncSecond",
125 "TruncTime",
126 "TruncWeek",
127 "TruncYear",
128 # math
129 "Abs",
130 "ACos",
131 "ASin",
132 "ATan",
133 "ATan2",
134 "Ceil",
135 "Cos",
136 "Cot",
137 "Degrees",
138 "Exp",
139 "Floor",
140 "Ln",
141 "Log",
142 "Mod",
143 "Pi",
144 "Power",
145 "Radians",
146 "Random",
147 "Round",
148 "Sign",
149 "Sin",
150 "Sqrt",
151 "Tan",
152 # text
153 "MD5",
154 "SHA1",
155 "SHA224",
156 "SHA256",
157 "SHA384",
158 "SHA512",
159 "Chr",
160 "Concat",
161 "ConcatPair",
162 "Left",
163 "Length",
164 "Lower",
165 "LPad",
166 "LTrim",
167 "Ord",
168 "Repeat",
169 "Replace",
170 "Reverse",
171 "Right",
172 "RPad",
173 "RTrim",
174 "StrIndex",
175 "Substr",
176 "Trim",
177 "Upper",
178 # window
179 "CumeDist",
180 "DenseRank",
181 "FirstValue",
182 "Lag",
183 "LastValue",
184 "Lead",
185 "NthValue",
186 "Ntile",
187 "PercentRank",
188 "Rank",
189 "RowNumber",
190]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""Database functions that do comparisons or type conversions."""
3from plain.models.db import NotSupportedError
4from plain.models.expressions import Func, Value
5from plain.models.fields import TextField
6from plain.models.fields.json import JSONField
7from plain.utils.regex_helper import _lazy_re_compile
10class Cast(Func):
11 """Coerce an expression to a new field type."""
13 function = "CAST"
14 template = "%(function)s(%(expressions)s AS %(db_type)s)"
16 def __init__(self, expression, output_field):
17 super().__init__(expression, output_field=output_field)
19 def as_sql(self, compiler, connection, **extra_context):
20 extra_context["db_type"] = self.output_field.cast_db_type(connection)
21 return super().as_sql(compiler, connection, **extra_context)
23 def as_sqlite(self, compiler, connection, **extra_context):
24 db_type = self.output_field.db_type(connection)
25 if db_type in {"datetime", "time"}:
26 # Use strftime as datetime/time don't keep fractional seconds.
27 template = "strftime(%%s, %(expressions)s)"
28 sql, params = super().as_sql(
29 compiler, connection, template=template, **extra_context
30 )
31 format_string = "%H:%M:%f" if db_type == "time" else "%Y-%m-%d %H:%M:%f"
32 params.insert(0, format_string)
33 return sql, params
34 elif db_type == "date":
35 template = "date(%(expressions)s)"
36 return super().as_sql(
37 compiler, connection, template=template, **extra_context
38 )
39 return self.as_sql(compiler, connection, **extra_context)
41 def as_mysql(self, compiler, connection, **extra_context):
42 template = None
43 output_type = self.output_field.get_internal_type()
44 # MySQL doesn't support explicit cast to float.
45 if output_type == "FloatField":
46 template = "(%(expressions)s + 0.0)"
47 # MariaDB doesn't support explicit cast to JSON.
48 elif output_type == "JSONField" and connection.mysql_is_mariadb:
49 template = "JSON_EXTRACT(%(expressions)s, '$')"
50 return self.as_sql(compiler, connection, template=template, **extra_context)
52 def as_postgresql(self, compiler, connection, **extra_context):
53 # CAST would be valid too, but the :: shortcut syntax is more readable.
54 # 'expressions' is wrapped in parentheses in case it's a complex
55 # expression.
56 return self.as_sql(
57 compiler,
58 connection,
59 template="(%(expressions)s)::%(db_type)s",
60 **extra_context,
61 )
64class Coalesce(Func):
65 """Return, from left to right, the first non-null expression."""
67 function = "COALESCE"
69 def __init__(self, *expressions, **extra):
70 if len(expressions) < 2:
71 raise ValueError("Coalesce must take at least two expressions")
72 super().__init__(*expressions, **extra)
74 @property
75 def empty_result_set_value(self):
76 for expression in self.get_source_expressions():
77 result = expression.empty_result_set_value
78 if result is NotImplemented or result is not None:
79 return result
80 return None
83class Collate(Func):
84 function = "COLLATE"
85 template = "%(expressions)s %(function)s %(collation)s"
86 # Inspired from
87 # https://www.postgresql.org/docs/current/sql-syntax-lexical.html#SQL-SYNTAX-IDENTIFIERS
88 collation_re = _lazy_re_compile(r"^[\w\-]+$")
90 def __init__(self, expression, collation):
91 if not (collation and self.collation_re.match(collation)):
92 raise ValueError(f"Invalid collation name: {collation!r}.")
93 self.collation = collation
94 super().__init__(expression)
96 def as_sql(self, compiler, connection, **extra_context):
97 extra_context.setdefault("collation", connection.ops.quote_name(self.collation))
98 return super().as_sql(compiler, connection, **extra_context)
101class Greatest(Func):
102 """
103 Return the maximum expression.
105 If any expression is null the return value is database-specific:
106 On PostgreSQL, the maximum not-null expression is returned.
107 On MySQL, Oracle, and SQLite, if any expression is null, null is returned.
108 """
110 function = "GREATEST"
112 def __init__(self, *expressions, **extra):
113 if len(expressions) < 2:
114 raise ValueError("Greatest must take at least two expressions")
115 super().__init__(*expressions, **extra)
117 def as_sqlite(self, compiler, connection, **extra_context):
118 """Use the MAX function on SQLite."""
119 return super().as_sqlite(compiler, connection, function="MAX", **extra_context)
122class JSONObject(Func):
123 function = "JSON_OBJECT"
124 output_field = JSONField()
126 def __init__(self, **fields):
127 expressions = []
128 for key, value in fields.items():
129 expressions.extend((Value(key), value))
130 super().__init__(*expressions)
132 def as_sql(self, compiler, connection, **extra_context):
133 if not connection.features.has_json_object_function:
134 raise NotSupportedError(
135 "JSONObject() is not supported on this database backend."
136 )
137 return super().as_sql(compiler, connection, **extra_context)
139 def as_postgresql(self, compiler, connection, **extra_context):
140 copy = self.copy()
141 copy.set_source_expressions(
142 [
143 Cast(expression, TextField()) if index % 2 == 0 else expression
144 for index, expression in enumerate(copy.get_source_expressions())
145 ]
146 )
147 return super(JSONObject, copy).as_sql(
148 compiler,
149 connection,
150 function="JSONB_BUILD_OBJECT",
151 **extra_context,
152 )
155class Least(Func):
156 """
157 Return the minimum expression.
159 If any expression is null the return value is database-specific:
160 On PostgreSQL, return the minimum not-null expression.
161 On MySQL, Oracle, and SQLite, if any expression is null, return null.
162 """
164 function = "LEAST"
166 def __init__(self, *expressions, **extra):
167 if len(expressions) < 2:
168 raise ValueError("Least must take at least two expressions")
169 super().__init__(*expressions, **extra)
171 def as_sqlite(self, compiler, connection, **extra_context):
172 """Use the MIN function on SQLite."""
173 return super().as_sqlite(compiler, connection, function="MIN", **extra_context)
176class NullIf(Func):
177 function = "NULLIF"
178 arity = 2
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from datetime import datetime
3from plain.models.expressions import Func
4from plain.models.fields import (
5 DateField,
6 DateTimeField,
7 DurationField,
8 Field,
9 IntegerField,
10 TimeField,
11)
12from plain.models.lookups import (
13 Transform,
14 YearExact,
15 YearGt,
16 YearGte,
17 YearLt,
18 YearLte,
19)
20from plain.utils import timezone
23class TimezoneMixin:
24 tzinfo = None
26 def get_tzname(self):
27 # Timezone conversions must happen to the input datetime *before*
28 # applying a function. 2015-12-31 23:00:00 -02:00 is stored in the
29 # database as 2016-01-01 01:00:00 +00:00. Any results should be
30 # based on the input datetime not the stored datetime.
31 if self.tzinfo is None:
32 return timezone.get_current_timezone_name()
33 else:
34 return timezone._get_timezone_name(self.tzinfo)
37class Extract(TimezoneMixin, Transform):
38 lookup_name = None
39 output_field = IntegerField()
41 def __init__(self, expression, lookup_name=None, tzinfo=None, **extra):
42 if self.lookup_name is None:
43 self.lookup_name = lookup_name
44 if self.lookup_name is None:
45 raise ValueError("lookup_name must be provided")
46 self.tzinfo = tzinfo
47 super().__init__(expression, **extra)
49 def as_sql(self, compiler, connection):
50 sql, params = compiler.compile(self.lhs)
51 lhs_output_field = self.lhs.output_field
52 if isinstance(lhs_output_field, DateTimeField):
53 tzname = self.get_tzname()
54 sql, params = connection.ops.datetime_extract_sql(
55 self.lookup_name, sql, tuple(params), tzname
56 )
57 elif self.tzinfo is not None:
58 raise ValueError("tzinfo can only be used with DateTimeField.")
59 elif isinstance(lhs_output_field, DateField):
60 sql, params = connection.ops.date_extract_sql(
61 self.lookup_name, sql, tuple(params)
62 )
63 elif isinstance(lhs_output_field, TimeField):
64 sql, params = connection.ops.time_extract_sql(
65 self.lookup_name, sql, tuple(params)
66 )
67 elif isinstance(lhs_output_field, DurationField):
68 if not connection.features.has_native_duration_field:
69 raise ValueError(
70 "Extract requires native DurationField database support."
71 )
72 sql, params = connection.ops.time_extract_sql(
73 self.lookup_name, sql, tuple(params)
74 )
75 else:
76 # resolve_expression has already validated the output_field so this
77 # assert should never be hit.
78 raise ValueError("Tried to Extract from an invalid type.")
79 return sql, params
81 def resolve_expression(
82 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
83 ):
84 copy = super().resolve_expression(
85 query, allow_joins, reuse, summarize, for_save
86 )
87 field = getattr(copy.lhs, "output_field", None)
88 if field is None:
89 return copy
90 if not isinstance(field, DateField | DateTimeField | TimeField | DurationField):
91 raise ValueError(
92 "Extract input expression must be DateField, DateTimeField, "
93 "TimeField, or DurationField."
94 )
95 # Passing dates to functions expecting datetimes is most likely a mistake.
96 if type(field) == DateField and copy.lookup_name in (
97 "hour",
98 "minute",
99 "second",
100 ):
101 raise ValueError(
102 f"Cannot extract time component '{copy.lookup_name}' from DateField '{field.name}'."
103 )
104 if isinstance(field, DurationField) and copy.lookup_name in (
105 "year",
106 "iso_year",
107 "month",
108 "week",
109 "week_day",
110 "iso_week_day",
111 "quarter",
112 ):
113 raise ValueError(
114 f"Cannot extract component '{copy.lookup_name}' from DurationField '{field.name}'."
115 )
116 return copy
119class ExtractYear(Extract):
120 lookup_name = "year"
123class ExtractIsoYear(Extract):
124 """Return the ISO-8601 week-numbering year."""
126 lookup_name = "iso_year"
129class ExtractMonth(Extract):
130 lookup_name = "month"
133class ExtractDay(Extract):
134 lookup_name = "day"
137class ExtractWeek(Extract):
138 """
139 Return 1-52 or 53, based on ISO-8601, i.e., Monday is the first of the
140 week.
141 """
143 lookup_name = "week"
146class ExtractWeekDay(Extract):
147 """
148 Return Sunday=1 through Saturday=7.
150 To replicate this in Python: (mydatetime.isoweekday() % 7) + 1
151 """
153 lookup_name = "week_day"
156class ExtractIsoWeekDay(Extract):
157 """Return Monday=1 through Sunday=7, based on ISO-8601."""
159 lookup_name = "iso_week_day"
162class ExtractQuarter(Extract):
163 lookup_name = "quarter"
166class ExtractHour(Extract):
167 lookup_name = "hour"
170class ExtractMinute(Extract):
171 lookup_name = "minute"
174class ExtractSecond(Extract):
175 lookup_name = "second"
178DateField.register_lookup(ExtractYear)
179DateField.register_lookup(ExtractMonth)
180DateField.register_lookup(ExtractDay)
181DateField.register_lookup(ExtractWeekDay)
182DateField.register_lookup(ExtractIsoWeekDay)
183DateField.register_lookup(ExtractWeek)
184DateField.register_lookup(ExtractIsoYear)
185DateField.register_lookup(ExtractQuarter)
187TimeField.register_lookup(ExtractHour)
188TimeField.register_lookup(ExtractMinute)
189TimeField.register_lookup(ExtractSecond)
191DateTimeField.register_lookup(ExtractHour)
192DateTimeField.register_lookup(ExtractMinute)
193DateTimeField.register_lookup(ExtractSecond)
195ExtractYear.register_lookup(YearExact)
196ExtractYear.register_lookup(YearGt)
197ExtractYear.register_lookup(YearGte)
198ExtractYear.register_lookup(YearLt)
199ExtractYear.register_lookup(YearLte)
201ExtractIsoYear.register_lookup(YearExact)
202ExtractIsoYear.register_lookup(YearGt)
203ExtractIsoYear.register_lookup(YearGte)
204ExtractIsoYear.register_lookup(YearLt)
205ExtractIsoYear.register_lookup(YearLte)
208class Now(Func):
209 template = "CURRENT_TIMESTAMP"
210 output_field = DateTimeField()
212 def as_postgresql(self, compiler, connection, **extra_context):
213 # PostgreSQL's CURRENT_TIMESTAMP means "the time at the start of the
214 # transaction". Use STATEMENT_TIMESTAMP to be cross-compatible with
215 # other databases.
216 return self.as_sql(
217 compiler, connection, template="STATEMENT_TIMESTAMP()", **extra_context
218 )
220 def as_mysql(self, compiler, connection, **extra_context):
221 return self.as_sql(
222 compiler, connection, template="CURRENT_TIMESTAMP(6)", **extra_context
223 )
225 def as_sqlite(self, compiler, connection, **extra_context):
226 return self.as_sql(
227 compiler,
228 connection,
229 template="STRFTIME('%%%%Y-%%%%m-%%%%d %%%%H:%%%%M:%%%%f', 'NOW')",
230 **extra_context,
231 )
234class TruncBase(TimezoneMixin, Transform):
235 kind = None
236 tzinfo = None
238 def __init__(
239 self,
240 expression,
241 output_field=None,
242 tzinfo=None,
243 **extra,
244 ):
245 self.tzinfo = tzinfo
246 super().__init__(expression, output_field=output_field, **extra)
248 def as_sql(self, compiler, connection):
249 sql, params = compiler.compile(self.lhs)
250 tzname = None
251 if isinstance(self.lhs.output_field, DateTimeField):
252 tzname = self.get_tzname()
253 elif self.tzinfo is not None:
254 raise ValueError("tzinfo can only be used with DateTimeField.")
255 if isinstance(self.output_field, DateTimeField):
256 sql, params = connection.ops.datetime_trunc_sql(
257 self.kind, sql, tuple(params), tzname
258 )
259 elif isinstance(self.output_field, DateField):
260 sql, params = connection.ops.date_trunc_sql(
261 self.kind, sql, tuple(params), tzname
262 )
263 elif isinstance(self.output_field, TimeField):
264 sql, params = connection.ops.time_trunc_sql(
265 self.kind, sql, tuple(params), tzname
266 )
267 else:
268 raise ValueError(
269 "Trunc only valid on DateField, TimeField, or DateTimeField."
270 )
271 return sql, params
273 def resolve_expression(
274 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
275 ):
276 copy = super().resolve_expression(
277 query, allow_joins, reuse, summarize, for_save
278 )
279 field = copy.lhs.output_field
280 # DateTimeField is a subclass of DateField so this works for both.
281 if not isinstance(field, DateField | TimeField):
282 raise TypeError(
283 f"{field.name!r} isn't a DateField, TimeField, or DateTimeField."
284 )
285 # If self.output_field was None, then accessing the field will trigger
286 # the resolver to assign it to self.lhs.output_field.
287 if not isinstance(copy.output_field, DateField | DateTimeField | TimeField):
288 raise ValueError(
289 "output_field must be either DateField, TimeField, or DateTimeField"
290 )
291 # Passing dates or times to functions expecting datetimes is most
292 # likely a mistake.
293 class_output_field = (
294 self.__class__.output_field
295 if isinstance(self.__class__.output_field, Field)
296 else None
297 )
298 output_field = class_output_field or copy.output_field
299 has_explicit_output_field = (
300 class_output_field or field.__class__ is not copy.output_field.__class__
301 )
302 if type(field) == DateField and (
303 isinstance(output_field, DateTimeField)
304 or copy.kind in ("hour", "minute", "second", "time")
305 ):
306 raise ValueError(
307 "Cannot truncate DateField '{}' to {}.".format(
308 field.name,
309 output_field.__class__.__name__
310 if has_explicit_output_field
311 else "DateTimeField",
312 )
313 )
314 elif isinstance(field, TimeField) and (
315 isinstance(output_field, DateTimeField)
316 or copy.kind in ("year", "quarter", "month", "week", "day", "date")
317 ):
318 raise ValueError(
319 "Cannot truncate TimeField '{}' to {}.".format(
320 field.name,
321 output_field.__class__.__name__
322 if has_explicit_output_field
323 else "DateTimeField",
324 )
325 )
326 return copy
328 def convert_value(self, value, expression, connection):
329 if isinstance(self.output_field, DateTimeField):
330 if value is not None:
331 value = value.replace(tzinfo=None)
332 value = timezone.make_aware(value, self.tzinfo)
333 elif not connection.features.has_zoneinfo_database:
334 raise ValueError(
335 "Database returned an invalid datetime value. Are time "
336 "zone definitions for your database installed?"
337 )
338 elif isinstance(value, datetime):
339 if value is None:
340 pass
341 elif isinstance(self.output_field, DateField):
342 value = value.date()
343 elif isinstance(self.output_field, TimeField):
344 value = value.time()
345 return value
348class Trunc(TruncBase):
349 def __init__(
350 self,
351 expression,
352 kind,
353 output_field=None,
354 tzinfo=None,
355 **extra,
356 ):
357 self.kind = kind
358 super().__init__(expression, output_field=output_field, tzinfo=tzinfo, **extra)
361class TruncYear(TruncBase):
362 kind = "year"
365class TruncQuarter(TruncBase):
366 kind = "quarter"
369class TruncMonth(TruncBase):
370 kind = "month"
373class TruncWeek(TruncBase):
374 """Truncate to midnight on the Monday of the week."""
376 kind = "week"
379class TruncDay(TruncBase):
380 kind = "day"
383class TruncDate(TruncBase):
384 kind = "date"
385 lookup_name = "date"
386 output_field = DateField()
388 def as_sql(self, compiler, connection):
389 # Cast to date rather than truncate to date.
390 sql, params = compiler.compile(self.lhs)
391 tzname = self.get_tzname()
392 return connection.ops.datetime_cast_date_sql(sql, tuple(params), tzname)
395class TruncTime(TruncBase):
396 kind = "time"
397 lookup_name = "time"
398 output_field = TimeField()
400 def as_sql(self, compiler, connection):
401 # Cast to time rather than truncate to time.
402 sql, params = compiler.compile(self.lhs)
403 tzname = self.get_tzname()
404 return connection.ops.datetime_cast_time_sql(sql, tuple(params), tzname)
407class TruncHour(TruncBase):
408 kind = "hour"
411class TruncMinute(TruncBase):
412 kind = "minute"
415class TruncSecond(TruncBase):
416 kind = "second"
419DateTimeField.register_lookup(TruncDate)
420DateTimeField.register_lookup(TruncTime)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.models.expressions import Func, Value
2from plain.models.fields import FloatField, IntegerField
3from plain.models.functions import Cast
4from plain.models.functions.mixins import (
5 FixDecimalInputMixin,
6 NumericOutputFieldMixin,
7)
8from plain.models.lookups import Transform
11class Abs(Transform):
12 function = "ABS"
13 lookup_name = "abs"
16class ACos(NumericOutputFieldMixin, Transform):
17 function = "ACOS"
18 lookup_name = "acos"
21class ASin(NumericOutputFieldMixin, Transform):
22 function = "ASIN"
23 lookup_name = "asin"
26class ATan(NumericOutputFieldMixin, Transform):
27 function = "ATAN"
28 lookup_name = "atan"
31class ATan2(NumericOutputFieldMixin, Func):
32 function = "ATAN2"
33 arity = 2
35 def as_sqlite(self, compiler, connection, **extra_context):
36 if not getattr(
37 connection.ops, "spatialite", False
38 ) or connection.ops.spatial_version >= (5, 0, 0):
39 return self.as_sql(compiler, connection)
40 # This function is usually ATan2(y, x), returning the inverse tangent
41 # of y / x, but it's ATan2(x, y) on SpatiaLite < 5.0.0.
42 # Cast integers to float to avoid inconsistent/buggy behavior if the
43 # arguments are mixed between integer and float or decimal.
44 # https://www.gaia-gis.it/fossil/libspatialite/tktview?name=0f72cca3a2
45 clone = self.copy()
46 clone.set_source_expressions(
47 [
48 Cast(expression, FloatField())
49 if isinstance(expression.output_field, IntegerField)
50 else expression
51 for expression in self.get_source_expressions()[::-1]
52 ]
53 )
54 return clone.as_sql(compiler, connection, **extra_context)
57class Ceil(Transform):
58 function = "CEILING"
59 lookup_name = "ceil"
62class Cos(NumericOutputFieldMixin, Transform):
63 function = "COS"
64 lookup_name = "cos"
67class Cot(NumericOutputFieldMixin, Transform):
68 function = "COT"
69 lookup_name = "cot"
72class Degrees(NumericOutputFieldMixin, Transform):
73 function = "DEGREES"
74 lookup_name = "degrees"
77class Exp(NumericOutputFieldMixin, Transform):
78 function = "EXP"
79 lookup_name = "exp"
82class Floor(Transform):
83 function = "FLOOR"
84 lookup_name = "floor"
87class Ln(NumericOutputFieldMixin, Transform):
88 function = "LN"
89 lookup_name = "ln"
92class Log(FixDecimalInputMixin, NumericOutputFieldMixin, Func):
93 function = "LOG"
94 arity = 2
96 def as_sqlite(self, compiler, connection, **extra_context):
97 if not getattr(connection.ops, "spatialite", False):
98 return self.as_sql(compiler, connection)
99 # This function is usually Log(b, x) returning the logarithm of x to
100 # the base b, but on SpatiaLite it's Log(x, b).
101 clone = self.copy()
102 clone.set_source_expressions(self.get_source_expressions()[::-1])
103 return clone.as_sql(compiler, connection, **extra_context)
106class Mod(FixDecimalInputMixin, NumericOutputFieldMixin, Func):
107 function = "MOD"
108 arity = 2
111class Pi(NumericOutputFieldMixin, Func):
112 function = "PI"
113 arity = 0
116class Power(NumericOutputFieldMixin, Func):
117 function = "POWER"
118 arity = 2
121class Radians(NumericOutputFieldMixin, Transform):
122 function = "RADIANS"
123 lookup_name = "radians"
126class Random(NumericOutputFieldMixin, Func):
127 function = "RANDOM"
128 arity = 0
130 def as_mysql(self, compiler, connection, **extra_context):
131 return super().as_sql(compiler, connection, function="RAND", **extra_context)
133 def as_sqlite(self, compiler, connection, **extra_context):
134 return super().as_sql(compiler, connection, function="RAND", **extra_context)
136 def get_group_by_cols(self):
137 return []
140class Round(FixDecimalInputMixin, Transform):
141 function = "ROUND"
142 lookup_name = "round"
143 arity = None # Override Transform's arity=1 to enable passing precision.
145 def __init__(self, expression, precision=0, **extra):
146 super().__init__(expression, precision, **extra)
148 def as_sqlite(self, compiler, connection, **extra_context):
149 precision = self.get_source_expressions()[1]
150 if isinstance(precision, Value) and precision.value < 0:
151 raise ValueError("SQLite does not support negative precision.")
152 return super().as_sqlite(compiler, connection, **extra_context)
154 def _resolve_output_field(self):
155 source = self.get_source_expressions()[0]
156 return source.output_field
159class Sign(Transform):
160 function = "SIGN"
161 lookup_name = "sign"
164class Sin(NumericOutputFieldMixin, Transform):
165 function = "SIN"
166 lookup_name = "sin"
169class Sqrt(NumericOutputFieldMixin, Transform):
170 function = "SQRT"
171 lookup_name = "sqrt"
174class Tan(NumericOutputFieldMixin, Transform):
175 function = "TAN"
176 lookup_name = "tan"
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import sys
3from plain.models.fields import DecimalField, FloatField, IntegerField
4from plain.models.functions import Cast
7class FixDecimalInputMixin:
8 def as_postgresql(self, compiler, connection, **extra_context):
9 # Cast FloatField to DecimalField as PostgreSQL doesn't support the
10 # following function signatures:
11 # - LOG(double, double)
12 # - MOD(double, double)
13 output_field = DecimalField(decimal_places=sys.float_info.dig, max_digits=1000)
14 clone = self.copy()
15 clone.set_source_expressions(
16 [
17 Cast(expression, output_field)
18 if isinstance(expression.output_field, FloatField)
19 else expression
20 for expression in self.get_source_expressions()
21 ]
22 )
23 return clone.as_sql(compiler, connection, **extra_context)
26class FixDurationInputMixin:
27 def as_mysql(self, compiler, connection, **extra_context):
28 sql, params = super().as_sql(compiler, connection, **extra_context)
29 if self.output_field.get_internal_type() == "DurationField":
30 sql = f"CAST({sql} AS SIGNED)"
31 return sql, params
34class NumericOutputFieldMixin:
35 def _resolve_output_field(self):
36 source_fields = self.get_source_fields()
37 if any(isinstance(s, DecimalField) for s in source_fields):
38 return DecimalField()
39 if any(isinstance(s, IntegerField) for s in source_fields):
40 return FloatField()
41 return super()._resolve_output_field() if source_fields else FloatField()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.models.expressions import Func, Value
2from plain.models.fields import CharField, IntegerField, TextField
3from plain.models.functions import Cast, Coalesce
4from plain.models.lookups import Transform
7class MySQLSHA2Mixin:
8 def as_mysql(self, compiler, connection, **extra_context):
9 return super().as_sql(
10 compiler,
11 connection,
12 template=f"SHA2(%(expressions)s, {self.function[3:]})",
13 **extra_context,
14 )
17class PostgreSQLSHAMixin:
18 def as_postgresql(self, compiler, connection, **extra_context):
19 return super().as_sql(
20 compiler,
21 connection,
22 template="ENCODE(DIGEST(%(expressions)s, '%(function)s'), 'hex')",
23 function=self.function.lower(),
24 **extra_context,
25 )
28class Chr(Transform):
29 function = "CHR"
30 lookup_name = "chr"
32 def as_mysql(self, compiler, connection, **extra_context):
33 return super().as_sql(
34 compiler,
35 connection,
36 function="CHAR",
37 template="%(function)s(%(expressions)s USING utf16)",
38 **extra_context,
39 )
41 def as_sqlite(self, compiler, connection, **extra_context):
42 return super().as_sql(compiler, connection, function="CHAR", **extra_context)
45class ConcatPair(Func):
46 """
47 Concatenate two arguments together. This is used by `Concat` because not
48 all backend databases support more than two arguments.
49 """
51 function = "CONCAT"
53 def as_sqlite(self, compiler, connection, **extra_context):
54 coalesced = self.coalesce()
55 return super(ConcatPair, coalesced).as_sql(
56 compiler,
57 connection,
58 template="%(expressions)s",
59 arg_joiner=" || ",
60 **extra_context,
61 )
63 def as_postgresql(self, compiler, connection, **extra_context):
64 copy = self.copy()
65 copy.set_source_expressions(
66 [
67 Cast(expression, TextField())
68 for expression in copy.get_source_expressions()
69 ]
70 )
71 return super(ConcatPair, copy).as_sql(
72 compiler,
73 connection,
74 **extra_context,
75 )
77 def as_mysql(self, compiler, connection, **extra_context):
78 # Use CONCAT_WS with an empty separator so that NULLs are ignored.
79 return super().as_sql(
80 compiler,
81 connection,
82 function="CONCAT_WS",
83 template="%(function)s('', %(expressions)s)",
84 **extra_context,
85 )
87 def coalesce(self):
88 # null on either side results in null for expression, wrap with coalesce
89 c = self.copy()
90 c.set_source_expressions(
91 [
92 Coalesce(expression, Value(""))
93 for expression in c.get_source_expressions()
94 ]
95 )
96 return c
99class Concat(Func):
100 """
101 Concatenate text fields together. Backends that result in an entire
102 null expression when any arguments are null will wrap each argument in
103 coalesce functions to ensure a non-null result.
104 """
106 function = None
107 template = "%(expressions)s"
109 def __init__(self, *expressions, **extra):
110 if len(expressions) < 2:
111 raise ValueError("Concat must take at least two expressions")
112 paired = self._paired(expressions)
113 super().__init__(paired, **extra)
115 def _paired(self, expressions):
116 # wrap pairs of expressions in successive concat functions
117 # exp = [a, b, c, d]
118 # -> ConcatPair(a, ConcatPair(b, ConcatPair(c, d))))
119 if len(expressions) == 2:
120 return ConcatPair(*expressions)
121 return ConcatPair(expressions[0], self._paired(expressions[1:]))
124class Left(Func):
125 function = "LEFT"
126 arity = 2
127 output_field = CharField()
129 def __init__(self, expression, length, **extra):
130 """
131 expression: the name of a field, or an expression returning a string
132 length: the number of characters to return from the start of the string
133 """
134 if not hasattr(length, "resolve_expression"):
135 if length < 1:
136 raise ValueError("'length' must be greater than 0.")
137 super().__init__(expression, length, **extra)
139 def get_substr(self):
140 return Substr(self.source_expressions[0], Value(1), self.source_expressions[1])
142 def as_sqlite(self, compiler, connection, **extra_context):
143 return self.get_substr().as_sqlite(compiler, connection, **extra_context)
146class Length(Transform):
147 """Return the number of characters in the expression."""
149 function = "LENGTH"
150 lookup_name = "length"
151 output_field = IntegerField()
153 def as_mysql(self, compiler, connection, **extra_context):
154 return super().as_sql(
155 compiler, connection, function="CHAR_LENGTH", **extra_context
156 )
159class Lower(Transform):
160 function = "LOWER"
161 lookup_name = "lower"
164class LPad(Func):
165 function = "LPAD"
166 output_field = CharField()
168 def __init__(self, expression, length, fill_text=Value(" "), **extra):
169 if (
170 not hasattr(length, "resolve_expression")
171 and length is not None
172 and length < 0
173 ):
174 raise ValueError("'length' must be greater or equal to 0.")
175 super().__init__(expression, length, fill_text, **extra)
178class LTrim(Transform):
179 function = "LTRIM"
180 lookup_name = "ltrim"
183class MD5(Transform):
184 function = "MD5"
185 lookup_name = "md5"
188class Ord(Transform):
189 function = "ASCII"
190 lookup_name = "ord"
191 output_field = IntegerField()
193 def as_mysql(self, compiler, connection, **extra_context):
194 return super().as_sql(compiler, connection, function="ORD", **extra_context)
196 def as_sqlite(self, compiler, connection, **extra_context):
197 return super().as_sql(compiler, connection, function="UNICODE", **extra_context)
200class Repeat(Func):
201 function = "REPEAT"
202 output_field = CharField()
204 def __init__(self, expression, number, **extra):
205 if (
206 not hasattr(number, "resolve_expression")
207 and number is not None
208 and number < 0
209 ):
210 raise ValueError("'number' must be greater or equal to 0.")
211 super().__init__(expression, number, **extra)
214class Replace(Func):
215 function = "REPLACE"
217 def __init__(self, expression, text, replacement=Value(""), **extra):
218 super().__init__(expression, text, replacement, **extra)
221class Reverse(Transform):
222 function = "REVERSE"
223 lookup_name = "reverse"
226class Right(Left):
227 function = "RIGHT"
229 def get_substr(self):
230 return Substr(
231 self.source_expressions[0], self.source_expressions[1] * Value(-1)
232 )
235class RPad(LPad):
236 function = "RPAD"
239class RTrim(Transform):
240 function = "RTRIM"
241 lookup_name = "rtrim"
244class SHA1(PostgreSQLSHAMixin, Transform):
245 function = "SHA1"
246 lookup_name = "sha1"
249class SHA224(MySQLSHA2Mixin, PostgreSQLSHAMixin, Transform):
250 function = "SHA224"
251 lookup_name = "sha224"
254class SHA256(MySQLSHA2Mixin, PostgreSQLSHAMixin, Transform):
255 function = "SHA256"
256 lookup_name = "sha256"
259class SHA384(MySQLSHA2Mixin, PostgreSQLSHAMixin, Transform):
260 function = "SHA384"
261 lookup_name = "sha384"
264class SHA512(MySQLSHA2Mixin, PostgreSQLSHAMixin, Transform):
265 function = "SHA512"
266 lookup_name = "sha512"
269class StrIndex(Func):
270 """
271 Return a positive integer corresponding to the 1-indexed position of the
272 first occurrence of a substring inside another string, or 0 if the
273 substring is not found.
274 """
276 function = "INSTR"
277 arity = 2
278 output_field = IntegerField()
280 def as_postgresql(self, compiler, connection, **extra_context):
281 return super().as_sql(compiler, connection, function="STRPOS", **extra_context)
284class Substr(Func):
285 function = "SUBSTRING"
286 output_field = CharField()
288 def __init__(self, expression, pos, length=None, **extra):
289 """
290 expression: the name of a field, or an expression returning a string
291 pos: an integer > 0, or an expression returning an integer
292 length: an optional number of characters to return
293 """
294 if not hasattr(pos, "resolve_expression"):
295 if pos < 1:
296 raise ValueError("'pos' must be greater than 0")
297 expressions = [expression, pos]
298 if length is not None:
299 expressions.append(length)
300 super().__init__(*expressions, **extra)
302 def as_sqlite(self, compiler, connection, **extra_context):
303 return super().as_sql(compiler, connection, function="SUBSTR", **extra_context)
306class Trim(Transform):
307 function = "TRIM"
308 lookup_name = "trim"
311class Upper(Transform):
312 function = "UPPER"
313 lookup_name = "upper"
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.models.expressions import Func
2from plain.models.fields import FloatField, IntegerField
4__all__ = [
5 "CumeDist",
6 "DenseRank",
7 "FirstValue",
8 "Lag",
9 "LastValue",
10 "Lead",
11 "NthValue",
12 "Ntile",
13 "PercentRank",
14 "Rank",
15 "RowNumber",
16]
19class CumeDist(Func):
20 function = "CUME_DIST"
21 output_field = FloatField()
22 window_compatible = True
25class DenseRank(Func):
26 function = "DENSE_RANK"
27 output_field = IntegerField()
28 window_compatible = True
31class FirstValue(Func):
32 arity = 1
33 function = "FIRST_VALUE"
34 window_compatible = True
37class LagLeadFunction(Func):
38 window_compatible = True
40 def __init__(self, expression, offset=1, default=None, **extra):
41 if expression is None:
42 raise ValueError(
43 f"{self.__class__.__name__} requires a non-null source expression."
44 )
45 if offset is None or offset <= 0:
46 raise ValueError(
47 f"{self.__class__.__name__} requires a positive integer for the offset."
48 )
49 args = (expression, offset)
50 if default is not None:
51 args += (default,)
52 super().__init__(*args, **extra)
54 def _resolve_output_field(self):
55 sources = self.get_source_expressions()
56 return sources[0].output_field
59class Lag(LagLeadFunction):
60 function = "LAG"
63class LastValue(Func):
64 arity = 1
65 function = "LAST_VALUE"
66 window_compatible = True
69class Lead(LagLeadFunction):
70 function = "LEAD"
73class NthValue(Func):
74 function = "NTH_VALUE"
75 window_compatible = True
77 def __init__(self, expression, nth=1, **extra):
78 if expression is None:
79 raise ValueError(
80 f"{self.__class__.__name__} requires a non-null source expression."
81 )
82 if nth is None or nth <= 0:
83 raise ValueError(
84 f"{self.__class__.__name__} requires a positive integer as for nth."
85 )
86 super().__init__(expression, nth, **extra)
88 def _resolve_output_field(self):
89 sources = self.get_source_expressions()
90 return sources[0].output_field
93class Ntile(Func):
94 function = "NTILE"
95 output_field = IntegerField()
96 window_compatible = True
98 def __init__(self, num_buckets=1, **extra):
99 if num_buckets <= 0:
100 raise ValueError("num_buckets must be greater than 0.")
101 super().__init__(num_buckets, **extra)
104class PercentRank(Func):
105 function = "PERCENT_RANK"
106 output_field = FloatField()
107 window_compatible = True
110class Rank(Func):
111 function = "RANK"
112 output_field = IntegerField()
113 window_compatible = True
116class RowNumber(Func):
117 function = "ROW_NUMBER"
118 output_field = IntegerField()
119 window_compatible = True
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from . import preflight # noqa
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.packages import PackageConfig
4class SessionsConfig(PackageConfig):
5 name = "plain.sessions"
6 label = "plainsessions"
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1# Cookie name. This can be whatever you want.
2SESSION_COOKIE_NAME = "sessionid"
3# Age of cookie, in seconds (default: 2 weeks).
4SESSION_COOKIE_AGE = 60 * 60 * 24 * 7 * 2
5# A string like "example.com", or None for standard domain cookie.
6SESSION_COOKIE_DOMAIN = None
7# Whether the session cookie should be secure (https:// only).
8SESSION_COOKIE_SECURE = True
9# The path of the session cookie.
10SESSION_COOKIE_PATH = "/"
11# Whether to use the HttpOnly flag.
12SESSION_COOKIE_HTTPONLY = True
13# Whether to set the flag restricting cookie leaks on cross-site requests.
14# This can be 'Lax', 'Strict', 'None', or False to disable the flag.
15SESSION_COOKIE_SAMESITE = "Lax"
16# Whether to save the session data on every request.
17SESSION_SAVE_EVERY_REQUEST = False
18# Whether a user's session cookie expires when the web browser is closed.
19SESSION_EXPIRE_AT_BROWSER_CLOSE = False
20# The module to store session data
21SESSION_ENGINE = "plain.sessions.backends.db"
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.exceptions import BadRequest, SuspiciousOperation
4class SuspiciousSession(SuspiciousOperation):
5 """The session may be tampered with"""
7 pass
10class SessionInterrupted(BadRequest):
11 """The session was interrupted."""
13 pass
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import time
2from importlib import import_module
4from plain.runtime import settings
5from plain.sessions.backends.base import UpdateError
6from plain.sessions.exceptions import SessionInterrupted
7from plain.utils.cache import patch_vary_headers
8from plain.utils.http import http_date
11class SessionMiddleware:
12 def __init__(self, get_response):
13 self.get_response = get_response
14 engine = import_module(settings.SESSION_ENGINE)
15 self.SessionStore = engine.SessionStore
17 def __call__(self, request):
18 session_key = request.COOKIES.get(settings.SESSION_COOKIE_NAME)
19 request.session = self.SessionStore(session_key)
21 response = self.get_response(request)
23 """
24 If request.session was modified, or if the configuration is to save the
25 session every time, save the changes and set a session cookie or delete
26 the session cookie if the session has been emptied.
27 """
28 try:
29 accessed = request.session.accessed
30 modified = request.session.modified
31 empty = request.session.is_empty()
32 except AttributeError:
33 return response
34 # First check if we need to delete this cookie.
35 # The session should be deleted only if the session is entirely empty.
36 if settings.SESSION_COOKIE_NAME in request.COOKIES and empty:
37 response.delete_cookie(
38 settings.SESSION_COOKIE_NAME,
39 path=settings.SESSION_COOKIE_PATH,
40 domain=settings.SESSION_COOKIE_DOMAIN,
41 samesite=settings.SESSION_COOKIE_SAMESITE,
42 )
43 patch_vary_headers(response, ("Cookie",))
44 else:
45 if accessed:
46 patch_vary_headers(response, ("Cookie",))
47 if (modified or settings.SESSION_SAVE_EVERY_REQUEST) and not empty:
48 if request.session.get_expire_at_browser_close():
49 max_age = None
50 expires = None
51 else:
52 max_age = request.session.get_expiry_age()
53 expires_time = time.time() + max_age
54 expires = http_date(expires_time)
55 # Save the session data and refresh the client cookie.
56 # Skip session save for 5xx responses.
57 if response.status_code < 500:
58 try:
59 request.session.save()
60 except UpdateError:
61 raise SessionInterrupted(
62 "The request's session was deleted before the "
63 "request completed. The user may have logged "
64 "out in a concurrent request, for example."
65 )
66 response.set_cookie(
67 settings.SESSION_COOKIE_NAME,
68 request.session.session_key,
69 max_age=max_age,
70 expires=expires,
71 domain=settings.SESSION_COOKIE_DOMAIN,
72 path=settings.SESSION_COOKIE_PATH,
73 secure=settings.SESSION_COOKIE_SECURE or None,
74 httponly=settings.SESSION_COOKIE_HTTPONLY or None,
75 samesite=settings.SESSION_COOKIE_SAMESITE,
76 )
77 return response
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain import models
4class SessionManager(models.Manager):
5 use_in_migrations = True
7 def encode(self, session_dict):
8 """
9 Return the given session dictionary serialized and encoded as a string.
10 """
11 session_store_class = self.model.get_session_store_class()
12 return session_store_class().encode(session_dict)
14 def save(self, session_key, session_dict, expire_date):
15 s = self.model(session_key, self.encode(session_dict), expire_date)
16 if session_dict:
17 s.save()
18 else:
19 s.delete() # Clear sessions with no data.
20 return s
23class Session(models.Model):
24 """
25 Plain provides full support for anonymous sessions. The session
26 framework lets you store and retrieve arbitrary data on a
27 per-site-visitor basis. It stores data on the server side and
28 abstracts the sending and receiving of cookies. Cookies contain a
29 session ID -- not the data itself.
31 The Plain sessions framework is entirely cookie-based. It does
32 not fall back to putting session IDs in URLs. This is an intentional
33 design decision. Not only does that behavior make URLs ugly, it makes
34 your site vulnerable to session-ID theft via the "Referer" header.
36 For complete documentation on using Sessions in your code, consult
37 the sessions documentation that is shipped with Plain (also available
38 on the Plain web site).
39 """
41 session_key = models.CharField(max_length=40, primary_key=True)
42 session_data = models.TextField()
43 expire_date = models.DateTimeField(db_index=True)
45 objects = SessionManager()
47 def __str__(self):
48 return self.session_key
50 @classmethod
51 def get_session_store_class(cls):
52 from plain.sessions.backends.db import SessionStore
54 return SessionStore
56 def get_decoded(self):
57 session_store_class = self.get_session_store_class()
58 return session_store_class().decode(self.session_data)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.preflight import Warning, register
2from plain.runtime import settings
5def add_session_cookie_message(message):
6 return message + (
7 " Using a secure-only session cookie makes it more difficult for "
8 "network traffic sniffers to hijack user sessions."
9 )
12W010 = Warning(
13 add_session_cookie_message(
14 "You have 'plain.sessions' in your INSTALLED_PACKAGES, "
15 "but you have not set SESSION_COOKIE_SECURE to True."
16 ),
17 id="security.W010",
18)
20W011 = Warning(
21 add_session_cookie_message(
22 "You have 'plain.sessions.middleware.SessionMiddleware' "
23 "in your MIDDLEWARE, but you have not set "
24 "SESSION_COOKIE_SECURE to True."
25 ),
26 id="security.W011",
27)
29W012 = Warning(
30 add_session_cookie_message("SESSION_COOKIE_SECURE is not set to True."),
31 id="security.W012",
32)
35def add_httponly_message(message):
36 return message + (
37 " Using an HttpOnly session cookie makes it more difficult for "
38 "cross-site scripting attacks to hijack user sessions."
39 )
42W013 = Warning(
43 add_httponly_message(
44 "You have 'plain.sessions' in your INSTALLED_PACKAGES, "
45 "but you have not set SESSION_COOKIE_HTTPONLY to True.",
46 ),
47 id="security.W013",
48)
50W014 = Warning(
51 add_httponly_message(
52 "You have 'plain.sessions.middleware.SessionMiddleware' "
53 "in your MIDDLEWARE, but you have not set "
54 "SESSION_COOKIE_HTTPONLY to True."
55 ),
56 id="security.W014",
57)
59W015 = Warning(
60 add_httponly_message("SESSION_COOKIE_HTTPONLY is not set to True."),
61 id="security.W015",
62)
65@register(deploy=True)
66def check_session_cookie_secure(package_configs, **kwargs):
67 if settings.SESSION_COOKIE_SECURE is True:
68 return []
69 errors = []
70 if _session_app():
71 errors.append(W010)
72 if _session_middleware():
73 errors.append(W011)
74 if len(errors) > 1:
75 errors = [W012]
76 return errors
79@register(deploy=True)
80def check_session_cookie_httponly(package_configs, **kwargs):
81 if settings.SESSION_COOKIE_HTTPONLY is True:
82 return []
83 errors = []
84 if _session_app():
85 errors.append(W013)
86 if _session_middleware():
87 errors.append(W014)
88 if len(errors) > 1:
89 errors = [W015]
90 return errors
93def _session_middleware():
94 return "plain.sessions.middleware.SessionMiddleware" in settings.MIDDLEWARE
97def _session_app():
98 return "plain.sessions" in settings.INSTALLED_PACKAGES
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from os import environ
3SECRET_KEY = "test"
4INSTALLED_PACKAGES = [
5 "plain.auth",
6 "plain.sessions",
7 "plain.models",
8 "plain.oauth",
9 "app.users",
10]
11DATABASES = {
12 "default": {
13 "ENGINE": "plain.models.backends.sqlite3",
14 "NAME": ":memory:",
15 }
16}
17MIDDLEWARE = [
18 "plain.sessions.middleware.SessionMiddleware",
19 "plain.auth.middleware.AuthenticationMiddleware",
20]
21AUTH_LOGIN_URL = "login"
22AUTH_USER_MODEL = "users.User"
24# OAuth providers to use for a real, interactive test
25# (in a real config you'd probably do environ["key"] to raise a KeyError if an env var is forgotten)
26OAUTH_LOGIN_PROVIDERS = {
27 "github": {
28 "class": "providers.github.GitHubOAuthProvider",
29 "kwargs": {
30 "client_id": environ.get("GITHUB_CLIENT_ID"),
31 "client_secret": environ.get("GITHUB_CLIENT_SECRET"),
32 },
33 },
34 "bitbucket": {
35 "class": "providers.bitbucket.BitbucketOAuthProvider",
36 "kwargs": {
37 "client_id": environ.get("BITBUCKET_KEY"),
38 "client_secret": environ.get("BITBUCKET_SECRET"),
39 },
40 },
41 "gitlab": {
42 "class": "providers.gitlab.GitLabOAuthProvider",
43 "kwargs": {
44 "client_id": environ.get("GITLAB_APPLICATION_ID"),
45 "client_secret": environ.get("GITLAB_APPLICATION_SECRET"),
46 "scope": "read_user",
47 },
48 },
49}
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import plain.oauth.urls
2from plain.auth.views import AuthViewMixin, LogoutView
3from plain.oauth.providers import get_provider_keys
4from plain.urls import include, path
5from plain.views import TemplateView
8class LoggedInView(AuthViewMixin, TemplateView):
9 template_name = "index.html"
11 def get_template_context(self):
12 context = super().get_template_context()
13 context["oauth_provider_keys"] = get_provider_keys()
14 return context
17class LoginView(TemplateView):
18 template_name = "login.html"
21urlpatterns = [
22 path("oauth/", include(plain.oauth.urls)),
23 path("login/", LoginView, name="login"),
24 path("logout/", LogoutView, name="logout"),
25 path("", LoggedInView),
26]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from .config import PackageConfig
2from .registry import packages
4__all__ = ["PackageConfig", "packages"]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-17 17:47 -0500
1import inspect
2import os
3from importlib import import_module
5from plain.exceptions import ImproperlyConfigured
6from plain.utils.module_loading import import_string, module_has_submodule
8CONFIG_MODULE_NAME = "config"
9MODELS_MODULE_NAME = "models"
12class PackageConfig:
13 """Class representing a Plain application and its configuration."""
15 migrations_module = "migrations"
17 def __init__(self, package_name, package_module):
18 # Full Python path to the application e.g. 'plain.staff.admin'.
19 self.name = package_name
21 # Root module for the application e.g. <module 'plain.staff.admin'
22 # from 'staff/__init__.py'>.
23 self.module = package_module
25 # Reference to the Packages registry that holds this PackageConfig. Set by the
26 # registry when it registers the PackageConfig instance.
27 self.packages = None
29 # The following attributes could be defined at the class level in a
30 # subclass, hence the test-and-set pattern.
32 # Last component of the Python path to the application e.g. 'admin'.
33 # This value must be unique across a Plain project.
34 if not hasattr(self, "label"):
35 self.label = package_name.rpartition(".")[2]
36 if not self.label.isidentifier():
37 raise ImproperlyConfigured(
38 "The app label '%s' is not a valid Python identifier." % self.label
39 )
41 # Filesystem path to the application directory e.g.
42 # '/path/to/admin'.
43 if not hasattr(self, "path"):
44 self.path = self._path_from_module(package_module)
46 # Module containing models e.g. <module 'plain.staff.models'
47 # from 'staff/models.py'>. Set by import_models().
48 # None if the application doesn't have a models module.
49 self.models_module = None
51 # Mapping of lowercase model names to model classes. Initially set to
52 # None to prevent accidental access before import_models() runs.
53 self.models = None
55 def __repr__(self):
56 return f"<{self.__class__.__name__}: {self.label}>"
58 def _path_from_module(self, module):
59 """Attempt to determine app's filesystem path from its module."""
60 # See #21874 for extended discussion of the behavior of this method in
61 # various cases.
62 # Convert to list because __path__ may not support indexing.
63 paths = list(getattr(module, "__path__", []))
64 if len(paths) != 1:
65 filename = getattr(module, "__file__", None)
66 if filename is not None:
67 paths = [os.path.dirname(filename)]
68 else:
69 # For unknown reasons, sometimes the list returned by __path__
70 # contains duplicates that must be removed (#25246).
71 paths = list(set(paths))
72 if len(paths) > 1:
73 raise ImproperlyConfigured(
74 "The app module {!r} has multiple filesystem locations ({!r}); "
75 "you must configure this app with an PackageConfig subclass "
76 "with a 'path' class attribute.".format(module, paths)
77 )
78 elif not paths:
79 raise ImproperlyConfigured(
80 "The app module %r has no filesystem location, "
81 "you must configure this app with an PackageConfig subclass "
82 "with a 'path' class attribute." % module
83 )
84 return paths[0]
86 @classmethod
87 def create(cls, entry):
88 """
89 Factory that creates an app config from an entry in INSTALLED_PACKAGES.
90 """
91 # create() eventually returns package_config_class(package_name, package_module).
92 package_config_class = None
93 package_name = None
94 package_module = None
96 # If import_module succeeds, entry points to the app module.
97 try:
98 package_module = import_module(entry)
99 except Exception:
100 pass
101 else:
102 # If package_module has an packages submodule that defines a single
103 # PackageConfig subclass, use it automatically.
104 # To prevent this, an PackageConfig subclass can declare a class
105 # variable default = False.
106 # If the packages module defines more than one PackageConfig subclass,
107 # the default one can declare default = True.
108 if module_has_submodule(package_module, CONFIG_MODULE_NAME):
109 mod_path = f"{entry}.{CONFIG_MODULE_NAME}"
110 mod = import_module(mod_path)
111 # Check if there's exactly one PackageConfig candidate,
112 # excluding those that explicitly define default = False.
113 package_configs = [
114 (name, candidate)
115 for name, candidate in inspect.getmembers(mod, inspect.isclass)
116 if (
117 issubclass(candidate, cls)
118 and candidate is not cls
119 and getattr(candidate, "default", True)
120 )
121 ]
122 if len(package_configs) == 1:
123 package_config_class = package_configs[0][1]
124 else:
125 # Check if there's exactly one PackageConfig subclass,
126 # among those that explicitly define default = True.
127 package_configs = [
128 (name, candidate)
129 for name, candidate in package_configs
130 if getattr(candidate, "default", False)
131 ]
132 if len(package_configs) > 1:
133 candidates = [repr(name) for name, _ in package_configs]
134 raise RuntimeError(
135 "{!r} declares more than one default PackageConfig: "
136 "{}.".format(mod_path, ", ".join(candidates))
137 )
138 elif len(package_configs) == 1:
139 package_config_class = package_configs[0][1]
141 # Use the default app config class if we didn't find anything.
142 if package_config_class is None:
143 package_config_class = cls
144 package_name = entry
146 # If import_string succeeds, entry is an app config class.
147 if package_config_class is None:
148 try:
149 package_config_class = import_string(entry)
150 except Exception:
151 pass
152 # If both import_module and import_string failed, it means that entry
153 # doesn't have a valid value.
154 if package_module is None and package_config_class is None:
155 # If the last component of entry starts with an uppercase letter,
156 # then it was likely intended to be an app config class; if not,
157 # an app module. Provide a nice error message in both cases.
158 mod_path, _, cls_name = entry.rpartition(".")
159 if mod_path and cls_name[0].isupper():
160 # We could simply re-trigger the string import exception, but
161 # we're going the extra mile and providing a better error
162 # message for typos in INSTALLED_PACKAGES.
163 # This may raise ImportError, which is the best exception
164 # possible if the module at mod_path cannot be imported.
165 mod = import_module(mod_path)
166 candidates = [
167 repr(name)
168 for name, candidate in inspect.getmembers(mod, inspect.isclass)
169 if issubclass(candidate, cls) and candidate is not cls
170 ]
171 msg = f"Module '{mod_path}' does not contain a '{cls_name}' class."
172 if candidates:
173 msg += " Choices are: %s." % ", ".join(candidates)
174 raise ImportError(msg)
175 else:
176 # Re-trigger the module import exception.
177 import_module(entry)
179 # Check for obvious errors. (This check prevents duck typing, but
180 # it could be removed if it became a problem in practice.)
181 if not issubclass(package_config_class, PackageConfig):
182 raise ImproperlyConfigured(
183 "'%s' isn't a subclass of PackageConfig." % entry
184 )
186 # Obtain package name here rather than in PackageClass.__init__ to keep
187 # all error checking for entries in INSTALLED_PACKAGES in one place.
188 if package_name is None:
189 try:
190 package_name = package_config_class.name
191 except AttributeError:
192 raise ImproperlyConfigured("'%s' must supply a name attribute." % entry)
194 # Ensure package_name points to a valid module.
195 try:
196 package_module = import_module(package_name)
197 except ImportError:
198 raise ImproperlyConfigured(
199 "Cannot import '{}'. Check that '{}.{}.name' is correct.".format(
200 package_name,
201 package_config_class.__module__,
202 package_config_class.__qualname__,
203 )
204 )
206 # Entry is a path to an app config class.
207 return package_config_class(package_name, package_module)
209 def get_model(self, model_name, require_ready=True):
210 """
211 Return the model with the given case-insensitive model_name.
213 Raise LookupError if no model exists with this name.
214 """
215 if require_ready:
216 self.packages.check_models_ready()
217 else:
218 self.packages.check_packages_ready()
219 try:
220 return self.models[model_name.lower()]
221 except KeyError:
222 raise LookupError(
223 f"Package '{self.label}' doesn't have a '{model_name}' model."
224 )
226 def get_models(self, include_auto_created=False, include_swapped=False):
227 """
228 Return an iterable of models.
230 By default, the following models aren't included:
232 - auto-created models for many-to-many relations without
233 an explicit intermediate table,
234 - models that have been swapped out.
236 Set the corresponding keyword argument to True to include such models.
237 Keyword arguments aren't documented; they're a private API.
238 """
239 self.packages.check_models_ready()
240 for model in self.models.values():
241 if model._meta.auto_created and not include_auto_created:
242 continue
243 if model._meta.swapped and not include_swapped:
244 continue
245 yield model
247 def import_models(self):
248 # Dictionary of models for this app, primarily maintained in the
249 # 'all_models' attribute of the Packages this PackageConfig is attached to.
250 self.models = self.packages.all_models[self.label]
252 if module_has_submodule(self.module, MODELS_MODULE_NAME):
253 models_module_name = f"{self.name}.{MODELS_MODULE_NAME}"
254 self.models_module = import_module(models_module_name)
256 def ready(self):
257 """
258 Override this method in subclasses to run code when Plain starts.
259 """
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import functools
2import sys
3import threading
4import warnings
5from collections import Counter, defaultdict
6from functools import partial
8from plain.exceptions import ImproperlyConfigured, PackageRegistryNotReady
10from .config import PackageConfig
13class Packages:
14 """
15 A registry that stores the configuration of installed applications.
17 It also keeps track of models, e.g. to provide reverse relations.
18 """
20 def __init__(self, installed_packages=()):
21 # installed_packages is set to None when creating the main registry
22 # because it cannot be populated at that point. Other registries must
23 # provide a list of installed packages and are populated immediately.
24 if installed_packages is None and hasattr(sys.modules[__name__], "packages"):
25 raise RuntimeError("You must supply an installed_packages argument.")
27 # Mapping of app labels => model names => model classes. Every time a
28 # model is imported, ModelBase.__new__ calls packages.register_model which
29 # creates an entry in all_models. All imported models are registered,
30 # regardless of whether they're defined in an installed application
31 # and whether the registry has been populated. Since it isn't possible
32 # to reimport a module safely (it could reexecute initialization code)
33 # all_models is never overridden or reset.
34 self.all_models = defaultdict(dict)
36 # Mapping of labels to PackageConfig instances for installed packages.
37 self.package_configs = {}
39 # Stack of package_configs. Used to store the current state in
40 # set_available_packages and set_installed_packages.
41 self.stored_package_configs = []
43 # Whether the registry is populated.
44 self.packages_ready = self.models_ready = self.ready = False
46 # Lock for thread-safe population.
47 self._lock = threading.RLock()
48 self.loading = False
50 # Maps ("package_label", "modelname") tuples to lists of functions to be
51 # called when the corresponding model is ready. Used by this class's
52 # `lazy_model_operation()` and `do_pending_operations()` methods.
53 self._pending_operations = defaultdict(list)
55 # Populate packages and models, unless it's the main registry.
56 if installed_packages is not None:
57 self.populate(installed_packages)
59 def populate(self, installed_packages=None):
60 """
61 Load application configurations and models.
63 Import each application module and then each model module.
65 It is thread-safe and idempotent, but not reentrant.
66 """
67 if self.ready:
68 return
70 # populate() might be called by two threads in parallel on servers
71 # that create threads before initializing the WSGI callable.
72 with self._lock:
73 if self.ready:
74 return
76 # An RLock prevents other threads from entering this section. The
77 # compare and set operation below is atomic.
78 if self.loading:
79 # Prevent reentrant calls to avoid running PackageConfig.ready()
80 # methods twice.
81 raise RuntimeError("populate() isn't reentrant")
82 self.loading = True
84 # Phase 1: initialize app configs and import app modules.
85 for entry in installed_packages:
86 if isinstance(entry, PackageConfig):
87 package_config = entry
88 else:
89 package_config = PackageConfig.create(entry)
90 if package_config.label in self.package_configs:
91 raise ImproperlyConfigured(
92 "Package labels aren't unique, "
93 "duplicates: %s" % package_config.label
94 )
96 self.package_configs[package_config.label] = package_config
97 package_config.packages = self
99 # Check for duplicate app names.
100 counts = Counter(
101 package_config.name for package_config in self.package_configs.values()
102 )
103 duplicates = [name for name, count in counts.most_common() if count > 1]
104 if duplicates:
105 raise ImproperlyConfigured(
106 "Package names aren't unique, "
107 "duplicates: %s" % ", ".join(duplicates)
108 )
110 self.packages_ready = True
112 # Phase 2: import models modules.
113 for package_config in self.package_configs.values():
114 package_config.import_models()
116 self.clear_cache()
118 self.models_ready = True
120 # Phase 3: run ready() methods of app configs.
121 for package_config in self.get_package_configs():
122 package_config.ready()
124 self.ready = True
126 def check_packages_ready(self):
127 """Raise an exception if all packages haven't been imported yet."""
128 if not self.packages_ready:
129 from plain.runtime import settings
131 # If "not ready" is due to unconfigured settings, accessing
132 # INSTALLED_PACKAGES raises a more helpful ImproperlyConfigured
133 # exception.
134 settings.INSTALLED_PACKAGES
135 raise PackageRegistryNotReady("Packages aren't loaded yet.")
137 def check_models_ready(self):
138 """Raise an exception if all models haven't been imported yet."""
139 if not self.models_ready:
140 raise PackageRegistryNotReady("Models aren't loaded yet.")
142 def get_package_configs(self):
143 """Import applications and return an iterable of app configs."""
144 self.check_packages_ready()
145 return self.package_configs.values()
147 def get_package_config(self, package_label):
148 """
149 Import applications and returns an app config for the given label.
151 Raise LookupError if no application exists with this label.
152 """
153 self.check_packages_ready()
154 try:
155 return self.package_configs[package_label]
156 except KeyError:
157 message = "No installed app with label '%s'." % package_label
158 for package_config in self.get_package_configs():
159 if package_config.name == package_label:
160 message += " Did you mean '%s'?" % package_config.label
161 break
162 raise LookupError(message)
164 # This method is performance-critical at least for Plain's test suite.
165 @functools.cache
166 def get_models(self, include_auto_created=False, include_swapped=False):
167 """
168 Return a list of all installed models.
170 By default, the following models aren't included:
172 - auto-created models for many-to-many relations without
173 an explicit intermediate table,
174 - models that have been swapped out.
176 Set the corresponding keyword argument to True to include such models.
177 """
178 self.check_models_ready()
180 result = []
181 for package_config in self.package_configs.values():
182 result.extend(
183 package_config.get_models(include_auto_created, include_swapped)
184 )
185 return result
187 def get_model(self, package_label, model_name=None, require_ready=True):
188 """
189 Return the model matching the given package_label and model_name.
191 As a shortcut, package_label may be in the form <package_label>.<model_name>.
193 model_name is case-insensitive.
195 Raise LookupError if no application exists with this label, or no
196 model exists with this name in the application. Raise ValueError if
197 called with a single argument that doesn't contain exactly one dot.
198 """
199 if require_ready:
200 self.check_models_ready()
201 else:
202 self.check_packages_ready()
204 if model_name is None:
205 package_label, model_name = package_label.split(".")
207 package_config = self.get_package_config(package_label)
209 if not require_ready and package_config.models is None:
210 package_config.import_models()
212 return package_config.get_model(model_name, require_ready=require_ready)
214 def register_model(self, package_label, model):
215 # Since this method is called when models are imported, it cannot
216 # perform imports because of the risk of import loops. It mustn't
217 # call get_package_config().
218 model_name = model._meta.model_name
219 app_models = self.all_models[package_label]
220 if model_name in app_models:
221 if (
222 model.__name__ == app_models[model_name].__name__
223 and model.__module__ == app_models[model_name].__module__
224 ):
225 warnings.warn(
226 "Model '{}.{}' was already registered. Reloading models is not "
227 "advised as it can lead to inconsistencies, most notably with "
228 "related models.".format(package_label, model_name),
229 RuntimeWarning,
230 stacklevel=2,
231 )
232 else:
233 raise RuntimeError(
234 "Conflicting '{}' models in application '{}': {} and {}.".format(
235 model_name, package_label, app_models[model_name], model
236 )
237 )
238 app_models[model_name] = model
239 self.do_pending_operations(model)
240 self.clear_cache()
242 def is_installed(self, package_name):
243 """
244 Check whether an application with this name exists in the registry.
246 package_name is the full name of the app e.g. 'plain.staff'.
247 """
248 self.check_packages_ready()
249 return any(ac.name == package_name for ac in self.package_configs.values())
251 def get_containing_package_config(self, object_name):
252 """
253 Look for an app config containing a given object.
255 object_name is the dotted Python path to the object.
257 Return the app config for the inner application in case of nesting.
258 Return None if the object isn't in any registered app config.
259 """
260 self.check_packages_ready()
261 candidates = []
262 for package_config in self.package_configs.values():
263 if object_name.startswith(package_config.name):
264 subpath = object_name.removeprefix(package_config.name)
265 if subpath == "" or subpath[0] == ".":
266 candidates.append(package_config)
267 if candidates:
268 return sorted(candidates, key=lambda ac: -len(ac.name))[0]
270 def get_registered_model(self, package_label, model_name):
271 """
272 Similar to get_model(), but doesn't require that an app exists with
273 the given package_label.
275 It's safe to call this method at import time, even while the registry
276 is being populated.
277 """
278 model = self.all_models[package_label].get(model_name.lower())
279 if model is None:
280 raise LookupError(f"Model '{package_label}.{model_name}' not registered.")
281 return model
283 @functools.cache
284 def get_swappable_settings_name(self, to_string):
285 """
286 For a given model string (e.g. "auth.User"), return the name of the
287 corresponding settings name if it refers to a swappable model. If the
288 referred model is not swappable, return None.
290 This method is decorated with @functools.cache because it's performance
291 critical when it comes to migrations. Since the swappable settings don't
292 change after Plain has loaded the settings, there is no reason to get
293 the respective settings attribute over and over again.
294 """
295 to_string = to_string.lower()
296 for model in self.get_models(include_swapped=True):
297 swapped = model._meta.swapped
298 # Is this model swapped out for the model given by to_string?
299 if swapped and swapped.lower() == to_string:
300 return model._meta.swappable
301 # Is this model swappable and the one given by to_string?
302 if model._meta.swappable and model._meta.label_lower == to_string:
303 return model._meta.swappable
304 return None
306 def set_available_packages(self, available):
307 """
308 Restrict the set of installed packages used by get_package_config[s].
310 available must be an iterable of application names.
312 set_available_packages() must be balanced with unset_available_packages().
314 Primarily used for performance optimization in TransactionTestCase.
316 This method is safe in the sense that it doesn't trigger any imports.
317 """
318 available = set(available)
319 installed = {
320 package_config.name for package_config in self.get_package_configs()
321 }
322 if not available.issubset(installed):
323 raise ValueError(
324 "Available packages isn't a subset of installed packages, extra packages: %s"
325 % ", ".join(available - installed)
326 )
328 self.stored_package_configs.append(self.package_configs)
329 self.package_configs = {
330 label: package_config
331 for label, package_config in self.package_configs.items()
332 if package_config.name in available
333 }
334 self.clear_cache()
336 def unset_available_packages(self):
337 """Cancel a previous call to set_available_packages()."""
338 self.package_configs = self.stored_package_configs.pop()
339 self.clear_cache()
341 def set_installed_packages(self, installed):
342 """
343 Enable a different set of installed packages for get_package_config[s].
345 installed must be an iterable in the same format as INSTALLED_PACKAGES.
347 set_installed_packages() must be balanced with unset_installed_packages(),
348 even if it exits with an exception.
350 Primarily used as a receiver of the setting_changed signal in tests.
352 This method may trigger new imports, which may add new models to the
353 registry of all imported models. They will stay in the registry even
354 after unset_installed_packages(). Since it isn't possible to replay
355 imports safely (e.g. that could lead to registering listeners twice),
356 models are registered when they're imported and never removed.
357 """
358 if not self.ready:
359 raise PackageRegistryNotReady("Package registry isn't ready yet.")
360 self.stored_package_configs.append(self.package_configs)
361 self.package_configs = {}
362 self.packages_ready = self.models_ready = self.loading = self.ready = False
363 self.clear_cache()
364 self.populate(installed)
366 def clear_cache(self):
367 """
368 Clear all internal caches, for methods that alter the app registry.
370 This is mostly used in tests.
371 """
372 # Call expire cache on each model. This will purge
373 # the relation tree and the fields cache.
374 self.get_models.cache_clear()
375 if self.ready:
376 # Circumvent self.get_models() to prevent that the cache is refilled.
377 # This particularly prevents that an empty value is cached while cloning.
378 for package_config in self.package_configs.values():
379 for model in package_config.get_models(include_auto_created=True):
380 model._meta._expire_cache()
382 def lazy_model_operation(self, function, *model_keys):
383 """
384 Take a function and a number of ("package_label", "modelname") tuples, and
385 when all the corresponding models have been imported and registered,
386 call the function with the model classes as its arguments.
388 The function passed to this method must accept exactly n models as
389 arguments, where n=len(model_keys).
390 """
391 # Base case: no arguments, just execute the function.
392 if not model_keys:
393 function()
394 # Recursive case: take the head of model_keys, wait for the
395 # corresponding model class to be imported and registered, then apply
396 # that argument to the supplied function. Pass the resulting partial
397 # to lazy_model_operation() along with the remaining model args and
398 # repeat until all models are loaded and all arguments are applied.
399 else:
400 next_model, *more_models = model_keys
402 # This will be executed after the class corresponding to next_model
403 # has been imported and registered. The `func` attribute provides
404 # duck-type compatibility with partials.
405 def apply_next_model(model):
406 next_function = partial(apply_next_model.func, model)
407 self.lazy_model_operation(next_function, *more_models)
409 apply_next_model.func = function
411 # If the model has already been imported and registered, partially
412 # apply it to the function now. If not, add it to the list of
413 # pending operations for the model, where it will be executed with
414 # the model class as its sole argument once the model is ready.
415 try:
416 model_class = self.get_registered_model(*next_model)
417 except LookupError:
418 self._pending_operations[next_model].append(apply_next_model)
419 else:
420 apply_next_model(model_class)
422 def do_pending_operations(self, model):
423 """
424 Take a newly-prepared model and pass it to each function waiting for
425 it. This is called at the very end of Packages.register_model().
426 """
427 key = model._meta.package_label, model._meta.model_name
428 for function in self._pending_operations.pop(key, []):
429 function(model)
432packages = Packages(installed_packages=None)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from .configure import configure_logging
2from .loggers import app_logger
3from .utils import log_response
5__all__ = ["app_logger", "log_response", "configure_logging"]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import logging
2import logging.config
3from os import environ
6def configure_logging(logging_settings):
7 # Load the defaults
8 default_logging = {
9 "version": 1,
10 "disable_existing_loggers": False,
11 "formatters": {
12 "simple": {
13 "format": "[%(levelname)s] %(message)s",
14 },
15 },
16 "handlers": {
17 "console": {
18 "level": "INFO",
19 "class": "logging.StreamHandler",
20 "formatter": "simple",
21 },
22 },
23 "loggers": {
24 "plain": {
25 "handlers": ["console"],
26 "level": environ.get("PLAIN_LOG_LEVEL", "INFO"),
27 },
28 "app": {
29 "handlers": ["console"],
30 "level": environ.get("APP_LOG_LEVEL", "INFO"),
31 "propagate": False,
32 },
33 },
34 }
35 logging.config.dictConfig(default_logging)
37 # Then customize it from settings
38 if logging_settings:
39 logging.config.dictConfig(logging_settings)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import logging
3app_logger = logging.getLogger("app")
6class KVLogger:
7 def __init__(self, logger):
8 self.logger = logger
9 self.context = {} # A dict that will be output in every log message
11 def log(self, level, message, **kwargs):
12 msg_kwargs = {
13 **kwargs,
14 **self.context, # Put these last so they're at the end of the line
15 }
16 self.logger.log(level, f"{message} {self._format_kwargs(msg_kwargs)}")
18 def _format_kwargs(self, kwargs):
19 outputs = []
21 for k, v in kwargs.items():
22 self._validate_key(k)
23 formatted_value = self._format_value(v)
24 outputs.append(f"{k}={formatted_value}")
26 return " ".join(outputs)
28 def _validate_key(self, key):
29 if " " in key:
30 raise ValueError("Keys cannot have spaces")
32 if "=" in key:
33 raise ValueError("Keys cannot have equals signs")
35 if '"' in key or "'" in key:
36 raise ValueError("Keys cannot have quotes")
38 def _format_value(self, value):
39 if isinstance(value, str):
40 s = value
41 else:
42 s = str(value)
44 if '"' in s:
45 # Escape quotes and surround it
46 s = s.replace('"', '\\"')
47 s = f'"{s}"'
48 elif s == "":
49 # Quote empty strings instead of printing nothing
50 s = '""'
51 elif any(char in s for char in [" ", "/", "'", ":", "=", "."]):
52 # Surround these with quotes for parsers
53 s = f'"{s}"'
55 return s
57 def info(self, message, **kwargs):
58 self.log(logging.INFO, message, **kwargs)
60 def debug(self, message, **kwargs):
61 self.log(logging.DEBUG, message, **kwargs)
63 def warning(self, message, **kwargs):
64 self.log(logging.WARNING, message, **kwargs)
66 def error(self, message, **kwargs):
67 self.log(logging.ERROR, message, **kwargs)
69 def critical(self, message, **kwargs):
70 self.log(logging.CRITICAL, message, **kwargs)
73# Make this accessible from the app_logger
74app_logger.kv = KVLogger(app_logger)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import logging
3request_logger = logging.getLogger("plain.request")
6def log_response(
7 message,
8 *args,
9 response=None,
10 request=None,
11 logger=request_logger,
12 level=None,
13 exception=None,
14):
15 """
16 Log errors based on Response status.
18 Log 5xx responses as errors and 4xx responses as warnings (unless a level
19 is given as a keyword argument). The Response status_code and the
20 request are passed to the logger's extra parameter.
21 """
22 # Check if the response has already been logged. Multiple requests to log
23 # the same response can be received in some cases, e.g., when the
24 # response is the result of an exception and is logged when the exception
25 # is caught, to record the exception.
26 if getattr(response, "_has_been_logged", False):
27 return
29 if level is None:
30 if response.status_code >= 500:
31 level = "error"
32 elif response.status_code >= 400:
33 level = "warning"
34 else:
35 level = "info"
37 getattr(logger, level)(
38 message,
39 *args,
40 extra={
41 "status_code": response.status_code,
42 "request": request,
43 },
44 exc_info=exception,
45 )
46 response._has_been_logged = True
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:27 -0500
1"""
2This module contains helper functions for controlling caching. It does so by
3managing the "Vary" header of responses. It includes functions to patch the
4header of response objects directly and decorators that change functions to do
5that header-patching themselves.
7For information on the Vary header, see RFC 9110 Section 12.5.5.
9Essentially, the "Vary" HTTP header defines which headers a cache should take
10into account when building its cache key. Requests with the same path but
11different header content for headers named in "Vary" need to get different
12cache keys to prevent delivery of wrong content.
14An example: i18n middleware would need to distinguish caches by the
15"Accept-language" header.
16"""
17import time
18from collections import defaultdict
19from hashlib import md5
21from plain.http import Response, ResponseNotModified
22from plain.logs import log_response
23from plain.runtime import settings
24from plain.utils.http import http_date, parse_etags, parse_http_date_safe, quote_etag
25from plain.utils.regex_helper import _lazy_re_compile
27cc_delim_re = _lazy_re_compile(r"\s*,\s*")
30def patch_cache_control(response, **kwargs):
31 """
32 Patch the Cache-Control header by adding all keyword arguments to it.
33 The transformation is as follows:
35 * All keyword parameter names are turned to lowercase, and underscores
36 are converted to hyphens.
37 * If the value of a parameter is True (exactly True, not just a
38 true value), only the parameter name is added to the header.
39 * All other parameters are added with their value, after applying
40 str() to it.
41 """
43 def dictitem(s):
44 t = s.split("=", 1)
45 if len(t) > 1:
46 return (t[0].lower(), t[1])
47 else:
48 return (t[0].lower(), True)
50 def dictvalue(*t):
51 if t[1] is True:
52 return t[0]
53 else:
54 return f"{t[0]}={t[1]}"
56 cc = defaultdict(set)
57 if response.get("Cache-Control"):
58 for field in cc_delim_re.split(response.headers["Cache-Control"]):
59 directive, value = dictitem(field)
60 if directive == "no-cache":
61 # no-cache supports multiple field names.
62 cc[directive].add(value)
63 else:
64 cc[directive] = value
66 # If there's already a max-age header but we're being asked to set a new
67 # max-age, use the minimum of the two ages. In practice this happens when
68 # a decorator and a piece of middleware both operate on a given view.
69 if "max-age" in cc and "max_age" in kwargs:
70 kwargs["max_age"] = min(int(cc["max-age"]), kwargs["max_age"])
72 # Allow overriding private caching and vice versa
73 if "private" in cc and "public" in kwargs:
74 del cc["private"]
75 elif "public" in cc and "private" in kwargs:
76 del cc["public"]
78 for k, v in kwargs.items():
79 directive = k.replace("_", "-")
80 if directive == "no-cache":
81 # no-cache supports multiple field names.
82 cc[directive].add(v)
83 else:
84 cc[directive] = v
86 directives = []
87 for directive, values in cc.items():
88 if isinstance(values, set):
89 if True in values:
90 # True takes precedence.
91 values = {True}
92 directives.extend([dictvalue(directive, value) for value in values])
93 else:
94 directives.append(dictvalue(directive, values))
95 cc = ", ".join(directives)
96 response.headers["Cache-Control"] = cc
99def get_max_age(response):
100 """
101 Return the max-age from the response Cache-Control header as an integer,
102 or None if it wasn't found or wasn't an integer.
103 """
104 if not response.has_header("Cache-Control"):
105 return
106 cc = dict(
107 _to_tuple(el) for el in cc_delim_re.split(response.headers["Cache-Control"])
108 )
109 try:
110 return int(cc["max-age"])
111 except (ValueError, TypeError, KeyError):
112 pass
115def set_response_etag(response):
116 if not response.streaming and response.content:
117 response.headers["ETag"] = quote_etag(
118 md5(response.content, usedforsecurity=False).hexdigest(),
119 )
120 return response
123def _precondition_failed(request):
124 response = Response(status=412)
125 log_response(
126 "Precondition Failed: %s",
127 request.path,
128 response=response,
129 request=request,
130 )
131 return response
134def _not_modified(request, response=None):
135 new_response = ResponseNotModified()
136 if response:
137 # Preserve the headers required by RFC 9110 Section 15.4.5, as well as
138 # Last-Modified.
139 for header in (
140 "Cache-Control",
141 "Content-Location",
142 "Date",
143 "ETag",
144 "Expires",
145 "Last-Modified",
146 "Vary",
147 ):
148 if header in response:
149 new_response.headers[header] = response.headers[header]
151 # Preserve cookies as per the cookie specification: "If a proxy server
152 # receives a response which contains a Set-cookie header, it should
153 # propagate the Set-cookie header to the client, regardless of whether
154 # the response was 304 (Not Modified) or 200 (OK).
155 # https://curl.haxx.se/rfc/cookie_spec.html
156 new_response.cookies = response.cookies
157 return new_response
160def get_conditional_response(request, etag=None, last_modified=None, response=None):
161 # Only return conditional responses on successful requests.
162 if response and not (200 <= response.status_code < 300):
163 return response
165 # Get HTTP request headers.
166 if_match_etags = parse_etags(request.META.get("HTTP_IF_MATCH", ""))
167 if_unmodified_since = request.META.get("HTTP_IF_UNMODIFIED_SINCE")
168 if_unmodified_since = if_unmodified_since and parse_http_date_safe(
169 if_unmodified_since
170 )
171 if_none_match_etags = parse_etags(request.META.get("HTTP_IF_NONE_MATCH", ""))
172 if_modified_since = request.META.get("HTTP_IF_MODIFIED_SINCE")
173 if_modified_since = if_modified_since and parse_http_date_safe(if_modified_since)
175 # Evaluation of request preconditions below follows RFC 9110 Section
176 # 13.2.2.
177 # Step 1: Test the If-Match precondition.
178 if if_match_etags and not _if_match_passes(etag, if_match_etags):
179 return _precondition_failed(request)
181 # Step 2: Test the If-Unmodified-Since precondition.
182 if (
183 not if_match_etags
184 and if_unmodified_since
185 and not _if_unmodified_since_passes(last_modified, if_unmodified_since)
186 ):
187 return _precondition_failed(request)
189 # Step 3: Test the If-None-Match precondition.
190 if if_none_match_etags and not _if_none_match_passes(etag, if_none_match_etags):
191 if request.method in ("GET", "HEAD"):
192 return _not_modified(request, response)
193 else:
194 return _precondition_failed(request)
196 # Step 4: Test the If-Modified-Since precondition.
197 if (
198 not if_none_match_etags
199 and if_modified_since
200 and not _if_modified_since_passes(last_modified, if_modified_since)
201 and request.method in ("GET", "HEAD")
202 ):
203 return _not_modified(request, response)
205 # Step 5: Test the If-Range precondition (not supported).
206 # Step 6: Return original response since there isn't a conditional response.
207 return response
210def _if_match_passes(target_etag, etags):
211 """
212 Test the If-Match comparison as defined in RFC 9110 Section 13.1.1.
213 """
214 if not target_etag:
215 # If there isn't an ETag, then there can't be a match.
216 return False
217 elif etags == ["*"]:
218 # The existence of an ETag means that there is "a current
219 # representation for the target resource", even if the ETag is weak,
220 # so there is a match to '*'.
221 return True
222 elif target_etag.startswith("W/"):
223 # A weak ETag can never strongly match another ETag.
224 return False
225 else:
226 # Since the ETag is strong, this will only return True if there's a
227 # strong match.
228 return target_etag in etags
231def _if_unmodified_since_passes(last_modified, if_unmodified_since):
232 """
233 Test the If-Unmodified-Since comparison as defined in RFC 9110 Section
234 13.1.4.
235 """
236 return last_modified and last_modified <= if_unmodified_since
239def _if_none_match_passes(target_etag, etags):
240 """
241 Test the If-None-Match comparison as defined in RFC 9110 Section 13.1.2.
242 """
243 if not target_etag:
244 # If there isn't an ETag, then there isn't a match.
245 return True
246 elif etags == ["*"]:
247 # The existence of an ETag means that there is "a current
248 # representation for the target resource", so there is a match to '*'.
249 return False
250 else:
251 # The comparison should be weak, so look for a match after stripping
252 # off any weak indicators.
253 target_etag = target_etag.strip("W/")
254 etags = (etag.strip("W/") for etag in etags)
255 return target_etag not in etags
258def _if_modified_since_passes(last_modified, if_modified_since):
259 """
260 Test the If-Modified-Since comparison as defined in RFC 9110 Section
261 13.1.3.
262 """
263 return not last_modified or last_modified > if_modified_since
266def patch_response_headers(response, cache_timeout=None):
267 """
268 Add HTTP caching headers to the given Response: Expires and
269 Cache-Control.
271 Each header is only added if it isn't already set.
273 cache_timeout is in seconds. The CACHE_MIDDLEWARE_SECONDS setting is used
274 by default.
275 """
276 if cache_timeout is None:
277 cache_timeout = settings.CACHE_MIDDLEWARE_SECONDS
278 if cache_timeout < 0:
279 cache_timeout = 0 # Can't have max-age negative
280 if not response.has_header("Expires"):
281 response.headers["Expires"] = http_date(time.time() + cache_timeout)
282 patch_cache_control(response, max_age=cache_timeout)
285def add_never_cache_headers(response):
286 """
287 Add headers to a response to indicate that a page should never be cached.
288 """
289 patch_response_headers(response, cache_timeout=-1)
290 patch_cache_control(
291 response, no_cache=True, no_store=True, must_revalidate=True, private=True
292 )
295def patch_vary_headers(response, newheaders):
296 """
297 Add (or update) the "Vary" header in the given Response object.
298 newheaders is a list of header names that should be in "Vary". If headers
299 contains an asterisk, then "Vary" header will consist of a single asterisk
300 '*'. Otherwise, existing headers in "Vary" aren't removed.
301 """
302 # Note that we need to keep the original order intact, because cache
303 # implementations may rely on the order of the Vary contents in, say,
304 # computing an MD5 hash.
305 if response.has_header("Vary"):
306 vary_headers = cc_delim_re.split(response.headers["Vary"])
307 else:
308 vary_headers = []
309 # Use .lower() here so we treat headers as case-insensitive.
310 existing_headers = {header.lower() for header in vary_headers}
311 additional_headers = [
312 newheader
313 for newheader in newheaders
314 if newheader.lower() not in existing_headers
315 ]
316 vary_headers += additional_headers
317 if "*" in vary_headers:
318 response.headers["Vary"] = "*"
319 else:
320 response.headers["Vary"] = ", ".join(vary_headers)
323def _to_tuple(s):
324 t = s.split("=", 1)
325 if len(t) == 2:
326 return t[0].lower(), t[1]
327 return t[0].lower(), True
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from threading import local
3from plain.runtime import settings as plain_settings
4from plain.utils.functional import cached_property
7class ConnectionProxy:
8 """Proxy for accessing a connection object's attributes."""
10 def __init__(self, connections, alias):
11 self.__dict__["_connections"] = connections
12 self.__dict__["_alias"] = alias
14 def __getattr__(self, item):
15 return getattr(self._connections[self._alias], item)
17 def __setattr__(self, name, value):
18 return setattr(self._connections[self._alias], name, value)
20 def __delattr__(self, name):
21 return delattr(self._connections[self._alias], name)
23 def __contains__(self, key):
24 return key in self._connections[self._alias]
26 def __eq__(self, other):
27 return self._connections[self._alias] == other
30class ConnectionDoesNotExist(Exception):
31 pass
34class BaseConnectionHandler:
35 settings_name = None
36 exception_class = ConnectionDoesNotExist
38 def __init__(self, settings=None):
39 self._settings = settings
40 self._connections = local()
42 @cached_property
43 def settings(self):
44 self._settings = self.configure_settings(self._settings)
45 return self._settings
47 def configure_settings(self, settings):
48 if settings is None:
49 settings = getattr(plain_settings, self.settings_name)
50 return settings
52 def create_connection(self, alias):
53 raise NotImplementedError("Subclasses must implement create_connection().")
55 def __getitem__(self, alias):
56 try:
57 return getattr(self._connections, alias)
58 except AttributeError:
59 if alias not in self.settings:
60 raise self.exception_class(f"The connection '{alias}' doesn't exist.")
61 conn = self.create_connection(alias)
62 setattr(self._connections, alias, conn)
63 return conn
65 def __setitem__(self, key, value):
66 setattr(self._connections, key, value)
68 def __delitem__(self, key):
69 delattr(self._connections, key)
71 def __iter__(self):
72 return iter(self.settings)
74 def all(self, initialized_only=False):
75 return [
76 self[alias]
77 for alias in self
78 # If initialized_only is True, return only initialized connections.
79 if not initialized_only or hasattr(self._connections, alias)
80 ]
82 def close_all(self):
83 for conn in self.all(initialized_only=True):
84 conn.close()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Plain's standard crypto functions and utilities.
3"""
4import hashlib
5import hmac
6import secrets
8from plain.runtime import settings
9from plain.utils.encoding import force_bytes
12class InvalidAlgorithm(ValueError):
13 """Algorithm is not supported by hashlib."""
15 pass
18def salted_hmac(key_salt, value, secret=None, *, algorithm="sha1"):
19 """
20 Return the HMAC of 'value', using a key generated from key_salt and a
21 secret (which defaults to settings.SECRET_KEY). Default algorithm is SHA1,
22 but any algorithm name supported by hashlib can be passed.
24 A different key_salt should be passed in for every application of HMAC.
25 """
26 if secret is None:
27 secret = settings.SECRET_KEY
29 key_salt = force_bytes(key_salt)
30 secret = force_bytes(secret)
31 try:
32 hasher = getattr(hashlib, algorithm)
33 except AttributeError as e:
34 raise InvalidAlgorithm(
35 "%r is not an algorithm accepted by the hashlib module." % algorithm
36 ) from e
37 # We need to generate a derived key from our base key. We can do this by
38 # passing the key_salt and our base key through a pseudo-random function.
39 key = hasher(key_salt + secret).digest()
40 # If len(key_salt + secret) > block size of the hash algorithm, the above
41 # line is redundant and could be replaced by key = key_salt + secret, since
42 # the hmac module does the same thing for keys longer than the block size.
43 # However, we need to ensure that we *always* do this.
44 return hmac.new(key, msg=force_bytes(value), digestmod=hasher)
47RANDOM_STRING_CHARS = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
50def get_random_string(length, allowed_chars=RANDOM_STRING_CHARS):
51 """
52 Return a securely generated random string.
54 The bit length of the returned value can be calculated with the formula:
55 log_2(len(allowed_chars)^length)
57 For example, with default `allowed_chars` (26+26+10), this gives:
58 * length: 12, bit length =~ 71 bits
59 * length: 22, bit length =~ 131 bits
60 """
61 return "".join(secrets.choice(allowed_chars) for i in range(length))
64def constant_time_compare(val1, val2):
65 """Return True if the two strings are equal, False otherwise."""
66 return secrets.compare_digest(force_bytes(val1), force_bytes(val2))
69def pbkdf2(password, salt, iterations, dklen=0, digest=None):
70 """Return the hash of password using pbkdf2."""
71 if digest is None:
72 digest = hashlib.sha256
73 dklen = dklen or None
74 password = force_bytes(password)
75 salt = force_bytes(salt)
76 return hashlib.pbkdf2_hmac(digest().name, password, salt, iterations, dklen)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import copy
2from collections.abc import Mapping
5class OrderedSet:
6 """
7 A set which keeps the ordering of the inserted items.
8 """
10 def __init__(self, iterable=None):
11 self.dict = dict.fromkeys(iterable or ())
13 def add(self, item):
14 self.dict[item] = None
16 def remove(self, item):
17 del self.dict[item]
19 def discard(self, item):
20 try:
21 self.remove(item)
22 except KeyError:
23 pass
25 def __iter__(self):
26 return iter(self.dict)
28 def __reversed__(self):
29 return reversed(self.dict)
31 def __contains__(self, item):
32 return item in self.dict
34 def __bool__(self):
35 return bool(self.dict)
37 def __len__(self):
38 return len(self.dict)
40 def __repr__(self):
41 data = repr(list(self.dict)) if self.dict else ""
42 return f"{self.__class__.__qualname__}({data})"
45class MultiValueDictKeyError(KeyError):
46 pass
49class MultiValueDict(dict):
50 """
51 A subclass of dictionary customized to handle multiple values for the
52 same key.
54 >>> d = MultiValueDict({'name': ['Adrian', 'Simon'], 'position': ['Developer']})
55 >>> d['name']
56 'Simon'
57 >>> d.getlist('name')
58 ['Adrian', 'Simon']
59 >>> d.getlist('doesnotexist')
60 []
61 >>> d.getlist('doesnotexist', ['Adrian', 'Simon'])
62 ['Adrian', 'Simon']
63 >>> d.get('lastname', 'nonexistent')
64 'nonexistent'
65 >>> d.setlist('lastname', ['Holovaty', 'Willison'])
67 This class exists to solve the irritating problem raised by cgi.parse_qs,
68 which returns a list for every key, even though most web forms submit
69 single name-value pairs.
70 """
72 def __init__(self, key_to_list_mapping=()):
73 super().__init__(key_to_list_mapping)
75 def __repr__(self):
76 return f"<{self.__class__.__name__}: {super().__repr__()}>"
78 def __getitem__(self, key):
79 """
80 Return the last data value for this key, or [] if it's an empty list;
81 raise KeyError if not found.
82 """
83 try:
84 list_ = super().__getitem__(key)
85 except KeyError:
86 raise MultiValueDictKeyError(key)
87 try:
88 return list_[-1]
89 except IndexError:
90 return []
92 def __setitem__(self, key, value):
93 super().__setitem__(key, [value])
95 def __copy__(self):
96 return self.__class__([(k, v[:]) for k, v in self.lists()])
98 def __deepcopy__(self, memo):
99 result = self.__class__()
100 memo[id(self)] = result
101 for key, value in dict.items(self):
102 dict.__setitem__(
103 result, copy.deepcopy(key, memo), copy.deepcopy(value, memo)
104 )
105 return result
107 def __getstate__(self):
108 return {**self.__dict__, "_data": {k: self._getlist(k) for k in self}}
110 def __setstate__(self, obj_dict):
111 data = obj_dict.pop("_data", {})
112 for k, v in data.items():
113 self.setlist(k, v)
114 self.__dict__.update(obj_dict)
116 def get(self, key, default=None):
117 """
118 Return the last data value for the passed key. If key doesn't exist
119 or value is an empty list, return `default`.
120 """
121 try:
122 val = self[key]
123 except KeyError:
124 return default
125 if val == []:
126 return default
127 return val
129 def _getlist(self, key, default=None, force_list=False):
130 """
131 Return a list of values for the key.
133 Used internally to manipulate values list. If force_list is True,
134 return a new copy of values.
135 """
136 try:
137 values = super().__getitem__(key)
138 except KeyError:
139 if default is None:
140 return []
141 return default
142 else:
143 if force_list:
144 values = list(values) if values is not None else None
145 return values
147 def getlist(self, key, default=None):
148 """
149 Return the list of values for the key. If key doesn't exist, return a
150 default value.
151 """
152 return self._getlist(key, default, force_list=True)
154 def setlist(self, key, list_):
155 super().__setitem__(key, list_)
157 def setdefault(self, key, default=None):
158 if key not in self:
159 self[key] = default
160 # Do not return default here because __setitem__() may store
161 # another value -- QueryDict.__setitem__() does. Look it up.
162 return self[key]
164 def setlistdefault(self, key, default_list=None):
165 if key not in self:
166 if default_list is None:
167 default_list = []
168 self.setlist(key, default_list)
169 # Do not return default_list here because setlist() may store
170 # another value -- QueryDict.setlist() does. Look it up.
171 return self._getlist(key)
173 def appendlist(self, key, value):
174 """Append an item to the internal list associated with key."""
175 self.setlistdefault(key).append(value)
177 def items(self):
178 """
179 Yield (key, value) pairs, where value is the last item in the list
180 associated with the key.
181 """
182 for key in self:
183 yield key, self[key]
185 def lists(self):
186 """Yield (key, list) pairs."""
187 return iter(super().items())
189 def values(self):
190 """Yield the last value on every key list."""
191 for key in self:
192 yield self[key]
194 def copy(self):
195 """Return a shallow copy of this object."""
196 return copy.copy(self)
198 def update(self, *args, **kwargs):
199 """Extend rather than replace existing key lists."""
200 if len(args) > 1:
201 raise TypeError("update expected at most 1 argument, got %d" % len(args))
202 if args:
203 arg = args[0]
204 if isinstance(arg, MultiValueDict):
205 for key, value_list in arg.lists():
206 self.setlistdefault(key).extend(value_list)
207 else:
208 if isinstance(arg, Mapping):
209 arg = arg.items()
210 for key, value in arg:
211 self.setlistdefault(key).append(value)
212 for key, value in kwargs.items():
213 self.setlistdefault(key).append(value)
215 def dict(self):
216 """Return current object as a dict with singular values."""
217 return {key: self[key] for key in self}
220class ImmutableList(tuple):
221 """
222 A tuple-like object that raises useful errors when it is asked to mutate.
224 Example::
226 >>> a = ImmutableList(range(5), warning="You cannot mutate this.")
227 >>> a[3] = '4'
228 Traceback (most recent call last):
229 ...
230 AttributeError: You cannot mutate this.
231 """
233 def __new__(cls, *args, warning="ImmutableList object is immutable.", **kwargs):
234 self = tuple.__new__(cls, *args, **kwargs)
235 self.warning = warning
236 return self
238 def complain(self, *args, **kwargs):
239 raise AttributeError(self.warning)
241 # All list mutation functions complain.
242 __delitem__ = complain
243 __delslice__ = complain
244 __iadd__ = complain
245 __imul__ = complain
246 __setitem__ = complain
247 __setslice__ = complain
248 append = complain
249 extend = complain
250 insert = complain
251 pop = complain
252 remove = complain
253 sort = complain
254 reverse = complain
257class DictWrapper(dict):
258 """
259 Wrap accesses to a dictionary so that certain values (those starting with
260 the specified prefix) are passed through a function before being returned.
261 The prefix is removed before looking up the real value.
263 Used by the SQL construction code to ensure that values are correctly
264 quoted before being used.
265 """
267 def __init__(self, data, func, prefix):
268 super().__init__(data)
269 self.func = func
270 self.prefix = prefix
272 def __getitem__(self, key):
273 """
274 Retrieve the real value after stripping the prefix string (if
275 present). If the prefix is present, pass the value through self.func
276 before returning, otherwise return the raw value.
277 """
278 use_func = key.startswith(self.prefix)
279 key = key.removeprefix(self.prefix)
280 value = super().__getitem__(key)
281 if use_func:
282 return self.func(value)
283 return value
286class CaseInsensitiveMapping(Mapping):
287 """
288 Mapping allowing case-insensitive key lookups. Original case of keys is
289 preserved for iteration and string representation.
291 Example::
293 >>> ci_map = CaseInsensitiveMapping({'name': 'Jane'})
294 >>> ci_map['Name']
295 Jane
296 >>> ci_map['NAME']
297 Jane
298 >>> ci_map['name']
299 Jane
300 >>> ci_map # original case preserved
301 {'name': 'Jane'}
302 """
304 def __init__(self, data):
305 self._store = {k.lower(): (k, v) for k, v in self._unpack_items(data)}
307 def __getitem__(self, key):
308 return self._store[key.lower()][1]
310 def __len__(self):
311 return len(self._store)
313 def __eq__(self, other):
314 return isinstance(other, Mapping) and {
315 k.lower(): v for k, v in self.items()
316 } == {k.lower(): v for k, v in other.items()}
318 def __iter__(self):
319 return (original_key for original_key, value in self._store.values())
321 def __repr__(self):
322 return repr(dict(self._store.values()))
324 def copy(self):
325 return self
327 @staticmethod
328 def _unpack_items(data):
329 # Explicitly test for dict first as the common case for performance,
330 # avoiding abc's __instancecheck__ and _abc_instancecheck for the
331 # general Mapping case.
332 if isinstance(data, dict | Mapping):
333 yield from data.items()
334 return
335 for i, elem in enumerate(data):
336 if len(elem) != 2:
337 raise ValueError(
338 f"dictionary update sequence element #{i} has length {len(elem)}; "
339 "2 is required."
340 )
341 if not isinstance(elem[0], str):
342 raise ValueError(
343 "Element key %r invalid, only strings are allowed" % elem[0]
344 )
345 yield elem
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""Functions to parse datetime objects."""
3# We're using regular expressions rather than time.strptime because:
4# - They provide both validation and parsing.
5# - They're more flexible for datetimes.
6# - The date/datetime/time constructors produce friendlier error messages.
8import datetime
10from plain.utils.regex_helper import _lazy_re_compile
11from plain.utils.timezone import get_fixed_timezone
13date_re = _lazy_re_compile(r"(?P<year>\d{4})-(?P<month>\d{1,2})-(?P<day>\d{1,2})$")
15time_re = _lazy_re_compile(
16 r"(?P<hour>\d{1,2}):(?P<minute>\d{1,2})"
17 r"(?::(?P<second>\d{1,2})(?:[\.,](?P<microsecond>\d{1,6})\d{0,6})?)?$"
18)
20datetime_re = _lazy_re_compile(
21 r"(?P<year>\d{4})-(?P<month>\d{1,2})-(?P<day>\d{1,2})"
22 r"[T ](?P<hour>\d{1,2}):(?P<minute>\d{1,2})"
23 r"(?::(?P<second>\d{1,2})(?:[\.,](?P<microsecond>\d{1,6})\d{0,6})?)?"
24 r"\s*(?P<tzinfo>Z|[+-]\d{2}(?::?\d{2})?)?$"
25)
27standard_duration_re = _lazy_re_compile(
28 r"^"
29 r"(?:(?P<days>-?\d+) (days?, )?)?"
30 r"(?P<sign>-?)"
31 r"((?:(?P<hours>\d+):)(?=\d+:\d+))?"
32 r"(?:(?P<minutes>\d+):)?"
33 r"(?P<seconds>\d+)"
34 r"(?:[\.,](?P<microseconds>\d{1,6})\d{0,6})?"
35 r"$"
36)
38# Support the sections of ISO 8601 date representation that are accepted by
39# timedelta
40iso8601_duration_re = _lazy_re_compile(
41 r"^(?P<sign>[-+]?)"
42 r"P"
43 r"(?:(?P<days>\d+([\.,]\d+)?)D)?"
44 r"(?:T"
45 r"(?:(?P<hours>\d+([\.,]\d+)?)H)?"
46 r"(?:(?P<minutes>\d+([\.,]\d+)?)M)?"
47 r"(?:(?P<seconds>\d+([\.,]\d+)?)S)?"
48 r")?"
49 r"$"
50)
52# Support PostgreSQL's day-time interval format, e.g. "3 days 04:05:06". The
53# year-month and mixed intervals cannot be converted to a timedelta and thus
54# aren't accepted.
55postgres_interval_re = _lazy_re_compile(
56 r"^"
57 r"(?:(?P<days>-?\d+) (days? ?))?"
58 r"(?:(?P<sign>[-+])?"
59 r"(?P<hours>\d+):"
60 r"(?P<minutes>\d\d):"
61 r"(?P<seconds>\d\d)"
62 r"(?:\.(?P<microseconds>\d{1,6}))?"
63 r")?$"
64)
67def parse_date(value):
68 """Parse a string and return a datetime.date.
70 Raise ValueError if the input is well formatted but not a valid date.
71 Return None if the input isn't well formatted.
72 """
73 try:
74 return datetime.date.fromisoformat(value)
75 except ValueError:
76 if match := date_re.match(value):
77 kw = {k: int(v) for k, v in match.groupdict().items()}
78 return datetime.date(**kw)
81def parse_time(value):
82 """Parse a string and return a datetime.time.
84 This function doesn't support time zone offsets.
86 Raise ValueError if the input is well formatted but not a valid time.
87 Return None if the input isn't well formatted, in particular if it
88 contains an offset.
89 """
90 try:
91 # The fromisoformat() method takes time zone info into account and
92 # returns a time with a tzinfo component, if possible. However, there
93 # are no circumstances where aware datetime.time objects make sense, so
94 # remove the time zone offset.
95 return datetime.time.fromisoformat(value).replace(tzinfo=None)
96 except ValueError:
97 if match := time_re.match(value):
98 kw = match.groupdict()
99 kw["microsecond"] = kw["microsecond"] and kw["microsecond"].ljust(6, "0")
100 kw = {k: int(v) for k, v in kw.items() if v is not None}
101 return datetime.time(**kw)
104def parse_datetime(value):
105 """Parse a string and return a datetime.datetime.
107 This function supports time zone offsets. When the input contains one,
108 the output uses a timezone with a fixed offset from UTC.
110 Raise ValueError if the input is well formatted but not a valid datetime.
111 Return None if the input isn't well formatted.
112 """
113 try:
114 return datetime.datetime.fromisoformat(value)
115 except ValueError:
116 if match := datetime_re.match(value):
117 kw = match.groupdict()
118 kw["microsecond"] = kw["microsecond"] and kw["microsecond"].ljust(6, "0")
119 tzinfo = kw.pop("tzinfo")
120 if tzinfo == "Z":
121 tzinfo = datetime.timezone.utc
122 elif tzinfo is not None:
123 offset_mins = int(tzinfo[-2:]) if len(tzinfo) > 3 else 0
124 offset = 60 * int(tzinfo[1:3]) + offset_mins
125 if tzinfo[0] == "-":
126 offset = -offset
127 tzinfo = get_fixed_timezone(offset)
128 kw = {k: int(v) for k, v in kw.items() if v is not None}
129 return datetime.datetime(**kw, tzinfo=tzinfo)
132def parse_duration(value):
133 """Parse a duration string and return a datetime.timedelta.
135 The preferred format for durations in Plain is '%d %H:%M:%S.%f'.
137 Also supports ISO 8601 representation and PostgreSQL's day-time interval
138 format.
139 """
140 match = (
141 standard_duration_re.match(value)
142 or iso8601_duration_re.match(value)
143 or postgres_interval_re.match(value)
144 )
145 if match:
146 kw = match.groupdict()
147 sign = -1 if kw.pop("sign", "+") == "-" else 1
148 if kw.get("microseconds"):
149 kw["microseconds"] = kw["microseconds"].ljust(6, "0")
150 kw = {k: float(v.replace(",", ".")) for k, v in kw.items() if v is not None}
151 days = datetime.timedelta(kw.pop("days", 0.0) or 0.0)
152 if match.re == iso8601_duration_re:
153 days *= sign
154 return days + sign * datetime.timedelta(**kw)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from importlib import import_module
4def deconstructible(*args, path=None):
5 """
6 Class decorator that allows the decorated class to be serialized
7 by the migrations subsystem.
9 The `path` kwarg specifies the import path.
10 """
12 def decorator(klass):
13 def __new__(cls, *args, **kwargs):
14 # We capture the arguments to make returning them trivial
15 obj = super(klass, cls).__new__(cls)
16 obj._constructor_args = (args, kwargs)
17 return obj
19 def deconstruct(obj):
20 """
21 Return a 3-tuple of class import path, positional arguments,
22 and keyword arguments.
23 """
24 # Fallback version
25 if path and type(obj) is klass:
26 module_name, _, name = path.rpartition(".")
27 else:
28 module_name = obj.__module__
29 name = obj.__class__.__name__
30 # Make sure it's actually there and not an inner class
31 module = import_module(module_name)
32 if not hasattr(module, name):
33 raise ValueError(
34 f"Could not find object {name} in {module_name}.\n"
35 "Please note that you cannot serialize things like inner "
36 "classes. Please move the object into the main module "
37 "body to use migrations."
38 )
39 return (
40 path
41 if path and type(obj) is klass
42 else f"{obj.__class__.__module__}.{name}",
43 obj._constructor_args[0],
44 obj._constructor_args[1],
45 )
47 klass.__new__ = staticmethod(__new__)
48 klass.deconstruct = deconstruct
50 return klass
52 if not args:
53 return decorator
54 return decorator(*args)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"Functions that help with dynamically creating decorators for views."
3from functools import partial, update_wrapper, wraps
6class classonlymethod(classmethod):
7 def __get__(self, instance, cls=None):
8 if instance is not None:
9 raise AttributeError(
10 "This method is available only on the class, not on instances."
11 )
12 return super().__get__(instance, cls)
15def _update_method_wrapper(_wrapper, decorator):
16 # _multi_decorate()'s bound_method isn't available in this scope. Cheat by
17 # using it on a dummy function.
18 @decorator
19 def dummy(*args, **kwargs):
20 pass
22 update_wrapper(_wrapper, dummy)
25def _multi_decorate(decorators, method):
26 """
27 Decorate `method` with one or more function decorators. `decorators` can be
28 a single decorator or an iterable of decorators.
29 """
30 if hasattr(decorators, "__iter__"):
31 # Apply a list/tuple of decorators if 'decorators' is one. Decorator
32 # functions are applied so that the call order is the same as the
33 # order in which they appear in the iterable.
34 decorators = decorators[::-1]
35 else:
36 decorators = [decorators]
38 def _wrapper(self, *args, **kwargs):
39 # bound_method has the signature that 'decorator' expects i.e. no
40 # 'self' argument, but it's a closure over self so it can call
41 # 'func'. Also, wrap method.__get__() in a function because new
42 # attributes can't be set on bound method objects, only on functions.
43 bound_method = wraps(method)(partial(method.__get__(self, type(self))))
44 for dec in decorators:
45 bound_method = dec(bound_method)
46 return bound_method(*args, **kwargs)
48 # Copy any attributes that a decorator adds to the function it decorates.
49 for dec in decorators:
50 _update_method_wrapper(_wrapper, dec)
51 # Preserve any existing attributes of 'method', including the name.
52 update_wrapper(_wrapper, method)
53 return _wrapper
56def method_decorator(decorator, name=""):
57 """
58 Convert a function decorator into a method decorator
59 """
61 # 'obj' can be a class or a function. If 'obj' is a function at the time it
62 # is passed to _dec, it will eventually be a method of the class it is
63 # defined on. If 'obj' is a class, the 'name' is required to be the name
64 # of the method that will be decorated.
65 def _dec(obj):
66 if not isinstance(obj, type):
67 return _multi_decorate(decorator, obj)
68 if not (name and hasattr(obj, name)):
69 raise ValueError(
70 "The keyword argument `name` must be the name of a method "
71 f"of the decorated class: {obj}. Got '{name}' instead."
72 )
73 method = getattr(obj, name)
74 if not callable(method):
75 raise TypeError(
76 f"Cannot decorate '{name}' as it isn't a callable attribute of "
77 f"{obj} ({method})."
78 )
79 _wrapper = _multi_decorate(decorator, method)
80 setattr(obj, name, _wrapper)
81 return obj
83 # Don't worry about making _dec look similar to a list/tuple as it's rather
84 # meaningless.
85 if not hasattr(decorator, "__iter__"):
86 update_wrapper(_dec, decorator)
87 # Change the name to aid debugging.
88 obj = decorator if hasattr(decorator, "__name__") else decorator.__class__
89 _dec.__name__ = "method_decorator(%s)" % obj.__name__
90 return _dec
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1class RemovedInDjango51Warning(DeprecationWarning):
2 pass
5class RemovedInDjango60Warning(PendingDeprecationWarning):
6 pass
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import datetime
4def _get_duration_components(duration):
5 days = duration.days
6 seconds = duration.seconds
7 microseconds = duration.microseconds
9 minutes = seconds // 60
10 seconds %= 60
12 hours = minutes // 60
13 minutes %= 60
15 return days, hours, minutes, seconds, microseconds
18def duration_string(duration):
19 """Version of str(timedelta) which is not English specific."""
20 days, hours, minutes, seconds, microseconds = _get_duration_components(duration)
22 string = f"{hours:02d}:{minutes:02d}:{seconds:02d}"
23 if days:
24 string = f"{days} " + string
25 if microseconds:
26 string += f".{microseconds:06d}"
28 return string
31def duration_iso_string(duration):
32 if duration < datetime.timedelta(0):
33 sign = "-"
34 duration *= -1
35 else:
36 sign = ""
38 days, hours, minutes, seconds, microseconds = _get_duration_components(duration)
39 ms = f".{microseconds:06d}" if microseconds else ""
40 return f"{sign}P{days}DT{hours:02d}H{minutes:02d}M{seconds:02d}{ms}S"
43def duration_microseconds(delta):
44 return (24 * 60 * 60 * delta.days + delta.seconds) * 1000000 + delta.microseconds
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import codecs
2import datetime
3import locale
4from decimal import Decimal
5from types import NoneType
6from urllib.parse import quote
8from plain.utils.functional import Promise
11class PlainUnicodeDecodeError(UnicodeDecodeError):
12 def __init__(self, obj, *args):
13 self.obj = obj
14 super().__init__(*args)
16 def __str__(self):
17 return f"{super().__str__()}. You passed in {self.obj!r} ({type(self.obj)})"
20_PROTECTED_TYPES = (
21 NoneType,
22 int,
23 float,
24 Decimal,
25 datetime.datetime,
26 datetime.date,
27 datetime.time,
28)
31def is_protected_type(obj):
32 """Determine if the object instance is of a protected type.
34 Objects of protected types are preserved as-is when passed to
35 force_str(strings_only=True).
36 """
37 return isinstance(obj, _PROTECTED_TYPES)
40def force_str(s, encoding="utf-8", strings_only=False, errors="strict"):
41 """
42 Similar to smart_str(), except that lazy instances are resolved to
43 strings, rather than kept as lazy objects.
45 If strings_only is True, don't convert (some) non-string-like objects.
46 """
47 # Handle the common case first for performance reasons.
48 if issubclass(type(s), str):
49 return s
50 if strings_only and is_protected_type(s):
51 return s
52 try:
53 if isinstance(s, bytes):
54 s = str(s, encoding, errors)
55 else:
56 s = str(s)
57 except UnicodeDecodeError as e:
58 raise PlainUnicodeDecodeError(s, *e.args)
59 return s
62def force_bytes(s, encoding="utf-8", strings_only=False, errors="strict"):
63 """
64 Similar to smart_bytes, except that lazy instances are resolved to
65 strings, rather than kept as lazy objects.
67 If strings_only is True, don't convert (some) non-string-like objects.
68 """
69 # Handle the common case first for performance reasons.
70 if isinstance(s, bytes):
71 if encoding == "utf-8":
72 return s
73 else:
74 return s.decode("utf-8", errors).encode(encoding, errors)
75 if strings_only and is_protected_type(s):
76 return s
77 if isinstance(s, memoryview):
78 return bytes(s)
79 return str(s).encode(encoding, errors)
82def iri_to_uri(iri):
83 """
84 Convert an Internationalized Resource Identifier (IRI) portion to a URI
85 portion that is suitable for inclusion in a URL.
87 This is the algorithm from RFC 3987 Section 3.1, slightly simplified since
88 the input is assumed to be a string rather than an arbitrary byte stream.
90 Take an IRI (string or UTF-8 bytes, e.g. '/I ♥ Plain/' or
91 b'/I \xe2\x99\xa5 Plain/') and return a string containing the encoded
92 result with ASCII chars only (e.g. '/I%20%E2%99%A5%20Plain/').
93 """
94 # The list of safe characters here is constructed from the "reserved" and
95 # "unreserved" characters specified in RFC 3986 Sections 2.2 and 2.3:
96 # reserved = gen-delims / sub-delims
97 # gen-delims = ":" / "/" / "?" / "#" / "[" / "]" / "@"
98 # sub-delims = "!" / "$" / "&" / "'" / "(" / ")"
99 # / "*" / "+" / "," / ";" / "="
100 # unreserved = ALPHA / DIGIT / "-" / "." / "_" / "~"
101 # Of the unreserved characters, urllib.parse.quote() already considers all
102 # but the ~ safe.
103 # The % character is also added to the list of safe characters here, as the
104 # end of RFC 3987 Section 3.1 specifically mentions that % must not be
105 # converted.
106 if iri is None:
107 return iri
108 elif isinstance(iri, Promise):
109 iri = str(iri)
110 return quote(iri, safe="/#%[]=:;$&()+,!?*@'~")
113# List of byte values that uri_to_iri() decodes from percent encoding.
114# First, the unreserved characters from RFC 3986:
115_ascii_ranges = [[45, 46, 95, 126], range(65, 91), range(97, 123)]
116_hextobyte = {
117 (fmt % char).encode(): bytes((char,))
118 for ascii_range in _ascii_ranges
119 for char in ascii_range
120 for fmt in ["%02x", "%02X"]
121}
122# And then everything above 128, because bytes ≥ 128 are part of multibyte
123# Unicode characters.
124_hexdig = "0123456789ABCDEFabcdef"
125_hextobyte.update(
126 {(a + b).encode(): bytes.fromhex(a + b) for a in _hexdig[8:] for b in _hexdig}
127)
130def uri_to_iri(uri):
131 """
132 Convert a Uniform Resource Identifier(URI) into an Internationalized
133 Resource Identifier(IRI).
135 This is the algorithm from RFC 3987 Section 3.2, excluding step 4.
137 Take an URI in ASCII bytes (e.g. '/I%20%E2%99%A5%20Plain/') and return
138 a string containing the encoded result (e.g. '/I%20♥%20Plain/').
139 """
140 if uri is None:
141 return uri
142 uri = force_bytes(uri)
143 # Fast selective unquote: First, split on '%' and then starting with the
144 # second block, decode the first 2 bytes if they represent a hex code to
145 # decode. The rest of the block is the part after '%AB', not containing
146 # any '%'. Add that to the output without further processing.
147 bits = uri.split(b"%")
148 if len(bits) == 1:
149 iri = uri
150 else:
151 parts = [bits[0]]
152 append = parts.append
153 hextobyte = _hextobyte
154 for item in bits[1:]:
155 hex = item[:2]
156 if hex in hextobyte:
157 append(hextobyte[item[:2]])
158 append(item[2:])
159 else:
160 append(b"%")
161 append(item)
162 iri = b"".join(parts)
163 return repercent_broken_unicode(iri).decode()
166def escape_uri_path(path):
167 """
168 Escape the unsafe characters from the path portion of a Uniform Resource
169 Identifier (URI).
170 """
171 # These are the "reserved" and "unreserved" characters specified in RFC
172 # 3986 Sections 2.2 and 2.3:
173 # reserved = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+" | "$" | ","
174 # unreserved = alphanum | mark
175 # mark = "-" | "_" | "." | "!" | "~" | "*" | "'" | "(" | ")"
176 # The list of safe characters here is constructed subtracting ";", "=",
177 # and "?" according to RFC 3986 Section 3.3.
178 # The reason for not subtracting and escaping "/" is that we are escaping
179 # the entire path, not a path segment.
180 return quote(path, safe="/:@&+$,-_.!~*'()")
183def punycode(domain):
184 """Return the Punycode of the given domain if it's non-ASCII."""
185 return domain.encode("idna").decode("ascii")
188def repercent_broken_unicode(path):
189 """
190 As per RFC 3987 Section 3.2, step three of converting a URI into an IRI,
191 repercent-encode any octet produced that is not part of a strictly legal
192 UTF-8 octet sequence.
193 """
194 while True:
195 try:
196 path.decode()
197 except UnicodeDecodeError as e:
198 # CVE-2019-14235: A recursion shouldn't be used since the exception
199 # handling uses massive amounts of memory
200 repercent = quote(path[e.start : e.end], safe=b"/#%[]=:;$&()+,!?*@'~")
201 path = path[: e.start] + repercent.encode() + path[e.end :]
202 else:
203 return path
206def filepath_to_uri(path):
207 """Convert a file system path to a URI portion that is suitable for
208 inclusion in a URL.
210 Encode certain chars that would normally be recognized as special chars
211 for URIs. Do not encode the ' character, as it is a valid character
212 within URIs. See the encodeURIComponent() JavaScript function for details.
213 """
214 if path is None:
215 return path
216 # I know about `os.sep` and `os.altsep` but I want to leave
217 # some flexibility for hardcoding separators.
218 return quote(str(path).replace("\\", "/"), safe="/~!*()'")
221def get_system_encoding():
222 """
223 The encoding for the character type functions. Fallback to 'ascii' if the
224 #encoding is unsupported by Python or could not be determined. See tickets
225 #10335 and #5846.
226 """
227 try:
228 encoding = locale.getlocale()[1] or "ascii"
229 codecs.lookup(encoding)
230 except Exception:
231 encoding = "ascii"
232 return encoding
235DEFAULT_LOCALE_ENCODING = get_system_encoding()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import copy
2import itertools
3import operator
4from functools import total_ordering, wraps
7class cached_property:
8 """
9 Decorator that converts a method with a single self argument into a
10 property cached on the instance.
12 A cached property can be made out of an existing method:
13 (e.g. ``url = cached_property(get_absolute_url)``).
14 """
16 name = None
18 @staticmethod
19 def func(instance):
20 raise TypeError(
21 "Cannot use cached_property instance without calling "
22 "__set_name__() on it."
23 )
25 def __init__(self, func):
26 self.real_func = func
27 self.__doc__ = getattr(func, "__doc__")
29 def __set_name__(self, owner, name):
30 if self.name is None:
31 self.name = name
32 self.func = self.real_func
33 elif name != self.name:
34 raise TypeError(
35 "Cannot assign the same cached_property to two different names "
36 f"({self.name!r} and {name!r})."
37 )
39 def __get__(self, instance, cls=None):
40 """
41 Call the function and put the return value in instance.__dict__ so that
42 subsequent attribute access on the instance returns the cached value
43 instead of calling cached_property.__get__().
44 """
45 if instance is None:
46 return self
47 res = instance.__dict__[self.name] = self.func(instance)
48 return res
51class classproperty:
52 """
53 Decorator that converts a method with a single cls argument into a property
54 that can be accessed directly from the class.
55 """
57 def __init__(self, method=None):
58 self.fget = method
60 def __get__(self, instance, cls=None):
61 return self.fget(cls)
63 def getter(self, method):
64 self.fget = method
65 return self
68class Promise:
69 """
70 Base class for the proxy class created in the closure of the lazy function.
71 It's used to recognize promises in code.
72 """
74 pass
77def lazy(func, *resultclasses):
78 """
79 Turn any callable into a lazy evaluated callable. result classes or types
80 is required -- at least one is needed so that the automatic forcing of
81 the lazy evaluation code is triggered. Results are not memoized; the
82 function is evaluated on every access.
83 """
85 @total_ordering
86 class __proxy__(Promise):
87 """
88 Encapsulate a function call and act as a proxy for methods that are
89 called on the result of that function. The function is not evaluated
90 until one of the methods on the result is called.
91 """
93 __prepared = False
95 def __init__(self, args, kw):
96 self.__args = args
97 self.__kw = kw
98 if not self.__prepared:
99 self.__prepare_class__()
100 self.__class__.__prepared = True
102 def __reduce__(self):
103 return (
104 _lazy_proxy_unpickle,
105 (func, self.__args, self.__kw) + resultclasses,
106 )
108 def __repr__(self):
109 return repr(self.__cast())
111 @classmethod
112 def __prepare_class__(cls):
113 for resultclass in resultclasses:
114 for type_ in resultclass.mro():
115 for method_name in type_.__dict__:
116 # All __promise__ return the same wrapper method, they
117 # look up the correct implementation when called.
118 if hasattr(cls, method_name):
119 continue
120 meth = cls.__promise__(method_name)
121 setattr(cls, method_name, meth)
122 cls._delegate_bytes = bytes in resultclasses
123 cls._delegate_text = str in resultclasses
124 if cls._delegate_bytes and cls._delegate_text:
125 raise ValueError(
126 "Cannot call lazy() with both bytes and text return types."
127 )
128 if cls._delegate_text:
129 cls.__str__ = cls.__text_cast
130 elif cls._delegate_bytes:
131 cls.__bytes__ = cls.__bytes_cast
133 @classmethod
134 def __promise__(cls, method_name):
135 # Builds a wrapper around some magic method
136 def __wrapper__(self, *args, **kw):
137 # Automatically triggers the evaluation of a lazy value and
138 # applies the given magic method of the result type.
139 res = func(*self.__args, **self.__kw)
140 return getattr(res, method_name)(*args, **kw)
142 return __wrapper__
144 def __text_cast(self):
145 return func(*self.__args, **self.__kw)
147 def __bytes_cast(self):
148 return bytes(func(*self.__args, **self.__kw))
150 def __bytes_cast_encoded(self):
151 return func(*self.__args, **self.__kw).encode()
153 def __cast(self):
154 if self._delegate_bytes:
155 return self.__bytes_cast()
156 elif self._delegate_text:
157 return self.__text_cast()
158 else:
159 return func(*self.__args, **self.__kw)
161 def __str__(self):
162 # object defines __str__(), so __prepare_class__() won't overload
163 # a __str__() method from the proxied class.
164 return str(self.__cast())
166 def __eq__(self, other):
167 if isinstance(other, Promise):
168 other = other.__cast()
169 return self.__cast() == other
171 def __lt__(self, other):
172 if isinstance(other, Promise):
173 other = other.__cast()
174 return self.__cast() < other
176 def __hash__(self):
177 return hash(self.__cast())
179 def __mod__(self, rhs):
180 if self._delegate_text:
181 return str(self) % rhs
182 return self.__cast() % rhs
184 def __add__(self, other):
185 return self.__cast() + other
187 def __radd__(self, other):
188 return other + self.__cast()
190 def __deepcopy__(self, memo):
191 # Instances of this class are effectively immutable. It's just a
192 # collection of functions. So we don't need to do anything
193 # complicated for copying.
194 memo[id(self)] = self
195 return self
197 @wraps(func)
198 def __wrapper__(*args, **kw):
199 # Creates the proxy object, instead of the actual value.
200 return __proxy__(args, kw)
202 return __wrapper__
205def _lazy_proxy_unpickle(func, args, kwargs, *resultclasses):
206 return lazy(func, *resultclasses)(*args, **kwargs)
209def lazystr(text):
210 """
211 Shortcut for the common case of a lazy callable that returns str.
212 """
213 return lazy(str, str)(text)
216def keep_lazy(*resultclasses):
217 """
218 A decorator that allows a function to be called with one or more lazy
219 arguments. If none of the args are lazy, the function is evaluated
220 immediately, otherwise a __proxy__ is returned that will evaluate the
221 function when needed.
222 """
223 if not resultclasses:
224 raise TypeError("You must pass at least one argument to keep_lazy().")
226 def decorator(func):
227 lazy_func = lazy(func, *resultclasses)
229 @wraps(func)
230 def wrapper(*args, **kwargs):
231 if any(
232 isinstance(arg, Promise)
233 for arg in itertools.chain(args, kwargs.values())
234 ):
235 return lazy_func(*args, **kwargs)
236 return func(*args, **kwargs)
238 return wrapper
240 return decorator
243def keep_lazy_text(func):
244 """
245 A decorator for functions that accept lazy arguments and return text.
246 """
247 return keep_lazy(str)(func)
250empty = object()
253def new_method_proxy(func):
254 def inner(self, *args):
255 if (_wrapped := self._wrapped) is empty:
256 self._setup()
257 _wrapped = self._wrapped
258 return func(_wrapped, *args)
260 inner._mask_wrapped = False
261 return inner
264class LazyObject:
265 """
266 A wrapper for another class that can be used to delay instantiation of the
267 wrapped class.
269 By subclassing, you have the opportunity to intercept and alter the
270 instantiation. If you don't need to do that, use SimpleLazyObject.
271 """
273 # Avoid infinite recursion when tracing __init__ (#19456).
274 _wrapped = None
276 def __init__(self):
277 # Note: if a subclass overrides __init__(), it will likely need to
278 # override __copy__() and __deepcopy__() as well.
279 self._wrapped = empty
281 def __getattribute__(self, name):
282 if name == "_wrapped":
283 # Avoid recursion when getting wrapped object.
284 return super().__getattribute__(name)
285 value = super().__getattribute__(name)
286 # If attribute is a proxy method, raise an AttributeError to call
287 # __getattr__() and use the wrapped object method.
288 if not getattr(value, "_mask_wrapped", True):
289 raise AttributeError
290 return value
292 __getattr__ = new_method_proxy(getattr)
294 def __setattr__(self, name, value):
295 if name == "_wrapped":
296 # Assign to __dict__ to avoid infinite __setattr__ loops.
297 self.__dict__["_wrapped"] = value
298 else:
299 if self._wrapped is empty:
300 self._setup()
301 setattr(self._wrapped, name, value)
303 def __delattr__(self, name):
304 if name == "_wrapped":
305 raise TypeError("can't delete _wrapped.")
306 if self._wrapped is empty:
307 self._setup()
308 delattr(self._wrapped, name)
310 def _setup(self):
311 """
312 Must be implemented by subclasses to initialize the wrapped object.
313 """
314 raise NotImplementedError(
315 "subclasses of LazyObject must provide a _setup() method"
316 )
318 # Because we have messed with __class__ below, we confuse pickle as to what
319 # class we are pickling. We're going to have to initialize the wrapped
320 # object to successfully pickle it, so we might as well just pickle the
321 # wrapped object since they're supposed to act the same way.
322 #
323 # Unfortunately, if we try to simply act like the wrapped object, the ruse
324 # will break down when pickle gets our id(). Thus we end up with pickle
325 # thinking, in effect, that we are a distinct object from the wrapped
326 # object, but with the same __dict__. This can cause problems (see #25389).
327 #
328 # So instead, we define our own __reduce__ method and custom unpickler. We
329 # pickle the wrapped object as the unpickler's argument, so that pickle
330 # will pickle it normally, and then the unpickler simply returns its
331 # argument.
332 def __reduce__(self):
333 if self._wrapped is empty:
334 self._setup()
335 return (unpickle_lazyobject, (self._wrapped,))
337 def __copy__(self):
338 if self._wrapped is empty:
339 # If uninitialized, copy the wrapper. Use type(self), not
340 # self.__class__, because the latter is proxied.
341 return type(self)()
342 else:
343 # If initialized, return a copy of the wrapped object.
344 return copy.copy(self._wrapped)
346 def __deepcopy__(self, memo):
347 if self._wrapped is empty:
348 # We have to use type(self), not self.__class__, because the
349 # latter is proxied.
350 result = type(self)()
351 memo[id(self)] = result
352 return result
353 return copy.deepcopy(self._wrapped, memo)
355 __bytes__ = new_method_proxy(bytes)
356 __str__ = new_method_proxy(str)
357 __bool__ = new_method_proxy(bool)
359 # Introspection support
360 __dir__ = new_method_proxy(dir)
362 # Need to pretend to be the wrapped class, for the sake of objects that
363 # care about this (especially in equality tests)
364 __class__ = property(new_method_proxy(operator.attrgetter("__class__")))
365 __eq__ = new_method_proxy(operator.eq)
366 __lt__ = new_method_proxy(operator.lt)
367 __gt__ = new_method_proxy(operator.gt)
368 __ne__ = new_method_proxy(operator.ne)
369 __hash__ = new_method_proxy(hash)
371 # List/Tuple/Dictionary methods support
372 __getitem__ = new_method_proxy(operator.getitem)
373 __setitem__ = new_method_proxy(operator.setitem)
374 __delitem__ = new_method_proxy(operator.delitem)
375 __iter__ = new_method_proxy(iter)
376 __len__ = new_method_proxy(len)
377 __contains__ = new_method_proxy(operator.contains)
380def unpickle_lazyobject(wrapped):
381 """
382 Used to unpickle lazy objects. Just return its argument, which will be the
383 wrapped object.
384 """
385 return wrapped
388class SimpleLazyObject(LazyObject):
389 """
390 A lazy object initialized from any function.
392 Designed for compound objects of unknown type. For builtins or objects of
393 known type, use plain.utils.functional.lazy.
394 """
396 def __init__(self, func):
397 """
398 Pass in a callable that returns the object to be wrapped.
400 If copies are made of the resulting SimpleLazyObject, which can happen
401 in various circumstances within Plain, then you must ensure that the
402 callable can be safely run more than once and will return the same
403 value.
404 """
405 self.__dict__["_setupfunc"] = func
406 super().__init__()
408 def _setup(self):
409 self._wrapped = self._setupfunc()
411 # Return a meaningful representation of the lazy object for debugging
412 # without evaluating the wrapped object.
413 def __repr__(self):
414 if self._wrapped is empty:
415 repr_attr = self._setupfunc
416 else:
417 repr_attr = self._wrapped
418 return f"<{type(self).__name__}: {repr_attr!r}>"
420 def __copy__(self):
421 if self._wrapped is empty:
422 # If uninitialized, copy the wrapper. Use SimpleLazyObject, not
423 # self.__class__, because the latter is proxied.
424 return SimpleLazyObject(self._setupfunc)
425 else:
426 # If initialized, return a copy of the wrapped object.
427 return copy.copy(self._wrapped)
429 def __deepcopy__(self, memo):
430 if self._wrapped is empty:
431 # We have to use SimpleLazyObject, not self.__class__, because the
432 # latter is proxied.
433 result = SimpleLazyObject(self._setupfunc)
434 memo[id(self)] = result
435 return result
436 return copy.deepcopy(self._wrapped, memo)
438 __add__ = new_method_proxy(operator.add)
440 @new_method_proxy
441 def __radd__(self, other):
442 return other + self
445def partition(predicate, values):
446 """
447 Split the values into two sets, based on the return value of the function
448 (True/False). e.g.:
450 >>> partition(lambda x: x > 3, range(5))
451 [0, 1, 2, 3], [4]
452 """
453 results = ([], [])
454 for item in values:
455 results[predicate(item)].append(item)
456 return results
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.utils.itercompat import is_iterable
4def make_hashable(value):
5 """
6 Attempt to make value hashable or raise a TypeError if it fails.
8 The returned value should generate the same hash for equal values.
9 """
10 if isinstance(value, dict):
11 return tuple(
12 [
13 (key, make_hashable(nested_value))
14 for key, nested_value in sorted(value.items())
15 ]
16 )
17 # Try hash to avoid converting a hashable iterable (e.g. string, frozenset)
18 # to a tuple.
19 try:
20 hash(value)
21 except TypeError:
22 if is_iterable(value):
23 return tuple(map(make_hashable, value))
24 # Non-hashable, non-iterable.
25 raise
26 return value
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""HTML utilities suitable for global use."""
3import html
4import json
5import re
6from html.parser import HTMLParser
7from urllib.parse import parse_qsl, quote, unquote, urlencode, urlsplit, urlunsplit
9from plain.utils.encoding import punycode
10from plain.utils.functional import Promise, keep_lazy, keep_lazy_text
11from plain.utils.http import RFC3986_GENDELIMS, RFC3986_SUBDELIMS
12from plain.utils.regex_helper import _lazy_re_compile
13from plain.utils.safestring import SafeData, SafeString, mark_safe
14from plain.utils.text import normalize_newlines
17@keep_lazy(SafeString)
18def escape(text):
19 """
20 Return the given text with ampersands, quotes and angle brackets encoded
21 for use in HTML.
23 Always escape input, even if it's already escaped and marked as such.
24 This may result in double-escaping. If this is a concern, use
25 conditional_escape() instead.
26 """
27 return SafeString(html.escape(str(text)))
30_js_escapes = {
31 ord("\\"): "\\u005C",
32 ord("'"): "\\u0027",
33 ord('"'): "\\u0022",
34 ord(">"): "\\u003E",
35 ord("<"): "\\u003C",
36 ord("&"): "\\u0026",
37 ord("="): "\\u003D",
38 ord("-"): "\\u002D",
39 ord(";"): "\\u003B",
40 ord("`"): "\\u0060",
41 ord("\u2028"): "\\u2028",
42 ord("\u2029"): "\\u2029",
43}
45# Escape every ASCII character with a value less than 32.
46_js_escapes.update((ord("%c" % z), "\\u%04X" % z) for z in range(32))
49@keep_lazy(SafeString)
50def escapejs(value):
51 """Hex encode characters for use in JavaScript strings."""
52 return mark_safe(str(value).translate(_js_escapes))
55_json_script_escapes = {
56 ord(">"): "\\u003E",
57 ord("<"): "\\u003C",
58 ord("&"): "\\u0026",
59}
62def json_script(value, element_id=None, encoder=None):
63 """
64 Escape all the HTML/XML special characters with their unicode escapes, so
65 value is safe to be output anywhere except for inside a tag attribute. Wrap
66 the escaped JSON in a script tag.
67 """
68 from plain.json import PlainJSONEncoder
70 json_str = json.dumps(value, cls=encoder or PlainJSONEncoder).translate(
71 _json_script_escapes
72 )
73 if element_id:
74 template = '<script id="{}" type="application/json">{}</script>'
75 args = (element_id, mark_safe(json_str))
76 else:
77 template = '<script type="application/json">{}</script>'
78 args = (mark_safe(json_str),)
79 return format_html(template, *args)
82def conditional_escape(text):
83 """
84 Similar to escape(), except that it doesn't operate on pre-escaped strings.
86 This function relies on the __html__ convention used both by Plain's
87 SafeData class and by third-party libraries like markupsafe.
88 """
89 if isinstance(text, Promise):
90 text = str(text)
91 if hasattr(text, "__html__"):
92 return text.__html__()
93 else:
94 return escape(text)
97def format_html(format_string, *args, **kwargs):
98 """
99 Similar to str.format, but pass all arguments through conditional_escape(),
100 and call mark_safe() on the result. This function should be used instead
101 of str.format or % interpolation to build up small HTML fragments.
102 """
103 args_safe = map(conditional_escape, args)
104 kwargs_safe = {k: conditional_escape(v) for (k, v) in kwargs.items()}
105 return mark_safe(format_string.format(*args_safe, **kwargs_safe))
108def format_html_join(sep, format_string, args_generator):
109 """
110 A wrapper of format_html, for the common case of a group of arguments that
111 need to be formatted using the same format string, and then joined using
112 'sep'. 'sep' is also passed through conditional_escape.
114 'args_generator' should be an iterator that returns the sequence of 'args'
115 that will be passed to format_html.
117 Example:
119 format_html_join('\n', "<li>{} {}</li>", ((u.first_name, u.last_name)
120 for u in users))
121 """
122 return mark_safe(
123 conditional_escape(sep).join(
124 format_html(format_string, *args) for args in args_generator
125 )
126 )
129@keep_lazy_text
130def linebreaks(value, autoescape=False):
131 """Convert newlines into <p> and <br>s."""
132 value = normalize_newlines(value)
133 paras = re.split("\n{2,}", str(value))
134 if autoescape:
135 paras = ["<p>%s</p>" % escape(p).replace("\n", "<br>") for p in paras]
136 else:
137 paras = ["<p>%s</p>" % p.replace("\n", "<br>") for p in paras]
138 return "\n\n".join(paras)
141class MLStripper(HTMLParser):
142 def __init__(self):
143 super().__init__(convert_charrefs=False)
144 self.reset()
145 self.fed = []
147 def handle_data(self, d):
148 self.fed.append(d)
150 def handle_entityref(self, name):
151 self.fed.append("&%s;" % name)
153 def handle_charref(self, name):
154 self.fed.append("&#%s;" % name)
156 def get_data(self):
157 return "".join(self.fed)
160def _strip_once(value):
161 """
162 Internal tag stripping utility used by strip_tags.
163 """
164 s = MLStripper()
165 s.feed(value)
166 s.close()
167 return s.get_data()
170@keep_lazy_text
171def strip_tags(value):
172 """Return the given HTML with all tags stripped."""
173 # Note: in typical case this loop executes _strip_once once. Loop condition
174 # is redundant, but helps to reduce number of executions of _strip_once.
175 value = str(value)
176 while "<" in value and ">" in value:
177 new_value = _strip_once(value)
178 if value.count("<") == new_value.count("<"):
179 # _strip_once wasn't able to detect more tags.
180 break
181 value = new_value
182 return value
185@keep_lazy_text
186def strip_spaces_between_tags(value):
187 """Return the given HTML with spaces between tags removed."""
188 return re.sub(r">\s+<", "><", str(value))
191def smart_urlquote(url):
192 """Quote a URL if it isn't already quoted."""
194 def unquote_quote(segment):
195 segment = unquote(segment)
196 # Tilde is part of RFC 3986 Section 2.3 Unreserved Characters,
197 # see also https://bugs.python.org/issue16285
198 return quote(segment, safe=RFC3986_SUBDELIMS + RFC3986_GENDELIMS + "~")
200 # Handle IDN before quoting.
201 try:
202 scheme, netloc, path, query, fragment = urlsplit(url)
203 except ValueError:
204 # invalid IPv6 URL (normally square brackets in hostname part).
205 return unquote_quote(url)
207 try:
208 netloc = punycode(netloc) # IDN -> ACE
209 except UnicodeError: # invalid domain part
210 return unquote_quote(url)
212 if query:
213 # Separately unquoting key/value, so as to not mix querystring separators
214 # included in query values. See #22267.
215 query_parts = [
216 (unquote(q[0]), unquote(q[1]))
217 for q in parse_qsl(query, keep_blank_values=True)
218 ]
219 # urlencode will take care of quoting
220 query = urlencode(query_parts)
222 path = unquote_quote(path)
223 fragment = unquote_quote(fragment)
225 return urlunsplit((scheme, netloc, path, query, fragment))
228class Urlizer:
229 """
230 Convert any URLs in text into clickable links.
232 Work on http://, https://, www. links, and also on links ending in one of
233 the original seven gTLDs (.com, .edu, .gov, .int, .mil, .net, and .org).
234 Links can have trailing punctuation (periods, commas, close-parens) and
235 leading punctuation (opening parens) and it'll still do the right thing.
236 """
238 trailing_punctuation_chars = ".,:;!"
239 wrapping_punctuation = [("(", ")"), ("[", "]")]
241 simple_url_re = _lazy_re_compile(r"^https?://\[?\w", re.IGNORECASE)
242 simple_url_2_re = _lazy_re_compile(
243 r"^www\.|^(?!http)\w[^@]+\.(com|edu|gov|int|mil|net|org)($|/.*)$", re.IGNORECASE
244 )
245 word_split_re = _lazy_re_compile(r"""([\s<>"']+)""")
247 mailto_template = "mailto:{local}@{domain}"
248 url_template = '<a href="{href}"{attrs}>{url}</a>'
250 def __call__(self, text, trim_url_limit=None, nofollow=False, autoescape=False):
251 """
252 If trim_url_limit is not None, truncate the URLs in the link text
253 longer than this limit to trim_url_limit - 1 characters and append an
254 ellipsis.
256 If nofollow is True, give the links a rel="nofollow" attribute.
258 If autoescape is True, autoescape the link text and URLs.
259 """
260 safe_input = isinstance(text, SafeData)
262 words = self.word_split_re.split(str(text))
263 return "".join(
264 [
265 self.handle_word(
266 word,
267 safe_input=safe_input,
268 trim_url_limit=trim_url_limit,
269 nofollow=nofollow,
270 autoescape=autoescape,
271 )
272 for word in words
273 ]
274 )
276 def handle_word(
277 self,
278 word,
279 *,
280 safe_input,
281 trim_url_limit=None,
282 nofollow=False,
283 autoescape=False,
284 ):
285 if "." in word or "@" in word or ":" in word:
286 # lead: Punctuation trimmed from the beginning of the word.
287 # middle: State of the word.
288 # trail: Punctuation trimmed from the end of the word.
289 lead, middle, trail = self.trim_punctuation(word)
290 # Make URL we want to point to.
291 url = None
292 nofollow_attr = ' rel="nofollow"' if nofollow else ""
293 if self.simple_url_re.match(middle):
294 url = smart_urlquote(html.unescape(middle))
295 elif self.simple_url_2_re.match(middle):
296 url = smart_urlquote("http://%s" % html.unescape(middle))
297 elif ":" not in middle and self.is_email_simple(middle):
298 local, domain = middle.rsplit("@", 1)
299 try:
300 domain = punycode(domain)
301 except UnicodeError:
302 return word
303 url = self.mailto_template.format(local=local, domain=domain)
304 nofollow_attr = ""
305 # Make link.
306 if url:
307 trimmed = self.trim_url(middle, limit=trim_url_limit)
308 if autoescape and not safe_input:
309 lead, trail = escape(lead), escape(trail)
310 trimmed = escape(trimmed)
311 middle = self.url_template.format(
312 href=escape(url),
313 attrs=nofollow_attr,
314 url=trimmed,
315 )
316 return mark_safe(f"{lead}{middle}{trail}")
317 else:
318 if safe_input:
319 return mark_safe(word)
320 elif autoescape:
321 return escape(word)
322 elif safe_input:
323 return mark_safe(word)
324 elif autoescape:
325 return escape(word)
326 return word
328 def trim_url(self, x, *, limit):
329 if limit is None or len(x) <= limit:
330 return x
331 return "%s…" % x[: max(0, limit - 1)]
333 def trim_punctuation(self, word):
334 """
335 Trim trailing and wrapping punctuation from `word`. Return the items of
336 the new state.
337 """
338 lead, middle, trail = "", word, ""
339 # Continue trimming until middle remains unchanged.
340 trimmed_something = True
341 while trimmed_something:
342 trimmed_something = False
343 # Trim wrapping punctuation.
344 for opening, closing in self.wrapping_punctuation:
345 if middle.startswith(opening):
346 middle = middle.removeprefix(opening)
347 lead += opening
348 trimmed_something = True
349 # Keep parentheses at the end only if they're balanced.
350 if (
351 middle.endswith(closing)
352 and middle.count(closing) == middle.count(opening) + 1
353 ):
354 middle = middle.removesuffix(closing)
355 trail = closing + trail
356 trimmed_something = True
357 # Trim trailing punctuation (after trimming wrapping punctuation,
358 # as encoded entities contain ';'). Unescape entities to avoid
359 # breaking them by removing ';'.
360 middle_unescaped = html.unescape(middle)
361 stripped = middle_unescaped.rstrip(self.trailing_punctuation_chars)
362 if middle_unescaped != stripped:
363 punctuation_count = len(middle_unescaped) - len(stripped)
364 trail = middle[-punctuation_count:] + trail
365 middle = middle[:-punctuation_count]
366 trimmed_something = True
367 return lead, middle, trail
369 @staticmethod
370 def is_email_simple(value):
371 """Return True if value looks like an email address."""
372 # An @ must be in the middle of the value.
373 if "@" not in value or value.startswith("@") or value.endswith("@"):
374 return False
375 try:
376 p1, p2 = value.split("@")
377 except ValueError:
378 # value contains more than one @.
379 return False
380 # Dot must be in p2 (e.g. example.com)
381 if "." not in p2 or p2.startswith("."):
382 return False
383 return True
386urlizer = Urlizer()
389@keep_lazy_text
390def urlize(text, trim_url_limit=None, nofollow=False, autoescape=False):
391 return urlizer(
392 text, trim_url_limit=trim_url_limit, nofollow=nofollow, autoescape=autoescape
393 )
396def avoid_wrapping(value):
397 """
398 Avoid text wrapping in the middle of a phrase by adding non-breaking
399 spaces where there previously were normal spaces.
400 """
401 return value.replace(" ", "\xa0")
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import base64
2import datetime
3import re
4import unicodedata
5from binascii import Error as BinasciiError
6from email.utils import formatdate
7from urllib.parse import quote, unquote, urlparse
8from urllib.parse import urlencode as original_urlencode
10from plain.utils.datastructures import MultiValueDict
11from plain.utils.regex_helper import _lazy_re_compile
13# Based on RFC 9110 Appendix A.
14ETAG_MATCH = _lazy_re_compile(
15 r"""
16 \A( # start of string and capture group
17 (?:W/)? # optional weak indicator
18 " # opening quote
19 [^"]* # any sequence of non-quote characters
20 " # end quote
21 )\Z # end of string and capture group
22""",
23 re.X,
24)
26MONTHS = "jan feb mar apr may jun jul aug sep oct nov dec".split()
27__D = r"(?P<day>[0-9]{2})"
28__D2 = r"(?P<day>[ 0-9][0-9])"
29__M = r"(?P<mon>\w{3})"
30__Y = r"(?P<year>[0-9]{4})"
31__Y2 = r"(?P<year>[0-9]{2})"
32__T = r"(?P<hour>[0-9]{2}):(?P<min>[0-9]{2}):(?P<sec>[0-9]{2})"
33RFC1123_DATE = _lazy_re_compile(rf"^\w{ 3} , {__D} {__M} {__Y} {__T} GMT$")
34RFC850_DATE = _lazy_re_compile(rf"^\w{ 6,9} , {__D}-{__M}-{__Y2} {__T} GMT$")
35ASCTIME_DATE = _lazy_re_compile(rf"^\w{ 3} {__M} {__D2} {__T} {__Y}$")
37RFC3986_GENDELIMS = ":/?#[]@"
38RFC3986_SUBDELIMS = "!$&'()*+,;="
41def urlencode(query, doseq=False):
42 """
43 A version of Python's urllib.parse.urlencode() function that can operate on
44 MultiValueDict and non-string values.
45 """
46 if isinstance(query, MultiValueDict):
47 query = query.lists()
48 elif hasattr(query, "items"):
49 query = query.items()
50 query_params = []
51 for key, value in query:
52 if value is None:
53 raise TypeError(
54 "Cannot encode None for key '%s' in a query string. Did you "
55 "mean to pass an empty string or omit the value?" % key
56 )
57 elif not doseq or isinstance(value, str | bytes):
58 query_val = value
59 else:
60 try:
61 itr = iter(value)
62 except TypeError:
63 query_val = value
64 else:
65 # Consume generators and iterators, when doseq=True, to
66 # work around https://bugs.python.org/issue31706.
67 query_val = []
68 for item in itr:
69 if item is None:
70 raise TypeError(
71 "Cannot encode None for key '%s' in a query "
72 "string. Did you mean to pass an empty string or "
73 "omit the value?" % key
74 )
75 elif not isinstance(item, bytes):
76 item = str(item)
77 query_val.append(item)
78 query_params.append((key, query_val))
79 return original_urlencode(query_params, doseq)
82def http_date(epoch_seconds=None):
83 """
84 Format the time to match the RFC 5322 date format as specified by RFC 9110
85 Section 5.6.7.
87 `epoch_seconds` is a floating point number expressed in seconds since the
88 epoch, in UTC - such as that outputted by time.time(). If set to None, it
89 defaults to the current time.
91 Output a string in the format 'Wdy, DD Mon YYYY HH:MM:SS GMT'.
92 """
93 return formatdate(epoch_seconds, usegmt=True)
96def parse_http_date(date):
97 """
98 Parse a date format as specified by HTTP RFC 9110 Section 5.6.7.
100 The three formats allowed by the RFC are accepted, even if only the first
101 one is still in widespread use.
103 Return an integer expressed in seconds since the epoch, in UTC.
104 """
105 # email.utils.parsedate() does the job for RFC 1123 dates; unfortunately
106 # RFC 9110 makes it mandatory to support RFC 850 dates too. So we roll
107 # our own RFC-compliant parsing.
108 for regex in RFC1123_DATE, RFC850_DATE, ASCTIME_DATE:
109 m = regex.match(date)
110 if m is not None:
111 break
112 else:
113 raise ValueError("%r is not in a valid HTTP date format" % date)
114 try:
115 tz = datetime.timezone.utc
116 year = int(m["year"])
117 if year < 100:
118 current_year = datetime.datetime.now(tz=tz).year
119 current_century = current_year - (current_year % 100)
120 if year - (current_year % 100) > 50:
121 # year that appears to be more than 50 years in the future are
122 # interpreted as representing the past.
123 year += current_century - 100
124 else:
125 year += current_century
126 month = MONTHS.index(m["mon"].lower()) + 1
127 day = int(m["day"])
128 hour = int(m["hour"])
129 min = int(m["min"])
130 sec = int(m["sec"])
131 result = datetime.datetime(year, month, day, hour, min, sec, tzinfo=tz)
132 return int(result.timestamp())
133 except Exception as exc:
134 raise ValueError("%r is not a valid date" % date) from exc
137def parse_http_date_safe(date):
138 """
139 Same as parse_http_date, but return None if the input is invalid.
140 """
141 try:
142 return parse_http_date(date)
143 except Exception:
144 pass
147# Base 36 functions: useful for generating compact URLs
150def base36_to_int(s):
151 """
152 Convert a base 36 string to an int. Raise ValueError if the input won't fit
153 into an int.
154 """
155 # To prevent overconsumption of server resources, reject any
156 # base36 string that is longer than 13 base36 digits (13 digits
157 # is sufficient to base36-encode any 64-bit integer)
158 if len(s) > 13:
159 raise ValueError("Base36 input too large")
160 return int(s, 36)
163def int_to_base36(i):
164 """Convert an integer to a base36 string."""
165 char_set = "0123456789abcdefghijklmnopqrstuvwxyz"
166 if i < 0:
167 raise ValueError("Negative base36 conversion input.")
168 if i < 36:
169 return char_set[i]
170 b36 = ""
171 while i != 0:
172 i, n = divmod(i, 36)
173 b36 = char_set[n] + b36
174 return b36
177def urlsafe_base64_encode(s):
178 """
179 Encode a bytestring to a base64 string for use in URLs. Strip any trailing
180 equal signs.
181 """
182 return base64.urlsafe_b64encode(s).rstrip(b"\n=").decode("ascii")
185def urlsafe_base64_decode(s):
186 """
187 Decode a base64 encoded string. Add back any trailing equal signs that
188 might have been stripped.
189 """
190 s = s.encode()
191 try:
192 return base64.urlsafe_b64decode(s.ljust(len(s) + len(s) % 4, b"="))
193 except (LookupError, BinasciiError) as e:
194 raise ValueError(e)
197def parse_etags(etag_str):
198 """
199 Parse a string of ETags given in an If-None-Match or If-Match header as
200 defined by RFC 9110. Return a list of quoted ETags, or ['*'] if all ETags
201 should be matched.
202 """
203 if etag_str.strip() == "*":
204 return ["*"]
205 else:
206 # Parse each ETag individually, and return any that are valid.
207 etag_matches = (ETAG_MATCH.match(etag.strip()) for etag in etag_str.split(","))
208 return [match[1] for match in etag_matches if match]
211def quote_etag(etag_str):
212 """
213 If the provided string is already a quoted ETag, return it. Otherwise, wrap
214 the string in quotes, making it a strong ETag.
215 """
216 if ETAG_MATCH.match(etag_str):
217 return etag_str
218 else:
219 return '"%s"' % etag_str
222def is_same_domain(host, pattern):
223 """
224 Return ``True`` if the host is either an exact match or a match
225 to the wildcard pattern.
227 Any pattern beginning with a period matches a domain and all of its
228 subdomains. (e.g. ``.example.com`` matches ``example.com`` and
229 ``foo.example.com``). Anything else is an exact string match.
230 """
231 if not pattern:
232 return False
234 pattern = pattern.lower()
235 return (
236 pattern[0] == "."
237 and (host.endswith(pattern) or host == pattern[1:])
238 or pattern == host
239 )
242def url_has_allowed_host_and_scheme(url, allowed_hosts, require_https=False):
243 """
244 Return ``True`` if the url uses an allowed host and a safe scheme.
246 Always return ``False`` on an empty url.
248 If ``require_https`` is ``True``, only 'https' will be considered a valid
249 scheme, as opposed to 'http' and 'https' with the default, ``False``.
251 Note: "True" doesn't entail that a URL is "safe". It may still be e.g.
252 quoted incorrectly. Ensure to also use plain.utils.encoding.iri_to_uri()
253 on the path component of untrusted URLs.
254 """
255 if url is not None:
256 url = url.strip()
257 if not url:
258 return False
259 if allowed_hosts is None:
260 allowed_hosts = set()
261 elif isinstance(allowed_hosts, str):
262 allowed_hosts = {allowed_hosts}
263 # Chrome treats \ completely as / in paths but it could be part of some
264 # basic auth credentials so we need to check both URLs.
265 return _url_has_allowed_host_and_scheme(
266 url, allowed_hosts, require_https=require_https
267 ) and _url_has_allowed_host_and_scheme(
268 url.replace("\\", "/"), allowed_hosts, require_https=require_https
269 )
272def _url_has_allowed_host_and_scheme(url, allowed_hosts, require_https=False):
273 # Chrome considers any URL with more than two slashes to be absolute, but
274 # urlparse is not so flexible. Treat any url with three slashes as unsafe.
275 if url.startswith("///"):
276 return False
277 try:
278 url_info = urlparse(url)
279 except ValueError: # e.g. invalid IPv6 addresses
280 return False
281 # Forbid URLs like http:///example.com - with a scheme, but without a hostname.
282 # In that URL, example.com is not the hostname but, a path component. However,
283 # Chrome will still consider example.com to be the hostname, so we must not
284 # allow this syntax.
285 if not url_info.netloc and url_info.scheme:
286 return False
287 # Forbid URLs that start with control characters. Some browsers (like
288 # Chrome) ignore quite a few control characters at the start of a
289 # URL and might consider the URL as scheme relative.
290 if unicodedata.category(url[0])[0] == "C":
291 return False
292 scheme = url_info.scheme
293 # Consider URLs without a scheme (e.g. //example.com/p) to be http.
294 if not url_info.scheme and url_info.netloc:
295 scheme = "http"
296 valid_schemes = ["https"] if require_https else ["http", "https"]
297 return (not url_info.netloc or url_info.netloc in allowed_hosts) and (
298 not scheme or scheme in valid_schemes
299 )
302def escape_leading_slashes(url):
303 """
304 If redirecting to an absolute path (two leading slashes), a slash must be
305 escaped to prevent browsers from handling the path as schemaless and
306 redirecting to another host.
307 """
308 if url.startswith("//"):
309 url = "/%2F{}".format(url.removeprefix("//"))
310 return url
313def _parseparam(s):
314 while s[:1] == ";":
315 s = s[1:]
316 end = s.find(";")
317 while end > 0 and (s.count('"', 0, end) - s.count('\\"', 0, end)) % 2:
318 end = s.find(";", end + 1)
319 if end < 0:
320 end = len(s)
321 f = s[:end]
322 yield f.strip()
323 s = s[end:]
326def parse_header_parameters(line):
327 """
328 Parse a Content-type like header.
329 Return the main content-type and a dictionary of options.
330 """
331 parts = _parseparam(";" + line)
332 key = parts.__next__().lower()
333 pdict = {}
334 for p in parts:
335 i = p.find("=")
336 if i >= 0:
337 has_encoding = False
338 name = p[:i].strip().lower()
339 if name.endswith("*"):
340 # Lang/encoding embedded in the value (like "filename*=UTF-8''file.ext")
341 # https://tools.ietf.org/html/rfc2231#section-4
342 name = name[:-1]
343 if p.count("'") == 2:
344 has_encoding = True
345 value = p[i + 1 :].strip()
346 if len(value) >= 2 and value[0] == value[-1] == '"':
347 value = value[1:-1]
348 value = value.replace("\\\\", "\\").replace('\\"', '"')
349 if has_encoding:
350 encoding, lang, value = value.split("'")
351 value = unquote(value, encoding=encoding)
352 pdict[name] = value
353 return key, pdict
356def content_disposition_header(as_attachment, filename):
357 """
358 Construct a Content-Disposition HTTP header value from the given filename
359 as specified by RFC 6266.
360 """
361 if filename:
362 disposition = "attachment" if as_attachment else "inline"
363 try:
364 filename.encode("ascii")
365 file_expr = 'filename="{}"'.format(
366 filename.replace("\\", "\\\\").replace('"', r"\"")
367 )
368 except UnicodeEncodeError:
369 file_expr = f"filename*=utf-8''{quote(filename)}"
370 return f"{disposition}; {file_expr}"
371 elif as_attachment:
372 return "attachment"
373 else:
374 return None
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import functools
2import inspect
5@functools.lru_cache(maxsize=512)
6def _get_func_parameters(func, remove_first):
7 parameters = tuple(inspect.signature(func).parameters.values())
8 if remove_first:
9 parameters = parameters[1:]
10 return parameters
13def _get_callable_parameters(meth_or_func):
14 is_method = inspect.ismethod(meth_or_func)
15 func = meth_or_func.__func__ if is_method else meth_or_func
16 return _get_func_parameters(func, remove_first=is_method)
19def get_func_args(func):
20 params = _get_callable_parameters(func)
21 return [
22 param.name
23 for param in params
24 if param.kind == inspect.Parameter.POSITIONAL_OR_KEYWORD
25 ]
28def get_func_full_args(func):
29 """
30 Return a list of (argument name, default value) tuples. If the argument
31 does not have a default value, omit it in the tuple. Arguments such as
32 *args and **kwargs are also included.
33 """
34 params = _get_callable_parameters(func)
35 args = []
36 for param in params:
37 name = param.name
38 # Ignore 'self'
39 if name == "self":
40 continue
41 if param.kind == inspect.Parameter.VAR_POSITIONAL:
42 name = "*" + name
43 elif param.kind == inspect.Parameter.VAR_KEYWORD:
44 name = "**" + name
45 if param.default != inspect.Parameter.empty:
46 args.append((name, param.default))
47 else:
48 args.append((name,))
49 return args
52def func_accepts_kwargs(func):
53 """Return True if function 'func' accepts keyword arguments **kwargs."""
54 return any(p for p in _get_callable_parameters(func) if p.kind == p.VAR_KEYWORD)
57def func_accepts_var_args(func):
58 """
59 Return True if function 'func' accepts positional arguments *args.
60 """
61 return any(p for p in _get_callable_parameters(func) if p.kind == p.VAR_POSITIONAL)
64def method_has_no_args(meth):
65 """Return True if a method only accepts 'self'."""
66 count = len(
67 [p for p in _get_callable_parameters(meth) if p.kind == p.POSITIONAL_OR_KEYWORD]
68 )
69 return count == 0 if inspect.ismethod(meth) else count == 1
72def func_supports_parameter(func, name):
73 return any(param.name == name for param in _get_callable_parameters(func))
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import ipaddress
3from plain.exceptions import ValidationError
6def clean_ipv6_address(
7 ip_str, unpack_ipv4=False, error_message="This is not a valid IPv6 address."
8):
9 """
10 Clean an IPv6 address string.
12 Raise ValidationError if the address is invalid.
14 Replace the longest continuous zero-sequence with "::", remove leading
15 zeroes, and make sure all hextets are lowercase.
17 Args:
18 ip_str: A valid IPv6 address.
19 unpack_ipv4: if an IPv4-mapped address is found,
20 return the plain IPv4 address (default=False).
21 error_message: An error message used in the ValidationError.
23 Return a compressed IPv6 address or the same value.
24 """
25 try:
26 addr = ipaddress.IPv6Address(int(ipaddress.IPv6Address(ip_str)))
27 except ValueError:
28 raise ValidationError(error_message, code="invalid")
30 if unpack_ipv4 and addr.ipv4_mapped:
31 return str(addr.ipv4_mapped)
32 elif addr.ipv4_mapped:
33 return "::ffff:%s" % str(addr.ipv4_mapped)
35 return str(addr)
38def is_valid_ipv6_address(ip_str):
39 """
40 Return whether or not the `ip_str` string is a valid IPv6 address.
41 """
42 try:
43 ipaddress.IPv6Address(ip_str)
44 except ValueError:
45 return False
46 return True
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1def is_iterable(x):
2 "An implementation independent way of checking for iterables"
3 try:
4 iter(x)
5 except TypeError:
6 return False
7 else:
8 return True
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import os
2import sys
3from importlib import import_module
4from importlib.util import find_spec as importlib_find
7def cached_import(module_path, class_name):
8 # Check whether module is loaded and fully initialized.
9 if not (
10 (module := sys.modules.get(module_path))
11 and (spec := getattr(module, "__spec__", None))
12 and getattr(spec, "_initializing", False) is False
13 ):
14 module = import_module(module_path)
15 return getattr(module, class_name)
18def import_string(dotted_path):
19 """
20 Import a dotted module path and return the attribute/class designated by the
21 last name in the path. Raise ImportError if the import failed.
22 """
23 try:
24 module_path, class_name = dotted_path.rsplit(".", 1)
25 except ValueError as err:
26 raise ImportError("%s doesn't look like a module path" % dotted_path) from err
28 try:
29 return cached_import(module_path, class_name)
30 except AttributeError as err:
31 raise ImportError(
32 f'Module "{module_path}" does not define a "{class_name}" attribute/class'
33 ) from err
36def module_has_submodule(package, module_name):
37 """See if 'module' is in 'package'."""
38 try:
39 package_name = package.__name__
40 package_path = package.__path__
41 except AttributeError:
42 # package isn't a package.
43 return False
45 full_module_name = package_name + "." + module_name
46 try:
47 return importlib_find(full_module_name, package_path) is not None
48 except ModuleNotFoundError:
49 # When module_name is an invalid dotted path, Python raises
50 # ModuleNotFoundError.
51 return False
54def module_dir(module):
55 """
56 Find the name of the directory that contains a module, if possible.
58 Raise ValueError otherwise, e.g. for namespace packages that are split
59 over several directories.
60 """
61 # Convert to list because __path__ may not support indexing.
62 paths = list(getattr(module, "__path__", []))
63 if len(paths) == 1:
64 return paths[0]
65 else:
66 filename = getattr(module, "__file__", None)
67 if filename is not None:
68 return os.path.dirname(filename)
69 raise ValueError("Cannot determine directory containing %s" % module)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Functions for reversing a regular expression (used in reverse URL resolving).
3Used internally by Plain and not intended for external use.
5This is not, and is not intended to be, a complete reg-exp decompiler. It
6should be good enough for a large class of URLS, however.
7"""
8import re
10from plain.utils.functional import SimpleLazyObject
12# Mapping of an escape character to a representative of that class. So, e.g.,
13# "\w" is replaced by "x" in a reverse URL. A value of None means to ignore
14# this sequence. Any missing key is mapped to itself.
15ESCAPE_MAPPINGS = {
16 "A": None,
17 "b": None,
18 "B": None,
19 "d": "0",
20 "D": "x",
21 "s": " ",
22 "S": "x",
23 "w": "x",
24 "W": "!",
25 "Z": None,
26}
29class Choice(list):
30 """Represent multiple possibilities at this point in a pattern string."""
33class Group(list):
34 """Represent a capturing group in the pattern string."""
37class NonCapture(list):
38 """Represent a non-capturing group in the pattern string."""
41def normalize(pattern):
42 r"""
43 Given a reg-exp pattern, normalize it to an iterable of forms that
44 suffice for reverse matching. This does the following:
46 (1) For any repeating sections, keeps the minimum number of occurrences
47 permitted (this means zero for optional groups).
48 (2) If an optional group includes parameters, include one occurrence of
49 that group (along with the zero occurrence case from step (1)).
50 (3) Select the first (essentially an arbitrary) element from any character
51 class. Select an arbitrary character for any unordered class (e.g. '.'
52 or '\w') in the pattern.
53 (4) Ignore look-ahead and look-behind assertions.
54 (5) Raise an error on any disjunctive ('|') constructs.
56 Plain's URLs for forward resolving are either all positional arguments or
57 all keyword arguments. That is assumed here, as well. Although reverse
58 resolving can be done using positional args when keyword args are
59 specified, the two cannot be mixed in the same reverse() call.
60 """
61 # Do a linear scan to work out the special features of this pattern. The
62 # idea is that we scan once here and collect all the information we need to
63 # make future decisions.
64 result = []
65 non_capturing_groups = []
66 consume_next = True
67 pattern_iter = next_char(iter(pattern))
68 num_args = 0
70 # A "while" loop is used here because later on we need to be able to peek
71 # at the next character and possibly go around without consuming another
72 # one at the top of the loop.
73 try:
74 ch, escaped = next(pattern_iter)
75 except StopIteration:
76 return [("", [])]
78 try:
79 while True:
80 if escaped:
81 result.append(ch)
82 elif ch == ".":
83 # Replace "any character" with an arbitrary representative.
84 result.append(".")
85 elif ch == "|":
86 # FIXME: One day we'll should do this, but not in 1.0.
87 raise NotImplementedError("Awaiting Implementation")
88 elif ch == "^":
89 pass
90 elif ch == "$":
91 break
92 elif ch == ")":
93 # This can only be the end of a non-capturing group, since all
94 # other unescaped parentheses are handled by the grouping
95 # section later (and the full group is handled there).
96 #
97 # We regroup everything inside the capturing group so that it
98 # can be quantified, if necessary.
99 start = non_capturing_groups.pop()
100 inner = NonCapture(result[start:])
101 result = result[:start] + [inner]
102 elif ch == "[":
103 # Replace ranges with the first character in the range.
104 ch, escaped = next(pattern_iter)
105 result.append(ch)
106 ch, escaped = next(pattern_iter)
107 while escaped or ch != "]":
108 ch, escaped = next(pattern_iter)
109 elif ch == "(":
110 # Some kind of group.
111 ch, escaped = next(pattern_iter)
112 if ch != "?" or escaped:
113 # A positional group
114 name = "_%d" % num_args
115 num_args += 1
116 result.append(Group((("%%(%s)s" % name), name)))
117 walk_to_end(ch, pattern_iter)
118 else:
119 ch, escaped = next(pattern_iter)
120 if ch in "!=<":
121 # All of these are ignorable. Walk to the end of the
122 # group.
123 walk_to_end(ch, pattern_iter)
124 elif ch == ":":
125 # Non-capturing group
126 non_capturing_groups.append(len(result))
127 elif ch != "P":
128 # Anything else, other than a named group, is something
129 # we cannot reverse.
130 raise ValueError("Non-reversible reg-exp portion: '(?%s'" % ch)
131 else:
132 ch, escaped = next(pattern_iter)
133 if ch not in ("<", "="):
134 raise ValueError(
135 "Non-reversible reg-exp portion: '(?P%s'" % ch
136 )
137 # We are in a named capturing group. Extra the name and
138 # then skip to the end.
139 if ch == "<":
140 terminal_char = ">"
141 # We are in a named backreference.
142 else:
143 terminal_char = ")"
144 name = []
145 ch, escaped = next(pattern_iter)
146 while ch != terminal_char:
147 name.append(ch)
148 ch, escaped = next(pattern_iter)
149 param = "".join(name)
150 # Named backreferences have already consumed the
151 # parenthesis.
152 if terminal_char != ")":
153 result.append(Group((("%%(%s)s" % param), param)))
154 walk_to_end(ch, pattern_iter)
155 else:
156 result.append(Group((("%%(%s)s" % param), None)))
157 elif ch in "*?+{":
158 # Quantifiers affect the previous item in the result list.
159 count, ch = get_quantifier(ch, pattern_iter)
160 if ch:
161 # We had to look ahead, but it wasn't need to compute the
162 # quantifier, so use this character next time around the
163 # main loop.
164 consume_next = False
166 if count == 0:
167 if contains(result[-1], Group):
168 # If we are quantifying a capturing group (or
169 # something containing such a group) and the minimum is
170 # zero, we must also handle the case of one occurrence
171 # being present. All the quantifiers (except {0,0},
172 # which we conveniently ignore) that have a 0 minimum
173 # also allow a single occurrence.
174 result[-1] = Choice([None, result[-1]])
175 else:
176 result.pop()
177 elif count > 1:
178 result.extend([result[-1]] * (count - 1))
179 else:
180 # Anything else is a literal.
181 result.append(ch)
183 if consume_next:
184 ch, escaped = next(pattern_iter)
185 consume_next = True
186 except StopIteration:
187 pass
188 except NotImplementedError:
189 # A case of using the disjunctive form. No results for you!
190 return [("", [])]
192 return list(zip(*flatten_result(result)))
195def next_char(input_iter):
196 r"""
197 An iterator that yields the next character from "pattern_iter", respecting
198 escape sequences. An escaped character is replaced by a representative of
199 its class (e.g. \w -> "x"). If the escaped character is one that is
200 skipped, it is not returned (the next character is returned instead).
202 Yield the next character, along with a boolean indicating whether it is a
203 raw (unescaped) character or not.
204 """
205 for ch in input_iter:
206 if ch != "\\":
207 yield ch, False
208 continue
209 ch = next(input_iter)
210 representative = ESCAPE_MAPPINGS.get(ch, ch)
211 if representative is None:
212 continue
213 yield representative, True
216def walk_to_end(ch, input_iter):
217 """
218 The iterator is currently inside a capturing group. Walk to the close of
219 this group, skipping over any nested groups and handling escaped
220 parentheses correctly.
221 """
222 if ch == "(":
223 nesting = 1
224 else:
225 nesting = 0
226 for ch, escaped in input_iter:
227 if escaped:
228 continue
229 elif ch == "(":
230 nesting += 1
231 elif ch == ")":
232 if not nesting:
233 return
234 nesting -= 1
237def get_quantifier(ch, input_iter):
238 """
239 Parse a quantifier from the input, where "ch" is the first character in the
240 quantifier.
242 Return the minimum number of occurrences permitted by the quantifier and
243 either None or the next character from the input_iter if the next character
244 is not part of the quantifier.
245 """
246 if ch in "*?+":
247 try:
248 ch2, escaped = next(input_iter)
249 except StopIteration:
250 ch2 = None
251 if ch2 == "?":
252 ch2 = None
253 if ch == "+":
254 return 1, ch2
255 return 0, ch2
257 quant = []
258 while ch != "}":
259 ch, escaped = next(input_iter)
260 quant.append(ch)
261 quant = quant[:-1]
262 values = "".join(quant).split(",")
264 # Consume the trailing '?', if necessary.
265 try:
266 ch, escaped = next(input_iter)
267 except StopIteration:
268 ch = None
269 if ch == "?":
270 ch = None
271 return int(values[0]), ch
274def contains(source, inst):
275 """
276 Return True if the "source" contains an instance of "inst". False,
277 otherwise.
278 """
279 if isinstance(source, inst):
280 return True
281 if isinstance(source, NonCapture):
282 for elt in source:
283 if contains(elt, inst):
284 return True
285 return False
288def flatten_result(source):
289 """
290 Turn the given source sequence into a list of reg-exp possibilities and
291 their arguments. Return a list of strings and a list of argument lists.
292 Each of the two lists will be of the same length.
293 """
294 if source is None:
295 return [""], [[]]
296 if isinstance(source, Group):
297 if source[1] is None:
298 params = []
299 else:
300 params = [source[1]]
301 return [source[0]], [params]
302 result = [""]
303 result_args = [[]]
304 pos = last = 0
305 for pos, elt in enumerate(source):
306 if isinstance(elt, str):
307 continue
308 piece = "".join(source[last:pos])
309 if isinstance(elt, Group):
310 piece += elt[0]
311 param = elt[1]
312 else:
313 param = None
314 last = pos + 1
315 for i in range(len(result)):
316 result[i] += piece
317 if param:
318 result_args[i].append(param)
319 if isinstance(elt, Choice | NonCapture):
320 if isinstance(elt, NonCapture):
321 elt = [elt]
322 inner_result, inner_args = [], []
323 for item in elt:
324 res, args = flatten_result(item)
325 inner_result.extend(res)
326 inner_args.extend(args)
327 new_result = []
328 new_args = []
329 for item, args in zip(result, result_args):
330 for i_item, i_args in zip(inner_result, inner_args):
331 new_result.append(item + i_item)
332 new_args.append(args[:] + i_args)
333 result = new_result
334 result_args = new_args
335 if pos >= last:
336 piece = "".join(source[last:])
337 for i in range(len(result)):
338 result[i] += piece
339 return result, result_args
342def _lazy_re_compile(regex, flags=0):
343 """Lazily compile a regex with flags."""
345 def _compile():
346 # Compile the regex if it was not passed pre-compiled.
347 if isinstance(regex, str | bytes):
348 return re.compile(regex, flags)
349 else:
350 assert not flags, "flags must be empty if regex is passed pre-compiled"
351 return regex
353 return SimpleLazyObject(_compile)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Functions for working with "safe strings": strings that can be displayed safely
3without further escaping in HTML. Marking something as a "safe string" means
4that the producer of the string has already turned characters that should not
5be interpreted by the HTML engine (e.g. '<') into the appropriate entities.
6"""
8from functools import wraps
10from plain.utils.functional import keep_lazy
13class SafeData:
14 __slots__ = ()
16 def __html__(self):
17 """
18 Return the html representation of a string for interoperability.
20 This allows other template engines to understand Plain's SafeData.
21 """
22 return self
25class SafeString(str, SafeData):
26 """
27 A str subclass that has been specifically marked as "safe" for HTML output
28 purposes.
29 """
31 __slots__ = ()
33 def __add__(self, rhs):
34 """
35 Concatenating a safe string with another safe bytestring or
36 safe string is safe. Otherwise, the result is no longer safe.
37 """
38 t = super().__add__(rhs)
39 if isinstance(rhs, SafeData):
40 return SafeString(t)
41 return t
43 def __str__(self):
44 return self
47SafeText = SafeString # For backwards compatibility since Plain 2.0.
50def _safety_decorator(safety_marker, func):
51 @wraps(func)
52 def wrapper(*args, **kwargs):
53 return safety_marker(func(*args, **kwargs))
55 return wrapper
58@keep_lazy(SafeString)
59def mark_safe(s):
60 """
61 Explicitly mark a string as safe for (HTML) output purposes. The returned
62 object can be used everywhere a string is appropriate.
64 If used on a method as a decorator, mark the returned data as safe.
66 Can be called multiple times on a single string.
67 """
68 if hasattr(s, "__html__"):
69 return s
70 if callable(s):
71 return _safety_decorator(mark_safe, s)
72 return SafeString(s)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import gzip
2import re
3import secrets
4import unicodedata
5from gzip import GzipFile
6from gzip import compress as gzip_compress
7from io import BytesIO
9from plain.exceptions import SuspiciousFileOperation
10from plain.utils.functional import SimpleLazyObject, keep_lazy_text, lazy
11from plain.utils.regex_helper import _lazy_re_compile
14@keep_lazy_text
15def capfirst(x):
16 """Capitalize the first letter of a string."""
17 if not x:
18 return x
19 if not isinstance(x, str):
20 x = str(x)
21 return x[0].upper() + x[1:]
24# Set up regular expressions
25re_words = _lazy_re_compile(r"<[^>]+?>|([^<>\s]+)", re.S)
26re_chars = _lazy_re_compile(r"<[^>]+?>|(.)", re.S)
27re_tag = _lazy_re_compile(r"<(/)?(\S+?)(?:(\s*/)|\s.*?)?>", re.S)
28re_newlines = _lazy_re_compile(r"\r\n|\r") # Used in normalize_newlines
29re_camel_case = _lazy_re_compile(r"(((?<=[a-z])[A-Z])|([A-Z](?![A-Z]|$)))")
32@keep_lazy_text
33def wrap(text, width):
34 """
35 A word-wrap function that preserves existing line breaks. Expects that
36 existing line breaks are posix newlines.
38 Preserve all white space except added line breaks consume the space on
39 which they break the line.
41 Don't wrap long words, thus the output text may have lines longer than
42 ``width``.
43 """
45 def _generator():
46 for line in text.splitlines(True): # True keeps trailing linebreaks
47 max_width = min((line.endswith("\n") and width + 1 or width), width)
48 while len(line) > max_width:
49 space = line[: max_width + 1].rfind(" ") + 1
50 if space == 0:
51 space = line.find(" ") + 1
52 if space == 0:
53 yield line
54 line = ""
55 break
56 yield "%s\n" % line[: space - 1]
57 line = line[space:]
58 max_width = min((line.endswith("\n") and width + 1 or width), width)
59 if line:
60 yield line
62 return "".join(_generator())
65class Truncator(SimpleLazyObject):
66 """
67 An object used to truncate text, either by characters or words.
68 """
70 def __init__(self, text):
71 super().__init__(lambda: str(text))
73 def add_truncation_text(self, text, truncate=None):
74 if truncate is None:
75 truncate = "%(truncated_text)s…"
76 if "%(truncated_text)s" in truncate:
77 return truncate % {"truncated_text": text}
78 # The truncation text didn't contain the %(truncated_text)s string
79 # replacement argument so just append it to the text.
80 if text.endswith(truncate):
81 # But don't append the truncation text if the current text already
82 # ends in this.
83 return text
84 return f"{text}{truncate}"
86 def chars(self, num, truncate=None, html=False):
87 """
88 Return the text truncated to be no longer than the specified number
89 of characters.
91 `truncate` specifies what should be used to notify that the string has
92 been truncated, defaulting to a translatable string of an ellipsis.
93 """
94 self._setup()
95 length = int(num)
96 text = unicodedata.normalize("NFC", self._wrapped)
98 # Calculate the length to truncate to (max length - end_text length)
99 truncate_len = length
100 for char in self.add_truncation_text("", truncate):
101 if not unicodedata.combining(char):
102 truncate_len -= 1
103 if truncate_len == 0:
104 break
105 if html:
106 return self._truncate_html(length, truncate, text, truncate_len, False)
107 return self._text_chars(length, truncate, text, truncate_len)
109 def _text_chars(self, length, truncate, text, truncate_len):
110 """Truncate a string after a certain number of chars."""
111 s_len = 0
112 end_index = None
113 for i, char in enumerate(text):
114 if unicodedata.combining(char):
115 # Don't consider combining characters
116 # as adding to the string length
117 continue
118 s_len += 1
119 if end_index is None and s_len > truncate_len:
120 end_index = i
121 if s_len > length:
122 # Return the truncated string
123 return self.add_truncation_text(text[: end_index or 0], truncate)
125 # Return the original string since no truncation was necessary
126 return text
128 def words(self, num, truncate=None, html=False):
129 """
130 Truncate a string after a certain number of words. `truncate` specifies
131 what should be used to notify that the string has been truncated,
132 defaulting to ellipsis.
133 """
134 self._setup()
135 length = int(num)
136 if html:
137 return self._truncate_html(length, truncate, self._wrapped, length, True)
138 return self._text_words(length, truncate)
140 def _text_words(self, length, truncate):
141 """
142 Truncate a string after a certain number of words.
144 Strip newlines in the string.
145 """
146 words = self._wrapped.split()
147 if len(words) > length:
148 words = words[:length]
149 return self.add_truncation_text(" ".join(words), truncate)
150 return " ".join(words)
152 def _truncate_html(self, length, truncate, text, truncate_len, words):
153 """
154 Truncate HTML to a certain number of chars (not counting tags and
155 comments), or, if words is True, then to a certain number of words.
156 Close opened tags if they were correctly closed in the given HTML.
158 Preserve newlines in the HTML.
159 """
160 if words and length <= 0:
161 return ""
163 html4_singlets = (
164 "br",
165 "col",
166 "link",
167 "base",
168 "img",
169 "param",
170 "area",
171 "hr",
172 "input",
173 )
175 # Count non-HTML chars/words and keep note of open tags
176 pos = 0
177 end_text_pos = 0
178 current_len = 0
179 open_tags = []
181 regex = re_words if words else re_chars
183 while current_len <= length:
184 m = regex.search(text, pos)
185 if not m:
186 # Checked through whole string
187 break
188 pos = m.end(0)
189 if m[1]:
190 # It's an actual non-HTML word or char
191 current_len += 1
192 if current_len == truncate_len:
193 end_text_pos = pos
194 continue
195 # Check for tag
196 tag = re_tag.match(m[0])
197 if not tag or current_len >= truncate_len:
198 # Don't worry about non tags or tags after our truncate point
199 continue
200 closing_tag, tagname, self_closing = tag.groups()
201 # Element names are always case-insensitive
202 tagname = tagname.lower()
203 if self_closing or tagname in html4_singlets:
204 pass
205 elif closing_tag:
206 # Check for match in open tags list
207 try:
208 i = open_tags.index(tagname)
209 except ValueError:
210 pass
211 else:
212 # SGML: An end tag closes, back to the matching start tag,
213 # all unclosed intervening start tags with omitted end tags
214 open_tags = open_tags[i + 1 :]
215 else:
216 # Add it to the start of the open tags list
217 open_tags.insert(0, tagname)
219 if current_len <= length:
220 return text
221 out = text[:end_text_pos]
222 truncate_text = self.add_truncation_text("", truncate)
223 if truncate_text:
224 out += truncate_text
225 # Close any tags still open
226 for tag in open_tags:
227 out += "</%s>" % tag
228 # Return string
229 return out
232@keep_lazy_text
233def get_valid_filename(name):
234 """
235 Return the given string converted to a string that can be used for a clean
236 filename. Remove leading and trailing spaces; convert other spaces to
237 underscores; and remove anything that is not an alphanumeric, dash,
238 underscore, or dot.
239 >>> get_valid_filename("john's portrait in 2004.jpg")
240 'johns_portrait_in_2004.jpg'
241 """
242 s = str(name).strip().replace(" ", "_")
243 s = re.sub(r"(?u)[^-\w.]", "", s)
244 if s in {"", ".", ".."}:
245 raise SuspiciousFileOperation("Could not derive file name from '%s'" % name)
246 return s
249@keep_lazy_text
250def get_text_list(list_, last_word="or"):
251 """
252 >>> get_text_list(['a', 'b', 'c', 'd'])
253 'a, b, c or d'
254 >>> get_text_list(['a', 'b', 'c'], 'and')
255 'a, b and c'
256 >>> get_text_list(['a', 'b'], 'and')
257 'a and b'
258 >>> get_text_list(['a'])
259 'a'
260 >>> get_text_list([])
261 ''
262 """
263 if not list_:
264 return ""
265 if len(list_) == 1:
266 return str(list_[0])
267 return "{} {} {}".format(
268 # Translators: This string is used as a separator between list elements
269 ", ".join(str(i) for i in list_[:-1]),
270 str(last_word),
271 str(list_[-1]),
272 )
275@keep_lazy_text
276def normalize_newlines(text):
277 """Normalize CRLF and CR newlines to just LF."""
278 return re_newlines.sub("\n", str(text))
281@keep_lazy_text
282def phone2numeric(phone):
283 """Convert a phone number with letters into its numeric equivalent."""
284 char2number = {
285 "a": "2",
286 "b": "2",
287 "c": "2",
288 "d": "3",
289 "e": "3",
290 "f": "3",
291 "g": "4",
292 "h": "4",
293 "i": "4",
294 "j": "5",
295 "k": "5",
296 "l": "5",
297 "m": "6",
298 "n": "6",
299 "o": "6",
300 "p": "7",
301 "q": "7",
302 "r": "7",
303 "s": "7",
304 "t": "8",
305 "u": "8",
306 "v": "8",
307 "w": "9",
308 "x": "9",
309 "y": "9",
310 "z": "9",
311 }
312 return "".join(char2number.get(c, c) for c in phone.lower())
315def _get_random_filename(max_random_bytes):
316 return b"a" * secrets.randbelow(max_random_bytes)
319def compress_string(s, *, max_random_bytes=None):
320 compressed_data = gzip_compress(s, compresslevel=6, mtime=0)
322 if not max_random_bytes:
323 return compressed_data
325 compressed_view = memoryview(compressed_data)
326 header = bytearray(compressed_view[:10])
327 header[3] = gzip.FNAME
329 filename = _get_random_filename(max_random_bytes) + b"\x00"
331 return bytes(header) + filename + compressed_view[10:]
334class StreamingBuffer(BytesIO):
335 def read(self):
336 ret = self.getvalue()
337 self.seek(0)
338 self.truncate()
339 return ret
342# Like compress_string, but for iterators of strings.
343def compress_sequence(sequence, *, max_random_bytes=None):
344 buf = StreamingBuffer()
345 filename = _get_random_filename(max_random_bytes) if max_random_bytes else None
346 with GzipFile(
347 filename=filename, mode="wb", compresslevel=6, fileobj=buf, mtime=0
348 ) as zfile:
349 # Output headers...
350 yield buf.read()
351 for item in sequence:
352 zfile.write(item)
353 data = buf.read()
354 if data:
355 yield data
356 yield buf.read()
359# Expression to match some_token and some_token="with spaces" (and similarly
360# for single-quoted strings).
361smart_split_re = _lazy_re_compile(
362 r"""
363 ((?:
364 [^\s'"]*
365 (?:
366 (?:"(?:[^"\\]|\\.)*" | '(?:[^'\\]|\\.)*')
367 [^\s'"]*
368 )+
369 ) | \S+)
370""",
371 re.VERBOSE,
372)
375def smart_split(text):
376 r"""
377 Generator that splits a string by spaces, leaving quoted phrases together.
378 Supports both single and double quotes, and supports escaping quotes with
379 backslashes. In the output, strings will keep their initial and trailing
380 quote marks and escaped quotes will remain escaped (the results can then
381 be further processed with unescape_string_literal()).
383 >>> list(smart_split(r'This is "a person\'s" test.'))
384 ['This', 'is', '"a person\\\'s"', 'test.']
385 >>> list(smart_split(r"Another 'person\'s' test."))
386 ['Another', "'person\\'s'", 'test.']
387 >>> list(smart_split(r'A "\"funky\" style" test.'))
388 ['A', '"\\"funky\\" style"', 'test.']
389 """
390 for bit in smart_split_re.finditer(str(text)):
391 yield bit[0]
394@keep_lazy_text
395def unescape_string_literal(s):
396 r"""
397 Convert quoted string literals to unquoted strings with escaped quotes and
398 backslashes unquoted::
400 >>> unescape_string_literal('"abc"')
401 'abc'
402 >>> unescape_string_literal("'abc'")
403 'abc'
404 >>> unescape_string_literal('"a \"bc\""')
405 'a "bc"'
406 >>> unescape_string_literal("'\'ab\' c'")
407 "'ab' c"
408 """
409 if not s or s[0] not in "\"'" or s[-1] != s[0]:
410 raise ValueError("Not a string literal: %r" % s)
411 quote = s[0]
412 return s[1:-1].replace(r"\%s" % quote, quote).replace(r"\\", "\\")
415@keep_lazy_text
416def slugify(value, allow_unicode=False):
417 """
418 Convert to ASCII if 'allow_unicode' is False. Convert spaces or repeated
419 dashes to single dashes. Remove characters that aren't alphanumerics,
420 underscores, or hyphens. Convert to lowercase. Also strip leading and
421 trailing whitespace, dashes, and underscores.
422 """
423 value = str(value)
424 if allow_unicode:
425 value = unicodedata.normalize("NFKC", value)
426 else:
427 value = (
428 unicodedata.normalize("NFKD", value)
429 .encode("ascii", "ignore")
430 .decode("ascii")
431 )
432 value = re.sub(r"[^\w\s-]", "", value.lower())
433 return re.sub(r"[-\s]+", "-", value).strip("-_")
436def camel_case_to_spaces(value):
437 """
438 Split CamelCase and convert to lowercase. Strip surrounding whitespace.
439 """
440 return re_camel_case.sub(r" \1", value).strip().lower()
443def _format_lazy(format_string, *args, **kwargs):
444 """
445 Apply str.format() on 'format_string' where format_string, args,
446 and/or kwargs might be lazy.
447 """
448 return format_string.format(*args, **kwargs)
451def pluralize(singular, plural, number):
452 if number == 1:
453 return singular
454 else:
455 return plural
458def pluralize_lazy(singular, plural, number):
459 def _lazy_number_unpickle(func, resultclass, number, kwargs):
460 return lazy_number(func, resultclass, number=number, **kwargs)
462 def lazy_number(func, resultclass, number=None, **kwargs):
463 if isinstance(number, int):
464 kwargs["number"] = number
465 proxy = lazy(func, resultclass)(**kwargs)
466 else:
467 original_kwargs = kwargs.copy()
469 class NumberAwareString(resultclass):
470 def __bool__(self):
471 return bool(kwargs["singular"])
473 def _get_number_value(self, values):
474 try:
475 return values[number]
476 except KeyError:
477 raise KeyError(
478 "Your dictionary lacks key '%s'. Please provide "
479 "it, because it is required to determine whether "
480 "string is singular or plural." % number
481 )
483 def _translate(self, number_value):
484 kwargs["number"] = number_value
485 return func(**kwargs)
487 def format(self, *args, **kwargs):
488 number_value = (
489 self._get_number_value(kwargs) if kwargs and number else args[0]
490 )
491 return self._translate(number_value).format(*args, **kwargs)
493 def __mod__(self, rhs):
494 if isinstance(rhs, dict) and number:
495 number_value = self._get_number_value(rhs)
496 else:
497 number_value = rhs
498 translated = self._translate(number_value)
499 try:
500 translated %= rhs
501 except TypeError:
502 # String doesn't contain a placeholder for the number.
503 pass
504 return translated
506 proxy = lazy(lambda **kwargs: NumberAwareString(), NumberAwareString)(
507 **kwargs
508 )
509 proxy.__reduce__ = lambda: (
510 _lazy_number_unpickle,
511 (func, resultclass, number, original_kwargs),
512 )
513 return proxy
515 return lazy_number(pluralize, str, singular=singular, plural=plural, number=number)
518format_lazy = lazy(_format_lazy, str)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import datetime
3from plain.utils.html import avoid_wrapping
4from plain.utils.text import pluralize_lazy
5from plain.utils.timezone import is_aware
7TIME_STRINGS = {
8 "year": pluralize_lazy("%(num)d year", "%(num)d years", "num"),
9 "month": pluralize_lazy("%(num)d month", "%(num)d months", "num"),
10 "week": pluralize_lazy("%(num)d week", "%(num)d weeks", "num"),
11 "day": pluralize_lazy("%(num)d day", "%(num)d days", "num"),
12 "hour": pluralize_lazy("%(num)d hour", "%(num)d hours", "num"),
13 "minute": pluralize_lazy("%(num)d minute", "%(num)d minutes", "num"),
14}
16TIME_STRINGS_KEYS = list(TIME_STRINGS.keys())
18TIME_CHUNKS = [
19 60 * 60 * 24 * 7, # week
20 60 * 60 * 24, # day
21 60 * 60, # hour
22 60, # minute
23]
25MONTHS_DAYS = (31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31)
28def timesince(d, now=None, reversed=False, time_strings=None, depth=2):
29 """
30 Take two datetime objects and return the time between d and now as a nicely
31 formatted string, e.g. "10 minutes". If d occurs after now, return
32 "0 minutes".
34 Units used are years, months, weeks, days, hours, and minutes.
35 Seconds and microseconds are ignored.
37 The algorithm takes into account the varying duration of years and months.
38 There is exactly "1 year, 1 month" between 2013/02/10 and 2014/03/10,
39 but also between 2007/08/10 and 2008/09/10 despite the delta being 393 days
40 in the former case and 397 in the latter.
42 Up to `depth` adjacent units will be displayed. For example,
43 "2 weeks, 3 days" and "1 year, 3 months" are possible outputs, but
44 "2 weeks, 3 hours" and "1 year, 5 days" are not.
46 `time_strings` is an optional dict of strings to replace the default
47 TIME_STRINGS dict.
49 `depth` is an optional integer to control the number of adjacent time
50 units returned.
52 Originally adapted from
53 https://web.archive.org/web/20060617175230/http://blog.natbat.co.uk/archive/2003/Jun/14/time_since
54 Modified to improve results for years and months.
55 """
56 if time_strings is None:
57 time_strings = TIME_STRINGS
58 if depth <= 0:
59 raise ValueError("depth must be greater than 0.")
60 # Convert datetime.date to datetime.datetime for comparison.
61 if not isinstance(d, datetime.datetime):
62 d = datetime.datetime(d.year, d.month, d.day)
63 if now and not isinstance(now, datetime.datetime):
64 now = datetime.datetime(now.year, now.month, now.day)
66 now = now or datetime.datetime.now(datetime.timezone.utc if is_aware(d) else None)
68 if reversed:
69 d, now = now, d
70 delta = now - d
72 # Ignore microseconds.
73 since = delta.days * 24 * 60 * 60 + delta.seconds
74 if since <= 0:
75 # d is in the future compared to now, stop processing.
76 return avoid_wrapping(time_strings["minute"] % {"num": 0})
78 # Get years and months.
79 total_months = (now.year - d.year) * 12 + (now.month - d.month)
80 if d.day > now.day or (d.day == now.day and d.time() > now.time()):
81 total_months -= 1
82 years, months = divmod(total_months, 12)
84 # Calculate the remaining time.
85 # Create a "pivot" datetime shifted from d by years and months, then use
86 # that to determine the other parts.
87 if years or months:
88 pivot_year = d.year + years
89 pivot_month = d.month + months
90 if pivot_month > 12:
91 pivot_month -= 12
92 pivot_year += 1
93 pivot = datetime.datetime(
94 pivot_year,
95 pivot_month,
96 min(MONTHS_DAYS[pivot_month - 1], d.day),
97 d.hour,
98 d.minute,
99 d.second,
100 tzinfo=d.tzinfo,
101 )
102 else:
103 pivot = d
104 remaining_time = (now - pivot).total_seconds()
105 partials = [years, months]
106 for chunk in TIME_CHUNKS:
107 count = int(remaining_time // chunk)
108 partials.append(count)
109 remaining_time -= chunk * count
111 # Find the first non-zero part (if any) and then build the result, until
112 # depth.
113 i = 0
114 for i, value in enumerate(partials):
115 if value != 0:
116 break
117 else:
118 return avoid_wrapping(time_strings["minute"] % {"num": 0})
120 result = []
121 current_depth = 0
122 while i < len(TIME_STRINGS_KEYS) and current_depth < depth:
123 value = partials[i]
124 if value == 0:
125 break
126 name = TIME_STRINGS_KEYS[i]
127 result.append(avoid_wrapping(time_strings[name] % {"num": value}))
128 current_depth += 1
129 i += 1
131 return ", ".join(result)
134def timeuntil(d, now=None, time_strings=None, depth=2):
135 """
136 Like timesince, but return a string measuring the time until the given time.
137 """
138 return timesince(d, now, reversed=True, time_strings=time_strings, depth=depth)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Timezone-related classes and functions.
3"""
5import functools
6import zoneinfo
7from contextlib import ContextDecorator
8from datetime import datetime, timedelta, timezone, tzinfo
9from threading import local
11from plain.runtime import settings
13__all__ = [
14 "get_fixed_timezone",
15 "get_default_timezone",
16 "get_default_timezone_name",
17 "get_current_timezone",
18 "get_current_timezone_name",
19 "activate",
20 "deactivate",
21 "override",
22 "localtime",
23 "now",
24 "is_aware",
25 "is_naive",
26 "make_aware",
27 "make_naive",
28]
31def get_fixed_timezone(offset):
32 """Return a tzinfo instance with a fixed offset from UTC."""
33 if isinstance(offset, timedelta):
34 offset = offset.total_seconds() // 60
35 sign = "-" if offset < 0 else "+"
36 hhmm = "%02d%02d" % divmod(abs(offset), 60)
37 name = sign + hhmm
38 return timezone(timedelta(minutes=offset), name)
41# In order to avoid accessing settings at compile time,
42# wrap the logic in a function and cache the result.
43@functools.lru_cache
44def get_default_timezone():
45 """
46 Return the default time zone as a tzinfo instance.
48 This is the time zone defined by settings.TIME_ZONE.
49 """
50 return zoneinfo.ZoneInfo(settings.TIME_ZONE)
53# This function exists for consistency with get_current_timezone_name
54def get_default_timezone_name():
55 """Return the name of the default time zone."""
56 return _get_timezone_name(get_default_timezone())
59_active = local()
62def get_current_timezone():
63 """Return the currently active time zone as a tzinfo instance."""
64 return getattr(_active, "value", get_default_timezone())
67def get_current_timezone_name():
68 """Return the name of the currently active time zone."""
69 return _get_timezone_name(get_current_timezone())
72def _get_timezone_name(timezone):
73 """
74 Return the offset for fixed offset timezones, or the name of timezone if
75 not set.
76 """
77 return timezone.tzname(None) or str(timezone)
80# Timezone selection functions.
82# These functions don't change os.environ['TZ'] and call time.tzset()
83# because it isn't thread safe.
86def activate(timezone):
87 """
88 Set the time zone for the current thread.
90 The ``timezone`` argument must be an instance of a tzinfo subclass or a
91 time zone name.
92 """
93 if isinstance(timezone, tzinfo):
94 _active.value = timezone
95 elif isinstance(timezone, str):
96 _active.value = zoneinfo.ZoneInfo(timezone)
97 else:
98 raise ValueError("Invalid timezone: %r" % timezone)
101def deactivate():
102 """
103 Unset the time zone for the current thread.
105 Plain will then use the time zone defined by settings.TIME_ZONE.
106 """
107 if hasattr(_active, "value"):
108 del _active.value
111class override(ContextDecorator):
112 """
113 Temporarily set the time zone for the current thread.
115 This is a context manager that uses plain.utils.timezone.activate()
116 to set the timezone on entry and restores the previously active timezone
117 on exit.
119 The ``timezone`` argument must be an instance of a ``tzinfo`` subclass, a
120 time zone name, or ``None``. If it is ``None``, Plain enables the default
121 time zone.
122 """
124 def __init__(self, timezone):
125 self.timezone = timezone
127 def __enter__(self):
128 self.old_timezone = getattr(_active, "value", None)
129 if self.timezone is None:
130 deactivate()
131 else:
132 activate(self.timezone)
134 def __exit__(self, exc_type, exc_value, traceback):
135 if self.old_timezone is None:
136 deactivate()
137 else:
138 _active.value = self.old_timezone
141# Utilities
144def localtime(value=None, timezone=None):
145 """
146 Convert an aware datetime.datetime to local time.
148 Only aware datetimes are allowed. When value is omitted, it defaults to
149 now().
151 Local time is defined by the current time zone, unless another time zone
152 is specified.
153 """
154 if value is None:
155 value = now()
156 if timezone is None:
157 timezone = get_current_timezone()
158 # Emulate the behavior of astimezone() on Python < 3.6.
159 if is_naive(value):
160 raise ValueError("localtime() cannot be applied to a naive datetime")
161 return value.astimezone(timezone)
164def now():
165 """
166 Return a timezone aware datetime.
167 """
168 return datetime.now(tz=timezone.utc)
171# By design, these four functions don't perform any checks on their arguments.
172# The caller should ensure that they don't receive an invalid value like None.
175def is_aware(value):
176 """
177 Determine if a given datetime.datetime is aware.
179 The concept is defined in Python's docs:
180 https://docs.python.org/library/datetime.html#datetime.tzinfo
182 Assuming value.tzinfo is either None or a proper datetime.tzinfo,
183 value.utcoffset() implements the appropriate logic.
184 """
185 return value.utcoffset() is not None
188def is_naive(value):
189 """
190 Determine if a given datetime.datetime is naive.
192 The concept is defined in Python's docs:
193 https://docs.python.org/library/datetime.html#datetime.tzinfo
195 Assuming value.tzinfo is either None or a proper datetime.tzinfo,
196 value.utcoffset() implements the appropriate logic.
197 """
198 return value.utcoffset() is None
201def make_aware(value, timezone=None):
202 """Make a naive datetime.datetime in a given time zone aware."""
203 if timezone is None:
204 timezone = get_current_timezone()
205 # Check that we won't overwrite the timezone of an aware datetime.
206 if is_aware(value):
207 raise ValueError("make_aware expects a naive datetime, got %s" % value)
208 # This may be wrong around DST changes!
209 return value.replace(tzinfo=timezone)
212def make_naive(value, timezone=None):
213 """Make an aware datetime.datetime naive in a given time zone."""
214 if timezone is None:
215 timezone = get_current_timezone()
216 # Emulate the behavior of astimezone() on Python < 3.6.
217 if is_naive(value):
218 raise ValueError("make_naive() cannot be applied to a naive datetime")
219 return value.astimezone(timezone).replace(tzinfo=None)
222def _datetime_ambiguous_or_imaginary(dt, tz):
223 return tz.utcoffset(dt.replace(fold=not dt.fold)) != tz.utcoffset(dt)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2A class for storing a tree graph. Primarily used for filter constructs in the
3ORM.
4"""
6import copy
8from plain.utils.hashable import make_hashable
11class Node:
12 """
13 A single internal node in the tree graph. A Node should be viewed as a
14 connection (the root) with the children being either leaf nodes or other
15 Node instances.
16 """
18 # Standard connector type. Clients usually won't use this at all and
19 # subclasses will usually override the value.
20 default = "DEFAULT"
22 def __init__(self, children=None, connector=None, negated=False):
23 """Construct a new Node. If no connector is given, use the default."""
24 self.children = children[:] if children else []
25 self.connector = connector or self.default
26 self.negated = negated
28 @classmethod
29 def create(cls, children=None, connector=None, negated=False):
30 """
31 Create a new instance using Node() instead of __init__() as some
32 subclasses, e.g. plain.models.query_utils.Q, may implement a custom
33 __init__() with a signature that conflicts with the one defined in
34 Node.__init__().
35 """
36 obj = Node(children, connector or cls.default, negated)
37 obj.__class__ = cls
38 return obj
40 def __str__(self):
41 template = "(NOT (%s: %s))" if self.negated else "(%s: %s)"
42 return template % (self.connector, ", ".join(str(c) for c in self.children))
44 def __repr__(self):
45 return f"<{self.__class__.__name__}: {self}>"
47 def __copy__(self):
48 obj = self.create(connector=self.connector, negated=self.negated)
49 obj.children = self.children # Don't [:] as .__init__() via .create() does.
50 return obj
52 copy = __copy__
54 def __deepcopy__(self, memodict):
55 obj = self.create(connector=self.connector, negated=self.negated)
56 obj.children = copy.deepcopy(self.children, memodict)
57 return obj
59 def __len__(self):
60 """Return the number of children this node has."""
61 return len(self.children)
63 def __bool__(self):
64 """Return whether or not this node has children."""
65 return bool(self.children)
67 def __contains__(self, other):
68 """Return True if 'other' is a direct child of this instance."""
69 return other in self.children
71 def __eq__(self, other):
72 return (
73 self.__class__ == other.__class__
74 and self.connector == other.connector
75 and self.negated == other.negated
76 and self.children == other.children
77 )
79 def __hash__(self):
80 return hash(
81 (
82 self.__class__,
83 self.connector,
84 self.negated,
85 *make_hashable(self.children),
86 )
87 )
89 def add(self, data, conn_type):
90 """
91 Combine this tree and the data represented by data using the
92 connector conn_type. The combine is done by squashing the node other
93 away if possible.
95 This tree (self) will never be pushed to a child node of the
96 combined tree, nor will the connector or negated properties change.
98 Return a node which can be used in place of data regardless if the
99 node other got squashed or not.
100 """
101 if self.connector != conn_type:
102 obj = self.copy()
103 self.connector = conn_type
104 self.children = [obj, data]
105 return data
106 elif (
107 isinstance(data, Node)
108 and not data.negated
109 and (data.connector == conn_type or len(data) == 1)
110 ):
111 # We can squash the other node's children directly into this node.
112 # We are just doing (AB)(CD) == (ABCD) here, with the addition that
113 # if the length of the other node is 1 the connector doesn't
114 # matter. However, for the len(self) == 1 case we don't want to do
115 # the squashing, as it would alter self.connector.
116 self.children.extend(data.children)
117 return self
118 else:
119 # We could use perhaps additional logic here to see if some
120 # children could be used for pushdown here.
121 self.children.append(data)
122 return data
124 def negate(self):
125 """Negate the sense of the root connector."""
126 self.negated = not self.negated
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from .core import Template, TemplateFileMissing
2from .jinja import (
3 register_template_extension,
4 register_template_filter,
5 register_template_global,
6)
8__all__ = [
9 "Template",
10 "TemplateFileMissing",
11 # Technically these are jinja-specific,
12 # but expected to be used pretty frequently so
13 # the shorter import is handy.
14 "register_template_extension",
15 "register_template_filter",
16 "register_template_global",
17]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import jinja2
3from .jinja import environment
6class TemplateFileMissing(Exception):
7 def __str__(self) -> str:
8 if self.args:
9 return f"Template file {self.args[0]} not found"
10 else:
11 return "Template file not found"
14class Template:
15 def __init__(self, filename: str) -> None:
16 self.filename = filename
18 try:
19 self._jinja_template = environment.get_template(filename)
20 except jinja2.TemplateNotFound:
21 raise TemplateFileMissing(filename)
23 def render(self, context: dict) -> str:
24 return self._jinja_template.render(context)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.internal.files.base import File
3__all__ = ["File"]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import os
2from io import BytesIO, StringIO, UnsupportedOperation
4from plain.internal.files.utils import FileProxyMixin
5from plain.utils.functional import cached_property
8class File(FileProxyMixin):
9 DEFAULT_CHUNK_SIZE = 64 * 2**10
11 def __init__(self, file, name=None):
12 self.file = file
13 if name is None:
14 name = getattr(file, "name", None)
15 self.name = name
16 if hasattr(file, "mode"):
17 self.mode = file.mode
19 def __str__(self):
20 return self.name or ""
22 def __repr__(self):
23 return "<{}: {}>".format(self.__class__.__name__, self or "None")
25 def __bool__(self):
26 return bool(self.name)
28 def __len__(self):
29 return self.size
31 @cached_property
32 def size(self):
33 if hasattr(self.file, "size"):
34 return self.file.size
35 if hasattr(self.file, "name"):
36 try:
37 return os.path.getsize(self.file.name)
38 except (OSError, TypeError):
39 pass
40 if hasattr(self.file, "tell") and hasattr(self.file, "seek"):
41 pos = self.file.tell()
42 self.file.seek(0, os.SEEK_END)
43 size = self.file.tell()
44 self.file.seek(pos)
45 return size
46 raise AttributeError("Unable to determine the file's size.")
48 def chunks(self, chunk_size=None):
49 """
50 Read the file and yield chunks of ``chunk_size`` bytes (defaults to
51 ``File.DEFAULT_CHUNK_SIZE``).
52 """
53 chunk_size = chunk_size or self.DEFAULT_CHUNK_SIZE
54 try:
55 self.seek(0)
56 except (AttributeError, UnsupportedOperation):
57 pass
59 while True:
60 data = self.read(chunk_size)
61 if not data:
62 break
63 yield data
65 def multiple_chunks(self, chunk_size=None):
66 """
67 Return ``True`` if you can expect multiple chunks.
69 NB: If a particular file representation is in memory, subclasses should
70 always return ``False`` -- there's no good reason to read from memory in
71 chunks.
72 """
73 return self.size > (chunk_size or self.DEFAULT_CHUNK_SIZE)
75 def __iter__(self):
76 # Iterate over this file-like object by newlines
77 buffer_ = None
78 for chunk in self.chunks():
79 for line in chunk.splitlines(True):
80 if buffer_:
81 if endswith_cr(buffer_) and not equals_lf(line):
82 # Line split after a \r newline; yield buffer_.
83 yield buffer_
84 # Continue with line.
85 else:
86 # Line either split without a newline (line
87 # continues after buffer_) or with \r\n
88 # newline (line == b'\n').
89 line = buffer_ + line
90 # buffer_ handled, clear it.
91 buffer_ = None
93 # If this is the end of a \n or \r\n line, yield.
94 if endswith_lf(line):
95 yield line
96 else:
97 buffer_ = line
99 if buffer_ is not None:
100 yield buffer_
102 def __enter__(self):
103 return self
105 def __exit__(self, exc_type, exc_value, tb):
106 self.close()
108 def open(self, mode=None):
109 if not self.closed:
110 self.seek(0)
111 elif self.name and os.path.exists(self.name):
112 self.file = open(self.name, mode or self.mode)
113 else:
114 raise ValueError("The file cannot be reopened.")
115 return self
117 def close(self):
118 self.file.close()
121class ContentFile(File):
122 """
123 A File-like object that takes just raw content, rather than an actual file.
124 """
126 def __init__(self, content, name=None):
127 stream_class = StringIO if isinstance(content, str) else BytesIO
128 super().__init__(stream_class(content), name=name)
129 self.size = len(content)
131 def __str__(self):
132 return "Raw content"
134 def __bool__(self):
135 return True
137 def open(self, mode=None):
138 self.seek(0)
139 return self
141 def close(self):
142 pass
144 def write(self, data):
145 self.__dict__.pop("size", None) # Clear the computed size.
146 return self.file.write(data)
149def endswith_cr(line):
150 """Return True if line (a text or bytestring) ends with '\r'."""
151 return line.endswith("\r" if isinstance(line, str) else b"\r")
154def endswith_lf(line):
155 """Return True if line (a text or bytestring) ends with '\n'."""
156 return line.endswith("\n" if isinstance(line, str) else b"\n")
159def equals_lf(line):
160 """Return True if line (a text or bytestring) equals '\n'."""
161 return line == ("\n" if isinstance(line, str) else b"\n")
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2The temp module provides a NamedTemporaryFile that can be reopened in the same
3process on any platform. Most platforms use the standard Python
4tempfile.NamedTemporaryFile class, but Windows users are given a custom class.
6This is needed because the Python implementation of NamedTemporaryFile uses the
7O_TEMPORARY flag under Windows, which prevents the file from being reopened
8if the same flag is not provided [1][2]. Note that this does not address the
9more general issue of opening a file for writing and reading in multiple
10processes in a manner that works across platforms.
12The custom version of NamedTemporaryFile doesn't support the same keyword
13arguments available in tempfile.NamedTemporaryFile.
151: https://mail.python.org/pipermail/python-list/2005-December/336957.html
162: https://bugs.python.org/issue14243
17"""
19import os
20import tempfile
22from plain.internal.files.utils import FileProxyMixin
24__all__ = (
25 "NamedTemporaryFile",
26 "gettempdir",
27)
30if os.name == "nt":
32 class TemporaryFile(FileProxyMixin):
33 """
34 Temporary file object constructor that supports reopening of the
35 temporary file in Windows.
37 Unlike tempfile.NamedTemporaryFile from the standard library,
38 __init__() doesn't support the 'delete', 'buffering', 'encoding', or
39 'newline' keyword arguments.
40 """
42 def __init__(self, mode="w+b", bufsize=-1, suffix="", prefix="", dir=None):
43 fd, name = tempfile.mkstemp(suffix=suffix, prefix=prefix, dir=dir)
44 self.name = name
45 self.file = os.fdopen(fd, mode, bufsize)
46 self.close_called = False
48 # Because close can be called during shutdown
49 # we need to cache os.unlink and access it
50 # as self.unlink only
51 unlink = os.unlink
53 def close(self):
54 if not self.close_called:
55 self.close_called = True
56 try:
57 self.file.close()
58 except OSError:
59 pass
60 try:
61 self.unlink(self.name)
62 except OSError:
63 pass
65 def __del__(self):
66 self.close()
68 def __enter__(self):
69 self.file.__enter__()
70 return self
72 def __exit__(self, exc, value, tb):
73 self.file.__exit__(exc, value, tb)
75 NamedTemporaryFile = TemporaryFile
76else:
77 NamedTemporaryFile = tempfile.NamedTemporaryFile
79gettempdir = tempfile.gettempdir
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Classes representing uploaded files.
3"""
5import os
6from io import BytesIO
8from plain.internal.files import temp as tempfile
9from plain.internal.files.base import File
10from plain.internal.files.utils import validate_file_name
11from plain.runtime import settings
13__all__ = (
14 "UploadedFile",
15 "TemporaryUploadedFile",
16 "InMemoryUploadedFile",
17 "SimpleUploadedFile",
18)
21class UploadedFile(File):
22 """
23 An abstract uploaded file (``TemporaryUploadedFile`` and
24 ``InMemoryUploadedFile`` are the built-in concrete subclasses).
26 An ``UploadedFile`` object behaves somewhat like a file object and
27 represents some file data that the user submitted with a form.
28 """
30 def __init__(
31 self,
32 file=None,
33 name=None,
34 content_type=None,
35 size=None,
36 charset=None,
37 content_type_extra=None,
38 ):
39 super().__init__(file, name)
40 self.size = size
41 self.content_type = content_type
42 self.charset = charset
43 self.content_type_extra = content_type_extra
45 def __repr__(self):
46 return f"<{self.__class__.__name__}: {self.name} ({self.content_type})>"
48 def _get_name(self):
49 return self._name
51 def _set_name(self, name):
52 # Sanitize the file name so that it can't be dangerous.
53 if name is not None:
54 # Just use the basename of the file -- anything else is dangerous.
55 name = os.path.basename(name)
57 # File names longer than 255 characters can cause problems on older OSes.
58 if len(name) > 255:
59 name, ext = os.path.splitext(name)
60 ext = ext[:255]
61 name = name[: 255 - len(ext)] + ext
63 name = validate_file_name(name)
65 self._name = name
67 name = property(_get_name, _set_name)
70class TemporaryUploadedFile(UploadedFile):
71 """
72 A file uploaded to a temporary location (i.e. stream-to-disk).
73 """
75 def __init__(self, name, content_type, size, charset, content_type_extra=None):
76 _, ext = os.path.splitext(name)
77 file = tempfile.NamedTemporaryFile(
78 suffix=".upload" + ext, dir=settings.FILE_UPLOAD_TEMP_DIR
79 )
80 super().__init__(file, name, content_type, size, charset, content_type_extra)
82 def temporary_file_path(self):
83 """Return the full path of this file."""
84 return self.file.name
86 def close(self):
87 try:
88 return self.file.close()
89 except FileNotFoundError:
90 # The file was moved or deleted before the tempfile could unlink
91 # it. Still sets self.file.close_called and calls
92 # self.file.file.close() before the exception.
93 pass
96class InMemoryUploadedFile(UploadedFile):
97 """
98 A file uploaded into memory (i.e. stream-to-memory).
99 """
101 def __init__(
102 self,
103 file,
104 field_name,
105 name,
106 content_type,
107 size,
108 charset,
109 content_type_extra=None,
110 ):
111 super().__init__(file, name, content_type, size, charset, content_type_extra)
112 self.field_name = field_name
114 def open(self, mode=None):
115 self.file.seek(0)
116 return self
118 def chunks(self, chunk_size=None):
119 self.file.seek(0)
120 yield self.read()
122 def multiple_chunks(self, chunk_size=None):
123 # Since it's in memory, we'll never have multiple chunks.
124 return False
127class SimpleUploadedFile(InMemoryUploadedFile):
128 """
129 A simple representation of a file, which just has content, size, and a name.
130 """
132 def __init__(self, name, content, content_type="text/plain"):
133 content = content or b""
134 super().__init__(
135 BytesIO(content), None, name, content_type, len(content), None, None
136 )
138 @classmethod
139 def from_dict(cls, file_dict):
140 """
141 Create a SimpleUploadedFile object from a dictionary with keys:
142 - filename
143 - content-type
144 - content
145 """
146 return cls(
147 file_dict["filename"],
148 file_dict["content"],
149 file_dict.get("content-type", "text/plain"),
150 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Base file upload handler classes, and the built-in concrete subclasses
3"""
5import os
6from io import BytesIO
8from plain.internal.files.uploadedfile import (
9 InMemoryUploadedFile,
10 TemporaryUploadedFile,
11)
12from plain.runtime import settings
13from plain.utils.module_loading import import_string
15__all__ = [
16 "UploadFileException",
17 "StopUpload",
18 "SkipFile",
19 "FileUploadHandler",
20 "TemporaryFileUploadHandler",
21 "MemoryFileUploadHandler",
22 "load_handler",
23 "StopFutureHandlers",
24]
27class UploadFileException(Exception):
28 """
29 Any error having to do with uploading files.
30 """
32 pass
35class StopUpload(UploadFileException):
36 """
37 This exception is raised when an upload must abort.
38 """
40 def __init__(self, connection_reset=False):
41 """
42 If ``connection_reset`` is ``True``, Plain knows will halt the upload
43 without consuming the rest of the upload. This will cause the browser to
44 show a "connection reset" error.
45 """
46 self.connection_reset = connection_reset
48 def __str__(self):
49 if self.connection_reset:
50 return "StopUpload: Halt current upload."
51 else:
52 return "StopUpload: Consume request data, then halt."
55class SkipFile(UploadFileException):
56 """
57 This exception is raised by an upload handler that wants to skip a given file.
58 """
60 pass
63class StopFutureHandlers(UploadFileException):
64 """
65 Upload handlers that have handled a file and do not want future handlers to
66 run should raise this exception instead of returning None.
67 """
69 pass
72class FileUploadHandler:
73 """
74 Base class for streaming upload handlers.
75 """
77 chunk_size = 64 * 2**10 # : The default chunk size is 64 KB.
79 def __init__(self, request=None):
80 self.file_name = None
81 self.content_type = None
82 self.content_length = None
83 self.charset = None
84 self.content_type_extra = None
85 self.request = request
87 def handle_raw_input(
88 self, input_data, META, content_length, boundary, encoding=None
89 ):
90 """
91 Handle the raw input from the client.
93 Parameters:
95 :input_data:
96 An object that supports reading via .read().
97 :META:
98 ``request.META``.
99 :content_length:
100 The (integer) value of the Content-Length header from the
101 client.
102 :boundary: The boundary from the Content-Type header. Be sure to
103 prepend two '--'.
104 """
105 pass
107 def new_file(
108 self,
109 field_name,
110 file_name,
111 content_type,
112 content_length,
113 charset=None,
114 content_type_extra=None,
115 ):
116 """
117 Signal that a new file has been started.
119 Warning: As with any data from the client, you should not trust
120 content_length (and sometimes won't even get it).
121 """
122 self.field_name = field_name
123 self.file_name = file_name
124 self.content_type = content_type
125 self.content_length = content_length
126 self.charset = charset
127 self.content_type_extra = content_type_extra
129 def receive_data_chunk(self, raw_data, start):
130 """
131 Receive data from the streamed upload parser. ``start`` is the position
132 in the file of the chunk.
133 """
134 raise NotImplementedError(
135 "subclasses of FileUploadHandler must provide a receive_data_chunk() method"
136 )
138 def file_complete(self, file_size):
139 """
140 Signal that a file has completed. File size corresponds to the actual
141 size accumulated by all the chunks.
143 Subclasses should return a valid ``UploadedFile`` object.
144 """
145 raise NotImplementedError(
146 "subclasses of FileUploadHandler must provide a file_complete() method"
147 )
149 def upload_complete(self):
150 """
151 Signal that the upload is complete. Subclasses should perform cleanup
152 that is necessary for this handler.
153 """
154 pass
156 def upload_interrupted(self):
157 """
158 Signal that the upload was interrupted. Subclasses should perform
159 cleanup that is necessary for this handler.
160 """
161 pass
164class TemporaryFileUploadHandler(FileUploadHandler):
165 """
166 Upload handler that streams data into a temporary file.
167 """
169 def new_file(self, *args, **kwargs):
170 """
171 Create the file object to append to as data is coming in.
172 """
173 super().new_file(*args, **kwargs)
174 self.file = TemporaryUploadedFile(
175 self.file_name, self.content_type, 0, self.charset, self.content_type_extra
176 )
178 def receive_data_chunk(self, raw_data, start):
179 self.file.write(raw_data)
181 def file_complete(self, file_size):
182 self.file.seek(0)
183 self.file.size = file_size
184 return self.file
186 def upload_interrupted(self):
187 if hasattr(self, "file"):
188 temp_location = self.file.temporary_file_path()
189 try:
190 self.file.close()
191 os.remove(temp_location)
192 except FileNotFoundError:
193 pass
196class MemoryFileUploadHandler(FileUploadHandler):
197 """
198 File upload handler to stream uploads into memory (used for small files).
199 """
201 def handle_raw_input(
202 self, input_data, META, content_length, boundary, encoding=None
203 ):
204 """
205 Use the content_length to signal whether or not this handler should be
206 used.
207 """
208 # Check the content-length header to see if we should
209 # If the post is too large, we cannot use the Memory handler.
210 self.activated = content_length <= settings.FILE_UPLOAD_MAX_MEMORY_SIZE
212 def new_file(self, *args, **kwargs):
213 super().new_file(*args, **kwargs)
214 if self.activated:
215 self.file = BytesIO()
216 raise StopFutureHandlers()
218 def receive_data_chunk(self, raw_data, start):
219 """Add the data to the BytesIO file."""
220 if self.activated:
221 self.file.write(raw_data)
222 else:
223 return raw_data
225 def file_complete(self, file_size):
226 """Return a file object if this handler is activated."""
227 if not self.activated:
228 return
230 self.file.seek(0)
231 return InMemoryUploadedFile(
232 file=self.file,
233 field_name=self.field_name,
234 name=self.file_name,
235 content_type=self.content_type,
236 size=file_size,
237 charset=self.charset,
238 content_type_extra=self.content_type_extra,
239 )
242def load_handler(path, *args, **kwargs):
243 """
244 Given a path to a handler, return an instance of that handler.
246 E.g.::
247 >>> from plain.http import HttpRequest
248 >>> request = HttpRequest()
249 >>> load_handler(
250 ... 'plain.internal.files.uploadhandler.TemporaryFileUploadHandler',
251 ... request,
252 ... )
253 <TemporaryFileUploadHandler object at 0x...>
254 """
255 return import_string(path)(*args, **kwargs)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import os
2import pathlib
4from plain.exceptions import SuspiciousFileOperation
7def validate_file_name(name, allow_relative_path=False):
8 # Remove potentially dangerous names
9 if os.path.basename(name) in {"", ".", ".."}:
10 raise SuspiciousFileOperation(f"Could not derive file name from '{name}'")
12 if allow_relative_path:
13 # Use PurePosixPath() because this branch is checked only in
14 # FileField.generate_filename() where all file paths are expected to be
15 # Unix style (with forward slashes).
16 path = pathlib.PurePosixPath(name)
17 if path.is_absolute() or ".." in path.parts:
18 raise SuspiciousFileOperation(
19 f"Detected path traversal attempt in '{name}'"
20 )
21 elif name != os.path.basename(name):
22 raise SuspiciousFileOperation(f"File name '{name}' includes path elements")
24 return name
27class FileProxyMixin:
28 """
29 A mixin class used to forward file methods to an underlying file
30 object. The internal file object has to be called "file"::
32 class FileProxy(FileProxyMixin):
33 def __init__(self, file):
34 self.file = file
35 """
37 encoding = property(lambda self: self.file.encoding)
38 fileno = property(lambda self: self.file.fileno)
39 flush = property(lambda self: self.file.flush)
40 isatty = property(lambda self: self.file.isatty)
41 newlines = property(lambda self: self.file.newlines)
42 read = property(lambda self: self.file.read)
43 readinto = property(lambda self: self.file.readinto)
44 readline = property(lambda self: self.file.readline)
45 readlines = property(lambda self: self.file.readlines)
46 seek = property(lambda self: self.file.seek)
47 tell = property(lambda self: self.file.tell)
48 truncate = property(lambda self: self.file.truncate)
49 write = property(lambda self: self.file.write)
50 writelines = property(lambda self: self.file.writelines)
52 @property
53 def closed(self):
54 return not self.file or self.file.closed
56 def readable(self):
57 if self.closed:
58 return False
59 if hasattr(self.file, "readable"):
60 return self.file.readable()
61 return True
63 def writable(self):
64 if self.closed:
65 return False
66 if hasattr(self.file, "writable"):
67 return self.file.writable()
68 return "w" in getattr(self.file, "mode", "")
70 def seekable(self):
71 if self.closed:
72 return False
73 if hasattr(self.file, "seekable"):
74 return self.file.seekable()
75 return True
77 def __iter__(self):
78 return iter(self.file)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.models.sql.query import * # NOQA
2from plain.models.sql.query import Query
3from plain.models.sql.subqueries import * # NOQA
4from plain.models.sql.where import AND, OR, XOR
6__all__ = ["Query", "AND", "OR", "XOR"]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import collections
2import json
3import re
4from functools import partial
5from itertools import chain
7from plain.exceptions import EmptyResultSet, FieldError, FullResultSet
8from plain.models.constants import LOOKUP_SEP
9from plain.models.db import DatabaseError, NotSupportedError
10from plain.models.expressions import F, OrderBy, RawSQL, Ref, Value
11from plain.models.functions import Cast, Random
12from plain.models.lookups import Lookup
13from plain.models.query_utils import select_related_descend
14from plain.models.sql.constants import (
15 CURSOR,
16 GET_ITERATOR_CHUNK_SIZE,
17 MULTI,
18 NO_RESULTS,
19 ORDER_DIR,
20 SINGLE,
21)
22from plain.models.sql.query import Query, get_order_dir
23from plain.models.sql.where import AND
24from plain.models.transaction import TransactionManagementError
25from plain.utils.functional import cached_property
26from plain.utils.hashable import make_hashable
27from plain.utils.regex_helper import _lazy_re_compile
30class PositionRef(Ref):
31 def __init__(self, ordinal, refs, source):
32 self.ordinal = ordinal
33 super().__init__(refs, source)
35 def as_sql(self, compiler, connection):
36 return str(self.ordinal), ()
39class SQLCompiler:
40 # Multiline ordering SQL clause may appear from RawSQL.
41 ordering_parts = _lazy_re_compile(
42 r"^(.*)\s(?:ASC|DESC).*",
43 re.MULTILINE | re.DOTALL,
44 )
46 def __init__(self, query, connection, using, elide_empty=True):
47 self.query = query
48 self.connection = connection
49 self.using = using
50 # Some queries, e.g. coalesced aggregation, need to be executed even if
51 # they would return an empty result set.
52 self.elide_empty = elide_empty
53 self.quote_cache = {"*": "*"}
54 # The select, klass_info, and annotations are needed by QuerySet.iterator()
55 # these are set as a side-effect of executing the query. Note that we calculate
56 # separately a list of extra select columns needed for grammatical correctness
57 # of the query, but these columns are not included in self.select.
58 self.select = None
59 self.annotation_col_map = None
60 self.klass_info = None
61 self._meta_ordering = None
63 def __repr__(self):
64 return (
65 f"<{self.__class__.__qualname__} "
66 f"model={self.query.model.__qualname__} "
67 f"connection={self.connection!r} using={self.using!r}>"
68 )
70 def setup_query(self, with_col_aliases=False):
71 if all(self.query.alias_refcount[a] == 0 for a in self.query.alias_map):
72 self.query.get_initial_alias()
73 self.select, self.klass_info, self.annotation_col_map = self.get_select(
74 with_col_aliases=with_col_aliases,
75 )
76 self.col_count = len(self.select)
78 def pre_sql_setup(self, with_col_aliases=False):
79 """
80 Do any necessary class setup immediately prior to producing SQL. This
81 is for things that can't necessarily be done in __init__ because we
82 might not have all the pieces in place at that time.
83 """
84 self.setup_query(with_col_aliases=with_col_aliases)
85 order_by = self.get_order_by()
86 self.where, self.having, self.qualify = self.query.where.split_having_qualify(
87 must_group_by=self.query.group_by is not None
88 )
89 extra_select = self.get_extra_select(order_by, self.select)
90 self.has_extra_select = bool(extra_select)
91 group_by = self.get_group_by(self.select + extra_select, order_by)
92 return extra_select, order_by, group_by
94 def get_group_by(self, select, order_by):
95 """
96 Return a list of 2-tuples of form (sql, params).
98 The logic of what exactly the GROUP BY clause contains is hard
99 to describe in other words than "if it passes the test suite,
100 then it is correct".
101 """
102 # Some examples:
103 # SomeModel.objects.annotate(Count('somecol'))
104 # GROUP BY: all fields of the model
105 #
106 # SomeModel.objects.values('name').annotate(Count('somecol'))
107 # GROUP BY: name
108 #
109 # SomeModel.objects.annotate(Count('somecol')).values('name')
110 # GROUP BY: all cols of the model
111 #
112 # SomeModel.objects.values('name', 'pk')
113 # .annotate(Count('somecol')).values('pk')
114 # GROUP BY: name, pk
115 #
116 # SomeModel.objects.values('name').annotate(Count('somecol')).values('pk')
117 # GROUP BY: name, pk
118 #
119 # In fact, the self.query.group_by is the minimal set to GROUP BY. It
120 # can't be ever restricted to a smaller set, but additional columns in
121 # HAVING, ORDER BY, and SELECT clauses are added to it. Unfortunately
122 # the end result is that it is impossible to force the query to have
123 # a chosen GROUP BY clause - you can almost do this by using the form:
124 # .values(*wanted_cols).annotate(AnAggregate())
125 # but any later annotations, extra selects, values calls that
126 # refer some column outside of the wanted_cols, order_by, or even
127 # filter calls can alter the GROUP BY clause.
129 # The query.group_by is either None (no GROUP BY at all), True
130 # (group by select fields), or a list of expressions to be added
131 # to the group by.
132 if self.query.group_by is None:
133 return []
134 expressions = []
135 group_by_refs = set()
136 if self.query.group_by is not True:
137 # If the group by is set to a list (by .values() call most likely),
138 # then we need to add everything in it to the GROUP BY clause.
139 # Backwards compatibility hack for setting query.group_by. Remove
140 # when we have public API way of forcing the GROUP BY clause.
141 # Converts string references to expressions.
142 for expr in self.query.group_by:
143 if not hasattr(expr, "as_sql"):
144 expr = self.query.resolve_ref(expr)
145 if isinstance(expr, Ref):
146 if expr.refs not in group_by_refs:
147 group_by_refs.add(expr.refs)
148 expressions.append(expr.source)
149 else:
150 expressions.append(expr)
151 # Note that even if the group_by is set, it is only the minimal
152 # set to group by. So, we need to add cols in select, order_by, and
153 # having into the select in any case.
154 selected_expr_positions = {}
155 for ordinal, (expr, _, alias) in enumerate(select, start=1):
156 if alias:
157 selected_expr_positions[expr] = ordinal
158 # Skip members of the select clause that are already explicitly
159 # grouped against.
160 if alias in group_by_refs:
161 continue
162 expressions.extend(expr.get_group_by_cols())
163 if not self._meta_ordering:
164 for expr, (sql, params, is_ref) in order_by:
165 # Skip references to the SELECT clause, as all expressions in
166 # the SELECT clause are already part of the GROUP BY.
167 if not is_ref:
168 expressions.extend(expr.get_group_by_cols())
169 having_group_by = self.having.get_group_by_cols() if self.having else ()
170 for expr in having_group_by:
171 expressions.append(expr)
172 result = []
173 seen = set()
174 expressions = self.collapse_group_by(expressions, having_group_by)
176 allows_group_by_select_index = (
177 self.connection.features.allows_group_by_select_index
178 )
179 for expr in expressions:
180 try:
181 sql, params = self.compile(expr)
182 except (EmptyResultSet, FullResultSet):
183 continue
184 if (
185 allows_group_by_select_index
186 and (position := selected_expr_positions.get(expr)) is not None
187 ):
188 sql, params = str(position), ()
189 else:
190 sql, params = expr.select_format(self, sql, params)
191 params_hash = make_hashable(params)
192 if (sql, params_hash) not in seen:
193 result.append((sql, params))
194 seen.add((sql, params_hash))
195 return result
197 def collapse_group_by(self, expressions, having):
198 # If the database supports group by functional dependence reduction,
199 # then the expressions can be reduced to the set of selected table
200 # primary keys as all other columns are functionally dependent on them.
201 if self.connection.features.allows_group_by_selected_pks:
202 # Filter out all expressions associated with a table's primary key
203 # present in the grouped columns. This is done by identifying all
204 # tables that have their primary key included in the grouped
205 # columns and removing non-primary key columns referring to them.
206 # Unmanaged models are excluded because they could be representing
207 # database views on which the optimization might not be allowed.
208 pks = {
209 expr
210 for expr in expressions
211 if (
212 hasattr(expr, "target")
213 and expr.target.primary_key
214 and self.connection.features.allows_group_by_selected_pks_on_model(
215 expr.target.model
216 )
217 )
218 }
219 aliases = {expr.alias for expr in pks}
220 expressions = [
221 expr
222 for expr in expressions
223 if expr in pks
224 or expr in having
225 or getattr(expr, "alias", None) not in aliases
226 ]
227 return expressions
229 def get_select(self, with_col_aliases=False):
230 """
231 Return three values:
232 - a list of 3-tuples of (expression, (sql, params), alias)
233 - a klass_info structure,
234 - a dictionary of annotations
236 The (sql, params) is what the expression will produce, and alias is the
237 "AS alias" for the column (possibly None).
239 The klass_info structure contains the following information:
240 - The base model of the query.
241 - Which columns for that model are present in the query (by
242 position of the select clause).
243 - related_klass_infos: [f, klass_info] to descent into
245 The annotations is a dictionary of {'attname': column position} values.
246 """
247 select = []
248 klass_info = None
249 annotations = {}
250 select_idx = 0
251 for alias, (sql, params) in self.query.extra_select.items():
252 annotations[alias] = select_idx
253 select.append((RawSQL(sql, params), alias))
254 select_idx += 1
255 assert not (self.query.select and self.query.default_cols)
256 select_mask = self.query.get_select_mask()
257 if self.query.default_cols:
258 cols = self.get_default_columns(select_mask)
259 else:
260 # self.query.select is a special case. These columns never go to
261 # any model.
262 cols = self.query.select
263 if cols:
264 select_list = []
265 for col in cols:
266 select_list.append(select_idx)
267 select.append((col, None))
268 select_idx += 1
269 klass_info = {
270 "model": self.query.model,
271 "select_fields": select_list,
272 }
273 for alias, annotation in self.query.annotation_select.items():
274 annotations[alias] = select_idx
275 select.append((annotation, alias))
276 select_idx += 1
278 if self.query.select_related:
279 related_klass_infos = self.get_related_selections(select, select_mask)
280 klass_info["related_klass_infos"] = related_klass_infos
282 def get_select_from_parent(klass_info):
283 for ki in klass_info["related_klass_infos"]:
284 if ki["from_parent"]:
285 ki["select_fields"] = (
286 klass_info["select_fields"] + ki["select_fields"]
287 )
288 get_select_from_parent(ki)
290 get_select_from_parent(klass_info)
292 ret = []
293 col_idx = 1
294 for col, alias in select:
295 try:
296 sql, params = self.compile(col)
297 except EmptyResultSet:
298 empty_result_set_value = getattr(
299 col, "empty_result_set_value", NotImplemented
300 )
301 if empty_result_set_value is NotImplemented:
302 # Select a predicate that's always False.
303 sql, params = "0", ()
304 else:
305 sql, params = self.compile(Value(empty_result_set_value))
306 except FullResultSet:
307 sql, params = self.compile(Value(True))
308 else:
309 sql, params = col.select_format(self, sql, params)
310 if alias is None and with_col_aliases:
311 alias = f"col{col_idx}"
312 col_idx += 1
313 ret.append((col, (sql, params), alias))
314 return ret, klass_info, annotations
316 def _order_by_pairs(self):
317 if self.query.extra_order_by:
318 ordering = self.query.extra_order_by
319 elif not self.query.default_ordering:
320 ordering = self.query.order_by
321 elif self.query.order_by:
322 ordering = self.query.order_by
323 elif (meta := self.query.get_meta()) and meta.ordering:
324 ordering = meta.ordering
325 self._meta_ordering = ordering
326 else:
327 ordering = []
328 if self.query.standard_ordering:
329 default_order, _ = ORDER_DIR["ASC"]
330 else:
331 default_order, _ = ORDER_DIR["DESC"]
333 selected_exprs = {}
334 if select := self.select:
335 for ordinal, (expr, _, alias) in enumerate(select, start=1):
336 pos_expr = PositionRef(ordinal, alias, expr)
337 if alias:
338 selected_exprs[alias] = pos_expr
339 selected_exprs[expr] = pos_expr
341 for field in ordering:
342 if hasattr(field, "resolve_expression"):
343 if isinstance(field, Value):
344 # output_field must be resolved for constants.
345 field = Cast(field, field.output_field)
346 if not isinstance(field, OrderBy):
347 field = field.asc()
348 if not self.query.standard_ordering:
349 field = field.copy()
350 field.reverse_ordering()
351 select_ref = selected_exprs.get(field.expression)
352 if select_ref or (
353 isinstance(field.expression, F)
354 and (select_ref := selected_exprs.get(field.expression.name))
355 ):
356 # Emulation of NULLS (FIRST|LAST) cannot be combined with
357 # the usage of ordering by position.
358 if (
359 field.nulls_first is None and field.nulls_last is None
360 ) or self.connection.features.supports_order_by_nulls_modifier:
361 field = field.copy()
362 field.expression = select_ref
363 # Alias collisions are not possible when dealing with
364 # combined queries so fallback to it if emulation of NULLS
365 # handling is required.
366 elif self.query.combinator:
367 field = field.copy()
368 field.expression = Ref(select_ref.refs, select_ref.source)
369 yield field, select_ref is not None
370 continue
371 if field == "?": # random
372 yield OrderBy(Random()), False
373 continue
375 col, order = get_order_dir(field, default_order)
376 descending = order == "DESC"
378 if select_ref := selected_exprs.get(col):
379 # Reference to expression in SELECT clause
380 yield (
381 OrderBy(
382 select_ref,
383 descending=descending,
384 ),
385 True,
386 )
387 continue
388 if col in self.query.annotations:
389 # References to an expression which is masked out of the SELECT
390 # clause.
391 if self.query.combinator and self.select:
392 # Don't use the resolved annotation because other
393 # combinated queries might define it differently.
394 expr = F(col)
395 else:
396 expr = self.query.annotations[col]
397 if isinstance(expr, Value):
398 # output_field must be resolved for constants.
399 expr = Cast(expr, expr.output_field)
400 yield OrderBy(expr, descending=descending), False
401 continue
403 if "." in field:
404 # This came in through an extra(order_by=...) addition. Pass it
405 # on verbatim.
406 table, col = col.split(".", 1)
407 yield (
408 OrderBy(
409 RawSQL(f"{self.quote_name_unless_alias(table)}.{col}", []),
410 descending=descending,
411 ),
412 False,
413 )
414 continue
416 if self.query.extra and col in self.query.extra:
417 if col in self.query.extra_select:
418 yield (
419 OrderBy(
420 Ref(col, RawSQL(*self.query.extra[col])),
421 descending=descending,
422 ),
423 True,
424 )
425 else:
426 yield (
427 OrderBy(RawSQL(*self.query.extra[col]), descending=descending),
428 False,
429 )
430 else:
431 if self.query.combinator and self.select:
432 # Don't use the first model's field because other
433 # combinated queries might define it differently.
434 yield OrderBy(F(col), descending=descending), False
435 else:
436 # 'col' is of the form 'field' or 'field1__field2' or
437 # '-field1__field2__field', etc.
438 yield from self.find_ordering_name(
439 field,
440 self.query.get_meta(),
441 default_order=default_order,
442 )
444 def get_order_by(self):
445 """
446 Return a list of 2-tuples of the form (expr, (sql, params, is_ref)) for
447 the ORDER BY clause.
449 The order_by clause can alter the select clause (for example it can add
450 aliases to clauses that do not yet have one, or it can add totally new
451 select clauses).
452 """
453 result = []
454 seen = set()
455 for expr, is_ref in self._order_by_pairs():
456 resolved = expr.resolve_expression(self.query, allow_joins=True, reuse=None)
457 if not is_ref and self.query.combinator and self.select:
458 src = resolved.expression
459 expr_src = expr.expression
460 for sel_expr, _, col_alias in self.select:
461 if src == sel_expr:
462 # When values() is used the exact alias must be used to
463 # reference annotations.
464 if (
465 self.query.has_select_fields
466 and col_alias in self.query.annotation_select
467 and not (
468 isinstance(expr_src, F) and col_alias == expr_src.name
469 )
470 ):
471 continue
472 resolved.set_source_expressions(
473 [Ref(col_alias if col_alias else src.target.column, src)]
474 )
475 break
476 else:
477 # Add column used in ORDER BY clause to the selected
478 # columns and to each combined query.
479 order_by_idx = len(self.query.select) + 1
480 col_alias = f"__orderbycol{order_by_idx}"
481 for q in self.query.combined_queries:
482 # If fields were explicitly selected through values()
483 # combined queries cannot be augmented.
484 if q.has_select_fields:
485 raise DatabaseError(
486 "ORDER BY term does not match any column in "
487 "the result set."
488 )
489 q.add_annotation(expr_src, col_alias)
490 self.query.add_select_col(resolved, col_alias)
491 resolved.set_source_expressions([Ref(col_alias, src)])
492 sql, params = self.compile(resolved)
493 # Don't add the same column twice, but the order direction is
494 # not taken into account so we strip it. When this entire method
495 # is refactored into expressions, then we can check each part as we
496 # generate it.
497 without_ordering = self.ordering_parts.search(sql)[1]
498 params_hash = make_hashable(params)
499 if (without_ordering, params_hash) in seen:
500 continue
501 seen.add((without_ordering, params_hash))
502 result.append((resolved, (sql, params, is_ref)))
503 return result
505 def get_extra_select(self, order_by, select):
506 extra_select = []
507 if self.query.distinct and not self.query.distinct_fields:
508 select_sql = [t[1] for t in select]
509 for expr, (sql, params, is_ref) in order_by:
510 without_ordering = self.ordering_parts.search(sql)[1]
511 if not is_ref and (without_ordering, params) not in select_sql:
512 extra_select.append((expr, (without_ordering, params), None))
513 return extra_select
515 def quote_name_unless_alias(self, name):
516 """
517 A wrapper around connection.ops.quote_name that doesn't quote aliases
518 for table names. This avoids problems with some SQL dialects that treat
519 quoted strings specially (e.g. PostgreSQL).
520 """
521 if name in self.quote_cache:
522 return self.quote_cache[name]
523 if (
524 (name in self.query.alias_map and name not in self.query.table_map)
525 or name in self.query.extra_select
526 or (
527 self.query.external_aliases.get(name)
528 and name not in self.query.table_map
529 )
530 ):
531 self.quote_cache[name] = name
532 return name
533 r = self.connection.ops.quote_name(name)
534 self.quote_cache[name] = r
535 return r
537 def compile(self, node):
538 vendor_impl = getattr(node, "as_" + self.connection.vendor, None)
539 if vendor_impl:
540 sql, params = vendor_impl(self, self.connection)
541 else:
542 sql, params = node.as_sql(self, self.connection)
543 return sql, params
545 def get_combinator_sql(self, combinator, all):
546 features = self.connection.features
547 compilers = [
548 query.get_compiler(self.using, self.connection, self.elide_empty)
549 for query in self.query.combined_queries
550 ]
551 if not features.supports_slicing_ordering_in_compound:
552 for compiler in compilers:
553 if compiler.query.is_sliced:
554 raise DatabaseError(
555 "LIMIT/OFFSET not allowed in subqueries of compound statements."
556 )
557 if compiler.get_order_by():
558 raise DatabaseError(
559 "ORDER BY not allowed in subqueries of compound statements."
560 )
561 elif self.query.is_sliced and combinator == "union":
562 for compiler in compilers:
563 # A sliced union cannot have its parts elided as some of them
564 # might be sliced as well and in the event where only a single
565 # part produces a non-empty resultset it might be impossible to
566 # generate valid SQL.
567 compiler.elide_empty = False
568 parts = ()
569 for compiler in compilers:
570 try:
571 # If the columns list is limited, then all combined queries
572 # must have the same columns list. Set the selects defined on
573 # the query on all combined queries, if not already set.
574 if not compiler.query.values_select and self.query.values_select:
575 compiler.query = compiler.query.clone()
576 compiler.query.set_values(
577 (
578 *self.query.extra_select,
579 *self.query.values_select,
580 *self.query.annotation_select,
581 )
582 )
583 part_sql, part_args = compiler.as_sql(with_col_aliases=True)
584 if compiler.query.combinator:
585 # Wrap in a subquery if wrapping in parentheses isn't
586 # supported.
587 if not features.supports_parentheses_in_compound:
588 part_sql = f"SELECT * FROM ({part_sql})"
589 # Add parentheses when combining with compound query if not
590 # already added for all compound queries.
591 elif (
592 self.query.subquery
593 or not features.supports_slicing_ordering_in_compound
594 ):
595 part_sql = f"({part_sql})"
596 elif (
597 self.query.subquery
598 and features.supports_slicing_ordering_in_compound
599 ):
600 part_sql = f"({part_sql})"
601 parts += ((part_sql, part_args),)
602 except EmptyResultSet:
603 # Omit the empty queryset with UNION and with DIFFERENCE if the
604 # first queryset is nonempty.
605 if combinator == "union" or (combinator == "difference" and parts):
606 continue
607 raise
608 if not parts:
609 raise EmptyResultSet
610 combinator_sql = self.connection.ops.set_operators[combinator]
611 if all and combinator == "union":
612 combinator_sql += " ALL"
613 braces = "{}"
614 if not self.query.subquery and features.supports_slicing_ordering_in_compound:
615 braces = "({})"
616 sql_parts, args_parts = zip(
617 *((braces.format(sql), args) for sql, args in parts)
618 )
619 result = [f" {combinator_sql} ".join(sql_parts)]
620 params = []
621 for part in args_parts:
622 params.extend(part)
623 return result, params
625 def get_qualify_sql(self):
626 where_parts = []
627 if self.where:
628 where_parts.append(self.where)
629 if self.having:
630 where_parts.append(self.having)
631 inner_query = self.query.clone()
632 inner_query.subquery = True
633 inner_query.where = inner_query.where.__class__(where_parts)
634 # Augment the inner query with any window function references that
635 # might have been masked via values() and alias(). If any masked
636 # aliases are added they'll be masked again to avoid fetching
637 # the data in the `if qual_aliases` branch below.
638 select = {
639 expr: alias for expr, _, alias in self.get_select(with_col_aliases=True)[0]
640 }
641 select_aliases = set(select.values())
642 qual_aliases = set()
643 replacements = {}
645 def collect_replacements(expressions):
646 while expressions:
647 expr = expressions.pop()
648 if expr in replacements:
649 continue
650 elif select_alias := select.get(expr):
651 replacements[expr] = select_alias
652 elif isinstance(expr, Lookup):
653 expressions.extend(expr.get_source_expressions())
654 elif isinstance(expr, Ref):
655 if expr.refs not in select_aliases:
656 expressions.extend(expr.get_source_expressions())
657 else:
658 num_qual_alias = len(qual_aliases)
659 select_alias = f"qual{num_qual_alias}"
660 qual_aliases.add(select_alias)
661 inner_query.add_annotation(expr, select_alias)
662 replacements[expr] = select_alias
664 collect_replacements(list(self.qualify.leaves()))
665 self.qualify = self.qualify.replace_expressions(
666 {expr: Ref(alias, expr) for expr, alias in replacements.items()}
667 )
668 order_by = []
669 for order_by_expr, *_ in self.get_order_by():
670 collect_replacements(order_by_expr.get_source_expressions())
671 order_by.append(
672 order_by_expr.replace_expressions(
673 {expr: Ref(alias, expr) for expr, alias in replacements.items()}
674 )
675 )
676 inner_query_compiler = inner_query.get_compiler(
677 self.using, connection=self.connection, elide_empty=self.elide_empty
678 )
679 inner_sql, inner_params = inner_query_compiler.as_sql(
680 # The limits must be applied to the outer query to avoid pruning
681 # results too eagerly.
682 with_limits=False,
683 # Force unique aliasing of selected columns to avoid collisions
684 # and make rhs predicates referencing easier.
685 with_col_aliases=True,
686 )
687 qualify_sql, qualify_params = self.compile(self.qualify)
688 result = [
689 "SELECT * FROM (",
690 inner_sql,
691 ")",
692 self.connection.ops.quote_name("qualify"),
693 "WHERE",
694 qualify_sql,
695 ]
696 if qual_aliases:
697 # If some select aliases were unmasked for filtering purposes they
698 # must be masked back.
699 cols = [self.connection.ops.quote_name(alias) for alias in select.values()]
700 result = [
701 "SELECT",
702 ", ".join(cols),
703 "FROM (",
704 *result,
705 ")",
706 self.connection.ops.quote_name("qualify_mask"),
707 ]
708 params = list(inner_params) + qualify_params
709 # As the SQL spec is unclear on whether or not derived tables
710 # ordering must propagate it has to be explicitly repeated on the
711 # outer-most query to ensure it's preserved.
712 if order_by:
713 ordering_sqls = []
714 for ordering in order_by:
715 ordering_sql, ordering_params = self.compile(ordering)
716 ordering_sqls.append(ordering_sql)
717 params.extend(ordering_params)
718 result.extend(["ORDER BY", ", ".join(ordering_sqls)])
719 return result, params
721 def as_sql(self, with_limits=True, with_col_aliases=False):
722 """
723 Create the SQL for this query. Return the SQL string and list of
724 parameters.
726 If 'with_limits' is False, any limit/offset information is not included
727 in the query.
728 """
729 refcounts_before = self.query.alias_refcount.copy()
730 try:
731 combinator = self.query.combinator
732 extra_select, order_by, group_by = self.pre_sql_setup(
733 with_col_aliases=with_col_aliases or bool(combinator),
734 )
735 for_update_part = None
736 # Is a LIMIT/OFFSET clause needed?
737 with_limit_offset = with_limits and self.query.is_sliced
738 combinator = self.query.combinator
739 features = self.connection.features
740 if combinator:
741 if not getattr(features, f"supports_select_{combinator}"):
742 raise NotSupportedError(
743 f"{combinator} is not supported on this database backend."
744 )
745 result, params = self.get_combinator_sql(
746 combinator, self.query.combinator_all
747 )
748 elif self.qualify:
749 result, params = self.get_qualify_sql()
750 order_by = None
751 else:
752 distinct_fields, distinct_params = self.get_distinct()
753 # This must come after 'select', 'ordering', and 'distinct'
754 # (see docstring of get_from_clause() for details).
755 from_, f_params = self.get_from_clause()
756 try:
757 where, w_params = (
758 self.compile(self.where) if self.where is not None else ("", [])
759 )
760 except EmptyResultSet:
761 if self.elide_empty:
762 raise
763 # Use a predicate that's always False.
764 where, w_params = "0 = 1", []
765 except FullResultSet:
766 where, w_params = "", []
767 try:
768 having, h_params = (
769 self.compile(self.having)
770 if self.having is not None
771 else ("", [])
772 )
773 except FullResultSet:
774 having, h_params = "", []
775 result = ["SELECT"]
776 params = []
778 if self.query.distinct:
779 distinct_result, distinct_params = self.connection.ops.distinct_sql(
780 distinct_fields,
781 distinct_params,
782 )
783 result += distinct_result
784 params += distinct_params
786 out_cols = []
787 for _, (s_sql, s_params), alias in self.select + extra_select:
788 if alias:
789 s_sql = f"{s_sql} AS {self.connection.ops.quote_name(alias)}"
790 params.extend(s_params)
791 out_cols.append(s_sql)
793 result += [", ".join(out_cols)]
794 if from_:
795 result += ["FROM", *from_]
796 elif self.connection.features.bare_select_suffix:
797 result += [self.connection.features.bare_select_suffix]
798 params.extend(f_params)
800 if self.query.select_for_update and features.has_select_for_update:
801 if (
802 self.connection.get_autocommit()
803 # Don't raise an exception when database doesn't
804 # support transactions, as it's a noop.
805 and features.supports_transactions
806 ):
807 raise TransactionManagementError(
808 "select_for_update cannot be used outside of a transaction."
809 )
811 if (
812 with_limit_offset
813 and not features.supports_select_for_update_with_limit
814 ):
815 raise NotSupportedError(
816 "LIMIT/OFFSET is not supported with "
817 "select_for_update on this database backend."
818 )
819 nowait = self.query.select_for_update_nowait
820 skip_locked = self.query.select_for_update_skip_locked
821 of = self.query.select_for_update_of
822 no_key = self.query.select_for_no_key_update
823 # If it's a NOWAIT/SKIP LOCKED/OF/NO KEY query but the
824 # backend doesn't support it, raise NotSupportedError to
825 # prevent a possible deadlock.
826 if nowait and not features.has_select_for_update_nowait:
827 raise NotSupportedError(
828 "NOWAIT is not supported on this database backend."
829 )
830 elif skip_locked and not features.has_select_for_update_skip_locked:
831 raise NotSupportedError(
832 "SKIP LOCKED is not supported on this database backend."
833 )
834 elif of and not features.has_select_for_update_of:
835 raise NotSupportedError(
836 "FOR UPDATE OF is not supported on this database backend."
837 )
838 elif no_key and not features.has_select_for_no_key_update:
839 raise NotSupportedError(
840 "FOR NO KEY UPDATE is not supported on this "
841 "database backend."
842 )
843 for_update_part = self.connection.ops.for_update_sql(
844 nowait=nowait,
845 skip_locked=skip_locked,
846 of=self.get_select_for_update_of_arguments(),
847 no_key=no_key,
848 )
850 if for_update_part and features.for_update_after_from:
851 result.append(for_update_part)
853 if where:
854 result.append(f"WHERE {where}")
855 params.extend(w_params)
857 grouping = []
858 for g_sql, g_params in group_by:
859 grouping.append(g_sql)
860 params.extend(g_params)
861 if grouping:
862 if distinct_fields:
863 raise NotImplementedError(
864 "annotate() + distinct(fields) is not implemented."
865 )
866 order_by = order_by or self.connection.ops.force_no_ordering()
867 result.append("GROUP BY {}".format(", ".join(grouping)))
868 if self._meta_ordering:
869 order_by = None
870 if having:
871 result.append(f"HAVING {having}")
872 params.extend(h_params)
874 if self.query.explain_info:
875 result.insert(
876 0,
877 self.connection.ops.explain_query_prefix(
878 self.query.explain_info.format,
879 **self.query.explain_info.options,
880 ),
881 )
883 if order_by:
884 ordering = []
885 for _, (o_sql, o_params, _) in order_by:
886 ordering.append(o_sql)
887 params.extend(o_params)
888 order_by_sql = "ORDER BY {}".format(", ".join(ordering))
889 if combinator and features.requires_compound_order_by_subquery:
890 result = ["SELECT * FROM (", *result, ")", order_by_sql]
891 else:
892 result.append(order_by_sql)
894 if with_limit_offset:
895 result.append(
896 self.connection.ops.limit_offset_sql(
897 self.query.low_mark, self.query.high_mark
898 )
899 )
901 if for_update_part and not features.for_update_after_from:
902 result.append(for_update_part)
904 if self.query.subquery and extra_select:
905 # If the query is used as a subquery, the extra selects would
906 # result in more columns than the left-hand side expression is
907 # expecting. This can happen when a subquery uses a combination
908 # of order_by() and distinct(), forcing the ordering expressions
909 # to be selected as well. Wrap the query in another subquery
910 # to exclude extraneous selects.
911 sub_selects = []
912 sub_params = []
913 for index, (select, _, alias) in enumerate(self.select, start=1):
914 if alias:
915 sub_selects.append(
916 "{}.{}".format(
917 self.connection.ops.quote_name("subquery"),
918 self.connection.ops.quote_name(alias),
919 )
920 )
921 else:
922 select_clone = select.relabeled_clone(
923 {select.alias: "subquery"}
924 )
925 subselect, subparams = select_clone.as_sql(
926 self, self.connection
927 )
928 sub_selects.append(subselect)
929 sub_params.extend(subparams)
930 return "SELECT {} FROM ({}) subquery".format(
931 ", ".join(sub_selects),
932 " ".join(result),
933 ), tuple(sub_params + params)
935 return " ".join(result), tuple(params)
936 finally:
937 # Finally do cleanup - get rid of the joins we created above.
938 self.query.reset_refcounts(refcounts_before)
940 def get_default_columns(
941 self, select_mask, start_alias=None, opts=None, from_parent=None
942 ):
943 """
944 Compute the default columns for selecting every field in the base
945 model. Will sometimes be called to pull in related models (e.g. via
946 select_related), in which case "opts" and "start_alias" will be given
947 to provide a starting point for the traversal.
949 Return a list of strings, quoted appropriately for use in SQL
950 directly, as well as a set of aliases used in the select statement (if
951 'as_pairs' is True, return a list of (alias, col_name) pairs instead
952 of strings as the first component and None as the second component).
953 """
954 result = []
955 if opts is None:
956 if (opts := self.query.get_meta()) is None:
957 return result
958 start_alias = start_alias or self.query.get_initial_alias()
959 # The 'seen_models' is used to optimize checking the needed parent
960 # alias for a given field. This also includes None -> start_alias to
961 # be used by local fields.
962 seen_models = {None: start_alias}
964 for field in opts.concrete_fields:
965 model = field.model._meta.concrete_model
966 # A proxy model will have a different model and concrete_model. We
967 # will assign None if the field belongs to this model.
968 if model == opts.model:
969 model = None
970 if (
971 from_parent
972 and model is not None
973 and issubclass(
974 from_parent._meta.concrete_model, model._meta.concrete_model
975 )
976 ):
977 # Avoid loading data for already loaded parents.
978 # We end up here in the case select_related() resolution
979 # proceeds from parent model to child model. In that case the
980 # parent model data is already present in the SELECT clause,
981 # and we want to avoid reloading the same data again.
982 continue
983 if select_mask and field not in select_mask:
984 continue
985 alias = self.query.join_parent_model(opts, model, start_alias, seen_models)
986 column = field.get_col(alias)
987 result.append(column)
988 return result
990 def get_distinct(self):
991 """
992 Return a quoted list of fields to use in DISTINCT ON part of the query.
994 This method can alter the tables in the query, and thus it must be
995 called before get_from_clause().
996 """
997 result = []
998 params = []
999 opts = self.query.get_meta()
1001 for name in self.query.distinct_fields:
1002 parts = name.split(LOOKUP_SEP)
1003 _, targets, alias, joins, path, _, transform_function = self._setup_joins(
1004 parts, opts, None
1005 )
1006 targets, alias, _ = self.query.trim_joins(targets, joins, path)
1007 for target in targets:
1008 if name in self.query.annotation_select:
1009 result.append(self.connection.ops.quote_name(name))
1010 else:
1011 r, p = self.compile(transform_function(target, alias))
1012 result.append(r)
1013 params.append(p)
1014 return result, params
1016 def find_ordering_name(
1017 self, name, opts, alias=None, default_order="ASC", already_seen=None
1018 ):
1019 """
1020 Return the table alias (the name might be ambiguous, the alias will
1021 not be) and column name for ordering by the given 'name' parameter.
1022 The 'name' is of the form 'field1__field2__...__fieldN'.
1023 """
1024 name, order = get_order_dir(name, default_order)
1025 descending = order == "DESC"
1026 pieces = name.split(LOOKUP_SEP)
1027 (
1028 field,
1029 targets,
1030 alias,
1031 joins,
1032 path,
1033 opts,
1034 transform_function,
1035 ) = self._setup_joins(pieces, opts, alias)
1037 # If we get to this point and the field is a relation to another model,
1038 # append the default ordering for that model unless it is the pk
1039 # shortcut or the attribute name of the field that is specified or
1040 # there are transforms to process.
1041 if (
1042 field.is_relation
1043 and opts.ordering
1044 and getattr(field, "attname", None) != pieces[-1]
1045 and name != "pk"
1046 and not getattr(transform_function, "has_transforms", False)
1047 ):
1048 # Firstly, avoid infinite loops.
1049 already_seen = already_seen or set()
1050 join_tuple = tuple(
1051 getattr(self.query.alias_map[j], "join_cols", None) for j in joins
1052 )
1053 if join_tuple in already_seen:
1054 raise FieldError("Infinite loop caused by ordering.")
1055 already_seen.add(join_tuple)
1057 results = []
1058 for item in opts.ordering:
1059 if hasattr(item, "resolve_expression") and not isinstance(
1060 item, OrderBy
1061 ):
1062 item = item.desc() if descending else item.asc()
1063 if isinstance(item, OrderBy):
1064 results.append(
1065 (item.prefix_references(f"{name}{LOOKUP_SEP}"), False)
1066 )
1067 continue
1068 results.extend(
1069 (expr.prefix_references(f"{name}{LOOKUP_SEP}"), is_ref)
1070 for expr, is_ref in self.find_ordering_name(
1071 item, opts, alias, order, already_seen
1072 )
1073 )
1074 return results
1075 targets, alias, _ = self.query.trim_joins(targets, joins, path)
1076 return [
1077 (OrderBy(transform_function(t, alias), descending=descending), False)
1078 for t in targets
1079 ]
1081 def _setup_joins(self, pieces, opts, alias):
1082 """
1083 Helper method for get_order_by() and get_distinct().
1085 get_ordering() and get_distinct() must produce same target columns on
1086 same input, as the prefixes of get_ordering() and get_distinct() must
1087 match. Executing SQL where this is not true is an error.
1088 """
1089 alias = alias or self.query.get_initial_alias()
1090 field, targets, opts, joins, path, transform_function = self.query.setup_joins(
1091 pieces, opts, alias
1092 )
1093 alias = joins[-1]
1094 return field, targets, alias, joins, path, opts, transform_function
1096 def get_from_clause(self):
1097 """
1098 Return a list of strings that are joined together to go after the
1099 "FROM" part of the query, as well as a list any extra parameters that
1100 need to be included. Subclasses, can override this to create a
1101 from-clause via a "select".
1103 This should only be called after any SQL construction methods that
1104 might change the tables that are needed. This means the select columns,
1105 ordering, and distinct must be done first.
1106 """
1107 result = []
1108 params = []
1109 for alias in tuple(self.query.alias_map):
1110 if not self.query.alias_refcount[alias]:
1111 continue
1112 try:
1113 from_clause = self.query.alias_map[alias]
1114 except KeyError:
1115 # Extra tables can end up in self.tables, but not in the
1116 # alias_map if they aren't in a join. That's OK. We skip them.
1117 continue
1118 clause_sql, clause_params = self.compile(from_clause)
1119 result.append(clause_sql)
1120 params.extend(clause_params)
1121 for t in self.query.extra_tables:
1122 alias, _ = self.query.table_alias(t)
1123 # Only add the alias if it's not already present (the table_alias()
1124 # call increments the refcount, so an alias refcount of one means
1125 # this is the only reference).
1126 if (
1127 alias not in self.query.alias_map
1128 or self.query.alias_refcount[alias] == 1
1129 ):
1130 result.append(f", {self.quote_name_unless_alias(alias)}")
1131 return result, params
1133 def get_related_selections(
1134 self,
1135 select,
1136 select_mask,
1137 opts=None,
1138 root_alias=None,
1139 cur_depth=1,
1140 requested=None,
1141 restricted=None,
1142 ):
1143 """
1144 Fill in the information needed for a select_related query. The current
1145 depth is measured as the number of connections away from the root model
1146 (for example, cur_depth=1 means we are looking at models with direct
1147 connections to the root model).
1148 """
1150 def _get_field_choices():
1151 direct_choices = (f.name for f in opts.fields if f.is_relation)
1152 reverse_choices = (
1153 f.field.related_query_name()
1154 for f in opts.related_objects
1155 if f.field.unique
1156 )
1157 return chain(
1158 direct_choices, reverse_choices, self.query._filtered_relations
1159 )
1161 related_klass_infos = []
1162 if not restricted and cur_depth > self.query.max_depth:
1163 # We've recursed far enough; bail out.
1164 return related_klass_infos
1166 if not opts:
1167 opts = self.query.get_meta()
1168 root_alias = self.query.get_initial_alias()
1170 # Setup for the case when only particular related fields should be
1171 # included in the related selection.
1172 fields_found = set()
1173 if requested is None:
1174 restricted = isinstance(self.query.select_related, dict)
1175 if restricted:
1176 requested = self.query.select_related
1178 def get_related_klass_infos(klass_info, related_klass_infos):
1179 klass_info["related_klass_infos"] = related_klass_infos
1181 for f in opts.fields:
1182 fields_found.add(f.name)
1184 if restricted:
1185 next = requested.get(f.name, {})
1186 if not f.is_relation:
1187 # If a non-related field is used like a relation,
1188 # or if a single non-relational field is given.
1189 if next or f.name in requested:
1190 raise FieldError(
1191 "Non-relational field given in select_related: '{}'. "
1192 "Choices are: {}".format(
1193 f.name,
1194 ", ".join(_get_field_choices()) or "(none)",
1195 )
1196 )
1197 else:
1198 next = False
1200 if not select_related_descend(f, restricted, requested, select_mask):
1201 continue
1202 related_select_mask = select_mask.get(f) or {}
1203 klass_info = {
1204 "model": f.remote_field.model,
1205 "field": f,
1206 "reverse": False,
1207 "local_setter": f.set_cached_value,
1208 "remote_setter": f.remote_field.set_cached_value
1209 if f.unique
1210 else lambda x, y: None,
1211 "from_parent": False,
1212 }
1213 related_klass_infos.append(klass_info)
1214 select_fields = []
1215 _, _, _, joins, _, _ = self.query.setup_joins([f.name], opts, root_alias)
1216 alias = joins[-1]
1217 columns = self.get_default_columns(
1218 related_select_mask, start_alias=alias, opts=f.remote_field.model._meta
1219 )
1220 for col in columns:
1221 select_fields.append(len(select))
1222 select.append((col, None))
1223 klass_info["select_fields"] = select_fields
1224 next_klass_infos = self.get_related_selections(
1225 select,
1226 related_select_mask,
1227 f.remote_field.model._meta,
1228 alias,
1229 cur_depth + 1,
1230 next,
1231 restricted,
1232 )
1233 get_related_klass_infos(klass_info, next_klass_infos)
1235 if restricted:
1236 related_fields = [
1237 (o.field, o.related_model)
1238 for o in opts.related_objects
1239 if o.field.unique and not o.many_to_many
1240 ]
1241 for related_field, model in related_fields:
1242 related_select_mask = select_mask.get(related_field) or {}
1243 if not select_related_descend(
1244 related_field,
1245 restricted,
1246 requested,
1247 related_select_mask,
1248 reverse=True,
1249 ):
1250 continue
1252 related_field_name = related_field.related_query_name()
1253 fields_found.add(related_field_name)
1255 join_info = self.query.setup_joins(
1256 [related_field_name], opts, root_alias
1257 )
1258 alias = join_info.joins[-1]
1259 from_parent = issubclass(model, opts.model) and model is not opts.model
1260 klass_info = {
1261 "model": model,
1262 "field": related_field,
1263 "reverse": True,
1264 "local_setter": related_field.remote_field.set_cached_value,
1265 "remote_setter": related_field.set_cached_value,
1266 "from_parent": from_parent,
1267 }
1268 related_klass_infos.append(klass_info)
1269 select_fields = []
1270 columns = self.get_default_columns(
1271 related_select_mask,
1272 start_alias=alias,
1273 opts=model._meta,
1274 from_parent=opts.model,
1275 )
1276 for col in columns:
1277 select_fields.append(len(select))
1278 select.append((col, None))
1279 klass_info["select_fields"] = select_fields
1280 next = requested.get(related_field.related_query_name(), {})
1281 next_klass_infos = self.get_related_selections(
1282 select,
1283 related_select_mask,
1284 model._meta,
1285 alias,
1286 cur_depth + 1,
1287 next,
1288 restricted,
1289 )
1290 get_related_klass_infos(klass_info, next_klass_infos)
1292 def local_setter(final_field, obj, from_obj):
1293 # Set a reverse fk object when relation is non-empty.
1294 if from_obj:
1295 final_field.remote_field.set_cached_value(from_obj, obj)
1297 def local_setter_noop(obj, from_obj):
1298 pass
1300 def remote_setter(name, obj, from_obj):
1301 setattr(from_obj, name, obj)
1303 for name in list(requested):
1304 # Filtered relations work only on the topmost level.
1305 if cur_depth > 1:
1306 break
1307 if name in self.query._filtered_relations:
1308 fields_found.add(name)
1309 final_field, _, join_opts, joins, _, _ = self.query.setup_joins(
1310 [name], opts, root_alias
1311 )
1312 model = join_opts.model
1313 alias = joins[-1]
1314 from_parent = (
1315 issubclass(model, opts.model) and model is not opts.model
1316 )
1317 klass_info = {
1318 "model": model,
1319 "field": final_field,
1320 "reverse": True,
1321 "local_setter": (
1322 partial(local_setter, final_field)
1323 if len(joins) <= 2
1324 else local_setter_noop
1325 ),
1326 "remote_setter": partial(remote_setter, name),
1327 "from_parent": from_parent,
1328 }
1329 related_klass_infos.append(klass_info)
1330 select_fields = []
1331 field_select_mask = select_mask.get((name, final_field)) or {}
1332 columns = self.get_default_columns(
1333 field_select_mask,
1334 start_alias=alias,
1335 opts=model._meta,
1336 from_parent=opts.model,
1337 )
1338 for col in columns:
1339 select_fields.append(len(select))
1340 select.append((col, None))
1341 klass_info["select_fields"] = select_fields
1342 next_requested = requested.get(name, {})
1343 next_klass_infos = self.get_related_selections(
1344 select,
1345 field_select_mask,
1346 opts=model._meta,
1347 root_alias=alias,
1348 cur_depth=cur_depth + 1,
1349 requested=next_requested,
1350 restricted=restricted,
1351 )
1352 get_related_klass_infos(klass_info, next_klass_infos)
1353 fields_not_found = set(requested).difference(fields_found)
1354 if fields_not_found:
1355 invalid_fields = (f"'{s}'" for s in fields_not_found)
1356 raise FieldError(
1357 "Invalid field name(s) given in select_related: {}. "
1358 "Choices are: {}".format(
1359 ", ".join(invalid_fields),
1360 ", ".join(_get_field_choices()) or "(none)",
1361 )
1362 )
1363 return related_klass_infos
1365 def get_select_for_update_of_arguments(self):
1366 """
1367 Return a quoted list of arguments for the SELECT FOR UPDATE OF part of
1368 the query.
1369 """
1371 def _get_parent_klass_info(klass_info):
1372 concrete_model = klass_info["model"]._meta.concrete_model
1373 for parent_model, parent_link in concrete_model._meta.parents.items():
1374 parent_list = parent_model._meta.get_parent_list()
1375 yield {
1376 "model": parent_model,
1377 "field": parent_link,
1378 "reverse": False,
1379 "select_fields": [
1380 select_index
1381 for select_index in klass_info["select_fields"]
1382 # Selected columns from a model or its parents.
1383 if (
1384 self.select[select_index][0].target.model == parent_model
1385 or self.select[select_index][0].target.model in parent_list
1386 )
1387 ],
1388 }
1390 def _get_first_selected_col_from_model(klass_info):
1391 """
1392 Find the first selected column from a model. If it doesn't exist,
1393 don't lock a model.
1395 select_fields is filled recursively, so it also contains fields
1396 from the parent models.
1397 """
1398 concrete_model = klass_info["model"]._meta.concrete_model
1399 for select_index in klass_info["select_fields"]:
1400 if self.select[select_index][0].target.model == concrete_model:
1401 return self.select[select_index][0]
1403 def _get_field_choices():
1404 """Yield all allowed field paths in breadth-first search order."""
1405 queue = collections.deque([(None, self.klass_info)])
1406 while queue:
1407 parent_path, klass_info = queue.popleft()
1408 if parent_path is None:
1409 path = []
1410 yield "self"
1411 else:
1412 field = klass_info["field"]
1413 if klass_info["reverse"]:
1414 field = field.remote_field
1415 path = parent_path + [field.name]
1416 yield LOOKUP_SEP.join(path)
1417 queue.extend(
1418 (path, klass_info)
1419 for klass_info in _get_parent_klass_info(klass_info)
1420 )
1421 queue.extend(
1422 (path, klass_info)
1423 for klass_info in klass_info.get("related_klass_infos", [])
1424 )
1426 if not self.klass_info:
1427 return []
1428 result = []
1429 invalid_names = []
1430 for name in self.query.select_for_update_of:
1431 klass_info = self.klass_info
1432 if name == "self":
1433 col = _get_first_selected_col_from_model(klass_info)
1434 else:
1435 for part in name.split(LOOKUP_SEP):
1436 klass_infos = (
1437 *klass_info.get("related_klass_infos", []),
1438 *_get_parent_klass_info(klass_info),
1439 )
1440 for related_klass_info in klass_infos:
1441 field = related_klass_info["field"]
1442 if related_klass_info["reverse"]:
1443 field = field.remote_field
1444 if field.name == part:
1445 klass_info = related_klass_info
1446 break
1447 else:
1448 klass_info = None
1449 break
1450 if klass_info is None:
1451 invalid_names.append(name)
1452 continue
1453 col = _get_first_selected_col_from_model(klass_info)
1454 if col is not None:
1455 if self.connection.features.select_for_update_of_column:
1456 result.append(self.compile(col)[0])
1457 else:
1458 result.append(self.quote_name_unless_alias(col.alias))
1459 if invalid_names:
1460 raise FieldError(
1461 "Invalid field name(s) given in select_for_update(of=(...)): {}. "
1462 "Only relational fields followed in the query are allowed. "
1463 "Choices are: {}.".format(
1464 ", ".join(invalid_names),
1465 ", ".join(_get_field_choices()),
1466 )
1467 )
1468 return result
1470 def get_converters(self, expressions):
1471 converters = {}
1472 for i, expression in enumerate(expressions):
1473 if expression:
1474 backend_converters = self.connection.ops.get_db_converters(expression)
1475 field_converters = expression.get_db_converters(self.connection)
1476 if backend_converters or field_converters:
1477 converters[i] = (backend_converters + field_converters, expression)
1478 return converters
1480 def apply_converters(self, rows, converters):
1481 connection = self.connection
1482 converters = list(converters.items())
1483 for row in map(list, rows):
1484 for pos, (convs, expression) in converters:
1485 value = row[pos]
1486 for converter in convs:
1487 value = converter(value, expression, connection)
1488 row[pos] = value
1489 yield row
1491 def results_iter(
1492 self,
1493 results=None,
1494 tuple_expected=False,
1495 chunked_fetch=False,
1496 chunk_size=GET_ITERATOR_CHUNK_SIZE,
1497 ):
1498 """Return an iterator over the results from executing this query."""
1499 if results is None:
1500 results = self.execute_sql(
1501 MULTI, chunked_fetch=chunked_fetch, chunk_size=chunk_size
1502 )
1503 fields = [s[0] for s in self.select[0 : self.col_count]]
1504 converters = self.get_converters(fields)
1505 rows = chain.from_iterable(results)
1506 if converters:
1507 rows = self.apply_converters(rows, converters)
1508 if tuple_expected:
1509 rows = map(tuple, rows)
1510 return rows
1512 def has_results(self):
1513 """
1514 Backends (e.g. NoSQL) can override this in order to use optimized
1515 versions of "query has any results."
1516 """
1517 return bool(self.execute_sql(SINGLE))
1519 def execute_sql(
1520 self, result_type=MULTI, chunked_fetch=False, chunk_size=GET_ITERATOR_CHUNK_SIZE
1521 ):
1522 """
1523 Run the query against the database and return the result(s). The
1524 return value is a single data item if result_type is SINGLE, or an
1525 iterator over the results if the result_type is MULTI.
1527 result_type is either MULTI (use fetchmany() to retrieve all rows),
1528 SINGLE (only retrieve a single row), or None. In this last case, the
1529 cursor is returned if any query is executed, since it's used by
1530 subclasses such as InsertQuery). It's possible, however, that no query
1531 is needed, as the filters describe an empty set. In that case, None is
1532 returned, to avoid any unnecessary database interaction.
1533 """
1534 result_type = result_type or NO_RESULTS
1535 try:
1536 sql, params = self.as_sql()
1537 if not sql:
1538 raise EmptyResultSet
1539 except EmptyResultSet:
1540 if result_type == MULTI:
1541 return iter([])
1542 else:
1543 return
1544 if chunked_fetch:
1545 cursor = self.connection.chunked_cursor()
1546 else:
1547 cursor = self.connection.cursor()
1548 try:
1549 cursor.execute(sql, params)
1550 except Exception:
1551 # Might fail for server-side cursors (e.g. connection closed)
1552 cursor.close()
1553 raise
1555 if result_type == CURSOR:
1556 # Give the caller the cursor to process and close.
1557 return cursor
1558 if result_type == SINGLE:
1559 try:
1560 val = cursor.fetchone()
1561 if val:
1562 return val[0 : self.col_count]
1563 return val
1564 finally:
1565 # done with the cursor
1566 cursor.close()
1567 if result_type == NO_RESULTS:
1568 cursor.close()
1569 return
1571 result = cursor_iter(
1572 cursor,
1573 self.connection.features.empty_fetchmany_value,
1574 self.col_count if self.has_extra_select else None,
1575 chunk_size,
1576 )
1577 if not chunked_fetch or not self.connection.features.can_use_chunked_reads:
1578 # If we are using non-chunked reads, we return the same data
1579 # structure as normally, but ensure it is all read into memory
1580 # before going any further. Use chunked_fetch if requested,
1581 # unless the database doesn't support it.
1582 return list(result)
1583 return result
1585 def as_subquery_condition(self, alias, columns, compiler):
1586 qn = compiler.quote_name_unless_alias
1587 qn2 = self.connection.ops.quote_name
1589 for index, select_col in enumerate(self.query.select):
1590 lhs_sql, lhs_params = self.compile(select_col)
1591 rhs = f"{qn(alias)}.{qn2(columns[index])}"
1592 self.query.where.add(RawSQL(f"{lhs_sql} = {rhs}", lhs_params), AND)
1594 sql, params = self.as_sql()
1595 return f"EXISTS ({sql})", params
1597 def explain_query(self):
1598 result = list(self.execute_sql())
1599 # Some backends return 1 item tuples with strings, and others return
1600 # tuples with integers and strings. Flatten them out into strings.
1601 format_ = self.query.explain_info.format
1602 output_formatter = json.dumps if format_ and format_.lower() == "json" else str
1603 for row in result[0]:
1604 if not isinstance(row, str):
1605 yield " ".join(output_formatter(c) for c in row)
1606 else:
1607 yield row
1610class SQLInsertCompiler(SQLCompiler):
1611 returning_fields = None
1612 returning_params = ()
1614 def field_as_sql(self, field, val):
1615 """
1616 Take a field and a value intended to be saved on that field, and
1617 return placeholder SQL and accompanying params. Check for raw values,
1618 expressions, and fields with get_placeholder() defined in that order.
1620 When field is None, consider the value raw and use it as the
1621 placeholder, with no corresponding parameters returned.
1622 """
1623 if field is None:
1624 # A field value of None means the value is raw.
1625 sql, params = val, []
1626 elif hasattr(val, "as_sql"):
1627 # This is an expression, let's compile it.
1628 sql, params = self.compile(val)
1629 elif hasattr(field, "get_placeholder"):
1630 # Some fields (e.g. geo fields) need special munging before
1631 # they can be inserted.
1632 sql, params = field.get_placeholder(val, self, self.connection), [val]
1633 else:
1634 # Return the common case for the placeholder
1635 sql, params = "%s", [val]
1637 # The following hook is only used by Oracle Spatial, which sometimes
1638 # needs to yield 'NULL' and [] as its placeholder and params instead
1639 # of '%s' and [None]. The 'NULL' placeholder is produced earlier by
1640 # OracleOperations.get_geom_placeholder(). The following line removes
1641 # the corresponding None parameter. See ticket #10888.
1642 params = self.connection.ops.modify_insert_params(sql, params)
1644 return sql, params
1646 def prepare_value(self, field, value):
1647 """
1648 Prepare a value to be used in a query by resolving it if it is an
1649 expression and otherwise calling the field's get_db_prep_save().
1650 """
1651 if hasattr(value, "resolve_expression"):
1652 value = value.resolve_expression(
1653 self.query, allow_joins=False, for_save=True
1654 )
1655 # Don't allow values containing Col expressions. They refer to
1656 # existing columns on a row, but in the case of insert the row
1657 # doesn't exist yet.
1658 if value.contains_column_references:
1659 raise ValueError(
1660 f'Failed to insert expression "{value}" on {field}. F() expressions '
1661 "can only be used to update, not to insert."
1662 )
1663 if value.contains_aggregate:
1664 raise FieldError(
1665 "Aggregate functions are not allowed in this query "
1666 f"({field.name}={value!r})."
1667 )
1668 if value.contains_over_clause:
1669 raise FieldError(
1670 f"Window expressions are not allowed in this query ({field.name}={value!r})."
1671 )
1672 return field.get_db_prep_save(value, connection=self.connection)
1674 def pre_save_val(self, field, obj):
1675 """
1676 Get the given field's value off the given obj. pre_save() is used for
1677 things like auto_now on DateTimeField. Skip it if this is a raw query.
1678 """
1679 if self.query.raw:
1680 return getattr(obj, field.attname)
1681 return field.pre_save(obj, add=True)
1683 def assemble_as_sql(self, fields, value_rows):
1684 """
1685 Take a sequence of N fields and a sequence of M rows of values, and
1686 generate placeholder SQL and parameters for each field and value.
1687 Return a pair containing:
1688 * a sequence of M rows of N SQL placeholder strings, and
1689 * a sequence of M rows of corresponding parameter values.
1691 Each placeholder string may contain any number of '%s' interpolation
1692 strings, and each parameter row will contain exactly as many params
1693 as the total number of '%s's in the corresponding placeholder row.
1694 """
1695 if not value_rows:
1696 return [], []
1698 # list of (sql, [params]) tuples for each object to be saved
1699 # Shape: [n_objs][n_fields][2]
1700 rows_of_fields_as_sql = (
1701 (self.field_as_sql(field, v) for field, v in zip(fields, row))
1702 for row in value_rows
1703 )
1705 # tuple like ([sqls], [[params]s]) for each object to be saved
1706 # Shape: [n_objs][2][n_fields]
1707 sql_and_param_pair_rows = (zip(*row) for row in rows_of_fields_as_sql)
1709 # Extract separate lists for placeholders and params.
1710 # Each of these has shape [n_objs][n_fields]
1711 placeholder_rows, param_rows = zip(*sql_and_param_pair_rows)
1713 # Params for each field are still lists, and need to be flattened.
1714 param_rows = [[p for ps in row for p in ps] for row in param_rows]
1716 return placeholder_rows, param_rows
1718 def as_sql(self):
1719 # We don't need quote_name_unless_alias() here, since these are all
1720 # going to be column names (so we can avoid the extra overhead).
1721 qn = self.connection.ops.quote_name
1722 opts = self.query.get_meta()
1723 insert_statement = self.connection.ops.insert_statement(
1724 on_conflict=self.query.on_conflict,
1725 )
1726 result = [f"{insert_statement} {qn(opts.db_table)}"]
1727 fields = self.query.fields or [opts.pk]
1728 result.append("({})".format(", ".join(qn(f.column) for f in fields)))
1730 if self.query.fields:
1731 value_rows = [
1732 [
1733 self.prepare_value(field, self.pre_save_val(field, obj))
1734 for field in fields
1735 ]
1736 for obj in self.query.objs
1737 ]
1738 else:
1739 # An empty object.
1740 value_rows = [
1741 [self.connection.ops.pk_default_value()] for _ in self.query.objs
1742 ]
1743 fields = [None]
1745 # Currently the backends just accept values when generating bulk
1746 # queries and generate their own placeholders. Doing that isn't
1747 # necessary and it should be possible to use placeholders and
1748 # expressions in bulk inserts too.
1749 can_bulk = (
1750 not self.returning_fields and self.connection.features.has_bulk_insert
1751 )
1753 placeholder_rows, param_rows = self.assemble_as_sql(fields, value_rows)
1755 on_conflict_suffix_sql = self.connection.ops.on_conflict_suffix_sql(
1756 fields,
1757 self.query.on_conflict,
1758 (f.column for f in self.query.update_fields),
1759 (f.column for f in self.query.unique_fields),
1760 )
1761 if (
1762 self.returning_fields
1763 and self.connection.features.can_return_columns_from_insert
1764 ):
1765 if self.connection.features.can_return_rows_from_bulk_insert:
1766 result.append(
1767 self.connection.ops.bulk_insert_sql(fields, placeholder_rows)
1768 )
1769 params = param_rows
1770 else:
1771 result.append("VALUES ({})".format(", ".join(placeholder_rows[0])))
1772 params = [param_rows[0]]
1773 if on_conflict_suffix_sql:
1774 result.append(on_conflict_suffix_sql)
1775 # Skip empty r_sql to allow subclasses to customize behavior for
1776 # 3rd party backends. Refs #19096.
1777 r_sql, self.returning_params = self.connection.ops.return_insert_columns(
1778 self.returning_fields
1779 )
1780 if r_sql:
1781 result.append(r_sql)
1782 params += [self.returning_params]
1783 return [(" ".join(result), tuple(chain.from_iterable(params)))]
1785 if can_bulk:
1786 result.append(self.connection.ops.bulk_insert_sql(fields, placeholder_rows))
1787 if on_conflict_suffix_sql:
1788 result.append(on_conflict_suffix_sql)
1789 return [(" ".join(result), tuple(p for ps in param_rows for p in ps))]
1790 else:
1791 if on_conflict_suffix_sql:
1792 result.append(on_conflict_suffix_sql)
1793 return [
1794 (" ".join(result + ["VALUES ({})".format(", ".join(p))]), vals)
1795 for p, vals in zip(placeholder_rows, param_rows)
1796 ]
1798 def execute_sql(self, returning_fields=None):
1799 assert not (
1800 returning_fields
1801 and len(self.query.objs) != 1
1802 and not self.connection.features.can_return_rows_from_bulk_insert
1803 )
1804 opts = self.query.get_meta()
1805 self.returning_fields = returning_fields
1806 with self.connection.cursor() as cursor:
1807 for sql, params in self.as_sql():
1808 cursor.execute(sql, params)
1809 if not self.returning_fields:
1810 return []
1811 if (
1812 self.connection.features.can_return_rows_from_bulk_insert
1813 and len(self.query.objs) > 1
1814 ):
1815 rows = self.connection.ops.fetch_returned_insert_rows(cursor)
1816 elif self.connection.features.can_return_columns_from_insert:
1817 assert len(self.query.objs) == 1
1818 rows = [
1819 self.connection.ops.fetch_returned_insert_columns(
1820 cursor,
1821 self.returning_params,
1822 )
1823 ]
1824 else:
1825 rows = [
1826 (
1827 self.connection.ops.last_insert_id(
1828 cursor,
1829 opts.db_table,
1830 opts.pk.column,
1831 ),
1832 )
1833 ]
1834 cols = [field.get_col(opts.db_table) for field in self.returning_fields]
1835 converters = self.get_converters(cols)
1836 if converters:
1837 rows = list(self.apply_converters(rows, converters))
1838 return rows
1841class SQLDeleteCompiler(SQLCompiler):
1842 @cached_property
1843 def single_alias(self):
1844 # Ensure base table is in aliases.
1845 self.query.get_initial_alias()
1846 return sum(self.query.alias_refcount[t] > 0 for t in self.query.alias_map) == 1
1848 @classmethod
1849 def _expr_refs_base_model(cls, expr, base_model):
1850 if isinstance(expr, Query):
1851 return expr.model == base_model
1852 if not hasattr(expr, "get_source_expressions"):
1853 return False
1854 return any(
1855 cls._expr_refs_base_model(source_expr, base_model)
1856 for source_expr in expr.get_source_expressions()
1857 )
1859 @cached_property
1860 def contains_self_reference_subquery(self):
1861 return any(
1862 self._expr_refs_base_model(expr, self.query.model)
1863 for expr in chain(
1864 self.query.annotations.values(), self.query.where.children
1865 )
1866 )
1868 def _as_sql(self, query):
1869 delete = f"DELETE FROM {self.quote_name_unless_alias(query.base_table)}"
1870 try:
1871 where, params = self.compile(query.where)
1872 except FullResultSet:
1873 return delete, ()
1874 return f"{delete} WHERE {where}", tuple(params)
1876 def as_sql(self):
1877 """
1878 Create the SQL for this query. Return the SQL string and list of
1879 parameters.
1880 """
1881 if self.single_alias and not self.contains_self_reference_subquery:
1882 return self._as_sql(self.query)
1883 innerq = self.query.clone()
1884 innerq.__class__ = Query
1885 innerq.clear_select_clause()
1886 pk = self.query.model._meta.pk
1887 innerq.select = [pk.get_col(self.query.get_initial_alias())]
1888 outerq = Query(self.query.model)
1889 if not self.connection.features.update_can_self_select:
1890 # Force the materialization of the inner query to allow reference
1891 # to the target table on MySQL.
1892 sql, params = innerq.get_compiler(connection=self.connection).as_sql()
1893 innerq = RawSQL(f"SELECT * FROM ({sql}) subquery", params)
1894 outerq.add_filter("pk__in", innerq)
1895 return self._as_sql(outerq)
1898class SQLUpdateCompiler(SQLCompiler):
1899 def as_sql(self):
1900 """
1901 Create the SQL for this query. Return the SQL string and list of
1902 parameters.
1903 """
1904 self.pre_sql_setup()
1905 if not self.query.values:
1906 return "", ()
1907 qn = self.quote_name_unless_alias
1908 values, update_params = [], []
1909 for field, model, val in self.query.values:
1910 if hasattr(val, "resolve_expression"):
1911 val = val.resolve_expression(
1912 self.query, allow_joins=False, for_save=True
1913 )
1914 if val.contains_aggregate:
1915 raise FieldError(
1916 "Aggregate functions are not allowed in this query "
1917 f"({field.name}={val!r})."
1918 )
1919 if val.contains_over_clause:
1920 raise FieldError(
1921 "Window expressions are not allowed in this query "
1922 f"({field.name}={val!r})."
1923 )
1924 elif hasattr(val, "prepare_database_save"):
1925 if field.remote_field:
1926 val = val.prepare_database_save(field)
1927 else:
1928 raise TypeError(
1929 f"Tried to update field {field} with a model instance, {val!r}. "
1930 f"Use a value compatible with {field.__class__.__name__}."
1931 )
1932 val = field.get_db_prep_save(val, connection=self.connection)
1934 # Getting the placeholder for the field.
1935 if hasattr(field, "get_placeholder"):
1936 placeholder = field.get_placeholder(val, self, self.connection)
1937 else:
1938 placeholder = "%s"
1939 name = field.column
1940 if hasattr(val, "as_sql"):
1941 sql, params = self.compile(val)
1942 values.append(f"{qn(name)} = {placeholder % sql}")
1943 update_params.extend(params)
1944 elif val is not None:
1945 values.append(f"{qn(name)} = {placeholder}")
1946 update_params.append(val)
1947 else:
1948 values.append(f"{qn(name)} = NULL")
1949 table = self.query.base_table
1950 result = [
1951 f"UPDATE {qn(table)} SET",
1952 ", ".join(values),
1953 ]
1954 try:
1955 where, params = self.compile(self.query.where)
1956 except FullResultSet:
1957 params = []
1958 else:
1959 result.append(f"WHERE {where}")
1960 return " ".join(result), tuple(update_params + params)
1962 def execute_sql(self, result_type):
1963 """
1964 Execute the specified update. Return the number of rows affected by
1965 the primary update query. The "primary update query" is the first
1966 non-empty query that is executed. Row counts for any subsequent,
1967 related queries are not available.
1968 """
1969 cursor = super().execute_sql(result_type)
1970 try:
1971 rows = cursor.rowcount if cursor else 0
1972 is_empty = cursor is None
1973 finally:
1974 if cursor:
1975 cursor.close()
1976 for query in self.query.get_related_updates():
1977 aux_rows = query.get_compiler(self.using).execute_sql(result_type)
1978 if is_empty and aux_rows:
1979 rows = aux_rows
1980 is_empty = False
1981 return rows
1983 def pre_sql_setup(self):
1984 """
1985 If the update depends on results from other tables, munge the "where"
1986 conditions to match the format required for (portable) SQL updates.
1988 If multiple updates are required, pull out the id values to update at
1989 this point so that they don't change as a result of the progressive
1990 updates.
1991 """
1992 refcounts_before = self.query.alias_refcount.copy()
1993 # Ensure base table is in the query
1994 self.query.get_initial_alias()
1995 count = self.query.count_active_tables()
1996 if not self.query.related_updates and count == 1:
1997 return
1998 query = self.query.chain(klass=Query)
1999 query.select_related = False
2000 query.clear_ordering(force=True)
2001 query.extra = {}
2002 query.select = []
2003 meta = query.get_meta()
2004 fields = [meta.pk.name]
2005 related_ids_index = []
2006 for related in self.query.related_updates:
2007 if all(
2008 path.join_field.primary_key for path in meta.get_path_to_parent(related)
2009 ):
2010 # If a primary key chain exists to the targeted related update,
2011 # then the meta.pk value can be used for it.
2012 related_ids_index.append((related, 0))
2013 else:
2014 # This branch will only be reached when updating a field of an
2015 # ancestor that is not part of the primary key chain of a MTI
2016 # tree.
2017 related_ids_index.append((related, len(fields)))
2018 fields.append(related._meta.pk.name)
2019 query.add_fields(fields)
2020 super().pre_sql_setup()
2022 must_pre_select = (
2023 count > 1 and not self.connection.features.update_can_self_select
2024 )
2026 # Now we adjust the current query: reset the where clause and get rid
2027 # of all the tables we don't need (since they're in the sub-select).
2028 self.query.clear_where()
2029 if self.query.related_updates or must_pre_select:
2030 # Either we're using the idents in multiple update queries (so
2031 # don't want them to change), or the db backend doesn't support
2032 # selecting from the updating table (e.g. MySQL).
2033 idents = []
2034 related_ids = collections.defaultdict(list)
2035 for rows in query.get_compiler(self.using).execute_sql(MULTI):
2036 idents.extend(r[0] for r in rows)
2037 for parent, index in related_ids_index:
2038 related_ids[parent].extend(r[index] for r in rows)
2039 self.query.add_filter("pk__in", idents)
2040 self.query.related_ids = related_ids
2041 else:
2042 # The fast path. Filters and updates in one query.
2043 self.query.add_filter("pk__in", query)
2044 self.query.reset_refcounts(refcounts_before)
2047class SQLAggregateCompiler(SQLCompiler):
2048 def as_sql(self):
2049 """
2050 Create the SQL for this query. Return the SQL string and list of
2051 parameters.
2052 """
2053 sql, params = [], []
2054 for annotation in self.query.annotation_select.values():
2055 ann_sql, ann_params = self.compile(annotation)
2056 ann_sql, ann_params = annotation.select_format(self, ann_sql, ann_params)
2057 sql.append(ann_sql)
2058 params.extend(ann_params)
2059 self.col_count = len(self.query.annotation_select)
2060 sql = ", ".join(sql)
2061 params = tuple(params)
2063 inner_query_sql, inner_query_params = self.query.inner_query.get_compiler(
2064 self.using,
2065 elide_empty=self.elide_empty,
2066 ).as_sql(with_col_aliases=True)
2067 sql = f"SELECT {sql} FROM ({inner_query_sql}) subquery"
2068 params += inner_query_params
2069 return sql, params
2072def cursor_iter(cursor, sentinel, col_count, itersize):
2073 """
2074 Yield blocks of rows from a cursor and ensure the cursor is closed when
2075 done.
2076 """
2077 try:
2078 for rows in iter((lambda: cursor.fetchmany(itersize)), sentinel):
2079 yield rows if col_count is None else [r[:col_count] for r in rows]
2080 finally:
2081 cursor.close()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Constants specific to the SQL storage portion of the ORM.
3"""
5# Size of each "chunk" for get_iterator calls.
6# Larger values are slightly faster at the expense of more storage space.
7GET_ITERATOR_CHUNK_SIZE = 100
9# Namedtuples for sql.* internal use.
11# How many results to expect from a cursor.execute call
12MULTI = "multi"
13SINGLE = "single"
14CURSOR = "cursor"
15NO_RESULTS = "no results"
17ORDER_DIR = {
18 "ASC": ("ASC", "DESC"),
19 "DESC": ("DESC", "ASC"),
20}
22# SQL join types.
23INNER = "INNER JOIN"
24LOUTER = "LEFT OUTER JOIN"
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Useful auxiliary data structures for query construction. Not useful outside
3the SQL domain.
4"""
6from plain.exceptions import FullResultSet
7from plain.models.sql.constants import INNER, LOUTER
10class MultiJoin(Exception):
11 """
12 Used by join construction code to indicate the point at which a
13 multi-valued join was attempted (if the caller wants to treat that
14 exceptionally).
15 """
17 def __init__(self, names_pos, path_with_names):
18 self.level = names_pos
19 # The path travelled, this includes the path to the multijoin.
20 self.names_with_path = path_with_names
23class Empty:
24 pass
27class Join:
28 """
29 Used by sql.Query and sql.SQLCompiler to generate JOIN clauses into the
30 FROM entry. For example, the SQL generated could be
31 LEFT OUTER JOIN "sometable" T1
32 ON ("othertable"."sometable_id" = "sometable"."id")
34 This class is primarily used in Query.alias_map. All entries in alias_map
35 must be Join compatible by providing the following attributes and methods:
36 - table_name (string)
37 - table_alias (possible alias for the table, can be None)
38 - join_type (can be None for those entries that aren't joined from
39 anything)
40 - parent_alias (which table is this join's parent, can be None similarly
41 to join_type)
42 - as_sql()
43 - relabeled_clone()
44 """
46 def __init__(
47 self,
48 table_name,
49 parent_alias,
50 table_alias,
51 join_type,
52 join_field,
53 nullable,
54 filtered_relation=None,
55 ):
56 # Join table
57 self.table_name = table_name
58 self.parent_alias = parent_alias
59 # Note: table_alias is not necessarily known at instantiation time.
60 self.table_alias = table_alias
61 # LOUTER or INNER
62 self.join_type = join_type
63 # A list of 2-tuples to use in the ON clause of the JOIN.
64 # Each 2-tuple will create one join condition in the ON clause.
65 self.join_cols = join_field.get_joining_columns()
66 # Along which field (or ForeignObjectRel in the reverse join case)
67 self.join_field = join_field
68 # Is this join nullabled?
69 self.nullable = nullable
70 self.filtered_relation = filtered_relation
72 def as_sql(self, compiler, connection):
73 """
74 Generate the full
75 LEFT OUTER JOIN sometable ON sometable.somecol = othertable.othercol, params
76 clause for this join.
77 """
78 join_conditions = []
79 params = []
80 qn = compiler.quote_name_unless_alias
81 qn2 = connection.ops.quote_name
83 # Add a join condition for each pair of joining columns.
84 for lhs_col, rhs_col in self.join_cols:
85 join_conditions.append(
86 f"{qn(self.parent_alias)}.{qn2(lhs_col)} = {qn(self.table_alias)}.{qn2(rhs_col)}"
87 )
89 # Add a single condition inside parentheses for whatever
90 # get_extra_restriction() returns.
91 extra_cond = self.join_field.get_extra_restriction(
92 self.table_alias, self.parent_alias
93 )
94 if extra_cond:
95 extra_sql, extra_params = compiler.compile(extra_cond)
96 join_conditions.append(f"({extra_sql})")
97 params.extend(extra_params)
98 if self.filtered_relation:
99 try:
100 extra_sql, extra_params = compiler.compile(self.filtered_relation)
101 except FullResultSet:
102 pass
103 else:
104 join_conditions.append(f"({extra_sql})")
105 params.extend(extra_params)
106 if not join_conditions:
107 # This might be a rel on the other end of an actual declared field.
108 declared_field = getattr(self.join_field, "field", self.join_field)
109 raise ValueError(
110 f"Join generated an empty ON clause. {declared_field.__class__} did not yield either "
111 "joining columns or extra restrictions."
112 )
113 on_clause_sql = " AND ".join(join_conditions)
114 alias_str = (
115 "" if self.table_alias == self.table_name else (f" {self.table_alias}")
116 )
117 sql = f"{self.join_type} {qn(self.table_name)}{alias_str} ON ({on_clause_sql})"
118 return sql, params
120 def relabeled_clone(self, change_map):
121 new_parent_alias = change_map.get(self.parent_alias, self.parent_alias)
122 new_table_alias = change_map.get(self.table_alias, self.table_alias)
123 if self.filtered_relation is not None:
124 filtered_relation = self.filtered_relation.clone()
125 filtered_relation.path = [
126 change_map.get(p, p) for p in self.filtered_relation.path
127 ]
128 else:
129 filtered_relation = None
130 return self.__class__(
131 self.table_name,
132 new_parent_alias,
133 new_table_alias,
134 self.join_type,
135 self.join_field,
136 self.nullable,
137 filtered_relation=filtered_relation,
138 )
140 @property
141 def identity(self):
142 return (
143 self.__class__,
144 self.table_name,
145 self.parent_alias,
146 self.join_field,
147 self.filtered_relation,
148 )
150 def __eq__(self, other):
151 if not isinstance(other, Join):
152 return NotImplemented
153 return self.identity == other.identity
155 def __hash__(self):
156 return hash(self.identity)
158 def equals(self, other):
159 # Ignore filtered_relation in equality check.
160 return self.identity[:-1] == other.identity[:-1]
162 def demote(self):
163 new = self.relabeled_clone({})
164 new.join_type = INNER
165 return new
167 def promote(self):
168 new = self.relabeled_clone({})
169 new.join_type = LOUTER
170 return new
173class BaseTable:
174 """
175 The BaseTable class is used for base table references in FROM clause. For
176 example, the SQL "foo" in
177 SELECT * FROM "foo" WHERE somecond
178 could be generated by this class.
179 """
181 join_type = None
182 parent_alias = None
183 filtered_relation = None
185 def __init__(self, table_name, alias):
186 self.table_name = table_name
187 self.table_alias = alias
189 def as_sql(self, compiler, connection):
190 alias_str = (
191 "" if self.table_alias == self.table_name else (f" {self.table_alias}")
192 )
193 base_sql = compiler.quote_name_unless_alias(self.table_name)
194 return base_sql + alias_str, []
196 def relabeled_clone(self, change_map):
197 return self.__class__(
198 self.table_name, change_map.get(self.table_alias, self.table_alias)
199 )
201 @property
202 def identity(self):
203 return self.__class__, self.table_name, self.table_alias
205 def __eq__(self, other):
206 if not isinstance(other, BaseTable):
207 return NotImplemented
208 return self.identity == other.identity
210 def __hash__(self):
211 return hash(self.identity)
213 def equals(self, other):
214 return self.identity == other.identity
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Create SQL statements for QuerySets.
4The code in here encapsulates all of the SQL construction so that QuerySets
5themselves do not have to (and could be backed by things other than SQL
6databases). The abstraction barrier only works one way: this module has to know
7all about the internals of models in order to get the information it needs.
8"""
10import copy
11import difflib
12import functools
13import sys
14from collections import Counter, namedtuple
15from collections.abc import Iterator, Mapping
16from itertools import chain, count, product
17from string import ascii_uppercase
19from plain.exceptions import FieldDoesNotExist, FieldError
20from plain.models.aggregates import Count
21from plain.models.constants import LOOKUP_SEP
22from plain.models.db import DEFAULT_DB_ALIAS, NotSupportedError, connections
23from plain.models.expressions import (
24 BaseExpression,
25 Col,
26 Exists,
27 F,
28 OuterRef,
29 Ref,
30 ResolvedOuterRef,
31 Value,
32)
33from plain.models.fields import Field
34from plain.models.fields.related_lookups import MultiColSource
35from plain.models.lookups import Lookup
36from plain.models.query_utils import (
37 Q,
38 check_rel_lookup_compatibility,
39 refs_expression,
40)
41from plain.models.sql.constants import INNER, LOUTER, ORDER_DIR, SINGLE
42from plain.models.sql.datastructures import BaseTable, Empty, Join, MultiJoin
43from plain.models.sql.where import AND, OR, ExtraWhere, NothingNode, WhereNode
44from plain.utils.functional import cached_property
45from plain.utils.regex_helper import _lazy_re_compile
46from plain.utils.tree import Node
48__all__ = ["Query", "RawQuery"]
50# Quotation marks ('"`[]), whitespace characters, semicolons, or inline
51# SQL comments are forbidden in column aliases.
52FORBIDDEN_ALIAS_PATTERN = _lazy_re_compile(r"['`\"\]\[;\s]|--|/\*|\*/")
54# Inspired from
55# https://www.postgresql.org/docs/current/sql-syntax-lexical.html#SQL-SYNTAX-IDENTIFIERS
56EXPLAIN_OPTIONS_PATTERN = _lazy_re_compile(r"[\w\-]+")
59def get_field_names_from_opts(opts):
60 if opts is None:
61 return set()
62 return set(
63 chain.from_iterable(
64 (f.name, f.attname) if f.concrete else (f.name,) for f in opts.get_fields()
65 )
66 )
69def get_children_from_q(q):
70 for child in q.children:
71 if isinstance(child, Node):
72 yield from get_children_from_q(child)
73 else:
74 yield child
77JoinInfo = namedtuple(
78 "JoinInfo",
79 ("final_field", "targets", "opts", "joins", "path", "transform_function"),
80)
83class RawQuery:
84 """A single raw SQL query."""
86 def __init__(self, sql, using, params=()):
87 self.params = params
88 self.sql = sql
89 self.using = using
90 self.cursor = None
92 # Mirror some properties of a normal query so that
93 # the compiler can be used to process results.
94 self.low_mark, self.high_mark = 0, None # Used for offset/limit
95 self.extra_select = {}
96 self.annotation_select = {}
98 def chain(self, using):
99 return self.clone(using)
101 def clone(self, using):
102 return RawQuery(self.sql, using, params=self.params)
104 def get_columns(self):
105 if self.cursor is None:
106 self._execute_query()
107 converter = connections[self.using].introspection.identifier_converter
108 return [converter(column_meta[0]) for column_meta in self.cursor.description]
110 def __iter__(self):
111 # Always execute a new query for a new iterator.
112 # This could be optimized with a cache at the expense of RAM.
113 self._execute_query()
114 if not connections[self.using].features.can_use_chunked_reads:
115 # If the database can't use chunked reads we need to make sure we
116 # evaluate the entire query up front.
117 result = list(self.cursor)
118 else:
119 result = self.cursor
120 return iter(result)
122 def __repr__(self):
123 return f"<{self.__class__.__name__}: {self}>"
125 @property
126 def params_type(self):
127 if self.params is None:
128 return None
129 return dict if isinstance(self.params, Mapping) else tuple
131 def __str__(self):
132 if self.params_type is None:
133 return self.sql
134 return self.sql % self.params_type(self.params)
136 def _execute_query(self):
137 connection = connections[self.using]
139 # Adapt parameters to the database, as much as possible considering
140 # that the target type isn't known. See #17755.
141 params_type = self.params_type
142 adapter = connection.ops.adapt_unknown_value
143 if params_type is tuple:
144 params = tuple(adapter(val) for val in self.params)
145 elif params_type is dict:
146 params = {key: adapter(val) for key, val in self.params.items()}
147 elif params_type is None:
148 params = None
149 else:
150 raise RuntimeError(f"Unexpected params type: {params_type}")
152 self.cursor = connection.cursor()
153 self.cursor.execute(self.sql, params)
156ExplainInfo = namedtuple("ExplainInfo", ("format", "options"))
159class Query(BaseExpression):
160 """A single SQL query."""
162 alias_prefix = "T"
163 empty_result_set_value = None
164 subq_aliases = frozenset([alias_prefix])
166 compiler = "SQLCompiler"
168 base_table_class = BaseTable
169 join_class = Join
171 default_cols = True
172 default_ordering = True
173 standard_ordering = True
175 filter_is_sticky = False
176 subquery = False
178 # SQL-related attributes.
179 # Select and related select clauses are expressions to use in the SELECT
180 # clause of the query. The select is used for cases where we want to set up
181 # the select clause to contain other than default fields (values(),
182 # subqueries...). Note that annotations go to annotations dictionary.
183 select = ()
184 # The group_by attribute can have one of the following forms:
185 # - None: no group by at all in the query
186 # - A tuple of expressions: group by (at least) those expressions.
187 # String refs are also allowed for now.
188 # - True: group by all select fields of the model
189 # See compiler.get_group_by() for details.
190 group_by = None
191 order_by = ()
192 low_mark = 0 # Used for offset/limit.
193 high_mark = None # Used for offset/limit.
194 distinct = False
195 distinct_fields = ()
196 select_for_update = False
197 select_for_update_nowait = False
198 select_for_update_skip_locked = False
199 select_for_update_of = ()
200 select_for_no_key_update = False
201 select_related = False
202 has_select_fields = False
203 # Arbitrary limit for select_related to prevents infinite recursion.
204 max_depth = 5
205 # Holds the selects defined by a call to values() or values_list()
206 # excluding annotation_select and extra_select.
207 values_select = ()
209 # SQL annotation-related attributes.
210 annotation_select_mask = None
211 _annotation_select_cache = None
213 # Set combination attributes.
214 combinator = None
215 combinator_all = False
216 combined_queries = ()
218 # These are for extensions. The contents are more or less appended verbatim
219 # to the appropriate clause.
220 extra_select_mask = None
221 _extra_select_cache = None
223 extra_tables = ()
224 extra_order_by = ()
226 # A tuple that is a set of model field names and either True, if these are
227 # the fields to defer, or False if these are the only fields to load.
228 deferred_loading = (frozenset(), True)
230 explain_info = None
232 def __init__(self, model, alias_cols=True):
233 self.model = model
234 self.alias_refcount = {}
235 # alias_map is the most important data structure regarding joins.
236 # It's used for recording which joins exist in the query and what
237 # types they are. The key is the alias of the joined table (possibly
238 # the table name) and the value is a Join-like object (see
239 # sql.datastructures.Join for more information).
240 self.alias_map = {}
241 # Whether to provide alias to columns during reference resolving.
242 self.alias_cols = alias_cols
243 # Sometimes the query contains references to aliases in outer queries (as
244 # a result of split_exclude). Correct alias quoting needs to know these
245 # aliases too.
246 # Map external tables to whether they are aliased.
247 self.external_aliases = {}
248 self.table_map = {} # Maps table names to list of aliases.
249 self.used_aliases = set()
251 self.where = WhereNode()
252 # Maps alias -> Annotation Expression.
253 self.annotations = {}
254 # These are for extensions. The contents are more or less appended
255 # verbatim to the appropriate clause.
256 self.extra = {} # Maps col_alias -> (col_sql, params).
258 self._filtered_relations = {}
260 @property
261 def output_field(self):
262 if len(self.select) == 1:
263 select = self.select[0]
264 return getattr(select, "target", None) or select.field
265 elif len(self.annotation_select) == 1:
266 return next(iter(self.annotation_select.values())).output_field
268 @cached_property
269 def base_table(self):
270 for alias in self.alias_map:
271 return alias
273 def __str__(self):
274 """
275 Return the query as a string of SQL with the parameter values
276 substituted in (use sql_with_params() to see the unsubstituted string).
278 Parameter values won't necessarily be quoted correctly, since that is
279 done by the database interface at execution time.
280 """
281 sql, params = self.sql_with_params()
282 return sql % params
284 def sql_with_params(self):
285 """
286 Return the query as an SQL string and the parameters that will be
287 substituted into the query.
288 """
289 return self.get_compiler(DEFAULT_DB_ALIAS).as_sql()
291 def __deepcopy__(self, memo):
292 """Limit the amount of work when a Query is deepcopied."""
293 result = self.clone()
294 memo[id(self)] = result
295 return result
297 def get_compiler(self, using=None, connection=None, elide_empty=True):
298 if using is None and connection is None:
299 raise ValueError("Need either using or connection")
300 if using:
301 connection = connections[using]
302 return connection.ops.compiler(self.compiler)(
303 self, connection, using, elide_empty
304 )
306 def get_meta(self):
307 """
308 Return the Options instance (the model._meta) from which to start
309 processing. Normally, this is self.model._meta, but it can be changed
310 by subclasses.
311 """
312 if self.model:
313 return self.model._meta
315 def clone(self):
316 """
317 Return a copy of the current Query. A lightweight alternative to
318 deepcopy().
319 """
320 obj = Empty()
321 obj.__class__ = self.__class__
322 # Copy references to everything.
323 obj.__dict__ = self.__dict__.copy()
324 # Clone attributes that can't use shallow copy.
325 obj.alias_refcount = self.alias_refcount.copy()
326 obj.alias_map = self.alias_map.copy()
327 obj.external_aliases = self.external_aliases.copy()
328 obj.table_map = self.table_map.copy()
329 obj.where = self.where.clone()
330 obj.annotations = self.annotations.copy()
331 if self.annotation_select_mask is not None:
332 obj.annotation_select_mask = self.annotation_select_mask.copy()
333 if self.combined_queries:
334 obj.combined_queries = tuple(
335 [query.clone() for query in self.combined_queries]
336 )
337 # _annotation_select_cache cannot be copied, as doing so breaks the
338 # (necessary) state in which both annotations and
339 # _annotation_select_cache point to the same underlying objects.
340 # It will get re-populated in the cloned queryset the next time it's
341 # used.
342 obj._annotation_select_cache = None
343 obj.extra = self.extra.copy()
344 if self.extra_select_mask is not None:
345 obj.extra_select_mask = self.extra_select_mask.copy()
346 if self._extra_select_cache is not None:
347 obj._extra_select_cache = self._extra_select_cache.copy()
348 if self.select_related is not False:
349 # Use deepcopy because select_related stores fields in nested
350 # dicts.
351 obj.select_related = copy.deepcopy(obj.select_related)
352 if "subq_aliases" in self.__dict__:
353 obj.subq_aliases = self.subq_aliases.copy()
354 obj.used_aliases = self.used_aliases.copy()
355 obj._filtered_relations = self._filtered_relations.copy()
356 # Clear the cached_property, if it exists.
357 obj.__dict__.pop("base_table", None)
358 return obj
360 def chain(self, klass=None):
361 """
362 Return a copy of the current Query that's ready for another operation.
363 The klass argument changes the type of the Query, e.g. UpdateQuery.
364 """
365 obj = self.clone()
366 if klass and obj.__class__ != klass:
367 obj.__class__ = klass
368 if not obj.filter_is_sticky:
369 obj.used_aliases = set()
370 obj.filter_is_sticky = False
371 if hasattr(obj, "_setup_query"):
372 obj._setup_query()
373 return obj
375 def relabeled_clone(self, change_map):
376 clone = self.clone()
377 clone.change_aliases(change_map)
378 return clone
380 def _get_col(self, target, field, alias):
381 if not self.alias_cols:
382 alias = None
383 return target.get_col(alias, field)
385 def get_aggregation(self, using, aggregate_exprs):
386 """
387 Return the dictionary with the values of the existing aggregations.
388 """
389 if not aggregate_exprs:
390 return {}
391 aggregates = {}
392 for alias, aggregate_expr in aggregate_exprs.items():
393 self.check_alias(alias)
394 aggregate = aggregate_expr.resolve_expression(
395 self, allow_joins=True, reuse=None, summarize=True
396 )
397 if not aggregate.contains_aggregate:
398 raise TypeError(f"{alias} is not an aggregate expression")
399 aggregates[alias] = aggregate
400 # Existing usage of aggregation can be determined by the presence of
401 # selected aggregates but also by filters against aliased aggregates.
402 _, having, qualify = self.where.split_having_qualify()
403 has_existing_aggregation = (
404 any(
405 getattr(annotation, "contains_aggregate", True)
406 for annotation in self.annotations.values()
407 )
408 or having
409 )
410 # Decide if we need to use a subquery.
411 #
412 # Existing aggregations would cause incorrect results as
413 # get_aggregation() must produce just one result and thus must not use
414 # GROUP BY.
415 #
416 # If the query has limit or distinct, or uses set operations, then
417 # those operations must be done in a subquery so that the query
418 # aggregates on the limit and/or distinct results instead of applying
419 # the distinct and limit after the aggregation.
420 if (
421 isinstance(self.group_by, tuple)
422 or self.is_sliced
423 or has_existing_aggregation
424 or qualify
425 or self.distinct
426 or self.combinator
427 ):
428 from plain.models.sql.subqueries import AggregateQuery
430 inner_query = self.clone()
431 inner_query.subquery = True
432 outer_query = AggregateQuery(self.model, inner_query)
433 inner_query.select_for_update = False
434 inner_query.select_related = False
435 inner_query.set_annotation_mask(self.annotation_select)
436 # Queries with distinct_fields need ordering and when a limit is
437 # applied we must take the slice from the ordered query. Otherwise
438 # no need for ordering.
439 inner_query.clear_ordering(force=False)
440 if not inner_query.distinct:
441 # If the inner query uses default select and it has some
442 # aggregate annotations, then we must make sure the inner
443 # query is grouped by the main model's primary key. However,
444 # clearing the select clause can alter results if distinct is
445 # used.
446 if inner_query.default_cols and has_existing_aggregation:
447 inner_query.group_by = (
448 self.model._meta.pk.get_col(inner_query.get_initial_alias()),
449 )
450 inner_query.default_cols = False
451 if not qualify:
452 # Mask existing annotations that are not referenced by
453 # aggregates to be pushed to the outer query unless
454 # filtering against window functions is involved as it
455 # requires complex realising.
456 annotation_mask = set()
457 for aggregate in aggregates.values():
458 annotation_mask |= aggregate.get_refs()
459 inner_query.set_annotation_mask(annotation_mask)
461 # Add aggregates to the outer AggregateQuery. This requires making
462 # sure all columns referenced by the aggregates are selected in the
463 # inner query. It is achieved by retrieving all column references
464 # by the aggregates, explicitly selecting them in the inner query,
465 # and making sure the aggregates are repointed to them.
466 col_refs = {}
467 for alias, aggregate in aggregates.items():
468 replacements = {}
469 for col in self._gen_cols([aggregate], resolve_refs=False):
470 if not (col_ref := col_refs.get(col)):
471 index = len(col_refs) + 1
472 col_alias = f"__col{index}"
473 col_ref = Ref(col_alias, col)
474 col_refs[col] = col_ref
475 inner_query.annotations[col_alias] = col
476 inner_query.append_annotation_mask([col_alias])
477 replacements[col] = col_ref
478 outer_query.annotations[alias] = aggregate.replace_expressions(
479 replacements
480 )
481 if (
482 inner_query.select == ()
483 and not inner_query.default_cols
484 and not inner_query.annotation_select_mask
485 ):
486 # In case of Model.objects[0:3].count(), there would be no
487 # field selected in the inner query, yet we must use a subquery.
488 # So, make sure at least one field is selected.
489 inner_query.select = (
490 self.model._meta.pk.get_col(inner_query.get_initial_alias()),
491 )
492 else:
493 outer_query = self
494 self.select = ()
495 self.default_cols = False
496 self.extra = {}
497 if self.annotations:
498 # Inline reference to existing annotations and mask them as
499 # they are unnecessary given only the summarized aggregations
500 # are requested.
501 replacements = {
502 Ref(alias, annotation): annotation
503 for alias, annotation in self.annotations.items()
504 }
505 self.annotations = {
506 alias: aggregate.replace_expressions(replacements)
507 for alias, aggregate in aggregates.items()
508 }
509 else:
510 self.annotations = aggregates
511 self.set_annotation_mask(aggregates)
513 empty_set_result = [
514 expression.empty_result_set_value
515 for expression in outer_query.annotation_select.values()
516 ]
517 elide_empty = not any(result is NotImplemented for result in empty_set_result)
518 outer_query.clear_ordering(force=True)
519 outer_query.clear_limits()
520 outer_query.select_for_update = False
521 outer_query.select_related = False
522 compiler = outer_query.get_compiler(using, elide_empty=elide_empty)
523 result = compiler.execute_sql(SINGLE)
524 if result is None:
525 result = empty_set_result
526 else:
527 converters = compiler.get_converters(outer_query.annotation_select.values())
528 result = next(compiler.apply_converters((result,), converters))
530 return dict(zip(outer_query.annotation_select, result))
532 def get_count(self, using):
533 """
534 Perform a COUNT() query using the current filter constraints.
535 """
536 obj = self.clone()
537 return obj.get_aggregation(using, {"__count": Count("*")})["__count"]
539 def has_filters(self):
540 return self.where
542 def exists(self, limit=True):
543 q = self.clone()
544 if not (q.distinct and q.is_sliced):
545 if q.group_by is True:
546 q.add_fields(
547 (f.attname for f in self.model._meta.concrete_fields), False
548 )
549 # Disable GROUP BY aliases to avoid orphaning references to the
550 # SELECT clause which is about to be cleared.
551 q.set_group_by(allow_aliases=False)
552 q.clear_select_clause()
553 if q.combined_queries and q.combinator == "union":
554 q.combined_queries = tuple(
555 combined_query.exists(limit=False)
556 for combined_query in q.combined_queries
557 )
558 q.clear_ordering(force=True)
559 if limit:
560 q.set_limits(high=1)
561 q.add_annotation(Value(1), "a")
562 return q
564 def has_results(self, using):
565 q = self.exists(using)
566 compiler = q.get_compiler(using=using)
567 return compiler.has_results()
569 def explain(self, using, format=None, **options):
570 q = self.clone()
571 for option_name in options:
572 if (
573 not EXPLAIN_OPTIONS_PATTERN.fullmatch(option_name)
574 or "--" in option_name
575 ):
576 raise ValueError(f"Invalid option name: {option_name!r}.")
577 q.explain_info = ExplainInfo(format, options)
578 compiler = q.get_compiler(using=using)
579 return "\n".join(compiler.explain_query())
581 def combine(self, rhs, connector):
582 """
583 Merge the 'rhs' query into the current one (with any 'rhs' effects
584 being applied *after* (that is, "to the right of") anything in the
585 current query. 'rhs' is not modified during a call to this function.
587 The 'connector' parameter describes how to connect filters from the
588 'rhs' query.
589 """
590 if self.model != rhs.model:
591 raise TypeError("Cannot combine queries on two different base models.")
592 if self.is_sliced:
593 raise TypeError("Cannot combine queries once a slice has been taken.")
594 if self.distinct != rhs.distinct:
595 raise TypeError("Cannot combine a unique query with a non-unique query.")
596 if self.distinct_fields != rhs.distinct_fields:
597 raise TypeError("Cannot combine queries with different distinct fields.")
599 # If lhs and rhs shares the same alias prefix, it is possible to have
600 # conflicting alias changes like T4 -> T5, T5 -> T6, which might end up
601 # as T4 -> T6 while combining two querysets. To prevent this, change an
602 # alias prefix of the rhs and update current aliases accordingly,
603 # except if the alias is the base table since it must be present in the
604 # query on both sides.
605 initial_alias = self.get_initial_alias()
606 rhs.bump_prefix(self, exclude={initial_alias})
608 # Work out how to relabel the rhs aliases, if necessary.
609 change_map = {}
610 conjunction = connector == AND
612 # Determine which existing joins can be reused. When combining the
613 # query with AND we must recreate all joins for m2m filters. When
614 # combining with OR we can reuse joins. The reason is that in AND
615 # case a single row can't fulfill a condition like:
616 # revrel__col=1 & revrel__col=2
617 # But, there might be two different related rows matching this
618 # condition. In OR case a single True is enough, so single row is
619 # enough, too.
620 #
621 # Note that we will be creating duplicate joins for non-m2m joins in
622 # the AND case. The results will be correct but this creates too many
623 # joins. This is something that could be fixed later on.
624 reuse = set() if conjunction else set(self.alias_map)
625 joinpromoter = JoinPromoter(connector, 2, False)
626 joinpromoter.add_votes(
627 j for j in self.alias_map if self.alias_map[j].join_type == INNER
628 )
629 rhs_votes = set()
630 # Now, add the joins from rhs query into the new query (skipping base
631 # table).
632 rhs_tables = list(rhs.alias_map)[1:]
633 for alias in rhs_tables:
634 join = rhs.alias_map[alias]
635 # If the left side of the join was already relabeled, use the
636 # updated alias.
637 join = join.relabeled_clone(change_map)
638 new_alias = self.join(join, reuse=reuse)
639 if join.join_type == INNER:
640 rhs_votes.add(new_alias)
641 # We can't reuse the same join again in the query. If we have two
642 # distinct joins for the same connection in rhs query, then the
643 # combined query must have two joins, too.
644 reuse.discard(new_alias)
645 if alias != new_alias:
646 change_map[alias] = new_alias
647 if not rhs.alias_refcount[alias]:
648 # The alias was unused in the rhs query. Unref it so that it
649 # will be unused in the new query, too. We have to add and
650 # unref the alias so that join promotion has information of
651 # the join type for the unused alias.
652 self.unref_alias(new_alias)
653 joinpromoter.add_votes(rhs_votes)
654 joinpromoter.update_join_types(self)
656 # Combine subqueries aliases to ensure aliases relabelling properly
657 # handle subqueries when combining where and select clauses.
658 self.subq_aliases |= rhs.subq_aliases
660 # Now relabel a copy of the rhs where-clause and add it to the current
661 # one.
662 w = rhs.where.clone()
663 w.relabel_aliases(change_map)
664 self.where.add(w, connector)
666 # Selection columns and extra extensions are those provided by 'rhs'.
667 if rhs.select:
668 self.set_select([col.relabeled_clone(change_map) for col in rhs.select])
669 else:
670 self.select = ()
672 if connector == OR:
673 # It would be nice to be able to handle this, but the queries don't
674 # really make sense (or return consistent value sets). Not worth
675 # the extra complexity when you can write a real query instead.
676 if self.extra and rhs.extra:
677 raise ValueError(
678 "When merging querysets using 'or', you cannot have "
679 "extra(select=...) on both sides."
680 )
681 self.extra.update(rhs.extra)
682 extra_select_mask = set()
683 if self.extra_select_mask is not None:
684 extra_select_mask.update(self.extra_select_mask)
685 if rhs.extra_select_mask is not None:
686 extra_select_mask.update(rhs.extra_select_mask)
687 if extra_select_mask:
688 self.set_extra_mask(extra_select_mask)
689 self.extra_tables += rhs.extra_tables
691 # Ordering uses the 'rhs' ordering, unless it has none, in which case
692 # the current ordering is used.
693 self.order_by = rhs.order_by or self.order_by
694 self.extra_order_by = rhs.extra_order_by or self.extra_order_by
696 def _get_defer_select_mask(self, opts, mask, select_mask=None):
697 if select_mask is None:
698 select_mask = {}
699 select_mask[opts.pk] = {}
700 # All concrete fields that are not part of the defer mask must be
701 # loaded. If a relational field is encountered it gets added to the
702 # mask for it be considered if `select_related` and the cycle continues
703 # by recursively calling this function.
704 for field in opts.concrete_fields:
705 field_mask = mask.pop(field.name, None)
706 if field_mask is None:
707 select_mask.setdefault(field, {})
708 elif field_mask:
709 if not field.is_relation:
710 raise FieldError(next(iter(field_mask)))
711 field_select_mask = select_mask.setdefault(field, {})
712 related_model = field.remote_field.model._meta.concrete_model
713 self._get_defer_select_mask(
714 related_model._meta, field_mask, field_select_mask
715 )
716 # Remaining defer entries must be references to reverse relationships.
717 # The following code is expected to raise FieldError if it encounters
718 # a malformed defer entry.
719 for field_name, field_mask in mask.items():
720 if filtered_relation := self._filtered_relations.get(field_name):
721 relation = opts.get_field(filtered_relation.relation_name)
722 field_select_mask = select_mask.setdefault((field_name, relation), {})
723 field = relation.field
724 else:
725 field = opts.get_field(field_name).field
726 field_select_mask = select_mask.setdefault(field, {})
727 related_model = field.model._meta.concrete_model
728 self._get_defer_select_mask(
729 related_model._meta, field_mask, field_select_mask
730 )
731 return select_mask
733 def _get_only_select_mask(self, opts, mask, select_mask=None):
734 if select_mask is None:
735 select_mask = {}
736 select_mask[opts.pk] = {}
737 # Only include fields mentioned in the mask.
738 for field_name, field_mask in mask.items():
739 field = opts.get_field(field_name)
740 field_select_mask = select_mask.setdefault(field, {})
741 if field_mask:
742 if not field.is_relation:
743 raise FieldError(next(iter(field_mask)))
744 related_model = field.remote_field.model._meta.concrete_model
745 self._get_only_select_mask(
746 related_model._meta, field_mask, field_select_mask
747 )
748 return select_mask
750 def get_select_mask(self):
751 """
752 Convert the self.deferred_loading data structure to an alternate data
753 structure, describing the field that *will* be loaded. This is used to
754 compute the columns to select from the database and also by the
755 QuerySet class to work out which fields are being initialized on each
756 model. Models that have all their fields included aren't mentioned in
757 the result, only those that have field restrictions in place.
758 """
759 field_names, defer = self.deferred_loading
760 if not field_names:
761 return {}
762 mask = {}
763 for field_name in field_names:
764 part_mask = mask
765 for part in field_name.split(LOOKUP_SEP):
766 part_mask = part_mask.setdefault(part, {})
767 opts = self.get_meta()
768 if defer:
769 return self._get_defer_select_mask(opts, mask)
770 return self._get_only_select_mask(opts, mask)
772 def table_alias(self, table_name, create=False, filtered_relation=None):
773 """
774 Return a table alias for the given table_name and whether this is a
775 new alias or not.
777 If 'create' is true, a new alias is always created. Otherwise, the
778 most recently created alias for the table (if one exists) is reused.
779 """
780 alias_list = self.table_map.get(table_name)
781 if not create and alias_list:
782 alias = alias_list[0]
783 self.alias_refcount[alias] += 1
784 return alias, False
786 # Create a new alias for this table.
787 if alias_list:
788 alias = "%s%d" % (self.alias_prefix, len(self.alias_map) + 1)
789 alias_list.append(alias)
790 else:
791 # The first occurrence of a table uses the table name directly.
792 alias = (
793 filtered_relation.alias if filtered_relation is not None else table_name
794 )
795 self.table_map[table_name] = [alias]
796 self.alias_refcount[alias] = 1
797 return alias, True
799 def ref_alias(self, alias):
800 """Increases the reference count for this alias."""
801 self.alias_refcount[alias] += 1
803 def unref_alias(self, alias, amount=1):
804 """Decreases the reference count for this alias."""
805 self.alias_refcount[alias] -= amount
807 def promote_joins(self, aliases):
808 """
809 Promote recursively the join type of given aliases and its children to
810 an outer join. If 'unconditional' is False, only promote the join if
811 it is nullable or the parent join is an outer join.
813 The children promotion is done to avoid join chains that contain a LOUTER
814 b INNER c. So, if we have currently a INNER b INNER c and a->b is promoted,
815 then we must also promote b->c automatically, or otherwise the promotion
816 of a->b doesn't actually change anything in the query results.
817 """
818 aliases = list(aliases)
819 while aliases:
820 alias = aliases.pop(0)
821 if self.alias_map[alias].join_type is None:
822 # This is the base table (first FROM entry) - this table
823 # isn't really joined at all in the query, so we should not
824 # alter its join type.
825 continue
826 # Only the first alias (skipped above) should have None join_type
827 assert self.alias_map[alias].join_type is not None
828 parent_alias = self.alias_map[alias].parent_alias
829 parent_louter = (
830 parent_alias and self.alias_map[parent_alias].join_type == LOUTER
831 )
832 already_louter = self.alias_map[alias].join_type == LOUTER
833 if (self.alias_map[alias].nullable or parent_louter) and not already_louter:
834 self.alias_map[alias] = self.alias_map[alias].promote()
835 # Join type of 'alias' changed, so re-examine all aliases that
836 # refer to this one.
837 aliases.extend(
838 join
839 for join in self.alias_map
840 if self.alias_map[join].parent_alias == alias
841 and join not in aliases
842 )
844 def demote_joins(self, aliases):
845 """
846 Change join type from LOUTER to INNER for all joins in aliases.
848 Similarly to promote_joins(), this method must ensure no join chains
849 containing first an outer, then an inner join are generated. If we
850 are demoting b->c join in chain a LOUTER b LOUTER c then we must
851 demote a->b automatically, or otherwise the demotion of b->c doesn't
852 actually change anything in the query results. .
853 """
854 aliases = list(aliases)
855 while aliases:
856 alias = aliases.pop(0)
857 if self.alias_map[alias].join_type == LOUTER:
858 self.alias_map[alias] = self.alias_map[alias].demote()
859 parent_alias = self.alias_map[alias].parent_alias
860 if self.alias_map[parent_alias].join_type == INNER:
861 aliases.append(parent_alias)
863 def reset_refcounts(self, to_counts):
864 """
865 Reset reference counts for aliases so that they match the value passed
866 in `to_counts`.
867 """
868 for alias, cur_refcount in self.alias_refcount.copy().items():
869 unref_amount = cur_refcount - to_counts.get(alias, 0)
870 self.unref_alias(alias, unref_amount)
872 def change_aliases(self, change_map):
873 """
874 Change the aliases in change_map (which maps old-alias -> new-alias),
875 relabelling any references to them in select columns and the where
876 clause.
877 """
878 # If keys and values of change_map were to intersect, an alias might be
879 # updated twice (e.g. T4 -> T5, T5 -> T6, so also T4 -> T6) depending
880 # on their order in change_map.
881 assert set(change_map).isdisjoint(change_map.values())
883 # 1. Update references in "select" (normal columns plus aliases),
884 # "group by" and "where".
885 self.where.relabel_aliases(change_map)
886 if isinstance(self.group_by, tuple):
887 self.group_by = tuple(
888 [col.relabeled_clone(change_map) for col in self.group_by]
889 )
890 self.select = tuple([col.relabeled_clone(change_map) for col in self.select])
891 self.annotations = self.annotations and {
892 key: col.relabeled_clone(change_map)
893 for key, col in self.annotations.items()
894 }
896 # 2. Rename the alias in the internal table/alias datastructures.
897 for old_alias, new_alias in change_map.items():
898 if old_alias not in self.alias_map:
899 continue
900 alias_data = self.alias_map[old_alias].relabeled_clone(change_map)
901 self.alias_map[new_alias] = alias_data
902 self.alias_refcount[new_alias] = self.alias_refcount[old_alias]
903 del self.alias_refcount[old_alias]
904 del self.alias_map[old_alias]
906 table_aliases = self.table_map[alias_data.table_name]
907 for pos, alias in enumerate(table_aliases):
908 if alias == old_alias:
909 table_aliases[pos] = new_alias
910 break
911 self.external_aliases = {
912 # Table is aliased or it's being changed and thus is aliased.
913 change_map.get(alias, alias): (aliased or alias in change_map)
914 for alias, aliased in self.external_aliases.items()
915 }
917 def bump_prefix(self, other_query, exclude=None):
918 """
919 Change the alias prefix to the next letter in the alphabet in a way
920 that the other query's aliases and this query's aliases will not
921 conflict. Even tables that previously had no alias will get an alias
922 after this call. To prevent changing aliases use the exclude parameter.
923 """
925 def prefix_gen():
926 """
927 Generate a sequence of characters in alphabetical order:
928 -> 'A', 'B', 'C', ...
930 When the alphabet is finished, the sequence will continue with the
931 Cartesian product:
932 -> 'AA', 'AB', 'AC', ...
933 """
934 alphabet = ascii_uppercase
935 prefix = chr(ord(self.alias_prefix) + 1)
936 yield prefix
937 for n in count(1):
938 seq = alphabet[alphabet.index(prefix) :] if prefix else alphabet
939 for s in product(seq, repeat=n):
940 yield "".join(s)
941 prefix = None
943 if self.alias_prefix != other_query.alias_prefix:
944 # No clashes between self and outer query should be possible.
945 return
947 # Explicitly avoid infinite loop. The constant divider is based on how
948 # much depth recursive subquery references add to the stack. This value
949 # might need to be adjusted when adding or removing function calls from
950 # the code path in charge of performing these operations.
951 local_recursion_limit = sys.getrecursionlimit() // 16
952 for pos, prefix in enumerate(prefix_gen()):
953 if prefix not in self.subq_aliases:
954 self.alias_prefix = prefix
955 break
956 if pos > local_recursion_limit:
957 raise RecursionError(
958 "Maximum recursion depth exceeded: too many subqueries."
959 )
960 self.subq_aliases = self.subq_aliases.union([self.alias_prefix])
961 other_query.subq_aliases = other_query.subq_aliases.union(self.subq_aliases)
962 if exclude is None:
963 exclude = {}
964 self.change_aliases(
965 {
966 alias: "%s%d" % (self.alias_prefix, pos)
967 for pos, alias in enumerate(self.alias_map)
968 if alias not in exclude
969 }
970 )
972 def get_initial_alias(self):
973 """
974 Return the first alias for this query, after increasing its reference
975 count.
976 """
977 if self.alias_map:
978 alias = self.base_table
979 self.ref_alias(alias)
980 elif self.model:
981 alias = self.join(self.base_table_class(self.get_meta().db_table, None))
982 else:
983 alias = None
984 return alias
986 def count_active_tables(self):
987 """
988 Return the number of tables in this query with a non-zero reference
989 count. After execution, the reference counts are zeroed, so tables
990 added in compiler will not be seen by this method.
991 """
992 return len([1 for count in self.alias_refcount.values() if count])
994 def join(self, join, reuse=None, reuse_with_filtered_relation=False):
995 """
996 Return an alias for the 'join', either reusing an existing alias for
997 that join or creating a new one. 'join' is either a base_table_class or
998 join_class.
1000 The 'reuse' parameter can be either None which means all joins are
1001 reusable, or it can be a set containing the aliases that can be reused.
1003 The 'reuse_with_filtered_relation' parameter is used when computing
1004 FilteredRelation instances.
1006 A join is always created as LOUTER if the lhs alias is LOUTER to make
1007 sure chains like t1 LOUTER t2 INNER t3 aren't generated. All new
1008 joins are created as LOUTER if the join is nullable.
1009 """
1010 if reuse_with_filtered_relation and reuse:
1011 reuse_aliases = [
1012 a for a, j in self.alias_map.items() if a in reuse and j.equals(join)
1013 ]
1014 else:
1015 reuse_aliases = [
1016 a
1017 for a, j in self.alias_map.items()
1018 if (reuse is None or a in reuse) and j == join
1019 ]
1020 if reuse_aliases:
1021 if join.table_alias in reuse_aliases:
1022 reuse_alias = join.table_alias
1023 else:
1024 # Reuse the most recent alias of the joined table
1025 # (a many-to-many relation may be joined multiple times).
1026 reuse_alias = reuse_aliases[-1]
1027 self.ref_alias(reuse_alias)
1028 return reuse_alias
1030 # No reuse is possible, so we need a new alias.
1031 alias, _ = self.table_alias(
1032 join.table_name, create=True, filtered_relation=join.filtered_relation
1033 )
1034 if join.join_type:
1035 if self.alias_map[join.parent_alias].join_type == LOUTER or join.nullable:
1036 join_type = LOUTER
1037 else:
1038 join_type = INNER
1039 join.join_type = join_type
1040 join.table_alias = alias
1041 self.alias_map[alias] = join
1042 return alias
1044 def join_parent_model(self, opts, model, alias, seen):
1045 """
1046 Make sure the given 'model' is joined in the query. If 'model' isn't
1047 a parent of 'opts' or if it is None this method is a no-op.
1049 The 'alias' is the root alias for starting the join, 'seen' is a dict
1050 of model -> alias of existing joins. It must also contain a mapping
1051 of None -> some alias. This will be returned in the no-op case.
1052 """
1053 if model in seen:
1054 return seen[model]
1055 chain = opts.get_base_chain(model)
1056 if not chain:
1057 return alias
1058 curr_opts = opts
1059 for int_model in chain:
1060 if int_model in seen:
1061 curr_opts = int_model._meta
1062 alias = seen[int_model]
1063 continue
1064 # Proxy model have elements in base chain
1065 # with no parents, assign the new options
1066 # object and skip to the next base in that
1067 # case
1068 if not curr_opts.parents[int_model]:
1069 curr_opts = int_model._meta
1070 continue
1071 link_field = curr_opts.get_ancestor_link(int_model)
1072 join_info = self.setup_joins([link_field.name], curr_opts, alias)
1073 curr_opts = int_model._meta
1074 alias = seen[int_model] = join_info.joins[-1]
1075 return alias or seen[None]
1077 def check_alias(self, alias):
1078 if FORBIDDEN_ALIAS_PATTERN.search(alias):
1079 raise ValueError(
1080 "Column aliases cannot contain whitespace characters, quotation marks, "
1081 "semicolons, or SQL comments."
1082 )
1084 def add_annotation(self, annotation, alias, select=True):
1085 """Add a single annotation expression to the Query."""
1086 self.check_alias(alias)
1087 annotation = annotation.resolve_expression(self, allow_joins=True, reuse=None)
1088 if select:
1089 self.append_annotation_mask([alias])
1090 else:
1091 self.set_annotation_mask(set(self.annotation_select).difference({alias}))
1092 self.annotations[alias] = annotation
1094 def resolve_expression(self, query, *args, **kwargs):
1095 clone = self.clone()
1096 # Subqueries need to use a different set of aliases than the outer query.
1097 clone.bump_prefix(query)
1098 clone.subquery = True
1099 clone.where.resolve_expression(query, *args, **kwargs)
1100 # Resolve combined queries.
1101 if clone.combinator:
1102 clone.combined_queries = tuple(
1103 [
1104 combined_query.resolve_expression(query, *args, **kwargs)
1105 for combined_query in clone.combined_queries
1106 ]
1107 )
1108 for key, value in clone.annotations.items():
1109 resolved = value.resolve_expression(query, *args, **kwargs)
1110 if hasattr(resolved, "external_aliases"):
1111 resolved.external_aliases.update(clone.external_aliases)
1112 clone.annotations[key] = resolved
1113 # Outer query's aliases are considered external.
1114 for alias, table in query.alias_map.items():
1115 clone.external_aliases[alias] = (
1116 isinstance(table, Join)
1117 and table.join_field.related_model._meta.db_table != alias
1118 ) or (
1119 isinstance(table, BaseTable) and table.table_name != table.table_alias
1120 )
1121 return clone
1123 def get_external_cols(self):
1124 exprs = chain(self.annotations.values(), self.where.children)
1125 return [
1126 col
1127 for col in self._gen_cols(exprs, include_external=True)
1128 if col.alias in self.external_aliases
1129 ]
1131 def get_group_by_cols(self, wrapper=None):
1132 # If wrapper is referenced by an alias for an explicit GROUP BY through
1133 # values() a reference to this expression and not the self must be
1134 # returned to ensure external column references are not grouped against
1135 # as well.
1136 external_cols = self.get_external_cols()
1137 if any(col.possibly_multivalued for col in external_cols):
1138 return [wrapper or self]
1139 return external_cols
1141 def as_sql(self, compiler, connection):
1142 # Some backends (e.g. Oracle) raise an error when a subquery contains
1143 # unnecessary ORDER BY clause.
1144 if (
1145 self.subquery
1146 and not connection.features.ignores_unnecessary_order_by_in_subqueries
1147 ):
1148 self.clear_ordering(force=False)
1149 for query in self.combined_queries:
1150 query.clear_ordering(force=False)
1151 sql, params = self.get_compiler(connection=connection).as_sql()
1152 if self.subquery:
1153 sql = f"({sql})"
1154 return sql, params
1156 def resolve_lookup_value(self, value, can_reuse, allow_joins):
1157 if hasattr(value, "resolve_expression"):
1158 value = value.resolve_expression(
1159 self,
1160 reuse=can_reuse,
1161 allow_joins=allow_joins,
1162 )
1163 elif isinstance(value, list | tuple):
1164 # The items of the iterable may be expressions and therefore need
1165 # to be resolved independently.
1166 values = (
1167 self.resolve_lookup_value(sub_value, can_reuse, allow_joins)
1168 for sub_value in value
1169 )
1170 type_ = type(value)
1171 if hasattr(type_, "_make"): # namedtuple
1172 return type_(*values)
1173 return type_(values)
1174 return value
1176 def solve_lookup_type(self, lookup, summarize=False):
1177 """
1178 Solve the lookup type from the lookup (e.g.: 'foobar__id__icontains').
1179 """
1180 lookup_splitted = lookup.split(LOOKUP_SEP)
1181 if self.annotations:
1182 annotation, expression_lookups = refs_expression(
1183 lookup_splitted, self.annotations
1184 )
1185 if annotation:
1186 expression = self.annotations[annotation]
1187 if summarize:
1188 expression = Ref(annotation, expression)
1189 return expression_lookups, (), expression
1190 _, field, _, lookup_parts = self.names_to_path(lookup_splitted, self.get_meta())
1191 field_parts = lookup_splitted[0 : len(lookup_splitted) - len(lookup_parts)]
1192 if len(lookup_parts) > 1 and not field_parts:
1193 raise FieldError(
1194 f'Invalid lookup "{lookup}" for model {self.get_meta().model.__name__}".'
1195 )
1196 return lookup_parts, field_parts, False
1198 def check_query_object_type(self, value, opts, field):
1199 """
1200 Check whether the object passed while querying is of the correct type.
1201 If not, raise a ValueError specifying the wrong object.
1202 """
1203 if hasattr(value, "_meta"):
1204 if not check_rel_lookup_compatibility(value._meta.model, opts, field):
1205 raise ValueError(
1206 f'Cannot query "{value}": Must be "{opts.object_name}" instance.'
1207 )
1209 def check_related_objects(self, field, value, opts):
1210 """Check the type of object passed to query relations."""
1211 if field.is_relation:
1212 # Check that the field and the queryset use the same model in a
1213 # query like .filter(author=Author.objects.all()). For example, the
1214 # opts would be Author's (from the author field) and value.model
1215 # would be Author.objects.all() queryset's .model (Author also).
1216 # The field is the related field on the lhs side.
1217 if (
1218 isinstance(value, Query)
1219 and not value.has_select_fields
1220 and not check_rel_lookup_compatibility(value.model, opts, field)
1221 ):
1222 raise ValueError(
1223 f'Cannot use QuerySet for "{value.model._meta.object_name}": Use a QuerySet for "{opts.object_name}".'
1224 )
1225 elif hasattr(value, "_meta"):
1226 self.check_query_object_type(value, opts, field)
1227 elif hasattr(value, "__iter__"):
1228 for v in value:
1229 self.check_query_object_type(v, opts, field)
1231 def check_filterable(self, expression):
1232 """Raise an error if expression cannot be used in a WHERE clause."""
1233 if hasattr(expression, "resolve_expression") and not getattr(
1234 expression, "filterable", True
1235 ):
1236 raise NotSupportedError(
1237 expression.__class__.__name__ + " is disallowed in the filter "
1238 "clause."
1239 )
1240 if hasattr(expression, "get_source_expressions"):
1241 for expr in expression.get_source_expressions():
1242 self.check_filterable(expr)
1244 def build_lookup(self, lookups, lhs, rhs):
1245 """
1246 Try to extract transforms and lookup from given lhs.
1248 The lhs value is something that works like SQLExpression.
1249 The rhs value is what the lookup is going to compare against.
1250 The lookups is a list of names to extract using get_lookup()
1251 and get_transform().
1252 """
1253 # __exact is the default lookup if one isn't given.
1254 *transforms, lookup_name = lookups or ["exact"]
1255 for name in transforms:
1256 lhs = self.try_transform(lhs, name)
1257 # First try get_lookup() so that the lookup takes precedence if the lhs
1258 # supports both transform and lookup for the name.
1259 lookup_class = lhs.get_lookup(lookup_name)
1260 if not lookup_class:
1261 # A lookup wasn't found. Try to interpret the name as a transform
1262 # and do an Exact lookup against it.
1263 lhs = self.try_transform(lhs, lookup_name)
1264 lookup_name = "exact"
1265 lookup_class = lhs.get_lookup(lookup_name)
1266 if not lookup_class:
1267 return
1269 lookup = lookup_class(lhs, rhs)
1270 # Interpret '__exact=None' as the sql 'is NULL'; otherwise, reject all
1271 # uses of None as a query value unless the lookup supports it.
1272 if lookup.rhs is None and not lookup.can_use_none_as_rhs:
1273 if lookup_name not in ("exact", "iexact"):
1274 raise ValueError("Cannot use None as a query value")
1275 return lhs.get_lookup("isnull")(lhs, True)
1277 # For Oracle '' is equivalent to null. The check must be done at this
1278 # stage because join promotion can't be done in the compiler. Using
1279 # DEFAULT_DB_ALIAS isn't nice but it's the best that can be done here.
1280 # A similar thing is done in is_nullable(), too.
1281 if (
1282 lookup_name == "exact"
1283 and lookup.rhs == ""
1284 and connections[DEFAULT_DB_ALIAS].features.interprets_empty_strings_as_nulls
1285 ):
1286 return lhs.get_lookup("isnull")(lhs, True)
1288 return lookup
1290 def try_transform(self, lhs, name):
1291 """
1292 Helper method for build_lookup(). Try to fetch and initialize
1293 a transform for name parameter from lhs.
1294 """
1295 transform_class = lhs.get_transform(name)
1296 if transform_class:
1297 return transform_class(lhs)
1298 else:
1299 output_field = lhs.output_field.__class__
1300 suggested_lookups = difflib.get_close_matches(
1301 name, output_field.get_lookups()
1302 )
1303 if suggested_lookups:
1304 suggestion = ", perhaps you meant {}?".format(
1305 " or ".join(suggested_lookups)
1306 )
1307 else:
1308 suggestion = "."
1309 raise FieldError(
1310 f"Unsupported lookup '{name}' for {output_field.__name__} or join on the field not "
1311 f"permitted{suggestion}"
1312 )
1314 def build_filter(
1315 self,
1316 filter_expr,
1317 branch_negated=False,
1318 current_negated=False,
1319 can_reuse=None,
1320 allow_joins=True,
1321 split_subq=True,
1322 reuse_with_filtered_relation=False,
1323 check_filterable=True,
1324 summarize=False,
1325 ):
1326 """
1327 Build a WhereNode for a single filter clause but don't add it
1328 to this Query. Query.add_q() will then add this filter to the where
1329 Node.
1331 The 'branch_negated' tells us if the current branch contains any
1332 negations. This will be used to determine if subqueries are needed.
1334 The 'current_negated' is used to determine if the current filter is
1335 negated or not and this will be used to determine if IS NULL filtering
1336 is needed.
1338 The difference between current_negated and branch_negated is that
1339 branch_negated is set on first negation, but current_negated is
1340 flipped for each negation.
1342 Note that add_filter will not do any negating itself, that is done
1343 upper in the code by add_q().
1345 The 'can_reuse' is a set of reusable joins for multijoins.
1347 If 'reuse_with_filtered_relation' is True, then only joins in can_reuse
1348 will be reused.
1350 The method will create a filter clause that can be added to the current
1351 query. However, if the filter isn't added to the query then the caller
1352 is responsible for unreffing the joins used.
1353 """
1354 if isinstance(filter_expr, dict):
1355 raise FieldError("Cannot parse keyword query as dict")
1356 if isinstance(filter_expr, Q):
1357 return self._add_q(
1358 filter_expr,
1359 branch_negated=branch_negated,
1360 current_negated=current_negated,
1361 used_aliases=can_reuse,
1362 allow_joins=allow_joins,
1363 split_subq=split_subq,
1364 check_filterable=check_filterable,
1365 summarize=summarize,
1366 )
1367 if hasattr(filter_expr, "resolve_expression"):
1368 if not getattr(filter_expr, "conditional", False):
1369 raise TypeError("Cannot filter against a non-conditional expression.")
1370 condition = filter_expr.resolve_expression(
1371 self, allow_joins=allow_joins, summarize=summarize
1372 )
1373 if not isinstance(condition, Lookup):
1374 condition = self.build_lookup(["exact"], condition, True)
1375 return WhereNode([condition], connector=AND), []
1376 arg, value = filter_expr
1377 if not arg:
1378 raise FieldError(f"Cannot parse keyword query {arg!r}")
1379 lookups, parts, reffed_expression = self.solve_lookup_type(arg, summarize)
1381 if check_filterable:
1382 self.check_filterable(reffed_expression)
1384 if not allow_joins and len(parts) > 1:
1385 raise FieldError("Joined field references are not permitted in this query")
1387 pre_joins = self.alias_refcount.copy()
1388 value = self.resolve_lookup_value(value, can_reuse, allow_joins)
1389 used_joins = {
1390 k for k, v in self.alias_refcount.items() if v > pre_joins.get(k, 0)
1391 }
1393 if check_filterable:
1394 self.check_filterable(value)
1396 if reffed_expression:
1397 condition = self.build_lookup(lookups, reffed_expression, value)
1398 return WhereNode([condition], connector=AND), []
1400 opts = self.get_meta()
1401 alias = self.get_initial_alias()
1402 allow_many = not branch_negated or not split_subq
1404 try:
1405 join_info = self.setup_joins(
1406 parts,
1407 opts,
1408 alias,
1409 can_reuse=can_reuse,
1410 allow_many=allow_many,
1411 reuse_with_filtered_relation=reuse_with_filtered_relation,
1412 )
1414 # Prevent iterator from being consumed by check_related_objects()
1415 if isinstance(value, Iterator):
1416 value = list(value)
1417 self.check_related_objects(join_info.final_field, value, join_info.opts)
1419 # split_exclude() needs to know which joins were generated for the
1420 # lookup parts
1421 self._lookup_joins = join_info.joins
1422 except MultiJoin as e:
1423 return self.split_exclude(filter_expr, can_reuse, e.names_with_path)
1425 # Update used_joins before trimming since they are reused to determine
1426 # which joins could be later promoted to INNER.
1427 used_joins.update(join_info.joins)
1428 targets, alias, join_list = self.trim_joins(
1429 join_info.targets, join_info.joins, join_info.path
1430 )
1431 if can_reuse is not None:
1432 can_reuse.update(join_list)
1434 if join_info.final_field.is_relation:
1435 if len(targets) == 1:
1436 col = self._get_col(targets[0], join_info.final_field, alias)
1437 else:
1438 col = MultiColSource(
1439 alias, targets, join_info.targets, join_info.final_field
1440 )
1441 else:
1442 col = self._get_col(targets[0], join_info.final_field, alias)
1444 condition = self.build_lookup(lookups, col, value)
1445 lookup_type = condition.lookup_name
1446 clause = WhereNode([condition], connector=AND)
1448 require_outer = (
1449 lookup_type == "isnull" and condition.rhs is True and not current_negated
1450 )
1451 if (
1452 current_negated
1453 and (lookup_type != "isnull" or condition.rhs is False)
1454 and condition.rhs is not None
1455 ):
1456 require_outer = True
1457 if lookup_type != "isnull":
1458 # The condition added here will be SQL like this:
1459 # NOT (col IS NOT NULL), where the first NOT is added in
1460 # upper layers of code. The reason for addition is that if col
1461 # is null, then col != someval will result in SQL "unknown"
1462 # which isn't the same as in Python. The Python None handling
1463 # is wanted, and it can be gotten by
1464 # (col IS NULL OR col != someval)
1465 # <=>
1466 # NOT (col IS NOT NULL AND col = someval).
1467 if (
1468 self.is_nullable(targets[0])
1469 or self.alias_map[join_list[-1]].join_type == LOUTER
1470 ):
1471 lookup_class = targets[0].get_lookup("isnull")
1472 col = self._get_col(targets[0], join_info.targets[0], alias)
1473 clause.add(lookup_class(col, False), AND)
1474 # If someval is a nullable column, someval IS NOT NULL is
1475 # added.
1476 if isinstance(value, Col) and self.is_nullable(value.target):
1477 lookup_class = value.target.get_lookup("isnull")
1478 clause.add(lookup_class(value, False), AND)
1479 return clause, used_joins if not require_outer else ()
1481 def add_filter(self, filter_lhs, filter_rhs):
1482 self.add_q(Q((filter_lhs, filter_rhs)))
1484 def add_q(self, q_object):
1485 """
1486 A preprocessor for the internal _add_q(). Responsible for doing final
1487 join promotion.
1488 """
1489 # For join promotion this case is doing an AND for the added q_object
1490 # and existing conditions. So, any existing inner join forces the join
1491 # type to remain inner. Existing outer joins can however be demoted.
1492 # (Consider case where rel_a is LOUTER and rel_a__col=1 is added - if
1493 # rel_a doesn't produce any rows, then the whole condition must fail.
1494 # So, demotion is OK.
1495 existing_inner = {
1496 a for a in self.alias_map if self.alias_map[a].join_type == INNER
1497 }
1498 clause, _ = self._add_q(q_object, self.used_aliases)
1499 if clause:
1500 self.where.add(clause, AND)
1501 self.demote_joins(existing_inner)
1503 def build_where(self, filter_expr):
1504 return self.build_filter(filter_expr, allow_joins=False)[0]
1506 def clear_where(self):
1507 self.where = WhereNode()
1509 def _add_q(
1510 self,
1511 q_object,
1512 used_aliases,
1513 branch_negated=False,
1514 current_negated=False,
1515 allow_joins=True,
1516 split_subq=True,
1517 check_filterable=True,
1518 summarize=False,
1519 ):
1520 """Add a Q-object to the current filter."""
1521 connector = q_object.connector
1522 current_negated ^= q_object.negated
1523 branch_negated = branch_negated or q_object.negated
1524 target_clause = WhereNode(connector=connector, negated=q_object.negated)
1525 joinpromoter = JoinPromoter(
1526 q_object.connector, len(q_object.children), current_negated
1527 )
1528 for child in q_object.children:
1529 child_clause, needed_inner = self.build_filter(
1530 child,
1531 can_reuse=used_aliases,
1532 branch_negated=branch_negated,
1533 current_negated=current_negated,
1534 allow_joins=allow_joins,
1535 split_subq=split_subq,
1536 check_filterable=check_filterable,
1537 summarize=summarize,
1538 )
1539 joinpromoter.add_votes(needed_inner)
1540 if child_clause:
1541 target_clause.add(child_clause, connector)
1542 needed_inner = joinpromoter.update_join_types(self)
1543 return target_clause, needed_inner
1545 def build_filtered_relation_q(
1546 self, q_object, reuse, branch_negated=False, current_negated=False
1547 ):
1548 """Add a FilteredRelation object to the current filter."""
1549 connector = q_object.connector
1550 current_negated ^= q_object.negated
1551 branch_negated = branch_negated or q_object.negated
1552 target_clause = WhereNode(connector=connector, negated=q_object.negated)
1553 for child in q_object.children:
1554 if isinstance(child, Node):
1555 child_clause = self.build_filtered_relation_q(
1556 child,
1557 reuse=reuse,
1558 branch_negated=branch_negated,
1559 current_negated=current_negated,
1560 )
1561 else:
1562 child_clause, _ = self.build_filter(
1563 child,
1564 can_reuse=reuse,
1565 branch_negated=branch_negated,
1566 current_negated=current_negated,
1567 allow_joins=True,
1568 split_subq=False,
1569 reuse_with_filtered_relation=True,
1570 )
1571 target_clause.add(child_clause, connector)
1572 return target_clause
1574 def add_filtered_relation(self, filtered_relation, alias):
1575 filtered_relation.alias = alias
1576 lookups = dict(get_children_from_q(filtered_relation.condition))
1577 relation_lookup_parts, relation_field_parts, _ = self.solve_lookup_type(
1578 filtered_relation.relation_name
1579 )
1580 if relation_lookup_parts:
1581 raise ValueError(
1582 "FilteredRelation's relation_name cannot contain lookups "
1583 f"(got {filtered_relation.relation_name!r})."
1584 )
1585 for lookup in chain(lookups):
1586 lookup_parts, lookup_field_parts, _ = self.solve_lookup_type(lookup)
1587 shift = 2 if not lookup_parts else 1
1588 lookup_field_path = lookup_field_parts[:-shift]
1589 for idx, lookup_field_part in enumerate(lookup_field_path):
1590 if len(relation_field_parts) > idx:
1591 if relation_field_parts[idx] != lookup_field_part:
1592 raise ValueError(
1593 "FilteredRelation's condition doesn't support "
1594 f"relations outside the {filtered_relation.relation_name!r} (got {lookup!r})."
1595 )
1596 else:
1597 raise ValueError(
1598 "FilteredRelation's condition doesn't support nested "
1599 f"relations deeper than the relation_name (got {lookup!r} for "
1600 f"{filtered_relation.relation_name!r})."
1601 )
1602 self._filtered_relations[filtered_relation.alias] = filtered_relation
1604 def names_to_path(self, names, opts, allow_many=True, fail_on_missing=False):
1605 """
1606 Walk the list of names and turns them into PathInfo tuples. A single
1607 name in 'names' can generate multiple PathInfos (m2m, for example).
1609 'names' is the path of names to travel, 'opts' is the model Options we
1610 start the name resolving from, 'allow_many' is as for setup_joins().
1611 If fail_on_missing is set to True, then a name that can't be resolved
1612 will generate a FieldError.
1614 Return a list of PathInfo tuples. In addition return the final field
1615 (the last used join field) and target (which is a field guaranteed to
1616 contain the same value as the final field). Finally, return those names
1617 that weren't found (which are likely transforms and the final lookup).
1618 """
1619 path, names_with_path = [], []
1620 for pos, name in enumerate(names):
1621 cur_names_with_path = (name, [])
1622 if name == "pk":
1623 name = opts.pk.name
1625 field = None
1626 filtered_relation = None
1627 try:
1628 if opts is None:
1629 raise FieldDoesNotExist
1630 field = opts.get_field(name)
1631 except FieldDoesNotExist:
1632 if name in self.annotation_select:
1633 field = self.annotation_select[name].output_field
1634 elif name in self._filtered_relations and pos == 0:
1635 filtered_relation = self._filtered_relations[name]
1636 if LOOKUP_SEP in filtered_relation.relation_name:
1637 parts = filtered_relation.relation_name.split(LOOKUP_SEP)
1638 filtered_relation_path, field, _, _ = self.names_to_path(
1639 parts,
1640 opts,
1641 allow_many,
1642 fail_on_missing,
1643 )
1644 path.extend(filtered_relation_path[:-1])
1645 else:
1646 field = opts.get_field(filtered_relation.relation_name)
1647 if field is not None:
1648 # Fields that contain one-to-many relations with a generic
1649 # model (like a GenericForeignKey) cannot generate reverse
1650 # relations and therefore cannot be used for reverse querying.
1651 if field.is_relation and not field.related_model:
1652 raise FieldError(
1653 f"Field {name!r} does not generate an automatic reverse "
1654 "relation and therefore cannot be used for reverse "
1655 "querying. If it is a GenericForeignKey, consider "
1656 "adding a GenericRelation."
1657 )
1658 try:
1659 model = field.model._meta.concrete_model
1660 except AttributeError:
1661 # QuerySet.annotate() may introduce fields that aren't
1662 # attached to a model.
1663 model = None
1664 else:
1665 # We didn't find the current field, so move position back
1666 # one step.
1667 pos -= 1
1668 if pos == -1 or fail_on_missing:
1669 available = sorted(
1670 [
1671 *get_field_names_from_opts(opts),
1672 *self.annotation_select,
1673 *self._filtered_relations,
1674 ]
1675 )
1676 raise FieldError(
1677 "Cannot resolve keyword '{}' into field. "
1678 "Choices are: {}".format(name, ", ".join(available))
1679 )
1680 break
1681 # Check if we need any joins for concrete inheritance cases (the
1682 # field lives in parent, but we are currently in one of its
1683 # children)
1684 if opts is not None and model is not opts.model:
1685 path_to_parent = opts.get_path_to_parent(model)
1686 if path_to_parent:
1687 path.extend(path_to_parent)
1688 cur_names_with_path[1].extend(path_to_parent)
1689 opts = path_to_parent[-1].to_opts
1690 if hasattr(field, "path_infos"):
1691 if filtered_relation:
1692 pathinfos = field.get_path_info(filtered_relation)
1693 else:
1694 pathinfos = field.path_infos
1695 if not allow_many:
1696 for inner_pos, p in enumerate(pathinfos):
1697 if p.m2m:
1698 cur_names_with_path[1].extend(pathinfos[0 : inner_pos + 1])
1699 names_with_path.append(cur_names_with_path)
1700 raise MultiJoin(pos + 1, names_with_path)
1701 last = pathinfos[-1]
1702 path.extend(pathinfos)
1703 final_field = last.join_field
1704 opts = last.to_opts
1705 targets = last.target_fields
1706 cur_names_with_path[1].extend(pathinfos)
1707 names_with_path.append(cur_names_with_path)
1708 else:
1709 # Local non-relational field.
1710 final_field = field
1711 targets = (field,)
1712 if fail_on_missing and pos + 1 != len(names):
1713 raise FieldError(
1714 f"Cannot resolve keyword {names[pos + 1]!r} into field. Join on '{name}'"
1715 " not permitted."
1716 )
1717 break
1718 return path, final_field, targets, names[pos + 1 :]
1720 def setup_joins(
1721 self,
1722 names,
1723 opts,
1724 alias,
1725 can_reuse=None,
1726 allow_many=True,
1727 reuse_with_filtered_relation=False,
1728 ):
1729 """
1730 Compute the necessary table joins for the passage through the fields
1731 given in 'names'. 'opts' is the Options class for the current model
1732 (which gives the table we are starting from), 'alias' is the alias for
1733 the table to start the joining from.
1735 The 'can_reuse' defines the reverse foreign key joins we can reuse. It
1736 can be None in which case all joins are reusable or a set of aliases
1737 that can be reused. Note that non-reverse foreign keys are always
1738 reusable when using setup_joins().
1740 The 'reuse_with_filtered_relation' can be used to force 'can_reuse'
1741 parameter and force the relation on the given connections.
1743 If 'allow_many' is False, then any reverse foreign key seen will
1744 generate a MultiJoin exception.
1746 Return the final field involved in the joins, the target field (used
1747 for any 'where' constraint), the final 'opts' value, the joins, the
1748 field path traveled to generate the joins, and a transform function
1749 that takes a field and alias and is equivalent to `field.get_col(alias)`
1750 in the simple case but wraps field transforms if they were included in
1751 names.
1753 The target field is the field containing the concrete value. Final
1754 field can be something different, for example foreign key pointing to
1755 that value. Final field is needed for example in some value
1756 conversions (convert 'obj' in fk__id=obj to pk val using the foreign
1757 key field for example).
1758 """
1759 joins = [alias]
1760 # The transform can't be applied yet, as joins must be trimmed later.
1761 # To avoid making every caller of this method look up transforms
1762 # directly, compute transforms here and create a partial that converts
1763 # fields to the appropriate wrapped version.
1765 def final_transformer(field, alias):
1766 if not self.alias_cols:
1767 alias = None
1768 return field.get_col(alias)
1770 # Try resolving all the names as fields first. If there's an error,
1771 # treat trailing names as lookups until a field can be resolved.
1772 last_field_exception = None
1773 for pivot in range(len(names), 0, -1):
1774 try:
1775 path, final_field, targets, rest = self.names_to_path(
1776 names[:pivot],
1777 opts,
1778 allow_many,
1779 fail_on_missing=True,
1780 )
1781 except FieldError as exc:
1782 if pivot == 1:
1783 # The first item cannot be a lookup, so it's safe
1784 # to raise the field error here.
1785 raise
1786 else:
1787 last_field_exception = exc
1788 else:
1789 # The transforms are the remaining items that couldn't be
1790 # resolved into fields.
1791 transforms = names[pivot:]
1792 break
1793 for name in transforms:
1795 def transform(field, alias, *, name, previous):
1796 try:
1797 wrapped = previous(field, alias)
1798 return self.try_transform(wrapped, name)
1799 except FieldError:
1800 # FieldError is raised if the transform doesn't exist.
1801 if isinstance(final_field, Field) and last_field_exception:
1802 raise last_field_exception
1803 else:
1804 raise
1806 final_transformer = functools.partial(
1807 transform, name=name, previous=final_transformer
1808 )
1809 final_transformer.has_transforms = True
1810 # Then, add the path to the query's joins. Note that we can't trim
1811 # joins at this stage - we will need the information about join type
1812 # of the trimmed joins.
1813 for join in path:
1814 if join.filtered_relation:
1815 filtered_relation = join.filtered_relation.clone()
1816 table_alias = filtered_relation.alias
1817 else:
1818 filtered_relation = None
1819 table_alias = None
1820 opts = join.to_opts
1821 if join.direct:
1822 nullable = self.is_nullable(join.join_field)
1823 else:
1824 nullable = True
1825 connection = self.join_class(
1826 opts.db_table,
1827 alias,
1828 table_alias,
1829 INNER,
1830 join.join_field,
1831 nullable,
1832 filtered_relation=filtered_relation,
1833 )
1834 reuse = can_reuse if join.m2m or reuse_with_filtered_relation else None
1835 alias = self.join(
1836 connection,
1837 reuse=reuse,
1838 reuse_with_filtered_relation=reuse_with_filtered_relation,
1839 )
1840 joins.append(alias)
1841 if filtered_relation:
1842 filtered_relation.path = joins[:]
1843 return JoinInfo(final_field, targets, opts, joins, path, final_transformer)
1845 def trim_joins(self, targets, joins, path):
1846 """
1847 The 'target' parameter is the final field being joined to, 'joins'
1848 is the full list of join aliases. The 'path' contain the PathInfos
1849 used to create the joins.
1851 Return the final target field and table alias and the new active
1852 joins.
1854 Always trim any direct join if the target column is already in the
1855 previous table. Can't trim reverse joins as it's unknown if there's
1856 anything on the other side of the join.
1857 """
1858 joins = joins[:]
1859 for pos, info in enumerate(reversed(path)):
1860 if len(joins) == 1 or not info.direct:
1861 break
1862 if info.filtered_relation:
1863 break
1864 join_targets = {t.column for t in info.join_field.foreign_related_fields}
1865 cur_targets = {t.column for t in targets}
1866 if not cur_targets.issubset(join_targets):
1867 break
1868 targets_dict = {
1869 r[1].column: r[0]
1870 for r in info.join_field.related_fields
1871 if r[1].column in cur_targets
1872 }
1873 targets = tuple(targets_dict[t.column] for t in targets)
1874 self.unref_alias(joins.pop())
1875 return targets, joins[-1], joins
1877 @classmethod
1878 def _gen_cols(cls, exprs, include_external=False, resolve_refs=True):
1879 for expr in exprs:
1880 if isinstance(expr, Col):
1881 yield expr
1882 elif include_external and callable(
1883 getattr(expr, "get_external_cols", None)
1884 ):
1885 yield from expr.get_external_cols()
1886 elif hasattr(expr, "get_source_expressions"):
1887 if not resolve_refs and isinstance(expr, Ref):
1888 continue
1889 yield from cls._gen_cols(
1890 expr.get_source_expressions(),
1891 include_external=include_external,
1892 resolve_refs=resolve_refs,
1893 )
1895 @classmethod
1896 def _gen_col_aliases(cls, exprs):
1897 yield from (expr.alias for expr in cls._gen_cols(exprs))
1899 def resolve_ref(self, name, allow_joins=True, reuse=None, summarize=False):
1900 annotation = self.annotations.get(name)
1901 if annotation is not None:
1902 if not allow_joins:
1903 for alias in self._gen_col_aliases([annotation]):
1904 if isinstance(self.alias_map[alias], Join):
1905 raise FieldError(
1906 "Joined field references are not permitted in this query"
1907 )
1908 if summarize:
1909 # Summarize currently means we are doing an aggregate() query
1910 # which is executed as a wrapped subquery if any of the
1911 # aggregate() elements reference an existing annotation. In
1912 # that case we need to return a Ref to the subquery's annotation.
1913 if name not in self.annotation_select:
1914 raise FieldError(
1915 f"Cannot aggregate over the '{name}' alias. Use annotate() "
1916 "to promote it."
1917 )
1918 return Ref(name, self.annotation_select[name])
1919 else:
1920 return annotation
1921 else:
1922 field_list = name.split(LOOKUP_SEP)
1923 annotation = self.annotations.get(field_list[0])
1924 if annotation is not None:
1925 for transform in field_list[1:]:
1926 annotation = self.try_transform(annotation, transform)
1927 return annotation
1928 join_info = self.setup_joins(
1929 field_list, self.get_meta(), self.get_initial_alias(), can_reuse=reuse
1930 )
1931 targets, final_alias, join_list = self.trim_joins(
1932 join_info.targets, join_info.joins, join_info.path
1933 )
1934 if not allow_joins and len(join_list) > 1:
1935 raise FieldError(
1936 "Joined field references are not permitted in this query"
1937 )
1938 if len(targets) > 1:
1939 raise FieldError(
1940 "Referencing multicolumn fields with F() objects isn't supported"
1941 )
1942 # Verify that the last lookup in name is a field or a transform:
1943 # transform_function() raises FieldError if not.
1944 transform = join_info.transform_function(targets[0], final_alias)
1945 if reuse is not None:
1946 reuse.update(join_list)
1947 return transform
1949 def split_exclude(self, filter_expr, can_reuse, names_with_path):
1950 """
1951 When doing an exclude against any kind of N-to-many relation, we need
1952 to use a subquery. This method constructs the nested query, given the
1953 original exclude filter (filter_expr) and the portion up to the first
1954 N-to-many relation field.
1956 For example, if the origin filter is ~Q(child__name='foo'), filter_expr
1957 is ('child__name', 'foo') and can_reuse is a set of joins usable for
1958 filters in the original query.
1960 We will turn this into equivalent of:
1961 WHERE NOT EXISTS(
1962 SELECT 1
1963 FROM child
1964 WHERE name = 'foo' AND child.parent_id = parent.id
1965 LIMIT 1
1966 )
1967 """
1968 # Generate the inner query.
1969 query = self.__class__(self.model)
1970 query._filtered_relations = self._filtered_relations
1971 filter_lhs, filter_rhs = filter_expr
1972 if isinstance(filter_rhs, OuterRef):
1973 filter_rhs = OuterRef(filter_rhs)
1974 elif isinstance(filter_rhs, F):
1975 filter_rhs = OuterRef(filter_rhs.name)
1976 query.add_filter(filter_lhs, filter_rhs)
1977 query.clear_ordering(force=True)
1978 # Try to have as simple as possible subquery -> trim leading joins from
1979 # the subquery.
1980 trimmed_prefix, contains_louter = query.trim_start(names_with_path)
1982 col = query.select[0]
1983 select_field = col.target
1984 alias = col.alias
1985 if alias in can_reuse:
1986 pk = select_field.model._meta.pk
1987 # Need to add a restriction so that outer query's filters are in effect for
1988 # the subquery, too.
1989 query.bump_prefix(self)
1990 lookup_class = select_field.get_lookup("exact")
1991 # Note that the query.select[0].alias is different from alias
1992 # due to bump_prefix above.
1993 lookup = lookup_class(pk.get_col(query.select[0].alias), pk.get_col(alias))
1994 query.where.add(lookup, AND)
1995 query.external_aliases[alias] = True
1997 lookup_class = select_field.get_lookup("exact")
1998 lookup = lookup_class(col, ResolvedOuterRef(trimmed_prefix))
1999 query.where.add(lookup, AND)
2000 condition, needed_inner = self.build_filter(Exists(query))
2002 if contains_louter:
2003 or_null_condition, _ = self.build_filter(
2004 (f"{trimmed_prefix}__isnull", True),
2005 current_negated=True,
2006 branch_negated=True,
2007 can_reuse=can_reuse,
2008 )
2009 condition.add(or_null_condition, OR)
2010 # Note that the end result will be:
2011 # (outercol NOT IN innerq AND outercol IS NOT NULL) OR outercol IS NULL.
2012 # This might look crazy but due to how IN works, this seems to be
2013 # correct. If the IS NOT NULL check is removed then outercol NOT
2014 # IN will return UNKNOWN. If the IS NULL check is removed, then if
2015 # outercol IS NULL we will not match the row.
2016 return condition, needed_inner
2018 def set_empty(self):
2019 self.where.add(NothingNode(), AND)
2020 for query in self.combined_queries:
2021 query.set_empty()
2023 def is_empty(self):
2024 return any(isinstance(c, NothingNode) for c in self.where.children)
2026 def set_limits(self, low=None, high=None):
2027 """
2028 Adjust the limits on the rows retrieved. Use low/high to set these,
2029 as it makes it more Pythonic to read and write. When the SQL query is
2030 created, convert them to the appropriate offset and limit values.
2032 Apply any limits passed in here to the existing constraints. Add low
2033 to the current low value and clamp both to any existing high value.
2034 """
2035 if high is not None:
2036 if self.high_mark is not None:
2037 self.high_mark = min(self.high_mark, self.low_mark + high)
2038 else:
2039 self.high_mark = self.low_mark + high
2040 if low is not None:
2041 if self.high_mark is not None:
2042 self.low_mark = min(self.high_mark, self.low_mark + low)
2043 else:
2044 self.low_mark = self.low_mark + low
2046 if self.low_mark == self.high_mark:
2047 self.set_empty()
2049 def clear_limits(self):
2050 """Clear any existing limits."""
2051 self.low_mark, self.high_mark = 0, None
2053 @property
2054 def is_sliced(self):
2055 return self.low_mark != 0 or self.high_mark is not None
2057 def has_limit_one(self):
2058 return self.high_mark is not None and (self.high_mark - self.low_mark) == 1
2060 def can_filter(self):
2061 """
2062 Return True if adding filters to this instance is still possible.
2064 Typically, this means no limits or offsets have been put on the results.
2065 """
2066 return not self.is_sliced
2068 def clear_select_clause(self):
2069 """Remove all fields from SELECT clause."""
2070 self.select = ()
2071 self.default_cols = False
2072 self.select_related = False
2073 self.set_extra_mask(())
2074 self.set_annotation_mask(())
2076 def clear_select_fields(self):
2077 """
2078 Clear the list of fields to select (but not extra_select columns).
2079 Some queryset types completely replace any existing list of select
2080 columns.
2081 """
2082 self.select = ()
2083 self.values_select = ()
2085 def add_select_col(self, col, name):
2086 self.select += (col,)
2087 self.values_select += (name,)
2089 def set_select(self, cols):
2090 self.default_cols = False
2091 self.select = tuple(cols)
2093 def add_distinct_fields(self, *field_names):
2094 """
2095 Add and resolve the given fields to the query's "distinct on" clause.
2096 """
2097 self.distinct_fields = field_names
2098 self.distinct = True
2100 def add_fields(self, field_names, allow_m2m=True):
2101 """
2102 Add the given (model) fields to the select set. Add the field names in
2103 the order specified.
2104 """
2105 alias = self.get_initial_alias()
2106 opts = self.get_meta()
2108 try:
2109 cols = []
2110 for name in field_names:
2111 # Join promotion note - we must not remove any rows here, so
2112 # if there is no existing joins, use outer join.
2113 join_info = self.setup_joins(
2114 name.split(LOOKUP_SEP), opts, alias, allow_many=allow_m2m
2115 )
2116 targets, final_alias, joins = self.trim_joins(
2117 join_info.targets,
2118 join_info.joins,
2119 join_info.path,
2120 )
2121 for target in targets:
2122 cols.append(join_info.transform_function(target, final_alias))
2123 if cols:
2124 self.set_select(cols)
2125 except MultiJoin:
2126 raise FieldError(f"Invalid field name: '{name}'")
2127 except FieldError:
2128 if LOOKUP_SEP in name:
2129 # For lookups spanning over relationships, show the error
2130 # from the model on which the lookup failed.
2131 raise
2132 elif name in self.annotations:
2133 raise FieldError(
2134 f"Cannot select the '{name}' alias. Use annotate() to promote "
2135 "it."
2136 )
2137 else:
2138 names = sorted(
2139 [
2140 *get_field_names_from_opts(opts),
2141 *self.extra,
2142 *self.annotation_select,
2143 *self._filtered_relations,
2144 ]
2145 )
2146 raise FieldError(
2147 "Cannot resolve keyword {!r} into field. Choices are: {}".format(
2148 name, ", ".join(names)
2149 )
2150 )
2152 def add_ordering(self, *ordering):
2153 """
2154 Add items from the 'ordering' sequence to the query's "order by"
2155 clause. These items are either field names (not column names) --
2156 possibly with a direction prefix ('-' or '?') -- or OrderBy
2157 expressions.
2159 If 'ordering' is empty, clear all ordering from the query.
2160 """
2161 errors = []
2162 for item in ordering:
2163 if isinstance(item, str):
2164 if item == "?":
2165 continue
2166 item = item.removeprefix("-")
2167 if item in self.annotations:
2168 continue
2169 if self.extra and item in self.extra:
2170 continue
2171 # names_to_path() validates the lookup. A descriptive
2172 # FieldError will be raise if it's not.
2173 self.names_to_path(item.split(LOOKUP_SEP), self.model._meta)
2174 elif not hasattr(item, "resolve_expression"):
2175 errors.append(item)
2176 if getattr(item, "contains_aggregate", False):
2177 raise FieldError(
2178 "Using an aggregate in order_by() without also including "
2179 f"it in annotate() is not allowed: {item}"
2180 )
2181 if errors:
2182 raise FieldError(f"Invalid order_by arguments: {errors}")
2183 if ordering:
2184 self.order_by += ordering
2185 else:
2186 self.default_ordering = False
2188 def clear_ordering(self, force=False, clear_default=True):
2189 """
2190 Remove any ordering settings if the current query allows it without
2191 side effects, set 'force' to True to clear the ordering regardless.
2192 If 'clear_default' is True, there will be no ordering in the resulting
2193 query (not even the model's default).
2194 """
2195 if not force and (
2196 self.is_sliced or self.distinct_fields or self.select_for_update
2197 ):
2198 return
2199 self.order_by = ()
2200 self.extra_order_by = ()
2201 if clear_default:
2202 self.default_ordering = False
2204 def set_group_by(self, allow_aliases=True):
2205 """
2206 Expand the GROUP BY clause required by the query.
2208 This will usually be the set of all non-aggregate fields in the
2209 return data. If the database backend supports grouping by the
2210 primary key, and the query would be equivalent, the optimization
2211 will be made automatically.
2212 """
2213 if allow_aliases and self.values_select:
2214 # If grouping by aliases is allowed assign selected value aliases
2215 # by moving them to annotations.
2216 group_by_annotations = {}
2217 values_select = {}
2218 for alias, expr in zip(self.values_select, self.select):
2219 if isinstance(expr, Col):
2220 values_select[alias] = expr
2221 else:
2222 group_by_annotations[alias] = expr
2223 self.annotations = {**group_by_annotations, **self.annotations}
2224 self.append_annotation_mask(group_by_annotations)
2225 self.select = tuple(values_select.values())
2226 self.values_select = tuple(values_select)
2227 group_by = list(self.select)
2228 for alias, annotation in self.annotation_select.items():
2229 if not (group_by_cols := annotation.get_group_by_cols()):
2230 continue
2231 if allow_aliases and not annotation.contains_aggregate:
2232 group_by.append(Ref(alias, annotation))
2233 else:
2234 group_by.extend(group_by_cols)
2235 self.group_by = tuple(group_by)
2237 def add_select_related(self, fields):
2238 """
2239 Set up the select_related data structure so that we only select
2240 certain related models (as opposed to all models, when
2241 self.select_related=True).
2242 """
2243 if isinstance(self.select_related, bool):
2244 field_dict = {}
2245 else:
2246 field_dict = self.select_related
2247 for field in fields:
2248 d = field_dict
2249 for part in field.split(LOOKUP_SEP):
2250 d = d.setdefault(part, {})
2251 self.select_related = field_dict
2253 def add_extra(self, select, select_params, where, params, tables, order_by):
2254 """
2255 Add data to the various extra_* attributes for user-created additions
2256 to the query.
2257 """
2258 if select:
2259 # We need to pair any placeholder markers in the 'select'
2260 # dictionary with their parameters in 'select_params' so that
2261 # subsequent updates to the select dictionary also adjust the
2262 # parameters appropriately.
2263 select_pairs = {}
2264 if select_params:
2265 param_iter = iter(select_params)
2266 else:
2267 param_iter = iter([])
2268 for name, entry in select.items():
2269 self.check_alias(name)
2270 entry = str(entry)
2271 entry_params = []
2272 pos = entry.find("%s")
2273 while pos != -1:
2274 if pos == 0 or entry[pos - 1] != "%":
2275 entry_params.append(next(param_iter))
2276 pos = entry.find("%s", pos + 2)
2277 select_pairs[name] = (entry, entry_params)
2278 self.extra.update(select_pairs)
2279 if where or params:
2280 self.where.add(ExtraWhere(where, params), AND)
2281 if tables:
2282 self.extra_tables += tuple(tables)
2283 if order_by:
2284 self.extra_order_by = order_by
2286 def clear_deferred_loading(self):
2287 """Remove any fields from the deferred loading set."""
2288 self.deferred_loading = (frozenset(), True)
2290 def add_deferred_loading(self, field_names):
2291 """
2292 Add the given list of model field names to the set of fields to
2293 exclude from loading from the database when automatic column selection
2294 is done. Add the new field names to any existing field names that
2295 are deferred (or removed from any existing field names that are marked
2296 as the only ones for immediate loading).
2297 """
2298 # Fields on related models are stored in the literal double-underscore
2299 # format, so that we can use a set datastructure. We do the foo__bar
2300 # splitting and handling when computing the SQL column names (as part of
2301 # get_columns()).
2302 existing, defer = self.deferred_loading
2303 if defer:
2304 # Add to existing deferred names.
2305 self.deferred_loading = existing.union(field_names), True
2306 else:
2307 # Remove names from the set of any existing "immediate load" names.
2308 if new_existing := existing.difference(field_names):
2309 self.deferred_loading = new_existing, False
2310 else:
2311 self.clear_deferred_loading()
2312 if new_only := set(field_names).difference(existing):
2313 self.deferred_loading = new_only, True
2315 def add_immediate_loading(self, field_names):
2316 """
2317 Add the given list of model field names to the set of fields to
2318 retrieve when the SQL is executed ("immediate loading" fields). The
2319 field names replace any existing immediate loading field names. If
2320 there are field names already specified for deferred loading, remove
2321 those names from the new field_names before storing the new names
2322 for immediate loading. (That is, immediate loading overrides any
2323 existing immediate values, but respects existing deferrals.)
2324 """
2325 existing, defer = self.deferred_loading
2326 field_names = set(field_names)
2327 if "pk" in field_names:
2328 field_names.remove("pk")
2329 field_names.add(self.get_meta().pk.name)
2331 if defer:
2332 # Remove any existing deferred names from the current set before
2333 # setting the new names.
2334 self.deferred_loading = field_names.difference(existing), False
2335 else:
2336 # Replace any existing "immediate load" field names.
2337 self.deferred_loading = frozenset(field_names), False
2339 def set_annotation_mask(self, names):
2340 """Set the mask of annotations that will be returned by the SELECT."""
2341 if names is None:
2342 self.annotation_select_mask = None
2343 else:
2344 self.annotation_select_mask = set(names)
2345 self._annotation_select_cache = None
2347 def append_annotation_mask(self, names):
2348 if self.annotation_select_mask is not None:
2349 self.set_annotation_mask(self.annotation_select_mask.union(names))
2351 def set_extra_mask(self, names):
2352 """
2353 Set the mask of extra select items that will be returned by SELECT.
2354 Don't remove them from the Query since they might be used later.
2355 """
2356 if names is None:
2357 self.extra_select_mask = None
2358 else:
2359 self.extra_select_mask = set(names)
2360 self._extra_select_cache = None
2362 def set_values(self, fields):
2363 self.select_related = False
2364 self.clear_deferred_loading()
2365 self.clear_select_fields()
2366 self.has_select_fields = True
2368 if fields:
2369 field_names = []
2370 extra_names = []
2371 annotation_names = []
2372 if not self.extra and not self.annotations:
2373 # Shortcut - if there are no extra or annotations, then
2374 # the values() clause must be just field names.
2375 field_names = list(fields)
2376 else:
2377 self.default_cols = False
2378 for f in fields:
2379 if f in self.extra_select:
2380 extra_names.append(f)
2381 elif f in self.annotation_select:
2382 annotation_names.append(f)
2383 else:
2384 field_names.append(f)
2385 self.set_extra_mask(extra_names)
2386 self.set_annotation_mask(annotation_names)
2387 selected = frozenset(field_names + extra_names + annotation_names)
2388 else:
2389 field_names = [f.attname for f in self.model._meta.concrete_fields]
2390 selected = frozenset(field_names)
2391 # Selected annotations must be known before setting the GROUP BY
2392 # clause.
2393 if self.group_by is True:
2394 self.add_fields(
2395 (f.attname for f in self.model._meta.concrete_fields), False
2396 )
2397 # Disable GROUP BY aliases to avoid orphaning references to the
2398 # SELECT clause which is about to be cleared.
2399 self.set_group_by(allow_aliases=False)
2400 self.clear_select_fields()
2401 elif self.group_by:
2402 # Resolve GROUP BY annotation references if they are not part of
2403 # the selected fields anymore.
2404 group_by = []
2405 for expr in self.group_by:
2406 if isinstance(expr, Ref) and expr.refs not in selected:
2407 expr = self.annotations[expr.refs]
2408 group_by.append(expr)
2409 self.group_by = tuple(group_by)
2411 self.values_select = tuple(field_names)
2412 self.add_fields(field_names, True)
2414 @property
2415 def annotation_select(self):
2416 """
2417 Return the dictionary of aggregate columns that are not masked and
2418 should be used in the SELECT clause. Cache this result for performance.
2419 """
2420 if self._annotation_select_cache is not None:
2421 return self._annotation_select_cache
2422 elif not self.annotations:
2423 return {}
2424 elif self.annotation_select_mask is not None:
2425 self._annotation_select_cache = {
2426 k: v
2427 for k, v in self.annotations.items()
2428 if k in self.annotation_select_mask
2429 }
2430 return self._annotation_select_cache
2431 else:
2432 return self.annotations
2434 @property
2435 def extra_select(self):
2436 if self._extra_select_cache is not None:
2437 return self._extra_select_cache
2438 if not self.extra:
2439 return {}
2440 elif self.extra_select_mask is not None:
2441 self._extra_select_cache = {
2442 k: v for k, v in self.extra.items() if k in self.extra_select_mask
2443 }
2444 return self._extra_select_cache
2445 else:
2446 return self.extra
2448 def trim_start(self, names_with_path):
2449 """
2450 Trim joins from the start of the join path. The candidates for trim
2451 are the PathInfos in names_with_path structure that are m2m joins.
2453 Also set the select column so the start matches the join.
2455 This method is meant to be used for generating the subquery joins &
2456 cols in split_exclude().
2458 Return a lookup usable for doing outerq.filter(lookup=self) and a
2459 boolean indicating if the joins in the prefix contain a LEFT OUTER join.
2460 _"""
2461 all_paths = []
2462 for _, paths in names_with_path:
2463 all_paths.extend(paths)
2464 contains_louter = False
2465 # Trim and operate only on tables that were generated for
2466 # the lookup part of the query. That is, avoid trimming
2467 # joins generated for F() expressions.
2468 lookup_tables = [
2469 t for t in self.alias_map if t in self._lookup_joins or t == self.base_table
2470 ]
2471 for trimmed_paths, path in enumerate(all_paths):
2472 if path.m2m:
2473 break
2474 if self.alias_map[lookup_tables[trimmed_paths + 1]].join_type == LOUTER:
2475 contains_louter = True
2476 alias = lookup_tables[trimmed_paths]
2477 self.unref_alias(alias)
2478 # The path.join_field is a Rel, lets get the other side's field
2479 join_field = path.join_field.field
2480 # Build the filter prefix.
2481 paths_in_prefix = trimmed_paths
2482 trimmed_prefix = []
2483 for name, path in names_with_path:
2484 if paths_in_prefix - len(path) < 0:
2485 break
2486 trimmed_prefix.append(name)
2487 paths_in_prefix -= len(path)
2488 trimmed_prefix.append(join_field.foreign_related_fields[0].name)
2489 trimmed_prefix = LOOKUP_SEP.join(trimmed_prefix)
2490 # Lets still see if we can trim the first join from the inner query
2491 # (that is, self). We can't do this for:
2492 # - LEFT JOINs because we would miss those rows that have nothing on
2493 # the outer side,
2494 # - INNER JOINs from filtered relations because we would miss their
2495 # filters.
2496 first_join = self.alias_map[lookup_tables[trimmed_paths + 1]]
2497 if first_join.join_type != LOUTER and not first_join.filtered_relation:
2498 select_fields = [r[0] for r in join_field.related_fields]
2499 select_alias = lookup_tables[trimmed_paths + 1]
2500 self.unref_alias(lookup_tables[trimmed_paths])
2501 extra_restriction = join_field.get_extra_restriction(
2502 None, lookup_tables[trimmed_paths + 1]
2503 )
2504 if extra_restriction:
2505 self.where.add(extra_restriction, AND)
2506 else:
2507 # TODO: It might be possible to trim more joins from the start of the
2508 # inner query if it happens to have a longer join chain containing the
2509 # values in select_fields. Lets punt this one for now.
2510 select_fields = [r[1] for r in join_field.related_fields]
2511 select_alias = lookup_tables[trimmed_paths]
2512 # The found starting point is likely a join_class instead of a
2513 # base_table_class reference. But the first entry in the query's FROM
2514 # clause must not be a JOIN.
2515 for table in self.alias_map:
2516 if self.alias_refcount[table] > 0:
2517 self.alias_map[table] = self.base_table_class(
2518 self.alias_map[table].table_name,
2519 table,
2520 )
2521 break
2522 self.set_select([f.get_col(select_alias) for f in select_fields])
2523 return trimmed_prefix, contains_louter
2525 def is_nullable(self, field):
2526 """
2527 Check if the given field should be treated as nullable.
2529 Some backends treat '' as null and Plain treats such fields as
2530 nullable for those backends. In such situations field.null can be
2531 False even if we should treat the field as nullable.
2532 """
2533 # We need to use DEFAULT_DB_ALIAS here, as QuerySet does not have
2534 # (nor should it have) knowledge of which connection is going to be
2535 # used. The proper fix would be to defer all decisions where
2536 # is_nullable() is needed to the compiler stage, but that is not easy
2537 # to do currently.
2538 return field.null or (
2539 field.empty_strings_allowed
2540 and connections[DEFAULT_DB_ALIAS].features.interprets_empty_strings_as_nulls
2541 )
2544def get_order_dir(field, default="ASC"):
2545 """
2546 Return the field name and direction for an order specification. For
2547 example, '-foo' is returned as ('foo', 'DESC').
2549 The 'default' param is used to indicate which way no prefix (or a '+'
2550 prefix) should sort. The '-' prefix always sorts the opposite way.
2551 """
2552 dirn = ORDER_DIR[default]
2553 if field[0] == "-":
2554 return field[1:], dirn[1]
2555 return field, dirn[0]
2558class JoinPromoter:
2559 """
2560 A class to abstract away join promotion problems for complex filter
2561 conditions.
2562 """
2564 def __init__(self, connector, num_children, negated):
2565 self.connector = connector
2566 self.negated = negated
2567 if self.negated:
2568 if connector == AND:
2569 self.effective_connector = OR
2570 else:
2571 self.effective_connector = AND
2572 else:
2573 self.effective_connector = self.connector
2574 self.num_children = num_children
2575 # Maps of table alias to how many times it is seen as required for
2576 # inner and/or outer joins.
2577 self.votes = Counter()
2579 def __repr__(self):
2580 return (
2581 f"{self.__class__.__qualname__}(connector={self.connector!r}, "
2582 f"num_children={self.num_children!r}, negated={self.negated!r})"
2583 )
2585 def add_votes(self, votes):
2586 """
2587 Add single vote per item to self.votes. Parameter can be any
2588 iterable.
2589 """
2590 self.votes.update(votes)
2592 def update_join_types(self, query):
2593 """
2594 Change join types so that the generated query is as efficient as
2595 possible, but still correct. So, change as many joins as possible
2596 to INNER, but don't make OUTER joins INNER if that could remove
2597 results from the query.
2598 """
2599 to_promote = set()
2600 to_demote = set()
2601 # The effective_connector is used so that NOT (a AND b) is treated
2602 # similarly to (a OR b) for join promotion.
2603 for table, votes in self.votes.items():
2604 # We must use outer joins in OR case when the join isn't contained
2605 # in all of the joins. Otherwise the INNER JOIN itself could remove
2606 # valid results. Consider the case where a model with rel_a and
2607 # rel_b relations is queried with rel_a__col=1 | rel_b__col=2. Now,
2608 # if rel_a join doesn't produce any results is null (for example
2609 # reverse foreign key or null value in direct foreign key), and
2610 # there is a matching row in rel_b with col=2, then an INNER join
2611 # to rel_a would remove a valid match from the query. So, we need
2612 # to promote any existing INNER to LOUTER (it is possible this
2613 # promotion in turn will be demoted later on).
2614 if self.effective_connector == OR and votes < self.num_children:
2615 to_promote.add(table)
2616 # If connector is AND and there is a filter that can match only
2617 # when there is a joinable row, then use INNER. For example, in
2618 # rel_a__col=1 & rel_b__col=2, if either of the rels produce NULL
2619 # as join output, then the col=1 or col=2 can't match (as
2620 # NULL=anything is always false).
2621 # For the OR case, if all children voted for a join to be inner,
2622 # then we can use INNER for the join. For example:
2623 # (rel_a__col__icontains=Alex | rel_a__col__icontains=Russell)
2624 # then if rel_a doesn't produce any rows, the whole condition
2625 # can't match. Hence we can safely use INNER join.
2626 if self.effective_connector == AND or (
2627 self.effective_connector == OR and votes == self.num_children
2628 ):
2629 to_demote.add(table)
2630 # Finally, what happens in cases where we have:
2631 # (rel_a__col=1|rel_b__col=2) & rel_a__col__gte=0
2632 # Now, we first generate the OR clause, and promote joins for it
2633 # in the first if branch above. Both rel_a and rel_b are promoted
2634 # to LOUTER joins. After that we do the AND case. The OR case
2635 # voted no inner joins but the rel_a__col__gte=0 votes inner join
2636 # for rel_a. We demote it back to INNER join (in AND case a single
2637 # vote is enough). The demotion is OK, if rel_a doesn't produce
2638 # rows, then the rel_a__col__gte=0 clause can't be true, and thus
2639 # the whole clause must be false. So, it is safe to use INNER
2640 # join.
2641 # Note that in this example we could just as well have the __gte
2642 # clause and the OR clause swapped. Or we could replace the __gte
2643 # clause with an OR clause containing rel_a__col=1|rel_a__col=2,
2644 # and again we could safely demote to INNER.
2645 query.promote_joins(to_promote)
2646 query.demote_joins(to_demote)
2647 return to_demote
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Query subclasses which provide extra functionality beyond simple data retrieval.
3"""
5from plain.exceptions import FieldError
6from plain.models.sql.constants import CURSOR, GET_ITERATOR_CHUNK_SIZE, NO_RESULTS
7from plain.models.sql.query import Query
9__all__ = ["DeleteQuery", "UpdateQuery", "InsertQuery", "AggregateQuery"]
12class DeleteQuery(Query):
13 """A DELETE SQL query."""
15 compiler = "SQLDeleteCompiler"
17 def do_query(self, table, where, using):
18 self.alias_map = {table: self.alias_map[table]}
19 self.where = where
20 cursor = self.get_compiler(using).execute_sql(CURSOR)
21 if cursor:
22 with cursor:
23 return cursor.rowcount
24 return 0
26 def delete_batch(self, pk_list, using):
27 """
28 Set up and execute delete queries for all the objects in pk_list.
30 More than one physical query may be executed if there are a
31 lot of values in pk_list.
32 """
33 # number of objects deleted
34 num_deleted = 0
35 field = self.get_meta().pk
36 for offset in range(0, len(pk_list), GET_ITERATOR_CHUNK_SIZE):
37 self.clear_where()
38 self.add_filter(
39 f"{field.attname}__in",
40 pk_list[offset : offset + GET_ITERATOR_CHUNK_SIZE],
41 )
42 num_deleted += self.do_query(
43 self.get_meta().db_table, self.where, using=using
44 )
45 return num_deleted
48class UpdateQuery(Query):
49 """An UPDATE SQL query."""
51 compiler = "SQLUpdateCompiler"
53 def __init__(self, *args, **kwargs):
54 super().__init__(*args, **kwargs)
55 self._setup_query()
57 def _setup_query(self):
58 """
59 Run on initialization and at the end of chaining. Any attributes that
60 would normally be set in __init__() should go here instead.
61 """
62 self.values = []
63 self.related_ids = None
64 self.related_updates = {}
66 def clone(self):
67 obj = super().clone()
68 obj.related_updates = self.related_updates.copy()
69 return obj
71 def update_batch(self, pk_list, values, using):
72 self.add_update_values(values)
73 for offset in range(0, len(pk_list), GET_ITERATOR_CHUNK_SIZE):
74 self.clear_where()
75 self.add_filter(
76 "pk__in", pk_list[offset : offset + GET_ITERATOR_CHUNK_SIZE]
77 )
78 self.get_compiler(using).execute_sql(NO_RESULTS)
80 def add_update_values(self, values):
81 """
82 Convert a dictionary of field name to value mappings into an update
83 query. This is the entry point for the public update() method on
84 querysets.
85 """
86 values_seq = []
87 for name, val in values.items():
88 field = self.get_meta().get_field(name)
89 direct = (
90 not (field.auto_created and not field.concrete) or not field.concrete
91 )
92 model = field.model._meta.concrete_model
93 if not direct or (field.is_relation and field.many_to_many):
94 raise FieldError(
95 f"Cannot update model field {field!r} (only non-relations and "
96 "foreign keys permitted)."
97 )
98 if model is not self.get_meta().concrete_model:
99 self.add_related_update(model, field, val)
100 continue
101 values_seq.append((field, model, val))
102 return self.add_update_fields(values_seq)
104 def add_update_fields(self, values_seq):
105 """
106 Append a sequence of (field, model, value) triples to the internal list
107 that will be used to generate the UPDATE query. Might be more usefully
108 called add_update_targets() to hint at the extra information here.
109 """
110 for field, model, val in values_seq:
111 if hasattr(val, "resolve_expression"):
112 # Resolve expressions here so that annotations are no longer needed
113 val = val.resolve_expression(self, allow_joins=False, for_save=True)
114 self.values.append((field, model, val))
116 def add_related_update(self, model, field, value):
117 """
118 Add (name, value) to an update query for an ancestor model.
120 Update are coalesced so that only one update query per ancestor is run.
121 """
122 self.related_updates.setdefault(model, []).append((field, None, value))
124 def get_related_updates(self):
125 """
126 Return a list of query objects: one for each update required to an
127 ancestor model. Each query will have the same filtering conditions as
128 the current query but will only update a single table.
129 """
130 if not self.related_updates:
131 return []
132 result = []
133 for model, values in self.related_updates.items():
134 query = UpdateQuery(model)
135 query.values = values
136 if self.related_ids is not None:
137 query.add_filter("pk__in", self.related_ids[model])
138 result.append(query)
139 return result
142class InsertQuery(Query):
143 compiler = "SQLInsertCompiler"
145 def __init__(
146 self, *args, on_conflict=None, update_fields=None, unique_fields=None, **kwargs
147 ):
148 super().__init__(*args, **kwargs)
149 self.fields = []
150 self.objs = []
151 self.on_conflict = on_conflict
152 self.update_fields = update_fields or []
153 self.unique_fields = unique_fields or []
155 def insert_values(self, fields, objs, raw=False):
156 self.fields = fields
157 self.objs = objs
158 self.raw = raw
161class AggregateQuery(Query):
162 """
163 Take another query as a parameter to the FROM clause and only select the
164 elements in the provided list.
165 """
167 compiler = "SQLAggregateCompiler"
169 def __init__(self, model, inner_query):
170 self.inner_query = inner_query
171 super().__init__(model)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Code to manage the creation and SQL rendering of 'where' constraints.
3"""
5import operator
6from functools import reduce
8from plain.exceptions import EmptyResultSet, FullResultSet
9from plain.models.expressions import Case, When
10from plain.models.lookups import Exact
11from plain.utils import tree
12from plain.utils.functional import cached_property
14# Connection types
15AND = "AND"
16OR = "OR"
17XOR = "XOR"
20class WhereNode(tree.Node):
21 """
22 An SQL WHERE clause.
24 The class is tied to the Query class that created it (in order to create
25 the correct SQL).
27 A child is usually an expression producing boolean values. Most likely the
28 expression is a Lookup instance.
30 However, a child could also be any class with as_sql() and either
31 relabeled_clone() method or relabel_aliases() and clone() methods and
32 contains_aggregate attribute.
33 """
35 default = AND
36 resolved = False
37 conditional = True
39 def split_having_qualify(self, negated=False, must_group_by=False):
40 """
41 Return three possibly None nodes: one for those parts of self that
42 should be included in the WHERE clause, one for those parts of self
43 that must be included in the HAVING clause, and one for those parts
44 that refer to window functions.
45 """
46 if not self.contains_aggregate and not self.contains_over_clause:
47 return self, None, None
48 in_negated = negated ^ self.negated
49 # Whether or not children must be connected in the same filtering
50 # clause (WHERE > HAVING > QUALIFY) to maintain logical semantic.
51 must_remain_connected = (
52 (in_negated and self.connector == AND)
53 or (not in_negated and self.connector == OR)
54 or self.connector == XOR
55 )
56 if (
57 must_remain_connected
58 and self.contains_aggregate
59 and not self.contains_over_clause
60 ):
61 # It's must cheaper to short-circuit and stash everything in the
62 # HAVING clause than split children if possible.
63 return None, self, None
64 where_parts = []
65 having_parts = []
66 qualify_parts = []
67 for c in self.children:
68 if hasattr(c, "split_having_qualify"):
69 where_part, having_part, qualify_part = c.split_having_qualify(
70 in_negated, must_group_by
71 )
72 if where_part is not None:
73 where_parts.append(where_part)
74 if having_part is not None:
75 having_parts.append(having_part)
76 if qualify_part is not None:
77 qualify_parts.append(qualify_part)
78 elif c.contains_over_clause:
79 qualify_parts.append(c)
80 elif c.contains_aggregate:
81 having_parts.append(c)
82 else:
83 where_parts.append(c)
84 if must_remain_connected and qualify_parts:
85 # Disjunctive heterogeneous predicates can be pushed down to
86 # qualify as long as no conditional aggregation is involved.
87 if not where_parts or (where_parts and not must_group_by):
88 return None, None, self
89 elif where_parts:
90 # In theory this should only be enforced when dealing with
91 # where_parts containing predicates against multi-valued
92 # relationships that could affect aggregation results but this
93 # is complex to infer properly.
94 raise NotImplementedError(
95 "Heterogeneous disjunctive predicates against window functions are "
96 "not implemented when performing conditional aggregation."
97 )
98 where_node = (
99 self.create(where_parts, self.connector, self.negated)
100 if where_parts
101 else None
102 )
103 having_node = (
104 self.create(having_parts, self.connector, self.negated)
105 if having_parts
106 else None
107 )
108 qualify_node = (
109 self.create(qualify_parts, self.connector, self.negated)
110 if qualify_parts
111 else None
112 )
113 return where_node, having_node, qualify_node
115 def as_sql(self, compiler, connection):
116 """
117 Return the SQL version of the where clause and the value to be
118 substituted in. Return '', [] if this node matches everything,
119 None, [] if this node is empty, and raise EmptyResultSet if this
120 node can't match anything.
121 """
122 result = []
123 result_params = []
124 if self.connector == AND:
125 full_needed, empty_needed = len(self.children), 1
126 else:
127 full_needed, empty_needed = 1, len(self.children)
129 if self.connector == XOR and not connection.features.supports_logical_xor:
130 # Convert if the database doesn't support XOR:
131 # a XOR b XOR c XOR ...
132 # to:
133 # (a OR b OR c OR ...) AND (a + b + c + ...) == 1
134 lhs = self.__class__(self.children, OR)
135 rhs_sum = reduce(
136 operator.add,
137 (Case(When(c, then=1), default=0) for c in self.children),
138 )
139 rhs = Exact(1, rhs_sum)
140 return self.__class__([lhs, rhs], AND, self.negated).as_sql(
141 compiler, connection
142 )
144 for child in self.children:
145 try:
146 sql, params = compiler.compile(child)
147 except EmptyResultSet:
148 empty_needed -= 1
149 except FullResultSet:
150 full_needed -= 1
151 else:
152 if sql:
153 result.append(sql)
154 result_params.extend(params)
155 else:
156 full_needed -= 1
157 # Check if this node matches nothing or everything.
158 # First check the amount of full nodes and empty nodes
159 # to make this node empty/full.
160 # Now, check if this node is full/empty using the
161 # counts.
162 if empty_needed == 0:
163 if self.negated:
164 raise FullResultSet
165 else:
166 raise EmptyResultSet
167 if full_needed == 0:
168 if self.negated:
169 raise EmptyResultSet
170 else:
171 raise FullResultSet
172 conn = f" {self.connector} "
173 sql_string = conn.join(result)
174 if not sql_string:
175 raise FullResultSet
176 if self.negated:
177 # Some backends (Oracle at least) need parentheses around the inner
178 # SQL in the negated case, even if the inner SQL contains just a
179 # single expression.
180 sql_string = f"NOT ({sql_string})"
181 elif len(result) > 1 or self.resolved:
182 sql_string = f"({sql_string})"
183 return sql_string, result_params
185 def get_group_by_cols(self):
186 cols = []
187 for child in self.children:
188 cols.extend(child.get_group_by_cols())
189 return cols
191 def get_source_expressions(self):
192 return self.children[:]
194 def set_source_expressions(self, children):
195 assert len(children) == len(self.children)
196 self.children = children
198 def relabel_aliases(self, change_map):
199 """
200 Relabel the alias values of any children. 'change_map' is a dictionary
201 mapping old (current) alias values to the new values.
202 """
203 for pos, child in enumerate(self.children):
204 if hasattr(child, "relabel_aliases"):
205 # For example another WhereNode
206 child.relabel_aliases(change_map)
207 elif hasattr(child, "relabeled_clone"):
208 self.children[pos] = child.relabeled_clone(change_map)
210 def clone(self):
211 clone = self.create(connector=self.connector, negated=self.negated)
212 for child in self.children:
213 if hasattr(child, "clone"):
214 child = child.clone()
215 clone.children.append(child)
216 return clone
218 def relabeled_clone(self, change_map):
219 clone = self.clone()
220 clone.relabel_aliases(change_map)
221 return clone
223 def replace_expressions(self, replacements):
224 if replacement := replacements.get(self):
225 return replacement
226 clone = self.create(connector=self.connector, negated=self.negated)
227 for child in self.children:
228 clone.children.append(child.replace_expressions(replacements))
229 return clone
231 def get_refs(self):
232 refs = set()
233 for child in self.children:
234 refs |= child.get_refs()
235 return refs
237 @classmethod
238 def _contains_aggregate(cls, obj):
239 if isinstance(obj, tree.Node):
240 return any(cls._contains_aggregate(c) for c in obj.children)
241 return obj.contains_aggregate
243 @cached_property
244 def contains_aggregate(self):
245 return self._contains_aggregate(self)
247 @classmethod
248 def _contains_over_clause(cls, obj):
249 if isinstance(obj, tree.Node):
250 return any(cls._contains_over_clause(c) for c in obj.children)
251 return obj.contains_over_clause
253 @cached_property
254 def contains_over_clause(self):
255 return self._contains_over_clause(self)
257 @property
258 def is_summary(self):
259 return any(child.is_summary for child in self.children)
261 @staticmethod
262 def _resolve_leaf(expr, query, *args, **kwargs):
263 if hasattr(expr, "resolve_expression"):
264 expr = expr.resolve_expression(query, *args, **kwargs)
265 return expr
267 @classmethod
268 def _resolve_node(cls, node, query, *args, **kwargs):
269 if hasattr(node, "children"):
270 for child in node.children:
271 cls._resolve_node(child, query, *args, **kwargs)
272 if hasattr(node, "lhs"):
273 node.lhs = cls._resolve_leaf(node.lhs, query, *args, **kwargs)
274 if hasattr(node, "rhs"):
275 node.rhs = cls._resolve_leaf(node.rhs, query, *args, **kwargs)
277 def resolve_expression(self, *args, **kwargs):
278 clone = self.clone()
279 clone._resolve_node(clone, *args, **kwargs)
280 clone.resolved = True
281 return clone
283 @cached_property
284 def output_field(self):
285 from plain.models.fields import BooleanField
287 return BooleanField()
289 @property
290 def _output_field_or_none(self):
291 return self.output_field
293 def select_format(self, compiler, sql, params):
294 # Wrap filters with a CASE WHEN expression if a database backend
295 # (e.g. Oracle) doesn't support boolean expression in SELECT or GROUP
296 # BY list.
297 if not compiler.connection.features.supports_boolean_expr_in_select_clause:
298 sql = f"CASE WHEN {sql} THEN 1 ELSE 0 END"
299 return sql, params
301 def get_db_converters(self, connection):
302 return self.output_field.get_db_converters(connection)
304 def get_lookup(self, lookup):
305 return self.output_field.get_lookup(lookup)
307 def leaves(self):
308 for child in self.children:
309 if isinstance(child, WhereNode):
310 yield from child.leaves()
311 else:
312 yield child
315class NothingNode:
316 """A node that matches nothing."""
318 contains_aggregate = False
319 contains_over_clause = False
321 def as_sql(self, compiler=None, connection=None):
322 raise EmptyResultSet
325class ExtraWhere:
326 # The contents are a black box - assume no aggregates or windows are used.
327 contains_aggregate = False
328 contains_over_clause = False
330 def __init__(self, sqls, params):
331 self.sqls = sqls
332 self.params = params
334 def as_sql(self, compiler=None, connection=None):
335 sqls = [f"({sql})" for sql in self.sqls]
336 return " AND ".join(sqls), list(self.params or ())
339class SubqueryConstraint:
340 # Even if aggregates or windows would be used in a subquery,
341 # the outer query isn't interested about those.
342 contains_aggregate = False
343 contains_over_clause = False
345 def __init__(self, alias, columns, targets, query_object):
346 self.alias = alias
347 self.columns = columns
348 self.targets = targets
349 query_object.clear_ordering(clear_default=True)
350 self.query_object = query_object
352 def as_sql(self, compiler, connection):
353 query = self.query_object
354 query.set_values(self.targets)
355 query_compiler = query.get_compiler(connection=connection)
356 return query_compiler.as_subquery_condition(self.alias, self.columns, compiler)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.exceptions import ObjectDoesNotExist
3from . import (
4 preflight, # noqa
5)
6from .aggregates import * # NOQA
7from .aggregates import __all__ as aggregates_all
8from .constraints import * # NOQA
9from .constraints import __all__ as constraints_all
10from .db import (
11 DEFAULT_DB_ALIAS,
12 PLAIN_VERSION_PICKLE_KEY,
13 DatabaseError,
14 DataError,
15 Error,
16 IntegrityError,
17 InterfaceError,
18 InternalError,
19 NotSupportedError,
20 OperationalError,
21 ProgrammingError,
22 close_old_connections,
23 connection,
24 connections,
25 reset_queries,
26 router,
27)
28from .deletion import (
29 CASCADE,
30 DO_NOTHING,
31 PROTECT,
32 RESTRICT,
33 SET,
34 SET_DEFAULT,
35 SET_NULL,
36 ProtectedError,
37 RestrictedError,
38)
39from .enums import * # NOQA
40from .enums import __all__ as enums_all
41from .expressions import (
42 Case,
43 Exists,
44 Expression,
45 ExpressionList,
46 ExpressionWrapper,
47 F,
48 Func,
49 OrderBy,
50 OuterRef,
51 RowRange,
52 Subquery,
53 Value,
54 ValueRange,
55 When,
56 Window,
57 WindowFrame,
58)
59from .fields import * # NOQA
60from .fields import __all__ as fields_all
61from .fields.json import JSONField
62from .fields.proxy import OrderWrt
63from .indexes import * # NOQA
64from .indexes import __all__ as indexes_all
65from .lookups import Lookup, Transform
66from .manager import Manager
67from .query import Prefetch, QuerySet, prefetch_related_objects
68from .query_utils import FilteredRelation, Q
70# Imports that would create circular imports if sorted
71from .base import DEFERRED, Model # isort:skip
72from .fields.related import ( # isort:skip
73 ForeignKey,
74 ForeignObject,
75 OneToOneField,
76 ManyToManyField,
77 ForeignObjectRel,
78 ManyToOneRel,
79 ManyToManyRel,
80 OneToOneRel,
81)
84__all__ = aggregates_all + constraints_all + enums_all + fields_all + indexes_all
85__all__ += [
86 "ObjectDoesNotExist",
87 "CASCADE",
88 "DO_NOTHING",
89 "PROTECT",
90 "RESTRICT",
91 "SET",
92 "SET_DEFAULT",
93 "SET_NULL",
94 "ProtectedError",
95 "RestrictedError",
96 "Case",
97 "Exists",
98 "Expression",
99 "ExpressionList",
100 "ExpressionWrapper",
101 "F",
102 "Func",
103 "OrderBy",
104 "OuterRef",
105 "RowRange",
106 "Subquery",
107 "Value",
108 "ValueRange",
109 "When",
110 "Window",
111 "WindowFrame",
112 "JSONField",
113 "OrderWrt",
114 "Lookup",
115 "Transform",
116 "Manager",
117 "Prefetch",
118 "Q",
119 "QuerySet",
120 "prefetch_related_objects",
121 "DEFERRED",
122 "Model",
123 "FilteredRelation",
124 "ForeignKey",
125 "ForeignObject",
126 "OneToOneField",
127 "ManyToManyField",
128 "ForeignObjectRel",
129 "ManyToOneRel",
130 "ManyToManyRel",
131 "OneToOneRel",
132]
134# DB-related exports
135__all__ += [
136 "connection",
137 "connections",
138 "router",
139 "reset_queries",
140 "close_old_connections",
141 "DatabaseError",
142 "IntegrityError",
143 "InternalError",
144 "ProgrammingError",
145 "DataError",
146 "NotSupportedError",
147 "Error",
148 "InterfaceError",
149 "OperationalError",
150 "DEFAULT_DB_ALIAS",
151 "PLAIN_VERSION_PICKLE_KEY",
152]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Classes to represent the definitions of aggregate functions.
3"""
5from plain.exceptions import FieldError, FullResultSet
6from plain.models.expressions import Case, Func, Star, Value, When
7from plain.models.fields import IntegerField
8from plain.models.functions.comparison import Coalesce
9from plain.models.functions.mixins import (
10 FixDurationInputMixin,
11 NumericOutputFieldMixin,
12)
14__all__ = [
15 "Aggregate",
16 "Avg",
17 "Count",
18 "Max",
19 "Min",
20 "StdDev",
21 "Sum",
22 "Variance",
23]
26class Aggregate(Func):
27 template = "%(function)s(%(distinct)s%(expressions)s)"
28 contains_aggregate = True
29 name = None
30 filter_template = "%s FILTER (WHERE %%(filter)s)"
31 window_compatible = True
32 allow_distinct = False
33 empty_result_set_value = None
35 def __init__(
36 self, *expressions, distinct=False, filter=None, default=None, **extra
37 ):
38 if distinct and not self.allow_distinct:
39 raise TypeError(f"{self.__class__.__name__} does not allow distinct.")
40 if default is not None and self.empty_result_set_value is not None:
41 raise TypeError(f"{self.__class__.__name__} does not allow default.")
42 self.distinct = distinct
43 self.filter = filter
44 self.default = default
45 super().__init__(*expressions, **extra)
47 def get_source_fields(self):
48 # Don't return the filter expression since it's not a source field.
49 return [e._output_field_or_none for e in super().get_source_expressions()]
51 def get_source_expressions(self):
52 source_expressions = super().get_source_expressions()
53 if self.filter:
54 return source_expressions + [self.filter]
55 return source_expressions
57 def set_source_expressions(self, exprs):
58 self.filter = self.filter and exprs.pop()
59 return super().set_source_expressions(exprs)
61 def resolve_expression(
62 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
63 ):
64 # Aggregates are not allowed in UPDATE queries, so ignore for_save
65 c = super().resolve_expression(query, allow_joins, reuse, summarize)
66 c.filter = c.filter and c.filter.resolve_expression(
67 query, allow_joins, reuse, summarize
68 )
69 if not summarize:
70 # Call Aggregate.get_source_expressions() to avoid
71 # returning self.filter and including that in this loop.
72 expressions = super(Aggregate, c).get_source_expressions()
73 for index, expr in enumerate(expressions):
74 if expr.contains_aggregate:
75 before_resolved = self.get_source_expressions()[index]
76 name = (
77 before_resolved.name
78 if hasattr(before_resolved, "name")
79 else repr(before_resolved)
80 )
81 raise FieldError(
82 f"Cannot compute {c.name}('{name}'): '{name}' is an aggregate"
83 )
84 if (default := c.default) is None:
85 return c
86 if hasattr(default, "resolve_expression"):
87 default = default.resolve_expression(query, allow_joins, reuse, summarize)
88 if default._output_field_or_none is None:
89 default.output_field = c._output_field_or_none
90 else:
91 default = Value(default, c._output_field_or_none)
92 c.default = None # Reset the default argument before wrapping.
93 coalesce = Coalesce(c, default, output_field=c._output_field_or_none)
94 coalesce.is_summary = c.is_summary
95 return coalesce
97 @property
98 def default_alias(self):
99 expressions = self.get_source_expressions()
100 if len(expressions) == 1 and hasattr(expressions[0], "name"):
101 return f"{expressions[0].name}__{self.name.lower()}"
102 raise TypeError("Complex expressions require an alias")
104 def get_group_by_cols(self):
105 return []
107 def as_sql(self, compiler, connection, **extra_context):
108 extra_context["distinct"] = "DISTINCT " if self.distinct else ""
109 if self.filter:
110 if connection.features.supports_aggregate_filter_clause:
111 try:
112 filter_sql, filter_params = self.filter.as_sql(compiler, connection)
113 except FullResultSet:
114 pass
115 else:
116 template = self.filter_template % extra_context.get(
117 "template", self.template
118 )
119 sql, params = super().as_sql(
120 compiler,
121 connection,
122 template=template,
123 filter=filter_sql,
124 **extra_context,
125 )
126 return sql, (*params, *filter_params)
127 else:
128 copy = self.copy()
129 copy.filter = None
130 source_expressions = copy.get_source_expressions()
131 condition = When(self.filter, then=source_expressions[0])
132 copy.set_source_expressions([Case(condition)] + source_expressions[1:])
133 return super(Aggregate, copy).as_sql(
134 compiler, connection, **extra_context
135 )
136 return super().as_sql(compiler, connection, **extra_context)
138 def _get_repr_options(self):
139 options = super()._get_repr_options()
140 if self.distinct:
141 options["distinct"] = self.distinct
142 if self.filter:
143 options["filter"] = self.filter
144 return options
147class Avg(FixDurationInputMixin, NumericOutputFieldMixin, Aggregate):
148 function = "AVG"
149 name = "Avg"
150 allow_distinct = True
153class Count(Aggregate):
154 function = "COUNT"
155 name = "Count"
156 output_field = IntegerField()
157 allow_distinct = True
158 empty_result_set_value = 0
160 def __init__(self, expression, filter=None, **extra):
161 if expression == "*":
162 expression = Star()
163 if isinstance(expression, Star) and filter is not None:
164 raise ValueError("Star cannot be used with filter. Please specify a field.")
165 super().__init__(expression, filter=filter, **extra)
168class Max(Aggregate):
169 function = "MAX"
170 name = "Max"
173class Min(Aggregate):
174 function = "MIN"
175 name = "Min"
178class StdDev(NumericOutputFieldMixin, Aggregate):
179 name = "StdDev"
181 def __init__(self, expression, sample=False, **extra):
182 self.function = "STDDEV_SAMP" if sample else "STDDEV_POP"
183 super().__init__(expression, **extra)
185 def _get_repr_options(self):
186 return {**super()._get_repr_options(), "sample": self.function == "STDDEV_SAMP"}
189class Sum(FixDurationInputMixin, Aggregate):
190 function = "SUM"
191 name = "Sum"
192 allow_distinct = True
195class Variance(NumericOutputFieldMixin, Aggregate):
196 name = "Variance"
198 def __init__(self, expression, sample=False, **extra):
199 self.function = "VAR_SAMP" if sample else "VAR_POP"
200 super().__init__(expression, **extra)
202 def _get_repr_options(self):
203 return {**super()._get_repr_options(), "sample": self.function == "VAR_SAMP"}
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import copy
2import inspect
3import warnings
4from functools import partialmethod
5from itertools import chain
7import plain.runtime
8from plain import preflight
9from plain.exceptions import (
10 NON_FIELD_ERRORS,
11 FieldDoesNotExist,
12 FieldError,
13 MultipleObjectsReturned,
14 ObjectDoesNotExist,
15 ValidationError,
16)
17from plain.models import transaction
18from plain.models.aggregates import Max
19from plain.models.constants import LOOKUP_SEP
20from plain.models.constraints import CheckConstraint, UniqueConstraint
21from plain.models.db import (
22 PLAIN_VERSION_PICKLE_KEY,
23 DatabaseError,
24 connection,
25 connections,
26 router,
27)
28from plain.models.deletion import CASCADE, Collector
29from plain.models.expressions import ExpressionWrapper, RawSQL, Value
30from plain.models.fields import NOT_PROVIDED, IntegerField
31from plain.models.fields.related import (
32 ForeignObjectRel,
33 OneToOneField,
34 lazy_related_operation,
35 resolve_relation,
36)
37from plain.models.functions import Coalesce
38from plain.models.manager import Manager
39from plain.models.options import Options
40from plain.models.query import F, Q
41from plain.models.signals import (
42 class_prepared,
43 post_init,
44 post_save,
45 pre_init,
46 pre_save,
47)
48from plain.models.utils import AltersData, make_model_tuple
49from plain.packages import packages
50from plain.utils.encoding import force_str
51from plain.utils.hashable import make_hashable
54class Deferred:
55 def __repr__(self):
56 return "<Deferred field>"
58 def __str__(self):
59 return "<Deferred field>"
62DEFERRED = Deferred()
65def subclass_exception(name, bases, module, attached_to):
66 """
67 Create exception subclass. Used by ModelBase below.
69 The exception is created in a way that allows it to be pickled, assuming
70 that the returned exception class will be added as an attribute to the
71 'attached_to' class.
72 """
73 return type(
74 name,
75 bases,
76 {
77 "__module__": module,
78 "__qualname__": f"{attached_to.__qualname__}.{name}",
79 },
80 )
83def _has_contribute_to_class(value):
84 # Only call contribute_to_class() if it's bound.
85 return not inspect.isclass(value) and hasattr(value, "contribute_to_class")
88class ModelBase(type):
89 """Metaclass for all models."""
91 def __new__(cls, name, bases, attrs, **kwargs):
92 super_new = super().__new__
94 # Also ensure initialization is only performed for subclasses of Model
95 # (excluding Model class itself).
96 parents = [b for b in bases if isinstance(b, ModelBase)]
97 if not parents:
98 return super_new(cls, name, bases, attrs)
100 # Create the class.
101 module = attrs.pop("__module__")
102 new_attrs = {"__module__": module}
103 classcell = attrs.pop("__classcell__", None)
104 if classcell is not None:
105 new_attrs["__classcell__"] = classcell
106 attr_meta = attrs.pop("Meta", None)
107 # Pass all attrs without a (Plain-specific) contribute_to_class()
108 # method to type.__new__() so that they're properly initialized
109 # (i.e. __set_name__()).
110 contributable_attrs = {}
111 for obj_name, obj in attrs.items():
112 if _has_contribute_to_class(obj):
113 contributable_attrs[obj_name] = obj
114 else:
115 new_attrs[obj_name] = obj
116 new_class = super_new(cls, name, bases, new_attrs, **kwargs)
118 abstract = getattr(attr_meta, "abstract", False)
119 meta = attr_meta or getattr(new_class, "Meta", None)
120 base_meta = getattr(new_class, "_meta", None)
122 package_label = None
124 # Look for an application configuration to attach the model to.
125 package_config = packages.get_containing_package_config(module)
127 if getattr(meta, "package_label", None) is None:
128 if package_config is None:
129 if not abstract:
130 raise RuntimeError(
131 f"Model class {module}.{name} doesn't declare an explicit "
132 "package_label and isn't in an application in "
133 "INSTALLED_PACKAGES."
134 )
136 else:
137 package_label = package_config.label
139 new_class.add_to_class("_meta", Options(meta, package_label))
140 if not abstract:
141 new_class.add_to_class(
142 "DoesNotExist",
143 subclass_exception(
144 "DoesNotExist",
145 tuple(
146 x.DoesNotExist
147 for x in parents
148 if hasattr(x, "_meta") and not x._meta.abstract
149 )
150 or (ObjectDoesNotExist,),
151 module,
152 attached_to=new_class,
153 ),
154 )
155 new_class.add_to_class(
156 "MultipleObjectsReturned",
157 subclass_exception(
158 "MultipleObjectsReturned",
159 tuple(
160 x.MultipleObjectsReturned
161 for x in parents
162 if hasattr(x, "_meta") and not x._meta.abstract
163 )
164 or (MultipleObjectsReturned,),
165 module,
166 attached_to=new_class,
167 ),
168 )
169 if base_meta and not base_meta.abstract:
170 # Non-abstract child classes inherit some attributes from their
171 # non-abstract parent (unless an ABC comes before it in the
172 # method resolution order).
173 if not hasattr(meta, "ordering"):
174 new_class._meta.ordering = base_meta.ordering
175 if not hasattr(meta, "get_latest_by"):
176 new_class._meta.get_latest_by = base_meta.get_latest_by
178 # Add remaining attributes (those with a contribute_to_class() method)
179 # to the class.
180 for obj_name, obj in contributable_attrs.items():
181 new_class.add_to_class(obj_name, obj)
183 # All the fields of any type declared on this model
184 new_fields = chain(
185 new_class._meta.local_fields,
186 new_class._meta.local_many_to_many,
187 new_class._meta.private_fields,
188 )
189 field_names = {f.name for f in new_fields}
191 new_class._meta.concrete_model = new_class
193 # Collect the parent links for multi-table inheritance.
194 parent_links = {}
195 for base in reversed([new_class] + parents):
196 # Conceptually equivalent to `if base is Model`.
197 if not hasattr(base, "_meta"):
198 continue
199 # Skip concrete parent classes.
200 if base != new_class and not base._meta.abstract:
201 continue
202 # Locate OneToOneField instances.
203 for field in base._meta.local_fields:
204 if isinstance(field, OneToOneField) and field.remote_field.parent_link:
205 related = resolve_relation(new_class, field.remote_field.model)
206 parent_links[make_model_tuple(related)] = field
208 # Track fields inherited from base models.
209 inherited_attributes = set()
210 # Do the appropriate setup for any model parents.
211 for base in new_class.mro():
212 if base not in parents or not hasattr(base, "_meta"):
213 # Things without _meta aren't functional models, so they're
214 # uninteresting parents.
215 inherited_attributes.update(base.__dict__)
216 continue
218 parent_fields = base._meta.local_fields + base._meta.local_many_to_many
219 if not base._meta.abstract:
220 # Check for clashes between locally declared fields and those
221 # on the base classes.
222 for field in parent_fields:
223 if field.name in field_names:
224 raise FieldError(
225 f"Local field {field.name!r} in class {name!r} clashes with field of "
226 f"the same name from base class {base.__name__!r}."
227 )
228 else:
229 inherited_attributes.add(field.name)
231 # Concrete classes...
232 base = base._meta.concrete_model
233 base_key = make_model_tuple(base)
234 if base_key in parent_links:
235 field = parent_links[base_key]
236 else:
237 attr_name = f"{base._meta.model_name}_ptr"
238 field = OneToOneField(
239 base,
240 on_delete=CASCADE,
241 name=attr_name,
242 auto_created=True,
243 parent_link=True,
244 )
246 if attr_name in field_names:
247 raise FieldError(
248 f"Auto-generated field '{attr_name}' in class {name!r} for "
249 f"parent_link to base class {base.__name__!r} clashes with "
250 "declared field of the same name."
251 )
253 # Only add the ptr field if it's not already present;
254 # e.g. migrations will already have it specified
255 if not hasattr(new_class, attr_name):
256 new_class.add_to_class(attr_name, field)
257 new_class._meta.parents[base] = field
258 else:
259 base_parents = base._meta.parents.copy()
261 # Add fields from abstract base class if it wasn't overridden.
262 for field in parent_fields:
263 if (
264 field.name not in field_names
265 and field.name not in new_class.__dict__
266 and field.name not in inherited_attributes
267 ):
268 new_field = copy.deepcopy(field)
269 new_class.add_to_class(field.name, new_field)
270 # Replace parent links defined on this base by the new
271 # field. It will be appropriately resolved if required.
272 if field.one_to_one:
273 for parent, parent_link in base_parents.items():
274 if field == parent_link:
275 base_parents[parent] = new_field
277 # Pass any non-abstract parent classes onto child.
278 new_class._meta.parents.update(base_parents)
280 # Inherit private fields (like GenericForeignKey) from the parent
281 # class
282 for field in base._meta.private_fields:
283 if field.name in field_names:
284 if not base._meta.abstract:
285 raise FieldError(
286 f"Local field {field.name!r} in class {name!r} clashes with field of "
287 f"the same name from base class {base.__name__!r}."
288 )
289 else:
290 field = copy.deepcopy(field)
291 if not base._meta.abstract:
292 field.mti_inherited = True
293 new_class.add_to_class(field.name, field)
295 # Copy indexes so that index names are unique when models extend an
296 # abstract model.
297 new_class._meta.indexes = [
298 copy.deepcopy(idx) for idx in new_class._meta.indexes
299 ]
301 if abstract:
302 # Abstract base models can't be instantiated and don't appear in
303 # the list of models for an app. We do the final setup for them a
304 # little differently from normal models.
305 attr_meta.abstract = False
306 new_class.Meta = attr_meta
307 return new_class
309 new_class._prepare()
310 new_class._meta.packages.register_model(
311 new_class._meta.package_label, new_class
312 )
313 return new_class
315 def add_to_class(cls, name, value):
316 if _has_contribute_to_class(value):
317 value.contribute_to_class(cls, name)
318 else:
319 setattr(cls, name, value)
321 def _prepare(cls):
322 """Create some methods once self._meta has been populated."""
323 opts = cls._meta
324 opts._prepare(cls)
326 if opts.order_with_respect_to:
327 cls.get_next_in_order = partialmethod(
328 cls._get_next_or_previous_in_order, is_next=True
329 )
330 cls.get_previous_in_order = partialmethod(
331 cls._get_next_or_previous_in_order, is_next=False
332 )
334 # Defer creating accessors on the foreign class until it has been
335 # created and registered. If remote_field is None, we're ordering
336 # with respect to a GenericForeignKey and don't know what the
337 # foreign class is - we'll add those accessors later in
338 # contribute_to_class().
339 if opts.order_with_respect_to.remote_field:
340 wrt = opts.order_with_respect_to
341 remote = wrt.remote_field.model
342 lazy_related_operation(make_foreign_order_accessors, cls, remote)
344 # Give the class a docstring -- its definition.
345 if cls.__doc__ is None:
346 cls.__doc__ = "{}({})".format(
347 cls.__name__,
348 ", ".join(f.name for f in opts.fields),
349 )
351 if not opts.managers:
352 if any(f.name == "objects" for f in opts.fields):
353 raise ValueError(
354 f"Model {cls.__name__} must specify a custom Manager, because it has a "
355 "field named 'objects'."
356 )
357 manager = Manager()
358 manager.auto_created = True
359 cls.add_to_class("objects", manager)
361 # Set the name of _meta.indexes. This can't be done in
362 # Options.contribute_to_class() because fields haven't been added to
363 # the model at that point.
364 for index in cls._meta.indexes:
365 if not index.name:
366 index.set_name_with_model(cls)
368 class_prepared.send(sender=cls)
370 @property
371 def _base_manager(cls):
372 return cls._meta.base_manager
374 @property
375 def _default_manager(cls):
376 return cls._meta.default_manager
379class ModelStateFieldsCacheDescriptor:
380 def __get__(self, instance, cls=None):
381 if instance is None:
382 return self
383 res = instance.fields_cache = {}
384 return res
387class ModelState:
388 """Store model instance state."""
390 db = None
391 # If true, uniqueness validation checks will consider this a new, unsaved
392 # object. Necessary for correct validation of new instances of objects with
393 # explicit (non-auto) PKs. This impacts validation only; it has no effect
394 # on the actual save.
395 adding = True
396 fields_cache = ModelStateFieldsCacheDescriptor()
399class Model(AltersData, metaclass=ModelBase):
400 def __init__(self, *args, **kwargs):
401 # Alias some things as locals to avoid repeat global lookups
402 cls = self.__class__
403 opts = self._meta
404 _setattr = setattr
405 _DEFERRED = DEFERRED
406 if opts.abstract:
407 raise TypeError("Abstract models cannot be instantiated.")
409 pre_init.send(sender=cls, args=args, kwargs=kwargs)
411 # Set up the storage for instance state
412 self._state = ModelState()
414 # There is a rather weird disparity here; if kwargs, it's set, then args
415 # overrides it. It should be one or the other; don't duplicate the work
416 # The reason for the kwargs check is that standard iterator passes in by
417 # args, and instantiation for iteration is 33% faster.
418 if len(args) > len(opts.concrete_fields):
419 # Daft, but matches old exception sans the err msg.
420 raise IndexError("Number of args exceeds number of fields")
422 if not kwargs:
423 fields_iter = iter(opts.concrete_fields)
424 # The ordering of the zip calls matter - zip throws StopIteration
425 # when an iter throws it. So if the first iter throws it, the second
426 # is *not* consumed. We rely on this, so don't change the order
427 # without changing the logic.
428 for val, field in zip(args, fields_iter):
429 if val is _DEFERRED:
430 continue
431 _setattr(self, field.attname, val)
432 else:
433 # Slower, kwargs-ready version.
434 fields_iter = iter(opts.fields)
435 for val, field in zip(args, fields_iter):
436 if val is _DEFERRED:
437 continue
438 _setattr(self, field.attname, val)
439 if kwargs.pop(field.name, NOT_PROVIDED) is not NOT_PROVIDED:
440 raise TypeError(
441 f"{cls.__qualname__}() got both positional and "
442 f"keyword arguments for field '{field.name}'."
443 )
445 # Now we're left with the unprocessed fields that *must* come from
446 # keywords, or default.
448 for field in fields_iter:
449 is_related_object = False
450 # Virtual field
451 if field.attname not in kwargs and field.column is None:
452 continue
453 if kwargs:
454 if isinstance(field.remote_field, ForeignObjectRel):
455 try:
456 # Assume object instance was passed in.
457 rel_obj = kwargs.pop(field.name)
458 is_related_object = True
459 except KeyError:
460 try:
461 # Object instance wasn't passed in -- must be an ID.
462 val = kwargs.pop(field.attname)
463 except KeyError:
464 val = field.get_default()
465 else:
466 try:
467 val = kwargs.pop(field.attname)
468 except KeyError:
469 # This is done with an exception rather than the
470 # default argument on pop because we don't want
471 # get_default() to be evaluated, and then not used.
472 # Refs #12057.
473 val = field.get_default()
474 else:
475 val = field.get_default()
477 if is_related_object:
478 # If we are passed a related instance, set it using the
479 # field.name instead of field.attname (e.g. "user" instead of
480 # "user_id") so that the object gets properly cached (and type
481 # checked) by the RelatedObjectDescriptor.
482 if rel_obj is not _DEFERRED:
483 _setattr(self, field.name, rel_obj)
484 else:
485 if val is not _DEFERRED:
486 _setattr(self, field.attname, val)
488 if kwargs:
489 property_names = opts._property_names
490 unexpected = ()
491 for prop, value in kwargs.items():
492 # Any remaining kwargs must correspond to properties or virtual
493 # fields.
494 if prop in property_names:
495 if value is not _DEFERRED:
496 _setattr(self, prop, value)
497 else:
498 try:
499 opts.get_field(prop)
500 except FieldDoesNotExist:
501 unexpected += (prop,)
502 else:
503 if value is not _DEFERRED:
504 _setattr(self, prop, value)
505 if unexpected:
506 unexpected_names = ", ".join(repr(n) for n in unexpected)
507 raise TypeError(
508 f"{cls.__name__}() got unexpected keyword arguments: "
509 f"{unexpected_names}"
510 )
511 super().__init__()
512 post_init.send(sender=cls, instance=self)
514 @classmethod
515 def from_db(cls, db, field_names, values):
516 if len(values) != len(cls._meta.concrete_fields):
517 values_iter = iter(values)
518 values = [
519 next(values_iter) if f.attname in field_names else DEFERRED
520 for f in cls._meta.concrete_fields
521 ]
522 new = cls(*values)
523 new._state.adding = False
524 new._state.db = db
525 return new
527 def __repr__(self):
528 return f"<{self.__class__.__name__}: {self}>"
530 def __str__(self):
531 return f"{self.__class__.__name__} object ({self.pk})"
533 def __eq__(self, other):
534 if not isinstance(other, Model):
535 return NotImplemented
536 if self._meta.concrete_model != other._meta.concrete_model:
537 return False
538 my_pk = self.pk
539 if my_pk is None:
540 return self is other
541 return my_pk == other.pk
543 def __hash__(self):
544 if self.pk is None:
545 raise TypeError("Model instances without primary key value are unhashable")
546 return hash(self.pk)
548 def __reduce__(self):
549 data = self.__getstate__()
550 data[PLAIN_VERSION_PICKLE_KEY] = plain.runtime.__version__
551 class_id = self._meta.package_label, self._meta.object_name
552 return model_unpickle, (class_id,), data
554 def __getstate__(self):
555 """Hook to allow choosing the attributes to pickle."""
556 state = self.__dict__.copy()
557 state["_state"] = copy.copy(state["_state"])
558 state["_state"].fields_cache = state["_state"].fields_cache.copy()
559 # memoryview cannot be pickled, so cast it to bytes and store
560 # separately.
561 _memoryview_attrs = []
562 for attr, value in state.items():
563 if isinstance(value, memoryview):
564 _memoryview_attrs.append((attr, bytes(value)))
565 if _memoryview_attrs:
566 state["_memoryview_attrs"] = _memoryview_attrs
567 for attr, value in _memoryview_attrs:
568 state.pop(attr)
569 return state
571 def __setstate__(self, state):
572 pickled_version = state.get(PLAIN_VERSION_PICKLE_KEY)
573 if pickled_version:
574 if pickled_version != plain.runtime.__version__:
575 warnings.warn(
576 f"Pickled model instance's Plain version {pickled_version} does not "
577 f"match the current version {plain.runtime.__version__}.",
578 RuntimeWarning,
579 stacklevel=2,
580 )
581 else:
582 warnings.warn(
583 "Pickled model instance's Plain version is not specified.",
584 RuntimeWarning,
585 stacklevel=2,
586 )
587 if "_memoryview_attrs" in state:
588 for attr, value in state.pop("_memoryview_attrs"):
589 state[attr] = memoryview(value)
590 self.__dict__.update(state)
592 def _get_pk_val(self, meta=None):
593 meta = meta or self._meta
594 return getattr(self, meta.pk.attname)
596 def _set_pk_val(self, value):
597 for parent_link in self._meta.parents.values():
598 if parent_link and parent_link != self._meta.pk:
599 setattr(self, parent_link.target_field.attname, value)
600 return setattr(self, self._meta.pk.attname, value)
602 pk = property(_get_pk_val, _set_pk_val)
604 def get_deferred_fields(self):
605 """
606 Return a set containing names of deferred fields for this instance.
607 """
608 return {
609 f.attname
610 for f in self._meta.concrete_fields
611 if f.attname not in self.__dict__
612 }
614 def refresh_from_db(self, using=None, fields=None):
615 """
616 Reload field values from the database.
618 By default, the reloading happens from the database this instance was
619 loaded from, or by the read router if this instance wasn't loaded from
620 any database. The using parameter will override the default.
622 Fields can be used to specify which fields to reload. The fields
623 should be an iterable of field attnames. If fields is None, then
624 all non-deferred fields are reloaded.
626 When accessing deferred fields of an instance, the deferred loading
627 of the field will call this method.
628 """
629 if fields is None:
630 self._prefetched_objects_cache = {}
631 else:
632 prefetched_objects_cache = getattr(self, "_prefetched_objects_cache", ())
633 for field in fields:
634 if field in prefetched_objects_cache:
635 del prefetched_objects_cache[field]
636 fields.remove(field)
637 if not fields:
638 return
639 if any(LOOKUP_SEP in f for f in fields):
640 raise ValueError(
641 f'Found "{LOOKUP_SEP}" in fields argument. Relations and transforms '
642 "are not allowed in fields."
643 )
645 hints = {"instance": self}
646 db_instance_qs = self.__class__._base_manager.db_manager(
647 using, hints=hints
648 ).filter(pk=self.pk)
650 # Use provided fields, if not set then reload all non-deferred fields.
651 deferred_fields = self.get_deferred_fields()
652 if fields is not None:
653 fields = list(fields)
654 db_instance_qs = db_instance_qs.only(*fields)
655 elif deferred_fields:
656 fields = [
657 f.attname
658 for f in self._meta.concrete_fields
659 if f.attname not in deferred_fields
660 ]
661 db_instance_qs = db_instance_qs.only(*fields)
663 db_instance = db_instance_qs.get()
664 non_loaded_fields = db_instance.get_deferred_fields()
665 for field in self._meta.concrete_fields:
666 if field.attname in non_loaded_fields:
667 # This field wasn't refreshed - skip ahead.
668 continue
669 setattr(self, field.attname, getattr(db_instance, field.attname))
670 # Clear cached foreign keys.
671 if field.is_relation and field.is_cached(self):
672 field.delete_cached_value(self)
674 # Clear cached relations.
675 for field in self._meta.related_objects:
676 if field.is_cached(self):
677 field.delete_cached_value(self)
679 # Clear cached private relations.
680 for field in self._meta.private_fields:
681 if field.is_relation and field.is_cached(self):
682 field.delete_cached_value(self)
684 self._state.db = db_instance._state.db
686 def serializable_value(self, field_name):
687 """
688 Return the value of the field name for this instance. If the field is
689 a foreign key, return the id value instead of the object. If there's
690 no Field object with this name on the model, return the model
691 attribute's value.
693 Used to serialize a field's value (in the serializer, or form output,
694 for example). Normally, you would just access the attribute directly
695 and not use this method.
696 """
697 try:
698 field = self._meta.get_field(field_name)
699 except FieldDoesNotExist:
700 return getattr(self, field_name)
701 return getattr(self, field.attname)
703 def save(
704 self,
705 *,
706 clean_and_validate=True,
707 force_insert=False,
708 force_update=False,
709 using=None,
710 update_fields=None,
711 ):
712 """
713 Save the current instance. Override this in a subclass if you want to
714 control the saving process.
716 The 'force_insert' and 'force_update' parameters can be used to insist
717 that the "save" must be an SQL insert or update (or equivalent for
718 non-SQL backends), respectively. Normally, they should not be set.
719 """
720 self._prepare_related_fields_for_save(operation_name="save")
722 using = using or router.db_for_write(self.__class__, instance=self)
723 if force_insert and (force_update or update_fields):
724 raise ValueError("Cannot force both insert and updating in model saving.")
726 deferred_fields = self.get_deferred_fields()
727 if update_fields is not None:
728 # If update_fields is empty, skip the save. We do also check for
729 # no-op saves later on for inheritance cases. This bailout is
730 # still needed for skipping signal sending.
731 if not update_fields:
732 return
734 update_fields = frozenset(update_fields)
735 field_names = self._meta._non_pk_concrete_field_names
736 non_model_fields = update_fields.difference(field_names)
738 if non_model_fields:
739 raise ValueError(
740 "The following fields do not exist in this model, are m2m "
741 "fields, or are non-concrete fields: {}".format(
742 ", ".join(non_model_fields)
743 )
744 )
746 # If saving to the same database, and this model is deferred, then
747 # automatically do an "update_fields" save on the loaded fields.
748 elif not force_insert and deferred_fields and using == self._state.db:
749 field_names = set()
750 for field in self._meta.concrete_fields:
751 if not field.primary_key and not hasattr(field, "through"):
752 field_names.add(field.attname)
753 loaded_fields = field_names.difference(deferred_fields)
754 if loaded_fields:
755 update_fields = frozenset(loaded_fields)
757 if clean_and_validate:
758 self.full_clean(exclude=deferred_fields)
760 self.save_base(
761 using=using,
762 force_insert=force_insert,
763 force_update=force_update,
764 update_fields=update_fields,
765 )
767 save.alters_data = True
769 def save_base(
770 self,
771 *,
772 raw=False,
773 force_insert=False,
774 force_update=False,
775 using=None,
776 update_fields=None,
777 ):
778 """
779 Handle the parts of saving which should be done only once per save,
780 yet need to be done in raw saves, too. This includes some sanity
781 checks and signal sending.
783 The 'raw' argument is telling save_base not to save any parent
784 models and not to do any changes to the values before save. This
785 is used by fixture loading.
786 """
787 using = using or router.db_for_write(self.__class__, instance=self)
788 assert not (force_insert and (force_update or update_fields))
789 assert update_fields is None or update_fields
790 cls = origin = self.__class__
791 meta = cls._meta
792 if not meta.auto_created:
793 pre_save.send(
794 sender=origin,
795 instance=self,
796 raw=raw,
797 using=using,
798 update_fields=update_fields,
799 )
800 # A transaction isn't needed if one query is issued.
801 if meta.parents:
802 context_manager = transaction.atomic(using=using, savepoint=False)
803 else:
804 context_manager = transaction.mark_for_rollback_on_error(using=using)
805 with context_manager:
806 parent_inserted = False
807 if not raw:
808 parent_inserted = self._save_parents(cls, using, update_fields)
809 updated = self._save_table(
810 raw,
811 cls,
812 force_insert or parent_inserted,
813 force_update,
814 using,
815 update_fields,
816 )
817 # Store the database on which the object was saved
818 self._state.db = using
819 # Once saved, this is no longer a to-be-added instance.
820 self._state.adding = False
822 # Signal that the save is complete
823 if not meta.auto_created:
824 post_save.send(
825 sender=origin,
826 instance=self,
827 created=(not updated),
828 update_fields=update_fields,
829 raw=raw,
830 using=using,
831 )
833 save_base.alters_data = True
835 def _save_parents(self, cls, using, update_fields):
836 """Save all the parents of cls using values from self."""
837 meta = cls._meta
838 inserted = False
839 for parent, field in meta.parents.items():
840 # Make sure the link fields are synced between parent and self.
841 if (
842 field
843 and getattr(self, parent._meta.pk.attname) is None
844 and getattr(self, field.attname) is not None
845 ):
846 setattr(self, parent._meta.pk.attname, getattr(self, field.attname))
847 parent_inserted = self._save_parents(
848 cls=parent, using=using, update_fields=update_fields
849 )
850 updated = self._save_table(
851 cls=parent,
852 using=using,
853 update_fields=update_fields,
854 force_insert=parent_inserted,
855 )
856 if not updated:
857 inserted = True
858 # Set the parent's PK value to self.
859 if field:
860 setattr(self, field.attname, self._get_pk_val(parent._meta))
861 # Since we didn't have an instance of the parent handy set
862 # attname directly, bypassing the descriptor. Invalidate
863 # the related object cache, in case it's been accidentally
864 # populated. A fresh instance will be re-built from the
865 # database if necessary.
866 if field.is_cached(self):
867 field.delete_cached_value(self)
868 return inserted
870 def _save_table(
871 self,
872 raw=False,
873 cls=None,
874 force_insert=False,
875 force_update=False,
876 using=None,
877 update_fields=None,
878 ):
879 """
880 Do the heavy-lifting involved in saving. Update or insert the data
881 for a single table.
882 """
883 meta = cls._meta
884 non_pks = [f for f in meta.local_concrete_fields if not f.primary_key]
886 if update_fields:
887 non_pks = [
888 f
889 for f in non_pks
890 if f.name in update_fields or f.attname in update_fields
891 ]
893 pk_val = self._get_pk_val(meta)
894 if pk_val is None:
895 pk_val = meta.pk.get_pk_value_on_save(self)
896 setattr(self, meta.pk.attname, pk_val)
897 pk_set = pk_val is not None
898 if not pk_set and (force_update or update_fields):
899 raise ValueError("Cannot force an update in save() with no primary key.")
900 updated = False
901 # Skip an UPDATE when adding an instance and primary key has a default.
902 if (
903 not raw
904 and not force_insert
905 and self._state.adding
906 and meta.pk.default
907 and meta.pk.default is not NOT_PROVIDED
908 ):
909 force_insert = True
910 # If possible, try an UPDATE. If that doesn't update anything, do an INSERT.
911 if pk_set and not force_insert:
912 base_qs = cls._base_manager.using(using)
913 values = [
914 (
915 f,
916 None,
917 (getattr(self, f.attname) if raw else f.pre_save(self, False)),
918 )
919 for f in non_pks
920 ]
921 forced_update = update_fields or force_update
922 updated = self._do_update(
923 base_qs, using, pk_val, values, update_fields, forced_update
924 )
925 if force_update and not updated:
926 raise DatabaseError("Forced update did not affect any rows.")
927 if update_fields and not updated:
928 raise DatabaseError("Save with update_fields did not affect any rows.")
929 if not updated:
930 if meta.order_with_respect_to:
931 # If this is a model with an order_with_respect_to
932 # autopopulate the _order field
933 field = meta.order_with_respect_to
934 filter_args = field.get_filter_kwargs_for_object(self)
935 self._order = (
936 cls._base_manager.using(using)
937 .filter(**filter_args)
938 .aggregate(
939 _order__max=Coalesce(
940 ExpressionWrapper(
941 Max("_order") + Value(1), output_field=IntegerField()
942 ),
943 Value(0),
944 ),
945 )["_order__max"]
946 )
947 fields = meta.local_concrete_fields
948 if not pk_set:
949 fields = [f for f in fields if f is not meta.auto_field]
951 returning_fields = meta.db_returning_fields
952 results = self._do_insert(
953 cls._base_manager, using, fields, returning_fields, raw
954 )
955 if results:
956 for value, field in zip(results[0], returning_fields):
957 setattr(self, field.attname, value)
958 return updated
960 def _do_update(self, base_qs, using, pk_val, values, update_fields, forced_update):
961 """
962 Try to update the model. Return True if the model was updated (if an
963 update query was done and a matching row was found in the DB).
964 """
965 filtered = base_qs.filter(pk=pk_val)
966 if not values:
967 # We can end up here when saving a model in inheritance chain where
968 # update_fields doesn't target any field in current model. In that
969 # case we just say the update succeeded. Another case ending up here
970 # is a model with just PK - in that case check that the PK still
971 # exists.
972 return update_fields is not None or filtered.exists()
973 if self._meta.select_on_save and not forced_update:
974 return (
975 filtered.exists()
976 and
977 # It may happen that the object is deleted from the DB right after
978 # this check, causing the subsequent UPDATE to return zero matching
979 # rows. The same result can occur in some rare cases when the
980 # database returns zero despite the UPDATE being executed
981 # successfully (a row is matched and updated). In order to
982 # distinguish these two cases, the object's existence in the
983 # database is again checked for if the UPDATE query returns 0.
984 (filtered._update(values) > 0 or filtered.exists())
985 )
986 return filtered._update(values) > 0
988 def _do_insert(self, manager, using, fields, returning_fields, raw):
989 """
990 Do an INSERT. If returning_fields is defined then this method should
991 return the newly created data for the model.
992 """
993 return manager._insert(
994 [self],
995 fields=fields,
996 returning_fields=returning_fields,
997 using=using,
998 raw=raw,
999 )
1001 def _prepare_related_fields_for_save(self, operation_name, fields=None):
1002 # Ensure that a model instance without a PK hasn't been assigned to
1003 # a ForeignKey, GenericForeignKey or OneToOneField on this model. If
1004 # the field is nullable, allowing the save would result in silent data
1005 # loss.
1006 for field in self._meta.concrete_fields:
1007 if fields and field not in fields:
1008 continue
1009 # If the related field isn't cached, then an instance hasn't been
1010 # assigned and there's no need to worry about this check.
1011 if field.is_relation and field.is_cached(self):
1012 obj = getattr(self, field.name, None)
1013 if not obj:
1014 continue
1015 # A pk may have been assigned manually to a model instance not
1016 # saved to the database (or auto-generated in a case like
1017 # UUIDField), but we allow the save to proceed and rely on the
1018 # database to raise an IntegrityError if applicable. If
1019 # constraints aren't supported by the database, there's the
1020 # unavoidable risk of data corruption.
1021 if obj.pk is None:
1022 # Remove the object from a related instance cache.
1023 if not field.remote_field.multiple:
1024 field.remote_field.delete_cached_value(obj)
1025 raise ValueError(
1026 f"{operation_name}() prohibited to prevent data loss due to unsaved "
1027 f"related object '{field.name}'."
1028 )
1029 elif getattr(self, field.attname) in field.empty_values:
1030 # Set related object if it has been saved after an
1031 # assignment.
1032 setattr(self, field.name, obj)
1033 # If the relationship's pk/to_field was changed, clear the
1034 # cached relationship.
1035 if getattr(obj, field.target_field.attname) != getattr(
1036 self, field.attname
1037 ):
1038 field.delete_cached_value(self)
1039 # GenericForeignKeys are private.
1040 for field in self._meta.private_fields:
1041 if fields and field not in fields:
1042 continue
1043 if (
1044 field.is_relation
1045 and field.is_cached(self)
1046 and hasattr(field, "fk_field")
1047 ):
1048 obj = field.get_cached_value(self, default=None)
1049 if obj and obj.pk is None:
1050 raise ValueError(
1051 f"{operation_name}() prohibited to prevent data loss due to "
1052 f"unsaved related object '{field.name}'."
1053 )
1055 def delete(self, using=None, keep_parents=False):
1056 if self.pk is None:
1057 raise ValueError(
1058 f"{self._meta.object_name} object can't be deleted because its {self._meta.pk.attname} attribute is set "
1059 "to None."
1060 )
1061 using = using or router.db_for_write(self.__class__, instance=self)
1062 collector = Collector(using=using, origin=self)
1063 collector.collect([self], keep_parents=keep_parents)
1064 return collector.delete()
1066 delete.alters_data = True
1068 def _get_FIELD_display(self, field):
1069 value = getattr(self, field.attname)
1070 choices_dict = dict(make_hashable(field.flatchoices))
1071 # force_str() to coerce lazy strings.
1072 return force_str(
1073 choices_dict.get(make_hashable(value), value), strings_only=True
1074 )
1076 def _get_next_or_previous_by_FIELD(self, field, is_next, **kwargs):
1077 if not self.pk:
1078 raise ValueError("get_next/get_previous cannot be used on unsaved objects.")
1079 op = "gt" if is_next else "lt"
1080 order = "" if is_next else "-"
1081 param = getattr(self, field.attname)
1082 q = Q.create([(field.name, param), (f"pk__{op}", self.pk)], connector=Q.AND)
1083 q = Q.create([q, (f"{field.name}__{op}", param)], connector=Q.OR)
1084 qs = (
1085 self.__class__._default_manager.using(self._state.db)
1086 .filter(**kwargs)
1087 .filter(q)
1088 .order_by(f"{order}{field.name}", f"{order}pk")
1089 )
1090 try:
1091 return qs[0]
1092 except IndexError:
1093 raise self.DoesNotExist(
1094 f"{self.__class__._meta.object_name} matching query does not exist."
1095 )
1097 def _get_next_or_previous_in_order(self, is_next):
1098 cachename = f"__{is_next}_order_cache"
1099 if not hasattr(self, cachename):
1100 op = "gt" if is_next else "lt"
1101 order = "_order" if is_next else "-_order"
1102 order_field = self._meta.order_with_respect_to
1103 filter_args = order_field.get_filter_kwargs_for_object(self)
1104 obj = (
1105 self.__class__._default_manager.filter(**filter_args)
1106 .filter(
1107 **{
1108 f"_order__{op}": self.__class__._default_manager.values(
1109 "_order"
1110 ).filter(**{self._meta.pk.name: self.pk})
1111 }
1112 )
1113 .order_by(order)[:1]
1114 .get()
1115 )
1116 setattr(self, cachename, obj)
1117 return getattr(self, cachename)
1119 def _get_field_value_map(self, meta, exclude=None):
1120 if exclude is None:
1121 exclude = set()
1122 meta = meta or self._meta
1123 return {
1124 field.name: Value(getattr(self, field.attname), field)
1125 for field in meta.local_concrete_fields
1126 if field.name not in exclude
1127 }
1129 def prepare_database_save(self, field):
1130 if self.pk is None:
1131 raise ValueError(
1132 f"Unsaved model instance {self!r} cannot be used in an ORM query."
1133 )
1134 return getattr(self, field.remote_field.get_related_field().attname)
1136 def clean(self):
1137 """
1138 Hook for doing any extra model-wide validation after clean() has been
1139 called on every field by self.clean_fields. Any ValidationError raised
1140 by this method will not be associated with a particular field; it will
1141 have a special-case association with the field defined by NON_FIELD_ERRORS.
1142 """
1143 pass
1145 def validate_unique(self, exclude=None):
1146 """
1147 Check unique constraints on the model and raise ValidationError if any
1148 failed.
1149 """
1150 unique_checks = self._get_unique_checks(exclude=exclude)
1152 if errors := self._perform_unique_checks(unique_checks):
1153 raise ValidationError(errors)
1155 def _get_unique_checks(self, exclude=None):
1156 """
1157 Return a list of checks to perform. Since validate_unique() could be
1158 called from a ModelForm, some fields may have been excluded; we can't
1159 perform a unique check on a model that is missing fields involved
1160 in that check. Fields that did not validate should also be excluded,
1161 but they need to be passed in via the exclude argument.
1162 """
1163 if exclude is None:
1164 exclude = set()
1165 unique_checks = []
1167 # Gather a list of checks for fields declared as unique and add them to
1168 # the list of checks.
1170 fields_with_class = [(self.__class__, self._meta.local_fields)]
1171 for parent_class in self._meta.get_parent_list():
1172 fields_with_class.append((parent_class, parent_class._meta.local_fields))
1174 for model_class, fields in fields_with_class:
1175 for f in fields:
1176 name = f.name
1177 if name in exclude:
1178 continue
1179 if f.unique:
1180 unique_checks.append((model_class, (name,)))
1182 return unique_checks
1184 def _perform_unique_checks(self, unique_checks):
1185 errors = {}
1187 for model_class, unique_check in unique_checks:
1188 # Try to look up an existing object with the same values as this
1189 # object's values for all the unique field.
1191 lookup_kwargs = {}
1192 for field_name in unique_check:
1193 f = self._meta.get_field(field_name)
1194 lookup_value = getattr(self, f.attname)
1195 # TODO: Handle multiple backends with different feature flags.
1196 if lookup_value is None or (
1197 lookup_value == ""
1198 and connection.features.interprets_empty_strings_as_nulls
1199 ):
1200 # no value, skip the lookup
1201 continue
1202 if f.primary_key and not self._state.adding:
1203 # no need to check for unique primary key when editing
1204 continue
1205 lookup_kwargs[str(field_name)] = lookup_value
1207 # some fields were skipped, no reason to do the check
1208 if len(unique_check) != len(lookup_kwargs):
1209 continue
1211 qs = model_class._default_manager.filter(**lookup_kwargs)
1213 # Exclude the current object from the query if we are editing an
1214 # instance (as opposed to creating a new one)
1215 # Note that we need to use the pk as defined by model_class, not
1216 # self.pk. These can be different fields because model inheritance
1217 # allows single model to have effectively multiple primary keys.
1218 # Refs #17615.
1219 model_class_pk = self._get_pk_val(model_class._meta)
1220 if not self._state.adding and model_class_pk is not None:
1221 qs = qs.exclude(pk=model_class_pk)
1222 if qs.exists():
1223 if len(unique_check) == 1:
1224 key = unique_check[0]
1225 else:
1226 key = NON_FIELD_ERRORS
1227 errors.setdefault(key, []).append(
1228 self.unique_error_message(model_class, unique_check)
1229 )
1231 return errors
1233 def unique_error_message(self, model_class, unique_check):
1234 opts = model_class._meta
1236 params = {
1237 "model": self,
1238 "model_class": model_class,
1239 "model_name": opts.model_name,
1240 "unique_check": unique_check,
1241 }
1243 if len(unique_check) == 1:
1244 field = opts.get_field(unique_check[0])
1245 params["field_label"] = field.name
1246 return ValidationError(
1247 message=field.error_messages["unique"],
1248 code="unique",
1249 params=params,
1250 )
1251 else:
1252 field_names = [opts.get_field(f).name for f in unique_check]
1254 # Put an "and" before the last one
1255 field_names[-1] = f"and {field_names[-1]}"
1257 if len(field_names) > 2:
1258 # Comma join if more than 2
1259 params["field_label"] = ", ".join(field_names)
1260 else:
1261 # Just a space if there are only 2
1262 params["field_label"] = " ".join(field_names)
1264 # Use the first field as the message format...
1265 message = opts.get_field(unique_check[0]).error_messages["unique"]
1267 return ValidationError(
1268 message=message,
1269 code="unique",
1270 params=params,
1271 )
1273 def get_constraints(self):
1274 constraints = [(self.__class__, self._meta.constraints)]
1275 for parent_class in self._meta.get_parent_list():
1276 if parent_class._meta.constraints:
1277 constraints.append((parent_class, parent_class._meta.constraints))
1278 return constraints
1280 def validate_constraints(self, exclude=None):
1281 constraints = self.get_constraints()
1282 using = router.db_for_write(self.__class__, instance=self)
1284 errors = {}
1285 for model_class, model_constraints in constraints:
1286 for constraint in model_constraints:
1287 try:
1288 constraint.validate(model_class, self, exclude=exclude, using=using)
1289 except ValidationError as e:
1290 if (
1291 getattr(e, "code", None) == "unique"
1292 and len(constraint.fields) == 1
1293 ):
1294 errors.setdefault(constraint.fields[0], []).append(e)
1295 else:
1296 errors = e.update_error_dict(errors)
1297 if errors:
1298 raise ValidationError(errors)
1300 def full_clean(
1301 self, *, exclude=None, validate_unique=True, validate_constraints=True
1302 ):
1303 """
1304 Call clean_fields(), clean(), validate_unique(), and
1305 validate_constraints() on the model. Raise a ValidationError for any
1306 errors that occur.
1307 """
1308 errors = {}
1309 if exclude is None:
1310 exclude = set()
1311 else:
1312 exclude = set(exclude)
1314 try:
1315 self.clean_fields(exclude=exclude)
1316 except ValidationError as e:
1317 errors = e.update_error_dict(errors)
1319 # Form.clean() is run even if other validation fails, so do the
1320 # same with Model.clean() for consistency.
1321 try:
1322 self.clean()
1323 except ValidationError as e:
1324 errors = e.update_error_dict(errors)
1326 # Run unique checks, but only for fields that passed validation.
1327 if validate_unique:
1328 for name in errors:
1329 if name != NON_FIELD_ERRORS and name not in exclude:
1330 exclude.add(name)
1331 try:
1332 self.validate_unique(exclude=exclude)
1333 except ValidationError as e:
1334 errors = e.update_error_dict(errors)
1336 # Run constraints checks, but only for fields that passed validation.
1337 if validate_constraints:
1338 for name in errors:
1339 if name != NON_FIELD_ERRORS and name not in exclude:
1340 exclude.add(name)
1341 try:
1342 self.validate_constraints(exclude=exclude)
1343 except ValidationError as e:
1344 errors = e.update_error_dict(errors)
1346 if errors:
1347 raise ValidationError(errors)
1349 def clean_fields(self, exclude=None):
1350 """
1351 Clean all fields and raise a ValidationError containing a dict
1352 of all validation errors if any occur.
1353 """
1354 if exclude is None:
1355 exclude = set()
1357 errors = {}
1358 for f in self._meta.fields:
1359 if f.name in exclude:
1360 continue
1361 # Skip validation for empty fields with blank=True. The developer
1362 # is responsible for making sure they have a valid value.
1363 raw_value = getattr(self, f.attname)
1364 if f.blank and raw_value in f.empty_values:
1365 continue
1366 try:
1367 setattr(self, f.attname, f.clean(raw_value, self))
1368 except ValidationError as e:
1369 errors[f.name] = e.error_list
1371 if errors:
1372 raise ValidationError(errors)
1374 @classmethod
1375 def check(cls, **kwargs):
1376 errors = [
1377 *cls._check_swappable(),
1378 *cls._check_managers(**kwargs),
1379 ]
1380 if not cls._meta.swapped:
1381 databases = kwargs.get("databases") or []
1382 errors += [
1383 *cls._check_fields(**kwargs),
1384 *cls._check_m2m_through_same_relationship(),
1385 *cls._check_long_column_names(databases),
1386 ]
1387 clash_errors = (
1388 *cls._check_id_field(),
1389 *cls._check_field_name_clashes(),
1390 *cls._check_model_name_db_lookup_clashes(),
1391 *cls._check_property_name_related_field_accessor_clashes(),
1392 *cls._check_single_primary_key(),
1393 )
1394 errors.extend(clash_errors)
1395 # If there are field name clashes, hide consequent column name
1396 # clashes.
1397 if not clash_errors:
1398 errors.extend(cls._check_column_name_clashes())
1399 errors += [
1400 *cls._check_indexes(databases),
1401 *cls._check_ordering(),
1402 *cls._check_constraints(databases),
1403 *cls._check_db_table_comment(databases),
1404 ]
1406 return errors
1408 @classmethod
1409 def _check_db_table_comment(cls, databases):
1410 if not cls._meta.db_table_comment:
1411 return []
1412 errors = []
1413 for db in databases:
1414 if not router.allow_migrate_model(db, cls):
1415 continue
1416 connection = connections[db]
1417 if not (
1418 connection.features.supports_comments
1419 or "supports_comments" in cls._meta.required_db_features
1420 ):
1421 errors.append(
1422 preflight.Warning(
1423 f"{connection.display_name} does not support comments on "
1424 f"tables (db_table_comment).",
1425 obj=cls,
1426 id="models.W046",
1427 )
1428 )
1429 return errors
1431 @classmethod
1432 def _check_swappable(cls):
1433 """Check if the swapped model exists."""
1434 errors = []
1435 if cls._meta.swapped:
1436 try:
1437 packages.get_model(cls._meta.swapped)
1438 except ValueError:
1439 errors.append(
1440 preflight.Error(
1441 f"'{cls._meta.swappable}' is not of the form 'package_label.package_name'.",
1442 id="models.E001",
1443 )
1444 )
1445 except LookupError:
1446 package_label, model_name = cls._meta.swapped.split(".")
1447 errors.append(
1448 preflight.Error(
1449 f"'{cls._meta.swappable}' references '{package_label}.{model_name}', which has not been "
1450 "installed, or is abstract.",
1451 id="models.E002",
1452 )
1453 )
1454 return errors
1456 @classmethod
1457 def _check_managers(cls, **kwargs):
1458 """Perform all manager checks."""
1459 errors = []
1460 for manager in cls._meta.managers:
1461 errors.extend(manager.check(**kwargs))
1462 return errors
1464 @classmethod
1465 def _check_fields(cls, **kwargs):
1466 """Perform all field checks."""
1467 errors = []
1468 for field in cls._meta.local_fields:
1469 errors.extend(field.check(**kwargs))
1470 for field in cls._meta.local_many_to_many:
1471 errors.extend(field.check(from_model=cls, **kwargs))
1472 return errors
1474 @classmethod
1475 def _check_m2m_through_same_relationship(cls):
1476 """Check if no relationship model is used by more than one m2m field."""
1478 errors = []
1479 seen_intermediary_signatures = []
1481 fields = cls._meta.local_many_to_many
1483 # Skip when the target model wasn't found.
1484 fields = (f for f in fields if isinstance(f.remote_field.model, ModelBase))
1486 # Skip when the relationship model wasn't found.
1487 fields = (f for f in fields if isinstance(f.remote_field.through, ModelBase))
1489 for f in fields:
1490 signature = (
1491 f.remote_field.model,
1492 cls,
1493 f.remote_field.through,
1494 f.remote_field.through_fields,
1495 )
1496 if signature in seen_intermediary_signatures:
1497 errors.append(
1498 preflight.Error(
1499 "The model has two identical many-to-many relations "
1500 f"through the intermediate model '{f.remote_field.through._meta.label}'.",
1501 obj=cls,
1502 id="models.E003",
1503 )
1504 )
1505 else:
1506 seen_intermediary_signatures.append(signature)
1507 return errors
1509 @classmethod
1510 def _check_id_field(cls):
1511 """Check if `id` field is a primary key."""
1512 fields = [
1513 f for f in cls._meta.local_fields if f.name == "id" and f != cls._meta.pk
1514 ]
1515 # fields is empty or consists of the invalid "id" field
1516 if fields and not fields[0].primary_key and cls._meta.pk.name == "id":
1517 return [
1518 preflight.Error(
1519 "'id' can only be used as a field name if the field also "
1520 "sets 'primary_key=True'.",
1521 obj=cls,
1522 id="models.E004",
1523 )
1524 ]
1525 else:
1526 return []
1528 @classmethod
1529 def _check_field_name_clashes(cls):
1530 """Forbid field shadowing in multi-table inheritance."""
1531 errors = []
1532 used_fields = {} # name or attname -> field
1534 # Check that multi-inheritance doesn't cause field name shadowing.
1535 for parent in cls._meta.get_parent_list():
1536 for f in parent._meta.local_fields:
1537 clash = used_fields.get(f.name) or used_fields.get(f.attname) or None
1538 if clash:
1539 errors.append(
1540 preflight.Error(
1541 f"The field '{clash.name}' from parent model "
1542 f"'{clash.model._meta}' clashes with the field '{f.name}' "
1543 f"from parent model '{f.model._meta}'.",
1544 obj=cls,
1545 id="models.E005",
1546 )
1547 )
1548 used_fields[f.name] = f
1549 used_fields[f.attname] = f
1551 # Check that fields defined in the model don't clash with fields from
1552 # parents, including auto-generated fields like multi-table inheritance
1553 # child accessors.
1554 for parent in cls._meta.get_parent_list():
1555 for f in parent._meta.get_fields():
1556 if f not in used_fields:
1557 used_fields[f.name] = f
1559 for f in cls._meta.local_fields:
1560 clash = used_fields.get(f.name) or used_fields.get(f.attname) or None
1561 # Note that we may detect clash between user-defined non-unique
1562 # field "id" and automatically added unique field "id", both
1563 # defined at the same model. This special case is considered in
1564 # _check_id_field and here we ignore it.
1565 id_conflict = (
1566 f.name == "id" and clash and clash.name == "id" and clash.model == cls
1567 )
1568 if clash and not id_conflict:
1569 errors.append(
1570 preflight.Error(
1571 f"The field '{f.name}' clashes with the field '{clash.name}' "
1572 f"from model '{clash.model._meta}'.",
1573 obj=f,
1574 id="models.E006",
1575 )
1576 )
1577 used_fields[f.name] = f
1578 used_fields[f.attname] = f
1580 return errors
1582 @classmethod
1583 def _check_column_name_clashes(cls):
1584 # Store a list of column names which have already been used by other fields.
1585 used_column_names = []
1586 errors = []
1588 for f in cls._meta.local_fields:
1589 _, column_name = f.get_attname_column()
1591 # Ensure the column name is not already in use.
1592 if column_name and column_name in used_column_names:
1593 errors.append(
1594 preflight.Error(
1595 f"Field '{f.name}' has column name '{column_name}' that is used by "
1596 "another field.",
1597 hint="Specify a 'db_column' for the field.",
1598 obj=cls,
1599 id="models.E007",
1600 )
1601 )
1602 else:
1603 used_column_names.append(column_name)
1605 return errors
1607 @classmethod
1608 def _check_model_name_db_lookup_clashes(cls):
1609 errors = []
1610 model_name = cls.__name__
1611 if model_name.startswith("_") or model_name.endswith("_"):
1612 errors.append(
1613 preflight.Error(
1614 f"The model name '{model_name}' cannot start or end with an underscore "
1615 "as it collides with the query lookup syntax.",
1616 obj=cls,
1617 id="models.E023",
1618 )
1619 )
1620 elif LOOKUP_SEP in model_name:
1621 errors.append(
1622 preflight.Error(
1623 f"The model name '{model_name}' cannot contain double underscores as "
1624 "it collides with the query lookup syntax.",
1625 obj=cls,
1626 id="models.E024",
1627 )
1628 )
1629 return errors
1631 @classmethod
1632 def _check_property_name_related_field_accessor_clashes(cls):
1633 errors = []
1634 property_names = cls._meta._property_names
1635 related_field_accessors = (
1636 f.get_attname()
1637 for f in cls._meta._get_fields(reverse=False)
1638 if f.is_relation and f.related_model is not None
1639 )
1640 for accessor in related_field_accessors:
1641 if accessor in property_names:
1642 errors.append(
1643 preflight.Error(
1644 f"The property '{accessor}' clashes with a related field "
1645 "accessor.",
1646 obj=cls,
1647 id="models.E025",
1648 )
1649 )
1650 return errors
1652 @classmethod
1653 def _check_single_primary_key(cls):
1654 errors = []
1655 if sum(1 for f in cls._meta.local_fields if f.primary_key) > 1:
1656 errors.append(
1657 preflight.Error(
1658 "The model cannot have more than one field with "
1659 "'primary_key=True'.",
1660 obj=cls,
1661 id="models.E026",
1662 )
1663 )
1664 return errors
1666 @classmethod
1667 def _check_indexes(cls, databases):
1668 """Check fields, names, and conditions of indexes."""
1669 errors = []
1670 references = set()
1671 for index in cls._meta.indexes:
1672 # Index name can't start with an underscore or a number, restricted
1673 # for cross-database compatibility with Oracle.
1674 if index.name[0] == "_" or index.name[0].isdigit():
1675 errors.append(
1676 preflight.Error(
1677 f"The index name '{index.name}' cannot start with an underscore "
1678 "or a number.",
1679 obj=cls,
1680 id="models.E033",
1681 ),
1682 )
1683 if len(index.name) > index.max_name_length:
1684 errors.append(
1685 preflight.Error(
1686 "The index name '%s' cannot be longer than %d "
1687 "characters." % (index.name, index.max_name_length),
1688 obj=cls,
1689 id="models.E034",
1690 ),
1691 )
1692 if index.contains_expressions:
1693 for expression in index.expressions:
1694 references.update(
1695 ref[0] for ref in cls._get_expr_references(expression)
1696 )
1697 for db in databases:
1698 if not router.allow_migrate_model(db, cls):
1699 continue
1700 connection = connections[db]
1701 if not (
1702 connection.features.supports_partial_indexes
1703 or "supports_partial_indexes" in cls._meta.required_db_features
1704 ) and any(index.condition is not None for index in cls._meta.indexes):
1705 errors.append(
1706 preflight.Warning(
1707 f"{connection.display_name} does not support indexes with conditions.",
1708 hint=(
1709 "Conditions will be ignored. Silence this warning "
1710 "if you don't care about it."
1711 ),
1712 obj=cls,
1713 id="models.W037",
1714 )
1715 )
1716 if not (
1717 connection.features.supports_covering_indexes
1718 or "supports_covering_indexes" in cls._meta.required_db_features
1719 ) and any(index.include for index in cls._meta.indexes):
1720 errors.append(
1721 preflight.Warning(
1722 f"{connection.display_name} does not support indexes with non-key columns.",
1723 hint=(
1724 "Non-key columns will be ignored. Silence this "
1725 "warning if you don't care about it."
1726 ),
1727 obj=cls,
1728 id="models.W040",
1729 )
1730 )
1731 if not (
1732 connection.features.supports_expression_indexes
1733 or "supports_expression_indexes" in cls._meta.required_db_features
1734 ) and any(index.contains_expressions for index in cls._meta.indexes):
1735 errors.append(
1736 preflight.Warning(
1737 f"{connection.display_name} does not support indexes on expressions.",
1738 hint=(
1739 "An index won't be created. Silence this warning "
1740 "if you don't care about it."
1741 ),
1742 obj=cls,
1743 id="models.W043",
1744 )
1745 )
1746 fields = [
1747 field for index in cls._meta.indexes for field, _ in index.fields_orders
1748 ]
1749 fields += [include for index in cls._meta.indexes for include in index.include]
1750 fields += references
1751 errors.extend(cls._check_local_fields(fields, "indexes"))
1752 return errors
1754 @classmethod
1755 def _check_local_fields(cls, fields, option):
1756 from plain import models
1758 # In order to avoid hitting the relation tree prematurely, we use our
1759 # own fields_map instead of using get_field()
1760 forward_fields_map = {}
1761 for field in cls._meta._get_fields(reverse=False):
1762 forward_fields_map[field.name] = field
1763 if hasattr(field, "attname"):
1764 forward_fields_map[field.attname] = field
1766 errors = []
1767 for field_name in fields:
1768 try:
1769 field = forward_fields_map[field_name]
1770 except KeyError:
1771 errors.append(
1772 preflight.Error(
1773 f"'{option}' refers to the nonexistent field '{field_name}'.",
1774 obj=cls,
1775 id="models.E012",
1776 )
1777 )
1778 else:
1779 if isinstance(field.remote_field, models.ManyToManyRel):
1780 errors.append(
1781 preflight.Error(
1782 f"'{option}' refers to a ManyToManyField '{field_name}', but "
1783 f"ManyToManyFields are not permitted in '{option}'.",
1784 obj=cls,
1785 id="models.E013",
1786 )
1787 )
1788 elif field not in cls._meta.local_fields:
1789 errors.append(
1790 preflight.Error(
1791 f"'{option}' refers to field '{field_name}' which is not local to model "
1792 f"'{cls._meta.object_name}'.",
1793 hint="This issue may be caused by multi-table inheritance.",
1794 obj=cls,
1795 id="models.E016",
1796 )
1797 )
1798 return errors
1800 @classmethod
1801 def _check_ordering(cls):
1802 """
1803 Check "ordering" option -- is it a list of strings and do all fields
1804 exist?
1805 """
1806 if cls._meta._ordering_clash:
1807 return [
1808 preflight.Error(
1809 "'ordering' and 'order_with_respect_to' cannot be used together.",
1810 obj=cls,
1811 id="models.E021",
1812 ),
1813 ]
1815 if cls._meta.order_with_respect_to or not cls._meta.ordering:
1816 return []
1818 if not isinstance(cls._meta.ordering, list | tuple):
1819 return [
1820 preflight.Error(
1821 "'ordering' must be a tuple or list (even if you want to order by "
1822 "only one field).",
1823 obj=cls,
1824 id="models.E014",
1825 )
1826 ]
1828 errors = []
1829 fields = cls._meta.ordering
1831 # Skip expressions and '?' fields.
1832 fields = (f for f in fields if isinstance(f, str) and f != "?")
1834 # Convert "-field" to "field".
1835 fields = (f.removeprefix("-") for f in fields)
1837 # Separate related fields and non-related fields.
1838 _fields = []
1839 related_fields = []
1840 for f in fields:
1841 if LOOKUP_SEP in f:
1842 related_fields.append(f)
1843 else:
1844 _fields.append(f)
1845 fields = _fields
1847 # Check related fields.
1848 for field in related_fields:
1849 _cls = cls
1850 fld = None
1851 for part in field.split(LOOKUP_SEP):
1852 try:
1853 # pk is an alias that won't be found by opts.get_field.
1854 if part == "pk":
1855 fld = _cls._meta.pk
1856 else:
1857 fld = _cls._meta.get_field(part)
1858 if fld.is_relation:
1859 _cls = fld.path_infos[-1].to_opts.model
1860 else:
1861 _cls = None
1862 except (FieldDoesNotExist, AttributeError):
1863 if fld is None or (
1864 fld.get_transform(part) is None and fld.get_lookup(part) is None
1865 ):
1866 errors.append(
1867 preflight.Error(
1868 "'ordering' refers to the nonexistent field, "
1869 f"related field, or lookup '{field}'.",
1870 obj=cls,
1871 id="models.E015",
1872 )
1873 )
1875 # Skip ordering on pk. This is always a valid order_by field
1876 # but is an alias and therefore won't be found by opts.get_field.
1877 fields = {f for f in fields if f != "pk"}
1879 # Check for invalid or nonexistent fields in ordering.
1880 invalid_fields = []
1882 # Any field name that is not present in field_names does not exist.
1883 # Also, ordering by m2m fields is not allowed.
1884 opts = cls._meta
1885 valid_fields = set(
1886 chain.from_iterable(
1887 (f.name, f.attname)
1888 if not (f.auto_created and not f.concrete)
1889 else (f.field.related_query_name(),)
1890 for f in chain(opts.fields, opts.related_objects)
1891 )
1892 )
1894 invalid_fields.extend(fields - valid_fields)
1896 for invalid_field in invalid_fields:
1897 errors.append(
1898 preflight.Error(
1899 "'ordering' refers to the nonexistent field, related "
1900 f"field, or lookup '{invalid_field}'.",
1901 obj=cls,
1902 id="models.E015",
1903 )
1904 )
1905 return errors
1907 @classmethod
1908 def _check_long_column_names(cls, databases):
1909 """
1910 Check that any auto-generated column names are shorter than the limits
1911 for each database in which the model will be created.
1912 """
1913 if not databases:
1914 return []
1915 errors = []
1916 allowed_len = None
1917 db_alias = None
1919 # Find the minimum max allowed length among all specified db_aliases.
1920 for db in databases:
1921 # skip databases where the model won't be created
1922 if not router.allow_migrate_model(db, cls):
1923 continue
1924 connection = connections[db]
1925 max_name_length = connection.ops.max_name_length()
1926 if max_name_length is None or connection.features.truncates_names:
1927 continue
1928 else:
1929 if allowed_len is None:
1930 allowed_len = max_name_length
1931 db_alias = db
1932 elif max_name_length < allowed_len:
1933 allowed_len = max_name_length
1934 db_alias = db
1936 if allowed_len is None:
1937 return errors
1939 for f in cls._meta.local_fields:
1940 _, column_name = f.get_attname_column()
1942 # Check if auto-generated name for the field is too long
1943 # for the database.
1944 if (
1945 f.db_column is None
1946 and column_name is not None
1947 and len(column_name) > allowed_len
1948 ):
1949 errors.append(
1950 preflight.Error(
1951 f'Autogenerated column name too long for field "{column_name}". '
1952 f'Maximum length is "{allowed_len}" for database "{db_alias}".',
1953 hint="Set the column name manually using 'db_column'.",
1954 obj=cls,
1955 id="models.E018",
1956 )
1957 )
1959 for f in cls._meta.local_many_to_many:
1960 # Skip nonexistent models.
1961 if isinstance(f.remote_field.through, str):
1962 continue
1964 # Check if auto-generated name for the M2M field is too long
1965 # for the database.
1966 for m2m in f.remote_field.through._meta.local_fields:
1967 _, rel_name = m2m.get_attname_column()
1968 if (
1969 m2m.db_column is None
1970 and rel_name is not None
1971 and len(rel_name) > allowed_len
1972 ):
1973 errors.append(
1974 preflight.Error(
1975 "Autogenerated column name too long for M2M field "
1976 f'"{rel_name}". Maximum length is "{allowed_len}" for database "{db_alias}".',
1977 hint=(
1978 "Use 'through' to create a separate model for "
1979 "M2M and then set column_name using 'db_column'."
1980 ),
1981 obj=cls,
1982 id="models.E019",
1983 )
1984 )
1986 return errors
1988 @classmethod
1989 def _get_expr_references(cls, expr):
1990 if isinstance(expr, Q):
1991 for child in expr.children:
1992 if isinstance(child, tuple):
1993 lookup, value = child
1994 yield tuple(lookup.split(LOOKUP_SEP))
1995 yield from cls._get_expr_references(value)
1996 else:
1997 yield from cls._get_expr_references(child)
1998 elif isinstance(expr, F):
1999 yield tuple(expr.name.split(LOOKUP_SEP))
2000 elif hasattr(expr, "get_source_expressions"):
2001 for src_expr in expr.get_source_expressions():
2002 yield from cls._get_expr_references(src_expr)
2004 @classmethod
2005 def _check_constraints(cls, databases):
2006 errors = []
2007 for db in databases:
2008 if not router.allow_migrate_model(db, cls):
2009 continue
2010 connection = connections[db]
2011 if not (
2012 connection.features.supports_table_check_constraints
2013 or "supports_table_check_constraints" in cls._meta.required_db_features
2014 ) and any(
2015 isinstance(constraint, CheckConstraint)
2016 for constraint in cls._meta.constraints
2017 ):
2018 errors.append(
2019 preflight.Warning(
2020 f"{connection.display_name} does not support check constraints.",
2021 hint=(
2022 "A constraint won't be created. Silence this "
2023 "warning if you don't care about it."
2024 ),
2025 obj=cls,
2026 id="models.W027",
2027 )
2028 )
2029 if not (
2030 connection.features.supports_partial_indexes
2031 or "supports_partial_indexes" in cls._meta.required_db_features
2032 ) and any(
2033 isinstance(constraint, UniqueConstraint)
2034 and constraint.condition is not None
2035 for constraint in cls._meta.constraints
2036 ):
2037 errors.append(
2038 preflight.Warning(
2039 f"{connection.display_name} does not support unique constraints with "
2040 "conditions.",
2041 hint=(
2042 "A constraint won't be created. Silence this "
2043 "warning if you don't care about it."
2044 ),
2045 obj=cls,
2046 id="models.W036",
2047 )
2048 )
2049 if not (
2050 connection.features.supports_deferrable_unique_constraints
2051 or "supports_deferrable_unique_constraints"
2052 in cls._meta.required_db_features
2053 ) and any(
2054 isinstance(constraint, UniqueConstraint)
2055 and constraint.deferrable is not None
2056 for constraint in cls._meta.constraints
2057 ):
2058 errors.append(
2059 preflight.Warning(
2060 f"{connection.display_name} does not support deferrable unique constraints.",
2061 hint=(
2062 "A constraint won't be created. Silence this "
2063 "warning if you don't care about it."
2064 ),
2065 obj=cls,
2066 id="models.W038",
2067 )
2068 )
2069 if not (
2070 connection.features.supports_covering_indexes
2071 or "supports_covering_indexes" in cls._meta.required_db_features
2072 ) and any(
2073 isinstance(constraint, UniqueConstraint) and constraint.include
2074 for constraint in cls._meta.constraints
2075 ):
2076 errors.append(
2077 preflight.Warning(
2078 f"{connection.display_name} does not support unique constraints with non-key "
2079 "columns.",
2080 hint=(
2081 "A constraint won't be created. Silence this "
2082 "warning if you don't care about it."
2083 ),
2084 obj=cls,
2085 id="models.W039",
2086 )
2087 )
2088 if not (
2089 connection.features.supports_expression_indexes
2090 or "supports_expression_indexes" in cls._meta.required_db_features
2091 ) and any(
2092 isinstance(constraint, UniqueConstraint)
2093 and constraint.contains_expressions
2094 for constraint in cls._meta.constraints
2095 ):
2096 errors.append(
2097 preflight.Warning(
2098 f"{connection.display_name} does not support unique constraints on "
2099 "expressions.",
2100 hint=(
2101 "A constraint won't be created. Silence this "
2102 "warning if you don't care about it."
2103 ),
2104 obj=cls,
2105 id="models.W044",
2106 )
2107 )
2108 fields = set(
2109 chain.from_iterable(
2110 (*constraint.fields, *constraint.include)
2111 for constraint in cls._meta.constraints
2112 if isinstance(constraint, UniqueConstraint)
2113 )
2114 )
2115 references = set()
2116 for constraint in cls._meta.constraints:
2117 if isinstance(constraint, UniqueConstraint):
2118 if (
2119 connection.features.supports_partial_indexes
2120 or "supports_partial_indexes"
2121 not in cls._meta.required_db_features
2122 ) and isinstance(constraint.condition, Q):
2123 references.update(
2124 cls._get_expr_references(constraint.condition)
2125 )
2126 if (
2127 connection.features.supports_expression_indexes
2128 or "supports_expression_indexes"
2129 not in cls._meta.required_db_features
2130 ) and constraint.contains_expressions:
2131 for expression in constraint.expressions:
2132 references.update(cls._get_expr_references(expression))
2133 elif isinstance(constraint, CheckConstraint):
2134 if (
2135 connection.features.supports_table_check_constraints
2136 or "supports_table_check_constraints"
2137 not in cls._meta.required_db_features
2138 ):
2139 if isinstance(constraint.check, Q):
2140 references.update(
2141 cls._get_expr_references(constraint.check)
2142 )
2143 if any(
2144 isinstance(expr, RawSQL)
2145 for expr in constraint.check.flatten()
2146 ):
2147 errors.append(
2148 preflight.Warning(
2149 f"Check constraint {constraint.name!r} contains "
2150 f"RawSQL() expression and won't be validated "
2151 f"during the model full_clean().",
2152 hint=(
2153 "Silence this warning if you don't care about "
2154 "it."
2155 ),
2156 obj=cls,
2157 id="models.W045",
2158 ),
2159 )
2160 for field_name, *lookups in references:
2161 # pk is an alias that won't be found by opts.get_field.
2162 if field_name != "pk":
2163 fields.add(field_name)
2164 if not lookups:
2165 # If it has no lookups it cannot result in a JOIN.
2166 continue
2167 try:
2168 if field_name == "pk":
2169 field = cls._meta.pk
2170 else:
2171 field = cls._meta.get_field(field_name)
2172 if not field.is_relation or field.many_to_many or field.one_to_many:
2173 continue
2174 except FieldDoesNotExist:
2175 continue
2176 # JOIN must happen at the first lookup.
2177 first_lookup = lookups[0]
2178 if (
2179 hasattr(field, "get_transform")
2180 and hasattr(field, "get_lookup")
2181 and field.get_transform(first_lookup) is None
2182 and field.get_lookup(first_lookup) is None
2183 ):
2184 errors.append(
2185 preflight.Error(
2186 f"'constraints' refers to the joined field '{LOOKUP_SEP.join([field_name] + lookups)}'.",
2187 obj=cls,
2188 id="models.E041",
2189 )
2190 )
2191 errors.extend(cls._check_local_fields(fields, "constraints"))
2192 return errors
2195############################################
2196# HELPER FUNCTIONS (CURRIED MODEL METHODS) #
2197############################################
2199# ORDERING METHODS #########################
2202def method_set_order(self, ordered_obj, id_list, using=None):
2203 order_wrt = ordered_obj._meta.order_with_respect_to
2204 filter_args = order_wrt.get_forward_related_filter(self)
2205 ordered_obj.objects.db_manager(using).filter(**filter_args).bulk_update(
2206 [ordered_obj(pk=pk, _order=order) for order, pk in enumerate(id_list)],
2207 ["_order"],
2208 )
2211def method_get_order(self, ordered_obj):
2212 order_wrt = ordered_obj._meta.order_with_respect_to
2213 filter_args = order_wrt.get_forward_related_filter(self)
2214 pk_name = ordered_obj._meta.pk.name
2215 return ordered_obj.objects.filter(**filter_args).values_list(pk_name, flat=True)
2218def make_foreign_order_accessors(model, related_model):
2219 setattr(
2220 related_model,
2221 f"get_{model.__name__.lower()}_order",
2222 partialmethod(method_get_order, model),
2223 )
2224 setattr(
2225 related_model,
2226 f"set_{model.__name__.lower()}_order",
2227 partialmethod(method_set_order, model),
2228 )
2231########
2232# MISC #
2233########
2236def model_unpickle(model_id):
2237 """Used to unpickle Model subclasses with deferred fields."""
2238 if isinstance(model_id, tuple):
2239 model = packages.get_model(*model_id)
2240 else:
2241 # Backwards compat - the model was cached directly in earlier versions.
2242 model = model_id
2243 return model.__new__(model)
2246model_unpickle.__safe_for_unpickle__ = True
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import os
2import subprocess
3import sys
4import time
5from itertools import takewhile
7import click
9from plain.models import migrations
10from plain.models.db import DEFAULT_DB_ALIAS, OperationalError, connections, router
11from plain.models.migrations.autodetector import MigrationAutodetector
12from plain.models.migrations.executor import MigrationExecutor
13from plain.models.migrations.loader import AmbiguityError, MigrationLoader
14from plain.models.migrations.migration import Migration, SwappableTuple
15from plain.models.migrations.optimizer import MigrationOptimizer
16from plain.models.migrations.questioner import (
17 InteractiveMigrationQuestioner,
18 MigrationQuestioner,
19 NonInteractiveMigrationQuestioner,
20)
21from plain.models.migrations.recorder import MigrationRecorder
22from plain.models.migrations.state import ModelState, ProjectState
23from plain.models.migrations.utils import get_migration_name_timestamp
24from plain.models.migrations.writer import MigrationWriter
25from plain.packages import packages
26from plain.runtime import settings
27from plain.utils.text import Truncator
30@click.group()
31def cli():
32 pass
35@cli.command()
36@click.option(
37 "--database",
38 default=DEFAULT_DB_ALIAS,
39 help=(
40 "Nominates a database onto which to open a shell. Defaults to the "
41 '"default" database.'
42 ),
43)
44@click.argument("parameters", nargs=-1)
45def db_shell(database, parameters):
46 """Runs the command-line client for specified database, or the default database if none is provided."""
47 connection = connections[database]
48 try:
49 connection.client.runshell(parameters)
50 except FileNotFoundError:
51 # Note that we're assuming the FileNotFoundError relates to the
52 # command missing. It could be raised for some other reason, in
53 # which case this error message would be inaccurate. Still, this
54 # message catches the common case.
55 click.secho(
56 f"You appear not to have the {connection.client.executable_name!r} program installed or on your path.",
57 fg="red",
58 err=True,
59 )
60 sys.exit(1)
61 except subprocess.CalledProcessError as e:
62 click.secho(
63 '"{}" returned non-zero exit status {}.'.format(
64 " ".join(e.cmd),
65 e.returncode,
66 ),
67 fg="red",
68 err=True,
69 )
70 sys.exit(e.returncode)
73@cli.command()
74def db_wait():
75 """Wait for the database to be ready"""
76 attempts = 0
77 while True:
78 attempts += 1
79 waiting_for = []
81 for conn in connections.all():
82 try:
83 conn.ensure_connection()
84 except OperationalError:
85 waiting_for.append(conn.alias)
87 if waiting_for:
88 click.secho(
89 f"Waiting for database (attempt {attempts}): {', '.join(waiting_for)}",
90 fg="yellow",
91 )
92 time.sleep(1.5)
93 else:
94 click.secho(f"Database ready: {', '.join(connections)}", fg="green")
95 break
98@cli.command()
99@click.argument("package_labels", nargs=-1)
100@click.option(
101 "--dry-run",
102 is_flag=True,
103 help="Just show what migrations would be made; don't actually write them.",
104)
105@click.option("--merge", is_flag=True, help="Enable fixing of migration conflicts.")
106@click.option("--empty", is_flag=True, help="Create an empty migration.")
107@click.option(
108 "--noinput",
109 "--no-input",
110 "no_input",
111 is_flag=True,
112 help="Tells Plain to NOT prompt the user for input of any kind.",
113)
114@click.option("-n", "--name", help="Use this name for migration file(s).")
115@click.option(
116 "--check",
117 is_flag=True,
118 help="Exit with a non-zero status if model changes are missing migrations and don't actually write them.",
119)
120@click.option(
121 "--update",
122 is_flag=True,
123 help="Merge model changes into the latest migration and optimize the resulting operations.",
124)
125@click.option(
126 "-v",
127 "--verbosity",
128 type=int,
129 default=1,
130 help="Verbosity level; 0=minimal output, 1=normal output, 2=verbose output, 3=very verbose output",
131)
132def makemigrations(
133 package_labels, dry_run, merge, empty, no_input, name, check, update, verbosity
134):
135 """Creates new migration(s) for packages."""
137 written_files = []
138 interactive = not no_input
139 migration_name = name
140 check_changes = check
142 def log(msg, level=1):
143 if verbosity >= level:
144 click.echo(msg)
146 def write_migration_files(changes, update_previous_migration_paths=None):
147 """Take a changes dict and write them out as migration files."""
148 directory_created = {}
149 for package_label, package_migrations in changes.items():
150 log(
151 click.style(f"Migrations for '{package_label}':", fg="cyan", bold=True),
152 level=1,
153 )
154 for migration in package_migrations:
155 writer = MigrationWriter(migration)
156 migration_string = os.path.relpath(writer.path)
157 log(f" {click.style(migration_string, fg='yellow')}\n", level=1)
158 for operation in migration.operations:
159 log(f" - {operation.describe()}", level=1)
161 if not dry_run:
162 migrations_directory = os.path.dirname(writer.path)
163 if not directory_created.get(package_label):
164 os.makedirs(migrations_directory, exist_ok=True)
165 init_path = os.path.join(migrations_directory, "__init__.py")
166 if not os.path.isfile(init_path):
167 open(init_path, "w").close()
168 directory_created[package_label] = True
170 migration_string = writer.as_string()
171 with open(writer.path, "w", encoding="utf-8") as fh:
172 fh.write(migration_string)
173 written_files.append(writer.path)
175 if update_previous_migration_paths:
176 prev_path = update_previous_migration_paths[package_label]
177 if writer.needs_manual_porting:
178 log(
179 click.style(
180 f"Updated migration {migration_string} requires manual porting.\n"
181 f"Previous migration {os.path.relpath(prev_path)} was kept and "
182 f"must be deleted after porting functions manually.",
183 fg="yellow",
184 ),
185 level=1,
186 )
187 else:
188 os.remove(prev_path)
189 log(f"Deleted {os.path.relpath(prev_path)}", level=1)
190 elif verbosity >= 3:
191 log(
192 click.style(
193 f"Full migrations file '{writer.filename}':",
194 fg="cyan",
195 bold=True,
196 ),
197 level=3,
198 )
199 log(writer.as_string(), level=3)
201 def write_to_last_migration_files(changes):
202 """Write changes to the last migration file for each package."""
203 loader = MigrationLoader(connections[DEFAULT_DB_ALIAS])
204 new_changes = {}
205 update_previous_migration_paths = {}
206 for package_label, package_migrations in changes.items():
207 leaf_migration_nodes = loader.graph.leaf_nodes(app=package_label)
208 if len(leaf_migration_nodes) == 0:
209 raise click.ClickException(
210 f"Package {package_label} has no migration, cannot update last migration."
211 )
212 leaf_migration_node = leaf_migration_nodes[0]
213 leaf_migration = loader.graph.nodes[leaf_migration_node]
215 if leaf_migration.replaces:
216 raise click.ClickException(
217 f"Cannot update squash migration '{leaf_migration}'."
218 )
219 if leaf_migration_node in loader.applied_migrations:
220 raise click.ClickException(
221 f"Cannot update applied migration '{leaf_migration}'."
222 )
224 depending_migrations = [
225 migration
226 for migration in loader.disk_migrations.values()
227 if leaf_migration_node in migration.dependencies
228 ]
229 if depending_migrations:
230 formatted_migrations = ", ".join(
231 [f"'{migration}'" for migration in depending_migrations]
232 )
233 raise click.ClickException(
234 f"Cannot update migration '{leaf_migration}' that migrations "
235 f"{formatted_migrations} depend on."
236 )
238 for migration in package_migrations:
239 leaf_migration.operations.extend(migration.operations)
240 for dependency in migration.dependencies:
241 if isinstance(dependency, SwappableTuple):
242 if settings.AUTH_USER_MODEL == dependency.setting:
243 leaf_migration.dependencies.append(
244 ("__setting__", "AUTH_USER_MODEL")
245 )
246 else:
247 leaf_migration.dependencies.append(dependency)
248 elif dependency[0] != migration.package_label:
249 leaf_migration.dependencies.append(dependency)
251 optimizer = MigrationOptimizer()
252 leaf_migration.operations = optimizer.optimize(
253 leaf_migration.operations, package_label
254 )
256 previous_migration_path = MigrationWriter(leaf_migration).path
257 suggested_name = (
258 leaf_migration.name[:4] + "_" + leaf_migration.suggest_name()
259 )
260 new_name = (
261 suggested_name
262 if leaf_migration.name != suggested_name
263 else leaf_migration.name + "_updated"
264 )
265 leaf_migration.name = new_name
267 new_changes[package_label] = [leaf_migration]
268 update_previous_migration_paths[package_label] = previous_migration_path
270 write_migration_files(new_changes, update_previous_migration_paths)
272 def handle_merge(loader, conflicts):
273 """Handle merging conflicting migrations."""
274 if interactive:
275 questioner = InteractiveMigrationQuestioner()
276 else:
277 questioner = MigrationQuestioner(defaults={"ask_merge": True})
279 for package_label, migration_names in conflicts.items():
280 log(click.style(f"Merging {package_label}", fg="cyan", bold=True), level=1)
282 merge_migrations = []
283 for migration_name in migration_names:
284 migration = loader.get_migration(package_label, migration_name)
285 migration.ancestry = [
286 mig
287 for mig in loader.graph.forwards_plan(
288 (package_label, migration_name)
289 )
290 if mig[0] == migration.package_label
291 ]
292 merge_migrations.append(migration)
294 def all_items_equal(seq):
295 return all(item == seq[0] for item in seq[1:])
297 merge_migrations_generations = zip(*(m.ancestry for m in merge_migrations))
298 common_ancestor_count = sum(
299 1 for _ in takewhile(all_items_equal, merge_migrations_generations)
300 )
301 if not common_ancestor_count:
302 raise ValueError(f"Could not find common ancestor of {migration_names}")
304 for migration in merge_migrations:
305 migration.branch = migration.ancestry[common_ancestor_count:]
306 migrations_ops = (
307 loader.get_migration(node_package, node_name).operations
308 for node_package, node_name in migration.branch
309 )
310 migration.merged_operations = sum(migrations_ops, [])
312 for migration in merge_migrations:
313 log(click.style(f" Branch {migration.name}", fg="yellow"), level=1)
314 for operation in migration.merged_operations:
315 log(f" - {operation.describe()}", level=1)
317 if questioner.ask_merge(package_label):
318 numbers = [
319 MigrationAutodetector.parse_number(migration.name)
320 for migration in merge_migrations
321 ]
322 biggest_number = (
323 max(x for x in numbers if x is not None) if numbers else 0
324 )
326 subclass = type(
327 "Migration",
328 (Migration,),
329 {
330 "dependencies": [
331 (package_label, migration.name)
332 for migration in merge_migrations
333 ],
334 },
335 )
337 parts = [f"{biggest_number + 1:04d}"]
338 if migration_name:
339 parts.append(migration_name)
340 else:
341 parts.append("merge")
342 leaf_names = "_".join(
343 sorted(migration.name for migration in merge_migrations)
344 )
345 if len(leaf_names) > 47:
346 parts.append(get_migration_name_timestamp())
347 else:
348 parts.append(leaf_names)
350 new_migration_name = "_".join(parts)
351 new_migration = subclass(new_migration_name, package_label)
352 writer = MigrationWriter(new_migration)
354 if not dry_run:
355 with open(writer.path, "w", encoding="utf-8") as fh:
356 fh.write(writer.as_string())
357 log(f"\nCreated new merge migration {writer.path}", level=1)
358 elif verbosity == 3:
359 log(
360 click.style(
361 f"Full merge migrations file '{writer.filename}':",
362 fg="cyan",
363 bold=True,
364 ),
365 level=3,
366 )
367 log(writer.as_string(), level=3)
369 # Validate package labels
370 package_labels = set(package_labels)
371 has_bad_labels = False
372 for package_label in package_labels:
373 try:
374 packages.get_package_config(package_label)
375 except LookupError as err:
376 click.echo(str(err), err=True)
377 has_bad_labels = True
378 if has_bad_labels:
379 sys.exit(2)
381 # Load the current graph state
382 loader = MigrationLoader(None, ignore_no_migrations=True)
384 # Raise an error if any migrations are applied before their dependencies.
385 consistency_check_labels = {
386 config.label for config in packages.get_package_configs()
387 }
388 # Non-default databases are only checked if database routers used.
389 aliases_to_check = connections if settings.DATABASE_ROUTERS else [DEFAULT_DB_ALIAS]
390 for alias in sorted(aliases_to_check):
391 connection = connections[alias]
392 if connection.settings_dict["ENGINE"] != "plain.models.backends.dummy" and any(
393 router.allow_migrate(
394 connection.alias, package_label, model_name=model._meta.object_name
395 )
396 for package_label in consistency_check_labels
397 for model in packages.get_package_config(package_label).get_models()
398 ):
399 loader.check_consistent_history(connection)
401 # Check for conflicts
402 conflicts = loader.detect_conflicts()
403 if package_labels:
404 conflicts = {
405 package_label: conflict
406 for package_label, conflict in conflicts.items()
407 if package_label in package_labels
408 }
410 if conflicts and not merge:
411 name_str = "; ".join(
412 "{} in {}".format(", ".join(names), package)
413 for package, names in conflicts.items()
414 )
415 raise click.ClickException(
416 f"Conflicting migrations detected; multiple leaf nodes in the "
417 f"migration graph: ({name_str}).\nTo fix them run "
418 f"'python manage.py makemigrations --merge'"
419 )
421 # Handle merge if requested
422 if merge and conflicts:
423 return handle_merge(loader, conflicts)
425 # Set up questioner
426 if interactive:
427 questioner = InteractiveMigrationQuestioner(
428 specified_packages=package_labels,
429 dry_run=dry_run,
430 )
431 else:
432 questioner = NonInteractiveMigrationQuestioner(
433 specified_packages=package_labels,
434 dry_run=dry_run,
435 verbosity=verbosity,
436 )
438 # Set up autodetector
439 autodetector = MigrationAutodetector(
440 loader.project_state(),
441 ProjectState.from_packages(packages),
442 questioner,
443 )
445 # Handle empty migrations if requested
446 if empty:
447 if not package_labels:
448 raise click.ClickException(
449 "You must supply at least one package label when using --empty."
450 )
451 changes = {
452 package: [Migration("custom", package)] for package in package_labels
453 }
454 changes = autodetector.arrange_for_graph(
455 changes=changes,
456 graph=loader.graph,
457 migration_name=migration_name,
458 )
459 write_migration_files(changes)
460 return
462 # Detect changes
463 changes = autodetector.changes(
464 graph=loader.graph,
465 trim_to_packages=package_labels or None,
466 convert_packages=package_labels or None,
467 migration_name=migration_name,
468 )
470 if not changes:
471 log(
472 "No changes detected"
473 if not package_labels
474 else f"No changes detected in {'package' if len(package_labels) == 1 else 'packages'} "
475 f"'{', '.join(package_labels)}'",
476 level=1,
477 )
478 else:
479 if check_changes:
480 sys.exit(1)
481 if update:
482 write_to_last_migration_files(changes)
483 else:
484 write_migration_files(changes)
487@cli.command()
488@click.argument("package_label", required=False)
489@click.argument("migration_name", required=False)
490@click.option(
491 "--noinput",
492 "--no-input",
493 "no_input",
494 is_flag=True,
495 help="Tells Plain to NOT prompt the user for input of any kind.",
496)
497@click.option(
498 "--database",
499 default=DEFAULT_DB_ALIAS,
500 help="Nominates a database to synchronize. Defaults to the 'default' database.",
501)
502@click.option(
503 "--fake", is_flag=True, help="Mark migrations as run without actually running them."
504)
505@click.option(
506 "--fake-initial",
507 is_flag=True,
508 help="Detect if tables already exist and fake-apply initial migrations if so. Make sure that the current database schema matches your initial migration before using this flag. Plain will only check for an existing table name.",
509)
510@click.option(
511 "--plan",
512 is_flag=True,
513 help="Shows a list of the migration actions that will be performed.",
514)
515@click.option(
516 "--check",
517 "check_unapplied",
518 is_flag=True,
519 help="Exits with a non-zero status if unapplied migrations exist and does not actually apply migrations.",
520)
521@click.option(
522 "--run-syncdb", is_flag=True, help="Creates tables for packages without migrations."
523)
524@click.option(
525 "--prune",
526 is_flag=True,
527 help="Delete nonexistent migrations from the plainmigrations table.",
528)
529@click.option(
530 "-v",
531 "--verbosity",
532 type=int,
533 default=1,
534 help="Verbosity level; 0=minimal output, 1=normal output, 2=verbose output, 3=very verbose output",
535)
536def migrate(
537 package_label,
538 migration_name,
539 no_input,
540 database,
541 fake,
542 fake_initial,
543 plan,
544 check_unapplied,
545 run_syncdb,
546 prune,
547 verbosity,
548):
549 """Updates database schema. Manages both packages with migrations and those without."""
551 def migration_progress_callback(action, migration=None, fake=False):
552 if verbosity >= 1:
553 compute_time = verbosity > 1
554 if action == "apply_start":
555 if compute_time:
556 start = time.monotonic()
557 click.echo(f" Applying {migration}...", nl=False)
558 elif action == "apply_success":
559 elapsed = f" ({time.monotonic() - start:.3f}s)" if compute_time else ""
560 if fake:
561 click.echo(click.style(f" FAKED{elapsed}", fg="green"))
562 else:
563 click.echo(click.style(f" OK{elapsed}", fg="green"))
564 elif action == "unapply_start":
565 if compute_time:
566 start = time.monotonic()
567 click.echo(f" Unapplying {migration}...", nl=False)
568 elif action == "unapply_success":
569 elapsed = f" ({time.monotonic() - start:.3f}s)" if compute_time else ""
570 if fake:
571 click.echo(click.style(f" FAKED{elapsed}", fg="green"))
572 else:
573 click.echo(click.style(f" OK{elapsed}", fg="green"))
574 elif action == "render_start":
575 if compute_time:
576 start = time.monotonic()
577 click.echo(" Rendering model states...", nl=False)
578 elif action == "render_success":
579 elapsed = f" ({time.monotonic() - start:.3f}s)" if compute_time else ""
580 click.echo(click.style(f" DONE{elapsed}", fg="green"))
582 def sync_packages(connection, package_labels):
583 """Run the old syncdb-style operation on a list of package_labels."""
584 with connection.cursor() as cursor:
585 tables = connection.introspection.table_names(cursor)
587 # Build the manifest of packages and models that are to be synchronized.
588 all_models = [
589 (
590 package_config.label,
591 router.get_migratable_models(
592 package_config, connection.alias, include_auto_created=False
593 ),
594 )
595 for package_config in packages.get_package_configs()
596 if package_config.models_module is not None
597 and package_config.label in package_labels
598 ]
600 def model_installed(model):
601 opts = model._meta
602 converter = connection.introspection.identifier_converter
603 return not (
604 (converter(opts.db_table) in tables)
605 or (
606 opts.auto_created
607 and converter(opts.auto_created._meta.db_table) in tables
608 )
609 )
611 manifest = {
612 package_name: list(filter(model_installed, model_list))
613 for package_name, model_list in all_models
614 }
616 # Create the tables for each model
617 if verbosity >= 1:
618 click.echo(" Creating tables...", color="cyan")
619 with connection.schema_editor() as editor:
620 for package_name, model_list in manifest.items():
621 for model in model_list:
622 # Never install unmanaged models, etc.
623 if not model._meta.can_migrate(connection):
624 continue
625 if verbosity >= 3:
626 click.echo(
627 f" Processing {package_name}.{model._meta.object_name} model"
628 )
629 if verbosity >= 1:
630 click.echo(f" Creating table {model._meta.db_table}")
631 editor.create_model(model)
633 # Deferred SQL is executed when exiting the editor's context.
634 if verbosity >= 1:
635 click.echo(" Running deferred SQL...", color="cyan")
637 def describe_operation(operation, backwards):
638 """Return a string that describes a migration operation for --plan."""
639 prefix = ""
640 is_error = False
641 if hasattr(operation, "code"):
642 code = operation.reverse_code if backwards else operation.code
643 action = (code.__doc__ or "") if code else None
644 elif hasattr(operation, "sql"):
645 action = operation.reverse_sql if backwards else operation.sql
646 else:
647 action = ""
648 if backwards:
649 prefix = "Undo "
650 if action is not None:
651 action = str(action).replace("\n", "")
652 elif backwards:
653 action = "IRREVERSIBLE"
654 is_error = True
655 if action:
656 action = " -> " + action
657 truncated = Truncator(action)
658 return prefix + operation.describe() + truncated.chars(40), is_error
660 # Get the database we're operating from
661 connection = connections[database]
663 # Hook for backends needing any database preparation
664 connection.prepare_database()
666 # Work out which packages have migrations and which do not
667 executor = MigrationExecutor(connection, migration_progress_callback)
669 # Raise an error if any migrations are applied before their dependencies.
670 executor.loader.check_consistent_history(connection)
672 # Before anything else, see if there's conflicting packages and drop out
673 # hard if there are any
674 conflicts = executor.loader.detect_conflicts()
675 if conflicts:
676 name_str = "; ".join(
677 "{} in {}".format(", ".join(names), package)
678 for package, names in conflicts.items()
679 )
680 raise click.ClickException(
681 "Conflicting migrations detected; multiple leaf nodes in the "
682 f"migration graph: ({name_str}).\nTo fix them run "
683 "'python manage.py makemigrations --merge'"
684 )
686 # If they supplied command line arguments, work out what they mean.
687 target_package_labels_only = True
688 if package_label:
689 try:
690 packages.get_package_config(package_label)
691 except LookupError as err:
692 raise click.ClickException(str(err))
693 if run_syncdb:
694 if package_label in executor.loader.migrated_packages:
695 raise click.ClickException(
696 f"Can't use run_syncdb with package '{package_label}' as it has migrations."
697 )
698 elif package_label not in executor.loader.migrated_packages:
699 raise click.ClickException(
700 f"Package '{package_label}' does not have migrations."
701 )
703 if package_label and migration_name:
704 if migration_name == "zero":
705 targets = [(package_label, None)]
706 else:
707 try:
708 migration = executor.loader.get_migration_by_prefix(
709 package_label, migration_name
710 )
711 except AmbiguityError:
712 raise click.ClickException(
713 f"More than one migration matches '{migration_name}' in package '{package_label}'. "
714 "Please be more specific."
715 )
716 except KeyError:
717 raise click.ClickException(
718 f"Cannot find a migration matching '{migration_name}' from package '{package_label}'."
719 )
720 target = (package_label, migration.name)
721 if (
722 target not in executor.loader.graph.nodes
723 and target in executor.loader.replacements
724 ):
725 incomplete_migration = executor.loader.replacements[target]
726 target = incomplete_migration.replaces[-1]
727 targets = [target]
728 target_package_labels_only = False
729 elif package_label:
730 targets = [
731 key for key in executor.loader.graph.leaf_nodes() if key[0] == package_label
732 ]
733 else:
734 targets = executor.loader.graph.leaf_nodes()
736 if prune:
737 if not package_label:
738 raise click.ClickException(
739 "Migrations can be pruned only when a package is specified."
740 )
741 if verbosity > 0:
742 click.echo("Pruning migrations:", color="cyan")
743 to_prune = set(executor.loader.applied_migrations) - set(
744 executor.loader.disk_migrations
745 )
746 squashed_migrations_with_deleted_replaced_migrations = [
747 migration_key
748 for migration_key, migration_obj in executor.loader.replacements.items()
749 if any(replaced in to_prune for replaced in migration_obj.replaces)
750 ]
751 if squashed_migrations_with_deleted_replaced_migrations:
752 click.echo(
753 click.style(
754 " Cannot use --prune because the following squashed "
755 "migrations have their 'replaces' attributes and may not "
756 "be recorded as applied:",
757 fg="yellow",
758 )
759 )
760 for migration in squashed_migrations_with_deleted_replaced_migrations:
761 package, name = migration
762 click.echo(f" {package}.{name}")
763 click.echo(
764 click.style(
765 " Re-run 'manage.py migrate' if they are not marked as "
766 "applied, and remove 'replaces' attributes in their "
767 "Migration classes.",
768 fg="yellow",
769 )
770 )
771 else:
772 to_prune = sorted(
773 migration for migration in to_prune if migration[0] == package_label
774 )
775 if to_prune:
776 for migration in to_prune:
777 package, name = migration
778 if verbosity > 0:
779 click.echo(
780 click.style(f" Pruning {package}.{name}", fg="yellow"),
781 nl=False,
782 )
783 executor.recorder.record_unapplied(package, name)
784 if verbosity > 0:
785 click.echo(click.style(" OK", fg="green"))
786 elif verbosity > 0:
787 click.echo(" No migrations to prune.")
789 migration_plan = executor.migration_plan(targets)
791 if plan:
792 click.echo("Planned operations:", color="cyan")
793 if not migration_plan:
794 click.echo(" No planned migration operations.")
795 else:
796 for migration, backwards in migration_plan:
797 click.echo(str(migration), color="cyan")
798 for operation in migration.operations:
799 message, is_error = describe_operation(operation, backwards)
800 if is_error:
801 click.echo(" " + message, fg="yellow")
802 else:
803 click.echo(" " + message)
804 if check_unapplied:
805 sys.exit(1)
806 return
808 if check_unapplied:
809 if migration_plan:
810 sys.exit(1)
811 return
813 if prune:
814 return
816 # At this point, ignore run_syncdb if there aren't any packages to sync.
817 run_syncdb = run_syncdb and executor.loader.unmigrated_packages
818 # Print some useful info
819 if verbosity >= 1:
820 click.echo("Operations to perform:", color="cyan")
821 if run_syncdb:
822 if package_label:
823 click.echo(
824 f" Synchronize unmigrated package: {package_label}", color="yellow"
825 )
826 else:
827 click.echo(
828 " Synchronize unmigrated packages: "
829 + (", ".join(sorted(executor.loader.unmigrated_packages))),
830 color="yellow",
831 )
832 if target_package_labels_only:
833 click.echo(
834 " Apply all migrations: "
835 + (", ".join(sorted({a for a, n in targets})) or "(none)"),
836 color="yellow",
837 )
838 else:
839 if targets[0][1] is None:
840 click.echo(f" Unapply all migrations: {targets[0][0]}", color="yellow")
841 else:
842 click.echo(
843 f" Target specific migration: {targets[0][1]}, from {targets[0][0]}",
844 color="yellow",
845 )
847 pre_migrate_state = executor._create_project_state(with_applied_migrations=True)
849 # Run the syncdb phase.
850 if run_syncdb:
851 if verbosity >= 1:
852 click.echo("Synchronizing packages without migrations:", color="cyan")
853 if package_label:
854 sync_packages(connection, [package_label])
855 else:
856 sync_packages(connection, executor.loader.unmigrated_packages)
858 # Migrate!
859 if verbosity >= 1:
860 click.echo("Running migrations:", color="cyan")
861 if not migration_plan:
862 if verbosity >= 1:
863 click.echo(" No migrations to apply.")
864 # If there's changes that aren't in migrations yet, tell them
865 # how to fix it.
866 autodetector = MigrationAutodetector(
867 executor.loader.project_state(),
868 ProjectState.from_packages(packages),
869 )
870 changes = autodetector.changes(graph=executor.loader.graph)
871 if changes:
872 click.echo(
873 click.style(
874 f" Your models in package(s): {', '.join(repr(package) for package in sorted(changes))} "
875 "have changes that are not yet reflected in a migration, and so won't be applied.",
876 fg="yellow",
877 )
878 )
879 click.echo(
880 click.style(
881 " Run 'manage.py makemigrations' to make new "
882 "migrations, and then re-run 'manage.py migrate' to "
883 "apply them.",
884 fg="yellow",
885 )
886 )
887 else:
888 post_migrate_state = executor.migrate(
889 targets,
890 plan=migration_plan,
891 state=pre_migrate_state.clone(),
892 fake=fake,
893 fake_initial=fake_initial,
894 )
895 # post_migrate signals have access to all models. Ensure that all models
896 # are reloaded in case any are delayed.
897 post_migrate_state.clear_delayed_packages_cache()
898 post_migrate_packages = post_migrate_state.packages
900 # Re-render models of real packages to include relationships now that
901 # we've got a final state. This wouldn't be necessary if real packages
902 # models were rendered with relationships in the first place.
903 with post_migrate_packages.bulk_update():
904 model_keys = []
905 for model_state in post_migrate_packages.real_models:
906 model_key = model_state.package_label, model_state.name_lower
907 model_keys.append(model_key)
908 post_migrate_packages.unregister_model(*model_key)
909 post_migrate_packages.render_multiple(
910 [ModelState.from_model(packages.get_model(*model)) for model in model_keys]
911 )
914@cli.command()
915@click.argument("package_label")
916@click.argument("migration_name")
917@click.option(
918 "--check",
919 is_flag=True,
920 help="Exit with a non-zero status if the migration can be optimized.",
921)
922@click.option(
923 "-v",
924 "--verbosity",
925 type=int,
926 default=1,
927 help="Verbosity level; 0=minimal output, 1=normal output, 2=verbose output, 3=very verbose output",
928)
929def optimize_migration(package_label, migration_name, check, verbosity):
930 """Optimizes the operations for the named migration."""
931 try:
932 packages.get_package_config(package_label)
933 except LookupError as err:
934 raise click.ClickException(str(err))
936 # Load the current graph state.
937 loader = MigrationLoader(None)
938 if package_label not in loader.migrated_packages:
939 raise click.ClickException(
940 f"Package '{package_label}' does not have migrations."
941 )
943 # Find a migration.
944 try:
945 migration = loader.get_migration_by_prefix(package_label, migration_name)
946 except AmbiguityError:
947 raise click.ClickException(
948 f"More than one migration matches '{migration_name}' in package "
949 f"'{package_label}'. Please be more specific."
950 )
951 except KeyError:
952 raise click.ClickException(
953 f"Cannot find a migration matching '{migration_name}' from package "
954 f"'{package_label}'."
955 )
957 # Optimize the migration.
958 optimizer = MigrationOptimizer()
959 new_operations = optimizer.optimize(migration.operations, migration.package_label)
960 if len(migration.operations) == len(new_operations):
961 if verbosity > 0:
962 click.echo("No optimizations possible.")
963 return
964 else:
965 if verbosity > 0:
966 click.echo(
967 f"Optimizing from {len(migration.operations)} operations to {len(new_operations)} operations."
968 )
969 if check:
970 sys.exit(1)
972 # Set the new migration optimizations.
973 migration.operations = new_operations
975 # Write out the optimized migration file.
976 writer = MigrationWriter(migration)
977 migration_file_string = writer.as_string()
978 if writer.needs_manual_porting:
979 if migration.replaces:
980 raise click.ClickException(
981 "Migration will require manual porting but is already a squashed "
982 "migration.\nTransition to a normal migration first."
983 )
984 # Make a new migration with those operations.
985 subclass = type(
986 "Migration",
987 (migrations.Migration,),
988 {
989 "dependencies": migration.dependencies,
990 "operations": new_operations,
991 "replaces": [(migration.package_label, migration.name)],
992 },
993 )
994 optimized_migration_name = f"{migration.name}_optimized"
995 optimized_migration = subclass(optimized_migration_name, package_label)
996 writer = MigrationWriter(optimized_migration)
997 migration_file_string = writer.as_string()
998 if verbosity > 0:
999 click.echo(click.style("Manual porting required", fg="yellow", bold=True))
1000 click.echo(
1001 " Your migrations contained functions that must be manually "
1002 "copied over,\n"
1003 " as we could not safely copy their implementation.\n"
1004 " See the comment at the top of the optimized migration for "
1005 "details."
1006 )
1008 with open(writer.path, "w", encoding="utf-8") as fh:
1009 fh.write(migration_file_string)
1011 if verbosity > 0:
1012 click.echo(
1013 click.style(f"Optimized migration {writer.path}", fg="green", bold=True)
1014 )
1017@cli.command()
1018@click.argument("package_labels", nargs=-1)
1019@click.option(
1020 "--database",
1021 default=DEFAULT_DB_ALIAS,
1022 help="Nominates a database to show migrations for. Defaults to the 'default' database.",
1023)
1024@click.option(
1025 "--format",
1026 type=click.Choice(["list", "plan"]),
1027 default="list",
1028 help="Output format.",
1029)
1030@click.option(
1031 "-v",
1032 "--verbosity",
1033 type=int,
1034 default=1,
1035 help="Verbosity level; 0=minimal output, 1=normal output, 2=verbose output, 3=very verbose output",
1036)
1037def show_migrations(package_labels, database, format, verbosity):
1038 """Shows all available migrations for the current project"""
1040 def _validate_package_names(package_names):
1041 has_bad_names = False
1042 for package_name in package_names:
1043 try:
1044 packages.get_package_config(package_name)
1045 except LookupError as err:
1046 click.echo(str(err), err=True)
1047 has_bad_names = True
1048 if has_bad_names:
1049 sys.exit(2)
1051 def show_list(connection, package_names):
1052 """
1053 Show a list of all migrations on the system, or only those of
1054 some named packages.
1055 """
1056 # Load migrations from disk/DB
1057 loader = MigrationLoader(connection, ignore_no_migrations=True)
1058 recorder = MigrationRecorder(connection)
1059 recorded_migrations = recorder.applied_migrations()
1060 graph = loader.graph
1061 # If we were passed a list of packages, validate it
1062 if package_names:
1063 _validate_package_names(package_names)
1064 # Otherwise, show all packages in alphabetic order
1065 else:
1066 package_names = sorted(loader.migrated_packages)
1067 # For each app, print its migrations in order from oldest (roots) to
1068 # newest (leaves).
1069 for package_name in package_names:
1070 click.secho(package_name, fg="cyan", bold=True)
1071 shown = set()
1072 for node in graph.leaf_nodes(package_name):
1073 for plan_node in graph.forwards_plan(node):
1074 if plan_node not in shown and plan_node[0] == package_name:
1075 # Give it a nice title if it's a squashed one
1076 title = plan_node[1]
1077 if graph.nodes[plan_node].replaces:
1078 title += f" ({len(graph.nodes[plan_node].replaces)} squashed migrations)"
1079 applied_migration = loader.applied_migrations.get(plan_node)
1080 # Mark it as applied/unapplied
1081 if applied_migration:
1082 if plan_node in recorded_migrations:
1083 output = f" [X] {title}"
1084 else:
1085 title += " Run 'manage.py migrate' to finish recording."
1086 output = f" [-] {title}"
1087 if verbosity >= 2 and hasattr(applied_migration, "applied"):
1088 output += f" (applied at {applied_migration.applied.strftime('%Y-%m-%d %H:%M:%S')})"
1089 click.echo(output)
1090 else:
1091 click.echo(f" [ ] {title}")
1092 shown.add(plan_node)
1093 # If we didn't print anything, then a small message
1094 if not shown:
1095 click.secho(" (no migrations)", fg="red")
1097 def show_plan(connection, package_names):
1098 """
1099 Show all known migrations (or only those of the specified package_names)
1100 in the order they will be applied.
1101 """
1102 # Load migrations from disk/DB
1103 loader = MigrationLoader(connection)
1104 graph = loader.graph
1105 if package_names:
1106 _validate_package_names(package_names)
1107 targets = [key for key in graph.leaf_nodes() if key[0] in package_names]
1108 else:
1109 targets = graph.leaf_nodes()
1110 plan = []
1111 seen = set()
1113 # Generate the plan
1114 for target in targets:
1115 for migration in graph.forwards_plan(target):
1116 if migration not in seen:
1117 node = graph.node_map[migration]
1118 plan.append(node)
1119 seen.add(migration)
1121 # Output
1122 def print_deps(node):
1123 out = []
1124 for parent in sorted(node.parents):
1125 out.append(f"{parent.key[0]}.{parent.key[1]}")
1126 if out:
1127 return f" ... ({', '.join(out)})"
1128 return ""
1130 for node in plan:
1131 deps = ""
1132 if verbosity >= 2:
1133 deps = print_deps(node)
1134 if node.key in loader.applied_migrations:
1135 click.echo(f"[X] {node.key[0]}.{node.key[1]}{deps}")
1136 else:
1137 click.echo(f"[ ] {node.key[0]}.{node.key[1]}{deps}")
1138 if not plan:
1139 click.secho("(no migrations)", fg="red")
1141 # Get the database we're operating from
1142 connection = connections[database]
1144 if format == "plan":
1145 show_plan(connection, package_labels)
1146 else:
1147 show_list(connection, package_labels)
1150@cli.command()
1151@click.argument("package_label")
1152@click.argument("start_migration_name", required=False)
1153@click.argument("migration_name")
1154@click.option(
1155 "--no-optimize",
1156 is_flag=True,
1157 help="Do not try to optimize the squashed operations.",
1158)
1159@click.option(
1160 "--noinput",
1161 "--no-input",
1162 "no_input",
1163 is_flag=True,
1164 help="Tells Plain to NOT prompt the user for input of any kind.",
1165)
1166@click.option("--squashed-name", help="Sets the name of the new squashed migration.")
1167@click.option(
1168 "-v",
1169 "--verbosity",
1170 type=int,
1171 default=1,
1172 help="Verbosity level; 0=minimal output, 1=normal output, 2=verbose output, 3=very verbose output",
1173)
1174def squash_migrations(
1175 package_label,
1176 start_migration_name,
1177 migration_name,
1178 no_optimize,
1179 no_input,
1180 squashed_name,
1181 verbosity,
1182):
1183 """
1184 Squashes an existing set of migrations (from first until specified) into a single new one.
1185 """
1186 interactive = not no_input
1188 def find_migration(loader, package_label, name):
1189 try:
1190 return loader.get_migration_by_prefix(package_label, name)
1191 except AmbiguityError:
1192 raise click.ClickException(
1193 f"More than one migration matches '{name}' in package '{package_label}'. Please be more specific."
1194 )
1195 except KeyError:
1196 raise click.ClickException(
1197 f"Cannot find a migration matching '{name}' from package '{package_label}'."
1198 )
1200 # Validate package_label
1201 try:
1202 packages.get_package_config(package_label)
1203 except LookupError as err:
1204 raise click.ClickException(str(err))
1206 # Load the current graph state, check the app and migration they asked for exists
1207 loader = MigrationLoader(connections[DEFAULT_DB_ALIAS])
1208 if package_label not in loader.migrated_packages:
1209 raise click.ClickException(
1210 f"Package '{package_label}' does not have migrations (so squashmigrations on it makes no sense)"
1211 )
1213 migration = find_migration(loader, package_label, migration_name)
1215 # Work out the list of predecessor migrations
1216 migrations_to_squash = [
1217 loader.get_migration(al, mn)
1218 for al, mn in loader.graph.forwards_plan(
1219 (migration.package_label, migration.name)
1220 )
1221 if al == migration.package_label
1222 ]
1224 if start_migration_name:
1225 start_migration = find_migration(loader, package_label, start_migration_name)
1226 start = loader.get_migration(
1227 start_migration.package_label, start_migration.name
1228 )
1229 try:
1230 start_index = migrations_to_squash.index(start)
1231 migrations_to_squash = migrations_to_squash[start_index:]
1232 except ValueError:
1233 raise click.ClickException(
1234 f"The migration '{start_migration}' cannot be found. Maybe it comes after "
1235 f"the migration '{migration}'?\n"
1236 f"Have a look at:\n"
1237 f" python manage.py showmigrations {package_label}\n"
1238 f"to debug this issue."
1239 )
1241 # Tell them what we're doing and optionally ask if we should proceed
1242 if verbosity > 0 or interactive:
1243 click.secho("Will squash the following migrations:", fg="cyan", bold=True)
1244 for migration in migrations_to_squash:
1245 click.echo(f" - {migration.name}")
1247 if interactive:
1248 if not click.confirm("Do you wish to proceed?"):
1249 return
1251 # Load the operations from all those migrations and concat together,
1252 # along with collecting external dependencies and detecting double-squashing
1253 operations = []
1254 dependencies = set()
1255 # We need to take all dependencies from the first migration in the list
1256 # as it may be 0002 depending on 0001
1257 first_migration = True
1258 for smigration in migrations_to_squash:
1259 if smigration.replaces:
1260 raise click.ClickException(
1261 "You cannot squash squashed migrations! Please transition it to a "
1262 "normal migration first"
1263 )
1264 operations.extend(smigration.operations)
1265 for dependency in smigration.dependencies:
1266 if isinstance(dependency, SwappableTuple):
1267 if settings.AUTH_USER_MODEL == dependency.setting:
1268 dependencies.add(("__setting__", "AUTH_USER_MODEL"))
1269 else:
1270 dependencies.add(dependency)
1271 elif dependency[0] != smigration.package_label or first_migration:
1272 dependencies.add(dependency)
1273 first_migration = False
1275 if no_optimize:
1276 if verbosity > 0:
1277 click.secho("(Skipping optimization.)", fg="yellow")
1278 new_operations = operations
1279 else:
1280 if verbosity > 0:
1281 click.secho("Optimizing...", fg="cyan")
1283 optimizer = MigrationOptimizer()
1284 new_operations = optimizer.optimize(operations, migration.package_label)
1286 if verbosity > 0:
1287 if len(new_operations) == len(operations):
1288 click.echo(" No optimizations possible.")
1289 else:
1290 click.echo(
1291 f" Optimized from {len(operations)} operations to {len(new_operations)} operations."
1292 )
1294 # Work out the value of replaces (any squashed ones we're re-squashing)
1295 # need to feed their replaces into ours
1296 replaces = []
1297 for migration in migrations_to_squash:
1298 if migration.replaces:
1299 replaces.extend(migration.replaces)
1300 else:
1301 replaces.append((migration.package_label, migration.name))
1303 # Make a new migration with those operations
1304 subclass = type(
1305 "Migration",
1306 (migrations.Migration,),
1307 {
1308 "dependencies": dependencies,
1309 "operations": new_operations,
1310 "replaces": replaces,
1311 },
1312 )
1313 if start_migration_name:
1314 if squashed_name:
1315 # Use the name from --squashed-name
1316 prefix, _ = start_migration.name.split("_", 1)
1317 name = f"{prefix}_{squashed_name}"
1318 else:
1319 # Generate a name
1320 name = f"{start_migration.name}_squashed_{migration.name}"
1321 new_migration = subclass(name, package_label)
1322 else:
1323 name = f"0001_{'squashed_' + migration.name if not squashed_name else squashed_name}"
1324 new_migration = subclass(name, package_label)
1325 new_migration.initial = True
1327 # Write out the new migration file
1328 writer = MigrationWriter(new_migration)
1329 if os.path.exists(writer.path):
1330 raise click.ClickException(
1331 f"Migration {new_migration.name} already exists. Use a different name."
1332 )
1333 with open(writer.path, "w", encoding="utf-8") as fh:
1334 fh.write(writer.as_string())
1336 if verbosity > 0:
1337 click.secho(
1338 f"Created new squashed migration {writer.path}", fg="green", bold=True
1339 )
1340 click.echo(
1341 " You should commit this migration but leave the old ones in place;\n"
1342 " the new migration will be used for new installs. Once you are sure\n"
1343 " all instances of the codebase have applied the migrations you squashed,\n"
1344 " you can delete them."
1345 )
1346 if writer.needs_manual_porting:
1347 click.secho("Manual porting required", fg="yellow", bold=True)
1348 click.echo(
1349 " Your migrations contained functions that must be manually copied over,\n"
1350 " as we could not safely copy their implementation.\n"
1351 " See the comment at the top of the squashed migration for details."
1352 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.packages import PackageConfig
4class PlainDBConfig(PackageConfig):
5 name = "plain.models"
6 # We wan to use the "migrations" module
7 # in this package but not for the standard purpose
8 migrations_module = None
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Constants used across the ORM in general.
3"""
5from enum import Enum
7# Separator used to split filter strings apart.
8LOOKUP_SEP = "__"
11class OnConflict(Enum):
12 IGNORE = "ignore"
13 UPDATE = "update"
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import warnings
2from enum import Enum
3from types import NoneType
5from plain.exceptions import FieldError, ValidationError
6from plain.models.db import DEFAULT_DB_ALIAS, connections
7from plain.models.expressions import Exists, ExpressionList, F, OrderBy
8from plain.models.indexes import IndexExpression
9from plain.models.lookups import Exact
10from plain.models.query_utils import Q
11from plain.models.sql.query import Query
12from plain.utils.deprecation import RemovedInDjango60Warning
14__all__ = ["BaseConstraint", "CheckConstraint", "Deferrable", "UniqueConstraint"]
17class BaseConstraint:
18 default_violation_error_message = "Constraint “%(name)s” is violated."
19 violation_error_code = None
20 violation_error_message = None
22 # RemovedInDjango60Warning: When the deprecation ends, replace with:
23 # def __init__(
24 # self, *, name, violation_error_code=None, violation_error_message=None
25 # ):
26 def __init__(
27 self, *args, name=None, violation_error_code=None, violation_error_message=None
28 ):
29 # RemovedInDjango60Warning.
30 if name is None and not args:
31 raise TypeError(
32 f"{self.__class__.__name__}.__init__() missing 1 required keyword-only "
33 f"argument: 'name'"
34 )
35 self.name = name
36 if violation_error_code is not None:
37 self.violation_error_code = violation_error_code
38 if violation_error_message is not None:
39 self.violation_error_message = violation_error_message
40 else:
41 self.violation_error_message = self.default_violation_error_message
42 # RemovedInDjango60Warning.
43 if args:
44 warnings.warn(
45 f"Passing positional arguments to {self.__class__.__name__} is "
46 f"deprecated.",
47 RemovedInDjango60Warning,
48 stacklevel=2,
49 )
50 for arg, attr in zip(args, ["name", "violation_error_message"]):
51 if arg:
52 setattr(self, attr, arg)
54 @property
55 def contains_expressions(self):
56 return False
58 def constraint_sql(self, model, schema_editor):
59 raise NotImplementedError("This method must be implemented by a subclass.")
61 def create_sql(self, model, schema_editor):
62 raise NotImplementedError("This method must be implemented by a subclass.")
64 def remove_sql(self, model, schema_editor):
65 raise NotImplementedError("This method must be implemented by a subclass.")
67 def validate(self, model, instance, exclude=None, using=DEFAULT_DB_ALIAS):
68 raise NotImplementedError("This method must be implemented by a subclass.")
70 def get_violation_error_message(self):
71 return self.violation_error_message % {"name": self.name}
73 def deconstruct(self):
74 path = f"{self.__class__.__module__}.{self.__class__.__name__}"
75 path = path.replace("plain.models.constraints", "plain.models")
76 kwargs = {"name": self.name}
77 if (
78 self.violation_error_message is not None
79 and self.violation_error_message != self.default_violation_error_message
80 ):
81 kwargs["violation_error_message"] = self.violation_error_message
82 if self.violation_error_code is not None:
83 kwargs["violation_error_code"] = self.violation_error_code
84 return (path, (), kwargs)
86 def clone(self):
87 _, args, kwargs = self.deconstruct()
88 return self.__class__(*args, **kwargs)
91class CheckConstraint(BaseConstraint):
92 def __init__(
93 self, *, check, name, violation_error_code=None, violation_error_message=None
94 ):
95 self.check = check
96 if not getattr(check, "conditional", False):
97 raise TypeError(
98 "CheckConstraint.check must be a Q instance or boolean expression."
99 )
100 super().__init__(
101 name=name,
102 violation_error_code=violation_error_code,
103 violation_error_message=violation_error_message,
104 )
106 def _get_check_sql(self, model, schema_editor):
107 query = Query(model=model, alias_cols=False)
108 where = query.build_where(self.check)
109 compiler = query.get_compiler(connection=schema_editor.connection)
110 sql, params = where.as_sql(compiler, schema_editor.connection)
111 return sql % tuple(schema_editor.quote_value(p) for p in params)
113 def constraint_sql(self, model, schema_editor):
114 check = self._get_check_sql(model, schema_editor)
115 return schema_editor._check_sql(self.name, check)
117 def create_sql(self, model, schema_editor):
118 check = self._get_check_sql(model, schema_editor)
119 return schema_editor._create_check_sql(model, self.name, check)
121 def remove_sql(self, model, schema_editor):
122 return schema_editor._delete_check_sql(model, self.name)
124 def validate(self, model, instance, exclude=None, using=DEFAULT_DB_ALIAS):
125 against = instance._get_field_value_map(meta=model._meta, exclude=exclude)
126 try:
127 if not Q(self.check).check(against, using=using):
128 raise ValidationError(
129 self.get_violation_error_message(), code=self.violation_error_code
130 )
131 except FieldError:
132 pass
134 def __repr__(self):
135 return "<{}: check={} name={}{}{}>".format(
136 self.__class__.__qualname__,
137 self.check,
138 repr(self.name),
139 (
140 ""
141 if self.violation_error_code is None
142 else f" violation_error_code={self.violation_error_code!r}"
143 ),
144 (
145 ""
146 if self.violation_error_message is None
147 or self.violation_error_message == self.default_violation_error_message
148 else f" violation_error_message={self.violation_error_message!r}"
149 ),
150 )
152 def __eq__(self, other):
153 if isinstance(other, CheckConstraint):
154 return (
155 self.name == other.name
156 and self.check == other.check
157 and self.violation_error_code == other.violation_error_code
158 and self.violation_error_message == other.violation_error_message
159 )
160 return super().__eq__(other)
162 def deconstruct(self):
163 path, args, kwargs = super().deconstruct()
164 kwargs["check"] = self.check
165 return path, args, kwargs
168class Deferrable(Enum):
169 DEFERRED = "deferred"
170 IMMEDIATE = "immediate"
172 # A similar format was proposed for Python 3.10.
173 def __repr__(self):
174 return f"{self.__class__.__qualname__}.{self._name_}"
177class UniqueConstraint(BaseConstraint):
178 def __init__(
179 self,
180 *expressions,
181 fields=(),
182 name=None,
183 condition=None,
184 deferrable=None,
185 include=None,
186 opclasses=(),
187 violation_error_code=None,
188 violation_error_message=None,
189 ):
190 if not name:
191 raise ValueError("A unique constraint must be named.")
192 if not expressions and not fields:
193 raise ValueError(
194 "At least one field or expression is required to define a "
195 "unique constraint."
196 )
197 if expressions and fields:
198 raise ValueError(
199 "UniqueConstraint.fields and expressions are mutually exclusive."
200 )
201 if not isinstance(condition, NoneType | Q):
202 raise ValueError("UniqueConstraint.condition must be a Q instance.")
203 if condition and deferrable:
204 raise ValueError("UniqueConstraint with conditions cannot be deferred.")
205 if include and deferrable:
206 raise ValueError("UniqueConstraint with include fields cannot be deferred.")
207 if opclasses and deferrable:
208 raise ValueError("UniqueConstraint with opclasses cannot be deferred.")
209 if expressions and deferrable:
210 raise ValueError("UniqueConstraint with expressions cannot be deferred.")
211 if expressions and opclasses:
212 raise ValueError(
213 "UniqueConstraint.opclasses cannot be used with expressions. "
214 "Use a custom OpClass() instead."
215 )
216 if not isinstance(deferrable, NoneType | Deferrable):
217 raise ValueError(
218 "UniqueConstraint.deferrable must be a Deferrable instance."
219 )
220 if not isinstance(include, NoneType | list | tuple):
221 raise ValueError("UniqueConstraint.include must be a list or tuple.")
222 if not isinstance(opclasses, list | tuple):
223 raise ValueError("UniqueConstraint.opclasses must be a list or tuple.")
224 if opclasses and len(fields) != len(opclasses):
225 raise ValueError(
226 "UniqueConstraint.fields and UniqueConstraint.opclasses must "
227 "have the same number of elements."
228 )
229 self.fields = tuple(fields)
230 self.condition = condition
231 self.deferrable = deferrable
232 self.include = tuple(include) if include else ()
233 self.opclasses = opclasses
234 self.expressions = tuple(
235 F(expression) if isinstance(expression, str) else expression
236 for expression in expressions
237 )
238 super().__init__(
239 name=name,
240 violation_error_code=violation_error_code,
241 violation_error_message=violation_error_message,
242 )
244 @property
245 def contains_expressions(self):
246 return bool(self.expressions)
248 def _get_condition_sql(self, model, schema_editor):
249 if self.condition is None:
250 return None
251 query = Query(model=model, alias_cols=False)
252 where = query.build_where(self.condition)
253 compiler = query.get_compiler(connection=schema_editor.connection)
254 sql, params = where.as_sql(compiler, schema_editor.connection)
255 return sql % tuple(schema_editor.quote_value(p) for p in params)
257 def _get_index_expressions(self, model, schema_editor):
258 if not self.expressions:
259 return None
260 index_expressions = []
261 for expression in self.expressions:
262 index_expression = IndexExpression(expression)
263 index_expression.set_wrapper_classes(schema_editor.connection)
264 index_expressions.append(index_expression)
265 return ExpressionList(*index_expressions).resolve_expression(
266 Query(model, alias_cols=False),
267 )
269 def constraint_sql(self, model, schema_editor):
270 fields = [model._meta.get_field(field_name) for field_name in self.fields]
271 include = [
272 model._meta.get_field(field_name).column for field_name in self.include
273 ]
274 condition = self._get_condition_sql(model, schema_editor)
275 expressions = self._get_index_expressions(model, schema_editor)
276 return schema_editor._unique_sql(
277 model,
278 fields,
279 self.name,
280 condition=condition,
281 deferrable=self.deferrable,
282 include=include,
283 opclasses=self.opclasses,
284 expressions=expressions,
285 )
287 def create_sql(self, model, schema_editor):
288 fields = [model._meta.get_field(field_name) for field_name in self.fields]
289 include = [
290 model._meta.get_field(field_name).column for field_name in self.include
291 ]
292 condition = self._get_condition_sql(model, schema_editor)
293 expressions = self._get_index_expressions(model, schema_editor)
294 return schema_editor._create_unique_sql(
295 model,
296 fields,
297 self.name,
298 condition=condition,
299 deferrable=self.deferrable,
300 include=include,
301 opclasses=self.opclasses,
302 expressions=expressions,
303 )
305 def remove_sql(self, model, schema_editor):
306 condition = self._get_condition_sql(model, schema_editor)
307 include = [
308 model._meta.get_field(field_name).column for field_name in self.include
309 ]
310 expressions = self._get_index_expressions(model, schema_editor)
311 return schema_editor._delete_unique_sql(
312 model,
313 self.name,
314 condition=condition,
315 deferrable=self.deferrable,
316 include=include,
317 opclasses=self.opclasses,
318 expressions=expressions,
319 )
321 def __repr__(self):
322 return "<{}:{}{}{}{}{}{}{}{}{}>".format(
323 self.__class__.__qualname__,
324 "" if not self.fields else f" fields={repr(self.fields)}",
325 "" if not self.expressions else f" expressions={repr(self.expressions)}",
326 f" name={repr(self.name)}",
327 "" if self.condition is None else f" condition={self.condition}",
328 "" if self.deferrable is None else f" deferrable={self.deferrable!r}",
329 "" if not self.include else f" include={repr(self.include)}",
330 "" if not self.opclasses else f" opclasses={repr(self.opclasses)}",
331 (
332 ""
333 if self.violation_error_code is None
334 else f" violation_error_code={self.violation_error_code!r}"
335 ),
336 (
337 ""
338 if self.violation_error_message is None
339 or self.violation_error_message == self.default_violation_error_message
340 else f" violation_error_message={self.violation_error_message!r}"
341 ),
342 )
344 def __eq__(self, other):
345 if isinstance(other, UniqueConstraint):
346 return (
347 self.name == other.name
348 and self.fields == other.fields
349 and self.condition == other.condition
350 and self.deferrable == other.deferrable
351 and self.include == other.include
352 and self.opclasses == other.opclasses
353 and self.expressions == other.expressions
354 and self.violation_error_code == other.violation_error_code
355 and self.violation_error_message == other.violation_error_message
356 )
357 return super().__eq__(other)
359 def deconstruct(self):
360 path, args, kwargs = super().deconstruct()
361 if self.fields:
362 kwargs["fields"] = self.fields
363 if self.condition:
364 kwargs["condition"] = self.condition
365 if self.deferrable:
366 kwargs["deferrable"] = self.deferrable
367 if self.include:
368 kwargs["include"] = self.include
369 if self.opclasses:
370 kwargs["opclasses"] = self.opclasses
371 return path, self.expressions, kwargs
373 def validate(self, model, instance, exclude=None, using=DEFAULT_DB_ALIAS):
374 queryset = model._default_manager.using(using)
375 if self.fields:
376 lookup_kwargs = {}
377 for field_name in self.fields:
378 if exclude and field_name in exclude:
379 return
380 field = model._meta.get_field(field_name)
381 lookup_value = getattr(instance, field.attname)
382 if lookup_value is None or (
383 lookup_value == ""
384 and connections[using].features.interprets_empty_strings_as_nulls
385 ):
386 # A composite constraint containing NULL value cannot cause
387 # a violation since NULL != NULL in SQL.
388 return
389 lookup_kwargs[field.name] = lookup_value
390 queryset = queryset.filter(**lookup_kwargs)
391 else:
392 # Ignore constraints with excluded fields.
393 if exclude:
394 for expression in self.expressions:
395 if hasattr(expression, "flatten"):
396 for expr in expression.flatten():
397 if isinstance(expr, F) and expr.name in exclude:
398 return
399 elif isinstance(expression, F) and expression.name in exclude:
400 return
401 replacements = {
402 F(field): value
403 for field, value in instance._get_field_value_map(
404 meta=model._meta, exclude=exclude
405 ).items()
406 }
407 expressions = []
408 for expr in self.expressions:
409 # Ignore ordering.
410 if isinstance(expr, OrderBy):
411 expr = expr.expression
412 expressions.append(Exact(expr, expr.replace_expressions(replacements)))
413 queryset = queryset.filter(*expressions)
414 model_class_pk = instance._get_pk_val(model._meta)
415 if not instance._state.adding and model_class_pk is not None:
416 queryset = queryset.exclude(pk=model_class_pk)
417 if not self.condition:
418 if queryset.exists():
419 if self.expressions:
420 raise ValidationError(
421 self.get_violation_error_message(),
422 code=self.violation_error_code,
423 )
424 # When fields are defined, use the unique_error_message() for
425 # backward compatibility.
426 for model, constraints in instance.get_constraints():
427 for constraint in constraints:
428 if constraint is self:
429 raise ValidationError(
430 instance.unique_error_message(model, self.fields),
431 )
432 else:
433 against = instance._get_field_value_map(meta=model._meta, exclude=exclude)
434 try:
435 if (self.condition & Exists(queryset.filter(self.condition))).check(
436 against, using=using
437 ):
438 raise ValidationError(
439 self.get_violation_error_message(),
440 code=self.violation_error_code,
441 )
442 except FieldError:
443 pass
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1# Copyright (c) Kenneth Reitz & individual contributors
2# All rights reserved.
4# Redistribution and use in source and binary forms, with or without modification,
5# are permitted provided that the following conditions are met:
7# 1. Redistributions of source code must retain the above copyright notice,
8# this list of conditions and the following disclaimer.
10# 2. Redistributions in binary form must reproduce the above copyright
11# notice, this list of conditions and the following disclaimer in the
12# documentation and/or other materials provided with the distribution.
14# 3. Neither the name of Plain nor the names of its contributors may be used
15# to endorse or promote products derived from this software without
16# specific prior written permission.
18# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
19# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
20# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
21# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR
22# ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
23# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
24# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
25# ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
26# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
27# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
28import logging
29import os
30import urllib.parse as urlparse
31from typing import Any, TypedDict
33DEFAULT_ENV = "DATABASE_URL"
35SCHEMES = {
36 "postgres": "plain.models.backends.postgresql",
37 "postgresql": "plain.models.backends.postgresql",
38 "pgsql": "plain.models.backends.postgresql",
39 "mysql": "plain.models.backends.mysql",
40 "mysql2": "plain.models.backends.mysql",
41 "sqlite": "plain.models.backends.sqlite3",
42}
44# Register database schemes in URLs.
45for key in SCHEMES.keys():
46 urlparse.uses_netloc.append(key)
49class DBConfig(TypedDict, total=False):
50 AUTOCOMMIT: bool
51 CONN_MAX_AGE: int | None
52 CONN_HEALTH_CHECKS: bool
53 DISABLE_SERVER_SIDE_CURSORS: bool
54 ENGINE: str
55 HOST: str
56 NAME: str
57 OPTIONS: dict[str, Any] | None
58 PASSWORD: str
59 PORT: str | int
60 TEST: dict[str, Any]
61 TIME_ZONE: str
62 USER: str
65def config(
66 env: str = DEFAULT_ENV,
67 default: str | None = None,
68 engine: str | None = None,
69 conn_max_age: int | None = 0,
70 conn_health_checks: bool = False,
71 ssl_require: bool = False,
72 test_options: dict | None = None,
73) -> DBConfig:
74 """Returns configured DATABASE dictionary from DATABASE_URL."""
75 s = os.environ.get(env, default)
77 if s is None:
78 logging.warning(f"No {env} environment variable set, and so no databases setup")
80 if s:
81 return parse(
82 s, engine, conn_max_age, conn_health_checks, ssl_require, test_options
83 )
85 return {}
88def parse(
89 url: str,
90 engine: str | None = None,
91 conn_max_age: int | None = 0,
92 conn_health_checks: bool = False,
93 ssl_require: bool = False,
94 test_options: dict | None = None,
95) -> DBConfig:
96 """Parses a database URL."""
97 if url == "sqlite://:memory:":
98 # this is a special case, because if we pass this URL into
99 # urlparse, urlparse will choke trying to interpret "memory"
100 # as a port number
101 return {"ENGINE": SCHEMES["sqlite"], "NAME": ":memory:"}
102 # note: no other settings are required for sqlite
104 # otherwise parse the url as normal
105 parsed_config: DBConfig = {}
107 if test_options is None:
108 test_options = {}
110 spliturl = urlparse.urlsplit(url)
112 # Split query strings from path.
113 path = spliturl.path[1:]
114 query = urlparse.parse_qs(spliturl.query)
116 # If we are using sqlite and we have no path, then assume we
117 # want an in-memory database (this is the behaviour of sqlalchemy)
118 if spliturl.scheme == "sqlite" and path == "":
119 path = ":memory:"
121 # Handle postgres percent-encoded paths.
122 hostname = spliturl.hostname or ""
123 if "%" in hostname:
124 # Switch to url.netloc to avoid lower cased paths
125 hostname = spliturl.netloc
126 if "@" in hostname:
127 hostname = hostname.rsplit("@", 1)[1]
128 # Use URL Parse library to decode % encodes
129 hostname = urlparse.unquote(hostname)
131 # Lookup specified engine.
132 if engine is None:
133 engine = SCHEMES.get(spliturl.scheme)
134 if engine is None:
135 raise ValueError(
136 "No support for '{}'. We support: {}".format(
137 spliturl.scheme, ", ".join(sorted(SCHEMES.keys()))
138 )
139 )
141 port = spliturl.port
143 # Update with environment configuration.
144 parsed_config.update(
145 {
146 "NAME": urlparse.unquote(path or ""),
147 "USER": urlparse.unquote(spliturl.username or ""),
148 "PASSWORD": urlparse.unquote(spliturl.password or ""),
149 "HOST": hostname,
150 "PORT": port or "",
151 "CONN_MAX_AGE": conn_max_age,
152 "CONN_HEALTH_CHECKS": conn_health_checks,
153 "ENGINE": engine,
154 }
155 )
156 if test_options:
157 parsed_config.update(
158 {
159 "TEST": test_options,
160 }
161 )
163 # Pass the query string into OPTIONS.
164 options: dict[str, Any] = {}
165 for key, values in query.items():
166 if spliturl.scheme == "mysql" and key == "ssl-ca":
167 options["ssl"] = {"ca": values[-1]}
168 continue
170 options[key] = values[-1]
172 if ssl_require:
173 options["sslmode"] = "require"
175 # Support for Postgres Schema URLs
176 if "currentSchema" in options and engine in (
177 "plain.models.backends.postgresql_psycopg2",
178 "plain.models.backends.postgresql",
179 ):
180 options["options"] = "-c search_path={}".format(options.pop("currentSchema"))
182 if options:
183 parsed_config["OPTIONS"] = options
185 return parsed_config
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import pkgutil
2from importlib import import_module
4from plain import signals
5from plain.exceptions import ImproperlyConfigured
6from plain.runtime import settings
7from plain.utils.connection import BaseConnectionHandler, ConnectionProxy
8from plain.utils.functional import cached_property
9from plain.utils.module_loading import import_string
11DEFAULT_DB_ALIAS = "default"
12PLAIN_VERSION_PICKLE_KEY = "_plain_version"
15class Error(Exception):
16 pass
19class InterfaceError(Error):
20 pass
23class DatabaseError(Error):
24 pass
27class DataError(DatabaseError):
28 pass
31class OperationalError(DatabaseError):
32 pass
35class IntegrityError(DatabaseError):
36 pass
39class InternalError(DatabaseError):
40 pass
43class ProgrammingError(DatabaseError):
44 pass
47class NotSupportedError(DatabaseError):
48 pass
51class DatabaseErrorWrapper:
52 """
53 Context manager and decorator that reraises backend-specific database
54 exceptions using Plain's common wrappers.
55 """
57 def __init__(self, wrapper):
58 """
59 wrapper is a database wrapper.
61 It must have a Database attribute defining PEP-249 exceptions.
62 """
63 self.wrapper = wrapper
65 def __enter__(self):
66 pass
68 def __exit__(self, exc_type, exc_value, traceback):
69 if exc_type is None:
70 return
71 for plain_exc_type in (
72 DataError,
73 OperationalError,
74 IntegrityError,
75 InternalError,
76 ProgrammingError,
77 NotSupportedError,
78 DatabaseError,
79 InterfaceError,
80 Error,
81 ):
82 db_exc_type = getattr(self.wrapper.Database, plain_exc_type.__name__)
83 if issubclass(exc_type, db_exc_type):
84 plain_exc_value = plain_exc_type(*exc_value.args)
85 # Only set the 'errors_occurred' flag for errors that may make
86 # the connection unusable.
87 if plain_exc_type not in (DataError, IntegrityError):
88 self.wrapper.errors_occurred = True
89 raise plain_exc_value.with_traceback(traceback) from exc_value
91 def __call__(self, func):
92 # Note that we are intentionally not using @wraps here for performance
93 # reasons. Refs #21109.
94 def inner(*args, **kwargs):
95 with self:
96 return func(*args, **kwargs)
98 return inner
101def load_backend(backend_name):
102 """
103 Return a database backend's "base" module given a fully qualified database
104 backend name, or raise an error if it doesn't exist.
105 """
106 try:
107 return import_module(f"{backend_name}.base")
108 except ImportError as e_user:
109 # The database backend wasn't found. Display a helpful error message
110 # listing all built-in database backends.
111 import plain.models.backends
113 builtin_backends = [
114 name
115 for _, name, ispkg in pkgutil.iter_modules(plain.models.backends.__path__)
116 if ispkg and name not in {"base", "dummy"}
117 ]
118 if backend_name not in [f"plain.models.backends.{b}" for b in builtin_backends]:
119 backend_reprs = map(repr, sorted(builtin_backends))
120 raise ImproperlyConfigured(
121 "{!r} isn't an available database backend or couldn't be "
122 "imported. Check the above exception. To use one of the "
123 "built-in backends, use 'plain.models.backends.XXX', where XXX "
124 "is one of:\n"
125 " {}".format(backend_name, ", ".join(backend_reprs))
126 ) from e_user
127 else:
128 # If there's some other error, this must be an error in Plain
129 raise
132class ConnectionHandler(BaseConnectionHandler):
133 settings_name = "DATABASES"
135 def configure_settings(self, databases):
136 databases = super().configure_settings(databases)
137 if databases == {}:
138 databases[DEFAULT_DB_ALIAS] = {"ENGINE": "plain.models.backends.dummy"}
139 elif DEFAULT_DB_ALIAS not in databases:
140 raise ImproperlyConfigured(
141 f"You must define a '{DEFAULT_DB_ALIAS}' database."
142 )
143 elif databases[DEFAULT_DB_ALIAS] == {}:
144 databases[DEFAULT_DB_ALIAS]["ENGINE"] = "plain.models.backends.dummy"
146 # Configure default settings.
147 for conn in databases.values():
148 conn.setdefault("AUTOCOMMIT", True)
149 conn.setdefault("ENGINE", "plain.models.backends.dummy")
150 if conn["ENGINE"] == "plain.models.backends." or not conn["ENGINE"]:
151 conn["ENGINE"] = "plain.models.backends.dummy"
152 conn.setdefault("CONN_MAX_AGE", 0)
153 conn.setdefault("CONN_HEALTH_CHECKS", False)
154 conn.setdefault("OPTIONS", {})
155 conn.setdefault("TIME_ZONE", None)
156 for setting in ["NAME", "USER", "PASSWORD", "HOST", "PORT"]:
157 conn.setdefault(setting, "")
159 test_settings = conn.setdefault("TEST", {})
160 default_test_settings = [
161 ("CHARSET", None),
162 ("COLLATION", None),
163 ("MIGRATE", True),
164 ("MIRROR", None),
165 ("NAME", None),
166 ]
167 for key, value in default_test_settings:
168 test_settings.setdefault(key, value)
169 return databases
171 @property
172 def databases(self):
173 # Maintained for backward compatibility as some 3rd party packages have
174 # made use of this private API in the past. It is no longer used within
175 # Plain itself.
176 return self.settings
178 def create_connection(self, alias):
179 db = self.settings[alias]
180 backend = load_backend(db["ENGINE"])
181 return backend.DatabaseWrapper(db, alias)
184class ConnectionRouter:
185 def __init__(self, routers=None):
186 """
187 If routers is not specified, default to settings.DATABASE_ROUTERS.
188 """
189 self._routers = routers
191 @cached_property
192 def routers(self):
193 if self._routers is None:
194 self._routers = settings.DATABASE_ROUTERS
195 routers = []
196 for r in self._routers:
197 if isinstance(r, str):
198 router = import_string(r)()
199 else:
200 router = r
201 routers.append(router)
202 return routers
204 def _router_func(action):
205 def _route_db(self, model, **hints):
206 chosen_db = None
207 for router in self.routers:
208 try:
209 method = getattr(router, action)
210 except AttributeError:
211 # If the router doesn't have a method, skip to the next one.
212 pass
213 else:
214 chosen_db = method(model, **hints)
215 if chosen_db:
216 return chosen_db
217 instance = hints.get("instance")
218 if instance is not None and instance._state.db:
219 return instance._state.db
220 return DEFAULT_DB_ALIAS
222 return _route_db
224 db_for_read = _router_func("db_for_read")
225 db_for_write = _router_func("db_for_write")
227 def allow_relation(self, obj1, obj2, **hints):
228 for router in self.routers:
229 try:
230 method = router.allow_relation
231 except AttributeError:
232 # If the router doesn't have a method, skip to the next one.
233 pass
234 else:
235 allow = method(obj1, obj2, **hints)
236 if allow is not None:
237 return allow
238 return obj1._state.db == obj2._state.db
240 def allow_migrate(self, db, package_label, **hints):
241 for router in self.routers:
242 try:
243 method = router.allow_migrate
244 except AttributeError:
245 # If the router doesn't have a method, skip to the next one.
246 continue
248 allow = method(db, package_label, **hints)
250 if allow is not None:
251 return allow
252 return True
254 def allow_migrate_model(self, db, model):
255 return self.allow_migrate(
256 db,
257 model._meta.package_label,
258 model_name=model._meta.model_name,
259 model=model,
260 )
262 def get_migratable_models(self, package_config, db, include_auto_created=False):
263 """Return app models allowed to be migrated on provided db."""
264 models = package_config.get_models(include_auto_created=include_auto_created)
265 return [model for model in models if self.allow_migrate_model(db, model)]
268connections = ConnectionHandler()
270router = ConnectionRouter()
272# For backwards compatibility. Prefer connections['default'] instead.
273connection = ConnectionProxy(connections, DEFAULT_DB_ALIAS)
276# Register an event to reset saved queries when a Plain request is started.
277def reset_queries(**kwargs):
278 for conn in connections.all(initialized_only=True):
279 conn.queries_log.clear()
282signals.request_started.connect(reset_queries)
285# Register an event to reset transaction state and close connections past
286# their lifetime.
287def close_old_connections(**kwargs):
288 for conn in connections.all(initialized_only=True):
289 conn.close_if_unusable_or_obsolete()
292signals.request_started.connect(close_old_connections)
293signals.request_finished.connect(close_old_connections)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from os import environ
3from . import database_url
5# Make DATABASES a required setting
6DATABASES: dict
8# Automatically configure DATABASES if a DATABASE_URL was given in the environment
9if "DATABASE_URL" in environ:
10 DATABASES = {
11 "default": database_url.parse(
12 environ["DATABASE_URL"],
13 # Enable persistent connections by default
14 conn_max_age=int(environ.get("DATABASE_CONN_MAX_AGE", 600)),
15 conn_health_checks=environ.get(
16 "DATABASE_CONN_HEALTH_CHECKS", "true"
17 ).lower()
18 in [
19 "true",
20 "1",
21 ],
22 )
23 }
25# Classes used to implement DB routing behavior.
26DATABASE_ROUTERS = []
28# The tablespaces to use for each model when not specified otherwise.
29DEFAULT_TABLESPACE = ""
30DEFAULT_INDEX_TABLESPACE = ""
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from collections import Counter, defaultdict
2from functools import partial, reduce
3from itertools import chain
4from operator import attrgetter, or_
6from plain.models import (
7 query_utils,
8 signals,
9 sql,
10 transaction,
11)
12from plain.models.db import IntegrityError, connections
13from plain.models.query import QuerySet
16class ProtectedError(IntegrityError):
17 def __init__(self, msg, protected_objects):
18 self.protected_objects = protected_objects
19 super().__init__(msg, protected_objects)
22class RestrictedError(IntegrityError):
23 def __init__(self, msg, restricted_objects):
24 self.restricted_objects = restricted_objects
25 super().__init__(msg, restricted_objects)
28def CASCADE(collector, field, sub_objs, using):
29 collector.collect(
30 sub_objs,
31 source=field.remote_field.model,
32 source_attr=field.name,
33 nullable=field.null,
34 fail_on_restricted=False,
35 )
36 if field.null and not connections[using].features.can_defer_constraint_checks:
37 collector.add_field_update(field, None, sub_objs)
40def PROTECT(collector, field, sub_objs, using):
41 raise ProtectedError(
42 f"Cannot delete some instances of model '{field.remote_field.model.__name__}' because they are "
43 f"referenced through a protected foreign key: '{sub_objs[0].__class__.__name__}.{field.name}'",
44 sub_objs,
45 )
48def RESTRICT(collector, field, sub_objs, using):
49 collector.add_restricted_objects(field, sub_objs)
50 collector.add_dependency(field.remote_field.model, field.model)
53def SET(value):
54 if callable(value):
56 def set_on_delete(collector, field, sub_objs, using):
57 collector.add_field_update(field, value(), sub_objs)
59 else:
61 def set_on_delete(collector, field, sub_objs, using):
62 collector.add_field_update(field, value, sub_objs)
64 set_on_delete.deconstruct = lambda: ("plain.models.SET", (value,), {})
65 set_on_delete.lazy_sub_objs = True
66 return set_on_delete
69def SET_NULL(collector, field, sub_objs, using):
70 collector.add_field_update(field, None, sub_objs)
73SET_NULL.lazy_sub_objs = True
76def SET_DEFAULT(collector, field, sub_objs, using):
77 collector.add_field_update(field, field.get_default(), sub_objs)
80SET_DEFAULT.lazy_sub_objs = True
83def DO_NOTHING(collector, field, sub_objs, using):
84 pass
87def get_candidate_relations_to_delete(opts):
88 # The candidate relations are the ones that come from N-1 and 1-1 relations.
89 # N-N (i.e., many-to-many) relations aren't candidates for deletion.
90 return (
91 f
92 for f in opts.get_fields(include_hidden=True)
93 if f.auto_created and not f.concrete and (f.one_to_one or f.one_to_many)
94 )
97class Collector:
98 def __init__(self, using, origin=None):
99 self.using = using
100 # A Model or QuerySet object.
101 self.origin = origin
102 # Initially, {model: {instances}}, later values become lists.
103 self.data = defaultdict(set)
104 # {(field, value): [instances, …]}
105 self.field_updates = defaultdict(list)
106 # {model: {field: {instances}}}
107 self.restricted_objects = defaultdict(partial(defaultdict, set))
108 # fast_deletes is a list of queryset-likes that can be deleted without
109 # fetching the objects into memory.
110 self.fast_deletes = []
112 # Tracks deletion-order dependency for databases without transactions
113 # or ability to defer constraint checks. Only concrete model classes
114 # should be included, as the dependencies exist only between actual
115 # database tables.
116 self.dependencies = defaultdict(set) # {model: {models}}
118 def add(self, objs, source=None, nullable=False, reverse_dependency=False):
119 """
120 Add 'objs' to the collection of objects to be deleted. If the call is
121 the result of a cascade, 'source' should be the model that caused it,
122 and 'nullable' should be set to True if the relation can be null.
124 Return a list of all objects that were not already collected.
125 """
126 if not objs:
127 return []
128 new_objs = []
129 model = objs[0].__class__
130 instances = self.data[model]
131 for obj in objs:
132 if obj not in instances:
133 new_objs.append(obj)
134 instances.update(new_objs)
135 # Nullable relationships can be ignored -- they are nulled out before
136 # deleting, and therefore do not affect the order in which objects have
137 # to be deleted.
138 if source is not None and not nullable:
139 self.add_dependency(source, model, reverse_dependency=reverse_dependency)
140 return new_objs
142 def add_dependency(self, model, dependency, reverse_dependency=False):
143 if reverse_dependency:
144 model, dependency = dependency, model
145 self.dependencies[model._meta.concrete_model].add(
146 dependency._meta.concrete_model
147 )
148 self.data.setdefault(dependency, self.data.default_factory())
150 def add_field_update(self, field, value, objs):
151 """
152 Schedule a field update. 'objs' must be a homogeneous iterable
153 collection of model instances (e.g. a QuerySet).
154 """
155 self.field_updates[field, value].append(objs)
157 def add_restricted_objects(self, field, objs):
158 if objs:
159 model = objs[0].__class__
160 self.restricted_objects[model][field].update(objs)
162 def clear_restricted_objects_from_set(self, model, objs):
163 if model in self.restricted_objects:
164 self.restricted_objects[model] = {
165 field: items - objs
166 for field, items in self.restricted_objects[model].items()
167 }
169 def clear_restricted_objects_from_queryset(self, model, qs):
170 if model in self.restricted_objects:
171 objs = set(
172 qs.filter(
173 pk__in=[
174 obj.pk
175 for objs in self.restricted_objects[model].values()
176 for obj in objs
177 ]
178 )
179 )
180 self.clear_restricted_objects_from_set(model, objs)
182 def _has_signal_listeners(self, model):
183 return signals.pre_delete.has_listeners(
184 model
185 ) or signals.post_delete.has_listeners(model)
187 def can_fast_delete(self, objs, from_field=None):
188 """
189 Determine if the objects in the given queryset-like or single object
190 can be fast-deleted. This can be done if there are no cascades, no
191 parents and no signal listeners for the object class.
193 The 'from_field' tells where we are coming from - we need this to
194 determine if the objects are in fact to be deleted. Allow also
195 skipping parent -> child -> parent chain preventing fast delete of
196 the child.
197 """
198 if from_field and from_field.remote_field.on_delete is not CASCADE:
199 return False
200 if hasattr(objs, "_meta"):
201 model = objs._meta.model
202 elif hasattr(objs, "model") and hasattr(objs, "_raw_delete"):
203 model = objs.model
204 else:
205 return False
206 if self._has_signal_listeners(model):
207 return False
208 # The use of from_field comes from the need to avoid cascade back to
209 # parent when parent delete is cascading to child.
210 opts = model._meta
211 return (
212 all(
213 link == from_field
214 for link in opts.concrete_model._meta.parents.values()
215 )
216 and
217 # Foreign keys pointing to this model.
218 all(
219 related.field.remote_field.on_delete is DO_NOTHING
220 for related in get_candidate_relations_to_delete(opts)
221 )
222 and (
223 # Something like generic foreign key.
224 not any(
225 hasattr(field, "bulk_related_objects")
226 for field in opts.private_fields
227 )
228 )
229 )
231 def get_del_batches(self, objs, fields):
232 """
233 Return the objs in suitably sized batches for the used connection.
234 """
235 field_names = [field.name for field in fields]
236 conn_batch_size = max(
237 connections[self.using].ops.bulk_batch_size(field_names, objs), 1
238 )
239 if len(objs) > conn_batch_size:
240 return [
241 objs[i : i + conn_batch_size]
242 for i in range(0, len(objs), conn_batch_size)
243 ]
244 else:
245 return [objs]
247 def collect(
248 self,
249 objs,
250 source=None,
251 nullable=False,
252 collect_related=True,
253 source_attr=None,
254 reverse_dependency=False,
255 keep_parents=False,
256 fail_on_restricted=True,
257 ):
258 """
259 Add 'objs' to the collection of objects to be deleted as well as all
260 parent instances. 'objs' must be a homogeneous iterable collection of
261 model instances (e.g. a QuerySet). If 'collect_related' is True,
262 related objects will be handled by their respective on_delete handler.
264 If the call is the result of a cascade, 'source' should be the model
265 that caused it and 'nullable' should be set to True, if the relation
266 can be null.
268 If 'reverse_dependency' is True, 'source' will be deleted before the
269 current model, rather than after. (Needed for cascading to parent
270 models, the one case in which the cascade follows the forwards
271 direction of an FK rather than the reverse direction.)
273 If 'keep_parents' is True, data of parent model's will be not deleted.
275 If 'fail_on_restricted' is False, error won't be raised even if it's
276 prohibited to delete such objects due to RESTRICT, that defers
277 restricted object checking in recursive calls where the top-level call
278 may need to collect more objects to determine whether restricted ones
279 can be deleted.
280 """
281 if self.can_fast_delete(objs):
282 self.fast_deletes.append(objs)
283 return
284 new_objs = self.add(
285 objs, source, nullable, reverse_dependency=reverse_dependency
286 )
287 if not new_objs:
288 return
290 model = new_objs[0].__class__
292 if not keep_parents:
293 # Recursively collect concrete model's parent models, but not their
294 # related objects. These will be found by meta.get_fields()
295 concrete_model = model._meta.concrete_model
296 for ptr in concrete_model._meta.parents.values():
297 if ptr:
298 parent_objs = [getattr(obj, ptr.name) for obj in new_objs]
299 self.collect(
300 parent_objs,
301 source=model,
302 source_attr=ptr.remote_field.related_name,
303 collect_related=False,
304 reverse_dependency=True,
305 fail_on_restricted=False,
306 )
307 if not collect_related:
308 return
310 if keep_parents:
311 parents = set(model._meta.get_parent_list())
312 model_fast_deletes = defaultdict(list)
313 protected_objects = defaultdict(list)
314 for related in get_candidate_relations_to_delete(model._meta):
315 # Preserve parent reverse relationships if keep_parents=True.
316 if keep_parents and related.model in parents:
317 continue
318 field = related.field
319 on_delete = field.remote_field.on_delete
320 if on_delete == DO_NOTHING:
321 continue
322 related_model = related.related_model
323 if self.can_fast_delete(related_model, from_field=field):
324 model_fast_deletes[related_model].append(field)
325 continue
326 batches = self.get_del_batches(new_objs, [field])
327 for batch in batches:
328 sub_objs = self.related_objects(related_model, [field], batch)
329 # Non-referenced fields can be deferred if no signal receivers
330 # are connected for the related model as they'll never be
331 # exposed to the user. Skip field deferring when some
332 # relationships are select_related as interactions between both
333 # features are hard to get right. This should only happen in
334 # the rare cases where .related_objects is overridden anyway.
335 if not (
336 sub_objs.query.select_related
337 or self._has_signal_listeners(related_model)
338 ):
339 referenced_fields = set(
340 chain.from_iterable(
341 (rf.attname for rf in rel.field.foreign_related_fields)
342 for rel in get_candidate_relations_to_delete(
343 related_model._meta
344 )
345 )
346 )
347 sub_objs = sub_objs.only(*tuple(referenced_fields))
348 if getattr(on_delete, "lazy_sub_objs", False) or sub_objs:
349 try:
350 on_delete(self, field, sub_objs, self.using)
351 except ProtectedError as error:
352 key = f"'{field.model.__name__}.{field.name}'"
353 protected_objects[key] += error.protected_objects
354 if protected_objects:
355 raise ProtectedError(
356 "Cannot delete some instances of model {!r} because they are "
357 "referenced through protected foreign keys: {}.".format(
358 model.__name__,
359 ", ".join(protected_objects),
360 ),
361 set(chain.from_iterable(protected_objects.values())),
362 )
363 for related_model, related_fields in model_fast_deletes.items():
364 batches = self.get_del_batches(new_objs, related_fields)
365 for batch in batches:
366 sub_objs = self.related_objects(related_model, related_fields, batch)
367 self.fast_deletes.append(sub_objs)
368 for field in model._meta.private_fields:
369 if hasattr(field, "bulk_related_objects"):
370 # It's something like generic foreign key.
371 sub_objs = field.bulk_related_objects(new_objs, self.using)
372 self.collect(
373 sub_objs, source=model, nullable=True, fail_on_restricted=False
374 )
376 if fail_on_restricted:
377 # Raise an error if collected restricted objects (RESTRICT) aren't
378 # candidates for deletion also collected via CASCADE.
379 for related_model, instances in self.data.items():
380 self.clear_restricted_objects_from_set(related_model, instances)
381 for qs in self.fast_deletes:
382 self.clear_restricted_objects_from_queryset(qs.model, qs)
383 if self.restricted_objects.values():
384 restricted_objects = defaultdict(list)
385 for related_model, fields in self.restricted_objects.items():
386 for field, objs in fields.items():
387 if objs:
388 key = f"'{related_model.__name__}.{field.name}'"
389 restricted_objects[key] += objs
390 if restricted_objects:
391 raise RestrictedError(
392 "Cannot delete some instances of model {!r} because "
393 "they are referenced through restricted foreign keys: "
394 "{}.".format(
395 model.__name__,
396 ", ".join(restricted_objects),
397 ),
398 set(chain.from_iterable(restricted_objects.values())),
399 )
401 def related_objects(self, related_model, related_fields, objs):
402 """
403 Get a QuerySet of the related model to objs via related fields.
404 """
405 predicate = query_utils.Q.create(
406 [(f"{related_field.name}__in", objs) for related_field in related_fields],
407 connector=query_utils.Q.OR,
408 )
409 return related_model._base_manager.using(self.using).filter(predicate)
411 def instances_with_model(self):
412 for model, instances in self.data.items():
413 for obj in instances:
414 yield model, obj
416 def sort(self):
417 sorted_models = []
418 concrete_models = set()
419 models = list(self.data)
420 while len(sorted_models) < len(models):
421 found = False
422 for model in models:
423 if model in sorted_models:
424 continue
425 dependencies = self.dependencies.get(model._meta.concrete_model)
426 if not (dependencies and dependencies.difference(concrete_models)):
427 sorted_models.append(model)
428 concrete_models.add(model._meta.concrete_model)
429 found = True
430 if not found:
431 return
432 self.data = {model: self.data[model] for model in sorted_models}
434 def delete(self):
435 # sort instance collections
436 for model, instances in self.data.items():
437 self.data[model] = sorted(instances, key=attrgetter("pk"))
439 # if possible, bring the models in an order suitable for databases that
440 # don't support transactions or cannot defer constraint checks until the
441 # end of a transaction.
442 self.sort()
443 # number of objects deleted for each model label
444 deleted_counter = Counter()
446 # Optimize for the case with a single obj and no dependencies
447 if len(self.data) == 1 and len(instances) == 1:
448 instance = list(instances)[0]
449 if self.can_fast_delete(instance):
450 with transaction.mark_for_rollback_on_error(self.using):
451 count = sql.DeleteQuery(model).delete_batch(
452 [instance.pk], self.using
453 )
454 setattr(instance, model._meta.pk.attname, None)
455 return count, {model._meta.label: count}
457 with transaction.atomic(using=self.using, savepoint=False):
458 # send pre_delete signals
459 for model, obj in self.instances_with_model():
460 if not model._meta.auto_created:
461 signals.pre_delete.send(
462 sender=model,
463 instance=obj,
464 using=self.using,
465 origin=self.origin,
466 )
468 # fast deletes
469 for qs in self.fast_deletes:
470 count = qs._raw_delete(using=self.using)
471 if count:
472 deleted_counter[qs.model._meta.label] += count
474 # update fields
475 for (field, value), instances_list in self.field_updates.items():
476 updates = []
477 objs = []
478 for instances in instances_list:
479 if (
480 isinstance(instances, QuerySet)
481 and instances._result_cache is None
482 ):
483 updates.append(instances)
484 else:
485 objs.extend(instances)
486 if updates:
487 combined_updates = reduce(or_, updates)
488 combined_updates.update(**{field.name: value})
489 if objs:
490 model = objs[0].__class__
491 query = sql.UpdateQuery(model)
492 query.update_batch(
493 list({obj.pk for obj in objs}), {field.name: value}, self.using
494 )
496 # reverse instance collections
497 for instances in self.data.values():
498 instances.reverse()
500 # delete instances
501 for model, instances in self.data.items():
502 query = sql.DeleteQuery(model)
503 pk_list = [obj.pk for obj in instances]
504 count = query.delete_batch(pk_list, self.using)
505 if count:
506 deleted_counter[model._meta.label] += count
508 if not model._meta.auto_created:
509 for obj in instances:
510 signals.post_delete.send(
511 sender=model,
512 instance=obj,
513 using=self.using,
514 origin=self.origin,
515 )
517 for model, instances in self.data.items():
518 for instance in instances:
519 setattr(instance, model._meta.pk.attname, None)
520 return sum(deleted_counter.values()), dict(deleted_counter)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import enum
2from types import DynamicClassAttribute
4from plain.utils.functional import Promise
6__all__ = ["Choices", "IntegerChoices", "TextChoices"]
9class ChoicesMeta(enum.EnumMeta):
10 """A metaclass for creating a enum choices."""
12 def __new__(metacls, classname, bases, classdict, **kwds):
13 labels = []
14 for key in classdict._member_names:
15 value = classdict[key]
16 if (
17 isinstance(value, list | tuple)
18 and len(value) > 1
19 and isinstance(value[-1], Promise | str)
20 ):
21 *value, label = value
22 value = tuple(value)
23 else:
24 label = key.replace("_", " ").title()
25 labels.append(label)
26 # Use dict.__setitem__() to suppress defenses against double
27 # assignment in enum's classdict.
28 dict.__setitem__(classdict, key, value)
29 cls = super().__new__(metacls, classname, bases, classdict, **kwds)
30 for member, label in zip(cls.__members__.values(), labels):
31 member._label_ = label
32 return enum.unique(cls)
34 def __contains__(cls, member):
35 if not isinstance(member, enum.Enum):
36 # Allow non-enums to match against member values.
37 return any(x.value == member for x in cls)
38 return super().__contains__(member)
40 @property
41 def names(cls):
42 empty = ["__empty__"] if hasattr(cls, "__empty__") else []
43 return empty + [member.name for member in cls]
45 @property
46 def choices(cls):
47 empty = [(None, cls.__empty__)] if hasattr(cls, "__empty__") else []
48 return empty + [(member.value, member.label) for member in cls]
50 @property
51 def labels(cls):
52 return [label for _, label in cls.choices]
54 @property
55 def values(cls):
56 return [value for value, _ in cls.choices]
59class Choices(enum.Enum, metaclass=ChoicesMeta):
60 """Class for creating enumerated choices."""
62 @DynamicClassAttribute
63 def label(self):
64 return self._label_
66 @property
67 def do_not_call_in_templates(self):
68 return True
70 def __str__(self):
71 """
72 Use value when cast to str, so that Choices set as model instance
73 attributes are rendered as expected in templates and similar contexts.
74 """
75 return str(self.value)
77 # A similar format was proposed for Python 3.10.
78 def __repr__(self):
79 return f"{self.__class__.__qualname__}.{self._name_}"
82class IntegerChoices(int, Choices):
83 """Class for creating enumerated integer choices."""
85 pass
88class TextChoices(str, Choices):
89 """Class for creating enumerated string choices."""
91 def _generate_next_value_(name, start, count, last_values):
92 return name
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import copy
2import datetime
3import functools
4import inspect
5from collections import defaultdict
6from decimal import Decimal
7from types import NoneType
8from uuid import UUID
10from plain.exceptions import EmptyResultSet, FieldError, FullResultSet
11from plain.models import fields
12from plain.models.constants import LOOKUP_SEP
13from plain.models.db import DatabaseError, NotSupportedError, connection
14from plain.models.query_utils import Q
15from plain.utils.deconstruct import deconstructible
16from plain.utils.functional import cached_property
17from plain.utils.hashable import make_hashable
20class SQLiteNumericMixin:
21 """
22 Some expressions with output_field=DecimalField() must be cast to
23 numeric to be properly filtered.
24 """
26 def as_sqlite(self, compiler, connection, **extra_context):
27 sql, params = self.as_sql(compiler, connection, **extra_context)
28 try:
29 if self.output_field.get_internal_type() == "DecimalField":
30 sql = f"CAST({sql} AS NUMERIC)"
31 except FieldError:
32 pass
33 return sql, params
36class Combinable:
37 """
38 Provide the ability to combine one or two objects with
39 some connector. For example F('foo') + F('bar').
40 """
42 # Arithmetic connectors
43 ADD = "+"
44 SUB = "-"
45 MUL = "*"
46 DIV = "/"
47 POW = "^"
48 # The following is a quoted % operator - it is quoted because it can be
49 # used in strings that also have parameter substitution.
50 MOD = "%%"
52 # Bitwise operators - note that these are generated by .bitand()
53 # and .bitor(), the '&' and '|' are reserved for boolean operator
54 # usage.
55 BITAND = "&"
56 BITOR = "|"
57 BITLEFTSHIFT = "<<"
58 BITRIGHTSHIFT = ">>"
59 BITXOR = "#"
61 def _combine(self, other, connector, reversed):
62 if not hasattr(other, "resolve_expression"):
63 # everything must be resolvable to an expression
64 other = Value(other)
66 if reversed:
67 return CombinedExpression(other, connector, self)
68 return CombinedExpression(self, connector, other)
70 #############
71 # OPERATORS #
72 #############
74 def __neg__(self):
75 return self._combine(-1, self.MUL, False)
77 def __add__(self, other):
78 return self._combine(other, self.ADD, False)
80 def __sub__(self, other):
81 return self._combine(other, self.SUB, False)
83 def __mul__(self, other):
84 return self._combine(other, self.MUL, False)
86 def __truediv__(self, other):
87 return self._combine(other, self.DIV, False)
89 def __mod__(self, other):
90 return self._combine(other, self.MOD, False)
92 def __pow__(self, other):
93 return self._combine(other, self.POW, False)
95 def __and__(self, other):
96 if getattr(self, "conditional", False) and getattr(other, "conditional", False):
97 return Q(self) & Q(other)
98 raise NotImplementedError(
99 "Use .bitand(), .bitor(), and .bitxor() for bitwise logical operations."
100 )
102 def bitand(self, other):
103 return self._combine(other, self.BITAND, False)
105 def bitleftshift(self, other):
106 return self._combine(other, self.BITLEFTSHIFT, False)
108 def bitrightshift(self, other):
109 return self._combine(other, self.BITRIGHTSHIFT, False)
111 def __xor__(self, other):
112 if getattr(self, "conditional", False) and getattr(other, "conditional", False):
113 return Q(self) ^ Q(other)
114 raise NotImplementedError(
115 "Use .bitand(), .bitor(), and .bitxor() for bitwise logical operations."
116 )
118 def bitxor(self, other):
119 return self._combine(other, self.BITXOR, False)
121 def __or__(self, other):
122 if getattr(self, "conditional", False) and getattr(other, "conditional", False):
123 return Q(self) | Q(other)
124 raise NotImplementedError(
125 "Use .bitand(), .bitor(), and .bitxor() for bitwise logical operations."
126 )
128 def bitor(self, other):
129 return self._combine(other, self.BITOR, False)
131 def __radd__(self, other):
132 return self._combine(other, self.ADD, True)
134 def __rsub__(self, other):
135 return self._combine(other, self.SUB, True)
137 def __rmul__(self, other):
138 return self._combine(other, self.MUL, True)
140 def __rtruediv__(self, other):
141 return self._combine(other, self.DIV, True)
143 def __rmod__(self, other):
144 return self._combine(other, self.MOD, True)
146 def __rpow__(self, other):
147 return self._combine(other, self.POW, True)
149 def __rand__(self, other):
150 raise NotImplementedError(
151 "Use .bitand(), .bitor(), and .bitxor() for bitwise logical operations."
152 )
154 def __ror__(self, other):
155 raise NotImplementedError(
156 "Use .bitand(), .bitor(), and .bitxor() for bitwise logical operations."
157 )
159 def __rxor__(self, other):
160 raise NotImplementedError(
161 "Use .bitand(), .bitor(), and .bitxor() for bitwise logical operations."
162 )
164 def __invert__(self):
165 return NegatedExpression(self)
168class BaseExpression:
169 """Base class for all query expressions."""
171 empty_result_set_value = NotImplemented
172 # aggregate specific fields
173 is_summary = False
174 _output_field_resolved_to_none = False
175 # Can the expression be used in a WHERE clause?
176 filterable = True
177 # Can the expression can be used as a source expression in Window?
178 window_compatible = False
180 def __init__(self, output_field=None):
181 if output_field is not None:
182 self.output_field = output_field
184 def __getstate__(self):
185 state = self.__dict__.copy()
186 state.pop("convert_value", None)
187 return state
189 def get_db_converters(self, connection):
190 return (
191 []
192 if self.convert_value is self._convert_value_noop
193 else [self.convert_value]
194 ) + self.output_field.get_db_converters(connection)
196 def get_source_expressions(self):
197 return []
199 def set_source_expressions(self, exprs):
200 assert not exprs
202 def _parse_expressions(self, *expressions):
203 return [
204 arg
205 if hasattr(arg, "resolve_expression")
206 else (F(arg) if isinstance(arg, str) else Value(arg))
207 for arg in expressions
208 ]
210 def as_sql(self, compiler, connection):
211 """
212 Responsible for returning a (sql, [params]) tuple to be included
213 in the current query.
215 Different backends can provide their own implementation, by
216 providing an `as_{vendor}` method and patching the Expression:
218 ```
219 def override_as_sql(self, compiler, connection):
220 # custom logic
221 return super().as_sql(compiler, connection)
222 setattr(Expression, 'as_' + connection.vendor, override_as_sql)
223 ```
225 Arguments:
226 * compiler: the query compiler responsible for generating the query.
227 Must have a compile method, returning a (sql, [params]) tuple.
228 Calling compiler(value) will return a quoted `value`.
230 * connection: the database connection used for the current query.
232 Return: (sql, params)
233 Where `sql` is a string containing ordered sql parameters to be
234 replaced with the elements of the list `params`.
235 """
236 raise NotImplementedError("Subclasses must implement as_sql()")
238 @cached_property
239 def contains_aggregate(self):
240 return any(
241 expr and expr.contains_aggregate for expr in self.get_source_expressions()
242 )
244 @cached_property
245 def contains_over_clause(self):
246 return any(
247 expr and expr.contains_over_clause for expr in self.get_source_expressions()
248 )
250 @cached_property
251 def contains_column_references(self):
252 return any(
253 expr and expr.contains_column_references
254 for expr in self.get_source_expressions()
255 )
257 def resolve_expression(
258 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
259 ):
260 """
261 Provide the chance to do any preprocessing or validation before being
262 added to the query.
264 Arguments:
265 * query: the backend query implementation
266 * allow_joins: boolean allowing or denying use of joins
267 in this query
268 * reuse: a set of reusable joins for multijoins
269 * summarize: a terminal aggregate clause
270 * for_save: whether this expression about to be used in a save or update
272 Return: an Expression to be added to the query.
273 """
274 c = self.copy()
275 c.is_summary = summarize
276 c.set_source_expressions(
277 [
278 expr.resolve_expression(query, allow_joins, reuse, summarize)
279 if expr
280 else None
281 for expr in c.get_source_expressions()
282 ]
283 )
284 return c
286 @property
287 def conditional(self):
288 return isinstance(self.output_field, fields.BooleanField)
290 @property
291 def field(self):
292 return self.output_field
294 @cached_property
295 def output_field(self):
296 """Return the output type of this expressions."""
297 output_field = self._resolve_output_field()
298 if output_field is None:
299 self._output_field_resolved_to_none = True
300 raise FieldError("Cannot resolve expression type, unknown output_field")
301 return output_field
303 @cached_property
304 def _output_field_or_none(self):
305 """
306 Return the output field of this expression, or None if
307 _resolve_output_field() didn't return an output type.
308 """
309 try:
310 return self.output_field
311 except FieldError:
312 if not self._output_field_resolved_to_none:
313 raise
315 def _resolve_output_field(self):
316 """
317 Attempt to infer the output type of the expression.
319 As a guess, if the output fields of all source fields match then simply
320 infer the same type here.
322 If a source's output field resolves to None, exclude it from this check.
323 If all sources are None, then an error is raised higher up the stack in
324 the output_field property.
325 """
326 # This guess is mostly a bad idea, but there is quite a lot of code
327 # (especially 3rd party Func subclasses) that depend on it, we'd need a
328 # deprecation path to fix it.
329 sources_iter = (
330 source for source in self.get_source_fields() if source is not None
331 )
332 for output_field in sources_iter:
333 for source in sources_iter:
334 if not isinstance(output_field, source.__class__):
335 raise FieldError(
336 f"Expression contains mixed types: {output_field.__class__.__name__}, {source.__class__.__name__}. You must "
337 "set output_field."
338 )
339 return output_field
341 @staticmethod
342 def _convert_value_noop(value, expression, connection):
343 return value
345 @cached_property
346 def convert_value(self):
347 """
348 Expressions provide their own converters because users have the option
349 of manually specifying the output_field which may be a different type
350 from the one the database returns.
351 """
352 field = self.output_field
353 internal_type = field.get_internal_type()
354 if internal_type == "FloatField":
355 return (
356 lambda value, expression, connection: None
357 if value is None
358 else float(value)
359 )
360 elif internal_type.endswith("IntegerField"):
361 return (
362 lambda value, expression, connection: None
363 if value is None
364 else int(value)
365 )
366 elif internal_type == "DecimalField":
367 return (
368 lambda value, expression, connection: None
369 if value is None
370 else Decimal(value)
371 )
372 return self._convert_value_noop
374 def get_lookup(self, lookup):
375 return self.output_field.get_lookup(lookup)
377 def get_transform(self, name):
378 return self.output_field.get_transform(name)
380 def relabeled_clone(self, change_map):
381 clone = self.copy()
382 clone.set_source_expressions(
383 [
384 e.relabeled_clone(change_map) if e is not None else None
385 for e in self.get_source_expressions()
386 ]
387 )
388 return clone
390 def replace_expressions(self, replacements):
391 if replacement := replacements.get(self):
392 return replacement
393 clone = self.copy()
394 source_expressions = clone.get_source_expressions()
395 clone.set_source_expressions(
396 [
397 expr.replace_expressions(replacements) if expr else None
398 for expr in source_expressions
399 ]
400 )
401 return clone
403 def get_refs(self):
404 refs = set()
405 for expr in self.get_source_expressions():
406 refs |= expr.get_refs()
407 return refs
409 def copy(self):
410 return copy.copy(self)
412 def prefix_references(self, prefix):
413 clone = self.copy()
414 clone.set_source_expressions(
415 [
416 F(f"{prefix}{expr.name}")
417 if isinstance(expr, F)
418 else expr.prefix_references(prefix)
419 for expr in self.get_source_expressions()
420 ]
421 )
422 return clone
424 def get_group_by_cols(self):
425 if not self.contains_aggregate:
426 return [self]
427 cols = []
428 for source in self.get_source_expressions():
429 cols.extend(source.get_group_by_cols())
430 return cols
432 def get_source_fields(self):
433 """Return the underlying field types used by this aggregate."""
434 return [e._output_field_or_none for e in self.get_source_expressions()]
436 def asc(self, **kwargs):
437 return OrderBy(self, **kwargs)
439 def desc(self, **kwargs):
440 return OrderBy(self, descending=True, **kwargs)
442 def reverse_ordering(self):
443 return self
445 def flatten(self):
446 """
447 Recursively yield this expression and all subexpressions, in
448 depth-first order.
449 """
450 yield self
451 for expr in self.get_source_expressions():
452 if expr:
453 if hasattr(expr, "flatten"):
454 yield from expr.flatten()
455 else:
456 yield expr
458 def select_format(self, compiler, sql, params):
459 """
460 Custom format for select clauses. For example, EXISTS expressions need
461 to be wrapped in CASE WHEN on Oracle.
462 """
463 if hasattr(self.output_field, "select_format"):
464 return self.output_field.select_format(compiler, sql, params)
465 return sql, params
468@deconstructible
469class Expression(BaseExpression, Combinable):
470 """An expression that can be combined with other expressions."""
472 @cached_property
473 def identity(self):
474 constructor_signature = inspect.signature(self.__init__)
475 args, kwargs = self._constructor_args
476 signature = constructor_signature.bind_partial(*args, **kwargs)
477 signature.apply_defaults()
478 arguments = signature.arguments.items()
479 identity = [self.__class__]
480 for arg, value in arguments:
481 if isinstance(value, fields.Field):
482 if value.name and value.model:
483 value = (value.model._meta.label, value.name)
484 else:
485 value = type(value)
486 else:
487 value = make_hashable(value)
488 identity.append((arg, value))
489 return tuple(identity)
491 def __eq__(self, other):
492 if not isinstance(other, Expression):
493 return NotImplemented
494 return other.identity == self.identity
496 def __hash__(self):
497 return hash(self.identity)
500# Type inference for CombinedExpression.output_field.
501# Missing items will result in FieldError, by design.
502#
503# The current approach for NULL is based on lowest common denominator behavior
504# i.e. if one of the supported databases is raising an error (rather than
505# return NULL) for `val <op> NULL`, then Plain raises FieldError.
507_connector_combinations = [
508 # Numeric operations - operands of same type.
509 {
510 connector: [
511 (fields.IntegerField, fields.IntegerField, fields.IntegerField),
512 (fields.FloatField, fields.FloatField, fields.FloatField),
513 (fields.DecimalField, fields.DecimalField, fields.DecimalField),
514 ]
515 for connector in (
516 Combinable.ADD,
517 Combinable.SUB,
518 Combinable.MUL,
519 # Behavior for DIV with integer arguments follows Postgres/SQLite,
520 # not MySQL/Oracle.
521 Combinable.DIV,
522 Combinable.MOD,
523 Combinable.POW,
524 )
525 },
526 # Numeric operations - operands of different type.
527 {
528 connector: [
529 (fields.IntegerField, fields.DecimalField, fields.DecimalField),
530 (fields.DecimalField, fields.IntegerField, fields.DecimalField),
531 (fields.IntegerField, fields.FloatField, fields.FloatField),
532 (fields.FloatField, fields.IntegerField, fields.FloatField),
533 ]
534 for connector in (
535 Combinable.ADD,
536 Combinable.SUB,
537 Combinable.MUL,
538 Combinable.DIV,
539 Combinable.MOD,
540 )
541 },
542 # Bitwise operators.
543 {
544 connector: [
545 (fields.IntegerField, fields.IntegerField, fields.IntegerField),
546 ]
547 for connector in (
548 Combinable.BITAND,
549 Combinable.BITOR,
550 Combinable.BITLEFTSHIFT,
551 Combinable.BITRIGHTSHIFT,
552 Combinable.BITXOR,
553 )
554 },
555 # Numeric with NULL.
556 {
557 connector: [
558 (field_type, NoneType, field_type),
559 (NoneType, field_type, field_type),
560 ]
561 for connector in (
562 Combinable.ADD,
563 Combinable.SUB,
564 Combinable.MUL,
565 Combinable.DIV,
566 Combinable.MOD,
567 Combinable.POW,
568 )
569 for field_type in (fields.IntegerField, fields.DecimalField, fields.FloatField)
570 },
571 # Date/DateTimeField/DurationField/TimeField.
572 {
573 Combinable.ADD: [
574 # Date/DateTimeField.
575 (fields.DateField, fields.DurationField, fields.DateTimeField),
576 (fields.DateTimeField, fields.DurationField, fields.DateTimeField),
577 (fields.DurationField, fields.DateField, fields.DateTimeField),
578 (fields.DurationField, fields.DateTimeField, fields.DateTimeField),
579 # DurationField.
580 (fields.DurationField, fields.DurationField, fields.DurationField),
581 # TimeField.
582 (fields.TimeField, fields.DurationField, fields.TimeField),
583 (fields.DurationField, fields.TimeField, fields.TimeField),
584 ],
585 },
586 {
587 Combinable.SUB: [
588 # Date/DateTimeField.
589 (fields.DateField, fields.DurationField, fields.DateTimeField),
590 (fields.DateTimeField, fields.DurationField, fields.DateTimeField),
591 (fields.DateField, fields.DateField, fields.DurationField),
592 (fields.DateField, fields.DateTimeField, fields.DurationField),
593 (fields.DateTimeField, fields.DateField, fields.DurationField),
594 (fields.DateTimeField, fields.DateTimeField, fields.DurationField),
595 # DurationField.
596 (fields.DurationField, fields.DurationField, fields.DurationField),
597 # TimeField.
598 (fields.TimeField, fields.DurationField, fields.TimeField),
599 (fields.TimeField, fields.TimeField, fields.DurationField),
600 ],
601 },
602]
604_connector_combinators = defaultdict(list)
607def register_combinable_fields(lhs, connector, rhs, result):
608 """
609 Register combinable types:
610 lhs <connector> rhs -> result
611 e.g.
612 register_combinable_fields(
613 IntegerField, Combinable.ADD, FloatField, FloatField
614 )
615 """
616 _connector_combinators[connector].append((lhs, rhs, result))
619for d in _connector_combinations:
620 for connector, field_types in d.items():
621 for lhs, rhs, result in field_types:
622 register_combinable_fields(lhs, connector, rhs, result)
625@functools.lru_cache(maxsize=128)
626def _resolve_combined_type(connector, lhs_type, rhs_type):
627 combinators = _connector_combinators.get(connector, ())
628 for combinator_lhs_type, combinator_rhs_type, combined_type in combinators:
629 if issubclass(lhs_type, combinator_lhs_type) and issubclass(
630 rhs_type, combinator_rhs_type
631 ):
632 return combined_type
635class CombinedExpression(SQLiteNumericMixin, Expression):
636 def __init__(self, lhs, connector, rhs, output_field=None):
637 super().__init__(output_field=output_field)
638 self.connector = connector
639 self.lhs = lhs
640 self.rhs = rhs
642 def __repr__(self):
643 return f"<{self.__class__.__name__}: {self}>"
645 def __str__(self):
646 return f"{self.lhs} {self.connector} {self.rhs}"
648 def get_source_expressions(self):
649 return [self.lhs, self.rhs]
651 def set_source_expressions(self, exprs):
652 self.lhs, self.rhs = exprs
654 def _resolve_output_field(self):
655 # We avoid using super() here for reasons given in
656 # Expression._resolve_output_field()
657 combined_type = _resolve_combined_type(
658 self.connector,
659 type(self.lhs._output_field_or_none),
660 type(self.rhs._output_field_or_none),
661 )
662 if combined_type is None:
663 raise FieldError(
664 f"Cannot infer type of {self.connector!r} expression involving these "
665 f"types: {self.lhs.output_field.__class__.__name__}, "
666 f"{self.rhs.output_field.__class__.__name__}. You must set "
667 f"output_field."
668 )
669 return combined_type()
671 def as_sql(self, compiler, connection):
672 expressions = []
673 expression_params = []
674 sql, params = compiler.compile(self.lhs)
675 expressions.append(sql)
676 expression_params.extend(params)
677 sql, params = compiler.compile(self.rhs)
678 expressions.append(sql)
679 expression_params.extend(params)
680 # order of precedence
681 expression_wrapper = "(%s)"
682 sql = connection.ops.combine_expression(self.connector, expressions)
683 return expression_wrapper % sql, expression_params
685 def resolve_expression(
686 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
687 ):
688 lhs = self.lhs.resolve_expression(
689 query, allow_joins, reuse, summarize, for_save
690 )
691 rhs = self.rhs.resolve_expression(
692 query, allow_joins, reuse, summarize, for_save
693 )
694 if not isinstance(self, DurationExpression | TemporalSubtraction):
695 try:
696 lhs_type = lhs.output_field.get_internal_type()
697 except (AttributeError, FieldError):
698 lhs_type = None
699 try:
700 rhs_type = rhs.output_field.get_internal_type()
701 except (AttributeError, FieldError):
702 rhs_type = None
703 if "DurationField" in {lhs_type, rhs_type} and lhs_type != rhs_type:
704 return DurationExpression(
705 self.lhs, self.connector, self.rhs
706 ).resolve_expression(
707 query,
708 allow_joins,
709 reuse,
710 summarize,
711 for_save,
712 )
713 datetime_fields = {"DateField", "DateTimeField", "TimeField"}
714 if (
715 self.connector == self.SUB
716 and lhs_type in datetime_fields
717 and lhs_type == rhs_type
718 ):
719 return TemporalSubtraction(self.lhs, self.rhs).resolve_expression(
720 query,
721 allow_joins,
722 reuse,
723 summarize,
724 for_save,
725 )
726 c = self.copy()
727 c.is_summary = summarize
728 c.lhs = lhs
729 c.rhs = rhs
730 return c
733class DurationExpression(CombinedExpression):
734 def compile(self, side, compiler, connection):
735 try:
736 output = side.output_field
737 except FieldError:
738 pass
739 else:
740 if output.get_internal_type() == "DurationField":
741 sql, params = compiler.compile(side)
742 return connection.ops.format_for_duration_arithmetic(sql), params
743 return compiler.compile(side)
745 def as_sql(self, compiler, connection):
746 if connection.features.has_native_duration_field:
747 return super().as_sql(compiler, connection)
748 connection.ops.check_expression_support(self)
749 expressions = []
750 expression_params = []
751 sql, params = self.compile(self.lhs, compiler, connection)
752 expressions.append(sql)
753 expression_params.extend(params)
754 sql, params = self.compile(self.rhs, compiler, connection)
755 expressions.append(sql)
756 expression_params.extend(params)
757 # order of precedence
758 expression_wrapper = "(%s)"
759 sql = connection.ops.combine_duration_expression(self.connector, expressions)
760 return expression_wrapper % sql, expression_params
762 def as_sqlite(self, compiler, connection, **extra_context):
763 sql, params = self.as_sql(compiler, connection, **extra_context)
764 if self.connector in {Combinable.MUL, Combinable.DIV}:
765 try:
766 lhs_type = self.lhs.output_field.get_internal_type()
767 rhs_type = self.rhs.output_field.get_internal_type()
768 except (AttributeError, FieldError):
769 pass
770 else:
771 allowed_fields = {
772 "DecimalField",
773 "DurationField",
774 "FloatField",
775 "IntegerField",
776 }
777 if lhs_type not in allowed_fields or rhs_type not in allowed_fields:
778 raise DatabaseError(
779 f"Invalid arguments for operator {self.connector}."
780 )
781 return sql, params
784class TemporalSubtraction(CombinedExpression):
785 output_field = fields.DurationField()
787 def __init__(self, lhs, rhs):
788 super().__init__(lhs, self.SUB, rhs)
790 def as_sql(self, compiler, connection):
791 connection.ops.check_expression_support(self)
792 lhs = compiler.compile(self.lhs)
793 rhs = compiler.compile(self.rhs)
794 return connection.ops.subtract_temporals(
795 self.lhs.output_field.get_internal_type(), lhs, rhs
796 )
799@deconstructible(path="plain.models.F")
800class F(Combinable):
801 """An object capable of resolving references to existing query objects."""
803 def __init__(self, name):
804 """
805 Arguments:
806 * name: the name of the field this expression references
807 """
808 self.name = name
810 def __repr__(self):
811 return f"{self.__class__.__name__}({self.name})"
813 def resolve_expression(
814 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
815 ):
816 return query.resolve_ref(self.name, allow_joins, reuse, summarize)
818 def replace_expressions(self, replacements):
819 return replacements.get(self, self)
821 def asc(self, **kwargs):
822 return OrderBy(self, **kwargs)
824 def desc(self, **kwargs):
825 return OrderBy(self, descending=True, **kwargs)
827 def __eq__(self, other):
828 return self.__class__ == other.__class__ and self.name == other.name
830 def __hash__(self):
831 return hash(self.name)
833 def copy(self):
834 return copy.copy(self)
837class ResolvedOuterRef(F):
838 """
839 An object that contains a reference to an outer query.
841 In this case, the reference to the outer query has been resolved because
842 the inner query has been used as a subquery.
843 """
845 contains_aggregate = False
846 contains_over_clause = False
848 def as_sql(self, *args, **kwargs):
849 raise ValueError(
850 "This queryset contains a reference to an outer query and may "
851 "only be used in a subquery."
852 )
854 def resolve_expression(self, *args, **kwargs):
855 col = super().resolve_expression(*args, **kwargs)
856 if col.contains_over_clause:
857 raise NotSupportedError(
858 f"Referencing outer query window expression is not supported: "
859 f"{self.name}."
860 )
861 # FIXME: Rename possibly_multivalued to multivalued and fix detection
862 # for non-multivalued JOINs (e.g. foreign key fields). This should take
863 # into account only many-to-many and one-to-many relationships.
864 col.possibly_multivalued = LOOKUP_SEP in self.name
865 return col
867 def relabeled_clone(self, relabels):
868 return self
870 def get_group_by_cols(self):
871 return []
874class OuterRef(F):
875 contains_aggregate = False
877 def resolve_expression(self, *args, **kwargs):
878 if isinstance(self.name, self.__class__):
879 return self.name
880 return ResolvedOuterRef(self.name)
882 def relabeled_clone(self, relabels):
883 return self
886@deconstructible(path="plain.models.Func")
887class Func(SQLiteNumericMixin, Expression):
888 """An SQL function call."""
890 function = None
891 template = "%(function)s(%(expressions)s)"
892 arg_joiner = ", "
893 arity = None # The number of arguments the function accepts.
895 def __init__(self, *expressions, output_field=None, **extra):
896 if self.arity is not None and len(expressions) != self.arity:
897 raise TypeError(
898 "'{}' takes exactly {} {} ({} given)".format(
899 self.__class__.__name__,
900 self.arity,
901 "argument" if self.arity == 1 else "arguments",
902 len(expressions),
903 )
904 )
905 super().__init__(output_field=output_field)
906 self.source_expressions = self._parse_expressions(*expressions)
907 self.extra = extra
909 def __repr__(self):
910 args = self.arg_joiner.join(str(arg) for arg in self.source_expressions)
911 extra = {**self.extra, **self._get_repr_options()}
912 if extra:
913 extra = ", ".join(
914 str(key) + "=" + str(val) for key, val in sorted(extra.items())
915 )
916 return f"{self.__class__.__name__}({args}, {extra})"
917 return f"{self.__class__.__name__}({args})"
919 def _get_repr_options(self):
920 """Return a dict of extra __init__() options to include in the repr."""
921 return {}
923 def get_source_expressions(self):
924 return self.source_expressions
926 def set_source_expressions(self, exprs):
927 self.source_expressions = exprs
929 def resolve_expression(
930 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
931 ):
932 c = self.copy()
933 c.is_summary = summarize
934 for pos, arg in enumerate(c.source_expressions):
935 c.source_expressions[pos] = arg.resolve_expression(
936 query, allow_joins, reuse, summarize, for_save
937 )
938 return c
940 def as_sql(
941 self,
942 compiler,
943 connection,
944 function=None,
945 template=None,
946 arg_joiner=None,
947 **extra_context,
948 ):
949 connection.ops.check_expression_support(self)
950 sql_parts = []
951 params = []
952 for arg in self.source_expressions:
953 try:
954 arg_sql, arg_params = compiler.compile(arg)
955 except EmptyResultSet:
956 empty_result_set_value = getattr(
957 arg, "empty_result_set_value", NotImplemented
958 )
959 if empty_result_set_value is NotImplemented:
960 raise
961 arg_sql, arg_params = compiler.compile(Value(empty_result_set_value))
962 except FullResultSet:
963 arg_sql, arg_params = compiler.compile(Value(True))
964 sql_parts.append(arg_sql)
965 params.extend(arg_params)
966 data = {**self.extra, **extra_context}
967 # Use the first supplied value in this order: the parameter to this
968 # method, a value supplied in __init__()'s **extra (the value in
969 # `data`), or the value defined on the class.
970 if function is not None:
971 data["function"] = function
972 else:
973 data.setdefault("function", self.function)
974 template = template or data.get("template", self.template)
975 arg_joiner = arg_joiner or data.get("arg_joiner", self.arg_joiner)
976 data["expressions"] = data["field"] = arg_joiner.join(sql_parts)
977 return template % data, params
979 def copy(self):
980 copy = super().copy()
981 copy.source_expressions = self.source_expressions[:]
982 copy.extra = self.extra.copy()
983 return copy
986@deconstructible(path="plain.models.Value")
987class Value(SQLiteNumericMixin, Expression):
988 """Represent a wrapped value as a node within an expression."""
990 # Provide a default value for `for_save` in order to allow unresolved
991 # instances to be compiled until a decision is taken in #25425.
992 for_save = False
994 def __init__(self, value, output_field=None):
995 """
996 Arguments:
997 * value: the value this expression represents. The value will be
998 added into the sql parameter list and properly quoted.
1000 * output_field: an instance of the model field type that this
1001 expression will return, such as IntegerField() or CharField().
1002 """
1003 super().__init__(output_field=output_field)
1004 self.value = value
1006 def __repr__(self):
1007 return f"{self.__class__.__name__}({self.value!r})"
1009 def as_sql(self, compiler, connection):
1010 connection.ops.check_expression_support(self)
1011 val = self.value
1012 output_field = self._output_field_or_none
1013 if output_field is not None:
1014 if self.for_save:
1015 val = output_field.get_db_prep_save(val, connection=connection)
1016 else:
1017 val = output_field.get_db_prep_value(val, connection=connection)
1018 if hasattr(output_field, "get_placeholder"):
1019 return output_field.get_placeholder(val, compiler, connection), [val]
1020 if val is None:
1021 # cx_Oracle does not always convert None to the appropriate
1022 # NULL type (like in case expressions using numbers), so we
1023 # use a literal SQL NULL
1024 return "NULL", []
1025 return "%s", [val]
1027 def resolve_expression(
1028 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
1029 ):
1030 c = super().resolve_expression(query, allow_joins, reuse, summarize, for_save)
1031 c.for_save = for_save
1032 return c
1034 def get_group_by_cols(self):
1035 return []
1037 def _resolve_output_field(self):
1038 if isinstance(self.value, str):
1039 return fields.CharField()
1040 if isinstance(self.value, bool):
1041 return fields.BooleanField()
1042 if isinstance(self.value, int):
1043 return fields.IntegerField()
1044 if isinstance(self.value, float):
1045 return fields.FloatField()
1046 if isinstance(self.value, datetime.datetime):
1047 return fields.DateTimeField()
1048 if isinstance(self.value, datetime.date):
1049 return fields.DateField()
1050 if isinstance(self.value, datetime.time):
1051 return fields.TimeField()
1052 if isinstance(self.value, datetime.timedelta):
1053 return fields.DurationField()
1054 if isinstance(self.value, Decimal):
1055 return fields.DecimalField()
1056 if isinstance(self.value, bytes):
1057 return fields.BinaryField()
1058 if isinstance(self.value, UUID):
1059 return fields.UUIDField()
1061 @property
1062 def empty_result_set_value(self):
1063 return self.value
1066class RawSQL(Expression):
1067 def __init__(self, sql, params, output_field=None):
1068 if output_field is None:
1069 output_field = fields.Field()
1070 self.sql, self.params = sql, params
1071 super().__init__(output_field=output_field)
1073 def __repr__(self):
1074 return f"{self.__class__.__name__}({self.sql}, {self.params})"
1076 def as_sql(self, compiler, connection):
1077 return f"({self.sql})", self.params
1079 def get_group_by_cols(self):
1080 return [self]
1082 def resolve_expression(
1083 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
1084 ):
1085 # Resolve parents fields used in raw SQL.
1086 if query.model:
1087 for parent in query.model._meta.get_parent_list():
1088 for parent_field in parent._meta.local_fields:
1089 _, column_name = parent_field.get_attname_column()
1090 if column_name.lower() in self.sql.lower():
1091 query.resolve_ref(
1092 parent_field.name, allow_joins, reuse, summarize
1093 )
1094 break
1095 return super().resolve_expression(
1096 query, allow_joins, reuse, summarize, for_save
1097 )
1100class Star(Expression):
1101 def __repr__(self):
1102 return "'*'"
1104 def as_sql(self, compiler, connection):
1105 return "*", []
1108class Col(Expression):
1109 contains_column_references = True
1110 possibly_multivalued = False
1112 def __init__(self, alias, target, output_field=None):
1113 if output_field is None:
1114 output_field = target
1115 super().__init__(output_field=output_field)
1116 self.alias, self.target = alias, target
1118 def __repr__(self):
1119 alias, target = self.alias, self.target
1120 identifiers = (alias, str(target)) if alias else (str(target),)
1121 return "{}({})".format(self.__class__.__name__, ", ".join(identifiers))
1123 def as_sql(self, compiler, connection):
1124 alias, column = self.alias, self.target.column
1125 identifiers = (alias, column) if alias else (column,)
1126 sql = ".".join(map(compiler.quote_name_unless_alias, identifiers))
1127 return sql, []
1129 def relabeled_clone(self, relabels):
1130 if self.alias is None:
1131 return self
1132 return self.__class__(
1133 relabels.get(self.alias, self.alias), self.target, self.output_field
1134 )
1136 def get_group_by_cols(self):
1137 return [self]
1139 def get_db_converters(self, connection):
1140 if self.target == self.output_field:
1141 return self.output_field.get_db_converters(connection)
1142 return self.output_field.get_db_converters(
1143 connection
1144 ) + self.target.get_db_converters(connection)
1147class Ref(Expression):
1148 """
1149 Reference to column alias of the query. For example, Ref('sum_cost') in
1150 qs.annotate(sum_cost=Sum('cost')) query.
1151 """
1153 def __init__(self, refs, source):
1154 super().__init__()
1155 self.refs, self.source = refs, source
1157 def __repr__(self):
1158 return f"{self.__class__.__name__}({self.refs}, {self.source})"
1160 def get_source_expressions(self):
1161 return [self.source]
1163 def set_source_expressions(self, exprs):
1164 (self.source,) = exprs
1166 def resolve_expression(
1167 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
1168 ):
1169 # The sub-expression `source` has already been resolved, as this is
1170 # just a reference to the name of `source`.
1171 return self
1173 def get_refs(self):
1174 return {self.refs}
1176 def relabeled_clone(self, relabels):
1177 return self
1179 def as_sql(self, compiler, connection):
1180 return connection.ops.quote_name(self.refs), []
1182 def get_group_by_cols(self):
1183 return [self]
1186class ExpressionList(Func):
1187 """
1188 An expression containing multiple expressions. Can be used to provide a
1189 list of expressions as an argument to another expression, like a partition
1190 clause.
1191 """
1193 template = "%(expressions)s"
1195 def __init__(self, *expressions, **extra):
1196 if not expressions:
1197 raise ValueError(
1198 f"{self.__class__.__name__} requires at least one expression."
1199 )
1200 super().__init__(*expressions, **extra)
1202 def __str__(self):
1203 return self.arg_joiner.join(str(arg) for arg in self.source_expressions)
1205 def as_sqlite(self, compiler, connection, **extra_context):
1206 # Casting to numeric is unnecessary.
1207 return self.as_sql(compiler, connection, **extra_context)
1210class OrderByList(Func):
1211 template = "ORDER BY %(expressions)s"
1213 def __init__(self, *expressions, **extra):
1214 expressions = (
1215 (
1216 OrderBy(F(expr[1:]), descending=True)
1217 if isinstance(expr, str) and expr[0] == "-"
1218 else expr
1219 )
1220 for expr in expressions
1221 )
1222 super().__init__(*expressions, **extra)
1224 def as_sql(self, *args, **kwargs):
1225 if not self.source_expressions:
1226 return "", ()
1227 return super().as_sql(*args, **kwargs)
1229 def get_group_by_cols(self):
1230 group_by_cols = []
1231 for order_by in self.get_source_expressions():
1232 group_by_cols.extend(order_by.get_group_by_cols())
1233 return group_by_cols
1236@deconstructible(path="plain.models.ExpressionWrapper")
1237class ExpressionWrapper(SQLiteNumericMixin, Expression):
1238 """
1239 An expression that can wrap another expression so that it can provide
1240 extra context to the inner expression, such as the output_field.
1241 """
1243 def __init__(self, expression, output_field):
1244 super().__init__(output_field=output_field)
1245 self.expression = expression
1247 def set_source_expressions(self, exprs):
1248 self.expression = exprs[0]
1250 def get_source_expressions(self):
1251 return [self.expression]
1253 def get_group_by_cols(self):
1254 if isinstance(self.expression, Expression):
1255 expression = self.expression.copy()
1256 expression.output_field = self.output_field
1257 return expression.get_group_by_cols()
1258 # For non-expressions e.g. an SQL WHERE clause, the entire
1259 # `expression` must be included in the GROUP BY clause.
1260 return super().get_group_by_cols()
1262 def as_sql(self, compiler, connection):
1263 return compiler.compile(self.expression)
1265 def __repr__(self):
1266 return f"{self.__class__.__name__}({self.expression})"
1269class NegatedExpression(ExpressionWrapper):
1270 """The logical negation of a conditional expression."""
1272 def __init__(self, expression):
1273 super().__init__(expression, output_field=fields.BooleanField())
1275 def __invert__(self):
1276 return self.expression.copy()
1278 def as_sql(self, compiler, connection):
1279 try:
1280 sql, params = super().as_sql(compiler, connection)
1281 except EmptyResultSet:
1282 features = compiler.connection.features
1283 if not features.supports_boolean_expr_in_select_clause:
1284 return "1=1", ()
1285 return compiler.compile(Value(True))
1286 ops = compiler.connection.ops
1287 # Some database backends (e.g. Oracle) don't allow EXISTS() and filters
1288 # to be compared to another expression unless they're wrapped in a CASE
1289 # WHEN.
1290 if not ops.conditional_expression_supported_in_where_clause(self.expression):
1291 return f"CASE WHEN {sql} = 0 THEN 1 ELSE 0 END", params
1292 return f"NOT {sql}", params
1294 def resolve_expression(
1295 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
1296 ):
1297 resolved = super().resolve_expression(
1298 query, allow_joins, reuse, summarize, for_save
1299 )
1300 if not getattr(resolved.expression, "conditional", False):
1301 raise TypeError("Cannot negate non-conditional expressions.")
1302 return resolved
1304 def select_format(self, compiler, sql, params):
1305 # Wrap boolean expressions with a CASE WHEN expression if a database
1306 # backend (e.g. Oracle) doesn't support boolean expression in SELECT or
1307 # GROUP BY list.
1308 expression_supported_in_where_clause = (
1309 compiler.connection.ops.conditional_expression_supported_in_where_clause
1310 )
1311 if (
1312 not compiler.connection.features.supports_boolean_expr_in_select_clause
1313 # Avoid double wrapping.
1314 and expression_supported_in_where_clause(self.expression)
1315 ):
1316 sql = f"CASE WHEN {sql} THEN 1 ELSE 0 END"
1317 return sql, params
1320@deconstructible(path="plain.models.When")
1321class When(Expression):
1322 template = "WHEN %(condition)s THEN %(result)s"
1323 # This isn't a complete conditional expression, must be used in Case().
1324 conditional = False
1326 def __init__(self, condition=None, then=None, **lookups):
1327 if lookups:
1328 if condition is None:
1329 condition, lookups = Q(**lookups), None
1330 elif getattr(condition, "conditional", False):
1331 condition, lookups = Q(condition, **lookups), None
1332 if condition is None or not getattr(condition, "conditional", False) or lookups:
1333 raise TypeError(
1334 "When() supports a Q object, a boolean expression, or lookups "
1335 "as a condition."
1336 )
1337 if isinstance(condition, Q) and not condition:
1338 raise ValueError("An empty Q() can't be used as a When() condition.")
1339 super().__init__(output_field=None)
1340 self.condition = condition
1341 self.result = self._parse_expressions(then)[0]
1343 def __str__(self):
1344 return f"WHEN {self.condition!r} THEN {self.result!r}"
1346 def __repr__(self):
1347 return f"<{self.__class__.__name__}: {self}>"
1349 def get_source_expressions(self):
1350 return [self.condition, self.result]
1352 def set_source_expressions(self, exprs):
1353 self.condition, self.result = exprs
1355 def get_source_fields(self):
1356 # We're only interested in the fields of the result expressions.
1357 return [self.result._output_field_or_none]
1359 def resolve_expression(
1360 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
1361 ):
1362 c = self.copy()
1363 c.is_summary = summarize
1364 if hasattr(c.condition, "resolve_expression"):
1365 c.condition = c.condition.resolve_expression(
1366 query, allow_joins, reuse, summarize, False
1367 )
1368 c.result = c.result.resolve_expression(
1369 query, allow_joins, reuse, summarize, for_save
1370 )
1371 return c
1373 def as_sql(self, compiler, connection, template=None, **extra_context):
1374 connection.ops.check_expression_support(self)
1375 template_params = extra_context
1376 sql_params = []
1377 condition_sql, condition_params = compiler.compile(self.condition)
1378 template_params["condition"] = condition_sql
1379 result_sql, result_params = compiler.compile(self.result)
1380 template_params["result"] = result_sql
1381 template = template or self.template
1382 return template % template_params, (
1383 *sql_params,
1384 *condition_params,
1385 *result_params,
1386 )
1388 def get_group_by_cols(self):
1389 # This is not a complete expression and cannot be used in GROUP BY.
1390 cols = []
1391 for source in self.get_source_expressions():
1392 cols.extend(source.get_group_by_cols())
1393 return cols
1396@deconstructible(path="plain.models.Case")
1397class Case(SQLiteNumericMixin, Expression):
1398 """
1399 An SQL searched CASE expression:
1401 CASE
1402 WHEN n > 0
1403 THEN 'positive'
1404 WHEN n < 0
1405 THEN 'negative'
1406 ELSE 'zero'
1407 END
1408 """
1410 template = "CASE %(cases)s ELSE %(default)s END"
1411 case_joiner = " "
1413 def __init__(self, *cases, default=None, output_field=None, **extra):
1414 if not all(isinstance(case, When) for case in cases):
1415 raise TypeError("Positional arguments must all be When objects.")
1416 super().__init__(output_field)
1417 self.cases = list(cases)
1418 self.default = self._parse_expressions(default)[0]
1419 self.extra = extra
1421 def __str__(self):
1422 return "CASE {}, ELSE {!r}".format(
1423 ", ".join(str(c) for c in self.cases),
1424 self.default,
1425 )
1427 def __repr__(self):
1428 return f"<{self.__class__.__name__}: {self}>"
1430 def get_source_expressions(self):
1431 return self.cases + [self.default]
1433 def set_source_expressions(self, exprs):
1434 *self.cases, self.default = exprs
1436 def resolve_expression(
1437 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
1438 ):
1439 c = self.copy()
1440 c.is_summary = summarize
1441 for pos, case in enumerate(c.cases):
1442 c.cases[pos] = case.resolve_expression(
1443 query, allow_joins, reuse, summarize, for_save
1444 )
1445 c.default = c.default.resolve_expression(
1446 query, allow_joins, reuse, summarize, for_save
1447 )
1448 return c
1450 def copy(self):
1451 c = super().copy()
1452 c.cases = c.cases[:]
1453 return c
1455 def as_sql(
1456 self, compiler, connection, template=None, case_joiner=None, **extra_context
1457 ):
1458 connection.ops.check_expression_support(self)
1459 if not self.cases:
1460 return compiler.compile(self.default)
1461 template_params = {**self.extra, **extra_context}
1462 case_parts = []
1463 sql_params = []
1464 default_sql, default_params = compiler.compile(self.default)
1465 for case in self.cases:
1466 try:
1467 case_sql, case_params = compiler.compile(case)
1468 except EmptyResultSet:
1469 continue
1470 except FullResultSet:
1471 default_sql, default_params = compiler.compile(case.result)
1472 break
1473 case_parts.append(case_sql)
1474 sql_params.extend(case_params)
1475 if not case_parts:
1476 return default_sql, default_params
1477 case_joiner = case_joiner or self.case_joiner
1478 template_params["cases"] = case_joiner.join(case_parts)
1479 template_params["default"] = default_sql
1480 sql_params.extend(default_params)
1481 template = template or template_params.get("template", self.template)
1482 sql = template % template_params
1483 if self._output_field_or_none is not None:
1484 sql = connection.ops.unification_cast_sql(self.output_field) % sql
1485 return sql, sql_params
1487 def get_group_by_cols(self):
1488 if not self.cases:
1489 return self.default.get_group_by_cols()
1490 return super().get_group_by_cols()
1493class Subquery(BaseExpression, Combinable):
1494 """
1495 An explicit subquery. It may contain OuterRef() references to the outer
1496 query which will be resolved when it is applied to that query.
1497 """
1499 template = "(%(subquery)s)"
1500 contains_aggregate = False
1501 empty_result_set_value = None
1503 def __init__(self, queryset, output_field=None, **extra):
1504 # Allow the usage of both QuerySet and sql.Query objects.
1505 self.query = getattr(queryset, "query", queryset).clone()
1506 self.query.subquery = True
1507 self.extra = extra
1508 super().__init__(output_field)
1510 def get_source_expressions(self):
1511 return [self.query]
1513 def set_source_expressions(self, exprs):
1514 self.query = exprs[0]
1516 def _resolve_output_field(self):
1517 return self.query.output_field
1519 def copy(self):
1520 clone = super().copy()
1521 clone.query = clone.query.clone()
1522 return clone
1524 @property
1525 def external_aliases(self):
1526 return self.query.external_aliases
1528 def get_external_cols(self):
1529 return self.query.get_external_cols()
1531 def as_sql(self, compiler, connection, template=None, **extra_context):
1532 connection.ops.check_expression_support(self)
1533 template_params = {**self.extra, **extra_context}
1534 subquery_sql, sql_params = self.query.as_sql(compiler, connection)
1535 template_params["subquery"] = subquery_sql[1:-1]
1537 template = template or template_params.get("template", self.template)
1538 sql = template % template_params
1539 return sql, sql_params
1541 def get_group_by_cols(self):
1542 return self.query.get_group_by_cols(wrapper=self)
1545class Exists(Subquery):
1546 template = "EXISTS(%(subquery)s)"
1547 output_field = fields.BooleanField()
1548 empty_result_set_value = False
1550 def __init__(self, queryset, **kwargs):
1551 super().__init__(queryset, **kwargs)
1552 self.query = self.query.exists()
1554 def select_format(self, compiler, sql, params):
1555 # Wrap EXISTS() with a CASE WHEN expression if a database backend
1556 # (e.g. Oracle) doesn't support boolean expression in SELECT or GROUP
1557 # BY list.
1558 if not compiler.connection.features.supports_boolean_expr_in_select_clause:
1559 sql = f"CASE WHEN {sql} THEN 1 ELSE 0 END"
1560 return sql, params
1563@deconstructible(path="plain.models.OrderBy")
1564class OrderBy(Expression):
1565 template = "%(expression)s %(ordering)s"
1566 conditional = False
1568 def __init__(self, expression, descending=False, nulls_first=None, nulls_last=None):
1569 if nulls_first and nulls_last:
1570 raise ValueError("nulls_first and nulls_last are mutually exclusive")
1571 if nulls_first is False or nulls_last is False:
1572 raise ValueError("nulls_first and nulls_last values must be True or None.")
1573 self.nulls_first = nulls_first
1574 self.nulls_last = nulls_last
1575 self.descending = descending
1576 if not hasattr(expression, "resolve_expression"):
1577 raise ValueError("expression must be an expression type")
1578 self.expression = expression
1580 def __repr__(self):
1581 return f"{self.__class__.__name__}({self.expression}, descending={self.descending})"
1583 def set_source_expressions(self, exprs):
1584 self.expression = exprs[0]
1586 def get_source_expressions(self):
1587 return [self.expression]
1589 def as_sql(self, compiler, connection, template=None, **extra_context):
1590 template = template or self.template
1591 if connection.features.supports_order_by_nulls_modifier:
1592 if self.nulls_last:
1593 template = f"{template} NULLS LAST"
1594 elif self.nulls_first:
1595 template = f"{template} NULLS FIRST"
1596 else:
1597 if self.nulls_last and not (
1598 self.descending and connection.features.order_by_nulls_first
1599 ):
1600 template = f"%(expression)s IS NULL, {template}"
1601 elif self.nulls_first and not (
1602 not self.descending and connection.features.order_by_nulls_first
1603 ):
1604 template = f"%(expression)s IS NOT NULL, {template}"
1605 connection.ops.check_expression_support(self)
1606 expression_sql, params = compiler.compile(self.expression)
1607 placeholders = {
1608 "expression": expression_sql,
1609 "ordering": "DESC" if self.descending else "ASC",
1610 **extra_context,
1611 }
1612 params *= template.count("%(expression)s")
1613 return (template % placeholders).rstrip(), params
1615 def get_group_by_cols(self):
1616 cols = []
1617 for source in self.get_source_expressions():
1618 cols.extend(source.get_group_by_cols())
1619 return cols
1621 def reverse_ordering(self):
1622 self.descending = not self.descending
1623 if self.nulls_first:
1624 self.nulls_last = True
1625 self.nulls_first = None
1626 elif self.nulls_last:
1627 self.nulls_first = True
1628 self.nulls_last = None
1629 return self
1631 def asc(self):
1632 self.descending = False
1634 def desc(self):
1635 self.descending = True
1638class Window(SQLiteNumericMixin, Expression):
1639 template = "%(expression)s OVER (%(window)s)"
1640 # Although the main expression may either be an aggregate or an
1641 # expression with an aggregate function, the GROUP BY that will
1642 # be introduced in the query as a result is not desired.
1643 contains_aggregate = False
1644 contains_over_clause = True
1646 def __init__(
1647 self,
1648 expression,
1649 partition_by=None,
1650 order_by=None,
1651 frame=None,
1652 output_field=None,
1653 ):
1654 self.partition_by = partition_by
1655 self.order_by = order_by
1656 self.frame = frame
1658 if not getattr(expression, "window_compatible", False):
1659 raise ValueError(
1660 f"Expression '{expression.__class__.__name__}' isn't compatible with OVER clauses."
1661 )
1663 if self.partition_by is not None:
1664 if not isinstance(self.partition_by, tuple | list):
1665 self.partition_by = (self.partition_by,)
1666 self.partition_by = ExpressionList(*self.partition_by)
1668 if self.order_by is not None:
1669 if isinstance(self.order_by, list | tuple):
1670 self.order_by = OrderByList(*self.order_by)
1671 elif isinstance(self.order_by, BaseExpression | str):
1672 self.order_by = OrderByList(self.order_by)
1673 else:
1674 raise ValueError(
1675 "Window.order_by must be either a string reference to a "
1676 "field, an expression, or a list or tuple of them."
1677 )
1678 super().__init__(output_field=output_field)
1679 self.source_expression = self._parse_expressions(expression)[0]
1681 def _resolve_output_field(self):
1682 return self.source_expression.output_field
1684 def get_source_expressions(self):
1685 return [self.source_expression, self.partition_by, self.order_by, self.frame]
1687 def set_source_expressions(self, exprs):
1688 self.source_expression, self.partition_by, self.order_by, self.frame = exprs
1690 def as_sql(self, compiler, connection, template=None):
1691 connection.ops.check_expression_support(self)
1692 if not connection.features.supports_over_clause:
1693 raise NotSupportedError("This backend does not support window expressions.")
1694 expr_sql, params = compiler.compile(self.source_expression)
1695 window_sql, window_params = [], ()
1697 if self.partition_by is not None:
1698 sql_expr, sql_params = self.partition_by.as_sql(
1699 compiler=compiler,
1700 connection=connection,
1701 template="PARTITION BY %(expressions)s",
1702 )
1703 window_sql.append(sql_expr)
1704 window_params += tuple(sql_params)
1706 if self.order_by is not None:
1707 order_sql, order_params = compiler.compile(self.order_by)
1708 window_sql.append(order_sql)
1709 window_params += tuple(order_params)
1711 if self.frame:
1712 frame_sql, frame_params = compiler.compile(self.frame)
1713 window_sql.append(frame_sql)
1714 window_params += tuple(frame_params)
1716 template = template or self.template
1718 return (
1719 template % {"expression": expr_sql, "window": " ".join(window_sql).strip()},
1720 (*params, *window_params),
1721 )
1723 def as_sqlite(self, compiler, connection):
1724 if isinstance(self.output_field, fields.DecimalField):
1725 # Casting to numeric must be outside of the window expression.
1726 copy = self.copy()
1727 source_expressions = copy.get_source_expressions()
1728 source_expressions[0].output_field = fields.FloatField()
1729 copy.set_source_expressions(source_expressions)
1730 return super(Window, copy).as_sqlite(compiler, connection)
1731 return self.as_sql(compiler, connection)
1733 def __str__(self):
1734 return "{} OVER ({}{}{})".format(
1735 str(self.source_expression),
1736 "PARTITION BY " + str(self.partition_by) if self.partition_by else "",
1737 str(self.order_by or ""),
1738 str(self.frame or ""),
1739 )
1741 def __repr__(self):
1742 return f"<{self.__class__.__name__}: {self}>"
1744 def get_group_by_cols(self):
1745 group_by_cols = []
1746 if self.partition_by:
1747 group_by_cols.extend(self.partition_by.get_group_by_cols())
1748 if self.order_by is not None:
1749 group_by_cols.extend(self.order_by.get_group_by_cols())
1750 return group_by_cols
1753class WindowFrame(Expression):
1754 """
1755 Model the frame clause in window expressions. There are two types of frame
1756 clauses which are subclasses, however, all processing and validation (by no
1757 means intended to be complete) is done here. Thus, providing an end for a
1758 frame is optional (the default is UNBOUNDED FOLLOWING, which is the last
1759 row in the frame).
1760 """
1762 template = "%(frame_type)s BETWEEN %(start)s AND %(end)s"
1764 def __init__(self, start=None, end=None):
1765 self.start = Value(start)
1766 self.end = Value(end)
1768 def set_source_expressions(self, exprs):
1769 self.start, self.end = exprs
1771 def get_source_expressions(self):
1772 return [self.start, self.end]
1774 def as_sql(self, compiler, connection):
1775 connection.ops.check_expression_support(self)
1776 start, end = self.window_frame_start_end(
1777 connection, self.start.value, self.end.value
1778 )
1779 return (
1780 self.template
1781 % {
1782 "frame_type": self.frame_type,
1783 "start": start,
1784 "end": end,
1785 },
1786 [],
1787 )
1789 def __repr__(self):
1790 return f"<{self.__class__.__name__}: {self}>"
1792 def get_group_by_cols(self):
1793 return []
1795 def __str__(self):
1796 if self.start.value is not None and self.start.value < 0:
1797 start = "%d %s" % (abs(self.start.value), connection.ops.PRECEDING)
1798 elif self.start.value is not None and self.start.value == 0:
1799 start = connection.ops.CURRENT_ROW
1800 else:
1801 start = connection.ops.UNBOUNDED_PRECEDING
1803 if self.end.value is not None and self.end.value > 0:
1804 end = "%d %s" % (self.end.value, connection.ops.FOLLOWING)
1805 elif self.end.value is not None and self.end.value == 0:
1806 end = connection.ops.CURRENT_ROW
1807 else:
1808 end = connection.ops.UNBOUNDED_FOLLOWING
1809 return self.template % {
1810 "frame_type": self.frame_type,
1811 "start": start,
1812 "end": end,
1813 }
1815 def window_frame_start_end(self, connection, start, end):
1816 raise NotImplementedError("Subclasses must implement window_frame_start_end().")
1819class RowRange(WindowFrame):
1820 frame_type = "ROWS"
1822 def window_frame_start_end(self, connection, start, end):
1823 return connection.ops.window_frame_rows_start_end(start, end)
1826class ValueRange(WindowFrame):
1827 frame_type = "RANGE"
1829 def window_frame_start_end(self, connection, start, end):
1830 return connection.ops.window_frame_range_start_end(start, end)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from types import NoneType
3from plain.models.backends.utils import names_digest, split_identifier
4from plain.models.expressions import Col, ExpressionList, F, Func, OrderBy
5from plain.models.functions import Collate
6from plain.models.query_utils import Q
7from plain.models.sql import Query
8from plain.utils.functional import partition
10__all__ = ["Index"]
13class Index:
14 suffix = "idx"
15 # The max length of the name of the index (restricted to 30 for
16 # cross-database compatibility with Oracle)
17 max_name_length = 30
19 def __init__(
20 self,
21 *expressions,
22 fields=(),
23 name=None,
24 db_tablespace=None,
25 opclasses=(),
26 condition=None,
27 include=None,
28 ):
29 if opclasses and not name:
30 raise ValueError("An index must be named to use opclasses.")
31 if not isinstance(condition, NoneType | Q):
32 raise ValueError("Index.condition must be a Q instance.")
33 if condition and not name:
34 raise ValueError("An index must be named to use condition.")
35 if not isinstance(fields, list | tuple):
36 raise ValueError("Index.fields must be a list or tuple.")
37 if not isinstance(opclasses, list | tuple):
38 raise ValueError("Index.opclasses must be a list or tuple.")
39 if not expressions and not fields:
40 raise ValueError(
41 "At least one field or expression is required to define an index."
42 )
43 if expressions and fields:
44 raise ValueError(
45 "Index.fields and expressions are mutually exclusive.",
46 )
47 if expressions and not name:
48 raise ValueError("An index must be named to use expressions.")
49 if expressions and opclasses:
50 raise ValueError(
51 "Index.opclasses cannot be used with expressions. Use "
52 "a custom OpClass() instead."
53 )
54 if opclasses and len(fields) != len(opclasses):
55 raise ValueError(
56 "Index.fields and Index.opclasses must have the same number of "
57 "elements."
58 )
59 if fields and not all(isinstance(field, str) for field in fields):
60 raise ValueError("Index.fields must contain only strings with field names.")
61 if include and not name:
62 raise ValueError("A covering index must be named.")
63 if not isinstance(include, NoneType | list | tuple):
64 raise ValueError("Index.include must be a list or tuple.")
65 self.fields = list(fields)
66 # A list of 2-tuple with the field name and ordering ('' or 'DESC').
67 self.fields_orders = [
68 (field_name.removeprefix("-"), "DESC" if field_name.startswith("-") else "")
69 for field_name in self.fields
70 ]
71 self.name = name or ""
72 self.db_tablespace = db_tablespace
73 self.opclasses = opclasses
74 self.condition = condition
75 self.include = tuple(include) if include else ()
76 self.expressions = tuple(
77 F(expression) if isinstance(expression, str) else expression
78 for expression in expressions
79 )
81 @property
82 def contains_expressions(self):
83 return bool(self.expressions)
85 def _get_condition_sql(self, model, schema_editor):
86 if self.condition is None:
87 return None
88 query = Query(model=model, alias_cols=False)
89 where = query.build_where(self.condition)
90 compiler = query.get_compiler(connection=schema_editor.connection)
91 sql, params = where.as_sql(compiler, schema_editor.connection)
92 return sql % tuple(schema_editor.quote_value(p) for p in params)
94 def create_sql(self, model, schema_editor, using="", **kwargs):
95 include = [
96 model._meta.get_field(field_name).column for field_name in self.include
97 ]
98 condition = self._get_condition_sql(model, schema_editor)
99 if self.expressions:
100 index_expressions = []
101 for expression in self.expressions:
102 index_expression = IndexExpression(expression)
103 index_expression.set_wrapper_classes(schema_editor.connection)
104 index_expressions.append(index_expression)
105 expressions = ExpressionList(*index_expressions).resolve_expression(
106 Query(model, alias_cols=False),
107 )
108 fields = None
109 col_suffixes = None
110 else:
111 fields = [
112 model._meta.get_field(field_name)
113 for field_name, _ in self.fields_orders
114 ]
115 if schema_editor.connection.features.supports_index_column_ordering:
116 col_suffixes = [order[1] for order in self.fields_orders]
117 else:
118 col_suffixes = [""] * len(self.fields_orders)
119 expressions = None
120 return schema_editor._create_index_sql(
121 model,
122 fields=fields,
123 name=self.name,
124 using=using,
125 db_tablespace=self.db_tablespace,
126 col_suffixes=col_suffixes,
127 opclasses=self.opclasses,
128 condition=condition,
129 include=include,
130 expressions=expressions,
131 **kwargs,
132 )
134 def remove_sql(self, model, schema_editor, **kwargs):
135 return schema_editor._delete_index_sql(model, self.name, **kwargs)
137 def deconstruct(self):
138 path = f"{self.__class__.__module__}.{self.__class__.__name__}"
139 path = path.replace("plain.models.indexes", "plain.models")
140 kwargs = {"name": self.name}
141 if self.fields:
142 kwargs["fields"] = self.fields
143 if self.db_tablespace is not None:
144 kwargs["db_tablespace"] = self.db_tablespace
145 if self.opclasses:
146 kwargs["opclasses"] = self.opclasses
147 if self.condition:
148 kwargs["condition"] = self.condition
149 if self.include:
150 kwargs["include"] = self.include
151 return (path, self.expressions, kwargs)
153 def clone(self):
154 """Create a copy of this Index."""
155 _, args, kwargs = self.deconstruct()
156 return self.__class__(*args, **kwargs)
158 def set_name_with_model(self, model):
159 """
160 Generate a unique name for the index.
162 The name is divided into 3 parts - table name (12 chars), field name
163 (8 chars) and unique hash + suffix (10 chars). Each part is made to
164 fit its size by truncating the excess length.
165 """
166 _, table_name = split_identifier(model._meta.db_table)
167 column_names = [
168 model._meta.get_field(field_name).column
169 for field_name, order in self.fields_orders
170 ]
171 column_names_with_order = [
172 (("-%s" if order else "%s") % column_name)
173 for column_name, (field_name, order) in zip(
174 column_names, self.fields_orders
175 )
176 ]
177 # The length of the parts of the name is based on the default max
178 # length of 30 characters.
179 hash_data = [table_name] + column_names_with_order + [self.suffix]
180 self.name = "{}_{}_{}".format(
181 table_name[:11],
182 column_names[0][:7],
183 f"{names_digest(*hash_data, length=6)}_{self.suffix}",
184 )
185 if len(self.name) > self.max_name_length:
186 raise ValueError(
187 "Index too long for multiple database support. Is self.suffix "
188 "longer than 3 characters?"
189 )
190 if self.name[0] == "_" or self.name[0].isdigit():
191 self.name = f"D{self.name[1:]}"
193 def __repr__(self):
194 return "<{}:{}{}{}{}{}{}{}>".format(
195 self.__class__.__qualname__,
196 "" if not self.fields else f" fields={repr(self.fields)}",
197 "" if not self.expressions else f" expressions={repr(self.expressions)}",
198 "" if not self.name else f" name={repr(self.name)}",
199 ""
200 if self.db_tablespace is None
201 else f" db_tablespace={repr(self.db_tablespace)}",
202 "" if self.condition is None else f" condition={self.condition}",
203 "" if not self.include else f" include={repr(self.include)}",
204 "" if not self.opclasses else f" opclasses={repr(self.opclasses)}",
205 )
207 def __eq__(self, other):
208 if self.__class__ == other.__class__:
209 return self.deconstruct() == other.deconstruct()
210 return NotImplemented
213class IndexExpression(Func):
214 """Order and wrap expressions for CREATE INDEX statements."""
216 template = "%(expressions)s"
217 wrapper_classes = (OrderBy, Collate)
219 def set_wrapper_classes(self, connection=None):
220 # Some databases (e.g. MySQL) treats COLLATE as an indexed expression.
221 if connection and connection.features.collate_as_index_expression:
222 self.wrapper_classes = tuple(
223 [
224 wrapper_cls
225 for wrapper_cls in self.wrapper_classes
226 if wrapper_cls is not Collate
227 ]
228 )
230 @classmethod
231 def register_wrappers(cls, *wrapper_classes):
232 cls.wrapper_classes = wrapper_classes
234 def resolve_expression(
235 self,
236 query=None,
237 allow_joins=True,
238 reuse=None,
239 summarize=False,
240 for_save=False,
241 ):
242 expressions = list(self.flatten())
243 # Split expressions and wrappers.
244 index_expressions, wrappers = partition(
245 lambda e: isinstance(e, self.wrapper_classes),
246 expressions,
247 )
248 wrapper_types = [type(wrapper) for wrapper in wrappers]
249 if len(wrapper_types) != len(set(wrapper_types)):
250 raise ValueError(
251 "Multiple references to {} can't be used in an indexed "
252 "expression.".format(
253 ", ".join(
254 [
255 wrapper_cls.__qualname__
256 for wrapper_cls in self.wrapper_classes
257 ]
258 )
259 )
260 )
261 if expressions[1 : len(wrappers) + 1] != wrappers:
262 raise ValueError(
263 "{} must be topmost expressions in an indexed expression.".format(
264 ", ".join(
265 [
266 wrapper_cls.__qualname__
267 for wrapper_cls in self.wrapper_classes
268 ]
269 )
270 )
271 )
272 # Wrap expressions in parentheses if they are not column references.
273 root_expression = index_expressions[1]
274 resolve_root_expression = root_expression.resolve_expression(
275 query,
276 allow_joins,
277 reuse,
278 summarize,
279 for_save,
280 )
281 if not isinstance(resolve_root_expression, Col):
282 root_expression = Func(root_expression, template="(%(expressions)s)")
284 if wrappers:
285 # Order wrappers and set their expressions.
286 wrappers = sorted(
287 wrappers,
288 key=lambda w: self.wrapper_classes.index(type(w)),
289 )
290 wrappers = [wrapper.copy() for wrapper in wrappers]
291 for i, wrapper in enumerate(wrappers[:-1]):
292 wrapper.set_source_expressions([wrappers[i + 1]])
293 # Set the root expression on the deepest wrapper.
294 wrappers[-1].set_source_expressions([root_expression])
295 self.set_source_expressions([wrappers[0]])
296 else:
297 # Use the root expression, if there are no wrappers.
298 self.set_source_expressions([root_expression])
299 return super().resolve_expression(
300 query, allow_joins, reuse, summarize, for_save
301 )
303 def as_sqlite(self, compiler, connection, **extra_context):
304 # Casting to numeric is unnecessary.
305 return self.as_sql(compiler, connection, **extra_context)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import itertools
2import math
4from plain.exceptions import EmptyResultSet, FullResultSet
5from plain.models.expressions import Expression, Func, Value
6from plain.models.fields import (
7 BooleanField,
8 CharField,
9 DateTimeField,
10 Field,
11 IntegerField,
12 UUIDField,
13)
14from plain.models.query_utils import RegisterLookupMixin
15from plain.utils.datastructures import OrderedSet
16from plain.utils.functional import cached_property
17from plain.utils.hashable import make_hashable
20class Lookup(Expression):
21 lookup_name = None
22 prepare_rhs = True
23 can_use_none_as_rhs = False
25 def __init__(self, lhs, rhs):
26 self.lhs, self.rhs = lhs, rhs
27 self.rhs = self.get_prep_lookup()
28 self.lhs = self.get_prep_lhs()
29 if hasattr(self.lhs, "get_bilateral_transforms"):
30 bilateral_transforms = self.lhs.get_bilateral_transforms()
31 else:
32 bilateral_transforms = []
33 if bilateral_transforms:
34 # Warn the user as soon as possible if they are trying to apply
35 # a bilateral transformation on a nested QuerySet: that won't work.
36 from plain.models.sql.query import Query # avoid circular import
38 if isinstance(rhs, Query):
39 raise NotImplementedError(
40 "Bilateral transformations on nested querysets are not implemented."
41 )
42 self.bilateral_transforms = bilateral_transforms
44 def apply_bilateral_transforms(self, value):
45 for transform in self.bilateral_transforms:
46 value = transform(value)
47 return value
49 def __repr__(self):
50 return f"{self.__class__.__name__}({self.lhs!r}, {self.rhs!r})"
52 def batch_process_rhs(self, compiler, connection, rhs=None):
53 if rhs is None:
54 rhs = self.rhs
55 if self.bilateral_transforms:
56 sqls, sqls_params = [], []
57 for p in rhs:
58 value = Value(p, output_field=self.lhs.output_field)
59 value = self.apply_bilateral_transforms(value)
60 value = value.resolve_expression(compiler.query)
61 sql, sql_params = compiler.compile(value)
62 sqls.append(sql)
63 sqls_params.extend(sql_params)
64 else:
65 _, params = self.get_db_prep_lookup(rhs, connection)
66 sqls, sqls_params = ["%s"] * len(params), params
67 return sqls, sqls_params
69 def get_source_expressions(self):
70 if self.rhs_is_direct_value():
71 return [self.lhs]
72 return [self.lhs, self.rhs]
74 def set_source_expressions(self, new_exprs):
75 if len(new_exprs) == 1:
76 self.lhs = new_exprs[0]
77 else:
78 self.lhs, self.rhs = new_exprs
80 def get_prep_lookup(self):
81 if not self.prepare_rhs or hasattr(self.rhs, "resolve_expression"):
82 return self.rhs
83 if hasattr(self.lhs, "output_field"):
84 if hasattr(self.lhs.output_field, "get_prep_value"):
85 return self.lhs.output_field.get_prep_value(self.rhs)
86 elif self.rhs_is_direct_value():
87 return Value(self.rhs)
88 return self.rhs
90 def get_prep_lhs(self):
91 if hasattr(self.lhs, "resolve_expression"):
92 return self.lhs
93 return Value(self.lhs)
95 def get_db_prep_lookup(self, value, connection):
96 return ("%s", [value])
98 def process_lhs(self, compiler, connection, lhs=None):
99 lhs = lhs or self.lhs
100 if hasattr(lhs, "resolve_expression"):
101 lhs = lhs.resolve_expression(compiler.query)
102 sql, params = compiler.compile(lhs)
103 if isinstance(lhs, Lookup):
104 # Wrapped in parentheses to respect operator precedence.
105 sql = f"({sql})"
106 return sql, params
108 def process_rhs(self, compiler, connection):
109 value = self.rhs
110 if self.bilateral_transforms:
111 if self.rhs_is_direct_value():
112 # Do not call get_db_prep_lookup here as the value will be
113 # transformed before being used for lookup
114 value = Value(value, output_field=self.lhs.output_field)
115 value = self.apply_bilateral_transforms(value)
116 value = value.resolve_expression(compiler.query)
117 if hasattr(value, "as_sql"):
118 sql, params = compiler.compile(value)
119 # Ensure expression is wrapped in parentheses to respect operator
120 # precedence but avoid double wrapping as it can be misinterpreted
121 # on some backends (e.g. subqueries on SQLite).
122 if sql and sql[0] != "(":
123 sql = f"({sql})"
124 return sql, params
125 else:
126 return self.get_db_prep_lookup(value, connection)
128 def rhs_is_direct_value(self):
129 return not hasattr(self.rhs, "as_sql")
131 def get_group_by_cols(self):
132 cols = []
133 for source in self.get_source_expressions():
134 cols.extend(source.get_group_by_cols())
135 return cols
137 @cached_property
138 def output_field(self):
139 return BooleanField()
141 @property
142 def identity(self):
143 return self.__class__, self.lhs, self.rhs
145 def __eq__(self, other):
146 if not isinstance(other, Lookup):
147 return NotImplemented
148 return self.identity == other.identity
150 def __hash__(self):
151 return hash(make_hashable(self.identity))
153 def resolve_expression(
154 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
155 ):
156 c = self.copy()
157 c.is_summary = summarize
158 c.lhs = self.lhs.resolve_expression(
159 query, allow_joins, reuse, summarize, for_save
160 )
161 if hasattr(self.rhs, "resolve_expression"):
162 c.rhs = self.rhs.resolve_expression(
163 query, allow_joins, reuse, summarize, for_save
164 )
165 return c
167 def select_format(self, compiler, sql, params):
168 # Wrap filters with a CASE WHEN expression if a database backend
169 # (e.g. Oracle) doesn't support boolean expression in SELECT or GROUP
170 # BY list.
171 if not compiler.connection.features.supports_boolean_expr_in_select_clause:
172 sql = f"CASE WHEN {sql} THEN 1 ELSE 0 END"
173 return sql, params
176class Transform(RegisterLookupMixin, Func):
177 """
178 RegisterLookupMixin() is first so that get_lookup() and get_transform()
179 first examine self and then check output_field.
180 """
182 bilateral = False
183 arity = 1
185 @property
186 def lhs(self):
187 return self.get_source_expressions()[0]
189 def get_bilateral_transforms(self):
190 if hasattr(self.lhs, "get_bilateral_transforms"):
191 bilateral_transforms = self.lhs.get_bilateral_transforms()
192 else:
193 bilateral_transforms = []
194 if self.bilateral:
195 bilateral_transforms.append(self.__class__)
196 return bilateral_transforms
199class BuiltinLookup(Lookup):
200 def process_lhs(self, compiler, connection, lhs=None):
201 lhs_sql, params = super().process_lhs(compiler, connection, lhs)
202 field_internal_type = self.lhs.output_field.get_internal_type()
203 db_type = self.lhs.output_field.db_type(connection=connection)
204 lhs_sql = connection.ops.field_cast_sql(db_type, field_internal_type) % lhs_sql
205 lhs_sql = (
206 connection.ops.lookup_cast(self.lookup_name, field_internal_type) % lhs_sql
207 )
208 return lhs_sql, list(params)
210 def as_sql(self, compiler, connection):
211 lhs_sql, params = self.process_lhs(compiler, connection)
212 rhs_sql, rhs_params = self.process_rhs(compiler, connection)
213 params.extend(rhs_params)
214 rhs_sql = self.get_rhs_op(connection, rhs_sql)
215 return f"{lhs_sql} {rhs_sql}", params
217 def get_rhs_op(self, connection, rhs):
218 return connection.operators[self.lookup_name] % rhs
221class FieldGetDbPrepValueMixin:
222 """
223 Some lookups require Field.get_db_prep_value() to be called on their
224 inputs.
225 """
227 get_db_prep_lookup_value_is_iterable = False
229 def get_db_prep_lookup(self, value, connection):
230 # For relational fields, use the 'target_field' attribute of the
231 # output_field.
232 field = getattr(self.lhs.output_field, "target_field", None)
233 get_db_prep_value = (
234 getattr(field, "get_db_prep_value", None)
235 or self.lhs.output_field.get_db_prep_value
236 )
237 return (
238 "%s",
239 [get_db_prep_value(v, connection, prepared=True) for v in value]
240 if self.get_db_prep_lookup_value_is_iterable
241 else [get_db_prep_value(value, connection, prepared=True)],
242 )
245class FieldGetDbPrepValueIterableMixin(FieldGetDbPrepValueMixin):
246 """
247 Some lookups require Field.get_db_prep_value() to be called on each value
248 in an iterable.
249 """
251 get_db_prep_lookup_value_is_iterable = True
253 def get_prep_lookup(self):
254 if hasattr(self.rhs, "resolve_expression"):
255 return self.rhs
256 prepared_values = []
257 for rhs_value in self.rhs:
258 if hasattr(rhs_value, "resolve_expression"):
259 # An expression will be handled by the database but can coexist
260 # alongside real values.
261 pass
262 elif self.prepare_rhs and hasattr(self.lhs.output_field, "get_prep_value"):
263 rhs_value = self.lhs.output_field.get_prep_value(rhs_value)
264 prepared_values.append(rhs_value)
265 return prepared_values
267 def process_rhs(self, compiler, connection):
268 if self.rhs_is_direct_value():
269 # rhs should be an iterable of values. Use batch_process_rhs()
270 # to prepare/transform those values.
271 return self.batch_process_rhs(compiler, connection)
272 else:
273 return super().process_rhs(compiler, connection)
275 def resolve_expression_parameter(self, compiler, connection, sql, param):
276 params = [param]
277 if hasattr(param, "resolve_expression"):
278 param = param.resolve_expression(compiler.query)
279 if hasattr(param, "as_sql"):
280 sql, params = compiler.compile(param)
281 return sql, params
283 def batch_process_rhs(self, compiler, connection, rhs=None):
284 pre_processed = super().batch_process_rhs(compiler, connection, rhs)
285 # The params list may contain expressions which compile to a
286 # sql/param pair. Zip them to get sql and param pairs that refer to the
287 # same argument and attempt to replace them with the result of
288 # compiling the param step.
289 sql, params = zip(
290 *(
291 self.resolve_expression_parameter(compiler, connection, sql, param)
292 for sql, param in zip(*pre_processed)
293 )
294 )
295 params = itertools.chain.from_iterable(params)
296 return sql, tuple(params)
299class PostgresOperatorLookup(Lookup):
300 """Lookup defined by operators on PostgreSQL."""
302 postgres_operator = None
304 def as_postgresql(self, compiler, connection):
305 lhs, lhs_params = self.process_lhs(compiler, connection)
306 rhs, rhs_params = self.process_rhs(compiler, connection)
307 params = tuple(lhs_params) + tuple(rhs_params)
308 return f"{lhs} {self.postgres_operator} {rhs}", params
311@Field.register_lookup
312class Exact(FieldGetDbPrepValueMixin, BuiltinLookup):
313 lookup_name = "exact"
315 def get_prep_lookup(self):
316 from plain.models.sql.query import Query # avoid circular import
318 if isinstance(self.rhs, Query):
319 if self.rhs.has_limit_one():
320 if not self.rhs.has_select_fields:
321 self.rhs.clear_select_clause()
322 self.rhs.add_fields(["pk"])
323 else:
324 raise ValueError(
325 "The QuerySet value for an exact lookup must be limited to "
326 "one result using slicing."
327 )
328 return super().get_prep_lookup()
330 def as_sql(self, compiler, connection):
331 # Avoid comparison against direct rhs if lhs is a boolean value. That
332 # turns "boolfield__exact=True" into "WHERE boolean_field" instead of
333 # "WHERE boolean_field = True" when allowed.
334 if (
335 isinstance(self.rhs, bool)
336 and getattr(self.lhs, "conditional", False)
337 and connection.ops.conditional_expression_supported_in_where_clause(
338 self.lhs
339 )
340 ):
341 lhs_sql, params = self.process_lhs(compiler, connection)
342 template = "%s" if self.rhs else "NOT %s"
343 return template % lhs_sql, params
344 return super().as_sql(compiler, connection)
347@Field.register_lookup
348class IExact(BuiltinLookup):
349 lookup_name = "iexact"
350 prepare_rhs = False
352 def process_rhs(self, qn, connection):
353 rhs, params = super().process_rhs(qn, connection)
354 if params:
355 params[0] = connection.ops.prep_for_iexact_query(params[0])
356 return rhs, params
359@Field.register_lookup
360class GreaterThan(FieldGetDbPrepValueMixin, BuiltinLookup):
361 lookup_name = "gt"
364@Field.register_lookup
365class GreaterThanOrEqual(FieldGetDbPrepValueMixin, BuiltinLookup):
366 lookup_name = "gte"
369@Field.register_lookup
370class LessThan(FieldGetDbPrepValueMixin, BuiltinLookup):
371 lookup_name = "lt"
374@Field.register_lookup
375class LessThanOrEqual(FieldGetDbPrepValueMixin, BuiltinLookup):
376 lookup_name = "lte"
379class IntegerFieldOverflow:
380 underflow_exception = EmptyResultSet
381 overflow_exception = EmptyResultSet
383 def process_rhs(self, compiler, connection):
384 rhs = self.rhs
385 if isinstance(rhs, int):
386 field_internal_type = self.lhs.output_field.get_internal_type()
387 min_value, max_value = connection.ops.integer_field_range(
388 field_internal_type
389 )
390 if min_value is not None and rhs < min_value:
391 raise self.underflow_exception
392 if max_value is not None and rhs > max_value:
393 raise self.overflow_exception
394 return super().process_rhs(compiler, connection)
397class IntegerFieldFloatRounding:
398 """
399 Allow floats to work as query values for IntegerField. Without this, the
400 decimal portion of the float would always be discarded.
401 """
403 def get_prep_lookup(self):
404 if isinstance(self.rhs, float):
405 self.rhs = math.ceil(self.rhs)
406 return super().get_prep_lookup()
409@IntegerField.register_lookup
410class IntegerFieldExact(IntegerFieldOverflow, Exact):
411 pass
414@IntegerField.register_lookup
415class IntegerGreaterThan(IntegerFieldOverflow, GreaterThan):
416 underflow_exception = FullResultSet
419@IntegerField.register_lookup
420class IntegerGreaterThanOrEqual(
421 IntegerFieldOverflow, IntegerFieldFloatRounding, GreaterThanOrEqual
422):
423 underflow_exception = FullResultSet
426@IntegerField.register_lookup
427class IntegerLessThan(IntegerFieldOverflow, IntegerFieldFloatRounding, LessThan):
428 overflow_exception = FullResultSet
431@IntegerField.register_lookup
432class IntegerLessThanOrEqual(IntegerFieldOverflow, LessThanOrEqual):
433 overflow_exception = FullResultSet
436@Field.register_lookup
437class In(FieldGetDbPrepValueIterableMixin, BuiltinLookup):
438 lookup_name = "in"
440 def get_prep_lookup(self):
441 from plain.models.sql.query import Query # avoid circular import
443 if isinstance(self.rhs, Query):
444 self.rhs.clear_ordering(clear_default=True)
445 if not self.rhs.has_select_fields:
446 self.rhs.clear_select_clause()
447 self.rhs.add_fields(["pk"])
448 return super().get_prep_lookup()
450 def process_rhs(self, compiler, connection):
451 db_rhs = getattr(self.rhs, "_db", None)
452 if db_rhs is not None and db_rhs != connection.alias:
453 raise ValueError(
454 "Subqueries aren't allowed across different databases. Force "
455 "the inner query to be evaluated using `list(inner_query)`."
456 )
458 if self.rhs_is_direct_value():
459 # Remove None from the list as NULL is never equal to anything.
460 try:
461 rhs = OrderedSet(self.rhs)
462 rhs.discard(None)
463 except TypeError: # Unhashable items in self.rhs
464 rhs = [r for r in self.rhs if r is not None]
466 if not rhs:
467 raise EmptyResultSet
469 # rhs should be an iterable; use batch_process_rhs() to
470 # prepare/transform those values.
471 sqls, sqls_params = self.batch_process_rhs(compiler, connection, rhs)
472 placeholder = "(" + ", ".join(sqls) + ")"
473 return (placeholder, sqls_params)
474 return super().process_rhs(compiler, connection)
476 def get_rhs_op(self, connection, rhs):
477 return f"IN {rhs}"
479 def as_sql(self, compiler, connection):
480 max_in_list_size = connection.ops.max_in_list_size()
481 if (
482 self.rhs_is_direct_value()
483 and max_in_list_size
484 and len(self.rhs) > max_in_list_size
485 ):
486 return self.split_parameter_list_as_sql(compiler, connection)
487 return super().as_sql(compiler, connection)
489 def split_parameter_list_as_sql(self, compiler, connection):
490 # This is a special case for databases which limit the number of
491 # elements which can appear in an 'IN' clause.
492 max_in_list_size = connection.ops.max_in_list_size()
493 lhs, lhs_params = self.process_lhs(compiler, connection)
494 rhs, rhs_params = self.batch_process_rhs(compiler, connection)
495 in_clause_elements = ["("]
496 params = []
497 for offset in range(0, len(rhs_params), max_in_list_size):
498 if offset > 0:
499 in_clause_elements.append(" OR ")
500 in_clause_elements.append(f"{lhs} IN (")
501 params.extend(lhs_params)
502 sqls = rhs[offset : offset + max_in_list_size]
503 sqls_params = rhs_params[offset : offset + max_in_list_size]
504 param_group = ", ".join(sqls)
505 in_clause_elements.append(param_group)
506 in_clause_elements.append(")")
507 params.extend(sqls_params)
508 in_clause_elements.append(")")
509 return "".join(in_clause_elements), params
512class PatternLookup(BuiltinLookup):
513 param_pattern = "%%%s%%"
514 prepare_rhs = False
516 def get_rhs_op(self, connection, rhs):
517 # Assume we are in startswith. We need to produce SQL like:
518 # col LIKE %s, ['thevalue%']
519 # For python values we can (and should) do that directly in Python,
520 # but if the value is for example reference to other column, then
521 # we need to add the % pattern match to the lookup by something like
522 # col LIKE othercol || '%%'
523 # So, for Python values we don't need any special pattern, but for
524 # SQL reference values or SQL transformations we need the correct
525 # pattern added.
526 if hasattr(self.rhs, "as_sql") or self.bilateral_transforms:
527 pattern = connection.pattern_ops[self.lookup_name].format(
528 connection.pattern_esc
529 )
530 return pattern.format(rhs)
531 else:
532 return super().get_rhs_op(connection, rhs)
534 def process_rhs(self, qn, connection):
535 rhs, params = super().process_rhs(qn, connection)
536 if self.rhs_is_direct_value() and params and not self.bilateral_transforms:
537 params[0] = self.param_pattern % connection.ops.prep_for_like_query(
538 params[0]
539 )
540 return rhs, params
543@Field.register_lookup
544class Contains(PatternLookup):
545 lookup_name = "contains"
548@Field.register_lookup
549class IContains(Contains):
550 lookup_name = "icontains"
553@Field.register_lookup
554class StartsWith(PatternLookup):
555 lookup_name = "startswith"
556 param_pattern = "%s%%"
559@Field.register_lookup
560class IStartsWith(StartsWith):
561 lookup_name = "istartswith"
564@Field.register_lookup
565class EndsWith(PatternLookup):
566 lookup_name = "endswith"
567 param_pattern = "%%%s"
570@Field.register_lookup
571class IEndsWith(EndsWith):
572 lookup_name = "iendswith"
575@Field.register_lookup
576class Range(FieldGetDbPrepValueIterableMixin, BuiltinLookup):
577 lookup_name = "range"
579 def get_rhs_op(self, connection, rhs):
580 return f"BETWEEN {rhs[0]} AND {rhs[1]}"
583@Field.register_lookup
584class IsNull(BuiltinLookup):
585 lookup_name = "isnull"
586 prepare_rhs = False
588 def as_sql(self, compiler, connection):
589 if not isinstance(self.rhs, bool):
590 raise ValueError(
591 "The QuerySet value for an isnull lookup must be True or False."
592 )
593 sql, params = self.process_lhs(compiler, connection)
594 if self.rhs:
595 return f"{sql} IS NULL", params
596 else:
597 return f"{sql} IS NOT NULL", params
600@Field.register_lookup
601class Regex(BuiltinLookup):
602 lookup_name = "regex"
603 prepare_rhs = False
605 def as_sql(self, compiler, connection):
606 if self.lookup_name in connection.operators:
607 return super().as_sql(compiler, connection)
608 else:
609 lhs, lhs_params = self.process_lhs(compiler, connection)
610 rhs, rhs_params = self.process_rhs(compiler, connection)
611 sql_template = connection.ops.regex_lookup(self.lookup_name)
612 return sql_template % (lhs, rhs), lhs_params + rhs_params
615@Field.register_lookup
616class IRegex(Regex):
617 lookup_name = "iregex"
620class YearLookup(Lookup):
621 def year_lookup_bounds(self, connection, year):
622 from plain.models.functions import ExtractIsoYear
624 iso_year = isinstance(self.lhs, ExtractIsoYear)
625 output_field = self.lhs.lhs.output_field
626 if isinstance(output_field, DateTimeField):
627 bounds = connection.ops.year_lookup_bounds_for_datetime_field(
628 year,
629 iso_year=iso_year,
630 )
631 else:
632 bounds = connection.ops.year_lookup_bounds_for_date_field(
633 year,
634 iso_year=iso_year,
635 )
636 return bounds
638 def as_sql(self, compiler, connection):
639 # Avoid the extract operation if the rhs is a direct value to allow
640 # indexes to be used.
641 if self.rhs_is_direct_value():
642 # Skip the extract part by directly using the originating field,
643 # that is self.lhs.lhs.
644 lhs_sql, params = self.process_lhs(compiler, connection, self.lhs.lhs)
645 rhs_sql, _ = self.process_rhs(compiler, connection)
646 rhs_sql = self.get_direct_rhs_sql(connection, rhs_sql)
647 start, finish = self.year_lookup_bounds(connection, self.rhs)
648 params.extend(self.get_bound_params(start, finish))
649 return f"{lhs_sql} {rhs_sql}", params
650 return super().as_sql(compiler, connection)
652 def get_direct_rhs_sql(self, connection, rhs):
653 return connection.operators[self.lookup_name] % rhs
655 def get_bound_params(self, start, finish):
656 raise NotImplementedError(
657 "subclasses of YearLookup must provide a get_bound_params() method"
658 )
661class YearExact(YearLookup, Exact):
662 def get_direct_rhs_sql(self, connection, rhs):
663 return "BETWEEN %s AND %s"
665 def get_bound_params(self, start, finish):
666 return (start, finish)
669class YearGt(YearLookup, GreaterThan):
670 def get_bound_params(self, start, finish):
671 return (finish,)
674class YearGte(YearLookup, GreaterThanOrEqual):
675 def get_bound_params(self, start, finish):
676 return (start,)
679class YearLt(YearLookup, LessThan):
680 def get_bound_params(self, start, finish):
681 return (start,)
684class YearLte(YearLookup, LessThanOrEqual):
685 def get_bound_params(self, start, finish):
686 return (finish,)
689class UUIDTextMixin:
690 """
691 Strip hyphens from a value when filtering a UUIDField on backends without
692 a native datatype for UUID.
693 """
695 def process_rhs(self, qn, connection):
696 if not connection.features.has_native_uuid_field:
697 from plain.models.functions import Replace
699 if self.rhs_is_direct_value():
700 self.rhs = Value(self.rhs)
701 self.rhs = Replace(
702 self.rhs, Value("-"), Value(""), output_field=CharField()
703 )
704 rhs, params = super().process_rhs(qn, connection)
705 return rhs, params
708@UUIDField.register_lookup
709class UUIDIExact(UUIDTextMixin, IExact):
710 pass
713@UUIDField.register_lookup
714class UUIDContains(UUIDTextMixin, Contains):
715 pass
718@UUIDField.register_lookup
719class UUIDIContains(UUIDTextMixin, IContains):
720 pass
723@UUIDField.register_lookup
724class UUIDStartsWith(UUIDTextMixin, StartsWith):
725 pass
728@UUIDField.register_lookup
729class UUIDIStartsWith(UUIDTextMixin, IStartsWith):
730 pass
733@UUIDField.register_lookup
734class UUIDEndsWith(UUIDTextMixin, EndsWith):
735 pass
738@UUIDField.register_lookup
739class UUIDIEndsWith(UUIDTextMixin, IEndsWith):
740 pass
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import copy
2import inspect
3from functools import wraps
4from importlib import import_module
6from plain.models.db import router
7from plain.models.query import QuerySet
10class BaseManager:
11 # To retain order, track each time a Manager instance is created.
12 creation_counter = 0
14 # Set to True for the 'objects' managers that are automatically created.
15 auto_created = False
17 #: If set to True the manager will be serialized into migrations and will
18 #: thus be available in e.g. RunPython operations.
19 use_in_migrations = False
21 def __new__(cls, *args, **kwargs):
22 # Capture the arguments to make returning them trivial.
23 obj = super().__new__(cls)
24 obj._constructor_args = (args, kwargs)
25 return obj
27 def __init__(self):
28 super().__init__()
29 self._set_creation_counter()
30 self.model = None
31 self.name = None
32 self._db = None
33 self._hints = {}
35 def __str__(self):
36 """Return "package_label.model_label.manager_name"."""
37 return f"{self.model._meta.label}.{self.name}"
39 def __class_getitem__(cls, *args, **kwargs):
40 return cls
42 def deconstruct(self):
43 """
44 Return a 5-tuple of the form (as_manager (True), manager_class,
45 queryset_class, args, kwargs).
47 Raise a ValueError if the manager is dynamically generated.
48 """
49 qs_class = self._queryset_class
50 if getattr(self, "_built_with_as_manager", False):
51 # using MyQuerySet.as_manager()
52 return (
53 True, # as_manager
54 None, # manager_class
55 f"{qs_class.__module__}.{qs_class.__name__}", # qs_class
56 None, # args
57 None, # kwargs
58 )
59 else:
60 module_name = self.__module__
61 name = self.__class__.__name__
62 # Make sure it's actually there and not an inner class
63 module = import_module(module_name)
64 if not hasattr(module, name):
65 raise ValueError(
66 f"Could not find manager {name} in {module_name}.\n"
67 "Please note that you need to inherit from managers you "
68 "dynamically generated with 'from_queryset()'."
69 )
70 return (
71 False, # as_manager
72 f"{module_name}.{name}", # manager_class
73 None, # qs_class
74 self._constructor_args[0], # args
75 self._constructor_args[1], # kwargs
76 )
78 def check(self, **kwargs):
79 return []
81 @classmethod
82 def _get_queryset_methods(cls, queryset_class):
83 def create_method(name, method):
84 @wraps(method)
85 def manager_method(self, *args, **kwargs):
86 return getattr(self.get_queryset(), name)(*args, **kwargs)
88 return manager_method
90 new_methods = {}
91 for name, method in inspect.getmembers(
92 queryset_class, predicate=inspect.isfunction
93 ):
94 # Only copy missing methods.
95 if hasattr(cls, name):
96 continue
97 # Only copy public methods or methods with the attribute
98 # queryset_only=False.
99 queryset_only = getattr(method, "queryset_only", None)
100 if queryset_only or (queryset_only is None and name.startswith("_")):
101 continue
102 # Copy the method onto the manager.
103 new_methods[name] = create_method(name, method)
104 return new_methods
106 @classmethod
107 def from_queryset(cls, queryset_class, class_name=None):
108 if class_name is None:
109 class_name = f"{cls.__name__}From{queryset_class.__name__}"
110 return type(
111 class_name,
112 (cls,),
113 {
114 "_queryset_class": queryset_class,
115 **cls._get_queryset_methods(queryset_class),
116 },
117 )
119 def contribute_to_class(self, cls, name):
120 self.name = self.name or name
121 self.model = cls
123 setattr(cls, name, ManagerDescriptor(self))
125 cls._meta.add_manager(self)
127 def _set_creation_counter(self):
128 """
129 Set the creation counter value for this instance and increment the
130 class-level copy.
131 """
132 self.creation_counter = BaseManager.creation_counter
133 BaseManager.creation_counter += 1
135 def db_manager(self, using=None, hints=None):
136 obj = copy.copy(self)
137 obj._db = using or self._db
138 obj._hints = hints or self._hints
139 return obj
141 @property
142 def db(self):
143 return self._db or router.db_for_read(self.model, **self._hints)
145 #######################
146 # PROXIES TO QUERYSET #
147 #######################
149 def get_queryset(self):
150 """
151 Return a new QuerySet object. Subclasses can override this method to
152 customize the behavior of the Manager.
153 """
154 return self._queryset_class(model=self.model, using=self._db, hints=self._hints)
156 def all(self):
157 # We can't proxy this method through the `QuerySet` like we do for the
158 # rest of the `QuerySet` methods. This is because `QuerySet.all()`
159 # works by creating a "copy" of the current queryset and in making said
160 # copy, all the cached `prefetch_related` lookups are lost. See the
161 # implementation of `RelatedManager.get_queryset()` for a better
162 # understanding of how this comes into play.
163 return self.get_queryset()
165 def __eq__(self, other):
166 return (
167 isinstance(other, self.__class__)
168 and self._constructor_args == other._constructor_args
169 )
171 def __hash__(self):
172 return id(self)
175class Manager(BaseManager.from_queryset(QuerySet)):
176 pass
179class ManagerDescriptor:
180 def __init__(self, manager):
181 self.manager = manager
183 def __get__(self, instance, cls=None):
184 if instance is not None:
185 raise AttributeError(
186 f"Manager isn't accessible via {cls.__name__} instances"
187 )
189 if cls._meta.abstract:
190 raise AttributeError(
191 f"Manager isn't available; {cls._meta.object_name} is abstract"
192 )
194 if cls._meta.swapped:
195 raise AttributeError(
196 f"Manager isn't available; '{cls._meta.label}' has been swapped for '{cls._meta.swapped}'"
197 )
199 return cls._meta.managers_map[self.manager.name]
202class EmptyManager(Manager):
203 def __init__(self, model):
204 super().__init__()
205 self.model = model
207 def get_queryset(self):
208 return super().get_queryset().none()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import bisect
2import copy
3import inspect
4from collections import defaultdict
6from plain.exceptions import FieldDoesNotExist
7from plain.models.constraints import UniqueConstraint
8from plain.models.db import connections
9from plain.models.fields import BigAutoField
10from plain.models.fields.proxy import OrderWrt
11from plain.models.manager import Manager
12from plain.models.query_utils import PathInfo
13from plain.packages import packages
14from plain.runtime import settings
15from plain.utils.datastructures import ImmutableList, OrderedSet
16from plain.utils.functional import cached_property
18PROXY_PARENTS = object()
20EMPTY_RELATION_TREE = ()
22IMMUTABLE_WARNING = (
23 "The return type of '%s' should never be mutated. If you want to manipulate this "
24 "list for your own use, make a copy first."
25)
27DEFAULT_NAMES = (
28 "db_table",
29 "db_table_comment",
30 "ordering",
31 "get_latest_by",
32 "order_with_respect_to",
33 "package_label",
34 "db_tablespace",
35 "abstract",
36 "managed",
37 "swappable",
38 "auto_created",
39 "packages",
40 "select_on_save",
41 "default_related_name",
42 "required_db_features",
43 "required_db_vendor",
44 "base_manager_name",
45 "default_manager_name",
46 "indexes",
47 "constraints",
48)
51def make_immutable_fields_list(name, data):
52 return ImmutableList(data, warning=IMMUTABLE_WARNING % name)
55class Options:
56 FORWARD_PROPERTIES = {
57 "fields",
58 "many_to_many",
59 "concrete_fields",
60 "local_concrete_fields",
61 "_non_pk_concrete_field_names",
62 "_forward_fields_map",
63 "managers",
64 "managers_map",
65 "base_manager",
66 "default_manager",
67 }
68 REVERSE_PROPERTIES = {"related_objects", "fields_map", "_relation_tree"}
70 default_packages = packages
72 def __init__(self, meta, package_label=None):
73 self._get_fields_cache = {}
74 self.local_fields = []
75 self.local_many_to_many = []
76 self.private_fields = []
77 self.local_managers = []
78 self.base_manager_name = None
79 self.default_manager_name = None
80 self.model_name = None
81 self.db_table = ""
82 self.db_table_comment = ""
83 self.ordering = []
84 self._ordering_clash = False
85 self.indexes = []
86 self.constraints = []
87 self.select_on_save = False
88 self.object_name = None
89 self.package_label = package_label
90 self.get_latest_by = None
91 self.order_with_respect_to = None
92 self.db_tablespace = settings.DEFAULT_TABLESPACE
93 self.required_db_features = []
94 self.required_db_vendor = None
95 self.meta = meta
96 self.pk = None
97 self.auto_field = None
98 self.abstract = False
99 self.managed = True
100 # For any non-abstract class, the concrete class is the model
101 # in the end of the proxy_for_model chain. In particular, for
102 # concrete models, the concrete_model is always the class itself.
103 self.concrete_model = None
104 self.swappable = None
105 self.parents = {}
106 self.auto_created = False
108 # List of all lookups defined in ForeignKey 'limit_choices_to' options
109 # from *other* models. Needed for some admin checks. Internal use only.
110 self.related_fkey_lookups = []
112 # A custom app registry to use, if you're making a separate model set.
113 self.packages = self.default_packages
115 self.default_related_name = None
117 @property
118 def label(self):
119 return f"{self.package_label}.{self.object_name}"
121 @property
122 def label_lower(self):
123 return f"{self.package_label}.{self.model_name}"
125 @property
126 def package_config(self):
127 # Don't go through get_package_config to avoid triggering imports.
128 return self.packages.package_configs.get(self.package_label)
130 def contribute_to_class(self, cls, name):
131 from plain.models.backends.utils import truncate_name
132 from plain.models.db import connection
134 cls._meta = self
135 self.model = cls
136 # First, construct the default values for these options.
137 self.object_name = cls.__name__
138 self.model_name = self.object_name.lower()
140 # Store the original user-defined values for each option,
141 # for use when serializing the model definition
142 self.original_attrs = {}
144 # Next, apply any overridden values from 'class Meta'.
145 if self.meta:
146 meta_attrs = self.meta.__dict__.copy()
147 for name in self.meta.__dict__:
148 # Ignore any private attributes that Plain doesn't care about.
149 # NOTE: We can't modify a dictionary's contents while looping
150 # over it, so we loop over the *original* dictionary instead.
151 if name.startswith("_"):
152 del meta_attrs[name]
153 for attr_name in DEFAULT_NAMES:
154 if attr_name in meta_attrs:
155 setattr(self, attr_name, meta_attrs.pop(attr_name))
156 self.original_attrs[attr_name] = getattr(self, attr_name)
157 elif hasattr(self.meta, attr_name):
158 setattr(self, attr_name, getattr(self.meta, attr_name))
159 self.original_attrs[attr_name] = getattr(self, attr_name)
161 # Package label/class name interpolation for names of constraints and
162 # indexes.
163 if not getattr(cls._meta, "abstract", False):
164 for attr_name in {"constraints", "indexes"}:
165 objs = getattr(self, attr_name, [])
166 setattr(self, attr_name, self._format_names_with_class(cls, objs))
168 # order_with_respect_and ordering are mutually exclusive.
169 self._ordering_clash = bool(self.ordering and self.order_with_respect_to)
171 # Any leftover attributes must be invalid.
172 if meta_attrs != {}:
173 raise TypeError(
174 "'class Meta' got invalid attribute(s): {}".format(
175 ",".join(meta_attrs)
176 )
177 )
179 del self.meta
181 # If the db_table wasn't provided, use the package_label + model_name.
182 if not self.db_table:
183 self.db_table = f"{self.package_label}_{self.model_name}"
184 self.db_table = truncate_name(
185 self.db_table, connection.ops.max_name_length()
186 )
188 def _format_names_with_class(self, cls, objs):
189 """Package label/class name interpolation for object names."""
190 new_objs = []
191 for obj in objs:
192 obj = obj.clone()
193 obj.name = obj.name % {
194 "package_label": cls._meta.package_label.lower(),
195 "class": cls.__name__.lower(),
196 }
197 new_objs.append(obj)
198 return new_objs
200 def _prepare(self, model):
201 if self.order_with_respect_to:
202 # The app registry will not be ready at this point, so we cannot
203 # use get_field().
204 query = self.order_with_respect_to
205 try:
206 self.order_with_respect_to = next(
207 f
208 for f in self._get_fields(reverse=False)
209 if f.name == query or f.attname == query
210 )
211 except StopIteration:
212 raise FieldDoesNotExist(
213 f"{self.object_name} has no field named '{query}'"
214 )
216 self.ordering = ("_order",)
217 if not any(
218 isinstance(field, OrderWrt) for field in model._meta.local_fields
219 ):
220 model.add_to_class("_order", OrderWrt())
221 else:
222 self.order_with_respect_to = None
224 if self.pk is None:
225 if self.parents:
226 # Promote the first parent link in lieu of adding yet another
227 # field.
228 field = next(iter(self.parents.values()))
229 # Look for a local field with the same name as the
230 # first parent link. If a local field has already been
231 # created, use it instead of promoting the parent
232 already_created = [
233 fld for fld in self.local_fields if fld.name == field.name
234 ]
235 if already_created:
236 field = already_created[0]
237 field.primary_key = True
238 self.setup_pk(field)
239 else:
240 auto = BigAutoField(primary_key=True, auto_created=True)
241 model.add_to_class("id", auto)
243 def add_manager(self, manager):
244 self.local_managers.append(manager)
245 self._expire_cache()
247 def add_field(self, field, private=False):
248 # Insert the given field in the order in which it was created, using
249 # the "creation_counter" attribute of the field.
250 # Move many-to-many related fields from self.fields into
251 # self.many_to_many.
252 if private:
253 self.private_fields.append(field)
254 elif field.is_relation and field.many_to_many:
255 bisect.insort(self.local_many_to_many, field)
256 else:
257 bisect.insort(self.local_fields, field)
258 self.setup_pk(field)
260 # If the field being added is a relation to another known field,
261 # expire the cache on this field and the forward cache on the field
262 # being referenced, because there will be new relationships in the
263 # cache. Otherwise, expire the cache of references *to* this field.
264 # The mechanism for getting at the related model is slightly odd -
265 # ideally, we'd just ask for field.related_model. However, related_model
266 # is a cached property, and all the models haven't been loaded yet, so
267 # we need to make sure we don't cache a string reference.
268 if (
269 field.is_relation
270 and hasattr(field.remote_field, "model")
271 and field.remote_field.model
272 ):
273 try:
274 field.remote_field.model._meta._expire_cache(forward=False)
275 except AttributeError:
276 pass
277 self._expire_cache()
278 else:
279 self._expire_cache(reverse=False)
281 def setup_pk(self, field):
282 if not self.pk and field.primary_key:
283 self.pk = field
285 def __repr__(self):
286 return f"<Options for {self.object_name}>"
288 def __str__(self):
289 return self.label_lower
291 def can_migrate(self, connection):
292 """
293 Return True if the model can/should be migrated on the `connection`.
294 `connection` can be either a real connection or a connection alias.
295 """
296 if self.swapped or not self.managed:
297 return False
298 if isinstance(connection, str):
299 connection = connections[connection]
300 if self.required_db_vendor:
301 return self.required_db_vendor == connection.vendor
302 if self.required_db_features:
303 return all(
304 getattr(connection.features, feat, False)
305 for feat in self.required_db_features
306 )
307 return True
309 @property
310 def swapped(self):
311 """
312 Has this model been swapped out for another? If so, return the model
313 name of the replacement; otherwise, return None.
315 For historical reasons, model name lookups using get_model() are
316 case insensitive, so we make sure we are case insensitive here.
317 """
318 if self.swappable:
319 swapped_for = getattr(settings, self.swappable, None)
320 if swapped_for:
321 try:
322 swapped_label, swapped_object = swapped_for.split(".")
323 except ValueError:
324 # setting not in the format package_label.model_name
325 # raising ImproperlyConfigured here causes problems with
326 # test cleanup code - instead it is raised in get_user_model
327 # or as part of validation.
328 return swapped_for
330 if f"{swapped_label}.{swapped_object.lower()}" != self.label_lower:
331 return swapped_for
332 return None
334 @cached_property
335 def managers(self):
336 managers = []
337 seen_managers = set()
338 bases = (b for b in self.model.mro() if hasattr(b, "_meta"))
339 for depth, base in enumerate(bases):
340 for manager in base._meta.local_managers:
341 if manager.name in seen_managers:
342 continue
344 manager = copy.copy(manager)
345 manager.model = self.model
346 seen_managers.add(manager.name)
347 managers.append((depth, manager.creation_counter, manager))
349 return make_immutable_fields_list(
350 "managers",
351 (m[2] for m in sorted(managers)),
352 )
354 @cached_property
355 def managers_map(self):
356 return {manager.name: manager for manager in self.managers}
358 @cached_property
359 def base_manager(self):
360 base_manager_name = self.base_manager_name
361 if not base_manager_name:
362 # Get the first parent's base_manager_name if there's one.
363 for parent in self.model.mro()[1:]:
364 if hasattr(parent, "_meta"):
365 if parent._base_manager.name != "_base_manager":
366 base_manager_name = parent._base_manager.name
367 break
369 if base_manager_name:
370 try:
371 return self.managers_map[base_manager_name]
372 except KeyError:
373 raise ValueError(
374 f"{self.object_name} has no manager named {base_manager_name!r}"
375 )
377 manager = Manager()
378 manager.name = "_base_manager"
379 manager.model = self.model
380 manager.auto_created = True
381 return manager
383 @cached_property
384 def default_manager(self):
385 default_manager_name = self.default_manager_name
386 if not default_manager_name and not self.local_managers:
387 # Get the first parent's default_manager_name if there's one.
388 for parent in self.model.mro()[1:]:
389 if hasattr(parent, "_meta"):
390 default_manager_name = parent._meta.default_manager_name
391 break
393 if default_manager_name:
394 try:
395 return self.managers_map[default_manager_name]
396 except KeyError:
397 raise ValueError(
398 f"{self.object_name} has no manager named {default_manager_name!r}"
399 )
401 if self.managers:
402 return self.managers[0]
404 @cached_property
405 def fields(self):
406 """
407 Return a list of all forward fields on the model and its parents,
408 excluding ManyToManyFields.
410 Private API intended only to be used by Plain itself; get_fields()
411 combined with filtering of field properties is the public API for
412 obtaining this field list.
413 """
415 # For legacy reasons, the fields property should only contain forward
416 # fields that are not private or with a m2m cardinality. Therefore we
417 # pass these three filters as filters to the generator.
418 # The third lambda is a longwinded way of checking f.related_model - we don't
419 # use that property directly because related_model is a cached property,
420 # and all the models may not have been loaded yet; we don't want to cache
421 # the string reference to the related_model.
422 def is_not_an_m2m_field(f):
423 return not (f.is_relation and f.many_to_many)
425 def is_not_a_generic_relation(f):
426 return not (f.is_relation and f.one_to_many)
428 def is_not_a_generic_foreign_key(f):
429 return not (
430 f.is_relation
431 and f.many_to_one
432 and not (hasattr(f.remote_field, "model") and f.remote_field.model)
433 )
435 return make_immutable_fields_list(
436 "fields",
437 (
438 f
439 for f in self._get_fields(reverse=False)
440 if is_not_an_m2m_field(f)
441 and is_not_a_generic_relation(f)
442 and is_not_a_generic_foreign_key(f)
443 ),
444 )
446 @cached_property
447 def concrete_fields(self):
448 """
449 Return a list of all concrete fields on the model and its parents.
451 Private API intended only to be used by Plain itself; get_fields()
452 combined with filtering of field properties is the public API for
453 obtaining this field list.
454 """
455 return make_immutable_fields_list(
456 "concrete_fields", (f for f in self.fields if f.concrete)
457 )
459 @cached_property
460 def local_concrete_fields(self):
461 """
462 Return a list of all concrete fields on the model.
464 Private API intended only to be used by Plain itself; get_fields()
465 combined with filtering of field properties is the public API for
466 obtaining this field list.
467 """
468 return make_immutable_fields_list(
469 "local_concrete_fields", (f for f in self.local_fields if f.concrete)
470 )
472 @cached_property
473 def many_to_many(self):
474 """
475 Return a list of all many to many fields on the model and its parents.
477 Private API intended only to be used by Plain itself; get_fields()
478 combined with filtering of field properties is the public API for
479 obtaining this list.
480 """
481 return make_immutable_fields_list(
482 "many_to_many",
483 (
484 f
485 for f in self._get_fields(reverse=False)
486 if f.is_relation and f.many_to_many
487 ),
488 )
490 @cached_property
491 def related_objects(self):
492 """
493 Return all related objects pointing to the current model. The related
494 objects can come from a one-to-one, one-to-many, or many-to-many field
495 relation type.
497 Private API intended only to be used by Plain itself; get_fields()
498 combined with filtering of field properties is the public API for
499 obtaining this field list.
500 """
501 all_related_fields = self._get_fields(
502 forward=False, reverse=True, include_hidden=True
503 )
504 return make_immutable_fields_list(
505 "related_objects",
506 (
507 obj
508 for obj in all_related_fields
509 if not obj.hidden or obj.field.many_to_many
510 ),
511 )
513 @cached_property
514 def _forward_fields_map(self):
515 res = {}
516 fields = self._get_fields(reverse=False)
517 for field in fields:
518 res[field.name] = field
519 # Due to the way Plain's internals work, get_field() should also
520 # be able to fetch a field by attname. In the case of a concrete
521 # field with relation, includes the *_id name too
522 try:
523 res[field.attname] = field
524 except AttributeError:
525 pass
526 return res
528 @cached_property
529 def fields_map(self):
530 res = {}
531 fields = self._get_fields(forward=False, include_hidden=True)
532 for field in fields:
533 res[field.name] = field
534 # Due to the way Plain's internals work, get_field() should also
535 # be able to fetch a field by attname. In the case of a concrete
536 # field with relation, includes the *_id name too
537 try:
538 res[field.attname] = field
539 except AttributeError:
540 pass
541 return res
543 def get_field(self, field_name):
544 """
545 Return a field instance given the name of a forward or reverse field.
546 """
547 try:
548 # In order to avoid premature loading of the relation tree
549 # (expensive) we prefer checking if the field is a forward field.
550 return self._forward_fields_map[field_name]
551 except KeyError:
552 # If the app registry is not ready, reverse fields are
553 # unavailable, therefore we throw a FieldDoesNotExist exception.
554 if not self.packages.models_ready:
555 raise FieldDoesNotExist(
556 f"{self.object_name} has no field named '{field_name}'. The app cache isn't ready yet, "
557 "so if this is an auto-created related field, it won't "
558 "be available yet."
559 )
561 try:
562 # Retrieve field instance by name from cached or just-computed
563 # field map.
564 return self.fields_map[field_name]
565 except KeyError:
566 raise FieldDoesNotExist(
567 f"{self.object_name} has no field named '{field_name}'"
568 )
570 def get_base_chain(self, model):
571 """
572 Return a list of parent classes leading to `model` (ordered from
573 closest to most distant ancestor). This has to handle the case where
574 `model` is a grandparent or even more distant relation.
575 """
576 if not self.parents:
577 return []
578 if model in self.parents:
579 return [model]
580 for parent in self.parents:
581 res = parent._meta.get_base_chain(model)
582 if res:
583 res.insert(0, parent)
584 return res
585 return []
587 def get_parent_list(self):
588 """
589 Return all the ancestors of this model as a list ordered by MRO.
590 Useful for determining if something is an ancestor, regardless of lineage.
591 """
592 result = OrderedSet(self.parents)
593 for parent in self.parents:
594 for ancestor in parent._meta.get_parent_list():
595 result.add(ancestor)
596 return list(result)
598 def get_ancestor_link(self, ancestor):
599 """
600 Return the field on the current model which points to the given
601 "ancestor". This is possible an indirect link (a pointer to a parent
602 model, which points, eventually, to the ancestor). Used when
603 constructing table joins for model inheritance.
605 Return None if the model isn't an ancestor of this one.
606 """
607 if ancestor in self.parents:
608 return self.parents[ancestor]
609 for parent in self.parents:
610 # Tries to get a link field from the immediate parent
611 parent_link = parent._meta.get_ancestor_link(ancestor)
612 if parent_link:
613 # In case of a proxied model, the first link
614 # of the chain to the ancestor is that parent
615 # links
616 return self.parents[parent] or parent_link
618 def get_path_to_parent(self, parent):
619 """
620 Return a list of PathInfos containing the path from the current
621 model to the parent model, or an empty list if parent is not a
622 parent of the current model.
623 """
624 if self.model is parent:
625 return []
626 # Skip the chain of proxy to the concrete proxied model.
627 proxied_model = self.concrete_model
628 path = []
629 opts = self
630 for int_model in self.get_base_chain(parent):
631 if int_model is proxied_model:
632 opts = int_model._meta
633 else:
634 final_field = opts.parents[int_model]
635 targets = (final_field.remote_field.get_related_field(),)
636 opts = int_model._meta
637 path.append(
638 PathInfo(
639 from_opts=final_field.model._meta,
640 to_opts=opts,
641 target_fields=targets,
642 join_field=final_field,
643 m2m=False,
644 direct=True,
645 filtered_relation=None,
646 )
647 )
648 return path
650 def get_path_from_parent(self, parent):
651 """
652 Return a list of PathInfos containing the path from the parent
653 model to the current model, or an empty list if parent is not a
654 parent of the current model.
655 """
656 if self.model is parent:
657 return []
658 model = self.concrete_model
659 # Get a reversed base chain including both the current and parent
660 # models.
661 chain = model._meta.get_base_chain(parent)
662 chain.reverse()
663 chain.append(model)
664 # Construct a list of the PathInfos between models in chain.
665 path = []
666 for i, ancestor in enumerate(chain[:-1]):
667 child = chain[i + 1]
668 link = child._meta.get_ancestor_link(ancestor)
669 path.extend(link.reverse_path_infos)
670 return path
672 def _populate_directed_relation_graph(self):
673 """
674 This method is used by each model to find its reverse objects. As this
675 method is very expensive and is accessed frequently (it looks up every
676 field in a model, in every app), it is computed on first access and then
677 is set as a property on every model.
678 """
679 related_objects_graph = defaultdict(list)
681 all_models = self.packages.get_models(include_auto_created=True)
682 for model in all_models:
683 opts = model._meta
684 # Abstract model's fields are copied to child models, hence we will
685 # see the fields from the child models.
686 if opts.abstract:
687 continue
688 fields_with_relations = (
689 f
690 for f in opts._get_fields(reverse=False, include_parents=False)
691 if f.is_relation and f.related_model is not None
692 )
693 for f in fields_with_relations:
694 if not isinstance(f.remote_field.model, str):
695 remote_label = f.remote_field.model._meta.concrete_model._meta.label
696 related_objects_graph[remote_label].append(f)
698 for model in all_models:
699 # Set the relation_tree using the internal __dict__. In this way
700 # we avoid calling the cached property. In attribute lookup,
701 # __dict__ takes precedence over a data descriptor (such as
702 # @cached_property). This means that the _meta._relation_tree is
703 # only called if related_objects is not in __dict__.
704 related_objects = related_objects_graph[
705 model._meta.concrete_model._meta.label
706 ]
707 model._meta.__dict__["_relation_tree"] = related_objects
708 # It seems it is possible that self is not in all_models, so guard
709 # against that with default for get().
710 return self.__dict__.get("_relation_tree", EMPTY_RELATION_TREE)
712 @cached_property
713 def _relation_tree(self):
714 return self._populate_directed_relation_graph()
716 def _expire_cache(self, forward=True, reverse=True):
717 # This method is usually called by packages.cache_clear(), when the
718 # registry is finalized, or when a new field is added.
719 if forward:
720 for cache_key in self.FORWARD_PROPERTIES:
721 if cache_key in self.__dict__:
722 delattr(self, cache_key)
723 if reverse and not self.abstract:
724 for cache_key in self.REVERSE_PROPERTIES:
725 if cache_key in self.__dict__:
726 delattr(self, cache_key)
727 self._get_fields_cache = {}
729 def get_fields(self, include_parents=True, include_hidden=False):
730 """
731 Return a list of fields associated to the model. By default, include
732 forward and reverse fields, fields derived from inheritance, but not
733 hidden fields. The returned fields can be changed using the parameters:
735 - include_parents: include fields derived from inheritance
736 - include_hidden: include fields that have a related_name that
737 starts with a "+"
738 """
739 if include_parents is False:
740 include_parents = PROXY_PARENTS
741 return self._get_fields(
742 include_parents=include_parents, include_hidden=include_hidden
743 )
745 def _get_fields(
746 self,
747 forward=True,
748 reverse=True,
749 include_parents=True,
750 include_hidden=False,
751 seen_models=None,
752 ):
753 """
754 Internal helper function to return fields of the model.
755 * If forward=True, then fields defined on this model are returned.
756 * If reverse=True, then relations pointing to this model are returned.
757 * If include_hidden=True, then fields with is_hidden=True are returned.
758 * The include_parents argument toggles if fields from parent models
759 should be included. It has three values: True, False, and
760 PROXY_PARENTS. When set to PROXY_PARENTS, the call will return all
761 fields defined for the current model or any of its parents in the
762 parent chain to the model's concrete model.
763 """
764 if include_parents not in (True, False, PROXY_PARENTS):
765 raise TypeError(f"Invalid argument for include_parents: {include_parents}")
766 # This helper function is used to allow recursion in ``get_fields()``
767 # implementation and to provide a fast way for Plain's internals to
768 # access specific subsets of fields.
770 # We must keep track of which models we have already seen. Otherwise we
771 # could include the same field multiple times from different models.
772 topmost_call = seen_models is None
773 if topmost_call:
774 seen_models = set()
775 seen_models.add(self.model)
777 # Creates a cache key composed of all arguments
778 cache_key = (forward, reverse, include_parents, include_hidden, topmost_call)
780 try:
781 # In order to avoid list manipulation. Always return a shallow copy
782 # of the results.
783 return self._get_fields_cache[cache_key]
784 except KeyError:
785 pass
787 fields = []
788 # Recursively call _get_fields() on each parent, with the same
789 # options provided in this call.
790 if include_parents is not False:
791 for parent in self.parents:
792 # In diamond inheritance it is possible that we see the same
793 # model from two different routes. In that case, avoid adding
794 # fields from the same parent again.
795 if parent in seen_models:
796 continue
797 if (
798 parent._meta.concrete_model != self.concrete_model
799 and include_parents == PROXY_PARENTS
800 ):
801 continue
802 for obj in parent._meta._get_fields(
803 forward=forward,
804 reverse=reverse,
805 include_parents=include_parents,
806 include_hidden=include_hidden,
807 seen_models=seen_models,
808 ):
809 if (
810 not getattr(obj, "parent_link", False)
811 or obj.model == self.concrete_model
812 ):
813 fields.append(obj)
814 if reverse:
815 # Tree is computed once and cached until the app cache is expired.
816 # It is composed of a list of fields pointing to the current model
817 # from other models.
818 all_fields = self._relation_tree
819 for field in all_fields:
820 # If hidden fields should be included or the relation is not
821 # intentionally hidden, add to the fields dict.
822 if include_hidden or not field.remote_field.hidden:
823 fields.append(field.remote_field)
825 if forward:
826 fields += self.local_fields
827 fields += self.local_many_to_many
828 # Private fields are recopied to each child model, and they get a
829 # different model as field.model in each child. Hence we have to
830 # add the private fields separately from the topmost call. If we
831 # did this recursively similar to local_fields, we would get field
832 # instances with field.model != self.model.
833 if topmost_call:
834 fields += self.private_fields
836 # In order to avoid list manipulation. Always
837 # return a shallow copy of the results
838 fields = make_immutable_fields_list("get_fields()", fields)
840 # Store result into cache for later access
841 self._get_fields_cache[cache_key] = fields
842 return fields
844 @cached_property
845 def total_unique_constraints(self):
846 """
847 Return a list of total unique constraints. Useful for determining set
848 of fields guaranteed to be unique for all rows.
849 """
850 return [
851 constraint
852 for constraint in self.constraints
853 if (
854 isinstance(constraint, UniqueConstraint)
855 and constraint.condition is None
856 and not constraint.contains_expressions
857 )
858 ]
860 @cached_property
861 def _property_names(self):
862 """Return a set of the names of the properties defined on the model."""
863 names = []
864 for name in dir(self.model):
865 attr = inspect.getattr_static(self.model, name)
866 if isinstance(attr, property):
867 names.append(name)
868 return frozenset(names)
870 @cached_property
871 def _non_pk_concrete_field_names(self):
872 """
873 Return a set of the non-pk concrete field names defined on the model.
874 """
875 names = []
876 for field in self.concrete_fields:
877 if not field.primary_key:
878 names.append(field.name)
879 if field.name != field.attname:
880 names.append(field.attname)
881 return frozenset(names)
883 @cached_property
884 def db_returning_fields(self):
885 """
886 Private API intended only to be used by Plain itself.
887 Fields to be returned after a database insert.
888 """
889 return [
890 field
891 for field in self._get_fields(
892 forward=True, reverse=False, include_parents=PROXY_PARENTS
893 )
894 if getattr(field, "db_returning", False)
895 ]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import inspect
2import types
3from collections import defaultdict
4from itertools import chain
6from plain.packages import packages
7from plain.preflight import Error, Warning, register
8from plain.runtime import settings
11@register
12def check_database_backends(databases=None, **kwargs):
13 if databases is None:
14 return []
16 from plain.models.db import connections
18 issues = []
19 for alias in databases:
20 conn = connections[alias]
21 issues.extend(conn.validation.check(**kwargs))
22 return issues
25@register
26def check_all_models(package_configs=None, **kwargs):
27 db_table_models = defaultdict(list)
28 indexes = defaultdict(list)
29 constraints = defaultdict(list)
30 errors = []
31 if package_configs is None:
32 models = packages.get_models()
33 else:
34 models = chain.from_iterable(
35 package_config.get_models() for package_config in package_configs
36 )
37 for model in models:
38 if model._meta.managed:
39 db_table_models[model._meta.db_table].append(model._meta.label)
40 if not inspect.ismethod(model.check):
41 errors.append(
42 Error(
43 f"The '{model.__name__}.check()' class method is currently overridden by {model.check!r}.",
44 obj=model,
45 id="models.E020",
46 )
47 )
48 else:
49 errors.extend(model.check(**kwargs))
50 for model_index in model._meta.indexes:
51 indexes[model_index.name].append(model._meta.label)
52 for model_constraint in model._meta.constraints:
53 constraints[model_constraint.name].append(model._meta.label)
54 if settings.DATABASE_ROUTERS:
55 error_class, error_id = Warning, "models.W035"
56 error_hint = (
57 "You have configured settings.DATABASE_ROUTERS. Verify that %s "
58 "are correctly routed to separate databases."
59 )
60 else:
61 error_class, error_id = Error, "models.E028"
62 error_hint = None
63 for db_table, model_labels in db_table_models.items():
64 if len(model_labels) != 1:
65 model_labels_str = ", ".join(model_labels)
66 errors.append(
67 error_class(
68 f"db_table '{db_table}' is used by multiple models: {model_labels_str}.",
69 obj=db_table,
70 hint=(error_hint % model_labels_str) if error_hint else None,
71 id=error_id,
72 )
73 )
74 for index_name, model_labels in indexes.items():
75 if len(model_labels) > 1:
76 model_labels = set(model_labels)
77 errors.append(
78 Error(
79 "index name '{}' is not unique {} {}.".format(
80 index_name,
81 "for model" if len(model_labels) == 1 else "among models:",
82 ", ".join(sorted(model_labels)),
83 ),
84 id="models.E029" if len(model_labels) == 1 else "models.E030",
85 ),
86 )
87 for constraint_name, model_labels in constraints.items():
88 if len(model_labels) > 1:
89 model_labels = set(model_labels)
90 errors.append(
91 Error(
92 "constraint name '{}' is not unique {} {}.".format(
93 constraint_name,
94 "for model" if len(model_labels) == 1 else "among models:",
95 ", ".join(sorted(model_labels)),
96 ),
97 id="models.E031" if len(model_labels) == 1 else "models.E032",
98 ),
99 )
100 return errors
103def _check_lazy_references(packages, ignore=None):
104 """
105 Ensure all lazy (i.e. string) model references have been resolved.
107 Lazy references are used in various places throughout Plain, primarily in
108 related fields and model signals. Identify those common cases and provide
109 more helpful error messages for them.
111 The ignore parameter is used by StatePackages to exclude swappable models from
112 this check.
113 """
114 pending_models = set(packages._pending_operations) - (ignore or set())
116 # Short circuit if there aren't any errors.
117 if not pending_models:
118 return []
120 from plain.models import signals
122 model_signals = {
123 signal: name
124 for name, signal in vars(signals).items()
125 if isinstance(signal, signals.ModelSignal)
126 }
128 def extract_operation(obj):
129 """
130 Take a callable found in Packages._pending_operations and identify the
131 original callable passed to Packages.lazy_model_operation(). If that
132 callable was a partial, return the inner, non-partial function and
133 any arguments and keyword arguments that were supplied with it.
135 obj is a callback defined locally in Packages.lazy_model_operation() and
136 annotated there with a `func` attribute so as to imitate a partial.
137 """
138 operation, args, keywords = obj, [], {}
139 while hasattr(operation, "func"):
140 args.extend(getattr(operation, "args", []))
141 keywords.update(getattr(operation, "keywords", {}))
142 operation = operation.func
143 return operation, args, keywords
145 def app_model_error(model_key):
146 try:
147 packages.get_package_config(model_key[0])
148 model_error = "app '{}' doesn't provide model '{}'".format(*model_key)
149 except LookupError:
150 model_error = f"app '{model_key[0]}' isn't installed"
151 return model_error
153 # Here are several functions which return CheckMessage instances for the
154 # most common usages of lazy operations throughout Plain. These functions
155 # take the model that was being waited on as an (package_label, modelname)
156 # pair, the original lazy function, and its positional and keyword args as
157 # determined by extract_operation().
159 def field_error(model_key, func, args, keywords):
160 error_msg = (
161 "The field %(field)s was declared with a lazy reference "
162 "to '%(model)s', but %(model_error)s."
163 )
164 params = {
165 "model": ".".join(model_key),
166 "field": keywords["field"],
167 "model_error": app_model_error(model_key),
168 }
169 return Error(error_msg % params, obj=keywords["field"], id="fields.E307")
171 def signal_connect_error(model_key, func, args, keywords):
172 error_msg = (
173 "%(receiver)s was connected to the '%(signal)s' signal with a "
174 "lazy reference to the sender '%(model)s', but %(model_error)s."
175 )
176 receiver = args[0]
177 # The receiver is either a function or an instance of class
178 # defining a `__call__` method.
179 if isinstance(receiver, types.FunctionType):
180 description = f"The function '{receiver.__name__}'"
181 elif isinstance(receiver, types.MethodType):
182 description = f"Bound method '{receiver.__self__.__class__.__name__}.{receiver.__name__}'"
183 else:
184 description = f"An instance of class '{receiver.__class__.__name__}'"
185 signal_name = model_signals.get(func.__self__, "unknown")
186 params = {
187 "model": ".".join(model_key),
188 "receiver": description,
189 "signal": signal_name,
190 "model_error": app_model_error(model_key),
191 }
192 return Error(error_msg % params, obj=receiver.__module__, id="signals.E001")
194 def default_error(model_key, func, args, keywords):
195 error_msg = (
196 "%(op)s contains a lazy reference to %(model)s, but %(model_error)s."
197 )
198 params = {
199 "op": func,
200 "model": ".".join(model_key),
201 "model_error": app_model_error(model_key),
202 }
203 return Error(error_msg % params, obj=func, id="models.E022")
205 # Maps common uses of lazy operations to corresponding error functions
206 # defined above. If a key maps to None, no error will be produced.
207 # default_error() will be used for usages that don't appear in this dict.
208 known_lazy = {
209 ("plain.models.fields.related", "resolve_related_class"): field_error,
210 ("plain.models.fields.related", "set_managed"): None,
211 ("plain.signals.dispatch.dispatcher", "connect"): signal_connect_error,
212 }
214 def build_error(model_key, func, args, keywords):
215 key = (func.__module__, func.__name__)
216 error_fn = known_lazy.get(key, default_error)
217 return error_fn(model_key, func, args, keywords) if error_fn else None
219 return sorted(
220 filter(
221 None,
222 (
223 build_error(model_key, *extract_operation(func))
224 for model_key in pending_models
225 for func in packages._pending_operations[model_key]
226 ),
227 ),
228 key=lambda error: error.msg,
229 )
232@register
233def check_lazy_references(package_configs=None, **kwargs):
234 return _check_lazy_references(packages)
237@register
238def check_database_tables(package_configs, **kwargs):
239 from plain.models.db import connection
241 databases = kwargs.get("databases", None)
242 if not databases:
243 return []
245 errors = []
247 for database in databases:
248 db_tables = connection.introspection.table_names()
249 model_tables = connection.introspection.plain_table_names()
251 unknown_tables = set(db_tables) - set(model_tables)
252 unknown_tables.discard("plainmigrations") # Know this could be there
253 if unknown_tables:
254 table_names = ", ".join(unknown_tables)
255 specific_hint = f'echo "DROP TABLE IF EXISTS {unknown_tables.pop()}" | plain models db-shell'
256 errors.append(
257 Warning(
258 f"Unknown tables in {database} database: {table_names}",
259 hint=(
260 "Tables may be from packages/models that have been uninstalled. "
261 "Make sure you have a backup and delete the tables manually "
262 f"(ex. `{specific_hint}`)."
263 ),
264 id="plain.models.W001",
265 )
266 )
268 return errors
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2The main QuerySet implementation. This provides the public API for the ORM.
3"""
5import copy
6import operator
7import warnings
8from itertools import chain, islice
10import plain.runtime
11from plain import exceptions
12from plain.exceptions import ValidationError
13from plain.models import (
14 sql,
15 transaction,
16)
17from plain.models.constants import LOOKUP_SEP, OnConflict
18from plain.models.db import (
19 PLAIN_VERSION_PICKLE_KEY,
20 IntegrityError,
21 NotSupportedError,
22 connections,
23 router,
24)
25from plain.models.expressions import Case, F, Value, When
26from plain.models.fields import (
27 AutoField,
28 DateField,
29 DateTimeField,
30 Field,
31)
32from plain.models.functions import Cast, Trunc
33from plain.models.query_utils import FilteredRelation, Q
34from plain.models.sql.constants import CURSOR, GET_ITERATOR_CHUNK_SIZE
35from plain.models.utils import (
36 AltersData,
37 create_namedtuple_class,
38 resolve_callables,
39)
40from plain.utils import timezone
41from plain.utils.functional import cached_property, partition
43# The maximum number of results to fetch in a get() query.
44MAX_GET_RESULTS = 21
46# The maximum number of items to display in a QuerySet.__repr__
47REPR_OUTPUT_SIZE = 20
50class BaseIterable:
51 def __init__(
52 self, queryset, chunked_fetch=False, chunk_size=GET_ITERATOR_CHUNK_SIZE
53 ):
54 self.queryset = queryset
55 self.chunked_fetch = chunked_fetch
56 self.chunk_size = chunk_size
59class ModelIterable(BaseIterable):
60 """Iterable that yields a model instance for each row."""
62 def __iter__(self):
63 queryset = self.queryset
64 db = queryset.db
65 compiler = queryset.query.get_compiler(using=db)
66 # Execute the query. This will also fill compiler.select, klass_info,
67 # and annotations.
68 results = compiler.execute_sql(
69 chunked_fetch=self.chunked_fetch, chunk_size=self.chunk_size
70 )
71 select, klass_info, annotation_col_map = (
72 compiler.select,
73 compiler.klass_info,
74 compiler.annotation_col_map,
75 )
76 model_cls = klass_info["model"]
77 select_fields = klass_info["select_fields"]
78 model_fields_start, model_fields_end = select_fields[0], select_fields[-1] + 1
79 init_list = [
80 f[0].target.attname for f in select[model_fields_start:model_fields_end]
81 ]
82 related_populators = get_related_populators(klass_info, select, db)
83 known_related_objects = [
84 (
85 field,
86 related_objs,
87 operator.attrgetter(
88 *[
89 field.attname
90 if from_field == "self"
91 else queryset.model._meta.get_field(from_field).attname
92 for from_field in field.from_fields
93 ]
94 ),
95 )
96 for field, related_objs in queryset._known_related_objects.items()
97 ]
98 for row in compiler.results_iter(results):
99 obj = model_cls.from_db(
100 db, init_list, row[model_fields_start:model_fields_end]
101 )
102 for rel_populator in related_populators:
103 rel_populator.populate(row, obj)
104 if annotation_col_map:
105 for attr_name, col_pos in annotation_col_map.items():
106 setattr(obj, attr_name, row[col_pos])
108 # Add the known related objects to the model.
109 for field, rel_objs, rel_getter in known_related_objects:
110 # Avoid overwriting objects loaded by, e.g., select_related().
111 if field.is_cached(obj):
112 continue
113 rel_obj_id = rel_getter(obj)
114 try:
115 rel_obj = rel_objs[rel_obj_id]
116 except KeyError:
117 pass # May happen in qs1 | qs2 scenarios.
118 else:
119 setattr(obj, field.name, rel_obj)
121 yield obj
124class RawModelIterable(BaseIterable):
125 """
126 Iterable that yields a model instance for each row from a raw queryset.
127 """
129 def __iter__(self):
130 # Cache some things for performance reasons outside the loop.
131 db = self.queryset.db
132 query = self.queryset.query
133 connection = connections[db]
134 compiler = connection.ops.compiler("SQLCompiler")(query, connection, db)
135 query_iterator = iter(query)
137 try:
138 (
139 model_init_names,
140 model_init_pos,
141 annotation_fields,
142 ) = self.queryset.resolve_model_init_order()
143 model_cls = self.queryset.model
144 if model_cls._meta.pk.attname not in model_init_names:
145 raise exceptions.FieldDoesNotExist(
146 "Raw query must include the primary key"
147 )
148 fields = [self.queryset.model_fields.get(c) for c in self.queryset.columns]
149 converters = compiler.get_converters(
150 [f.get_col(f.model._meta.db_table) if f else None for f in fields]
151 )
152 if converters:
153 query_iterator = compiler.apply_converters(query_iterator, converters)
154 for values in query_iterator:
155 # Associate fields to values
156 model_init_values = [values[pos] for pos in model_init_pos]
157 instance = model_cls.from_db(db, model_init_names, model_init_values)
158 if annotation_fields:
159 for column, pos in annotation_fields:
160 setattr(instance, column, values[pos])
161 yield instance
162 finally:
163 # Done iterating the Query. If it has its own cursor, close it.
164 if hasattr(query, "cursor") and query.cursor:
165 query.cursor.close()
168class ValuesIterable(BaseIterable):
169 """
170 Iterable returned by QuerySet.values() that yields a dict for each row.
171 """
173 def __iter__(self):
174 queryset = self.queryset
175 query = queryset.query
176 compiler = query.get_compiler(queryset.db)
178 # extra(select=...) cols are always at the start of the row.
179 names = [
180 *query.extra_select,
181 *query.values_select,
182 *query.annotation_select,
183 ]
184 indexes = range(len(names))
185 for row in compiler.results_iter(
186 chunked_fetch=self.chunked_fetch, chunk_size=self.chunk_size
187 ):
188 yield {names[i]: row[i] for i in indexes}
191class ValuesListIterable(BaseIterable):
192 """
193 Iterable returned by QuerySet.values_list(flat=False) that yields a tuple
194 for each row.
195 """
197 def __iter__(self):
198 queryset = self.queryset
199 query = queryset.query
200 compiler = query.get_compiler(queryset.db)
202 if queryset._fields:
203 # extra(select=...) cols are always at the start of the row.
204 names = [
205 *query.extra_select,
206 *query.values_select,
207 *query.annotation_select,
208 ]
209 fields = [
210 *queryset._fields,
211 *(f for f in query.annotation_select if f not in queryset._fields),
212 ]
213 if fields != names:
214 # Reorder according to fields.
215 index_map = {name: idx for idx, name in enumerate(names)}
216 rowfactory = operator.itemgetter(*[index_map[f] for f in fields])
217 return map(
218 rowfactory,
219 compiler.results_iter(
220 chunked_fetch=self.chunked_fetch, chunk_size=self.chunk_size
221 ),
222 )
223 return compiler.results_iter(
224 tuple_expected=True,
225 chunked_fetch=self.chunked_fetch,
226 chunk_size=self.chunk_size,
227 )
230class NamedValuesListIterable(ValuesListIterable):
231 """
232 Iterable returned by QuerySet.values_list(named=True) that yields a
233 namedtuple for each row.
234 """
236 def __iter__(self):
237 queryset = self.queryset
238 if queryset._fields:
239 names = queryset._fields
240 else:
241 query = queryset.query
242 names = [
243 *query.extra_select,
244 *query.values_select,
245 *query.annotation_select,
246 ]
247 tuple_class = create_namedtuple_class(*names)
248 new = tuple.__new__
249 for row in super().__iter__():
250 yield new(tuple_class, row)
253class FlatValuesListIterable(BaseIterable):
254 """
255 Iterable returned by QuerySet.values_list(flat=True) that yields single
256 values.
257 """
259 def __iter__(self):
260 queryset = self.queryset
261 compiler = queryset.query.get_compiler(queryset.db)
262 for row in compiler.results_iter(
263 chunked_fetch=self.chunked_fetch, chunk_size=self.chunk_size
264 ):
265 yield row[0]
268class QuerySet(AltersData):
269 """Represent a lazy database lookup for a set of objects."""
271 def __init__(self, model=None, query=None, using=None, hints=None):
272 self.model = model
273 self._db = using
274 self._hints = hints or {}
275 self._query = query or sql.Query(self.model)
276 self._result_cache = None
277 self._sticky_filter = False
278 self._for_write = False
279 self._prefetch_related_lookups = ()
280 self._prefetch_done = False
281 self._known_related_objects = {} # {rel_field: {pk: rel_obj}}
282 self._iterable_class = ModelIterable
283 self._fields = None
284 self._defer_next_filter = False
285 self._deferred_filter = None
287 @property
288 def query(self):
289 if self._deferred_filter:
290 negate, args, kwargs = self._deferred_filter
291 self._filter_or_exclude_inplace(negate, args, kwargs)
292 self._deferred_filter = None
293 return self._query
295 @query.setter
296 def query(self, value):
297 if value.values_select:
298 self._iterable_class = ValuesIterable
299 self._query = value
301 def as_manager(cls):
302 # Address the circular dependency between `Queryset` and `Manager`.
303 from plain.models.manager import Manager
305 manager = Manager.from_queryset(cls)()
306 manager._built_with_as_manager = True
307 return manager
309 as_manager.queryset_only = True
310 as_manager = classmethod(as_manager)
312 ########################
313 # PYTHON MAGIC METHODS #
314 ########################
316 def __deepcopy__(self, memo):
317 """Don't populate the QuerySet's cache."""
318 obj = self.__class__()
319 for k, v in self.__dict__.items():
320 if k == "_result_cache":
321 obj.__dict__[k] = None
322 else:
323 obj.__dict__[k] = copy.deepcopy(v, memo)
324 return obj
326 def __getstate__(self):
327 # Force the cache to be fully populated.
328 self._fetch_all()
329 return {**self.__dict__, PLAIN_VERSION_PICKLE_KEY: plain.runtime.__version__}
331 def __setstate__(self, state):
332 pickled_version = state.get(PLAIN_VERSION_PICKLE_KEY)
333 if pickled_version:
334 if pickled_version != plain.runtime.__version__:
335 warnings.warn(
336 f"Pickled queryset instance's Plain version {pickled_version} does not "
337 f"match the current version {plain.runtime.__version__}.",
338 RuntimeWarning,
339 stacklevel=2,
340 )
341 else:
342 warnings.warn(
343 "Pickled queryset instance's Plain version is not specified.",
344 RuntimeWarning,
345 stacklevel=2,
346 )
347 self.__dict__.update(state)
349 def __repr__(self):
350 data = list(self[: REPR_OUTPUT_SIZE + 1])
351 if len(data) > REPR_OUTPUT_SIZE:
352 data[-1] = "...(remaining elements truncated)..."
353 return f"<{self.__class__.__name__} {data!r}>"
355 def __len__(self):
356 self._fetch_all()
357 return len(self._result_cache)
359 def __iter__(self):
360 """
361 The queryset iterator protocol uses three nested iterators in the
362 default case:
363 1. sql.compiler.execute_sql()
364 - Returns 100 rows at time (constants.GET_ITERATOR_CHUNK_SIZE)
365 using cursor.fetchmany(). This part is responsible for
366 doing some column masking, and returning the rows in chunks.
367 2. sql.compiler.results_iter()
368 - Returns one row at time. At this point the rows are still just
369 tuples. In some cases the return values are converted to
370 Python values at this location.
371 3. self.iterator()
372 - Responsible for turning the rows into model objects.
373 """
374 self._fetch_all()
375 return iter(self._result_cache)
377 def __bool__(self):
378 self._fetch_all()
379 return bool(self._result_cache)
381 def __getitem__(self, k):
382 """Retrieve an item or slice from the set of results."""
383 if not isinstance(k, int | slice):
384 raise TypeError(
385 f"QuerySet indices must be integers or slices, not {type(k).__name__}."
386 )
387 if (isinstance(k, int) and k < 0) or (
388 isinstance(k, slice)
389 and (
390 (k.start is not None and k.start < 0)
391 or (k.stop is not None and k.stop < 0)
392 )
393 ):
394 raise ValueError("Negative indexing is not supported.")
396 if self._result_cache is not None:
397 return self._result_cache[k]
399 if isinstance(k, slice):
400 qs = self._chain()
401 if k.start is not None:
402 start = int(k.start)
403 else:
404 start = None
405 if k.stop is not None:
406 stop = int(k.stop)
407 else:
408 stop = None
409 qs.query.set_limits(start, stop)
410 return list(qs)[:: k.step] if k.step else qs
412 qs = self._chain()
413 qs.query.set_limits(k, k + 1)
414 qs._fetch_all()
415 return qs._result_cache[0]
417 def __class_getitem__(cls, *args, **kwargs):
418 return cls
420 def __and__(self, other):
421 self._check_operator_queryset(other, "&")
422 self._merge_sanity_check(other)
423 if isinstance(other, EmptyQuerySet):
424 return other
425 if isinstance(self, EmptyQuerySet):
426 return self
427 combined = self._chain()
428 combined._merge_known_related_objects(other)
429 combined.query.combine(other.query, sql.AND)
430 return combined
432 def __or__(self, other):
433 self._check_operator_queryset(other, "|")
434 self._merge_sanity_check(other)
435 if isinstance(self, EmptyQuerySet):
436 return other
437 if isinstance(other, EmptyQuerySet):
438 return self
439 query = (
440 self
441 if self.query.can_filter()
442 else self.model._base_manager.filter(pk__in=self.values("pk"))
443 )
444 combined = query._chain()
445 combined._merge_known_related_objects(other)
446 if not other.query.can_filter():
447 other = other.model._base_manager.filter(pk__in=other.values("pk"))
448 combined.query.combine(other.query, sql.OR)
449 return combined
451 def __xor__(self, other):
452 self._check_operator_queryset(other, "^")
453 self._merge_sanity_check(other)
454 if isinstance(self, EmptyQuerySet):
455 return other
456 if isinstance(other, EmptyQuerySet):
457 return self
458 query = (
459 self
460 if self.query.can_filter()
461 else self.model._base_manager.filter(pk__in=self.values("pk"))
462 )
463 combined = query._chain()
464 combined._merge_known_related_objects(other)
465 if not other.query.can_filter():
466 other = other.model._base_manager.filter(pk__in=other.values("pk"))
467 combined.query.combine(other.query, sql.XOR)
468 return combined
470 ####################################
471 # METHODS THAT DO DATABASE QUERIES #
472 ####################################
474 def _iterator(self, use_chunked_fetch, chunk_size):
475 iterable = self._iterable_class(
476 self,
477 chunked_fetch=use_chunked_fetch,
478 chunk_size=chunk_size or 2000,
479 )
480 if not self._prefetch_related_lookups or chunk_size is None:
481 yield from iterable
482 return
484 iterator = iter(iterable)
485 while results := list(islice(iterator, chunk_size)):
486 prefetch_related_objects(results, *self._prefetch_related_lookups)
487 yield from results
489 def iterator(self, chunk_size=None):
490 """
491 An iterator over the results from applying this QuerySet to the
492 database. chunk_size must be provided for QuerySets that prefetch
493 related objects. Otherwise, a default chunk_size of 2000 is supplied.
494 """
495 if chunk_size is None:
496 if self._prefetch_related_lookups:
497 raise ValueError(
498 "chunk_size must be provided when using QuerySet.iterator() after "
499 "prefetch_related()."
500 )
501 elif chunk_size <= 0:
502 raise ValueError("Chunk size must be strictly positive.")
503 use_chunked_fetch = not connections[self.db].settings_dict.get(
504 "DISABLE_SERVER_SIDE_CURSORS"
505 )
506 return self._iterator(use_chunked_fetch, chunk_size)
508 def aggregate(self, *args, **kwargs):
509 """
510 Return a dictionary containing the calculations (aggregation)
511 over the current queryset.
513 If args is present the expression is passed as a kwarg using
514 the Aggregate object's default alias.
515 """
516 if self.query.distinct_fields:
517 raise NotImplementedError("aggregate() + distinct(fields) not implemented.")
518 self._validate_values_are_expressions(
519 (*args, *kwargs.values()), method_name="aggregate"
520 )
521 for arg in args:
522 # The default_alias property raises TypeError if default_alias
523 # can't be set automatically or AttributeError if it isn't an
524 # attribute.
525 try:
526 arg.default_alias
527 except (AttributeError, TypeError):
528 raise TypeError("Complex aggregates require an alias")
529 kwargs[arg.default_alias] = arg
531 return self.query.chain().get_aggregation(self.db, kwargs)
533 def count(self):
534 """
535 Perform a SELECT COUNT() and return the number of records as an
536 integer.
538 If the QuerySet is already fully cached, return the length of the
539 cached results set to avoid multiple SELECT COUNT(*) calls.
540 """
541 if self._result_cache is not None:
542 return len(self._result_cache)
544 return self.query.get_count(using=self.db)
546 def get(self, *args, **kwargs):
547 """
548 Perform the query and return a single object matching the given
549 keyword arguments.
550 """
551 if self.query.combinator and (args or kwargs):
552 raise NotSupportedError(
553 f"Calling QuerySet.get(...) with filters after {self.query.combinator}() is not "
554 "supported."
555 )
556 clone = self._chain() if self.query.combinator else self.filter(*args, **kwargs)
557 if self.query.can_filter() and not self.query.distinct_fields:
558 clone = clone.order_by()
559 limit = None
560 if (
561 not clone.query.select_for_update
562 or connections[clone.db].features.supports_select_for_update_with_limit
563 ):
564 limit = MAX_GET_RESULTS
565 clone.query.set_limits(high=limit)
566 num = len(clone)
567 if num == 1:
568 return clone._result_cache[0]
569 if not num:
570 raise self.model.DoesNotExist(
571 f"{self.model._meta.object_name} matching query does not exist."
572 )
573 raise self.model.MultipleObjectsReturned(
574 "get() returned more than one {} -- it returned {}!".format(
575 self.model._meta.object_name,
576 num if not limit or num < limit else "more than %s" % (limit - 1),
577 )
578 )
580 def create(self, **kwargs):
581 """
582 Create a new object with the given kwargs, saving it to the database
583 and returning the created object.
584 """
585 obj = self.model(**kwargs)
586 self._for_write = True
587 obj.save(force_insert=True, using=self.db)
588 return obj
590 def _prepare_for_bulk_create(self, objs):
591 for obj in objs:
592 if obj.pk is None:
593 # Populate new PK values.
594 obj.pk = obj._meta.pk.get_pk_value_on_save(obj)
595 obj._prepare_related_fields_for_save(operation_name="bulk_create")
597 def _check_bulk_create_options(
598 self, ignore_conflicts, update_conflicts, update_fields, unique_fields
599 ):
600 if ignore_conflicts and update_conflicts:
601 raise ValueError(
602 "ignore_conflicts and update_conflicts are mutually exclusive."
603 )
604 db_features = connections[self.db].features
605 if ignore_conflicts:
606 if not db_features.supports_ignore_conflicts:
607 raise NotSupportedError(
608 "This database backend does not support ignoring conflicts."
609 )
610 return OnConflict.IGNORE
611 elif update_conflicts:
612 if not db_features.supports_update_conflicts:
613 raise NotSupportedError(
614 "This database backend does not support updating conflicts."
615 )
616 if not update_fields:
617 raise ValueError(
618 "Fields that will be updated when a row insertion fails "
619 "on conflicts must be provided."
620 )
621 if unique_fields and not db_features.supports_update_conflicts_with_target:
622 raise NotSupportedError(
623 "This database backend does not support updating "
624 "conflicts with specifying unique fields that can trigger "
625 "the upsert."
626 )
627 if not unique_fields and db_features.supports_update_conflicts_with_target:
628 raise ValueError(
629 "Unique fields that can trigger the upsert must be provided."
630 )
631 # Updating primary keys and non-concrete fields is forbidden.
632 if any(not f.concrete or f.many_to_many for f in update_fields):
633 raise ValueError(
634 "bulk_create() can only be used with concrete fields in "
635 "update_fields."
636 )
637 if any(f.primary_key for f in update_fields):
638 raise ValueError(
639 "bulk_create() cannot be used with primary keys in "
640 "update_fields."
641 )
642 if unique_fields:
643 if any(not f.concrete or f.many_to_many for f in unique_fields):
644 raise ValueError(
645 "bulk_create() can only be used with concrete fields "
646 "in unique_fields."
647 )
648 return OnConflict.UPDATE
649 return None
651 def bulk_create(
652 self,
653 objs,
654 batch_size=None,
655 ignore_conflicts=False,
656 update_conflicts=False,
657 update_fields=None,
658 unique_fields=None,
659 ):
660 """
661 Insert each of the instances into the database. Do *not* call
662 save() on each of the instances, do not send any pre/post_save
663 signals, and do not set the primary key attribute if it is an
664 autoincrement field (except if features.can_return_rows_from_bulk_insert=True).
665 Multi-table models are not supported.
666 """
667 # When you bulk insert you don't get the primary keys back (if it's an
668 # autoincrement, except if can_return_rows_from_bulk_insert=True), so
669 # you can't insert into the child tables which references this. There
670 # are two workarounds:
671 # 1) This could be implemented if you didn't have an autoincrement pk
672 # 2) You could do it by doing O(n) normal inserts into the parent
673 # tables to get the primary keys back and then doing a single bulk
674 # insert into the childmost table.
675 # We currently set the primary keys on the objects when using
676 # PostgreSQL via the RETURNING ID clause. It should be possible for
677 # Oracle as well, but the semantics for extracting the primary keys is
678 # trickier so it's not done yet.
679 if batch_size is not None and batch_size <= 0:
680 raise ValueError("Batch size must be a positive integer.")
681 # Check that the parents share the same concrete model with the our
682 # model to detect the inheritance pattern ConcreteGrandParent ->
683 # MultiTableParent -> ProxyChild. Simply checking self.model._meta.proxy
684 # would not identify that case as involving multiple tables.
685 for parent in self.model._meta.get_parent_list():
686 if parent._meta.concrete_model is not self.model._meta.concrete_model:
687 raise ValueError("Can't bulk create a multi-table inherited model")
688 if not objs:
689 return objs
690 opts = self.model._meta
691 if unique_fields:
692 # Primary key is allowed in unique_fields.
693 unique_fields = [
694 self.model._meta.get_field(opts.pk.name if name == "pk" else name)
695 for name in unique_fields
696 ]
697 if update_fields:
698 update_fields = [self.model._meta.get_field(name) for name in update_fields]
699 on_conflict = self._check_bulk_create_options(
700 ignore_conflicts,
701 update_conflicts,
702 update_fields,
703 unique_fields,
704 )
705 self._for_write = True
706 fields = opts.concrete_fields
707 objs = list(objs)
708 self._prepare_for_bulk_create(objs)
709 with transaction.atomic(using=self.db, savepoint=False):
710 objs_with_pk, objs_without_pk = partition(lambda o: o.pk is None, objs)
711 if objs_with_pk:
712 returned_columns = self._batched_insert(
713 objs_with_pk,
714 fields,
715 batch_size,
716 on_conflict=on_conflict,
717 update_fields=update_fields,
718 unique_fields=unique_fields,
719 )
720 for obj_with_pk, results in zip(objs_with_pk, returned_columns):
721 for result, field in zip(results, opts.db_returning_fields):
722 if field != opts.pk:
723 setattr(obj_with_pk, field.attname, result)
724 for obj_with_pk in objs_with_pk:
725 obj_with_pk._state.adding = False
726 obj_with_pk._state.db = self.db
727 if objs_without_pk:
728 fields = [f for f in fields if not isinstance(f, AutoField)]
729 returned_columns = self._batched_insert(
730 objs_without_pk,
731 fields,
732 batch_size,
733 on_conflict=on_conflict,
734 update_fields=update_fields,
735 unique_fields=unique_fields,
736 )
737 connection = connections[self.db]
738 if (
739 connection.features.can_return_rows_from_bulk_insert
740 and on_conflict is None
741 ):
742 assert len(returned_columns) == len(objs_without_pk)
743 for obj_without_pk, results in zip(objs_without_pk, returned_columns):
744 for result, field in zip(results, opts.db_returning_fields):
745 setattr(obj_without_pk, field.attname, result)
746 obj_without_pk._state.adding = False
747 obj_without_pk._state.db = self.db
749 return objs
751 def bulk_update(self, objs, fields, batch_size=None):
752 """
753 Update the given fields in each of the given objects in the database.
754 """
755 if batch_size is not None and batch_size <= 0:
756 raise ValueError("Batch size must be a positive integer.")
757 if not fields:
758 raise ValueError("Field names must be given to bulk_update().")
759 objs = tuple(objs)
760 if any(obj.pk is None for obj in objs):
761 raise ValueError("All bulk_update() objects must have a primary key set.")
762 fields = [self.model._meta.get_field(name) for name in fields]
763 if any(not f.concrete or f.many_to_many for f in fields):
764 raise ValueError("bulk_update() can only be used with concrete fields.")
765 if any(f.primary_key for f in fields):
766 raise ValueError("bulk_update() cannot be used with primary key fields.")
767 if not objs:
768 return 0
769 for obj in objs:
770 obj._prepare_related_fields_for_save(
771 operation_name="bulk_update", fields=fields
772 )
773 # PK is used twice in the resulting update query, once in the filter
774 # and once in the WHEN. Each field will also have one CAST.
775 self._for_write = True
776 connection = connections[self.db]
777 max_batch_size = connection.ops.bulk_batch_size(["pk", "pk"] + fields, objs)
778 batch_size = min(batch_size, max_batch_size) if batch_size else max_batch_size
779 requires_casting = connection.features.requires_casted_case_in_updates
780 batches = (objs[i : i + batch_size] for i in range(0, len(objs), batch_size))
781 updates = []
782 for batch_objs in batches:
783 update_kwargs = {}
784 for field in fields:
785 when_statements = []
786 for obj in batch_objs:
787 attr = getattr(obj, field.attname)
788 if not hasattr(attr, "resolve_expression"):
789 attr = Value(attr, output_field=field)
790 when_statements.append(When(pk=obj.pk, then=attr))
791 case_statement = Case(*when_statements, output_field=field)
792 if requires_casting:
793 case_statement = Cast(case_statement, output_field=field)
794 update_kwargs[field.attname] = case_statement
795 updates.append(([obj.pk for obj in batch_objs], update_kwargs))
796 rows_updated = 0
797 queryset = self.using(self.db)
798 with transaction.atomic(using=self.db, savepoint=False):
799 for pks, update_kwargs in updates:
800 rows_updated += queryset.filter(pk__in=pks).update(**update_kwargs)
801 return rows_updated
803 bulk_update.alters_data = True
805 def get_or_create(self, defaults=None, **kwargs):
806 """
807 Look up an object with the given kwargs, creating one if necessary.
808 Return a tuple of (object, created), where created is a boolean
809 specifying whether an object was created.
810 """
811 # The get() needs to be targeted at the write database in order
812 # to avoid potential transaction consistency problems.
813 self._for_write = True
814 try:
815 return self.get(**kwargs), False
816 except self.model.DoesNotExist:
817 params = self._extract_model_params(defaults, **kwargs)
818 # Try to create an object using passed params.
819 try:
820 with transaction.atomic(using=self.db):
821 params = dict(resolve_callables(params))
822 return self.create(**params), True
823 except (IntegrityError, ValidationError):
824 # Since create() also validates by default,
825 # we can get any kind of ValidationError here,
826 # or it can flow through and get an IntegrityError from the database.
827 # The main thing we're concerned about is uniqueness failures,
828 # but ValidationError could include other things too.
829 # In all cases though it should be fine to try the get() again
830 # and return an existing object.
831 try:
832 return self.get(**kwargs), False
833 except self.model.DoesNotExist:
834 pass
835 raise
837 def update_or_create(self, defaults=None, create_defaults=None, **kwargs):
838 """
839 Look up an object with the given kwargs, updating one with defaults
840 if it exists, otherwise create a new one. Optionally, an object can
841 be created with different values than defaults by using
842 create_defaults.
843 Return a tuple (object, created), where created is a boolean
844 specifying whether an object was created.
845 """
846 if create_defaults is None:
847 update_defaults = create_defaults = defaults or {}
848 else:
849 update_defaults = defaults or {}
850 self._for_write = True
851 with transaction.atomic(using=self.db):
852 # Lock the row so that a concurrent update is blocked until
853 # update_or_create() has performed its save.
854 obj, created = self.select_for_update().get_or_create(
855 create_defaults, **kwargs
856 )
857 if created:
858 return obj, created
859 for k, v in resolve_callables(update_defaults):
860 setattr(obj, k, v)
862 update_fields = set(update_defaults)
863 concrete_field_names = self.model._meta._non_pk_concrete_field_names
864 # update_fields does not support non-concrete fields.
865 if concrete_field_names.issuperset(update_fields):
866 # Add fields which are set on pre_save(), e.g. auto_now fields.
867 # This is to maintain backward compatibility as these fields
868 # are not updated unless explicitly specified in the
869 # update_fields list.
870 for field in self.model._meta.local_concrete_fields:
871 if not (
872 field.primary_key or field.__class__.pre_save is Field.pre_save
873 ):
874 update_fields.add(field.name)
875 if field.name != field.attname:
876 update_fields.add(field.attname)
877 obj.save(using=self.db, update_fields=update_fields)
878 else:
879 obj.save(using=self.db)
880 return obj, False
882 def _extract_model_params(self, defaults, **kwargs):
883 """
884 Prepare `params` for creating a model instance based on the given
885 kwargs; for use by get_or_create().
886 """
887 defaults = defaults or {}
888 params = {k: v for k, v in kwargs.items() if LOOKUP_SEP not in k}
889 params.update(defaults)
890 property_names = self.model._meta._property_names
891 invalid_params = []
892 for param in params:
893 try:
894 self.model._meta.get_field(param)
895 except exceptions.FieldDoesNotExist:
896 # It's okay to use a model's property if it has a setter.
897 if not (param in property_names and getattr(self.model, param).fset):
898 invalid_params.append(param)
899 if invalid_params:
900 raise exceptions.FieldError(
901 "Invalid field name(s) for model {}: '{}'.".format(
902 self.model._meta.object_name,
903 "', '".join(sorted(invalid_params)),
904 )
905 )
906 return params
908 def _earliest(self, *fields):
909 """
910 Return the earliest object according to fields (if given) or by the
911 model's Meta.get_latest_by.
912 """
913 if fields:
914 order_by = fields
915 else:
916 order_by = getattr(self.model._meta, "get_latest_by")
917 if order_by and not isinstance(order_by, tuple | list):
918 order_by = (order_by,)
919 if order_by is None:
920 raise ValueError(
921 "earliest() and latest() require either fields as positional "
922 "arguments or 'get_latest_by' in the model's Meta."
923 )
924 obj = self._chain()
925 obj.query.set_limits(high=1)
926 obj.query.clear_ordering(force=True)
927 obj.query.add_ordering(*order_by)
928 return obj.get()
930 def earliest(self, *fields):
931 if self.query.is_sliced:
932 raise TypeError("Cannot change a query once a slice has been taken.")
933 return self._earliest(*fields)
935 def latest(self, *fields):
936 """
937 Return the latest object according to fields (if given) or by the
938 model's Meta.get_latest_by.
939 """
940 if self.query.is_sliced:
941 raise TypeError("Cannot change a query once a slice has been taken.")
942 return self.reverse()._earliest(*fields)
944 def first(self):
945 """Return the first object of a query or None if no match is found."""
946 if self.ordered:
947 queryset = self
948 else:
949 self._check_ordering_first_last_queryset_aggregation(method="first")
950 queryset = self.order_by("pk")
951 for obj in queryset[:1]:
952 return obj
954 def last(self):
955 """Return the last object of a query or None if no match is found."""
956 if self.ordered:
957 queryset = self.reverse()
958 else:
959 self._check_ordering_first_last_queryset_aggregation(method="last")
960 queryset = self.order_by("-pk")
961 for obj in queryset[:1]:
962 return obj
964 def in_bulk(self, id_list=None, *, field_name="pk"):
965 """
966 Return a dictionary mapping each of the given IDs to the object with
967 that ID. If `id_list` isn't provided, evaluate the entire QuerySet.
968 """
969 if self.query.is_sliced:
970 raise TypeError("Cannot use 'limit' or 'offset' with in_bulk().")
971 opts = self.model._meta
972 unique_fields = [
973 constraint.fields[0]
974 for constraint in opts.total_unique_constraints
975 if len(constraint.fields) == 1
976 ]
977 if (
978 field_name != "pk"
979 and not opts.get_field(field_name).unique
980 and field_name not in unique_fields
981 and self.query.distinct_fields != (field_name,)
982 ):
983 raise ValueError(
984 f"in_bulk()'s field_name must be a unique field but {field_name!r} isn't."
985 )
986 if id_list is not None:
987 if not id_list:
988 return {}
989 filter_key = f"{field_name}__in"
990 batch_size = connections[self.db].features.max_query_params
991 id_list = tuple(id_list)
992 # If the database has a limit on the number of query parameters
993 # (e.g. SQLite), retrieve objects in batches if necessary.
994 if batch_size and batch_size < len(id_list):
995 qs = ()
996 for offset in range(0, len(id_list), batch_size):
997 batch = id_list[offset : offset + batch_size]
998 qs += tuple(self.filter(**{filter_key: batch}))
999 else:
1000 qs = self.filter(**{filter_key: id_list})
1001 else:
1002 qs = self._chain()
1003 return {getattr(obj, field_name): obj for obj in qs}
1005 def delete(self):
1006 """Delete the records in the current QuerySet."""
1007 self._not_support_combined_queries("delete")
1008 if self.query.is_sliced:
1009 raise TypeError("Cannot use 'limit' or 'offset' with delete().")
1010 if self.query.distinct or self.query.distinct_fields:
1011 raise TypeError("Cannot call delete() after .distinct().")
1012 if self._fields is not None:
1013 raise TypeError("Cannot call delete() after .values() or .values_list()")
1015 del_query = self._chain()
1017 # The delete is actually 2 queries - one to find related objects,
1018 # and one to delete. Make sure that the discovery of related
1019 # objects is performed on the same database as the deletion.
1020 del_query._for_write = True
1022 # Disable non-supported fields.
1023 del_query.query.select_for_update = False
1024 del_query.query.select_related = False
1025 del_query.query.clear_ordering(force=True)
1027 from plain.models.deletion import Collector
1029 collector = Collector(using=del_query.db, origin=self)
1030 collector.collect(del_query)
1031 deleted, _rows_count = collector.delete()
1033 # Clear the result cache, in case this QuerySet gets reused.
1034 self._result_cache = None
1035 return deleted, _rows_count
1037 delete.alters_data = True
1038 delete.queryset_only = True
1040 def _raw_delete(self, using):
1041 """
1042 Delete objects found from the given queryset in single direct SQL
1043 query. No signals are sent and there is no protection for cascades.
1044 """
1045 query = self.query.clone()
1046 query.__class__ = sql.DeleteQuery
1047 cursor = query.get_compiler(using).execute_sql(CURSOR)
1048 if cursor:
1049 with cursor:
1050 return cursor.rowcount
1051 return 0
1053 _raw_delete.alters_data = True
1055 def update(self, **kwargs):
1056 """
1057 Update all elements in the current QuerySet, setting all the given
1058 fields to the appropriate values.
1059 """
1060 self._not_support_combined_queries("update")
1061 if self.query.is_sliced:
1062 raise TypeError("Cannot update a query once a slice has been taken.")
1063 self._for_write = True
1064 query = self.query.chain(sql.UpdateQuery)
1065 query.add_update_values(kwargs)
1067 # Inline annotations in order_by(), if possible.
1068 new_order_by = []
1069 for col in query.order_by:
1070 alias = col
1071 descending = False
1072 if isinstance(alias, str) and alias.startswith("-"):
1073 alias = alias.removeprefix("-")
1074 descending = True
1075 if annotation := query.annotations.get(alias):
1076 if getattr(annotation, "contains_aggregate", False):
1077 raise exceptions.FieldError(
1078 f"Cannot update when ordering by an aggregate: {annotation}"
1079 )
1080 if descending:
1081 annotation = annotation.desc()
1082 new_order_by.append(annotation)
1083 else:
1084 new_order_by.append(col)
1085 query.order_by = tuple(new_order_by)
1087 # Clear any annotations so that they won't be present in subqueries.
1088 query.annotations = {}
1089 with transaction.mark_for_rollback_on_error(using=self.db):
1090 rows = query.get_compiler(self.db).execute_sql(CURSOR)
1091 self._result_cache = None
1092 return rows
1094 update.alters_data = True
1096 def _update(self, values):
1097 """
1098 A version of update() that accepts field objects instead of field names.
1099 Used primarily for model saving and not intended for use by general
1100 code (it requires too much poking around at model internals to be
1101 useful at that level).
1102 """
1103 if self.query.is_sliced:
1104 raise TypeError("Cannot update a query once a slice has been taken.")
1105 query = self.query.chain(sql.UpdateQuery)
1106 query.add_update_fields(values)
1107 # Clear any annotations so that they won't be present in subqueries.
1108 query.annotations = {}
1109 self._result_cache = None
1110 return query.get_compiler(self.db).execute_sql(CURSOR)
1112 _update.alters_data = True
1113 _update.queryset_only = False
1115 def exists(self):
1116 """
1117 Return True if the QuerySet would have any results, False otherwise.
1118 """
1119 if self._result_cache is None:
1120 return self.query.has_results(using=self.db)
1121 return bool(self._result_cache)
1123 def contains(self, obj):
1124 """
1125 Return True if the QuerySet contains the provided obj,
1126 False otherwise.
1127 """
1128 self._not_support_combined_queries("contains")
1129 if self._fields is not None:
1130 raise TypeError(
1131 "Cannot call QuerySet.contains() after .values() or .values_list()."
1132 )
1133 try:
1134 if obj._meta.concrete_model != self.model._meta.concrete_model:
1135 return False
1136 except AttributeError:
1137 raise TypeError("'obj' must be a model instance.")
1138 if obj.pk is None:
1139 raise ValueError("QuerySet.contains() cannot be used on unsaved objects.")
1140 if self._result_cache is not None:
1141 return obj in self._result_cache
1142 return self.filter(pk=obj.pk).exists()
1144 def _prefetch_related_objects(self):
1145 # This method can only be called once the result cache has been filled.
1146 prefetch_related_objects(self._result_cache, *self._prefetch_related_lookups)
1147 self._prefetch_done = True
1149 def explain(self, *, format=None, **options):
1150 """
1151 Runs an EXPLAIN on the SQL query this QuerySet would perform, and
1152 returns the results.
1153 """
1154 return self.query.explain(using=self.db, format=format, **options)
1156 ##################################################
1157 # PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS #
1158 ##################################################
1160 def raw(self, raw_query, params=(), translations=None, using=None):
1161 if using is None:
1162 using = self.db
1163 qs = RawQuerySet(
1164 raw_query,
1165 model=self.model,
1166 params=params,
1167 translations=translations,
1168 using=using,
1169 )
1170 qs._prefetch_related_lookups = self._prefetch_related_lookups[:]
1171 return qs
1173 def _values(self, *fields, **expressions):
1174 clone = self._chain()
1175 if expressions:
1176 clone = clone.annotate(**expressions)
1177 clone._fields = fields
1178 clone.query.set_values(fields)
1179 return clone
1181 def values(self, *fields, **expressions):
1182 fields += tuple(expressions)
1183 clone = self._values(*fields, **expressions)
1184 clone._iterable_class = ValuesIterable
1185 return clone
1187 def values_list(self, *fields, flat=False, named=False):
1188 if flat and named:
1189 raise TypeError("'flat' and 'named' can't be used together.")
1190 if flat and len(fields) > 1:
1191 raise TypeError(
1192 "'flat' is not valid when values_list is called with more than one "
1193 "field."
1194 )
1196 field_names = {f for f in fields if not hasattr(f, "resolve_expression")}
1197 _fields = []
1198 expressions = {}
1199 counter = 1
1200 for field in fields:
1201 if hasattr(field, "resolve_expression"):
1202 field_id_prefix = getattr(
1203 field, "default_alias", field.__class__.__name__.lower()
1204 )
1205 while True:
1206 field_id = field_id_prefix + str(counter)
1207 counter += 1
1208 if field_id not in field_names:
1209 break
1210 expressions[field_id] = field
1211 _fields.append(field_id)
1212 else:
1213 _fields.append(field)
1215 clone = self._values(*_fields, **expressions)
1216 clone._iterable_class = (
1217 NamedValuesListIterable
1218 if named
1219 else FlatValuesListIterable
1220 if flat
1221 else ValuesListIterable
1222 )
1223 return clone
1225 def dates(self, field_name, kind, order="ASC"):
1226 """
1227 Return a list of date objects representing all available dates for
1228 the given field_name, scoped to 'kind'.
1229 """
1230 if kind not in ("year", "month", "week", "day"):
1231 raise ValueError("'kind' must be one of 'year', 'month', 'week', or 'day'.")
1232 if order not in ("ASC", "DESC"):
1233 raise ValueError("'order' must be either 'ASC' or 'DESC'.")
1234 return (
1235 self.annotate(
1236 datefield=Trunc(field_name, kind, output_field=DateField()),
1237 plain_field=F(field_name),
1238 )
1239 .values_list("datefield", flat=True)
1240 .distinct()
1241 .filter(plain_field__isnull=False)
1242 .order_by(("-" if order == "DESC" else "") + "datefield")
1243 )
1245 def datetimes(self, field_name, kind, order="ASC", tzinfo=None):
1246 """
1247 Return a list of datetime objects representing all available
1248 datetimes for the given field_name, scoped to 'kind'.
1249 """
1250 if kind not in ("year", "month", "week", "day", "hour", "minute", "second"):
1251 raise ValueError(
1252 "'kind' must be one of 'year', 'month', 'week', 'day', "
1253 "'hour', 'minute', or 'second'."
1254 )
1255 if order not in ("ASC", "DESC"):
1256 raise ValueError("'order' must be either 'ASC' or 'DESC'.")
1258 if tzinfo is None:
1259 tzinfo = timezone.get_current_timezone()
1261 return (
1262 self.annotate(
1263 datetimefield=Trunc(
1264 field_name,
1265 kind,
1266 output_field=DateTimeField(),
1267 tzinfo=tzinfo,
1268 ),
1269 plain_field=F(field_name),
1270 )
1271 .values_list("datetimefield", flat=True)
1272 .distinct()
1273 .filter(plain_field__isnull=False)
1274 .order_by(("-" if order == "DESC" else "") + "datetimefield")
1275 )
1277 def none(self):
1278 """Return an empty QuerySet."""
1279 clone = self._chain()
1280 clone.query.set_empty()
1281 return clone
1283 ##################################################################
1284 # PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET #
1285 ##################################################################
1287 def all(self):
1288 """
1289 Return a new QuerySet that is a copy of the current one. This allows a
1290 QuerySet to proxy for a model manager in some cases.
1291 """
1292 return self._chain()
1294 def filter(self, *args, **kwargs):
1295 """
1296 Return a new QuerySet instance with the args ANDed to the existing
1297 set.
1298 """
1299 self._not_support_combined_queries("filter")
1300 return self._filter_or_exclude(False, args, kwargs)
1302 def exclude(self, *args, **kwargs):
1303 """
1304 Return a new QuerySet instance with NOT (args) ANDed to the existing
1305 set.
1306 """
1307 self._not_support_combined_queries("exclude")
1308 return self._filter_or_exclude(True, args, kwargs)
1310 def _filter_or_exclude(self, negate, args, kwargs):
1311 if (args or kwargs) and self.query.is_sliced:
1312 raise TypeError("Cannot filter a query once a slice has been taken.")
1313 clone = self._chain()
1314 if self._defer_next_filter:
1315 self._defer_next_filter = False
1316 clone._deferred_filter = negate, args, kwargs
1317 else:
1318 clone._filter_or_exclude_inplace(negate, args, kwargs)
1319 return clone
1321 def _filter_or_exclude_inplace(self, negate, args, kwargs):
1322 if negate:
1323 self._query.add_q(~Q(*args, **kwargs))
1324 else:
1325 self._query.add_q(Q(*args, **kwargs))
1327 def complex_filter(self, filter_obj):
1328 """
1329 Return a new QuerySet instance with filter_obj added to the filters.
1331 filter_obj can be a Q object or a dictionary of keyword lookup
1332 arguments.
1334 This exists to support framework features such as 'limit_choices_to',
1335 and usually it will be more natural to use other methods.
1336 """
1337 if isinstance(filter_obj, Q):
1338 clone = self._chain()
1339 clone.query.add_q(filter_obj)
1340 return clone
1341 else:
1342 return self._filter_or_exclude(False, args=(), kwargs=filter_obj)
1344 def _combinator_query(self, combinator, *other_qs, all=False):
1345 # Clone the query to inherit the select list and everything
1346 clone = self._chain()
1347 # Clear limits and ordering so they can be reapplied
1348 clone.query.clear_ordering(force=True)
1349 clone.query.clear_limits()
1350 clone.query.combined_queries = (self.query,) + tuple(
1351 qs.query for qs in other_qs
1352 )
1353 clone.query.combinator = combinator
1354 clone.query.combinator_all = all
1355 return clone
1357 def union(self, *other_qs, all=False):
1358 # If the query is an EmptyQuerySet, combine all nonempty querysets.
1359 if isinstance(self, EmptyQuerySet):
1360 qs = [q for q in other_qs if not isinstance(q, EmptyQuerySet)]
1361 if not qs:
1362 return self
1363 if len(qs) == 1:
1364 return qs[0]
1365 return qs[0]._combinator_query("union", *qs[1:], all=all)
1366 return self._combinator_query("union", *other_qs, all=all)
1368 def intersection(self, *other_qs):
1369 # If any query is an EmptyQuerySet, return it.
1370 if isinstance(self, EmptyQuerySet):
1371 return self
1372 for other in other_qs:
1373 if isinstance(other, EmptyQuerySet):
1374 return other
1375 return self._combinator_query("intersection", *other_qs)
1377 def difference(self, *other_qs):
1378 # If the query is an EmptyQuerySet, return it.
1379 if isinstance(self, EmptyQuerySet):
1380 return self
1381 return self._combinator_query("difference", *other_qs)
1383 def select_for_update(self, nowait=False, skip_locked=False, of=(), no_key=False):
1384 """
1385 Return a new QuerySet instance that will select objects with a
1386 FOR UPDATE lock.
1387 """
1388 if nowait and skip_locked:
1389 raise ValueError("The nowait option cannot be used with skip_locked.")
1390 obj = self._chain()
1391 obj._for_write = True
1392 obj.query.select_for_update = True
1393 obj.query.select_for_update_nowait = nowait
1394 obj.query.select_for_update_skip_locked = skip_locked
1395 obj.query.select_for_update_of = of
1396 obj.query.select_for_no_key_update = no_key
1397 return obj
1399 def select_related(self, *fields):
1400 """
1401 Return a new QuerySet instance that will select related objects.
1403 If fields are specified, they must be ForeignKey fields and only those
1404 related objects are included in the selection.
1406 If select_related(None) is called, clear the list.
1407 """
1408 self._not_support_combined_queries("select_related")
1409 if self._fields is not None:
1410 raise TypeError(
1411 "Cannot call select_related() after .values() or .values_list()"
1412 )
1414 obj = self._chain()
1415 if fields == (None,):
1416 obj.query.select_related = False
1417 elif fields:
1418 obj.query.add_select_related(fields)
1419 else:
1420 obj.query.select_related = True
1421 return obj
1423 def prefetch_related(self, *lookups):
1424 """
1425 Return a new QuerySet instance that will prefetch the specified
1426 Many-To-One and Many-To-Many related objects when the QuerySet is
1427 evaluated.
1429 When prefetch_related() is called more than once, append to the list of
1430 prefetch lookups. If prefetch_related(None) is called, clear the list.
1431 """
1432 self._not_support_combined_queries("prefetch_related")
1433 clone = self._chain()
1434 if lookups == (None,):
1435 clone._prefetch_related_lookups = ()
1436 else:
1437 for lookup in lookups:
1438 if isinstance(lookup, Prefetch):
1439 lookup = lookup.prefetch_to
1440 lookup = lookup.split(LOOKUP_SEP, 1)[0]
1441 if lookup in self.query._filtered_relations:
1442 raise ValueError(
1443 "prefetch_related() is not supported with FilteredRelation."
1444 )
1445 clone._prefetch_related_lookups = clone._prefetch_related_lookups + lookups
1446 return clone
1448 def annotate(self, *args, **kwargs):
1449 """
1450 Return a query set in which the returned objects have been annotated
1451 with extra data or aggregations.
1452 """
1453 self._not_support_combined_queries("annotate")
1454 return self._annotate(args, kwargs, select=True)
1456 def alias(self, *args, **kwargs):
1457 """
1458 Return a query set with added aliases for extra data or aggregations.
1459 """
1460 self._not_support_combined_queries("alias")
1461 return self._annotate(args, kwargs, select=False)
1463 def _annotate(self, args, kwargs, select=True):
1464 self._validate_values_are_expressions(
1465 args + tuple(kwargs.values()), method_name="annotate"
1466 )
1467 annotations = {}
1468 for arg in args:
1469 # The default_alias property may raise a TypeError.
1470 try:
1471 if arg.default_alias in kwargs:
1472 raise ValueError(
1473 f"The named annotation '{arg.default_alias}' conflicts with the "
1474 "default name for another annotation."
1475 )
1476 except TypeError:
1477 raise TypeError("Complex annotations require an alias")
1478 annotations[arg.default_alias] = arg
1479 annotations.update(kwargs)
1481 clone = self._chain()
1482 names = self._fields
1483 if names is None:
1484 names = set(
1485 chain.from_iterable(
1486 (field.name, field.attname)
1487 if hasattr(field, "attname")
1488 else (field.name,)
1489 for field in self.model._meta.get_fields()
1490 )
1491 )
1493 for alias, annotation in annotations.items():
1494 if alias in names:
1495 raise ValueError(
1496 f"The annotation '{alias}' conflicts with a field on " "the model."
1497 )
1498 if isinstance(annotation, FilteredRelation):
1499 clone.query.add_filtered_relation(annotation, alias)
1500 else:
1501 clone.query.add_annotation(
1502 annotation,
1503 alias,
1504 select=select,
1505 )
1506 for alias, annotation in clone.query.annotations.items():
1507 if alias in annotations and annotation.contains_aggregate:
1508 if clone._fields is None:
1509 clone.query.group_by = True
1510 else:
1511 clone.query.set_group_by()
1512 break
1514 return clone
1516 def order_by(self, *field_names):
1517 """Return a new QuerySet instance with the ordering changed."""
1518 if self.query.is_sliced:
1519 raise TypeError("Cannot reorder a query once a slice has been taken.")
1520 obj = self._chain()
1521 obj.query.clear_ordering(force=True, clear_default=False)
1522 obj.query.add_ordering(*field_names)
1523 return obj
1525 def distinct(self, *field_names):
1526 """
1527 Return a new QuerySet instance that will select only distinct results.
1528 """
1529 self._not_support_combined_queries("distinct")
1530 if self.query.is_sliced:
1531 raise TypeError(
1532 "Cannot create distinct fields once a slice has been taken."
1533 )
1534 obj = self._chain()
1535 obj.query.add_distinct_fields(*field_names)
1536 return obj
1538 def extra(
1539 self,
1540 select=None,
1541 where=None,
1542 params=None,
1543 tables=None,
1544 order_by=None,
1545 select_params=None,
1546 ):
1547 """Add extra SQL fragments to the query."""
1548 self._not_support_combined_queries("extra")
1549 if self.query.is_sliced:
1550 raise TypeError("Cannot change a query once a slice has been taken.")
1551 clone = self._chain()
1552 clone.query.add_extra(select, select_params, where, params, tables, order_by)
1553 return clone
1555 def reverse(self):
1556 """Reverse the ordering of the QuerySet."""
1557 if self.query.is_sliced:
1558 raise TypeError("Cannot reverse a query once a slice has been taken.")
1559 clone = self._chain()
1560 clone.query.standard_ordering = not clone.query.standard_ordering
1561 return clone
1563 def defer(self, *fields):
1564 """
1565 Defer the loading of data for certain fields until they are accessed.
1566 Add the set of deferred fields to any existing set of deferred fields.
1567 The only exception to this is if None is passed in as the only
1568 parameter, in which case removal all deferrals.
1569 """
1570 self._not_support_combined_queries("defer")
1571 if self._fields is not None:
1572 raise TypeError("Cannot call defer() after .values() or .values_list()")
1573 clone = self._chain()
1574 if fields == (None,):
1575 clone.query.clear_deferred_loading()
1576 else:
1577 clone.query.add_deferred_loading(fields)
1578 return clone
1580 def only(self, *fields):
1581 """
1582 Essentially, the opposite of defer(). Only the fields passed into this
1583 method and that are not already specified as deferred are loaded
1584 immediately when the queryset is evaluated.
1585 """
1586 self._not_support_combined_queries("only")
1587 if self._fields is not None:
1588 raise TypeError("Cannot call only() after .values() or .values_list()")
1589 if fields == (None,):
1590 # Can only pass None to defer(), not only(), as the rest option.
1591 # That won't stop people trying to do this, so let's be explicit.
1592 raise TypeError("Cannot pass None as an argument to only().")
1593 for field in fields:
1594 field = field.split(LOOKUP_SEP, 1)[0]
1595 if field in self.query._filtered_relations:
1596 raise ValueError("only() is not supported with FilteredRelation.")
1597 clone = self._chain()
1598 clone.query.add_immediate_loading(fields)
1599 return clone
1601 def using(self, alias):
1602 """Select which database this QuerySet should execute against."""
1603 clone = self._chain()
1604 clone._db = alias
1605 return clone
1607 ###################################
1608 # PUBLIC INTROSPECTION ATTRIBUTES #
1609 ###################################
1611 @property
1612 def ordered(self):
1613 """
1614 Return True if the QuerySet is ordered -- i.e. has an order_by()
1615 clause or a default ordering on the model (or is empty).
1616 """
1617 if isinstance(self, EmptyQuerySet):
1618 return True
1619 if self.query.extra_order_by or self.query.order_by:
1620 return True
1621 elif (
1622 self.query.default_ordering
1623 and self.query.get_meta().ordering
1624 and
1625 # A default ordering doesn't affect GROUP BY queries.
1626 not self.query.group_by
1627 ):
1628 return True
1629 else:
1630 return False
1632 @property
1633 def db(self):
1634 """Return the database used if this query is executed now."""
1635 if self._for_write:
1636 return self._db or router.db_for_write(self.model, **self._hints)
1637 return self._db or router.db_for_read(self.model, **self._hints)
1639 ###################
1640 # PRIVATE METHODS #
1641 ###################
1643 def _insert(
1644 self,
1645 objs,
1646 fields,
1647 returning_fields=None,
1648 raw=False,
1649 using=None,
1650 on_conflict=None,
1651 update_fields=None,
1652 unique_fields=None,
1653 ):
1654 """
1655 Insert a new record for the given model. This provides an interface to
1656 the InsertQuery class and is how Model.save() is implemented.
1657 """
1658 self._for_write = True
1659 if using is None:
1660 using = self.db
1661 query = sql.InsertQuery(
1662 self.model,
1663 on_conflict=on_conflict,
1664 update_fields=update_fields,
1665 unique_fields=unique_fields,
1666 )
1667 query.insert_values(fields, objs, raw=raw)
1668 return query.get_compiler(using=using).execute_sql(returning_fields)
1670 _insert.alters_data = True
1671 _insert.queryset_only = False
1673 def _batched_insert(
1674 self,
1675 objs,
1676 fields,
1677 batch_size,
1678 on_conflict=None,
1679 update_fields=None,
1680 unique_fields=None,
1681 ):
1682 """
1683 Helper method for bulk_create() to insert objs one batch at a time.
1684 """
1685 connection = connections[self.db]
1686 ops = connection.ops
1687 max_batch_size = max(ops.bulk_batch_size(fields, objs), 1)
1688 batch_size = min(batch_size, max_batch_size) if batch_size else max_batch_size
1689 inserted_rows = []
1690 bulk_return = connection.features.can_return_rows_from_bulk_insert
1691 for item in [objs[i : i + batch_size] for i in range(0, len(objs), batch_size)]:
1692 if bulk_return and on_conflict is None:
1693 inserted_rows.extend(
1694 self._insert(
1695 item,
1696 fields=fields,
1697 using=self.db,
1698 returning_fields=self.model._meta.db_returning_fields,
1699 )
1700 )
1701 else:
1702 self._insert(
1703 item,
1704 fields=fields,
1705 using=self.db,
1706 on_conflict=on_conflict,
1707 update_fields=update_fields,
1708 unique_fields=unique_fields,
1709 )
1710 return inserted_rows
1712 def _chain(self):
1713 """
1714 Return a copy of the current QuerySet that's ready for another
1715 operation.
1716 """
1717 obj = self._clone()
1718 if obj._sticky_filter:
1719 obj.query.filter_is_sticky = True
1720 obj._sticky_filter = False
1721 return obj
1723 def _clone(self):
1724 """
1725 Return a copy of the current QuerySet. A lightweight alternative
1726 to deepcopy().
1727 """
1728 c = self.__class__(
1729 model=self.model,
1730 query=self.query.chain(),
1731 using=self._db,
1732 hints=self._hints,
1733 )
1734 c._sticky_filter = self._sticky_filter
1735 c._for_write = self._for_write
1736 c._prefetch_related_lookups = self._prefetch_related_lookups[:]
1737 c._known_related_objects = self._known_related_objects
1738 c._iterable_class = self._iterable_class
1739 c._fields = self._fields
1740 return c
1742 def _fetch_all(self):
1743 if self._result_cache is None:
1744 self._result_cache = list(self._iterable_class(self))
1745 if self._prefetch_related_lookups and not self._prefetch_done:
1746 self._prefetch_related_objects()
1748 def _next_is_sticky(self):
1749 """
1750 Indicate that the next filter call and the one following that should
1751 be treated as a single filter. This is only important when it comes to
1752 determining when to reuse tables for many-to-many filters. Required so
1753 that we can filter naturally on the results of related managers.
1755 This doesn't return a clone of the current QuerySet (it returns
1756 "self"). The method is only used internally and should be immediately
1757 followed by a filter() that does create a clone.
1758 """
1759 self._sticky_filter = True
1760 return self
1762 def _merge_sanity_check(self, other):
1763 """Check that two QuerySet classes may be merged."""
1764 if self._fields is not None and (
1765 set(self.query.values_select) != set(other.query.values_select)
1766 or set(self.query.extra_select) != set(other.query.extra_select)
1767 or set(self.query.annotation_select) != set(other.query.annotation_select)
1768 ):
1769 raise TypeError(
1770 f"Merging '{self.__class__.__name__}' classes must involve the same values in each case."
1771 )
1773 def _merge_known_related_objects(self, other):
1774 """
1775 Keep track of all known related objects from either QuerySet instance.
1776 """
1777 for field, objects in other._known_related_objects.items():
1778 self._known_related_objects.setdefault(field, {}).update(objects)
1780 def resolve_expression(self, *args, **kwargs):
1781 if self._fields and len(self._fields) > 1:
1782 # values() queryset can only be used as nested queries
1783 # if they are set up to select only a single field.
1784 raise TypeError("Cannot use multi-field values as a filter value.")
1785 query = self.query.resolve_expression(*args, **kwargs)
1786 query._db = self._db
1787 return query
1789 resolve_expression.queryset_only = True
1791 def _add_hints(self, **hints):
1792 """
1793 Update hinting information for use by routers. Add new key/values or
1794 overwrite existing key/values.
1795 """
1796 self._hints.update(hints)
1798 def _has_filters(self):
1799 """
1800 Check if this QuerySet has any filtering going on. This isn't
1801 equivalent with checking if all objects are present in results, for
1802 example, qs[1:]._has_filters() -> False.
1803 """
1804 return self.query.has_filters()
1806 @staticmethod
1807 def _validate_values_are_expressions(values, method_name):
1808 invalid_args = sorted(
1809 str(arg) for arg in values if not hasattr(arg, "resolve_expression")
1810 )
1811 if invalid_args:
1812 raise TypeError(
1813 "QuerySet.{}() received non-expression(s): {}.".format(
1814 method_name,
1815 ", ".join(invalid_args),
1816 )
1817 )
1819 def _not_support_combined_queries(self, operation_name):
1820 if self.query.combinator:
1821 raise NotSupportedError(
1822 f"Calling QuerySet.{operation_name}() after {self.query.combinator}() is not supported."
1823 )
1825 def _check_operator_queryset(self, other, operator_):
1826 if self.query.combinator or other.query.combinator:
1827 raise TypeError(f"Cannot use {operator_} operator with combined queryset.")
1829 def _check_ordering_first_last_queryset_aggregation(self, method):
1830 if isinstance(self.query.group_by, tuple) and not any(
1831 col.output_field is self.model._meta.pk for col in self.query.group_by
1832 ):
1833 raise TypeError(
1834 f"Cannot use QuerySet.{method}() on an unordered queryset performing "
1835 f"aggregation. Add an ordering with order_by()."
1836 )
1839class InstanceCheckMeta(type):
1840 def __instancecheck__(self, instance):
1841 return isinstance(instance, QuerySet) and instance.query.is_empty()
1844class EmptyQuerySet(metaclass=InstanceCheckMeta):
1845 """
1846 Marker class to checking if a queryset is empty by .none():
1847 isinstance(qs.none(), EmptyQuerySet) -> True
1848 """
1850 def __init__(self, *args, **kwargs):
1851 raise TypeError("EmptyQuerySet can't be instantiated")
1854class RawQuerySet:
1855 """
1856 Provide an iterator which converts the results of raw SQL queries into
1857 annotated model instances.
1858 """
1860 def __init__(
1861 self,
1862 raw_query,
1863 model=None,
1864 query=None,
1865 params=(),
1866 translations=None,
1867 using=None,
1868 hints=None,
1869 ):
1870 self.raw_query = raw_query
1871 self.model = model
1872 self._db = using
1873 self._hints = hints or {}
1874 self.query = query or sql.RawQuery(sql=raw_query, using=self.db, params=params)
1875 self.params = params
1876 self.translations = translations or {}
1877 self._result_cache = None
1878 self._prefetch_related_lookups = ()
1879 self._prefetch_done = False
1881 def resolve_model_init_order(self):
1882 """Resolve the init field names and value positions."""
1883 converter = connections[self.db].introspection.identifier_converter
1884 model_init_fields = [
1885 f for f in self.model._meta.fields if converter(f.column) in self.columns
1886 ]
1887 annotation_fields = [
1888 (column, pos)
1889 for pos, column in enumerate(self.columns)
1890 if column not in self.model_fields
1891 ]
1892 model_init_order = [
1893 self.columns.index(converter(f.column)) for f in model_init_fields
1894 ]
1895 model_init_names = [f.attname for f in model_init_fields]
1896 return model_init_names, model_init_order, annotation_fields
1898 def prefetch_related(self, *lookups):
1899 """Same as QuerySet.prefetch_related()"""
1900 clone = self._clone()
1901 if lookups == (None,):
1902 clone._prefetch_related_lookups = ()
1903 else:
1904 clone._prefetch_related_lookups = clone._prefetch_related_lookups + lookups
1905 return clone
1907 def _prefetch_related_objects(self):
1908 prefetch_related_objects(self._result_cache, *self._prefetch_related_lookups)
1909 self._prefetch_done = True
1911 def _clone(self):
1912 """Same as QuerySet._clone()"""
1913 c = self.__class__(
1914 self.raw_query,
1915 model=self.model,
1916 query=self.query,
1917 params=self.params,
1918 translations=self.translations,
1919 using=self._db,
1920 hints=self._hints,
1921 )
1922 c._prefetch_related_lookups = self._prefetch_related_lookups[:]
1923 return c
1925 def _fetch_all(self):
1926 if self._result_cache is None:
1927 self._result_cache = list(self.iterator())
1928 if self._prefetch_related_lookups and not self._prefetch_done:
1929 self._prefetch_related_objects()
1931 def __len__(self):
1932 self._fetch_all()
1933 return len(self._result_cache)
1935 def __bool__(self):
1936 self._fetch_all()
1937 return bool(self._result_cache)
1939 def __iter__(self):
1940 self._fetch_all()
1941 return iter(self._result_cache)
1943 def iterator(self):
1944 yield from RawModelIterable(self)
1946 def __repr__(self):
1947 return f"<{self.__class__.__name__}: {self.query}>"
1949 def __getitem__(self, k):
1950 return list(self)[k]
1952 @property
1953 def db(self):
1954 """Return the database used if this query is executed now."""
1955 return self._db or router.db_for_read(self.model, **self._hints)
1957 def using(self, alias):
1958 """Select the database this RawQuerySet should execute against."""
1959 return RawQuerySet(
1960 self.raw_query,
1961 model=self.model,
1962 query=self.query.chain(using=alias),
1963 params=self.params,
1964 translations=self.translations,
1965 using=alias,
1966 )
1968 @cached_property
1969 def columns(self):
1970 """
1971 A list of model field names in the order they'll appear in the
1972 query results.
1973 """
1974 columns = self.query.get_columns()
1975 # Adjust any column names which don't match field names
1976 for query_name, model_name in self.translations.items():
1977 # Ignore translations for nonexistent column names
1978 try:
1979 index = columns.index(query_name)
1980 except ValueError:
1981 pass
1982 else:
1983 columns[index] = model_name
1984 return columns
1986 @cached_property
1987 def model_fields(self):
1988 """A dict mapping column names to model field names."""
1989 converter = connections[self.db].introspection.identifier_converter
1990 model_fields = {}
1991 for field in self.model._meta.fields:
1992 name, column = field.get_attname_column()
1993 model_fields[converter(column)] = field
1994 return model_fields
1997class Prefetch:
1998 def __init__(self, lookup, queryset=None, to_attr=None):
1999 # `prefetch_through` is the path we traverse to perform the prefetch.
2000 self.prefetch_through = lookup
2001 # `prefetch_to` is the path to the attribute that stores the result.
2002 self.prefetch_to = lookup
2003 if queryset is not None and (
2004 isinstance(queryset, RawQuerySet)
2005 or (
2006 hasattr(queryset, "_iterable_class")
2007 and not issubclass(queryset._iterable_class, ModelIterable)
2008 )
2009 ):
2010 raise ValueError(
2011 "Prefetch querysets cannot use raw(), values(), and values_list()."
2012 )
2013 if to_attr:
2014 self.prefetch_to = LOOKUP_SEP.join(
2015 lookup.split(LOOKUP_SEP)[:-1] + [to_attr]
2016 )
2018 self.queryset = queryset
2019 self.to_attr = to_attr
2021 def __getstate__(self):
2022 obj_dict = self.__dict__.copy()
2023 if self.queryset is not None:
2024 queryset = self.queryset._chain()
2025 # Prevent the QuerySet from being evaluated
2026 queryset._result_cache = []
2027 queryset._prefetch_done = True
2028 obj_dict["queryset"] = queryset
2029 return obj_dict
2031 def add_prefix(self, prefix):
2032 self.prefetch_through = prefix + LOOKUP_SEP + self.prefetch_through
2033 self.prefetch_to = prefix + LOOKUP_SEP + self.prefetch_to
2035 def get_current_prefetch_to(self, level):
2036 return LOOKUP_SEP.join(self.prefetch_to.split(LOOKUP_SEP)[: level + 1])
2038 def get_current_to_attr(self, level):
2039 parts = self.prefetch_to.split(LOOKUP_SEP)
2040 to_attr = parts[level]
2041 as_attr = self.to_attr and level == len(parts) - 1
2042 return to_attr, as_attr
2044 def get_current_queryset(self, level):
2045 if self.get_current_prefetch_to(level) == self.prefetch_to:
2046 return self.queryset
2047 return None
2049 def __eq__(self, other):
2050 if not isinstance(other, Prefetch):
2051 return NotImplemented
2052 return self.prefetch_to == other.prefetch_to
2054 def __hash__(self):
2055 return hash((self.__class__, self.prefetch_to))
2058def normalize_prefetch_lookups(lookups, prefix=None):
2059 """Normalize lookups into Prefetch objects."""
2060 ret = []
2061 for lookup in lookups:
2062 if not isinstance(lookup, Prefetch):
2063 lookup = Prefetch(lookup)
2064 if prefix:
2065 lookup.add_prefix(prefix)
2066 ret.append(lookup)
2067 return ret
2070def prefetch_related_objects(model_instances, *related_lookups):
2071 """
2072 Populate prefetched object caches for a list of model instances based on
2073 the lookups/Prefetch instances given.
2074 """
2075 if not model_instances:
2076 return # nothing to do
2078 # We need to be able to dynamically add to the list of prefetch_related
2079 # lookups that we look up (see below). So we need some book keeping to
2080 # ensure we don't do duplicate work.
2081 done_queries = {} # dictionary of things like 'foo__bar': [results]
2083 auto_lookups = set() # we add to this as we go through.
2084 followed_descriptors = set() # recursion protection
2086 all_lookups = normalize_prefetch_lookups(reversed(related_lookups))
2087 while all_lookups:
2088 lookup = all_lookups.pop()
2089 if lookup.prefetch_to in done_queries:
2090 if lookup.queryset is not None:
2091 raise ValueError(
2092 f"'{lookup.prefetch_to}' lookup was already seen with a different queryset. "
2093 "You may need to adjust the ordering of your lookups."
2094 )
2096 continue
2098 # Top level, the list of objects to decorate is the result cache
2099 # from the primary QuerySet. It won't be for deeper levels.
2100 obj_list = model_instances
2102 through_attrs = lookup.prefetch_through.split(LOOKUP_SEP)
2103 for level, through_attr in enumerate(through_attrs):
2104 # Prepare main instances
2105 if not obj_list:
2106 break
2108 prefetch_to = lookup.get_current_prefetch_to(level)
2109 if prefetch_to in done_queries:
2110 # Skip any prefetching, and any object preparation
2111 obj_list = done_queries[prefetch_to]
2112 continue
2114 # Prepare objects:
2115 good_objects = True
2116 for obj in obj_list:
2117 # Since prefetching can re-use instances, it is possible to have
2118 # the same instance multiple times in obj_list, so obj might
2119 # already be prepared.
2120 if not hasattr(obj, "_prefetched_objects_cache"):
2121 try:
2122 obj._prefetched_objects_cache = {}
2123 except (AttributeError, TypeError):
2124 # Must be an immutable object from
2125 # values_list(flat=True), for example (TypeError) or
2126 # a QuerySet subclass that isn't returning Model
2127 # instances (AttributeError), either in Plain or a 3rd
2128 # party. prefetch_related() doesn't make sense, so quit.
2129 good_objects = False
2130 break
2131 if not good_objects:
2132 break
2134 # Descend down tree
2136 # We assume that objects retrieved are homogeneous (which is the premise
2137 # of prefetch_related), so what applies to first object applies to all.
2138 first_obj = obj_list[0]
2139 to_attr = lookup.get_current_to_attr(level)[0]
2140 prefetcher, descriptor, attr_found, is_fetched = get_prefetcher(
2141 first_obj, through_attr, to_attr
2142 )
2144 if not attr_found:
2145 raise AttributeError(
2146 f"Cannot find '{through_attr}' on {first_obj.__class__.__name__} object, '{lookup.prefetch_through}' is an invalid "
2147 "parameter to prefetch_related()"
2148 )
2150 if level == len(through_attrs) - 1 and prefetcher is None:
2151 # Last one, this *must* resolve to something that supports
2152 # prefetching, otherwise there is no point adding it and the
2153 # developer asking for it has made a mistake.
2154 raise ValueError(
2155 f"'{lookup.prefetch_through}' does not resolve to an item that supports "
2156 "prefetching - this is an invalid parameter to "
2157 "prefetch_related()."
2158 )
2160 obj_to_fetch = None
2161 if prefetcher is not None:
2162 obj_to_fetch = [obj for obj in obj_list if not is_fetched(obj)]
2164 if obj_to_fetch:
2165 obj_list, additional_lookups = prefetch_one_level(
2166 obj_to_fetch,
2167 prefetcher,
2168 lookup,
2169 level,
2170 )
2171 # We need to ensure we don't keep adding lookups from the
2172 # same relationships to stop infinite recursion. So, if we
2173 # are already on an automatically added lookup, don't add
2174 # the new lookups from relationships we've seen already.
2175 if not (
2176 prefetch_to in done_queries
2177 and lookup in auto_lookups
2178 and descriptor in followed_descriptors
2179 ):
2180 done_queries[prefetch_to] = obj_list
2181 new_lookups = normalize_prefetch_lookups(
2182 reversed(additional_lookups), prefetch_to
2183 )
2184 auto_lookups.update(new_lookups)
2185 all_lookups.extend(new_lookups)
2186 followed_descriptors.add(descriptor)
2187 else:
2188 # Either a singly related object that has already been fetched
2189 # (e.g. via select_related), or hopefully some other property
2190 # that doesn't support prefetching but needs to be traversed.
2192 # We replace the current list of parent objects with the list
2193 # of related objects, filtering out empty or missing values so
2194 # that we can continue with nullable or reverse relations.
2195 new_obj_list = []
2196 for obj in obj_list:
2197 if through_attr in getattr(obj, "_prefetched_objects_cache", ()):
2198 # If related objects have been prefetched, use the
2199 # cache rather than the object's through_attr.
2200 new_obj = list(obj._prefetched_objects_cache.get(through_attr))
2201 else:
2202 try:
2203 new_obj = getattr(obj, through_attr)
2204 except exceptions.ObjectDoesNotExist:
2205 continue
2206 if new_obj is None:
2207 continue
2208 # We special-case `list` rather than something more generic
2209 # like `Iterable` because we don't want to accidentally match
2210 # user models that define __iter__.
2211 if isinstance(new_obj, list):
2212 new_obj_list.extend(new_obj)
2213 else:
2214 new_obj_list.append(new_obj)
2215 obj_list = new_obj_list
2218def get_prefetcher(instance, through_attr, to_attr):
2219 """
2220 For the attribute 'through_attr' on the given instance, find
2221 an object that has a get_prefetch_queryset().
2222 Return a 4 tuple containing:
2223 (the object with get_prefetch_queryset (or None),
2224 the descriptor object representing this relationship (or None),
2225 a boolean that is False if the attribute was not found at all,
2226 a function that takes an instance and returns a boolean that is True if
2227 the attribute has already been fetched for that instance)
2228 """
2230 def has_to_attr_attribute(instance):
2231 return hasattr(instance, to_attr)
2233 prefetcher = None
2234 is_fetched = has_to_attr_attribute
2236 # For singly related objects, we have to avoid getting the attribute
2237 # from the object, as this will trigger the query. So we first try
2238 # on the class, in order to get the descriptor object.
2239 rel_obj_descriptor = getattr(instance.__class__, through_attr, None)
2240 if rel_obj_descriptor is None:
2241 attr_found = hasattr(instance, through_attr)
2242 else:
2243 attr_found = True
2244 if rel_obj_descriptor:
2245 # singly related object, descriptor object has the
2246 # get_prefetch_queryset() method.
2247 if hasattr(rel_obj_descriptor, "get_prefetch_queryset"):
2248 prefetcher = rel_obj_descriptor
2249 is_fetched = rel_obj_descriptor.is_cached
2250 else:
2251 # descriptor doesn't support prefetching, so we go ahead and get
2252 # the attribute on the instance rather than the class to
2253 # support many related managers
2254 rel_obj = getattr(instance, through_attr)
2255 if hasattr(rel_obj, "get_prefetch_queryset"):
2256 prefetcher = rel_obj
2257 if through_attr != to_attr:
2258 # Special case cached_property instances because hasattr
2259 # triggers attribute computation and assignment.
2260 if isinstance(
2261 getattr(instance.__class__, to_attr, None), cached_property
2262 ):
2264 def has_cached_property(instance):
2265 return to_attr in instance.__dict__
2267 is_fetched = has_cached_property
2268 else:
2270 def in_prefetched_cache(instance):
2271 return through_attr in instance._prefetched_objects_cache
2273 is_fetched = in_prefetched_cache
2274 return prefetcher, rel_obj_descriptor, attr_found, is_fetched
2277def prefetch_one_level(instances, prefetcher, lookup, level):
2278 """
2279 Helper function for prefetch_related_objects().
2281 Run prefetches on all instances using the prefetcher object,
2282 assigning results to relevant caches in instance.
2284 Return the prefetched objects along with any additional prefetches that
2285 must be done due to prefetch_related lookups found from default managers.
2286 """
2287 # prefetcher must have a method get_prefetch_queryset() which takes a list
2288 # of instances, and returns a tuple:
2290 # (queryset of instances of self.model that are related to passed in instances,
2291 # callable that gets value to be matched for returned instances,
2292 # callable that gets value to be matched for passed in instances,
2293 # boolean that is True for singly related objects,
2294 # cache or field name to assign to,
2295 # boolean that is True when the previous argument is a cache name vs a field name).
2297 # The 'values to be matched' must be hashable as they will be used
2298 # in a dictionary.
2300 (
2301 rel_qs,
2302 rel_obj_attr,
2303 instance_attr,
2304 single,
2305 cache_name,
2306 is_descriptor,
2307 ) = prefetcher.get_prefetch_queryset(instances, lookup.get_current_queryset(level))
2308 # We have to handle the possibility that the QuerySet we just got back
2309 # contains some prefetch_related lookups. We don't want to trigger the
2310 # prefetch_related functionality by evaluating the query. Rather, we need
2311 # to merge in the prefetch_related lookups.
2312 # Copy the lookups in case it is a Prefetch object which could be reused
2313 # later (happens in nested prefetch_related).
2314 additional_lookups = [
2315 copy.copy(additional_lookup)
2316 for additional_lookup in getattr(rel_qs, "_prefetch_related_lookups", ())
2317 ]
2318 if additional_lookups:
2319 # Don't need to clone because the manager should have given us a fresh
2320 # instance, so we access an internal instead of using public interface
2321 # for performance reasons.
2322 rel_qs._prefetch_related_lookups = ()
2324 all_related_objects = list(rel_qs)
2326 rel_obj_cache = {}
2327 for rel_obj in all_related_objects:
2328 rel_attr_val = rel_obj_attr(rel_obj)
2329 rel_obj_cache.setdefault(rel_attr_val, []).append(rel_obj)
2331 to_attr, as_attr = lookup.get_current_to_attr(level)
2332 # Make sure `to_attr` does not conflict with a field.
2333 if as_attr and instances:
2334 # We assume that objects retrieved are homogeneous (which is the premise
2335 # of prefetch_related), so what applies to first object applies to all.
2336 model = instances[0].__class__
2337 try:
2338 model._meta.get_field(to_attr)
2339 except exceptions.FieldDoesNotExist:
2340 pass
2341 else:
2342 msg = "to_attr={} conflicts with a field on the {} model."
2343 raise ValueError(msg.format(to_attr, model.__name__))
2345 # Whether or not we're prefetching the last part of the lookup.
2346 leaf = len(lookup.prefetch_through.split(LOOKUP_SEP)) - 1 == level
2348 for obj in instances:
2349 instance_attr_val = instance_attr(obj)
2350 vals = rel_obj_cache.get(instance_attr_val, [])
2352 if single:
2353 val = vals[0] if vals else None
2354 if as_attr:
2355 # A to_attr has been given for the prefetch.
2356 setattr(obj, to_attr, val)
2357 elif is_descriptor:
2358 # cache_name points to a field name in obj.
2359 # This field is a descriptor for a related object.
2360 setattr(obj, cache_name, val)
2361 else:
2362 # No to_attr has been given for this prefetch operation and the
2363 # cache_name does not point to a descriptor. Store the value of
2364 # the field in the object's field cache.
2365 obj._state.fields_cache[cache_name] = val
2366 else:
2367 if as_attr:
2368 setattr(obj, to_attr, vals)
2369 else:
2370 manager = getattr(obj, to_attr)
2371 if leaf and lookup.queryset is not None:
2372 qs = manager._apply_rel_filters(lookup.queryset)
2373 else:
2374 qs = manager.get_queryset()
2375 qs._result_cache = vals
2376 # We don't want the individual qs doing prefetch_related now,
2377 # since we have merged this into the current work.
2378 qs._prefetch_done = True
2379 obj._prefetched_objects_cache[cache_name] = qs
2380 return all_related_objects, additional_lookups
2383class RelatedPopulator:
2384 """
2385 RelatedPopulator is used for select_related() object instantiation.
2387 The idea is that each select_related() model will be populated by a
2388 different RelatedPopulator instance. The RelatedPopulator instances get
2389 klass_info and select (computed in SQLCompiler) plus the used db as
2390 input for initialization. That data is used to compute which columns
2391 to use, how to instantiate the model, and how to populate the links
2392 between the objects.
2394 The actual creation of the objects is done in populate() method. This
2395 method gets row and from_obj as input and populates the select_related()
2396 model instance.
2397 """
2399 def __init__(self, klass_info, select, db):
2400 self.db = db
2401 # Pre-compute needed attributes. The attributes are:
2402 # - model_cls: the possibly deferred model class to instantiate
2403 # - either:
2404 # - cols_start, cols_end: usually the columns in the row are
2405 # in the same order model_cls.__init__ expects them, so we
2406 # can instantiate by model_cls(*row[cols_start:cols_end])
2407 # - reorder_for_init: When select_related descends to a child
2408 # class, then we want to reuse the already selected parent
2409 # data. However, in this case the parent data isn't necessarily
2410 # in the same order that Model.__init__ expects it to be, so
2411 # we have to reorder the parent data. The reorder_for_init
2412 # attribute contains a function used to reorder the field data
2413 # in the order __init__ expects it.
2414 # - pk_idx: the index of the primary key field in the reordered
2415 # model data. Used to check if a related object exists at all.
2416 # - init_list: the field attnames fetched from the database. For
2417 # deferred models this isn't the same as all attnames of the
2418 # model's fields.
2419 # - related_populators: a list of RelatedPopulator instances if
2420 # select_related() descends to related models from this model.
2421 # - local_setter, remote_setter: Methods to set cached values on
2422 # the object being populated and on the remote object. Usually
2423 # these are Field.set_cached_value() methods.
2424 select_fields = klass_info["select_fields"]
2425 from_parent = klass_info["from_parent"]
2426 if not from_parent:
2427 self.cols_start = select_fields[0]
2428 self.cols_end = select_fields[-1] + 1
2429 self.init_list = [
2430 f[0].target.attname for f in select[self.cols_start : self.cols_end]
2431 ]
2432 self.reorder_for_init = None
2433 else:
2434 attname_indexes = {
2435 select[idx][0].target.attname: idx for idx in select_fields
2436 }
2437 model_init_attnames = (
2438 f.attname for f in klass_info["model"]._meta.concrete_fields
2439 )
2440 self.init_list = [
2441 attname for attname in model_init_attnames if attname in attname_indexes
2442 ]
2443 self.reorder_for_init = operator.itemgetter(
2444 *[attname_indexes[attname] for attname in self.init_list]
2445 )
2447 self.model_cls = klass_info["model"]
2448 self.pk_idx = self.init_list.index(self.model_cls._meta.pk.attname)
2449 self.related_populators = get_related_populators(klass_info, select, self.db)
2450 self.local_setter = klass_info["local_setter"]
2451 self.remote_setter = klass_info["remote_setter"]
2453 def populate(self, row, from_obj):
2454 if self.reorder_for_init:
2455 obj_data = self.reorder_for_init(row)
2456 else:
2457 obj_data = row[self.cols_start : self.cols_end]
2458 if obj_data[self.pk_idx] is None:
2459 obj = None
2460 else:
2461 obj = self.model_cls.from_db(self.db, self.init_list, obj_data)
2462 for rel_iter in self.related_populators:
2463 rel_iter.populate(row, obj)
2464 self.local_setter(from_obj, obj)
2465 if obj is not None:
2466 self.remote_setter(obj, from_obj)
2469def get_related_populators(klass_info, select, db):
2470 iterators = []
2471 related_klass_infos = klass_info.get("related_klass_infos", [])
2472 for rel_klass_info in related_klass_infos:
2473 rel_cls = RelatedPopulator(rel_klass_info, select, db)
2474 iterators.append(rel_cls)
2475 return iterators
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Various data structures used in query construction.
4Factored out from plain.models.query to avoid making the main module very
5large and/or so that they can be used by other modules without getting into
6circular import difficulties.
7"""
9import functools
10import inspect
11import logging
12from collections import namedtuple
14from plain.exceptions import FieldError
15from plain.models.constants import LOOKUP_SEP
16from plain.models.db import DEFAULT_DB_ALIAS, DatabaseError, connections
17from plain.utils import tree
19logger = logging.getLogger("plain.models")
21# PathInfo is used when converting lookups (fk__somecol). The contents
22# describe the relation in Model terms (model Options and Fields for both
23# sides of the relation. The join_field is the field backing the relation.
24PathInfo = namedtuple(
25 "PathInfo",
26 "from_opts to_opts target_fields join_field m2m direct filtered_relation",
27)
30def subclasses(cls):
31 yield cls
32 for subclass in cls.__subclasses__():
33 yield from subclasses(subclass)
36class Q(tree.Node):
37 """
38 Encapsulate filters as objects that can then be combined logically (using
39 `&` and `|`).
40 """
42 # Connection types
43 AND = "AND"
44 OR = "OR"
45 XOR = "XOR"
46 default = AND
47 conditional = True
49 def __init__(self, *args, _connector=None, _negated=False, **kwargs):
50 super().__init__(
51 children=[*args, *sorted(kwargs.items())],
52 connector=_connector,
53 negated=_negated,
54 )
56 def _combine(self, other, conn):
57 if getattr(other, "conditional", False) is False:
58 raise TypeError(other)
59 if not self:
60 return other.copy()
61 if not other and isinstance(other, Q):
62 return self.copy()
64 obj = self.create(connector=conn)
65 obj.add(self, conn)
66 obj.add(other, conn)
67 return obj
69 def __or__(self, other):
70 return self._combine(other, self.OR)
72 def __and__(self, other):
73 return self._combine(other, self.AND)
75 def __xor__(self, other):
76 return self._combine(other, self.XOR)
78 def __invert__(self):
79 obj = self.copy()
80 obj.negate()
81 return obj
83 def resolve_expression(
84 self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False
85 ):
86 # We must promote any new joins to left outer joins so that when Q is
87 # used as an expression, rows aren't filtered due to joins.
88 clause, joins = query._add_q(
89 self,
90 reuse,
91 allow_joins=allow_joins,
92 split_subq=False,
93 check_filterable=False,
94 summarize=summarize,
95 )
96 query.promote_joins(joins)
97 return clause
99 def flatten(self):
100 """
101 Recursively yield this Q object and all subexpressions, in depth-first
102 order.
103 """
104 yield self
105 for child in self.children:
106 if isinstance(child, tuple):
107 # Use the lookup.
108 child = child[1]
109 if hasattr(child, "flatten"):
110 yield from child.flatten()
111 else:
112 yield child
114 def check(self, against, using=DEFAULT_DB_ALIAS):
115 """
116 Do a database query to check if the expressions of the Q instance
117 matches against the expressions.
118 """
119 # Avoid circular imports.
120 from plain.models.expressions import Value
121 from plain.models.fields import BooleanField
122 from plain.models.functions import Coalesce
123 from plain.models.sql import Query
124 from plain.models.sql.constants import SINGLE
126 query = Query(None)
127 for name, value in against.items():
128 if not hasattr(value, "resolve_expression"):
129 value = Value(value)
130 query.add_annotation(value, name, select=False)
131 query.add_annotation(Value(1), "_check")
132 # This will raise a FieldError if a field is missing in "against".
133 if connections[using].features.supports_comparing_boolean_expr:
134 query.add_q(Q(Coalesce(self, True, output_field=BooleanField())))
135 else:
136 query.add_q(self)
137 compiler = query.get_compiler(using=using)
138 try:
139 return compiler.execute_sql(SINGLE) is not None
140 except DatabaseError as e:
141 logger.warning("Got a database error calling check() on %r: %s", self, e)
142 return True
144 def deconstruct(self):
145 path = f"{self.__class__.__module__}.{self.__class__.__name__}"
146 if path.startswith("plain.models.query_utils"):
147 path = path.replace("plain.models.query_utils", "plain.models")
148 args = tuple(self.children)
149 kwargs = {}
150 if self.connector != self.default:
151 kwargs["_connector"] = self.connector
152 if self.negated:
153 kwargs["_negated"] = True
154 return path, args, kwargs
157class DeferredAttribute:
158 """
159 A wrapper for a deferred-loading field. When the value is read from this
160 object the first time, the query is executed.
161 """
163 def __init__(self, field):
164 self.field = field
166 def __get__(self, instance, cls=None):
167 """
168 Retrieve and caches the value from the datastore on the first lookup.
169 Return the cached value.
170 """
171 if instance is None:
172 return self
173 data = instance.__dict__
174 field_name = self.field.attname
175 if field_name not in data:
176 # Let's see if the field is part of the parent chain. If so we
177 # might be able to reuse the already loaded value. Refs #18343.
178 val = self._check_parent_chain(instance)
179 if val is None:
180 instance.refresh_from_db(fields=[field_name])
181 else:
182 data[field_name] = val
183 return data[field_name]
185 def _check_parent_chain(self, instance):
186 """
187 Check if the field value can be fetched from a parent field already
188 loaded in the instance. This can be done if the to-be fetched
189 field is a primary key field.
190 """
191 opts = instance._meta
192 link_field = opts.get_ancestor_link(self.field.model)
193 if self.field.primary_key and self.field != link_field:
194 return getattr(instance, link_field.attname)
195 return None
198class class_or_instance_method:
199 """
200 Hook used in RegisterLookupMixin to return partial functions depending on
201 the caller type (instance or class of models.Field).
202 """
204 def __init__(self, class_method, instance_method):
205 self.class_method = class_method
206 self.instance_method = instance_method
208 def __get__(self, instance, owner):
209 if instance is None:
210 return functools.partial(self.class_method, owner)
211 return functools.partial(self.instance_method, instance)
214class RegisterLookupMixin:
215 def _get_lookup(self, lookup_name):
216 return self.get_lookups().get(lookup_name, None)
218 @functools.cache
219 def get_class_lookups(cls):
220 class_lookups = [
221 parent.__dict__.get("class_lookups", {}) for parent in inspect.getmro(cls)
222 ]
223 return cls.merge_dicts(class_lookups)
225 def get_instance_lookups(self):
226 class_lookups = self.get_class_lookups()
227 if instance_lookups := getattr(self, "instance_lookups", None):
228 return {**class_lookups, **instance_lookups}
229 return class_lookups
231 get_lookups = class_or_instance_method(get_class_lookups, get_instance_lookups)
232 get_class_lookups = classmethod(get_class_lookups)
234 def get_lookup(self, lookup_name):
235 from plain.models.lookups import Lookup
237 found = self._get_lookup(lookup_name)
238 if found is None and hasattr(self, "output_field"):
239 return self.output_field.get_lookup(lookup_name)
240 if found is not None and not issubclass(found, Lookup):
241 return None
242 return found
244 def get_transform(self, lookup_name):
245 from plain.models.lookups import Transform
247 found = self._get_lookup(lookup_name)
248 if found is None and hasattr(self, "output_field"):
249 return self.output_field.get_transform(lookup_name)
250 if found is not None and not issubclass(found, Transform):
251 return None
252 return found
254 @staticmethod
255 def merge_dicts(dicts):
256 """
257 Merge dicts in reverse to preference the order of the original list. e.g.,
258 merge_dicts([a, b]) will preference the keys in 'a' over those in 'b'.
259 """
260 merged = {}
261 for d in reversed(dicts):
262 merged.update(d)
263 return merged
265 @classmethod
266 def _clear_cached_class_lookups(cls):
267 for subclass in subclasses(cls):
268 subclass.get_class_lookups.cache_clear()
270 def register_class_lookup(cls, lookup, lookup_name=None):
271 if lookup_name is None:
272 lookup_name = lookup.lookup_name
273 if "class_lookups" not in cls.__dict__:
274 cls.class_lookups = {}
275 cls.class_lookups[lookup_name] = lookup
276 cls._clear_cached_class_lookups()
277 return lookup
279 def register_instance_lookup(self, lookup, lookup_name=None):
280 if lookup_name is None:
281 lookup_name = lookup.lookup_name
282 if "instance_lookups" not in self.__dict__:
283 self.instance_lookups = {}
284 self.instance_lookups[lookup_name] = lookup
285 return lookup
287 register_lookup = class_or_instance_method(
288 register_class_lookup, register_instance_lookup
289 )
290 register_class_lookup = classmethod(register_class_lookup)
292 def _unregister_class_lookup(cls, lookup, lookup_name=None):
293 """
294 Remove given lookup from cls lookups. For use in tests only as it's
295 not thread-safe.
296 """
297 if lookup_name is None:
298 lookup_name = lookup.lookup_name
299 del cls.class_lookups[lookup_name]
300 cls._clear_cached_class_lookups()
302 def _unregister_instance_lookup(self, lookup, lookup_name=None):
303 """
304 Remove given lookup from instance lookups. For use in tests only as
305 it's not thread-safe.
306 """
307 if lookup_name is None:
308 lookup_name = lookup.lookup_name
309 del self.instance_lookups[lookup_name]
311 _unregister_lookup = class_or_instance_method(
312 _unregister_class_lookup, _unregister_instance_lookup
313 )
314 _unregister_class_lookup = classmethod(_unregister_class_lookup)
317def select_related_descend(field, restricted, requested, select_mask, reverse=False):
318 """
319 Return True if this field should be used to descend deeper for
320 select_related() purposes. Used by both the query construction code
321 (compiler.get_related_selections()) and the model instance creation code
322 (compiler.klass_info).
324 Arguments:
325 * field - the field to be checked
326 * restricted - a boolean field, indicating if the field list has been
327 manually restricted using a requested clause)
328 * requested - The select_related() dictionary.
329 * select_mask - the dictionary of selected fields.
330 * reverse - boolean, True if we are checking a reverse select related
331 """
332 if not field.remote_field:
333 return False
334 if field.remote_field.parent_link and not reverse:
335 return False
336 if restricted:
337 if reverse and field.related_query_name() not in requested:
338 return False
339 if not reverse and field.name not in requested:
340 return False
341 if not restricted and field.null:
342 return False
343 if (
344 restricted
345 and select_mask
346 and field.name in requested
347 and field not in select_mask
348 ):
349 raise FieldError(
350 f"Field {field.model._meta.object_name}.{field.name} cannot be both "
351 "deferred and traversed using select_related at the same time."
352 )
353 return True
356def refs_expression(lookup_parts, annotations):
357 """
358 Check if the lookup_parts contains references to the given annotations set.
359 Because the LOOKUP_SEP is contained in the default annotation names, check
360 each prefix of the lookup_parts for a match.
361 """
362 for n in range(1, len(lookup_parts) + 1):
363 level_n_lookup = LOOKUP_SEP.join(lookup_parts[0:n])
364 if annotations.get(level_n_lookup):
365 return level_n_lookup, lookup_parts[n:]
366 return None, ()
369def check_rel_lookup_compatibility(model, target_opts, field):
370 """
371 Check that self.model is compatible with target_opts. Compatibility
372 is OK if:
373 1) model and opts match (where proxy inheritance is removed)
374 2) model is parent of opts' model or the other way around
375 """
377 def check(opts):
378 return (
379 model._meta.concrete_model == opts.concrete_model
380 or opts.concrete_model in model._meta.get_parent_list()
381 or model in opts.get_parent_list()
382 )
384 # If the field is a primary key, then doing a query against the field's
385 # model is ok, too. Consider the case:
386 # class Restaurant(models.Model):
387 # place = OneToOneField(Place, primary_key=True):
388 # Restaurant.objects.filter(pk__in=Restaurant.objects.all()).
389 # If we didn't have the primary key check, then pk__in (== place__in) would
390 # give Place's opts as the target opts, but Restaurant isn't compatible
391 # with that. This logic applies only to primary keys, as when doing __in=qs,
392 # we are going to turn this into __in=qs.values('pk') later on.
393 return check(target_opts) or (
394 getattr(field, "primary_key", False) and check(field.model._meta)
395 )
398class FilteredRelation:
399 """Specify custom filtering in the ON clause of SQL joins."""
401 def __init__(self, relation_name, *, condition=Q()):
402 if not relation_name:
403 raise ValueError("relation_name cannot be empty.")
404 self.relation_name = relation_name
405 self.alias = None
406 if not isinstance(condition, Q):
407 raise ValueError("condition argument must be a Q() instance.")
408 self.condition = condition
409 self.path = []
411 def __eq__(self, other):
412 if not isinstance(other, self.__class__):
413 return NotImplemented
414 return (
415 self.relation_name == other.relation_name
416 and self.alias == other.alias
417 and self.condition == other.condition
418 )
420 def clone(self):
421 clone = FilteredRelation(self.relation_name, condition=self.condition)
422 clone.alias = self.alias
423 clone.path = self.path[:]
424 return clone
426 def resolve_expression(self, *args, **kwargs):
427 """
428 QuerySet.annotate() only accepts expression-like arguments
429 (with a resolve_expression() method).
430 """
431 raise NotImplementedError("FilteredRelation.resolve_expression() is unused.")
433 def as_sql(self, compiler, connection):
434 # Resolve the condition in Join.filtered_relation.
435 query = compiler.query
436 where = query.build_filtered_relation_q(self.condition, reuse=set(self.path))
437 return compiler.compile(where)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from functools import partial
3from plain.models.utils import make_model_tuple
4from plain.signals.dispatch import Signal
6class_prepared = Signal()
9class ModelSignal(Signal):
10 """
11 Signal subclass that allows the sender to be lazily specified as a string
12 of the `package_label.ModelName` form.
13 """
15 def _lazy_method(self, method, packages, receiver, sender, **kwargs):
16 from plain.models.options import Options
18 # This partial takes a single optional argument named "sender".
19 partial_method = partial(method, receiver, **kwargs)
20 if isinstance(sender, str):
21 packages = packages or Options.default_packages
22 packages.lazy_model_operation(partial_method, make_model_tuple(sender))
23 else:
24 return partial_method(sender)
26 def connect(
27 self, receiver, sender=None, weak=True, dispatch_uid=None, packages=None
28 ):
29 self._lazy_method(
30 super().connect,
31 packages,
32 receiver,
33 sender,
34 weak=weak,
35 dispatch_uid=dispatch_uid,
36 )
38 def disconnect(self, receiver=None, sender=None, dispatch_uid=None, packages=None):
39 return self._lazy_method(
40 super().disconnect, packages, receiver, sender, dispatch_uid=dispatch_uid
41 )
44pre_init = ModelSignal(use_caching=True)
45post_init = ModelSignal(use_caching=True)
47pre_save = ModelSignal(use_caching=True)
48post_save = ModelSignal(use_caching=True)
50pre_delete = ModelSignal(use_caching=True)
51post_delete = ModelSignal(use_caching=True)
53m2m_changed = ModelSignal(use_caching=True)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from contextlib import ContextDecorator, contextmanager
3from plain.models.db import (
4 DEFAULT_DB_ALIAS,
5 DatabaseError,
6 Error,
7 ProgrammingError,
8 connections,
9)
12class TransactionManagementError(ProgrammingError):
13 """Transaction management is used improperly."""
15 pass
18def get_connection(using=None):
19 """
20 Get a database connection by name, or the default database connection
21 if no name is provided. This is a private API.
22 """
23 if using is None:
24 using = DEFAULT_DB_ALIAS
25 return connections[using]
28def get_autocommit(using=None):
29 """Get the autocommit status of the connection."""
30 return get_connection(using).get_autocommit()
33def set_autocommit(autocommit, using=None):
34 """Set the autocommit status of the connection."""
35 return get_connection(using).set_autocommit(autocommit)
38def commit(using=None):
39 """Commit a transaction."""
40 get_connection(using).commit()
43def rollback(using=None):
44 """Roll back a transaction."""
45 get_connection(using).rollback()
48def savepoint(using=None):
49 """
50 Create a savepoint (if supported and required by the backend) inside the
51 current transaction. Return an identifier for the savepoint that will be
52 used for the subsequent rollback or commit.
53 """
54 return get_connection(using).savepoint()
57def savepoint_rollback(sid, using=None):
58 """
59 Roll back the most recent savepoint (if one exists). Do nothing if
60 savepoints are not supported.
61 """
62 get_connection(using).savepoint_rollback(sid)
65def savepoint_commit(sid, using=None):
66 """
67 Commit the most recent savepoint (if one exists). Do nothing if
68 savepoints are not supported.
69 """
70 get_connection(using).savepoint_commit(sid)
73def clean_savepoints(using=None):
74 """
75 Reset the counter used to generate unique savepoint ids in this thread.
76 """
77 get_connection(using).clean_savepoints()
80def get_rollback(using=None):
81 """Get the "needs rollback" flag -- for *advanced use* only."""
82 return get_connection(using).get_rollback()
85def set_rollback(rollback, using=None):
86 """
87 Set or unset the "needs rollback" flag -- for *advanced use* only.
89 When `rollback` is `True`, trigger a rollback when exiting the innermost
90 enclosing atomic block that has `savepoint=True` (that's the default). Use
91 this to force a rollback without raising an exception.
93 When `rollback` is `False`, prevent such a rollback. Use this only after
94 rolling back to a known-good state! Otherwise, you break the atomic block
95 and data corruption may occur.
96 """
97 return get_connection(using).set_rollback(rollback)
100@contextmanager
101def mark_for_rollback_on_error(using=None):
102 """
103 Internal low-level utility to mark a transaction as "needs rollback" when
104 an exception is raised while not enforcing the enclosed block to be in a
105 transaction. This is needed by Model.save() and friends to avoid starting a
106 transaction when in autocommit mode and a single query is executed.
108 It's equivalent to:
110 connection = get_connection(using)
111 if connection.get_autocommit():
112 yield
113 else:
114 with transaction.atomic(using=using, savepoint=False):
115 yield
117 but it uses low-level utilities to avoid performance overhead.
118 """
119 try:
120 yield
121 except Exception as exc:
122 connection = get_connection(using)
123 if connection.in_atomic_block:
124 connection.needs_rollback = True
125 connection.rollback_exc = exc
126 raise
129def on_commit(func, using=None, robust=False):
130 """
131 Register `func` to be called when the current transaction is committed.
132 If the current transaction is rolled back, `func` will not be called.
133 """
134 get_connection(using).on_commit(func, robust)
137#################################
138# Decorators / context managers #
139#################################
142class Atomic(ContextDecorator):
143 """
144 Guarantee the atomic execution of a given block.
146 An instance can be used either as a decorator or as a context manager.
148 When it's used as a decorator, __call__ wraps the execution of the
149 decorated function in the instance itself, used as a context manager.
151 When it's used as a context manager, __enter__ creates a transaction or a
152 savepoint, depending on whether a transaction is already in progress, and
153 __exit__ commits the transaction or releases the savepoint on normal exit,
154 and rolls back the transaction or to the savepoint on exceptions.
156 It's possible to disable the creation of savepoints if the goal is to
157 ensure that some code runs within a transaction without creating overhead.
159 A stack of savepoints identifiers is maintained as an attribute of the
160 connection. None denotes the absence of a savepoint.
162 This allows reentrancy even if the same AtomicWrapper is reused. For
163 example, it's possible to define `oa = atomic('other')` and use `@oa` or
164 `with oa:` multiple times.
166 Since database connections are thread-local, this is thread-safe.
168 An atomic block can be tagged as durable. In this case, raise a
169 RuntimeError if it's nested within another atomic block. This guarantees
170 that database changes in a durable block are committed to the database when
171 the block exists without error.
173 This is a private API.
174 """
176 def __init__(self, using, savepoint, durable):
177 self.using = using
178 self.savepoint = savepoint
179 self.durable = durable
180 self._from_testcase = False
182 def __enter__(self):
183 connection = get_connection(self.using)
185 if (
186 self.durable
187 and connection.atomic_blocks
188 and not connection.atomic_blocks[-1]._from_testcase
189 ):
190 raise RuntimeError(
191 "A durable atomic block cannot be nested within another "
192 "atomic block."
193 )
194 if not connection.in_atomic_block:
195 # Reset state when entering an outermost atomic block.
196 connection.commit_on_exit = True
197 connection.needs_rollback = False
198 if not connection.get_autocommit():
199 # Pretend we're already in an atomic block to bypass the code
200 # that disables autocommit to enter a transaction, and make a
201 # note to deal with this case in __exit__.
202 connection.in_atomic_block = True
203 connection.commit_on_exit = False
205 if connection.in_atomic_block:
206 # We're already in a transaction; create a savepoint, unless we
207 # were told not to or we're already waiting for a rollback. The
208 # second condition avoids creating useless savepoints and prevents
209 # overwriting needs_rollback until the rollback is performed.
210 if self.savepoint and not connection.needs_rollback:
211 sid = connection.savepoint()
212 connection.savepoint_ids.append(sid)
213 else:
214 connection.savepoint_ids.append(None)
215 else:
216 connection.set_autocommit(
217 False, force_begin_transaction_with_broken_autocommit=True
218 )
219 connection.in_atomic_block = True
221 if connection.in_atomic_block:
222 connection.atomic_blocks.append(self)
224 def __exit__(self, exc_type, exc_value, traceback):
225 connection = get_connection(self.using)
227 if connection.in_atomic_block:
228 connection.atomic_blocks.pop()
230 if connection.savepoint_ids:
231 sid = connection.savepoint_ids.pop()
232 else:
233 # Prematurely unset this flag to allow using commit or rollback.
234 connection.in_atomic_block = False
236 try:
237 if connection.closed_in_transaction:
238 # The database will perform a rollback by itself.
239 # Wait until we exit the outermost block.
240 pass
242 elif exc_type is None and not connection.needs_rollback:
243 if connection.in_atomic_block:
244 # Release savepoint if there is one
245 if sid is not None:
246 try:
247 connection.savepoint_commit(sid)
248 except DatabaseError:
249 try:
250 connection.savepoint_rollback(sid)
251 # The savepoint won't be reused. Release it to
252 # minimize overhead for the database server.
253 connection.savepoint_commit(sid)
254 except Error:
255 # If rolling back to a savepoint fails, mark for
256 # rollback at a higher level and avoid shadowing
257 # the original exception.
258 connection.needs_rollback = True
259 raise
260 else:
261 # Commit transaction
262 try:
263 connection.commit()
264 except DatabaseError:
265 try:
266 connection.rollback()
267 except Error:
268 # An error during rollback means that something
269 # went wrong with the connection. Drop it.
270 connection.close()
271 raise
272 else:
273 # This flag will be set to True again if there isn't a savepoint
274 # allowing to perform the rollback at this level.
275 connection.needs_rollback = False
276 if connection.in_atomic_block:
277 # Roll back to savepoint if there is one, mark for rollback
278 # otherwise.
279 if sid is None:
280 connection.needs_rollback = True
281 else:
282 try:
283 connection.savepoint_rollback(sid)
284 # The savepoint won't be reused. Release it to
285 # minimize overhead for the database server.
286 connection.savepoint_commit(sid)
287 except Error:
288 # If rolling back to a savepoint fails, mark for
289 # rollback at a higher level and avoid shadowing
290 # the original exception.
291 connection.needs_rollback = True
292 else:
293 # Roll back transaction
294 try:
295 connection.rollback()
296 except Error:
297 # An error during rollback means that something
298 # went wrong with the connection. Drop it.
299 connection.close()
301 finally:
302 # Outermost block exit when autocommit was enabled.
303 if not connection.in_atomic_block:
304 if connection.closed_in_transaction:
305 connection.connection = None
306 else:
307 connection.set_autocommit(True)
308 # Outermost block exit when autocommit was disabled.
309 elif not connection.savepoint_ids and not connection.commit_on_exit:
310 if connection.closed_in_transaction:
311 connection.connection = None
312 else:
313 connection.in_atomic_block = False
316def atomic(using=None, savepoint=True, durable=False):
317 # Bare decorator: @atomic -- although the first argument is called
318 # `using`, it's actually the function being decorated.
319 if callable(using):
320 return Atomic(DEFAULT_DB_ALIAS, savepoint, durable)(using)
321 # Decorator: @atomic(...) or context manager: with atomic(...): ...
322 else:
323 return Atomic(using, savepoint, durable)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import functools
2from collections import namedtuple
5def make_model_tuple(model):
6 """
7 Take a model or a string of the form "package_label.ModelName" and return a
8 corresponding ("package_label", "modelname") tuple. If a tuple is passed in,
9 assume it's a valid model tuple already and return it unchanged.
10 """
11 try:
12 if isinstance(model, tuple):
13 model_tuple = model
14 elif isinstance(model, str):
15 package_label, model_name = model.split(".")
16 model_tuple = package_label, model_name.lower()
17 else:
18 model_tuple = model._meta.package_label, model._meta.model_name
19 assert len(model_tuple) == 2
20 return model_tuple
21 except (ValueError, AssertionError):
22 raise ValueError(
23 f"Invalid model reference '{model}'. String model references "
24 "must be of the form 'package_label.ModelName'."
25 )
28def resolve_callables(mapping):
29 """
30 Generate key/value pairs for the given mapping where the values are
31 evaluated if they're callable.
32 """
33 for k, v in mapping.items():
34 yield k, v() if callable(v) else v
37def unpickle_named_row(names, values):
38 return create_namedtuple_class(*names)(*values)
41@functools.lru_cache
42def create_namedtuple_class(*names):
43 # Cache type() with @lru_cache since it's too slow to be called for every
44 # QuerySet evaluation.
45 def __reduce__(self):
46 return unpickle_named_row, (names, tuple(self))
48 return type(
49 "Row",
50 (namedtuple("Row", names),),
51 {"__reduce__": __reduce__, "__slots__": ()},
52 )
55class AltersData:
56 """
57 Make subclasses preserve the alters_data attribute on overridden methods.
58 """
60 def __init_subclass__(cls, **kwargs):
61 for fn_name, fn in vars(cls).items():
62 if callable(fn) and not hasattr(fn, "alters_data"):
63 for base in cls.__bases__:
64 if base_fn := getattr(base, fn_name, None):
65 if hasattr(base_fn, "alters_data"):
66 fn.alters_data = base_fn.alters_data
67 break
69 super().__init_subclass__(**kwargs)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""Multi-consumer multi-producer dispatching mechanism
3Originally based on pydispatch (BSD) https://pypi.org/project/PyDispatcher/2.0.1/
4See license.txt for original license.
6Heavily modified for Plain's purposes.
7"""
9from plain.signals.dispatch.dispatcher import Signal, receiver # NOQA
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import logging
2import threading
3import weakref
5from plain.utils.inspect import func_accepts_kwargs
7logger = logging.getLogger("plain.signals.dispatch")
10def _make_id(target):
11 if hasattr(target, "__func__"):
12 return (id(target.__self__), id(target.__func__))
13 return id(target)
16NONE_ID = _make_id(None)
18# A marker for caching
19NO_RECEIVERS = object()
22class Signal:
23 """
24 Base class for all signals
26 Internal attributes:
28 receivers
29 { receiverkey (id) : weakref(receiver) }
30 """
32 def __init__(self, use_caching=False):
33 """
34 Create a new signal.
35 """
36 self.receivers = []
37 self.lock = threading.Lock()
38 self.use_caching = use_caching
39 # For convenience we create empty caches even if they are not used.
40 # A note about caching: if use_caching is defined, then for each
41 # distinct sender we cache the receivers that sender has in
42 # 'sender_receivers_cache'. The cache is cleaned when .connect() or
43 # .disconnect() is called and populated on send().
44 self.sender_receivers_cache = weakref.WeakKeyDictionary() if use_caching else {}
45 self._dead_receivers = False
47 def connect(self, receiver, sender=None, weak=True, dispatch_uid=None):
48 """
49 Connect receiver to sender for signal.
51 Arguments:
53 receiver
54 A function or an instance method which is to receive signals.
55 Receivers must be hashable objects. Receivers can be
56 asynchronous.
58 If weak is True, then receiver must be weak referenceable.
60 Receivers must be able to accept keyword arguments.
62 If a receiver is connected with a dispatch_uid argument, it
63 will not be added if another receiver was already connected
64 with that dispatch_uid.
66 sender
67 The sender to which the receiver should respond. Must either be
68 a Python object, or None to receive events from any sender.
70 weak
71 Whether to use weak references to the receiver. By default, the
72 module will attempt to use weak references to the receiver
73 objects. If this parameter is false, then strong references will
74 be used.
76 dispatch_uid
77 An identifier used to uniquely identify a particular instance of
78 a receiver. This will usually be a string, though it may be
79 anything hashable.
80 """
81 from plain.runtime import settings
83 # If DEBUG is on, check that we got a good receiver
84 if settings.configured and settings.DEBUG:
85 if not callable(receiver):
86 raise TypeError("Signal receivers must be callable.")
87 # Check for **kwargs
88 if not func_accepts_kwargs(receiver):
89 raise ValueError(
90 "Signal receivers must accept keyword arguments (**kwargs)."
91 )
93 if dispatch_uid:
94 lookup_key = (dispatch_uid, _make_id(sender))
95 else:
96 lookup_key = (_make_id(receiver), _make_id(sender))
98 if weak:
99 ref = weakref.ref
100 receiver_object = receiver
101 # Check for bound methods
102 if hasattr(receiver, "__self__") and hasattr(receiver, "__func__"):
103 ref = weakref.WeakMethod
104 receiver_object = receiver.__self__
105 receiver = ref(receiver)
106 weakref.finalize(receiver_object, self._remove_receiver)
108 with self.lock:
109 self._clear_dead_receivers()
110 if not any(r_key == lookup_key for r_key, _ in self.receivers):
111 self.receivers.append((lookup_key, receiver))
112 self.sender_receivers_cache.clear()
114 def disconnect(self, receiver=None, sender=None, dispatch_uid=None):
115 """
116 Disconnect receiver from sender for signal.
118 If weak references are used, disconnect need not be called. The receiver
119 will be removed from dispatch automatically.
121 Arguments:
123 receiver
124 The registered receiver to disconnect. May be none if
125 dispatch_uid is specified.
127 sender
128 The registered sender to disconnect
130 dispatch_uid
131 the unique identifier of the receiver to disconnect
132 """
133 if dispatch_uid:
134 lookup_key = (dispatch_uid, _make_id(sender))
135 else:
136 lookup_key = (_make_id(receiver), _make_id(sender))
138 disconnected = False
139 with self.lock:
140 self._clear_dead_receivers()
141 for index in range(len(self.receivers)):
142 r_key, *_ = self.receivers[index]
143 if r_key == lookup_key:
144 disconnected = True
145 del self.receivers[index]
146 break
147 self.sender_receivers_cache.clear()
148 return disconnected
150 def has_listeners(self, sender=None):
151 sync_receivers = self._live_receivers(sender)
152 return bool(sync_receivers)
154 def send(self, sender, **named):
155 """
156 Send signal from sender to all connected receivers.
158 If any receiver raises an error, the error propagates back through send,
159 terminating the dispatch loop. So it's possible that all receivers
160 won't be called if an error is raised.
162 If any receivers are asynchronous, they are called after all the
163 synchronous receivers via a single call to async_to_sync(). They are
164 also executed concurrently with asyncio.gather().
166 Arguments:
168 sender
169 The sender of the signal. Either a specific object or None.
171 named
172 Named arguments which will be passed to receivers.
174 Return a list of tuple pairs [(receiver, response), ... ].
175 """
176 if (
177 not self.receivers
178 or self.sender_receivers_cache.get(sender) is NO_RECEIVERS
179 ):
180 return []
181 responses = []
182 sync_receivers = self._live_receivers(sender)
183 for receiver in sync_receivers:
184 response = receiver(signal=self, sender=sender, **named)
185 responses.append((receiver, response))
186 return responses
188 def _log_robust_failure(self, receiver, err):
189 logger.error(
190 "Error calling %s in Signal.send_robust() (%s)",
191 receiver.__qualname__,
192 err,
193 exc_info=err,
194 )
196 def send_robust(self, sender, **named):
197 """
198 Send signal from sender to all connected receivers catching errors.
200 If any receivers are asynchronous, they are called after all the
201 synchronous receivers via a single call to async_to_sync(). They are
202 also executed concurrently with asyncio.gather().
204 Arguments:
206 sender
207 The sender of the signal. Can be any Python object (normally one
208 registered with a connect if you actually want something to
209 occur).
211 named
212 Named arguments which will be passed to receivers.
214 Return a list of tuple pairs [(receiver, response), ... ].
216 If any receiver raises an error (specifically any subclass of
217 Exception), return the error instance as the result for that receiver.
218 """
219 if (
220 not self.receivers
221 or self.sender_receivers_cache.get(sender) is NO_RECEIVERS
222 ):
223 return []
225 # Call each receiver with whatever arguments it can accept.
226 # Return a list of tuple pairs [(receiver, response), ... ].
227 responses = []
228 sync_receivers = self._live_receivers(sender)
229 for receiver in sync_receivers:
230 try:
231 response = receiver(signal=self, sender=sender, **named)
232 except Exception as err:
233 self._log_robust_failure(receiver, err)
234 responses.append((receiver, err))
235 else:
236 responses.append((receiver, response))
237 return responses
239 def _clear_dead_receivers(self):
240 # Note: caller is assumed to hold self.lock.
241 if self._dead_receivers:
242 self._dead_receivers = False
243 self.receivers = [
244 r
245 for r in self.receivers
246 if not (isinstance(r[1], weakref.ReferenceType) and r[1]() is None)
247 ]
249 def _live_receivers(self, sender):
250 """
251 Filter sequence of receivers to get resolved, live receivers.
253 This checks for weak references and resolves them, then returning only
254 live receivers.
255 """
256 receivers = None
257 if self.use_caching and not self._dead_receivers:
258 receivers = self.sender_receivers_cache.get(sender)
259 # We could end up here with NO_RECEIVERS even if we do check this case in
260 # .send() prior to calling _live_receivers() due to concurrent .send() call.
261 if receivers is NO_RECEIVERS:
262 return []
263 if receivers is None:
264 with self.lock:
265 self._clear_dead_receivers()
266 senderkey = _make_id(sender)
267 receivers = []
268 for (_receiverkey, r_senderkey), receiver in self.receivers:
269 if r_senderkey == NONE_ID or r_senderkey == senderkey:
270 receivers.append(receiver)
271 if self.use_caching:
272 if not receivers:
273 self.sender_receivers_cache[sender] = NO_RECEIVERS
274 else:
275 # Note, we must cache the weakref versions.
276 self.sender_receivers_cache[sender] = receivers
277 non_weak_sync_receivers = []
278 for receiver in receivers:
279 if isinstance(receiver, weakref.ReferenceType):
280 # Dereference the weak reference.
281 receiver = receiver()
282 if receiver is not None:
283 non_weak_sync_receivers.append(receiver)
284 else:
285 non_weak_sync_receivers.append(receiver)
286 return non_weak_sync_receivers
288 def _remove_receiver(self, receiver=None):
289 # Mark that the self.receivers list has dead weakrefs. If so, we will
290 # clean those up in connect, disconnect and _live_receivers while
291 # holding self.lock. Note that doing the cleanup here isn't a good
292 # idea, _remove_receiver() will be called as side effect of garbage
293 # collection, and so the call can happen while we are already holding
294 # self.lock.
295 self._dead_receivers = True
298def receiver(signal, **kwargs):
299 """
300 A decorator for connecting receivers to signals. Used by passing in the
301 signal (or list of signals) and keyword arguments to connect::
303 @receiver(post_save, sender=MyModel)
304 def signal_receiver(sender, **kwargs):
305 ...
307 @receiver([post_save, post_delete], sender=MyModel)
308 def signals_receiver(sender, **kwargs):
309 ...
310 """
312 def _decorator(func):
313 if isinstance(signal, list | tuple):
314 for s in signal:
315 s.connect(func, **kwargs)
316 else:
317 signal.connect(func, **kwargs)
318 return func
320 return _decorator
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1# Generated by Plain 4.0.3 on 2022-03-16 19:11
3import plain.models.deletion
4from plain import models
5from plain.models import migrations
6from plain.runtime import settings
9class Migration(migrations.Migration):
10 initial = True
12 dependencies = [
13 migrations.swappable_dependency(settings.AUTH_USER_MODEL),
14 ]
16 operations = [
17 migrations.CreateModel(
18 name="OAuthConnection",
19 fields=[
20 (
21 "id",
22 models.BigAutoField(
23 auto_created=True,
24 primary_key=True,
25 ),
26 ),
27 ("created_at", models.DateTimeField(auto_now_add=True)),
28 ("updated_at", models.DateTimeField(auto_now=True)),
29 ("provider_key", models.CharField(db_index=True, max_length=100)),
30 ("provider_user_id", models.CharField(db_index=True, max_length=100)),
31 ("access_token", models.CharField(blank=True, max_length=100)),
32 ("refresh_token", models.CharField(blank=True, max_length=100)),
33 (
34 "access_token_expires_at",
35 models.DateTimeField(blank=True, null=True),
36 ),
37 (
38 "refresh_token_expires_at",
39 models.DateTimeField(blank=True, null=True),
40 ),
41 (
42 "user",
43 models.ForeignKey(
44 on_delete=plain.models.deletion.CASCADE,
45 related_name="oauth_connections",
46 to=settings.AUTH_USER_MODEL,
47 ),
48 ),
49 ],
50 ),
51 ]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1# Generated by Plain 4.0.3 on 2022-03-18 18:24
3from plain import models
4from plain.models import migrations
7class Migration(migrations.Migration):
8 dependencies = [
9 ("plainoauth", "0001_initial"),
10 ]
12 operations = [
13 migrations.AlterModelOptions(
14 name="oauthconnection",
15 options={
16 "ordering": ("provider_key",),
17 },
18 ),
19 migrations.AlterField(
20 model_name="oauthconnection",
21 name="access_token",
22 field=models.CharField(max_length=100),
23 ),
24 ]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1# Generated by Plain 4.0.6 on 2022-08-11 19:18
3from plain import models
4from plain.models import migrations
7class Migration(migrations.Migration):
8 dependencies = [
9 ("plainoauth", "0002_alter_oauthconnection_options_and_more"),
10 ]
12 operations = [
13 migrations.AlterField(
14 model_name="oauthconnection",
15 name="access_token",
16 field=models.CharField(max_length=300),
17 ),
18 migrations.AlterField(
19 model_name="oauthconnection",
20 name="refresh_token",
21 field=models.CharField(blank=True, max_length=300),
22 ),
23 ]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1# Generated by Plain 5.0.dev20230806030948 on 2023-08-08 19:32
3from plain import models
4from plain.models import migrations
7class Migration(migrations.Migration):
8 dependencies = [
9 ("plainoauth", "0003_alter_oauthconnection_access_token_and_more"),
10 ]
12 operations = [
13 migrations.AlterField(
14 model_name="oauthconnection",
15 name="access_token",
16 field=models.CharField(max_length=2000),
17 ),
18 migrations.AlterField(
19 model_name="oauthconnection",
20 name="refresh_token",
21 field=models.CharField(blank=True, max_length=2000),
22 ),
23 ]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1# Generated by Plain 0.3.0 on 2024-08-16 16:46
3from plain import models
4from plain.models import migrations
7class Migration(migrations.Migration):
8 dependencies = [
9 ("users", "__first__"),
10 ("plainoauth", "0004_alter_oauthconnection_access_token_and_more"),
11 ]
13 operations = [
14 migrations.AddConstraint(
15 model_name="oauthconnection",
16 constraint=models.UniqueConstraint(
17 fields=("provider_key", "provider_user_id"),
18 name="unique_oauth_provider_user_id",
19 ),
20 ),
21 ]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2This module contains helper functions for controlling caching. It does so by
3managing the "Vary" header of responses. It includes functions to patch the
4header of response objects directly and decorators that change functions to do
5that header-patching themselves.
7For information on the Vary header, see RFC 9110 Section 12.5.5.
9Essentially, the "Vary" HTTP header defines which headers a cache should take
10into account when building its cache key. Requests with the same path but
11different header content for headers named in "Vary" need to get different
12cache keys to prevent delivery of wrong content.
14An example: i18n middleware would need to distinguish caches by the
15"Accept-language" header.
16"""
18import time
19from collections import defaultdict
20from hashlib import md5
22from plain.http import Response, ResponseNotModified
23from plain.logs import log_response
24from plain.runtime import settings
25from plain.utils.http import http_date, parse_etags, parse_http_date_safe, quote_etag
26from plain.utils.regex_helper import _lazy_re_compile
28cc_delim_re = _lazy_re_compile(r"\s*,\s*")
31def patch_cache_control(response, **kwargs):
32 """
33 Patch the Cache-Control header by adding all keyword arguments to it.
34 The transformation is as follows:
36 * All keyword parameter names are turned to lowercase, and underscores
37 are converted to hyphens.
38 * If the value of a parameter is True (exactly True, not just a
39 true value), only the parameter name is added to the header.
40 * All other parameters are added with their value, after applying
41 str() to it.
42 """
44 def dictitem(s):
45 t = s.split("=", 1)
46 if len(t) > 1:
47 return (t[0].lower(), t[1])
48 else:
49 return (t[0].lower(), True)
51 def dictvalue(*t):
52 if t[1] is True:
53 return t[0]
54 else:
55 return f"{t[0]}={t[1]}"
57 cc = defaultdict(set)
58 if response.get("Cache-Control"):
59 for field in cc_delim_re.split(response.headers["Cache-Control"]):
60 directive, value = dictitem(field)
61 if directive == "no-cache":
62 # no-cache supports multiple field names.
63 cc[directive].add(value)
64 else:
65 cc[directive] = value
67 # If there's already a max-age header but we're being asked to set a new
68 # max-age, use the minimum of the two ages. In practice this happens when
69 # a decorator and a piece of middleware both operate on a given view.
70 if "max-age" in cc and "max_age" in kwargs:
71 kwargs["max_age"] = min(int(cc["max-age"]), kwargs["max_age"])
73 # Allow overriding private caching and vice versa
74 if "private" in cc and "public" in kwargs:
75 del cc["private"]
76 elif "public" in cc and "private" in kwargs:
77 del cc["public"]
79 for k, v in kwargs.items():
80 directive = k.replace("_", "-")
81 if directive == "no-cache":
82 # no-cache supports multiple field names.
83 cc[directive].add(v)
84 else:
85 cc[directive] = v
87 directives = []
88 for directive, values in cc.items():
89 if isinstance(values, set):
90 if True in values:
91 # True takes precedence.
92 values = {True}
93 directives.extend([dictvalue(directive, value) for value in values])
94 else:
95 directives.append(dictvalue(directive, values))
96 cc = ", ".join(directives)
97 response.headers["Cache-Control"] = cc
100def get_max_age(response):
101 """
102 Return the max-age from the response Cache-Control header as an integer,
103 or None if it wasn't found or wasn't an integer.
104 """
105 if not response.has_header("Cache-Control"):
106 return
107 cc = dict(
108 _to_tuple(el) for el in cc_delim_re.split(response.headers["Cache-Control"])
109 )
110 try:
111 return int(cc["max-age"])
112 except (ValueError, TypeError, KeyError):
113 pass
116def set_response_etag(response):
117 if not response.streaming and response.content:
118 response.headers["ETag"] = quote_etag(
119 md5(response.content, usedforsecurity=False).hexdigest(),
120 )
121 return response
124def _precondition_failed(request):
125 response = Response(status=412)
126 log_response(
127 "Precondition Failed: %s",
128 request.path,
129 response=response,
130 request=request,
131 )
132 return response
135def _not_modified(request, response=None):
136 new_response = ResponseNotModified()
137 if response:
138 # Preserve the headers required by RFC 9110 Section 15.4.5, as well as
139 # Last-Modified.
140 for header in (
141 "Cache-Control",
142 "Content-Location",
143 "Date",
144 "ETag",
145 "Expires",
146 "Last-Modified",
147 "Vary",
148 ):
149 if header in response:
150 new_response.headers[header] = response.headers[header]
152 # Preserve cookies as per the cookie specification: "If a proxy server
153 # receives a response which contains a Set-cookie header, it should
154 # propagate the Set-cookie header to the client, regardless of whether
155 # the response was 304 (Not Modified) or 200 (OK).
156 # https://curl.haxx.se/rfc/cookie_spec.html
157 new_response.cookies = response.cookies
158 return new_response
161def get_conditional_response(request, etag=None, last_modified=None, response=None):
162 # Only return conditional responses on successful requests.
163 if response and not (200 <= response.status_code < 300):
164 return response
166 # Get HTTP request headers.
167 if_match_etags = parse_etags(request.META.get("HTTP_IF_MATCH", ""))
168 if_unmodified_since = request.META.get("HTTP_IF_UNMODIFIED_SINCE")
169 if_unmodified_since = if_unmodified_since and parse_http_date_safe(
170 if_unmodified_since
171 )
172 if_none_match_etags = parse_etags(request.META.get("HTTP_IF_NONE_MATCH", ""))
173 if_modified_since = request.META.get("HTTP_IF_MODIFIED_SINCE")
174 if_modified_since = if_modified_since and parse_http_date_safe(if_modified_since)
176 # Evaluation of request preconditions below follows RFC 9110 Section
177 # 13.2.2.
178 # Step 1: Test the If-Match precondition.
179 if if_match_etags and not _if_match_passes(etag, if_match_etags):
180 return _precondition_failed(request)
182 # Step 2: Test the If-Unmodified-Since precondition.
183 if (
184 not if_match_etags
185 and if_unmodified_since
186 and not _if_unmodified_since_passes(last_modified, if_unmodified_since)
187 ):
188 return _precondition_failed(request)
190 # Step 3: Test the If-None-Match precondition.
191 if if_none_match_etags and not _if_none_match_passes(etag, if_none_match_etags):
192 if request.method in ("GET", "HEAD"):
193 return _not_modified(request, response)
194 else:
195 return _precondition_failed(request)
197 # Step 4: Test the If-Modified-Since precondition.
198 if (
199 not if_none_match_etags
200 and if_modified_since
201 and not _if_modified_since_passes(last_modified, if_modified_since)
202 and request.method in ("GET", "HEAD")
203 ):
204 return _not_modified(request, response)
206 # Step 5: Test the If-Range precondition (not supported).
207 # Step 6: Return original response since there isn't a conditional response.
208 return response
211def _if_match_passes(target_etag, etags):
212 """
213 Test the If-Match comparison as defined in RFC 9110 Section 13.1.1.
214 """
215 if not target_etag:
216 # If there isn't an ETag, then there can't be a match.
217 return False
218 elif etags == ["*"]:
219 # The existence of an ETag means that there is "a current
220 # representation for the target resource", even if the ETag is weak,
221 # so there is a match to '*'.
222 return True
223 elif target_etag.startswith("W/"):
224 # A weak ETag can never strongly match another ETag.
225 return False
226 else:
227 # Since the ETag is strong, this will only return True if there's a
228 # strong match.
229 return target_etag in etags
232def _if_unmodified_since_passes(last_modified, if_unmodified_since):
233 """
234 Test the If-Unmodified-Since comparison as defined in RFC 9110 Section
235 13.1.4.
236 """
237 return last_modified and last_modified <= if_unmodified_since
240def _if_none_match_passes(target_etag, etags):
241 """
242 Test the If-None-Match comparison as defined in RFC 9110 Section 13.1.2.
243 """
244 if not target_etag:
245 # If there isn't an ETag, then there isn't a match.
246 return True
247 elif etags == ["*"]:
248 # The existence of an ETag means that there is "a current
249 # representation for the target resource", so there is a match to '*'.
250 return False
251 else:
252 # The comparison should be weak, so look for a match after stripping
253 # off any weak indicators.
254 target_etag = target_etag.strip("W/")
255 etags = (etag.strip("W/") for etag in etags)
256 return target_etag not in etags
259def _if_modified_since_passes(last_modified, if_modified_since):
260 """
261 Test the If-Modified-Since comparison as defined in RFC 9110 Section
262 13.1.3.
263 """
264 return not last_modified or last_modified > if_modified_since
267def patch_response_headers(response, cache_timeout=None):
268 """
269 Add HTTP caching headers to the given Response: Expires and
270 Cache-Control.
272 Each header is only added if it isn't already set.
274 cache_timeout is in seconds. The CACHE_MIDDLEWARE_SECONDS setting is used
275 by default.
276 """
277 if cache_timeout is None:
278 cache_timeout = settings.CACHE_MIDDLEWARE_SECONDS
279 if cache_timeout < 0:
280 cache_timeout = 0 # Can't have max-age negative
281 if not response.has_header("Expires"):
282 response.headers["Expires"] = http_date(time.time() + cache_timeout)
283 patch_cache_control(response, max_age=cache_timeout)
286def add_never_cache_headers(response):
287 """
288 Add headers to a response to indicate that a page should never be cached.
289 """
290 patch_response_headers(response, cache_timeout=-1)
291 patch_cache_control(
292 response, no_cache=True, no_store=True, must_revalidate=True, private=True
293 )
296def patch_vary_headers(response, newheaders):
297 """
298 Add (or update) the "Vary" header in the given Response object.
299 newheaders is a list of header names that should be in "Vary". If headers
300 contains an asterisk, then "Vary" header will consist of a single asterisk
301 '*'. Otherwise, existing headers in "Vary" aren't removed.
302 """
303 # Note that we need to keep the original order intact, because cache
304 # implementations may rely on the order of the Vary contents in, say,
305 # computing an MD5 hash.
306 if response.has_header("Vary"):
307 vary_headers = cc_delim_re.split(response.headers["Vary"])
308 else:
309 vary_headers = []
310 # Use .lower() here so we treat headers as case-insensitive.
311 existing_headers = {header.lower() for header in vary_headers}
312 additional_headers = [
313 newheader
314 for newheader in newheaders
315 if newheader.lower() not in existing_headers
316 ]
317 vary_headers += additional_headers
318 if "*" in vary_headers:
319 response.headers["Vary"] = "*"
320 else:
321 response.headers["Vary"] = ", ".join(vary_headers)
324def _to_tuple(s):
325 t = s.split("=", 1)
326 if len(t) == 2:
327 return t[0].lower(), t[1]
328 return t[0].lower(), True
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from threading import local
3from plain.runtime import settings as plain_settings
4from plain.utils.functional import cached_property
7class ConnectionProxy:
8 """Proxy for accessing a connection object's attributes."""
10 def __init__(self, connections, alias):
11 self.__dict__["_connections"] = connections
12 self.__dict__["_alias"] = alias
14 def __getattr__(self, item):
15 return getattr(self._connections[self._alias], item)
17 def __setattr__(self, name, value):
18 return setattr(self._connections[self._alias], name, value)
20 def __delattr__(self, name):
21 return delattr(self._connections[self._alias], name)
23 def __contains__(self, key):
24 return key in self._connections[self._alias]
26 def __eq__(self, other):
27 return self._connections[self._alias] == other
30class ConnectionDoesNotExist(Exception):
31 pass
34class BaseConnectionHandler:
35 settings_name = None
36 exception_class = ConnectionDoesNotExist
38 def __init__(self, settings=None):
39 self._settings = settings
40 self._connections = local()
42 @cached_property
43 def settings(self):
44 self._settings = self.configure_settings(self._settings)
45 return self._settings
47 def configure_settings(self, settings):
48 if settings is None:
49 settings = getattr(plain_settings, self.settings_name)
50 return settings
52 def create_connection(self, alias):
53 raise NotImplementedError("Subclasses must implement create_connection().")
55 def __getitem__(self, alias):
56 try:
57 return getattr(self._connections, alias)
58 except AttributeError:
59 if alias not in self.settings:
60 raise self.exception_class(f"The connection '{alias}' doesn't exist.")
61 conn = self.create_connection(alias)
62 setattr(self._connections, alias, conn)
63 return conn
65 def __setitem__(self, key, value):
66 setattr(self._connections, key, value)
68 def __delitem__(self, key):
69 delattr(self._connections, key)
71 def __iter__(self):
72 return iter(self.settings)
74 def all(self, initialized_only=False):
75 return [
76 self[alias]
77 for alias in self
78 # If initialized_only is True, return only initialized connections.
79 if not initialized_only or hasattr(self._connections, alias)
80 ]
82 def close_all(self):
83 for conn in self.all(initialized_only=True):
84 conn.close()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Plain's standard crypto functions and utilities.
3"""
5import hashlib
6import hmac
7import secrets
9from plain.runtime import settings
10from plain.utils.encoding import force_bytes
13class InvalidAlgorithm(ValueError):
14 """Algorithm is not supported by hashlib."""
16 pass
19def salted_hmac(key_salt, value, secret=None, *, algorithm="sha1"):
20 """
21 Return the HMAC of 'value', using a key generated from key_salt and a
22 secret (which defaults to settings.SECRET_KEY). Default algorithm is SHA1,
23 but any algorithm name supported by hashlib can be passed.
25 A different key_salt should be passed in for every application of HMAC.
26 """
27 if secret is None:
28 secret = settings.SECRET_KEY
30 key_salt = force_bytes(key_salt)
31 secret = force_bytes(secret)
32 try:
33 hasher = getattr(hashlib, algorithm)
34 except AttributeError as e:
35 raise InvalidAlgorithm(
36 f"{algorithm!r} is not an algorithm accepted by the hashlib module."
37 ) from e
38 # We need to generate a derived key from our base key. We can do this by
39 # passing the key_salt and our base key through a pseudo-random function.
40 key = hasher(key_salt + secret).digest()
41 # If len(key_salt + secret) > block size of the hash algorithm, the above
42 # line is redundant and could be replaced by key = key_salt + secret, since
43 # the hmac module does the same thing for keys longer than the block size.
44 # However, we need to ensure that we *always* do this.
45 return hmac.new(key, msg=force_bytes(value), digestmod=hasher)
48RANDOM_STRING_CHARS = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
51def get_random_string(length, allowed_chars=RANDOM_STRING_CHARS):
52 """
53 Return a securely generated random string.
55 The bit length of the returned value can be calculated with the formula:
56 log_2(len(allowed_chars)^length)
58 For example, with default `allowed_chars` (26+26+10), this gives:
59 * length: 12, bit length =~ 71 bits
60 * length: 22, bit length =~ 131 bits
61 """
62 return "".join(secrets.choice(allowed_chars) for i in range(length))
65def constant_time_compare(val1, val2):
66 """Return True if the two strings are equal, False otherwise."""
67 return secrets.compare_digest(force_bytes(val1), force_bytes(val2))
70def pbkdf2(password, salt, iterations, dklen=0, digest=None):
71 """Return the hash of password using pbkdf2."""
72 if digest is None:
73 digest = hashlib.sha256
74 dklen = dklen or None
75 password = force_bytes(password)
76 salt = force_bytes(salt)
77 return hashlib.pbkdf2_hmac(digest().name, password, salt, iterations, dklen)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import copy
2from collections.abc import Mapping
5class OrderedSet:
6 """
7 A set which keeps the ordering of the inserted items.
8 """
10 def __init__(self, iterable=None):
11 self.dict = dict.fromkeys(iterable or ())
13 def add(self, item):
14 self.dict[item] = None
16 def remove(self, item):
17 del self.dict[item]
19 def discard(self, item):
20 try:
21 self.remove(item)
22 except KeyError:
23 pass
25 def __iter__(self):
26 return iter(self.dict)
28 def __reversed__(self):
29 return reversed(self.dict)
31 def __contains__(self, item):
32 return item in self.dict
34 def __bool__(self):
35 return bool(self.dict)
37 def __len__(self):
38 return len(self.dict)
40 def __repr__(self):
41 data = repr(list(self.dict)) if self.dict else ""
42 return f"{self.__class__.__qualname__}({data})"
45class MultiValueDictKeyError(KeyError):
46 pass
49class MultiValueDict(dict):
50 """
51 A subclass of dictionary customized to handle multiple values for the
52 same key.
54 >>> d = MultiValueDict({'name': ['Adrian', 'Simon'], 'position': ['Developer']})
55 >>> d['name']
56 'Simon'
57 >>> d.getlist('name')
58 ['Adrian', 'Simon']
59 >>> d.getlist('doesnotexist')
60 []
61 >>> d.getlist('doesnotexist', ['Adrian', 'Simon'])
62 ['Adrian', 'Simon']
63 >>> d.get('lastname', 'nonexistent')
64 'nonexistent'
65 >>> d.setlist('lastname', ['Holovaty', 'Willison'])
67 This class exists to solve the irritating problem raised by cgi.parse_qs,
68 which returns a list for every key, even though most web forms submit
69 single name-value pairs.
70 """
72 def __init__(self, key_to_list_mapping=()):
73 super().__init__(key_to_list_mapping)
75 def __repr__(self):
76 return f"<{self.__class__.__name__}: {super().__repr__()}>"
78 def __getitem__(self, key):
79 """
80 Return the last data value for this key, or [] if it's an empty list;
81 raise KeyError if not found.
82 """
83 try:
84 list_ = super().__getitem__(key)
85 except KeyError:
86 raise MultiValueDictKeyError(key)
87 try:
88 return list_[-1]
89 except IndexError:
90 return []
92 def __setitem__(self, key, value):
93 super().__setitem__(key, [value])
95 def __copy__(self):
96 return self.__class__([(k, v[:]) for k, v in self.lists()])
98 def __deepcopy__(self, memo):
99 result = self.__class__()
100 memo[id(self)] = result
101 for key, value in dict.items(self):
102 dict.__setitem__(
103 result, copy.deepcopy(key, memo), copy.deepcopy(value, memo)
104 )
105 return result
107 def __getstate__(self):
108 return {**self.__dict__, "_data": {k: self._getlist(k) for k in self}}
110 def __setstate__(self, obj_dict):
111 data = obj_dict.pop("_data", {})
112 for k, v in data.items():
113 self.setlist(k, v)
114 self.__dict__.update(obj_dict)
116 def get(self, key, default=None):
117 """
118 Return the last data value for the passed key. If key doesn't exist
119 or value is an empty list, return `default`.
120 """
121 try:
122 val = self[key]
123 except KeyError:
124 return default
125 if val == []:
126 return default
127 return val
129 def _getlist(self, key, default=None, force_list=False):
130 """
131 Return a list of values for the key.
133 Used internally to manipulate values list. If force_list is True,
134 return a new copy of values.
135 """
136 try:
137 values = super().__getitem__(key)
138 except KeyError:
139 if default is None:
140 return []
141 return default
142 else:
143 if force_list:
144 values = list(values) if values is not None else None
145 return values
147 def getlist(self, key, default=None):
148 """
149 Return the list of values for the key. If key doesn't exist, return a
150 default value.
151 """
152 return self._getlist(key, default, force_list=True)
154 def setlist(self, key, list_):
155 super().__setitem__(key, list_)
157 def setdefault(self, key, default=None):
158 if key not in self:
159 self[key] = default
160 # Do not return default here because __setitem__() may store
161 # another value -- QueryDict.__setitem__() does. Look it up.
162 return self[key]
164 def setlistdefault(self, key, default_list=None):
165 if key not in self:
166 if default_list is None:
167 default_list = []
168 self.setlist(key, default_list)
169 # Do not return default_list here because setlist() may store
170 # another value -- QueryDict.setlist() does. Look it up.
171 return self._getlist(key)
173 def appendlist(self, key, value):
174 """Append an item to the internal list associated with key."""
175 self.setlistdefault(key).append(value)
177 def items(self):
178 """
179 Yield (key, value) pairs, where value is the last item in the list
180 associated with the key.
181 """
182 for key in self:
183 yield key, self[key]
185 def lists(self):
186 """Yield (key, list) pairs."""
187 return iter(super().items())
189 def values(self):
190 """Yield the last value on every key list."""
191 for key in self:
192 yield self[key]
194 def copy(self):
195 """Return a shallow copy of this object."""
196 return copy.copy(self)
198 def update(self, *args, **kwargs):
199 """Extend rather than replace existing key lists."""
200 if len(args) > 1:
201 raise TypeError("update expected at most 1 argument, got %d" % len(args))
202 if args:
203 arg = args[0]
204 if isinstance(arg, MultiValueDict):
205 for key, value_list in arg.lists():
206 self.setlistdefault(key).extend(value_list)
207 else:
208 if isinstance(arg, Mapping):
209 arg = arg.items()
210 for key, value in arg:
211 self.setlistdefault(key).append(value)
212 for key, value in kwargs.items():
213 self.setlistdefault(key).append(value)
215 def dict(self):
216 """Return current object as a dict with singular values."""
217 return {key: self[key] for key in self}
220class ImmutableList(tuple):
221 """
222 A tuple-like object that raises useful errors when it is asked to mutate.
224 Example::
226 >>> a = ImmutableList(range(5), warning="You cannot mutate this.")
227 >>> a[3] = '4'
228 Traceback (most recent call last):
229 ...
230 AttributeError: You cannot mutate this.
231 """
233 def __new__(cls, *args, warning="ImmutableList object is immutable.", **kwargs):
234 self = tuple.__new__(cls, *args, **kwargs)
235 self.warning = warning
236 return self
238 def complain(self, *args, **kwargs):
239 raise AttributeError(self.warning)
241 # All list mutation functions complain.
242 __delitem__ = complain
243 __delslice__ = complain
244 __iadd__ = complain
245 __imul__ = complain
246 __setitem__ = complain
247 __setslice__ = complain
248 append = complain
249 extend = complain
250 insert = complain
251 pop = complain
252 remove = complain
253 sort = complain
254 reverse = complain
257class DictWrapper(dict):
258 """
259 Wrap accesses to a dictionary so that certain values (those starting with
260 the specified prefix) are passed through a function before being returned.
261 The prefix is removed before looking up the real value.
263 Used by the SQL construction code to ensure that values are correctly
264 quoted before being used.
265 """
267 def __init__(self, data, func, prefix):
268 super().__init__(data)
269 self.func = func
270 self.prefix = prefix
272 def __getitem__(self, key):
273 """
274 Retrieve the real value after stripping the prefix string (if
275 present). If the prefix is present, pass the value through self.func
276 before returning, otherwise return the raw value.
277 """
278 use_func = key.startswith(self.prefix)
279 key = key.removeprefix(self.prefix)
280 value = super().__getitem__(key)
281 if use_func:
282 return self.func(value)
283 return value
286class CaseInsensitiveMapping(Mapping):
287 """
288 Mapping allowing case-insensitive key lookups. Original case of keys is
289 preserved for iteration and string representation.
291 Example::
293 >>> ci_map = CaseInsensitiveMapping({'name': 'Jane'})
294 >>> ci_map['Name']
295 Jane
296 >>> ci_map['NAME']
297 Jane
298 >>> ci_map['name']
299 Jane
300 >>> ci_map # original case preserved
301 {'name': 'Jane'}
302 """
304 def __init__(self, data):
305 self._store = {k.lower(): (k, v) for k, v in self._unpack_items(data)}
307 def __getitem__(self, key):
308 return self._store[key.lower()][1]
310 def __len__(self):
311 return len(self._store)
313 def __eq__(self, other):
314 return isinstance(other, Mapping) and {
315 k.lower(): v for k, v in self.items()
316 } == {k.lower(): v for k, v in other.items()}
318 def __iter__(self):
319 return (original_key for original_key, value in self._store.values())
321 def __repr__(self):
322 return repr(dict(self._store.values()))
324 def copy(self):
325 return self
327 @staticmethod
328 def _unpack_items(data):
329 # Explicitly test for dict first as the common case for performance,
330 # avoiding abc's __instancecheck__ and _abc_instancecheck for the
331 # general Mapping case.
332 if isinstance(data, dict | Mapping):
333 yield from data.items()
334 return
335 for i, elem in enumerate(data):
336 if len(elem) != 2:
337 raise ValueError(
338 f"dictionary update sequence element #{i} has length {len(elem)}; "
339 "2 is required."
340 )
341 if not isinstance(elem[0], str):
342 raise ValueError(
343 f"Element key {elem[0]!r} invalid, only strings are allowed"
344 )
345 yield elem
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""Functions to parse datetime objects."""
3# We're using regular expressions rather than time.strptime because:
4# - They provide both validation and parsing.
5# - They're more flexible for datetimes.
6# - The date/datetime/time constructors produce friendlier error messages.
8import datetime
10from plain.utils.regex_helper import _lazy_re_compile
11from plain.utils.timezone import get_fixed_timezone
13date_re = _lazy_re_compile(r"(?P<year>\d{4})-(?P<month>\d{1,2})-(?P<day>\d{1,2})$")
15time_re = _lazy_re_compile(
16 r"(?P<hour>\d{1,2}):(?P<minute>\d{1,2})"
17 r"(?::(?P<second>\d{1,2})(?:[\.,](?P<microsecond>\d{1,6})\d{0,6})?)?$"
18)
20datetime_re = _lazy_re_compile(
21 r"(?P<year>\d{4})-(?P<month>\d{1,2})-(?P<day>\d{1,2})"
22 r"[T ](?P<hour>\d{1,2}):(?P<minute>\d{1,2})"
23 r"(?::(?P<second>\d{1,2})(?:[\.,](?P<microsecond>\d{1,6})\d{0,6})?)?"
24 r"\s*(?P<tzinfo>Z|[+-]\d{2}(?::?\d{2})?)?$"
25)
27standard_duration_re = _lazy_re_compile(
28 r"^"
29 r"(?:(?P<days>-?\d+) (days?, )?)?"
30 r"(?P<sign>-?)"
31 r"((?:(?P<hours>\d+):)(?=\d+:\d+))?"
32 r"(?:(?P<minutes>\d+):)?"
33 r"(?P<seconds>\d+)"
34 r"(?:[\.,](?P<microseconds>\d{1,6})\d{0,6})?"
35 r"$"
36)
38# Support the sections of ISO 8601 date representation that are accepted by
39# timedelta
40iso8601_duration_re = _lazy_re_compile(
41 r"^(?P<sign>[-+]?)"
42 r"P"
43 r"(?:(?P<days>\d+([\.,]\d+)?)D)?"
44 r"(?:T"
45 r"(?:(?P<hours>\d+([\.,]\d+)?)H)?"
46 r"(?:(?P<minutes>\d+([\.,]\d+)?)M)?"
47 r"(?:(?P<seconds>\d+([\.,]\d+)?)S)?"
48 r")?"
49 r"$"
50)
52# Support PostgreSQL's day-time interval format, e.g. "3 days 04:05:06". The
53# year-month and mixed intervals cannot be converted to a timedelta and thus
54# aren't accepted.
55postgres_interval_re = _lazy_re_compile(
56 r"^"
57 r"(?:(?P<days>-?\d+) (days? ?))?"
58 r"(?:(?P<sign>[-+])?"
59 r"(?P<hours>\d+):"
60 r"(?P<minutes>\d\d):"
61 r"(?P<seconds>\d\d)"
62 r"(?:\.(?P<microseconds>\d{1,6}))?"
63 r")?$"
64)
67def parse_date(value):
68 """Parse a string and return a datetime.date.
70 Raise ValueError if the input is well formatted but not a valid date.
71 Return None if the input isn't well formatted.
72 """
73 try:
74 return datetime.date.fromisoformat(value)
75 except ValueError:
76 if match := date_re.match(value):
77 kw = {k: int(v) for k, v in match.groupdict().items()}
78 return datetime.date(**kw)
81def parse_time(value):
82 """Parse a string and return a datetime.time.
84 This function doesn't support time zone offsets.
86 Raise ValueError if the input is well formatted but not a valid time.
87 Return None if the input isn't well formatted, in particular if it
88 contains an offset.
89 """
90 try:
91 # The fromisoformat() method takes time zone info into account and
92 # returns a time with a tzinfo component, if possible. However, there
93 # are no circumstances where aware datetime.time objects make sense, so
94 # remove the time zone offset.
95 return datetime.time.fromisoformat(value).replace(tzinfo=None)
96 except ValueError:
97 if match := time_re.match(value):
98 kw = match.groupdict()
99 kw["microsecond"] = kw["microsecond"] and kw["microsecond"].ljust(6, "0")
100 kw = {k: int(v) for k, v in kw.items() if v is not None}
101 return datetime.time(**kw)
104def parse_datetime(value):
105 """Parse a string and return a datetime.datetime.
107 This function supports time zone offsets. When the input contains one,
108 the output uses a timezone with a fixed offset from UTC.
110 Raise ValueError if the input is well formatted but not a valid datetime.
111 Return None if the input isn't well formatted.
112 """
113 try:
114 return datetime.datetime.fromisoformat(value)
115 except ValueError:
116 if match := datetime_re.match(value):
117 kw = match.groupdict()
118 kw["microsecond"] = kw["microsecond"] and kw["microsecond"].ljust(6, "0")
119 tzinfo = kw.pop("tzinfo")
120 if tzinfo == "Z":
121 tzinfo = datetime.UTC
122 elif tzinfo is not None:
123 offset_mins = int(tzinfo[-2:]) if len(tzinfo) > 3 else 0
124 offset = 60 * int(tzinfo[1:3]) + offset_mins
125 if tzinfo[0] == "-":
126 offset = -offset
127 tzinfo = get_fixed_timezone(offset)
128 kw = {k: int(v) for k, v in kw.items() if v is not None}
129 return datetime.datetime(**kw, tzinfo=tzinfo)
132def parse_duration(value):
133 """Parse a duration string and return a datetime.timedelta.
135 The preferred format for durations in Plain is '%d %H:%M:%S.%f'.
137 Also supports ISO 8601 representation and PostgreSQL's day-time interval
138 format.
139 """
140 match = (
141 standard_duration_re.match(value)
142 or iso8601_duration_re.match(value)
143 or postgres_interval_re.match(value)
144 )
145 if match:
146 kw = match.groupdict()
147 sign = -1 if kw.pop("sign", "+") == "-" else 1
148 if kw.get("microseconds"):
149 kw["microseconds"] = kw["microseconds"].ljust(6, "0")
150 kw = {k: float(v.replace(",", ".")) for k, v in kw.items() if v is not None}
151 days = datetime.timedelta(kw.pop("days", 0.0) or 0.0)
152 if match.re == iso8601_duration_re:
153 days *= sign
154 return days + sign * datetime.timedelta(**kw)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from importlib import import_module
4def deconstructible(*args, path=None):
5 """
6 Class decorator that allows the decorated class to be serialized
7 by the migrations subsystem.
9 The `path` kwarg specifies the import path.
10 """
12 def decorator(klass):
13 def __new__(cls, *args, **kwargs):
14 # We capture the arguments to make returning them trivial
15 obj = super(klass, cls).__new__(cls)
16 obj._constructor_args = (args, kwargs)
17 return obj
19 def deconstruct(obj):
20 """
21 Return a 3-tuple of class import path, positional arguments,
22 and keyword arguments.
23 """
24 # Fallback version
25 if path and type(obj) is klass:
26 module_name, _, name = path.rpartition(".")
27 else:
28 module_name = obj.__module__
29 name = obj.__class__.__name__
30 # Make sure it's actually there and not an inner class
31 module = import_module(module_name)
32 if not hasattr(module, name):
33 raise ValueError(
34 f"Could not find object {name} in {module_name}.\n"
35 "Please note that you cannot serialize things like inner "
36 "classes. Please move the object into the main module "
37 "body to use migrations."
38 )
39 return (
40 path
41 if path and type(obj) is klass
42 else f"{obj.__class__.__module__}.{name}",
43 obj._constructor_args[0],
44 obj._constructor_args[1],
45 )
47 klass.__new__ = staticmethod(__new__)
48 klass.deconstruct = deconstruct
50 return klass
52 if not args:
53 return decorator
54 return decorator(*args)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"Functions that help with dynamically creating decorators for views."
3from functools import partial, update_wrapper, wraps
6class classonlymethod(classmethod):
7 def __get__(self, instance, cls=None):
8 if instance is not None:
9 raise AttributeError(
10 "This method is available only on the class, not on instances."
11 )
12 return super().__get__(instance, cls)
15def _update_method_wrapper(_wrapper, decorator):
16 # _multi_decorate()'s bound_method isn't available in this scope. Cheat by
17 # using it on a dummy function.
18 @decorator
19 def dummy(*args, **kwargs):
20 pass
22 update_wrapper(_wrapper, dummy)
25def _multi_decorate(decorators, method):
26 """
27 Decorate `method` with one or more function decorators. `decorators` can be
28 a single decorator or an iterable of decorators.
29 """
30 if hasattr(decorators, "__iter__"):
31 # Apply a list/tuple of decorators if 'decorators' is one. Decorator
32 # functions are applied so that the call order is the same as the
33 # order in which they appear in the iterable.
34 decorators = decorators[::-1]
35 else:
36 decorators = [decorators]
38 def _wrapper(self, *args, **kwargs):
39 # bound_method has the signature that 'decorator' expects i.e. no
40 # 'self' argument, but it's a closure over self so it can call
41 # 'func'. Also, wrap method.__get__() in a function because new
42 # attributes can't be set on bound method objects, only on functions.
43 bound_method = wraps(method)(partial(method.__get__(self, type(self))))
44 for dec in decorators:
45 bound_method = dec(bound_method)
46 return bound_method(*args, **kwargs)
48 # Copy any attributes that a decorator adds to the function it decorates.
49 for dec in decorators:
50 _update_method_wrapper(_wrapper, dec)
51 # Preserve any existing attributes of 'method', including the name.
52 update_wrapper(_wrapper, method)
53 return _wrapper
56def method_decorator(decorator, name=""):
57 """
58 Convert a function decorator into a method decorator
59 """
61 # 'obj' can be a class or a function. If 'obj' is a function at the time it
62 # is passed to _dec, it will eventually be a method of the class it is
63 # defined on. If 'obj' is a class, the 'name' is required to be the name
64 # of the method that will be decorated.
65 def _dec(obj):
66 if not isinstance(obj, type):
67 return _multi_decorate(decorator, obj)
68 if not (name and hasattr(obj, name)):
69 raise ValueError(
70 "The keyword argument `name` must be the name of a method "
71 f"of the decorated class: {obj}. Got '{name}' instead."
72 )
73 method = getattr(obj, name)
74 if not callable(method):
75 raise TypeError(
76 f"Cannot decorate '{name}' as it isn't a callable attribute of "
77 f"{obj} ({method})."
78 )
79 _wrapper = _multi_decorate(decorator, method)
80 setattr(obj, name, _wrapper)
81 return obj
83 # Don't worry about making _dec look similar to a list/tuple as it's rather
84 # meaningless.
85 if not hasattr(decorator, "__iter__"):
86 update_wrapper(_dec, decorator)
87 # Change the name to aid debugging.
88 obj = decorator if hasattr(decorator, "__name__") else decorator.__class__
89 _dec.__name__ = f"method_decorator({obj.__name__})"
90 return _dec
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1class RemovedInDjango51Warning(DeprecationWarning):
2 pass
5class RemovedInDjango60Warning(PendingDeprecationWarning):
6 pass
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
4def _get_duration_components(duration):
5 days = duration.days
6 seconds = duration.seconds
7 microseconds = duration.microseconds
9 minutes = seconds // 60
10 seconds %= 60
12 hours = minutes // 60
13 minutes %= 60
15 return days, hours, minutes, seconds, microseconds
18def duration_string(duration):
19 """Version of str(timedelta) which is not English specific."""
20 days, hours, minutes, seconds, microseconds = _get_duration_components(duration)
22 string = f"{hours:02d}:{minutes:02d}:{seconds:02d}"
23 if days:
24 string = f"{days} " + string
25 if microseconds:
26 string += f".{microseconds:06d}"
28 return string
31def duration_iso_string(duration):
32 if duration < datetime.timedelta(0):
33 sign = "-"
34 duration *= -1
35 else:
36 sign = ""
38 days, hours, minutes, seconds, microseconds = _get_duration_components(duration)
39 ms = f".{microseconds:06d}" if microseconds else ""
40 return f"{sign}P{days}DT{hours:02d}H{minutes:02d}M{seconds:02d}{ms}S"
43def duration_microseconds(delta):
44 return (24 * 60 * 60 * delta.days + delta.seconds) * 1000000 + delta.microseconds
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import codecs
2import datetime
3import locale
4from decimal import Decimal
5from types import NoneType
6from urllib.parse import quote
8from plain.utils.functional import Promise
11class PlainUnicodeDecodeError(UnicodeDecodeError):
12 def __init__(self, obj, *args):
13 self.obj = obj
14 super().__init__(*args)
16 def __str__(self):
17 return f"{super().__str__()}. You passed in {self.obj!r} ({type(self.obj)})"
20_PROTECTED_TYPES = (
21 NoneType,
22 int,
23 float,
24 Decimal,
25 datetime.datetime,
26 datetime.date,
27 datetime.time,
28)
31def is_protected_type(obj):
32 """Determine if the object instance is of a protected type.
34 Objects of protected types are preserved as-is when passed to
35 force_str(strings_only=True).
36 """
37 return isinstance(obj, _PROTECTED_TYPES)
40def force_str(s, encoding="utf-8", strings_only=False, errors="strict"):
41 """
42 Similar to smart_str(), except that lazy instances are resolved to
43 strings, rather than kept as lazy objects.
45 If strings_only is True, don't convert (some) non-string-like objects.
46 """
47 # Handle the common case first for performance reasons.
48 if issubclass(type(s), str):
49 return s
50 if strings_only and is_protected_type(s):
51 return s
52 try:
53 if isinstance(s, bytes):
54 s = str(s, encoding, errors)
55 else:
56 s = str(s)
57 except UnicodeDecodeError as e:
58 raise PlainUnicodeDecodeError(s, *e.args)
59 return s
62def force_bytes(s, encoding="utf-8", strings_only=False, errors="strict"):
63 """
64 Similar to smart_bytes, except that lazy instances are resolved to
65 strings, rather than kept as lazy objects.
67 If strings_only is True, don't convert (some) non-string-like objects.
68 """
69 # Handle the common case first for performance reasons.
70 if isinstance(s, bytes):
71 if encoding == "utf-8":
72 return s
73 else:
74 return s.decode("utf-8", errors).encode(encoding, errors)
75 if strings_only and is_protected_type(s):
76 return s
77 if isinstance(s, memoryview):
78 return bytes(s)
79 return str(s).encode(encoding, errors)
82def iri_to_uri(iri):
83 """
84 Convert an Internationalized Resource Identifier (IRI) portion to a URI
85 portion that is suitable for inclusion in a URL.
87 This is the algorithm from RFC 3987 Section 3.1, slightly simplified since
88 the input is assumed to be a string rather than an arbitrary byte stream.
90 Take an IRI (string or UTF-8 bytes, e.g. '/I ♥ Plain/' or
91 b'/I \xe2\x99\xa5 Plain/') and return a string containing the encoded
92 result with ASCII chars only (e.g. '/I%20%E2%99%A5%20Plain/').
93 """
94 # The list of safe characters here is constructed from the "reserved" and
95 # "unreserved" characters specified in RFC 3986 Sections 2.2 and 2.3:
96 # reserved = gen-delims / sub-delims
97 # gen-delims = ":" / "/" / "?" / "#" / "[" / "]" / "@"
98 # sub-delims = "!" / "$" / "&" / "'" / "(" / ")"
99 # / "*" / "+" / "," / ";" / "="
100 # unreserved = ALPHA / DIGIT / "-" / "." / "_" / "~"
101 # Of the unreserved characters, urllib.parse.quote() already considers all
102 # but the ~ safe.
103 # The % character is also added to the list of safe characters here, as the
104 # end of RFC 3987 Section 3.1 specifically mentions that % must not be
105 # converted.
106 if iri is None:
107 return iri
108 elif isinstance(iri, Promise):
109 iri = str(iri)
110 return quote(iri, safe="/#%[]=:;$&()+,!?*@'~")
113# List of byte values that uri_to_iri() decodes from percent encoding.
114# First, the unreserved characters from RFC 3986:
115_ascii_ranges = [[45, 46, 95, 126], range(65, 91), range(97, 123)]
116_hextobyte = {
117 (fmt % char).encode(): bytes((char,))
118 for ascii_range in _ascii_ranges
119 for char in ascii_range
120 for fmt in ["%02x", "%02X"]
121}
122# And then everything above 128, because bytes ≥ 128 are part of multibyte
123# Unicode characters.
124_hexdig = "0123456789ABCDEFabcdef"
125_hextobyte.update(
126 {(a + b).encode(): bytes.fromhex(a + b) for a in _hexdig[8:] for b in _hexdig}
127)
130def uri_to_iri(uri):
131 """
132 Convert a Uniform Resource Identifier(URI) into an Internationalized
133 Resource Identifier(IRI).
135 This is the algorithm from RFC 3987 Section 3.2, excluding step 4.
137 Take an URI in ASCII bytes (e.g. '/I%20%E2%99%A5%20Plain/') and return
138 a string containing the encoded result (e.g. '/I%20♥%20Plain/').
139 """
140 if uri is None:
141 return uri
142 uri = force_bytes(uri)
143 # Fast selective unquote: First, split on '%' and then starting with the
144 # second block, decode the first 2 bytes if they represent a hex code to
145 # decode. The rest of the block is the part after '%AB', not containing
146 # any '%'. Add that to the output without further processing.
147 bits = uri.split(b"%")
148 if len(bits) == 1:
149 iri = uri
150 else:
151 parts = [bits[0]]
152 append = parts.append
153 hextobyte = _hextobyte
154 for item in bits[1:]:
155 hex = item[:2]
156 if hex in hextobyte:
157 append(hextobyte[item[:2]])
158 append(item[2:])
159 else:
160 append(b"%")
161 append(item)
162 iri = b"".join(parts)
163 return repercent_broken_unicode(iri).decode()
166def escape_uri_path(path):
167 """
168 Escape the unsafe characters from the path portion of a Uniform Resource
169 Identifier (URI).
170 """
171 # These are the "reserved" and "unreserved" characters specified in RFC
172 # 3986 Sections 2.2 and 2.3:
173 # reserved = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+" | "$" | ","
174 # unreserved = alphanum | mark
175 # mark = "-" | "_" | "." | "!" | "~" | "*" | "'" | "(" | ")"
176 # The list of safe characters here is constructed subtracting ";", "=",
177 # and "?" according to RFC 3986 Section 3.3.
178 # The reason for not subtracting and escaping "/" is that we are escaping
179 # the entire path, not a path segment.
180 return quote(path, safe="/:@&+$,-_.!~*'()")
183def punycode(domain):
184 """Return the Punycode of the given domain if it's non-ASCII."""
185 return domain.encode("idna").decode("ascii")
188def repercent_broken_unicode(path):
189 """
190 As per RFC 3987 Section 3.2, step three of converting a URI into an IRI,
191 repercent-encode any octet produced that is not part of a strictly legal
192 UTF-8 octet sequence.
193 """
194 while True:
195 try:
196 path.decode()
197 except UnicodeDecodeError as e:
198 # CVE-2019-14235: A recursion shouldn't be used since the exception
199 # handling uses massive amounts of memory
200 repercent = quote(path[e.start : e.end], safe=b"/#%[]=:;$&()+,!?*@'~")
201 path = path[: e.start] + repercent.encode() + path[e.end :]
202 else:
203 return path
206def filepath_to_uri(path):
207 """Convert a file system path to a URI portion that is suitable for
208 inclusion in a URL.
210 Encode certain chars that would normally be recognized as special chars
211 for URIs. Do not encode the ' character, as it is a valid character
212 within URIs. See the encodeURIComponent() JavaScript function for details.
213 """
214 if path is None:
215 return path
216 # I know about `os.sep` and `os.altsep` but I want to leave
217 # some flexibility for hardcoding separators.
218 return quote(str(path).replace("\\", "/"), safe="/~!*()'")
221def get_system_encoding():
222 """
223 The encoding for the character type functions. Fallback to 'ascii' if the
224 #encoding is unsupported by Python or could not be determined. See tickets
225 #10335 and #5846.
226 """
227 try:
228 encoding = locale.getlocale()[1] or "ascii"
229 codecs.lookup(encoding)
230 except Exception:
231 encoding = "ascii"
232 return encoding
235DEFAULT_LOCALE_ENCODING = get_system_encoding()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import copy
2import itertools
3import operator
4from functools import total_ordering, wraps
7class cached_property:
8 """
9 Decorator that converts a method with a single self argument into a
10 property cached on the instance.
12 A cached property can be made out of an existing method:
13 (e.g. ``url = cached_property(get_absolute_url)``).
14 """
16 name = None
18 @staticmethod
19 def func(instance):
20 raise TypeError(
21 "Cannot use cached_property instance without calling "
22 "__set_name__() on it."
23 )
25 def __init__(self, func):
26 self.real_func = func
27 self.__doc__ = getattr(func, "__doc__")
29 def __set_name__(self, owner, name):
30 if self.name is None:
31 self.name = name
32 self.func = self.real_func
33 elif name != self.name:
34 raise TypeError(
35 "Cannot assign the same cached_property to two different names "
36 f"({self.name!r} and {name!r})."
37 )
39 def __get__(self, instance, cls=None):
40 """
41 Call the function and put the return value in instance.__dict__ so that
42 subsequent attribute access on the instance returns the cached value
43 instead of calling cached_property.__get__().
44 """
45 if instance is None:
46 return self
47 res = instance.__dict__[self.name] = self.func(instance)
48 return res
51class classproperty:
52 """
53 Decorator that converts a method with a single cls argument into a property
54 that can be accessed directly from the class.
55 """
57 def __init__(self, method=None):
58 self.fget = method
60 def __get__(self, instance, cls=None):
61 return self.fget(cls)
63 def getter(self, method):
64 self.fget = method
65 return self
68class Promise:
69 """
70 Base class for the proxy class created in the closure of the lazy function.
71 It's used to recognize promises in code.
72 """
74 pass
77def lazy(func, *resultclasses):
78 """
79 Turn any callable into a lazy evaluated callable. result classes or types
80 is required -- at least one is needed so that the automatic forcing of
81 the lazy evaluation code is triggered. Results are not memoized; the
82 function is evaluated on every access.
83 """
85 @total_ordering
86 class __proxy__(Promise):
87 """
88 Encapsulate a function call and act as a proxy for methods that are
89 called on the result of that function. The function is not evaluated
90 until one of the methods on the result is called.
91 """
93 __prepared = False
95 def __init__(self, args, kw):
96 self.__args = args
97 self.__kw = kw
98 if not self.__prepared:
99 self.__prepare_class__()
100 self.__class__.__prepared = True
102 def __reduce__(self):
103 return (
104 _lazy_proxy_unpickle,
105 (func, self.__args, self.__kw) + resultclasses,
106 )
108 def __repr__(self):
109 return repr(self.__cast())
111 @classmethod
112 def __prepare_class__(cls):
113 for resultclass in resultclasses:
114 for type_ in resultclass.mro():
115 for method_name in type_.__dict__:
116 # All __promise__ return the same wrapper method, they
117 # look up the correct implementation when called.
118 if hasattr(cls, method_name):
119 continue
120 meth = cls.__promise__(method_name)
121 setattr(cls, method_name, meth)
122 cls._delegate_bytes = bytes in resultclasses
123 cls._delegate_text = str in resultclasses
124 if cls._delegate_bytes and cls._delegate_text:
125 raise ValueError(
126 "Cannot call lazy() with both bytes and text return types."
127 )
128 if cls._delegate_text:
129 cls.__str__ = cls.__text_cast
130 elif cls._delegate_bytes:
131 cls.__bytes__ = cls.__bytes_cast
133 @classmethod
134 def __promise__(cls, method_name):
135 # Builds a wrapper around some magic method
136 def __wrapper__(self, *args, **kw):
137 # Automatically triggers the evaluation of a lazy value and
138 # applies the given magic method of the result type.
139 res = func(*self.__args, **self.__kw)
140 return getattr(res, method_name)(*args, **kw)
142 return __wrapper__
144 def __text_cast(self):
145 return func(*self.__args, **self.__kw)
147 def __bytes_cast(self):
148 return bytes(func(*self.__args, **self.__kw))
150 def __bytes_cast_encoded(self):
151 return func(*self.__args, **self.__kw).encode()
153 def __cast(self):
154 if self._delegate_bytes:
155 return self.__bytes_cast()
156 elif self._delegate_text:
157 return self.__text_cast()
158 else:
159 return func(*self.__args, **self.__kw)
161 def __str__(self):
162 # object defines __str__(), so __prepare_class__() won't overload
163 # a __str__() method from the proxied class.
164 return str(self.__cast())
166 def __eq__(self, other):
167 if isinstance(other, Promise):
168 other = other.__cast()
169 return self.__cast() == other
171 def __lt__(self, other):
172 if isinstance(other, Promise):
173 other = other.__cast()
174 return self.__cast() < other
176 def __hash__(self):
177 return hash(self.__cast())
179 def __mod__(self, rhs):
180 if self._delegate_text:
181 return str(self) % rhs
182 return self.__cast() % rhs
184 def __add__(self, other):
185 return self.__cast() + other
187 def __radd__(self, other):
188 return other + self.__cast()
190 def __deepcopy__(self, memo):
191 # Instances of this class are effectively immutable. It's just a
192 # collection of functions. So we don't need to do anything
193 # complicated for copying.
194 memo[id(self)] = self
195 return self
197 @wraps(func)
198 def __wrapper__(*args, **kw):
199 # Creates the proxy object, instead of the actual value.
200 return __proxy__(args, kw)
202 return __wrapper__
205def _lazy_proxy_unpickle(func, args, kwargs, *resultclasses):
206 return lazy(func, *resultclasses)(*args, **kwargs)
209def lazystr(text):
210 """
211 Shortcut for the common case of a lazy callable that returns str.
212 """
213 return lazy(str, str)(text)
216def keep_lazy(*resultclasses):
217 """
218 A decorator that allows a function to be called with one or more lazy
219 arguments. If none of the args are lazy, the function is evaluated
220 immediately, otherwise a __proxy__ is returned that will evaluate the
221 function when needed.
222 """
223 if not resultclasses:
224 raise TypeError("You must pass at least one argument to keep_lazy().")
226 def decorator(func):
227 lazy_func = lazy(func, *resultclasses)
229 @wraps(func)
230 def wrapper(*args, **kwargs):
231 if any(
232 isinstance(arg, Promise)
233 for arg in itertools.chain(args, kwargs.values())
234 ):
235 return lazy_func(*args, **kwargs)
236 return func(*args, **kwargs)
238 return wrapper
240 return decorator
243def keep_lazy_text(func):
244 """
245 A decorator for functions that accept lazy arguments and return text.
246 """
247 return keep_lazy(str)(func)
250empty = object()
253def new_method_proxy(func):
254 def inner(self, *args):
255 if (_wrapped := self._wrapped) is empty:
256 self._setup()
257 _wrapped = self._wrapped
258 return func(_wrapped, *args)
260 inner._mask_wrapped = False
261 return inner
264class LazyObject:
265 """
266 A wrapper for another class that can be used to delay instantiation of the
267 wrapped class.
269 By subclassing, you have the opportunity to intercept and alter the
270 instantiation. If you don't need to do that, use SimpleLazyObject.
271 """
273 # Avoid infinite recursion when tracing __init__ (#19456).
274 _wrapped = None
276 def __init__(self):
277 # Note: if a subclass overrides __init__(), it will likely need to
278 # override __copy__() and __deepcopy__() as well.
279 self._wrapped = empty
281 def __getattribute__(self, name):
282 if name == "_wrapped":
283 # Avoid recursion when getting wrapped object.
284 return super().__getattribute__(name)
285 value = super().__getattribute__(name)
286 # If attribute is a proxy method, raise an AttributeError to call
287 # __getattr__() and use the wrapped object method.
288 if not getattr(value, "_mask_wrapped", True):
289 raise AttributeError
290 return value
292 __getattr__ = new_method_proxy(getattr)
294 def __setattr__(self, name, value):
295 if name == "_wrapped":
296 # Assign to __dict__ to avoid infinite __setattr__ loops.
297 self.__dict__["_wrapped"] = value
298 else:
299 if self._wrapped is empty:
300 self._setup()
301 setattr(self._wrapped, name, value)
303 def __delattr__(self, name):
304 if name == "_wrapped":
305 raise TypeError("can't delete _wrapped.")
306 if self._wrapped is empty:
307 self._setup()
308 delattr(self._wrapped, name)
310 def _setup(self):
311 """
312 Must be implemented by subclasses to initialize the wrapped object.
313 """
314 raise NotImplementedError(
315 "subclasses of LazyObject must provide a _setup() method"
316 )
318 # Because we have messed with __class__ below, we confuse pickle as to what
319 # class we are pickling. We're going to have to initialize the wrapped
320 # object to successfully pickle it, so we might as well just pickle the
321 # wrapped object since they're supposed to act the same way.
322 #
323 # Unfortunately, if we try to simply act like the wrapped object, the ruse
324 # will break down when pickle gets our id(). Thus we end up with pickle
325 # thinking, in effect, that we are a distinct object from the wrapped
326 # object, but with the same __dict__. This can cause problems (see #25389).
327 #
328 # So instead, we define our own __reduce__ method and custom unpickler. We
329 # pickle the wrapped object as the unpickler's argument, so that pickle
330 # will pickle it normally, and then the unpickler simply returns its
331 # argument.
332 def __reduce__(self):
333 if self._wrapped is empty:
334 self._setup()
335 return (unpickle_lazyobject, (self._wrapped,))
337 def __copy__(self):
338 if self._wrapped is empty:
339 # If uninitialized, copy the wrapper. Use type(self), not
340 # self.__class__, because the latter is proxied.
341 return type(self)()
342 else:
343 # If initialized, return a copy of the wrapped object.
344 return copy.copy(self._wrapped)
346 def __deepcopy__(self, memo):
347 if self._wrapped is empty:
348 # We have to use type(self), not self.__class__, because the
349 # latter is proxied.
350 result = type(self)()
351 memo[id(self)] = result
352 return result
353 return copy.deepcopy(self._wrapped, memo)
355 __bytes__ = new_method_proxy(bytes)
356 __str__ = new_method_proxy(str)
357 __bool__ = new_method_proxy(bool)
359 # Introspection support
360 __dir__ = new_method_proxy(dir)
362 # Need to pretend to be the wrapped class, for the sake of objects that
363 # care about this (especially in equality tests)
364 __class__ = property(new_method_proxy(operator.attrgetter("__class__")))
365 __eq__ = new_method_proxy(operator.eq)
366 __lt__ = new_method_proxy(operator.lt)
367 __gt__ = new_method_proxy(operator.gt)
368 __ne__ = new_method_proxy(operator.ne)
369 __hash__ = new_method_proxy(hash)
371 # List/Tuple/Dictionary methods support
372 __getitem__ = new_method_proxy(operator.getitem)
373 __setitem__ = new_method_proxy(operator.setitem)
374 __delitem__ = new_method_proxy(operator.delitem)
375 __iter__ = new_method_proxy(iter)
376 __len__ = new_method_proxy(len)
377 __contains__ = new_method_proxy(operator.contains)
380def unpickle_lazyobject(wrapped):
381 """
382 Used to unpickle lazy objects. Just return its argument, which will be the
383 wrapped object.
384 """
385 return wrapped
388class SimpleLazyObject(LazyObject):
389 """
390 A lazy object initialized from any function.
392 Designed for compound objects of unknown type. For builtins or objects of
393 known type, use plain.utils.functional.lazy.
394 """
396 def __init__(self, func):
397 """
398 Pass in a callable that returns the object to be wrapped.
400 If copies are made of the resulting SimpleLazyObject, which can happen
401 in various circumstances within Plain, then you must ensure that the
402 callable can be safely run more than once and will return the same
403 value.
404 """
405 self.__dict__["_setupfunc"] = func
406 super().__init__()
408 def _setup(self):
409 self._wrapped = self._setupfunc()
411 # Return a meaningful representation of the lazy object for debugging
412 # without evaluating the wrapped object.
413 def __repr__(self):
414 if self._wrapped is empty:
415 repr_attr = self._setupfunc
416 else:
417 repr_attr = self._wrapped
418 return f"<{type(self).__name__}: {repr_attr!r}>"
420 def __copy__(self):
421 if self._wrapped is empty:
422 # If uninitialized, copy the wrapper. Use SimpleLazyObject, not
423 # self.__class__, because the latter is proxied.
424 return SimpleLazyObject(self._setupfunc)
425 else:
426 # If initialized, return a copy of the wrapped object.
427 return copy.copy(self._wrapped)
429 def __deepcopy__(self, memo):
430 if self._wrapped is empty:
431 # We have to use SimpleLazyObject, not self.__class__, because the
432 # latter is proxied.
433 result = SimpleLazyObject(self._setupfunc)
434 memo[id(self)] = result
435 return result
436 return copy.deepcopy(self._wrapped, memo)
438 __add__ = new_method_proxy(operator.add)
440 @new_method_proxy
441 def __radd__(self, other):
442 return other + self
445def partition(predicate, values):
446 """
447 Split the values into two sets, based on the return value of the function
448 (True/False). e.g.:
450 >>> partition(lambda x: x > 3, range(5))
451 [0, 1, 2, 3], [4]
452 """
453 results = ([], [])
454 for item in values:
455 results[predicate(item)].append(item)
456 return results
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.utils.itercompat import is_iterable
4def make_hashable(value):
5 """
6 Attempt to make value hashable or raise a TypeError if it fails.
8 The returned value should generate the same hash for equal values.
9 """
10 if isinstance(value, dict):
11 return tuple(
12 [
13 (key, make_hashable(nested_value))
14 for key, nested_value in sorted(value.items())
15 ]
16 )
17 # Try hash to avoid converting a hashable iterable (e.g. string, frozenset)
18 # to a tuple.
19 try:
20 hash(value)
21 except TypeError:
22 if is_iterable(value):
23 return tuple(map(make_hashable, value))
24 # Non-hashable, non-iterable.
25 raise
26 return value
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""HTML utilities suitable for global use."""
3import html
4import json
5import re
6from html.parser import HTMLParser
7from urllib.parse import parse_qsl, quote, unquote, urlencode, urlsplit, urlunsplit
9from plain.utils.encoding import punycode
10from plain.utils.functional import Promise, keep_lazy, keep_lazy_text
11from plain.utils.http import RFC3986_GENDELIMS, RFC3986_SUBDELIMS
12from plain.utils.regex_helper import _lazy_re_compile
13from plain.utils.safestring import SafeData, SafeString, mark_safe
14from plain.utils.text import normalize_newlines
17@keep_lazy(SafeString)
18def escape(text):
19 """
20 Return the given text with ampersands, quotes and angle brackets encoded
21 for use in HTML.
23 Always escape input, even if it's already escaped and marked as such.
24 This may result in double-escaping. If this is a concern, use
25 conditional_escape() instead.
26 """
27 return SafeString(html.escape(str(text)))
30_js_escapes = {
31 ord("\\"): "\\u005C",
32 ord("'"): "\\u0027",
33 ord('"'): "\\u0022",
34 ord(">"): "\\u003E",
35 ord("<"): "\\u003C",
36 ord("&"): "\\u0026",
37 ord("="): "\\u003D",
38 ord("-"): "\\u002D",
39 ord(";"): "\\u003B",
40 ord("`"): "\\u0060",
41 ord("\u2028"): "\\u2028",
42 ord("\u2029"): "\\u2029",
43}
45# Escape every ASCII character with a value less than 32.
46_js_escapes.update((ord("%c" % z), f"\\u{z:04X}") for z in range(32))
49@keep_lazy(SafeString)
50def escapejs(value):
51 """Hex encode characters for use in JavaScript strings."""
52 return mark_safe(str(value).translate(_js_escapes))
55_json_script_escapes = {
56 ord(">"): "\\u003E",
57 ord("<"): "\\u003C",
58 ord("&"): "\\u0026",
59}
62def json_script(value, element_id=None, encoder=None):
63 """
64 Escape all the HTML/XML special characters with their unicode escapes, so
65 value is safe to be output anywhere except for inside a tag attribute. Wrap
66 the escaped JSON in a script tag.
67 """
68 from plain.json import PlainJSONEncoder
70 json_str = json.dumps(value, cls=encoder or PlainJSONEncoder).translate(
71 _json_script_escapes
72 )
73 if element_id:
74 template = '<script id="{}" type="application/json">{}</script>'
75 args = (element_id, mark_safe(json_str))
76 else:
77 template = '<script type="application/json">{}</script>'
78 args = (mark_safe(json_str),)
79 return format_html(template, *args)
82def conditional_escape(text):
83 """
84 Similar to escape(), except that it doesn't operate on pre-escaped strings.
86 This function relies on the __html__ convention used both by Plain's
87 SafeData class and by third-party libraries like markupsafe.
88 """
89 if isinstance(text, Promise):
90 text = str(text)
91 if hasattr(text, "__html__"):
92 return text.__html__()
93 else:
94 return escape(text)
97def format_html(format_string, *args, **kwargs):
98 """
99 Similar to str.format, but pass all arguments through conditional_escape(),
100 and call mark_safe() on the result. This function should be used instead
101 of str.format or % interpolation to build up small HTML fragments.
102 """
103 args_safe = map(conditional_escape, args)
104 kwargs_safe = {k: conditional_escape(v) for (k, v) in kwargs.items()}
105 return mark_safe(format_string.format(*args_safe, **kwargs_safe))
108def format_html_join(sep, format_string, args_generator):
109 """
110 A wrapper of format_html, for the common case of a group of arguments that
111 need to be formatted using the same format string, and then joined using
112 'sep'. 'sep' is also passed through conditional_escape.
114 'args_generator' should be an iterator that returns the sequence of 'args'
115 that will be passed to format_html.
117 Example:
119 format_html_join('\n', "<li>{} {}</li>", ((u.first_name, u.last_name)
120 for u in users))
121 """
122 return mark_safe(
123 conditional_escape(sep).join(
124 format_html(format_string, *args) for args in args_generator
125 )
126 )
129@keep_lazy_text
130def linebreaks(value, autoescape=False):
131 """Convert newlines into <p> and <br>s."""
132 value = normalize_newlines(value)
133 paras = re.split("\n{2,}", str(value))
134 if autoescape:
135 paras = ["<p>{}</p>".format(escape(p).replace("\n", "<br>")) for p in paras]
136 else:
137 paras = ["<p>{}</p>".format(p.replace("\n", "<br>")) for p in paras]
138 return "\n\n".join(paras)
141class MLStripper(HTMLParser):
142 def __init__(self):
143 super().__init__(convert_charrefs=False)
144 self.reset()
145 self.fed = []
147 def handle_data(self, d):
148 self.fed.append(d)
150 def handle_entityref(self, name):
151 self.fed.append(f"&{name};")
153 def handle_charref(self, name):
154 self.fed.append(f"&#{name};")
156 def get_data(self):
157 return "".join(self.fed)
160def _strip_once(value):
161 """
162 Internal tag stripping utility used by strip_tags.
163 """
164 s = MLStripper()
165 s.feed(value)
166 s.close()
167 return s.get_data()
170@keep_lazy_text
171def strip_tags(value):
172 """Return the given HTML with all tags stripped."""
173 # Note: in typical case this loop executes _strip_once once. Loop condition
174 # is redundant, but helps to reduce number of executions of _strip_once.
175 value = str(value)
176 while "<" in value and ">" in value:
177 new_value = _strip_once(value)
178 if value.count("<") == new_value.count("<"):
179 # _strip_once wasn't able to detect more tags.
180 break
181 value = new_value
182 return value
185@keep_lazy_text
186def strip_spaces_between_tags(value):
187 """Return the given HTML with spaces between tags removed."""
188 return re.sub(r">\s+<", "><", str(value))
191def smart_urlquote(url):
192 """Quote a URL if it isn't already quoted."""
194 def unquote_quote(segment):
195 segment = unquote(segment)
196 # Tilde is part of RFC 3986 Section 2.3 Unreserved Characters,
197 # see also https://bugs.python.org/issue16285
198 return quote(segment, safe=RFC3986_SUBDELIMS + RFC3986_GENDELIMS + "~")
200 # Handle IDN before quoting.
201 try:
202 scheme, netloc, path, query, fragment = urlsplit(url)
203 except ValueError:
204 # invalid IPv6 URL (normally square brackets in hostname part).
205 return unquote_quote(url)
207 try:
208 netloc = punycode(netloc) # IDN -> ACE
209 except UnicodeError: # invalid domain part
210 return unquote_quote(url)
212 if query:
213 # Separately unquoting key/value, so as to not mix querystring separators
214 # included in query values. See #22267.
215 query_parts = [
216 (unquote(q[0]), unquote(q[1]))
217 for q in parse_qsl(query, keep_blank_values=True)
218 ]
219 # urlencode will take care of quoting
220 query = urlencode(query_parts)
222 path = unquote_quote(path)
223 fragment = unquote_quote(fragment)
225 return urlunsplit((scheme, netloc, path, query, fragment))
228class Urlizer:
229 """
230 Convert any URLs in text into clickable links.
232 Work on http://, https://, www. links, and also on links ending in one of
233 the original seven gTLDs (.com, .edu, .gov, .int, .mil, .net, and .org).
234 Links can have trailing punctuation (periods, commas, close-parens) and
235 leading punctuation (opening parens) and it'll still do the right thing.
236 """
238 trailing_punctuation_chars = ".,:;!"
239 wrapping_punctuation = [("(", ")"), ("[", "]")]
241 simple_url_re = _lazy_re_compile(r"^https?://\[?\w", re.IGNORECASE)
242 simple_url_2_re = _lazy_re_compile(
243 r"^www\.|^(?!http)\w[^@]+\.(com|edu|gov|int|mil|net|org)($|/.*)$", re.IGNORECASE
244 )
245 word_split_re = _lazy_re_compile(r"""([\s<>"']+)""")
247 mailto_template = "mailto:{local}@{domain}"
248 url_template = '<a href="{href}"{attrs}>{url}</a>'
250 def __call__(self, text, trim_url_limit=None, nofollow=False, autoescape=False):
251 """
252 If trim_url_limit is not None, truncate the URLs in the link text
253 longer than this limit to trim_url_limit - 1 characters and append an
254 ellipsis.
256 If nofollow is True, give the links a rel="nofollow" attribute.
258 If autoescape is True, autoescape the link text and URLs.
259 """
260 safe_input = isinstance(text, SafeData)
262 words = self.word_split_re.split(str(text))
263 return "".join(
264 [
265 self.handle_word(
266 word,
267 safe_input=safe_input,
268 trim_url_limit=trim_url_limit,
269 nofollow=nofollow,
270 autoescape=autoescape,
271 )
272 for word in words
273 ]
274 )
276 def handle_word(
277 self,
278 word,
279 *,
280 safe_input,
281 trim_url_limit=None,
282 nofollow=False,
283 autoescape=False,
284 ):
285 if "." in word or "@" in word or ":" in word:
286 # lead: Punctuation trimmed from the beginning of the word.
287 # middle: State of the word.
288 # trail: Punctuation trimmed from the end of the word.
289 lead, middle, trail = self.trim_punctuation(word)
290 # Make URL we want to point to.
291 url = None
292 nofollow_attr = ' rel="nofollow"' if nofollow else ""
293 if self.simple_url_re.match(middle):
294 url = smart_urlquote(html.unescape(middle))
295 elif self.simple_url_2_re.match(middle):
296 url = smart_urlquote(f"http://{html.unescape(middle)}")
297 elif ":" not in middle and self.is_email_simple(middle):
298 local, domain = middle.rsplit("@", 1)
299 try:
300 domain = punycode(domain)
301 except UnicodeError:
302 return word
303 url = self.mailto_template.format(local=local, domain=domain)
304 nofollow_attr = ""
305 # Make link.
306 if url:
307 trimmed = self.trim_url(middle, limit=trim_url_limit)
308 if autoescape and not safe_input:
309 lead, trail = escape(lead), escape(trail)
310 trimmed = escape(trimmed)
311 middle = self.url_template.format(
312 href=escape(url),
313 attrs=nofollow_attr,
314 url=trimmed,
315 )
316 return mark_safe(f"{lead}{middle}{trail}")
317 else:
318 if safe_input:
319 return mark_safe(word)
320 elif autoescape:
321 return escape(word)
322 elif safe_input:
323 return mark_safe(word)
324 elif autoescape:
325 return escape(word)
326 return word
328 def trim_url(self, x, *, limit):
329 if limit is None or len(x) <= limit:
330 return x
331 return f"{x[: max(0, limit - 1)]}…"
333 def trim_punctuation(self, word):
334 """
335 Trim trailing and wrapping punctuation from `word`. Return the items of
336 the new state.
337 """
338 lead, middle, trail = "", word, ""
339 # Continue trimming until middle remains unchanged.
340 trimmed_something = True
341 while trimmed_something:
342 trimmed_something = False
343 # Trim wrapping punctuation.
344 for opening, closing in self.wrapping_punctuation:
345 if middle.startswith(opening):
346 middle = middle.removeprefix(opening)
347 lead += opening
348 trimmed_something = True
349 # Keep parentheses at the end only if they're balanced.
350 if (
351 middle.endswith(closing)
352 and middle.count(closing) == middle.count(opening) + 1
353 ):
354 middle = middle.removesuffix(closing)
355 trail = closing + trail
356 trimmed_something = True
357 # Trim trailing punctuation (after trimming wrapping punctuation,
358 # as encoded entities contain ';'). Unescape entities to avoid
359 # breaking them by removing ';'.
360 middle_unescaped = html.unescape(middle)
361 stripped = middle_unescaped.rstrip(self.trailing_punctuation_chars)
362 if middle_unescaped != stripped:
363 punctuation_count = len(middle_unescaped) - len(stripped)
364 trail = middle[-punctuation_count:] + trail
365 middle = middle[:-punctuation_count]
366 trimmed_something = True
367 return lead, middle, trail
369 @staticmethod
370 def is_email_simple(value):
371 """Return True if value looks like an email address."""
372 # An @ must be in the middle of the value.
373 if "@" not in value or value.startswith("@") or value.endswith("@"):
374 return False
375 try:
376 p1, p2 = value.split("@")
377 except ValueError:
378 # value contains more than one @.
379 return False
380 # Dot must be in p2 (e.g. example.com)
381 if "." not in p2 or p2.startswith("."):
382 return False
383 return True
386urlizer = Urlizer()
389@keep_lazy_text
390def urlize(text, trim_url_limit=None, nofollow=False, autoescape=False):
391 return urlizer(
392 text, trim_url_limit=trim_url_limit, nofollow=nofollow, autoescape=autoescape
393 )
396def avoid_wrapping(value):
397 """
398 Avoid text wrapping in the middle of a phrase by adding non-breaking
399 spaces where there previously were normal spaces.
400 """
401 return value.replace(" ", "\xa0")
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import base64
2import datetime
3import re
4import unicodedata
5from binascii import Error as BinasciiError
6from email.utils import formatdate
7from urllib.parse import quote, unquote, urlparse
8from urllib.parse import urlencode as original_urlencode
10from plain.utils.datastructures import MultiValueDict
11from plain.utils.regex_helper import _lazy_re_compile
13# Based on RFC 9110 Appendix A.
14ETAG_MATCH = _lazy_re_compile(
15 r"""
16 \A( # start of string and capture group
17 (?:W/)? # optional weak indicator
18 " # opening quote
19 [^"]* # any sequence of non-quote characters
20 " # end quote
21 )\Z # end of string and capture group
22""",
23 re.X,
24)
26MONTHS = "jan feb mar apr may jun jul aug sep oct nov dec".split()
27__D = r"(?P<day>[0-9]{2})"
28__D2 = r"(?P<day>[ 0-9][0-9])"
29__M = r"(?P<mon>\w{3})"
30__Y = r"(?P<year>[0-9]{4})"
31__Y2 = r"(?P<year>[0-9]{2})"
32__T = r"(?P<hour>[0-9]{2}):(?P<min>[0-9]{2}):(?P<sec>[0-9]{2})"
33RFC1123_DATE = _lazy_re_compile(rf"^\w{ 3} , {__D} {__M} {__Y} {__T} GMT$")
34RFC850_DATE = _lazy_re_compile(rf"^\w{ 6,9} , {__D}-{__M}-{__Y2} {__T} GMT$")
35ASCTIME_DATE = _lazy_re_compile(rf"^\w{ 3} {__M} {__D2} {__T} {__Y}$")
37RFC3986_GENDELIMS = ":/?#[]@"
38RFC3986_SUBDELIMS = "!$&'()*+,;="
41def urlencode(query, doseq=False):
42 """
43 A version of Python's urllib.parse.urlencode() function that can operate on
44 MultiValueDict and non-string values.
45 """
46 if isinstance(query, MultiValueDict):
47 query = query.lists()
48 elif hasattr(query, "items"):
49 query = query.items()
50 query_params = []
51 for key, value in query:
52 if value is None:
53 raise TypeError(
54 f"Cannot encode None for key '{key}' in a query string. Did you "
55 "mean to pass an empty string or omit the value?"
56 )
57 elif not doseq or isinstance(value, str | bytes):
58 query_val = value
59 else:
60 try:
61 itr = iter(value)
62 except TypeError:
63 query_val = value
64 else:
65 # Consume generators and iterators, when doseq=True, to
66 # work around https://bugs.python.org/issue31706.
67 query_val = []
68 for item in itr:
69 if item is None:
70 raise TypeError(
71 f"Cannot encode None for key '{key}' in a query "
72 "string. Did you mean to pass an empty string or "
73 "omit the value?"
74 )
75 elif not isinstance(item, bytes):
76 item = str(item)
77 query_val.append(item)
78 query_params.append((key, query_val))
79 return original_urlencode(query_params, doseq)
82def http_date(epoch_seconds=None):
83 """
84 Format the time to match the RFC 5322 date format as specified by RFC 9110
85 Section 5.6.7.
87 `epoch_seconds` is a floating point number expressed in seconds since the
88 epoch, in UTC - such as that outputted by time.time(). If set to None, it
89 defaults to the current time.
91 Output a string in the format 'Wdy, DD Mon YYYY HH:MM:SS GMT'.
92 """
93 return formatdate(epoch_seconds, usegmt=True)
96def parse_http_date(date):
97 """
98 Parse a date format as specified by HTTP RFC 9110 Section 5.6.7.
100 The three formats allowed by the RFC are accepted, even if only the first
101 one is still in widespread use.
103 Return an integer expressed in seconds since the epoch, in UTC.
104 """
105 # email.utils.parsedate() does the job for RFC 1123 dates; unfortunately
106 # RFC 9110 makes it mandatory to support RFC 850 dates too. So we roll
107 # our own RFC-compliant parsing.
108 for regex in RFC1123_DATE, RFC850_DATE, ASCTIME_DATE:
109 m = regex.match(date)
110 if m is not None:
111 break
112 else:
113 raise ValueError(f"{date!r} is not in a valid HTTP date format")
114 try:
115 tz = datetime.UTC
116 year = int(m["year"])
117 if year < 100:
118 current_year = datetime.datetime.now(tz=tz).year
119 current_century = current_year - (current_year % 100)
120 if year - (current_year % 100) > 50:
121 # year that appears to be more than 50 years in the future are
122 # interpreted as representing the past.
123 year += current_century - 100
124 else:
125 year += current_century
126 month = MONTHS.index(m["mon"].lower()) + 1
127 day = int(m["day"])
128 hour = int(m["hour"])
129 min = int(m["min"])
130 sec = int(m["sec"])
131 result = datetime.datetime(year, month, day, hour, min, sec, tzinfo=tz)
132 return int(result.timestamp())
133 except Exception as exc:
134 raise ValueError(f"{date!r} is not a valid date") from exc
137def parse_http_date_safe(date):
138 """
139 Same as parse_http_date, but return None if the input is invalid.
140 """
141 try:
142 return parse_http_date(date)
143 except Exception:
144 pass
147# Base 36 functions: useful for generating compact URLs
150def base36_to_int(s):
151 """
152 Convert a base 36 string to an int. Raise ValueError if the input won't fit
153 into an int.
154 """
155 # To prevent overconsumption of server resources, reject any
156 # base36 string that is longer than 13 base36 digits (13 digits
157 # is sufficient to base36-encode any 64-bit integer)
158 if len(s) > 13:
159 raise ValueError("Base36 input too large")
160 return int(s, 36)
163def int_to_base36(i):
164 """Convert an integer to a base36 string."""
165 char_set = "0123456789abcdefghijklmnopqrstuvwxyz"
166 if i < 0:
167 raise ValueError("Negative base36 conversion input.")
168 if i < 36:
169 return char_set[i]
170 b36 = ""
171 while i != 0:
172 i, n = divmod(i, 36)
173 b36 = char_set[n] + b36
174 return b36
177def urlsafe_base64_encode(s):
178 """
179 Encode a bytestring to a base64 string for use in URLs. Strip any trailing
180 equal signs.
181 """
182 return base64.urlsafe_b64encode(s).rstrip(b"\n=").decode("ascii")
185def urlsafe_base64_decode(s):
186 """
187 Decode a base64 encoded string. Add back any trailing equal signs that
188 might have been stripped.
189 """
190 s = s.encode()
191 try:
192 return base64.urlsafe_b64decode(s.ljust(len(s) + len(s) % 4, b"="))
193 except (LookupError, BinasciiError) as e:
194 raise ValueError(e)
197def parse_etags(etag_str):
198 """
199 Parse a string of ETags given in an If-None-Match or If-Match header as
200 defined by RFC 9110. Return a list of quoted ETags, or ['*'] if all ETags
201 should be matched.
202 """
203 if etag_str.strip() == "*":
204 return ["*"]
205 else:
206 # Parse each ETag individually, and return any that are valid.
207 etag_matches = (ETAG_MATCH.match(etag.strip()) for etag in etag_str.split(","))
208 return [match[1] for match in etag_matches if match]
211def quote_etag(etag_str):
212 """
213 If the provided string is already a quoted ETag, return it. Otherwise, wrap
214 the string in quotes, making it a strong ETag.
215 """
216 if ETAG_MATCH.match(etag_str):
217 return etag_str
218 else:
219 return f'"{etag_str}"'
222def is_same_domain(host, pattern):
223 """
224 Return ``True`` if the host is either an exact match or a match
225 to the wildcard pattern.
227 Any pattern beginning with a period matches a domain and all of its
228 subdomains. (e.g. ``.example.com`` matches ``example.com`` and
229 ``foo.example.com``). Anything else is an exact string match.
230 """
231 if not pattern:
232 return False
234 pattern = pattern.lower()
235 return (
236 pattern[0] == "."
237 and (host.endswith(pattern) or host == pattern[1:])
238 or pattern == host
239 )
242def url_has_allowed_host_and_scheme(url, allowed_hosts, require_https=False):
243 """
244 Return ``True`` if the url uses an allowed host and a safe scheme.
246 Always return ``False`` on an empty url.
248 If ``require_https`` is ``True``, only 'https' will be considered a valid
249 scheme, as opposed to 'http' and 'https' with the default, ``False``.
251 Note: "True" doesn't entail that a URL is "safe". It may still be e.g.
252 quoted incorrectly. Ensure to also use plain.utils.encoding.iri_to_uri()
253 on the path component of untrusted URLs.
254 """
255 if url is not None:
256 url = url.strip()
257 if not url:
258 return False
259 if allowed_hosts is None:
260 allowed_hosts = set()
261 elif isinstance(allowed_hosts, str):
262 allowed_hosts = {allowed_hosts}
263 # Chrome treats \ completely as / in paths but it could be part of some
264 # basic auth credentials so we need to check both URLs.
265 return _url_has_allowed_host_and_scheme(
266 url, allowed_hosts, require_https=require_https
267 ) and _url_has_allowed_host_and_scheme(
268 url.replace("\\", "/"), allowed_hosts, require_https=require_https
269 )
272def _url_has_allowed_host_and_scheme(url, allowed_hosts, require_https=False):
273 # Chrome considers any URL with more than two slashes to be absolute, but
274 # urlparse is not so flexible. Treat any url with three slashes as unsafe.
275 if url.startswith("///"):
276 return False
277 try:
278 url_info = urlparse(url)
279 except ValueError: # e.g. invalid IPv6 addresses
280 return False
281 # Forbid URLs like http:///example.com - with a scheme, but without a hostname.
282 # In that URL, example.com is not the hostname but, a path component. However,
283 # Chrome will still consider example.com to be the hostname, so we must not
284 # allow this syntax.
285 if not url_info.netloc and url_info.scheme:
286 return False
287 # Forbid URLs that start with control characters. Some browsers (like
288 # Chrome) ignore quite a few control characters at the start of a
289 # URL and might consider the URL as scheme relative.
290 if unicodedata.category(url[0])[0] == "C":
291 return False
292 scheme = url_info.scheme
293 # Consider URLs without a scheme (e.g. //example.com/p) to be http.
294 if not url_info.scheme and url_info.netloc:
295 scheme = "http"
296 valid_schemes = ["https"] if require_https else ["http", "https"]
297 return (not url_info.netloc or url_info.netloc in allowed_hosts) and (
298 not scheme or scheme in valid_schemes
299 )
302def escape_leading_slashes(url):
303 """
304 If redirecting to an absolute path (two leading slashes), a slash must be
305 escaped to prevent browsers from handling the path as schemaless and
306 redirecting to another host.
307 """
308 if url.startswith("//"):
309 url = "/%2F{}".format(url.removeprefix("//"))
310 return url
313def _parseparam(s):
314 while s[:1] == ";":
315 s = s[1:]
316 end = s.find(";")
317 while end > 0 and (s.count('"', 0, end) - s.count('\\"', 0, end)) % 2:
318 end = s.find(";", end + 1)
319 if end < 0:
320 end = len(s)
321 f = s[:end]
322 yield f.strip()
323 s = s[end:]
326def parse_header_parameters(line):
327 """
328 Parse a Content-type like header.
329 Return the main content-type and a dictionary of options.
330 """
331 parts = _parseparam(";" + line)
332 key = parts.__next__().lower()
333 pdict = {}
334 for p in parts:
335 i = p.find("=")
336 if i >= 0:
337 has_encoding = False
338 name = p[:i].strip().lower()
339 if name.endswith("*"):
340 # Lang/encoding embedded in the value (like "filename*=UTF-8''file.ext")
341 # https://tools.ietf.org/html/rfc2231#section-4
342 name = name[:-1]
343 if p.count("'") == 2:
344 has_encoding = True
345 value = p[i + 1 :].strip()
346 if len(value) >= 2 and value[0] == value[-1] == '"':
347 value = value[1:-1]
348 value = value.replace("\\\\", "\\").replace('\\"', '"')
349 if has_encoding:
350 encoding, lang, value = value.split("'")
351 value = unquote(value, encoding=encoding)
352 pdict[name] = value
353 return key, pdict
356def content_disposition_header(as_attachment, filename):
357 """
358 Construct a Content-Disposition HTTP header value from the given filename
359 as specified by RFC 6266.
360 """
361 if filename:
362 disposition = "attachment" if as_attachment else "inline"
363 try:
364 filename.encode("ascii")
365 file_expr = 'filename="{}"'.format(
366 filename.replace("\\", "\\\\").replace('"', r"\"")
367 )
368 except UnicodeEncodeError:
369 file_expr = f"filename*=utf-8''{quote(filename)}"
370 return f"{disposition}; {file_expr}"
371 elif as_attachment:
372 return "attachment"
373 else:
374 return None
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import functools
2import inspect
5@functools.lru_cache(maxsize=512)
6def _get_func_parameters(func, remove_first):
7 parameters = tuple(inspect.signature(func).parameters.values())
8 if remove_first:
9 parameters = parameters[1:]
10 return parameters
13def _get_callable_parameters(meth_or_func):
14 is_method = inspect.ismethod(meth_or_func)
15 func = meth_or_func.__func__ if is_method else meth_or_func
16 return _get_func_parameters(func, remove_first=is_method)
19def get_func_args(func):
20 params = _get_callable_parameters(func)
21 return [
22 param.name
23 for param in params
24 if param.kind == inspect.Parameter.POSITIONAL_OR_KEYWORD
25 ]
28def get_func_full_args(func):
29 """
30 Return a list of (argument name, default value) tuples. If the argument
31 does not have a default value, omit it in the tuple. Arguments such as
32 *args and **kwargs are also included.
33 """
34 params = _get_callable_parameters(func)
35 args = []
36 for param in params:
37 name = param.name
38 # Ignore 'self'
39 if name == "self":
40 continue
41 if param.kind == inspect.Parameter.VAR_POSITIONAL:
42 name = "*" + name
43 elif param.kind == inspect.Parameter.VAR_KEYWORD:
44 name = "**" + name
45 if param.default != inspect.Parameter.empty:
46 args.append((name, param.default))
47 else:
48 args.append((name,))
49 return args
52def func_accepts_kwargs(func):
53 """Return True if function 'func' accepts keyword arguments **kwargs."""
54 return any(p for p in _get_callable_parameters(func) if p.kind == p.VAR_KEYWORD)
57def func_accepts_var_args(func):
58 """
59 Return True if function 'func' accepts positional arguments *args.
60 """
61 return any(p for p in _get_callable_parameters(func) if p.kind == p.VAR_POSITIONAL)
64def method_has_no_args(meth):
65 """Return True if a method only accepts 'self'."""
66 count = len(
67 [p for p in _get_callable_parameters(meth) if p.kind == p.POSITIONAL_OR_KEYWORD]
68 )
69 return count == 0 if inspect.ismethod(meth) else count == 1
72def func_supports_parameter(func, name):
73 return any(param.name == name for param in _get_callable_parameters(func))
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import ipaddress
3from plain.exceptions import ValidationError
6def clean_ipv6_address(
7 ip_str, unpack_ipv4=False, error_message="This is not a valid IPv6 address."
8):
9 """
10 Clean an IPv6 address string.
12 Raise ValidationError if the address is invalid.
14 Replace the longest continuous zero-sequence with "::", remove leading
15 zeroes, and make sure all hextets are lowercase.
17 Args:
18 ip_str: A valid IPv6 address.
19 unpack_ipv4: if an IPv4-mapped address is found,
20 return the plain IPv4 address (default=False).
21 error_message: An error message used in the ValidationError.
23 Return a compressed IPv6 address or the same value.
24 """
25 try:
26 addr = ipaddress.IPv6Address(int(ipaddress.IPv6Address(ip_str)))
27 except ValueError:
28 raise ValidationError(error_message, code="invalid")
30 if unpack_ipv4 and addr.ipv4_mapped:
31 return str(addr.ipv4_mapped)
32 elif addr.ipv4_mapped:
33 return f"::ffff:{str(addr.ipv4_mapped)}"
35 return str(addr)
38def is_valid_ipv6_address(ip_str):
39 """
40 Return whether or not the `ip_str` string is a valid IPv6 address.
41 """
42 try:
43 ipaddress.IPv6Address(ip_str)
44 except ValueError:
45 return False
46 return True
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1def is_iterable(x):
2 "An implementation independent way of checking for iterables"
3 try:
4 iter(x)
5 except TypeError:
6 return False
7 else:
8 return True
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import os
2import sys
3from importlib import import_module
4from importlib.util import find_spec as importlib_find
7def cached_import(module_path, class_name):
8 # Check whether module is loaded and fully initialized.
9 if not (
10 (module := sys.modules.get(module_path))
11 and (spec := getattr(module, "__spec__", None))
12 and getattr(spec, "_initializing", False) is False
13 ):
14 module = import_module(module_path)
15 return getattr(module, class_name)
18def import_string(dotted_path):
19 """
20 Import a dotted module path and return the attribute/class designated by the
21 last name in the path. Raise ImportError if the import failed.
22 """
23 try:
24 module_path, class_name = dotted_path.rsplit(".", 1)
25 except ValueError as err:
26 raise ImportError(f"{dotted_path} doesn't look like a module path") from err
28 try:
29 return cached_import(module_path, class_name)
30 except AttributeError as err:
31 raise ImportError(
32 f'Module "{module_path}" does not define a "{class_name}" attribute/class'
33 ) from err
36def module_has_submodule(package, module_name):
37 """See if 'module' is in 'package'."""
38 try:
39 package_name = package.__name__
40 package_path = package.__path__
41 except AttributeError:
42 # package isn't a package.
43 return False
45 full_module_name = package_name + "." + module_name
46 try:
47 return importlib_find(full_module_name, package_path) is not None
48 except ModuleNotFoundError:
49 # When module_name is an invalid dotted path, Python raises
50 # ModuleNotFoundError.
51 return False
54def module_dir(module):
55 """
56 Find the name of the directory that contains a module, if possible.
58 Raise ValueError otherwise, e.g. for namespace packages that are split
59 over several directories.
60 """
61 # Convert to list because __path__ may not support indexing.
62 paths = list(getattr(module, "__path__", []))
63 if len(paths) == 1:
64 return paths[0]
65 else:
66 filename = getattr(module, "__file__", None)
67 if filename is not None:
68 return os.path.dirname(filename)
69 raise ValueError(f"Cannot determine directory containing {module}")
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Functions for reversing a regular expression (used in reverse URL resolving).
3Used internally by Plain and not intended for external use.
5This is not, and is not intended to be, a complete reg-exp decompiler. It
6should be good enough for a large class of URLS, however.
7"""
9import re
11from plain.utils.functional import SimpleLazyObject
13# Mapping of an escape character to a representative of that class. So, e.g.,
14# "\w" is replaced by "x" in a reverse URL. A value of None means to ignore
15# this sequence. Any missing key is mapped to itself.
16ESCAPE_MAPPINGS = {
17 "A": None,
18 "b": None,
19 "B": None,
20 "d": "0",
21 "D": "x",
22 "s": " ",
23 "S": "x",
24 "w": "x",
25 "W": "!",
26 "Z": None,
27}
30class Choice(list):
31 """Represent multiple possibilities at this point in a pattern string."""
34class Group(list):
35 """Represent a capturing group in the pattern string."""
38class NonCapture(list):
39 """Represent a non-capturing group in the pattern string."""
42def normalize(pattern):
43 r"""
44 Given a reg-exp pattern, normalize it to an iterable of forms that
45 suffice for reverse matching. This does the following:
47 (1) For any repeating sections, keeps the minimum number of occurrences
48 permitted (this means zero for optional groups).
49 (2) If an optional group includes parameters, include one occurrence of
50 that group (along with the zero occurrence case from step (1)).
51 (3) Select the first (essentially an arbitrary) element from any character
52 class. Select an arbitrary character for any unordered class (e.g. '.'
53 or '\w') in the pattern.
54 (4) Ignore look-ahead and look-behind assertions.
55 (5) Raise an error on any disjunctive ('|') constructs.
57 Plain's URLs for forward resolving are either all positional arguments or
58 all keyword arguments. That is assumed here, as well. Although reverse
59 resolving can be done using positional args when keyword args are
60 specified, the two cannot be mixed in the same reverse() call.
61 """
62 # Do a linear scan to work out the special features of this pattern. The
63 # idea is that we scan once here and collect all the information we need to
64 # make future decisions.
65 result = []
66 non_capturing_groups = []
67 consume_next = True
68 pattern_iter = next_char(iter(pattern))
69 num_args = 0
71 # A "while" loop is used here because later on we need to be able to peek
72 # at the next character and possibly go around without consuming another
73 # one at the top of the loop.
74 try:
75 ch, escaped = next(pattern_iter)
76 except StopIteration:
77 return [("", [])]
79 try:
80 while True:
81 if escaped:
82 result.append(ch)
83 elif ch == ".":
84 # Replace "any character" with an arbitrary representative.
85 result.append(".")
86 elif ch == "|":
87 # FIXME: One day we'll should do this, but not in 1.0.
88 raise NotImplementedError("Awaiting Implementation")
89 elif ch == "^":
90 pass
91 elif ch == "$":
92 break
93 elif ch == ")":
94 # This can only be the end of a non-capturing group, since all
95 # other unescaped parentheses are handled by the grouping
96 # section later (and the full group is handled there).
97 #
98 # We regroup everything inside the capturing group so that it
99 # can be quantified, if necessary.
100 start = non_capturing_groups.pop()
101 inner = NonCapture(result[start:])
102 result = result[:start] + [inner]
103 elif ch == "[":
104 # Replace ranges with the first character in the range.
105 ch, escaped = next(pattern_iter)
106 result.append(ch)
107 ch, escaped = next(pattern_iter)
108 while escaped or ch != "]":
109 ch, escaped = next(pattern_iter)
110 elif ch == "(":
111 # Some kind of group.
112 ch, escaped = next(pattern_iter)
113 if ch != "?" or escaped:
114 # A positional group
115 name = "_%d" % num_args
116 num_args += 1
117 result.append(Group(((f"%({name})s"), name)))
118 walk_to_end(ch, pattern_iter)
119 else:
120 ch, escaped = next(pattern_iter)
121 if ch in "!=<":
122 # All of these are ignorable. Walk to the end of the
123 # group.
124 walk_to_end(ch, pattern_iter)
125 elif ch == ":":
126 # Non-capturing group
127 non_capturing_groups.append(len(result))
128 elif ch != "P":
129 # Anything else, other than a named group, is something
130 # we cannot reverse.
131 raise ValueError(f"Non-reversible reg-exp portion: '(?{ch}'")
132 else:
133 ch, escaped = next(pattern_iter)
134 if ch not in ("<", "="):
135 raise ValueError(
136 f"Non-reversible reg-exp portion: '(?P{ch}'"
137 )
138 # We are in a named capturing group. Extra the name and
139 # then skip to the end.
140 if ch == "<":
141 terminal_char = ">"
142 # We are in a named backreference.
143 else:
144 terminal_char = ")"
145 name = []
146 ch, escaped = next(pattern_iter)
147 while ch != terminal_char:
148 name.append(ch)
149 ch, escaped = next(pattern_iter)
150 param = "".join(name)
151 # Named backreferences have already consumed the
152 # parenthesis.
153 if terminal_char != ")":
154 result.append(Group(((f"%({param})s"), param)))
155 walk_to_end(ch, pattern_iter)
156 else:
157 result.append(Group(((f"%({param})s"), None)))
158 elif ch in "*?+{":
159 # Quantifiers affect the previous item in the result list.
160 count, ch = get_quantifier(ch, pattern_iter)
161 if ch:
162 # We had to look ahead, but it wasn't need to compute the
163 # quantifier, so use this character next time around the
164 # main loop.
165 consume_next = False
167 if count == 0:
168 if contains(result[-1], Group):
169 # If we are quantifying a capturing group (or
170 # something containing such a group) and the minimum is
171 # zero, we must also handle the case of one occurrence
172 # being present. All the quantifiers (except {0,0},
173 # which we conveniently ignore) that have a 0 minimum
174 # also allow a single occurrence.
175 result[-1] = Choice([None, result[-1]])
176 else:
177 result.pop()
178 elif count > 1:
179 result.extend([result[-1]] * (count - 1))
180 else:
181 # Anything else is a literal.
182 result.append(ch)
184 if consume_next:
185 ch, escaped = next(pattern_iter)
186 consume_next = True
187 except StopIteration:
188 pass
189 except NotImplementedError:
190 # A case of using the disjunctive form. No results for you!
191 return [("", [])]
193 return list(zip(*flatten_result(result)))
196def next_char(input_iter):
197 r"""
198 An iterator that yields the next character from "pattern_iter", respecting
199 escape sequences. An escaped character is replaced by a representative of
200 its class (e.g. \w -> "x"). If the escaped character is one that is
201 skipped, it is not returned (the next character is returned instead).
203 Yield the next character, along with a boolean indicating whether it is a
204 raw (unescaped) character or not.
205 """
206 for ch in input_iter:
207 if ch != "\\":
208 yield ch, False
209 continue
210 ch = next(input_iter)
211 representative = ESCAPE_MAPPINGS.get(ch, ch)
212 if representative is None:
213 continue
214 yield representative, True
217def walk_to_end(ch, input_iter):
218 """
219 The iterator is currently inside a capturing group. Walk to the close of
220 this group, skipping over any nested groups and handling escaped
221 parentheses correctly.
222 """
223 if ch == "(":
224 nesting = 1
225 else:
226 nesting = 0
227 for ch, escaped in input_iter:
228 if escaped:
229 continue
230 elif ch == "(":
231 nesting += 1
232 elif ch == ")":
233 if not nesting:
234 return
235 nesting -= 1
238def get_quantifier(ch, input_iter):
239 """
240 Parse a quantifier from the input, where "ch" is the first character in the
241 quantifier.
243 Return the minimum number of occurrences permitted by the quantifier and
244 either None or the next character from the input_iter if the next character
245 is not part of the quantifier.
246 """
247 if ch in "*?+":
248 try:
249 ch2, escaped = next(input_iter)
250 except StopIteration:
251 ch2 = None
252 if ch2 == "?":
253 ch2 = None
254 if ch == "+":
255 return 1, ch2
256 return 0, ch2
258 quant = []
259 while ch != "}":
260 ch, escaped = next(input_iter)
261 quant.append(ch)
262 quant = quant[:-1]
263 values = "".join(quant).split(",")
265 # Consume the trailing '?', if necessary.
266 try:
267 ch, escaped = next(input_iter)
268 except StopIteration:
269 ch = None
270 if ch == "?":
271 ch = None
272 return int(values[0]), ch
275def contains(source, inst):
276 """
277 Return True if the "source" contains an instance of "inst". False,
278 otherwise.
279 """
280 if isinstance(source, inst):
281 return True
282 if isinstance(source, NonCapture):
283 for elt in source:
284 if contains(elt, inst):
285 return True
286 return False
289def flatten_result(source):
290 """
291 Turn the given source sequence into a list of reg-exp possibilities and
292 their arguments. Return a list of strings and a list of argument lists.
293 Each of the two lists will be of the same length.
294 """
295 if source is None:
296 return [""], [[]]
297 if isinstance(source, Group):
298 if source[1] is None:
299 params = []
300 else:
301 params = [source[1]]
302 return [source[0]], [params]
303 result = [""]
304 result_args = [[]]
305 pos = last = 0
306 for pos, elt in enumerate(source):
307 if isinstance(elt, str):
308 continue
309 piece = "".join(source[last:pos])
310 if isinstance(elt, Group):
311 piece += elt[0]
312 param = elt[1]
313 else:
314 param = None
315 last = pos + 1
316 for i in range(len(result)):
317 result[i] += piece
318 if param:
319 result_args[i].append(param)
320 if isinstance(elt, Choice | NonCapture):
321 if isinstance(elt, NonCapture):
322 elt = [elt]
323 inner_result, inner_args = [], []
324 for item in elt:
325 res, args = flatten_result(item)
326 inner_result.extend(res)
327 inner_args.extend(args)
328 new_result = []
329 new_args = []
330 for item, args in zip(result, result_args):
331 for i_item, i_args in zip(inner_result, inner_args):
332 new_result.append(item + i_item)
333 new_args.append(args[:] + i_args)
334 result = new_result
335 result_args = new_args
336 if pos >= last:
337 piece = "".join(source[last:])
338 for i in range(len(result)):
339 result[i] += piece
340 return result, result_args
343def _lazy_re_compile(regex, flags=0):
344 """Lazily compile a regex with flags."""
346 def _compile():
347 # Compile the regex if it was not passed pre-compiled.
348 if isinstance(regex, str | bytes):
349 return re.compile(regex, flags)
350 else:
351 assert not flags, "flags must be empty if regex is passed pre-compiled"
352 return regex
354 return SimpleLazyObject(_compile)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Functions for working with "safe strings": strings that can be displayed safely
3without further escaping in HTML. Marking something as a "safe string" means
4that the producer of the string has already turned characters that should not
5be interpreted by the HTML engine (e.g. '<') into the appropriate entities.
6"""
8from functools import wraps
10from plain.utils.functional import keep_lazy
13class SafeData:
14 __slots__ = ()
16 def __html__(self):
17 """
18 Return the html representation of a string for interoperability.
20 This allows other template engines to understand Plain's SafeData.
21 """
22 return self
25class SafeString(str, SafeData):
26 """
27 A str subclass that has been specifically marked as "safe" for HTML output
28 purposes.
29 """
31 __slots__ = ()
33 def __add__(self, rhs):
34 """
35 Concatenating a safe string with another safe bytestring or
36 safe string is safe. Otherwise, the result is no longer safe.
37 """
38 t = super().__add__(rhs)
39 if isinstance(rhs, SafeData):
40 return SafeString(t)
41 return t
43 def __str__(self):
44 return self
47SafeText = SafeString # For backwards compatibility since Plain 2.0.
50def _safety_decorator(safety_marker, func):
51 @wraps(func)
52 def wrapper(*args, **kwargs):
53 return safety_marker(func(*args, **kwargs))
55 return wrapper
58@keep_lazy(SafeString)
59def mark_safe(s):
60 """
61 Explicitly mark a string as safe for (HTML) output purposes. The returned
62 object can be used everywhere a string is appropriate.
64 If used on a method as a decorator, mark the returned data as safe.
66 Can be called multiple times on a single string.
67 """
68 if hasattr(s, "__html__"):
69 return s
70 if callable(s):
71 return _safety_decorator(mark_safe, s)
72 return SafeString(s)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import gzip
2import re
3import secrets
4import unicodedata
5from gzip import GzipFile
6from gzip import compress as gzip_compress
7from io import BytesIO
9from plain.exceptions import SuspiciousFileOperation
10from plain.utils.functional import SimpleLazyObject, keep_lazy_text, lazy
11from plain.utils.regex_helper import _lazy_re_compile
14@keep_lazy_text
15def capfirst(x):
16 """Capitalize the first letter of a string."""
17 if not x:
18 return x
19 if not isinstance(x, str):
20 x = str(x)
21 return x[0].upper() + x[1:]
24# Set up regular expressions
25re_words = _lazy_re_compile(r"<[^>]+?>|([^<>\s]+)", re.S)
26re_chars = _lazy_re_compile(r"<[^>]+?>|(.)", re.S)
27re_tag = _lazy_re_compile(r"<(/)?(\S+?)(?:(\s*/)|\s.*?)?>", re.S)
28re_newlines = _lazy_re_compile(r"\r\n|\r") # Used in normalize_newlines
29re_camel_case = _lazy_re_compile(r"(((?<=[a-z])[A-Z])|([A-Z](?![A-Z]|$)))")
32@keep_lazy_text
33def wrap(text, width):
34 """
35 A word-wrap function that preserves existing line breaks. Expects that
36 existing line breaks are posix newlines.
38 Preserve all white space except added line breaks consume the space on
39 which they break the line.
41 Don't wrap long words, thus the output text may have lines longer than
42 ``width``.
43 """
45 def _generator():
46 for line in text.splitlines(True): # True keeps trailing linebreaks
47 max_width = min((line.endswith("\n") and width + 1 or width), width)
48 while len(line) > max_width:
49 space = line[: max_width + 1].rfind(" ") + 1
50 if space == 0:
51 space = line.find(" ") + 1
52 if space == 0:
53 yield line
54 line = ""
55 break
56 yield f"{line[: space - 1]}\n"
57 line = line[space:]
58 max_width = min((line.endswith("\n") and width + 1 or width), width)
59 if line:
60 yield line
62 return "".join(_generator())
65class Truncator(SimpleLazyObject):
66 """
67 An object used to truncate text, either by characters or words.
68 """
70 def __init__(self, text):
71 super().__init__(lambda: str(text))
73 def add_truncation_text(self, text, truncate=None):
74 if truncate is None:
75 truncate = "%(truncated_text)s…"
76 if "%(truncated_text)s" in truncate:
77 return truncate % {"truncated_text": text}
78 # The truncation text didn't contain the %(truncated_text)s string
79 # replacement argument so just append it to the text.
80 if text.endswith(truncate):
81 # But don't append the truncation text if the current text already
82 # ends in this.
83 return text
84 return f"{text}{truncate}"
86 def chars(self, num, truncate=None, html=False):
87 """
88 Return the text truncated to be no longer than the specified number
89 of characters.
91 `truncate` specifies what should be used to notify that the string has
92 been truncated, defaulting to a translatable string of an ellipsis.
93 """
94 self._setup()
95 length = int(num)
96 text = unicodedata.normalize("NFC", self._wrapped)
98 # Calculate the length to truncate to (max length - end_text length)
99 truncate_len = length
100 for char in self.add_truncation_text("", truncate):
101 if not unicodedata.combining(char):
102 truncate_len -= 1
103 if truncate_len == 0:
104 break
105 if html:
106 return self._truncate_html(length, truncate, text, truncate_len, False)
107 return self._text_chars(length, truncate, text, truncate_len)
109 def _text_chars(self, length, truncate, text, truncate_len):
110 """Truncate a string after a certain number of chars."""
111 s_len = 0
112 end_index = None
113 for i, char in enumerate(text):
114 if unicodedata.combining(char):
115 # Don't consider combining characters
116 # as adding to the string length
117 continue
118 s_len += 1
119 if end_index is None and s_len > truncate_len:
120 end_index = i
121 if s_len > length:
122 # Return the truncated string
123 return self.add_truncation_text(text[: end_index or 0], truncate)
125 # Return the original string since no truncation was necessary
126 return text
128 def words(self, num, truncate=None, html=False):
129 """
130 Truncate a string after a certain number of words. `truncate` specifies
131 what should be used to notify that the string has been truncated,
132 defaulting to ellipsis.
133 """
134 self._setup()
135 length = int(num)
136 if html:
137 return self._truncate_html(length, truncate, self._wrapped, length, True)
138 return self._text_words(length, truncate)
140 def _text_words(self, length, truncate):
141 """
142 Truncate a string after a certain number of words.
144 Strip newlines in the string.
145 """
146 words = self._wrapped.split()
147 if len(words) > length:
148 words = words[:length]
149 return self.add_truncation_text(" ".join(words), truncate)
150 return " ".join(words)
152 def _truncate_html(self, length, truncate, text, truncate_len, words):
153 """
154 Truncate HTML to a certain number of chars (not counting tags and
155 comments), or, if words is True, then to a certain number of words.
156 Close opened tags if they were correctly closed in the given HTML.
158 Preserve newlines in the HTML.
159 """
160 if words and length <= 0:
161 return ""
163 html4_singlets = (
164 "br",
165 "col",
166 "link",
167 "base",
168 "img",
169 "param",
170 "area",
171 "hr",
172 "input",
173 )
175 # Count non-HTML chars/words and keep note of open tags
176 pos = 0
177 end_text_pos = 0
178 current_len = 0
179 open_tags = []
181 regex = re_words if words else re_chars
183 while current_len <= length:
184 m = regex.search(text, pos)
185 if not m:
186 # Checked through whole string
187 break
188 pos = m.end(0)
189 if m[1]:
190 # It's an actual non-HTML word or char
191 current_len += 1
192 if current_len == truncate_len:
193 end_text_pos = pos
194 continue
195 # Check for tag
196 tag = re_tag.match(m[0])
197 if not tag or current_len >= truncate_len:
198 # Don't worry about non tags or tags after our truncate point
199 continue
200 closing_tag, tagname, self_closing = tag.groups()
201 # Element names are always case-insensitive
202 tagname = tagname.lower()
203 if self_closing or tagname in html4_singlets:
204 pass
205 elif closing_tag:
206 # Check for match in open tags list
207 try:
208 i = open_tags.index(tagname)
209 except ValueError:
210 pass
211 else:
212 # SGML: An end tag closes, back to the matching start tag,
213 # all unclosed intervening start tags with omitted end tags
214 open_tags = open_tags[i + 1 :]
215 else:
216 # Add it to the start of the open tags list
217 open_tags.insert(0, tagname)
219 if current_len <= length:
220 return text
221 out = text[:end_text_pos]
222 truncate_text = self.add_truncation_text("", truncate)
223 if truncate_text:
224 out += truncate_text
225 # Close any tags still open
226 for tag in open_tags:
227 out += f"</{tag}>"
228 # Return string
229 return out
232@keep_lazy_text
233def get_valid_filename(name):
234 """
235 Return the given string converted to a string that can be used for a clean
236 filename. Remove leading and trailing spaces; convert other spaces to
237 underscores; and remove anything that is not an alphanumeric, dash,
238 underscore, or dot.
239 >>> get_valid_filename("john's portrait in 2004.jpg")
240 'johns_portrait_in_2004.jpg'
241 """
242 s = str(name).strip().replace(" ", "_")
243 s = re.sub(r"(?u)[^-\w.]", "", s)
244 if s in {"", ".", ".."}:
245 raise SuspiciousFileOperation(f"Could not derive file name from '{name}'")
246 return s
249@keep_lazy_text
250def get_text_list(list_, last_word="or"):
251 """
252 >>> get_text_list(['a', 'b', 'c', 'd'])
253 'a, b, c or d'
254 >>> get_text_list(['a', 'b', 'c'], 'and')
255 'a, b and c'
256 >>> get_text_list(['a', 'b'], 'and')
257 'a and b'
258 >>> get_text_list(['a'])
259 'a'
260 >>> get_text_list([])
261 ''
262 """
263 if not list_:
264 return ""
265 if len(list_) == 1:
266 return str(list_[0])
267 return "{} {} {}".format(
268 # Translators: This string is used as a separator between list elements
269 ", ".join(str(i) for i in list_[:-1]),
270 str(last_word),
271 str(list_[-1]),
272 )
275@keep_lazy_text
276def normalize_newlines(text):
277 """Normalize CRLF and CR newlines to just LF."""
278 return re_newlines.sub("\n", str(text))
281@keep_lazy_text
282def phone2numeric(phone):
283 """Convert a phone number with letters into its numeric equivalent."""
284 char2number = {
285 "a": "2",
286 "b": "2",
287 "c": "2",
288 "d": "3",
289 "e": "3",
290 "f": "3",
291 "g": "4",
292 "h": "4",
293 "i": "4",
294 "j": "5",
295 "k": "5",
296 "l": "5",
297 "m": "6",
298 "n": "6",
299 "o": "6",
300 "p": "7",
301 "q": "7",
302 "r": "7",
303 "s": "7",
304 "t": "8",
305 "u": "8",
306 "v": "8",
307 "w": "9",
308 "x": "9",
309 "y": "9",
310 "z": "9",
311 }
312 return "".join(char2number.get(c, c) for c in phone.lower())
315def _get_random_filename(max_random_bytes):
316 return b"a" * secrets.randbelow(max_random_bytes)
319def compress_string(s, *, max_random_bytes=None):
320 compressed_data = gzip_compress(s, compresslevel=6, mtime=0)
322 if not max_random_bytes:
323 return compressed_data
325 compressed_view = memoryview(compressed_data)
326 header = bytearray(compressed_view[:10])
327 header[3] = gzip.FNAME
329 filename = _get_random_filename(max_random_bytes) + b"\x00"
331 return bytes(header) + filename + compressed_view[10:]
334class StreamingBuffer(BytesIO):
335 def read(self):
336 ret = self.getvalue()
337 self.seek(0)
338 self.truncate()
339 return ret
342# Like compress_string, but for iterators of strings.
343def compress_sequence(sequence, *, max_random_bytes=None):
344 buf = StreamingBuffer()
345 filename = _get_random_filename(max_random_bytes) if max_random_bytes else None
346 with GzipFile(
347 filename=filename, mode="wb", compresslevel=6, fileobj=buf, mtime=0
348 ) as zfile:
349 # Output headers...
350 yield buf.read()
351 for item in sequence:
352 zfile.write(item)
353 data = buf.read()
354 if data:
355 yield data
356 yield buf.read()
359# Expression to match some_token and some_token="with spaces" (and similarly
360# for single-quoted strings).
361smart_split_re = _lazy_re_compile(
362 r"""
363 ((?:
364 [^\s'"]*
365 (?:
366 (?:"(?:[^"\\]|\\.)*" | '(?:[^'\\]|\\.)*')
367 [^\s'"]*
368 )+
369 ) | \S+)
370""",
371 re.VERBOSE,
372)
375def smart_split(text):
376 r"""
377 Generator that splits a string by spaces, leaving quoted phrases together.
378 Supports both single and double quotes, and supports escaping quotes with
379 backslashes. In the output, strings will keep their initial and trailing
380 quote marks and escaped quotes will remain escaped (the results can then
381 be further processed with unescape_string_literal()).
383 >>> list(smart_split(r'This is "a person\'s" test.'))
384 ['This', 'is', '"a person\\\'s"', 'test.']
385 >>> list(smart_split(r"Another 'person\'s' test."))
386 ['Another', "'person\\'s'", 'test.']
387 >>> list(smart_split(r'A "\"funky\" style" test.'))
388 ['A', '"\\"funky\\" style"', 'test.']
389 """
390 for bit in smart_split_re.finditer(str(text)):
391 yield bit[0]
394@keep_lazy_text
395def unescape_string_literal(s):
396 r"""
397 Convert quoted string literals to unquoted strings with escaped quotes and
398 backslashes unquoted::
400 >>> unescape_string_literal('"abc"')
401 'abc'
402 >>> unescape_string_literal("'abc'")
403 'abc'
404 >>> unescape_string_literal('"a \"bc\""')
405 'a "bc"'
406 >>> unescape_string_literal("'\'ab\' c'")
407 "'ab' c"
408 """
409 if not s or s[0] not in "\"'" or s[-1] != s[0]:
410 raise ValueError(f"Not a string literal: {s!r}")
411 quote = s[0]
412 return s[1:-1].replace(rf"\{quote}", quote).replace(r"\\", "\\")
415@keep_lazy_text
416def slugify(value, allow_unicode=False):
417 """
418 Convert to ASCII if 'allow_unicode' is False. Convert spaces or repeated
419 dashes to single dashes. Remove characters that aren't alphanumerics,
420 underscores, or hyphens. Convert to lowercase. Also strip leading and
421 trailing whitespace, dashes, and underscores.
422 """
423 value = str(value)
424 if allow_unicode:
425 value = unicodedata.normalize("NFKC", value)
426 else:
427 value = (
428 unicodedata.normalize("NFKD", value)
429 .encode("ascii", "ignore")
430 .decode("ascii")
431 )
432 value = re.sub(r"[^\w\s-]", "", value.lower())
433 return re.sub(r"[-\s]+", "-", value).strip("-_")
436def camel_case_to_spaces(value):
437 """
438 Split CamelCase and convert to lowercase. Strip surrounding whitespace.
439 """
440 return re_camel_case.sub(r" \1", value).strip().lower()
443def _format_lazy(format_string, *args, **kwargs):
444 """
445 Apply str.format() on 'format_string' where format_string, args,
446 and/or kwargs might be lazy.
447 """
448 return format_string.format(*args, **kwargs)
451def pluralize(singular, plural, number):
452 if number == 1:
453 return singular
454 else:
455 return plural
458def pluralize_lazy(singular, plural, number):
459 def _lazy_number_unpickle(func, resultclass, number, kwargs):
460 return lazy_number(func, resultclass, number=number, **kwargs)
462 def lazy_number(func, resultclass, number=None, **kwargs):
463 if isinstance(number, int):
464 kwargs["number"] = number
465 proxy = lazy(func, resultclass)(**kwargs)
466 else:
467 original_kwargs = kwargs.copy()
469 class NumberAwareString(resultclass):
470 def __bool__(self):
471 return bool(kwargs["singular"])
473 def _get_number_value(self, values):
474 try:
475 return values[number]
476 except KeyError:
477 raise KeyError(
478 f"Your dictionary lacks key '{number}'. Please provide "
479 "it, because it is required to determine whether "
480 "string is singular or plural."
481 )
483 def _translate(self, number_value):
484 kwargs["number"] = number_value
485 return func(**kwargs)
487 def format(self, *args, **kwargs):
488 number_value = (
489 self._get_number_value(kwargs) if kwargs and number else args[0]
490 )
491 return self._translate(number_value).format(*args, **kwargs)
493 def __mod__(self, rhs):
494 if isinstance(rhs, dict) and number:
495 number_value = self._get_number_value(rhs)
496 else:
497 number_value = rhs
498 translated = self._translate(number_value)
499 try:
500 translated %= rhs
501 except TypeError:
502 # String doesn't contain a placeholder for the number.
503 pass
504 return translated
506 proxy = lazy(lambda **kwargs: NumberAwareString(), NumberAwareString)(
507 **kwargs
508 )
509 proxy.__reduce__ = lambda: (
510 _lazy_number_unpickle,
511 (func, resultclass, number, original_kwargs),
512 )
513 return proxy
515 return lazy_number(pluralize, str, singular=singular, plural=plural, number=number)
518format_lazy = lazy(_format_lazy, str)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
3from plain.utils.html import avoid_wrapping
4from plain.utils.text import pluralize_lazy
5from plain.utils.timezone import is_aware
7TIME_STRINGS = {
8 "year": pluralize_lazy("%(num)d year", "%(num)d years", "num"),
9 "month": pluralize_lazy("%(num)d month", "%(num)d months", "num"),
10 "week": pluralize_lazy("%(num)d week", "%(num)d weeks", "num"),
11 "day": pluralize_lazy("%(num)d day", "%(num)d days", "num"),
12 "hour": pluralize_lazy("%(num)d hour", "%(num)d hours", "num"),
13 "minute": pluralize_lazy("%(num)d minute", "%(num)d minutes", "num"),
14}
16TIME_STRINGS_KEYS = list(TIME_STRINGS.keys())
18TIME_CHUNKS = [
19 60 * 60 * 24 * 7, # week
20 60 * 60 * 24, # day
21 60 * 60, # hour
22 60, # minute
23]
25MONTHS_DAYS = (31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31)
28def timesince(d, now=None, reversed=False, time_strings=None, depth=2):
29 """
30 Take two datetime objects and return the time between d and now as a nicely
31 formatted string, e.g. "10 minutes". If d occurs after now, return
32 "0 minutes".
34 Units used are years, months, weeks, days, hours, and minutes.
35 Seconds and microseconds are ignored.
37 The algorithm takes into account the varying duration of years and months.
38 There is exactly "1 year, 1 month" between 2013/02/10 and 2014/03/10,
39 but also between 2007/08/10 and 2008/09/10 despite the delta being 393 days
40 in the former case and 397 in the latter.
42 Up to `depth` adjacent units will be displayed. For example,
43 "2 weeks, 3 days" and "1 year, 3 months" are possible outputs, but
44 "2 weeks, 3 hours" and "1 year, 5 days" are not.
46 `time_strings` is an optional dict of strings to replace the default
47 TIME_STRINGS dict.
49 `depth` is an optional integer to control the number of adjacent time
50 units returned.
52 Originally adapted from
53 https://web.archive.org/web/20060617175230/http://blog.natbat.co.uk/archive/2003/Jun/14/time_since
54 Modified to improve results for years and months.
55 """
56 if time_strings is None:
57 time_strings = TIME_STRINGS
58 if depth <= 0:
59 raise ValueError("depth must be greater than 0.")
60 # Convert datetime.date to datetime.datetime for comparison.
61 if not isinstance(d, datetime.datetime):
62 d = datetime.datetime(d.year, d.month, d.day)
63 if now and not isinstance(now, datetime.datetime):
64 now = datetime.datetime(now.year, now.month, now.day)
66 now = now or datetime.datetime.now(datetime.UTC if is_aware(d) else None)
68 if reversed:
69 d, now = now, d
70 delta = now - d
72 # Ignore microseconds.
73 since = delta.days * 24 * 60 * 60 + delta.seconds
74 if since <= 0:
75 # d is in the future compared to now, stop processing.
76 return avoid_wrapping(time_strings["minute"] % {"num": 0})
78 # Get years and months.
79 total_months = (now.year - d.year) * 12 + (now.month - d.month)
80 if d.day > now.day or (d.day == now.day and d.time() > now.time()):
81 total_months -= 1
82 years, months = divmod(total_months, 12)
84 # Calculate the remaining time.
85 # Create a "pivot" datetime shifted from d by years and months, then use
86 # that to determine the other parts.
87 if years or months:
88 pivot_year = d.year + years
89 pivot_month = d.month + months
90 if pivot_month > 12:
91 pivot_month -= 12
92 pivot_year += 1
93 pivot = datetime.datetime(
94 pivot_year,
95 pivot_month,
96 min(MONTHS_DAYS[pivot_month - 1], d.day),
97 d.hour,
98 d.minute,
99 d.second,
100 tzinfo=d.tzinfo,
101 )
102 else:
103 pivot = d
104 remaining_time = (now - pivot).total_seconds()
105 partials = [years, months]
106 for chunk in TIME_CHUNKS:
107 count = int(remaining_time // chunk)
108 partials.append(count)
109 remaining_time -= chunk * count
111 # Find the first non-zero part (if any) and then build the result, until
112 # depth.
113 i = 0
114 for i, value in enumerate(partials):
115 if value != 0:
116 break
117 else:
118 return avoid_wrapping(time_strings["minute"] % {"num": 0})
120 result = []
121 current_depth = 0
122 while i < len(TIME_STRINGS_KEYS) and current_depth < depth:
123 value = partials[i]
124 if value == 0:
125 break
126 name = TIME_STRINGS_KEYS[i]
127 result.append(avoid_wrapping(time_strings[name] % {"num": value}))
128 current_depth += 1
129 i += 1
131 return ", ".join(result)
134def timeuntil(d, now=None, time_strings=None, depth=2):
135 """
136 Like timesince, but return a string measuring the time until the given time.
137 """
138 return timesince(d, now, reversed=True, time_strings=time_strings, depth=depth)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Timezone-related classes and functions.
3"""
5import functools
6import zoneinfo
7from contextlib import ContextDecorator
8from datetime import UTC, datetime, timedelta, timezone, tzinfo
9from threading import local
11from plain.runtime import settings
13__all__ = [
14 "get_fixed_timezone",
15 "get_default_timezone",
16 "get_default_timezone_name",
17 "get_current_timezone",
18 "get_current_timezone_name",
19 "activate",
20 "deactivate",
21 "override",
22 "localtime",
23 "now",
24 "is_aware",
25 "is_naive",
26 "make_aware",
27 "make_naive",
28]
31def get_fixed_timezone(offset):
32 """Return a tzinfo instance with a fixed offset from UTC."""
33 if isinstance(offset, timedelta):
34 offset = offset.total_seconds() // 60
35 sign = "-" if offset < 0 else "+"
36 hhmm = "%02d%02d" % divmod(abs(offset), 60)
37 name = sign + hhmm
38 return timezone(timedelta(minutes=offset), name)
41# In order to avoid accessing settings at compile time,
42# wrap the logic in a function and cache the result.
43@functools.lru_cache
44def get_default_timezone():
45 """
46 Return the default time zone as a tzinfo instance.
48 This is the time zone defined by settings.TIME_ZONE.
49 """
50 return zoneinfo.ZoneInfo(settings.TIME_ZONE)
53# This function exists for consistency with get_current_timezone_name
54def get_default_timezone_name():
55 """Return the name of the default time zone."""
56 return _get_timezone_name(get_default_timezone())
59_active = local()
62def get_current_timezone():
63 """Return the currently active time zone as a tzinfo instance."""
64 return getattr(_active, "value", get_default_timezone())
67def get_current_timezone_name():
68 """Return the name of the currently active time zone."""
69 return _get_timezone_name(get_current_timezone())
72def _get_timezone_name(timezone):
73 """
74 Return the offset for fixed offset timezones, or the name of timezone if
75 not set.
76 """
77 return timezone.tzname(None) or str(timezone)
80# Timezone selection functions.
82# These functions don't change os.environ['TZ'] and call time.tzset()
83# because it isn't thread safe.
86def activate(timezone):
87 """
88 Set the time zone for the current thread.
90 The ``timezone`` argument must be an instance of a tzinfo subclass or a
91 time zone name.
92 """
93 if isinstance(timezone, tzinfo):
94 _active.value = timezone
95 elif isinstance(timezone, str):
96 _active.value = zoneinfo.ZoneInfo(timezone)
97 else:
98 raise ValueError(f"Invalid timezone: {timezone!r}")
101def deactivate():
102 """
103 Unset the time zone for the current thread.
105 Plain will then use the time zone defined by settings.TIME_ZONE.
106 """
107 if hasattr(_active, "value"):
108 del _active.value
111class override(ContextDecorator):
112 """
113 Temporarily set the time zone for the current thread.
115 This is a context manager that uses plain.utils.timezone.activate()
116 to set the timezone on entry and restores the previously active timezone
117 on exit.
119 The ``timezone`` argument must be an instance of a ``tzinfo`` subclass, a
120 time zone name, or ``None``. If it is ``None``, Plain enables the default
121 time zone.
122 """
124 def __init__(self, timezone):
125 self.timezone = timezone
127 def __enter__(self):
128 self.old_timezone = getattr(_active, "value", None)
129 if self.timezone is None:
130 deactivate()
131 else:
132 activate(self.timezone)
134 def __exit__(self, exc_type, exc_value, traceback):
135 if self.old_timezone is None:
136 deactivate()
137 else:
138 _active.value = self.old_timezone
141# Utilities
144def localtime(value=None, timezone=None):
145 """
146 Convert an aware datetime.datetime to local time.
148 Only aware datetimes are allowed. When value is omitted, it defaults to
149 now().
151 Local time is defined by the current time zone, unless another time zone
152 is specified.
153 """
154 if value is None:
155 value = now()
156 if timezone is None:
157 timezone = get_current_timezone()
158 # Emulate the behavior of astimezone() on Python < 3.6.
159 if is_naive(value):
160 raise ValueError("localtime() cannot be applied to a naive datetime")
161 return value.astimezone(timezone)
164def now():
165 """
166 Return a timezone aware datetime.
167 """
168 return datetime.now(tz=UTC)
171# By design, these four functions don't perform any checks on their arguments.
172# The caller should ensure that they don't receive an invalid value like None.
175def is_aware(value):
176 """
177 Determine if a given datetime.datetime is aware.
179 The concept is defined in Python's docs:
180 https://docs.python.org/library/datetime.html#datetime.tzinfo
182 Assuming value.tzinfo is either None or a proper datetime.tzinfo,
183 value.utcoffset() implements the appropriate logic.
184 """
185 return value.utcoffset() is not None
188def is_naive(value):
189 """
190 Determine if a given datetime.datetime is naive.
192 The concept is defined in Python's docs:
193 https://docs.python.org/library/datetime.html#datetime.tzinfo
195 Assuming value.tzinfo is either None or a proper datetime.tzinfo,
196 value.utcoffset() implements the appropriate logic.
197 """
198 return value.utcoffset() is None
201def make_aware(value, timezone=None):
202 """Make a naive datetime.datetime in a given time zone aware."""
203 if timezone is None:
204 timezone = get_current_timezone()
205 # Check that we won't overwrite the timezone of an aware datetime.
206 if is_aware(value):
207 raise ValueError(f"make_aware expects a naive datetime, got {value}")
208 # This may be wrong around DST changes!
209 return value.replace(tzinfo=timezone)
212def make_naive(value, timezone=None):
213 """Make an aware datetime.datetime naive in a given time zone."""
214 if timezone is None:
215 timezone = get_current_timezone()
216 # Emulate the behavior of astimezone() on Python < 3.6.
217 if is_naive(value):
218 raise ValueError("make_naive() cannot be applied to a naive datetime")
219 return value.astimezone(timezone).replace(tzinfo=None)
222def _datetime_ambiguous_or_imaginary(dt, tz):
223 return tz.utcoffset(dt.replace(fold=not dt.fold)) != tz.utcoffset(dt)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2A class for storing a tree graph. Primarily used for filter constructs in the
3ORM.
4"""
6import copy
8from plain.utils.hashable import make_hashable
11class Node:
12 """
13 A single internal node in the tree graph. A Node should be viewed as a
14 connection (the root) with the children being either leaf nodes or other
15 Node instances.
16 """
18 # Standard connector type. Clients usually won't use this at all and
19 # subclasses will usually override the value.
20 default = "DEFAULT"
22 def __init__(self, children=None, connector=None, negated=False):
23 """Construct a new Node. If no connector is given, use the default."""
24 self.children = children[:] if children else []
25 self.connector = connector or self.default
26 self.negated = negated
28 @classmethod
29 def create(cls, children=None, connector=None, negated=False):
30 """
31 Create a new instance using Node() instead of __init__() as some
32 subclasses, e.g. plain.models.query_utils.Q, may implement a custom
33 __init__() with a signature that conflicts with the one defined in
34 Node.__init__().
35 """
36 obj = Node(children, connector or cls.default, negated)
37 obj.__class__ = cls
38 return obj
40 def __str__(self):
41 template = "(NOT (%s: %s))" if self.negated else "(%s: %s)"
42 return template % (self.connector, ", ".join(str(c) for c in self.children))
44 def __repr__(self):
45 return f"<{self.__class__.__name__}: {self}>"
47 def __copy__(self):
48 obj = self.create(connector=self.connector, negated=self.negated)
49 obj.children = self.children # Don't [:] as .__init__() via .create() does.
50 return obj
52 copy = __copy__
54 def __deepcopy__(self, memodict):
55 obj = self.create(connector=self.connector, negated=self.negated)
56 obj.children = copy.deepcopy(self.children, memodict)
57 return obj
59 def __len__(self):
60 """Return the number of children this node has."""
61 return len(self.children)
63 def __bool__(self):
64 """Return whether or not this node has children."""
65 return bool(self.children)
67 def __contains__(self, other):
68 """Return True if 'other' is a direct child of this instance."""
69 return other in self.children
71 def __eq__(self, other):
72 return (
73 self.__class__ == other.__class__
74 and self.connector == other.connector
75 and self.negated == other.negated
76 and self.children == other.children
77 )
79 def __hash__(self):
80 return hash(
81 (
82 self.__class__,
83 self.connector,
84 self.negated,
85 *make_hashable(self.children),
86 )
87 )
89 def add(self, data, conn_type):
90 """
91 Combine this tree and the data represented by data using the
92 connector conn_type. The combine is done by squashing the node other
93 away if possible.
95 This tree (self) will never be pushed to a child node of the
96 combined tree, nor will the connector or negated properties change.
98 Return a node which can be used in place of data regardless if the
99 node other got squashed or not.
100 """
101 if self.connector != conn_type:
102 obj = self.copy()
103 self.connector = conn_type
104 self.children = [obj, data]
105 return data
106 elif (
107 isinstance(data, Node)
108 and not data.negated
109 and (data.connector == conn_type or len(data) == 1)
110 ):
111 # We can squash the other node's children directly into this node.
112 # We are just doing (AB)(CD) == (ABCD) here, with the addition that
113 # if the length of the other node is 1 the connector doesn't
114 # matter. However, for the len(self) == 1 case we don't want to do
115 # the squashing, as it would alter self.connector.
116 self.children.extend(data.children)
117 return self
118 else:
119 # We could use perhaps additional logic here to see if some
120 # children could be used for pushdown here.
121 self.children.append(data)
122 return data
124 def negate(self):
125 """Negate the sense of the root connector."""
126 self.negated = not self.negated
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from . import preflight # noqa
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.packages import PackageConfig
4class SessionsConfig(PackageConfig):
5 name = "plain.sessions"
6 label = "plainsessions"
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1# Cookie name. This can be whatever you want.
2SESSION_COOKIE_NAME = "sessionid"
3# Age of cookie, in seconds (default: 2 weeks).
4SESSION_COOKIE_AGE = 60 * 60 * 24 * 7 * 2
5# A string like "example.com", or None for standard domain cookie.
6SESSION_COOKIE_DOMAIN = None
7# Whether the session cookie should be secure (https:// only).
8SESSION_COOKIE_SECURE = True
9# The path of the session cookie.
10SESSION_COOKIE_PATH = "/"
11# Whether to use the HttpOnly flag.
12SESSION_COOKIE_HTTPONLY = True
13# Whether to set the flag restricting cookie leaks on cross-site requests.
14# This can be 'Lax', 'Strict', 'None', or False to disable the flag.
15SESSION_COOKIE_SAMESITE = "Lax"
16# Whether to save the session data on every request.
17SESSION_SAVE_EVERY_REQUEST = False
18# Whether a user's session cookie expires when the web browser is closed.
19SESSION_EXPIRE_AT_BROWSER_CLOSE = False
20# The module to store session data
21SESSION_ENGINE = "plain.sessions.backends.db"
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.exceptions import BadRequest, SuspiciousOperation
4class SuspiciousSession(SuspiciousOperation):
5 """The session may be tampered with"""
7 pass
10class SessionInterrupted(BadRequest):
11 """The session was interrupted."""
13 pass
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import time
2from importlib import import_module
4from plain.runtime import settings
5from plain.sessions.backends.base import UpdateError
6from plain.sessions.exceptions import SessionInterrupted
7from plain.utils.cache import patch_vary_headers
8from plain.utils.http import http_date
11class SessionMiddleware:
12 def __init__(self, get_response):
13 self.get_response = get_response
14 engine = import_module(settings.SESSION_ENGINE)
15 self.SessionStore = engine.SessionStore
17 def __call__(self, request):
18 session_key = request.COOKIES.get(settings.SESSION_COOKIE_NAME)
19 request.session = self.SessionStore(session_key)
21 response = self.get_response(request)
23 """
24 If request.session was modified, or if the configuration is to save the
25 session every time, save the changes and set a session cookie or delete
26 the session cookie if the session has been emptied.
27 """
28 try:
29 accessed = request.session.accessed
30 modified = request.session.modified
31 empty = request.session.is_empty()
32 except AttributeError:
33 return response
34 # First check if we need to delete this cookie.
35 # The session should be deleted only if the session is entirely empty.
36 if settings.SESSION_COOKIE_NAME in request.COOKIES and empty:
37 response.delete_cookie(
38 settings.SESSION_COOKIE_NAME,
39 path=settings.SESSION_COOKIE_PATH,
40 domain=settings.SESSION_COOKIE_DOMAIN,
41 samesite=settings.SESSION_COOKIE_SAMESITE,
42 )
43 patch_vary_headers(response, ("Cookie",))
44 else:
45 if accessed:
46 patch_vary_headers(response, ("Cookie",))
47 if (modified or settings.SESSION_SAVE_EVERY_REQUEST) and not empty:
48 if request.session.get_expire_at_browser_close():
49 max_age = None
50 expires = None
51 else:
52 max_age = request.session.get_expiry_age()
53 expires_time = time.time() + max_age
54 expires = http_date(expires_time)
55 # Save the session data and refresh the client cookie.
56 # Skip session save for 5xx responses.
57 if response.status_code < 500:
58 try:
59 request.session.save()
60 except UpdateError:
61 raise SessionInterrupted(
62 "The request's session was deleted before the "
63 "request completed. The user may have logged "
64 "out in a concurrent request, for example."
65 )
66 response.set_cookie(
67 settings.SESSION_COOKIE_NAME,
68 request.session.session_key,
69 max_age=max_age,
70 expires=expires,
71 domain=settings.SESSION_COOKIE_DOMAIN,
72 path=settings.SESSION_COOKIE_PATH,
73 secure=settings.SESSION_COOKIE_SECURE or None,
74 httponly=settings.SESSION_COOKIE_HTTPONLY or None,
75 samesite=settings.SESSION_COOKIE_SAMESITE,
76 )
77 return response
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain import models
4class SessionManager(models.Manager):
5 use_in_migrations = True
7 def encode(self, session_dict):
8 """
9 Return the given session dictionary serialized and encoded as a string.
10 """
11 session_store_class = self.model.get_session_store_class()
12 return session_store_class().encode(session_dict)
14 def save(self, session_key, session_dict, expire_date):
15 s = self.model(session_key, self.encode(session_dict), expire_date)
16 if session_dict:
17 s.save()
18 else:
19 s.delete() # Clear sessions with no data.
20 return s
23class Session(models.Model):
24 """
25 Plain provides full support for anonymous sessions. The session
26 framework lets you store and retrieve arbitrary data on a
27 per-site-visitor basis. It stores data on the server side and
28 abstracts the sending and receiving of cookies. Cookies contain a
29 session ID -- not the data itself.
31 The Plain sessions framework is entirely cookie-based. It does
32 not fall back to putting session IDs in URLs. This is an intentional
33 design decision. Not only does that behavior make URLs ugly, it makes
34 your site vulnerable to session-ID theft via the "Referer" header.
36 For complete documentation on using Sessions in your code, consult
37 the sessions documentation that is shipped with Plain (also available
38 on the Plain web site).
39 """
41 session_key = models.CharField(max_length=40, primary_key=True)
42 session_data = models.TextField()
43 expire_date = models.DateTimeField(db_index=True)
45 objects = SessionManager()
47 def __str__(self):
48 return self.session_key
50 @classmethod
51 def get_session_store_class(cls):
52 from plain.sessions.backends.db import SessionStore
54 return SessionStore
56 def get_decoded(self):
57 session_store_class = self.get_session_store_class()
58 return session_store_class().decode(self.session_data)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.preflight import Warning, register
2from plain.runtime import settings
5def add_session_cookie_message(message):
6 return message + (
7 " Using a secure-only session cookie makes it more difficult for "
8 "network traffic sniffers to hijack user sessions."
9 )
12W010 = Warning(
13 add_session_cookie_message(
14 "You have 'plain.sessions' in your INSTALLED_PACKAGES, "
15 "but you have not set SESSION_COOKIE_SECURE to True."
16 ),
17 id="security.W010",
18)
20W011 = Warning(
21 add_session_cookie_message(
22 "You have 'plain.sessions.middleware.SessionMiddleware' "
23 "in your MIDDLEWARE, but you have not set "
24 "SESSION_COOKIE_SECURE to True."
25 ),
26 id="security.W011",
27)
29W012 = Warning(
30 add_session_cookie_message("SESSION_COOKIE_SECURE is not set to True."),
31 id="security.W012",
32)
35def add_httponly_message(message):
36 return message + (
37 " Using an HttpOnly session cookie makes it more difficult for "
38 "cross-site scripting attacks to hijack user sessions."
39 )
42W013 = Warning(
43 add_httponly_message(
44 "You have 'plain.sessions' in your INSTALLED_PACKAGES, "
45 "but you have not set SESSION_COOKIE_HTTPONLY to True.",
46 ),
47 id="security.W013",
48)
50W014 = Warning(
51 add_httponly_message(
52 "You have 'plain.sessions.middleware.SessionMiddleware' "
53 "in your MIDDLEWARE, but you have not set "
54 "SESSION_COOKIE_HTTPONLY to True."
55 ),
56 id="security.W014",
57)
59W015 = Warning(
60 add_httponly_message("SESSION_COOKIE_HTTPONLY is not set to True."),
61 id="security.W015",
62)
65@register(deploy=True)
66def check_session_cookie_secure(package_configs, **kwargs):
67 if settings.SESSION_COOKIE_SECURE is True:
68 return []
69 errors = []
70 if _session_app():
71 errors.append(W010)
72 if _session_middleware():
73 errors.append(W011)
74 if len(errors) > 1:
75 errors = [W012]
76 return errors
79@register(deploy=True)
80def check_session_cookie_httponly(package_configs, **kwargs):
81 if settings.SESSION_COOKIE_HTTPONLY is True:
82 return []
83 errors = []
84 if _session_app():
85 errors.append(W013)
86 if _session_middleware():
87 errors.append(W014)
88 if len(errors) > 1:
89 errors = [W015]
90 return errors
93def _session_middleware():
94 return "plain.sessions.middleware.SessionMiddleware" in settings.MIDDLEWARE
97def _session_app():
98 return "plain.sessions" in settings.INSTALLED_PACKAGES
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Global Plain exception and warning classes.
3"""
4import operator
6from plain.utils.hashable import make_hashable
9class FieldDoesNotExist(Exception):
10 """The requested model field does not exist"""
12 pass
15class PackageRegistryNotReady(Exception):
16 """The plain.packages registry is not populated yet"""
18 pass
21class ObjectDoesNotExist(Exception):
22 """The requested object does not exist"""
24 silent_variable_failure = True
27class MultipleObjectsReturned(Exception):
28 """The query returned multiple objects when only one was expected."""
30 pass
33class SuspiciousOperation(Exception):
34 """The user did something suspicious"""
37class SuspiciousMultipartForm(SuspiciousOperation):
38 """Suspect MIME request in multipart form data"""
40 pass
43class SuspiciousFileOperation(SuspiciousOperation):
44 """A Suspicious filesystem operation was attempted"""
46 pass
49class DisallowedHost(SuspiciousOperation):
50 """HTTP_HOST header contains invalid value"""
52 pass
55class DisallowedRedirect(SuspiciousOperation):
56 """Redirect to scheme not in allowed list"""
58 pass
61class TooManyFieldsSent(SuspiciousOperation):
62 """
63 The number of fields in a GET or POST request exceeded
64 settings.DATA_UPLOAD_MAX_NUMBER_FIELDS.
65 """
67 pass
70class TooManyFilesSent(SuspiciousOperation):
71 """
72 The number of fields in a GET or POST request exceeded
73 settings.DATA_UPLOAD_MAX_NUMBER_FILES.
74 """
76 pass
79class RequestDataTooBig(SuspiciousOperation):
80 """
81 The size of the request (excluding any file uploads) exceeded
82 settings.DATA_UPLOAD_MAX_MEMORY_SIZE.
83 """
85 pass
88class RequestAborted(Exception):
89 """The request was closed before it was completed, or timed out."""
91 pass
94class BadRequest(Exception):
95 """The request is malformed and cannot be processed."""
97 pass
100class PermissionDenied(Exception):
101 """The user did not have permission to do that"""
103 pass
106class ViewDoesNotExist(Exception):
107 """The requested view does not exist"""
109 pass
112class ImproperlyConfigured(Exception):
113 """Plain is somehow improperly configured"""
115 pass
118class FieldError(Exception):
119 """Some kind of problem with a model field."""
121 pass
124NON_FIELD_ERRORS = "__all__"
127class ValidationError(Exception):
128 """An error while validating data."""
130 def __init__(self, message, code=None, params=None):
131 """
132 The `message` argument can be a single error, a list of errors, or a
133 dictionary that maps field names to lists of errors. What we define as
134 an "error" can be either a simple string or an instance of
135 ValidationError with its message attribute set, and what we define as
136 list or dictionary can be an actual `list` or `dict` or an instance
137 of ValidationError with its `error_list` or `error_dict` attribute set.
138 """
139 super().__init__(message, code, params)
141 if isinstance(message, ValidationError):
142 if hasattr(message, "error_dict"):
143 message = message.error_dict
144 elif not hasattr(message, "message"):
145 message = message.error_list
146 else:
147 message, code, params = message.message, message.code, message.params
149 if isinstance(message, dict):
150 self.error_dict = {}
151 for field, messages in message.items():
152 if not isinstance(messages, ValidationError):
153 messages = ValidationError(messages)
154 self.error_dict[field] = messages.error_list
156 elif isinstance(message, list):
157 self.error_list = []
158 for message in message:
159 # Normalize plain strings to instances of ValidationError.
160 if not isinstance(message, ValidationError):
161 message = ValidationError(message)
162 if hasattr(message, "error_dict"):
163 self.error_list.extend(sum(message.error_dict.values(), []))
164 else:
165 self.error_list.extend(message.error_list)
167 else:
168 self.message = message
169 self.code = code
170 self.params = params
171 self.error_list = [self]
173 @property
174 def message_dict(self):
175 # Trigger an AttributeError if this ValidationError
176 # doesn't have an error_dict.
177 getattr(self, "error_dict")
179 return dict(self)
181 @property
182 def messages(self):
183 if hasattr(self, "error_dict"):
184 return sum(dict(self).values(), [])
185 return list(self)
187 def update_error_dict(self, error_dict):
188 if hasattr(self, "error_dict"):
189 for field, error_list in self.error_dict.items():
190 error_dict.setdefault(field, []).extend(error_list)
191 else:
192 error_dict.setdefault(NON_FIELD_ERRORS, []).extend(self.error_list)
193 return error_dict
195 def __iter__(self):
196 if hasattr(self, "error_dict"):
197 for field, errors in self.error_dict.items():
198 yield field, list(ValidationError(errors))
199 else:
200 for error in self.error_list:
201 message = error.message
202 if error.params:
203 message %= error.params
204 yield str(message)
206 def __str__(self):
207 if hasattr(self, "error_dict"):
208 return repr(dict(self))
209 return repr(list(self))
211 def __repr__(self):
212 return "ValidationError(%s)" % self
214 def __eq__(self, other):
215 if not isinstance(other, ValidationError):
216 return NotImplemented
217 return hash(self) == hash(other)
219 def __hash__(self):
220 if hasattr(self, "message"):
221 return hash(
222 (
223 self.message,
224 self.code,
225 make_hashable(self.params),
226 )
227 )
228 if hasattr(self, "error_dict"):
229 return hash(make_hashable(self.error_dict))
230 return hash(tuple(sorted(self.error_list, key=operator.attrgetter("message"))))
233class EmptyResultSet(Exception):
234 """A database query predicate is impossible."""
236 pass
239class FullResultSet(Exception):
240 """A database query predicate is matches everything."""
242 pass
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import datetime
2import decimal
3import json
4import uuid
6from plain.utils.duration import duration_iso_string
7from plain.utils.functional import Promise
8from plain.utils.timezone import is_aware
11class PlainJSONEncoder(json.JSONEncoder):
12 """
13 JSONEncoder subclass that knows how to encode date/time, decimal types, and
14 UUIDs.
15 """
17 def default(self, o):
18 # See "Date Time String Format" in the ECMA-262 specification.
19 if isinstance(o, datetime.datetime):
20 r = o.isoformat()
21 if o.microsecond:
22 r = r[:23] + r[26:]
23 if r.endswith("+00:00"):
24 r = r.removesuffix("+00:00") + "Z"
25 return r
26 elif isinstance(o, datetime.date):
27 return o.isoformat()
28 elif isinstance(o, datetime.time):
29 if is_aware(o):
30 raise ValueError("JSON can't represent timezone-aware times.")
31 r = o.isoformat()
32 if o.microsecond:
33 r = r[:12]
34 return r
35 elif isinstance(o, datetime.timedelta):
36 return duration_iso_string(o)
37 elif isinstance(o, decimal.Decimal | uuid.UUID | Promise):
38 return str(o)
39 else:
40 return super().default(o)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import collections.abc
2import inspect
3import warnings
4from math import ceil
6from plain.utils.functional import cached_property
7from plain.utils.inspect import method_has_no_args
10class UnorderedObjectListWarning(RuntimeWarning):
11 pass
14class InvalidPage(Exception):
15 pass
18class PageNotAnInteger(InvalidPage):
19 pass
22class EmptyPage(InvalidPage):
23 pass
26class Paginator:
27 # Translators: String used to replace omitted page numbers in elided page
28 # range generated by paginators, e.g. [1, 2, '…', 5, 6, 7, '…', 9, 10].
29 ELLIPSIS = "…"
31 def __init__(self, object_list, per_page, orphans=0, allow_empty_first_page=True):
32 self.object_list = object_list
33 self._check_object_list_is_ordered()
34 self.per_page = int(per_page)
35 self.orphans = int(orphans)
36 self.allow_empty_first_page = allow_empty_first_page
38 def __iter__(self):
39 for page_number in self.page_range:
40 yield self.page(page_number)
42 def validate_number(self, number):
43 """Validate the given 1-based page number."""
44 try:
45 if isinstance(number, float) and not number.is_integer():
46 raise ValueError
47 number = int(number)
48 except (TypeError, ValueError):
49 raise PageNotAnInteger("That page number is not an integer")
50 if number < 1:
51 raise EmptyPage("That page number is less than 1")
52 if number > self.num_pages:
53 raise EmptyPage("That page contains no results")
54 return number
56 def get_page(self, number):
57 """
58 Return a valid page, even if the page argument isn't a number or isn't
59 in range.
60 """
61 try:
62 number = self.validate_number(number)
63 except PageNotAnInteger:
64 number = 1
65 except EmptyPage:
66 number = self.num_pages
67 return self.page(number)
69 def page(self, number):
70 """Return a Page object for the given 1-based page number."""
71 number = self.validate_number(number)
72 bottom = (number - 1) * self.per_page
73 top = bottom + self.per_page
74 if top + self.orphans >= self.count:
75 top = self.count
76 return self._get_page(self.object_list[bottom:top], number, self)
78 def _get_page(self, *args, **kwargs):
79 """
80 Return an instance of a single page.
82 This hook can be used by subclasses to use an alternative to the
83 standard :cls:`Page` object.
84 """
85 return Page(*args, **kwargs)
87 @cached_property
88 def count(self):
89 """Return the total number of objects, across all pages."""
90 c = getattr(self.object_list, "count", None)
91 if callable(c) and not inspect.isbuiltin(c) and method_has_no_args(c):
92 return c()
93 return len(self.object_list)
95 @cached_property
96 def num_pages(self):
97 """Return the total number of pages."""
98 if self.count == 0 and not self.allow_empty_first_page:
99 return 0
100 hits = max(1, self.count - self.orphans)
101 return ceil(hits / self.per_page)
103 @property
104 def page_range(self):
105 """
106 Return a 1-based range of pages for iterating through within
107 a template for loop.
108 """
109 return range(1, self.num_pages + 1)
111 def _check_object_list_is_ordered(self):
112 """
113 Warn if self.object_list is unordered (typically a QuerySet).
114 """
115 ordered = getattr(self.object_list, "ordered", None)
116 if ordered is not None and not ordered:
117 obj_list_repr = (
118 f"{self.object_list.model} {self.object_list.__class__.__name__}"
119 if hasattr(self.object_list, "model")
120 else f"{self.object_list!r}"
121 )
122 warnings.warn(
123 "Pagination may yield inconsistent results with an unordered "
124 f"object_list: {obj_list_repr}.",
125 UnorderedObjectListWarning,
126 stacklevel=3,
127 )
130class Page(collections.abc.Sequence):
131 def __init__(self, object_list, number, paginator):
132 self.object_list = object_list
133 self.number = number
134 self.paginator = paginator
136 def __repr__(self):
137 return f"<Page {self.number} of {self.paginator.num_pages}>"
139 def __len__(self):
140 return len(self.object_list)
142 def __getitem__(self, index):
143 if not isinstance(index, int | slice):
144 raise TypeError(
145 "Page indices must be integers or slices, not %s."
146 % type(index).__name__
147 )
148 # The object_list is converted to a list so that if it was a QuerySet
149 # it won't be a database hit per __getitem__.
150 if not isinstance(self.object_list, list):
151 self.object_list = list(self.object_list)
152 return self.object_list[index]
154 def has_next(self):
155 return self.number < self.paginator.num_pages
157 def has_previous(self):
158 return self.number > 1
160 def has_other_pages(self):
161 return self.has_previous() or self.has_next()
163 def next_page_number(self):
164 return self.paginator.validate_number(self.number + 1)
166 def previous_page_number(self):
167 return self.paginator.validate_number(self.number - 1)
169 def start_index(self):
170 """
171 Return the 1-based index of the first object on this page,
172 relative to total objects in the paginator.
173 """
174 # Special case, return zero if no items.
175 if self.paginator.count == 0:
176 return 0
177 return (self.paginator.per_page * (self.number - 1)) + 1
179 def end_index(self):
180 """
181 Return the 1-based index of the last object on this page,
182 relative to total objects found (hits).
183 """
184 # Special case for the last page because there can be orphans.
185 if self.number == self.paginator.num_pages:
186 return self.paginator.count
187 return self.number * self.paginator.per_page
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Functions for creating and restoring url-safe signed JSON objects.
4The format used looks like this:
6>>> signing.dumps("hello")
7'ImhlbGxvIg:1QaUZC:YIye-ze3TTx7gtSv422nZA4sgmk'
9There are two components here, separated by a ':'. The first component is a
10URLsafe base64 encoded JSON of the object passed to dumps(). The second
11component is a base64 encoded hmac/SHA-256 hash of "$first_component:$secret"
13signing.loads(s) checks the signature and returns the deserialized object.
14If the signature fails, a BadSignature exception is raised.
16>>> signing.loads("ImhlbGxvIg:1QaUZC:YIye-ze3TTx7gtSv422nZA4sgmk")
17'hello'
18>>> signing.loads("ImhlbGxvIg:1QaUZC:YIye-ze3TTx7gtSv42-modified")
19...
20BadSignature: Signature "ImhlbGxvIg:1QaUZC:YIye-ze3TTx7gtSv42-modified" does not match
22You can optionally compress the JSON prior to base64 encoding it to save
23space, using the compress=True argument. This checks if compression actually
24helps and only applies compression if the result is a shorter string:
26>>> signing.dumps(list(range(1, 20)), compress=True)
27'.eJwFwcERACAIwLCF-rCiILN47r-GyZVJsNgkxaFxoDgxcOHGxMKD_T7vhAml:1QaUaL:BA0thEZrp4FQVXIXuOvYJtLJSrQ'
29The fact that the string is compressed is signalled by the prefixed '.' at the
30start of the base64 JSON.
32There are 65 url-safe characters: the 64 used by url-safe base64 and the ':'.
33These functions make use of all of them.
34"""
36import base64
37import datetime
38import json
39import time
40import zlib
42from plain.runtime import settings
43from plain.utils.crypto import constant_time_compare, salted_hmac
44from plain.utils.encoding import force_bytes
45from plain.utils.module_loading import import_string
46from plain.utils.regex_helper import _lazy_re_compile
48_SEP_UNSAFE = _lazy_re_compile(r"^[A-z0-9-_=]*$")
49BASE62_ALPHABET = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
52class BadSignature(Exception):
53 """Signature does not match."""
55 pass
58class SignatureExpired(BadSignature):
59 """Signature timestamp is older than required max_age."""
61 pass
64def b62_encode(s):
65 if s == 0:
66 return "0"
67 sign = "-" if s < 0 else ""
68 s = abs(s)
69 encoded = ""
70 while s > 0:
71 s, remainder = divmod(s, 62)
72 encoded = BASE62_ALPHABET[remainder] + encoded
73 return sign + encoded
76def b62_decode(s):
77 if s == "0":
78 return 0
79 sign = 1
80 if s[0] == "-":
81 s = s[1:]
82 sign = -1
83 decoded = 0
84 for digit in s:
85 decoded = decoded * 62 + BASE62_ALPHABET.index(digit)
86 return sign * decoded
89def b64_encode(s):
90 return base64.urlsafe_b64encode(s).strip(b"=")
93def b64_decode(s):
94 pad = b"=" * (-len(s) % 4)
95 return base64.urlsafe_b64decode(s + pad)
98def base64_hmac(salt, value, key, algorithm="sha1"):
99 return b64_encode(
100 salted_hmac(salt, value, key, algorithm=algorithm).digest()
101 ).decode()
104def _cookie_signer_key(key):
105 # SECRET_KEYS items may be str or bytes.
106 return b"plain.http.cookies" + force_bytes(key)
109def get_cookie_signer(salt="plain.signing.get_cookie_signer"):
110 Signer = import_string(settings.COOKIE_SIGNING_BACKEND)
111 return Signer(
112 key=_cookie_signer_key(settings.SECRET_KEY),
113 fallback_keys=map(_cookie_signer_key, settings.SECRET_KEY_FALLBACKS),
114 salt=salt,
115 )
118class JSONSerializer:
119 """
120 Simple wrapper around json to be used in signing.dumps and
121 signing.loads.
122 """
124 def dumps(self, obj):
125 return json.dumps(obj, separators=(",", ":")).encode("latin-1")
127 def loads(self, data):
128 return json.loads(data.decode("latin-1"))
131def dumps(
132 obj, key=None, salt="plain.signing", serializer=JSONSerializer, compress=False
133):
134 """
135 Return URL-safe, hmac signed base64 compressed JSON string. If key is
136 None, use settings.SECRET_KEY instead. The hmac algorithm is the default
137 Signer algorithm.
139 If compress is True (not the default), check if compressing using zlib can
140 save some space. Prepend a '.' to signify compression. This is included
141 in the signature, to protect against zip bombs.
143 Salt can be used to namespace the hash, so that a signed string is
144 only valid for a given namespace. Leaving this at the default
145 value or re-using a salt value across different parts of your
146 application without good cause is a security risk.
148 The serializer is expected to return a bytestring.
149 """
150 return TimestampSigner(key=key, salt=salt).sign_object(
151 obj, serializer=serializer, compress=compress
152 )
155def loads(
156 s,
157 key=None,
158 salt="plain.signing",
159 serializer=JSONSerializer,
160 max_age=None,
161 fallback_keys=None,
162):
163 """
164 Reverse of dumps(), raise BadSignature if signature fails.
166 The serializer is expected to accept a bytestring.
167 """
168 return TimestampSigner(
169 key=key, salt=salt, fallback_keys=fallback_keys
170 ).unsign_object(
171 s,
172 serializer=serializer,
173 max_age=max_age,
174 )
177class Signer:
178 def __init__(
179 self,
180 *,
181 key=None,
182 sep=":",
183 salt=None,
184 algorithm="sha256",
185 fallback_keys=None,
186 ):
187 self.key = key or settings.SECRET_KEY
188 self.fallback_keys = (
189 fallback_keys
190 if fallback_keys is not None
191 else settings.SECRET_KEY_FALLBACKS
192 )
193 self.sep = sep
194 self.salt = salt or f"{self.__class__.__module__}.{self.__class__.__name__}"
195 self.algorithm = algorithm
197 if _SEP_UNSAFE.match(self.sep):
198 raise ValueError(
199 "Unsafe Signer separator: %r (cannot be empty or consist of "
200 "only A-z0-9-_=)" % sep,
201 )
203 def signature(self, value, key=None):
204 key = key or self.key
205 return base64_hmac(self.salt + "signer", value, key, algorithm=self.algorithm)
207 def sign(self, value):
208 return f"{value}{self.sep}{self.signature(value)}"
210 def unsign(self, signed_value):
211 if self.sep not in signed_value:
212 raise BadSignature('No "%s" found in value' % self.sep)
213 value, sig = signed_value.rsplit(self.sep, 1)
214 for key in [self.key, *self.fallback_keys]:
215 if constant_time_compare(sig, self.signature(value, key)):
216 return value
217 raise BadSignature('Signature "%s" does not match' % sig)
219 def sign_object(self, obj, serializer=JSONSerializer, compress=False):
220 """
221 Return URL-safe, hmac signed base64 compressed JSON string.
223 If compress is True (not the default), check if compressing using zlib
224 can save some space. Prepend a '.' to signify compression. This is
225 included in the signature, to protect against zip bombs.
227 The serializer is expected to return a bytestring.
228 """
229 data = serializer().dumps(obj)
230 # Flag for if it's been compressed or not.
231 is_compressed = False
233 if compress:
234 # Avoid zlib dependency unless compress is being used.
235 compressed = zlib.compress(data)
236 if len(compressed) < (len(data) - 1):
237 data = compressed
238 is_compressed = True
239 base64d = b64_encode(data).decode()
240 if is_compressed:
241 base64d = "." + base64d
242 return self.sign(base64d)
244 def unsign_object(self, signed_obj, serializer=JSONSerializer, **kwargs):
245 # Signer.unsign() returns str but base64 and zlib compression operate
246 # on bytes.
247 base64d = self.unsign(signed_obj, **kwargs).encode()
248 decompress = base64d[:1] == b"."
249 if decompress:
250 # It's compressed; uncompress it first.
251 base64d = base64d[1:]
252 data = b64_decode(base64d)
253 if decompress:
254 data = zlib.decompress(data)
255 return serializer().loads(data)
258class TimestampSigner(Signer):
259 def timestamp(self):
260 return b62_encode(int(time.time()))
262 def sign(self, value):
263 value = f"{value}{self.sep}{self.timestamp()}"
264 return super().sign(value)
266 def unsign(self, value, max_age=None):
267 """
268 Retrieve original value and check it wasn't signed more
269 than max_age seconds ago.
270 """
271 result = super().unsign(value)
272 value, timestamp = result.rsplit(self.sep, 1)
273 timestamp = b62_decode(timestamp)
274 if max_age is not None:
275 if isinstance(max_age, datetime.timedelta):
276 max_age = max_age.total_seconds()
277 # Check timestamp is not older than max_age
278 age = time.time() - timestamp
279 if age > max_age:
280 raise SignatureExpired(f"Signature age {age} > {max_age} seconds")
281 return value
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import ipaddress
2import math
3import re
4from pathlib import Path
5from urllib.parse import urlsplit, urlunsplit
7from plain.exceptions import ValidationError
8from plain.utils.deconstruct import deconstructible
9from plain.utils.encoding import punycode
10from plain.utils.ipv6 import is_valid_ipv6_address
11from plain.utils.regex_helper import _lazy_re_compile
12from plain.utils.text import pluralize_lazy
14# These values, if given to validate(), will trigger the self.required check.
15EMPTY_VALUES = (None, "", [], (), {})
18@deconstructible
19class RegexValidator:
20 regex = ""
21 message = "Enter a valid value."
22 code = "invalid"
23 inverse_match = False
24 flags = 0
26 def __init__(
27 self, regex=None, message=None, code=None, inverse_match=None, flags=None
28 ):
29 if regex is not None:
30 self.regex = regex
31 if message is not None:
32 self.message = message
33 if code is not None:
34 self.code = code
35 if inverse_match is not None:
36 self.inverse_match = inverse_match
37 if flags is not None:
38 self.flags = flags
39 if self.flags and not isinstance(self.regex, str):
40 raise TypeError(
41 "If the flags are set, regex must be a regular expression string."
42 )
44 self.regex = _lazy_re_compile(self.regex, self.flags)
46 def __call__(self, value):
47 """
48 Validate that the input contains (or does *not* contain, if
49 inverse_match is True) a match for the regular expression.
50 """
51 regex_matches = self.regex.search(str(value))
52 invalid_input = regex_matches if self.inverse_match else not regex_matches
53 if invalid_input:
54 raise ValidationError(self.message, code=self.code, params={"value": value})
56 def __eq__(self, other):
57 return (
58 isinstance(other, RegexValidator)
59 and self.regex.pattern == other.regex.pattern
60 and self.regex.flags == other.regex.flags
61 and (self.message == other.message)
62 and (self.code == other.code)
63 and (self.inverse_match == other.inverse_match)
64 )
67@deconstructible
68class URLValidator(RegexValidator):
69 ul = "\u00a1-\uffff" # Unicode letters range (must not be a raw string).
71 # IP patterns
72 ipv4_re = (
73 r"(?:0|25[0-5]|2[0-4][0-9]|1[0-9]?[0-9]?|[1-9][0-9]?)"
74 r"(?:\.(?:0|25[0-5]|2[0-4][0-9]|1[0-9]?[0-9]?|[1-9][0-9]?)){3}"
75 )
76 ipv6_re = r"\[[0-9a-f:.]+\]" # (simple regex, validated later)
78 # Host patterns
79 hostname_re = (
80 r"[a-z" + ul + r"0-9](?:[a-z" + ul + r"0-9-]{0,61}[a-z" + ul + r"0-9])?"
81 )
82 # Max length for domain name labels is 63 characters per RFC 1034 sec. 3.1
83 domain_re = r"(?:\.(?!-)[a-z" + ul + r"0-9-]{1,63}(?<!-))*"
84 tld_re = (
85 r"\." # dot
86 r"(?!-)" # can't start with a dash
87 r"(?:[a-z" + ul + "-]{2,63}" # domain label
88 r"|xn--[a-z0-9]{1,59})" # or punycode label
89 r"(?<!-)" # can't end with a dash
90 r"\.?" # may have a trailing dot
91 )
92 host_re = "(" + hostname_re + domain_re + tld_re + "|localhost)"
94 regex = _lazy_re_compile(
95 r"^(?:[a-z0-9.+-]*)://" # scheme is validated separately
96 r"(?:[^\s:@/]+(?::[^\s:@/]*)?@)?" # user:pass authentication
97 r"(?:" + ipv4_re + "|" + ipv6_re + "|" + host_re + ")"
98 r"(?::[0-9]{1,5})?" # port
99 r"(?:[/?#][^\s]*)?" # resource path
100 r"\Z",
101 re.IGNORECASE,
102 )
103 message = "Enter a valid URL."
104 schemes = ["http", "https", "ftp", "ftps"]
105 unsafe_chars = frozenset("\t\r\n")
107 def __init__(self, schemes=None, **kwargs):
108 super().__init__(**kwargs)
109 if schemes is not None:
110 self.schemes = schemes
112 def __call__(self, value):
113 if not isinstance(value, str):
114 raise ValidationError(self.message, code=self.code, params={"value": value})
115 if self.unsafe_chars.intersection(value):
116 raise ValidationError(self.message, code=self.code, params={"value": value})
117 # Check if the scheme is valid.
118 scheme = value.split("://")[0].lower()
119 if scheme not in self.schemes:
120 raise ValidationError(self.message, code=self.code, params={"value": value})
122 # Then check full URL
123 try:
124 splitted_url = urlsplit(value)
125 except ValueError:
126 raise ValidationError(self.message, code=self.code, params={"value": value})
127 try:
128 super().__call__(value)
129 except ValidationError as e:
130 # Trivial case failed. Try for possible IDN domain
131 if value:
132 scheme, netloc, path, query, fragment = splitted_url
133 try:
134 netloc = punycode(netloc) # IDN -> ACE
135 except UnicodeError: # invalid domain part
136 raise e
137 url = urlunsplit((scheme, netloc, path, query, fragment))
138 super().__call__(url)
139 else:
140 raise
141 else:
142 # Now verify IPv6 in the netloc part
143 host_match = re.search(r"^\[(.+)\](?::[0-9]{1,5})?$", splitted_url.netloc)
144 if host_match:
145 potential_ip = host_match[1]
146 try:
147 validate_ipv6_address(potential_ip)
148 except ValidationError:
149 raise ValidationError(
150 self.message, code=self.code, params={"value": value}
151 )
153 # The maximum length of a full host name is 253 characters per RFC 1034
154 # section 3.1. It's defined to be 255 bytes or less, but this includes
155 # one byte for the length of the name and one byte for the trailing dot
156 # that's used to indicate absolute names in DNS.
157 if splitted_url.hostname is None or len(splitted_url.hostname) > 253:
158 raise ValidationError(self.message, code=self.code, params={"value": value})
161integer_validator = RegexValidator(
162 _lazy_re_compile(r"^-?\d+\Z"),
163 message="Enter a valid integer.",
164 code="invalid",
165)
168def validate_integer(value):
169 return integer_validator(value)
172@deconstructible
173class EmailValidator:
174 message = "Enter a valid email address."
175 code = "invalid"
176 user_regex = _lazy_re_compile(
177 # dot-atom
178 r"(^[-!#$%&'*+/=?^_`{}|~0-9A-Z]+(\.[-!#$%&'*+/=?^_`{}|~0-9A-Z]+)*\Z"
179 # quoted-string
180 r'|^"([\001-\010\013\014\016-\037!#-\[\]-\177]|\\[\001-\011\013\014\016-\177])'
181 r'*"\Z)',
182 re.IGNORECASE,
183 )
184 domain_regex = _lazy_re_compile(
185 # max length for domain name labels is 63 characters per RFC 1034
186 r"((?:[A-Z0-9](?:[A-Z0-9-]{0,61}[A-Z0-9])?\.)+)(?:[A-Z0-9-]{2,63}(?<!-))\Z",
187 re.IGNORECASE,
188 )
189 literal_regex = _lazy_re_compile(
190 # literal form, ipv4 or ipv6 address (SMTP 4.1.3)
191 r"\[([A-F0-9:.]+)\]\Z",
192 re.IGNORECASE,
193 )
194 domain_allowlist = ["localhost"]
196 def __init__(self, message=None, code=None, allowlist=None):
197 if message is not None:
198 self.message = message
199 if code is not None:
200 self.code = code
201 if allowlist is not None:
202 self.domain_allowlist = allowlist
204 def __call__(self, value):
205 if not value or "@" not in value:
206 raise ValidationError(self.message, code=self.code, params={"value": value})
208 user_part, domain_part = value.rsplit("@", 1)
210 if not self.user_regex.match(user_part):
211 raise ValidationError(self.message, code=self.code, params={"value": value})
213 if domain_part not in self.domain_allowlist and not self.validate_domain_part(
214 domain_part
215 ):
216 # Try for possible IDN domain-part
217 try:
218 domain_part = punycode(domain_part)
219 except UnicodeError:
220 pass
221 else:
222 if self.validate_domain_part(domain_part):
223 return
224 raise ValidationError(self.message, code=self.code, params={"value": value})
226 def validate_domain_part(self, domain_part):
227 if self.domain_regex.match(domain_part):
228 return True
230 literal_match = self.literal_regex.match(domain_part)
231 if literal_match:
232 ip_address = literal_match[1]
233 try:
234 validate_ipv46_address(ip_address)
235 return True
236 except ValidationError:
237 pass
238 return False
240 def __eq__(self, other):
241 return (
242 isinstance(other, EmailValidator)
243 and (self.domain_allowlist == other.domain_allowlist)
244 and (self.message == other.message)
245 and (self.code == other.code)
246 )
249validate_email = EmailValidator()
251slug_re = _lazy_re_compile(r"^[-a-zA-Z0-9_]+\Z")
252validate_slug = RegexValidator(
253 slug_re,
254 # Translators: "letters" means latin letters: a-z and A-Z.
255 "Enter a valid “slug” consisting of letters, numbers, underscores or hyphens.",
256 "invalid",
257)
259slug_unicode_re = _lazy_re_compile(r"^[-\w]+\Z")
260validate_unicode_slug = RegexValidator(
261 slug_unicode_re,
262 "Enter a valid “slug” consisting of Unicode letters, numbers, underscores, or hyphens."
263 "invalid",
264)
267def validate_ipv4_address(value):
268 try:
269 ipaddress.IPv4Address(value)
270 except ValueError:
271 raise ValidationError(
272 "Enter a valid IPv4 address.", code="invalid", params={"value": value}
273 )
276def validate_ipv6_address(value):
277 if not is_valid_ipv6_address(value):
278 raise ValidationError(
279 "Enter a valid IPv6 address.", code="invalid", params={"value": value}
280 )
283def validate_ipv46_address(value):
284 try:
285 validate_ipv4_address(value)
286 except ValidationError:
287 try:
288 validate_ipv6_address(value)
289 except ValidationError:
290 raise ValidationError(
291 "Enter a valid IPv4 or IPv6 address.",
292 code="invalid",
293 params={"value": value},
294 )
297ip_address_validator_map = {
298 "both": ([validate_ipv46_address], "Enter a valid IPv4 or IPv6 address."),
299 "ipv4": ([validate_ipv4_address], "Enter a valid IPv4 address."),
300 "ipv6": ([validate_ipv6_address], "Enter a valid IPv6 address."),
301}
304def ip_address_validators(protocol, unpack_ipv4):
305 """
306 Depending on the given parameters, return the appropriate validators for
307 the GenericIPAddressField.
308 """
309 if protocol != "both" and unpack_ipv4:
310 raise ValueError(
311 "You can only use `unpack_ipv4` if `protocol` is set to 'both'"
312 )
313 try:
314 return ip_address_validator_map[protocol.lower()]
315 except KeyError:
316 raise ValueError(
317 "The protocol '{}' is unknown. Supported: {}".format(
318 protocol, list(ip_address_validator_map)
319 )
320 )
323def int_list_validator(sep=",", message=None, code="invalid", allow_negative=False):
324 regexp = _lazy_re_compile(
325 r"^{neg}\d+(?:{sep}{neg}\d+)*\Z".format(
326 neg="(-)?" if allow_negative else "",
327 sep=re.escape(sep),
328 )
329 )
330 return RegexValidator(regexp, message=message, code=code)
333validate_comma_separated_integer_list = int_list_validator(
334 message="Enter only digits separated by commas.",
335)
338@deconstructible
339class BaseValidator:
340 message = "Ensure this value is %(limit_value)s (it is %(show_value)s)."
341 code = "limit_value"
343 def __init__(self, limit_value, message=None):
344 self.limit_value = limit_value
345 if message:
346 self.message = message
348 def __call__(self, value):
349 cleaned = self.clean(value)
350 limit_value = (
351 self.limit_value() if callable(self.limit_value) else self.limit_value
352 )
353 params = {"limit_value": limit_value, "show_value": cleaned, "value": value}
354 if self.compare(cleaned, limit_value):
355 raise ValidationError(self.message, code=self.code, params=params)
357 def __eq__(self, other):
358 if not isinstance(other, self.__class__):
359 return NotImplemented
360 return (
361 self.limit_value == other.limit_value
362 and self.message == other.message
363 and self.code == other.code
364 )
366 def compare(self, a, b):
367 return a is not b
369 def clean(self, x):
370 return x
373@deconstructible
374class MaxValueValidator(BaseValidator):
375 message = "Ensure this value is less than or equal to %(limit_value)s."
376 code = "max_value"
378 def compare(self, a, b):
379 return a > b
382@deconstructible
383class MinValueValidator(BaseValidator):
384 message = "Ensure this value is greater than or equal to %(limit_value)s."
385 code = "min_value"
387 def compare(self, a, b):
388 return a < b
391@deconstructible
392class StepValueValidator(BaseValidator):
393 message = "Ensure this value is a multiple of step size %(limit_value)s."
394 code = "step_size"
396 def compare(self, a, b):
397 return not math.isclose(math.remainder(a, b), 0, abs_tol=1e-9)
400@deconstructible
401class MinLengthValidator(BaseValidator):
402 message = pluralize_lazy(
403 "Ensure this value has at least %(limit_value)d character (it has "
404 "%(show_value)d).",
405 "Ensure this value has at least %(limit_value)d characters (it has "
406 "%(show_value)d).",
407 "limit_value",
408 )
409 code = "min_length"
411 def compare(self, a, b):
412 return a < b
414 def clean(self, x):
415 return len(x)
418@deconstructible
419class MaxLengthValidator(BaseValidator):
420 message = pluralize_lazy(
421 "Ensure this value has at most %(limit_value)d character (it has "
422 "%(show_value)d).",
423 "Ensure this value has at most %(limit_value)d characters (it has "
424 "%(show_value)d).",
425 "limit_value",
426 )
427 code = "max_length"
429 def compare(self, a, b):
430 return a > b
432 def clean(self, x):
433 return len(x)
436@deconstructible
437class DecimalValidator:
438 """
439 Validate that the input does not exceed the maximum number of digits
440 expected, otherwise raise ValidationError.
441 """
443 messages = {
444 "invalid": "Enter a number.",
445 "max_digits": pluralize_lazy(
446 "Ensure that there are no more than %(max)s digit in total.",
447 "Ensure that there are no more than %(max)s digits in total.",
448 "max",
449 ),
450 "max_decimal_places": pluralize_lazy(
451 "Ensure that there are no more than %(max)s decimal place.",
452 "Ensure that there are no more than %(max)s decimal places.",
453 "max",
454 ),
455 "max_whole_digits": pluralize_lazy(
456 "Ensure that there are no more than %(max)s digit before the decimal "
457 "point.",
458 "Ensure that there are no more than %(max)s digits before the decimal "
459 "point.",
460 "max",
461 ),
462 }
464 def __init__(self, max_digits, decimal_places):
465 self.max_digits = max_digits
466 self.decimal_places = decimal_places
468 def __call__(self, value):
469 digit_tuple, exponent = value.as_tuple()[1:]
470 if exponent in {"F", "n", "N"}:
471 raise ValidationError(
472 self.messages["invalid"], code="invalid", params={"value": value}
473 )
474 if exponent >= 0:
475 digits = len(digit_tuple)
476 if digit_tuple != (0,):
477 # A positive exponent adds that many trailing zeros.
478 digits += exponent
479 decimals = 0
480 else:
481 # If the absolute value of the negative exponent is larger than the
482 # number of digits, then it's the same as the number of digits,
483 # because it'll consume all of the digits in digit_tuple and then
484 # add abs(exponent) - len(digit_tuple) leading zeros after the
485 # decimal point.
486 if abs(exponent) > len(digit_tuple):
487 digits = decimals = abs(exponent)
488 else:
489 digits = len(digit_tuple)
490 decimals = abs(exponent)
491 whole_digits = digits - decimals
493 if self.max_digits is not None and digits > self.max_digits:
494 raise ValidationError(
495 self.messages["max_digits"],
496 code="max_digits",
497 params={"max": self.max_digits, "value": value},
498 )
499 if self.decimal_places is not None and decimals > self.decimal_places:
500 raise ValidationError(
501 self.messages["max_decimal_places"],
502 code="max_decimal_places",
503 params={"max": self.decimal_places, "value": value},
504 )
505 if (
506 self.max_digits is not None
507 and self.decimal_places is not None
508 and whole_digits > (self.max_digits - self.decimal_places)
509 ):
510 raise ValidationError(
511 self.messages["max_whole_digits"],
512 code="max_whole_digits",
513 params={"max": (self.max_digits - self.decimal_places), "value": value},
514 )
516 def __eq__(self, other):
517 return (
518 isinstance(other, self.__class__)
519 and self.max_digits == other.max_digits
520 and self.decimal_places == other.decimal_places
521 )
524@deconstructible
525class FileExtensionValidator:
526 message = "File extension “%(extension)s” is not allowed. Allowed extensions are: %(allowed_extensions)s."
527 code = "invalid_extension"
529 def __init__(self, allowed_extensions=None, message=None, code=None):
530 if allowed_extensions is not None:
531 allowed_extensions = [
532 allowed_extension.lower() for allowed_extension in allowed_extensions
533 ]
534 self.allowed_extensions = allowed_extensions
535 if message is not None:
536 self.message = message
537 if code is not None:
538 self.code = code
540 def __call__(self, value):
541 extension = Path(value.name).suffix[1:].lower()
542 if (
543 self.allowed_extensions is not None
544 and extension not in self.allowed_extensions
545 ):
546 raise ValidationError(
547 self.message,
548 code=self.code,
549 params={
550 "extension": extension,
551 "allowed_extensions": ", ".join(self.allowed_extensions),
552 "value": value,
553 },
554 )
556 def __eq__(self, other):
557 return (
558 isinstance(other, self.__class__)
559 and self.allowed_extensions == other.allowed_extensions
560 and self.message == other.message
561 and self.code == other.code
562 )
565def get_available_image_extensions():
566 try:
567 from PIL import Image
568 except ImportError:
569 return []
570 else:
571 Image.init()
572 return [ext.lower()[1:] for ext in Image.EXTENSION]
575def validate_image_file_extension(value):
576 return FileExtensionValidator(allowed_extensions=get_available_image_extensions())(
577 value
578 )
581@deconstructible
582class ProhibitNullCharactersValidator:
583 """Validate that the string doesn't contain the null character."""
585 message = "Null characters are not allowed."
586 code = "null_characters_not_allowed"
588 def __init__(self, message=None, code=None):
589 if message is not None:
590 self.message = message
591 if code is not None:
592 self.code = code
594 def __call__(self, value):
595 if "\x00" in str(value):
596 raise ValidationError(self.message, code=self.code, params={"value": value})
598 def __eq__(self, other):
599 return (
600 isinstance(other, self.__class__)
601 and self.message == other.message
602 and self.code == other.code
603 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.packages import PackageConfig
4class PlainOAuthConfig(PackageConfig):
5 name = "plain.oauth"
6 label = "plainoauth" # Primarily for migrations
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1OAUTH_LOGIN_PROVIDERS: dict
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1class OAuthError(Exception):
2 """Base class for OAuth errors"""
4 pass
7class OAuthStateMismatchError(OAuthError):
8 pass
11class OAuthUserAlreadyExistsError(OAuthError):
12 pass
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from typing import TYPE_CHECKING
3from plain import models
4from plain.auth import get_user_model
5from plain.exceptions import ValidationError
6from plain.models import transaction
7from plain.models.db import IntegrityError, OperationalError, ProgrammingError
8from plain.preflight import Error
9from plain.runtime import settings
10from plain.utils import timezone
12from .exceptions import OAuthUserAlreadyExistsError
14if TYPE_CHECKING:
15 from .providers import OAuthToken, OAuthUser
18# TODO preflight check for deploy that ensures all provider keys in db are also in settings?
21class OAuthConnection(models.Model):
22 created_at = models.DateTimeField(auto_now_add=True)
23 updated_at = models.DateTimeField(auto_now=True)
25 user = models.ForeignKey(
26 settings.AUTH_USER_MODEL,
27 on_delete=models.CASCADE,
28 related_name="oauth_connections",
29 )
31 # The key used to refer to this provider type (in settings)
32 provider_key = models.CharField(max_length=100, db_index=True)
34 # The unique ID of the user on the provider's system
35 provider_user_id = models.CharField(max_length=100, db_index=True)
37 # Token data
38 access_token = models.CharField(max_length=2000)
39 refresh_token = models.CharField(max_length=2000, blank=True)
40 access_token_expires_at = models.DateTimeField(blank=True, null=True)
41 refresh_token_expires_at = models.DateTimeField(blank=True, null=True)
43 class Meta:
44 constraints = [
45 models.UniqueConstraint(
46 fields=["provider_key", "provider_user_id"],
47 name="unique_oauth_provider_user_id",
48 )
49 ]
50 ordering = ("provider_key",)
52 def __str__(self):
53 return f"{self.provider_key}[{self.user}:{self.provider_user_id}]"
55 def refresh_access_token(self) -> None:
56 from .providers import OAuthToken, get_oauth_provider_instance
58 provider_instance = get_oauth_provider_instance(provider_key=self.provider_key)
59 oauth_token = OAuthToken(
60 access_token=self.access_token,
61 refresh_token=self.refresh_token,
62 access_token_expires_at=self.access_token_expires_at,
63 refresh_token_expires_at=self.refresh_token_expires_at,
64 )
65 refreshed_oauth_token = provider_instance.refresh_oauth_token(
66 oauth_token=oauth_token
67 )
68 self.set_token_fields(refreshed_oauth_token)
69 self.save()
71 def set_token_fields(self, oauth_token: "OAuthToken"):
72 self.access_token = oauth_token.access_token
73 self.refresh_token = oauth_token.refresh_token
74 self.access_token_expires_at = oauth_token.access_token_expires_at
75 self.refresh_token_expires_at = oauth_token.refresh_token_expires_at
77 def set_user_fields(self, oauth_user: "OAuthUser"):
78 self.provider_user_id = oauth_user.id
80 def access_token_expired(self) -> bool:
81 return (
82 self.access_token_expires_at is not None
83 and self.access_token_expires_at < timezone.now()
84 )
86 def refresh_token_expired(self) -> bool:
87 return (
88 self.refresh_token_expires_at is not None
89 and self.refresh_token_expires_at < timezone.now()
90 )
92 @classmethod
93 def get_or_create_user(
94 cls, *, provider_key: str, oauth_token: "OAuthToken", oauth_user: "OAuthUser"
95 ) -> "OAuthConnection":
96 try:
97 connection = cls.objects.get(
98 provider_key=provider_key,
99 provider_user_id=oauth_user.id,
100 )
101 connection.set_token_fields(oauth_token)
102 connection.save()
103 return connection
104 except cls.DoesNotExist:
105 with transaction.atomic():
106 # If email needs to be unique, then we expect
107 # that to be taken care of on the user model itself
108 try:
109 user = get_user_model()(
110 **oauth_user.user_model_fields,
111 )
112 user.save()
113 except (IntegrityError, ValidationError):
114 raise OAuthUserAlreadyExistsError()
116 return cls.connect(
117 user=user,
118 provider_key=provider_key,
119 oauth_token=oauth_token,
120 oauth_user=oauth_user,
121 )
123 @classmethod
124 def connect(
125 cls,
126 *,
127 user: settings.AUTH_USER_MODEL,
128 provider_key: str,
129 oauth_token: "OAuthToken",
130 oauth_user: "OAuthUser",
131 ) -> "OAuthConnection":
132 """
133 Connect will either create a new connection or update an existing connection
134 """
135 try:
136 connection = cls.objects.get(
137 user=user,
138 provider_key=provider_key,
139 provider_user_id=oauth_user.id,
140 )
141 except cls.DoesNotExist:
142 # Create our own instance (not using get_or_create)
143 # so that any created signals contain the token fields too
144 connection = cls(
145 user=user,
146 provider_key=provider_key,
147 provider_user_id=oauth_user.id,
148 )
150 connection.set_user_fields(oauth_user)
151 connection.set_token_fields(oauth_token)
152 connection.save()
154 return connection
156 @classmethod
157 def check(cls, **kwargs):
158 """
159 A system check for ensuring that provider_keys in the database are also present in settings.
161 Note that the --database flag is required for this to work:
162 python manage.py check --database default
163 """
164 errors = super().check(**kwargs)
166 databases = kwargs.get("databases", None)
167 if not databases:
168 return errors
170 from .providers import get_provider_keys
172 for database in databases:
173 try:
174 keys_in_db = set(
175 cls.objects.using(database)
176 .values_list("provider_key", flat=True)
177 .distinct()
178 )
179 except (OperationalError, ProgrammingError):
180 # Check runs on manage.py migrate, and the table may not exist yet
181 # or it may not be installed on the particular database intentionally
182 continue
184 keys_in_settings = set(get_provider_keys())
186 if keys_in_db - keys_in_settings:
187 errors.append(
188 Error(
189 "The following OAuth providers are in the database but not in the settings: {}".format(
190 ", ".join(keys_in_db - keys_in_settings)
191 ),
192 id="plain.oauth.E001",
193 )
194 )
196 return errors
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import datetime
2import secrets
3from typing import Any
4from urllib.parse import urlencode
6from plain.auth import login as auth_login
7from plain.http import HttpRequest, Response, ResponseRedirect
8from plain.runtime import settings
9from plain.urls import reverse
10from plain.utils.crypto import get_random_string
11from plain.utils.module_loading import import_string
13from .exceptions import OAuthError, OAuthStateMismatchError
14from .models import OAuthConnection
16SESSION_STATE_KEY = "plainoauth_state"
17SESSION_NEXT_KEY = "plainoauth_next"
20class OAuthToken:
21 def __init__(
22 self,
23 *,
24 access_token: str,
25 refresh_token: str = "",
26 access_token_expires_at: datetime.datetime = None,
27 refresh_token_expires_at: datetime.datetime = None,
28 ):
29 self.access_token = access_token
30 self.refresh_token = refresh_token
31 self.access_token_expires_at = access_token_expires_at
32 self.refresh_token_expires_at = refresh_token_expires_at
35class OAuthUser:
36 def __init__(self, *, id: str, **user_model_fields: dict):
37 self.id = id # ID on the provider's system
38 self.user_model_fields = user_model_fields
40 def __str__(self):
41 if "email" in self.user_model_fields:
42 return self.user_model_fields["email"]
43 if "username" in self.user_model_fields:
44 return self.user_model_fields["username"]
45 return str(self.id)
48class OAuthProvider:
49 authorization_url = ""
51 def __init__(
52 self,
53 *,
54 # Provided automatically
55 provider_key: str,
56 # Required as kwargs in OAUTH_LOGIN_PROVIDERS setting
57 client_id: str,
58 client_secret: str,
59 # Not necessarily required, but commonly used
60 scope: str = "",
61 ):
62 self.provider_key = provider_key
63 self.client_id = client_id
64 self.client_secret = client_secret
65 self.scope = scope
67 def get_authorization_url_params(self, *, request: HttpRequest) -> dict:
68 return {
69 "redirect_uri": self.get_callback_url(request=request),
70 "client_id": self.get_client_id(),
71 "scope": self.get_scope(),
72 "state": self.generate_state(),
73 "response_type": "code",
74 }
76 def refresh_oauth_token(self, *, oauth_token: OAuthToken) -> OAuthToken:
77 raise NotImplementedError()
79 def get_oauth_token(self, *, code: str, request: HttpRequest) -> OAuthToken:
80 raise NotImplementedError()
82 def get_oauth_user(self, *, oauth_token: OAuthToken) -> OAuthUser:
83 raise NotImplementedError()
85 def get_authorization_url(self, *, request: HttpRequest) -> str:
86 return self.authorization_url
88 def get_client_id(self) -> str:
89 return self.client_id
91 def get_client_secret(self) -> str:
92 return self.client_secret
94 def get_scope(self) -> str:
95 return self.scope
97 def get_callback_url(self, *, request: HttpRequest) -> str:
98 url = reverse("oauth:callback", kwargs={"provider": self.provider_key})
99 return request.build_absolute_uri(url)
101 def generate_state(self) -> str:
102 return get_random_string(length=32)
104 def check_request_state(self, *, request: HttpRequest) -> None:
105 if error := request.GET.get("error"):
106 raise OAuthError(error)
108 state = request.GET["state"]
109 expected_state = request.session.pop(SESSION_STATE_KEY)
110 if not secrets.compare_digest(state, expected_state):
111 raise OAuthStateMismatchError()
113 def handle_login_request(
114 self, *, request: HttpRequest, redirect_to: str = ""
115 ) -> Response:
116 authorization_url = self.get_authorization_url(request=request)
117 authorization_params = self.get_authorization_url_params(request=request)
119 if "state" in authorization_params:
120 # Store the state in the session so we can check on callback
121 request.session[SESSION_STATE_KEY] = authorization_params["state"]
123 # Store next url in session so we can get it on the callback request
124 if redirect_to:
125 request.session[SESSION_NEXT_KEY] = redirect_to
126 elif "next" in request.POST:
127 request.session[SESSION_NEXT_KEY] = request.POST["next"]
129 # Sort authorization params for consistency
130 sorted_authorization_params = sorted(authorization_params.items())
131 redirect_url = authorization_url + "?" + urlencode(sorted_authorization_params)
132 return ResponseRedirect(redirect_url)
134 def handle_connect_request(
135 self, *, request: HttpRequest, redirect_to: str = ""
136 ) -> Response:
137 return self.handle_login_request(request=request, redirect_to=redirect_to)
139 def handle_disconnect_request(self, *, request: HttpRequest) -> Response:
140 provider_user_id = request.POST["provider_user_id"]
141 connection = OAuthConnection.objects.get(
142 provider_key=self.provider_key, provider_user_id=provider_user_id
143 )
144 connection.delete()
145 redirect_url = self.get_disconnect_redirect_url(request=request)
146 return ResponseRedirect(redirect_url)
148 def handle_callback_request(self, *, request: HttpRequest) -> Response:
149 self.check_request_state(request=request)
151 oauth_token = self.get_oauth_token(code=request.GET["code"], request=request)
152 oauth_user = self.get_oauth_user(oauth_token=oauth_token)
154 if request.user:
155 connection = OAuthConnection.connect(
156 user=request.user,
157 provider_key=self.provider_key,
158 oauth_token=oauth_token,
159 oauth_user=oauth_user,
160 )
161 user = connection.user
162 else:
163 connection = OAuthConnection.get_or_create_user(
164 provider_key=self.provider_key,
165 oauth_token=oauth_token,
166 oauth_user=oauth_user,
167 )
169 user = connection.user
171 self.login(request=request, user=user)
173 redirect_url = self.get_login_redirect_url(request=request)
174 return ResponseRedirect(redirect_url)
176 def login(self, *, request: HttpRequest, user: Any) -> Response:
177 auth_login(request=request, user=user)
179 def get_login_redirect_url(self, *, request: HttpRequest) -> str:
180 return request.session.pop(SESSION_NEXT_KEY, "/")
182 def get_disconnect_redirect_url(self, *, request: HttpRequest) -> str:
183 return request.POST.get("next", "/")
186def get_oauth_provider_instance(*, provider_key: str) -> OAuthProvider:
187 OAUTH_LOGIN_PROVIDERS = getattr(settings, "OAUTH_LOGIN_PROVIDERS", {})
188 provider_class_path = OAUTH_LOGIN_PROVIDERS[provider_key]["class"]
189 provider_class = import_string(provider_class_path)
190 provider_kwargs = OAUTH_LOGIN_PROVIDERS[provider_key].get("kwargs", {})
191 return provider_class(provider_key=provider_key, **provider_kwargs)
194def get_provider_keys() -> list[str]:
195 return list(getattr(settings, "OAUTH_LOGIN_PROVIDERS", {}).keys())
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.urls import include, path
3from . import views
5default_namespace = "oauth"
7urlpatterns = [
8 path(
9 "<str:provider>/",
10 include(
11 [
12 # Login and Signup are both handled here, because the intent is the same
13 path("login/", views.OAuthLoginView, name="login"),
14 path("connect/", views.OAuthConnectView, name="connect"),
15 path(
16 "disconnect/",
17 views.OAuthDisconnectView,
18 name="disconnect",
19 ),
20 path("callback/", views.OAuthCallbackView, name="callback"),
21 ]
22 ),
23 ),
24]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import logging
3from plain.auth.views import AuthViewMixin
4from plain.http import ResponseBadRequest, ResponseRedirect
5from plain.templates import Template
6from plain.views import View
8from .exceptions import (
9 OAuthError,
10 OAuthStateMismatchError,
11 OAuthUserAlreadyExistsError,
12)
13from .providers import get_oauth_provider_instance
15logger = logging.getLogger(__name__)
18class OAuthLoginView(View):
19 def post(self):
20 request = self.request
21 provider = self.url_kwargs["provider"]
22 if request.user:
23 return ResponseRedirect("/")
25 provider_instance = get_oauth_provider_instance(provider_key=provider)
26 return provider_instance.handle_login_request(request=request)
29class OAuthCallbackView(View):
30 """
31 The callback view is used for signup, login, and connect.
32 """
34 def get(self):
35 request = self.request
36 provider = self.url_kwargs["provider"]
37 provider_instance = get_oauth_provider_instance(provider_key=provider)
38 try:
39 return provider_instance.handle_callback_request(request=request)
40 except OAuthUserAlreadyExistsError:
41 template = Template("oauth/error.html")
42 return ResponseBadRequest(
43 template.render(
44 {
45 "oauth_error": "A user already exists with this email address. Please log in first and then connect this OAuth provider to the existing account."
46 }
47 )
48 )
49 except OAuthStateMismatchError:
50 template = Template("oauth/error.html")
51 return ResponseBadRequest(
52 template.render(
53 {
54 "oauth_error": "The state parameter did not match. Please try again."
55 }
56 )
57 )
58 except OAuthError as e:
59 logger.exception("OAuth error")
60 template = Template("oauth/error.html")
61 return ResponseBadRequest(template.render({"oauth_error": str(e)}))
64class OAuthConnectView(AuthViewMixin, View):
65 def post(self):
66 request = self.request
67 provider = self.url_kwargs["provider"]
68 provider_instance = get_oauth_provider_instance(provider_key=provider)
69 return provider_instance.handle_connect_request(request=request)
72class OAuthDisconnectView(AuthViewMixin, View):
73 def post(self):
74 request = self.request
75 provider = self.url_kwargs["provider"]
76 provider_instance = get_oauth_provider_instance(provider_key=provider)
77 # try:
78 return provider_instance.handle_disconnect_request(request=request)
79 # except OAuthCannotDisconnectError:
80 # return render(
81 # request,
82 # "oauth/error.html",
83 # {
84 # "oauth_error": "This connection can't be removed. You must have a usable password or at least one active connection."
85 # },
86 # status=400,
87 # )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.http.cookie import parse_cookie
2from plain.http.request import (
3 HttpHeaders,
4 HttpRequest,
5 QueryDict,
6 RawPostDataException,
7 UnreadablePostError,
8)
9from plain.http.response import (
10 BadHeaderError,
11 FileResponse,
12 Http404,
13 JsonResponse,
14 Response,
15 ResponseBadRequest,
16 ResponseBase,
17 ResponseForbidden,
18 ResponseGone,
19 ResponseNotAllowed,
20 ResponseNotFound,
21 ResponseNotModified,
22 ResponsePermanentRedirect,
23 ResponseRedirect,
24 ResponseServerError,
25 StreamingResponse,
26)
28__all__ = [
29 "parse_cookie",
30 "HttpHeaders",
31 "HttpRequest",
32 "QueryDict",
33 "RawPostDataException",
34 "UnreadablePostError",
35 "Response",
36 "ResponseBase",
37 "StreamingResponse",
38 "ResponseRedirect",
39 "ResponsePermanentRedirect",
40 "ResponseNotModified",
41 "ResponseBadRequest",
42 "ResponseForbidden",
43 "ResponseNotFound",
44 "ResponseNotAllowed",
45 "ResponseGone",
46 "ResponseServerError",
47 "Http404",
48 "BadHeaderError",
49 "JsonResponse",
50 "FileResponse",
51]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from http import cookies
4def parse_cookie(cookie):
5 """
6 Return a dictionary parsed from a `Cookie:` header string.
7 """
8 cookiedict = {}
9 for chunk in cookie.split(";"):
10 if "=" in chunk:
11 key, val = chunk.split("=", 1)
12 else:
13 # Assume an empty name per
14 # https://bugzilla.mozilla.org/show_bug.cgi?id=169091
15 key, val = "", chunk
16 key, val = key.strip(), val.strip()
17 if key or val:
18 # unquote using Python's algorithm.
19 cookiedict[key] = cookies._unquote(val)
20 return cookiedict
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Multi-part parsing for file uploads.
4Exposes one class, ``MultiPartParser``, which feeds chunks of uploaded data to
5file upload handlers for processing.
6"""
7import base64
8import binascii
9import collections
10import html
12from plain.exceptions import (
13 RequestDataTooBig,
14 SuspiciousMultipartForm,
15 TooManyFieldsSent,
16 TooManyFilesSent,
17)
18from plain.internal.files.uploadhandler import SkipFile, StopFutureHandlers, StopUpload
19from plain.runtime import settings
20from plain.utils.datastructures import MultiValueDict
21from plain.utils.encoding import force_str
22from plain.utils.http import parse_header_parameters
23from plain.utils.regex_helper import _lazy_re_compile
25__all__ = ("MultiPartParser", "MultiPartParserError", "InputStreamExhausted")
28class MultiPartParserError(Exception):
29 pass
32class InputStreamExhausted(Exception):
33 """
34 No more reads are allowed from this device.
35 """
37 pass
40RAW = "raw"
41FILE = "file"
42FIELD = "field"
43FIELD_TYPES = frozenset([FIELD, RAW])
46class MultiPartParser:
47 """
48 An RFC 7578 multipart/form-data parser.
50 ``MultiValueDict.parse()`` reads the input stream in ``chunk_size`` chunks
51 and returns a tuple of ``(MultiValueDict(POST), MultiValueDict(FILES))``.
52 """
54 boundary_re = _lazy_re_compile(r"[ -~]{0,200}[!-~]")
56 def __init__(self, META, input_data, upload_handlers, encoding=None):
57 """
58 Initialize the MultiPartParser object.
60 :META:
61 The standard ``META`` dictionary in Plain request objects.
62 :input_data:
63 The raw post data, as a file-like object.
64 :upload_handlers:
65 A list of UploadHandler instances that perform operations on the
66 uploaded data.
67 :encoding:
68 The encoding with which to treat the incoming data.
69 """
70 # Content-Type should contain multipart and the boundary information.
71 content_type = META.get("CONTENT_TYPE", "")
72 if not content_type.startswith("multipart/"):
73 raise MultiPartParserError("Invalid Content-Type: %s" % content_type)
75 try:
76 content_type.encode("ascii")
77 except UnicodeEncodeError:
78 raise MultiPartParserError(
79 "Invalid non-ASCII Content-Type in multipart: %s"
80 % force_str(content_type)
81 )
83 # Parse the header to get the boundary to split the parts.
84 _, opts = parse_header_parameters(content_type)
85 boundary = opts.get("boundary")
86 if not boundary or not self.boundary_re.fullmatch(boundary):
87 raise MultiPartParserError(
88 "Invalid boundary in multipart: %s" % force_str(boundary)
89 )
91 # Content-Length should contain the length of the body we are about
92 # to receive.
93 try:
94 content_length = int(META.get("CONTENT_LENGTH", 0))
95 except (ValueError, TypeError):
96 content_length = 0
98 if content_length < 0:
99 # This means we shouldn't continue...raise an error.
100 raise MultiPartParserError("Invalid content length: %r" % content_length)
102 self._boundary = boundary.encode("ascii")
103 self._input_data = input_data
105 # For compatibility with low-level network APIs (with 32-bit integers),
106 # the chunk size should be < 2^31, but still divisible by 4.
107 possible_sizes = [x.chunk_size for x in upload_handlers if x.chunk_size]
108 self._chunk_size = min([2**31 - 4] + possible_sizes)
110 self._meta = META
111 self._encoding = encoding or settings.DEFAULT_CHARSET
112 self._content_length = content_length
113 self._upload_handlers = upload_handlers
115 def parse(self):
116 # Call the actual parse routine and close all open files in case of
117 # errors. This is needed because if exceptions are thrown the
118 # MultiPartParser will not be garbage collected immediately and
119 # resources would be kept alive. This is only needed for errors because
120 # the Request object closes all uploaded files at the end of the
121 # request.
122 try:
123 return self._parse()
124 except Exception:
125 if hasattr(self, "_files"):
126 for _, files in self._files.lists():
127 for fileobj in files:
128 fileobj.close()
129 raise
131 def _parse(self):
132 """
133 Parse the POST data and break it into a FILES MultiValueDict and a POST
134 MultiValueDict.
136 Return a tuple containing the POST and FILES dictionary, respectively.
137 """
138 from plain.http import QueryDict
140 encoding = self._encoding
141 handlers = self._upload_handlers
143 # HTTP spec says that Content-Length >= 0 is valid
144 # handling content-length == 0 before continuing
145 if self._content_length == 0:
146 return QueryDict(encoding=self._encoding), MultiValueDict()
148 # See if any of the handlers take care of the parsing.
149 # This allows overriding everything if need be.
150 for handler in handlers:
151 result = handler.handle_raw_input(
152 self._input_data,
153 self._meta,
154 self._content_length,
155 self._boundary,
156 encoding,
157 )
158 # Check to see if it was handled
159 if result is not None:
160 return result[0], result[1]
162 # Create the data structures to be used later.
163 self._post = QueryDict(mutable=True)
164 self._files = MultiValueDict()
166 # Instantiate the parser and stream:
167 stream = LazyStream(ChunkIter(self._input_data, self._chunk_size))
169 # Whether or not to signal a file-completion at the beginning of the loop.
170 old_field_name = None
171 counters = [0] * len(handlers)
173 # Number of bytes that have been read.
174 num_bytes_read = 0
175 # To count the number of keys in the request.
176 num_post_keys = 0
177 # To count the number of files in the request.
178 num_files = 0
179 # To limit the amount of data read from the request.
180 read_size = None
181 # Whether a file upload is finished.
182 uploaded_file = True
184 try:
185 for item_type, meta_data, field_stream in Parser(stream, self._boundary):
186 if old_field_name:
187 # We run this at the beginning of the next loop
188 # since we cannot be sure a file is complete until
189 # we hit the next boundary/part of the multipart content.
190 self.handle_file_complete(old_field_name, counters)
191 old_field_name = None
192 uploaded_file = True
194 if (
195 item_type in FIELD_TYPES
196 and settings.DATA_UPLOAD_MAX_NUMBER_FIELDS is not None
197 ):
198 # Avoid storing more than DATA_UPLOAD_MAX_NUMBER_FIELDS.
199 num_post_keys += 1
200 # 2 accounts for empty raw fields before and after the
201 # last boundary.
202 if settings.DATA_UPLOAD_MAX_NUMBER_FIELDS + 2 < num_post_keys:
203 raise TooManyFieldsSent(
204 "The number of GET/POST parameters exceeded "
205 "settings.DATA_UPLOAD_MAX_NUMBER_FIELDS."
206 )
208 try:
209 disposition = meta_data["content-disposition"][1]
210 field_name = disposition["name"].strip()
211 except (KeyError, IndexError, AttributeError):
212 continue
214 transfer_encoding = meta_data.get("content-transfer-encoding")
215 if transfer_encoding is not None:
216 transfer_encoding = transfer_encoding[0].strip()
217 field_name = force_str(field_name, encoding, errors="replace")
219 if item_type == FIELD:
220 # Avoid reading more than DATA_UPLOAD_MAX_MEMORY_SIZE.
221 if settings.DATA_UPLOAD_MAX_MEMORY_SIZE is not None:
222 read_size = (
223 settings.DATA_UPLOAD_MAX_MEMORY_SIZE - num_bytes_read
224 )
226 # This is a post field, we can just set it in the post
227 if transfer_encoding == "base64":
228 raw_data = field_stream.read(size=read_size)
229 num_bytes_read += len(raw_data)
230 try:
231 data = base64.b64decode(raw_data)
232 except binascii.Error:
233 data = raw_data
234 else:
235 data = field_stream.read(size=read_size)
236 num_bytes_read += len(data)
238 # Add two here to make the check consistent with the
239 # x-www-form-urlencoded check that includes '&='.
240 num_bytes_read += len(field_name) + 2
241 if (
242 settings.DATA_UPLOAD_MAX_MEMORY_SIZE is not None
243 and num_bytes_read > settings.DATA_UPLOAD_MAX_MEMORY_SIZE
244 ):
245 raise RequestDataTooBig(
246 "Request body exceeded "
247 "settings.DATA_UPLOAD_MAX_MEMORY_SIZE."
248 )
250 self._post.appendlist(
251 field_name, force_str(data, encoding, errors="replace")
252 )
253 elif item_type == FILE:
254 # Avoid storing more than DATA_UPLOAD_MAX_NUMBER_FILES.
255 num_files += 1
256 if (
257 settings.DATA_UPLOAD_MAX_NUMBER_FILES is not None
258 and num_files > settings.DATA_UPLOAD_MAX_NUMBER_FILES
259 ):
260 raise TooManyFilesSent(
261 "The number of files exceeded "
262 "settings.DATA_UPLOAD_MAX_NUMBER_FILES."
263 )
264 # This is a file, use the handler...
265 file_name = disposition.get("filename")
266 if file_name:
267 file_name = force_str(file_name, encoding, errors="replace")
268 file_name = self.sanitize_file_name(file_name)
269 if not file_name:
270 continue
272 content_type, content_type_extra = meta_data.get(
273 "content-type", ("", {})
274 )
275 content_type = content_type.strip()
276 charset = content_type_extra.get("charset")
278 try:
279 content_length = int(meta_data.get("content-length")[0])
280 except (IndexError, TypeError, ValueError):
281 content_length = None
283 counters = [0] * len(handlers)
284 uploaded_file = False
285 try:
286 for handler in handlers:
287 try:
288 handler.new_file(
289 field_name,
290 file_name,
291 content_type,
292 content_length,
293 charset,
294 content_type_extra,
295 )
296 except StopFutureHandlers:
297 break
299 for chunk in field_stream:
300 if transfer_encoding == "base64":
301 # We only special-case base64 transfer encoding
302 # We should always decode base64 chunks by
303 # multiple of 4, ignoring whitespace.
305 stripped_chunk = b"".join(chunk.split())
307 remaining = len(stripped_chunk) % 4
308 while remaining != 0:
309 over_chunk = field_stream.read(4 - remaining)
310 if not over_chunk:
311 break
312 stripped_chunk += b"".join(over_chunk.split())
313 remaining = len(stripped_chunk) % 4
315 try:
316 chunk = base64.b64decode(stripped_chunk)
317 except Exception as exc:
318 # Since this is only a chunk, any error is
319 # an unfixable error.
320 raise MultiPartParserError(
321 "Could not decode base64 data."
322 ) from exc
324 for i, handler in enumerate(handlers):
325 chunk_length = len(chunk)
326 chunk = handler.receive_data_chunk(chunk, counters[i])
327 counters[i] += chunk_length
328 if chunk is None:
329 # Don't continue if the chunk received by
330 # the handler is None.
331 break
333 except SkipFile:
334 self._close_files()
335 # Just use up the rest of this file...
336 exhaust(field_stream)
337 else:
338 # Handle file upload completions on next iteration.
339 old_field_name = field_name
340 else:
341 # If this is neither a FIELD nor a FILE, exhaust the field
342 # stream. Note: There could be an error here at some point,
343 # but there will be at least two RAW types (before and
344 # after the other boundaries). This branch is usually not
345 # reached at all, because a missing content-disposition
346 # header will skip the whole boundary.
347 exhaust(field_stream)
348 except StopUpload as e:
349 self._close_files()
350 if not e.connection_reset:
351 exhaust(self._input_data)
352 else:
353 if not uploaded_file:
354 for handler in handlers:
355 handler.upload_interrupted()
356 # Make sure that the request data is all fed
357 exhaust(self._input_data)
359 # Signal that the upload has completed.
360 # any() shortcircuits if a handler's upload_complete() returns a value.
361 any(handler.upload_complete() for handler in handlers)
362 self._post._mutable = False
363 return self._post, self._files
365 def handle_file_complete(self, old_field_name, counters):
366 """
367 Handle all the signaling that takes place when a file is complete.
368 """
369 for i, handler in enumerate(self._upload_handlers):
370 file_obj = handler.file_complete(counters[i])
371 if file_obj:
372 # If it returns a file object, then set the files dict.
373 self._files.appendlist(
374 force_str(old_field_name, self._encoding, errors="replace"),
375 file_obj,
376 )
377 break
379 def sanitize_file_name(self, file_name):
380 """
381 Sanitize the filename of an upload.
383 Remove all possible path separators, even though that might remove more
384 than actually required by the target system. Filenames that could
385 potentially cause problems (current/parent dir) are also discarded.
387 It should be noted that this function could still return a "filepath"
388 like "C:some_file.txt" which is handled later on by the storage layer.
389 So while this function does sanitize filenames to some extent, the
390 resulting filename should still be considered as untrusted user input.
391 """
392 file_name = html.unescape(file_name)
393 file_name = file_name.rsplit("/")[-1]
394 file_name = file_name.rsplit("\\")[-1]
395 # Remove non-printable characters.
396 file_name = "".join([char for char in file_name if char.isprintable()])
398 if file_name in {"", ".", ".."}:
399 return None
400 return file_name
402 IE_sanitize = sanitize_file_name
404 def _close_files(self):
405 # Free up all file handles.
406 # FIXME: this currently assumes that upload handlers store the file as 'file'
407 # We should document that...
408 # (Maybe add handler.free_file to complement new_file)
409 for handler in self._upload_handlers:
410 if hasattr(handler, "file"):
411 handler.file.close()
414class LazyStream:
415 """
416 The LazyStream wrapper allows one to get and "unget" bytes from a stream.
418 Given a producer object (an iterator that yields bytestrings), the
419 LazyStream object will support iteration, reading, and keeping a "look-back"
420 variable in case you need to "unget" some bytes.
421 """
423 def __init__(self, producer, length=None):
424 """
425 Every LazyStream must have a producer when instantiated.
427 A producer is an iterable that returns a string each time it
428 is called.
429 """
430 self._producer = producer
431 self._empty = False
432 self._leftover = b""
433 self.length = length
434 self.position = 0
435 self._remaining = length
436 self._unget_history = []
438 def tell(self):
439 return self.position
441 def read(self, size=None):
442 def parts():
443 remaining = self._remaining if size is None else size
444 # do the whole thing in one shot if no limit was provided.
445 if remaining is None:
446 yield b"".join(self)
447 return
449 # otherwise do some bookkeeping to return exactly enough
450 # of the stream and stashing any extra content we get from
451 # the producer
452 while remaining != 0:
453 assert remaining > 0, "remaining bytes to read should never go negative"
455 try:
456 chunk = next(self)
457 except StopIteration:
458 return
459 else:
460 emitting = chunk[:remaining]
461 self.unget(chunk[remaining:])
462 remaining -= len(emitting)
463 yield emitting
465 return b"".join(parts())
467 def __next__(self):
468 """
469 Used when the exact number of bytes to read is unimportant.
471 Return whatever chunk is conveniently returned from the iterator.
472 Useful to avoid unnecessary bookkeeping if performance is an issue.
473 """
474 if self._leftover:
475 output = self._leftover
476 self._leftover = b""
477 else:
478 output = next(self._producer)
479 self._unget_history = []
480 self.position += len(output)
481 return output
483 def close(self):
484 """
485 Used to invalidate/disable this lazy stream.
487 Replace the producer with an empty list. Any leftover bytes that have
488 already been read will still be reported upon read() and/or next().
489 """
490 self._producer = []
492 def __iter__(self):
493 return self
495 def unget(self, bytes):
496 """
497 Place bytes back onto the front of the lazy stream.
499 Future calls to read() will return those bytes first. The
500 stream position and thus tell() will be rewound.
501 """
502 if not bytes:
503 return
504 self._update_unget_history(len(bytes))
505 self.position -= len(bytes)
506 self._leftover = bytes + self._leftover
508 def _update_unget_history(self, num_bytes):
509 """
510 Update the unget history as a sanity check to see if we've pushed
511 back the same number of bytes in one chunk. If we keep ungetting the
512 same number of bytes many times (here, 50), we're mostly likely in an
513 infinite loop of some sort. This is usually caused by a
514 maliciously-malformed MIME request.
515 """
516 self._unget_history = [num_bytes] + self._unget_history[:49]
517 number_equal = len(
518 [
519 current_number
520 for current_number in self._unget_history
521 if current_number == num_bytes
522 ]
523 )
525 if number_equal > 40:
526 raise SuspiciousMultipartForm(
527 "The multipart parser got stuck, which shouldn't happen with"
528 " normal uploaded files. Check for malicious upload activity;"
529 " if there is none, report this to the Plain developers."
530 )
533class ChunkIter:
534 """
535 An iterable that will yield chunks of data. Given a file-like object as the
536 constructor, yield chunks of read operations from that object.
537 """
539 def __init__(self, flo, chunk_size=64 * 1024):
540 self.flo = flo
541 self.chunk_size = chunk_size
543 def __next__(self):
544 try:
545 data = self.flo.read(self.chunk_size)
546 except InputStreamExhausted:
547 raise StopIteration()
548 if data:
549 return data
550 else:
551 raise StopIteration()
553 def __iter__(self):
554 return self
557class InterBoundaryIter:
558 """
559 A Producer that will iterate over boundaries.
560 """
562 def __init__(self, stream, boundary):
563 self._stream = stream
564 self._boundary = boundary
566 def __iter__(self):
567 return self
569 def __next__(self):
570 try:
571 return LazyStream(BoundaryIter(self._stream, self._boundary))
572 except InputStreamExhausted:
573 raise StopIteration()
576class BoundaryIter:
577 """
578 A Producer that is sensitive to boundaries.
580 Will happily yield bytes until a boundary is found. Will yield the bytes
581 before the boundary, throw away the boundary bytes themselves, and push the
582 post-boundary bytes back on the stream.
584 The future calls to next() after locating the boundary will raise a
585 StopIteration exception.
586 """
588 def __init__(self, stream, boundary):
589 self._stream = stream
590 self._boundary = boundary
591 self._done = False
592 # rollback an additional six bytes because the format is like
593 # this: CRLF<boundary>[--CRLF]
594 self._rollback = len(boundary) + 6
596 # Try to use mx fast string search if available. Otherwise
597 # use Python find. Wrap the latter for consistency.
598 unused_char = self._stream.read(1)
599 if not unused_char:
600 raise InputStreamExhausted()
601 self._stream.unget(unused_char)
603 def __iter__(self):
604 return self
606 def __next__(self):
607 if self._done:
608 raise StopIteration()
610 stream = self._stream
611 rollback = self._rollback
613 bytes_read = 0
614 chunks = []
615 for bytes in stream:
616 bytes_read += len(bytes)
617 chunks.append(bytes)
618 if bytes_read > rollback:
619 break
620 if not bytes:
621 break
622 else:
623 self._done = True
625 if not chunks:
626 raise StopIteration()
628 chunk = b"".join(chunks)
629 boundary = self._find_boundary(chunk)
631 if boundary:
632 end, next = boundary
633 stream.unget(chunk[next:])
634 self._done = True
635 return chunk[:end]
636 else:
637 # make sure we don't treat a partial boundary (and
638 # its separators) as data
639 if not chunk[:-rollback]: # and len(chunk) >= (len(self._boundary) + 6):
640 # There's nothing left, we should just return and mark as done.
641 self._done = True
642 return chunk
643 else:
644 stream.unget(chunk[-rollback:])
645 return chunk[:-rollback]
647 def _find_boundary(self, data):
648 """
649 Find a multipart boundary in data.
651 Should no boundary exist in the data, return None. Otherwise, return
652 a tuple containing the indices of the following:
653 * the end of current encapsulation
654 * the start of the next encapsulation
655 """
656 index = data.find(self._boundary)
657 if index < 0:
658 return None
659 else:
660 end = index
661 next = index + len(self._boundary)
662 # backup over CRLF
663 last = max(0, end - 1)
664 if data[last : last + 1] == b"\n":
665 end -= 1
666 last = max(0, end - 1)
667 if data[last : last + 1] == b"\r":
668 end -= 1
669 return end, next
672def exhaust(stream_or_iterable):
673 """Exhaust an iterator or stream."""
674 try:
675 iterator = iter(stream_or_iterable)
676 except TypeError:
677 iterator = ChunkIter(stream_or_iterable, 16384)
678 collections.deque(iterator, maxlen=0) # consume iterator quickly.
681def parse_boundary_stream(stream, max_header_size):
682 """
683 Parse one and exactly one stream that encapsulates a boundary.
684 """
685 # Stream at beginning of header, look for end of header
686 # and parse it if found. The header must fit within one
687 # chunk.
688 chunk = stream.read(max_header_size)
690 # 'find' returns the top of these four bytes, so we'll
691 # need to munch them later to prevent them from polluting
692 # the payload.
693 header_end = chunk.find(b"\r\n\r\n")
695 if header_end == -1:
696 # we find no header, so we just mark this fact and pass on
697 # the stream verbatim
698 stream.unget(chunk)
699 return (RAW, {}, stream)
701 header = chunk[:header_end]
703 # here we place any excess chunk back onto the stream, as
704 # well as throwing away the CRLFCRLF bytes from above.
705 stream.unget(chunk[header_end + 4 :])
707 TYPE = RAW
708 outdict = {}
710 # Eliminate blank lines
711 for line in header.split(b"\r\n"):
712 # This terminology ("main value" and "dictionary of
713 # parameters") is from the Python docs.
714 try:
715 main_value_pair, params = parse_header_parameters(line.decode())
716 name, value = main_value_pair.split(":", 1)
717 params = {k: v.encode() for k, v in params.items()}
718 except ValueError: # Invalid header.
719 continue
721 if name == "content-disposition":
722 TYPE = FIELD
723 if params.get("filename"):
724 TYPE = FILE
726 outdict[name] = value, params
728 if TYPE == RAW:
729 stream.unget(chunk)
731 return (TYPE, outdict, stream)
734class Parser:
735 def __init__(self, stream, boundary):
736 self._stream = stream
737 self._separator = b"--" + boundary
739 def __iter__(self):
740 boundarystream = InterBoundaryIter(self._stream, self._separator)
741 for sub_stream in boundarystream:
742 # Iterate over each part
743 yield parse_boundary_stream(sub_stream, 1024)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-17 22:03 -0500
1import codecs
2import copy
3import uuid
4from io import BytesIO
5from itertools import chain
6from urllib.parse import parse_qsl, quote, urlencode, urljoin, urlsplit
8from plain import signing
9from plain.exceptions import (
10 DisallowedHost,
11 ImproperlyConfigured,
12 RequestDataTooBig,
13 TooManyFieldsSent,
14)
15from plain.http.multipartparser import (
16 MultiPartParser,
17 MultiPartParserError,
18 TooManyFilesSent,
19)
20from plain.internal.files import uploadhandler
21from plain.runtime import settings
22from plain.utils.datastructures import (
23 CaseInsensitiveMapping,
24 ImmutableList,
25 MultiValueDict,
26)
27from plain.utils.encoding import escape_uri_path, iri_to_uri
28from plain.utils.functional import cached_property
29from plain.utils.http import is_same_domain, parse_header_parameters
30from plain.utils.regex_helper import _lazy_re_compile
32RAISE_ERROR = object()
33host_validation_re = _lazy_re_compile(
34 r"^([a-z0-9.-]+|\[[a-f0-9]*:[a-f0-9\.:]+\])(:[0-9]+)?$"
35)
38class UnreadablePostError(OSError):
39 pass
42class RawPostDataException(Exception):
43 """
44 You cannot access raw_post_data from a request that has
45 multipart/* POST data if it has been accessed via POST,
46 FILES, etc..
47 """
49 pass
52class HttpRequest:
53 """A basic HTTP request."""
55 # The encoding used in GET/POST dicts. None means use default setting.
56 _encoding = None
57 _upload_handlers = []
59 non_picklable_attrs = frozenset(["resolver_match", "_stream"])
61 def __init__(self):
62 # WARNING: The `WSGIRequest` subclass doesn't call `super`.
63 # Any variable assignment made here should also happen in
64 # `WSGIRequest.__init__()`.
66 # A unique ID we can use to trace this request
67 self.unique_id = str(uuid.uuid4())
69 self.GET = QueryDict(mutable=True)
70 self.POST = QueryDict(mutable=True)
71 self.COOKIES = {}
72 self.META = {}
73 self.FILES = MultiValueDict()
75 self.path = ""
76 self.path_info = ""
77 self.method = None
78 self.resolver_match = None
79 self.content_type = None
80 self.content_params = None
82 def __repr__(self):
83 if self.method is None or not self.get_full_path():
84 return "<%s>" % self.__class__.__name__
85 return f"<{self.__class__.__name__}: {self.method} {self.get_full_path()!r}>"
87 def __getstate__(self):
88 obj_dict = self.__dict__.copy()
89 for attr in self.non_picklable_attrs:
90 if attr in obj_dict:
91 del obj_dict[attr]
92 return obj_dict
94 def __deepcopy__(self, memo):
95 obj = copy.copy(self)
96 for attr in self.non_picklable_attrs:
97 if hasattr(self, attr):
98 setattr(obj, attr, copy.deepcopy(getattr(self, attr), memo))
99 memo[id(self)] = obj
100 return obj
102 @cached_property
103 def headers(self):
104 return HttpHeaders(self.META)
106 @cached_property
107 def accepted_types(self):
108 """Return a list of MediaType instances."""
109 return parse_accept_header(self.headers.get("Accept", "*/*"))
111 def accepts(self, media_type):
112 return any(
113 accepted_type.match(media_type) for accepted_type in self.accepted_types
114 )
116 def _set_content_type_params(self, meta):
117 """Set content_type, content_params, and encoding."""
118 self.content_type, self.content_params = parse_header_parameters(
119 meta.get("CONTENT_TYPE", "")
120 )
121 if "charset" in self.content_params:
122 try:
123 codecs.lookup(self.content_params["charset"])
124 except LookupError:
125 pass
126 else:
127 self.encoding = self.content_params["charset"]
129 def _get_raw_host(self):
130 """
131 Return the HTTP host using the environment or request headers. Skip
132 allowed hosts protection, so may return an insecure host.
133 """
134 # We try three options, in order of decreasing preference.
135 if settings.USE_X_FORWARDED_HOST and ("HTTP_X_FORWARDED_HOST" in self.META):
136 host = self.META["HTTP_X_FORWARDED_HOST"]
137 elif "HTTP_HOST" in self.META:
138 host = self.META["HTTP_HOST"]
139 else:
140 # Reconstruct the host using the algorithm from PEP 333.
141 host = self.META["SERVER_NAME"]
142 server_port = self.get_port()
143 if server_port != ("443" if self.is_https() else "80"):
144 host = f"{host}:{server_port}"
145 return host
147 def get_host(self):
148 """Return the HTTP host using the environment or request headers."""
149 host = self._get_raw_host()
151 # Allow variants of localhost if ALLOWED_HOSTS is empty and DEBUG=True.
152 allowed_hosts = settings.ALLOWED_HOSTS
153 if settings.DEBUG and not allowed_hosts:
154 allowed_hosts = [".localhost", "127.0.0.1", "[::1]"]
156 domain, port = split_domain_port(host)
157 if domain and validate_host(domain, allowed_hosts):
158 return host
159 else:
160 msg = "Invalid HTTP_HOST header: %r." % host
161 if domain:
162 msg += " You may need to add %r to ALLOWED_HOSTS." % domain
163 else:
164 msg += (
165 " The domain name provided is not valid according to RFC 1034/1035."
166 )
167 raise DisallowedHost(msg)
169 def get_port(self):
170 """Return the port number for the request as a string."""
171 if settings.USE_X_FORWARDED_PORT and "HTTP_X_FORWARDED_PORT" in self.META:
172 port = self.META["HTTP_X_FORWARDED_PORT"]
173 else:
174 port = self.META["SERVER_PORT"]
175 return str(port)
177 def get_full_path(self, force_append_slash=False):
178 return self._get_full_path(self.path, force_append_slash)
180 def get_full_path_info(self, force_append_slash=False):
181 return self._get_full_path(self.path_info, force_append_slash)
183 def _get_full_path(self, path, force_append_slash):
184 # RFC 3986 requires query string arguments to be in the ASCII range.
185 # Rather than crash if this doesn't happen, we encode defensively.
186 return "{}{}{}".format(
187 escape_uri_path(path),
188 "/" if force_append_slash and not path.endswith("/") else "",
189 ("?" + iri_to_uri(self.META.get("QUERY_STRING", "")))
190 if self.META.get("QUERY_STRING", "")
191 else "",
192 )
194 def get_signed_cookie(self, key, default=RAISE_ERROR, salt="", max_age=None):
195 """
196 Attempt to return a signed cookie. If the signature fails or the
197 cookie has expired, raise an exception, unless the `default` argument
198 is provided, in which case return that value.
199 """
200 try:
201 cookie_value = self.COOKIES[key]
202 except KeyError:
203 if default is not RAISE_ERROR:
204 return default
205 else:
206 raise
207 try:
208 value = signing.get_cookie_signer(salt=key + salt).unsign(
209 cookie_value, max_age=max_age
210 )
211 except signing.BadSignature:
212 if default is not RAISE_ERROR:
213 return default
214 else:
215 raise
216 return value
218 def build_absolute_uri(self, location=None):
219 """
220 Build an absolute URI from the location and the variables available in
221 this request. If no ``location`` is specified, build the absolute URI
222 using request.get_full_path(). If the location is absolute, convert it
223 to an RFC 3987 compliant URI and return it. If location is relative or
224 is scheme-relative (i.e., ``//example.com/``), urljoin() it to a base
225 URL constructed from the request variables.
226 """
227 if location is None:
228 # Make it an absolute url (but schemeless and domainless) for the
229 # edge case that the path starts with '//'.
230 location = "//%s" % self.get_full_path()
231 else:
232 # Coerce lazy locations.
233 location = str(location)
234 bits = urlsplit(location)
235 if not (bits.scheme and bits.netloc):
236 # Handle the simple, most common case. If the location is absolute
237 # and a scheme or host (netloc) isn't provided, skip an expensive
238 # urljoin() as long as no path segments are '.' or '..'.
239 if (
240 bits.path.startswith("/")
241 and not bits.scheme
242 and not bits.netloc
243 and "/./" not in bits.path
244 and "/../" not in bits.path
245 ):
246 # If location starts with '//' but has no netloc, reuse the
247 # schema and netloc from the current request. Strip the double
248 # slashes and continue as if it wasn't specified.
249 location = self._current_scheme_host + location.removeprefix("//")
250 else:
251 # Join the constructed URL with the provided location, which
252 # allows the provided location to apply query strings to the
253 # base path.
254 location = urljoin(self._current_scheme_host + self.path, location)
255 return iri_to_uri(location)
257 @cached_property
258 def _current_scheme_host(self):
259 return f"{self.scheme}://{self.get_host()}"
261 def _get_scheme(self):
262 """
263 Hook for subclasses like WSGIRequest to implement. Return 'http' by
264 default.
265 """
266 return "http"
268 @property
269 def scheme(self):
270 if settings.HTTPS_PROXY_HEADER:
271 try:
272 header, secure_value = settings.HTTPS_PROXY_HEADER
273 except ValueError:
274 raise ImproperlyConfigured(
275 "The HTTPS_PROXY_HEADER setting must be a tuple containing "
276 "two values."
277 )
278 header_value = self.META.get(header)
279 if header_value is not None:
280 header_value, *_ = header_value.split(",", 1)
281 return "https" if header_value.strip() == secure_value else "http"
282 return self._get_scheme()
284 def is_https(self):
285 return self.scheme == "https"
287 @property
288 def encoding(self):
289 return self._encoding
291 @encoding.setter
292 def encoding(self, val):
293 """
294 Set the encoding used for GET/POST accesses. If the GET or POST
295 dictionary has already been created, remove and recreate it on the
296 next access (so that it is decoded correctly).
297 """
298 self._encoding = val
299 if hasattr(self, "GET"):
300 del self.GET
301 if hasattr(self, "_post"):
302 del self._post
304 def _initialize_handlers(self):
305 self._upload_handlers = [
306 uploadhandler.load_handler(handler, self)
307 for handler in settings.FILE_UPLOAD_HANDLERS
308 ]
310 @property
311 def upload_handlers(self):
312 if not self._upload_handlers:
313 # If there are no upload handlers defined, initialize them from settings.
314 self._initialize_handlers()
315 return self._upload_handlers
317 @upload_handlers.setter
318 def upload_handlers(self, upload_handlers):
319 if hasattr(self, "_files"):
320 raise AttributeError(
321 "You cannot set the upload handlers after the upload has been "
322 "processed."
323 )
324 self._upload_handlers = upload_handlers
326 def parse_file_upload(self, META, post_data):
327 """Return a tuple of (POST QueryDict, FILES MultiValueDict)."""
328 self.upload_handlers = ImmutableList(
329 self.upload_handlers,
330 warning=(
331 "You cannot alter upload handlers after the upload has been "
332 "processed."
333 ),
334 )
335 parser = MultiPartParser(META, post_data, self.upload_handlers, self.encoding)
336 return parser.parse()
338 @property
339 def body(self):
340 if not hasattr(self, "_body"):
341 if self._read_started:
342 raise RawPostDataException(
343 "You cannot access body after reading from request's data stream"
344 )
346 # Limit the maximum request data size that will be handled in-memory.
347 if (
348 settings.DATA_UPLOAD_MAX_MEMORY_SIZE is not None
349 and int(self.META.get("CONTENT_LENGTH") or 0)
350 > settings.DATA_UPLOAD_MAX_MEMORY_SIZE
351 ):
352 raise RequestDataTooBig(
353 "Request body exceeded settings.DATA_UPLOAD_MAX_MEMORY_SIZE."
354 )
356 try:
357 self._body = self.read()
358 except OSError as e:
359 raise UnreadablePostError(*e.args) from e
360 finally:
361 self._stream.close()
362 self._stream = BytesIO(self._body)
363 return self._body
365 def _mark_post_parse_error(self):
366 self._post = QueryDict()
367 self._files = MultiValueDict()
369 def _load_post_and_files(self):
370 """Populate self._post and self._files if the content-type is a form type"""
371 if self.method != "POST":
372 self._post, self._files = (
373 QueryDict(encoding=self._encoding),
374 MultiValueDict(),
375 )
376 return
377 if self._read_started and not hasattr(self, "_body"):
378 self._mark_post_parse_error()
379 return
381 if self.content_type == "multipart/form-data":
382 if hasattr(self, "_body"):
383 # Use already read data
384 data = BytesIO(self._body)
385 else:
386 data = self
387 try:
388 self._post, self._files = self.parse_file_upload(self.META, data)
389 except (MultiPartParserError, TooManyFilesSent):
390 # An error occurred while parsing POST data. Since when
391 # formatting the error the request handler might access
392 # self.POST, set self._post and self._file to prevent
393 # attempts to parse POST data again.
394 self._mark_post_parse_error()
395 raise
396 elif self.content_type == "application/x-www-form-urlencoded":
397 self._post, self._files = (
398 QueryDict(self.body, encoding=self._encoding),
399 MultiValueDict(),
400 )
401 else:
402 self._post, self._files = (
403 QueryDict(encoding=self._encoding),
404 MultiValueDict(),
405 )
407 def close(self):
408 if hasattr(self, "_files"):
409 for f in chain.from_iterable(list_[1] for list_ in self._files.lists()):
410 f.close()
412 # File-like and iterator interface.
413 #
414 # Expects self._stream to be set to an appropriate source of bytes by
415 # a corresponding request subclass (e.g. WSGIRequest).
416 # Also when request data has already been read by request.POST or
417 # request.body, self._stream points to a BytesIO instance
418 # containing that data.
420 def read(self, *args, **kwargs):
421 self._read_started = True
422 try:
423 return self._stream.read(*args, **kwargs)
424 except OSError as e:
425 raise UnreadablePostError(*e.args) from e
427 def readline(self, *args, **kwargs):
428 self._read_started = True
429 try:
430 return self._stream.readline(*args, **kwargs)
431 except OSError as e:
432 raise UnreadablePostError(*e.args) from e
434 def __iter__(self):
435 return iter(self.readline, b"")
437 def readlines(self):
438 return list(self)
441class HttpHeaders(CaseInsensitiveMapping):
442 HTTP_PREFIX = "HTTP_"
443 # PEP 333 gives two headers which aren't prepended with HTTP_.
444 UNPREFIXED_HEADERS = {"CONTENT_TYPE", "CONTENT_LENGTH"}
446 def __init__(self, environ):
447 headers = {}
448 for header, value in environ.items():
449 name = self.parse_header_name(header)
450 if name:
451 headers[name] = value
452 super().__init__(headers)
454 def __getitem__(self, key):
455 """Allow header lookup using underscores in place of hyphens."""
456 return super().__getitem__(key.replace("_", "-"))
458 @classmethod
459 def parse_header_name(cls, header):
460 if header.startswith(cls.HTTP_PREFIX):
461 header = header.removeprefix(cls.HTTP_PREFIX)
462 elif header not in cls.UNPREFIXED_HEADERS:
463 return None
464 return header.replace("_", "-").title()
466 @classmethod
467 def to_wsgi_name(cls, header):
468 header = header.replace("-", "_").upper()
469 if header in cls.UNPREFIXED_HEADERS:
470 return header
471 return f"{cls.HTTP_PREFIX}{header}"
473 @classmethod
474 def to_asgi_name(cls, header):
475 return header.replace("-", "_").upper()
477 @classmethod
478 def to_wsgi_names(cls, headers):
479 return {
480 cls.to_wsgi_name(header_name): value
481 for header_name, value in headers.items()
482 }
484 @classmethod
485 def to_asgi_names(cls, headers):
486 return {
487 cls.to_asgi_name(header_name): value
488 for header_name, value in headers.items()
489 }
492class QueryDict(MultiValueDict):
493 """
494 A specialized MultiValueDict which represents a query string.
496 A QueryDict can be used to represent GET or POST data. It subclasses
497 MultiValueDict since keys in such data can be repeated, for instance
498 in the data from a form with a <select multiple> field.
500 By default QueryDicts are immutable, though the copy() method
501 will always return a mutable copy.
503 Both keys and values set on this class are converted from the given encoding
504 (DEFAULT_CHARSET by default) to str.
505 """
507 # These are both reset in __init__, but is specified here at the class
508 # level so that unpickling will have valid values
509 _mutable = True
510 _encoding = None
512 def __init__(self, query_string=None, mutable=False, encoding=None):
513 super().__init__()
514 self.encoding = encoding or settings.DEFAULT_CHARSET
515 query_string = query_string or ""
516 parse_qsl_kwargs = {
517 "keep_blank_values": True,
518 "encoding": self.encoding,
519 "max_num_fields": settings.DATA_UPLOAD_MAX_NUMBER_FIELDS,
520 }
521 if isinstance(query_string, bytes):
522 # query_string normally contains URL-encoded data, a subset of ASCII.
523 try:
524 query_string = query_string.decode(self.encoding)
525 except UnicodeDecodeError:
526 # ... but some user agents are misbehaving :-(
527 query_string = query_string.decode("iso-8859-1")
528 try:
529 for key, value in parse_qsl(query_string, **parse_qsl_kwargs):
530 self.appendlist(key, value)
531 except ValueError as e:
532 # ValueError can also be raised if the strict_parsing argument to
533 # parse_qsl() is True. As that is not used by Plain, assume that
534 # the exception was raised by exceeding the value of max_num_fields
535 # instead of fragile checks of exception message strings.
536 raise TooManyFieldsSent(
537 "The number of GET/POST parameters exceeded "
538 "settings.DATA_UPLOAD_MAX_NUMBER_FIELDS."
539 ) from e
540 self._mutable = mutable
542 @classmethod
543 def fromkeys(cls, iterable, value="", mutable=False, encoding=None):
544 """
545 Return a new QueryDict with keys (may be repeated) from an iterable and
546 values from value.
547 """
548 q = cls("", mutable=True, encoding=encoding)
549 for key in iterable:
550 q.appendlist(key, value)
551 if not mutable:
552 q._mutable = False
553 return q
555 @property
556 def encoding(self):
557 if self._encoding is None:
558 self._encoding = settings.DEFAULT_CHARSET
559 return self._encoding
561 @encoding.setter
562 def encoding(self, value):
563 self._encoding = value
565 def _assert_mutable(self):
566 if not self._mutable:
567 raise AttributeError("This QueryDict instance is immutable")
569 def __setitem__(self, key, value):
570 self._assert_mutable()
571 key = bytes_to_text(key, self.encoding)
572 value = bytes_to_text(value, self.encoding)
573 super().__setitem__(key, value)
575 def __delitem__(self, key):
576 self._assert_mutable()
577 super().__delitem__(key)
579 def __copy__(self):
580 result = self.__class__("", mutable=True, encoding=self.encoding)
581 for key, value in self.lists():
582 result.setlist(key, value)
583 return result
585 def __deepcopy__(self, memo):
586 result = self.__class__("", mutable=True, encoding=self.encoding)
587 memo[id(self)] = result
588 for key, value in self.lists():
589 result.setlist(copy.deepcopy(key, memo), copy.deepcopy(value, memo))
590 return result
592 def setlist(self, key, list_):
593 self._assert_mutable()
594 key = bytes_to_text(key, self.encoding)
595 list_ = [bytes_to_text(elt, self.encoding) for elt in list_]
596 super().setlist(key, list_)
598 def setlistdefault(self, key, default_list=None):
599 self._assert_mutable()
600 return super().setlistdefault(key, default_list)
602 def appendlist(self, key, value):
603 self._assert_mutable()
604 key = bytes_to_text(key, self.encoding)
605 value = bytes_to_text(value, self.encoding)
606 super().appendlist(key, value)
608 def pop(self, key, *args):
609 self._assert_mutable()
610 return super().pop(key, *args)
612 def popitem(self):
613 self._assert_mutable()
614 return super().popitem()
616 def clear(self):
617 self._assert_mutable()
618 super().clear()
620 def setdefault(self, key, default=None):
621 self._assert_mutable()
622 key = bytes_to_text(key, self.encoding)
623 default = bytes_to_text(default, self.encoding)
624 return super().setdefault(key, default)
626 def copy(self):
627 """Return a mutable copy of this object."""
628 return self.__deepcopy__({})
630 def urlencode(self, safe=None):
631 """
632 Return an encoded string of all query string arguments.
634 `safe` specifies characters which don't require quoting, for example::
636 >>> q = QueryDict(mutable=True)
637 >>> q['next'] = '/a&b/'
638 >>> q.urlencode()
639 'next=%2Fa%26b%2F'
640 >>> q.urlencode(safe='/')
641 'next=/a%26b/'
642 """
643 output = []
644 if safe:
645 safe = safe.encode(self.encoding)
647 def encode(k, v):
648 return f"{quote(k, safe)}={quote(v, safe)}"
650 else:
652 def encode(k, v):
653 return urlencode({k: v})
655 for k, list_ in self.lists():
656 output.extend(
657 encode(k.encode(self.encoding), str(v).encode(self.encoding))
658 for v in list_
659 )
660 return "&".join(output)
663class MediaType:
664 def __init__(self, media_type_raw_line):
665 full_type, self.params = parse_header_parameters(
666 media_type_raw_line if media_type_raw_line else ""
667 )
668 self.main_type, _, self.sub_type = full_type.partition("/")
670 def __str__(self):
671 params_str = "".join(f"; {k}={v}" for k, v in self.params.items())
672 return "{}{}{}".format(
673 self.main_type,
674 ("/%s" % self.sub_type) if self.sub_type else "",
675 params_str,
676 )
678 def __repr__(self):
679 return f"<{self.__class__.__qualname__}: {self}>"
681 @property
682 def is_all_types(self):
683 return self.main_type == "*" and self.sub_type == "*"
685 def match(self, other):
686 if self.is_all_types:
687 return True
688 other = MediaType(other)
689 if self.main_type == other.main_type and self.sub_type in {"*", other.sub_type}:
690 return True
691 return False
694# It's neither necessary nor appropriate to use
695# plain.utils.encoding.force_str() for parsing URLs and form inputs. Thus,
696# this slightly more restricted function, used by QueryDict.
697def bytes_to_text(s, encoding):
698 """
699 Convert bytes objects to strings, using the given encoding. Illegally
700 encoded input characters are replaced with Unicode "unknown" codepoint
701 (\ufffd).
703 Return any non-bytes objects without change.
704 """
705 if isinstance(s, bytes):
706 return str(s, encoding, "replace")
707 else:
708 return s
711def split_domain_port(host):
712 """
713 Return a (domain, port) tuple from a given host.
715 Returned domain is lowercased. If the host is invalid, the domain will be
716 empty.
717 """
718 host = host.lower()
720 if not host_validation_re.match(host):
721 return "", ""
723 if host[-1] == "]":
724 # It's an IPv6 address without a port.
725 return host, ""
726 bits = host.rsplit(":", 1)
727 domain, port = bits if len(bits) == 2 else (bits[0], "")
728 # Remove a trailing dot (if present) from the domain.
729 domain = domain.removesuffix(".")
730 return domain, port
733def validate_host(host, allowed_hosts):
734 """
735 Validate the given host for this site.
737 Check that the host looks valid and matches a host or host pattern in the
738 given list of ``allowed_hosts``. Any pattern beginning with a period
739 matches a domain and all its subdomains (e.g. ``.example.com`` matches
740 ``example.com`` and any subdomain), ``*`` matches anything, and anything
741 else must match exactly.
743 Note: This function assumes that the given host is lowercased and has
744 already had the port, if any, stripped off.
746 Return ``True`` for a valid host, ``False`` otherwise.
747 """
748 return any(
749 pattern == "*" or is_same_domain(host, pattern) for pattern in allowed_hosts
750 )
753def parse_accept_header(header):
754 return [MediaType(token) for token in header.split(",") if token.strip()]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:27 -0500
1import datetime
2import io
3import json
4import mimetypes
5import os
6import re
7import sys
8import time
9from email.header import Header
10from http.client import responses
11from http.cookies import SimpleCookie
12from urllib.parse import urlparse
14from plain import signals, signing
15from plain.exceptions import DisallowedRedirect
16from plain.json import PlainJSONEncoder
17from plain.runtime import settings
18from plain.utils import timezone
19from plain.utils.datastructures import CaseInsensitiveMapping
20from plain.utils.encoding import iri_to_uri
21from plain.utils.http import content_disposition_header, http_date
22from plain.utils.regex_helper import _lazy_re_compile
24_charset_from_content_type_re = _lazy_re_compile(
25 r";\s*charset=(?P<charset>[^\s;]+)", re.I
26)
29class ResponseHeaders(CaseInsensitiveMapping):
30 def __init__(self, data):
31 """
32 Populate the initial data using __setitem__ to ensure values are
33 correctly encoded.
34 """
35 self._store = {}
36 if data:
37 for header, value in self._unpack_items(data):
38 self[header] = value
40 def _convert_to_charset(self, value, charset, mime_encode=False):
41 """
42 Convert headers key/value to ascii/latin-1 native strings.
43 `charset` must be 'ascii' or 'latin-1'. If `mime_encode` is True and
44 `value` can't be represented in the given charset, apply MIME-encoding.
45 """
46 try:
47 if isinstance(value, str):
48 # Ensure string is valid in given charset
49 value.encode(charset)
50 elif isinstance(value, bytes):
51 # Convert bytestring using given charset
52 value = value.decode(charset)
53 else:
54 value = str(value)
55 # Ensure string is valid in given charset.
56 value.encode(charset)
57 if "\n" in value or "\r" in value:
58 raise BadHeaderError(
59 f"Header values can't contain newlines (got {value!r})"
60 )
61 except UnicodeError as e:
62 # Encoding to a string of the specified charset failed, but we
63 # don't know what type that value was, or if it contains newlines,
64 # which we may need to check for before sending it to be
65 # encoded for multiple character sets.
66 if (isinstance(value, bytes) and (b"\n" in value or b"\r" in value)) or (
67 isinstance(value, str) and ("\n" in value or "\r" in value)
68 ):
69 raise BadHeaderError(
70 f"Header values can't contain newlines (got {value!r})"
71 ) from e
72 if mime_encode:
73 value = Header(value, "utf-8", maxlinelen=sys.maxsize).encode()
74 else:
75 e.reason += ", HTTP response headers must be in %s format" % charset
76 raise
77 return value
79 def __delitem__(self, key):
80 self.pop(key)
82 def __setitem__(self, key, value):
83 key = self._convert_to_charset(key, "ascii")
84 value = self._convert_to_charset(value, "latin-1", mime_encode=True)
85 self._store[key.lower()] = (key, value)
87 def pop(self, key, default=None):
88 return self._store.pop(key.lower(), default)
90 def setdefault(self, key, value):
91 if key not in self:
92 self[key] = value
95class BadHeaderError(ValueError):
96 pass
99class ResponseBase:
100 """
101 An HTTP response base class with dictionary-accessed headers.
103 This class doesn't handle content. It should not be used directly.
104 Use the Response and StreamingResponse subclasses instead.
105 """
107 status_code = 200
109 def __init__(
110 self, content_type=None, status=None, reason=None, charset=None, headers=None
111 ):
112 self.headers = ResponseHeaders(headers)
113 self._charset = charset
114 if "Content-Type" not in self.headers:
115 if content_type is None:
116 content_type = f"text/html; charset={self.charset}"
117 self.headers["Content-Type"] = content_type
118 elif content_type:
119 raise ValueError(
120 "'headers' must not contain 'Content-Type' when the "
121 "'content_type' parameter is provided."
122 )
123 self._resource_closers = []
124 # This parameter is set by the handler. It's necessary to preserve the
125 # historical behavior of request_finished.
126 self._handler_class = None
127 self.cookies = SimpleCookie()
128 self.closed = False
129 if status is not None:
130 try:
131 self.status_code = int(status)
132 except (ValueError, TypeError):
133 raise TypeError("HTTP status code must be an integer.")
135 if not 100 <= self.status_code <= 599:
136 raise ValueError("HTTP status code must be an integer from 100 to 599.")
137 self._reason_phrase = reason
139 @property
140 def reason_phrase(self):
141 if self._reason_phrase is not None:
142 return self._reason_phrase
143 # Leave self._reason_phrase unset in order to use the default
144 # reason phrase for status code.
145 return responses.get(self.status_code, "Unknown Status Code")
147 @reason_phrase.setter
148 def reason_phrase(self, value):
149 self._reason_phrase = value
151 @property
152 def charset(self):
153 if self._charset is not None:
154 return self._charset
155 # The Content-Type header may not yet be set, because the charset is
156 # being inserted *into* it.
157 if content_type := self.headers.get("Content-Type"):
158 if matched := _charset_from_content_type_re.search(content_type):
159 # Extract the charset and strip its double quotes.
160 # Note that having parsed it from the Content-Type, we don't
161 # store it back into the _charset for later intentionally, to
162 # allow for the Content-Type to be switched again later.
163 return matched["charset"].replace('"', "")
164 return settings.DEFAULT_CHARSET
166 @charset.setter
167 def charset(self, value):
168 self._charset = value
170 def serialize_headers(self):
171 """HTTP headers as a bytestring."""
172 return b"\r\n".join(
173 [
174 key.encode("ascii") + b": " + value.encode("latin-1")
175 for key, value in self.headers.items()
176 ]
177 )
179 __bytes__ = serialize_headers
181 @property
182 def _content_type_for_repr(self):
183 return (
184 ', "%s"' % self.headers["Content-Type"]
185 if "Content-Type" in self.headers
186 else ""
187 )
189 def __setitem__(self, header, value):
190 self.headers[header] = value
192 def __delitem__(self, header):
193 del self.headers[header]
195 def __getitem__(self, header):
196 return self.headers[header]
198 def has_header(self, header):
199 """Case-insensitive check for a header."""
200 return header in self.headers
202 __contains__ = has_header
204 def items(self):
205 return self.headers.items()
207 def get(self, header, alternate=None):
208 return self.headers.get(header, alternate)
210 def set_cookie(
211 self,
212 key,
213 value="",
214 max_age=None,
215 expires=None,
216 path="/",
217 domain=None,
218 secure=False,
219 httponly=False,
220 samesite=None,
221 ):
222 """
223 Set a cookie.
225 ``expires`` can be:
226 - a string in the correct format,
227 - a naive ``datetime.datetime`` object in UTC,
228 - an aware ``datetime.datetime`` object in any time zone.
229 If it is a ``datetime.datetime`` object then calculate ``max_age``.
231 ``max_age`` can be:
232 - int/float specifying seconds,
233 - ``datetime.timedelta`` object.
234 """
235 self.cookies[key] = value
236 if expires is not None:
237 if isinstance(expires, datetime.datetime):
238 if timezone.is_naive(expires):
239 expires = timezone.make_aware(expires, datetime.timezone.utc)
240 delta = expires - datetime.datetime.now(tz=datetime.timezone.utc)
241 # Add one second so the date matches exactly (a fraction of
242 # time gets lost between converting to a timedelta and
243 # then the date string).
244 delta += datetime.timedelta(seconds=1)
245 # Just set max_age - the max_age logic will set expires.
246 expires = None
247 if max_age is not None:
248 raise ValueError("'expires' and 'max_age' can't be used together.")
249 max_age = max(0, delta.days * 86400 + delta.seconds)
250 else:
251 self.cookies[key]["expires"] = expires
252 else:
253 self.cookies[key]["expires"] = ""
254 if max_age is not None:
255 if isinstance(max_age, datetime.timedelta):
256 max_age = max_age.total_seconds()
257 self.cookies[key]["max-age"] = int(max_age)
258 # IE requires expires, so set it if hasn't been already.
259 if not expires:
260 self.cookies[key]["expires"] = http_date(time.time() + max_age)
261 if path is not None:
262 self.cookies[key]["path"] = path
263 if domain is not None:
264 self.cookies[key]["domain"] = domain
265 if secure:
266 self.cookies[key]["secure"] = True
267 if httponly:
268 self.cookies[key]["httponly"] = True
269 if samesite:
270 if samesite.lower() not in ("lax", "none", "strict"):
271 raise ValueError('samesite must be "lax", "none", or "strict".')
272 self.cookies[key]["samesite"] = samesite
274 def setdefault(self, key, value):
275 """Set a header unless it has already been set."""
276 self.headers.setdefault(key, value)
278 def set_signed_cookie(self, key, value, salt="", **kwargs):
279 value = signing.get_cookie_signer(salt=key + salt).sign(value)
280 return self.set_cookie(key, value, **kwargs)
282 def delete_cookie(self, key, path="/", domain=None, samesite=None):
283 # Browsers can ignore the Set-Cookie header if the cookie doesn't use
284 # the secure flag and:
285 # - the cookie name starts with "__Host-" or "__Secure-", or
286 # - the samesite is "none".
287 secure = key.startswith(("__Secure-", "__Host-")) or (
288 samesite and samesite.lower() == "none"
289 )
290 self.set_cookie(
291 key,
292 max_age=0,
293 path=path,
294 domain=domain,
295 secure=secure,
296 expires="Thu, 01 Jan 1970 00:00:00 GMT",
297 samesite=samesite,
298 )
300 # Common methods used by subclasses
302 def make_bytes(self, value):
303 """Turn a value into a bytestring encoded in the output charset."""
304 # Per PEP 3333, this response body must be bytes. To avoid returning
305 # an instance of a subclass, this function returns `bytes(value)`.
306 # This doesn't make a copy when `value` already contains bytes.
308 # Handle string types -- we can't rely on force_bytes here because:
309 # - Python attempts str conversion first
310 # - when self._charset != 'utf-8' it re-encodes the content
311 if isinstance(value, bytes | memoryview):
312 return bytes(value)
313 if isinstance(value, str):
314 return bytes(value.encode(self.charset))
315 # Handle non-string types.
316 return str(value).encode(self.charset)
318 # These methods partially implement the file-like object interface.
319 # See https://docs.python.org/library/io.html#io.IOBase
321 # The WSGI server must call this method upon completion of the request.
322 # See http://blog.dscpl.com.au/2012/10/obligations-for-calling-close-on.html
323 def close(self):
324 for closer in self._resource_closers:
325 try:
326 closer()
327 except Exception:
328 pass
329 # Free resources that were still referenced.
330 self._resource_closers.clear()
331 self.closed = True
332 signals.request_finished.send(sender=self._handler_class)
334 def write(self, content):
335 raise OSError("This %s instance is not writable" % self.__class__.__name__)
337 def flush(self):
338 pass
340 def tell(self):
341 raise OSError(
342 "This %s instance cannot tell its position" % self.__class__.__name__
343 )
345 # These methods partially implement a stream-like object interface.
346 # See https://docs.python.org/library/io.html#io.IOBase
348 def readable(self):
349 return False
351 def seekable(self):
352 return False
354 def writable(self):
355 return False
357 def writelines(self, lines):
358 raise OSError("This %s instance is not writable" % self.__class__.__name__)
361class Response(ResponseBase):
362 """
363 An HTTP response class with a string as content.
365 This content can be read, appended to, or replaced.
366 """
368 streaming = False
369 non_picklable_attrs = frozenset(
370 [
371 "resolver_match",
372 # Non-picklable attributes added by test clients.
373 "client",
374 "context",
375 "json",
376 "templates",
377 ]
378 )
380 def __init__(self, content=b"", *args, **kwargs):
381 super().__init__(*args, **kwargs)
382 # Content is a bytestring. See the `content` property methods.
383 self.content = content
385 def __getstate__(self):
386 obj_dict = self.__dict__.copy()
387 for attr in self.non_picklable_attrs:
388 if attr in obj_dict:
389 del obj_dict[attr]
390 return obj_dict
392 def __repr__(self):
393 return "<%(cls)s status_code=%(status_code)d%(content_type)s>" % {
394 "cls": self.__class__.__name__,
395 "status_code": self.status_code,
396 "content_type": self._content_type_for_repr,
397 }
399 def serialize(self):
400 """Full HTTP message, including headers, as a bytestring."""
401 return self.serialize_headers() + b"\r\n\r\n" + self.content
403 __bytes__ = serialize
405 @property
406 def content(self):
407 return b"".join(self._container)
409 @content.setter
410 def content(self, value):
411 # Consume iterators upon assignment to allow repeated iteration.
412 if hasattr(value, "__iter__") and not isinstance(
413 value, bytes | memoryview | str
414 ):
415 content = b"".join(self.make_bytes(chunk) for chunk in value)
416 if hasattr(value, "close"):
417 try:
418 value.close()
419 except Exception:
420 pass
421 else:
422 content = self.make_bytes(value)
423 # Create a list of properly encoded bytestrings to support write().
424 self._container = [content]
426 def __iter__(self):
427 return iter(self._container)
429 def write(self, content):
430 self._container.append(self.make_bytes(content))
432 def tell(self):
433 return len(self.content)
435 def getvalue(self):
436 return self.content
438 def writable(self):
439 return True
441 def writelines(self, lines):
442 for line in lines:
443 self.write(line)
446class StreamingResponse(ResponseBase):
447 """
448 A streaming HTTP response class with an iterator as content.
450 This should only be iterated once, when the response is streamed to the
451 client. However, it can be appended to or replaced with a new iterator
452 that wraps the original content (or yields entirely new content).
453 """
455 streaming = True
457 def __init__(self, streaming_content=(), *args, **kwargs):
458 super().__init__(*args, **kwargs)
459 # `streaming_content` should be an iterable of bytestrings.
460 # See the `streaming_content` property methods.
461 self.streaming_content = streaming_content
463 def __repr__(self):
464 return "<%(cls)s status_code=%(status_code)d%(content_type)s>" % {
465 "cls": self.__class__.__qualname__,
466 "status_code": self.status_code,
467 "content_type": self._content_type_for_repr,
468 }
470 @property
471 def content(self):
472 raise AttributeError(
473 "This %s instance has no `content` attribute. Use "
474 "`streaming_content` instead." % self.__class__.__name__
475 )
477 @property
478 def streaming_content(self):
479 return map(self.make_bytes, self._iterator)
481 @streaming_content.setter
482 def streaming_content(self, value):
483 self._set_streaming_content(value)
485 def _set_streaming_content(self, value):
486 # Ensure we can never iterate on "value" more than once.
487 self._iterator = iter(value)
488 if hasattr(value, "close"):
489 self._resource_closers.append(value.close)
491 def __iter__(self):
492 return iter(self.streaming_content)
494 def getvalue(self):
495 return b"".join(self.streaming_content)
498class FileResponse(StreamingResponse):
499 """
500 A streaming HTTP response class optimized for files.
501 """
503 block_size = 4096
505 def __init__(self, *args, as_attachment=False, filename="", **kwargs):
506 self.as_attachment = as_attachment
507 self.filename = filename
508 self._no_explicit_content_type = (
509 "content_type" not in kwargs or kwargs["content_type"] is None
510 )
511 super().__init__(*args, **kwargs)
513 def _set_streaming_content(self, value):
514 if not hasattr(value, "read"):
515 self.file_to_stream = None
516 return super()._set_streaming_content(value)
518 self.file_to_stream = filelike = value
519 if hasattr(filelike, "close"):
520 self._resource_closers.append(filelike.close)
521 value = iter(lambda: filelike.read(self.block_size), b"")
522 self.set_headers(filelike)
523 super()._set_streaming_content(value)
525 def set_headers(self, filelike):
526 """
527 Set some common response headers (Content-Length, Content-Type, and
528 Content-Disposition) based on the `filelike` response content.
529 """
530 filename = getattr(filelike, "name", "")
531 filename = filename if isinstance(filename, str) else ""
532 seekable = hasattr(filelike, "seek") and (
533 not hasattr(filelike, "seekable") or filelike.seekable()
534 )
535 if hasattr(filelike, "tell"):
536 if seekable:
537 initial_position = filelike.tell()
538 filelike.seek(0, io.SEEK_END)
539 self.headers["Content-Length"] = filelike.tell() - initial_position
540 filelike.seek(initial_position)
541 elif hasattr(filelike, "getbuffer"):
542 self.headers["Content-Length"] = (
543 filelike.getbuffer().nbytes - filelike.tell()
544 )
545 elif os.path.exists(filename):
546 self.headers["Content-Length"] = (
547 os.path.getsize(filename) - filelike.tell()
548 )
549 elif seekable:
550 self.headers["Content-Length"] = sum(
551 iter(lambda: len(filelike.read(self.block_size)), 0)
552 )
553 filelike.seek(-int(self.headers["Content-Length"]), io.SEEK_END)
555 filename = os.path.basename(self.filename or filename)
556 if self._no_explicit_content_type:
557 if filename:
558 content_type, encoding = mimetypes.guess_type(filename)
559 # Encoding isn't set to prevent browsers from automatically
560 # uncompressing files.
561 content_type = {
562 "br": "application/x-brotli",
563 "bzip2": "application/x-bzip",
564 "compress": "application/x-compress",
565 "gzip": "application/gzip",
566 "xz": "application/x-xz",
567 }.get(encoding, content_type)
568 self.headers["Content-Type"] = (
569 content_type or "application/octet-stream"
570 )
571 else:
572 self.headers["Content-Type"] = "application/octet-stream"
574 if content_disposition := content_disposition_header(
575 self.as_attachment, filename
576 ):
577 self.headers["Content-Disposition"] = content_disposition
580class ResponseRedirectBase(Response):
581 allowed_schemes = ["http", "https", "ftp"]
583 def __init__(self, redirect_to, *args, **kwargs):
584 super().__init__(*args, **kwargs)
585 self["Location"] = iri_to_uri(redirect_to)
586 parsed = urlparse(str(redirect_to))
587 if parsed.scheme and parsed.scheme not in self.allowed_schemes:
588 raise DisallowedRedirect(
589 "Unsafe redirect to URL with protocol '%s'" % parsed.scheme
590 )
592 url = property(lambda self: self["Location"])
594 def __repr__(self):
595 return (
596 '<%(cls)s status_code=%(status_code)d%(content_type)s, url="%(url)s">'
597 % {
598 "cls": self.__class__.__name__,
599 "status_code": self.status_code,
600 "content_type": self._content_type_for_repr,
601 "url": self.url,
602 }
603 )
606class ResponseRedirect(ResponseRedirectBase):
607 """HTTP 302 response"""
609 status_code = 302
612class ResponsePermanentRedirect(ResponseRedirectBase):
613 """HTTP 301 response"""
615 status_code = 301
618class ResponseNotModified(Response):
619 """HTTP 304 response"""
621 status_code = 304
623 def __init__(self, *args, **kwargs):
624 super().__init__(*args, **kwargs)
625 del self["content-type"]
627 @Response.content.setter
628 def content(self, value):
629 if value:
630 raise AttributeError(
631 "You cannot set content to a 304 (Not Modified) response"
632 )
633 self._container = []
636class ResponseBadRequest(Response):
637 """HTTP 400 response"""
639 status_code = 400
642class ResponseNotFound(Response):
643 """HTTP 404 response"""
645 status_code = 404
648class ResponseForbidden(Response):
649 """HTTP 403 response"""
651 status_code = 403
654class ResponseNotAllowed(Response):
655 """HTTP 405 response"""
657 status_code = 405
659 def __init__(self, permitted_methods, *args, **kwargs):
660 super().__init__(*args, **kwargs)
661 self["Allow"] = ", ".join(permitted_methods)
663 def __repr__(self):
664 return "<%(cls)s [%(methods)s] status_code=%(status_code)d%(content_type)s>" % {
665 "cls": self.__class__.__name__,
666 "status_code": self.status_code,
667 "content_type": self._content_type_for_repr,
668 "methods": self["Allow"],
669 }
672class ResponseGone(Response):
673 """HTTP 410 response"""
675 status_code = 410
678class ResponseServerError(Response):
679 """HTTP 500 response"""
681 status_code = 500
684class Http404(Exception):
685 pass
688class JsonResponse(Response):
689 """
690 An HTTP response class that consumes data to be serialized to JSON.
692 :param data: Data to be dumped into json. By default only ``dict`` objects
693 are allowed to be passed due to a security flaw before ECMAScript 5. See
694 the ``safe`` parameter for more information.
695 :param encoder: Should be a json encoder class. Defaults to
696 ``plain.json.PlainJSONEncoder``.
697 :param safe: Controls if only ``dict`` objects may be serialized. Defaults
698 to ``True``.
699 :param json_dumps_params: A dictionary of kwargs passed to json.dumps().
700 """
702 def __init__(
703 self,
704 data,
705 encoder=PlainJSONEncoder,
706 safe=True,
707 json_dumps_params=None,
708 **kwargs,
709 ):
710 if safe and not isinstance(data, dict):
711 raise TypeError(
712 "In order to allow non-dict objects to be serialized set the "
713 "safe parameter to False."
714 )
715 if json_dumps_params is None:
716 json_dumps_params = {}
717 kwargs.setdefault("content_type", "application/json")
718 data = json.dumps(data, cls=encoder, **json_dumps_params)
719 super().__init__(content=data, **kwargs)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.runtime import settings
4class DefaultHeadersMiddleware:
5 def __init__(self, get_response):
6 self.get_response = get_response
8 def __call__(self, request):
9 response = self.get_response(request)
11 for header, value in settings.DEFAULT_RESPONSE_HEADERS.items():
12 response.headers.setdefault(header, value)
14 # Add the Content-Length header to non-streaming responses if not
15 # already set.
16 if not response.streaming and not response.has_header("Content-Length"):
17 response.headers["Content-Length"] = str(len(response.content))
19 return response
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import re
3from plain.http import ResponsePermanentRedirect
4from plain.runtime import settings
7class HttpsRedirectMiddleware:
8 def __init__(self, get_response):
9 self.get_response = get_response
11 # Settings for https (compile regexes once)
12 self.https_redirect_enabled = settings.HTTPS_REDIRECT_ENABLED
13 self.https_redirect_host = settings.HTTPS_REDIRECT_HOST
14 self.https_redirect_exempt = [
15 re.compile(r) for r in settings.HTTPS_REDIRECT_EXEMPT
16 ]
18 def __call__(self, request):
19 """
20 Rewrite the URL based on settings.APPEND_SLASH
21 """
23 if redirect_response := self.maybe_https_redirect(request):
24 return redirect_response
26 return self.get_response(request)
28 def maybe_https_redirect(self, request):
29 path = request.path.lstrip("/")
30 if (
31 self.https_redirect_enabled
32 and not request.is_https()
33 and not any(pattern.search(path) for pattern in self.https_redirect_exempt)
34 ):
35 host = self.https_redirect_host or request.get_host()
36 return ResponsePermanentRedirect(f"https://{host}{request.get_full_path()}")
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.http import ResponsePermanentRedirect
2from plain.runtime import settings
3from plain.urls import is_valid_path
4from plain.utils.http import escape_leading_slashes
7class RedirectSlashMiddleware:
8 def __init__(self, get_response):
9 self.get_response = get_response
11 def __call__(self, request):
12 """
13 Rewrite the URL based on settings.APPEND_SLASH
14 """
16 response = self.get_response(request)
18 """
19 When the status code of the response is 404, it may redirect to a path
20 with an appended slash if should_redirect_with_slash() returns True.
21 """
22 # If the given URL is "Not Found", then check if we should redirect to
23 # a path with a slash appended.
24 if response.status_code == 404 and self.should_redirect_with_slash(request):
25 return ResponsePermanentRedirect(self.get_full_path_with_slash(request))
27 return response
29 def should_redirect_with_slash(self, request):
30 """
31 Return True if settings.APPEND_SLASH is True and appending a slash to
32 the request path turns an invalid path into a valid one.
33 """
34 if settings.APPEND_SLASH and not request.path_info.endswith("/"):
35 urlconf = getattr(request, "urlconf", None)
36 if not is_valid_path(request.path_info, urlconf):
37 match = is_valid_path(f"{request.path_info}/", urlconf)
38 if match:
39 view = match.func
40 return getattr(view, "should_append_slash", True)
41 return False
43 def get_full_path_with_slash(self, request):
44 """
45 Return the full path of the request with a trailing slash appended.
47 Raise a RuntimeError if settings.DEBUG is True and request.method is
48 POST, PUT, or PATCH.
49 """
50 new_path = request.get_full_path(force_append_slash=True)
51 # Prevent construction of scheme relative urls.
52 new_path = escape_leading_slashes(new_path)
53 if settings.DEBUG and request.method in ("POST", "PUT", "PATCH"):
54 raise RuntimeError(
55 f"You called this URL via {request.method}, but the URL doesn't end "
56 "in a slash and you have APPEND_SLASH set. Plain can't "
57 f"redirect to the slash URL while maintaining {request.method} data. "
58 f"Change your form to point to {request.get_host() + new_path} (note the trailing "
59 "slash), or set APPEND_SLASH=False in your Plain settings."
60 )
61 return new_path
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from .base import (
2 clear_url_caches,
3 get_urlconf,
4 is_valid_path,
5 resolve,
6 reverse,
7 reverse_lazy,
8 set_urlconf,
9)
10from .conf import include, path, re_path
11from .converters import register_converter
12from .exceptions import NoReverseMatch, Resolver404
13from .resolvers import (
14 ResolverMatch,
15 URLPattern,
16 URLResolver,
17 get_ns_resolver,
18 get_resolver,
19)
21__all__ = [
22 "NoReverseMatch",
23 "URLPattern",
24 "URLResolver",
25 "Resolver404",
26 "ResolverMatch",
27 "clear_url_caches",
28 "get_ns_resolver",
29 "get_resolver",
30 "get_urlconf",
31 "include",
32 "is_valid_path",
33 "path",
34 "re_path",
35 "register_converter",
36 "resolve",
37 "reverse",
38 "reverse_lazy",
39 "set_urlconf",
40]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from threading import local
3from plain.utils.functional import lazy
5from .exceptions import NoReverseMatch, Resolver404
6from .resolvers import _get_cached_resolver, get_ns_resolver, get_resolver
8# Overridden URLconfs for each thread are stored here.
9_urlconfs = local()
12def resolve(path, urlconf=None):
13 if urlconf is None:
14 urlconf = get_urlconf()
15 return get_resolver(urlconf).resolve(path)
18def reverse(viewname, urlconf=None, args=None, kwargs=None, using_namespace=None):
19 if urlconf is None:
20 urlconf = get_urlconf()
21 resolver = get_resolver(urlconf)
22 args = args or []
23 kwargs = kwargs or {}
25 if not isinstance(viewname, str):
26 view = viewname
27 else:
28 *path, view = viewname.split(":")
30 if using_namespace:
31 current_path = using_namespace.split(":")
32 current_path.reverse()
33 else:
34 current_path = None
36 resolved_path = []
37 ns_pattern = ""
38 ns_converters = {}
39 for ns in path:
40 current_ns = current_path.pop() if current_path else None
41 # Lookup the name to see if it could be an app identifier.
42 try:
43 app_list = resolver.app_dict[ns]
44 # Yes! Path part matches an app in the current Resolver.
45 if current_ns and current_ns in app_list:
46 # If we are reversing for a particular app, use that
47 # namespace.
48 ns = current_ns
49 elif ns not in app_list:
50 # The name isn't shared by one of the instances (i.e.,
51 # the default) so pick the first instance as the default.
52 ns = app_list[0]
53 except KeyError:
54 pass
56 if ns != current_ns:
57 current_path = None
59 try:
60 extra, resolver = resolver.namespace_dict[ns]
61 resolved_path.append(ns)
62 ns_pattern += extra
63 ns_converters.update(resolver.pattern.converters)
64 except KeyError as key:
65 if resolved_path:
66 raise NoReverseMatch(
67 "{} is not a registered namespace inside '{}'".format(
68 key, ":".join(resolved_path)
69 )
70 )
71 else:
72 raise NoReverseMatch("%s is not a registered namespace" % key)
73 if ns_pattern:
74 resolver = get_ns_resolver(
75 ns_pattern, resolver, tuple(ns_converters.items())
76 )
78 return resolver.reverse(view, *args, **kwargs)
81reverse_lazy = lazy(reverse, str)
84def clear_url_caches():
85 _get_cached_resolver.cache_clear()
86 get_ns_resolver.cache_clear()
89def set_urlconf(urlconf_name):
90 """
91 Set the URLconf for the current thread (overriding the default one in
92 settings). If urlconf_name is None, revert back to the default.
93 """
94 if urlconf_name:
95 _urlconfs.value = urlconf_name
96 else:
97 if hasattr(_urlconfs, "value"):
98 del _urlconfs.value
101def get_urlconf(default=None):
102 """
103 Return the root URLconf to use for the current thread if it has been
104 changed from the default one.
105 """
106 return getattr(_urlconfs, "value", default)
109def is_valid_path(path, urlconf=None):
110 """
111 Return the ResolverMatch if the given path resolves against the default URL
112 resolver, False otherwise. This is a convenience method to make working
113 with "is this a match?" cases easier, avoiding try...except blocks.
114 """
115 try:
116 return resolve(path, urlconf)
117 except Resolver404:
118 return False
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""Functions for use in URLsconfs."""
2from functools import partial
4from plain.exceptions import ImproperlyConfigured
6from .resolvers import (
7 RegexPattern,
8 RoutePattern,
9 URLPattern,
10 URLResolver,
11)
14def include(arg, namespace=None):
15 default_namespace = None
16 if isinstance(arg, tuple):
17 # Callable returning a namespace hint.
18 try:
19 urlconf_module, default_namespace = arg
20 except ValueError:
21 if namespace:
22 raise ImproperlyConfigured(
23 "Cannot override the namespace for a dynamic module that "
24 "provides a namespace."
25 )
26 raise ImproperlyConfigured(
27 "Passing a %d-tuple to include() is not supported. Pass a "
28 "2-tuple containing the list of patterns and default_namespace, and "
29 "provide the namespace argument to include() instead." % len(arg)
30 )
31 else:
32 # No namespace hint - use manually provided namespace.
33 urlconf_module = arg
35 patterns = getattr(urlconf_module, "urlpatterns", urlconf_module)
36 default_namespace = getattr(urlconf_module, "default_namespace", default_namespace)
37 if namespace and not default_namespace:
38 raise ImproperlyConfigured(
39 "Specifying a namespace in include() without providing an default_namespace "
40 "is not supported. Set the default_namespace attribute in the included "
41 "module, or pass a 2-tuple containing the list of patterns and "
42 "default_namespace instead.",
43 )
44 namespace = namespace or default_namespace
45 # Make sure the patterns can be iterated through (without this, some
46 # testcases will break).
47 if isinstance(patterns, list | tuple):
48 for url_pattern in patterns:
49 getattr(url_pattern, "pattern", None)
50 return (urlconf_module, default_namespace, namespace)
53def _path(route, view, kwargs=None, name=None, Pattern=None):
54 from plain.views import View
56 if kwargs is not None and not isinstance(kwargs, dict):
57 raise TypeError(
58 f"kwargs argument must be a dict, but got {kwargs.__class__.__name__}."
59 )
61 if isinstance(view, list | tuple):
62 # For include(...) processing.
63 pattern = Pattern(route, is_endpoint=False)
64 urlconf_module, default_namespace, namespace = view
65 return URLResolver(
66 pattern,
67 urlconf_module,
68 kwargs,
69 default_namespace=default_namespace,
70 namespace=namespace,
71 )
73 if isinstance(view, View):
74 view_cls_name = view.__class__.__name__
75 raise TypeError(
76 f"view must be a callable, pass {view_cls_name} or {view_cls_name}.as_view(*args, **kwargs), not "
77 f"{view_cls_name}()."
78 )
80 # Automatically call view.as_view() for class-based views
81 if as_view := getattr(view, "as_view", None):
82 pattern = Pattern(route, name=name, is_endpoint=True)
83 return URLPattern(pattern, as_view(), kwargs, name)
85 # Function-based views or view_class.as_view() usage
86 if callable(view):
87 pattern = Pattern(route, name=name, is_endpoint=True)
88 return URLPattern(pattern, view, kwargs, name)
90 raise TypeError("view must be a callable or a list/tuple in the case of include().")
93path = partial(_path, Pattern=RoutePattern)
94re_path = partial(_path, Pattern=RegexPattern)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import functools
2import uuid
5class IntConverter:
6 regex = "[0-9]+"
8 def to_python(self, value):
9 return int(value)
11 def to_url(self, value):
12 return str(value)
15class StringConverter:
16 regex = "[^/]+"
18 def to_python(self, value):
19 return value
21 def to_url(self, value):
22 return value
25class UUIDConverter:
26 regex = "[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}"
28 def to_python(self, value):
29 return uuid.UUID(value)
31 def to_url(self, value):
32 return str(value)
35class SlugConverter(StringConverter):
36 regex = "[-a-zA-Z0-9_]+"
39class PathConverter(StringConverter):
40 regex = ".+"
43DEFAULT_CONVERTERS = {
44 "int": IntConverter(),
45 "path": PathConverter(),
46 "slug": SlugConverter(),
47 "str": StringConverter(),
48 "uuid": UUIDConverter(),
49}
52REGISTERED_CONVERTERS = {}
55def register_converter(converter, type_name):
56 REGISTERED_CONVERTERS[type_name] = converter()
57 get_converters.cache_clear()
60@functools.cache
61def get_converters():
62 return {**DEFAULT_CONVERTERS, **REGISTERED_CONVERTERS}
65def get_converter(raw_converter):
66 return get_converters()[raw_converter]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.http import Http404
4class Resolver404(Http404):
5 pass
8class NoReverseMatch(Exception):
9 pass
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2This module converts requested URLs to callback view functions.
4URLResolver is the main class here. Its resolve() method takes a URL (as
5a string) and returns a ResolverMatch object which provides access to all
6attributes of the resolved URL match.
7"""
8import functools
9import inspect
10import re
11import string
12from importlib import import_module
13from pickle import PicklingError
14from threading import local
15from urllib.parse import quote
17from plain.exceptions import ImproperlyConfigured
18from plain.preflight import Error, Warning
19from plain.preflight.urls import check_resolver
20from plain.runtime import settings
21from plain.utils.datastructures import MultiValueDict
22from plain.utils.functional import cached_property
23from plain.utils.http import RFC3986_SUBDELIMS, escape_leading_slashes
24from plain.utils.regex_helper import _lazy_re_compile, normalize
26from .converters import get_converter
27from .exceptions import NoReverseMatch, Resolver404
30class ResolverMatch:
31 def __init__(
32 self,
33 func,
34 args,
35 kwargs,
36 url_name=None,
37 default_namespaces=None,
38 namespaces=None,
39 route=None,
40 tried=None,
41 captured_kwargs=None,
42 extra_kwargs=None,
43 ):
44 self.func = func
45 self.args = args
46 self.kwargs = kwargs
47 self.url_name = url_name
48 self.route = route
49 self.tried = tried
50 self.captured_kwargs = captured_kwargs
51 self.extra_kwargs = extra_kwargs
53 # If a URLRegexResolver doesn't have a namespace or default_namespace, it passes
54 # in an empty value.
55 self.default_namespaces = (
56 [x for x in default_namespaces if x] if default_namespaces else []
57 )
58 self.default_namespace = ":".join(self.default_namespaces)
59 self.namespaces = [x for x in namespaces if x] if namespaces else []
60 self.namespace = ":".join(self.namespaces)
62 if hasattr(func, "view_class"):
63 func = func.view_class
64 if not hasattr(func, "__name__"):
65 # A class-based view
66 self._func_path = func.__class__.__module__ + "." + func.__class__.__name__
67 else:
68 # A function-based view
69 self._func_path = func.__module__ + "." + func.__name__
71 view_path = url_name or self._func_path
72 self.view_name = ":".join(self.namespaces + [view_path])
74 def __getitem__(self, index):
75 return (self.func, self.args, self.kwargs)[index]
77 def __repr__(self):
78 if isinstance(self.func, functools.partial):
79 func = repr(self.func)
80 else:
81 func = self._func_path
82 return (
83 "ResolverMatch(func={}, args={!r}, kwargs={!r}, url_name={!r}, "
84 "default_namespaces={!r}, namespaces={!r}, route={!r}{}{})".format(
85 func,
86 self.args,
87 self.kwargs,
88 self.url_name,
89 self.default_namespaces,
90 self.namespaces,
91 self.route,
92 f", captured_kwargs={self.captured_kwargs!r}"
93 if self.captured_kwargs
94 else "",
95 f", extra_kwargs={self.extra_kwargs!r}" if self.extra_kwargs else "",
96 )
97 )
99 def __reduce_ex__(self, protocol):
100 raise PicklingError(f"Cannot pickle {self.__class__.__qualname__}.")
103def get_resolver(urlconf=None):
104 if urlconf is None:
105 urlconf = settings.ROOT_URLCONF
106 return _get_cached_resolver(urlconf)
109@functools.cache
110def _get_cached_resolver(urlconf=None):
111 return URLResolver(RegexPattern(r"^/"), urlconf)
114@functools.cache
115def get_ns_resolver(ns_pattern, resolver, converters):
116 # Build a namespaced resolver for the given parent URLconf pattern.
117 # This makes it possible to have captured parameters in the parent
118 # URLconf pattern.
119 pattern = RegexPattern(ns_pattern)
120 pattern.converters = dict(converters)
121 ns_resolver = URLResolver(pattern, resolver.url_patterns)
122 return URLResolver(RegexPattern(r"^/"), [ns_resolver])
125class CheckURLMixin:
126 def describe(self):
127 """
128 Format the URL pattern for display in warning messages.
129 """
130 description = f"'{self}'"
131 if self.name:
132 description += f" [name='{self.name}']"
133 return description
135 def _check_pattern_startswith_slash(self):
136 """
137 Check that the pattern does not begin with a forward slash.
138 """
139 regex_pattern = self.regex.pattern
140 if not settings.APPEND_SLASH:
141 # Skip check as it can be useful to start a URL pattern with a slash
142 # when APPEND_SLASH=False.
143 return []
144 if regex_pattern.startswith(("/", "^/", "^\\/")) and not regex_pattern.endswith(
145 "/"
146 ):
147 warning = Warning(
148 "Your URL pattern {} has a route beginning with a '/'. Remove this "
149 "slash as it is unnecessary. If this pattern is targeted in an "
150 "include(), ensure the include() pattern has a trailing '/'.".format(
151 self.describe()
152 ),
153 id="urls.W002",
154 )
155 return [warning]
156 else:
157 return []
160class RegexPattern(CheckURLMixin):
161 def __init__(self, regex, name=None, is_endpoint=False):
162 self._regex = regex
163 self._regex_dict = {}
164 self._is_endpoint = is_endpoint
165 self.name = name
166 self.converters = {}
167 self.regex = self._compile(str(regex))
169 def match(self, path):
170 match = (
171 self.regex.fullmatch(path)
172 if self._is_endpoint and self.regex.pattern.endswith("$")
173 else self.regex.search(path)
174 )
175 if match:
176 # If there are any named groups, use those as kwargs, ignoring
177 # non-named groups. Otherwise, pass all non-named arguments as
178 # positional arguments.
179 kwargs = match.groupdict()
180 args = () if kwargs else match.groups()
181 kwargs = {k: v for k, v in kwargs.items() if v is not None}
182 return path[match.end() :], args, kwargs
183 return None
185 def check(self):
186 warnings = []
187 warnings.extend(self._check_pattern_startswith_slash())
188 if not self._is_endpoint:
189 warnings.extend(self._check_include_trailing_dollar())
190 return warnings
192 def _check_include_trailing_dollar(self):
193 regex_pattern = self.regex.pattern
194 if regex_pattern.endswith("$") and not regex_pattern.endswith(r"\$"):
195 return [
196 Warning(
197 "Your URL pattern {} uses include with a route ending with a '$'. "
198 "Remove the dollar from the route to avoid problems including "
199 "URLs.".format(self.describe()),
200 id="urls.W001",
201 )
202 ]
203 else:
204 return []
206 def _compile(self, regex):
207 """Compile and return the given regular expression."""
208 try:
209 return re.compile(regex)
210 except re.error as e:
211 raise ImproperlyConfigured(
212 f'"{regex}" is not a valid regular expression: {e}'
213 ) from e
215 def __str__(self):
216 return str(self._regex)
219_PATH_PARAMETER_COMPONENT_RE = _lazy_re_compile(
220 r"<(?:(?P<converter>[^>:]+):)?(?P<parameter>[^>]+)>"
221)
224def _route_to_regex(route, is_endpoint=False):
225 """
226 Convert a path pattern into a regular expression. Return the regular
227 expression and a dictionary mapping the capture names to the converters.
228 For example, 'foo/<int:pk>' returns '^foo\\/(?P<pk>[0-9]+)'
229 and {'pk': <plain.urls.converters.IntConverter>}.
230 """
231 original_route = route
232 parts = ["^"]
233 converters = {}
234 while True:
235 match = _PATH_PARAMETER_COMPONENT_RE.search(route)
236 if not match:
237 parts.append(re.escape(route))
238 break
239 elif not set(match.group()).isdisjoint(string.whitespace):
240 raise ImproperlyConfigured(
241 "URL route '%s' cannot contain whitespace in angle brackets "
242 "<…>." % original_route
243 )
244 parts.append(re.escape(route[: match.start()]))
245 route = route[match.end() :]
246 parameter = match["parameter"]
247 if not parameter.isidentifier():
248 raise ImproperlyConfigured(
249 "URL route '{}' uses parameter name {!r} which isn't a valid "
250 "Python identifier.".format(original_route, parameter)
251 )
252 raw_converter = match["converter"]
253 if raw_converter is None:
254 # If a converter isn't specified, the default is `str`.
255 raw_converter = "str"
256 try:
257 converter = get_converter(raw_converter)
258 except KeyError as e:
259 raise ImproperlyConfigured(
260 "URL route {!r} uses invalid converter {!r}.".format(
261 original_route, raw_converter
262 )
263 ) from e
264 converters[parameter] = converter
265 parts.append("(?P<" + parameter + ">" + converter.regex + ")")
266 if is_endpoint:
267 parts.append(r"\Z")
268 return "".join(parts), converters
271class RoutePattern(CheckURLMixin):
272 def __init__(self, route, name=None, is_endpoint=False):
273 self._route = route
274 self._regex_dict = {}
275 self._is_endpoint = is_endpoint
276 self.name = name
277 self.converters = _route_to_regex(str(route), is_endpoint)[1]
278 self.regex = self._compile(str(route))
280 def match(self, path):
281 match = self.regex.search(path)
282 if match:
283 # RoutePattern doesn't allow non-named groups so args are ignored.
284 kwargs = match.groupdict()
285 for key, value in kwargs.items():
286 converter = self.converters[key]
287 try:
288 kwargs[key] = converter.to_python(value)
289 except ValueError:
290 return None
291 return path[match.end() :], (), kwargs
292 return None
294 def check(self):
295 warnings = self._check_pattern_startswith_slash()
296 route = self._route
297 if "(?P<" in route or route.startswith("^") or route.endswith("$"):
298 warnings.append(
299 Warning(
300 "Your URL pattern {} has a route that contains '(?P<', begins "
301 "with a '^', or ends with a '$'. This was likely an oversight "
302 "when migrating to plain.urls.path().".format(self.describe()),
303 id="2_0.W001",
304 )
305 )
306 return warnings
308 def _compile(self, route):
309 return re.compile(_route_to_regex(route, self._is_endpoint)[0])
311 def __str__(self):
312 return str(self._route)
315class URLPattern:
316 def __init__(self, pattern, callback, default_args=None, name=None):
317 self.pattern = pattern
318 self.callback = callback # the view
319 self.default_args = default_args or {}
320 self.name = name
322 def __repr__(self):
323 return f"<{self.__class__.__name__} {self.pattern.describe()}>"
325 def check(self):
326 warnings = self._check_pattern_name()
327 warnings.extend(self.pattern.check())
328 warnings.extend(self._check_callback())
329 return warnings
331 def _check_pattern_name(self):
332 """
333 Check that the pattern name does not contain a colon.
334 """
335 if self.pattern.name is not None and ":" in self.pattern.name:
336 warning = Warning(
337 "Your URL pattern {} has a name including a ':'. Remove the colon, to "
338 "avoid ambiguous namespace references.".format(self.pattern.describe()),
339 id="urls.W003",
340 )
341 return [warning]
342 else:
343 return []
345 def _check_callback(self):
346 from plain.views import View
348 view = self.callback
349 if inspect.isclass(view) and issubclass(view, View):
350 return [
351 Error(
352 "Your URL pattern {} has an invalid view, pass {}.as_view() "
353 "instead of {}.".format(
354 self.pattern.describe(),
355 view.__name__,
356 view.__name__,
357 ),
358 id="urls.E009",
359 )
360 ]
361 return []
363 def resolve(self, path):
364 match = self.pattern.match(path)
365 if match:
366 new_path, args, captured_kwargs = match
367 # Pass any default args as **kwargs.
368 kwargs = {**captured_kwargs, **self.default_args}
369 return ResolverMatch(
370 self.callback,
371 args,
372 kwargs,
373 self.pattern.name,
374 route=str(self.pattern),
375 captured_kwargs=captured_kwargs,
376 extra_kwargs=self.default_args,
377 )
379 @cached_property
380 def lookup_str(self):
381 """
382 A string that identifies the view (e.g. 'path.to.view_function' or
383 'path.to.ClassBasedView').
384 """
385 callback = self.callback
386 if isinstance(callback, functools.partial):
387 callback = callback.func
388 if hasattr(callback, "view_class"):
389 callback = callback.view_class
390 elif not hasattr(callback, "__name__"):
391 return callback.__module__ + "." + callback.__class__.__name__
392 return callback.__module__ + "." + callback.__qualname__
395class URLResolver:
396 def __init__(
397 self,
398 pattern,
399 urlconf_name,
400 default_kwargs=None,
401 default_namespace=None,
402 namespace=None,
403 ):
404 self.pattern = pattern
405 # urlconf_name is the dotted Python path to the module defining
406 # urlpatterns. It may also be an object with an urlpatterns attribute
407 # or urlpatterns itself.
408 self.urlconf_name = urlconf_name
409 self.callback = None
410 self.default_kwargs = default_kwargs or {}
411 self.namespace = namespace
412 self.default_namespace = default_namespace
413 self._reverse_dict = {}
414 self._namespace_dict = {}
415 self._app_dict = {}
416 # set of dotted paths to all functions and classes that are used in
417 # urlpatterns
418 self._callback_strs = set()
419 self._populated = False
420 self._local = local()
422 def __repr__(self):
423 if isinstance(self.urlconf_name, list) and self.urlconf_name:
424 # Don't bother to output the whole list, it can be huge
425 urlconf_repr = "<%s list>" % self.urlconf_name[0].__class__.__name__
426 else:
427 urlconf_repr = repr(self.urlconf_name)
428 return "<{} {} ({}:{}) {}>".format(
429 self.__class__.__name__,
430 urlconf_repr,
431 self.default_namespace,
432 self.namespace,
433 self.pattern.describe(),
434 )
436 def check(self):
437 messages = []
438 for pattern in self.url_patterns:
439 messages.extend(check_resolver(pattern))
440 return messages or self.pattern.check()
442 def _populate(self):
443 # Short-circuit if called recursively in this thread to prevent
444 # infinite recursion. Concurrent threads may call this at the same
445 # time and will need to continue, so set 'populating' on a
446 # thread-local variable.
447 if getattr(self._local, "populating", False):
448 return
449 try:
450 self._local.populating = True
451 lookups = MultiValueDict()
452 namespaces = {}
453 packages = {}
454 for url_pattern in reversed(self.url_patterns):
455 p_pattern = url_pattern.pattern.regex.pattern
456 p_pattern = p_pattern.removeprefix("^")
457 if isinstance(url_pattern, URLPattern):
458 self._callback_strs.add(url_pattern.lookup_str)
459 bits = normalize(url_pattern.pattern.regex.pattern)
460 lookups.appendlist(
461 url_pattern.callback,
462 (
463 bits,
464 p_pattern,
465 url_pattern.default_args,
466 url_pattern.pattern.converters,
467 ),
468 )
469 if url_pattern.name is not None:
470 lookups.appendlist(
471 url_pattern.name,
472 (
473 bits,
474 p_pattern,
475 url_pattern.default_args,
476 url_pattern.pattern.converters,
477 ),
478 )
479 else: # url_pattern is a URLResolver.
480 url_pattern._populate()
481 if url_pattern.default_namespace:
482 packages.setdefault(url_pattern.default_namespace, []).append(
483 url_pattern.namespace
484 )
485 namespaces[url_pattern.namespace] = (p_pattern, url_pattern)
486 else:
487 for name in url_pattern.reverse_dict:
488 for (
489 matches,
490 pat,
491 defaults,
492 converters,
493 ) in url_pattern.reverse_dict.getlist(name):
494 new_matches = normalize(p_pattern + pat)
495 lookups.appendlist(
496 name,
497 (
498 new_matches,
499 p_pattern + pat,
500 {**defaults, **url_pattern.default_kwargs},
501 {
502 **self.pattern.converters,
503 **url_pattern.pattern.converters,
504 **converters,
505 },
506 ),
507 )
508 for namespace, (
509 prefix,
510 sub_pattern,
511 ) in url_pattern.namespace_dict.items():
512 current_converters = url_pattern.pattern.converters
513 sub_pattern.pattern.converters.update(current_converters)
514 namespaces[namespace] = (p_pattern + prefix, sub_pattern)
515 for (
516 default_namespace,
517 namespace_list,
518 ) in url_pattern.app_dict.items():
519 packages.setdefault(default_namespace, []).extend(
520 namespace_list
521 )
522 self._callback_strs.update(url_pattern._callback_strs)
523 self._namespace_dict = namespaces
524 self._app_dict = packages
525 self._reverse_dict = lookups
526 self._populated = True
527 finally:
528 self._local.populating = False
530 @property
531 def reverse_dict(self):
532 if not self._reverse_dict:
533 self._populate()
534 return self._reverse_dict
536 @property
537 def namespace_dict(self):
538 if not self._namespace_dict:
539 self._populate()
540 return self._namespace_dict
542 @property
543 def app_dict(self):
544 if not self._app_dict:
545 self._populate()
546 return self._app_dict
548 @staticmethod
549 def _extend_tried(tried, pattern, sub_tried=None):
550 if sub_tried is None:
551 tried.append([pattern])
552 else:
553 tried.extend([pattern, *t] for t in sub_tried)
555 @staticmethod
556 def _join_route(route1, route2):
557 """Join two routes, without the starting ^ in the second route."""
558 if not route1:
559 return route2
560 route2 = route2.removeprefix("^")
561 return route1 + route2
563 def _is_callback(self, name):
564 if not self._populated:
565 self._populate()
566 return name in self._callback_strs
568 def resolve(self, path):
569 path = str(path) # path may be a reverse_lazy object
570 tried = []
571 match = self.pattern.match(path)
572 if match:
573 new_path, args, kwargs = match
574 for pattern in self.url_patterns:
575 try:
576 sub_match = pattern.resolve(new_path)
577 except Resolver404 as e:
578 self._extend_tried(tried, pattern, e.args[0].get("tried"))
579 else:
580 if sub_match:
581 # Merge captured arguments in match with submatch
582 sub_match_dict = {**kwargs, **self.default_kwargs}
583 # Update the sub_match_dict with the kwargs from the sub_match.
584 sub_match_dict.update(sub_match.kwargs)
585 # If there are *any* named groups, ignore all non-named groups.
586 # Otherwise, pass all non-named arguments as positional
587 # arguments.
588 sub_match_args = sub_match.args
589 if not sub_match_dict:
590 sub_match_args = args + sub_match.args
591 current_route = (
592 ""
593 if isinstance(pattern, URLPattern)
594 else str(pattern.pattern)
595 )
596 self._extend_tried(tried, pattern, sub_match.tried)
597 return ResolverMatch(
598 sub_match.func,
599 sub_match_args,
600 sub_match_dict,
601 sub_match.url_name,
602 [self.default_namespace] + sub_match.default_namespaces,
603 [self.namespace] + sub_match.namespaces,
604 self._join_route(current_route, sub_match.route),
605 tried,
606 captured_kwargs=sub_match.captured_kwargs,
607 extra_kwargs={
608 **self.default_kwargs,
609 **sub_match.extra_kwargs,
610 },
611 )
612 tried.append([pattern])
613 raise Resolver404({"tried": tried, "path": new_path})
614 raise Resolver404({"path": path})
616 @cached_property
617 def urlconf_module(self):
618 if isinstance(self.urlconf_name, str):
619 return import_module(self.urlconf_name)
620 else:
621 return self.urlconf_name
623 @cached_property
624 def url_patterns(self):
625 # urlconf_module might be a valid set of patterns, so we default to it
626 patterns = getattr(self.urlconf_module, "urlpatterns", self.urlconf_module)
627 try:
628 iter(patterns)
629 except TypeError as e:
630 msg = (
631 "The included URLconf '{name}' does not appear to have "
632 "any patterns in it. If you see the 'urlpatterns' variable "
633 "with valid patterns in the file then the issue is probably "
634 "caused by a circular import."
635 )
636 raise ImproperlyConfigured(msg.format(name=self.urlconf_name)) from e
637 return patterns
639 def reverse(self, lookup_view, *args, **kwargs):
640 if args and kwargs:
641 raise ValueError("Don't mix *args and **kwargs in call to reverse()!")
643 if not self._populated:
644 self._populate()
646 possibilities = self.reverse_dict.getlist(lookup_view)
648 for possibility, pattern, defaults, converters in possibilities:
649 for result, params in possibility:
650 if args:
651 if len(args) != len(params):
652 continue
653 candidate_subs = dict(zip(params, args))
654 else:
655 if set(kwargs).symmetric_difference(params).difference(defaults):
656 continue
657 matches = True
658 for k, v in defaults.items():
659 if k in params:
660 continue
661 if kwargs.get(k, v) != v:
662 matches = False
663 break
664 if not matches:
665 continue
666 candidate_subs = kwargs
667 # Convert the candidate subs to text using Converter.to_url().
668 text_candidate_subs = {}
669 match = True
670 for k, v in candidate_subs.items():
671 if k in converters:
672 try:
673 text_candidate_subs[k] = converters[k].to_url(v)
674 except ValueError:
675 match = False
676 break
677 else:
678 text_candidate_subs[k] = str(v)
679 if not match:
680 continue
681 # WSGI provides decoded URLs, without %xx escapes, and the URL
682 # resolver operates on such URLs. First substitute arguments
683 # without quoting to build a decoded URL and look for a match.
684 # Then, if we have a match, redo the substitution with quoted
685 # arguments in order to return a properly encoded URL.
687 # There was a lot of script_prefix handling code before,
688 # so this is a crutch to leave the below as-is for now.
689 _prefix = "/"
691 candidate_pat = _prefix.replace("%", "%%") + result
692 if re.search(
693 f"^{re.escape(_prefix)}{pattern}",
694 candidate_pat % text_candidate_subs,
695 ):
696 # safe characters from `pchar` definition of RFC 3986
697 url = quote(
698 candidate_pat % text_candidate_subs,
699 safe=RFC3986_SUBDELIMS + "/~:@",
700 )
701 # Don't allow construction of scheme relative urls.
702 return escape_leading_slashes(url)
703 # lookup_view can be URL name or callable, but callables are not
704 # friendly in error messages.
705 m = getattr(lookup_view, "__module__", None)
706 n = getattr(lookup_view, "__name__", None)
707 if m is not None and n is not None:
708 lookup_view_s = f"{m}.{n}"
709 else:
710 lookup_view_s = lookup_view
712 patterns = [pattern for (_, pattern, _, _) in possibilities]
713 if patterns:
714 if args:
715 arg_msg = f"arguments '{args}'"
716 elif kwargs:
717 arg_msg = "keyword arguments '%s'" % kwargs
718 else:
719 arg_msg = "no arguments"
720 msg = "Reverse for '%s' with %s not found. %d pattern(s) tried: %s" % (
721 lookup_view_s,
722 arg_msg,
723 len(patterns),
724 patterns,
725 )
726 else:
727 msg = (
728 f"Reverse for '{lookup_view_s}' not found. '{lookup_view_s}' is not "
729 "a valid view function or pattern name."
730 )
731 raise NoReverseMatch(msg)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from .configure import configure_logging
2from .loggers import app_logger
3from .utils import log_response
5__all__ = ["app_logger", "log_response", "configure_logging"]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import logging
2import logging.config
3from os import environ
6def configure_logging(logging_settings):
7 # Load the defaults
8 default_logging = {
9 "version": 1,
10 "disable_existing_loggers": False,
11 "formatters": {
12 "simple": {
13 "format": "[%(levelname)s] %(message)s",
14 },
15 },
16 "handlers": {
17 "console": {
18 "level": "INFO",
19 "class": "logging.StreamHandler",
20 "formatter": "simple",
21 },
22 },
23 "loggers": {
24 "plain": {
25 "handlers": ["console"],
26 "level": environ.get("PLAIN_LOG_LEVEL", "INFO"),
27 },
28 "app": {
29 "handlers": ["console"],
30 "level": environ.get("APP_LOG_LEVEL", "INFO"),
31 "propagate": False,
32 },
33 },
34 }
35 logging.config.dictConfig(default_logging)
37 # Then customize it from settings
38 if logging_settings:
39 logging.config.dictConfig(logging_settings)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import logging
3app_logger = logging.getLogger("app")
6class KVLogger:
7 def __init__(self, logger):
8 self.logger = logger
9 self.context = {} # A dict that will be output in every log message
11 def log(self, level, message, **kwargs):
12 msg_kwargs = {
13 **kwargs,
14 **self.context, # Put these last so they're at the end of the line
15 }
16 self.logger.log(level, f"{message} {self._format_kwargs(msg_kwargs)}")
18 def _format_kwargs(self, kwargs):
19 outputs = []
21 for k, v in kwargs.items():
22 self._validate_key(k)
23 formatted_value = self._format_value(v)
24 outputs.append(f"{k}={formatted_value}")
26 return " ".join(outputs)
28 def _validate_key(self, key):
29 if " " in key:
30 raise ValueError("Keys cannot have spaces")
32 if "=" in key:
33 raise ValueError("Keys cannot have equals signs")
35 if '"' in key or "'" in key:
36 raise ValueError("Keys cannot have quotes")
38 def _format_value(self, value):
39 if isinstance(value, str):
40 s = value
41 else:
42 s = str(value)
44 if '"' in s:
45 # Escape quotes and surround it
46 s = s.replace('"', '\\"')
47 s = f'"{s}"'
48 elif s == "":
49 # Quote empty strings instead of printing nothing
50 s = '""'
51 elif any(char in s for char in [" ", "/", "'", ":", "=", "."]):
52 # Surround these with quotes for parsers
53 s = f'"{s}"'
55 return s
57 def info(self, message, **kwargs):
58 self.log(logging.INFO, message, **kwargs)
60 def debug(self, message, **kwargs):
61 self.log(logging.DEBUG, message, **kwargs)
63 def warning(self, message, **kwargs):
64 self.log(logging.WARNING, message, **kwargs)
66 def error(self, message, **kwargs):
67 self.log(logging.ERROR, message, **kwargs)
69 def critical(self, message, **kwargs):
70 self.log(logging.CRITICAL, message, **kwargs)
73# Make this accessible from the app_logger
74app_logger.kv = KVLogger(app_logger)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import logging
3request_logger = logging.getLogger("plain.request")
6def log_response(
7 message,
8 *args,
9 response=None,
10 request=None,
11 logger=request_logger,
12 level=None,
13 exception=None,
14):
15 """
16 Log errors based on Response status.
18 Log 5xx responses as errors and 4xx responses as warnings (unless a level
19 is given as a keyword argument). The Response status_code and the
20 request are passed to the logger's extra parameter.
21 """
22 # Check if the response has already been logged. Multiple requests to log
23 # the same response can be received in some cases, e.g., when the
24 # response is the result of an exception and is logged when the exception
25 # is caught, to record the exception.
26 if getattr(response, "_has_been_logged", False):
27 return
29 if level is None:
30 if response.status_code >= 500:
31 level = "error"
32 elif response.status_code >= 400:
33 level = "warning"
34 else:
35 level = "info"
37 getattr(logger, level)(
38 message,
39 *args,
40 extra={
41 "status_code": response.status_code,
42 "request": request,
43 },
44 exc_info=exception,
45 )
46 response._has_been_logged = True
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.runtime import settings
2from plain.utils.functional import LazyObject
3from plain.utils.module_loading import import_string
5from .defaults import create_default_environment, get_template_dirs
8class JinjaEnvironment(LazyObject):
9 def _setup(self):
10 environment_setting = settings.JINJA_ENVIRONMENT
12 if isinstance(environment_setting, str):
13 environment = import_string(environment_setting)()
14 else:
15 environment = environment_setting()
17 self._wrapped = environment
20environment = JinjaEnvironment()
22__all__ = ["environment", "create_default_environment", "get_template_dirs"]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import functools
2from importlib import import_module
3from pathlib import Path
5from jinja2 import Environment, StrictUndefined
7from plain.packages import packages
8from plain.runtime import settings
9from plain.utils.module_loading import import_string, module_has_submodule
11from .filters import default_filters
12from .globals import default_globals
15@functools.lru_cache
16def _get_app_template_dirs():
17 """
18 Return an iterable of paths of directories to load app templates from.
20 dirname is the name of the subdirectory containing templates inside
21 installed applications.
22 """
23 dirname = "templates"
24 template_dirs = [
25 Path(package_config.path) / dirname
26 for package_config in packages.get_package_configs()
27 if package_config.path and (Path(package_config.path) / dirname).is_dir()
28 ]
29 # Immutable return value because it will be cached and shared by callers.
30 return tuple(template_dirs)
33def _get_installed_extensions() -> tuple[list, dict, dict]:
34 """Automatically load extensions, globals, filters from INSTALLED_PACKAGES jinja module and root jinja module"""
35 extensions = []
36 globals = {}
37 filters = {}
39 for package_config in packages.get_package_configs():
40 if module_has_submodule(package_config.module, "jinja"):
41 module = import_module(f"{package_config.name}.jinja")
42 else:
43 continue
45 if hasattr(module, "extensions"):
46 extensions.extend(module.extensions)
48 if hasattr(module, "globals"):
49 globals.update(module.globals)
51 if hasattr(module, "filters"):
52 filters.update(module.filters)
54 try:
55 import jinja
57 if hasattr(jinja, "extensions"):
58 extensions.extend(jinja.extensions)
60 if hasattr(jinja, "globals"):
61 globals.update(jinja.globals)
63 if hasattr(jinja, "filters"):
64 filters.update(jinja.filters)
65 except ImportError:
66 pass
68 return extensions, globals, filters
71def finalize_callable_error(obj):
72 """Prevent direct rendering of a callable (likely just forgotten ()) by raising a TypeError"""
73 if callable(obj):
74 raise TypeError(f"{obj} is callable, did you forget parentheses?")
76 # TODO find a way to prevent <object representation> from being rendered
77 # if obj.__class__.__str__ is object.__str__:
78 # raise TypeError(f"{obj} does not have a __str__ method")
80 return obj
83def get_template_dirs():
84 jinja_templates = Path(__file__).parent / "templates"
85 app_templates = settings.path.parent / "templates"
86 return (jinja_templates, app_templates) + _get_app_template_dirs()
89def create_default_environment(include_packages=True, **environment_kwargs):
90 """
91 This default jinja environment, also used by the error rendering and internal views so
92 customization needs to happen by using this function, not settings that hook in internally.
93 """
94 loader = import_string(settings.JINJA_LOADER)(get_template_dirs())
95 kwargs = {
96 "loader": loader,
97 "autoescape": True,
98 "auto_reload": settings.DEBUG,
99 "undefined": StrictUndefined,
100 "finalize": finalize_callable_error,
101 "extensions": ["jinja2.ext.loopcontrols", "jinja2.ext.debug"],
102 }
103 kwargs.update(**environment_kwargs)
104 env = Environment(**kwargs)
106 # Load the top-level defaults
107 env.globals.update(default_globals)
108 env.filters.update(default_filters)
110 if include_packages:
111 app_extensions, app_globals, app_filters = _get_installed_extensions()
113 for extension in app_extensions:
114 env.add_extension(extension)
116 env.globals.update(app_globals)
117 env.filters.update(app_filters)
119 return env
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import datetime
2from itertools import islice
4from plain.utils.html import json_script
5from plain.utils.timesince import timesince, timeuntil
6from plain.utils.timezone import localtime
9def localtime_filter(value, timezone=None):
10 """Converts a datetime to local time in a template."""
11 if not value:
12 # Without this, we get the current localtime
13 # which doesn't make sense as a filter
14 raise ValueError("localtime filter requires a datetime")
15 return localtime(value, timezone)
18default_filters = {
19 # The standard Python ones
20 "strftime": datetime.datetime.strftime,
21 "strptime": datetime.datetime.strptime,
22 # To convert to user time zone
23 "localtime": localtime_filter,
24 "timeuntil": timeuntil,
25 "timesince": timesince,
26 "json_script": json_script,
27 "islice": islice, # slice for dict.items()
28}
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.paginator import Paginator
2from plain.utils import timezone
5def url(viewname, *args, **kwargs):
6 # A modified reverse that lets you pass args directly, excluding urlconf
7 from plain.urls import reverse
9 return reverse(viewname, args=args, kwargs=kwargs)
12def asset(url_path):
13 # An explicit callable we can control, but also delay the import of asset.urls->views->templates
14 # for circular import reasons
15 from plain.assets.urls import get_asset_url
17 return get_asset_url(url_path)
20default_globals = {
21 "asset": asset,
22 "url": url,
23 "Paginator": Paginator,
24 "now": timezone.now,
25 "localtime": timezone.localtime,
26}
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:27 -0500
1"""
2Cross Site Request Forgery Middleware.
4This module provides a middleware that implements protection
5against request forgeries from other sites.
6"""
7import logging
8import string
9from collections import defaultdict
10from urllib.parse import urlparse
12from plain.exceptions import DisallowedHost
13from plain.http import HttpHeaders, UnreadablePostError
14from plain.logs import log_response
15from plain.runtime import settings
16from plain.utils.cache import patch_vary_headers
17from plain.utils.crypto import constant_time_compare, get_random_string
18from plain.utils.functional import cached_property
19from plain.utils.http import is_same_domain
20from plain.utils.regex_helper import _lazy_re_compile
22logger = logging.getLogger("plain.security.csrf")
23# This matches if any character is not in CSRF_ALLOWED_CHARS.
24invalid_token_chars_re = _lazy_re_compile("[^a-zA-Z0-9]")
26REASON_BAD_ORIGIN = "Origin checking failed - %s does not match any trusted origins."
27REASON_NO_REFERER = "Referer checking failed - no Referer."
28REASON_BAD_REFERER = "Referer checking failed - %s does not match any trusted origins."
29REASON_NO_CSRF_COOKIE = "CSRF cookie not set."
30REASON_CSRF_TOKEN_MISSING = "CSRF token missing."
31REASON_MALFORMED_REFERER = "Referer checking failed - Referer is malformed."
32REASON_INSECURE_REFERER = (
33 "Referer checking failed - Referer is insecure while host is secure."
34)
35# The reason strings below are for passing to InvalidTokenFormat. They are
36# phrases without a subject because they can be in reference to either the CSRF
37# cookie or non-cookie token.
38REASON_INCORRECT_LENGTH = "has incorrect length"
39REASON_INVALID_CHARACTERS = "has invalid characters"
41CSRF_SECRET_LENGTH = 32
42CSRF_TOKEN_LENGTH = 2 * CSRF_SECRET_LENGTH
43CSRF_ALLOWED_CHARS = string.ascii_letters + string.digits
44CSRF_SESSION_KEY = "_csrftoken"
47def _get_new_csrf_string():
48 return get_random_string(CSRF_SECRET_LENGTH, allowed_chars=CSRF_ALLOWED_CHARS)
51def _mask_cipher_secret(secret):
52 """
53 Given a secret (assumed to be a string of CSRF_ALLOWED_CHARS), generate a
54 token by adding a mask and applying it to the secret.
55 """
56 mask = _get_new_csrf_string()
57 chars = CSRF_ALLOWED_CHARS
58 pairs = zip((chars.index(x) for x in secret), (chars.index(x) for x in mask))
59 cipher = "".join(chars[(x + y) % len(chars)] for x, y in pairs)
60 return mask + cipher
63def _unmask_cipher_token(token):
64 """
65 Given a token (assumed to be a string of CSRF_ALLOWED_CHARS, of length
66 CSRF_TOKEN_LENGTH, and that its first half is a mask), use it to decrypt
67 the second half to produce the original secret.
68 """
69 mask = token[:CSRF_SECRET_LENGTH]
70 token = token[CSRF_SECRET_LENGTH:]
71 chars = CSRF_ALLOWED_CHARS
72 pairs = zip((chars.index(x) for x in token), (chars.index(x) for x in mask))
73 return "".join(chars[x - y] for x, y in pairs) # Note negative values are ok
76def _add_new_csrf_cookie(request):
77 """Generate a new random CSRF_COOKIE value, and add it to request.META."""
78 csrf_secret = _get_new_csrf_string()
79 request.META.update(
80 {
81 "CSRF_COOKIE": csrf_secret,
82 "CSRF_COOKIE_NEEDS_UPDATE": True,
83 }
84 )
85 return csrf_secret
88def get_token(request):
89 """
90 Return the CSRF token required for a POST form. The token is an
91 alphanumeric value. A new token is created if one is not already set.
93 A side effect of calling this function is to make the csrf_protect
94 decorator and the CsrfViewMiddleware add a CSRF cookie and a 'Vary: Cookie'
95 header to the outgoing response. For this reason, you may need to use this
96 function lazily, as is done by the csrf context processor.
97 """
98 if "CSRF_COOKIE" in request.META:
99 csrf_secret = request.META["CSRF_COOKIE"]
100 # Since the cookie is being used, flag to send the cookie in
101 # process_response() (even if the client already has it) in order to
102 # renew the expiry timer.
103 request.META["CSRF_COOKIE_NEEDS_UPDATE"] = True
104 else:
105 csrf_secret = _add_new_csrf_cookie(request)
106 return _mask_cipher_secret(csrf_secret)
109def rotate_token(request):
110 """
111 Change the CSRF token in use for a request - should be done on login
112 for security purposes.
113 """
114 _add_new_csrf_cookie(request)
117class InvalidTokenFormat(Exception):
118 def __init__(self, reason):
119 self.reason = reason
122def _check_token_format(token):
123 """
124 Raise an InvalidTokenFormat error if the token has an invalid length or
125 characters that aren't allowed. The token argument can be a CSRF cookie
126 secret or non-cookie CSRF token, and either masked or unmasked.
127 """
128 if len(token) not in (CSRF_TOKEN_LENGTH, CSRF_SECRET_LENGTH):
129 raise InvalidTokenFormat(REASON_INCORRECT_LENGTH)
130 # Make sure all characters are in CSRF_ALLOWED_CHARS.
131 if invalid_token_chars_re.search(token):
132 raise InvalidTokenFormat(REASON_INVALID_CHARACTERS)
135def _does_token_match(request_csrf_token, csrf_secret):
136 """
137 Return whether the given CSRF token matches the given CSRF secret, after
138 unmasking the token if necessary.
140 This function assumes that the request_csrf_token argument has been
141 validated to have the correct length (CSRF_SECRET_LENGTH or
142 CSRF_TOKEN_LENGTH characters) and allowed characters, and that if it has
143 length CSRF_TOKEN_LENGTH, it is a masked secret.
144 """
145 # Only unmask tokens that are exactly CSRF_TOKEN_LENGTH characters long.
146 if len(request_csrf_token) == CSRF_TOKEN_LENGTH:
147 request_csrf_token = _unmask_cipher_token(request_csrf_token)
148 assert len(request_csrf_token) == CSRF_SECRET_LENGTH
149 return constant_time_compare(request_csrf_token, csrf_secret)
152class RejectRequest(Exception):
153 def __init__(self, reason):
154 self.reason = reason
157class CsrfViewMiddleware:
158 """
159 Require a present and correct csrfmiddlewaretoken for POST requests that
160 have a CSRF cookie, and set an outgoing CSRF cookie.
162 This middleware should be used in conjunction with the {% csrf_token %}
163 template tag.
164 """
166 def __init__(self, get_response):
167 self.get_response = get_response
169 def __call__(self, request):
170 try:
171 csrf_secret = self._get_secret(request)
172 except InvalidTokenFormat:
173 _add_new_csrf_cookie(request)
174 else:
175 if csrf_secret is not None:
176 # Use the same secret next time. If the secret was originally
177 # masked, this also causes it to be replaced with the unmasked
178 # form, but only in cases where the secret is already getting
179 # saved anyways.
180 request.META["CSRF_COOKIE"] = csrf_secret
182 response = self.get_response(request)
184 if request.META.get("CSRF_COOKIE_NEEDS_UPDATE"):
185 self._set_csrf_cookie(request, response)
186 # Unset the flag to prevent _set_csrf_cookie() from being
187 # unnecessarily called again in process_response() by other
188 # instances of CsrfViewMiddleware. This can happen e.g. when both a
189 # decorator and middleware are used. However,
190 # CSRF_COOKIE_NEEDS_UPDATE is still respected in subsequent calls
191 # e.g. in case rotate_token() is called in process_response() later
192 # by custom middleware but before those subsequent calls.
193 request.META["CSRF_COOKIE_NEEDS_UPDATE"] = False
195 return response
197 @cached_property
198 def csrf_trusted_origins_hosts(self):
199 return [
200 urlparse(origin).netloc.lstrip("*")
201 for origin in settings.CSRF_TRUSTED_ORIGINS
202 ]
204 @cached_property
205 def allowed_origins_exact(self):
206 return {origin for origin in settings.CSRF_TRUSTED_ORIGINS if "*" not in origin}
208 @cached_property
209 def allowed_origin_subdomains(self):
210 """
211 A mapping of allowed schemes to list of allowed netlocs, where all
212 subdomains of the netloc are allowed.
213 """
214 allowed_origin_subdomains = defaultdict(list)
215 for parsed in (
216 urlparse(origin)
217 for origin in settings.CSRF_TRUSTED_ORIGINS
218 if "*" in origin
219 ):
220 allowed_origin_subdomains[parsed.scheme].append(parsed.netloc.lstrip("*"))
221 return allowed_origin_subdomains
223 def _reject(self, request, reason):
224 from .views import CsrfFailureView
226 response = CsrfFailureView.as_view()(request, reason=reason)
227 log_response(
228 "Forbidden (%s): %s",
229 reason,
230 request.path,
231 response=response,
232 request=request,
233 logger=logger,
234 )
235 return response
237 def _get_secret(self, request):
238 """
239 Return the CSRF secret originally associated with the request, or None
240 if it didn't have one.
242 If the CSRF_USE_SESSIONS setting is false, raises InvalidTokenFormat if
243 the request's secret has invalid characters or an invalid length.
244 """
245 try:
246 csrf_secret = request.COOKIES[settings.CSRF_COOKIE_NAME]
247 except KeyError:
248 csrf_secret = None
249 else:
250 # This can raise InvalidTokenFormat.
251 _check_token_format(csrf_secret)
253 if csrf_secret is None:
254 return None
255 return csrf_secret
257 def _set_csrf_cookie(self, request, response):
258 response.set_cookie(
259 settings.CSRF_COOKIE_NAME,
260 request.META["CSRF_COOKIE"],
261 max_age=settings.CSRF_COOKIE_AGE,
262 domain=settings.CSRF_COOKIE_DOMAIN,
263 path=settings.CSRF_COOKIE_PATH,
264 secure=settings.CSRF_COOKIE_SECURE,
265 httponly=settings.CSRF_COOKIE_HTTPONLY,
266 samesite=settings.CSRF_COOKIE_SAMESITE,
267 )
268 # Set the Vary header since content varies with the CSRF cookie.
269 patch_vary_headers(response, ("Cookie",))
271 def _origin_verified(self, request):
272 request_origin = request.META["HTTP_ORIGIN"]
273 try:
274 good_host = request.get_host()
275 except DisallowedHost:
276 pass
277 else:
278 good_origin = "{}://{}".format(
279 "https" if request.is_https() else "http",
280 good_host,
281 )
282 if request_origin == good_origin:
283 return True
284 if request_origin in self.allowed_origins_exact:
285 return True
286 try:
287 parsed_origin = urlparse(request_origin)
288 except ValueError:
289 return False
290 request_scheme = parsed_origin.scheme
291 request_netloc = parsed_origin.netloc
292 return any(
293 is_same_domain(request_netloc, host)
294 for host in self.allowed_origin_subdomains.get(request_scheme, ())
295 )
297 def _check_referer(self, request):
298 referer = request.META.get("HTTP_REFERER")
299 if referer is None:
300 raise RejectRequest(REASON_NO_REFERER)
302 try:
303 referer = urlparse(referer)
304 except ValueError:
305 raise RejectRequest(REASON_MALFORMED_REFERER)
307 # Make sure we have a valid URL for Referer.
308 if "" in (referer.scheme, referer.netloc):
309 raise RejectRequest(REASON_MALFORMED_REFERER)
311 # Ensure that our Referer is also secure.
312 if referer.scheme != "https":
313 raise RejectRequest(REASON_INSECURE_REFERER)
315 if any(
316 is_same_domain(referer.netloc, host)
317 for host in self.csrf_trusted_origins_hosts
318 ):
319 return
320 # Allow matching the configured cookie domain.
321 good_referer = settings.CSRF_COOKIE_DOMAIN
322 if good_referer is None:
323 # If no cookie domain is configured, allow matching the current
324 # host:port exactly if it's permitted by ALLOWED_HOSTS.
325 try:
326 # request.get_host() includes the port.
327 good_referer = request.get_host()
328 except DisallowedHost:
329 raise RejectRequest(REASON_BAD_REFERER % referer.geturl())
330 else:
331 server_port = request.get_port()
332 if server_port not in ("443", "80"):
333 good_referer = f"{good_referer}:{server_port}"
335 if not is_same_domain(referer.netloc, good_referer):
336 raise RejectRequest(REASON_BAD_REFERER % referer.geturl())
338 def _bad_token_message(self, reason, token_source):
339 if token_source != "POST":
340 # Assume it is a settings.CSRF_HEADER_NAME value.
341 header_name = HttpHeaders.parse_header_name(token_source)
342 token_source = f"the {header_name!r} HTTP header"
343 return f"CSRF token from {token_source} {reason}."
345 def _check_token(self, request):
346 # Access csrf_secret via self._get_secret() as rotate_token() may have
347 # been called by an authentication middleware during the
348 # process_request() phase.
349 try:
350 csrf_secret = self._get_secret(request)
351 except InvalidTokenFormat as exc:
352 raise RejectRequest(f"CSRF cookie {exc.reason}.")
354 if csrf_secret is None:
355 # No CSRF cookie. For POST requests, we insist on a CSRF cookie,
356 # and in this way we can avoid all CSRF attacks, including login
357 # CSRF.
358 raise RejectRequest(REASON_NO_CSRF_COOKIE)
360 # Check non-cookie token for match.
361 request_csrf_token = ""
362 if request.method == "POST":
363 try:
364 request_csrf_token = request.POST.get("csrfmiddlewaretoken", "")
365 except UnreadablePostError:
366 # Handle a broken connection before we've completed reading the
367 # POST data. process_view shouldn't raise any exceptions, so
368 # we'll ignore and serve the user a 403 (assuming they're still
369 # listening, which they probably aren't because of the error).
370 pass
372 if request_csrf_token == "":
373 # Fall back to X-CSRFToken, to make things easier for AJAX, and
374 # possible for PUT/DELETE.
375 try:
376 # This can have length CSRF_SECRET_LENGTH or CSRF_TOKEN_LENGTH,
377 # depending on whether the client obtained the token from
378 # the DOM or the cookie (and if the cookie, whether the cookie
379 # was masked or unmasked).
380 request_csrf_token = request.META[settings.CSRF_HEADER_NAME]
381 except KeyError:
382 raise RejectRequest(REASON_CSRF_TOKEN_MISSING)
383 token_source = settings.CSRF_HEADER_NAME
384 else:
385 token_source = "POST"
387 try:
388 _check_token_format(request_csrf_token)
389 except InvalidTokenFormat as exc:
390 reason = self._bad_token_message(exc.reason, token_source)
391 raise RejectRequest(reason)
393 if not _does_token_match(request_csrf_token, csrf_secret):
394 reason = self._bad_token_message("incorrect", token_source)
395 raise RejectRequest(reason)
397 def process_view(self, request, callback, callback_args, callback_kwargs):
398 # Wait until request.META["CSRF_COOKIE"] has been manipulated before
399 # bailing out, so that get_token still works
400 if getattr(callback, "csrf_exempt", False):
401 return None
403 # Assume that anything not defined as 'safe' by RFC 9110 needs protection
404 if request.method in ("GET", "HEAD", "OPTIONS", "TRACE"):
405 return None
407 if getattr(request, "_dont_enforce_csrf_checks", False):
408 # Mechanism to turn off CSRF checks for test suite. It comes after
409 # the creation of CSRF cookies, so that everything else continues
410 # to work exactly the same (e.g. cookies are sent, etc.), but
411 # before any branches that call the _reject method.
412 return None
414 # Reject the request if the Origin header doesn't match an allowed
415 # value.
416 if "HTTP_ORIGIN" in request.META:
417 if not self._origin_verified(request):
418 return self._reject(
419 request, REASON_BAD_ORIGIN % request.META["HTTP_ORIGIN"]
420 )
421 elif request.is_https():
422 # If the Origin header wasn't provided, reject HTTPS requests if
423 # the Referer header doesn't match an allowed value.
424 #
425 # Suppose user visits http://example.com/
426 # An active network attacker (man-in-the-middle, MITM) sends a
427 # POST form that targets https://example.com/detonate-bomb/ and
428 # submits it via JavaScript.
429 #
430 # The attacker will need to provide a CSRF cookie and token, but
431 # that's no problem for a MITM and the session-independent secret
432 # we're using. So the MITM can circumvent the CSRF protection. This
433 # is true for any HTTP connection, but anyone using HTTPS expects
434 # better! For this reason, for https://example.com/ we need
435 # additional protection that treats http://example.com/ as
436 # completely untrusted. Under HTTPS, Barth et al. found that the
437 # Referer header is missing for same-domain requests in only about
438 # 0.2% of cases or less, so we can use strict Referer checking.
439 try:
440 self._check_referer(request)
441 except RejectRequest as exc:
442 return self._reject(request, exc.reason)
444 try:
445 self._check_token(request)
446 except RejectRequest as exc:
447 return self._reject(request, exc.reason)
449 return None
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""Plain Unit Test framework."""
3from plain.test.client import Client, RequestFactory
5__all__ = [
6 "Client",
7 "RequestFactory",
8]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:27 -0500
1import json
2import mimetypes
3import os
4import sys
5from functools import partial
6from http import HTTPStatus
7from http.cookies import SimpleCookie
8from importlib import import_module
9from io import BytesIO, IOBase
10from itertools import chain
11from urllib.parse import unquote_to_bytes, urljoin, urlparse, urlsplit
13from plain.http import HttpHeaders, HttpRequest, QueryDict
14from plain.internal.handlers.base import BaseHandler
15from plain.internal.handlers.wsgi import WSGIRequest
16from plain.json import PlainJSONEncoder
17from plain.runtime import settings
18from plain.signals import got_request_exception, request_started
19from plain.urls import resolve
20from plain.utils.encoding import force_bytes
21from plain.utils.functional import SimpleLazyObject
22from plain.utils.http import urlencode
23from plain.utils.itercompat import is_iterable
24from plain.utils.regex_helper import _lazy_re_compile
26__all__ = (
27 "Client",
28 "RedirectCycleError",
29 "RequestFactory",
30 "encode_file",
31 "encode_multipart",
32)
35BOUNDARY = "BoUnDaRyStRiNg"
36MULTIPART_CONTENT = "multipart/form-data; boundary=%s" % BOUNDARY
37CONTENT_TYPE_RE = _lazy_re_compile(r".*; charset=([\w-]+);?")
38# Structured suffix spec: https://tools.ietf.org/html/rfc6838#section-4.2.8
39JSON_CONTENT_TYPE_RE = _lazy_re_compile(r"^application\/(.+\+)?json")
42class ContextList(list):
43 """
44 A wrapper that provides direct key access to context items contained
45 in a list of context objects.
46 """
48 def __getitem__(self, key):
49 if isinstance(key, str):
50 for subcontext in self:
51 if key in subcontext:
52 return subcontext[key]
53 raise KeyError(key)
54 else:
55 return super().__getitem__(key)
57 def get(self, key, default=None):
58 try:
59 return self.__getitem__(key)
60 except KeyError:
61 return default
63 def __contains__(self, key):
64 try:
65 self[key]
66 except KeyError:
67 return False
68 return True
70 def keys(self):
71 """
72 Flattened keys of subcontexts.
73 """
74 return set(chain.from_iterable(d for subcontext in self for d in subcontext))
77class RedirectCycleError(Exception):
78 """The test client has been asked to follow a redirect loop."""
80 def __init__(self, message, last_response):
81 super().__init__(message)
82 self.last_response = last_response
83 self.redirect_chain = last_response.redirect_chain
86class FakePayload(IOBase):
87 """
88 A wrapper around BytesIO that restricts what can be read since data from
89 the network can't be sought and cannot be read outside of its content
90 length. This makes sure that views can't do anything under the test client
91 that wouldn't work in real life.
92 """
94 def __init__(self, initial_bytes=None):
95 self.__content = BytesIO()
96 self.__len = 0
97 self.read_started = False
98 if initial_bytes is not None:
99 self.write(initial_bytes)
101 def __len__(self):
102 return self.__len
104 def read(self, size=-1, /):
105 if not self.read_started:
106 self.__content.seek(0)
107 self.read_started = True
108 if size == -1 or size is None:
109 size = self.__len
110 assert (
111 self.__len >= size
112 ), "Cannot read more than the available bytes from the HTTP incoming data."
113 content = self.__content.read(size)
114 self.__len -= len(content)
115 return content
117 def readline(self, size=-1, /):
118 if not self.read_started:
119 self.__content.seek(0)
120 self.read_started = True
121 if size == -1 or size is None:
122 size = self.__len
123 assert (
124 self.__len >= size
125 ), "Cannot read more than the available bytes from the HTTP incoming data."
126 content = self.__content.readline(size)
127 self.__len -= len(content)
128 return content
130 def write(self, b, /):
131 if self.read_started:
132 raise ValueError("Unable to write a payload after it's been read")
133 content = force_bytes(b)
134 self.__content.write(content)
135 self.__len += len(content)
138def conditional_content_removal(request, response):
139 """
140 Simulate the behavior of most web servers by removing the content of
141 responses for HEAD requests, 1xx, 204, and 304 responses. Ensure
142 compliance with RFC 9112 Section 6.3.
143 """
144 if 100 <= response.status_code < 200 or response.status_code in (204, 304):
145 if response.streaming:
146 response.streaming_content = []
147 else:
148 response.content = b""
149 if request.method == "HEAD":
150 if response.streaming:
151 response.streaming_content = []
152 else:
153 response.content = b""
154 return response
157class ClientHandler(BaseHandler):
158 """
159 An HTTP Handler that can be used for testing purposes. Use the WSGI
160 interface to compose requests, but return the raw Response object with
161 the originating WSGIRequest attached to its ``wsgi_request`` attribute.
162 """
164 def __init__(self, enforce_csrf_checks=True, *args, **kwargs):
165 self.enforce_csrf_checks = enforce_csrf_checks
166 super().__init__(*args, **kwargs)
168 def __call__(self, environ):
169 # Set up middleware if needed. We couldn't do this earlier, because
170 # settings weren't available.
171 if self._middleware_chain is None:
172 self.load_middleware()
174 request_started.send(sender=self.__class__, environ=environ)
175 request = WSGIRequest(environ)
176 # sneaky little hack so that we can easily get round
177 # CsrfViewMiddleware. This makes life easier, and is probably
178 # required for backwards compatibility with external tests against
179 # admin views.
180 request._dont_enforce_csrf_checks = not self.enforce_csrf_checks
182 # Request goes through middleware.
183 response = self.get_response(request)
185 # Simulate behaviors of most web servers.
186 conditional_content_removal(request, response)
188 # Attach the originating request to the response so that it could be
189 # later retrieved.
190 response.wsgi_request = request
192 # Emulate a WSGI server by calling the close method on completion.
193 response.close()
195 return response
198def encode_multipart(boundary, data):
199 """
200 Encode multipart POST data from a dictionary of form values.
202 The key will be used as the form data name; the value will be transmitted
203 as content. If the value is a file, the contents of the file will be sent
204 as an application/octet-stream; otherwise, str(value) will be sent.
205 """
206 lines = []
208 def to_bytes(s):
209 return force_bytes(s, settings.DEFAULT_CHARSET)
211 # Not by any means perfect, but good enough for our purposes.
212 def is_file(thing):
213 return hasattr(thing, "read") and callable(thing.read)
215 # Each bit of the multipart form data could be either a form value or a
216 # file, or a *list* of form values and/or files. Remember that HTTP field
217 # names can be duplicated!
218 for key, value in data.items():
219 if value is None:
220 raise TypeError(
221 "Cannot encode None for key '%s' as POST data. Did you mean "
222 "to pass an empty string or omit the value?" % key
223 )
224 elif is_file(value):
225 lines.extend(encode_file(boundary, key, value))
226 elif not isinstance(value, str) and is_iterable(value):
227 for item in value:
228 if is_file(item):
229 lines.extend(encode_file(boundary, key, item))
230 else:
231 lines.extend(
232 to_bytes(val)
233 for val in [
234 "--%s" % boundary,
235 'Content-Disposition: form-data; name="%s"' % key,
236 "",
237 item,
238 ]
239 )
240 else:
241 lines.extend(
242 to_bytes(val)
243 for val in [
244 "--%s" % boundary,
245 'Content-Disposition: form-data; name="%s"' % key,
246 "",
247 value,
248 ]
249 )
251 lines.extend(
252 [
253 to_bytes("--%s--" % boundary),
254 b"",
255 ]
256 )
257 return b"\r\n".join(lines)
260def encode_file(boundary, key, file):
261 def to_bytes(s):
262 return force_bytes(s, settings.DEFAULT_CHARSET)
264 # file.name might not be a string. For example, it's an int for
265 # tempfile.TemporaryFile().
266 file_has_string_name = hasattr(file, "name") and isinstance(file.name, str)
267 filename = os.path.basename(file.name) if file_has_string_name else ""
269 if hasattr(file, "content_type"):
270 content_type = file.content_type
271 elif filename:
272 content_type = mimetypes.guess_type(filename)[0]
273 else:
274 content_type = None
276 if content_type is None:
277 content_type = "application/octet-stream"
278 filename = filename or key
279 return [
280 to_bytes("--%s" % boundary),
281 to_bytes(
282 f'Content-Disposition: form-data; name="{key}"; filename="{filename}"'
283 ),
284 to_bytes("Content-Type: %s" % content_type),
285 b"",
286 to_bytes(file.read()),
287 ]
290class RequestFactory:
291 """
292 Class that lets you create mock Request objects for use in testing.
294 Usage:
296 rf = RequestFactory()
297 get_request = rf.get('/hello/')
298 post_request = rf.post('/submit/', {'foo': 'bar'})
300 Once you have a request object you can pass it to any view function,
301 just as if that view had been hooked up using a URLconf.
302 """
304 def __init__(self, *, json_encoder=PlainJSONEncoder, headers=None, **defaults):
305 self.json_encoder = json_encoder
306 self.defaults = defaults
307 self.cookies = SimpleCookie()
308 self.errors = BytesIO()
309 if headers:
310 self.defaults.update(HttpHeaders.to_wsgi_names(headers))
312 def _base_environ(self, **request):
313 """
314 The base environment for a request.
315 """
316 # This is a minimal valid WSGI environ dictionary, plus:
317 # - HTTP_COOKIE: for cookie support,
318 # - REMOTE_ADDR: often useful, see #8551.
319 # See https://www.python.org/dev/peps/pep-3333/#environ-variables
320 return {
321 "HTTP_COOKIE": "; ".join(
322 sorted(
323 f"{morsel.key}={morsel.coded_value}"
324 for morsel in self.cookies.values()
325 )
326 ),
327 "PATH_INFO": "/",
328 "REMOTE_ADDR": "127.0.0.1",
329 "REQUEST_METHOD": "GET",
330 "SCRIPT_NAME": "",
331 "SERVER_NAME": "testserver",
332 "SERVER_PORT": "80",
333 "SERVER_PROTOCOL": "HTTP/1.1",
334 "wsgi.version": (1, 0),
335 "wsgi.url_scheme": "http",
336 "wsgi.input": FakePayload(b""),
337 "wsgi.errors": self.errors,
338 "wsgi.multiprocess": True,
339 "wsgi.multithread": False,
340 "wsgi.run_once": False,
341 **self.defaults,
342 **request,
343 }
345 def request(self, **request):
346 "Construct a generic request object."
347 return WSGIRequest(self._base_environ(**request))
349 def _encode_data(self, data, content_type):
350 if content_type is MULTIPART_CONTENT:
351 return encode_multipart(BOUNDARY, data)
352 else:
353 # Encode the content so that the byte representation is correct.
354 match = CONTENT_TYPE_RE.match(content_type)
355 if match:
356 charset = match[1]
357 else:
358 charset = settings.DEFAULT_CHARSET
359 return force_bytes(data, encoding=charset)
361 def _encode_json(self, data, content_type):
362 """
363 Return encoded JSON if data is a dict, list, or tuple and content_type
364 is application/json.
365 """
366 should_encode = JSON_CONTENT_TYPE_RE.match(content_type) and isinstance(
367 data, dict | list | tuple
368 )
369 return json.dumps(data, cls=self.json_encoder) if should_encode else data
371 def _get_path(self, parsed):
372 path = parsed.path
373 # If there are parameters, add them
374 if parsed.params:
375 path += ";" + parsed.params
376 path = unquote_to_bytes(path)
377 # Replace the behavior where non-ASCII values in the WSGI environ are
378 # arbitrarily decoded with ISO-8859-1.
379 # Refs comment in `get_bytes_from_wsgi()`.
380 return path.decode("iso-8859-1")
382 def get(self, path, data=None, secure=True, *, headers=None, **extra):
383 """Construct a GET request."""
384 data = {} if data is None else data
385 return self.generic(
386 "GET",
387 path,
388 secure=secure,
389 headers=headers,
390 **{
391 "QUERY_STRING": urlencode(data, doseq=True),
392 **extra,
393 },
394 )
396 def post(
397 self,
398 path,
399 data=None,
400 content_type=MULTIPART_CONTENT,
401 secure=True,
402 *,
403 headers=None,
404 **extra,
405 ):
406 """Construct a POST request."""
407 data = self._encode_json({} if data is None else data, content_type)
408 post_data = self._encode_data(data, content_type)
410 return self.generic(
411 "POST",
412 path,
413 post_data,
414 content_type,
415 secure=secure,
416 headers=headers,
417 **extra,
418 )
420 def head(self, path, data=None, secure=True, *, headers=None, **extra):
421 """Construct a HEAD request."""
422 data = {} if data is None else data
423 return self.generic(
424 "HEAD",
425 path,
426 secure=secure,
427 headers=headers,
428 **{
429 "QUERY_STRING": urlencode(data, doseq=True),
430 **extra,
431 },
432 )
434 def trace(self, path, secure=True, *, headers=None, **extra):
435 """Construct a TRACE request."""
436 return self.generic("TRACE", path, secure=secure, headers=headers, **extra)
438 def options(
439 self,
440 path,
441 data="",
442 content_type="application/octet-stream",
443 secure=True,
444 *,
445 headers=None,
446 **extra,
447 ):
448 "Construct an OPTIONS request."
449 return self.generic(
450 "OPTIONS", path, data, content_type, secure=secure, headers=headers, **extra
451 )
453 def put(
454 self,
455 path,
456 data="",
457 content_type="application/octet-stream",
458 secure=True,
459 *,
460 headers=None,
461 **extra,
462 ):
463 """Construct a PUT request."""
464 data = self._encode_json(data, content_type)
465 return self.generic(
466 "PUT", path, data, content_type, secure=secure, headers=headers, **extra
467 )
469 def patch(
470 self,
471 path,
472 data="",
473 content_type="application/octet-stream",
474 secure=True,
475 *,
476 headers=None,
477 **extra,
478 ):
479 """Construct a PATCH request."""
480 data = self._encode_json(data, content_type)
481 return self.generic(
482 "PATCH", path, data, content_type, secure=secure, headers=headers, **extra
483 )
485 def delete(
486 self,
487 path,
488 data="",
489 content_type="application/octet-stream",
490 secure=True,
491 *,
492 headers=None,
493 **extra,
494 ):
495 """Construct a DELETE request."""
496 data = self._encode_json(data, content_type)
497 return self.generic(
498 "DELETE", path, data, content_type, secure=secure, headers=headers, **extra
499 )
501 def generic(
502 self,
503 method,
504 path,
505 data="",
506 content_type="application/octet-stream",
507 secure=True,
508 *,
509 headers=None,
510 **extra,
511 ):
512 """Construct an arbitrary HTTP request."""
513 parsed = urlparse(str(path)) # path can be lazy
514 data = force_bytes(data, settings.DEFAULT_CHARSET)
515 r = {
516 "PATH_INFO": self._get_path(parsed),
517 "REQUEST_METHOD": method,
518 "SERVER_PORT": "443" if secure else "80",
519 "wsgi.url_scheme": "https" if secure else "http",
520 }
521 if data:
522 r.update(
523 {
524 "CONTENT_LENGTH": str(len(data)),
525 "CONTENT_TYPE": content_type,
526 "wsgi.input": FakePayload(data),
527 }
528 )
529 if headers:
530 extra.update(HttpHeaders.to_wsgi_names(headers))
531 r.update(extra)
532 # If QUERY_STRING is absent or empty, we want to extract it from the URL.
533 if not r.get("QUERY_STRING"):
534 # WSGI requires latin-1 encoded strings. See get_path_info().
535 query_string = parsed[4].encode().decode("iso-8859-1")
536 r["QUERY_STRING"] = query_string
537 return self.request(**r)
540class ClientMixin:
541 """
542 Mixin with common methods between Client and AsyncClient.
543 """
545 def store_exc_info(self, **kwargs):
546 """Store exceptions when they are generated by a view."""
547 self.exc_info = sys.exc_info()
549 def check_exception(self, response):
550 """
551 Look for a signaled exception, clear the current context exception
552 data, re-raise the signaled exception, and clear the signaled exception
553 from the local cache.
554 """
555 response.exc_info = self.exc_info
556 if self.exc_info:
557 _, exc_value, _ = self.exc_info
558 self.exc_info = None
559 if self.raise_request_exception:
560 raise exc_value
562 @property
563 def session(self):
564 """Return the current session variables."""
565 engine = import_module(settings.SESSION_ENGINE)
566 cookie = self.cookies.get(settings.SESSION_COOKIE_NAME)
567 if cookie:
568 return engine.SessionStore(cookie.value)
569 session = engine.SessionStore()
570 session.save()
571 self.cookies[settings.SESSION_COOKIE_NAME] = session.session_key
572 return session
574 def force_login(self, user):
575 self._login(user)
577 def _login(self, user):
578 from plain.auth import login
580 # Create a fake request to store login details.
581 request = HttpRequest()
582 if self.session:
583 request.session = self.session
584 else:
585 engine = import_module(settings.SESSION_ENGINE)
586 request.session = engine.SessionStore()
587 login(request, user)
588 # Save the session values.
589 request.session.save()
590 # Set the cookie to represent the session.
591 session_cookie = settings.SESSION_COOKIE_NAME
592 self.cookies[session_cookie] = request.session.session_key
593 cookie_data = {
594 "max-age": None,
595 "path": "/",
596 "domain": settings.SESSION_COOKIE_DOMAIN,
597 "secure": settings.SESSION_COOKIE_SECURE or None,
598 "expires": None,
599 }
600 self.cookies[session_cookie].update(cookie_data)
602 def logout(self):
603 """Log out the user by removing the cookies and session object."""
604 from plain.auth import get_user, logout
606 request = HttpRequest()
607 if self.session:
608 request.session = self.session
609 request.user = get_user(request)
610 else:
611 engine = import_module(settings.SESSION_ENGINE)
612 request.session = engine.SessionStore()
613 logout(request)
614 self.cookies = SimpleCookie()
616 def _parse_json(self, response, **extra):
617 if not hasattr(response, "_json"):
618 if not JSON_CONTENT_TYPE_RE.match(response.get("Content-Type")):
619 raise ValueError(
620 'Content-Type header is "%s", not "application/json"'
621 % response.get("Content-Type")
622 )
623 response._json = json.loads(
624 response.content.decode(response.charset), **extra
625 )
626 return response._json
629class Client(ClientMixin, RequestFactory):
630 """
631 A class that can act as a client for testing purposes.
633 It allows the user to compose GET and POST requests, and
634 obtain the response that the server gave to those requests.
635 The server Response objects are annotated with the details
636 of the contexts and templates that were rendered during the
637 process of serving the request.
639 Client objects are stateful - they will retain cookie (and
640 thus session) details for the lifetime of the Client instance.
642 This is not intended as a replacement for Twill/Selenium or
643 the like - it is here to allow testing against the
644 contexts and templates produced by a view, rather than the
645 HTML rendered to the end-user.
646 """
648 def __init__(
649 self,
650 enforce_csrf_checks=False,
651 raise_request_exception=True,
652 *,
653 headers=None,
654 **defaults,
655 ):
656 super().__init__(headers=headers, **defaults)
657 self.handler = ClientHandler(enforce_csrf_checks)
658 self.raise_request_exception = raise_request_exception
659 self.exc_info = None
660 self.extra = None
661 self.headers = None
663 def request(self, **request):
664 """
665 Make a generic request. Compose the environment dictionary and pass
666 to the handler, return the result of the handler. Assume defaults for
667 the query environment, which can be overridden using the arguments to
668 the request.
669 """
670 environ = self._base_environ(**request)
672 # Capture exceptions created by the handler.
673 exception_uid = "request-exception-%s" % id(request)
674 got_request_exception.connect(self.store_exc_info, dispatch_uid=exception_uid)
675 try:
676 response = self.handler(environ)
677 finally:
678 # signals.template_rendered.disconnect(dispatch_uid=signal_uid)
679 got_request_exception.disconnect(dispatch_uid=exception_uid)
680 # Check for signaled exceptions.
681 self.check_exception(response)
682 # Save the client and request that stimulated the response.
683 response.client = self
684 response.request = request
685 response.json = partial(self._parse_json, response)
687 # If the request had a user attached, make it available on the response.
688 if hasattr(response.wsgi_request, "user"):
689 response.user = response.wsgi_request.user
691 # Attach the ResolverMatch instance to the response.
692 urlconf = getattr(response.wsgi_request, "urlconf", None)
693 response.resolver_match = SimpleLazyObject(
694 lambda: resolve(request["PATH_INFO"], urlconf=urlconf),
695 )
697 # Update persistent cookie data.
698 if response.cookies:
699 self.cookies.update(response.cookies)
700 return response
702 def get(
703 self,
704 path,
705 data=None,
706 follow=False,
707 secure=True,
708 *,
709 headers=None,
710 **extra,
711 ):
712 """Request a response from the server using GET."""
713 self.extra = extra
714 self.headers = headers
715 response = super().get(path, data=data, secure=secure, headers=headers, **extra)
716 if follow:
717 response = self._handle_redirects(
718 response, data=data, headers=headers, **extra
719 )
720 return response
722 def post(
723 self,
724 path,
725 data=None,
726 content_type=MULTIPART_CONTENT,
727 follow=False,
728 secure=True,
729 *,
730 headers=None,
731 **extra,
732 ):
733 """Request a response from the server using POST."""
734 self.extra = extra
735 self.headers = headers
736 response = super().post(
737 path,
738 data=data,
739 content_type=content_type,
740 secure=secure,
741 headers=headers,
742 **extra,
743 )
744 if follow:
745 response = self._handle_redirects(
746 response, data=data, content_type=content_type, headers=headers, **extra
747 )
748 return response
750 def head(
751 self,
752 path,
753 data=None,
754 follow=False,
755 secure=True,
756 *,
757 headers=None,
758 **extra,
759 ):
760 """Request a response from the server using HEAD."""
761 self.extra = extra
762 self.headers = headers
763 response = super().head(
764 path, data=data, secure=secure, headers=headers, **extra
765 )
766 if follow:
767 response = self._handle_redirects(
768 response, data=data, headers=headers, **extra
769 )
770 return response
772 def options(
773 self,
774 path,
775 data="",
776 content_type="application/octet-stream",
777 follow=False,
778 secure=True,
779 *,
780 headers=None,
781 **extra,
782 ):
783 """Request a response from the server using OPTIONS."""
784 self.extra = extra
785 self.headers = headers
786 response = super().options(
787 path,
788 data=data,
789 content_type=content_type,
790 secure=secure,
791 headers=headers,
792 **extra,
793 )
794 if follow:
795 response = self._handle_redirects(
796 response, data=data, content_type=content_type, headers=headers, **extra
797 )
798 return response
800 def put(
801 self,
802 path,
803 data="",
804 content_type="application/octet-stream",
805 follow=False,
806 secure=True,
807 *,
808 headers=None,
809 **extra,
810 ):
811 """Send a resource to the server using PUT."""
812 self.extra = extra
813 self.headers = headers
814 response = super().put(
815 path,
816 data=data,
817 content_type=content_type,
818 secure=secure,
819 headers=headers,
820 **extra,
821 )
822 if follow:
823 response = self._handle_redirects(
824 response, data=data, content_type=content_type, headers=headers, **extra
825 )
826 return response
828 def patch(
829 self,
830 path,
831 data="",
832 content_type="application/octet-stream",
833 follow=False,
834 secure=True,
835 *,
836 headers=None,
837 **extra,
838 ):
839 """Send a resource to the server using PATCH."""
840 self.extra = extra
841 self.headers = headers
842 response = super().patch(
843 path,
844 data=data,
845 content_type=content_type,
846 secure=secure,
847 headers=headers,
848 **extra,
849 )
850 if follow:
851 response = self._handle_redirects(
852 response, data=data, content_type=content_type, headers=headers, **extra
853 )
854 return response
856 def delete(
857 self,
858 path,
859 data="",
860 content_type="application/octet-stream",
861 follow=False,
862 secure=True,
863 *,
864 headers=None,
865 **extra,
866 ):
867 """Send a DELETE request to the server."""
868 self.extra = extra
869 self.headers = headers
870 response = super().delete(
871 path,
872 data=data,
873 content_type=content_type,
874 secure=secure,
875 headers=headers,
876 **extra,
877 )
878 if follow:
879 response = self._handle_redirects(
880 response, data=data, content_type=content_type, headers=headers, **extra
881 )
882 return response
884 def trace(
885 self,
886 path,
887 data="",
888 follow=False,
889 secure=True,
890 *,
891 headers=None,
892 **extra,
893 ):
894 """Send a TRACE request to the server."""
895 self.extra = extra
896 self.headers = headers
897 response = super().trace(
898 path, data=data, secure=secure, headers=headers, **extra
899 )
900 if follow:
901 response = self._handle_redirects(
902 response, data=data, headers=headers, **extra
903 )
904 return response
906 def _handle_redirects(
907 self,
908 response,
909 data="",
910 content_type="",
911 headers=None,
912 **extra,
913 ):
914 """
915 Follow any redirects by requesting responses from the server using GET.
916 """
917 response.redirect_chain = []
918 redirect_status_codes = (
919 HTTPStatus.MOVED_PERMANENTLY,
920 HTTPStatus.FOUND,
921 HTTPStatus.SEE_OTHER,
922 HTTPStatus.TEMPORARY_REDIRECT,
923 HTTPStatus.PERMANENT_REDIRECT,
924 )
925 while response.status_code in redirect_status_codes:
926 response_url = response.url
927 redirect_chain = response.redirect_chain
928 redirect_chain.append((response_url, response.status_code))
930 url = urlsplit(response_url)
931 if url.scheme:
932 extra["wsgi.url_scheme"] = url.scheme
933 if url.hostname:
934 extra["SERVER_NAME"] = url.hostname
935 if url.port:
936 extra["SERVER_PORT"] = str(url.port)
938 path = url.path
939 # RFC 3986 Section 6.2.3: Empty path should be normalized to "/".
940 if not path and url.netloc:
941 path = "/"
942 # Prepend the request path to handle relative path redirects
943 if not path.startswith("/"):
944 path = urljoin(response.request["PATH_INFO"], path)
946 if response.status_code in (
947 HTTPStatus.TEMPORARY_REDIRECT,
948 HTTPStatus.PERMANENT_REDIRECT,
949 ):
950 # Preserve request method and query string (if needed)
951 # post-redirect for 307/308 responses.
952 request_method = response.request["REQUEST_METHOD"].lower()
953 if request_method not in ("get", "head"):
954 extra["QUERY_STRING"] = url.query
955 request_method = getattr(self, request_method)
956 else:
957 request_method = self.get
958 data = QueryDict(url.query)
959 content_type = None
961 response = request_method(
962 path,
963 data=data,
964 content_type=content_type,
965 follow=False,
966 headers=headers,
967 **extra,
968 )
969 response.redirect_chain = redirect_chain
971 if redirect_chain[-1] in redirect_chain[:-1]:
972 # Check that we're not redirecting to somewhere we've already
973 # been to, to prevent loops.
974 raise RedirectCycleError(
975 "Redirect loop detected.", last_response=response
976 )
977 if len(redirect_chain) > 20:
978 # Such a lengthy chain likely also means a loop, but one with
979 # a growing path, changing view, or changing query argument;
980 # 20 is the value of "network.http.redirection-limit" from Firefox.
981 raise RedirectCycleError("Too many redirects.", last_response=response)
983 return response
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from .migration import Migration, swappable_dependency # NOQA
2from .operations import * # NOQA
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import functools
2import re
3from graphlib import TopologicalSorter
4from itertools import chain
6from plain import models
7from plain.models.migrations import operations
8from plain.models.migrations.migration import Migration
9from plain.models.migrations.operations.models import AlterModelOptions
10from plain.models.migrations.optimizer import MigrationOptimizer
11from plain.models.migrations.questioner import MigrationQuestioner
12from plain.models.migrations.utils import (
13 COMPILED_REGEX_TYPE,
14 RegexObject,
15 resolve_relation,
16)
17from plain.runtime import settings
20class MigrationAutodetector:
21 """
22 Take a pair of ProjectStates and compare them to see what the first would
23 need doing to make it match the second (the second usually being the
24 project's current state).
26 Note that this naturally operates on entire projects at a time,
27 as it's likely that changes interact (for example, you can't
28 add a ForeignKey without having a migration to add the table it
29 depends on first). A user interface may offer single-app usage
30 if it wishes, with the caveat that it may not always be possible.
31 """
33 def __init__(self, from_state, to_state, questioner=None):
34 self.from_state = from_state
35 self.to_state = to_state
36 self.questioner = questioner or MigrationQuestioner()
37 self.existing_packages = {app for app, model in from_state.models}
39 def changes(
40 self, graph, trim_to_packages=None, convert_packages=None, migration_name=None
41 ):
42 """
43 Main entry point to produce a list of applicable changes.
44 Take a graph to base names on and an optional set of packages
45 to try and restrict to (restriction is not guaranteed)
46 """
47 changes = self._detect_changes(convert_packages, graph)
48 changes = self.arrange_for_graph(changes, graph, migration_name)
49 if trim_to_packages:
50 changes = self._trim_to_packages(changes, trim_to_packages)
51 return changes
53 def deep_deconstruct(self, obj):
54 """
55 Recursive deconstruction for a field and its arguments.
56 Used for full comparison for rename/alter; sometimes a single-level
57 deconstruction will not compare correctly.
58 """
59 if isinstance(obj, list):
60 return [self.deep_deconstruct(value) for value in obj]
61 elif isinstance(obj, tuple):
62 return tuple(self.deep_deconstruct(value) for value in obj)
63 elif isinstance(obj, dict):
64 return {key: self.deep_deconstruct(value) for key, value in obj.items()}
65 elif isinstance(obj, functools.partial):
66 return (
67 obj.func,
68 self.deep_deconstruct(obj.args),
69 self.deep_deconstruct(obj.keywords),
70 )
71 elif isinstance(obj, COMPILED_REGEX_TYPE):
72 return RegexObject(obj)
73 elif isinstance(obj, type):
74 # If this is a type that implements 'deconstruct' as an instance method,
75 # avoid treating this as being deconstructible itself - see #22951
76 return obj
77 elif hasattr(obj, "deconstruct"):
78 deconstructed = obj.deconstruct()
79 if isinstance(obj, models.Field):
80 # we have a field which also returns a name
81 deconstructed = deconstructed[1:]
82 path, args, kwargs = deconstructed
83 return (
84 path,
85 [self.deep_deconstruct(value) for value in args],
86 {key: self.deep_deconstruct(value) for key, value in kwargs.items()},
87 )
88 else:
89 return obj
91 def only_relation_agnostic_fields(self, fields):
92 """
93 Return a definition of the fields that ignores field names and
94 what related fields actually relate to. Used for detecting renames (as
95 the related fields change during renames).
96 """
97 fields_def = []
98 for name, field in sorted(fields.items()):
99 deconstruction = self.deep_deconstruct(field)
100 if field.remote_field and field.remote_field.model:
101 deconstruction[2].pop("to", None)
102 fields_def.append(deconstruction)
103 return fields_def
105 def _detect_changes(self, convert_packages=None, graph=None):
106 """
107 Return a dict of migration plans which will achieve the
108 change from from_state to to_state. The dict has app labels
109 as keys and a list of migrations as values.
111 The resulting migrations aren't specially named, but the names
112 do matter for dependencies inside the set.
114 convert_packages is the list of packages to convert to use migrations
115 (i.e. to make initial migrations for, in the usual case)
117 graph is an optional argument that, if provided, can help improve
118 dependency generation and avoid potential circular dependencies.
119 """
120 # The first phase is generating all the operations for each app
121 # and gathering them into a big per-app list.
122 # Then go through that list, order it, and split into migrations to
123 # resolve dependencies caused by M2Ms and FKs.
124 self.generated_operations = {}
125 self.altered_indexes = {}
126 self.altered_constraints = {}
127 self.renamed_fields = {}
129 # Prepare some old/new state and model lists, ignoring unmigrated packages.
130 self.old_model_keys = set()
131 self.old_unmanaged_keys = set()
132 self.new_model_keys = set()
133 self.new_unmanaged_keys = set()
134 for (package_label, model_name), model_state in self.from_state.models.items():
135 if not model_state.options.get("managed", True):
136 self.old_unmanaged_keys.add((package_label, model_name))
137 elif package_label not in self.from_state.real_packages:
138 self.old_model_keys.add((package_label, model_name))
140 for (package_label, model_name), model_state in self.to_state.models.items():
141 if not model_state.options.get("managed", True):
142 self.new_unmanaged_keys.add((package_label, model_name))
143 elif package_label not in self.from_state.real_packages or (
144 convert_packages and package_label in convert_packages
145 ):
146 self.new_model_keys.add((package_label, model_name))
148 self.from_state.resolve_fields_and_relations()
149 self.to_state.resolve_fields_and_relations()
151 # Renames have to come first
152 self.generate_renamed_models()
154 # Prepare lists of fields and generate through model map
155 self._prepare_field_lists()
156 self._generate_through_model_map()
158 # Generate non-rename model operations
159 self.generate_deleted_models()
160 self.generate_created_models()
161 self.generate_altered_options()
162 self.generate_altered_managers()
163 self.generate_altered_db_table_comment()
165 # Create the renamed fields and store them in self.renamed_fields.
166 # They are used by create_altered_indexes(), generate_altered_fields(),
167 # generate_removed_altered_index(), and
168 # generate_altered_index().
169 self.create_renamed_fields()
170 # Create the altered indexes and store them in self.altered_indexes.
171 # This avoids the same computation in generate_removed_indexes()
172 # and generate_added_indexes().
173 self.create_altered_indexes()
174 self.create_altered_constraints()
175 # Generate index removal operations before field is removed
176 self.generate_removed_constraints()
177 self.generate_removed_indexes()
178 # Generate field renaming operations.
179 self.generate_renamed_fields()
180 self.generate_renamed_indexes()
181 # Generate field operations.
182 self.generate_removed_fields()
183 self.generate_added_fields()
184 self.generate_altered_fields()
185 self.generate_altered_order_with_respect_to()
186 self.generate_added_indexes()
187 self.generate_added_constraints()
188 self.generate_altered_db_table()
190 self._sort_migrations()
191 self._build_migration_list(graph)
192 self._optimize_migrations()
194 return self.migrations
196 def _prepare_field_lists(self):
197 """
198 Prepare field lists and a list of the fields that used through models
199 in the old state so dependencies can be made from the through model
200 deletion to the field that uses it.
201 """
202 self.kept_model_keys = self.old_model_keys & self.new_model_keys
203 self.kept_unmanaged_keys = self.old_unmanaged_keys & self.new_unmanaged_keys
204 self.through_users = {}
205 self.old_field_keys = {
206 (package_label, model_name, field_name)
207 for package_label, model_name in self.kept_model_keys
208 for field_name in self.from_state.models[
209 package_label,
210 self.renamed_models.get((package_label, model_name), model_name),
211 ].fields
212 }
213 self.new_field_keys = {
214 (package_label, model_name, field_name)
215 for package_label, model_name in self.kept_model_keys
216 for field_name in self.to_state.models[package_label, model_name].fields
217 }
219 def _generate_through_model_map(self):
220 """Through model map generation."""
221 for package_label, model_name in sorted(self.old_model_keys):
222 old_model_name = self.renamed_models.get(
223 (package_label, model_name), model_name
224 )
225 old_model_state = self.from_state.models[package_label, old_model_name]
226 for field_name, field in old_model_state.fields.items():
227 if hasattr(field, "remote_field") and getattr(
228 field.remote_field, "through", None
229 ):
230 through_key = resolve_relation(
231 field.remote_field.through, package_label, model_name
232 )
233 self.through_users[through_key] = (
234 package_label,
235 old_model_name,
236 field_name,
237 )
239 @staticmethod
240 def _resolve_dependency(dependency):
241 """
242 Return the resolved dependency and a boolean denoting whether or not
243 it was swappable.
244 """
245 if dependency[0] != "__setting__":
246 return dependency, False
247 resolved_package_label, resolved_object_name = getattr(
248 settings, dependency[1]
249 ).split(".")
250 return (resolved_package_label, resolved_object_name.lower()) + dependency[
251 2:
252 ], True
254 def _build_migration_list(self, graph=None):
255 """
256 Chop the lists of operations up into migrations with dependencies on
257 each other. Do this by going through an app's list of operations until
258 one is found that has an outgoing dependency that isn't in another
259 app's migration yet (hasn't been chopped off its list). Then chop off
260 the operations before it into a migration and move onto the next app.
261 If the loops completes without doing anything, there's a circular
262 dependency (which _should_ be impossible as the operations are
263 all split at this point so they can't depend and be depended on).
264 """
265 self.migrations = {}
266 num_ops = sum(len(x) for x in self.generated_operations.values())
267 chop_mode = False
268 while num_ops:
269 # On every iteration, we step through all the packages and see if there
270 # is a completed set of operations.
271 # If we find that a subset of the operations are complete we can
272 # try to chop it off from the rest and continue, but we only
273 # do this if we've already been through the list once before
274 # without any chopping and nothing has changed.
275 for package_label in sorted(self.generated_operations):
276 chopped = []
277 dependencies = set()
278 for operation in list(self.generated_operations[package_label]):
279 deps_satisfied = True
280 operation_dependencies = set()
281 for dep in operation._auto_deps:
282 # Temporarily resolve the swappable dependency to
283 # prevent circular references. While keeping the
284 # dependency checks on the resolved model, add the
285 # swappable dependencies.
286 original_dep = dep
287 dep, is_swappable_dep = self._resolve_dependency(dep)
288 if dep[0] != package_label:
289 # External app dependency. See if it's not yet
290 # satisfied.
291 for other_operation in self.generated_operations.get(
292 dep[0], []
293 ):
294 if self.check_dependency(other_operation, dep):
295 deps_satisfied = False
296 break
297 if not deps_satisfied:
298 break
299 else:
300 if is_swappable_dep:
301 operation_dependencies.add(
302 (original_dep[0], original_dep[1])
303 )
304 elif dep[0] in self.migrations:
305 operation_dependencies.add(
306 (dep[0], self.migrations[dep[0]][-1].name)
307 )
308 else:
309 # If we can't find the other app, we add a
310 # first/last dependency, but only if we've
311 # already been through once and checked
312 # everything.
313 if chop_mode:
314 # If the app already exists, we add a
315 # dependency on the last migration, as
316 # we don't know which migration
317 # contains the target field. If it's
318 # not yet migrated or has no
319 # migrations, we use __first__.
320 if graph and graph.leaf_nodes(dep[0]):
321 operation_dependencies.add(
322 graph.leaf_nodes(dep[0])[0]
323 )
324 else:
325 operation_dependencies.add(
326 (dep[0], "__first__")
327 )
328 else:
329 deps_satisfied = False
330 if deps_satisfied:
331 chopped.append(operation)
332 dependencies.update(operation_dependencies)
333 del self.generated_operations[package_label][0]
334 else:
335 break
336 # Make a migration! Well, only if there's stuff to put in it
337 if dependencies or chopped:
338 if not self.generated_operations[package_label] or chop_mode:
339 subclass = type(
340 "Migration",
341 (Migration,),
342 {"operations": [], "dependencies": []},
343 )
344 instance = subclass(
345 "auto_%i"
346 % (len(self.migrations.get(package_label, [])) + 1),
347 package_label,
348 )
349 instance.dependencies = list(dependencies)
350 instance.operations = chopped
351 instance.initial = package_label not in self.existing_packages
352 self.migrations.setdefault(package_label, []).append(instance)
353 chop_mode = False
354 else:
355 self.generated_operations[package_label] = (
356 chopped + self.generated_operations[package_label]
357 )
358 new_num_ops = sum(len(x) for x in self.generated_operations.values())
359 if new_num_ops == num_ops:
360 if not chop_mode:
361 chop_mode = True
362 else:
363 raise ValueError(
364 f"Cannot resolve operation dependencies: {self.generated_operations!r}"
365 )
366 num_ops = new_num_ops
368 def _sort_migrations(self):
369 """
370 Reorder to make things possible. Reordering may be needed so FKs work
371 nicely inside the same app.
372 """
373 for package_label, ops in sorted(self.generated_operations.items()):
374 ts = TopologicalSorter()
375 for op in ops:
376 ts.add(op)
377 for dep in op._auto_deps:
378 # Resolve intra-app dependencies to handle circular
379 # references involving a swappable model.
380 dep = self._resolve_dependency(dep)[0]
381 if dep[0] != package_label:
382 continue
383 ts.add(op, *(x for x in ops if self.check_dependency(x, dep)))
384 self.generated_operations[package_label] = list(ts.static_order())
386 def _optimize_migrations(self):
387 # Add in internal dependencies among the migrations
388 for package_label, migrations in self.migrations.items():
389 for m1, m2 in zip(migrations, migrations[1:]):
390 m2.dependencies.append((package_label, m1.name))
392 # De-dupe dependencies
393 for migrations in self.migrations.values():
394 for migration in migrations:
395 migration.dependencies = list(set(migration.dependencies))
397 # Optimize migrations
398 for package_label, migrations in self.migrations.items():
399 for migration in migrations:
400 migration.operations = MigrationOptimizer().optimize(
401 migration.operations, package_label
402 )
404 def check_dependency(self, operation, dependency):
405 """
406 Return True if the given operation depends on the given dependency,
407 False otherwise.
408 """
409 # Created model
410 if dependency[2] is None and dependency[3] is True:
411 return (
412 isinstance(operation, operations.CreateModel)
413 and operation.name_lower == dependency[1].lower()
414 )
415 # Created field
416 elif dependency[2] is not None and dependency[3] is True:
417 return (
418 isinstance(operation, operations.CreateModel)
419 and operation.name_lower == dependency[1].lower()
420 and any(dependency[2] == x for x, y in operation.fields)
421 ) or (
422 isinstance(operation, operations.AddField)
423 and operation.model_name_lower == dependency[1].lower()
424 and operation.name_lower == dependency[2].lower()
425 )
426 # Removed field
427 elif dependency[2] is not None and dependency[3] is False:
428 return (
429 isinstance(operation, operations.RemoveField)
430 and operation.model_name_lower == dependency[1].lower()
431 and operation.name_lower == dependency[2].lower()
432 )
433 # Removed model
434 elif dependency[2] is None and dependency[3] is False:
435 return (
436 isinstance(operation, operations.DeleteModel)
437 and operation.name_lower == dependency[1].lower()
438 )
439 # Field being altered
440 elif dependency[2] is not None and dependency[3] == "alter":
441 return (
442 isinstance(operation, operations.AlterField)
443 and operation.model_name_lower == dependency[1].lower()
444 and operation.name_lower == dependency[2].lower()
445 )
446 # order_with_respect_to being unset for a field
447 elif dependency[2] is not None and dependency[3] == "order_wrt_unset":
448 return (
449 isinstance(operation, operations.AlterOrderWithRespectTo)
450 and operation.name_lower == dependency[1].lower()
451 and (operation.order_with_respect_to or "").lower()
452 != dependency[2].lower()
453 )
454 # Unknown dependency. Raise an error.
455 else:
456 raise ValueError(f"Can't handle dependency {dependency!r}")
458 def add_operation(
459 self, package_label, operation, dependencies=None, beginning=False
460 ):
461 # Dependencies are
462 # (package_label, model_name, field_name, create/delete as True/False)
463 operation._auto_deps = dependencies or []
464 if beginning:
465 self.generated_operations.setdefault(package_label, []).insert(0, operation)
466 else:
467 self.generated_operations.setdefault(package_label, []).append(operation)
469 def swappable_first_key(self, item):
470 """
471 Place potential swappable models first in lists of created models (only
472 real way to solve #22783).
473 """
474 try:
475 model_state = self.to_state.models[item]
476 base_names = {
477 base if isinstance(base, str) else base.__name__
478 for base in model_state.bases
479 }
480 string_version = f"{item[0]}.{item[1]}"
481 if (
482 model_state.options.get("swappable")
483 or "BaseUser" in base_names
484 or "AbstractBaseUser" in base_names
485 or settings.AUTH_USER_MODEL.lower() == string_version.lower()
486 ):
487 return ("___" + item[0], "___" + item[1])
488 except LookupError:
489 pass
490 return item
492 def generate_renamed_models(self):
493 """
494 Find any renamed models, generate the operations for them, and remove
495 the old entry from the model lists. Must be run before other
496 model-level generation.
497 """
498 self.renamed_models = {}
499 self.renamed_models_rel = {}
500 added_models = self.new_model_keys - self.old_model_keys
501 for package_label, model_name in sorted(added_models):
502 model_state = self.to_state.models[package_label, model_name]
503 model_fields_def = self.only_relation_agnostic_fields(model_state.fields)
505 removed_models = self.old_model_keys - self.new_model_keys
506 for rem_package_label, rem_model_name in removed_models:
507 if rem_package_label == package_label:
508 rem_model_state = self.from_state.models[
509 rem_package_label, rem_model_name
510 ]
511 rem_model_fields_def = self.only_relation_agnostic_fields(
512 rem_model_state.fields
513 )
514 if model_fields_def == rem_model_fields_def:
515 if self.questioner.ask_rename_model(
516 rem_model_state, model_state
517 ):
518 dependencies = []
519 fields = list(model_state.fields.values()) + [
520 field.remote_field
521 for relations in self.to_state.relations[
522 package_label, model_name
523 ].values()
524 for field in relations.values()
525 ]
526 for field in fields:
527 if field.is_relation:
528 dependencies.extend(
529 self._get_dependencies_for_foreign_key(
530 package_label,
531 model_name,
532 field,
533 self.to_state,
534 )
535 )
536 self.add_operation(
537 package_label,
538 operations.RenameModel(
539 old_name=rem_model_state.name,
540 new_name=model_state.name,
541 ),
542 dependencies=dependencies,
543 )
544 self.renamed_models[package_label, model_name] = (
545 rem_model_name
546 )
547 renamed_models_rel_key = f"{rem_model_state.package_label}.{rem_model_state.name_lower}"
548 self.renamed_models_rel[renamed_models_rel_key] = (
549 f"{model_state.package_label}.{model_state.name_lower}"
550 )
551 self.old_model_keys.remove(
552 (rem_package_label, rem_model_name)
553 )
554 self.old_model_keys.add((package_label, model_name))
555 break
557 def generate_created_models(self):
558 """
559 Find all new models (both managed and unmanaged) and make create
560 operations for them as well as separate operations to create any
561 foreign key or M2M relationships (these are optimized later, if
562 possible).
564 Defer any model options that refer to collections of fields that might
565 be deferred.
566 """
567 old_keys = self.old_model_keys | self.old_unmanaged_keys
568 added_models = self.new_model_keys - old_keys
569 added_unmanaged_models = self.new_unmanaged_keys - old_keys
570 all_added_models = chain(
571 sorted(added_models, key=self.swappable_first_key, reverse=True),
572 sorted(added_unmanaged_models, key=self.swappable_first_key, reverse=True),
573 )
574 for package_label, model_name in all_added_models:
575 model_state = self.to_state.models[package_label, model_name]
576 # Gather related fields
577 related_fields = {}
578 primary_key_rel = None
579 for field_name, field in model_state.fields.items():
580 if field.remote_field:
581 if field.remote_field.model:
582 if field.primary_key:
583 primary_key_rel = field.remote_field.model
584 elif not field.remote_field.parent_link:
585 related_fields[field_name] = field
586 if getattr(field.remote_field, "through", None):
587 related_fields[field_name] = field
589 # Are there indexes to defer?
590 indexes = model_state.options.pop("indexes")
591 constraints = model_state.options.pop("constraints")
592 order_with_respect_to = model_state.options.pop(
593 "order_with_respect_to", None
594 )
595 # Depend on the deletion of any possible proxy version of us
596 dependencies = [
597 (package_label, model_name, None, False),
598 ]
599 # Depend on all bases
600 for base in model_state.bases:
601 if isinstance(base, str) and "." in base:
602 base_package_label, base_name = base.split(".", 1)
603 dependencies.append((base_package_label, base_name, None, True))
604 # Depend on the removal of base fields if the new model has
605 # a field with the same name.
606 old_base_model_state = self.from_state.models.get(
607 (base_package_label, base_name)
608 )
609 new_base_model_state = self.to_state.models.get(
610 (base_package_label, base_name)
611 )
612 if old_base_model_state and new_base_model_state:
613 removed_base_fields = (
614 set(old_base_model_state.fields)
615 .difference(
616 new_base_model_state.fields,
617 )
618 .intersection(model_state.fields)
619 )
620 for removed_base_field in removed_base_fields:
621 dependencies.append(
622 (
623 base_package_label,
624 base_name,
625 removed_base_field,
626 False,
627 )
628 )
629 # Depend on the other end of the primary key if it's a relation
630 if primary_key_rel:
631 dependencies.append(
632 resolve_relation(
633 primary_key_rel,
634 package_label,
635 model_name,
636 )
637 + (None, True)
638 )
639 # Generate creation operation
640 self.add_operation(
641 package_label,
642 operations.CreateModel(
643 name=model_state.name,
644 fields=[
645 d
646 for d in model_state.fields.items()
647 if d[0] not in related_fields
648 ],
649 options=model_state.options,
650 bases=model_state.bases,
651 managers=model_state.managers,
652 ),
653 dependencies=dependencies,
654 beginning=True,
655 )
657 # Don't add operations which modify the database for unmanaged models
658 if not model_state.options.get("managed", True):
659 continue
661 # Generate operations for each related field
662 for name, field in sorted(related_fields.items()):
663 dependencies = self._get_dependencies_for_foreign_key(
664 package_label,
665 model_name,
666 field,
667 self.to_state,
668 )
669 # Depend on our own model being created
670 dependencies.append((package_label, model_name, None, True))
671 # Make operation
672 self.add_operation(
673 package_label,
674 operations.AddField(
675 model_name=model_name,
676 name=name,
677 field=field,
678 ),
679 dependencies=list(set(dependencies)),
680 )
681 # Generate other opns
682 if order_with_respect_to:
683 self.add_operation(
684 package_label,
685 operations.AlterOrderWithRespectTo(
686 name=model_name,
687 order_with_respect_to=order_with_respect_to,
688 ),
689 dependencies=[
690 (package_label, model_name, order_with_respect_to, True),
691 (package_label, model_name, None, True),
692 ],
693 )
694 related_dependencies = [
695 (package_label, model_name, name, True)
696 for name in sorted(related_fields)
697 ]
698 related_dependencies.append((package_label, model_name, None, True))
699 for index in indexes:
700 self.add_operation(
701 package_label,
702 operations.AddIndex(
703 model_name=model_name,
704 index=index,
705 ),
706 dependencies=related_dependencies,
707 )
708 for constraint in constraints:
709 self.add_operation(
710 package_label,
711 operations.AddConstraint(
712 model_name=model_name,
713 constraint=constraint,
714 ),
715 dependencies=related_dependencies,
716 )
718 def generate_deleted_models(self):
719 """
720 Find all deleted models (managed and unmanaged) and make delete
721 operations for them as well as separate operations to delete any
722 foreign key or M2M relationships (these are optimized later, if
723 possible).
725 Also bring forward removal of any model options that refer to
726 collections of fields - the inverse of generate_created_models().
727 """
728 new_keys = self.new_model_keys | self.new_unmanaged_keys
729 deleted_models = self.old_model_keys - new_keys
730 deleted_unmanaged_models = self.old_unmanaged_keys - new_keys
731 all_deleted_models = chain(
732 sorted(deleted_models), sorted(deleted_unmanaged_models)
733 )
734 for package_label, model_name in all_deleted_models:
735 model_state = self.from_state.models[package_label, model_name]
736 # Gather related fields
737 related_fields = {}
738 for field_name, field in model_state.fields.items():
739 if field.remote_field:
740 if field.remote_field.model:
741 related_fields[field_name] = field
742 if getattr(field.remote_field, "through", None):
743 related_fields[field_name] = field
745 # Then remove each related field
746 for name in sorted(related_fields):
747 self.add_operation(
748 package_label,
749 operations.RemoveField(
750 model_name=model_name,
751 name=name,
752 ),
753 )
754 # Finally, remove the model.
755 # This depends on both the removal/alteration of all incoming fields
756 # and the removal of all its own related fields, and if it's
757 # a through model the field that references it.
758 dependencies = []
759 relations = self.from_state.relations
760 for (
761 related_object_package_label,
762 object_name,
763 ), relation_related_fields in relations[package_label, model_name].items():
764 for field_name, field in relation_related_fields.items():
765 dependencies.append(
766 (related_object_package_label, object_name, field_name, False),
767 )
768 if not field.many_to_many:
769 dependencies.append(
770 (
771 related_object_package_label,
772 object_name,
773 field_name,
774 "alter",
775 ),
776 )
778 for name in sorted(related_fields):
779 dependencies.append((package_label, model_name, name, False))
780 # We're referenced in another field's through=
781 through_user = self.through_users.get(
782 (package_label, model_state.name_lower)
783 )
784 if through_user:
785 dependencies.append(
786 (through_user[0], through_user[1], through_user[2], False)
787 )
788 # Finally, make the operation, deduping any dependencies
789 self.add_operation(
790 package_label,
791 operations.DeleteModel(
792 name=model_state.name,
793 ),
794 dependencies=list(set(dependencies)),
795 )
797 def create_renamed_fields(self):
798 """Work out renamed fields."""
799 self.renamed_operations = []
800 old_field_keys = self.old_field_keys.copy()
801 for package_label, model_name, field_name in sorted(
802 self.new_field_keys - old_field_keys
803 ):
804 old_model_name = self.renamed_models.get(
805 (package_label, model_name), model_name
806 )
807 old_model_state = self.from_state.models[package_label, old_model_name]
808 new_model_state = self.to_state.models[package_label, model_name]
809 field = new_model_state.get_field(field_name)
810 # Scan to see if this is actually a rename!
811 field_dec = self.deep_deconstruct(field)
812 for rem_package_label, rem_model_name, rem_field_name in sorted(
813 old_field_keys - self.new_field_keys
814 ):
815 if rem_package_label == package_label and rem_model_name == model_name:
816 old_field = old_model_state.get_field(rem_field_name)
817 old_field_dec = self.deep_deconstruct(old_field)
818 if (
819 field.remote_field
820 and field.remote_field.model
821 and "to" in old_field_dec[2]
822 ):
823 old_rel_to = old_field_dec[2]["to"]
824 if old_rel_to in self.renamed_models_rel:
825 old_field_dec[2]["to"] = self.renamed_models_rel[old_rel_to]
826 old_field.set_attributes_from_name(rem_field_name)
827 old_db_column = old_field.get_attname_column()[1]
828 if old_field_dec == field_dec or (
829 # Was the field renamed and db_column equal to the
830 # old field's column added?
831 old_field_dec[0:2] == field_dec[0:2]
832 and dict(old_field_dec[2], db_column=old_db_column)
833 == field_dec[2]
834 ):
835 if self.questioner.ask_rename(
836 model_name, rem_field_name, field_name, field
837 ):
838 self.renamed_operations.append(
839 (
840 rem_package_label,
841 rem_model_name,
842 old_field.db_column,
843 rem_field_name,
844 package_label,
845 model_name,
846 field,
847 field_name,
848 )
849 )
850 old_field_keys.remove(
851 (rem_package_label, rem_model_name, rem_field_name)
852 )
853 old_field_keys.add((package_label, model_name, field_name))
854 self.renamed_fields[
855 package_label, model_name, field_name
856 ] = rem_field_name
857 break
859 def generate_renamed_fields(self):
860 """Generate RenameField operations."""
861 for (
862 rem_package_label,
863 rem_model_name,
864 rem_db_column,
865 rem_field_name,
866 package_label,
867 model_name,
868 field,
869 field_name,
870 ) in self.renamed_operations:
871 # A db_column mismatch requires a prior noop AlterField for the
872 # subsequent RenameField to be a noop on attempts at preserving the
873 # old name.
874 if rem_db_column != field.db_column:
875 altered_field = field.clone()
876 altered_field.name = rem_field_name
877 self.add_operation(
878 package_label,
879 operations.AlterField(
880 model_name=model_name,
881 name=rem_field_name,
882 field=altered_field,
883 ),
884 )
885 self.add_operation(
886 package_label,
887 operations.RenameField(
888 model_name=model_name,
889 old_name=rem_field_name,
890 new_name=field_name,
891 ),
892 )
893 self.old_field_keys.remove(
894 (rem_package_label, rem_model_name, rem_field_name)
895 )
896 self.old_field_keys.add((package_label, model_name, field_name))
898 def generate_added_fields(self):
899 """Make AddField operations."""
900 for package_label, model_name, field_name in sorted(
901 self.new_field_keys - self.old_field_keys
902 ):
903 self._generate_added_field(package_label, model_name, field_name)
905 def _generate_added_field(self, package_label, model_name, field_name):
906 field = self.to_state.models[package_label, model_name].get_field(field_name)
907 # Adding a field always depends at least on its removal.
908 dependencies = [(package_label, model_name, field_name, False)]
909 # Fields that are foreignkeys/m2ms depend on stuff.
910 if field.remote_field and field.remote_field.model:
911 dependencies.extend(
912 self._get_dependencies_for_foreign_key(
913 package_label,
914 model_name,
915 field,
916 self.to_state,
917 )
918 )
919 # You can't just add NOT NULL fields with no default or fields
920 # which don't allow empty strings as default.
921 time_fields = (models.DateField, models.DateTimeField, models.TimeField)
922 preserve_default = (
923 field.null
924 or field.has_default()
925 or field.many_to_many
926 or (field.blank and field.empty_strings_allowed)
927 or (isinstance(field, time_fields) and field.auto_now)
928 )
929 if not preserve_default:
930 field = field.clone()
931 if isinstance(field, time_fields) and field.auto_now_add:
932 field.default = self.questioner.ask_auto_now_add_addition(
933 field_name, model_name
934 )
935 else:
936 field.default = self.questioner.ask_not_null_addition(
937 field_name, model_name
938 )
939 if (
940 field.unique
941 and field.default is not models.NOT_PROVIDED
942 and callable(field.default)
943 ):
944 self.questioner.ask_unique_callable_default_addition(field_name, model_name)
945 self.add_operation(
946 package_label,
947 operations.AddField(
948 model_name=model_name,
949 name=field_name,
950 field=field,
951 preserve_default=preserve_default,
952 ),
953 dependencies=dependencies,
954 )
956 def generate_removed_fields(self):
957 """Make RemoveField operations."""
958 for package_label, model_name, field_name in sorted(
959 self.old_field_keys - self.new_field_keys
960 ):
961 self._generate_removed_field(package_label, model_name, field_name)
963 def _generate_removed_field(self, package_label, model_name, field_name):
964 self.add_operation(
965 package_label,
966 operations.RemoveField(
967 model_name=model_name,
968 name=field_name,
969 ),
970 # We might need to depend on the removal of an
971 # order_with_respect_to or index operation;
972 # this is safely ignored if there isn't one
973 dependencies=[
974 (package_label, model_name, field_name, "order_wrt_unset"),
975 ],
976 )
978 def generate_altered_fields(self):
979 """
980 Make AlterField operations, or possibly RemovedField/AddField if alter
981 isn't possible.
982 """
983 for package_label, model_name, field_name in sorted(
984 self.old_field_keys & self.new_field_keys
985 ):
986 # Did the field change?
987 old_model_name = self.renamed_models.get(
988 (package_label, model_name), model_name
989 )
990 old_field_name = self.renamed_fields.get(
991 (package_label, model_name, field_name), field_name
992 )
993 old_field = self.from_state.models[package_label, old_model_name].get_field(
994 old_field_name
995 )
996 new_field = self.to_state.models[package_label, model_name].get_field(
997 field_name
998 )
999 dependencies = []
1000 # Implement any model renames on relations; these are handled by RenameModel
1001 # so we need to exclude them from the comparison
1002 if hasattr(new_field, "remote_field") and getattr(
1003 new_field.remote_field, "model", None
1004 ):
1005 rename_key = resolve_relation(
1006 new_field.remote_field.model, package_label, model_name
1007 )
1008 if rename_key in self.renamed_models:
1009 new_field.remote_field.model = old_field.remote_field.model
1010 # Handle ForeignKey which can only have a single to_field.
1011 remote_field_name = getattr(new_field.remote_field, "field_name", None)
1012 if remote_field_name:
1013 to_field_rename_key = rename_key + (remote_field_name,)
1014 if to_field_rename_key in self.renamed_fields:
1015 # Repoint both model and field name because to_field
1016 # inclusion in ForeignKey.deconstruct() is based on
1017 # both.
1018 new_field.remote_field.model = old_field.remote_field.model
1019 new_field.remote_field.field_name = (
1020 old_field.remote_field.field_name
1021 )
1022 # Handle ForeignObjects which can have multiple from_fields/to_fields.
1023 from_fields = getattr(new_field, "from_fields", None)
1024 if from_fields:
1025 from_rename_key = (package_label, model_name)
1026 new_field.from_fields = tuple(
1027 [
1028 self.renamed_fields.get(
1029 from_rename_key + (from_field,), from_field
1030 )
1031 for from_field in from_fields
1032 ]
1033 )
1034 new_field.to_fields = tuple(
1035 [
1036 self.renamed_fields.get(rename_key + (to_field,), to_field)
1037 for to_field in new_field.to_fields
1038 ]
1039 )
1040 dependencies.extend(
1041 self._get_dependencies_for_foreign_key(
1042 package_label,
1043 model_name,
1044 new_field,
1045 self.to_state,
1046 )
1047 )
1048 if hasattr(new_field, "remote_field") and getattr(
1049 new_field.remote_field, "through", None
1050 ):
1051 rename_key = resolve_relation(
1052 new_field.remote_field.through, package_label, model_name
1053 )
1054 if rename_key in self.renamed_models:
1055 new_field.remote_field.through = old_field.remote_field.through
1056 old_field_dec = self.deep_deconstruct(old_field)
1057 new_field_dec = self.deep_deconstruct(new_field)
1058 # If the field was confirmed to be renamed it means that only
1059 # db_column was allowed to change which generate_renamed_fields()
1060 # already accounts for by adding an AlterField operation.
1061 if old_field_dec != new_field_dec and old_field_name == field_name:
1062 both_m2m = old_field.many_to_many and new_field.many_to_many
1063 neither_m2m = not old_field.many_to_many and not new_field.many_to_many
1064 if both_m2m or neither_m2m:
1065 # Either both fields are m2m or neither is
1066 preserve_default = True
1067 if (
1068 old_field.null
1069 and not new_field.null
1070 and not new_field.has_default()
1071 and not new_field.many_to_many
1072 ):
1073 field = new_field.clone()
1074 new_default = self.questioner.ask_not_null_alteration(
1075 field_name, model_name
1076 )
1077 if new_default is not models.NOT_PROVIDED:
1078 field.default = new_default
1079 preserve_default = False
1080 else:
1081 field = new_field
1082 self.add_operation(
1083 package_label,
1084 operations.AlterField(
1085 model_name=model_name,
1086 name=field_name,
1087 field=field,
1088 preserve_default=preserve_default,
1089 ),
1090 dependencies=dependencies,
1091 )
1092 else:
1093 # We cannot alter between m2m and concrete fields
1094 self._generate_removed_field(package_label, model_name, field_name)
1095 self._generate_added_field(package_label, model_name, field_name)
1097 def create_altered_indexes(self):
1098 option_name = operations.AddIndex.option_name
1100 for package_label, model_name in sorted(self.kept_model_keys):
1101 old_model_name = self.renamed_models.get(
1102 (package_label, model_name), model_name
1103 )
1104 old_model_state = self.from_state.models[package_label, old_model_name]
1105 new_model_state = self.to_state.models[package_label, model_name]
1107 old_indexes = old_model_state.options[option_name]
1108 new_indexes = new_model_state.options[option_name]
1109 added_indexes = [idx for idx in new_indexes if idx not in old_indexes]
1110 removed_indexes = [idx for idx in old_indexes if idx not in new_indexes]
1111 renamed_indexes = []
1112 # Find renamed indexes.
1113 remove_from_added = []
1114 remove_from_removed = []
1115 for new_index in added_indexes:
1116 new_index_dec = new_index.deconstruct()
1117 new_index_name = new_index_dec[2].pop("name")
1118 for old_index in removed_indexes:
1119 old_index_dec = old_index.deconstruct()
1120 old_index_name = old_index_dec[2].pop("name")
1121 # Indexes are the same except for the names.
1122 if (
1123 new_index_dec == old_index_dec
1124 and new_index_name != old_index_name
1125 ):
1126 renamed_indexes.append((old_index_name, new_index_name, None))
1127 remove_from_added.append(new_index)
1128 remove_from_removed.append(old_index)
1130 # Remove renamed indexes from the lists of added and removed
1131 # indexes.
1132 added_indexes = [
1133 idx for idx in added_indexes if idx not in remove_from_added
1134 ]
1135 removed_indexes = [
1136 idx for idx in removed_indexes if idx not in remove_from_removed
1137 ]
1139 self.altered_indexes.update(
1140 {
1141 (package_label, model_name): {
1142 "added_indexes": added_indexes,
1143 "removed_indexes": removed_indexes,
1144 "renamed_indexes": renamed_indexes,
1145 }
1146 }
1147 )
1149 def generate_added_indexes(self):
1150 for (package_label, model_name), alt_indexes in self.altered_indexes.items():
1151 dependencies = self._get_dependencies_for_model(package_label, model_name)
1152 for index in alt_indexes["added_indexes"]:
1153 self.add_operation(
1154 package_label,
1155 operations.AddIndex(
1156 model_name=model_name,
1157 index=index,
1158 ),
1159 dependencies=dependencies,
1160 )
1162 def generate_removed_indexes(self):
1163 for (package_label, model_name), alt_indexes in self.altered_indexes.items():
1164 for index in alt_indexes["removed_indexes"]:
1165 self.add_operation(
1166 package_label,
1167 operations.RemoveIndex(
1168 model_name=model_name,
1169 name=index.name,
1170 ),
1171 )
1173 def generate_renamed_indexes(self):
1174 for (package_label, model_name), alt_indexes in self.altered_indexes.items():
1175 for old_index_name, new_index_name, old_fields in alt_indexes[
1176 "renamed_indexes"
1177 ]:
1178 self.add_operation(
1179 package_label,
1180 operations.RenameIndex(
1181 model_name=model_name,
1182 new_name=new_index_name,
1183 old_name=old_index_name,
1184 old_fields=old_fields,
1185 ),
1186 )
1188 def create_altered_constraints(self):
1189 option_name = operations.AddConstraint.option_name
1190 for package_label, model_name in sorted(self.kept_model_keys):
1191 old_model_name = self.renamed_models.get(
1192 (package_label, model_name), model_name
1193 )
1194 old_model_state = self.from_state.models[package_label, old_model_name]
1195 new_model_state = self.to_state.models[package_label, model_name]
1197 old_constraints = old_model_state.options[option_name]
1198 new_constraints = new_model_state.options[option_name]
1199 add_constraints = [c for c in new_constraints if c not in old_constraints]
1200 rem_constraints = [c for c in old_constraints if c not in new_constraints]
1202 self.altered_constraints.update(
1203 {
1204 (package_label, model_name): {
1205 "added_constraints": add_constraints,
1206 "removed_constraints": rem_constraints,
1207 }
1208 }
1209 )
1211 def generate_added_constraints(self):
1212 for (
1213 package_label,
1214 model_name,
1215 ), alt_constraints in self.altered_constraints.items():
1216 dependencies = self._get_dependencies_for_model(package_label, model_name)
1217 for constraint in alt_constraints["added_constraints"]:
1218 self.add_operation(
1219 package_label,
1220 operations.AddConstraint(
1221 model_name=model_name,
1222 constraint=constraint,
1223 ),
1224 dependencies=dependencies,
1225 )
1227 def generate_removed_constraints(self):
1228 for (
1229 package_label,
1230 model_name,
1231 ), alt_constraints in self.altered_constraints.items():
1232 for constraint in alt_constraints["removed_constraints"]:
1233 self.add_operation(
1234 package_label,
1235 operations.RemoveConstraint(
1236 model_name=model_name,
1237 name=constraint.name,
1238 ),
1239 )
1241 @staticmethod
1242 def _get_dependencies_for_foreign_key(
1243 package_label, model_name, field, project_state
1244 ):
1245 remote_field_model = None
1246 if hasattr(field.remote_field, "model"):
1247 remote_field_model = field.remote_field.model
1248 else:
1249 relations = project_state.relations[package_label, model_name]
1250 for (remote_package_label, remote_model_name), fields in relations.items():
1251 if any(
1252 field == related_field.remote_field
1253 for related_field in fields.values()
1254 ):
1255 remote_field_model = f"{remote_package_label}.{remote_model_name}"
1256 break
1257 # Account for FKs to swappable models
1258 swappable_setting = getattr(field, "swappable_setting", None)
1259 if swappable_setting is not None:
1260 dep_package_label = "__setting__"
1261 dep_object_name = swappable_setting
1262 else:
1263 dep_package_label, dep_object_name = resolve_relation(
1264 remote_field_model,
1265 package_label,
1266 model_name,
1267 )
1268 dependencies = [(dep_package_label, dep_object_name, None, True)]
1269 if getattr(field.remote_field, "through", None):
1270 through_package_label, through_object_name = resolve_relation(
1271 field.remote_field.through,
1272 package_label,
1273 model_name,
1274 )
1275 dependencies.append(
1276 (through_package_label, through_object_name, None, True)
1277 )
1278 return dependencies
1280 def _get_dependencies_for_model(self, package_label, model_name):
1281 """Return foreign key dependencies of the given model."""
1282 dependencies = []
1283 model_state = self.to_state.models[package_label, model_name]
1284 for field in model_state.fields.values():
1285 if field.is_relation:
1286 dependencies.extend(
1287 self._get_dependencies_for_foreign_key(
1288 package_label,
1289 model_name,
1290 field,
1291 self.to_state,
1292 )
1293 )
1294 return dependencies
1296 def _get_altered_foo_together_operations(self, option_name):
1297 for package_label, model_name in sorted(self.kept_model_keys):
1298 old_model_name = self.renamed_models.get(
1299 (package_label, model_name), model_name
1300 )
1301 old_model_state = self.from_state.models[package_label, old_model_name]
1302 new_model_state = self.to_state.models[package_label, model_name]
1304 # We run the old version through the field renames to account for those
1305 old_value = old_model_state.options.get(option_name)
1306 old_value = (
1307 {
1308 tuple(
1309 self.renamed_fields.get((package_label, model_name, n), n)
1310 for n in unique
1311 )
1312 for unique in old_value
1313 }
1314 if old_value
1315 else set()
1316 )
1318 new_value = new_model_state.options.get(option_name)
1319 new_value = set(new_value) if new_value else set()
1321 if old_value != new_value:
1322 dependencies = []
1323 for foo_togethers in new_value:
1324 for field_name in foo_togethers:
1325 field = new_model_state.get_field(field_name)
1326 if field.remote_field and field.remote_field.model:
1327 dependencies.extend(
1328 self._get_dependencies_for_foreign_key(
1329 package_label,
1330 model_name,
1331 field,
1332 self.to_state,
1333 )
1334 )
1335 yield (
1336 old_value,
1337 new_value,
1338 package_label,
1339 model_name,
1340 dependencies,
1341 )
1343 def _generate_removed_altered_foo_together(self, operation):
1344 for (
1345 old_value,
1346 new_value,
1347 package_label,
1348 model_name,
1349 dependencies,
1350 ) in self._get_altered_foo_together_operations(operation.option_name):
1351 removal_value = new_value.intersection(old_value)
1352 if removal_value or old_value:
1353 self.add_operation(
1354 package_label,
1355 operation(
1356 name=model_name, **{operation.option_name: removal_value}
1357 ),
1358 dependencies=dependencies,
1359 )
1361 def generate_altered_db_table(self):
1362 models_to_check = self.kept_model_keys.union(self.kept_unmanaged_keys)
1363 for package_label, model_name in sorted(models_to_check):
1364 old_model_name = self.renamed_models.get(
1365 (package_label, model_name), model_name
1366 )
1367 old_model_state = self.from_state.models[package_label, old_model_name]
1368 new_model_state = self.to_state.models[package_label, model_name]
1369 old_db_table_name = old_model_state.options.get("db_table")
1370 new_db_table_name = new_model_state.options.get("db_table")
1371 if old_db_table_name != new_db_table_name:
1372 self.add_operation(
1373 package_label,
1374 operations.AlterModelTable(
1375 name=model_name,
1376 table=new_db_table_name,
1377 ),
1378 )
1380 def generate_altered_db_table_comment(self):
1381 models_to_check = self.kept_model_keys.union(self.kept_unmanaged_keys)
1382 for package_label, model_name in sorted(models_to_check):
1383 old_model_name = self.renamed_models.get(
1384 (package_label, model_name), model_name
1385 )
1386 old_model_state = self.from_state.models[package_label, old_model_name]
1387 new_model_state = self.to_state.models[package_label, model_name]
1389 old_db_table_comment = old_model_state.options.get("db_table_comment")
1390 new_db_table_comment = new_model_state.options.get("db_table_comment")
1391 if old_db_table_comment != new_db_table_comment:
1392 self.add_operation(
1393 package_label,
1394 operations.AlterModelTableComment(
1395 name=model_name,
1396 table_comment=new_db_table_comment,
1397 ),
1398 )
1400 def generate_altered_options(self):
1401 """
1402 Work out if any non-schema-affecting options have changed and make an
1403 operation to represent them in state changes (in case Python code in
1404 migrations needs them).
1405 """
1406 models_to_check = self.kept_model_keys.union(
1407 self.kept_unmanaged_keys,
1408 # unmanaged converted to managed
1409 self.old_unmanaged_keys & self.new_model_keys,
1410 # managed converted to unmanaged
1411 self.old_model_keys & self.new_unmanaged_keys,
1412 )
1414 for package_label, model_name in sorted(models_to_check):
1415 old_model_name = self.renamed_models.get(
1416 (package_label, model_name), model_name
1417 )
1418 old_model_state = self.from_state.models[package_label, old_model_name]
1419 new_model_state = self.to_state.models[package_label, model_name]
1420 old_options = {
1421 key: value
1422 for key, value in old_model_state.options.items()
1423 if key in AlterModelOptions.ALTER_OPTION_KEYS
1424 }
1425 new_options = {
1426 key: value
1427 for key, value in new_model_state.options.items()
1428 if key in AlterModelOptions.ALTER_OPTION_KEYS
1429 }
1430 if old_options != new_options:
1431 self.add_operation(
1432 package_label,
1433 operations.AlterModelOptions(
1434 name=model_name,
1435 options=new_options,
1436 ),
1437 )
1439 def generate_altered_order_with_respect_to(self):
1440 for package_label, model_name in sorted(self.kept_model_keys):
1441 old_model_name = self.renamed_models.get(
1442 (package_label, model_name), model_name
1443 )
1444 old_model_state = self.from_state.models[package_label, old_model_name]
1445 new_model_state = self.to_state.models[package_label, model_name]
1446 if old_model_state.options.get(
1447 "order_with_respect_to"
1448 ) != new_model_state.options.get("order_with_respect_to"):
1449 # Make sure it comes second if we're adding
1450 # (removal dependency is part of RemoveField)
1451 dependencies = []
1452 if new_model_state.options.get("order_with_respect_to"):
1453 dependencies.append(
1454 (
1455 package_label,
1456 model_name,
1457 new_model_state.options["order_with_respect_to"],
1458 True,
1459 )
1460 )
1461 # Actually generate the operation
1462 self.add_operation(
1463 package_label,
1464 operations.AlterOrderWithRespectTo(
1465 name=model_name,
1466 order_with_respect_to=new_model_state.options.get(
1467 "order_with_respect_to"
1468 ),
1469 ),
1470 dependencies=dependencies,
1471 )
1473 def generate_altered_managers(self):
1474 for package_label, model_name in sorted(self.kept_model_keys):
1475 old_model_name = self.renamed_models.get(
1476 (package_label, model_name), model_name
1477 )
1478 old_model_state = self.from_state.models[package_label, old_model_name]
1479 new_model_state = self.to_state.models[package_label, model_name]
1480 if old_model_state.managers != new_model_state.managers:
1481 self.add_operation(
1482 package_label,
1483 operations.AlterModelManagers(
1484 name=model_name,
1485 managers=new_model_state.managers,
1486 ),
1487 )
1489 def arrange_for_graph(self, changes, graph, migration_name=None):
1490 """
1491 Take a result from changes() and a MigrationGraph, and fix the names
1492 and dependencies of the changes so they extend the graph from the leaf
1493 nodes for each app.
1494 """
1495 leaves = graph.leaf_nodes()
1496 name_map = {}
1497 for package_label, migrations in list(changes.items()):
1498 if not migrations:
1499 continue
1500 # Find the app label's current leaf node
1501 app_leaf = None
1502 for leaf in leaves:
1503 if leaf[0] == package_label:
1504 app_leaf = leaf
1505 break
1506 # Do they want an initial migration for this app?
1507 if app_leaf is None and not self.questioner.ask_initial(package_label):
1508 # They don't.
1509 for migration in migrations:
1510 name_map[(package_label, migration.name)] = (
1511 package_label,
1512 "__first__",
1513 )
1514 del changes[package_label]
1515 continue
1516 # Work out the next number in the sequence
1517 if app_leaf is None:
1518 next_number = 1
1519 else:
1520 next_number = (self.parse_number(app_leaf[1]) or 0) + 1
1521 # Name each migration
1522 for i, migration in enumerate(migrations):
1523 if i == 0 and app_leaf:
1524 migration.dependencies.append(app_leaf)
1525 new_name_parts = ["%04i" % next_number]
1526 if migration_name:
1527 new_name_parts.append(migration_name)
1528 elif i == 0 and not app_leaf:
1529 new_name_parts.append("initial")
1530 else:
1531 new_name_parts.append(migration.suggest_name()[:100])
1532 new_name = "_".join(new_name_parts)
1533 name_map[(package_label, migration.name)] = (package_label, new_name)
1534 next_number += 1
1535 migration.name = new_name
1536 # Now fix dependencies
1537 for migrations in changes.values():
1538 for migration in migrations:
1539 migration.dependencies = [
1540 name_map.get(d, d) for d in migration.dependencies
1541 ]
1542 return changes
1544 def _trim_to_packages(self, changes, package_labels):
1545 """
1546 Take changes from arrange_for_graph() and set of app labels, and return
1547 a modified set of changes which trims out as many migrations that are
1548 not in package_labels as possible. Note that some other migrations may
1549 still be present as they may be required dependencies.
1550 """
1551 # Gather other app dependencies in a first pass
1552 app_dependencies = {}
1553 for package_label, migrations in changes.items():
1554 for migration in migrations:
1555 for dep_package_label, name in migration.dependencies:
1556 app_dependencies.setdefault(package_label, set()).add(
1557 dep_package_label
1558 )
1559 required_packages = set(package_labels)
1560 # Keep resolving till there's no change
1561 old_required_packages = None
1562 while old_required_packages != required_packages:
1563 old_required_packages = set(required_packages)
1564 required_packages.update(
1565 *[
1566 app_dependencies.get(package_label, ())
1567 for package_label in required_packages
1568 ]
1569 )
1570 # Remove all migrations that aren't needed
1571 for package_label in list(changes):
1572 if package_label not in required_packages:
1573 del changes[package_label]
1574 return changes
1576 @classmethod
1577 def parse_number(cls, name):
1578 """
1579 Given a migration name, try to extract a number from the beginning of
1580 it. For a squashed migration such as '0001_squashed_0004…', return the
1581 second number. If no number is found, return None.
1582 """
1583 if squashed_match := re.search(r".*_squashed_(\d+)", name):
1584 return int(squashed_match[1])
1585 match = re.match(r"^\d+", name)
1586 if match:
1587 return int(match[0])
1588 return None
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.models.db import DatabaseError
4class AmbiguityError(Exception):
5 """More than one migration matches a name prefix."""
7 pass
10class BadMigrationError(Exception):
11 """There's a bad migration (unreadable/bad format/etc.)."""
13 pass
16class CircularDependencyError(Exception):
17 """There's an impossible-to-resolve circular dependency."""
19 pass
22class InconsistentMigrationHistory(Exception):
23 """An applied migration has some of its dependencies not applied."""
25 pass
28class InvalidBasesError(ValueError):
29 """A model's base classes can't be resolved."""
31 pass
34class IrreversibleError(RuntimeError):
35 """An irreversible migration is about to be reversed."""
37 pass
40class NodeNotFoundError(LookupError):
41 """An attempt on a node is made that is not available in the graph."""
43 def __init__(self, message, node, origin=None):
44 self.message = message
45 self.origin = origin
46 self.node = node
48 def __str__(self):
49 return self.message
51 def __repr__(self):
52 return f"NodeNotFoundError({self.node!r})"
55class MigrationSchemaMissing(DatabaseError):
56 pass
59class InvalidMigrationPlan(ValueError):
60 pass
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.models import migrations
2from plain.models.db import router
3from plain.packages.registry import packages as global_packages
5from .exceptions import InvalidMigrationPlan
6from .loader import MigrationLoader
7from .recorder import MigrationRecorder
8from .state import ProjectState
11class MigrationExecutor:
12 """
13 End-to-end migration execution - load migrations and run them up or down
14 to a specified set of targets.
15 """
17 def __init__(self, connection, progress_callback=None):
18 self.connection = connection
19 self.loader = MigrationLoader(self.connection)
20 self.recorder = MigrationRecorder(self.connection)
21 self.progress_callback = progress_callback
23 def migration_plan(self, targets, clean_start=False):
24 """
25 Given a set of targets, return a list of (Migration instance, backwards?).
26 """
27 plan = []
28 if clean_start:
29 applied = {}
30 else:
31 applied = dict(self.loader.applied_migrations)
32 for target in targets:
33 # If the target is (package_label, None), that means unmigrate everything
34 if target[1] is None:
35 for root in self.loader.graph.root_nodes():
36 if root[0] == target[0]:
37 for migration in self.loader.graph.backwards_plan(root):
38 if migration in applied:
39 plan.append((self.loader.graph.nodes[migration], True))
40 applied.pop(migration)
41 # If the migration is already applied, do backwards mode,
42 # otherwise do forwards mode.
43 elif target in applied:
44 # If the target is missing, it's likely a replaced migration.
45 # Reload the graph without replacements.
46 if (
47 self.loader.replace_migrations
48 and target not in self.loader.graph.node_map
49 ):
50 self.loader.replace_migrations = False
51 self.loader.build_graph()
52 return self.migration_plan(targets, clean_start=clean_start)
53 # Don't migrate backwards all the way to the target node (that
54 # may roll back dependencies in other packages that don't need to
55 # be rolled back); instead roll back through target's immediate
56 # child(ren) in the same app, and no further.
57 next_in_app = sorted(
58 n
59 for n in self.loader.graph.node_map[target].children
60 if n[0] == target[0]
61 )
62 for node in next_in_app:
63 for migration in self.loader.graph.backwards_plan(node):
64 if migration in applied:
65 plan.append((self.loader.graph.nodes[migration], True))
66 applied.pop(migration)
67 else:
68 for migration in self.loader.graph.forwards_plan(target):
69 if migration not in applied:
70 plan.append((self.loader.graph.nodes[migration], False))
71 applied[migration] = self.loader.graph.nodes[migration]
72 return plan
74 def _create_project_state(self, with_applied_migrations=False):
75 """
76 Create a project state including all the applications without
77 migrations and applied migrations if with_applied_migrations=True.
78 """
79 state = ProjectState(real_packages=self.loader.unmigrated_packages)
80 if with_applied_migrations:
81 # Create the forwards plan Plain would follow on an empty database
82 full_plan = self.migration_plan(
83 self.loader.graph.leaf_nodes(), clean_start=True
84 )
85 applied_migrations = {
86 self.loader.graph.nodes[key]
87 for key in self.loader.applied_migrations
88 if key in self.loader.graph.nodes
89 }
90 for migration, _ in full_plan:
91 if migration in applied_migrations:
92 migration.mutate_state(state, preserve=False)
93 return state
95 def migrate(self, targets, plan=None, state=None, fake=False, fake_initial=False):
96 """
97 Migrate the database up to the given targets.
99 Plain first needs to create all project states before a migration is
100 (un)applied and in a second step run all the database operations.
101 """
102 # The plain_migrations table must be present to record applied
103 # migrations, but don't create it if there are no migrations to apply.
104 if plan == []:
105 if not self.recorder.has_table():
106 return self._create_project_state(with_applied_migrations=False)
107 else:
108 self.recorder.ensure_schema()
110 if plan is None:
111 plan = self.migration_plan(targets)
112 # Create the forwards plan Plain would follow on an empty database
113 full_plan = self.migration_plan(
114 self.loader.graph.leaf_nodes(), clean_start=True
115 )
117 all_forwards = all(not backwards for mig, backwards in plan)
118 all_backwards = all(backwards for mig, backwards in plan)
120 if not plan:
121 if state is None:
122 # The resulting state should include applied migrations.
123 state = self._create_project_state(with_applied_migrations=True)
124 elif all_forwards == all_backwards:
125 # This should only happen if there's a mixed plan
126 raise InvalidMigrationPlan(
127 "Migration plans with both forwards and backwards migrations "
128 "are not supported. Please split your migration process into "
129 "separate plans of only forwards OR backwards migrations.",
130 plan,
131 )
132 elif all_forwards:
133 if state is None:
134 # The resulting state should still include applied migrations.
135 state = self._create_project_state(with_applied_migrations=True)
136 state = self._migrate_all_forwards(
137 state, plan, full_plan, fake=fake, fake_initial=fake_initial
138 )
139 else:
140 # No need to check for `elif all_backwards` here, as that condition
141 # would always evaluate to true.
142 state = self._migrate_all_backwards(plan, full_plan, fake=fake)
144 self.check_replacements()
146 return state
148 def _migrate_all_forwards(self, state, plan, full_plan, fake, fake_initial):
149 """
150 Take a list of 2-tuples of the form (migration instance, False) and
151 apply them in the order they occur in the full_plan.
152 """
153 migrations_to_run = {m[0] for m in plan}
154 for migration, _ in full_plan:
155 if not migrations_to_run:
156 # We remove every migration that we applied from these sets so
157 # that we can bail out once the last migration has been applied
158 # and don't always run until the very end of the migration
159 # process.
160 break
161 if migration in migrations_to_run:
162 if "packages" not in state.__dict__:
163 if self.progress_callback:
164 self.progress_callback("render_start")
165 state.packages # Render all -- performance critical
166 if self.progress_callback:
167 self.progress_callback("render_success")
168 state = self.apply_migration(
169 state, migration, fake=fake, fake_initial=fake_initial
170 )
171 migrations_to_run.remove(migration)
173 return state
175 def _migrate_all_backwards(self, plan, full_plan, fake):
176 """
177 Take a list of 2-tuples of the form (migration instance, True) and
178 unapply them in reverse order they occur in the full_plan.
180 Since unapplying a migration requires the project state prior to that
181 migration, Plain will compute the migration states before each of them
182 in a first run over the plan and then unapply them in a second run over
183 the plan.
184 """
185 migrations_to_run = {m[0] for m in plan}
186 # Holds all migration states prior to the migrations being unapplied
187 states = {}
188 state = self._create_project_state()
189 applied_migrations = {
190 self.loader.graph.nodes[key]
191 for key in self.loader.applied_migrations
192 if key in self.loader.graph.nodes
193 }
194 if self.progress_callback:
195 self.progress_callback("render_start")
196 for migration, _ in full_plan:
197 if not migrations_to_run:
198 # We remove every migration that we applied from this set so
199 # that we can bail out once the last migration has been applied
200 # and don't always run until the very end of the migration
201 # process.
202 break
203 if migration in migrations_to_run:
204 if "packages" not in state.__dict__:
205 state.packages # Render all -- performance critical
206 # The state before this migration
207 states[migration] = state
208 # The old state keeps as-is, we continue with the new state
209 state = migration.mutate_state(state, preserve=True)
210 migrations_to_run.remove(migration)
211 elif migration in applied_migrations:
212 # Only mutate the state if the migration is actually applied
213 # to make sure the resulting state doesn't include changes
214 # from unrelated migrations.
215 migration.mutate_state(state, preserve=False)
216 if self.progress_callback:
217 self.progress_callback("render_success")
219 for migration, _ in plan:
220 self.unapply_migration(states[migration], migration, fake=fake)
221 applied_migrations.remove(migration)
223 # Generate the post migration state by starting from the state before
224 # the last migration is unapplied and mutating it to include all the
225 # remaining applied migrations.
226 last_unapplied_migration = plan[-1][0]
227 state = states[last_unapplied_migration]
228 for index, (migration, _) in enumerate(full_plan):
229 if migration == last_unapplied_migration:
230 for migration, _ in full_plan[index:]:
231 if migration in applied_migrations:
232 migration.mutate_state(state, preserve=False)
233 break
235 return state
237 def apply_migration(self, state, migration, fake=False, fake_initial=False):
238 """Run a migration forwards."""
239 migration_recorded = False
240 if self.progress_callback:
241 self.progress_callback("apply_start", migration, fake)
242 if not fake:
243 if fake_initial:
244 # Test to see if this is an already-applied initial migration
245 applied, state = self.detect_soft_applied(state, migration)
246 if applied:
247 fake = True
248 if not fake:
249 # Alright, do it normally
250 with self.connection.schema_editor(
251 atomic=migration.atomic
252 ) as schema_editor:
253 state = migration.apply(state, schema_editor)
254 if not schema_editor.deferred_sql:
255 self.record_migration(migration)
256 migration_recorded = True
257 if not migration_recorded:
258 self.record_migration(migration)
259 # Report progress
260 if self.progress_callback:
261 self.progress_callback("apply_success", migration, fake)
262 return state
264 def record_migration(self, migration):
265 # For replacement migrations, record individual statuses
266 if migration.replaces:
267 for package_label, name in migration.replaces:
268 self.recorder.record_applied(package_label, name)
269 else:
270 self.recorder.record_applied(migration.package_label, migration.name)
272 def unapply_migration(self, state, migration, fake=False):
273 """Run a migration backwards."""
274 if self.progress_callback:
275 self.progress_callback("unapply_start", migration, fake)
276 if not fake:
277 with self.connection.schema_editor(
278 atomic=migration.atomic
279 ) as schema_editor:
280 state = migration.unapply(state, schema_editor)
281 # For replacement migrations, also record individual statuses.
282 if migration.replaces:
283 for package_label, name in migration.replaces:
284 self.recorder.record_unapplied(package_label, name)
285 self.recorder.record_unapplied(migration.package_label, migration.name)
286 # Report progress
287 if self.progress_callback:
288 self.progress_callback("unapply_success", migration, fake)
289 return state
291 def check_replacements(self):
292 """
293 Mark replacement migrations applied if their replaced set all are.
295 Do this unconditionally on every migrate, rather than just when
296 migrations are applied or unapplied, to correctly handle the case
297 when a new squash migration is pushed to a deployment that already had
298 all its replaced migrations applied. In this case no new migration will
299 be applied, but the applied state of the squashed migration must be
300 maintained.
301 """
302 applied = self.recorder.applied_migrations()
303 for key, migration in self.loader.replacements.items():
304 all_applied = all(m in applied for m in migration.replaces)
305 if all_applied and key not in applied:
306 self.recorder.record_applied(*key)
308 def detect_soft_applied(self, project_state, migration):
309 """
310 Test whether a migration has been implicitly applied - that the
311 tables or columns it would create exist. This is intended only for use
312 on initial migrations (as it only looks for CreateModel and AddField).
313 """
315 def should_skip_detecting_model(migration, model):
316 """
317 No need to detect tables for unmanaged models, or
318 models that can't be migrated on the current database.
319 """
320 return not model._meta.managed or not router.allow_migrate(
321 self.connection.alias,
322 migration.package_label,
323 model_name=model._meta.model_name,
324 )
326 if migration.initial is None:
327 # Bail if the migration isn't the first one in its app
328 if any(
329 app == migration.package_label for app, name in migration.dependencies
330 ):
331 return False, project_state
332 elif migration.initial is False:
333 # Bail if it's NOT an initial migration
334 return False, project_state
336 if project_state is None:
337 after_state = self.loader.project_state(
338 (migration.package_label, migration.name), at_end=True
339 )
340 else:
341 after_state = migration.mutate_state(project_state)
342 packages = after_state.packages
343 found_create_model_migration = False
344 found_add_field_migration = False
345 fold_identifier_case = self.connection.features.ignores_table_name_case
346 with self.connection.cursor() as cursor:
347 existing_table_names = set(
348 self.connection.introspection.table_names(cursor)
349 )
350 if fold_identifier_case:
351 existing_table_names = {
352 name.casefold() for name in existing_table_names
353 }
354 # Make sure all create model and add field operations are done
355 for operation in migration.operations:
356 if isinstance(operation, migrations.CreateModel):
357 model = packages.get_model(migration.package_label, operation.name)
358 if model._meta.swapped:
359 # We have to fetch the model to test with from the
360 # main app cache, as it's not a direct dependency.
361 model = global_packages.get_model(model._meta.swapped)
362 if should_skip_detecting_model(migration, model):
363 continue
364 db_table = model._meta.db_table
365 if fold_identifier_case:
366 db_table = db_table.casefold()
367 if db_table not in existing_table_names:
368 return False, project_state
369 found_create_model_migration = True
370 elif isinstance(operation, migrations.AddField):
371 model = packages.get_model(
372 migration.package_label, operation.model_name
373 )
374 if model._meta.swapped:
375 # We have to fetch the model to test with from the
376 # main app cache, as it's not a direct dependency.
377 model = global_packages.get_model(model._meta.swapped)
378 if should_skip_detecting_model(migration, model):
379 continue
381 table = model._meta.db_table
382 field = model._meta.get_field(operation.name)
384 # Handle implicit many-to-many tables created by AddField.
385 if field.many_to_many:
386 through_db_table = field.remote_field.through._meta.db_table
387 if fold_identifier_case:
388 through_db_table = through_db_table.casefold()
389 if through_db_table not in existing_table_names:
390 return False, project_state
391 else:
392 found_add_field_migration = True
393 continue
394 with self.connection.cursor() as cursor:
395 columns = self.connection.introspection.get_table_description(
396 cursor, table
397 )
398 for column in columns:
399 field_column = field.column
400 column_name = column.name
401 if fold_identifier_case:
402 column_name = column_name.casefold()
403 field_column = field_column.casefold()
404 if column_name == field_column:
405 found_add_field_migration = True
406 break
407 else:
408 return False, project_state
409 # If we get this far and we found at least one CreateModel or AddField
410 # migration, the migration is considered implicitly applied.
411 return (found_create_model_migration or found_add_field_migration), after_state
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from functools import total_ordering
3from plain.models.migrations.state import ProjectState
5from .exceptions import CircularDependencyError, NodeNotFoundError
8@total_ordering
9class Node:
10 """
11 A single node in the migration graph. Contains direct links to adjacent
12 nodes in either direction.
13 """
15 def __init__(self, key):
16 self.key = key
17 self.children = set()
18 self.parents = set()
20 def __eq__(self, other):
21 return self.key == other
23 def __lt__(self, other):
24 return self.key < other
26 def __hash__(self):
27 return hash(self.key)
29 def __getitem__(self, item):
30 return self.key[item]
32 def __str__(self):
33 return str(self.key)
35 def __repr__(self):
36 return f"<{self.__class__.__name__}: ({self.key[0]!r}, {self.key[1]!r})>"
38 def add_child(self, child):
39 self.children.add(child)
41 def add_parent(self, parent):
42 self.parents.add(parent)
45class DummyNode(Node):
46 """
47 A node that doesn't correspond to a migration file on disk.
48 (A squashed migration that was removed, for example.)
50 After the migration graph is processed, all dummy nodes should be removed.
51 If there are any left, a nonexistent dependency error is raised.
52 """
54 def __init__(self, key, origin, error_message):
55 super().__init__(key)
56 self.origin = origin
57 self.error_message = error_message
59 def raise_error(self):
60 raise NodeNotFoundError(self.error_message, self.key, origin=self.origin)
63class MigrationGraph:
64 """
65 Represent the digraph of all migrations in a project.
67 Each migration is a node, and each dependency is an edge. There are
68 no implicit dependencies between numbered migrations - the numbering is
69 merely a convention to aid file listing. Every new numbered migration
70 has a declared dependency to the previous number, meaning that VCS
71 branch merges can be detected and resolved.
73 Migrations files can be marked as replacing another set of migrations -
74 this is to support the "squash" feature. The graph handler isn't responsible
75 for these; instead, the code to load them in here should examine the
76 migration files and if the replaced migrations are all either unapplied
77 or not present, it should ignore the replaced ones, load in just the
78 replacing migration, and repoint any dependencies that pointed to the
79 replaced migrations to point to the replacing one.
81 A node should be a tuple: (app_path, migration_name). The tree special-cases
82 things within an app - namely, root nodes and leaf nodes ignore dependencies
83 to other packages.
84 """
86 def __init__(self):
87 self.node_map = {}
88 self.nodes = {}
90 def add_node(self, key, migration):
91 assert key not in self.node_map
92 node = Node(key)
93 self.node_map[key] = node
94 self.nodes[key] = migration
96 def add_dummy_node(self, key, origin, error_message):
97 node = DummyNode(key, origin, error_message)
98 self.node_map[key] = node
99 self.nodes[key] = None
101 def add_dependency(self, migration, child, parent, skip_validation=False):
102 """
103 This may create dummy nodes if they don't yet exist. If
104 `skip_validation=True`, validate_consistency() should be called
105 afterward.
106 """
107 if child not in self.nodes:
108 error_message = (
109 f"Migration {migration} dependencies reference nonexistent"
110 f" child node {child!r}"
111 )
112 self.add_dummy_node(child, migration, error_message)
113 if parent not in self.nodes:
114 error_message = (
115 f"Migration {migration} dependencies reference nonexistent"
116 f" parent node {parent!r}"
117 )
118 self.add_dummy_node(parent, migration, error_message)
119 self.node_map[child].add_parent(self.node_map[parent])
120 self.node_map[parent].add_child(self.node_map[child])
121 if not skip_validation:
122 self.validate_consistency()
124 def remove_replaced_nodes(self, replacement, replaced):
125 """
126 Remove each of the `replaced` nodes (when they exist). Any
127 dependencies that were referencing them are changed to reference the
128 `replacement` node instead.
129 """
130 # Cast list of replaced keys to set to speed up lookup later.
131 replaced = set(replaced)
132 try:
133 replacement_node = self.node_map[replacement]
134 except KeyError as err:
135 raise NodeNotFoundError(
136 f"Unable to find replacement node {replacement!r}. It was either never added"
137 " to the migration graph, or has been removed.",
138 replacement,
139 ) from err
140 for replaced_key in replaced:
141 self.nodes.pop(replaced_key, None)
142 replaced_node = self.node_map.pop(replaced_key, None)
143 if replaced_node:
144 for child in replaced_node.children:
145 child.parents.remove(replaced_node)
146 # We don't want to create dependencies between the replaced
147 # node and the replacement node as this would lead to
148 # self-referencing on the replacement node at a later iteration.
149 if child.key not in replaced:
150 replacement_node.add_child(child)
151 child.add_parent(replacement_node)
152 for parent in replaced_node.parents:
153 parent.children.remove(replaced_node)
154 # Again, to avoid self-referencing.
155 if parent.key not in replaced:
156 replacement_node.add_parent(parent)
157 parent.add_child(replacement_node)
159 def remove_replacement_node(self, replacement, replaced):
160 """
161 The inverse operation to `remove_replaced_nodes`. Almost. Remove the
162 replacement node `replacement` and remap its child nodes to `replaced`
163 - the list of nodes it would have replaced. Don't remap its parent
164 nodes as they are expected to be correct already.
165 """
166 self.nodes.pop(replacement, None)
167 try:
168 replacement_node = self.node_map.pop(replacement)
169 except KeyError as err:
170 raise NodeNotFoundError(
171 f"Unable to remove replacement node {replacement!r}. It was either never added"
172 " to the migration graph, or has been removed already.",
173 replacement,
174 ) from err
175 replaced_nodes = set()
176 replaced_nodes_parents = set()
177 for key in replaced:
178 replaced_node = self.node_map.get(key)
179 if replaced_node:
180 replaced_nodes.add(replaced_node)
181 replaced_nodes_parents |= replaced_node.parents
182 # We're only interested in the latest replaced node, so filter out
183 # replaced nodes that are parents of other replaced nodes.
184 replaced_nodes -= replaced_nodes_parents
185 for child in replacement_node.children:
186 child.parents.remove(replacement_node)
187 for replaced_node in replaced_nodes:
188 replaced_node.add_child(child)
189 child.add_parent(replaced_node)
190 for parent in replacement_node.parents:
191 parent.children.remove(replacement_node)
192 # NOTE: There is no need to remap parent dependencies as we can
193 # assume the replaced nodes already have the correct ancestry.
195 def validate_consistency(self):
196 """Ensure there are no dummy nodes remaining in the graph."""
197 [n.raise_error() for n in self.node_map.values() if isinstance(n, DummyNode)]
199 def forwards_plan(self, target):
200 """
201 Given a node, return a list of which previous nodes (dependencies) must
202 be applied, ending with the node itself. This is the list you would
203 follow if applying the migrations to a database.
204 """
205 if target not in self.nodes:
206 raise NodeNotFoundError(f"Node {target!r} not a valid node", target)
207 return self.iterative_dfs(self.node_map[target])
209 def backwards_plan(self, target):
210 """
211 Given a node, return a list of which dependent nodes (dependencies)
212 must be unapplied, ending with the node itself. This is the list you
213 would follow if removing the migrations from a database.
214 """
215 if target not in self.nodes:
216 raise NodeNotFoundError(f"Node {target!r} not a valid node", target)
217 return self.iterative_dfs(self.node_map[target], forwards=False)
219 def iterative_dfs(self, start, forwards=True):
220 """Iterative depth-first search for finding dependencies."""
221 visited = []
222 visited_set = set()
223 stack = [(start, False)]
224 while stack:
225 node, processed = stack.pop()
226 if node in visited_set:
227 pass
228 elif processed:
229 visited_set.add(node)
230 visited.append(node.key)
231 else:
232 stack.append((node, True))
233 stack += [
234 (n, False)
235 for n in sorted(node.parents if forwards else node.children)
236 ]
237 return visited
239 def root_nodes(self, app=None):
240 """
241 Return all root nodes - that is, nodes with no dependencies inside
242 their app. These are the starting point for an app.
243 """
244 roots = set()
245 for node in self.nodes:
246 if all(key[0] != node[0] for key in self.node_map[node].parents) and (
247 not app or app == node[0]
248 ):
249 roots.add(node)
250 return sorted(roots)
252 def leaf_nodes(self, app=None):
253 """
254 Return all leaf nodes - that is, nodes with no dependents in their app.
255 These are the "most current" version of an app's schema.
256 Having more than one per app is technically an error, but one that
257 gets handled further up, in the interactive command - it's usually the
258 result of a VCS merge and needs some user input.
259 """
260 leaves = set()
261 for node in self.nodes:
262 if all(key[0] != node[0] for key in self.node_map[node].children) and (
263 not app or app == node[0]
264 ):
265 leaves.add(node)
266 return sorted(leaves)
268 def ensure_not_cyclic(self):
269 # Algo from GvR:
270 # https://neopythonic.blogspot.com/2009/01/detecting-cycles-in-directed-graph.html
271 todo = set(self.nodes)
272 while todo:
273 node = todo.pop()
274 stack = [node]
275 while stack:
276 top = stack[-1]
277 for child in self.node_map[top].children:
278 # Use child.key instead of child to speed up the frequent
279 # hashing.
280 node = child.key
281 if node in stack:
282 cycle = stack[stack.index(node) :]
283 raise CircularDependencyError(
284 ", ".join("{}.{}".format(*n) for n in cycle)
285 )
286 if node in todo:
287 stack.append(node)
288 todo.remove(node)
289 break
290 else:
291 node = stack.pop()
293 def __str__(self):
294 return "Graph: {} nodes, {} edges".format(*self._nodes_and_edges())
296 def __repr__(self):
297 nodes, edges = self._nodes_and_edges()
298 return f"<{self.__class__.__name__}: nodes={nodes}, edges={edges}>"
300 def _nodes_and_edges(self):
301 return len(self.nodes), sum(
302 len(node.parents) for node in self.node_map.values()
303 )
305 def _generate_plan(self, nodes, at_end):
306 plan = []
307 for node in nodes:
308 for migration in self.forwards_plan(node):
309 if migration not in plan and (at_end or migration not in nodes):
310 plan.append(migration)
311 return plan
313 def make_state(self, nodes=None, at_end=True, real_packages=None):
314 """
315 Given a migration node or nodes, return a complete ProjectState for it.
316 If at_end is False, return the state before the migration has run.
317 If nodes is not provided, return the overall most current project state.
318 """
319 if nodes is None:
320 nodes = list(self.leaf_nodes())
321 if not nodes:
322 return ProjectState()
323 if not isinstance(nodes[0], tuple):
324 nodes = [nodes]
325 plan = self._generate_plan(nodes, at_end)
326 project_state = ProjectState(real_packages=real_packages)
327 for node in plan:
328 project_state = self.nodes[node].mutate_state(project_state, preserve=False)
329 return project_state
331 def __contains__(self, node):
332 return node in self.nodes
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import pkgutil
2import sys
3from importlib import import_module, reload
5from plain.models.migrations.graph import MigrationGraph
6from plain.models.migrations.recorder import MigrationRecorder
7from plain.packages import packages
9from .exceptions import (
10 AmbiguityError,
11 BadMigrationError,
12 InconsistentMigrationHistory,
13 NodeNotFoundError,
14)
16MIGRATIONS_MODULE_NAME = "migrations"
19class MigrationLoader:
20 """
21 Load migration files from disk and their status from the database.
23 Migration files are expected to live in the "migrations" directory of
24 an app. Their names are entirely unimportant from a code perspective,
25 but will probably follow the 1234_name.py convention.
27 On initialization, this class will scan those directories, and open and
28 read the Python files, looking for a class called Migration, which should
29 inherit from plain.models.migrations.Migration. See
30 plain.models.migrations.migration for what that looks like.
32 Some migrations will be marked as "replacing" another set of migrations.
33 These are loaded into a separate set of migrations away from the main ones.
34 If all the migrations they replace are either unapplied or missing from
35 disk, then they are injected into the main set, replacing the named migrations.
36 Any dependency pointers to the replaced migrations are re-pointed to the
37 new migration.
39 This does mean that this class MUST also talk to the database as well as
40 to disk, but this is probably fine. We're already not just operating
41 in memory.
42 """
44 def __init__(
45 self,
46 connection,
47 load=True,
48 ignore_no_migrations=False,
49 replace_migrations=True,
50 ):
51 self.connection = connection
52 self.disk_migrations = None
53 self.applied_migrations = None
54 self.ignore_no_migrations = ignore_no_migrations
55 self.replace_migrations = replace_migrations
56 if load:
57 self.build_graph()
59 @classmethod
60 def migrations_module(cls, package_label):
61 """
62 Return the path to the migrations module for the specified package_label
63 and a boolean indicating if the module is specified in
64 settings.MIGRATION_MODULE.
65 """
67 app = packages.get_package_config(package_label)
68 if app.migrations_module is None:
69 return None, True
70 explicit = app.migrations_module != MIGRATIONS_MODULE_NAME
71 return f"{app.name}.{app.migrations_module}", explicit
73 def load_disk(self):
74 """Load the migrations from all INSTALLED_PACKAGES from disk."""
75 self.disk_migrations = {}
76 self.unmigrated_packages = set()
77 self.migrated_packages = set()
78 for package_config in packages.get_package_configs():
79 # Get the migrations module directory
80 module_name, explicit = self.migrations_module(package_config.label)
81 if module_name is None:
82 self.unmigrated_packages.add(package_config.label)
83 continue
84 was_loaded = module_name in sys.modules
85 try:
86 module = import_module(module_name)
87 except ModuleNotFoundError as e:
88 if (explicit and self.ignore_no_migrations) or (
89 not explicit and MIGRATIONS_MODULE_NAME in e.name.split(".")
90 ):
91 self.unmigrated_packages.add(package_config.label)
92 continue
93 raise
94 else:
95 # Module is not a package (e.g. migrations.py).
96 if not hasattr(module, "__path__"):
97 self.unmigrated_packages.add(package_config.label)
98 continue
99 # Empty directories are namespaces. Namespace packages have no
100 # __file__ and don't use a list for __path__. See
101 # https://docs.python.org/3/reference/import.html#namespace-packages
102 if getattr(module, "__file__", None) is None and not isinstance(
103 module.__path__, list
104 ):
105 self.unmigrated_packages.add(package_config.label)
106 continue
107 # Force a reload if it's already loaded (tests need this)
108 if was_loaded:
109 reload(module)
110 self.migrated_packages.add(package_config.label)
111 migration_names = {
112 name
113 for _, name, is_pkg in pkgutil.iter_modules(module.__path__)
114 if not is_pkg and name[0] not in "_~"
115 }
116 # Load migrations
117 for migration_name in migration_names:
118 migration_path = f"{module_name}.{migration_name}"
119 try:
120 migration_module = import_module(migration_path)
121 except ImportError as e:
122 if "bad magic number" in str(e):
123 raise ImportError(
124 f"Couldn't import {migration_path!r} as it appears to be a stale "
125 ".pyc file."
126 ) from e
127 else:
128 raise
129 if not hasattr(migration_module, "Migration"):
130 raise BadMigrationError(
131 f"Migration {migration_name} in app {package_config.label} has no Migration class"
132 )
133 self.disk_migrations[package_config.label, migration_name] = (
134 migration_module.Migration(
135 migration_name,
136 package_config.label,
137 )
138 )
140 def get_migration(self, package_label, name_prefix):
141 """Return the named migration or raise NodeNotFoundError."""
142 return self.graph.nodes[package_label, name_prefix]
144 def get_migration_by_prefix(self, package_label, name_prefix):
145 """
146 Return the migration(s) which match the given app label and name_prefix.
147 """
148 # Do the search
149 results = []
150 for migration_package_label, migration_name in self.disk_migrations:
151 if migration_package_label == package_label and migration_name.startswith(
152 name_prefix
153 ):
154 results.append((migration_package_label, migration_name))
155 if len(results) > 1:
156 raise AmbiguityError(
157 f"There is more than one migration for '{package_label}' with the prefix '{name_prefix}'"
158 )
159 elif not results:
160 raise KeyError(
161 f"There is no migration for '{package_label}' with the prefix "
162 f"'{name_prefix}'"
163 )
164 else:
165 return self.disk_migrations[results[0]]
167 def check_key(self, key, current_package):
168 if (key[1] != "__first__" and key[1] != "__latest__") or key in self.graph:
169 return key
170 # Special-case __first__, which means "the first migration" for
171 # migrated packages, and is ignored for unmigrated packages. It allows
172 # makemigrations to declare dependencies on packages before they even have
173 # migrations.
174 if key[0] == current_package:
175 # Ignore __first__ references to the same app (#22325)
176 return
177 if key[0] in self.unmigrated_packages:
178 # This app isn't migrated, but something depends on it.
179 # The models will get auto-added into the state, though
180 # so we're fine.
181 return
182 if key[0] in self.migrated_packages:
183 try:
184 if key[1] == "__first__":
185 return self.graph.root_nodes(key[0])[0]
186 else: # "__latest__"
187 return self.graph.leaf_nodes(key[0])[0]
188 except IndexError:
189 if self.ignore_no_migrations:
190 return None
191 else:
192 raise ValueError(f"Dependency on app with no migrations: {key[0]}")
193 raise ValueError(f"Dependency on unknown app: {key[0]}")
195 def add_internal_dependencies(self, key, migration):
196 """
197 Internal dependencies need to be added first to ensure `__first__`
198 dependencies find the correct root node.
199 """
200 for parent in migration.dependencies:
201 # Ignore __first__ references to the same app.
202 if parent[0] == key[0] and parent[1] != "__first__":
203 self.graph.add_dependency(migration, key, parent, skip_validation=True)
205 def add_external_dependencies(self, key, migration):
206 for parent in migration.dependencies:
207 # Skip internal dependencies
208 if key[0] == parent[0]:
209 continue
210 parent = self.check_key(parent, key[0])
211 if parent is not None:
212 self.graph.add_dependency(migration, key, parent, skip_validation=True)
213 for child in migration.run_before:
214 child = self.check_key(child, key[0])
215 if child is not None:
216 self.graph.add_dependency(migration, child, key, skip_validation=True)
218 def build_graph(self):
219 """
220 Build a migration dependency graph using both the disk and database.
221 You'll need to rebuild the graph if you apply migrations. This isn't
222 usually a problem as generally migration stuff runs in a one-shot process.
223 """
224 # Load disk data
225 self.load_disk()
226 # Load database data
227 if self.connection is None:
228 self.applied_migrations = {}
229 else:
230 recorder = MigrationRecorder(self.connection)
231 self.applied_migrations = recorder.applied_migrations()
232 # To start, populate the migration graph with nodes for ALL migrations
233 # and their dependencies. Also make note of replacing migrations at this step.
234 self.graph = MigrationGraph()
235 self.replacements = {}
236 for key, migration in self.disk_migrations.items():
237 self.graph.add_node(key, migration)
238 # Replacing migrations.
239 if migration.replaces:
240 self.replacements[key] = migration
241 for key, migration in self.disk_migrations.items():
242 # Internal (same app) dependencies.
243 self.add_internal_dependencies(key, migration)
244 # Add external dependencies now that the internal ones have been resolved.
245 for key, migration in self.disk_migrations.items():
246 self.add_external_dependencies(key, migration)
247 # Carry out replacements where possible and if enabled.
248 if self.replace_migrations:
249 for key, migration in self.replacements.items():
250 # Get applied status of each of this migration's replacement
251 # targets.
252 applied_statuses = [
253 (target in self.applied_migrations) for target in migration.replaces
254 ]
255 # The replacing migration is only marked as applied if all of
256 # its replacement targets are.
257 if all(applied_statuses):
258 self.applied_migrations[key] = migration
259 else:
260 self.applied_migrations.pop(key, None)
261 # A replacing migration can be used if either all or none of
262 # its replacement targets have been applied.
263 if all(applied_statuses) or (not any(applied_statuses)):
264 self.graph.remove_replaced_nodes(key, migration.replaces)
265 else:
266 # This replacing migration cannot be used because it is
267 # partially applied. Remove it from the graph and remap
268 # dependencies to it (#25945).
269 self.graph.remove_replacement_node(key, migration.replaces)
270 # Ensure the graph is consistent.
271 try:
272 self.graph.validate_consistency()
273 except NodeNotFoundError as exc:
274 # Check if the missing node could have been replaced by any squash
275 # migration but wasn't because the squash migration was partially
276 # applied before. In that case raise a more understandable exception
277 # (#23556).
278 # Get reverse replacements.
279 reverse_replacements = {}
280 for key, migration in self.replacements.items():
281 for replaced in migration.replaces:
282 reverse_replacements.setdefault(replaced, set()).add(key)
283 # Try to reraise exception with more detail.
284 if exc.node in reverse_replacements:
285 candidates = reverse_replacements.get(exc.node, set())
286 is_replaced = any(
287 candidate in self.graph.nodes for candidate in candidates
288 )
289 if not is_replaced:
290 tries = ", ".join("{}.{}".format(*c) for c in candidates)
291 raise NodeNotFoundError(
292 f"Migration {exc.origin} depends on nonexistent node ('{exc.node[0]}', '{exc.node[1]}'). "
293 f"Plain tried to replace migration {exc.node[0]}.{exc.node[1]} with any of [{tries}] "
294 "but wasn't able to because some of the replaced migrations "
295 "are already applied.",
296 exc.node,
297 ) from exc
298 raise
299 self.graph.ensure_not_cyclic()
301 def check_consistent_history(self, connection):
302 """
303 Raise InconsistentMigrationHistory if any applied migrations have
304 unapplied dependencies.
305 """
306 recorder = MigrationRecorder(connection)
307 applied = recorder.applied_migrations()
308 for migration in applied:
309 # If the migration is unknown, skip it.
310 if migration not in self.graph.nodes:
311 continue
312 for parent in self.graph.node_map[migration].parents:
313 if parent not in applied:
314 # Skip unapplied squashed migrations that have all of their
315 # `replaces` applied.
316 if parent in self.replacements:
317 if all(
318 m in applied for m in self.replacements[parent].replaces
319 ):
320 continue
321 raise InconsistentMigrationHistory(
322 f"Migration {migration[0]}.{migration[1]} is applied before its dependency "
323 f"{parent[0]}.{parent[1]} on database '{connection.alias}'."
324 )
326 def detect_conflicts(self):
327 """
328 Look through the loaded graph and detect any conflicts - packages
329 with more than one leaf migration. Return a dict of the app labels
330 that conflict with the migration names that conflict.
331 """
332 seen_packages = {}
333 conflicting_packages = set()
334 for package_label, migration_name in self.graph.leaf_nodes():
335 if package_label in seen_packages:
336 conflicting_packages.add(package_label)
337 seen_packages.setdefault(package_label, set()).add(migration_name)
338 return {
339 package_label: sorted(seen_packages[package_label])
340 for package_label in conflicting_packages
341 }
343 def project_state(self, nodes=None, at_end=True):
344 """
345 Return a ProjectState object representing the most recent state
346 that the loaded migrations represent.
348 See graph.make_state() for the meaning of "nodes" and "at_end".
349 """
350 return self.graph.make_state(
351 nodes=nodes, at_end=at_end, real_packages=self.unmigrated_packages
352 )
354 def collect_sql(self, plan):
355 """
356 Take a migration plan and return a list of collected SQL statements
357 that represent the best-efforts version of that plan.
358 """
359 statements = []
360 state = None
361 for migration, backwards in plan:
362 with self.connection.schema_editor(
363 collect_sql=True, atomic=migration.atomic
364 ) as schema_editor:
365 if state is None:
366 state = self.project_state(
367 (migration.package_label, migration.name), at_end=False
368 )
369 if not backwards:
370 state = migration.apply(state, schema_editor, collect_sql=True)
371 else:
372 state = migration.unapply(state, schema_editor, collect_sql=True)
373 statements.extend(schema_editor.collected_sql)
374 return statements
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import re
3from plain.models.migrations.utils import get_migration_name_timestamp
4from plain.models.transaction import atomic
6from .exceptions import IrreversibleError
9class Migration:
10 """
11 The base class for all migrations.
13 Migration files will import this from plain.models.migrations.Migration
14 and subclass it as a class called Migration. It will have one or more
15 of the following attributes:
17 - operations: A list of Operation instances, probably from
18 plain.models.migrations.operations
19 - dependencies: A list of tuples of (app_path, migration_name)
20 - run_before: A list of tuples of (app_path, migration_name)
21 - replaces: A list of migration_names
23 Note that all migrations come out of migrations and into the Loader or
24 Graph as instances, having been initialized with their app label and name.
25 """
27 # Operations to apply during this migration, in order.
28 operations = []
30 # Other migrations that should be run before this migration.
31 # Should be a list of (app, migration_name).
32 dependencies = []
34 # Other migrations that should be run after this one (i.e. have
35 # this migration added to their dependencies). Useful to make third-party
36 # packages' migrations run after your AUTH_USER replacement, for example.
37 run_before = []
39 # Migration names in this app that this migration replaces. If this is
40 # non-empty, this migration will only be applied if all these migrations
41 # are not applied.
42 replaces = []
44 # Is this an initial migration? Initial migrations are skipped on
45 # --fake-initial if the table or fields already exist. If None, check if
46 # the migration has any dependencies to determine if there are dependencies
47 # to tell if db introspection needs to be done. If True, always perform
48 # introspection. If False, never perform introspection.
49 initial = None
51 # Whether to wrap the whole migration in a transaction. Only has an effect
52 # on database backends which support transactional DDL.
53 atomic = True
55 def __init__(self, name, package_label):
56 self.name = name
57 self.package_label = package_label
58 # Copy dependencies & other attrs as we might mutate them at runtime
59 self.operations = list(self.__class__.operations)
60 self.dependencies = list(self.__class__.dependencies)
61 self.run_before = list(self.__class__.run_before)
62 self.replaces = list(self.__class__.replaces)
64 def __eq__(self, other):
65 return (
66 isinstance(other, Migration)
67 and self.name == other.name
68 and self.package_label == other.package_label
69 )
71 def __repr__(self):
72 return f"<Migration {self.package_label}.{self.name}>"
74 def __str__(self):
75 return f"{self.package_label}.{self.name}"
77 def __hash__(self):
78 return hash(f"{self.package_label}.{self.name}")
80 def mutate_state(self, project_state, preserve=True):
81 """
82 Take a ProjectState and return a new one with the migration's
83 operations applied to it. Preserve the original object state by
84 default and return a mutated state from a copy.
85 """
86 new_state = project_state
87 if preserve:
88 new_state = project_state.clone()
90 for operation in self.operations:
91 operation.state_forwards(self.package_label, new_state)
92 return new_state
94 def apply(self, project_state, schema_editor, collect_sql=False):
95 """
96 Take a project_state representing all migrations prior to this one
97 and a schema_editor for a live database and apply the migration
98 in a forwards order.
100 Return the resulting project state for efficient reuse by following
101 Migrations.
102 """
103 for operation in self.operations:
104 # If this operation cannot be represented as SQL, place a comment
105 # there instead
106 if collect_sql:
107 schema_editor.collected_sql.append("--")
108 schema_editor.collected_sql.append(f"-- {operation.describe()}")
109 schema_editor.collected_sql.append("--")
110 if not operation.reduces_to_sql:
111 schema_editor.collected_sql.append(
112 "-- THIS OPERATION CANNOT BE WRITTEN AS SQL"
113 )
114 continue
115 collected_sql_before = len(schema_editor.collected_sql)
116 # Save the state before the operation has run
117 old_state = project_state.clone()
118 operation.state_forwards(self.package_label, project_state)
119 # Run the operation
120 atomic_operation = operation.atomic or (
121 self.atomic and operation.atomic is not False
122 )
123 if not schema_editor.atomic_migration and atomic_operation:
124 # Force a transaction on a non-transactional-DDL backend or an
125 # atomic operation inside a non-atomic migration.
126 with atomic(schema_editor.connection.alias):
127 operation.database_forwards(
128 self.package_label, schema_editor, old_state, project_state
129 )
130 else:
131 # Normal behaviour
132 operation.database_forwards(
133 self.package_label, schema_editor, old_state, project_state
134 )
135 if collect_sql and collected_sql_before == len(schema_editor.collected_sql):
136 schema_editor.collected_sql.append("-- (no-op)")
137 return project_state
139 def unapply(self, project_state, schema_editor, collect_sql=False):
140 """
141 Take a project_state representing all migrations prior to this one
142 and a schema_editor for a live database and apply the migration
143 in a reverse order.
145 The backwards migration process consists of two phases:
147 1. The intermediate states from right before the first until right
148 after the last operation inside this migration are preserved.
149 2. The operations are applied in reverse order using the states
150 recorded in step 1.
151 """
152 # Construct all the intermediate states we need for a reverse migration
153 to_run = []
154 new_state = project_state
155 # Phase 1
156 for operation in self.operations:
157 # If it's irreversible, error out
158 if not operation.reversible:
159 raise IrreversibleError(
160 f"Operation {operation} in {self} is not reversible"
161 )
162 # Preserve new state from previous run to not tamper the same state
163 # over all operations
164 new_state = new_state.clone()
165 old_state = new_state.clone()
166 operation.state_forwards(self.package_label, new_state)
167 to_run.insert(0, (operation, old_state, new_state))
169 # Phase 2
170 for operation, to_state, from_state in to_run:
171 if collect_sql:
172 schema_editor.collected_sql.append("--")
173 schema_editor.collected_sql.append(f"-- {operation.describe()}")
174 schema_editor.collected_sql.append("--")
175 if not operation.reduces_to_sql:
176 schema_editor.collected_sql.append(
177 "-- THIS OPERATION CANNOT BE WRITTEN AS SQL"
178 )
179 continue
180 collected_sql_before = len(schema_editor.collected_sql)
181 atomic_operation = operation.atomic or (
182 self.atomic and operation.atomic is not False
183 )
184 if not schema_editor.atomic_migration and atomic_operation:
185 # Force a transaction on a non-transactional-DDL backend or an
186 # atomic operation inside a non-atomic migration.
187 with atomic(schema_editor.connection.alias):
188 operation.database_backwards(
189 self.package_label, schema_editor, from_state, to_state
190 )
191 else:
192 # Normal behaviour
193 operation.database_backwards(
194 self.package_label, schema_editor, from_state, to_state
195 )
196 if collect_sql and collected_sql_before == len(schema_editor.collected_sql):
197 schema_editor.collected_sql.append("-- (no-op)")
198 return project_state
200 def suggest_name(self):
201 """
202 Suggest a name for the operations this migration might represent. Names
203 are not guaranteed to be unique, but put some effort into the fallback
204 name to avoid VCS conflicts if possible.
205 """
206 if self.initial:
207 return "initial"
209 raw_fragments = [op.migration_name_fragment for op in self.operations]
210 fragments = [re.sub(r"\W+", "_", name) for name in raw_fragments if name]
212 if not fragments or len(fragments) != len(self.operations):
213 return f"auto_{get_migration_name_timestamp()}"
215 name = fragments[0]
216 for fragment in fragments[1:]:
217 new_name = f"{name}_{fragment}"
218 if len(new_name) > 52:
219 name = f"{name}_and_more"
220 break
221 name = new_name
222 return name
225class SwappableTuple(tuple):
226 """
227 Subclass of tuple so Plain can tell this was originally a swappable
228 dependency when it reads the migration file.
229 """
231 def __new__(cls, value, setting):
232 self = tuple.__new__(cls, value)
233 self.setting = setting
234 return self
237def swappable_dependency(value):
238 """Turn a setting value into a dependency."""
239 return SwappableTuple((value.split(".", 1)[0], "__first__"), value)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1class MigrationOptimizer:
2 """
3 Power the optimization process, where you provide a list of Operations
4 and you are returned a list of equal or shorter length - operations
5 are merged into one if possible.
7 For example, a CreateModel and an AddField can be optimized into a
8 new CreateModel, and CreateModel and DeleteModel can be optimized into
9 nothing.
10 """
12 def optimize(self, operations, package_label):
13 """
14 Main optimization entry point. Pass in a list of Operation instances,
15 get out a new list of Operation instances.
17 Unfortunately, due to the scope of the optimization (two combinable
18 operations might be separated by several hundred others), this can't be
19 done as a peephole optimization with checks/output implemented on
20 the Operations themselves; instead, the optimizer looks at each
21 individual operation and scans forwards in the list to see if there
22 are any matches, stopping at boundaries - operations which can't
23 be optimized over (RunSQL, operations on the same field/model, etc.)
25 The inner loop is run until the starting list is the same as the result
26 list, and then the result is returned. This means that operation
27 optimization must be stable and always return an equal or shorter list.
28 """
29 # Internal tracking variable for test assertions about # of loops
30 if package_label is None:
31 raise TypeError("package_label must be a str.")
32 self._iterations = 0
33 while True:
34 result = self.optimize_inner(operations, package_label)
35 self._iterations += 1
36 if result == operations:
37 return result
38 operations = result
40 def optimize_inner(self, operations, package_label):
41 """Inner optimization loop."""
42 new_operations = []
43 for i, operation in enumerate(operations):
44 right = True # Should we reduce on the right or on the left.
45 # Compare it to each operation after it
46 for j, other in enumerate(operations[i + 1 :]):
47 result = operation.reduce(other, package_label)
48 if isinstance(result, list):
49 in_between = operations[i + 1 : i + j + 1]
50 if right:
51 new_operations.extend(in_between)
52 new_operations.extend(result)
53 elif all(
54 op.reduce(other, package_label) is True for op in in_between
55 ):
56 # Perform a left reduction if all of the in-between
57 # operations can optimize through other.
58 new_operations.extend(result)
59 new_operations.extend(in_between)
60 else:
61 # Otherwise keep trying.
62 new_operations.append(operation)
63 break
64 new_operations.extend(operations[i + j + 2 :])
65 return new_operations
66 elif not result:
67 # Can't perform a right reduction.
68 right = False
69 else:
70 new_operations.append(operation)
71 return new_operations
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
2import importlib
3import os
4import sys
6from plain.models.fields import NOT_PROVIDED
7from plain.packages import packages
8from plain.utils import timezone
10from .loader import MigrationLoader
13class MigrationQuestioner:
14 """
15 Give the autodetector responses to questions it might have.
16 This base class has a built-in noninteractive mode, but the
17 interactive subclass is what the command-line arguments will use.
18 """
20 def __init__(self, defaults=None, specified_packages=None, dry_run=None):
21 self.defaults = defaults or {}
22 self.specified_packages = specified_packages or set()
23 self.dry_run = dry_run
25 def ask_initial(self, package_label):
26 """Should we create an initial migration for the app?"""
27 # If it was specified on the command line, definitely true
28 if package_label in self.specified_packages:
29 return True
30 # Otherwise, we look to see if it has a migrations module
31 # without any Python files in it, apart from __init__.py.
32 # Packages from the new app template will have these; the Python
33 # file check will ensure we skip South ones.
34 try:
35 package_config = packages.get_package_config(package_label)
36 except LookupError: # It's a fake app.
37 return self.defaults.get("ask_initial", False)
38 migrations_import_path, _ = MigrationLoader.migrations_module(
39 package_config.label
40 )
41 if migrations_import_path is None:
42 # It's an application with migrations disabled.
43 return self.defaults.get("ask_initial", False)
44 try:
45 migrations_module = importlib.import_module(migrations_import_path)
46 except ImportError:
47 return self.defaults.get("ask_initial", False)
48 else:
49 if getattr(migrations_module, "__file__", None):
50 filenames = os.listdir(os.path.dirname(migrations_module.__file__))
51 elif hasattr(migrations_module, "__path__"):
52 if len(migrations_module.__path__) > 1:
53 return False
54 filenames = os.listdir(list(migrations_module.__path__)[0])
55 return not any(x.endswith(".py") for x in filenames if x != "__init__.py")
57 def ask_not_null_addition(self, field_name, model_name):
58 """Adding a NOT NULL field to a model."""
59 # None means quit
60 return None
62 def ask_not_null_alteration(self, field_name, model_name):
63 """Changing a NULL field to NOT NULL."""
64 # None means quit
65 return None
67 def ask_rename(self, model_name, old_name, new_name, field_instance):
68 """Was this field really renamed?"""
69 return self.defaults.get("ask_rename", False)
71 def ask_rename_model(self, old_model_state, new_model_state):
72 """Was this model really renamed?"""
73 return self.defaults.get("ask_rename_model", False)
75 def ask_merge(self, package_label):
76 """Should these migrations really be merged?"""
77 return self.defaults.get("ask_merge", False)
79 def ask_auto_now_add_addition(self, field_name, model_name):
80 """Adding an auto_now_add field to a model."""
81 # None means quit
82 return None
84 def ask_unique_callable_default_addition(self, field_name, model_name):
85 """Adding a unique field with a callable default."""
86 # None means continue.
87 return None
90class InteractiveMigrationQuestioner(MigrationQuestioner):
91 def __init__(
92 self, defaults=None, specified_packages=None, dry_run=None, prompt_output=None
93 ):
94 super().__init__(
95 defaults=defaults, specified_packages=specified_packages, dry_run=dry_run
96 )
97 self.prompt_output = prompt_output or sys.stdout
99 def _boolean_input(self, question, default=None):
100 self.prompt_output.write(f"{question} ", ending="")
101 result = input()
102 if not result and default is not None:
103 return default
104 while not result or result[0].lower() not in "yn":
105 self.prompt_output.write("Please answer yes or no: ", ending="")
106 result = input()
107 return result[0].lower() == "y"
109 def _choice_input(self, question, choices):
110 self.prompt_output.write(f"{question}")
111 for i, choice in enumerate(choices):
112 self.prompt_output.write(f" {i + 1}) {choice}")
113 self.prompt_output.write("Select an option: ", ending="")
114 result = input()
115 while True:
116 try:
117 value = int(result)
118 except ValueError:
119 pass
120 else:
121 if 0 < value <= len(choices):
122 return value
123 self.prompt_output.write("Please select a valid option: ", ending="")
124 result = input()
126 def _ask_default(self, default=""):
127 """
128 Prompt for a default value.
130 The ``default`` argument allows providing a custom default value (as a
131 string) which will be shown to the user and used as the return value
132 if the user doesn't provide any other input.
133 """
134 self.prompt_output.write("Please enter the default value as valid Python.")
135 if default:
136 self.prompt_output.write(
137 f"Accept the default '{default}' by pressing 'Enter' or "
138 f"provide another value."
139 )
140 self.prompt_output.write(
141 "The datetime and plain.utils.timezone modules are available, so "
142 "it is possible to provide e.g. timezone.now as a value."
143 )
144 self.prompt_output.write("Type 'exit' to exit this prompt")
145 while True:
146 if default:
147 prompt = f"[default: {default}] >>> "
148 else:
149 prompt = ">>> "
150 self.prompt_output.write(prompt, ending="")
151 code = input()
152 if not code and default:
153 code = default
154 if not code:
155 self.prompt_output.write(
156 "Please enter some code, or 'exit' (without quotes) to exit."
157 )
158 elif code == "exit":
159 sys.exit(1)
160 else:
161 try:
162 return eval(code, {}, {"datetime": datetime, "timezone": timezone})
163 except (SyntaxError, NameError) as e:
164 self.prompt_output.write(f"Invalid input: {e}")
166 def ask_not_null_addition(self, field_name, model_name):
167 """Adding a NOT NULL field to a model."""
168 if not self.dry_run:
169 choice = self._choice_input(
170 f"It is impossible to add a non-nullable field '{field_name}' "
171 f"to {model_name} without specifying a default. This is "
172 f"because the database needs something to populate existing "
173 f"rows.\n"
174 f"Please select a fix:",
175 [
176 (
177 "Provide a one-off default now (will be set on all existing "
178 "rows with a null value for this column)"
179 ),
180 "Quit and manually define a default value in models.py.",
181 ],
182 )
183 if choice == 2:
184 sys.exit(3)
185 else:
186 return self._ask_default()
187 return None
189 def ask_not_null_alteration(self, field_name, model_name):
190 """Changing a NULL field to NOT NULL."""
191 if not self.dry_run:
192 choice = self._choice_input(
193 f"It is impossible to change a nullable field '{field_name}' "
194 f"on {model_name} to non-nullable without providing a "
195 f"default. This is because the database needs something to "
196 f"populate existing rows.\n"
197 f"Please select a fix:",
198 [
199 (
200 "Provide a one-off default now (will be set on all existing "
201 "rows with a null value for this column)"
202 ),
203 "Ignore for now. Existing rows that contain NULL values "
204 "will have to be handled manually, for example with a "
205 "RunPython or RunSQL operation.",
206 "Quit and manually define a default value in models.py.",
207 ],
208 )
209 if choice == 2:
210 return NOT_PROVIDED
211 elif choice == 3:
212 sys.exit(3)
213 else:
214 return self._ask_default()
215 return None
217 def ask_rename(self, model_name, old_name, new_name, field_instance):
218 """Was this field really renamed?"""
219 msg = "Was %s.%s renamed to %s.%s (a %s)? [y/N]"
220 return self._boolean_input(
221 msg
222 % (
223 model_name,
224 old_name,
225 model_name,
226 new_name,
227 field_instance.__class__.__name__,
228 ),
229 False,
230 )
232 def ask_rename_model(self, old_model_state, new_model_state):
233 """Was this model really renamed?"""
234 msg = "Was the model %s.%s renamed to %s? [y/N]"
235 return self._boolean_input(
236 msg
237 % (
238 old_model_state.package_label,
239 old_model_state.name,
240 new_model_state.name,
241 ),
242 False,
243 )
245 def ask_merge(self, package_label):
246 return self._boolean_input(
247 (
248 "\nMerging will only work if the operations printed above do not conflict\n"
249 "with each other (working on different fields or models)\n"
250 "Should these migration branches be merged? [y/N]"
251 ),
252 False,
253 )
255 def ask_auto_now_add_addition(self, field_name, model_name):
256 """Adding an auto_now_add field to a model."""
257 if not self.dry_run:
258 choice = self._choice_input(
259 f"It is impossible to add the field '{field_name}' with "
260 f"'auto_now_add=True' to {model_name} without providing a "
261 f"default. This is because the database needs something to "
262 f"populate existing rows.\n",
263 [
264 "Provide a one-off default now which will be set on all "
265 "existing rows",
266 "Quit and manually define a default value in models.py.",
267 ],
268 )
269 if choice == 2:
270 sys.exit(3)
271 else:
272 return self._ask_default(default="timezone.now")
273 return None
275 def ask_unique_callable_default_addition(self, field_name, model_name):
276 """Adding a unique field with a callable default."""
277 if not self.dry_run:
278 choice = self._choice_input(
279 f"Callable default on unique field {model_name}.{field_name} "
280 f"will not generate unique values upon migrating.\n"
281 f"Please choose how to proceed:\n",
282 [
283 "Continue making this migration as the first step in "
284 "writing a manual migration to generate unique values.",
285 "Quit and edit field options in models.py.",
286 ],
287 )
288 if choice == 2:
289 sys.exit(3)
290 return None
293class NonInteractiveMigrationQuestioner(MigrationQuestioner):
294 def __init__(
295 self,
296 defaults=None,
297 specified_packages=None,
298 dry_run=None,
299 verbosity=1,
300 log=None,
301 ):
302 self.verbosity = verbosity
303 self.log = log
304 super().__init__(
305 defaults=defaults,
306 specified_packages=specified_packages,
307 dry_run=dry_run,
308 )
310 def log_lack_of_migration(self, field_name, model_name, reason):
311 if self.verbosity > 0:
312 self.log(
313 f"Field '{field_name}' on model '{model_name}' not migrated: "
314 f"{reason}."
315 )
317 def ask_not_null_addition(self, field_name, model_name):
318 # We can't ask the user, so act like the user aborted.
319 self.log_lack_of_migration(
320 field_name,
321 model_name,
322 "it is impossible to add a non-nullable field without specifying "
323 "a default",
324 )
325 sys.exit(3)
327 def ask_not_null_alteration(self, field_name, model_name):
328 # We can't ask the user, so set as not provided.
329 self.log(
330 f"Field '{field_name}' on model '{model_name}' given a default of "
331 f"NOT PROVIDED and must be corrected."
332 )
333 return NOT_PROVIDED
335 def ask_auto_now_add_addition(self, field_name, model_name):
336 # We can't ask the user, so act like the user aborted.
337 self.log_lack_of_migration(
338 field_name,
339 model_name,
340 "it is impossible to add a field with 'auto_now_add=True' without "
341 "specifying a default",
342 )
343 sys.exit(3)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain import models
2from plain.models.db import DatabaseError
3from plain.packages.registry import Packages
4from plain.utils.functional import classproperty
5from plain.utils.timezone import now
7from .exceptions import MigrationSchemaMissing
10class MigrationRecorder:
11 """
12 Deal with storing migration records in the database.
14 Because this table is actually itself used for dealing with model
15 creation, it's the one thing we can't do normally via migrations.
16 We manually handle table creation/schema updating (using schema backend)
17 and then have a floating model to do queries with.
19 If a migration is unapplied its row is removed from the table. Having
20 a row in the table always means a migration is applied.
21 """
23 _migration_class = None
25 @classproperty
26 def Migration(cls):
27 """
28 Lazy load to avoid PackageRegistryNotReady if installed packages import
29 MigrationRecorder.
30 """
31 if cls._migration_class is None:
33 class Migration(models.Model):
34 app = models.CharField(max_length=255)
35 name = models.CharField(max_length=255)
36 applied = models.DateTimeField(default=now)
38 class Meta:
39 packages = Packages()
40 package_label = "migrations"
41 db_table = "plainmigrations"
43 def __str__(self):
44 return f"Migration {self.name} for {self.app}"
46 cls._migration_class = Migration
47 return cls._migration_class
49 def __init__(self, connection):
50 self.connection = connection
52 @property
53 def migration_qs(self):
54 return self.Migration.objects.using(self.connection.alias)
56 def has_table(self):
57 """Return True if the plainmigrations table exists."""
58 with self.connection.cursor() as cursor:
59 tables = self.connection.introspection.table_names(cursor)
60 return self.Migration._meta.db_table in tables
62 def ensure_schema(self):
63 """Ensure the table exists and has the correct schema."""
64 # If the table's there, that's fine - we've never changed its schema
65 # in the codebase.
66 if self.has_table():
67 return
68 # Make the table
69 try:
70 with self.connection.schema_editor() as editor:
71 editor.create_model(self.Migration)
72 except DatabaseError as exc:
73 raise MigrationSchemaMissing(
74 f"Unable to create the plainmigrations table ({exc})"
75 )
77 def applied_migrations(self):
78 """
79 Return a dict mapping (package_name, migration_name) to Migration instances
80 for all applied migrations.
81 """
82 if self.has_table():
83 return {
84 (migration.app, migration.name): migration
85 for migration in self.migration_qs
86 }
87 else:
88 # If the plainmigrations table doesn't exist, then no migrations
89 # are applied.
90 return {}
92 def record_applied(self, app, name):
93 """Record that a migration was applied."""
94 self.ensure_schema()
95 self.migration_qs.create(app=app, name=name)
97 def record_unapplied(self, app, name):
98 """Record that a migration was unapplied."""
99 self.ensure_schema()
100 self.migration_qs.filter(app=app, name=name).delete()
102 def flush(self):
103 """Delete all migration records. Useful for testing migrations."""
104 self.migration_qs.all().delete()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import builtins
2import collections.abc
3import datetime
4import decimal
5import enum
6import functools
7import math
8import os
9import pathlib
10import re
11import types
12import uuid
14from plain import models
15from plain.models.migrations.operations.base import Operation
16from plain.models.migrations.utils import COMPILED_REGEX_TYPE, RegexObject
17from plain.runtime.user_settings import SettingsReference
18from plain.utils.functional import LazyObject, Promise
21class BaseSerializer:
22 def __init__(self, value):
23 self.value = value
25 def serialize(self):
26 raise NotImplementedError(
27 "Subclasses of BaseSerializer must implement the serialize() method."
28 )
31class BaseSequenceSerializer(BaseSerializer):
32 def _format(self):
33 raise NotImplementedError(
34 "Subclasses of BaseSequenceSerializer must implement the _format() method."
35 )
37 def serialize(self):
38 imports = set()
39 strings = []
40 for item in self.value:
41 item_string, item_imports = serializer_factory(item).serialize()
42 imports.update(item_imports)
43 strings.append(item_string)
44 value = self._format()
45 return value % (", ".join(strings)), imports
48class BaseSimpleSerializer(BaseSerializer):
49 def serialize(self):
50 return repr(self.value), set()
53class ChoicesSerializer(BaseSerializer):
54 def serialize(self):
55 return serializer_factory(self.value.value).serialize()
58class DateTimeSerializer(BaseSerializer):
59 """For datetime.*, except datetime.datetime."""
61 def serialize(self):
62 return repr(self.value), {"import datetime"}
65class DatetimeDatetimeSerializer(BaseSerializer):
66 """For datetime.datetime."""
68 def serialize(self):
69 if self.value.tzinfo is not None and self.value.tzinfo != datetime.UTC:
70 self.value = self.value.astimezone(datetime.UTC)
71 imports = ["import datetime"]
72 return repr(self.value), set(imports)
75class DecimalSerializer(BaseSerializer):
76 def serialize(self):
77 return repr(self.value), {"from decimal import Decimal"}
80class DeconstructableSerializer(BaseSerializer):
81 @staticmethod
82 def serialize_deconstructed(path, args, kwargs):
83 name, imports = DeconstructableSerializer._serialize_path(path)
84 strings = []
85 for arg in args:
86 arg_string, arg_imports = serializer_factory(arg).serialize()
87 strings.append(arg_string)
88 imports.update(arg_imports)
89 for kw, arg in sorted(kwargs.items()):
90 arg_string, arg_imports = serializer_factory(arg).serialize()
91 imports.update(arg_imports)
92 strings.append(f"{kw}={arg_string}")
93 return "{}({})".format(name, ", ".join(strings)), imports
95 @staticmethod
96 def _serialize_path(path):
97 module, name = path.rsplit(".", 1)
98 if module == "plain.models":
99 imports = {"from plain import models"}
100 name = f"models.{name}"
101 else:
102 imports = {f"import {module}"}
103 name = path
104 return name, imports
106 def serialize(self):
107 return self.serialize_deconstructed(*self.value.deconstruct())
110class DictionarySerializer(BaseSerializer):
111 def serialize(self):
112 imports = set()
113 strings = []
114 for k, v in sorted(self.value.items()):
115 k_string, k_imports = serializer_factory(k).serialize()
116 v_string, v_imports = serializer_factory(v).serialize()
117 imports.update(k_imports)
118 imports.update(v_imports)
119 strings.append((k_string, v_string))
120 return "{{{}}}".format(", ".join(f"{k}: {v}" for k, v in strings)), imports
123class EnumSerializer(BaseSerializer):
124 def serialize(self):
125 enum_class = self.value.__class__
126 module = enum_class.__module__
127 if issubclass(enum_class, enum.Flag):
128 members = list(self.value)
129 else:
130 members = (self.value,)
131 return (
132 " | ".join(
133 [
134 f"{module}.{enum_class.__qualname__}[{item.name!r}]"
135 for item in members
136 ]
137 ),
138 {f"import {module}"},
139 )
142class FloatSerializer(BaseSimpleSerializer):
143 def serialize(self):
144 if math.isnan(self.value) or math.isinf(self.value):
145 return f'float("{self.value}")', set()
146 return super().serialize()
149class FrozensetSerializer(BaseSequenceSerializer):
150 def _format(self):
151 return "frozenset([%s])"
154class FunctionTypeSerializer(BaseSerializer):
155 def serialize(self):
156 if getattr(self.value, "__self__", None) and isinstance(
157 self.value.__self__, type
158 ):
159 klass = self.value.__self__
160 module = klass.__module__
161 return f"{module}.{klass.__name__}.{self.value.__name__}", {
162 f"import {module}"
163 }
164 # Further error checking
165 if self.value.__name__ == "<lambda>":
166 raise ValueError("Cannot serialize function: lambda")
167 if self.value.__module__ is None:
168 raise ValueError(f"Cannot serialize function {self.value!r}: No module")
170 module_name = self.value.__module__
172 if "<" not in self.value.__qualname__: # Qualname can include <locals>
173 return f"{module_name}.{self.value.__qualname__}", {
174 f"import {self.value.__module__}"
175 }
177 raise ValueError(
178 f"Could not find function {self.value.__name__} in {module_name}.\n"
179 )
182class FunctoolsPartialSerializer(BaseSerializer):
183 def serialize(self):
184 # Serialize functools.partial() arguments
185 func_string, func_imports = serializer_factory(self.value.func).serialize()
186 args_string, args_imports = serializer_factory(self.value.args).serialize()
187 keywords_string, keywords_imports = serializer_factory(
188 self.value.keywords
189 ).serialize()
190 # Add any imports needed by arguments
191 imports = {"import functools", *func_imports, *args_imports, *keywords_imports}
192 return (
193 f"functools.{self.value.__class__.__name__}({func_string}, *{args_string}, **{keywords_string})",
194 imports,
195 )
198class IterableSerializer(BaseSerializer):
199 def serialize(self):
200 imports = set()
201 strings = []
202 for item in self.value:
203 item_string, item_imports = serializer_factory(item).serialize()
204 imports.update(item_imports)
205 strings.append(item_string)
206 # When len(strings)==0, the empty iterable should be serialized as
207 # "()", not "(,)" because (,) is invalid Python syntax.
208 value = "(%s)" if len(strings) != 1 else "(%s,)"
209 return value % (", ".join(strings)), imports
212class ModelFieldSerializer(DeconstructableSerializer):
213 def serialize(self):
214 attr_name, path, args, kwargs = self.value.deconstruct()
215 return self.serialize_deconstructed(path, args, kwargs)
218class ModelManagerSerializer(DeconstructableSerializer):
219 def serialize(self):
220 as_manager, manager_path, qs_path, args, kwargs = self.value.deconstruct()
221 if as_manager:
222 name, imports = self._serialize_path(qs_path)
223 return f"{name}.as_manager()", imports
224 else:
225 return self.serialize_deconstructed(manager_path, args, kwargs)
228class OperationSerializer(BaseSerializer):
229 def serialize(self):
230 from plain.models.migrations.writer import OperationWriter
232 string, imports = OperationWriter(self.value, indentation=0).serialize()
233 # Nested operation, trailing comma is handled in upper OperationWriter._write()
234 return string.rstrip(","), imports
237class PathLikeSerializer(BaseSerializer):
238 def serialize(self):
239 return repr(os.fspath(self.value)), {}
242class PathSerializer(BaseSerializer):
243 def serialize(self):
244 # Convert concrete paths to pure paths to avoid issues with migrations
245 # generated on one platform being used on a different platform.
246 prefix = "Pure" if isinstance(self.value, pathlib.Path) else ""
247 return f"pathlib.{prefix}{self.value!r}", {"import pathlib"}
250class RegexSerializer(BaseSerializer):
251 def serialize(self):
252 regex_pattern, pattern_imports = serializer_factory(
253 self.value.pattern
254 ).serialize()
255 # Turn off default implicit flags (e.g. re.U) because regexes with the
256 # same implicit and explicit flags aren't equal.
257 flags = self.value.flags ^ re.compile("").flags
258 regex_flags, flag_imports = serializer_factory(flags).serialize()
259 imports = {"import re", *pattern_imports, *flag_imports}
260 args = [regex_pattern]
261 if flags:
262 args.append(regex_flags)
263 return "re.compile({})".format(", ".join(args)), imports
266class SequenceSerializer(BaseSequenceSerializer):
267 def _format(self):
268 return "[%s]"
271class SetSerializer(BaseSequenceSerializer):
272 def _format(self):
273 # Serialize as a set literal except when value is empty because {}
274 # is an empty dict.
275 return "{%s}" if self.value else "set(%s)"
278class SettingsReferenceSerializer(BaseSerializer):
279 def serialize(self):
280 return f"settings.{self.value.setting_name}", {
281 "from plain.runtime import settings"
282 }
285class TupleSerializer(BaseSequenceSerializer):
286 def _format(self):
287 # When len(value)==0, the empty tuple should be serialized as "()",
288 # not "(,)" because (,) is invalid Python syntax.
289 return "(%s)" if len(self.value) != 1 else "(%s,)"
292class TypeSerializer(BaseSerializer):
293 def serialize(self):
294 special_cases = [
295 (models.Model, "models.Model", ["from plain import models"]),
296 (types.NoneType, "types.NoneType", ["import types"]),
297 ]
298 for case, string, imports in special_cases:
299 if case is self.value:
300 return string, set(imports)
301 if hasattr(self.value, "__module__"):
302 module = self.value.__module__
303 if module == builtins.__name__:
304 return self.value.__name__, set()
305 else:
306 return f"{module}.{self.value.__qualname__}", {f"import {module}"}
309class UUIDSerializer(BaseSerializer):
310 def serialize(self):
311 return f"uuid.{repr(self.value)}", {"import uuid"}
314class Serializer:
315 _registry = {
316 # Some of these are order-dependent.
317 frozenset: FrozensetSerializer,
318 list: SequenceSerializer,
319 set: SetSerializer,
320 tuple: TupleSerializer,
321 dict: DictionarySerializer,
322 models.Choices: ChoicesSerializer,
323 enum.Enum: EnumSerializer,
324 datetime.datetime: DatetimeDatetimeSerializer,
325 (datetime.date, datetime.timedelta, datetime.time): DateTimeSerializer,
326 SettingsReference: SettingsReferenceSerializer,
327 float: FloatSerializer,
328 (bool, int, types.NoneType, bytes, str, range): BaseSimpleSerializer,
329 decimal.Decimal: DecimalSerializer,
330 (functools.partial, functools.partialmethod): FunctoolsPartialSerializer,
331 (
332 types.FunctionType,
333 types.BuiltinFunctionType,
334 types.MethodType,
335 ): FunctionTypeSerializer,
336 collections.abc.Iterable: IterableSerializer,
337 (COMPILED_REGEX_TYPE, RegexObject): RegexSerializer,
338 uuid.UUID: UUIDSerializer,
339 pathlib.PurePath: PathSerializer,
340 os.PathLike: PathLikeSerializer,
341 }
343 @classmethod
344 def register(cls, type_, serializer):
345 if not issubclass(serializer, BaseSerializer):
346 raise ValueError(
347 f"'{serializer.__name__}' must inherit from 'BaseSerializer'."
348 )
349 cls._registry[type_] = serializer
351 @classmethod
352 def unregister(cls, type_):
353 cls._registry.pop(type_)
356def serializer_factory(value):
357 if isinstance(value, Promise):
358 value = str(value)
359 elif isinstance(value, LazyObject):
360 # The unwrapped value is returned as the first item of the arguments
361 # tuple.
362 value = value.__reduce__()[1][0]
364 if isinstance(value, models.Field):
365 return ModelFieldSerializer(value)
366 if isinstance(value, models.manager.BaseManager):
367 return ModelManagerSerializer(value)
368 if isinstance(value, Operation):
369 return OperationSerializer(value)
370 if isinstance(value, type):
371 return TypeSerializer(value)
372 # Anything that knows how to deconstruct itself.
373 if hasattr(value, "deconstruct"):
374 return DeconstructableSerializer(value)
375 for type_, serializer_cls in Serializer._registry.items():
376 if isinstance(value, type_):
377 return serializer_cls(value)
378 raise ValueError(
379 f"Cannot serialize: {value!r}\nThere are some values Plain cannot serialize into "
380 "migration files."
381 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import copy
2from collections import defaultdict
3from contextlib import contextmanager
4from functools import partial
6from plain import models
7from plain.exceptions import FieldDoesNotExist
8from plain.models.fields import NOT_PROVIDED
9from plain.models.fields.related import RECURSIVE_RELATIONSHIP_CONSTANT
10from plain.models.migrations.utils import field_is_referenced, get_references
11from plain.models.options import DEFAULT_NAMES
12from plain.models.utils import make_model_tuple
13from plain.packages import PackageConfig
14from plain.packages.registry import Packages
15from plain.packages.registry import packages as global_packages
16from plain.runtime import settings
17from plain.utils.functional import cached_property
18from plain.utils.module_loading import import_string
20from .exceptions import InvalidBasesError
21from .utils import resolve_relation
24def _get_package_label_and_model_name(model, package_label=""):
25 if isinstance(model, str):
26 split = model.split(".", 1)
27 return tuple(split) if len(split) == 2 else (package_label, split[0])
28 else:
29 return model._meta.package_label, model._meta.model_name
32def _get_related_models(m):
33 """Return all models that have a direct relationship to the given model."""
34 related_models = [
35 subclass
36 for subclass in m.__subclasses__()
37 if issubclass(subclass, models.Model)
38 ]
39 related_fields_models = set()
40 for f in m._meta.get_fields(include_parents=True, include_hidden=True):
41 if (
42 f.is_relation
43 and f.related_model is not None
44 and not isinstance(f.related_model, str)
45 ):
46 related_fields_models.add(f.model)
47 related_models.append(f.related_model)
48 return related_models
51def get_related_models_tuples(model):
52 """
53 Return a list of typical (package_label, model_name) tuples for all related
54 models for the given model.
55 """
56 return {
57 (rel_mod._meta.package_label, rel_mod._meta.model_name)
58 for rel_mod in _get_related_models(model)
59 }
62def get_related_models_recursive(model):
63 """
64 Return all models that have a direct or indirect relationship
65 to the given model.
67 Relationships are either defined by explicit relational fields, like
68 ForeignKey, ManyToManyField or OneToOneField, or by inheriting from another
69 model (a superclass is related to its subclasses, but not vice versa). Note,
70 however, that a model inheriting from a concrete model is also related to
71 its superclass through the implicit *_ptr OneToOneField on the subclass.
72 """
73 seen = set()
74 queue = _get_related_models(model)
75 for rel_mod in queue:
76 rel_package_label, rel_model_name = (
77 rel_mod._meta.package_label,
78 rel_mod._meta.model_name,
79 )
80 if (rel_package_label, rel_model_name) in seen:
81 continue
82 seen.add((rel_package_label, rel_model_name))
83 queue.extend(_get_related_models(rel_mod))
84 return seen - {(model._meta.package_label, model._meta.model_name)}
87class ProjectState:
88 """
89 Represent the entire project's overall state. This is the item that is
90 passed around - do it here rather than at the app level so that cross-app
91 FKs/etc. resolve properly.
92 """
94 def __init__(self, models=None, real_packages=None):
95 self.models = models or {}
96 # Packages to include from main registry, usually unmigrated ones
97 if real_packages is None:
98 real_packages = set()
99 else:
100 assert isinstance(real_packages, set)
101 self.real_packages = real_packages
102 self.is_delayed = False
103 # {remote_model_key: {model_key: {field_name: field}}}
104 self._relations = None
106 @property
107 def relations(self):
108 if self._relations is None:
109 self.resolve_fields_and_relations()
110 return self._relations
112 def add_model(self, model_state):
113 model_key = model_state.package_label, model_state.name_lower
114 self.models[model_key] = model_state
115 if self._relations is not None:
116 self.resolve_model_relations(model_key)
117 if "packages" in self.__dict__: # hasattr would cache the property
118 self.reload_model(*model_key)
120 def remove_model(self, package_label, model_name):
121 model_key = package_label, model_name
122 del self.models[model_key]
123 if self._relations is not None:
124 self._relations.pop(model_key, None)
125 # Call list() since _relations can change size during iteration.
126 for related_model_key, model_relations in list(self._relations.items()):
127 model_relations.pop(model_key, None)
128 if not model_relations:
129 del self._relations[related_model_key]
130 if "packages" in self.__dict__: # hasattr would cache the property
131 self.packages.unregister_model(*model_key)
132 # Need to do this explicitly since unregister_model() doesn't clear
133 # the cache automatically (#24513)
134 self.packages.clear_cache()
136 def rename_model(self, package_label, old_name, new_name):
137 # Add a new model.
138 old_name_lower = old_name.lower()
139 new_name_lower = new_name.lower()
140 renamed_model = self.models[package_label, old_name_lower].clone()
141 renamed_model.name = new_name
142 self.models[package_label, new_name_lower] = renamed_model
143 # Repoint all fields pointing to the old model to the new one.
144 old_model_tuple = (package_label, old_name_lower)
145 new_remote_model = f"{package_label}.{new_name}"
146 to_reload = set()
147 for model_state, name, field, reference in get_references(
148 self, old_model_tuple
149 ):
150 changed_field = None
151 if reference.to:
152 changed_field = field.clone()
153 changed_field.remote_field.model = new_remote_model
154 if reference.through:
155 if changed_field is None:
156 changed_field = field.clone()
157 changed_field.remote_field.through = new_remote_model
158 if changed_field:
159 model_state.fields[name] = changed_field
160 to_reload.add((model_state.package_label, model_state.name_lower))
161 if self._relations is not None:
162 old_name_key = package_label, old_name_lower
163 new_name_key = package_label, new_name_lower
164 if old_name_key in self._relations:
165 self._relations[new_name_key] = self._relations.pop(old_name_key)
166 for model_relations in self._relations.values():
167 if old_name_key in model_relations:
168 model_relations[new_name_key] = model_relations.pop(old_name_key)
169 # Reload models related to old model before removing the old model.
170 self.reload_models(to_reload, delay=True)
171 # Remove the old model.
172 self.remove_model(package_label, old_name_lower)
173 self.reload_model(package_label, new_name_lower, delay=True)
175 def alter_model_options(self, package_label, model_name, options, option_keys=None):
176 model_state = self.models[package_label, model_name]
177 model_state.options = {**model_state.options, **options}
178 if option_keys:
179 for key in option_keys:
180 if key not in options:
181 model_state.options.pop(key, False)
182 self.reload_model(package_label, model_name, delay=True)
184 def remove_model_options(
185 self, package_label, model_name, option_name, value_to_remove
186 ):
187 model_state = self.models[package_label, model_name]
188 if objs := model_state.options.get(option_name):
189 model_state.options[option_name] = [
190 obj for obj in objs if tuple(obj) != tuple(value_to_remove)
191 ]
192 self.reload_model(package_label, model_name, delay=True)
194 def alter_model_managers(self, package_label, model_name, managers):
195 model_state = self.models[package_label, model_name]
196 model_state.managers = list(managers)
197 self.reload_model(package_label, model_name, delay=True)
199 def _append_option(self, package_label, model_name, option_name, obj):
200 model_state = self.models[package_label, model_name]
201 model_state.options[option_name] = [*model_state.options[option_name], obj]
202 self.reload_model(package_label, model_name, delay=True)
204 def _remove_option(self, package_label, model_name, option_name, obj_name):
205 model_state = self.models[package_label, model_name]
206 objs = model_state.options[option_name]
207 model_state.options[option_name] = [obj for obj in objs if obj.name != obj_name]
208 self.reload_model(package_label, model_name, delay=True)
210 def add_index(self, package_label, model_name, index):
211 self._append_option(package_label, model_name, "indexes", index)
213 def remove_index(self, package_label, model_name, index_name):
214 self._remove_option(package_label, model_name, "indexes", index_name)
216 def rename_index(self, package_label, model_name, old_index_name, new_index_name):
217 model_state = self.models[package_label, model_name]
218 objs = model_state.options["indexes"]
220 new_indexes = []
221 for obj in objs:
222 if obj.name == old_index_name:
223 obj = obj.clone()
224 obj.name = new_index_name
225 new_indexes.append(obj)
227 model_state.options["indexes"] = new_indexes
228 self.reload_model(package_label, model_name, delay=True)
230 def add_constraint(self, package_label, model_name, constraint):
231 self._append_option(package_label, model_name, "constraints", constraint)
233 def remove_constraint(self, package_label, model_name, constraint_name):
234 self._remove_option(package_label, model_name, "constraints", constraint_name)
236 def add_field(self, package_label, model_name, name, field, preserve_default):
237 # If preserve default is off, don't use the default for future state.
238 if not preserve_default:
239 field = field.clone()
240 field.default = NOT_PROVIDED
241 else:
242 field = field
243 model_key = package_label, model_name
244 self.models[model_key].fields[name] = field
245 if self._relations is not None:
246 self.resolve_model_field_relations(model_key, name, field)
247 # Delay rendering of relationships if it's not a relational field.
248 delay = not field.is_relation
249 self.reload_model(*model_key, delay=delay)
251 def remove_field(self, package_label, model_name, name):
252 model_key = package_label, model_name
253 model_state = self.models[model_key]
254 old_field = model_state.fields.pop(name)
255 if self._relations is not None:
256 self.resolve_model_field_relations(model_key, name, old_field)
257 # Delay rendering of relationships if it's not a relational field.
258 delay = not old_field.is_relation
259 self.reload_model(*model_key, delay=delay)
261 def alter_field(self, package_label, model_name, name, field, preserve_default):
262 if not preserve_default:
263 field = field.clone()
264 field.default = NOT_PROVIDED
265 else:
266 field = field
267 model_key = package_label, model_name
268 fields = self.models[model_key].fields
269 if self._relations is not None:
270 old_field = fields.pop(name)
271 if old_field.is_relation:
272 self.resolve_model_field_relations(model_key, name, old_field)
273 fields[name] = field
274 if field.is_relation:
275 self.resolve_model_field_relations(model_key, name, field)
276 else:
277 fields[name] = field
278 # TODO: investigate if old relational fields must be reloaded or if
279 # it's sufficient if the new field is (#27737).
280 # Delay rendering of relationships if it's not a relational field and
281 # not referenced by a foreign key.
282 delay = not field.is_relation and not field_is_referenced(
283 self, model_key, (name, field)
284 )
285 self.reload_model(*model_key, delay=delay)
287 def rename_field(self, package_label, model_name, old_name, new_name):
288 model_key = package_label, model_name
289 model_state = self.models[model_key]
290 # Rename the field.
291 fields = model_state.fields
292 try:
293 found = fields.pop(old_name)
294 except KeyError:
295 raise FieldDoesNotExist(
296 f"{package_label}.{model_name} has no field named '{old_name}'"
297 )
298 fields[new_name] = found
299 for field in fields.values():
300 # Fix from_fields to refer to the new field.
301 from_fields = getattr(field, "from_fields", None)
302 if from_fields:
303 field.from_fields = tuple(
304 [
305 new_name if from_field_name == old_name else from_field_name
306 for from_field_name in from_fields
307 ]
308 )
310 # Fix to_fields to refer to the new field.
311 delay = True
312 references = get_references(self, model_key, (old_name, found))
313 for *_, field, reference in references:
314 delay = False
315 if reference.to:
316 remote_field, to_fields = reference.to
317 if getattr(remote_field, "field_name", None) == old_name:
318 remote_field.field_name = new_name
319 if to_fields:
320 field.to_fields = tuple(
321 [
322 new_name if to_field_name == old_name else to_field_name
323 for to_field_name in to_fields
324 ]
325 )
326 if self._relations is not None:
327 old_name_lower = old_name.lower()
328 new_name_lower = new_name.lower()
329 for to_model in self._relations.values():
330 if old_name_lower in to_model[model_key]:
331 field = to_model[model_key].pop(old_name_lower)
332 field.name = new_name_lower
333 to_model[model_key][new_name_lower] = field
334 self.reload_model(*model_key, delay=delay)
336 def _find_reload_model(self, package_label, model_name, delay=False):
337 if delay:
338 self.is_delayed = True
340 related_models = set()
342 try:
343 old_model = self.packages.get_model(package_label, model_name)
344 except LookupError:
345 pass
346 else:
347 # Get all relations to and from the old model before reloading,
348 # as _meta.packages may change
349 if delay:
350 related_models = get_related_models_tuples(old_model)
351 else:
352 related_models = get_related_models_recursive(old_model)
354 # Get all outgoing references from the model to be rendered
355 model_state = self.models[(package_label, model_name)]
356 # Directly related models are the models pointed to by ForeignKeys,
357 # OneToOneFields, and ManyToManyFields.
358 direct_related_models = set()
359 for field in model_state.fields.values():
360 if field.is_relation:
361 if field.remote_field.model == RECURSIVE_RELATIONSHIP_CONSTANT:
362 continue
363 rel_package_label, rel_model_name = _get_package_label_and_model_name(
364 field.related_model, package_label
365 )
366 direct_related_models.add((rel_package_label, rel_model_name.lower()))
368 # For all direct related models recursively get all related models.
369 related_models.update(direct_related_models)
370 for rel_package_label, rel_model_name in direct_related_models:
371 try:
372 rel_model = self.packages.get_model(rel_package_label, rel_model_name)
373 except LookupError:
374 pass
375 else:
376 if delay:
377 related_models.update(get_related_models_tuples(rel_model))
378 else:
379 related_models.update(get_related_models_recursive(rel_model))
381 # Include the model itself
382 related_models.add((package_label, model_name))
384 return related_models
386 def reload_model(self, package_label, model_name, delay=False):
387 if "packages" in self.__dict__: # hasattr would cache the property
388 related_models = self._find_reload_model(package_label, model_name, delay)
389 self._reload(related_models)
391 def reload_models(self, models, delay=True):
392 if "packages" in self.__dict__: # hasattr would cache the property
393 related_models = set()
394 for package_label, model_name in models:
395 related_models.update(
396 self._find_reload_model(package_label, model_name, delay)
397 )
398 self._reload(related_models)
400 def _reload(self, related_models):
401 # Unregister all related models
402 with self.packages.bulk_update():
403 for rel_package_label, rel_model_name in related_models:
404 self.packages.unregister_model(rel_package_label, rel_model_name)
406 states_to_be_rendered = []
407 # Gather all models states of those models that will be rerendered.
408 # This includes:
409 # 1. All related models of unmigrated packages
410 for model_state in self.packages.real_models:
411 if (model_state.package_label, model_state.name_lower) in related_models:
412 states_to_be_rendered.append(model_state)
414 # 2. All related models of migrated packages
415 for rel_package_label, rel_model_name in related_models:
416 try:
417 model_state = self.models[rel_package_label, rel_model_name]
418 except KeyError:
419 pass
420 else:
421 states_to_be_rendered.append(model_state)
423 # Render all models
424 self.packages.render_multiple(states_to_be_rendered)
426 def update_model_field_relation(
427 self,
428 model,
429 model_key,
430 field_name,
431 field,
432 concretes,
433 ):
434 remote_model_key = resolve_relation(model, *model_key)
435 if (
436 remote_model_key[0] not in self.real_packages
437 and remote_model_key in concretes
438 ):
439 remote_model_key = concretes[remote_model_key]
440 relations_to_remote_model = self._relations[remote_model_key]
441 if field_name in self.models[model_key].fields:
442 # The assert holds because it's a new relation, or an altered
443 # relation, in which case references have been removed by
444 # alter_field().
445 assert field_name not in relations_to_remote_model[model_key]
446 relations_to_remote_model[model_key][field_name] = field
447 else:
448 del relations_to_remote_model[model_key][field_name]
449 if not relations_to_remote_model[model_key]:
450 del relations_to_remote_model[model_key]
452 def resolve_model_field_relations(
453 self,
454 model_key,
455 field_name,
456 field,
457 concretes=None,
458 ):
459 remote_field = field.remote_field
460 if not remote_field:
461 return
462 if concretes is None:
463 concretes = self._get_concrete_models_mapping()
465 self.update_model_field_relation(
466 remote_field.model,
467 model_key,
468 field_name,
469 field,
470 concretes,
471 )
473 through = getattr(remote_field, "through", None)
474 if not through:
475 return
476 self.update_model_field_relation(
477 through, model_key, field_name, field, concretes
478 )
480 def resolve_model_relations(self, model_key, concretes=None):
481 if concretes is None:
482 concretes = self._get_concrete_models_mapping()
484 model_state = self.models[model_key]
485 for field_name, field in model_state.fields.items():
486 self.resolve_model_field_relations(model_key, field_name, field, concretes)
488 def resolve_fields_and_relations(self):
489 # Resolve fields.
490 for model_state in self.models.values():
491 for field_name, field in model_state.fields.items():
492 field.name = field_name
493 # Resolve relations.
494 # {remote_model_key: {model_key: {field_name: field}}}
495 self._relations = defaultdict(partial(defaultdict, dict))
496 concretes = self._get_concrete_models_mapping()
498 for model_key in concretes:
499 self.resolve_model_relations(model_key, concretes)
501 def get_concrete_model_key(self, model):
502 (concrete_models_mapping,) = self._get_concrete_models_mapping()
503 model_key = make_model_tuple(model)
504 return concrete_models_mapping[model_key]
506 def _get_concrete_models_mapping(self):
507 concrete_models_mapping = {}
508 for model_key, model_state in self.models.items():
509 concrete_models_mapping[model_key] = model_key
510 return concrete_models_mapping
512 def clone(self):
513 """Return an exact copy of this ProjectState."""
514 new_state = ProjectState(
515 models={k: v.clone() for k, v in self.models.items()},
516 real_packages=self.real_packages,
517 )
518 if "packages" in self.__dict__:
519 new_state.packages = self.packages.clone()
520 new_state.is_delayed = self.is_delayed
521 return new_state
523 def clear_delayed_packages_cache(self):
524 if self.is_delayed and "packages" in self.__dict__:
525 del self.__dict__["packages"]
527 @cached_property
528 def packages(self):
529 return StatePackages(self.real_packages, self.models)
531 @classmethod
532 def from_packages(cls, packages):
533 """Take an Packages and return a ProjectState matching it."""
534 app_models = {}
535 for model in packages.get_models(include_swapped=True):
536 model_state = ModelState.from_model(model)
537 app_models[(model_state.package_label, model_state.name_lower)] = (
538 model_state
539 )
540 return cls(app_models)
542 def __eq__(self, other):
543 return self.models == other.models and self.real_packages == other.real_packages
546class PackageConfigStub(PackageConfig):
547 """Stub of an PackageConfig. Only provides a label and a dict of models."""
549 def __init__(self, label):
550 self.packages = None
551 self.models = {}
552 # Package-label and package-name are not the same thing, so technically passing
553 # in the label here is wrong. In practice, migrations don't care about
554 # the package name, but we need something unique, and the label works fine.
555 self.label = label
556 self.name = label
558 def import_models(self):
559 self.models = self.packages.all_models[self.label]
562class StatePackages(Packages):
563 """
564 Subclass of the global Packages registry class to better handle dynamic model
565 additions and removals.
566 """
568 def __init__(self, real_packages, models, ignore_swappable=False):
569 # Any packages in self.real_packages should have all their models included
570 # in the render. We don't use the original model instances as there
571 # are some variables that refer to the Packages object.
572 # FKs/M2Ms from real packages are also not included as they just
573 # mess things up with partial states (due to lack of dependencies)
574 self.real_models = []
575 for package_label in real_packages:
576 app = global_packages.get_package_config(package_label)
577 for model in app.get_models():
578 self.real_models.append(ModelState.from_model(model, exclude_rels=True))
579 # Populate the app registry with a stub for each application.
580 package_labels = {model_state.package_label for model_state in models.values()}
581 package_configs = [
582 PackageConfigStub(label)
583 for label in sorted([*real_packages, *package_labels])
584 ]
585 super().__init__(package_configs)
587 # These locks get in the way of copying as implemented in clone(),
588 # which is called whenever Plain duplicates a StatePackages before
589 # updating it.
590 self._lock = None
592 self.render_multiple([*models.values(), *self.real_models])
594 # There shouldn't be any operations pending at this point.
595 from plain.models.preflight import _check_lazy_references
597 ignore = (
598 {make_model_tuple(settings.AUTH_USER_MODEL)} if ignore_swappable else set()
599 )
600 errors = _check_lazy_references(self, ignore=ignore)
601 if errors:
602 raise ValueError("\n".join(error.msg for error in errors))
604 @contextmanager
605 def bulk_update(self):
606 # Avoid clearing each model's cache for each change. Instead, clear
607 # all caches when we're finished updating the model instances.
608 ready = self.ready
609 self.ready = False
610 try:
611 yield
612 finally:
613 self.ready = ready
614 self.clear_cache()
616 def render_multiple(self, model_states):
617 # We keep trying to render the models in a loop, ignoring invalid
618 # base errors, until the size of the unrendered models doesn't
619 # decrease by at least one, meaning there's a base dependency loop/
620 # missing base.
621 if not model_states:
622 return
623 # Prevent that all model caches are expired for each render.
624 with self.bulk_update():
625 unrendered_models = model_states
626 while unrendered_models:
627 new_unrendered_models = []
628 for model in unrendered_models:
629 try:
630 model.render(self)
631 except InvalidBasesError:
632 new_unrendered_models.append(model)
633 if len(new_unrendered_models) == len(unrendered_models):
634 raise InvalidBasesError(
635 f"Cannot resolve bases for {new_unrendered_models!r}\nThis can happen if you are "
636 "inheriting models from an app with migrations (e.g. "
637 "contrib.auth)\n in an app with no migrations"
638 )
639 unrendered_models = new_unrendered_models
641 def clone(self):
642 """Return a clone of this registry."""
643 clone = StatePackages([], {})
644 clone.all_models = copy.deepcopy(self.all_models)
646 for package_label in self.package_configs:
647 package_config = PackageConfigStub(package_label)
648 package_config.packages = clone
649 package_config.import_models()
650 clone.package_configs[package_label] = package_config
652 # No need to actually clone them, they'll never change
653 clone.real_models = self.real_models
654 return clone
656 def register_model(self, package_label, model):
657 self.all_models[package_label][model._meta.model_name] = model
658 if package_label not in self.package_configs:
659 self.package_configs[package_label] = PackageConfigStub(package_label)
660 self.package_configs[package_label].packages = self
661 self.package_configs[package_label].models[model._meta.model_name] = model
662 self.do_pending_operations(model)
663 self.clear_cache()
665 def unregister_model(self, package_label, model_name):
666 try:
667 del self.all_models[package_label][model_name]
668 del self.package_configs[package_label].models[model_name]
669 except KeyError:
670 pass
673class ModelState:
674 """
675 Represent a Plain Model. Don't use the actual Model class as it's not
676 designed to have its options changed - instead, mutate this one and then
677 render it into a Model as required.
679 Note that while you are allowed to mutate .fields, you are not allowed
680 to mutate the Field instances inside there themselves - you must instead
681 assign new ones, as these are not detached during a clone.
682 """
684 def __init__(
685 self, package_label, name, fields, options=None, bases=None, managers=None
686 ):
687 self.package_label = package_label
688 self.name = name
689 self.fields = dict(fields)
690 self.options = options or {}
691 self.options.setdefault("indexes", [])
692 self.options.setdefault("constraints", [])
693 self.bases = bases or (models.Model,)
694 self.managers = managers or []
695 for name, field in self.fields.items():
696 # Sanity-check that fields are NOT already bound to a model.
697 if hasattr(field, "model"):
698 raise ValueError(
699 f'ModelState.fields cannot be bound to a model - "{name}" is.'
700 )
701 # Sanity-check that relation fields are NOT referring to a model class.
702 if field.is_relation and hasattr(field.related_model, "_meta"):
703 raise ValueError(
704 f'ModelState.fields cannot refer to a model class - "{name}.to" does. '
705 "Use a string reference instead."
706 )
707 if field.many_to_many and hasattr(field.remote_field.through, "_meta"):
708 raise ValueError(
709 f'ModelState.fields cannot refer to a model class - "{name}.through" '
710 "does. Use a string reference instead."
711 )
712 # Sanity-check that indexes have their name set.
713 for index in self.options["indexes"]:
714 if not index.name:
715 raise ValueError(
716 "Indexes passed to ModelState require a name attribute. "
717 f"{index!r} doesn't have one."
718 )
720 @cached_property
721 def name_lower(self):
722 return self.name.lower()
724 def get_field(self, field_name):
725 if field_name == "_order":
726 field_name = self.options.get("order_with_respect_to", field_name)
727 return self.fields[field_name]
729 @classmethod
730 def from_model(cls, model, exclude_rels=False):
731 """Given a model, return a ModelState representing it."""
732 # Deconstruct the fields
733 fields = []
734 for field in model._meta.local_fields:
735 if getattr(field, "remote_field", None) and exclude_rels:
736 continue
737 if isinstance(field, models.OrderWrt):
738 continue
739 name = field.name
740 try:
741 fields.append((name, field.clone()))
742 except TypeError as e:
743 raise TypeError(
744 f"Couldn't reconstruct field {name} on {model._meta.label}: {e}"
745 )
746 if not exclude_rels:
747 for field in model._meta.local_many_to_many:
748 name = field.name
749 try:
750 fields.append((name, field.clone()))
751 except TypeError as e:
752 raise TypeError(
753 f"Couldn't reconstruct m2m field {name} on {model._meta.object_name}: {e}"
754 )
755 # Extract the options
756 options = {}
757 for name in DEFAULT_NAMES:
758 # Ignore some special options
759 if name in ["packages", "package_label"]:
760 continue
761 elif name in model._meta.original_attrs:
762 if name == "indexes":
763 indexes = [idx.clone() for idx in model._meta.indexes]
764 for index in indexes:
765 if not index.name:
766 index.set_name_with_model(model)
767 options["indexes"] = indexes
768 elif name == "constraints":
769 options["constraints"] = [
770 con.clone() for con in model._meta.constraints
771 ]
772 else:
773 options[name] = model._meta.original_attrs[name]
774 # If we're ignoring relationships, remove all field-listing model
775 # options (that option basically just means "make a stub model")
776 if exclude_rels:
777 if "order_with_respect_to" in options:
778 del options["order_with_respect_to"]
779 # Private fields are ignored, so remove options that refer to them.
780 elif options.get("order_with_respect_to") in {
781 field.name for field in model._meta.private_fields
782 }:
783 del options["order_with_respect_to"]
785 def flatten_bases(model):
786 bases = []
787 for base in model.__bases__:
788 if hasattr(base, "_meta") and base._meta.abstract:
789 bases.extend(flatten_bases(base))
790 else:
791 bases.append(base)
792 return bases
794 # We can't rely on __mro__ directly because we only want to flatten
795 # abstract models and not the whole tree. However by recursing on
796 # __bases__ we may end up with duplicates and ordering issues, we
797 # therefore discard any duplicates and reorder the bases according
798 # to their index in the MRO.
799 flattened_bases = sorted(
800 set(flatten_bases(model)), key=lambda x: model.__mro__.index(x)
801 )
803 # Make our record
804 bases = tuple(
805 (base._meta.label_lower if hasattr(base, "_meta") else base)
806 for base in flattened_bases
807 )
808 # Ensure at least one base inherits from models.Model
809 if not any(
810 (isinstance(base, str) or issubclass(base, models.Model)) for base in bases
811 ):
812 bases = (models.Model,)
814 managers = []
815 manager_names = set()
816 default_manager_shim = None
817 for manager in model._meta.managers:
818 if manager.name in manager_names:
819 # Skip overridden managers.
820 continue
821 elif manager.use_in_migrations:
822 # Copy managers usable in migrations.
823 new_manager = copy.copy(manager)
824 new_manager._set_creation_counter()
825 elif manager is model._base_manager or manager is model._default_manager:
826 # Shim custom managers used as default and base managers.
827 new_manager = models.Manager()
828 new_manager.model = manager.model
829 new_manager.name = manager.name
830 if manager is model._default_manager:
831 default_manager_shim = new_manager
832 else:
833 continue
834 manager_names.add(manager.name)
835 managers.append((manager.name, new_manager))
837 # Ignore a shimmed default manager called objects if it's the only one.
838 if managers == [("objects", default_manager_shim)]:
839 managers = []
841 # Construct the new ModelState
842 return cls(
843 model._meta.package_label,
844 model._meta.object_name,
845 fields,
846 options,
847 bases,
848 managers,
849 )
851 def construct_managers(self):
852 """Deep-clone the managers using deconstruction."""
853 # Sort all managers by their creation counter
854 sorted_managers = sorted(self.managers, key=lambda v: v[1].creation_counter)
855 for mgr_name, manager in sorted_managers:
856 as_manager, manager_path, qs_path, args, kwargs = manager.deconstruct()
857 if as_manager:
858 qs_class = import_string(qs_path)
859 yield mgr_name, qs_class.as_manager()
860 else:
861 manager_class = import_string(manager_path)
862 yield mgr_name, manager_class(*args, **kwargs)
864 def clone(self):
865 """Return an exact copy of this ModelState."""
866 return self.__class__(
867 package_label=self.package_label,
868 name=self.name,
869 fields=dict(self.fields),
870 # Since options are shallow-copied here, operations such as
871 # AddIndex must replace their option (e.g 'indexes') rather
872 # than mutating it.
873 options=dict(self.options),
874 bases=self.bases,
875 managers=list(self.managers),
876 )
878 def render(self, packages):
879 """Create a Model object from our current state into the given packages."""
880 # First, make a Meta object
881 meta_contents = {
882 "package_label": self.package_label,
883 "packages": packages,
884 **self.options,
885 }
886 meta = type("Meta", (), meta_contents)
887 # Then, work out our bases
888 try:
889 bases = tuple(
890 (packages.get_model(base) if isinstance(base, str) else base)
891 for base in self.bases
892 )
893 except LookupError:
894 raise InvalidBasesError(
895 f"Cannot resolve one or more bases from {self.bases!r}"
896 )
897 # Clone fields for the body, add other bits.
898 body = {name: field.clone() for name, field in self.fields.items()}
899 body["Meta"] = meta
900 body["__module__"] = "__fake__"
902 # Restore managers
903 body.update(self.construct_managers())
904 # Then, make a Model object (packages.register_model is called in __new__)
905 return type(self.name, bases, body)
907 def get_index_by_name(self, name):
908 for index in self.options["indexes"]:
909 if index.name == name:
910 return index
911 raise ValueError(f"No index named {name} on model {self.name}")
913 def get_constraint_by_name(self, name):
914 for constraint in self.options["constraints"]:
915 if constraint.name == name:
916 return constraint
917 raise ValueError(f"No constraint named {name} on model {self.name}")
919 def __repr__(self):
920 return f"<{self.__class__.__name__}: '{self.package_label}.{self.name}'>"
922 def __eq__(self, other):
923 return (
924 (self.package_label == other.package_label)
925 and (self.name == other.name)
926 and (len(self.fields) == len(other.fields))
927 and all(
928 k1 == k2 and f1.deconstruct()[1:] == f2.deconstruct()[1:]
929 for (k1, f1), (k2, f2) in zip(
930 sorted(self.fields.items()),
931 sorted(other.fields.items()),
932 )
933 )
934 and (self.options == other.options)
935 and (self.bases == other.bases)
936 and (self.managers == other.managers)
937 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
2import re
3from collections import namedtuple
5from plain.models.fields.related import RECURSIVE_RELATIONSHIP_CONSTANT
7FieldReference = namedtuple("FieldReference", "to through")
9COMPILED_REGEX_TYPE = type(re.compile(""))
12class RegexObject:
13 def __init__(self, obj):
14 self.pattern = obj.pattern
15 self.flags = obj.flags
17 def __eq__(self, other):
18 if not isinstance(other, RegexObject):
19 return NotImplemented
20 return self.pattern == other.pattern and self.flags == other.flags
23def get_migration_name_timestamp():
24 return datetime.datetime.now().strftime("%Y%m%d_%H%M")
27def resolve_relation(model, package_label=None, model_name=None):
28 """
29 Turn a model class or model reference string and return a model tuple.
31 package_label and model_name are used to resolve the scope of recursive and
32 unscoped model relationship.
33 """
34 if isinstance(model, str):
35 if model == RECURSIVE_RELATIONSHIP_CONSTANT:
36 if package_label is None or model_name is None:
37 raise TypeError(
38 "package_label and model_name must be provided to resolve "
39 "recursive relationships."
40 )
41 return package_label, model_name
42 if "." in model:
43 package_label, model_name = model.split(".", 1)
44 return package_label, model_name.lower()
45 if package_label is None:
46 raise TypeError(
47 "package_label must be provided to resolve unscoped model relationships."
48 )
49 return package_label, model.lower()
50 return model._meta.package_label, model._meta.model_name
53def field_references(
54 model_tuple,
55 field,
56 reference_model_tuple,
57 reference_field_name=None,
58 reference_field=None,
59):
60 """
61 Return either False or a FieldReference if `field` references provided
62 context.
64 False positives can be returned if `reference_field_name` is provided
65 without `reference_field` because of the introspection limitation it
66 incurs. This should not be an issue when this function is used to determine
67 whether or not an optimization can take place.
68 """
69 remote_field = field.remote_field
70 if not remote_field:
71 return False
72 references_to = None
73 references_through = None
74 if resolve_relation(remote_field.model, *model_tuple) == reference_model_tuple:
75 to_fields = getattr(field, "to_fields", None)
76 if (
77 reference_field_name is None
78 or
79 # Unspecified to_field(s).
80 to_fields is None
81 or
82 # Reference to primary key.
83 (
84 None in to_fields
85 and (reference_field is None or reference_field.primary_key)
86 )
87 or
88 # Reference to field.
89 reference_field_name in to_fields
90 ):
91 references_to = (remote_field, to_fields)
92 through = getattr(remote_field, "through", None)
93 if through and resolve_relation(through, *model_tuple) == reference_model_tuple:
94 through_fields = remote_field.through_fields
95 if (
96 reference_field_name is None
97 or
98 # Unspecified through_fields.
99 through_fields is None
100 or
101 # Reference to field.
102 reference_field_name in through_fields
103 ):
104 references_through = (remote_field, through_fields)
105 if not (references_to or references_through):
106 return False
107 return FieldReference(references_to, references_through)
110def get_references(state, model_tuple, field_tuple=()):
111 """
112 Generator of (model_state, name, field, reference) referencing
113 provided context.
115 If field_tuple is provided only references to this particular field of
116 model_tuple will be generated.
117 """
118 for state_model_tuple, model_state in state.models.items():
119 for name, field in model_state.fields.items():
120 reference = field_references(
121 state_model_tuple, field, model_tuple, *field_tuple
122 )
123 if reference:
124 yield model_state, name, field, reference
127def field_is_referenced(state, model_tuple, field_tuple):
128 """Return whether `field_tuple` is referenced by any state models."""
129 return next(get_references(state, model_tuple, field_tuple), None) is not None
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import os
2import re
3from importlib import import_module
5from plain.models import migrations
6from plain.models.migrations.loader import MigrationLoader
7from plain.models.migrations.serializer import Serializer, serializer_factory
8from plain.packages import packages
9from plain.runtime import __version__
10from plain.utils.inspect import get_func_args
11from plain.utils.module_loading import module_dir
12from plain.utils.timezone import now
15class OperationWriter:
16 def __init__(self, operation, indentation=2):
17 self.operation = operation
18 self.buff = []
19 self.indentation = indentation
21 def serialize(self):
22 def _write(_arg_name, _arg_value):
23 if _arg_name in self.operation.serialization_expand_args and isinstance(
24 _arg_value, list | tuple | dict
25 ):
26 if isinstance(_arg_value, dict):
27 self.feed(f"{_arg_name}={ ")
28 self.indent()
29 for key, value in _arg_value.items():
30 key_string, key_imports = MigrationWriter.serialize(key)
31 arg_string, arg_imports = MigrationWriter.serialize(value)
32 args = arg_string.splitlines()
33 if len(args) > 1:
34 self.feed(f"{key_string}: {args[0]}")
35 for arg in args[1:-1]:
36 self.feed(arg)
37 self.feed(f"{args[-1]},")
38 else:
39 self.feed(f"{key_string}: {arg_string},")
40 imports.update(key_imports)
41 imports.update(arg_imports)
42 self.unindent()
43 self.feed("},")
44 else:
45 self.feed(f"{_arg_name}=[")
46 self.indent()
47 for item in _arg_value:
48 arg_string, arg_imports = MigrationWriter.serialize(item)
49 args = arg_string.splitlines()
50 if len(args) > 1:
51 for arg in args[:-1]:
52 self.feed(arg)
53 self.feed(f"{args[-1]},")
54 else:
55 self.feed(f"{arg_string},")
56 imports.update(arg_imports)
57 self.unindent()
58 self.feed("],")
59 else:
60 arg_string, arg_imports = MigrationWriter.serialize(_arg_value)
61 args = arg_string.splitlines()
62 if len(args) > 1:
63 self.feed(f"{_arg_name}={args[0]}")
64 for arg in args[1:-1]:
65 self.feed(arg)
66 self.feed(f"{args[-1]},")
67 else:
68 self.feed(f"{_arg_name}={arg_string},")
69 imports.update(arg_imports)
71 imports = set()
72 name, args, kwargs = self.operation.deconstruct()
73 operation_args = get_func_args(self.operation.__init__)
75 # See if this operation is in plain.models.migrations. If it is,
76 # We can just use the fact we already have that imported,
77 # otherwise, we need to add an import for the operation class.
78 if getattr(migrations, name, None) == self.operation.__class__:
79 self.feed(f"migrations.{name}(")
80 else:
81 imports.add(f"import {self.operation.__class__.__module__}")
82 self.feed(f"{self.operation.__class__.__module__}.{name}(")
84 self.indent()
86 for i, arg in enumerate(args):
87 arg_value = arg
88 arg_name = operation_args[i]
89 _write(arg_name, arg_value)
91 i = len(args)
92 # Only iterate over remaining arguments
93 for arg_name in operation_args[i:]:
94 if arg_name in kwargs: # Don't sort to maintain signature order
95 arg_value = kwargs[arg_name]
96 _write(arg_name, arg_value)
98 self.unindent()
99 self.feed("),")
100 return self.render(), imports
102 def indent(self):
103 self.indentation += 1
105 def unindent(self):
106 self.indentation -= 1
108 def feed(self, line):
109 self.buff.append(" " * (self.indentation * 4) + line)
111 def render(self):
112 return "\n".join(self.buff)
115class MigrationWriter:
116 """
117 Take a Migration instance and is able to produce the contents
118 of the migration file from it.
119 """
121 def __init__(self, migration, include_header=True):
122 self.migration = migration
123 self.include_header = include_header
124 self.needs_manual_porting = False
126 def as_string(self):
127 """Return a string of the file contents."""
128 items = {
129 "replaces_str": "",
130 "initial_str": "",
131 }
133 imports = set()
135 # Deconstruct operations
136 operations = []
137 for operation in self.migration.operations:
138 operation_string, operation_imports = OperationWriter(operation).serialize()
139 imports.update(operation_imports)
140 operations.append(operation_string)
141 items["operations"] = "\n".join(operations) + "\n" if operations else ""
143 # Format dependencies and write out swappable dependencies right
144 dependencies = []
145 for dependency in self.migration.dependencies:
146 if dependency[0] == "__setting__":
147 dependencies.append(
148 f" migrations.swappable_dependency(settings.{dependency[1]}),"
149 )
150 imports.add("from plain.runtime import settings")
151 else:
152 dependencies.append(f" {self.serialize(dependency)[0]},")
153 items["dependencies"] = "\n".join(dependencies) + "\n" if dependencies else ""
155 # Format imports nicely, swapping imports of functions from migration files
156 # for comments
157 migration_imports = set()
158 for line in list(imports):
159 if re.match(r"^import (.*)\.\d+[^\s]*$", line):
160 migration_imports.add(line.split("import")[1].strip())
161 imports.remove(line)
162 self.needs_manual_porting = True
164 imports.add("from plain.models import migrations")
166 # Sort imports by the package / module to be imported (the part after
167 # "from" in "from ... import ..." or after "import" in "import ...").
168 # First group the "import" statements, then "from ... import ...".
169 sorted_imports = sorted(
170 imports, key=lambda i: (i.split()[0] == "from", i.split()[1])
171 )
172 items["imports"] = "\n".join(sorted_imports) + "\n" if imports else ""
173 if migration_imports:
174 items["imports"] += (
175 "\n\n# Functions from the following migrations need manual "
176 "copying.\n# Move them and any dependencies into this file, "
177 "then update the\n# RunPython operations to refer to the local "
178 "versions:\n# {}"
179 ).format("\n# ".join(sorted(migration_imports)))
180 # If there's a replaces, make a string for it
181 if self.migration.replaces:
182 items["replaces_str"] = (
183 f"\n replaces = {self.serialize(self.migration.replaces)[0]}\n"
184 )
185 # Hinting that goes into comment
186 if self.include_header:
187 items["migration_header"] = MIGRATION_HEADER_TEMPLATE % {
188 "version": __version__,
189 "timestamp": now().strftime("%Y-%m-%d %H:%M"),
190 }
191 else:
192 items["migration_header"] = ""
194 if self.migration.initial:
195 items["initial_str"] = "\n initial = True\n"
197 return MIGRATION_TEMPLATE % items
199 @property
200 def basedir(self):
201 migrations_package_name, _ = MigrationLoader.migrations_module(
202 self.migration.package_label
203 )
205 if migrations_package_name is None:
206 raise ValueError(
207 f"Plain can't create migrations for app '{self.migration.package_label}' because "
208 "migrations have been disabled via the MIGRATION_MODULES "
209 "setting."
210 )
212 # See if we can import the migrations module directly
213 try:
214 migrations_module = import_module(migrations_package_name)
215 except ImportError:
216 pass
217 else:
218 try:
219 return module_dir(migrations_module)
220 except ValueError:
221 pass
223 # Alright, see if it's a direct submodule of the app
224 package_config = packages.get_package_config(self.migration.package_label)
225 (
226 maybe_package_name,
227 _,
228 migrations_package_basename,
229 ) = migrations_package_name.rpartition(".")
230 if package_config.name == maybe_package_name:
231 return os.path.join(package_config.path, migrations_package_basename)
233 # In case of using MIGRATION_MODULES setting and the custom package
234 # doesn't exist, create one, starting from an existing package
235 existing_dirs, missing_dirs = migrations_package_name.split("."), []
236 while existing_dirs:
237 missing_dirs.insert(0, existing_dirs.pop(-1))
238 try:
239 base_module = import_module(".".join(existing_dirs))
240 except (ImportError, ValueError):
241 continue
242 else:
243 try:
244 base_dir = module_dir(base_module)
245 except ValueError:
246 continue
247 else:
248 break
249 else:
250 raise ValueError(
251 "Could not locate an appropriate location to create "
252 f"migrations package {migrations_package_name}. Make sure the toplevel "
253 "package exists and can be imported."
254 )
256 final_dir = os.path.join(base_dir, *missing_dirs)
257 os.makedirs(final_dir, exist_ok=True)
258 for missing_dir in missing_dirs:
259 base_dir = os.path.join(base_dir, missing_dir)
260 with open(os.path.join(base_dir, "__init__.py"), "w"):
261 pass
263 return final_dir
265 @property
266 def filename(self):
267 return f"{self.migration.name}.py"
269 @property
270 def path(self):
271 return os.path.join(self.basedir, self.filename)
273 @classmethod
274 def serialize(cls, value):
275 return serializer_factory(value).serialize()
277 @classmethod
278 def register_serializer(cls, type_, serializer):
279 Serializer.register(type_, serializer)
281 @classmethod
282 def unregister_serializer(cls, type_):
283 Serializer.unregister(type_)
286MIGRATION_HEADER_TEMPLATE = """\
287# Generated by Plain %(version)s on %(timestamp)s
289"""
292MIGRATION_TEMPLATE = """\
293%(migration_header)s%(imports)s
295class Migration(migrations.Migration):
296%(replaces_str)s%(initial_str)s
297 dependencies = [
298%(dependencies)s\
299 ]
301 operations = [
302%(operations)s\
303 ]
304"""
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-17 21:27 -0500
1import importlib.metadata
2import sys
3from importlib.metadata import entry_points
4from pathlib import Path
6from .user_settings import Settings
8try:
9 __version__ = importlib.metadata.version("plain")
10except importlib.metadata.PackageNotFoundError:
11 __version__ = "dev"
14# Made available without setup or settings
15APP_PATH = Path.cwd() / "app"
17# from plain.runtime import settings
18settings = Settings()
21class AppPathNotFound(RuntimeError):
22 pass
25def setup():
26 """
27 Configure the settings (this happens as a side effect of accessing the
28 first setting), configure logging and populate the app registry.
29 """
31 # Packages can hook into the setup process through an entrypoint.
32 for entry_point in entry_points().select(group="plain.setup"):
33 entry_point.load()()
35 from plain.logs import configure_logging
36 from plain.packages import packages
38 if not APP_PATH.exists():
39 raise AppPathNotFound(
40 "No app directory found. Are you sure you're in a Plain project?"
41 )
43 # Automatically put the project dir on the Python path
44 # which doesn't otherwise happen when you run `plain` commands.
45 # This makes "app.<module>" imports and relative imports work.
46 if APP_PATH.parent not in sys.path:
47 sys.path.insert(0, APP_PATH.parent.as_posix())
49 configure_logging(settings.LOGGING)
51 packages.populate(settings.INSTALLED_PACKAGES)
54__all__ = [
55 "setup",
56 "settings",
57 "APP_PATH",
58 "__version__",
59]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-17 22:06 -0500
1"""
2Default Plain settings. Override these with settings in the module pointed to
3by the PLAIN_SETTINGS_MODULE environment variable.
4"""
5from pathlib import Path
7from plain.runtime import APP_PATH as default_app_path
9####################
10# CORE #
11####################
13DEBUG: bool = False
15PLAIN_TEMP_PATH: Path = default_app_path.parent / ".plain"
17# Hosts/domain names that are valid for this site.
18# "*" matches anything, ".example.com" matches example.com and all subdomains
19ALLOWED_HOSTS: list[str] = []
21# Local time zone for this installation. All choices can be found here:
22# https://en.wikipedia.org/wiki/List_of_tz_zones_by_name (although not all
23# systems may support all possibilities). This is interpreted as the default
24# user time zone.
25TIME_ZONE: str = "UTC"
27# Default charset to use for all Response objects, if a MIME type isn't
28# manually specified. It's used to construct the Content-Type header.
29DEFAULT_CHARSET = "utf-8"
31# List of strings representing installed packages.
32INSTALLED_PACKAGES: list[str] = []
34# Whether to append trailing slashes to URLs.
35APPEND_SLASH = True
37# Default headers for all responses.
38DEFAULT_RESPONSE_HEADERS = {
39 # "Content-Security-Policy": "default-src 'self'",
40 # https://hstspreload.org/
41 # "Strict-Transport-Security": "max-age=31536000; includeSubDomains; preload",
42 "Cross-Origin-Opener-Policy": "same-origin",
43 "Referrer-Policy": "same-origin",
44 "X-Content-Type-Options": "nosniff",
45 "X-Frame-Options": "DENY",
46}
48# Whether to redirect all non-HTTPS requests to HTTPS.
49HTTPS_REDIRECT_ENABLED = True
50HTTPS_REDIRECT_EXEMPT = []
51HTTPS_REDIRECT_HOST = None
53# If your Plain app is behind a proxy that sets a header to specify secure
54# connections, AND that proxy ensures that user-submitted headers with the
55# same name are ignored (so that people can't spoof it), set this value to
56# a tuple of (header_name, header_value). For any requests that come in with
57# that header/value, request.is_https() will return True.
58# WARNING! Only set this if you fully understand what you're doing. Otherwise,
59# you may be opening yourself up to a security risk.
60HTTPS_PROXY_HEADER = None
62# Whether to use the X-Forwarded-Host and X-Forwarded-Port headers
63# when determining the host and port for the request.
64USE_X_FORWARDED_HOST = False
65USE_X_FORWARDED_PORT = False
67# A secret key for this particular Plain installation. Used in secret-key
68# hashing algorithms. Set this in your settings, or Plain will complain
69# loudly.
70SECRET_KEY: str
72# List of secret keys used to verify the validity of signatures. This allows
73# secret key rotation.
74SECRET_KEY_FALLBACKS: list[str] = []
76ROOT_URLCONF = "app.urls"
78# List of upload handler classes to be applied in order.
79FILE_UPLOAD_HANDLERS = [
80 "plain.internal.files.uploadhandler.MemoryFileUploadHandler",
81 "plain.internal.files.uploadhandler.TemporaryFileUploadHandler",
82]
84# Maximum size, in bytes, of a request before it will be streamed to the
85# file system instead of into memory.
86FILE_UPLOAD_MAX_MEMORY_SIZE = 2621440 # i.e. 2.5 MB
88# Maximum size in bytes of request data (excluding file uploads) that will be
89# read before a SuspiciousOperation (RequestDataTooBig) is raised.
90DATA_UPLOAD_MAX_MEMORY_SIZE = 2621440 # i.e. 2.5 MB
92# Maximum number of GET/POST parameters that will be read before a
93# SuspiciousOperation (TooManyFieldsSent) is raised.
94DATA_UPLOAD_MAX_NUMBER_FIELDS = 1000
96# Maximum number of files encoded in a multipart upload that will be read
97# before a SuspiciousOperation (TooManyFilesSent) is raised.
98DATA_UPLOAD_MAX_NUMBER_FILES = 100
100# Directory in which upload streamed files will be temporarily saved. A value of
101# `None` will make Plain use the operating system's default temporary directory
102# (i.e. "/tmp" on *nix systems).
103FILE_UPLOAD_TEMP_DIR = None
105# User-defined overrides for error views by status code
106HTTP_ERROR_VIEWS: dict[int] = {}
108##############
109# MIDDLEWARE #
110##############
112# List of middleware to use. Order is important; in the request phase, these
113# middleware will be applied in the order given, and in the response
114# phase the middleware will be applied in reverse order.
115MIDDLEWARE: list[str] = []
117###########
118# SIGNING #
119###########
121COOKIE_SIGNING_BACKEND = "plain.signing.TimestampSigner"
123########
124# CSRF #
125########
127# Settings for CSRF cookie.
128CSRF_COOKIE_NAME = "csrftoken"
129CSRF_COOKIE_AGE = 60 * 60 * 24 * 7 * 52
130CSRF_COOKIE_DOMAIN = None
131CSRF_COOKIE_PATH = "/"
132CSRF_COOKIE_SECURE = True
133CSRF_COOKIE_HTTPONLY = False
134CSRF_COOKIE_SAMESITE = "Lax"
135CSRF_HEADER_NAME = "HTTP_X_CSRFTOKEN"
136CSRF_TRUSTED_ORIGINS: list[str] = []
138###########
139# LOGGING #
140###########
142# Custom logging configuration.
143LOGGING = {}
145###############
146# ASSETS #
147###############
149# Whether to redirect the original asset path to the fingerprinted path.
150ASSETS_REDIRECT_ORIGINAL = True
152# If assets are served by a CDN, use this URL to prefix asset paths.
153# Ex. "https://cdn.example.com/assets/"
154ASSETS_BASE_URL: str = ""
156####################
157# PREFLIGHT CHECKS #
158####################
160# List of all issues generated by system checks that should be silenced. Light
161# issues like warnings, infos or debugs will not generate a message. Silencing
162# serious issues like errors and criticals does not result in hiding the
163# message, but Plain will not stop you from e.g. running server.
164SILENCED_PREFLIGHT_CHECKS = []
166#############
167# Templates #
168#############
170JINJA_LOADER = "jinja2.loaders.FileSystemLoader"
171JINJA_ENVIRONMENT = "plain.templates.jinja.defaults.create_default_environment"
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-17 17:47 -0500
1import importlib
2import json
3import os
4import time
5import types
6import typing
7from pathlib import Path
9from plain.exceptions import ImproperlyConfigured
10from plain.packages import PackageConfig
12ENVIRONMENT_VARIABLE = "PLAIN_SETTINGS_MODULE"
13ENV_SETTINGS_PREFIX = "PLAIN_"
14CUSTOM_SETTINGS_PREFIX = "APP_"
17class Settings:
18 """
19 Settings and configuration for Plain.
21 This class handles loading settings from the module specified by the
22 PLAIN_SETTINGS_MODULE environment variable, as well as from default settings,
23 environment variables, and explicit settings in the settings module.
25 Lazy initialization is implemented to defer loading until settings are first accessed.
26 """
28 def __init__(self, settings_module=None):
29 self._settings_module = settings_module
30 self._settings = {}
31 self._errors = [] # Collect configuration errors
32 self.configured = False
34 def _setup(self):
35 if self.configured:
36 return
37 else:
38 self.configured = True
40 self._settings = {} # Maps setting names to SettingDefinition instances
42 # Determine the settings module
43 if self._settings_module is None:
44 self._settings_module = os.environ.get(ENVIRONMENT_VARIABLE, "app.settings")
46 # First load the global settings from plain
47 self._load_module_settings(
48 importlib.import_module("plain.runtime.global_settings")
49 )
51 # Import the user's settings module
52 try:
53 mod = importlib.import_module(self._settings_module)
54 except ImportError as e:
55 raise ImproperlyConfigured(
56 f"Could not import settings '{self._settings_module}': {e}"
57 )
59 # Keep a reference to the settings.py module path
60 self.path = Path(mod.__file__).resolve()
62 # Load default settings from installed packages
63 self._load_default_settings(mod)
64 # Load environment settings
65 self._load_env_settings()
66 # Load explicit settings from the settings module
67 self._load_explicit_settings(mod)
68 # Check for any required settings that are missing
69 self._check_required_settings()
70 # Check for any collected errors
71 self._raise_errors_if_any()
73 def _load_module_settings(self, module):
74 annotations = getattr(module, "__annotations__", {})
75 settings = dir(module)
77 for setting in settings:
78 if setting.isupper():
79 if setting in self._settings:
80 self._errors.append(f"Duplicate setting '{setting}'.")
81 continue
83 setting_value = getattr(module, setting)
84 self._settings[setting] = SettingDefinition(
85 name=setting,
86 default_value=setting_value,
87 annotation=annotations.get(setting, None),
88 module=module,
89 )
91 # Store any annotations that didn't have a value (these are required settings)
92 for setting, annotation in annotations.items():
93 if setting not in self._settings:
94 self._settings[setting] = SettingDefinition(
95 name=setting,
96 default_value=None,
97 annotation=annotation,
98 module=module,
99 required=True,
100 )
102 def _load_default_settings(self, settings_module):
103 for entry in getattr(settings_module, "INSTALLED_PACKAGES", []):
104 try:
105 if isinstance(entry, PackageConfig):
106 app_settings = entry.module.default_settings
107 else:
108 app_settings = importlib.import_module(f"{entry}.default_settings")
109 except ModuleNotFoundError:
110 continue
112 self._load_module_settings(app_settings)
114 def _load_env_settings(self):
115 env_settings = {
116 k[len(ENV_SETTINGS_PREFIX) :]: v
117 for k, v in os.environ.items()
118 if k.startswith(ENV_SETTINGS_PREFIX) and k.isupper()
119 }
120 for setting, value in env_settings.items():
121 if setting in self._settings:
122 setting_def = self._settings[setting]
123 try:
124 parsed_value = _parse_env_value(value, setting_def.annotation)
125 setting_def.set_value(parsed_value, "env")
126 except ImproperlyConfigured as e:
127 self._errors.append(str(e))
129 def _load_explicit_settings(self, settings_module):
130 for setting in dir(settings_module):
131 if setting.isupper():
132 setting_value = getattr(settings_module, setting)
134 if setting in self._settings:
135 setting_def = self._settings[setting]
136 try:
137 setting_def.set_value(setting_value, "explicit")
138 except ImproperlyConfigured as e:
139 self._errors.append(str(e))
140 continue
142 elif setting.startswith(CUSTOM_SETTINGS_PREFIX):
143 # Accept custom settings prefixed with '{CUSTOM_SETTINGS_PREFIX}'
144 setting_def = SettingDefinition(
145 name=setting,
146 default_value=None,
147 annotation=None,
148 required=False,
149 )
150 try:
151 setting_def.set_value(setting_value, "explicit")
152 except ImproperlyConfigured as e:
153 self._errors.append(str(e))
154 continue
155 self._settings[setting] = setting_def
156 else:
157 # Collect unrecognized settings individually
158 self._errors.append(
159 f"Unknown setting '{setting}'. Custom settings must start with '{CUSTOM_SETTINGS_PREFIX}'."
160 )
162 if hasattr(time, "tzset") and self.TIME_ZONE:
163 zoneinfo_root = Path("/usr/share/zoneinfo")
164 zone_info_file = zoneinfo_root.joinpath(*self.TIME_ZONE.split("/"))
165 if zoneinfo_root.exists() and not zone_info_file.exists():
166 self._errors.append(
167 f"Invalid TIME_ZONE setting '{self.TIME_ZONE}'. Timezone file not found."
168 )
169 else:
170 os.environ["TZ"] = self.TIME_ZONE
171 time.tzset()
173 def _check_required_settings(self):
174 missing = [k for k, v in self._settings.items() if v.required and not v.is_set]
175 if missing:
176 self._errors.append(f"Missing required setting(s): {', '.join(missing)}.")
178 def _raise_errors_if_any(self):
179 if self._errors:
180 errors = ["- " + e for e in self._errors]
181 raise ImproperlyConfigured(
182 "Settings configuration errors:\n" + "\n".join(errors)
183 )
185 def __getattr__(self, name):
186 # Avoid recursion by directly returning internal attributes
187 if not name.isupper():
188 return object.__getattribute__(self, name)
190 self._setup()
192 if name in self._settings:
193 return self._settings[name].value
194 else:
195 raise AttributeError(f"'Settings' object has no attribute '{name}'")
197 def __setattr__(self, name, value):
198 # Handle internal attributes without recursion
199 if not name.isupper():
200 object.__setattr__(self, name, value)
201 else:
202 if name in self._settings:
203 self._settings[name].set_value(value, "runtime")
204 self._raise_errors_if_any()
205 else:
206 object.__setattr__(self, name, value)
208 def __repr__(self):
209 if not self.configured:
210 return "<Settings [Unevaluated]>"
211 return f'<Settings "{self._settings_module}">'
214def _parse_env_value(value, annotation):
215 if not annotation:
216 raise ImproperlyConfigured("Type hint required to set from environment.")
218 if annotation is bool:
219 # Special case for bools
220 return value.lower() in ("true", "1", "yes")
221 elif annotation is str:
222 return value
223 else:
224 # Parse other types using JSON
225 try:
226 return json.loads(value)
227 except json.JSONDecodeError as e:
228 raise ImproperlyConfigured(
229 f"Invalid JSON value for setting: {e.msg}"
230 ) from e
233class SettingDefinition:
234 """Store detailed information about settings."""
236 def __init__(
237 self, name, default_value=None, annotation=None, module=None, required=False
238 ):
239 self.name = name
240 self.default_value = default_value
241 self.annotation = annotation
242 self.module = module
243 self.required = required
244 self.value = default_value
245 self.source = "default" # 'default', 'env', 'explicit', or 'runtime'
246 self.is_set = False # Indicates if the value was set explicitly
248 def set_value(self, value, source):
249 self.check_type(value)
250 self.value = value
251 self.source = source
252 self.is_set = True
254 def check_type(self, obj):
255 if not self.annotation:
256 return
258 if not SettingDefinition._is_instance_of_type(obj, self.annotation):
259 raise ImproperlyConfigured(
260 f"'{self.name}': Expected type {self.annotation}, but got {type(obj)}."
261 )
263 @staticmethod
264 def _is_instance_of_type(value, type_hint) -> bool:
265 # Simple types
266 if isinstance(type_hint, type):
267 return isinstance(value, type_hint)
269 # Union types
270 if (
271 typing.get_origin(type_hint) is typing.Union
272 or typing.get_origin(type_hint) is types.UnionType
273 ):
274 return any(
275 SettingDefinition._is_instance_of_type(value, arg)
276 for arg in typing.get_args(type_hint)
277 )
279 # List types
280 if typing.get_origin(type_hint) is list:
281 return isinstance(value, list) and all(
282 SettingDefinition._is_instance_of_type(
283 item, typing.get_args(type_hint)[0]
284 )
285 for item in value
286 )
288 # Tuple types
289 if typing.get_origin(type_hint) is tuple:
290 return isinstance(value, tuple) and all(
291 SettingDefinition._is_instance_of_type(
292 item, typing.get_args(type_hint)[i]
293 )
294 for i, item in enumerate(value)
295 )
297 raise ValueError(f"Unsupported type hint: {type_hint}")
299 def __str__(self):
300 return f"SettingDefinition(name={self.name}, value={self.value}, source={self.source})"
303class SettingsReference(str):
304 """
305 String subclass which references a current settings value. It's treated as
306 the value in memory but serializes to a settings.NAME attribute reference.
307 """
309 def __new__(self, value, setting_name):
310 return str.__new__(self, value)
312 def __init__(self, value, setting_name):
313 self.setting_name = setting_name
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import logging
2import types
4from plain.exceptions import ImproperlyConfigured
5from plain.logs import log_response
6from plain.runtime import settings
7from plain.signals import request_finished
8from plain.urls import get_resolver, set_urlconf
9from plain.utils.module_loading import import_string
11from .exception import convert_exception_to_response
13logger = logging.getLogger("plain.request")
16# These middleware classes are always used by Plain.
17BUILTIN_MIDDLEWARE = [
18 "plain.internal.middleware.headers.DefaultHeadersMiddleware",
19 "plain.internal.middleware.https.HttpsRedirectMiddleware",
20 "plain.internal.middleware.slash.RedirectSlashMiddleware",
21 "plain.csrf.middleware.CsrfViewMiddleware",
22]
25class BaseHandler:
26 _view_middleware = None
27 _middleware_chain = None
29 def load_middleware(self):
30 """
31 Populate middleware lists from settings.MIDDLEWARE.
33 Must be called after the environment is fixed (see __call__ in subclasses).
34 """
35 self._view_middleware = []
37 get_response = self._get_response
38 handler = convert_exception_to_response(get_response)
40 middlewares = reversed(BUILTIN_MIDDLEWARE + settings.MIDDLEWARE)
42 for middleware_path in middlewares:
43 middleware = import_string(middleware_path)
44 mw_instance = middleware(handler)
46 if mw_instance is None:
47 raise ImproperlyConfigured(
48 f"Middleware factory {middleware_path} returned None."
49 )
51 if hasattr(mw_instance, "process_view"):
52 self._view_middleware.insert(
53 0,
54 mw_instance.process_view,
55 )
57 handler = convert_exception_to_response(mw_instance)
59 # We only assign to this when initialization is complete as it is used
60 # as a flag for initialization being complete.
61 self._middleware_chain = handler
63 def get_response(self, request):
64 """Return a Response object for the given HttpRequest."""
65 # Setup default url resolver for this thread
66 set_urlconf(settings.ROOT_URLCONF)
67 response = self._middleware_chain(request)
68 response._resource_closers.append(request.close)
69 if response.status_code >= 400:
70 log_response(
71 "%s: %s",
72 response.reason_phrase,
73 request.path,
74 response=response,
75 request=request,
76 )
77 return response
79 def _get_response(self, request):
80 """
81 Resolve and call the view, then apply view, exception, and
82 template_response middleware. This method is everything that happens
83 inside the request/response middleware.
84 """
85 response = None
86 callback, callback_args, callback_kwargs = self.resolve_request(request)
88 # Apply view middleware
89 for middleware_method in self._view_middleware:
90 response = middleware_method(
91 request, callback, callback_args, callback_kwargs
92 )
93 if response:
94 break
96 if response is None:
97 response = callback(request, *callback_args, **callback_kwargs)
99 # Complain if the view returned None (a common error).
100 self.check_response(response, callback)
102 return response
104 def resolve_request(self, request):
105 """
106 Retrieve/set the urlconf for the request. Return the view resolved,
107 with its args and kwargs.
108 """
109 # Work out the resolver.
110 if hasattr(request, "urlconf"):
111 urlconf = request.urlconf
112 set_urlconf(urlconf)
113 resolver = get_resolver(urlconf)
114 else:
115 resolver = get_resolver()
116 # Resolve the view, and assign the match object back to the request.
117 resolver_match = resolver.resolve(request.path_info)
118 request.resolver_match = resolver_match
119 return resolver_match
121 def check_response(self, response, callback, name=None):
122 """
123 Raise an error if the view returned None or an uncalled coroutine.
124 """
125 if not name:
126 if isinstance(callback, types.FunctionType): # FBV
127 name = f"The view {callback.__module__}.{callback.__name__}"
128 else: # CBV
129 name = f"The view {callback.__module__}.{callback.__class__.__name__}.__call__"
130 if response is None:
131 raise ValueError(
132 f"{name} didn't return a Response object. It returned None " "instead."
133 )
136def reset_urlconf(sender, **kwargs):
137 """Reset the URLconf after each request is finished."""
138 set_urlconf(None)
141request_finished.connect(reset_urlconf)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import logging
2from functools import wraps
4from plain import signals
5from plain.exceptions import (
6 BadRequest,
7 PermissionDenied,
8 RequestDataTooBig,
9 SuspiciousOperation,
10 TooManyFieldsSent,
11 TooManyFilesSent,
12)
13from plain.http import Http404, ResponseServerError
14from plain.http.multipartparser import MultiPartParserError
15from plain.logs import log_response
16from plain.runtime import settings
17from plain.utils.module_loading import import_string
18from plain.views.errors import ErrorView
21def convert_exception_to_response(get_response):
22 """
23 Wrap the given get_response callable in exception-to-response conversion.
25 All exceptions will be converted. All known 4xx exceptions (Http404,
26 PermissionDenied, MultiPartParserError, SuspiciousOperation) will be
27 converted to the appropriate response, and all other exceptions will be
28 converted to 500 responses.
30 This decorator is automatically applied to all middleware to ensure that
31 no middleware leaks an exception and that the next middleware in the stack
32 can rely on getting a response instead of an exception.
33 """
35 @wraps(get_response)
36 def inner(request):
37 try:
38 response = get_response(request)
39 except Exception as exc:
40 response = response_for_exception(request, exc)
41 return response
43 return inner
46def response_for_exception(request, exc):
47 if isinstance(exc, Http404):
48 response = get_exception_response(request, 404)
50 elif isinstance(exc, PermissionDenied):
51 response = get_exception_response(request, 403)
52 log_response(
53 "Forbidden (Permission denied): %s",
54 request.path,
55 response=response,
56 request=request,
57 exception=exc,
58 )
60 elif isinstance(exc, MultiPartParserError):
61 response = get_exception_response(request, 400)
62 log_response(
63 "Bad request (Unable to parse request body): %s",
64 request.path,
65 response=response,
66 request=request,
67 exception=exc,
68 )
70 elif isinstance(exc, BadRequest):
71 response = get_exception_response(request, 400)
72 log_response(
73 "%s: %s",
74 str(exc),
75 request.path,
76 response=response,
77 request=request,
78 exception=exc,
79 )
80 elif isinstance(exc, SuspiciousOperation):
81 if isinstance(exc, RequestDataTooBig | TooManyFieldsSent | TooManyFilesSent):
82 # POST data can't be accessed again, otherwise the original
83 # exception would be raised.
84 request._mark_post_parse_error()
86 # The request logger receives events for any problematic request
87 # The security logger receives events for all SuspiciousOperations
88 security_logger = logging.getLogger(f"plain.security.{exc.__class__.__name__}")
89 security_logger.error(
90 str(exc),
91 exc_info=exc,
92 extra={"status_code": 400, "request": request},
93 )
94 response = get_exception_response(request, 400)
96 else:
97 signals.got_request_exception.send(sender=None, request=request)
98 response = get_exception_response(request, 500)
99 log_response(
100 "%s: %s",
101 response.reason_phrase,
102 request.path,
103 response=response,
104 request=request,
105 exception=exc,
106 )
108 # Force a TemplateResponse to be rendered.
109 if not getattr(response, "is_rendered", True) and callable(
110 getattr(response, "render", None)
111 ):
112 response = response.render()
114 return response
117def get_exception_response(request, status_code):
118 try:
119 return get_error_view(status_code)(request)
120 except Exception:
121 signals.got_request_exception.send(sender=None, request=request)
122 return handle_uncaught_exception()
125def handle_uncaught_exception():
126 """
127 Processing for any otherwise uncaught exceptions (those that will
128 generate HTTP 500 responses).
129 """
130 return ResponseServerError()
133def get_error_view(status_code):
134 views_by_status = settings.HTTP_ERROR_VIEWS
135 if status_code in views_by_status:
136 view = views_by_status[status_code]
137 if isinstance(view, str):
138 # Import the view if it's a string
139 view = import_string(view)
140 return view.as_view()
142 # Create a standard view for any other status code
143 return ErrorView.as_view(status_code=status_code)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import uuid
2from io import IOBase
4from plain import signals
5from plain.http import HttpRequest, QueryDict, parse_cookie
6from plain.internal.handlers import base
7from plain.utils.encoding import repercent_broken_unicode
8from plain.utils.functional import cached_property
9from plain.utils.regex_helper import _lazy_re_compile
11_slashes_re = _lazy_re_compile(rb"/+")
14class LimitedStream(IOBase):
15 """
16 Wrap another stream to disallow reading it past a number of bytes.
18 Based on the implementation from werkzeug.wsgi.LimitedStream
19 See https://github.com/pallets/werkzeug/blob/dbf78f67/src/werkzeug/wsgi.py#L828
20 """
22 def __init__(self, stream, limit):
23 self._read = stream.read
24 self._readline = stream.readline
25 self._pos = 0
26 self.limit = limit
28 def read(self, size=-1, /):
29 _pos = self._pos
30 limit = self.limit
31 if _pos >= limit:
32 return b""
33 if size == -1 or size is None:
34 size = limit - _pos
35 else:
36 size = min(size, limit - _pos)
37 data = self._read(size)
38 self._pos += len(data)
39 return data
41 def readline(self, size=-1, /):
42 _pos = self._pos
43 limit = self.limit
44 if _pos >= limit:
45 return b""
46 if size == -1 or size is None:
47 size = limit - _pos
48 else:
49 size = min(size, limit - _pos)
50 line = self._readline(size)
51 self._pos += len(line)
52 return line
55class WSGIRequest(HttpRequest):
56 non_picklable_attrs = HttpRequest.non_picklable_attrs | frozenset(["environ"])
57 meta_non_picklable_attrs = frozenset(["wsgi.errors", "wsgi.input"])
59 def __init__(self, environ):
60 # A unique ID we can use to trace this request
61 self.unique_id = str(uuid.uuid4())
63 script_name = get_script_name(environ)
64 # If PATH_INFO is empty (e.g. accessing the SCRIPT_NAME URL without a
65 # trailing slash), operate as if '/' was requested.
66 path_info = get_path_info(environ) or "/"
67 self.environ = environ
68 self.path_info = path_info
69 # be careful to only replace the first slash in the path because of
70 # http://test/something and http://test//something being different as
71 # stated in RFC 3986.
72 self.path = "{}/{}".format(
73 script_name.rstrip("/"), path_info.replace("/", "", 1)
74 )
75 self.META = environ
76 self.META["PATH_INFO"] = path_info
77 self.META["SCRIPT_NAME"] = script_name
78 self.method = environ["REQUEST_METHOD"].upper()
79 # Set content_type, content_params, and encoding.
80 self._set_content_type_params(environ)
81 try:
82 content_length = int(environ.get("CONTENT_LENGTH"))
83 except (ValueError, TypeError):
84 content_length = 0
85 self._stream = LimitedStream(self.environ["wsgi.input"], content_length)
86 self._read_started = False
87 self.resolver_match = None
89 def __getstate__(self):
90 state = super().__getstate__()
91 for attr in self.meta_non_picklable_attrs:
92 if attr in state["META"]:
93 del state["META"][attr]
94 return state
96 def _get_scheme(self):
97 return self.environ.get("wsgi.url_scheme")
99 @cached_property
100 def GET(self):
101 # The WSGI spec says 'QUERY_STRING' may be absent.
102 raw_query_string = get_bytes_from_wsgi(self.environ, "QUERY_STRING", "")
103 return QueryDict(raw_query_string, encoding=self._encoding)
105 def _get_post(self):
106 if not hasattr(self, "_post"):
107 self._load_post_and_files()
108 return self._post
110 def _set_post(self, post):
111 self._post = post
113 @cached_property
114 def COOKIES(self):
115 raw_cookie = get_str_from_wsgi(self.environ, "HTTP_COOKIE", "")
116 return parse_cookie(raw_cookie)
118 @property
119 def FILES(self):
120 if not hasattr(self, "_files"):
121 self._load_post_and_files()
122 return self._files
124 POST = property(_get_post, _set_post)
127class WSGIHandler(base.BaseHandler):
128 request_class = WSGIRequest
130 def __init__(self, *args, **kwargs):
131 super().__init__(*args, **kwargs)
132 self.load_middleware()
134 def __call__(self, environ, start_response):
135 signals.request_started.send(sender=self.__class__, environ=environ)
136 request = self.request_class(environ)
137 response = self.get_response(request)
139 response._handler_class = self.__class__
141 status = "%d %s" % (response.status_code, response.reason_phrase)
142 response_headers = [
143 *response.items(),
144 *(("Set-Cookie", c.output(header="")) for c in response.cookies.values()),
145 ]
146 start_response(status, response_headers)
147 if getattr(response, "file_to_stream", None) is not None and environ.get(
148 "wsgi.file_wrapper"
149 ):
150 # If `wsgi.file_wrapper` is used the WSGI server does not call
151 # .close on the response, but on the file wrapper. Patch it to use
152 # response.close instead which takes care of closing all files.
153 response.file_to_stream.close = response.close
154 response = environ["wsgi.file_wrapper"](
155 response.file_to_stream, response.block_size
156 )
157 return response
160def get_path_info(environ):
161 """Return the HTTP request's PATH_INFO as a string."""
162 path_info = get_bytes_from_wsgi(environ, "PATH_INFO", "/")
164 return repercent_broken_unicode(path_info).decode()
167def get_script_name(environ):
168 """
169 Return the equivalent of the HTTP request's SCRIPT_NAME environment
170 variable. If Apache mod_rewrite is used, return what would have been
171 the script name prior to any rewriting (so it's the script name as seen
172 from the client's perspective).
173 """
174 # If Apache's mod_rewrite had a whack at the URL, Apache set either
175 # SCRIPT_URL or REDIRECT_URL to the full resource URL before applying any
176 # rewrites. Unfortunately not every web server (lighttpd!) passes this
177 # information through all the time, so FORCE_SCRIPT_NAME, above, is still
178 # needed.
179 script_url = get_bytes_from_wsgi(environ, "SCRIPT_URL", "") or get_bytes_from_wsgi(
180 environ, "REDIRECT_URL", ""
181 )
183 if script_url:
184 if b"//" in script_url:
185 # mod_wsgi squashes multiple successive slashes in PATH_INFO,
186 # do the same with script_url before manipulating paths (#17133).
187 script_url = _slashes_re.sub(b"/", script_url)
188 path_info = get_bytes_from_wsgi(environ, "PATH_INFO", "")
189 script_name = script_url.removesuffix(path_info)
190 else:
191 script_name = get_bytes_from_wsgi(environ, "SCRIPT_NAME", "")
193 return script_name.decode()
196def get_bytes_from_wsgi(environ, key, default):
197 """
198 Get a value from the WSGI environ dictionary as bytes.
200 key and default should be strings.
201 """
202 value = environ.get(key, default)
203 # Non-ASCII values in the WSGI environ are arbitrarily decoded with
204 # ISO-8859-1. This is wrong for Plain websites where UTF-8 is the default.
205 # Re-encode to recover the original bytestring.
206 return value.encode("iso-8859-1")
209def get_str_from_wsgi(environ, key, default):
210 """
211 Get a value from the WSGI environ dictionary as str.
213 key and default should be str objects.
214 """
215 value = get_bytes_from_wsgi(environ, key, default)
216 return value.decode(errors="replace")
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Helpers to manipulate deferred DDL statements that might need to be adjusted or
3discarded within when executing a migration.
4"""
5from copy import deepcopy
8class Reference:
9 """Base class that defines the reference interface."""
11 def references_table(self, table):
12 """
13 Return whether or not this instance references the specified table.
14 """
15 return False
17 def references_column(self, table, column):
18 """
19 Return whether or not this instance references the specified column.
20 """
21 return False
23 def rename_table_references(self, old_table, new_table):
24 """
25 Rename all references to the old_name to the new_table.
26 """
27 pass
29 def rename_column_references(self, table, old_column, new_column):
30 """
31 Rename all references to the old_column to the new_column.
32 """
33 pass
35 def __repr__(self):
36 return f"<{self.__class__.__name__} {str(self)!r}>"
38 def __str__(self):
39 raise NotImplementedError(
40 "Subclasses must define how they should be converted to string."
41 )
44class Table(Reference):
45 """Hold a reference to a table."""
47 def __init__(self, table, quote_name):
48 self.table = table
49 self.quote_name = quote_name
51 def references_table(self, table):
52 return self.table == table
54 def rename_table_references(self, old_table, new_table):
55 if self.table == old_table:
56 self.table = new_table
58 def __str__(self):
59 return self.quote_name(self.table)
62class TableColumns(Table):
63 """Base class for references to multiple columns of a table."""
65 def __init__(self, table, columns):
66 self.table = table
67 self.columns = columns
69 def references_column(self, table, column):
70 return self.table == table and column in self.columns
72 def rename_column_references(self, table, old_column, new_column):
73 if self.table == table:
74 for index, column in enumerate(self.columns):
75 if column == old_column:
76 self.columns[index] = new_column
79class Columns(TableColumns):
80 """Hold a reference to one or many columns."""
82 def __init__(self, table, columns, quote_name, col_suffixes=()):
83 self.quote_name = quote_name
84 self.col_suffixes = col_suffixes
85 super().__init__(table, columns)
87 def __str__(self):
88 def col_str(column, idx):
89 col = self.quote_name(column)
90 try:
91 suffix = self.col_suffixes[idx]
92 if suffix:
93 col = f"{col} {suffix}"
94 except IndexError:
95 pass
96 return col
98 return ", ".join(
99 col_str(column, idx) for idx, column in enumerate(self.columns)
100 )
103class IndexName(TableColumns):
104 """Hold a reference to an index name."""
106 def __init__(self, table, columns, suffix, create_index_name):
107 self.suffix = suffix
108 self.create_index_name = create_index_name
109 super().__init__(table, columns)
111 def __str__(self):
112 return self.create_index_name(self.table, self.columns, self.suffix)
115class IndexColumns(Columns):
116 def __init__(self, table, columns, quote_name, col_suffixes=(), opclasses=()):
117 self.opclasses = opclasses
118 super().__init__(table, columns, quote_name, col_suffixes)
120 def __str__(self):
121 def col_str(column, idx):
122 # Index.__init__() guarantees that self.opclasses is the same
123 # length as self.columns.
124 col = f"{self.quote_name(column)} {self.opclasses[idx]}"
125 try:
126 suffix = self.col_suffixes[idx]
127 if suffix:
128 col = f"{col} {suffix}"
129 except IndexError:
130 pass
131 return col
133 return ", ".join(
134 col_str(column, idx) for idx, column in enumerate(self.columns)
135 )
138class ForeignKeyName(TableColumns):
139 """Hold a reference to a foreign key name."""
141 def __init__(
142 self,
143 from_table,
144 from_columns,
145 to_table,
146 to_columns,
147 suffix_template,
148 create_fk_name,
149 ):
150 self.to_reference = TableColumns(to_table, to_columns)
151 self.suffix_template = suffix_template
152 self.create_fk_name = create_fk_name
153 super().__init__(
154 from_table,
155 from_columns,
156 )
158 def references_table(self, table):
159 return super().references_table(table) or self.to_reference.references_table(
160 table
161 )
163 def references_column(self, table, column):
164 return super().references_column(
165 table, column
166 ) or self.to_reference.references_column(table, column)
168 def rename_table_references(self, old_table, new_table):
169 super().rename_table_references(old_table, new_table)
170 self.to_reference.rename_table_references(old_table, new_table)
172 def rename_column_references(self, table, old_column, new_column):
173 super().rename_column_references(table, old_column, new_column)
174 self.to_reference.rename_column_references(table, old_column, new_column)
176 def __str__(self):
177 suffix = self.suffix_template % {
178 "to_table": self.to_reference.table,
179 "to_column": self.to_reference.columns[0],
180 }
181 return self.create_fk_name(self.table, self.columns, suffix)
184class Statement(Reference):
185 """
186 Statement template and formatting parameters container.
188 Allows keeping a reference to a statement without interpolating identifiers
189 that might have to be adjusted if they're referencing a table or column
190 that is removed
191 """
193 def __init__(self, template, **parts):
194 self.template = template
195 self.parts = parts
197 def references_table(self, table):
198 return any(
199 hasattr(part, "references_table") and part.references_table(table)
200 for part in self.parts.values()
201 )
203 def references_column(self, table, column):
204 return any(
205 hasattr(part, "references_column") and part.references_column(table, column)
206 for part in self.parts.values()
207 )
209 def rename_table_references(self, old_table, new_table):
210 for part in self.parts.values():
211 if hasattr(part, "rename_table_references"):
212 part.rename_table_references(old_table, new_table)
214 def rename_column_references(self, table, old_column, new_column):
215 for part in self.parts.values():
216 if hasattr(part, "rename_column_references"):
217 part.rename_column_references(table, old_column, new_column)
219 def __str__(self):
220 return self.template % self.parts
223class Expressions(TableColumns):
224 def __init__(self, table, expressions, compiler, quote_value):
225 self.compiler = compiler
226 self.expressions = expressions
227 self.quote_value = quote_value
228 columns = [
229 col.target.column
230 for col in self.compiler.query._gen_cols([self.expressions])
231 ]
232 super().__init__(table, columns)
234 def rename_table_references(self, old_table, new_table):
235 if self.table != old_table:
236 return
237 self.expressions = self.expressions.relabeled_clone({old_table: new_table})
238 super().rename_table_references(old_table, new_table)
240 def rename_column_references(self, table, old_column, new_column):
241 if self.table != table:
242 return
243 expressions = deepcopy(self.expressions)
244 self.columns = []
245 for col in self.compiler.query._gen_cols([expressions]):
246 if col.target.column == old_column:
247 col.target.column = new_column
248 self.columns.append(col.target.column)
249 self.expressions = expressions
251 def __str__(self):
252 sql, params = self.compiler.compile(self.expressions)
253 params = map(self.quote_value, params)
254 return sql % tuple(params)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.signals.dispatch import Signal
3connection_created = Signal()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import datetime
2import decimal
3import functools
4import logging
5import time
6from contextlib import contextmanager
7from hashlib import md5
9from plain.models.db import NotSupportedError
10from plain.utils.dateparse import parse_time
12logger = logging.getLogger("plain.models.backends")
15class CursorWrapper:
16 def __init__(self, cursor, db):
17 self.cursor = cursor
18 self.db = db
20 WRAP_ERROR_ATTRS = frozenset(["fetchone", "fetchmany", "fetchall", "nextset"])
22 def __getattr__(self, attr):
23 cursor_attr = getattr(self.cursor, attr)
24 if attr in CursorWrapper.WRAP_ERROR_ATTRS:
25 return self.db.wrap_database_errors(cursor_attr)
26 else:
27 return cursor_attr
29 def __iter__(self):
30 with self.db.wrap_database_errors:
31 yield from self.cursor
33 def __enter__(self):
34 return self
36 def __exit__(self, type, value, traceback):
37 # Close instead of passing through to avoid backend-specific behavior
38 # (#17671). Catch errors liberally because errors in cleanup code
39 # aren't useful.
40 try:
41 self.close()
42 except self.db.Database.Error:
43 pass
45 # The following methods cannot be implemented in __getattr__, because the
46 # code must run when the method is invoked, not just when it is accessed.
48 def callproc(self, procname, params=None, kparams=None):
49 # Keyword parameters for callproc aren't supported in PEP 249, but the
50 # database driver may support them (e.g. cx_Oracle).
51 if kparams is not None and not self.db.features.supports_callproc_kwargs:
52 raise NotSupportedError(
53 "Keyword parameters for callproc are not supported on this "
54 "database backend."
55 )
56 self.db.validate_no_broken_transaction()
57 with self.db.wrap_database_errors:
58 if params is None and kparams is None:
59 return self.cursor.callproc(procname)
60 elif kparams is None:
61 return self.cursor.callproc(procname, params)
62 else:
63 params = params or ()
64 return self.cursor.callproc(procname, params, kparams)
66 def execute(self, sql, params=None):
67 return self._execute_with_wrappers(
68 sql, params, many=False, executor=self._execute
69 )
71 def executemany(self, sql, param_list):
72 return self._execute_with_wrappers(
73 sql, param_list, many=True, executor=self._executemany
74 )
76 def _execute_with_wrappers(self, sql, params, many, executor):
77 context = {"connection": self.db, "cursor": self}
78 for wrapper in reversed(self.db.execute_wrappers):
79 executor = functools.partial(wrapper, executor)
80 return executor(sql, params, many, context)
82 def _execute(self, sql, params, *ignored_wrapper_args):
83 self.db.validate_no_broken_transaction()
84 with self.db.wrap_database_errors:
85 if params is None:
86 # params default might be backend specific.
87 return self.cursor.execute(sql)
88 else:
89 return self.cursor.execute(sql, params)
91 def _executemany(self, sql, param_list, *ignored_wrapper_args):
92 self.db.validate_no_broken_transaction()
93 with self.db.wrap_database_errors:
94 return self.cursor.executemany(sql, param_list)
97class CursorDebugWrapper(CursorWrapper):
98 # XXX callproc isn't instrumented at this time.
100 def execute(self, sql, params=None):
101 with self.debug_sql(sql, params, use_last_executed_query=True):
102 return super().execute(sql, params)
104 def executemany(self, sql, param_list):
105 with self.debug_sql(sql, param_list, many=True):
106 return super().executemany(sql, param_list)
108 @contextmanager
109 def debug_sql(
110 self, sql=None, params=None, use_last_executed_query=False, many=False
111 ):
112 start = time.monotonic()
113 try:
114 yield
115 finally:
116 stop = time.monotonic()
117 duration = stop - start
118 if use_last_executed_query:
119 sql = self.db.ops.last_executed_query(self.cursor, sql, params)
120 try:
121 times = len(params) if many else ""
122 except TypeError:
123 # params could be an iterator.
124 times = "?"
125 self.db.queries_log.append(
126 {
127 "sql": f"{times} times: {sql}" if many else sql,
128 "time": "%.3f" % duration,
129 }
130 )
131 logger.debug(
132 "(%.3f) %s; args=%s; alias=%s",
133 duration,
134 sql,
135 params,
136 self.db.alias,
137 extra={
138 "duration": duration,
139 "sql": sql,
140 "params": params,
141 "alias": self.db.alias,
142 },
143 )
146@contextmanager
147def debug_transaction(connection, sql):
148 start = time.monotonic()
149 try:
150 yield
151 finally:
152 if connection.queries_logged:
153 stop = time.monotonic()
154 duration = stop - start
155 connection.queries_log.append(
156 {
157 "sql": "%s" % sql,
158 "time": "%.3f" % duration,
159 }
160 )
161 logger.debug(
162 "(%.3f) %s; args=%s; alias=%s",
163 duration,
164 sql,
165 None,
166 connection.alias,
167 extra={
168 "duration": duration,
169 "sql": sql,
170 "alias": connection.alias,
171 },
172 )
175def split_tzname_delta(tzname):
176 """
177 Split a time zone name into a 3-tuple of (name, sign, offset).
178 """
179 for sign in ["+", "-"]:
180 if sign in tzname:
181 name, offset = tzname.rsplit(sign, 1)
182 if offset and parse_time(offset):
183 return name, sign, offset
184 return tzname, None, None
187###############################################
188# Converters from database (string) to Python #
189###############################################
192def typecast_date(s):
193 return (
194 datetime.date(*map(int, s.split("-"))) if s else None
195 ) # return None if s is null
198def typecast_time(s): # does NOT store time zone information
199 if not s:
200 return None
201 hour, minutes, seconds = s.split(":")
202 if "." in seconds: # check whether seconds have a fractional part
203 seconds, microseconds = seconds.split(".")
204 else:
205 microseconds = "0"
206 return datetime.time(
207 int(hour), int(minutes), int(seconds), int((microseconds + "000000")[:6])
208 )
211def typecast_timestamp(s): # does NOT store time zone information
212 # "2005-07-29 15:48:00.590358-05"
213 # "2005-07-29 09:56:00-05"
214 if not s:
215 return None
216 if " " not in s:
217 return typecast_date(s)
218 d, t = s.split()
219 # Remove timezone information.
220 if "-" in t:
221 t, _ = t.split("-", 1)
222 elif "+" in t:
223 t, _ = t.split("+", 1)
224 dates = d.split("-")
225 times = t.split(":")
226 seconds = times[2]
227 if "." in seconds: # check whether seconds have a fractional part
228 seconds, microseconds = seconds.split(".")
229 else:
230 microseconds = "0"
231 return datetime.datetime(
232 int(dates[0]),
233 int(dates[1]),
234 int(dates[2]),
235 int(times[0]),
236 int(times[1]),
237 int(seconds),
238 int((microseconds + "000000")[:6]),
239 )
242###############################################
243# Converters from Python to database (string) #
244###############################################
247def split_identifier(identifier):
248 """
249 Split an SQL identifier into a two element tuple of (namespace, name).
251 The identifier could be a table, column, or sequence name might be prefixed
252 by a namespace.
253 """
254 try:
255 namespace, name = identifier.split('"."')
256 except ValueError:
257 namespace, name = "", identifier
258 return namespace.strip('"'), name.strip('"')
261def truncate_name(identifier, length=None, hash_len=4):
262 """
263 Shorten an SQL identifier to a repeatable mangled version with the given
264 length.
266 If a quote stripped name contains a namespace, e.g. USERNAME"."TABLE,
267 truncate the table portion only.
268 """
269 namespace, name = split_identifier(identifier)
271 if length is None or len(name) <= length:
272 return identifier
274 digest = names_digest(name, length=hash_len)
275 return "{}{}{}".format(
276 '%s"."' % namespace if namespace else "",
277 name[: length - hash_len],
278 digest,
279 )
282def names_digest(*args, length):
283 """
284 Generate a 32-bit digest of a set of arguments that can be used to shorten
285 identifying names.
286 """
287 h = md5(usedforsecurity=False)
288 for arg in args:
289 h.update(arg.encode())
290 return h.hexdigest()[:length]
293def format_number(value, max_digits, decimal_places):
294 """
295 Format a number into a string with the requisite number of digits and
296 decimal places.
297 """
298 if value is None:
299 return None
300 context = decimal.getcontext().copy()
301 if max_digits is not None:
302 context.prec = max_digits
303 if decimal_places is not None:
304 value = value.quantize(
305 decimal.Decimal(1).scaleb(-decimal_places), context=context
306 )
307 else:
308 context.traps[decimal.Rounded] = 1
309 value = context.create_decimal(value)
310 return f"{value:f}"
313def strip_quotes(table_name):
314 """
315 Strip quotes off of quoted table names to make them safe for use in index
316 names, sequence names, etc. For example '"USER"."TABLE"' (an Oracle naming
317 scheme) becomes 'USER"."TABLE'.
318 """
319 has_quotes = table_name.startswith('"') and table_name.endswith('"')
320 return table_name[1:-1] if has_quotes else table_name
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.internal.files.base import File
3__all__ = ["File"]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import os
2from io import BytesIO, StringIO, UnsupportedOperation
4from plain.internal.files.utils import FileProxyMixin
5from plain.utils.functional import cached_property
8class File(FileProxyMixin):
9 DEFAULT_CHUNK_SIZE = 64 * 2**10
11 def __init__(self, file, name=None):
12 self.file = file
13 if name is None:
14 name = getattr(file, "name", None)
15 self.name = name
16 if hasattr(file, "mode"):
17 self.mode = file.mode
19 def __str__(self):
20 return self.name or ""
22 def __repr__(self):
23 return "<{}: {}>".format(self.__class__.__name__, self or "None")
25 def __bool__(self):
26 return bool(self.name)
28 def __len__(self):
29 return self.size
31 @cached_property
32 def size(self):
33 if hasattr(self.file, "size"):
34 return self.file.size
35 if hasattr(self.file, "name"):
36 try:
37 return os.path.getsize(self.file.name)
38 except (OSError, TypeError):
39 pass
40 if hasattr(self.file, "tell") and hasattr(self.file, "seek"):
41 pos = self.file.tell()
42 self.file.seek(0, os.SEEK_END)
43 size = self.file.tell()
44 self.file.seek(pos)
45 return size
46 raise AttributeError("Unable to determine the file's size.")
48 def chunks(self, chunk_size=None):
49 """
50 Read the file and yield chunks of ``chunk_size`` bytes (defaults to
51 ``File.DEFAULT_CHUNK_SIZE``).
52 """
53 chunk_size = chunk_size or self.DEFAULT_CHUNK_SIZE
54 try:
55 self.seek(0)
56 except (AttributeError, UnsupportedOperation):
57 pass
59 while True:
60 data = self.read(chunk_size)
61 if not data:
62 break
63 yield data
65 def multiple_chunks(self, chunk_size=None):
66 """
67 Return ``True`` if you can expect multiple chunks.
69 NB: If a particular file representation is in memory, subclasses should
70 always return ``False`` -- there's no good reason to read from memory in
71 chunks.
72 """
73 return self.size > (chunk_size or self.DEFAULT_CHUNK_SIZE)
75 def __iter__(self):
76 # Iterate over this file-like object by newlines
77 buffer_ = None
78 for chunk in self.chunks():
79 for line in chunk.splitlines(True):
80 if buffer_:
81 if endswith_cr(buffer_) and not equals_lf(line):
82 # Line split after a \r newline; yield buffer_.
83 yield buffer_
84 # Continue with line.
85 else:
86 # Line either split without a newline (line
87 # continues after buffer_) or with \r\n
88 # newline (line == b'\n').
89 line = buffer_ + line
90 # buffer_ handled, clear it.
91 buffer_ = None
93 # If this is the end of a \n or \r\n line, yield.
94 if endswith_lf(line):
95 yield line
96 else:
97 buffer_ = line
99 if buffer_ is not None:
100 yield buffer_
102 def __enter__(self):
103 return self
105 def __exit__(self, exc_type, exc_value, tb):
106 self.close()
108 def open(self, mode=None):
109 if not self.closed:
110 self.seek(0)
111 elif self.name and os.path.exists(self.name):
112 self.file = open(self.name, mode or self.mode)
113 else:
114 raise ValueError("The file cannot be reopened.")
115 return self
117 def close(self):
118 self.file.close()
121class ContentFile(File):
122 """
123 A File-like object that takes just raw content, rather than an actual file.
124 """
126 def __init__(self, content, name=None):
127 stream_class = StringIO if isinstance(content, str) else BytesIO
128 super().__init__(stream_class(content), name=name)
129 self.size = len(content)
131 def __str__(self):
132 return "Raw content"
134 def __bool__(self):
135 return True
137 def open(self, mode=None):
138 self.seek(0)
139 return self
141 def close(self):
142 pass
144 def write(self, data):
145 self.__dict__.pop("size", None) # Clear the computed size.
146 return self.file.write(data)
149def endswith_cr(line):
150 """Return True if line (a text or bytestring) ends with '\r'."""
151 return line.endswith("\r" if isinstance(line, str) else b"\r")
154def endswith_lf(line):
155 """Return True if line (a text or bytestring) ends with '\n'."""
156 return line.endswith("\n" if isinstance(line, str) else b"\n")
159def equals_lf(line):
160 """Return True if line (a text or bytestring) equals '\n'."""
161 return line == ("\n" if isinstance(line, str) else b"\n")
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2The temp module provides a NamedTemporaryFile that can be reopened in the same
3process on any platform. Most platforms use the standard Python
4tempfile.NamedTemporaryFile class, but Windows users are given a custom class.
6This is needed because the Python implementation of NamedTemporaryFile uses the
7O_TEMPORARY flag under Windows, which prevents the file from being reopened
8if the same flag is not provided [1][2]. Note that this does not address the
9more general issue of opening a file for writing and reading in multiple
10processes in a manner that works across platforms.
12The custom version of NamedTemporaryFile doesn't support the same keyword
13arguments available in tempfile.NamedTemporaryFile.
151: https://mail.python.org/pipermail/python-list/2005-December/336957.html
162: https://bugs.python.org/issue14243
17"""
19import os
20import tempfile
22from plain.internal.files.utils import FileProxyMixin
24__all__ = (
25 "NamedTemporaryFile",
26 "gettempdir",
27)
30if os.name == "nt":
32 class TemporaryFile(FileProxyMixin):
33 """
34 Temporary file object constructor that supports reopening of the
35 temporary file in Windows.
37 Unlike tempfile.NamedTemporaryFile from the standard library,
38 __init__() doesn't support the 'delete', 'buffering', 'encoding', or
39 'newline' keyword arguments.
40 """
42 def __init__(self, mode="w+b", bufsize=-1, suffix="", prefix="", dir=None):
43 fd, name = tempfile.mkstemp(suffix=suffix, prefix=prefix, dir=dir)
44 self.name = name
45 self.file = os.fdopen(fd, mode, bufsize)
46 self.close_called = False
48 # Because close can be called during shutdown
49 # we need to cache os.unlink and access it
50 # as self.unlink only
51 unlink = os.unlink
53 def close(self):
54 if not self.close_called:
55 self.close_called = True
56 try:
57 self.file.close()
58 except OSError:
59 pass
60 try:
61 self.unlink(self.name)
62 except OSError:
63 pass
65 def __del__(self):
66 self.close()
68 def __enter__(self):
69 self.file.__enter__()
70 return self
72 def __exit__(self, exc, value, tb):
73 self.file.__exit__(exc, value, tb)
75 NamedTemporaryFile = TemporaryFile
76else:
77 NamedTemporaryFile = tempfile.NamedTemporaryFile
79gettempdir = tempfile.gettempdir
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Classes representing uploaded files.
3"""
5import os
6from io import BytesIO
8from plain.internal.files import temp as tempfile
9from plain.internal.files.base import File
10from plain.internal.files.utils import validate_file_name
11from plain.runtime import settings
13__all__ = (
14 "UploadedFile",
15 "TemporaryUploadedFile",
16 "InMemoryUploadedFile",
17 "SimpleUploadedFile",
18)
21class UploadedFile(File):
22 """
23 An abstract uploaded file (``TemporaryUploadedFile`` and
24 ``InMemoryUploadedFile`` are the built-in concrete subclasses).
26 An ``UploadedFile`` object behaves somewhat like a file object and
27 represents some file data that the user submitted with a form.
28 """
30 def __init__(
31 self,
32 file=None,
33 name=None,
34 content_type=None,
35 size=None,
36 charset=None,
37 content_type_extra=None,
38 ):
39 super().__init__(file, name)
40 self.size = size
41 self.content_type = content_type
42 self.charset = charset
43 self.content_type_extra = content_type_extra
45 def __repr__(self):
46 return f"<{self.__class__.__name__}: {self.name} ({self.content_type})>"
48 def _get_name(self):
49 return self._name
51 def _set_name(self, name):
52 # Sanitize the file name so that it can't be dangerous.
53 if name is not None:
54 # Just use the basename of the file -- anything else is dangerous.
55 name = os.path.basename(name)
57 # File names longer than 255 characters can cause problems on older OSes.
58 if len(name) > 255:
59 name, ext = os.path.splitext(name)
60 ext = ext[:255]
61 name = name[: 255 - len(ext)] + ext
63 name = validate_file_name(name)
65 self._name = name
67 name = property(_get_name, _set_name)
70class TemporaryUploadedFile(UploadedFile):
71 """
72 A file uploaded to a temporary location (i.e. stream-to-disk).
73 """
75 def __init__(self, name, content_type, size, charset, content_type_extra=None):
76 _, ext = os.path.splitext(name)
77 file = tempfile.NamedTemporaryFile(
78 suffix=".upload" + ext, dir=settings.FILE_UPLOAD_TEMP_DIR
79 )
80 super().__init__(file, name, content_type, size, charset, content_type_extra)
82 def temporary_file_path(self):
83 """Return the full path of this file."""
84 return self.file.name
86 def close(self):
87 try:
88 return self.file.close()
89 except FileNotFoundError:
90 # The file was moved or deleted before the tempfile could unlink
91 # it. Still sets self.file.close_called and calls
92 # self.file.file.close() before the exception.
93 pass
96class InMemoryUploadedFile(UploadedFile):
97 """
98 A file uploaded into memory (i.e. stream-to-memory).
99 """
101 def __init__(
102 self,
103 file,
104 field_name,
105 name,
106 content_type,
107 size,
108 charset,
109 content_type_extra=None,
110 ):
111 super().__init__(file, name, content_type, size, charset, content_type_extra)
112 self.field_name = field_name
114 def open(self, mode=None):
115 self.file.seek(0)
116 return self
118 def chunks(self, chunk_size=None):
119 self.file.seek(0)
120 yield self.read()
122 def multiple_chunks(self, chunk_size=None):
123 # Since it's in memory, we'll never have multiple chunks.
124 return False
127class SimpleUploadedFile(InMemoryUploadedFile):
128 """
129 A simple representation of a file, which just has content, size, and a name.
130 """
132 def __init__(self, name, content, content_type="text/plain"):
133 content = content or b""
134 super().__init__(
135 BytesIO(content), None, name, content_type, len(content), None, None
136 )
138 @classmethod
139 def from_dict(cls, file_dict):
140 """
141 Create a SimpleUploadedFile object from a dictionary with keys:
142 - filename
143 - content-type
144 - content
145 """
146 return cls(
147 file_dict["filename"],
148 file_dict["content"],
149 file_dict.get("content-type", "text/plain"),
150 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1"""
2Base file upload handler classes, and the built-in concrete subclasses
3"""
4import os
5from io import BytesIO
7from plain.internal.files.uploadedfile import (
8 InMemoryUploadedFile,
9 TemporaryUploadedFile,
10)
11from plain.runtime import settings
12from plain.utils.module_loading import import_string
14__all__ = [
15 "UploadFileException",
16 "StopUpload",
17 "SkipFile",
18 "FileUploadHandler",
19 "TemporaryFileUploadHandler",
20 "MemoryFileUploadHandler",
21 "load_handler",
22 "StopFutureHandlers",
23]
26class UploadFileException(Exception):
27 """
28 Any error having to do with uploading files.
29 """
31 pass
34class StopUpload(UploadFileException):
35 """
36 This exception is raised when an upload must abort.
37 """
39 def __init__(self, connection_reset=False):
40 """
41 If ``connection_reset`` is ``True``, Plain knows will halt the upload
42 without consuming the rest of the upload. This will cause the browser to
43 show a "connection reset" error.
44 """
45 self.connection_reset = connection_reset
47 def __str__(self):
48 if self.connection_reset:
49 return "StopUpload: Halt current upload."
50 else:
51 return "StopUpload: Consume request data, then halt."
54class SkipFile(UploadFileException):
55 """
56 This exception is raised by an upload handler that wants to skip a given file.
57 """
59 pass
62class StopFutureHandlers(UploadFileException):
63 """
64 Upload handlers that have handled a file and do not want future handlers to
65 run should raise this exception instead of returning None.
66 """
68 pass
71class FileUploadHandler:
72 """
73 Base class for streaming upload handlers.
74 """
76 chunk_size = 64 * 2**10 # : The default chunk size is 64 KB.
78 def __init__(self, request=None):
79 self.file_name = None
80 self.content_type = None
81 self.content_length = None
82 self.charset = None
83 self.content_type_extra = None
84 self.request = request
86 def handle_raw_input(
87 self, input_data, META, content_length, boundary, encoding=None
88 ):
89 """
90 Handle the raw input from the client.
92 Parameters:
94 :input_data:
95 An object that supports reading via .read().
96 :META:
97 ``request.META``.
98 :content_length:
99 The (integer) value of the Content-Length header from the
100 client.
101 :boundary: The boundary from the Content-Type header. Be sure to
102 prepend two '--'.
103 """
104 pass
106 def new_file(
107 self,
108 field_name,
109 file_name,
110 content_type,
111 content_length,
112 charset=None,
113 content_type_extra=None,
114 ):
115 """
116 Signal that a new file has been started.
118 Warning: As with any data from the client, you should not trust
119 content_length (and sometimes won't even get it).
120 """
121 self.field_name = field_name
122 self.file_name = file_name
123 self.content_type = content_type
124 self.content_length = content_length
125 self.charset = charset
126 self.content_type_extra = content_type_extra
128 def receive_data_chunk(self, raw_data, start):
129 """
130 Receive data from the streamed upload parser. ``start`` is the position
131 in the file of the chunk.
132 """
133 raise NotImplementedError(
134 "subclasses of FileUploadHandler must provide a receive_data_chunk() method"
135 )
137 def file_complete(self, file_size):
138 """
139 Signal that a file has completed. File size corresponds to the actual
140 size accumulated by all the chunks.
142 Subclasses should return a valid ``UploadedFile`` object.
143 """
144 raise NotImplementedError(
145 "subclasses of FileUploadHandler must provide a file_complete() method"
146 )
148 def upload_complete(self):
149 """
150 Signal that the upload is complete. Subclasses should perform cleanup
151 that is necessary for this handler.
152 """
153 pass
155 def upload_interrupted(self):
156 """
157 Signal that the upload was interrupted. Subclasses should perform
158 cleanup that is necessary for this handler.
159 """
160 pass
163class TemporaryFileUploadHandler(FileUploadHandler):
164 """
165 Upload handler that streams data into a temporary file.
166 """
168 def new_file(self, *args, **kwargs):
169 """
170 Create the file object to append to as data is coming in.
171 """
172 super().new_file(*args, **kwargs)
173 self.file = TemporaryUploadedFile(
174 self.file_name, self.content_type, 0, self.charset, self.content_type_extra
175 )
177 def receive_data_chunk(self, raw_data, start):
178 self.file.write(raw_data)
180 def file_complete(self, file_size):
181 self.file.seek(0)
182 self.file.size = file_size
183 return self.file
185 def upload_interrupted(self):
186 if hasattr(self, "file"):
187 temp_location = self.file.temporary_file_path()
188 try:
189 self.file.close()
190 os.remove(temp_location)
191 except FileNotFoundError:
192 pass
195class MemoryFileUploadHandler(FileUploadHandler):
196 """
197 File upload handler to stream uploads into memory (used for small files).
198 """
200 def handle_raw_input(
201 self, input_data, META, content_length, boundary, encoding=None
202 ):
203 """
204 Use the content_length to signal whether or not this handler should be
205 used.
206 """
207 # Check the content-length header to see if we should
208 # If the post is too large, we cannot use the Memory handler.
209 self.activated = content_length <= settings.FILE_UPLOAD_MAX_MEMORY_SIZE
211 def new_file(self, *args, **kwargs):
212 super().new_file(*args, **kwargs)
213 if self.activated:
214 self.file = BytesIO()
215 raise StopFutureHandlers()
217 def receive_data_chunk(self, raw_data, start):
218 """Add the data to the BytesIO file."""
219 if self.activated:
220 self.file.write(raw_data)
221 else:
222 return raw_data
224 def file_complete(self, file_size):
225 """Return a file object if this handler is activated."""
226 if not self.activated:
227 return
229 self.file.seek(0)
230 return InMemoryUploadedFile(
231 file=self.file,
232 field_name=self.field_name,
233 name=self.file_name,
234 content_type=self.content_type,
235 size=file_size,
236 charset=self.charset,
237 content_type_extra=self.content_type_extra,
238 )
241def load_handler(path, *args, **kwargs):
242 """
243 Given a path to a handler, return an instance of that handler.
245 E.g.::
246 >>> from plain.http import HttpRequest
247 >>> request = HttpRequest()
248 >>> load_handler(
249 ... 'plain.internal.files.uploadhandler.TemporaryFileUploadHandler',
250 ... request,
251 ... )
252 <TemporaryFileUploadHandler object at 0x...>
253 """
254 return import_string(path)(*args, **kwargs)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import os
2import pathlib
4from plain.exceptions import SuspiciousFileOperation
7def validate_file_name(name, allow_relative_path=False):
8 # Remove potentially dangerous names
9 if os.path.basename(name) in {"", ".", ".."}:
10 raise SuspiciousFileOperation("Could not derive file name from '%s'" % name)
12 if allow_relative_path:
13 # Use PurePosixPath() because this branch is checked only in
14 # FileField.generate_filename() where all file paths are expected to be
15 # Unix style (with forward slashes).
16 path = pathlib.PurePosixPath(name)
17 if path.is_absolute() or ".." in path.parts:
18 raise SuspiciousFileOperation(
19 "Detected path traversal attempt in '%s'" % name
20 )
21 elif name != os.path.basename(name):
22 raise SuspiciousFileOperation("File name '%s' includes path elements" % name)
24 return name
27class FileProxyMixin:
28 """
29 A mixin class used to forward file methods to an underlying file
30 object. The internal file object has to be called "file"::
32 class FileProxy(FileProxyMixin):
33 def __init__(self, file):
34 self.file = file
35 """
37 encoding = property(lambda self: self.file.encoding)
38 fileno = property(lambda self: self.file.fileno)
39 flush = property(lambda self: self.file.flush)
40 isatty = property(lambda self: self.file.isatty)
41 newlines = property(lambda self: self.file.newlines)
42 read = property(lambda self: self.file.read)
43 readinto = property(lambda self: self.file.readinto)
44 readline = property(lambda self: self.file.readline)
45 readlines = property(lambda self: self.file.readlines)
46 seek = property(lambda self: self.file.seek)
47 tell = property(lambda self: self.file.tell)
48 truncate = property(lambda self: self.file.truncate)
49 write = property(lambda self: self.file.write)
50 writelines = property(lambda self: self.file.writelines)
52 @property
53 def closed(self):
54 return not self.file or self.file.closed
56 def readable(self):
57 if self.closed:
58 return False
59 if hasattr(self.file, "readable"):
60 return self.file.readable()
61 return True
63 def writable(self):
64 if self.closed:
65 return False
66 if hasattr(self.file, "writable"):
67 return self.file.writable()
68 return "w" in getattr(self.file, "mode", "")
70 def seekable(self):
71 if self.closed:
72 return False
73 if hasattr(self.file, "seekable"):
74 return self.file.seekable()
75 return True
77 def __iter__(self):
78 return iter(self.file)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from .migration import Migration, swappable_dependency # NOQA
2from .operations import * # NOQA
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import functools
2import re
3from graphlib import TopologicalSorter
4from itertools import chain
6from plain import models
7from plain.models.migrations import operations
8from plain.models.migrations.migration import Migration
9from plain.models.migrations.operations.models import AlterModelOptions
10from plain.models.migrations.optimizer import MigrationOptimizer
11from plain.models.migrations.questioner import MigrationQuestioner
12from plain.models.migrations.utils import (
13 COMPILED_REGEX_TYPE,
14 RegexObject,
15 resolve_relation,
16)
17from plain.runtime import settings
20class MigrationAutodetector:
21 """
22 Take a pair of ProjectStates and compare them to see what the first would
23 need doing to make it match the second (the second usually being the
24 project's current state).
26 Note that this naturally operates on entire projects at a time,
27 as it's likely that changes interact (for example, you can't
28 add a ForeignKey without having a migration to add the table it
29 depends on first). A user interface may offer single-app usage
30 if it wishes, with the caveat that it may not always be possible.
31 """
33 def __init__(self, from_state, to_state, questioner=None):
34 self.from_state = from_state
35 self.to_state = to_state
36 self.questioner = questioner or MigrationQuestioner()
37 self.existing_packages = {app for app, model in from_state.models}
39 def changes(
40 self, graph, trim_to_packages=None, convert_packages=None, migration_name=None
41 ):
42 """
43 Main entry point to produce a list of applicable changes.
44 Take a graph to base names on and an optional set of packages
45 to try and restrict to (restriction is not guaranteed)
46 """
47 changes = self._detect_changes(convert_packages, graph)
48 changes = self.arrange_for_graph(changes, graph, migration_name)
49 if trim_to_packages:
50 changes = self._trim_to_packages(changes, trim_to_packages)
51 return changes
53 def deep_deconstruct(self, obj):
54 """
55 Recursive deconstruction for a field and its arguments.
56 Used for full comparison for rename/alter; sometimes a single-level
57 deconstruction will not compare correctly.
58 """
59 if isinstance(obj, list):
60 return [self.deep_deconstruct(value) for value in obj]
61 elif isinstance(obj, tuple):
62 return tuple(self.deep_deconstruct(value) for value in obj)
63 elif isinstance(obj, dict):
64 return {key: self.deep_deconstruct(value) for key, value in obj.items()}
65 elif isinstance(obj, functools.partial):
66 return (
67 obj.func,
68 self.deep_deconstruct(obj.args),
69 self.deep_deconstruct(obj.keywords),
70 )
71 elif isinstance(obj, COMPILED_REGEX_TYPE):
72 return RegexObject(obj)
73 elif isinstance(obj, type):
74 # If this is a type that implements 'deconstruct' as an instance method,
75 # avoid treating this as being deconstructible itself - see #22951
76 return obj
77 elif hasattr(obj, "deconstruct"):
78 deconstructed = obj.deconstruct()
79 if isinstance(obj, models.Field):
80 # we have a field which also returns a name
81 deconstructed = deconstructed[1:]
82 path, args, kwargs = deconstructed
83 return (
84 path,
85 [self.deep_deconstruct(value) for value in args],
86 {key: self.deep_deconstruct(value) for key, value in kwargs.items()},
87 )
88 else:
89 return obj
91 def only_relation_agnostic_fields(self, fields):
92 """
93 Return a definition of the fields that ignores field names and
94 what related fields actually relate to. Used for detecting renames (as
95 the related fields change during renames).
96 """
97 fields_def = []
98 for name, field in sorted(fields.items()):
99 deconstruction = self.deep_deconstruct(field)
100 if field.remote_field and field.remote_field.model:
101 deconstruction[2].pop("to", None)
102 fields_def.append(deconstruction)
103 return fields_def
105 def _detect_changes(self, convert_packages=None, graph=None):
106 """
107 Return a dict of migration plans which will achieve the
108 change from from_state to to_state. The dict has app labels
109 as keys and a list of migrations as values.
111 The resulting migrations aren't specially named, but the names
112 do matter for dependencies inside the set.
114 convert_packages is the list of packages to convert to use migrations
115 (i.e. to make initial migrations for, in the usual case)
117 graph is an optional argument that, if provided, can help improve
118 dependency generation and avoid potential circular dependencies.
119 """
120 # The first phase is generating all the operations for each app
121 # and gathering them into a big per-app list.
122 # Then go through that list, order it, and split into migrations to
123 # resolve dependencies caused by M2Ms and FKs.
124 self.generated_operations = {}
125 self.altered_indexes = {}
126 self.altered_constraints = {}
127 self.renamed_fields = {}
129 # Prepare some old/new state and model lists, ignoring unmigrated packages.
130 self.old_model_keys = set()
131 self.old_unmanaged_keys = set()
132 self.new_model_keys = set()
133 self.new_unmanaged_keys = set()
134 for (package_label, model_name), model_state in self.from_state.models.items():
135 if not model_state.options.get("managed", True):
136 self.old_unmanaged_keys.add((package_label, model_name))
137 elif package_label not in self.from_state.real_packages:
138 self.old_model_keys.add((package_label, model_name))
140 for (package_label, model_name), model_state in self.to_state.models.items():
141 if not model_state.options.get("managed", True):
142 self.new_unmanaged_keys.add((package_label, model_name))
143 elif package_label not in self.from_state.real_packages or (
144 convert_packages and package_label in convert_packages
145 ):
146 self.new_model_keys.add((package_label, model_name))
148 self.from_state.resolve_fields_and_relations()
149 self.to_state.resolve_fields_and_relations()
151 # Renames have to come first
152 self.generate_renamed_models()
154 # Prepare lists of fields and generate through model map
155 self._prepare_field_lists()
156 self._generate_through_model_map()
158 # Generate non-rename model operations
159 self.generate_deleted_models()
160 self.generate_created_models()
161 self.generate_altered_options()
162 self.generate_altered_managers()
163 self.generate_altered_db_table_comment()
165 # Create the renamed fields and store them in self.renamed_fields.
166 # They are used by create_altered_indexes(), generate_altered_fields(),
167 # generate_removed_altered_index(), and
168 # generate_altered_index().
169 self.create_renamed_fields()
170 # Create the altered indexes and store them in self.altered_indexes.
171 # This avoids the same computation in generate_removed_indexes()
172 # and generate_added_indexes().
173 self.create_altered_indexes()
174 self.create_altered_constraints()
175 # Generate index removal operations before field is removed
176 self.generate_removed_constraints()
177 self.generate_removed_indexes()
178 # Generate field renaming operations.
179 self.generate_renamed_fields()
180 self.generate_renamed_indexes()
181 # Generate field operations.
182 self.generate_removed_fields()
183 self.generate_added_fields()
184 self.generate_altered_fields()
185 self.generate_altered_order_with_respect_to()
186 self.generate_added_indexes()
187 self.generate_added_constraints()
188 self.generate_altered_db_table()
190 self._sort_migrations()
191 self._build_migration_list(graph)
192 self._optimize_migrations()
194 return self.migrations
196 def _prepare_field_lists(self):
197 """
198 Prepare field lists and a list of the fields that used through models
199 in the old state so dependencies can be made from the through model
200 deletion to the field that uses it.
201 """
202 self.kept_model_keys = self.old_model_keys & self.new_model_keys
203 self.kept_unmanaged_keys = self.old_unmanaged_keys & self.new_unmanaged_keys
204 self.through_users = {}
205 self.old_field_keys = {
206 (package_label, model_name, field_name)
207 for package_label, model_name in self.kept_model_keys
208 for field_name in self.from_state.models[
209 package_label,
210 self.renamed_models.get((package_label, model_name), model_name),
211 ].fields
212 }
213 self.new_field_keys = {
214 (package_label, model_name, field_name)
215 for package_label, model_name in self.kept_model_keys
216 for field_name in self.to_state.models[package_label, model_name].fields
217 }
219 def _generate_through_model_map(self):
220 """Through model map generation."""
221 for package_label, model_name in sorted(self.old_model_keys):
222 old_model_name = self.renamed_models.get(
223 (package_label, model_name), model_name
224 )
225 old_model_state = self.from_state.models[package_label, old_model_name]
226 for field_name, field in old_model_state.fields.items():
227 if hasattr(field, "remote_field") and getattr(
228 field.remote_field, "through", None
229 ):
230 through_key = resolve_relation(
231 field.remote_field.through, package_label, model_name
232 )
233 self.through_users[through_key] = (
234 package_label,
235 old_model_name,
236 field_name,
237 )
239 @staticmethod
240 def _resolve_dependency(dependency):
241 """
242 Return the resolved dependency and a boolean denoting whether or not
243 it was swappable.
244 """
245 if dependency[0] != "__setting__":
246 return dependency, False
247 resolved_package_label, resolved_object_name = getattr(
248 settings, dependency[1]
249 ).split(".")
250 return (resolved_package_label, resolved_object_name.lower()) + dependency[
251 2:
252 ], True
254 def _build_migration_list(self, graph=None):
255 """
256 Chop the lists of operations up into migrations with dependencies on
257 each other. Do this by going through an app's list of operations until
258 one is found that has an outgoing dependency that isn't in another
259 app's migration yet (hasn't been chopped off its list). Then chop off
260 the operations before it into a migration and move onto the next app.
261 If the loops completes without doing anything, there's a circular
262 dependency (which _should_ be impossible as the operations are
263 all split at this point so they can't depend and be depended on).
264 """
265 self.migrations = {}
266 num_ops = sum(len(x) for x in self.generated_operations.values())
267 chop_mode = False
268 while num_ops:
269 # On every iteration, we step through all the packages and see if there
270 # is a completed set of operations.
271 # If we find that a subset of the operations are complete we can
272 # try to chop it off from the rest and continue, but we only
273 # do this if we've already been through the list once before
274 # without any chopping and nothing has changed.
275 for package_label in sorted(self.generated_operations):
276 chopped = []
277 dependencies = set()
278 for operation in list(self.generated_operations[package_label]):
279 deps_satisfied = True
280 operation_dependencies = set()
281 for dep in operation._auto_deps:
282 # Temporarily resolve the swappable dependency to
283 # prevent circular references. While keeping the
284 # dependency checks on the resolved model, add the
285 # swappable dependencies.
286 original_dep = dep
287 dep, is_swappable_dep = self._resolve_dependency(dep)
288 if dep[0] != package_label:
289 # External app dependency. See if it's not yet
290 # satisfied.
291 for other_operation in self.generated_operations.get(
292 dep[0], []
293 ):
294 if self.check_dependency(other_operation, dep):
295 deps_satisfied = False
296 break
297 if not deps_satisfied:
298 break
299 else:
300 if is_swappable_dep:
301 operation_dependencies.add(
302 (original_dep[0], original_dep[1])
303 )
304 elif dep[0] in self.migrations:
305 operation_dependencies.add(
306 (dep[0], self.migrations[dep[0]][-1].name)
307 )
308 else:
309 # If we can't find the other app, we add a
310 # first/last dependency, but only if we've
311 # already been through once and checked
312 # everything.
313 if chop_mode:
314 # If the app already exists, we add a
315 # dependency on the last migration, as
316 # we don't know which migration
317 # contains the target field. If it's
318 # not yet migrated or has no
319 # migrations, we use __first__.
320 if graph and graph.leaf_nodes(dep[0]):
321 operation_dependencies.add(
322 graph.leaf_nodes(dep[0])[0]
323 )
324 else:
325 operation_dependencies.add(
326 (dep[0], "__first__")
327 )
328 else:
329 deps_satisfied = False
330 if deps_satisfied:
331 chopped.append(operation)
332 dependencies.update(operation_dependencies)
333 del self.generated_operations[package_label][0]
334 else:
335 break
336 # Make a migration! Well, only if there's stuff to put in it
337 if dependencies or chopped:
338 if not self.generated_operations[package_label] or chop_mode:
339 subclass = type(
340 "Migration",
341 (Migration,),
342 {"operations": [], "dependencies": []},
343 )
344 instance = subclass(
345 "auto_%i"
346 % (len(self.migrations.get(package_label, [])) + 1),
347 package_label,
348 )
349 instance.dependencies = list(dependencies)
350 instance.operations = chopped
351 instance.initial = package_label not in self.existing_packages
352 self.migrations.setdefault(package_label, []).append(instance)
353 chop_mode = False
354 else:
355 self.generated_operations[package_label] = (
356 chopped + self.generated_operations[package_label]
357 )
358 new_num_ops = sum(len(x) for x in self.generated_operations.values())
359 if new_num_ops == num_ops:
360 if not chop_mode:
361 chop_mode = True
362 else:
363 raise ValueError(
364 "Cannot resolve operation dependencies: %r"
365 % self.generated_operations
366 )
367 num_ops = new_num_ops
369 def _sort_migrations(self):
370 """
371 Reorder to make things possible. Reordering may be needed so FKs work
372 nicely inside the same app.
373 """
374 for package_label, ops in sorted(self.generated_operations.items()):
375 ts = TopologicalSorter()
376 for op in ops:
377 ts.add(op)
378 for dep in op._auto_deps:
379 # Resolve intra-app dependencies to handle circular
380 # references involving a swappable model.
381 dep = self._resolve_dependency(dep)[0]
382 if dep[0] != package_label:
383 continue
384 ts.add(op, *(x for x in ops if self.check_dependency(x, dep)))
385 self.generated_operations[package_label] = list(ts.static_order())
387 def _optimize_migrations(self):
388 # Add in internal dependencies among the migrations
389 for package_label, migrations in self.migrations.items():
390 for m1, m2 in zip(migrations, migrations[1:]):
391 m2.dependencies.append((package_label, m1.name))
393 # De-dupe dependencies
394 for migrations in self.migrations.values():
395 for migration in migrations:
396 migration.dependencies = list(set(migration.dependencies))
398 # Optimize migrations
399 for package_label, migrations in self.migrations.items():
400 for migration in migrations:
401 migration.operations = MigrationOptimizer().optimize(
402 migration.operations, package_label
403 )
405 def check_dependency(self, operation, dependency):
406 """
407 Return True if the given operation depends on the given dependency,
408 False otherwise.
409 """
410 # Created model
411 if dependency[2] is None and dependency[3] is True:
412 return (
413 isinstance(operation, operations.CreateModel)
414 and operation.name_lower == dependency[1].lower()
415 )
416 # Created field
417 elif dependency[2] is not None and dependency[3] is True:
418 return (
419 isinstance(operation, operations.CreateModel)
420 and operation.name_lower == dependency[1].lower()
421 and any(dependency[2] == x for x, y in operation.fields)
422 ) or (
423 isinstance(operation, operations.AddField)
424 and operation.model_name_lower == dependency[1].lower()
425 and operation.name_lower == dependency[2].lower()
426 )
427 # Removed field
428 elif dependency[2] is not None and dependency[3] is False:
429 return (
430 isinstance(operation, operations.RemoveField)
431 and operation.model_name_lower == dependency[1].lower()
432 and operation.name_lower == dependency[2].lower()
433 )
434 # Removed model
435 elif dependency[2] is None and dependency[3] is False:
436 return (
437 isinstance(operation, operations.DeleteModel)
438 and operation.name_lower == dependency[1].lower()
439 )
440 # Field being altered
441 elif dependency[2] is not None and dependency[3] == "alter":
442 return (
443 isinstance(operation, operations.AlterField)
444 and operation.model_name_lower == dependency[1].lower()
445 and operation.name_lower == dependency[2].lower()
446 )
447 # order_with_respect_to being unset for a field
448 elif dependency[2] is not None and dependency[3] == "order_wrt_unset":
449 return (
450 isinstance(operation, operations.AlterOrderWithRespectTo)
451 and operation.name_lower == dependency[1].lower()
452 and (operation.order_with_respect_to or "").lower()
453 != dependency[2].lower()
454 )
455 # Unknown dependency. Raise an error.
456 else:
457 raise ValueError(f"Can't handle dependency {dependency!r}")
459 def add_operation(
460 self, package_label, operation, dependencies=None, beginning=False
461 ):
462 # Dependencies are
463 # (package_label, model_name, field_name, create/delete as True/False)
464 operation._auto_deps = dependencies or []
465 if beginning:
466 self.generated_operations.setdefault(package_label, []).insert(0, operation)
467 else:
468 self.generated_operations.setdefault(package_label, []).append(operation)
470 def swappable_first_key(self, item):
471 """
472 Place potential swappable models first in lists of created models (only
473 real way to solve #22783).
474 """
475 try:
476 model_state = self.to_state.models[item]
477 base_names = {
478 base if isinstance(base, str) else base.__name__
479 for base in model_state.bases
480 }
481 string_version = f"{item[0]}.{item[1]}"
482 if (
483 model_state.options.get("swappable")
484 or "BaseUser" in base_names
485 or "AbstractBaseUser" in base_names
486 or settings.AUTH_USER_MODEL.lower() == string_version.lower()
487 ):
488 return ("___" + item[0], "___" + item[1])
489 except LookupError:
490 pass
491 return item
493 def generate_renamed_models(self):
494 """
495 Find any renamed models, generate the operations for them, and remove
496 the old entry from the model lists. Must be run before other
497 model-level generation.
498 """
499 self.renamed_models = {}
500 self.renamed_models_rel = {}
501 added_models = self.new_model_keys - self.old_model_keys
502 for package_label, model_name in sorted(added_models):
503 model_state = self.to_state.models[package_label, model_name]
504 model_fields_def = self.only_relation_agnostic_fields(model_state.fields)
506 removed_models = self.old_model_keys - self.new_model_keys
507 for rem_package_label, rem_model_name in removed_models:
508 if rem_package_label == package_label:
509 rem_model_state = self.from_state.models[
510 rem_package_label, rem_model_name
511 ]
512 rem_model_fields_def = self.only_relation_agnostic_fields(
513 rem_model_state.fields
514 )
515 if model_fields_def == rem_model_fields_def:
516 if self.questioner.ask_rename_model(
517 rem_model_state, model_state
518 ):
519 dependencies = []
520 fields = list(model_state.fields.values()) + [
521 field.remote_field
522 for relations in self.to_state.relations[
523 package_label, model_name
524 ].values()
525 for field in relations.values()
526 ]
527 for field in fields:
528 if field.is_relation:
529 dependencies.extend(
530 self._get_dependencies_for_foreign_key(
531 package_label,
532 model_name,
533 field,
534 self.to_state,
535 )
536 )
537 self.add_operation(
538 package_label,
539 operations.RenameModel(
540 old_name=rem_model_state.name,
541 new_name=model_state.name,
542 ),
543 dependencies=dependencies,
544 )
545 self.renamed_models[
546 package_label, model_name
547 ] = rem_model_name
548 renamed_models_rel_key = "{}.{}".format(
549 rem_model_state.package_label,
550 rem_model_state.name_lower,
551 )
552 self.renamed_models_rel[
553 renamed_models_rel_key
554 ] = f"{model_state.package_label}.{model_state.name_lower}"
555 self.old_model_keys.remove(
556 (rem_package_label, rem_model_name)
557 )
558 self.old_model_keys.add((package_label, model_name))
559 break
561 def generate_created_models(self):
562 """
563 Find all new models (both managed and unmanaged) and make create
564 operations for them as well as separate operations to create any
565 foreign key or M2M relationships (these are optimized later, if
566 possible).
568 Defer any model options that refer to collections of fields that might
569 be deferred.
570 """
571 old_keys = self.old_model_keys | self.old_unmanaged_keys
572 added_models = self.new_model_keys - old_keys
573 added_unmanaged_models = self.new_unmanaged_keys - old_keys
574 all_added_models = chain(
575 sorted(added_models, key=self.swappable_first_key, reverse=True),
576 sorted(added_unmanaged_models, key=self.swappable_first_key, reverse=True),
577 )
578 for package_label, model_name in all_added_models:
579 model_state = self.to_state.models[package_label, model_name]
580 # Gather related fields
581 related_fields = {}
582 primary_key_rel = None
583 for field_name, field in model_state.fields.items():
584 if field.remote_field:
585 if field.remote_field.model:
586 if field.primary_key:
587 primary_key_rel = field.remote_field.model
588 elif not field.remote_field.parent_link:
589 related_fields[field_name] = field
590 if getattr(field.remote_field, "through", None):
591 related_fields[field_name] = field
593 # Are there indexes to defer?
594 indexes = model_state.options.pop("indexes")
595 constraints = model_state.options.pop("constraints")
596 order_with_respect_to = model_state.options.pop(
597 "order_with_respect_to", None
598 )
599 # Depend on the deletion of any possible proxy version of us
600 dependencies = [
601 (package_label, model_name, None, False),
602 ]
603 # Depend on all bases
604 for base in model_state.bases:
605 if isinstance(base, str) and "." in base:
606 base_package_label, base_name = base.split(".", 1)
607 dependencies.append((base_package_label, base_name, None, True))
608 # Depend on the removal of base fields if the new model has
609 # a field with the same name.
610 old_base_model_state = self.from_state.models.get(
611 (base_package_label, base_name)
612 )
613 new_base_model_state = self.to_state.models.get(
614 (base_package_label, base_name)
615 )
616 if old_base_model_state and new_base_model_state:
617 removed_base_fields = (
618 set(old_base_model_state.fields)
619 .difference(
620 new_base_model_state.fields,
621 )
622 .intersection(model_state.fields)
623 )
624 for removed_base_field in removed_base_fields:
625 dependencies.append(
626 (
627 base_package_label,
628 base_name,
629 removed_base_field,
630 False,
631 )
632 )
633 # Depend on the other end of the primary key if it's a relation
634 if primary_key_rel:
635 dependencies.append(
636 resolve_relation(
637 primary_key_rel,
638 package_label,
639 model_name,
640 )
641 + (None, True)
642 )
643 # Generate creation operation
644 self.add_operation(
645 package_label,
646 operations.CreateModel(
647 name=model_state.name,
648 fields=[
649 d
650 for d in model_state.fields.items()
651 if d[0] not in related_fields
652 ],
653 options=model_state.options,
654 bases=model_state.bases,
655 managers=model_state.managers,
656 ),
657 dependencies=dependencies,
658 beginning=True,
659 )
661 # Don't add operations which modify the database for unmanaged models
662 if not model_state.options.get("managed", True):
663 continue
665 # Generate operations for each related field
666 for name, field in sorted(related_fields.items()):
667 dependencies = self._get_dependencies_for_foreign_key(
668 package_label,
669 model_name,
670 field,
671 self.to_state,
672 )
673 # Depend on our own model being created
674 dependencies.append((package_label, model_name, None, True))
675 # Make operation
676 self.add_operation(
677 package_label,
678 operations.AddField(
679 model_name=model_name,
680 name=name,
681 field=field,
682 ),
683 dependencies=list(set(dependencies)),
684 )
685 # Generate other opns
686 if order_with_respect_to:
687 self.add_operation(
688 package_label,
689 operations.AlterOrderWithRespectTo(
690 name=model_name,
691 order_with_respect_to=order_with_respect_to,
692 ),
693 dependencies=[
694 (package_label, model_name, order_with_respect_to, True),
695 (package_label, model_name, None, True),
696 ],
697 )
698 related_dependencies = [
699 (package_label, model_name, name, True)
700 for name in sorted(related_fields)
701 ]
702 related_dependencies.append((package_label, model_name, None, True))
703 for index in indexes:
704 self.add_operation(
705 package_label,
706 operations.AddIndex(
707 model_name=model_name,
708 index=index,
709 ),
710 dependencies=related_dependencies,
711 )
712 for constraint in constraints:
713 self.add_operation(
714 package_label,
715 operations.AddConstraint(
716 model_name=model_name,
717 constraint=constraint,
718 ),
719 dependencies=related_dependencies,
720 )
722 def generate_deleted_models(self):
723 """
724 Find all deleted models (managed and unmanaged) and make delete
725 operations for them as well as separate operations to delete any
726 foreign key or M2M relationships (these are optimized later, if
727 possible).
729 Also bring forward removal of any model options that refer to
730 collections of fields - the inverse of generate_created_models().
731 """
732 new_keys = self.new_model_keys | self.new_unmanaged_keys
733 deleted_models = self.old_model_keys - new_keys
734 deleted_unmanaged_models = self.old_unmanaged_keys - new_keys
735 all_deleted_models = chain(
736 sorted(deleted_models), sorted(deleted_unmanaged_models)
737 )
738 for package_label, model_name in all_deleted_models:
739 model_state = self.from_state.models[package_label, model_name]
740 # Gather related fields
741 related_fields = {}
742 for field_name, field in model_state.fields.items():
743 if field.remote_field:
744 if field.remote_field.model:
745 related_fields[field_name] = field
746 if getattr(field.remote_field, "through", None):
747 related_fields[field_name] = field
749 # Then remove each related field
750 for name in sorted(related_fields):
751 self.add_operation(
752 package_label,
753 operations.RemoveField(
754 model_name=model_name,
755 name=name,
756 ),
757 )
758 # Finally, remove the model.
759 # This depends on both the removal/alteration of all incoming fields
760 # and the removal of all its own related fields, and if it's
761 # a through model the field that references it.
762 dependencies = []
763 relations = self.from_state.relations
764 for (
765 related_object_package_label,
766 object_name,
767 ), relation_related_fields in relations[package_label, model_name].items():
768 for field_name, field in relation_related_fields.items():
769 dependencies.append(
770 (related_object_package_label, object_name, field_name, False),
771 )
772 if not field.many_to_many:
773 dependencies.append(
774 (
775 related_object_package_label,
776 object_name,
777 field_name,
778 "alter",
779 ),
780 )
782 for name in sorted(related_fields):
783 dependencies.append((package_label, model_name, name, False))
784 # We're referenced in another field's through=
785 through_user = self.through_users.get(
786 (package_label, model_state.name_lower)
787 )
788 if through_user:
789 dependencies.append(
790 (through_user[0], through_user[1], through_user[2], False)
791 )
792 # Finally, make the operation, deduping any dependencies
793 self.add_operation(
794 package_label,
795 operations.DeleteModel(
796 name=model_state.name,
797 ),
798 dependencies=list(set(dependencies)),
799 )
801 def create_renamed_fields(self):
802 """Work out renamed fields."""
803 self.renamed_operations = []
804 old_field_keys = self.old_field_keys.copy()
805 for package_label, model_name, field_name in sorted(
806 self.new_field_keys - old_field_keys
807 ):
808 old_model_name = self.renamed_models.get(
809 (package_label, model_name), model_name
810 )
811 old_model_state = self.from_state.models[package_label, old_model_name]
812 new_model_state = self.to_state.models[package_label, model_name]
813 field = new_model_state.get_field(field_name)
814 # Scan to see if this is actually a rename!
815 field_dec = self.deep_deconstruct(field)
816 for rem_package_label, rem_model_name, rem_field_name in sorted(
817 old_field_keys - self.new_field_keys
818 ):
819 if rem_package_label == package_label and rem_model_name == model_name:
820 old_field = old_model_state.get_field(rem_field_name)
821 old_field_dec = self.deep_deconstruct(old_field)
822 if (
823 field.remote_field
824 and field.remote_field.model
825 and "to" in old_field_dec[2]
826 ):
827 old_rel_to = old_field_dec[2]["to"]
828 if old_rel_to in self.renamed_models_rel:
829 old_field_dec[2]["to"] = self.renamed_models_rel[old_rel_to]
830 old_field.set_attributes_from_name(rem_field_name)
831 old_db_column = old_field.get_attname_column()[1]
832 if old_field_dec == field_dec or (
833 # Was the field renamed and db_column equal to the
834 # old field's column added?
835 old_field_dec[0:2] == field_dec[0:2]
836 and dict(old_field_dec[2], db_column=old_db_column)
837 == field_dec[2]
838 ):
839 if self.questioner.ask_rename(
840 model_name, rem_field_name, field_name, field
841 ):
842 self.renamed_operations.append(
843 (
844 rem_package_label,
845 rem_model_name,
846 old_field.db_column,
847 rem_field_name,
848 package_label,
849 model_name,
850 field,
851 field_name,
852 )
853 )
854 old_field_keys.remove(
855 (rem_package_label, rem_model_name, rem_field_name)
856 )
857 old_field_keys.add((package_label, model_name, field_name))
858 self.renamed_fields[
859 package_label, model_name, field_name
860 ] = rem_field_name
861 break
863 def generate_renamed_fields(self):
864 """Generate RenameField operations."""
865 for (
866 rem_package_label,
867 rem_model_name,
868 rem_db_column,
869 rem_field_name,
870 package_label,
871 model_name,
872 field,
873 field_name,
874 ) in self.renamed_operations:
875 # A db_column mismatch requires a prior noop AlterField for the
876 # subsequent RenameField to be a noop on attempts at preserving the
877 # old name.
878 if rem_db_column != field.db_column:
879 altered_field = field.clone()
880 altered_field.name = rem_field_name
881 self.add_operation(
882 package_label,
883 operations.AlterField(
884 model_name=model_name,
885 name=rem_field_name,
886 field=altered_field,
887 ),
888 )
889 self.add_operation(
890 package_label,
891 operations.RenameField(
892 model_name=model_name,
893 old_name=rem_field_name,
894 new_name=field_name,
895 ),
896 )
897 self.old_field_keys.remove(
898 (rem_package_label, rem_model_name, rem_field_name)
899 )
900 self.old_field_keys.add((package_label, model_name, field_name))
902 def generate_added_fields(self):
903 """Make AddField operations."""
904 for package_label, model_name, field_name in sorted(
905 self.new_field_keys - self.old_field_keys
906 ):
907 self._generate_added_field(package_label, model_name, field_name)
909 def _generate_added_field(self, package_label, model_name, field_name):
910 field = self.to_state.models[package_label, model_name].get_field(field_name)
911 # Adding a field always depends at least on its removal.
912 dependencies = [(package_label, model_name, field_name, False)]
913 # Fields that are foreignkeys/m2ms depend on stuff.
914 if field.remote_field and field.remote_field.model:
915 dependencies.extend(
916 self._get_dependencies_for_foreign_key(
917 package_label,
918 model_name,
919 field,
920 self.to_state,
921 )
922 )
923 # You can't just add NOT NULL fields with no default or fields
924 # which don't allow empty strings as default.
925 time_fields = (models.DateField, models.DateTimeField, models.TimeField)
926 preserve_default = (
927 field.null
928 or field.has_default()
929 or field.many_to_many
930 or (field.blank and field.empty_strings_allowed)
931 or (isinstance(field, time_fields) and field.auto_now)
932 )
933 if not preserve_default:
934 field = field.clone()
935 if isinstance(field, time_fields) and field.auto_now_add:
936 field.default = self.questioner.ask_auto_now_add_addition(
937 field_name, model_name
938 )
939 else:
940 field.default = self.questioner.ask_not_null_addition(
941 field_name, model_name
942 )
943 if (
944 field.unique
945 and field.default is not models.NOT_PROVIDED
946 and callable(field.default)
947 ):
948 self.questioner.ask_unique_callable_default_addition(field_name, model_name)
949 self.add_operation(
950 package_label,
951 operations.AddField(
952 model_name=model_name,
953 name=field_name,
954 field=field,
955 preserve_default=preserve_default,
956 ),
957 dependencies=dependencies,
958 )
960 def generate_removed_fields(self):
961 """Make RemoveField operations."""
962 for package_label, model_name, field_name in sorted(
963 self.old_field_keys - self.new_field_keys
964 ):
965 self._generate_removed_field(package_label, model_name, field_name)
967 def _generate_removed_field(self, package_label, model_name, field_name):
968 self.add_operation(
969 package_label,
970 operations.RemoveField(
971 model_name=model_name,
972 name=field_name,
973 ),
974 # We might need to depend on the removal of an
975 # order_with_respect_to or index operation;
976 # this is safely ignored if there isn't one
977 dependencies=[
978 (package_label, model_name, field_name, "order_wrt_unset"),
979 ],
980 )
982 def generate_altered_fields(self):
983 """
984 Make AlterField operations, or possibly RemovedField/AddField if alter
985 isn't possible.
986 """
987 for package_label, model_name, field_name in sorted(
988 self.old_field_keys & self.new_field_keys
989 ):
990 # Did the field change?
991 old_model_name = self.renamed_models.get(
992 (package_label, model_name), model_name
993 )
994 old_field_name = self.renamed_fields.get(
995 (package_label, model_name, field_name), field_name
996 )
997 old_field = self.from_state.models[package_label, old_model_name].get_field(
998 old_field_name
999 )
1000 new_field = self.to_state.models[package_label, model_name].get_field(
1001 field_name
1002 )
1003 dependencies = []
1004 # Implement any model renames on relations; these are handled by RenameModel
1005 # so we need to exclude them from the comparison
1006 if hasattr(new_field, "remote_field") and getattr(
1007 new_field.remote_field, "model", None
1008 ):
1009 rename_key = resolve_relation(
1010 new_field.remote_field.model, package_label, model_name
1011 )
1012 if rename_key in self.renamed_models:
1013 new_field.remote_field.model = old_field.remote_field.model
1014 # Handle ForeignKey which can only have a single to_field.
1015 remote_field_name = getattr(new_field.remote_field, "field_name", None)
1016 if remote_field_name:
1017 to_field_rename_key = rename_key + (remote_field_name,)
1018 if to_field_rename_key in self.renamed_fields:
1019 # Repoint both model and field name because to_field
1020 # inclusion in ForeignKey.deconstruct() is based on
1021 # both.
1022 new_field.remote_field.model = old_field.remote_field.model
1023 new_field.remote_field.field_name = (
1024 old_field.remote_field.field_name
1025 )
1026 # Handle ForeignObjects which can have multiple from_fields/to_fields.
1027 from_fields = getattr(new_field, "from_fields", None)
1028 if from_fields:
1029 from_rename_key = (package_label, model_name)
1030 new_field.from_fields = tuple(
1031 [
1032 self.renamed_fields.get(
1033 from_rename_key + (from_field,), from_field
1034 )
1035 for from_field in from_fields
1036 ]
1037 )
1038 new_field.to_fields = tuple(
1039 [
1040 self.renamed_fields.get(rename_key + (to_field,), to_field)
1041 for to_field in new_field.to_fields
1042 ]
1043 )
1044 dependencies.extend(
1045 self._get_dependencies_for_foreign_key(
1046 package_label,
1047 model_name,
1048 new_field,
1049 self.to_state,
1050 )
1051 )
1052 if hasattr(new_field, "remote_field") and getattr(
1053 new_field.remote_field, "through", None
1054 ):
1055 rename_key = resolve_relation(
1056 new_field.remote_field.through, package_label, model_name
1057 )
1058 if rename_key in self.renamed_models:
1059 new_field.remote_field.through = old_field.remote_field.through
1060 old_field_dec = self.deep_deconstruct(old_field)
1061 new_field_dec = self.deep_deconstruct(new_field)
1062 # If the field was confirmed to be renamed it means that only
1063 # db_column was allowed to change which generate_renamed_fields()
1064 # already accounts for by adding an AlterField operation.
1065 if old_field_dec != new_field_dec and old_field_name == field_name:
1066 both_m2m = old_field.many_to_many and new_field.many_to_many
1067 neither_m2m = not old_field.many_to_many and not new_field.many_to_many
1068 if both_m2m or neither_m2m:
1069 # Either both fields are m2m or neither is
1070 preserve_default = True
1071 if (
1072 old_field.null
1073 and not new_field.null
1074 and not new_field.has_default()
1075 and not new_field.many_to_many
1076 ):
1077 field = new_field.clone()
1078 new_default = self.questioner.ask_not_null_alteration(
1079 field_name, model_name
1080 )
1081 if new_default is not models.NOT_PROVIDED:
1082 field.default = new_default
1083 preserve_default = False
1084 else:
1085 field = new_field
1086 self.add_operation(
1087 package_label,
1088 operations.AlterField(
1089 model_name=model_name,
1090 name=field_name,
1091 field=field,
1092 preserve_default=preserve_default,
1093 ),
1094 dependencies=dependencies,
1095 )
1096 else:
1097 # We cannot alter between m2m and concrete fields
1098 self._generate_removed_field(package_label, model_name, field_name)
1099 self._generate_added_field(package_label, model_name, field_name)
1101 def create_altered_indexes(self):
1102 option_name = operations.AddIndex.option_name
1104 for package_label, model_name in sorted(self.kept_model_keys):
1105 old_model_name = self.renamed_models.get(
1106 (package_label, model_name), model_name
1107 )
1108 old_model_state = self.from_state.models[package_label, old_model_name]
1109 new_model_state = self.to_state.models[package_label, model_name]
1111 old_indexes = old_model_state.options[option_name]
1112 new_indexes = new_model_state.options[option_name]
1113 added_indexes = [idx for idx in new_indexes if idx not in old_indexes]
1114 removed_indexes = [idx for idx in old_indexes if idx not in new_indexes]
1115 renamed_indexes = []
1116 # Find renamed indexes.
1117 remove_from_added = []
1118 remove_from_removed = []
1119 for new_index in added_indexes:
1120 new_index_dec = new_index.deconstruct()
1121 new_index_name = new_index_dec[2].pop("name")
1122 for old_index in removed_indexes:
1123 old_index_dec = old_index.deconstruct()
1124 old_index_name = old_index_dec[2].pop("name")
1125 # Indexes are the same except for the names.
1126 if (
1127 new_index_dec == old_index_dec
1128 and new_index_name != old_index_name
1129 ):
1130 renamed_indexes.append((old_index_name, new_index_name, None))
1131 remove_from_added.append(new_index)
1132 remove_from_removed.append(old_index)
1134 # Remove renamed indexes from the lists of added and removed
1135 # indexes.
1136 added_indexes = [
1137 idx for idx in added_indexes if idx not in remove_from_added
1138 ]
1139 removed_indexes = [
1140 idx for idx in removed_indexes if idx not in remove_from_removed
1141 ]
1143 self.altered_indexes.update(
1144 {
1145 (package_label, model_name): {
1146 "added_indexes": added_indexes,
1147 "removed_indexes": removed_indexes,
1148 "renamed_indexes": renamed_indexes,
1149 }
1150 }
1151 )
1153 def generate_added_indexes(self):
1154 for (package_label, model_name), alt_indexes in self.altered_indexes.items():
1155 dependencies = self._get_dependencies_for_model(package_label, model_name)
1156 for index in alt_indexes["added_indexes"]:
1157 self.add_operation(
1158 package_label,
1159 operations.AddIndex(
1160 model_name=model_name,
1161 index=index,
1162 ),
1163 dependencies=dependencies,
1164 )
1166 def generate_removed_indexes(self):
1167 for (package_label, model_name), alt_indexes in self.altered_indexes.items():
1168 for index in alt_indexes["removed_indexes"]:
1169 self.add_operation(
1170 package_label,
1171 operations.RemoveIndex(
1172 model_name=model_name,
1173 name=index.name,
1174 ),
1175 )
1177 def generate_renamed_indexes(self):
1178 for (package_label, model_name), alt_indexes in self.altered_indexes.items():
1179 for old_index_name, new_index_name, old_fields in alt_indexes[
1180 "renamed_indexes"
1181 ]:
1182 self.add_operation(
1183 package_label,
1184 operations.RenameIndex(
1185 model_name=model_name,
1186 new_name=new_index_name,
1187 old_name=old_index_name,
1188 old_fields=old_fields,
1189 ),
1190 )
1192 def create_altered_constraints(self):
1193 option_name = operations.AddConstraint.option_name
1194 for package_label, model_name in sorted(self.kept_model_keys):
1195 old_model_name = self.renamed_models.get(
1196 (package_label, model_name), model_name
1197 )
1198 old_model_state = self.from_state.models[package_label, old_model_name]
1199 new_model_state = self.to_state.models[package_label, model_name]
1201 old_constraints = old_model_state.options[option_name]
1202 new_constraints = new_model_state.options[option_name]
1203 add_constraints = [c for c in new_constraints if c not in old_constraints]
1204 rem_constraints = [c for c in old_constraints if c not in new_constraints]
1206 self.altered_constraints.update(
1207 {
1208 (package_label, model_name): {
1209 "added_constraints": add_constraints,
1210 "removed_constraints": rem_constraints,
1211 }
1212 }
1213 )
1215 def generate_added_constraints(self):
1216 for (
1217 package_label,
1218 model_name,
1219 ), alt_constraints in self.altered_constraints.items():
1220 dependencies = self._get_dependencies_for_model(package_label, model_name)
1221 for constraint in alt_constraints["added_constraints"]:
1222 self.add_operation(
1223 package_label,
1224 operations.AddConstraint(
1225 model_name=model_name,
1226 constraint=constraint,
1227 ),
1228 dependencies=dependencies,
1229 )
1231 def generate_removed_constraints(self):
1232 for (
1233 package_label,
1234 model_name,
1235 ), alt_constraints in self.altered_constraints.items():
1236 for constraint in alt_constraints["removed_constraints"]:
1237 self.add_operation(
1238 package_label,
1239 operations.RemoveConstraint(
1240 model_name=model_name,
1241 name=constraint.name,
1242 ),
1243 )
1245 @staticmethod
1246 def _get_dependencies_for_foreign_key(
1247 package_label, model_name, field, project_state
1248 ):
1249 remote_field_model = None
1250 if hasattr(field.remote_field, "model"):
1251 remote_field_model = field.remote_field.model
1252 else:
1253 relations = project_state.relations[package_label, model_name]
1254 for (remote_package_label, remote_model_name), fields in relations.items():
1255 if any(
1256 field == related_field.remote_field
1257 for related_field in fields.values()
1258 ):
1259 remote_field_model = f"{remote_package_label}.{remote_model_name}"
1260 break
1261 # Account for FKs to swappable models
1262 swappable_setting = getattr(field, "swappable_setting", None)
1263 if swappable_setting is not None:
1264 dep_package_label = "__setting__"
1265 dep_object_name = swappable_setting
1266 else:
1267 dep_package_label, dep_object_name = resolve_relation(
1268 remote_field_model,
1269 package_label,
1270 model_name,
1271 )
1272 dependencies = [(dep_package_label, dep_object_name, None, True)]
1273 if getattr(field.remote_field, "through", None):
1274 through_package_label, through_object_name = resolve_relation(
1275 field.remote_field.through,
1276 package_label,
1277 model_name,
1278 )
1279 dependencies.append(
1280 (through_package_label, through_object_name, None, True)
1281 )
1282 return dependencies
1284 def _get_dependencies_for_model(self, package_label, model_name):
1285 """Return foreign key dependencies of the given model."""
1286 dependencies = []
1287 model_state = self.to_state.models[package_label, model_name]
1288 for field in model_state.fields.values():
1289 if field.is_relation:
1290 dependencies.extend(
1291 self._get_dependencies_for_foreign_key(
1292 package_label,
1293 model_name,
1294 field,
1295 self.to_state,
1296 )
1297 )
1298 return dependencies
1300 def _get_altered_foo_together_operations(self, option_name):
1301 for package_label, model_name in sorted(self.kept_model_keys):
1302 old_model_name = self.renamed_models.get(
1303 (package_label, model_name), model_name
1304 )
1305 old_model_state = self.from_state.models[package_label, old_model_name]
1306 new_model_state = self.to_state.models[package_label, model_name]
1308 # We run the old version through the field renames to account for those
1309 old_value = old_model_state.options.get(option_name)
1310 old_value = (
1311 {
1312 tuple(
1313 self.renamed_fields.get((package_label, model_name, n), n)
1314 for n in unique
1315 )
1316 for unique in old_value
1317 }
1318 if old_value
1319 else set()
1320 )
1322 new_value = new_model_state.options.get(option_name)
1323 new_value = set(new_value) if new_value else set()
1325 if old_value != new_value:
1326 dependencies = []
1327 for foo_togethers in new_value:
1328 for field_name in foo_togethers:
1329 field = new_model_state.get_field(field_name)
1330 if field.remote_field and field.remote_field.model:
1331 dependencies.extend(
1332 self._get_dependencies_for_foreign_key(
1333 package_label,
1334 model_name,
1335 field,
1336 self.to_state,
1337 )
1338 )
1339 yield (
1340 old_value,
1341 new_value,
1342 package_label,
1343 model_name,
1344 dependencies,
1345 )
1347 def _generate_removed_altered_foo_together(self, operation):
1348 for (
1349 old_value,
1350 new_value,
1351 package_label,
1352 model_name,
1353 dependencies,
1354 ) in self._get_altered_foo_together_operations(operation.option_name):
1355 removal_value = new_value.intersection(old_value)
1356 if removal_value or old_value:
1357 self.add_operation(
1358 package_label,
1359 operation(
1360 name=model_name, **{operation.option_name: removal_value}
1361 ),
1362 dependencies=dependencies,
1363 )
1365 def generate_altered_db_table(self):
1366 models_to_check = self.kept_model_keys.union(self.kept_unmanaged_keys)
1367 for package_label, model_name in sorted(models_to_check):
1368 old_model_name = self.renamed_models.get(
1369 (package_label, model_name), model_name
1370 )
1371 old_model_state = self.from_state.models[package_label, old_model_name]
1372 new_model_state = self.to_state.models[package_label, model_name]
1373 old_db_table_name = old_model_state.options.get("db_table")
1374 new_db_table_name = new_model_state.options.get("db_table")
1375 if old_db_table_name != new_db_table_name:
1376 self.add_operation(
1377 package_label,
1378 operations.AlterModelTable(
1379 name=model_name,
1380 table=new_db_table_name,
1381 ),
1382 )
1384 def generate_altered_db_table_comment(self):
1385 models_to_check = self.kept_model_keys.union(self.kept_unmanaged_keys)
1386 for package_label, model_name in sorted(models_to_check):
1387 old_model_name = self.renamed_models.get(
1388 (package_label, model_name), model_name
1389 )
1390 old_model_state = self.from_state.models[package_label, old_model_name]
1391 new_model_state = self.to_state.models[package_label, model_name]
1393 old_db_table_comment = old_model_state.options.get("db_table_comment")
1394 new_db_table_comment = new_model_state.options.get("db_table_comment")
1395 if old_db_table_comment != new_db_table_comment:
1396 self.add_operation(
1397 package_label,
1398 operations.AlterModelTableComment(
1399 name=model_name,
1400 table_comment=new_db_table_comment,
1401 ),
1402 )
1404 def generate_altered_options(self):
1405 """
1406 Work out if any non-schema-affecting options have changed and make an
1407 operation to represent them in state changes (in case Python code in
1408 migrations needs them).
1409 """
1410 models_to_check = self.kept_model_keys.union(
1411 self.kept_unmanaged_keys,
1412 # unmanaged converted to managed
1413 self.old_unmanaged_keys & self.new_model_keys,
1414 # managed converted to unmanaged
1415 self.old_model_keys & self.new_unmanaged_keys,
1416 )
1418 for package_label, model_name in sorted(models_to_check):
1419 old_model_name = self.renamed_models.get(
1420 (package_label, model_name), model_name
1421 )
1422 old_model_state = self.from_state.models[package_label, old_model_name]
1423 new_model_state = self.to_state.models[package_label, model_name]
1424 old_options = {
1425 key: value
1426 for key, value in old_model_state.options.items()
1427 if key in AlterModelOptions.ALTER_OPTION_KEYS
1428 }
1429 new_options = {
1430 key: value
1431 for key, value in new_model_state.options.items()
1432 if key in AlterModelOptions.ALTER_OPTION_KEYS
1433 }
1434 if old_options != new_options:
1435 self.add_operation(
1436 package_label,
1437 operations.AlterModelOptions(
1438 name=model_name,
1439 options=new_options,
1440 ),
1441 )
1443 def generate_altered_order_with_respect_to(self):
1444 for package_label, model_name in sorted(self.kept_model_keys):
1445 old_model_name = self.renamed_models.get(
1446 (package_label, model_name), model_name
1447 )
1448 old_model_state = self.from_state.models[package_label, old_model_name]
1449 new_model_state = self.to_state.models[package_label, model_name]
1450 if old_model_state.options.get(
1451 "order_with_respect_to"
1452 ) != new_model_state.options.get("order_with_respect_to"):
1453 # Make sure it comes second if we're adding
1454 # (removal dependency is part of RemoveField)
1455 dependencies = []
1456 if new_model_state.options.get("order_with_respect_to"):
1457 dependencies.append(
1458 (
1459 package_label,
1460 model_name,
1461 new_model_state.options["order_with_respect_to"],
1462 True,
1463 )
1464 )
1465 # Actually generate the operation
1466 self.add_operation(
1467 package_label,
1468 operations.AlterOrderWithRespectTo(
1469 name=model_name,
1470 order_with_respect_to=new_model_state.options.get(
1471 "order_with_respect_to"
1472 ),
1473 ),
1474 dependencies=dependencies,
1475 )
1477 def generate_altered_managers(self):
1478 for package_label, model_name in sorted(self.kept_model_keys):
1479 old_model_name = self.renamed_models.get(
1480 (package_label, model_name), model_name
1481 )
1482 old_model_state = self.from_state.models[package_label, old_model_name]
1483 new_model_state = self.to_state.models[package_label, model_name]
1484 if old_model_state.managers != new_model_state.managers:
1485 self.add_operation(
1486 package_label,
1487 operations.AlterModelManagers(
1488 name=model_name,
1489 managers=new_model_state.managers,
1490 ),
1491 )
1493 def arrange_for_graph(self, changes, graph, migration_name=None):
1494 """
1495 Take a result from changes() and a MigrationGraph, and fix the names
1496 and dependencies of the changes so they extend the graph from the leaf
1497 nodes for each app.
1498 """
1499 leaves = graph.leaf_nodes()
1500 name_map = {}
1501 for package_label, migrations in list(changes.items()):
1502 if not migrations:
1503 continue
1504 # Find the app label's current leaf node
1505 app_leaf = None
1506 for leaf in leaves:
1507 if leaf[0] == package_label:
1508 app_leaf = leaf
1509 break
1510 # Do they want an initial migration for this app?
1511 if app_leaf is None and not self.questioner.ask_initial(package_label):
1512 # They don't.
1513 for migration in migrations:
1514 name_map[(package_label, migration.name)] = (
1515 package_label,
1516 "__first__",
1517 )
1518 del changes[package_label]
1519 continue
1520 # Work out the next number in the sequence
1521 if app_leaf is None:
1522 next_number = 1
1523 else:
1524 next_number = (self.parse_number(app_leaf[1]) or 0) + 1
1525 # Name each migration
1526 for i, migration in enumerate(migrations):
1527 if i == 0 and app_leaf:
1528 migration.dependencies.append(app_leaf)
1529 new_name_parts = ["%04i" % next_number]
1530 if migration_name:
1531 new_name_parts.append(migration_name)
1532 elif i == 0 and not app_leaf:
1533 new_name_parts.append("initial")
1534 else:
1535 new_name_parts.append(migration.suggest_name()[:100])
1536 new_name = "_".join(new_name_parts)
1537 name_map[(package_label, migration.name)] = (package_label, new_name)
1538 next_number += 1
1539 migration.name = new_name
1540 # Now fix dependencies
1541 for migrations in changes.values():
1542 for migration in migrations:
1543 migration.dependencies = [
1544 name_map.get(d, d) for d in migration.dependencies
1545 ]
1546 return changes
1548 def _trim_to_packages(self, changes, package_labels):
1549 """
1550 Take changes from arrange_for_graph() and set of app labels, and return
1551 a modified set of changes which trims out as many migrations that are
1552 not in package_labels as possible. Note that some other migrations may
1553 still be present as they may be required dependencies.
1554 """
1555 # Gather other app dependencies in a first pass
1556 app_dependencies = {}
1557 for package_label, migrations in changes.items():
1558 for migration in migrations:
1559 for dep_package_label, name in migration.dependencies:
1560 app_dependencies.setdefault(package_label, set()).add(
1561 dep_package_label
1562 )
1563 required_packages = set(package_labels)
1564 # Keep resolving till there's no change
1565 old_required_packages = None
1566 while old_required_packages != required_packages:
1567 old_required_packages = set(required_packages)
1568 required_packages.update(
1569 *[
1570 app_dependencies.get(package_label, ())
1571 for package_label in required_packages
1572 ]
1573 )
1574 # Remove all migrations that aren't needed
1575 for package_label in list(changes):
1576 if package_label not in required_packages:
1577 del changes[package_label]
1578 return changes
1580 @classmethod
1581 def parse_number(cls, name):
1582 """
1583 Given a migration name, try to extract a number from the beginning of
1584 it. For a squashed migration such as '0001_squashed_0004…', return the
1585 second number. If no number is found, return None.
1586 """
1587 if squashed_match := re.search(r".*_squashed_(\d+)", name):
1588 return int(squashed_match[1])
1589 match = re.match(r"^\d+", name)
1590 if match:
1591 return int(match[0])
1592 return None
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.models.db import DatabaseError
4class AmbiguityError(Exception):
5 """More than one migration matches a name prefix."""
7 pass
10class BadMigrationError(Exception):
11 """There's a bad migration (unreadable/bad format/etc.)."""
13 pass
16class CircularDependencyError(Exception):
17 """There's an impossible-to-resolve circular dependency."""
19 pass
22class InconsistentMigrationHistory(Exception):
23 """An applied migration has some of its dependencies not applied."""
25 pass
28class InvalidBasesError(ValueError):
29 """A model's base classes can't be resolved."""
31 pass
34class IrreversibleError(RuntimeError):
35 """An irreversible migration is about to be reversed."""
37 pass
40class NodeNotFoundError(LookupError):
41 """An attempt on a node is made that is not available in the graph."""
43 def __init__(self, message, node, origin=None):
44 self.message = message
45 self.origin = origin
46 self.node = node
48 def __str__(self):
49 return self.message
51 def __repr__(self):
52 return f"NodeNotFoundError({self.node!r})"
55class MigrationSchemaMissing(DatabaseError):
56 pass
59class InvalidMigrationPlan(ValueError):
60 pass
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.models import migrations
2from plain.models.db import router
3from plain.packages.registry import packages as global_packages
5from .exceptions import InvalidMigrationPlan
6from .loader import MigrationLoader
7from .recorder import MigrationRecorder
8from .state import ProjectState
11class MigrationExecutor:
12 """
13 End-to-end migration execution - load migrations and run them up or down
14 to a specified set of targets.
15 """
17 def __init__(self, connection, progress_callback=None):
18 self.connection = connection
19 self.loader = MigrationLoader(self.connection)
20 self.recorder = MigrationRecorder(self.connection)
21 self.progress_callback = progress_callback
23 def migration_plan(self, targets, clean_start=False):
24 """
25 Given a set of targets, return a list of (Migration instance, backwards?).
26 """
27 plan = []
28 if clean_start:
29 applied = {}
30 else:
31 applied = dict(self.loader.applied_migrations)
32 for target in targets:
33 # If the target is (package_label, None), that means unmigrate everything
34 if target[1] is None:
35 for root in self.loader.graph.root_nodes():
36 if root[0] == target[0]:
37 for migration in self.loader.graph.backwards_plan(root):
38 if migration in applied:
39 plan.append((self.loader.graph.nodes[migration], True))
40 applied.pop(migration)
41 # If the migration is already applied, do backwards mode,
42 # otherwise do forwards mode.
43 elif target in applied:
44 # If the target is missing, it's likely a replaced migration.
45 # Reload the graph without replacements.
46 if (
47 self.loader.replace_migrations
48 and target not in self.loader.graph.node_map
49 ):
50 self.loader.replace_migrations = False
51 self.loader.build_graph()
52 return self.migration_plan(targets, clean_start=clean_start)
53 # Don't migrate backwards all the way to the target node (that
54 # may roll back dependencies in other packages that don't need to
55 # be rolled back); instead roll back through target's immediate
56 # child(ren) in the same app, and no further.
57 next_in_app = sorted(
58 n
59 for n in self.loader.graph.node_map[target].children
60 if n[0] == target[0]
61 )
62 for node in next_in_app:
63 for migration in self.loader.graph.backwards_plan(node):
64 if migration in applied:
65 plan.append((self.loader.graph.nodes[migration], True))
66 applied.pop(migration)
67 else:
68 for migration in self.loader.graph.forwards_plan(target):
69 if migration not in applied:
70 plan.append((self.loader.graph.nodes[migration], False))
71 applied[migration] = self.loader.graph.nodes[migration]
72 return plan
74 def _create_project_state(self, with_applied_migrations=False):
75 """
76 Create a project state including all the applications without
77 migrations and applied migrations if with_applied_migrations=True.
78 """
79 state = ProjectState(real_packages=self.loader.unmigrated_packages)
80 if with_applied_migrations:
81 # Create the forwards plan Plain would follow on an empty database
82 full_plan = self.migration_plan(
83 self.loader.graph.leaf_nodes(), clean_start=True
84 )
85 applied_migrations = {
86 self.loader.graph.nodes[key]
87 for key in self.loader.applied_migrations
88 if key in self.loader.graph.nodes
89 }
90 for migration, _ in full_plan:
91 if migration in applied_migrations:
92 migration.mutate_state(state, preserve=False)
93 return state
95 def migrate(self, targets, plan=None, state=None, fake=False, fake_initial=False):
96 """
97 Migrate the database up to the given targets.
99 Plain first needs to create all project states before a migration is
100 (un)applied and in a second step run all the database operations.
101 """
102 # The plain_migrations table must be present to record applied
103 # migrations, but don't create it if there are no migrations to apply.
104 if plan == []:
105 if not self.recorder.has_table():
106 return self._create_project_state(with_applied_migrations=False)
107 else:
108 self.recorder.ensure_schema()
110 if plan is None:
111 plan = self.migration_plan(targets)
112 # Create the forwards plan Plain would follow on an empty database
113 full_plan = self.migration_plan(
114 self.loader.graph.leaf_nodes(), clean_start=True
115 )
117 all_forwards = all(not backwards for mig, backwards in plan)
118 all_backwards = all(backwards for mig, backwards in plan)
120 if not plan:
121 if state is None:
122 # The resulting state should include applied migrations.
123 state = self._create_project_state(with_applied_migrations=True)
124 elif all_forwards == all_backwards:
125 # This should only happen if there's a mixed plan
126 raise InvalidMigrationPlan(
127 "Migration plans with both forwards and backwards migrations "
128 "are not supported. Please split your migration process into "
129 "separate plans of only forwards OR backwards migrations.",
130 plan,
131 )
132 elif all_forwards:
133 if state is None:
134 # The resulting state should still include applied migrations.
135 state = self._create_project_state(with_applied_migrations=True)
136 state = self._migrate_all_forwards(
137 state, plan, full_plan, fake=fake, fake_initial=fake_initial
138 )
139 else:
140 # No need to check for `elif all_backwards` here, as that condition
141 # would always evaluate to true.
142 state = self._migrate_all_backwards(plan, full_plan, fake=fake)
144 self.check_replacements()
146 return state
148 def _migrate_all_forwards(self, state, plan, full_plan, fake, fake_initial):
149 """
150 Take a list of 2-tuples of the form (migration instance, False) and
151 apply them in the order they occur in the full_plan.
152 """
153 migrations_to_run = {m[0] for m in plan}
154 for migration, _ in full_plan:
155 if not migrations_to_run:
156 # We remove every migration that we applied from these sets so
157 # that we can bail out once the last migration has been applied
158 # and don't always run until the very end of the migration
159 # process.
160 break
161 if migration in migrations_to_run:
162 if "packages" not in state.__dict__:
163 if self.progress_callback:
164 self.progress_callback("render_start")
165 state.packages # Render all -- performance critical
166 if self.progress_callback:
167 self.progress_callback("render_success")
168 state = self.apply_migration(
169 state, migration, fake=fake, fake_initial=fake_initial
170 )
171 migrations_to_run.remove(migration)
173 return state
175 def _migrate_all_backwards(self, plan, full_plan, fake):
176 """
177 Take a list of 2-tuples of the form (migration instance, True) and
178 unapply them in reverse order they occur in the full_plan.
180 Since unapplying a migration requires the project state prior to that
181 migration, Plain will compute the migration states before each of them
182 in a first run over the plan and then unapply them in a second run over
183 the plan.
184 """
185 migrations_to_run = {m[0] for m in plan}
186 # Holds all migration states prior to the migrations being unapplied
187 states = {}
188 state = self._create_project_state()
189 applied_migrations = {
190 self.loader.graph.nodes[key]
191 for key in self.loader.applied_migrations
192 if key in self.loader.graph.nodes
193 }
194 if self.progress_callback:
195 self.progress_callback("render_start")
196 for migration, _ in full_plan:
197 if not migrations_to_run:
198 # We remove every migration that we applied from this set so
199 # that we can bail out once the last migration has been applied
200 # and don't always run until the very end of the migration
201 # process.
202 break
203 if migration in migrations_to_run:
204 if "packages" not in state.__dict__:
205 state.packages # Render all -- performance critical
206 # The state before this migration
207 states[migration] = state
208 # The old state keeps as-is, we continue with the new state
209 state = migration.mutate_state(state, preserve=True)
210 migrations_to_run.remove(migration)
211 elif migration in applied_migrations:
212 # Only mutate the state if the migration is actually applied
213 # to make sure the resulting state doesn't include changes
214 # from unrelated migrations.
215 migration.mutate_state(state, preserve=False)
216 if self.progress_callback:
217 self.progress_callback("render_success")
219 for migration, _ in plan:
220 self.unapply_migration(states[migration], migration, fake=fake)
221 applied_migrations.remove(migration)
223 # Generate the post migration state by starting from the state before
224 # the last migration is unapplied and mutating it to include all the
225 # remaining applied migrations.
226 last_unapplied_migration = plan[-1][0]
227 state = states[last_unapplied_migration]
228 for index, (migration, _) in enumerate(full_plan):
229 if migration == last_unapplied_migration:
230 for migration, _ in full_plan[index:]:
231 if migration in applied_migrations:
232 migration.mutate_state(state, preserve=False)
233 break
235 return state
237 def apply_migration(self, state, migration, fake=False, fake_initial=False):
238 """Run a migration forwards."""
239 migration_recorded = False
240 if self.progress_callback:
241 self.progress_callback("apply_start", migration, fake)
242 if not fake:
243 if fake_initial:
244 # Test to see if this is an already-applied initial migration
245 applied, state = self.detect_soft_applied(state, migration)
246 if applied:
247 fake = True
248 if not fake:
249 # Alright, do it normally
250 with self.connection.schema_editor(
251 atomic=migration.atomic
252 ) as schema_editor:
253 state = migration.apply(state, schema_editor)
254 if not schema_editor.deferred_sql:
255 self.record_migration(migration)
256 migration_recorded = True
257 if not migration_recorded:
258 self.record_migration(migration)
259 # Report progress
260 if self.progress_callback:
261 self.progress_callback("apply_success", migration, fake)
262 return state
264 def record_migration(self, migration):
265 # For replacement migrations, record individual statuses
266 if migration.replaces:
267 for package_label, name in migration.replaces:
268 self.recorder.record_applied(package_label, name)
269 else:
270 self.recorder.record_applied(migration.package_label, migration.name)
272 def unapply_migration(self, state, migration, fake=False):
273 """Run a migration backwards."""
274 if self.progress_callback:
275 self.progress_callback("unapply_start", migration, fake)
276 if not fake:
277 with self.connection.schema_editor(
278 atomic=migration.atomic
279 ) as schema_editor:
280 state = migration.unapply(state, schema_editor)
281 # For replacement migrations, also record individual statuses.
282 if migration.replaces:
283 for package_label, name in migration.replaces:
284 self.recorder.record_unapplied(package_label, name)
285 self.recorder.record_unapplied(migration.package_label, migration.name)
286 # Report progress
287 if self.progress_callback:
288 self.progress_callback("unapply_success", migration, fake)
289 return state
291 def check_replacements(self):
292 """
293 Mark replacement migrations applied if their replaced set all are.
295 Do this unconditionally on every migrate, rather than just when
296 migrations are applied or unapplied, to correctly handle the case
297 when a new squash migration is pushed to a deployment that already had
298 all its replaced migrations applied. In this case no new migration will
299 be applied, but the applied state of the squashed migration must be
300 maintained.
301 """
302 applied = self.recorder.applied_migrations()
303 for key, migration in self.loader.replacements.items():
304 all_applied = all(m in applied for m in migration.replaces)
305 if all_applied and key not in applied:
306 self.recorder.record_applied(*key)
308 def detect_soft_applied(self, project_state, migration):
309 """
310 Test whether a migration has been implicitly applied - that the
311 tables or columns it would create exist. This is intended only for use
312 on initial migrations (as it only looks for CreateModel and AddField).
313 """
315 def should_skip_detecting_model(migration, model):
316 """
317 No need to detect tables for unmanaged models, or
318 models that can't be migrated on the current database.
319 """
320 return not model._meta.managed or not router.allow_migrate(
321 self.connection.alias,
322 migration.package_label,
323 model_name=model._meta.model_name,
324 )
326 if migration.initial is None:
327 # Bail if the migration isn't the first one in its app
328 if any(
329 app == migration.package_label for app, name in migration.dependencies
330 ):
331 return False, project_state
332 elif migration.initial is False:
333 # Bail if it's NOT an initial migration
334 return False, project_state
336 if project_state is None:
337 after_state = self.loader.project_state(
338 (migration.package_label, migration.name), at_end=True
339 )
340 else:
341 after_state = migration.mutate_state(project_state)
342 packages = after_state.packages
343 found_create_model_migration = False
344 found_add_field_migration = False
345 fold_identifier_case = self.connection.features.ignores_table_name_case
346 with self.connection.cursor() as cursor:
347 existing_table_names = set(
348 self.connection.introspection.table_names(cursor)
349 )
350 if fold_identifier_case:
351 existing_table_names = {
352 name.casefold() for name in existing_table_names
353 }
354 # Make sure all create model and add field operations are done
355 for operation in migration.operations:
356 if isinstance(operation, migrations.CreateModel):
357 model = packages.get_model(migration.package_label, operation.name)
358 if model._meta.swapped:
359 # We have to fetch the model to test with from the
360 # main app cache, as it's not a direct dependency.
361 model = global_packages.get_model(model._meta.swapped)
362 if should_skip_detecting_model(migration, model):
363 continue
364 db_table = model._meta.db_table
365 if fold_identifier_case:
366 db_table = db_table.casefold()
367 if db_table not in existing_table_names:
368 return False, project_state
369 found_create_model_migration = True
370 elif isinstance(operation, migrations.AddField):
371 model = packages.get_model(
372 migration.package_label, operation.model_name
373 )
374 if model._meta.swapped:
375 # We have to fetch the model to test with from the
376 # main app cache, as it's not a direct dependency.
377 model = global_packages.get_model(model._meta.swapped)
378 if should_skip_detecting_model(migration, model):
379 continue
381 table = model._meta.db_table
382 field = model._meta.get_field(operation.name)
384 # Handle implicit many-to-many tables created by AddField.
385 if field.many_to_many:
386 through_db_table = field.remote_field.through._meta.db_table
387 if fold_identifier_case:
388 through_db_table = through_db_table.casefold()
389 if through_db_table not in existing_table_names:
390 return False, project_state
391 else:
392 found_add_field_migration = True
393 continue
394 with self.connection.cursor() as cursor:
395 columns = self.connection.introspection.get_table_description(
396 cursor, table
397 )
398 for column in columns:
399 field_column = field.column
400 column_name = column.name
401 if fold_identifier_case:
402 column_name = column_name.casefold()
403 field_column = field_column.casefold()
404 if column_name == field_column:
405 found_add_field_migration = True
406 break
407 else:
408 return False, project_state
409 # If we get this far and we found at least one CreateModel or AddField
410 # migration, the migration is considered implicitly applied.
411 return (found_create_model_migration or found_add_field_migration), after_state
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from functools import total_ordering
3from plain.models.migrations.state import ProjectState
5from .exceptions import CircularDependencyError, NodeNotFoundError
8@total_ordering
9class Node:
10 """
11 A single node in the migration graph. Contains direct links to adjacent
12 nodes in either direction.
13 """
15 def __init__(self, key):
16 self.key = key
17 self.children = set()
18 self.parents = set()
20 def __eq__(self, other):
21 return self.key == other
23 def __lt__(self, other):
24 return self.key < other
26 def __hash__(self):
27 return hash(self.key)
29 def __getitem__(self, item):
30 return self.key[item]
32 def __str__(self):
33 return str(self.key)
35 def __repr__(self):
36 return f"<{self.__class__.__name__}: ({self.key[0]!r}, {self.key[1]!r})>"
38 def add_child(self, child):
39 self.children.add(child)
41 def add_parent(self, parent):
42 self.parents.add(parent)
45class DummyNode(Node):
46 """
47 A node that doesn't correspond to a migration file on disk.
48 (A squashed migration that was removed, for example.)
50 After the migration graph is processed, all dummy nodes should be removed.
51 If there are any left, a nonexistent dependency error is raised.
52 """
54 def __init__(self, key, origin, error_message):
55 super().__init__(key)
56 self.origin = origin
57 self.error_message = error_message
59 def raise_error(self):
60 raise NodeNotFoundError(self.error_message, self.key, origin=self.origin)
63class MigrationGraph:
64 """
65 Represent the digraph of all migrations in a project.
67 Each migration is a node, and each dependency is an edge. There are
68 no implicit dependencies between numbered migrations - the numbering is
69 merely a convention to aid file listing. Every new numbered migration
70 has a declared dependency to the previous number, meaning that VCS
71 branch merges can be detected and resolved.
73 Migrations files can be marked as replacing another set of migrations -
74 this is to support the "squash" feature. The graph handler isn't responsible
75 for these; instead, the code to load them in here should examine the
76 migration files and if the replaced migrations are all either unapplied
77 or not present, it should ignore the replaced ones, load in just the
78 replacing migration, and repoint any dependencies that pointed to the
79 replaced migrations to point to the replacing one.
81 A node should be a tuple: (app_path, migration_name). The tree special-cases
82 things within an app - namely, root nodes and leaf nodes ignore dependencies
83 to other packages.
84 """
86 def __init__(self):
87 self.node_map = {}
88 self.nodes = {}
90 def add_node(self, key, migration):
91 assert key not in self.node_map
92 node = Node(key)
93 self.node_map[key] = node
94 self.nodes[key] = migration
96 def add_dummy_node(self, key, origin, error_message):
97 node = DummyNode(key, origin, error_message)
98 self.node_map[key] = node
99 self.nodes[key] = None
101 def add_dependency(self, migration, child, parent, skip_validation=False):
102 """
103 This may create dummy nodes if they don't yet exist. If
104 `skip_validation=True`, validate_consistency() should be called
105 afterward.
106 """
107 if child not in self.nodes:
108 error_message = (
109 f"Migration {migration} dependencies reference nonexistent"
110 f" child node {child!r}"
111 )
112 self.add_dummy_node(child, migration, error_message)
113 if parent not in self.nodes:
114 error_message = (
115 f"Migration {migration} dependencies reference nonexistent"
116 f" parent node {parent!r}"
117 )
118 self.add_dummy_node(parent, migration, error_message)
119 self.node_map[child].add_parent(self.node_map[parent])
120 self.node_map[parent].add_child(self.node_map[child])
121 if not skip_validation:
122 self.validate_consistency()
124 def remove_replaced_nodes(self, replacement, replaced):
125 """
126 Remove each of the `replaced` nodes (when they exist). Any
127 dependencies that were referencing them are changed to reference the
128 `replacement` node instead.
129 """
130 # Cast list of replaced keys to set to speed up lookup later.
131 replaced = set(replaced)
132 try:
133 replacement_node = self.node_map[replacement]
134 except KeyError as err:
135 raise NodeNotFoundError(
136 "Unable to find replacement node {!r}. It was either never added"
137 " to the migration graph, or has been removed.".format(replacement),
138 replacement,
139 ) from err
140 for replaced_key in replaced:
141 self.nodes.pop(replaced_key, None)
142 replaced_node = self.node_map.pop(replaced_key, None)
143 if replaced_node:
144 for child in replaced_node.children:
145 child.parents.remove(replaced_node)
146 # We don't want to create dependencies between the replaced
147 # node and the replacement node as this would lead to
148 # self-referencing on the replacement node at a later iteration.
149 if child.key not in replaced:
150 replacement_node.add_child(child)
151 child.add_parent(replacement_node)
152 for parent in replaced_node.parents:
153 parent.children.remove(replaced_node)
154 # Again, to avoid self-referencing.
155 if parent.key not in replaced:
156 replacement_node.add_parent(parent)
157 parent.add_child(replacement_node)
159 def remove_replacement_node(self, replacement, replaced):
160 """
161 The inverse operation to `remove_replaced_nodes`. Almost. Remove the
162 replacement node `replacement` and remap its child nodes to `replaced`
163 - the list of nodes it would have replaced. Don't remap its parent
164 nodes as they are expected to be correct already.
165 """
166 self.nodes.pop(replacement, None)
167 try:
168 replacement_node = self.node_map.pop(replacement)
169 except KeyError as err:
170 raise NodeNotFoundError(
171 "Unable to remove replacement node {!r}. It was either never added"
172 " to the migration graph, or has been removed already.".format(
173 replacement
174 ),
175 replacement,
176 ) from err
177 replaced_nodes = set()
178 replaced_nodes_parents = set()
179 for key in replaced:
180 replaced_node = self.node_map.get(key)
181 if replaced_node:
182 replaced_nodes.add(replaced_node)
183 replaced_nodes_parents |= replaced_node.parents
184 # We're only interested in the latest replaced node, so filter out
185 # replaced nodes that are parents of other replaced nodes.
186 replaced_nodes -= replaced_nodes_parents
187 for child in replacement_node.children:
188 child.parents.remove(replacement_node)
189 for replaced_node in replaced_nodes:
190 replaced_node.add_child(child)
191 child.add_parent(replaced_node)
192 for parent in replacement_node.parents:
193 parent.children.remove(replacement_node)
194 # NOTE: There is no need to remap parent dependencies as we can
195 # assume the replaced nodes already have the correct ancestry.
197 def validate_consistency(self):
198 """Ensure there are no dummy nodes remaining in the graph."""
199 [n.raise_error() for n in self.node_map.values() if isinstance(n, DummyNode)]
201 def forwards_plan(self, target):
202 """
203 Given a node, return a list of which previous nodes (dependencies) must
204 be applied, ending with the node itself. This is the list you would
205 follow if applying the migrations to a database.
206 """
207 if target not in self.nodes:
208 raise NodeNotFoundError(f"Node {target!r} not a valid node", target)
209 return self.iterative_dfs(self.node_map[target])
211 def backwards_plan(self, target):
212 """
213 Given a node, return a list of which dependent nodes (dependencies)
214 must be unapplied, ending with the node itself. This is the list you
215 would follow if removing the migrations from a database.
216 """
217 if target not in self.nodes:
218 raise NodeNotFoundError(f"Node {target!r} not a valid node", target)
219 return self.iterative_dfs(self.node_map[target], forwards=False)
221 def iterative_dfs(self, start, forwards=True):
222 """Iterative depth-first search for finding dependencies."""
223 visited = []
224 visited_set = set()
225 stack = [(start, False)]
226 while stack:
227 node, processed = stack.pop()
228 if node in visited_set:
229 pass
230 elif processed:
231 visited_set.add(node)
232 visited.append(node.key)
233 else:
234 stack.append((node, True))
235 stack += [
236 (n, False)
237 for n in sorted(node.parents if forwards else node.children)
238 ]
239 return visited
241 def root_nodes(self, app=None):
242 """
243 Return all root nodes - that is, nodes with no dependencies inside
244 their app. These are the starting point for an app.
245 """
246 roots = set()
247 for node in self.nodes:
248 if all(key[0] != node[0] for key in self.node_map[node].parents) and (
249 not app or app == node[0]
250 ):
251 roots.add(node)
252 return sorted(roots)
254 def leaf_nodes(self, app=None):
255 """
256 Return all leaf nodes - that is, nodes with no dependents in their app.
257 These are the "most current" version of an app's schema.
258 Having more than one per app is technically an error, but one that
259 gets handled further up, in the interactive command - it's usually the
260 result of a VCS merge and needs some user input.
261 """
262 leaves = set()
263 for node in self.nodes:
264 if all(key[0] != node[0] for key in self.node_map[node].children) and (
265 not app or app == node[0]
266 ):
267 leaves.add(node)
268 return sorted(leaves)
270 def ensure_not_cyclic(self):
271 # Algo from GvR:
272 # https://neopythonic.blogspot.com/2009/01/detecting-cycles-in-directed-graph.html
273 todo = set(self.nodes)
274 while todo:
275 node = todo.pop()
276 stack = [node]
277 while stack:
278 top = stack[-1]
279 for child in self.node_map[top].children:
280 # Use child.key instead of child to speed up the frequent
281 # hashing.
282 node = child.key
283 if node in stack:
284 cycle = stack[stack.index(node) :]
285 raise CircularDependencyError(
286 ", ".join("{}.{}".format(*n) for n in cycle)
287 )
288 if node in todo:
289 stack.append(node)
290 todo.remove(node)
291 break
292 else:
293 node = stack.pop()
295 def __str__(self):
296 return "Graph: {} nodes, {} edges".format(*self._nodes_and_edges())
298 def __repr__(self):
299 nodes, edges = self._nodes_and_edges()
300 return f"<{self.__class__.__name__}: nodes={nodes}, edges={edges}>"
302 def _nodes_and_edges(self):
303 return len(self.nodes), sum(
304 len(node.parents) for node in self.node_map.values()
305 )
307 def _generate_plan(self, nodes, at_end):
308 plan = []
309 for node in nodes:
310 for migration in self.forwards_plan(node):
311 if migration not in plan and (at_end or migration not in nodes):
312 plan.append(migration)
313 return plan
315 def make_state(self, nodes=None, at_end=True, real_packages=None):
316 """
317 Given a migration node or nodes, return a complete ProjectState for it.
318 If at_end is False, return the state before the migration has run.
319 If nodes is not provided, return the overall most current project state.
320 """
321 if nodes is None:
322 nodes = list(self.leaf_nodes())
323 if not nodes:
324 return ProjectState()
325 if not isinstance(nodes[0], tuple):
326 nodes = [nodes]
327 plan = self._generate_plan(nodes, at_end)
328 project_state = ProjectState(real_packages=real_packages)
329 for node in plan:
330 project_state = self.nodes[node].mutate_state(project_state, preserve=False)
331 return project_state
333 def __contains__(self, node):
334 return node in self.nodes
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import pkgutil
2import sys
3from importlib import import_module, reload
5from plain.models.migrations.graph import MigrationGraph
6from plain.models.migrations.recorder import MigrationRecorder
7from plain.packages import packages
9from .exceptions import (
10 AmbiguityError,
11 BadMigrationError,
12 InconsistentMigrationHistory,
13 NodeNotFoundError,
14)
16MIGRATIONS_MODULE_NAME = "migrations"
19class MigrationLoader:
20 """
21 Load migration files from disk and their status from the database.
23 Migration files are expected to live in the "migrations" directory of
24 an app. Their names are entirely unimportant from a code perspective,
25 but will probably follow the 1234_name.py convention.
27 On initialization, this class will scan those directories, and open and
28 read the Python files, looking for a class called Migration, which should
29 inherit from plain.models.migrations.Migration. See
30 plain.models.migrations.migration for what that looks like.
32 Some migrations will be marked as "replacing" another set of migrations.
33 These are loaded into a separate set of migrations away from the main ones.
34 If all the migrations they replace are either unapplied or missing from
35 disk, then they are injected into the main set, replacing the named migrations.
36 Any dependency pointers to the replaced migrations are re-pointed to the
37 new migration.
39 This does mean that this class MUST also talk to the database as well as
40 to disk, but this is probably fine. We're already not just operating
41 in memory.
42 """
44 def __init__(
45 self,
46 connection,
47 load=True,
48 ignore_no_migrations=False,
49 replace_migrations=True,
50 ):
51 self.connection = connection
52 self.disk_migrations = None
53 self.applied_migrations = None
54 self.ignore_no_migrations = ignore_no_migrations
55 self.replace_migrations = replace_migrations
56 if load:
57 self.build_graph()
59 @classmethod
60 def migrations_module(cls, package_label):
61 """
62 Return the path to the migrations module for the specified package_label
63 and a boolean indicating if the module is specified in
64 settings.MIGRATION_MODULE.
65 """
67 app = packages.get_package_config(package_label)
68 if app.migrations_module is None:
69 return None, True
70 explicit = app.migrations_module != MIGRATIONS_MODULE_NAME
71 return f"{app.name}.{app.migrations_module}", explicit
73 def load_disk(self):
74 """Load the migrations from all INSTALLED_PACKAGES from disk."""
75 self.disk_migrations = {}
76 self.unmigrated_packages = set()
77 self.migrated_packages = set()
78 for package_config in packages.get_package_configs():
79 # Get the migrations module directory
80 module_name, explicit = self.migrations_module(package_config.label)
81 if module_name is None:
82 self.unmigrated_packages.add(package_config.label)
83 continue
84 was_loaded = module_name in sys.modules
85 try:
86 module = import_module(module_name)
87 except ModuleNotFoundError as e:
88 if (explicit and self.ignore_no_migrations) or (
89 not explicit and MIGRATIONS_MODULE_NAME in e.name.split(".")
90 ):
91 self.unmigrated_packages.add(package_config.label)
92 continue
93 raise
94 else:
95 # Module is not a package (e.g. migrations.py).
96 if not hasattr(module, "__path__"):
97 self.unmigrated_packages.add(package_config.label)
98 continue
99 # Empty directories are namespaces. Namespace packages have no
100 # __file__ and don't use a list for __path__. See
101 # https://docs.python.org/3/reference/import.html#namespace-packages
102 if getattr(module, "__file__", None) is None and not isinstance(
103 module.__path__, list
104 ):
105 self.unmigrated_packages.add(package_config.label)
106 continue
107 # Force a reload if it's already loaded (tests need this)
108 if was_loaded:
109 reload(module)
110 self.migrated_packages.add(package_config.label)
111 migration_names = {
112 name
113 for _, name, is_pkg in pkgutil.iter_modules(module.__path__)
114 if not is_pkg and name[0] not in "_~"
115 }
116 # Load migrations
117 for migration_name in migration_names:
118 migration_path = f"{module_name}.{migration_name}"
119 try:
120 migration_module = import_module(migration_path)
121 except ImportError as e:
122 if "bad magic number" in str(e):
123 raise ImportError(
124 "Couldn't import %r as it appears to be a stale "
125 ".pyc file." % migration_path
126 ) from e
127 else:
128 raise
129 if not hasattr(migration_module, "Migration"):
130 raise BadMigrationError(
131 "Migration {} in app {} has no Migration class".format(
132 migration_name, package_config.label
133 )
134 )
135 self.disk_migrations[
136 package_config.label, migration_name
137 ] = migration_module.Migration(
138 migration_name,
139 package_config.label,
140 )
142 def get_migration(self, package_label, name_prefix):
143 """Return the named migration or raise NodeNotFoundError."""
144 return self.graph.nodes[package_label, name_prefix]
146 def get_migration_by_prefix(self, package_label, name_prefix):
147 """
148 Return the migration(s) which match the given app label and name_prefix.
149 """
150 # Do the search
151 results = []
152 for migration_package_label, migration_name in self.disk_migrations:
153 if migration_package_label == package_label and migration_name.startswith(
154 name_prefix
155 ):
156 results.append((migration_package_label, migration_name))
157 if len(results) > 1:
158 raise AmbiguityError(
159 "There is more than one migration for '{}' with the prefix '{}'".format(
160 package_label, name_prefix
161 )
162 )
163 elif not results:
164 raise KeyError(
165 f"There is no migration for '{package_label}' with the prefix "
166 f"'{name_prefix}'"
167 )
168 else:
169 return self.disk_migrations[results[0]]
171 def check_key(self, key, current_package):
172 if (key[1] != "__first__" and key[1] != "__latest__") or key in self.graph:
173 return key
174 # Special-case __first__, which means "the first migration" for
175 # migrated packages, and is ignored for unmigrated packages. It allows
176 # makemigrations to declare dependencies on packages before they even have
177 # migrations.
178 if key[0] == current_package:
179 # Ignore __first__ references to the same app (#22325)
180 return
181 if key[0] in self.unmigrated_packages:
182 # This app isn't migrated, but something depends on it.
183 # The models will get auto-added into the state, though
184 # so we're fine.
185 return
186 if key[0] in self.migrated_packages:
187 try:
188 if key[1] == "__first__":
189 return self.graph.root_nodes(key[0])[0]
190 else: # "__latest__"
191 return self.graph.leaf_nodes(key[0])[0]
192 except IndexError:
193 if self.ignore_no_migrations:
194 return None
195 else:
196 raise ValueError(
197 "Dependency on app with no migrations: %s" % key[0]
198 )
199 raise ValueError("Dependency on unknown app: %s" % key[0])
201 def add_internal_dependencies(self, key, migration):
202 """
203 Internal dependencies need to be added first to ensure `__first__`
204 dependencies find the correct root node.
205 """
206 for parent in migration.dependencies:
207 # Ignore __first__ references to the same app.
208 if parent[0] == key[0] and parent[1] != "__first__":
209 self.graph.add_dependency(migration, key, parent, skip_validation=True)
211 def add_external_dependencies(self, key, migration):
212 for parent in migration.dependencies:
213 # Skip internal dependencies
214 if key[0] == parent[0]:
215 continue
216 parent = self.check_key(parent, key[0])
217 if parent is not None:
218 self.graph.add_dependency(migration, key, parent, skip_validation=True)
219 for child in migration.run_before:
220 child = self.check_key(child, key[0])
221 if child is not None:
222 self.graph.add_dependency(migration, child, key, skip_validation=True)
224 def build_graph(self):
225 """
226 Build a migration dependency graph using both the disk and database.
227 You'll need to rebuild the graph if you apply migrations. This isn't
228 usually a problem as generally migration stuff runs in a one-shot process.
229 """
230 # Load disk data
231 self.load_disk()
232 # Load database data
233 if self.connection is None:
234 self.applied_migrations = {}
235 else:
236 recorder = MigrationRecorder(self.connection)
237 self.applied_migrations = recorder.applied_migrations()
238 # To start, populate the migration graph with nodes for ALL migrations
239 # and their dependencies. Also make note of replacing migrations at this step.
240 self.graph = MigrationGraph()
241 self.replacements = {}
242 for key, migration in self.disk_migrations.items():
243 self.graph.add_node(key, migration)
244 # Replacing migrations.
245 if migration.replaces:
246 self.replacements[key] = migration
247 for key, migration in self.disk_migrations.items():
248 # Internal (same app) dependencies.
249 self.add_internal_dependencies(key, migration)
250 # Add external dependencies now that the internal ones have been resolved.
251 for key, migration in self.disk_migrations.items():
252 self.add_external_dependencies(key, migration)
253 # Carry out replacements where possible and if enabled.
254 if self.replace_migrations:
255 for key, migration in self.replacements.items():
256 # Get applied status of each of this migration's replacement
257 # targets.
258 applied_statuses = [
259 (target in self.applied_migrations) for target in migration.replaces
260 ]
261 # The replacing migration is only marked as applied if all of
262 # its replacement targets are.
263 if all(applied_statuses):
264 self.applied_migrations[key] = migration
265 else:
266 self.applied_migrations.pop(key, None)
267 # A replacing migration can be used if either all or none of
268 # its replacement targets have been applied.
269 if all(applied_statuses) or (not any(applied_statuses)):
270 self.graph.remove_replaced_nodes(key, migration.replaces)
271 else:
272 # This replacing migration cannot be used because it is
273 # partially applied. Remove it from the graph and remap
274 # dependencies to it (#25945).
275 self.graph.remove_replacement_node(key, migration.replaces)
276 # Ensure the graph is consistent.
277 try:
278 self.graph.validate_consistency()
279 except NodeNotFoundError as exc:
280 # Check if the missing node could have been replaced by any squash
281 # migration but wasn't because the squash migration was partially
282 # applied before. In that case raise a more understandable exception
283 # (#23556).
284 # Get reverse replacements.
285 reverse_replacements = {}
286 for key, migration in self.replacements.items():
287 for replaced in migration.replaces:
288 reverse_replacements.setdefault(replaced, set()).add(key)
289 # Try to reraise exception with more detail.
290 if exc.node in reverse_replacements:
291 candidates = reverse_replacements.get(exc.node, set())
292 is_replaced = any(
293 candidate in self.graph.nodes for candidate in candidates
294 )
295 if not is_replaced:
296 tries = ", ".join("{}.{}".format(*c) for c in candidates)
297 raise NodeNotFoundError(
298 "Migration {0} depends on nonexistent node ('{1}', '{2}'). "
299 "Plain tried to replace migration {1}.{2} with any of [{3}] "
300 "but wasn't able to because some of the replaced migrations "
301 "are already applied.".format(
302 exc.origin, exc.node[0], exc.node[1], tries
303 ),
304 exc.node,
305 ) from exc
306 raise
307 self.graph.ensure_not_cyclic()
309 def check_consistent_history(self, connection):
310 """
311 Raise InconsistentMigrationHistory if any applied migrations have
312 unapplied dependencies.
313 """
314 recorder = MigrationRecorder(connection)
315 applied = recorder.applied_migrations()
316 for migration in applied:
317 # If the migration is unknown, skip it.
318 if migration not in self.graph.nodes:
319 continue
320 for parent in self.graph.node_map[migration].parents:
321 if parent not in applied:
322 # Skip unapplied squashed migrations that have all of their
323 # `replaces` applied.
324 if parent in self.replacements:
325 if all(
326 m in applied for m in self.replacements[parent].replaces
327 ):
328 continue
329 raise InconsistentMigrationHistory(
330 "Migration {}.{} is applied before its dependency "
331 "{}.{} on database '{}'.".format(
332 migration[0],
333 migration[1],
334 parent[0],
335 parent[1],
336 connection.alias,
337 )
338 )
340 def detect_conflicts(self):
341 """
342 Look through the loaded graph and detect any conflicts - packages
343 with more than one leaf migration. Return a dict of the app labels
344 that conflict with the migration names that conflict.
345 """
346 seen_packages = {}
347 conflicting_packages = set()
348 for package_label, migration_name in self.graph.leaf_nodes():
349 if package_label in seen_packages:
350 conflicting_packages.add(package_label)
351 seen_packages.setdefault(package_label, set()).add(migration_name)
352 return {
353 package_label: sorted(seen_packages[package_label])
354 for package_label in conflicting_packages
355 }
357 def project_state(self, nodes=None, at_end=True):
358 """
359 Return a ProjectState object representing the most recent state
360 that the loaded migrations represent.
362 See graph.make_state() for the meaning of "nodes" and "at_end".
363 """
364 return self.graph.make_state(
365 nodes=nodes, at_end=at_end, real_packages=self.unmigrated_packages
366 )
368 def collect_sql(self, plan):
369 """
370 Take a migration plan and return a list of collected SQL statements
371 that represent the best-efforts version of that plan.
372 """
373 statements = []
374 state = None
375 for migration, backwards in plan:
376 with self.connection.schema_editor(
377 collect_sql=True, atomic=migration.atomic
378 ) as schema_editor:
379 if state is None:
380 state = self.project_state(
381 (migration.package_label, migration.name), at_end=False
382 )
383 if not backwards:
384 state = migration.apply(state, schema_editor, collect_sql=True)
385 else:
386 state = migration.unapply(state, schema_editor, collect_sql=True)
387 statements.extend(schema_editor.collected_sql)
388 return statements
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import re
3from plain.models.migrations.utils import get_migration_name_timestamp
4from plain.models.transaction import atomic
6from .exceptions import IrreversibleError
9class Migration:
10 """
11 The base class for all migrations.
13 Migration files will import this from plain.models.migrations.Migration
14 and subclass it as a class called Migration. It will have one or more
15 of the following attributes:
17 - operations: A list of Operation instances, probably from
18 plain.models.migrations.operations
19 - dependencies: A list of tuples of (app_path, migration_name)
20 - run_before: A list of tuples of (app_path, migration_name)
21 - replaces: A list of migration_names
23 Note that all migrations come out of migrations and into the Loader or
24 Graph as instances, having been initialized with their app label and name.
25 """
27 # Operations to apply during this migration, in order.
28 operations = []
30 # Other migrations that should be run before this migration.
31 # Should be a list of (app, migration_name).
32 dependencies = []
34 # Other migrations that should be run after this one (i.e. have
35 # this migration added to their dependencies). Useful to make third-party
36 # packages' migrations run after your AUTH_USER replacement, for example.
37 run_before = []
39 # Migration names in this app that this migration replaces. If this is
40 # non-empty, this migration will only be applied if all these migrations
41 # are not applied.
42 replaces = []
44 # Is this an initial migration? Initial migrations are skipped on
45 # --fake-initial if the table or fields already exist. If None, check if
46 # the migration has any dependencies to determine if there are dependencies
47 # to tell if db introspection needs to be done. If True, always perform
48 # introspection. If False, never perform introspection.
49 initial = None
51 # Whether to wrap the whole migration in a transaction. Only has an effect
52 # on database backends which support transactional DDL.
53 atomic = True
55 def __init__(self, name, package_label):
56 self.name = name
57 self.package_label = package_label
58 # Copy dependencies & other attrs as we might mutate them at runtime
59 self.operations = list(self.__class__.operations)
60 self.dependencies = list(self.__class__.dependencies)
61 self.run_before = list(self.__class__.run_before)
62 self.replaces = list(self.__class__.replaces)
64 def __eq__(self, other):
65 return (
66 isinstance(other, Migration)
67 and self.name == other.name
68 and self.package_label == other.package_label
69 )
71 def __repr__(self):
72 return f"<Migration {self.package_label}.{self.name}>"
74 def __str__(self):
75 return f"{self.package_label}.{self.name}"
77 def __hash__(self):
78 return hash(f"{self.package_label}.{self.name}")
80 def mutate_state(self, project_state, preserve=True):
81 """
82 Take a ProjectState and return a new one with the migration's
83 operations applied to it. Preserve the original object state by
84 default and return a mutated state from a copy.
85 """
86 new_state = project_state
87 if preserve:
88 new_state = project_state.clone()
90 for operation in self.operations:
91 operation.state_forwards(self.package_label, new_state)
92 return new_state
94 def apply(self, project_state, schema_editor, collect_sql=False):
95 """
96 Take a project_state representing all migrations prior to this one
97 and a schema_editor for a live database and apply the migration
98 in a forwards order.
100 Return the resulting project state for efficient reuse by following
101 Migrations.
102 """
103 for operation in self.operations:
104 # If this operation cannot be represented as SQL, place a comment
105 # there instead
106 if collect_sql:
107 schema_editor.collected_sql.append("--")
108 schema_editor.collected_sql.append("-- %s" % operation.describe())
109 schema_editor.collected_sql.append("--")
110 if not operation.reduces_to_sql:
111 schema_editor.collected_sql.append(
112 "-- THIS OPERATION CANNOT BE WRITTEN AS SQL"
113 )
114 continue
115 collected_sql_before = len(schema_editor.collected_sql)
116 # Save the state before the operation has run
117 old_state = project_state.clone()
118 operation.state_forwards(self.package_label, project_state)
119 # Run the operation
120 atomic_operation = operation.atomic or (
121 self.atomic and operation.atomic is not False
122 )
123 if not schema_editor.atomic_migration and atomic_operation:
124 # Force a transaction on a non-transactional-DDL backend or an
125 # atomic operation inside a non-atomic migration.
126 with atomic(schema_editor.connection.alias):
127 operation.database_forwards(
128 self.package_label, schema_editor, old_state, project_state
129 )
130 else:
131 # Normal behaviour
132 operation.database_forwards(
133 self.package_label, schema_editor, old_state, project_state
134 )
135 if collect_sql and collected_sql_before == len(schema_editor.collected_sql):
136 schema_editor.collected_sql.append("-- (no-op)")
137 return project_state
139 def unapply(self, project_state, schema_editor, collect_sql=False):
140 """
141 Take a project_state representing all migrations prior to this one
142 and a schema_editor for a live database and apply the migration
143 in a reverse order.
145 The backwards migration process consists of two phases:
147 1. The intermediate states from right before the first until right
148 after the last operation inside this migration are preserved.
149 2. The operations are applied in reverse order using the states
150 recorded in step 1.
151 """
152 # Construct all the intermediate states we need for a reverse migration
153 to_run = []
154 new_state = project_state
155 # Phase 1
156 for operation in self.operations:
157 # If it's irreversible, error out
158 if not operation.reversible:
159 raise IrreversibleError(
160 f"Operation {operation} in {self} is not reversible"
161 )
162 # Preserve new state from previous run to not tamper the same state
163 # over all operations
164 new_state = new_state.clone()
165 old_state = new_state.clone()
166 operation.state_forwards(self.package_label, new_state)
167 to_run.insert(0, (operation, old_state, new_state))
169 # Phase 2
170 for operation, to_state, from_state in to_run:
171 if collect_sql:
172 schema_editor.collected_sql.append("--")
173 schema_editor.collected_sql.append("-- %s" % operation.describe())
174 schema_editor.collected_sql.append("--")
175 if not operation.reduces_to_sql:
176 schema_editor.collected_sql.append(
177 "-- THIS OPERATION CANNOT BE WRITTEN AS SQL"
178 )
179 continue
180 collected_sql_before = len(schema_editor.collected_sql)
181 atomic_operation = operation.atomic or (
182 self.atomic and operation.atomic is not False
183 )
184 if not schema_editor.atomic_migration and atomic_operation:
185 # Force a transaction on a non-transactional-DDL backend or an
186 # atomic operation inside a non-atomic migration.
187 with atomic(schema_editor.connection.alias):
188 operation.database_backwards(
189 self.package_label, schema_editor, from_state, to_state
190 )
191 else:
192 # Normal behaviour
193 operation.database_backwards(
194 self.package_label, schema_editor, from_state, to_state
195 )
196 if collect_sql and collected_sql_before == len(schema_editor.collected_sql):
197 schema_editor.collected_sql.append("-- (no-op)")
198 return project_state
200 def suggest_name(self):
201 """
202 Suggest a name for the operations this migration might represent. Names
203 are not guaranteed to be unique, but put some effort into the fallback
204 name to avoid VCS conflicts if possible.
205 """
206 if self.initial:
207 return "initial"
209 raw_fragments = [op.migration_name_fragment for op in self.operations]
210 fragments = [re.sub(r"\W+", "_", name) for name in raw_fragments if name]
212 if not fragments or len(fragments) != len(self.operations):
213 return "auto_%s" % get_migration_name_timestamp()
215 name = fragments[0]
216 for fragment in fragments[1:]:
217 new_name = f"{name}_{fragment}"
218 if len(new_name) > 52:
219 name = f"{name}_and_more"
220 break
221 name = new_name
222 return name
225class SwappableTuple(tuple):
226 """
227 Subclass of tuple so Plain can tell this was originally a swappable
228 dependency when it reads the migration file.
229 """
231 def __new__(cls, value, setting):
232 self = tuple.__new__(cls, value)
233 self.setting = setting
234 return self
237def swappable_dependency(value):
238 """Turn a setting value into a dependency."""
239 return SwappableTuple((value.split(".", 1)[0], "__first__"), value)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1class MigrationOptimizer:
2 """
3 Power the optimization process, where you provide a list of Operations
4 and you are returned a list of equal or shorter length - operations
5 are merged into one if possible.
7 For example, a CreateModel and an AddField can be optimized into a
8 new CreateModel, and CreateModel and DeleteModel can be optimized into
9 nothing.
10 """
12 def optimize(self, operations, package_label):
13 """
14 Main optimization entry point. Pass in a list of Operation instances,
15 get out a new list of Operation instances.
17 Unfortunately, due to the scope of the optimization (two combinable
18 operations might be separated by several hundred others), this can't be
19 done as a peephole optimization with checks/output implemented on
20 the Operations themselves; instead, the optimizer looks at each
21 individual operation and scans forwards in the list to see if there
22 are any matches, stopping at boundaries - operations which can't
23 be optimized over (RunSQL, operations on the same field/model, etc.)
25 The inner loop is run until the starting list is the same as the result
26 list, and then the result is returned. This means that operation
27 optimization must be stable and always return an equal or shorter list.
28 """
29 # Internal tracking variable for test assertions about # of loops
30 if package_label is None:
31 raise TypeError("package_label must be a str.")
32 self._iterations = 0
33 while True:
34 result = self.optimize_inner(operations, package_label)
35 self._iterations += 1
36 if result == operations:
37 return result
38 operations = result
40 def optimize_inner(self, operations, package_label):
41 """Inner optimization loop."""
42 new_operations = []
43 for i, operation in enumerate(operations):
44 right = True # Should we reduce on the right or on the left.
45 # Compare it to each operation after it
46 for j, other in enumerate(operations[i + 1 :]):
47 result = operation.reduce(other, package_label)
48 if isinstance(result, list):
49 in_between = operations[i + 1 : i + j + 1]
50 if right:
51 new_operations.extend(in_between)
52 new_operations.extend(result)
53 elif all(
54 op.reduce(other, package_label) is True for op in in_between
55 ):
56 # Perform a left reduction if all of the in-between
57 # operations can optimize through other.
58 new_operations.extend(result)
59 new_operations.extend(in_between)
60 else:
61 # Otherwise keep trying.
62 new_operations.append(operation)
63 break
64 new_operations.extend(operations[i + j + 2 :])
65 return new_operations
66 elif not result:
67 # Can't perform a right reduction.
68 right = False
69 else:
70 new_operations.append(operation)
71 return new_operations
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import datetime
2import importlib
3import os
4import sys
6from plain.models.fields import NOT_PROVIDED
7from plain.packages import packages
8from plain.utils import timezone
10from .loader import MigrationLoader
13class MigrationQuestioner:
14 """
15 Give the autodetector responses to questions it might have.
16 This base class has a built-in noninteractive mode, but the
17 interactive subclass is what the command-line arguments will use.
18 """
20 def __init__(self, defaults=None, specified_packages=None, dry_run=None):
21 self.defaults = defaults or {}
22 self.specified_packages = specified_packages or set()
23 self.dry_run = dry_run
25 def ask_initial(self, package_label):
26 """Should we create an initial migration for the app?"""
27 # If it was specified on the command line, definitely true
28 if package_label in self.specified_packages:
29 return True
30 # Otherwise, we look to see if it has a migrations module
31 # without any Python files in it, apart from __init__.py.
32 # Packages from the new app template will have these; the Python
33 # file check will ensure we skip South ones.
34 try:
35 package_config = packages.get_package_config(package_label)
36 except LookupError: # It's a fake app.
37 return self.defaults.get("ask_initial", False)
38 migrations_import_path, _ = MigrationLoader.migrations_module(
39 package_config.label
40 )
41 if migrations_import_path is None:
42 # It's an application with migrations disabled.
43 return self.defaults.get("ask_initial", False)
44 try:
45 migrations_module = importlib.import_module(migrations_import_path)
46 except ImportError:
47 return self.defaults.get("ask_initial", False)
48 else:
49 if getattr(migrations_module, "__file__", None):
50 filenames = os.listdir(os.path.dirname(migrations_module.__file__))
51 elif hasattr(migrations_module, "__path__"):
52 if len(migrations_module.__path__) > 1:
53 return False
54 filenames = os.listdir(list(migrations_module.__path__)[0])
55 return not any(x.endswith(".py") for x in filenames if x != "__init__.py")
57 def ask_not_null_addition(self, field_name, model_name):
58 """Adding a NOT NULL field to a model."""
59 # None means quit
60 return None
62 def ask_not_null_alteration(self, field_name, model_name):
63 """Changing a NULL field to NOT NULL."""
64 # None means quit
65 return None
67 def ask_rename(self, model_name, old_name, new_name, field_instance):
68 """Was this field really renamed?"""
69 return self.defaults.get("ask_rename", False)
71 def ask_rename_model(self, old_model_state, new_model_state):
72 """Was this model really renamed?"""
73 return self.defaults.get("ask_rename_model", False)
75 def ask_merge(self, package_label):
76 """Should these migrations really be merged?"""
77 return self.defaults.get("ask_merge", False)
79 def ask_auto_now_add_addition(self, field_name, model_name):
80 """Adding an auto_now_add field to a model."""
81 # None means quit
82 return None
84 def ask_unique_callable_default_addition(self, field_name, model_name):
85 """Adding a unique field with a callable default."""
86 # None means continue.
87 return None
90class InteractiveMigrationQuestioner(MigrationQuestioner):
91 def __init__(
92 self, defaults=None, specified_packages=None, dry_run=None, prompt_output=None
93 ):
94 super().__init__(
95 defaults=defaults, specified_packages=specified_packages, dry_run=dry_run
96 )
97 self.prompt_output = prompt_output or sys.stdout
99 def _boolean_input(self, question, default=None):
100 self.prompt_output.write(f"{question} ", ending="")
101 result = input()
102 if not result and default is not None:
103 return default
104 while not result or result[0].lower() not in "yn":
105 self.prompt_output.write("Please answer yes or no: ", ending="")
106 result = input()
107 return result[0].lower() == "y"
109 def _choice_input(self, question, choices):
110 self.prompt_output.write(f"{question}")
111 for i, choice in enumerate(choices):
112 self.prompt_output.write(f" {i + 1}) {choice}")
113 self.prompt_output.write("Select an option: ", ending="")
114 result = input()
115 while True:
116 try:
117 value = int(result)
118 except ValueError:
119 pass
120 else:
121 if 0 < value <= len(choices):
122 return value
123 self.prompt_output.write("Please select a valid option: ", ending="")
124 result = input()
126 def _ask_default(self, default=""):
127 """
128 Prompt for a default value.
130 The ``default`` argument allows providing a custom default value (as a
131 string) which will be shown to the user and used as the return value
132 if the user doesn't provide any other input.
133 """
134 self.prompt_output.write("Please enter the default value as valid Python.")
135 if default:
136 self.prompt_output.write(
137 f"Accept the default '{default}' by pressing 'Enter' or "
138 f"provide another value."
139 )
140 self.prompt_output.write(
141 "The datetime and plain.utils.timezone modules are available, so "
142 "it is possible to provide e.g. timezone.now as a value."
143 )
144 self.prompt_output.write("Type 'exit' to exit this prompt")
145 while True:
146 if default:
147 prompt = f"[default: {default}] >>> "
148 else:
149 prompt = ">>> "
150 self.prompt_output.write(prompt, ending="")
151 code = input()
152 if not code and default:
153 code = default
154 if not code:
155 self.prompt_output.write(
156 "Please enter some code, or 'exit' (without quotes) to exit."
157 )
158 elif code == "exit":
159 sys.exit(1)
160 else:
161 try:
162 return eval(code, {}, {"datetime": datetime, "timezone": timezone})
163 except (SyntaxError, NameError) as e:
164 self.prompt_output.write("Invalid input: %s" % e)
166 def ask_not_null_addition(self, field_name, model_name):
167 """Adding a NOT NULL field to a model."""
168 if not self.dry_run:
169 choice = self._choice_input(
170 f"It is impossible to add a non-nullable field '{field_name}' "
171 f"to {model_name} without specifying a default. This is "
172 f"because the database needs something to populate existing "
173 f"rows.\n"
174 f"Please select a fix:",
175 [
176 (
177 "Provide a one-off default now (will be set on all existing "
178 "rows with a null value for this column)"
179 ),
180 "Quit and manually define a default value in models.py.",
181 ],
182 )
183 if choice == 2:
184 sys.exit(3)
185 else:
186 return self._ask_default()
187 return None
189 def ask_not_null_alteration(self, field_name, model_name):
190 """Changing a NULL field to NOT NULL."""
191 if not self.dry_run:
192 choice = self._choice_input(
193 f"It is impossible to change a nullable field '{field_name}' "
194 f"on {model_name} to non-nullable without providing a "
195 f"default. This is because the database needs something to "
196 f"populate existing rows.\n"
197 f"Please select a fix:",
198 [
199 (
200 "Provide a one-off default now (will be set on all existing "
201 "rows with a null value for this column)"
202 ),
203 "Ignore for now. Existing rows that contain NULL values "
204 "will have to be handled manually, for example with a "
205 "RunPython or RunSQL operation.",
206 "Quit and manually define a default value in models.py.",
207 ],
208 )
209 if choice == 2:
210 return NOT_PROVIDED
211 elif choice == 3:
212 sys.exit(3)
213 else:
214 return self._ask_default()
215 return None
217 def ask_rename(self, model_name, old_name, new_name, field_instance):
218 """Was this field really renamed?"""
219 msg = "Was %s.%s renamed to %s.%s (a %s)? [y/N]"
220 return self._boolean_input(
221 msg
222 % (
223 model_name,
224 old_name,
225 model_name,
226 new_name,
227 field_instance.__class__.__name__,
228 ),
229 False,
230 )
232 def ask_rename_model(self, old_model_state, new_model_state):
233 """Was this model really renamed?"""
234 msg = "Was the model %s.%s renamed to %s? [y/N]"
235 return self._boolean_input(
236 msg
237 % (
238 old_model_state.package_label,
239 old_model_state.name,
240 new_model_state.name,
241 ),
242 False,
243 )
245 def ask_merge(self, package_label):
246 return self._boolean_input(
247 (
248 "\nMerging will only work if the operations printed above do not conflict\n"
249 "with each other (working on different fields or models)\n"
250 "Should these migration branches be merged? [y/N]"
251 ),
252 False,
253 )
255 def ask_auto_now_add_addition(self, field_name, model_name):
256 """Adding an auto_now_add field to a model."""
257 if not self.dry_run:
258 choice = self._choice_input(
259 f"It is impossible to add the field '{field_name}' with "
260 f"'auto_now_add=True' to {model_name} without providing a "
261 f"default. This is because the database needs something to "
262 f"populate existing rows.\n",
263 [
264 "Provide a one-off default now which will be set on all "
265 "existing rows",
266 "Quit and manually define a default value in models.py.",
267 ],
268 )
269 if choice == 2:
270 sys.exit(3)
271 else:
272 return self._ask_default(default="timezone.now")
273 return None
275 def ask_unique_callable_default_addition(self, field_name, model_name):
276 """Adding a unique field with a callable default."""
277 if not self.dry_run:
278 choice = self._choice_input(
279 f"Callable default on unique field {model_name}.{field_name} "
280 f"will not generate unique values upon migrating.\n"
281 f"Please choose how to proceed:\n",
282 [
283 "Continue making this migration as the first step in "
284 "writing a manual migration to generate unique values.",
285 "Quit and edit field options in models.py.",
286 ],
287 )
288 if choice == 2:
289 sys.exit(3)
290 return None
293class NonInteractiveMigrationQuestioner(MigrationQuestioner):
294 def __init__(
295 self,
296 defaults=None,
297 specified_packages=None,
298 dry_run=None,
299 verbosity=1,
300 log=None,
301 ):
302 self.verbosity = verbosity
303 self.log = log
304 super().__init__(
305 defaults=defaults,
306 specified_packages=specified_packages,
307 dry_run=dry_run,
308 )
310 def log_lack_of_migration(self, field_name, model_name, reason):
311 if self.verbosity > 0:
312 self.log(
313 f"Field '{field_name}' on model '{model_name}' not migrated: "
314 f"{reason}."
315 )
317 def ask_not_null_addition(self, field_name, model_name):
318 # We can't ask the user, so act like the user aborted.
319 self.log_lack_of_migration(
320 field_name,
321 model_name,
322 "it is impossible to add a non-nullable field without specifying "
323 "a default",
324 )
325 sys.exit(3)
327 def ask_not_null_alteration(self, field_name, model_name):
328 # We can't ask the user, so set as not provided.
329 self.log(
330 f"Field '{field_name}' on model '{model_name}' given a default of "
331 f"NOT PROVIDED and must be corrected."
332 )
333 return NOT_PROVIDED
335 def ask_auto_now_add_addition(self, field_name, model_name):
336 # We can't ask the user, so act like the user aborted.
337 self.log_lack_of_migration(
338 field_name,
339 model_name,
340 "it is impossible to add a field with 'auto_now_add=True' without "
341 "specifying a default",
342 )
343 sys.exit(3)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain import models
2from plain.models.db import DatabaseError
3from plain.packages.registry import Packages
4from plain.utils.functional import classproperty
5from plain.utils.timezone import now
7from .exceptions import MigrationSchemaMissing
10class MigrationRecorder:
11 """
12 Deal with storing migration records in the database.
14 Because this table is actually itself used for dealing with model
15 creation, it's the one thing we can't do normally via migrations.
16 We manually handle table creation/schema updating (using schema backend)
17 and then have a floating model to do queries with.
19 If a migration is unapplied its row is removed from the table. Having
20 a row in the table always means a migration is applied.
21 """
23 _migration_class = None
25 @classproperty
26 def Migration(cls):
27 """
28 Lazy load to avoid PackageRegistryNotReady if installed packages import
29 MigrationRecorder.
30 """
31 if cls._migration_class is None:
33 class Migration(models.Model):
34 app = models.CharField(max_length=255)
35 name = models.CharField(max_length=255)
36 applied = models.DateTimeField(default=now)
38 class Meta:
39 packages = Packages()
40 package_label = "migrations"
41 db_table = "plainmigrations"
43 def __str__(self):
44 return f"Migration {self.name} for {self.app}"
46 cls._migration_class = Migration
47 return cls._migration_class
49 def __init__(self, connection):
50 self.connection = connection
52 @property
53 def migration_qs(self):
54 return self.Migration.objects.using(self.connection.alias)
56 def has_table(self):
57 """Return True if the plainmigrations table exists."""
58 with self.connection.cursor() as cursor:
59 tables = self.connection.introspection.table_names(cursor)
60 return self.Migration._meta.db_table in tables
62 def ensure_schema(self):
63 """Ensure the table exists and has the correct schema."""
64 # If the table's there, that's fine - we've never changed its schema
65 # in the codebase.
66 if self.has_table():
67 return
68 # Make the table
69 try:
70 with self.connection.schema_editor() as editor:
71 editor.create_model(self.Migration)
72 except DatabaseError as exc:
73 raise MigrationSchemaMissing(
74 "Unable to create the plainmigrations table (%s)" % exc
75 )
77 def applied_migrations(self):
78 """
79 Return a dict mapping (package_name, migration_name) to Migration instances
80 for all applied migrations.
81 """
82 if self.has_table():
83 return {
84 (migration.app, migration.name): migration
85 for migration in self.migration_qs
86 }
87 else:
88 # If the plainmigrations table doesn't exist, then no migrations
89 # are applied.
90 return {}
92 def record_applied(self, app, name):
93 """Record that a migration was applied."""
94 self.ensure_schema()
95 self.migration_qs.create(app=app, name=name)
97 def record_unapplied(self, app, name):
98 """Record that a migration was unapplied."""
99 self.ensure_schema()
100 self.migration_qs.filter(app=app, name=name).delete()
102 def flush(self):
103 """Delete all migration records. Useful for testing migrations."""
104 self.migration_qs.all().delete()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import builtins
2import collections.abc
3import datetime
4import decimal
5import enum
6import functools
7import math
8import os
9import pathlib
10import re
11import types
12import uuid
14from plain import models
15from plain.models.migrations.operations.base import Operation
16from plain.models.migrations.utils import COMPILED_REGEX_TYPE, RegexObject
17from plain.runtime.user_settings import SettingsReference
18from plain.utils.functional import LazyObject, Promise
21class BaseSerializer:
22 def __init__(self, value):
23 self.value = value
25 def serialize(self):
26 raise NotImplementedError(
27 "Subclasses of BaseSerializer must implement the serialize() method."
28 )
31class BaseSequenceSerializer(BaseSerializer):
32 def _format(self):
33 raise NotImplementedError(
34 "Subclasses of BaseSequenceSerializer must implement the _format() method."
35 )
37 def serialize(self):
38 imports = set()
39 strings = []
40 for item in self.value:
41 item_string, item_imports = serializer_factory(item).serialize()
42 imports.update(item_imports)
43 strings.append(item_string)
44 value = self._format()
45 return value % (", ".join(strings)), imports
48class BaseSimpleSerializer(BaseSerializer):
49 def serialize(self):
50 return repr(self.value), set()
53class ChoicesSerializer(BaseSerializer):
54 def serialize(self):
55 return serializer_factory(self.value.value).serialize()
58class DateTimeSerializer(BaseSerializer):
59 """For datetime.*, except datetime.datetime."""
61 def serialize(self):
62 return repr(self.value), {"import datetime"}
65class DatetimeDatetimeSerializer(BaseSerializer):
66 """For datetime.datetime."""
68 def serialize(self):
69 if self.value.tzinfo is not None and self.value.tzinfo != datetime.timezone.utc:
70 self.value = self.value.astimezone(datetime.timezone.utc)
71 imports = ["import datetime"]
72 return repr(self.value), set(imports)
75class DecimalSerializer(BaseSerializer):
76 def serialize(self):
77 return repr(self.value), {"from decimal import Decimal"}
80class DeconstructableSerializer(BaseSerializer):
81 @staticmethod
82 def serialize_deconstructed(path, args, kwargs):
83 name, imports = DeconstructableSerializer._serialize_path(path)
84 strings = []
85 for arg in args:
86 arg_string, arg_imports = serializer_factory(arg).serialize()
87 strings.append(arg_string)
88 imports.update(arg_imports)
89 for kw, arg in sorted(kwargs.items()):
90 arg_string, arg_imports = serializer_factory(arg).serialize()
91 imports.update(arg_imports)
92 strings.append(f"{kw}={arg_string}")
93 return "{}({})".format(name, ", ".join(strings)), imports
95 @staticmethod
96 def _serialize_path(path):
97 module, name = path.rsplit(".", 1)
98 if module == "plain.models":
99 imports = {"from plain import models"}
100 name = "models.%s" % name
101 else:
102 imports = {"import %s" % module}
103 name = path
104 return name, imports
106 def serialize(self):
107 return self.serialize_deconstructed(*self.value.deconstruct())
110class DictionarySerializer(BaseSerializer):
111 def serialize(self):
112 imports = set()
113 strings = []
114 for k, v in sorted(self.value.items()):
115 k_string, k_imports = serializer_factory(k).serialize()
116 v_string, v_imports = serializer_factory(v).serialize()
117 imports.update(k_imports)
118 imports.update(v_imports)
119 strings.append((k_string, v_string))
120 return "{%s}" % (", ".join(f"{k}: {v}" for k, v in strings)), imports
123class EnumSerializer(BaseSerializer):
124 def serialize(self):
125 enum_class = self.value.__class__
126 module = enum_class.__module__
127 if issubclass(enum_class, enum.Flag):
128 members = list(self.value)
129 else:
130 members = (self.value,)
131 return (
132 " | ".join(
133 [
134 f"{module}.{enum_class.__qualname__}[{item.name!r}]"
135 for item in members
136 ]
137 ),
138 {"import %s" % module},
139 )
142class FloatSerializer(BaseSimpleSerializer):
143 def serialize(self):
144 if math.isnan(self.value) or math.isinf(self.value):
145 return f'float("{self.value}")', set()
146 return super().serialize()
149class FrozensetSerializer(BaseSequenceSerializer):
150 def _format(self):
151 return "frozenset([%s])"
154class FunctionTypeSerializer(BaseSerializer):
155 def serialize(self):
156 if getattr(self.value, "__self__", None) and isinstance(
157 self.value.__self__, type
158 ):
159 klass = self.value.__self__
160 module = klass.__module__
161 return f"{module}.{klass.__name__}.{self.value.__name__}", {
162 "import %s" % module
163 }
164 # Further error checking
165 if self.value.__name__ == "<lambda>":
166 raise ValueError("Cannot serialize function: lambda")
167 if self.value.__module__ is None:
168 raise ValueError("Cannot serialize function %r: No module" % self.value)
170 module_name = self.value.__module__
172 if "<" not in self.value.__qualname__: # Qualname can include <locals>
173 return f"{module_name}.{self.value.__qualname__}", {
174 "import %s" % self.value.__module__
175 }
177 raise ValueError(
178 f"Could not find function {self.value.__name__} in {module_name}.\n"
179 )
182class FunctoolsPartialSerializer(BaseSerializer):
183 def serialize(self):
184 # Serialize functools.partial() arguments
185 func_string, func_imports = serializer_factory(self.value.func).serialize()
186 args_string, args_imports = serializer_factory(self.value.args).serialize()
187 keywords_string, keywords_imports = serializer_factory(
188 self.value.keywords
189 ).serialize()
190 # Add any imports needed by arguments
191 imports = {"import functools", *func_imports, *args_imports, *keywords_imports}
192 return (
193 "functools.{}({}, *{}, **{})".format(
194 self.value.__class__.__name__,
195 func_string,
196 args_string,
197 keywords_string,
198 ),
199 imports,
200 )
203class IterableSerializer(BaseSerializer):
204 def serialize(self):
205 imports = set()
206 strings = []
207 for item in self.value:
208 item_string, item_imports = serializer_factory(item).serialize()
209 imports.update(item_imports)
210 strings.append(item_string)
211 # When len(strings)==0, the empty iterable should be serialized as
212 # "()", not "(,)" because (,) is invalid Python syntax.
213 value = "(%s)" if len(strings) != 1 else "(%s,)"
214 return value % (", ".join(strings)), imports
217class ModelFieldSerializer(DeconstructableSerializer):
218 def serialize(self):
219 attr_name, path, args, kwargs = self.value.deconstruct()
220 return self.serialize_deconstructed(path, args, kwargs)
223class ModelManagerSerializer(DeconstructableSerializer):
224 def serialize(self):
225 as_manager, manager_path, qs_path, args, kwargs = self.value.deconstruct()
226 if as_manager:
227 name, imports = self._serialize_path(qs_path)
228 return "%s.as_manager()" % name, imports
229 else:
230 return self.serialize_deconstructed(manager_path, args, kwargs)
233class OperationSerializer(BaseSerializer):
234 def serialize(self):
235 from plain.models.migrations.writer import OperationWriter
237 string, imports = OperationWriter(self.value, indentation=0).serialize()
238 # Nested operation, trailing comma is handled in upper OperationWriter._write()
239 return string.rstrip(","), imports
242class PathLikeSerializer(BaseSerializer):
243 def serialize(self):
244 return repr(os.fspath(self.value)), {}
247class PathSerializer(BaseSerializer):
248 def serialize(self):
249 # Convert concrete paths to pure paths to avoid issues with migrations
250 # generated on one platform being used on a different platform.
251 prefix = "Pure" if isinstance(self.value, pathlib.Path) else ""
252 return f"pathlib.{prefix}{self.value!r}", {"import pathlib"}
255class RegexSerializer(BaseSerializer):
256 def serialize(self):
257 regex_pattern, pattern_imports = serializer_factory(
258 self.value.pattern
259 ).serialize()
260 # Turn off default implicit flags (e.g. re.U) because regexes with the
261 # same implicit and explicit flags aren't equal.
262 flags = self.value.flags ^ re.compile("").flags
263 regex_flags, flag_imports = serializer_factory(flags).serialize()
264 imports = {"import re", *pattern_imports, *flag_imports}
265 args = [regex_pattern]
266 if flags:
267 args.append(regex_flags)
268 return "re.compile(%s)" % ", ".join(args), imports
271class SequenceSerializer(BaseSequenceSerializer):
272 def _format(self):
273 return "[%s]"
276class SetSerializer(BaseSequenceSerializer):
277 def _format(self):
278 # Serialize as a set literal except when value is empty because {}
279 # is an empty dict.
280 return "{%s}" if self.value else "set(%s)"
283class SettingsReferenceSerializer(BaseSerializer):
284 def serialize(self):
285 return "settings.%s" % self.value.setting_name, {
286 "from plain.runtime import settings"
287 }
290class TupleSerializer(BaseSequenceSerializer):
291 def _format(self):
292 # When len(value)==0, the empty tuple should be serialized as "()",
293 # not "(,)" because (,) is invalid Python syntax.
294 return "(%s)" if len(self.value) != 1 else "(%s,)"
297class TypeSerializer(BaseSerializer):
298 def serialize(self):
299 special_cases = [
300 (models.Model, "models.Model", ["from plain import models"]),
301 (types.NoneType, "types.NoneType", ["import types"]),
302 ]
303 for case, string, imports in special_cases:
304 if case is self.value:
305 return string, set(imports)
306 if hasattr(self.value, "__module__"):
307 module = self.value.__module__
308 if module == builtins.__name__:
309 return self.value.__name__, set()
310 else:
311 return f"{module}.{self.value.__qualname__}", {"import %s" % module}
314class UUIDSerializer(BaseSerializer):
315 def serialize(self):
316 return "uuid.%s" % repr(self.value), {"import uuid"}
319class Serializer:
320 _registry = {
321 # Some of these are order-dependent.
322 frozenset: FrozensetSerializer,
323 list: SequenceSerializer,
324 set: SetSerializer,
325 tuple: TupleSerializer,
326 dict: DictionarySerializer,
327 models.Choices: ChoicesSerializer,
328 enum.Enum: EnumSerializer,
329 datetime.datetime: DatetimeDatetimeSerializer,
330 (datetime.date, datetime.timedelta, datetime.time): DateTimeSerializer,
331 SettingsReference: SettingsReferenceSerializer,
332 float: FloatSerializer,
333 (bool, int, types.NoneType, bytes, str, range): BaseSimpleSerializer,
334 decimal.Decimal: DecimalSerializer,
335 (functools.partial, functools.partialmethod): FunctoolsPartialSerializer,
336 (
337 types.FunctionType,
338 types.BuiltinFunctionType,
339 types.MethodType,
340 ): FunctionTypeSerializer,
341 collections.abc.Iterable: IterableSerializer,
342 (COMPILED_REGEX_TYPE, RegexObject): RegexSerializer,
343 uuid.UUID: UUIDSerializer,
344 pathlib.PurePath: PathSerializer,
345 os.PathLike: PathLikeSerializer,
346 }
348 @classmethod
349 def register(cls, type_, serializer):
350 if not issubclass(serializer, BaseSerializer):
351 raise ValueError(
352 "'%s' must inherit from 'BaseSerializer'." % serializer.__name__
353 )
354 cls._registry[type_] = serializer
356 @classmethod
357 def unregister(cls, type_):
358 cls._registry.pop(type_)
361def serializer_factory(value):
362 if isinstance(value, Promise):
363 value = str(value)
364 elif isinstance(value, LazyObject):
365 # The unwrapped value is returned as the first item of the arguments
366 # tuple.
367 value = value.__reduce__()[1][0]
369 if isinstance(value, models.Field):
370 return ModelFieldSerializer(value)
371 if isinstance(value, models.manager.BaseManager):
372 return ModelManagerSerializer(value)
373 if isinstance(value, Operation):
374 return OperationSerializer(value)
375 if isinstance(value, type):
376 return TypeSerializer(value)
377 # Anything that knows how to deconstruct itself.
378 if hasattr(value, "deconstruct"):
379 return DeconstructableSerializer(value)
380 for type_, serializer_cls in Serializer._registry.items():
381 if isinstance(value, type_):
382 return serializer_cls(value)
383 raise ValueError(
384 "Cannot serialize: %r\nThere are some values Plain cannot serialize into "
385 "migration files." % value
386 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import copy
2from collections import defaultdict
3from contextlib import contextmanager
4from functools import partial
6from plain import models
7from plain.exceptions import FieldDoesNotExist
8from plain.models.fields import NOT_PROVIDED
9from plain.models.fields.related import RECURSIVE_RELATIONSHIP_CONSTANT
10from plain.models.migrations.utils import field_is_referenced, get_references
11from plain.models.options import DEFAULT_NAMES
12from plain.models.utils import make_model_tuple
13from plain.packages import PackageConfig
14from plain.packages.registry import Packages
15from plain.packages.registry import packages as global_packages
16from plain.runtime import settings
17from plain.utils.functional import cached_property
18from plain.utils.module_loading import import_string
20from .exceptions import InvalidBasesError
21from .utils import resolve_relation
24def _get_package_label_and_model_name(model, package_label=""):
25 if isinstance(model, str):
26 split = model.split(".", 1)
27 return tuple(split) if len(split) == 2 else (package_label, split[0])
28 else:
29 return model._meta.package_label, model._meta.model_name
32def _get_related_models(m):
33 """Return all models that have a direct relationship to the given model."""
34 related_models = [
35 subclass
36 for subclass in m.__subclasses__()
37 if issubclass(subclass, models.Model)
38 ]
39 related_fields_models = set()
40 for f in m._meta.get_fields(include_parents=True, include_hidden=True):
41 if (
42 f.is_relation
43 and f.related_model is not None
44 and not isinstance(f.related_model, str)
45 ):
46 related_fields_models.add(f.model)
47 related_models.append(f.related_model)
48 return related_models
51def get_related_models_tuples(model):
52 """
53 Return a list of typical (package_label, model_name) tuples for all related
54 models for the given model.
55 """
56 return {
57 (rel_mod._meta.package_label, rel_mod._meta.model_name)
58 for rel_mod in _get_related_models(model)
59 }
62def get_related_models_recursive(model):
63 """
64 Return all models that have a direct or indirect relationship
65 to the given model.
67 Relationships are either defined by explicit relational fields, like
68 ForeignKey, ManyToManyField or OneToOneField, or by inheriting from another
69 model (a superclass is related to its subclasses, but not vice versa). Note,
70 however, that a model inheriting from a concrete model is also related to
71 its superclass through the implicit *_ptr OneToOneField on the subclass.
72 """
73 seen = set()
74 queue = _get_related_models(model)
75 for rel_mod in queue:
76 rel_package_label, rel_model_name = (
77 rel_mod._meta.package_label,
78 rel_mod._meta.model_name,
79 )
80 if (rel_package_label, rel_model_name) in seen:
81 continue
82 seen.add((rel_package_label, rel_model_name))
83 queue.extend(_get_related_models(rel_mod))
84 return seen - {(model._meta.package_label, model._meta.model_name)}
87class ProjectState:
88 """
89 Represent the entire project's overall state. This is the item that is
90 passed around - do it here rather than at the app level so that cross-app
91 FKs/etc. resolve properly.
92 """
94 def __init__(self, models=None, real_packages=None):
95 self.models = models or {}
96 # Packages to include from main registry, usually unmigrated ones
97 if real_packages is None:
98 real_packages = set()
99 else:
100 assert isinstance(real_packages, set)
101 self.real_packages = real_packages
102 self.is_delayed = False
103 # {remote_model_key: {model_key: {field_name: field}}}
104 self._relations = None
106 @property
107 def relations(self):
108 if self._relations is None:
109 self.resolve_fields_and_relations()
110 return self._relations
112 def add_model(self, model_state):
113 model_key = model_state.package_label, model_state.name_lower
114 self.models[model_key] = model_state
115 if self._relations is not None:
116 self.resolve_model_relations(model_key)
117 if "packages" in self.__dict__: # hasattr would cache the property
118 self.reload_model(*model_key)
120 def remove_model(self, package_label, model_name):
121 model_key = package_label, model_name
122 del self.models[model_key]
123 if self._relations is not None:
124 self._relations.pop(model_key, None)
125 # Call list() since _relations can change size during iteration.
126 for related_model_key, model_relations in list(self._relations.items()):
127 model_relations.pop(model_key, None)
128 if not model_relations:
129 del self._relations[related_model_key]
130 if "packages" in self.__dict__: # hasattr would cache the property
131 self.packages.unregister_model(*model_key)
132 # Need to do this explicitly since unregister_model() doesn't clear
133 # the cache automatically (#24513)
134 self.packages.clear_cache()
136 def rename_model(self, package_label, old_name, new_name):
137 # Add a new model.
138 old_name_lower = old_name.lower()
139 new_name_lower = new_name.lower()
140 renamed_model = self.models[package_label, old_name_lower].clone()
141 renamed_model.name = new_name
142 self.models[package_label, new_name_lower] = renamed_model
143 # Repoint all fields pointing to the old model to the new one.
144 old_model_tuple = (package_label, old_name_lower)
145 new_remote_model = f"{package_label}.{new_name}"
146 to_reload = set()
147 for model_state, name, field, reference in get_references(
148 self, old_model_tuple
149 ):
150 changed_field = None
151 if reference.to:
152 changed_field = field.clone()
153 changed_field.remote_field.model = new_remote_model
154 if reference.through:
155 if changed_field is None:
156 changed_field = field.clone()
157 changed_field.remote_field.through = new_remote_model
158 if changed_field:
159 model_state.fields[name] = changed_field
160 to_reload.add((model_state.package_label, model_state.name_lower))
161 if self._relations is not None:
162 old_name_key = package_label, old_name_lower
163 new_name_key = package_label, new_name_lower
164 if old_name_key in self._relations:
165 self._relations[new_name_key] = self._relations.pop(old_name_key)
166 for model_relations in self._relations.values():
167 if old_name_key in model_relations:
168 model_relations[new_name_key] = model_relations.pop(old_name_key)
169 # Reload models related to old model before removing the old model.
170 self.reload_models(to_reload, delay=True)
171 # Remove the old model.
172 self.remove_model(package_label, old_name_lower)
173 self.reload_model(package_label, new_name_lower, delay=True)
175 def alter_model_options(self, package_label, model_name, options, option_keys=None):
176 model_state = self.models[package_label, model_name]
177 model_state.options = {**model_state.options, **options}
178 if option_keys:
179 for key in option_keys:
180 if key not in options:
181 model_state.options.pop(key, False)
182 self.reload_model(package_label, model_name, delay=True)
184 def remove_model_options(
185 self, package_label, model_name, option_name, value_to_remove
186 ):
187 model_state = self.models[package_label, model_name]
188 if objs := model_state.options.get(option_name):
189 model_state.options[option_name] = [
190 obj for obj in objs if tuple(obj) != tuple(value_to_remove)
191 ]
192 self.reload_model(package_label, model_name, delay=True)
194 def alter_model_managers(self, package_label, model_name, managers):
195 model_state = self.models[package_label, model_name]
196 model_state.managers = list(managers)
197 self.reload_model(package_label, model_name, delay=True)
199 def _append_option(self, package_label, model_name, option_name, obj):
200 model_state = self.models[package_label, model_name]
201 model_state.options[option_name] = [*model_state.options[option_name], obj]
202 self.reload_model(package_label, model_name, delay=True)
204 def _remove_option(self, package_label, model_name, option_name, obj_name):
205 model_state = self.models[package_label, model_name]
206 objs = model_state.options[option_name]
207 model_state.options[option_name] = [obj for obj in objs if obj.name != obj_name]
208 self.reload_model(package_label, model_name, delay=True)
210 def add_index(self, package_label, model_name, index):
211 self._append_option(package_label, model_name, "indexes", index)
213 def remove_index(self, package_label, model_name, index_name):
214 self._remove_option(package_label, model_name, "indexes", index_name)
216 def rename_index(self, package_label, model_name, old_index_name, new_index_name):
217 model_state = self.models[package_label, model_name]
218 objs = model_state.options["indexes"]
220 new_indexes = []
221 for obj in objs:
222 if obj.name == old_index_name:
223 obj = obj.clone()
224 obj.name = new_index_name
225 new_indexes.append(obj)
227 model_state.options["indexes"] = new_indexes
228 self.reload_model(package_label, model_name, delay=True)
230 def add_constraint(self, package_label, model_name, constraint):
231 self._append_option(package_label, model_name, "constraints", constraint)
233 def remove_constraint(self, package_label, model_name, constraint_name):
234 self._remove_option(package_label, model_name, "constraints", constraint_name)
236 def add_field(self, package_label, model_name, name, field, preserve_default):
237 # If preserve default is off, don't use the default for future state.
238 if not preserve_default:
239 field = field.clone()
240 field.default = NOT_PROVIDED
241 else:
242 field = field
243 model_key = package_label, model_name
244 self.models[model_key].fields[name] = field
245 if self._relations is not None:
246 self.resolve_model_field_relations(model_key, name, field)
247 # Delay rendering of relationships if it's not a relational field.
248 delay = not field.is_relation
249 self.reload_model(*model_key, delay=delay)
251 def remove_field(self, package_label, model_name, name):
252 model_key = package_label, model_name
253 model_state = self.models[model_key]
254 old_field = model_state.fields.pop(name)
255 if self._relations is not None:
256 self.resolve_model_field_relations(model_key, name, old_field)
257 # Delay rendering of relationships if it's not a relational field.
258 delay = not old_field.is_relation
259 self.reload_model(*model_key, delay=delay)
261 def alter_field(self, package_label, model_name, name, field, preserve_default):
262 if not preserve_default:
263 field = field.clone()
264 field.default = NOT_PROVIDED
265 else:
266 field = field
267 model_key = package_label, model_name
268 fields = self.models[model_key].fields
269 if self._relations is not None:
270 old_field = fields.pop(name)
271 if old_field.is_relation:
272 self.resolve_model_field_relations(model_key, name, old_field)
273 fields[name] = field
274 if field.is_relation:
275 self.resolve_model_field_relations(model_key, name, field)
276 else:
277 fields[name] = field
278 # TODO: investigate if old relational fields must be reloaded or if
279 # it's sufficient if the new field is (#27737).
280 # Delay rendering of relationships if it's not a relational field and
281 # not referenced by a foreign key.
282 delay = not field.is_relation and not field_is_referenced(
283 self, model_key, (name, field)
284 )
285 self.reload_model(*model_key, delay=delay)
287 def rename_field(self, package_label, model_name, old_name, new_name):
288 model_key = package_label, model_name
289 model_state = self.models[model_key]
290 # Rename the field.
291 fields = model_state.fields
292 try:
293 found = fields.pop(old_name)
294 except KeyError:
295 raise FieldDoesNotExist(
296 f"{package_label}.{model_name} has no field named '{old_name}'"
297 )
298 fields[new_name] = found
299 for field in fields.values():
300 # Fix from_fields to refer to the new field.
301 from_fields = getattr(field, "from_fields", None)
302 if from_fields:
303 field.from_fields = tuple(
304 [
305 new_name if from_field_name == old_name else from_field_name
306 for from_field_name in from_fields
307 ]
308 )
310 # Fix to_fields to refer to the new field.
311 delay = True
312 references = get_references(self, model_key, (old_name, found))
313 for *_, field, reference in references:
314 delay = False
315 if reference.to:
316 remote_field, to_fields = reference.to
317 if getattr(remote_field, "field_name", None) == old_name:
318 remote_field.field_name = new_name
319 if to_fields:
320 field.to_fields = tuple(
321 [
322 new_name if to_field_name == old_name else to_field_name
323 for to_field_name in to_fields
324 ]
325 )
326 if self._relations is not None:
327 old_name_lower = old_name.lower()
328 new_name_lower = new_name.lower()
329 for to_model in self._relations.values():
330 if old_name_lower in to_model[model_key]:
331 field = to_model[model_key].pop(old_name_lower)
332 field.name = new_name_lower
333 to_model[model_key][new_name_lower] = field
334 self.reload_model(*model_key, delay=delay)
336 def _find_reload_model(self, package_label, model_name, delay=False):
337 if delay:
338 self.is_delayed = True
340 related_models = set()
342 try:
343 old_model = self.packages.get_model(package_label, model_name)
344 except LookupError:
345 pass
346 else:
347 # Get all relations to and from the old model before reloading,
348 # as _meta.packages may change
349 if delay:
350 related_models = get_related_models_tuples(old_model)
351 else:
352 related_models = get_related_models_recursive(old_model)
354 # Get all outgoing references from the model to be rendered
355 model_state = self.models[(package_label, model_name)]
356 # Directly related models are the models pointed to by ForeignKeys,
357 # OneToOneFields, and ManyToManyFields.
358 direct_related_models = set()
359 for field in model_state.fields.values():
360 if field.is_relation:
361 if field.remote_field.model == RECURSIVE_RELATIONSHIP_CONSTANT:
362 continue
363 rel_package_label, rel_model_name = _get_package_label_and_model_name(
364 field.related_model, package_label
365 )
366 direct_related_models.add((rel_package_label, rel_model_name.lower()))
368 # For all direct related models recursively get all related models.
369 related_models.update(direct_related_models)
370 for rel_package_label, rel_model_name in direct_related_models:
371 try:
372 rel_model = self.packages.get_model(rel_package_label, rel_model_name)
373 except LookupError:
374 pass
375 else:
376 if delay:
377 related_models.update(get_related_models_tuples(rel_model))
378 else:
379 related_models.update(get_related_models_recursive(rel_model))
381 # Include the model itself
382 related_models.add((package_label, model_name))
384 return related_models
386 def reload_model(self, package_label, model_name, delay=False):
387 if "packages" in self.__dict__: # hasattr would cache the property
388 related_models = self._find_reload_model(package_label, model_name, delay)
389 self._reload(related_models)
391 def reload_models(self, models, delay=True):
392 if "packages" in self.__dict__: # hasattr would cache the property
393 related_models = set()
394 for package_label, model_name in models:
395 related_models.update(
396 self._find_reload_model(package_label, model_name, delay)
397 )
398 self._reload(related_models)
400 def _reload(self, related_models):
401 # Unregister all related models
402 with self.packages.bulk_update():
403 for rel_package_label, rel_model_name in related_models:
404 self.packages.unregister_model(rel_package_label, rel_model_name)
406 states_to_be_rendered = []
407 # Gather all models states of those models that will be rerendered.
408 # This includes:
409 # 1. All related models of unmigrated packages
410 for model_state in self.packages.real_models:
411 if (model_state.package_label, model_state.name_lower) in related_models:
412 states_to_be_rendered.append(model_state)
414 # 2. All related models of migrated packages
415 for rel_package_label, rel_model_name in related_models:
416 try:
417 model_state = self.models[rel_package_label, rel_model_name]
418 except KeyError:
419 pass
420 else:
421 states_to_be_rendered.append(model_state)
423 # Render all models
424 self.packages.render_multiple(states_to_be_rendered)
426 def update_model_field_relation(
427 self,
428 model,
429 model_key,
430 field_name,
431 field,
432 concretes,
433 ):
434 remote_model_key = resolve_relation(model, *model_key)
435 if (
436 remote_model_key[0] not in self.real_packages
437 and remote_model_key in concretes
438 ):
439 remote_model_key = concretes[remote_model_key]
440 relations_to_remote_model = self._relations[remote_model_key]
441 if field_name in self.models[model_key].fields:
442 # The assert holds because it's a new relation, or an altered
443 # relation, in which case references have been removed by
444 # alter_field().
445 assert field_name not in relations_to_remote_model[model_key]
446 relations_to_remote_model[model_key][field_name] = field
447 else:
448 del relations_to_remote_model[model_key][field_name]
449 if not relations_to_remote_model[model_key]:
450 del relations_to_remote_model[model_key]
452 def resolve_model_field_relations(
453 self,
454 model_key,
455 field_name,
456 field,
457 concretes=None,
458 ):
459 remote_field = field.remote_field
460 if not remote_field:
461 return
462 if concretes is None:
463 concretes = self._get_concrete_models_mapping()
465 self.update_model_field_relation(
466 remote_field.model,
467 model_key,
468 field_name,
469 field,
470 concretes,
471 )
473 through = getattr(remote_field, "through", None)
474 if not through:
475 return
476 self.update_model_field_relation(
477 through, model_key, field_name, field, concretes
478 )
480 def resolve_model_relations(self, model_key, concretes=None):
481 if concretes is None:
482 concretes = self._get_concrete_models_mapping()
484 model_state = self.models[model_key]
485 for field_name, field in model_state.fields.items():
486 self.resolve_model_field_relations(model_key, field_name, field, concretes)
488 def resolve_fields_and_relations(self):
489 # Resolve fields.
490 for model_state in self.models.values():
491 for field_name, field in model_state.fields.items():
492 field.name = field_name
493 # Resolve relations.
494 # {remote_model_key: {model_key: {field_name: field}}}
495 self._relations = defaultdict(partial(defaultdict, dict))
496 concretes = self._get_concrete_models_mapping()
498 for model_key in concretes:
499 self.resolve_model_relations(model_key, concretes)
501 def get_concrete_model_key(self, model):
502 (concrete_models_mapping,) = self._get_concrete_models_mapping()
503 model_key = make_model_tuple(model)
504 return concrete_models_mapping[model_key]
506 def _get_concrete_models_mapping(self):
507 concrete_models_mapping = {}
508 for model_key, model_state in self.models.items():
509 concrete_models_mapping[model_key] = model_key
510 return concrete_models_mapping
512 def clone(self):
513 """Return an exact copy of this ProjectState."""
514 new_state = ProjectState(
515 models={k: v.clone() for k, v in self.models.items()},
516 real_packages=self.real_packages,
517 )
518 if "packages" in self.__dict__:
519 new_state.packages = self.packages.clone()
520 new_state.is_delayed = self.is_delayed
521 return new_state
523 def clear_delayed_packages_cache(self):
524 if self.is_delayed and "packages" in self.__dict__:
525 del self.__dict__["packages"]
527 @cached_property
528 def packages(self):
529 return StatePackages(self.real_packages, self.models)
531 @classmethod
532 def from_packages(cls, packages):
533 """Take an Packages and return a ProjectState matching it."""
534 app_models = {}
535 for model in packages.get_models(include_swapped=True):
536 model_state = ModelState.from_model(model)
537 app_models[
538 (model_state.package_label, model_state.name_lower)
539 ] = model_state
540 return cls(app_models)
542 def __eq__(self, other):
543 return self.models == other.models and self.real_packages == other.real_packages
546class PackageConfigStub(PackageConfig):
547 """Stub of an PackageConfig. Only provides a label and a dict of models."""
549 def __init__(self, label):
550 self.packages = None
551 self.models = {}
552 # Package-label and package-name are not the same thing, so technically passing
553 # in the label here is wrong. In practice, migrations don't care about
554 # the package name, but we need something unique, and the label works fine.
555 self.label = label
556 self.name = label
558 def import_models(self):
559 self.models = self.packages.all_models[self.label]
562class StatePackages(Packages):
563 """
564 Subclass of the global Packages registry class to better handle dynamic model
565 additions and removals.
566 """
568 def __init__(self, real_packages, models, ignore_swappable=False):
569 # Any packages in self.real_packages should have all their models included
570 # in the render. We don't use the original model instances as there
571 # are some variables that refer to the Packages object.
572 # FKs/M2Ms from real packages are also not included as they just
573 # mess things up with partial states (due to lack of dependencies)
574 self.real_models = []
575 for package_label in real_packages:
576 app = global_packages.get_package_config(package_label)
577 for model in app.get_models():
578 self.real_models.append(ModelState.from_model(model, exclude_rels=True))
579 # Populate the app registry with a stub for each application.
580 package_labels = {model_state.package_label for model_state in models.values()}
581 package_configs = [
582 PackageConfigStub(label)
583 for label in sorted([*real_packages, *package_labels])
584 ]
585 super().__init__(package_configs)
587 # These locks get in the way of copying as implemented in clone(),
588 # which is called whenever Plain duplicates a StatePackages before
589 # updating it.
590 self._lock = None
592 self.render_multiple([*models.values(), *self.real_models])
594 # There shouldn't be any operations pending at this point.
595 from plain.models.preflight import _check_lazy_references
597 ignore = (
598 {make_model_tuple(settings.AUTH_USER_MODEL)} if ignore_swappable else set()
599 )
600 errors = _check_lazy_references(self, ignore=ignore)
601 if errors:
602 raise ValueError("\n".join(error.msg for error in errors))
604 @contextmanager
605 def bulk_update(self):
606 # Avoid clearing each model's cache for each change. Instead, clear
607 # all caches when we're finished updating the model instances.
608 ready = self.ready
609 self.ready = False
610 try:
611 yield
612 finally:
613 self.ready = ready
614 self.clear_cache()
616 def render_multiple(self, model_states):
617 # We keep trying to render the models in a loop, ignoring invalid
618 # base errors, until the size of the unrendered models doesn't
619 # decrease by at least one, meaning there's a base dependency loop/
620 # missing base.
621 if not model_states:
622 return
623 # Prevent that all model caches are expired for each render.
624 with self.bulk_update():
625 unrendered_models = model_states
626 while unrendered_models:
627 new_unrendered_models = []
628 for model in unrendered_models:
629 try:
630 model.render(self)
631 except InvalidBasesError:
632 new_unrendered_models.append(model)
633 if len(new_unrendered_models) == len(unrendered_models):
634 raise InvalidBasesError(
635 "Cannot resolve bases for %r\nThis can happen if you are "
636 "inheriting models from an app with migrations (e.g. "
637 "contrib.auth)\n in an app with no migrations"
638 % new_unrendered_models
639 )
640 unrendered_models = new_unrendered_models
642 def clone(self):
643 """Return a clone of this registry."""
644 clone = StatePackages([], {})
645 clone.all_models = copy.deepcopy(self.all_models)
647 for package_label in self.package_configs:
648 package_config = PackageConfigStub(package_label)
649 package_config.packages = clone
650 package_config.import_models()
651 clone.package_configs[package_label] = package_config
653 # No need to actually clone them, they'll never change
654 clone.real_models = self.real_models
655 return clone
657 def register_model(self, package_label, model):
658 self.all_models[package_label][model._meta.model_name] = model
659 if package_label not in self.package_configs:
660 self.package_configs[package_label] = PackageConfigStub(package_label)
661 self.package_configs[package_label].packages = self
662 self.package_configs[package_label].models[model._meta.model_name] = model
663 self.do_pending_operations(model)
664 self.clear_cache()
666 def unregister_model(self, package_label, model_name):
667 try:
668 del self.all_models[package_label][model_name]
669 del self.package_configs[package_label].models[model_name]
670 except KeyError:
671 pass
674class ModelState:
675 """
676 Represent a Plain Model. Don't use the actual Model class as it's not
677 designed to have its options changed - instead, mutate this one and then
678 render it into a Model as required.
680 Note that while you are allowed to mutate .fields, you are not allowed
681 to mutate the Field instances inside there themselves - you must instead
682 assign new ones, as these are not detached during a clone.
683 """
685 def __init__(
686 self, package_label, name, fields, options=None, bases=None, managers=None
687 ):
688 self.package_label = package_label
689 self.name = name
690 self.fields = dict(fields)
691 self.options = options or {}
692 self.options.setdefault("indexes", [])
693 self.options.setdefault("constraints", [])
694 self.bases = bases or (models.Model,)
695 self.managers = managers or []
696 for name, field in self.fields.items():
697 # Sanity-check that fields are NOT already bound to a model.
698 if hasattr(field, "model"):
699 raise ValueError(
700 'ModelState.fields cannot be bound to a model - "%s" is.' % name
701 )
702 # Sanity-check that relation fields are NOT referring to a model class.
703 if field.is_relation and hasattr(field.related_model, "_meta"):
704 raise ValueError(
705 'ModelState.fields cannot refer to a model class - "%s.to" does. '
706 "Use a string reference instead." % name
707 )
708 if field.many_to_many and hasattr(field.remote_field.through, "_meta"):
709 raise ValueError(
710 'ModelState.fields cannot refer to a model class - "%s.through" '
711 "does. Use a string reference instead." % name
712 )
713 # Sanity-check that indexes have their name set.
714 for index in self.options["indexes"]:
715 if not index.name:
716 raise ValueError(
717 "Indexes passed to ModelState require a name attribute. "
718 "%r doesn't have one." % index
719 )
721 @cached_property
722 def name_lower(self):
723 return self.name.lower()
725 def get_field(self, field_name):
726 if field_name == "_order":
727 field_name = self.options.get("order_with_respect_to", field_name)
728 return self.fields[field_name]
730 @classmethod
731 def from_model(cls, model, exclude_rels=False):
732 """Given a model, return a ModelState representing it."""
733 # Deconstruct the fields
734 fields = []
735 for field in model._meta.local_fields:
736 if getattr(field, "remote_field", None) and exclude_rels:
737 continue
738 if isinstance(field, models.OrderWrt):
739 continue
740 name = field.name
741 try:
742 fields.append((name, field.clone()))
743 except TypeError as e:
744 raise TypeError(
745 f"Couldn't reconstruct field {name} on {model._meta.label}: {e}"
746 )
747 if not exclude_rels:
748 for field in model._meta.local_many_to_many:
749 name = field.name
750 try:
751 fields.append((name, field.clone()))
752 except TypeError as e:
753 raise TypeError(
754 "Couldn't reconstruct m2m field {} on {}: {}".format(
755 name,
756 model._meta.object_name,
757 e,
758 )
759 )
760 # Extract the options
761 options = {}
762 for name in DEFAULT_NAMES:
763 # Ignore some special options
764 if name in ["packages", "package_label"]:
765 continue
766 elif name in model._meta.original_attrs:
767 if name == "indexes":
768 indexes = [idx.clone() for idx in model._meta.indexes]
769 for index in indexes:
770 if not index.name:
771 index.set_name_with_model(model)
772 options["indexes"] = indexes
773 elif name == "constraints":
774 options["constraints"] = [
775 con.clone() for con in model._meta.constraints
776 ]
777 else:
778 options[name] = model._meta.original_attrs[name]
779 # If we're ignoring relationships, remove all field-listing model
780 # options (that option basically just means "make a stub model")
781 if exclude_rels:
782 if "order_with_respect_to" in options:
783 del options["order_with_respect_to"]
784 # Private fields are ignored, so remove options that refer to them.
785 elif options.get("order_with_respect_to") in {
786 field.name for field in model._meta.private_fields
787 }:
788 del options["order_with_respect_to"]
790 def flatten_bases(model):
791 bases = []
792 for base in model.__bases__:
793 if hasattr(base, "_meta") and base._meta.abstract:
794 bases.extend(flatten_bases(base))
795 else:
796 bases.append(base)
797 return bases
799 # We can't rely on __mro__ directly because we only want to flatten
800 # abstract models and not the whole tree. However by recursing on
801 # __bases__ we may end up with duplicates and ordering issues, we
802 # therefore discard any duplicates and reorder the bases according
803 # to their index in the MRO.
804 flattened_bases = sorted(
805 set(flatten_bases(model)), key=lambda x: model.__mro__.index(x)
806 )
808 # Make our record
809 bases = tuple(
810 (base._meta.label_lower if hasattr(base, "_meta") else base)
811 for base in flattened_bases
812 )
813 # Ensure at least one base inherits from models.Model
814 if not any(
815 (isinstance(base, str) or issubclass(base, models.Model)) for base in bases
816 ):
817 bases = (models.Model,)
819 managers = []
820 manager_names = set()
821 default_manager_shim = None
822 for manager in model._meta.managers:
823 if manager.name in manager_names:
824 # Skip overridden managers.
825 continue
826 elif manager.use_in_migrations:
827 # Copy managers usable in migrations.
828 new_manager = copy.copy(manager)
829 new_manager._set_creation_counter()
830 elif manager is model._base_manager or manager is model._default_manager:
831 # Shim custom managers used as default and base managers.
832 new_manager = models.Manager()
833 new_manager.model = manager.model
834 new_manager.name = manager.name
835 if manager is model._default_manager:
836 default_manager_shim = new_manager
837 else:
838 continue
839 manager_names.add(manager.name)
840 managers.append((manager.name, new_manager))
842 # Ignore a shimmed default manager called objects if it's the only one.
843 if managers == [("objects", default_manager_shim)]:
844 managers = []
846 # Construct the new ModelState
847 return cls(
848 model._meta.package_label,
849 model._meta.object_name,
850 fields,
851 options,
852 bases,
853 managers,
854 )
856 def construct_managers(self):
857 """Deep-clone the managers using deconstruction."""
858 # Sort all managers by their creation counter
859 sorted_managers = sorted(self.managers, key=lambda v: v[1].creation_counter)
860 for mgr_name, manager in sorted_managers:
861 as_manager, manager_path, qs_path, args, kwargs = manager.deconstruct()
862 if as_manager:
863 qs_class = import_string(qs_path)
864 yield mgr_name, qs_class.as_manager()
865 else:
866 manager_class = import_string(manager_path)
867 yield mgr_name, manager_class(*args, **kwargs)
869 def clone(self):
870 """Return an exact copy of this ModelState."""
871 return self.__class__(
872 package_label=self.package_label,
873 name=self.name,
874 fields=dict(self.fields),
875 # Since options are shallow-copied here, operations such as
876 # AddIndex must replace their option (e.g 'indexes') rather
877 # than mutating it.
878 options=dict(self.options),
879 bases=self.bases,
880 managers=list(self.managers),
881 )
883 def render(self, packages):
884 """Create a Model object from our current state into the given packages."""
885 # First, make a Meta object
886 meta_contents = {
887 "package_label": self.package_label,
888 "packages": packages,
889 **self.options,
890 }
891 meta = type("Meta", (), meta_contents)
892 # Then, work out our bases
893 try:
894 bases = tuple(
895 (packages.get_model(base) if isinstance(base, str) else base)
896 for base in self.bases
897 )
898 except LookupError:
899 raise InvalidBasesError(
900 f"Cannot resolve one or more bases from {self.bases!r}"
901 )
902 # Clone fields for the body, add other bits.
903 body = {name: field.clone() for name, field in self.fields.items()}
904 body["Meta"] = meta
905 body["__module__"] = "__fake__"
907 # Restore managers
908 body.update(self.construct_managers())
909 # Then, make a Model object (packages.register_model is called in __new__)
910 return type(self.name, bases, body)
912 def get_index_by_name(self, name):
913 for index in self.options["indexes"]:
914 if index.name == name:
915 return index
916 raise ValueError(f"No index named {name} on model {self.name}")
918 def get_constraint_by_name(self, name):
919 for constraint in self.options["constraints"]:
920 if constraint.name == name:
921 return constraint
922 raise ValueError(f"No constraint named {name} on model {self.name}")
924 def __repr__(self):
925 return f"<{self.__class__.__name__}: '{self.package_label}.{self.name}'>"
927 def __eq__(self, other):
928 return (
929 (self.package_label == other.package_label)
930 and (self.name == other.name)
931 and (len(self.fields) == len(other.fields))
932 and all(
933 k1 == k2 and f1.deconstruct()[1:] == f2.deconstruct()[1:]
934 for (k1, f1), (k2, f2) in zip(
935 sorted(self.fields.items()),
936 sorted(other.fields.items()),
937 )
938 )
939 and (self.options == other.options)
940 and (self.bases == other.bases)
941 and (self.managers == other.managers)
942 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import datetime
2import re
3from collections import namedtuple
5from plain.models.fields.related import RECURSIVE_RELATIONSHIP_CONSTANT
7FieldReference = namedtuple("FieldReference", "to through")
9COMPILED_REGEX_TYPE = type(re.compile(""))
12class RegexObject:
13 def __init__(self, obj):
14 self.pattern = obj.pattern
15 self.flags = obj.flags
17 def __eq__(self, other):
18 if not isinstance(other, RegexObject):
19 return NotImplemented
20 return self.pattern == other.pattern and self.flags == other.flags
23def get_migration_name_timestamp():
24 return datetime.datetime.now().strftime("%Y%m%d_%H%M")
27def resolve_relation(model, package_label=None, model_name=None):
28 """
29 Turn a model class or model reference string and return a model tuple.
31 package_label and model_name are used to resolve the scope of recursive and
32 unscoped model relationship.
33 """
34 if isinstance(model, str):
35 if model == RECURSIVE_RELATIONSHIP_CONSTANT:
36 if package_label is None or model_name is None:
37 raise TypeError(
38 "package_label and model_name must be provided to resolve "
39 "recursive relationships."
40 )
41 return package_label, model_name
42 if "." in model:
43 package_label, model_name = model.split(".", 1)
44 return package_label, model_name.lower()
45 if package_label is None:
46 raise TypeError(
47 "package_label must be provided to resolve unscoped model relationships."
48 )
49 return package_label, model.lower()
50 return model._meta.package_label, model._meta.model_name
53def field_references(
54 model_tuple,
55 field,
56 reference_model_tuple,
57 reference_field_name=None,
58 reference_field=None,
59):
60 """
61 Return either False or a FieldReference if `field` references provided
62 context.
64 False positives can be returned if `reference_field_name` is provided
65 without `reference_field` because of the introspection limitation it
66 incurs. This should not be an issue when this function is used to determine
67 whether or not an optimization can take place.
68 """
69 remote_field = field.remote_field
70 if not remote_field:
71 return False
72 references_to = None
73 references_through = None
74 if resolve_relation(remote_field.model, *model_tuple) == reference_model_tuple:
75 to_fields = getattr(field, "to_fields", None)
76 if (
77 reference_field_name is None
78 or
79 # Unspecified to_field(s).
80 to_fields is None
81 or
82 # Reference to primary key.
83 (
84 None in to_fields
85 and (reference_field is None or reference_field.primary_key)
86 )
87 or
88 # Reference to field.
89 reference_field_name in to_fields
90 ):
91 references_to = (remote_field, to_fields)
92 through = getattr(remote_field, "through", None)
93 if through and resolve_relation(through, *model_tuple) == reference_model_tuple:
94 through_fields = remote_field.through_fields
95 if (
96 reference_field_name is None
97 or
98 # Unspecified through_fields.
99 through_fields is None
100 or
101 # Reference to field.
102 reference_field_name in through_fields
103 ):
104 references_through = (remote_field, through_fields)
105 if not (references_to or references_through):
106 return False
107 return FieldReference(references_to, references_through)
110def get_references(state, model_tuple, field_tuple=()):
111 """
112 Generator of (model_state, name, field, reference) referencing
113 provided context.
115 If field_tuple is provided only references to this particular field of
116 model_tuple will be generated.
117 """
118 for state_model_tuple, model_state in state.models.items():
119 for name, field in model_state.fields.items():
120 reference = field_references(
121 state_model_tuple, field, model_tuple, *field_tuple
122 )
123 if reference:
124 yield model_state, name, field, reference
127def field_is_referenced(state, model_tuple, field_tuple):
128 """Return whether `field_tuple` is referenced by any state models."""
129 return next(get_references(state, model_tuple, field_tuple), None) is not None
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import os
2import re
3from importlib import import_module
5from plain.models import migrations
6from plain.models.migrations.loader import MigrationLoader
7from plain.models.migrations.serializer import Serializer, serializer_factory
8from plain.packages import packages
9from plain.runtime import __version__
10from plain.utils.inspect import get_func_args
11from plain.utils.module_loading import module_dir
12from plain.utils.timezone import now
15class OperationWriter:
16 def __init__(self, operation, indentation=2):
17 self.operation = operation
18 self.buff = []
19 self.indentation = indentation
21 def serialize(self):
22 def _write(_arg_name, _arg_value):
23 if _arg_name in self.operation.serialization_expand_args and isinstance(
24 _arg_value, list | tuple | dict
25 ):
26 if isinstance(_arg_value, dict):
27 self.feed("%s={" % _arg_name)
28 self.indent()
29 for key, value in _arg_value.items():
30 key_string, key_imports = MigrationWriter.serialize(key)
31 arg_string, arg_imports = MigrationWriter.serialize(value)
32 args = arg_string.splitlines()
33 if len(args) > 1:
34 self.feed(f"{key_string}: {args[0]}")
35 for arg in args[1:-1]:
36 self.feed(arg)
37 self.feed("%s," % args[-1])
38 else:
39 self.feed(f"{key_string}: {arg_string},")
40 imports.update(key_imports)
41 imports.update(arg_imports)
42 self.unindent()
43 self.feed("},")
44 else:
45 self.feed("%s=[" % _arg_name)
46 self.indent()
47 for item in _arg_value:
48 arg_string, arg_imports = MigrationWriter.serialize(item)
49 args = arg_string.splitlines()
50 if len(args) > 1:
51 for arg in args[:-1]:
52 self.feed(arg)
53 self.feed("%s," % args[-1])
54 else:
55 self.feed("%s," % arg_string)
56 imports.update(arg_imports)
57 self.unindent()
58 self.feed("],")
59 else:
60 arg_string, arg_imports = MigrationWriter.serialize(_arg_value)
61 args = arg_string.splitlines()
62 if len(args) > 1:
63 self.feed(f"{_arg_name}={args[0]}")
64 for arg in args[1:-1]:
65 self.feed(arg)
66 self.feed("%s," % args[-1])
67 else:
68 self.feed(f"{_arg_name}={arg_string},")
69 imports.update(arg_imports)
71 imports = set()
72 name, args, kwargs = self.operation.deconstruct()
73 operation_args = get_func_args(self.operation.__init__)
75 # See if this operation is in plain.models.migrations. If it is,
76 # We can just use the fact we already have that imported,
77 # otherwise, we need to add an import for the operation class.
78 if getattr(migrations, name, None) == self.operation.__class__:
79 self.feed("migrations.%s(" % name)
80 else:
81 imports.add("import %s" % (self.operation.__class__.__module__))
82 self.feed(f"{self.operation.__class__.__module__}.{name}(")
84 self.indent()
86 for i, arg in enumerate(args):
87 arg_value = arg
88 arg_name = operation_args[i]
89 _write(arg_name, arg_value)
91 i = len(args)
92 # Only iterate over remaining arguments
93 for arg_name in operation_args[i:]:
94 if arg_name in kwargs: # Don't sort to maintain signature order
95 arg_value = kwargs[arg_name]
96 _write(arg_name, arg_value)
98 self.unindent()
99 self.feed("),")
100 return self.render(), imports
102 def indent(self):
103 self.indentation += 1
105 def unindent(self):
106 self.indentation -= 1
108 def feed(self, line):
109 self.buff.append(" " * (self.indentation * 4) + line)
111 def render(self):
112 return "\n".join(self.buff)
115class MigrationWriter:
116 """
117 Take a Migration instance and is able to produce the contents
118 of the migration file from it.
119 """
121 def __init__(self, migration, include_header=True):
122 self.migration = migration
123 self.include_header = include_header
124 self.needs_manual_porting = False
126 def as_string(self):
127 """Return a string of the file contents."""
128 items = {
129 "replaces_str": "",
130 "initial_str": "",
131 }
133 imports = set()
135 # Deconstruct operations
136 operations = []
137 for operation in self.migration.operations:
138 operation_string, operation_imports = OperationWriter(operation).serialize()
139 imports.update(operation_imports)
140 operations.append(operation_string)
141 items["operations"] = "\n".join(operations) + "\n" if operations else ""
143 # Format dependencies and write out swappable dependencies right
144 dependencies = []
145 for dependency in self.migration.dependencies:
146 if dependency[0] == "__setting__":
147 dependencies.append(
148 " migrations.swappable_dependency(settings.%s),"
149 % dependency[1]
150 )
151 imports.add("from plain.runtime import settings")
152 else:
153 dependencies.append(" %s," % self.serialize(dependency)[0])
154 items["dependencies"] = "\n".join(dependencies) + "\n" if dependencies else ""
156 # Format imports nicely, swapping imports of functions from migration files
157 # for comments
158 migration_imports = set()
159 for line in list(imports):
160 if re.match(r"^import (.*)\.\d+[^\s]*$", line):
161 migration_imports.add(line.split("import")[1].strip())
162 imports.remove(line)
163 self.needs_manual_porting = True
165 imports.add("from plain.models import migrations")
167 # Sort imports by the package / module to be imported (the part after
168 # "from" in "from ... import ..." or after "import" in "import ...").
169 # First group the "import" statements, then "from ... import ...".
170 sorted_imports = sorted(
171 imports, key=lambda i: (i.split()[0] == "from", i.split()[1])
172 )
173 items["imports"] = "\n".join(sorted_imports) + "\n" if imports else ""
174 if migration_imports:
175 items["imports"] += (
176 "\n\n# Functions from the following migrations need manual "
177 "copying.\n# Move them and any dependencies into this file, "
178 "then update the\n# RunPython operations to refer to the local "
179 "versions:\n# %s"
180 ) % "\n# ".join(sorted(migration_imports))
181 # If there's a replaces, make a string for it
182 if self.migration.replaces:
183 items["replaces_str"] = (
184 "\n replaces = %s\n" % self.serialize(self.migration.replaces)[0]
185 )
186 # Hinting that goes into comment
187 if self.include_header:
188 items["migration_header"] = MIGRATION_HEADER_TEMPLATE % {
189 "version": __version__,
190 "timestamp": now().strftime("%Y-%m-%d %H:%M"),
191 }
192 else:
193 items["migration_header"] = ""
195 if self.migration.initial:
196 items["initial_str"] = "\n initial = True\n"
198 return MIGRATION_TEMPLATE % items
200 @property
201 def basedir(self):
202 migrations_package_name, _ = MigrationLoader.migrations_module(
203 self.migration.package_label
204 )
206 if migrations_package_name is None:
207 raise ValueError(
208 "Plain can't create migrations for app '%s' because "
209 "migrations have been disabled via the MIGRATION_MODULES "
210 "setting." % self.migration.package_label
211 )
213 # See if we can import the migrations module directly
214 try:
215 migrations_module = import_module(migrations_package_name)
216 except ImportError:
217 pass
218 else:
219 try:
220 return module_dir(migrations_module)
221 except ValueError:
222 pass
224 # Alright, see if it's a direct submodule of the app
225 package_config = packages.get_package_config(self.migration.package_label)
226 (
227 maybe_package_name,
228 _,
229 migrations_package_basename,
230 ) = migrations_package_name.rpartition(".")
231 if package_config.name == maybe_package_name:
232 return os.path.join(package_config.path, migrations_package_basename)
234 # In case of using MIGRATION_MODULES setting and the custom package
235 # doesn't exist, create one, starting from an existing package
236 existing_dirs, missing_dirs = migrations_package_name.split("."), []
237 while existing_dirs:
238 missing_dirs.insert(0, existing_dirs.pop(-1))
239 try:
240 base_module = import_module(".".join(existing_dirs))
241 except (ImportError, ValueError):
242 continue
243 else:
244 try:
245 base_dir = module_dir(base_module)
246 except ValueError:
247 continue
248 else:
249 break
250 else:
251 raise ValueError(
252 "Could not locate an appropriate location to create "
253 "migrations package %s. Make sure the toplevel "
254 "package exists and can be imported." % migrations_package_name
255 )
257 final_dir = os.path.join(base_dir, *missing_dirs)
258 os.makedirs(final_dir, exist_ok=True)
259 for missing_dir in missing_dirs:
260 base_dir = os.path.join(base_dir, missing_dir)
261 with open(os.path.join(base_dir, "__init__.py"), "w"):
262 pass
264 return final_dir
266 @property
267 def filename(self):
268 return "%s.py" % self.migration.name
270 @property
271 def path(self):
272 return os.path.join(self.basedir, self.filename)
274 @classmethod
275 def serialize(cls, value):
276 return serializer_factory(value).serialize()
278 @classmethod
279 def register_serializer(cls, type_, serializer):
280 Serializer.register(type_, serializer)
282 @classmethod
283 def unregister_serializer(cls, type_):
284 Serializer.unregister(type_)
287MIGRATION_HEADER_TEMPLATE = """\
288# Generated by Plain %(version)s on %(timestamp)s
290"""
293MIGRATION_TEMPLATE = """\
294%(migration_header)s%(imports)s
296class Migration(migrations.Migration):
297%(replaces_str)s%(initial_str)s
298 dependencies = [
299%(dependencies)s\
300 ]
302 operations = [
303%(operations)s\
304 ]
305"""
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
3import requests
5from plain.oauth.exceptions import OAuthError
6from plain.oauth.providers import OAuthProvider, OAuthToken, OAuthUser
7from plain.utils import timezone
10class GitHubOAuthProvider(OAuthProvider):
11 authorization_url = "https://github.com/login/oauth/authorize"
13 github_token_url = "https://github.com/login/oauth/access_token"
14 github_user_url = "https://api.github.com/user"
15 github_emails_url = "https://api.github.com/user/emails"
17 def _get_token(self, request_data):
18 response = requests.post(
19 self.github_token_url,
20 headers={
21 "Accept": "application/json",
22 },
23 data=request_data,
24 )
25 response.raise_for_status()
26 data = response.json()
28 oauth_token = OAuthToken(
29 access_token=data["access_token"],
30 )
32 # Expiration and refresh tokens are optional in GitHub depending on the app
33 if "expires_in" in data:
34 oauth_token.access_token_expires_at = timezone.now() + datetime.timedelta(
35 seconds=data["expires_in"]
36 )
38 if "refresh_token" in data:
39 oauth_token.refresh_token = data["refresh_token"]
41 if "refresh_token_expires_in" in data:
42 oauth_token.refresh_token_expires_at = timezone.now() + datetime.timedelta(
43 seconds=data["refresh_token_expires_in"]
44 )
46 return oauth_token
48 def get_oauth_token(self, *, code, request):
49 return self._get_token(
50 {
51 "client_id": self.get_client_id(),
52 "client_secret": self.get_client_secret(),
53 "code": code,
54 }
55 )
57 def refresh_oauth_token(self, *, oauth_token):
58 return self._get_token(
59 {
60 "client_id": self.get_client_id(),
61 "client_secret": self.get_client_secret(),
62 "refresh_token": oauth_token.refresh_token,
63 "grant_type": "refresh_token",
64 }
65 )
67 def get_oauth_user(self, *, oauth_token):
68 response = requests.get(
69 self.github_user_url,
70 headers={
71 "Accept": "application/json",
72 "Authorization": f"token {oauth_token.access_token}",
73 },
74 )
75 response.raise_for_status()
76 data = response.json()
77 user_id = data["id"]
78 username = data["login"]
80 # Use the verified, primary email address (not the public profile email, which is optional anyway)
81 response = requests.get(
82 self.github_emails_url,
83 headers={
84 "Accept": "application/json",
85 "Authorization": f"token {oauth_token.access_token}",
86 },
87 )
88 response.raise_for_status()
90 try:
91 verified_primary_email = [
92 x["email"] for x in response.json() if x["primary"] and x["verified"]
93 ][0]
94 except IndexError:
95 raise OAuthError("A verified primary email address is required on GitHub")
97 return OAuthUser(
98 id=user_id,
99 email=verified_primary_email,
100 username=username,
101 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Cross Site Request Forgery Middleware.
4This module provides a middleware that implements protection
5against request forgeries from other sites.
6"""
8import logging
9import string
10from collections import defaultdict
11from urllib.parse import urlparse
13from plain.exceptions import DisallowedHost
14from plain.http import HttpHeaders, UnreadablePostError
15from plain.logs import log_response
16from plain.runtime import settings
17from plain.utils.cache import patch_vary_headers
18from plain.utils.crypto import constant_time_compare, get_random_string
19from plain.utils.functional import cached_property
20from plain.utils.http import is_same_domain
21from plain.utils.regex_helper import _lazy_re_compile
23logger = logging.getLogger("plain.security.csrf")
24# This matches if any character is not in CSRF_ALLOWED_CHARS.
25invalid_token_chars_re = _lazy_re_compile("[^a-zA-Z0-9]")
27REASON_BAD_ORIGIN = "Origin checking failed - %s does not match any trusted origins."
28REASON_NO_REFERER = "Referer checking failed - no Referer."
29REASON_BAD_REFERER = "Referer checking failed - %s does not match any trusted origins."
30REASON_NO_CSRF_COOKIE = "CSRF cookie not set."
31REASON_CSRF_TOKEN_MISSING = "CSRF token missing."
32REASON_MALFORMED_REFERER = "Referer checking failed - Referer is malformed."
33REASON_INSECURE_REFERER = (
34 "Referer checking failed - Referer is insecure while host is secure."
35)
36# The reason strings below are for passing to InvalidTokenFormat. They are
37# phrases without a subject because they can be in reference to either the CSRF
38# cookie or non-cookie token.
39REASON_INCORRECT_LENGTH = "has incorrect length"
40REASON_INVALID_CHARACTERS = "has invalid characters"
42CSRF_SECRET_LENGTH = 32
43CSRF_TOKEN_LENGTH = 2 * CSRF_SECRET_LENGTH
44CSRF_ALLOWED_CHARS = string.ascii_letters + string.digits
45CSRF_SESSION_KEY = "_csrftoken"
48def _get_new_csrf_string():
49 return get_random_string(CSRF_SECRET_LENGTH, allowed_chars=CSRF_ALLOWED_CHARS)
52def _mask_cipher_secret(secret):
53 """
54 Given a secret (assumed to be a string of CSRF_ALLOWED_CHARS), generate a
55 token by adding a mask and applying it to the secret.
56 """
57 mask = _get_new_csrf_string()
58 chars = CSRF_ALLOWED_CHARS
59 pairs = zip((chars.index(x) for x in secret), (chars.index(x) for x in mask))
60 cipher = "".join(chars[(x + y) % len(chars)] for x, y in pairs)
61 return mask + cipher
64def _unmask_cipher_token(token):
65 """
66 Given a token (assumed to be a string of CSRF_ALLOWED_CHARS, of length
67 CSRF_TOKEN_LENGTH, and that its first half is a mask), use it to decrypt
68 the second half to produce the original secret.
69 """
70 mask = token[:CSRF_SECRET_LENGTH]
71 token = token[CSRF_SECRET_LENGTH:]
72 chars = CSRF_ALLOWED_CHARS
73 pairs = zip((chars.index(x) for x in token), (chars.index(x) for x in mask))
74 return "".join(chars[x - y] for x, y in pairs) # Note negative values are ok
77def _add_new_csrf_cookie(request):
78 """Generate a new random CSRF_COOKIE value, and add it to request.META."""
79 csrf_secret = _get_new_csrf_string()
80 request.META.update(
81 {
82 "CSRF_COOKIE": csrf_secret,
83 "CSRF_COOKIE_NEEDS_UPDATE": True,
84 }
85 )
86 return csrf_secret
89def get_token(request):
90 """
91 Return the CSRF token required for a POST form. The token is an
92 alphanumeric value. A new token is created if one is not already set.
94 A side effect of calling this function is to make the csrf_protect
95 decorator and the CsrfViewMiddleware add a CSRF cookie and a 'Vary: Cookie'
96 header to the outgoing response. For this reason, you may need to use this
97 function lazily, as is done by the csrf context processor.
98 """
99 if "CSRF_COOKIE" in request.META:
100 csrf_secret = request.META["CSRF_COOKIE"]
101 # Since the cookie is being used, flag to send the cookie in
102 # process_response() (even if the client already has it) in order to
103 # renew the expiry timer.
104 request.META["CSRF_COOKIE_NEEDS_UPDATE"] = True
105 else:
106 csrf_secret = _add_new_csrf_cookie(request)
107 return _mask_cipher_secret(csrf_secret)
110def rotate_token(request):
111 """
112 Change the CSRF token in use for a request - should be done on login
113 for security purposes.
114 """
115 _add_new_csrf_cookie(request)
118class InvalidTokenFormat(Exception):
119 def __init__(self, reason):
120 self.reason = reason
123def _check_token_format(token):
124 """
125 Raise an InvalidTokenFormat error if the token has an invalid length or
126 characters that aren't allowed. The token argument can be a CSRF cookie
127 secret or non-cookie CSRF token, and either masked or unmasked.
128 """
129 if len(token) not in (CSRF_TOKEN_LENGTH, CSRF_SECRET_LENGTH):
130 raise InvalidTokenFormat(REASON_INCORRECT_LENGTH)
131 # Make sure all characters are in CSRF_ALLOWED_CHARS.
132 if invalid_token_chars_re.search(token):
133 raise InvalidTokenFormat(REASON_INVALID_CHARACTERS)
136def _does_token_match(request_csrf_token, csrf_secret):
137 """
138 Return whether the given CSRF token matches the given CSRF secret, after
139 unmasking the token if necessary.
141 This function assumes that the request_csrf_token argument has been
142 validated to have the correct length (CSRF_SECRET_LENGTH or
143 CSRF_TOKEN_LENGTH characters) and allowed characters, and that if it has
144 length CSRF_TOKEN_LENGTH, it is a masked secret.
145 """
146 # Only unmask tokens that are exactly CSRF_TOKEN_LENGTH characters long.
147 if len(request_csrf_token) == CSRF_TOKEN_LENGTH:
148 request_csrf_token = _unmask_cipher_token(request_csrf_token)
149 assert len(request_csrf_token) == CSRF_SECRET_LENGTH
150 return constant_time_compare(request_csrf_token, csrf_secret)
153class RejectRequest(Exception):
154 def __init__(self, reason):
155 self.reason = reason
158class CsrfViewMiddleware:
159 """
160 Require a present and correct csrfmiddlewaretoken for POST requests that
161 have a CSRF cookie, and set an outgoing CSRF cookie.
163 This middleware should be used in conjunction with the {% csrf_token %}
164 template tag.
165 """
167 def __init__(self, get_response):
168 self.get_response = get_response
170 def __call__(self, request):
171 try:
172 csrf_secret = self._get_secret(request)
173 except InvalidTokenFormat:
174 _add_new_csrf_cookie(request)
175 else:
176 if csrf_secret is not None:
177 # Use the same secret next time. If the secret was originally
178 # masked, this also causes it to be replaced with the unmasked
179 # form, but only in cases where the secret is already getting
180 # saved anyways.
181 request.META["CSRF_COOKIE"] = csrf_secret
183 response = self.get_response(request)
185 if request.META.get("CSRF_COOKIE_NEEDS_UPDATE"):
186 self._set_csrf_cookie(request, response)
187 # Unset the flag to prevent _set_csrf_cookie() from being
188 # unnecessarily called again in process_response() by other
189 # instances of CsrfViewMiddleware. This can happen e.g. when both a
190 # decorator and middleware are used. However,
191 # CSRF_COOKIE_NEEDS_UPDATE is still respected in subsequent calls
192 # e.g. in case rotate_token() is called in process_response() later
193 # by custom middleware but before those subsequent calls.
194 request.META["CSRF_COOKIE_NEEDS_UPDATE"] = False
196 return response
198 @cached_property
199 def csrf_trusted_origins_hosts(self):
200 return [
201 urlparse(origin).netloc.lstrip("*")
202 for origin in settings.CSRF_TRUSTED_ORIGINS
203 ]
205 @cached_property
206 def allowed_origins_exact(self):
207 return {origin for origin in settings.CSRF_TRUSTED_ORIGINS if "*" not in origin}
209 @cached_property
210 def allowed_origin_subdomains(self):
211 """
212 A mapping of allowed schemes to list of allowed netlocs, where all
213 subdomains of the netloc are allowed.
214 """
215 allowed_origin_subdomains = defaultdict(list)
216 for parsed in (
217 urlparse(origin)
218 for origin in settings.CSRF_TRUSTED_ORIGINS
219 if "*" in origin
220 ):
221 allowed_origin_subdomains[parsed.scheme].append(parsed.netloc.lstrip("*"))
222 return allowed_origin_subdomains
224 def _reject(self, request, reason):
225 from .views import CsrfFailureView
227 response = CsrfFailureView.as_view()(request, reason=reason)
228 log_response(
229 "Forbidden (%s): %s",
230 reason,
231 request.path,
232 response=response,
233 request=request,
234 logger=logger,
235 )
236 return response
238 def _get_secret(self, request):
239 """
240 Return the CSRF secret originally associated with the request, or None
241 if it didn't have one.
243 If the CSRF_USE_SESSIONS setting is false, raises InvalidTokenFormat if
244 the request's secret has invalid characters or an invalid length.
245 """
246 try:
247 csrf_secret = request.COOKIES[settings.CSRF_COOKIE_NAME]
248 except KeyError:
249 csrf_secret = None
250 else:
251 # This can raise InvalidTokenFormat.
252 _check_token_format(csrf_secret)
254 if csrf_secret is None:
255 return None
256 return csrf_secret
258 def _set_csrf_cookie(self, request, response):
259 response.set_cookie(
260 settings.CSRF_COOKIE_NAME,
261 request.META["CSRF_COOKIE"],
262 max_age=settings.CSRF_COOKIE_AGE,
263 domain=settings.CSRF_COOKIE_DOMAIN,
264 path=settings.CSRF_COOKIE_PATH,
265 secure=settings.CSRF_COOKIE_SECURE,
266 httponly=settings.CSRF_COOKIE_HTTPONLY,
267 samesite=settings.CSRF_COOKIE_SAMESITE,
268 )
269 # Set the Vary header since content varies with the CSRF cookie.
270 patch_vary_headers(response, ("Cookie",))
272 def _origin_verified(self, request):
273 request_origin = request.META["HTTP_ORIGIN"]
274 try:
275 good_host = request.get_host()
276 except DisallowedHost:
277 pass
278 else:
279 good_origin = "{}://{}".format(
280 "https" if request.is_https() else "http",
281 good_host,
282 )
283 if request_origin == good_origin:
284 return True
285 if request_origin in self.allowed_origins_exact:
286 return True
287 try:
288 parsed_origin = urlparse(request_origin)
289 except ValueError:
290 return False
291 request_scheme = parsed_origin.scheme
292 request_netloc = parsed_origin.netloc
293 return any(
294 is_same_domain(request_netloc, host)
295 for host in self.allowed_origin_subdomains.get(request_scheme, ())
296 )
298 def _check_referer(self, request):
299 referer = request.META.get("HTTP_REFERER")
300 if referer is None:
301 raise RejectRequest(REASON_NO_REFERER)
303 try:
304 referer = urlparse(referer)
305 except ValueError:
306 raise RejectRequest(REASON_MALFORMED_REFERER)
308 # Make sure we have a valid URL for Referer.
309 if "" in (referer.scheme, referer.netloc):
310 raise RejectRequest(REASON_MALFORMED_REFERER)
312 # Ensure that our Referer is also secure.
313 if referer.scheme != "https":
314 raise RejectRequest(REASON_INSECURE_REFERER)
316 if any(
317 is_same_domain(referer.netloc, host)
318 for host in self.csrf_trusted_origins_hosts
319 ):
320 return
321 # Allow matching the configured cookie domain.
322 good_referer = settings.CSRF_COOKIE_DOMAIN
323 if good_referer is None:
324 # If no cookie domain is configured, allow matching the current
325 # host:port exactly if it's permitted by ALLOWED_HOSTS.
326 try:
327 # request.get_host() includes the port.
328 good_referer = request.get_host()
329 except DisallowedHost:
330 raise RejectRequest(REASON_BAD_REFERER % referer.geturl())
331 else:
332 server_port = request.get_port()
333 if server_port not in ("443", "80"):
334 good_referer = f"{good_referer}:{server_port}"
336 if not is_same_domain(referer.netloc, good_referer):
337 raise RejectRequest(REASON_BAD_REFERER % referer.geturl())
339 def _bad_token_message(self, reason, token_source):
340 if token_source != "POST":
341 # Assume it is a settings.CSRF_HEADER_NAME value.
342 header_name = HttpHeaders.parse_header_name(token_source)
343 token_source = f"the {header_name!r} HTTP header"
344 return f"CSRF token from {token_source} {reason}."
346 def _check_token(self, request):
347 # Access csrf_secret via self._get_secret() as rotate_token() may have
348 # been called by an authentication middleware during the
349 # process_request() phase.
350 try:
351 csrf_secret = self._get_secret(request)
352 except InvalidTokenFormat as exc:
353 raise RejectRequest(f"CSRF cookie {exc.reason}.")
355 if csrf_secret is None:
356 # No CSRF cookie. For POST requests, we insist on a CSRF cookie,
357 # and in this way we can avoid all CSRF attacks, including login
358 # CSRF.
359 raise RejectRequest(REASON_NO_CSRF_COOKIE)
361 # Check non-cookie token for match.
362 request_csrf_token = ""
363 if request.method == "POST":
364 try:
365 request_csrf_token = request.POST.get("csrfmiddlewaretoken", "")
366 except UnreadablePostError:
367 # Handle a broken connection before we've completed reading the
368 # POST data. process_view shouldn't raise any exceptions, so
369 # we'll ignore and serve the user a 403 (assuming they're still
370 # listening, which they probably aren't because of the error).
371 pass
373 if request_csrf_token == "":
374 # Fall back to X-CSRFToken, to make things easier for AJAX, and
375 # possible for PUT/DELETE.
376 try:
377 # This can have length CSRF_SECRET_LENGTH or CSRF_TOKEN_LENGTH,
378 # depending on whether the client obtained the token from
379 # the DOM or the cookie (and if the cookie, whether the cookie
380 # was masked or unmasked).
381 request_csrf_token = request.META[settings.CSRF_HEADER_NAME]
382 except KeyError:
383 raise RejectRequest(REASON_CSRF_TOKEN_MISSING)
384 token_source = settings.CSRF_HEADER_NAME
385 else:
386 token_source = "POST"
388 try:
389 _check_token_format(request_csrf_token)
390 except InvalidTokenFormat as exc:
391 reason = self._bad_token_message(exc.reason, token_source)
392 raise RejectRequest(reason)
394 if not _does_token_match(request_csrf_token, csrf_secret):
395 reason = self._bad_token_message("incorrect", token_source)
396 raise RejectRequest(reason)
398 def process_view(self, request, callback, callback_args, callback_kwargs):
399 # Wait until request.META["CSRF_COOKIE"] has been manipulated before
400 # bailing out, so that get_token still works
401 if getattr(callback, "csrf_exempt", False):
402 return None
404 # Assume that anything not defined as 'safe' by RFC 9110 needs protection
405 if request.method in ("GET", "HEAD", "OPTIONS", "TRACE"):
406 return None
408 if getattr(request, "_dont_enforce_csrf_checks", False):
409 # Mechanism to turn off CSRF checks for test suite. It comes after
410 # the creation of CSRF cookies, so that everything else continues
411 # to work exactly the same (e.g. cookies are sent, etc.), but
412 # before any branches that call the _reject method.
413 return None
415 # Reject the request if the Origin header doesn't match an allowed
416 # value.
417 if "HTTP_ORIGIN" in request.META:
418 if not self._origin_verified(request):
419 return self._reject(
420 request, REASON_BAD_ORIGIN % request.META["HTTP_ORIGIN"]
421 )
422 elif request.is_https():
423 # If the Origin header wasn't provided, reject HTTPS requests if
424 # the Referer header doesn't match an allowed value.
425 #
426 # Suppose user visits http://example.com/
427 # An active network attacker (man-in-the-middle, MITM) sends a
428 # POST form that targets https://example.com/detonate-bomb/ and
429 # submits it via JavaScript.
430 #
431 # The attacker will need to provide a CSRF cookie and token, but
432 # that's no problem for a MITM and the session-independent secret
433 # we're using. So the MITM can circumvent the CSRF protection. This
434 # is true for any HTTP connection, but anyone using HTTPS expects
435 # better! For this reason, for https://example.com/ we need
436 # additional protection that treats http://example.com/ as
437 # completely untrusted. Under HTTPS, Barth et al. found that the
438 # Referer header is missing for same-domain requests in only about
439 # 0.2% of cases or less, so we can use strict Referer checking.
440 try:
441 self._check_referer(request)
442 except RejectRequest as exc:
443 return self._reject(request, exc.reason)
445 try:
446 self._check_token(request)
447 except RejectRequest as exc:
448 return self._reject(request, exc.reason)
450 return None
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import plain.sessions.models
2from plain import models
3from plain.models import migrations
6class Migration(migrations.Migration):
7 dependencies = []
9 operations = [
10 migrations.CreateModel(
11 name="Session",
12 fields=[
13 (
14 "session_key",
15 models.CharField(
16 max_length=40,
17 primary_key=True,
18 ),
19 ),
20 ("session_data", models.TextField()),
21 (
22 "expire_date",
23 models.DateTimeField(db_index=True),
24 ),
25 ],
26 options={
27 "abstract": False,
28 },
29 managers=[
30 ("objects", plain.sessions.models.SessionManager()),
31 ],
32 ),
33 ]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1# Generated by Plain 5.0.dev20230814020017 on 2023-08-14 02:09
3from plain import models
4from plain.models import migrations
7class Migration(migrations.Migration):
8 dependencies = [
9 ("plainsessions", "0001_initial"),
10 ]
12 operations = [
13 migrations.AlterModelOptions(
14 name="session",
15 options={},
16 ),
17 migrations.AlterField(
18 model_name="session",
19 name="expire_date",
20 field=models.DateTimeField(db_index=True),
21 ),
22 migrations.AlterField(
23 model_name="session",
24 name="session_data",
25 field=models.TextField(),
26 ),
27 migrations.AlterField(
28 model_name="session",
29 name="session_key",
30 field=models.CharField(max_length=40, primary_key=True),
31 ),
32 ]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import logging
2import string
3from datetime import datetime, timedelta
5from plain import signing
6from plain.runtime import settings
7from plain.utils import timezone
8from plain.utils.crypto import get_random_string
10# session_key should not be case sensitive because some backends can store it
11# on case insensitive file systems.
12VALID_KEY_CHARS = string.ascii_lowercase + string.digits
15class CreateError(Exception):
16 """
17 Used internally as a consistent exception type to catch from save (see the
18 docstring for SessionBase.save() for details).
19 """
21 pass
24class UpdateError(Exception):
25 """
26 Occurs if Plain tries to update a session that was deleted.
27 """
29 pass
32class SessionBase:
33 """
34 Base class for all Session classes.
35 """
37 __not_given = object()
39 def __init__(self, session_key=None):
40 self._session_key = session_key
41 self.accessed = False
42 self.modified = False
44 def __contains__(self, key):
45 return key in self._session
47 def __getitem__(self, key):
48 return self._session[key]
50 def __setitem__(self, key, value):
51 self._session[key] = value
52 self.modified = True
54 def __delitem__(self, key):
55 del self._session[key]
56 self.modified = True
58 @property
59 def key_salt(self):
60 return "plain.sessions." + self.__class__.__qualname__
62 def get(self, key, default=None):
63 return self._session.get(key, default)
65 def pop(self, key, default=__not_given):
66 self.modified = self.modified or key in self._session
67 args = () if default is self.__not_given else (default,)
68 return self._session.pop(key, *args)
70 def setdefault(self, key, value):
71 if key in self._session:
72 return self._session[key]
73 else:
74 self.modified = True
75 self._session[key] = value
76 return value
78 def encode(self, session_dict):
79 "Return the given session dictionary serialized and encoded as a string."
80 return signing.dumps(
81 session_dict,
82 salt=self.key_salt,
83 compress=True,
84 )
86 def decode(self, session_data):
87 try:
88 return signing.loads(session_data, salt=self.key_salt)
89 except signing.BadSignature:
90 logger = logging.getLogger("plain.security.SuspiciousSession")
91 logger.warning("Session data corrupted")
92 except Exception:
93 # ValueError, unpickling exceptions. If any of these happen, just
94 # return an empty dictionary (an empty session).
95 pass
96 return {}
98 def update(self, dict_):
99 self._session.update(dict_)
100 self.modified = True
102 def has_key(self, key):
103 return key in self._session
105 def keys(self):
106 return self._session.keys()
108 def values(self):
109 return self._session.values()
111 def items(self):
112 return self._session.items()
114 def clear(self):
115 # To avoid unnecessary persistent storage accesses, we set up the
116 # internals directly (loading data wastes time, since we are going to
117 # set it to an empty dict anyway).
118 self._session_cache = {}
119 self.accessed = True
120 self.modified = True
122 def is_empty(self):
123 "Return True when there is no session_key and the session is empty."
124 try:
125 return not self._session_key and not self._session_cache
126 except AttributeError:
127 return True
129 def _get_new_session_key(self):
130 "Return session key that isn't being used."
131 while True:
132 session_key = get_random_string(32, VALID_KEY_CHARS)
133 if not self.exists(session_key):
134 return session_key
136 def _get_or_create_session_key(self):
137 if self._session_key is None:
138 self._session_key = self._get_new_session_key()
139 return self._session_key
141 def _validate_session_key(self, key):
142 """
143 Key must be truthy and at least 8 characters long. 8 characters is an
144 arbitrary lower bound for some minimal key security.
145 """
146 return key and len(key) >= 8
148 def _get_session_key(self):
149 return self.__session_key
151 def _set_session_key(self, value):
152 """
153 Validate session key on assignment. Invalid values will set to None.
154 """
155 if self._validate_session_key(value):
156 self.__session_key = value
157 else:
158 self.__session_key = None
160 session_key = property(_get_session_key)
161 _session_key = property(_get_session_key, _set_session_key)
163 def _get_session(self, no_load=False):
164 """
165 Lazily load session from storage (unless "no_load" is True, when only
166 an empty dict is stored) and store it in the current instance.
167 """
168 self.accessed = True
169 try:
170 return self._session_cache
171 except AttributeError:
172 if self.session_key is None or no_load:
173 self._session_cache = {}
174 else:
175 self._session_cache = self.load()
176 return self._session_cache
178 _session = property(_get_session)
180 def get_session_cookie_age(self):
181 return settings.SESSION_COOKIE_AGE
183 def get_expiry_age(self, **kwargs):
184 """Get the number of seconds until the session expires.
186 Optionally, this function accepts `modification` and `expiry` keyword
187 arguments specifying the modification and expiry of the session.
188 """
189 try:
190 modification = kwargs["modification"]
191 except KeyError:
192 modification = timezone.now()
193 # Make the difference between "expiry=None passed in kwargs" and
194 # "expiry not passed in kwargs", in order to guarantee not to trigger
195 # self.load() when expiry is provided.
196 try:
197 expiry = kwargs["expiry"]
198 except KeyError:
199 expiry = self.get("_session_expiry")
201 if not expiry: # Checks both None and 0 cases
202 return self.get_session_cookie_age()
203 if not isinstance(expiry, datetime | str):
204 return expiry
205 if isinstance(expiry, str):
206 expiry = datetime.fromisoformat(expiry)
207 delta = expiry - modification
208 return delta.days * 86400 + delta.seconds
210 def get_expiry_date(self, **kwargs):
211 """Get session the expiry date (as a datetime object).
213 Optionally, this function accepts `modification` and `expiry` keyword
214 arguments specifying the modification and expiry of the session.
215 """
216 try:
217 modification = kwargs["modification"]
218 except KeyError:
219 modification = timezone.now()
220 # Same comment as in get_expiry_age
221 try:
222 expiry = kwargs["expiry"]
223 except KeyError:
224 expiry = self.get("_session_expiry")
226 if isinstance(expiry, datetime):
227 return expiry
228 elif isinstance(expiry, str):
229 return datetime.fromisoformat(expiry)
230 expiry = expiry or self.get_session_cookie_age()
231 return modification + timedelta(seconds=expiry)
233 def set_expiry(self, value):
234 """
235 Set a custom expiration for the session. ``value`` can be an integer,
236 a Python ``datetime`` or ``timedelta`` object or ``None``.
238 If ``value`` is an integer, the session will expire after that many
239 seconds of inactivity. If set to ``0`` then the session will expire on
240 browser close.
242 If ``value`` is a ``datetime`` or ``timedelta`` object, the session
243 will expire at that specific future time.
245 If ``value`` is ``None``, the session uses the global session expiry
246 policy.
247 """
248 if value is None:
249 # Remove any custom expiration for this session.
250 try:
251 del self["_session_expiry"]
252 except KeyError:
253 pass
254 return
255 if isinstance(value, timedelta):
256 value = timezone.now() + value
257 if isinstance(value, datetime):
258 value = value.isoformat()
259 self["_session_expiry"] = value
261 def get_expire_at_browser_close(self):
262 """
263 Return ``True`` if the session is set to expire when the browser
264 closes, and ``False`` if there's an expiry date. Use
265 ``get_expiry_date()`` or ``get_expiry_age()`` to find the actual expiry
266 date/age, if there is one.
267 """
268 if (expiry := self.get("_session_expiry")) is None:
269 return settings.SESSION_EXPIRE_AT_BROWSER_CLOSE
270 return expiry == 0
272 def flush(self):
273 """
274 Remove the current session data from the database and regenerate the
275 key.
276 """
277 self.clear()
278 self.delete()
279 self._session_key = None
281 def cycle_key(self):
282 """
283 Create a new session key, while retaining the current session data.
284 """
285 data = self._session
286 key = self.session_key
287 self.create()
288 self._session_cache = data
289 if key:
290 self.delete(key)
292 # Methods that child classes must implement.
294 def exists(self, session_key):
295 """
296 Return True if the given session_key already exists.
297 """
298 raise NotImplementedError(
299 "subclasses of SessionBase must provide an exists() method"
300 )
302 def create(self):
303 """
304 Create a new session instance. Guaranteed to create a new object with
305 a unique key and will have saved the result once (with empty data)
306 before the method returns.
307 """
308 raise NotImplementedError(
309 "subclasses of SessionBase must provide a create() method"
310 )
312 def save(self, must_create=False):
313 """
314 Save the session data. If 'must_create' is True, create a new session
315 object (or raise CreateError). Otherwise, only update an existing
316 object and don't create one (raise UpdateError if needed).
317 """
318 raise NotImplementedError(
319 "subclasses of SessionBase must provide a save() method"
320 )
322 def delete(self, session_key=None):
323 """
324 Delete the session data under this key. If the key is None, use the
325 current session key value.
326 """
327 raise NotImplementedError(
328 "subclasses of SessionBase must provide a delete() method"
329 )
331 def load(self):
332 """
333 Load the session data and return a dictionary.
334 """
335 raise NotImplementedError(
336 "subclasses of SessionBase must provide a load() method"
337 )
339 @classmethod
340 def clear_expired(cls):
341 """
342 Remove expired sessions from the session store.
344 If this operation isn't possible on a given backend, it should raise
345 NotImplementedError. If it isn't necessary, because the backend has
346 a built-in expiration mechanism, it should be a no-op.
347 """
348 raise NotImplementedError("This backend does not support clear_expired().")
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import logging
3from plain.exceptions import SuspiciousOperation
4from plain.models import DatabaseError, IntegrityError, router, transaction
5from plain.sessions.backends.base import CreateError, SessionBase, UpdateError
6from plain.utils import timezone
7from plain.utils.functional import cached_property
10class SessionStore(SessionBase):
11 """
12 Implement database session store.
13 """
15 def __init__(self, session_key=None):
16 super().__init__(session_key)
18 @classmethod
19 def get_model_class(cls):
20 # Avoids a circular import and allows importing SessionStore when
21 # plain.sessions is not in INSTALLED_PACKAGES.
22 from plain.sessions.models import Session
24 return Session
26 @cached_property
27 def model(self):
28 return self.get_model_class()
30 def _get_session_from_db(self):
31 try:
32 return self.model.objects.get(
33 session_key=self.session_key, expire_date__gt=timezone.now()
34 )
35 except (self.model.DoesNotExist, SuspiciousOperation) as e:
36 if isinstance(e, SuspiciousOperation):
37 logger = logging.getLogger(f"plain.security.{e.__class__.__name__}")
38 logger.warning(str(e))
39 self._session_key = None
41 def load(self):
42 s = self._get_session_from_db()
43 return self.decode(s.session_data) if s else {}
45 def exists(self, session_key):
46 return self.model.objects.filter(session_key=session_key).exists()
48 def create(self):
49 while True:
50 self._session_key = self._get_new_session_key()
51 try:
52 # Save immediately to ensure we have a unique entry in the
53 # database.
54 self.save(must_create=True)
55 except CreateError:
56 # Key wasn't unique. Try again.
57 continue
58 self.modified = True
59 return
61 def create_model_instance(self, data):
62 """
63 Return a new instance of the session model object, which represents the
64 current session state. Intended to be used for saving the session data
65 to the database.
66 """
67 return self.model(
68 session_key=self._get_or_create_session_key(),
69 session_data=self.encode(data),
70 expire_date=self.get_expiry_date(),
71 )
73 def save(self, must_create=False):
74 """
75 Save the current session data to the database. If 'must_create' is
76 True, raise a database error if the saving operation doesn't create a
77 new entry (as opposed to possibly updating an existing entry).
78 """
79 if self.session_key is None:
80 return self.create()
81 data = self._get_session(no_load=must_create)
82 obj = self.create_model_instance(data)
83 using = router.db_for_write(self.model, instance=obj)
84 try:
85 with transaction.atomic(using=using):
86 obj.save(
87 clean_and_validate=False,
88 force_insert=must_create,
89 force_update=not must_create,
90 using=using,
91 )
92 except IntegrityError:
93 if must_create:
94 raise CreateError
95 raise
96 except DatabaseError:
97 if not must_create:
98 raise UpdateError
99 raise
101 def delete(self, session_key=None):
102 if session_key is None:
103 if self.session_key is None:
104 return
105 session_key = self.session_key
106 try:
107 self.model.objects.get(session_key=session_key).delete()
108 except self.model.DoesNotExist:
109 pass
111 @classmethod
112 def clear_expired(cls):
113 cls.get_model_class().objects.filter(expire_date__lt=timezone.now()).delete()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from .base import View
2from .forms import FormView
3from .objects import CreateView, DeleteView, DetailView, ListView, UpdateView
4from .redirect import RedirectView
5from .templates import TemplateView
7__all__ = [
8 "View",
9 "TemplateView",
10 "RedirectView",
11 "FormView",
12 "DetailView",
13 "CreateView",
14 "UpdateView",
15 "DeleteView",
16 "ListView",
17 "AuthViewMixin",
18]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:05 -0500
1import logging
3from plain.http import (
4 HttpRequest,
5 JsonResponse,
6 Response,
7 ResponseBase,
8 ResponseNotAllowed,
9)
10from plain.utils.decorators import classonlymethod
12from .exceptions import ResponseException
14logger = logging.getLogger("plain.request")
17class View:
18 request: HttpRequest
19 url_args: tuple
20 url_kwargs: dict
22 def __init__(self, *args, **kwargs) -> None:
23 # Views can customize their init, which receives
24 # the args and kwargs from as_view()
25 pass
27 def setup(self, request: HttpRequest, *args, **kwargs) -> None:
28 if hasattr(self, "get") and not hasattr(self, "head"):
29 self.head = self.get
31 self.request = request
32 self.url_args = args
33 self.url_kwargs = kwargs
35 @classonlymethod
36 def as_view(cls, *init_args, **init_kwargs):
37 def view(request, *args, **kwargs):
38 v = cls(*init_args, **init_kwargs)
39 v.setup(request, *args, **kwargs)
40 try:
41 return v.get_response()
42 except ResponseException as e:
43 return e.response
45 # Copy possible attributes set by decorators, e.g. @csrf_exempt, from
46 # the dispatch method.
47 view.__dict__.update(cls.get_response.__dict__)
48 view.view_class = cls
50 return view
52 def get_request_handler(self) -> callable:
53 """Return the handler for the current request method."""
55 if not self.request.method:
56 raise AttributeError("HTTP method is not set")
58 handler = getattr(self, self.request.method.lower(), None)
60 if not handler:
61 logger.warning(
62 "Method Not Allowed (%s): %s",
63 self.request.method,
64 self.request.path,
65 extra={"status_code": 405, "request": self.request},
66 )
67 raise ResponseException(ResponseNotAllowed(self._allowed_methods()))
69 return handler
71 def get_response(self) -> ResponseBase:
72 handler = self.get_request_handler()
74 result = handler()
76 if isinstance(result, ResponseBase):
77 return result
79 if isinstance(result, str):
80 return Response(result)
82 if isinstance(result, list):
83 return JsonResponse(result, safe=False)
85 if isinstance(result, dict):
86 return JsonResponse(result)
88 if isinstance(result, int):
89 return Response(status=result)
91 # Allow tuple for (status_code, content)?
93 raise ValueError(f"Unexpected view return type: {type(result)}")
95 def options(self) -> Response:
96 """Handle responding to requests for the OPTIONS HTTP verb."""
97 response = Response()
98 response.headers["Allow"] = ", ".join(self._allowed_methods())
99 response.headers["Content-Length"] = "0"
100 return response
102 def _allowed_methods(self) -> list[str]:
103 known_http_method_names = [
104 "get",
105 "post",
106 "put",
107 "patch",
108 "delete",
109 "head",
110 "options",
111 "trace",
112 ]
113 return [m.upper() for m in known_http_method_names if hasattr(self, m)]
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.http import ResponseBase
2from plain.templates import TemplateFileMissing
4from .templates import TemplateView
7class ErrorView(TemplateView):
8 status_code: int
10 def __init__(self, status_code=None) -> None:
11 # Allow creating an ErrorView with a status code
12 # e.g. ErrorView.as_view(status_code=404)
13 if status_code is not None:
14 self.status_code = status_code
16 def get_template_names(self) -> list[str]:
17 return [f"{self.status_code}.html", "error.html"]
19 def get_request_handler(self):
20 return self.get # All methods (post, patch, etc.) will use the get()
22 def get_response(self) -> ResponseBase:
23 response = super().get_response()
24 # Set the status code we want
25 response.status_code = self.status_code
26 return response
28 def get(self):
29 try:
30 return super().get()
31 except TemplateFileMissing:
32 return self.status_code
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1class ResponseException(Exception):
2 def __init__(self, response):
3 self.response = response
4 super().__init__(response)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from collections.abc import Callable
2from typing import TYPE_CHECKING
4from plain.exceptions import ImproperlyConfigured
5from plain.http import Response, ResponseRedirect
7from .templates import TemplateView
9if TYPE_CHECKING:
10 from plain.forms import BaseForm
13class FormView(TemplateView):
14 """A view for displaying a form and rendering a template response."""
16 form_class: type["BaseForm"] | None = None
17 success_url: Callable | str | None = None
19 def get_form(self) -> "BaseForm":
20 """Return an instance of the form to be used in this view."""
21 if not self.form_class:
22 raise ImproperlyConfigured(
23 "No form class provided. Define {cls}.form_class or override "
24 "{cls}.get_form().".format(cls=self.__class__.__name__)
25 )
26 return self.form_class(**self.get_form_kwargs())
28 def get_form_kwargs(self) -> dict:
29 """Return the keyword arguments for instantiating the form."""
30 kwargs: dict = {
31 "initial": {}, # Make it easier to set keys in subclasses
32 }
34 if hasattr(self, "request") and self.request.method in ("POST", "PUT"):
35 kwargs.update(
36 {
37 "data": self.request.POST,
38 "files": self.request.FILES,
39 }
40 )
41 return kwargs
43 def get_success_url(self) -> str:
44 """Return the URL to redirect to after processing a valid form."""
45 if not self.success_url:
46 raise ImproperlyConfigured("No URL to redirect to. Provide a success_url.")
47 return str(self.success_url) # success_url may be lazy
49 def form_valid(self, form: "BaseForm") -> Response:
50 """If the form is valid, redirect to the supplied URL."""
51 return ResponseRedirect(self.get_success_url())
53 def form_invalid(self, form: "BaseForm") -> Response:
54 """If the form is invalid, render the invalid form."""
55 context = {
56 **self.get_template_context(),
57 "form": form,
58 }
59 return self.get_template().render(context)
61 def get_template_context(self) -> dict:
62 """Insert the form into the context dict."""
63 context = super().get_template_context()
64 context["form"] = self.get_form()
65 return context
67 def post(self) -> Response:
68 """
69 Handle POST requests: instantiate a form instance with the passed
70 POST variables and then check if it's valid.
71 """
72 form = self.get_form()
73 if form.is_valid():
74 return self.form_valid(form)
75 else:
76 return self.form_invalid(form)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.exceptions import ImproperlyConfigured, ObjectDoesNotExist
2from plain.http import Http404, Response, ResponseRedirect
4from .forms import FormView
5from .templates import TemplateView
8class ObjectTemplateViewMixin:
9 context_object_name = ""
11 def get(self) -> Response:
12 self.load_object()
13 return self.render_template()
15 def load_object(self) -> None:
16 try:
17 self.object = self.get_object()
18 except ObjectDoesNotExist:
19 raise Http404
21 if not self.object:
22 # Also raise 404 if the object is None
23 raise Http404
25 def get_object(self): # Intentionally untyped... subclasses must override this.
26 raise NotImplementedError(
27 f"get_object() is not implemented on {self.__class__.__name__}"
28 )
30 def get_template_context(self) -> dict:
31 """Insert the single object into the context dict."""
32 context = super().get_template_context() # type: ignore
33 context["object"] = self.object
34 if self.context_object_name:
35 context[self.context_object_name] = self.object
36 elif hasattr(self.object, "_meta"):
37 context[self.object._meta.model_name] = self.object
38 return context
40 def get_template_names(self) -> list[str]:
41 """
42 Return a list of template names to be used for the request. May not be
43 called if render_to_response() is overridden. Return the following list:
45 * the value of ``template_name`` on the view (if provided)
46 object instance that the view is operating upon (if available)
47 * ``<package_label>/<model_name><template_name_suffix>.html``
48 """
49 if self.template_name: # type: ignore
50 return [self.template_name] # type: ignore
52 # If template_name isn't specified, it's not a problem --
53 # we just start with an empty list.
54 names = []
56 # The least-specific option is the default <app>/<model>_detail.html;
57 # only use this if the object in question is a model.
58 if hasattr(self.object, "_meta"):
59 object_meta = self.object._meta
60 names.append(
61 f"{object_meta.package_label}/{object_meta.model_name}{self.template_name_suffix}.html"
62 )
64 return names
67class DetailView(ObjectTemplateViewMixin, TemplateView):
68 """
69 Render a "detail" view of an object.
71 By default this is a model instance looked up from `self.queryset`, but the
72 view will support display of *any* object by overriding `self.get_object()`.
73 """
75 template_name_suffix = "_detail"
78class CreateView(ObjectTemplateViewMixin, FormView):
79 """
80 View for creating a new object, with a response rendered by a template.
81 """
83 def post(self) -> Response:
84 """
85 Handle POST requests: instantiate a form instance with the passed
86 POST variables and then check if it's valid.
87 """
88 # Context expects self.object to exist
89 self.load_object()
90 return super().post()
92 def load_object(self) -> None:
93 self.object = None
95 # TODO? would rather you have to specify this...
96 def get_success_url(self):
97 """Return the URL to redirect to after processing a valid form."""
98 if self.success_url:
99 url = self.success_url.format(**self.object.__dict__)
100 else:
101 try:
102 url = self.object.get_absolute_url()
103 except AttributeError:
104 raise ImproperlyConfigured(
105 "No URL to redirect to. Either provide a url or define"
106 " a get_absolute_url method on the Model."
107 )
108 return url
110 def form_valid(self, form):
111 """If the form is valid, save the associated model."""
112 self.object = form.save()
113 return super().form_valid(form)
116class UpdateView(ObjectTemplateViewMixin, FormView):
117 """View for updating an object, with a response rendered by a template."""
119 template_name_suffix = "_form"
121 def post(self) -> Response:
122 """
123 Handle POST requests: instantiate a form instance with the passed
124 POST variables and then check if it's valid.
125 """
126 self.load_object()
127 return super().post()
129 def get_success_url(self):
130 """Return the URL to redirect to after processing a valid form."""
131 if self.success_url:
132 url = self.success_url.format(**self.object.__dict__)
133 else:
134 try:
135 url = self.object.get_absolute_url()
136 except AttributeError:
137 raise ImproperlyConfigured(
138 "No URL to redirect to. Either provide a url or define"
139 " a get_absolute_url method on the Model."
140 )
141 return url
143 def form_valid(self, form):
144 """If the form is valid, save the associated model."""
145 self.object = form.save()
146 return super().form_valid(form)
148 def get_form_kwargs(self):
149 """Return the keyword arguments for instantiating the form."""
150 kwargs = super().get_form_kwargs()
151 kwargs.update({"instance": self.object})
152 return kwargs
155class DeleteView(ObjectTemplateViewMixin, TemplateView):
156 """
157 View for deleting an object retrieved with self.get_object(), with a
158 response rendered by a template.
159 """
161 template_name_suffix = "_confirm_delete"
163 def get_form_kwargs(self):
164 """Return the keyword arguments for instantiating the form."""
165 kwargs = super().get_form_kwargs()
166 kwargs.update({"instance": self.object})
167 return kwargs
169 def get_success_url(self):
170 if self.success_url:
171 return self.success_url.format(**self.object.__dict__)
172 else:
173 raise ImproperlyConfigured("No URL to redirect to. Provide a success_url.")
175 def post(self):
176 self.load_object()
177 self.object.delete()
178 return ResponseRedirect(self.get_success_url())
181class ListView(TemplateView):
182 """
183 Render some list of objects, set by `self.get_queryset()`, with a response
184 rendered by a template.
185 """
187 template_name_suffix = "_list"
188 context_object_name = "objects"
190 def get(self) -> Response:
191 self.objects = self.get_objects()
192 return super().get()
194 def get_objects(self):
195 raise NotImplementedError(
196 f"get_objects() is not implemented on {self.__class__.__name__}"
197 )
199 def get_template_context(self) -> dict:
200 """Insert the single object into the context dict."""
201 context = super().get_template_context() # type: ignore
202 context[self.context_object_name] = self.objects
203 return context
205 def get_template_names(self) -> list[str]:
206 """
207 Return a list of template names to be used for the request. May not be
208 called if render_to_response() is overridden. Return the following list:
210 * the value of ``template_name`` on the view (if provided)
211 object instance that the view is operating upon (if available)
212 * ``<package_label>/<model_name><template_name_suffix>.html``
213 """
214 if self.template_name: # type: ignore
215 return [self.template_name] # type: ignore
217 # If template_name isn't specified, it's not a problem --
218 # we just start with an empty list.
219 names = []
221 # The least-specific option is the default <app>/<model>_detail.html;
222 # only use this if the object in question is a model.
223 if hasattr(self.objects, "model") and hasattr(self.objects.model, "_meta"):
224 object_meta = self.objects.model._meta
225 names.append(
226 f"{object_meta.package_label}/{object_meta.model_name}{self.template_name_suffix}.html"
227 )
229 return names
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import logging
3from plain.http import (
4 ResponseGone,
5 ResponsePermanentRedirect,
6 ResponseRedirect,
7)
8from plain.urls import reverse
10from .base import View
12logger = logging.getLogger("plain.request")
15class RedirectView(View):
16 """Provide a redirect on any GET request."""
18 permanent = False
19 url: str | None = None
20 pattern_name: str | None = None
21 query_string = False
23 def get_redirect_url(self):
24 """
25 Return the URL redirect to. Keyword arguments from the URL pattern
26 match generating the redirect request are provided as kwargs to this
27 method.
28 """
29 if self.url:
30 url = self.url % self.url_kwargs
31 elif self.pattern_name:
32 url = reverse(self.pattern_name, args=self.url_args, kwargs=self.url_kwargs)
33 else:
34 return None
36 args = self.request.META.get("QUERY_STRING", "")
37 if args and self.query_string:
38 url = f"{url}?{args}"
39 return url
41 def get(self):
42 url = self.get_redirect_url()
43 if url:
44 if self.permanent:
45 return ResponsePermanentRedirect(url)
46 else:
47 return ResponseRedirect(url)
48 else:
49 logger.warning(
50 "Gone: %s",
51 self.request.path,
52 extra={"status_code": 410, "request": self.request},
53 )
54 return ResponseGone()
56 def head(self):
57 return self.get()
59 def post(self):
60 return self.get()
62 def options(self):
63 return self.get()
65 def delete(self):
66 return self.get()
68 def put(self):
69 return self.get()
71 def patch(self):
72 return self.get()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.csrf.middleware import get_token
2from plain.exceptions import ImproperlyConfigured
3from plain.runtime import settings
4from plain.templates import Template, TemplateFileMissing
5from plain.utils.functional import lazy
6from plain.utils.html import format_html
7from plain.utils.safestring import SafeString
9from .base import View
12def csrf_input(request):
13 return format_html(
14 '<input type="hidden" name="csrfmiddlewaretoken" value="{}">',
15 get_token(request),
16 )
19csrf_input_lazy = lazy(csrf_input, SafeString, str)
20csrf_token_lazy = lazy(get_token, str)
23class TemplateView(View):
24 """
25 Render a template. Pass keyword arguments from the URLconf to the context.
26 """
28 template_name: str | None = None
30 def get_template_context(self) -> dict:
31 return {
32 "request": self.request,
33 "csrf_input": csrf_input_lazy(self.request),
34 "csrf_token": csrf_token_lazy(self.request),
35 "DEBUG": settings.DEBUG,
36 }
38 def get_template_names(self) -> list[str]:
39 """
40 Return a list of template names to be used for the request. Must return
41 a list. May not be called if render_to_response() is overridden.
42 """
43 if self.template_name is None:
44 raise ImproperlyConfigured(
45 "TemplateView requires either a definition of "
46 "'template_name' or an implementation of 'get_template_names()'"
47 )
48 else:
49 return [self.template_name]
51 def get_template(self) -> Template:
52 template_names = self.get_template_names()
54 for template_name in template_names:
55 try:
56 return Template(template_name)
57 except TemplateFileMissing:
58 pass
60 raise TemplateFileMissing(template_names)
62 def render_template(self) -> str:
63 return self.get_template().render(self.get_template_context())
65 def get(self):
66 return self.render_template()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import _thread
2import copy
3import datetime
4import logging
5import threading
6import time
7import warnings
8import zoneinfo
9from collections import deque
10from contextlib import contextmanager
12from plain.models.backends import utils
13from plain.models.backends.base.validation import BaseDatabaseValidation
14from plain.models.backends.signals import connection_created
15from plain.models.backends.utils import debug_transaction
16from plain.models.db import (
17 DEFAULT_DB_ALIAS,
18 DatabaseError,
19 DatabaseErrorWrapper,
20 NotSupportedError,
21)
22from plain.models.transaction import TransactionManagementError
23from plain.runtime import settings
24from plain.utils.functional import cached_property
26NO_DB_ALIAS = "__no_db__"
27RAN_DB_VERSION_CHECK = set()
29logger = logging.getLogger("plain.models.backends.base")
32class BaseDatabaseWrapper:
33 """Represent a database connection."""
35 # Mapping of Field objects to their column types.
36 data_types = {}
37 # Mapping of Field objects to their SQL suffix such as AUTOINCREMENT.
38 data_types_suffix = {}
39 # Mapping of Field objects to their SQL for CHECK constraints.
40 data_type_check_constraints = {}
41 ops = None
42 vendor = "unknown"
43 display_name = "unknown"
44 SchemaEditorClass = None
45 # Classes instantiated in __init__().
46 client_class = None
47 creation_class = None
48 features_class = None
49 introspection_class = None
50 ops_class = None
51 validation_class = BaseDatabaseValidation
53 queries_limit = 9000
55 def __init__(self, settings_dict, alias=DEFAULT_DB_ALIAS):
56 # Connection related attributes.
57 # The underlying database connection.
58 self.connection = None
59 # `settings_dict` should be a dictionary containing keys such as
60 # NAME, USER, etc. It's called `settings_dict` instead of `settings`
61 # to disambiguate it from Plain settings modules.
62 self.settings_dict = settings_dict
63 self.alias = alias
64 # Query logging in debug mode or when explicitly enabled.
65 self.queries_log = deque(maxlen=self.queries_limit)
66 self.force_debug_cursor = False
68 # Transaction related attributes.
69 # Tracks if the connection is in autocommit mode. Per PEP 249, by
70 # default, it isn't.
71 self.autocommit = False
72 # Tracks if the connection is in a transaction managed by 'atomic'.
73 self.in_atomic_block = False
74 # Increment to generate unique savepoint ids.
75 self.savepoint_state = 0
76 # List of savepoints created by 'atomic'.
77 self.savepoint_ids = []
78 # Stack of active 'atomic' blocks.
79 self.atomic_blocks = []
80 # Tracks if the outermost 'atomic' block should commit on exit,
81 # ie. if autocommit was active on entry.
82 self.commit_on_exit = True
83 # Tracks if the transaction should be rolled back to the next
84 # available savepoint because of an exception in an inner block.
85 self.needs_rollback = False
86 self.rollback_exc = None
88 # Connection termination related attributes.
89 self.close_at = None
90 self.closed_in_transaction = False
91 self.errors_occurred = False
92 self.health_check_enabled = False
93 self.health_check_done = False
95 # Thread-safety related attributes.
96 self._thread_sharing_lock = threading.Lock()
97 self._thread_sharing_count = 0
98 self._thread_ident = _thread.get_ident()
100 # A list of no-argument functions to run when the transaction commits.
101 # Each entry is an (sids, func, robust) tuple, where sids is a set of
102 # the active savepoint IDs when this function was registered and robust
103 # specifies whether it's allowed for the function to fail.
104 self.run_on_commit = []
106 # Should we run the on-commit hooks the next time set_autocommit(True)
107 # is called?
108 self.run_commit_hooks_on_set_autocommit_on = False
110 # A stack of wrappers to be invoked around execute()/executemany()
111 # calls. Each entry is a function taking five arguments: execute, sql,
112 # params, many, and context. It's the function's responsibility to
113 # call execute(sql, params, many, context).
114 self.execute_wrappers = []
116 self.client = self.client_class(self)
117 self.creation = self.creation_class(self)
118 self.features = self.features_class(self)
119 self.introspection = self.introspection_class(self)
120 self.ops = self.ops_class(self)
121 self.validation = self.validation_class(self)
123 def __repr__(self):
124 return (
125 f"<{self.__class__.__qualname__} "
126 f"vendor={self.vendor!r} alias={self.alias!r}>"
127 )
129 def ensure_timezone(self):
130 """
131 Ensure the connection's timezone is set to `self.timezone_name` and
132 return whether it changed or not.
133 """
134 return False
136 @cached_property
137 def timezone(self):
138 """
139 Return a tzinfo of the database connection time zone.
141 This is only used when time zone support is enabled. When a datetime is
142 read from the database, it is always returned in this time zone.
144 When the database backend supports time zones, it doesn't matter which
145 time zone Plain uses, as long as aware datetimes are used everywhere.
146 Other users connecting to the database can choose their own time zone.
148 When the database backend doesn't support time zones, the time zone
149 Plain uses may be constrained by the requirements of other users of
150 the database.
151 """
152 if self.settings_dict["TIME_ZONE"] is None:
153 return datetime.timezone.utc
154 else:
155 return zoneinfo.ZoneInfo(self.settings_dict["TIME_ZONE"])
157 @cached_property
158 def timezone_name(self):
159 """
160 Name of the time zone of the database connection.
161 """
162 if self.settings_dict["TIME_ZONE"] is None:
163 return "UTC"
164 else:
165 return self.settings_dict["TIME_ZONE"]
167 @property
168 def queries_logged(self):
169 return self.force_debug_cursor or settings.DEBUG
171 @property
172 def queries(self):
173 if len(self.queries_log) == self.queries_log.maxlen:
174 warnings.warn(
175 "Limit for query logging exceeded, only the last {} queries "
176 "will be returned.".format(self.queries_log.maxlen)
177 )
178 return list(self.queries_log)
180 def get_database_version(self):
181 """Return a tuple of the database's version."""
182 raise NotImplementedError(
183 "subclasses of BaseDatabaseWrapper may require a get_database_version() "
184 "method."
185 )
187 def check_database_version_supported(self):
188 """
189 Raise an error if the database version isn't supported by this
190 version of Plain.
191 """
192 if (
193 self.features.minimum_database_version is not None
194 and self.get_database_version() < self.features.minimum_database_version
195 ):
196 db_version = ".".join(map(str, self.get_database_version()))
197 min_db_version = ".".join(map(str, self.features.minimum_database_version))
198 raise NotSupportedError(
199 f"{self.display_name} {min_db_version} or later is required "
200 f"(found {db_version})."
201 )
203 # ##### Backend-specific methods for creating connections and cursors #####
205 def get_connection_params(self):
206 """Return a dict of parameters suitable for get_new_connection."""
207 raise NotImplementedError(
208 "subclasses of BaseDatabaseWrapper may require a get_connection_params() "
209 "method"
210 )
212 def get_new_connection(self, conn_params):
213 """Open a connection to the database."""
214 raise NotImplementedError(
215 "subclasses of BaseDatabaseWrapper may require a get_new_connection() "
216 "method"
217 )
219 def init_connection_state(self):
220 """Initialize the database connection settings."""
221 global RAN_DB_VERSION_CHECK
222 if self.alias not in RAN_DB_VERSION_CHECK:
223 self.check_database_version_supported()
224 RAN_DB_VERSION_CHECK.add(self.alias)
226 def create_cursor(self, name=None):
227 """Create a cursor. Assume that a connection is established."""
228 raise NotImplementedError(
229 "subclasses of BaseDatabaseWrapper may require a create_cursor() method"
230 )
232 # ##### Backend-specific methods for creating connections #####
234 def connect(self):
235 """Connect to the database. Assume that the connection is closed."""
236 # In case the previous connection was closed while in an atomic block
237 self.in_atomic_block = False
238 self.savepoint_ids = []
239 self.atomic_blocks = []
240 self.needs_rollback = False
241 # Reset parameters defining when to close/health-check the connection.
242 self.health_check_enabled = self.settings_dict["CONN_HEALTH_CHECKS"]
243 max_age = self.settings_dict["CONN_MAX_AGE"]
244 self.close_at = None if max_age is None else time.monotonic() + max_age
245 self.closed_in_transaction = False
246 self.errors_occurred = False
247 # New connections are healthy.
248 self.health_check_done = True
249 # Establish the connection
250 conn_params = self.get_connection_params()
251 self.connection = self.get_new_connection(conn_params)
252 self.set_autocommit(self.settings_dict["AUTOCOMMIT"])
253 self.init_connection_state()
254 connection_created.send(sender=self.__class__, connection=self)
256 self.run_on_commit = []
258 def ensure_connection(self):
259 """Guarantee that a connection to the database is established."""
260 if self.connection is None:
261 with self.wrap_database_errors:
262 self.connect()
264 # ##### Backend-specific wrappers for PEP-249 connection methods #####
266 def _prepare_cursor(self, cursor):
267 """
268 Validate the connection is usable and perform database cursor wrapping.
269 """
270 self.validate_thread_sharing()
271 if self.queries_logged:
272 wrapped_cursor = self.make_debug_cursor(cursor)
273 else:
274 wrapped_cursor = self.make_cursor(cursor)
275 return wrapped_cursor
277 def _cursor(self, name=None):
278 self.close_if_health_check_failed()
279 self.ensure_connection()
280 with self.wrap_database_errors:
281 return self._prepare_cursor(self.create_cursor(name))
283 def _commit(self):
284 if self.connection is not None:
285 with debug_transaction(self, "COMMIT"), self.wrap_database_errors:
286 return self.connection.commit()
288 def _rollback(self):
289 if self.connection is not None:
290 with debug_transaction(self, "ROLLBACK"), self.wrap_database_errors:
291 return self.connection.rollback()
293 def _close(self):
294 if self.connection is not None:
295 with self.wrap_database_errors:
296 return self.connection.close()
298 # ##### Generic wrappers for PEP-249 connection methods #####
300 def cursor(self):
301 """Create a cursor, opening a connection if necessary."""
302 return self._cursor()
304 def commit(self):
305 """Commit a transaction and reset the dirty flag."""
306 self.validate_thread_sharing()
307 self.validate_no_atomic_block()
308 self._commit()
309 # A successful commit means that the database connection works.
310 self.errors_occurred = False
311 self.run_commit_hooks_on_set_autocommit_on = True
313 def rollback(self):
314 """Roll back a transaction and reset the dirty flag."""
315 self.validate_thread_sharing()
316 self.validate_no_atomic_block()
317 self._rollback()
318 # A successful rollback means that the database connection works.
319 self.errors_occurred = False
320 self.needs_rollback = False
321 self.run_on_commit = []
323 def close(self):
324 """Close the connection to the database."""
325 self.validate_thread_sharing()
326 self.run_on_commit = []
328 # Don't call validate_no_atomic_block() to avoid making it difficult
329 # to get rid of a connection in an invalid state. The next connect()
330 # will reset the transaction state anyway.
331 if self.closed_in_transaction or self.connection is None:
332 return
333 try:
334 self._close()
335 finally:
336 if self.in_atomic_block:
337 self.closed_in_transaction = True
338 self.needs_rollback = True
339 else:
340 self.connection = None
342 # ##### Backend-specific savepoint management methods #####
344 def _savepoint(self, sid):
345 with self.cursor() as cursor:
346 cursor.execute(self.ops.savepoint_create_sql(sid))
348 def _savepoint_rollback(self, sid):
349 with self.cursor() as cursor:
350 cursor.execute(self.ops.savepoint_rollback_sql(sid))
352 def _savepoint_commit(self, sid):
353 with self.cursor() as cursor:
354 cursor.execute(self.ops.savepoint_commit_sql(sid))
356 def _savepoint_allowed(self):
357 # Savepoints cannot be created outside a transaction
358 return self.features.uses_savepoints and not self.get_autocommit()
360 # ##### Generic savepoint management methods #####
362 def savepoint(self):
363 """
364 Create a savepoint inside the current transaction. Return an
365 identifier for the savepoint that will be used for the subsequent
366 rollback or commit. Do nothing if savepoints are not supported.
367 """
368 if not self._savepoint_allowed():
369 return
371 thread_ident = _thread.get_ident()
372 tid = str(thread_ident).replace("-", "")
374 self.savepoint_state += 1
375 sid = "s%s_x%d" % (tid, self.savepoint_state)
377 self.validate_thread_sharing()
378 self._savepoint(sid)
380 return sid
382 def savepoint_rollback(self, sid):
383 """
384 Roll back to a savepoint. Do nothing if savepoints are not supported.
385 """
386 if not self._savepoint_allowed():
387 return
389 self.validate_thread_sharing()
390 self._savepoint_rollback(sid)
392 # Remove any callbacks registered while this savepoint was active.
393 self.run_on_commit = [
394 (sids, func, robust)
395 for (sids, func, robust) in self.run_on_commit
396 if sid not in sids
397 ]
399 def savepoint_commit(self, sid):
400 """
401 Release a savepoint. Do nothing if savepoints are not supported.
402 """
403 if not self._savepoint_allowed():
404 return
406 self.validate_thread_sharing()
407 self._savepoint_commit(sid)
409 def clean_savepoints(self):
410 """
411 Reset the counter used to generate unique savepoint ids in this thread.
412 """
413 self.savepoint_state = 0
415 # ##### Backend-specific transaction management methods #####
417 def _set_autocommit(self, autocommit):
418 """
419 Backend-specific implementation to enable or disable autocommit.
420 """
421 raise NotImplementedError(
422 "subclasses of BaseDatabaseWrapper may require a _set_autocommit() method"
423 )
425 # ##### Generic transaction management methods #####
427 def get_autocommit(self):
428 """Get the autocommit state."""
429 self.ensure_connection()
430 return self.autocommit
432 def set_autocommit(
433 self, autocommit, force_begin_transaction_with_broken_autocommit=False
434 ):
435 """
436 Enable or disable autocommit.
438 The usual way to start a transaction is to turn autocommit off.
439 SQLite does not properly start a transaction when disabling
440 autocommit. To avoid this buggy behavior and to actually enter a new
441 transaction, an explicit BEGIN is required. Using
442 force_begin_transaction_with_broken_autocommit=True will issue an
443 explicit BEGIN with SQLite. This option will be ignored for other
444 backends.
445 """
446 self.validate_no_atomic_block()
447 self.close_if_health_check_failed()
448 self.ensure_connection()
450 start_transaction_under_autocommit = (
451 force_begin_transaction_with_broken_autocommit
452 and not autocommit
453 and hasattr(self, "_start_transaction_under_autocommit")
454 )
456 if start_transaction_under_autocommit:
457 self._start_transaction_under_autocommit()
458 elif autocommit:
459 self._set_autocommit(autocommit)
460 else:
461 with debug_transaction(self, "BEGIN"):
462 self._set_autocommit(autocommit)
463 self.autocommit = autocommit
465 if autocommit and self.run_commit_hooks_on_set_autocommit_on:
466 self.run_and_clear_commit_hooks()
467 self.run_commit_hooks_on_set_autocommit_on = False
469 def get_rollback(self):
470 """Get the "needs rollback" flag -- for *advanced use* only."""
471 if not self.in_atomic_block:
472 raise TransactionManagementError(
473 "The rollback flag doesn't work outside of an 'atomic' block."
474 )
475 return self.needs_rollback
477 def set_rollback(self, rollback):
478 """
479 Set or unset the "needs rollback" flag -- for *advanced use* only.
480 """
481 if not self.in_atomic_block:
482 raise TransactionManagementError(
483 "The rollback flag doesn't work outside of an 'atomic' block."
484 )
485 self.needs_rollback = rollback
487 def validate_no_atomic_block(self):
488 """Raise an error if an atomic block is active."""
489 if self.in_atomic_block:
490 raise TransactionManagementError(
491 "This is forbidden when an 'atomic' block is active."
492 )
494 def validate_no_broken_transaction(self):
495 if self.needs_rollback:
496 raise TransactionManagementError(
497 "An error occurred in the current transaction. You can't "
498 "execute queries until the end of the 'atomic' block."
499 ) from self.rollback_exc
501 # ##### Foreign key constraints checks handling #####
503 @contextmanager
504 def constraint_checks_disabled(self):
505 """
506 Disable foreign key constraint checking.
507 """
508 disabled = self.disable_constraint_checking()
509 try:
510 yield
511 finally:
512 if disabled:
513 self.enable_constraint_checking()
515 def disable_constraint_checking(self):
516 """
517 Backends can implement as needed to temporarily disable foreign key
518 constraint checking. Should return True if the constraints were
519 disabled and will need to be reenabled.
520 """
521 return False
523 def enable_constraint_checking(self):
524 """
525 Backends can implement as needed to re-enable foreign key constraint
526 checking.
527 """
528 pass
530 def check_constraints(self, table_names=None):
531 """
532 Backends can override this method if they can apply constraint
533 checking (e.g. via "SET CONSTRAINTS ALL IMMEDIATE"). Should raise an
534 IntegrityError if any invalid foreign key references are encountered.
535 """
536 pass
538 # ##### Connection termination handling #####
540 def is_usable(self):
541 """
542 Test if the database connection is usable.
544 This method may assume that self.connection is not None.
546 Actual implementations should take care not to raise exceptions
547 as that may prevent Plain from recycling unusable connections.
548 """
549 raise NotImplementedError(
550 "subclasses of BaseDatabaseWrapper may require an is_usable() method"
551 )
553 def close_if_health_check_failed(self):
554 """Close existing connection if it fails a health check."""
555 if (
556 self.connection is None
557 or not self.health_check_enabled
558 or self.health_check_done
559 ):
560 return
562 if not self.is_usable():
563 self.close()
564 self.health_check_done = True
566 def close_if_unusable_or_obsolete(self):
567 """
568 Close the current connection if unrecoverable errors have occurred
569 or if it outlived its maximum age.
570 """
571 if self.connection is not None:
572 self.health_check_done = False
573 # If the application didn't restore the original autocommit setting,
574 # don't take chances, drop the connection.
575 if self.get_autocommit() != self.settings_dict["AUTOCOMMIT"]:
576 self.close()
577 return
579 # If an exception other than DataError or IntegrityError occurred
580 # since the last commit / rollback, check if the connection works.
581 if self.errors_occurred:
582 if self.is_usable():
583 self.errors_occurred = False
584 self.health_check_done = True
585 else:
586 self.close()
587 return
589 if self.close_at is not None and time.monotonic() >= self.close_at:
590 self.close()
591 return
593 # ##### Thread safety handling #####
595 @property
596 def allow_thread_sharing(self):
597 with self._thread_sharing_lock:
598 return self._thread_sharing_count > 0
600 def inc_thread_sharing(self):
601 with self._thread_sharing_lock:
602 self._thread_sharing_count += 1
604 def dec_thread_sharing(self):
605 with self._thread_sharing_lock:
606 if self._thread_sharing_count <= 0:
607 raise RuntimeError(
608 "Cannot decrement the thread sharing count below zero."
609 )
610 self._thread_sharing_count -= 1
612 def validate_thread_sharing(self):
613 """
614 Validate that the connection isn't accessed by another thread than the
615 one which originally created it, unless the connection was explicitly
616 authorized to be shared between threads (via the `inc_thread_sharing()`
617 method). Raise an exception if the validation fails.
618 """
619 if not (self.allow_thread_sharing or self._thread_ident == _thread.get_ident()):
620 raise DatabaseError(
621 "DatabaseWrapper objects created in a "
622 "thread can only be used in that same thread. The object "
623 "with alias '{}' was created in thread id {} and this is "
624 "thread id {}.".format(
625 self.alias, self._thread_ident, _thread.get_ident()
626 )
627 )
629 # ##### Miscellaneous #####
631 def prepare_database(self):
632 """
633 Hook to do any database check or preparation, generally called before
634 migrating a project or an app.
635 """
636 pass
638 @cached_property
639 def wrap_database_errors(self):
640 """
641 Context manager and decorator that re-throws backend-specific database
642 exceptions using Plain's common wrappers.
643 """
644 return DatabaseErrorWrapper(self)
646 def chunked_cursor(self):
647 """
648 Return a cursor that tries to avoid caching in the database (if
649 supported by the database), otherwise return a regular cursor.
650 """
651 return self.cursor()
653 def make_debug_cursor(self, cursor):
654 """Create a cursor that logs all queries in self.queries_log."""
655 return utils.CursorDebugWrapper(cursor, self)
657 def make_cursor(self, cursor):
658 """Create a cursor without debug logging."""
659 return utils.CursorWrapper(cursor, self)
661 @contextmanager
662 def temporary_connection(self):
663 """
664 Context manager that ensures that a connection is established, and
665 if it opened one, closes it to avoid leaving a dangling connection.
666 This is useful for operations outside of the request-response cycle.
668 Provide a cursor: with self.temporary_connection() as cursor: ...
669 """
670 must_close = self.connection is None
671 try:
672 with self.cursor() as cursor:
673 yield cursor
674 finally:
675 if must_close:
676 self.close()
678 @contextmanager
679 def _nodb_cursor(self):
680 """
681 Return a cursor from an alternative connection to be used when there is
682 no need to access the main database, specifically for test db
683 creation/deletion. This also prevents the production database from
684 being exposed to potential child threads while (or after) the test
685 database is destroyed. Refs #10868, #17786, #16969.
686 """
687 conn = self.__class__({**self.settings_dict, "NAME": None}, alias=NO_DB_ALIAS)
688 try:
689 with conn.cursor() as cursor:
690 yield cursor
691 finally:
692 conn.close()
694 def schema_editor(self, *args, **kwargs):
695 """
696 Return a new instance of this backend's SchemaEditor.
697 """
698 if self.SchemaEditorClass is None:
699 raise NotImplementedError(
700 "The SchemaEditorClass attribute of this database wrapper is still None"
701 )
702 return self.SchemaEditorClass(self, *args, **kwargs)
704 def on_commit(self, func, robust=False):
705 if not callable(func):
706 raise TypeError("on_commit()'s callback must be a callable.")
707 if self.in_atomic_block:
708 # Transaction in progress; save for execution on commit.
709 self.run_on_commit.append((set(self.savepoint_ids), func, robust))
710 elif not self.get_autocommit():
711 raise TransactionManagementError(
712 "on_commit() cannot be used in manual transaction management"
713 )
714 else:
715 # No transaction in progress and in autocommit mode; execute
716 # immediately.
717 if robust:
718 try:
719 func()
720 except Exception as e:
721 logger.error(
722 f"Error calling {func.__qualname__} in on_commit() (%s).",
723 e,
724 exc_info=True,
725 )
726 else:
727 func()
729 def run_and_clear_commit_hooks(self):
730 self.validate_no_atomic_block()
731 current_run_on_commit = self.run_on_commit
732 self.run_on_commit = []
733 while current_run_on_commit:
734 _, func, robust = current_run_on_commit.pop(0)
735 if robust:
736 try:
737 func()
738 except Exception as e:
739 logger.error(
740 f"Error calling {func.__qualname__} in on_commit() during "
741 f"transaction (%s).",
742 e,
743 exc_info=True,
744 )
745 else:
746 func()
748 @contextmanager
749 def execute_wrapper(self, wrapper):
750 """
751 Return a context manager under which the wrapper is applied to suitable
752 database query executions.
753 """
754 self.execute_wrappers.append(wrapper)
755 try:
756 yield
757 finally:
758 self.execute_wrappers.pop()
760 def copy(self, alias=None):
761 """
762 Return a copy of this connection.
764 For tests that require two connections to the same database.
765 """
766 settings_dict = copy.deepcopy(self.settings_dict)
767 if alias is None:
768 alias = self.alias
769 return type(self)(settings_dict, alias)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import os
2import subprocess
5class BaseDatabaseClient:
6 """Encapsulate backend-specific methods for opening a client shell."""
8 # This should be a string representing the name of the executable
9 # (e.g., "psql"). Subclasses must override this.
10 executable_name = None
12 def __init__(self, connection):
13 # connection is an instance of BaseDatabaseWrapper.
14 self.connection = connection
16 @classmethod
17 def settings_to_cmd_args_env(cls, settings_dict, parameters):
18 raise NotImplementedError(
19 "subclasses of BaseDatabaseClient must provide a "
20 "settings_to_cmd_args_env() method or override a runshell()."
21 )
23 def runshell(self, parameters):
24 args, env = self.settings_to_cmd_args_env(
25 self.connection.settings_dict, parameters
26 )
27 env = {**os.environ, **env} if env else None
28 subprocess.run(args, env=env, check=True)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import os
2import sys
4from plain.packages import packages
5from plain.runtime import settings
7# The prefix to put on the default database name when creating
8# the test database.
9TEST_DATABASE_PREFIX = "test_"
12class BaseDatabaseCreation:
13 """
14 Encapsulate backend-specific differences pertaining to creation and
15 destruction of the test database.
16 """
18 def __init__(self, connection):
19 self.connection = connection
21 def _nodb_cursor(self):
22 return self.connection._nodb_cursor()
24 def log(self, msg):
25 sys.stderr.write(msg + os.linesep)
27 def create_test_db(
28 self, verbosity=1, autoclobber=False, serialize=True, keepdb=False
29 ):
30 """
31 Create a test database, prompting the user for confirmation if the
32 database already exists. Return the name of the test database created.
33 """
34 from plain.models.cli import migrate
36 test_database_name = self._get_test_db_name()
38 if verbosity >= 1:
39 action = "Creating"
40 if keepdb:
41 action = "Using existing"
43 self.log(
44 "{} test database for alias {}...".format(
45 action,
46 self._get_database_display_str(verbosity, test_database_name),
47 )
48 )
50 # We could skip this call if keepdb is True, but we instead
51 # give it the keepdb param. This is to handle the case
52 # where the test DB doesn't exist, in which case we need to
53 # create it, then just not destroy it. If we instead skip
54 # this, we will get an exception.
55 self._create_test_db(verbosity, autoclobber, keepdb)
57 self.connection.close()
58 settings.DATABASES[self.connection.alias]["NAME"] = test_database_name
59 self.connection.settings_dict["NAME"] = test_database_name
61 try:
62 if self.connection.settings_dict["TEST"]["MIGRATE"] is False:
63 # Disable migrations for all packages.
64 for app in packages.get_package_configs():
65 app._old_migrations_module = app.migrations_module
66 app.migrations_module = None
67 # We report migrate messages at one level lower than that
68 # requested. This ensures we don't get flooded with messages during
69 # testing (unless you really ask to be flooded).
70 migrate.callback(
71 package_label=None,
72 migration_name=None,
73 no_input=True,
74 database=self.connection.alias,
75 fake=False,
76 fake_initial=False,
77 plan=False,
78 check_unapplied=False,
79 run_syncdb=True,
80 prune=False,
81 verbosity=max(verbosity - 1, 0),
82 )
83 finally:
84 if self.connection.settings_dict["TEST"]["MIGRATE"] is False:
85 for app in packages.get_package_configs():
86 app.migrations_module = app._old_migrations_module
87 del app._old_migrations_module
89 # We then serialize the current state of the database into a string
90 # and store it on the connection. This slightly horrific process is so people
91 # who are testing on databases without transactions or who are using
92 # a TransactionTestCase still get a clean database on every test run.
93 # if serialize:
94 # self.connection._test_serialized_contents = self.serialize_db_to_string()
96 # Ensure a connection for the side effect of initializing the test database.
97 self.connection.ensure_connection()
99 return test_database_name
101 def set_as_test_mirror(self, primary_settings_dict):
102 """
103 Set this database up to be used in testing as a mirror of a primary
104 database whose settings are given.
105 """
106 self.connection.settings_dict["NAME"] = primary_settings_dict["NAME"]
108 # def serialize_db_to_string(self):
109 # """
110 # Serialize all data in the database into a JSON string.
111 # Designed only for test runner usage; will not handle large
112 # amounts of data.
113 # """
115 # # Iteratively return every object for all models to serialize.
116 # def get_objects():
117 # from plain.models.migrations.loader import MigrationLoader
119 # loader = MigrationLoader(self.connection)
120 # for package_config in packages.get_package_configs():
121 # if (
122 # package_config.models_module is not None
123 # and package_config.label in loader.migrated_packages
124 # ):
125 # for model in package_config.get_models():
126 # if model._meta.can_migrate(
127 # self.connection
128 # ) and router.allow_migrate_model(self.connection.alias, model):
129 # queryset = model._base_manager.using(
130 # self.connection.alias,
131 # ).order_by(model._meta.pk.name)
132 # yield from queryset.iterator()
134 # # Serialize to a string
135 # out = StringIO()
136 # serializers.serialize("json", get_objects(), indent=None, stream=out)
137 # return out.getvalue()
139 # def deserialize_db_from_string(self, data):
140 # """
141 # Reload the database with data from a string generated by
142 # the serialize_db_to_string() method.
143 # """
144 # data = StringIO(data)
145 # table_names = set()
146 # # Load data in a transaction to handle forward references and cycles.
147 # with atomic(using=self.connection.alias):
148 # # Disable constraint checks, because some databases (MySQL) doesn't
149 # # support deferred checks.
150 # with self.connection.constraint_checks_disabled():
151 # for obj in serializers.deserialize(
152 # "json", data, using=self.connection.alias
153 # ):
154 # obj.save()
155 # table_names.add(obj.object.__class__._meta.db_table)
156 # # Manually check for any invalid keys that might have been added,
157 # # because constraint checks were disabled.
158 # self.connection.check_constraints(table_names=table_names)
160 def _get_database_display_str(self, verbosity, database_name):
161 """
162 Return display string for a database for use in various actions.
163 """
164 return "'{}'{}".format(
165 self.connection.alias,
166 (" ('%s')" % database_name) if verbosity >= 2 else "",
167 )
169 def _get_test_db_name(self):
170 """
171 Internal implementation - return the name of the test DB that will be
172 created. Only useful when called from create_test_db() and
173 _create_test_db() and when no external munging is done with the 'NAME'
174 settings.
175 """
176 if self.connection.settings_dict["TEST"]["NAME"]:
177 return self.connection.settings_dict["TEST"]["NAME"]
178 return TEST_DATABASE_PREFIX + self.connection.settings_dict["NAME"]
180 def _execute_create_test_db(self, cursor, parameters, keepdb=False):
181 cursor.execute("CREATE DATABASE {dbname} {suffix}".format(**parameters))
183 def _create_test_db(self, verbosity, autoclobber, keepdb=False):
184 """
185 Internal implementation - create the test db tables.
186 """
187 test_database_name = self._get_test_db_name()
188 test_db_params = {
189 "dbname": self.connection.ops.quote_name(test_database_name),
190 "suffix": self.sql_table_creation_suffix(),
191 }
192 # Create the test database and connect to it.
193 with self._nodb_cursor() as cursor:
194 try:
195 self._execute_create_test_db(cursor, test_db_params, keepdb)
196 except Exception as e:
197 # if we want to keep the db, then no need to do any of the below,
198 # just return and skip it all.
199 if keepdb:
200 return test_database_name
202 self.log("Got an error creating the test database: %s" % e)
203 if not autoclobber:
204 confirm = input(
205 "Type 'yes' if you would like to try deleting the test "
206 "database '%s', or 'no' to cancel: " % test_database_name
207 )
208 if autoclobber or confirm == "yes":
209 try:
210 if verbosity >= 1:
211 self.log(
212 "Destroying old test database for alias {}...".format(
213 self._get_database_display_str(
214 verbosity, test_database_name
215 ),
216 )
217 )
218 cursor.execute(
219 "DROP DATABASE {dbname}".format(**test_db_params)
220 )
221 self._execute_create_test_db(cursor, test_db_params, keepdb)
222 except Exception as e:
223 self.log("Got an error recreating the test database: %s" % e)
224 sys.exit(2)
225 else:
226 self.log("Tests cancelled.")
227 sys.exit(1)
229 return test_database_name
231 def clone_test_db(self, suffix, verbosity=1, autoclobber=False, keepdb=False):
232 """
233 Clone a test database.
234 """
235 source_database_name = self.connection.settings_dict["NAME"]
237 if verbosity >= 1:
238 action = "Cloning test database"
239 if keepdb:
240 action = "Using existing clone"
241 self.log(
242 "{} for alias {}...".format(
243 action,
244 self._get_database_display_str(verbosity, source_database_name),
245 )
246 )
248 # We could skip this call if keepdb is True, but we instead
249 # give it the keepdb param. See create_test_db for details.
250 self._clone_test_db(suffix, verbosity, keepdb)
252 def get_test_db_clone_settings(self, suffix):
253 """
254 Return a modified connection settings dict for the n-th clone of a DB.
255 """
256 # When this function is called, the test database has been created
257 # already and its name has been copied to settings_dict['NAME'] so
258 # we don't need to call _get_test_db_name.
259 orig_settings_dict = self.connection.settings_dict
260 return {
261 **orig_settings_dict,
262 "NAME": "{}_{}".format(orig_settings_dict["NAME"], suffix),
263 }
265 def _clone_test_db(self, suffix, verbosity, keepdb=False):
266 """
267 Internal implementation - duplicate the test db tables.
268 """
269 raise NotImplementedError(
270 "The database backend doesn't support cloning databases. "
271 "Disable the option to run tests in parallel processes."
272 )
274 def destroy_test_db(
275 self, old_database_name=None, verbosity=1, keepdb=False, suffix=None
276 ):
277 """
278 Destroy a test database, prompting the user for confirmation if the
279 database already exists.
280 """
281 self.connection.close()
282 if suffix is None:
283 test_database_name = self.connection.settings_dict["NAME"]
284 else:
285 test_database_name = self.get_test_db_clone_settings(suffix)["NAME"]
287 if verbosity >= 1:
288 action = "Destroying"
289 if keepdb:
290 action = "Preserving"
291 self.log(
292 "{} test database for alias {}...".format(
293 action,
294 self._get_database_display_str(verbosity, test_database_name),
295 )
296 )
298 # if we want to preserve the database
299 # skip the actual destroying piece.
300 if not keepdb:
301 self._destroy_test_db(test_database_name, verbosity)
303 # Restore the original database name
304 if old_database_name is not None:
305 settings.DATABASES[self.connection.alias]["NAME"] = old_database_name
306 self.connection.settings_dict["NAME"] = old_database_name
308 def _destroy_test_db(self, test_database_name, verbosity):
309 """
310 Internal implementation - remove the test db tables.
311 """
312 # Remove the test database to clean up after
313 # ourselves. Connect to the previous database (not the test database)
314 # to do so, because it's not allowed to delete a database while being
315 # connected to it.
316 with self._nodb_cursor() as cursor:
317 cursor.execute(
318 "DROP DATABASE %s" % self.connection.ops.quote_name(test_database_name)
319 )
321 def sql_table_creation_suffix(self):
322 """
323 SQL to append to the end of the test table creation statements.
324 """
325 return ""
327 def test_db_signature(self):
328 """
329 Return a tuple with elements of self.connection.settings_dict (a
330 DATABASES setting value) that uniquely identify a database
331 accordingly to the RDBMS particularities.
332 """
333 settings_dict = self.connection.settings_dict
334 return (
335 settings_dict["HOST"],
336 settings_dict["PORT"],
337 settings_dict["ENGINE"],
338 self._get_test_db_name(),
339 )
341 def setup_worker_connection(self, _worker_id):
342 settings_dict = self.get_test_db_clone_settings(str(_worker_id))
343 # connection.settings_dict must be updated in place for changes to be
344 # reflected in plain.models.connections. If the following line assigned
345 # connection.settings_dict = settings_dict, new threads would connect
346 # to the default database instead of the appropriate clone.
347 self.connection.settings_dict.update(settings_dict)
348 self.connection.close()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.models.db import ProgrammingError
2from plain.utils.functional import cached_property
5class BaseDatabaseFeatures:
6 # An optional tuple indicating the minimum supported database version.
7 minimum_database_version = None
8 gis_enabled = False
9 # Oracle can't group by LOB (large object) data types.
10 allows_group_by_lob = True
11 allows_group_by_selected_pks = False
12 allows_group_by_select_index = True
13 empty_fetchmany_value = []
14 update_can_self_select = True
16 # Does the backend distinguish between '' and None?
17 interprets_empty_strings_as_nulls = False
19 # Does the backend allow inserting duplicate NULL rows in a nullable
20 # unique field? All core backends implement this correctly, but other
21 # databases such as SQL Server do not.
22 supports_nullable_unique_constraints = True
24 # Does the backend support initially deferrable unique constraints?
25 supports_deferrable_unique_constraints = False
27 can_use_chunked_reads = True
28 can_return_columns_from_insert = False
29 can_return_rows_from_bulk_insert = False
30 has_bulk_insert = True
31 uses_savepoints = True
32 can_release_savepoints = False
34 # If True, don't use integer foreign keys referring to, e.g., positive
35 # integer primary keys.
36 related_fields_match_type = False
37 allow_sliced_subqueries_with_in = True
38 has_select_for_update = False
39 has_select_for_update_nowait = False
40 has_select_for_update_skip_locked = False
41 has_select_for_update_of = False
42 has_select_for_no_key_update = False
43 # Does the database's SELECT FOR UPDATE OF syntax require a column rather
44 # than a table?
45 select_for_update_of_column = False
47 # Does the default test database allow multiple connections?
48 # Usually an indication that the test database is in-memory
49 test_db_allows_multiple_connections = True
51 # Can an object be saved without an explicit primary key?
52 supports_unspecified_pk = False
54 # Can a fixture contain forward references? i.e., are
55 # FK constraints checked at the end of transaction, or
56 # at the end of each save operation?
57 supports_forward_references = True
59 # Does the backend truncate names properly when they are too long?
60 truncates_names = False
62 # Is there a REAL datatype in addition to floats/doubles?
63 has_real_datatype = False
64 supports_subqueries_in_group_by = True
66 # Does the backend ignore unnecessary ORDER BY clauses in subqueries?
67 ignores_unnecessary_order_by_in_subqueries = True
69 # Is there a true datatype for uuid?
70 has_native_uuid_field = False
72 # Is there a true datatype for timedeltas?
73 has_native_duration_field = False
75 # Does the database driver supports same type temporal data subtraction
76 # by returning the type used to store duration field?
77 supports_temporal_subtraction = False
79 # Does the __regex lookup support backreferencing and grouping?
80 supports_regex_backreferencing = True
82 # Can date/datetime lookups be performed using a string?
83 supports_date_lookup_using_string = True
85 # Can datetimes with timezones be used?
86 supports_timezones = True
88 # Does the database have a copy of the zoneinfo database?
89 has_zoneinfo_database = True
91 # When performing a GROUP BY, is an ORDER BY NULL required
92 # to remove any ordering?
93 requires_explicit_null_ordering_when_grouping = False
95 # Does the backend order NULL values as largest or smallest?
96 nulls_order_largest = False
98 # Does the backend support NULLS FIRST and NULLS LAST in ORDER BY?
99 supports_order_by_nulls_modifier = True
101 # Does the backend orders NULLS FIRST by default?
102 order_by_nulls_first = False
104 # The database's limit on the number of query parameters.
105 max_query_params = None
107 # Can an object have an autoincrement primary key of 0?
108 allows_auto_pk_0 = True
110 # Do we need to NULL a ForeignKey out, or can the constraint check be
111 # deferred
112 can_defer_constraint_checks = False
114 # Does the backend support tablespaces? Default to False because it isn't
115 # in the SQL standard.
116 supports_tablespaces = False
118 # Does the backend reset sequences between tests?
119 supports_sequence_reset = True
121 # Can the backend introspect the default value of a column?
122 can_introspect_default = True
124 # Confirm support for introspected foreign keys
125 # Every database can do this reliably, except MySQL,
126 # which can't do it for MyISAM tables
127 can_introspect_foreign_keys = True
129 # Map fields which some backends may not be able to differentiate to the
130 # field it's introspected as.
131 introspected_field_types = {
132 "AutoField": "AutoField",
133 "BigAutoField": "BigAutoField",
134 "BigIntegerField": "BigIntegerField",
135 "BinaryField": "BinaryField",
136 "BooleanField": "BooleanField",
137 "CharField": "CharField",
138 "DurationField": "DurationField",
139 "GenericIPAddressField": "GenericIPAddressField",
140 "IntegerField": "IntegerField",
141 "PositiveBigIntegerField": "PositiveBigIntegerField",
142 "PositiveIntegerField": "PositiveIntegerField",
143 "PositiveSmallIntegerField": "PositiveSmallIntegerField",
144 "SmallAutoField": "SmallAutoField",
145 "SmallIntegerField": "SmallIntegerField",
146 "TimeField": "TimeField",
147 }
149 # Can the backend introspect the column order (ASC/DESC) for indexes?
150 supports_index_column_ordering = True
152 # Does the backend support introspection of materialized views?
153 can_introspect_materialized_views = False
155 # Support for the DISTINCT ON clause
156 can_distinct_on_fields = False
158 # Does the backend prevent running SQL queries in broken transactions?
159 atomic_transactions = True
161 # Can we roll back DDL in a transaction?
162 can_rollback_ddl = False
164 schema_editor_uses_clientside_param_binding = False
166 # Does it support operations requiring references rename in a transaction?
167 supports_atomic_references_rename = True
169 # Can we issue more than one ALTER COLUMN clause in an ALTER TABLE?
170 supports_combined_alters = False
172 # Does it support foreign keys?
173 supports_foreign_keys = True
175 # Can it create foreign key constraints inline when adding columns?
176 can_create_inline_fk = True
178 # Can an index be renamed?
179 can_rename_index = False
181 # Does it automatically index foreign keys?
182 indexes_foreign_keys = True
184 # Does it support CHECK constraints?
185 supports_column_check_constraints = True
186 supports_table_check_constraints = True
187 # Does the backend support introspection of CHECK constraints?
188 can_introspect_check_constraints = True
190 # Does the backend support 'pyformat' style ("... %(name)s ...", {'name': value})
191 # parameter passing? Note this can be provided by the backend even if not
192 # supported by the Python driver
193 supports_paramstyle_pyformat = True
195 # Does the backend require literal defaults, rather than parameterized ones?
196 requires_literal_defaults = False
198 # Does the backend require a connection reset after each material schema change?
199 connection_persists_old_columns = False
201 # What kind of error does the backend throw when accessing closed cursor?
202 closed_cursor_error_class = ProgrammingError
204 # Does 'a' LIKE 'A' match?
205 has_case_insensitive_like = False
207 # Suffix for backends that don't support "SELECT xxx;" queries.
208 bare_select_suffix = ""
210 # If NULL is implied on columns without needing to be explicitly specified
211 implied_column_null = False
213 # Does the backend support "select for update" queries with limit (and offset)?
214 supports_select_for_update_with_limit = True
216 # Does the backend ignore null expressions in GREATEST and LEAST queries unless
217 # every expression is null?
218 greatest_least_ignores_nulls = False
220 # Can the backend clone databases for parallel test execution?
221 # Defaults to False to allow third-party backends to opt-in.
222 can_clone_databases = False
224 # Does the backend consider table names with different casing to
225 # be equal?
226 ignores_table_name_case = False
228 # Place FOR UPDATE right after FROM clause. Used on MSSQL.
229 for_update_after_from = False
231 # Combinatorial flags
232 supports_select_union = True
233 supports_select_intersection = True
234 supports_select_difference = True
235 supports_slicing_ordering_in_compound = False
236 supports_parentheses_in_compound = True
237 requires_compound_order_by_subquery = False
239 # Does the database support SQL 2003 FILTER (WHERE ...) in aggregate
240 # expressions?
241 supports_aggregate_filter_clause = False
243 # Does the backend support indexing a TextField?
244 supports_index_on_text_field = True
246 # Does the backend support window expressions (expression OVER (...))?
247 supports_over_clause = False
248 supports_frame_range_fixed_distance = False
249 only_supports_unbounded_with_preceding_and_following = False
251 # Does the backend support CAST with precision?
252 supports_cast_with_precision = True
254 # How many second decimals does the database return when casting a value to
255 # a type with time?
256 time_cast_precision = 6
258 # SQL to create a procedure for use by the Plain test suite. The
259 # functionality of the procedure isn't important.
260 create_test_procedure_without_params_sql = None
261 create_test_procedure_with_int_param_sql = None
263 # SQL to create a table with a composite primary key for use by the Plain
264 # test suite.
265 create_test_table_with_composite_primary_key = None
267 # Does the backend support keyword parameters for cursor.callproc()?
268 supports_callproc_kwargs = False
270 # What formats does the backend EXPLAIN syntax support?
271 supported_explain_formats = set()
273 # Does the backend support the default parameter in lead() and lag()?
274 supports_default_in_lead_lag = True
276 # Does the backend support ignoring constraint or uniqueness errors during
277 # INSERT?
278 supports_ignore_conflicts = True
279 # Does the backend support updating rows on constraint or uniqueness errors
280 # during INSERT?
281 supports_update_conflicts = False
282 supports_update_conflicts_with_target = False
284 # Does this backend require casting the results of CASE expressions used
285 # in UPDATE statements to ensure the expression has the correct type?
286 requires_casted_case_in_updates = False
288 # Does the backend support partial indexes (CREATE INDEX ... WHERE ...)?
289 supports_partial_indexes = True
290 supports_functions_in_partial_indexes = True
291 # Does the backend support covering indexes (CREATE INDEX ... INCLUDE ...)?
292 supports_covering_indexes = False
293 # Does the backend support indexes on expressions?
294 supports_expression_indexes = True
295 # Does the backend treat COLLATE as an indexed expression?
296 collate_as_index_expression = False
298 # Does the backend support boolean expressions in SELECT and GROUP BY
299 # clauses?
300 supports_boolean_expr_in_select_clause = True
301 # Does the backend support comparing boolean expressions in WHERE clauses?
302 # Eg: WHERE (price > 0) IS NOT NULL
303 supports_comparing_boolean_expr = True
305 # Does the backend support JSONField?
306 supports_json_field = True
307 # Can the backend introspect a JSONField?
308 can_introspect_json_field = True
309 # Does the backend support primitives in JSONField?
310 supports_primitives_in_json_field = True
311 # Is there a true datatype for JSON?
312 has_native_json_field = False
313 # Does the backend use PostgreSQL-style JSON operators like '->'?
314 has_json_operators = False
315 # Does the backend support __contains and __contained_by lookups for
316 # a JSONField?
317 supports_json_field_contains = True
318 # Does value__d__contains={'f': 'g'} (without a list around the dict) match
319 # {'d': [{'f': 'g'}]}?
320 json_key_contains_list_matching_requires_list = False
321 # Does the backend support JSONObject() database function?
322 has_json_object_function = True
324 # Does the backend support column collations?
325 supports_collation_on_charfield = True
326 supports_collation_on_textfield = True
327 # Does the backend support non-deterministic collations?
328 supports_non_deterministic_collations = True
330 # Does the backend support column and table comments?
331 supports_comments = False
332 # Does the backend support column comments in ADD COLUMN statements?
333 supports_comments_inline = False
335 # Does the backend support the logical XOR operator?
336 supports_logical_xor = False
338 # Set to (exception, message) if null characters in text are disallowed.
339 prohibits_null_characters_in_text_exception = None
341 # Does the backend support unlimited character columns?
342 supports_unlimited_charfield = False
344 # Collation names for use by the Plain test suite.
345 test_collations = {
346 "ci": None, # Case-insensitive.
347 "cs": None, # Case-sensitive.
348 "non_default": None, # Non-default.
349 "swedish_ci": None, # Swedish case-insensitive.
350 }
351 # SQL template override for tests.aggregation.tests.NowUTC
352 test_now_utc_template = None
354 def __init__(self, connection):
355 self.connection = connection
357 @cached_property
358 def supports_explaining_query_execution(self):
359 """Does this backend support explaining query execution?"""
360 return self.connection.ops.explain_prefix is not None
362 @cached_property
363 def supports_transactions(self):
364 """Confirm support for transactions."""
365 with self.connection.cursor() as cursor:
366 cursor.execute("CREATE TABLE ROLLBACK_TEST (X INT)")
367 self.connection.set_autocommit(False)
368 cursor.execute("INSERT INTO ROLLBACK_TEST (X) VALUES (8)")
369 self.connection.rollback()
370 self.connection.set_autocommit(True)
371 cursor.execute("SELECT COUNT(X) FROM ROLLBACK_TEST")
372 (count,) = cursor.fetchone()
373 cursor.execute("DROP TABLE ROLLBACK_TEST")
374 return count == 0
376 def allows_group_by_selected_pks_on_model(self, model):
377 if not self.allows_group_by_selected_pks:
378 return False
379 return model._meta.managed
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from collections import namedtuple
3# Structure returned by DatabaseIntrospection.get_table_list()
4TableInfo = namedtuple("TableInfo", ["name", "type"])
6# Structure returned by the DB-API cursor.description interface (PEP 249)
7FieldInfo = namedtuple(
8 "FieldInfo",
9 "name type_code display_size internal_size precision scale null_ok "
10 "default collation",
11)
14class BaseDatabaseIntrospection:
15 """Encapsulate backend-specific introspection utilities."""
17 data_types_reverse = {}
19 def __init__(self, connection):
20 self.connection = connection
22 def get_field_type(self, data_type, description):
23 """
24 Hook for a database backend to use the cursor description to
25 match a Plain field type to a database column.
27 For Oracle, the column data_type on its own is insufficient to
28 distinguish between a FloatField and IntegerField, for example.
29 """
30 return self.data_types_reverse[data_type]
32 def identifier_converter(self, name):
33 """
34 Apply a conversion to the identifier for the purposes of comparison.
36 The default identifier converter is for case sensitive comparison.
37 """
38 return name
40 def table_names(self, cursor=None, include_views=False):
41 """
42 Return a list of names of all tables that exist in the database.
43 Sort the returned table list by Python's default sorting. Do NOT use
44 the database's ORDER BY here to avoid subtle differences in sorting
45 order between databases.
46 """
48 def get_names(cursor):
49 return sorted(
50 ti.name
51 for ti in self.get_table_list(cursor)
52 if include_views or ti.type == "t"
53 )
55 if cursor is None:
56 with self.connection.cursor() as cursor:
57 return get_names(cursor)
58 return get_names(cursor)
60 def get_table_list(self, cursor):
61 """
62 Return an unsorted list of TableInfo named tuples of all tables and
63 views that exist in the database.
64 """
65 raise NotImplementedError(
66 "subclasses of BaseDatabaseIntrospection may require a get_table_list() "
67 "method"
68 )
70 def get_table_description(self, cursor, table_name):
71 """
72 Return a description of the table with the DB-API cursor.description
73 interface.
74 """
75 raise NotImplementedError(
76 "subclasses of BaseDatabaseIntrospection may require a "
77 "get_table_description() method."
78 )
80 def get_migratable_models(self):
81 from plain.models.db import router
82 from plain.packages import packages
84 return (
85 model
86 for package_config in packages.get_package_configs()
87 for model in router.get_migratable_models(
88 package_config, self.connection.alias
89 )
90 if model._meta.can_migrate(self.connection)
91 )
93 def plain_table_names(self, only_existing=False, include_views=True):
94 """
95 Return a list of all table names that have associated Plain models and
96 are in INSTALLED_PACKAGES.
98 If only_existing is True, include only the tables in the database.
99 """
100 tables = set()
101 for model in self.get_migratable_models():
102 if not model._meta.managed:
103 continue
104 tables.add(model._meta.db_table)
105 tables.update(
106 f.m2m_db_table()
107 for f in model._meta.local_many_to_many
108 if f.remote_field.through._meta.managed
109 )
110 tables = list(tables)
111 if only_existing:
112 existing_tables = set(self.table_names(include_views=include_views))
113 tables = [
114 t for t in tables if self.identifier_converter(t) in existing_tables
115 ]
116 return tables
118 def installed_models(self, tables):
119 """
120 Return a set of all models represented by the provided list of table
121 names.
122 """
123 tables = set(map(self.identifier_converter, tables))
124 return {
125 m
126 for m in self.get_migratable_models()
127 if self.identifier_converter(m._meta.db_table) in tables
128 }
130 def sequence_list(self):
131 """
132 Return a list of information about all DB sequences for all models in
133 all packages.
134 """
135 sequence_list = []
136 with self.connection.cursor() as cursor:
137 for model in self.get_migratable_models():
138 if not model._meta.managed:
139 continue
140 if model._meta.swapped:
141 continue
142 sequence_list.extend(
143 self.get_sequences(
144 cursor, model._meta.db_table, model._meta.local_fields
145 )
146 )
147 for f in model._meta.local_many_to_many:
148 # If this is an m2m using an intermediate table,
149 # we don't need to reset the sequence.
150 if f.remote_field.through._meta.auto_created:
151 sequence = self.get_sequences(cursor, f.m2m_db_table())
152 sequence_list.extend(
153 sequence or [{"table": f.m2m_db_table(), "column": None}]
154 )
155 return sequence_list
157 def get_sequences(self, cursor, table_name, table_fields=()):
158 """
159 Return a list of introspected sequences for table_name. Each sequence
160 is a dict: {'table': <table_name>, 'column': <column_name>}. An optional
161 'name' key can be added if the backend supports named sequences.
162 """
163 raise NotImplementedError(
164 "subclasses of BaseDatabaseIntrospection may require a get_sequences() "
165 "method"
166 )
168 def get_relations(self, cursor, table_name):
169 """
170 Return a dictionary of {field_name: (field_name_other_table, other_table)}
171 representing all foreign keys in the given table.
172 """
173 raise NotImplementedError(
174 "subclasses of BaseDatabaseIntrospection may require a "
175 "get_relations() method."
176 )
178 def get_primary_key_column(self, cursor, table_name):
179 """
180 Return the name of the primary key column for the given table.
181 """
182 columns = self.get_primary_key_columns(cursor, table_name)
183 return columns[0] if columns else None
185 def get_primary_key_columns(self, cursor, table_name):
186 """Return a list of primary key columns for the given table."""
187 for constraint in self.get_constraints(cursor, table_name).values():
188 if constraint["primary_key"]:
189 return constraint["columns"]
190 return None
192 def get_constraints(self, cursor, table_name):
193 """
194 Retrieve any constraints or keys (unique, pk, fk, check, index)
195 across one or more columns.
197 Return a dict mapping constraint names to their attributes,
198 where attributes is a dict with keys:
199 * columns: List of columns this covers
200 * primary_key: True if primary key, False otherwise
201 * unique: True if this is a unique constraint, False otherwise
202 * foreign_key: (table, column) of target, or None
203 * check: True if check constraint, False otherwise
204 * index: True if index, False otherwise.
205 * orders: The order (ASC/DESC) defined for the columns of indexes
206 * type: The type of the index (btree, hash, etc.)
208 Some backends may return special constraint names that don't exist
209 if they don't name constraints of a certain type (e.g. SQLite)
210 """
211 raise NotImplementedError(
212 "subclasses of BaseDatabaseIntrospection may require a get_constraints() "
213 "method"
214 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import datetime
2import decimal
3import json
4from importlib import import_module
6import sqlparse
8from plain.models.backends import utils
9from plain.models.db import NotSupportedError
10from plain.utils import timezone
11from plain.utils.encoding import force_str
14class BaseDatabaseOperations:
15 """
16 Encapsulate backend-specific differences, such as the way a backend
17 performs ordering or calculates the ID of a recently-inserted row.
18 """
20 compiler_module = "plain.models.sql.compiler"
22 # Integer field safe ranges by `internal_type` as documented
23 # in docs/ref/models/fields.txt.
24 integer_field_ranges = {
25 "SmallIntegerField": (-32768, 32767),
26 "IntegerField": (-2147483648, 2147483647),
27 "BigIntegerField": (-9223372036854775808, 9223372036854775807),
28 "PositiveBigIntegerField": (0, 9223372036854775807),
29 "PositiveSmallIntegerField": (0, 32767),
30 "PositiveIntegerField": (0, 2147483647),
31 "SmallAutoField": (-32768, 32767),
32 "AutoField": (-2147483648, 2147483647),
33 "BigAutoField": (-9223372036854775808, 9223372036854775807),
34 }
35 set_operators = {
36 "union": "UNION",
37 "intersection": "INTERSECT",
38 "difference": "EXCEPT",
39 }
40 # Mapping of Field.get_internal_type() (typically the model field's class
41 # name) to the data type to use for the Cast() function, if different from
42 # DatabaseWrapper.data_types.
43 cast_data_types = {}
44 # CharField data type if the max_length argument isn't provided.
45 cast_char_field_without_max_length = None
47 # Start and end points for window expressions.
48 PRECEDING = "PRECEDING"
49 FOLLOWING = "FOLLOWING"
50 UNBOUNDED_PRECEDING = "UNBOUNDED " + PRECEDING
51 UNBOUNDED_FOLLOWING = "UNBOUNDED " + FOLLOWING
52 CURRENT_ROW = "CURRENT ROW"
54 # Prefix for EXPLAIN queries, or None EXPLAIN isn't supported.
55 explain_prefix = None
57 def __init__(self, connection):
58 self.connection = connection
59 self._cache = None
61 def autoinc_sql(self, table, column):
62 """
63 Return any SQL needed to support auto-incrementing primary keys, or
64 None if no SQL is necessary.
66 This SQL is executed when a table is created.
67 """
68 return None
70 def bulk_batch_size(self, fields, objs):
71 """
72 Return the maximum allowed batch size for the backend. The fields
73 are the fields going to be inserted in the batch, the objs contains
74 all the objects to be inserted.
75 """
76 return len(objs)
78 def format_for_duration_arithmetic(self, sql):
79 raise NotImplementedError(
80 "subclasses of BaseDatabaseOperations may require a "
81 "format_for_duration_arithmetic() method."
82 )
84 def cache_key_culling_sql(self):
85 """
86 Return an SQL query that retrieves the first cache key greater than the
87 n smallest.
89 This is used by the 'db' cache backend to determine where to start
90 culling.
91 """
92 cache_key = self.quote_name("cache_key")
93 return f"SELECT {cache_key} FROM %s ORDER BY {cache_key} LIMIT 1 OFFSET %%s"
95 def unification_cast_sql(self, output_field):
96 """
97 Given a field instance, return the SQL that casts the result of a union
98 to that type. The resulting string should contain a '%s' placeholder
99 for the expression being cast.
100 """
101 return "%s"
103 def date_extract_sql(self, lookup_type, sql, params):
104 """
105 Given a lookup_type of 'year', 'month', or 'day', return the SQL that
106 extracts a value from the given date field field_name.
107 """
108 raise NotImplementedError(
109 "subclasses of BaseDatabaseOperations may require a date_extract_sql() "
110 "method"
111 )
113 def date_trunc_sql(self, lookup_type, sql, params, tzname=None):
114 """
115 Given a lookup_type of 'year', 'month', or 'day', return the SQL that
116 truncates the given date or datetime field field_name to a date object
117 with only the given specificity.
119 If `tzname` is provided, the given value is truncated in a specific
120 timezone.
121 """
122 raise NotImplementedError(
123 "subclasses of BaseDatabaseOperations may require a date_trunc_sql() "
124 "method."
125 )
127 def datetime_cast_date_sql(self, sql, params, tzname):
128 """
129 Return the SQL to cast a datetime value to date value.
130 """
131 raise NotImplementedError(
132 "subclasses of BaseDatabaseOperations may require a "
133 "datetime_cast_date_sql() method."
134 )
136 def datetime_cast_time_sql(self, sql, params, tzname):
137 """
138 Return the SQL to cast a datetime value to time value.
139 """
140 raise NotImplementedError(
141 "subclasses of BaseDatabaseOperations may require a "
142 "datetime_cast_time_sql() method"
143 )
145 def datetime_extract_sql(self, lookup_type, sql, params, tzname):
146 """
147 Given a lookup_type of 'year', 'month', 'day', 'hour', 'minute', or
148 'second', return the SQL that extracts a value from the given
149 datetime field field_name.
150 """
151 raise NotImplementedError(
152 "subclasses of BaseDatabaseOperations may require a datetime_extract_sql() "
153 "method"
154 )
156 def datetime_trunc_sql(self, lookup_type, sql, params, tzname):
157 """
158 Given a lookup_type of 'year', 'month', 'day', 'hour', 'minute', or
159 'second', return the SQL that truncates the given datetime field
160 field_name to a datetime object with only the given specificity.
161 """
162 raise NotImplementedError(
163 "subclasses of BaseDatabaseOperations may require a datetime_trunc_sql() "
164 "method"
165 )
167 def time_trunc_sql(self, lookup_type, sql, params, tzname=None):
168 """
169 Given a lookup_type of 'hour', 'minute' or 'second', return the SQL
170 that truncates the given time or datetime field field_name to a time
171 object with only the given specificity.
173 If `tzname` is provided, the given value is truncated in a specific
174 timezone.
175 """
176 raise NotImplementedError(
177 "subclasses of BaseDatabaseOperations may require a time_trunc_sql() method"
178 )
180 def time_extract_sql(self, lookup_type, sql, params):
181 """
182 Given a lookup_type of 'hour', 'minute', or 'second', return the SQL
183 that extracts a value from the given time field field_name.
184 """
185 return self.date_extract_sql(lookup_type, sql, params)
187 def deferrable_sql(self):
188 """
189 Return the SQL to make a constraint "initially deferred" during a
190 CREATE TABLE statement.
191 """
192 return ""
194 def distinct_sql(self, fields, params):
195 """
196 Return an SQL DISTINCT clause which removes duplicate rows from the
197 result set. If any fields are given, only check the given fields for
198 duplicates.
199 """
200 if fields:
201 raise NotSupportedError(
202 "DISTINCT ON fields is not supported by this database backend"
203 )
204 else:
205 return ["DISTINCT"], []
207 def fetch_returned_insert_columns(self, cursor, returning_params):
208 """
209 Given a cursor object that has just performed an INSERT...RETURNING
210 statement into a table, return the newly created data.
211 """
212 return cursor.fetchone()
214 def field_cast_sql(self, db_type, internal_type):
215 """
216 Given a column type (e.g. 'BLOB', 'VARCHAR') and an internal type
217 (e.g. 'GenericIPAddressField'), return the SQL to cast it before using
218 it in a WHERE statement. The resulting string should contain a '%s'
219 placeholder for the column being searched against.
220 """
221 return "%s"
223 def force_no_ordering(self):
224 """
225 Return a list used in the "ORDER BY" clause to force no ordering at
226 all. Return an empty list to include nothing in the ordering.
227 """
228 return []
230 def for_update_sql(self, nowait=False, skip_locked=False, of=(), no_key=False):
231 """
232 Return the FOR UPDATE SQL clause to lock rows for an update operation.
233 """
234 return "FOR{} UPDATE{}{}{}".format(
235 " NO KEY" if no_key else "",
236 " OF %s" % ", ".join(of) if of else "",
237 " NOWAIT" if nowait else "",
238 " SKIP LOCKED" if skip_locked else "",
239 )
241 def _get_limit_offset_params(self, low_mark, high_mark):
242 offset = low_mark or 0
243 if high_mark is not None:
244 return (high_mark - offset), offset
245 elif offset:
246 return self.connection.ops.no_limit_value(), offset
247 return None, offset
249 def limit_offset_sql(self, low_mark, high_mark):
250 """Return LIMIT/OFFSET SQL clause."""
251 limit, offset = self._get_limit_offset_params(low_mark, high_mark)
252 return " ".join(
253 sql
254 for sql in (
255 ("LIMIT %d" % limit) if limit else None,
256 ("OFFSET %d" % offset) if offset else None,
257 )
258 if sql
259 )
261 def last_executed_query(self, cursor, sql, params):
262 """
263 Return a string of the query last executed by the given cursor, with
264 placeholders replaced with actual values.
266 `sql` is the raw query containing placeholders and `params` is the
267 sequence of parameters. These are used by default, but this method
268 exists for database backends to provide a better implementation
269 according to their own quoting schemes.
270 """
272 # Convert params to contain string values.
273 def to_string(s):
274 return force_str(s, strings_only=True, errors="replace")
276 if isinstance(params, list | tuple):
277 u_params = tuple(to_string(val) for val in params)
278 elif params is None:
279 u_params = ()
280 else:
281 u_params = {to_string(k): to_string(v) for k, v in params.items()}
283 return f"QUERY = {sql!r} - PARAMS = {u_params!r}"
285 def last_insert_id(self, cursor, table_name, pk_name):
286 """
287 Given a cursor object that has just performed an INSERT statement into
288 a table that has an auto-incrementing ID, return the newly created ID.
290 `pk_name` is the name of the primary-key column.
291 """
292 return cursor.lastrowid
294 def lookup_cast(self, lookup_type, internal_type=None):
295 """
296 Return the string to use in a query when performing lookups
297 ("contains", "like", etc.). It should contain a '%s' placeholder for
298 the column being searched against.
299 """
300 return "%s"
302 def max_in_list_size(self):
303 """
304 Return the maximum number of items that can be passed in a single 'IN'
305 list condition, or None if the backend does not impose a limit.
306 """
307 return None
309 def max_name_length(self):
310 """
311 Return the maximum length of table and column names, or None if there
312 is no limit.
313 """
314 return None
316 def no_limit_value(self):
317 """
318 Return the value to use for the LIMIT when we are wanting "LIMIT
319 infinity". Return None if the limit clause can be omitted in this case.
320 """
321 raise NotImplementedError(
322 "subclasses of BaseDatabaseOperations may require a no_limit_value() method"
323 )
325 def pk_default_value(self):
326 """
327 Return the value to use during an INSERT statement to specify that
328 the field should use its default value.
329 """
330 return "DEFAULT"
332 def prepare_sql_script(self, sql):
333 """
334 Take an SQL script that may contain multiple lines and return a list
335 of statements to feed to successive cursor.execute() calls.
337 Since few databases are able to process raw SQL scripts in a single
338 cursor.execute() call and PEP 249 doesn't talk about this use case,
339 the default implementation is conservative.
340 """
341 return [
342 sqlparse.format(statement, strip_comments=True)
343 for statement in sqlparse.split(sql)
344 if statement
345 ]
347 def process_clob(self, value):
348 """
349 Return the value of a CLOB column, for backends that return a locator
350 object that requires additional processing.
351 """
352 return value
354 def return_insert_columns(self, fields):
355 """
356 For backends that support returning columns as part of an insert query,
357 return the SQL and params to append to the INSERT query. The returned
358 fragment should contain a format string to hold the appropriate column.
359 """
360 pass
362 def compiler(self, compiler_name):
363 """
364 Return the SQLCompiler class corresponding to the given name,
365 in the namespace corresponding to the `compiler_module` attribute
366 on this backend.
367 """
368 if self._cache is None:
369 self._cache = import_module(self.compiler_module)
370 return getattr(self._cache, compiler_name)
372 def quote_name(self, name):
373 """
374 Return a quoted version of the given table, index, or column name. Do
375 not quote the given name if it's already been quoted.
376 """
377 raise NotImplementedError(
378 "subclasses of BaseDatabaseOperations may require a quote_name() method"
379 )
381 def regex_lookup(self, lookup_type):
382 """
383 Return the string to use in a query when performing regular expression
384 lookups (using "regex" or "iregex"). It should contain a '%s'
385 placeholder for the column being searched against.
387 If the feature is not supported (or part of it is not supported), raise
388 NotImplementedError.
389 """
390 raise NotImplementedError(
391 "subclasses of BaseDatabaseOperations may require a regex_lookup() method"
392 )
394 def savepoint_create_sql(self, sid):
395 """
396 Return the SQL for starting a new savepoint. Only required if the
397 "uses_savepoints" feature is True. The "sid" parameter is a string
398 for the savepoint id.
399 """
400 return "SAVEPOINT %s" % self.quote_name(sid)
402 def savepoint_commit_sql(self, sid):
403 """
404 Return the SQL for committing the given savepoint.
405 """
406 return "RELEASE SAVEPOINT %s" % self.quote_name(sid)
408 def savepoint_rollback_sql(self, sid):
409 """
410 Return the SQL for rolling back the given savepoint.
411 """
412 return "ROLLBACK TO SAVEPOINT %s" % self.quote_name(sid)
414 def set_time_zone_sql(self):
415 """
416 Return the SQL that will set the connection's time zone.
418 Return '' if the backend doesn't support time zones.
419 """
420 return ""
422 def sequence_reset_by_name_sql(self, style, sequences):
423 """
424 Return a list of the SQL statements required to reset sequences
425 passed in `sequences`.
427 The `style` argument is a Style object as returned by either
428 color_style() or no_style() in plain.internal.legacy.management.color.
429 """
430 return []
432 def sequence_reset_sql(self, style, model_list):
433 """
434 Return a list of the SQL statements required to reset sequences for
435 the given models.
437 The `style` argument is a Style object as returned by either
438 color_style() or no_style() in plain.internal.legacy.management.color.
439 """
440 return [] # No sequence reset required by default.
442 def start_transaction_sql(self):
443 """Return the SQL statement required to start a transaction."""
444 return "BEGIN;"
446 def end_transaction_sql(self, success=True):
447 """Return the SQL statement required to end a transaction."""
448 if not success:
449 return "ROLLBACK;"
450 return "COMMIT;"
452 def tablespace_sql(self, tablespace, inline=False):
453 """
454 Return the SQL that will be used in a query to define the tablespace.
456 Return '' if the backend doesn't support tablespaces.
458 If `inline` is True, append the SQL to a row; otherwise append it to
459 the entire CREATE TABLE or CREATE INDEX statement.
460 """
461 return ""
463 def prep_for_like_query(self, x):
464 """Prepare a value for use in a LIKE query."""
465 return str(x).replace("\\", "\\\\").replace("%", r"\%").replace("_", r"\_")
467 # Same as prep_for_like_query(), but called for "iexact" matches, which
468 # need not necessarily be implemented using "LIKE" in the backend.
469 prep_for_iexact_query = prep_for_like_query
471 def validate_autopk_value(self, value):
472 """
473 Certain backends do not accept some values for "serial" fields
474 (for example zero in MySQL). Raise a ValueError if the value is
475 invalid, otherwise return the validated value.
476 """
477 return value
479 def adapt_unknown_value(self, value):
480 """
481 Transform a value to something compatible with the backend driver.
483 This method only depends on the type of the value. It's designed for
484 cases where the target type isn't known, such as .raw() SQL queries.
485 As a consequence it may not work perfectly in all circumstances.
486 """
487 if isinstance(value, datetime.datetime): # must be before date
488 return self.adapt_datetimefield_value(value)
489 elif isinstance(value, datetime.date):
490 return self.adapt_datefield_value(value)
491 elif isinstance(value, datetime.time):
492 return self.adapt_timefield_value(value)
493 elif isinstance(value, decimal.Decimal):
494 return self.adapt_decimalfield_value(value)
495 else:
496 return value
498 def adapt_integerfield_value(self, value, internal_type):
499 return value
501 def adapt_datefield_value(self, value):
502 """
503 Transform a date value to an object compatible with what is expected
504 by the backend driver for date columns.
505 """
506 if value is None:
507 return None
508 return str(value)
510 def adapt_datetimefield_value(self, value):
511 """
512 Transform a datetime value to an object compatible with what is expected
513 by the backend driver for datetime columns.
514 """
515 if value is None:
516 return None
517 # Expression values are adapted by the database.
518 if hasattr(value, "resolve_expression"):
519 return value
521 return str(value)
523 def adapt_timefield_value(self, value):
524 """
525 Transform a time value to an object compatible with what is expected
526 by the backend driver for time columns.
527 """
528 if value is None:
529 return None
530 # Expression values are adapted by the database.
531 if hasattr(value, "resolve_expression"):
532 return value
534 if timezone.is_aware(value):
535 raise ValueError("Plain does not support timezone-aware times.")
536 return str(value)
538 def adapt_decimalfield_value(self, value, max_digits=None, decimal_places=None):
539 """
540 Transform a decimal.Decimal value to an object compatible with what is
541 expected by the backend driver for decimal (numeric) columns.
542 """
543 return utils.format_number(value, max_digits, decimal_places)
545 def adapt_ipaddressfield_value(self, value):
546 """
547 Transform a string representation of an IP address into the expected
548 type for the backend driver.
549 """
550 return value or None
552 def adapt_json_value(self, value, encoder):
553 return json.dumps(value, cls=encoder)
555 def year_lookup_bounds_for_date_field(self, value, iso_year=False):
556 """
557 Return a two-elements list with the lower and upper bound to be used
558 with a BETWEEN operator to query a DateField value using a year
559 lookup.
561 `value` is an int, containing the looked-up year.
562 If `iso_year` is True, return bounds for ISO-8601 week-numbering years.
563 """
564 if iso_year:
565 first = datetime.date.fromisocalendar(value, 1, 1)
566 second = datetime.date.fromisocalendar(
567 value + 1, 1, 1
568 ) - datetime.timedelta(days=1)
569 else:
570 first = datetime.date(value, 1, 1)
571 second = datetime.date(value, 12, 31)
572 first = self.adapt_datefield_value(first)
573 second = self.adapt_datefield_value(second)
574 return [first, second]
576 def year_lookup_bounds_for_datetime_field(self, value, iso_year=False):
577 """
578 Return a two-elements list with the lower and upper bound to be used
579 with a BETWEEN operator to query a DateTimeField value using a year
580 lookup.
582 `value` is an int, containing the looked-up year.
583 If `iso_year` is True, return bounds for ISO-8601 week-numbering years.
584 """
585 if iso_year:
586 first = datetime.datetime.fromisocalendar(value, 1, 1)
587 second = datetime.datetime.fromisocalendar(
588 value + 1, 1, 1
589 ) - datetime.timedelta(microseconds=1)
590 else:
591 first = datetime.datetime(value, 1, 1)
592 second = datetime.datetime(value, 12, 31, 23, 59, 59, 999999)
594 # Make sure that datetimes are aware in the current timezone
595 tz = timezone.get_current_timezone()
596 first = timezone.make_aware(first, tz)
597 second = timezone.make_aware(second, tz)
599 first = self.adapt_datetimefield_value(first)
600 second = self.adapt_datetimefield_value(second)
601 return [first, second]
603 def get_db_converters(self, expression):
604 """
605 Return a list of functions needed to convert field data.
607 Some field types on some backends do not provide data in the correct
608 format, this is the hook for converter functions.
609 """
610 return []
612 def convert_durationfield_value(self, value, expression, connection):
613 if value is not None:
614 return datetime.timedelta(0, 0, value)
616 def check_expression_support(self, expression):
617 """
618 Check that the backend supports the provided expression.
620 This is used on specific backends to rule out known expressions
621 that have problematic or nonexistent implementations. If the
622 expression has a known problem, the backend should raise
623 NotSupportedError.
624 """
625 pass
627 def conditional_expression_supported_in_where_clause(self, expression):
628 """
629 Return True, if the conditional expression is supported in the WHERE
630 clause.
631 """
632 return True
634 def combine_expression(self, connector, sub_expressions):
635 """
636 Combine a list of subexpressions into a single expression, using
637 the provided connecting operator. This is required because operators
638 can vary between backends (e.g., Oracle with %% and &) and between
639 subexpression types (e.g., date expressions).
640 """
641 conn = " %s " % connector
642 return conn.join(sub_expressions)
644 def combine_duration_expression(self, connector, sub_expressions):
645 return self.combine_expression(connector, sub_expressions)
647 def binary_placeholder_sql(self, value):
648 """
649 Some backends require special syntax to insert binary content (MySQL
650 for example uses '_binary %s').
651 """
652 return "%s"
654 def modify_insert_params(self, placeholder, params):
655 """
656 Allow modification of insert parameters. Needed for Oracle Spatial
657 backend due to #10888.
658 """
659 return params
661 def integer_field_range(self, internal_type):
662 """
663 Given an integer field internal type (e.g. 'PositiveIntegerField'),
664 return a tuple of the (min_value, max_value) form representing the
665 range of the column type bound to the field.
666 """
667 return self.integer_field_ranges[internal_type]
669 def subtract_temporals(self, internal_type, lhs, rhs):
670 if self.connection.features.supports_temporal_subtraction:
671 lhs_sql, lhs_params = lhs
672 rhs_sql, rhs_params = rhs
673 return f"({lhs_sql} - {rhs_sql})", (*lhs_params, *rhs_params)
674 raise NotSupportedError(
675 "This backend does not support %s subtraction." % internal_type
676 )
678 def window_frame_start(self, start):
679 if isinstance(start, int):
680 if start < 0:
681 return "%d %s" % (abs(start), self.PRECEDING)
682 elif start == 0:
683 return self.CURRENT_ROW
684 elif start is None:
685 return self.UNBOUNDED_PRECEDING
686 raise ValueError(
687 "start argument must be a negative integer, zero, or None, but got '%s'."
688 % start
689 )
691 def window_frame_end(self, end):
692 if isinstance(end, int):
693 if end == 0:
694 return self.CURRENT_ROW
695 elif end > 0:
696 return "%d %s" % (end, self.FOLLOWING)
697 elif end is None:
698 return self.UNBOUNDED_FOLLOWING
699 raise ValueError(
700 "end argument must be a positive integer, zero, or None, but got '%s'."
701 % end
702 )
704 def window_frame_rows_start_end(self, start=None, end=None):
705 """
706 Return SQL for start and end points in an OVER clause window frame.
707 """
708 if not self.connection.features.supports_over_clause:
709 raise NotSupportedError("This backend does not support window expressions.")
710 return self.window_frame_start(start), self.window_frame_end(end)
712 def window_frame_range_start_end(self, start=None, end=None):
713 start_, end_ = self.window_frame_rows_start_end(start, end)
714 features = self.connection.features
715 if features.only_supports_unbounded_with_preceding_and_following and (
716 (start and start < 0) or (end and end > 0)
717 ):
718 raise NotSupportedError(
719 "%s only supports UNBOUNDED together with PRECEDING and "
720 "FOLLOWING." % self.connection.display_name
721 )
722 return start_, end_
724 def explain_query_prefix(self, format=None, **options):
725 if not self.connection.features.supports_explaining_query_execution:
726 raise NotSupportedError(
727 "This backend does not support explaining query execution."
728 )
729 if format:
730 supported_formats = self.connection.features.supported_explain_formats
731 normalized_format = format.upper()
732 if normalized_format not in supported_formats:
733 msg = "%s is not a recognized format." % normalized_format
734 if supported_formats:
735 msg += " Allowed formats: %s" % ", ".join(sorted(supported_formats))
736 else:
737 msg += (
738 f" {self.connection.display_name} does not support any formats."
739 )
740 raise ValueError(msg)
741 if options:
742 raise ValueError("Unknown options: %s" % ", ".join(sorted(options.keys())))
743 return self.explain_prefix
745 def insert_statement(self, on_conflict=None):
746 return "INSERT INTO"
748 def on_conflict_suffix_sql(self, fields, on_conflict, update_fields, unique_fields):
749 return ""
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import logging
2import operator
3from datetime import datetime
5from plain.models.backends.ddl_references import (
6 Columns,
7 Expressions,
8 ForeignKeyName,
9 IndexName,
10 Statement,
11 Table,
12)
13from plain.models.backends.utils import names_digest, split_identifier, truncate_name
14from plain.models.constraints import Deferrable
15from plain.models.indexes import Index
16from plain.models.sql import Query
17from plain.models.transaction import TransactionManagementError, atomic
18from plain.runtime import settings
19from plain.utils import timezone
21logger = logging.getLogger("plain.models.backends.schema")
24def _is_relevant_relation(relation, altered_field):
25 """
26 When altering the given field, must constraints on its model from the given
27 relation be temporarily dropped?
28 """
29 field = relation.field
30 if field.many_to_many:
31 # M2M reverse field
32 return False
33 if altered_field.primary_key and field.to_fields == [None]:
34 # Foreign key constraint on the primary key, which is being altered.
35 return True
36 # Is the constraint targeting the field being altered?
37 return altered_field.name in field.to_fields
40def _all_related_fields(model):
41 # Related fields must be returned in a deterministic order.
42 return sorted(
43 model._meta._get_fields(
44 forward=False,
45 reverse=True,
46 include_hidden=True,
47 include_parents=False,
48 ),
49 key=operator.attrgetter("name"),
50 )
53def _related_non_m2m_objects(old_field, new_field):
54 # Filter out m2m objects from reverse relations.
55 # Return (old_relation, new_relation) tuples.
56 related_fields = zip(
57 (
58 obj
59 for obj in _all_related_fields(old_field.model)
60 if _is_relevant_relation(obj, old_field)
61 ),
62 (
63 obj
64 for obj in _all_related_fields(new_field.model)
65 if _is_relevant_relation(obj, new_field)
66 ),
67 )
68 for old_rel, new_rel in related_fields:
69 yield old_rel, new_rel
70 yield from _related_non_m2m_objects(
71 old_rel.remote_field,
72 new_rel.remote_field,
73 )
76class BaseDatabaseSchemaEditor:
77 """
78 This class and its subclasses are responsible for emitting schema-changing
79 statements to the databases - model creation/removal/alteration, field
80 renaming, index fiddling, and so on.
81 """
83 # Overrideable SQL templates
84 sql_create_table = "CREATE TABLE %(table)s (%(definition)s)"
85 sql_rename_table = "ALTER TABLE %(old_table)s RENAME TO %(new_table)s"
86 sql_retablespace_table = "ALTER TABLE %(table)s SET TABLESPACE %(new_tablespace)s"
87 sql_delete_table = "DROP TABLE %(table)s CASCADE"
89 sql_create_column = "ALTER TABLE %(table)s ADD COLUMN %(column)s %(definition)s"
90 sql_alter_column = "ALTER TABLE %(table)s %(changes)s"
91 sql_alter_column_type = "ALTER COLUMN %(column)s TYPE %(type)s%(collation)s"
92 sql_alter_column_null = "ALTER COLUMN %(column)s DROP NOT NULL"
93 sql_alter_column_not_null = "ALTER COLUMN %(column)s SET NOT NULL"
94 sql_alter_column_default = "ALTER COLUMN %(column)s SET DEFAULT %(default)s"
95 sql_alter_column_no_default = "ALTER COLUMN %(column)s DROP DEFAULT"
96 sql_alter_column_no_default_null = sql_alter_column_no_default
97 sql_delete_column = "ALTER TABLE %(table)s DROP COLUMN %(column)s CASCADE"
98 sql_rename_column = (
99 "ALTER TABLE %(table)s RENAME COLUMN %(old_column)s TO %(new_column)s"
100 )
101 sql_update_with_default = (
102 "UPDATE %(table)s SET %(column)s = %(default)s WHERE %(column)s IS NULL"
103 )
105 sql_unique_constraint = "UNIQUE (%(columns)s)%(deferrable)s"
106 sql_check_constraint = "CHECK (%(check)s)"
107 sql_delete_constraint = "ALTER TABLE %(table)s DROP CONSTRAINT %(name)s"
108 sql_constraint = "CONSTRAINT %(name)s %(constraint)s"
110 sql_create_check = "ALTER TABLE %(table)s ADD CONSTRAINT %(name)s CHECK (%(check)s)"
111 sql_delete_check = sql_delete_constraint
113 sql_create_unique = (
114 "ALTER TABLE %(table)s ADD CONSTRAINT %(name)s "
115 "UNIQUE (%(columns)s)%(deferrable)s"
116 )
117 sql_delete_unique = sql_delete_constraint
119 sql_create_fk = (
120 "ALTER TABLE %(table)s ADD CONSTRAINT %(name)s FOREIGN KEY (%(column)s) "
121 "REFERENCES %(to_table)s (%(to_column)s)%(deferrable)s"
122 )
123 sql_create_inline_fk = None
124 sql_create_column_inline_fk = None
125 sql_delete_fk = sql_delete_constraint
127 sql_create_index = (
128 "CREATE INDEX %(name)s ON %(table)s "
129 "(%(columns)s)%(include)s%(extra)s%(condition)s"
130 )
131 sql_create_unique_index = (
132 "CREATE UNIQUE INDEX %(name)s ON %(table)s "
133 "(%(columns)s)%(include)s%(condition)s"
134 )
135 sql_rename_index = "ALTER INDEX %(old_name)s RENAME TO %(new_name)s"
136 sql_delete_index = "DROP INDEX %(name)s"
138 sql_create_pk = (
139 "ALTER TABLE %(table)s ADD CONSTRAINT %(name)s PRIMARY KEY (%(columns)s)"
140 )
141 sql_delete_pk = sql_delete_constraint
143 sql_delete_procedure = "DROP PROCEDURE %(procedure)s"
145 sql_alter_table_comment = "COMMENT ON TABLE %(table)s IS %(comment)s"
146 sql_alter_column_comment = "COMMENT ON COLUMN %(table)s.%(column)s IS %(comment)s"
148 def __init__(self, connection, collect_sql=False, atomic=True):
149 self.connection = connection
150 self.collect_sql = collect_sql
151 if self.collect_sql:
152 self.collected_sql = []
153 self.atomic_migration = self.connection.features.can_rollback_ddl and atomic
155 # State-managing methods
157 def __enter__(self):
158 self.deferred_sql = []
159 if self.atomic_migration:
160 self.atomic = atomic(self.connection.alias)
161 self.atomic.__enter__()
162 return self
164 def __exit__(self, exc_type, exc_value, traceback):
165 if exc_type is None:
166 for sql in self.deferred_sql:
167 self.execute(sql)
168 if self.atomic_migration:
169 self.atomic.__exit__(exc_type, exc_value, traceback)
171 # Core utility functions
173 def execute(self, sql, params=()):
174 """Execute the given SQL statement, with optional parameters."""
175 # Don't perform the transactional DDL check if SQL is being collected
176 # as it's not going to be executed anyway.
177 if (
178 not self.collect_sql
179 and self.connection.in_atomic_block
180 and not self.connection.features.can_rollback_ddl
181 ):
182 raise TransactionManagementError(
183 "Executing DDL statements while in a transaction on databases "
184 "that can't perform a rollback is prohibited."
185 )
186 # Account for non-string statement objects.
187 sql = str(sql)
188 # Log the command we're running, then run it
189 logger.debug(
190 "%s; (params %r)", sql, params, extra={"params": params, "sql": sql}
191 )
192 if self.collect_sql:
193 ending = "" if sql.rstrip().endswith(";") else ";"
194 if params is not None:
195 self.collected_sql.append(
196 (sql % tuple(map(self.quote_value, params))) + ending
197 )
198 else:
199 self.collected_sql.append(sql + ending)
200 else:
201 with self.connection.cursor() as cursor:
202 cursor.execute(sql, params)
204 def quote_name(self, name):
205 return self.connection.ops.quote_name(name)
207 def table_sql(self, model):
208 """Take a model and return its table definition."""
209 # Create column SQL, add FK deferreds if needed.
210 column_sqls = []
211 params = []
212 for field in model._meta.local_fields:
213 # SQL.
214 definition, extra_params = self.column_sql(model, field)
215 if definition is None:
216 continue
217 # Check constraints can go on the column SQL here.
218 db_params = field.db_parameters(connection=self.connection)
219 if db_params["check"]:
220 definition += " " + self.sql_check_constraint % db_params
221 # Autoincrement SQL (for backends with inline variant).
222 col_type_suffix = field.db_type_suffix(connection=self.connection)
223 if col_type_suffix:
224 definition += " %s" % col_type_suffix
225 params.extend(extra_params)
226 # FK.
227 if field.remote_field and field.db_constraint:
228 to_table = field.remote_field.model._meta.db_table
229 to_column = field.remote_field.model._meta.get_field(
230 field.remote_field.field_name
231 ).column
232 if self.sql_create_inline_fk:
233 definition += " " + self.sql_create_inline_fk % {
234 "to_table": self.quote_name(to_table),
235 "to_column": self.quote_name(to_column),
236 }
237 elif self.connection.features.supports_foreign_keys:
238 self.deferred_sql.append(
239 self._create_fk_sql(
240 model, field, "_fk_%(to_table)s_%(to_column)s"
241 )
242 )
243 # Add the SQL to our big list.
244 column_sqls.append(f"{self.quote_name(field.column)} {definition}")
245 # Autoincrement SQL (for backends with post table definition
246 # variant).
247 if field.get_internal_type() in (
248 "AutoField",
249 "BigAutoField",
250 "SmallAutoField",
251 ):
252 autoinc_sql = self.connection.ops.autoinc_sql(
253 model._meta.db_table, field.column
254 )
255 if autoinc_sql:
256 self.deferred_sql.extend(autoinc_sql)
257 constraints = [
258 constraint.constraint_sql(model, self)
259 for constraint in model._meta.constraints
260 ]
261 sql = self.sql_create_table % {
262 "table": self.quote_name(model._meta.db_table),
263 "definition": ", ".join(
264 str(constraint)
265 for constraint in (*column_sqls, *constraints)
266 if constraint
267 ),
268 }
269 if model._meta.db_tablespace:
270 tablespace_sql = self.connection.ops.tablespace_sql(
271 model._meta.db_tablespace
272 )
273 if tablespace_sql:
274 sql += " " + tablespace_sql
275 return sql, params
277 # Field <-> database mapping functions
279 def _iter_column_sql(
280 self, column_db_type, params, model, field, field_db_params, include_default
281 ):
282 yield column_db_type
283 if collation := field_db_params.get("collation"):
284 yield self._collate_sql(collation)
285 if self.connection.features.supports_comments_inline and field.db_comment:
286 yield self._comment_sql(field.db_comment)
287 # Work out nullability.
288 null = field.null
289 # Include a default value, if requested.
290 include_default = (
291 include_default
292 and not self.skip_default(field)
293 and
294 # Don't include a default value if it's a nullable field and the
295 # default cannot be dropped in the ALTER COLUMN statement (e.g.
296 # MySQL longtext and longblob).
297 not (null and self.skip_default_on_alter(field))
298 )
299 if include_default:
300 default_value = self.effective_default(field)
301 if default_value is not None:
302 column_default = "DEFAULT " + self._column_default_sql(field)
303 if self.connection.features.requires_literal_defaults:
304 # Some databases can't take defaults as a parameter (Oracle).
305 # If this is the case, the individual schema backend should
306 # implement prepare_default().
307 yield column_default % self.prepare_default(default_value)
308 else:
309 yield column_default
310 params.append(default_value)
311 # Oracle treats the empty string ('') as null, so coerce the null
312 # option whenever '' is a possible value.
313 if (
314 field.empty_strings_allowed
315 and not field.primary_key
316 and self.connection.features.interprets_empty_strings_as_nulls
317 ):
318 null = True
319 if not null:
320 yield "NOT NULL"
321 elif not self.connection.features.implied_column_null:
322 yield "NULL"
323 if field.primary_key:
324 yield "PRIMARY KEY"
325 elif field.unique:
326 yield "UNIQUE"
327 # Optionally add the tablespace if it's an implicitly indexed column.
328 tablespace = field.db_tablespace or model._meta.db_tablespace
329 if (
330 tablespace
331 and self.connection.features.supports_tablespaces
332 and field.unique
333 ):
334 yield self.connection.ops.tablespace_sql(tablespace, inline=True)
336 def column_sql(self, model, field, include_default=False):
337 """
338 Return the column definition for a field. The field must already have
339 had set_attributes_from_name() called.
340 """
341 # Get the column's type and use that as the basis of the SQL.
342 field_db_params = field.db_parameters(connection=self.connection)
343 column_db_type = field_db_params["type"]
344 # Check for fields that aren't actually columns (e.g. M2M).
345 if column_db_type is None:
346 return None, None
347 params = []
348 return (
349 " ".join(
350 # This appends to the params being returned.
351 self._iter_column_sql(
352 column_db_type,
353 params,
354 model,
355 field,
356 field_db_params,
357 include_default,
358 )
359 ),
360 params,
361 )
363 def skip_default(self, field):
364 """
365 Some backends don't accept default values for certain columns types
366 (i.e. MySQL longtext and longblob).
367 """
368 return False
370 def skip_default_on_alter(self, field):
371 """
372 Some backends don't accept default values for certain columns types
373 (i.e. MySQL longtext and longblob) in the ALTER COLUMN statement.
374 """
375 return False
377 def prepare_default(self, value):
378 """
379 Only used for backends which have requires_literal_defaults feature
380 """
381 raise NotImplementedError(
382 "subclasses of BaseDatabaseSchemaEditor for backends which have "
383 "requires_literal_defaults must provide a prepare_default() method"
384 )
386 def _column_default_sql(self, field):
387 """
388 Return the SQL to use in a DEFAULT clause. The resulting string should
389 contain a '%s' placeholder for a default value.
390 """
391 return "%s"
393 @staticmethod
394 def _effective_default(field):
395 # This method allows testing its logic without a connection.
396 if field.has_default():
397 default = field.get_default()
398 elif not field.null and field.blank and field.empty_strings_allowed:
399 if field.get_internal_type() == "BinaryField":
400 default = b""
401 else:
402 default = ""
403 elif getattr(field, "auto_now", False) or getattr(field, "auto_now_add", False):
404 internal_type = field.get_internal_type()
405 if internal_type == "DateTimeField":
406 default = timezone.now()
407 else:
408 default = datetime.now()
409 if internal_type == "DateField":
410 default = default.date()
411 elif internal_type == "TimeField":
412 default = default.time()
413 else:
414 default = None
415 return default
417 def effective_default(self, field):
418 """Return a field's effective database default value."""
419 return field.get_db_prep_save(self._effective_default(field), self.connection)
421 def quote_value(self, value):
422 """
423 Return a quoted version of the value so it's safe to use in an SQL
424 string. This is not safe against injection from user code; it is
425 intended only for use in making SQL scripts or preparing default values
426 for particularly tricky backends (defaults are not user-defined, though,
427 so this is safe).
428 """
429 raise NotImplementedError()
431 # Actions
433 def create_model(self, model):
434 """
435 Create a table and any accompanying indexes or unique constraints for
436 the given `model`.
437 """
438 sql, params = self.table_sql(model)
439 # Prevent using [] as params, in the case a literal '%' is used in the
440 # definition.
441 self.execute(sql, params or None)
443 if self.connection.features.supports_comments:
444 # Add table comment.
445 if model._meta.db_table_comment:
446 self.alter_db_table_comment(model, None, model._meta.db_table_comment)
447 # Add column comments.
448 if not self.connection.features.supports_comments_inline:
449 for field in model._meta.local_fields:
450 if field.db_comment:
451 field_db_params = field.db_parameters(
452 connection=self.connection
453 )
454 field_type = field_db_params["type"]
455 self.execute(
456 *self._alter_column_comment_sql(
457 model, field, field_type, field.db_comment
458 )
459 )
460 # Add any field index (deferred as SQLite _remake_table needs it).
461 self.deferred_sql.extend(self._model_indexes_sql(model))
463 # Make M2M tables
464 for field in model._meta.local_many_to_many:
465 if field.remote_field.through._meta.auto_created:
466 self.create_model(field.remote_field.through)
468 def delete_model(self, model):
469 """Delete a model from the database."""
470 # Handle auto-created intermediary models
471 for field in model._meta.local_many_to_many:
472 if field.remote_field.through._meta.auto_created:
473 self.delete_model(field.remote_field.through)
475 # Delete the table
476 self.execute(
477 self.sql_delete_table
478 % {
479 "table": self.quote_name(model._meta.db_table),
480 }
481 )
482 # Remove all deferred statements referencing the deleted table.
483 for sql in list(self.deferred_sql):
484 if isinstance(sql, Statement) and sql.references_table(
485 model._meta.db_table
486 ):
487 self.deferred_sql.remove(sql)
489 def add_index(self, model, index):
490 """Add an index on a model."""
491 if (
492 index.contains_expressions
493 and not self.connection.features.supports_expression_indexes
494 ):
495 return None
496 # Index.create_sql returns interpolated SQL which makes params=None a
497 # necessity to avoid escaping attempts on execution.
498 self.execute(index.create_sql(model, self), params=None)
500 def remove_index(self, model, index):
501 """Remove an index from a model."""
502 if (
503 index.contains_expressions
504 and not self.connection.features.supports_expression_indexes
505 ):
506 return None
507 self.execute(index.remove_sql(model, self))
509 def rename_index(self, model, old_index, new_index):
510 if self.connection.features.can_rename_index:
511 self.execute(
512 self._rename_index_sql(model, old_index.name, new_index.name),
513 params=None,
514 )
515 else:
516 self.remove_index(model, old_index)
517 self.add_index(model, new_index)
519 def add_constraint(self, model, constraint):
520 """Add a constraint to a model."""
521 sql = constraint.create_sql(model, self)
522 if sql:
523 # Constraint.create_sql returns interpolated SQL which makes
524 # params=None a necessity to avoid escaping attempts on execution.
525 self.execute(sql, params=None)
527 def remove_constraint(self, model, constraint):
528 """Remove a constraint from a model."""
529 sql = constraint.remove_sql(model, self)
530 if sql:
531 self.execute(sql)
533 def alter_db_table(self, model, old_db_table, new_db_table):
534 """Rename the table a model points to."""
535 if old_db_table == new_db_table or (
536 self.connection.features.ignores_table_name_case
537 and old_db_table.lower() == new_db_table.lower()
538 ):
539 return
540 self.execute(
541 self.sql_rename_table
542 % {
543 "old_table": self.quote_name(old_db_table),
544 "new_table": self.quote_name(new_db_table),
545 }
546 )
547 # Rename all references to the old table name.
548 for sql in self.deferred_sql:
549 if isinstance(sql, Statement):
550 sql.rename_table_references(old_db_table, new_db_table)
552 def alter_db_table_comment(self, model, old_db_table_comment, new_db_table_comment):
553 self.execute(
554 self.sql_alter_table_comment
555 % {
556 "table": self.quote_name(model._meta.db_table),
557 "comment": self.quote_value(new_db_table_comment or ""),
558 }
559 )
561 def alter_db_tablespace(self, model, old_db_tablespace, new_db_tablespace):
562 """Move a model's table between tablespaces."""
563 self.execute(
564 self.sql_retablespace_table
565 % {
566 "table": self.quote_name(model._meta.db_table),
567 "old_tablespace": self.quote_name(old_db_tablespace),
568 "new_tablespace": self.quote_name(new_db_tablespace),
569 }
570 )
572 def add_field(self, model, field):
573 """
574 Create a field on a model. Usually involves adding a column, but may
575 involve adding a table instead (for M2M fields).
576 """
577 # Special-case implicit M2M tables
578 if field.many_to_many and field.remote_field.through._meta.auto_created:
579 return self.create_model(field.remote_field.through)
580 # Get the column's definition
581 definition, params = self.column_sql(model, field, include_default=True)
582 # It might not actually have a column behind it
583 if definition is None:
584 return
585 if col_type_suffix := field.db_type_suffix(connection=self.connection):
586 definition += f" {col_type_suffix}"
587 # Check constraints can go on the column SQL here
588 db_params = field.db_parameters(connection=self.connection)
589 if db_params["check"]:
590 definition += " " + self.sql_check_constraint % db_params
591 if (
592 field.remote_field
593 and self.connection.features.supports_foreign_keys
594 and field.db_constraint
595 ):
596 constraint_suffix = "_fk_%(to_table)s_%(to_column)s"
597 # Add FK constraint inline, if supported.
598 if self.sql_create_column_inline_fk:
599 to_table = field.remote_field.model._meta.db_table
600 to_column = field.remote_field.model._meta.get_field(
601 field.remote_field.field_name
602 ).column
603 namespace, _ = split_identifier(model._meta.db_table)
604 definition += " " + self.sql_create_column_inline_fk % {
605 "name": self._fk_constraint_name(model, field, constraint_suffix),
606 "namespace": "%s." % self.quote_name(namespace)
607 if namespace
608 else "",
609 "column": self.quote_name(field.column),
610 "to_table": self.quote_name(to_table),
611 "to_column": self.quote_name(to_column),
612 "deferrable": self.connection.ops.deferrable_sql(),
613 }
614 # Otherwise, add FK constraints later.
615 else:
616 self.deferred_sql.append(
617 self._create_fk_sql(model, field, constraint_suffix)
618 )
619 # Build the SQL and run it
620 sql = self.sql_create_column % {
621 "table": self.quote_name(model._meta.db_table),
622 "column": self.quote_name(field.column),
623 "definition": definition,
624 }
625 self.execute(sql, params)
626 # Drop the default if we need to
627 # (Plain usually does not use in-database defaults)
628 if (
629 not self.skip_default_on_alter(field)
630 and self.effective_default(field) is not None
631 ):
632 changes_sql, params = self._alter_column_default_sql(
633 model, None, field, drop=True
634 )
635 sql = self.sql_alter_column % {
636 "table": self.quote_name(model._meta.db_table),
637 "changes": changes_sql,
638 }
639 self.execute(sql, params)
640 # Add field comment, if required.
641 if (
642 field.db_comment
643 and self.connection.features.supports_comments
644 and not self.connection.features.supports_comments_inline
645 ):
646 field_type = db_params["type"]
647 self.execute(
648 *self._alter_column_comment_sql(
649 model, field, field_type, field.db_comment
650 )
651 )
652 # Add an index, if required
653 self.deferred_sql.extend(self._field_indexes_sql(model, field))
654 # Reset connection if required
655 if self.connection.features.connection_persists_old_columns:
656 self.connection.close()
658 def remove_field(self, model, field):
659 """
660 Remove a field from a model. Usually involves deleting a column,
661 but for M2Ms may involve deleting a table.
662 """
663 # Special-case implicit M2M tables
664 if field.many_to_many and field.remote_field.through._meta.auto_created:
665 return self.delete_model(field.remote_field.through)
666 # It might not actually have a column behind it
667 if field.db_parameters(connection=self.connection)["type"] is None:
668 return
669 # Drop any FK constraints, MySQL requires explicit deletion
670 if field.remote_field:
671 fk_names = self._constraint_names(model, [field.column], foreign_key=True)
672 for fk_name in fk_names:
673 self.execute(self._delete_fk_sql(model, fk_name))
674 # Delete the column
675 sql = self.sql_delete_column % {
676 "table": self.quote_name(model._meta.db_table),
677 "column": self.quote_name(field.column),
678 }
679 self.execute(sql)
680 # Reset connection if required
681 if self.connection.features.connection_persists_old_columns:
682 self.connection.close()
683 # Remove all deferred statements referencing the deleted column.
684 for sql in list(self.deferred_sql):
685 if isinstance(sql, Statement) and sql.references_column(
686 model._meta.db_table, field.column
687 ):
688 self.deferred_sql.remove(sql)
690 def alter_field(self, model, old_field, new_field, strict=False):
691 """
692 Allow a field's type, uniqueness, nullability, default, column,
693 constraints, etc. to be modified.
694 `old_field` is required to compute the necessary changes.
695 If `strict` is True, raise errors if the old column does not match
696 `old_field` precisely.
697 """
698 if not self._field_should_be_altered(old_field, new_field):
699 return
700 # Ensure this field is even column-based
701 old_db_params = old_field.db_parameters(connection=self.connection)
702 old_type = old_db_params["type"]
703 new_db_params = new_field.db_parameters(connection=self.connection)
704 new_type = new_db_params["type"]
705 if (old_type is None and old_field.remote_field is None) or (
706 new_type is None and new_field.remote_field is None
707 ):
708 raise ValueError(
709 "Cannot alter field {} into {} - they do not properly define "
710 "db_type (are you using a badly-written custom field?)".format(
711 old_field, new_field
712 ),
713 )
714 elif (
715 old_type is None
716 and new_type is None
717 and (
718 old_field.remote_field.through
719 and new_field.remote_field.through
720 and old_field.remote_field.through._meta.auto_created
721 and new_field.remote_field.through._meta.auto_created
722 )
723 ):
724 return self._alter_many_to_many(model, old_field, new_field, strict)
725 elif (
726 old_type is None
727 and new_type is None
728 and (
729 old_field.remote_field.through
730 and new_field.remote_field.through
731 and not old_field.remote_field.through._meta.auto_created
732 and not new_field.remote_field.through._meta.auto_created
733 )
734 ):
735 # Both sides have through models; this is a no-op.
736 return
737 elif old_type is None or new_type is None:
738 raise ValueError(
739 "Cannot alter field {} into {} - they are not compatible types "
740 "(you cannot alter to or from M2M fields, or add or remove "
741 "through= on M2M fields)".format(old_field, new_field)
742 )
744 self._alter_field(
745 model,
746 old_field,
747 new_field,
748 old_type,
749 new_type,
750 old_db_params,
751 new_db_params,
752 strict,
753 )
755 def _field_db_check(self, field, field_db_params):
756 # Always check constraints with the same mocked column name to avoid
757 # recreating constrains when the column is renamed.
758 check_constraints = self.connection.data_type_check_constraints
759 data = field.db_type_parameters(self.connection)
760 data["column"] = "__column_name__"
761 try:
762 return check_constraints[field.get_internal_type()] % data
763 except KeyError:
764 return None
766 def _alter_field(
767 self,
768 model,
769 old_field,
770 new_field,
771 old_type,
772 new_type,
773 old_db_params,
774 new_db_params,
775 strict=False,
776 ):
777 """Perform a "physical" (non-ManyToMany) field update."""
778 # Drop any FK constraints, we'll remake them later
779 fks_dropped = set()
780 if (
781 self.connection.features.supports_foreign_keys
782 and old_field.remote_field
783 and old_field.db_constraint
784 and self._field_should_be_altered(
785 old_field,
786 new_field,
787 ignore={"db_comment"},
788 )
789 ):
790 fk_names = self._constraint_names(
791 model, [old_field.column], foreign_key=True
792 )
793 if strict and len(fk_names) != 1:
794 raise ValueError(
795 "Found wrong number ({}) of foreign key constraints for {}.{}".format(
796 len(fk_names),
797 model._meta.db_table,
798 old_field.column,
799 )
800 )
801 for fk_name in fk_names:
802 fks_dropped.add((old_field.column,))
803 self.execute(self._delete_fk_sql(model, fk_name))
804 # Has unique been removed?
805 if old_field.unique and (
806 not new_field.unique or self._field_became_primary_key(old_field, new_field)
807 ):
808 # Find the unique constraint for this field
809 meta_constraint_names = {
810 constraint.name for constraint in model._meta.constraints
811 }
812 constraint_names = self._constraint_names(
813 model,
814 [old_field.column],
815 unique=True,
816 primary_key=False,
817 exclude=meta_constraint_names,
818 )
819 if strict and len(constraint_names) != 1:
820 raise ValueError(
821 "Found wrong number ({}) of unique constraints for {}.{}".format(
822 len(constraint_names),
823 model._meta.db_table,
824 old_field.column,
825 )
826 )
827 for constraint_name in constraint_names:
828 self.execute(self._delete_unique_sql(model, constraint_name))
829 # Drop incoming FK constraints if the field is a primary key or unique,
830 # which might be a to_field target, and things are going to change.
831 old_collation = old_db_params.get("collation")
832 new_collation = new_db_params.get("collation")
833 drop_foreign_keys = (
834 self.connection.features.supports_foreign_keys
835 and (
836 (old_field.primary_key and new_field.primary_key)
837 or (old_field.unique and new_field.unique)
838 )
839 and ((old_type != new_type) or (old_collation != new_collation))
840 )
841 if drop_foreign_keys:
842 # '_meta.related_field' also contains M2M reverse fields, these
843 # will be filtered out
844 for _old_rel, new_rel in _related_non_m2m_objects(old_field, new_field):
845 rel_fk_names = self._constraint_names(
846 new_rel.related_model, [new_rel.field.column], foreign_key=True
847 )
848 for fk_name in rel_fk_names:
849 self.execute(self._delete_fk_sql(new_rel.related_model, fk_name))
850 # Removed an index? (no strict check, as multiple indexes are possible)
851 # Remove indexes if db_index switched to False or a unique constraint
852 # will now be used in lieu of an index. The following lines from the
853 # truth table show all True cases; the rest are False:
854 #
855 # old_field.db_index | old_field.unique | new_field.db_index | new_field.unique
856 # ------------------------------------------------------------------------------
857 # True | False | False | False
858 # True | False | False | True
859 # True | False | True | True
860 if (
861 old_field.db_index
862 and not old_field.unique
863 and (not new_field.db_index or new_field.unique)
864 ):
865 # Find the index for this field
866 meta_index_names = {index.name for index in model._meta.indexes}
867 # Retrieve only BTREE indexes since this is what's created with
868 # db_index=True.
869 index_names = self._constraint_names(
870 model,
871 [old_field.column],
872 index=True,
873 type_=Index.suffix,
874 exclude=meta_index_names,
875 )
876 for index_name in index_names:
877 # The only way to check if an index was created with
878 # db_index=True or with Index(['field'], name='foo')
879 # is to look at its name (refs #28053).
880 self.execute(self._delete_index_sql(model, index_name))
881 # Change check constraints?
882 old_db_check = self._field_db_check(old_field, old_db_params)
883 new_db_check = self._field_db_check(new_field, new_db_params)
884 if old_db_check != new_db_check and old_db_check:
885 meta_constraint_names = {
886 constraint.name for constraint in model._meta.constraints
887 }
888 constraint_names = self._constraint_names(
889 model,
890 [old_field.column],
891 check=True,
892 exclude=meta_constraint_names,
893 )
894 if strict and len(constraint_names) != 1:
895 raise ValueError(
896 "Found wrong number ({}) of check constraints for {}.{}".format(
897 len(constraint_names),
898 model._meta.db_table,
899 old_field.column,
900 )
901 )
902 for constraint_name in constraint_names:
903 self.execute(self._delete_check_sql(model, constraint_name))
904 # Have they renamed the column?
905 if old_field.column != new_field.column:
906 self.execute(
907 self._rename_field_sql(
908 model._meta.db_table, old_field, new_field, new_type
909 )
910 )
911 # Rename all references to the renamed column.
912 for sql in self.deferred_sql:
913 if isinstance(sql, Statement):
914 sql.rename_column_references(
915 model._meta.db_table, old_field.column, new_field.column
916 )
917 # Next, start accumulating actions to do
918 actions = []
919 null_actions = []
920 post_actions = []
921 # Type suffix change? (e.g. auto increment).
922 old_type_suffix = old_field.db_type_suffix(connection=self.connection)
923 new_type_suffix = new_field.db_type_suffix(connection=self.connection)
924 # Type, collation, or comment change?
925 if (
926 old_type != new_type
927 or old_type_suffix != new_type_suffix
928 or old_collation != new_collation
929 or (
930 self.connection.features.supports_comments
931 and old_field.db_comment != new_field.db_comment
932 )
933 ):
934 fragment, other_actions = self._alter_column_type_sql(
935 model, old_field, new_field, new_type, old_collation, new_collation
936 )
937 actions.append(fragment)
938 post_actions.extend(other_actions)
939 # When changing a column NULL constraint to NOT NULL with a given
940 # default value, we need to perform 4 steps:
941 # 1. Add a default for new incoming writes
942 # 2. Update existing NULL rows with new default
943 # 3. Replace NULL constraint with NOT NULL
944 # 4. Drop the default again.
945 # Default change?
946 needs_database_default = False
947 if old_field.null and not new_field.null:
948 old_default = self.effective_default(old_field)
949 new_default = self.effective_default(new_field)
950 if (
951 not self.skip_default_on_alter(new_field)
952 and old_default != new_default
953 and new_default is not None
954 ):
955 needs_database_default = True
956 actions.append(
957 self._alter_column_default_sql(model, old_field, new_field)
958 )
959 # Nullability change?
960 if old_field.null != new_field.null:
961 fragment = self._alter_column_null_sql(model, old_field, new_field)
962 if fragment:
963 null_actions.append(fragment)
964 # Only if we have a default and there is a change from NULL to NOT NULL
965 four_way_default_alteration = new_field.has_default() and (
966 old_field.null and not new_field.null
967 )
968 if actions or null_actions:
969 if not four_way_default_alteration:
970 # If we don't have to do a 4-way default alteration we can
971 # directly run a (NOT) NULL alteration
972 actions += null_actions
973 # Combine actions together if we can (e.g. postgres)
974 if self.connection.features.supports_combined_alters and actions:
975 sql, params = tuple(zip(*actions))
976 actions = [(", ".join(sql), sum(params, []))]
977 # Apply those actions
978 for sql, params in actions:
979 self.execute(
980 self.sql_alter_column
981 % {
982 "table": self.quote_name(model._meta.db_table),
983 "changes": sql,
984 },
985 params,
986 )
987 if four_way_default_alteration:
988 # Update existing rows with default value
989 self.execute(
990 self.sql_update_with_default
991 % {
992 "table": self.quote_name(model._meta.db_table),
993 "column": self.quote_name(new_field.column),
994 "default": "%s",
995 },
996 [new_default],
997 )
998 # Since we didn't run a NOT NULL change before we need to do it
999 # now
1000 for sql, params in null_actions:
1001 self.execute(
1002 self.sql_alter_column
1003 % {
1004 "table": self.quote_name(model._meta.db_table),
1005 "changes": sql,
1006 },
1007 params,
1008 )
1009 if post_actions:
1010 for sql, params in post_actions:
1011 self.execute(sql, params)
1012 # If primary_key changed to False, delete the primary key constraint.
1013 if old_field.primary_key and not new_field.primary_key:
1014 self._delete_primary_key(model, strict)
1015 # Added a unique?
1016 if self._unique_should_be_added(old_field, new_field):
1017 self.execute(self._create_unique_sql(model, [new_field]))
1018 # Added an index? Add an index if db_index switched to True or a unique
1019 # constraint will no longer be used in lieu of an index. The following
1020 # lines from the truth table show all True cases; the rest are False:
1021 #
1022 # old_field.db_index | old_field.unique | new_field.db_index | new_field.unique
1023 # ------------------------------------------------------------------------------
1024 # False | False | True | False
1025 # False | True | True | False
1026 # True | True | True | False
1027 if (
1028 (not old_field.db_index or old_field.unique)
1029 and new_field.db_index
1030 and not new_field.unique
1031 ):
1032 self.execute(self._create_index_sql(model, fields=[new_field]))
1033 # Type alteration on primary key? Then we need to alter the column
1034 # referring to us.
1035 rels_to_update = []
1036 if drop_foreign_keys:
1037 rels_to_update.extend(_related_non_m2m_objects(old_field, new_field))
1038 # Changed to become primary key?
1039 if self._field_became_primary_key(old_field, new_field):
1040 # Make the new one
1041 self.execute(self._create_primary_key_sql(model, new_field))
1042 # Update all referencing columns
1043 rels_to_update.extend(_related_non_m2m_objects(old_field, new_field))
1044 # Handle our type alters on the other end of rels from the PK stuff above
1045 for old_rel, new_rel in rels_to_update:
1046 rel_db_params = new_rel.field.db_parameters(connection=self.connection)
1047 rel_type = rel_db_params["type"]
1048 rel_collation = rel_db_params.get("collation")
1049 old_rel_db_params = old_rel.field.db_parameters(connection=self.connection)
1050 old_rel_collation = old_rel_db_params.get("collation")
1051 fragment, other_actions = self._alter_column_type_sql(
1052 new_rel.related_model,
1053 old_rel.field,
1054 new_rel.field,
1055 rel_type,
1056 old_rel_collation,
1057 rel_collation,
1058 )
1059 self.execute(
1060 self.sql_alter_column
1061 % {
1062 "table": self.quote_name(new_rel.related_model._meta.db_table),
1063 "changes": fragment[0],
1064 },
1065 fragment[1],
1066 )
1067 for sql, params in other_actions:
1068 self.execute(sql, params)
1069 # Does it have a foreign key?
1070 if (
1071 self.connection.features.supports_foreign_keys
1072 and new_field.remote_field
1073 and (
1074 fks_dropped or not old_field.remote_field or not old_field.db_constraint
1075 )
1076 and new_field.db_constraint
1077 ):
1078 self.execute(
1079 self._create_fk_sql(model, new_field, "_fk_%(to_table)s_%(to_column)s")
1080 )
1081 # Rebuild FKs that pointed to us if we previously had to drop them
1082 if drop_foreign_keys:
1083 for _, rel in rels_to_update:
1084 if rel.field.db_constraint:
1085 self.execute(
1086 self._create_fk_sql(rel.related_model, rel.field, "_fk")
1087 )
1088 # Does it have check constraints we need to add?
1089 if old_db_check != new_db_check and new_db_check:
1090 constraint_name = self._create_index_name(
1091 model._meta.db_table, [new_field.column], suffix="_check"
1092 )
1093 self.execute(
1094 self._create_check_sql(model, constraint_name, new_db_params["check"])
1095 )
1096 # Drop the default if we need to
1097 # (Plain usually does not use in-database defaults)
1098 if needs_database_default:
1099 changes_sql, params = self._alter_column_default_sql(
1100 model, old_field, new_field, drop=True
1101 )
1102 sql = self.sql_alter_column % {
1103 "table": self.quote_name(model._meta.db_table),
1104 "changes": changes_sql,
1105 }
1106 self.execute(sql, params)
1107 # Reset connection if required
1108 if self.connection.features.connection_persists_old_columns:
1109 self.connection.close()
1111 def _alter_column_null_sql(self, model, old_field, new_field):
1112 """
1113 Hook to specialize column null alteration.
1115 Return a (sql, params) fragment to set a column to null or non-null
1116 as required by new_field, or None if no changes are required.
1117 """
1118 if (
1119 self.connection.features.interprets_empty_strings_as_nulls
1120 and new_field.empty_strings_allowed
1121 ):
1122 # The field is nullable in the database anyway, leave it alone.
1123 return
1124 else:
1125 new_db_params = new_field.db_parameters(connection=self.connection)
1126 sql = (
1127 self.sql_alter_column_null
1128 if new_field.null
1129 else self.sql_alter_column_not_null
1130 )
1131 return (
1132 sql
1133 % {
1134 "column": self.quote_name(new_field.column),
1135 "type": new_db_params["type"],
1136 },
1137 [],
1138 )
1140 def _alter_column_default_sql(self, model, old_field, new_field, drop=False):
1141 """
1142 Hook to specialize column default alteration.
1144 Return a (sql, params) fragment to add or drop (depending on the drop
1145 argument) a default to new_field's column.
1146 """
1147 new_default = self.effective_default(new_field)
1148 default = self._column_default_sql(new_field)
1149 params = [new_default]
1151 if drop:
1152 params = []
1153 elif self.connection.features.requires_literal_defaults:
1154 # Some databases (Oracle) can't take defaults as a parameter
1155 # If this is the case, the SchemaEditor for that database should
1156 # implement prepare_default().
1157 default = self.prepare_default(new_default)
1158 params = []
1160 new_db_params = new_field.db_parameters(connection=self.connection)
1161 if drop:
1162 if new_field.null:
1163 sql = self.sql_alter_column_no_default_null
1164 else:
1165 sql = self.sql_alter_column_no_default
1166 else:
1167 sql = self.sql_alter_column_default
1168 return (
1169 sql
1170 % {
1171 "column": self.quote_name(new_field.column),
1172 "type": new_db_params["type"],
1173 "default": default,
1174 },
1175 params,
1176 )
1178 def _alter_column_type_sql(
1179 self, model, old_field, new_field, new_type, old_collation, new_collation
1180 ):
1181 """
1182 Hook to specialize column type alteration for different backends,
1183 for cases when a creation type is different to an alteration type
1184 (e.g. SERIAL in PostgreSQL, PostGIS fields).
1186 Return a two-tuple of: an SQL fragment of (sql, params) to insert into
1187 an ALTER TABLE statement and a list of extra (sql, params) tuples to
1188 run once the field is altered.
1189 """
1190 other_actions = []
1191 if collate_sql := self._collate_sql(
1192 new_collation, old_collation, model._meta.db_table
1193 ):
1194 collate_sql = f" {collate_sql}"
1195 else:
1196 collate_sql = ""
1197 # Comment change?
1198 comment_sql = ""
1199 if self.connection.features.supports_comments and not new_field.many_to_many:
1200 if old_field.db_comment != new_field.db_comment:
1201 # PostgreSQL and Oracle can't execute 'ALTER COLUMN ...' and
1202 # 'COMMENT ON ...' at the same time.
1203 sql, params = self._alter_column_comment_sql(
1204 model, new_field, new_type, new_field.db_comment
1205 )
1206 if sql:
1207 other_actions.append((sql, params))
1208 if new_field.db_comment:
1209 comment_sql = self._comment_sql(new_field.db_comment)
1210 return (
1211 (
1212 self.sql_alter_column_type
1213 % {
1214 "column": self.quote_name(new_field.column),
1215 "type": new_type,
1216 "collation": collate_sql,
1217 "comment": comment_sql,
1218 },
1219 [],
1220 ),
1221 other_actions,
1222 )
1224 def _alter_column_comment_sql(self, model, new_field, new_type, new_db_comment):
1225 return (
1226 self.sql_alter_column_comment
1227 % {
1228 "table": self.quote_name(model._meta.db_table),
1229 "column": self.quote_name(new_field.column),
1230 "comment": self._comment_sql(new_db_comment),
1231 },
1232 [],
1233 )
1235 def _comment_sql(self, comment):
1236 return self.quote_value(comment or "")
1238 def _alter_many_to_many(self, model, old_field, new_field, strict):
1239 """Alter M2Ms to repoint their to= endpoints."""
1240 # Rename the through table
1241 if (
1242 old_field.remote_field.through._meta.db_table
1243 != new_field.remote_field.through._meta.db_table
1244 ):
1245 self.alter_db_table(
1246 old_field.remote_field.through,
1247 old_field.remote_field.through._meta.db_table,
1248 new_field.remote_field.through._meta.db_table,
1249 )
1250 # Repoint the FK to the other side
1251 self.alter_field(
1252 new_field.remote_field.through,
1253 # The field that points to the target model is needed, so we can
1254 # tell alter_field to change it - this is m2m_reverse_field_name()
1255 # (as opposed to m2m_field_name(), which points to our model).
1256 old_field.remote_field.through._meta.get_field(
1257 old_field.m2m_reverse_field_name()
1258 ),
1259 new_field.remote_field.through._meta.get_field(
1260 new_field.m2m_reverse_field_name()
1261 ),
1262 )
1263 self.alter_field(
1264 new_field.remote_field.through,
1265 # for self-referential models we need to alter field from the other end too
1266 old_field.remote_field.through._meta.get_field(old_field.m2m_field_name()),
1267 new_field.remote_field.through._meta.get_field(new_field.m2m_field_name()),
1268 )
1270 def _create_index_name(self, table_name, column_names, suffix=""):
1271 """
1272 Generate a unique name for an index/unique constraint.
1274 The name is divided into 3 parts: the table name, the column names,
1275 and a unique digest and suffix.
1276 """
1277 _, table_name = split_identifier(table_name)
1278 hash_suffix_part = "{}{}".format(
1279 names_digest(table_name, *column_names, length=8),
1280 suffix,
1281 )
1282 max_length = self.connection.ops.max_name_length() or 200
1283 # If everything fits into max_length, use that name.
1284 index_name = "{}_{}_{}".format(
1285 table_name, "_".join(column_names), hash_suffix_part
1286 )
1287 if len(index_name) <= max_length:
1288 return index_name
1289 # Shorten a long suffix.
1290 if len(hash_suffix_part) > max_length / 3:
1291 hash_suffix_part = hash_suffix_part[: max_length // 3]
1292 other_length = (max_length - len(hash_suffix_part)) // 2 - 1
1293 index_name = "{}_{}_{}".format(
1294 table_name[:other_length],
1295 "_".join(column_names)[:other_length],
1296 hash_suffix_part,
1297 )
1298 # Prepend D if needed to prevent the name from starting with an
1299 # underscore or a number (not permitted on Oracle).
1300 if index_name[0] == "_" or index_name[0].isdigit():
1301 index_name = "D%s" % index_name[:-1]
1302 return index_name
1304 def _get_index_tablespace_sql(self, model, fields, db_tablespace=None):
1305 if db_tablespace is None:
1306 if len(fields) == 1 and fields[0].db_tablespace:
1307 db_tablespace = fields[0].db_tablespace
1308 elif settings.DEFAULT_INDEX_TABLESPACE:
1309 db_tablespace = settings.DEFAULT_INDEX_TABLESPACE
1310 elif model._meta.db_tablespace:
1311 db_tablespace = model._meta.db_tablespace
1312 if db_tablespace is not None:
1313 return " " + self.connection.ops.tablespace_sql(db_tablespace)
1314 return ""
1316 def _index_condition_sql(self, condition):
1317 if condition:
1318 return " WHERE " + condition
1319 return ""
1321 def _index_include_sql(self, model, columns):
1322 if not columns or not self.connection.features.supports_covering_indexes:
1323 return ""
1324 return Statement(
1325 " INCLUDE (%(columns)s)",
1326 columns=Columns(model._meta.db_table, columns, self.quote_name),
1327 )
1329 def _create_index_sql(
1330 self,
1331 model,
1332 *,
1333 fields=None,
1334 name=None,
1335 suffix="",
1336 using="",
1337 db_tablespace=None,
1338 col_suffixes=(),
1339 sql=None,
1340 opclasses=(),
1341 condition=None,
1342 include=None,
1343 expressions=None,
1344 ):
1345 """
1346 Return the SQL statement to create the index for one or several fields
1347 or expressions. `sql` can be specified if the syntax differs from the
1348 standard (GIS indexes, ...).
1349 """
1350 fields = fields or []
1351 expressions = expressions or []
1352 compiler = Query(model, alias_cols=False).get_compiler(
1353 connection=self.connection,
1354 )
1355 tablespace_sql = self._get_index_tablespace_sql(
1356 model, fields, db_tablespace=db_tablespace
1357 )
1358 columns = [field.column for field in fields]
1359 sql_create_index = sql or self.sql_create_index
1360 table = model._meta.db_table
1362 def create_index_name(*args, **kwargs):
1363 nonlocal name
1364 if name is None:
1365 name = self._create_index_name(*args, **kwargs)
1366 return self.quote_name(name)
1368 return Statement(
1369 sql_create_index,
1370 table=Table(table, self.quote_name),
1371 name=IndexName(table, columns, suffix, create_index_name),
1372 using=using,
1373 columns=(
1374 self._index_columns(table, columns, col_suffixes, opclasses)
1375 if columns
1376 else Expressions(table, expressions, compiler, self.quote_value)
1377 ),
1378 extra=tablespace_sql,
1379 condition=self._index_condition_sql(condition),
1380 include=self._index_include_sql(model, include),
1381 )
1383 def _delete_index_sql(self, model, name, sql=None):
1384 return Statement(
1385 sql or self.sql_delete_index,
1386 table=Table(model._meta.db_table, self.quote_name),
1387 name=self.quote_name(name),
1388 )
1390 def _rename_index_sql(self, model, old_name, new_name):
1391 return Statement(
1392 self.sql_rename_index,
1393 table=Table(model._meta.db_table, self.quote_name),
1394 old_name=self.quote_name(old_name),
1395 new_name=self.quote_name(new_name),
1396 )
1398 def _index_columns(self, table, columns, col_suffixes, opclasses):
1399 return Columns(table, columns, self.quote_name, col_suffixes=col_suffixes)
1401 def _model_indexes_sql(self, model):
1402 """
1403 Return a list of all index SQL statements (field indexes, Meta.indexes) for the specified model.
1404 """
1405 if not model._meta.managed or model._meta.swapped:
1406 return []
1407 output = []
1408 for field in model._meta.local_fields:
1409 output.extend(self._field_indexes_sql(model, field))
1411 for index in model._meta.indexes:
1412 if (
1413 not index.contains_expressions
1414 or self.connection.features.supports_expression_indexes
1415 ):
1416 output.append(index.create_sql(model, self))
1417 return output
1419 def _field_indexes_sql(self, model, field):
1420 """
1421 Return a list of all index SQL statements for the specified field.
1422 """
1423 output = []
1424 if self._field_should_be_indexed(model, field):
1425 output.append(self._create_index_sql(model, fields=[field]))
1426 return output
1428 def _field_should_be_altered(self, old_field, new_field, ignore=None):
1429 ignore = ignore or set()
1430 _, old_path, old_args, old_kwargs = old_field.deconstruct()
1431 _, new_path, new_args, new_kwargs = new_field.deconstruct()
1432 # Don't alter when:
1433 # - changing only a field name
1434 # - changing an attribute that doesn't affect the schema
1435 # - changing an attribute in the provided set of ignored attributes
1436 # - adding only a db_column and the column name is not changed
1437 for attr in ignore.union(old_field.non_db_attrs):
1438 old_kwargs.pop(attr, None)
1439 for attr in ignore.union(new_field.non_db_attrs):
1440 new_kwargs.pop(attr, None)
1441 return self.quote_name(old_field.column) != self.quote_name(
1442 new_field.column
1443 ) or (old_path, old_args, old_kwargs) != (new_path, new_args, new_kwargs)
1445 def _field_should_be_indexed(self, model, field):
1446 return field.db_index and not field.unique
1448 def _field_became_primary_key(self, old_field, new_field):
1449 return not old_field.primary_key and new_field.primary_key
1451 def _unique_should_be_added(self, old_field, new_field):
1452 return (
1453 not new_field.primary_key
1454 and new_field.unique
1455 and (not old_field.unique or old_field.primary_key)
1456 )
1458 def _rename_field_sql(self, table, old_field, new_field, new_type):
1459 return self.sql_rename_column % {
1460 "table": self.quote_name(table),
1461 "old_column": self.quote_name(old_field.column),
1462 "new_column": self.quote_name(new_field.column),
1463 "type": new_type,
1464 }
1466 def _create_fk_sql(self, model, field, suffix):
1467 table = Table(model._meta.db_table, self.quote_name)
1468 name = self._fk_constraint_name(model, field, suffix)
1469 column = Columns(model._meta.db_table, [field.column], self.quote_name)
1470 to_table = Table(field.target_field.model._meta.db_table, self.quote_name)
1471 to_column = Columns(
1472 field.target_field.model._meta.db_table,
1473 [field.target_field.column],
1474 self.quote_name,
1475 )
1476 deferrable = self.connection.ops.deferrable_sql()
1477 return Statement(
1478 self.sql_create_fk,
1479 table=table,
1480 name=name,
1481 column=column,
1482 to_table=to_table,
1483 to_column=to_column,
1484 deferrable=deferrable,
1485 )
1487 def _fk_constraint_name(self, model, field, suffix):
1488 def create_fk_name(*args, **kwargs):
1489 return self.quote_name(self._create_index_name(*args, **kwargs))
1491 return ForeignKeyName(
1492 model._meta.db_table,
1493 [field.column],
1494 split_identifier(field.target_field.model._meta.db_table)[1],
1495 [field.target_field.column],
1496 suffix,
1497 create_fk_name,
1498 )
1500 def _delete_fk_sql(self, model, name):
1501 return self._delete_constraint_sql(self.sql_delete_fk, model, name)
1503 def _deferrable_constraint_sql(self, deferrable):
1504 if deferrable is None:
1505 return ""
1506 if deferrable == Deferrable.DEFERRED:
1507 return " DEFERRABLE INITIALLY DEFERRED"
1508 if deferrable == Deferrable.IMMEDIATE:
1509 return " DEFERRABLE INITIALLY IMMEDIATE"
1511 def _unique_sql(
1512 self,
1513 model,
1514 fields,
1515 name,
1516 condition=None,
1517 deferrable=None,
1518 include=None,
1519 opclasses=None,
1520 expressions=None,
1521 ):
1522 if (
1523 deferrable
1524 and not self.connection.features.supports_deferrable_unique_constraints
1525 ):
1526 return None
1527 if condition or include or opclasses or expressions:
1528 # Databases support conditional, covering, and functional unique
1529 # constraints via a unique index.
1530 sql = self._create_unique_sql(
1531 model,
1532 fields,
1533 name=name,
1534 condition=condition,
1535 include=include,
1536 opclasses=opclasses,
1537 expressions=expressions,
1538 )
1539 if sql:
1540 self.deferred_sql.append(sql)
1541 return None
1542 constraint = self.sql_unique_constraint % {
1543 "columns": ", ".join([self.quote_name(field.column) for field in fields]),
1544 "deferrable": self._deferrable_constraint_sql(deferrable),
1545 }
1546 return self.sql_constraint % {
1547 "name": self.quote_name(name),
1548 "constraint": constraint,
1549 }
1551 def _create_unique_sql(
1552 self,
1553 model,
1554 fields,
1555 name=None,
1556 condition=None,
1557 deferrable=None,
1558 include=None,
1559 opclasses=None,
1560 expressions=None,
1561 ):
1562 if (
1563 (
1564 deferrable
1565 and not self.connection.features.supports_deferrable_unique_constraints
1566 )
1567 or (condition and not self.connection.features.supports_partial_indexes)
1568 or (include and not self.connection.features.supports_covering_indexes)
1569 or (
1570 expressions and not self.connection.features.supports_expression_indexes
1571 )
1572 ):
1573 return None
1575 compiler = Query(model, alias_cols=False).get_compiler(
1576 connection=self.connection
1577 )
1578 table = model._meta.db_table
1579 columns = [field.column for field in fields]
1580 if name is None:
1581 name = self._unique_constraint_name(table, columns, quote=True)
1582 else:
1583 name = self.quote_name(name)
1584 if condition or include or opclasses or expressions:
1585 sql = self.sql_create_unique_index
1586 else:
1587 sql = self.sql_create_unique
1588 if columns:
1589 columns = self._index_columns(
1590 table, columns, col_suffixes=(), opclasses=opclasses
1591 )
1592 else:
1593 columns = Expressions(table, expressions, compiler, self.quote_value)
1594 return Statement(
1595 sql,
1596 table=Table(table, self.quote_name),
1597 name=name,
1598 columns=columns,
1599 condition=self._index_condition_sql(condition),
1600 deferrable=self._deferrable_constraint_sql(deferrable),
1601 include=self._index_include_sql(model, include),
1602 )
1604 def _unique_constraint_name(self, table, columns, quote=True):
1605 if quote:
1607 def create_unique_name(*args, **kwargs):
1608 return self.quote_name(self._create_index_name(*args, **kwargs))
1610 else:
1611 create_unique_name = self._create_index_name
1613 return IndexName(table, columns, "_uniq", create_unique_name)
1615 def _delete_unique_sql(
1616 self,
1617 model,
1618 name,
1619 condition=None,
1620 deferrable=None,
1621 include=None,
1622 opclasses=None,
1623 expressions=None,
1624 ):
1625 if (
1626 (
1627 deferrable
1628 and not self.connection.features.supports_deferrable_unique_constraints
1629 )
1630 or (condition and not self.connection.features.supports_partial_indexes)
1631 or (include and not self.connection.features.supports_covering_indexes)
1632 or (
1633 expressions and not self.connection.features.supports_expression_indexes
1634 )
1635 ):
1636 return None
1637 if condition or include or opclasses or expressions:
1638 sql = self.sql_delete_index
1639 else:
1640 sql = self.sql_delete_unique
1641 return self._delete_constraint_sql(sql, model, name)
1643 def _check_sql(self, name, check):
1644 return self.sql_constraint % {
1645 "name": self.quote_name(name),
1646 "constraint": self.sql_check_constraint % {"check": check},
1647 }
1649 def _create_check_sql(self, model, name, check):
1650 if not self.connection.features.supports_table_check_constraints:
1651 return None
1652 return Statement(
1653 self.sql_create_check,
1654 table=Table(model._meta.db_table, self.quote_name),
1655 name=self.quote_name(name),
1656 check=check,
1657 )
1659 def _delete_check_sql(self, model, name):
1660 if not self.connection.features.supports_table_check_constraints:
1661 return None
1662 return self._delete_constraint_sql(self.sql_delete_check, model, name)
1664 def _delete_constraint_sql(self, template, model, name):
1665 return Statement(
1666 template,
1667 table=Table(model._meta.db_table, self.quote_name),
1668 name=self.quote_name(name),
1669 )
1671 def _constraint_names(
1672 self,
1673 model,
1674 column_names=None,
1675 unique=None,
1676 primary_key=None,
1677 index=None,
1678 foreign_key=None,
1679 check=None,
1680 type_=None,
1681 exclude=None,
1682 ):
1683 """Return all constraint names matching the columns and conditions."""
1684 if column_names is not None:
1685 column_names = [
1686 self.connection.introspection.identifier_converter(
1687 truncate_name(name, self.connection.ops.max_name_length())
1688 )
1689 if self.connection.features.truncates_names
1690 else self.connection.introspection.identifier_converter(name)
1691 for name in column_names
1692 ]
1693 with self.connection.cursor() as cursor:
1694 constraints = self.connection.introspection.get_constraints(
1695 cursor, model._meta.db_table
1696 )
1697 result = []
1698 for name, infodict in constraints.items():
1699 if column_names is None or column_names == infodict["columns"]:
1700 if unique is not None and infodict["unique"] != unique:
1701 continue
1702 if primary_key is not None and infodict["primary_key"] != primary_key:
1703 continue
1704 if index is not None and infodict["index"] != index:
1705 continue
1706 if check is not None and infodict["check"] != check:
1707 continue
1708 if foreign_key is not None and not infodict["foreign_key"]:
1709 continue
1710 if type_ is not None and infodict["type"] != type_:
1711 continue
1712 if not exclude or name not in exclude:
1713 result.append(name)
1714 return result
1716 def _delete_primary_key(self, model, strict=False):
1717 constraint_names = self._constraint_names(model, primary_key=True)
1718 if strict and len(constraint_names) != 1:
1719 raise ValueError(
1720 "Found wrong number ({}) of PK constraints for {}".format(
1721 len(constraint_names),
1722 model._meta.db_table,
1723 )
1724 )
1725 for constraint_name in constraint_names:
1726 self.execute(self._delete_primary_key_sql(model, constraint_name))
1728 def _create_primary_key_sql(self, model, field):
1729 return Statement(
1730 self.sql_create_pk,
1731 table=Table(model._meta.db_table, self.quote_name),
1732 name=self.quote_name(
1733 self._create_index_name(
1734 model._meta.db_table, [field.column], suffix="_pk"
1735 )
1736 ),
1737 columns=Columns(model._meta.db_table, [field.column], self.quote_name),
1738 )
1740 def _delete_primary_key_sql(self, model, name):
1741 return self._delete_constraint_sql(self.sql_delete_pk, model, name)
1743 def _collate_sql(self, collation, old_collation=None, table_name=None):
1744 return "COLLATE " + self.quote_name(collation) if collation else ""
1746 def remove_procedure(self, procedure_name, param_types=()):
1747 sql = self.sql_delete_procedure % {
1748 "procedure": self.quote_name(procedure_name),
1749 "param_types": ",".join(param_types),
1750 }
1751 self.execute(sql)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1class BaseDatabaseValidation:
2 """Encapsulate backend-specific validation."""
4 def __init__(self, connection):
5 self.connection = connection
7 def check(self, **kwargs):
8 return []
10 def check_field(self, field, **kwargs):
11 errors = []
12 # Backends may implement a check_field_type() method.
13 if (
14 hasattr(self, "check_field_type")
15 and
16 # Ignore any related fields.
17 not getattr(field, "remote_field", None)
18 ):
19 # Ignore fields with unsupported features.
20 db_supports_all_required_features = all(
21 getattr(self.connection.features, feature, False)
22 for feature in field.model._meta.required_db_features
23 )
24 if db_supports_all_required_features:
25 field_type = field.db_type(self.connection)
26 # Ignore non-concrete fields.
27 if field_type is not None:
28 errors.extend(self.check_field_type(field, field_type))
29 return errors
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from .fields import AddField, AlterField, RemoveField, RenameField
2from .models import (
3 AddConstraint,
4 AddIndex,
5 AlterModelManagers,
6 AlterModelOptions,
7 AlterModelTable,
8 AlterModelTableComment,
9 AlterOrderWithRespectTo,
10 CreateModel,
11 DeleteModel,
12 RemoveConstraint,
13 RemoveIndex,
14 RenameIndex,
15 RenameModel,
16)
17from .special import RunPython, RunSQL, SeparateDatabaseAndState
19__all__ = [
20 "CreateModel",
21 "DeleteModel",
22 "AlterModelTable",
23 "AlterModelTableComment",
24 "RenameModel",
25 "AlterModelOptions",
26 "AddIndex",
27 "RemoveIndex",
28 "RenameIndex",
29 "AddField",
30 "RemoveField",
31 "AlterField",
32 "RenameField",
33 "AddConstraint",
34 "RemoveConstraint",
35 "SeparateDatabaseAndState",
36 "RunSQL",
37 "RunPython",
38 "AlterOrderWithRespectTo",
39 "AlterModelManagers",
40]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.models.db import router
4class Operation:
5 """
6 Base class for migration operations.
8 It's responsible for both mutating the in-memory model state
9 (see db/migrations/state.py) to represent what it performs, as well
10 as actually performing it against a live database.
12 Note that some operations won't modify memory state at all (e.g. data
13 copying operations), and some will need their modifications to be
14 optionally specified by the user (e.g. custom Python code snippets)
16 Due to the way this class deals with deconstruction, it should be
17 considered immutable.
18 """
20 # If this migration can be run in reverse.
21 # Some operations are impossible to reverse, like deleting data.
22 reversible = True
24 # Can this migration be represented as SQL? (things like RunPython cannot)
25 reduces_to_sql = True
27 # Should this operation be forced as atomic even on backends with no
28 # DDL transaction support (i.e., does it have no DDL, like RunPython)
29 atomic = False
31 # Should this operation be considered safe to elide and optimize across?
32 elidable = False
34 serialization_expand_args = []
36 def __new__(cls, *args, **kwargs):
37 # We capture the arguments to make returning them trivial
38 self = object.__new__(cls)
39 self._constructor_args = (args, kwargs)
40 return self
42 def deconstruct(self):
43 """
44 Return a 3-tuple of class import path (or just name if it lives
45 under plain.models.migrations), positional arguments, and keyword
46 arguments.
47 """
48 return (
49 self.__class__.__name__,
50 self._constructor_args[0],
51 self._constructor_args[1],
52 )
54 def state_forwards(self, package_label, state):
55 """
56 Take the state from the previous migration, and mutate it
57 so that it matches what this migration would perform.
58 """
59 raise NotImplementedError(
60 "subclasses of Operation must provide a state_forwards() method"
61 )
63 def database_forwards(self, package_label, schema_editor, from_state, to_state):
64 """
65 Perform the mutation on the database schema in the normal
66 (forwards) direction.
67 """
68 raise NotImplementedError(
69 "subclasses of Operation must provide a database_forwards() method"
70 )
72 def database_backwards(self, package_label, schema_editor, from_state, to_state):
73 """
74 Perform the mutation on the database schema in the reverse
75 direction - e.g. if this were CreateModel, it would in fact
76 drop the model's table.
77 """
78 raise NotImplementedError(
79 "subclasses of Operation must provide a database_backwards() method"
80 )
82 def describe(self):
83 """
84 Output a brief summary of what the action does.
85 """
86 return f"{self.__class__.__name__}: {self._constructor_args}"
88 @property
89 def migration_name_fragment(self):
90 """
91 A filename part suitable for automatically naming a migration
92 containing this operation, or None if not applicable.
93 """
94 return None
96 def references_model(self, name, package_label):
97 """
98 Return True if there is a chance this operation references the given
99 model name (as a string), with an app label for accuracy.
101 Used for optimization. If in doubt, return True;
102 returning a false positive will merely make the optimizer a little
103 less efficient, while returning a false negative may result in an
104 unusable optimized migration.
105 """
106 return True
108 def references_field(self, model_name, name, package_label):
109 """
110 Return True if there is a chance this operation references the given
111 field name, with an app label for accuracy.
113 Used for optimization. If in doubt, return True.
114 """
115 return self.references_model(model_name, package_label)
117 def allow_migrate_model(self, connection_alias, model):
118 """
119 Return whether or not a model may be migrated.
121 This is a thin wrapper around router.allow_migrate_model() that
122 preemptively rejects any swapped out or unmanaged model.
123 """
124 if not model._meta.can_migrate(connection_alias):
125 return False
127 return router.allow_migrate_model(connection_alias, model)
129 def reduce(self, operation, package_label):
130 """
131 Return either a list of operations the actual operation should be
132 replaced with or a boolean that indicates whether or not the specified
133 operation can be optimized across.
134 """
135 if self.elidable:
136 return [operation]
137 elif operation.elidable:
138 return [self]
139 return False
141 def __repr__(self):
142 return "<{} {}{}>".format(
143 self.__class__.__name__,
144 ", ".join(map(repr, self._constructor_args[0])),
145 ",".join(" {}={!r}".format(*x) for x in self._constructor_args[1].items()),
146 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.models.fields import NOT_PROVIDED
2from plain.models.migrations.utils import field_references
3from plain.utils.functional import cached_property
5from .base import Operation
8class FieldOperation(Operation):
9 def __init__(self, model_name, name, field=None):
10 self.model_name = model_name
11 self.name = name
12 self.field = field
14 @cached_property
15 def model_name_lower(self):
16 return self.model_name.lower()
18 @cached_property
19 def name_lower(self):
20 return self.name.lower()
22 def is_same_model_operation(self, operation):
23 return self.model_name_lower == operation.model_name_lower
25 def is_same_field_operation(self, operation):
26 return (
27 self.is_same_model_operation(operation)
28 and self.name_lower == operation.name_lower
29 )
31 def references_model(self, name, package_label):
32 name_lower = name.lower()
33 if name_lower == self.model_name_lower:
34 return True
35 if self.field:
36 return bool(
37 field_references(
38 (package_label, self.model_name_lower),
39 self.field,
40 (package_label, name_lower),
41 )
42 )
43 return False
45 def references_field(self, model_name, name, package_label):
46 model_name_lower = model_name.lower()
47 # Check if this operation locally references the field.
48 if model_name_lower == self.model_name_lower:
49 if name == self.name:
50 return True
51 elif (
52 self.field
53 and hasattr(self.field, "from_fields")
54 and name in self.field.from_fields
55 ):
56 return True
57 # Check if this operation remotely references the field.
58 if self.field is None:
59 return False
60 return bool(
61 field_references(
62 (package_label, self.model_name_lower),
63 self.field,
64 (package_label, model_name_lower),
65 name,
66 )
67 )
69 def reduce(self, operation, package_label):
70 return super().reduce(
71 operation, package_label
72 ) or not operation.references_field(self.model_name, self.name, package_label)
75class AddField(FieldOperation):
76 """Add a field to a model."""
78 def __init__(self, model_name, name, field, preserve_default=True):
79 self.preserve_default = preserve_default
80 super().__init__(model_name, name, field)
82 def deconstruct(self):
83 kwargs = {
84 "model_name": self.model_name,
85 "name": self.name,
86 "field": self.field,
87 }
88 if self.preserve_default is not True:
89 kwargs["preserve_default"] = self.preserve_default
90 return (self.__class__.__name__, [], kwargs)
92 def state_forwards(self, package_label, state):
93 state.add_field(
94 package_label,
95 self.model_name_lower,
96 self.name,
97 self.field,
98 self.preserve_default,
99 )
101 def database_forwards(self, package_label, schema_editor, from_state, to_state):
102 to_model = to_state.packages.get_model(package_label, self.model_name)
103 if self.allow_migrate_model(schema_editor.connection.alias, to_model):
104 from_model = from_state.packages.get_model(package_label, self.model_name)
105 field = to_model._meta.get_field(self.name)
106 if not self.preserve_default:
107 field.default = self.field.default
108 schema_editor.add_field(
109 from_model,
110 field,
111 )
112 if not self.preserve_default:
113 field.default = NOT_PROVIDED
115 def database_backwards(self, package_label, schema_editor, from_state, to_state):
116 from_model = from_state.packages.get_model(package_label, self.model_name)
117 if self.allow_migrate_model(schema_editor.connection.alias, from_model):
118 schema_editor.remove_field(
119 from_model, from_model._meta.get_field(self.name)
120 )
122 def describe(self):
123 return f"Add field {self.name} to {self.model_name}"
125 @property
126 def migration_name_fragment(self):
127 return f"{self.model_name_lower}_{self.name_lower}"
129 def reduce(self, operation, package_label):
130 if isinstance(operation, FieldOperation) and self.is_same_field_operation(
131 operation
132 ):
133 if isinstance(operation, AlterField):
134 return [
135 AddField(
136 model_name=self.model_name,
137 name=operation.name,
138 field=operation.field,
139 ),
140 ]
141 elif isinstance(operation, RemoveField):
142 return []
143 elif isinstance(operation, RenameField):
144 return [
145 AddField(
146 model_name=self.model_name,
147 name=operation.new_name,
148 field=self.field,
149 ),
150 ]
151 return super().reduce(operation, package_label)
154class RemoveField(FieldOperation):
155 """Remove a field from a model."""
157 def deconstruct(self):
158 kwargs = {
159 "model_name": self.model_name,
160 "name": self.name,
161 }
162 return (self.__class__.__name__, [], kwargs)
164 def state_forwards(self, package_label, state):
165 state.remove_field(package_label, self.model_name_lower, self.name)
167 def database_forwards(self, package_label, schema_editor, from_state, to_state):
168 from_model = from_state.packages.get_model(package_label, self.model_name)
169 if self.allow_migrate_model(schema_editor.connection.alias, from_model):
170 schema_editor.remove_field(
171 from_model, from_model._meta.get_field(self.name)
172 )
174 def database_backwards(self, package_label, schema_editor, from_state, to_state):
175 to_model = to_state.packages.get_model(package_label, self.model_name)
176 if self.allow_migrate_model(schema_editor.connection.alias, to_model):
177 from_model = from_state.packages.get_model(package_label, self.model_name)
178 schema_editor.add_field(from_model, to_model._meta.get_field(self.name))
180 def describe(self):
181 return f"Remove field {self.name} from {self.model_name}"
183 @property
184 def migration_name_fragment(self):
185 return f"remove_{self.model_name_lower}_{self.name_lower}"
187 def reduce(self, operation, package_label):
188 from .models import DeleteModel
190 if (
191 isinstance(operation, DeleteModel)
192 and operation.name_lower == self.model_name_lower
193 ):
194 return [operation]
195 return super().reduce(operation, package_label)
198class AlterField(FieldOperation):
199 """
200 Alter a field's database column (e.g. null, max_length) to the provided
201 new field.
202 """
204 def __init__(self, model_name, name, field, preserve_default=True):
205 self.preserve_default = preserve_default
206 super().__init__(model_name, name, field)
208 def deconstruct(self):
209 kwargs = {
210 "model_name": self.model_name,
211 "name": self.name,
212 "field": self.field,
213 }
214 if self.preserve_default is not True:
215 kwargs["preserve_default"] = self.preserve_default
216 return (self.__class__.__name__, [], kwargs)
218 def state_forwards(self, package_label, state):
219 state.alter_field(
220 package_label,
221 self.model_name_lower,
222 self.name,
223 self.field,
224 self.preserve_default,
225 )
227 def database_forwards(self, package_label, schema_editor, from_state, to_state):
228 to_model = to_state.packages.get_model(package_label, self.model_name)
229 if self.allow_migrate_model(schema_editor.connection.alias, to_model):
230 from_model = from_state.packages.get_model(package_label, self.model_name)
231 from_field = from_model._meta.get_field(self.name)
232 to_field = to_model._meta.get_field(self.name)
233 if not self.preserve_default:
234 to_field.default = self.field.default
235 schema_editor.alter_field(from_model, from_field, to_field)
236 if not self.preserve_default:
237 to_field.default = NOT_PROVIDED
239 def database_backwards(self, package_label, schema_editor, from_state, to_state):
240 self.database_forwards(package_label, schema_editor, from_state, to_state)
242 def describe(self):
243 return f"Alter field {self.name} on {self.model_name}"
245 @property
246 def migration_name_fragment(self):
247 return f"alter_{self.model_name_lower}_{self.name_lower}"
249 def reduce(self, operation, package_label):
250 if isinstance(
251 operation, AlterField | RemoveField
252 ) and self.is_same_field_operation(operation):
253 return [operation]
254 elif (
255 isinstance(operation, RenameField)
256 and self.is_same_field_operation(operation)
257 and self.field.db_column is None
258 ):
259 return [
260 operation,
261 AlterField(
262 model_name=self.model_name,
263 name=operation.new_name,
264 field=self.field,
265 ),
266 ]
267 return super().reduce(operation, package_label)
270class RenameField(FieldOperation):
271 """Rename a field on the model. Might affect db_column too."""
273 def __init__(self, model_name, old_name, new_name):
274 self.old_name = old_name
275 self.new_name = new_name
276 super().__init__(model_name, old_name)
278 @cached_property
279 def old_name_lower(self):
280 return self.old_name.lower()
282 @cached_property
283 def new_name_lower(self):
284 return self.new_name.lower()
286 def deconstruct(self):
287 kwargs = {
288 "model_name": self.model_name,
289 "old_name": self.old_name,
290 "new_name": self.new_name,
291 }
292 return (self.__class__.__name__, [], kwargs)
294 def state_forwards(self, package_label, state):
295 state.rename_field(
296 package_label, self.model_name_lower, self.old_name, self.new_name
297 )
299 def database_forwards(self, package_label, schema_editor, from_state, to_state):
300 to_model = to_state.packages.get_model(package_label, self.model_name)
301 if self.allow_migrate_model(schema_editor.connection.alias, to_model):
302 from_model = from_state.packages.get_model(package_label, self.model_name)
303 schema_editor.alter_field(
304 from_model,
305 from_model._meta.get_field(self.old_name),
306 to_model._meta.get_field(self.new_name),
307 )
309 def database_backwards(self, package_label, schema_editor, from_state, to_state):
310 to_model = to_state.packages.get_model(package_label, self.model_name)
311 if self.allow_migrate_model(schema_editor.connection.alias, to_model):
312 from_model = from_state.packages.get_model(package_label, self.model_name)
313 schema_editor.alter_field(
314 from_model,
315 from_model._meta.get_field(self.new_name),
316 to_model._meta.get_field(self.old_name),
317 )
319 def describe(self):
320 return f"Rename field {self.old_name} on {self.model_name} to {self.new_name}"
322 @property
323 def migration_name_fragment(self):
324 return f"rename_{self.old_name_lower}_{self.model_name_lower}_{self.new_name_lower}"
326 def references_field(self, model_name, name, package_label):
327 return self.references_model(model_name, package_label) and (
328 name.lower() == self.old_name_lower or name.lower() == self.new_name_lower
329 )
331 def reduce(self, operation, package_label):
332 if (
333 isinstance(operation, RenameField)
334 and self.is_same_model_operation(operation)
335 and self.new_name_lower == operation.old_name_lower
336 ):
337 return [
338 RenameField(
339 self.model_name,
340 self.old_name,
341 operation.new_name,
342 ),
343 ]
344 # Skip `FieldOperation.reduce` as we want to run `references_field`
345 # against self.old_name and self.new_name.
346 return super(FieldOperation, self).reduce(operation, package_label) or not (
347 operation.references_field(self.model_name, self.old_name, package_label)
348 or operation.references_field(self.model_name, self.new_name, package_label)
349 )
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain import models
2from plain.models.migrations.operations.base import Operation
3from plain.models.migrations.state import ModelState
4from plain.models.migrations.utils import field_references, resolve_relation
5from plain.utils.functional import cached_property
7from .fields import AddField, AlterField, FieldOperation, RemoveField, RenameField
10def _check_for_duplicates(arg_name, objs):
11 used_vals = set()
12 for val in objs:
13 if val in used_vals:
14 raise ValueError(
15 f"Found duplicate value {val} in CreateModel {arg_name} argument."
16 )
17 used_vals.add(val)
20class ModelOperation(Operation):
21 def __init__(self, name):
22 self.name = name
24 @cached_property
25 def name_lower(self):
26 return self.name.lower()
28 def references_model(self, name, package_label):
29 return name.lower() == self.name_lower
31 def reduce(self, operation, package_label):
32 return super().reduce(operation, package_label) or self.can_reduce_through(
33 operation, package_label
34 )
36 def can_reduce_through(self, operation, package_label):
37 return not operation.references_model(self.name, package_label)
40class CreateModel(ModelOperation):
41 """Create a model's table."""
43 serialization_expand_args = ["fields", "options", "managers"]
45 def __init__(self, name, fields, options=None, bases=None, managers=None):
46 self.fields = fields
47 self.options = options or {}
48 self.bases = bases or (models.Model,)
49 self.managers = managers or []
50 super().__init__(name)
51 # Sanity-check that there are no duplicated field names, bases, or
52 # manager names
53 _check_for_duplicates("fields", (name for name, _ in self.fields))
54 _check_for_duplicates(
55 "bases",
56 (
57 base._meta.label_lower
58 if hasattr(base, "_meta")
59 else base.lower()
60 if isinstance(base, str)
61 else base
62 for base in self.bases
63 ),
64 )
65 _check_for_duplicates("managers", (name for name, _ in self.managers))
67 def deconstruct(self):
68 kwargs = {
69 "name": self.name,
70 "fields": self.fields,
71 }
72 if self.options:
73 kwargs["options"] = self.options
74 if self.bases and self.bases != (models.Model,):
75 kwargs["bases"] = self.bases
76 if self.managers and self.managers != [("objects", models.Manager())]:
77 kwargs["managers"] = self.managers
78 return (self.__class__.__qualname__, [], kwargs)
80 def state_forwards(self, package_label, state):
81 state.add_model(
82 ModelState(
83 package_label,
84 self.name,
85 list(self.fields),
86 dict(self.options),
87 tuple(self.bases),
88 list(self.managers),
89 )
90 )
92 def database_forwards(self, package_label, schema_editor, from_state, to_state):
93 model = to_state.packages.get_model(package_label, self.name)
94 if self.allow_migrate_model(schema_editor.connection.alias, model):
95 schema_editor.create_model(model)
97 def database_backwards(self, package_label, schema_editor, from_state, to_state):
98 model = from_state.packages.get_model(package_label, self.name)
99 if self.allow_migrate_model(schema_editor.connection.alias, model):
100 schema_editor.delete_model(model)
102 def describe(self):
103 return f"Create model {self.name}"
105 @property
106 def migration_name_fragment(self):
107 return self.name_lower
109 def references_model(self, name, package_label):
110 name_lower = name.lower()
111 if name_lower == self.name_lower:
112 return True
114 # Check we didn't inherit from the model
115 reference_model_tuple = (package_label, name_lower)
116 for base in self.bases:
117 if (
118 base is not models.Model
119 and isinstance(base, models.base.ModelBase | str)
120 and resolve_relation(base, package_label) == reference_model_tuple
121 ):
122 return True
124 # Check we have no FKs/M2Ms with it
125 for _name, field in self.fields:
126 if field_references(
127 (package_label, self.name_lower), field, reference_model_tuple
128 ):
129 return True
130 return False
132 def reduce(self, operation, package_label):
133 if (
134 isinstance(operation, DeleteModel)
135 and self.name_lower == operation.name_lower
136 ):
137 return []
138 elif (
139 isinstance(operation, RenameModel)
140 and self.name_lower == operation.old_name_lower
141 ):
142 return [
143 CreateModel(
144 operation.new_name,
145 fields=self.fields,
146 options=self.options,
147 bases=self.bases,
148 managers=self.managers,
149 ),
150 ]
151 elif (
152 isinstance(operation, AlterModelOptions)
153 and self.name_lower == operation.name_lower
154 ):
155 options = {**self.options, **operation.options}
156 for key in operation.ALTER_OPTION_KEYS:
157 if key not in operation.options:
158 options.pop(key, None)
159 return [
160 CreateModel(
161 self.name,
162 fields=self.fields,
163 options=options,
164 bases=self.bases,
165 managers=self.managers,
166 ),
167 ]
168 elif (
169 isinstance(operation, AlterModelManagers)
170 and self.name_lower == operation.name_lower
171 ):
172 return [
173 CreateModel(
174 self.name,
175 fields=self.fields,
176 options=self.options,
177 bases=self.bases,
178 managers=operation.managers,
179 ),
180 ]
181 elif (
182 isinstance(operation, AlterOrderWithRespectTo)
183 and self.name_lower == operation.name_lower
184 ):
185 return [
186 CreateModel(
187 self.name,
188 fields=self.fields,
189 options={
190 **self.options,
191 "order_with_respect_to": operation.order_with_respect_to,
192 },
193 bases=self.bases,
194 managers=self.managers,
195 ),
196 ]
197 elif (
198 isinstance(operation, FieldOperation)
199 and self.name_lower == operation.model_name_lower
200 ):
201 if isinstance(operation, AddField):
202 return [
203 CreateModel(
204 self.name,
205 fields=self.fields + [(operation.name, operation.field)],
206 options=self.options,
207 bases=self.bases,
208 managers=self.managers,
209 ),
210 ]
211 elif isinstance(operation, AlterField):
212 return [
213 CreateModel(
214 self.name,
215 fields=[
216 (n, operation.field if n == operation.name else v)
217 for n, v in self.fields
218 ],
219 options=self.options,
220 bases=self.bases,
221 managers=self.managers,
222 ),
223 ]
224 elif isinstance(operation, RemoveField):
225 options = self.options.copy()
227 order_with_respect_to = options.get("order_with_respect_to")
228 if order_with_respect_to == operation.name_lower:
229 del options["order_with_respect_to"]
230 return [
231 CreateModel(
232 self.name,
233 fields=[
234 (n, v)
235 for n, v in self.fields
236 if n.lower() != operation.name_lower
237 ],
238 options=options,
239 bases=self.bases,
240 managers=self.managers,
241 ),
242 ]
243 elif isinstance(operation, RenameField):
244 options = self.options.copy()
246 order_with_respect_to = options.get("order_with_respect_to")
247 if order_with_respect_to == operation.old_name:
248 options["order_with_respect_to"] = operation.new_name
249 return [
250 CreateModel(
251 self.name,
252 fields=[
253 (operation.new_name if n == operation.old_name else n, v)
254 for n, v in self.fields
255 ],
256 options=options,
257 bases=self.bases,
258 managers=self.managers,
259 ),
260 ]
261 return super().reduce(operation, package_label)
264class DeleteModel(ModelOperation):
265 """Drop a model's table."""
267 def deconstruct(self):
268 kwargs = {
269 "name": self.name,
270 }
271 return (self.__class__.__qualname__, [], kwargs)
273 def state_forwards(self, package_label, state):
274 state.remove_model(package_label, self.name_lower)
276 def database_forwards(self, package_label, schema_editor, from_state, to_state):
277 model = from_state.packages.get_model(package_label, self.name)
278 if self.allow_migrate_model(schema_editor.connection.alias, model):
279 schema_editor.delete_model(model)
281 def database_backwards(self, package_label, schema_editor, from_state, to_state):
282 model = to_state.packages.get_model(package_label, self.name)
283 if self.allow_migrate_model(schema_editor.connection.alias, model):
284 schema_editor.create_model(model)
286 def references_model(self, name, package_label):
287 # The deleted model could be referencing the specified model through
288 # related fields.
289 return True
291 def describe(self):
292 return f"Delete model {self.name}"
294 @property
295 def migration_name_fragment(self):
296 return f"delete_{self.name_lower}"
299class RenameModel(ModelOperation):
300 """Rename a model."""
302 def __init__(self, old_name, new_name):
303 self.old_name = old_name
304 self.new_name = new_name
305 super().__init__(old_name)
307 @cached_property
308 def old_name_lower(self):
309 return self.old_name.lower()
311 @cached_property
312 def new_name_lower(self):
313 return self.new_name.lower()
315 def deconstruct(self):
316 kwargs = {
317 "old_name": self.old_name,
318 "new_name": self.new_name,
319 }
320 return (self.__class__.__qualname__, [], kwargs)
322 def state_forwards(self, package_label, state):
323 state.rename_model(package_label, self.old_name, self.new_name)
325 def database_forwards(self, package_label, schema_editor, from_state, to_state):
326 new_model = to_state.packages.get_model(package_label, self.new_name)
327 if self.allow_migrate_model(schema_editor.connection.alias, new_model):
328 old_model = from_state.packages.get_model(package_label, self.old_name)
329 # Move the main table
330 schema_editor.alter_db_table(
331 new_model,
332 old_model._meta.db_table,
333 new_model._meta.db_table,
334 )
335 # Alter the fields pointing to us
336 for related_object in old_model._meta.related_objects:
337 if related_object.related_model == old_model:
338 model = new_model
339 related_key = (package_label, self.new_name_lower)
340 else:
341 model = related_object.related_model
342 related_key = (
343 related_object.related_model._meta.package_label,
344 related_object.related_model._meta.model_name,
345 )
346 to_field = to_state.packages.get_model(*related_key)._meta.get_field(
347 related_object.field.name
348 )
349 schema_editor.alter_field(
350 model,
351 related_object.field,
352 to_field,
353 )
354 # Rename M2M fields whose name is based on this model's name.
355 fields = zip(
356 old_model._meta.local_many_to_many, new_model._meta.local_many_to_many
357 )
358 for old_field, new_field in fields:
359 # Skip self-referential fields as these are renamed above.
360 if (
361 new_field.model == new_field.related_model
362 or not new_field.remote_field.through._meta.auto_created
363 ):
364 continue
365 # Rename columns and the M2M table.
366 schema_editor._alter_many_to_many(
367 new_model,
368 old_field,
369 new_field,
370 strict=False,
371 )
373 def database_backwards(self, package_label, schema_editor, from_state, to_state):
374 self.new_name_lower, self.old_name_lower = (
375 self.old_name_lower,
376 self.new_name_lower,
377 )
378 self.new_name, self.old_name = self.old_name, self.new_name
380 self.database_forwards(package_label, schema_editor, from_state, to_state)
382 self.new_name_lower, self.old_name_lower = (
383 self.old_name_lower,
384 self.new_name_lower,
385 )
386 self.new_name, self.old_name = self.old_name, self.new_name
388 def references_model(self, name, package_label):
389 return (
390 name.lower() == self.old_name_lower or name.lower() == self.new_name_lower
391 )
393 def describe(self):
394 return f"Rename model {self.old_name} to {self.new_name}"
396 @property
397 def migration_name_fragment(self):
398 return f"rename_{self.old_name_lower}_{self.new_name_lower}"
400 def reduce(self, operation, package_label):
401 if (
402 isinstance(operation, RenameModel)
403 and self.new_name_lower == operation.old_name_lower
404 ):
405 return [
406 RenameModel(
407 self.old_name,
408 operation.new_name,
409 ),
410 ]
411 # Skip `ModelOperation.reduce` as we want to run `references_model`
412 # against self.new_name.
413 return super(ModelOperation, self).reduce(
414 operation, package_label
415 ) or not operation.references_model(self.new_name, package_label)
418class ModelOptionOperation(ModelOperation):
419 def reduce(self, operation, package_label):
420 if (
421 isinstance(operation, self.__class__ | DeleteModel)
422 and self.name_lower == operation.name_lower
423 ):
424 return [operation]
425 return super().reduce(operation, package_label)
428class AlterModelTable(ModelOptionOperation):
429 """Rename a model's table."""
431 def __init__(self, name, table):
432 self.table = table
433 super().__init__(name)
435 def deconstruct(self):
436 kwargs = {
437 "name": self.name,
438 "table": self.table,
439 }
440 return (self.__class__.__qualname__, [], kwargs)
442 def state_forwards(self, package_label, state):
443 state.alter_model_options(
444 package_label, self.name_lower, {"db_table": self.table}
445 )
447 def database_forwards(self, package_label, schema_editor, from_state, to_state):
448 new_model = to_state.packages.get_model(package_label, self.name)
449 if self.allow_migrate_model(schema_editor.connection.alias, new_model):
450 old_model = from_state.packages.get_model(package_label, self.name)
451 schema_editor.alter_db_table(
452 new_model,
453 old_model._meta.db_table,
454 new_model._meta.db_table,
455 )
456 # Rename M2M fields whose name is based on this model's db_table
457 for old_field, new_field in zip(
458 old_model._meta.local_many_to_many, new_model._meta.local_many_to_many
459 ):
460 if new_field.remote_field.through._meta.auto_created:
461 schema_editor.alter_db_table(
462 new_field.remote_field.through,
463 old_field.remote_field.through._meta.db_table,
464 new_field.remote_field.through._meta.db_table,
465 )
467 def database_backwards(self, package_label, schema_editor, from_state, to_state):
468 return self.database_forwards(
469 package_label, schema_editor, from_state, to_state
470 )
472 def describe(self):
473 return "Rename table for {} to {}".format(
474 self.name,
475 self.table if self.table is not None else "(default)",
476 )
478 @property
479 def migration_name_fragment(self):
480 return f"alter_{self.name_lower}_table"
483class AlterModelTableComment(ModelOptionOperation):
484 def __init__(self, name, table_comment):
485 self.table_comment = table_comment
486 super().__init__(name)
488 def deconstruct(self):
489 kwargs = {
490 "name": self.name,
491 "table_comment": self.table_comment,
492 }
493 return (self.__class__.__qualname__, [], kwargs)
495 def state_forwards(self, package_label, state):
496 state.alter_model_options(
497 package_label, self.name_lower, {"db_table_comment": self.table_comment}
498 )
500 def database_forwards(self, package_label, schema_editor, from_state, to_state):
501 new_model = to_state.packages.get_model(package_label, self.name)
502 if self.allow_migrate_model(schema_editor.connection.alias, new_model):
503 old_model = from_state.packages.get_model(package_label, self.name)
504 schema_editor.alter_db_table_comment(
505 new_model,
506 old_model._meta.db_table_comment,
507 new_model._meta.db_table_comment,
508 )
510 def database_backwards(self, package_label, schema_editor, from_state, to_state):
511 return self.database_forwards(
512 package_label, schema_editor, from_state, to_state
513 )
515 def describe(self):
516 return f"Alter {self.name} table comment"
518 @property
519 def migration_name_fragment(self):
520 return f"alter_{self.name_lower}_table_comment"
523class AlterOrderWithRespectTo(ModelOptionOperation):
524 """Represent a change with the order_with_respect_to option."""
526 option_name = "order_with_respect_to"
528 def __init__(self, name, order_with_respect_to):
529 self.order_with_respect_to = order_with_respect_to
530 super().__init__(name)
532 def deconstruct(self):
533 kwargs = {
534 "name": self.name,
535 "order_with_respect_to": self.order_with_respect_to,
536 }
537 return (self.__class__.__qualname__, [], kwargs)
539 def state_forwards(self, package_label, state):
540 state.alter_model_options(
541 package_label,
542 self.name_lower,
543 {self.option_name: self.order_with_respect_to},
544 )
546 def database_forwards(self, package_label, schema_editor, from_state, to_state):
547 to_model = to_state.packages.get_model(package_label, self.name)
548 if self.allow_migrate_model(schema_editor.connection.alias, to_model):
549 from_model = from_state.packages.get_model(package_label, self.name)
550 # Remove a field if we need to
551 if (
552 from_model._meta.order_with_respect_to
553 and not to_model._meta.order_with_respect_to
554 ):
555 schema_editor.remove_field(
556 from_model, from_model._meta.get_field("_order")
557 )
558 # Add a field if we need to (altering the column is untouched as
559 # it's likely a rename)
560 elif (
561 to_model._meta.order_with_respect_to
562 and not from_model._meta.order_with_respect_to
563 ):
564 field = to_model._meta.get_field("_order")
565 if not field.has_default():
566 field.default = 0
567 schema_editor.add_field(
568 from_model,
569 field,
570 )
572 def database_backwards(self, package_label, schema_editor, from_state, to_state):
573 self.database_forwards(package_label, schema_editor, from_state, to_state)
575 def references_field(self, model_name, name, package_label):
576 return self.references_model(model_name, package_label) and (
577 self.order_with_respect_to is None or name == self.order_with_respect_to
578 )
580 def describe(self):
581 return (
582 f"Set order_with_respect_to on {self.name} to {self.order_with_respect_to}"
583 )
585 @property
586 def migration_name_fragment(self):
587 return f"alter_{self.name_lower}_order_with_respect_to"
590class AlterModelOptions(ModelOptionOperation):
591 """
592 Set new model options that don't directly affect the database schema
593 (like ordering). Python code in migrations
594 may still need them.
595 """
597 # Model options we want to compare and preserve in an AlterModelOptions op
598 ALTER_OPTION_KEYS = [
599 "base_manager_name",
600 "default_manager_name",
601 "default_related_name",
602 "get_latest_by",
603 "managed",
604 "ordering",
605 "select_on_save",
606 ]
608 def __init__(self, name, options):
609 self.options = options
610 super().__init__(name)
612 def deconstruct(self):
613 kwargs = {
614 "name": self.name,
615 "options": self.options,
616 }
617 return (self.__class__.__qualname__, [], kwargs)
619 def state_forwards(self, package_label, state):
620 state.alter_model_options(
621 package_label,
622 self.name_lower,
623 self.options,
624 self.ALTER_OPTION_KEYS,
625 )
627 def database_forwards(self, package_label, schema_editor, from_state, to_state):
628 pass
630 def database_backwards(self, package_label, schema_editor, from_state, to_state):
631 pass
633 def describe(self):
634 return f"Change Meta options on {self.name}"
636 @property
637 def migration_name_fragment(self):
638 return f"alter_{self.name_lower}_options"
641class AlterModelManagers(ModelOptionOperation):
642 """Alter the model's managers."""
644 serialization_expand_args = ["managers"]
646 def __init__(self, name, managers):
647 self.managers = managers
648 super().__init__(name)
650 def deconstruct(self):
651 return (self.__class__.__qualname__, [self.name, self.managers], {})
653 def state_forwards(self, package_label, state):
654 state.alter_model_managers(package_label, self.name_lower, self.managers)
656 def database_forwards(self, package_label, schema_editor, from_state, to_state):
657 pass
659 def database_backwards(self, package_label, schema_editor, from_state, to_state):
660 pass
662 def describe(self):
663 return f"Change managers on {self.name}"
665 @property
666 def migration_name_fragment(self):
667 return f"alter_{self.name_lower}_managers"
670class IndexOperation(Operation):
671 option_name = "indexes"
673 @cached_property
674 def model_name_lower(self):
675 return self.model_name.lower()
678class AddIndex(IndexOperation):
679 """Add an index on a model."""
681 def __init__(self, model_name, index):
682 self.model_name = model_name
683 if not index.name:
684 raise ValueError(
685 "Indexes passed to AddIndex operations require a name "
686 f"argument. {index!r} doesn't have one."
687 )
688 self.index = index
690 def state_forwards(self, package_label, state):
691 state.add_index(package_label, self.model_name_lower, self.index)
693 def database_forwards(self, package_label, schema_editor, from_state, to_state):
694 model = to_state.packages.get_model(package_label, self.model_name)
695 if self.allow_migrate_model(schema_editor.connection.alias, model):
696 schema_editor.add_index(model, self.index)
698 def database_backwards(self, package_label, schema_editor, from_state, to_state):
699 model = from_state.packages.get_model(package_label, self.model_name)
700 if self.allow_migrate_model(schema_editor.connection.alias, model):
701 schema_editor.remove_index(model, self.index)
703 def deconstruct(self):
704 kwargs = {
705 "model_name": self.model_name,
706 "index": self.index,
707 }
708 return (
709 self.__class__.__qualname__,
710 [],
711 kwargs,
712 )
714 def describe(self):
715 if self.index.expressions:
716 return "Create index {} on {} on model {}".format(
717 self.index.name,
718 ", ".join([str(expression) for expression in self.index.expressions]),
719 self.model_name,
720 )
721 return "Create index {} on field(s) {} of model {}".format(
722 self.index.name,
723 ", ".join(self.index.fields),
724 self.model_name,
725 )
727 @property
728 def migration_name_fragment(self):
729 return f"{self.model_name_lower}_{self.index.name.lower()}"
732class RemoveIndex(IndexOperation):
733 """Remove an index from a model."""
735 def __init__(self, model_name, name):
736 self.model_name = model_name
737 self.name = name
739 def state_forwards(self, package_label, state):
740 state.remove_index(package_label, self.model_name_lower, self.name)
742 def database_forwards(self, package_label, schema_editor, from_state, to_state):
743 model = from_state.packages.get_model(package_label, self.model_name)
744 if self.allow_migrate_model(schema_editor.connection.alias, model):
745 from_model_state = from_state.models[package_label, self.model_name_lower]
746 index = from_model_state.get_index_by_name(self.name)
747 schema_editor.remove_index(model, index)
749 def database_backwards(self, package_label, schema_editor, from_state, to_state):
750 model = to_state.packages.get_model(package_label, self.model_name)
751 if self.allow_migrate_model(schema_editor.connection.alias, model):
752 to_model_state = to_state.models[package_label, self.model_name_lower]
753 index = to_model_state.get_index_by_name(self.name)
754 schema_editor.add_index(model, index)
756 def deconstruct(self):
757 kwargs = {
758 "model_name": self.model_name,
759 "name": self.name,
760 }
761 return (
762 self.__class__.__qualname__,
763 [],
764 kwargs,
765 )
767 def describe(self):
768 return f"Remove index {self.name} from {self.model_name}"
770 @property
771 def migration_name_fragment(self):
772 return f"remove_{self.model_name_lower}_{self.name.lower()}"
775class RenameIndex(IndexOperation):
776 """Rename an index."""
778 def __init__(self, model_name, new_name, old_name=None, old_fields=None):
779 if not old_name and not old_fields:
780 raise ValueError(
781 "RenameIndex requires one of old_name and old_fields arguments to be "
782 "set."
783 )
784 if old_name and old_fields:
785 raise ValueError(
786 "RenameIndex.old_name and old_fields are mutually exclusive."
787 )
788 self.model_name = model_name
789 self.new_name = new_name
790 self.old_name = old_name
791 self.old_fields = old_fields
793 @cached_property
794 def old_name_lower(self):
795 return self.old_name.lower()
797 @cached_property
798 def new_name_lower(self):
799 return self.new_name.lower()
801 def deconstruct(self):
802 kwargs = {
803 "model_name": self.model_name,
804 "new_name": self.new_name,
805 }
806 if self.old_name:
807 kwargs["old_name"] = self.old_name
808 if self.old_fields:
809 kwargs["old_fields"] = self.old_fields
810 return (self.__class__.__qualname__, [], kwargs)
812 def state_forwards(self, package_label, state):
813 if self.old_fields:
814 state.add_index(
815 package_label,
816 self.model_name_lower,
817 models.Index(fields=self.old_fields, name=self.new_name),
818 )
819 else:
820 state.rename_index(
821 package_label, self.model_name_lower, self.old_name, self.new_name
822 )
824 def database_forwards(self, package_label, schema_editor, from_state, to_state):
825 model = to_state.packages.get_model(package_label, self.model_name)
826 if not self.allow_migrate_model(schema_editor.connection.alias, model):
827 return
829 if self.old_fields:
830 from_model = from_state.packages.get_model(package_label, self.model_name)
831 columns = [
832 from_model._meta.get_field(field).column for field in self.old_fields
833 ]
834 matching_index_name = schema_editor._constraint_names(
835 from_model, column_names=columns, index=True
836 )
837 if len(matching_index_name) != 1:
838 raise ValueError(
839 "Found wrong number ({}) of indexes for {}({}).".format(
840 len(matching_index_name),
841 from_model._meta.db_table,
842 ", ".join(columns),
843 )
844 )
845 old_index = models.Index(
846 fields=self.old_fields,
847 name=matching_index_name[0],
848 )
849 else:
850 from_model_state = from_state.models[package_label, self.model_name_lower]
851 old_index = from_model_state.get_index_by_name(self.old_name)
852 # Don't alter when the index name is not changed.
853 if old_index.name == self.new_name:
854 return
856 to_model_state = to_state.models[package_label, self.model_name_lower]
857 new_index = to_model_state.get_index_by_name(self.new_name)
858 schema_editor.rename_index(model, old_index, new_index)
860 def database_backwards(self, package_label, schema_editor, from_state, to_state):
861 if self.old_fields:
862 # Backward operation with unnamed index is a no-op.
863 return
865 self.new_name_lower, self.old_name_lower = (
866 self.old_name_lower,
867 self.new_name_lower,
868 )
869 self.new_name, self.old_name = self.old_name, self.new_name
871 self.database_forwards(package_label, schema_editor, from_state, to_state)
873 self.new_name_lower, self.old_name_lower = (
874 self.old_name_lower,
875 self.new_name_lower,
876 )
877 self.new_name, self.old_name = self.old_name, self.new_name
879 def describe(self):
880 if self.old_name:
881 return (
882 f"Rename index {self.old_name} on {self.model_name} to {self.new_name}"
883 )
884 return (
885 f"Rename unnamed index for {self.old_fields} on {self.model_name} to "
886 f"{self.new_name}"
887 )
889 @property
890 def migration_name_fragment(self):
891 if self.old_name:
892 return f"rename_{self.old_name_lower}_{self.new_name_lower}"
893 return "rename_{}_{}_{}".format(
894 self.model_name_lower,
895 "_".join(self.old_fields),
896 self.new_name_lower,
897 )
899 def reduce(self, operation, package_label):
900 if (
901 isinstance(operation, RenameIndex)
902 and self.model_name_lower == operation.model_name_lower
903 and operation.old_name
904 and self.new_name_lower == operation.old_name_lower
905 ):
906 return [
907 RenameIndex(
908 self.model_name,
909 new_name=operation.new_name,
910 old_name=self.old_name,
911 old_fields=self.old_fields,
912 )
913 ]
914 return super().reduce(operation, package_label)
917class AddConstraint(IndexOperation):
918 option_name = "constraints"
920 def __init__(self, model_name, constraint):
921 self.model_name = model_name
922 self.constraint = constraint
924 def state_forwards(self, package_label, state):
925 state.add_constraint(package_label, self.model_name_lower, self.constraint)
927 def database_forwards(self, package_label, schema_editor, from_state, to_state):
928 model = to_state.packages.get_model(package_label, self.model_name)
929 if self.allow_migrate_model(schema_editor.connection.alias, model):
930 schema_editor.add_constraint(model, self.constraint)
932 def database_backwards(self, package_label, schema_editor, from_state, to_state):
933 model = to_state.packages.get_model(package_label, self.model_name)
934 if self.allow_migrate_model(schema_editor.connection.alias, model):
935 schema_editor.remove_constraint(model, self.constraint)
937 def deconstruct(self):
938 return (
939 self.__class__.__name__,
940 [],
941 {
942 "model_name": self.model_name,
943 "constraint": self.constraint,
944 },
945 )
947 def describe(self):
948 return f"Create constraint {self.constraint.name} on model {self.model_name}"
950 @property
951 def migration_name_fragment(self):
952 return f"{self.model_name_lower}_{self.constraint.name.lower()}"
955class RemoveConstraint(IndexOperation):
956 option_name = "constraints"
958 def __init__(self, model_name, name):
959 self.model_name = model_name
960 self.name = name
962 def state_forwards(self, package_label, state):
963 state.remove_constraint(package_label, self.model_name_lower, self.name)
965 def database_forwards(self, package_label, schema_editor, from_state, to_state):
966 model = to_state.packages.get_model(package_label, self.model_name)
967 if self.allow_migrate_model(schema_editor.connection.alias, model):
968 from_model_state = from_state.models[package_label, self.model_name_lower]
969 constraint = from_model_state.get_constraint_by_name(self.name)
970 schema_editor.remove_constraint(model, constraint)
972 def database_backwards(self, package_label, schema_editor, from_state, to_state):
973 model = to_state.packages.get_model(package_label, self.model_name)
974 if self.allow_migrate_model(schema_editor.connection.alias, model):
975 to_model_state = to_state.models[package_label, self.model_name_lower]
976 constraint = to_model_state.get_constraint_by_name(self.name)
977 schema_editor.add_constraint(model, constraint)
979 def deconstruct(self):
980 return (
981 self.__class__.__name__,
982 [],
983 {
984 "model_name": self.model_name,
985 "name": self.name,
986 },
987 )
989 def describe(self):
990 return f"Remove constraint {self.name} from model {self.model_name}"
992 @property
993 def migration_name_fragment(self):
994 return f"remove_{self.model_name_lower}_{self.name.lower()}"
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.models.db import router
3from .base import Operation
6class SeparateDatabaseAndState(Operation):
7 """
8 Take two lists of operations - ones that will be used for the database,
9 and ones that will be used for the state change. This allows operations
10 that don't support state change to have it applied, or have operations
11 that affect the state or not the database, or so on.
12 """
14 serialization_expand_args = ["database_operations", "state_operations"]
16 def __init__(self, database_operations=None, state_operations=None):
17 self.database_operations = database_operations or []
18 self.state_operations = state_operations or []
20 def deconstruct(self):
21 kwargs = {}
22 if self.database_operations:
23 kwargs["database_operations"] = self.database_operations
24 if self.state_operations:
25 kwargs["state_operations"] = self.state_operations
26 return (self.__class__.__qualname__, [], kwargs)
28 def state_forwards(self, package_label, state):
29 for state_operation in self.state_operations:
30 state_operation.state_forwards(package_label, state)
32 def database_forwards(self, package_label, schema_editor, from_state, to_state):
33 # We calculate state separately in here since our state functions aren't useful
34 for database_operation in self.database_operations:
35 to_state = from_state.clone()
36 database_operation.state_forwards(package_label, to_state)
37 database_operation.database_forwards(
38 package_label, schema_editor, from_state, to_state
39 )
40 from_state = to_state
42 def database_backwards(self, package_label, schema_editor, from_state, to_state):
43 # We calculate state separately in here since our state functions aren't useful
44 to_states = {}
45 for dbop in self.database_operations:
46 to_states[dbop] = to_state
47 to_state = to_state.clone()
48 dbop.state_forwards(package_label, to_state)
49 # to_state now has the states of all the database_operations applied
50 # which is the from_state for the backwards migration of the last
51 # operation.
52 for database_operation in reversed(self.database_operations):
53 from_state = to_state
54 to_state = to_states[database_operation]
55 database_operation.database_backwards(
56 package_label, schema_editor, from_state, to_state
57 )
59 def describe(self):
60 return "Custom state/database change combination"
63class RunSQL(Operation):
64 """
65 Run some raw SQL. A reverse SQL statement may be provided.
67 Also accept a list of operations that represent the state change effected
68 by this SQL change, in case it's custom column/table creation/deletion.
69 """
71 noop = ""
73 def __init__(
74 self, sql, reverse_sql=None, state_operations=None, hints=None, elidable=False
75 ):
76 self.sql = sql
77 self.reverse_sql = reverse_sql
78 self.state_operations = state_operations or []
79 self.hints = hints or {}
80 self.elidable = elidable
82 def deconstruct(self):
83 kwargs = {
84 "sql": self.sql,
85 }
86 if self.reverse_sql is not None:
87 kwargs["reverse_sql"] = self.reverse_sql
88 if self.state_operations:
89 kwargs["state_operations"] = self.state_operations
90 if self.hints:
91 kwargs["hints"] = self.hints
92 return (self.__class__.__qualname__, [], kwargs)
94 @property
95 def reversible(self):
96 return self.reverse_sql is not None
98 def state_forwards(self, package_label, state):
99 for state_operation in self.state_operations:
100 state_operation.state_forwards(package_label, state)
102 def database_forwards(self, package_label, schema_editor, from_state, to_state):
103 if router.allow_migrate(
104 schema_editor.connection.alias, package_label, **self.hints
105 ):
106 self._run_sql(schema_editor, self.sql)
108 def database_backwards(self, package_label, schema_editor, from_state, to_state):
109 if self.reverse_sql is None:
110 raise NotImplementedError("You cannot reverse this operation")
111 if router.allow_migrate(
112 schema_editor.connection.alias, package_label, **self.hints
113 ):
114 self._run_sql(schema_editor, self.reverse_sql)
116 def describe(self):
117 return "Raw SQL operation"
119 def _run_sql(self, schema_editor, sqls):
120 if isinstance(sqls, list | tuple):
121 for sql in sqls:
122 params = None
123 if isinstance(sql, list | tuple):
124 elements = len(sql)
125 if elements == 2:
126 sql, params = sql
127 else:
128 raise ValueError("Expected a 2-tuple but got %d" % elements)
129 schema_editor.execute(sql, params=params)
130 elif sqls != RunSQL.noop:
131 statements = schema_editor.connection.ops.prepare_sql_script(sqls)
132 for statement in statements:
133 schema_editor.execute(statement, params=None)
136class RunPython(Operation):
137 """
138 Run Python code in a context suitable for doing versioned ORM operations.
139 """
141 reduces_to_sql = False
143 def __init__(
144 self, code, reverse_code=None, atomic=None, hints=None, elidable=False
145 ):
146 self.atomic = atomic
147 # Forwards code
148 if not callable(code):
149 raise ValueError("RunPython must be supplied with a callable")
150 self.code = code
151 # Reverse code
152 if reverse_code is None:
153 self.reverse_code = None
154 else:
155 if not callable(reverse_code):
156 raise ValueError("RunPython must be supplied with callable arguments")
157 self.reverse_code = reverse_code
158 self.hints = hints or {}
159 self.elidable = elidable
161 def deconstruct(self):
162 kwargs = {
163 "code": self.code,
164 }
165 if self.reverse_code is not None:
166 kwargs["reverse_code"] = self.reverse_code
167 if self.atomic is not None:
168 kwargs["atomic"] = self.atomic
169 if self.hints:
170 kwargs["hints"] = self.hints
171 return (self.__class__.__qualname__, [], kwargs)
173 @property
174 def reversible(self):
175 return self.reverse_code is not None
177 def state_forwards(self, package_label, state):
178 # RunPython objects have no state effect. To add some, combine this
179 # with SeparateDatabaseAndState.
180 pass
182 def database_forwards(self, package_label, schema_editor, from_state, to_state):
183 # RunPython has access to all models. Ensure that all models are
184 # reloaded in case any are delayed.
185 from_state.clear_delayed_packages_cache()
186 if router.allow_migrate(
187 schema_editor.connection.alias, package_label, **self.hints
188 ):
189 # We now execute the Python code in a context that contains a 'models'
190 # object, representing the versioned models as an app registry.
191 # We could try to override the global cache, but then people will still
192 # use direct imports, so we go with a documentation approach instead.
193 self.code(from_state.packages, schema_editor)
195 def database_backwards(self, package_label, schema_editor, from_state, to_state):
196 if self.reverse_code is None:
197 raise NotImplementedError("You cannot reverse this operation")
198 if router.allow_migrate(
199 schema_editor.connection.alias, package_label, **self.hints
200 ):
201 self.reverse_code(from_state.packages, schema_editor)
203 def describe(self):
204 return "Raw Python operation"
206 @staticmethod
207 def noop(packages, schema_editor):
208 return None
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from .cli import cli
3__all__ = ["cli"]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import os
2import sys
4import click
5from dotenv import load_dotenv
7import pytest
10@click.command(
11 context_settings={
12 "ignore_unknown_options": True,
13 }
14)
15@click.argument("pytest_args", nargs=-1, type=click.UNPROCESSED)
16def cli(pytest_args):
17 """Run tests with pytest"""
19 if os.path.exists(".env.test"):
20 click.secho("Loading environment variables from .env.test", fg="yellow")
21 load_dotenv(".env.test")
23 returncode = pytest.main(list(pytest_args))
24 if returncode:
25 sys.exit(returncode)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import pytest
2from plain.runtime import settings as plain_settings
3from plain.runtime import setup
4from plain.test.client import Client, RequestFactory
7def pytest_configure(config):
8 # Run Plain setup before anything else
9 setup()
12@pytest.fixture(autouse=True, scope="session")
13def _allowed_hosts_testserver():
14 # Add testserver to ALLOWED_HOSTS so the test client can make requests
15 plain_settings.ALLOWED_HOSTS = [*plain_settings.ALLOWED_HOSTS, "testserver"]
18@pytest.fixture
19def client() -> Client:
20 """A Plain test client instance."""
21 return Client()
24@pytest.fixture
25def request_factory() -> RequestFactory:
26 """A Plain RequestFactory instance."""
27 return RequestFactory()
30@pytest.fixture
31def settings():
32 class SettingsProxy:
33 def __init__(self):
34 self._original = {}
36 def __getattr__(self, name):
37 return getattr(plain_settings, name)
39 def __setattr__(self, name, value):
40 if name.startswith("_"):
41 super().__setattr__(name, value)
42 else:
43 if name not in self._original:
44 self._original[name] = getattr(plain_settings, name, None)
45 setattr(plain_settings, name, value)
47 def _restore(self):
48 for key, value in self._original.items():
49 setattr(plain_settings, key, value)
51 proxy = SettingsProxy()
52 yield proxy
53 proxy._restore()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import importlib.metadata
2import sys
3from importlib.metadata import entry_points
4from pathlib import Path
6from .user_settings import Settings
8try:
9 __version__ = importlib.metadata.version("plain")
10except importlib.metadata.PackageNotFoundError:
11 __version__ = "dev"
14# Made available without setup or settings
15APP_PATH = Path.cwd() / "app"
17# from plain.runtime import settings
18settings = Settings()
21class AppPathNotFound(RuntimeError):
22 pass
25def setup():
26 """
27 Configure the settings (this happens as a side effect of accessing the
28 first setting), configure logging and populate the app registry.
29 """
31 # Packages can hook into the setup process through an entrypoint.
32 for entry_point in entry_points().select(group="plain.setup"):
33 entry_point.load()()
35 from plain.logs import configure_logging
36 from plain.packages import packages
38 if not APP_PATH.exists():
39 raise AppPathNotFound(
40 "No app directory found. Are you sure you're in a Plain project?"
41 )
43 # Automatically put the project dir on the Python path
44 # which doesn't otherwise happen when you run `plain` commands.
45 # This makes "app.<module>" imports and relative imports work.
46 if APP_PATH.parent not in sys.path:
47 sys.path.insert(0, APP_PATH.parent.as_posix())
49 configure_logging(settings.LOGGING)
51 packages.populate(settings.INSTALLED_PACKAGES)
54__all__ = [
55 "setup",
56 "settings",
57 "APP_PATH",
58 "__version__",
59]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Default Plain settings. Override these with settings in the module pointed to
3by the PLAIN_SETTINGS_MODULE environment variable.
4"""
6from pathlib import Path
8from plain.runtime import APP_PATH as default_app_path
10####################
11# CORE #
12####################
14DEBUG: bool = False
16PLAIN_TEMP_PATH: Path = default_app_path.parent / ".plain"
18# Hosts/domain names that are valid for this site.
19# "*" matches anything, ".example.com" matches example.com and all subdomains
20ALLOWED_HOSTS: list[str] = []
22# Local time zone for this installation. All choices can be found here:
23# https://en.wikipedia.org/wiki/List_of_tz_zones_by_name (although not all
24# systems may support all possibilities). This is interpreted as the default
25# user time zone.
26TIME_ZONE: str = "UTC"
28# Default charset to use for all Response objects, if a MIME type isn't
29# manually specified. It's used to construct the Content-Type header.
30DEFAULT_CHARSET = "utf-8"
32# List of strings representing installed packages.
33INSTALLED_PACKAGES: list[str] = []
35# Whether to append trailing slashes to URLs.
36APPEND_SLASH = True
38# Default headers for all responses.
39DEFAULT_RESPONSE_HEADERS = {
40 # "Content-Security-Policy": "default-src 'self'",
41 # https://hstspreload.org/
42 # "Strict-Transport-Security": "max-age=31536000; includeSubDomains; preload",
43 "Cross-Origin-Opener-Policy": "same-origin",
44 "Referrer-Policy": "same-origin",
45 "X-Content-Type-Options": "nosniff",
46 "X-Frame-Options": "DENY",
47}
49# Whether to redirect all non-HTTPS requests to HTTPS.
50HTTPS_REDIRECT_ENABLED = True
51HTTPS_REDIRECT_EXEMPT = []
52HTTPS_REDIRECT_HOST = None
54# If your Plain app is behind a proxy that sets a header to specify secure
55# connections, AND that proxy ensures that user-submitted headers with the
56# same name are ignored (so that people can't spoof it), set this value to
57# a tuple of (header_name, header_value). For any requests that come in with
58# that header/value, request.is_https() will return True.
59# WARNING! Only set this if you fully understand what you're doing. Otherwise,
60# you may be opening yourself up to a security risk.
61HTTPS_PROXY_HEADER = None
63# Whether to use the X-Forwarded-Host and X-Forwarded-Port headers
64# when determining the host and port for the request.
65USE_X_FORWARDED_HOST = False
66USE_X_FORWARDED_PORT = False
68# A secret key for this particular Plain installation. Used in secret-key
69# hashing algorithms. Set this in your settings, or Plain will complain
70# loudly.
71SECRET_KEY: str
73# List of secret keys used to verify the validity of signatures. This allows
74# secret key rotation.
75SECRET_KEY_FALLBACKS: list[str] = []
77ROOT_URLCONF = "app.urls"
79# List of upload handler classes to be applied in order.
80FILE_UPLOAD_HANDLERS = [
81 "plain.internal.files.uploadhandler.MemoryFileUploadHandler",
82 "plain.internal.files.uploadhandler.TemporaryFileUploadHandler",
83]
85# Maximum size, in bytes, of a request before it will be streamed to the
86# file system instead of into memory.
87FILE_UPLOAD_MAX_MEMORY_SIZE = 2621440 # i.e. 2.5 MB
89# Maximum size in bytes of request data (excluding file uploads) that will be
90# read before a SuspiciousOperation (RequestDataTooBig) is raised.
91DATA_UPLOAD_MAX_MEMORY_SIZE = 2621440 # i.e. 2.5 MB
93# Maximum number of GET/POST parameters that will be read before a
94# SuspiciousOperation (TooManyFieldsSent) is raised.
95DATA_UPLOAD_MAX_NUMBER_FIELDS = 1000
97# Maximum number of files encoded in a multipart upload that will be read
98# before a SuspiciousOperation (TooManyFilesSent) is raised.
99DATA_UPLOAD_MAX_NUMBER_FILES = 100
101# Directory in which upload streamed files will be temporarily saved. A value of
102# `None` will make Plain use the operating system's default temporary directory
103# (i.e. "/tmp" on *nix systems).
104FILE_UPLOAD_TEMP_DIR = None
106# User-defined overrides for error views by status code
107HTTP_ERROR_VIEWS: dict[int] = {}
109##############
110# MIDDLEWARE #
111##############
113# List of middleware to use. Order is important; in the request phase, these
114# middleware will be applied in the order given, and in the response
115# phase the middleware will be applied in reverse order.
116MIDDLEWARE: list[str] = []
118###########
119# SIGNING #
120###########
122COOKIE_SIGNING_BACKEND = "plain.signing.TimestampSigner"
124########
125# CSRF #
126########
128# Settings for CSRF cookie.
129CSRF_COOKIE_NAME = "csrftoken"
130CSRF_COOKIE_AGE = 60 * 60 * 24 * 7 * 52
131CSRF_COOKIE_DOMAIN = None
132CSRF_COOKIE_PATH = "/"
133CSRF_COOKIE_SECURE = True
134CSRF_COOKIE_HTTPONLY = False
135CSRF_COOKIE_SAMESITE = "Lax"
136CSRF_HEADER_NAME = "HTTP_X_CSRFTOKEN"
137CSRF_TRUSTED_ORIGINS: list[str] = []
139###########
140# LOGGING #
141###########
143# Custom logging configuration.
144LOGGING = {}
146###############
147# ASSETS #
148###############
150# Whether to redirect the original asset path to the fingerprinted path.
151ASSETS_REDIRECT_ORIGINAL = True
153# If assets are served by a CDN, use this URL to prefix asset paths.
154# Ex. "https://cdn.example.com/assets/"
155ASSETS_BASE_URL: str = ""
157####################
158# PREFLIGHT CHECKS #
159####################
161# List of all issues generated by system checks that should be silenced. Light
162# issues like warnings, infos or debugs will not generate a message. Silencing
163# serious issues like errors and criticals does not result in hiding the
164# message, but Plain will not stop you from e.g. running server.
165SILENCED_PREFLIGHT_CHECKS = []
167#############
168# Templates #
169#############
171TEMPLATES_JINJA_ENVIRONMENT = "plain.templates.jinja.DefaultEnvironment"
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import importlib
2import json
3import os
4import time
5import types
6import typing
7from pathlib import Path
9from plain.exceptions import ImproperlyConfigured
10from plain.packages import PackageConfig
12ENVIRONMENT_VARIABLE = "PLAIN_SETTINGS_MODULE"
13ENV_SETTINGS_PREFIX = "PLAIN_"
14CUSTOM_SETTINGS_PREFIX = "APP_"
17class Settings:
18 """
19 Settings and configuration for Plain.
21 This class handles loading settings from the module specified by the
22 PLAIN_SETTINGS_MODULE environment variable, as well as from default settings,
23 environment variables, and explicit settings in the settings module.
25 Lazy initialization is implemented to defer loading until settings are first accessed.
26 """
28 def __init__(self, settings_module=None):
29 self._settings_module = settings_module
30 self._settings = {}
31 self._errors = [] # Collect configuration errors
32 self.configured = False
34 def _setup(self):
35 if self.configured:
36 return
37 else:
38 self.configured = True
40 self._settings = {} # Maps setting names to SettingDefinition instances
42 # Determine the settings module
43 if self._settings_module is None:
44 self._settings_module = os.environ.get(ENVIRONMENT_VARIABLE, "app.settings")
46 # First load the global settings from plain
47 self._load_module_settings(
48 importlib.import_module("plain.runtime.global_settings")
49 )
51 # Import the user's settings module
52 try:
53 mod = importlib.import_module(self._settings_module)
54 except ImportError as e:
55 raise ImproperlyConfigured(
56 f"Could not import settings '{self._settings_module}': {e}"
57 )
59 # Keep a reference to the settings.py module path
60 self.path = Path(mod.__file__).resolve()
62 # Load default settings from installed packages
63 self._load_default_settings(mod)
64 # Load environment settings
65 self._load_env_settings()
66 # Load explicit settings from the settings module
67 self._load_explicit_settings(mod)
68 # Check for any required settings that are missing
69 self._check_required_settings()
70 # Check for any collected errors
71 self._raise_errors_if_any()
73 def _load_module_settings(self, module):
74 annotations = getattr(module, "__annotations__", {})
75 settings = dir(module)
77 for setting in settings:
78 if setting.isupper():
79 if setting in self._settings:
80 self._errors.append(f"Duplicate setting '{setting}'.")
81 continue
83 setting_value = getattr(module, setting)
84 self._settings[setting] = SettingDefinition(
85 name=setting,
86 default_value=setting_value,
87 annotation=annotations.get(setting, None),
88 module=module,
89 )
91 # Store any annotations that didn't have a value (these are required settings)
92 for setting, annotation in annotations.items():
93 if setting not in self._settings:
94 self._settings[setting] = SettingDefinition(
95 name=setting,
96 default_value=None,
97 annotation=annotation,
98 module=module,
99 required=True,
100 )
102 def _load_default_settings(self, settings_module):
103 for entry in getattr(settings_module, "INSTALLED_PACKAGES", []):
104 try:
105 if isinstance(entry, PackageConfig):
106 app_settings = entry.module.default_settings
107 else:
108 app_settings = importlib.import_module(f"{entry}.default_settings")
109 except ModuleNotFoundError:
110 continue
112 self._load_module_settings(app_settings)
114 def _load_env_settings(self):
115 env_settings = {
116 k[len(ENV_SETTINGS_PREFIX) :]: v
117 for k, v in os.environ.items()
118 if k.startswith(ENV_SETTINGS_PREFIX) and k.isupper()
119 }
120 for setting, value in env_settings.items():
121 if setting in self._settings:
122 setting_def = self._settings[setting]
123 try:
124 parsed_value = _parse_env_value(value, setting_def.annotation)
125 setting_def.set_value(parsed_value, "env")
126 except ImproperlyConfigured as e:
127 self._errors.append(str(e))
129 def _load_explicit_settings(self, settings_module):
130 for setting in dir(settings_module):
131 if setting.isupper():
132 setting_value = getattr(settings_module, setting)
134 if setting in self._settings:
135 setting_def = self._settings[setting]
136 try:
137 setting_def.set_value(setting_value, "explicit")
138 except ImproperlyConfigured as e:
139 self._errors.append(str(e))
140 continue
142 elif setting.startswith(CUSTOM_SETTINGS_PREFIX):
143 # Accept custom settings prefixed with '{CUSTOM_SETTINGS_PREFIX}'
144 setting_def = SettingDefinition(
145 name=setting,
146 default_value=None,
147 annotation=None,
148 required=False,
149 )
150 try:
151 setting_def.set_value(setting_value, "explicit")
152 except ImproperlyConfigured as e:
153 self._errors.append(str(e))
154 continue
155 self._settings[setting] = setting_def
156 else:
157 # Collect unrecognized settings individually
158 self._errors.append(
159 f"Unknown setting '{setting}'. Custom settings must start with '{CUSTOM_SETTINGS_PREFIX}'."
160 )
162 if hasattr(time, "tzset") and self.TIME_ZONE:
163 zoneinfo_root = Path("/usr/share/zoneinfo")
164 zone_info_file = zoneinfo_root.joinpath(*self.TIME_ZONE.split("/"))
165 if zoneinfo_root.exists() and not zone_info_file.exists():
166 self._errors.append(
167 f"Invalid TIME_ZONE setting '{self.TIME_ZONE}'. Timezone file not found."
168 )
169 else:
170 os.environ["TZ"] = self.TIME_ZONE
171 time.tzset()
173 def _check_required_settings(self):
174 missing = [k for k, v in self._settings.items() if v.required and not v.is_set]
175 if missing:
176 self._errors.append(f"Missing required setting(s): {', '.join(missing)}.")
178 def _raise_errors_if_any(self):
179 if self._errors:
180 errors = ["- " + e for e in self._errors]
181 raise ImproperlyConfigured(
182 "Settings configuration errors:\n" + "\n".join(errors)
183 )
185 def __getattr__(self, name):
186 # Avoid recursion by directly returning internal attributes
187 if not name.isupper():
188 return object.__getattribute__(self, name)
190 self._setup()
192 if name in self._settings:
193 return self._settings[name].value
194 else:
195 raise AttributeError(f"'Settings' object has no attribute '{name}'")
197 def __setattr__(self, name, value):
198 # Handle internal attributes without recursion
199 if not name.isupper():
200 object.__setattr__(self, name, value)
201 else:
202 if name in self._settings:
203 self._settings[name].set_value(value, "runtime")
204 self._raise_errors_if_any()
205 else:
206 object.__setattr__(self, name, value)
208 def __repr__(self):
209 if not self.configured:
210 return "<Settings [Unevaluated]>"
211 return f'<Settings "{self._settings_module}">'
214def _parse_env_value(value, annotation):
215 if not annotation:
216 raise ImproperlyConfigured("Type hint required to set from environment.")
218 if annotation is bool:
219 # Special case for bools
220 return value.lower() in ("true", "1", "yes")
221 elif annotation is str:
222 return value
223 else:
224 # Parse other types using JSON
225 try:
226 return json.loads(value)
227 except json.JSONDecodeError as e:
228 raise ImproperlyConfigured(
229 f"Invalid JSON value for setting: {e.msg}"
230 ) from e
233class SettingDefinition:
234 """Store detailed information about settings."""
236 def __init__(
237 self, name, default_value=None, annotation=None, module=None, required=False
238 ):
239 self.name = name
240 self.default_value = default_value
241 self.annotation = annotation
242 self.module = module
243 self.required = required
244 self.value = default_value
245 self.source = "default" # 'default', 'env', 'explicit', or 'runtime'
246 self.is_set = False # Indicates if the value was set explicitly
248 def set_value(self, value, source):
249 self.check_type(value)
250 self.value = value
251 self.source = source
252 self.is_set = True
254 def check_type(self, obj):
255 if not self.annotation:
256 return
258 if not SettingDefinition._is_instance_of_type(obj, self.annotation):
259 raise ImproperlyConfigured(
260 f"'{self.name}': Expected type {self.annotation}, but got {type(obj)}."
261 )
263 @staticmethod
264 def _is_instance_of_type(value, type_hint) -> bool:
265 # Simple types
266 if isinstance(type_hint, type):
267 return isinstance(value, type_hint)
269 # Union types
270 if (
271 typing.get_origin(type_hint) is typing.Union
272 or typing.get_origin(type_hint) is types.UnionType
273 ):
274 return any(
275 SettingDefinition._is_instance_of_type(value, arg)
276 for arg in typing.get_args(type_hint)
277 )
279 # List types
280 if typing.get_origin(type_hint) is list:
281 return isinstance(value, list) and all(
282 SettingDefinition._is_instance_of_type(
283 item, typing.get_args(type_hint)[0]
284 )
285 for item in value
286 )
288 # Tuple types
289 if typing.get_origin(type_hint) is tuple:
290 return isinstance(value, tuple) and all(
291 SettingDefinition._is_instance_of_type(
292 item, typing.get_args(type_hint)[i]
293 )
294 for i, item in enumerate(value)
295 )
297 raise ValueError(f"Unsupported type hint: {type_hint}")
299 def __str__(self):
300 return f"SettingDefinition(name={self.name}, value={self.value}, source={self.source})"
303class SettingsReference(str):
304 """
305 String subclass which references a current settings value. It's treated as
306 the value in memory but serializes to a settings.NAME attribute reference.
307 """
309 def __new__(self, value, setting_name):
310 return str.__new__(self, value)
312 def __init__(self, value, setting_name):
313 self.setting_name = setting_name
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from .config import PackageConfig
2from .registry import packages
4__all__ = ["PackageConfig", "packages"]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import inspect
2import os
3from importlib import import_module
5from plain.exceptions import ImproperlyConfigured
6from plain.utils.module_loading import import_string, module_has_submodule
8CONFIG_MODULE_NAME = "config"
9MODELS_MODULE_NAME = "models"
12class PackageConfig:
13 """Class representing a Plain application and its configuration."""
15 migrations_module = "migrations"
17 def __init__(self, package_name, package_module):
18 # Full Python path to the application e.g. 'plain.staff.admin'.
19 self.name = package_name
21 # Root module for the application e.g. <module 'plain.staff.admin'
22 # from 'staff/__init__.py'>.
23 self.module = package_module
25 # Reference to the Packages registry that holds this PackageConfig. Set by the
26 # registry when it registers the PackageConfig instance.
27 self.packages = None
29 # The following attributes could be defined at the class level in a
30 # subclass, hence the test-and-set pattern.
32 # Last component of the Python path to the application e.g. 'admin'.
33 # This value must be unique across a Plain project.
34 if not hasattr(self, "label"):
35 self.label = package_name.rpartition(".")[2]
36 if not self.label.isidentifier():
37 raise ImproperlyConfigured(
38 f"The app label '{self.label}' is not a valid Python identifier."
39 )
41 # Filesystem path to the application directory e.g.
42 # '/path/to/admin'.
43 if not hasattr(self, "path"):
44 self.path = self._path_from_module(package_module)
46 # Module containing models e.g. <module 'plain.staff.models'
47 # from 'staff/models.py'>. Set by import_models().
48 # None if the application doesn't have a models module.
49 self.models_module = None
51 # Mapping of lowercase model names to model classes. Initially set to
52 # None to prevent accidental access before import_models() runs.
53 self.models = None
55 def __repr__(self):
56 return f"<{self.__class__.__name__}: {self.label}>"
58 def _path_from_module(self, module):
59 """Attempt to determine app's filesystem path from its module."""
60 # See #21874 for extended discussion of the behavior of this method in
61 # various cases.
62 # Convert to list because __path__ may not support indexing.
63 paths = list(getattr(module, "__path__", []))
64 if len(paths) != 1:
65 filename = getattr(module, "__file__", None)
66 if filename is not None:
67 paths = [os.path.dirname(filename)]
68 else:
69 # For unknown reasons, sometimes the list returned by __path__
70 # contains duplicates that must be removed (#25246).
71 paths = list(set(paths))
72 if len(paths) > 1:
73 raise ImproperlyConfigured(
74 f"The app module {module!r} has multiple filesystem locations ({paths!r}); "
75 "you must configure this app with an PackageConfig subclass "
76 "with a 'path' class attribute."
77 )
78 elif not paths:
79 raise ImproperlyConfigured(
80 f"The app module {module!r} has no filesystem location, "
81 "you must configure this app with an PackageConfig subclass "
82 "with a 'path' class attribute."
83 )
84 return paths[0]
86 @classmethod
87 def create(cls, entry):
88 """
89 Factory that creates an app config from an entry in INSTALLED_PACKAGES.
90 """
91 # create() eventually returns package_config_class(package_name, package_module).
92 package_config_class = None
93 package_name = None
94 package_module = None
96 # If import_module succeeds, entry points to the app module.
97 try:
98 package_module = import_module(entry)
99 except Exception:
100 pass
101 else:
102 # If package_module has an packages submodule that defines a single
103 # PackageConfig subclass, use it automatically.
104 # To prevent this, an PackageConfig subclass can declare a class
105 # variable default = False.
106 # If the packages module defines more than one PackageConfig subclass,
107 # the default one can declare default = True.
108 if module_has_submodule(package_module, CONFIG_MODULE_NAME):
109 mod_path = f"{entry}.{CONFIG_MODULE_NAME}"
110 mod = import_module(mod_path)
111 # Check if there's exactly one PackageConfig candidate,
112 # excluding those that explicitly define default = False.
113 package_configs = [
114 (name, candidate)
115 for name, candidate in inspect.getmembers(mod, inspect.isclass)
116 if (
117 issubclass(candidate, cls)
118 and candidate is not cls
119 and getattr(candidate, "default", True)
120 )
121 ]
122 if len(package_configs) == 1:
123 package_config_class = package_configs[0][1]
124 else:
125 # Check if there's exactly one PackageConfig subclass,
126 # among those that explicitly define default = True.
127 package_configs = [
128 (name, candidate)
129 for name, candidate in package_configs
130 if getattr(candidate, "default", False)
131 ]
132 if len(package_configs) > 1:
133 candidates = [repr(name) for name, _ in package_configs]
134 raise RuntimeError(
135 "{!r} declares more than one default PackageConfig: "
136 "{}.".format(mod_path, ", ".join(candidates))
137 )
138 elif len(package_configs) == 1:
139 package_config_class = package_configs[0][1]
141 # Use the default app config class if we didn't find anything.
142 if package_config_class is None:
143 package_config_class = cls
144 package_name = entry
146 # If import_string succeeds, entry is an app config class.
147 if package_config_class is None:
148 try:
149 package_config_class = import_string(entry)
150 except Exception:
151 pass
152 # If both import_module and import_string failed, it means that entry
153 # doesn't have a valid value.
154 if package_module is None and package_config_class is None:
155 # If the last component of entry starts with an uppercase letter,
156 # then it was likely intended to be an app config class; if not,
157 # an app module. Provide a nice error message in both cases.
158 mod_path, _, cls_name = entry.rpartition(".")
159 if mod_path and cls_name[0].isupper():
160 # We could simply re-trigger the string import exception, but
161 # we're going the extra mile and providing a better error
162 # message for typos in INSTALLED_PACKAGES.
163 # This may raise ImportError, which is the best exception
164 # possible if the module at mod_path cannot be imported.
165 mod = import_module(mod_path)
166 candidates = [
167 repr(name)
168 for name, candidate in inspect.getmembers(mod, inspect.isclass)
169 if issubclass(candidate, cls) and candidate is not cls
170 ]
171 msg = f"Module '{mod_path}' does not contain a '{cls_name}' class."
172 if candidates:
173 msg += " Choices are: {}.".format(", ".join(candidates))
174 raise ImportError(msg)
175 else:
176 # Re-trigger the module import exception.
177 import_module(entry)
179 # Check for obvious errors. (This check prevents duck typing, but
180 # it could be removed if it became a problem in practice.)
181 if not issubclass(package_config_class, PackageConfig):
182 raise ImproperlyConfigured(f"'{entry}' isn't a subclass of PackageConfig.")
184 # Obtain package name here rather than in PackageClass.__init__ to keep
185 # all error checking for entries in INSTALLED_PACKAGES in one place.
186 if package_name is None:
187 try:
188 package_name = package_config_class.name
189 except AttributeError:
190 raise ImproperlyConfigured(f"'{entry}' must supply a name attribute.")
192 # Ensure package_name points to a valid module.
193 try:
194 package_module = import_module(package_name)
195 except ImportError:
196 raise ImproperlyConfigured(
197 f"Cannot import '{package_name}'. Check that '{package_config_class.__module__}.{package_config_class.__qualname__}.name' is correct."
198 )
200 # Entry is a path to an app config class.
201 return package_config_class(package_name, package_module)
203 def get_model(self, model_name, require_ready=True):
204 """
205 Return the model with the given case-insensitive model_name.
207 Raise LookupError if no model exists with this name.
208 """
209 if require_ready:
210 self.packages.check_models_ready()
211 else:
212 self.packages.check_packages_ready()
213 try:
214 return self.models[model_name.lower()]
215 except KeyError:
216 raise LookupError(
217 f"Package '{self.label}' doesn't have a '{model_name}' model."
218 )
220 def get_models(self, include_auto_created=False, include_swapped=False):
221 """
222 Return an iterable of models.
224 By default, the following models aren't included:
226 - auto-created models for many-to-many relations without
227 an explicit intermediate table,
228 - models that have been swapped out.
230 Set the corresponding keyword argument to True to include such models.
231 Keyword arguments aren't documented; they're a private API.
232 """
233 self.packages.check_models_ready()
234 for model in self.models.values():
235 if model._meta.auto_created and not include_auto_created:
236 continue
237 if model._meta.swapped and not include_swapped:
238 continue
239 yield model
241 def import_models(self):
242 # Dictionary of models for this app, primarily maintained in the
243 # 'all_models' attribute of the Packages this PackageConfig is attached to.
244 self.models = self.packages.all_models[self.label]
246 if module_has_submodule(self.module, MODELS_MODULE_NAME):
247 models_module_name = f"{self.name}.{MODELS_MODULE_NAME}"
248 self.models_module = import_module(models_module_name)
250 def ready(self):
251 """
252 Override this method in subclasses to run code when Plain starts.
253 """
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import functools
2import sys
3import threading
4import warnings
5from collections import Counter, defaultdict
6from functools import partial
8from plain.exceptions import ImproperlyConfigured, PackageRegistryNotReady
10from .config import PackageConfig
13class Packages:
14 """
15 A registry that stores the configuration of installed applications.
17 It also keeps track of models, e.g. to provide reverse relations.
18 """
20 def __init__(self, installed_packages=()):
21 # installed_packages is set to None when creating the main registry
22 # because it cannot be populated at that point. Other registries must
23 # provide a list of installed packages and are populated immediately.
24 if installed_packages is None and hasattr(sys.modules[__name__], "packages"):
25 raise RuntimeError("You must supply an installed_packages argument.")
27 # Mapping of app labels => model names => model classes. Every time a
28 # model is imported, ModelBase.__new__ calls packages.register_model which
29 # creates an entry in all_models. All imported models are registered,
30 # regardless of whether they're defined in an installed application
31 # and whether the registry has been populated. Since it isn't possible
32 # to reimport a module safely (it could reexecute initialization code)
33 # all_models is never overridden or reset.
34 self.all_models = defaultdict(dict)
36 # Mapping of labels to PackageConfig instances for installed packages.
37 self.package_configs = {}
39 # Stack of package_configs. Used to store the current state in
40 # set_available_packages and set_installed_packages.
41 self.stored_package_configs = []
43 # Whether the registry is populated.
44 self.packages_ready = self.models_ready = self.ready = False
46 # Lock for thread-safe population.
47 self._lock = threading.RLock()
48 self.loading = False
50 # Maps ("package_label", "modelname") tuples to lists of functions to be
51 # called when the corresponding model is ready. Used by this class's
52 # `lazy_model_operation()` and `do_pending_operations()` methods.
53 self._pending_operations = defaultdict(list)
55 # Populate packages and models, unless it's the main registry.
56 if installed_packages is not None:
57 self.populate(installed_packages)
59 def populate(self, installed_packages=None):
60 """
61 Load application configurations and models.
63 Import each application module and then each model module.
65 It is thread-safe and idempotent, but not reentrant.
66 """
67 if self.ready:
68 return
70 # populate() might be called by two threads in parallel on servers
71 # that create threads before initializing the WSGI callable.
72 with self._lock:
73 if self.ready:
74 return
76 # An RLock prevents other threads from entering this section. The
77 # compare and set operation below is atomic.
78 if self.loading:
79 # Prevent reentrant calls to avoid running PackageConfig.ready()
80 # methods twice.
81 raise RuntimeError("populate() isn't reentrant")
82 self.loading = True
84 # Phase 1: initialize app configs and import app modules.
85 for entry in installed_packages:
86 if isinstance(entry, PackageConfig):
87 package_config = entry
88 else:
89 package_config = PackageConfig.create(entry)
90 if package_config.label in self.package_configs:
91 raise ImproperlyConfigured(
92 "Package labels aren't unique, "
93 f"duplicates: {package_config.label}"
94 )
96 self.package_configs[package_config.label] = package_config
97 package_config.packages = self
99 # Check for duplicate app names.
100 counts = Counter(
101 package_config.name for package_config in self.package_configs.values()
102 )
103 duplicates = [name for name, count in counts.most_common() if count > 1]
104 if duplicates:
105 raise ImproperlyConfigured(
106 "Package names aren't unique, " "duplicates: {}".format(
107 ", ".join(duplicates)
108 )
109 )
111 self.packages_ready = True
113 # Phase 2: import models modules.
114 for package_config in self.package_configs.values():
115 package_config.import_models()
117 self.clear_cache()
119 self.models_ready = True
121 # Phase 3: run ready() methods of app configs.
122 for package_config in self.get_package_configs():
123 package_config.ready()
125 self.ready = True
127 def check_packages_ready(self):
128 """Raise an exception if all packages haven't been imported yet."""
129 if not self.packages_ready:
130 from plain.runtime import settings
132 # If "not ready" is due to unconfigured settings, accessing
133 # INSTALLED_PACKAGES raises a more helpful ImproperlyConfigured
134 # exception.
135 settings.INSTALLED_PACKAGES
136 raise PackageRegistryNotReady("Packages aren't loaded yet.")
138 def check_models_ready(self):
139 """Raise an exception if all models haven't been imported yet."""
140 if not self.models_ready:
141 raise PackageRegistryNotReady("Models aren't loaded yet.")
143 def get_package_configs(self):
144 """Import applications and return an iterable of app configs."""
145 self.check_packages_ready()
146 return self.package_configs.values()
148 def get_package_config(self, package_label):
149 """
150 Import applications and returns an app config for the given label.
152 Raise LookupError if no application exists with this label.
153 """
154 self.check_packages_ready()
155 try:
156 return self.package_configs[package_label]
157 except KeyError:
158 message = f"No installed app with label '{package_label}'."
159 for package_config in self.get_package_configs():
160 if package_config.name == package_label:
161 message += f" Did you mean '{package_config.label}'?"
162 break
163 raise LookupError(message)
165 # This method is performance-critical at least for Plain's test suite.
166 @functools.cache
167 def get_models(self, include_auto_created=False, include_swapped=False):
168 """
169 Return a list of all installed models.
171 By default, the following models aren't included:
173 - auto-created models for many-to-many relations without
174 an explicit intermediate table,
175 - models that have been swapped out.
177 Set the corresponding keyword argument to True to include such models.
178 """
179 self.check_models_ready()
181 result = []
182 for package_config in self.package_configs.values():
183 result.extend(
184 package_config.get_models(include_auto_created, include_swapped)
185 )
186 return result
188 def get_model(self, package_label, model_name=None, require_ready=True):
189 """
190 Return the model matching the given package_label and model_name.
192 As a shortcut, package_label may be in the form <package_label>.<model_name>.
194 model_name is case-insensitive.
196 Raise LookupError if no application exists with this label, or no
197 model exists with this name in the application. Raise ValueError if
198 called with a single argument that doesn't contain exactly one dot.
199 """
200 if require_ready:
201 self.check_models_ready()
202 else:
203 self.check_packages_ready()
205 if model_name is None:
206 package_label, model_name = package_label.split(".")
208 package_config = self.get_package_config(package_label)
210 if not require_ready and package_config.models is None:
211 package_config.import_models()
213 return package_config.get_model(model_name, require_ready=require_ready)
215 def register_model(self, package_label, model):
216 # Since this method is called when models are imported, it cannot
217 # perform imports because of the risk of import loops. It mustn't
218 # call get_package_config().
219 model_name = model._meta.model_name
220 app_models = self.all_models[package_label]
221 if model_name in app_models:
222 if (
223 model.__name__ == app_models[model_name].__name__
224 and model.__module__ == app_models[model_name].__module__
225 ):
226 warnings.warn(
227 f"Model '{package_label}.{model_name}' was already registered. Reloading models is not "
228 "advised as it can lead to inconsistencies, most notably with "
229 "related models.",
230 RuntimeWarning,
231 stacklevel=2,
232 )
233 else:
234 raise RuntimeError(
235 f"Conflicting '{model_name}' models in application '{package_label}': {app_models[model_name]} and {model}."
236 )
237 app_models[model_name] = model
238 self.do_pending_operations(model)
239 self.clear_cache()
241 def is_installed(self, package_name):
242 """
243 Check whether an application with this name exists in the registry.
245 package_name is the full name of the app e.g. 'plain.staff'.
246 """
247 self.check_packages_ready()
248 return any(ac.name == package_name for ac in self.package_configs.values())
250 def get_containing_package_config(self, object_name):
251 """
252 Look for an app config containing a given object.
254 object_name is the dotted Python path to the object.
256 Return the app config for the inner application in case of nesting.
257 Return None if the object isn't in any registered app config.
258 """
259 self.check_packages_ready()
260 candidates = []
261 for package_config in self.package_configs.values():
262 if object_name.startswith(package_config.name):
263 subpath = object_name.removeprefix(package_config.name)
264 if subpath == "" or subpath[0] == ".":
265 candidates.append(package_config)
266 if candidates:
267 return sorted(candidates, key=lambda ac: -len(ac.name))[0]
269 def get_registered_model(self, package_label, model_name):
270 """
271 Similar to get_model(), but doesn't require that an app exists with
272 the given package_label.
274 It's safe to call this method at import time, even while the registry
275 is being populated.
276 """
277 model = self.all_models[package_label].get(model_name.lower())
278 if model is None:
279 raise LookupError(f"Model '{package_label}.{model_name}' not registered.")
280 return model
282 @functools.cache
283 def get_swappable_settings_name(self, to_string):
284 """
285 For a given model string (e.g. "auth.User"), return the name of the
286 corresponding settings name if it refers to a swappable model. If the
287 referred model is not swappable, return None.
289 This method is decorated with @functools.cache because it's performance
290 critical when it comes to migrations. Since the swappable settings don't
291 change after Plain has loaded the settings, there is no reason to get
292 the respective settings attribute over and over again.
293 """
294 to_string = to_string.lower()
295 for model in self.get_models(include_swapped=True):
296 swapped = model._meta.swapped
297 # Is this model swapped out for the model given by to_string?
298 if swapped and swapped.lower() == to_string:
299 return model._meta.swappable
300 # Is this model swappable and the one given by to_string?
301 if model._meta.swappable and model._meta.label_lower == to_string:
302 return model._meta.swappable
303 return None
305 def set_available_packages(self, available):
306 """
307 Restrict the set of installed packages used by get_package_config[s].
309 available must be an iterable of application names.
311 set_available_packages() must be balanced with unset_available_packages().
313 Primarily used for performance optimization in TransactionTestCase.
315 This method is safe in the sense that it doesn't trigger any imports.
316 """
317 available = set(available)
318 installed = {
319 package_config.name for package_config in self.get_package_configs()
320 }
321 if not available.issubset(installed):
322 raise ValueError(
323 "Available packages isn't a subset of installed packages, extra packages: {}".format(
324 ", ".join(available - installed)
325 )
326 )
328 self.stored_package_configs.append(self.package_configs)
329 self.package_configs = {
330 label: package_config
331 for label, package_config in self.package_configs.items()
332 if package_config.name in available
333 }
334 self.clear_cache()
336 def unset_available_packages(self):
337 """Cancel a previous call to set_available_packages()."""
338 self.package_configs = self.stored_package_configs.pop()
339 self.clear_cache()
341 def set_installed_packages(self, installed):
342 """
343 Enable a different set of installed packages for get_package_config[s].
345 installed must be an iterable in the same format as INSTALLED_PACKAGES.
347 set_installed_packages() must be balanced with unset_installed_packages(),
348 even if it exits with an exception.
350 Primarily used as a receiver of the setting_changed signal in tests.
352 This method may trigger new imports, which may add new models to the
353 registry of all imported models. They will stay in the registry even
354 after unset_installed_packages(). Since it isn't possible to replay
355 imports safely (e.g. that could lead to registering listeners twice),
356 models are registered when they're imported and never removed.
357 """
358 if not self.ready:
359 raise PackageRegistryNotReady("Package registry isn't ready yet.")
360 self.stored_package_configs.append(self.package_configs)
361 self.package_configs = {}
362 self.packages_ready = self.models_ready = self.loading = self.ready = False
363 self.clear_cache()
364 self.populate(installed)
366 def clear_cache(self):
367 """
368 Clear all internal caches, for methods that alter the app registry.
370 This is mostly used in tests.
371 """
372 # Call expire cache on each model. This will purge
373 # the relation tree and the fields cache.
374 self.get_models.cache_clear()
375 if self.ready:
376 # Circumvent self.get_models() to prevent that the cache is refilled.
377 # This particularly prevents that an empty value is cached while cloning.
378 for package_config in self.package_configs.values():
379 for model in package_config.get_models(include_auto_created=True):
380 model._meta._expire_cache()
382 def lazy_model_operation(self, function, *model_keys):
383 """
384 Take a function and a number of ("package_label", "modelname") tuples, and
385 when all the corresponding models have been imported and registered,
386 call the function with the model classes as its arguments.
388 The function passed to this method must accept exactly n models as
389 arguments, where n=len(model_keys).
390 """
391 # Base case: no arguments, just execute the function.
392 if not model_keys:
393 function()
394 # Recursive case: take the head of model_keys, wait for the
395 # corresponding model class to be imported and registered, then apply
396 # that argument to the supplied function. Pass the resulting partial
397 # to lazy_model_operation() along with the remaining model args and
398 # repeat until all models are loaded and all arguments are applied.
399 else:
400 next_model, *more_models = model_keys
402 # This will be executed after the class corresponding to next_model
403 # has been imported and registered. The `func` attribute provides
404 # duck-type compatibility with partials.
405 def apply_next_model(model):
406 next_function = partial(apply_next_model.func, model)
407 self.lazy_model_operation(next_function, *more_models)
409 apply_next_model.func = function
411 # If the model has already been imported and registered, partially
412 # apply it to the function now. If not, add it to the list of
413 # pending operations for the model, where it will be executed with
414 # the model class as its sole argument once the model is ready.
415 try:
416 model_class = self.get_registered_model(*next_model)
417 except LookupError:
418 self._pending_operations[next_model].append(apply_next_model)
419 else:
420 apply_next_model(model_class)
422 def do_pending_operations(self, model):
423 """
424 Take a newly-prepared model and pass it to each function waiting for
425 it. This is called at the very end of Packages.register_model().
426 """
427 key = model._meta.package_label, model._meta.model_name
428 for function in self._pending_operations.pop(key, []):
429 function(model)
432packages = Packages(installed_packages=None)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import pytest
3from plain.signals import request_finished, request_started
5from .. import transaction
6from ..backends.base.base import BaseDatabaseWrapper
7from ..db import close_old_connections, connections
8from .utils import (
9 setup_databases,
10 teardown_databases,
11)
14@pytest.fixture(autouse=True)
15def _db_disabled():
16 """
17 Every test should use this fixture by default to prevent
18 access to the normal database.
19 """
21 def cursor_disabled(self):
22 pytest.fail("Database access not allowed without the `db` fixture")
24 BaseDatabaseWrapper._old_cursor = BaseDatabaseWrapper.cursor
25 BaseDatabaseWrapper.cursor = cursor_disabled
27 yield
29 BaseDatabaseWrapper.cursor = BaseDatabaseWrapper._old_cursor
32@pytest.fixture(scope="session")
33def setup_db(request):
34 """
35 This fixture is called automatically by `db`,
36 so a test database will only be setup if the `db` fixture is used.
37 """
38 verbosity = request.config.option.verbose
40 # Set up the test db across the entire session
41 _old_db_config = setup_databases(verbosity=verbosity)
43 # Keep connections open during request client / testing
44 request_started.disconnect(close_old_connections)
45 request_finished.disconnect(close_old_connections)
47 yield _old_db_config
49 # Put the signals back...
50 request_started.connect(close_old_connections)
51 request_finished.connect(close_old_connections)
53 # When the test session is done, tear down the test db
54 teardown_databases(_old_db_config, verbosity=verbosity)
57@pytest.fixture()
58def db(setup_db):
59 # Set .cursor() back to the original implementation
60 BaseDatabaseWrapper.cursor = BaseDatabaseWrapper._old_cursor
62 # Keep track of the atomic blocks so we can roll them back
63 atomics = {}
65 for connection in connections.all():
66 # By default we use transactions to rollback changes,
67 # so we need to ensure the database supports transactions
68 if not connection.features.supports_transactions:
69 pytest.fail("Database does not support transactions")
71 # Clear the queries log before each test?
72 # connection.queries_log.clear()
74 atomic = transaction.atomic(using=connection.alias)
75 atomic._from_testcase = True # TODO remove this somehow?
76 atomic.__enter__()
77 atomics[connection] = atomic
79 yield setup_db
81 for connection, atomic in atomics.items():
82 if (
83 connection.features.can_defer_constraint_checks
84 and not connection.needs_rollback
85 and connection.is_usable()
86 ):
87 connection.check_constraints()
89 transaction.set_rollback(True, using=connection.alias)
90 atomic.__exit__(None, None, None)
92 connection.close()
95# @pytest.fixture(scope="function")
96# def transactional_db(request, _plain_db_setup):
97# BaseDatabaseWrapper.cursor = BaseDatabaseWrapper._cursor
99# yield
101# # Flush databases instead of rolling back transactions...
103# connections.close_all()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.exceptions import ImproperlyConfigured
2from plain.models import DEFAULT_DB_ALIAS, connections
5def setup_databases(
6 verbosity,
7 *,
8 keepdb=False,
9 debug_sql=False,
10 aliases=None,
11 serialized_aliases=None,
12 **kwargs,
13):
14 """Create the test databases."""
16 test_databases, mirrored_aliases = get_unique_databases_and_mirrors(aliases)
18 old_names = []
20 for db_name, aliases in test_databases.values():
21 first_alias = None
22 for alias in aliases:
23 connection = connections[alias]
24 old_names.append((connection, db_name, first_alias is None))
26 # Actually create the database for the first connection
27 if first_alias is None:
28 first_alias = alias
29 serialize_alias = (
30 serialized_aliases is None or alias in serialized_aliases
31 )
32 connection.creation.create_test_db(
33 verbosity=verbosity,
34 autoclobber=True,
35 keepdb=keepdb,
36 serialize=serialize_alias,
37 )
38 # Configure all other connections as mirrors of the first one
39 else:
40 connections[alias].creation.set_as_test_mirror(
41 connections[first_alias].settings_dict
42 )
44 # Configure the test mirrors.
45 for alias, mirror_alias in mirrored_aliases.items():
46 connections[alias].creation.set_as_test_mirror(
47 connections[mirror_alias].settings_dict
48 )
50 if debug_sql:
51 for alias in connections:
52 connections[alias].force_debug_cursor = True
54 return old_names
57def get_unique_databases_and_mirrors(aliases=None):
58 """
59 Figure out which databases actually need to be created.
61 Deduplicate entries in DATABASES that correspond the same database or are
62 configured as test mirrors.
64 Return two values:
65 - test_databases: ordered mapping of signatures to (name, list of aliases)
66 where all aliases share the same underlying database.
67 - mirrored_aliases: mapping of mirror aliases to original aliases.
68 """
69 if aliases is None:
70 aliases = connections
71 mirrored_aliases = {}
72 test_databases = {}
73 dependencies = {}
74 default_sig = connections[DEFAULT_DB_ALIAS].creation.test_db_signature()
76 for alias in connections:
77 connection = connections[alias]
78 test_settings = connection.settings_dict["TEST"]
80 if test_settings["MIRROR"]:
81 # If the database is marked as a test mirror, save the alias.
82 mirrored_aliases[alias] = test_settings["MIRROR"]
83 elif alias in aliases:
84 # Store a tuple with DB parameters that uniquely identify it.
85 # If we have two aliases with the same values for that tuple,
86 # we only need to create the test database once.
87 item = test_databases.setdefault(
88 connection.creation.test_db_signature(),
89 (connection.settings_dict["NAME"], []),
90 )
91 # The default database must be the first because data migrations
92 # use the default alias by default.
93 if alias == DEFAULT_DB_ALIAS:
94 item[1].insert(0, alias)
95 else:
96 item[1].append(alias)
98 if "DEPENDENCIES" in test_settings:
99 dependencies[alias] = test_settings["DEPENDENCIES"]
100 else:
101 if (
102 alias != DEFAULT_DB_ALIAS
103 and connection.creation.test_db_signature() != default_sig
104 ):
105 dependencies[alias] = test_settings.get(
106 "DEPENDENCIES", [DEFAULT_DB_ALIAS]
107 )
109 test_databases = dict(dependency_ordered(test_databases.items(), dependencies))
110 return test_databases, mirrored_aliases
113def teardown_databases(old_config, verbosity, keepdb=False):
114 """Destroy all the non-mirror databases."""
115 for connection, old_name, destroy in old_config:
116 if destroy:
117 connection.creation.destroy_test_db(old_name, verbosity, keepdb)
120def dependency_ordered(test_databases, dependencies):
121 """
122 Reorder test_databases into an order that honors the dependencies
123 described in TEST[DEPENDENCIES].
124 """
125 ordered_test_databases = []
126 resolved_databases = set()
128 # Maps db signature to dependencies of all its aliases
129 dependencies_map = {}
131 # Check that no database depends on its own alias
132 for sig, (_, aliases) in test_databases:
133 all_deps = set()
134 for alias in aliases:
135 all_deps.update(dependencies.get(alias, []))
136 if not all_deps.isdisjoint(aliases):
137 raise ImproperlyConfigured(
138 "Circular dependency: databases %r depend on each other, "
139 "but are aliases." % aliases
140 )
141 dependencies_map[sig] = all_deps
143 while test_databases:
144 changed = False
145 deferred = []
147 # Try to find a DB that has all its dependencies met
148 for signature, (db_name, aliases) in test_databases:
149 if dependencies_map[signature].issubset(resolved_databases):
150 resolved_databases.update(aliases)
151 ordered_test_databases.append((signature, (db_name, aliases)))
152 changed = True
153 else:
154 deferred.append((signature, (db_name, aliases)))
156 if not changed:
157 raise ImproperlyConfigured("Circular dependency in TEST[DEPENDENCIES]")
158 test_databases = deferred
159 return ordered_test_databases
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:27 -0500
1import logging
2import types
4from plain.exceptions import ImproperlyConfigured
5from plain.logs import log_response
6from plain.runtime import settings
7from plain.signals import request_finished
8from plain.urls import get_resolver, set_urlconf
9from plain.utils.module_loading import import_string
11from .exception import convert_exception_to_response
13logger = logging.getLogger("plain.request")
16# These middleware classes are always used by Plain.
17BUILTIN_MIDDLEWARE = [
18 "plain.internal.middleware.headers.DefaultHeadersMiddleware",
19 "plain.internal.middleware.https.HttpsRedirectMiddleware",
20 "plain.internal.middleware.slash.RedirectSlashMiddleware",
21 "plain.csrf.middleware.CsrfViewMiddleware",
22]
25class BaseHandler:
26 _view_middleware = None
27 _middleware_chain = None
29 def load_middleware(self):
30 """
31 Populate middleware lists from settings.MIDDLEWARE.
33 Must be called after the environment is fixed (see __call__ in subclasses).
34 """
35 self._view_middleware = []
37 get_response = self._get_response
38 handler = convert_exception_to_response(get_response)
40 middlewares = reversed(BUILTIN_MIDDLEWARE + settings.MIDDLEWARE)
42 for middleware_path in middlewares:
43 middleware = import_string(middleware_path)
44 mw_instance = middleware(handler)
46 if mw_instance is None:
47 raise ImproperlyConfigured(
48 "Middleware factory %s returned None." % middleware_path
49 )
51 if hasattr(mw_instance, "process_view"):
52 self._view_middleware.insert(
53 0,
54 mw_instance.process_view,
55 )
57 handler = convert_exception_to_response(mw_instance)
59 # We only assign to this when initialization is complete as it is used
60 # as a flag for initialization being complete.
61 self._middleware_chain = handler
63 def get_response(self, request):
64 """Return a Response object for the given HttpRequest."""
65 # Setup default url resolver for this thread
66 set_urlconf(settings.ROOT_URLCONF)
67 response = self._middleware_chain(request)
68 response._resource_closers.append(request.close)
69 if response.status_code >= 400:
70 log_response(
71 "%s: %s",
72 response.reason_phrase,
73 request.path,
74 response=response,
75 request=request,
76 )
77 return response
79 def _get_response(self, request):
80 """
81 Resolve and call the view, then apply view, exception, and
82 template_response middleware. This method is everything that happens
83 inside the request/response middleware.
84 """
85 response = None
86 callback, callback_args, callback_kwargs = self.resolve_request(request)
88 # Apply view middleware
89 for middleware_method in self._view_middleware:
90 response = middleware_method(
91 request, callback, callback_args, callback_kwargs
92 )
93 if response:
94 break
96 if response is None:
97 response = callback(request, *callback_args, **callback_kwargs)
99 # Complain if the view returned None (a common error).
100 self.check_response(response, callback)
102 return response
104 def resolve_request(self, request):
105 """
106 Retrieve/set the urlconf for the request. Return the view resolved,
107 with its args and kwargs.
108 """
109 # Work out the resolver.
110 if hasattr(request, "urlconf"):
111 urlconf = request.urlconf
112 set_urlconf(urlconf)
113 resolver = get_resolver(urlconf)
114 else:
115 resolver = get_resolver()
116 # Resolve the view, and assign the match object back to the request.
117 resolver_match = resolver.resolve(request.path_info)
118 request.resolver_match = resolver_match
119 return resolver_match
121 def check_response(self, response, callback, name=None):
122 """
123 Raise an error if the view returned None or an uncalled coroutine.
124 """
125 if not name:
126 if isinstance(callback, types.FunctionType): # FBV
127 name = f"The view {callback.__module__}.{callback.__name__}"
128 else: # CBV
129 name = "The view {}.{}.__call__".format(
130 callback.__module__,
131 callback.__class__.__name__,
132 )
133 if response is None:
134 raise ValueError(
135 "%s didn't return a Response object. It returned None "
136 "instead." % name
137 )
140def reset_urlconf(sender, **kwargs):
141 """Reset the URLconf after each request is finished."""
142 set_urlconf(None)
145request_finished.connect(reset_urlconf)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import logging
2from functools import wraps
4from plain import signals
5from plain.exceptions import (
6 BadRequest,
7 PermissionDenied,
8 RequestDataTooBig,
9 SuspiciousOperation,
10 TooManyFieldsSent,
11 TooManyFilesSent,
12)
13from plain.http import Http404, ResponseServerError
14from plain.http.multipartparser import MultiPartParserError
15from plain.logs import log_response
16from plain.runtime import settings
17from plain.utils.module_loading import import_string
18from plain.views.errors import ErrorView
21def convert_exception_to_response(get_response):
22 """
23 Wrap the given get_response callable in exception-to-response conversion.
25 All exceptions will be converted. All known 4xx exceptions (Http404,
26 PermissionDenied, MultiPartParserError, SuspiciousOperation) will be
27 converted to the appropriate response, and all other exceptions will be
28 converted to 500 responses.
30 This decorator is automatically applied to all middleware to ensure that
31 no middleware leaks an exception and that the next middleware in the stack
32 can rely on getting a response instead of an exception.
33 """
35 @wraps(get_response)
36 def inner(request):
37 try:
38 response = get_response(request)
39 except Exception as exc:
40 response = response_for_exception(request, exc)
41 return response
43 return inner
46def response_for_exception(request, exc):
47 if isinstance(exc, Http404):
48 response = get_exception_response(request, 404)
50 elif isinstance(exc, PermissionDenied):
51 response = get_exception_response(request, 403)
52 log_response(
53 "Forbidden (Permission denied): %s",
54 request.path,
55 response=response,
56 request=request,
57 exception=exc,
58 )
60 elif isinstance(exc, MultiPartParserError):
61 response = get_exception_response(request, 400)
62 log_response(
63 "Bad request (Unable to parse request body): %s",
64 request.path,
65 response=response,
66 request=request,
67 exception=exc,
68 )
70 elif isinstance(exc, BadRequest):
71 response = get_exception_response(request, 400)
72 log_response(
73 "%s: %s",
74 str(exc),
75 request.path,
76 response=response,
77 request=request,
78 exception=exc,
79 )
80 elif isinstance(exc, SuspiciousOperation):
81 if isinstance(exc, RequestDataTooBig | TooManyFieldsSent | TooManyFilesSent):
82 # POST data can't be accessed again, otherwise the original
83 # exception would be raised.
84 request._mark_post_parse_error()
86 # The request logger receives events for any problematic request
87 # The security logger receives events for all SuspiciousOperations
88 security_logger = logging.getLogger(
89 "plain.security.%s" % exc.__class__.__name__
90 )
91 security_logger.error(
92 str(exc),
93 exc_info=exc,
94 extra={"status_code": 400, "request": request},
95 )
96 response = get_exception_response(request, 400)
98 else:
99 signals.got_request_exception.send(sender=None, request=request)
100 response = get_exception_response(request, 500)
101 log_response(
102 "%s: %s",
103 response.reason_phrase,
104 request.path,
105 response=response,
106 request=request,
107 exception=exc,
108 )
110 # Force a TemplateResponse to be rendered.
111 if not getattr(response, "is_rendered", True) and callable(
112 getattr(response, "render", None)
113 ):
114 response = response.render()
116 return response
119def get_exception_response(request, status_code):
120 try:
121 return get_error_view(status_code)(request)
122 except Exception:
123 signals.got_request_exception.send(sender=None, request=request)
124 return handle_uncaught_exception()
127def handle_uncaught_exception():
128 """
129 Processing for any otherwise uncaught exceptions (those that will
130 generate HTTP 500 responses).
131 """
132 return ResponseServerError()
135def get_error_view(status_code):
136 views_by_status = settings.HTTP_ERROR_VIEWS
137 if status_code in views_by_status:
138 view = views_by_status[status_code]
139 if isinstance(view, str):
140 # Import the view if it's a string
141 view = import_string(view)
142 return view.as_view()
144 # Create a standard view for any other status code
145 return ErrorView.as_view(status_code=status_code)
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import uuid
2from io import IOBase
4from plain import signals
5from plain.http import HttpRequest, QueryDict, parse_cookie
6from plain.internal.handlers import base
7from plain.utils.encoding import repercent_broken_unicode
8from plain.utils.functional import cached_property
9from plain.utils.regex_helper import _lazy_re_compile
11_slashes_re = _lazy_re_compile(rb"/+")
14class LimitedStream(IOBase):
15 """
16 Wrap another stream to disallow reading it past a number of bytes.
18 Based on the implementation from werkzeug.wsgi.LimitedStream
19 See https://github.com/pallets/werkzeug/blob/dbf78f67/src/werkzeug/wsgi.py#L828
20 """
22 def __init__(self, stream, limit):
23 self._read = stream.read
24 self._readline = stream.readline
25 self._pos = 0
26 self.limit = limit
28 def read(self, size=-1, /):
29 _pos = self._pos
30 limit = self.limit
31 if _pos >= limit:
32 return b""
33 if size == -1 or size is None:
34 size = limit - _pos
35 else:
36 size = min(size, limit - _pos)
37 data = self._read(size)
38 self._pos += len(data)
39 return data
41 def readline(self, size=-1, /):
42 _pos = self._pos
43 limit = self.limit
44 if _pos >= limit:
45 return b""
46 if size == -1 or size is None:
47 size = limit - _pos
48 else:
49 size = min(size, limit - _pos)
50 line = self._readline(size)
51 self._pos += len(line)
52 return line
55class WSGIRequest(HttpRequest):
56 non_picklable_attrs = HttpRequest.non_picklable_attrs | frozenset(["environ"])
57 meta_non_picklable_attrs = frozenset(["wsgi.errors", "wsgi.input"])
59 def __init__(self, environ):
60 # A unique ID we can use to trace this request
61 self.unique_id = str(uuid.uuid4())
63 script_name = get_script_name(environ)
64 # If PATH_INFO is empty (e.g. accessing the SCRIPT_NAME URL without a
65 # trailing slash), operate as if '/' was requested.
66 path_info = get_path_info(environ) or "/"
67 self.environ = environ
68 self.path_info = path_info
69 # be careful to only replace the first slash in the path because of
70 # http://test/something and http://test//something being different as
71 # stated in RFC 3986.
72 self.path = "{}/{}".format(
73 script_name.rstrip("/"), path_info.replace("/", "", 1)
74 )
75 self.META = environ
76 self.META["PATH_INFO"] = path_info
77 self.META["SCRIPT_NAME"] = script_name
78 self.method = environ["REQUEST_METHOD"].upper()
79 # Set content_type, content_params, and encoding.
80 self._set_content_type_params(environ)
81 try:
82 content_length = int(environ.get("CONTENT_LENGTH"))
83 except (ValueError, TypeError):
84 content_length = 0
85 self._stream = LimitedStream(self.environ["wsgi.input"], content_length)
86 self._read_started = False
87 self.resolver_match = None
89 def __getstate__(self):
90 state = super().__getstate__()
91 for attr in self.meta_non_picklable_attrs:
92 if attr in state["META"]:
93 del state["META"][attr]
94 return state
96 def _get_scheme(self):
97 return self.environ.get("wsgi.url_scheme")
99 @cached_property
100 def GET(self):
101 # The WSGI spec says 'QUERY_STRING' may be absent.
102 raw_query_string = get_bytes_from_wsgi(self.environ, "QUERY_STRING", "")
103 return QueryDict(raw_query_string, encoding=self._encoding)
105 def _get_post(self):
106 if not hasattr(self, "_post"):
107 self._load_post_and_files()
108 return self._post
110 def _set_post(self, post):
111 self._post = post
113 @cached_property
114 def COOKIES(self):
115 raw_cookie = get_str_from_wsgi(self.environ, "HTTP_COOKIE", "")
116 return parse_cookie(raw_cookie)
118 @property
119 def FILES(self):
120 if not hasattr(self, "_files"):
121 self._load_post_and_files()
122 return self._files
124 POST = property(_get_post, _set_post)
127class WSGIHandler(base.BaseHandler):
128 request_class = WSGIRequest
130 def __init__(self, *args, **kwargs):
131 super().__init__(*args, **kwargs)
132 self.load_middleware()
134 def __call__(self, environ, start_response):
135 signals.request_started.send(sender=self.__class__, environ=environ)
136 request = self.request_class(environ)
137 response = self.get_response(request)
139 response._handler_class = self.__class__
141 status = "%d %s" % (response.status_code, response.reason_phrase)
142 response_headers = [
143 *response.items(),
144 *(("Set-Cookie", c.output(header="")) for c in response.cookies.values()),
145 ]
146 start_response(status, response_headers)
147 if getattr(response, "file_to_stream", None) is not None and environ.get(
148 "wsgi.file_wrapper"
149 ):
150 # If `wsgi.file_wrapper` is used the WSGI server does not call
151 # .close on the response, but on the file wrapper. Patch it to use
152 # response.close instead which takes care of closing all files.
153 response.file_to_stream.close = response.close
154 response = environ["wsgi.file_wrapper"](
155 response.file_to_stream, response.block_size
156 )
157 return response
160def get_path_info(environ):
161 """Return the HTTP request's PATH_INFO as a string."""
162 path_info = get_bytes_from_wsgi(environ, "PATH_INFO", "/")
164 return repercent_broken_unicode(path_info).decode()
167def get_script_name(environ):
168 """
169 Return the equivalent of the HTTP request's SCRIPT_NAME environment
170 variable. If Apache mod_rewrite is used, return what would have been
171 the script name prior to any rewriting (so it's the script name as seen
172 from the client's perspective).
173 """
174 # If Apache's mod_rewrite had a whack at the URL, Apache set either
175 # SCRIPT_URL or REDIRECT_URL to the full resource URL before applying any
176 # rewrites. Unfortunately not every web server (lighttpd!) passes this
177 # information through all the time, so FORCE_SCRIPT_NAME, above, is still
178 # needed.
179 script_url = get_bytes_from_wsgi(environ, "SCRIPT_URL", "") or get_bytes_from_wsgi(
180 environ, "REDIRECT_URL", ""
181 )
183 if script_url:
184 if b"//" in script_url:
185 # mod_wsgi squashes multiple successive slashes in PATH_INFO,
186 # do the same with script_url before manipulating paths (#17133).
187 script_url = _slashes_re.sub(b"/", script_url)
188 path_info = get_bytes_from_wsgi(environ, "PATH_INFO", "")
189 script_name = script_url.removesuffix(path_info)
190 else:
191 script_name = get_bytes_from_wsgi(environ, "SCRIPT_NAME", "")
193 return script_name.decode()
196def get_bytes_from_wsgi(environ, key, default):
197 """
198 Get a value from the WSGI environ dictionary as bytes.
200 key and default should be strings.
201 """
202 value = environ.get(key, default)
203 # Non-ASCII values in the WSGI environ are arbitrarily decoded with
204 # ISO-8859-1. This is wrong for Plain websites where UTF-8 is the default.
205 # Re-encode to recover the original bytestring.
206 return value.encode("iso-8859-1")
209def get_str_from_wsgi(environ, key, default):
210 """
211 Get a value from the WSGI environ dictionary as str.
213 key and default should be str objects.
214 """
215 value = get_bytes_from_wsgi(environ, key, default)
216 return value.decode(errors="replace")
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from .sessions import get_user, get_user_model, login, logout
3__all__ = ["login", "logout", "get_user_model", "get_user"]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.packages import PackageConfig
4class AuthConfig(PackageConfig):
5 name = "plain.auth"
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from importlib.util import find_spec
3AUTH_USER_MODEL: str
4AUTH_LOGIN_URL: str
6if find_spec("plain.passwords"):
7 # Automatically invalidate sessions on password field change,
8 # if the plain-passwords is installed. You can change this value
9 # if your password field is named differently, or you want
10 # to use a different field to invalidate sessions.
11 AUTH_USER_SESSION_HASH_FIELD: str = "password"
12else:
13 AUTH_USER_SESSION_HASH_FIELD: str = ""
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain import auth
2from plain.exceptions import ImproperlyConfigured
3from plain.utils.functional import SimpleLazyObject
6def get_user(request):
7 if not hasattr(request, "_cached_user"):
8 request._cached_user = auth.get_user(request)
9 return request._cached_user
12class AuthenticationMiddleware:
13 def __init__(self, get_response):
14 self.get_response = get_response
16 def __call__(self, request):
17 if not hasattr(request, "session"):
18 raise ImproperlyConfigured(
19 "The Plain authentication middleware requires session "
20 "middleware to be installed. Edit your MIDDLEWARE setting to "
21 "insert "
22 "'plain.sessions.middleware.SessionMiddleware' before "
23 "'plain.auth.middleware.AuthenticationMiddleware'."
24 )
25 request.user = SimpleLazyObject(lambda: get_user(request))
26 response = self.get_response(request)
27 return response
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.csrf.middleware import rotate_token
2from plain.exceptions import ImproperlyConfigured
3from plain.packages import packages as plain_packages
4from plain.runtime import settings
5from plain.utils.crypto import constant_time_compare, salted_hmac
7from .signals import user_logged_in, user_logged_out
9USER_ID_SESSION_KEY = "_auth_user_id"
10USER_HASH_SESSION_KEY = "_auth_user_hash"
13def _get_user_id_from_session(request):
14 # This value in the session is always serialized to a string, so we need
15 # to convert it back to Python whenever we access it.
16 return get_user_model()._meta.pk.to_python(request.session[USER_ID_SESSION_KEY])
19def get_session_auth_hash(user):
20 """
21 Return an HMAC of the password field.
22 """
23 return _get_session_auth_hash(user)
26def get_session_auth_fallback_hash(user):
27 for fallback_secret in settings.SECRET_KEY_FALLBACKS:
28 yield _get_session_auth_hash(user, secret=fallback_secret)
31def _get_session_auth_hash(user, secret=None):
32 key_salt = "plain.auth.get_session_auth_hash"
33 return salted_hmac(
34 key_salt,
35 getattr(user, settings.AUTH_USER_SESSION_HASH_FIELD),
36 secret=secret,
37 algorithm="sha256",
38 ).hexdigest()
41def login(request, user):
42 """
43 Persist a user id and a backend in the request. This way a user doesn't
44 have to reauthenticate on every request. Note that data set during
45 the anonymous session is retained when the user logs in.
46 """
47 if settings.AUTH_USER_SESSION_HASH_FIELD:
48 session_auth_hash = get_session_auth_hash(user)
49 else:
50 session_auth_hash = ""
52 if USER_ID_SESSION_KEY in request.session:
53 if _get_user_id_from_session(request) != user.pk:
54 # To avoid reusing another user's session, create a new, empty
55 # session if the existing session corresponds to a different
56 # authenticated user.
57 request.session.flush()
58 elif session_auth_hash and not constant_time_compare(
59 request.session.get(USER_HASH_SESSION_KEY, ""), session_auth_hash
60 ):
61 # If the session hash does not match the current hash, reset the
62 # session. Most likely this means the password was changed.
63 request.session.flush()
64 else:
65 request.session.cycle_key()
67 request.session[USER_ID_SESSION_KEY] = user._meta.pk.value_to_string(user)
68 request.session[USER_HASH_SESSION_KEY] = session_auth_hash
69 if hasattr(request, "user"):
70 request.user = user
71 rotate_token(request)
72 user_logged_in.send(sender=user.__class__, request=request, user=user)
75def logout(request):
76 """
77 Remove the authenticated user's ID from the request and flush their session
78 data.
79 """
80 # Dispatch the signal before the user is logged out so the receivers have a
81 # chance to find out *who* logged out.
82 user = getattr(request, "user", None)
83 user_logged_out.send(sender=user.__class__, request=request, user=user)
84 request.session.flush()
85 if hasattr(request, "user"):
86 request.user = None
89def get_user_model():
90 """
91 Return the User model that is active in this project.
92 """
93 try:
94 return plain_packages.get_model(settings.AUTH_USER_MODEL, require_ready=False)
95 except ValueError:
96 raise ImproperlyConfigured(
97 "AUTH_USER_MODEL must be of the form 'package_label.model_name'"
98 )
99 except LookupError:
100 raise ImproperlyConfigured(
101 f"AUTH_USER_MODEL refers to model '{settings.AUTH_USER_MODEL}' that has not been installed"
102 )
105def get_user(request):
106 """
107 Return the user model instance associated with the given request session.
108 If no user is retrieved, return None.
109 """
110 if USER_ID_SESSION_KEY not in request.session:
111 return None
113 user_id = _get_user_id_from_session(request)
115 UserModel = get_user_model()
116 try:
117 user = UserModel._default_manager.get(pk=user_id)
118 except UserModel.DoesNotExist:
119 return None
121 # If the user models defines a specific field to also hash and compare
122 # (like password), then we verify that the hash of that field is still
123 # the same as when the session was created.
124 #
125 # If it has changed (i.e. password changed), then the session
126 # is no longer valid and cleared out.
127 if settings.AUTH_USER_SESSION_HASH_FIELD:
128 session_hash = request.session.get(USER_HASH_SESSION_KEY)
129 if not session_hash:
130 session_hash_verified = False
131 else:
132 session_auth_hash = get_session_auth_hash(user)
133 session_hash_verified = constant_time_compare(
134 session_hash, session_auth_hash
135 )
136 if not session_hash_verified:
137 # If the current secret does not verify the session, try
138 # with the fallback secrets and stop when a matching one is
139 # found.
140 if session_hash and any(
141 constant_time_compare(session_hash, fallback_auth_hash)
142 for fallback_auth_hash in get_session_auth_fallback_hash(user)
143 ):
144 request.session.cycle_key()
145 request.session[USER_HASH_SESSION_KEY] = session_auth_hash
146 else:
147 request.session.flush()
148 user = None
150 return user
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.signals.dispatch import Signal
3user_logged_in = Signal()
4user_login_failed = Signal()
5user_logged_out = Signal()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.urls import NoReverseMatch, reverse
2from plain.utils.functional import Promise
5def resolve_url(to, *args, **kwargs):
6 """
7 Return a URL appropriate for the arguments passed.
9 The arguments could be:
11 * A model: the model's `get_absolute_url()` function will be called.
13 * A view name, possibly with arguments: `urls.reverse()` will be used
14 to reverse-resolve the name.
16 * A URL, which will be returned as-is.
17 """
18 # If it's a model, use get_absolute_url()
19 if hasattr(to, "get_absolute_url"):
20 return to.get_absolute_url()
22 if isinstance(to, Promise):
23 # Expand the lazy instance, as it can cause issues when it is passed
24 # further to some Python functions like urlparse.
25 to = str(to)
27 # Handle relative URLs
28 if isinstance(to, str) and to.startswith(("./", "../")):
29 return to
31 # Next try a reverse URL resolution.
32 try:
33 return reverse(to, args=args, kwargs=kwargs)
34 except NoReverseMatch:
35 # If this is a callable, re-raise.
36 if callable(to):
37 raise
38 # If this doesn't "feel" like a URL, re-raise.
39 if "/" not in to and "." not in to:
40 raise
42 # Finally, fall back and assume it's a URL
43 return to
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from urllib.parse import urlparse, urlunparse
3from plain.exceptions import PermissionDenied
4from plain.http import (
5 Http404,
6 QueryDict,
7 Response,
8 ResponseRedirect,
9)
10from plain.runtime import settings
11from plain.urls import reverse
12from plain.views import View
14from .sessions import logout
15from .utils import resolve_url
18class LoginRequired(Exception):
19 def __init__(self, login_url=None, redirect_field_name="next"):
20 self.login_url = login_url or settings.AUTH_LOGIN_URL
21 self.redirect_field_name = redirect_field_name
24class AuthViewMixin:
25 login_required = True
26 staff_required = False
27 login_url = None
29 def check_auth(self) -> None:
30 """
31 Raises either LoginRequired or PermissionDenied.
32 - LoginRequired can specify a login_url and redirect_field_name
33 - PermissionDenied can specify a message
34 """
36 if not hasattr(self, "request"):
37 raise AttributeError(
38 "AuthViewMixin requires the request attribute to be set."
39 )
41 if self.login_required and not self.request.user:
42 raise LoginRequired(login_url=self.login_url)
44 if impersonator := getattr(self.request, "impersonator", None):
45 # Impersonators should be able to view staff pages while impersonating.
46 # There's probably never a case where an impersonator isn't staff, but it can be configured.
47 if self.staff_required and not impersonator.is_staff:
48 raise PermissionDenied(
49 "You do not have permission to access this page."
50 )
51 elif self.staff_required and not self.request.user.is_staff:
52 # Show a 404 so we don't expose staff urls to non-staff users
53 raise Http404()
55 def get_response(self) -> Response:
56 if not hasattr(self, "request"):
57 raise AttributeError(
58 "AuthViewMixin requires the request attribute to be set."
59 )
61 try:
62 self.check_auth()
63 except LoginRequired as e:
64 # Ideally this could be handled elsewhere... like PermissionDenied
65 # also seems like this code is used multiple places anyway...
66 # could be easier to get redirect query param
67 path = self.request.build_absolute_uri()
68 resolved_login_url = reverse(e.login_url)
69 # If the login url is the same scheme and net location then use the
70 # path as the "next" url.
71 login_scheme, login_netloc = urlparse(resolved_login_url)[:2]
72 current_scheme, current_netloc = urlparse(path)[:2]
73 if (not login_scheme or login_scheme == current_scheme) and (
74 not login_netloc or login_netloc == current_netloc
75 ):
76 path = self.request.get_full_path()
77 return redirect_to_login(
78 path,
79 resolved_login_url,
80 e.redirect_field_name,
81 )
83 return super().get_response() # type: ignore
86class LogoutView(View):
87 def post(self):
88 logout(self.request)
89 return ResponseRedirect("/")
92def redirect_to_login(next, login_url=None, redirect_field_name="next"):
93 """
94 Redirect the user to the login page, passing the given 'next' page.
95 """
96 resolved_url = resolve_url(login_url or settings.AUTH_LOGIN_URL)
98 login_url_parts = list(urlparse(resolved_url))
99 if redirect_field_name:
100 querystring = QueryDict(login_url_parts[4], mutable=True)
101 querystring[redirect_field_name] = next
102 login_url_parts[4] = querystring.urlencode(safe="/")
104 return ResponseRedirect(urlunparse(login_url_parts))
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.signals.dispatch import Signal
3request_started = Signal()
4request_finished = Signal()
5got_request_exception = Signal()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Global Plain exception and warning classes.
3"""
5import operator
7from plain.utils.hashable import make_hashable
10class FieldDoesNotExist(Exception):
11 """The requested model field does not exist"""
13 pass
16class PackageRegistryNotReady(Exception):
17 """The plain.packages registry is not populated yet"""
19 pass
22class ObjectDoesNotExist(Exception):
23 """The requested object does not exist"""
25 silent_variable_failure = True
28class MultipleObjectsReturned(Exception):
29 """The query returned multiple objects when only one was expected."""
31 pass
34class SuspiciousOperation(Exception):
35 """The user did something suspicious"""
38class SuspiciousMultipartForm(SuspiciousOperation):
39 """Suspect MIME request in multipart form data"""
41 pass
44class SuspiciousFileOperation(SuspiciousOperation):
45 """A Suspicious filesystem operation was attempted"""
47 pass
50class DisallowedHost(SuspiciousOperation):
51 """HTTP_HOST header contains invalid value"""
53 pass
56class DisallowedRedirect(SuspiciousOperation):
57 """Redirect to scheme not in allowed list"""
59 pass
62class TooManyFieldsSent(SuspiciousOperation):
63 """
64 The number of fields in a GET or POST request exceeded
65 settings.DATA_UPLOAD_MAX_NUMBER_FIELDS.
66 """
68 pass
71class TooManyFilesSent(SuspiciousOperation):
72 """
73 The number of fields in a GET or POST request exceeded
74 settings.DATA_UPLOAD_MAX_NUMBER_FILES.
75 """
77 pass
80class RequestDataTooBig(SuspiciousOperation):
81 """
82 The size of the request (excluding any file uploads) exceeded
83 settings.DATA_UPLOAD_MAX_MEMORY_SIZE.
84 """
86 pass
89class RequestAborted(Exception):
90 """The request was closed before it was completed, or timed out."""
92 pass
95class BadRequest(Exception):
96 """The request is malformed and cannot be processed."""
98 pass
101class PermissionDenied(Exception):
102 """The user did not have permission to do that"""
104 pass
107class ViewDoesNotExist(Exception):
108 """The requested view does not exist"""
110 pass
113class ImproperlyConfigured(Exception):
114 """Plain is somehow improperly configured"""
116 pass
119class FieldError(Exception):
120 """Some kind of problem with a model field."""
122 pass
125NON_FIELD_ERRORS = "__all__"
128class ValidationError(Exception):
129 """An error while validating data."""
131 def __init__(self, message, code=None, params=None):
132 """
133 The `message` argument can be a single error, a list of errors, or a
134 dictionary that maps field names to lists of errors. What we define as
135 an "error" can be either a simple string or an instance of
136 ValidationError with its message attribute set, and what we define as
137 list or dictionary can be an actual `list` or `dict` or an instance
138 of ValidationError with its `error_list` or `error_dict` attribute set.
139 """
140 super().__init__(message, code, params)
142 if isinstance(message, ValidationError):
143 if hasattr(message, "error_dict"):
144 message = message.error_dict
145 elif not hasattr(message, "message"):
146 message = message.error_list
147 else:
148 message, code, params = message.message, message.code, message.params
150 if isinstance(message, dict):
151 self.error_dict = {}
152 for field, messages in message.items():
153 if not isinstance(messages, ValidationError):
154 messages = ValidationError(messages)
155 self.error_dict[field] = messages.error_list
157 elif isinstance(message, list):
158 self.error_list = []
159 for message in message:
160 # Normalize plain strings to instances of ValidationError.
161 if not isinstance(message, ValidationError):
162 message = ValidationError(message)
163 if hasattr(message, "error_dict"):
164 self.error_list.extend(sum(message.error_dict.values(), []))
165 else:
166 self.error_list.extend(message.error_list)
168 else:
169 self.message = message
170 self.code = code
171 self.params = params
172 self.error_list = [self]
174 @property
175 def message_dict(self):
176 # Trigger an AttributeError if this ValidationError
177 # doesn't have an error_dict.
178 getattr(self, "error_dict")
180 return dict(self)
182 @property
183 def messages(self):
184 if hasattr(self, "error_dict"):
185 return sum(dict(self).values(), [])
186 return list(self)
188 def update_error_dict(self, error_dict):
189 if hasattr(self, "error_dict"):
190 for field, error_list in self.error_dict.items():
191 error_dict.setdefault(field, []).extend(error_list)
192 else:
193 error_dict.setdefault(NON_FIELD_ERRORS, []).extend(self.error_list)
194 return error_dict
196 def __iter__(self):
197 if hasattr(self, "error_dict"):
198 for field, errors in self.error_dict.items():
199 yield field, list(ValidationError(errors))
200 else:
201 for error in self.error_list:
202 message = error.message
203 if error.params:
204 message %= error.params
205 yield str(message)
207 def __str__(self):
208 if hasattr(self, "error_dict"):
209 return repr(dict(self))
210 return repr(list(self))
212 def __repr__(self):
213 return f"ValidationError({self})"
215 def __eq__(self, other):
216 if not isinstance(other, ValidationError):
217 return NotImplemented
218 return hash(self) == hash(other)
220 def __hash__(self):
221 if hasattr(self, "message"):
222 return hash(
223 (
224 self.message,
225 self.code,
226 make_hashable(self.params),
227 )
228 )
229 if hasattr(self, "error_dict"):
230 return hash(make_hashable(self.error_dict))
231 return hash(tuple(sorted(self.error_list, key=operator.attrgetter("message"))))
234class EmptyResultSet(Exception):
235 """A database query predicate is impossible."""
237 pass
240class FullResultSet(Exception):
241 """A database query predicate is matches everything."""
243 pass
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
2import decimal
3import json
4import uuid
6from plain.utils.duration import duration_iso_string
7from plain.utils.functional import Promise
8from plain.utils.timezone import is_aware
11class PlainJSONEncoder(json.JSONEncoder):
12 """
13 JSONEncoder subclass that knows how to encode date/time, decimal types, and
14 UUIDs.
15 """
17 def default(self, o):
18 # See "Date Time String Format" in the ECMA-262 specification.
19 if isinstance(o, datetime.datetime):
20 r = o.isoformat()
21 if o.microsecond:
22 r = r[:23] + r[26:]
23 if r.endswith("+00:00"):
24 r = r.removesuffix("+00:00") + "Z"
25 return r
26 elif isinstance(o, datetime.date):
27 return o.isoformat()
28 elif isinstance(o, datetime.time):
29 if is_aware(o):
30 raise ValueError("JSON can't represent timezone-aware times.")
31 r = o.isoformat()
32 if o.microsecond:
33 r = r[:12]
34 return r
35 elif isinstance(o, datetime.timedelta):
36 return duration_iso_string(o)
37 elif isinstance(o, decimal.Decimal | uuid.UUID | Promise):
38 return str(o)
39 else:
40 return super().default(o)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import collections.abc
2import inspect
3import warnings
4from math import ceil
6from plain.utils.functional import cached_property
7from plain.utils.inspect import method_has_no_args
10class UnorderedObjectListWarning(RuntimeWarning):
11 pass
14class InvalidPage(Exception):
15 pass
18class PageNotAnInteger(InvalidPage):
19 pass
22class EmptyPage(InvalidPage):
23 pass
26class Paginator:
27 # Translators: String used to replace omitted page numbers in elided page
28 # range generated by paginators, e.g. [1, 2, '…', 5, 6, 7, '…', 9, 10].
29 ELLIPSIS = "…"
31 def __init__(self, object_list, per_page, orphans=0, allow_empty_first_page=True):
32 self.object_list = object_list
33 self._check_object_list_is_ordered()
34 self.per_page = int(per_page)
35 self.orphans = int(orphans)
36 self.allow_empty_first_page = allow_empty_first_page
38 def __iter__(self):
39 for page_number in self.page_range:
40 yield self.page(page_number)
42 def validate_number(self, number):
43 """Validate the given 1-based page number."""
44 try:
45 if isinstance(number, float) and not number.is_integer():
46 raise ValueError
47 number = int(number)
48 except (TypeError, ValueError):
49 raise PageNotAnInteger("That page number is not an integer")
50 if number < 1:
51 raise EmptyPage("That page number is less than 1")
52 if number > self.num_pages:
53 raise EmptyPage("That page contains no results")
54 return number
56 def get_page(self, number):
57 """
58 Return a valid page, even if the page argument isn't a number or isn't
59 in range.
60 """
61 try:
62 number = self.validate_number(number)
63 except PageNotAnInteger:
64 number = 1
65 except EmptyPage:
66 number = self.num_pages
67 return self.page(number)
69 def page(self, number):
70 """Return a Page object for the given 1-based page number."""
71 number = self.validate_number(number)
72 bottom = (number - 1) * self.per_page
73 top = bottom + self.per_page
74 if top + self.orphans >= self.count:
75 top = self.count
76 return self._get_page(self.object_list[bottom:top], number, self)
78 def _get_page(self, *args, **kwargs):
79 """
80 Return an instance of a single page.
82 This hook can be used by subclasses to use an alternative to the
83 standard :cls:`Page` object.
84 """
85 return Page(*args, **kwargs)
87 @cached_property
88 def count(self):
89 """Return the total number of objects, across all pages."""
90 c = getattr(self.object_list, "count", None)
91 if callable(c) and not inspect.isbuiltin(c) and method_has_no_args(c):
92 return c()
93 return len(self.object_list)
95 @cached_property
96 def num_pages(self):
97 """Return the total number of pages."""
98 if self.count == 0 and not self.allow_empty_first_page:
99 return 0
100 hits = max(1, self.count - self.orphans)
101 return ceil(hits / self.per_page)
103 @property
104 def page_range(self):
105 """
106 Return a 1-based range of pages for iterating through within
107 a template for loop.
108 """
109 return range(1, self.num_pages + 1)
111 def _check_object_list_is_ordered(self):
112 """
113 Warn if self.object_list is unordered (typically a QuerySet).
114 """
115 ordered = getattr(self.object_list, "ordered", None)
116 if ordered is not None and not ordered:
117 obj_list_repr = (
118 f"{self.object_list.model} {self.object_list.__class__.__name__}"
119 if hasattr(self.object_list, "model")
120 else f"{self.object_list!r}"
121 )
122 warnings.warn(
123 "Pagination may yield inconsistent results with an unordered "
124 f"object_list: {obj_list_repr}.",
125 UnorderedObjectListWarning,
126 stacklevel=3,
127 )
130class Page(collections.abc.Sequence):
131 def __init__(self, object_list, number, paginator):
132 self.object_list = object_list
133 self.number = number
134 self.paginator = paginator
136 def __repr__(self):
137 return f"<Page {self.number} of {self.paginator.num_pages}>"
139 def __len__(self):
140 return len(self.object_list)
142 def __getitem__(self, index):
143 if not isinstance(index, int | slice):
144 raise TypeError(
145 f"Page indices must be integers or slices, not {type(index).__name__}."
146 )
147 # The object_list is converted to a list so that if it was a QuerySet
148 # it won't be a database hit per __getitem__.
149 if not isinstance(self.object_list, list):
150 self.object_list = list(self.object_list)
151 return self.object_list[index]
153 def has_next(self):
154 return self.number < self.paginator.num_pages
156 def has_previous(self):
157 return self.number > 1
159 def has_other_pages(self):
160 return self.has_previous() or self.has_next()
162 def next_page_number(self):
163 return self.paginator.validate_number(self.number + 1)
165 def previous_page_number(self):
166 return self.paginator.validate_number(self.number - 1)
168 def start_index(self):
169 """
170 Return the 1-based index of the first object on this page,
171 relative to total objects in the paginator.
172 """
173 # Special case, return zero if no items.
174 if self.paginator.count == 0:
175 return 0
176 return (self.paginator.per_page * (self.number - 1)) + 1
178 def end_index(self):
179 """
180 Return the 1-based index of the last object on this page,
181 relative to total objects found (hits).
182 """
183 # Special case for the last page because there can be orphans.
184 if self.number == self.paginator.num_pages:
185 return self.paginator.count
186 return self.number * self.paginator.per_page
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Functions for creating and restoring url-safe signed JSON objects.
4The format used looks like this:
6>>> signing.dumps("hello")
7'ImhlbGxvIg:1QaUZC:YIye-ze3TTx7gtSv422nZA4sgmk'
9There are two components here, separated by a ':'. The first component is a
10URLsafe base64 encoded JSON of the object passed to dumps(). The second
11component is a base64 encoded hmac/SHA-256 hash of "$first_component:$secret"
13signing.loads(s) checks the signature and returns the deserialized object.
14If the signature fails, a BadSignature exception is raised.
16>>> signing.loads("ImhlbGxvIg:1QaUZC:YIye-ze3TTx7gtSv422nZA4sgmk")
17'hello'
18>>> signing.loads("ImhlbGxvIg:1QaUZC:YIye-ze3TTx7gtSv42-modified")
19...
20BadSignature: Signature "ImhlbGxvIg:1QaUZC:YIye-ze3TTx7gtSv42-modified" does not match
22You can optionally compress the JSON prior to base64 encoding it to save
23space, using the compress=True argument. This checks if compression actually
24helps and only applies compression if the result is a shorter string:
26>>> signing.dumps(list(range(1, 20)), compress=True)
27'.eJwFwcERACAIwLCF-rCiILN47r-GyZVJsNgkxaFxoDgxcOHGxMKD_T7vhAml:1QaUaL:BA0thEZrp4FQVXIXuOvYJtLJSrQ'
29The fact that the string is compressed is signalled by the prefixed '.' at the
30start of the base64 JSON.
32There are 65 url-safe characters: the 64 used by url-safe base64 and the ':'.
33These functions make use of all of them.
34"""
36import base64
37import datetime
38import json
39import time
40import zlib
42from plain.runtime import settings
43from plain.utils.crypto import constant_time_compare, salted_hmac
44from plain.utils.encoding import force_bytes
45from plain.utils.module_loading import import_string
46from plain.utils.regex_helper import _lazy_re_compile
48_SEP_UNSAFE = _lazy_re_compile(r"^[A-z0-9-_=]*$")
49BASE62_ALPHABET = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
52class BadSignature(Exception):
53 """Signature does not match."""
55 pass
58class SignatureExpired(BadSignature):
59 """Signature timestamp is older than required max_age."""
61 pass
64def b62_encode(s):
65 if s == 0:
66 return "0"
67 sign = "-" if s < 0 else ""
68 s = abs(s)
69 encoded = ""
70 while s > 0:
71 s, remainder = divmod(s, 62)
72 encoded = BASE62_ALPHABET[remainder] + encoded
73 return sign + encoded
76def b62_decode(s):
77 if s == "0":
78 return 0
79 sign = 1
80 if s[0] == "-":
81 s = s[1:]
82 sign = -1
83 decoded = 0
84 for digit in s:
85 decoded = decoded * 62 + BASE62_ALPHABET.index(digit)
86 return sign * decoded
89def b64_encode(s):
90 return base64.urlsafe_b64encode(s).strip(b"=")
93def b64_decode(s):
94 pad = b"=" * (-len(s) % 4)
95 return base64.urlsafe_b64decode(s + pad)
98def base64_hmac(salt, value, key, algorithm="sha1"):
99 return b64_encode(
100 salted_hmac(salt, value, key, algorithm=algorithm).digest()
101 ).decode()
104def _cookie_signer_key(key):
105 # SECRET_KEYS items may be str or bytes.
106 return b"plain.http.cookies" + force_bytes(key)
109def get_cookie_signer(salt="plain.signing.get_cookie_signer"):
110 Signer = import_string(settings.COOKIE_SIGNING_BACKEND)
111 return Signer(
112 key=_cookie_signer_key(settings.SECRET_KEY),
113 fallback_keys=map(_cookie_signer_key, settings.SECRET_KEY_FALLBACKS),
114 salt=salt,
115 )
118class JSONSerializer:
119 """
120 Simple wrapper around json to be used in signing.dumps and
121 signing.loads.
122 """
124 def dumps(self, obj):
125 return json.dumps(obj, separators=(",", ":")).encode("latin-1")
127 def loads(self, data):
128 return json.loads(data.decode("latin-1"))
131def dumps(
132 obj, key=None, salt="plain.signing", serializer=JSONSerializer, compress=False
133):
134 """
135 Return URL-safe, hmac signed base64 compressed JSON string. If key is
136 None, use settings.SECRET_KEY instead. The hmac algorithm is the default
137 Signer algorithm.
139 If compress is True (not the default), check if compressing using zlib can
140 save some space. Prepend a '.' to signify compression. This is included
141 in the signature, to protect against zip bombs.
143 Salt can be used to namespace the hash, so that a signed string is
144 only valid for a given namespace. Leaving this at the default
145 value or re-using a salt value across different parts of your
146 application without good cause is a security risk.
148 The serializer is expected to return a bytestring.
149 """
150 return TimestampSigner(key=key, salt=salt).sign_object(
151 obj, serializer=serializer, compress=compress
152 )
155def loads(
156 s,
157 key=None,
158 salt="plain.signing",
159 serializer=JSONSerializer,
160 max_age=None,
161 fallback_keys=None,
162):
163 """
164 Reverse of dumps(), raise BadSignature if signature fails.
166 The serializer is expected to accept a bytestring.
167 """
168 return TimestampSigner(
169 key=key, salt=salt, fallback_keys=fallback_keys
170 ).unsign_object(
171 s,
172 serializer=serializer,
173 max_age=max_age,
174 )
177class Signer:
178 def __init__(
179 self,
180 *,
181 key=None,
182 sep=":",
183 salt=None,
184 algorithm="sha256",
185 fallback_keys=None,
186 ):
187 self.key = key or settings.SECRET_KEY
188 self.fallback_keys = (
189 fallback_keys
190 if fallback_keys is not None
191 else settings.SECRET_KEY_FALLBACKS
192 )
193 self.sep = sep
194 self.salt = salt or f"{self.__class__.__module__}.{self.__class__.__name__}"
195 self.algorithm = algorithm
197 if _SEP_UNSAFE.match(self.sep):
198 raise ValueError(
199 f"Unsafe Signer separator: {sep!r} (cannot be empty or consist of "
200 "only A-z0-9-_=)",
201 )
203 def signature(self, value, key=None):
204 key = key or self.key
205 return base64_hmac(self.salt + "signer", value, key, algorithm=self.algorithm)
207 def sign(self, value):
208 return f"{value}{self.sep}{self.signature(value)}"
210 def unsign(self, signed_value):
211 if self.sep not in signed_value:
212 raise BadSignature(f'No "{self.sep}" found in value')
213 value, sig = signed_value.rsplit(self.sep, 1)
214 for key in [self.key, *self.fallback_keys]:
215 if constant_time_compare(sig, self.signature(value, key)):
216 return value
217 raise BadSignature(f'Signature "{sig}" does not match')
219 def sign_object(self, obj, serializer=JSONSerializer, compress=False):
220 """
221 Return URL-safe, hmac signed base64 compressed JSON string.
223 If compress is True (not the default), check if compressing using zlib
224 can save some space. Prepend a '.' to signify compression. This is
225 included in the signature, to protect against zip bombs.
227 The serializer is expected to return a bytestring.
228 """
229 data = serializer().dumps(obj)
230 # Flag for if it's been compressed or not.
231 is_compressed = False
233 if compress:
234 # Avoid zlib dependency unless compress is being used.
235 compressed = zlib.compress(data)
236 if len(compressed) < (len(data) - 1):
237 data = compressed
238 is_compressed = True
239 base64d = b64_encode(data).decode()
240 if is_compressed:
241 base64d = "." + base64d
242 return self.sign(base64d)
244 def unsign_object(self, signed_obj, serializer=JSONSerializer, **kwargs):
245 # Signer.unsign() returns str but base64 and zlib compression operate
246 # on bytes.
247 base64d = self.unsign(signed_obj, **kwargs).encode()
248 decompress = base64d[:1] == b"."
249 if decompress:
250 # It's compressed; uncompress it first.
251 base64d = base64d[1:]
252 data = b64_decode(base64d)
253 if decompress:
254 data = zlib.decompress(data)
255 return serializer().loads(data)
258class TimestampSigner(Signer):
259 def timestamp(self):
260 return b62_encode(int(time.time()))
262 def sign(self, value):
263 value = f"{value}{self.sep}{self.timestamp()}"
264 return super().sign(value)
266 def unsign(self, value, max_age=None):
267 """
268 Retrieve original value and check it wasn't signed more
269 than max_age seconds ago.
270 """
271 result = super().unsign(value)
272 value, timestamp = result.rsplit(self.sep, 1)
273 timestamp = b62_decode(timestamp)
274 if max_age is not None:
275 if isinstance(max_age, datetime.timedelta):
276 max_age = max_age.total_seconds()
277 # Check timestamp is not older than max_age
278 age = time.time() - timestamp
279 if age > max_age:
280 raise SignatureExpired(f"Signature age {age} > {max_age} seconds")
281 return value
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import ipaddress
2import math
3import re
4from pathlib import Path
5from urllib.parse import urlsplit, urlunsplit
7from plain.exceptions import ValidationError
8from plain.utils.deconstruct import deconstructible
9from plain.utils.encoding import punycode
10from plain.utils.ipv6 import is_valid_ipv6_address
11from plain.utils.regex_helper import _lazy_re_compile
12from plain.utils.text import pluralize_lazy
14# These values, if given to validate(), will trigger the self.required check.
15EMPTY_VALUES = (None, "", [], (), {})
18@deconstructible
19class RegexValidator:
20 regex = ""
21 message = "Enter a valid value."
22 code = "invalid"
23 inverse_match = False
24 flags = 0
26 def __init__(
27 self, regex=None, message=None, code=None, inverse_match=None, flags=None
28 ):
29 if regex is not None:
30 self.regex = regex
31 if message is not None:
32 self.message = message
33 if code is not None:
34 self.code = code
35 if inverse_match is not None:
36 self.inverse_match = inverse_match
37 if flags is not None:
38 self.flags = flags
39 if self.flags and not isinstance(self.regex, str):
40 raise TypeError(
41 "If the flags are set, regex must be a regular expression string."
42 )
44 self.regex = _lazy_re_compile(self.regex, self.flags)
46 def __call__(self, value):
47 """
48 Validate that the input contains (or does *not* contain, if
49 inverse_match is True) a match for the regular expression.
50 """
51 regex_matches = self.regex.search(str(value))
52 invalid_input = regex_matches if self.inverse_match else not regex_matches
53 if invalid_input:
54 raise ValidationError(self.message, code=self.code, params={"value": value})
56 def __eq__(self, other):
57 return (
58 isinstance(other, RegexValidator)
59 and self.regex.pattern == other.regex.pattern
60 and self.regex.flags == other.regex.flags
61 and (self.message == other.message)
62 and (self.code == other.code)
63 and (self.inverse_match == other.inverse_match)
64 )
67@deconstructible
68class URLValidator(RegexValidator):
69 ul = "\u00a1-\uffff" # Unicode letters range (must not be a raw string).
71 # IP patterns
72 ipv4_re = (
73 r"(?:0|25[0-5]|2[0-4][0-9]|1[0-9]?[0-9]?|[1-9][0-9]?)"
74 r"(?:\.(?:0|25[0-5]|2[0-4][0-9]|1[0-9]?[0-9]?|[1-9][0-9]?)){3}"
75 )
76 ipv6_re = r"\[[0-9a-f:.]+\]" # (simple regex, validated later)
78 # Host patterns
79 hostname_re = (
80 r"[a-z" + ul + r"0-9](?:[a-z" + ul + r"0-9-]{0,61}[a-z" + ul + r"0-9])?"
81 )
82 # Max length for domain name labels is 63 characters per RFC 1034 sec. 3.1
83 domain_re = r"(?:\.(?!-)[a-z" + ul + r"0-9-]{1,63}(?<!-))*"
84 tld_re = (
85 r"\." # dot
86 r"(?!-)" # can't start with a dash
87 r"(?:[a-z" + ul + "-]{2,63}" # domain label
88 r"|xn--[a-z0-9]{1,59})" # or punycode label
89 r"(?<!-)" # can't end with a dash
90 r"\.?" # may have a trailing dot
91 )
92 host_re = "(" + hostname_re + domain_re + tld_re + "|localhost)"
94 regex = _lazy_re_compile(
95 r"^(?:[a-z0-9.+-]*)://" # scheme is validated separately
96 r"(?:[^\s:@/]+(?::[^\s:@/]*)?@)?" # user:pass authentication
97 r"(?:" + ipv4_re + "|" + ipv6_re + "|" + host_re + ")"
98 r"(?::[0-9]{1,5})?" # port
99 r"(?:[/?#][^\s]*)?" # resource path
100 r"\Z",
101 re.IGNORECASE,
102 )
103 message = "Enter a valid URL."
104 schemes = ["http", "https", "ftp", "ftps"]
105 unsafe_chars = frozenset("\t\r\n")
107 def __init__(self, schemes=None, **kwargs):
108 super().__init__(**kwargs)
109 if schemes is not None:
110 self.schemes = schemes
112 def __call__(self, value):
113 if not isinstance(value, str):
114 raise ValidationError(self.message, code=self.code, params={"value": value})
115 if self.unsafe_chars.intersection(value):
116 raise ValidationError(self.message, code=self.code, params={"value": value})
117 # Check if the scheme is valid.
118 scheme = value.split("://")[0].lower()
119 if scheme not in self.schemes:
120 raise ValidationError(self.message, code=self.code, params={"value": value})
122 # Then check full URL
123 try:
124 splitted_url = urlsplit(value)
125 except ValueError:
126 raise ValidationError(self.message, code=self.code, params={"value": value})
127 try:
128 super().__call__(value)
129 except ValidationError as e:
130 # Trivial case failed. Try for possible IDN domain
131 if value:
132 scheme, netloc, path, query, fragment = splitted_url
133 try:
134 netloc = punycode(netloc) # IDN -> ACE
135 except UnicodeError: # invalid domain part
136 raise e
137 url = urlunsplit((scheme, netloc, path, query, fragment))
138 super().__call__(url)
139 else:
140 raise
141 else:
142 # Now verify IPv6 in the netloc part
143 host_match = re.search(r"^\[(.+)\](?::[0-9]{1,5})?$", splitted_url.netloc)
144 if host_match:
145 potential_ip = host_match[1]
146 try:
147 validate_ipv6_address(potential_ip)
148 except ValidationError:
149 raise ValidationError(
150 self.message, code=self.code, params={"value": value}
151 )
153 # The maximum length of a full host name is 253 characters per RFC 1034
154 # section 3.1. It's defined to be 255 bytes or less, but this includes
155 # one byte for the length of the name and one byte for the trailing dot
156 # that's used to indicate absolute names in DNS.
157 if splitted_url.hostname is None or len(splitted_url.hostname) > 253:
158 raise ValidationError(self.message, code=self.code, params={"value": value})
161integer_validator = RegexValidator(
162 _lazy_re_compile(r"^-?\d+\Z"),
163 message="Enter a valid integer.",
164 code="invalid",
165)
168def validate_integer(value):
169 return integer_validator(value)
172@deconstructible
173class EmailValidator:
174 message = "Enter a valid email address."
175 code = "invalid"
176 user_regex = _lazy_re_compile(
177 # dot-atom
178 r"(^[-!#$%&'*+/=?^_`{}|~0-9A-Z]+(\.[-!#$%&'*+/=?^_`{}|~0-9A-Z]+)*\Z"
179 # quoted-string
180 r'|^"([\001-\010\013\014\016-\037!#-\[\]-\177]|\\[\001-\011\013\014\016-\177])'
181 r'*"\Z)',
182 re.IGNORECASE,
183 )
184 domain_regex = _lazy_re_compile(
185 # max length for domain name labels is 63 characters per RFC 1034
186 r"((?:[A-Z0-9](?:[A-Z0-9-]{0,61}[A-Z0-9])?\.)+)(?:[A-Z0-9-]{2,63}(?<!-))\Z",
187 re.IGNORECASE,
188 )
189 literal_regex = _lazy_re_compile(
190 # literal form, ipv4 or ipv6 address (SMTP 4.1.3)
191 r"\[([A-F0-9:.]+)\]\Z",
192 re.IGNORECASE,
193 )
194 domain_allowlist = ["localhost"]
196 def __init__(self, message=None, code=None, allowlist=None):
197 if message is not None:
198 self.message = message
199 if code is not None:
200 self.code = code
201 if allowlist is not None:
202 self.domain_allowlist = allowlist
204 def __call__(self, value):
205 if not value or "@" not in value:
206 raise ValidationError(self.message, code=self.code, params={"value": value})
208 user_part, domain_part = value.rsplit("@", 1)
210 if not self.user_regex.match(user_part):
211 raise ValidationError(self.message, code=self.code, params={"value": value})
213 if domain_part not in self.domain_allowlist and not self.validate_domain_part(
214 domain_part
215 ):
216 # Try for possible IDN domain-part
217 try:
218 domain_part = punycode(domain_part)
219 except UnicodeError:
220 pass
221 else:
222 if self.validate_domain_part(domain_part):
223 return
224 raise ValidationError(self.message, code=self.code, params={"value": value})
226 def validate_domain_part(self, domain_part):
227 if self.domain_regex.match(domain_part):
228 return True
230 literal_match = self.literal_regex.match(domain_part)
231 if literal_match:
232 ip_address = literal_match[1]
233 try:
234 validate_ipv46_address(ip_address)
235 return True
236 except ValidationError:
237 pass
238 return False
240 def __eq__(self, other):
241 return (
242 isinstance(other, EmailValidator)
243 and (self.domain_allowlist == other.domain_allowlist)
244 and (self.message == other.message)
245 and (self.code == other.code)
246 )
249validate_email = EmailValidator()
251slug_re = _lazy_re_compile(r"^[-a-zA-Z0-9_]+\Z")
252validate_slug = RegexValidator(
253 slug_re,
254 # Translators: "letters" means latin letters: a-z and A-Z.
255 "Enter a valid “slug” consisting of letters, numbers, underscores or hyphens.",
256 "invalid",
257)
259slug_unicode_re = _lazy_re_compile(r"^[-\w]+\Z")
260validate_unicode_slug = RegexValidator(
261 slug_unicode_re,
262 "Enter a valid “slug” consisting of Unicode letters, numbers, underscores, or hyphens."
263 "invalid",
264)
267def validate_ipv4_address(value):
268 try:
269 ipaddress.IPv4Address(value)
270 except ValueError:
271 raise ValidationError(
272 "Enter a valid IPv4 address.", code="invalid", params={"value": value}
273 )
276def validate_ipv6_address(value):
277 if not is_valid_ipv6_address(value):
278 raise ValidationError(
279 "Enter a valid IPv6 address.", code="invalid", params={"value": value}
280 )
283def validate_ipv46_address(value):
284 try:
285 validate_ipv4_address(value)
286 except ValidationError:
287 try:
288 validate_ipv6_address(value)
289 except ValidationError:
290 raise ValidationError(
291 "Enter a valid IPv4 or IPv6 address.",
292 code="invalid",
293 params={"value": value},
294 )
297ip_address_validator_map = {
298 "both": ([validate_ipv46_address], "Enter a valid IPv4 or IPv6 address."),
299 "ipv4": ([validate_ipv4_address], "Enter a valid IPv4 address."),
300 "ipv6": ([validate_ipv6_address], "Enter a valid IPv6 address."),
301}
304def ip_address_validators(protocol, unpack_ipv4):
305 """
306 Depending on the given parameters, return the appropriate validators for
307 the GenericIPAddressField.
308 """
309 if protocol != "both" and unpack_ipv4:
310 raise ValueError(
311 "You can only use `unpack_ipv4` if `protocol` is set to 'both'"
312 )
313 try:
314 return ip_address_validator_map[protocol.lower()]
315 except KeyError:
316 raise ValueError(
317 f"The protocol '{protocol}' is unknown. Supported: {list(ip_address_validator_map)}"
318 )
321def int_list_validator(sep=",", message=None, code="invalid", allow_negative=False):
322 regexp = _lazy_re_compile(
323 r"^{neg}\d+(?:{sep}{neg}\d+)*\Z".format(
324 neg="(-)?" if allow_negative else "",
325 sep=re.escape(sep),
326 )
327 )
328 return RegexValidator(regexp, message=message, code=code)
331validate_comma_separated_integer_list = int_list_validator(
332 message="Enter only digits separated by commas.",
333)
336@deconstructible
337class BaseValidator:
338 message = "Ensure this value is %(limit_value)s (it is %(show_value)s)."
339 code = "limit_value"
341 def __init__(self, limit_value, message=None):
342 self.limit_value = limit_value
343 if message:
344 self.message = message
346 def __call__(self, value):
347 cleaned = self.clean(value)
348 limit_value = (
349 self.limit_value() if callable(self.limit_value) else self.limit_value
350 )
351 params = {"limit_value": limit_value, "show_value": cleaned, "value": value}
352 if self.compare(cleaned, limit_value):
353 raise ValidationError(self.message, code=self.code, params=params)
355 def __eq__(self, other):
356 if not isinstance(other, self.__class__):
357 return NotImplemented
358 return (
359 self.limit_value == other.limit_value
360 and self.message == other.message
361 and self.code == other.code
362 )
364 def compare(self, a, b):
365 return a is not b
367 def clean(self, x):
368 return x
371@deconstructible
372class MaxValueValidator(BaseValidator):
373 message = "Ensure this value is less than or equal to %(limit_value)s."
374 code = "max_value"
376 def compare(self, a, b):
377 return a > b
380@deconstructible
381class MinValueValidator(BaseValidator):
382 message = "Ensure this value is greater than or equal to %(limit_value)s."
383 code = "min_value"
385 def compare(self, a, b):
386 return a < b
389@deconstructible
390class StepValueValidator(BaseValidator):
391 message = "Ensure this value is a multiple of step size %(limit_value)s."
392 code = "step_size"
394 def compare(self, a, b):
395 return not math.isclose(math.remainder(a, b), 0, abs_tol=1e-9)
398@deconstructible
399class MinLengthValidator(BaseValidator):
400 message = pluralize_lazy(
401 "Ensure this value has at least %(limit_value)d character (it has "
402 "%(show_value)d).",
403 "Ensure this value has at least %(limit_value)d characters (it has "
404 "%(show_value)d).",
405 "limit_value",
406 )
407 code = "min_length"
409 def compare(self, a, b):
410 return a < b
412 def clean(self, x):
413 return len(x)
416@deconstructible
417class MaxLengthValidator(BaseValidator):
418 message = pluralize_lazy(
419 "Ensure this value has at most %(limit_value)d character (it has "
420 "%(show_value)d).",
421 "Ensure this value has at most %(limit_value)d characters (it has "
422 "%(show_value)d).",
423 "limit_value",
424 )
425 code = "max_length"
427 def compare(self, a, b):
428 return a > b
430 def clean(self, x):
431 return len(x)
434@deconstructible
435class DecimalValidator:
436 """
437 Validate that the input does not exceed the maximum number of digits
438 expected, otherwise raise ValidationError.
439 """
441 messages = {
442 "invalid": "Enter a number.",
443 "max_digits": pluralize_lazy(
444 "Ensure that there are no more than %(max)s digit in total.",
445 "Ensure that there are no more than %(max)s digits in total.",
446 "max",
447 ),
448 "max_decimal_places": pluralize_lazy(
449 "Ensure that there are no more than %(max)s decimal place.",
450 "Ensure that there are no more than %(max)s decimal places.",
451 "max",
452 ),
453 "max_whole_digits": pluralize_lazy(
454 "Ensure that there are no more than %(max)s digit before the decimal "
455 "point.",
456 "Ensure that there are no more than %(max)s digits before the decimal "
457 "point.",
458 "max",
459 ),
460 }
462 def __init__(self, max_digits, decimal_places):
463 self.max_digits = max_digits
464 self.decimal_places = decimal_places
466 def __call__(self, value):
467 digit_tuple, exponent = value.as_tuple()[1:]
468 if exponent in {"F", "n", "N"}:
469 raise ValidationError(
470 self.messages["invalid"], code="invalid", params={"value": value}
471 )
472 if exponent >= 0:
473 digits = len(digit_tuple)
474 if digit_tuple != (0,):
475 # A positive exponent adds that many trailing zeros.
476 digits += exponent
477 decimals = 0
478 else:
479 # If the absolute value of the negative exponent is larger than the
480 # number of digits, then it's the same as the number of digits,
481 # because it'll consume all of the digits in digit_tuple and then
482 # add abs(exponent) - len(digit_tuple) leading zeros after the
483 # decimal point.
484 if abs(exponent) > len(digit_tuple):
485 digits = decimals = abs(exponent)
486 else:
487 digits = len(digit_tuple)
488 decimals = abs(exponent)
489 whole_digits = digits - decimals
491 if self.max_digits is not None and digits > self.max_digits:
492 raise ValidationError(
493 self.messages["max_digits"],
494 code="max_digits",
495 params={"max": self.max_digits, "value": value},
496 )
497 if self.decimal_places is not None and decimals > self.decimal_places:
498 raise ValidationError(
499 self.messages["max_decimal_places"],
500 code="max_decimal_places",
501 params={"max": self.decimal_places, "value": value},
502 )
503 if (
504 self.max_digits is not None
505 and self.decimal_places is not None
506 and whole_digits > (self.max_digits - self.decimal_places)
507 ):
508 raise ValidationError(
509 self.messages["max_whole_digits"],
510 code="max_whole_digits",
511 params={"max": (self.max_digits - self.decimal_places), "value": value},
512 )
514 def __eq__(self, other):
515 return (
516 isinstance(other, self.__class__)
517 and self.max_digits == other.max_digits
518 and self.decimal_places == other.decimal_places
519 )
522@deconstructible
523class FileExtensionValidator:
524 message = "File extension “%(extension)s” is not allowed. Allowed extensions are: %(allowed_extensions)s."
525 code = "invalid_extension"
527 def __init__(self, allowed_extensions=None, message=None, code=None):
528 if allowed_extensions is not None:
529 allowed_extensions = [
530 allowed_extension.lower() for allowed_extension in allowed_extensions
531 ]
532 self.allowed_extensions = allowed_extensions
533 if message is not None:
534 self.message = message
535 if code is not None:
536 self.code = code
538 def __call__(self, value):
539 extension = Path(value.name).suffix[1:].lower()
540 if (
541 self.allowed_extensions is not None
542 and extension not in self.allowed_extensions
543 ):
544 raise ValidationError(
545 self.message,
546 code=self.code,
547 params={
548 "extension": extension,
549 "allowed_extensions": ", ".join(self.allowed_extensions),
550 "value": value,
551 },
552 )
554 def __eq__(self, other):
555 return (
556 isinstance(other, self.__class__)
557 and self.allowed_extensions == other.allowed_extensions
558 and self.message == other.message
559 and self.code == other.code
560 )
563def get_available_image_extensions():
564 try:
565 from PIL import Image
566 except ImportError:
567 return []
568 else:
569 Image.init()
570 return [ext.lower()[1:] for ext in Image.EXTENSION]
573def validate_image_file_extension(value):
574 return FileExtensionValidator(allowed_extensions=get_available_image_extensions())(
575 value
576 )
579@deconstructible
580class ProhibitNullCharactersValidator:
581 """Validate that the string doesn't contain the null character."""
583 message = "Null characters are not allowed."
584 code = "null_characters_not_allowed"
586 def __init__(self, message=None, code=None):
587 if message is not None:
588 self.message = message
589 if code is not None:
590 self.code = code
592 def __call__(self, value):
593 if "\x00" in str(value):
594 raise ValidationError(self.message, code=self.code, params={"value": value})
596 def __eq__(self, other):
597 return (
598 isinstance(other, self.__class__)
599 and self.message == other.message
600 and self.code == other.code
601 )
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1from plain.signals.dispatch import Signal
3request_started = Signal()
4request_finished = Signal()
5got_request_exception = Signal()
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import logging
2import string
3from datetime import datetime, timedelta
5from plain import signing
6from plain.runtime import settings
7from plain.utils import timezone
8from plain.utils.crypto import get_random_string
10# session_key should not be case sensitive because some backends can store it
11# on case insensitive file systems.
12VALID_KEY_CHARS = string.ascii_lowercase + string.digits
15class CreateError(Exception):
16 """
17 Used internally as a consistent exception type to catch from save (see the
18 docstring for SessionBase.save() for details).
19 """
21 pass
24class UpdateError(Exception):
25 """
26 Occurs if Plain tries to update a session that was deleted.
27 """
29 pass
32class SessionBase:
33 """
34 Base class for all Session classes.
35 """
37 __not_given = object()
39 def __init__(self, session_key=None):
40 self._session_key = session_key
41 self.accessed = False
42 self.modified = False
44 def __contains__(self, key):
45 return key in self._session
47 def __getitem__(self, key):
48 return self._session[key]
50 def __setitem__(self, key, value):
51 self._session[key] = value
52 self.modified = True
54 def __delitem__(self, key):
55 del self._session[key]
56 self.modified = True
58 @property
59 def key_salt(self):
60 return "plain.sessions." + self.__class__.__qualname__
62 def get(self, key, default=None):
63 return self._session.get(key, default)
65 def pop(self, key, default=__not_given):
66 self.modified = self.modified or key in self._session
67 args = () if default is self.__not_given else (default,)
68 return self._session.pop(key, *args)
70 def setdefault(self, key, value):
71 if key in self._session:
72 return self._session[key]
73 else:
74 self.modified = True
75 self._session[key] = value
76 return value
78 def encode(self, session_dict):
79 "Return the given session dictionary serialized and encoded as a string."
80 return signing.dumps(
81 session_dict,
82 salt=self.key_salt,
83 compress=True,
84 )
86 def decode(self, session_data):
87 try:
88 return signing.loads(session_data, salt=self.key_salt)
89 except signing.BadSignature:
90 logger = logging.getLogger("plain.security.SuspiciousSession")
91 logger.warning("Session data corrupted")
92 except Exception:
93 # ValueError, unpickling exceptions. If any of these happen, just
94 # return an empty dictionary (an empty session).
95 pass
96 return {}
98 def update(self, dict_):
99 self._session.update(dict_)
100 self.modified = True
102 def has_key(self, key):
103 return key in self._session
105 def keys(self):
106 return self._session.keys()
108 def values(self):
109 return self._session.values()
111 def items(self):
112 return self._session.items()
114 def clear(self):
115 # To avoid unnecessary persistent storage accesses, we set up the
116 # internals directly (loading data wastes time, since we are going to
117 # set it to an empty dict anyway).
118 self._session_cache = {}
119 self.accessed = True
120 self.modified = True
122 def is_empty(self):
123 "Return True when there is no session_key and the session is empty."
124 try:
125 return not self._session_key and not self._session_cache
126 except AttributeError:
127 return True
129 def _get_new_session_key(self):
130 "Return session key that isn't being used."
131 while True:
132 session_key = get_random_string(32, VALID_KEY_CHARS)
133 if not self.exists(session_key):
134 return session_key
136 def _get_or_create_session_key(self):
137 if self._session_key is None:
138 self._session_key = self._get_new_session_key()
139 return self._session_key
141 def _validate_session_key(self, key):
142 """
143 Key must be truthy and at least 8 characters long. 8 characters is an
144 arbitrary lower bound for some minimal key security.
145 """
146 return key and len(key) >= 8
148 def _get_session_key(self):
149 return self.__session_key
151 def _set_session_key(self, value):
152 """
153 Validate session key on assignment. Invalid values will set to None.
154 """
155 if self._validate_session_key(value):
156 self.__session_key = value
157 else:
158 self.__session_key = None
160 session_key = property(_get_session_key)
161 _session_key = property(_get_session_key, _set_session_key)
163 def _get_session(self, no_load=False):
164 """
165 Lazily load session from storage (unless "no_load" is True, when only
166 an empty dict is stored) and store it in the current instance.
167 """
168 self.accessed = True
169 try:
170 return self._session_cache
171 except AttributeError:
172 if self.session_key is None or no_load:
173 self._session_cache = {}
174 else:
175 self._session_cache = self.load()
176 return self._session_cache
178 _session = property(_get_session)
180 def get_session_cookie_age(self):
181 return settings.SESSION_COOKIE_AGE
183 def get_expiry_age(self, **kwargs):
184 """Get the number of seconds until the session expires.
186 Optionally, this function accepts `modification` and `expiry` keyword
187 arguments specifying the modification and expiry of the session.
188 """
189 try:
190 modification = kwargs["modification"]
191 except KeyError:
192 modification = timezone.now()
193 # Make the difference between "expiry=None passed in kwargs" and
194 # "expiry not passed in kwargs", in order to guarantee not to trigger
195 # self.load() when expiry is provided.
196 try:
197 expiry = kwargs["expiry"]
198 except KeyError:
199 expiry = self.get("_session_expiry")
201 if not expiry: # Checks both None and 0 cases
202 return self.get_session_cookie_age()
203 if not isinstance(expiry, datetime | str):
204 return expiry
205 if isinstance(expiry, str):
206 expiry = datetime.fromisoformat(expiry)
207 delta = expiry - modification
208 return delta.days * 86400 + delta.seconds
210 def get_expiry_date(self, **kwargs):
211 """Get session the expiry date (as a datetime object).
213 Optionally, this function accepts `modification` and `expiry` keyword
214 arguments specifying the modification and expiry of the session.
215 """
216 try:
217 modification = kwargs["modification"]
218 except KeyError:
219 modification = timezone.now()
220 # Same comment as in get_expiry_age
221 try:
222 expiry = kwargs["expiry"]
223 except KeyError:
224 expiry = self.get("_session_expiry")
226 if isinstance(expiry, datetime):
227 return expiry
228 elif isinstance(expiry, str):
229 return datetime.fromisoformat(expiry)
230 expiry = expiry or self.get_session_cookie_age()
231 return modification + timedelta(seconds=expiry)
233 def set_expiry(self, value):
234 """
235 Set a custom expiration for the session. ``value`` can be an integer,
236 a Python ``datetime`` or ``timedelta`` object or ``None``.
238 If ``value`` is an integer, the session will expire after that many
239 seconds of inactivity. If set to ``0`` then the session will expire on
240 browser close.
242 If ``value`` is a ``datetime`` or ``timedelta`` object, the session
243 will expire at that specific future time.
245 If ``value`` is ``None``, the session uses the global session expiry
246 policy.
247 """
248 if value is None:
249 # Remove any custom expiration for this session.
250 try:
251 del self["_session_expiry"]
252 except KeyError:
253 pass
254 return
255 if isinstance(value, timedelta):
256 value = timezone.now() + value
257 if isinstance(value, datetime):
258 value = value.isoformat()
259 self["_session_expiry"] = value
261 def get_expire_at_browser_close(self):
262 """
263 Return ``True`` if the session is set to expire when the browser
264 closes, and ``False`` if there's an expiry date. Use
265 ``get_expiry_date()`` or ``get_expiry_age()`` to find the actual expiry
266 date/age, if there is one.
267 """
268 if (expiry := self.get("_session_expiry")) is None:
269 return settings.SESSION_EXPIRE_AT_BROWSER_CLOSE
270 return expiry == 0
272 def flush(self):
273 """
274 Remove the current session data from the database and regenerate the
275 key.
276 """
277 self.clear()
278 self.delete()
279 self._session_key = None
281 def cycle_key(self):
282 """
283 Create a new session key, while retaining the current session data.
284 """
285 data = self._session
286 key = self.session_key
287 self.create()
288 self._session_cache = data
289 if key:
290 self.delete(key)
292 # Methods that child classes must implement.
294 def exists(self, session_key):
295 """
296 Return True if the given session_key already exists.
297 """
298 raise NotImplementedError(
299 "subclasses of SessionBase must provide an exists() method"
300 )
302 def create(self):
303 """
304 Create a new session instance. Guaranteed to create a new object with
305 a unique key and will have saved the result once (with empty data)
306 before the method returns.
307 """
308 raise NotImplementedError(
309 "subclasses of SessionBase must provide a create() method"
310 )
312 def save(self, must_create=False):
313 """
314 Save the session data. If 'must_create' is True, create a new session
315 object (or raise CreateError). Otherwise, only update an existing
316 object and don't create one (raise UpdateError if needed).
317 """
318 raise NotImplementedError(
319 "subclasses of SessionBase must provide a save() method"
320 )
322 def delete(self, session_key=None):
323 """
324 Delete the session data under this key. If the key is None, use the
325 current session key value.
326 """
327 raise NotImplementedError(
328 "subclasses of SessionBase must provide a delete() method"
329 )
331 def load(self):
332 """
333 Load the session data and return a dictionary.
334 """
335 raise NotImplementedError(
336 "subclasses of SessionBase must provide a load() method"
337 )
339 @classmethod
340 def clear_expired(cls):
341 """
342 Remove expired sessions from the session store.
344 If this operation isn't possible on a given backend, it should raise
345 NotImplementedError. If it isn't necessary, because the backend has
346 a built-in expiration mechanism, it should be a no-op.
347 """
348 raise NotImplementedError("This backend does not support clear_expired().")
« prev ^ index » next coverage.py v7.6.1, created at 2024-10-16 22:04 -0500
1import logging
3from plain.exceptions import SuspiciousOperation
4from plain.models import DatabaseError, IntegrityError, router, transaction
5from plain.sessions.backends.base import CreateError, SessionBase, UpdateError
6from plain.utils import timezone
7from plain.utils.functional import cached_property
10class SessionStore(SessionBase):
11 """
12 Implement database session store.
13 """
15 def __init__(self, session_key=None):
16 super().__init__(session_key)
18 @classmethod
19 def get_model_class(cls):
20 # Avoids a circular import and allows importing SessionStore when
21 # plain.sessions is not in INSTALLED_PACKAGES.
22 from plain.sessions.models import Session
24 return Session
26 @cached_property
27 def model(self):
28 return self.get_model_class()
30 def _get_session_from_db(self):
31 try:
32 return self.model.objects.get(
33 session_key=self.session_key, expire_date__gt=timezone.now()
34 )
35 except (self.model.DoesNotExist, SuspiciousOperation) as e:
36 if isinstance(e, SuspiciousOperation):
37 logger = logging.getLogger("plain.security.%s" % e.__class__.__name__)
38 logger.warning(str(e))
39 self._session_key = None
41 def load(self):
42 s = self._get_session_from_db()
43 return self.decode(s.session_data) if s else {}
45 def exists(self, session_key):
46 return self.model.objects.filter(session_key=session_key).exists()
48 def create(self):
49 while True:
50 self._session_key = self._get_new_session_key()
51 try:
52 # Save immediately to ensure we have a unique entry in the
53 # database.
54 self.save(must_create=True)
55 except CreateError:
56 # Key wasn't unique. Try again.
57 continue
58 self.modified = True
59 return
61 def create_model_instance(self, data):
62 """
63 Return a new instance of the session model object, which represents the
64 current session state. Intended to be used for saving the session data
65 to the database.
66 """
67 return self.model(
68 session_key=self._get_or_create_session_key(),
69 session_data=self.encode(data),
70 expire_date=self.get_expiry_date(),
71 )
73 def save(self, must_create=False):
74 """
75 Save the current session data to the database. If 'must_create' is
76 True, raise a database error if the saving operation doesn't create a
77 new entry (as opposed to possibly updating an existing entry).
78 """
79 if self.session_key is None:
80 return self.create()
81 data = self._get_session(no_load=must_create)
82 obj = self.create_model_instance(data)
83 using = router.db_for_write(self.model, instance=obj)
84 try:
85 with transaction.atomic(using=using):
86 obj.save(
87 clean_and_validate=False,
88 force_insert=must_create,
89 force_update=not must_create,
90 using=using,
91 )
92 except IntegrityError:
93 if must_create:
94 raise CreateError
95 raise
96 except DatabaseError:
97 if not must_create:
98 raise UpdateError
99 raise
101 def delete(self, session_key=None):
102 if session_key is None:
103 if self.session_key is None:
104 return
105 session_key = self.session_key
106 try:
107 self.model.objects.get(session_key=session_key).delete()
108 except self.model.DoesNotExist:
109 pass
111 @classmethod
112 def clear_expired(cls):
113 cls.get_model_class().objects.filter(expire_date__lt=timezone.now()).delete()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1# Generated by Plain 4.0.3 on 2022-03-16 19:11
3import plain.models.deletion
4from plain import models
5from plain.models import migrations
6from plain.runtime import settings
9class Migration(migrations.Migration):
10 initial = True
12 dependencies = [
13 migrations.swappable_dependency(settings.AUTH_USER_MODEL),
14 ]
16 operations = [
17 migrations.CreateModel(
18 name="OAuthConnection",
19 fields=[
20 (
21 "id",
22 models.BigAutoField(
23 auto_created=True,
24 primary_key=True,
25 ),
26 ),
27 ("created_at", models.DateTimeField(auto_now_add=True)),
28 ("updated_at", models.DateTimeField(auto_now=True)),
29 ("provider_key", models.CharField(db_index=True, max_length=100)),
30 ("provider_user_id", models.CharField(db_index=True, max_length=100)),
31 ("access_token", models.CharField(blank=True, max_length=100)),
32 ("refresh_token", models.CharField(blank=True, max_length=100)),
33 (
34 "access_token_expires_at",
35 models.DateTimeField(blank=True, null=True),
36 ),
37 (
38 "refresh_token_expires_at",
39 models.DateTimeField(blank=True, null=True),
40 ),
41 (
42 "user",
43 models.ForeignKey(
44 on_delete=plain.models.deletion.CASCADE,
45 related_name="oauth_connections",
46 to=settings.AUTH_USER_MODEL,
47 ),
48 ),
49 ],
50 ),
51 ]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1# Generated by Plain 4.0.3 on 2022-03-18 18:24
3from plain import models
4from plain.models import migrations
7class Migration(migrations.Migration):
8 dependencies = [
9 ("plainoauth", "0001_initial"),
10 ]
12 operations = [
13 migrations.AlterModelOptions(
14 name="oauthconnection",
15 options={
16 "ordering": ("provider_key",),
17 },
18 ),
19 migrations.AlterField(
20 model_name="oauthconnection",
21 name="access_token",
22 field=models.CharField(max_length=100),
23 ),
24 ]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1# Generated by Plain 4.0.6 on 2022-08-11 19:18
3from plain import models
4from plain.models import migrations
7class Migration(migrations.Migration):
8 dependencies = [
9 ("plainoauth", "0002_alter_oauthconnection_options_and_more"),
10 ]
12 operations = [
13 migrations.AlterField(
14 model_name="oauthconnection",
15 name="access_token",
16 field=models.CharField(max_length=300),
17 ),
18 migrations.AlterField(
19 model_name="oauthconnection",
20 name="refresh_token",
21 field=models.CharField(blank=True, max_length=300),
22 ),
23 ]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1# Generated by Plain 5.0.dev20230806030948 on 2023-08-08 19:32
3from plain import models
4from plain.models import migrations
7class Migration(migrations.Migration):
8 dependencies = [
9 ("plainoauth", "0003_alter_oauthconnection_access_token_and_more"),
10 ]
12 operations = [
13 migrations.AlterField(
14 model_name="oauthconnection",
15 name="access_token",
16 field=models.CharField(max_length=2000),
17 ),
18 migrations.AlterField(
19 model_name="oauthconnection",
20 name="refresh_token",
21 field=models.CharField(blank=True, max_length=2000),
22 ),
23 ]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1# Generated by Plain 0.3.0 on 2024-08-16 16:46
3from plain import models
4from plain.models import migrations
7class Migration(migrations.Migration):
8 dependencies = [
9 ("users", "__first__"),
10 ("plainoauth", "0004_alter_oauthconnection_access_token_and_more"),
11 ]
13 operations = [
14 migrations.AddConstraint(
15 model_name="oauthconnection",
16 constraint=models.UniqueConstraint(
17 fields=("provider_key", "provider_user_id"),
18 name="unique_oauth_provider_user_id",
19 ),
20 ),
21 ]
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1"""
2Helpers to manipulate deferred DDL statements that might need to be adjusted or
3discarded within when executing a migration.
4"""
6from copy import deepcopy
9class Reference:
10 """Base class that defines the reference interface."""
12 def references_table(self, table):
13 """
14 Return whether or not this instance references the specified table.
15 """
16 return False
18 def references_column(self, table, column):
19 """
20 Return whether or not this instance references the specified column.
21 """
22 return False
24 def rename_table_references(self, old_table, new_table):
25 """
26 Rename all references to the old_name to the new_table.
27 """
28 pass
30 def rename_column_references(self, table, old_column, new_column):
31 """
32 Rename all references to the old_column to the new_column.
33 """
34 pass
36 def __repr__(self):
37 return f"<{self.__class__.__name__} {str(self)!r}>"
39 def __str__(self):
40 raise NotImplementedError(
41 "Subclasses must define how they should be converted to string."
42 )
45class Table(Reference):
46 """Hold a reference to a table."""
48 def __init__(self, table, quote_name):
49 self.table = table
50 self.quote_name = quote_name
52 def references_table(self, table):
53 return self.table == table
55 def rename_table_references(self, old_table, new_table):
56 if self.table == old_table:
57 self.table = new_table
59 def __str__(self):
60 return self.quote_name(self.table)
63class TableColumns(Table):
64 """Base class for references to multiple columns of a table."""
66 def __init__(self, table, columns):
67 self.table = table
68 self.columns = columns
70 def references_column(self, table, column):
71 return self.table == table and column in self.columns
73 def rename_column_references(self, table, old_column, new_column):
74 if self.table == table:
75 for index, column in enumerate(self.columns):
76 if column == old_column:
77 self.columns[index] = new_column
80class Columns(TableColumns):
81 """Hold a reference to one or many columns."""
83 def __init__(self, table, columns, quote_name, col_suffixes=()):
84 self.quote_name = quote_name
85 self.col_suffixes = col_suffixes
86 super().__init__(table, columns)
88 def __str__(self):
89 def col_str(column, idx):
90 col = self.quote_name(column)
91 try:
92 suffix = self.col_suffixes[idx]
93 if suffix:
94 col = f"{col} {suffix}"
95 except IndexError:
96 pass
97 return col
99 return ", ".join(
100 col_str(column, idx) for idx, column in enumerate(self.columns)
101 )
104class IndexName(TableColumns):
105 """Hold a reference to an index name."""
107 def __init__(self, table, columns, suffix, create_index_name):
108 self.suffix = suffix
109 self.create_index_name = create_index_name
110 super().__init__(table, columns)
112 def __str__(self):
113 return self.create_index_name(self.table, self.columns, self.suffix)
116class IndexColumns(Columns):
117 def __init__(self, table, columns, quote_name, col_suffixes=(), opclasses=()):
118 self.opclasses = opclasses
119 super().__init__(table, columns, quote_name, col_suffixes)
121 def __str__(self):
122 def col_str(column, idx):
123 # Index.__init__() guarantees that self.opclasses is the same
124 # length as self.columns.
125 col = f"{self.quote_name(column)} {self.opclasses[idx]}"
126 try:
127 suffix = self.col_suffixes[idx]
128 if suffix:
129 col = f"{col} {suffix}"
130 except IndexError:
131 pass
132 return col
134 return ", ".join(
135 col_str(column, idx) for idx, column in enumerate(self.columns)
136 )
139class ForeignKeyName(TableColumns):
140 """Hold a reference to a foreign key name."""
142 def __init__(
143 self,
144 from_table,
145 from_columns,
146 to_table,
147 to_columns,
148 suffix_template,
149 create_fk_name,
150 ):
151 self.to_reference = TableColumns(to_table, to_columns)
152 self.suffix_template = suffix_template
153 self.create_fk_name = create_fk_name
154 super().__init__(
155 from_table,
156 from_columns,
157 )
159 def references_table(self, table):
160 return super().references_table(table) or self.to_reference.references_table(
161 table
162 )
164 def references_column(self, table, column):
165 return super().references_column(
166 table, column
167 ) or self.to_reference.references_column(table, column)
169 def rename_table_references(self, old_table, new_table):
170 super().rename_table_references(old_table, new_table)
171 self.to_reference.rename_table_references(old_table, new_table)
173 def rename_column_references(self, table, old_column, new_column):
174 super().rename_column_references(table, old_column, new_column)
175 self.to_reference.rename_column_references(table, old_column, new_column)
177 def __str__(self):
178 suffix = self.suffix_template % {
179 "to_table": self.to_reference.table,
180 "to_column": self.to_reference.columns[0],
181 }
182 return self.create_fk_name(self.table, self.columns, suffix)
185class Statement(Reference):
186 """
187 Statement template and formatting parameters container.
189 Allows keeping a reference to a statement without interpolating identifiers
190 that might have to be adjusted if they're referencing a table or column
191 that is removed
192 """
194 def __init__(self, template, **parts):
195 self.template = template
196 self.parts = parts
198 def references_table(self, table):
199 return any(
200 hasattr(part, "references_table") and part.references_table(table)
201 for part in self.parts.values()
202 )
204 def references_column(self, table, column):
205 return any(
206 hasattr(part, "references_column") and part.references_column(table, column)
207 for part in self.parts.values()
208 )
210 def rename_table_references(self, old_table, new_table):
211 for part in self.parts.values():
212 if hasattr(part, "rename_table_references"):
213 part.rename_table_references(old_table, new_table)
215 def rename_column_references(self, table, old_column, new_column):
216 for part in self.parts.values():
217 if hasattr(part, "rename_column_references"):
218 part.rename_column_references(table, old_column, new_column)
220 def __str__(self):
221 return self.template % self.parts
224class Expressions(TableColumns):
225 def __init__(self, table, expressions, compiler, quote_value):
226 self.compiler = compiler
227 self.expressions = expressions
228 self.quote_value = quote_value
229 columns = [
230 col.target.column
231 for col in self.compiler.query._gen_cols([self.expressions])
232 ]
233 super().__init__(table, columns)
235 def rename_table_references(self, old_table, new_table):
236 if self.table != old_table:
237 return
238 self.expressions = self.expressions.relabeled_clone({old_table: new_table})
239 super().rename_table_references(old_table, new_table)
241 def rename_column_references(self, table, old_column, new_column):
242 if self.table != table:
243 return
244 expressions = deepcopy(self.expressions)
245 self.columns = []
246 for col in self.compiler.query._gen_cols([expressions]):
247 if col.target.column == old_column:
248 col.target.column = new_column
249 self.columns.append(col.target.column)
250 self.expressions = expressions
252 def __str__(self):
253 sql, params = self.compiler.compile(self.expressions)
254 params = map(self.quote_value, params)
255 return sql % tuple(params)
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.signals.dispatch import Signal
3connection_created = Signal()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import datetime
2import decimal
3import functools
4import logging
5import time
6from contextlib import contextmanager
7from hashlib import md5
9from plain.models.db import NotSupportedError
10from plain.utils.dateparse import parse_time
12logger = logging.getLogger("plain.models.backends")
15class CursorWrapper:
16 def __init__(self, cursor, db):
17 self.cursor = cursor
18 self.db = db
20 WRAP_ERROR_ATTRS = frozenset(["fetchone", "fetchmany", "fetchall", "nextset"])
22 def __getattr__(self, attr):
23 cursor_attr = getattr(self.cursor, attr)
24 if attr in CursorWrapper.WRAP_ERROR_ATTRS:
25 return self.db.wrap_database_errors(cursor_attr)
26 else:
27 return cursor_attr
29 def __iter__(self):
30 with self.db.wrap_database_errors:
31 yield from self.cursor
33 def __enter__(self):
34 return self
36 def __exit__(self, type, value, traceback):
37 # Close instead of passing through to avoid backend-specific behavior
38 # (#17671). Catch errors liberally because errors in cleanup code
39 # aren't useful.
40 try:
41 self.close()
42 except self.db.Database.Error:
43 pass
45 # The following methods cannot be implemented in __getattr__, because the
46 # code must run when the method is invoked, not just when it is accessed.
48 def callproc(self, procname, params=None, kparams=None):
49 # Keyword parameters for callproc aren't supported in PEP 249, but the
50 # database driver may support them (e.g. cx_Oracle).
51 if kparams is not None and not self.db.features.supports_callproc_kwargs:
52 raise NotSupportedError(
53 "Keyword parameters for callproc are not supported on this "
54 "database backend."
55 )
56 self.db.validate_no_broken_transaction()
57 with self.db.wrap_database_errors:
58 if params is None and kparams is None:
59 return self.cursor.callproc(procname)
60 elif kparams is None:
61 return self.cursor.callproc(procname, params)
62 else:
63 params = params or ()
64 return self.cursor.callproc(procname, params, kparams)
66 def execute(self, sql, params=None):
67 return self._execute_with_wrappers(
68 sql, params, many=False, executor=self._execute
69 )
71 def executemany(self, sql, param_list):
72 return self._execute_with_wrappers(
73 sql, param_list, many=True, executor=self._executemany
74 )
76 def _execute_with_wrappers(self, sql, params, many, executor):
77 context = {"connection": self.db, "cursor": self}
78 for wrapper in reversed(self.db.execute_wrappers):
79 executor = functools.partial(wrapper, executor)
80 return executor(sql, params, many, context)
82 def _execute(self, sql, params, *ignored_wrapper_args):
83 self.db.validate_no_broken_transaction()
84 with self.db.wrap_database_errors:
85 if params is None:
86 # params default might be backend specific.
87 return self.cursor.execute(sql)
88 else:
89 return self.cursor.execute(sql, params)
91 def _executemany(self, sql, param_list, *ignored_wrapper_args):
92 self.db.validate_no_broken_transaction()
93 with self.db.wrap_database_errors:
94 return self.cursor.executemany(sql, param_list)
97class CursorDebugWrapper(CursorWrapper):
98 # XXX callproc isn't instrumented at this time.
100 def execute(self, sql, params=None):
101 with self.debug_sql(sql, params, use_last_executed_query=True):
102 return super().execute(sql, params)
104 def executemany(self, sql, param_list):
105 with self.debug_sql(sql, param_list, many=True):
106 return super().executemany(sql, param_list)
108 @contextmanager
109 def debug_sql(
110 self, sql=None, params=None, use_last_executed_query=False, many=False
111 ):
112 start = time.monotonic()
113 try:
114 yield
115 finally:
116 stop = time.monotonic()
117 duration = stop - start
118 if use_last_executed_query:
119 sql = self.db.ops.last_executed_query(self.cursor, sql, params)
120 try:
121 times = len(params) if many else ""
122 except TypeError:
123 # params could be an iterator.
124 times = "?"
125 self.db.queries_log.append(
126 {
127 "sql": f"{times} times: {sql}" if many else sql,
128 "time": f"{duration:.3f}",
129 }
130 )
131 logger.debug(
132 "(%.3f) %s; args=%s; alias=%s",
133 duration,
134 sql,
135 params,
136 self.db.alias,
137 extra={
138 "duration": duration,
139 "sql": sql,
140 "params": params,
141 "alias": self.db.alias,
142 },
143 )
146@contextmanager
147def debug_transaction(connection, sql):
148 start = time.monotonic()
149 try:
150 yield
151 finally:
152 if connection.queries_logged:
153 stop = time.monotonic()
154 duration = stop - start
155 connection.queries_log.append(
156 {
157 "sql": f"{sql}",
158 "time": f"{duration:.3f}",
159 }
160 )
161 logger.debug(
162 "(%.3f) %s; args=%s; alias=%s",
163 duration,
164 sql,
165 None,
166 connection.alias,
167 extra={
168 "duration": duration,
169 "sql": sql,
170 "alias": connection.alias,
171 },
172 )
175def split_tzname_delta(tzname):
176 """
177 Split a time zone name into a 3-tuple of (name, sign, offset).
178 """
179 for sign in ["+", "-"]:
180 if sign in tzname:
181 name, offset = tzname.rsplit(sign, 1)
182 if offset and parse_time(offset):
183 return name, sign, offset
184 return tzname, None, None
187###############################################
188# Converters from database (string) to Python #
189###############################################
192def typecast_date(s):
193 return (
194 datetime.date(*map(int, s.split("-"))) if s else None
195 ) # return None if s is null
198def typecast_time(s): # does NOT store time zone information
199 if not s:
200 return None
201 hour, minutes, seconds = s.split(":")
202 if "." in seconds: # check whether seconds have a fractional part
203 seconds, microseconds = seconds.split(".")
204 else:
205 microseconds = "0"
206 return datetime.time(
207 int(hour), int(minutes), int(seconds), int((microseconds + "000000")[:6])
208 )
211def typecast_timestamp(s): # does NOT store time zone information
212 # "2005-07-29 15:48:00.590358-05"
213 # "2005-07-29 09:56:00-05"
214 if not s:
215 return None
216 if " " not in s:
217 return typecast_date(s)
218 d, t = s.split()
219 # Remove timezone information.
220 if "-" in t:
221 t, _ = t.split("-", 1)
222 elif "+" in t:
223 t, _ = t.split("+", 1)
224 dates = d.split("-")
225 times = t.split(":")
226 seconds = times[2]
227 if "." in seconds: # check whether seconds have a fractional part
228 seconds, microseconds = seconds.split(".")
229 else:
230 microseconds = "0"
231 return datetime.datetime(
232 int(dates[0]),
233 int(dates[1]),
234 int(dates[2]),
235 int(times[0]),
236 int(times[1]),
237 int(seconds),
238 int((microseconds + "000000")[:6]),
239 )
242###############################################
243# Converters from Python to database (string) #
244###############################################
247def split_identifier(identifier):
248 """
249 Split an SQL identifier into a two element tuple of (namespace, name).
251 The identifier could be a table, column, or sequence name might be prefixed
252 by a namespace.
253 """
254 try:
255 namespace, name = identifier.split('"."')
256 except ValueError:
257 namespace, name = "", identifier
258 return namespace.strip('"'), name.strip('"')
261def truncate_name(identifier, length=None, hash_len=4):
262 """
263 Shorten an SQL identifier to a repeatable mangled version with the given
264 length.
266 If a quote stripped name contains a namespace, e.g. USERNAME"."TABLE,
267 truncate the table portion only.
268 """
269 namespace, name = split_identifier(identifier)
271 if length is None or len(name) <= length:
272 return identifier
274 digest = names_digest(name, length=hash_len)
275 return "{}{}{}".format(
276 f'{namespace}"."' if namespace else "",
277 name[: length - hash_len],
278 digest,
279 )
282def names_digest(*args, length):
283 """
284 Generate a 32-bit digest of a set of arguments that can be used to shorten
285 identifying names.
286 """
287 h = md5(usedforsecurity=False)
288 for arg in args:
289 h.update(arg.encode())
290 return h.hexdigest()[:length]
293def format_number(value, max_digits, decimal_places):
294 """
295 Format a number into a string with the requisite number of digits and
296 decimal places.
297 """
298 if value is None:
299 return None
300 context = decimal.getcontext().copy()
301 if max_digits is not None:
302 context.prec = max_digits
303 if decimal_places is not None:
304 value = value.quantize(
305 decimal.Decimal(1).scaleb(-decimal_places), context=context
306 )
307 else:
308 context.traps[decimal.Rounded] = 1
309 value = context.create_decimal(value)
310 return f"{value:f}"
313def strip_quotes(table_name):
314 """
315 Strip quotes off of quoted table names to make them safe for use in index
316 names, sequence names, etc. For example '"USER"."TABLE"' (an Oracle naming
317 scheme) becomes 'USER"."TABLE'.
318 """
319 has_quotes = table_name.startswith('"') and table_name.endswith('"')
320 return table_name[1:-1] if has_quotes else table_name
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from tests.providers.github import GitHubOAuthProvider
3from plain.oauth.providers import OAuthToken, OAuthUser
6class DummyGitHubOAuthProvider(GitHubOAuthProvider):
7 def generate_state(self) -> str:
8 return "dummy_state"
10 def get_oauth_token(self, code, request):
11 return OAuthToken(access_token="gho_key")
13 def get_oauth_user(self, oauth_token):
14 return OAuthUser(
15 id="99",
16 username="userone",
17 email="user@example.com",
18 )
21def test_github_provider(db, client, settings):
22 settings.OAUTH_LOGIN_PROVIDERS = {
23 "github": {
24 "class": "provider_tests.test_github.DummyGitHubOAuthProvider",
25 "kwargs": {
26 "client_id": "test_id",
27 "client_secret": "test_secret",
28 "scope": "user",
29 },
30 }
31 }
33 # Login required for this view
34 response = client.get("/")
35 assert response.status_code == 302
36 assert response.url == "/login/?next=/"
38 # User clicks the login link (form submit)
39 response = client.post("/oauth/github/login/")
40 assert response.status_code == 302
41 assert (
42 response.url
43 == "https://github.com/login/oauth/authorize?client_id=test_id&redirect_uri=https%3A%2F%2Ftestserver%2Foauth%2Fgithub%2Fcallback%2F&response_type=code&scope=user&state=dummy_state"
44 )
46 # GitHub redirects to the callback url
47 response = client.get("/oauth/github/callback/?code=test_code&state=dummy_state")
48 assert response.status_code == 302
49 assert response.url == "/"
51 # Now logged in
52 response = client.get("/")
53 assert response.status_code == 200
54 assert b"Hello userone!\n" in response.content
56 # Check the user and connection that was created
57 user = response.user
58 assert user.username == "userone"
59 assert user.email == "user@example.com"
60 connections = user.oauth_connections.all()
61 assert len(connections) == 1
62 assert connections[0].provider_key == "github"
63 assert connections[0].provider_user_id == "99"
64 assert connections[0].access_token == "gho_key"
65 assert connections[0].refresh_token == ""
66 assert connections[0].access_token_expires_at is None
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1import pytest
3from plain.signals import request_finished, request_started
5from .. import transaction
6from ..backends.base.base import BaseDatabaseWrapper
7from ..db import close_old_connections, connections
8from .utils import (
9 setup_databases,
10 teardown_databases,
11)
14@pytest.fixture(autouse=True)
15def _db_disabled():
16 """
17 Every test should use this fixture by default to prevent
18 access to the normal database.
19 """
21 def cursor_disabled(self):
22 pytest.fail("Database access not allowed without the `db` fixture")
24 BaseDatabaseWrapper._old_cursor = BaseDatabaseWrapper.cursor
25 BaseDatabaseWrapper.cursor = cursor_disabled
27 yield
29 BaseDatabaseWrapper.cursor = BaseDatabaseWrapper._old_cursor
32@pytest.fixture(scope="session")
33def setup_db(request):
34 """
35 This fixture is called automatically by `db`,
36 so a test database will only be setup if the `db` fixture is used.
37 """
38 verbosity = request.config.option.verbose
40 # Set up the test db across the entire session
41 _old_db_config = setup_databases(verbosity=verbosity)
43 # Keep connections open during request client / testing
44 request_started.disconnect(close_old_connections)
45 request_finished.disconnect(close_old_connections)
47 yield _old_db_config
49 # Put the signals back...
50 request_started.connect(close_old_connections)
51 request_finished.connect(close_old_connections)
53 # When the test session is done, tear down the test db
54 teardown_databases(_old_db_config, verbosity=verbosity)
57@pytest.fixture
58def db(setup_db):
59 # Set .cursor() back to the original implementation
60 BaseDatabaseWrapper.cursor = BaseDatabaseWrapper._old_cursor
62 # Keep track of the atomic blocks so we can roll them back
63 atomics = {}
65 for connection in connections.all():
66 # By default we use transactions to rollback changes,
67 # so we need to ensure the database supports transactions
68 if not connection.features.supports_transactions:
69 pytest.fail("Database does not support transactions")
71 # Clear the queries log before each test?
72 # connection.queries_log.clear()
74 atomic = transaction.atomic(using=connection.alias)
75 atomic._from_testcase = True # TODO remove this somehow?
76 atomic.__enter__()
77 atomics[connection] = atomic
79 yield setup_db
81 for connection, atomic in atomics.items():
82 if (
83 connection.features.can_defer_constraint_checks
84 and not connection.needs_rollback
85 and connection.is_usable()
86 ):
87 connection.check_constraints()
89 transaction.set_rollback(True, using=connection.alias)
90 atomic.__exit__(None, None, None)
92 connection.close()
95# @pytest.fixture(scope="function")
96# def transactional_db(request, _plain_db_setup):
97# BaseDatabaseWrapper.cursor = BaseDatabaseWrapper._cursor
99# yield
101# # Flush databases instead of rolling back transactions...
103# connections.close_all()
« prev ^ index » next coverage.py v7.6.9, created at 2024-12-23 11:16 -0600
1from plain.exceptions import ImproperlyConfigured
2from plain.models import DEFAULT_DB_ALIAS, connections
5def setup_databases(
6 verbosity,
7 *,
8 keepdb=False,
9 debug_sql=False,
10 aliases=None,
11 serialized_aliases=None,
12 **kwargs,
13):
14 """Create the test databases."""
16 test_databases, mirrored_aliases = get_unique_databases_and_mirrors(aliases)
18 old_names = []
20 for db_name, aliases in test_databases.values():
21 first_alias = None
22 for alias in aliases:
23 connection = connections[alias]
24 old_names.append((connection, db_name, first_alias is None))
26 # Actually create the database for the first connection
27 if first_alias is None:
28 first_alias = alias
29 serialize_alias = (
30 serialized_aliases is None or alias in serialized_aliases
31 )
32 connection.creation.create_test_db(
33 verbosity=verbosity,
34 autoclobber=True,
35 keepdb=keepdb,
36 serialize=serialize_alias,
37 )
38 # Configure all other connections as mirrors of the first one
39 else:
40 connections[alias].creation.set_as_test_mirror(
41 connections[first_alias].settings_dict
42 )
44 # Configure the test mirrors.
45 for alias, mirror_alias in mirrored_aliases.items():
46 connections[alias].creation.set_as_test_mirror(
47 connections[mirror_alias].settings_dict
48 )
50 if debug_sql:
51 for alias in connections:
52 connections[alias].force_debug_cursor = True
54 return old_names
57def get_unique_databases_and_mirrors(aliases=None):
58 """
59 Figure out which databases actually need to be created.
61 Deduplicate entries in DATABASES that correspond the same database or are
62 configured as test mirrors.
64 Return two values:
65 - test_databases: ordered mapping of signatures to (name, list of aliases)
66 where all aliases share the same underlying database.
67 - mirrored_aliases: mapping of mirror aliases to original aliases.
68 """
69 if aliases is None:
70 aliases = connections
71 mirrored_aliases = {}
72 test_databases = {}
73 dependencies = {}
74 default_sig = connections[DEFAULT_DB_ALIAS].creation.test_db_signature()
76 for alias in connections:
77 connection = connections[alias]
78 test_settings = connection.settings_dict["TEST"]
80 if test_settings["MIRROR"]:
81 # If the database is marked as a test mirror, save the alias.
82 mirrored_aliases[alias] = test_settings["MIRROR"]
83 elif alias in aliases:
84 # Store a tuple with DB parameters that uniquely identify it.
85 # If we have two aliases with the same values for that tuple,
86 # we only need to create the test database once.
87 item = test_databases.setdefault(
88 connection.creation.test_db_signature(),
89 (connection.settings_dict["NAME"], []),
90 )
91 # The default database must be the first because data migrations
92 # use the default alias by default.
93 if alias == DEFAULT_DB_ALIAS:
94 item[1].insert(0, alias)
95 else:
96 item[1].append(alias)
98 if "DEPENDENCIES" in test_settings:
99 dependencies[alias] = test_settings["DEPENDENCIES"]
100 else:
101 if (
102 alias != DEFAULT_DB_ALIAS
103 and connection.creation.test_db_signature() != default_sig
104 ):
105 dependencies[alias] = test_settings.get(
106 "DEPENDENCIES", [DEFAULT_DB_ALIAS]
107 )
109 test_databases = dict(dependency_ordered(test_databases.items(), dependencies))
110 return test_databases, mirrored_aliases
113def teardown_databases(old_config, verbosity, keepdb=False):
114 """Destroy all the non-mirror databases."""
115 for connection, old_name, destroy in old_config:
116 if destroy:
117 connection.creation.destroy_test_db(old_name, verbosity, keepdb)
120def dependency_ordered(test_databases, dependencies):
121 """
122 Reorder test_databases into an order that honors the dependencies
123 described in TEST[DEPENDENCIES].
124 """
125 ordered_test_databases = []
126 resolved_databases = set()
128 # Maps db signature to dependencies of all its aliases
129 dependencies_map = {}
131 # Check that no database depends on its own alias
132 for sig, (_, aliases) in test_databases:
133 all_deps = set()
134 for alias in aliases:
135 all_deps.update(dependencies.get(alias, []))
136 if not all_deps.isdisjoint(aliases):
137 raise ImproperlyConfigured(
138 f"Circular dependency: databases {aliases!r} depend on each other, "
139 "but are aliases."
140 )
141 dependencies_map[sig] = all_deps
143 while test_databases:
144 changed = False
145 deferred = []
147 # Try to find a DB that has all its dependencies met
148 for signature, (db_name, aliases) in test_databases:
149 if dependencies_map[signature].issubset(resolved_databases):
150 resolved_databases.update(aliases)
151 ordered_test_databases.append((signature, (db_name, aliases)))
152 changed = True
153 else:
154 deferred.append((signature, (db_name, aliases)))
156 if not changed:
157 raise ImproperlyConfigured("Circular dependency in TEST[DEPENDENCIES]")
158 test_databases = deferred
159 return ordered_test_databases
{{ oauth_error }}
{% endblock %} ```  ### Connecting and disconnecting OAuth accounts To connect and disconnect OAuth accounts, you can add a series of forms to a user/profile settings page. Here's an very basic example: ```html {% extends "base.html" %} {% block content %} Hello {{ request.user }}!