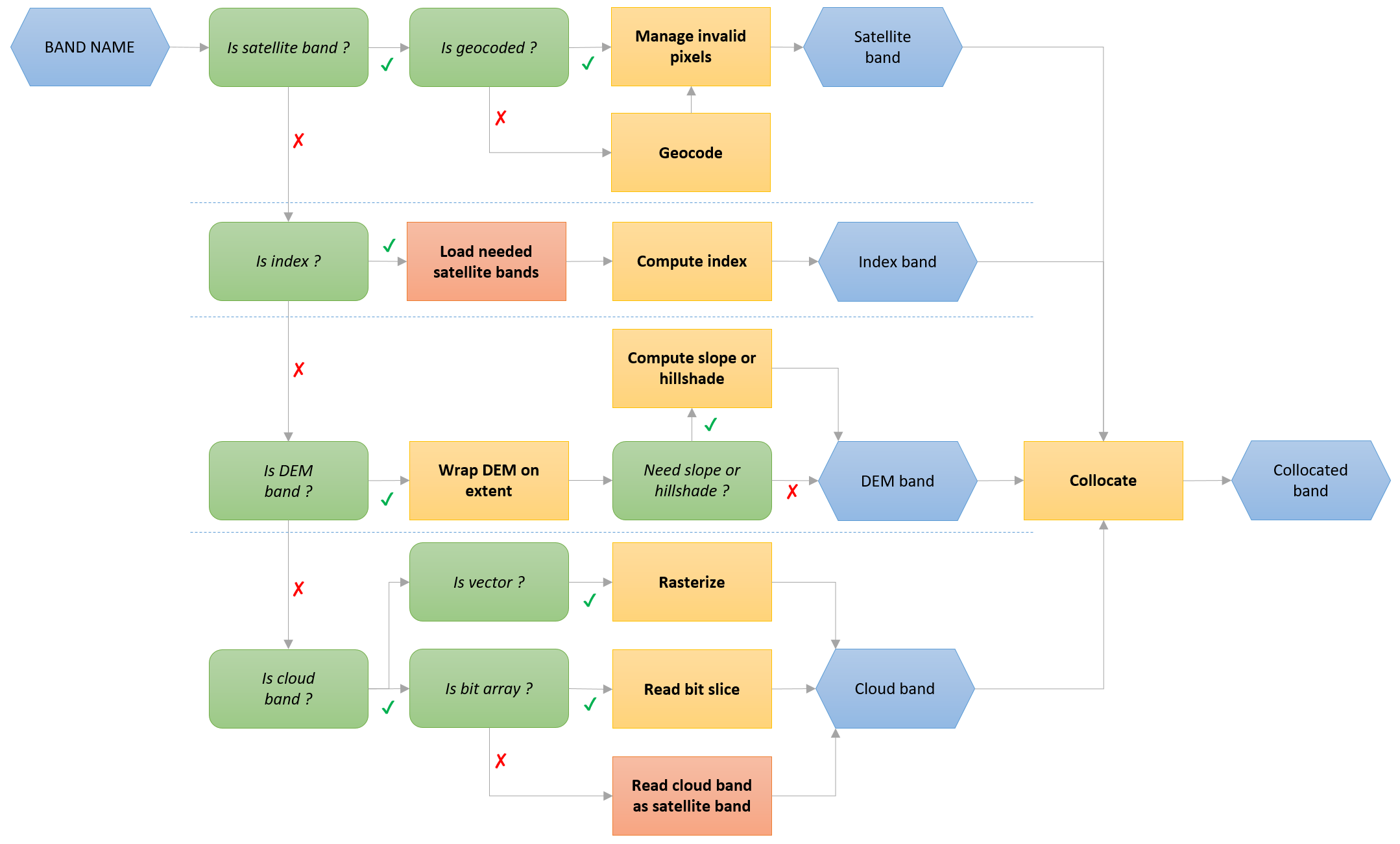
Module eoreader.bands.alias
Aliases for bands and index, created in order to import just this file and not OpticalBandNames, SarBandNames and index.
To use it, simply type:
>>> from eoreader.bands.alias import *
>>> GREEN
<OpticalBandNames.GREEN: 'GREEN'>
>>> HH
<SarBandNames.HH: 'HH'>
>>> NDVI
<function NDVI at 0x00000261F6FFA950>
Expand source code
"""
Aliases for bands and index, created in order to import just this file and not `OpticalBandNames`, `SarBandNames` and `index`.
To use it, simply type:
```python
>>> from eoreader.bands.alias import *
>>> GREEN
<OpticalBandNames.GREEN: 'GREEN'>
>>> HH
<SarBandNames.HH: 'HH'>
>>> NDVI
<function NDVI at 0x00000261F6FFA950>
```
"""
# Module name begins with _ to not be imported with *
import typing as _tp
from eoreader.bands import index as _idx
from eoreader.bands.bands import CloudsBandNames as _clouds
from eoreader.bands.bands import DemBandNames as _dem
from eoreader.bands.bands import OpticalBandNames as _obn
from eoreader.bands.bands import SarBandNames as _sbn
from eoreader.exceptions import InvalidTypeError
# -- OPTICAL BANDS --
CA = _obn.CA # Coastal aerosol
BLUE = _obn.BLUE
GREEN = _obn.GREEN
RED = _obn.RED
VRE_1 = _obn.VRE_1
VRE_2 = _obn.VRE_2
VRE_3 = _obn.VRE_3
NIR = _obn.NIR
NARROW_NIR = _obn.NARROW_NIR
WV = _obn.WV # Water vapour
FNIR = _obn.FAR_NIR
SWIR_CIRRUS = _obn.SWIR_CIRRUS # Optical band based on cirrus
SWIR_1 = _obn.SWIR_1
SWIR_2 = _obn.SWIR_2
MIR = _obn.MIR
TIR_1 = _obn.TIR_1
TIR_2 = _obn.TIR_2
PAN = _obn.PAN
# -- SAR BANDS --
VV = _sbn.VV
VV_DSPK = _sbn.VV_DSPK
HH = _sbn.HH
HH_DSPK = _sbn.HH_DSPK
VH = _sbn.VH
VH_DSPK = _sbn.VH_DSPK
HV = _sbn.HV
HV_DSPK = _sbn.HV_DSPK
# -- INDEX --
RGI = _idx.RGI
NDVI = _idx.NDVI
TCBRI = _idx.TCBRI
TCGRE = _idx.TCGRE
TCWET = _idx.TCWET
NDRE2 = _idx.NDRE2
NDRE3 = _idx.NDRE3
GLI = _idx.GLI
GNDVI = _idx.GNDVI
RI = _idx.RI
NDGRI = _idx.NDGRI
CIG = _idx.CIG
NDMI = _idx.NDMI
DSWI = _idx.DSWI
SRSWIR = _idx.SRSWIR
RDI = _idx.RDI
NDWI = _idx.NDWI
BAI = _idx.BAI
NBR = _idx.NBR
MNDWI = _idx.MNDWI
AWEInsh = _idx.AWEInsh
AWEIsh = _idx.AWEIsh
WI = _idx.WI
AFRI_1_6 = _idx.AFRI_1_6
AFRI_2_1 = _idx.AFRI_2_1
BSI = _idx.BSI
# -- DEM --
DEM = _dem.DEM
SLOPE = _dem.SLOPE
HILLSHADE = _dem.HILLSHADE
# -- CLOUDS --
RAW_CLOUDS = _clouds.RAW_CLOUDS
CLOUDS = _clouds.CLOUDS
SHADOWS = _clouds.SHADOWS
CIRRUS = _clouds.CIRRUS # Cirrus detected
ALL_CLOUDS = _clouds.ALL_CLOUDS
def is_clouds(classif: _tp.Any) -> bool:
"""
Returns True if we have a Clouds-related keyword
```python
>>> from eoreader.bands.alias import *
>>> is_clouds(NDVI)
False
>>> is_clouds(HH)
False
>>> is_clouds(GREEN)
False
>>> is_clouds(SLOPE)
False
>>> is_clouds(CLOUDS)
True
```
"""
try:
is_valid = classif in _clouds
except TypeError:
is_valid = False
return is_valid
def is_dem(dem: _tp.Any) -> bool:
"""
Returns True if we have a DEM-related keyword
```python
>>> from eoreader.bands.alias import *
>>> is_dem(NDVI)
False
>>> is_dem(HH)
False
>>> is_dem(GREEN)
False
>>> is_dem(SLOPE)
True
>>> is_dem(CLOUDS)
False
```
"""
try:
is_valid = dem in _dem
except TypeError:
is_valid = False
return is_valid
def is_index(idx: _tp.Any) -> bool:
"""
Returns True if is an index function from the `bands.index` module
```python
>>> from eoreader.bands.alias import *
>>> is_index(NDVI)
True
>>> is_index(HH)
False
>>> is_index(GREEN)
False
>>> is_index(SLOPE)
False
>>> is_index(CLOUDS)
False
```
Args:
idx (Any): Anything that could be an index
Returns:
bool: True if the index asked is an index function (such as `index.NDVI`)
"""
return "index" in idx.__module__ and idx.__name__ in _idx.get_all_index_names()
def is_optical_band(band: _tp.Any) -> bool:
"""
Returns True if is an optical band (from `OpticalBandNames`)
```python
>>> from eoreader.bands.alias import *
>>> is_optical_band(NDVI)
False
>>> is_optical_band(HH)
False
>>> is_optical_band(GREEN)
True
>>> is_optical_band(SLOPE)
False
>>> is_optical_band(CLOUDS)
False
```
Args:
band (Any): Anything that could be an optical band
Returns:
bool: True if the band asked is an optical band
"""
try:
is_valid = band in _obn
except TypeError:
is_valid = False
return is_valid
def is_sar_band(band: _tp.Any) -> bool:
"""
Returns True if is a SAR band (from `SarBandNames`)
```python
>>> from eoreader.bands.alias import *
>>> is_sar_band(NDVI)
False
>>> is_sar_band(HH)
True
>>> is_sar_band(GREEN)
False
>>> is_sar_band(SLOPE)
False
>>> is_sar_band(CLOUDS)
False
```
Args:
band (Any): Anything that could be a SAR band
Returns:
bool: True if the band asked is a SAR band
"""
try:
is_valid = band in _sbn
except TypeError:
is_valid = False
return is_valid
def is_band(band: _tp.Any) -> bool:
"""
Returns True if is a band (from both `SarBandNames` or `OpticalBandNames`)
```python
>>> from eoreader.bands.alias import *
>>> is_band(NDVI)
False
>>> is_band(HH)
True
>>> is_band(GREEN)
True
>>> is_band(SLOPE)
False
>>> is_band(CLOUDS)
False
```
Args:
band (Any): Anything that could be a band
Returns:
bool: True if the band asked is a band
"""
return is_sar_band(band) or is_optical_band(band)
def to_band(to_convert: list) -> list:
"""
Convert a string (or real value) to any alias, band or index.
You can pass the name or the value of the bands.
```python
>>> to_band(["NDVI", "GREEN", RED, "VH_DSPK", "SLOPE", DEM, "CLOUDS", CLOUDS])
[<function NDVI at 0x00000154DDB12488>,
<OpticalBandNames.GREEN: 'GREEN'>,
<OpticalBandNames.RED: 'RED'>,
<SarBandNames.VH_DSPK: 'VH_DSPK'>,
<DemBandNames.SLOPE: 'SLOPE'>,
<DemBandNames.DEM: 'DEM'>,
<ClassifBandNames.CLOUDS: 'CLOUDS'>,
<ClassifBandNames.CLOUDS: 'CLOUDS'>]
```
Args:
to_convert (list): Values to convert into band objects
Returns:
list: converted values
"""
if not isinstance(to_convert, list):
to_convert = [to_convert]
bands = []
for tc in to_convert:
band_or_idx = None
# Try legit types
if isinstance(tc, str):
# Try index
if hasattr(_idx, tc):
band_or_idx = getattr(_idx, tc)
else:
try:
band_or_idx = _sbn.convert_from(tc)[0]
except TypeError:
try:
band_or_idx = _obn.convert_from(tc)[0]
except TypeError:
try:
band_or_idx = _dem.convert_from(tc)[0]
except TypeError:
try:
band_or_idx = _clouds.convert_from(tc)[0]
except TypeError:
pass
elif is_index(tc) or is_band(tc) or is_dem(tc) or is_clouds(tc):
band_or_idx = tc
# Store it
if band_or_idx:
bands.append(band_or_idx)
else:
raise InvalidTypeError(f"Unknown band or index: {tc}")
return bands
def to_str(to_convert: list) -> list:
"""
Convert a string (or real value) to any alias, band or index.
You can pass the name or the value of the bands.
```python
>>> to_str(["NDVI", "GREEN", RED, "VH_DSPK", "SLOPE", DEM, "CLOUDS", CLOUDS])
['NDVI', 'GREEN', 'RED', 'VH_DSPK', 'SLOPE', 'DEM', 'CLOUDS', 'CLOUDS']
```
Args:
to_convert (list): Values to convert into str
Returns:
list: str bands
"""
if not isinstance(to_convert, list):
to_convert = [to_convert]
bands_str = []
for tc in to_convert:
if isinstance(tc, str):
band_str = tc
else:
try:
band_str = tc.name
except AttributeError:
band_str = tc.__name__
bands_str.append(band_str)
return bands_strFunctions
def is_clouds(
classif)
-
Returns True if we have a Clouds-related keyword
>>> from eoreader.bands.alias import * >>> is_clouds(NDVI) False >>> is_clouds(HH) False >>> is_clouds(GREEN) False >>> is_clouds(SLOPE) False >>> is_clouds(CLOUDS) TrueExpand source code
def is_clouds(classif: _tp.Any) -> bool: """ Returns True if we have a Clouds-related keyword ```python >>> from eoreader.bands.alias import * >>> is_clouds(NDVI) False >>> is_clouds(HH) False >>> is_clouds(GREEN) False >>> is_clouds(SLOPE) False >>> is_clouds(CLOUDS) True ``` """ try: is_valid = classif in _clouds except TypeError: is_valid = False return is_valid def is_dem(
dem)
-
Returns True if we have a DEM-related keyword
>>> from eoreader.bands.alias import * >>> is_dem(NDVI) False >>> is_dem(HH) False >>> is_dem(GREEN) False >>> is_dem(SLOPE) True >>> is_dem(CLOUDS) FalseExpand source code
def is_dem(dem: _tp.Any) -> bool: """ Returns True if we have a DEM-related keyword ```python >>> from eoreader.bands.alias import * >>> is_dem(NDVI) False >>> is_dem(HH) False >>> is_dem(GREEN) False >>> is_dem(SLOPE) True >>> is_dem(CLOUDS) False ``` """ try: is_valid = dem in _dem except TypeError: is_valid = False return is_valid def is_index(
idx)
-
Returns True if is an index function from the
bands.indexmodule>>> from eoreader.bands.alias import * >>> is_index(NDVI) True >>> is_index(HH) False >>> is_index(GREEN) False >>> is_index(SLOPE) False >>> is_index(CLOUDS) FalseArgs
idx:Any- Anything that could be an index
Returns
bool- True if the index asked is an index function (such as
index.NDVI)
Expand source code
def is_index(idx: _tp.Any) -> bool: """ Returns True if is an index function from the `bands.index` module ```python >>> from eoreader.bands.alias import * >>> is_index(NDVI) True >>> is_index(HH) False >>> is_index(GREEN) False >>> is_index(SLOPE) False >>> is_index(CLOUDS) False ``` Args: idx (Any): Anything that could be an index Returns: bool: True if the index asked is an index function (such as `index.NDVI`) """ return "index" in idx.__module__ and idx.__name__ in _idx.get_all_index_names() def is_optical_band(
band)
-
Returns True if is an optical band (from
OpticalBandNames)>>> from eoreader.bands.alias import * >>> is_optical_band(NDVI) False >>> is_optical_band(HH) False >>> is_optical_band(GREEN) True >>> is_optical_band(SLOPE) False >>> is_optical_band(CLOUDS) FalseArgs
band:Any- Anything that could be an optical band
Returns
bool- True if the band asked is an optical band
Expand source code
def is_optical_band(band: _tp.Any) -> bool: """ Returns True if is an optical band (from `OpticalBandNames`) ```python >>> from eoreader.bands.alias import * >>> is_optical_band(NDVI) False >>> is_optical_band(HH) False >>> is_optical_band(GREEN) True >>> is_optical_band(SLOPE) False >>> is_optical_band(CLOUDS) False ``` Args: band (Any): Anything that could be an optical band Returns: bool: True if the band asked is an optical band """ try: is_valid = band in _obn except TypeError: is_valid = False return is_valid def is_sar_band(
band)
-
Returns True if is a SAR band (from
SarBandNames)>>> from eoreader.bands.alias import * >>> is_sar_band(NDVI) False >>> is_sar_band(HH) True >>> is_sar_band(GREEN) False >>> is_sar_band(SLOPE) False >>> is_sar_band(CLOUDS) FalseArgs
band:Any- Anything that could be a SAR band
Returns
bool- True if the band asked is a SAR band
Expand source code
def is_sar_band(band: _tp.Any) -> bool: """ Returns True if is a SAR band (from `SarBandNames`) ```python >>> from eoreader.bands.alias import * >>> is_sar_band(NDVI) False >>> is_sar_band(HH) True >>> is_sar_band(GREEN) False >>> is_sar_band(SLOPE) False >>> is_sar_band(CLOUDS) False ``` Args: band (Any): Anything that could be a SAR band Returns: bool: True if the band asked is a SAR band """ try: is_valid = band in _sbn except TypeError: is_valid = False return is_valid def is_band(
band)
-
Returns True if is a band (from both
SarBandNamesorOpticalBandNames)>>> from eoreader.bands.alias import * >>> is_band(NDVI) False >>> is_band(HH) True >>> is_band(GREEN) True >>> is_band(SLOPE) False >>> is_band(CLOUDS) FalseArgs
band:Any- Anything that could be a band
Returns
bool- True if the band asked is a band
Expand source code
def is_band(band: _tp.Any) -> bool: """ Returns True if is a band (from both `SarBandNames` or `OpticalBandNames`) ```python >>> from eoreader.bands.alias import * >>> is_band(NDVI) False >>> is_band(HH) True >>> is_band(GREEN) True >>> is_band(SLOPE) False >>> is_band(CLOUDS) False ``` Args: band (Any): Anything that could be a band Returns: bool: True if the band asked is a band """ return is_sar_band(band) or is_optical_band(band) def to_band(
to_convert)
-
Convert a string (or real value) to any alias, band or index.
You can pass the name or the value of the bands.
>>> to_band(["NDVI", "GREEN", RED, "VH_DSPK", "SLOPE", DEM, "CLOUDS", CLOUDS]) [<function NDVI at 0x00000154DDB12488>, <OpticalBandNames.GREEN: 'GREEN'>, <OpticalBandNames.RED: 'RED'>, <SarBandNames.VH_DSPK: 'VH_DSPK'>, <DemBandNames.SLOPE: 'SLOPE'>, <DemBandNames.DEM: 'DEM'>, <ClassifBandNames.CLOUDS: 'CLOUDS'>, <ClassifBandNames.CLOUDS: 'CLOUDS'>]Args
to_convert:list- Values to convert into band objects
Returns
list- converted values
Expand source code
def to_band(to_convert: list) -> list: """ Convert a string (or real value) to any alias, band or index. You can pass the name or the value of the bands. ```python >>> to_band(["NDVI", "GREEN", RED, "VH_DSPK", "SLOPE", DEM, "CLOUDS", CLOUDS]) [<function NDVI at 0x00000154DDB12488>, <OpticalBandNames.GREEN: 'GREEN'>, <OpticalBandNames.RED: 'RED'>, <SarBandNames.VH_DSPK: 'VH_DSPK'>, <DemBandNames.SLOPE: 'SLOPE'>, <DemBandNames.DEM: 'DEM'>, <ClassifBandNames.CLOUDS: 'CLOUDS'>, <ClassifBandNames.CLOUDS: 'CLOUDS'>] ``` Args: to_convert (list): Values to convert into band objects Returns: list: converted values """ if not isinstance(to_convert, list): to_convert = [to_convert] bands = [] for tc in to_convert: band_or_idx = None # Try legit types if isinstance(tc, str): # Try index if hasattr(_idx, tc): band_or_idx = getattr(_idx, tc) else: try: band_or_idx = _sbn.convert_from(tc)[0] except TypeError: try: band_or_idx = _obn.convert_from(tc)[0] except TypeError: try: band_or_idx = _dem.convert_from(tc)[0] except TypeError: try: band_or_idx = _clouds.convert_from(tc)[0] except TypeError: pass elif is_index(tc) or is_band(tc) or is_dem(tc) or is_clouds(tc): band_or_idx = tc # Store it if band_or_idx: bands.append(band_or_idx) else: raise InvalidTypeError(f"Unknown band or index: {tc}") return bands def to_str(
to_convert)
-
Convert a string (or real value) to any alias, band or index.
You can pass the name or the value of the bands.
>>> to_str(["NDVI", "GREEN", RED, "VH_DSPK", "SLOPE", DEM, "CLOUDS", CLOUDS]) ['NDVI', 'GREEN', 'RED', 'VH_DSPK', 'SLOPE', 'DEM', 'CLOUDS', 'CLOUDS']Args
to_convert:list- Values to convert into str
Returns
list- str bands
Expand source code
def to_str(to_convert: list) -> list: """ Convert a string (or real value) to any alias, band or index. You can pass the name or the value of the bands. ```python >>> to_str(["NDVI", "GREEN", RED, "VH_DSPK", "SLOPE", DEM, "CLOUDS", CLOUDS]) ['NDVI', 'GREEN', 'RED', 'VH_DSPK', 'SLOPE', 'DEM', 'CLOUDS', 'CLOUDS'] ``` Args: to_convert (list): Values to convert into str Returns: list: str bands """ if not isinstance(to_convert, list): to_convert = [to_convert] bands_str = [] for tc in to_convert: if isinstance(tc, str): band_str = tc else: try: band_str = tc.name except AttributeError: band_str = tc.__name__ bands_str.append(band_str) return bands_str
 EOReader
EOReader





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}